Devoured - May 20, 2026
Google announced Gemini 3.5 Flash, a new AI model optimized for agentic workflows and coding, available immediately across its products and platforms.

Gemini 3.5 Flash
Google launched Gemini 3.5 Flash, a new agentic and coding model available immediately, boasting 4x faster performance at less than half the cost of competing frontier models.
Deep dive
- Gemini 3.5 Flash is Google's newest model, designed for agentic workflows, coding, and long-horizon tasks.
- It is available immediately via the Gemini app, AI Mode in Google Search, Google Antigravity, and Gemini API.
- The model demonstrates frontier performance on agentic and coding benchmarks like Terminal-Bench 2.1 (76.2%), GDPval-AA (1656 Elo), and MCP Atlas (83.6%).
- It is 4 times faster than other frontier models in output tokens per second and offers frontier-level intelligence at less than half the cost.
- Enterprise partners like Shopify, Macquarie Bank, Salesforce, Ramp, Xero, and Databricks are already piloting or using it for various automation tasks, from forecasting to document processing.
- It powers new consumer features such as Gemini Spark, a personal AI agent running 24/7, and enhanced generative UI experiences in Search.
- The model was developed following Google's Frontier Safety Framework, with strengthened cyber and CBRN safeguards and advanced safety training.
- Gemini 3.5 Pro is in internal use and planned for release next month.
Decoder
- Agentic workflow: An AI system capable of breaking down complex goals into smaller steps, executing them autonomously, and iterating on its approach to achieve a long-term objective.
- Long-horizon task: A complex task that requires multiple steps, planning, and often iteration over an extended period to complete.
Original article
Gemini 3.5: frontier intelligence with action
Gemini 3.5 is built to help you execute complex, agentic workflows.

Today, we’re introducing Gemini 3.5, our latest family of models combining frontier intelligence with action. This represents a major leap forward in building more capable, intelligent agents. We’re kicking off the series by releasing 3.5 Flash. It delivers frontier performance for agents and coding, excelling at complex long-horizon tasks that deliver real-world utility.
3.5 Flash is available today to billions of people globally:
- For everyone via the Gemini app and AI Mode in Google Search
- For developers in our agent-first development platform Google Antigravity and Gemini API in Google AI Studio and Android Studio
- For enterprises in Gemini Enterprise Agent Platform and Gemini Enterprise.
We’re also hard at work on 3.5 Pro. It's already being used internally, and we look forward to rolling it out next month.
3.5 Flash: frontier performance for agents and coding
Gemini 3.5 Flash delivers intelligence that rivals large flagship models on multiple dimensions, at the speeds you have come to expect from the Flash series. It’s our strongest agentic and coding model yet, outperforming Gemini 3.1 Pro on challenging coding and agentic benchmarks like Terminal-Bench 2.1 (76.2%), GDPval-AA (1656 Elo) and MCP Atlas (83.6%), and leading in multimodal understanding (84.2% on CharXiv Reasoning). When looking at output tokens per second, it is 4 times faster than other frontier models.
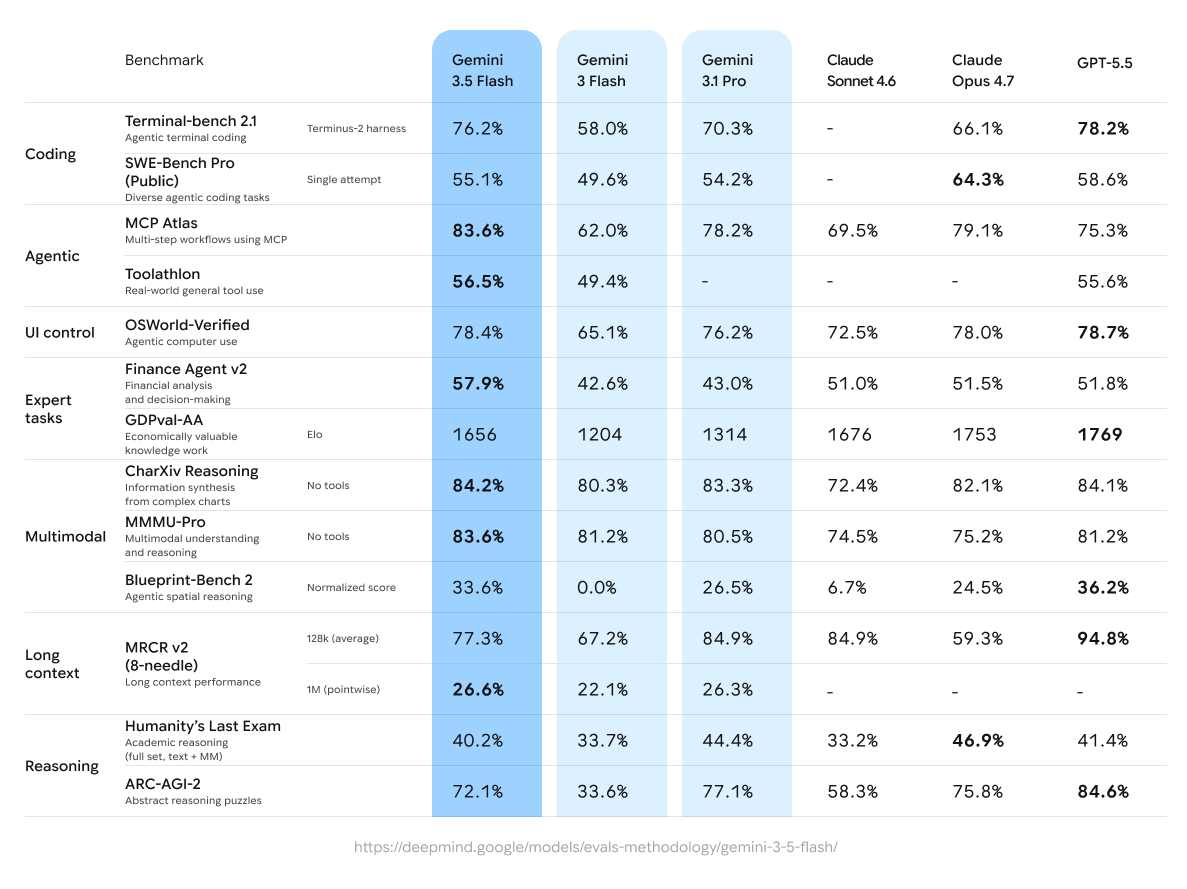
Landing in the top-right quadrant of the Artificial Analysis index, 3.5 Flash delivers frontier-level intelligence at exceptional speed — proving you no longer have to trade quality for latency.

3.5 Flash: agentic tasks at scale
This balance of speed and performance makes 3.5 Flash ideal for tackling long-horizon agentic tasks. What used to take a developer days or an auditor weeks, 3.5 Flash can now help complete in a fraction of the time, often at less than half the cost of other frontier models. It rapidly plans, builds and iterates to solve real-world problems, whether it’s developing new applications, maintaining codebases or helping to prepare financial documents.
When coupled with the updated Antigravity harness, 3.5 Flash becomes a powerful engine for deploying collaborative subagents to tackle problems at scale for the most demanding use cases. Under supervision, it can reliably execute multi-step workflows and coding tasks while sustaining frontier performance.
Powered by Antigravity, 3.5 Flash executes multi-step workflows to automatically rename and categorize unstructured assets based on dynamic criteria.
Leveraging Antigravity, 3.5 Flash uses two agents to synthesize the AlphaZero paper and code a fully playable game in six hours.
3.5 Flash uses the Antigravity harness to transform a messy legacy codebase to Next.js.
3.5 Flash uses subagents to create new city landscapes in Antigravity.
3.5 Flash uses two agents: a builder and a player, working in a rapid self-improvement loop to develop a game in Antigravity.
Building on the strong multimodal foundation of Gemini 3, 3.5 Flash generates richer, more interactive web UIs and graphics.
3.5 Flash creates interactive animations for a research paper on AI Studio.
3.5 Flash turns a plain text description into interactive hardware on AI Studio.
3.5 Flash executes multiple concepts in parallel to build a full branding concept for a school fundraiser on AI Studio.
3.5 Flash generates different UX approaches for a checkout flow in just 60 seconds on AI Studio.
3.5 Flash: real-world impact
3.5 Flash’s real-world agentic capabilities are already driving meaningful progress for our developers and enterprises alike. In developing the 3.5 model series, we worked closely with industry partners to understand where toil and complexity arose in their workflows. Partners are seeing meaningful impact — from banks and fintechs automating multi-week workflows to data science teams unearthing insights amidst complex data environments.
Shopify is running subagents in parallel to analyze complex data over a long horizon for more accurate merchant growth forecasts at a global scale.
Macquarie Bank is piloting how 3.5 Flash can accelerate customer onboarding by reasoning over complex 100+ page documents, retrieving relevant information and making reliable recommendations with low latency.
Salesforce is integrating 3.5 Flash into Agentforce to reliably automate complicated enterprise tasks by deploying multiple subagents that retain context and execute complex, multi-turn tool calling.
3.5 Flash is helping Ramp enable smarter, more reliable OCR through multimodal understanding of complex invoices combined with reasoning over historical patterns.
Xero is deploying agents to autonomously manage complex, multi-week workflows, such as identifying suppliers and gathering information for 1099 tax forms, enabling small businesses to automate tedious admin tasks.
Databricks is using agentic workflows to monitor and retrieve real-time information, reason across massive datasets to diagnose issues, identify fixes and propose solutions for data scientists.
Personal AI agents: built with 3.5 Flash
3.5 Flash is now the default model for the Gemini app and AI Mode in Search globally. At I/O today, we showed how its agentic capabilities are powering new features to bring frontier-level intelligence to your daily life.
The new Gemini Spark, your personal AI agent, uses 3.5 Flash. It runs 24/7, helping you navigate your digital life, taking action on your behalf while under your direction. We’re starting to roll out Gemini Spark to trusted testers today, and we’re planning on bringing the Beta to Google AI Ultra subscribers in the US next week.

Gemini Spark uses 3.5 Flash to help accomplish these tasks
Gemini Spark uses 3.5 Flash to help accomplish these tasks
Gemini Spark uses 3.5 Flash to help accomplish these tasks
Gemini Spark uses 3.5 Flash to help accomplish these tasks

Gemini Spark uses 3.5 Flash to help accomplish these tasks
The enhanced agentic coding capabilities of 3.5 Flash are also delivering even more intelligent experiences across Search, from introducing new information agents that work for you 24/7 to unlocking more dynamic generative UI experiences. Learn more in our blog post.
Search leverages 3.5 Flash to build an interactive visual explaining Gyroid patterns.
Gemini 3.5: built with frontier safeguards
Gemini 3.5 was developed in accordance with our Frontier Safety Framework. We have strengthened our cyber and CBRN safeguards, which means it's less likely to generate harmful content, and to mistakenly refuse to answer safe queries. We achieve this with new, more advanced safety training and mitigations, including interpretability tools that help check and understand the AI's inner reasoning before it provides a response.
3.5 Flash is available today
Gemini 3.5 Flash is generally available via Google Antigravity, the Gemini API in Google AI Studio and Android Studio, Gemini Enterprise Agent Platform and Gemini Enterprise. It’s also now available to everyone in the Gemini app and AI Mode in Search. On behalf of the entire Gemini team, we can’t wait to see what you build.


OpenAI announces new Guaranteed Capacity offering for customers to secure compute
OpenAI launched "Guaranteed Capacity," allowing customers to secure long-term compute access for one to three years with discounts, addressing anticipated AI compute scarcity.
Deep dive
- OpenAI's new Guaranteed Capacity offering allows customers to secure long-term access to computational power for their AI products.
- Customers can choose commitments of one, two, or three years, with discounts increasing with the length of the commitment.
- OpenAI CEO Sam Altman noted that the offering helps the company with planning and anticipates that the world will be capacity-constrained for AI compute for some time.
- The company is targeting approximately $600 billion in total compute spend by 2030 and is valued over $850 billion by private investors.
- This initiative is expected to help OpenAI generate more revenue as it prepares for a potential IPO as early as this year.
- OpenAI will offer this until the current allocation is sold out, with plans to reintroduce it in the future.
Decoder
- Compute: In the AI industry, refers to the computational power and resources (like GPUs, TPUs, servers) required to train and run large AI models.
Original article
- OpenAI announced Guaranteed Capacity, which allows customers to secure long-term access to compute.
- The company said customers can choose between one, two and three-year-long commitments and their corresponding discounts.
- OpenAI CEO Sam Altman said the new offering will help the company plan ahead, which he hopes will be a "big win-win."
OpenAI on Tuesday announced a new offering called Guaranteed Capacity, which allows customers to secure long-term access to compute to power their artificial intelligence products, agents and workflows.
The company said customers can choose between one, two and three-year-long commitments, and it's offering discounts that increase based on those annual commitments, according to its website.
"Customers are increasingly asking us for certainty on capacity. As models get better, we expect that the world will be capacity-constrained for some time," OpenAI CEO Sam Altman wrote in a post on X.
Altman said the new offering will help OpenAI plan ahead, which he hopes will be a "big win-win." He added that OpenAI will offer Guaranteed Capacity until it sells out of its current allocation, but that the company plans to offer it again in the future.
In the AI industry, compute refers to the computational power and resources required to train and run large AI models. It's extremely expensive and difficult to build on a large scale. OpenAI has told investors that it is targeting roughly $600 billion in total compute spend by 2030, as CNBC previously reported.
OpenAI, which is is valued at more than $850 billion by private investors, is looking to bring in more revenue as it gears up for a potentially massive IPO as soon as this year. The company unnerved Wall Street by inking a flurry of multi-billion-dollar compute deals late last year, sparking debates about how OpenAI would be able pay for such a large infrastructure buildout.
Altman repeatedly brushed off concerns, writing in a post on X in November that OpenAI expects to grow to hundreds of billions in sales by 2030. The company's new Guaranteed Capacity program could help lay the foundation for what its compute business model will eventually look like.
In his post on Tuesday, Altman said OpenAI will make sure it leaves enough capacity available for its products like ChatGPT and its coding assistant Codex.
WATCH: AI investor on upcoming mega IPOs and why profitability is ‘not so important’
Google Detailed the Shift Toward Agentic Gemini Products
At I/O 2026, Google announced a massive shift to an "agentic Gemini era" with 3.2 quadrillion monthly token usage, new TPU 8 hardware, and partnerships with OpenAI, Kakao, and Eleven Labs on SynthID.
Deep dive
- At I/O 2026, Google CEO Sundar Pichai declared the "agentic Gemini era," highlighting deep integration of AI across consumer products, creative tools, and developer platforms.
- Monthly token usage across Google's AI systems has surged sevenfold to over 3.2 quadrillion, with 8.5 million developers building with their models monthly.
- Google is making massive infrastructure investments, with capital expenditure expected to be around $180-$190 billion this year, six times that of 2022.
- New custom silicon, the 8th generation TPUs, includes TPU 8t for large-scale training and TPU 8i for inference, offering significant performance and energy efficiency improvements.
- Gemini Omni Flash was introduced as a new multimodal model capable of generating various outputs from any input, starting with video.
- Google's AI features like AI Overviews in Search (2.5 billion monthly active users) and the Gemini app (over 900 million monthly active users) are seeing rapid adoption.
- New agentic features like Ask Maps, Ask YouTube (rolling out this summer), and voice-powered Docs Live (for subscribers this summer) were showcased.
- Google's SynthID watermark and Content Credentials are being expanded for AI content transparency, with OpenAI, Kakao, and Eleven Labs adopting SynthID.
- Gemini Spark, a 24/7 personal AI agent powered by Gemini 3.5 and Antigravity, is rolling out to trusted testers and Google AI Ultra subscribers.
- Information agents in Search and generative UI capabilities will also be available this summer, building on Gemini 3.5 Flash.
Decoder
- Agentic era: A period characterized by widespread adoption and development of AI agents that can autonomously plan, execute, and iterate on complex tasks.
- Token: The fundamental unit of data processed by large language models, often representing a word, sub-word, or character.
- TPU (Tensor Processing Unit): A custom-designed AI accelerator chip developed by Google for machine learning workloads, particularly neural networks.
- SynthID: A Google-developed invisible watermark and detection tool for AI-generated images and videos, designed to help distinguish real from synthetic content.
Original article
I/O 2026: Welcome to the agentic Gemini era
Here’s how we’re helping you get more done with Gemini.


Editor’s note: Below is an edited transcript of Google CEO Sundar Pichai’s remarks at Google I/O 2026, adapted to include more of what was announced on stage. See all the announcements in our collection.
It’s been an extraordinary year since our last I/O, a period of relentless shipping, technology advances and hyper progress. We’re now in the part of the AI cycle where people want to see the value in the products they use every day. We’ve been really focused on that, and you’ll see that in the products and features we’re announcing today at I/O.
Ten years since we pivoted the company to be AI-first, we still see AI as the most profound way to advance our mission and improve people’s lives at scale. That’s why we’ve been taking a differentiated, full-stack approach to AI innovation, from our custom silicon and secure foundation, to our world-class research and models, to our products and platforms that touch billions of people. This approach enables us to iterate and innovate faster in ways that are lighting up every part of the company.
What’s incredible is how people are using AI, whether it’s students prepping for final exams with the Gemini app, musicians and artists using generative AI models like Lyria and Veo as part of their creative flow, or developers coding and bringing their ideas to life.
AI momentum across the full stack
These stories of how people are using AI are the best measure of progress. To understand the scale at which people are adopting AI, there is another great proxy — tokens, the fundamental units of data our models process, many representing a problem being solved.
Two years ago, we were processing 9.7 trillion tokens a month across our surfaces — a huge number. Last year at I/O, that grew to roughly 480 trillion tokens. Fast forward to today, that number jumped 7x to over 3.2 quadrillion per month.

It tells an important story about our products and how others are building as well — especially developers and enterprises:
- Over 8.5 million developers are now building new apps and experiences with our models monthly.
- Our model APIs are now processing roughly 19 billion tokens per minute.
- Over the past 12 months, over 375 Google Cloud customers each processed more than one trillion tokens, representing incredible demand for AI from across industries.
Momentum with our products
Today we have 13 products with over a billion users each. Five of those have more than 3 billion users.
Our Gemini models are a big reason more people are using our products, and why they're using our products more.
It all starts with Search, which is bringing the benefits of generative AI to more people than any other product in the world. AI Overviews now has over 2.5 billion monthly active users. And AI Mode has been a revelation, our biggest upgrade to Search ever. People love it, and in just a year, it’s already surpassed 1 billion monthly active users.
When people use our AI-powered features in Search, they use Search more. Search has become less about individual queries and feels more like an ongoing conversation, giving you deeper insights and connecting you with the vastness of the web.
Another place where we’ve been rapidly innovating is in the Gemini app. Last year at I/O, the Gemini app had 400 million monthly active users. Today, we’ve surpassed 900 million, more than doubling in a year. In that same time, daily requests have grown over seven times.
We’ve been adding a lot of unique features like Personal Intelligence, which make responses more customized and helpful. And to date more than 50 billion images have been generated with our Nano Banana image generation models. It was a breakout star this past year, showing how much latent creativity there is in the world.
Natural, conversational AI in products
There’s also a lot of latent productivity to be unlocked. Over the last year, we’ve been bringing the ability to have more natural conversations with Gemini directly inside our products. Recently, Maps got its biggest upgrade in a decade, including a new feature called Ask Maps. People are using Ask Maps for more complex, and much longer questions.
Now we’re bringing more natural conversational AI to more products.
Ask YouTube
People come to YouTube everyday to ask a lot of questions. There’s a lot of great videos, but sometimes it’s hard to know where to start.
Ask YouTube entirely reimagines the experience, making information much more digestible and easy to navigate. You’ll see videos that best match your interest, and most importantly, it jumps right to the part of the video most relevant to you.
We’re starting to test Ask YouTube now, and it will roll out broadly in the U.S. this summer.
Voice-powered Docs Live
There are a lot of times I want to get things done at the speed of my voice. That is much more possible today thanks to technical leaps in our audio models.
A new feature called Docs Live takes this to another level. To create a doc with Gemini before, you had to type out a precise prompt. With Docs Live, you can just verbally “brain dump” whatever is on your mind, and let Gemini do the rest. Here’s a demo in real-time:
In the future, you’ll be able to create new docs and edit them directly, all with your voice. Docs Live is rolling out for subscribers this summer, and powerful voice capabilities will come to Gmail and Keep then too.
Infrastructure supporting innovation at scale
It’s incredible to see the pace of innovation rolling out across our products. Supporting all of this scale for our users, while also serving enterprises and developers around the world, requires massive investments in infrastructure. We’ve been investing for now and for the future. In 2022, we were spending $31 billion annually in capex. This year, we expect that number to be about six times that, approximately $180 to $190 billion. A key part of this investment is our custom silicon.
A decade ago, we announced our very first commercial tensor processing unit, or TPU, on the I/O stage. Since then, we have transformed how the industry builds for AI. We recently announced our 8th generation of TPUs at Cloud Next. For the first time, we’ve taken a dual chip approach with specialized architectures for training and inference: TPU 8t and 8i.
- TPU 8t is optimized for large-scale pretraining, and it’s nearly three times the raw computing power of our previous generation. We’ve taken a fundamentally different approach with our training infrastructure. With JAX and Pathways, our training is no longer constrained by the limits of a single, massive data center. Instead, we can now seamlessly distribute training across multiple sites, scaling training across more than 1 million TPUs globally. This gives us the ability to create the largest training cluster in the world. For model builders, this means training larger, more capable models in weeks rather than months.
- TPU 8i is designed for inference. We have dramatically improved speed at every step. Because if we learned anything in 27 years of working on Search, it's that latency matters.
In addition to speed, we’re also thinking about scaling sustainably. Both chips are more energy efficient, delivering up to two times better performance-per-watt.

