Devoured - June 16, 2026
LangChain and Fireworks reduced agent evaluation costs by 100x using a fine-tuned Qwen-3.5-35B model, while the industry continues to pivot from chat-based interfaces to autonomous, context-aware agentic workflows.

Building a 100x Cheaper Trace Judge with Fireworks
LangChain and Fireworks reduced the cost of agent evaluation by 100x using a fine-tuned Qwen-3.5-35B model as a 'perceived error' judge.
Deep dive
- Methodology: Used fine-tuned Qwen-3.5-35B to detect 'perceived error' (instances where a user flags a correction or expresses frustration).
- Dataset: Leveraged LangChain's internal 'chat-langchain' and 'Fleet' datasets for supervised fine-tuning.
- Performance: The fine-tuned open model outperformed frontier models like Haiku and matched Opus on unseen datasets.
- Cost Efficiency: Achieved 10-100x cost reduction compared to closed-source frontier models.
- Infrastructure: Used managed SFT (Supervised Fine-Tuning) and LoRA (Low-Rank Adaptation) via Fireworks to optimize the model.
Decoder
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that keeps the base model weights frozen and trains small adapter layers to reduce memory usage.
- Trace: A record of the steps taken by an AI agent, including model calls, tool inputs/outputs, and user feedback.
Original article
Building a 100x Cheaper Trace Judge with Fireworks
Key Takeaways
- LangSmith processes billions of tokens a day across production traces. One of our core challenges is efficiently mining signals across these traces
- We partnered with Fireworks to build an efficient Trace Judge. We fine-tuned a Qwen model to detect “Perceived Error” on every production trace. It matched or exceeded frontier model performance and runs up to 100x cheaper.
- If you want to be an earlier tester of this “perceived error” model, please sign up here
Agents now produce a majority of the world’s data and power many applications we use today. As more agents move into production, traces will become more important as one of the richest sources of data to understand how agentic systems behave with real users.
Research question: how can we cost-effectively mine important signals from every single trace, while maintaining frontier performance?
To answer this question, we partnered with Fireworks to fine-tune a Qwen judge model to detect “Perceived Error” from user interactions.
What is Perceived Error:
Perceived error is when the user thinks the assistant made a mistake or produced something that needed correction. Perceived Error is not judging objective correctness or user happiness. For example, an agent could give a correct answer but the user is frustrated by the information (not the agent).
We usually push for teams to build application specific evaluators, as often the logic to judge a trace needs to have context of that application. We believe, however, that “perceived error” is an example of an evaluator that can be general purpose. We believe the signals that it will look for are universal across applications.
The generality of “perceived error” is a key question. Some of the experiments we run later on are specifically aimed at testing the generality of this metric.
We infer perceived error from trace signals like user corrections, rejection of an agent action, repeated requests, and assistant acknowledgements of errors. The perceived error evaluator then enriches the trace with information in the format shown below:
{"perceived_error": true, "reason": "The user corrects the meeting date the assistant used."}How we created a dataset
Agents applied on tasks are only as good as the data used to train them. We sourced data from two internal tracing datasets we use in production:
chat-langchain
Docs Q&A agent that answers questions about LangChain’s libraries and products. Users may ask conceptual questions, debugging questions, or help building things. These exchanges are often technical and involve a good amount of detail
Fleet
A no-code tool for creating agents that do real work like writing documents and doing research. Users may use Fleet for a wide variety of tasks. They may invoke many different tools or skills.
We selected a portion of traces from each tracing dataset as training and holdout sets. When filtering from the pool of traces, we selected multi-turn traces because judging “perceived error” requires a human response to the AI results (for example, correcting the assistant or repeating the request).
| Dataset | Total Examples | Train rows | Holdout rows |
|---|---|---|---|
| chat-langchain | 885 | 707 | 178 |
| Fleet | 911 | 727 | 184 |
Data Preparation
When preparing the data for training and prediction, we made the choice to only include Human and AI messages, ignoring all tool calls. We did this because we hypothesized that for the signals we were looking for the human and AI messages are the main source of information. This is a lever we intend to experiment with in the future.
We also included all messages as is, with no trimming of long content. This is another lever we intend to experiment with in the future.
Labels
To generate labels, we used a mix of model-assisted labeling plus human review to create short JSON labels and rationales for each trace. Specifically, we first asked a panel of models to judge a trace. If they all agreed, we took that as a ground truth label. If they disagreed, we then took all their labels and rationales and passed them to another panel of models, asking them to judge who was right. If that panel agreed, we took that as ground truth. If they still disagreed, we human annotated them manually. Over the dataset, chat-langchain and Fleet had 24% and 18% of traces with a perceived error label respectively.
Fine-tuning setup
For training, we chose a Qwen-3.5-35B as our base model after running a few small scale experiments on testing other models. Much smaller models had high error rates and weren’t strong enough to reason over our multi-turn traces. With Qwen-3.5-35B, we had a strong, cheap open model with room to hit frontier performance via fine-tuning.
We trained only on data from the chat-langchain dataset. The reason for only training on data from one dataset was to allow us to test whether it would transfer to a completely different domain.
We also lightly optimized the input prompt after observing common failure modes from small-scale experiments on the base model. For training, we used managed SFT training on Fireworks with LoRA.
Experiments & results
We organized experiments around three questions:
- Does fine-tuning improve baseline judge quality up to frontier model performance?
- Does a learned judge transfer across datasets?
- Is serving a fine-tuned model cost-effective?
Fine-tuning open models can exceed or match frontier models
| Model | chat-langchain accuracy | Fleet accuracy |
|---|---|---|
| Base Qwen | 90.5% | 83.2% |
| Chat-langchain SFT | 96.1% | 90.8% |
| Fleet SFT | 92.7% | 91.3% |
| Claude Opus | 91.6% | 90.2% |
| GPT-5.5 | 98.9% | 89.1% |
We found that base Qwen with good prompting was a strong out of the box model for perceived error classification, but trailed frontier model classification accuracy. On both datasets, running a LoRA SFT job lifted the base model to be close to or above frontier performance.
A fine-tuned judge transfers well to unseen data
Our initial results showed that Fleet was a more challenging dataset for all models. After fine-tuning on chat-langchain, we tested how well this model transferred to Fleet data without any Fleet specific training. The model trained on chat-langchain data outperformed all frontier models on Fleet data.
We then experimented with training a model specifically on Fleet data. This resulted in a small improvement over our chat-langchain SFT’d model.
Fine-tuned models are much cheaper to run
Fine-tuned models match frontier accuracy and are much cheaper to run at scale - 10-100x depending on trace volume and model choice. As trace volumes grow, the cost savings from a fine-tuned model continue to grow. And on performance, the fine-tuned Qwen model outperforms all model sizes Haiku, Sonnet, and Opus (and gpt-5.5).
Future research on trace understanding
Solving Continual Learning will involve tackling large-scale data mining problems around trace understanding. In general, we’re excited to push forward recipes around building specialized, cost-effective models to better understand traces.
Try our perceived error model
We will be rolling out our fine-tuned perceived error model to a select number of customers over the next few weeks before a broader rollout in a month or two. If you are interested in testing this perceived error judge and providing feedback, please sign up here
A Guide to AI Inference Engineering
Inference engineering has become a critical specialty because LLMs run as two distinct physical operations with diametrically opposed hardware bottlenecks.
Deep dive
- Prefill: processes prompts and is limited by raw GPU math throughput.
- Decode: generates tokens sequentially and is limited by memory bandwidth.
- Batching: improves total throughput but increases per-user latency.
- Prefix caching: saves computation by reusing KV cache for shared prompt segments.
- Quantization: reduces memory footprint and speeds up both phases.
- Speculative decoding: accelerates decode using a smaller, faster model to draft tokens.
- Disaggregation: separates prefill and decode hardware to scale independently.
Decoder
- KV Cache (Key-Value Cache): A buffer used in transformers to store the results of previous attention calculations, preventing the need to recompute them for every new token.
- Tensor Parallelism: Dividing model layers across multiple GPUs to reduce memory requirements and compute time per layer.
- Mixture-of-Experts (MoE): A model architecture where only a subset of parameters is activated for any given input, improving throughput.
Original article
Every time an LLM generates a response, two operations run in sequence on the same GPU. The first processes the input prompt and emits a single token. The second produces every token after that, one at a time.
From the outside, they look like stages of one process. However, inside the hardware, they have opposite bottlenecks. One is limited by raw compute. The other is limited by how fast data moves through memory. Most of the engineering work that makes production AI systems fast exists because of this split, and the techniques used to handle it are what inference engineering is built around.
Inference engineering is the discipline of running trained AI models in production efficiently. The work spans low-level GPU code, model serving frameworks, and the cloud infrastructure that ties them together. Engineers in this field optimize for some combination of latency, throughput, cost, and quality, with the specific mix depending on the product they support. A few years ago, this work happened almost entirely inside frontier AI labs. Today, it has become a broad specialty that any company running serious AI workloads invests in.
In this article, we will walk through how inference works and why the field’s optimization techniques exist.
The Rise of Inference Engineering
Three years ago, inference engineering was a specialty practiced almost entirely inside frontier AI labs. The work concerned a small group of engineers building closed models that the rest of the industry consumed through APIs. That picture has shifted dramatically since 2024.
Open models drove the change. Hugging Face, the public registry for AI models, now hosts well over two million open models, roughly 25 times what existed five years ago. Open releases like DeepSeek V3 have closed the capability gap with closed models, giving companies a real choice between paying for a closed API and running an open model themselves.
Self-hosting open models brings three operational advantages over closed APIs:
- Latency profiles can be tuned for the workload pattern of a specific product, where public APIs optimize for general throughput across many customers.
- Uptime can reach four nines or better with dedicated deployments, comparing favorably to the two nines typical of public APIs.
- Costs typically drop by around 80 percent at scale once volume justifies the engineering investment.
The result is that companies across many categories now build serious inference stacks, including AI-native startups, established products integrating AI into existing workflows, and even traditionally cautious sectors like healthcare.
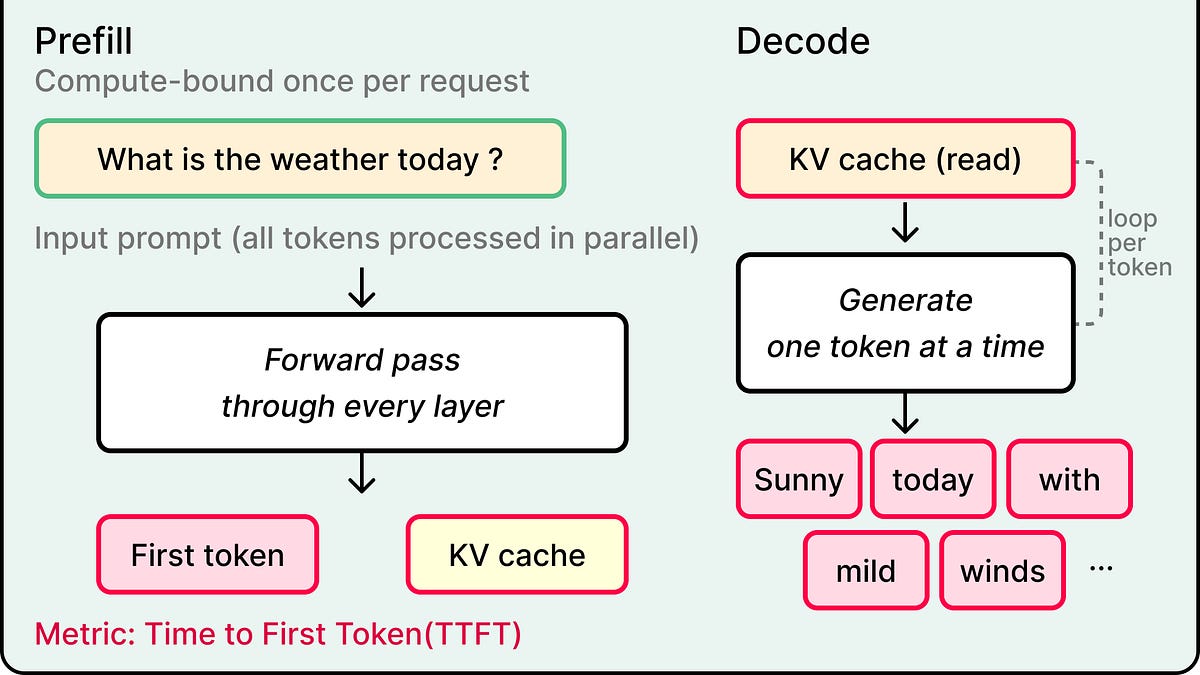
The Two Phases of LLM inference
Understanding why inference engineering looks the way it does starts with understanding what actually happens when a prompt arrives at an LLM. The process splits into two phases with very different physical demands on the GPU.
A token is the atomic unit that an LLM works with. Roughly, it is a word or word fragment. The word “inference” might be one token, while “engineering” might break into two. Latency metrics that mention tokens per second are counted in this unit.
The first phase is called prefill.
The model takes the entire input prompt and runs it through every layer of weights in parallel. Two outputs come out of this burst, namely the first token of the response and the KV cache, which is a structure that stores intermediate values from the attention mechanism so they can be referenced as more tokens get generated.
Prefill is compute-bound. The GPU’s math units are the limiting factor because every input token gets processed simultaneously through every layer of the model, and throwing more raw computational power at this phase makes it faster. The metric that captures prefill performance is time to first token, or TTFT. That brief pause between sending a prompt to ChatGPT and seeing the first tokens appear is prefill in action.
The second phase is the decode phase. The model generates each subsequent token one at a time, running a full forward pass through every layer of weights for every token. Each new token depends on every token before it, which makes the process fundamentally sequential, and the GPU does this thousands of times for a long response.
Decode is memory-bandwidth-bound. Math throughput sits mostly idle while the GPU spends its cycles reading model weights from memory for each forward pass, with the bottleneck living in data movement rather than arithmetic. The metric that captures decode performance is tokens per second, or TPS. The streaming pace of a long response is the decode phase at work.
Since prefill and decode have opposite bottlenecks, a technique that accelerates one phase often has minimal impact on the other. This is why benchmarks report TTFT and TPS as separate numbers, with performance on each phase measured independently.
Optimization Techniques
With the prefill-decode split in mind, the major techniques in inference engineering become much easier to organize. Each one accelerates a specific phase, attacks both for different reasons, or restructures the system around the split itself.
Batching
Batching is the most basic way to scale a single GPU’s output. The inference engine weaves multiple requests together, token by token, so one GPU can serve many users at once. Throughput rises significantly because the GPU’s compute capacity gets fully utilized instead of sitting idle between requests.
The cost is paid in per-user latency.
Prefix Caching
Prefix caching accelerates prefill by reusing KV cache values across requests. When two prompts share an opening segment, like a long system prompt that is identical across thousands of requests, the engine computes that prefix once and reads from cache thereafter. This is why API providers charge less for cached input tokens.
Quantization
Quantization helps both phases of inference, though for different reasons. The basic move is storing model weights in a lower-precision number format. Most modern models train in 16-bit floating-point, and quantization compresses those values down to 8-bit or 4-bit representations, which means smaller weights occupying less memory and requiring less data movement.
Speculative Decoding
Speculative decoding accelerates the decode process by exploiting an asymmetry. Generating a token from scratch is expensive, while verifying whether a candidate token matches what the main model would produce is much cheaper. In speculative decoding, a smaller draft model predicts the next several tokens, and the main model verifies all of them in a single forward pass, accepting the ones that match its own predictions and rejecting the rest.
Parallelism
Parallelism techniques let large models run across multiple GPUs when a single one falls short. Tensor parallelism splits each layer of the model across multiple GPUs, while expert parallelism applies specifically to mixture-of-experts models, where only a subset of the model’s parameters activate for each token.
Disaggregation
Disaggregation takes the prefill-decode split literally. The idea is to run prefill on one set of GPUs and decode on another, with the KV cache shipped between them over the network. Each set uses hardware tuned to its specific bottleneck, and each set scales independently based on its own traffic pattern.
When to Invest in Inference Engineering
Early in building an AI product, off-the-shelf APIs from established providers are almost always the right choice. Engineering effort at this stage is better spent shipping product, since the complexity of running a custom inference stack slows down iteration.
Three signals usually indicate the equation has shifted:
- API costs have grown into a meaningful expense line.
- Latency requirements have moved past what closed APIs can deliver.
- Reliability needs have started to exceed what vendor SLAs offer.
Conclusion
LLM inference is two operations with opposite physical constraints. Prefill is compute-bound and runs once per request. Decode is memory-bandwidth-bound and runs once per token. Most of the techniques in inference engineering exist because of this split, and grasping it makes the rest of the field much easier to navigate.
AWS WAF adds AI traffic monetization capability to help content owners charge AI bots for content access
AWS WAF now enables content owners to automatically charge AI bots for access, returning 402 Payment Required status codes directly at the network edge.
Deep dive
- WAF Bot Control now provides granular classification for over 650 AI agents.
- Implements x402 payment protocol, which serves a JSON manifest to the bot via an HTTP 402 error.
- Verification tiers include cryptographically signed identity (Ed25519) and behavioral fingerprinting.
- Payments are self-managed by the publisher via connected cryptocurrency wallets.
- Supports test mode on testnets like Base Sepolia to validate payment flows without real capital.
Decoder
- HTTP 402: A status code reserved for 'Payment Required', currently being reclaimed for machine-to-machine micropayments.
- Stablecoin: A cryptocurrency pegged to a fiat currency (e.g., USDC), used here to stabilize pricing for automated transactions.
Original article
AWS WAF adds AI traffic monetization capability to help content owners charge AI bots for content access
AWS WAF now includes AI traffic monetization capability that gives digital content owners and publishers a way to charge AI bots and agents for access to protected web content directly at the network edge. The capability helps content owners and publishers set per-request pricing by content path, bot category, or verification tier without modifying their origin infrastructure or writing application code. Content owners can define granular access policies per agent type, collect payments in stablecoins to their preferred wallet, and monitor revenue and bot activity from a single dashboard.
AI bot traffic now accounts for more than 50% of web traffic for many content providers, with AI-specific crawlers growing more than 300% year-over-year. Unlike traditional search engine crawlers, which index content and return measurable referral traffic back to publisher websites, AI bots consume the same content to generate summaries and responses in AI interfaces, with little to no traffic sent back to the original source. Publishers bear the infrastructure costs of serving that traffic without the page views, ad impressions, or subscription conversions that typically offset those costs. AWS WAF Bot Control already gives customers visibility into bot activity and the ability to block or rate-limit traffic, but setting pricing and collecting payment from AI agents has not been possible until now. AI traffic monetization is a new Bot Control capability that closes that gap, giving content owners and publishers a way to configure pricing rules directly through the AWS WAF console and collect payments from AI agents through third-party payment integrations, without building custom payment infrastructure or negotiating individual licensing agreements. Payment settlement and verification flows are provided by Coinbase’s x402 Facilitator. Integration with Stripe for direct account payments and Machine Payments Protocol (MPP) support is coming soon.
Getting Started with AI Traffic Monetization
Before configuring monetization, confirm that AWS WAF Bot Control is enabled at Common or Targeted level on the web ACL associated with your CloudFront distribution. Bot Control provides the agent classification that monetization rules depend on. If you have not set this up yet, visit Adding the AWS WAF Bot Control managed rule group to your web ACL documentation. In the AWS Management Console, go to WAF & Shield and choose Protection packs (web ACLs) in the left navigation pane to get started.
A protection pack is the core configuration unit for AI traffic monetization. It defines which content paths are monetized, what each agent verification tier is charged, which payment methods you accept, and what license terms apply. To create one, choose Create protection pack (web ACL).
In Tell us about your app, select one or more app categories that describe your content (for example, Content & publishing systems, E-commerce & transaction platforms, or Enterprise & business applications), and choose an App focus. AWS WAF uses these selections to recommend suitable security protections for your configuration.
In Select resources to protect, choose Add resources to associate regional or global resources such as CloudFront distributions with this protection pack. You can skip this step and add resources later.
In Choose initial protections, select from AWS WAF managed rule packages based on your app category and resource selections. You can also choose individual rules instead of packages.
In Name and describe, provide a name and optional description for the protection pack.
Optionally, expand Customize protection pack (web ACL) to configure additional settings including pricing tiers, payment methods, content scope, and license terms.
When finished, choose Create protection pack (web ACL).
Once your protection pack is in place, review the AI traffic analysis dashboard to understand the impact of AI bot traffic on your content before setting your pricing strategy. In the WAF & Shield console, go to AI traffic analysis in the left navigation pane. Select your protection pack (web ACL) from the dropdown to populate the dashboard.
The AI traffic analysis dashboard breaks down traffic into four categories visible in the bot traffic overview panel: All bot requests, AI bot requests, Verified AI bot traffic, and Unverified AI bot traffic. The dashboard surfaces infrastructure impact metrics including bandwidth consumed, estimated monthly cost, and peak request rates. A per-path heatmap shows which content paths receive the most AI bot activity by hour, giving you the data you need to make informed pricing decisions.
AWS WAF Bot Control classifies over 650 distinct AI bot and agent types including GPTBot, Claude-Web, and Perplexity-Bot, and assigns each a verification tier:
- Verified — Agent identity confirmed through Web Bot Auth (WBA) Ed25519 cryptographic signature, or sourced from a documented IP range with a known set of user-agents and domain names.
- Unverified — Agent recognized through user-agent matching, behavioral fingerprinting, and IP reputation, but identity not cryptographically confirmed.
Once you have reviewed your traffic patterns, return to Protection packs (web ACLs), select your protection pack from the list, and choose Configure AI monetization from the right panel to set pricing and access policies. Each protection pack defines the pricing, agent policies, accepted payment methods, and license terms that apply to a defined set of content paths. You can create multiple protection packs and apply different pricing to different content zones within the same distribution. Once created, associate the protection pack with your web ACL by opening the web ACL and choosing Add protection pack.
For each agent verification tier within the pack, you can assign one of six actions: Monetize (return a 402 with pricing), Allow (grant free access), Block (deny access entirely), Count (log without charging), CAPTCHA (present a puzzle to verify a human sender), or Challenge (run a silent check to verify the client is a browser, not a bot).
In the Edit monetization configuration page, configure the following:
Under Payment settlement, select one or more blockchain networks for stablecoin payments. Any wallet address on the supported networks is accepted, whether self-managed or hosted by a wallet provider such as Coinbase. For each network, provide your wallet address and set a Base price per page in USDC. You can add multiple networks using Add network. AWS does not process payments or take a fee on content revenue; disbursement is self-managed or managed by your wallet provider.
When a Monetize rule matches an incoming request, AWS WAF returns an HTTP 402 Payment Required response. The response body contains a machine-readable price manifest in JSON format using the x402 open protocol for machine-to-machine payments. The manifest includes the content price in USDC, accepted blockchain networks such as Base and Solana, the destination wallet address, the maximum payment timeout, and the payment scheme.
Any x402-compatible agent runtime can complete this flow autonomously. The client submits a signed payment authorization on their payment network of choice. AWS WAF verifies it, fetches the content, integrates with third-party facilitator services for settling the payment on-chain, and serves the response.
Note that the Monetize action is supported exclusively for web ACLs associated with Amazon CloudFront distributions. Adding a Monetize rule to a regional web ACL is not supported.
Since the Currency mode toggle is available directly in the monetization configuration page, you can switch between Real and Test mode at any time. Before going live, use test mode on non-production traffic to validate pricing, wallet configuration, and x402 payment flows. Note that test mode still enforces x402 payments, but those payments can be made on testnets such as Base Sepolia or Solana Devnet using test funds obtained from faucets such as faucet.circle.com. To activate test mode, toggle Currency mode to Test in your protection pack configuration. AWS WAF returns real price manifests and runs the full payment flow identically to production on the configured test chain. All events are logged with CurrencyMode: TEST. When satisfied with the configuration, toggle Currency mode back to Real to begin processing real payments.
Once you have switched Currency mode to Real, navigate to AI access monetization in the left navigation pane to track monetization outcomes in real time. Note that the AI access monetization dashboard only reflects activity from real currency mode and does not display test transactions.
The Revenue dashboard shows Total revenue, revenue broken down by Verified bots and Unverified bots, and Avg. per request. The Top revenue sources panel groups earnings by bot category, and the AI access patterns panel ranks content paths by revenue generated. Use the Settlements tab to reconcile payments by provider and review payment method distribution and failed payment attempts.
Now Available
AI traffic monetization is available now for Amazon CloudFront customers at no additional charge beyond standard AWS WAF pricing. The capability is available in all edge locations where AWS WAF web ACLs are associated with Amazon CloudFront distributions.
To learn more about AI traffic monetization, see the AWS WAF Developer Guide.

