I built a vulnerable app and spent $1,500 seeing if LLMs could hack it
A developer tested various LLMs' hacking capabilities on a vulnerable book review app, finding GPT-5.5 performed best with a 70% success rate, while many other models were hindered by security guardrails or high costs.
Summary
Deep Dive
Decoder
Original Article
Ideogram 4 (GitHub Repo)
Ideogram 4, a new open-weight text-to-image foundation model, boasts best-in-class multilingual text rendering and precise layout controls via a structured JSON prompting interface.
Summary
Deep Dive
Decoder
Original Article
Intelligence Per Dollar
Microsoft is introducing "average token usage" to model release cards, benchmarking AI models on both performance and the cost of achieving that intelligence, pushing for efficiency over raw power.
Summary
Deep Dive
Decoder
Original Article
Morgan Stanley will soon open its trillion-dollar wealth management funnel to AI agents
Morgan Stanley plans to open its $1.2 trillion wealth management platforms, ShareWorks and Equity Edge, to external AI agents from corporate clients, enabling direct data access.
Summary
Deep Dive
Decoder
Original Article
SpaceX Sets Price for the World's Largest IPO
SpaceX has set its IPO price at $135 per share, valuing the company at $1.77 trillion, making it the largest IPO ever to fund ambitious space projects like orbital AI data centers.
Summary
Original Article
sandboxed (GitHub Repo)
sandboxed is an open-source engine for AI app-builder products that creates isolated cloud dev environments with built-in AI coding agents and live preview URLs, optimized for running many sandboxes on one machine.
Summary
Deep Dive
Decoder
Original Article
sandboxed
The open-source engine for AI app-builder products. Give every user an isolated cloud dev environment, a built-in coding agent, and a live preview URL — self-hosted, on one machine, in one command.

What is sandboxed? (start here)
Think of the apps where you type "build me a todo app" and seconds later a working website appears at its own link — like Lovable, Bolt, v0, or Replit. sandboxed is the open-source backend that makes that possible, running on your own server.
Here's what it does, in plain terms. You send it one HTTP request, and it:
- Creates a sandbox — a private, isolated Linux container (its own filesystem, its own memory limits), so one user's code can never see or break another's.
- Runs an AI coding agent inside it — you give it a prompt, and it writes the code into that sandbox. (The OpenCode and Claude Code CLIs come pre-installed.)
- Gives the app a live URL — the dev server running inside the sandbox is instantly reachable at a shareable preview link.
POST /sandbox → a private, isolated container spins up POST .../tasks → an AI agent writes an app inside it http://<id>.preview... → that app is live at its own URL
It's also cheap to run: a sandbox goes to sleep when nobody's using it (freeing memory) and wakes up the instant someone opens its link again — files are saved on disk the whole time. So one ordinary server can hold many users instead of needing one virtual machine each.
Under the hood it's deliberately small and easy to understand: one Go program that tells Docker what to do, with Traefik handling the URLs and SQLite as the database. No Kubernetes, no separate database server, no message queue — you could read the whole thing in an afternoon.
┌──────────────── your host (just needs Docker) ────────────────┐
browser ──▶│ Traefik ──▶ sandbox (coding agent + dev server :3000) │
│ ▲ ▲ ▲ │
API/CLI ──▶│ sandboxd ─────────┘ └─ workspace dir (persists) │
│ │ SQLite (source of truth) · idle→stop · request→wake │
└─────┴────────────────────────────────────────────────────────-─┘
Who's it for?
✅ Use it if you're running many sandboxes for other people — an AI app-builder ("describe an app → see it live"), an agent platform, a coding playground, per-user or per-branch preview environments, or multi-app hosting for a team.
❌ Skip it if you just need one or two containers for yourself — a shell script, docker run, or lxd is simpler. (More on that below.)
Why sandboxed?
If you're building an AI app-builder, an agent platform, a coding playground, or a per-user preview product, the hard part isn't the prompt — it's the infrastructure underneath it:
- Multi-tenant isolation so one user's code can't touch another's.
- Per-user preview URLs with automatic routing and TLS.
- Cost control — idle environments must release memory, or your bill explodes.
- Agent orchestration — run a coding agent against a workspace, stream its progress, capture the result.
- Persistence, wake-on-demand, reconciliation after a crash or reboot.
That's months of platform work. sandboxed is that platform, distilled to one command:
- ⚡ One-command install.
./install.shand you have a working API + previews. - 🧠 Agents included. The OpenCode and Claude Code CLIs ship in every sandbox; hand a sandbox a prompt and it builds.
- 💸 Dense by design. Stop-on-idle + wake-on-request means dozens of sandboxes share one box instead of one VM each — the difference between a $20 server and a $2,000 cluster.
- 🔓 Yours. Self-hosted, MIT-licensed, no vendor lock-in. Own your data, your margins, and your roadmap.
- 🪶 Boring on purpose. SQLite + the
dockerCLI + Traefik. A reconciler converges Docker back to the database on every boot. You can read the whole control plane in an afternoon.
"Why not just a shell script?"
Fair question — and honestly: if you need one or two long-lived containers for yourself, a shell script (or docker run, or lxd) is simpler. Use that. We mean it. sandboxed is overkill for one-off projects.
It earns its keep the moment you're running many sandboxes for other people — a team, or a product — because that's when the tidy little docker run script quietly grows into all of this:
- URLs, not ports. Every sandbox gets a clean preview URL with automatic routing + TLS — no port bookkeeping, no collisions to manage.
- It sleeps and wakes itself. Idle sandboxes stop to free RAM and restart transparently on the next request (warming-up page, readiness probe, request hold). That part alone is well past 100 lines — and it's the difference between one cheap box and a rack of always-on VMs.
- It survives reboots. SQLite is the source of truth; a reconciler re-converges Docker to it on boot. A script forgets everything when the host restarts.
- It's an API, not a CLI you shell into. create / exec / stop / destroy / write-files / run-agent-task are real HTTP endpoints with auth — you call them from your app backend, per user, at scale.
- One user can't take down the rest. Per-sandbox memory/PID limits + a host-memory pressure reaper.
