Devoured - May 15, 2026
Apple's ChatGPT integration and OpenAI's legal exploration against Apple, combined with new AI agent development environments and tools, signal a dynamic shift in developer tooling and platform strategies.
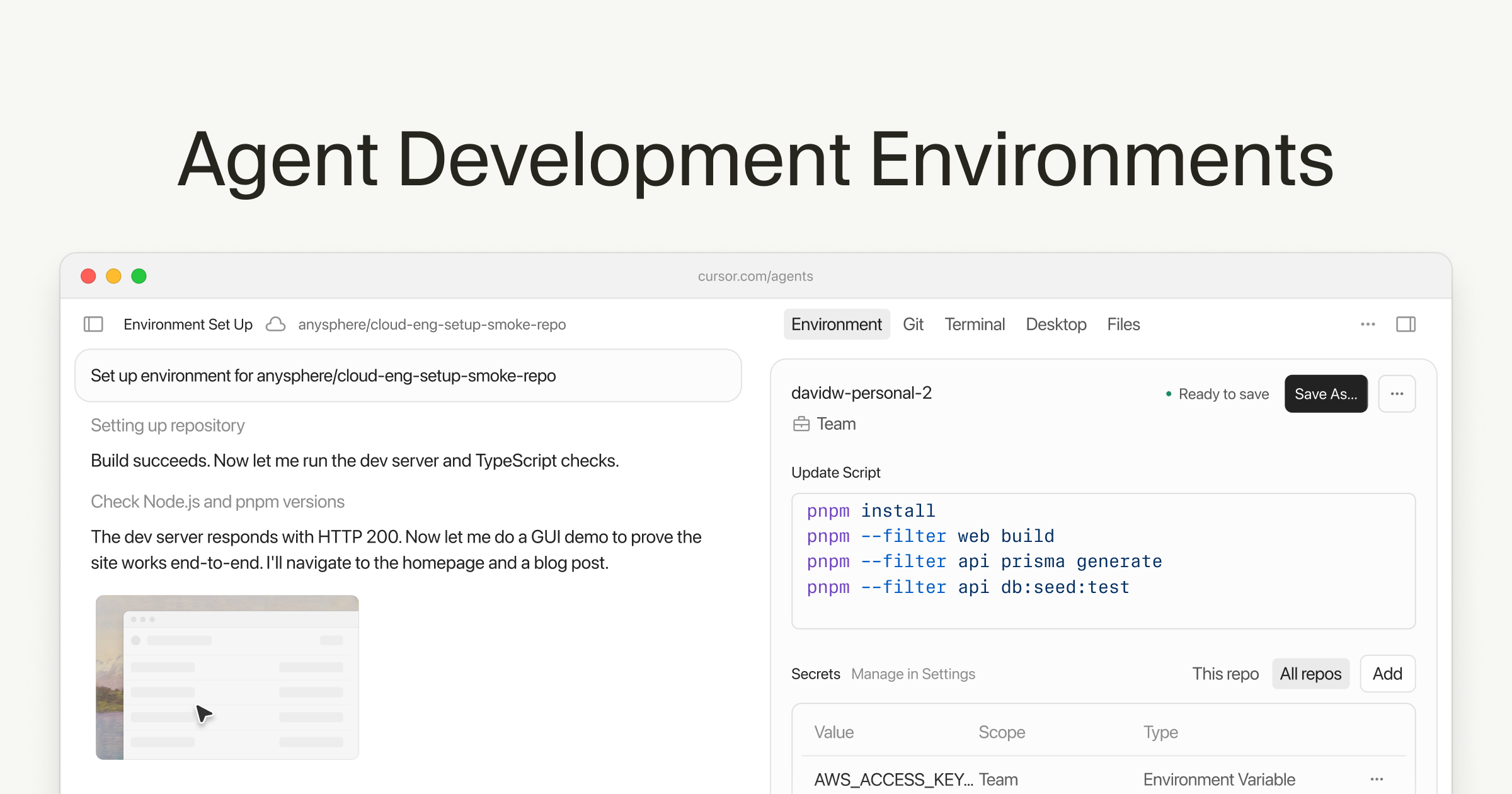
Cloud Agent Development Environments
Cursor launched new cloud-based development environments for autonomous coding agents, enabling multi-repo support, configuration as code, and enhanced governance for parallel agent fleets.
Deep dive
- New tools support multi-repo environments, allowing agents to reason across multiple codebases simultaneously, useful for microservices architectures.* Environment configuration is enhanced with Dockerfile-based "configuration as code", including build secrets (scoped to build step, not agent) and 70% faster builds due to upgraded layer caching.* Cursor can auto-configure Dockerfiles by inspecting repositories and identifying required dependencies, rolling out to Enterprise teams.* Agent-led environment setup is improved with interactive prompts for missing credentials and validation, with a fallback to a base image on failure.* Governance and security features include version history with rollback capabilities, admin-only rollback restrictions, and an audit log of environment changes.* Egress and secrets can now be scoped at the individual development environment level, enhancing security isolation for parallel agent fleets.
Decoder
- Multi-repo environment: A development environment configured to include and manage multiple independent code repositories simultaneously, allowing tools and agents to work across them.* Configuration as code: The practice of managing and provisioning computer infrastructure and application configurations using machine-readable definition files, such as Dockerfiles, rather than manual interactive processes.* Build secrets: Sensitive information, like API keys or private registry credentials, securely injected into a build process without being exposed to the final runtime environment or committed to source control.* Layer caching: In container image building (e.g., Docker), reusing intermediate image layers from previous builds to speed up subsequent builds, only rebuilding changed layers.* Egress controls: Network security rules that govern and restrict outbound connections from a specific environment, often to an allowlist of permitted destinations.
Original article
Full article content is not available for inline reading.
2028: Two scenarios for global AI leadership
Anthropic's new paper outlines two 2028 global AI leadership scenarios, arguing that US policy action on compute export controls and distillation attacks is crucial to maintain its lead over China and ensure democratic AI governance.
Deep dive
- Anthropic's paper models two scenarios for global AI leadership by 2028: one with a US lead, and one with China as a close competitor.* The US currently holds a strong lead in AI compute due to American and allied innovation in advanced chips and effective export controls by past administrations.* Chinese AI labs remain competitive by exploiting loopholes in export controls (smuggling, offshore data centers) and performing "distillation attacks" to replicate US frontier models.* A key policy recommendation is to close these loopholes and deter distillation attacks to secure a 12-24 month lead for the US and its allies.* This lead is seen as crucial for democracies to set global AI norms, ensure safety, and prevent authoritarian regimes from using AI for repression and military advantage.* The paper cites the "Mythos Preview" model, released by Anthropic as part of Project Glasswing in April, as an example of accelerating AI capabilities, which allowed Firefox to fix more security bugs last month than in all of 2025.* It emphasizes that compute advantage compounds into algorithmic advantage, making continued control over advanced semiconductors critical.* The competition is framed across four fronts: Intelligence, Domestic Adoption, Global Distribution, and Resilience, with Intelligence being the most important driver.
Decoder
- Compute advantage: A strategic lead in the availability and capability of advanced computer processing power, specifically high-end GPUs and AI accelerators, crucial for training and deploying large AI models.* Export controls: Government regulations that restrict the sale or transfer of certain technologies, products, or data to foreign countries, often for national security or foreign policy reasons.* Distillation attack: A method where an attacker systematically queries a larger, more capable AI model (often a proprietary "teacher" model) to generate data, which is then used to train a smaller, less computationally intensive "student" model to mimic the teacher's capabilities, essentially illicitly extracting its innovations.* SME (Semiconductor Manufacturing Equipment): The specialized machinery and tools used in the fabrication process of semiconductor chips, a highly advanced and capital-intensive industry.* Open-weight models: AI models where the trained model weights are publicly released, allowing anyone to download, inspect, modify, and run them, often used synonymously with "open-source models" in this context.
Original article
Full article content is not available for inline reading.

Genkit Middleware
Google's Genkit open-source framework now offers middleware for AI-powered agentic applications, enabling retries, fallbacks, human approval, and observability.
Deep dive
- Genkit is an open-source framework by Google for building full-stack, AI-powered and agentic applications.
- It supports TypeScript, Go, Dart, and will soon support Python.
- The new middleware system, announced May 14, 2026, allows developers to intercept and extend
generate()calls. - Middleware hooks attach at three layers:
Generate(once per tool-loop iteration),Model(once per model API call), andTool(once per tool execution). - Pre-built middleware includes:
Retry(with exponential backoff),Fallback(to alternative models like Claude),ToolApproval(for human-in-the-loop confirmation),Skills(injects content from SKILL.md files), andFilesystem(scoped access to local filesystem). - Developers can build custom middleware, demonstrated with a ~20-line content filter example.
- Middleware can be composed and stacked, with explicit order of execution.
- The Genkit Developer UI allows inspection, testing, and debugging of middleware execution.
Decoder
- Agentic application: An application built around an AI "agent" that can autonomously perform complex tasks by breaking them down, using tools, and adapting its actions based on feedback.
- Middleware: Software that provides services to applications beyond those available from the operating system, often used to intercept and modify requests or responses in a pipeline.
- Tool loop: In agentic AI, a repeated cycle where an AI model generates an output, uses external tools based on that output, processes the tool's results, and then feeds those results back into a new model call until a task is completed.
Original article
Full article content is not available for inline reading.

