Could this be the moment that drug manufacturing takes off in orbit?
Varda Space Industries signed a deal with United Therapeutics Corporation, marking the first time a major public pharma company is using its own capital for drug development in microgravity.
Summary
Deep Dive
Decoder
Original Article
Browsers Treat Big Sites Differently
Safari and Firefox deliberately ship domain-specific code to make major sites like TikTok and Netflix work, effectively patching broken websites instead of waiting for developers.
Summary
Deep Dive
Decoder
Original Article
When 36,000 Tiny Files Break Your Spark Pipeline: A Deep Dive into S3 DNS Exhaustion and the Small File Problem
36,000 tiny Parquet files on S3 can crash Spark pipelines with UnknownHostException by exhausting DNS and S3 API limits, revealing a critical small file problem.
Summary
Deep Dive
Decoder
Original Article
Why your AI agent has amnesia and why forgetting is the fix
Microsoft developed a novel memory architecture for AI agents that "forgets" less relevant data, achieving 97.2% retention precision and stabilizing at 400-500 memories to prevent "amnesia" in long workflows.
Summary
Deep Dive
Decoder
Original Article
Migrating Data Ingestion Systems at Meta Scale
Meta successfully migrated its massive data ingestion system to a new architecture using a rigorous "Shadow → Reverse Shadow → Cleanup" phased approach, ensuring data integrity across petabytes of social graph data.
Summary
Deep Dive
Decoder
Original Article
Quack: The DuckDB Client-Server Protocol
DuckDB introduces "Quack," a new HTTP-based client-server protocol enabling multiple DuckDB instances to communicate and concurrently write to the same database, overcoming its previous in-process-only limitation.
Summary
Deep Dive
Decoder
Original Article
Strong views on PostgreSQL VIEWs
PostgreSQL views, while offering logical abstraction, create hidden complexities through rigid schema dependencies, attribute number coupling, and the "SELECT *" trap, making schema evolution painful despite transactional DDL and query planner improvements.
Summary
Deep Dive
Decoder
Original Article
Agentic Design System - From Chatbot to Orchestration
Romina Kavcic argues that design systems are evolving into "agentic" operational infrastructure by 2026, requiring components to become contracts with semantic metadata for AI interpretation and orchestration.
Summary
Deep Dive
Decoder
Original Article
Amazon ditches Rufus chatbot, launches Alexa shopping agent in AI strategy pivot
Amazon is pivoting its AI shopping strategy, ditching the standalone Rufus chatbot in favor of an enhanced Alexa for Shopping agent integrated directly into its e-commerce platform.
Summary
Decoder
Original Article
AI Gateway production index
Vercel's AI Gateway data shows Anthropic leading in spend despite higher prices, Google leading in volume, and agentic workloads accounting for 59% of token volume.
Summary
Decoder
Original Article
The Notion Developer Platform
Notion launched its Developer Platform, featuring a CLI, workers, database sync, and robust API support for building and integrating AI agent tools.
Summary
Decoder
Original Article
AI is the New Netflix
AI workflows and cloud sync are dramatically increasing broadband upstream traffic, signaling the end of the traditional asymmetric "fat downstream, thin upstream" internet model.
Summary
Deep Dive
Decoder
Original Article
LinkedIn becomes the latest name on a 100,000-job tech layoff list
LinkedIn is cutting 5% of its workforce, joining a tech industry layoff wave that has displaced over 100,000 workers while major companies pour $725 billion into AI infrastructure.
Summary
Deep Dive
Original Article
Data Projects: Managing Data Assets at Netflix Scale
Netflix launched "Data Projects" to replace its legacy ACL system with durable team-owned app identities and scoped roles, streamlining data asset management and reducing permission churn.
Summary
Deep Dive
Decoder
Original Article
We need to talk about dbt
Pedram Navid argues that dbt's rapid venture-funded growth is alienating its core community by neglecting dbt Core, developer ergonomics, and making dbt Cloud a poor IDE experience.
Summary
Deep Dive
Decoder
Original Article
April 2026 PDC State of Data Modeling Survey Results Are In!
An April 2026 survey found organizational issues, not tooling, are the overwhelming pain point in data modeling, with 28.1% wanting training and only 4.8% desiring better tools.
Summary
Deep Dive
Decoder
Original Article
Lakehouse statistics and why query engines get lost
Lakehouse query engines often struggle with performance and cost due to missing, optional, or inconsistent statistical metadata across formats like Iceberg, Delta Lake, and Parquet.