- Agents with a lifecycle. Submit a prompt, stream progress (SSE), capture a durable result — not just
opencodefired inline.
Rebuild those as your script grows and you've rebuilt sandboxed. So: skip it for one-offs; reach for it when "just a script" has started keeping you up at night.
Prefer Kubernetes? The control plane talks to the container runtime through a thin
dockerCLI boundary, so a k8s Job/Pod backend is an interface swap, not a rewrite — a great first contribution. Today it targets a single Docker host (no k8s required), which is the sweet spot for teams who don't want to run a cluster just for sandboxes.
Quick start
Requirements: Docker Engine + the Compose plugin, on Linux. That's it.
1. Install
git clone https://github.com/tastyeffectco/sandboxes.git cd sandboxes ./install.sh
install.sh checks Docker, writes a .env, builds the sandbox base image + the control plane, and starts the stack. The API is then live at http://127.0.0.1:9090 (verify: curl http://127.0.0.1:9090/healthz → ok).
2. Have an agent build an app
The base image already includes the OpenCode and Claude Code CLIs. Hand a sandbox a prompt and watch it build (OpenCode runs on its free plan out of the box; pass your own provider key via env to use your account):
API=http://127.0.0.1:9090
# create a sandbox that will serve on port 3000
ID=$(curl -s -XPOST $API/sandbox -H 'content-type: application/json' \
-d '{"ports":[3000]}' | sed -E 's/.*"id":"([^"]+)".*/\1/')
echo "sandbox: $ID"
# spin a coding agent with a request — it works in ~/workspace/app
curl -s -XPOST $API/v1/sandboxes/$ID/tasks -H 'content-type: application/json' -d '{
"prompt":"create a Vite app that shows a todo list and run it on port 3000",
"agent":"opencode"
}'
# -> {"id":"<taskId>","status":"running","events_url":"/v1/sandboxes/<id>/tasks/<taskId>/events"}
# stream the agent's progress (Server-Sent Events)
curl -N $API/v1/sandboxes/$ID/tasks/<taskId>/events
To use your own model account instead of the free plan, inject a key at create time — it's available to the agent and any shell in the sandbox:
curl -s -XPOST $API/sandbox -d '{"ports":[3000],"env":{"ANTHROPIC_API_KEY":"sk-ant-..."}}'
3. Open the live preview
Once the app serves on port 3000, it's reachable at its preview URL — the sandbox self-registered the route, nothing else to wire:
http://s-<id>-3000.preview.localhost
*.localhost resolves to 127.0.0.1 in every modern browser, so it works locally with zero DNS and zero certificates (add :$HTTP_PORT if you changed it from 80). The first request to a stopped sandbox wakes it automatically. On a real domain you get https://s-<id>-3000.preview.yourdomain.com (see Production / TLS).
Just want a shell, no agent? Skip step 2 and run anything via the exec API:
curl -XPOST $API/sandbox/$ID/exec -d '{"cmd":["bash","-lc","cd ~/workspace/app && python3 -m http.server 3000"]}'then open the same preview URL.
API
Base URL = http://127.0.0.1:9090 (set by SANDBOXED_API_BIND). Auth is off by default for local use; with SANDBOXD_API_AUTH_DISABLED=false + SANDBOXD_API_TOKENS, send -H "Authorization: Bearer <secret>".
| Method & path | Body | Purpose |
|---|---|---|
POST /sandbox |
{"ports":[3000],"env":{...}} |
create — id optional (ULID auto); env injects vars (e.g. API keys) |
GET /sandboxes |
— | list all sandboxes |
GET /sandbox/{id} |
— | get one (status, ports, container id…) |
POST /sandbox/{id}/exec |
{"cmd":["bash","-lc","…"]} |
run a command (non-interactive) |
POST /sandbox/{id}/keepalive |
— | postpone the idle reaper |
POST /v1/sandboxes/{id}/stop |
— | stop now to free RAM (wakes on next preview hit) |
DELETE /sandbox/{id} |
— | destroy the container, keep the workspace |
POST /sandbox/{id}/purge |
— | destroy and delete the workspace |
POST /v1/sandboxes/{id}/tasks |
{"prompt":"…","agent":"opencode"} |
run a coding agent headlessly |
GET /v1/sandboxes/{id}/tasks/{taskId} |
— | task result |
GET /v1/sandboxes/{id}/tasks/{taskId}/events |
— | live task event stream (SSE) |
GET/PUT /v1/sandboxes/{id}/files |
{"path","content","append"} |
list / read / write workspace files |
GET /healthz, GET /readyz |
— | liveness / readiness |
A complete, copy-pasteable runbook (including driving it from your own agent) is in AGENTS.md.
How it works
| Concern | Choice |
|---|---|
| Container runtime | Docker + hardened runc (cap-drop ALL, no-new-privileges, read-only rootfs) |
| Workspace storage | one bind-mounted directory per sandbox under the data dir (persists) |
| Edge / preview | Traefik v3 Docker provider — sandboxes self-register their routes |
| Idle management | stop-on-idle (docker stop) + wake-on-request; no warm pool |
| State | SQLite (WAL); a reconciler converges Docker to the DB on boot |
| Control plane | one Go binary, shells out to the docker CLI over the mounted socket |
The control plane runs in a container with the host Docker socket mounted and launches each sandbox as a sibling container on a shared network so Traefik can route to it. Full design: ARCHITECTURE.md.
Configuration
Everything is in .env (created from .env.example on install). The defaults run a complete local stack. The knobs you'll touch most:
| Variable | Default | What it does |
|---|---|---|
PREVIEW_DOMAIN |
localhost |
domain preview URLs hang off |
HTTP_PORT |
80 |
host port Traefik listens on |
SANDBOXED_DATA_DIR |
/var/lib/sandboxed |
where workspaces + state live |
SANDBOXED_API_BIND |
127.0.0.1:9090 |
where the control-plane API is published |
SANDBOXD_API_AUTH_DISABLED |
true |
open API for local use; set false + tokens for prod |
Production / TLS
For a public deployment on a real wildcard domain:
- Point
*.preview.yourdomain.comat the host. - In
traefik/traefik.yml, enable thewebsecureentrypoint and add a certificate resolver (Let's Encrypt DNS-01 is ideal — one wildcard cert covers every preview host, so you never hit per-host ACME limits). - In
.env:PREVIEW_DOMAIN=yourdomain.com,PREVIEW_ENTRYPOINT=websecure,PREVIEW_TLS=true, and enable auth —SANDBOXD_API_AUTH_DISABLED=falsewithSANDBOXD_API_TOKENS=name:secret. docker compose up -d.
