Predictive Data Debugging: Reveal and Shape What Your Model Learns, Before You Train
Goodfire researchers developed a technique to identify and mitigate problematic model behaviors before training by inspecting preference datasets.
Summary
Deep Dive
Decoder
Original Article
SkillSpector (GitHub Repo)
NVIDIA released SkillSpector to scan AI agent skills for vulnerabilities like prompt injection, data exfiltration, and malicious code patterns before installation.
Summary
Deep Dive
Decoder
Original Article
First Steps Toward Automated AI Research
Recursive's autonomous research system outperformed human-led open-source communities by discovering novel architectural and kernel optimizations for language model training.
Summary
Deep Dive
Decoder
Original Article
Homebrew 6.0.0
Homebrew 6.0.0 launches with mandatory tap trust, Linux sandboxing, and a new internal JSON API to improve security and performance.
Summary
Deep Dive
Decoder
Original Article
How Terry Tao Became an Evangelist for AI in Math
Fields Medalist Terrence Tao is advocating for a new era of experimental mathematics powered by large language models and formal verification systems.
Summary
Deep Dive
Decoder
Original Article
Anthropic Claude Fable 5 on AWS: Mythos-class capabilities with built-in safeguards now available
Anthropic's Claude Fable 5 model is now available on AWS, featuring advanced software engineering capabilities and automated routing of high-risk prompts to older models.
Summary
Decoder
Original Article
How formal verification makes AWS Nitro the first formally verified cloud hypervisor
AWS has formally verified the Nitro Isolation Engine, a Rust-based hypervisor component that provides mathematical proof of virtual machine isolation.
Summary
Deep Dive
Decoder
Original Article
Now available: Amazon EC2 M9g and M9gd instances powered by new AWS Graviton5 processors
AWS launched Graviton5 instances, which offer 25% higher performance and introduce the formally verified Nitro Isolation Engine to improve multi-tenant security.
Summary
Deep Dive
Decoder
Original Article
Finding Optimal Tokenizers
A new research approach uses integer linear programming and cycle constraints to find provably optimal tokenizers for text data.
Summary
Deep Dive
Decoder
Original Article
Making a vintage LLM from scratch
A hobbyist successfully trained a 340M parameter 'Vintage LLM' from scratch using $80 in cloud compute and 1800s-era literature.
Summary
Deep Dive
Decoder
Original Article
Xiaomi's new open source, agentic AI coding harness MiMo Code beats Claude Code at ultra-long, 200+ step tasks
Xiaomi’s open-source MiMo Code assistant uses a unique subagent for long-horizon memory, outperforming Claude Code on 200+ step tasks.
Summary
Decoder
Original Article
Optimizing PyTorch with Fused MLPs
This guide explains the mechanisms behind fusing neural network layers to improve execution speed in PyTorch.
Summary
Decoder
Original Article
After nearly breaking, NASA's Deep Space Network “worked well” on Artemis II
NASA successfully updated processes for its Deep Space Network to handle the intense data demands of the Artemis II moon mission without failures.
Summary
Deep Dive
Decoder
Original Article
Building a Good Vertical Agent
Vertical AI agents perform best when structured with a memory hierarchy rather than simply stuffing more raw data into a large context window.
Summary
Deep Dive
Decoder
Original Article
Why AI hasn't replaced software engineers, and won't
Coding agents automate the 'execute' phase of software development, but engineers remain essential for the 'decide' and 'deliver' phases, according to Arvind Narayanan and Sayash Kapoor.
Summary
Deep Dive
Decoder
Original Article
Software Is Made Between Commits
The Zed team is introducing DeltaDB, a version control system that logs conversations between developers and AI agents as shared artifacts alongside code edits.
Summary
Deep Dive
Decoder
Original Article
First Drive: The 2027 Rivian R2 entirely changes the EV game
Rivian began customer deliveries of the $60,000 R2, an electric SUV designed for mass-market appeal with significant engineering simplifications to reduce weight and cost.
Summary
Deep Dive
Decoder
Original Article
Doing nothing at work
Software engineers should maintain 80% utilization to ensure they have the bandwidth to tackle the high-impact outlier opportunities that actually move the needle.
