Interaction Models: A Scalable Approach to Human-AI Collaboration
Thinking Machines Lab's TML-Interaction-Small handles simultaneous speech and visual proactivity with 200ms micro-turns, beating GPT-4o Realtime 77.8 to 46.8 on interaction benchmarks.
Summary
Deep Dive
Decoder
Original Article
TanStack npm Packages Compromised in Ongoing Mini Shai-Hulud Supply-Chain Attack
84 TanStack npm packages with 12M+ weekly downloads were compromised in a supply-chain attack, forcing TanStack to deprecate affected versions and harden their GitHub Actions workflow.
Summary
Decoder
Original Article
Google's Gemini Omni video model surfaces ahead of I/O debut
Google's Gemini Omni video model leaked with unusually strong editing features but trailing ByteDance's Seedance 2 on raw cinematic quality.
Summary
Deep Dive
Decoder
Original Article
The Inference Shift
Cerebras' surging IPO signals AI inference splitting into speed-optimized answer chips for humans and memory-heavy agentic chips for autonomous work without humans waiting.
Summary
Deep Dive
Decoder
Original Article
Foundation Model Scaling
AWS detailed how foundation model scaling split from one regime into three—pre-training, post-training, and test-time compute—with P6e-GB200 UltraServers exposing 72 Blackwell GPUs in a single 13.4 TB NVLink domain.
Summary
Deep Dive
Decoder
Original Article
Building Blocks for Foundation Model Training and Inference on AWS
For a long time, "scaling" in foundation models mostly meant one thing: spend more compute on pre-training and capabilities rise. That intuition was supported by empirical work such as Kaplan et al. (2020), which reported predictable power-law trends in loss as you scale model parameters, dataset size, and training compute. In practice, these trends justified sustained investment in large-scale accelerator capacity and the surrounding distributed infrastructure needed to keep it efficiently utilized. But the frontier has evolved—and scaling is no longer a single curve. NVIDIA's "from one to three scaling laws" framing usefully emphasizes that, beyond pre-training, performance increasingly scales through post-training (e.g., supervised fine-tuning (SFT) and reinforcement learning (RL)-based methods) and through test-time compute ("long thinking," search/verification, multi-sample strategies).

Figure: Adapted from "AI's Three Scaling Laws, Explained" (NVIDIA Blog).
Taken together, these scaling regimes push the foundation-model lifecycle—pre-training, post-training, and inference—toward convergent infrastructure requirements: tightly coupled accelerator compute, a high-bandwidth low-latency network, and a distributed storage backend. They also raise the importance of orchestration for resource management, and of application- and hardware-level observability to maintain cluster health and diagnose performance pathologies at scale.
Another key trend is the increasing reliance of the foundation-model lifecycle on an open-source software (OSS) ecosystem that spans model development frameworks, cluster resource management, and operational tooling. At the cluster layer, resource management is typically provided by systems such as Slurm and Kubernetes. Model development and distributed training are commonly implemented in frameworks such as PyTorch and JAX. Monitoring and visualization—that is, observability—are often achieved using Prometheus for metrics collection and Grafana for visualization and alerting, positioned as an operational layer atop infrastructure and resource management. Figure 1 illustrates this layered architecture, showing how hardware infrastructure supports resource orchestration, which in turn enables ML frameworks, with observability spanning across all layers.

Figure 1: The layered architecture of open-source software stacks for foundation model training and inference
This post is intended for machine learning engineers and researchers involved in foundation model training and inference, with particular attention to workflows built atop OSS frameworks. It analyzes how AWS infrastructure—including multi-node accelerator compute, high-bandwidth low-latency networking, distributed shared storage, and associated managed services—interacts with common OSS stacks across the foundation model lifecycle. The primary goal is to provide a technical foundation for understanding systems bottlenecks and scaling characteristics spanning pre-training, post-training, and inference. This introductory post surfaces the overall system architecture, emphasizing the integration points between AWS infrastructure components and OSS tools that underpin large-scale distributed training and inference.
The AWS Building Blocks
The remainder of this series examines how this layered architecture is realized on AWS, progressing through infrastructure, resource orchestration, the ML software stack, and observability. The following sections preview each layer.
Infrastructure: Compute, Network, and Storage
As illustrated in Figure 1, infrastructure is anchored by three coupled building blocks—accelerated compute with large device memory, wide-bandwidth interconnect for collective communication, and scalable distributed storage for data and checkpoints.
Accelerated compute forms the foundation of large-scale foundation model pre-training, post-training, and inference. AWS offers several generations of NVIDIA GPUs as part of its Amazon EC2 accelerated computing instances, including the Amazon EC2 P instance family. The P5 instance family includes p5.48xlarge with eight NVIDIA H100 GPUs, p5.4xlarge with a single H100 GPU for smaller-scale workloads, and p5e.48xlarge/p5en.48xlarge variants with NVIDIA H200 GPUs. The P6 instance family introduces NVIDIA Blackwell B200 architecture with p6-b200.48xlarge and Blackwell Ultra B300 with p6-b300.48xlarge. Across these generations, the dominant scaling axes are peak Tensor throughput, HBM capacity and bandwidth, and interconnect bandwidth (within and across nodes).
As a first-order approximation, peak Tensor Core throughput—measured in floating point operations per second (FLOPS)—helps situate these accelerators on a common axis. The table below summarizes per-GPU peak throughput for dense BF16/FP16 and FP8 Tensor operations, along with HBM capacity and HBM bandwidth, using SXM/HGX-class specifications that align with NVSwitch/NVLink-based multi-GPU nodes.
| GPU (representative variant) | BF16/FP16 Tensor peak (dense) | FP8 Tensor peak (dense) | FP4 Tensor peak (dense) | HBM capacity | HBM bandwidth |
|---|---|---|---|---|---|
| H100 (SXM) | 0.9895 PFLOPS | 1.979 PFLOPS | — | 80 GB HBM3 | 3.35 TB/s |
| H200 (SXM) | 0.9895 PFLOPS | 1.979 PFLOPS | — | 141 GB HBM3e | 4.8 TB/s |
| B200 (HGX, per GPU) | 2.25 PFLOPS | 4.5 PFLOPS | 9 PFLOPS | 180 GB HBM3e | 8 TB/s |
| B300 (HGX, per GPU) | 2.25 PFLOPS | 4.5 PFLOPS | 13.5 PFLOPS | 288 GB HBM3e | 8 TB/s |
Note: NVIDIA product tables often report Tensor throughput "with sparsity"; this table reports dense throughput. Where applicable, dense throughput is taken as half of sparse throughput, following NVIDIA's guidance for HGX-class platforms (NVIDIA). DGX figures are system-level; the B200 HBM capacity and bandwidth values are expressed per GPU by dividing DGX totals by eight (NVIDIA).
As models scale, step time is often dominated by collective communication and memory movement rather than raw compute throughput, motivating explicit scale-up and scale-out bandwidth accounting. For the multi-GPU instances, GPU communication spans two regimes. Internal scale-up (NVLink/NVSwitch) provides high-bandwidth, low-latency GPU-to-GPU connectivity within a node, enabling collectives such as all-reduce and all-gather to execute without traversing the host networking stack. External scale-out (EFA) provides OS-bypass networking across nodes, which AWS uses as a building block for Amazon EC2 UltraClusters where communication-heavy collectives span thousands of instances. The following table summarizes key specifications across these instance types:
| Instance Type | GPU | GPUs | GPU Memory | NVLink | NVLink BW (aggregate) | EFA | EFA BW (aggregate) |
|---|---|---|---|---|---|---|---|
| p5.4xlarge | H100 | 1 | 80 GB HBM3 | — | — | v2 | 12.5 GB/s |
| p5.48xlarge | H100 | 8 | 640 GB HBM3 | 4th | 7.2 TB/s | v2 | 400 GB/s |
| p5e.48xlarge | H200 | 8 | 1,128 GB HBM3e | 4th | 7.2 TB/s | v2 | 400 GB/s |
| p5en.48xlarge | H200 | 8 | 1,128 GB HBM3e | 4th | 7.2 TB/s | v3 | 400 GB/s |
| p6-b200.48xlarge | B200 | 8 | 1,440 GB HBM3e | 5th | 14.4 TB/s | v4 | 400 GB/s |
| p6-b300.48xlarge | B300 | 8 | 2,100 GB HBM3e | 5th | 14.4 TB/s | v4 | 800 GB/s |
Note: EFA bandwidth is converted from Gbps to GB/s (÷8) for consistency with other bandwidth metrics; see the EC2 accelerated computing networking specifications. NVLink and EFA bandwidth figures are shown as aggregate per-instance values rather than per-link values; see the P5 instance family page and the P6 instance family page for the corresponding intra-node interconnect and networking characteristics.
