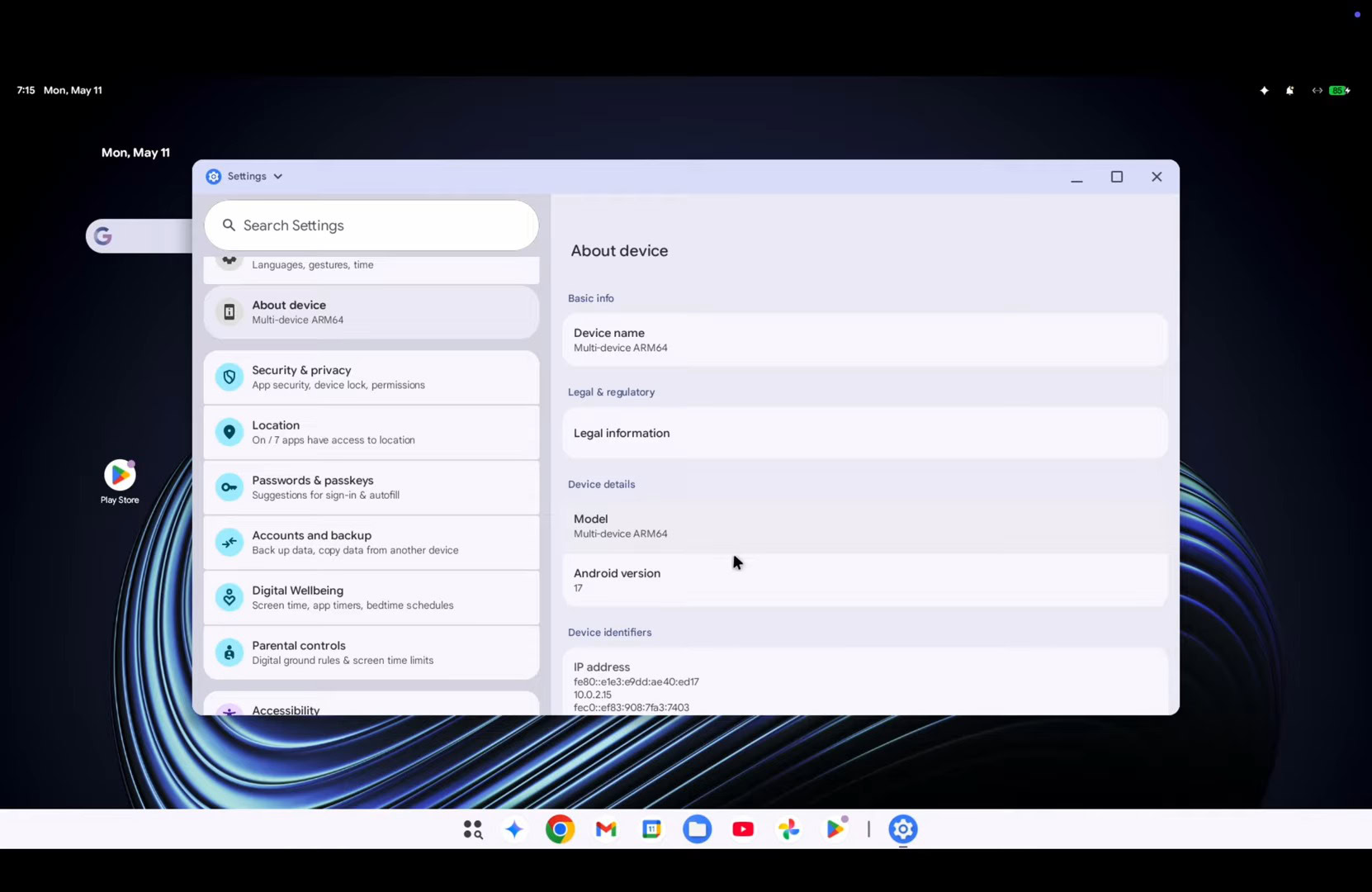
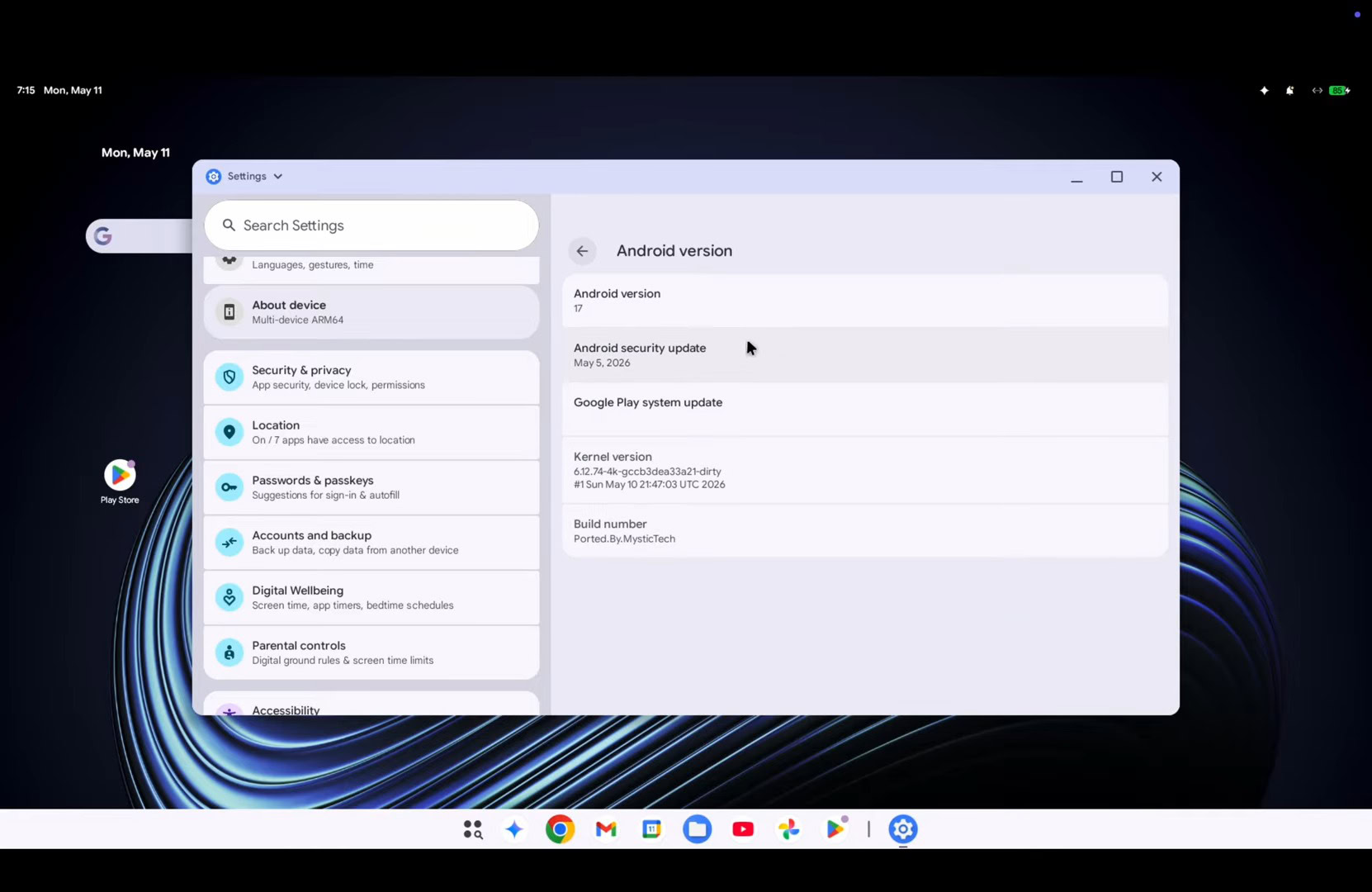
How to achieve truly serverless GPUs
Modal cut GPU inference server boot time 40x by snapshotting CUDA contexts directly into memory, taking replica spin-up from 2000 seconds to 50 seconds across 15 million production deployments.
Summary
Deep Dive
Decoder
Original Article
Fast mode for Claude Opus 4.7
Anthropic launches Claude Opus 4.7 fast mode in research preview for API and seven developer tools, opt-in now but set to become default.
Summary
Original Article
Compute Optimal Tokenization
Training 1,300 models revealed the industry-standard 20 tokens per parameter scaling law is a BPE tokenizer artifact, not a universal constant.
Summary
Deep Dive
Decoder
Original Article
Compute Optimal Tokenization
Authors: Tomasz Limisiewicz, Artidoro Pagnoni, Srini Iyer, Mike Lewis, Sachin Mehta, Alisa Liu, Margaret Li, Gargi Ghosh, Luke Zettlemoyer
Paper: https://arxiv.org/abs/2605.01188v1
Code: https://co-tok.github.io
TL;DR
WHAT was done? The authors systematically derived compression-aware neural scaling laws by training nearly 1,300 models to determine how information granularity (bytes per token) impacts optimal compute allocation.
WHY it matters? This work proves that the widely accepted heuristic of scaling models by 20 tokens per parameter is an artifact of specific subword tokenizers. Establishing a tokenizer-agnostic scaling law based on bytes provides a robust framework for maximizing compute efficiency across diverse languages and modalities.
Executive summary: For research teams optimizing large-scale pre-training runs, the tokenization scheme is often treated as a static preprocessing step. This paper reframes tokenization as a dynamic scaling variable. By optimizing the "compression rate" (information density), the authors demonstrate that training data should scale proportionally to model parameters in bytes, not tokens. Furthermore, they reveal that the optimal compression rate is compute-dependent, requiring lower compression as FLOP budgets scale up, thus offering a new blueprint for training highly efficient, massively multilingual foundation models.

