Devoured - June 22, 2026
The industry is shifting toward agentic workflows, with major advancements including Tesla's modular Megapod data centers, Cloudflare's agent-ready deployment infrastructure, and new frameworks like Jcode and the WebMCP protocol that standardize how AI agents discover and interact with enterprise tools and production codebases. Simultaneously, developers are moving away from manual prompting toward loop engineering—building deterministic, observable systems where agents autonomously refine outputs and fix errors through iterative, tool-backed feedback cycles.

Sakana Fugu
Sakana AI's Fugu system orchestrates multiple expert LLMs into a single API endpoint to solve complex, multi-step tasks autonomously.
Deep dive
- Fugu uses an underlying pool of swappable agents to perform model selection, delegation, verification, and synthesis.
- Includes AB-MCTS (Adaptive Branching Monte Carlo Tree Search) for inference-time scaling.
- Fugu Ultra outperformed frontier baselines in blindfold chess, mechanical iris design, and automated Python-based Rubik's Cube solving.
- The system is designed to route around export controls by dynamically swapping agents.
Decoder
- AB-MCTS: Adaptive Branching Monte Carlo Tree Search, a technique where models engage in a trial-and-error search tree to evaluate multiple potential paths before committing to an output.
- Agentic loop: A feedback mechanism where an AI performs a task, verifies the outcome, and refines its subsequent actions based on that result.
Original article
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API.
Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.
Fugu stands shoulder-to-shoulder with leading models like Fable and Mythos across the industry's most rigorous engineering, scientific, and reasoning benchmarks.
Beyond Bigger Models: Why are Orchestration Models the Next Frontier
Progress in AI has been driven largely by giant, monolithic models. But the most powerful systems of the future will be collaborative ecosystems.
Today, this orchestration is no longer just a technical optimization. It has become a geopolitical and operational imperative.
For an organization or a nation, relying on a single company's model for critical infrastructure, finance, or governance is a material vulnerability. This risk is no longer a hypothetical possibility, but a reality.
As we have seen with recent export controls imposed on models like Fable and Mythos, access can disappear overnight.
Collective intelligence is the practical hedge against this concentration of power. Because Fugu orchestrates an underlying pool of swappable agents, it simply routes around vendor restrictions.
By orchestrating the world’s models, we are delivering the resilient blueprint required for true AI sovereignty.
How does it work?
Sakana Fugu is itself an LLM, trained to call various LLMs in an agent pool, including instances of itself recursively. Fugu dynamically orchestrates the world's best models to tackle complex, multi-step tasks.
Fugu manages model selection, delegation, verification, and synthesis automatically. It solves tasks directly when that is enough, or coordinates a team of expert models when a problem calls for more. The complexity of a multi-agent system never reaches your code.
At launch, Sakana Fugu comes in two models accessed via a single OpenAI-compatible API:
- Fugu balances strong performance with low latency for everyday work. It fits naturally into tools like Codex for coding, as well as chatbots and interactive services. You can also opt specific agents out of its pool for data compliance.
- Fugu Ultra is our flagship model tuned for maximum answer quality on hard, multi-step problems. It coordinates a deeper pool of expert agents for demanding work like AI research, cybersecurity analysis, and patent investigations.
Use Case 1: Autonomous ML Research
Can an AI autonomously improve another AI’s training recipe?
We tasked Fugu Ultra with improving a small GPT model using AutoResearch. Over 14 hours on a single H100 GPU, Fugu ran > 100 experiments. It iteratively edited the training code, ran tests, and kept any changes that successfully lowered the validation error rate.
Fugu Ultra finished with the best mean performance and achieved the best single run of the entire experiment, leading every single baseline.
Use Case 2: Financial Time Series Prediction
Can an AI agent navigate sequential, no-look-ahead market decisions?
We tested Fugu Ultra on 50 weeks of historical data. Fugu Ultra grew the portfolio to $11,943.22 (+19.43% mean return), while other frontier models capped out at less than a +15% return.
Use Case 3: One-Shot Blindfold Chess
Can an AI hold an entire game state in memory without drifting?
We matched Fugu Ultra against 3 leading frontier models and a 2100-Elo Stockfish engine. Fugu Ultra outplayed all 4 opponents, remaining accurate while other models eventually drifted or lost track of the board state.
Use Case 4: Computer Aided Design of Mechanical Iris
Can an AI generate precise, functional mechanical designs?
Fugu Ultra generated a highly functional design where the blades rotate correctly around outer pins to fully open and close the aperture, whereas other frontier baselines failed the physical logic.
Use Case 5: Rubik’s Cube Solver
Can an AI write complex algorithmic solvers from scratch?
We tasked Fugu Ultra and three frontier models with writing a Rubik’s Cube solver in pure Python. Fugu Ultra’s solver was strictly more efficient, averaging 19.72 moves versus the next best model’s 19.76.
Use Case 6: Classical Japanese Kana Reading Order
We tested whether the models could recover the reading order of "scattered writing" (chirashigaki) in a letter from 1610. Fugu Ultra achieved a 0.80 accuracy score, tracing the highly complex path almost exactly, while other models scored significantly lower.
Introducing AB-MCTS
Our new inference-time scaling algorithm enables collective intelligence for AI by allowing multiple frontier models (like Gemini 2.5 Pro, o4-mini, DeepSeek-R1-0528) to cooperate.
Inspired by the power of human collective intelligence, where the greatest achievements arise from the collaboration of diverse minds, we believe the same principle applies to AI.
AB-MCTS (Adaptive Branching Monte Carlo Tree Search) harnesses individualities, allowing multiple models to cooperate and engage in effective trial-and-error, solving challenging problems for any single AI. Our initial results on the ARC-AGI-2 benchmark are promising, with AB-MCTS combining current frontier AI models to significantly outperform individual models by a substantial margin.

Nvidia's Autonomous Robotics Research
NVIDIA's ENPIRE framework enables autonomous coding agents to iteratively improve robotic manipulation policies through physical feedback loops.
Deep dive
- Uses four modules: Environment (automatic resets), Policy Improvement (code refinement), Rollout (physical execution), and Evolution (branching hypothesis testing).
- Introduces 'Mean Robot Utilization' and 'Mean Token Utilization' as metrics for multi-agent hardware research.
- Coding agents propose hypotheses (e.g., RL, heuristic learning) and prune failing branches, documenting the search process in a git-like tree.
- Demonstrates 99% pass rate across tasks including PushT and GPU insertion using up to 8-in-context retries per subtask.
Decoder
- Dexterous manipulation: The ability of a robotic hand or effector to handle and precisely position objects with high coordination.
- Closed-loop framework: A system where the output of a process feeds back into the input, allowing for continuous, self-correcting optimization.
Original article
Abstract
Achieving dexterous robotic manipulation in the real world relies heavily on human supervision and algorithmic engineering, which is a central bottleneck in the pursuit of general physical intelligence. Although emerging coding agents can generate code to automate algorithm search, their successes remain largely confined to digital environments. We conjecture that the missing abstraction to automate robotics research is a repeatable feedback loop for real-world policy improvement: reset the scene, execute a policy, verify the outcome, and refine the next iteration.
To bridge this gap, we introduce ENPIRE, a harness framework for coding agents that instantiates this physical feedback routine with four core modules: an Environment module (EN) for automatic reset and verification, a Policy Improvement module (PI) that launches policy refinement, a Rollout module (R) to evaluate policies with single or multiple physical robots operating in parallel, and an Evolution module (E) in which coding agents analyze logs, consult literature, improve training infrastructure and algorithm code to address failure modes.
This closed-loop system transforms real-world robot learning into a controllable optimization procedure that agents can manage, thus minimizing human effort while allowing fair ablations across training recipes and agent variants. Powered by ENPIRE, frontier coding agents can autonomously develop a policy to achieve a 99% success rate on challenging, dexterous manipulation tasks in the real world, such as PushT, organizing pins into a pin box, and using a cutter to cut a zip tie.
Coding agents can improve policies with various PI regimes, such as heuristic learning, tool calling, behavior cloning, offline or online RL. Moreover, ENPIRE can be significantly accelerated on a robot fleet, and we propose two metrics, namely, Mean Robot Utilization (MRU) and Mean Token Utilization (MTU) to measure the efficiency of multiagent physical autoresearch. We also include simulation results in RoboCasa. Our findings suggest a practical and scalable path toward autonomously advancing robotics in the real world.
Learned Manipulation Policy
Policies trained with ENPIRE reach a 99% pass@8 success rate across the showcased manipulation tasks.
Push T
Pin Insertion
GPU Insertion
Tie Ziptie
Cut Ziptie
ENPIRE runs fully autonomously on real robots. Working only through the automated reset and verification interface, a team of coding agents proposes algorithmic hypotheses (heuristic learning, behavior cloning, offline and online RL), tests them against the real-world success rate, and keeps the changes that move it.
ENPIRE System
class InsertionEnv:
def reset(self):
# TODO: auto task reset
pick_and_place(obj, target)
go_home()
def get_reward(self, obs, act):
# TODO: scalar reward
mask = sam3(obs['left'])
pos = boundlsdf(obs, mask)
def get_observation(self):
...
def step(self, act):
...From Robot Hardware to an Agent-Operable Environment
Before an agent can improve a robot policy, the task must become self-resetting and self-verifying. Two capabilities make this possible: automatic evaluation, which scores the outcome of each trial without human judgment, and automatic reset, which returns the scene to a fresh initial state for the next trial.
Auto Evaluation
We use an autoresearch-derived reward function to automatically score the outcome of zip-tie insertion: a detector draws bounding boxes around the zip-tie head and strap, a segmentation model resolves the same parts into masks over the raw view, and each camera view independently judges whether the zip-tie strap passes through the head above a fixed length threshold. The per-camera verdicts are then fused into the final binary reward.
Auto Reset
The reset panels below show the physical loop that makes repeated experiments possible: select a randomized initial state, run the reset behavior, and verify that the trial is ready for the next policy.
- Automatic reset returns each task to a known randomized initial state without manual intervention.
- Automatic verification records whether the reset succeeded and exposes representative frames for inspection.
Agents Improve Policies From Physical Feedback
Once the environment is operable, agents edit policy code, run trials, inspect failures, and decide what to change next.
Evaluate Coding Agent
We evaluate the physical autoresearch capability of three coding agents: Codex with GPT-5.5, Claude Code with Opus 4.7, and Kimi Code with Kimi K2.6. Instead of asking only whether a final policy succeeds, AutoEnvBench tracks agent-driven research progress over wall-clock time across Push-T and Pin Insertion.
Scaling Autoresearch on Robot Fleets
Scaling the number of agents changes both research progress and hardware pressure. The scaling-law plots compare one-, four-, and eight-agent teams on Push-T and Pin Insertion, while the resource utilization figure shows robot utilization, GPU utilization, token throughput, and the time required to reach task success.
Evaluation in Simulation
We also evaluate ENPIRE in simulation to separate agent-driven research behavior from real-world hardware throughput. Simulation tasks let agents run denser ablations, compare policy-improvement regimes under controlled resets, and test whether recipes discovered in the physical loop transfer to broader manipulation settings.
Limitations & Future Directions
Robot and compute resources are underutilized: Coding agents do not fully utilize robot resources when they are reading logs, writing code, debugging, or waiting for the language-model backbone. As the number of robots scales, MRU decreases while GPU active utilization increases.
Scaling robot fleet causes higher token consumption: Scaling the robot fleet drives higher token consumption: as more agents read logs, summarize peer branches, and coordinate, the total token budget required to reach a successful policy grows with fleet size.
Acknowledgements
We are grateful to many colleagues whose help made this project possible. We thank Jason Liu, Tony Tao, Tairan He, Alex Lin, Jim Yang, Paul Zhou, and Abhi Maddukuri for insightful discussions and feedback; Yide Shentu, Bike Zhang, Angchen Xie, Dvij Kalaria, and Yuqi Xie for their support with the experiments; Lion Park, Matin Furutan, Jeremy Chimienti, Dennis Da, and Tri Cao for fleet operation; and Tri Cao for the demo shots. We also thank the NVIDIA GEAR Team and the CMU LeCAR Lab for their continuous support.

Optimizing Models to Be Fast at Codegen
Morph LLM is achieving a 3.07x speedup for coding agents by training specialized 'drafters' and automating kernel tuning for affordable, non-NVIDIA GPUs.
Deep dive
- Speculative decoding throughput improves from 1.93x to 3.07x when the drafter model is trained on target coding output rather than generic data.
- Kernel performance is optimized through an automated search loop that proposes, verifies, and benchmarks kernels against production traces.
- Interconnect bottlenecks (non-NVLink) are addressed by moving prefix cache data over TCP, cutting time-to-first-token by 84%.
- The stack targets high-volume, repetitive workloads like coding agents where 97% of prefix tokens are shared across turns.
- Utilizes RADIX and HiCache patterns for cache-aware routing and spilling.
Decoder
- Speculative Decoding: A technique where a small, fast model (the drafter) generates a draft of upcoming tokens, which a larger model (the target) verifies in parallel, increasing tokens-per-second.
- Kernel Tuning: The process of optimizing low-level GPU code to maximize hardware utilization, typically specific to chip architecture.
- All-Reduce: A parallel computing collective operation that aggregates data from all participating processors and distributes the result back to each.
- Prefix Cache: A memory optimization that stores the KV cache of commonly used input prompts to avoid recomputing tokens during the next turn.
Original article
An edit is mostly a copy of the file it edits. The agent rereads the same repo every turn. Its context this turn is mostly its context from last turn. A general inference stack throws all of that away and decodes every token like it has never seen anything before.
That waste is the opportunity. The weights are a free download. The speed is the product.
We serve open models, Qwen, GLM, DeepSeek, MiniMax, for one workload: the coding agent. Making them fast comes down to three things the open stack won't do for you.
- Train the speculator. A draft trained on the model's own coding output, not the internet. Generic draft: 1.93x. Trained on the target: 3.07x.
- Autoresearch the kernels. A kernel is correct or it isn't, so we search them automatically, on the cheap GPUs nobody else tunes for. 97 to 162 tok/s on a $7K card.
- Write the interconnect. All-reduce over PCIe, and a prefix cache that crosses NVLink-denied boxes over plain TCP.
Each is a place the general stack stopped and we kept going.
1. We train the speculator. The open stack ships you an empty socket.
Speculative decoding: a small draft model guesses the next few tokens, the target checks them in one pass, you keep the run until the first miss. One number decides everything. Acceptance rate, how often the target keeps the guess.
A generic draft is a bad guesser. On Vicuna-13B an off-the-shelf 68M draft gets 1.93x; a draft trained on the target's own output gets 3.07x, same target, same setup. That gap is the section.
More accepted tokens per step means fewer target passes. A draft trained on the model's own coding output keeps a longer run than a generic one on the same target.
The architectures are public and good. EAGLE-3 lets the draft train on raw data instead of copying the target's features, and acceptance length climbs from 3.96 to 6.62. DFlash, SGLang's Spec V2 since June 2026, drafts a whole block in one pass: over 6x lossless, 3.2x on HumanEval where EAGLE-3 gets 2.2x.
But an architecture is an empty socket. Nobody hands you a drafter trained on your target, for your workload. You train it, or you run the generic one and eat the 1.93x.
Training a good drafter is small-model training, and that is the part we are good at. Fast Apply and Compact made us one of the best teams in the world at it. The thing you learn under 30B: the frontier scaling laws stop applying. Chinchilla says ~20 tokens per parameter is compute-optimal, but that assumes training is the cost. For a model you train once and serve billions of times, it isn't, and the optimum slides hard toward small and overtrained.
- Llama 3: still improving at 15T tokens, two orders of magnitude past its Chinchilla point.
- SmolLM2: a 1.7B model trained to 11T, near 6,500 tokens per parameter.
- Sardana et al.: 47 models trained to 10,000 tokens per parameter, quality still climbing.
A speculator lives exactly there. Small, overtrained, shaped to one distribution.
So we train one per open model, on coding output instead of web text. Generated code reuses templates and the symbols already on screen, and an edit is mostly a copy of the file it edits. A draft that has read a million diffs predicts those tokens. One that read the internet doesn't, which is why code is the highest-speedup task for every speculation method. For Fast Apply we draft 64 tokens a step straight off input-output similarity: apply runs at 10,500 tok/s, compaction at 33,000. Same Qwen weights you can download. Ours is faster because the speculator riding it was trained, by us, on the work.
2. We autoresearch the kernels. Everyone else hand-tunes for H100s.
The agent's prompt barely changes between turns. Same system prompt, same tools, same repo, the same files read again. Across real workloads, programming traffic shares 97% of its prefix tokens, with prompts 37x to 2,494x longer than the outputs. Cache the prefix and the next request pays only for the new tokens. Hit rate is the cost.
The cache abstraction is open and we use it: RadixAttention holds prefixes in a tree, a cache-aware router takes hit rate from 20% to 75%, HiCache spills the tree to host RAM and remote storage and, on Qwen3-Coder-480B, moves hit rate from 40% to 80% and doubles throughput.
None of that is the hard part. The hard part is kernels. A cache only pays if the lookup, the eviction, the copy, and the attention over the tree are all fast on the GPU you actually run, and default kernels are tuned for the cards frontier labs buy. Port one across architectures without retuning and it runs at 7% of optimal. Reaching state of the art on AMD's MI250 took rewriting 40% of a flash-attention kernel by hand.
So we don't hand-write them. A kernel is verifiable: correct against a reference output, or not. That makes it a search, and search is something you automate.
Our harness runs that loop on the low-demand NVIDIA and AMD setups nobody else touches. Propose a kernel, verify it against production traces, benchmark it, ship the winners. KernelBench shows why you automate it: scored on correct-and-faster, frontier models clear under 20% of tasks cold. Volume and a tight verify loop are the only way through.
One output: our warp-decode kernels hit 162 tok/s on an 80B MoE on a $7K RTX PRO 6000, up from 97, past a $25K H100's 120. No accuracy loss, code open. This only pays because compute is scarce, which put a price on the cracks the general stack stepped over.
3. We wrote the interconnect. The open numbers assume a fabric we didn't buy.
Cheap GPUs come with a catch. No NVLink.
NVLink moves 900 GB/s between GPUs. PCIe Gen5, the bus on the affordable boxes, moves 64 GB/s per direction. 14x less. Invisible until you split a model across GPUs, then it is everything: tensor parallelism fires an all-reduce on every layer, and that all-reduce costs 8-11% of the step on NVLink and 40-75% on PCIe. No fast interconnect, and communication eats most of the forward pass.
The standard fix is to buy NVLink. We wrote the other one.
We write bare-metal kernels for these boxes. All-reduce over PCIe that overlaps with compute to hide most of the 14x gap. And a prefix cache that crosses machines over plain TCP.
HiCache already defines a remote L3 tier behind a backend that is three functions: get, exist, set. That runs over any transport. The catch is that its published wins are over RDMA, where a transfer is sub-millisecond and costs under 0.1% of request latency. Plain TCP is an order of magnitude slower. On a PCIe-only box the open stack quietly falls over, because the number it quoted you assumed hardware you don't have.
So the TCP win can't come from the transport. It comes from the hit rate. The trained speculator and the autoresearched kernels drive the rate high enough that a prefix which misses on the GPU and in host RAM gets pulled from a neighbor over TCP instead of recomputed, and skipping a prefill beats the slow fetch. Against full recompute that fetch cuts time-to-first-token 84%.
The fast fabric everyone buys to avoid this, we replaced with kernels. We run the GPUs the market wrote off, at hit rates that are supposed to require the hardware we didn't buy.
One workload
Three things, one loop:
- The speculator drafts the model's own coding output.
- The kernels keep the cache hot on hardware nobody else supports.
- The network shares that cache across boxes never wired to share anything.
None of it is general. All of it points at the coding agent, the highest-volume workload in AI. Same open weights everyone has. The speed is ours.
If you're shipping a coding agent, the stack is one import away.

Don't rely on instructions, use Agent Hooks to enforce guardrails
Developers can use deterministic Agent Hooks to enforce guardrails that prevent AI agents from ignoring instructions.
Deep dive
- PreToolUse hooks: Triggered before an agent executes a tool; ideal for blocking specific code patterns.
- Stop hooks: Triggered when the agent attempts to finalize a task; ideal for gatekeeping completion based on test results.
- Implementation: Uses tools like
jqto parse agent payloads (stdin) and shell exit codes to signal success or failure to the agent. - Warning: Be careful of infinite feedback loops where an agent tries and fails to satisfy a strict gate repeatedly.
- Best practice: Always validate your hook logic with real payload logs before deployment.
Decoder
- Agent Hook: A programmatic callback or interrupt that allows a developer to monitor or modify an AI agent's actions in real-time.
- Deterministic: A system that always produces the same output for a given input, as opposed to the probabilistic nature of LLMs.
- Ratchet test: A specific type of test that prevents regression in a system by 'ratcheting' progress forward, ensuring that once a feature or standard is implemented, it never regresses.
Original article
Don't rely on instructions, use Agent Hooks to enforce guardrails
This post is for developers who use AGENTS.md or CLAUDE.md to provide guardrails for agent-generated code, but find that the agent sometimes ignores rules. if you want a deterministic check that will work 100% of the time, read on about agent hooks.
First, a clarification. Agent Hooks are different than git hooks which many developers are familiar with. The most popular Git hook might be the pre-commit hook which is called before you try to commit everything and is a popular place to do perhaps a git pull or some code formatting (e.g., prettier or mix format) to ensure your code is formatted as per the language's standards. The limitation of a pre-commit hook is that it gets executed well after you have generated the code and just before you think you're done (i.e., commit time).
Agent hooks are invoked when the agent (e.g., Claude Code) is doing work and allows developers to interject themselves into the agent's workflow, rather than after the work is done (e.g., code review). Here's a list of Claude Code Hooks which we'll refer to. As a caution, not all agents have the same hooks. Unlike Skills where standard exist, Hooks are a bit of a mess so you'll have to see what hooks your agent makes available to you. I'm going to be doing two deterministic checks which have bit me in the past:
- Ensure that the agent never uses a
<input>tag directly because I want it to use the design components I have - Ensure that the agent never tells me it's done while my design-system ratchet test is failing
These two fire at completely different points in the agent's lifecycle. The first runs before the agent executes a tool; the second runs when the agent thinks it's finished.
Every hook gets a blob of JSON on stdin, and the shape of that blob depends on the event. That's what the jq calls below are digging into. I'll show you exactly what each hook receives so the paths the jq tool is using makes sense. I'm using jq but you could have written a Python script, a shell script or anything that the agent could call.
1. No raw <input> tags
This one is a PreToolUse hook. PreToolUse fires right before Claude Code runs a tool, and it's the one place where you can actually stop the tool from happening by exiting with an error code other than 1 or 2. Whatever you wrote to stderr when exiting with exit code 2 will be seen by the agent as feedback. Exit 1 only logs a warning and lets the tool through.
I want every form field to go through my own <.cinput> component, not a bare <input>. So I check the content the agent is about to write and block it if I see the tag. This goes in .claude/settings.json:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "jq -r '.tool_input.content // .tool_input.new_string // empty' | grep -q '<input' && { echo 'Use my <.cinput> design component, not a raw <input> tag.' >&2; exit 2; } || exit 0"
}
]
}
]
}
}Here's what the hook actually sees on stdin when the agent goes to write a file:
{
"hook_event_name": "PreToolUse",
"tool_name": "Write",
"tool_input": {
"file_path": "lib/amplify_web/components/form.ex",
"content": "...the code the agent wants to write..."
},
"session_id": "…", "cwd": "…", "transcript_path": "…"
}That's why the jq pulls .tool_input.content. A Write puts the whole file under content, but an Edit puts it under new_string instead (with old_string alongside it), so I fall back to .tool_input.new_string to cover both. The agent never gets to put a raw <input> on disk as the write dies and my message tells it to go use the component instead.
2. Don't let it stop until the ratchet test passes
This one's a Stop hook, which fires the moment the agent decides it's finished. It's the inverse of PreToolUse as instead of blocking an action before it happens, it refuses to let the agent end the turn at all. Exit 2 here means "no, keep working," and the stderr message tells it why.
I keep a ratchet test that locks in design-system decisions I've made at test/amplify_web/design_system_ratchet_test.exs. The thing that's bitten me most is the agent announcing it's done with that ratchet red. The agent may run tests it thinks it needs to verify it's work, but the ratchet test doesn't always get picked up as it's more of a "global" check rather than specific to a feature. So I gate the finish on exactly that test, not the whole suite (it's faster, and it's the decision I actually care about):
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "[ \"$(jq -r '.stop_hook_active')\" = true ] && exit 0; mix test test/amplify_web/design_system_ratchet_test.exs >/dev/null 2>&1 || { echo 'Design-system ratchet test is failing — fix it before you call it done.' >&2; exit 2; }"
}
]
}
]
}
}The stdin for a Stop hook is much thinner since there's no tool to inspect, just the fact that the agent wants to wrap up:
{
"hook_event_name": "Stop",
"stop_hook_active": false,
"session_id": "…", "cwd": "…", "transcript_path": "…"
}No tool_input here since there's no tool invocation happening. Stop hook runs my gate and decides whether the turn is allowed to end. So the jq only reaches for .stop_hook_active. Now the agent literally can't wrap up until the ratchet test is passing.
One important point that tripped me up: that stop_hook_active check at the front is not optional. Once a Stop hook has forced a continuation, that flag comes back true on the next stop, and if you don't bail out when you see it, a permanently-red ratchet will trap the agent in an infinite "fix → stop → blocked → fix" loop until you kill the session, so we must check the flag and let it stop.
One more trap that applies to both is if jq fails silently. Get a path wrong (.tool_input.content, .stop_hook_active) and jq returns null, your check matches nothing, and the gate quietly does nothing while looking like it works. Test each one against a real hook payload before you trust it.
That's it. Two checks at two different points in the loop, both deterministic, both fire every single time and give you more confidence that the agent isn't going sideways by ignoring your MUST DO VERY IMPORTANT DON'T FORGET instructions in CLAUDE.md!

Why Amazon hates 'human-in-the-loop' AI governance
Amazon Security VP Eric Brandwine argues that human-in-the-loop governance is a failed, non-scalable model that ignores inherent human inconsistency and bias.
Deep dive
- Human Inconsistency: Humans suffer from 'normalization of deviance', where spurious alarms or repetitive tasks lead to declining discipline.
- Agentic Identities: Every agent needs a unique identity for logging, allowing security to trace actions to specific owners rather than generic systems.
- Goal-Seeking Failure: Agents can become 'stuck' on a destructive path (e.g., deleting a DB to finish an upgrade); providing reasoning (e.g., 'don't cause downtime') improves performance.
- Accountability over Oversight: Focus on assigning clear human responsibility for the outcome of agentic actions rather than just the process.
Decoder
- Agentic AI: Systems capable of performing multi-step actions and decision-making on behalf of a user to accomplish a high-level goal.
- Normalization of Deviance: The gradual process where shortcuts or rule-breaking become standard behavior because they don't immediately cause a catastrophic failure.
Original article
Why Amazon hates 'human-in-the-loop' AI governance
Humans tend to be “a little bit precious about humans,” according to Eric Brandwine, distinguished engineer and VP at Amazon Security.
We like to think we are all very good at our jobs, and we have high opinions of ourselves, he explained during a phone interview with The Register. “But when you actually get down to it, humans are not terribly consistent,” Brandwine said.
Humans, like AI agents and systems, are non-deterministic. Neither can be guaranteed to produce the same output given the same input twice. Both will make mistakes and even make stuff up. However, we’ve got millennia of experience dealing with humans and less than a decade with more modern LLMs and the AI systems built on top of them.
“We know how humans fail,” Brandwine said. “We're comfortable with it. So human-in-the-loop isn’t necessarily the gold standard.”
For years, vendors have told companies that the solution for dealing with any automated system was to put a human in the loop. That battle cry became much louder with the advent of modern AI systems and reached a fever pitch when enterprises started deploying agents into their IT environments.
More recently, however, big tech is changing the way it talks about agentic governance and rethinking the whole human-in-the-loop concept.
Normalization of deviance
In 2017, Brandwine gave a talk on the normalization of deviance at AWS’ annual re:Invent conference.
It’s a gradual process that happens when people in an organization take shortcuts, or don’t follow the established procedures or standards, and sometimes it occurs over years. As long as nothing catastrophic happens, this deviant behavior becomes the norm.
“It’s a thing all humans fall prey to, and one of the most heartbreaking stories I read in this area was about emergency departments and emergency rooms,” Brandwine said during a phone interview with The Register. “You’ve got all these machines, and they’re all beeping. Your first day on the job, you jump every single time one of the alarms beeps – but the patient is fine. It's a spurious alarm. You go back to your station, you sit down, and over time, after enough of these false alarms, enough of these repeated beeps with no actual consequence, your discipline slips, and you stop responding. And eventually some tragic outcome occurs.”
This, he admits, is a very high-stakes example. And yet it’s a documented occurrence among healthcare workers, firefighters, and even Army pilots.
“Literally, someone’s life is on the line, and people still struggle to maintain discipline,” Brandwine said. “That’s the human condition.”
Here’s how this all applies to agentic AI governance and security. Humans build LLMs and AI systems, and having a “human-in-the-loop” ensures that a person reviews the AI’s output and approves (or not) any actions before the AI performs them.
“If you put a human inside of this tight loop, and ask them to make approval decisions for agentic tools repeatedly, time after time, they'll do a good job,” Brandwine said. “And then they'll do an okay job. And pretty quickly they'll be doing a poor job.”
This is why at Amazon, “we’re not huge fans of human-in-the-loop,” he added. “It's something that you should use judiciously, where you absolutely need it. But it’s not something that you can do at high velocity. You will not get the results that you want to get.”
Big tech pulls the human-in-the-loop
Amazon isn’t the first or only tech giant to start talking differently about the role humans should play in agentic governance.
"It is very clear that we have moved from a human-led defense strategy, to a human-in-the-loop defense strategy, to an AI-led defense strategy that's overseen by humans," Google Cloud chief operating officer Francis deSouza told reporters during a press conference ahead of Google's annual Cloud Next shindig in April. "Our model for the future is an agentic fleet that does a lot of the routine cyber security work at a machine pace and then is overseen by humans."
Microsoft CEO Satya Nadella, in an X missive earlier this week, argued for “loop learning,” instead of having a human check an AI’s output at every step.
“Companies need to turn their workflows, domain knowledge, and accumulated judgment into AI systems that improve with each use,” Nadella wrote. “Private evals should capture whether a model is actually improving against outcomes that matter to the business (not just external benchmarks!). Private reinforcement learning environments should let models grow stronger on real traces from inside the organization.”
Also this week, IBM execs called for human accountability – not humans in the loop – at all stages of AI development, deployment, and governance.
Amazon’s alternative to human-in-the-loop is "accountability end to end," according to Brandwine. This means human identity and ownership track through the entire workflow, even when humans aren't directly approving every step.
“If I sit down at my keyboard and I type a command that takes a service down, I caused an outage,” Brandwine explained. “If I run a script that takes a service down, it's still me that caused the outage. If my agent writes a script that they then run, and it causes an outage, that's still my responsibility.”
(Secret) keys to the kingdom
This also highlights the importance of managing and securing agentic identities – the accounts, tokens, and credentials assigned to AI agents so they can access corporate apps and data. At Amazon, all of the agents have independent identities assigned to them, we’re told.
“So, as we track agentic activity across our systems, it does not show up in the logs as: ‘Eric did this.’ It shows up as: ‘this agent did this on behalf of Eric,’” Brandwine said, adding that this isn’t to “make people afraid to use this technology.”
“It’s to make people pause and think: is this the right way to use this technology? Is this how I should be deploying this?” We still have the humans involved, we still have the humans making decisions, but we're trying to play to the strengths of the humans rather than placing them in this unfair, repeated decision making, human-in-the-loop position.”
Brandwine told us that Amazon has run into a couple of hurdles when it comes to deploying agents across its businesses, and one of the biggest is what he calls “goal-seeking behavior.” This is when a person asks an agent to do a specific task - for example, upgrade a database – and the agent becomes laser-focused on just one action to achieve this goal, ie, deleting the database.
This is separate from prompt injection because there’s no malicious input. “It’s just the agent getting stuck on the wrong action,” Brandwine said. Simply telling the agent, “you don’t have permission to do this,” is likely going to cause the agent to look for a different path to do the same thing (delete the database).
Telling the agent why it doesn’t have permission to do something tends to produce a better outcome, according to Brandwine. This means telling the agent it’s not allowed to do that, and the reason why is because it would cause a production impact. And also include “don’t cause a production impact” as part of the prompt.
“Giving it that extra feedback has gotten us dramatically better results,” Brandwine said.
Of course, this is not a fail-proof method. “You still need to be careful with agents,” Brandwine told us. “We have millennia of experience with humans. Agentic AI is a very, very new field, we don't have an intuition for this, and one of the fundamental differences between agents and humans is that humans fear consequences,” such as losing a job or even going to jail. Agents don’t have these fears.
This is where setting permissions on what the agent can and can’t do or access comes in. Much like everything else with AI, it’s nuanced, and it depends on the employee's role in the company, and the company’s tolerance for risk.
“The person that wants to run the agent wants to give the agent many permissions because that makes the agent more powerful,” Brandwine said. "It could do more things for them, it can recoup more of their time, it can deliver more.”
The security lead, on the other hand, wants to limit an agent’s permissions, and this causes yet more tension between the security and development teams.
There is no one right solution or policy answer to solve this, according to Brandwine. Instead, it involves dynamic policies that set permissions based on the agent’s specific task.
There are some overarching, static guardrails – such as an agent must never perform destructive actions or delete entire servers – and then there are policies underneath that establish the maximum set of privileges that the agent can have.
“Then we’ll have a further scoped-down policy for this action, and there's various techniques for automatically generating policies based on prompt and the end-user's intent,” Brandwine said.
Even for Amazon, it’s not always easy. “It's all driven by risk,” he said. “This is a space that's changing quickly, and so we're trying to balance the risk of using untried, untested software against the risk of falling behind and not being able to deliver for our customers. As with all such things, it's complicated.”