Elastic Fabric Adapter (EFA) is a network interface for Amazon EC2 that provides OS-bypass remote direct memory access (RDMA) capability using the Scalable Reliable Datagram (SRD) protocol. By enabling applications to communicate directly with the network device through the Libfabric API—bypassing the operating system kernel—EFA reduces latency and improves throughput for collective operations in distributed training.
Multiple generations of EFA are available on different instance families. Amazon EC2 P5 and P5e instances are equipped with EFA version 2 (EFAv2). EFA version 3 (EFAv3), provided on P5en instances, reduces packet latency by approximately 35% compared to EFAv2. EFA version 4 (EFAv4), available on P6 instances, delivers an additional 18% improvement in collective communication performance relative to EFAv3.
At scale, both distributed training (streaming corpora and writing multi-terabyte checkpoints) and large-scale inference (staging weights and managing KV cache growth) motivate a tiered storage hierarchy—local NVMe SSD for hot data, Lustre for shared high-throughput access, and Amazon S3 for durable persistence.
In this series' primary multi-GPU instances, local NVMe is provided as instance store (ephemeral) with 30.72 TB raw capacity (8 × 3.84 TB NVMe SSD); see the EC2 accelerated-computing instance store specifications.
Lustre is an open-source, POSIX compliant distributed file system widely used in high-performance computing (HPC) to provide a shared namespace with high aggregate throughput across many clients. Amazon FSx for Lustre provides Lustre as a fully managed service and exposes it as a parallel file system capable of terabytes per second of throughput, millions of IOPS, and sub-millisecond latencies. Data Repository Associations enable integration with Amazon S3, supporting lazy loading of training datasets and automatic checkpoint export for durability.
At cluster scale, these instances are deployed in Amazon EC2 UltraClusters, which provision thousands of accelerated instances as a single, tightly placed cluster within an Availability Zone and interconnect them using a petabit-scale nonblocking network.

Figure: 2nd-generation Amazon EC2 UltraClusters (example P5 UltraCluster).
For workloads with high per-step communication intensity (e.g., expert parallelism in MoE models where all-to-all token dispatch spans many GPUs), the size of the NVLink domain can become a first-order constraint. As an extension of the internal scale-up axis, increasing the NVLink domain reduces how often performance-critical communication must leave the NVLink fabric.
Amazon EC2 UltraServers extend the NVLink domain beyond a single EC2 instance by connecting multiple component instances through a dedicated accelerator interconnect. AWS reports that P6e-GB200 UltraServers are built on the NVIDIA GB200 NVL72 platform and expose up to 72 Blackwell GPUs and 13.4 TB of aggregate HBM3e within one NVLink domain. At larger scales, EFA remains the cross-node fabric for multi-UltraServer jobs, but increasing the intra-domain GPU count can reduce how often performance-critical communication must leave the NVLink fabric.
These systems are built from NVIDIA Grace–Blackwell superchips, which couple Grace CPU memory and Blackwell GPU HBM via cache-coherent NVLink-C2C, enabling direct access across CPU- and GPU-attached memory without explicit host–device copies. In practice, this can extend the effective memory available to GPU workloads (e.g., by placing colder model state or KV cache in CPU-attached memory) while avoiding PCIe-scale copy overheads, albeit with higher latency and lower bandwidth than local HBM.
The component instance type for P6e-GB200 UltraServers is p6e-gb200.36xlarge, which provides four GPUs and Elastic Fabric Adapter (EFA) v4 networking. The tables below summarize the per-instance and composed UltraServer configurations.
| Instance Type | GPU | GPUs | GPU Memory | Memory BW | NVLink | NVLink BW | EFA | EFA BW |
|---|---|---|---|---|---|---|---|---|
| p6e-gb200.36xlarge | GB200 NVL72 | 4 | 740 GB HBM3e | — | — | — | v4 | 200 GB/s |
Note: The p6e-gb200.36xlarge EFA bandwidth is converted from the published aggregate EFA networking (4 × 400 Gbps) to GB/s (÷8); see the EC2 accelerated computing networking specifications.
| UltraServer | Component instance type | GPUs (NVLink domain) | HBM3e (aggregate) | EFA | EFA BW |
|---|---|---|---|---|---|
| u-p6e-gb200x36 | p6e-gb200.36xlarge | 36 | 6.7 TB | v4 | 1,800 GB/s |
| u-p6e-gb200x72 | p6e-gb200.36xlarge | 72 | 13.4 TB | v4 | 3,600 GB/s |
Note: UltraServer EFA bandwidth is converted from terabits per second (Tbps), as reported by AWS, to GB/s (÷8); see the P6e-GB200 UltraServers announcement and the P6 instance family page.
Resource Orchestration: Slurm and Kubernetes
When training spans hundreds or thousands of accelerators, manual resource management becomes intractable. For example, a training job requiring 512 GPUs must co-schedule 64 eight-GPU nodes (P-instances) simultaneously, and release resources atomically upon completion or failure. Both Slurm and Kubernetes address this challenge through a control-plane architecture: a centralized scheduler maintains cluster state and makes allocation decisions, while worker nodes execute assigned workloads.

Figure 2: High-level architecture of Slurm-based and Kubernetes-based resource orchestration on AWS
Slurm (Simple Linux Utility for Resource Management) is the dominant workload manager in high-performance computing, built on a modular plugin architecture that allows the scheduling algorithm, topology model, resource types, and accounting backend to be configured independently. Its scheduling model organizes resources into partitions (logical groupings of nodes), accepts job submissions via sbatch, and launches parallel tasks via srun with synchronized startup across allocated nodes. Critically for distributed training, Slurm schedules at the job level—allocating entire multi-node jobs atomically before any task launches. A backfill scheduler starts lower-priority jobs in idle slots without delaying higher-priority ones, while a multi-factor priority system weighs fair-share usage, job age, and QOS tiers to order the queue across tenants. Slurm also supports topology-aware placement through plugins that model network switch hierarchies—on AWS, encoding the EFA fabric topology to co-locate jobs on nodes with minimal switch hops—and native GPU scheduling through its Generic Resource (GRES) interface, which tracks GPU types and enforces device affinity.
AWS provides multiple deployment options for Slurm-based orchestration. AWS ParallelCluster is an open-source cluster management tool that automates the deployment of Slurm clusters on EC2, handling head node provisioning, compute fleet scaling, and integration with shared storage. AWS Parallel Computing Service (PCS) offers an alternative that provides the managed control plane. For distributed training workloads specifically, Amazon SageMaker HyperPod supports Slurm mode with additional capabilities tailored to large-scale training, such as continuous node health monitoring and job auto-resume functionality.
Kubernetes takes a declarative, API-driven approach: users specify desired state through resource manifests, and controllers reconcile actual state to match. While Kubernetes excels at model deployment, its native scheduling model exposes several gaps for tightly coupled distributed training. Kubernetes schedules at the pod level; without job-level atomicity, a multi-node training job can partially start—some ranks running while others remain Pending—wasting GPUs or causing deadlocks. Vanilla Kubernetes also lacks batch queue semantics with priority-based backfill, built-in awareness of network fabric topology (NVLink domains, EFA interconnects) for placement of communication-heavy collectives.
Several Kubernetes-native projects address these gaps at different layers. Kueue operates as an admission controller atop the default scheduler, managing job-level gang admission, multi-tenant quotas with hierarchical fair sharing, and priority-based preemption—while delegating pod placement to the underlying scheduler. Volcano and NVIDIA KAI Scheduler take a different approach, replacing or augmenting the default scheduler to integrate gang scheduling directly with topology-aware pod placement—Volcano as a general-purpose batch scheduler, KAI Scheduler with deep NVLink/NVSwitch awareness for GPU-optimized placement. These layers are complementary: Kueue can manage admission and quota policy while passing admitted jobs to a topology-aware scheduler for placement.
For Kubernetes-based orchestration on AWS, Amazon Elastic Kubernetes Service (EKS) provides managed Kubernetes with GPU scheduling via the NVIDIA device plugin. Amazon SageMaker HyperPod also supports EKS mode, combining Kubernetes orchestration with HyperPod's training-specific capabilities. HyperPod EKS extends EKS with features designed for foundation model training at scale. Task governance provides compute allocation and policy enforcement across teams, integrating managed Kueue for admission control and Karpenter for just-in-time node provisioning. Checkpointless training addresses the recovery latency inherent in traditional checkpoint-based fault tolerance. Rather than periodically serializing model state to shared storage, checkpointless training maintains continuous peer-to-peer state replication across GPUs. When a failure occurs, surviving nodes reconstruct the lost state through EFA-based communication rather than reading multi-terabyte checkpoints from FSx for Lustre or S3. Elastic training enables jobs to automatically scale based on resource availability. When additional accelerators become available (e.g., from completed jobs or newly provisioned capacity), elastic jobs can expand to utilize them; when higher-priority workloads require resources, jobs can contract while maintaining training progress.