Details
The Tokenization Artifact Bottleneck in Neural Scaling
Foundation model scaling is largely governed by established scaling laws, most notably the heuristic derived in Training Compute-Optimal Large Language Models (Chinchilla), which posits an optimal ratio of approximately 20 training tokens per model parameter. However, a critical blind spot in this heuristic is its reliance on a fixed tokenization scheme. Expressing data volume strictly in tokens ignores the variable information density that each token represents, essentially binding fundamental scaling behavior to the arbitrary mechanics of Byte-Pair Encoding (BPE) tokenizers. This study isolates the token as a variable to identify the true invariant in scaling behavior, exposing the extent to which popular tokenizers inherently skew compute allocation.
Reinforcing Recursive Language Models
RL fine-tuning closes the gap: Daniel Kim and Rehaan Ahmad's 4B Qwen matches Claude Sonnet 4.6 on evidence selection, 8x faster.
Summary
Deep Dive
Decoder
Original Article
Cactus Needle (GitHub Repo)
Cactus Compute distilled Gemini 3.1 into a 26M-parameter model that outperforms Qwen-0.6B at function calling and runs 6,000 tokens/sec on MacBooks.
Summary
Deep Dive
Decoder
Original Article
Building Self-Repairing Agent Loops
OpenAI demonstrates agent loops that automatically fix stale code examples through structured review, repair, and validation cycles until tests pass.
Summary
Deep Dive
Decoder
Original Article
AI for the Real World: A conversation with Yann LeCun
Yann LeCun argues LLMs will never reach human-level intelligence because language represents only a tiny fraction of human understanding.
Summary
Decoder
Original Article
Gemini Intelligence Comes to Android
Google's Gemini Intelligence brings autonomous task agents to Android that shop across apps, browse the web, and create widgets from natural language.
Summary
Deep Dive
Decoder
Original Article
Google announced a number of new Gemini Intelligence-branded AI features at its Android Show: I/O Edition event on Tuesday. These include the ability for AI to complete tasks across apps, browse the web, fill out forms, dictate speech, and even allow you to vibe-code your own Android widgets.
Gemini gets more powerful
The company had already introduced some agentic capabilities, such as ordering food or booking a ride, to Gemini at the Samsung Galaxy S26 launch earlier this year. There, Google announced that Gemini would soon be able to perform more complex tasks, like booking a front-row bike for a spin class, finding a class syllabus in Gmail, and then searching for books related to that topic.

Now Google's AI assistant will be able to handle a multistep process, like copying a grocery list from your notes app, then adding items to the cart in your shopping app. To use this feature, you'll press the phone's power button and describe the task. Meanwhile, the content on the phone's screen acts as the context for the assistant. Google noted that Gemini will wait for your final confirmation to complete the checkout.
In addition, a feature first introduced in January had allowed Gemini to browse the web for you and complete tasks like booking an appointment, as part of an experimental rollout. Today, Google said this auto-browse feature is making its way to Android, too.
In late June, Android devices will also get Gemini in Chrome, an AI feature that will help users summarize content or ask questions about what is on the web page, similar to how Gemini in Chrome works on the desktop.
Another small but useful addition is that Gemini will be able to fill out forms on your behalf after learning details about you through Personal Intelligence. (Google said this feature is opt-in, and you can turn it off via settings anytime.)
Plus, Gemini will come to Android's Gboard keyboard. Google is using Gemini's multimodal capabilities by introducing a feature called Rambler in Gboard, which is similar to those found in other AI-powered dictation apps. The feature will let you speak in your own tone, transcribe the speech, and format it by removing filler words.

Vibe-code your own Android widgets
Vibe-coding apps are picking up pace, and Google wants to give Android users a taste of this, too.
The company is introducing a way for users to build Android widgets by describing them in natural language. For example, users can build a meal-planning widget using query text like, "Suggest three high-protein meal prep recipes every week."

The idea of creating a widget is not novel to Gemini. Notably, the hardware startup Nothing also released a similar tool last year.
Google said that Gemini Intelligence will follow the company's Material 3 expressive design language in its features.
The company said that these AI-powered features will first make their way to the latest Samsung Galaxy and Google Pixel devices this summer and will be available across other Android devices later this year.
Claude for Legal (GitHub Repo)
Anthropic released Claude for Legal on GitHub with 12 practice-area plugins, 100+ workflow agents, and a security-reviewed marketplace for community legal skills.
Summary
Deep Dive
Decoder
Original Article
Qwen-Image-2.0 Technical Report
Qwen-Image-2.0 generates slides, posters, and comics from 1K-token prompts with accurate multilingual typography and photorealistic rendering in a unified model.
Summary
Deep Dive
Decoder
Original Article
Android is getting a big AI overhaul in 2026
Google bypasses Android 17 for its AI features, shipping app automation, Gemini widgets, and Auto Browse through Play Services and app updates instead.
Summary
Deep Dive
Decoder
Original Article
Redis and the Cost of Ambition
Redis Inc's 2024 licensing betrayal and decade of feature bloat spawned Valkey, a fork that wins by ignoring AI hype and optimizing what made 2011 Redis indispensable.
Summary
Deep Dive
Decoder
Original Article
Amazon employees are “tokenmaxxing” due to pressure to use AI tools
Amazon employees are automating busywork with MeshClaw AI agents just to hit token consumption targets tracked on internal leaderboards.