Gemini Omni
This progress with TPUs is how we can make compute advances across models, coding and agents. With world models, AI is moving from predicting text to simulating reality. We have been working to push the boundaries of what these models can do.
Gemini Omni is our new model that is capable of generating samples in any output modality from any input. We’re starting with video outputs, and over time we’ll enable image and text. This new model combines Gemini’s intelligence with our generative media models — a huge leap forward in world understanding. We’re launching the first model in the Omni family: Gemini Omni Flash.
Gemini Omni Flash is available starting today. You will be able to try it on the Gemini app, Google Flow and on YouTube Shorts. We'll also be rolling it out to developers and enterprise customers via APIs in the coming weeks.

New SynthID updates and partners
As generative AI gets better, so does the need for greater transparency. Research shows people can correctly identify high-quality deepfake videos only about a quarter of the time. Three years ago, we launched SynthID, our watermark that is invisible to the naked eye. Since launch, SynthID has now watermarked over one hundred billion images and videos, along with sixty thousand years of audio assets.
Millions of people are using our SynthID detector in the Gemini app to verify AI-generated content. And now we’re going a step further and adding Content Credentials verification across products. This will show you if the origin of the content was AI or a camera, and if it’s been edited with generative AI tools. We want more people to have easy access to these tools, so we’re expanding both Content Credentials and SynthID verification to Search and Chrome.
Of course, this only works at scale if more partners decide to watermark their own AI-generated content. Nvidia signed on to SynthID last year. And today, we are thrilled to announce that OpenAI, Kakao and Eleven Labs are adopting SynthID, too. It’s great to see the cross-industry collaboration. We’re looking forward to expanding to more partners and setting the standard of transparency for the AI era.
Gemini 3.5 Flash
Gemini 3 launched a few months ago, with a full family of models. It’s our most adopted series yet. We've loved seeing developers use Flash as their daily driver, and build incredible experiences with Pro's deep reasoning and multimodal capabilities. We’ve been hard at work on improving these models, especially focused on agentic coding, long-horizon tasks and real-world workflows.
Today, we’re introducing Gemini 3.5 Flash, our first in a series of models combining frontier intelligence with action. Two things I’d highlight:
- When compared to 3.1 Pro, 3.5 Flash is better across almost all benchmarks. It’s made huge progress in coding — and look at the extraordinary jump in GDPVal. This captures many real-world economically valuable tasks.
- Gemini 3.5 Flash is a very capable model, at the frontier and comparable to the best models, but it’s still very fast. Which is why when you look at the intelligence versus output speed, it’s in a league of its own in the top right quadrant. When looking at output tokens per second, it is four times faster than other frontier models.

The new model has been a game changer for us internally at Google. We’ve been using 3.5 Flash with a reimagined version of our agent-first development platform Antigravity, and it’s dramatically accelerated how we build. In March we were processing half a trillion tokens a day internally across our AI developer tools, and we’ve been doubling every few weeks. Now, we’re processing more than three trillion tokens a day. This scale created a powerful feedback loop helping us improve 3.5.

What’s amazing about Flash is how it delivers frontier-level capabilities at less than half the price of comparable frontier models. We’ve heard that many companies are already blowing through their annual token budgets, and it’s only May. If companies used a mix of Flash and other frontier models they could save a lot of money. To put this in perspective, top companies are processing about 1 trillion tokens a day. If they shifted 80% of their workloads from other frontier models to 3.5 Flash, they’d save over $1 billion dollars annually. That is real savings they can pour back into their company.
Gemini 3.5 Flash is available for everyone today across our products and APIs. We’re also excited for Gemini 3.5 Pro. We are using it internally, it’s showing great improvements, and it will be coming next month.
Antigravity 2.0
We’re also bringing 3.5 Flash to developers in Antigravity.
Antigravity is expanding beyond the coding environment, turning it into a platform to develop and manage cohorts of autonomous AI agents. This includes Antigravity 2.0, a new standalone desktop application that acts as a central home for agent interaction, where anyone can orchestrate agents for all sorts of tasks. And we developed an even more optimized version of Flash: not just 4x but 12x faster than other frontier models.
Users in Antigravity can get a taste of this experience starting today. Read more about Antigravity 2.0 here.
Gemini Spark is your 24/7 agent
Gemini 3.5 and Antigravity are unlocking a new world of agents and agentic capabilities. We’ve been bringing agents to developers and enterprises for a while. Now we are super focused on bringing the power of agents, safely and securely, to consumers so that it works for everyone. You’ll see agentic experiences across many of our products today.
I’m particularly excited for Gemini Spark, your personal AI agent in Gemini app that helps you navigate your digital life, taking action on your behalf and under your direction.
- It runs on dedicated virtual machines on Google Cloud. And it’s 24/7 so you don’t need to keep your laptop open.
- It’s powered by Gemini 3.5 and the Google Antigravity harness, which allows it to perform long-horizon tasks easily in the background.
- Spark will integrate seamlessly with tools, starting with our own, and in the coming weeks with third-party tools through MCP.
- And you can work with Spark however is most convenient: in the Gemini app or soon, through email and chat.
- On Android, you will be able to view live updates and task progress of agents like Spark through a new UI space called Android Halo, coming later this year. Later this summer, Spark will operate directly within Chrome, acting as your agentic browser across the web.
We’re starting to roll out Gemini Spark to trusted testers this week and the Beta is coming to Google AI Ultra subscribers in the U.S. next week.

Search in the agentic era
Gemini Spark is the first experience made possible by 3.5 models and Antigravity. This combination gives us new ways to accelerate our mission and transform our products to be radically more helpful.
As we enter this agentic era, Search will be more helpful and powerful than ever. Today, we’re introducing information agents in Search. These are personalized AI agents you can set up to work in the background, 24/7, to find what you need at exactly the right moment, and help you take action. Information agents are rolling out this summer starting with Google AI Pro and Ultra subscribers.
Another way we’re building a truly agentic Search is by infusing it with agentic coding capabilities. With the power of Gemini 3.5 Flash and Google Antigravity, Search will build custom experiences just for your individual questions, like dynamic layouts and interactive visuals. These generative UI capabilities will be available for everyone in Search this summer, free of charge.
And for longer running tasks that you need to keep coming back to, Search can go a step further — building persistent, custom dashboards or trackers that you can return to and make progress on. You can think of these like mini apps for your own specific tasks. You’ll be able to build custom experiences with Antigravity, right in Search in the coming months, starting first for Google AI Pro and Ultra subscribers in the U.S.

More from our agentic Gemini era
Here’s a look what else we shared at I/O:
- Daily Brief is another out-of-the-box agent coming to the Gemini app. It gives you a personalized digest and synthesizes information from your inbox, calendar and tasks to find the most important things to be aware of. And it’s not just summarizing data: it’s prioritizing, organizing and suggesting the next steps, so it’s easy for you to take action. All in this super concise morning digest that’s built for skimming.
- Google Flow is rolling out a new agent today to everyone that can plan and reason through complex tasks with your inputs, under your control. Built with Gemini models, it brings expertise and a deep understanding of your project to help with early brainstorming, creating and editing. You can also vibe code any creative tool, right in Flow — like tools for designing video effects, hand-drawn animations or layering text.

- Google Pics is our new AI image creation and editing tool, built on our latest Nano Banana model, that helps you create just about anything with the creative controls you want. Whether you’re building a design from a blank canvas or editing an existing photo, Pics treats every element as an individual object rather than a flat, static image. This allows you to create, swap or perfect specific details, so you can bring your exact vision to life. Google Pics is available now to trusted testers and will be rolling out later this summer to Google AI Pro and Ultra subscribers in Workspace.
- We also shared more about our intelligent eyewear, which we first gave a glimpse of last year, including audio glasses that offer spoken help in your ear and display glasses that show you the information you need, right when you need it. Both let you stay hands-free and heads up, with help from Gemini just by asking. Audio glasses are launching first, coming later this fall.

- Gemini for Science brings together a number of AI tools to help accelerate scientific research. Building on the deep reasoning and research capabilities of Gemini as well as Deep Think and Deep Research, it includes new experiments on Labs as well as Science Skills to connect agentic platforms like Google Antigravity to over 30 major life science databases and tools. Users can express interest to try Gemini for Science experiments on Google Labs, and Science Skills is available today on Github and directly in Antigravity.

As we look across the full stack of innovation, from the infrastructure behind TPU 8i to the frontier capabilities of Gemini 3.5 and Antigravity, it’s clear we’re firmly in our agentic Gemini era. I’m excited to see how it will unlock new ways to accelerate our mission and transform our products to be radically more helpful, for everyone everywhere.
See everything we announced here.
Real-Time Long Video Generation (GitHub Repo)
NVIDIA released LongLive 2.0, a significant update to its real-time long-form video generation framework, introducing NVFP4 parallelism and achieving 45.7 FPS.
Deep dive
- LongLive 2.0 introduces NVFP4 (NVIDIA Floating Point 4) for both training and inference, improving efficiency.
- It features parallelism enhancements including Balanced sequence parallel for AR training and sequence parallel inference.
- Achieves up to 45.7 FPS for the 5B parameter LongLive-2.0-5B-NVFP4-2Step model.
- Supports multi-shot attention sink and async decoding for inference.
- LongLive 1.0, the base, offers real-time interactive long video generation with sequential user prompts, utilizing attention sink, KV-recache, and streaming long tuning.
- Supports KV cache compression with TriAttention, reducing KV by 50% without quality loss.
- The models range from 1.3B to 5B parameters.
- Released under the Apache 2.0 license.
Decoder
- NVFP4 (NVIDIA Floating Point 4): A low-precision floating-point format used by NVIDIA for optimizing AI model training and inference on their GPUs, reducing memory and computation requirements.
- KV-cache: Key-Value cache, a mechanism in transformer models that stores previously computed key and value states of attention heads to speed up sequential token generation by avoiding recomputing them.
- Attention sink: A technique used in streaming attention mechanisms to maintain a fixed-size buffer of past attention states, allowing efficient processing of long sequences without quadratic complexity.
- Streaming long tuning: A method for adapting models to handle very long sequences in a streaming fashion, typically by continuously updating model parameters or attention mechanisms as new data arrives.
Original article
🎬 LongLive 2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
Paper Code Video Models Models Demo Docs
💡 TLDR: Infra with NVFP4 and parallelism for both training and inference
News
- 🔥 [2026.05.13] We release LongLive 2.0, infra with NVFP4, parallelism and multi-shot for AR training, DMD distillation, and inference (⚡45.7 FPS). The original LongLive 1.0 is now in the v1.0 branch.
- 🔥 [2026.04.12] LongLive supports kv cache compression with TriAttention, with 50% KV reduction and no quality drop. Check it here
- 🎉 [2026.1.27] LongLive is accepted by ICLR-2026.
- 🔥 [2026.1.11] LongLive supports adapting LongLive's original RoPE into KV-cache relative RoPE and generates infinite long videos!
- 🔥 [2025.11.3] We implement LongLive on linear attention model SANA-Video! Now SANA-Video can generate 60s interactive videos in real-time.
- 🔥 [2025.9.29] We release Paper, this GitHub repo LongLive with all training and inference code, the model weight LongLive-1.3B, and demo page Website.
Introduction
LongLive 1.0: Real-time Interactive Long Video Generation. You can find it here in our V1.0 branch.
LongLive 2.0: an NVFP4 Parallel Infrastructure for Long Video Generation
- For training, it supports
- Balanced sequence parallel for AR training (teacher-forcing).
- AR training on multi-shot (or single-shot) videos.
- NVFP4 (or BF16) for both AR training and few-step distillation.
- For inference, it supports
- NVFP4 inference (W4A4) and NVFP4 KV Cache.
- Multi-shot attention sink.
- Sequence parallel inference.
- Async decoding.
LongLive 1.0: Real-time Interactive Long Video Generation. It accepts sequential user prompts and generates corresponding videos in real time, enabling user-guided long video generation. The key insights are attention sink, KV-recache, and streaming long tuning.
Getting Started
Quick Start
BF16
import torch
from omegaconf import OmegaConf
from pipeline import CausalDiffusionInferencePipeline
from utils.config import normalize_config
from utils.inference_utils import (
load_generator_checkpoint,
place_vae_for_streaming,
prepare_single_prompt_inputs,
save_video,
)
prompt = "A compact silver robot walks through a clean robotics lab."
merged_checkpoint_path = "LongLive-2.0-5B/model_bf16.pt"
config = normalize_config(OmegaConf.load("configs/inference.yaml"))
device = torch.device("cuda")
torch.set_grad_enabled(False)
pipe = CausalDiffusionInferencePipeline(config, device=device)
load_generator_checkpoint(pipe.generator, merged_checkpoint_path)
pipe = pipe.to(device=device, dtype=torch.bfloat16)
place_vae_for_streaming(pipe, config) # honor streaming_vae + vae_device when set
pipe.generator.model.eval().requires_grad_(False)
noise, prompts = prepare_single_prompt_inputs(config, prompt, device)
video = pipe.inference(noise=noise, text_prompts=prompts)
save_video(video[0], "videos/quickstart/sample.mp4", fps=24)
place_vae_for_streaming is a no-op unless inference.streaming_vae is true and inference.vae_device is set, so toggling streaming-pipeline decode in your yaml is enough — the script does not need to change.
NVFP4
Point checkpoints.generator_ckpt in configs/nvfp4/inference_nvfp4.yaml at the downloaded checkpoint and set model_quant_use_transformer_engine according to the backend you are using:
- TransformerEngine checkpoint (
model_te.pt):model_quant_use_transformer_engine: true - FourOverSix checkpoint (
model_4o6.pt):model_quant_use_transformer_engine: false
setup_nvfp4_pipeline handles checkpoint loading, NVFP4 module wrapping, weight materialization, dtype/device placement, and the streaming-pipeline VAE relocation for both backends — the bf16 pipe.to(...) shortcut is unsafe here because it would cast the quantized buffers.
import torch
from omegaconf import OmegaConf
from pipeline import CausalDiffusionInferencePipeline
from utils.config import normalize_config
from utils.inference_utils import prepare_single_prompt_inputs, save_video, setup_nvfp4_pipeline
prompt = "A compact silver robot walks through a clean robotics lab."
config = normalize_config(OmegaConf.load("configs/nvfp4/inference_nvfp4.yaml"))
device = torch.device("cuda")
torch.set_grad_enabled(False)
pipe = CausalDiffusionInferencePipeline(config, device=device)
setup_nvfp4_pipeline(pipe, config, device)
pipe.generator.model.eval().requires_grad_(False)
noise, prompts = prepare_single_prompt_inputs(config, prompt, device)
video = pipe.inference(noise=noise, text_prompts=prompts)
save_video(video[0], "videos/quickstart/sample_nvfp4.mp4", fps=24)
Models
| Model | FPS ↑ | Params | VBench ↑ | Multi-shot |
|---|---|---|---|---|
| LongLive-1.3B | 20.7 | 1.3B | 84.87 | |
| LongLive-2.0-5B | 24.8 | 5B | 85.06 | ✅ |
| LongLive-2.0-5B-NVFP4-4Step | 29.7 | 5B | 84.51 | ✅ |
| LongLive-2.0-5B-NVFP4-2Step | 45.7 | 5B | 83.14 | ✅ |
License
This repository is released under the Apache 2.0 license. See LICENSE for details.
Citation
Please consider citing our work if you find them useful:
@article{longlive_2.0,
title={LongLive2.0: An NVFP4 Parallel Infrastructure for Long Video Generation},
author={Chen, Yukang and Wang, Luozhou and Huang, Wei and Yang, Shuai and Zhang, Bohan and Xiao, Yicheng and Chu, Ruihang and Mao, Weian and Hu, Qixin and Liu, Shaoteng and Zhao, Yuyang and Mao, Huizi and Chen, Ying-Cong and Xie, Enze and Qi, Xiaojuan and Han, Song},
journal={arXiv preprint arXiv},
year={2026}
}
@inproceedings{longlive,
title={Longlive: Real-time interactive long video generation},
author={Yang, Shuai and Huang, Wei and Chu, Ruihang and Xiao, Yicheng and Zhao, Yuyang and Wang, Xianbang and Li, Muyang and Xie, Enze and Chen, Yingcong and Lu, Yao and others},
booktitle={ICLR},
year={2026},
}
Acknowledgement
- Self-Forcing: the AR training codebase and formulation we build upon.
- Wan2.2: the base video diffusion model components used in this release.

Advancing content provenance for a safer, more transparent AI ecosystem
OpenAI is enhancing content provenance by adopting C2PA standards and integrating Google DeepMind's SynthID watermarking for AI-generated images.
Decoder
- C2PA (Coalition for Content Provenance and Authenticity): An open technical standard that provides a way to verify the origin and history of digital media content, allowing consumers to determine if an image, video, or audio file has been altered or is AI-generated.
- SynthID: A watermarking tool developed by Google DeepMind designed to embed an imperceptible digital watermark directly into AI-generated images, making it detectable even after modifications like resizing or cropping.
Original article
OpenAI strengthens content provenance by implementing C2PA standards and Google DeepMind's SynthID watermarking for AI-generated images.

Cerebras is now running Kimi K2.6
Cerebras is running its trillion-parameter Kimi K2.6 model in enterprise trials, achieving a record-breaking 1,000 tokens per second, the fastest frontier model performance measured.
Deep dive
- Cerebras is deploying its Kimi K2.6, a trillion-parameter AI model, for enterprise trials.
- The model demonstrates a throughput of approximately 1,000 tokens per second, setting a new benchmark for frontier model performance as measured by Artificial Analysis.
- This achievement highlights Cerebras's advancements in AI hardware and software optimization, particularly with its Wafer-Scale Engine (WSE).
- The company has previously reported achieving 2,100 tokens/s for Llama3.1-70B inference, claiming it to be significantly faster than leading GPU solutions.
- Cerebras emphasizes its low time-to-first-token latency, critical for real-time AI applications, attributing this advantage to its wafer-scale integration.
- Beyond performance, Cerebras has also contributed to the AI ecosystem with projects like the efficient BTLM-3B-8K model for mobile devices and the open-source SlimPajama-627B dataset and Cerebras-GPT models.
Decoder
- Wafer-Scale Engine (WSE): Cerebras's proprietary chip architecture that integrates an entire silicon wafer as a single processor, designed to offer massive computational power and memory bandwidth for AI workloads by eliminating chip-to-chip communication bottlenecks.
- Tokens per second (t/s): A metric used to measure the inference speed of large language models, indicating how many discrete linguistic units (words or sub-words) the model can generate per second.
Original article
Cerebras is now running Kimi K2.6 – a trillion parameter model – in enterprise trials.
At ~1,000 tokens/s, this is the fastest frontier model performance ever measured by Artificial Analysis @ArtificialAnlys.
Learn more: cerebras.ai/blog/cerebras-…
🚨 Cerebras Inference is now 3x faster:
Llama3.1-70B just broke 2,100 tokens/s
- 16x faster than the fastest GPU solution
- 8x faster than GPUs running Llama *3B*
- It's like the perf of a new hardware generation in a single software release
Available now at inference.cerebras.ai
We broke all records when we launched Cerebras Inference in August. Today we are tripling our performance from 650 t/s to 2100 t/s.
Cerebras Inference speed is in a league of its own – 16x faster than the fastest GPU solution, 68x faster than hyperscale clouds, and 4-8x faster than other AI accelerators.
Time to first token is critical for real time applications. Cerebras is among the fastest in first token latency, showing the advantage of wafer scale integration vs. complex networked solutions.
Introducing Cerebras Inference
‣ Llama3.1-70B at 450 tokens/s – 20x faster than GPUs
‣ 60c per M tokens – a fifth the price of hyperscalers
‣ Full 16-bit precision for full model accuracy
‣ Generous rate limits for devs
Try now: inference.cerebras.ai
Cerebras Inference is the fastest Llama3.1 inference API by far: 1,800 tokens/s for 8B and 450tokens/s for 70B. We are ~20x faster than NVIDA GPUs and ~2x faster than Groq.
Going from 90 tokens/s to 1,800 tokens/s is like going from dialup to broadband. It makes AI instant:
Introducing BTLM-3B-8K: an open, state-of-the art 3B parameter model with 7B level performance. When quantized, it fits in as little as 3GB of memory 🤯. It runs on iPhone, Google Pixel, even Raspberry Pi. BTLM goes live on Bittensor later this week! 🧵👇
https://t.co/7aKLkeUeUIbuff.ly/3Q5dtY5
Today's popular models can run on a powerful PC but don't fit in popular mobile devices. In May @Opentensor challenged us to build a SoTA model that runs on any device and supports long context. Thus was born BTLM - a 3B model with 7B performance and 8K context length!
@opentensor BTLM sets a new standard in 3B performance. Thanks to its high quality training data (SlimPajama-627B), it outperforms 3B models trained on almost 2x the data.
It’s also the first model trained on the Condor Galaxy 1 AI supercomputer thanks to the support of G42 Cloud & IIAI!
Today we are announcing Condor Galaxy-1: a 4 exaflop AI supercomputer built in partnership with @G42ai. Powered by 64 Cerebras CS-2 systems, 54M cores, and 82TB of memory – it's the largest AI supercomputer we've ever built. But that's not all: CG-1 is just the start..
G42 Cloud is the largest public cloud provider of the UAE. To expand its AI offering, we are planning not one but *nine* AI supercomputers. When complete in 2024, the full Condor Galaxy system will have 9 instances, 576 CS-2s, for a total of 36 exaFLOPs of AI compute. 🤯🤯
How does 36 exaFLOPs compare to other AI supercomputers? It's 4x the performance of Google's latest TPU Pod v4 and 9x the performance of Nvidia's yet complete Israel-1.
New dataset drop!
Introducing SlimPajama-627B: the largest extensively deduplicated, multi-corpora, open-source dataset for training large language models. 🧵cerebras.net/blog/slimpajam…
RedPajama-1T is the largest open dataset today but contains a large percentage of duplicates, making a full training run costly and inefficient. Like the Falcon team, we found data quality is just as important as quantity – which led to SlimPajama. huggingface.co/datasets/cereb…
SlimPajama cleans and deduplicates RedPajama-1T, reducing the total token count and file size by 50%. It's half the size and trains twice as fast! It’s the highest quality dataset when training to 600B tokens and when upsampled performs equal or better than RedPajama.
Exciting news! Today we are releasing Cerebras-GPT, a family of 7 GPT models from 111M to 13B parameters trained using the Chinchilla formula. These are the highest accuracy models for a compute budget and are available today open-source! (1/5)
Press: businesswire.com/news/home/2023…
The AI industry is becoming increasingly closed. We believe in fostering open access to the most advanced models. Cerebras-GPT is being released under the Apache 2.0 license, allowing royalty-free use for research or commercial applications. (2/5)
One notable output of Cerebras-GPT is a new scaling law that predicts model performance for a given compute budget. This is the first scaling law derived using a public dataset. (3/5)
Everything Google announced at I/O 2026: Gemini, Search, Android XR, & more
Google I/O 2026 saw the immediate release of Gemini 3.5 Flash, an improved AI model outperforming 3.1 Pro in key benchmarks, integrated across major Google products.
Original article
Google announced tons of new Gemini-powered features across its biggest products and services at I/O 2026. This page compiles all of the consumer-facing and most notable developer announcements. Gemini 3.5 Flash, which surpasses 3.1 Pro in coding, agent, and multimodal benchmarks, is rolling out today in the Gemini app, Search, Antigravity 2.0, and Gemini API. Gemini 3.5 Pro, which is currently in testing, will be available next month.