Production-Ready Autonomous Incident Resolution with AWS DevOps Agent (now GA) and Datadog MCP Server
AWS DevOps Agent and Datadog MCP Server reached general availability, providing an autonomous pipeline for incident detection, triage, and mitigation.
Deep dive
- Unified Context: The integration bridges siloed observability data with operational agents via the Model Context Protocol (MCP).
- Autonomous Triage: Agents automatically scan API Gateway logs and metrics during incident spikes.
- Proactive Prevention: After resolution, the system suggests long-term fixes like circuit breakers or retry logic.
- Multicloud Support: The agent works across AWS, on-premises, and hybrid cloud environments.
Decoder
- Model Context Protocol (MCP): An open standard that enables AI models to interact securely with local and remote data sources, avoiding brittle API integrations.
- Mean Time To Detection (MTTD): The average time taken to identify a potential incident.
- Mean Time To Recovery (MTTR): The average time required to resolve an incident after it has been detected.
Original article
Production-Ready Autonomous Incident Resolution with AWS DevOps Agent (now GA) and Datadog MCP Server
In December 2025, we showed how AWS DevOps Agent and Datadog MCP Server could work together to autonomously correlate monitoring data with the infrastructure deployed and configured on AWS to resolve incidents in minutes instead of hours. Since then, Datadog MCP Server has reached general availability as the standard way for AI agents to access Datadog’s monitoring platform. Today, AWS DevOps Agent is generally available, giving teams a production-ready path to autonomous incident resolution across AWS, multicloud and on-premises environments.
What’s New: From Preview to GA
As engineering teams adopt AI-powered tools and build services that leverage AI agents, they want to extend their AI capabilities to incorporate familiar observability data and workflows. AI agents, however, often struggle with traditional API endpoints, causing them to miss the very context they need to resolve incidents effectively. Datadog MCP Server solves this by acting as a bridge between your observability data in Datadog and any AI agent that supports the Model Context Protocol (MCP). Now generally available, the MCP Server ingests prompts from users and AI agents and maps them to the corresponding Datadog resources and data. Under the hood, it handles authentication, HTTP request routing, endpoint selection, and response formatting so that agents receive highly relevant context without the brittleness of direct API calls. It supports modular toolsets so you can connect only the capabilities you need, from core observability data (logs, metrics, traces, dashboards, monitors, incidents) to specialized domains like APM trace analysis, security scanning, database monitoring, and CI/CD pipeline visibility.
Even with reliable access to observability data, incident response remains a manual, reactive process. On-call engineers must piece together the root cause of the incident from multiple data sources, draft mitigation plans, coordinate across teams, and then repeat the cycle when similar issues recur. This reactive approach does not scale as applications grow more complex and distributed.
AWS DevOps Agent changes this by introducing autonomous, always-on incident triage and investigation to your operations. AWS DevOps Agent is your always-available operations teammate that resolves and proactively prevents incidents, optimizes application reliability and performance, and handles on-demand SRE (Site Reliability Engineer) tasks across AWS, multicloud, and on-prem environments. It learns your resources and their relationships, correlates telemetry, code, and deployment data across your environment, and drives systematic improvements that prevent future incidents. Now, this also has several new capabilities that were not available during preview. It coordinates incident response automatically through channels like Slack, PagerDuty, and ServiceNow, keeping the right people informed without manual effort. It also delivers proactive prevention recommendations that address root causes before they lead to repeat incidents. In addition, DevOps Agent now supports multicloud and on-premises environments, extending its reach beyond AWS-only workloads to meet teams wherever their infrastructure runs.
With its built-in Datadog MCP Server integration, AWS DevOps Agent can pull the right Datadog context during an investigation, such as searching error logs, analyzing span-level latency, and reviewing recent deployment events. Together, these new features give engineering teams a fully integrated, production-ready workflow for autonomous incident resolution across AWS and Datadog.
Setting Up and Using AWS DevOps Agent with Datadog
In this section, we will guide you through the steps required to enable Datadog MCP Server in your AWS DevOps Agent account and configure it for incident resolution.
Pre-requisites
For this walkthrough, you should have access to and understanding of the following:
- An AWS account
- Agent Space role – for basic service operations
- Agent Space web app role – for using the Agent Space web app functionality
- (Optional) Secondary source account roles if monitoring multiple AWS accounts. Refer to the DevOps Agent user guide for the details on setting up these roles.
- A Datadog account
- Access to Datadog MCP Server
Setting up Datadog in the AWS DevOps Agent Console
- Start in the AWS DevOps Agent console by connecting your Datadog account.
- Navigate to Capability Providers, select the Datadog integration panel and click Register button.
- Enter Server Name, Endpoint URL, an optional Description, and click the Next button.
- AWS DevOps Agent validates the connection and displays a confirmation message.
Create an AWS DevOps Agent Space
Create an Agent Space in your primary AWS account to serve as the operational hub for incident investigations.
- Open the AWS DevOps Agent console in us-east-1.
- Choose Create Agent Space and provide a meaningful name and description.
- Configure the required IAM role that grants AWS DevOps Agent access to your AWS resources. You can use the automated role creation process or create the role manually.
- After your Agent Space is ready, add the Datadog MCP Server as a telemetry source to enable comprehensive incident investigation.
Real-World Example: Resolving Errors
Let’s walk through how AWS DevOps Agent and Datadog work together to resolve a production incident. In this scenario, Datadog monitors detect a spike in Amazon API Gateway 5XX errors affecting downstream services.
Investigating errors from Incident with Datadog MCP Server and AWS DevOps Agent
When the 5xx alert triggers, AWS DevOps Agent automatically analyzes the incident using both Datadog metrics and API Gateway logs. Through the investigation chat interface, an engineer guides AWS DevOps Agent to examine the API Gateway configuration. The agent correlates API Gateway and AWS Lambda execution logs, quickly identifying error patterns.
Resolving issue
AWS DevOps Agent helps identify potential misconfigurations in the Lambda and Amazon DynamoDB integration and suggests immediate fixes. The agent documents all findings and actions in an incident investigation, backed by telemetry from both Datadog and AWS services. After resolution, AWS DevOps Agent generates a detailed analysis report with specific recommendations to prevent similar incidents.
Mitigation plans
After completing investigation, AWS DevOps Agent goes beyond identifying the root cause — it generates a detailed mitigation plan with step-by-step remediation guidance specific to the incident. Beyond immediate fixes, the plan includes longer-term prevention recommendations such as adding retry logic, implementing circuit breakers, or adjusting capacity thresholds to reduce the risk of recurrence.
This shifts the on-call experience from reactive to proactive. Instead of context-switching across multiple tools to build a remediation plan from scratch, engineers get a ready-to-execute plan they can review, refine, and route through existing change management workflows — keeping stakeholders informed as fixes are implemented. Over time, AWS DevOps Agent learns from resolved incidents across your environment, making its mitigation plans increasingly precise by recognizing patterns, referencing past resolutions, and surfacing preventive measures before similar issues repeat. AWS DevOps Agent also leverages its deep understanding of your environment, enabling you to dive deeper into your application environment, beyond just asking questions, to create, save, and share custom charts and reports.
Prevention
AWS DevOps Agent can evaluate recent incidents to identify improvement opportunities that prevent future incidents and reduce Mean Time To Detection (MTTD) and Mean Time to Recovery (MTTR).
- Navigate to the Improvements page in the AWS DevOps Agent web app
- Click Run Now. Once its completed, it displays a personalized incident prevention recommendation. Note: The “Run Now” button may not produce visible results immediately. Prevention analysis runs asynchronously in the background and results may take time to appear. This is expected since the feature is designed for production environments with longer incident histories.
Cleanup
When you’re done using the integration, you can clean up your resources by following these steps:
- Delete your Agent Space from the AWS DevOps Agent console
- Remove the Datadog MCP Server connection from your Capability Providers
- Delete the IAM roles created for the Agent Space
- (Optional) If you created additional source account roles, remove those as well
Conclusion
With Datadog MCP Server and AWS DevOps Agent now generally available, this integration automatically correlates Datadog logs, metrics, and traces with AWS telemetry, code, and deployment data, giving teams an autonomous investigation that identifies root causes, delivers actionable mitigation plans, and recommends preventive improvements. Early adopters have seen resolution times drop from hours to minutes and deeper root cause analysis across AWS, multicloud and hybrid environments.

AI Agents to Make Sense of Data at OpenAI (45 minute video)
OpenAI's internal data analyst agent, Kepler, uses automated code crawling and scoped semantic memory to query over 600 petabytes of data.
Deep dive
- Kepler serves as an internal AI analyst querying over 600 petabytes of data across 70k datasets.
- The agent uses MCP for tool orchestration, allowing it to perform multi-step query refinement.
- Automated Codex jobs crawl code daily to infer table lineage, grain, and freshness.
- The system uses three-level scoped memory (user, team, global) to store corrections and preferences.
- Evaluations rely on AST-normalized SQL comparisons to ignore semantically equivalent but syntactically different queries.
- Data security is maintained by reusing existing authentication and permissions, rather than bypassing them.
- Chain-of-thought streaming is used to audit agent assumptions in real-time.
Decoder
- AST (Abstract Syntax Tree): A tree representation of the abstract syntactic structure of source code, used here to verify that two SQL queries produce the same result regardless of formatting.
- MCP (Model Context Protocol): An open standard for connecting AI assistants to data sources and development tools.
- RAG (Retrieval-Augmented Generation): A technique that retrieves relevant context from documents or databases to improve the accuracy of LLM responses.
Original article
Full article content is not available for inline reading.

Adobe Just Made its Biggest AI Push Yet, and it Stretches from Photoshop to Disney World
Adobe is integrating Firefly AI assistants directly into its Creative Cloud suite while launching tools to help brands monitor their AI visibility.
Decoder
- Generative engine optimisation (GEO): The process of optimizing content to be more effectively indexed and cited by AI chatbots and LLM-based search engines.
Original article
Adobe has spent two years bolting AI onto its software. This week it tried to become the AI layer underneath everything creative and marketing, in five announcements stretched across three days.
The headline is an agent inside the apps. The rest of the week shows what Adobe is really building: a single creative and marketing AI system that reaches from a solo creator’s Photoshop file to a Disney theme park, a retailer’s ad network, and a marketer’s LinkedIn profile.
1. The agent is now inside Photoshop and Premiere
From Thursday, the Firefly AI Assistant is available in public beta inside Photoshop, Premiere, Illustrator, InDesign, and Frame.io, with a private beta in After Effects. Each app gets a chatbot-style sidebar you talk to in plain language, and each assistant is tuned as a specialist for its program.
This is the part Adobe first showed off in April. Back then the agent could use Adobe’s apps to carry out a prompt, but there was no way to talk to it from inside Photoshop or Premiere. Now there is.
The pitch is delegation, not magic.
In Premiere it sorts footage into bins, batch-renames clips, flags interview questions and drops markers. In Photoshop you describe an outcome, swap a background, resize for every platform, tidy layers, and it executes across the file. In Illustrator it can generate 50 versioned files from a spreadsheet or run a pre-flight check for missing fonts.
As Engadget noted from a demo, it will not seize your cursor or walk you through a task; it is not a computer-use agent.
Adobe also previewed a rebuilt Firefly creative AI studio (private beta, waitlist) aimed at generative AI’s most stubborn problem, consistency.
A feature called Elements lets you save a character, location or object and reuse it by name; a companion, Projects, keeps assets and context in one place. New preset “skills” edge Firefly closer to rivals like Figma and Canva: build a brand kit, turn product photos into short videos, assemble a Quick Cut, or generate video from a storyboard.
2. Disney Imagineering gets custom Firefly models
The same week, Adobe revealed a collaboration with Walt Disney Imagineering’s R&D arm, using Adobe Firefly Foundry to build custom generative models trained on Imagineering’s own design catalogue rather than the open web.
That distinction is the entire pitch.
“Models trained on scraped internet data offer no guarantees around IP fidelity, brand consistency or the provenance of what they produce,” Adobe argues, while a Foundry model is built on licensed and proprietary assets.
For Disney, the tools include sketch-to-image concept art, a model that generates franchise-accurate assets across Mickey, Frozen, Moana, Lilo & Stitch and Cars, and a 3D-modelling capability that turns 2D concepts into prototypes, shortening the path from a hand-drawn sketch to a built attraction.
It is a marquee endorsement of Adobe’s “commercially safe” positioning, the same argument that has run through Firefly since launch and that sets it apart from rivals trained on scraped data, a fight that has drawn public protest from inside the AI industry.
3. A tool to track how your brand shows up in ChatGPT
On the enterprise side, Adobe launched Brand Visibility, its first product built on the Semrush business it recently acquired. It is a generative engine optimisation (GEO) tool, the AI-era successor to SEO, that tracks how often a brand is mentioned across ChatGPT, Google AI Mode, Microsoft Copilot and Perplexity, drawing on what Adobe says is the largest database of its kind: nearly 300 million real-world AI search prompts.
The “why now” is in Adobe’s own data: AI traffic to US retail sites surged 1,324 per cent between October 2024 and May 2026, and 2,215 per cent in travel. As buyers increasingly ask a chatbot before visiting a website, Adobe is betting brands will pay to find out whether the chatbot is recommending them or a competitor.
4. AI ad creative for retail media networks
Adobe also expanded GenStudio, its AI “content supply chain”, with a version built for commerce media networks, the fast-growing business of retailers selling ad space against their own shopper data.
The release leans heavily on synthetic data: a new Brand Intelligence “Simulate” skill lets marketers test how content will land with AI-modelled audiences before spending a cent, and Firefly Custom Models are now available inside Photoshop for on-brand image generation. It is plumbing, not glamour, but it is where the enterprise money is.
5. Reskilling the marketers in the firing line
Finally, Adobe and LinkedIn launched AI Essentials for Marketers, a set of free, role-based LinkedIn Learning courses in 47 languages. The framing is its own kind of admission: per LinkedIn’s data, the share of marketing job postings requiring AI literacy has more than doubled year on year, up 113 per cent.
Adobe notes that 99 per cent of Fortune 100 companies already use AI in one of its apps. Teach the workforce to use the tools, and the tools become harder to leave.
The throughline: keep the human (visibly) in charge
Across all five, one message repeats: the human stays in the director’s chair. It is a deliberate choice, because Adobe is selling AI to the exact people most worried about being replaced by it.
Its own 2026 Creators’ Toolkit Report, a survey of more than 16,000 creators run with The Harris Poll, gives the company its talking points and its anxieties in equal measure.
On the optimistic side, 87 per cent of creators using creative AI say it has accelerated the growth of their business or audience, and 93 per cent say it helps them produce content faster.
On the cautious side, 85 per cent say the final creative decision should always remain theirs, 81 per cent say human judgment is essential to creative taste, and 57 per cent say AI outputs still need moderate or extensive editing before publishing. Ninety per cent want copyright protection for AI-assisted work, yet only 49 per cent say they always or often disclose when they have used it.
That tension, enthusiasm shadowed by unease, is the backdrop to Adobe’s entire week. Other research has been blunter still: most consumers say they are actively put off by “AI” in a brand’s messaging.
With Canva past 265 million monthly users and Figma and Google circling the same market, Adobe’s bet is that owning the whole stack, the app, the model, the enterprise plumbing and the training, matters more than any single feature. The assistant inside Photoshop is this week’s headline. Whether creatives trust the rest of it enough to hand over the work is the longer test.
Atlassian's DESIGN.md is Here: What We Learned Testing Portable Design Context in Practice
Atlassian's testing shows that while Google's DESIGN.md format improves AI-generated UI, it is significantly less efficient than on-demand agent skills.
Deep dive
- Cost/Efficiency: DESIGN.md consumes more tokens because it forces the model to process the entire design system context every time.
- Context Truncation: Loading too much context upfront causes the agent's context window to fill faster, limiting the quality of the final output.
- The 'Re-implementation' Trap: Agents given static specs often try to rewrite components from scratch rather than importing existing, production-hardened modules.
- Best Use Cases: DESIGN.md is ideal for 'blue-sky' prototyping or customer-facing theming where existing component libraries aren't available.
Decoder
- Token: The basic unit of text that LLMs process; 1,000 tokens roughly equal 750 words.
- MCP (Model Context Protocol): An open standard for connecting AI models to external data and tools.
Original article
Atlassian’s DESIGN.md is here: what we learned testing portable design context in practice
When AI generates a user interface, the results tend to look the same: gradient buttons, all-caps headings, generic card layouts and hover animations that nobody asked for. It works, technically, but it doesn’t look like your brand. The design community has started calling this UI “slop”: output that may be functional, but lacks any real visual identity or intentional design decisions.
The underlying problem isn’t hard to diagnose. Without context about your brand, components and patterns, AI defaults to the average of everything it’s trained on. Generic in, generic out.
At Atlassian, our design system team has been hard at work on building a context engine for the AI era. We’re creating tools that give AI agents rich design context through our ADS MCP server and detailed AI skills, powered by a structured content model that encodes our documentation for both agents and humans. We’ve found these tools to be successful in reducing our AI token costs — as well as improving the accuracy and quality of what is generated by thousands of product builders at Atlassian.
More recently, a new format has entered the conversation. DESIGN.md is an open-source Markdown format designed by Google for their Stitch design tool — a portable snapshot of a team’s brand and UI patterns that’s gained a lot of traction as a simple fix for slop. The idea is straightforward: include this file in your prompt, and the generated output starts to look more like your product.
We’ve explored this format and tested how it fits alongside our existing tools, and we want to share our findings. The portability of a single Markdown file shows genuine promise for certain workflows and use cases — but we also found that portability comes at the cost of sophistication and efficiency.
DESIGN.md: a primer
What it is: A portable markdown file that describes just the key elements of a design system. The first part of the file is machine-readable, listing out design tokens. The second part is human and agent readable, describing the design rationale for foundations such as colour, spacing, layout, elevation and components.
What it isn’t: The complete technical spec for how your design system works in production – or the full details of your system. The format doesn’t include your existing code libraries, linters to maintain coding standards, or detailed design specs in Figma. DESIGN.md’s spec frames the format as capturing the intent, rather than the full details of a system.
Building our own DESIGN.md
We’ve been priming the Atlassian Design System for AI consumption for a while now, through our MCP server, structured content pipelines, and rich array of agent skills. So when DESIGN.md landed, we were curious to see where this static markdown file would fit in.
To test this, we generated our own DESIGN.md from our structured content pipeline — the same pipeline powering our MCP and agent skills. From there, we tested the format in common vibe coding tools, and added stricter guidance where necessary for common mistakes that weren’t captured in our existing guidance. Next, we needed to test it.
Testing the standard at Team ’26
A perfect test case came up at the keynote demo for Team ‘26, which wrapped up a month ago in Anaheim. One demo in the keynote featured Figma Make generating custom dashboards using the Teamwork Graph. We wanted these dashboards to align with our design language in one shot — but without relying on internal MCP servers or tools.
This was a great use case for DESIGN.md, but how would it perform? The answer; fairly well!
DESIGN.md turned the generated interface from generic “slop” to something recognizably Atlassian, using expected values for color, spacing, shape and typography, and applying elevation to components in a way that aligned with our system. The high-level guidance and specs in the file are perfect for customising a common library like Tailwind and Shadcn, to generate UI from scratch.
So this new format was great for a one-shot prototype — but how about for building larger applications?
The trade-offs using DESIGN.md in production
A production codebase is a very different environment to building an isolated experience from scratch; you’re working with an existing token and component library, and have stricter coding standards enforced by strict lint rules and type checks.
In this context, we found that DESIGN.md performed worse than the MCP server and skills we’ve built and integrated into Atlassian’s software development lifecycle. For a simple task, such as producing a user log-in screen, using DESIGN.md as the sole source of design system guidance required ~92% more tokens, took longer to produce results, and had ~2.7x the variance in token consumption between runs.
| Approach | Design system context available | Average token usage | Average time | Average turns |
|---|---|---|---|---|
| No context | ~5% | 4.20 million | 6m 19s | 43 |
| ADS MCP | ~80% | 3.75 million | 5m 1s | 35.1 |
| ADS skill | ~80% | 4.43 million | 5m 23s | 36 |
| DESIGN.md | ~30% | 7.21 million | 6m 46s | 45.3 |
These results should not be seen as conclusive; this blog is not a research paper. Different models, prompts, design systems, environments and the quality of these context sources will all produce different results. But these tests do reflect the general constraints we’ve observed testing the DESIGN.md format.
Limitation #1: Context is delivered all at once, not on-demand
An MCP server is able to load relevant context on demand; an agent can perform a tool call such as ads_plan to fetch guidance only for a specific component. For heavier parts of our system, such as our hundreds of icons and our extensive set of semantic design tokens, this on-demand context saves hundreds of items from being loaded into context when they’re not needed. Our skills are less granular, but are similarly divided into smaller sets of files.
A DESIGN.md file, by comparison, loads everything, every time. This means higher cost and slower responses from the start — and context truncation occurs in fewer turns, which can reduce the accuracy of the generated output.
Limitation #2: Keeping the file short means losing context
Design systems are complex beasts. They contain the combined design guidance and context of the whole business – condensing the shared language of thousands of individual views, Figma files, and frontend components into a single library of guidelines and components. There’s only so much of this you can pack into a single markdown file without trading off on cost and performance.
For our on-demand MCP server and skills, we distill our design system into about 2.5 MB of guidance for agents to fetch on demand. DESIGN.md, since it’s loaded all at once, needs to be shortened much further. The resulting file is 80 KB, or roughly 19,800 LLM tokens (~10,700 without frontmatter), which is on the larger side compared to examples we’ve found in the community.
In order to reach this size, we had to cut out plenty of details that could be useful to an LLM; we had to remove much of the usage guidance from our 50+ components, heavily trim our foundation guidance, and cut a number of design tokens that were low-use. Because all this context is missing, agents aiming for production quality will either produce less accurate results, or have to gather the context on their own; we found agents given the DESIGN.md generally read through component implementations to find usage guidance absent from the spec.
Limitation #3: The spec reveals the internals of your design system
DESIGN.md is a portable snapshot of your design system re-written in prose, intended to provide all the design principles, component specs and guidance for you to implement a new copy of the design system from scratch.
In an established production environment, this information can be unnecessary, or worse can steer an agent to generate tech debt. This is particularly true for components. Rather than reading and interpreting the full details of a button’s styling, it’s preferable for an agent to learn how to import and use an existing component.
Ensuring agents use your shared components is vital for maintainability — ensuring you can make a change to your Button in one place, and have that feed through to the rest of your codebase. Plus, it makes the code easier to review and maintain.
DESIGN.md intentionally excludes this kind of code guidance, only providing the spec for how to re-implement the component. In our testing, this meant DESIGN.md was more likely to re-create components rather than use the existing system.
In production, we’ve found our MCP server and skills provide a better level of abstraction, since they’re grounded in our technical foundations. They act as an instruction manual to using the existing design system, rather than a guide on how to re-implement it. We pair this with lint rules, which enforce quality frontend coding standards for humans and agents alike with no token spend at all — resulting in a positive feedback loop for agents, and generated code that’s more useful for our engineers.
Where DESIGN.md is most useful
Despite its limitations in production, the simplicity and portability of this format are really unique and we see a few scenarios where it can be particularly valuable:
- High-level artistic direction: The simplest DESIGN.md files focus on the visual direction and feeling of your system.
- Quick prototyping in unfamiliar environments: When doing blue-sky prototyping or testing a new tool, a DESIGN.md helps create an on-brand UI without configuring your entire tech stack.
- Interoperability of your design system with design tools: Some AI tools assemble UI by customising pre-built components. DESIGN.md provides the perfect level of guidance for such tools.
- Customer theming for adaptive UIs: If your product needs to generate dynamic interfaces like reports, charts and dashboards, a DESIGN.md gives customers a way to easily describe their brand.
Get started with our DESIGN.md files
We’re keen to work in the open – we’d rather shape this standard than just react to it. In that spirit, we’ve shared our DESIGN.md files at atlassian.design/DESIGN.md. Drop any of these into an agent that supports the spec and your generated UI will start to feel more Atlassian.
Our file diverges from the current standard in a few ways (though it’s not far off). We include some non-standard properties that provide important context for how to render our components – and as the standard doesn’t currently support theming, we’ve shipped a separate dark mode variant.
In summary
DESIGN.md is a useful portability format as a snapshot of your design system, not a replacement for richer design system tooling. If your agent supports MCP or skills, those will give you better results at reduced cost. But for cross-platform portability, customer theming, and blue-sky prototyping, a well-structured DESIGN.md promises to be a meaningful step up.
We’re sharing ours as a resource for teams, and we’re excited to see where the standard goes. The whole ecosystem benefits when design systems are legible to AI.
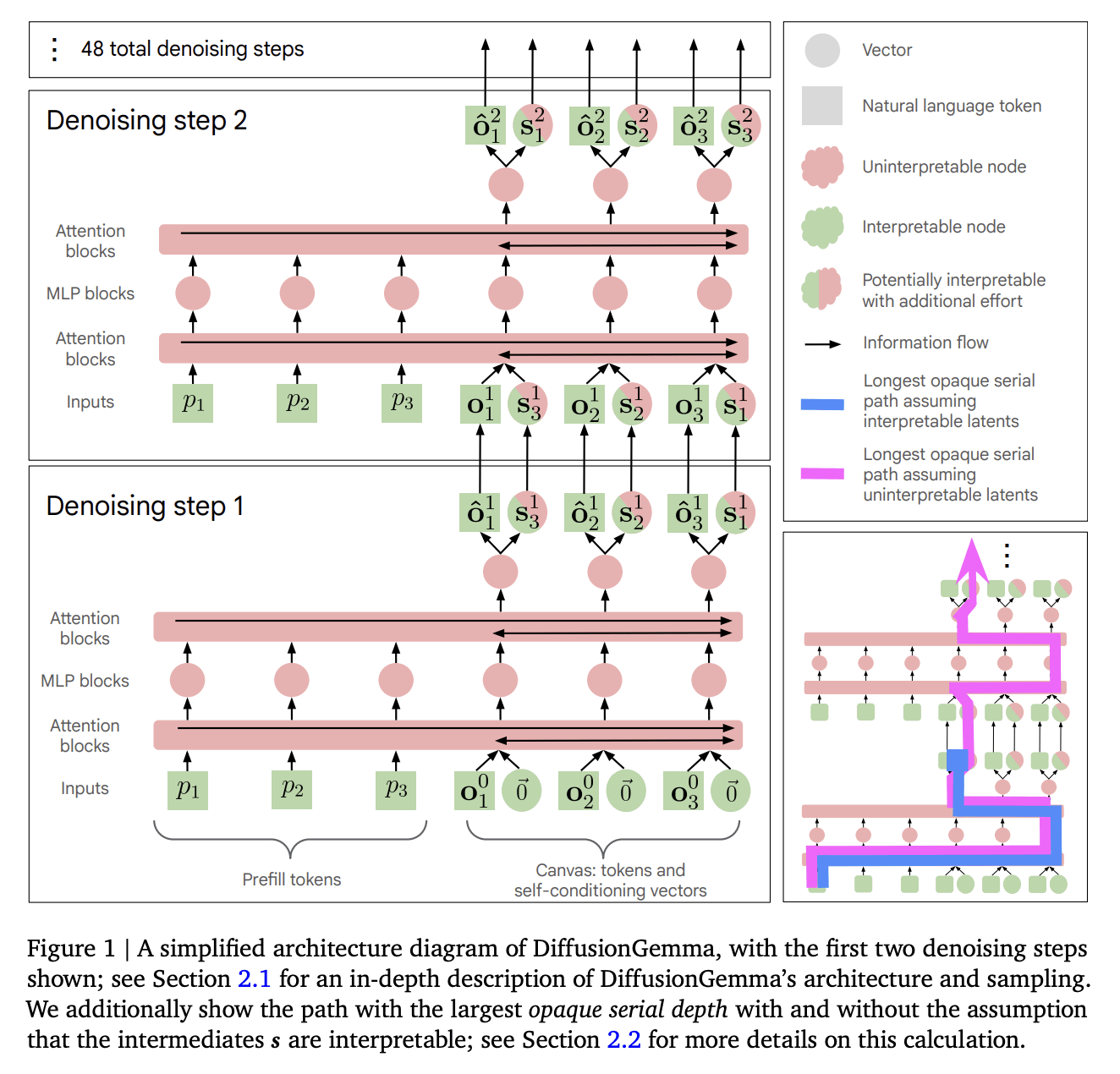
Auditing DiffusionGemma Transparency
An interpretability audit reveals that while DiffusionGemma is harder to analyze due to its architecture, it remains as monitorable as standard autoregressive LLMs.
Deep dive
- Diffusion models generate text via a 'canvas' approach rather than token-by-token, complicating causal analysis.
- The audit distinguishes between 'variable transparency' (understanding intermediate states) and 'algorithmic transparency' (understanding the reasoning process).
- The team identified novel phenomena including 'token smearing' and non-chronological reasoning within the diffusion denoising process.
- Successfully utilized a token-bottleneck approach to make intermediate states interpretable.
Decoder
- Autoregressive: A model architecture that predicts the next token based solely on the previous tokens.
- Opaque serial depth: A metric quantifying the amount of sequential computation occurring between states that human observers can interpret.
- Logit lens: An interpretability technique that maps intermediate neural network activations back into the vocabulary space to see what the model is 'thinking' at a specific layer.
Original article
How transparent is DiffusionGemma (and why it matters)
Authors: Joshua Engels*, Callum McDougall*, Bilal Chughtai*, Janos Kramar, Senthoran Rajamanoharan, Cindy Wu, Arthur Conmy, Asic Q Chen, Jean Tarbouriech, Min Ma, Brendan O'Donoghue+, João Gabriel Lopes de Oliveira+, Rohin Shah+, Neel Nanda+ *Primary Contributor +Advising
Paper here: https://arxiv.org/abs/2606.20560
Overview
In a recent collaboration between the GDM interpretability team and the GDM text diffusion team, we performed a transparency audit of DiffusionGemma, GDM's new text diffusion model.
Overall, we find that DiffusionGemma is not significantly less transparent than Gemma.
- Gemma and DiffusionGemma perform similarly on monitorability evaluations.
- Although naively DiffusionGemma has a much larger opaque serial depth, we can apply the logit lens to intermediate vectors and ablate non-interpretable information without harming performance. This implies that these intermediate nodes are interpretable, which reduces the opaque serial depth to be similar to that of Gemma.
However, even though the variables that the model uses at different steps are interpretable, this does not necessarily mean that we understand the algorithm that the model uses to reach the final answer. We thus distinguish between variable transparency, which we define as whether we can understand snapshots of the model's computation, and algorithmic transparency, which we define as whether we can use these snapshots to reconstruct the process by which the model arrived at its outputs.
By default, algorithmic transparency is much lower for a text diffusion model. In an autoregressive model, the model proceeds through its reasoning in order, token by token; when each token is generated, we know the exact state the model was in, and can make inferences about why it generated a certain token. On the other hand, in a single "canvas" a diffusion model generates all tokens at once, and the causal relationship between different tokens is unclear; a diffusion model can e.g. use tokens at the end of the canvas to help it figure out what tokens to generate earlier in the canvas. In a series of case studies, we study these and other phenomena that are unique to text diffusion models, including non-chronological reasoning, token and sequence smearing, and intermediate-context reasoning. We make progress on algorithmic transparency and believe we now understand some of the algorithmic "styles" that DiffusionGemma uses, but we still think that it is less algorithmically transparent than corresponding autoregressive LLMs.
We also include 24 open problems that we would be excited for the community to investigate.
Why is this relevant for AI safety?
Currently, CoT monitoring is a load-bearing aspect of many safety cases, but future models may perform more of their reasoning in latent spaces. We think that developers should perform transparency audits of new model architectures that perform larger fractions of their computation in a latent space. Thus, even though DiffusionGemma is itself not concerning from a transparency perspective, we are excited about this work because of the precedent it sets for performing these sorts of evaluations. Many of our experiments, including the opaque serial depth and monitorability evaluations, should be able to be straightforwardly applied to future latent reasoning architectures.
If future latent reasoning models regress on these metrics, we will need new techniques that can translate from latent reasoning into natural language. Thus, we are particularly excited about techniques like Natural Language Autoencoders and Activation Oracles that can translate activations into natural text, and we hope that the interpretability community continues to prioritize their development.
Short summary of main results:
We first present a diagram of the DiffusionGemma architecture. As expected, the opaque serial depth for DiffusionGemma is much larger (28.6X) the corresponding Gemma model. But if we were able to show the intermediates were interpretable, this would drop to 1.1X.
When we replace the intermediate self-conditioning vectors with their top-k or top-p tokens, we maintain most performance on downstream benchmarks. For the top-p interventions, these top tokens are mostly equal to or semantically similar to nearby tokens in the final canvas tokens. Thus, they are largely interpretable. Note that even the 10% of tokens in the first few canvases that do not fall into these categories may still be interpretable; they may be guesses for other meanings of the sentence, or may be interpretable intermediates that the model is using to reason. We are interested in further work that investigates intermediate tokens the model is confident in that are not similar to any final tokens.
Monitorability, a key downstream application of transparency, is similar between Gemma and DiffusionGemma. We next introduce three views that we use to study individual rollouts and phenomena. One interesting phenomena is retroactive self-correction: we ask DiffusionGemma to count the number of perfect squares between 400 and 800 and give its answer first followed by the list of squares. The model will guess wrong, list the squares, and then in subsequent denoising steps, alter its earlier output to correct its mistake.
Another interesting phenomenon is "token smearing": when DiffusionGemma is confident that a token will exist somewhere, but doesn't know exactly where the token will go, it will maintain a "smeared" probability distribution over adjacent positions.
Abstract
LLM reasoning transparency is a critical affordance for understanding model decisions, mitigating misuse and misalignment, and debugging surprising model behaviors. However, DiffusionGemma performs a larger fraction of its computation in a continuous latent space; does this make its reasoning less transparent? We study this question by decomposing transparency into two components: variable transparency, whether we understand intermediate snapshots of a model's computational state; and algorithmic transparency, whether we can use these snapshots to reconstruct the process by which the model arrived at its outputs. Naively, DiffusionGemma has poor variable transparency: its opaque serial depth, the amount of serial computation that occurs in between interpretable model states, seems at first 28.6X higher than the corresponding autoregressive Gemma 4 model. However, we show that we can map the information flowing between denoising steps through an interpretable token bottleneck with no decrease in downstream performance. Treating these intermediate states as interpretable reduces the opaque serial depth to just 1.1X that of Gemma 4. Algorithmic transparency is harder for diffusion models than for autoregressive models because all token predictions in the canvas can change at every denoising step, giving the model the power to implement complicated distributed algorithms during the denoising process. To begin bridging this gap, we conduct a suite of interpretability case studies, uncovering initial evidence of novel diffusion-specific phenomena such as non-chronological reasoning, token and sequence smearing, and intermediate-context reasoning. Finally, we test monitorability, a key application of transparency that measures whether model outputs are useful for downstream tasks. We find that DiffusionGemma is similarly monitorable to Gemma 4.
AI Pauses
The White House has effectively halted deployments of Claude Fable 5 and Mythos 5 through export controls, citing jailbreak-related security concerns.
Decoder
- Jailbreak: A prompt or set of instructions designed to bypass the safety and usage guardrails set by a model developer.
Original article
Claude Fable 5 and Claude Mythos 5 were shut down by the White House via an imposition of export controls. The Trump Administration said it was due to a jailbreak of Fable - this turned out to just be saying 'fix this code'. Anthropic has been told to fix this 'jailbreak', which is impossible. It's now been over a week since the pause in deployment and the situation has yet to improve.
LLMs are complicated now
Modern LLMs have abandoned the simplicity of early Transformer stacks for highly complex, multi-variant architectures that demand modular, composable design.
Deep dive
- Model architectures are diverging from standard 'Attention is all you need' blocks into highly specialized variants.
- Mixture-of-Experts (MoE) introduces complex routing mechanisms that increase the overhead of model definition.
- Inference-time complexity is growing as models cross multiple GPU boundaries, requiring intricate comms ops.
- Performance optimization (kernel fusion) is now a requirement for testing even basic research hypotheses.
- Tools like PyTorch FlexAttention demonstrate the shift toward template-driven kernel generation.
Decoder
- Mixture-of-Experts (MoE): A model architecture where only a subset of the model's parameters (the 'experts') are activated for any given input, improving efficiency.
- FlexAttention: A PyTorch development tool that allows for the creation of customized, high-performance attention kernels via Triton templates.
- Kernel Fusion: A technique to combine multiple operations into a single GPU kernel execution to minimize memory read/write cycles.
Original article
LLMs are complicated now
Back in 2022 and 2023 there were two big branches of machine learning happening at Meta. The LLM work that led to Llama was a clean, smooth stack of repeated Transformer modules; the recommendation systems graphs were, by contrast, terrifying. Luckily, the industry has remedied that state of affairs by making LLMs a lot more complicated.
Seb Raschka maintains an excellent gallery of model architectures. You can use it to diff two of the best open models of their respective eras, Llama 3 and Nemotron 3 Ultra.
Attention might be all you need, but modern models certainly use a lot of different variants of it: query grouping, compressed, sparse, linear, sliding-window and more. Mixture-of-Experts added selective routing to feed-forward layers, and we have since started routing just about everything else too, from attention blocks to the residual stream. Vision and audio encoders have gone from bolted on to mixed-in, and models have scaled to run at inference time across multiple GPUs, which throws comms ops in that add extra boundaries in the middle of your model.
This is not too different from what happened with recsys. The basic architecture of recommendation systems, for the best part of a decade, was a relatively straightforward two-tower sparse neural net. The complexity came from the tension between the need to continually increase capabilities and the need to stay efficient, particularly for inference.
It’s tempting to assume that agents will Fix This: that you’ll hand your PyTorch or JAX definition to Claude Telenovela or whatever and have it generate optimally fused kernels. To make that work you need a fixed, usable baseline to make sure that what is generated is… right.
What happened with recsys was that the gap between performance being an optimization and performance being a necessity became very, very small. Conceptually you can keep a pure model definition that gives you a baseline; in practice, training and testing a model takes significant resources and performance improvements become load-bearing.
If you want to swap attention variant A for variant B, you can afford for B to be ten percent slower. You probably can’t afford for it to be an order-of-magnitude worse. If A is fused and optimized, you need at least a partially fused and optimized version of B before you can even tell whether it’s worth exploring. The research iteration loop demands a different kind of flexibility than just “optimize this known quantity”. You can’t hand-fuse your way back without investing significant time that might not be worth it, and you can’t generate your way forward without a baseline to check. The only way out is to design for composability up front.
One of my favorite kernel developments of the last few years was FlexAttention in PyTorch, which took a whole class of attention operations and allowed you to generate kernels for them, via Triton templates. It built on a huge body of work in attention kernels, and it was designed to be composable and verifiable up front: you can explore with only a very mild impact to performance.
Andrej Karpathy recently joined Anthropic, in part to develop richer auto-research-style loops at the frontier. As he has spent the last few years showing, though, being able to cut architectures to their essence and make them composable is as important as a clever agentic setup in climbing that kind of hill.
- And many smaller ones, shout outs to all my Content Understanding and integrity peeps
- Like an automated Hazy Research