Summary
Deep Dive
Decoder
Original Article
What Is Code?
Code's value shifts from machine instructions to conceptual models as LLMs generate syntax but risk accumulating 'cognitive debt' without understanding.
Summary
Deep Dive
Decoder
Original Article
AI-assisted testing, extensions updates, and more: k6 2.0 is here
Grafana k6 2.0 embeds a Model Context Protocol server so AI assistants like Claude Code can write, run, and validate performance tests programmatically.
Summary
Deep Dive
Decoder
Original Article
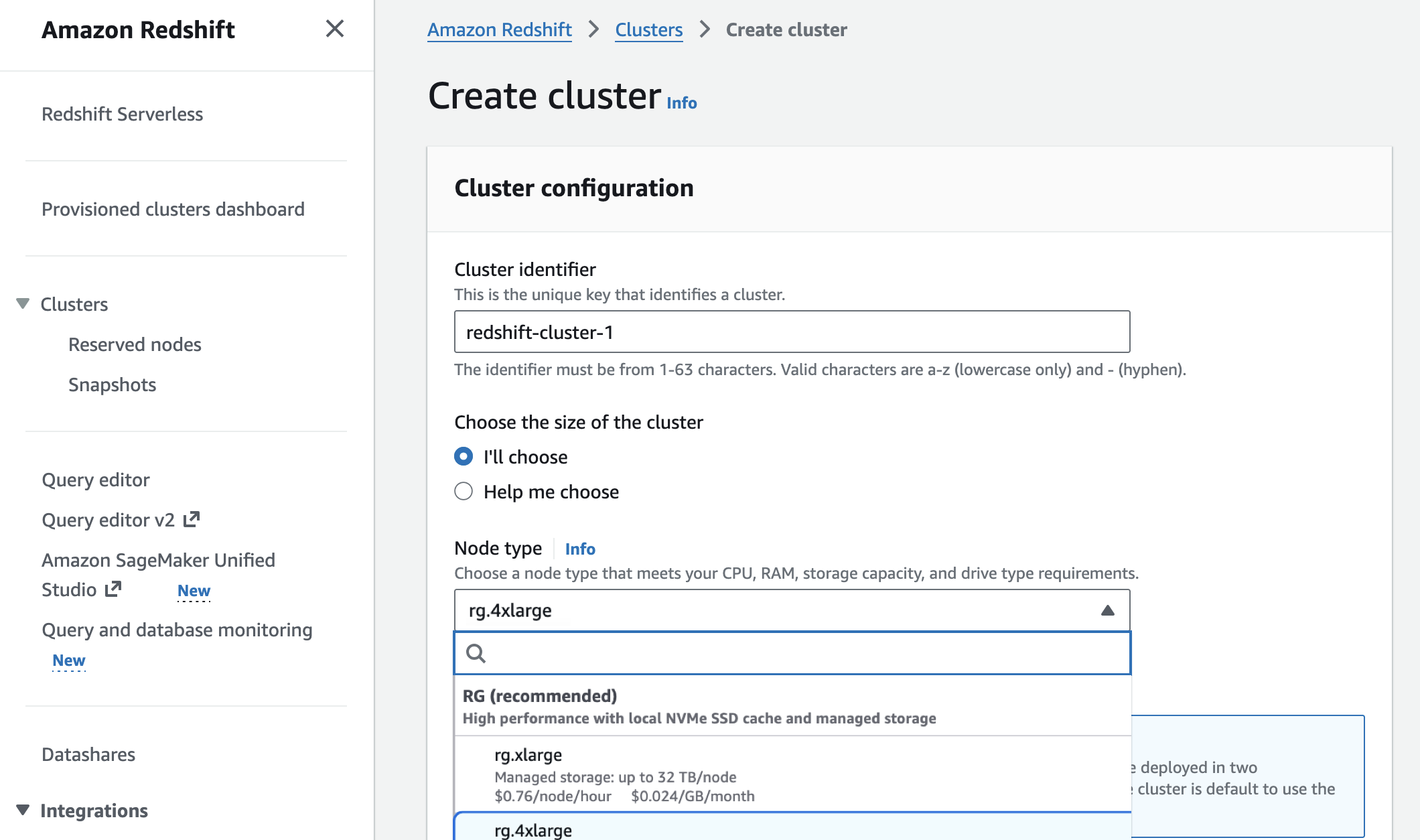
Amazon Redshift introduces AWS Graviton-based RG instances with an integrated data lake query engine
AWS eliminated Redshift Spectrum's $5/TB data lake scanning fees while launching Graviton-based RG instances that run 2.2x faster than RA3 at 30% lower cost per vCPU.
Summary
Deep Dive
Decoder
Original Article
Amazon Redshift introduces AWS Graviton-based RG instances with an integrated data lake query engine
Since 2013, Amazon Redshift has given the full power of a data warehouse in the cloud, at a fraction of the on-premises cost. Every architectural generation—from dense compute to Amazon RA3 instances, from provisioned to Amazon Redshift Serverless—has made each query cheaper, faster, and more efficient than the last.