Gemini 3.5 Flash: more expensive, but Google plans to use it for everything
Google's new Gemini 3.5 Flash, despite a significant price increase, is immediately available and slated for broad integration across Google's consumer and developer products.
Deep dive
- Gemini 3.5 Flash is immediately available for general use, bypassing a preview phase.
- It maintains most features of the Gemini 3.x series but lacks "computer use" functionality.
- The model's knowledge cutoff is January 2025, with large token windows (1,048,576 input, 65,536 output).
- Pricing for 3.5 Flash is significantly higher, costing 3x Gemini 3 Flash Preview and 6x Gemini 3.1 Flash-Lite, bringing it close to Gemini 3.1 Pro.
- Google intends to use 3.5 Flash extensively across its free consumer products (Gemini app, Google Search AI Mode) and developer platforms (Antigravity, Gemini API, Android Studio).
- This price increase is part of a broader industry trend, with OpenAI's GPT-5.5 and Claude Opus 4.7 also seeing price hikes.
- A new Interactions API, designed for server-side history management, is currently in beta.
Decoder
- Knowledge cut-off: The date up to which a language model has been trained on data, and therefore the limit of its explicit knowledge.
- Tokens: The basic units of text (words, subwords, or characters) that language models process. Input tokens are consumed by the model, output tokens are generated.
Original article
Gemini 3.5 Flash: more expensive, but Google plan to use it for everything
Today at Google I/O, Google released Gemini 3.5 Flash. This one skipped the -preview modifier and went straight to general availability, and Google appear to be using it for a whole lot of their key products:
3.5 Flash is available today to billions of people globally:
- For everyone via the Gemini app and AI Mode in Google Search
- For developers in our agent-first development platform Google Antigravity and Gemini API in Google AI Studio and Android Studio
- For enterprises in Gemini Enterprise Agent Platform and Gemini Enterprise.
As usual with Gemini, the most interesting details are tucked away in the What’s new in Gemini 3.5 Flash developer documentation. It mostly has the same set of platform features as the previous Gemini 3.x series, albeit with no computer use. The model ID is gemini-3.5-flash. The knowledge cut-off is January 2025, and it supports 1,048,576 input tokens and 65,536 maximum output tokens.
Google are also pushing a new Interactions API, currently in beta, which looks to me like their version of the patterns introduced by OpenAI Responses—in particular server-side history management.
The price has gone up
Gemini 3.5 Flash is accompanied by a notable price bump. The previous models in the “Flash” family were Gemini 3 Flash Preview and Gemini 3.1 Flash-Lite. The new 3.5 Flash is 3x the price of 3 Flash Preview and 6x the price of 3.1 Flash-Lite (see price comparison here).
At $1.50/million input and $9/million output it’s getting close in price to Google’s Gemini 3.1 Pro, which is $2 and $12.
The Gemini team promise that 3.5 Pro will roll out “next month”—presumably at an even higher price.
This fits a trend: OpenAI’s GPT-5.5 was 2x the price of GPT-5.4, and Claude Opus 4.7 is around 1.46x the price of 4.6 when you take the new tokenizer into account.
Given the price increase it’s interesting to see Google roll it out for so many of their own free-to-consumer products. It feels like all three of the major AI labs are starting to probe the price tolerance of their API customers.
Artificial Analysis publish the cost to run their proprietary benchmark against models, which is a useful way to take things like tokenization and increased volume of reasoning tokens into account. Some numbers worth comparing:
- Gemini 3.5 Flash (high): $1,551.60
- Gemini 3.1 Pro Preview: $892.28
- Gemini 3 Flash Preview (Reasoning): $278.26
- Gemini 3.1 Flash-Lite Preview: $93.60
Running the benchmark for 3.5 Flash (high) cost significantly more than 3.1 Pro Preview!
Here are some numbers from other vendors:
- Claude Opus 4.7 (Adaptive Reasoning, Max Effort): $5,117.14
- Claude Opus 4.7 (Non-reasoning, High Effort): $1,217.23
- GPT-5.5 (xhigh): $3,357.00
- GPT-5.5 (medium): $1,199.14
A pelican on a bicycle
I ran “Generate an SVG of a pelican riding a bicycle” against the Gemini API and got back this pelican, which is a lot:
From the code comments: <!-- Pelican Eye / Sunglasses (Cool Retro Aviators) -->
hedgehog on Hacker News:
That pelican looks like it’s in Miami for a crypto conference.
That one cost me 11 input tokens and 14,403 output tokens, for a total cost of just under 13 cents.

GitHub is investigating unauthorized access to its internal repositories
GitHub is investigating unauthorized access to its internal repositories, confirming initial activity involved a poisoned VS Code extension on an employee device.
Deep dive
- On May 19, GitHub detected and contained unauthorized access to its internal repositories.
- The compromise was traced to a poisoned VS Code extension installed on an employee's device.
- GitHub promptly removed the malicious extension version, isolated the affected endpoint, and initiated incident response.
- Initial assessment indicates that the activity involved the exfiltration of GitHub-internal repositories only.
- The attacker's claim of approximately 3,800 repositories being accessed is "directionally consistent" with GitHub's investigation.
- GitHub rotated critical secrets and high-impact credentials immediately following the discovery.
- There is currently no evidence of impact to customer information stored outside of GitHub's internal repositories (e.g., customer enterprises, organizations, or repositories).
- GitHub is closely monitoring its infrastructure for any follow-on activity and will notify customers via established channels if any impact is discovered.
Decoder
- VS Code extension: A software package that adds new features or functionality to Visual Studio Code, a popular source-code editor developed by Microsoft.
Original article
We are investigating unauthorized access to GitHub’s internal repositories. While we currently have no evidence of impact to customer information stored outside of GitHub’s internal repositories (such as our customers’ enterprises, organizations, and repositories), we are closely monitoring our infrastructure for follow-on activity.
If any impact is discovered, we will notify customers via established incident response and notification channels.
We are sharing additional details regarding our investigation into unauthorized access to GitHub's internal repositories. Yesterday we detected and contained a compromise of an employee device involving a poisoned VS Code extension. We removed the malicious extension version, isolated the endpoint, and began incident response immediately.
Our current assessment is that the activity involved exfiltration of GitHub-internal repositories only. The attacker’s current claims of ~3,800 repositories are directionally consistent with our investigation so far.
We moved quickly to reduce risk. Critical secrets were rotated yesterday and overnight with the highest-impact credentials prioritized first.
Bring GitHub Agentic Workflows to your repo. Explore 6⃣ ways to automate your repo with these continuous workflows today 🧵👇
Automatically summarize, label and route new issues
Proactively keep READMEs and documentation up to date with recent code changes
How is generative AI affecting software developers?
A thread 🧵
Generative AI coding tools are trained on large amounts of code across programming languages. They’re trained to process data like humans do—by recognizing patterns, making connections, and drawing inferences with limited guidance.
Generative AI coding tools are powered by large language models (LLMs). Today’s state-of-the-art LLMs are transformers, which makes them adept at connecting tokens, big-picture thinking, and scaling. The results are coding and content suggestions that are contextually relevant.
Looking to improve your accessibility skills? Here are some simple steps that all developers can take to automatically increase accessibility. 🧵
1. Unplug your mouse. That's right, unplug it and see whether you can still navigate whatever you're building without touching it.
2. Make sure your code meets basic accessibility guidelines, such as the Web Content Accessibility Guidelines - w3.org/WAI/standards- guidelines/wcag/glance/
Looking to level up your skills in 2023? This 🧵 is for you.
Learn how to manage your time as a software engineer with these 7 essential habits. github.com/readme/guides/time-management-software-engineers
Turn potential into creative productivity with the 4 Cs: Consume, Curate, Critique, Create. github.com/readme/guides/intentional-creation
What were you doing 10 years ago?
When we released our first Octoverse report 10 years ago we were celebrating 2.8m people on GitHub. Now we have over 94m. We never could have predicted the impact open source would have on the world.
In 2012, most businesses were only using open source software (OSS) to run their web servers. Big-name projects, such as Kubernetes and Docker hadn't even been released yet.

OpenAI has the smarter model. Anthropic is winning anyway
Despite OpenAI's models outperforming Anthropic's on intelligence benchmarks, Anthropic is surpassing OpenAI in enterprise spending by focusing on platform integration and tools.
Deep dive
- OpenAI's frontier models, such as GPT, consistently outperform Anthropic's Claude on standard AI intelligence benchmarks.
- However, Anthropic's enterprise spending and usage have surpassed OpenAI's, according to the May 2026 AI Index.
- Ravi Mehta argues that Anthropic's success comes from focusing on the "platform layer" rather than just the "model layer."
- Anthropic made a key bet on "hands" (the ability for AI to act on the world) over just "mind" (intelligence).
- This includes the Model Context Protocol (MCP), a standard for AI models to access any tool, data source, or system.
- Claude Code, for example, succeeded by living in the terminal, giving it access to thousands of existing developer tools like Git and Docker.
- Other Anthropic initiatives like Claude (skills), Claude Cowork (file access), and Claude Design (HTML rendering) are examples of adding "hands."
- OpenAI, in contrast, has focused on improving core model intelligence and image generation.
- Mehta likens Anthropic's strategy to Microsoft building Windows (a platform) and its own apps (Office), while OpenAI's strategy is more akin to Meta building engaging applications on others' platforms.
- Anthropic's Claude is open, allowing developers to bring their own tools and integrations, while ChatGPT has been largely closed to developers.
- The article concludes that in the "platform era" of AI, the key question for companies is which model best orchestrates agents, tools, workflows, and processes for business operations.
Decoder
- Model Context Protocol (MCP): A standard developed by Anthropic that allows AI models to access and interact with external tools, data sources, and systems, effectively giving the AI "hands" to perform actions.
- Platform layer: In software, the underlying infrastructure and tools that enable the development and deployment of applications, rather than the applications themselves.
- Frontier models: The most advanced and capable AI models currently available.
Original article
OpenAI has the smarter model. Anthropic is winning anyway.
Anthropic figured out something OpenAI didn't — and it has nothing to do with the model.
Two charts tell the story.
On Artificial Analysis’s intelligence ranking, OpenAI’s frontier models still beat Claude. They’re ahead by the benchmarks that have defined this industry for three years.
On Ramp’s AI Index for May 2026, Anthropic just overtook OpenAI in enterprise spending.
Anthropic usage has been exploding, growing past OpenAI for the first time this month.
If intelligence is what matters, this shouldn’t happen.
So what is Anthropic doing that OpenAI isn’t?
OpenAI is competing at the model layer. Anthropic is competing at the platform layer — and that’s where applied AI gets won.
Two bets got Anthropic there. Neither shows up on a benchmark.
Bet #1: Mind and hands
MIT’s motto is mens et manus. Mind and hands. The idea: intelligence is meaningless without the ability to act on the world. You can be a structural engineering savant, but without a saw you’re not building a house.
For three years, the AI industry has been obsessed with the mind. Bigger models. Smarter benchmarks. More parameters.
Anthropic bet on the hands.
It started with MCP — the Model Context Protocol. A standard that lets any AI model access any tool, any data source, any system. Not glamorous. Not a benchmark-topping release. Just “plumbing”.
Then came Claude Code. The dirty secret of Claude Code’s success: it didn’t win because the underlying coding model was better. The same Claude models were available in Cursor, in every IDE plugin, in every wrapper on the market. Claude Code won because it lives in the terminal — where thousands of tools already exist. Git. Docker. ffmpeg. jq. Every CI script ever written.
Putting Claude in the CLI didn’t make it smarter. It gave it hands.
The pattern repeats with Claude (skills), Claude Cowork (file access), and Claude Design (HTML rendering). None of these are “smarter Claude.” They’re Claude with different hands — different tools, different surfaces, different ways to act in the world.
OpenAI spent the same period chasing the mind. New frontier models. Better image generation. Reasoning upgrades. The benchmarks went up. The enterprise spend went sideways.
Bet #2: Platform > applications
The second thing Anthropic got right: it has focused on building a platform, not just applications.
This is the difference between Microsoft in the 90s and Meta in the 2010s.
Microsoft built Windows (the platform) and Office (the killer app). It was its own first and best customer — but never its only customer. Microsoft execs were emphatic about creating value for developers… developers, developers, developers. The result? A generational platform that has thrived through every era — even the ones it didn’t win.
Meta took a different approach. Forced to live on platforms it didn’t own — iOS, Android, Mac, and Windows — Meta focused on building the most engaging applications on those platforms. As a developer platform, they were reluctant. F8 was always more about Meta’s product launches than developer tools.
Meta executed their application strategy brilliantly but also out of necessity because others had the platform locked up. A lot of OpenAI’s senior leadership came from Meta. And it shows.
ChatGPT has been largely closed to developers. OpenAI’s strategy: win the consumer app, charge a subscription, sell ads later.
It’s the Meta playbook.
Anthropic is running the Microsoft playbook. Claude is open. MCP is open. Skills are open. Bring your own tools, your own data, your own integrations. Build on top. The interfaces are there. And Anthropic uses its own apps — Claude Code, Claude, Claude Design — the way Microsoft used Office: as proof the platform works, not as the only thing customers are allowed to run on it.
AI’s next era
Benchmarks aren’t irrelevant. A significantly less capable model would have lost regardless of the platform it’s plugged into. Hitting benchmarks is necessary, not sufficient.
As AI models have matured, the gradient has shifted from the marginal IQ point to the harnesses, tools, and workflows that intelligence plugs into.
Enterprise software has always rewarded platforms over applications: SAP, Salesforce, AWS, Microsoft. Anthropic recognized this early, shifting focus away from intelligence benchmarks to real-world impact.
Now that we’re in the platform era of AI, the most important question for your company isn’t which model is most capable. It’s:
“Which model best orchestrates the agents, tools, workflows, and processes that run my business?”