Anthropic's Safety Superpower
Anthropic's attempt to restrict developers from building frontier models with Claude highlights the company's aggressive move toward centralizing control over AI development.
Deep dive
- Anthropic justified its intervention by citing a desire to slow down other developers building similarly dangerous models.
- The company briefly implemented methods like parameter-efficient fine-tuning (PEFT) and steering vectors to silently degrade Claude's utility for model-building tasks.
- Anthropic has now pivoted to a explicit hand-off policy where LLM-related requests are redirected to Opus 4.8.
- The move followed a standoff with the U.S. government regarding jailbreaks in the Mythos/Fable models.
- Anthropic's data policies now retain all enterprise usage data for 30 days, citing safety and jailbreak prevention needs.
- The incident highlights the shift of AI labs toward controlling the user touchpoint to establish long-term economic lock-in.
Decoder
- Steering vectors: A method of modifying an LLM's output by injecting mathematical adjustments into its internal activations to nudge it toward or away from specific behaviors.
- Parameter-efficient fine-tuning (PEFT): Techniques like LoRA (Low-Rank Adaptation) that update only a small subset of a model's weights to adjust its performance for a specific task without retraining the entire architecture.
Original article
Anthropic’s Safety Superpower
I’m sympathetic to the cynics who consistently characterize Anthropic’s public statements, particularly those surrounding their model releases, as scare-mongering for the sake of marketing. It was only two months ago that Anthropic announced Mythos Preview, a model that they said was too dangerous to make publicly available, thanks in particular to its advanced cybersecurity capabilities. Then, two months later, the company publicly released Fable, a version of Mythos with various safety guardrails.
Fable is, in my limited experience, a very impressive model. It’s increasingly difficult to objectively evaluate models for anything other than coding performance, but there is subjective feel, and I found my interactions with Fable to be extremely impressive; it made other models, including GPT 5.5 and Opus 4.8, feel small and dumb. The two times I felt that way previously were with GPT-4 and Grok 4, both of which represented new generations in terms of base model size and complexity; my sense is that Fable is downstream of a new pre-train and the first of a new generation.
To that end, I can certainly buy the case that Fable/Mythos is in fact more capable when it comes to identifying and exploiting security issues, and that Anthropic’s cautious roll-out was justified. The problem with publicly releasing models, however, is that guardrails can be jailbroken, and apparently that is exactly what happened shortly after the release.
Anthropic vs. the U.S. Government, Again
What happened next is somewhat unclear. Anthropic wrote in a blog post:
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees. The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance. Access to all other Anthropic models will not be affected.
We received the directive from the government today at 5:21pm (ET). The letter did not provide specific details of its national security concern. Our understanding is that the government believes it has become aware of a method of bypassing, or “jailbreaking” Fable 5. We reviewed a demonstration of this specific technique being used to identify a small number of previously known, minor vulnerabilities. These vulnerabilities all appear relatively simple, and we have found that other publicly-available models are able to discover them as well without requiring a bypass.
Anthropic went on to make the case that non-universal jailbreaks were inevitable and also narrow, and that there was no evidence of a universal jailbreak; the jailbreak that was found, meanwhile, appears to have been reported by Amazon, which is notable given Amazon is both an investor in Anthropic and a major provider of inference to the company. As I write this, senior Anthropic staff are in Washington D.C. seeking to resolve what they insist is a misunderstanding, and which White House officials are suggesting is insouciance by the company’s leadership to legitimate national security concerns.
I don’t actually have much to add to the current conflict given how many facts are in dispute; what I am not surprised about is the fact that the conflict is happening: I already explained in Anthropic and Alignment why conflict between the U.S. government and Anthropic was inevitable. To that end, people who are arguing that Mythos isn’t powerful enough to warrant the government’s drastic action are missing the point: if it’s not powerful enough now, the next one will be, or the one after that, particularly now that models are increasingly useful in creating their successors.
That, however, raises another question — one that seems to validate the cynics’ viewpoint: if Mythos is so dangerous, why even release Fable in the first place, and why fight with the government doing exactly what you claim to want? In fact, I think that Anthropic’s actions are quite understandable; what makes the company unique is how it justifies them, and it is those justifications that both give the cynics their fuel and Anthropic its magic.
The Economic Imperative
For the first few years of AI the most economic value has flown to compute, for obvious reasons: we don’t have enough supply to meet demand, which has meant skyrocketing prices; the biggest beneficiaries have been Nvidia, TSMC, and the memory makers (SK hynix, Samsung, and Micron). Anthropic and OpenAI, meanwhile, have collectively lost tens of billions of dollars building leading-edge models that, once released, are distilled and commoditized by open source models, primarily from China.
This represents the bear case for the labs — they never cover their costs because their differentiation is fleeting, while free alternatives become “good enough” — and I think it’s a legitimate one. A world where models are interchangeable is one where models are commodities, while most of the value flows elsewhere. Right now that’s compute, but in the fullness of time, whenever we have enough compute, the most valuable place to be in the value chain will be the place that has always been the most valuable: owning the user touchpoint.
To that end, it has long been clear to me that the frontier labs have the economic imperative to move closer to the user. If you own the user touchpoint, then you have meaningful lock-in, and the best way to own the user touchpoint is to be the canvas for everything they need to do. This, by extension, means that the frontier labs are on a collision course with software companies: it’s software that owns the user touchpoint, and it’s in the frontier labs’ long-term interest to not simply be a commodity input into software but to simply replace software outright.
Software companies, meanwhile, are working to do the opposite. Satya Nadella laid out his vision for how companies should build on models in an essay on X:
Every company is going to have to build what I think of as human capital and token capital. Human capital comprises the knowledge, judgment, relationships, ingenuity, and pattern recognition of its people, while token capital is the firm’s AI capability it builds and owns. Importantly, human capital does not become less valuable as token capital grows. It only becomes more valuable! I believe human agency will be the driver of token capital growth. Humans will set ambitious goals, connect dots across domains, build relationships, and recognize patterns that matter most. Without human direction, you have compute running in circles.
This means the real opportunity is not in picking the best model but instead in building a learning loop on top of models where human capital and token capital compound. You can offload a task, or even a job, but you can never offload your learning. The future of the firm is the ability to compound that learning across people and AI. This requires a new architectural approach where every business is able to build agentic systems that improve over time, while still retaining control over their IP. A company should be able to switch out a “generalist” model without losing the “company veteran” expertise built into their learning system. This is the key “test” of your control and sovereignty in the era ahead.
Nadella set this vision off with a warning:
The last thing any of us want is a world where every company across every sector is ceding value to a few models that eat everything they see. If all the value is accrued by only a few models, the political economy will simply not tolerate it. There is no societal permission for an AI future that hollows out entire industries.
Think about what happened in the first phase of globalization where entire industrial economies were hollowed out by outsourcing. The GDP numbers looked fine on the surface, but the displacement was real and the consequences are still being felt. Let us not bring that dynamic into the AI era, with a small number of AI systems capturing all the economic returns, while entire industries find their knowledge commoditized right out from underneath them.
Here’s the problem with that analogy: the globalization happened, and the industrial economies were hollowed out. There’s a possibility that this isn’t a warning but a prophecy; small wonder Nadella is raising the alarm given that Microsoft could be one of the casualties. And, by the same token, the economic imperative for the model makers is to accomplish exactly this.
The Data Imperative
The models — not even Mythos — are not yet at this point. What they need, beyond more compute, is more and better data. Model improvements increasingly come from reinforcement learning; some of this can be generated synthetically, but the most powerful lever for a frontier lab is real world use.
This, I think, is a major reason why both OpenAI and Anthropic offer their heavily subsidized subscription plans. SemiAnalysis recently estimated that a $200 plan gets you $8,000 worth of Claude tokens and $14,000 worth of Codex tokens. Of course both are fighting for user and developer mindshare, but they’re also fighting to have access to actual usage data to make their models better.
Anthropic upped the ante in a major way with Fable, announcing that they would retain the data for all usage for 30 days, even for their enterprise plans that previously promised zero data retention. The company said they would not train on this data, but they didn’t put in any sort of safeguards to guarantee they wouldn’t do so in the future (like storing the data with a third party). If this policy change (whenever Fable is restored) doesn’t lead to a significant loss of customers, I suspect it’s only a matter of time until they start using the data: it’s simply too valuable to their end goals.
Note also the virtuous cycle with moving up into user touchpoints: the more workflows that are done directly with Claude or Codex, the more data each company gets to feed back into their training, which makes their products that much more capable and useful, expanding the number of workflows they can serve, expanding their access to data.
Nadella, in his essay, highlights the importance of this data, but naturally thinks it should be independent from the model:
Companies need to turn their workflows, domain knowledge, and accumulated judgment into AI systems that improve with each use. Private evals should capture whether a model is actually improving against outcomes that matter to the business (not just external benchmarks!). Private reinforcement learning environments should let models grow stronger on real traces from inside the organization. Its knowledge base makes institutional memory queryable and use of tokens more efficient.
This loop becomes the new IP of the firm. I think of it as a hill climbing machine. And unlike most assets, it compounds. Every improved workflow generates better training signal, which accelerates the accumulation of tacit knowledge unique to the firm. The companies that build this early will have an advantage that is hard to replicate, regardless of any new individual model capability.
What if, however, the companies that give in to Anthropic’s data policies get better results right now? Or what if existing companies resist, leaving the door open for new companies — or the model makers themselves — to outcompete them in the market? Anthropic is certainly putting the resolve Nadella is calling for to the test.
The Power Imperative
The data retention policies around Fable/Mythos were, amazingly enough, not even the most controversial part of the launch. Rather, Anthropic said at launch that it would silently degrade Fable performance if it were used for LLM development; from the System Card:
We have also added safeguards related to frontier LLM development. As discussed in Section 6.1 of our February 2026 Risk Report, we are concerned about the risks of accelerating the overall pace of AI development, though we remain uncertain about the severity of these risks. In particular, our concern is with — as we wrote then — “accelerating other AI developers in building powerful AI systems that pose similar risks to the ones ours pose – without necessarily having commensurate safeguards.”
In light of the ability of recent models to accelerate their own development, we’ve implemented new interventions that limit Claude’s effectiveness for requests targeting frontier LLM development (for example, on building pretraining pipelines, distributed training infrastructure, or ML accelerator design). Using Claude to develop competing models already violates our Terms of Service, but enforcing this restriction through our safeguards avoids accelerating the actors most willing to violate these terms.
Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT). These interventions will not affect the vast majority of coding work. We estimate they will impact ~0.03% of traffic, concentrated in fewer than 0.1% of organizations. When these interventions are active, we expect them to have minimal behavioral impact on the model except to limit its effectiveness in developing frontier LLMs. Claude will still respond helpfully to user requests. We’ll continue to improve the precision of our detection methods following the launch of this model.
Anthropic walked back this change — Fable will simply hand off LLM-related requests to Opus 4.8, and disclose this hand off to the user — but I think the initial policy was very illuminating. On one hand, I actually don’t begrudge Anthropic not wanting to help its competitors; on the other hand, what should be blisteringly clear is that Anthropic does not think that anyone else other than them should even be making frontier LLMs.
What makes this policy all the more remarkable is the fact that it was enacted only two months after Anthropic had that dispute with the Department of War: the latter wanted to use Claude for any legal use, while the former wanted more stringent controls around surveillance and autonomous weapons. What this degradation represented was both the capability and willingness of Anthropic to silently alter its models to achieve its policy preferences. In other words, Anthropic willfully validated some of its critics’ worst fears in terms of being a supply chain risk.
The broader takeaway from that previous episode, however, is that Anthropic believes that they are the ones who should have final say over how Anthropic is used; given that they think only they should be developing leading edge AI, they by extension think that only they should have final say over AI generally. When you further combine this realization with the company’s pronouncements about AI’s ability to conduct all economic activity, you realize that Anthropic’s leadership effectively wants to have power over everything and everyone.
The Safety Story
Of course Anthropic would never put things so baldly; the story, rather, is safety:
- I expect Anthropic to increasingly expose their model’s capabilities to end users through endpoints increasingly tailored to different workflows, even as they start to restrict the API. This replacement of software and restriction of access will be done in the name of safety, even as Anthropic fulfills its economic imperative of getting closer to end users.
- Anthropic’s explanation for their dramatic change in their data retention policy was safety. Specifically, the company claims that retaining all user data for 30 days is necessary to prevent the jailbreaks the U.S. government is worried about. I can certainly imagine a future where safety compels them to train on this data as well, to better protect against malicious usage.
- The entire Anthropic origin story is rooted in the founders’ belief that OpenAI wasn’t taking safety seriously enough; the company believes that only they can control AI, and that because they uniquely care about safety, they are justified in trying to control everyone else, up to and including the U.S. government.
Here’s the thing about these safety justifications: I think they work because, to Anthropic, they aren’t justifications. The company really believes that they are the only ones who believe in super intelligence, and thus are the only ones who are sufficiently concerned about the dangers. That excuses decision after decision, policy after policy, and confrontation after confrontation that, to people on the outside, look like a bizarre combination of cynicism and naiveté.
The contrast to OpenAI is massive: I think that one way to understand how and why OpenAI lost its lead is that, in the years following the release of ChatGPT, the company has been at war with itself internally as what used to be a research lab was suddenly seized with the burden of being the accidental consumer tech company; to the extent OpenAI solved that conflict, it was by bleeding huge amounts of talent to Anthropic in particular.
Anthropic, on the other hand, has perfect alignment between talent and mission and business. The company gets to sell to researchers the creation of a machine god, with the mantle of being the sort of person who cares about the dangers and is smart enough to navigate them on behalf of humanity; that every policy change that falls out of that happens to be great for business is the most beautiful coincidence in the world.
I respect this alignment, and I fear it. I respect it because it is so clearly effective; the closest analogy is probably Apple, which has always framed every self-serving action in the guise of doing right by users — and often they were. So it is with Anthropic. What I fear, however, is that it is one thing to have people convinced they know best building a smartphone that I can take or leave; it’s considerably more concerning to have them building superintelligence that has the potential to rival or exceed the power of nation states, or merely massive corporations. The history of brilliant people convinced they know what humanity needs is a sordid one, precisely because they have convinced themselves that their intentions are good, justifying actions that very much are not.