Summary
Deep Dive
Decoder
Original Article
Can Kafka Queues Make Consumers Faster? Part 2: Head-Of-Line Blocking
Kafka's new Share Groups (Queues) linearly scale consumer throughput for I/O-bound workloads by avoiding Head-Of-Line Blocking, supporting more consumers than partitions, but at the cost of losing message ordering guarantees.
Summary
Deep Dive
Decoder
Original Article
Can Kafka Queues Make Consumers Faster? Part 2: Head-Of-Line Blocking
Go slow to go fast.
A few weeks ago, I published my findings about the new Apache Kafka feature: Queues.
Check the post if you haven’t already!
I kept receiving the same feedback:
-
Obviously, with all the additional overhead that comes with Queues, it won’t be faster than a consumer with a much simpler standard consumer group (it wasn’t obvious to me 🤷).
-
Queues will likely perform much better when messages are processed with some delay, e.g., due to external IO. This is because Queues can essentially avoid hitting the Head-Of-Line Blocking problem.
Head-Of-Line Blocking?
Apache Kafka and similar systems use partitions as the smallest unit of parallelism. A topic with 4 partitions can be processed by up to 4 instances in the same consumer group (unless you add more groups reading the same topic, or start adding asynchronous message processing, which adds a lot of complexity very quickly).
And because only one instance processes a partition at a time, any delay in processing stalls the entire partition. For example, imagine a pipeline that needs to call an external API for enrichment for about half of the records. If that API is briefly unavailable, the pipeline can’t process any messages, even the ones that don’t need to be enriched.
Queues should solve this: a share group (new primitive) can have more active instances than partitions. My previous benchmark showed that this doesn’t really provide any advantage when message processing doesn’t have delays (so data is processed as fast as possible). So, let’s add some delays?
The Benchmark
The benchmark setup was identical to the one in the previous post.
The only difference: both standard and share group consumers had a configurable delay, modelling some kind of IO.
I wanted to see how delays affect throughput and whether share groups can keep scaling as new instances are added.
Results
I tried a few different delays:
-
200ms. Each instance could process records at a 5 rec/s rate.
-
20ms. Each instance could process records at a 50 rec/s rate.
-
5ms. Each instance could process records at a ~196 rec/s rate.
-
1ms. Each instance could process records at a ~925 rec/s rate.
The last two rates show that, at lower latencies, batch processing impact (Kafka consumer polls data in batches) becomes apparent.
But what’s more important: the numbers looked exactly the same for the standard and the share consumer at 4 instances. I couldn’t scale out the standard consumer (the test topic only had 4 partitions). But the share consumer can be scaled out!
So I tried 8, 16 and 32 instances. And all of them showed a linear increase in the total processing rate! Individual instances performed at the same rate, and there was no overhead as the number of instances grew. This will likely hit a bottleneck at some point, but this test shows that it’s very easy to achieve at least an 8x increase in throughput!