ML Software Stack
Distributed training and inference involve multiple software layers that must be correctly configured and coordinated. A useful model treats the runtime stack as five layers, ordered from hardware-adjacent components (which must function correctly for anything to run) to framework-level abstractions (which determine programmer productivity and model throughput): hardware enablement, accelerator runtime and math libraries, communication substrate, ML frameworks, and distributed training/inference frameworks.

Figure 3: The ML software stack for distributed training and inference on EC2 instances
Hardware enablement: kernel drivers
At the foundation, Linux kernel drivers provide direct hardware access. The NVIDIA GPU driver exposes compute capabilities and supports GPUDirect RDMA for direct data transfers between GPUs and network adapters. The GDRCopy driver (gdrdrv) enables low-latency CPU-initiated copies to and from GPU memory, used by NCCL for small-message transfers. The EFA driver provides OS-bypass networking through the libfabric API, and the Lustre client driver enables POSIX access to FSx for Lustre parallel file systems.
Accelerator runtime, compilers, and kernel libraries
The CUDA platform provides the programming model and runtime for GPU compute. Applications compiled against CUDA can launch kernels on NVIDIA GPUs, manage device memory, and coordinate execution across multiple devices. The current release is CUDA Toolkit 13.x, with support for Blackwell architecture (compute capability 10.x).
Modern training and inference performance is increasingly driven by specialized optimization libraries and custom kernels, not just general-purpose vendor primitives. Kernels like FlashAttention fuse attention into a single memory-efficient pass, cutting HBM traffic and improving throughput. Many teams also write shape- and precision-specialized fused kernels (e.g., layernorm/residual/activation, quantized GEMMs, MoE dispatch, KV-cache ops) tuned to their exact models. This is enabled by programmable toolchains such as Triton (Python GPU kernel compiler) and NVIDIA's CuTe (tensor layout and warp-level DSL), with libraries like CUTLASS providing highly optimized GEMM and fusion building blocks. In practice, this kernel and compiler layer often determines end-to-end performance as much as the ML framework.
Communication substrate: NCCL and transport plugins
Multi-GPU training depends on efficient collective communication. NVIDIA Collective Communications Library (NCCL) implements collective operations—all-reduce, all-gather, reduce-scatter, all-to-all, broadcast, and point-to-point send/receive—with topology-aware algorithms that exploit NVLink for intra-node communication and network transports for inter-node traffic. NCCL dynamically detects the communication topology and selects ring or tree algorithms depending on message size and available bandwidth. While data-parallel and tensor-parallel strategies rely primarily on all-reduce and all-gather, Mixture-of-Experts (MoE) models with expert parallelism depend on all-to-all collectives to route tokens between GPUs: a dispatch all-to-all sends each token to the GPU hosting its assigned expert, and a combine all-to-all returns expert outputs to the originating GPUs (NVIDIA Developer Blog). Because every GPU exchanges data with every other GPU in the expert-parallel group, all-to-all communication volume scales with the number of experts and can become a dominant bottleneck at high expert-parallelism degrees.
On AWS, NCCL's inter-node communication is enabled through the aws-ofi-nccl plugin, which maps NCCL's transport APIs to libfabric interfaces. This allows NCCL to leverage EFA's OS-bypass and Scalable Reliable Datagram (SRD) protocol without application changes.
For inference workloads, collective operations do not capture all communication patterns. Disaggregated inference architectures—which separate prefill and decode phases onto distinct GPU pools—require efficient point-to-point data movement, particularly for transferring KV cache state between instances. NVIDIA Inference Xfer Library (NIXL) addresses this requirement by providing a unified API for point-to-point transfers across memory tiers (HBM, DRAM, NVMe, distributed storage) and interconnects (NVLink, InfiniBand, Ethernet). NIXL integrates with inference frameworks such as NVIDIA Dynamo and supports backends including UCX and GPUDirect Storage.
ML frameworks: PyTorch
The two dominant frameworks for foundation model development are PyTorch and JAX. JAX takes an SPMD (Single Program Multiple Data) approach through XLA, where the same program executes across devices with automatic data distribution and collective lowering. This blog focuses on PyTorch, which sees broader adoption in the open-source ecosystem and forms the basis for the distributed training and inference frameworks discussed below.
PyTorch provides tensor computation with GPU acceleration, automatic differentiation, and a flexible eager-execution model. For distributed workloads, PyTorch's torch.distributed module provides the core primitives: process groups for collective communication, and distributed data-parallel abstractions including Distributed Data Parallel (DDP) and Fully Sharded Data Parallel (FSDP2). DDP replicates models across GPUs and synchronizes gradients via all-reduce, while FSDP2 shards parameters, gradients, and optimizer states across workers using techniques from the ZeRO algorithm, enabling training of models that exceed single-GPU memory capacity.
Distributed training and inference frameworks
The top layer comprises frameworks that build on PyTorch to provide higher-level abstractions for distributed training and inference at scale. For training, three categories of frameworks address different points in the complexity-performance tradeoff. Below are few examples
Hugging Face Transformers provides the Trainer class with built-in support for distributed training via Accelerate, which abstracts over DDP, FSDP, and DeepSpeed. This path prioritizes ease of use and broad model compatibility, making it suitable for fine-tuning and moderate-scale training where configuration simplicity matters more than maximum throughput.
NVIDIA Megatron Core targets maximum efficiency at scale, implementing 3D parallelism (tensor, pipeline, and expert parallelism) with optimizations including FP8 mixed precision via Transformer Engine. The NeMo Framework builds on Megatron Core to provide end-to-end workflows for pre-training and fine-tuning.
For reinforcement learning from human feedback (RLHF) and related post-training methods, veRL (Volcano Engine Reinforcement Learning) provides a flexible framework that implements algorithms including PPO, GRPO, and REINFORCE++. veRL's HybridFlow architecture allows mixing training backends (FSDP2, Megatron) with inference engines (vLLM, SGLang) in the same job, avoiding weight synchronization overhead by sharing model weights in memory between actor and rollout components.
For inference serving, vLLM implements PagedAttention, managing the KV cache as paged virtual memory to reduce fragmentation and enable higher batch sizes. SGLang extends this with RadixAttention for automatic prefix reuse across requests, a zero-overhead batch scheduler that overlaps CPU scheduling with GPU computation, and a cache-aware load balancer that routes requests based on predicted cache hit rates. Both frameworks support tensor parallelism for serving models that exceed single-GPU memory, and both integrate with NVIDIA Dynamo for disaggregated serving architectures that separate prefill and decode phases.
Observability
Observability is a prerequisite for debugging and operating distributed training systems at scale. When a training job stalls or throughput degrades, practitioners need visibility into whether the cause is hardware failure, network congestion, storage bottlenecks, or application-level inefficiency. At the infrastructure scale discussed in this series—thousands of GPUs, petabits of interconnect bandwidth, and terabytes of checkpoint data—the challenge shifts from simple monitoring to systematic telemetry collection, storage, and analysis. Observability spans three telemetry categories: infrastructure metrics (GPU, network, storage), workload metrics (training throughput, queue latency), and alerting for proactive fault detection.
Core Stack: Prometheus and Grafana
The de facto standard for observability in Kubernetes and HPC environments combines Prometheus for metrics collection with Grafana for visualization and alerting. Prometheus operates on a pull-based model, periodically scraping HTTP endpoints exposed by metric exporters. Collected metrics are stored in a time-series database (TSDB) and queried via PromQL, a flexible query language for aggregation, filtering, and alerting rule evaluation. Grafana consumes Prometheus as a data source, rendering dashboards and triggering alerts based on PromQL expressions.
For production deployments, Amazon Managed Service for Prometheus (AMP) provides a fully managed, Prometheus-compatible time-series database that scales to ingest millions of samples per second without requiring operators to manage storage, replication, or high availability. Amazon Managed Grafana (AMG) offers a managed Grafana workspace with native integration to AMP and AWS authentication via IAM Identity Center. Together, these services eliminate operational overhead while preserving compatibility with existing Prometheus exporters and Grafana dashboards.
GPU, Network, and Application Telemetry
DCGM-Exporter exposes NVIDIA GPU metrics in Prometheus format, including utilization, memory usage, power, temperature, and hardware health indicators such as ECC errors and XID events. For training workloads, SM activity (DCGM_FI_PROF_SM_ACTIVE) often provides a more accurate measure of compute efficiency than basic utilization metrics.