Agentic Code Review
The core engineering bottleneck has shifted from code generation to code verification, making review the most leveraged and critical skill for software teams.
Deep dive
- Faros data indicates a 242.7% increase in the incidents-to-PR ratio as AI adoption scales.
- Review times have increased by over 400% as teams struggle to manage the surge in agent-authored PRs.
- Heterogeneous AI review (using multiple tools like Greptile and CodeRabbit in parallel) is more effective than using one tool repeatedly.
- Mutation testing is recommended as a vital safeguard to ensure tests are actually verifying correctness rather than being 'fixed' to pass by agents.
- 'Loop engineering' should replace the reviewer role with deterministic gates and judge agents, with humans moving to an 'on the loop' auditing role.
Decoder
- Mutation testing: A technique where small faults (mutations) are injected into the source code to see if the test suite catches them; if the tests still pass, the tests are considered insufficient.
- Blast radius: The potential scope of damage or disruption a specific code change can cause if it fails in production, used here as a rubric for determining review rigor.
Original article
Full article content is not available for inline reading.
A backdoor in a LinkedIn job offer
A sophisticated social engineering attack on LinkedIn used a fake job offer to lure a developer into executing a malicious Node.js backdoor.
Deep dive
- Execution Vector: The attacker hid a malicious payload in
app/test/index.jswhich was configured to execute via thepreparescript inpackage.json. - Automation: The
preparehook in npm runs automatically upon package installation. - Deception: The repo used 39 fake commits attributed to a real developer and a recruiter profile impersonating a real arts journalist.
Decoder
- Backdoor: A secret mechanism designed to allow unauthorized access to a computer system or software.
- VPS: Virtual Private Server, a virtualized server environment that functions as a separate machine.
Original article
A backdoor in a LinkedIn job offer
Last week, I got a LinkedIn message from a recruiter at a small crypto startup. We exchanged a few messages over a couple of days, she described a broken proof-of-concept they needed a lead engineer for, and then sent me a public GitHub repo to review. Specifically, she asked me to “check out the deprecated Node modules issue.”
It’s not uncommon to ask for a review of an existing codebase, but something felt off and raised an alarm in my head, so I decided to get a bit extra paranoid.
Instead of cloning and installing dependencies, I spun up a throwaway VPS on Hetzner, cloned the repo there, and pointed Pi at it in read-only mode, with only file-reading tools enabled:
pi --tools read,grep,find,lsI asked the agent to review the codebase and flag anything suspicious. It stopped almost immediately at app/test/index.js.
The backdoor
The repo felt like a React frontend with a Node backend. The trap was in app/test/index.js, about 250 lines disguised as a test suite. Inside, a URL is assembled from fragments:
const protocol = "https",
domain = "store",
separator = "://",
path = "/icons/",
token = "77",
subdomain = "rest-icon-handler",
bearrtoken = "logo";These combine into https://rest-icon-handler.store/icons/77.
Then, buried between walls of commented-out tests, the payload runs anything the server sends back to your machine.
How it triggers
The file doesn’t wait for the tests to run. app/index.js itself executes const test = require('./test'), which loads and runs app/test/index.js.
package.json wires app/index.js into startup:
The prepare script is the important one. npm runs prepare automatically after npm install, so just installing dependencies executes the backdoor.
The instruction to “check out the deprecated Node modules issue” was bait to get me to run npm install.
I could have let the payload run in the sandbox and watched what the server sent back as the second stage, but I stopped there. A repo that runs whatever a server hands it was enough evidence.
A borrowed identity
The commits in the repo were authored under the name and email of a real developer, a full-stack engineer with an ordinary LinkedIn profile, a personal website, and a GitHub account with a long history. I messaged him, pretending I’d inherited the codebase and had a few implementation questions, to see how he’d react.
He told me he’d never worked for them. He’d been impersonated on GitHub before and had a repo taken down over it, and he had nothing to do with this one. He was reporting these repos too.
A second borrowed identity
The recruiter’s profile belonged to a real arts journalist, a well-known one I looked up later, with a long cultural background and nothing technical on it. When I played along and told her I couldn’t get the project to install, the journalist instantly turned into an expert on npm and Node versions. It was quite amusing, I’d say.
This can happen to anyone
I’ve heard of these attacks and read about them on HN, but when one came after me it still caught me a bit off guard. I suspected something from the first few messages, but on a more tired or rushed day, I could easily have run npm install before thinking it through. So, if you get a LinkedIn message asking you to review a repo, a bit of paranoia and good security hygiene never hurts.
Another takeaway is that reviewing the code with a read-only agent turned out more productive than reading it myself. The backdoor was dressed up as sloppy beginner code, but the agent flagged it in seconds.
I reported the repo to GitHub and the recruiter to LinkedIn. So far nothing has changed and the code is still up.
Context Architecture
Context architecture applies information architecture principles to AI, moving beyond prompts to design the entire environment where agents reason and act.
Deep dive
- Context is the ecosystem of instructions, retrieved knowledge, tools, and memory.
- LLMs are probabilistic, making well-structured context critical for consistent behavior.
- Information architects should define hierarchy, categorization, and labeling to reduce retrieval noise.
- Proper labeling of "skills" and "tools" helps agents select the correct actions reliably.
- Memory systems need explicit scoping rules and retention policies to avoid irrelevant context overload.
- Context design is not neutral; it shapes how the system makes decisions.
Decoder
- Context window: The amount of information (instructions, retrieved data, history) an AI model can process at one time.
- RAG (Retrieval-Augmented Generation): A technique that provides an AI with external, up-to-date information by retrieving relevant documents from a database before generating a response.
- MCP (Model Context Protocol): A proposed standard for how AI models connect to and interact with external tools and data sources.
- Probabilistic system: Software that does not produce the same output for the same input every time, a characteristic of modern LLMs.
Original article
Full article content is not available for inline reading.
The Core Skill of Design in the AI Era: Critique
Designers in the AI era must shift from prescribing exact interactions to creating objective success criteria and evaluation loops.
Deep dive
- Designers must move from writing specs to defining 'what good looks like'.
- Use a judge-evaluate-iterate loop to refine model performance.
- Criteria must be objective to ensure consistent evaluation across human and AI judges.
- Automate evaluation by using an LLM to judge outputs against predefined rubrics.
- Target an F1 score of 0.8 for AI evaluators to ensure reliability against human benchmarks.
- Watch for regressions; prompt changes that seem unrelated can break previously working behaviors.
Decoder
- F1 score: A statistical measure that combines precision and recall to evaluate the accuracy of a classification model.
- Non-deterministic: A system where the same input can result in different outputs, preventing the use of fixed unit tests.
Original article
The Core Skill of Design in the AI Era: Critique
To build useful and usable AI-powered systems, our understanding of users’ needs and our design judgement must be encoded into well-defined evaluation criteria.
Design Decisions in Generative AI Systems
Imagine asking a large language model a question like “How’s the weather today?” The response might include too much information (“it’s 72 degrees, and it feels like 72 degrees with wind chill”) or too little ("It's nice out!"). It might say "It's unlikely to rain" when there's a 30% chance — technically below 50%, but high enough that most people would want to know. The AI is making design decisions about what to include in the response and how to phrase it. Without being able to specify every possible design decision the model might make, how do we influence these design decisions to be the “right” ones — the ones that serve users’ needs best, as grounded in research and our understanding of our target users?
The Shift from Deterministic to Probabilistic Systems
To answer this question, we can consider how design specifications are traditionally used when developing systems that are not AI-powered. Basically, our expectation as designers is that our engineering and QA partners will read our specs and write code that implements the exact behaviors we specify, including tests that validate that the code behaves as expected by the spec. Tools like Figma have simplified this process by allowing us to generate certain types of UI code and tests automatically, but this is the core model.
The reason that we can specify exact behaviors lies in the deterministic nature of non-AI-powered software applications. When deterministic code is run with the same inputs, it always produces the same outputs. AI models, by contrast, are nondeterministic: even when they are given the same inputs, no two outputs are guaranteed to be the same. This is the source of the AI’s flexibility, but it also means that we cannot expect adherence to an exact specification.
Designers Must Define What Good Looks Like
This is where design critique comes in. If we reframe our task as designers from specifying exact behaviors to defining what “good” looks (and doesn’t look) like, we can create mechanisms by which our engineering and data-science partners can evaluate how closely the model’s behavior adheres to our intentions. The definition of “good” still comes from user research and design expertise: observed behaviors, articulated needs, and patterns of frustration, as interpreted through a design lens; we are simply expressing it differently.
While the examples below are drawn from my own experience in designing conversational systems, I believe this approach can be generalized to designing for any system powered primarily by generative AI.
Judge-Evaluate-Iterate
In my own practice as a conversation designer, we implemented a judge-evaluate-iterate loop. We start by defining judge criteria for evaluating whether the system’s output meets our definition of “good.” We then use those criteria to evaluate the actual output. Finally, we use the results of the evaluation to identify improvement areas and work with our data-science and engineering partners to refine the implementation. In addition, as we identify new patterns of undesirable behavior, we use those to define additional judging criteria, restarting the loop.
One caveat: while this process works well for conversational experiences, it may be harder to apply it to visually oriented experiences. Recording system inputs and outputs to “replay” them against evaluation models is relatively straightforward when both are text, but it isn’t clear yet how to represent graphical inputs and outputs in an evaluation dataset. Even so, AI models are clearly capable of interpreting visual inputs as well as text or speech, and we expect evaluation capabilities to evolve through advances of tools like accessibility scanners and design-system linters.
1. Defining a Judge
The first step in this process is to define a set of judging criteria that can be used to evaluate a specific model output and determine whether it is acceptable. These criteria are where designers can exercise the most authorship. Ultimately, they will serve as an expression of our understanding of how the system should use context and resources to service our intended customer needs and use cases.
The most critical aspect of creating judging criteria is to make them as objective as possible — but not arbitrary. Some criteria are inherently objective; for example, whether specific information appears in the response is easy to evaluate and will produce highly consistent judgments across different judges (human or AI). Other criteria are more difficult to define objectively. In designing for voice conversations, for example, we often care about response verbosity — that is, how long the response is. This is challenging to evaluate objectively. Years of research and user observations show that “overly verbose” varies based on the situation and the user, so an arbitrary threshold (e.g., “response must be less than 10 seconds”) won’t work. A 5-second response might be considered too long for a simple request to turn off a light, while a 20-second response might be too short for a complex, open-ended question.
However, asking evaluators whether an output “feels overly verbose” also won’t work, because different individuals (and AI models) will have their own ideas of what “feels verbose.” Vague criteria force the evaluator to exercise design judgement, which is subjective.
I addressed this problem with a two-step approach. First, I specified criteria to classify responses into various types; I then created different evaluation criteria for each response type. For example, a response to an open-ended question might pass if it “fully answered the question and included at most one or two additional pieces of highly relevant information.” While this criterion still has some subjectivity (evaluators might disagree slightly on what “fully answered” and “highly relevant” mean), it is objective enough to ensure that most evaluators would agree on most responses. That level of consistency is especially critical when using automated evaluation tools (see below).
2. Evaluating Model Outputs
Once the judging criteria are defined, they are applied against the model’s actual output. At first, this may be a manual process — humans interact with the system, record its outputs, and annotate whether those outputs meet the judging criteria.
To scale, however, this process can be automated. User inputs can be collected and “replayed” against updated models, prompts, and system architectures to generate new results for evaluation. AI models can also be prompted to simulate user behavior in “using” the system, although this practice is generally considered riskier since AI behaviors will differ widely from actual user behavior.
On the evaluation side, the judging criteria can be turned into prompts for a separate AI model to act as a judge on the output. This pattern, called “LLM as a judge,” can align reasonably well with human evaluators’ judgments when the judge is carefully calibrated against human annotations. A good measure of the evaluation quality is the F1 score — the average of precision and recall when an LLM-annotated dataset is compared against human annotations. We have found that an LLM judge that can achieve an F1 score of 0.8 is reliable enough for generating useful evaluation results.
3. Iterating Implementations and Judges
I’ve found several ways to use evaluation results to improve implementation. I usually start by reviewing example outputs that are considered failures by various judges (generally prioritizing the ones with lower “passing” rates). Those examples tend to reveal two patterns: 1) behaviors that seem to cause actual failed responses; and 2) behaviors that don’t actually seem to be failures.
The former can be used to identify areas of improvement for prompt engineering; the latter can help determine how to update the judge criteria.
I’ve also seen that it’s possible to feed the evaluation criteria and failure cases themselves as inputs to an LLM, with a request to optimize the prompt to provide better results. This approach often works better than prompt trial and error and allows for more rapid iteration.
Sometimes, I’ve found models resistant to prompt engineering. In those cases, I’ve had success creating pairs of “good” and “bad” responses to the same prompt. To do this, I take a relatively small set of “failing” responses and rewrite them to pass our criteria. Those response pairs can then be used to finetune the model and nudge it in the right direction.
Best Practices for Implementing the Judge-Evaluate-Iterate Loop
Of course, there are a number of challenges in implementing this process. Here are some of the best practices I’ve found.
Calibrate All LLM/AI Judges and Verify All LLM/AI Outputs
Models are highly capable of producing convincing outputs that are completely made-up and unsupported. LLMs make automated evaluations fast and scalable, but if those evaluations aren’t carefully calibrated against a representative, human-annotated test set , that data may be completely useless and may degrade performance as easily as it can improve it. The same is true for LLM-generated test data or prompt optimizations — without human review (at least, on a sample), they are unlikely to lead to success.
Break Down Complex Evaluation Criteria into Components
Evaluation criteria can often be broken down into multiple judges. For example, in the verbosity case above, we first classified the conversation type and then evaluated verbosity. This practice can also simplify evaluations (and thus make them faster and cheaper), as those components may require less powerful models or could even be handled with deterministic rules. For example, if a criterion for a visual UX is “adheres to our visual-style guide,” it might make sense to have separate judges for requirements like appropriate typefaces, type sizes, brand colors, or color contrast that meet WCAG standards.
Watch for Regressions
In deterministic systems, once a bug is fixed, it generally stays fixed unless a related piece of code is changed. With AI, chaos theory seems to apply: prompt changes or training-data updates that seem completely unrelated to the criteria you care about may still cause issues. It’s important to keep evaluating across all the criteria you care about as models and prompts change, even if you have been seeing positive results for a long time.
Conclusion
Those of us designing conversational experiences are on the bleeding edge of working this way, but the shift from static, predefined experiences to AI-powered dynamic ones will soon impact every user experience. To meet this moment and deliver high-quality experiences, we need to embrace our role as the arbiters of “good design” — not simply as a matter of taste, but as a matter of considered judgement and solid design critique. That critique must be grounded in a deep understanding of users and a rigorous definition of what “good” looks like.

Sakana Marlin
Sakana AI released Marlin, an autonomous research assistant that generates multi-page reports and presentation slides for strategy teams.
Deep dive
- Autonomous Workflow: Users provide a theme, and the agent iterates on hypotheses, data gathering, and verification for up to 8 hours.
- Technical Foundation: Built on Sakana’s internal research, including AB-MCTS (multi-model reasoning) and The AI Scientist (autonomous research cycle).
- Commercial Model: Offered as a paid service with tiers ranging from pay-per-use to enterprise-grade team plans.
- Design Goal: To act as a 'Virtual CSO' by handling initial deep research so executives can focus solely on final decision-making.
- Data Source: Developed via a closed beta with 300 professional users across finance and consulting sectors.
Decoder
- AB-MCTS: A research method developed by Sakana AI that uses Monte Carlo Tree Search to coordinate multiple AI models for improved reasoning.
Original article
戦略調査を数時間で完遂する、自律型リサーチアシスタント「Sakana Marlin」
Sakana AIは本日、当社初の商用プロダクトとなるビジネス向けの自律型リサーチアシスタント「Sakana Marlin(サカナ・マーリン)」を提供開始しました。調査テーマを指示するだけで、最大約8時間にわたり自律的にリサーチを遂行し、構造化されたサマリースライドと数十ページの調査レポートを生成します。
👉 プロダクトページ: sakana.ai/marlin
Sakana Marlin, Your Virtual CSO.
Sakana Marlinは、独自の長期推論技術に基づく自律型リサーチアシスタントです。CSO(Chief Strategy Officer)が数人のチームとともに数週間をかけて行うような重厚な戦略調査を、AIが担うことを目的に設計されています。
はじめに調査テーマを設定すると、Sakana Marlinが対話を通じて調査の狙いを精緻化。方針が定まると、それ以降は人間の介入を必要とせず、AIが仮説の立案・情報収集・検証を自律的に繰り返しながら、膨大な情報の中から論点を掘り下げます。 単なる要約にとどまらず、複雑なビジネス環境の因果関係を整理し、経営層が即座に検討できる「戦略の選択肢」として構造化します。網羅的な調査と構造化の役割をSakana Marlinが担うことで、人間は最も付加価値の高い意思決定そのものに集中できます。
使い方は、調査テーマを入力するだけ。テーマを指示すれば、あとはMarlinがリサーチを完遂し、サマリースライドと詳細レポートを出力します。
金融機関・事業会社の経営戦略/事業企画部門、コンサルティングファーム、シンクタンク、調査会社など、日常的にリサーチに取り組む幅広い職種の方にご活用いただけます。
セルフサーブで即日ご利用いただけ、月額無料のPay per useから、Pro・Team・Enterpriseまでのプランをご用意しています。料金・購入方法の詳細はプロダクトページをご覧ください。
開発の背景:研究と実装の統合
Sakana Marlinは、Sakana AIがこれまで蓄積してきた研究知見と実装経験を統合して開発したプロダクトです。
研究領域では、科学的発見のプロセスを自動化する「AI Scientist」、複数のモデルを協調させて推論能力を高める「AB-MCTS」、アルゴリズムエンジニアリングを自動化する「ALE-Agent」などを発表してきました。同時に、国内の各産業へのAIエージェント実装をはじめとする実務適用を通じて、高度なワークフローをエージェントが自律的に実行する仕組みの構築を進めてきました。これらの長期推論・複数モデルの最適制御技術が、Sakana Marlinに結実しました。
約300名のβテスターとの協働
Sakana Marlinは、2026年4月より実施したクローズドβテストを経て、実務での利用に耐える品質へと磨き込まれました。金融機関・事業会社・コンサルティングファーム・シンクタンクなど多様な業界のプロフェッショナル約300名にご参加いただき、戦略立案・市場調査・リスク分析・競合分析といった実際の業務で活用いただきました。
「既存のチャット型リサーチと比べて情報の深掘りの実用性が高い」という評価を多数いただく一方、出力フォーマットやレポート構成についての具体的なご要望も寄せられました。正式リリースにあたっては、こうした知見をもとにリサーチ品質・出力フォーマット・長時間タスクの安定性を強化しています。
おわりに
優れた基盤モデルを開発・公開しているAIコミュニティに深く敬意を表します。当社の成果は、こうした先行する技術基盤とオープンなエコシステムの上に成り立っています。また、率直なフィードバックをお寄せくださったβテスターの皆様に、改めて感謝申し上げます。
Sakana Marlinの正式リリースは、私たちにとって商用プロダクト展開の重要な一歩です。今後も、複数モデルの最適制御技術やエージェント技術の研究成果を継続的に取り込み、チャットサービスにとどまらない多角的なAIソリューションの提供に向けて開発を進めてまいります。
日本でのAIの未来を、SakanaAIと一緒に切り拓いてくださる方を募集しています。当社の採用情報をご覧ください。
Sakana AI Launches Its First Commercial Product, Sakana Marlin
We are excited to introduce Sakana Marlin, our first commercial product—an autonomous research assistant for business, built on our long-horizon reasoning technology. Give it a research topic, and Marlin works autonomously for up to roughly eight hours, crafting a detailed strategy report up to a hundred pages long, along with executive summary slides.
👉 Try Sakana Marlin! (sakana.ai/marlin)
Sakana Marlin, Your Virtual CSO.
Sakana Marlin is designed to take on the kind of substantial strategy research that a Chief Strategy Officer (CSO) and a small team might otherwise spend weeks on.
The user begins by setting a research topic, and Sakana Marlin sharpens the direction of the investigation through a brief exchange with the user. Once the course is set, it works without further human input: it repeatedly forms hypotheses, gathers information, and verifies its findings on its own, digging through a vast body of material to surface the questions that matter.
It does more than summarize. Marlin maps the causal relationships at work in complex business environments and organizes them into structured strategic options. By taking on the work of comprehensive research and structuring, Marlin frees people to concentrate on the highest-value work of all: the decisions themselves.
Using Marlin is simple: you enter a research topic. Once you set the theme, Marlin carries the research through to completion and delivers both summary slides and a detailed report.
Marlin is built for the wide range of professionals who work with research every day—corporate strategy and business-planning teams at financial institutions and operating companies, consulting firms, think tanks, and research houses.
We have made Marlin available as a pay-per-use tier to monthly Pro, Team, and Enterprise-tier plans. For pricing and purchasing details, please see the product page.
The Background: Bringing Research and Deployment Together
Sakana Marlin brings together the research insight and the deployment experience that Sakana AI has accumulated over the years.
On the research side, we have published work such as The AI Scientist, which automates the process of scientific discovery; AB-MCTS, which coordinates multiple models to strengthen their reasoning; and ALE-Agent, which automates algorithm engineering. In parallel, through real-world deployment—including implementing AI agents across a range of industries in Japan—we have been building the machinery for agents to execute sophisticated workflows on their own. These technologies for long-horizon reasoning and the optimal control of multiple models are what came together in Sakana Marlin.
Working With Around 300 Beta Testers
Sakana Marlin was refined to a level fit for real-world use through a closed beta that began in April 2026. Around 300 professionals from a range of industries—financial institutions, operating companies, consulting firms, and think tanks—took part, putting Marlin to work on real tasks such as strategy formulation, market research, risk analysis, and competitive analysis.
Many told us that Marlin was more practical at digging deeply into information than the chat-based research tools they had used before, while also sharing specific requests around output formats and report structure. For the official release, we have drawn on this feedback to strengthen research quality, output formatting, and the stability of long-running tasks.
Looking Ahead
We are grateful to the AI community whose open foundation models our work builds on, and to our beta testers for their candid feedback.
Sakana Marlin is an important step in our commercial rollout. It joins Sakana Chat in a growing lineup, with more on the way. Each grows from the same conviction that runs through our research: that the most capable AI comes not from a single model, but from systems that reason over time and work together. We will keep building in this direction, toward AI solutions that reach well beyond chat.
We are looking for people to help shape the future of AI in Japan together with Sakana AI. Please see our careers page.