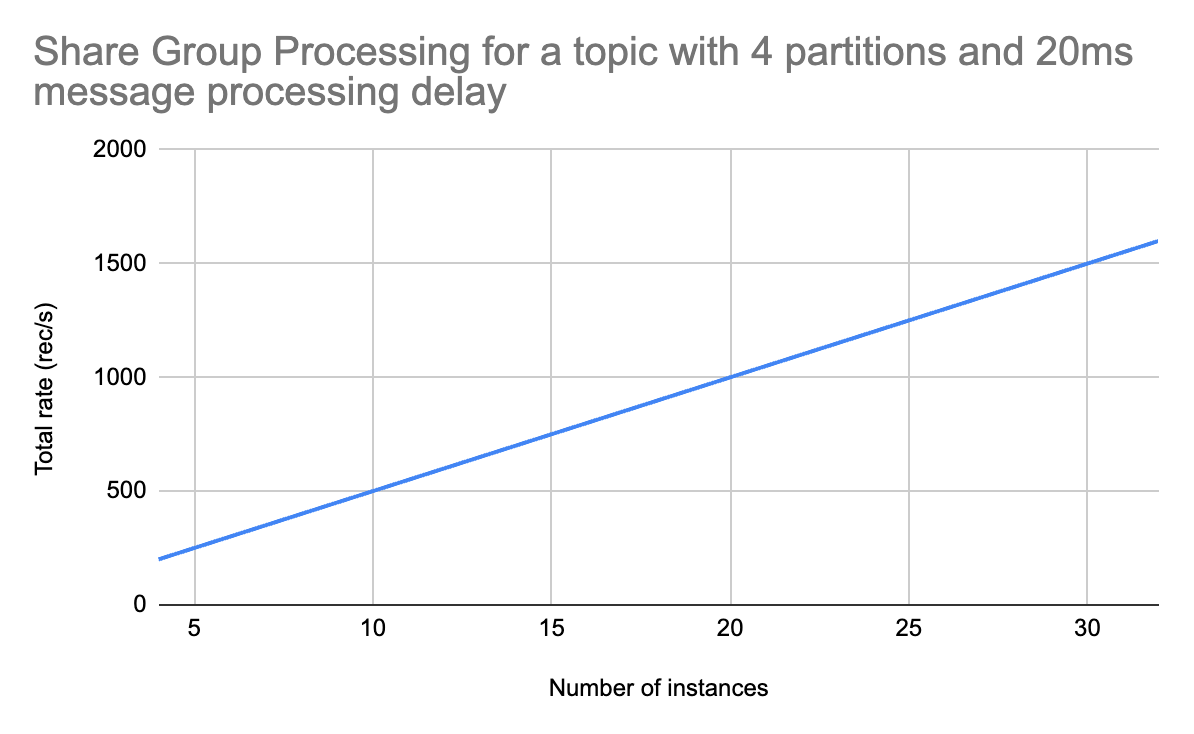
Summary
Kafka Queues is a great building block for things like job queuing, but it can also be used for scaling consumers! As long as consumers perform some form of head-of-line blocking, share groups can be used to scale processing beyond the number of partitions.
The biggest downside is losing ordering guarantees. Because several instances can consume data from the same partition, the ordering is no longer guaranteed. This can be a deal-breaker for many systems, so make sure to confirm if ordering is important before switching to share groups!
Other Posts
I recently wrote Apache Flink: Postgres to Postgres Replication with Flink CDC, which you may find interesting.
Advanced Apache Flink
Advanced Apache Flink is an on-demand course focused on Flink internals, production deployment best practices, and advanced patterns.
Agentic search models
Agentic search models are emerging to orchestrate entire retrieval workflows, replacing traditional brittle stacks with LLMs specifically trained for domain-specific search, prioritizing smaller size and lower latency over general-purpose frontier models.
Summary
Deep Dive
Decoder
Original Article
Stop Starting Data Projects
Many data projects fail because engineers build solutions in isolation; instead, focus on stakeholder workflows, define "done" upfront, ship ugly MVPs quickly, and communicate constantly to ensure adoption and reduce wasted effort.
Summary
Deep Dive
Decoder
Original Article
Postgres has had a good 30-year run – is DuckDB coming for its crown?
DuckDB's co-creator Hannes Mühleisen unveiled Quack, a new client-server protocol enabling transaction-oriented workloads and 36X faster bulk inserts than Postgres.
Summary
Deep Dive
Decoder
Original Article
Complete End-To-End Build of ETL Pipeline in AWS
A reusable AWS ETL pattern leverages ECS Fargate and DuckDB for single-node data processing, avoiding Spark-heavy solutions like Glue.
Summary
Decoder
Original Article
Amazon launches an AI shopping assistant for the search bar, powered by Alexa+
Amazon launched "Alexa for Shopping," an AI assistant replacing Rufus, integrated into its search bar and capable of shopping across Amazon and other retailers.
Summary
Decoder
Original Article
Designers are a Rare Breed
Designers, a mere 0.25% of the US workforce, will find AI tools like Claude Design raise the design quality floor for businesses, not replace their irreplaceable expertise.
Summary
Original Article
Designers are a Rare Breed
AI is raising the floor. The ceiling is yours.
Welcome to Unknown Arts — I’m Patrick, your field guide to the creative frontier. Join thousands of builders around the world navigating what’s next.
Designers are a rare breed.
It’s easy to forget if you’ve built your community around design, but the data is clear: designers make up roughly 0.25% of the US workforce, or about one in every 400 workers. Only 16% of US companies say they pursue design as a structured process. The rest handle it ad hoc, or not at all. They do just enough to get by.
I’ve lived this firsthand. Most of my career has been in cybersecurity startups, where design is chronically scarce. The largest team I worked on in the last decade had fewer than ten designers at a company with over a thousand employees.