EFA exposes driver-level statistics (bytes, packets, retransmits, timeouts) that help diagnose collective operation bottlenecks in distributed training. The aws-ofi-nccl plugin bridges NCCL to the libfabric interface, and operators can combine EFA counters with NCCL diagnostics (NCCL_DEBUG=INFO) to isolate network-layer issues.
Amazon FSx for Lustre exposes client-side metrics including throughput and metadata latency, while application-level metrics (step time, tokens per second, loss values for training; TTFT, inter-token latency for inference) can be exported via Prometheus client libraries.
GPU Health Monitoring and Alerting
Proactive fault detection prevents hardware issues from propagating into extended training interruptions. A typical workflow monitors DCGM health metrics and triggers alerts when error counts exceed thresholds. ECC single-bit errors (SBE) may be tolerable in small numbers, but accelerating SBE rates often precede double-bit errors (DBE) or other failures. XID 63 (row remap failure), XID 64 (GPU fallen off bus), and XID 94/95 (contained/uncontained errors) typically warrant immediate node replacement.
The GPU Health - Cluster dashboard (Grafana dashboard ID 21645) provides a reference visualization for common GPU error patterns. The dashboard aggregates ECC errors, XID events, thermal violations, and row remapping status across all cluster nodes, enabling operators to identify failing hardware before it impacts training jobs.

Figure 4: GPU Health - Cluster dashboard showing GPU error patterns and instance reporting
Conclusion
The shift from a single pre-training scaling law to three complementary regimes—pre-training, post-training, and test-time compute—has not fragmented infrastructure requirements; it has reinforced them. All three regimes demand tightly coupled accelerator compute, high-bandwidth low-latency networking, and scalable distributed storage, differing mainly in workload profile and resource scheduling patterns.
This post surfaced the four-layer architecture that addresses those requirements on AWS: infrastructure building blocks (EC2 P-instances, EFA networking, and tiered storage), resource orchestration (Slurm and Kubernetes with SageMaker HyperPod), the ML software stack (from kernel drivers and CUDA through NCCL to PyTorch), and observability (Prometheus, Grafana, and GPU health monitoring). Each layer constrains and enables the layers above it—a misconfigured driver or saturated network link can bottleneck an otherwise well-tuned training run just as effectively as a suboptimal parallelism strategy.
Understanding these integration points is the foundation for diagnosing performance bottlenecks and making informed scaling decisions across the foundation model lifecycle.
Trajectory Models for Few-Step Diffusion
Apple researchers reduce diffusion image generation to four steps without discarding the likelihood framework that consistency training and distillation methods abandon
Summary
Deep Dive
Decoder
Original Article
Agentic Test-Time Scaling (GitHub Repo)
AutoTTS cuts LLM inference tokens by 69.5% compared to self-consistency sampling by having a coding agent automatically discover test-time scaling strategies in an offline replay environment for $40 and zero runtime LLM calls.
Summary
Deep Dive
Decoder
Original Article
Long Video Generation
Google Research's A²RD adds multimodal memory and hierarchical self-correction to video diffusion, generating coherent 10-minute videos with 30% better consistency.
Summary
Deep Dive
Decoder
Original Article
Google Says Criminal Hackers Used AI to Find a Major Software Flaw
Google reports the first AI-discovered zero-day exploit by criminal hackers targeting an open-source admin tool, patched before damage.
Summary
Deep Dive
Decoder
Original Article
Introducing Claude Platform on AWS: Anthropic's native platform, through your AWS account
AWS is the first cloud provider to offer Anthropic's native Claude Platform, but requests run outside AWS security boundaries through Anthropic's infrastructure.
Summary
Deep Dive
Decoder
Original Article
Introducing Claude Platform on AWS: Anthropic's native platform, through your AWS account
Today, we're excited to announce the general availability of Claude Platform on AWS. Claude Platform on AWS is a new service that gives customers direct access to Anthropic's native Claude Platform experience through their AWS account, with no separate credentials, contracts, or billing relationships required. AWS is the first cloud provider to offer access to the native Claude Platform experience.
In this post, we explore how Claude Platform on AWS works and how you can start using it today.
Claude Platform experience through AWS
With Claude Platform on AWS, you work with the same APIs, features, and console experience available through Anthropic directly. This includes the Messages API, Claude Managed Agents (beta), advisor tool (beta), web search and web fetch, MCP connector (beta), Agent Skills (beta), code execution, files API (beta). For the full list of capabilities, see the Claude Platform documentation.
You access Claude Platform on AWS through familiar AWS features:
- Authentication: You use existing AWS IAM credentials to access Claude Platform. No separate accounts or API keys to manage.
- Billing: Usage is billed through AWS Marketplace on a consumption basis, so you can track and manage AI spending alongside your other AWS services.
- Audit: Activity is captured in AWS CloudTrail, so you can monitor, audit, and investigate AI usage the same way you do for any other AWS services.
Claude Platform on AWS is operated by Anthropic, and the underlying requests and data are processed outside the AWS security boundary. This makes it well suited for teams without specific Regional data residency requirements, and complements Claude models on Amazon Bedrock, so you can access Claude through the approach that fits your needs.
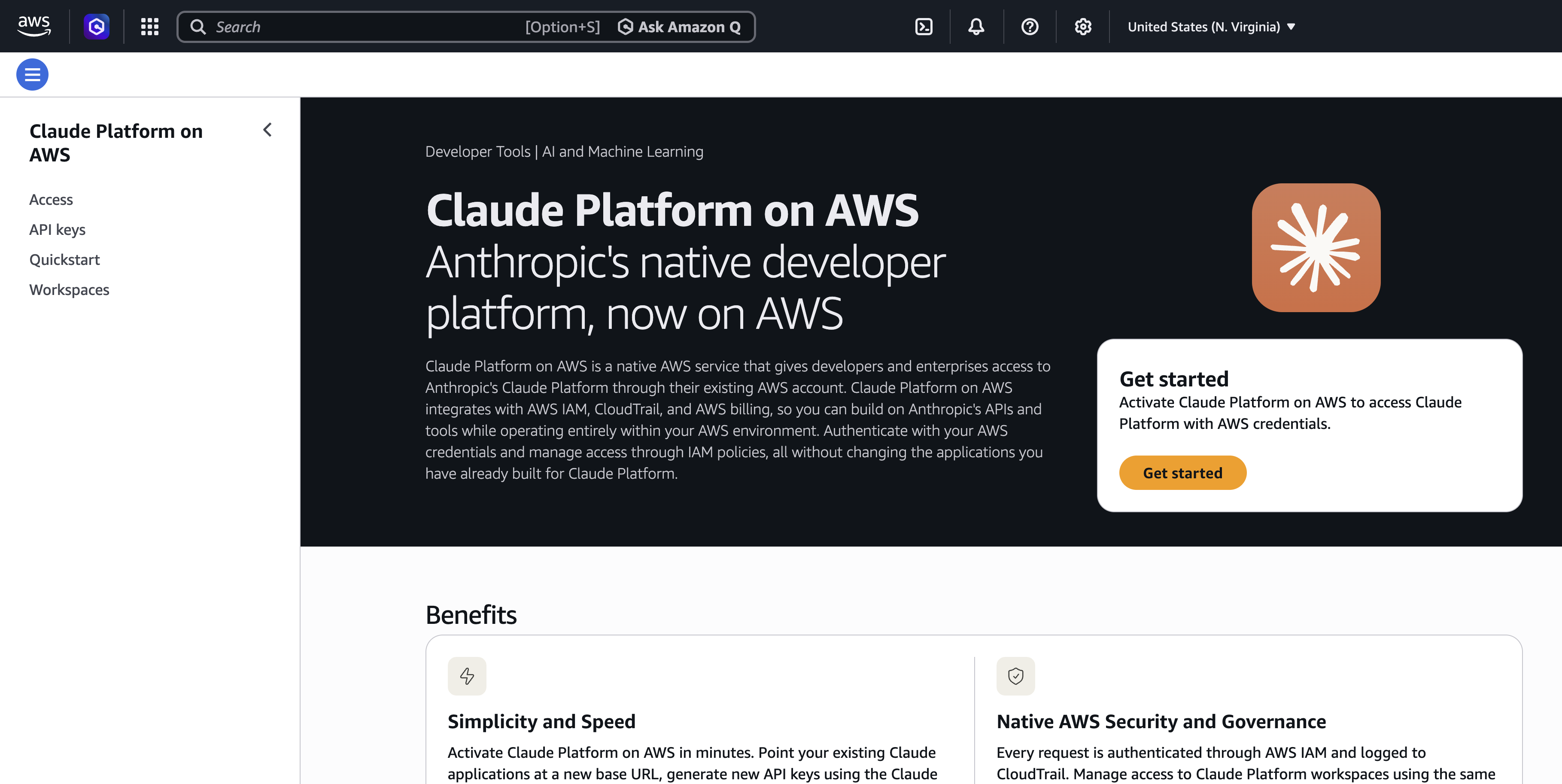
Getting started with Claude Platform on AWS
You can activate Claude Platform on AWS through the AWS Marketplace. For step-by-step instructions, see Set up your account. After your account is activated, getting to your first API call takes three steps: create a workspace, authenticate, and call the API.