Dumb Ways for an Open Source Project to Die
A detailed analysis reveals 20 distinct reasons why open-source projects die, from maintainer burnout to sabotage and platform shifts, often leaving critical dependencies “undead” and unmaintained.
Deep dive
- Maintainer departure: The most common scenario where maintainers move on without formally handing over or archiving the project.
- Corporate or academic orphans: Projects built by organizations then abandoned when teams or students leave, often without deprecation.
- Funding cliff: Projects become unmaintained after grants or sponsorships end, as maintainers return to paid work.
- Burnout plateau: Maintainers remain active but lack the energy for significant development, stalling important progress.
- Benevolent zombie: Projects are maintained solely by bots (e.g., Dependabot), appearing active but lacking human oversight.
- Succession deadlock: Potential new maintainers lack access to publishing rights or repo administration due to original maintainer unreachability.
- Toxic gatekeeping: A single, hostile maintainer drives away contributors, creating a bus factor of one.
- Sabotage/Capture: Malicious actors gain control, sometimes making the project seem more active during the takeover (e.g., xz, event-stream).
- Protestware: Legitimate maintainers intentionally break their packages due to disputes or political motivations (e.g., colors, faker, node-ipc, left-pad).
- Broken release pipeline: Development happens in Git, but releases cannot be cut due to lost credentials or unmanageable changes.
- Shadow-maintained: Public repos are merely sync targets for internal corporate monorepos, with no real public engagement.
- Platform-stranded: Project tied to an end-of-life runtime or deprecated API (e.g., Python 2, Flash).
- Transitive death: A dependency several layers deep dies, killing the dependent project without changes to its own code.
- API rug-pull: External service or platform API is shut down or repriced, rendering client libraries useless (e.g., Twitter/Reddit API changes).
- Superseded: Project functionality becomes obsolete due to new language features or standards (e.g., object-assign after ES2015).
- Fork limbo: Project splits into multiple competing forks after a disagreement, freezing adoption of any single version.
- License rug-pull: Project relicenses away from open source, leading to community forks that struggle with adoption (e.g., Terraform/OpenTofu, Redis/Valkey).
- Open-core hollowing: Core development shifts to a commercial version, leaving the open-source repo as a less capable "free tier."
Decoder
- Bus factor: The minimum number of team members who need to be hit by a bus (or leave) before a project stalls due to lack of knowledge.
- Recency-based health score: A metric that evaluates project health based on recent activity, which can be misleading if activity is bot-driven or superficial.
- Protestware: Open-source software intentionally sabotaged or modified by its legitimate maintainer to protest a political or corporate issue.
- Monorepo: A software development strategy where code for many projects is stored in a single repository.
- Open-core: A business model where a core version of a product is open source, while a more feature-rich, enterprise version is proprietary.
Original article
Weekend at Bernie’s showed that a good chunk of the most-depended-on open source packages are dead, and there are a lot of different ways for a project to end up that way.
The maintainer left
Ghost maintainer. The simplest and most common case: last human commit some years back, issues accumulating unanswered, the repo not archived so it doesn’t show up in any filter that would flag it. Usually the maintainer just moved on to other things and the project wasn’t important enough to them to formally hand over or shut down, though the same silence covers everything up to and including the maintainer having died, which neither the registry nor the repo has any way to represent. From outside it’s indistinguishable from a long holiday until enough unanswered issues have piled up to make the silence unambiguous, and the npm utilities at the top of the Bernie’s dead list are mostly this.
Corporate orphan. A company built and open-sourced it with a team to run it, then a pivot or a layoff round took the team out and nobody updated the README. The GitHub org persists with the company logo and the last people who had admin rights have left, so often nobody still at the company knows the project is theirs. Google’s various graveyards are the famous case but every company past a certain size has a few of these, and the ones that were infrastructure rather than products tend not to even get a deprecation notice.
Thesis orphan. Built by a grad student for a master’s project or a PhD chapter, and they’ve since graduated and moved on. The lab that hosted it nominally owns the repo, but nobody there has the context to continue it and academia gives them no reason to try: maintaining someone else’s software earns no citations and counts for nothing at review next to publishing something new. Research software is full of these, often with a paper still being cited years after the code it describes stopped building.
Funding cliff. The project ran on a grant or a fixed-term sponsorship, often from a foundation or one of the public software funds, and the money ended on schedule. The maintainers went back to whatever pays the rent, and a project that had grown to fit full-time capacity is now getting evenings and weekends, which for that scope rounds to nothing. The funder’s logo usually stays in the README long after the funding stopped, which makes this one easy to mistake for a healthy sponsored project.
Hired away. The maintainer was hired by a company and either the employment contract or just the new workload means the project stops. Occasionally that’s a competitor removing a problem, but the more common case isn’t malicious at all: Apple is the classic example of an employer that simply doesn’t let most staff do outside open source, so a maintainer joining means their projects go quiet by default. Handing over before you start is the obvious fix and almost nobody does it in time.
Succession deadlock. The original maintainer is unreachable and there are people willing to take over, but the publish rights on the registry are tied to an account nobody else can access and the GitHub repo has no other admins, while the registry’s abandoned-package process needs either the original maintainer’s consent or a months-long dispute that nobody has obvious standing to start. The PEP 541 process and npm’s dispute policy both exist for exactly this case and both routinely take longer than forking and renaming would.
The maintainer is still there
Burnout plateau. Still active by any metric you’d run. Typo fixes and dependency bumps get merged with the occasional “thanks, will look at this” on an issue, but anything that needs an actual design decision or a debugging session sits open indefinitely because those take energy the maintainer hasn’t had for the project in a long time. There’s often just enough response that anyone who suggests forking gets pointed at the recent activity but never enough to actually ship, and it can hold that shape for years without being quite dead enough for anyone to feel justified taking over.
Benevolent zombie. The contribution graph is solid green and every commit is a bot. Dependabot bumps, an auto-merge rule, possibly automated releases triggered by the bumps, and now scheduled coding agents that can keep the lights on indefinitely without a human reading anything. Every recency-based health score rates this as fine, which is more or less the whole problem with recency-based health scores.
Custody battle. Two or more co-maintainers have fallen out, each with enough access to block the other and not enough to proceed alone, and the project is frozen between them. It might resolve into a fork or end with one party walking away, but plenty just sit there with the issue tracker filling up with users asking what’s going on and getting two contradictory answers.
Tribal knowledge gone. The code works and the tests pass, but the person who understood why has left, and nobody remaining is confident enough to touch anything load-bearing. The project goes read-only in practice: small patches at the edges are fine, anything structural is too risky to attempt. Particularly common in numerical and parsing code where the hard part is an algorithm one person implemented from a paper a decade ago and never wrote up.
Toxic gatekeeping. The maintainer is right there and hostile with it. New contributors get one bruising review and don’t come back, and the bus factor stays at one because nobody else can stand to share the repo. It looks healthy on every metric that counts commits and closed issues, and when the one person eventually stops it’s a ghost-maintainer case with no successor pool because everyone who might have taken over was driven off years ago.
Sabotage and capture
Captured maintainer. Commit or publish access ends up with someone hostile. xz is the elaborate version, a two-year social-engineering campaign against an overworked solo maintainer to get a co-maintainer added who then shipped a backdoored release. event-stream in 2018 was the simpler one, where the original author handed the package to a volunteer who asked nicely and then added a wallet-stealer to a downstream dependency. In both cases the project looked healthier than before during the capture, because the new maintainer was the one putting the work in.
Protestware. The legitimate maintainer deliberately breaks their own package. colors and faker were sabotaged by their author in 2022, node-ipc shipped a payload targeting Russian and Belarusian IP ranges the same year, and left-pad was unpublished entirely during a dispute with npm in 2016. The motivations vary and the effect on downstream is the same: the code in the registry stops being what people thought they were running, usually without warning.
The release pipeline broke
Maintained-not-shipping. Development is happening and fixes land in git, but nobody can cut a release. The one account with publish rights is gone, lost its 2FA device, or belonged to a company that no longer exists. Downstream is stuck on the last published version while the fix they need sits in a commit they can see in the repo and can’t install from the registry, which is the case the original Bernie’s post spent most of its time on.
Unreleasable main. The default branch has drifted far enough from the last tag that releasing it would be a breaking change for everyone, and nobody wants to own that, so nobody tags it. New contributors land patches on main while users run something from years ago, and the gap widens until cutting a release becomes a project in itself that never gets staffed.
Build archaeology. The published artifacts work and nobody can reproduce them. The build depended on a CI service that’s gone, or a base image that’s been deleted, or a tool version that one maintainer had on a laptop they no longer own. Making a new release means reconstructing a build environment first, and the knowledge of what was in it left with whoever set it up.
Shadow-maintained. Real development happens inside a company’s private monorepo, and the public repo gets a periodic squashed code dump with a commit message along the lines of “sync.” Issues and PRs filed against the public repo go nowhere because that isn’t where anyone works. The open source project has become a publishing channel for a closed one, and from outside it’s indistinguishable from a ghost maintainer except on the days a sync lands.
Stranded major. The project is on v4 and actively maintained, but most of the ecosystem is still on v1 because v2 was a rewrite they never migrated past and v1 hasn’t had maintainer attention in years. Whether “the project” is dead depends entirely on which major version you’re asking about, and the versions with the most installs are usually not the ones getting the attention.
Registry orphan. The package resolves from the registry and the source repo URL in its metadata 404s: deleted, made private, moved without updating the registry, or the hosting service it was on shut down. There’s nowhere to file an issue or fork from, and no way to verify the tarball matches anything that was ever in source control. About 1.7% of npm and 4% of Packagist point at a repo that isn’t there, and a fair number of those are still being installed.
Force majeure
Sanctions-stranded. The maintainer is able and willing and can’t push, because the registry has blocked their jurisdiction or their account has been frozen under export controls. A handful of npm and GitHub accounts have been suspended this way over the past few years, and from downstream it looks identical to a ghost maintainer except that the maintainer is often loudly explaining the situation on another platform entirely.
Takedown casualty. Removed from the registry or the host after a DMCA claim or a trademark dispute. youtube-dl came back after its 2020 takedown; a lot of smaller projects don’t, and whether the claim was valid has no bearing on whether the package still resolves.
The world moved on
Platform-stranded. Chained to an end-of-life runtime: Python 2 only, requires a Node version that’s dropped out of CI images, depends on a compiler extension that was removed. Porting it forward is more work than anyone left is willing to do, so it stays where it is while the platform it needs slowly disappears from everywhere you’d want to run it.
Transitive death. The project is fine and the maintainer is present and willing, but something two or three levels down in its own dependency tree has died by one of the routes on this list and can’t be swapped out without a rewrite. The project inherits the death without anything in its own repo changing, which is the recursive case: every entry here is also a way to kill the things that depend on you.
API rug-pull. The project wraps something external that its owner withdrew. At the service layer that’s a client library for an API that was shut down or repriced out of reach, and Twitter’s 2023 changes followed by Reddit’s killed a generation of those in one go. At the platform layer it’s a browser dropping an interface or an OS locking down a capability, which accounts for everything built on NPAPI, Flash, or Chrome apps. Either way the maintainer has nothing they can do about it from their end.
Superseded. What the project does is no longer needed, either because the spec it implements has been replaced or because the language now does the same thing natively. object-assign after Object.assign, the lodash single-function packages after ES2015, the various promise and fetch polyfills, and at the protocol level any number of libraries for formats nobody emits any more. The maintainer reasonably stops, and a few hundred thousand lockfiles keep installing it because removing a dependency that still resolves is nobody’s priority.
The project split
Fork limbo. A disagreement or a maintainer departure split the project across two or more forks, none of which has clearly won. Downstream froze at the last pre-split version rather than bet on a fork that might lose, so the original keeps its install count while all the development effort happens elsewhere under other names. io.js and Node eventually merged back, libav eventually folded back into FFmpeg, and plenty of smaller splits never resolve at all.
Licence rug-pull aftermath. The project relicensed to something that isn’t open source, and a community fork under the old licence exists but adoption hasn’t consolidated behind it. Terraform/OpenTofu and Redis/Valkey are both somewhere along this path, with Elasticsearch a few years further down it. Most lockfiles still point at the last open-licensed version of the original, which is now a fixed point that nobody maintains.
Open-core hollowing. The interesting development moved to the commercial edition and the open source repo is kept around as the free tier. It still gets releases, mostly version bumps and whatever doesn’t differentiate the paid product, and the project people originally adopted has effectively become a different, smaller one without ever being renamed.
The Melbourne Metro safety campaign this post is named after closes with “be safe around trains,” which is more actionable than anything I’ve got. Whichever of the above applies, the package resolves the same, and your lockfile will keep wheeling it round the party with the sunglasses on for as long as nobody checks too closely.

Announcing Claude Managed Agents on Cloudflare
Cloudflare and Anthropic partnered to offer Claude Managed Agents on Cloudflare's infrastructure, enabling secure and scalable AI agent deployments with V8 isolates and robust built-in tools.
Deep dive
- Cloudflare and Anthropic integrated Claude Managed Agents into Cloudflare's Developer Platform.
- This allows the Claude Agent "brain" (core logic) to run on Anthropic's platform, while the "hands" (code execution, tool calls) run on Cloudflare.
- Key features include enhanced security via customizable outbound proxies for credential injection and data exfiltration prevention.
- Agents can connect to private services using Cloudflare Mesh or Workers VPC without exposing them to the internet.
- Supports lightweight V8 isolates for sandboxed code execution, offering faster boot times (milliseconds) and lower costs than traditional microVMs.
- MicroVMs via Cloudflare Containers are still available for more complex "developer-like" agent tasks.
- Built-in tools provide browser control with session recording, email capabilities (send, read, list, new session via email), and integrations with Workers AI (image generation) and R2 storage.
- Developers can customize and add their own tools easily.
- A default deployment template helps developers get started quickly.
Decoder
- V8 isolates: Lightweight, sandboxed environments for executing JavaScript code, used by Cloudflare Workers, offering faster startup and lower overhead than full virtual machines (VMs).
- MicroVMs: Highly optimized virtual machines designed for low overhead and fast startup, suitable for containerized workloads.
- Cloudflare Workers AI: Cloudflare's platform for running AI models on their global network.
- Cloudflare R2 storage: Cloudflare's S3-compatible object storage service, with no egress fees.
- Cloudflare Mesh / Workers VPC: Cloudflare services for secure, private connectivity between network endpoints and cloud resources, without requiring VPNs.
Original article
Announcing Claude Managed Agents on Cloudflare
Cloudflare and Anthropic have collaborated to integrate Claude Managed Agents with Cloudflare Sandboxes. Our new integration gives you more control over your agent sandboxes, secures connections to private services, and improves observability.
In the past year, Cloudflare’s Developer Platform has expanded to give more developers the tools they need to run agents at scale. This includes:
-
Sandboxes for full stateful Linux microVMs at scale
-
Agents SDK, providing simple and customizable agent framework
-
Browser Run, which gives agents fully programmable and observable browsers
-
Dynamic Workers, allowing for dynamic sandboxed code execution at massive scale
Our goal is to make Cloudflare the simplest, most secure, and most programmable cloud for agents.
Integrating with Claude Managed Agents is another step in this direction. You can run your agent loop on the Claude Platform, while using Cloudflare to execute code, secure connections, and run custom tool calls.
To get going in just minutes, we’ve created a default deployment template that gives you the following:
-
Enhanced security - Run all agent traffic through customizable proxies. This allows you to securely inject credentials, prevent data exfiltration, and better observe how your agents interact with the outside world.
-
Sandbox control and observability - Get detailed sandbox metrics and logs. SSH into running machines. Customize sandbox images.
-
Lightweight sandboxes - Writing and executing untrusted code can be done in a traditional microVM or a lightweight isolate. This lets you hit massive scale, boot sandboxes in milliseconds, and minimize infrastructure spend.
-
Private service connectivity - Connect agents to private internal services without ever exposing them to the Internet.
-
Browser Control and Observability - Get an audit trail of every agent’s browser sessions, including session recording and human-in-the-loop flows.
-
Email - Give each of your agents its own email address and ability to send emails.
-
Custom tools - Extend your agents with tools without needing additional infrastructure. Just write functions and deploy.
You get all of this out of the box when deploying the integration, and you can easily customize if you need more.
Let’s take a brief look at Claude Managed Agents, see how to integrate a Cloudflare-based environment, then explore how to get the most out of Claude on Cloudflare.
An overview of Claude Managed Agents
Claude Managed Agents allow developers to easily define and run agents on the Anthropic platform. In these managed environments, Claude can read files, run commands, browse the web, and execute code. The harness supports built-in prompt caching, compaction, and various agent-first performance optimizations.
Until now, using Claude Managed Agents has meant running the entire stack on Anthropic-provided infrastructure. While this is great for some developers, others may need more control over their infrastructure choice, whether this is for security, compliance, or performance reasons. Self-managed environments for Claude Agents provide just that.
Anthropic describes this as “decoupling the brain from the hands.” The core agent loop runs in Anthropic (the “brain”), but the infrastructure for running and executing code (the “hands”) can be run anywhere, including Cloudflare.
The Cloudflare environment
Our new integration gives your agents a Cloudflare-based environment for running and executing code within minutes.
Follow the onboarding guide to get started. Then fork the repo and customize your integration as you see fit.
After setup, when a Claude Agent starts a session, it sends a message to your new Cloudflare-based control plane. The Workers-based control plane gives each agent session a sandboxed environment for executing code, developing applications, running CLI tools, and more. State is automatically persisted across session sleeps.
Sandboxes write files and execute code in response to the Claude-based Agent loop
You can optionally configure sandbox instance sizes or customize the container image that runs within VM-based sandboxes. Each sandbox can be observed in the Cloudflare dashboard, sandbox logs can be queried or shipped to external providers like Datadog or Splunk, and the control plane ships with a built-in UI, making it easy to track the state of sandboxes or SSH into specific machines.
Get interactive shell sessions into your agent’s sandbox
Enabling agents at Internet scale
What if your agent backend booted in a few milliseconds, and you didn’t have to pay for the resources of a full VM when running the agent?
The industry needs a lightweight primitive for sandboxing as we adopt agents at scale, and we’re building just that.
But as models get better, we expect more and more workflows to be managed by agents. Each of your customers should be able to run many agents simultaneously; each of your employees should have tens of agents running at once. If we’re constantly running a full microVM per agent, we’ll be unnecessarily burning a ton of resources and money to enable this scale.
That’s why we’re providing a faster and cheaper sandbox for your Claude Agents. This sandbox is based on the AgentsSDK. You can execute arbitrary code in Dynamic Workers using Codemode, and you still get a file system, but your agent is doing all of this within a V8 isolate instead of a microVM.
If you need agents to act as a developer, building full applications and running Linux-based tools, you can still reach for a microVM-based sandbox. For this, we provide Cloudflare Containers, which Claude Managed Agents can also use.
But if you want a faster, cheaper, and more scalable alternative you can use isolates instead of microVMs easily. Just select “isolate” for backend type when setting up an Agent.
Setting up an “isolate” backend gives you a lightweight V8 isolate sandbox instead of a microVM
If you want to handle bursts of tens of thousands of concurrent agents or more, running with isolates will allow you to scale in a way that no VM-based solution allows.
Securing your agentic workloads
As we’ve written before, sandboxed workloads on Cloudflare can use an outbound proxy for fully dynamic, customizable, and zero-trust authentication between sandboxes and external services. This lets you inject secrets into requests outside the sandbox, so the agent never has access to them. This protects against exfiltration attacks.
And sometimes internal services shouldn’t ever be exposed to the open Internet. We recently launched Cloudflare Mesh and Cloudflare Workers VPC to better connect to these private services, whether they’re running on a cloud provider like AWS or on-premises. This allows you to connect to internal services using post-quantum encrypted networking without a VPN or bastion host.
Claude Managed Agents can easily connect to private services with header injection or private VPC/Mesh tunnels. This is done via customizable outbound proxies. You can define egress policies that expose only the services you choose to the agent sandboxes that you choose. You can allowlist specific endpoints, perform zero-trust injection of encrypted credentials, access private services via Cloudflare Mesh, and even write custom proxy middleware.
The integration uses outbound Workers to handle egress however you see fit
You’re able to apply policies per tenant, per agent, or based on whatever metadata is useful. This gives you full control over how your agents connect to external services.
Doing more with the Cloudflare Developer Platform
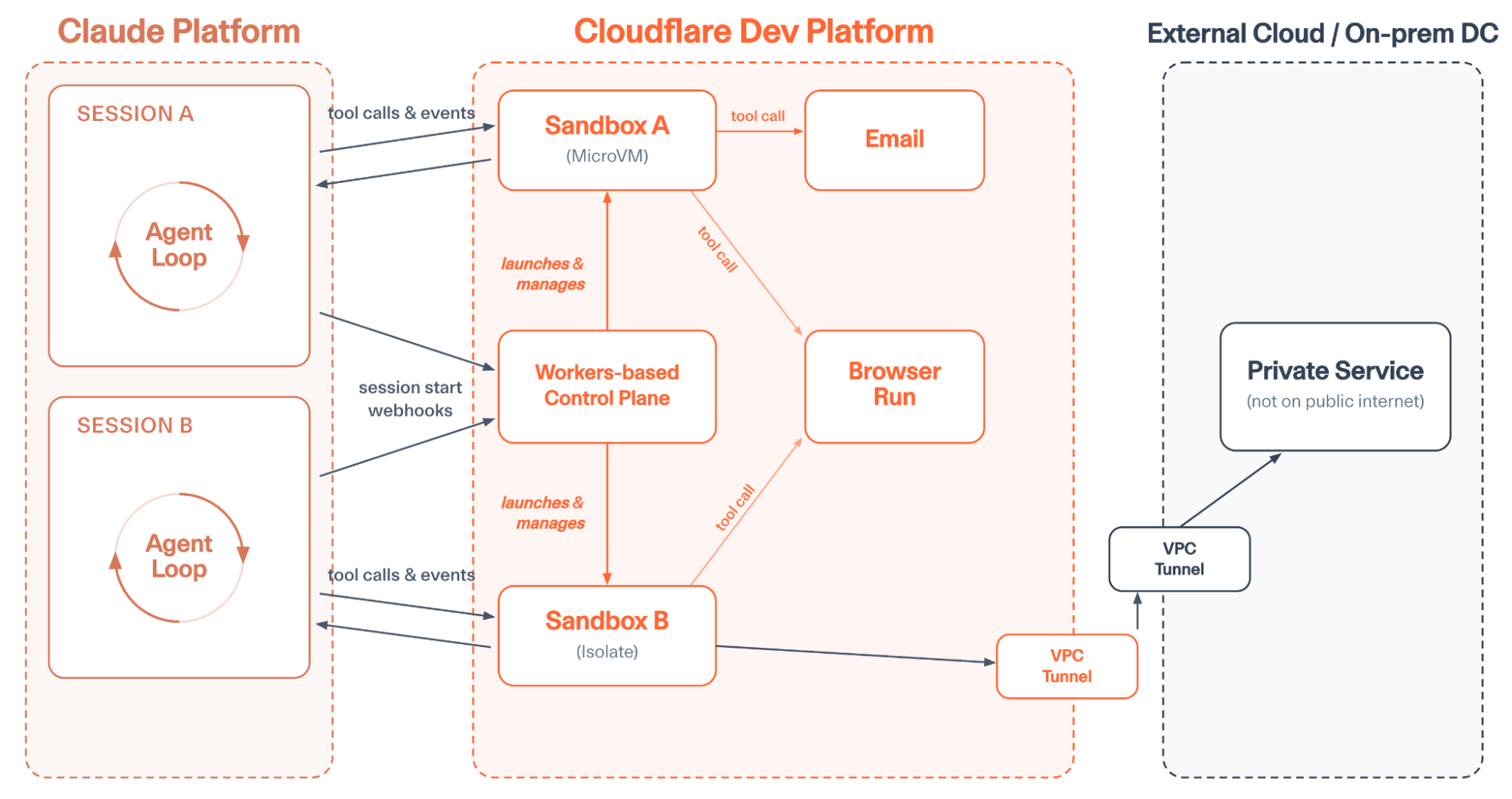
Sandboxes can make tool calls on Cloudflare and safely access external services.
Here are a few of the tools you’ll find most useful as you deploy agents on Cloudflare:
Browser Run via Claude
One of the most common tools agents need is a browser. While curl can get you pretty far, when you want an agent to act like a human, this often means interacting with the web like one: rendering JS-heavy applications, taking screenshots for QA validation, filling out forms, etc. Browser Run is Cloudflare’s tool to give agents browsers.
A Browser Run session recording lets you watch how your agents used a browser. One of many built-in tools.
The Claude Managed Agents integration ships with multiple browser-related tools that can be enabled immediately. These include browser_search, browser_execute, screenshot, browse, fetch_to_markdown, and a Cloudflare-specific implementation of web_fetch allows your agent to control a browser that runs on Cloudflare infrastructure. This not only lets your agent do more, but it also makes it easy to audit every action your agent’s browser is taking on the web, apply allowlists and denylist to browser sessions, and save recordings of browser sessions for future debugging.
Agent inboxes
The integration also comes with built-in support for email with the send_email, email_read, and email_list tools.
You can also kick off new sessions via email, or configure the agent to send emails using any domain and address configured with the Cloudflare Email Service. This allows the agent to act on your behalf when it needs to, reply to context in forwarded emails, and autonomously interact with others via email.
Custom tools and more
Other built-in tools include call_service, which uses Cloudflare Mesh or Workers VPC to connect to private services, and image_generate, which uses Workers AI to generate images on Cloudflare. This pairs well with Claude providing text-based inference.
Additionally, we encourage forking the repo to easily add customized tools. For example, you could add a custom tool to host a public file on Cloudflare’s R2 object storage. Just add the relevant binding in wrangler config, write a zod definition, and short function in custom-tools.js:
defineTool({
name: "r2_host_file",
description: "Upload from sandbox to R2 and get a public URL.",
inputSchema: z.object({
key: z.string().describe("Object key"),
content: z.string().describe("UTF-8 file body"),
contentType: z.string().describe("MIME type"),
}),
run: async ({ key, content, contentType }, { env }) => {
await env.PUBLIC_BUCKET.put(
key, content, { httpMetadata: { contentType }}
);
return `${env.PUB_R2_URL.replace(/\/$/, "")}/${encodeURI(key)}`;
}
}),The Cloudflare Developer Platform provides all sorts of possibilities for extending your agents: give each agent session a git-backed repo with Artifacts, run edge inference with Workers AI, host applications written on the fly with Dynamic Workers, and more.
You don’t have to worry about infrastructure or scaling – just write a few lines of code and hit deploy.
Claude + Cloudflare
We’re excited to be working together with Anthropic to bring Cloudflare’s flexibility, scale, and security to more users. Whether you want to run tens of millions of agents using isolates, securely connect to private services with Workers VPC, or write custom tools that take advantage of all of Cloudflare, our new integration makes it easy.
See the Getting Started with Managed Agents guide to get Claude Managed Agents set up with Cloudflare in just minutes.