So when Claude Design dropped recently and the usual online anxiety started up again, I had a different reaction than most. Not fear for my job, but optimism for a world with a higher floor of design quality.
What tools like Claude Design represent isn’t a replacement for designers at businesses that already hire them. It’s design finally starting to reach the vast majority of businesses that never would have hired a designer in the first place.
I don’t see that as a threat. I see it as a massive expansion of who gets to work with good design foundations. Designers included.
Appreciation isn’t craft
No tool automatically closes the gap between recognizing good design and being able to make it. It’s worth noting where most people actually stand in terms of recognizing good design in the first place: they don’t have particularly good taste (sorry, but it’s true). A smaller group has solid taste but doesn’t have the ability to execute on it. Those who can do both are a rare subset of an already rare group. (If you’re reading this I imagine you fall into one of the two later camps)
There’s a whole genre of video on YouTube built around this idea: give a novice top-of-the-line professional equipment, give an expert the most basic gear that gets the job done, and see what happens. Spoiler alert: the expert wins every time. Specific knowledge, built through years of reps, shapes the output in ways no tool can replicate.
What this means for you
If you’ve always cared about design but never had access to professional support, this is good news. The floor is rising. Solid design work that used to require a specialist is increasingly within reach.
And if you’re a designer, the right response is confidence. Raising the floor doesn’t flatten your ceiling. If anything, the best designers stand to gain the most from these tools: more leverage, more reach, more impact than any previous generation has had access to.
Think about the odds you’ve already beaten as a designer. You’re one of just a fraction of a percent of total workers and most companies don’t even practice your craft in any routine way. You chose a rare path, built real skills, and made it work despite the odds.
New tools don’t change that. You’ll figure them out. Approach them with a beginner’s mind, staying curious and willing to evolve. That’s what every great craftsperson has always done: they find new ways to do their best work as new resources become available. This is no different.
You beat the odds to get here. Now beat them again.
Until next time,
Patrick

📚 Go deeper
-
Introducing Claude Design — Anthropic — The official company announcement.
-
“Be a Skill Surfer” — Unknown Arts — The framing I keep coming back to as tools change faster than ever. Expertise is the thing worth protecting. Everything else is a wave to ride.
-
“Taste for Makers” — Paul Graham — A short essay arguing that taste is real, learnable, and inseparable from doing great work. A useful counterweight to the “AI can do it now” narrative, because taste and craft are not the same thing and Graham explains why better than most.
Find this useful? Share it with someone who might also get value.
How to make Claude Code follow your design system in Figma
To make Claude Code adhere to design system governance in Figma, the author developed four "Skills" that enforce token and component library usage during canvas construction.
Summary
Decoder
Original Article
Extract Styles From Any Website — miromiro (Website)
MiroMiro is a Chrome extension that extracts full CSS, Tailwind code, design tokens, images, and Lottie animations from any website, aiding AI-driven development.
Summary
Decoder
Original Article
How to do UX research in the Age of AI
AI excels at data analysis but still struggles to grasp nuanced human behavior, making in-person contextual UX research critically important for deep insights.
Summary
Decoder
Original Article
Apple is working to incorporate AI agents on the App Store
Apple is exploring ways to integrate AI agents into the App Store while maintaining its strict privacy and security standards to protect revenue streams and user trust.
Summary
Decoder
Original Article
A Start-Up Aiming to Make Geothermal Energy Mainstream Goes Public
Geothermal energy startup Fervo Energy raised $1.89 billion in an IPO, signaling investor confidence in the sector as tech companies seek clean power for the AI boom.
Summary
Decoder
Original Article
Anthropic wants small businesses to use Claude
Anthropic is launching "Claude for Small Business" to integrate its AI assistant with common business tools across various operational functions.
Summary
Original Article
Blue Origin may need external funding to hit ambitious launch targets
Jeff Bezos' Blue Origin might seek its first external funding to meet ambitious goals of 100 launches per year, amidst high development costs and competition with SpaceX.
Summary
Decoder
Original Article
Anthropic Was Behind. Now It's the AI Boom's Front-Runner
Anthropic has reportedly received investment offers valuing it over $900 billion, surpassing OpenAI's earlier $852 billion valuation.
Summary
Original Article
Apple's latest acquisition further confirms a new priority for the company
Apple acquired Patchflyer, makers of Color.io, confirming its focus on building a robust Creator Studio ecosystem for professional content creators.