Unlocking asynchronicity in continuous batching
Hugging Face demonstrates how asynchronous batching using CUDA streams and events can boost LLM inference GPU utilization by 22%, dramatically speeding up generation.
Deep dive
- Synchronous batching in LLM inference leads to CPU and GPU idling in turns, wasting up to a quarter of total runtime.
- Asynchronous batching aims to parallelize CPU batch preparation for batch N+1 with GPU computation for batch N.
- This method, implemented in Hugging Face's
transformerslibrary, achieved a 22% speedup (from 300.6s to 234.5s) and boosted GPU utilization from 76% to 99.4%. - The core technique uses CUDA streams to allow concurrent GPU operations and CUDA events to enforce dependencies between operations across streams.
- Non-default CUDA streams are crucial as the default stream is synchronizing, blocking CPU and other streams.
- Three dedicated streams are used: Host-to-Device (H2D) for input transfer, Compute for model forward pass, and Device-to-Host (D2H) for output transfer.
- CUDA events (e.g.,
h2d_done,compute_done) are recorded in one stream and waited upon by another to ensure correct execution order. - To prevent race conditions, two sets of input/output tensors are used and alternated between (slot A and slot B).
- CUDA graphs, usually specific to memory addresses, can be used with a memory pool to avoid doubling VRAM usage for dual slots.
- A "carry-over" mechanism replaces placeholder tokens in batch N+1's inputs with actual tokens from batch N's outputs after batch N completes.
- The final result is a pipeline where the CPU quickly dispatches all GPU work, then prepares the next batch in parallel, only blocking at the very end to process outputs.
Decoder
- Continuous batching: An optimization technique for LLM inference where multiple ongoing requests are batched together dynamically, ensuring the GPU is always busy and reducing padding.
- CUDA streams: Ordered queues of GPU operations (kernel launches, memory copies) that execute sequentially within the stream but can run concurrently with operations in other streams.
- CUDA events: Markers that can be recorded into a CUDA stream; when the GPU reaches the marker, the event is set, and other streams can be instructed to wait for that event before proceeding.
- KV cache: "Key-Value cache," a memory optimization for LLMs where previously computed keys and values for attention layers are stored to avoid redundant computation during token generation.
- FlashAttention: An optimized attention algorithm that speeds up and reduces memory usage for attention computations in transformers, especially for long sequences.
- CUDA graphs: A feature that allows a sequence of CUDA operations to be recorded once and then replayed efficiently, reducing CPU overhead for repeated patterns.
Original article
Full article content is not available for inline reading.

Microsoft is quietly shopping for an OpenAI replacement
Microsoft, after amending its OpenAI deal on April 27, is reportedly pursuing acquisitions of AI startups like Inception, signaling a strategy to diversify beyond its primary AI partner.
Deep dive
- Microsoft amended its deal with OpenAI on April 27, 2026, ending its exclusive license to OpenAI models.
- The amendment also freed OpenAI to sell on other cloud platforms (like AWS) and removed the AGI clause that would have affected Microsoft's IP rights.
- Microsoft retains its IP license through 2032, a 27% stake (worth $135bn), and an Azure-first deployment clause for new OpenAI products.
- Reuters reported on May 14, 2026, that Microsoft is actively canvassing AI startups for acquisitions or strategic deals.
- A previous attempt to acquire Cursor, a code-generation startup, fell apart due to potential regulatory conflicts with GitHub Copilot, leading Elon Musk's SpaceX-xAI to acquire an option instead.
- Microsoft is now reportedly in active talks with Inception, a Palo Alto startup spun out of Stanford by Professor Stefano Ermon, which specializes in diffusion-based language models (processing tokens in parallel at over 1,000 tokens/second).
- Microsoft's M12 fund already participated in Inception's $50m round last November.
- Mustafa Suleyman leads Microsoft's MAI Superintelligence team, which shipped three foundation models (MAI-Transcribe-1, MAI-Voice-1, MAI-Image-2) in April, targeting a frontier general-purpose LLM by 2027.
- The strategy aims to acquire talent and architectural diversity underneath the AGI race, focusing on code generation and model architecture.
Decoder
- AGI clause: A contractual provision that would trigger specific changes (e.g., to intellectual property rights) once an AI system reaches Artificial General Intelligence, a hypothetical point where AI can perform any intellectual task a human can.
- Diffusion-based language models: A class of generative AI models (distinct from autoregressive models) that generate data by iteratively denoising a random input, processing tokens in parallel rather than sequentially.
- Autoregressive models: Generative AI models (like most current LLMs) that predict the next token in a sequence based on all preceding tokens, generating output one token at a time.
Original article
The company that put $13bn into OpenAI now wants the option not to need it. Cursor was the first try and fell apart over GitHub Copilot; talks with Stanford diffusion-LLM startup Inception are alive, and the broader strategy belongs to Mustafa Suleyman.
Reuters reported on Wednesday, citing five people familiar with the matter, that the company has been quietly canvassing AI startups for acquisitions or strategic deals as it builds out the option to operate without OpenAI.
Three weeks after rewriting the contract that bound it to OpenAI for the better part of a decade, that option is no longer theoretical.
The most concrete attempt so far ended in retreat. This spring, Microsoft weighed buying Cursor, the code-generation startup whose annualised revenue went from zero to $2bn in three years, then walked away.
The internal verdict was that owning GitHub Copilot and acquiring Cursor at the same time was a regulatory fight Microsoft did not want to pick. Days later, Elon Musk’s newly merged SpaceX-xAI vehicle bought a $60bn option on Cursor instead, with a $10bn breakup fee attached. The losing bidder paid nothing, kept Copilot, and lost the asset.
The active conversation now is with Inception, a Palo Alto startup spun out of Stanford by professor Stefano Ermon. Inception is one of the very few groups outside the major labs building diffusion-based language models rather than autoregressive ones, an architecture that processes tokens in parallel instead of one at a time and which Ermon claims runs at over 1,000 tokens per second.
Microsoft’s M12 fund already participated in the company’s $50m round last November. Reuters reports the parent company is now in talks about something larger.
Both deals belong to the same brief: stock up on talent and architectural diversity before the in-house programme has to carry the weight on its own. That programme has a name and a leader.
The MAI Superintelligence team, set up in November 2025 under Mustafa Suleyman, shipped its first three foundation models in April: MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2. A frontier general-purpose LLM is, per Suleyman’s own March memo, the 2027 target.
The trigger for all of this is the deal Microsoft signed on 27 April. The amendment ended Microsoft’s exclusive licence to OpenAI’s models, freed OpenAI to sell on AWS and any other cloud, and removed the so-called AGI clause that would have triggered changes to Microsoft’s IP rights once OpenAI’s board declared the threshold reached.
Microsoft kept the IP licence through 2032, a 27% stake worth roughly $135bn at last disclosure, and an Azure-first deployment clause for new OpenAI products. What it gave up, in plain English, was the implicit assumption that OpenAI would be the only frontier lab Microsoft would ever need.
There is something quietly funny about a company spending $13bn on a partner and then immediately starting a shadow procurement process for the replacement. Microsoft does not put it that way, and Reuters’ sources do not quote anyone using the word replacement.
Both Cursor and Inception target the same gap, which is not the AGI race itself but the layer underneath it: code generation, model architecture, the working assumption that whoever owns the developer surface owns the next decade.
What Suleyman has not said publicly is which of the startups currently sitting in Microsoft’s pipeline get bought, which get partnered with, and which get watched until someone else buys them first. SpaceX has made it expensive to be the second bidder for the same asset.
The pipeline itself is the news, but whether it produces a named acquisition before year-end is the next thing to watch for us.
Get the TNW newsletter
Get the most important tech news in your inbox each week.
Also tagged with
- Microsoft

Toto 2.0: Time series forecasting enters the scaling era
Datadog has released Toto 2.0, an open-weights family of time series forecasting models up to 2.5B parameters on Hugging Face, demonstrating improved performance and scalability without saturation.
Decoder
- Time series forecasting: The process of predicting future values of a variable based on its past values, often used for data that changes over time, like stock prices, sensor readings, or website traffic.
- Open-weights: Refers to a model where the trained parameters (weights) are publicly released, allowing anyone to download, use, and further develop the model.
- Hugging Face: A popular platform and community for machine learning, providing tools, datasets, and pretrained models, often for natural language processing and computer vision.
- CRPS (Continuous Ranked Probability Score): A metric used to evaluate the quality of probabilistic forecasts, measuring how well the predicted distribution of outcomes aligns with the actual observed outcomes.
- MASE (Mean Absolute Scaled Error): A measure of point forecast accuracy, normalized against a naive seasonal baseline, making it suitable for comparing forecasts across different time series.
Original article
Full article content is not available for inline reading.

