
When LLMs Get Personal (20 minute read)
Personalized LLM responses maintain a stable semantic core across users despite surface variation, meaning optimization for AI search remains viable.
Deep dive
- The article introduces a mathematical framework modeling LLM answers as Y(q,u) ≈ C(q) ⊕ V(q,u), where C(q) is the shared core driven by the query and V(q,u) is the variable margin influenced by user context
- Four factors enforce a shared core across personalized answers: shared model priors (same underlying model training), overlapping retrieval neighborhoods (similar source material), product constraints (systems tuned to minimize entropy and maintain coherence), and probability mass concentration in decoding
- The author defines "answer archetypes" as compressed representations at the substance level, decomposing answers into topic conclusion (T), entities/examples (E), framing (F), and practical conclusion (C)
- Personalization operates at multiple stages including query interpretation (same text implies different intents), retrieval neighborhood selection, framing emphasis, and surface realization
- An experiment comparing ChatGPT responses across logged-out, author's account, and spouse's account shows complete word-level differences but reveals recurring concepts, entities (like "The Pitt"), structural patterns (bulleted lists), and categorical organization
- LLM-based search differs from classical SEO because personalization affects the system earlier and more deeply (before retrieval, during context construction, during generation) rather than just perturbing a shared ranking
- The key insight is that the space of materially distinct answers is much smaller than the space of possible token sequences, with most variation being semantically equivalent rewording
- Studies from Graphite show that only 10 answer variations are sufficient to observe core trends, with answers converging to similar concepts as response count increases
- The article debunks three myths: that personalization means totally different answers, that probabilistic outputs are patternless, and that personalization makes optimization impossible
- For brands, the implication is that being heavily represented in the model's training data and semantic core matters more than optimizing for individual personalized variations
Decoder
- Answer archetype: A compressed representation of an LLM response focusing on substance (topic, entities, framing, conclusion) rather than exact wording
- Semantic core: The stable content and concepts that remain consistent across multiple LLM answers to the same question, regardless of personalization
- Stochastic: A system that produces different outputs from the same input according to a probability distribution, rather than deterministic identical results
- Entropy minimization: The tendency of LLM systems to reduce randomness and uncertainty in outputs, pushing answers toward coherent, familiar patterns
- Shared priors: Common learned representations and associations from the model's training data that influence all users' answers
- AEO/GEO/LLMO: AI Engine Optimization / Generative Engine Optimization / Large Language Model Optimization, various terms for optimizing content to appear in LLM-generated answers
- Probability mass concentration: The mathematical tendency for LLMs to strongly favor certain outputs over others, making some answer types much more likely despite theoretically infinite possibilities
- Retrieval neighborhood: The conceptual region of semantic space from which relevant source material is pulled to construct an answer
Original article
When LLMs Get Personal
As AI answers become more personalized, do stable patterns still exist?
In my last two posts, I approached the heavily polarizing topic of AI search (yes, remarkably, it's still polarized) from two related angles.
First, I argued mathematically that AI search is a different optimization problem than classical search. Second, I argued that the content that tends to surface in LLM answers is shaped by retrieval and generation mechanics, specifically entropy minimization. Different types of articles will be used to answer different types of questions; LLM's don't ONLY like lists and summaries nor do they only prefer long-form content.
The underlying theme of my writings is the debate that keeps coming up around LLM-based search (or, pick your favorite acronym: AEO/GEO/LLMO). One camp wants to collapse it back into SEO before LLM's existed and say this is all basically the same game with a new interface. The other wants to treat it as a total rupture, as if everything we learned from search can be thrown out.
My consistent point of view is that the reality lies somewhere in the middle.
In the latest spin on this debate, the theme of personalization in LLM responses is being lobbed into the discourse like a mini-grenade.
The specific framing is roughly as follows:
if LLM answers are assembled through content retrieval and generation, and those systems are conditioned on the user, isn't every answer going to be different? What's the point of even optimizing for LLM's, then?

This is where the conversation tends to get fuzzy.