Summary
Decoder
Original Article
Instagram's new ‘Instants' feature combines elements from Snapchat and BeReal
Instagram is globally launching "Instants," a new disappearing, unedited photo feature for close friends, mimicking Snapchat and BeReal, to promote authentic sharing.
Summary
Original Article
Apple's folding iPhone suddenly doesn't sound so 'Ultra'
Apple's rumored folding iPhone, potentially named "iPhone Ultra" and costing around $2,000, might forgo Face ID for Touch ID to achieve a thinner design.
Summary
Original Article
TailGrids UI (Website)
TailGrids UI offers a comprehensive React component library with over 600 free and pro components, blocks, and templates built on Tailwind CSS, supporting faster web development.
Summary
Decoder
Original Article
How to Create Websites with Great UX Designs: Principles and Examples
Webflow outlines six core principlesuser-first, usability, consistency, accessibility, hierarchy, and contextthat define great website UX design, showcasing seven example sites.
Summary
Original Article
People tend to remember how a website made them feel, even if they forget how it looks.
Websites with quality user experiences (UXs) help visitors navigate smoothly through layouts and pages so that they can quickly find what they need and take action. When visitors enjoy the overall feeling they get while using a site, they should be more likely to remember it, return, and build a positive association with the company or brand
Read on to learn about core UX design principles and see examples of websites with great UX design.
What makes a website’s UX design great
Great UX is when people can move smoothly through a website, understand what they see, get the intended message, and complete actions without issues. User interface (UI) design contributes to those successes by focusing on visual elements like buttons and colors, but UX is the broader experience that all the site’s elements combine to create.
UX designers follow several core principles:
- User first. A user-first website organizes content and actions in a way that makes sense from the visitor’s point of view, by considering their goals, questions, expectations, and likely next steps.
- Usability. Visitors should be able to find information, move between pages through clear menus and links, understand what actions are available, and follow through on their goals.
- Consistency. Similar elements must behave in standard ways across the site, so visitors only have to grasp the layouts and navigation once and then explore confidently.
- Accessibility. Great UX shouldn’t depend on perfect vision, hearing, or dexterity — the website should be usable for everyone.
- Hierarchy. Pages guide attention through visual hierarchy, using design to show visitors what matters most on each page and where to look next.
- Context. Effective sites give people the right information at the right moments, in a format that’s suited to their needs and personalized where possible.
Why UX can make or break a website
Great UX helps a website do its job faster and more effectively. When each next step feels obvious and natural, people are more likely to stay longer and complete desired actions (e.g., fill a contact form, complete a purchase, read a blog post).
For example, a strong UX on a renovation company’s site might lay out services and service areas in a highly readable format, provide social proof through testimonials and case studies, share clear pricing details, and use a prominent ‘Request a quote’ call to action (CTA) to encourage conversions.
These elements help visitors go from awareness to action with minimal interruptions and effort. That’s why websites with good user experiences tend to attract more customers and increase brand awareness, giving each client a solid foundation for long-term growth.
7 websites with great UX designs
Here are seven examples that show what websites with great user experiences can look and feel like.
- Modash
- Outseta
- January AI
- MarqVision
- Anrok
- MA Quilts
- Eleken
1. Modash
Modash’s website shows how great UX turns a complex, feature-heavy pitch into a more digestible and guided browsing journey. Instead of making visitors decode how the product functions, this site does much of that work for them.
Key UX choices:
- Clear workflow labels. Titles like “Manage,” “Discover,” “Track,” and “Pay” break the product’s features into simple categories so visitors can understand the basics faster.
- Multiple next steps. Information about free trials, demos, pricing, and product tours appears early, giving each user a path that matches their intent instead of using one CTA for everyone.
- Immediate social proof. Trial details and client logos appear near the top of the homepage, building trust and product confidence.
2. Outseta
Outseta’s website demonstrates how SaaS and other membership-focused businesses can simplify a multi-tool product to make its value proposition clear.
Key UX choices:
- Workflow-based navigation. Clear workflow labels with corresponding links to relevant tools help people understand the product quickly and map features to their pain points.
- Outcome-focused elements. Customer testimonials sit between course offerings and contact forms, mixing sales copy with more plain-language examples of how real users benefit from the product.
- Self-qualification paths. The phrase “Is Outseta for me?” doubles as a button that takes users to a dedicated page outlining who the platform is best for to help with decision making.