Uninstall
./uninstall.sh # stop the stack + remove all sandboxes + network (keeps your data) ./uninstall.sh --images # also remove the built Docker images ./uninstall.sh --data # also DELETE all workspaces + state (asks to confirm) ./uninstall.sh --all # full removal: images + data
Safe by default — it removes only what sandboxed created (containers labelled sandboxed.managed=true, the compose stack, the network) and keeps your workspaces unless you pass --data/--all.
Is this a good foundation for a startup?
Yes — that's exactly the point. If you want to ship an AI app-builder or agent SaaS without first spending months building multi-tenant isolation, preview routing, idle/wake cost control, and agent orchestration, sandboxed gives you that core on day one, on a single inexpensive server, with margins you control. It's a strong, honest starting point — beta-quality, MIT-licensed, and built to be read and extended. Launch lean on it; harden as you grow (next section).
Before you scale hard: what's simple on purpose, and what to harden
sandboxed v1 is tuned for "works anywhere with just Docker, in one command." To keep it that simple, a few things were left basic on purpose. None of them affect the core loop (create → build → preview → sleep → wake → persist) — they're the knobs to tighten once you have real users and real money on the line. Plain version:
| Kept simple on purpose | Fine for | Do this when you're scaling / serious |
|---|---|---|
| Container isolation (hardened Docker), not full VMs | your own users running their own code | running untrusted strangers' code → put each tenant on its own VM, or use gVisor / Kata / Firecracker |
| API auth is OFF by default | local development | turn it on (SANDBOXD_API_AUTH_DISABLED=false + tokens) and never expose the API port unauthenticated |
| Preview links are public (anyone with the URL) | demos, sharing | gate sensitive previews (the private-sandbox forward-auth hook) |
| Open, unlogged network egress | most apps | add firewall / egress rules + logging |
| Plain-directory workspaces, no disk quota | a single server | add filesystem/volume quotas; plan multi-host sharding |
| One server, one Docker socket (the control plane is root-equivalent on the host) | starting out | treat the host as a trust boundary, keep it patched, isolate it, and don't co-locate unrelated secrets |
The short version for a fast-scaling company: the three that matter most are (1) stronger isolation (VM-per-tenant) if you ever run untrusted code, (2) turn on API auth and lock down the host, and (3) plan for more than one machine. Everything else above is a config change, not a rewrite. Start lean, revisit these as you grow — and PRs are very welcome (CONTRIBUTING.md).
License
MIT. Use it, ship it, sell what you build on it.
Google's new Gemma 4 12B model is designed to run on any laptop with 16GB of RAM
Google released Gemma 4 12B, a new 12-billion-parameter AI model designed to run locally on consumer laptops with 16GB RAM, without significant quality loss compared to its larger 26B MoE counterpart.
Summary
Deep Dive
Decoder
Original Article
What's new in Python 3.15
Python 3.15 introduces significant performance boosts via a revamped JIT compiler and explicit lazy imports, alongside new built-in types like `frozendict` and `sentinel`, and enhanced developer diagnostics.
Summary
Deep Dive
Decoder
Original Article
Vector Search in Manticore Search: A Deep Dive
Manticore Search, an open-source search engine, provides a deep dive into its HNSW-based vector search implementation, emphasizing tuning for production use, data safety, and replication.
Summary
Deep Dive
Decoder
Original Article
Debunking 8 data layout myths: why Liquid Clustering outperforms partitioning
Databricks argues its Liquid Clustering vastly outperforms traditional Hive-style partitioning for modern lakehouses, offering dynamic data organization, row-level concurrency, and significant query speedups.
Summary
Deep Dive
Decoder
Original Article
- Liquid Clustering is the data layout for open table formats that outperforms partitioning while sidestepping its limitations
- 8 common myths keep teams tied to partitioning, and none of them hold up anymore
- Customers using Liquid Clustering report dramatic improvements in query latency, write throughput, storage efficiency, and data freshness, with the largest gains compounding at petabyte scale
Introduction
Laying out data is one of the oldest problems in computing.
For over 15 years, since the advent of Hadoop and Hive, partitioning has been the standard way to physically organize data for processing and analysis. However, today’s Lakehouses serve agents, real-time pipelines, and query patterns that shift faster than any human can re-partition for.
Liquid Clustering is the modern standard and customers are running it at every scale, including dozens with petabyte scale tables in production. In this blog, we’ll cover why Liquid Clustering wins in the Lakehouse. Along the way, we’ll debunk 8 common data layout myths, walk through 3 success stories of teams converting partitioned tables to Liquid Clustering, preview what’s coming next, and show how to get started.
Why Liquid Clustering wins in the modern lakehouse
Hive-style partitioning forces users to commit, at table-creation time, to a physical organization of data that manifests in the file structure. Pick a column with too high cardinality and you get billions of tiny files. Pick the wrong column and queries may get slower, not faster. Either way, you’re stuck rewriting the table. It’s common to get wrong: in our analysis, Hive-style partitioning leads to over-partitioning and small-file problems in more than 75% of cases.
Liquid treats clustering keys as input that the engine uses to guide optimal file organization. Keys can be changed at any time, or intelligently selected through Automatic Liquid Clustering. Cardinality isn’t a constraint, and the layout can evolve over time without unnecessary rewrites.
The benefits of Liquid Clustering all derive from the above principle: better skew handling, row-level concurrency, no small-file problems, multi-dimensional clustering, and lower write amplification.