For over a decade, as data volumes have grown and analytics requirements have evolved, organizations increasingly leverage both data warehouse tables for structured, frequently-accessed data and data lakes for cost-effective storage of diverse datasets. Add AI agents to the mix and they query your data warehouse at a scale that dwarfs typical human usage, leading to spiraling operational costs.
Amazon Redshift has doubled down on its core strengths to meet the demands of any workload — whether driven by humans or AI agents. For example, in March 2026, Amazon Redshift improved the performance of business intelligence (BI) dashboards and ETL workloads by speeding up new queries by up to 7 times. This significantly improves the response times of low-latency SQL queries, such as those used in near-real-time analytics applications, BI dashboards, ETL pipelines, and autonomous, goal-seeking AI agents.
Today, we're announcing Amazon Redshift RG instances, a new instance family powered by AWS Graviton. RG instances deliver better performance, running data warehouse workloads up to 2.2x as fast as RA3 instances at 30% lower price per vCPU. Their integrated data lake query engine lets you run SQL analytics across your data warehouse and data lake from a single engine with performance up to 2.4x as fast as RA3 for Apache Iceberg and up to 1.5x as fast as RA3 for Apache Parquet. This blend of speed, cost efficiency, and an integrated data lake query engine makes Redshift RG instances well-suited to handle the high query volumes and low-latency requirements of today's analytics and agentic AI workloads.
You can compare new RG instances and current RA3 instances:
| Current RA3 Instance | Recommended RG instance | vCPU | Memory (GB) | Primary Use Case |
ra3.xlplus |
rg.xlarge |
4 | 32 | Small cluster departmental analytics |
ra3.4xlarge |
rg.4xlarge |
12 → 16 (1.33:1) | 96 GB → 128 GB (1.33:1) | Standard production workloads, medium data volumes |
This approach reduces total analytics costs for customers running combined data warehouse and data lake workloads, while simplifying operations through a single system for querying both warehouse tables and Amazon Simple Storage Service (Amazon S3) data lakes. We recommend using the AWS Pricing Calculator with your specific workload patterns to estimate savings.
Getting started with Amazon Redshift RG instances
You can launch new clusters or migrate existing clusters through the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS API. The integrated data lake query engine is enabled by default.
In the Amazon Redshift console, you can choose new RG instances when you create a cluster.
You can migrate previous-generation instances to RG instances with optimal paths based on your cluster configuration to estimate costs, validate compatibility, and automate execution.
- Elastic Resize—in-place migration with 10-15 minutes downtime for compatible configurations
- Snapshot and Restore—create a RG cluster from an RA3 snapshot. This is best for customers who want to make configuration changes during the migration
Your external tables, schemas, and query syntax—including existing Spectrum queries—remain unchanged. There is no need to recreate external tables or modify application code. To learn more, visit the Redshift Management Guide.
Amazon Redshift now executes data lake queries on cluster nodes—the same compute that processes data warehouse workloads. As a result, Amazon Redshift Spectrum is no longer required. Data lake queries stay within your VPC boundary, use existing IAM roles, and incur zero per-terabyte scanning charges. This removes the $5/TB Spectrum scanning fees that previously added to total Redshift costs.
Now available
Amazon Redshift RG instances are now available in the following AWS Regions: US East (N. Virginia, Ohio), US West (N. California, Oregon), Asia Pacific (Hong Kong, Hyderabad, Jakarta, Malaysia, Melbourne, Mumbai, Osaka, Seoul, Singapore, Sydney, Taiwan, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, Milan, London, Paris, Spain, Stockholm), and South America (São Paulo). For Regional availability and a future roadmap, visit the AWS Capabilities by Region. For Redshift Provisioned, you can select On-Demand Instances with hourly billing and no commitments or choose Reserved Instances for cost savings. To learn more, visit the Amazon Redshift Pricing page.
Give RG instances a try in the Redshift console and send feedback to AWS re:Post for Amazon Redshift or through your usual AWS Support contacts.
Migrating Data Ingestion Systems at Meta Scale
Meta's zero-downtime migration of petabyte-scale MySQL ingestion swapped production and shadow jobs mid-flight to enable instant rollback.
Summary
Deep Dive
Decoder
Original Article
When "idle" isn't idle: how a Linux kernel optimization became a QUIC bug
Cloudflare spent weeks finding a 3-line QUIC bug: a ported TCP idle optimization measured from sends, not ACKs, trapping bandwidth at minimum after loss.
Summary
Deep Dive
Decoder
Original Article
With faster node startup for GKE, say goodbye to cold-start latency
Google cut GKE Autopilot node startup by 4x for GPU workloads through VM provisioning architecture changes, eliminating cold-start over-provisioning
Summary
Deep Dive
Decoder
Original Article
Quack: The DuckDB Client-Server Protocol
DuckDB launched Quack, an HTTP-based client-server protocol that beats PostgreSQL at small writes and transfers 60 million rows in under 5 seconds.