3. January AI

January AI’s website presents technical, medical-heavy content via a minimalist design that avoids overwhelming visitors with too much information too quickly.
Key UX choices:
- Audience segmentation. “Enterprise Solutions” and “Consumers” tabs split the target audience into distinct categories, helping each visitor understand where they belong before they explore further.
- Clear product ladder. A dedicated section highlights “January Mirror,” “Lifestyle Intelligence,” and the January app as core features. It also breaks the complex health platform’s functionality into smaller steps for non-technical visitors and anyone who’s simply in a hurry.
- Consistent CTAs. Each CTA button has the same simple black-and-white design and similar concise labels, so users see them immediately whenever and wherever they‘re ready to take action.
UX design websites from the Webflow community
Find inspiration from the Webflow community for your UX design website.
4. MarqVision
MarqVision’s website offers solutions to high-stakes problems like brand protection and unauthorized sales through fake products. Its UX focuses on reassuring visitors that the brand is trustworthy and can help with these sensitive needs.
Key UX choices:
- Problem-based navigation. Pain points like unauthorized sales, impersonation, content protection, and trademark management have separate links in the navigation menu, along with descriptions that provide context, so people can jump straight to the most relevant messaging.
- Industry pathways. The navigation bar also leads to landing pages for specific industries, such as fashion and pharmaceuticals, giving visitors an alternative way to narrow down their searches.
- Stats and badges. The homepage features case studies, customer logos, a 4.9-star rating badge, and key statistics like “24/7 monitoring” and “99% accuracy” — all of these elements help build credibility.
5. Anrok
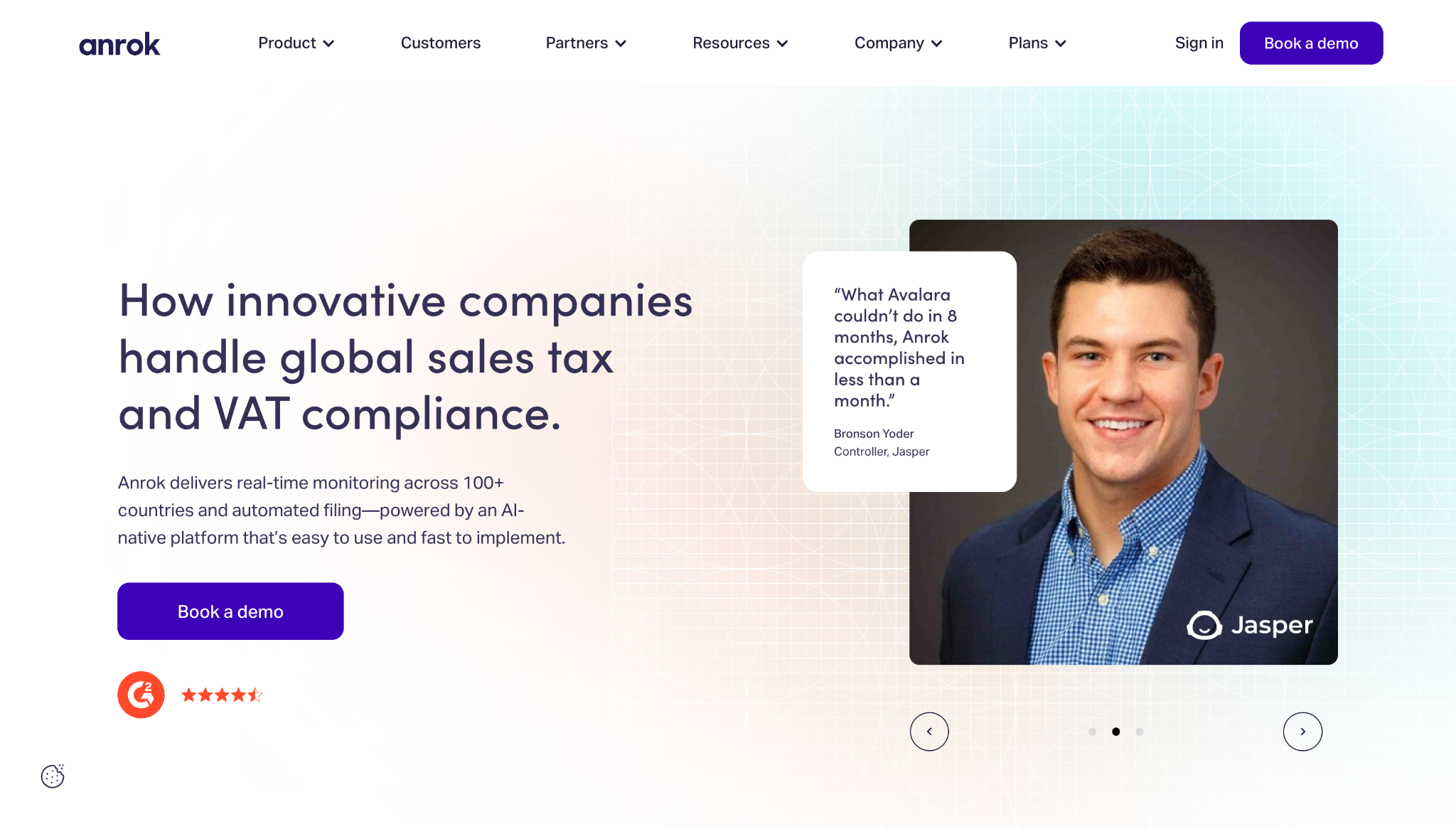
Anrok’s website shows how you can turn a stressful, compliance-related topic like sales taxation into an enjoyable user experience.