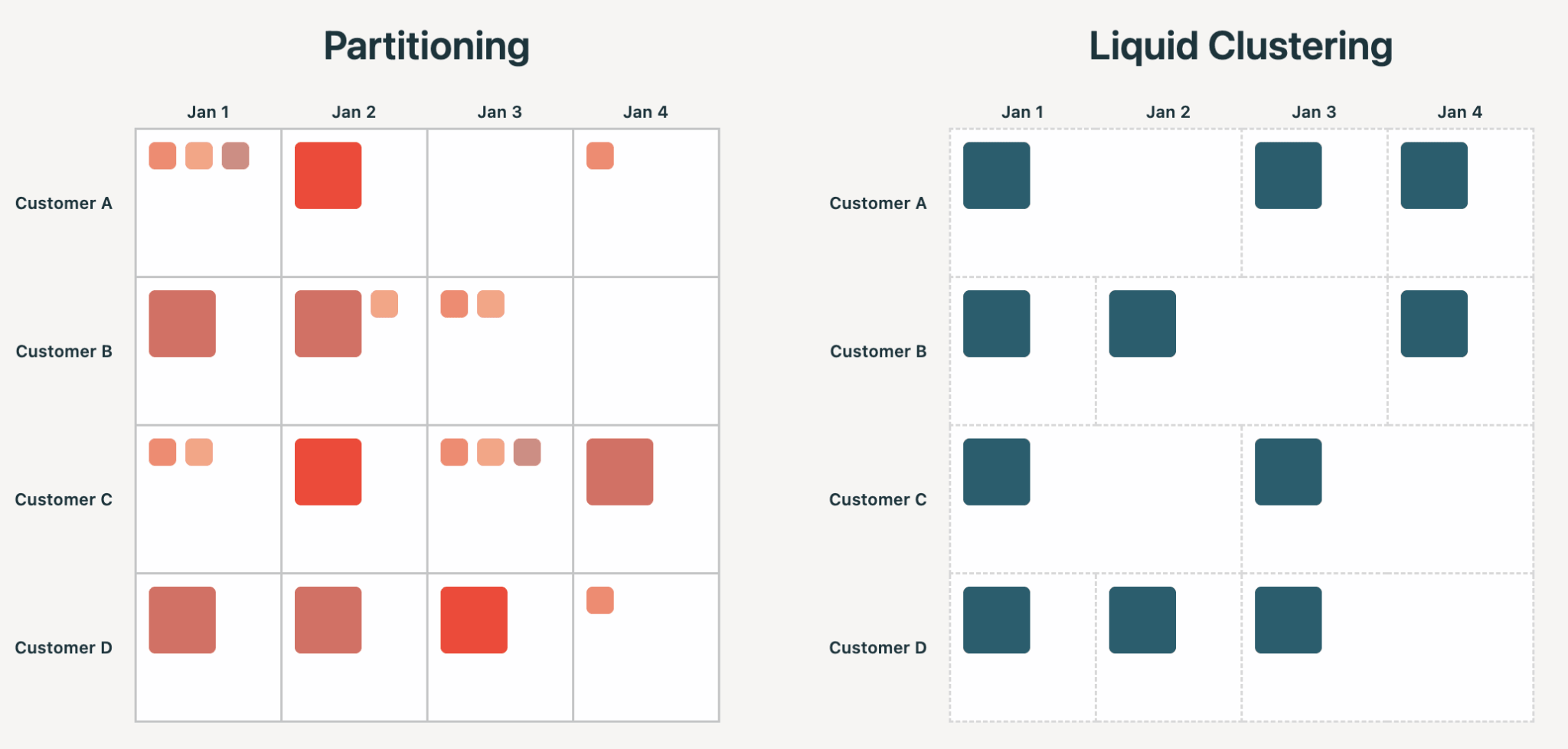
In 2026, the layout should be an implementation detail of the table, with every engine that reads or writes benefitting from it. This is increasingly important as agents enter the Lakehouse, generating and consuming more data than ever. Humans and agents need forgiving interfaces, free of the potential side-effects of Hive-style partitioning.
Debunking 8 common data layout myths
Liquid Clustering became Generally Available in 2024. Since then, we’ve iterated on it non-stop with customers running it at scale. In that time, some common myths about Liquid Clustering and partitioning have persisted, and today we want to debunk them.
Myth #1: Partitioning is faster because it can prune directories instead of files
The myth goes: With partitioning, Spark or other engines can prune whole directories without opening any files inside of them.
Reality: Directory-pruning does not exist on modern open table formats like Delta and Iceberg. Delta, for example, uses a transaction log to track every data file along with per-column statistics, and pruning happens against those statistics, not the directory structure. The engine never lists directories to plan a query. It reads the transaction log, evaluates filters against statistics, and skips files that don’t match. Liquid Clustering uses the same mechanism. Whether your data lives in `date=x/hour=y/` or a flat directory of clustered files, the engine prunes at file granularity. There is no directory-level shortcut to lose.
Myth #2: Partitioning is better when filtering on a low-cardinality column
The myth goes: For a column with a small number of distinct values, partitioning gives you perfect data separation and good file sizes.
Reality: Liquid Clustering automatically detects when to apply low-cardinality optimizations. For example, if you cluster by (date, user_id), and date has low cardinality, the system aims for each file to contain rows from only a single date. Higher-cardinality columns, like user_id, are then automatically used for finer-grained sorting within each date's files, without having to rely on other sorting techniques like Z-Ordering.