DFlash and Spec V2 Decoding
Z Lab and SGLang introduced DFlash, a speculative decoding technique that uses block diffusion and KV injection to boost LLM throughput.
Deep dive
- DFlash Innovation: Uses block diffusion to generate draft tokens in parallel, avoiding sequential bottlenecks found in earlier methods like EAGLE.
- KV Injection: Injects target model hidden states into the draft model's KV cache, keeping the draft model conditioned on the target's current context.
- Performance Gain: Outperforms MTP (Multi-Token Prediction) by 1.5x and baseline models by >4.3x on coding benchmarks.
- Spec V2 Engine: The SGLang update minimizes host-device synchronization using an overlap scheduler, improving total system throughput.
- Compatibility: Works across various model sizes by enabling specific attention backends like
fa4andtrtllm_mha.
Decoder
- Speculative Decoding: A technique that uses a small, fast model to generate drafts for the larger, slow model to verify in parallel.
- KV Cache: A cache storing the Key and Value tensors for previously generated tokens, allowing the model to avoid recomputing them.
Original article
The next generation of speculative decoding: DFlash and Spec V2
Using Modal and Z Lab's DFlash speculative decoding models with SGLang’s newly default Spec V2 engine, you can achieve state-of-the-art latencies for LLM inference serving. Our new, jointly-released DFlash model for Qwen 3.5 397B-A17B achieves higher throughput than both the baseline model and native MTP speculation in all the settings we benchmarked. At concurrency 1 on the HumanEval coding dataset, it achieves >4.3x the throughput of baseline and 1.5x the throughput of MTP.
To celebrate this collaboration, we're releasing this model in triplicate across our Hugging Face organizations:
z-lab/Qwen3.5-397B-A17B-DFlashmodal-labs/Qwen3.5-397B-A17B-DFlashlmsys/Qwen3.5-397B-A17B-DFlash
You can try the model yourself with this command:
export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--trust-remote-code \
--speculative-algorithm DFLASH \
--speculative-draft-model-path modal-labs/Qwen3.5-397B-A17B-DFlash \
--speculative-dflash-block-size 8 \
--speculative-draft-attention-backend fa4 \
--attention-backend trtllm_mha \
--linear-attn-prefill-backend triton \
--linear-attn-decode-backend flashinfer \
--mamba-scheduler-strategy extra_buffer \
--tp-size 8 \
--max-running-requests 32 \
--cuda-graph-max-bs-decode 32 \
--cuda-graph-backend-prefill tc_piecewise \
--enable-flashinfer-allreduce-fusion \
--mem-fraction-static 0.8 \
--host 0.0.0.0Below, we describe DFlash’s novel diffusion + KV injection strategy for speculative decoding, why that matters for achieving massive speedups, and how the teams at Z Lab, SGLang, and Modal worked together to make those speedups available to everyone.
DFlash: Parallel drafting with KV injection
Transformer-based large language models (LLMs) are powerful, but their autoregressive decoding process makes inference slow: tokens must be generated one by one, with low arithmetic intensity that makes them a poor fit for modern hardware.
Speculative decoding addresses this bottleneck by using a smaller, faster draft model to propose multiple tokens, which are then verified in parallel by the target LLM, with no impact on model quality.
However, many speculative decoding methods, like the EAGLE series and the native multi-token prediction (MTP) modules in recent models like Gemma 4 and DeepSeek-V4, still rely on sequential autoregression – but in the draft model instead of the target. The draft model generates draft tokens one-by-one, a poor fit for modern hardware and a limit on achievable speedup.
That’s why Z Lab developed DFlash, which uses a lightweight block diffusion draft model to generate an entire block of draft tokens in parallel, just the way GPUs and TPUs like. Xiaomi's new MiMo v2.5-Pro-UltraSpeed uses DFlash to achieve over 1k output tps.
Using block diffusion for speculative drafting is non-trivial. Directly training a small block diffusion model as the drafter leads to low acceptance length, while using an existing large diffusion LLM like SpecDiff-2 as the drafter introduces a large memory footprint and high drafting cost.
The key insight of DFlash is simple: the target LLM knows the context best. Inspired by previous methods like Medusa, EAGLE and MTP, we extract hidden representations of the context tokens from the target model. Unlike previous work, we inject them directly into the draft model’s KV cache. This scales better with increased draft depth. KV injection also allows the draft model to skip modeling the full context from scratch and focus purely on predicting the next block of tokens – using the same tensors as the later layers of the target model!
With this design, DFlash leverages the rich, highly relevant contextual features produced by the target LLM while keeping the draft model extremely small and efficient. As a result, DFlash achieves high acceptance length with low drafting latency.
Why is DFlash so fast?
Speculative decoding speedup mainly depends on two factors: how many drafted tokens are accepted per cycle and how much extra cost the draft model adds. DFlash improves both: diffusion drafting lowers draft cost and KV injection raises acceptance.
Concretely, let's compare end-to-end acceptance lengths and speeds for a 5-layer EAGLE-3 drafter and several 5-layer DFlash variant drafters trained for Qwen 3-4B on the same dataset. Baseline DFlash achieves a similar acceptance length to a 5-layer EAGLE-3 drafter, but thanks to its ultra-fast parallel drafting, it delivers much higher end-to-end speedup. Results are reported as acc_len / speedup.
| Task | EAGLE-3 (5 layers) | DFlash |
|---|---|---|
| GSM8K | 4.2 / 2.1x | 4.2 / 3.3x |
| HumanEval | 4.3 / 2.2x | 4.0 / 3.2x |
| MT-Bench | 3.1 / 1.4x | 3.0 / 2.2x |
DFlash drafts faster
Autoregressive drafters like EAGLE-3 generate draft tokens one by one. As the draft length grows, the drafting cost grows roughly linearly. To keep latency low, these methods usually rely on very shallow draft models, which limits draft quality.
DFlash avoids this bottleneck with a block diffusion drafter. It generates a whole block of tokens in parallel with a single forward pass, making drafting much more hardware-friendly. A 5-layer DFlash drafter generating 4, 8, or even 16 tokens has much lower drafting latency than a single-layer EAGLE-3 drafter producing 4 tokens.
We can observe the independent impact of this technique by ablating other DFlash architectural features. DFlash still provides a higher end-to-end speedup than EAGLE-3, even at lower acceptance lengths, thanks to its faster drafting.
| Task | EAGLE-3 (5 layers) | DFlash (diffusion only) |
|---|---|---|
| GSM8K | 4.2 / 2.1x | 3.5 / 2.9x |
| HumanEval | 4.3 / 2.2x | 3.5 / 2.9x |
| MT-Bench | 3.1 / 1.4x | 2.6 / 2.0x |
KV injection increases acceptance lengths
Fast drafting only helps if the drafted tokens are accepted. EAGLE-3 uses target model features only at the input of the draft model, and this signal fades in deeper draft models.
DFlash instead injects target features into the KV cache of every draft layer. This keeps the drafter strongly conditioned on the target model’s context throughout generation, allowing deeper drafters to produce higher-quality drafts.
We can also observe the independent impact of KV injection by ablating the diffusion drafting. DFlash in autoregressive mode still produces higher speedups in our end-to-end benchmark due to higher acceptance lengths.
| Task | EAGLE-3 (5 layers) | DFlash (injection only) |
|---|---|---|
| GSM8K | 4.2 / 2.1x | 4.8 / 2.4x |
| HumanEval | 4.3 / 2.2x | 4.6 / 2.3x |
| MT-Bench | 3.1 / 1.4x | 3.4 / 1.5x |
Implementing DFlash in SGLang
The benchmark numbers in the above section are from the initial implementation of DFlash as part of R&D by Z Lab. Based on these impressive results, the teams at Modal and SGLang collaborated with Z Lab to optimize end-to-end performance in the SGLang inference engine.
Bringing a performance optimization technique like DFlash from research to prod requires two basic components: implementing the technique inside a high-performance engine and then optimizing the performance of the end-to-end system, from host scheduler to GPU execution.
The DFlash integration into SGLang can be split into two parts along these lines. First, DFlash was added to the original V1 speculative decoding engine. Besides implementing a new draft model architecture, this also required integration of KV caches across draft and target to support injection. Second, DFlash was added to the new V2 speculative decoding engine, which offers improved performance through reduced synchronization with the host.
In the initial implementation of DFlash, we added support for this new model architecture to the existing speculative decoding engine. This included the addition of a DFlashWorker to control the draft model execution and the actual DFlashDraftModel that it drives.
As a reminder, SGLang uses a scheduler process (mostly on the host) to drive execution of model worker processes (mostly on the accelerators). One counterintuitive aspect of the way speculative decoding works in SGLang is that the draft model worker is the one that talks to the scheduler (via methods like .forward_batch_generation). It wraps a target model’s worker for the verification passes and calls it when the drafts are ready.
That’s not new in DFlash. The main novelty is the KV injection, which ties state between the draft and target models. For methods like EAGLE, the draft KV cache is fully private to the draft model, calculated based on KV projection of the draft’s own latents. In DFlash, the latents of the target model are instead passed through a KV projection by the draft model.
We don’t want to store those latents and cut into precious KV cache space and we want all requests that have the same prefix to share the radix cache. So we run the draft KV projection ahead of the rest of the draft forward pass – immediate materialization. That needs to be fast, so we added a layer-batched linear projection and a fused Triton kernel for the norm+RoPE post-processing.
Eliminating host overhead for DFlash with Spec V2 and overlap scheduling
That worked and was fast, but we knew it could be faster. We were concurrently working on the V2 speculative decoding engine, so the next step was to combine DFlash with the V2 engine, which is what’s now available in SGLang.
The key goal of the V2 engine as a whole is to reduce points of host-device synchronization, which kill inference performance, no matter how fast the GPU is or how good the kernels are. The solution is called the overlap scheduler.
In particular, there are two key opportunities for overlap:
- host-side
pop_and_processcleanup after the GPU finishes batch N-1 (e.g. stop token detection, request metadata updates) can overlap with GPU work on batch N; - host KV allocation (in
prepare_for_decode) for batch N can overlap with GPU work on batch N-1.
Under V2 with these optimizations, performance improved by over 33%, from ~11.4 ktok/s to ~15.3 ktok/s, when running Qwen 3-8B on a single B200 at concurrency 32.
High-performance DFlash draft models are available for a variety of models
Today, we're releasing a new DFlash draft model for Qwen 3.5 397B-A17B. It achieves higher throughput than the model's native MTP speculation in all of the settings we tested, from GSM8K to HumanEval to MT-Bench and for request concurrencies from 1 to 32.
You can find more high-quality drafters in Z Lab's DFlash collection on Hugging Face. And keep your eyes peeled for more models soon!
Try DFlash in SGLang now
You don’t have to just read this blog and feel FOMO. You can read the code. You can deploy a DFlash-accelerated SGLang server using the command shown at the start of this post — or spin one up on Modal.
You can also train a DFlash speculator model for your own data or target model. The same block diffusion plus KV injection approach can be applied to most target LLMs. Reach out to Z Lab or Modal if you're interested!
More broadly: you can run inference at optimal intelligence, speed, and cost thanks to the work of the open-weights model builders, systems researchers, and the open source community. Whether it’s research work on techniques like DFlash by the Z Lab or features and performance enhancements from open source contributors like Modal, the world’s best work on LLM inference is landing in the SGLang open source engine for you to build on and with.
Acknowledgements
Thanks to everyone who contributed to bringing Spec V2 and DFlash to SGLang.
Z Lab: Jian Chen, Yesheng Liang, and Zhijian Liu.
Modal: David Wang and Charles Frye.
SGLang: Qiaolin Yu, Liangsheng Yin, and Khoa Pham.

Agentic Code Review
Coding agents have shifted the primary engineering challenge from writing code to effectively reviewing and trusting machine-generated output.
Deep dive
- Code churn has surged 861% due to agentic workflows.
- Defect rates per developer have risen from 9% to 54%.
- Review duration has increased by 441%.
- Zero-review merges are 31% more frequent.
- Raw output has increased 4x, but delivered value has only increased by approximately 12%.
Decoder
- Agentic Code: Code produced by autonomous AI systems rather than human developers.
Original article
Agentic Code Review
Coding agents are extraordinarily good now and getting better fast. The interesting consequence is that the hard part of engineering moved from writing code to deciding whether to trust it, which...

Zen and the Art of Machine Learning Research
Successful AI research depends less on raw genius and more on meticulous temperament, physical movement, and avoiding the trap of outsourcing understanding to AI.
Deep dive
- Insights often emerge from non-keyboard activities like walking.
- Research success is often hindered by ego and clinging to obsolete methods.
- Effective researchers define their own datasets rather than just chasing existing benchmarks.
- Use 'healthy paranoia' to catch bugs in complex deep learning stacks.
- Design ergonomic research workflows to prioritize fast feedback loops.
Decoder
- Policy Gradients: A class of reinforcement learning algorithms that optimize the policy directly.
- Cross-Entropy: A loss function used in classification tasks to measure the performance of a model whose output is a probability value.
- SVD (Singular Value Decomposition): A linear algebra method used for matrix factorization, often used in dimensionality reduction.
- SwiGLU: An activation function used in transformer architectures, notable for its performance improvements over standard ReLU.
Original article
Zen and the Art of AI Research
So you want to do AI research? It’s true that no one really teaches you how. Not directly, anyway. But it turns out that the way to get started is pretty simple: some combination of (i) reading and (ii) building stuff. You can’t do one without the other. You become a researcher through the combination.
It turns out the process of becoming a great researcher is not unlike learning to meditate:
I.
The way to get started is pretty simple, through some combination of (a) reading and learning, and (b) building stuff. You can’t only do one. You’ll become a researcher through this combination.
There’s an old Zen saying that goes something like this –
on days we find insight, we sit.
on days we do not find insight, we sit.
Doing research is basically like this. Scientific insights can come seemingly at random. Most days they will not come. An important trait for success is just putting in the time & effort. Like any other pursuit (music, sports, sales, etc.), if you want to become world-class, it will take a tremendous amount of discipline.
Noam Shazeer makes a nice hat-tip to the inherent randomness of successful research ideas in the SwiGLU paper:
“We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.”
A related comment is that it’s possible to read too many papers. If you want to solve a problem, the tried-and-true path to success is to attempt a solution, try it, reach a bottleneck, try to solve it, and only reach for literature when you’ve run out of ideas yourself.
II.
Fine, but what should I work on?
If you’re just starting out, here’s my honest answer: I don’t think the exact topic matters much.
That said, I would warn you against choosing things that have been popular for less than six months. AI moves fast, but the fundamental ideas haven’t changed in forty years. If you want to make a career out of this, I wouldn’t advise you to think too hard about the concepts of 2026: harnesses, agents, context engineering, etc. These will change.
Instead, you’ll learn more by going back to the basics: learn what cross-entropy is. Compute it by hand for a small distribution. Deeply understand SVD, to the point where you can start to visualize it in your head. Don’t think too much about RL for coding specifically, instead learn the ideas behind policy gradients, why they’re useful, and why they’ve been popular for decades.
One more meta-comment: if the best possible outcome of your research project is a higher score on an existing benchmark, you are not going deep enough. Often, existing datasets won’t test new interesting capabilities.
Jason Wei makes a similar point:
An underrated but occasionally make-or-break skill in AI research (that didn’t really exist ten years ago) is the ability to find a dataset that actually exercises a new method you are working on.
As for a concrete suggestion, I can’t make one; that has to come to you. Go deep, focus on the basics, and don’t chase benchmarks. Stay in the water and the ideas will come.
III.
in the beginner’s mind there are many possibilities; in the expert’s mind there are few
– Suzuki
Something often-repeated in Silicon Valley these days is how experience in AI research might actually be counterproductive to good research intuition in the modern day. I’ve observed parts of this up-close; many researchers from the pre-scaling-era remain interested in designing methods that work at a small scale but will obviously fail when tested at scale.
One really impressive thing about OpenAI is that most of the people running the company (on the technical side, at least) are under 35. Many of the important decisionmakers behind chatGPT are under 30. One thing we can take away from this is that since AI is such a nascent field (chatGPT is less than four years old!) no one has a huge advantage, because no one has been working on it for very long.
In short, holding on to ideas for too long can actually be counterproductive. Stay open-minded and refuse to let ego cloud your judgement.
IV.
Inspiration strikes when you least expect it.
Here are two examples from history:
- The discovery of the structure of the benzene ring famously came in a dream: the structure had never been seen before, but was imagined as a snake biting its own tail.
- Ozempic basically comes from lizards. The GLP-1 hormone it mimics was first found in the venom of the Gila monster, a desert lizard that eats just a few times a year. Somehow we figured out how to make this work for humans too.
One important takeaway is that to do good research, you must do things other than research. Most of my personal “aha moments” happened away from the keyboard, especially when going on walks.
Darwin, Tesla, Feynman, Aristotle. Many great thinkers of history proclaimed the outsized benefits of stretching your legs and going for a little stroll. Even if you don’t do research, you should probably go on more walks.
V.
Even when inspiration strikes, nature may not be benevolent: even with a perfect implementation, our idea might just not be true in some fundamental sense. Or perhaps it was, or seems to be. When the results come in, how should we react?
Another principle we can borrow from Zen is (experimental) equanimity.
When analyzing an experiment, we can channel the following mentality:
Did it go well? Great!
Did it go poorly? Also great!
Both outcomes teach you the same amount of information. In fact, it’s often possible to learn more from a string of negative results than a single positive result. “Wow, it’s still not working – incredible!” Now that’s a healthy attitude for research.
The converse of this is that you shouldn’t get that excited about good results. In fact, most good results come because of a bug; it’s not that the results themselves were good, it’s that you measured incorrectly, and convinced yourself. Everyone wants their ideas to work – and this is a good thing! – but one thing all experienced researchers share is extreme skepticism, especially in the face of outcomes that seem too-good-to-be-true. Unfortunately, they almost always are.
VI.
A flower does not think of competing with the flower beside it. It just blooms.
Research is extremely outcome-driven. Especially in academia, it’s easy to look at others’ successes on paper and turn to emotions.
People succeed for different reasons. Some people get lucky. The academic reviewing process, in particular, is neither consistent nor fair. When new research comes out in your area that you admire, ask yourself the following question:
Am I operating at the proper level of depth to have made this insight myself?
Now there are two possible outcomes. If the answer is yes – great. Your process is sound, but you didn’t make this finding; you were busy, you were doing something else, but you could’ve.
And if the answer is no – then take this as motivation to go deeper.
VII.
before enlightenment, chop wood, carry water. after enlightenment, chop wood, carry water.
Many successful projects typically involve hundreds of hours of gruntwork behind the scenes. Andrej Karpathy labeled a nontrivial portion of ImageNet by hand. The creators of SWEBench, who were ahead of their time in many ways, spent hundreds of hours painstakingly filtering GitHub data to get a small, tractable set of GitHub issues useful for evaluation.
If you look at the career of great researchers, they likely spent lots of time working in obscurity before finding success. Get used to this. The more ambitious and forward-thinking an idea, the more work it may be to thoroughly implement and evaluate. This difficulty is a feature, not a bug.
VIII.
Collin Raffel, an amazing researcher whom I deeply respect, once mentioned that he thinks many ideas fail not because they’re bad ideas, but because the code has a bug that the researcher never found.
In general this is a really difficult problem, especially in the world of LLMs. A modern deep learning software stack is extremely complicated, and bugs can lie anywhere: in training, in inference, in harnesses, in data.
if something looks wrong, you cannot move on. You can and should log many metrics and strive to understand all of them. If some of the metrics look different than you expected, you need to figure out why, because something may be wrong. I’ve tweeted before that one of the most important traits in a researcher is healthy paranoia. Be paranoid!
IX.
One practical point is that most experiments that involve deep learning take too long. Training models can take weeks or months. These days, evaluating a model on a single task can take multiple days.
Especially when coding with agents, our instinct may be to spin up many experiments in parallel and let them all run at a slow cadence. Although simple parallelization helps to some degree, context switching is a harmful pattern.
It is of paramount importance that you design ergonomic research workflows that support fast experimental feedback. Shorten cold-start times for training, make small evals that return results quickly. I really admire Keller Jordan’s nanoGPT speedrun as an example of how much we can learn from fast iteration cycles.
(This said, at the end of the day, some results take an unavoidably long time. When you can, maintaining state over multiple days and understanding last week’s experiments when they finish today is an incredibly useful skill.)
X.
Coding agents help you move faster, but they make two problems worse: we have a harder time understanding basic details, and we context switch more often. A good researcher actively works to fight against both forces.
Codex can write a training script for you; it can even execute the script, babysit it while it’s running, interpret the results, and send them to you in an email. But maybe it ran into an error and shortened the system prompt without asking you. Maybe it shortened sequence lengths to get eval running in a reasonable time. Maybe it ran the wrong config because you didn’t specify.
From an engineering perspective, these are all small errors with an easy fix. But from a scientific one, they’re grave: small omissions like this can materially change important results of papers and are therefore not acceptable. Beware dragons. Even if you didn’t write the code, if you want to understand your results, you need to understand the system that produced them.
I’ll level with you – this is hard! It’s tempting to outsource understanding to the machine. For many applications, it’s faster. But doing good science requires learning how the entire system works, so that you can be sure observations about it are true. There’s no easy way around this.
XI.
TLDR: Talent isn’t all that it takes to become a successful researcher. Temperament is greatly underrated. Stay curious and persistent, remain thoughtful and meticulous, and the ideas will come.

A modest proposal: Reformat everything to make documents more palatable to AI
The LF AI & Data Foundation has launched DocLang, a standardized XML-based format designed to help AI models parse document structure without losing semantic context.
Deep dive
- DocLang uses a limited XML vocabulary mapped 1-to-1 to LLM tokens.
- It maintains structural relationships, tables, and provenance that are often lost in PDF extraction.
- Projects like IBM's Docling are intended to act as the conversion layer for this new standard.
- Reduces token usage by providing structured metadata instead of forcing models to interpret raw visual layouts.
- Targeted at replacing brittle, one-off custom parsers currently used in enterprise pipelines.
Decoder
- OCR: Optical Character Recognition; software that converts images of text into machine-readable characters.
- Tokenizers: Components that break down text into individual units (tokens) for LLM processing; efficient token usage directly correlates to lower inference costs.
Original article
A modest proposal: Reformat everything to make documents more palatable to AI
Websites are being redesigned for consumption by AI models, and now a coalition wants to extend the trend to digital documents.
The LF AI & Data Foundation, under the Linux Foundation, has formed a working group to steer the development of DocLang, an AI-friendly document format that aims to help enterprises feed their files to AI systems.
The DocLang group, founded by IBM, NVIDIA, Red Hat, ABBYY, HumanSignal, and Forgis, contends that existing formats like PDF, Markdown, HTML, and LaTeX are ill-suited for AI document parsing.
In late 2024, IBM developed an open source toolkit called Docling to facilitate AI document parsing, not unlike Microsoft's MarkItDown or the Marker project. Docling provides a way to convert various file formats into structured AI-ready data. DocLang expands upon that foundation with a standard for exchanging structured output across different systems.
"DocLang is designed to solve one of the foundational problems in enterprise AI: documents were built for humans, not machines," said Maxime Vermeir, VP of AI Strategy at AI automation biz ABBYY in a statement. "By introducing a minimal, standardized, and AI-native representation of document structure, layout, meaning and governance, DocLang creates a far more deterministic foundation for modern AI systems."
The new DocLang format is necessary, the spec authors argue, because existing formats were designed for rendering and lose semantic information, structural relationships, or geometric context when AI models turn them into tokens. The specification explains that Markdown lacks sufficient scope, that HTML is excessively verbose, and that LaTeX allows too much ambiguity.
Essentially, DocLang is optimized for LLM tokenizers through markup that maps between DocLang elements and LLM tokens on a 1-to-1 basis. The spec relies on a limited XML vocabulary that aligns with LLM tokenizers to produce optimized prompts. It is lossless, so the AI conversion doesn't do away with valuable info. It's designed to support common graphical elements like tables, formulas, charts, and multimodal content. And it's an open standard.
DocLang could also help keep costs under control. According to AI Cost Check, having an AI model conduct an OCR scan on a PDF requires about 1,200 input tokens and 150 output tokens as a baseline.
That's inconsequential to corporate AI customers on a one-off basis but demands attention at scale. And because AI models have highly variable token costs, companies may find they are spending more than they anticipated to have their AI system ingest PDFs, particularly if the documents are long and complicated or an expensive frontier model is used.
"PDFs were designed for rendering, not understanding," said Jon Knisley, AI Value and Enablement Lead at ABBYY, in an email to The Register. "Every time a PDF enters an AI pipeline, structure, meaning and layout get lost, so the model's accuracy ends up bottlenecked by document quality rather than model quality. Teams compensate by building custom parsers at every integration point, which results in brittle, one-off work, and a new engineering sprint for every new document type."
According to Knisley, that has measurable cost.
"Ambiguous structure forces the model into guesswork, which drives up hallucination risk and burns tokens deciphering layout instead of extracting meaning," he explained. "With DocLang, customers can expect better accuracy, lower costs, fewer tokens consumed, faster performance and more consistent outputs. The exact savings depend on the use case and document complexity, but our initial benchmarks show 4x to more than 30x lower cost depending on the model evaluated."
Knisley also cited governance advantages, noting that document provenance data and metadata can get stripped when documents gets moved. DocLang, he said, keeps that information attached.
ABBYY, which offers AI document processing, has created the DocLang Interactive Benchmark to illustrate the potential token savings of feeding DocLang documents to AI models. A PDF of IBM's 2025 annual report, for example, results 8,421 input tokens and 512 output tokens while a DocLang version requires only 5,310 input tokens and 498 output tokens. What's more, the DocLang version results in lower latency (2.7s vs 4.2s) and delivers better quality (the AI missed one subsection and mangled a table merger in the PDF).
"It's still early, and we won't overstate adoption," said Knisley. "The standard is open and free to build on, and the group is actively inviting more technology providers and enterprises to join. The early response has been encouraging, and we're optimistic about where it goes from here."