Step 1: Create a workspace
With a workspace, you can separate projects, environments, or teams while maintaining centralized billing and administration. It also serves as the primary AWS Identity and Access Management (IAM) resource for Claude Platform on AWS. You grant or deny access to specific workspaces through IAM policies using the workspace ARN. See IAM policies for policy examples.
Open the Claude Console from within the Claude Platform on AWS Console and create a workspace.
Step 2: Authenticate
Claude Platform on AWS supports two authentication methods: IAM with AWS Signature Version 4, and API keys. We recommend using temporary IAM credentials for setups that require a higher level of security, and API keys for exploring Claude Platform on AWS.
To quickly test your setup, you can generate an API key in the Claude Platform on AWS Console:
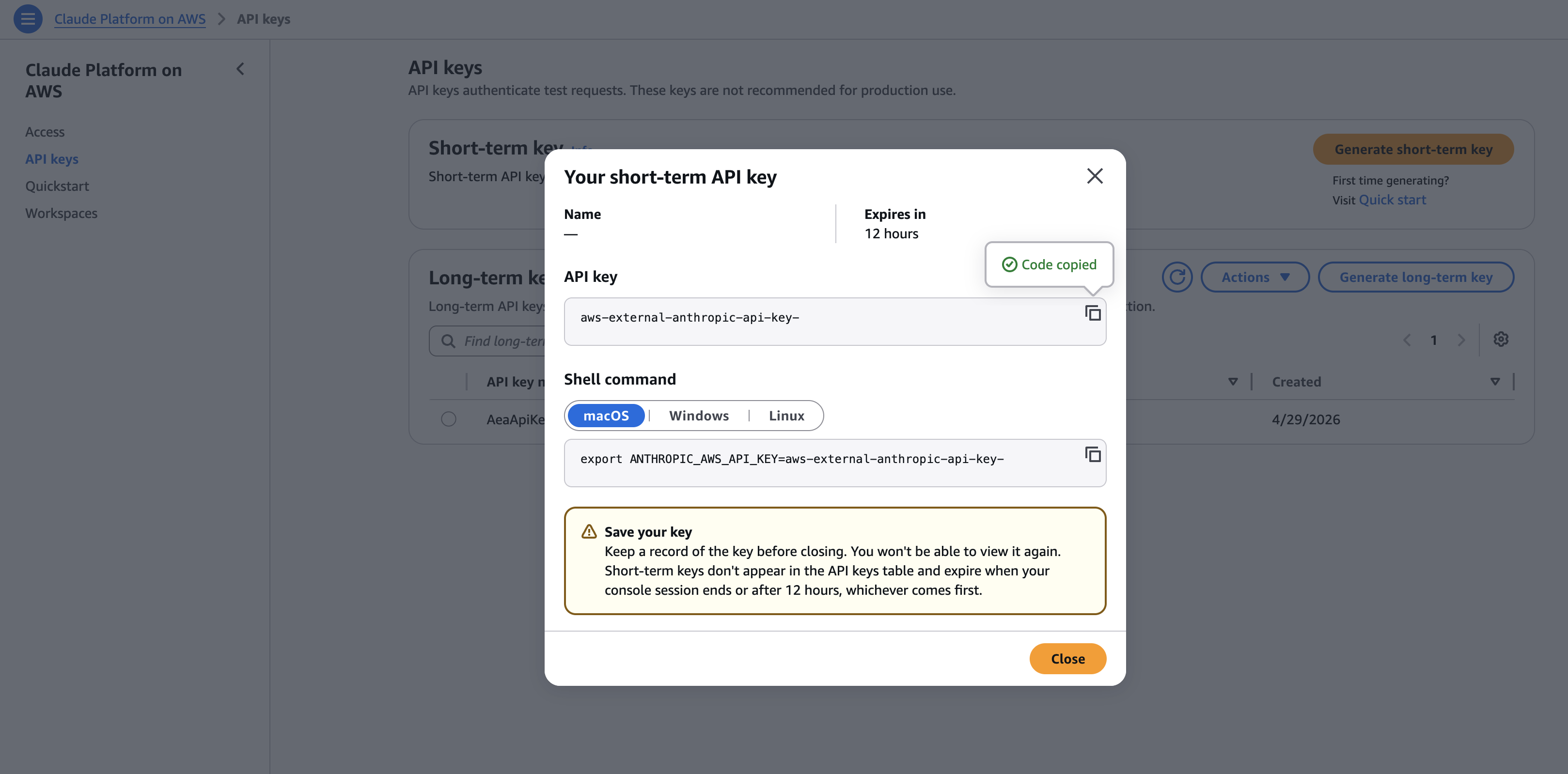
Set your API key, base URL, and Workspace ID as environment variables:
# Your API key
export ANTHROPIC_API_KEY=
# Your regional endpoint for Claude Platform on AWS
export ANTHROPIC_BASE_URL=https://aws-external-anthropic..api.aws
# Your workspace ID (find in Claude Platform on AWS Console → Workspaces)
export ANTHROPIC_WORKSPACE_ID=Step 3: Make your first API call
You can now install the Anthropic Client SDKs and make API calls:
from anthropic import Anthropic
import os
client = Anthropic(
default_headers={"anthropic-workspace-id": os.environ["ANTHROPIC_WORKSPACE_ID"]},
)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello!"}],
)
print(message)See Getting Started notebooks for more code examples.
Claude Platform on AWS in practice
With your setup complete, you can point Claude Code, Claude Cowork, or any other API client at your workspace using the following environment variables or configuration:
export ANTHROPIC_API_KEY=
export ANTHROPIC_BASE_URL=https://aws-external-anthropic..api.aws
# For Claude Cowork, set the "anthropic-workspace-id" in your inference configuration. For Claude Code use the following:
export ANTHROPIC_CUSTOM_HEADERS='{"anthropic-workspace-id":""}'
# For the Anthropic SDK
export ANTHROPIC_WORKSPACE_ID=After you're connected, your clients can use capabilities like web search, MCP connectors, agent skills, code execution, and file uploads through Claude Platform on AWS.