Summary
Deep Dive
Decoder
Original Article
Cloudflare Launches “Artifacts” Beta, Introducing Git-Like Versioning for AI Agents
Cloudflare launched Artifacts beta on May 8, bringing Git-style version control to AI agent outputs for rollback, audit trails, and collaborative governance.
Summary
Deep Dive
Original Article
Meta to release Muse Spark in Voice Mode and Meta Glasses
Meta rolled out Muse Spark, a compact foundation model powering voice AI across WhatsApp, Instagram, Facebook, and Ray-Ban Meta glasses with real-time camera recognition.
Summary
Original Article
Google Eyes AI Data Centers in Space
Google and SpaceX are discussing orbital AI data centers as SpaceX prepares a $1.75 trillion IPO claiming space compute will soon undercut ground facilities.
Summary
Original Article
Report: Google and SpaceX in talks to put data centers into orbit

Google and SpaceX are in talks to launch orbital data centers in space, reports The Wall Street Journal, citing sources familiar with the matter.
The potential deal comes as SpaceX gears up for its $1.75 trillion IPO later this year, selling investors on the idea that data centers in space will be the cheapest place to put AI compute within the next few years. It also follows Anthropic's deal with SpaceX last week to use computing resources from xAI's data center in Memphis, Tennessee, with the potential to work together on orbital ones in the future. (SpaceX acquired xAI in February.)
Google is reportedly talking to other rocket-launch companies as well. The company also plans to launch prototype satellites by 2027 as part of an initiative called Project Suncatcher, announced late last year.
Elon Musk has created hype for orbital data centers, claiming they are cheaper to operate. Advocates also point out they are free from the local backlash that U.S. ground-based buildouts attract. However, as TechCrunch recently reported, today's terrestrial data centers are much cheaper than those in orbit once satellite construction and launch costs are factored in.
Google invested $900 million in SpaceX in 2015, according to regulatory filings.
TechCrunch has reached out to Google and SpaceX for comment.
Semis Memo: Supply Chain Inheritance
Texas Instruments is raising prices instead of expanding capacity as AI data centers inherit the power supply chain built for EVs.
Summary
Decoder
Original Article
What Parameter Golf taught us
AI coding agents contributed meaningfully to OpenAI's Parameter Golf, where 1,000+ participants submitted 2,000 model optimization entries.
Summary
Decoder
Original Article
Agentic search models
SID and Glean released specialized search LLMs (SID-1, Waldo) that orchestrate simple retrieval tools instead of building complex search pipelines.
Summary
Original Article
Perceptron Mk1 shocks with highly performant video analysis AI model 80-90% cheaper than Anthropic, OpenAI & Google
Perceptron's Mk1 video model prices 80-90% below OpenAI, Anthropic, and Google
Summary
Original Article
Google's Android-powered laptops are called Googlebooks, and they're coming this year
Google announced Googlebooks, Android laptops that activate Gemini AI with cursor wiggles and stream phone apps to the desktop.
Summary
Original Article
Google took its first swing at laptops with Chromebooks way back in 2011. These web-first laptops have seen success over the years, mostly in enterprise and education. Google insists Chromebooks aren't going away, but the company's focus has shifted to something new: Googlebooks. That's what Google has decided to call the new line of Android-powered laptops, which will begin shipping later this year.
If you thought other Google products were steeped in Gemini, you haven't seen anything yet.
Google says it designed Googlebooks from the ground up with Gemini Intelligence, and it all starts with the cursor. Google calls this the Magic Pointer. Just wiggle the cursor back and forth, and it will activate a full-screen Gemini experience. The AI will see what's on your screen so it can make contextual suggestions and pull in data from multiple apps.
What can you do with that? Well, it's all a bit vague. Google's demos show how Magic Pointer can be used to select multiple images and instantly combine them with Nano Banana. Google also says you can use the cursor in AI mode to do things like suggest a calendar appointment simply by pointing it at the date in an email. Magic Cue, which has been available on Pixel phones since last year, will also be part of Googlebooks. This feature can recommend actions and surface information based on context like messages and emails.
There's definitely a problem with discoverability in AI features, but it's uncertain how many useful things generative AI can do with screen context. The best Microsoft could manage was Recall, and we all know how that went. So far, Google's Magic Cue on phones hasn't been a game changer—in fact, it rarely shows up at all. Can a laptop do any better?
Google's AI-generated widgets from Android phones will also come over to Googlebooks. The widgets are more limited than you might expect, though. They can collect data from the web, as well as certain content from your Google apps, to create a "personalized dashboard" for your home screen. The format and style will be adapted to the laptop form factor.
Phone apps and not phone apps
Google seems to be avoiding an explicit mention of Android when discussing Googlebooks, but that's the underlying software. That gives the devices access to a wide variety of apps—Google tried for years to shoehorn Android apps into Chrome OS with limited success, but it should be easier with laptops that run the apps natively.
These devices will have the Play Store, of course, but the rest of the software situation is hazy. Google is in the process of certifying third-party app stores for Android while also clamping down on sideloaded APKs, and we don't know where Googlebooks will end up in the openness spectrum. Google has refused to comment on specifics right now, saying only that it will have more to share regarding its "app ecosystem partners" closer to launch.
