.png)
DigitalOcean Dedicated Inference: A Technical Deep Dive (6 minute read)
DigitalOcean launched Dedicated Inference, a managed service for hosting large language models on dedicated GPUs with KV cache-aware routing and predictable economics for high-volume inference workloads.
Deep dive
- Separates control plane (endpoint lifecycle management via regional API services) from data plane (direct inference traffic through VPC-native load balancers to GPU nodes)
- Uses vLLM as the core inference engine paired with LLM-d for Kubernetes-native distributed inference patterns
- Implements intelligent routing via Kubernetes Gateway API with an Inference Extension that understands queue depth, replica health, and KV cache affinity
- Endpoint Picker component on CPU nodes selects optimal GPU replica based on whether it already cached the prompt prefix, not just round-robin distribution
- One DOKS cluster per VPC can host multiple isolated Dedicated Inference deployments using Kubernetes namespaces and Custom Resource Definitions
- Exposes both public and private endpoints through regional network load balancers, supporting internet and VPC-only access patterns
- Platform manages Kubernetes capacity provisioning, GPU pool coordination, gateway configuration, and reconciliation loops; users control model selection, replica counts, and scaling policies
- Designed for workloads where predictable GPU-hour economics matter more than burst elasticity—think coding assistants serving 2,000 concurrent engineers, not occasional API calls
- OpenAI-compatible API surface means existing client libraries work without modification
- Lifecycle management follows Kubernetes operator reconciliation pattern: observe desired state, act with retries and backoff, surface clear status instead of partial failures
Decoder
- vLLM: Open-source inference engine optimized for serving large language models on GPUs with efficient memory management
- KV cache: Saved attention key-value tensors from previously processed tokens; reusing cached prefixes avoids recomputing the same prompt context
- KV cache-aware routing: Load balancing strategy that prefers sending requests to replicas that already cached relevant prompt prefixes, reducing redundant computation
- Kubernetes Gateway API: Standard API for configuring HTTP/TLS routing into Kubernetes clusters, successor to Ingress
- Control plane vs data plane: Architectural split where control plane handles management operations (create/update/delete endpoints) and data plane handles high-throughput inference requests
- LLM-d: Kubernetes-oriented stack for distributed inference with prefix-cache-aware routing and LLM-specific scaling patterns
- DOKS: DigitalOcean Kubernetes Service, their managed Kubernetes offering
- Replica: Horizontally scaled copy of the same model server running in a separate pod/process
- Day-two operations: Ongoing operational tasks after initial deployment—monitoring, scaling, upgrades, incident response
Original article
DigitalOcean Dedicated Inference: A Technical Deep Dive
Getting a model to answer 10 inference requests concurrently is tricky but simple enough; getting it to handle 2,000 engineers hitting a coding assistant with long contexts, all day, without runaway costs, is where teams stall. A working endpoint is only the beginning. Teams need to identify the supporting hardware and wire up the right components—serving, scaling, observability, and cost guardrails—so the deployment can support expected SLAs and SLOs under real, sustained load.
DigitalOcean already offers Serverless Inference on the DigitalOcean AI Platform: a fast path to models from OpenAI, Anthropic, Meta, or other providers, with minimal setup and token-based pricing. This offering works well for many use cases. However, when you need your own weights, predictable performance on dedicated GPUs, and economics that favor sustained, high-volume token generation over pay-per-token bursts, a different approach makes sense
Dedicated Inference, our managed LLM hosting service on the DigitalOcean AI Platform, fills that gap.
Dedicated Inference deploys and operates an opinionated inference stack on dedicated GPUs, with Kubernetes-native orchestration under the hood. You interact through the control plane and APIs you already use in the DigitalOcean ecosystem; the data plane exposes public and private endpoints so applications inside, or outside, your VPC can call your models securely.
The service is designed to collapse a vast combinatorial space—GPU SKUs, runtimes, routers, autoscaling policies—into guided defaults so teams hit production milestones faster than DIY stacks, while retaining knobs that matter for model serving: replicas, scaling behavior, and advanced optimizations as you roll out your product roadmap.
What we manage vs. what you control
Every managed product draws a line between operator-owned and customer-owned concerns. Dedicated Inference aims to put day-two operations—cluster lifecycle integration, ingress, core serving and routing components, and the glue between them—on the platform side, while leaving model choice, capacity, and workload-specific tuning with you.
Typically platform-managed:
- Provisioning and lifecycle of the underlying orchestration footprint in line with product design (for example, managed Kubernetes integration and GPU pool coordination).
- Core inference engine and orchestration integration, including patterns that matter at scale: intelligent routing, autoscaling hooks, and production-oriented serving paths.
- Endpoint creation, health and scaling workflows, and the operational automation required to keep endpoints aligned with declared configuration.
In your hands:
- Selecting models (including bring-your-own-model paths where supported), GPU profiles, and replica counts appropriate to your SLOs and budget.