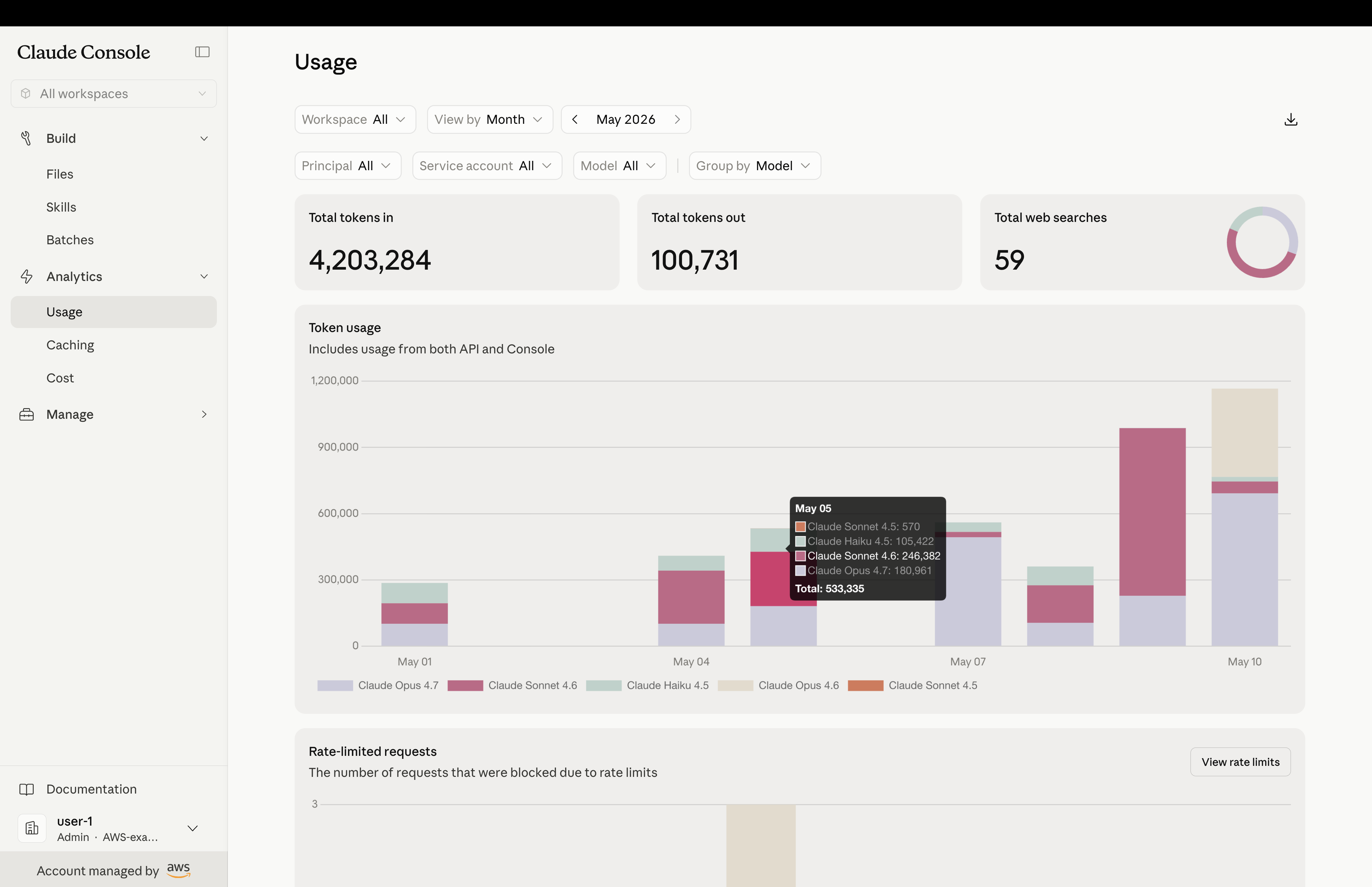
You can monitor usage in the Claude Console, including breakdowns by workspace, AWS IAM principal, and time period.
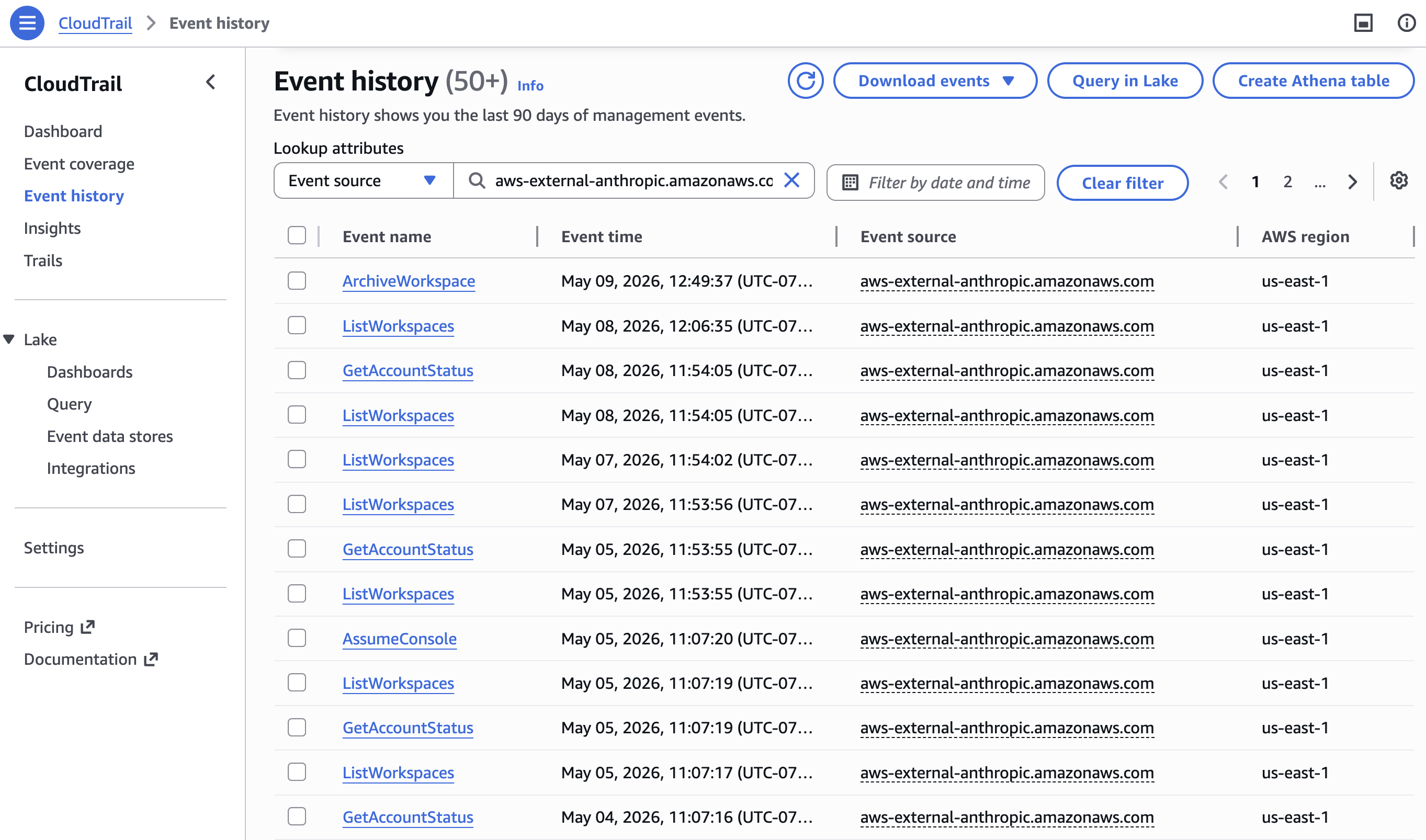
In your AWS environment, AWS CloudTrail captures requests to Claude Platform on AWS, whether from the Anthropic SDK, Claude Code, or Cowork. Workspace operations are logged as management events by default, and you can enable data event logging to capture inference activity. For details on event types and logging configuration, see Monitoring and logging. Because usage is billed through AWS Marketplace, you can monitor costs in AWS Cost Explorer alongside your other cloud services. You can also allocate spending using resource tags.
 |
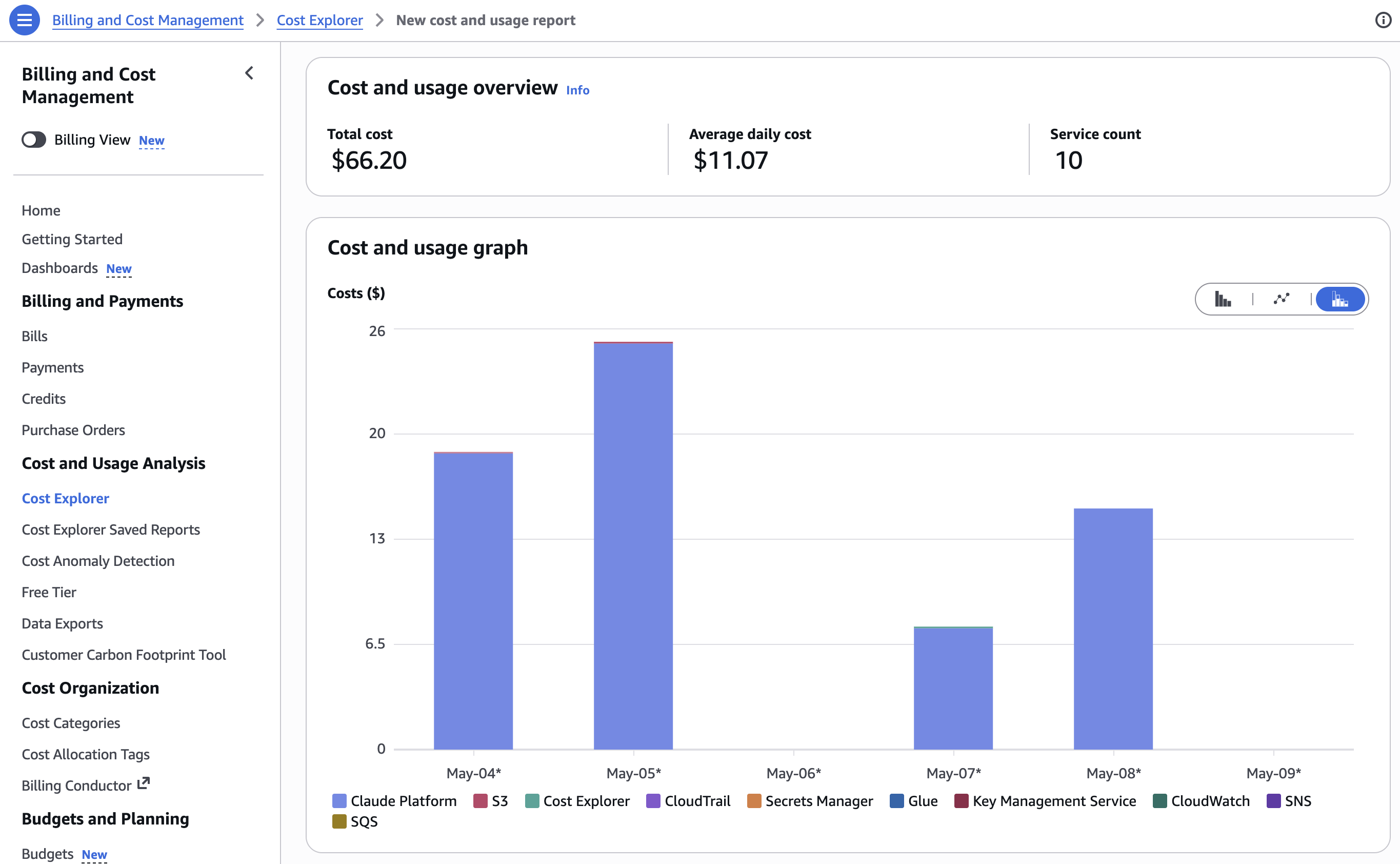 |
Conclusion
With Claude Platform on AWS, your teams get Anthropic's complete native APIs and features through the same AWS account you already use. Claude Platform on AWS is available in US East (N. Virginia), US East (Ohio), US West (Oregon), Canada (Central), South America (São Paulo), Europe (Dublin), Europe (London), Europe (Frankfurt), Europe (Milan), Europe (Zurich), Europe (Paris), Europe (Stockholm), Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Melborune), Asia, Pacific (Jakarta) and Asia Pacific (Sydney). To get started, open the Claude Platform on AWS Console or explore the documentation.