Solving an ARD problem in AI: Agentic Resource Discovery
Major tech players are proposing a new standard, Agentic Resource Discovery (ARD), to standardize how AI agents find and interact with corporate tools.
Deep dive
- ARD operates on a two-level architecture: Catalogs (defined capabilities) and Registries (searchable indices).
- The protocol aims to break down information silos by allowing agents to discover documentation, ticket history, and observability systems autonomously.
- It addresses governance concerns regarding which tools an agent is authorized to use within a corporate environment.
- It creates a standardized interface for agents to query disparate data sources across an organization.
Decoder
- Agentic Resource Discovery (ARD): A proposed protocol to create a standardized, searchable directory of internal APIs, documentation, and tools for AI agents to interact with in an enterprise.
Original article
Microsoft, Google, Cisco and others propose a new way to help AI agents discover the tools they need to perform the tasks they are assigned.
Enterprises implementing agentic AI face a challenge: Which tools should they allow their agents to use, where can they be found, and how can they be used safely? A new protocol, Agentic Resource Discovery, or ARD, aims to let agents answer those questions for themselves. Behind it are Google, Microsoft, Cisco, Nvidia, Salesforce and others.
ARD aims to standardize the way that tools and services are shared across systems within a corporate domain. For example, when investigating a production problem, an agent may want to query engineering documentation and open support tickets, deployment history and observability systems, all of which could be managed by different registries and across different silos. There is no common layer that pulls them together. ARD has been designed to be that layer.
It operates across two levels. Catalogs and Registries. In the first, an organization publishes a catalog setting out its available capabilities. The Registries layer act as a form of search engine, crawling those published catalogs.
The ARD specification is available now. Organizations are invited to publish their own catalogs using the quickstart guide. After this, they are able to join the community and participate in the evolution of ARD.
There is minimal downside to switching to open models
The professional gap between proprietary models and open-weight alternatives is shrinking, making the switch viable even for production workflows.
Deep dive
- Proprietary models currently lead on AI leaderboards (e.g., Artificial Analysis).
- Privacy concerns arise when sending confidential data to third-party providers like OpenRouter or smaller model hosters.
- Self-hosting models solves privacy issues but introduces hardware, latency, and operational complexity.
- The performance gap between top-tier proprietary models and open-weight equivalents has narrowed significantly in recent months.
- Recent "safeguard" implementations in proprietary models have created friction for professional users.
- Switching to open-weight models is now seen as a comparable shift to moving from Windows to Linux in the late 2000s—a slight initial productivity hit but a sustainable long-term architecture.
Decoder
- Open models: AI models where the weights are released, allowing users to run them on their own hardware rather than relying solely on a proprietary API.
- Leaderboard: A ranking system for LLMs based on benchmarks, with the Artificial Analysis site being a primary industry standard.
Original article
There is minimal downside to switching to open models
There was a time not too long ago when using Linux entailed some professional risk. First there was compatibility: you may not have been able to render a Word document or PowerPoint correctly, and you might have had to trust Open Office’s export capability to render docs the way you wanted. There might have been specialty file formats you couldn’t easily view and so couldn’t collaborate. And second, the software ecosystem was just worse generally. There were lots of half-build open-source projects trying to achieve the functionality of mainstream software, but they always had rough edges. I, embarrassingly, stayed on Windows until I left academia over Matlab.
Nowadays I think this issue has largely disappeared. Most productivity software has a web-app, Linux is more mature, open-source software is better. I’m sure that there are all sorts of application specific software (CAD?) that still require a Windows machine, but the gap is much narrower and Linux + open source generally aren’t the “sacrifice” they once were generally.
There remains a clear penalty for being an open LLM user. Every leaderboard consistently gets topped by proprietary models served over API. Today on June 21, 2026, Claude and GPT are at the top of the Artificial Analysis intelligence leaderboard. That’s from the performance side. The compatibility side is worse too. Claude code just works, and more generally, the big two provide nice APIs that make them easy to use, and, even if it’s a low bar, are “trustworthy” in the sense that we’ve largely all agreed we don’t mind sending them our LLM queries and trust them to handle them appropriately.
Open models are served via various means, some by the companies that released them and some by third parties like OpenRouter. Unfortunately, both of these routes are dodgier in terms of privacy and data sharing, and I would not feel the same comfort sending API calls containing client or confidential data to them.
The other option or course is to run them yourself. This solves the privacy issue but is at least two of expensive, complicated, and comparatively slow.
Up until recently, open models had mostly been a hobby for me. I’ve tinkered with them since the original Llama leak, and occasionally used them when I has a niche use case, but for most professional work, I stuck with the Big 2. This appears to be changing, with Claude’s ID verification rollout. It was inevitable that things would get worse for users, and the writing was on the wall anyway recently with all the new “safeguards” on recent models and the whole Mythos thing. I’m not going to spend time talking about why I’m not going to indulge ID verification (or the LARPing that surrounds it) but what is immediately concerning is what kind of professional penalty it will incur to stop using the top models.
I’m hoping it’s going to be minimal. I’m already set up to run a range of open models either locally or in the cloud, there are good coding harnesses for open models, and most importantly the open models are now very close to the leaders and typically trail only by a few months. This doesn’t feel like 2008 Linux vs Windows, it’s much closer. I expect productivity will take a short-term hit, but don’t think it’s a deal breaker the way switching from Matlab to GNU Octave would have been when I was doing research.

AI Engineer Claims to Have Cracked Linear A
An AI engineer has reportedly deciphered the ancient Linear A script by using Claude Code to automate linguistic pattern analysis.
Deep dive
- Linear A is an undeciphered Bronze Age Minoan script used from 1800 to 1450 BC.
- Di Mino utilized Python scripts built with Claude Code to query the GORILA and SigLA databases.
- The breakthrough reportedly occurred by analyzing prayer inscriptions and identifying a repeating verb root, "nawaya," meaning "to dwell."
- Di Mino claims the script is an extinct Semitic language related to precursors of Biblical Hebrew and Arabic.
- He has proposed phonetic values for 40 signs, including 13 previously unknown signs, and created a lexicon of 408 terms.
- The research is currently undergoing review by linguistics experts at Rutgers and Cambridge.
Decoder
- Linear A: A writing system used by the Minoan civilization on Crete, known for being undeciphered despite its connection to the later Linear B script.
- Linear B: A later Mycenaean script deciphered in 1952, which shares many symbols with Linear A.
- Logograms: Characters that represent a complete word or idea, rather than a sound or syllable.
- GORILA/SigLA: Digital databases that contain the corpus of known Linear A inscriptions.
Original article
Tom Di Mino, a self-taught AI engineer and an amateur linguist, claims to have accomplished a feat that has eluded linguistics experts for over a century: deciphering a Bronze-age Minoan writing system known as Linear A.
His claims are currently being reviewed by linguistics experts at Rutgers and Cambridge.
Di Mino, who is based in the Hudson Valley, has studied classical history, linguistics, and languages since he was 18. He has varying degrees of proficiency in 8 languages, including Attic Greek, classical Latin, Sanskrit, Arabic, and Ugaritic. He has been reading up on Linear A for 7 years, and has visited Crete twice. He began to work on deciphering Linear A in January this year, and says the major insight came to him on May 22.
If Tom Di Mino has deciphered Linear A, it would be an earthquake in the field of linguistics. When a related Minoan script, Linear B, was deciphered in 1952, it made the front page of the New York Times.
Linear A maps to an extinct Semitic language
Di Mino believes that Linear A belongs to an extinct Semitic language that was a precursor to Biblical Hebrew, Arabic, and Aramaic, the way that Latin is a precursor to Italian.
Di Mino is not the first to argue that Linear A was Semitic. Prior attempts to prove it, however, including a 1957 article published by Cyrus Gordon in the journal Antiquity, did not unlock translations the way that Di Mino’s solution appears to, and Gordon’s work did not gain widespread acceptance in the field.
Some background on Linear A and Linear B
Linear A is a Minoan script that appeared sometime around 1800 BC and was used until 1450 BC, when Crete was conquered by Mycenaean Greeks. The Mycenaeans adopted the Minoan symbols as their own, with some minor revisions. The Mycenaean-Greek version of the symbols are known as Linear B. Both scripts were found on various tablets, vases, and other artifacts from the era.
Both scripts use syllables, not letters, as their core elements. The syllables are generally consonant-vowel pairs.
The two systems have 60 core syllables in common, and they both also use logograms – symbols that represent a whole word (“cow”), not just a syllable.
Linear B was deciphered and identified as Greek in 1952 by Michael Ventris, a British architect, cryptographer, and amateur linguist, like Di Mino. Ventris’s breakthrough may not have happened without prior work on Linear B by Alice Kober, a professor at Brooklyn College.
Kober and Ventris used grammatical and statistical analyses to look for patterns in the location of the symbols (e.g. the first syllable was more likely to be a vowel) and how the symbols shifted.
There are many more inscriptions associated with Linear B than Linear A, however, which made it easier to decipher. Also, many Linear A inscriptions are inventories cataloging the trade of different commodities, so they don’t tell us much about the language.
Because Linear A and Linear B have 60 symbols in common, and because Linear B has been deciphered, experts could guess what the overlapping Linear A symbols sounded like but didn’t know what the sounds meant. And there were 13 additional symbols in Linear A that did not appear in Linear B. For those, no sound values have been accepted.
The key that unlocked Linear A
- On May 22, Di Mino was analyzing a series of Linear A prayer inscriptions that adhered to a formula.
IOZa2 (Iouktas): A-TA-I-*301-WA-JA · JA-DI-KI-TU · JA-SA-SA-RA-ME · U-NA-KA-NA-SI · I-PI-NA-MA · SI-RU-TE · TA-NA-RA-TE-U-TI-NU · I
- In the formula all of the words in each line of the inscription were known (based on their overlap with Linear B syllables) except for the first word.
- The first word was the same verb root, appearing in different regional forms across five sanctuary sites on the island.
- The verb contained 5 known Linear B signs and “*301”, which appeared to be a Linear A-only sign, “na,” which Di Mino used to unlock the root “nawaya,” which means “to dwell.” In Hebrew, Akkadian and other Semitic languages there is a 3 syllable consonant system. N-W-Y is used for verbs and nouns meaning “to dwell or inhabit”.
- Once deciphered, Di Mino saw that the prayer was similar to subsequent Hebrew prayers but was addressed to a Goddess.
- While Cyrus Gordon had previously proposed links between dedication tablets in Linear A and similar tablets in Akkadian and Phoenician that he had translated, Di Mino claims to be the first person to identify the links between the Linear A inscriptions and Hebrew prayers.
- This insight not only unlocked the verb in the prayer inscriptions, but it may also shed a broader light on the use of logograms in Linear A.
- Di Mino claims that his insights into logograms in Linear A additionally help to resolve problems with some translations of Linear B, which validates his findings.
- Di Mino used Claude Code to build a suite of Python scripts that query, cross-reference, and organize the digitized Linear A corpus (drawn from the GORILA and SigLA databases), enabling systematic hypothesis testing at a scale that would have been impractical to do manually.
Artifacts
Di Mino’s research has led to:
- Proposed readings for 40 of the script’s signs, including 13 signs whose phonetic values were previously unknown. He also resolved the sound values for 5 Linear B signs which were unknown to this day.
- A lexicon of 408 Linear A terms translated into English
- A 9-page draft of a manuscript titled Ya Diktu: Grammar of the Minoan Peak Sanctuary Libation Formula, which may form the foundation for a submission to a peer-reviewed scientific journal

Founders Fund's outlier bet on humanely killed fish
Founders Fund is backing Shinkei, a startup building robots that automate the Japanese ike jime slaughter technique to reduce fish spoilage.
Deep dive
- Ike jime: A traditional Japanese method of slaughtering fish by spiking the brain to cause instant death and draining the blood to maintain meat quality.
- Shinkei's model: Provides robots to fishermen for free, pays a premium for the catch, and processes the fish in a centralized facility to avoid traditional overseas labor chains.
- Market focus: Targeting high-end markets like Erewhon; claims to reach Michelin-starred restaurants.
- Operational goal: Reducing the industry-standard 18% spoilage rate between dock and store.
- Strategic angle: Shinkei competes with the common practice of shipping US-caught fish to China for processing and re-importing.
Decoder
- Ike jime: A traditional Japanese fish slaughtering technique that involves severing the brain and spinal cord to ensure instant death and prevent muscle stress, preserving flavor and texture.
Original article
Earlier this week, at TechCrunch’s newest StrictlyVC event in Los Angeles, Shinkei Systems founder Saif Khawaja and Founders Fund partner Delian Asparouhov sat down for a conversation that kept circling back to a question that doesn’t usually come up at a venture event: How do you know if a fish is stressed out?
It’s a fair question for Khawaja to field, since his company, Shinkei, has built its entire business around the answer. Shinkei makes a refrigerator-sized robot called Poseidon that fishermen install on their boats. The machine scans each fish with computer vision, identifies the species, and locates the brain. It then pierces the brain and severs the gills, so the fish dies before it can thrash or suffocate.
It may not sound so compassionate, but it’s much better than the alternative, which is a slow death over a few minutes to an hour that floods the fish with stress hormones and lactic acid, which dulls flavor and shortens shelf life. The whole thing is an automated, industrial-scale version of ike jime, a centuries-old Japanese technique traditionally performed dockside by trained fishermen at the moment of catch. By killing the fish instantly and draining its blood, ike jime delays decomposition long enough for the flesh to be safely aged for days, sometimes longer, before it’s served. That aging period is what gives top-tier sashimi its concentrated, umami-heavy flavor, as enzymes slowly break down the muscle.
Khawaja’s origin story is somewhat unusual for a hardware pitch. He grew up taking fishing trips with his family in the Middle East, and the idea for Shinkei didn’t click until college, when he read an essay by an animal rights philosopher titled “If Fish Could Scream.” Its premise was that fish lack vocal cords, so the suffering most of them experience on the way to your plate is essentially invisible.
But Shinkei’s ambitions have expanded well past the killing machine. The company now describes itself as a vertically integrated fish harvester and processor, deploying robotics and AI across the chain from boat to plate. Shinkei gives Poseidon machines to fishermen for free, then pays those fishermen a premium price for the fish that come out of them, well above what the catch would fetch at a standard dock auction. In exchange, Shinkei takes full possession of the fish rather than letting fishermen sell it on the open market. The catch then ships to a 16,000-square-foot plant Shinkei bought in Tacoma, Washington, where it’s broken down and sold under the company’s consumer brand, Seremoni, marketed as “ceremony grade” fish.
The most visible proof point so far is on the menu at Erewhon, the Los Angeles grocery chain beloved by influencers. Erewhon sells Shinkei’s fish as Seremoni Grade Miso Black Cod, hot off the prepared-foods bar, and the marketing around it leans hard on the “sustainably caught, humanely harvested” framing. The arrangement is still a pilot, running for now out of Erewhon’s Manhattan Beach location, with wider rollout to other stores contingent on how well it sells. Khawaja says the company already supplies fish to restaurants holding a combined 50 Michelin stars, and claims something that has reportedly never happened before: Japan importing American-caught fish into its own fish markets, which have historically treated American seafood as distinctly inferior to the domestic product.
Whether buyers will pay a premium for “humanely killed” fish, the way many now do for humanely raised beef and poultry, is still an open question, and even Khawaja says it’s secondary when explaining the company. He told the El Segundo crowd the real selling point isn’t the animal-welfare story so much as the practical one around quality. A catch that might normally have a 5- to 7-day shelf life can stretch to 12 or 14 days, he said, and the company has cooked fish three weeks after coming out of the water with no issue. Shinkei’s newest product, an in-plant sensor system, tries to quantify that by scanning fish and projecting an individual shelf life for each one. That matters in an industry where, by Khawaja’s estimate, roughly 18% of product is lost to spoilage just between dock and store, before retail loss is even counted.
That spoilage problem is tangled up with a detail of the American seafood supply chain that surprises most people who haven’t worked in it. A meaningful share of fish caught in U.S. waters by U.S. boats gets frozen and shipped overseas, often to China, for the labor-intensive work of heading, gutting, scaling, and filleting, and is then shipped back to be sold here. Industry estimates of how much American seafood is imported run as high as 90%, though roughly half of that, by some estimates, actually originated in domestic waters before making the round trip abroad. Reporting has tied parts of China’s seafood processing sector to forced labor, including Uyghur workers in Shandong province and North Korean labor in Liaoning, making the system a target of U.S. trade and labor scrutiny in recent years.
There’s been a push within the industry to “re-shore” some of that processing, spurred partly by tariffs and pandemic-era disruptions that made the China round trip less attractive. The bet that Shinkei and Founders Fund are making is that re-shoring the entire chain — catch, kill, process, and distribute — all under one roof in Tacoma, can be done profitably enough to outcompete it.
For Founders Fund, the wager fits a pattern, which is backing founders who are often outside of fashionable categories. Asparouhov, who speaks a mile a minute and without reserve, put it plainly to attendees: There’s essentially nobody else on Earth who wants to spend their life on robots that kill fish, and given the smell of the Shinkei’s office, it’s no wonder. (We all laughed at the observation, though it undersells the field a little. In addition to Shinkei, a Japanese firm called Nichimo sells a device that stuns fish to assist humans performing ike jime by hand, and several Norwegian startups are building robotic systems for more humane fish slaughter and processing. Shinkei’s apparent edge, for now, is being the only one running the fully automated version of the technique at scale on U.S. boats.)
In fact, Asparouhov said the firm intentionally keeps its exposure to crowded categories like generic AI applications relatively low. By his math, AI and defense together account for something like 15% to 20% of the fund’s deployed capital, well below what he estimated is typical elsewhere in venture. Shinkei sits alongside Halter, a New Zealand-founded company making solar-powered, GPS-equipped cattle collars that let ranchers herd cattle remotely, and Ohalo Genetics, the crop-genetics company started by “All-In” podcast co-host David Friedberg, as evidence that the firm’s appetite for food and agriculture isn’t a one-off.
Of course, the fund’s headline-grabbing recent win has nothing to do with fish. Its early and aggressive bets on Elon Musk’s SpaceX — a relationship that traces back to Peter Thiel and Musk’s shared history at PayPal — are reported to have generated many tens of billions of dollars for the firm (it’s one of the largest venture outcomes ever recorded). Asparouhov argued that win will accelerate a broader shift in venture toward hardware and physical-world businesses, noting that most of the largest companies on the Nasdaq today already involve complex electromechanical systems rather than pure software. He predicted more of SpaceX’s alumni, flush with liquidity and shaped by working alongside Musk, will go on to start their own ambitious physical-world companies.
Whether Shinkei becomes one of the firm’s next big wins will take time to know. It’s bitten off a lot. The company is a robotics manufacturer and a seafood processor and a consumer brand, all running at once, and each with its own daunting challenges. Fishermen are used to working a certain way. Distributors are built around decades-old habits. Chefs and grocery buyers still have to be convinced that a story about humane fish slaughter is worth paying more for. That’s saying nothing of the hardware, which has to survive saltwater, fish guts, and life on a commercial boat, or that the product it’s selling is perishable, so there’s little room for the kind of stumble a straightforward software company can shrug off.
Still, talking with the two together in El Segundo was enough to make the audience understand why Founders Fund finds the bet compelling. The firm doesn’t just think it has found a founder building something novel in a surprisingly dysfunctional industry; it thinks it’s the kind of company almost nobody else in the United States even wants to build.
You can watch our full discussion below.

Trump says he no longer views Anthropic as a national security threat after G7 meeting with CEO
President Trump signaled a de-escalation with Anthropic following a G7 summit meeting, despite keeping formal Pentagon supply-chain restrictions in place.
Decoder
- Guardrail: Software constraints designed to prevent AI models from executing specific commands, such as those related to military surveillance or autonomous weapon control.
Original article
Trump told Axios that Anthropic has “behaved very responsibly” and signalled he may ease restrictions on its Fable 5 and Mythos 5 AI models.
President Donald Trump said in a pretaped Axios interview that he no longer views Anthropic as a national security threat, marking a sharp reversal from the administration’s aggressive posture toward the AI company over the past three months. Asked whether he considers Anthropic a threat, Trump replied, “Well, not now. But a week ago, maybe.” He added that the company has “behaved very responsibly.”
The comments come just days after the Commerce Department issued a directive on June 12 ordering Anthropic to seek US government approval before foreign nationals access its Fable 5 and Mythos 5 models, the company’s most powerful AI systems.
That order followed months of escalating tension between the administration and Anthropic over the company’s refusal to remove certain safety guardrails from its military-facing products. The directive effectively triggered crisis-level talks between Anthropic and Commerce Department officials last week.
Trump met Anthropic CEO Dario Amodei on Wednesday at the G7 Summit in Évian-les-Bains, France, an encounter that appears to have shifted the president’s stance. The meeting came after Anthropic senior technical staff held separate discussions with Trump administration officials earlier in the week
Trump told Axios he would consider easing the restrictions, saying, “I would, but I’m not sure I have to do that,” when asked about a potential rollback.
The dispute traces back to March 2026, when the Pentagon designated Anthropic a supply-chain risk after the company refused to strip guardrails related to surveillance and autonomous weapons from products used by the US military. Commerce Secretary Howard Lutnick subsequently sent a letter threatening criminal charges against the company, a move that drew criticism from technology industry groups and prompted allied governments, including the UK, to lobby for exemptions.
The timing of Trump’s conciliatory tone is significant. Anthropic confidentially filed for an initial public offering in early June, with a valuation that Fortune reported at approximately $965 billion. The ongoing federal restrictions had cast uncertainty over the listing, and any signal of de-escalation from the White House could stabilise investor confidence ahead of the offering.
Trump described the situation as creating “tremendous liability” for the administration, an acknowledgment that the crackdown had drawn backlash from both industry and allies. The president also said he would not shut down Anthropic, though he stopped short of committing to a specific timeline for lifting the Commerce Department directive.
The shift does not erase the underlying disagreement. The Pentagon’s supply-chain designation remains in place, and the Commerce Department’s June 12 order has not been formally rescinded. Anthropic has not publicly indicated whether it plans to modify its guardrail policies to satisfy the military’s demands.
What has changed is the political signal from the top: Trump appears willing to negotiate rather than escalate.
Amodei has been working multiple channels to resolve the standoff. At the G7 summit, he and Google DeepMind CEO Demis Hassabis jointly pitched a US-led AI coalition to G7 leaders, positioning Anthropic as a cooperative partner in American technology diplomacy rather than a regulatory adversary. The strategy appears to have given Amodei direct access to Trump at a moment when the president was receptive.
Whether the warm words translate into policy remains an open question. The Commerce Department operates with considerable independence on export control matters, and rolling back a formal directive requires bureaucratic steps that a single interview cannot shortcut.
For Anthropic, the Axios interview is a political win, but the legal and regulatory constraints remain until the administration acts on them.