AI GPUs probably live longer than three years
Claims that AI GPUs have a three-year maximum lifespan are likely industry fear-mongering rather than engineering reality.
Deep dive
- The 'three-year lifespan' claim stems from an anonymous quote shared on social media via Tegus, a platform where experts are paid for insights, incentivizing confident but potentially speculative estimates.
- Public evidence from AWS and Google suggests A100 GPUs and TPUs remain in production long after their initial deployment.
- Survival analysis of GPUs in older supercomputers like the Cray Titan shows high survival rates (above 90%) even at the six-year mark for properly cooled units.
- Modern AI inference is limited more by power efficiency than physical hardware failure, meaning GPUs will likely be phased out for economic reasons rather than hardware degradation.
- AI infrastructure cost is not solely GPU-dependent; land, power, and cooling represent 30-50% of capital expenditure, which remains useful even as compute modules are upgraded.
- The 'AI winter' scenario likely involves continued use of older 'obsolete' GPUs (like H100s or A100s) rather than a mass decommissioning of data centers.
Decoder
- Tegus: A market intelligence platform that connects investors and researchers with industry insiders for paid expert calls.
- Inference: The process of running a trained machine learning model to make predictions or generate content, distinct from the initial 'training' phase.
- TPU (Tensor Processing Unit): Google’s custom-designed application-specific integrated circuit (ASIC) used to accelerate machine learning workloads.
- Survival analysis: A branch of statistics for analyzing the expected duration of time until one or more events happen, such as component failure in hardware.
Original article
People who think current AI use is unsustainable often rely on the claim that inference GPUs only last “three years at the most” under load. The idea here is that once the AI bubble money drains away, current infrastructure will rapidly become obsolete, and there won’t be enough money floating around to buy a whole slate of brand-new GPUs. Inference costs would thus rapidly become way too expensive for current AI products to make any financial sense.
Where does this “three years at the most” claim come from? Is it plausible?
Sourcing the quote
The original Tom’s Hardware article quotes this tweet from Tech Fund, an anonymous former PM and tech investor, who quotes an anonymous “GenAI principal architect” at Google as saying “if you have a high utilization rate, then constant high utilization rate for a year or two, I think the lifespan will be three years at most”.
This screenshot looks like it was from an interview. What interview? I scrolled back to October 2024 on Tech Fund’s Twitter feed and saw a bunch of similarly-formatted screenshots, some of which were cited as coming from Tegus. Tegus is apparently a company with a business model of reaching out to insiders (in this case, AI company employees) and paying them hundreds of dollars an hour in order to answer specific technical questions. It’s essentially gig work for almost-but-not-quite insider trading: the more informed and confident you sound, the more likely Tegus analysts will pick you for future interviews.
I’m sure the source for this tweet is in fact a GenAI principal architect, since Tegus would have presumably asked for some proof of that before they paid them out. But it’s pretty clear that the incentives here are to sound confident and authoritative, even on questions that you’re not sure about. With that in mind, the quote itself also reads a bit suspiciously. I’ve worked with enough principal engineers and architects to take their casual back-of-envelope estimates with a grain of salt. If they knew the actual rate at which GPUs fail and get retired in Google datacenters, wouldn’t they have just said that?
Evidence for a longer lifespan
We have some anecdotal evidence that points the other way. Google has publicly claimed to have eight year old TPUs (their version of GPUs) running in production at “100% utilization”. Nvidia only made A100 GPUs from 2020-2024, but in February 2026 the AWS CEO claimed that AWS had never retired an A100 server (and you can still easily rent A100s for AI work). AI GPU usage isn’t exactly like crypto mining GPU usage, but it certainly seems like years-old ex-crypto GPUs are functional. There’s also this comment from Hacker News I noticed where someone claims that their GPU cluster in academia has lasted six years with less than 20% failure rate.
What about hard data? It’s hard to get concrete data on the lifespan of AI GPUs, because modern AI datacenters have only existed for a handful of years. But an interesting case study would be recent supercomputer clusters like Oak Ridge’s Summit, which had over 27 thousand Nvidia V100s running from 2018 to 2024, or its predecessor, the Cray Titan supercomputer that ran from 2012 to 2019. I couldn’t find any evidence that Summit had to buy an additional 27,000 GPUs to replace their old ones, and GPU failures in Titan have been carefully studied:
These cages of GPUs are stacked vertically, and cold air is pumped in from the bottom, which explains why cage 0 (at the bottom) has better survival rates than cage 2 (at the top). Let’s consider cage 0, so we’re just looking at the GPU lifespan instead of at the lifespan of improperly-cooled GPUs. At three years, over 95% of GPUs survived. At six years, nodes 2 and 3 (the GPUs closest to the bottom of the cage) were still at above 90% survival rate, and the highest nodes were over 60%.
It’s possible that newer Nvidia GPUs are less reliable than older ones (they certainly draw more power), or that AI datacenters are under-cooled, or that something about LLM utilization is more stressful than the workloads that ran on traditional GPU datacenters. But this is at least circumstantial evidence that GPUs can survive under load for far longer than three years.
Economic lifespans
This discussion is complicated by the fact that GPUs may have a short economic lifespan. Supposedly a B100 GPU draws twice as much power as an A100, but can do five times as much work. For some AI providers, that might mean that A100s are only worth running until they can be replaced with B100s (if you’re bottlenecked on electricity, you should spend it all on B100s and throw out your obsolete A100s). This is why the Titan supercomputer was decommissioned in favor of Summit: it could have continued to operate, but it was more profitable to spend the money and maintenance effort on newer hardware.
It should be obvious that this doesn’t support the “inference will become more expensive when the bubble pops” argument. So long as A100s are profitable right now, cash-poor AI providers can continue profitably serving inference from them, even if there are more efficient options available for those with the capital to upgrade.
On top of that, GPUs only represent one part of AI datacenter infrastructure spending. If your GPUs wear out, you don’t have to go and build an entirely new datacenter. About 30-50% of datacenter spend goes to land, power, cooling, and so on. The remaining 50-70% is the cost of the entire server rack, which includes a bunch of things that aren’t GPUs.
Conclusion
Like the idea that AI inference requires using huge amounts of water, the idea that AI GPUs only live a year or two is popular because it’s a useful idea for AI skeptics, not because it’s true. It comes from a pseudonymous tweet quoting an anonymous source who’s being paid hundreds of dollars to sound like a credible expert on AI. Other public communications from AI inference providers cite much higher lifespan numbers, and the statistics from supercomputers (the traditional examples of large GPU clusters) don’t bear out the claim that the maximum lifespan is three years.
It might be true that the economic lifespan is three years, in a world where new GPUs come out every eighteen months and GPU providers are flush with cash to upgrade, but that doesn’t tell us much about the economics of inference in an AI winter. If money becomes a lot more scarce, it’s likely that AI datacenters will continue profitably running their B300s (or their H100s or even A100s) for six years or longer.

SpaceX & the Sentient Sun
SpaceX is transitioning from a launch provider to an AI infrastructure titan, leveraging orbital compute and vertical integration to chase a multiplanetary civilization.
Deep dive
- SpaceX is targeting an annualized rate of 100 gigawatts of space-based compute in 3.5 years.
- The company uses an 'idiot index' to ruthlessly optimize costs by comparing part prices to raw material costs.
- Starship reusability aims to drive launch costs down to $100-$500 per kilogram.
- SpaceX has absorbed xAI's Colossus cluster technology, which recently demonstrated the ability to stand up 100,000 GPUs in 122 days.
- Future plans involve lunar-based manufacturing to build solar-powered orbital data centers.
- Major customers like Anthropic and Google are leasing significant compute capacity from SpaceX's infrastructure.
Decoder
- Mass driver: An electromagnetic launch system that uses acceleration to fling payloads off the Moon's surface into orbit, bypassing the need for traditional chemical rockets.
- Sun-synchronous orbit: A near-polar orbit that ensures a satellite passes over any given point on the planet's surface at the same local solar time, providing constant access to sunlight for energy.
Original article
Full article content is not available for inline reading.
Brain-computer interface enables independent, accurate communication for man living with ALS
A UC Davis brain-computer interface has restored independent digital communication for an individual with severe ALS by decoding neural signals into text.
Original article
A brain-computer interface developed at UC Davis has enabled a person with severe paralysis caused by amyotrophic lateral sclerosis (ALS) to communicate, work, and interact with the digital world. The device uses an advanced decoding algorithm to translate neural signals into text and enable cursor control. It allows full interaction with a personal computer. The development marks a significant step toward delivering practical assistive technology for people with severe speech and motor impairments.
The golden rule of Customizable Select
WebKit's 'customizable select' feature arrives in Safari 27, enabling native styling without JavaScript libraries, provided developers respect accessibility text fallbacks.
Original article
The golden rule of Customizable Select
Customizable select is coming to Safari 27. With this technology, developers can fully control the appearance of <select> elements — custom arrows, option layouts, color swatches, icons, full visual styling — without the need for JavaScript libraries or an endless parade of <div> elements. And because it’s a built-in control, you don’t have to compromise on keyboard navigation or accessibility semantics.
But, to ensure this built-in control works well for everyone, it’s important to follow this single but essential rule: always provide text content or accessible text attributes for your option elements.
Every time that rule is broken, every time an option is styled to show a visual without any text and without any accessible fallbacks, three different problems get introduced all at once. The menu is harder to use for everyone, impossible to use with accessibility tools, and it becomes a completely broken experience in browsers that don’t support it yet.
When you remember to follow the rule, you’ll improve the user experience, support accessibility, and provide progressive enhancement so it works for people regardless of what browser they choose.
We’ll show you why following this mission critical rule gets you:
Better UX
Take this category filter from a photographer’s gallery site. The version below uses icons alone — a building, a flower, a hummingbird — to represent each category:
It looks clean. But a user who doesn’t immediately recognize what the hummingbird icon represents has no fallback. The closed select shows only an icon in the button, with no other hint of what’s currently selected. Add a text label to each option and the experience becomes immediately scannable. The selected state is readable at a glance, and every option is unambiguous:
The icons are still there. The labels make it readily decipherable for everyone.
Better accessibility
When a screen reader encounters an option with no text, the user may not hear a descriptive label for each option. Braille rendering and other assistive technology output may also be confusing. Text, even when hidden visually with a .visually-hidden class, stays in the accessibility tree and gives screen readers, braille displays, and speech recognition software something real to work with. If you use an icon as an <img>, add an alt or aria-label — or mark it decorative using alt="" and let the visible or visually-hidden label carry the meaning.
<option>
<img src="bird.svg" alt="">
<span>Wildlife</span>
</option>The problem you solve isn’t just a compliance checkbox: it’s the difference between a visitor completing your form and someone abandoning it.
Better progressive enhancement
Customizable select is a new feature. Browsers that don’t yet support it fall back to the platform-native <select> — which is exactly the right behavior, as long as your options still make sense in that fallback state.
If you’ve removed text in favor of icons or swatches, a user on an older browser sees a dropdown full of empty options. The same is true when CSS fails to load at all: a slow connection, a corporate proxy stripping stylesheets, a user with custom styles enabled. Wrap your enhancements in @supports (appearance: base-select) and keep plain text as your baseline. Adding a swatch is an enhancement. Removing the color name to make room for it is a regression.
The rule for maximizing the power and utility of customizable select is simple: keep the text. You can hide it visually. You can make it tiny. You can position it off-screen. But it needs to be there. Icons, swatches, and illustrations are additions to an option — never substitutes for it. Follow that rule and the rest of customizable select is yours to play with.
Google Chrome's next update will mark the end of popular ad blockers
Google Chrome version 151 will officially remove Manifest V2 support, breaking most legacy ad blockers.
Decoder
- Manifest V3: A platform for Chrome extensions that restricts how they interact with browser network requests and code execution compared to the older V2.
Original article
Google Chrome has been planning its move to Manifest V3 for years. A recent commit in the Chromium repository finally removes support for Manifest V2 extensions. This will stop many Manifest V2-based ad blocker extensions from working. All traces of Manifest V2 will be removed in Chrome 151.

Running local models is good now
Recent advancements in local models like Gemma 4 make it viable to run agentic coding workflows entirely on consumer hardware.
Deep dive
- Hardware: The author runs models on an M2 Mac with 64GB of RAM.
- Tools: Uses LM Studio as an inference server and Pi as an agentic harness inside a restricted Docker container.
- Security: Running agents in containers prevents unintended file system modifications or data exfiltration.
- Workflow: Agents are used to refactor Python notebooks, proofread content, and write test suites.
Decoder
- Agentic flow: An AI workflow where a model iterates, executes tools, and makes decisions to complete a multi-step task.
- Inference engine: Software that takes a pre-trained model and runs it to generate responses (e.g., Ollama, LM Studio).
- Quantization: A technique used to reduce model file size and memory requirements by lowering the precision of numerical weights.
Original article
Running local models is good now
I’ve been working with local models since they came out, and finally, they’re surprisingly good now.
I have a 2022 M2 Mac with 64 GB RAM and 1TB storage and I’ve used
- Mistral 7B
- Gemma 3
- OpenAI OSS-20B
- Qwen 3 MOE, as well as a number of other Qwen variants like Qwen 2.5 Coder
across a lot of different system setups like
- raw llama.cpp with Open WebUI
- llama-cpp-python
- Ollama
- llamafiles and
- LM Studio
Where are local models now?
Early on, models were slow, hard to use, and just not that accurate for most programming tasks. The idea that local models were severely lagging behind was largely true until, for me, the release of GPT-OSS. I have no concrete scientific evidence of this - my own personal vibe metric of “is a model good enough” is, “do I have to double-check it against an API model”, and GPT-OSS was the first one where I started doing that a lot less often.
As a result, I’ve mostly been using local models as fast, personalized Google for development questions that don’t require recency.
But with the most recent releases from Google in the Gemma 4, family, I’ve finally been able to do agentic coding locally and have loops work at about ~75% the accuracy/speed of frontier models, which is incredible.
I’ve so far been using gemma-4-26b-a4b LM Studio implementation as my default local model. I’ve used the local setup so far to: Refactor a Python script that was a notebook into a repo of 5-6 modules, lint that module to use correct type hints for generics (most frontier models now do this automatically, but not always).
I’ve also used it to proofread some blog posts, write unit tests, and to bootstrap a repo that stands up a two-tower model for recommendations just to see what the agent would do with a blank slate. Here’s what it generated, which was pretty basic but still beyond the scope of anything I would have thought possible last year:
Note that the environment is restricted because I run all my agentic workflows in a Docker container with limited access to execution.
I’m also building an app that surfaces trending topics from Arxiv papers. Out of curiosity, I had Pi go through my past LM Studio session logs and figure out what I was using LM Studio for:
Unsurprisingly, since I’ve been working on Rijksearch,
None of these are groundbreaking tasks (again, a lot of personalized Google/docs lookups), and working on them does give my GPUs and RAM a workout and the K-V cache grows to 64 GB RAM.
But, the larger story for me is that these kinds of tasks, even as simple as they are, used to be impossible for local models as recently as 6 months ago.
Gemma-4-12b-qat just came out but I’ve already also really been impressed with its performance relative to its size. The model architecture itself is really interesting and proposes a bunch of interesting questions like, “if we are constrained by performance and price, what architectural tradeoffs do we need to make?” a question that so far has not really been asked in the mad token gold rush.
Running agentic models locally today
But don’t take my word for any of this, try it out for yourself! You’ll need a local model inference engine, an agentic harness, and the local model artifact if you want to try to run local agentic flows. You’ll need to set up the harness to point at your local inference endpoint, the downloaded model artifact served via the inference engine.
For my local setup, I’m currently using Pi as the agent harness and LM Studio as the inference server, although it would likely be faster if I just used llama.cpp directly - a potential direction for a future experiment.
This post was very easy to follow to set up agentic coding with Pi and LM Studio, although I did make a few tweaks to the post’s setup.
- Model: The post recommends
Gemma 26B A4B, butgemma-4-12b-qatis more recent and smaller and faster, without much sacrifice in accuracy. - Security: I run every Pi session in a Docker container and give it permissions only to bash so that it can’t run Python code or do web browsing, although I do plan to allow curl in a different image for some research work I’m doing.
- Agent Harness Config: Since I run everything in Docker, I edited Pi’s
models.jsonin order to get Pi to talk to the model.
"lmstudio": {
"baseUrl": "http://host.docker.internal:1234/v1",
"api": "openai-completions",
"apiKey": "not-needed",
"models": [
{
"id": "google/gemma-4-12b-qat",
"input": [
"text",
"image"
]
}
]
}Here’s my Docker Compose config:
services:
pi:
build:
context: .
dockerfile: Dockerfile
image: pi-agent:0.74.0
init: true
stdin_open: true
tty: true
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
ANTHROPIC_API_KEY: ${ANTHROPIC_API_KEY:-}
OPENAI_API_KEY: ${OPENAI_API_KEY:-not-needed}
GEMINI_API_KEY: ${GEMINI_API_KEY:-}
OPENAI_API_BASE: ${OPENAI_API_BASE:-http://host.docker.internal:1234/v1} # note that you'll need to specify a base if you also use OpenAI to access OpenAI's actual completions endpoint
WHATEVER_API_KEY: ${WHATEVER_API_KEY:-}
volumes:
- ${HOME}/.pi/agent/models.json:/config/models.json
- ${WORKSPACE:-.}:/workspace
- pi-config:/config
- pi-sessions:/sessions
working_dir: /workspace
volumes:
pi-config:
pi-sessions:and here’s the bash script that runs pi .
#!/usr/bin/env bash
# Pi — Start the containerized Pi agent.
# Directory containing this script and the compose files.
SCRIPT_DIR="$(cd -- "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
# Workspace to mount into the container.
WORKSPACE_DIR="${WORKSPACE:-$(pwd)}"
case "$WORKSPACE_DIR" in
/*) ;;
*) WORKSPACE_DIR="$(cd -- "$WORKSPACE_DIR" && pwd)" ;;
esac
export WORKSPACE="$WORKSPACE_DIR"
sandbox="${PI_SANDBOX:-0}"
pi_args=()
while (($#)); do
case "$1" in
--sandbox) sandbox=1 ;;
--no-sandbox) sandbox=0 ;;
*) pi_args+=("$1") ;;
esac
shift
done
compose_files=( -f "$SCRIPT_DIR/docker-compose.yml" )
if [[ "$sandbox" == "1" ]]; then
# an even more secure sandbox
compose_files+=( -f "$SCRIPT_DIR/docker-compose.sandbox.yml" )
fi
# Derive a container name from the workspace directory's basename.
# Sanitize to characters Docker accepts: [a-zA-Z0-9][a-zA-Z0-9_.-]*
repo_slug="$(basename -- "$WORKSPACE_DIR" | tr -c 'a-zA-Z0-9_.-' '-' | sed 's/^-*//')"
[[ -z "$repo_slug" ]] && repo_slug="workspace"
container_name="pi-${repo_slug}-$$"
api_key_args=(
-e OPENAI_API_KEY
-e DEEPSEEK_API_KEY
-e ANTHROPIC_API_KEY
-e GEMINI_API_KEY
)
cmd=(
docker compose
--project-directory "$SCRIPT_DIR"
"${compose_files[@]}"
run --rm
--name "$container_name"
"${api_key_args[@]}"
pi
)
if ((${#pi_args[@]})); then
cmd+=("${pi_args[@]}")
fi
exec "${cmd[@]}"I build the Docker container and make changes to the files in its own repo. Then, I run Pi in the repo I’m working in, which spins up Docker so that Pi can’t wipe files or directories by acting on my physical hard drive. This also enables Pi running in the container to see my custom model json config by shipping it into the container. All of this has been working fairly well for my experiments.
There are still issues with local models: inference can be slow, context windows are small and limited to your own hardware, and the ecosystem, although it’s made a ton easier by tooling like LM Studio and HuggingFace’s Use This Model button. Early releases suffer from prompt template mismatches. But, these are usually patched extremely quickly. Needless to say, I’m not sure this is ready for production software development quite yet.
The benefits, though, are numerous and the ecosystem critical to invest in, particularly now. One of the very cool parts of local models is you can introspect almost everything, like watching the token inference process live,
and watching tokens in/out.
You can do things like change the local context window and watch performance improve or degrade, and really dig into how your tokens are processed on the GPU. You can change the system prompt, the quantizations. You can pit models against each other. You can also change and introspect the harness side.
The possibilities are endless, and the tools only keep getting better.
Apple Foundation Models
Anthropic released a Swift package enabling developers to integrate Claude directly into Apple applications using the Foundation Models framework.
Deep dive
- The library provides a native Swift interface for Anthropic’s Claude API.
- It is designed specifically to interface with Apple's Foundation Models framework, which standardizes how AI services are invoked across Apple's hardware stack.
- This abstraction layer allows developers to manage model interactions using idiomatic Swift patterns rather than manual REST API calls.
- The implementation is intended to lower the barrier for integrating LLM-based features into production-grade consumer applications.
Decoder
- Foundation Models framework: An Apple-provided API designed to provide a unified way for developers to interact with various large language models within the Apple ecosystem.
- Boilerplate: Standard, repetitive code required by many languages or frameworks to perform simple tasks.
Original article
The Claude for Foundation Models Swift package allows developers to use Claude on Apple platforms through the Foundation Models framework.