World's first native color LiDAR gives machines human-like vision
Ouster's new Rev8 sensor family introduces the world's first LIDAR with native color, fusing color directly into every data point for human-like machine vision.
Deep dive
- Ouster's new Rev8 sensor family is the first LiDAR to fuse color directly into every point of data, providing native color.
- This differs from traditional systems that combine monochrome LiDAR for geometry with separate cameras for color, which introduces calibration errors and latency.
- The flagship OS1 Max model is a 256-channel sensor with a detection range up to 200 meters at 10% reflectivity and up to 500 meters under optimal conditions.
- It operates across extreme lighting conditions, from near-total darkness (1 lux) to intense direct sunlight (2,000,000 lux), with 48-bit color depth and 116 dB dynamic range.
- The technology is built on Ouster's L4 chip, co-developed with Fujifilm, which processes up to 20 trillion photons per second.
- CEO Angus Pacala states Rev8 doubles the range and resolution of its previous Rev7 generation.
- Early adopters include Google, Volvo Autonomous Solutions, Skydio, PlusAI, and Seegrid.
- Ouster acquired computer vision specialist StereoLabs in February 2026 for $38 million plus shares, signaling a move towards offering full perception platforms.
- Rev8 sensors are available to order, with shipments expected to begin this quarter.
Decoder
- LIDAR (Light Detection and Ranging): A remote sensing method that uses pulsed laser to measure distances, generating precise 3D maps of environments.
- Native color LiDAR: A LiDAR sensor that captures both 3D geometric data and color information simultaneously within each data point, rather than fusing data from separate LiDAR and color camera sensors.
- Reflectivity: The percentage of light that a surface reflects. Lower reflectivity (e.g., 10%) means the surface absorbs most light, making it harder for sensors to detect.
- Lux: A unit of illuminance, measuring luminous flux per unit area. It quantifies how much light illuminates a surface.
- Dynamic range: The ratio between the brightest and darkest measurable light intensities in an image or sensor output.
Original article
Full article content is not available for inline reading.

Apple's Security Has Been Tough to Crack. Mythos Helped Find a Way In
Security researchers leveraged Anthropic's Mythos AI model to discover a complex privilege escalation exploit circumventing Apple's macOS security.
Decoder
- Privilege escalation: A type of network attack where an attacker gains higher-level access than intended, often allowing them to execute commands or access data they shouldn't.
Original article
Security researchers claim to have discovered a way to circumvent Apple's security technology by using techniques they discovered while testing an early version of Anthropic's Mythos AI model in April. Their privilege escalation exploit links together two bugs and a handful of methods to gain unauthorized access. Apple is currently reviewing the researchers' findings. The attack required human cybersecurity expertise and could not have been pulled off by Mythos alone. The researchers plan to release details of the attack once Apple has patched the underlying issues.

OpenAI x Microsoft
Leaked emails from the Musk v. Altman lawsuit reveal Microsoft CEO Satya Nadella's aggressive strategy to control OpenAI's IP and internal structures while Sam Altman navigated the November 2023 board crisis.
Deep dive
- A July 2022 email from Satya Nadella to Microsoft executives expresses concern about Microsoft's financial exposure to OpenAI, projecting a $4 billion P&L loss the following year.
- Nadella stated his goal was for Microsoft to "own – the silicon, infra, foundational model IP and 'know how'" to gain control of its destiny, rather than being "a very thin layer on top of NVIDIA and all the IP is with Open AI."
- He proposed funding OpenAI's hardware and operational expenses in return for full IP rights and embedding Microsoft staff across OpenAI's stack to ensure self-sufficiency.
- Texts from November 2023 show Sam Altman communicating with Nadella and Kevin Scott during the period he was removed from OpenAI's board.
- Altman discussed potential board configurations, including a 5-member board and a smaller board of Bret Taylor, Larry Summers, Adam D'Angelo, and himself as CEO.
- Nadella and Scott explicitly rejected Diane Greene and Bing Gordon as potential board members due to conflicts with Microsoft's cloud business, with Nadella giving a "Strong strong no" for Greene.
- An October 2020 text from Sam Altman to Elon Musk defends the Microsoft partnership as the best way to secure "many billions of dollars" needed to compete with DeepMind while retaining autonomy.
- Elon Musk criticized the partnership on Twitter in September 2020, stating "OpenAI is essentially captured by Microsoft."
- Microsoft's board investment memos from 2019 to 2024 were also included in the leak.
Decoder
- P&L (Profit & Loss): A financial statement summarizing revenues, costs, and expenses incurred during a specific period.
- AGI (Artificial General Intelligence): Hypothetical AI that can understand, learn, and apply intelligence to a wide range of problems, similar to human intelligence.
- P&L review: A business meeting to review the profit and loss statement and discuss financial performance.
Original article
Full article content is not available for inline reading.
Kubernetes v1.36: Advancing Workload-Aware Scheduling
Kubernetes v1.36 overhauls scheduling for AI/ML and batch workloads by introducing a PodGroup API for atomic, topology-aware gang scheduling and dynamic resource allocation.
Deep dive
- Kubernetes v1.36 focuses on workload-aware scheduling improvements.
- Splits the Workload API (static template) from the new PodGroup API (runtime state) in
scheduling.k8s.io/v1alpha2. - Introduces a dedicated PodGroup scheduling cycle in kube-scheduler for atomic processing of entire groups.
- Supports gang scheduling, where pods are scheduled together if
minCountrequirement is met, preventing partial deployments. - Adds topology-aware scheduling to co-locate pods within physical or logical domains (e.g., racks) to reduce network latency, especially for AI/ML.
- Debuts workload-aware preemption, which treats an entire PodGroup as a single preemptor unit, pre-empting across multiple nodes simultaneously.
- Enhances Dynamic Resource Allocation (DRA) to allow PodGroups to represent the replicable unit for ResourceClaimTemplates, enabling high-cardinality sharing of devices like GPUs.
- Integrates with the Job controller to automatically create Workload and PodGroup objects for specific types of parallel Jobs (static, indexed, fully-parallel).
- All these features are alpha in v1.36 and require feature gates to be enabled.
- Future plans include graduating APIs to Beta, multi-level Workload hierarchies, and broader controller integration.
Decoder
- Gang scheduling: A scheduling technique where a group of interdependent tasks (pods in Kubernetes) are scheduled to run simultaneously, or not at all, to avoid deadlocks and improve performance.
- Topology-aware scheduling: A scheduling strategy that considers the physical or logical arrangement of resources (e.g., racks, zones) within a cluster to place interdependent workloads closer together, minimizing communication latency.
- Dynamic Resource Allocation (DRA): A Kubernetes feature allowing pods to make detailed, dynamic requests for specialized devices like GPUs or TPUs, rather than relying on static resource definitions.
Original article
Full article content is not available for inline reading.
Kubernetes v1.36: PSI Metrics for Kubernetes Graduates to GA
Kubernetes v1.36 has graduated Pressure Stall Information (PSI) metrics to general availability, providing crucial signals for identifying CPU, memory, and I/O resource saturation at the node, pod, and container levels.
Deep dive
- Pressure Stall Information (PSI) metrics, a Linux kernel feature since 2018, have graduated to General Availability (GA) in Kubernetes v1.36, as announced by Maria Fernanda Romano Silva of Google Cloud.
- PSI provides high-fidelity signals for identifying resource saturation (CPU, memory, I/O) by showing the absolute time tasks spend stalled and 10s, 60s, and 300s moving averages, offering more insight than traditional utilization metrics.
- The metrics are available at the node, pod, and container levels, helping operators identify and address resource contention before it leads to outages.
- Extensive performance testing by SIG Node on high-density workloads (80+ pods) confirmed that Kubelet's collection of PSI metrics is highly lightweight, adding negligible overhead (around 0.1 cores or 2.5% of total node capacity).
- The underlying kernel-level overhead of enabling PSI was also found to be minimal (0.037 to 0.125 cores, or 0.925%-3.125% of total node capacity).
- Improvements between beta (v1.34) and stable (v1.36) include smarter metric emission, where the Kubelet now detects underlying OS PSI support before reporting, preventing misleading zero-valued metrics.
- To utilize PSI, Kubernetes nodes must be running Linux kernel version 4.20 or later, use cgroup v2, and have PSI enabled at the OS level (kernel compiled with
CONFIG_PSI=yand not booted withpsi=0). - Once prerequisites are met, PSI metrics can be collected and visualized by scraping the
/metrics/cadvisorendpoint with a Prometheus-compatible solution or by querying the Summary API.
Decoder
- Pressure Stall Information (PSI): A Linux kernel feature that provides real-time metrics on how much time processes spend waiting for CPU, memory, or I/O resources due to contention, indicating resource saturation rather than just utilization.
- cgroup v2: The second version of the Linux control group interface, which provides a unified hierarchy for managing and monitoring system resources for groups of processes.
Original article
Full article content is not available for inline reading.
Introducing Grok Build
xAI introduced Grok Build, a new terminal-based coding agent for SuperGrok Heavy subscribers, supporting subagents and headless automation.
Decoder
- Coding agent: An AI system designed to understand, generate, and execute code within a development environment, often automating programming tasks.* Subagent: A smaller, specialized AI agent that operates under a main agent to handle specific parts of a larger task.* Worktree: In version control systems like Git, a worktree is an additional working tree associated with the same repository, allowing developers to work on multiple branches simultaneously without switching branches in the main working directory.* Headless mode: Software operation without a graphical user interface, often used for automation and scripting.
Original article
Grok Build is a coding agent that runs from the terminal. It is now in early beta for SuperGrok Heavy subscribers. AGENTS.md, plugin, hooks, skills, and MCP servers all work out of the box. Grok Build supports subagents for larger tasks, and it also supports deep worktree integrations, so users can launch subagents in their own worktrees. There is a headless mode that allows the easy running of agents inside scripts and automations.
How We Built Secure, Scalable Agent Sandbox Infrastructure
A technical post by Larsencc describes two primary approaches to sandboxing code-executing agents – isolating the tool or isolating the agent – favoring agent isolation for enhanced security and scalability.
Decoder
- Sandboxing: A security mechanism for running programs in an isolated environment, preventing them from accessing or modifying system resources outside their designated boundaries, often used for untrusted code.* Statelessness: A characteristic of a system or component where no information about past interactions (state) is retained, meaning each request or operation is processed independently.* Network hop: A segment of a network path that a data packet traverses from one network device (like a router or server) to another.
Original article
There are two ways to sandbox an agent that can execute code: isolate the tool or isolate the agent. Agents should have nothing worth stealing and nothing worth reserving. Isolating the agent requires an extra network hop on every operation and more services to deploy, but there are no secrets to steal, no state to preserve, and agents can be killed, restarted, and scaled independently.