You might not have to install very many apps on a Googlebook, though. The platform will integrate deeply with your Android phone, allowing you to stream apps right to your laptop. A dedicated button in the taskbar lists all the apps on your phone. Click one, and it will appear on the Googlebook in a floating window. It's similar if you need a file from your phone—Googlebooks can seamlessly transfer files from your phone when you need them.
Glowing up later this year
Google has not discussed any plans to build its own Googlebook. Instead, most of the OEMs that have been making Chromebooks will also offer Googlebooks when they launch, including Acer, Asus, Dell, HP, and Lenovo. You can expect devices with varying prices and hardware configurations, but you'll know they're Googlebooks from the Glowbar on the lid.

This illuminated design feature is reminiscent of the bar on some older Google devices like the Pixel C tablet and Chromebook Pixel. On those devices, the light bar would indicate the battery level. Google says the bar on Googlebooks is both "functional and beautiful," but it hasn't explained the functionality yet. We've asked for details.
Once again, SpaceX has set a new record for the tallest rocket ever built
SpaceX's Starship V3 cleared fueling tests for a May 19 launch, standing 408 feet tall with 18 million pounds of thrust—both new records.
Summary
Original Article
SpaceX and Google Are in Talks to Launch Data Centers in Orbit
SpaceX pitched orbital data centers to IPO investors as Google pursues Project Suncatcher to launch cloud infrastructure in space.
Summary
Original Article
Why senior developers fail to communicate their expertise
The phrase 'Can we try something quicker?' helps senior developers reframe complexity management as uncertainty reduction for stakeholders.
Summary
Original Article
Apple Plans Customizable Camera for Pros, Siri Design Changes in iOS 27
Apple will let users fully customize the iPhone Camera app in iOS 27, with movable controls and customizable feature placement targeting pro photographers.
Summary
Original Article
SpaceX eyes global spaceports as Starship launch ambitions grow ahead of IPO
SpaceX eyes global spaceports for thousands of annual Starship launches ahead of June IPO targeting $75B at $1.75T valuation.
Summary
Decoder
Original Article
SpaceX eyes global spaceports as Starship launch ambitions grow ahead of IPO

May 12 (Reuters) - SpaceX is scouting potential U.S. and overseas locations to build "spaceports", CEO Elon Musk said in a post on X on Tuesday, as the company prepares for a future in which its massive Starship rocket could launch thousands of times a year.
Unlike traditional expendable rockets, Starship is designed for rapid reuse with minimal refurbishment, a capability SpaceX says is essential for lowering launch costs and enabling thousands of flights annually.
The fully reusable rocket system, designed to carry more than 100 metric tons of cargo, is central to Musk's long-term plans for Mars colonization, satellite deployment and rapid global transportation.
"It's no secret that we intend to launch Starship a lot, targeting thousands of flights per year," the company also said in a statement posted online, adding that such a cadence would require launches from "many different locations."
Musk had previously said future spaceports could operate more like airports, handling multiple launches a day with rapid rocket turnaround times.
SpaceX is targeting a June listing, which is expected to be the world's biggest initial public offering, as the rocket maker seeks to raise as much as $75 billion at a valuation of roughly $1.75 trillion, sources had earlier told Reuters.
It currently launches Starship test flights from its Starbase facility in Texas and is developing additional infrastructure in Florida. The expansion push comes as commercial launch activity surges globally, straining capacity at major launch sites.
SpaceX said Starship's twelfth test flight, scheduled as soon as May 19, would debut next-generation versions of the rocket, Super Heavy booster and Raptor engines as it tests upgrades aimed at enabling full and rapid rocket reusability.
AI economics
Despite 900M users at OpenAI and enterprise deals at Anthropic, no AI lab generates enough profit to self-fund its next cluster.
Summary
Deep Dive
Decoder
Original Article
Massive leak reveals Google's Aluminium OS with a 16-minute video
Mystic Leaks posted a 16-minute Aluminium OS demo showing Link to iOS integration and web-wrapped Google apps ahead of Google's I/O announcement.
Summary
Decoder
Original Article
Massive leak reveals Google's Aluminium OS with a 16-minute video
Screenshots and hands-on footage show off a familiar setup wizard, virtual desktops, and even "Link to iOS" integration.
TL;DR
- Leaker Mystic Leaks shared screenshots and a 16-minute video of Google's Aluminium OS ahead of its official debut.
- Key features include a bottom app dock, compact side-sliding Quick Settings, virtual desktops integrated into the Recents view, and a "Link to iOS" app.
- The OS currently feels like "plain Android" optimized for larger screens, with many Google apps appearing as web-wrapped versions rather than native desktop software.
Google is hosting The Android Show: I/O Edition later today, where we hope to learn more about Aluminium OS and Google's plan for Android on desktops. If you can't wait, this new leak is giving us a thorough look at Aluminium OS before Google gets around to it.