Key UX choices:
- Utility-first navigation. The site has an animated coverage map showing tax and VAT rates in the United States and Europe, helping visitors understand these key numbers at a glance.
- Clear workflow. Features like financial stack integration, tax calculation, and automated file reporting appear sequentially to demonstrate how customers can turn messy tax problems into manageable processes.
- Proof in the header. The hero section includes customer quotes with photographs of recognizable company executives, which adds social proof to Anrok’s core promise.
6. MA Quilts

MA Quilts’ website offers inspiration to anyone building portfolio sites for creative clients. Exploring this website illustrates how a simple structure can guide attention and convey a client’s visual identity.
Key UX choices:
- Clear navigation. There are only a few paths in the expandable hamburger menu, and they have straightforward labels like “Quilts,” “About,” “Process,” “Blog,” and “Contact.”
- Prominent product placement. The homepage quickly transitions from the brand statement to the company’s best pieces, along with a “See all quilts” button that leads to more featured products.
- Design that reflects the core offering. The minimal layout and short copy leave room for imagery to lead the experience, which is well-suited to such a visual-forward product.
7. Eleken
Eleken’s website speaks directly to visitors’ pain points by matching messaging, content structure, and conversion paths to user intent.
Key UX choices:
- Context-based client logos. Hovering over each client logo shows the company’s industry and project, such as “EdTech and Product Redesign” or “Recruiting and Team Extension,” so visitors can find relevant social proof fast.
- Outcome spotlights. Case studies highlight measurable results, such as lower dropoff rates and higher customer satisfaction, which builds on the client logo section’s messaging and encourages visitors to convert.
- Scroll-based interactions. An orange ball responds to scrolling behavior, showing a delivery timeline and step-by-step trial process while making the experience more engaging.
Build engaging user experiences with Webflow
A website with a good user experience design often looks impressive, but what really matters is that it helps people move forward without hesitation. When you take the time to create a clear content structure, helpful navigation, a brand-relevant design, and fluid interactions, you deliver user experiences that elevate your clients’ websites and get results.
Webflow gives you the tools to build effective UI/UX systems for all your projects. You can design visually and update quickly thanks to Webflow’s composable CMS. Built-in performance tools help pages load quickly and feel smooth to use, while workflow features support seamless collaboration and publishing.
Use Webflow to create a great user experience every time.
The modern web design process
Discover the processes and tools behind high-performing websites in this free ebook.
Try Webflow for as long as you like with our free Starter plan. Purchase a paid Site plan to publish, host, and unlock additional features.
Try Webflow for as long as you like with our free Starter plan. Purchase a paid Site plan to publish, host, and unlock additional features.
What is Urban Density Design? A Clear Guide to How Cities Get Built Denser
Urban density design plans cities to fit more people and uses while improving livability and quality public spaces, not just building taller structures.
Summary
Decoder
Original Article
Virality Predictor (Website)
Higgsfield.ai's Virality Predictor allows users to upload short video clips and receive AI-modeled insights on their hook strength, attention curve, and viral potential.
Summary
Original Article
1,000 Record Covers: The Book that Proves Album Art is High Art
Michael Ochs's '1,000 Record Covers' by TASCHEN presents 574 pages of album art from the 1960s–1990s, arguing for its recognition as high art.