- Configuring scaling behavior and, over time, advanced serving options that map to your latency, throughput, and cost goals.
- Connecting applications via stable HTTP APIs consistent with common LLM client stacks.
Dedicated Inference overview
Dedicated Inference builds on industry-standard building blocks so customers benefit from community momentum and continuous improvement:
- vLLM as a capable, widely adopted inference engine for large language models on modern GPUs.
- LLM-d as a Kubernetes-oriented stack for distributed inference patterns—precise prefix-cache aware routing, scaling concerns that differ from traditional HTTP services, and room to grow into more advanced topologies as workloads demand.
This combination reflects a deliberate choice: meet customers where they are today (OpenAI-compatible APIs, familiar GPU offerings on DigitalOcean) while staying aligned with where the ecosystem is moving on routing, replication, and scale-out inference.
For readers who want more depth on why LLM routing differs from classic load balancing—and how prefix cache awareness changes the game—see our article on Load Balancing and Scaling LLM Serving.
High-level architecture
The system design separates a control plane (how endpoints are created, updated, listed, and deleted) from a data plane (how chat/completions request traffic reaches your models). That mirrors the management requests, which take a path built for regional placement and durable lifecycle work. Inference requests take a direct, low-latency path in front of your GPUs.
Control plane: central entry, regional execution
What does "control plane" mean here? In this split, the control plane is everything that handles management traffic: management rpc for Dedicated Inference endpoints, plus the durable bookkeeping that turns your declared intent into running DI infrastructure. It is separate from the data plane, which is the hot path for inference (chat/completions-style) requests once an endpoint is healthy.

Central API layer: Requests originating from the DigitalOcean Cloud UI, automation workflows, or the public API are routed through a centralized API layer first. This layer maintains the mapping of endpoint ownership by region and transparently forwards each request to the appropriate regional backend. This design follows a multi-region fan-out model, where regional endpoints are addressed using stable identifiers.
Regional Dedicated Inference service: Each region operates a control-plane service responsible for the full lifecycle management of instances within its scope. This includes persisting the desired state, reconciling it with the observed state, advancing lifecycle status (e.g., creating → active), and enqueuing the workflows that provision or mutate the underlying infrastructure. In this context, lifecycle refers to the state machine governing transitions from requested to running and reachable. An instance represents the managed inference deployment as a whole—encompassing both its control-plane record and the associated backing resources.
Separate worker-style components perform integrations that need retries, backoff, and idempotency—calling the Kubernetes API, watching object status, and publishing lifecycle updates back to the core service. This is similar to the reconciler pattern familiar from Kubernetes operators: observe desired state, act, repeat until reality matches intent. Use case: transient API errors or slow node startups do not wedge the user-facing API; the system keeps trying and surfaces a clear status instead of a half-applied state