Summary
Deep Dive
Decoder
Original Article
Agent Substrate Can Power Agents on Kubernetes with kagent
Solo.io and Google are collaborating on Agent Substrate, an open-source framework that enables Kubernetes to efficiently run, suspend, and resume sandboxed AI agents.
Summary
Deep Dive
Decoder
Original Article
Safe Terraform auto-apply with conftest
Teams can safely enable Terraform auto-apply by using conftest to programmatically validate infrastructure plans against deterministic, version-controlled policies.
Summary
Decoder
Original Article
How We Moved Discord Voice to the Edge
Discord migrated 80% of its voice traffic to Cloudflare's edge network, achieving significant latency drops through custom hardware-software optimization.
Summary
Deep Dive
Decoder
Original Article
Infinite Cardinality Metrics: Custom metrics built for modern systems
Datadog introduced Infinite Cardinality Metrics, a new pricing model shifting costs from unique tag combinations to total data volume.
Summary
Deep Dive
Decoder
Original Article
The Benefits of Cognitive Inclusion in UX Research
UX researchers at Fable found that including people with cognitive disabilities in testing surfaces nearly twice as many usability issues as general population studies.
Summary
Deep Dive
Decoder
Original Article
How To Make Your Design System AI-Ready
AI-generated prototypes are failing because of implicit design debt, necessitating a shift toward highly structured, documentation-heavy design systems.
Summary
Deep Dive
Decoder
Original Article
Animation Vocabulary (Website)
This animation vocabulary serves as a standardized reference guide for developers to describe motion patterns when prompting AI or collaborating with designers.
Summary
Decoder
Original Article
VHS Video Effect (Website)
ntsc-rs brings authentic VHS-style degradation to modern video workflows using high-performance Rust algorithms instead of basic color overlays.
Summary
Deep Dive
Decoder
Original Article
OpenAI Acquired Ona for Long-Running Agents
OpenAI is acquiring Ona to bolster its Codex platform with persistent cloud orchestration for long-running AI agents.
Summary
Original Article
Anthropic backtracks on policy that 'sabotaged' researchers' work
Anthropic will make its internal safety guardrails transparent after researchers discovered their Claude Fable 5 model was silently downgrading requests.
Summary
Original Article
Can Compute Commoditize if it's Not Fungible?
CoreWeave’s argument that GPU compute is non-fungible serves as both a technical reality and a deliberate strategy to maintain higher margins.
Summary
Decoder
Original Article
Oracle shares tumble 11% on increased capital raise, cash concerns
Oracle stock dropped 11% after the company announced a $20 billion capital raise and reported negative free cash flow due to massive AI infrastructure spending.
Summary
Deep Dive
Decoder
Original Article
Mythos-class models will diffuse throughout the world by 2029
Current scaling trends suggest that high-performance open-weight models capable of running on consumer laptops will reach frontier-level capabilities by early 2029.
Summary
Deep Dive
Decoder
Original Article
Model capabilities improve over time, but open-weight models lag the frontier
I often ask Claude mundane questions about cooking, fitness, and cars, among other things, and I can’t say I’ve found Fable 5 to be some magical step change vs. previous Claude models (e.g., Opus 4.7) at answering my day-to-day questions. I was already in awe of the fact that for $20/month I can have functionally unlimited access to incredible intelligence in my pocket; Fable 5 may be smarter, but it’s probably not going to help me plan a date night dinner any better. There are diminishing marginal returns to intelligence; the majority of my (and probably most consumers’) day-to-day AI usage isn’t going to really benefit from a smarter model.
Let’s shift focus to the enterprise. There’s a vast array of jobs to be done and people to do them: lawyers and executive assistants and nurses and customer service workers and account managers and accountants. Seriously, there is a LOT of white-collar work being done today in the US. You could imagine some tier-system that bucketed these types of work into difficulty levels: manual data-entry would probably be pretty low on the list; (some) work done by biology researchers or lawyers or software engineers would probably be higher up on the list.