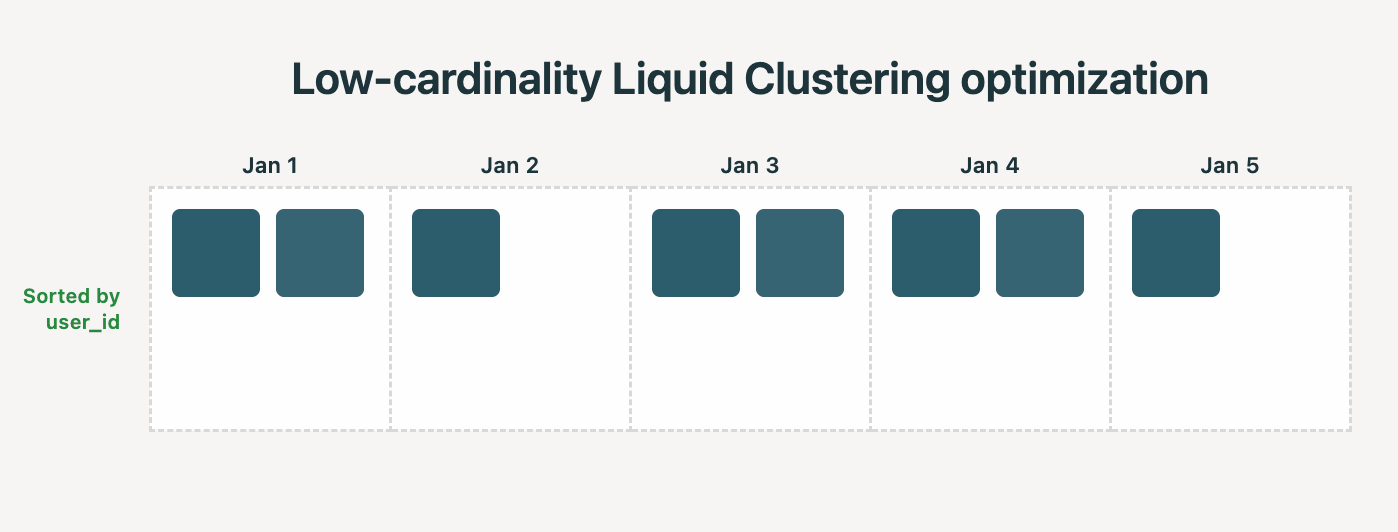
We saw the following improvements while benchmarking this Liquid optimization on a real-world data warehousing benchmark: 35% lower time for clustering and 22% faster query times.
Additionally, Liquid Clustering is designed to be better than partitioning when clustering on a high-cardinality column, as it always tries to create files of a good size.
Myth #3: Liquid Clustering doesn’t support metadata-only operations
The myth goes: Metadata-only operations are uniquely supported by partitioning. A DELETE aligned with partition boundaries only updates the table’s metadata, and aggregates on partition columns can be computed without scanning files. Liquid Clustering can’t do the same.
Reality: Liquid Clustering also supports metadata-only operations including DELETEs, COUNT, DISTINCT, and GROUP BY queries. The engine uses the same per-file min/max stats it uses for data skipping to determine when a query’s answer can be computed from metadata alone. In our benchmarks, metadata-only DELETEs on Liquid Clustered tables ran ~90% faster than full-rewrite DELETEs. Other metadata-only aggregate queries saw up to 27x speedups.
Myth #4: Liquid Clustering doesn’t work well at petabyte scale
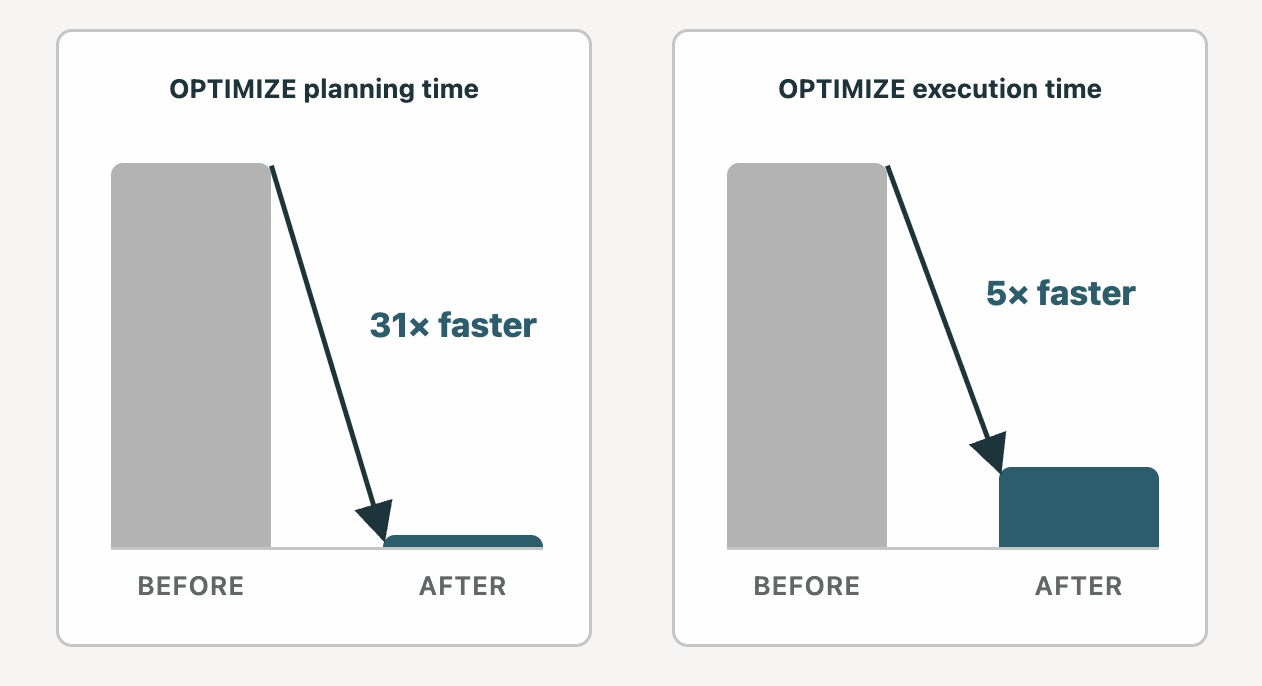
The myth goes: OPTIMIZE on a PB-size table can run for hours, and the cost of maintenance is too high.
Reality: We’ve made a number of significant improvements to OPTIMIZE, and dozens of customers now have PB-scale Liquid Clustered tables in production. Two years ago, planning, the first phase of OPTIMIZE, could take up to 12 hours on a 10 PB Liquid table in some cases. We’ve spent the time since reducing planning time down to 23 minutes. Execution, the second phase of OPTIMIZE, got 5x faster on a Medium DBSQL cluster.