Codex is getting easier to automate and customize around your code
OpenAI's Codex now offers hooks and programmatic access tokens, enabling easier automation and customization of its coding loop for Business and Enterprise teams.
Decoder
- Hooks: Programmable points in a software system or workflow where custom code can be injected and executed in response to specific events, allowing for customization and extension of functionality.* Programmatic access tokens: Secure, scoped credentials (like API keys) that allow automated systems or scripts to authenticate and interact with a service or API, rather than requiring a user's full login.* CI/CD (Continuous Integration/Continuous Delivery): A set of practices in software development that involve frequently integrating code changes, running automated tests, and delivering software updates reliably and efficiently.
Original article
Codex is getting easier to automate and customize around your code.
🪝 Hooks customize the Codex loop with scripts that run at key points in a task:
- Run validators before or after work
- Scan prompts for secrets
- Log conversations to internal systems
- Create memories or customize behavior by repo or directory
⚙️ Programmatic access tokens provide scoped credentials for Business and Enterprise teams:
- Create tokens from ChatGPT workspace settings
- Use them in CI, release workflows, and internal automations
- Set expirations or revoke access when needed
- Keep usage tied back to the workspace
Open Responses: an open-source spec for building multi-provider, interoperable LLM interfaces built on top of the original OpenAI Responses API.
- Multi-provider by default
- Useful for real-world workflows
- Extensible without fragmentation
Build agentic systems without rewriting your stack for every model: openresponses.org
https://x.com/ben_burtenshaw/status/2011869403097305271
https://x.com/vercel_dev/status/2011874375885341147?s=20
GPT-5.2-Codex is now available in the Responses API—the same model available in Codex.
It’s strong at complex long-running tasks like building new features, refactoring code, and finding bugs.
Plus, it’s the most cyber-capable model yet, helping to find and understand codebase vulnerabilities.
platform.openai.com/docs/models/gp…
Check out our prompting guide to get the most out of Codex models: cookbook.openai.com/examples/gpt-5…
Here’s what our customers are saying about GPT-5.2-Codex in the API 👇
https://x.com/cursor_ai/status/2011500027945033904?s=20
🆕 Codex now officially supports skills
Skills are reusable bundles of instructions, scripts, and resources that help Codex complete specific tasks.
You can call a skill directly with $.skill-name, or let Codex choose the right one based on your prompt.
Following the agentskills.io standard, a skill is just a folder: SKILL.md for instructions + metadata, with optional scripts, references, and assets.
We’re looking forward to collaborating on the standard so it’s easy to share and use skill across different tools.
You can install scripts for just yourself in (~/.codex/skills), or for everyone working on a project in (repo_path/.codex/skills).
We’ve also bundled a few handy system skills with Codex, such as plan, skill-creator, and skill-installer.
developers.openai.com/codex/skills
You can now get more Codex usage from your plan and credits with three updates today:
- GPT-5-Codex-Mini — a more compact and cost-efficient version of GPT-5-Codex
- 50% higher rate limits for ChatGPT Plus, Business, and Edu
- Priority processing for ChatGPT Pro and Enterprise
GPT-5-Codex-Mini allows roughly 4x more usage than GPT-5-Codex, at a slight capability tradeoff due to the more compact model.
Available in the CLI and IDE extension when you sign in with ChatGPT, with API support coming soon.
Select GPT-5-Codex-Mini for easier tasks or to extend usage when you’re close to hitting rate limits.
Codex will also suggest switching to it when you reach 90% of your limits, so you can work longer without interruptions.
Two big updates to the Responses API today.
- Connectors — Pull context from Gmail, Google Calendar, Dropbox, and more in a single API call.
- Conversations — Persist chat threads for your users, without running your own database.
More below:
Build rich experiences with connectors to:
- Read emails
- Fetch calendar events
- Search files and chats
Gmail, Google Calendar, Drive, Dropbox, Teams, Outlook Calendar + Email, and SharePoint are available now.
They work with deep research, too!
platform.openai.com/docs/guides/to…
Here’s a demo app that shows how you can connect your app to Google Calendar and fetch upcoming events: github.com/openai/openai-…
Six tips for coding with GPT-5:
Raindrop Workshop (GitHub Repo)
Raindrop Workshop, a new local debugger for AI agents, allows Claude Code to watch traces, write evaluations, and self-heal code.
Deep dive
- Raindrop Workshop is an open-source local debugger for AI agents.
- It offers livestreamed traces, showing every token, tool call, and decision an agent makes.
- It integrates with coding agents like Claude Code, Codex, Devin, Cursor, and OpenCode.
- A key feature is its "self-healing eval loop," where an agent can write an eval, run itself, detect failures, fix the code, and re-run until assertions pass.
- It supports local replay to debug production traces.
- Compatible with TypeScript, Python, Go, and Rust, and various AI SDKs (Vercel AI, OpenAI Agents, Anthropic, LangChain, etc.) and providers (AWS Bedrock, Azure OpenAI, Vertex AI).
- Installation is via a
curlcommand or building from source withbun. - The UI runs locally via
http://localhost:5899. - Licensed under MIT.
Decoder
- AI Agent: An artificial intelligence program designed to autonomously perform tasks by observing its environment, processing information, making decisions, and taking actions.
- Trace: A record of the sequence of operations, events, and data flows within a program or system, used for debugging and understanding execution.
- Eval loop: A process where an AI agent generates code, runs an evaluation or test against it, identifies errors, and then iteratively attempts to fix the code based on the evaluation feedback.
Original article
Full article content is not available for inline reading.

Igor Babuschkin Seeks Up To $1 Billion For River AI
Igor Babuschkin, an xAI cofounder, is raising up to $1 billion for his new AI research startup, River AI, committing $100 million of his own money.
Deep dive
- Igor Babuschkin, a cofounder of xAI, is launching a new AI research startup called River AI.
- He is reportedly seeking to raise up to $1 billion in funding, with a target valuation of up to $5 billion.
- Babuschkin is personally committing up to $100 million of his own capital.
- VC firm General Catalyst is in talks to lead the funding round.
- River AI was incorporated in Nevada on April 20, 2026.
- Forbes framed River AI as part of a trend of "neolabs" – researcher-led startups like Richard Socher's Recursive Intelligence and a venture by DeepMind alumnus David Silver.
- The article notes that these ventures often fund long-horizon research rather than immediate product launches.
- This trend intensifies competition for research talent and large-scale compute resources.
Decoder
- Neolab: A term used to describe a new generation of AI research laboratories, typically founded by prominent researchers, often well-funded and focused on long-term foundational AI research.
Original article
Full article content is not available for inline reading.