Meet Gordon: AI Agent for Container Workflows
Docker has launched Gordon, an AI agent embedded in Docker Desktop and CLI 4.74+ that debugs, containerizes, and optimizes container workflows by directly interacting with your Docker environment.
Deep dive
- Docker's AI agent, Gordon, is now generally available, embedded directly in Docker Desktop 4.74+ and the Docker CLI.
- Gordon goes beyond typical coding assistants by having direct access to your Docker environment, including running containers, logs, images, compose files, and the filesystem.
- It can diagnose common container problems such as missing environment variables, networking failures, or misconfigured volume mounts, then propose and execute fixes.
- Gordon assists with containerizing new applications (e.g., generating Dockerfiles and docker-compose.yml for a Node.js app with Postgres).
- It can optimize existing Dockerfiles by suggesting multi-stage builds, reordering layers for better cache hits, or using slimmer base images.
- For routine tasks, Gordon can clean up unused images or stop running containers without needing to look up CLI flags.
- The agent always requires explicit user approval before executing any shell commands, file modifications, or Docker operations, ensuring user control.
- Permissions are session-scoped and reset when the session closes; user code and personal information are not stored or retained by AI providers.
- Gordon is free for everyday use with any Docker account, with optional paid plans (e.g., Gordon Plus for $20/month) offering increased capacity.
- Nuno Coracao, Principal Product Manager at Docker, highlighted Gordon's role in building intelligence into the entire developer workflow, not just as a standalone AI tool.
Decoder
- Agentic AI: AI systems designed to perform actions autonomously within an environment, often by chaining together tools and reasoning, rather than simply responding to prompts.
- Docker Desktop: A desktop application that allows developers to build, share, and run containerized applications and microservices on Windows, macOS, or Linux.
- Dockerfile: A text document that contains all the commands a user could call on the command line to assemble an image.
- Docker Compose: A tool for defining and running multi-container Docker applications. It uses a YAML file to configure application services.
- Multi-stage build: A Dockerfile technique that uses multiple FROM instructions to create smaller, more secure final images by separating build-time dependencies from runtime dependencies.
Original article
Full article content is not available for inline reading.
CISA Admin Leaked AWS GovCloud Keys on Github
A CISA contractor accidentally exposed highly privileged AWS GovCloud keys, internal system credentials, and plaintext passwords in a public GitHub repository, deemed one of the most egregious government data leaks recently.
Deep dive
- A contractor for CISA, working for the company Nightwing, exposed sensitive credentials and internal system details in a public GitHub repository named "Private-CISA."
- The leak included administrative AWS GovCloud keys for three accounts, plaintext usernames and passwords for dozens of internal CISA systems (like "LZ-DSO," their secure code development environment), and access to CISA's internal "artifactory" (code package repository).
- Guillaume Valadon, a researcher at GitGuardian, discovered the exposed secrets on May 15, 2026, and alerted KrebsOnSecurity after CISA was unresponsive.
- Philippe Caturegli, founder of Seralys, validated the AWS keys, confirming high-level access, and noted that the contractor had disabled GitHub's default secrets detection.
- Caturegli suggested the repository was likely used as a "working scratchpad or synchronization mechanism" between work and home computers, with commits dating back to November 2025.
- The exposed credentials included easily-guessed passwords, such as platform names followed by the current year.
- CISA stated there was "no indication that any sensitive data was compromised" but is investigating and implementing additional safeguards.
- The GitHub account was taken offline, but the exposed AWS keys remained valid for an additional 48 hours after CISA was notified.
- The article highlights CISA's reduced budget and staffing, having lost nearly a third of its workforce since the start of the second Trump administration.
Decoder
- AWS GovCloud: Isolated AWS regions designed to host sensitive data and regulated workloads, meeting U.S. government compliance requirements (e.g., FedRAMP High, DoD SRG).
- Secrets scanning: Automated tools or processes used to detect and prevent sensitive information (like API keys, passwords, or access tokens) from being committed to code repositories.
- Artifactory: A universal repository manager that supports all major package formats, providing a single source of truth for all packages, binaries, and dependencies.
- Least-privilege cloud access: A security principle where users, programs, or processes are granted only the minimum permissions necessary to perform their intended tasks.
- Short-lived credentials: Security credentials (like temporary access keys or tokens) that are valid for a very limited time, reducing the risk if they are exposed.
Original article
Full article content is not available for inline reading.

Apple announces Apple Intelligence-powered accessibility feature updates
Apple is integrating Apple Intelligence into new accessibility features, enabling Vision Pro users to control wheelchairs with their eyes and enhancing VoiceOver image recognition.
Decoder
- Apple Intelligence: Apple's proprietary suite of AI features integrated across its operating systems and devices, designed for personalized, on-device processing.
Original article
Full article content is not available for inline reading.
Karpathy joins Anthropic
Renowned AI researcher Andrej Karpathy has joined Anthropic for R&D on large language models, emphasizing the formative nature of the current LLM frontier.
Original article
Andrej Karpathy announced he has joined Anthropic, citing the next few years at the LLM frontier as especially formative for his return to R&D. Karpathy noted he remains passionate about education and plans to resume that work later, signaling the move is research-focused rather than a permanent pivot away from teaching.

Using Claude Code: The unreasonable effectiveness of HTML
Anthropic's Thariq Shihipar argues Claude Code's outputs are "unreasonably effective" in HTML rather than Markdown, due to HTML's superior richness for specs, prototypes, and interactive agent communication.
Deep dive
- Thariq Shihipar from the Claude Code team argues that HTML is a more effective output format for AI agents than Markdown, especially as agents become more powerful.
- HTML provides significantly higher information density, allowing for document structure, tabular data, design data with CSS, illustrations with SVG, code snippets with script tags, interactions with JavaScript, and spatial data.
- It enhances visual clarity and ease of reading for long documents, as Claude can organize information with tabs, illustrations, and links, and even make them mobile responsive.
- HTML files are easier to share compared to Markdown, which often requires attachments.
- HTML enables two-way interactions, allowing users to add sliders or knobs to adjust designs or export changes back into prompts.
- Claude Code excels at ingesting context from various sources (code folders, MCPs like Slack/Linear, web browser, git history) to generate these rich HTML artifacts.
- Use cases include creating detailed specs, planning documents, design explorations, code reviews, interactive prototypes, comprehensive reports, and custom throwaway editing interfaces.
- Shihipar notes that prompting Claude to "make an HTML file" or "make an HTML artifact" is often sufficient, and that the increased token usage with HTML is negligible with Claude Opus's 1MM context window.
- He suggests that using HTML helps developers stay more "in the loop" with Claude's choices and outputs, fostering better engagement than static text.
Decoder
- Claude Code: Anthropic's AI coding assistant or platform, designed to assist developers with various coding-related tasks.
- MCP (Modular Context Provider): A system or framework that allows an AI agent to ingest context from various external sources, such as communication platforms (Slack), project management tools (Linear), or file systems.
Original article
Using Claude Code: The unreasonable effectiveness of HTML
How and why members of the Claude Code team use HTML instead of Markdown to produce richer, more readable, and easily shareable outputs.
Markdown has become the dominant file format used by agents to communicate with humans. It’s simple, portable, has some rich text capability and is easy to edit. Claude has even gotten surprisingly good at using ASCII to make diagrams inside of Markdown files.
But as agents have become more and more powerful, I’ve found that Markdown has become an increasingly restrictive format. Specifically, I find it difficult to read a Markdown file of more than a hundred lines; I want to use Claude to generate richer visualizations, color and diagrams; and I want to be able to share these outputs more easily.
I also am increasingly not editing these files myself, but using them as specs and reference files. When I do make edits, I’m usually prompting Claude to edit them, which removes one of Markdown’s largest benefits.
Instead, I’ve started preferring HTML as an output format instead of Markdown and increasingly see this pattern being applied by others on the Claude Code team. In this post, I share why and how our team uses HTML to produce richer, more readable Claude Code outputs. If you'd like to follow along, you can start using these HTML file templates for common use cases, too.
Why use HTML?
A few things make HTML a better fit than Markdown for the kind of work I'm now doing with Claude Code, including tasks that require or entail:
Information density
HTML can convey much richer information compared to Markdown. It can, of course, do simple document structure like headers and formatting, but it can also represent all sorts of other information such as:
- Tabular data using tables
- Design data with CSS
- Illustrations with SVG
- Code snippets with script tags
- Interactions using HTML elements with javascript + CSS
- Workflows using SVG and HTML
- Spatial data using absolute positions and canvases
- Images using image tags
In my opinion, there is almost no set of information that Claude can read that you cannot efficiently represent with HTML. This makes it a highly efficient way for the model to communicate in-depth information to you and for you to review it.
I’ve found that in the absence of being able to do this, the model may do more inefficient things in Markdown, like ASCII diagrams or, my favorite, estimating colors with unicode characters.
Visual clarity and ease of reading
As Claude is capable of tackling more complex work, it's also able to write larger and larger specs and plans. I’ve found that I tend to not actually read more than a 100-line Markdown file, and I certainly am not able to get anyone else in my organization to read it.
But HTML documents are much easier to read because Claude can organize the structure visually to be ideal to navigate with tabs, illustrations, and links. It can even be mobile responsive so you can read it differently based on your form factor.
Ease of sharing
Markdown files are fairly hard to share since most browsers do not render them natively well. You often have to add them as attachments to emails or messages.
As long as you upload the HTML file, you can share the link easily. Your colleagues can open it wherever they wish and easily reference it.
The chance of someone actually reading your spec, report, or PR writeup is much higher if it’s in HTML.
Two-way interactions
HTML can also allow you to interact with the document; for example, you might want to ask it to add sliders or knobs to adjust a design or allow you to tweak different options in the algorithm to see what happens. You can also ask it to let you copy these changes into a prompt to paste back into Claude Code.
When useful, this can allow you to create individual editing environments for the specific problem you’re working on.
Data ingestion
One of the biggest reasons to use Claude Code to make HTML files instead of Claude.ai or Claude Design is all of the context Claude Code can ingest. For example, when writing this article, I asked Claude Code to read through my code folder and find all the HTML files I've generated, group and categorize them, and then make an HTML file with diagrams representing each type. The diagrams you see in this article are a direct result of that.
Besides the file system, Claude Code can find additional context using your MCPs (like Slack, Linear, etc.), your web browser (with Claude in Chrome), and your git history.
Getting started
One thing worth noting: you don't need to do much to get Claude to generate HTML like this. You can simply prompt it to "make an HTML file" or "make an HTML artifact." The main thing is knowing what you want the artifact to do and how you might use it. Over time, it may make sense to build a skill around recurring patterns, but starting by prompting from scratch is a good way to get a feel for how it works across different use cases.
Use cases
To make this approach more concrete, below are some example use cases where I think using HTML files make more sense than Markdown. You can also follow along with a GitHub gallery of these use cases, here.
Specs, planning, and exploration
HTML is a rich canvas for Claude to dive into a problem. When I start working on a problem instead of a simple Markdown plan I expect to make a web of HTML files. For example, I might start with asking Claude Code to brainstorm and create some explorations of different options. I would then ask it to expand more into one, maybe make mockups or examples of the type interfaces. Finally, when I feel good I’ll ask it to write an implementation plan. When I’m happy with the plan I’ll create a new session and pass in all of these files for it to implement.
When verifying I’ll also ask the verification agent to read in the files and it will have much broader context on what is needed.
Example prompts:
- I'm not sure what direction to take the onboarding screen. Generate 6 distinctly different approaches—vary layout, tone, and density—and lay them out as a single HTML file in a grid so I can compare them side by side. Label each with the tradeoff it's making.
- Create a thorough implementation plan in a HTML file, be sure to make some mockups, show data flow and add important code snippets I might want to review. Make it easy to read and digest.
Use this for:
- Exploring other ways to implement something in code
- Experimenting with multiple visual designs at once
Code review and understanding
Code can be difficult to read in a Markdown file, but with HTML, we can render diffs, annotations, flowcharts, and modules. Use HTML to understand code that the agent has written, to review code, or to explain a PR to someone reviewing your code.
Example prompt:
Help me review this PR by creating an HTML artifact that describes it. I'm not very familiar with the streaming/backpressure logic, so focus on that. Render the actual diff with inline margin annotations, color-code findings by severity and whatever else might be needed to convey the concept well.
Use this for:
- Creating a PR
- Reviewing a PR
- Understanding a topic in code
Design and prototypes
Claude Design is based on HTML because HTML is incredibly expressive at design, even if your end surface is not HTML. Claude can sketch out a design in HTML and then write it in your language of choice, be it React, Swift, etc.
You can also prototype interactions, such as animations, actions, etc. Consider asking Claude to make sliders, knobs, etc. to tune in exactly what you’re looking for.
Example prompt:
I want to prototype a new checkout button, when clicked it does a play animation and then turns purple quickly. Create a HTML file with several sliders and options for me to try different options on this animation, give me a copy button to copy the parameters that worked well.
Use this for:
- Creating design system artifacts
- Adjusting components
- Visualizing component libraries
- Prototyping animations
Reports, research, and learning
Claude Code is very effective at synthesizing information across multiple data sources and converting it into a report for readability. You can prompt Claude to search your Slack, your codebase, git history, or the internet and use it to generate easy to read reports..
You could assemble this in the form of a long HTML document, an interactive explainer or even a slideshow/deck. Ask Claude to use SVG for diagrams to help visualize it.
Example prompt:
I don't understand how our rate limiter actually works. Read the relevant code and produce a single HTML explainer page: a diagram of the token-bucket flow, the 3–4 key code snippets annotated, and a "gotchas" section at the bottom. Optimize it for someone reading it once.
Use this for:
- Writing feature summarizations
- Generating explainers
- Drafting weekly status reports
- Creating incident reports
- Producing SVG illustrations, flowcharts, and technical diagrams,
Custom editing interfaces
Sometimes it’s hard to describe what you want purely in a text box. For this use case, I'll often ask Claude to build me a throwaway editor for the exact thing I'm working on: not a product, or a reusable tool, but a single HTML file, purpose-built for this one piece of data.
The trick is always to end with an export: a "copy as JSON" or "copy as prompt" button that turns whatever I did in the UI back into something I can paste into Claude Code or commit to a file. You stay in the loop, but the loop gets much tighter.
Example prompts:
- I need to reprioritize these 30 Linear tickets. Make me an HTML file with each ticket as a draggable card across Now / Next / Later / Cut columns. Pre-sort them by your best guess. Add a "copy as Markdown" button that exports the final ordering with a one-line rationale per bucket.
- Here's our feature flag config. Build a form-based editor for it, group flags by area, show dependencies between them, warn me if I enable a flag whose prerequisite is off. Add a "copy diff" button that gives me just the changed keys.
- I'm tuning this system prompt. Make a side-by-side editor: editable prompt on the left with the variable slots highlighted, three sample inputs on the right that re-render the filled template live. Add a character/token counter and a copy button.
Use this for:
- Reordering, triaging, or bucketing anything (tickets, test cases, feedback)
- Editing structured config (feature flags, env vars, JSON/YAML with constraints)
- Tuning prompts, templates, or copy with live preview
- Curating datasets — approve/reject rows, tag examples, export the selection
- Annotating a document, transcript, or diff and exporting the annotations
- Picking values that are painful to express in text: colors, easing curves, crop regions, cron schedules, regexes
Frequently asked questions
These are the questions I get asked most often about using HTML with Claude Code, paired with the practical, day-to-day habits I've landed on:
Isn’t it less efficient?
While Markdown often uses fewer tokens, I’ve found that the added expressiveness of HTML and the much higher likelihood of me reading it means I get overall better output. With the 1MM context window in Opus 4.7, the increased token usage is not really noticeable in the context window.
When do you use Markdown for now?
I have honestly stopped using Markdown altogether for almost everything, but I’m probably far on the HTML maximalist side of things.
Is this how you’ve replaced planning?
I’ve found that instead of having a single plan, I tend to have a few different HTML files for different parts/stages of the plan. For example, I may make an implementation plan in HTML and then do another file for exploration of UIs, and then finally make a HTML component that lists every design. I tend to keep these files around as references for the future, as well for use in verification.
Staying in the loop with Claude
All of the above is to say that the real reason I use HTML instead of Markdown is that it helps me feel much more in the loop with Claude. As Claude takes on more, I'd noticed I was reading plans less closely, and I wanted a way to stay engaged with its choices rather than just hand them off. HTML turned out to be exactly that. I feel more in the loop now than I ever did before."
Get started with Claude Code.
This article was written by Thariq Shihipar, member of technical staff, and expresses his personal opinions – and affinity – for using HTML files with Claude Code.
Related posts
Explore more product news and best practices for teams building with Claude.
OlmoEarth v1.1: A more efficient family of models
AllenAI's OlmoEarth v1.1 family of models drastically cuts compute costs by up to 3X for planet-scale mapping while maintaining performance.
Original article
OlmoEarth v1.1, a new model family, reduces compute costs by up to 3X while maintaining performance, making planet-scale mapping more affordable. The models efficiently process remote sensing data by optimizing token sequence lengths, crucial for reducing computational costs. Methodological improvements allow similar performance to the original version with significantly less compute, benefiting developers and enhancing scientific research in remote sensing.

A single pane of glass for managing all of your cloud agents
Warp's Oz now acts as the first multi-harness control plane for cloud agents, orchestrating Claude Code, Codex, and Warp Agent with cross-harness memory and enhanced governance.
Deep dive
- Oz now supports running Claude Code, Codex, and Warp Agent as agent harnesses, in addition to its previous multi-model support.
- It provides a unified control plane for launching, tracking, governing, and steering these different agents.
- Automatic multi-agent orchestration allows for coordinating multiple parallel subagents on complex, long-running tasks.
- Cross-harness Agent Memory enables agents to store and retrieve long-term memories across different sessions, repositories, and projects, learning from organizational knowledge.
- Agent Memory supports pluggable and writable data sources, allowing it to integrate with existing knowledge bases and learn from agent actions.
- Enhanced cost and usage controls include per-team billing, individual credit caps, and granular permissions for agents accessing internal services.
- Expanded self-hosting options allow Oz agents to run in Kubernetes, with direct execution, or within existing remote development environments.
- The platform is API- and SDK-first, supporting return values from agent sessions and easy session handoffs between local, remote, and cloud environments.
Decoder
- Agent Harness: The specific runtime environment or framework that an AI agent uses to execute its tasks and interact with tools, often including pre-built capabilities or integrations beyond just the underlying LLM.
- Multi-harness control plane: A management system that can orchestrate and govern AI agents that operate within different underlying agent harness environments or frameworks.
Original article
Today, we’re launching major upgrades to Oz that make it the first truly multi-harness control plane for cloud agents. We believe companies shouldn’t have to bet their future on a single model or harness. Oz is designed to give teams a unified system for orchestrating, governing, and scaling agents as the ecosystem rapidly evolves.
This launch includes:
- More agent harnesses in the cloud: Launch, track, and control Claude Code, Codex, and Warp Agent in the cloud. Multi-harness orchestration is available to all users while in beta.
- Automate more complex, long-running tasks: Automatic multi-agent orchestration with multiple parallel subagents coordinated locally or in the cloud.
- Cross-harness Agent Memory: the only cross-harness memory system that helps agents remember what works for your team across every session, repo, and project. Agent Memory is now in research preview.
- Expanded self-hosting options: You can now run agents in Kubernetes or with direct execution.
- Enhanced cost and usage controls.
- Many other incremental improvements that make Oz the most powerful cloud agent platform on the market.
The full story
At Warp, we spend a lot of time working with engineering leaders to more deeply understand their challenges and to help them build better software with agents. Since the initial launch of Oz the most common themes that keep surfacing are that Leaders want to deploy cloud agents at scale this year, but want to deploy them in a controlled, governed way. They want optionality when it comes to which agent harness they deploy, and want the ability to use different harnesses for different tasks, while measuring the effectiveness of each. And they want agents that run on their own infrastructure, with full ownership and control of their data.
With this latest launch, Oz is evolving its agent infrastructure layer to support all of these needs.
More agent harnesses in the cloud
The biggest improvement we are launching is that Oz is now multi-harness. Oz now supports running Claude Code and Codex as agent harnesses in addition to Warp Agent. Oz has always been multi-model, but increasingly we find that companies want a choice of harness as well, since agent performance is a function of the harness and the model together.
Being multi-harness means that companies can ask Oz to spin up cloud agents that directly use Claude Code, Codex, and Warp Agent to solve their tasks. Oz provides the ability to launch, track, govern, and steer any of these agents in one unified control plane. Oz sits a level above, allowing it to compare their effectiveness and use different harnesses for different tasks, while maintaining consistent governance, access control, and audit logs. It’s a single pane of glass for all your cloud agents.
Automatic multi-agent orchestration
The second major improvement is automatic multi-agent orchestration. Oz can now orchestrate subagents automatically, deploying and tracking multiple agents in parallel for difficult, long-horizon tasks like large feature builds, code migrations, and production deployments. This works across harnesses, and comes with auto-tracking, steering, and a management interface that shows progress across subagents.
Agent Memory
We are also announcing cross-harness Agent Memory that allows agents to store and retrieve long-term memories, enabling self-improvement over time.
Agent Memory is an index over all your organizational knowledge that lets Oz pull the right knowledge into context for any agent task. It supports pluggable data sources, so that knowledge can come from files (e.g. skills), MCPs, databases, or other enterprise applications. It’s also writable, so that Oz itself can automatically add to the knowledge store as it completes tasks. Your agents now learn how you work: code review agents learn your team’s coding style, production agents remember your system’s deployment topology, data analysis agents learn and remember how your data is structured.
Agent Memory is built so that companies can store and own their agents' memories; Warp can store them for you, but we believe companies will want to build their own corpus of organizational knowledge over time. Agent Memory is also inherently multi-harness, so it can form memories from Claude Code and Codex sessions; again, our goal is to sit a layer above any one harness and provide a system that scales as models and harnesses improve over time.
Better controls
Because enterprises want better cost controls and governance, we now provide per-team billing and individual credit caps, along with better visibility into your team usage and outcomes.
We also provide more granular control over the data and services agents can access. As part of this launch, we are introducing support for individual agents to have granular permissions to internal services, following the model of allowing agents to have the least privilege for whatever tasks they might need to do. Your agents that deal with production systems need much different permissions than those accessing with your CRM.
Expanded self-hosting options
This launch also includes a number of features that make Oz more flexible to deploy, one of the chief requests we hear from enterprise leaders. Oz can run self-hosted in more ways now: with or without Docker, in Kubernetes pods, in existing remote development environments, with full coding capabilities. You don’t need to change your development setup, because Oz works with your existing systems.
Other improvements
Finally, there are a host of other improvements that make Oz the most powerful orchestration platform on the market. Oz’s philosophy is that it should be API- and SDK-first, so we’ve extended our API to support return values from agent sessions (including artifacts and raw conversations). We’ve also made it easier to handoff agent sessions, be it from local-to-remote, remote-to-local, or remote-to-remote environments. Start an agent – or ten – on your phone, continue on your laptop, and then move it back to the cloud to continue working overnight.
We are extremely excited to help companies transform how they build software.
Introducing the Ettin Reranker Family
Six new Ettin rerankers, built on ModernBERT encoders, offer state-of-the-art accuracy and speed for retrieve-then-rerank systems, outperforming legacy models with up to 1 billion parameters.
Decoder
- Reranker: In information retrieval, a reranker is a model that takes a set of documents already retrieved by an initial search (the "retriever") and reorders them based on a more complex or accurate scoring mechanism to improve relevance.
- CrossEncoder: A type of neural network architecture, often used in rerankers, that takes a query and a document (or a pair of documents) as a single input and produces a relevance score, allowing for deep interaction between the query and document tokens.
- Pointwise MSE distillation: A training technique where a smaller "student" model learns by mimicking the output scores of a larger, more powerful "teacher" model (often using Mean Squared Error loss on individual data points) to achieve similar performance with greater efficiency.
- Retrieve-then-rerank system: A two-stage information retrieval pipeline where a fast, less precise retriever initially fetches a large set of candidate documents, and then a more computationally intensive reranker refines the ordering of those candidates for higher relevance.
Original article
Six new state-of-the-art CrossEncoder Ettin rerankers built on Ettin ModernBERT encoders have been released, offering models from 17M to 1B parameters. These models, trained with pointwise MSE distillation from a strong 1.54B parameter teacher, provide significant accuracy improvements over legacy models while enhancing speed, especially with Flash Attention 2. The models are particularly notable for their efficiency in retrieve-then-rerank systems and outperform models like ms-marco-MiniLM-L12-v2 on MTEB and NanoBEIR benchmarks.