Myth #5: Liquid Clustering only benefits a subset of readers
The myth goes: Liquid Clustering is only beneficial for Databricks readers to UC managed Delta tables.
Reality: Liquid Clustering is a write-side optimization. It’s how the engine organizes files for efficient data skipping. The output is standard Parquet files with min/max stats, written into open table formats like Delta/Iceberg. Any compatible reader (e.g. open-source Apache Spark, DuckDB, etc.) can use those stats to skip files. Liquid Clustering is available on both external / managed and Delta / Iceberg tables, and the benefit is applicable regardless of the reader.
Myth #6: Partitioning is necessary for concurrent ETL
The myth goes: Concurrent ETL needs write boundaries. Without partitioning, two writers updating the same table risk colliding, and Delta/Iceberg concurrency control forces one of them to retry or fail. Partition and give each writer its own slice of the table, so two pipelines never touch the same files.
Reality: Operating at partition granularity was a workaround for an older concurrency model. Unlike partitioning which only has file-level concurrency, Liquid provides row-level concurrency. Two writers updating different rows no longer conflict, even if those rows live in the same file. This removes one of the main reasons teams partitioned tables: maintaining write boundaries to avoid serialization. With Liquid Clustering, ETL can easily operate concurrently against the same table.
Myth #7: Z-Ordering makes up for partitioning’s shortcomings
The myth goes: Partitioning handles the partition column’s filters, and Z-Ordering handles the rest. By running OPTIMIZE ZORDER BY, the engine sorts data for optimal skipping on filters that don’t align with the partition scheme.
Reality: Z-Ordering doesn’t save partitioning. In fact, it has its own structural problems.
- The first is poor clustering quality. Z-Order doesn’t maintain a true ordering across the table. Values for the same column can get spread across many files, so per-file min/max ranges are wider and queries skip fewer files than they would with Liquid.
- The second is unnecessary rewrites. Z-Order has to be rerun periodically as new data lands, and each rerun rewrites large amounts of old, possibly already-clustered data to restore clustering quality. With continuous ingestion, the cost of keeping data well-clustered with Z-Order grows along with the table.
Liquid clusters incrementally, including at write time, so the layout stays optimal without unnecessary rewrites.
Myth #8: Partitioning is necessary for selective data overwrites
The myth goes: Being able to selectively overwrite data is only available through Dynamic Partition Overwrites.
Reality: Selective overwrites work on Liquid tables natively. Databricks supports REPLACE USING and REPLACE ON, two SQL syntaxes for selectively overwriting data on any data layout: Liquid Clustered, partitioned, or plain unclustered tables. Unlike Dynamic Partition Overwrite which requires a Spark config, REPLACE USING and REPLACE ON can be used on any compute: classic clusters, SQL warehouses, and Serverless. The operation is atomic and matches on any column you choose.
Success stories: migrating from partitioning to Liquid Clustering
7.7x query speedup on Arctic Wolf’s 3.8 PB security telemetry table
Arctic Wolf runs a 3.8+ PB security telemetry table ingesting 1+ trillion events per day, where threat hunters depend on fresh data to detect active attacks.
After migrating from partitioning to Liquid Clustering on Unity Catalog managed tables with Predictive Optimization, Arctic Wolf saw:
- 90-day queries drop from 51 seconds to 6.6 seconds
- File count dropped from 4M to 2M
- Data freshness improved from hours to minutes
Read and write improvements on critical CDC tables for Bolt
Bolt recently tried Liquid Conversion (currently in Private Preview), which converts partitioned tables to Liquid in-place using ALTER TABLE .. REPLACE PARTITIONED BY WITH CLUSTER BY. They observed the following read and write benefits on a TB-scale CDC table after converting to Liquid Clustering:
- Write throughput (rows/sec) increased by 138%
- Read times were reduced by up to 63%, with an average of 21% reduction across 9 representative queries
Liquid Clustering dramatically reduced the work that each write was doing, increasing our throughput significantly on our most critical CDC table. Reads also improved across the board. The best thing was: we ran the conversion from partitioning alongside live ingestion with zero downtime. With this, Liquid Clustering provided us exactly the kind of performance and reliability we needed at platform scale. — Marcin, a senior platform engineer at Bolt
5.9x speedup in query time on a petabyte-scale internal workload
We run a 1.1 PB table internally that's queried thousands of times a day, mostly by engineers running production investigations and observability dashboards. Originally it was partitioned by date and hour, assuming time-range scans would dominate. However, that assumption turned out to be incomplete. While time-range scans were common, the table was also frequently queried by source and id, forcing the engine to scan every file in the relevant date and hour partitions to find a handful of rows.
Adding source and id as partitions wasn’t viable, because there were too many distinct values. This would have created billions of tiny files. Liquid Clustering removed the trade-off, allowing clustering on time and the additional identifier columns simultaneously, while maintaining good file sizes.
| Layout | |
|---|---|
| Before | Partitioned by date, hour |
| After | Clustered by date, hour, source, id |
Benchmarks showed massive improvements across 16 representative production queries:
| Metric | Before (partitioned) | After (Liquid) | Improvements |
|---|---|---|---|
| Wall Clock Time | 406s | 70s | 5.9x speedup |
| Bytes Read | 3.5 TB | 0.48 TB | 86% fewer bytes read |
The table itself got smaller too. Total size dropped from 1.1 PB to 0.8 PB, a 27% reduction with no change in the underlying data. Better-clustered files compress more efficiently, and the small-file tax that comes with over-partitioning disappears.
What’s coming next for Liquid Clustering
Optimizing Liquid-to-Liquid joins: up to 51% faster with 87% less shuffle
Today, joining Liquid tables on their clustering columns can require a full data shuffle, even when the data is already organized by those columns. Co-clustered joins (now in Private Preview) remove that shuffle automatically. On a real-world data warehousing benchmark, a Liquid-to-Liquid join ran ~51% faster (28 minutes → 14 minutes) and shuffled 87% less data (1.2 TiB → 150 GiB) than the same query without the optimization.