Nvidia's Jensen Huang bets on this British startup to build 'next frontier' of AI
Nvidia's Jensen Huang is partnering with David Silver's new British AI startup, Ineffable Intelligence, to develop "superlearners" using reinforcement learning on Nvidia's Grace Blackwell chips.
Decoder
- Reinforcement learning: A type of machine learning where an agent learns to make decisions by performing actions in an environment to maximize a reward, rather than being explicitly programmed or trained on labeled datasets.
Original article
Key Points
- Nvidia will partner with British startup Ineffable Intelligence to develop new AI systems, the companies announced in Wednesday.
- Unlike many leading AI models that are trained on human data, Ineffable is focusing on reinforcement learning, which is when AI models learn from experience.
- "The next frontier of AI is superlearners — systems that learn continuously from experience," said Jensen Huang, founder and CEO of Nvidia.
Nvidia has announced a partnership with an AI startup, just months after it was founded by a former top scientist at Google DeepMind.
Ineffable Intelligence, which is pursuing superintelligence and was founded in late 2025 by UCL professor and former lead of DeepMind's reinforcement learning team, David Silver, will enter into an engineering-level collaboration with the chip giant to build "AI systems that learn by trial and error," the company said on Wednesday.
The London-based company announced a record $1.1 billion seed round in April, co-led by U.S. venture capitalists Sequoia and Lightspeed, with participation from Nvidia, DST Global, Index, Google and the U.K.'s Sovereign AI Fund.
"The next frontier of AI is superlearners — systems that learn continuously from experience," said Nvidia CEO Jensen Huang.
He added: "We are thrilled to partner with Ineffable Intelligence to codesign the infrastructure for large-scale reinforcement learning as they push the frontier of AI and pioneer a new generation of intelligent systems."
'The next frontier of AI'
Unlike many leading AI models that are trained on human data, Ineffable Intelligence will focus on reinforcement learning, which is when AI models learn from experience.
"The system will train on rich forms of experience that are quite distinct from human language and other human data, and may require novel model architectures and training algorithms," the company said.
Nvidia and Ineffable will focus on building a pipeline that can feed reinforcement learning systems at scale, with engineers from both companies teaming up, it added. The work will use Nvidia's Grace Blackwell chips, alongside its Vera Rubin platform.
"Researchers have largely solved the easier problem of AI: how to build systems that know all the things humans already know," Silver said.
"But now we need to solve the harder problem of AI: how to build systems that discover new knowledge for themselves. That requires a very different approach — systems that learn from experience."
Next-gen AI labs
Ineffable is one of several new AI labs set up by former top researchers at Big Tech companies to launch in recent months, with investors funneling billions into the ventures.
On Wednesday, a months-old startup called Recursive Superintelligence — founded by former Google DeepMind engineer Tim Rocktäschel — announced it had raised to $650 million. AMI Labs announced a $1 billion raise in March, months after its founder, Yann LeCun, announced he was leaving his role as Meta's AI chief.
In the past year, former staff at OpenAI, DeepMind, Anthropic and xAI have also raised hundreds of millions from investors for months-old ventures, including AI labs Periodic Labs and Humans&.

OpenSquilla launches open-source AI agent to cut token costs
OpenSquilla launched an Apache-2.0 licensed open-source Python AI agent runtime, claiming 60-80% reduction in token costs through efficient context reuse and a four-tier cognitive memory architecture.
Decoder
- Token: The basic unit of data an LLM processes, typically a word, part of a word, or punctuation mark. The number of tokens directly impacts processing time and cost.
- Syscall-level sandbox isolation: A security mechanism that restricts an application's ability to make system calls, thereby limiting its access to the operating system's resources and preventing unauthorized actions.
- Bubblewrap/Seatbelt: Specific tools used for process isolation and sandboxing on Linux and macOS, respectively, to enhance security.
Original article
Full article content is not available for inline reading.
Apple-OpenAI Alliance Frays, Setting Up Possible Legal Fight
OpenAI is reportedly considering legal action against Apple, claiming their two-year partnership hasn't delivered expected subscriber growth and deeper app ecosystem integration.
Original article
OpenAI may be preparing legal action against Apple as it has failed to see the expected benefits from their two-year-old partnership. The startup has enlisted an outside legal firm to help with the situation. OpenAI had believed that the partnership would coax more users into subscribing to its services and had expected deeper integration into Apple's app ecosystem. It claims that Apple hasn't made an honest effort within the partnership. Apple is set to open up its platform to rival providers later this year.
Helix-02 robots now sustain full factory-style 8-hour shifts without intervention
Figure AI claims its Helix-02 humanoid robots can now autonomously perform eight-hour shifts, coordinating movement and manipulating objects in dynamic environments.
Decoder
- Proprioception: The sense of the relative position of one's own body parts and strength of effort being used in movement.
- Neural network: A computational model inspired by the structure and function of biological neural networks, used in machine learning for tasks like pattern recognition and decision-making.
- Long-horizon tasks: Complex tasks that involve multiple steps, sustained activity, and planning over an extended period, often requiring adaptability and problem-solving.
Original article
Figure AI claims that its humanoid robots can now run full eight-hour shifts autonomously. The company's Helix-02 system allows humanoid robots to walk, manipulate objects, balance, and coordinate movement continuously using onboard sensors. It supports multi-robot collaboration. The unified neural network combines vision, touch, proprioception, and whole-body control into a single learning system designed for long-horizon tasks in dynamic environments. It enables robots to complete multi-minute tasks without resets or human intervention.
The ultimate guide to /goal
The `/goal` feature, which defines a "done state" for coding agents to work towards, has been integrated into OpenAI's Codex CLI and Claude Code.
Decoder
- Primitive (in programming): A fundamental, basic building block or operation that cannot be broken down into simpler parts within a given system.
- Coding agents: AI systems designed to assist or autonomously perform programming tasks, such as writing code, debugging, or refactoring.
- OpenAI's Codex CLI: A command-line interface tool that provides access to OpenAI's Codex model, which can translate natural language into code.
- Claude Code: A coding-focused version or feature of Anthropic's Claude AI model.
Original article
/goal is becoming a primitive for coding agents. The feature gives coding workers jobs with a defined done state. With /goal, users write down what 'done' looks like, and agents work towards it until it gets there. The feature appeared in OpenAI's Codex CLI a few weeks ago, and Claude Code just added it this week.
fate (GitHub Repo)
fate is a new React data client inspired by Relay and GraphQL, offering view composition, normalized caching, data masking, and type-safe data fetching with a minimal API.
Deep dive
- fate is a modern data client for React, inspired by Relay and GraphQL, designed for composable, declarative, and predictable data fetching and state management.
- It combines view composition, a normalized cache, data masking, Async React features (Actions, Suspense, use), and type-safe data fetching.
- Components declare their data requirements using co-located "views," which are then composed into a single network request per screen to minimize requests and eliminate waterfalls.
- The framework maintains a normalized cache, enabling efficient data updates, optimistic updates for mutations, and live view updates via Server-Sent Events.
- fate enforces strict data selection for each view and masks (hides) data not explicitly requested, preventing accidental coupling and reducing overfetching.
- It is built with just JavaScript, has a minimal API, and no DSL, distinguishing itself from GraphQL which requires its own type system and query language.
- The project aims to provide GraphQL/Relay ergonomics (fragments co-located with components, normalized cache, compiler for hoisting fragments) for developers using tRPC or other type-safe RPC frameworks.
- fate requires React 19.2+ and is currently in alpha, not production-ready.
- Developers can start with
vp create fate my-appusing templates for Void app with Drizzle, tRPC with Drizzle, or tRPC with Prisma.
Decoder
- Relay: A JavaScript framework for building data-driven React applications, developed by Facebook, that uses GraphQL for data fetching.
- GraphQL: A query language for APIs and a runtime for fulfilling those queries with your existing data.
- Normalized cache: A data caching strategy where each unique entity (e.g., a
UserorPost) is stored once in a single, consistent location, and references to these entities are used throughout the application. This prevents data duplication and simplifies updates. - Data masking: In the context of
fate, it refers to the practice of preventing components from accessing data fields that they did not explicitly request in their view definition. - Async React features: Modern features in React, such as
Suspenseanduse, that facilitate asynchronous operations and concurrent rendering, allowing components to "suspend" rendering while waiting for data or other async work. - DSL (Domain-Specific Language): A specialized computer language designed for a particular application domain.
- tRPC: A TypeScript framework for building end-to-end type-safe APIs without GraphQL or REST.
Original article
Full article content is not available for inline reading.
Programming languages used to be LOCK IN
Simon Willison notes that programming languages are losing their "lock-in" effect, enabling easier migration, exemplified by Bun moving from Zig to Rust and AI-driven rewrites to React Native.
Decoder
- Coding agent: An AI system capable of generating, modifying, or refactoring code based on specifications or existing codebase analysis, often autonomously or semi-autonomously.
Original article
Full article content is not available for inline reading.
A few words on DS4
The DwarfStar 4 project will prioritize quality benchmarks, local CI, more ports, and distributed inference for better performance.
Decoder
- DwarfStar 4 (DS4): An unspecified project (likely an open-source initiative based on antirez.com context, potentially related to AI or a database given antirez is Salvatore Sanfilippo, creator of Redis). It focuses on distributed inference and quality benchmarks.
- Continuous Integration (CI): A software development practice where developers frequently integrate their code into a shared repository, after which automated builds and tests are run.
- Distributed inference: The process of running an AI model's prediction phase across multiple computational devices or machines to handle large workloads or improve latency.
Original article
The DwarfStar 4 project will focus on quality benchmarks, potentially adding a coding agent, a local hardware setup that can run CI tests to ensure long-term quality, more ports, and distributed inference (both serial and parallel).