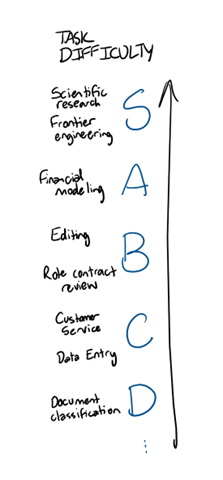
But the same law of diminishing marginal returns applies: beyond a certain point, hiring a smarter-than-necessary human doesn’t really improve performance. And if you wanted to augment or automate this labor – diminishing marginal returns applies to model intelligence also. But again, there’s a diversity of tasks, and new models can continue to push the frontier forward for some while not being materially better on others. Fable 5 is clearly a gamechanger for hardcore software engineering and beating Pokemon; I haven’t seen notable performance improvements in my Chipotle burrito-bowl ordering workflow.
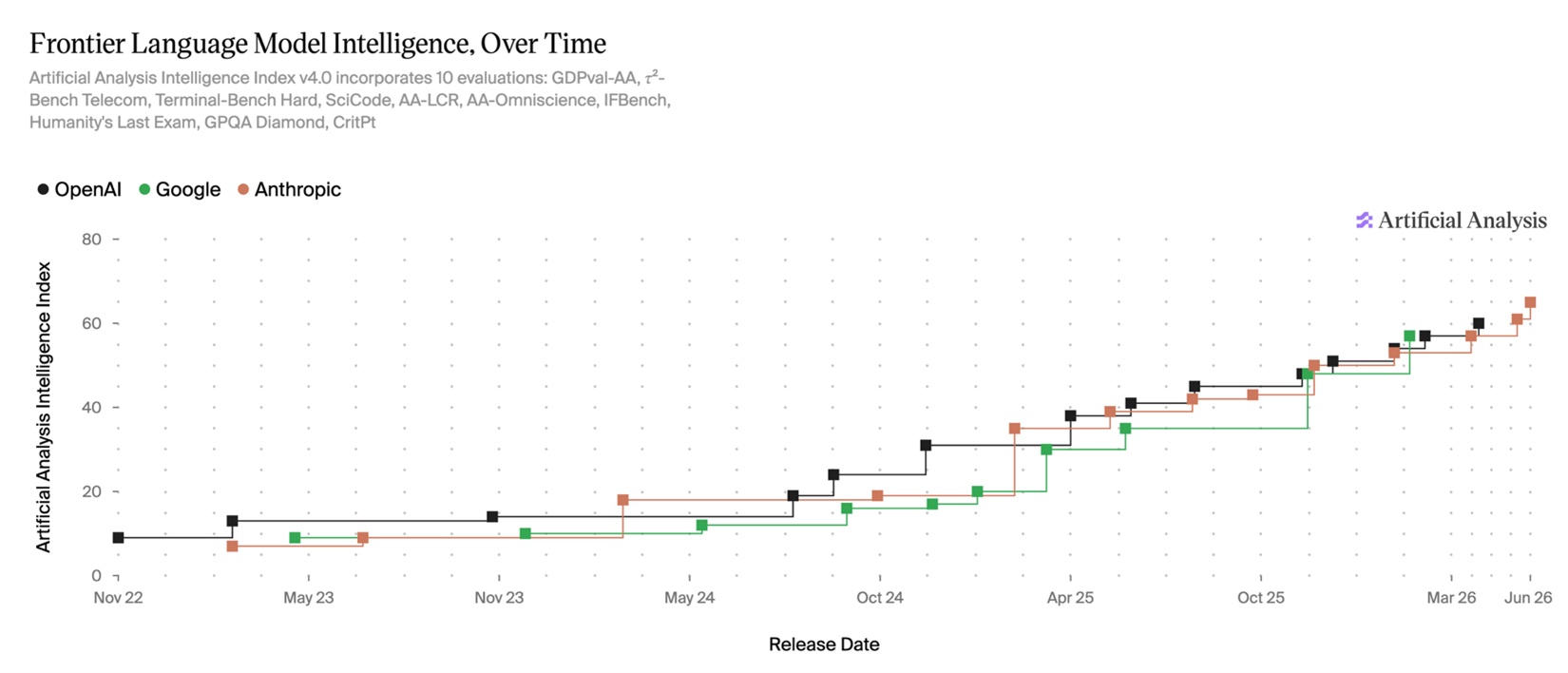
The Artificial Analysis Intelligence Index v4 (AAII) measures model performance across a variety of domains; it’s an “index fund of benchmarks” in a sense. No evaluation is perfect, but for the purposes of this discussion, this feels like the most useful one. I also like the Epoch Capabilities Index.