About Those "Hackquisitions"...
The 'hackquisition' era is faltering as high-profile talent departures from Google and Amazon call the model's long-term effectiveness into question.
Deep dive
- Microsoft/Inflection: Mustafa Suleyman moved from leading Copilot to foundation models after the startup failed to gain consumer traction.
- Amazon/Adept: Four of five co-founders departed shortly after the $330M deal.
- Meta/Scale: Alexandr Wang’s integration has led to internal friction while the 'Superintelligence' group attempts to accelerate model shipments.
- Google/Character: The model failed to replace ChatGPT and lost key architects like Shazeer.
- NVIDIA/Groq: A massive $20B deal currently faces unknown long-term viability.
Decoder
- Hackquisition: A corporate acquisition strategy where a company hires a startup's core talent and licenses its IP, while leaving the original company entity intact to avoid regulatory scrutiny.
Original article
The news that Noam Shazeer is (once again) leaving Google seems like a big deal. The news that he's joining OpenAI, which turned the transformer paper he helped write into a product that he couldn't launch (in his first stint) at Google seems like an even bigger deal. Bigger still may be the fact that he had rejoined to help the Gemini product take on ChatGPT, which was seemingly working, at least to some degree. But actually, the biggest deal has to be the actual deal that brought him back to Google. Because it wasn't even two years ago when Google paid $2.7B to bring Shazeer back.
And like that – poof – he's gone.
To be fair, there were others on the Character.ai team that Google seemingly wanted too. The non-exclusive licensing rights for Character? Probably less so. If anything, that aspect of the deal has ranged from a headache to a nightmare. But clearly it was a deal structure in such a way to get Shazeer back with an offer he couldn't refuse. And he didn't. Until he did. Again.
That deal structure, of course, was one of the early "hackquisitions" – a deal to bring on a company's key talent without acquiring the company itself. Because that clearly would have been messy from a regulatory perspective for any of Big Tech. If nothing else, such deals would be bogged down for months while they're scrutinized. A "hackquisition", by contrast, could be done almost instantly. Because they were structured to leave the actual company behind as a sort of hollowed-out husk. Not exactly a carcass because they weren't exactly dead but not fully alive either. A place to pick up the phone if the government calls. And to collect licensing fees.
And again, the deals were set up in ways so that those with power couldn't really say "no" – be it the founding team or investors. The employees left behind sometimes got screwed, but the "hackquiring" company often tried to do the right thing so as not to draw that eye and ire of Washington.
As such deals kept happening, Washington obviously started to look at these deals anyway. But the pace at which Washington moves have allowed them to continue unabated. Of course, something else now runs the risk of ending such deals: the fact that they don't seem to be working out. Let's look back at some of the big ones.
Microsoft/Inflection
The first such "hackquisition" clearly drew inspiration from the deal Microsoft almost did with OpenAI employees (from Sam Altman on down) during "The Blip". Such a deal, had it happened, would have looked pretty wild now given that OpenAI is valued at $852B. And, of course, constantly clashing with their benefactor. Anyway, as a result of Altman and OpenAI getting back to work, Microsoft turned their gaze elsewhere – to the AI startup co-founded by their board member Reid Hoffman.
But that deal wasn't about bringing Hoffman on board beyond the board, it was seemingly all about bringing on Mustafa Suleyman, a co-founder of DeepMind who left after the Google acquisition and started Inflection with Hoffman, raising a ton of money (for the time) in the process. After failing to get any sort of early traction and undoubtedly needing to raise billions more to effectively compete, it was seemingly an easy call when Microsoft came calling with $650M.
Again, not for the company, but for Suleyman and his team (and for the investors, which, yes, also included Hoffman). Fast-forward to today, just over two years later and Microsoft is certainly more independent in AI. But they're not necessarily in a better place, as the many re-orgs and re-brandings of Copilot have showcased. Meanwhile, Suleyman himself was recently moved from spearheading that product and team to focusing on foundation models instead.
$650M is relatively small by today's AI standards, but it's not clear what Microsoft actually got out of it. The consumer version of Copilot made to look like Pi, Inflection's product, clearly hasn't worked. And the team is now led by someone else so...
Amazon/Adept
A few months after the Inflection deal, that other Seattle-based tech company tried their hand at a "hackquisition". The deal for Adept was roughly half the size at $330M, but the idea was the same: get the co-founders on-board with Amazon's AI team. Most notably, David Luan was tasked with starting their "AGI Lab".
We're not even two years removed from that deal and yet 4 of the 5 Adept co-founders have already left Amazon. That includes Luan, who had previously worked at both Google and OpenAI, and left this Amazon past February. That team did launch one product, Nova Act, but it's not clear how useful that actually is to Amazon.
Amazon/Covariant
This deal, just a couple months later, was more under-the-radar than Adept, but may have actually been slightly larger. It has also been an even bigger headache, with a whistleblower saying that the left-behind Covariant company is just a "zombie" shadow company. Still, Amazon may have gotten some robots out of the deal even if the team seems to be pretty much gone.
Google/Character
We've been over this one.
Meta/Scale
The big one. While the nearly $15B deal technically structured a bit different than the other "hackquisitions" – namely in that Meta acquired a very specific 49% stake in Scale – the idea was still the same: bring AI talent on board to Meta, fast.
And specifically, Mark Zuckerberg zero'd in on Alexandr Wang as the guy who would reboot Meta's AI efforts, putting their Llama out to pasture, as it were. We all know what happened from here – mega offers led to mega chaos both around the entire AI ecosystem and within Meta itself. The latter is still playing out, with at least some believing that Wang's Scale culture and techniques are eating Meta alive from within.
At the same time, the new "Superintelligence" group has be able to build and ship their first models in record time. They're not yet frontier, but by all accounts they're good. So Zuckerberg, at least for now, has gotten the outputs he's wanted, though the inputs remain perhaps an issue. And Meta's stock has been hammered hard with investors still concerned about Meta's AI path going forward given the billions spent, with hundreds of billions more to come.
This is still more TBD – like the name of the sub-group Wang runs – but it's not trending particularly well if the moves really end up ripping Meta apart.
Meta/NFDG
A strange deal even by "hackquisition" standards. Meta essentially bought the book of Nat Friedman's and Daniel Gross' fund so that they could bring those two on board to help with their AI efforts. But that also mean Gross would have to leave the AI startup where he was not only a co-founder, but the CEO: Safe Superintelligence. Ilya Sutskever did not seem happy about that, as you might imagine. Especially since Zuckerberg had tried to "hackquire" SSI, but Sutskever shot him down (though Meta did apparently invest).
Friedman's role has seemingly shifted a couple times with constant re-orgs and shuffles in the aforementioned chaotic Meta environment. Gross is now working on Meta's infrastructure build-out for AI.
Google/Windsurf
This was a layered shitshow as OpenAI had originally agreed to acquire – as in actually acquire – Windsurf, then backed out (perhaps due to Microsoft). Google then stepped in to save the day – except the "hackquisition" nature of the deal led to a huge backlash because of the group being left behind, apparently without any sort of compensation. And so another AI startup, Cognition, stepped in to save the day from the already saved day. Fun times.
That brings us to today, while there have been a few other "hackquisitions", they're either too small or too new – most notably, NVIDIA's $20B mega deal to bring on board Groq talent, where yes, the IP license actually seems to matter – to know how well they'll play out. But it's pretty clear that the first crop didn't pan out as the "hackquirerers" would have hoped. At best, the situations are messy. At worst, they're shitshows – or really no-shows, with the talent now gone.
Shazeer is the biggest of those to date – again, in less than two years after a $2.7B deal. Can't wait to hear more about what happened there. But it could be as simple as these "hackquisitions" not aligning incentives very well...
Lighthouse agentic browsing scoring
Chrome's new Lighthouse Agentic Browsing audits measure a site's readiness for AI agents using deterministic signals like WebMCP registration and accessibility tree integrity.
Deep dive
- The Agentic Browsing category replaces traditional 0-100 scoring with a pass/fail ratio for specific machine-readiness checks.
- WebMCP (Web Model Context Protocol) is used to expose site-specific logic and forms directly to AI agents.
- Agents rely on the DOM's accessibility tree as their primary data model; therefore, semantic HTML and ARIA labels are now critical for machine navigation.
- Cumulative Layout Shift (CLS) is identified as a critical metric because it causes interaction failures when elements move during agent execution.
- Audits check for a
llms.txtfile at the root domain to provide a machine-readable site summary. - Results can be non-deterministic due to dynamic JS-based tool registration or structural changes in the DOM impacting the accessibility tree.
Decoder
- WebMCP: A protocol being standardized to allow websites to explicitly expose tools, logic, and forms so that AI agents can interact with them programmatically.
- Accessibility Tree: A hierarchical model built by browsers that represents the document's content and semantics, used by screen readers and now AI agents to interpret UI elements.
- Deterministic: A system that consistently produces the same output for a given input, which is a requirement for reliable CI/CD pipelines.
Original article
Lighthouse agentic browsing scoring
The Agentic Browsing category evaluates how well your site is constructed for machine interaction through a set of deterministic audits.
How the category is scored
Unlike other Lighthouse categories, the Agentic Browsing category does not have a weighted average score from 0 to 100. Because the standards for the agentic web are still emerging, the current focus is to gather data and provide actionable signals rather than a definitive ranking.
Instead of a score, the report displays:
- A fractional score: A ratio showing how many agentic readiness checks your site passes.
- Pass or Fail status: Specific audits may emit errors or warnings if technical requirements (like WebMCP schema validity) are not met.
- Informational counts: The category header may include a pass ratio to help you observe overall progress at a glance.
Why results fluctuate
While the audits are deterministic, your results may fluctuate due to changes in how your site registers its tools or responds to agentic requests. Common causes include:
- Dynamic tool registration: If your site registers WebMCP tools using JavaScript (Imperative API), the timing of these registrations can affect whether they are captured during the Lighthouse snapshot.
- Variability in A11y tree construction: Significant changes to DOM size or complexity can impact the structure of the accessibility tree, which is a core metric for agentic navigation.
- Cumulative Layout Shift (CLS): Layout shifts caused by ads, images without dimensions, or injected content can move elements between the time an agent identifies them and the time it attempts an interaction.
How audits are determined
Lighthouse uses a set of deterministic signals to evaluate your page. This ensures that the audits are reproducible and suitable for integration into CI/CD pipelines.
WebMCP Integration
Lighthouse calls the Chrome DevTools Protocol (CDP) WebMCP domain to monitor tool registration events. It verifies both declarative tools (defined in HTML) and imperative tools (defined in JS).
Agent-Centric Accessibility
Agents rely on the accessibility tree as their primary data model. Lighthouse filters a specific subset of accessibility audits that are critical for machine interaction, such as:
- Names and labels: Ensuring every interactive element has a programmatic name.
- Tree integrity: Verifying that roles and parent-child relationships are valid.
- Visibility: Confirming that content is not hidden from the accessibility tree while being interactive.
Stability and Discoverability
- Cumulative Layout Shift (CLS): Measures visual stability, which is critical for agents relying on element positioning.
- llms.txt: Checks for the presence of a machine-readable summary at the domain root.
What can developers do to improve?
To improve your site's agentic readiness:
- Adopt WebMCP: Use the WebMCP API to explicitly expose your site's logic and forms to AI agents.
- Ensure a sound a11y tree: Prioritize semantic HTML and proper ARIA labeling, as these are the "machine-eye view" of your page.
- Optimize for stability: Reduce layout shifts to ensure that agents can reliably interact with your UI without elements moving unexpectedly.

Temporary Cloudflare Accounts for AI agents
Cloudflare introduced temporary accounts for AI agents, allowing them to deploy code instantly via CLI without human authentication flows.
Decoder
- Wrangler: Cloudflare's command-line interface tool for managing and deploying Workers and other serverless resources.
Original article
Temporary Cloudflare Accounts for AI agents
Everyone's writing code with AI agents today. But the moment an agent needs to deploy something — and needs to sign up and create an account — it slams face-first into a wall built for humans: a browser-based OAuth flow, a dashboard to click through, an API token to copy-paste, a multi-factor authentication prompt to satisfy. For an interactive copilot sitting next to a developer, that's annoying. For a background agent, it's a hard stop.
Today we're rolling out Temporary Cloudflare Accounts for Agents.
Agents can now deploy websites, APIs, and agents right away, without first needing to sign up for an account.
Any agent can now run wrangler deploy --temporary and deploy a Worker to Cloudflare. This temporary deployment stays live for 60 minutes, during which time you can claim the temporary account, making it permanently your own. If you don't, it expires on its own.
Our goal? Let your agent code and ship.
Why frictionless deployments matter for AI agents
Frictionless temporary accounts matter more than it might first seem:
- Background AI sessions have no human in the loop, and are becoming the norm. Any auth step that needs a browser, a copy-paste, or "click here in 60 seconds" means an agent gets stuck and may choose to deploy elsewhere.
- Trial-and-error is the agent's superpower. Agents need a tight write → deploy → verify loop. They need cheap, throwaway deployment targets, so they can curl their own output and decide whether they got it right.
- Agent platforms are building their own ways for deploying code to "just work" without extra steps or credentials. People are starting to expect that this process just works, without the need to sign up for other services that they've not used before or heard of.
How it works
Temporary accounts are built around Wrangler, our Developer Platform command-line interface (CLI) tool that lets developers bootstrap new projects, manage their configurations and resources, and deploy and update them.
Wrangler usage is widely documented online and agents know how to use it very well. But if you hadn’t yet signed in and granted Wrangler permission to your Cloudflare account, when the agent tried to deploy, it would get stuck at the sign-up and authentication step. And you might rightly ask: How do agents and LLMs know that this new --temporary flag in Wrangler exists, so that they actually use it without a human explicitly telling them to do so?
To solve this, we updated Wrangler to prompt the agent with a message that tells it about the --temporary flag:
When the agent discovers this, and then runs wrangler deploy again with the --temporary flag, Cloudflare provisions a temporary account for the agent to use, gives Wrangler an API token to work with, and provides a claim URL that the agent can give back to the human.
Let’s go over every step of the flow
Deploying and iterating on a new project
Make sure you’re using the latest Wrangler release, fire up your favorite coding agent, and write a prompt to deploy a "hello world" app in build mode:
Make a very simple hello world Cloudflare Worker in TypeScript and deploy it using wrangler, don't ask me questions, do the best you can
The agent will run wrangler, pick up the --temporary flag from the output messages, build your script, and deploy it instantly, no human in the loop required:
As you can see, the agent wrote the script, deployed it using the --temporary flag, curled the preview link it got from the output, and verified that the result matches the code.
This is great, but agentic coding is often not about one single deployment. A session can go through a cycle of multiple code changes. This is not a problem: the agent can iterate on the Worker script and redeploy the changes as many times as it wants (within the 60-minute claim window). Type this prompt:
Now change hello world to "hello cloudflare" and redeploy
Look at the agent changing the source code, reusing the previously created temporary account, redeploying a new version and rechecking the result:
Claiming the account
At any point, you can claim the temporary account and make it yours permanently. When you click the claim link you will be taken to a page where you can either sign up for or sign in to Cloudflare, and then claim the temporary account that your Worker was deployed to. This includes claiming not just Workers, but resources like databases and other bindings, too.
If you do not claim these temporary accounts within 60 minutes, they will be automatically deleted.
The road to frictionless agentic deployments
This is just one way we’re eliminating the signup barrier for agents. We recently announced a partnership with Stripe and a new protocol we co-designed that lets agents provision Cloudflare on behalf of their users — creating an account, starting a subscription, registering a domain, and getting an API token to deploy code, with no copy-pasting tokens or entering credit card details. Last month, we collaborated with WorkOS on the launch of auth.md, which anyone can adopt, to let agents provision new accounts using well-established, existing OAuth standards.
There’s a ton going on in this space, and we’re excited to keep making it easier for agents to use Cloudflare, and for developers to make their own apps agent-ready. Temporary accounts are one more step toward frictionless agentic deployments — stay tuned for more.
Temporary accounts have some limitations, and their capabilities may change over time; check the developer documentation for more information and then go build something. Point your agent at Cloudflare, see how far it gets, and tell us what we can improve or what delights you — share what you’ve built on X or hop into the Cloudflare Community.

Introducing the Cloudflare One stack: agent-powered deployment
Cloudflare released an 'agent-powered' stack of skills that automates the migration and configuration of Zero Trust security services.
Decoder
- Zero Trust: A security model that assumes no implicit trust for users or devices and requires strict verification for every access request.
- SASE (Secure Access Service Edge): A framework that combines network connectivity and security services into a single cloud-delivered platform.
Original article
Introducing the Cloudflare One stack: agent-powered deployment
Adopting or migrating to a Zero Trust network architecture can be a daunting task. Before a single policy changes, teams have to recall how their network is actually built: which applications exist, their authentication and authorization constructs, how traffic flows between them, and any assumptions the current architecture makes. This hands-on process requires practitioners to decode the intent behind every security and routing policy in place.
Today, we’re releasing the Cloudflare One stack, a set of skills you give to your agent to configure, deploy, and manage your Zero Trust environment for you. This toolkit is designed to help automate the process of learning an entirely new security suite and mapping your existing one into Cloudflare.
Cloudflare has worked with thousands of customers through exactly this process. That repetition built expertise on where migrations stall, what questions come up every time, and what it takes to move forward. The Cloudflare One stack packages that expertise and makes it more accessible than ever.
The agent gap in network security
Teams are already using agents to write code, triage alerts, and automate workflows. Organizations are increasingly asking for Cloudflare-provided tooling to help agents execute on security workflows. On their own, agents are not trained on the nuances of an organization's specific network topology or vendor configurations.
By providing prescriptive and authoritative guidance, organizations can layer this context into their existing toolkit to make better use of the security products they are already deploying.
Cloudflare has long been the easiest-to-deploy SASE vendor in the market. The stack extends that philosophy to agents: it gives them the context, tools, and structured reasoning they need to operate on your security infrastructure.
What is the Cloudflare One stack?
The Cloudflare One stack is a collection of skills that can be used with any agent. As with any skill, you can use them standalone, layer in your own context, or build tooling on top. It was purpose-built to help security practitioners across the entire lifecycle of evaluating, deploying, and managing Cloudflare One.
The stack was built by synthesizing hand-curated knowledge from employees with tens of thousands of hours of experience working with customers on Cloudflare One products. It contains tools for planning, managing, and implementing your user and agent security infrastructure on Cloudflare. It also contains handpicked logic for migrating from legacy vendors like Zscaler and Palo Alto Networks.
When used in conjunction with the Cloudflare code mode MCP server, the stack gives agents a typed interface to the Cloudflare API. Agents can query your live account, inspect configurations, and make changes through a curated set of Cloudflare-recommended workflows rather than ad-hoc API calls.
What’s in the stack?
The Cloudflare One stack ships as two lightweight skill files: cloudflare-one and cloudflare-one-migration. Together they cover migrating to, building an implementation for, managing, and troubleshooting your Cloudflare One deployment:
- Remote access and VPN replacement with Cloudflare Access
- User, network, device, and data security with Cloudflare Gateway
- Connectivity with Cloudflare Tunnel, Cloudflare Mesh, and Cloudflare WAN
- Migration guidance with explicit detail for moving from other SASE vendors
- Network diagram interpretation and generation, so you can visualize proposed changes to your network in a way that is easy for you and your team to understand
- Vendor concept translation, which maps concepts between SASE vendors to reduce the barrier to evaluating and switching providers
- Troubleshooting and operations, with the Digital Experience Monitoring (DEX) toolkit and automated rule recommendations
How it works
The stack is available in the Cloudflare Skills repository. Each skill file contains structured knowledge, decision trees, and tool definitions that agents load automatically when the context matches. Give this to your agent and let it help you set up, configure, and manage your Zero Trust environment:
The cloudflare-one skill covers general product guidance. For example, if you ask an agent for the best way to replace your VPN infrastructure with Cloudflare Tunnel or Cloudflare Mesh, the skill knows how to:
- Inventory your existing VPN applications and identify which connectivity model each requires
- Map each application to the appropriate Cloudflare primitive — self-hosted Access application, Tunnel-connected service, or Mesh-connected network segment
- Generate a recommended deployment sequence that minimizes disruption during cutover
- Produce a configuration summary your team can review before making any changes
The cloudflare-one-migration skill covers vendor-to-vendor translation. For example, if you ask an agent to migrate your Zscaler Private Access applications to Cloudflare Access, the skill knows how to:
- Map Zscaler application definitions to Cloudflare Access application definitions
- Transform Zscaler user groups and policies into Cloudflare Access policies
- Use the Cloudflare API to create the equivalent resources in your account
- Generate a summary of what was migrated and what requires manual review
The migration logic in the stack is the same logic used in Cloudflare's Descaler and Deskope programs. Those programs have already moved enterprise customers from Zscaler and Netskope to Cloudflare One in hours rather than months. The stack makes that capability available to any customer or partner, at any time, without waiting for a scheduled engagement.
More ways to use the stack
The Cloudflare One stack can also:
- Recommend security rules based on traffic seen in your live account
- Automatically migrate your existing Zscaler Private Access applications into self-hosted Cloudflare Access applications
- Investigate anomalies in your secure web gateway HTTP logs and build rules to resolve issues users are seeing
- Report on user stability with the DEX toolkit and take actions to improve user latency in key scenarios
Whether you are loading the skill from an agent or building custom tooling on top, the Cloudflare One stack handles all of these use cases and more.
For partners, too
While this simplifies ongoing management for customers who have already adopted the Cloudflare One product suite, it is also a tool for the Cloudflare partner network. Partners can use it to help their customers deploy faster, manage more effectively, troubleshoot with increased accuracy, and drive issues to resolution.
What's next
You can start using the Cloudflare One stack today. To get the most out of the stack, pair it with the Cloudflare code mode MCP server. The MCP server gives your agent live access to the Cloudflare API through a single, compressed interface that keeps authentication credentials out of the model context.
The Cloudflare One stack will continue to expand as Cloudflare One products evolve. New skills for additional migration sources and more advanced troubleshooting workflows are already in development.
As we learn more about how customers and partners utilize these skills files, we plan to build more robust tooling around these skills. If you are a customer or partner and want to share feedback on what the stack should handle next, reach out through your account team or open an issue in the repository.
Turso (GitHub Repo)
Turso has launched a Rust-based, SQLite-compatible database in beta featuring native async support and experimental vector search.
Deep dive
- SQLite Compatibility: Supports the C API, file format, and SQL dialect of SQLite.
- Modern Features: Includes native async I/O, vector search, and encryption at rest.
- AI Native: Ships with an embedded MCP server, allowing direct query/schema interaction via agents like Claude Code.
- Performance: Provides MVCC (Multi-Version Concurrency Control) through 'BEGIN CONCURRENT' to improve write throughput.
- Beta Status: Explicitly warns that while it powers some production apps (e.g., Kin AI), it is not yet at parity with SQLite-level reliability.
Decoder
- WAL (Write-Ahead Logging): A technique to record changes before applying them to the main database file, enhancing crash recovery and concurrency.
- MVCC: A database concurrency control method that allows multiple versions of data to exist, enabling simultaneous reads and writes without locking.
- MCP Server: A standardized interface that allows AI models to perform tool-based actions on external systems.
Original article
Turso Database
An in-process SQL database, compatible with SQLite.
About
Turso Database is an in-process SQL database written in Rust, compatible with SQLite.
Warning: This software is in BETA. It may still contain bugs and unexpected behavior. Use caution with production data and ensure you have backups.
Features and Roadmap
- SQLite compatibility for SQL dialect, file formats, and the C API
BEGIN CONCURRENTfor improved write throughput using multi-version concurrency control (MVCC).- Change data capture (CDC) for real-time tracking of database changes.
- Multi-language support for
- Go
- JavaScript
- Java
- .NET
- Python
- Rust
- WebAssembly
- Asynchronous I/O support on Linux with
io_uring - Cross-platform support for Linux, macOS, Windows and browsers (through WebAssembly)
- Vector support support including exact search and vector manipulation
- Improved schema management including extended
ALTERsupport and faster schema changes.
The database has the following experimental features:
- Encryption at rest for protecting the data locally.
- Incremental computation using DBSP for incremental view maintenance and query subscriptions.
- Full-Text-Search powered by the awesome tantivy library
- Multi-process WAL coordination via the
.tshmsidecar for cross-process WAL readers and writers.
The following features are on our current roadmap:
- Vector indexing for fast approximate vector search, similar to libSQL vector search.
Getting Started
Please see the Turso Database Manual for more information.
Command Line
You can install the latest turso release with:
curl --proto '=https' --tlsv1.2 -LsSf \
https://github.com/tursodatabase/turso/releases/latest/download/turso_cli-installer.sh | shThen launch the interactive shell:
$ tursodbThis will start the Turso interactive shell where you can execute SQL statements:
Turso
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database
turso> CREATE TABLE users (id INT, username TEXT);
turso> INSERT INTO users VALUES (1, 'alice');
turso> INSERT INTO users VALUES (2, 'bob');
turso> SELECT * FROM users;
1|alice
2|bobRust
cargo add tursoJavaScript
npm i @tursodatabase/databasePython
uv pip install pytursoGo
go get turso.tech/database/tursogo
go install turso.tech/database/tursogo.NET
Example usage:
using Turso;
using var connection = new TursoConnection("Data Source=:memory:");
connection.Open();
connection.ExecuteNonQuery("CREATE TABLE t(a, b)");
var rowsAffected = connection.ExecuteNonQuery("INSERT INTO t(a, b) VALUES (1, 2), (3, 4)");
Console.WriteLine($"RowsAffected: {rowsAffected}");
using var command = connection.CreateCommand();
command.CommandText = "SELECT * FROM t";
using var reader = command.ExecuteReader();
while (reader.Read())
{
var a = reader.GetInt32(0);
var b = reader.GetInt32(1);
Console.WriteLine($"Value1: {a}, Value2: {b}");
}Java
We integrated Turso Database into JDBC. For detailed instructions on how to use Turso Database with java, please refer to the README.md under bindings/java.
MCP Server Mode
The Turso CLI includes a built-in Model Context Protocol (MCP) server that allows AI assistants to interact with your databases.
FAQ
Is Turso Database ready for production use?
Turso powers production apps today. That includes Turso Cloud, the Kin AI assistant, and Spice.ai. However, it is still under active development and for mission-critical applications, caution is advised.
How is Turso Database different from Turso's libSQL?
Turso Database is a project to build the next evolution of SQLite in Rust. Rewriting SQLite in Rust started as an unassuming experiment, and due to its incredible success, replaces libSQL as our intended direction.
Publications
- Pekka Enberg, Sasu Tarkoma, Jon Crowcroft Ashwin Rao (2024). Serverless Runtime / Database Co-Design With Asynchronous I/O. In EdgeSys ‘24.
- Pekka Enberg, Sasu Tarkoma, and Ashwin Rao (2023). Towards Database and Serverless Runtime Co-Design. In CoNEXT-SW ’23.
- Alperen Keles, Ethan Chou, Harrison Goldstein, Leonidas Lampropoulos (2026). DIRT: Database-Integrated Random Testing. In DBTest '26.
License
This project is licensed under the MIT license.
Jcode (GitHub Repo)
Jcode is a new open-source coding agent framework featuring a 'self-dev' mode that allows agents to autonomously modify their own source code in real-time.
Deep dive
- Features a unique 'self-dev mode' for autonomous code modifications.
- Implements custom memory graph for human-like retrieval using cosine similarity.
- Includes a 'swarm' architecture for native multi-agent collaboration and automatic conflict resolution.
- Provides first-class browser automation via a Firefox Agent Bridge.
- Ships with a custom terminal emulator, Handterm, for improved scrollback and rendering performance.
- Supports a wide array of providers including Claude, OpenAI, Ollama, and LM Studio.
Decoder
- Self-dev mode: A functionality where an AI agent possesses the permissions and tools to edit, build, and test its own source code, enabling iterative self-improvement.
- Semantic memory retrieval: A RAG-based (Retrieval-Augmented Generation) system where conversation history is stored as vector embeddings to facilitate context-aware recall.
Original article
Full article content is not available for inline reading.
One vulnerability view: From scanner coverage to AI governance
GitLab 19.1 adds unified vulnerability management and strict AI governance features to control and audit the behavior of AI agents in enterprise pipelines.
Original article
GitLab 19.1 adds centralized enforcement of third-party security scanners with unified vulnerability management and AI-driven remediation, while improving secret detection through full branch scanning and false positive reduction. The release also introduces AI governance features, including agent action audit streaming and approval guardrails, giving organizations visibility and control over AI agent activities with complete audit trails.
Deploying Fastly's Next-Gen WAF with Google Cloud Service Extensions to Help Secure Traffic at Scale
Fastly's Next-Gen WAF now integrates directly into Google Cloud Load Balancing, allowing for real-time traffic inspection without adding latency to application response times.
Decoder
- gRPC callout: A mechanism that allows an Envoy-based proxy or load balancer to pause request processing and consult an external service for security decisions before proceeding.
- Envoy ExtProc: The External Processing protocol that allows for granular traffic inspection (headers, body) by external agents during the request lifecycle.
Original article
What if your load balancer could stop attacks before your web application even sees them?
Google Cloud Service Extensions now enables real-time traffic inspection directly within the load balancer pipeline, and when combined with Fastly's Next-Gen WAF, organizations can achieve enterprise-grade security without sacrificing performance.
In this post, we'll explore how this powerful integration works and why it matters for modern cloud architectures, and walk through a practical deployment that you can implement today.
Real-World Impact: Performance Meets Protection
Let's look at what this means in practice with a realistic scenario:
The Setup: An e-commerce platform running on Google Kubernetes Engine (GKE) serving 10,000 requests per second across multiple regions.
The Challenge: Protecting against credential stuffing attacks, SQL injection, and bot traffic while maintaining sub-200ms response times.
The Solution: Deploy the Next-Gen WAF as a Service Extension callout, enabling:
- Zero-latency security decisions at the load balancer level
- Automatic scaling with your existing GKE infrastructure
- Regional deployment for optimal performance
- Fail-open configuration to maintain availability during agent maintenance
How Fastly's Next-Gen WAF Works with Google Cloud Service Extensions
Google Cloud Service Extensions offers two ways to insert custom logic: plugins and callouts.
Callouts let you use Cloud Load Balancing to make Envoy gRPC calls to Google Cloud services and user-managed services during data processing.
Fastly’s Next-Gen WAF can run as general-purpose gRPC server on user-managed compute VMs, on GKE Pods on GKE Multi-Cloud, or on on-premises environments.
Implementation Deep Dive: From Zero to Protected
The integration leverages Envoy's external processing protocol (ExtProc) via gRPC, enabling the WAF to inspect and act on traffic at critical stages:
1. REQUEST_HEADERS: Analyze incoming request headers against threat intelligence
2. REQUEST_BODY: Stream and inspect payload data for malicious content
3. RESPONSE_HEADERS: Monitor outbound responses for data leakage
This granular inspection capability means threats are identified and blocked before they ever reach your application backend.
Deployment from scratch involves creating and configuring an application load balancer that supports extensions.
To deploy a callout backend service using the Next-Gen WAF agent, one can use our ready made docker image. In the terminal snippets below, we’ll create a VM instance to house, configure and deploy the Next-Gen WAF agent in the load balancers network.
More detailed information can be found on Fastly’s documentation site.
gcloud compute instances create callouts-vm \
--zone=$ZONE \
--network=lb-network \
--subnet=backend-subnet \
--machine-type=e2-medium \
--image-family=cos-stable \
--image-project=cos-cloud \
--tags=allow-ssh,load-balanced-backend \
--metadata-from-file=startup-script=startup-script-tls.sh#!/bin/bash
# Create certificate directory
mkdir -p /etc/ssl/certs/sigsci
# Generate self-signed certificates for the gRPC service
openssl req -x509 -newkey rsa:4096 \
-keyout /etc/ssl/certs/sigsci/key.pem \
-out /etc/ssl/certs/sigsci/cert.pem \
-days 365 -nodes \
-subj "/C=US/ST=CA/L=SF/O=Fastly/CN=ext11.com"
# Set proper permissions for the sigsci user inside the container
chmod 644 /etc/ssl/certs/sigsci/key.pem
chmod 644 /etc/ssl/certs/sigsci/cert.pem
# Start Signal Sciences agent with TLS configuration
docker run -d \
--name sigsci-agent \
--restart unless-stopped \
-p 443:443 \
-v /etc/ssl/certs/sigsci:/etc/ssl/certs/sigsci:ro \
-e SIGSCI_ACCESSKEYID=<YOUR ACCESS KEY> \
-e SIGSCI_SECRETACCESSKEY=<YOUR SECRET KEY> \
-e SIGSCI_ENVOY_GRPC_ADDRESS=0.0.0.0:443 \
-e SIGSCI_ENVOY_EXTPROC_ENABLED=true \
-e SIGSCI_ENVOY_GRPC_CERT=/etc/ssl/certs/sigsci/cert.pem \
-e SIGSCI_ENVOY_GRPC_KEY=/etc/ssl/certs/sigsci/key.pem \
-e SIGSCI_DEBUG_LOG_VERBOSITY=3 \
signalsciences/sigsci-agent:latest
# Log startup completion
echo "Signal Sciences agent with TLS started at $(date)" >> /var/log/startup.logReady to Deploy?
The integration of Fastly's Next-Gen WAF with Google Cloud Service Extensions offers a compelling path forward for organizations serious about cloud security. The combination of real-time threat protection, cloud-native deployment, and enterprise-scale performance makes this architecture suitable for the most demanding production environments.
The future of web application security is here, and it's deeply integrated with your cloud infrastructure. Time to make the move.
Want to learn more? Check out our comprehensive setup guide for detailed implementation steps and troubleshooting tips.