Bitcoin trader recovers $400,000 using Claude AI after getting 'stoned' and losing wallet password 11 years ago
A Bitcoin trader recovered $400,000 worth of BTC, lost for 11 years, by using Anthropic's Claude AI to find and decrypt an old wallet backup.
Deep dive
- X user cprkrn lost access to 5 Bitcoin, currently valued at almost $400,000, 11 years ago after changing the wallet password while impaired.
- They had been trying to recover the wallet using the open-source tool
btcrecoverwithout success. - After finding an old mnemonic seed phrase that confirmed the wallet's identity, cprkrn dumped their entire college computer files into Anthropic's Claude AI.
- Claude successfully identified an older wallet backup file from December 2019.
- Crucially, Claude discovered a bug in how
btcrecoverwas combining shared keys and passwords, which was preventing previous recovery attempts. - Once this configuration issue was resolved, Claude was able to decrypt the private keys using
btcrecover, allowing the user to transfer the BTC. - This highlights AI's capability to find hidden files and diagnose subtle software configuration problems within large, unstructured datasets.
Decoder
- Mnemonic seed phrase: A list of words that stores all the information needed to recover a cryptocurrency wallet.
- HD key tree (Hierarchical Deterministic key tree): A system where a single seed phrase can generate a tree of keys for multiple cryptocurrency addresses.
- btcrecover: An open-source tool used for recovering lost Bitcoin wallet passwords.
Original article
Full article content is not available for inline reading.

Introducing Prempti: Runtime security for AI coding agents, powered by Falco
Prempti is an open-source security tool using Falco to intercept and evaluate AI coding agent actions in real-time, preventing sensitive file access or risky commands.
Deep dive
- Prempti is an open-source security tool for AI coding agents.
- Uses Falco's real-time detection engine.
- Intercepts agent tool calls before execution.
- Evaluates actions against Falco rules.
- Offers "Allow," "Deny," or "Ask" verdicts for agent actions.
- Protects sensitive paths like ~/.ssh/.
- Prevents credential theft, prompt injection, unauthorized network calls.
- Runs as a lightweight user-space service, no root or kernel modules needed.
- Default rules cover working-directory boundaries, sensitive path protection, destructive commands.
- Can operate in "guardrails" (enforce) or "monitor" mode.
- Rules are defined in YAML.
- Includes a Claude Code skill for drafting and validating custom rules.
- Developed by Sysdig, Director of Open Source and Technical Marketing Jonas Rosland.
Decoder
- Falco: An open-source cloud-native runtime security project that detects abnormal behavior in applications and containers.
- Prompt injection: A type of vulnerability in large language models where malicious input can override or manipulate the intended behavior of the AI.
Original article
Full article content is not available for inline reading.

Ship code within minutes with the Gemini CLI DevOps Extension
Google's Gemini CLI DevOps Extension streamlines AI-assisted code deployment, enabling conversational CI/CD pipeline generation and secure infrastructure provisioning across Google Cloud services.
Deep dive
- Gemini CLI DevOps Extension bridges local AI-assisted development (inner loop) and production deployment (outer loop).
- Introduced by Karl Weinmeister, Director, Developer Relations at Google.
- Supports Gemini CLI, Claude Code, and Antigravity.
- Uses specialized AI skills (e.g.,
google-cicd-deploy), a Go-based Model Context Protocol (MCP) server for Google Cloud manipulation, and a local RAG knowledge base of architecture patterns. - For "inner loop" deployments, it allows natural language prompts to deploy to Cloud Run or Cloud Storage.
- Performs pre-deployment security scans for leaked secrets (e.g., Stripe API keys) using "shift-left security."
- Automatically analyzes applications (e.g.,
package.json) and containerizes them using Google Cloud buildpacks if no Dockerfile exists. - Asks clarifying questions (e.g., region, public access) before deployment.
- For "outer loop" (production), it generates Cloud Build pipelines and provisions infrastructure (e.g., Artifact Registry, GitHub connections) conversationally.
- Ensures security by operating within local Application Default Credentials (ADC) permissions and using verifiable MCP tools.
- Emphasizes least privilege for local ADCs and service accounts.
Decoder
- Inner loop: The rapid, local cycle of writing, testing, and debugging code during development.
- Outer loop: The processes involved in building, testing, deploying, and monitoring code in production environments, typically involving CI/CD pipelines.
- Model Context Protocol (MCP): A protocol used by AI agents to interact with tools and services in a structured, verifiable way.
- Retrieval-Augmented Generation (RAG): An AI technique that combines information retrieval with text generation, allowing a language model to augment its responses with factual data from an external knowledge base.
Original article
Full article content is not available for inline reading.

Building an end-to-end agentic SRE using AWS DevOps Agent
AWS DevOps Agent enables autonomous SRE workflows by correlating telemetry across CloudWatch, Splunk, and GitHub to investigate incidents, generate mitigation plans, and provide agent-ready remediation specs.
Deep dive
- AWS DevOps Agent is a frontier agent for autonomous SRE workflows.
- Investigates incidents, identifies root causes, and recommends mitigation plans without constant human intervention.
- Supports multi-cloud and hybrid environments.
- Architecture involves Demo Application, Splunk, and AWS DevOps Agent accounts.
- Integrates with Amazon CloudWatch (alarms), Amazon EventBridge, AWS Lambda (webhook handler), Splunk (log aggregation), GitHub (deployment history), and Slack (communication).
- Incident flow: CloudWatch alarm -> EventBridge -> Lambda -> DevOps Agent webhook.
- Agent queries Splunk logs via MCP, retrieves GitHub deployment history, correlates CloudWatch metrics.
- Generates detailed mitigation plans with remediation steps, success criteria, and rollback procedures.
- Communication via Slack, providing updates and root causes to on-call engineers.
- Uses "DevOps Agent Spaces" to define investigation scope and tool access.
- Webhooks secured with HMAC.
- Splunk integration requires enabling Splunk MCP Server and using Better Webhooks for alerts.
- GitHub integration provides read-only access and deployment events correlation.
- DevOps Agent Skills (Markdown instructions) guide investigations and use of telemetry sources.
- Produces "agent-ready specs" for coding agents like Kiro to implement code-level fixes.
Decoder
- Agentic SRE: An approach to Site Reliability Engineering (SRE) that leverages AI agents to autonomously perform tasks like incident investigation, root cause analysis, and remediation, reducing human intervention.
- Mean Time To Resolution (MTTR): A metric used to measure the average time it takes to resolve an incident from its detection to full restoration of service.
- Model Context Protocol (MCP): A protocol used by AI agents to interact with tools and services in a structured, verifiable way.
- Kiro: An example of a coding agent mentioned in the article that can consume "agent-ready specs" to implement code changes for remediation.
Original article
Full article content is not available for inline reading.
Shell Tool Testing
The `prove` command and Test Anything Protocol (TAP) offer a lightweight, language-agnostic way to test Unix shell tools without heavy frameworks, simplifying test suite management.
Deep dive
- Automated testing is crucial for shell tools and Kakoune plugins.
- Many shell script test harnesses exist, but often require third-party libraries.
provecommand (from Perl ecosystem) is a language-agnostic test runner.proveis similar to Python'sunittestbut works with any language outputting TAP.- Test Anything Protocol (TAP) is a plain-text, human-readable format for test results (e.g.,
ok N - description,not ok N - description). - TAP includes
TAP version Xand1..N(total tests expected). - By default,
provelooks fort/*.tfiles; can be configured via.provercto use--ext testfort/*.testfiles. - Tests should be isolated using temporary directories created with
mktemp -dand cleaned up withrm -rf. - A shared
common.shscript can provide helper functions likereport_okandreport_not_okto automate test numbering and TAP output. common.shcan also handle bailouts (stopping on first failure), strict mode checks, and capturing stdout/stderr.
Decoder
prove: A command-line utility from the Perl ecosystem used to discover, run, and summarize test results in various formats, notably TAP.- Test Anything Protocol (TAP): A simple, human-readable, line-based text format for reporting test results, commonly used for automated testing.
mktemp -d: A Unix command that securely creates a unique temporary directory.common.sh: A common practice in shell scripting for a shared script to include reusable functions and setup for a test suite.
Original article
Full article content is not available for inline reading.
Agent pull requests are everywhere. Here's how to review them
Agent-generated pull requests, while appearing clean, often introduce subtle redundancy and technical debt, demanding focused human review on CI integrity, logic paths, and security vulnerabilities.
Deep dive
- AI agent-generated pull requests are becoming common.
- Often appear "cleaner" and pass tests, but can introduce subtle issues.
- Issues include duplicated utilities, unnecessary code, and increased technical debt.
- Human judgment and contextual review are more critical than ever.
- Review Focus Areas:
- Block weakened CI: Ensure agents don't remove or simplify critical tests.
- Catch duplicated utilities: Agents might not be aware of existing helper functions.
- Trace critical logic paths: Understand how agents modify core application behavior.
- Validate security boundaries: Scrutinize LLM workflows for prompt injections or data exfiltration risks.
- Require scoped changes with failing pre-change tests: Ensure agent changes are targeted and address a specific, demonstrable problem.
- The article is authored by Andrea Griffiths, Senior Developer Advocate at GitHub.
Decoder
- Agent-generated pull requests: Code changes proposed and submitted to a version control system (like Git) by an artificial intelligence agent rather than a human developer.
- CI (Continuous Integration): A software development practice where developers frequently integrate their code into a shared repository, with each integration verified by automated builds and tests.
- LLM (Large Language Model): An artificial intelligence model trained on vast amounts of text data to understand and generate human-like language.
Original article
Full article content is not available for inline reading.
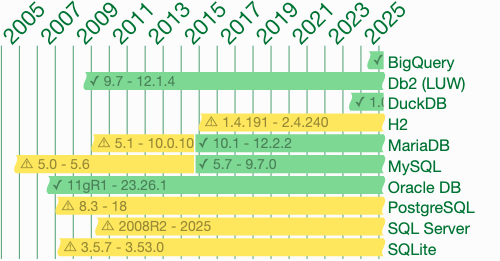
Order by Has Come a Long Way
SQL's `ORDER BY` clause has significantly evolved to support non-selected columns and expressions, making it more flexible, and users should prioritize execution plans over simplistic "filter early" advice.
Deep dive
ORDER BYwas initially highly restricted in SQL, only allowing references to selected columns, no expressions, no explicit null ordering, and only as the last clause.- SQL:1999 significantly expanded
ORDER BYto allow non-selected columns and arbitrary expressions. To achieve this, the standard specifies a "syntactic transformation" where the database engine internally adds the non-selected column to theSELECTlist and then removes it from the final result. - SQL:2003 introduced explicit
NULLS FIRST | LASTordering, as the default placement of null values was previously implementation-defined. - SQL:2008 allowed
ORDER BYwithin subqueries, primarily to support clauses likeFETCH FIRST(similar toLIMITorTOP) for truncating results. - The article highlights three distinct "orders" in SQL: syntactic (how clauses are written), logical (how the standard defines evaluation), and actual execution (what the database engine truly does).
- It strongly advises against applying generalized performance mantras like "filter early" to syntactical or logical order, stressing that database engines have optimized push-down filtering for decades.
- Developers should examine the actual execution plan generated by their database to understand and optimize query performance, rather than relying on oversimplified infographics.
Original article
Full article content is not available for inline reading.