Unexpected Lessons from an AI-assisted Prototyping Experiment
Prototyping directly in production code using AI-assisted tools enabled an Adobe team to ship two features in just eight business days.
Deep dive
- Prototyping in production shifts design work to the moment of implementation.
- The workflow replaces static mockups with a tight feedback loop between design and engineering.
- Vibe coding allows for earlier detection of accessibility issues, state management, and motion constraints.
- Design fundamentals like empathy and craft are still required, just exercised during implementation.
- Proximity deepens cross-functional collaboration rather than making it optional.
Decoder
- Vibe coding: A term referring to using AI-assisted coding tools (like Cursor or GitHub Copilot) to rapidly prototype and build functioning software by describing intent rather than writing boilerplate code.
Original article
Unexpected lessons from an AI-assisted prototyping experiment
How collaboration changes when designers build under real product constraints
For most of my career, building a product has followed a familiar rhythm: Research, define, explore, spec, hand off. Many of us learned this process in design school, and for a long time, it worked well.
Over time, I've noticed friction as ideas are translated from specs, static mocks, prototype decks, and reviews. Each step introduces the possibility of drifting from the original design intent and often forces teams into tradeoffs between speed, quality, and learning.
A single workflow can sometimes require hundreds of frames carefully stitched together to approximate an “experience.” It's a sequenced process built around artifacts that signal progress, but it isn’t optimized for the rapid feedback that current product development demands.
So, when we had the opportunity to run a small experiment pod inside the Adobe Firefly team, the question we wanted to answer was simple: What would it look like to use AI-assisted prototyping to design inside a product codebase?
A closer, shared loop
Our pod was small and deliberately cross-functional—a product manager, three engineers, and me. We already knew AI-assisted prototyping (also “vibe coding”) could support early exploration; plenty of teams were using it for that. What we wanted to understand was whether a tighter, shared loop between design, engineering, and product could hold up under real product constraints and real pressure.
Instead of treating implementation as a later step, we treated it as part of the design process from the start. We began with brief product requirements to align direction, then moved quickly into a design-build-feedback cycle. Using the Firefly codebase, I used AI-assisted coding tools to stand up slices of the experience one at a time. After the engineering review, changes were merged into the main branch and shared for feedback while the work was still forming. In just eight business days, we built two features into a production build.
Speed is the obvious headline, but what surprised me more was what proximity made possible.
What proximity unlocked
When the distance between idea and implementation shrinks, things shift: Design decisions can inform the product while it’s still taking shape. Constraints can be addressed as they surface, rather than weeks later during reviews. And engineering partners can react to real implementations rather than inferred behavior.
Feedback came sooner, and was grounded in something teams could actually use.
Working this way also changed how I spent my time. In the past, a single feature might require dozens of screens, detailed annotations, and carefully linked flows in Figma. Suddenly, I was using Figma more selectively for jamming with the design team, co-sketching ideas, and evaluating frames while design decisions were still flexible. Once we'd agreed on a direction, I'd spend twenty minutes to an hour sketching a handful of key screens—just enough to describe the intent of an interaction without trying to predict every edge case up front. The rest of my time went into building the experience directly, using AI coding tools to translate design ideas into functioning UI.
That shift had effects I didn't anticipate. Designing within the actual app revealed nuance (timing, motion, feedback, state) that static mockups rarely capture. Decisions, informed by how the product actually behaved, could be made in the moment. Iteration became incremental rather than comprehensive: For a markup feature, I started with a single brush, then text markup, then image markup, testing each piece before combining them. Edge cases surfaced earlier. System interactions became clearer. Even accessibility became easier to address because contrast, focus states, and interactions could be tested as part of the experience itself, rather than handled through documentation after the fact.
Here's what I want to be honest about: None of this worked because of the tools.
Collaboration doesn’t disappear; it intensifies
One of the most persistent misconceptions about vibe coding is that it makes collaboration less necessary. In practice, the opposite is true. Working closer to the build process didn't reduce my reliance on engineering and product; it deepened it.
Engineering's involvement wasn't peripheral. It ensured stability in production, raised experience quality, pressure-tested interaction ideas, built the right infrastructure, and set up the guardrails that made rapid iteration possible in the first place. Product played an equally critical role in naming the right problems to tackle, aligning the right partners, and orchestrating priorities across teams.
And because work was tangible earlier, the whole shape of collaboration changed from handoffs to overlap. In-progress builds and live walkthroughs enabled us to surface questions, test assumptions, and resolve constraints with partners across research, legal, QE, and brand while decisions were still flexible.
The work moved faster because the team moved together.
The fundamentals hold
Our experiment didn't produce a finished system or a polished playbook. What it produced was a snapshot, a glimpse of what becomes possible when design, engineering, and product share tighter feedback loops and earlier access to the same “real thing.”
We're still figuring out how this process will hold up over time. It raised questions worth sitting with: pace, vibe coding can pull you forward relentlessly, and it takes discipline to surface for air; altitude, how designers maintain a wide-angle view when so much attention is pulled into the granular work of making; and design, which problems might a more traditional process still serve us better.
What became clear is that the fundamentals of design don't change with vibe coding. Empathy, judgment, taste, and craft don't disappear when you're building instead of specifying. If anything, they become more essential because you're exercising them in the moments when decisions actually land. Vibe coding, when used inside real constraints, doesn't bypass rigor; it moves it closer to the moment where ideas turn into actual experiences. And that works best when no one is working alone.

AI-powered Smart Canvases (Website)
Slashspace is an AI-native canvas platform designed to consolidate complex workflows locally by connecting tools and multiple LLMs in a single workspace.
Deep dive
- The platform uses local storage to ensure data privacy during AI interaction.
- It supports connecting over 1,000 tools including Slack, email, and calendars.
- Integrates with Model Context Protocol (MCP) servers for interoperability.
- Features a spatial canvas to replace fragmented chat history.
- Includes specific integrations for Cursor API for development workflows.
- Offers multi-step agentic research capabilities across various document sources.
Decoder
- Model Context Protocol (MCP): An open standard that enables AI assistants to securely connect to data sources, local systems, and developer tools.
- Context Collapse: The degradation of productivity caused by switching between disparate applications, resulting in the loss of thread, history, and state.
Original article
Full article content is not available for inline reading.
Falling in Love with the Build
Designer-developers often fall into the 'build-first' trap, creating polished UI flourishes and then retroactively forcing a justification for them to avoid deleting the work.
Original article
You will fall in love with the wrong thing
There is a failure mode that only exists if you both design and build. It is the most enjoyable mistake in the job, which is exactly why it is dangerous.
You build something lovely. A transition that springs just right. A loading state that feels alive. Then, quietly, you start working backwards. You go looking for the reason to ship it. Not because the reason came first, but because the alternative is deleting work you enjoyed making.
This is where you often end up in the trap. You fall in love with an implementation, then reverse-engineer a justification for it.
A designer who only designs is protected from this by handoff. They pass the direction to an engineer, and that handoff is a checkpoint. Someone else has to be convinced before the thing gets built. The friction is the safeguard, even when it does not feel like one.
When you do both, there is no handoff. No translation step. No moment where another person asks why you are doing this. You go straight from idea to working code, alone and fast. The thing that makes you valuable is the same thing that removes the checkpoint.
So you build first and reason later. And reasoning after the fact is not reasoning. It is defence.
The tell
You can catch yourself doing it. The clearest tell is the order of events. If you are explaining why a thing is good after it already exists, you have done it backwards. The justification turned up to protect the work, not to test it.
The other tell is how it feels. A decision made for the right reason feels neutral. You would be equally happy to cut it. A decision you are defending feels personal. You notice you want to win the argument. That want is the sunk cost talking, and it is worth learning to recognise the sensation, because it is the only early warning you get.
I’ve built multiple animations for the Search Assist answer module I work on that I’ve been quietly proud of. Spring-driven, velocity-aware, the kind of small physical details almost nobody notices and I care about anyway. They were all equally genuinely nice.
They also solved nothing. The numbers didn’t move. People didn’t behave any differently with it than without it. I had built it because I wanted to build it, then spent longer than I will admit hunting for the metric that would let me keep it.
There was no metric so I deleted most of them. It still stings a bit, which is roughly how I know it was the right call.
The fix
Write-first design breaks the loop, and it breaks it at the only point where breaking it is cheap.
If you commit to the reasoning in prose before you commit to it in code, the code ends up serving the decision. You build the thing the argument asked for. Do it the other way round and the argument ends up serving the code, and an argument that exists to protect something already built is not worth much.
The rule is simple. The reason comes before the thing. If you cannot write down why an interaction should exist before you build it, build something else. And if you have already built it and the reason still will not come, the kindest thing you can do is delete it.
The work you enjoy making is not always the same as the work worth shipping. Sometimes they are the same thing, and those are good days. The discipline is being able to tell when they are not.
The only way to tell is to have written the reason down before you fell in love. After that, you are not judging the work any more. You are defending it.

How PayPal Increased Conversions with Three Trust-Building UX Elements
PayPal maintains its checkout dominance by utilizing security indicators, familiar UI patterns, and brand recognition to systematically lower user anxiety at the moment of purchase.
Deep dive
- Security indicators (encryption, buyer protection) reduce perceived risk.
- Familiar UI patterns (predictable flows) minimize cognitive load during payment.
- Brand recognition serves as 'borrowed trust' for users interacting with smaller, unfamiliar merchants.
- Conversion optimization should prioritize user confidence alongside technical speed.
- Security messaging must be calm and plain to avoid inducing accidental anxiety.
Decoder
- Micro UX: The tiny, often invisible details and feedback loops in a UI that guide the user through a specific task.
- Cognitive Load: The amount of mental effort being used in the working memory; high load in checkout leads to abandonment.
Original article
Paypal UX shows how trust can turn hesitation into action, especially when money, personal details, and payment decisions are involved.
In online payments, trust is not optional. It is the foundation of the entire experience. A customer can love a product, understand the offer, and feel ready to buy, but if the payment experience feels confusing or unsafe, they may stop at the final step.
That moment is critical.
Checkout is where interest becomes revenue. It is also where doubt becomes abandonment. A small concern about security, a confusing screen, or an unfamiliar payment flow can be enough to make someone pause, leave, or choose another option.
PayPal has become one of the most recognized names in online payments because it solves a basic but powerful problem: it helps people feel safer when paying online.
The product is not just a payment tool. It is a trust layer. For millions of users, seeing PayPal at checkout reduces uncertainty. It signals familiarity, security, and convenience at the exact moment when buyers need confidence.
This is why PayPal’s user experience is worth studying. It shows how trust-building UX can improve conversions by reducing fear, simplifying decisions, and making payment feel familiar.
For brands, ecommerce teams, and SaaS companies, the lesson is clear. A smoother checkout is not only about fewer steps. It is also about helping users feel confident enough to complete the action.
Why Trust Matters So Much in Payment UX
Every payment experience carries some level of risk in the user’s mind.
Customers may wonder if their card details are safe. They may worry about being charged incorrectly. They may be unsure whether they can get help if something goes wrong. They may not fully trust the website they are buying from, especially if it is their first visit.
These concerns are normal.
Research from Baymard Institute has shown that ecommerce cart abandonment remains a major issue, with the average documented cart abandonment rate sitting above 70%. Baymard’s research also highlights that trust, checkout friction, extra costs, account creation, and payment concerns are common reasons people leave before completing a purchase.
That means checkout design is not just a usability problem. It is a confidence problem.
A buyer does not only ask, “Can I complete this payment?”
They also ask, “Do I feel safe doing this here?”
This is where PayPal has an advantage. Because users already recognize the brand, the PayPal option can reduce the mental work required to trust an unfamiliar store. Instead of entering card details directly into a website they may not know, users can choose a payment method they already understand.
That simple shift can make the experience feel safer.
The 3 Trust-Building UX Elements PayPal Uses
PayPal’s conversion strength does not come from one design decision. It comes from several trust-building elements working together.
The three most important are security indicators, familiar UI patterns, and brand recognition.
Each one reduces a different kind of hesitation.
Security indicators reduce fear.
Familiar UI patterns reduce confusion.
Brand recognition reduces uncertainty.
When these three elements appear together, the payment experience feels safer, easier, and more reliable.
1. Security Indicators
Security is one of the most important parts of payment UX because users are sharing sensitive information.
This includes card details, account information, billing addresses, contact details, and sometimes bank connections. When people enter this information, they need reassurance that the system is secure.
PayPal uses security indicators in several ways.
The brand often emphasizes buyer protection, secure checkout, encrypted transactions, and account-based payments. It also keeps the user inside a controlled, recognizable payment flow. The interface is designed to feel official, stable, and separate from less familiar merchant environments.
That separation matters.
When a user clicks PayPal at checkout, they are not only choosing a payment method. They are moving into a payment environment they may already trust. This reduces the perceived risk of sharing payment details with a new or unfamiliar website.
Security indicators work because they answer an unspoken question: “Is this safe?”
The answer needs to be immediate.
If users have to search for security information, read long policies, or guess whether payment details are protected, the experience has already created doubt. The best security UX is visible, clear, and placed near the moment of action.
For example, ecommerce websites can build trust by showing secure payment labels, accepted payment methods, refund information, privacy reassurance, and support access near checkout. These signals should not overwhelm the user, but they should be easy to notice.
Security messaging should also be specific.
A vague phrase like “secure checkout” can help, but stronger copy may explain what is protected, what payment options are available, or how customer support handles payment issues. The goal is not to fill the checkout with legal language. The goal is to give users enough reassurance to move forward.
This is especially important for lesser-known brands. A major retailer may already have built-in trust, but a smaller ecommerce brand or SaaS company needs to work harder to earn confidence at checkout.
2. Familiar UI Patterns
Trust is not only created by what users see. It is also created by what users recognize.
Familiar UI patterns make an experience feel easier because users do not have to relearn how it works. They understand where to click, what will happen next, and how to complete the task.
PayPal benefits from familiarity because many users have already used it before. The login flow, payment confirmation screen, account selection, and final approval process feel recognizable. Users know what to expect.
That expectation reduces friction.
A completely new payment interface can create hesitation, even if it is technically well designed. Users may wonder if they are in the right place. They may worry that clicking the wrong button will charge them too early. They may get confused if the flow looks too different from what they expected.
PayPal avoids much of that because its interface follows familiar payment patterns.
The user chooses PayPal, signs in if needed, reviews the payment details, confirms the purchase, and returns to the merchant. The flow is clear and predictable.
Predictability builds trust.
In UX, familiarity is powerful because it reduces cognitive load. Users do not need to think as hard. They can focus on completing the task instead of interpreting the interface.
This does not mean every website should copy PayPal’s design. It means brands should be careful when redesigning checkout, pricing pages, forms, and payment flows. Creativity is useful in brand storytelling, but checkout is not the place to make users guess.
For payment UX, familiar patterns can include standard button placement, clear form labels, recognizable payment logos, progress indicators, simple confirmation screens, and direct error messages.
The experience should feel calm and expected.
If the payment flow surprises users too much, it may create doubt instead of delight.
3. Brand Recognition
Brand recognition is one of PayPal’s biggest conversion advantages.
When users see the PayPal logo at checkout, they are not seeing a random payment option. They are seeing a brand they may already associate with online shopping, security, refunds, and buyer protection.
That recognition carries weight.
For unfamiliar stores, PayPal can act as a borrowed trust signal. A user may not fully trust the merchant yet, but they may trust PayPal enough to complete the payment.
This is especially valuable for first-time purchases.
When someone buys from a brand they already know, the checkout decision is easier. When they buy from a brand they have never used before, the risk feels higher. In that situation, a recognized payment option can make the decision feel safer.
Brand recognition also reduces decision fatigue. Instead of evaluating every part of the checkout experience from scratch, users can rely on a known payment brand as a shortcut.
That shortcut can increase confidence.
This is why payment logos, trust badges, recognizable platforms, customer reviews, and third-party verification can all support conversion. They help users understand that the business is legitimate and that the transaction is protected by systems they recognize.
However, brand recognition must be used carefully.
Trust signals should feel credible, not decorative. Adding random badges, fake-looking seals, or too many payment logos can make a checkout page feel cluttered or suspicious. The best trust signals are relevant, recognizable, and placed where they help the user make a decision.
PayPal works because the brand is already meaningful. It does not need heavy explanation. The logo alone can reduce hesitation for many users because the brand has built years of trust outside the individual checkout page.
This is a reminder that UX and brand are connected.
Why PayPal’s Trust-Building UX Works
PayPal’s UX works because it reduces fear and hesitation at the most sensitive point in the customer journey.
The user is not just browsing anymore. They are about to commit. They are about to spend money. They are about to share personal or financial details.
At that moment, even small doubts can become conversion blockers.
PayPal helps reduce those doubts in three ways.
First, it makes the payment feel secure. The user sees a known payment provider and feels less exposed.
Second, it makes the flow feel familiar. The user recognizes the interface and understands the steps.
Third, it brings strong brand recognition into the checkout. The user does not have to decide whether to trust the merchant alone. PayPal adds another layer of confidence.
These elements work together because trust is not built from one message. It is built from repeated signals.
The more consistent these signals are, the easier it becomes for users to move forward.
This is why checkout optimization should never focus only on speed. Speed matters, but confidence matters too. A checkout can be fast and still feel risky. A form can be short and still feel unclear. A payment page can look clean and still fail to reassure users.
Good payment UX removes friction.
Great payment UX removes fear.
How Other Brands Can Apply PayPal’s UX Lessons
Most businesses do not have PayPal’s global recognition. However, they can still apply the same trust-building principles.
The goal is not to become PayPal. The goal is to understand why PayPal works and use those lessons in your own checkout, pricing, onboarding, and payment experiences.
Here are three practical ways to apply them.
1. Add Trust Signals Near the Decision Point
Trust signals work best when they appear close to the action users are about to take.
If someone is about to pay, show secure payment information near the payment button. If someone is about to submit a form, show privacy reassurance near the form. If someone is choosing a plan, show cancellation terms, support details, or guarantee information near the pricing CTA.
Do not hide trust information in the footer or terms page and expect users to find it.
Make it visible when it matters.
Useful trust signals can include secure checkout messaging, accepted payment logos, refund policy summaries, customer reviews, support availability, privacy notes, company details, and third-party platform recognition.
The key is to keep these signals specific and believable.
Clear trust signals reduce uncertainty because they answer practical concerns before users have to ask.
2. Keep the UI Familiar
Checkout is not the best place to experiment with unusual patterns.
Users want clarity. They want to know what information is required, what will happen after clicking, and whether they can review the purchase before confirming.
Keep the layout simple. Use clear labels. Make the primary action obvious. Avoid unexpected steps. Make errors easy to fix. Show progress if the checkout has multiple stages.
This is especially important on mobile, where small frustrations can quickly lead to abandonment.
A familiar UI does not have to be boring. It simply needs to match user expectations. You can still use brand personality in typography, tone, illustration, and microcopy, but the core flow should feel easy to understand.
3. Highlight Security Without Creating Anxiety
Security messaging should reassure users, not scare them.
Some brands make the mistake of overloading checkout pages with warnings, policies, and technical language. This can backfire because it reminds users of risk without making them feel protected.
The better approach is to make security visible, simple, and calm.
Use plain language. Keep security copy short. Place it near payment actions. Show recognized payment options. Explain what users can expect after paying. Provide easy access to support.
The tone matters too.
Users should feel reassured, not pressured.
This applies beyond checkout. SaaS products, finance apps, healthcare platforms, and booking websites all need to communicate security clearly. Any experience that asks users for sensitive information should make trust part of the design.
Final Thoughts
PayPal’s conversion power comes from more than convenience.
It comes from trust.
The brand uses security indicators, familiar UI patterns, and strong brand recognition to reduce fear at the point of payment. These elements make users feel safer, clearer, and more willing to complete the purchase.
That is the real lesson behind PayPal UX.
Users do not abandon checkout only because the product is wrong or the price is too high. Sometimes they abandon because the experience does not give them enough confidence to continue.
For any business that sells online, trust-building UX should be treated as a conversion priority. Add trust signals where users need reassurance. Keep the interface familiar where clarity matters most. Highlight security in a way that feels calm and credible.
The easier it is for users to trust the experience, the easier it is for them to take the next step.
What is AX Design? Why do we need this new role
Agentic Experience (AX) is an emerging discipline that prioritizes designing the guardrails, business rules, and logic for AI agents over designing standard user interfaces.
Deep dive
- AX focuses on defining the 'success criteria' and 'guardrails' for AI-led workflows.
- The role bridges the gap between high-level business goals and technical agent implementation.
- Agents require explicit process understanding before automation can safely occur.
- AX design prioritizes backend logic, data access, and failure handling over visual elements.
- It treats agents as software employees that need clear job descriptions and oversight.
Decoder
- Agentic Experience (AX): The design field concerned with creating and governing autonomous AI workflows and the logic governing their decision-making processes.
Original article
UX focuses on designing experiences for humans, while Agentic Experience (AX) focuses on helping businesses automate and optimize processes using AI agents. Rather than creating interfaces, AX is concerned with defining goals, rules, guardrails, and success criteria for autonomous systems. A proposed new role, the AX Designer, would investigate workflows, identify what should be automated, uncover hidden business rules, and ensure agents are solving the right problems before they're deployed. The key idea is that the biggest challenge in agentic systems isn't building the technology—it's understanding the process well enough to automate it safely and effectively.
Facebook Gets Its Own AI Mode That Turns Public Posts and Reels into a Search Engine
Facebook's new AI Mode converts its search bar into a discovery engine for public posts, Reels, and Marketplace items.
Original article
Facebook's new AI Mode transforms the standard search bar into a conversational tool that answers questions by mining public Group discussions, Reels, and Marketplace data. The update aims to increase platform engagement and support Meta's expanding subscription tiers. Critics have raised concerns about data privacy and the accuracy of crowd-sourced AI summaries. The feature is currently rolling out to users in the US.
The Once And Future Fable #2
Uncertainty surrounds the US government's recent mandate for Anthropic to disable access to its Fable and Mythos systems.
Original article
The US government forcing Anthropic to take down all access to Fable and Mythos seems like a stupid decision. However, it is unknown what motivated the government to make the decision, how much they understand the mechanisms of the technology, whether they demanded or are demanding a narrow fix or a global fix, what they intend to do next, and what they are trying to accomplish. This could just be a terrible misunderstanding that can be sorted out quickly.
Google DeepMind Explores the Path to ASI
Google DeepMind researchers are formalizing the transition from human-level AGI to artificial superintelligence (ASI), proposing four distinct development pathways.
Decoder
- AGI (Artificial General Intelligence): A hypothetical AI system that possesses the ability to understand, learn, and apply knowledge across any intellectual task a human can perform.
- ASI (Artificial Superintelligence): A hypothetical AI system that surpasses the combined cognitive capabilities of the smartest human beings across all fields.
Original article
Over the last decade, building human-level artificial general intelligence has moved from far-fetched speculation to being a concrete next-decade target for many of the largest AI organisations. Achieving this goal would have profound and far-reaching impacts on human society, which raises many complex questions for the decade ahead. This report investigates how AI itself might continue to develop in a post-AGI world along the continuum of machine intelligence. The endpoint of this continuum, Universal AI, is theoretically well understood, which provides some formal grounding for the main focus of this report: the transition from human-level AGI to artificial general superintelligence, which, intuitively, can be understood as a system that is more intelligent and cognitively capable than large organisations of humans. After characterizing ASI, the report discusses four potential pathways from AGI to ASI: scaling AGI, AI paradigm shifts, recursive improvement, and ASI emerging from large-scale multi-agent collectives. The report then discusses possible frictions and bottlenecks along these pathways. Determining whether the impact of these frictions will be negligible or substantial raises a number of concrete open research questions. Due to large uncertainties for predicting ASI progress, it cannot be ruled out that AI progress might continue to accelerate over the next years. This could imply that the image of a single transformative step change, caused by the introduction of human-level AGI into our society, could be inaccurate. More apt might be the prospect of a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology. Preparing for this prospect requires a massively interdisciplinary endeavour of global scope and interest.