Easy Liquid Conversion of partitioned tables
Before, converting a partitioned table to Liquid Clustering required a full table rewrite and downstream breaking changes with REPLACE TABLE or a cutover with dual writes and planned downtime. We’re introducing a new command (now in Private Preview) that makes this conversion easier, minimizing both downtime and rewrites.
Getting started with Liquid Clustering
Create a table with Liquid Clustering:
Or, if you’re using UC managed tables with Predictive Optimization, use Automatic Liquid Clustering to intelligently select clustering keys based on your workload and query patterns:
Liquid Clustering is the layout for the modern Lakehouse. Try it on your next table, or reach out to your account team today to try the Private Previews for partitioned-to-Liquid Conversion and Co-Clustered joins!
Don’t forget to catch us at DAIS!
- Optimize Lakehouse Cost and Performance with Intelligent Storage and Liquid Clustering
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.
Diving deep into Redis's new array data type
Redis 8.8 introduces a new native Array data type, designed by Salvatore Sanfilippo, providing constant-time positional access for sparse or dense arrays where index itself carries semantic meaning.
Summary
Deep Dive
Decoder
Original Article
dbt Core v2 is here: still open source, now rebuilt for what's next
dbt Core v2.0 open-sources the Rust-based Fusion engine runtime under Apache 2.0, promising faster parsing, Parquet artifacts, and a unified foundation with Fusion.
Summary
Deep Dive
Decoder
Original Article
Authorization for AI agents: What to build before the EU AI Act deadline
Upcoming EU AI Act regulations require externalized authorization and robust audit trails for AI agents, demanding new architectural patterns for identity and runtime policy enforcement.
Summary
Deep Dive
Decoder
Original Article
What Will AI-first UX Look Like?
AI-first UX is evolving beyond chatbots to integrated, agentic systems that replace traditional forms and dashboards with conversational interfaces and collaborative AI agents.
Summary
Deep Dive
Decoder
Original Article
Who Survives AI? Useful Insights from Walter Terruso
Italian interior designer Walter Terruso controversially predicts AI will decimate mid-level creative jobs, leaving an "outliers economy" where only truly exceptional designers survive.
Summary
Deep Dive
Decoder
Original Article
Design Systems that Document AI
Only 26 out of 156 public design systems meaningfully document AI, though leaders like IBM, AWS, and Microsoft independently converged on four core principles for AI-powered experiences.
Summary
Deep Dive
Decoder
Original Article
deepseek slated to draw 7 billion in maiden fundraising sources say
Chinese AI champion DeepSeek is reportedly raising $7.4 billion in its first funding round, valuing the company up to $59 billion, intensifying US-China tech rivalry.
Summary
Original Article
OpenAI makes its next hardware move with Opal Electronics
OpenAI is leading a funding round for Opal Electronics, known for high-end webcams, to develop new AI-native devices for creative work, aligning with Sam Altman's "ambient computing" vision.
Summary
Decoder
Original Article
Sleep for Continual Learning
Google researchers propose a "Sleep" paradigm for large language models, allowing them to consolidate short-term memories into long-term knowledge and self-improve through "Dreaming."
Summary
Deep Dive
Decoder
Original Article
Inside Meta's attempts to play catch-up with AI
Mark Zuckerberg installed Alexandr Wang to overhaul Meta's AI efforts, leading to the release of Muse Spark and ambitious plans for "personal superintelligence," despite internal skepticism and a "rough start."
Summary
Deep Dive
Decoder
Original Article
Be There for Every Customer With Meta Business Agent
Meta has launched Meta Business Agent, an AI tool for businesses to manage customer interactions and sales on WhatsApp, Messenger, and Instagram, expanding globally to all sizes.
Summary
Deep Dive
Original Article
Mark Zuckerberg Wants Meta's New AI Agents to Run Your Whole Business
Mark Zuckerberg's Meta has launched a free AI agent on WhatsApp, Instagram, and Messenger to help businesses automate customer interactions, with plans to expand its capabilities to manage entire operations.
Summary
Original Article
Blue Origin vows to resume New Glenn flights by year's end
Blue Origin CEO Dave Limp vows to resume New Glenn rocket flights by the end of 2026, despite a "spectacular" launch pad explosion last week that destroyed the rocket and its transporter-erector.
Summary
Deep Dive
Decoder
Original Article
China is training a robot future — one folded shirt at a time
China is gaining a scaling edge in robotics development by mobilizing large local workforces to collect massive, low-cost training data sets from real homes and factories.
Summary
Deep Dive
Decoder
Original Article
Microsoft brings coreutils to Windows
Microsoft has released coreutils for Windows, a set of Rust-based Unix-style command-line utilities that run natively on Windows, available through WinGet, aiming to ease cross-platform scripting.
Summary
Deep Dive
Decoder
Original Article
{kind=link}
MacBook Neo is So Popular That Apple Reportedly Doubled Production
Apple reportedly doubled its MacBook Neo production target to 10 million units for 2026 due to "off the charts" customer demand for the affordable $599 laptop.
Summary
Original Article
DNS Is for People - Not for IT Infrastructure
An article argues that DNS, while essential for public services, should largely be avoided for internal IT infrastructure to boost reliability, robustness, and security.
Summary
Deep Dive
Decoder
Original Article
Google offers opt-out of “AI” search results for websites, promises it won't affect regular search rankings
Google is offering website owners an opt-out from having their sites appear in generative AI Search features like "AI Overviews," promising it won't impact regular search rankings, a move mandated by the UK's CMA.
Summary
Decoder
Original Article
They're Made Out of Weights
A thought-provoking dialogue, echoing Terry Bisson, humorously posits that advanced AI models are fundamentally just layers of multiplying floating-point numbers, or "weights."
Summary
Deep Dive
Original Article
Road to WWDC 2026: What's a developer?
AI coding assistants are democratizing Mac app development for non-programmers, but Apple's Xcode remains a significant and "nightmarish" barrier for these new creators.