Model performance has only improved over time, and I see no reason why it shouldn’t continue to improve in the future. Let’s turn our task difficulty tier list into a y-axis and show model performance over time. This is just illustrative; a precise mapping from AAII score to capabilities on real world tasks is unclear, and I’m not trying to make a prediction that doctors or lawyers or software engineers will be automated by 20XX. I’m merely saying that (1) the frontier models have gotten better over time, that (2) they’ll probably continue to do so, and that (3) as they get better and better, more and more tasks will reach the asymptote for diminishing marginal returns to model intelligence.
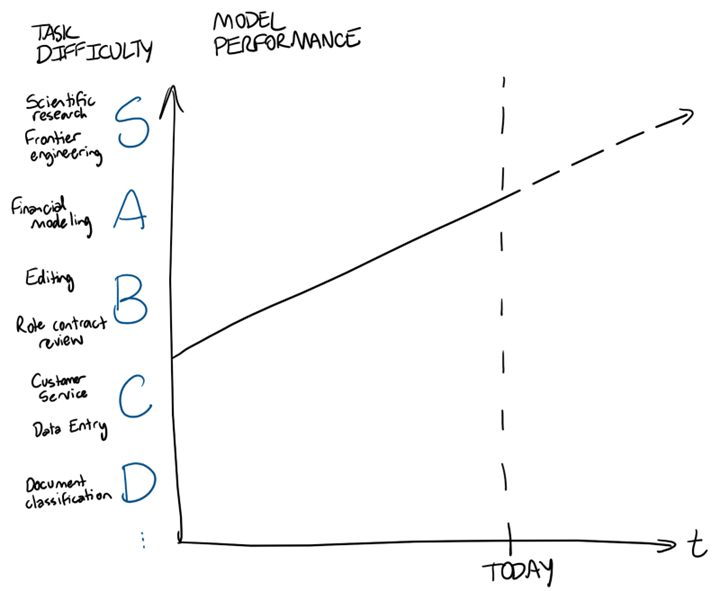
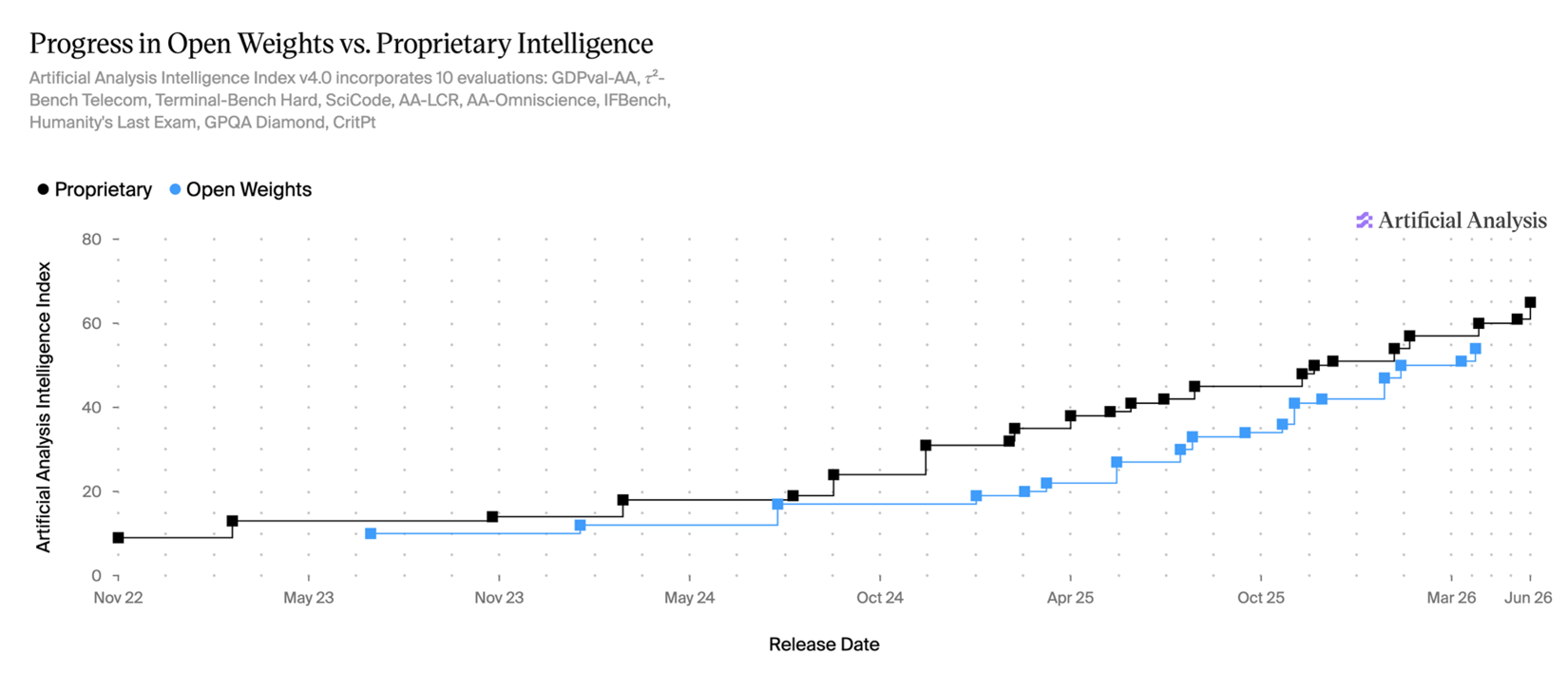
Behind the frontier lies open-weight models: models that theoretically anyone could run with the right compute hardware. Open-weight models are usually substantially cheaper vs. models from Google / Anthropic / OpenAI, but are also less intelligent. How far behind open-weight models are vs. the frontier is up for debate, but for now let’s assume the answer is ~4 months or so on benchmarks [1].