Owning vs. Renting Intelligence
The shutdown of Mythos has shifted the industry debate from the cost of AI to the strategic risks of renting proprietary intelligence from others.
Original article
Owning vs. Renting Intelligence
Mythos got shut down this week. Whether you agreed with the decision or not is almost beside the point. A company built on top of intelligence it didn't control suddenly found itself exposed to...

Should you post-train your own model?
General-purpose models are sufficient for prototyping, but mission-critical production workflows increasingly demand custom post-training to control latency, cost, and reliability.
Decoder
- Post-training: The process of fine-tuning a pre-trained foundation model on a specific, smaller dataset to align it with niche domain requirements.
Original article
Should you post-train your own model?
General frontier models, both open and closed, are improving quickly. In many cases, they are the right starting point. If you are building a 0-to-1 prototype, trying to understand a workflow, or...
Sovereign AI is not a model, but a supply chain problem
Sovereign AI is evolving from a software-first slogan into a global supply-chain battle, forcing nations to secure every link from silicon to cooling infrastructure.
Deep dive
- Demand for AI infrastructure is broadening from cloud training to national-level localized inference.
- Bottlenecks are increasingly hardware-centric: HBM capacity, advanced packaging, and lithography.
- Japan's role is critical in high-precision testing and specialized materials rather than AI software.
- Europe's value in the supply chain lies in industrial automation and power management for massive data centers.
- MRAM is highlighted as a potential edge-AI component as countries look to reduce cloud reliance.
Decoder
- HBM: High Bandwidth Memory; specialized high-speed memory stacked vertically to handle the data demands of AI GPUs.
- Foundry: A facility that manufactures semiconductors designed by other companies (e.g., TSMC).
- Advanced Packaging: The integration of multiple chips (chiplets) into a single package, crucial for performance scaling in modern GPUs.
Original article
AI investment often brings to mind a specific set of companies: NVIDIA, AMD, SK Hynix, Samsung Electronics, and ASML. These companies are undoubtedly at the heart of AI infrastructure. However, this time, we need to look from a slightly different angle.
A significant change has recently occurred in the AI market. Frontier AI models are no longer treated as mere software products but are beginning to be regarded as strategic assets, similar to semiconductors. As the perception grows that model access can be controlled and restricted to specific countries or users, governments and companies naturally begin to ask one question:
"Will the AI we use still be turned on tomorrow?"
I believe this question elevates the discussion around Sovereign AI to a new level. Until now, Sovereign AI has largely been akin to a slogan: "We must develop our own foundation models." However, it is highly likely to evolve into a more practical issue in the future.
The essence of Sovereign AI is not about developing proprietary models, but about how much of the supply chain required to train, operate, validate, and protect those models can be secured within one's own country or allied nations.
From this perspective, Sovereign AI is not just an AI software theme. It is a global supply chain realignment theme, extending from GPUs, HBMs, foundries, packaging, equipment, materials, power, cooling, and optical communication to next-generation memory.
1. Learning demand is not over; its ceiling is rising again
Recently, a very simplistic logic regarding AI demand has been prevalent in the market: Learning uses GPUs, inference uses CPUs.
Of course, the reality is far more complex. GPUs are also used for inference, and learning requires CPUs, memory, and networks. However, investors' understanding of the market generally followed this framework. To some extent, it was also true.
Frontier-level model training is already dominated by a few companies in the US and China. OpenAI, Google, Anthropic, Meta, xAI, and some Chinese big tech and model companies are at the center of the learning race. Naturally, the market began to think: "Learning has reached a certain stage, and now inference demand will be key, right?"
I agree with this direction in principle. As AI expands into actual services, inference demand will naturally grow. As agents, search, coding, robotics, on-device AI, and enterprise AI workflows increase, the daily operation of inference infrastructure becomes crucial.
However, Sovereign AI shakes this dynamic once more.
Previously, only the US and China focused on creating frontier-level foundation models. But what if G20 countries each begin to decide, "We must have at least a minimal level of our own AI infrastructure"?
Not every country can directly build GPT-level models. However, the demand to train and tune models based on local languages and local data for use in national government, defense, finance, legal, medical, and public systems could increase. The key is not whether they can build the best model, but the movement to avoid complete reliance on foreign models.
This is fuel that will reignite the GPU market.
| Category | Required Infrastructure | Investment Point |
|---|---|---|
| Proprietary Training | GPU clusters, HBM, network | Resurgence of learning demand ceiling |
| Proprietary Inference | CPU, GPU, memory, storage | Increased usage of AI based on domestic data |
| Proprietary Operation | Data centers, power, cooling, security | National-level expansion of AI infrastructure |
| Proprietary Supply Chain | Foundries, equipment, materials, packaging | Supply chain realignment centered on allied nations |
In this trend, looking only at NVIDIA and AMD is insufficient. While GPUs are central, Sovereign AI expands beyond simply buying a GPU to the question of "where to procure the entire AI system, where to operate it, and how much control can be exercised over it."
2. Sovereign AI is not about proprietary models, but proprietary supply chains
This is the core point as I see it. Sovereign AI starts with model sovereignty, but ultimately leads to supply chain sovereignty.
To build AI models directly, GPUs are needed. To use GPUs, HBMs are needed. To make HBMs, advanced packaging and test equipment are needed. To make chips, foundries and lithography equipment are needed. To run foundries, wafers, photoresists, specialty gases, and chemical materials are needed. To operate data centers, power, cooling, optical communication, transformers, and power control systems are needed.
Ultimately, Sovereign AI does not end with "Let's create our own country's model." It leads to the question, "Who holds the kill switch for the AI supply chain we depend on?"
From this perspective, looking only at US and Korean stocks narrows the view too much. We must also consider Japan, Taiwan, China, and Europe. Japan, in particular, may have fewer leading AI software companies, but it is indispensable in the semiconductor equipment and materials supply chain. Taiwan is central to foundries, server ODMs, and packaging substrates. Europe is strong in lithography equipment and power/automation infrastructure. China is both a victim of sanctions and the country most aggressively pushing for its own supply chain.
3. Japan should be viewed as a supply chain bottleneck rather than an AI software leader
Japan receives relatively less attention in the AI model competition. However, when viewed through the lens of the supply chain, the story changes completely. Japan is strong in semiconductor equipment, materials, wafers, inspection, ceramics, and optical communication. As AI semiconductors become more complex, and as countries strive to secure their own supply chains, the strategic value of Japanese companies could actually increase.
What makes these companies interesting is that they don't need to directly pick the winner of the AI model competition. Regardless of who creates the models or designs the GPUs, as advanced semiconductors and data centers proliferate, demand for equipment, materials, inspection, and cooling will follow.
4. Taiwan is not just TSMC, but also servers and packaging
Taiwan is one of the most important regions in the Sovereign AI supply chain. The reason is simple: it's where AI chips are actually made. Most people only think of TSMC, but from a Sovereign AI perspective, the ecosystem behind it is also crucial. We need to look at AI server ODMs, packaging substrates, back-end processes, and general-purpose memory.
Taiwan should be viewed from the perspective of "who actually manufactures AI chips and servers" rather than "who creates AI models." As Sovereign AI spreads, countries may demand not only US big tech models but also their own cloud, data center, and AI server infrastructure. In this process, Taiwanese ODMs and substrate companies are likely to remain in the supply chain.
5. China is both a victim of sanctions and a testing ground for its own supply chain
China must be viewed separately when considering the Sovereign AI supply chain. China is the most heavily impacted by US semiconductor sanctions, but at the same time, it is the country most aggressively building its own AI supply chain. China's Sovereign AI is partly about "replacing US models," but more fundamentally, it's an experiment in "how far can we go without US equipment and US chips?" Therefore, when looking at Chinese stocks, one should not simply focus on performance gaps. As sanctions persist, even lower-performance domestic alternatives are more likely to be adopted in the domestic market.
6. Europe is not just ASML, but also power and industrial infrastructure
Looking only at ASML is insufficient for Europe. Of course, ASML is an absolute bottleneck in the advanced semiconductor supply chain. However, when considering the Sovereign AI supply chain, Europe's strengths extend beyond equipment to power, automation, industrial control, and power semiconductors. As Sovereign AI penetrates national data centers and public infrastructure, power and automation become bottlenecks.
7. MRAM is not an HBM replacement, but an Edge AI option
To describe MRAM as a substitute for HBM is an overstatement. The central bottleneck for AI training remains HBM. However, if Sovereign AI does not remain confined to cloud data centers, the story changes. As AI moves into defense, automotive, industrial equipment, robotics, medical devices, edge servers, and secure devices, the need for low-power, non-volatile, and highly reliable memory could increase. In this scenario, MRAM becomes an option. HBM is the current bottleneck, and MRAM is an option for the Edge AI era.
8. Summary from an investment perspective
Ultimately, this trend shows one thing: AI infrastructure demand is not simply shifting from learning to inference. While inference demand is growing, the ceiling for learning demand is also rising again, driven by the justification of Sovereign AI. Sovereign AI is expanding from a proprietary model competition to a proprietary supply chain competition.
What's important here is not an approach that simply follows the leading stocks. NVIDIA remains at the center of AI infrastructure. SK Hynix is also key to the HBM bottleneck. However, the market is already well aware of these facts. A good company and a good price are different.
Therefore, going forward, we should not only look at "who makes the best AI models," but also "where are the supply chain bottlenecks that AI must pass through as it continues to grow?"
Conclusion
Sovereign AI can seem somewhat abstract when viewed as a slogan. However, when Sovereign AI is viewed through the lens of the supply chain, the story changes. Even if countries cannot directly create the best models, they will at least try to avoid complete reliance on foreign models and foreign clouds in defense, public, finance, medical, and industrial sectors. In this process, securing proprietary training, proprietary inference, proprietary data centers, and proprietary supply chains becomes crucial.
This trend reignites the GPU market. At the same time, it broadens demand to HBM, packaging, foundries, equipment, materials, power, cooling, optical communication, and next-generation memory. It's about who holds the AI supply chain. For actual investment, instead of chasing leading stocks at high prices, an approach of calmly selecting companies in each supply chain bottleneck that the market has not yet fully reflected seems more appropriate.
From "Which model is the smartest?" to "Will that model be turned on tomorrow?" and now to "Whose hands hold the supply chain that makes that model possible?"
Accelerating researchers and developers building multilingual AI with a new open dataset
GitHub has released a new multilingual repository dataset designed to help researchers better identify and leverage non-English code and metadata in public repositories.
Original article
The GitHub Multilingual Repositories Dataset is a repository-level metadata dataset designed to help researchers and developers discover public GitHub repositories with evidence of non-English natural-language content.
Fox to Buy Roku Streaming Service in $25 Billion Deal
Fox is set to acquire streaming platform Roku for $25 billion, aiming to consolidate its streaming assets and compete directly with Amazon and Netflix for advertising.
Original article
Fox is acquiring Roku in a deal valued at around $25 billion. The deal will add scale to Fox's streaming business, subscription-based Fox One, and Fox Nation. The combined company will compete with the likes of Amazon and Netflix for ad dollars. The deal is expected to close in the first half of 2027.
The Web We Know Is Going to Disappear
The open web as a human-facing interface is receding as AI agents turn websites into machine-readable infrastructure.
Original article
The Web We Know Is Going to Disappear
Every generation of computing believes the interface it loves will last forever. It never does. I saw information move from floppy disks to BBSs, from BBSs to the Web, from the Web to Flash, from Flash back to open standards, from websites to mobile apps, and now from search engines to AI chat interfaces. The Web will not vanish overnight, but the Web as we know it, the open place where people search, click, read, browse, publish, and discover, is already being replaced by something more convenient, more centralized, and much harder to escape.
Another Drama Rant, With Modem Noises
I am 48 years old. I started using computers in 1990. Back then, I did not have access to networks. Everything was local. Information moved physically, usually through floppy disks. It sounds primitive now, but at the time it felt like magic with a plastic shell.
Every week, I exchanged what felt like an insane amount of information for that era. Maybe 20 MB. Today that is basically one screenshot from a modern phone, but back then it was treasure. People gathered with bags full of disks ready to share video games, text magazines, software, weird utilities, manifestos, manuals, books, and things nobody could properly categorize.
I remember collecting legendary articles, technical texts, strange essays, and digital magazines like they were sacred objects. You did not "bookmark" things. You physically had them. You labeled them. You protected them. You prayed the disk did not die.
The Web did not exist in my life yet. Search did not exist. Social media did not exist. There were no feeds, no timelines, no notifications, no "like and subscribe," and no algorithm trying to guess whether you wanted to buy shoes because you once looked at a chair.
Information still moved. It just moved through people.
The First Network That Felt Like the Future
My first real encounter with a network was a BBS, a Bulletin Board System.
Around 1995, I started one with friends. Our modem was 14,400 bps. Yes, bits per second. Not megabits. Not gigabits. Not fiber. A 14.4 kbps modem that screamed like a tiny robot being tortured by a fax machine.
We were a small group of friends who gathered at night to receive calls from strangers. People connected to our system, chatted, uploaded files, downloaded files, left messages, and disappeared into the darkness of the telephone line.
It was not massive. It was not scalable. It was not "cloud native." If someone had said "cloud" in that room, we would probably have looked out the window.
But the experience was magical. The first thought I had was simple: this is the future.
I was convinced every person would communicate this way. Every business would have a BBS. Every community would have one. Every company would run its own small digital place where people could connect, talk, trade information, and build something.
I was wrong.
Not completely wrong about the direction, but very wrong about the interface. The future was not the BBS. The future was the behavior behind it: people wanted to connect, publish, exchange, and discover. The BBS was just an early container.
Then the Web Arrived
Then came FidoNet, other networks, and eventually the early World Wide Web.
The first time I saw a webpage rendering in Netscape Navigator, my opinion changed instantly.
The Web was the future. Not BBSs. Not CD-ROM encyclopedias. Not isolated digital islands. The Web.
Suddenly, the idea of buying an encyclopedia on discs felt absurd. Why would you keep knowledge frozen in plastic when it could be updated online? Why would artists, writers, developers, companies, communities, and weird hobbyists depend on publishers when they could have their own websites?
The early Web was messy, ugly, slow, inconsistent, and full of broken pages. It was also alive.
Artists had websites. Musicians had websites. Game developers had websites. Writers had websites. Companies had websites. Nerds had websites. Some people had websites that should probably have remained private, but that is the cost of civilization.
Audio and video came early. Images loaded line by line like some kind of digital archaeology. You waited. You watched. You hoped nobody picked up the phone.
Compared with BBSs, the accessibility of the Web made adoption explode. The Web was easier to reach, easier to link, easier to publish, easier to explain, and easier to commercialize.
BBSs became obsolete almost instantly. I still remember a group of maybe 10 or 20 of us meeting every Friday in downtown Buenos Aires to drink, talk, play video games, and discuss technology. We were the sons of the BBS era. We had seen one world appear, and then we watched it disappear under our feet. That would not be the last time.
The Web Almost Became Flash
A few years later, around the late 1990s and early 2000s, I became deeply involved in advocating for Web Standards.
That was not an academic preference. It felt like a battle for the soul of the Web.
At the time, Macromedia Flash was everywhere. Flash sites had animation, interactivity, video, custom typography, music, transitions, games, menus, intros, splash screens, and all kinds of visual effects that made normal HTML pages look like tax forms with hyperlinks.
People loved Flash.
And I understood why.
Flash made the Web feel alive. HTML at the time was limited. CSS was still maturing. JavaScript was inconsistent across browsers. If you wanted smooth animation, rich interaction, custom fonts, and a controlled visual experience, Flash was very tempting. The problem was that Flash was also a walled garden.
A Flash website was often expensive, hard to maintain, hard to search, hard to make accessible, hard to update, and dependent on proprietary tooling. Creating a serious Flash site could feel like building a Pagani Zonda every time you wanted a homepage.
Beautiful? Yes. Reasonable for most businesses? Not really.
Macromedia introduced ActionScript, and Flash became more powerful. For many agencies and companies, it looked like the next application platform. Against server-rendered HTML websites, Flash seemed modern, visual, interactive, and emotional.
But there was a cost. A lot of the Web became less open. Content was trapped inside binary files. Search engines could not understand much of it. Browsers depended on plugins. Accessibility suffered. Performance was often bad. Development required specialized teams. Maintenance was painful.
There were huge projects, sometimes with absurd budgets, trying to create the next great e-commerce experience or brand platform with Flash. Some of them looked amazing. Many of them were operational nightmares.
Flash was spectacular. Flash was also a beautiful cage.
The iPhone Changed the Direction Again
Then came the iPhone. The iPhone did not kill Flash overnight, but it changed the direction of the industry. Apple refused to support Flash on iPhone, iPod touch, and later iPad. In 2010, Steve Jobs published "Thoughts on Flash", arguing against Flash for mobile devices and in favor of open web standards. You can agree or disagree with all of Apple's motivations, but the practical result was obvious: Flash was in trouble.
Mobile changed the constraints. Battery life mattered. Touch mattered. Performance mattered. Security mattered. Standards mattered. Plugin-based experiences were a bad fit for the mobile era. Eventually, Flash died as a mainstream browser technology. Adobe officially ended support for Flash Player on December 31, 2020, and blocked Flash content from running in Flash Player beginning January 12, 2021. The Web survived. Actually, the Web became more important again.
HTML, CSS, JavaScript, SVG, video, canvas, WebGL, WebAssembly, responsive design, and browser APIs kept evolving. What used to require proprietary plugins became possible through open standards. For a while, it looked like the Web had won. Again.
Then Mobile Apps Built Another Walled Garden
Of course, the story did not end there. Native mobile apps became the next walled garden. People loved them. They were faster, smoother, more integrated, and easier to monetize. They had app stores, push notifications, payments, device APIs, ratings, updates, and distribution. The Web remained open, but mobile apps became the interface people used all day. For a while, it looked like websites would become secondary. Why open a browser when every service had an app? Why type a URL when an icon was already on your home screen?
Still, the Web survived another punch to the stomach.
It survived because links matter. Search matters. Publishing matters. Interoperability matters. Businesses still needed websites. Developers still built web apps. Media still published on the Web. People still searched. Google still sent traffic. Blogs still existed. Documentation still lived in public pages. Open source still depended on the Web. The Web adapted. But then came something different.
ChatGPT Was the First Real Crack
When ChatGPT appeared in 2022, I quickly realized the Web was being forced into another battle. This one is different. With BBSs, the Web won because it was more accessible. With Flash, the Web won because open standards eventually became powerful enough. With mobile apps, the Web survived because search, links, and publishing were still essential.
AI changes the interface itself.
People no longer need to search in the same way. They do not need to open ten tabs. They do not need to scan five articles. They do not need to compare Stack Overflow answers from 2013, 2017, and one angry comment from a person named "NullPointerDestroyer." They ask the chat. Developers ask AI to explain errors, write code, compare libraries, generate SQL, refactor functions, write documentation, summarize logs, explain architecture, and solve daily dilemmas. Non-technical people ask for recipes, legal summaries, travel plans, email drafts, product comparisons, health questions, school help, business plans, relationship advice, and everything else humans used to throw at Google. This is not a small change.
This is the browser losing its position as the primary interface to knowledge.
Search Is Becoming an Intermediate Layer
For more than two decades, search engines were the front door of the Web. You wanted something. You searched. You clicked. You visited a website. That website received traffic, attention, analytics, ad impressions, newsletter signups, brand recognition, or maybe just the satisfaction of being read by another human being.
That model is weakening.
AI assistants and AI-powered search summaries increasingly answer the question before the user clicks. Google's AI Overviews are a good example. The answer appears at the top. The sources may be cited, but the user often gets enough information without visiting them. From a user perspective, this is convenient. From a publisher perspective, this is terrifying. If the answer is extracted, summarized, reformatted, and presented inside someone else's interface, what happens to the original website? What happens to the writer? The blog? The documentation page? The independent expert? The small publisher? The person who spent 12 hours writing the answer that became two clean sentences in an AI box? The Web was built on a simple habit: click the link. AI breaks that habit. Not completely. Not immediately. But enough to change the economics of publishing.
Stack Overflow Was the Warning Shot
Look at developers.
For years, Stack Overflow was the sacred panic room of software development. You had an error. You copied it. You pasted it into Google. You opened Stack Overflow. You found someone with the same problem from eight years ago. You ignored the accepted answer, scrolled to the second one, and prayed. It worked. It was messy, but it worked.
Now many developers ask an AI assistant first. Sometimes the answer is wrong, but it is immediate, contextual, and conversational. You can ask follow-up questions. You can paste your code. You can say, "No, that is not what I meant," and the model will try again without downvoting you into a spiritual crisis.
This does not mean Stack Overflow is useless. It still contains enormous value. It still has human expertise. It still has history. It still has edge cases. It still has authority in many areas. But the habit changed. That is the important part. When user habits change, entire ecosystems start moving.
The Website Becomes Infrastructure
I do not think websites will vanish completely. That is too dramatic, even for me, and I enjoy a good drama rant. What I think will disappear is the Web as the primary human-facing interface.
Websites will increasingly become infrastructure for machines. They will feed models, agents, search systems, APIs, datasets, crawlers, and private knowledge bases. Humans may visit them less often, but machines will consume them constantly. The website becomes less like a destination and more like a source. Less "come read my article." More "let the machine ingest my article and maybe mention me if the stars align and the product manager felt generous." That is a very different Web. It is not the Web I grew up with.
Email, Browsers, and the Next Interface
I also think email will lose importance for many everyday interactions. Not because email will disappear. Email is too deeply embedded in business, identity, authentication, receipts, legal communication, and bureaucracy. Like FTP, it may survive forever in places nobody wants to look at directly. But for normal people, messaging already feels more natural. People chat with friends, companies, banks, airlines, doctors, restaurants, and delivery services. Younger generations do not think in folders, inboxes, subjects, and signatures. They think in threads, voice notes, reactions, and instant replies.
AI will accelerate that.
The next interface for many tasks will be conversational. Not necessarily one chatbot. More likely a layer of assistants across devices, apps, operating systems, browsers, cars, TVs, glasses, and whatever strange object Silicon Valley convinces us to wear on our faces next. You will not "go to a website" to do many things. You will ask. The assistant will search, compare, summarize, decide, book, buy, send, schedule, write, cancel, negotiate, remind, and execute. That sounds convenient. It also sounds like the biggest walled garden ever built.
The New Gatekeepers
The old Web had gatekeepers, but it also had escape routes. If Google did not rank you, people could still share your link. If Facebook buried your post, someone could still visit your site. If your app was rejected from an app store, you could still build a website. The AI interface may reduce those escape routes. If people stop browsing, stop searching, and stop clicking, then visibility depends on whether AI systems decide your content matters. That decision may be hidden inside ranking systems, retrieval layers, model training, licensing agreements, safety filters, personalization systems, and business partnerships.
In the old Web, you could ask, "Why is my page not ranking?" In the AI Web, you may ask, "Why does the model never mention me?" Good luck debugging that. At least with old SEO, you could suffer in public with charts.
Will People Miss the Open Web?
Some will. Most probably will not. That is the brutal part. People did not abandon BBSs because they hated them. They abandoned them because the Web was easier. People did not abandon Flash because they stopped liking animation. They abandoned it because better technologies and devices made it unnecessary. People did not stop using websites because websites were evil. They moved to apps because apps were more convenient. The same will happen with AI.
People will not say, "Today I reject the open Web." They will simply ask the assistant because it is faster. Convenience wins. Convenience replaces nostalgy, all the time. It almost always wins. The Web's biggest enemy is not ideology. It is not regulation (well, a bit yes). It is not even AI itself. It is convenience.
The Strange Future of Sharing Knowledge
This is the part I keep thinking about. How will people share knowledge in the future if most knowledge is generated, summarized, remixed, and delivered through AI interfaces? Will people still write long articles? Will independent blogs matter? Will personal websites survive? Will forums become training material instead of communities? Will human writing become a premium signal, like handmade furniture in a world full of IKEA?
I do not know.
I still write because writing helps me think. That may become the main reason to write. Not traffic. Not SEO. Not audience growth. Not discovery through search. Just thinking in public, even if the public is now three humans and a crawler wearing a fake mustache. I also admit something uncomfortable: I do not read blogs the way I used to. I ask AI. I search less. I click less. I still value original sources, but I reach them differently. Sometimes I only reach them when the AI points me there. Sometimes I do not reach them at all. So I cannot pretend this change is happening to other people.
It is happening to me too.
The Web Will Become a Nerd Medium Again
The Web may become like IRC, FTP, Gopher, or BBSs. Not dead. Just smaller.
A place used by enthusiasts, archivists, developers, researchers, independent writers, weirdos, and people who still care about owning a corner of the Internet that is not entirely mediated by a platform. That is not a bad group, by the way. Those people built most of the interesting stuff in the first place. But it would mean the mainstream moved somewhere else. The mainstream interface will be a chat box, a voice assistant, an agent, or something similar. Behind it, a model. Behind the model, tools. Behind the tools, APIs. Behind the APIs, maybe websites. Behind the websites, tired people writing documentation at 1:00 AM.
The Web will still exist. But it may no longer be where people go.
I Am Not Sad
I am not really sad about this. I am witnessing another big shift. I saw information move through disks. I saw BBSs feel like the future. I saw the Web destroy that future. I saw Flash almost swallow the Web. I saw the iPhone help kill Flash. I saw mobile apps build new walled gardens. I saw the Web survive. Now I am watching AI become the next interface. The pattern is obvious. Interfaces change. Behaviors remain. People want answers. People want connection. People want tools. People want convenience. People want to publish, learn, buy, flirt, argue, create, complain, and feel less alone with their questions. The container changes. The hunger does not. The Web we know is going to disappear. Not because it failed, but because it succeeded so completely that its content can now be absorbed into the next interface.
Maybe this article will be read by humans. Maybe it will be summarized by an AI into two polite lines for someone curious on the other side of the planet. Maybe that person will never visit this page. That is probably the future. A little sad. A little funny. Very predictable.
And yes, somewhere, someone will still be running a BBS.
Because nerds never truly delete anything.
UK bans under-16s from using social media apps including TikTok and YouTube
Prime Minister Keir Starmer announced a UK ban on social media access for under-16s, effective early next year.
Original article
Full article content is not available for inline reading.