Leaker Mystic Leaks has shared an extensive leak about Aluminium OS on their Telegram channel. The leak includes details about the OS, screenshots, and even a 16-minute-long hands-on video of Aluminium OS.
This build of Aluminium OS is running on a MacBook Pro through the UTM emulator.
The leaker notes that Google's Aluminium OS is "essentially plain Android" but with several desktop-experience features, such as:
- Desktop folders
- Virtual desktops
- Optimized Quick Settings and Notifications Panel
- Optimized apps like Task Manager
- Ecosystem between your laptop and mobile devices (including Apple iPhones through Link to iOS).
Going a step further, the leaker calls the current Aluminium OS experience an upgraded version of Samsung DeX instead of an actual desktop-class OS. The experience in its current form lacks mouse and keyboard-optimized apps — even the Google apps pictured are web versions wrapped in a window.
There's more information on the Aluminium OS experience in the video below (skip to the 2:15 mark to avoid the long booting time):
The setup screen will allow users to set up Aluminium OS hardware for work and personal needs through the regular Google setup wizard we're familiar with on our Android phones. Once you complete the setup and land on the home screen, you see an app dock at the bottom (with an app drawer button), the ever-familiar Google Search bar, the ever-familiar icons for the Play Store, and a folder full of Google apps.
The Quick Settings panel slides down from the side in a compact form factor when you tap and pull on the battery indicator in the status bar. A similarly compact Notification Panel slides down when you click on the notification icon on the status bar. Even the Settings app and the lock screen are quite similar to those on Android phones and tablets.
The video shows Recent apps being assigned as a shortcut for the bottom-right corner. When Recent apps are accessed, users will also be able to access virtual desktops, letting them organize different workspace setups and easily switch between them. We also see the Link to iOS app installed on the system.
So far, based on this very limited hands-on leak, Aluminium OS feels underwhelming. Hopefully, Google has more tricks up its sleeve to pique people's interest in this new software endeavor. We hope to learn more soon, either through leaks or straight from the company.
LDAP secrets management now available in IBM Vault Enterprise 2.0
HashiCorp Vault Enterprise 2.0 eliminates high-privilege master accounts in LDAP through self-managed credential rotation with centralized scheduling.
Summary
Decoder
Original Article
Amazon CloudWatch Logs Insights supports querying by log group tags
CloudWatch Logs Insights now queries by tags instead of explicit group names, auto-updating as your tagged infrastructure changes.
Summary
Original Article
The Complexity of Simplicity
Bryan Cantrill argues complexity spreads like a virus in software, requiring leaders who know what to say 'No' to prevent systems from accreting unnecessary features.
Summary
Original Article
The most important Design System in 2026 that designers missed was built by a developer
shadcn/ui, built by a developer, became the default design system for Figma Make, Cursor, and Claude's AI-generated code while designers weren't looking.
Summary
Decoder
Original Article
eBay rejects GameStop's $56 billion takeover bid, calling it ‘neither credible nor attractive'
GameStop CEO Ryan Cohen's audacious $56 billion bid to acquire the much-larger eBay was rejected as neither credible nor attractive.
Summary
Original Article
Amazon launches 30-minute delivery across the US
Amazon undercuts DoorDash and Instacart with $3.99 30-minute delivery, expanding to tens of millions of Prime members by year-end.
Summary
Original Article
WhatsApp is getting iOS 26's Liquid Glass glow-up, and it's surprisingly gorgeous
WhatsApp is adopting Apple's iOS 26 'Liquid Glass' design language with transparency, blur, and fluid animations in its iPhone app redesign.
Summary
Original Article
Have your views on AI changed? Here's what our creative community had to say
A year after peak AI anxiety, creatives who tested tools like Gemini 3 on real client work mostly found them not ready for production.
Summary
Decoder
Original Article
Create Winning Short-form Content in Seconds (Website)
VC-backed Fastlane generates a month of TikTok content from your URL in 30 seconds, one user claimed 31.8M views from a single video.
Summary
Original Article
Reference Board (Website)
Reference Board auto-tags moodboard images by color, style, and OCR'd text across iPhone, iPad, and Mac without manual sorting.
Summary
Original Article
User Journey Maps: How UX Teams Turn Friction Into Better Products
User journey maps reveal why users abandon products, but only deliver value when built from user research instead of internal assumptions.
Summary
Decoder
Original Article
Designing Data-intensive Applications — Advice for Interaction Designers
After solo-building a data product, this 30-year design veteran's key lesson: data structure should drive UI, not decorate it.
Summary
Original Article
Top 10 Cool Design Gadgets for Creative Professionals in 2026
Apple launches M5 chip across iPad Pro, MacBook Pro, and Vision Pro with up to 6.7x faster 3D rendering, headlining a design hardware roundup.
Summary
Original Article
iOS 26 adds fun way to customize your iPhone wallpaper, here's how to use it
iOS 26's Spatial Scenes turns any photo in your library into a 3D wallpaper with depth and motion effects.
Summary
Original Article
New York Design Week is Here
NYCxDESIGN transforms New York into North America's design capital May 14-20 with ICFF furniture fair and 70-designer light exhibition at The Seaport.