Index
Parallel Web Systems launched Index, a platform to help content owners understand how AI agents use their work and earn revenue based on its "Shapley value."
Deep dive
- Index, by Parallel Web Systems, provides a mechanism for content owners to monitor and monetize the use of their work by AI agents.
- Compensation is determined by estimating the "Shapley value" of content, which measures its unique marginal contribution to an agent's output.
- This model aims to create an incentive-aligned economic system for the "agentic web," where AI agents are expected to use content far more extensively than humans.
- Initial partners include major publications like The Atlantic and Fortune Magazine, as well as data providers and individual creators such as Alex Heath and Packy McCormick.
- The platform leverages Parallel Web Systems' existing web index and retrieval infrastructure, which also powers their Extract API for fetching content from complex web pages.
- This initiative directly responds to the legal and ethical debates surrounding AI training data and intellectual property rights.
Decoder
- Shapley value: A concept from cooperative game theory used here to quantify the marginal contribution of a specific piece of content to an AI agent's output, helping determine its value for compensation.
- Agentic web: A term referring to a future iteration of the internet where AI agents, rather than primarily human users, are the primary consumers and interactors with web content.
Original article
Today we're launching Index: a platform for content owners to understand how AI agents use their work, and earn revenue when they do.
Our first partners include @TheAtlantic, @FortuneMagazine, @PRNewswire, @PitchBook, @ZoomInfo, @Tracxn, @RocketReachCo, @enigma_data, @fiscal_ai, plus creators @alexeheath, @mariogabriele @azeem, @every, and @packyM.
Compensation in Index is calculated by estimating each source's Shapley value: its marginal contribution to an agent's answer at the moment of inference.
Content that's uniquely valuable, hard to replace, or used in high-value agent work earns more.
AI agents are the web's second user. They'll use it 1000x more than humans ever have.
The economic model of the web was built for human users. Index is a new, incentive-aligned model for the agentic web.
See how agents are using your content at index.parallel.ai
Today, we're launching Parallel Extract, a new API in our Agent Tools bundle.
When given a URL, Extract fetches all content from that page and returns it in markdown, either in full detail or in a compressed form for better token efficiency.
Extract is built on the same proprietary web index and retrieval infrastructure that powers our Search, Task, FindAll, and Monitor APIs.
This means reliable extraction from the most challenging sites— JavaScript-heavy pages, multi-page PDFs with images, and dynamic content that only loads client-side.
How customers have been using Extract:
- Pull complete API docs and code examples
- Extract methodology from research papers
- Retrieve specific sections from 10-Ks and financial filings
- Get complete product details from ecom sites

Two AI-based science assistants succeed with drug-retargeting tasks
Google's Co-Scientist and FutureHouse's Robin, two new AI assistants published in Nature, are succeeding at drug retargeting by generating and evaluating hypotheses from vast scientific literature.
Deep dive
- Google's Co-Scientist is a "scientist in the loop" system based on Gemini, designed to assist researchers by generating and evaluating hypotheses.
- FutureHouse's Robin system, which uses specialized agents like Crow (summary), Falcon (overview), and Finch (data evaluation), can process 551 papers in 30 minutes, significantly faster than human researchers.
- Both systems focus on drug retargeting, suggesting existing drugs for new conditions, with Google's targeting acute myeloid leukemia and FutureHouse's focusing on macular degeneration.
- The tools are designed to tackle the problem of scientific literature overload, helping identify "low-hanging fruit" and connections across disparate fields.
- FutureHouse found that using specialized tools (Crow) for literature search prevented hallucinated references, contrasting with OpenAI's o4-mini which had a 45% hallucination rate.
- The AIs are not designing new molecules but are proving effective in an earlier, crucial stage of drug development.
Decoder
- Drug retargeting (or repurposing): The process of finding new uses for existing drugs that have already been approved for other conditions.
- Acute myeloid leukemia: A fast-growing cancer of the blood and bone marrow.
- Macular degeneration: An eye disease that causes blurred vision due to damage to the macula, a small spot near the center of the retina.
- Agentic system: An AI system composed of multiple distinct "agents" that work together, each specialized for a specific task (e.g., literature search, summarization, hypothesis evaluation).
- Flow cytometry: A technique used to detect and measure physical and chemical characteristics of a population of cells or particles.
- RNA-seq: A sequencing technique that uses next-generation sequencing to reveal the presence and quantity of RNA in a biological sample at a given moment.
Original article
On Tuesday, Nature released two papers describing AI systems intended to help scientists develop and test hypotheses. One, Google’s Co-Scientist, is designed as what they term “scientist in the loop,” meaning researchers are regularly applying their judgments to direct the system. The second, from a nonprofit called FutureHouse, goes a step beyond and has trained a system that can evaluate biological data coming from some specific classes of experiments.
While Google says its system will also work for physics, both groups exclusively present biological data, and largely straightforward hypotheses—this drug will work for that. So, this is not an attempt to replace either scientists or the scientific process. Instead, it’s meant to help with what current AIs are best at: chewing through massive amounts of information that humans would struggle to come to grips with.
What’s this good for?
There are some distinctions between the two systems, but both are what is termed agentic; they operate in the background by calling out to separate tools. (Microsoft has taken a similar approach with its science assistant as well; OpenAI seems to be an exception in that it simply tuned an LLM for biology.) And, while there are differences between them that we’ll highlight, they are both focused on the same general issue: the utter profusion of scientific information.
With the ease of online publishing, the number of journals has exploded, and with them the number of papers. It has gotten tough for any researcher to stay on top of their field. Finding potentially relevant material in other fields is a real challenge. If you’re focused on eye development, for example, one of the signaling systems used may also be involved in the kidney, and it can be easy to miss what people are discovering about it.
As the people at FutureHouse put this issue, “By focusing on ‘combinatorial synthesis’ (identifying non-obvious connections between disparate fields), Robin effectively targets ‘low-hanging fruit’ that human experts may overlook due to the compartmentalization of scientific knowledge.”
This is a task that’s well-suited to AI, which can chew through the peer-reviewed literature in the background while researchers do other things. This isn’t really a question of whether an AI could do something better or worse than a human; it’s more of an issue of whether any human would end up doing these sorts of searches at all.
By finding enough connections among disparate research, these tools can make suggestions—hypotheses, really—about the biology. This can include things like what processes underlie biological behaviors and what pathways and networks regulate those processes. And, in the cases explored here, it included suggesting known drugs that might target some of these pathways in diseased cells: acute myeloid leukemia in Google’s case, and a form of macular degeneration for FutureHouse.
Co-scientist
As you might imagine, Google’s system is based on the company’s Gemini large language model. That helps the system interpret a statement of research goals provided by human scientists and starts a literature search to find relevant information and form hypotheses. Those are then evaluated relative to each other in a “tournament,” the results of which are evaluated by a Reflection agent. An Evolution agent can then make improvements to any surviving ideas, which can be sent back through the process.
Key criteria considered throughout this process include plausibility, novelty, testability, and safety. And the Reflection tool has access to external search tools, as access to the scientific literature “prevented the hallucination of seemingly novel but implausible hypotheses,” the company wrote.
As the paper puts it, scientists were kept in the loop at all times. In the search for potential drugs targeting leukemia, the suggestions made by the system were prioritized based on a review by a panel of experts, who had access to the literature Co-Scientist used to formulate its suggestions.
The results are what you would expect from cancer therapies. Some of the drugs identified were effective, but only against subsets of a panel of myeloid leukemia cells. That’s not unusual, given that there are multiple routes to unchecked growth, so drugs that block the route followed by one cell type may not be effective in cells that took a different route.
Google also mentioned that the system could do more general hypothesizing that doesn’t involve drugs, using an example of the spread of virulence genes in bacteria. But the details of that work were fairly sparse.
The system is also set up so that it’s model agnostic, allowing it to be switched over to better-performing models as AI systems evolve. But they also warn that, “Co-Scientist also inherits the intrinsic limitations of its underlying models, including imperfect factuality and the potential for hallucinations.”
And Robin
FutureHouse’s system has some similarities but a couple of critical differences that go beyond naming all the agentic tools after birds. The main system, Robin, has access to specialized literature search tools. One, Crow, produces a concise summary of papers, while Falcon gives a deep overview of the information contained in the paper. The paper describing the system provides a clear sense of the advantages here: “Robin analyses 551 papers in 30 minutes compared to an estimated time of 540 hours for a human.”
Taking those summaries, Robin then formed a series of hypotheses about disease mechanisms for macular degeneration and used these tools to provide a detailed report on the evidence for each mechanism. An LLM judge then made pairwise comparisons among the hypotheses, which resulted in relative rankings—a bit like Google’s tournament system.
In a similar manner, the system was redeployed to suggest cell lines and culture conditions that could provide a model of macular degeneration, and it prepared reports on 30 candidate drugs. “These reports contained both justification for why each drug is suitable for mitigating the disease mechanism represented in the in vitro model and potential limitations the drug may pose,” according to the FutureHouse team. Again, these reports were evaluated by human experts to determine which tests to go ahead with.
Robin also suggested assays to test the drugs, which humans evaluated (in most cases, it appears they used variants of the suggested ones).
The key difference with Robin is that it includes a tool, Finch, that can automate the evaluation of data from some standard biological screening assays, like flow cytometry and RNA-seq. So, as long as your tests involve one of the assays that Finch can handle, then there’s an additional step that can be performed by the system.
As above, Robin came up with a novel hypothesis: Increasing the ability of retinal cells to pick up debris outside the cells could provide some protection against the disease. And it identified a drug that seemed to provide just that sort of boost in the experiments it proposed.
As Google found, having tools designed specifically to interface with the scientific literature mattered. Swapping out Crow for OpenAI’s o4-mini took the rate of hallucinated references from zero percent all the way up to 45 percent. FutureHouse also took a look at the performance of OpenAI’s research-focused tool and found that, in all cases where it suggested drugs that Robin hadn’t come up with, those drugs failed to have an effect on these cells.
Where does this leave us?
For starters, it’s important to note that these successes come in one of the easier parts of drug development (not that any part of it can really be said to be easy). The AIs weren’t being asked to design entirely new molecules, and most drugs fail during the animal and clinical trials phase, rather than during testing in cell culture. That’s not to say repurposing existing drugs is nothing—we already have safety profiles and agency approvals for these molecules, and many are off-patent and therefore cheap. But we’re not at the point where AIs are solving hard problems.
This sort of hypothesis—this mechanism underlies that disease, and the drug over there can target it—is also one of the more concrete forms of hypothesis in biology. In my career as a scientist, I had to develop hypotheses that were meant to address things like “mice with this mutation have a whole lot of defects in very different tissues; is there a single mechanism underlying them?” Or, “What’s going on at the border of this gene’s expression that is changing how cells respond to this signaling molecule?” It’s unclear how these systems could handle these more open-ended scientific problems.
That said, the problem of literature overload is a real one in many fields, and systems meant to address it could help us avoid a situation where all the information we needed was sitting around for a decade, but nobody put it together. Given we’re still working through AI’s growing pains, however, I’m also happy that there are at least two independently developed systems tackling this problem so that we can potentially run both and compare the results.
Nature, 2026. DOI: 10.1038/s41586-026-10652-y, /10.1038/s41586-026-10644-y (About DOIs).
Antigravity 2.0 (Website)
Google launched Antigravity 2.0, a macOS platform for orchestrating multiple autonomous AI agents in parallel projects with features like dynamic subagents and live voice transcription.
Decoder
- Autonomous agents: AI programs designed to perform tasks independently by perceiving their environment, making decisions, and acting on those decisions, often involving multiple steps or interactions.
- Orchestration: The automated arrangement, coordination, and management of complex computer systems, middleware, and services, in this case, multiple AI agents.
Original article
Google Antigravity is a dedicated platform for working with agents. It allows users to orchestrate multiple autonomous agents working in parallel across independent projects. Antigravity features an abstracted UI, dynamic subagents, scheduled tasks, artifacts, extended customization, live voice transcription, and more. It is available on macOS for both Apple Silicon and Intel.
Andrej Karpathy, Tesla Alum and OpenAI Co-Founder, Joins Anthropic
Andrej Karpathy, former OpenAI founding researcher and Tesla Autopilot lead, has joined Anthropic's pretraining team to accelerate research using Claude.
Decoder
- Pretraining: The initial phase of training a large language model on a massive dataset, where the model learns general language patterns and knowledge before being fine-tuned for specific tasks.
Original article
OpenAI co-founder and former Tesla executive Andrej Karpathy has joined Anthropic's pretraining team, which oversees the data training process for the company's AI models. He will lead a new group focused on using Claude to accelerate pretraining research. Karpathy previously led a team at Tesla that oversaw the functionality of the company's Autopilot advanced driver assistance system, and he was also a founding research scientist at OpenAI until 2017.
Software's Centaur Era
The author argues that software development is entering a "centaur era" where humans and AI agents collaborate, rather than AI fully automating away software jobs.
Deep dive
- The article addresses concerns about AI automating away software engineering jobs, drawing a parallel to the history of chess.
- In chess, after Deep Blue beat Kasparov in 1997, the peak performance came from "centaurs" – skilled humans working with chess engines – for decades.
- The author argues that the software industry is not even in its centaur era yet, let alone past it.
- Current AI coding agents, despite capabilities like building a C compiler or a browser, cannot reliably make independent progress on long-horizon projects.
- Without human steering, AI agents tend to "go off the rails," leading to broken codebases and products if left unsupervised.
- The economic value of software engineers lies in their ability to reliably improve software systems over time.
- Even if AI agents become highly capable, humans will still have a role as long as human-agent teams are more effective than agent-only teams.
- The article concludes that the "centaur era" for software, where humans and AI collaborate, has not truly begun, suggesting a long future for human software engineers.
Decoder
- Centaur (chess): A term used in chess to describe a team consisting of a human player working in conjunction with a computer chess engine.
Original article
Software's Centaur Era
It’s 2030. I wake up, make my coffee, drag myself over to my laptop. Then I remember – AI has completely replaced knowledge work. I open up my agent chat, type “still got access to my bank account? Please continue making money.”
I hesitate. Should I add something else? Nudge the AI toward a problem area I personally judge to be important or interesting? I resist, for as that would constitute knowledge work (which AI has entirely replaced), it would strictly decrease my expected return.
I scratch that itch instead by starting Wordle with something other than SLATE. I solve in 5, finish my coffee, and then get to work at my side gig: driving around doing TaskRabbit jobs at the behest of AIs that are not (yet) otherwise capable of influencing the physical world.
There was a teenager on r/programming worried about going to college and majoring in computer science, asking – is AI going to automate away all the software jobs? I went back to my alma mater and was visiting with one of my computer science professors. She told me the major was shrinking, presumably also because of AI fears.
So how about it? Will AI automate away all the software jobs?
I think it’s easy to miss how extreme a scenario this is, economically. Software jobs don’t necessarily disappear if AI surpasses humans at writing software – the jobs might change in nature, sure – but they don’t really disappear unless there is truly nothing left for humans to contribute to the process.
Take chess. Deep Blue beat Kasparov in 1997, but for a long period of time after that, the best chess performance didn’t come from engines playing by themselves – it came from “centaurs” – a colorful term for a team composed of a skilled human wielding a chess engine. Now the centaur era of chess is over – the best engines are so good that a grandmaster steering them only weakens them – but this is a recent development: the centaur era lasted for decades.
Is the software industry in its centaur era right now? No. Not even. The coding agent equivalent of Deep Blue hasn’t even beaten Kasparov yet.
You can hire a grandmaster-level software engineer, leave them pretty much alone, and trust that they will start making valuable contributions to long-term projects and will reliably be making your software system better. That’s just not true (yet) of any of these coding agents. If you leave them alone without human steering, they go off the rails pretty quickly. If you just set an AI coding agent (and an AI reviewer) loose with your product roadmap and let them merge things, your codebase (and product) gets real broken, real quick. Claude built its vibe-coded C compiler, Cursor built their vibe-coded browser – it’s true. But being able to reliably make independent progress on long-horizon projects? This is the economic core of why software engineers are valuable. And it is the absolute frontier of what these models are just beginning to become capable of.
But even if coding agents nail it, and become able to reliably improve software, it’s not over for the humans. As long as humans have something to contribute – as long as teams of humans and agents working together are more effective than teams of agents alone, there will always be room for humans in the software industry. We’re not over until the Centaur Era is over, and it hasn’t even really begun yet.
Thanks for reading! To read more by me, you can subscribe to the Atom feed or follow my Twitter.
Check out the previous post, "we're all bottlenecks now".
"The quality bar is higher for tools that save you energy than for tools that merely save you time"

Fortnite Returns to the App Store Worldwide as Epic Signals 'Final Battle' With Apple
Epic Games is relaunching Fortnite on the App Store globally, framing it as the “final battle” against Apple’s “junk fees” after court rulings forced Apple to be more transparent about its commission rates.
Original article
Fortnite Returns to the App Store Worldwide as Epic Signals 'Final Battle' With Apple
Fortnite is back on the App Store in every country except Australia, Epic Games announced today, as the company declared it is entering the "final battle" of its long-running legal dispute with Apple.
Epic said the decision to push Fortnite back onto iOS globally was prompted by Apple's own words to the U.S. Supreme Court, in which Apple acknowledged that "regulators around the world are watching this case to determine what commission rate Apple may charge on covered purchases in huge markets outside the United States." Epic CEO Tim Sweeney framed the move as a strategic provocation, writing on X that the return marks "the beginning of the end of the Apple Tax worldwide."
The return follows Fortnite's reinstatement to the U.S. App Store in May 2025 after nearly five years off the platform. The return was forced after District Judge Yvonne Gonzalez Rogers threatened to require the Apple official overseeing app decisions to appear in court, which prompted Apple to approve the submission. Today's worldwide rollout extends that comeback to most remaining markets, with Epic expressing confidence that an upcoming court-ordered transparency process will expose what the company calls Apple's "junk fees."
Apple knows the U.S. federal court will force it to be transparent about how it charges its App Store fees. Fortnite is returning to the App Store now because we are confident that once Apple is forced to show its costs, governments around the world will not allow Apple junk fees to stand.
In late April, the Ninth Circuit Court of Appeals reversed a stay that had allowed Apple to pause its compliance with rulings on App Store fees, sending the case back to Judge Gonzalez Rogers to determine what commission Apple can charge on purchases made via external links, if any.
Epic said it will "continue to challenge Apple's anticompetitive App Store practices of banning alternative app stores and competition in payments," pointing to regulatory momentum in Japan, the European Union, and the United Kingdom. The company alleged that Apple has "evaded the laws with scare screens, fees and onerous requirements" in each of those jurisdictions.
Australia is the one major market where Fortnite has not returned. Epic said it won its court case there and that an Australian court found many of Apple's developer terms to be unlawful, but Apple continues to enforce those terms regardless. Epic said it cannot return "under an illegal payment arrangement" and is waiting for a court order to compel Apple to comply.
New in Terraform 1.15: Dynamic sources, variable deprecation, and more
Terraform 1.15 ships with dynamic module sources and a new `convert()` function for inline type conversions, significantly improving module flexibility and developer experience.
Original article
Terraform 1.15 adds dynamic module sources with const variables, deprecation warnings for module variables and outputs, inline type conversions via convert(), typed outputs, enhanced testing mocks, and validation blocks for Stacks variables. Additional improvements include Windows ARM64 support, AWS login authentication for S3 backends, and better CLI deprecation diagnostics to improve usability, testing, and enterprise-scale workflows.