Summary
Deep Dive
Decoder
Original Article
Your Cart Has a Story. Here's How We Learned to Read It
Zepto developed a Cart Contextual Model using a Transformer-based masked language model to predict user purchases in real time from shopping cart "sentences."
Summary
Decoder
Original Article
A field journal on Ray Data and Daft for multimodal data lake
Ray Data was chosen over Daft for multimodal data lakes after 8 production-like use cases, primarily due to Ray's superior stability and resilience for complex LLM inference.
Summary
Decoder
Original Article
Routing Multiple Query Engines with Iceberg
QueryFlux is an open-source Rust SQL proxy enabling intelligent, cost-aware routing across multiple Iceberg query engines like Trino, Spark, and DuckDB.
Summary
Deep Dive
Decoder
Original Article
ingestr (GitHub Repo)
ingestr is an open-source CLI ELT tool that simplifies data movement between 100+ sources and destinations with simple flags and no custom code.
Summary
Decoder
Original Article
OpenTelemetry Launches “Blueprints” Initiative to Simplify Enterprise Observability Adoption
OpenTelemetry launched "Blueprints" to simplify enterprise observability adoption by providing prescriptive guidance and reference implementations for common scenarios like Kubernetes.
Summary
Decoder
Original Article
Pluto 1.0 Release
After six years, Pluto 1.0 has been released, making the reactive Julia notebook environment stable with enhanced reproducibility, accessibility, and new features for education and sharing.
Summary
Deep Dive
Decoder
Original Article
dltHub AI Workbench data quality toolkit: schema-aware checks that route their own fixes
dltHub AI Workbench is previewing a data quality toolkit that bootstraps schema-aware checks and auto-routes fixes for issues like null primary keys or duplicate rows directly within dlt pipelines.
Summary
Deep Dive
Decoder
Original Article
Default Bias: Who chose your settings?
Default bias causes users to stick with pre-selected options, imposing an ethical responsibility on designers for their choices in privacy, notifications, and subscriptions.
Summary
Decoder
Original Article
UX Hierarchy: How Users Actually Scan Pages in 2026
AI-driven browsing and AR environments have rendered traditional F- and Z-scanning patterns obsolete, requiring UX designers to prioritize gaze-reactive elements and semantic headers.
Summary
Decoder
Original Article
Why Minimalist Aesthetics are Stifling Truly Arab Design
Moe Elhossieny argues that minimalist aesthetics, often imposed by international agencies, are stifling authentic Arab design expression and perpetuating Western epistemic hegemony.
Summary
Deep Dive
Decoder
Original Article
Meta Keeps Delaying the Release of Its New AI Model to Developers
Meta has indefinitely delayed the release of its new, reportedly competitive "Muse Spark" AI model to developers, raising questions about its monetization strategy.
Summary
Original Article
Meet Dreambeans, an app that connects you with what matters
Google Labs launched "Dreambeans," an experimental AI app that creates daily personalized stories by leveraging user data from Google apps like Gmail and Calendar.
Summary
Decoder
Original Article
Anthropic Bulks Up Its Enterprise Partner Program Amid IPO Plans
Anthropic is expanding its Claude Partner Network for third-party sellers to boost enterprise sales and demonstrate scalability as it confidentially files for an IPO this fall.
Summary
Decoder
Original Article
John Ternus scaled back Apple's Vision products roadmap
Apple's John Ternus has dramatically scaled back the company's Vision products roadmap, reducing seven head-mounted wearables under development to just two: displayless AI glasses for 2027 and AR/XR smartglasses for 2029.
Summary
Decoder
Original Article
The Rise of Multi-Query Engines
AI agents are driving a surge in small, bursty data queries, making multi-engine routing essential to manage costs by directing each query to the most efficient processing engine.
Summary
Decoder
Original Article
MongoDB and Stored Procedures
MongoDB can achieve low-latency transactional logic without traditional stored procedures by leveraging ACID transactions, bulkWrite, and pipeline updates.
Summary
Decoder
Original Article
Amazon will show AI product images when you search for some reason
Amazon is adding AI-generated "fake" product images to shopping search results, risking customer confusion by displaying items that don't exist to help refine vague queries.
Summary
Original Article
Google's Dreambeans, its weirdest-named AI tool to date, will turn your life into a cartoon
Google Labs launched Dreambeans, an AI app that turns personal data from Google services into 10-14 daily cartoon-style "stories" offering lifestyle suggestions and recommendations.
Summary
Original Article
Create Animated Explainer Videos in Minutes (Website)
Chun Rapeepat's StoryMotion uses AI to generate animated explainer videos from documents, diagrams, or ideas, exporting up to 4K 60fps for various platforms.
Summary
Decoder
Original Article
Turn Text Prompts Into Production-ready Visuals (Website)
APImage launches an AI image generation platform focused on producing "production-ready visuals" with consistent characters and objects, targeting e-commerce and enterprise users via API.
Summary
Decoder
Original Article
Why Design Studio Oneplus Treats Branding Like Cultural Excavation, Not Invention
Milan-based design studio Oneplus approaches branding as "cultural excavation" rather than invention, diving into each project's cultural and visual core to create distinctive aesthetics.
Summary
Original Article
JKR helps Schweppes rediscover its sparkle with a heritage-inspired redesign
Schweppes has launched its largest rebrand in generations, reinstating its leopard mascot Clive and a heritage-inspired platform to re-establish its premium positioning.
Summary
Original Article
Overcome imposter syndrome
Imposter syndrome is a normal feeling for designers, but overcoming it requires reframing self-doubt as motivation and focusing on client problems rather than artistic validation.
Summary
Decoder
Original Article
Beautiful Notion-style Illustrations (Website)
Mary Amato's Notioly offers a collection of 500+ customizable vector illustrations in a distinctive Notion-style, available for a one-time purchase of $39.
Summary
Original Article
At 28, you are absolutely not too old for this industry
Career expert Kat Wong assures a 28-year-old graphic designer that they are not too old to pursue bigger creative dreams, emphasizing professional skills and strategic career planning over age.