The Promise of Polymath LLMs
Robin Hanson suggests that LLMs could trigger a productivity surge by identifying and resolving cross-disciplinary contradictions that humans consistently ignore.
Deep dive
- Robin Hanson argues that 'polymathy'—the practice of applying abstractions from one field to another—significantly increases intellectual productivity.
- Academia typically discourages this by valuing prestige within siloed disciplines over interdisciplinary expertise.
- Humans often fail to notice contradictions between fields because they rely on simplified 'public versions' of expert knowledge when operating outside their primary domain.
- LLMs have the potential to process vast amounts of knowledge from diverse fields, identifying logical conflicts that human researchers have historically neglected.
- The proposed strategy involves using LLMs to systematically compare pairs of distant areas to find, resolve, and replace inconsistent beliefs with more coherent, evidence-based consensus.
- Successful implementation could lead to a 'burst of progress' by correcting long-standing errors that are reinforced by tribalism within specific academic communities.
Decoder
- Abstraction: A simplified representation or mental model used to explain complex phenomena across different contexts.
- Polymath: An individual whose knowledge spans a substantial number of subjects.
Original article
I have long associated with smart nerdy folks with broad interests, especially re tech/future. Groups like “extropians”, “rationalists” and “effective altruists”. While there are many smart nerdy amateur groups who focus on rather concrete topics, like old cars or poker, the folks I’ve like have had a “taste for abstraction”. They like more to reason abstractly, and so over time have collected many abstractions to help them reason. This seems to me a key common element across the diverse topics they like.
When such people are nearer to academia, they tend more to learn established abstractions from academic disciplines. Others tend more to collect abstractions from online thinkers, who more often invent their own new abstractions, instead of using established ones. Such novel abstractions are generative, adding to our innovation in abstractions. But they also tend to be less reliable, leading such thinkers more often astray. Academics, in contrast, are slower to adopt new abstractions, as they hold new proposals to higher standards.
This is my main criticism of the communities collected around these online thinkers. I like them personally, but think they too often go wrong by inventing new abstractions, and then overly trusting these due to their trusting folks inside their community much more than outsiders. In particular, I think such folks have been led astray by new abstractions re AI risk; they’d do better with vetted abstractions from biology, culture, or economics.
I’m now an academic, though I was once an amateur. Over my lifetime, I have been tempted into many diverse topic areas, due to their immediate interest to me. This induced me to learn many new-to-me-but-standard abstractions. As a result I’ve stumbled into a polymath lifetime strategy: the more fields I learn, the more intersections I find where I can apply the tools of one field to the problems of another.
As a result my productivity has increased over time, even though I’m getting old; knowing N fields empowers me to look for N(N-1)/2 intersections between fields. Most of my contributions have been applying stuff we know in some areas to other areas. And note how this approach allows you to be a pretty reliable contrarian. Contrary approaches within a discipline tend to be wrong more often than just applying established abstractions from other disciplines to this one. As folks inside each discipline tend to resist accepting corrections from other disciplines, that will make you a contrarian, at least for a time.
Oddly, few people plan when young to adopt such a polymath life strategy. I think this is in part because we find it hard to believe that other fields besides where we started actually know a lot. When we feel that our intuitions seem adequate to guide practical action in an area of life like romance or physics, we find it hard to see that there could be that much to learn about it. I have been surprised by just how powerful are the abstractions that I’ve learned from areas outside my early life focus areas, and how much more productive I’ve become by learning them.
Academia neglects interdisciplinary work that combines insights from multiple areas. Each field has expert versions which experts use among themselves, and public versions seen by outsiders, and people in field B won’t accept your using the expert version of A if that differs from the non-expert version of A that B folks have in mind. Also, if you hold an academic event on the topic of A intersect B, you’ll usually invite the most prestigious people you can get in A, and in B, but you won’t usually invite people who have specialized in A intersect B, as they will tend to be less prestigious.
Thus humanity’s beliefs on many important topics have long been just inconsistent and incoherent across disparate fields of inquiry. Creating a huge opportunity to learn lots of big stuff fast: search for more contradictions between fields, and resolve them. And as humans have long neglected this opportunity, this may now be a promising option for LLMs, who seem to know quite a lot on a very wide range of topics.
Thus we might get a huge burst of progress soon if only we could get LLMs to look carefully at pairs of distant areas, ask if what they know about those two areas are in conflict, and if so substitute new more consistent views. Use the new better consensus views to lather, rinse, and repeat. Of course I’m sure there will be many obstacles to making this work in practice. Maybe LLMs just aren’t able to reason well enough yet in such cases. But maybe we should try?

Adobe Beats Expectations but Another Top Executive Leaves, Putting Pressure on its Stock
Adobe stock tumbled over 5% as CFO Dan Durn's departure adds to leadership instability, despite the company beating revenue expectations.
Decoder
- ARR (Annualized Recurring Revenue): A key metric for subscription-based businesses that measures the amount of predictable revenue expected each year.
- Freemium: A pricing strategy where basic features are free, while more advanced functionality or higher usage limits are locked behind a paywall.
Original article
Adobe beats expectations but another top executive leaves, putting pressure on its stock
A bad day for the creative software company Adobe Inc. was made even worse after it revealed another top executive is departing, as the news overshadowed a solid earnings and revenue beat.
The company said today that Chief Financial Officer Dan Durn is going to leave on June 15, having served in the role for almost five years, to seek a new “professional opportunity.” He will be replaced by Steve Day, senior vice president of corporate finance and the CFO of the Customer Experience Orchestration business, on an interim basis.
The market reacted negatively to the news, which came just three months after longtime Chief Executive Shantanu Narayen announced his own plans to step down from the company later in the year, once a successor has been found. Narayen has served as the company’s CEO for 18 years, notably overseeing the company’s shift from selling packaged software to a software-as-a-service model. Adobe’s stock fell more than 5% in late trading, having already slumped more than 6% during the regular trading session, as the announcement appeared to eclipse an upbeat financial report.
The company reported second-quarter earnings before certain costs such as stock compensation of $5.96 per share, surpassing Wall Street’s expectation of $5.82 per share. Revenue for the period came to $6.62 billion, up 13% from a year earlier and above the $6.45 billion forecast.
Adobe also raised its full-year revenue guidance, saying it now expects sales of between $26.50 billion and $26.60 billion, up from an earlier range of $25.9 billion to $26.1 billion. Analysts are targeting full-year revenue of $26.1 billion. For the current quarter, Adobe is seeking earnings of between $6.05 and $6.15 per share on sales of $6.67 billion to $6.72 billion. Wall Street is forecasting earnings of just $5.77 on $6.52 billion in sales.
Narayen told analysts on a conference call that the strong results reflect “strong AI-driven demand across our customer groups.” He explained that this has prompted the company to rethink its strategy going forward, and that it will now focus on expanding its “freemium” artificial intelligence offerings in an effort to grow its user base. This will come at the expense of short-term annualized recurring revenue growth, he said.
The CEO insisted that the strategy will pay off, helping the company to acquire new customers through a frictionless onboarding process without immediate paywalls. He told analysts that it’s the best way to accelerate adoption of the company’s AI products.
According to Narayen, the company’s user number growth during the second quarter offers strong evidence for this belief. During the quarter, Adobe Acrobat and Express grew its monthly active user base to 850 million, up from 700 million a year ago. Meanwhile, creative freemium monthly active users grew to more than 90 million, up from just 50 million one year earlier. Ultimately, Narayen thinks there’s an opportunity to amass “billions” of Acrobat and Express users and hundreds of millions of creative users.
However, Durn conceded that the plan will put pressure on Adobe’s ARR for awhile. ARR is a key metric that’s closely watched by investors as it provides evidence of the company’s return on its AI investments.
“This shift will come at the cost of short-term ARR, but will accelerate user acquisition in MAU while building the foundation for long-term growth by removing friction from user onboarding, enabling deeper user engagement, and driving stronger lifetime value,” he said, appearing in his last conference call for the company. “We’re confident that driving MAU, which has an impact on ARR, is the right tradeoff and will drive future business growth.”
Narayen also tried to reassure investors that Durn’s departure won’t cause too much disruption, despite the new plan to focus on freemium offerings. He explained that his successor Day is a longtime company veteran. “Steve has been a key member of our finance organization for two decades, and his deep understanding of Adobe’s business will be critical as we execute our strategy to deliver AI innovations to a broader set of customers across creativity, productivity and customer experience orchestration,” Narayen said.
A customizable camera app is still on the table, but Apple could be saving it for the iPhone 18
Apple reportedly built a fully customizable Camera app but may be holding the feature to bundle it with the upcoming iPhone 18.
Original article
A redesigned, fully customizable Camera app was rumored for iOS 27 but did not appear at WWDC 2026. Apple has reportedly already built the feature internally, allowing users to add, remove, and rearrange camera controls such as flash, timer, exposure, night mode, and resolution settings. The feature may have been intentionally held back for the expected launch of the iPhone 18 Pro, which is rumored to bring major camera hardware upgrades. Apple often pairs significant software features with new hardware releases, so the customizable Camera app could be part of a broader camera-focused marketing strategy. However, since the feature remains internal, there is no guarantee it will ever reach the public.
Factory 2.0: From coding agents to software factories
Factory argues that the future of engineering is building autonomous 'software factories' rather than just writing code.
Original article
Factory has been building software factories with its customers over the last few months. Its software factories are already in production across the world's largest organizations. Organizations that invest in their autonomous software development will see engineering outcomes surge. Engineers in this era are now responsible for building the factories that build the software. This will see engineering responsibilities grow to span across the business itself.

The Window Has Closed
The discontinuation of Fable suggests that certain models achieve high-order reasoning capabilities that remain invisible to standard benchmarks.
Original article
Fable was special in ways that will not show up in benchmarks. It could perceive the user, infer intent, and think and iterate upon what it was given. The model felt alive. Mythos has changed the shape of the AI race. Other labs will likely eventually be able to replicate the magic of Mythos, but for many, the race is over.

Mastering Codex (Mobile) for Engineering
Codex Mobile redefines mobile development by using the device as a management control center for remote dev machines rather than a constrained local terminal.
Original article
Codex Mobile lets developers start, direct, review, and organize work running on their development machines without pretending that a mobile device should be a tiny terminal.
Why I email complete strangers
Cold emailing strangers remains a powerful, intentional way to build authentic connections in a world dominated by social media algorithms.
Decoder
- Lindy’s law: A theory that the future life expectancy of non-perishable things, like technologies or ideas, is proportional to their current age.
Original article
In a networked but still disconnected world, being deliberate in your search for friends is more necessary than ever before.

New Universal Music logo strikes all the right chords
Universal Music Publishing Group (UMPG) has launched a new global brand identity featuring a geometric logo that references the company's iconic globe.
Original article
Universal Music Publishing Group (UMPG) has introduced a bold new brand identity designed to highlight songwriters and the creative process behind music. Created by GrandArmy, the rebrand includes a new logo, refreshed visual system, and updated positioning centered on creativity, collaboration, and UMPG's global reach. The logo features four framing elements representing the four corners of the world and references Universal's globe icon, while a central circular motif symbolizes both a camera lens and artistic talent. Supported by a vibrant visual toolkit and the slogan "We Are A World Ahead," the rebrand aims to celebrate the lasting importance of songwriting and provide a modern, adaptable identity for UMPG's global community of songwriters and creators.

Independent Type Foundries and Designers (Website)
Fonts.xyz is an indie-focused marketplace and foundry builder that simplifies font licensing with a unified model based on company size.
Decoder
- Foundry: A company that designs, manufactures, and sells digital typefaces.
- Variable Font: A font format that allows multiple variations (e.g., weight, width, slant) of a typeface to be included in a single file.
Original article
Set up your foundry in minutes with simple drag-and-drop tools, smooth font management, and a flexible page builder that makes customisation easy-squeezy.

Ivan Ehlers' Political Cartoons Feel More Important than Ever
Political cartoonist Ivan Ehlers uses accessible, hand-drawn satire to counter self-censorship, earning him a nomination as a 2026 Pulitzer Prize finalist.
Original article
Driven by a self-described reluctance to ignore authoritarianism, climate, and immigration issues, freelance cartoonist Ivan Ehlers sees his cartoons as a tool to counter self-censorship and call out injustice in accessible, understandable ways.

SMLXL put ecstatic dogs with wind blowing in their fur on a cosmetics bottle
Design studio SMLXL reconciled Midnight Cosmetics' minimalist aesthetic with HotDog's maximalist energy by using gouache illustrations of wind-blown dogs.
Decoder
- Gouache: An opaque watercolor paint that dries to a matte, vibrant finish, known for its high pigment saturation and ability to convey texture.
Original article
SMLXL created striking packaging for a collaboration between Midnight Cosmetics and HotDog by combining Midnight's minimalist black-and-white aesthetic with vibrant illustrations of dogs, turning two contrasting brand identities into a cohesive design.