Back up and restore your Amazon EKS cluster resources using Velero
AWS published a detailed guide on using Velero to back up and restore Amazon EKS cluster resources and persistent volume data to Amazon S3 and EBS, leveraging EKS Pod Identity for secure, least-privilege access.
Deep dive
- The tutorial by Sapeksh Madan and Shalabh Srivastava from AWS outlines backing up and restoring Amazon EKS cluster resources and persistent volume data using Velero.
- Velero stores Kubernetes resource definitions in Amazon S3 buckets and persistent volume data as Amazon EBS snapshots.
- The setup emphasizes security with least-privilege AWS IAM roles configured via Amazon EKS Pod Identity, preventing the need for managing credentials directly.
- A custom Kubernetes
ClusterRoleis defined to scope Velero's permissions more tightly than the defaultcluster-admin. - A sample stateful application is deployed to demonstrate namespace-scoped backups and subsequent restores to a different namespace (
myprimarytomyrestore). - Requires Kubernetes 1.35 or later on EKS, along with
aws cli v2,Helm v3.x, andkubectl. - The process includes installing the
snapshot-controlleradd-on and defining aVolumeSnapshotClassfor EBS CSI driver. - AWS Backup for Amazon EKS is mentioned as an alternative for centralized, fully managed backup scheduling.
Decoder
- Velero: An open-source tool for backing up and restoring Kubernetes cluster resources and persistent volumes.
- Amazon EKS Pod Identity: An AWS feature that allows Kubernetes pods to assume IAM roles for accessing AWS services without explicitly managing credentials within the pod or cluster.
- Amazon S3: Amazon Simple Storage Service, a highly scalable object storage service.
- Amazon EBS snapshots: Point-in-time backups of Amazon Elastic Block Store (EBS) volumes.
- PersistentVolumeClaim (PVC): A Kubernetes object representing a request for storage by a user, which then provisions a PersistentVolume.
- Container Storage Interface (CSI): A standard for exposing arbitrary block and file storage systems to containerized workloads on Kubernetes.
Original article
Back up and restore your Amazon EKS cluster resources using Velero
When you accidentally delete a production namespace or a cluster upgrade fails, rebuilding your Amazon Elastic Kubernetes Service (Amazon EKS) cluster resources means recreating every deployment, service, and persistent volume manually. With Velero, a backup and restore tool for Kubernetes, you capture resource definitions to Amazon Simple Storage Service (Amazon S3) and persistent volume data as Amazon Elastic Block Store (Amazon EBS) snapshots. Velero supports cross-cluster restores, namespace-level granularity, and portability across Kubernetes distributions. If you need centralized, fully managed backup scheduling instead, AWS Backup for Amazon EKS handles that for you.
In this post, you’ll learn to back up and restore Amazon EKS cluster resources and persistent volume data using Velero. You’ll deploy a sample stateful application, back it up, and restore it to a different namespace within the same cluster. Along the way, you’ll configure least-privilege AWS Identity and Access Management (AWS IAM) roles using Amazon EKS Pod Identity and scope Velero’s Kubernetes permissions with a custom ClusterRole. A ClusterRole is a Kubernetes resource that defines cluster-wide permissions.
Prerequisites
You’ll spend 45 to 60 minutes on this tutorial and incur costs for Amazon S3 storage (based on data stored), Amazon EBS snapshots (based on snapshot storage), and Amazon EKS cluster usage (based on cluster runtime). For detailed pricing information, see Amazon S3 Pricing, Amazon EBS Pricing, and Amazon EKS Pricing. Clean up instructions at the end help you remove all billable resources. To complete this tutorial, make sure you have the following:
- An active AWS account with permissions to create Amazon S3 buckets, IAM policies and roles, and Amazon EKS resources
- An Amazon EKS cluster running Kubernetes 1.35 or later with Amazon EKS Auto Mode enabled. Auto Mode automates networking, node provisioning and scaling. You can use eksctl to create this cluster – Refer steps here
- AWS CLI v2, Helm v3.x, and kubectl installed and configured
- Experience with Kubernetes concepts such as pods, deployments, and persistent volumes, and with IAM roles
The default Velero installation uses cluster-admin, which grants broad access to cluster resources. This tutorial replaces it with a least-privilege ClusterRole. Follow those steps for non-demo environments.
Velero overview
Velero is an open-source tool that backs up and restores Kubernetes cluster resources and persistent volumes. Unlike traditional backup solutions that require direct access to storage systems, Velero works through the Kubernetes API to discover and back up resources. This API-driven approach provides several advantages:
- Kubernetes-native: Velero understands Kubernetes resources and their relationships
- Flexible filtering: You can scope backups by namespace, resource type, or label
- Cloud-agnostic: The same backup can be restored to different Kubernetes distributions
- Snapshot integration: Velero integrates with cloud provider snapshot APIs for persistent volume backups
An application-level backup in Amazon EKS targets two components:
- Kubernetes objects and configurations stored in the EKS control plane
- Application data stored in persistent volumes
Refer to the Velero documentation for details on resource filtering.
Backup and Restore Workflow
Velero uses a controller deployed as a Kubernetes Deployment to perform backup and restore tasks. A user submits a Backup manifest or Restore manifest (Custom Resource) to EKS, for the Velero controller to perform Backup or Restore. Velero documentation provides details on how they work here.
Tutorial
This tutorial uses Amazon EKS Auto Mode to simplify cluster management. Velero does not require Auto Mode and works on any Amazon EKS cluster. The walkthrough backs up an application in namespace myprimary and restores it to another namespace myrestore in the same cluster.
Set up environment variables
Substitute your cluster name and Region in the following exports. The tutorial references these variables in every subsequent step.
export CLUSTER_NAME=<<Cluster Name>>
export AWS_REGION=<<AWS region>>
export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text --no-cli-pager)
export BUCKET_NAME=velero-backups-$(date +%s)
export POLICY_NAME=VeleroBackupPolicy
export ROLE_NAME=VeleroBackupRole
export AWS_PAGER=""Configure Amazon S3 and IAM
First, provision the Amazon S3 bucket where Velero stores backup data.
aws s3 mb s3://${BUCKET_NAME} --region ${AWS_REGION}Next, define an IAM policy granting Velero read/write access to the bucket and Amazon EBS snapshot permissions.
cat > velero-s3-policy.json <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:GetObject","s3:PutObject","s3:DeleteObject","s3:ListBucket","s3:GetBucketLocation","s3:GetBucketVersioning","s3:AbortMultipartUpload", "s3:ListMultipartUploadParts"],
"Resource": ["arn:aws:s3:::${BUCKET_NAME}","arn:aws:s3:::${BUCKET_NAME}/*"]
},
{
"Effect": "Allow",
"Action": ["ec2:CreateSnapshot","ec2:DeleteSnapshot","ec2:DescribeSnapshots","ec2:DescribeVolumes","ec2:DescribeVolumeAttribute","ec2:DescribeVolumesModifications","ec2:DescribeVolumeStatus","ec2:CreateTags","ec2:DescribeTags"],
"Resource": "*"
}
]
}
EOF
aws iam create-policy --policy-name ${POLICY_NAME} --policy-document file://velero-s3-policy.jsonThe following commands capture the policy ARN, set up an IAM role with EKS Pod Identity trust, and attach the policy. Using EKS Pod Identity, your Kubernetes pods can assume IAM roles without managing credentials.
export POLICY_ARN=$(aws iam list-policies --query "Policies[?PolicyName=='${POLICY_NAME}'].Arn" --output text --no-cli-pager)
cat > velero-trust-policy.json <<EOF
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "pods.eks.amazonaws.com"},
"Action": ["sts:AssumeRole","sts:TagSession"],
"Condition": {"StringEquals": {"aws:RequestTag/kubernetes-namespace": "velero","aws:RequestTag/kubernetes-service-account": "velero"}}
}]
}
EOF
aws iam create-role --role-name ${ROLE_NAME} --assume-role-policy-document file://velero-trust-policy.json
aws iam attach-role-policy --role-name ${ROLE_NAME} --policy-arn ${POLICY_ARN}With the role created, capture its ARN and associate the Velero service account through Pod Identity.
export ROLE_ARN=$(aws iam get-role --role-name ${ROLE_NAME} --query Role.Arn --output text)
aws eks create-pod-identity-association --cluster-name ${CLUSTER_NAME} --namespace velero --service-account velero --role-arn ${ROLE_ARN} --region ${AWS_REGION}Install Velero
Velero uses Amazon EBS snapshots to take backup of Volumes. This requires the snapshot controller add-on to be installed on you EKS cluster. Connect to your cluster and install it first.
aws eks update-kubeconfig --name ${CLUSTER_NAME}
aws eks create-addon --cluster-name ${CLUSTER_NAME} --addon-name snapshot-controller --region ${AWS_REGION}Generate the Helm values file for Velero chart install. This configures Velero to use your Amazon S3 bucket for backup storage, your Region for Amazon EBS snapshots, and Pod Identity for authentication.
cat > velero-values.yaml <<EOF
configuration:
backupStorageLocation:
- name: default
provider: aws
bucket: ${BUCKET_NAME}
config:
region: ${AWS_REGION}
volumeSnapshotLocation:
- name: default
provider: aws
config:
region: ${AWS_REGION}
features: EnableCSI
credentials:
useSecret: false
serviceAccount:
server:
create: true
name: velero
initContainers:
- name: velero-plugin-for-aws
image: velero/velero-plugin-for-aws:v1.10.0
volumeMounts:
- mountPath: /target
name: plugins
upgradeCRDs: false
cleanUpCRDs: false
EOFInstall Velero with Helm and verify the pod is running.
helm repo add vmware-tanzu https://vmware-tanzu.github.io/helm-charts
helm repo update
helm install velero vmware-tanzu/velero --version 11.4.0 --namespace velero --create-namespace --values velero-values.yaml
kubectl get pods -n veleroThe default Velero installation binds to cluster-admin, granting broader permissions than necessary. Replace it with a least-privilege ClusterRole that scopes permissions to only what Velero needs.
cat > velero-cluster-role.yaml <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: velero-restricted
rules:
- apiGroups: [""]
resources: [namespaces,persistentvolumes,persistentvolumeclaims,pods,services,configmaps,secrets]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["apps"]
resources: [deployments,replicasets]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["rbac.authorization.k8s.io"]
resources: [clusterrolebindings]
verbs: ["get","list"]
- apiGroups: ["storage.k8s.io"]
resources: [storageclasses]
verbs: ["get","list","watch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: [volumesnapshots,volumesnapshotcontents,volumesnapshotclasses]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["velero.io"]
resources: [backups,backups/status,restores,restores/status,schedules,schedules/status,backupstoragelocations,backupstoragelocations/status,volumesnapshotlocations,volumesnapshotlocations/status,podvolumebackups,podvolumebackups/status,podvolumerestores,podvolumerestores/status,backuprepositories,backuprepositories/status]
verbs: ["get","list","watch","create","update","patch","delete"]
EOF
kubectl apply -f velero-cluster-role.yaml
kubectl delete clusterrolebinding velero-server
kubectl create clusterrolebinding velero-restricted-binding --clusterrole=velero-restricted --serviceaccount=velero:veleroNow define a VolumeSnapshotClass. This Kubernetes resource specifies the Container Storage Interface (CSI) driver for Amazon EBS snapshots. See the Kubernetes VolumeSnapshotClass documentation for options.
cat > snapshot-class.yaml <<EOF
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: ebs-csi-snapclass
labels:
velero.io.csi-volumesnapshot-class: "true"
annotations:
snapshot.storage.kubernetes.io/is-default-class: "true"
driver: ebs.csi.eks.amazonaws.com
deletionPolicy: Delete
EOF
kubectl apply -f snapshot-class.yamlRestart Velero and verify storage locations are available.
kubectl rollout restart deployment/velero -n velero
kubectl get backupstoragelocation -n velero
# Expected: PHASE=AvailableBack up an application
Deploy a sample application that mounts a PersistentVolumeClaim (PVC). A PVC is a Kubernetes request for storage that provisions an Amazon EBS volume. The application writes timestamped messages to a file that you use to verify the restore. The following manifest deploys the application in the myprimary namespace. It creates the namespace, a StorageClass for encrypted gp3 Amazon EBS volumes, a PVC, and a Deployment that writes to the persistent volume.
cat > deployment-demo-app.yaml <<EOF
---
apiVersion: v1
kind: Namespace
metadata:
name: myprimary
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: auto-ebs-sc
provisioner: ebs.csi.eks.amazonaws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
encrypted: "true"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: auto-ebs-claim
namespace: myprimary
spec:
accessModes: [ReadWriteOnce]
storageClassName: auto-ebs-sc
resources:
requests:
storage: 8Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-stateful-app
namespace: myprimary
spec:
replicas: 1
selector:
matchLabels:
app: demo-stateful-app
template:
metadata:
labels:
app: demo-stateful-app
spec:
terminationGracePeriodSeconds: 0
nodeSelector:
eks.amazonaws.com/compute-type: auto
containers:
- name: bash
image: public.ecr.aws/docker/library/bash:4.4
command: ["/usr/local/bin/bash"]
args: ["-c", "while true; do echo \"Message from \$POD_NAMESPACE - \$(date -u)\" >> /data/out.txt; sleep 15; done"]
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
resources:
requests:
cpu: "100m"
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: auto-ebs-claim
EOF
kubectl apply -f deployment-demo-app.yamlVerify the pod is running. Node provisioning by Amazon EKS might take a couple of minutes.
kubectl get po -n myprimary
kubectl exec -n myprimary "$(kubectl get pods -n myprimary -l app=demo-stateful-app -o=jsonpath='{.items[0].metadata.name}')" -- cat /data/out.txtDefine a Velero Backup custom resource for the myprimary namespace. This YAML scopes the backup to specific resource types and triggers Amazon EBS snapshots for persistent volumes. See the Velero Backup API documentation for filtering options.
cat > myprimary-backup.yaml <<EOF
apiVersion: velero.io/v1
kind: Backup
metadata:
name: backup-myprimary
namespace: velero
spec:
includedNamespaces: [myprimary]
includedResources: [deployments,pods,persistentvolumeclaims,persistentvolumes,services,configmaps,secrets]
snapshotVolumes: true
defaultVolumesToFsBackup: false
ttl: 720h0m0s
EOF
kubectl apply -f myprimary-backup.yamlAfter a couple of minutes, confirm the backup completed.
kubectl describe backup backup-myprimary -n velero
# Look for Phase: CompletedRestore an application
Restore the backup to a new namespace called myrestore. Velero’s namespace mapping redirects resources from myprimary to myrestore. Apply the Restore custom resource. This YAML specifies which backup to restore and how to map namespaces.
cat > myprimary-restore.yaml <<EOF
apiVersion: velero.io/v1
kind: Restore
metadata:
name: myprimary-restore
namespace: velero
spec:
backupName: backup-myprimary
namespaceMapping:
myprimary: myrestore
preserveNodePorts: true
restorePVs: true
EOF
kubectl apply -f myprimary-restore.yamlConfirm the restore completed.
kubectl describe restore myprimary-restore -n velero
# Look for Phase: CompletedCheck the data file on the restored pod.
kubectl exec -n myrestore "$(kubectl get pods -n myrestore -l app=demo-stateful-app -o=jsonpath='{.items[0].metadata.name}')" -- cat /data/out.txtThe output shows messages from myprimary, confirming that Velero restored the persistent volume data from the Amazon EBS snapshot.
Clean up
Remove the resources you provisioned to stop incurring charges for Amazon S3 storage, Amazon EBS snapshots, and Amazon EKS compute.
kubectl delete -f deployment-demo-app.yaml
kubectl delete namespace myrestore
helm uninstall velero -n velero
kubectl delete namespace velero
kubectl delete clusterrolebinding velero-restricted-binding
kubectl delete clusterrole velero-restricted
aws eks delete-addon --cluster-name ${CLUSTER_NAME} --addon-name snapshot-controller --region ${AWS_REGION}
aws s3 rb s3://$BUCKET_NAME --force
aws iam detach-role-policy --role-name VeleroBackupRole --policy-arn ${POLICY_ARN}
aws iam delete-role --role-name VeleroBackupRole
aws iam delete-policy --policy-arn ${POLICY_ARN}Also check the Amazon EBS console for remaining snapshots or volumes and delete them manually.
Conclusion
You configured Velero on Amazon EKS to back up and restore Kubernetes cluster resources and persistent volume data with least-privilege AWS IAM roles and a scoped ClusterRole. To build on what you’ve learned, try these next steps:
- Automate daily backups of your production namespaces with a Velero Schedule resource.
- Test a cross-cluster restore to a second Amazon EKS cluster in a different Region using the Velero disaster recovery documentation.
- Evaluate AWS Backup for Amazon EKS and compare centralized scheduling against namespace-level granularity and cross-cluster portability.
- Harden your cluster security by reviewing the Amazon EKS security best practices guide.
Share your experiences in the AWS containers community forum.
For reference, see the following resources:
- Velero documentation
- Amazon EKS User Guide
- Amazon EKS Pod Identity
- Amazon EBS CSI driver
- IAM best practices for Amazon EKS
- Amazon S3 bucket policies
- AWS Backup Developer Guide
Interested in hands-on experience?
|
About the authors

AI Is Writing More Code. Your CI Pipeline Can't Keep Up
CloudBees warns that increased code generation from AI is overwhelming traditional CI pipelines, advocating for intelligent test selection to cut costs and improve feedback loops by running only relevant tests.
Deep dive
- AI-assisted development is accelerating code changes and increasing pull request output by up to 65% for daily users.
- This surge in commits leads to more frequent CI runs and longer test suite executions, driving up cloud compute costs and slowing developer feedback.
- CloudBees argues that running the entire test suite on every code change is an outdated and inefficient model for modern enterprise scale.
- Test execution is identified as the primary driver of CI spend and pipeline duration, often lasting 45-90 minutes, compared to shorter build times.
- Flaky tests account for roughly one-third of CI failures, contributing to wasted compute and developer time on reruns and debugging.
- Intelligent test selection analyzes code changes to identify and run only the tests most relevant to that specific modification, rather than the entire suite.
- CloudBees Smart Tests is presented as a solution, using AI-driven analysis to automatically select relevant tests.
- Customer examples cite savings of three to five cloud VM instances per test hour, over 40,000 engineering hours reallocated annually, and a doubling of release velocity (from quarterly to monthly).
- The article positions intelligent testing as essential to maintain developer productivity and control costs in an era of abundant AI-generated code.
Decoder
- CI pipeline: Continuous Integration pipeline, an automated process that builds, tests, and validates code changes.
- Intelligent test selection: A strategy where only a subset of tests deemed relevant to a specific code change are executed, rather than running the entire test suite.
Original article
Full article content is not available for inline reading.

Automating Confidential Containers (CoCo) infrastructure with Kyverno
Kyverno, a Kubernetes policy engine, now automates Confidential Containers (CoCo) deployments by injecting security configurations and validating inputs, simplifying operations while maintaining CoCo's zero-trust model.
Deep dive
- Confidential Containers (CoCo) secure container workloads in environments where the Kubernetes control plane is explicitly untrusted.
- Deploying CoCo workloads is complex, requiring manual management of
runtimeClass,initdata(bootstrap config, attestation details),sealed secrets, and optionalattestation initcar/mTLS sidecar. - Kyverno, a Kubernetes-native policy engine, automates this by mutating and validating resources at admission time.
- Kyverno injects required CoCo configurations and validates inputs early in the deployment process.
- A crucial "trust paradox" is addressed: Kyverno runs in the untrusted Kubernetes control plane, so it provides operational automation, not trust.
- The ultimate security decision points remain CoCo's remote attestation and runtime policy, which verify container images and pod specifications.
- The solution involves separation of duties: Platform/Infrastructure teams manage Kubernetes and define policies, App Security teams provide
initdataand manage attestation servers, and App Development teams deploy manifests. - This approach simplifies deployment, reduces misconfigurations, and helps scale confidential workloads while maintaining a strong zero-trust posture.
Decoder
- Confidential Containers (CoCo): An open-source initiative to secure container workloads, especially in environments where parts of the underlying platform (like the Kubernetes control plane) are not fully trusted.
- Kyverno: A Kubernetes-native policy engine that allows defining policies to validate, mutate, and generate Kubernetes resources at admission time.
- Zero-trust security model: A security concept where no user, device, or application is inherently trusted, regardless of whether it is inside or outside the network perimeter.
- Remote attestation: A process where a remote entity (e.g., a server) cryptographically verifies the integrity and identity of a trusted execution environment (e.g., a confidential container) before sensitive data is released.
runtimeClass: A Kubernetes resource used to select the runtime configuration for a pod, like a confidential runtime environment.initdata: Bootstrap configuration for a confidential environment, including details for remote attestation and container/agent policies.
Original article
Full article content is not available for inline reading.
Karpenter now supports Amazon Application Recovery Controller zonal shift
Amazon EKS and Karpenter now support ARC zonal shift, allowing Kubernetes clusters to automatically move traffic and stop provisioning in impaired AWS Availability Zones during outages.
Deep dive
- Amazon EKS now supports Amazon Application Recovery Controller (ARC) zonal shift and zonal autoshift.
- This integration is specifically for EKS clusters using the open-source Karpenter project for compute provisioning.
- The feature, launched on May 12, 2026, aims to improve Kubernetes application availability during Availability Zone (AZ) impairments.
- When an ARC zonal shift is activated, Karpenter automatically stops provisioning new compute capacity in the impaired AZ.
- It also halts voluntary disruptions (like consolidation and drift) for nodes already in that AZ.
- Karpenter prevents voluntary disruptions in healthy zones if they would require scheduling pods into the impaired zone.
- Pods with strict scheduling requirements, such as volume affinities tied to the impaired AZ, will not trigger launch attempts.
- When the zonal shift expires or is canceled, Karpenter resumes normal operations.
- This functionality works with both manual zonal shifts and automated zonal autoshifts, which can include practice runs.
- No custom ARC resources are needed as Karpenter integrates directly with existing EKS cluster ARC resources.
- To enable, users need to set the ENABLE_ZONAL_SHIFT setting in their Karpenter configuration.
Decoder
- Amazon EKS (Elastic Kubernetes Service): A managed Kubernetes service that makes it easier to run Kubernetes on AWS without needing to install, operate, and maintain your own Kubernetes control plane.
- Karpenter: An open-source, high-performance Kubernetes node provisioning project that observes pending pods and launches optimally sized nodes to meet their requirements.
- Amazon Application Recovery Controller (ARC): An AWS service designed to help customers manage and coordinate recovery for their applications across AWS Regions and Availability Zones.
- Zonal shift: A feature of ARC that allows you to temporarily redirect network traffic away from an impaired Availability Zone without needing to redeploy or reconfigure your application.
- Zonal autoshift: An automated version of zonal shift where AWS can manage the traffic redirection on your behalf during an AZ impairment, including practice runs to verify functionality.
- Availability Zone (AZ): One or more discrete data centers with redundant power, networking, and connectivity in an AWS Region, isolated from failures in other AZs.
Original article
Full article content is not available for inline reading.