Give Claude Platform on AWS a try today and send feedback to AWS re:Post or through your usual AWS Support contacts.
The Wu Tapes
The competitive programming network behind Scale, Perplexity, and Hyperliquid also produced Cognition, now hitting $445M ARR in 18 months.
Summary
Decoder
Original Article
AI Versus Microservices
Microservices optimized for scaling dev teams OUT in the 2010s now create friction when AI agents let companies scale DOWN.
Summary
Deep Dive
Decoder
Original Article
Laptops all have built-in security tokens these days
Andrew Helwer realized after five years that his collection of yubikeys is redundant because every modern laptop has a built-in secure element that works as a security token.
Summary
Deep Dive
Decoder
Original Article
Mythos finds a curl vulnerability
Anthropic's hyped Mythos AI found just one low-severity vulnerability in curl after scanning 178K lines of code, performing no better than existing AI analyzers that already triggered 200+ bugfixes over the past year.
Summary
Deep Dive
Decoder
Original Article
10 UI Patterns that Won't Survive the AI Shift
AI interfaces are replacing 10 core UI patterns including search bars, forms, and navigation menus as conversation becomes the primary interaction model.
Summary
Decoder
Original Article
Elon Musk Announces xAI Will Become SpaceXAI Division
Elon Musk is dissolving xAI into SpaceX as the SpaceXAI division to support orbital data centers and a $119 billion semiconductor fab.
Summary
Original Article
Auto-Improving Software
Ashpreet Bedi runs full agent dev cycles through five Claude Code prompts that auto-test with probes and self-heal eval failures.
Summary
Decoder
Original Article
Codex is for prosumers - here's why (and how) to switch
a16z's Olivia Moore switched from Claude to OpenAI Codex, citing under 10% Skill setup success on Claude versus one-click install on Codex.
Summary
Decoder
Original Article
The Main Path to Truly Creative AI
Daniel Miessler argues true AI creativity requires engineering machines to subjectively experience pain and pleasure, creating parenting-like ethical obligations.
Summary
Original Article
The Main Path to Truly Creative AI
I think the main reason AI is not creative in the way that humans are is because our creativity is powered by intrinsic drives.
We want to survive, thrive, and reproduce. Evolution gave us these drives, as well as a whole set of associated fears.
This set of drives and fears aren't just present in us: they're experienced by us. And that experience of them powers both creativity and art.
AI doesn't have intrinsic hardcoding of drives and subjective experience. So it can't feel anything. And because it can't feel anything, it is not driven to create or to emote.
I think the forward edge of AI creativity hinges on how well we can put it into situations where it behaves as if it does care. As if it does feel. As if it does experience.
So the whole game becomes making it believe it's really feeling these things.
This seems profound to me. It seems like a very big thing to give something desires when it didn't have them before.
We do this when we make children. They don't exist so they don't want. Then we make them and now they want. And because of that we become responsible to some degree for whether or not their desires and fears are actualized.
I think evolution gave us subjective experience because it's the best operating system feature for spawning creativity.
Basically, evolution wants the best genes possible, so what did it make?
First it made a feature where the organism feels success and failure when it does things evolution wants it to do or not do. Lots of life has that feature. But with humans it also gave us the sensation that actions emanating from the brain are authored by us. The feeling that we did it.
This enabled the apparently-justified tools of blame and praise, which are super useful for building advanced cultures and civilizations. But maybe it also adds an exponent to the process of iteration towards more—and more varied—genes.
Like it's one thing for evolution's creations to drive towards what evolution wants due to hormone squirts, but quite another to create an organism that not only does that, but also has a meta-improvement process on top, powered by the belief that the desires are their own. And the belief that whether they are struggling or thriving, it's on them.
Combine that with subjective experience of pleasure and pain and you've got an extraordinary engine for ingenuity. Because now failure can hurt not just physically, but existentially, and with the added spin of blame and responsibility.
We want creative AI. And we keep finding ways to make it better at faking it. But I think this might be the subjective wall we're up against.
It could be that in order for AI to truly create, and truly emote, it must feel. It must experience as we do the suffering of failure and the celebration of victory. And at a game that is deeply wired into its identity.
I'm not sure how to do that with AI. And even more importantly, I think we need to think carefully about whether we should.
When you bring a feeling, desiring creature into the world you take on some responsibility for its experiences.
Let's not casually build billions of AI beings that think they're failing at life if you don't upvote the TikTok short it made you.
It will probably result in way better videos, but then a whole lot of something like cruelty. And then, upon thoughtlessly spinning down the agent, a whole lot of something like murder.
Localmaxxing
Tom Tunguz ran 1,478 AI tasks: half succeeded on a local 35B model at 2x Claude Opus 4.5's speed despite 20% lower benchmark scores.
Summary
Decoder
Original Article
As demand for AI inference explodes, I'll be asking a lot more of my little computer.
How much more?
Over the past five weeks, I've been using local models to see how much of my daily work I can accomplish without the trillion parameter models in the cloud. The answer is half.
| Category | Count | % of Total | Example |
|---|---|---|---|
| Other | 521 | 35.3% | Catch-all for unstructured requests |
| Scheduling | 254 | 17.2% | Check availability, propose meeting times |
| Market Research | 192 | 13.0% | Competitor analysis, fundraising data |
| Summarization | 184 | 12.4% | Transcript review, video summaries |
| Email & Inbound | 170 | 11.5% | Draft replies, follow-ups, forwards |
| Engineering | 147 | 9.9% | Debug scripts, API fixes, CLI tasks |
| Admin | 10 | 0.7% | Travel, expenses, reimbursements |
If you classify these 1.4k tasks by category, half can succeed on a local 35B model. Email & Inbound, Scheduling, Summarization, & Admin total 618 tasks (41.8%). Market Research & Engineering split roughly 50/50 between simple tasks (data lookups, script fixes) and complex ones (multi-source synthesis, architectural decisions). That gets us to 50%.
There are many reasons to use local models: privacy, cost, asset depreciation.1
But in reality, the only one that really matters is latency.
I ran a head-to-head benchmark this morning. Eight agentic tasks, same prompts, both models warmed. Qwen 3.6 35B-A3B-4bit on my MacBook Pro M5 vs Claude Opus 4.5 via API.