DigitalOcean Kubernetes and capacity: The platform first helps ensure that sufficient DigitalOcean Kubernetes capacity is available within the target VPC, attaches the required GPU and supporting CPU node capacity, rolls out the managed inference stack (gateway and model workloads), and creates regional network load balancers for public and private endpoints.
Data plane: VPC-native traffic, gateway-routed requests
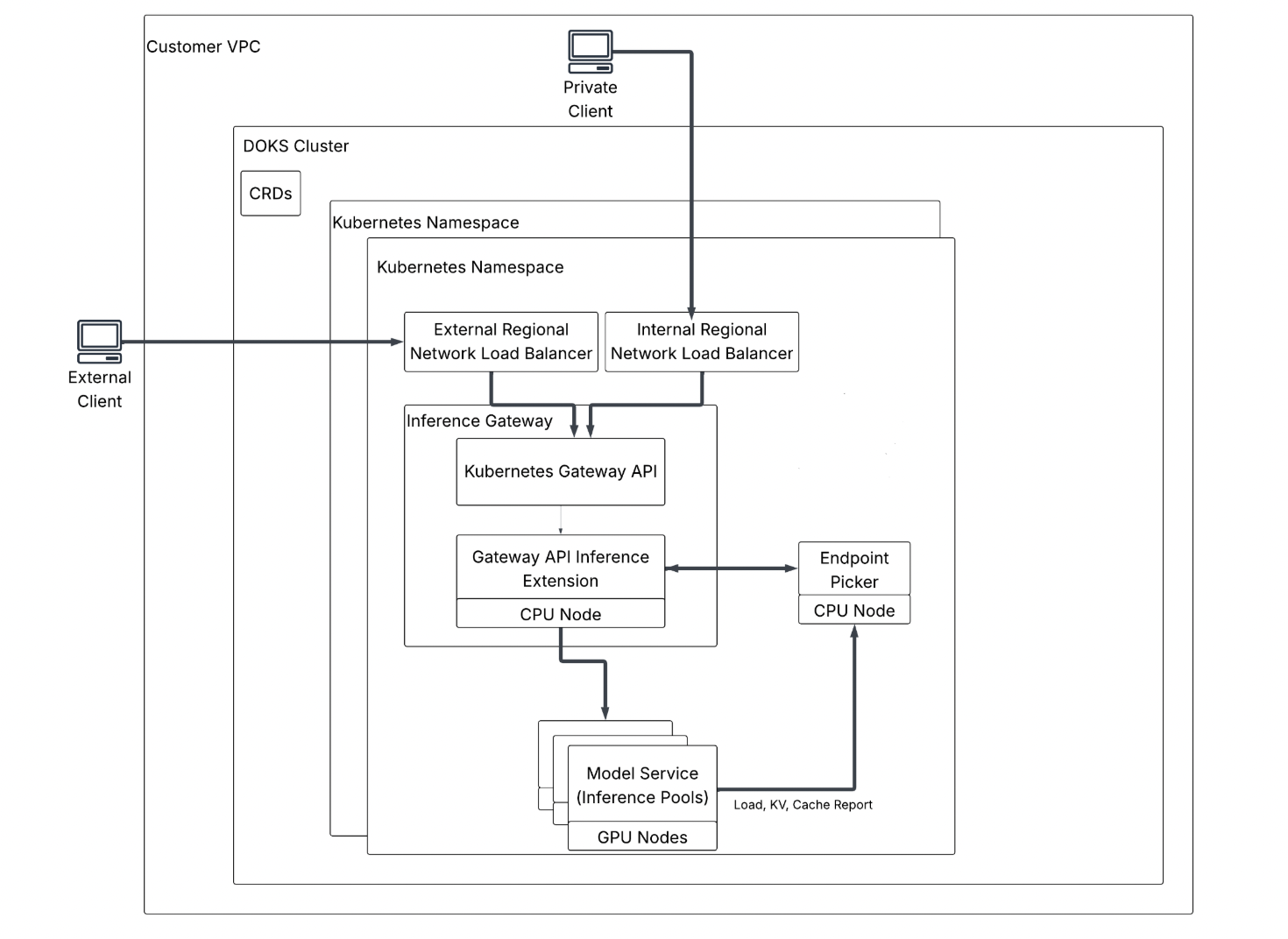
Client Contract & Endpoint connectivity: Once an endpoint is active, clients send OpenAI-compatible API requests (for example, HTTPS to /v1/chat/completions-style routes). Your public endpoint FQDN resolves to an external regional network load balancer (L4); your private endpoint resolves to an internal regional network load balancer, so the same inference stack can be reached from the public internet or stays on your private VPC network. In both cases, traffic is OpenAI-shaped JSON carrying model ID, messages, and generation parameters.
Cluster placement and VPC isolation: Inside the VPC, workloads run on DOKS. One cluster per VPC can host multiple Dedicated Inference deployments, each isolated by a Kubernetes namespace. Desired gateway and model wiring is expressed as Custom Resources (CRDs—Custom Resource Definitions): declarative objects you kubectl apply (or the platform applies for you) instead of imperative scripts.
Inference Gateway and Kubernetes Gateway API: After the NLB, traffic hits the Inference Gateway, implemented with the upstream Kubernetes Gateway API—the community standard for describing HTTP/TLS routing into a cluster.
Gateway API Inference Extension (inference-aware routing): Below the gateway, the Gateway API Inference Extension teaches routing about inference signals: queue depth, replica health, and KV cache affinity (preferring a replica that already holds key/value tensors for a reusable prompt prefix so work is not recomputed from scratch). KV cache is the saved attention state for prior tokens; inference-aware routing is deliberately not simple round robin, because the cheapest replica is often the one that already cached your prefix.
Endpoint Picker: On CPU nodes, the Endpoint Picker is the component that talks to the Inference Extension and selects which GPU replica should receive each request.
Model Service and inference pools: On GPU nodes, the Model Service—backed by inference pools in configuration—runs your model replicas (distinct pods/processes that can serve the same model ID). Each replica reports load, KV, and cache metadata upstream so the Endpoint Picker's choices stay accurate through rollouts, crashes, and autoscaling events. Replica is a horizontally scaled copy of the same model server; pool is the grouping of those replicas for routing and capacity.
Who is Dedicated Inference for?
Dedicated Inference is aimed at builders who already know they need GPUs, but who would rather not become a full-time inference platform team:
- Teams that self-host on raw GPU Droplets or Kubernetes and want to offload orchestration, baseline optimizations, and repetitive infra work while keeping API-level ownership of their applications.
- Teams that have graduated from Serverless Inference and need hardware-level control or BYOM without abandoning managed operations.
- Organizations with consistent inference demand where predictable GPU-hour economics and performance isolation matter more than pure burst elasticity.
Inference is no longer a novelty layer; it is part of the core application stack. That shift raises the bar for reliability, performance, and cost predictability. Dedicated Inference is for teams that need production-grade, dedicated GPU inference with a managed path from model selection to a stable endpoint—so you spend engineering cycles on products and prompts, not on reinventing the serving platform.