Inventing a New Programming Language for Web Development Was a Mistake
Wasp, a full-stack web framework startup, admits its custom DSL was a mistake, citing developer adoption friction and tooling headaches, and is now migrating to a TypeScript SDK.
Deep dive
- Wasp, founded in 2021 by Matija Sosic and his twin brother, and backed by Y Combinator with over $5 million, aimed to build a full-stack web framework for JavaScript (React, Node.js, Prisma) that abstracted common web app patterns.
- The founders initially decided to create a new domain-specific language (DSL) to achieve a high-level, stack-agnostic specification of app requirements, believing it would offer cleaner syntax and runtime independence.
- After five years, Wasp is abandoning its custom DSL, recognizing it was a mistake that created significant friction for developer adoption.
- Key issues included developers misinterpreting "wasp-lang" as a JavaScript replacement, skepticism about IDE and tooling compatibility, and the unexpectedly high cost and difficulty of developing robust tooling for a custom language.
- The team realized Wasp's core value was its ability to maintain a high-level, compile-time understanding of the entire full-stack application, which proved more important than the specific language used for definition.
- Wasp is transitioning to a TypeScript SDK as the primary interface, which leverages existing tooling, is familiar to developers, and still allows for the same deep application understanding.
- The article suggests a renewed interest in opinionated, full-stack frameworks like Django, Rails, and Laravel, and that Wasp aims to provide a similar "it just works" experience for the JS ecosystem, particularly noting its compatibility with AI code generation.
Decoder
- DSL (Domain-Specific Language): A programming language or specification language designed to be highly specialized for a particular application domain, offering concise syntax and abstractions for that specific area.
Original article
Full article content is not available for inline reading.

Origin Lab Raises $8M to Help Video Game Companies Sell Data to World-model Builders
Origin Lab secured $8 million in seed funding to build a marketplace connecting video game companies with AI labs needing data to train physical "world models."
Decoder
- World models: AI models designed to understand how the physical world works, how objects move, and interact, used for tasks like robotics or physical simulation, contrasting with text-based language models.
- AMI Labs: An AI research lab associated with Yann LeCun, focused on advancing AI understanding and capabilities.
- World Labs: An AI research initiative, possibly associated with Fei-Fei Li, focused on AI that interacts with and understands the physical world.
Original article
Full article content is not available for inline reading.

What the Design-to-code Loop Unlocks
Figma's new Codex integration enables a "design-to-code loop" by allowing live UIs to be imported, refined collaboratively, and exported back to Codex with design context.
Decoder
- Codex: A tool or platform that integrates with Figma, likely for frontend development, facilitating the conversion of designs into code or vice versa.
Original article
Full article content is not available for inline reading.
10 Common Component Architecture Mistakes in Figma Design Systems
An article from zeroheight.com details ten common Figma component architecture mistakes, like over-using variants and misusing shapes, that can degrade design system quality.
Deep dive
- The article identifies 10 common mistakes that undermine Figma design systems.
- Over-reliance on "variant properties" can make components complex and costly.
- Misusing shapes instead of "frames" leads to poor responsiveness and layout issues.
- Not using "auto layout" effectively hinders flexible and scalable component design.
- Improperly scoped state properties can cause inconsistencies across component states.
- Lack of clear naming conventions makes systems hard to navigate and use.
- Not leveraging "variables and modes" for design tokens leads to manual updates.
- Ignoring the "slots" pattern makes components less flexible for content injection.
- Neglecting documentation for component usage and guidelines.
- Creating overly complex components instead of simpler, composable ones.
- Failing to audit and refactor existing components as the system evolves.
- Implementing fixes like better use of auto layout, variables, and proper state management can significantly improve design system quality.
Decoder
- Figma variants: A feature in Figma that allows designers to combine multiple versions of a component into a single, organized component set, making it easier to manage different states or styles (e.g., primary button, secondary button).
- Figma frames: A container element in Figma used for structuring layouts and creating responsive designs, distinct from basic shapes like rectangles.
- Auto Layout (Figma): A feature in Figma that automatically adjusts the size and position of layers within a frame based on its content, making components responsive and easier to maintain.
- Figma variables and modes: New features in Figma that allow designers to define reusable values (like colors, spacing) as variables and apply different sets of these variables (modes) to design mockups, facilitating dark mode or different theme implementations.
- Slots (Figma design systems): A design pattern where a component has designated "empty" areas (often represented by placeholder components) that can be filled with other components or content, making the parent component more flexible and reusable without creating endless variants.
Original article
Ten common Figma component architecture mistakes — from over-using costly variant properties to misusing shapes instead of frames — can quietly erode design system quality and user trust. Fixes include adopting slots, variables and modes, auto layout, and properly scoped state properties. Understanding each feature's constraints and tradeoffs leads to sharper decisions and components built to last.
Many modern AI products fail user onboarding by relying on blank prompt boxes, hindering adoption by forcing users to invent workflows without guidance.
Deep dive
- Many AI products default to a blank prompt box for user initiation.
- This "empty state" design paradigm replaces decades of traditional UX onboarding.
- Traditional UX typically provides context, guidance, and clear starting points for users.
- The blank prompt box forces users to invent prompts and workflows without prior understanding of the tool's capabilities.
- This lack of guidance often leads to increased first-session drop-off rates as users become frustrated.
- Better onboarding would include worked examples, clear starting actions, and visible product limitations.
- Interactive guidance is needed to help users achieve quick, early success and understand core functionalities.
- The goal is to provide immediate value before users need to master complex prompting or the tool's intricacies.
- This design oversight can significantly hinder broader adoption and user satisfaction with new AI tools.
Original article
Many modern AI products rely on a blank prompt box as their main onboarding experience, replacing decades of UX practices that traditionally helped users understand what a product could do and how to start using it effectively. This approach often increases first-session drop-off because users are asked to invent prompts and workflows before they have any context, forcing them to think harder instead of guiding them toward quick success. A better AI onboarding experience would use worked examples, clear starting actions, visible limitations, and interactive guidance that helps users achieve something useful before needing to master prompting.

The Star Fox Controversy Shows How Easy it is to Overdesign a Beloved Character
Nintendo fans criticize the new Star Fox 64 remake for Switch 2, arguing its more realistic character designs sacrifice original charm and identity for improved graphics.
Original article
Full article content is not available for inline reading.

OpenAI Explores Legal Action Against Apple
OpenAI is reportedly exploring legal action against Apple, citing dissatisfaction with ChatGPT's "buried" integration within iOS and failure to meet subscriber growth projections from their June 2024 partnership.
Original article
Full article content is not available for inline reading.