Open-weight models also come in a variety of sizes. For example, the Gemma 4 family of open-weight models from Google comes in E2B, E4B, 12B, 26B A4B, and 31B sizes. Understanding the alphabet soup isn’t important, but larger models (more parameters) typically correlates to more intelligence, while smaller models can run on smaller and less expensive devices (e.g., phones, laptops). Let’s add two more lines to our graph above: one for the cutting edge of open-weight models, and another for what could feasibly run on an average laptop.
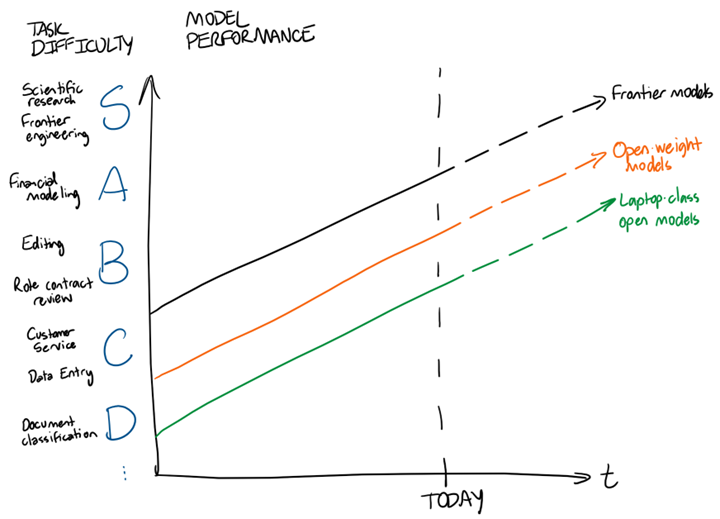
When will these laptop-class open-weight models reach today’s frontier capabilities?
When should we expect to see a model at the level of Fable 5 that’s small enough to run on today’s run-of-the-mill MacBook Air? My predictions are in the table below: each row represents a different model capability level, and each column represents how much RAM a specific device (e.g., a laptop) would need. Today, $1,000 gets you a machine in the leftmost column, and $5,000 gets you something in the rightmost column – I haven’t factored in any progress on the laptop side of things, and that alone makes this a conservative estimate, but I also think that the timelines in the table below could accelerate even more if the rate of progress picks up (and lately, it has). Note that these timelines are for performance parity on benchmarks; real-world performance parity likely will lag by another 6-12 months or so.