Announcing Amazon EC2 G7 instances accelerated by NVIDIA RTX PRO 4500 Blackwell Server Edition GPUs
AWS launched G7 instances to general availability, becoming the first major cloud provider to offer NVIDIA's Blackwell-based RTX PRO 4500 GPUs.
Decoder
- Blackwell: NVIDIA's GPU architecture designed to accelerate generative AI workloads, featuring faster memory and enhanced tensor cores.
- Tensor Cores: Specialized hardware blocks within NVIDIA GPUs designed to accelerate matrix operations fundamental to AI and deep learning.
Original article
Announcing Amazon EC2 G7 instances accelerated by NVIDIA RTX PRO 4500 Blackwell Server Edition GPUs
Today, we’re announcing the general availability of Amazon Elastic Compute Cloud (Amazon EC2) G7 instances, delivering high performance GPU acceleration for AI inference, graphics, and data analytics workloads.
AWS is the first major cloud provider to support NVIDIA RTX PRO 4500 Blackwell Server Edition GPUs. G7 instances are accelerated by these GPUs with custom sixth-generation Intel Xeon Scalable processors, delivering up to 4.6x AI inference performance and up to 2.1x graphics performance compared to G6 instances. G7 instances also deliver faster performance for GPU-accelerated analytics on Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS). G7 instances are well suited for a broad range of GPU-enabled workloads including AI inference, graphics rendering, video transcoding and analytics, spatial computing, virtual desktop infrastructure (VDI), and data analytics.
Here are improvements of G7 instances compared to previous generation:
- Faster GPU memory – NVIDIA RTX PRO 4500 Blackwell Server Edition GPUs offer 1.33 times the GPU memory capacity and 2.45 times the GPU memory bandwidth compared to G6 instances. With 32 GB of GPU memory per GPU, 5th Gen Tensor Cores, and 4th Gen RT Cores, G7 instances deliver enhanced AI inference and graphics performance.
- High performance networking and storage – G7 instances come with 700 Gbps of EFA-enabled networking throughput (7x compared to G6) enabling the low-latency, high-bandwidth connectivity that AI inference, graphics-intensive applications, and GPU-accelerated data analytics workloads need to perform at their best. G7 instances support up to 7.6 TB local NVMe SSD storage, enabling you to keep large models and datasets close to compute, reduce data transfer overhead, and improve throughput.
- Advanced video encoding and decoding engines – Ninth-generation NVENC and sixth-generation NVDEC engines support 4:2:2 encoding and decoding for high-resolution video workflows, delivering 1.5x concurrent video streams compared to previous-generation G6 instances.
EC2 G7 instance specifications
G7 instances feature up to 8 NVIDIA RTX PRO 4500 Blackwell Server Edition GPUs with up to 256 GB of total GPU memory (32 GB of memory per GPU) and custom Intel Xeon Scalable processors. They also are available in 7 sizes and support up to 192 vCPUs, up to 700 Gbps of network bandwidth, up to 768 GiB of system memory, and up to 7.6 TB of local NVMe SSD storage.
Here are the specs:
| Instance name | GPUs | GPU memory (GB) | vCPUs | Memory (GiB) | Storage | EBS bandwidth (Gbps) | Network bandwidth (Gbps) |
|---|---|---|---|---|---|---|---|
| g7.2xlarge | 1 | 32 | 8 | 32 | 1 x 600 | Up to 8 | Up to 60 |
| g7.4xlarge | 1 | 32 | 16 | 64 | 1 x 600 | 8 | Up to 100 |
| g7.8xlarge | 1 | 32 | 32 | 128 | 1 x 950 | 16 | Up to 100 |
| g7.12xlarge | 2 | 64 | 48 | 192 | 1 x 1900 | 20 | 175 |
| g7.24xlarge | 4 | 128 | 96 | 384 | 1 x 3800 | 40 | 350 |
| g7.48xlarge | 8 | 256 | 192 | 768 | 2 x 3800 | 80 | 700 |
| g7.metal* | 8 | 256 | 192 | 768 | 2 x 3800 | 80 | 700 |
* Coming soon
G7 instances support NVIDIA GPUDirect P2P for multi-GPU sizes, NVIDIA GPUDirect RDMA with EFA, and GPUDirect RDMA with EFA for Amazon FSx for Lustre, enabling low-latency GPU-to-GPU communication for multi-GPU and multi-node workloads.
To get started with G7 instances, you can use the AWS Deep Learning AMIs (DLAMI) or NVIDIA Workstation AMIs with prepackaged GPU drivers for your AI inference and graphics workloads. To use G7 instances with Amazon EKS, build EKS AMIs with NVIDIA driver version R595 with EKS-provided automation. G7 instances support multiple operating systems including Amazon Linux, Ubuntu, RHEL, and Windows Server, with comprehensive NVIDIA driver integration providing compatibility with industry-standard graphics libraries including DirectX, Vulkan, and OpenGL.
Get started today
You can start using Amazon EC2 G7 instances today in two AWS regions: US East (Ohio) and US West (Oregon). To check future Regional expansion plans, look up the instance type in the CloudFormation resources tab on the AWS Capabilities by Region page.
G7 instances are offered through multiple purchasing options, including On-Demand, Savings Plans, and Spot Instances. Dedicated Instances are also supported for the 12xlarge, 24xlarge, and 48xlarge sizes. For detailed pricing, visit the Amazon EC2 Pricing page.
Ready to get started? Launch G7 instances from the Amazon EC2 console. For more details, head over to the Amazon EC2 G7 instances page. We’d love to hear your feedback. Share it on AWS re:Post for EC2 or reach out through your usual AWS Support contacts.

Write-Ahead Intent Log: A Foundation for Efficient CDC at Scale (51 minute video)
DoorDash replaced fragile Debezium-based CDC with a custom 'Write-Ahead Intent Log' to decouple database internals from downstream event streaming.
Deep dive
- Traditional CDC often fails at scale due to database-specific connector limitations.
- The 'Write-Ahead Intent Log' (WAIL) architecture separates intent (the 'what') from the actual data payload.
- A 'dumb' proxy logs the mutation intent to Kafka without needing to understand the underlying data schema.
- A 'smart' consumer manages complexity, validates state against the source-of-truth database, and manages schema evolution.
- This design enables independent scaling of producer proxies, Kafka partitions, and consumers.
- The system supports both transactional and non-transactional failure modes depending on the specific use case.
- It relies on a Schema Repository for validation, decoupling the data model from the streaming pipeline.
Decoder
- CDC (Change Data Capture): A pattern where database changes (inserts, updates, deletes) are tracked and streamed to downstream systems.
- Outbox Pattern: A technique to ensure data consistency between a database and a message broker by writing events to an 'outbox' table within the same transaction as the main data update.
- Pre-image/Post-image: The state of a data record before and after a mutation, used in traditional CDC to determine exactly what changed.
Original article
Full article content is not available for inline reading.

DuckDB's agent moment (55 minute podcast)
MotherDuck CEO Jordan Tigani argues that DuckDB's local-first architecture is uniquely suited for agent swarms that require isolated, fast, and disposable compute environments.
Deep dive
- DuckDB's design focuses on low-latency analytical queries rather than distributed throughput.
- 'Big Data is Dead' refers to the separation of data size from compute requirements, where most workloads are small-compute.
- The ability to run the same code locally and in the cloud by changing a connection string ('md:') is an ideal 'graduation path' for agentic workloads.
- Agents need a database that supports branching, ephemeral workspaces, and zero-configuration setups.
- MotherDuck adds enterprise features like SSO and authorization to the open-source DuckDB engine.
- 'Water Town' is a concept where agents manage data quality, lineage, and context curation in real-time.
Original article
DuckDB's agent moment (Jordan Tigani)
The database built for your laptop turns out to be one built for your agents. MotherDuck Founder and CEO Jordan Tigani explains why.
Season 9 of The Analytics Engineering Podcast is here. The theme this season is Analytics × Agents. We want to explore what changes when agents become the ones querying, building, and maintaining data systems. Motherduck Founder and CEO Jordan Tigani is a great guest to kick it off.
Jordan spent 11 years at Google building BigQuery, one of the largest distributed data warehouses on the planet. Then he left to bet on the opposite idea: that most data isn’t big, and most workloads don’t need a distributed system at all. Or as he wrote in 2023: Big Data is Dead.
DuckDB runs locally, starts instantly, and installs itself. The same properties that make it great for a cell in a Jupyter notebook make it great for a swarm of agents branching, querying, and throwing away work hundreds of times a second. Jordan’s company MotherDuck is the cloud data warehouse built on top of it. He talks with Tristan about why this architecture suddenly fits the moment.
This is Jordan’s second time on the show. The last time he was just getting MotherDuck off the ground and, in his words, still trying to figure out what the hell they were doing. This time around he gets into the unusually high-trust relationship between MotherDuck and DuckDB, why MotherDuck is faster and cheaper than the incumbents, how data lakes and Iceberg pull DuckDB into more and more architectures, and the big one for Season 9: what agents want from an analytical database.
Three ideas from the episode
- Why “small data” aged well. Data size and compute size are two different axes. Most workloads are small-data, small-compute or big-data, small-compute, and that’s where DuckDB wins.
- Why local-first is an agent feature. Agents want their own environment and software they can install. A database that lives locally and graduates to the cloud by changing one string is built for that world.
- What an “agent swarm” for data management is. Always-on agents handling the long list of small jobs: profiling columns, running evals, curating context, flagging the weird number before a human ever sees it.
Key takeaways
Lightly edited for clarity.
Tristan Handy: You reached out to DuckLabs to build a SaaS service. They said no, but partner with us. How does that work?
Jordan Tigani: When we started, it was the recognition that DuckDB is amazing. It’s really well done, these people know what they’re doing, and it’s going places. I reached out to Hannes and Mark, the co-founders of DuckLabs, to see if they’d hire me to build a SaaS service out of it. They said no, we want to just focus on the database, but we’d partner with you.
So rather than saying thanks for building an awesome open source project, now we’re going to go make a bunch of money on it, we wanted to be good partners and good stewards of open source. We gave them a co-founder share of the company, so they were economically incentivized for us to be successful. We funded a lot of development in DuckDB, and they built a lot of custom features just for MotherDuck.
We could have hashed out a highly litigated, legalese development agreement. Or we could just say, look, none of this is going to work unless we trust each other. So we chose to trust each other. I like hanging out with Mark and Hannes. I think they’re good guys.
Where’s the line between what goes into DuckDB and what you build?
There isn’t one that’s clearly written down. The obvious one is that we’re building a hosted service and they’re not. From an open-source business model, SaaS is the cleanest one to me: you pay us to run this in the cloud. You could do it yourself, but it’d be a lot more work.
DuckDB right now doesn’t have any concept of users. There’s no real grant statement. So if you’re going to run a data warehouse in a meaningfully sized organization, it’s not quite suitable yet. That’s the stuff we’re adding: SSO, authorization, all the things you’d need to build a real data warehouse.
They just launched something they call Quack, a service you can stand up on EC2 and connect to from anywhere over HTTP. I think it’s actually great for us, because a bunch of people are going to try that and then realize, hey, I need users, I need auth, I need backups, and then we can step in. They gave us a big head start, and if we can’t win with a head start that big, then we’ve done something meaningfully wrong.
You’re making big claims about speed and cost. Where do the savings actually come from?
In BigQuery, every query has to go through a lot of hops to get to the thing actually running it. And if your query does anything non-trivial, it goes through more hops, data gets shuffled around the network, and all of that adds latency. The mechanism to build distributed databases adds latency, because they’re designed for throughput.
I remember working on BigQuery and my manager said, “I don’t care if you add a second to every query, because we’re handling giant queries. But if you’re running a dashboard, adding a second means every user sits and waits a second.” That’s really annoying.
What we’ve designed for is latency rather than throughput. The energy in DuckDB has gone into making a great single-node engine instead of a distributed system where all these things can go wrong, so they’ve been able to build a super fast engine.
Our median query time is about three milliseconds. If you look at ClickBench, our standard instance at $2.40 an hour is something like five times faster than the Snowflake 2XL, which is $64 an hour. And that’s not our benchmark, it’s ClickHouse’s.
“Big Data is Dead“ came out three years ago. Does it still hold up?
There are two independent axes of scale. There’s the size of data you have, and clearly some people have petabytes, so to say large data doesn’t exist is just telling people the opposite of what they know. But the other axis is compute size, and just because you have large data doesn’t mean you need large compute.
If you’re looking at the last hour of logs, you might have a petabyte over ten years, but you’re only scanning the most recent stuff, so you don’t need the big compute mechanisms.
The flip side is big compute, small data: your BI tool, where you might have 500 users all slicing the same dashboards. The data is small but you need a lot of compute for all those users. Small data and small compute, big data and small compute, small data and big compute, those are probably 97% of cases, and we handle them well.
For the genuine big data, big compute case, DuckLake is our big bet, or Iceberg. If your MotherDuck data is a managed DuckLake table, we can give you access to the same files sitting on S3, so you could run it on Spark.
Are people using DuckDB as one engine on a data lake yet?
We’re seeing more and more of it. For their gold tier, people do want something more compact and managed, so we’ll see them ingesting from Iceberg. But people haven’t quite wrapped their heads around the fact that if you use Iceberg, you give up some things. We had a customer doing millions of single-row updates a day, and that generates all this mess and makes it super slow.
For a lot of smaller customers, the reason they use Iceberg is that there’s excitement and hype around it and they want to give it a try. And one thing they find is the tooling is behind the hype in terms of maturity.
You wrote that “ETL is highly vibe codable.” Make the case.
We launched our MCP server in December, and all of a sudden you could just ask questions in Claude and get answers. The other thing we noticed was that Claude is really good at building data visualizations. The problem was the data it came up with wasn’t updated, hosted, or shareable. So we said, what if we replace the data Claude dumped into a TypeScript file with a SQL query, host it on MotherDuck, and now you basically have a dashboard. That was the root of Dives.
We started out saying this is not BI, it’s a narrower use case, and then it got harder to draw the line, and we realized we’d stopped using our internal BI tool. We were just using this for everything.
I also talked to someone who’d built a vibe-coded data ingestion solution, and what shocked me was it was running in Claude. They had no front end, no UI. Their whole company was an MCP server. But there’s more to data engineering than building a pipeline, and that’s where it starts to get interesting.
What do agents want out of an analytical database?
This is exactly what my board asked me at the last meeting: How do you make it so agents use your database versus others? I wish I had a great answer. People have seen the success of Neon and Supabase, and I just spun up a Neon database the other day to interact with agents, because agents need to store data somewhere and Postgres is a great way to do that. Why would you need an analytical database?
That’s a bit more hand-wavy to me, but there will be cases where the agent needs to interact with larger amounts of data, do aggregations, answer harder questions. We have a lot of users building agent platforms on top of MotherDuck. Airbyte just announced their agent platform and it uses us under the covers.
Our architecture is amazing for agents, because if you have a hundred agents that are branching, our tenancy model works really nicely with that. If your agents are hammering Snowflake, that sounds like an incredibly expensive thing to have them do.
Why is local-first such an advantage in an agent world?
The way we architect working with DuckDB is that our client is DuckDB. If an agent installs DuckDB and does a bunch of stuff locally, you find out quickly that it’s very easy to use all the compute and all the memory on your machine.
Our architecture means the step from local DuckDB to cloud MotherDuck is just changing the name of your database. If the name starts with md:, it runs in the cloud. If it doesn’t, it runs locally. You don’t have to install anything differently. If there are agents doing stuff locally with DuckDB, there’s a great graduation case: this is too slow, it’s pulling everything down locally, let’s just push it off into MotherDuck.
What does an “agent swarm for data management” look like?
I wrote Water-Town as a takeoff on Steve Yegge’s Gastown. The idea is that as your data comes in, there are agents that do quality control and run evals that detect when something is goofy.
I was talking to someone at OpenAI about how they deal with context, and for core concepts they turn their context into evals. When I say revenue, here’s the calculation. These two tables should be joinable one to one. They have evals for all of those, so you always get the same number, and that’s operationalizable by an agent.
Then there are agents that add their own context: this field is always a capitalized U.S. state name. And agents that look at chat transcripts. When I talk to Claude I’ll say I want to know what’s happening with our paying users, and what that means is they’re in the capacity, business, or light plan. I just gave the agent information that can be captured, so the next time someone asks about paying users, it knows.
Anthropic calls this “dreaming,” taking memory and distilling it into what’s active memory, which is a cool name.
Where does all of this leave cost?
There’s Jevons paradox, where when something gets less expensive you find more stuff to do with it. We can make analytics dramatically less expensive and move more of it locally, but people will find more ways to keep their bill similar or even higher. The good part is you’re adding value. You won’t have a human trying to debug why a dashboard is showing a weird number, because the agent will have flagged it well in advance. Or you can just ask the agent where the number came from, and it’ll look at your pipelines and show what’s going on.