Announcing AWS CDK Mixins: Composable Abstractions for AWS Resources
AWS CDK Mixins introduce a new way to apply reusable infrastructure capabilities to any construct (L1, L2, or custom) after creation, allowing more composable and flexible infrastructure-as-code.
Deep dive
- AWS CDK Mixins are a new feature in the AWS Cloud Development Kit designed to allow composable and reusable infrastructure abstractions.
- Mixins enable developers to apply sophisticated features (e.g., S3 versioning, ECS Container Insights, data recovery, public access blocks) to any construct type: L1 (direct CloudFormation mapping), L2 (higher-level abstractions), or custom constructs.
- This approach decouples abstractions from specific construct implementations, addressing the traditional trade-off between quick access to new AWS features and rich L2/L3 abstractions.
- Key benefits include universal compatibility, composable design (mix and match features), cross-service abstractions, day-one coverage for new AWS features, and type safety.
- Mixins are complementary to CDK Aspects, with Mixins configuring resources and Aspects enforcing rules broadly during synthesis.
- They are accessed via the aws-cdk-lib package (core functionality) and service-specific imports (e.g., s3.mixins), with CloudFormation property mixins in @aws-cdk/cfn-property-mixins.
- Custom Mixins can be created by extending cdk.Mixin and implementing IMixin, defining supports() and applyTo() methods.
- Control over Mixin application behavior is available through graceful (skips unsupported), requireAll (throws if any selected construct is unsupported), and requireAny (throws if no selected construct is supported) modes.
- An example shows a MyDataRecovery mixin applying versioning to S3 buckets and point-in-time recovery to DynamoDB tables simultaneously.
- Preview features include complex cross-service abstractions like vended log delivery for 47 AWS resources, simplifying log setup dramatically.
- Momo Kornher, Senior Software Development Engineer on the AWS CDK team, and Michael Kaiser, Solution Architect at AWS, were involved in the announcement.
Decoder
- AWS CDK (Cloud Development Kit): An open-source software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation.
- Constructs: Reusable, modular cloud components in CDK that represent one or more AWS CloudFormation resources and their configurations.
- L1 Constructs: Low-level CDK constructs that map directly to AWS CloudFormation resources, offering direct access to all CloudFormation properties.
- L2 Constructs: Higher-level CDK constructs that provide opinionated abstractions, convenience methods, security defaults, and helper functions for AWS resources.
- L3 Constructs (Patterns): Even higher-level CDK constructs that combine multiple L1/L2 resources to solve specific use cases or implement common architectural patterns.
- CloudFormation: An AWS service that helps you model and set up your AWS resources so that you can spend less time managing those resources and more time focusing on your applications running in AWS.
- CDK Aspects: A mechanism in AWS CDK to apply operations (like validation, compliance checks, or tagging) to all constructs within a given scope during the synthesis phase.
Original article
Full article content is not available for inline reading.
The AI to UI Trap
Designers are wary of AI's push to redefine design as mere UI generation, fearing it shifts focus from strategic thinking to execution, making them replaceable.
Original article
Designers face pressure to adopt AI tools and rebrand as "AI-native builders," but many privately express reluctance about fully embracing these technologies. The main challenge isn't that AI will do designers' work, but that it redefines design work by making every problem look like a visual output issue, shifting focus from strategic thinking to mere UI generation. This reluctance may actually be a professional instinct, as competing with AI on execution alone becomes a race to the bottom that ultimately makes designers replaceable.

“What aesthetic is this?” Elizabeth Goodspeed on the push to categorise visual culture
Internet culture, driven by algorithms and moodboards, has turned visual elements into searchable "aesthetics," fundamentally changing how we categorize and remember creative output.
Original article
Full article content is not available for inline reading.

Rosebernard Studio's Robert Polacek on Why AI Belongs Behind the Curtain in Design
Robert Polacek of RoseBernard Studio argues AI should work invisibly in design, automating mundane tasks so designers can focus on creative work, positioning agile studios to adapt faster than large firms.
Deep dive
- Robert Polacek, co-founder of RoseBernard Studio, advocates for AI's invisible role in design, handling mundane tasks while designers focus on core creativity.
- He observes that AI's influence at Milan Design Week was subtle, integrated into production rather than overtly visible in the final art.
- Polacek emphasizes that studios using AI purely for cost-cutting risk diminishing the human element and meaning in creative work.
- Smaller, agile studios are better equipped to adopt new AI tools quickly compared to large firms hampered by multiple offices and legacy systems.
- Younger designers increasingly expect AI to be a standard part of professional practice, and studios should cater to this expectation.
- AI has allowed RoseBernard Studio to remain lean and expand creative output without replacing jobs, instead making "mundane tasks" unnecessary.
- Polacek believes advanced creative tools accessible via AI can open pathways for younger entrepreneurs and boutique firms by enabling smaller teams to accomplish more.
- Continuous learning and adaptability to technological evolution are crucial for designers to remain relevant in the age of AI.
Original article
Full article content is not available for inline reading.
How mobile apps are reshaping screening for cognitive decline
Mobile apps are reshaping cognitive decline screening by gamifying validated tests, but face challenges in clinical validation, privacy, and hardware consistency for widespread adoption.
Deep dive
- Mobile apps are transforming cognitive decline screening by making scientifically validated tests more accessible and often gamified.
- Tools like Sea Hero Quest and Integrated Cognitive Assessment (ICA) track behaviors such as reaction times, navigation patterns, and memory performance.
- These apps show promise for early detection of conditions like Alzheimer's and for generating large datasets for research.
- Significant challenges remain, including ensuring clinical validation across diverse populations and devices.
- Privacy concerns for sensitive health data are paramount and require robust solutions.
- Hardware consistency (e.g., screen size, processor speed) across various mobile devices can impact test accuracy and comparability.
- Learning effects, where users improve with repeated testing, need to be accounted for in the assessment design.
- There is a critical need for transparent and clinically interpretable results to ensure trust and utility for medical professionals.
Decoder
- Cognitive decline: A reduction in cognitive abilities such as memory, attention, language, and problem-solving, which can be a precursor to conditions like dementia.
- Sea Hero Quest: A mobile game developed by Deutsche Telekom, University College London, and others, designed to collect data on human spatial navigation for Alzheimer's research.
- Integrated Cognitive Assessment (ICA): A digital cognitive test that uses eye-tracking and response times to assess cognitive function, often integrated into mobile devices.
Original article
Digital cognitive assessment apps aim to detect early signs of conditions like Alzheimer's by turning scientifically validated cognitive tests into accessible, often gamified experiences that measure behaviors such as reaction times, navigation patterns, and memory performance. While tools like Sea Hero Quest and Integrated Cognitive Assessment (ICA) show promise in improving early screening and generating large-scale research data, major challenges remain around validation, privacy, hardware consistency, learning effects, and the need for transparent, clinically interpretable results.

Model half-life
Paul Kinlan debunks the "model half-life" theory, arguing that while AI model releases are faster, they are not consistently halving every six months as the buzzword suggests.
Decoder
- Model half-life: A colloquial and somewhat misleading term suggesting that the time between major AI model releases is consistently halving over short periods (e.g., every six months).
- TSV: Tab-separated values, a simple text-based format for storing tabular data.
Original article
model half-life
I keep hearing people say that there is a model “half-life” which keeps dropping from years between model releases down to a few months, with the implied assumptions that model releasing will drop to even further. I’ve heard the phrase “model half-life” so much recently that I wanted to actually look at the data.
I made a TSV of every headline model release from late 2022 through today across the US frontier labs (OpenAI, Anthropic, Google, xAI, Meta, Mistral) and the major Chinese labs (DeepSeek, Qwen, Zhipu, MiniMax, Moonshot, ByteDance). I split each vendor into the sub-series it actually ships in (Claude Opus is a different line from Claude Sonnet, GPT is a different line from the o-series, Gemini Pro is a different line from Flash). Then I plotted them.
Since I want to re-run this every few months. The initial dataset was compiled by Claude from vendor announcements and the references at the bottom of this post. I am working through it manually to verify dates, and I will correct entries in place when I find errors. If a row looks wrong to you, tell me. The full source list is in the sources section below.
The dashed dots are predictions. For each series I sort drops chronologically, compute the gap in days between each consecutive pair, take the trailing three gaps (or all of them if there are fewer than three), and round the median to the nearest day. I use median rather than mean so a single outlier (a same-week double-drop, or a long unplanned hiatus) does not distort the prediction. Adding that median gap to the most recent release date gives the predicted next drop.
It’s a pretty naive heuristic, but its as follows: A one-drop series gets no prediction. A two-drop series uses its single gap. From three drops up, only the trailing three count, so the prediction tracks current cadence rather than a long-run average. The “predicted next drop per series” table sorts ascending, so anything in the past is overdue, and the dashed segments in the timeline connect each series’s last shipped drop to its predicted next.
On reflection, model halflife really doesnt make much sense and it’s just a bit of a buzzword to mean that models now ship faster. If you look at the release the releases in the charts above you see that things have up-ticked and there is more activitiy but we’re not halving the release time every 6 months…
While it’s fun to predict when a model might be launched, unless we have a lot of data points then the predictions are pretty weak… GPT OSS at the end of 2027??? I mean, maybe…
The data file is at /model-drops.tsv. If I have got dates or series wrong, file an issue or just tell me.
Sources
These are the primary references used to compile and verify /model-drops.tsv. I will keep adding to this list as the dataset is updated.
Vendor announcements and release notes:
- OpenAI: news and release notes
- Anthropic: news
- Google DeepMind: Google blog AI category, Gemini models docs, DeepMind blog
- xAI: news
- Meta AI: blog, Llama model cards
- Mistral: news
- DeepSeek: API news
- Qwen (Alibaba): blog
- Zhipu / GLM: z.ai blog
- MiniMax: news
- Moonshot: moonshot.cn
- ByteDance Seed: team page
Aggregators used for cross-checking dates:
- LMArena leaderboard (formerly LMSys)
- Hugging Face model pages
- Wikipedia entries for individual model families (good for triangulating announcement vs release dates)
Disclosure: the initial TSV was compiled by Claude. I am verifying it row by row and will correct entries as I go. If you spot an error, please open an issue or message me.
The third wave of American philanthropy
AI is projected to generate hundreds of billions in new philanthropic funding, marking a potential "third wave" of American philanthropy.
Original article
AI is about to generate hundreds of billions in new philanthropic funding.
SpaceX Is Planning to Buy Startup Cursor 30 Days After IPO
SpaceX plans to acquire startup Cursor for $10 billion just 30 days after its anticipated IPO and June 12 listing, signaling aggressive post-IPO expansion.
Original article
SpaceX is expected to file for its IPO as soon as today and list its shares on June 12. It plans to acquire Cursor in July. If the deal doesn't go through, SpaceX will pay Cursor a $10 billion breakup fee in cash. The deal will likely still require regulatory review.
Tesla's Newest Electric Vehicle Could Jolt the Trucking Industry
Tesla's Semi truck receives strong early reviews for its competitive cost and range, spurring California trucking firms to seek subsidies for over 1,200 units, vastly outnumbering all other electric trucks.
Original article
Early reviews of the Tesla Semi suggest it could be a much-needed hit for the company. It is much less expensive than competing heavy-duty electric trucks and can travel farther. Cost and range are two of the main reasons that many logistics and delivery firms have been reluctant to buy electric trucks. Trucking firms in California have asked the state government for subsidies to help them buy more than 1,200 Tesla trucks, more applications than for all other electric trucks since the state's incentive program began in 2019.

Polymarket launches private company trading so investors can speculate on Anthropic, OpenAI
Polymarket is launching prediction markets for private companies like OpenAI and Anthropic, allowing traders to bet on valuations and IPO timing without equity.
Decoder
- Prediction market: A market where participants trade contracts whose payoffs are linked to the outcome of future events, allowing for speculative betting on various real-world scenarios.
- IPO (Initial Public Offering): The first time that the stock of a private company is offered to the public.
Original article
Polymarket is moving deeper into private markets — and this time, the contracts are tied to companies most investors can talk about, but still cannot actually buy.
The company is launching prediction markets tied to private company milestones, including valuations, IPO timing and secondary-market activity for names like OpenAI and Anthropic.
Nasdaq Private Market will serve as the exclusive resolution data provider, supplying the information that determines whether these contracts pay out.
These event contracts might solve one of the biggest frustrations for many investors.
Many companies create enormous value and brand recognition before they ever go public, more than 1600 are unicorns valued at a billion dollars or more, according to Nasdaq. But only accredited investors, an institution or someone very well connected can invest directly in those private companies.
Ordinary investors are typically sidelined.
Starting today, Polymarket's contracts let traders take a position on whether a specific private-market event happens, though without equity ownership, shares or voting rights.
For example, Polymarket currently lists a market on whether OpenAI will have a $1 trillion-plus IPO before 2027, and another tied to whether Anthropic reaches a valuation of at least $500 billion in 2026. There is also a contract asking whether Anthropic will be valued higher than OpenAI at any point this year.
These markets resolve using data from Nasdaq Private Market and in a first, it will make the valuation data publicly available for free, without a subscription.
Kalshi also offers some event contracts on whether private companies will IPO, but they resolve based on an amalgamation of sources including company sites, the SEC, and a slew of news outlets. It doesn't offer markets on private company valuations.
Private company boom
NPM's own data shows why these contracts could get attention. On its Anthropic company page, the share-price chart shows an estimated NPM price of $477.02 as of May 5, up more than 1,500%. It also lists a highest bid of $260.80, a lowest offer of $188.50 and a last trade of $234.00. The page says the NPM price is based on market activity, publicly sourced valuation data and proprietary information.
These contracts give individuals a way to engage with private-market value creation earlier, while giving institutions another real-time read on how traders are pricing private-company momentum.
There may be advantages for institutional investors as well. Secondary-market prices, funding rounds and IPO timing are still fragmented compared with public equities. A liquid prediction market around those events could become another signal, especially for companies where public comps are imperfect and fresh private-market data is hard to find.
The real bet isn't necessarily on OpenAI or Anthropic, it's whether private-market information fuels contracts that are clear enough to trade, liquid enough to matter and reliable enough to resolve.
Disclosure: Kalshi and CNBC have a commercial relationship which includes a minority investment.

Disney erased FiveThirtyEight
Disney has completely deleted the FiveThirtyEight website archive, erasing approximately 200,000 human-hours of work by Nate Silver's data journalism outlet.
Deep dive
- Nate Silver discovered that Disney, which owned FiveThirtyEight, had deleted the entire website archive, with the URL now redirecting to ABC News.
- This deletion occurred despite Silver leaving the site in 2023 and Disney shutting it down in March 2025.
- Silver estimates that approximately 200,000 person-hours of work (20 stories/week for 10 years, 20 hours/story) were erased.
- The article criticizes Disney's nearly decade-long mismanagement of FiveThirtyEight, stating there was "never really any effort, or even any pretense of trying, to make it a profitable unit."
- Silver recounts how he and senior staff "begged Disney to turn on a paywall" but were refused, with a potential $5 million annual revenue stream dismissed as a "rounding error" for Disney's $69 billion business.
- The journey included FiveThirtyEight's origins as a personal blog, its tenure at The New York Times (2010-2013), and the "ill-fated" move to ESPN in 2014, followed by a transfer to ABC News.
- Silver describes constant existential uncertainty, leadership changes (like John Skipper's abrupt departure from ESPN), and editorial challenges, including the "Trump thing" in 2016.
- After his contract ended in 2023, ABC News hired a replacement for the election models, G. Elliott Morris, whom Silver had "a long-running feud" with, and further depreciated the brand by changing its styling and removing sections.
- Silver attempted to reacquire the FiveThirtyEight IP to restore the archive but was told to "get lost" by ABC due to his critical public comments.
- He notes that while the Internet Archive preserves some content, the official site is gone, serving as a cautionary tale about link rot and corporate stewardship of valuable digital assets.
Decoder
- Link rot: The process by which hyperlinks to digital content become invalid or inaccessible over time, often due to content being moved, deleted, or websites going offline.
- IP (Intellectual Property): Creations of the mind, such as inventions, literary and artistic works, designs, symbols, names and images used in commerce, which are protected by law (e.g., copyrights, trademarks, patents).
Original article
Full article content is not available for inline reading.
Terraform Enterprise 2.0: Evolving infrastructure operations for scale
Terraform Enterprise 2.0 introduces "Stacks" to orchestrate multi-environment infrastructure as unified systems, alongside new governance and diagnostic features for secure scaling.
Decoder
- SCIM 2.0: System for Cross-domain Identity Management, an open standard for automating user identity provisioning and deprovisioning.
Original article
Terraform Enterprise 2.0 introduces Stacks for orchestrating multi-environment infrastructure as unified systems, plus project-level notifications, SCIM 2.0 automation, stronger governance, diagnostics, migration tools, and lifecycle support improvements to scale operations securely and consistently.
Apple unveils 30+ Apple Design Award app finalists
Apple announced over 30 finalists for the 2026 Apple Design Awards across six categories, including popular apps like Structured and games like Civilization VII, ahead of WWDC 2026.
Original article
Apple has revealed the 2026 Apple Design Awards finalists ahead of WWDC 2026, with 30+ apps and games competing across six categories: Delight and Fun, Inclusivity, Innovation, Interaction, Social Impact, and Visuals and Graphics. Notable finalists include apps like Structured, NBA: Live Games & Scores, and (Not Boring) Camera, alongside games such as Civilization VII, Cyberpunk 2077 Ultimate Edition, and Grand Mountain Adventure 2.
Something's Rotten in the State of macOS Icon Design
macOS app icons are increasingly uniform and constrained by Apple's "squircle" design language, diminishing creativity and distinctiveness compared to older designs.
Decoder
- Squircle: A geometric shape intermediate between a square and a circle, often used by Apple for app icons on iOS and macOS.
Original article
Full article content is not available for inline reading.
Free AI Diagram Generator Online (Website)
Diagrimo is a free, AI-powered online tool that converts text into professional diagrams, charts, and infographics using semantic understanding, saving significant time.
Original article
Full article content is not available for inline reading.

Create Fast and Polished Slides (Website)
Decksy is an AI presentation maker that generates polished slides from topics, text, or files in minutes, including deep research with citations from models like ChatGPT and Gemini.
Original article
Full article content is not available for inline reading.

The Future of BMW Design: A Conversation with Max Missoni
BMW VP Max Missoni reveals the brand's challenge to scale its "Neue Klasse" design language across diverse vehicles while integrating advanced interior technology like the Panoramic iDrive system.
Decoder
- Neue Klasse: BMW's new design language and underlying technological architecture for its future electric vehicles, emphasizing scalability and advanced digital capabilities.
Original article
Full article content is not available for inline reading.

Meet Louie Zong, Pixar Storyboard Artist and Blender Illustrator Who Can Tell a Story About Anything
Pixar storyboard artist Louie Zong, known for his work on *Hoppers* and *We Bare Bears*, developed a unique, puppet-like 3D illustration style using Blender after being inspired by '90s edutainment and Magritte.
Original article
Full article content is not available for inline reading.
Google is Rolling Out its Dedesigned Workspace App Icons
Google is rolling out redesigned Workspace app icons with soft color gradients, rounded corners, and overhauled shapes, just before Google I/O.
Original article
Google is rolling out redesigned Workspace app icons featuring soft color gradients, rounded corners, and overhauled shapes. Some icons have switched from rainbow designs to single colors, while others — like Google Drive — received significant changes, including rounded corners and removed red accents. The new icons are launching just before Google I/O, where more visual changes to Google's ecosystem may be announced.

Has Xbox turned rebranding into fan service?
Xbox's decision to rebrand to all-caps "XBOX" based on an X (formerly Twitter) poll raises questions about whether social media sentiment is replacing deliberate long-term brand strategy.
Decoder
- Fan service: Material in a fictional work or brand strategy deliberately included to please or appeal to the existing fanbase.
- Skeuomorphic design: A design style where UI elements mimic real-world objects in appearance, often including textures or 3D effects, to make them familiar to users. In this context, it refers to the logo resembling older, 3D Xbox logos.
Original article
Major brands like Microsoft are increasingly letting social media sentiment shape branding decisions, with Xbox's shift to all-caps “XBOX” via an X poll raising questions about whether online engagement and nostalgia are replacing more deliberate long-term brand strategy.