Elon Musk's SpaceXAI has been bleeding staff since its merger
Elon Musk's SpaceXAI has lost over 50 top researchers and engineers, including key leaders, since its February merger, with staff reportedly fleeing due to an intense work culture and doubts about its model development.
Deep dive
- SpaceXAI, formerly xAI, has experienced over 50 departures of researchers and engineers since its merger in February 2026.
- Key leaders across coding, world models, and Grok voice have left.
- At least 11 xAI employees defected to Meta and at least seven to Mira Murati's Thinking Machines Lab.
- The core pre-training team has reportedly dwindled to a handful of people, raising concerns about the company's commitment to developing leading AI models.
- Exits are partly attributed to Elon Musk's culture of extreme work and unrealistic deadlines, which led to cutting corners on Grok development.
- Some departures may also be driven by employees wanting to cash out vested shares or seeking liquidity ahead of potential IPOs.
- The article questions SpaceXAI's ability to develop leading models given the significant loss of talent.
Decoder
- Pre-training: The initial phase of training a large language model on a massive dataset, where it learns general language understanding and generation capabilities before any specific fine-tuning.
- World models: AI models designed to learn a predictive representation of their environment, allowing agents to plan and reason more effectively.
Original article
Full article content is not available for inline reading.
Work with Codex from anywhere
OpenAI has integrated its AI coding assistant, Codex, into the ChatGPT mobile app, allowing developers to access their work from anywhere.
Original article
Codex is now available in the ChatGPT mobile app, enabling seamless remote access to ongoing work on laptops, devboxes, or remote environments.
Netflix Staffing for ‘INKubator' AI-Powered Experimental Animation Studio
Netflix launched "INKubator," an artist-led animation studio to explore experimental GenAI-native production pipelines for animated shorts and specials.
Decoder
- GenAI-native production pipelines: Workflows and tools specifically designed to leverage generative AI from the ground up in the content creation process.
Original article
Netflix's INKubator is an artist-led animation incubator that provides creators with an artist-focused environment to experiment in. It allows artists to explore how new tools and workflows can be leveraged to enhance their storytelling capabilities alongside traditional animation creative processes. The studio launched quietly in March. It will focus on creating animated shorts and specials using experimental GenAI-native production pipelines.

The great memory panic of 2026
Apple could exploit a projected 2026 memory shortage, pushing device bill of materials from 15% to 40% for rivals, potentially eliminating marginal competitors and increasing its market share.
Decoder
- Bill of materials (BOM): A comprehensive list of raw materials, components, and instructions needed to manufacture a product.
Original article
Full article content is not available for inline reading.
Amazon Leo aims to double its pace as it gets set to roll out its satellite broadband network
Amazon is accelerating the deployment of its Project Kuiper satellite broadband network, Amazon Leo, as its launch approaches.
Decoder
- Project Kuiper: Amazon's low Earth orbit (LEO) satellite broadband network initiative, designed to provide high-speed, low-latency internet to unserved and underserved communities worldwide.
Original article
The official launch of Amazon Leo isn't that far away.
Amazon Route 53 Resolver endpoints now support additional capabilities for IPv6 query traffic
Amazon Route 53 Resolver now supports DNS64 on inbound endpoints for IPv6-only clients and IPv6 forwarding on outbound endpoints, easing hybrid IPv4/IPv6 network communication on AWS.
Decoder
- DNS64: A mechanism that synthesizes AAAA (IPv6) records for domains that only have A (IPv4) records, enabling IPv6-only clients to communicate with IPv4 services.
Original article
Full article content is not available for inline reading.
iOS 27's new design leak sounds a lot like what I've been wanting most
Leaks suggest iOS 27 will refine Apple's "Liquid Glass" design, potentially bringing back permanently visible tab bars and integrating search into the main navigation for improved usability.
Decoder
- Liquid Glass design: Apple's modern iOS design language, characterized by transparency, depth, and fluid animations.
Original article
iOS 27 will introduce broader refinements to Apple's Liquid Glass design, including redesigned tab bars, new animations, and updates to apps like Safari and Siri, with one potentially major usability improvement: Apple may stop collapsing tab bars while scrolling. iOS 26's minimized tab bars in apps like Music, Photos, and Podcasts make navigation slower by requiring extra taps. Reintegrating search back into the main tab bar—already seen in the App Store and Games apps—strongly suggests Apple is responding to criticism and restoring permanently visible navigation across iOS 27.
Productivity Hacks for Designers in 2026
Designers in 2026 need to master a blend of skills, using productivity hacks like personal component libraries, time-boxing, and AI note-taking to manage diverse responsibilities.
Original article
Being a UX designer in 2026 requires juggling multiple skills, including product design, AI tools, strategy, presentations, networking, portfolio building, and content creation. Key productivity hacks include building a personal component library before you need it, using proper file naming conventions, time-boxing exploration to 90 minutes, making critiques asynchronous by default, and using AI note-taking apps to handle meeting documentation. These strategies help designers avoid repetitive work, improve organization, and focus on actual design decisions rather than administrative tasks.
The thinking was never just mine
AI tools like Anthropic's Claude are reframing human creativity by acting as rapid iteration partners, making the collaborative nature of idea generation unusually visible.
Original article
AI tools like Anthropic's Claude can function more like rapid iteration partners than answer machines, helping people explore and refine ideas far faster than they could alone. Creativity has likely always been shaped by outside influences — conversations, books, criticism, memories, and culture — but AI makes that process unusually visible through prompts and chat histories. What ultimately makes an idea feel “yours” may not be pure originality, but the judgment behind it: the consistent pattern of choices, refinements, rejections, and instincts that shape the final outcome.
Product Design with AI - It's not witchcraft, so you still need to know YOUR craft
AI is lowering barriers to product creation but risks generating fragile systems, making deep product and UX design skills more critical than ever.
Original article
AI is lowering the barrier to building products, but also making it easier for people to create systems they don't fully understand, leading to polished but fragile apps, workflows, and experiences. Rather than replacing product and UX design, this shift may make those disciplines more important, since the real challenge is no longer shipping quickly but building products that are coherent, trustworthy, and genuinely useful. AI works best as a tool that amplifies existing expertise — helping with repetitive tasks, research synthesis, documentation, and workflows. Speed alone has never guaranteed success. Blindly using AI without understanding simply allows teams and individuals to fail faster.

Image to Video AI Generator Online (Website)
ImageToVideoAI is an online platform that uses AI models like Seedance 2 and Grok Imagine to transform static images into professional-quality videos, offering creative control via text prompts.
Original article
Full article content is not available for inline reading.
Tey Bannerman on Why AI Strategy is the New Essential Skill for Design Leaders
Tey Bannerman, a former McKinsey partner, is launching an "AI Strategy for Design Leaders" course on June 18, emphasizing a shift from pixel production to strategic thinking in the AI era.
Original article
Design leadership in the AI era demands a shift from pixel production to strategic thinking. As AI compresses the production layer of design, human skills like ethical judgment, contextual understanding, and systems thinking become the true differentiators. To address this gap, Tey Bannerman, former McKinsey partner and software engineer, is leading "AI Strategy for Design Leaders," a new course launching June 18 structured as three 90-minute live online modules culminating in a personalized 30-day action plan.

Daniel Craig's design input on a James Bond poster has sparked a heated debate
A resurfaced photo of Daniel Craig giving feedback on the 2006 Casino Royale poster has reignited debate on whether non-designers should influence professional graphic design decisions.
Original article
Full article content is not available for inline reading.
Onboarding in the AI Era: My First 100 Days at Ramp
At fast-paced companies like Ramp, new employees must quickly adapt to a weekly shipping cadence or risk becoming a burden.
Original article
Ramp is a fast company that ships every week - employees must match the pace, or they'll become a tax on it.

IKEA PS 2026: A Celebration of Playful Functionality
IKEA's 10th experimental PS 2026 collection features 12 designers creating "playful functionality" furniture for compact living, led by Maria O'Brian.
Decoder
- IKEA PS collection: A recurring experimental collection from IKEA, launched in 1995 as an acronym for post scriptum, featuring innovative and accessible designs outside their standard catalog.
Original article
IKEA PS 2026 marks the tenth edition of IKEA's experimental collection, featuring 12 designers who created "talking" objects that combine playful functionality with joy. The collection focuses on compact living solutions where every piece must be both entertaining and practical, challenging the notion that simplicity equals boredom. Led by Maria O'Brian, the designers developed furniture with descriptive names that reflect interactive features like folding, clicking, and transforming to maximize small spaces.
5,000+ Free Brand SVG Icons (Website)
thesvg.org offers over 5,000 free, open-source brand SVG icons, providing a quick way for developers and designers to search and implement common brand assets.
Original article
Search, copy, and ship brand icons in seconds. Free, open-source, and community-driven.

ASCII Wireframe Editor (Website)
Mockdown is a free browser-based ASCII wireframe editor that lets users quickly create UI mockups and lo-fi prototypes using drag-and-drop components.
Original article
Mockdown is a free browser-based ASCII wireframe editor that allows users to create UI mockups, lo-fi prototypes, and text diagrams.

Masterful Storytelling Through Color And Light: The Captivating Character Designs Of Tiago Calliari
Brazilian visual development artist Tiago Calliari, known for his work with DreamWorks Animation, showcases masterful storytelling through color and light in his character designs.
Original article
Full article content is not available for inline reading.

Designers can transition from executors to trusted creative leads by proactively expanding small briefs into larger strategic ideas, showcasing capabilities beyond initial client expectations.
Original article
Full article content is not available for inline reading.