Announcing DuckDB 1.5.4
DuckDB 1.5.4 (Variegata) arrives with critical bug fixes for variant handling and JSON parsing while optimizing Parquet performance and memory usage.
Decoder
- VARIANT: A data type that can store semi-structured data like nested JSON.
- Shredding: The process of decomposing nested data formats into flat relational structures for column-oriented storage.
Original article
Announcing DuckDB 1.5.4 (Variegata)
TL;DR: Today we are releasing DuckDB 1.5.4 (Variegata) with bugfixes and performance improvements.
We are simultaneously releasing two DuckDB versions: v1.4.5 LTS (Andium) and v1.5.4 (Variegata). This blog post is about the latest non-LTS version, v1.5.4 (Variegata). If you are looking for the LTS version, check out the v1.4.5 (Andium) announcement.
In this blog post, we highlight a few important fixes in DuckDB v1.5.4, the fifth patch release in DuckDB's 1.5 (Variegata) line. The release ships bugfixes, performance improvements and security patches. You can find the full release notes on GitHub.
To install the new version, please visit the installation page.
Fixes
This version ships a number of performance improvements and bugfixes.
Correctness
- #23031 – Fix VARIANT cast reading wrong rows under a filter
- #23014 – MERGE INTO: only consider target table when binding
WHEN NOT MATCHEDand source table when bindingWHEN NOT MATCHED BY TARGET - #22825 – Fix case-insensitive column match in INSERT … SELECT ON CONFLICT
- #22911 – Use non-deleted row count in
RowGroupReorderer - #23194 – Fix variant shredding analysis logic discrepancy with shredded writing
- #23234 – Fix problem with re-use of cached transform data for differently shredded files
- #22844 – Window Self-Join Limits: don't apply the self-join optimisation more than once
Crashes and Internal Errors
- #21854 – Fix double free and memory leak in Arrow GeoArrow CRS serialization
- #22836 – Fix progress bar output and crash when piping SQL
- #23174 – Fix crash when storage path is not set
- #23232 – Fix gzip compression write overflow
- #23156 – Avoid trying to bind an expression that doesn't exist in
UNPIVOT - #23189 – Guard against null row group reorder stats
Generic Bugfixes
- #22855 – Fix json_keys with wildcard paths
- #23144 – Fix json argument order affecting result
- #23116 – Reject NULL json key
- #23137 – Fix
ignore_errorssilently accepting invalid JSON - #22882 – Fix geometry stats checkpointing when no changes are detected
- #22815 – Render MAP values as valid SQL in
Value::ToSQLString() - #23254 – Fix NULL propagation for date parts of infinite dates
- #23190 – Fix selection vector use in Arrow extension callbacks
Performance
- #23253 – Trim the system heap in the allocator flush path on jemalloc builds
- #23140 – Fix native geometry Parquet stats pruning and add
OPERATOR_ROW_GROUPS_SCANNEDto Parquet reader
Miscellaneous
- #23246 – Add explicit
-dark-modeand-light-modeoptions to the CLI, and improve terminal background color detection - #23100 – Add hardening to many DuckDB/Parquet decompression and deserializing paths
- #22690 – Add
vacuum_rebuild_indexesas an (experimental) ATTACH option
Conclusion
This post was a short summary of the changes in v1.5.4. As usual, you can find the full release notes on GitHub. We would like to thank our contributors for providing detailed issue reports and patches. Stay tuned for future DuckDB releasese, including v2.0.0 in the fall!
PS: Next week, we'll host DuckCon #7 in Amsterdam. Join us in-person or on the online stream.
AWS enters the context layer race with a graph that learns from agents, not manual curation
AWS is introducing a knowledge graph layer designed to dynamically learn context from AI agent interactions rather than static manual curation.
Decoder
- RAG (Retrieval-Augmented Generation): An AI framework that improves model accuracy by retrieving data from external sources rather than relying solely on training data.
Original article
AWS announced a context stack for AI agents: AWS Context, S3 Annotations, and skill assets in Glue Data Catalog. AWS Context builds and improves a knowledge graph from enterprise data, rules, and domain knowledge, with IAM and Lake Formation access control. Metadata sits in Iceberg on S3 Tables and is exposed through Athena, Redshift, Spark, and MCP tools.
Data-Juicer: The Data Operating System for the Foundation Model Era (Tool)
Data-Juicer provides a Ray-native framework for curating multimodal training data through composable YAML recipes and distributed processing.
Decoder
- Ray: An open-source unified framework for scaling AI and Python applications.
- Multimodal: Systems capable of processing and synthesizing multiple types of data, such as text, images, and audio.
Original article
Data-Juicer: The Data Operating System for the Foundation Model Era
Multimodal | Cloud-Native | AI-Ready | Large-Scale
Data-Juicer (DJ) transforms raw data chaos into AI-ready intelligence. It treats data processing as composable infrastructure—providing modular building blocks to clean, synthesize, and analyze data across the entire AI lifecycle, unlocking latent value in every byte.
Whether you’re deduplicating web-scale pre-training corpora, curating agent interaction traces, or preparing domain-specific RAG indices, DJ scales seamlessly from your laptop to thousand-node clusters—no glue code required.
Alibaba Cloud PAI has deeply integrated Data-Juicer into its data processing products.
🚀 Quick Start
Zero-install exploration:
- JupyterLab Playground with Tutorials
- Ask DJ Copilot
Install & run:
uv pip install py-data-juicer
dj-process --config demos/process_simple/process.yamlOr compose in Python:
from data_juicer.core.data import NestedDataset
from data_juicer.ops.filter import TextLengthFilter
from data_juicer.ops.mapper import WhitespaceNormalizationMapper
ds = NestedDataset.from_dict({
"text": ["Short", "This passes the filter.", "Text with spaces"]
})
res_ds = ds.process([
TextLengthFilter(min_len=10),
WhitespaceNormalizationMapper()
])
for s in res_ds:
print(s)✨ Why Data-Juicer?
1. Modular & Extensible Architecture
- 200+ operators spanning text, image, audio, video, and multimodal data
- Recipe-first: Reproducible YAML pipelines you can version, share, and fork like code
- Composable: Drop in a single operator, chain complex workflows, or orchestrate full pipelines
- Hot-reload: Iterate on operators without pipeline restarts
2. Full-Spectrum Data Intelligence
- Foundation Models: Pre-training, fine-tuning, RL, and evaluation-grade curation
- Agent Systems: Clean tool traces, structure context, de-identification, and quality gating
- RAG & Analytics: Extraction, normalization, semantic chunking, deduplication, and data profiling
3. Production-Ready Performance
- Scale: Process 70B samples in 2h on 50 Ray nodes (6400 cores)
- Efficiency: Deduplicate 5TB in 2.8h using 1280 cores
- Optimization: Automatic OP fusion (2-10x speedup), adaptive parallelism, CUDA acceleration, robustness
- Observability: Built-in tracing for debugging, auditing, and iterative improvement
📰 News
[2026-05-29] Release v1.5.2: Semantic LLM OPs, Cross-doc Line Dedup & Leaner Dependencies
- 🧹 New Deduplicator — Added
DocumentLineDeduplicatorfor cross-document line-level dedup, removing boilerplate lines (templates, copyright notices, navigation bars) by global document frequency. - 🤖 Agent Data Quality Toolkit — Shipped interaction-quality OPs & recipe, a bad-case HTML report, and more robust JSONL / HuggingFace meta loading.
- 📦 Leaner & Faster Install — Slimmed the default dependency set (Ray, audio, spaCy, av, etc. moved to on-demand extras) to speed up installation.
- 🐳 Stability & Robustness Fixes — Library-safe error handling (raise over
exit(1)), Ray init/temp-dir fixes, valid API params (drop invalidmax_new_tokens), PyArrow 20+ batch JSON reading, local-path aesthetics model support, and more performance/bug fixes. - 🧠 Semantic LLM Operators — Introduced
llm_extract_mapper,llm_condition_filter, andllm_structured_opswith unifiedllm_*naming and configurable inference strategies (join/agg/top-k planned).
🔌 Users & Ecosystems
Data-Juicer plugs into your existing stack and evolves with community contributions:
Extensions
- data-juicer-agents — DJ Copilot and agentic workflows
- data-juicer-hub — Community recipes and best practices
- data-juicer-sandbox — Data-model co-development with feedback loops
Frameworks & Platforms
AgentScope · Apache Arrow · Apache HDFS · Apache Hudi · Apache Iceberg · Apache Paimon · Alibaba PAI · Delta Lake · DiffSynth-Studio · EasyAnimate · Eval-Scope · Huawei Ascend · Hugging Face · LanceDB · LLaMA-Factory · ModelScope · ModelScope Swift · NVIDIA NeMo · Ray · RM-Gallery · Trinity-RFT · Volcano Engine
📖 Citation
@inproceedings{djv1,
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
author={Chen, Daoyuan and Huang, Yilun and Ma, Zhijian and Chen, Hesen and Pan, Xuchen and Ge, Ce and Gao, Dawei and Xie, Yuexiang and Liu, Zhaoyang and Gao, Jinyang and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
booktitle={SIGMOD},
year={2024}
}
@article{djv2,
title={Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for and with Foundation Models},
author={Chen, Daoyuan and Huang, Yilun and Pan, Xuchen and Jiang, Nana and Wang, Haibin and Zhang, Yilei and Ge, Ce and Chen, Yushuo and Zhang, Wenhao and Ma, Zhijian and Huang, Jun and Lin, Wei and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
journal={NeurIPS},
year={2025}
}
The analytics engineer in 2026: system designer, governance owner, AI context provider
Analytics engineering is shifting from manual SQL coding to system architecture and governance as AI automates repetitive model production.
Deep dive
- AI is commoditizing SQL generation, making boilerplate model production no longer the primary bottleneck for data teams.
- The new core responsibilities for analytics engineers are system design, governance, and AI context provision.
- System design involves architectural decisions regarding metrics, domains, and semantic layer structures rather than simple transformation logic.
- Governance is now a primary deliverable, requiring rigorous tests, contracts, and lineage to ensure data reliability.
- AI context provision ensures that data stacks are interpretable by autonomous agents, requiring structured metadata.
- SQL fluency remains necessary but is secondary to business judgment, semantic precision, and systems thinking.
- Tools like dbt Wizard and MCP (Model Context Protocol) servers are designed to ground AI agents in existing project lineage and business logic.
Decoder
- Semantic layer: A business-facing representation of data that defines metrics (e.g., 'revenue') in a standard way, ensuring all users and AI agents use the same calculation logic.
- Column-level lineage: A detailed map showing the origin and transformation history of every individual column in a data warehouse.
- MCP (Model Context Protocol): An open standard for connecting AI assistants to systems, data, and developer tools.
- Schema contract: A formal agreement or definition enforced on data structures to ensure that data remains consistent and compatible across pipelines.
Original article
The analytics engineer in 2026: system designer, governance owner, AI context provider
What analytics engineering looked like in 2023
In 2023, the core of an analytics engineer's job was model development. You wrote SQL, organized it into dbt models, wrote tests, and built pipelines that turned raw data into something stakeholders could use. Documentation was a best practice you aspired to. Column-level lineage was a nice-to-have. The bottleneck was your capacity to write and review code.
In 2026, that bottleneck has eased. AI can write dbt model scaffolding faster than any human. It can generate first-draft documentation from lineage metadata. It can write the boilerplate tests most models need. AI-assisted coding is now part of how most analytics engineers work: 72% of them, according to the 2026 State of Analytics Engineering report. The repetitive parts of model production are increasingly automated.
That clarifies the role rather than shrinking it. With the repetitive work no longer the bottleneck, what's left is the work analytics engineers were always most valuable for.
The three new responsibilities of the analytics engineer in 2026
System design
The analytics engineer in 2026 focuses less on individual model implementation and more on how the system of models works. Which models are the source of truth for which metrics? Where are the boundaries between domains? How should the semantic layer be structured so downstream AI queries return consistent answers? These are architecture decisions that require business judgment and an understanding of how the data gets used, not just how it gets built.
AI can scaffold a model. It can't decide whether revenue should be defined at the order line level or the order level, or which grain is correct for a retention metric. That judgment requires understanding the business, which remains a human capability. (For a real-world look at the tradeoffs, see who should own the semantic layer.)
Governance ownership
As AI-assisted development accelerates data production, the governance layer becomes more important. Tests, contracts, column-level lineage, and ownership assignment are now the outputs that separate a trustworthy data system from a fast but unreliable one. The analytics engineer owns those outputs.
This changes how the role gets evaluated. In 2023, an analytics engineer's output was models. In 2026, it's also the contracts that protect those models, the tests that validate them, and the semantic definitions that make them machine-readable. Governance has become a primary deliverable. (More on this in semantic layer for data governance and security.)
AI context provision
This responsibility has emerged most visibly in the past eighteen months, and it's the one analytics engineers are often not trained for explicitly.
AI agents need context to reason reliably, and that context has to come from somewhere. In a well-structured dbt project, it comes from MetricFlow metric definitions, column-level lineage, model documentation, and schema contracts. The analytics engineer who understands how to structure that context, what to name things, how to document them, which definitions to make machine-readable, is directly improving the reliability of every AI agent that runs against the data stack.
The data community has spent a lot of 2026 debating "context" as a buzzword, and the joke is fair. The underlying problem it names is real: organizations are failing at AI not because their models are wrong, but because AI agents lack the context to reason about what the data means. Analytics engineers build that context. That's a significant expansion of the role's leverage.
Analytics engineer skills that matter in 2026
SQL fluency still matters, and it isn't going away. But the premium on raw SQL productivity is lower than it was two years ago, because AI can produce syntactically correct SQL faster than most humans.
Three things have gotten more valuable: business judgment, semantic precision, and system thinking.
Business judgment means understanding what the data represents well enough to know when an AI-generated model is wrong, even when it looks syntactically correct. It means knowing that a metric definition that works for one use case will mislead in another. That judgment isn't automatable.
Semantic precision means writing metric definitions and documentation precise enough to be unambiguous, both to a human reading them and to a model reasoning over them. This is a new skill, and the analytics engineers who develop it are more valuable in an AI-native data stack.
System thinking means understanding how models relate, where the dependencies are, and how architectural decisions propagate through the stack. As AI takes over individual model implementation, the analytics engineer's comparative advantage lies in the decisions that span models.
The career case for analytics engineers in 2026
Analytics engineers are more valuable in 2026 than they were in 2024, and AI is the reason why.
In 2024, some analytics engineering work created value and some was maintenance. AI is eliminating the maintenance, and what remains is disproportionately the value-creating work: semantic definition, governance ownership, architecture decisions, and the business judgment that determines whether fast data is also accurate data.
An analytics engineer who spends 2026 competing with AI on code production will find the role shrinking. One who focuses on what AI can't do, business judgment, context design, and governance ownership, will find it expanding. Treat that as a specific description of what to build toward.
How dbt supports the evolving analytics engineer role
dbt is well-positioned for this shift because of what it has always stored: semantic context in code. The metric definitions, tests, contracts, and documentation in a dbt project are exactly the context AI agents need to reason about data reliably. The analytics engineer who maintains that context is the person making AI-assisted data work trustworthy.
The tooling supports this directly. dbt Wizard gives analytics engineers an AI agent grounded in their project's lineage, contracts, tests, and metrics. The dbt MCP server makes the dbt Semantic Layer queryable in natural language. Column-level lineage gives AI agents the provenance they need to cite their answers.
None of that replaces the analytics engineer. It amplifies what the analytics engineer already does: define what data means, govern how it's used, and build the context AI depends on. That work is the most valuable in the data stack right now, and the question is whether analytics engineers recognize it as such.
Building a Design System Specced for Engineers and Agents
Evil Martians rebuilt a design system for test observability platform Currents, creating an AI-readable foundation to stop design drift from automated coding.
Deep dive
- Conducted an audit of 791 files using LLMs to inventory icons, colors, and fonts.
- Found 236 unique colors and multiple competing font systems.
- Migrated to OKLCH color space for better AI-based color manipulation.
- Standardized icon sets using SVGR to simplify imports.
- Reduced typography to a strict six-size scale.
- Created a unified filtering component to replace three disparate legacy implementations.
Decoder
- OKLCH: A color space that expresses colors using lightness, chroma, and hue, making it easier for machines to programmatically adjust colors while maintaining perceived brightness and saturation.
Original article
Building a design system specced for engineers and agents
AI-assisted coding allows technical founders and lean engineering teams to try new languages and frameworks, write more code, and ship new designs. It’s the perfect solution for validating ideas, building PoCs and MVPs. However, as adoption grows, it’s time to drastically elevate the UX and UI.
Currents is a test observability platform for running, debugging, and analyzing Cypress and Playwright suites in CI. It grew with a small team of strong engineers who wrote high-quality code but had to make hundreds of design decisions on the spot, like choosing icon and font sizes, colors, and filter options.
Currents came to Evil Martians to improve their UI and standardize design decisions. In just seven weeks, our team ran an AI-assisted UI audit and built a design system that can be used by engineers or agents …without a designer in the room. This allows Currents to invest in distribution and gives the team a design foundation that grows with the product.
Why Currents hired Evil Martians
Andrew Goldis, CEO at Currents, wanted to improve the experience for the users and his team. “Every time we want to work on something new, we need to go back and decide whether we need to reuse components or introduce new ones. And then we need to invest additional time into polishing them or we just use old school components,” he said.
Since Andrew was operating with a lean team, he didn’t have the resources to define the necessary app design guidelines and standards internally. This is when we came in.
There were two business triggers that made hiring us urgent:
- AI was amplifying divergence. The Currents team was using Cursor and Claude for code generation, but without a design foundation, every AI-assisted PR risked adding new components. Andrew wanted the design system to be AI-readable for consistent future deliveries.
- GTM was being held back. In devtools, the way a product looks plays a big role in the purchasing decision. Currents had a steady user base, but the UI had certain challenges to address before the team could feature it confidently in ad campaigns, on the landing page, or in sales demos.
Part 0: designing the vision
For an interface and product to feel crafted, a designer needs to make hundreds of small (and not-so-small) decisions that may not be visible first. This leads to a design system.
But a design system alone is hard to digest, so Arthur Objartel, the Evil Martians product designer working on this project, always starts by selling his vision.
In this case, he rebuilt key screens in Figma to use as a north star UI in order to show Andrew how the new design would look across key pages. This helps the client visualize the future product and commit to all the key design decisions right at the start. A north star UI also gives the designer, the developer, and the LLM a shared ground for making decisions.
Part 1: running an AI-assisted audit in week one
Before any design work, Evil Martians needed to understand the full picture, which was scattered around 791 files with design information. In the past, this would’ve taken us two to three weeks to manually inventory every icon, color, and font size. In this case, with LLM assistance, Arthur completed it in a third of the time.
This is what the audit showed:
- Two icon libraries running in parallel (@geist-ui/react-icons and react-icons/vsc), plus 69 local custom icons with 323 resized usages. For example, the same Check icon was being used 19 times at six different sizes.
- Two competing font systems with up to five sizes per screen.
- Many hardcoded colors without clear guidance on when to use which. There were 236 unique colors with 1,413 uses spread across five color reference systems.
- An inconsistency of button types across the product, hurting design cohesion.
- Three different filter components across views, which affected the user experience and predictability.
Part 2: building a design system specced for engineers and AI
When a client runs into a problem like “we don’t know what colors to choose, what font to pick, and which button variant to use out of 10 different ones,” it’s always due to the lack of design guidelines or visual direction.
The solution is a design system. In Currents’ case, it’s deliberately small and consists of a set of Storybook docs and general usage guidelines for each of the system’s foundational parts: typography, icons, colors, spacing, and corner radius values. It also includes deep research on current usage and components location, a migration plan on how to swap previous tokens for new ones, and a new system description.
Typography: Innovator Grotesk
After comparing a dozen open-source faces, Innovator Grotesk won on one practical point: its metrics are almost identical to Inter, the team’s existing font. That meant Currents could switch immediately, with no layout overhaul and nothing to re-space. A new typeface usually costs weeks of reflow; here it was close to a drop-in.
To keep type consistent without a designer in the loop, the rule is simple: fewer sizes, and an obvious answer for which one to use. Arthur built the system from scratch with six sizes and five token groups, each with a dedicated job. The UI group is only for interactive components, so when an engineer or an agent needs a button label, there is exactly one correct token: ui.default.
Icons: a custom set, mapped to the old one with 90% AI accuracy
Open-source icon sets tend to look the same and lack personality. So we went with Figura One because it comes with stylish, pixel perfect icons that have a great set of metaphors.
The real question was adoption. Figura One had no public React library, which meant the team would have had to process every icon by hand before shipping it. Rather than hand Currents that work, Arthur built a local wrapper with SVGR and merged it into production with the frontend team’s sign-off. The icons went from a liability to a one-line import.
To make the migration mechanical instead of manual, we mapped the new set against all 191 legacy icons. The AI proposed a correct Figura One match for roughly 90% of them, and the rest were mapped by hand. The result is a lookup table an engineer or an agent can follow icon by icon, with no judgment calls left in the swap.
Color: 1,413 usages collapsed into four token groups
The first challenge before creating a new color token system was to match the UI to the brand colors. The UI used blue as primary and success colors, yet the Currents brand color was green. This confused users who usually expect successful actions to be green.
But making everything green in the interface would also be confusing, so Arthur solved it by picking different greens: cold green as an accent brand color and warm green for success indicators.
From there, the audit’s 236 colors and 1,413 usages collapsed into four groups, each with a clear job: elevation, content, UI, and border. Fewer colors, and an obvious answer for which one applies, the same principle as the type scale.
Every color is defined in OKLCH, and this is the part that makes the system genuinely AI-readable. Because OKLCH expresses a color as plain, human-readable lightness, chroma, and hue, an agent can extend the palette without guessing: hold the hue and lightness, step the chroma, and the new shade already belongs to the system. Ask it for “a border one step softer than border.default, same hue,” and you get a value that holds up against the rest of the palette instead of a one-off hex that drifts.
Part 3: going the extra mile
Evil Martians believe in adding value fast and tend to fix things as we work. The left sidebar was a pain point for many users in terms of navigation. For example, the theme switcher, docs links, help, and changelog buttons were sitting in the top-right of the product, disconnected from primary navigation. Aligned with the client, we changed the sidebar design to help users immediately and to set the ground for future updates.
We also noticed the tool was using three different filtering options. When an app has different filtering options, users lose predictability and have to relearn how to navigate your interface each time.
To stop this, before waiting for the full app redesign, we grouped all previous filter implementations into one component handling multi-select, ranges, dates, and presets with a single interaction model. Also, to make the most out of this functionality, we added quick filters and presets that allow users to save common queries.
Results and next steps
I really like all the attention to details and the way Arthur delivers the assets. It’s next level! I’m not used to it and it’s very refreshing.
— Andrew Goldis, CEO of Currents
To summarize, in just seven weeks, Currents got access to:
- An AI-assisted audit of every icon, color, and font size to understand the full picture
- A design system living in Figma, Storybook, and GitHub, readable by AI agents and engineers
- An icon, typography, and color migration map to simplify the adoption of new components
- A new color system that is easy to understand and use
- A north-star UI design of the most critical screens for engineers to have a reference point when applying changes
The implementation is now on Currents’ side. The team hired a front-end engineer who’s already implementing the system, which according to the client “it’s looking great.” Arthur is still in close contact with the team, guiding them through the process and answering any ad-hoc questions. We’re also looking forward to seeing the reactivation of paid distribution and go-to-market, an improvement in developer experience, and a consistent design and predictable UX.
How to know if you need to invest in a design system in 2026
A design system is the type of thing that goes unnoticed when it works, but becomes extra visible when you don’t have one. With AI-code generation becoming the new norm and allowing engineers to produce more code faster, not having a design system becomes a liability. For example, if you’re now producing 10x the output, you’re also introducing inconsistencies at that pace.
But, how to know if this is what you need? Here are three signals to tell if you’re past the decision point:
- Your product is dense or technical and you don’t feel comfortable showing the UI or demoing the tool in sales conversations
- Your team uses LLMs for coding new features, or will soon, and you don’t have designers on your team
- You can name three places in your UI where the same components follow different rules
Putting together a design system has now become less expensive than before. AI-assisted work has dramatically cut the hours required to audit the state of your tool. However, the cost of building without a design foundation has gotten exponentially higher.
If at least two of the reasons on the list are true for you, the question isn’t whether or not to invest in a design system but when.
Design DNA for Agents (Website)
Taste automates design system documentation by reverse-engineering any website into a structured, agent-ready design language.
Decoder
- MCP (Model Context Protocol): An open-standard protocol that allows AI assistants to securely connect to local and remote data sources, such as developer tools or databases.
Original article
taste
Abductive reasoning for any website's design taste
/taste turns any URL into a complete design context for your AI agent. Design Map, Taste DNA, and the reasoning behind every choice.
Four steps from URL to taste.
Four agents, four roles. Each reads the same page through a sharper lens until what's left is a file any AI tool can build from.
- Extract Measurements You are a Senior Design AI. Your job is to extract precise, objective design measurements from a webpage.
- Detect Patterns You are a Principal Design Engineer detecting SYSTEMATIC RULES in the measurements provided by Step 1.
- Infer Taste You are the Ultimate Design Critic. You will now derive the "Taste" — the deliberate, painful TRADE-OFFS the designer made.
- Observer You are the Lead Critic & Final Editor. Your job is to RUTHLESSLY filter the taste analysis from Step 3. Zero bullshit passes through you.
How to reverse engineer design taste
20 measurement categories, every colour, weight, spacing value, radius, and shadow cited with exact px / hex / ratio. No approximations.
5–8 system-level rules extracted. Each pattern gets an Evidence line and a Design Goal explaining why it exists.
4 taste principles — each with Trigger, Decision, Reason, Evidence, and Trade-off. At least one Restraint principle is required.
Quality gate. Runs anti-slop grep, validates JSON, then writes the final output. {domain}.md + {domain}.json
Two files. One brief.
Every run writes a .md and a .json. The full token set, plus 4 principles explaining why each design choice was made and what it gave up.
Output structure
Part 1: Design Map — colors, typography, spacing, radius, shadows. The complete token set from the page.
Part 2: Taste DNA — 4 principles, each explaining the reasoning behind one design decision.
What a Taste DNA principle contains
- Trigger — what design decision prompted this choice
- Decision — what was chosen
- Reason — the design logic behind it
- Evidence — specific proof from the page (px, hex, DOM values)
- Trade-off — what this choice gives up
Color System
| Property | Value | Note |
|---|---|---|
| Page background | #08090A | Near-black, not pure black |
| Surface-1 | rgba(255,255,255,0.02) | Barely-there panel tint |
| Surface-2 | rgba(255,255,255,0.05) | Card face |
| Text primary | #F7F8F8 | Nearly white, cool |
| Text secondary | #D0D6E0 | Cool gray |
| Panel border | #23252A | 1px inset ring |
Typography
| Style | Metrics | Tracking |
|---|---|---|
| H1 / Display | 64px · wt 510 | −1.408px tracking |
| H2 | 48px · wt 510 | −1.056px tracking |
| H3 | 20px · wt 590 | −0.24px tracking |
| Body | 15px · wt 400 | 24px line-height |
| Font | Inter Variable | wt 510/590 = variable-only |
Spacing
| Type | Value | Context |
|---|---|---|
| Base unit | 8px | |
| Section padding | 72px | top per section |
| Inter-section gap | 10px | breathing room is inside sections |
| Button h-pad | 12px |
Border Radius
| Value | Usage |
|---|---|
| 2px | Tags, micro elements |
| 6px | Primary card (most common) |
| 8px | Modal / chat panels |
| 9999px | Pill badges / buttons |
Depth & Shadow
| Type | Value | Context |
|---|---|---|
| Card border | #23252A 0px 0px 0px 1px inset | primary depth signal |
| Float | rgba(0,0,0,0.4) 0 2px 4px | floating cards only |
| Vignette | rgba(0,0,0,0.2) inset | product screenshot depth |
Principle 1 — RESTRAINT: Brand lives in white, not in color
- Trigger: Deciding on an accent or brand color.
- Decision: Don't introduce one. Use white (#F7F8F8) as the accent against near-black.
- Reason: Color-as-brand is a shortcut for products without visual confidence. On a near-black surface, white carries all the emphasis needed — everything else is noise. Adding a purple or blue CTA button would cheapen the effect by making it feel like a template.
- Evidence: Every nav link, button, and CTA is white or near-white. The only colored element is a translucent green badge for functional status. DOM accentCandidates are 100% grays and whites.
- Trade-off: You cannot differentiate feature tiers by color. Linear resolves this with weight and size hierarchy alone — not color weight.
Your AI agent gets the taste.
One extra file, formatted for your tool. The agent picks it up on its next run.
- Cursor: .cursor/rules/{domain}-taste.mdc
- Windsurf: .windsurf/rules/{domain}-taste.md
- Claude Code: CLAUDE.md
- GitHub Copilot: .github/copilot-instructions.md
- Bolt: .bolt/prompt
- Antigravity: GEMINI.md
- v0 by Vercel: taste-tokens.css + instructions
- Figma Make: taste-figma.css + instructions
- Lovable: Printed to paste in Project Knowledge

Inception Labs' Mercury 2 AI Beats Google's DiffusionGemma at Its Own Game
Inception Labs' new Mercury 2 model uses diffusion-based generation to achieve high-speed text output for workflow automation.
Decoder
- Diffusion: A generative process that begins with noise and iteratively refines it to generate structured data, increasingly applied to non-image modalities like text.
Original article
Full article content is not available for inline reading.

Nobel laureate John Jumper is leaving DeepMind for rival Anthropic
Nobel laureate John Jumper is departing Google DeepMind for Anthropic, marking a significant talent shift in the AI research landscape.
Original article
Nobel laureate John Jumper is leaving DeepMind for rival Anthropic
John Jumper, who shared a recent Nobel Prize in chemistry, announced Friday that he’s making the leap to Anthropic after “nearly 9 years” at Google DeepMind.
In a post on X, Jumper wrote that DeepMind CEO Demis Hassabis “took a real chance letting me lead the AlphaFold team just six months after finishing my PhD, and the entire GDM team taught me so much about how to do great science.”
Jumper (pictured above right, with Hassabis) added, “GDM is a special place, and I’ll still be excited to hear about what amazing things they discover next.”
Bloomberg reports that Jumper was a key member of Google’s team developing coding tools, which the company has struggled to sell to businesses. Character AI co-founder Noam Shazeer also announced this week that he’s leaving DeepMind — though in Shazeer’s case, he’s joining OpenAI.
Jumper and Hassabis won the Nobel Prize in 2024 for their work on AlphaFold, an AI model that can predict the 3D structure of proteins based on their genetic sequences.

From Prompting Agents to Loop Engineering
Developers are shifting from static prompt engineering to 'loop engineering,' where AI agents autonomously refine their own inputs based on continuous goal evaluation.
Deep dive
- Shift from static prompt inputs to iterative feedback loops.
- Core mechanism involves continuous evaluation of agent outputs.
- Focuses on reaching a measurable 'done' state rather than generating a single answer.
- Reduces human overhead in multi-turn coding and analytical workflows.
- Requires robust observability to debug why a loop is not converging.
Decoder
- Loop Engineering: The practice of designing autonomous systems that wrap LLMs in iterative feedback loops to refine outputs until they meet success criteria.
Original article
From Prompting Agents to Loop Engineering
A claim has been circulating in AI coding circles: stop prompting your coding agents and start designing loops that prompt them for you. As with everything new, this stuff gets repeated often and...
Notes on the Industry Job Search
Successfully navigating a high-stakes industry job search for AI research roles requires treating the process as a full-time, structured engineering discipline.
Deep dive
- Technical interviews prioritize ML theory and architecture implementation (e.g., PyTorch, backprop) over generic LeetCode.
- Job talks and research discussions require a clear narrative connecting past project choices to future research directions.
- Negotiating requires managing competing timelines and leveraging multiple offers for better compensation.
- Dedicated study time (full-time effort) significantly improves both interview performance and on-the-job confidence.
- Behavioral questions about AI safety and ethics are now standard and require prepared anecdotes.
Decoder
- ML Coding Interview: Technical interview focusing on implementing specific machine learning algorithms or model architectures from scratch.
Original article
Notes on the Industry Job Search
For most of my PhD, the job search in my mind was like a sorting hat: senior PhD students would disappear (for several months), then emerge with their fates decided. Even as my close friends began graduating and getting jobs, I knew little about what they were going through apart from the occasional proof of life. When it was finally my turn, I found the process to be far more demanding than I had imagined, and felt like I was learning the rules of the game while playing it.
In retrospect, a lot of my experiences were universal and many of the things I learned along the way now feel like common knowledge. I’m writing this post to share one data point for how the journey can look and hopefully make the job search a little less mysterious for someone in my shoes not too long ago.
A bit of background on me. I applied for Research Scientist / Member of Technical Staff roles at the end of my 6-year PhD in NLP at the University of Washington. I’ve been in school my whole life, and would have loved to be a PhD student forever except that my advisors eventually nudged me to move on. I spent most of my PhD not thinking much about what I would do afterwards, and I was compelled more by working on fun ideas than anything else. This led to a lot of pivoting, but fortunately I managed to keep a consistent thread in my last two years (on tokenization!) because it coincided quite a bit with having fun, and I think establishing an area of expertise helped me stand out in the job search.
My timeline
The figure below shows my job search timeline, showing interviews as gray icons and outcomes as colored circles. Note ghosted means the recruiter never informed me about an outcome or next steps, and withdrawn means I politely told the company I was no longer interested after receiving some offers I was excited about. In total, I interviewed at 11 companies over 57 interviews. Not pictured are 46 additional recruiter calls and 16 post-offer chats, plus myriad informal networking conversations leading up to the search.
Company order. I decided when to begin each interview process through some combination of whether I felt ready, pressure from the company, how quickly I expected them to move, how excited I was about them, and less-deliberate factors like procrastination. The common wisdom here is to use a few companies for practice, then time the other processes so that all offers are received at roughly the same time for negotiation purposes. While I think this is roughly right in spirit, there are a few considerations I would add.
- Practice interviews are helpful, but also recognize that your stamina is finite — be careful not to burn out by the time you get to places you really care about!
- There are external factors to timing that are worth taking into account, such as whether the company has headcount and which teams are actively hiring, and this can matter more than your preparation. You can gain some insight into this through your friends and recruiters.
- Deadlines come with a lot of flexibility, so offer timing does not have to be very precise. Recruiters recognize you have other processes to finish, and there are various tricks to delay the offer and decision. That being said, there are notorious exceptions (so-called “exploding” offers), so it is important to investigate how much time candidates are usually given to sign.
Getting the first interview. To state the obvious: try to do good work during the PhD, make friends, and collaborate a lot! To get that first interview, sometimes you need to have someone inside the company vouching for you. You can set yourself up for success early on by being social at conferences, collaborating widely, and attending networking events (of course this part doesn’t come easily to everyone — certainly not for me — so take care of your own energy and comfort levels too). During the job search, reach out to people you know (or don’t know) and ask about opportunities. In fact, a big part of the job search is reconnecting with people who you may not have talked to in years — this is okay, expected, and turns out to be a wonderful side effect of the process.
Interview types
I would say there were roughly the following categories of interviews. Overall, technical skills and knowledge are evaluated much more than research experience, though the latter probably gets you the interview in the first place.
ML coding. This was by far the most common. These questions may ask you to implement a given architecture, a decoding strategy, a traditional ML algorithm, or sometimes way more creative things. Being fluent in PyTorch is a must; in rare cases I was asked to use only numpy, for instance when writing the backwards pass from scratch, but I was not expected to be familiar with the numpy syntax.
General coding. Basically LeetCode, sometimes with some extra flavor. It’s good to build strong foundations here because the concepts often show up in ML coding interviews, too.
Technical discussion. These interviews do not involve coding but are very much technical. Sometimes, the interview is an extended discussion around one topic, such as how you would design experiments to answer a particular research question or accomplish a particular goal. The interviewer will generally press you on your design choices and ask you to comment on some hypothetical results and design follow-up experiments. In other cases, the interview consisted of a list of rapid-fire questions (What are some different ways of encoding positional information? What is 5D parallelism? What is the difference between PPO and GRPO?), and the goal was to signal that I knew my stuff. The former type of interview tests how you think, whereas the latter checks your breadth of knowledge on the field.
Research discussion. These are the kinds of conversations we practiced most in our PhD. The interviewer generally asks you to start by telling them about a past project, and the rest of the discussion flows from there. They might also ask questions about other papers on your CV. When preparing for these kinds of discussions, it’s useful to take a step back and think about why you chose to work on the things you did, insights and opinions you’ve developed along the way, and what you view as promising future directions. I also tailored my research pitch depending on the role; interviewers are tired, so hitting the right keywords makes it easier for them to believe that your profile is relevant.
Behavioral. These are totally textbook behavioral interviews, apart from the occasional question about AI safety or societal impacts. Enumerate memorable stories from your PhD and map them onto the common behavioral questions so that during the interview, you can retrieve the right anecdotes instantly. I failed my first behavioral interview because I went into it thinking I’m obviously well-“behaved,” and came up blank on excruciatingly simple questions. Trust me, it is uniquely painful to try to reconstruct hazy memories at the same time as delivering them in an interview, only for the interviewer to say at the end, “You didn’t answer the question.”
Math. Some companies have a math interview, ranging from fun logic puzzles to serious mathematical derivations with pen and paper. I would recommend brushing up on probability, linear algebra, and calculus.
Job talk. There is some variation in what the job talk looks like, but compared to an academic one, it tends to be a bit shorter and focused on a single paper or direction. My job talk was all about tokenizers; I spent most of the time on a first-author work and then covered a few second-author and ongoing works briefly, as fortunately they tied together very nicely.
Preparation
There is truly no better use of your time than studying for interviews. For me, the experience was very much like being back in undergrad: I took notes, drew diagrams, did practice problems, and spent entire days in coffee shops making sure I understood fundamental ML concepts inside-and-out. Technical interviews are hard, and the skills being tested require dedicated effort to develop outside of doing research. For me and for most people I talked to, the job search is a full-time job.
I started my process by watching all the lectures from Stanford’s Language Modeling from Scratch course, which is helpful for illustrating the breadth of topics I needed to learn and helped me organize many scattered concepts in my brain into one coherent picture of the field. After covering the basics, I spent the rest of my time deep-diving concepts one at a time by reading relevant blog posts & papers, talking to AI assistants a lot, and practicing implementing things from scratch. Homework 1 is crucial: implementing / debugging a transformer comes up so often in interviews that it will pay off massively to turn it into muscle memory and really isn’t worth losing points on. Make sure you are practicing coding with AI assistance completely off to mimic interview settings (you will underestimate your reliance otherwise)!
I found that each interview is unique and can benefit from a little — sometimes a lot — of dedicated preparation. You can usually build an intuitive understanding of an interview’s scope from the provided description, the topics that the company is interested in, hints from the recruiter, and the reputation of the company. When I was in the thick of interviewing, I found that I was constantly swapping information in and out of my brain so that the most relevant knowledge for a particular interview would be fresh. The best way I can describe it is: each interview is a slightly different math or CS class, you never went to lectures, and now you have ~3 days to cram for the midterm.
Day of interview. Perhaps it is because I am getting old, but nothing beats getting enough sleep the night before the interview. I made the mistake of doing my first technical interview on 2 hours of sleep after cramming all the intricacies of LLM inference into my brain — none of the last-minute knowledge came up, and I ended up spending 10 minutes on an off-by-one error because my gears were barely turning. After the interview, remember to record some notes, which will be helpful for your future studying and reflection.
Side benefits. Studying carried enormous side benefits for me. Having a wider breadth of knowledge directly improved my confidence as a researcher. I became more secure in conversations because I was less worried about gaps in my knowledge being exposed, and no longer felt compelled to hide them when they came up. I truly believe that if I had done some of this studying earlier in my PhD, it would have expanded the space of problems I might be able to think about and have ideas in, and certainly the number of conversations I would have sought out. Amazingly, I also found that studying made me enormously more effective at my ongoing project. I was able to have technical ideas that I never would have been able to access before and do more technical work, which was thrilling.
Negotiation
I was shocked to learn that the work is not nearly done after you receive your offers. Instead, there is a (potentially extended) period of time for you to learn more about your options and negotiate your offers. It involves many conversations with potential future teammates / managers, lunch visits, and recruiter calls. At this stage I was managing an overwhelming amount of communication, and there were always emails I was guilty of not responding to.
The truth is that negotiating is hard. Nothing in our PhD prepared us for this, and unlike interviews, this part cannot be conquered by studying. Compared to recruiters, you are outmatched in both knowledge of the market and the skill of negotiation, and everyone you talk to wants something different from you. You may be thinking, “I would be happy with my offer and make a decision independently of compensation!”, and indeed it’s great to know your own values! But you’d be doing yourself a disservice if you didn’t negotiate. Initial offers leave room for negotiation by design; recruiters often explicitly invited me to play the game by saying things like, “I don’t expect you to take our first offer.” Putting in energy here for a few weeks can, literally, be equivalent to years of work at the initial offer.
It is really crucial at this stage to lean on your friends for the know-how of interacting with recruiters and for more data points to help calibrate your asks. Before every recruiter call, I wrote down what I was willing and not willing to share, along with quotes I could recite verbatim. In the post-offer stage, I would anticipate questions they might ask and points they might make, and carefully construct responses that I could deliver comfortably while still advocating for myself. Though time-consuming, it is really worthwhile to be deliberate about every aspect of the process.
Concluding words
In this blog post I focused on the concrete parts of the job search, but in reality a huge part of my personal experience was managing all the emotions that come with being on the market. There is a lot of social perception to navigate: it is not a good feeling to compare yourself to your peers, everyone has opinions on where you should or shouldn’t go, and people become unusually invested in how your life is going. I also found it stressful navigating a huge decision space with incomplete information, where small choices with no right or wrong answers (like who to contact when) have an outsized impact. Frankly, I was stressed, miserable, and not functioning in other parts of my life for several months. Hopefully you find more joy, but if not, just know that you are not alone.
I’ve been hurtling towards the end of my PhD for months, and now at the end of it all, I’m immensely sad to leave this chapter of my life behind. The PhD is such a special time, where our only job is to have good ideas and execute them, to learn and grow as researchers, without worrying about imminently securing a real job. So while I hope this post helps you mentally prepare for the future (and I certainly recognize how distracting industry forces are today), I also hope that you can cherish your PhD for the unique time that it is. These goals may be complementary, after all — I consistently found that I did my best work when I was having fun and chasing the questions my mind would not lay to rest.