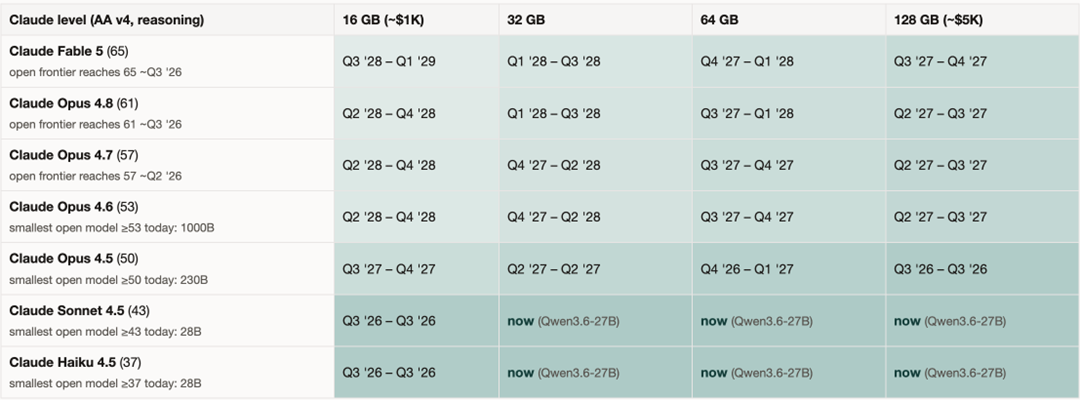
If you’re interested in how I arrived at these numbers, you can find a full analysis here (download the file and open it in Chrome), and the full data and Python scripts behind it here.
What does Fable 5 being diffuse throughout the economy entail?
I doubt consumers will care much about running on-device models. ChatGPT Free-tier consumers probably don’t care about having access to the smartest models and probably aren’t running into rate limits all that often; they probably do care about ease of use (not having to set anything up), a strong memory system, and access to multimodal outputs (image generation has clearly caught on with the consumer crowd). Seeing ads here and there won’t be much of a turn off (see: Instagram, Google Search). Paid consumers probably won’t care much about on-device models either: if you care about model intelligence, you’re sticking with the closed-weight frontier, if you care about rate limits, I imagine a more built out ads engine can solve that (would you rather wait for your limits to reset, or press on with ads if the option were presented to you?).
It’s a different story in the enterprise. Excluding FOMO-driven tokenmaxxing, enterprises make decisions by looking at basic ROI calculations, and if the 90th percentile of businesses are spending $7200/year/employee on AI spend [2], there’s going to be a pretty strong incentive to switch over to an open-weight model that costs ~20% of that or to a local model that’s free. The unknowable trillion-dollar-question is for what workloads frontier models will continue to command positive ROI over their open-weight and local counterparts. I can see a world where frontier models continue to be worth their price in fields like life sciences, healthcare, finance, law, and engineering (whether physical or digital) over the next handful of years. I also can see a world where e.g., Opus 5.5 is good enough for the vast majority of tasks done in the vast majority of enterprises, and companies that run the numbers conclude that buying every power user a ~$5,000 laptop with an RTX Spark inside is the right capex-opex tradeoff.
And though I hate to end on a sour note, anyone having easy (I took me 30 minutes and 4 prompts to get Claude to install an open weight model on my machine) access to the cybersecurity capabilities of a Mythos-class model is certainly a terrifying thought. Sufficiently empowered, just one bad actor can ruin a lot of people’s day.
[1] Note that on-paper performance ≠ real-world performance, especially for open-weight models. Open and closed-weight models have fundamentally different incentive structures; open labs are empirically more prone to “benchmaxxing” (inflating benchmark numbers relative to real-world performance) vs. closed labs which sell model usage. Nathan Lambert (a massive proponent of open-weight models) specifically calls out the AAII for under-estimating the real-world gap in model performance. Therefore, every "Claude-level by date X" estimate in this post should be read as benchmark-score parity; practical parity on messy, real-world work typically comes down the line (roughly ~6-12 months later).