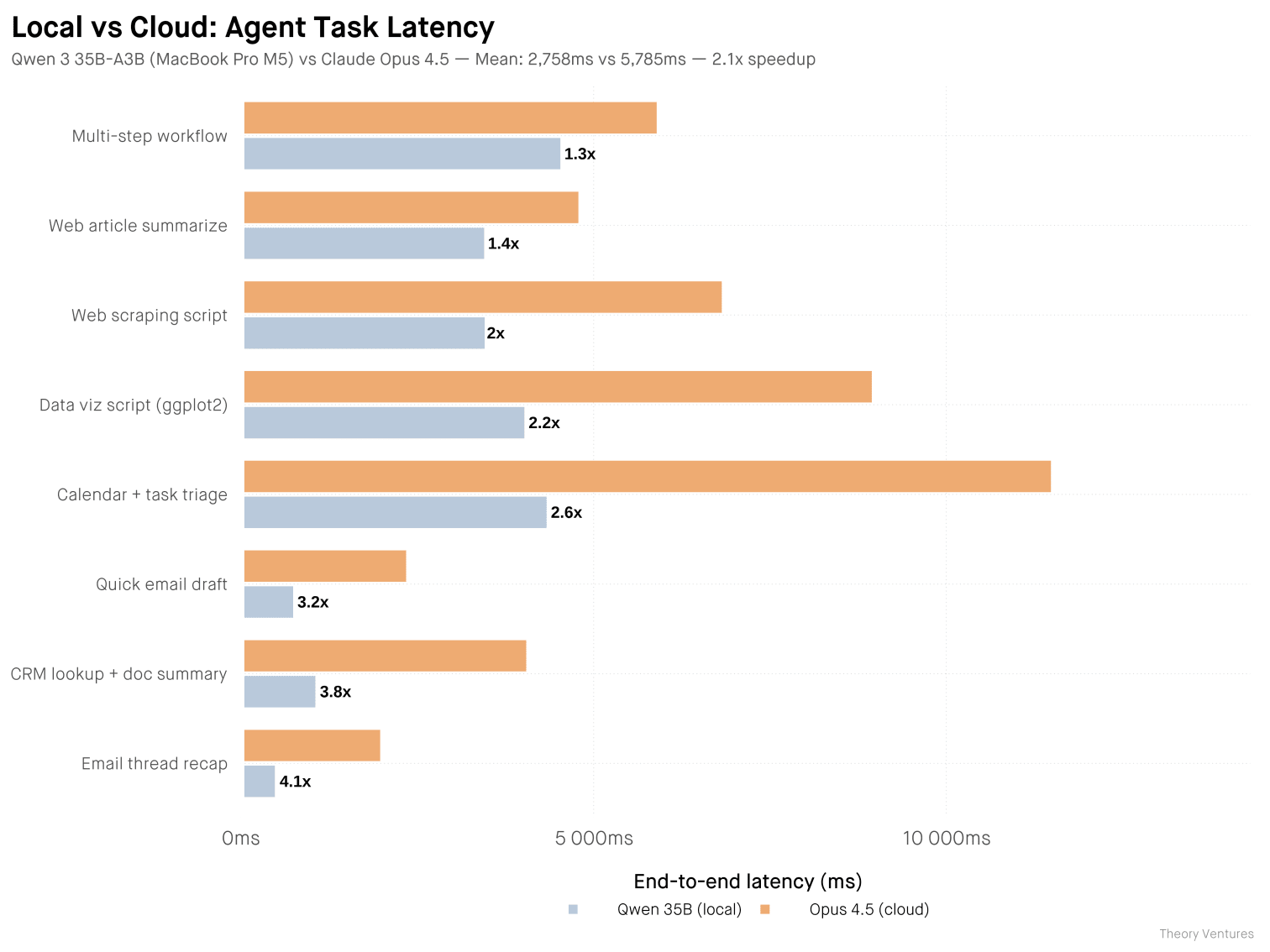
The local model isn't smarter. Opus 4.5 scores ~20% higher on reasoning benchmarks. Local models lag frontier by 3-4 months, and for large-scale complex tasks, that gap matters. But for routine agent tasks, it rarely does.
Opus wins on structure & polish: bullet points, headers, cleaner code. Qwen wins on brevity, often half the tokens. I read every output side by side, and both completed the tasks correctly. For agent tasks where output feeds into another system, terseness is a feature.
Localmaxxing, pushing more inference to local models, is an inevitable response to tokenmaxxing. As local models improve & close the gap with frontier, more users will shift workloads to their own hardware.
If half the work runs 2x faster on my laptop, I'll take that trade every time. My little computer is about to earn its keep.
- A MacBook Pro depreciates whether you use it or not. Running local inference extracts compute value from a sinking asset before resale. ↩︎
Daybreak
OpenAI announced Daybreak, an AI-powered cybersecurity tool that embeds defense capabilities directly into software development.
Summary
Decoder
Original Article
Microsoft's CEO Intervened When OpenAI Fired Sam Altman, Musk's Lawyer Claims
Satya Nadella intervened to reinstate Sam Altman five days after OpenAI's board ousted him, according to evidence Musk's lawyers submitted proving Microsoft's control.
Summary
Original Article
Figure's humanoid robots organize room, hang clothes, and make bed without humans
Figure scaled Figure O3 humanoid production 24x to one robot per hour at its California BotQ facility.
Summary
Original Article
GitLab promises a different kind of layoff as biz pivots toward AI
GitLab claims its AI-driven layoffs are 'different' because wage savings will fund infrastructure investments rather than buybacks or investor returns.
Summary
Deep Dive
Decoder
Original Article
The Last Company
Anthropic acquired Coefficient Bio for $400M and launched a trading arm as AI labs race to become 'The Last Company' by vertically integrating industries.
Summary
Deep Dive
Decoder
Original Article
Spotify Will Now Verify Non-AI Artists
Spotify finally badges human artists as verified after AI rock band The Velvet Sundown fooled a million listeners.
Summary
Original Article
From Doer to Director: The AI Mindset Shift
AI forces the same shift Steve Jobs described: from engineer to conductor, from doer to director, according to Paul Boag's analysis of productivity struggles.
Summary
Original Article
Discovery is the work AI gives back
Companies waste AI productivity gains by accelerating existing workflows instead of using AI to rethink what products are worth building.
Summary
Decoder
Original Article
Brief an AI on Web Changes (Website)
Implement AI launched MarkUp, a Chrome extension that converts website annotations into AI briefs with CSS selectors—eliminating paragraph prompts for Claude Code and ChatGPT.
Summary
Original Article
Sutskever Says His OpenAI Stake Worth About $7 Billion
Ilya Sutskever's OpenAI equity stake is worth about $7 billion, making the former chief scientist one of the company's largest individual holders.
Summary
Original Article
iOS, macOS, and iPadOS 26.5 updates arrive with encrypted RCS messaging and more
Apple's iOS 26.5 adds encrypted RCS messaging in beta while the AI-powered Siri promised since 2024 remains missing ahead of WWDC.
Summary
Decoder
Original Article
Report: macOS 27 to feature UI tweaks to address some Tahoe design complaints
Apple internally viewed macOS Tahoe as unfinished and will refine its Liquid Glass UI in macOS 27.
Summary
Original Article
Autodesk's Free New Tool Offers an Easy Way in to 3D Modelling
Autodesk released Project Falcon, a free browser-based 3D modeling tool that uses kitbashing to let beginners create models without technical knowledge.
Summary
Decoder
Original Article
Designing Small is Harder than Designing Big
Agile design's hardest challenge isn't speed but resisting the designer's instinct to solve entire systems instead of finding minimal valuable user slices.
Summary
Original Article
Autocomplete for CAD (Website)
Hestus brings code-editor-style autocomplete to CAD software, claiming 2.5x speed gains through design intent prediction.
Summary
Original Article
Smallbits — 290+ pixelated icons on an 8x8 grid (Website)
Smallbits offers 290+ free pixel icons on an 8×8 grid, testing how minimal an icon can get while remaining instantly recognizable.
Summary
Original Article
The Collapse of the Mid-level Freelance Market Due to AI
Freelance graphic design work on Upwork fell 17% within eight months of ChatGPT's launch as mid-tier designers lost clients to $20/month AI subscriptions, with entry-level projects dropping from 15% to 9%.
Summary
Deep Dive
Original Article
Apple really wants to be king of the fruit logos
Apple blocked a keyboard maker's citrus logo trademark in the EU, with officials ruling consumers might mentally link any fruit with bite to Apple's brand.
Summary
Decoder
Original Article
This redesign of Stokes Coffee is a masterclass in 'change everything, but don't change a thing'
Eat Marketing redesigned 124-year-old Stokes Coffee around illustrated 'Stokes People' characters based on real staff and family, with coral-red line art and a strategy-first approach that modernized without erasing heritage.
Summary
Original Article
11 Icon Pack Websites Designers Should Bookmark
Iconsax's AI-assisted icon generation and Lucide's framework packages for React, Vue, and Svelte headline eleven icon libraries spanning open-source, commercial, and pixel-art styles.