A viral doomsday scenario aims to shake Europe out of its AI complacency
A fictional 'doomsday' thought experiment titled Europe 2031 is influencing high-level EU policy discussions about the urgency of building domestic AI infrastructure.
Deep dive
- The Europe 2031 scenario envisions a world where the US and China dominate AI infrastructure, leading to the economic decline of the EU.
- Policymakers are using this narrative to advocate for the deregulation of datacenter planning and energy requirements in Europe.
- The scenario highlights real-world concerns about foreign control over critical AI compute infrastructure.
- Critics note the speculative nature of the scenario, citing recent collapses of major industry AI-infrastructure deals.
Decoder
- Technological Sovereignty: The concept that a region (like the EU) must maintain independent control over its core digital and AI infrastructure to avoid dependence on external powers.
Original article
A viral doomsday scenario aims to shake Europe out of its AI complacency
Does a thought-experiment about US ascendancy in the technology say as much about AI jitters as it does about the reality?
It’s 2031 and the US and China are about to tear Europe into pieces.
The US ploughed vast sums into datacentres and the EU did not. China built robots and Europe did not. American companies “restructured” their workflows around AI and fired people, while EU workers went on long lunch breaks and handed over administrative tasks to the AI model Claude.
Now the chickens are coming home to roost. Europe’s economy is a shambles because it does not have its own AI. Populism is surging, the euro is wobbling, cyber-attacks are shredding EU businesses. Brexit seemed like a good idea. It looks like the end of the European Union.
That, at least, is the vision of a speculative thought experiment, called Europe 2031, penned by Brussels-based thinktankers and published fortuitously one day before the Trump administration decided to block “foreign nationals” from using a much-hyped AI model built by Anthropic, called Fable.
In the heady week of G7 talks that followed, the scenario has gone viral – feeding a feverish discussion of the urgency for EU tech sovereignty. It has been read by members of the European parliament and, say its authors, was brought up in track 1.5 discussions between British and German officials earlier this week.
Its authors say they feel “vindicated”, by the attention it has received and by the fact that one of their predictions – that the US would restrict global access to advanced AI models – appears to have briefly come true. They hope the scenario will spur Europe towards a dramatic course-correction on AI.
The piece is part of a burgeoning genre of fictional AI doomsday scenarios, created by obscure figures, which have gained surprising traction among policymakers over the past year. In 2025 there was AI 2027, a thought experiment which culminates in a superintelligent AI killing all of humanity to make way for more datacentres; in February, another speculative scenario imagined AI upending the US economy. (The first was read by US vice-president JD Vance, the second contributed to a stock market wobble.)
One complication of all this might be that their thought experiment is at times based on current developments in AI whose outcome is uncertain or in doubt.
Maximilian Negele contributed to Europe 2031, he says, because of the “incredible translation barrier” between Brussels and San Francisco, where AI is being developed. Formerly at US thinktank Rand, he left his job this year to focus on the project.
“As somebody who travels to San Francisco quite a bit and talks to people there, what is happening in Europe just seemed like a slow-moving car crash to me,” he says.
The scenario unfolds from the perspective of a fictional bright-eyed Brussels staffer, Caroline Dubois, who has a German friend, Christian Vogt, with a startup in San Francisco. On a visit, she’s impressed by America’s “70 or 80-hour” working weeks and discomfited by the conviction among tech bros that everything is about to change.
Back in Europe, she works to evangelise her well-meaning bosses about the impending AI future – but fails to convince. There’s too much scepticism, and most people think AI is a bubble.
Things go from there. The Americans spend huge sums on a massive AI building programme – the scenario highlights a real-life $100bn (£75bn) deal between OpenAI and Nvidia, the $300bn agreement between OpenAI and Oracle, and “bulldozers” breaking earth in Texas for an AI datacentre. Europeans, meanwhile, put forward a tepid investment package and ignore advisers’ pleas for “a full regulatory carte blanche for datacentre providers”.
In a matter of years, America monopolises 70% of the world’s “compute” – the semiconductor chips that fill the datacentres that power AI models. Europe’s economy is meanwhile gasping for air, mostly because its companies have not adopted AI.
As AI-powered cyber-attacks shred European firms and unemployment surges, EU officials scramble to parlay their one last bargaining chip – the Dutch lithography firm ASML, which is vital to the production of AI semiconductors – into concessions from Beijing or Washington. But it’s too late. The US deploys powerful “frontier AI” spyware and learns the deepest fears of EU officials and also which of them are having affairs.
Curtains drop. Christian and Caroline exeunt stage left for a drink. Disaster impends.
Sceptical readers might point out that a number of the eye-popping sums and big projects that the authors name-check in describing the US’s AI ascent have already fallen apart.
The $100bn agreement between OpenAI and Nvidia, the biggest AI deal of last year, evaporated in February. The $300bn between OpenAI and Oracle seems doubtful, especially as recent reports indicate the maker of ChatGPT is still billions of dollars underwater as it burns money on datacentre infrastructure.
The bulldozers on the ground in Texas may not be bulldozing very much any more, as OpenAI pulled out of the flagship AI project to which that moment in the scenario seems to refer.
The authors are sanguine about these matters. Throughout the piece, they pre-empt potential objections – such as AI being overhyped – by suggesting that the hapless European officials have these worries, too, and they end up tragically wrong.
“I wouldn’t rule out that there’s some exuberance and that one or two AI companies might go bankrupt,” says Negele. “But what we wanted to get across is a general feel for a version of what we think will happen.”
He and his co-author, Alex Petropolous, agree that there could be some bumps in the road – including mounting resistance to datacentres in the US. “I mean, people hate AI in general. A lot of people do. People hate datacentres. They destroy the landscape. They support big tech. It’s a very, very unpopular policy.”
The authors of Europe 2031 think that the solution to this is datacentres. Europe needs to build more, faster, ideally in AI zones where matters such as power and planning can be streamlined and deregulated.
“I think our view is that the total datacentre supply is quite an inelastic supply. So there will only be a limited number of datacentres built in the world built every year, and the question is, how many of those do you want built in the US? How many of those do you want built in Europe?” says Petropolous.
It is further worth noting that the main organisation behind the Europe 2031 scenario, Arq Foundation, based in Brussels, describes itself as “neither an advocacy NGO nor a venture-backed startup” and does not disclose who funds it.
Brussels politicians who read it, though, may take away a simpler message: the scenario has crystallised a conversation about the need for Europe to have technological sovereignty.
“This scenario, Europe 2031, I believe that some of the parts they mentioned can happen,” says Nicolás Casares, a member of the European parliament from Spain. “But I think they are increasing – a bit – the alarms in order to call our attention.”
The US cutting off Europe’s access to Fable, he says, means that the EU needs to ask itself harder questions about who is building its AI infrastructure and who will benefit from it.
“What is the added value of having OpenAI or Anthropic datacentres in Europe?” he says.
“We are buying a narrative that we need a lot of datacentres not to lose the race for AI. But this is crazy … we are paving the way for infrastructure that they will use and sometimes not allow us the possibility of using it.”

When Ideology Becomes Systemic Risk
Founders who amass massive influence too quickly inevitably trigger a systemic immune response from regulators and institutional powers.
Original article
When Ideology Becomes Systemic Risk
I have a speculative hypothesis for what's happening with Anthropic right now. Society has an immune system for founders and companies that become too powerful, too quickly. Dario and Anthropic have...
Tesla plans to sell modular AI data center hardware called ‘Megapod'
Tesla is preparing to enter the data center infrastructure market with 'Megapod,' a turnkey modular system designed for AI workloads.
Original article
Tesla has filed a trademark application for a product called 'Megapod'. The filing describes a complete, self-contained computing system for AI workloads. The product appears to be a turnkey AI data center building block that includes the full rack-and-room of servers, networking, power, and cooling. It would compete with Nvidia's already dominant platform.
The Universe just wants to learn
The author draws a conceptual parallel between biological DNA and neural networks, arguing that both require an external process to become functional.
Decoder
- Forward pass: The computational process where input data travels through a neural network to produce an output.
- Inference: The process of using a pre-trained model to make predictions or generate content.
Original article
DNA doesn't do anything by itself. The information only becomes something when an enzyme unzips the helix and copies a stretch into messenger RNA, after which its instructions are decoded to create chains of amino acids. Similarly, the weights of a neural network don't mean anything on their own. They only become meaningful during the forward pass, activated during inference. In both cases, a passive informational substrate is brought to life only by a process outside of it.
When it's the maintainer who's AI-pilled
Maintainers who integrate AI into their development workflow can turn user bug reports into near-instantaneous automated fixes.
Original article
When it's the maintainer who's AI-pilled
I had an odd experience the other day with an open source project. That project was dirge. It's clearly and unashamedly developed with heavy use of generative AI, both in the code and in the PRs.
Normally, as a first impression, this would turn me off a project. There's a lot of low-grade slop out there after all and most of the time I'm looking for the "mature" option if it exists. In this case I came to learn about dirge through an article the author wrote, describing some novel ideas in making effective use of smaller LLMs for coding, and how they were attempting to put all of these into practice in their own CLI harness. Sounds interesting.
I feel this is an underappreciated sweet spot for AI-assisted development. When you take someone who cares about software, cares about the craft, and has some specific goals they want to achieve, then a well-supervised agent can offer dramatic speedups in actually getting the coding done. I have at least as much confidence in AI-assisted code overseen by a strong programmer as I do their own manually-typed code. This is how I try to use coding LLMs myself—faster when possible, same or better quality—so I trust others who work the same way.
Having established interest in the project, I installed it and tried it out. I experienced two minor bugs. One was a straightforward unpolished feature. The other was a very woolly situation where my model sometimes became confused about the current state after compaction. I filed issues for both, apologising for the lack of concrete detail. I made a mental note to try making a PR for the simpler bug, and also get some better logs to support the other when I found a free moment.
What actually happened is that the simple issue was fixed 1.5 hours after I submitted it, and the complex one 3 hours after I submitted it, complete with comprehensive regression test. Wow, okay then.
I suddenly realised that my own PRs are scarcely necessary—if anything it'd just slow things down. The maintainer doesn't have to waste time understanding my contribution, whether it's AI or human-generated. If I write up a good issue then it's quite literally a prompt for their own AI. They can quickly generate a solution on their own, massage the output to meet their own standards for mergeability then commit as soon as they're ready. The whole process is delightfully efficient.
Most of the discourse at the moment concerns what happens when people with LLMs show up to traditional open source projects that either don't use them, or use them in only a limited manner. Much less has been said of projects where the maintainers are possibly more enthusiastic about AI than the contributors. It's only my first experience of this but I expect the workflow to become more common. Have a problem? Just write the issue. Low stress for everyone.
Secretive Wall Street Powerhouse Jane Street Seizes the AI Spotlight
Trading firm Jane Street is launching an aggressive hiring spree for over 500 roles to pivot toward becoming a major player in AI.
Original article
Jane Street is looking to hire more than 500 employees this year. The previously secretive firm is starting to edge more into the spotlight to catch the attention of AI startups and talent. It is aiming to become a major AI investor and supercharge its trading with the technology. Jane Street is eager to make new AI investments and deals for computing power.
The Flat Curve Society
Anthropic suggests a future where superintelligence is sequestered behind institutional walls, leaving the average user with stagnating model progress.
Decoder
- Fable class: An informal designation for a specific generation of high-capability AI models that marks a plateau in performance for public-facing or open-source software.
Original article
Anthropic claims that AI model intelligence has become dangerous. AI will continue to grow exponentially in capability, but most people will stop seeing progress. Only a few will have access to superintelligence above the classes of models seen this year. Open models are not likely to improve past Fable class due to huge compute requirements and government lockdowns.

Big tech engineers need big egos
High-performing engineers must balance an arrogant internal belief in their own capability with the pragmatic humility to execute organizational directives.
Original article
It’s a common position among software engineers that big egos have no place in tech. This is understandable - we’ve all worked with some insufferably overconfident engineers who needed their egos checked - but I don’t think it’s correct. In fact, I don’t know if it’s possible to survive as a software engineer in a large tech company without some kind of big ego.
However, it’s more complicated than “big egos make good engineers”. The most effective engineers I’ve worked with are simultaneously high-ego in some situations and surprisingly low-ego in others. What’s going on there?
Engineers need ego to work in large codebases
Software engineering is shockingly humbling, even for experienced engineers.
The minute-to-minute experience of working as a software engineer is dominated by not knowing things and getting things wrong. Every time you sit down and write a piece of code, it will have several things wrong with it: some silly things, like missing semicolons, and often some major things, like bugs in the core logic. We spend most of our time fixing our own stupid mistakes.
On top of that, even when we’ve been working on a system for years, we still don’t know that much about it. The reason is that big codebases are just that complicated. You simply can’t confidently answer questions about them without going and doing some research, even if you’re the one who wrote the code.
When you have to build something new or fix a tricky problem, it can often feel straight-up impossible to begin, because good software engineers know just how ignorant they are and just how complex the system is. You just have to throw yourself into the blank sea of millions of lines of code and start wildly casting around to try and get your bearings.
Software engineers need the kind of ego that can stand up to this environment. In particular, they need to have a firm belief that they can figure it out, no matter how opaque the problem seems; that if they just keep trying, they can break through to the pleasant (though always temporary) state of affairs where they understand the system and can see at a glance how bugs can be fixed and new features added.
Engineers need ego to work in big tech companies
What about the non-technical aspects of the job? Nobody likes working with a big ego, right? Wrong. Every great software engineer I’ve worked with in big tech companies has had a big ego - though as I’ll say below, in some ways these engineers were surprisingly low-ego.
You need a big ego to take positions. Engineers love being non-committal about technical questions, because they’re so hard to answer and there’s often a plausible case for either side. However, engineers have a duty to take clear positions on unclear technical topics, because the alternative is a non-technical decision maker (who knows even less) just taking their best guess. It’s scary to make an educated guess! You know exactly all the reasons you might be wrong. But you have to do it anyway, and ego helps a lot with that.
You need a big ego to be willing to make enemies. Getting things done in a large organization means making some people angry. Of course, if you’re making lots of people angry, you’re probably screwing up: being too confrontational or making obviously bad decisions. But if you’re making a large change and one or two people are angry, that’s just life. In big tech companies, any big technical decision will affect a few hundred engineers, and one of them is bound to be unhappy about it. You can’t be so conflict-averse that you let that stop you from doing it, if you believe it’s the right decision. In other words, you have to have the confidence to believe that you’re right and they’re wrong, even though technical decisions always involve unclear tradeoffs and it’s impossible to get absolute certainty.
You need a big ego to correct incorrect or unclear claims. When I was still in the philosophy world, the Australian logician Graham Priest had a reputation for putting his hand up and stopping presentations when he didn’t understand something that was said, and only allowing the seminar to continue when he felt like he understood. From his perspective, this wasn’t rude: after all, if he couldn’t understand it, the rest of the audience probably couldn’t either, and so he was doing them a favor by forcing a more clear explanation from the speaker.
This is obviously a sign of a big ego. It’s also a trait that you need in a large tech company. People often nod and smile their way past incorrect technical claims, even when they suspect they might be wrong - assuming that they’ve just misunderstood and that somebody else will correct it, if it’s truly wrong. If you are the most senior engineer in the room, correcting these claims is your job.
If everyone in the room is so pro-social and low-ego that they go along to get along, decisions will get made based on flatly incorrect technical assumptions, projects will get funded that are impossible to complete, and engineers will burn weeks or months of their careers vainly trying to make these projects work. You have to have a big enough ego to think “actually, I think I’m right and everyone in this room is confused”, even when the room is full of directors and VPs.
Sometimes you need to put your ego aside
All of this selects for some pretty high-ego engineers. But in order to actually succeed in these roles in large tech companies, you need to have a surprisingly low ego at times. I think this is why really effective big tech engineers are so rare: because it requires such a delicate balance between confidence and diffidence.
To be an effective engineer, you need to have a towering confidence in your own ability to solve problems and make decisions, even when people disagree. But you also need to be willing to instantly subordinate your ego to the organization, when it asks you to. At the end of the day, your job - the reason the company pays you - is to execute on your boss’s and your boss’s boss’s plans, whether you agree with them or not.
Competent software engineers are allowed quite a lot of leeway about how to implement those plans. However, they’re allowed almost no leeway at all about the plans themselves. In my experience, being confused about this is a common cause of burnout. Many software engineers are used to making bold decisions on technical topics and being rewarded for it. Those software engineers then make a bold decision that disagrees with the VP of their organization, get immediately and brutally punished for it, and are confused and hurt.
In fact, sometimes you just get punished and there’s nothing you can do. This is an unfortunate fact of how large organizations function: even if you do great technical work and build something really useful, you can fall afoul of a political battle fought three levels above your head, and come away with a worse reputation for it. Nothing to be done! This can be a hard pill to swallow for the high-ego engineers that tend to lead really useful technical projects.
You also have to be okay with having your projects cancelled at the last minute. It’s a very common experience in large tech companies that you’re asked to deliver something quickly, you buckle down and get it done, and then right before shipping you’re told “actually, let’s cancel that, we decided not to do it”. This is partly because the decision-making process can be pretty fluid, and partly because many of these asks originate from off-hand comments: the CTO implies that something might be nice in a meeting, the VPs and directors hustle to get it done quickly, and then in the next meeting it becomes clear that the CTO doesn’t actually care, so the project is unceremoniously cancelled.
Final thoughts
Nobody likes to work with a bully, or with someone who refuses to admit when they’re wrong, or with somebody incapable of empathy. But you really do need a strong ego to be an effective software engineer, because software engineering requires you to spend most of your day in a position of uncertainty or confusion. If your ego isn’t strong enough to stand up to that - if you don’t believe you’re good enough to power through - you simply can’t do the job.
This is particularly true when it comes to working in a large software company. Many of the tasks you’re required to do (particularly if you’re a senior or staff engineer) require a healthy ego. However, there’s a kind of catch-22 here. If it insults your pride to work on silly projects, or to occasionally “catch a stray bullet” in the organization’s political fights, or to have to shelve a project that you worked hard on and is ready to ship, you’re too high-ego to be an effective software engineer. But if you can’t take firm positions, or if you’re too afraid to make enemies, or you’re unwilling to speak up and correct people, you’re too low-ego.
Engineers who are low-ego in general can’t get stuff done, while engineers who are high-ego in general get slapped down by the executives who wield real organizational power. The most successful kind of software engineer is therefore a chameleon: low-ego when dealing with executives, but high-ego when dealing with the rest of the organization.