[2] Note that Ramp customers are probably skewed toward higher-growth.
What's the better business model for an AI lab, subscription or API?
AI labs are likely to restrict access to the newest models and features from subscription plans because subscription margins are significantly lower than API usage.
Summary
Deep Dive
Decoder
Original Article
SpaceX IPO Raises $75 Billion in Biggest Debut of All Time
SpaceX raised $75 billion in its IPO, marking the largest debut in history with demand exceeding four times the available shares.
Summary
Original Article
Jeff Bezos Wants to Build an ‘Artificial General Engineer'
Jeff Bezos is launching a new venture called Prometheus to develop AI-driven engineering tools for hardware design and physical manufacturing.
Summary
Decoder
Original Article
My AI Opinions
Scott Alexander details his personal AI outlook, predicting a 50% chance of AGI by 2034 and arguing that recursive self-improvement remains the key unknown variable.
Summary
Deep Dive
Decoder
Original Article
Formal methods and the future of programming
Jane Street is forming a formal methods team, betting that the rise of agentic coding makes mathematical verification of generated code essential.
Summary
Decoder
Original Article
Static types and shovels
The resurgence of static typing is driven by the evolution of type systems that actually assist developers rather than merely acting as bureaucratic paperweights.
Summary
Deep Dive
Decoder
Original Article
Amazon Now Lets You Design Custom Merch Using AI
Amazon has integrated AI-driven merchandise design into its shopping app, allowing users to generate products like T-shirts and tumblers via Alexa prompts.
Summary
Original Article
Meta's Edits app is getting an AI assistant and a desktop version
Meta is evolving its Edits video-editing app with a forthcoming desktop version and an AI assistant designed to keep creators within the Instagram ecosystem.
Summary
Original Article
Dieter Rams avoids computers. His ten rules still fit designing for AI
Dieter Rams’ 10 principles of good design—designed for physical objects—offer a necessary framework for curbing the current AI feature bloat.
Summary
Original Article
The Largest Library of Open-Source UI (Website)
Uiiverse offers a massive, community-driven repository of UI components available in HTML, CSS, Tailwind, React, and Figma formats.
Summary
Original Article
Clay Global rebrands the ‘Google for the semiconductor industry'
Clay Global modernized the brand identity for Partstack by simplifying complex semiconductor search interfaces into a cleaner, more readable design language.
Summary
Original Article
Design Influence isn't About Always Being Right. It's About Being a Strategic Advisor
Effective design influence comes from acting as a strategic advisor rather than an ego-driven advocate for individual preferences.
Summary
Original Article
House Robots Are Coming—and They Will Be Dangerously Cute
Colin Angle, the creator of the Roomba, has launched 'The Familiar,' a non-connected social robot designed for emotional bonding instead of data harvesting.
Summary
Original Article
Waymo launches premier subscription tier for $29.99 a month, starting in select cities
Waymo launched a $29.99 monthly 'Waymo Premier' subscription to capture revenue from high-frequency robotaxi users in San Francisco, Los Angeles, and Phoenix.
Summary
Original Article
A Greyscale iPhone Setup that Works in Everyday Life
Fabian Hemmert shares a method for automating greyscale iPhone settings based on the specific app currently in use to combat screen time without sacrificing accessibility.
Summary
Original Article
iOS 27 revamps AirPods settings in a big way, here's the new design
Apple is simplifying AirPods management in iOS 27 with a redesigned, icon-driven interface that replaces the previous cluttered settings list.
Summary
Original Article
Why We Should Be Designing for Connection, Not Perfection
Human-centric design is seeing a resurgence as brands like Nike and Ocado prioritize emotional connection over the polished, synthetic output of AI.
Summary
Original Article
The "Vibe Coding" Crisis: Is Web Design Becoming a Commodity?
The rise of AI-driven 'vibe coding' is enabling instant website creation, but risks turning the web into a sea of homogenized algorithmic averages.
Summary
Decoder
Original Article
There's a Spirit in Everything, and Maki Yamaguchi is Vividly Bringing Them to Life
New York-based illustrator Maki Yamaguchi balances folklore and scientific themes using a signature style that juxtaposes bold brushwork with delicate detail.