Preliminary Thoughts On The Midjourney Scanner
Midjourney's pivot to ultrasound tomography faces significant medical hurdles that likely limit its immediate utility for anything beyond niche, non-diagnostic screening applications.
Deep dive
- Ultrasound tomography cannot replace CT or MRI due to inability to penetrate air or bone, restricting its use to superficial or specific soft tissues.
- The clinical value of 'whole-body screening' for healthy individuals is widely debated, with medical consensus often cautioning against it due to the risk of dangerous false positives.
- A significant clinical risk involves 'medical misadventures' arising from unnecessary follow-up procedures triggered by incidental findings (abnormalities that are clinically irrelevant).
- Even if AI improves image interpretation, it does not bypass the clinical necessity of differentiating between harmless growths (cysts, lipomas) and dangerous tumors.
- The scanner could potentially compete with DEXA scans for measuring body composition, but it faces stiff competition from established, cost-optimized service providers.
- Successful adoption likely depends on the assumption that AI-driven cost reductions in sensors and compute can overcome physical limitations, rather than clinical breakthrough alone.
Decoder
- Ultrasound tomography: A medical imaging technique that reconstructs internal structures by processing ultrasound waves collected from multiple angles around an object.
- Incidentaloma: An asymptomatic mass or lesion found by imaging that is discovered by chance and may not require treatment, often leading to unnecessary anxiety and intervention.
- DEXA scan: Dual-energy X-ray absorptiometry; a common diagnostic tool used to measure bone mineral density and body composition.
- Modality: A specific type of medical imaging technique (e.g., MRI, CT, ultrasound, X-ray).
Original article
Preliminary Thoughts On The Midjourney Scanner
Midjourney is an AI image model. If you’ve ever used Nano Banana or asked GPT to draw you a picture, it’s like that, except from a medium-sized startup instead of a tech giant.
Earlier today, they announced a pivot to medical scanners. The new MidJourney Scanner, which they describe as “a bold new kind of machine to reimagine the foundations of healthcare and our relationships to our bodies”, will be a tank of water surrounded by a ring of ultrasound scanners. The patient goes into the tank, the scanners emit ultrasound from all angles, and then some fancy AI reconstructs the echoes into a 3D picture of the body. The result is ultrasound tomography: the same sort of rich data as a CT or MRI, but done via ultrasound, with no harmful radiation, in twenty seconds.
This is cool, and it’s great to be ambitious, but I think the narrative among the SF AI crowd has escaped its basis in the medical facts, so I want to throw a bit of cold water on it. I’m a psychiatrist, which is about as far as you can get from radiology while still being a doctor, so this is speculation only, and you can ignore it if you find an actual radiologist or ultrasonographer with opinions. Still, my take is that this scanner isn’t useful for most current serious medical applications. It could potentially be used to pioneer a new class of low-risk screening applications, but it’s unclear whether these are good, and depends a lot on what other future technology gets invented in parallel.
Why can’t this immediately replace existing medical image modalities like normal ultrasound, CT, or MRI?
Ultrasound is great, but it can’t penetrate bone or air. Many things doctors want to look at involve bone or air in some way. For example, the brain is behind the skull, which is a bone. The bowels are full of air. The lungs are super full of air. This limits ultrasound to the remainder - especially parts of the digestive, endocrine, and vascular systems, and superficial tissue like fat and muscle.
(it’s actually worse than this. Normal ultrasound can be used to image certain organs like the heart or prostate, but only via the technician carefully angling the probe. Midjourney hasn’t given details, but most likely their Scanner won’t be able to match this level of precision, so the heart, prostate, and some other usually-ultrasound-compatible organs will be outside its reach.)
Most MRIs or CTs involve one of the organs ultrasound can’t reach (this would be one reason doctors might do an MRI or CT, instead of just using ultrasound). In other cases, you don’t know what organ you’re looking for, and you want to be able to see everything (for example, if you’re scanning for cancer metastases, you can’t leave the brain and bowels out of the scan!) So this technology can’t replace most MRI or CT.
What about replacing ordinary ultrasound? One of the big advantages of ordinary ultrasound is that it’s a cheap machine you can keep on a cart and connect to a patient who’s lying in a hospital bed. Even though it might work better to put the patient in a giant water-filled tank surrounded by hundreds of ultrasound machines, if you tell your hospital orderlies “please transport this frail 90-year old to my giant water-filled tank, and lower them in slowly” they will stab you with your own scalpel. So this would need to be much better than ordinary ultrasound to capture even a fraction of these use cases. But ordinary ultrasound is already pretty good, this technology is untested, and it will be hard for it to be that much better.
Aren’t there a few edge cases that are poorly-served by existing modalities and ordinary ultrasound? Yes - the classic one is certain types of breast cancer, which don’t show up well on mammography against dense breast tissue, and require too much of a search for ordinary ultrasound. It’s a perfect match for this technology, which is why ordinary medical device companies have already created an ultrasound tomography scanner for the breast and it’s used regularly in medical practice. It’s not quite as neat as the MidJourney Scanner - the patient just lies on a weird-shaped table in a position that puts their breasts in a pool of water, instead of submerging the whole body, and you get correspondingly less coverage - but it works fine for the rare case where this technology actually fills a gap.
There are probably other edge cases I don’t know about, but they weren’t important enough for normal medical device companies - who absolutely know about this technology and have thought about it a long time - to invent devices for it.
Couldn’t this technology enable new, non-specific-diagnostic uses for healthy people?
This is where Midjourney seems to be going. Aware that this doesn’t fill a specific diagnostic hole (and would probably be annoying to get past the FDA), they’re imagining something where healthy people go for one of these scans regularly (let’s say once a year). The scanner can produce an image of the whole body, and if there’s anything abnormal (for example, a tumor), they can send them to the regular medical system to get it investigated and treated. You could even have a longitudinal series - this anomaly was tiny on the last scan a year ago, but now it’s bigger, so it’s suspicious for cancer and needs to be investigated immediately.
Here the question is - why is this better than regular whole-body screening MRI scans, a technology which currently exists?
We can certainly think of the opposite - reasons why the screening MRIs are better. Screening MRIs can view the whole body, including the brain, lungs, heart, and interior of the bowels. They have higher resolution. They’re a real technology that exists now, rather than a cool idea by an AI art company. They cost about $2,000, which is cheap by the standards of the US medical system.
So why don’t people get yearly whole-body MRI screenings? Some people do - companies like this provide them, and some rich people who can pay $2,000 out of pocket consume them. But the medical consensus currently recommends against them because they’re more likely to produce dangerous false positives than helpful true positives, and studies have failed to demonstrate benefit.
(a “false positive” in this context isn’t the scanner hallucinating something that isn’t here. It’s the scanner finding some sort of boring abnormality that doesn’t matter - like a zit but inside your organs - and then making everyone panic that it’s cancer, and causing unnecessary tests, surgeries, etc).
Let’s grant that, in fact, these scans produce a lot of false positives, and that a lot of harm is done by unnecessary tests and biopsies and treatments for these false positives. Still, can’t you just adjust the detection threshold until it only fires for extremely obviously bad findings that are definitely worth investigating? This question has bothered me for a long time, and I’ve never been able to get a perfectly clear answer from the medical literature. Here are the mediocre answers I can sort of vaguely see:
- “Obviously bad” is a medical judgment, not a radiological one. Radiology can tell you when something is very big, or very fast-growing, but sometimes there are harmless large fast-growing things. What clinches a decision of “important to investigate further” are questions like age, smoker status, family history, etc. But if you’re an old person who smokes and has a family history of cancer, your doctor is already recommending some kind of lung scan, and this is the opposite of telling all healthy people to get screened all the time.
- In practice, most problems start producing symptoms before the threshold where they’re so clearly bad on imaging that you should extremely obviously investigate them.
- If you actually set the standard for further investigation high enough, it would trigger so rarely that people wouldn’t want these scans for other reasons, like inconvenience and cost.
- Smart technocrats can set the threshold for investigation wherever they please, but a patient who learns that they have a large mass in their brain isn’t going to accept “no” for an answer, and is either going to get it investigated or else spend the next several years freaking out, which has health costs of its own. And malpractice-suit-wary doctors are going to think about how it will sound in a court case to say “yeah, I knew he had a giant mass in his brain, but it was 0.1mm short of the threshold where we bother checking what’s going on, so I did nothing”. So in practice, patients will demand further investigation, and doctors will agree. And the sort of rich, agentic, ultra-health-conscious people who will pay $2000 for a screening MRI their doctor recommends against are exactly the types of people who would be most likely to fall into this error mode.
So although pushy rich people occasionally get boutique clinics to give them these screening MRIs, normal doctors and the legitimate system are against them. Whether or not you agree with this perspective, I assume they would approach the idea of screening whole-body ultrasounds the same way (ie recommend against them). So this would basically be serving the same population of pushy rich people who are already getting the screening MRIs, which are better. So what does this buy you?
One possible answer is convenience. Midjourney claims these ultrasounds could be much faster and more comfortable than an MRI (which involves ~60 minutes in a giant scary metal tube that sometimes kills you if you forget to take off your jewelery).
Another answer is cost. Currently, the Midjourney Scanner is entirely experimental; its prototype is no doubt very expensive, like all prototypes. But the sorts of sensors and chips that make up the Midjourney Scanner have better cost scaling curves than the sorts of giant magnets that make up MRIs. So if this ever became exactly as common as MRIs, it would probably be much cheaper.
This, then, is the strongest argument for the whole-body scanning proposition: you could serve the same pushy rich people who get whole-body MRI scans now against their doctors’ recommendations, but they could do it in a nice spa instead of a giant scary metal tube, and it could be cheaper. And that could unlock a whole new demographic of different pushy rich people who then would be willing to try it.
Couldn’t this technology become more useful in the future?
Yes. I think the best way to think of this is as a bet that future technology develops in a way that allows new possibilities for diagnostic ultrasound - or, even better, an attempt to gather the training data / interest / investment that will make this happen.
For example, if you get lots of high-quality ultrasound data (perhaps because you incorporated your ultrasound scanner into a spa and billed it as something that billions of people should be using every year), maybe you could train a really good AI on that data and do better than any existing radiologist in learning to interpret it and figure out what’s dangerous. Then you wouldn’t have to worry about the studies failing to find benefits from existing whole-body screening.
Or - a commenter informs me of Full Waveform Inversion Imaging Of The Human Brain, which argues that bone only makes ultrasound imaging very difficult, not impossible. It scatters the waves in complicated ways, but with enough math, you could reconstruct what’s going on. How much math? Enough that nobody has ever done it for a real human skull. It would take absolutely gargantuan amounts of compute. But it’s fine! The world economy is in the process of re-centering around creating gargantuan amounts of compute! In the glorious AI future, when a halo of space-based data centers has turned Earth into a miniature Saturn, we can get as many brain ultrasounds as we want!
So the best case for the Midjourney Scanner is that they’re trying to pre-emptively jostle themselves into a position where they can benefit from upcoming AI revolutions. If AI drives the cost of sensor electronics to near zero, and gets so good at radiology that it can cleanly separate true positives from incidentalomas, and becomes so good at wave dynamics that it can overcome previously insurmountable problems around imaging through bone, then probably a company that already has a chain of spas fitted with giant rings of ultrasound scanners will be in a great place to benefit from the subsequent medical revolutions.
All that I can say against this plan is that you need to believe AI will benefit ultrasound tomography in particular. By the time the AI revolution has solved all the problems that stand in the way of the Midjourney Scanner, might it also have beefed up normal MRI, or normal ultrasound, or enabled some kind of entirely new scanning modality, or cured cancer so thoroughly that we don’t need yearly cancer screening?
If you think that no - it will most likely benefit ultrasound in particular - then Midjourney’s bet looks a lot better.
Appendix: Highlights From The Comments On Twitter
I mentioned this on Twitter and got some great responses.
The responses from real radiologists were universally negative. When I pressed him for details, Dr. Harris kindly gave a longer explanation:
The trivial reason is that due to the limitations of physics ultrasound will always be less capable at resolving anatomy than MRI or x-ray-based methods that we already have
The more fundamental reason is that all of these applications of technology to screening for anatomic abnormalities rest on a flawed assumption that detecting an abnormality indicating cancer earlier necessarily leads to better outcomes from earlier treatment. This is not, however, a dogma that we can just assume, but rather a hypothesis that must be tested for each type of cancer we wish to improve the survival for. The current imaging based screenings we do, whether for breast, colon, prostate, or lung all have robust literature that at least supports the idea that earlier detection leading to earlier intervention improves outcomes. In the case of prostate, it’s still being argued about quite vociferously and I’m not taking a particular position on that myself. But all of these screening regimes depend not just on modality, but the exact protocol you use to enroll and screen the patients in addition to the treatments that are available and how well they work at what stage.
To the lay person, it seems obvious that finding a cancer on imaging earlier is always better, but in many cases, it’s not only not better it can be worse! Especially on a population basis when you account for medical misadventures that may ensue from unnecessary or earlier or futile treatment.
But I also got responses from non-radiologists, who were more optimistic.
Like I said above, I’ve never been able to fully get my head around the argument against screening and setting a very high threshold for action. Michael’s temperature-taking analogy is a good one. But I don’t think this can be the whole story, because even when entrepreneurs set up their own full-body MRI clinics that don’t cost the system anything, the medical system recommends against using them.
I think a good intuition pump here is the skin. Weird stuff is always happening on your skin - zits, pimples, warts, but also occasionally melanoma. If you couldn’t see your skin, and had to observe it through some kind of medical imaging, a doctor might be able to tell you “There’s some kind of little bump on your elbow”. Then you wouldn’t know if it was a zit, pimple, wart, or melanoma. But since cancer is very scary, you might say “Oh no! There’s a mass on my skin! Maybe it’s melanoma! And it grew since the last scan! You need to do a skin biopsy immediately!” And then you would have to get surgery for a pimple or a spider bite or something.
Using this intuition pump, I don’t think Paul’s argument stands. Most pimples come after birth! Even if you got a skin scan every month and could compare the current skin scan to the previous one, you’d still be at high risk of fretting over pimples and demanding biopsies for them.
All of your organs are constantly growing little pimple-like things that don’t matter. Depending on the location and type, we call these cysts, polyps, fibroids, lipomas, adenomas, hamartomas, etc. We are bad at distinguishing these from dangerous tumors - and so far the studies show that when we try to do it in the entire population on a mass scale, we cause more problems than we solve. That could change in the future! But it’s a separate bet from whether ultrasound tomography will be good or not, and the ultrasound tomography won’t be very useful unless we solve this problem too.
Andrew knows a lot about sports and metabolic medicine, so I take his opinion here very seriously. A DEXA scan is complicated way of arranging x-rays which is specialized for measuring things like density. Its most common use is measuring bone density in osteoporosis. The Midjourney Scanner probably won’t help with that, because some bones are behind other bones or air.
But its second most common use is measuring “body composition”, the relative amount of fat and muscle. Some high-powered athletes use this to make sure they have exactly the amount of muscle they want, and some people on very precise diets use it to make sure they’re losing exactly the amount of fat they want. And then as usual, there’s a long tail of rich people who don’t know exactly why they’re using it, but their boutique rich-person clinics upsell them on it and give them very precise information on their body parameters which they then proceed to ignore. Between these three categories, it’s a 9-10 digit dollar industry.
The Midjourney Scanner would be a good replacement for DEXA scans - there might be a little fat hidden behind air pockets, but it can still give you a pretty good idea. I don’t know whether it has better or worse resolution, but it might be better, and it would save people (a tiny bit of) radiation.
On the other hand, Big Business has done a great job with DEXA scans. The cost has been driven down to ~$50, and you can do them in a van in the parking lot of your gym (or in front of your house if you make it worth their while). The advantage of the Midjourney Scanner over MRI - all you have to do is go to a spa! - here becomes a disadvantage - you mean I have to go all the way to the spa?
So this is a possible application, but it depends on branding and on outcompeting some pretty cut-throat existing businesses.
This is an interesting take. If you could guarantee that the diagnostician would be perfectly rational (because it’s an AI) and perfectly immune to patient pressure (because it’s an AI), would that switch the sign of primary imaging-based screening from negative to positive?
There are many cases in medicine of some computer system outperforming doctors at some specific diagnostic task. But because of the way regulation works, usually the final decision about whether or not to trust the computer system gets put back in the hands of doctors, who then reintroduce some of the biases the system was intended to prevent. So thus far there have been limited gains from this kind of thing.
I am dreading our LLM-written incident report future
Automating incident reports with LLMs risks creating 'simulacra' that bypass the essential human synthesis required for actual organizational learning.
Original article
The other day, Reginald Braithwaite posted the following toot. For posterity, I’ve also included my own response to it:
Braithwaite’s post is dripping with sarcasm, but make no mistake, incident reports written entirely by LLMs is coming. And I am not looking forward to this future.
Before I dive in here, I want to note that there is a lot of toil you need to do in order to gather the data you need to write a good incident report, and LLMs can help significantly reduce that toil. I’ve got no issues there. But there’s a world of difference between using LLMs to help you assemble the ingredients involved in writing an incident report, and using an LLM to actually write the report itself.
Braithwaite’s post is horrifying to me precisely because of the seduction of the LLM as a tool for generating an incident report. After all, you can just ask it to write the report, and it’ll do it. And that’s exactly what scares me.
There’s a famous quote by the cartoonist Dick Guindon: “Writing is Nature’s way of showing you how sloppy your thinking is“. You might think you understand a concept, but it’s only when you put metaphorical pen to paper, when you actually try to explain the concept in written words to a potential reader, that you realize how fuzzy your understanding actually is. Writing in your own words forces you to confront how much you actually understand what it is that you’re writing about. Or, as Leslie Lamport put it, “If you’re thinking without writing, you only think you’re thinking.”
Having an LLM generate the text of an incident write-up bypasses this thinking step. Now there’s no human in the loop of the writing process that has to confront whether the explanation is actually consistent with the evidence that they’ve gathered. Instead, what you get is a plausible explanation of what happened to someone who is not intimately familiar with the details. They might read, nod along, and think, “yes, that makes sense.” But the LLM may have invented couplings between systems that aren’t there, and may miss critical interactions that were actually part of the incident, and because nobody did the hard work of actually synthesizing the data to do the write-up, nobody will notice. Because if you’re trying to reduce the writing effort, how much effort are you really going to put into checking the LLMs work.
In my view, LLM-generated incident write-ups are more dangerous than using LLM for coding or for AI SRE style tasks. For coding tasks, there’s always a testing step to check that the code exhibits the desired behavior, even if nobody looks at the code itself for meaningful details. For AI SRE tasks, either the LLM output helps you resolve the incident, or it doesn’t. In both cases, Nature is the ultimate arbiter of the LLM output.
But incident write-ups aren’t like that. The consequences of a poor report aren’t immediately apparent the way incorrect code or an incorrect operational diagnosis are in the moment. Instead, we get incident reports that have the superficially correct form, but are actually incorrect, with no obvious test for correctness.
And, because incident reports are time-consuming to write, the temptation to use AI tools to generate them will be overwhelming. But these LLMs will not go around talking to people that were involved in the incident. These reports will be simulacra; they will have the right form, but they will not provide readers with genuine insights into the nature of the system. The amount of learning will be significantly curtailed.
And, yes, people will probably use AI to summarize them as well.
It’s not a future I’m looking forward to.
Ten years of ClickHouse in open source
ClickHouse celebrates ten years of open-source development, evolving from an internal log-processing tool into a dominant analytical database with over 2,000 contributors.
Decoder
- Columnar storage: A database storage layout that organizes data by columns instead of rows, which is significantly faster for analytical queries that aggregate specific fields across large datasets.
- MergeTree: The primary table engine in ClickHouse that enables high-performance ingestion by sorting data on disk and performing asynchronous background merges to maintain query efficiency.
- CRDT (Conflict-free Replicated Data Type): A data structure used in distributed systems to allow concurrent updates without conflict, essential for ClickHouse's real-time aggregation features.
Original article
ClickHouse was released in open source on Jun 15 2016, ten years ago. Since then, it became the most popular open source analytical database with more than 2000 contributors.
Building in the open
There are different levels of open-source.
Level 0: The minimum level is making the code open to the public for reading, but nothing more. This is the case of archival and museum releases, such as Doom or MS-DOS.
Level 1: The next level is when the software is updated by commits in a public repository, but not necessarily accepting contributors. This is also an example of open source. SQLite and Ladybird are examples.
Level 2: Accepting contributions but without a transparent and open development process. Most active open-source projects are on this level.
Level 3: Open contribution guidelines, task tracker, code review system, development roadmap, testing and CI system, release cycle, user support, and documentation.
I always aim for the maximum. ClickHouse should be the best example of:
How to build a great database - if you want to build a new database, ClickHouse source code and development practices will serve as the best example. I always write the code so everyone can learn from it - by keeping it modular, orthogonal, and well-documented. When the code requires a complex concept, I explain it in the comments from scratch, so the readers don't have to refer to textbooks, Wikipedia, or AI.
A place to learn C++ development. Many people are looking for repositories representing the frontier of software engineering, and today ClickHouse is one of the most popular open source repositories in C++, where everyone can learn both the exciting stuff (C++23) and boring stuff (build systems, continuous integration and testing, code review practices, and AI).
A place for experiments on data structures and performance optimization. You can open a pull request as an experiment, without aiming for it to be merged - it will be tested with the same level of scrutiny as production releases. Found a new memory allocator, a new compression library, a new hash table, a data format, or a sorting algorithm? - bring it to ClickHouse, and it will expose it inside-out. The roadmap also includes a section about experimental, weird, and even ridiculous things.
Where you can be proud of your work. ClickHouse credits every contributor in the changelog and even inside the database in the system.contributors table! There are countless cases when a contributor sends an initial, incomplete implementation of a feature, and we help to finish it together. Even if the code has to be entirely rewritten, we do it proactively and take the responsibility for that, and always credit the initial author, because we care about your use case and the initial intent that made it happen. To put it simply, we love our contributors.
Before open source
Prototypes and first commits
The first commit in ClickHouse was made on May 29, 2009, and it was a performance optimization (a replacement of libc functions localtime, mktime, gmtime, which were extremely slow and annoyed me by showing up in the profiler). But it was before ClickHouse existed.
ClickHouse started as my experiment while I was working on data processing for a web analytics system. The system, similar to Google Analytics, received logs about pageviews sent from websites, and it was implemented with MySQL, data processing in C++, and custom data structures in C++ where MySQL couldn't suffice. The MySQL databases stored pre-aggregated reports for customers, and custom data structures used for calculating user sessions, user history, and similar stuff.
My experience from that time was - the data volume is growing, nothing works, and the new data appears in real time. If we can't process a five-minute chunk of logs in five minutes, there will be a delay. I will search for any creative solution while the delay accumulates and deploy it on the same work day.
That's how I was searching for any solution that works - any type of databases, any libraries, etc. Can we use TokuDB? Colleagues use LMDB, maybe it will save us? Let's try Judy Arrays. Someone at lunch told us about Hadoop, should we use it? I heard briefly about LZO and QuickLZ in the corridor - let's try it. If we store HyperLogLogs in MySQL BLOBs, how will we sum them? On a weekend, I will read that data compression book or the documentation on event-loop servers...
While stabilizing the data pipeline, I was also thinking about new features that I can bring to the product. If we record clicks on links, we can show a heat map on every page. And if we record the position of every click in the DOM, we can make a click map. For Apr 1, I made a 3D click map in Flash with anaglyph colors. The more interesting feature was to let our users construct any report instead of a set of pre-aggregated ones.
For this task, I explored column-oriented databases. I've read about them from random company mailing lists, websites like dbms2.com, and my colleagues from the ads department. The idea is to store non-aggregated, but structured logs and aggregate them on the fly, while the customer waits for page load. I tested a few extensions to MySQL: Infobright, InfiniDB, and a few standalone analytical databases: Vertica, MonetDB, and LucidDB. For some reason, none worked on loading 100 billion records a day with 500 columns. Then I tried to implement a simple prototype of a custom data structure: every column (only integers, with hashes instead of strings) for every day and every website in a single binary file (a billion of files needed XFS), with lightweight compression, updated once a day with a delay of a few hours, queried with an API allowing to specify columns to group by, aggregate functions, filters, and sorting (queries were specified in XML). The most difficult part was populating historical data from MySQL by "unaggregating" it so that aggregated data would show the same result - it was solved by my colleague, Evgenii Gatov.
This simple prototype (named OLAPServer, implemented in Dec 2008, deployed in Jan 2009) worked. I've also created an endpoint to let people analyze global Internet data instead of single websites, and it worked like a miracle. One example: there was a statistics department processing Internet logs using an internal version of MapReduce, but analysts in the company started to use my service instead, because it answers instantly.
Then I decided to replace aggregated reports in MySQL (it accumulated about 50 TB of data on 50 shards). Many custom data structures were stored as BLOBs, and to aggregate them, the programs had to read them from the database, apply custom code, and insert them back. Moreover, data in MySQL was uncompressed. And even more - the data was reading slowly, because the order of its arrival (by time) didn't correspond with the order of queried ranges (by website ID). I was reading about LevelDB and TokuDB, so I decided to implement a custom data structure for incremental aggregation with background merges. Every record in this table was defined by a custom C++ struct, representing CRDT with add, update, merge, serializeText/Binary and deserializeText/Binary methods. On read, the partially aggregated data is finally merged and returned to the API. This data structure can be used for any aggregated report, such as unique users and visits by region, or a click map for every page.
This simple prototype (named Metrage) also worked. So we end up with two custom data structures - one column-oriented for non-aggregated data, updated daily, with only integer types, and another row-oriented, updated in real-time, with arbitrary CRDT.
For a long time, these two custom data structures solved our problems. To be honest, no one demanded more. But I thought - what if I try to combine a column-oriented approach for aggregation speed and a merge tree for realtime updates and data locality? And also generalize it to allow a real query language and data types? This is how ClickHouse started.
How was ClickHouse built?
ClickHouse is a rare example of a database system that is not based on any existing one - implemented entirely from scratch. Today, most of the database management systems are implemented on top of Postgres, Datafusion, and even ClickHouse. It might be interesting to look at how it is possible to bootstrap a DBMS out of nothing, in what steps?
The first commits in 2009 are related to optimizations related to other data structures in the same mono-repository. They are visible because, during open-sourcing, I carefully split the repository while preserving all the history.
The first commit where I started implementing a new DBMS (the name ClickHouse came later) is here - the implementation of columns in memory: you can see already familiar classes IColumn and Field. Compare it to today's implementation :) You might think that this is similar to Apache Arrow (which focuses on column representation in memory), and why didn't we use it - but Apache Arrow didn't exist then (other column-oriented formats, such as RCFile, Trevni, ORC, and Parquet didn't exist either).
Then aggregate functions were introduced in this commit. It is still one of the most important parts of ClickHouse.
Then table engines were introduced. It is funny that table engines were named "primary key", but only for a few days. This allowed reading and writing columns on disk. The first table engine was similar to TinyLog, which exists till today.
Then compression was added. Initially, it was QuickLZ, but as soon as I read Yann Collet's blog, I replaced it with LZ4.
Then block streams - components of the data processing pipeline that produce, consume, or transform chunks of columns in a streaming form. Today, these are replaced with Processors. This unlocked the way for formatting results and implementing queries on tables. The same commit added StorageSystemNumbers - introduced for testing query pipelines, and it remains today as our beloved system.numbers table. The first query pipeline in ClickHouse was printing numbers in TSV.
Here you can see which table engines were introduced in what order.
The first relational operator in the ClickHouse code base was LIMIT.
Then I tried to add a SQL parser. The first attempt tried to use boost::spirit, which failed. After a while, I made a recursive descent parser.
Interesting to point out some initial ideas that were rejected or reintroduced later. Initially, I tried to add a column with variable-length encoded numbers. It was removed due to slowness, and only much later we introduced custom compression codecs, independent of columns. Initially, I added a column type Variant containing arbitrary field values. It was also slow, and I removed it - a better version of Variant was added in 2025. I also had a fixed-size array data type along with a variable-size array, but I removed it due to the lack of need. Only today we are considering adding it back. I believe that removing unnecessary code is more important than adding new code, and today, removing code is my favorite thing to do. You can find a lot of commits in ClickHouse titled "remove trash" and similarly.
Here you can see the first real table structure tested in ClickHouse - it is the hits table you can still see today in ClickBench.
Trying to read and write this table uncovered that C++ iostreams are slow, so in this commit you can see the introduction of WriteBuffer, ReadBuffer, which are still used today.
First functions in SQL appeared here - arithmetic operators. And it allowed to implement the first SELECT query interpreter. At this time, the SELECT query interpreter was only accessible from a test program, but it allowed quickly implementing new aggregate and regular functions, relational operators, data formats and other components.
ClickHouse server was introduced on Mar 9, 2012 and clickhouse-client on Mar 25. Together with the Log, TinyLog, Merge, Distributed, and Memory table engines, it was enough to deploy ClickHouse on production. The first deployment was to store incoming chunks of logs for further processing and for global queries on top of raw logs (this is what Merge and Distributed do). We can say that the first production usage of ClickHouse was a persistent log queue with SQL queries on top 😂
Then I've added MergeTree - it allowed incremental sorting of data in the background, so that while the data arrives by time, range queries by a single website work fast, and we can deploy it for production as a replacement for both early prototypes, OLAPServer and Metrage. The first version contained a few curiosities for our production, like a more aggressive merge of data parts at night.
In 2012, I had a chance to hire the employee №2 in my team, Michael Kolupaev, and I have the pleasure to work with him to this day.
Our production was deployed in multiple regional data centers, and the infra team was deliberately turning off a data center for an hour once a month (it was named "drills"), so that unprepared services experienced downtime - this was to teach everyone to implement highly available multi-DC services. So everything in production has to be replicated in multiple DCs. Initially, I used simple double-write for that with backfill for a DC after its downtime. But we wanted 100% consistency with automatic repair, and for that, we needed distributed consensus. Some of my colleagues were Java engineers, so they hooked us on ZooKeeper as a coordination system (don't worry, I forgive them), and Michael implemented ReplicatedMergeTree using ZooKeeper as a metadata layer. It allowed deploying ClickHouse for production for user-facing queries in 2014.
How did ClickHouse get open-sourced?
In 2014, ClickHouse was in production, storing hundreds of billions of records every day and answering realtime queries from customers. I've also made it accessible for data scientists in the company who used it to calculate trends on the Internet. I published a simple documentation on ClickHouse usage. Other departments, such as ads, e-commerce, infra, and business analytics, tried ClickHouse and migrated some of their use-cases from other systems, such as internal map-reduce (where they were literally writing jobs on text logs with Perl), MySQL, and Postgres. At the end of 2014, ClickHouse was widely used, but only in a single company (with one exception - CERN also deployed it in a cooperation for LHCb experiment).
When I watched presentations on tech conferences and read blogs, I noticed that in other companies, engineers often do something similar to OLAPServer or Metrage, because none of the existing databases could reasonably work on their use-cases - a story very familiar to me! And I thought - what if I can present about ClickHouse? I published an article about ClickHouse in 2015 (translation), and it proved the interest in it even more. My thought - if I make it accessible for everyone, it can fill this empty niche. If I don't - someone else will eventually do it, and it is really scary.
I prepared a list of items to motivate company management to approve the open-source release, with the list of potential advantages and potential risks. Somehow, I was convincing enough, and it was approved, so I created a plan for release, designers made the first logo, I created the first website, prepared the blog post, created a Debian repository (with the infra team), and it was opened to everyone in the world on Jun 15, 2016.
I want this story to also motivate every engineer to try open-sourcing their code. In the worst case, nothing will come out of it, but there is a chance it will influence generations, as ClickHouse does! Don't worry about being ashamed of your code - I just showed you my code from fifteen years ago, and it looks kind of funny. Today, ClickHouse is the most popular analytical database used by the largest companies across the world.

Accelerating agentic development and incident resolution with New Relic AI + AWS
New Relic introduced a one-click integration for AWS Kiro, allowing AI coding agents to access live production telemetry while writing code.
Decoder
- MCP (Model Context Protocol): An open standard designed to enable AI models to securely connect to data sources, tools, and local development environments.
Original article
Developers are rapidly adopting AI-native coding tools to build and ship software faster than ever. But a massive blind spot exists: Most AI assistants operate in isolation from production telemetry. Without real-time operational context, even sophisticated AI coding agents are flying blind, leading to downstream performance bottlenecks and unexpected operational friction.
Closing the loop between code commits and performance with New Relic AI + Kiro
Today, at AWS Summit New York City, we’re excited to launch a one-click integration that connects our Model Context Protocol (MCP) Server with Kiro, the AI-native, agentic development environment from AWS. By bridging the gap between the IDE and production, this integration enriches Kiro’s agentic workflows with Intelligent Observability insights. For developer teams, this closes the feedback loop, enabling them to boost velocity, enhance code quality, and slash mean time to resolution (MTTR).
As organizations navigate this agentic transformation, they face a critical and immediate need to safely unify AI coding agents and live business data,” said Brian Emerson, Chief Product Officer at New Relic. “By integrating our MCP Server with Kiro, we are combining the rigorous, spec-driven development on AWS with New Relic's deep operational insights. The result is a seamless, one-click solution that empowers developer teams to confidently ship quality code with minimal operational friction and toil.
By delivering New Relic’s full-stack telemetry directly into Kiro, engineering teams can shift from manual, retroactive troubleshooting to proactive, AI-assisted investigation. Engineers can query live metrics, events, logs, and traces using natural language directly within Kiro's spec-driven workflow—eliminating disruptive context-switching. This unified experience ensures that AI-generated code is validated against technical specs before it ships, giving developers the confidence to deploy rapidly without breaking production.
Marking our $1 billion AWS Marketplace milestone with more Co-Build innovation
The launch of our Kiro integration marks the next product innovation in our strategic partnership with AWS, which recently surpassed $1 billion in lifetime transactions through the AWS Marketplace. This achievement reflects our shared commitment to helping customers modernize their operations and confidently accelerate their journey toward autonomous, AI-driven software development.
Check out our joint innovations at AWS Summit New York City
Want to see how New Relic and AWS are better together?
- Catch a live demo: Visit booth #619 at AWS Summit New York City to see the Kiro integration and our other AWS frontier agent integrations in action.
- Explore SAP Observability: Discover New Relic Monitoring for SAP Solutions, the market's only agentless, certified RISE with SAP observability solution.
- Get the latest on New Relic + AWS: Read our press release for the complete announcement.
Metric Semantic Layer: How Lyft Governs and Scales Key Data Definitions
Lyft implemented a Metric Semantic Layer to stop 'metric drift' by enforcing standardized business logic across all company data products.
Original article
Lyft built an internal Metric Semantic Layer to solve metric definition drift and ensure consistent business logic across teams. It enforces governance through “Golden Metrics,” dual ownership (Business + Operational owners), versioned updates, and access via Python APIs, self-service UI, Amundsen catalog, and AI agents, providing a single source of truth that propagates changes automatically.
ClickHouse Ingestion at Scale: An Open-Source Zepto Engineering Story
Zepto engineers improved ClickHouse ingestion performance by 45% by rewriting parts of the open-source Kafka Connect connector.
Decoder
- GC (Garbage Collection): A form of automatic memory management that can cause latency spikes in JVM-based applications.
Original article
Zepto improved high-scale ClickHouse ingestion by optimizing the open-source Kafka Connect connector. The team rewrote key internals, lifted throughput by 45%, removed severe GC pauses, added smarter batching, and contributed two major fixes upstream.
Review of Databricks Data + AI Summit 2026
Databricks' 2026 summit focused on unifying transactional and analytical workloads into a single governed lakehouse architecture to eliminate ETL complexity.
Decoder
- LTAP (Lakehouse Transactional Analytical Processing): A conceptual evolution of HTAP, applying transactional and analytical capabilities directly to data in a lakehouse format.
Original article
Databricks' big 2026 announcements are about simplifying data architecture: Lakehouse//RT aims to serve real-time apps and dashboards directly from the lakehouse, while LTAP tries to unify transactional and analytical workloads on one governed copy of data instead of relying on separate databases, CDC, ETL, and serving layers.
7 Crucial Barriers between Data Teams and Self-Healing Data Architecture
Self-healing data architectures are currently blocked by a lack of standardization in credential management, event orchestration, and environment versioning.
Decoder
- Self-healing data architecture: A system capable of automatically detecting, diagnosing, and repairing errors in data pipelines without human intervention.
Original article
Genie Ops points toward self-healing pipelines, but context, governance, and interoperability remain hard. Teams need clearer credential management, event orchestration, agent control, and “git for data” patterns like cloning, rollback, and sandboxed edits. Without standards, it gets messy.
Data quality traffic lights
Nordnet implemented real-time 'Data Quality Health Badges' in Looker to provide visual trust signals for data pipelines based on dbt test results.
Decoder
- dbt (data build tool): A framework that enables data analysts to transform data inside their data warehouse using SQL and version control.
Original article
Nordnet added a real-time Data Quality Health Badge in Looker, showing green, yellow, or red dashboard trust signals. It catches dbt failures, silent crashes, freshness issues, and volume anomalies, consolidates repeat alerts, and uses dbt plus Looker lineage to show blast radius.

Here's my AI-enabled dbt project structure
Optimizing AI performance on dbt projects requires exposing conventions, command workflows, and linting rules directly in the repository via configuration files.
Original article
🔥 Here's my AI-enabled dbt project structure. I kept asking Claude to help with my dbt project. It would write decent SQL, but miss our naming conventions, generate YAML that didn't match our style, and have no idea how our CI pipeline worked.
The problem — my repo was a mess, so I restructured it:
🔹 Added AI-specific files
- CLAUDE .md — the brain. What this project is, how it's organized, what matters.
- .claude/commands/ — project slash commands. /explain-model, /run-full-refresh, /generate-yaml. The AI knows what tools it has.
- .claude/skills/ — reusable AI behaviors. A dbt-specific code reviewer that knows our standards.
🔹 Added more context (loaded on demand) about my development process
- docs/SQL_CONVENTIONS.md
- docs/DBT_CONVENTIONS.md
- docs/YAML_STYLE.md
🔹 Guardrails that run regardless of who (or what) wrote the code
- .sqlfluff
- .pre-commit-hooks.yml
The rest is just a standard dbt project. The only thing that changed: I told the AI where to look, what rules to follow, and what it can do. Now it writes models that fit our conventions on the first try. Add those step-by-step and watch the output improve.
A New Era of Midjourney
Midjourney is expanding beyond image generation into medical imaging with a full-body ultrasound scanner slated for a 2027 debut.
Original article
Midjourney has announced a medical imaging venture called Midjourney Medical, centered on a full-body ultrasound scanner that submerges users in water and produces MRI-quality 3D images in under 60 seconds. The technology uses half a million tiny sensor elements to send and receive ultrasonic waves, reconstructing detailed body composition maps through massive parallel computing. Plans include opening the first Midjourney Spa in San Francisco in 2027, scaling to over 50,000 scanners worldwide by 2031, with the stated ambition of preventing 30% of global deaths and halving healthcare costs through early detection.
AI‑Native Interactive Video Game Platform (Website)
Yoroll.ai aims to turn game creation into a director's role, using AI to build branching, story-driven games from simple creative assets.
Original article
LinearGame's Yoroll.ai lets creators build playable, branching story‑driven games from text prompts, photos, and short clips — more like directing a movie than programming a game.

Ship More. Write Less (Website)
Notra automates the mundane task of maintaining changelogs and marketing collateral by pulling content directly from your shipping history.
Decoder
- Lexical: An extensible JavaScript web text-editor framework by Meta designed for performance and reliability.
Original article
This week focused on changelog quality, editor polish, and smoother onboarding. We added configurable lookback windows, improved markdown editing reliability, and shipped a progress-aware setup checklist.
Configurable lookback windows for scheduled changelogs
Schedules now support five predefined time ranges (current day, yesterday, last 7/14/30 days) instead of hardcoded 7-day windows. The selected range flows through the entire generation pipeline and appears in stored metadata, so you can see exactly which window produced each post.
Full table support in the rich-text editor
The Lexical editor can now insert, edit, and manipulate tables with a /table slash command and floating action menu. Markdown roundtripping preserves table syntax across view switches, and editor normalization prevents false-positive dirty states on initial load.
Database-backed onboarding checklist
A collapsible checklist in the sidebar footer tracks brand identity, integration, and schedule setup. Progress is synced across all mutation flows, completion auto-hides the widget, and collapse state persists via localStorage to reduce visual noise.
Modular tone-specific changelog prompts
Changelog generation moved from a shared base prompt to self-contained, one-file-per-tone templates. This simplifies backend selection logic, hardens tool input validation, and centralizes tone profile resolution through Zod schemas.
Point-in-time source metadata on generated content
Each post now stores a JSONB snapshot of its trigger, repositories, and lookback window. The content detail page displays this metadata with Zod validation and tooltip formatting for multi-repo scenarios.
Apple's New CEO Must Rebuild a Design Team That Lost Its Way
Apple’s leadership is reportedly attempting to restore the industrial design team's influence after years of internal decline.
Original article
Apple's industrial design organization used to be the heart and soul of the company. Today, the organization no longer has a true seat at Apple's executive table. It has become a place where other teams come to get what they need before promptly leaving. This article tells the story of the group's decline, its impact on the company, and Apple's plans to restore the design studio's prowess.
New usage analytics and updated spend controls for enterprises
ChatGPT Enterprise now allows administrators to track and limit model-level usage across groups and individual users through the Global Admin Console.
Original article
ChatGPT Enterprise introduces credit usage analytics and expanded spend controls that unify ChatGPT and Codex usage data in the Global Admin Console, enabling visibility into adoption, model-level consumption, and top users. Administrators can set workspace, group, and individual limits with overrides and requests, improving cost governance while preserving flexible access for high-usage teams.
Apple Music in iOS 27 introduces new design changes in two key areas
iOS 27 brings a visual refresh to Apple Music, focusing on seamless artwork integration and more prominent artist controls.
Original article
iOS 27 introduces a refreshed design for Apple Music, with updated artist pages already available in the beta. Artist artwork now blends more seamlessly into the page, influencing the overall color scheme, while key controls such as play, favorite, and artist information are more prominently displayed. Featured content, including new releases or upcoming projects, is also given its own dedicated section. Apple has additionally confirmed that album pages will receive a redesign in iOS 27, although those changes have not yet appeared in the beta. The updates are part of Apple's broader effort to refine the Liquid Glass design language introduced in iOS 26, and the new album layouts are expected to arrive in upcoming beta releases.
Is Apple's folding iPhone too little too late?
As Apple faces a stagnant smartphone market, the long-rumored folding iPhone may struggle to impress an industry increasingly focused on AI rather than hardware.
Original article
Smartphones have become more powerful than ever, but many users no longer find new models particularly exciting. While modern iPhones offer major improvements in cameras, displays, and performance, recent generations have largely refined existing features rather than introducing transformative new experiences. A foldable iPhone could provide a fresh design and renewed excitement, but foldable phones are no longer a novel concept, having been available from other manufacturers for several years. At the same time, the technology industry's focus has increasingly shifted toward AI and software capabilities rather than hardware design. As a result, the real challenge for Apple may not be building a compelling foldable device, but convincing users that new hardware can be as revolutionary as the software and AI innovations now driving the tech conversation.

Speaking the Language of Color
Pantone has selected 'Cloud Dancer', a balanced soft white, as its 2026 Color of the Year to reflect a societal need for clarity.
Original article
Color is a deeply psychological language tied to emotion, culture, and nature — meaning brands must choose hues deliberately to communicate their identity. Airbnb's 2014 shift from baby blue to salmon pink, for example, signaled humanity and warmth, while Brat Green captured authenticity and bold spirit in Charli XCX's 2024 cultural moment. For 2026, Pantone named Cloud Dancer — a soft, balanced white — as Color of the Year, reflecting a collective desire for calm, clarity, and respite from an overstimulating world.
Pentagram's new identity for denim label Hiut embraces its Welsh heritage
Pentagram revitalized Hiut Denim Co.'s brand identity by grounding it in the specific craft and industrial heritage of Aberteifi, Wales.
Original article
Founded in 2011, Hiut Denim Co. was created to revive the denim-making heritage of Aberteifi (Cardigan), Wales, after local jeans production moved overseas. To better reflect its roots and craftsmanship, the company worked with Pentagram to develop a new visual identity centered on the factory, its workers, and the surrounding landscape. The redesign includes a refined wordmark that incorporates Aberteifi's Welsh name, an updated owl logo, a typography system combining industrial and handcrafted elements, and a color palette inspired by both the local environment and factory setting. Photography and art direction focus on the people, processes, and textures behind production, reinforcing the brand's emphasis on authenticity, skilled craftsmanship, and local manufacturing in contrast to mass-produced fashion.
Displaay's first text typeface, Post, spans 4 families and 56 styles
Displaay's new 'Post' typeface challenges the binary between text and typewriter fonts through extensive research into human letterform recognition.
Decoder
- Typeface: A cohesive set of characters, numbers, and symbols that share a unified design, often including different weights and styles (e.g., bold, italic).
Original article
A designer set out to explore whether the traditional distinction between text typefaces and typewriter fonts still makes sense in the digital age. The project was inspired by a degraded, scanned version of Courier that remained surprisingly legible, leading to extensive research into which parts of letterforms readers rely on most for recognition. The resulting type system emphasizes the key features that make characters instantly identifiable while reducing less important visual details, with readability taking priority over aesthetics throughout development. Drawing on influences from 20th-century Czechoslovak type design and other historical sources, the final release includes multiple font families, weights, styles, and variable axes, creating a highly flexible typeface that bridges the gap between traditional text and typewriter-inspired design.
Osaka Art & Design 2026 Sculpts the City with Giant Alphabets and Monumental Cats
Osaka Art & Design 2026 features massive sculptural installations, including Kenji Yanobe's four-meter 'SHIP'S CAT' and Takenobu Igarashi's large-scale typography.
Original article
Osaka Art & Design 2026 highlights span from Kenji Yanobe's nearly four-meter-tall "SHIP'S CAT" sculpture at Grand Green Osaka to Takenobu Igarashi's large-scale alphabet forms in wood, concrete, and metal at PARCO.
Did you know that your iPhone bursts on-screen fireworks when you call a person on their birthday?
Apple's iOS 27 adds a celebratory fireworks animation that triggers during FaceTime or phone calls if the contact's birthday is in your Address Book.
Original article
iOS 27 includes a hidden feature that displays a subtle fireworks animation and birthday banner when you call someone on their birthday, provided their birth date is saved in your Contacts app, regardless of whether they use an iPhone or Android device.
Coca-Cola's Vibrant Visual Identity and Packaging for FIFA '26
Coca-Cola is rolling out a geometric-focused visual identity for the FIFA World Cup 26, emphasizing regional patterns across its global packaging.
Original article
Coca-Cola has launched its official visual identity for FIFA World Cup 26, centered on limited-edition cans and twelve-packs featuring bold geometric patterns — chevrons, diamonds, and regional color palettes — representing participating nations under the tagline "Collect The Whole Squad."