People hear "personalization" and jump quickly to the idea that every user is now living inside a completely bespoke answer universe. At the same time, there's an equally weak counterpoint floating around that personalization is mostly superficial and that the answer is still basically the same for everyone.
My guess is that both of those views miss the more interesting middle.
LLM answers can vary across users, sessions, and contexts while still sharing a large amount of semantic structure. That should not be surprising. These systems are probabilistic, but they are also built on shared model priors, overlapping retrieval neighborhoods, and the same bottlenecks in context construction and decoding. So even when two answers are not identical, they may still be much closer than people assume in the parts that actually matter.
That is the question I want to explore here.
At the token level, the space of possible outputs is effectively unbounded. That observation is technically true and mostly useless. The more interesting question is whether the space of materially distinct answers is much smaller - and whether answers to the same question, across different users, tend to share a stable common core with variation concentrated more at the margins.
There is plenty of writing about AI search that stays very tactical: screenshots, heuristics, surface-level advice. There is also a more technical conversation about retrieval, ranking, generation, and system design that often stays too abstract to connect back to the questions people actually care about. As always, I'm more interested in the middle ground: using the structure of the systems to explain practical behavior with a little more precision.
So this post is an attempt to reason through personalization in AI answers at that level.
The core hypothesis is simple:
LLM answers can be personalized without becoming arbitrary and totally random.
Even when different users get different answers to the same question, those answers will often share many common elements because they are shaped by the same underlying machinery.
Definitions
- Classical search
- Search systems where the primary output is an ordered list of documents or links in response to a query.
- LLM-based search
- Systems where a large language model generates a synthesized answer to a user query, potentially conditioned on retrieved material, rather than primarily returning a ranked list.
- Generated answer
- The natural language response produced by the model, separate from surrounding UI elements like citations, source cards, links, or other modules.
- Personalization
- Any mechanism by which an answer depends on more than just the explicit query. This can include user history, saved memory, account state, session context, location, or other contextual signals.
- Materially distinct answer
- An answer that differs in a way that matters substantively. That could mean different entities, different examples, different framing, different recommendations, or a meaningfully different practical conclusion.
- Shared core
- The semantic content that remains stable across many answers to the same question.
- Variable margin
- The part of the answer most likely to shift across users or runs: examples, emphasis, framing, ordering, local detail, and so on.
- Answer archetype
- A compressed representation of an answer at the level of substance rather than surface wording.
- Stochastic
- A system is stochastic if it can produce different outputs from the same input according to a probability distribution, rather than always producing the exact same result. In the context of LLMs, this means the same question can yield different answers across runs, even when the underlying model is the same.
Assumptions
A few assumptions are doing work in this post.
First, I am not assuming access to internal logs, retrieval traces, memory stores, prompts, or product internals from any model provider. I am assuming the model providers honor the underlying mathematics of LLM's, though.
Second, I am mostly talking about search-like or explanation-like prompts here. Questions where there is some shared topic structure: product comparisons, learning paths, informational queries, workflow questions, high-level guidance. This is less about creative writing, roleplay, or open-ended generation.
Third, I am assuming that token-level variation is usually less important than semantic variation. If one answer says essentially the same thing with slightly different wording, that is not especially interesting.
Disclaimer
I'm the co-founder and CTO of Noble, a company that works in the space of LLM visibility and brand mentions. That practical context influences how I think about these systems, but this post is not a pitch for Noble or for any particular product.
The question here is broader than brand visibility anyway. It applies to educational queries, product queries, software discovery, workflow questions, planning questions, and a lot of the general "AI search" surface that people increasingly interact with.
What I'm trying to do here is reason from system structure rather than from anecdotes. There is already plenty of discussion of AI search that stays at the level of screenshots and vibes. I think there is room for a more explicit model of what personalization is likely doing and what it is probably not doing.
Myths Debunked
Before getting into the math, I want to clear out a few bad framings that tend to show up whenever people talk about personalization in AI answers.
The point here is not to overstate the certainty of any one model of how these systems behave. It is to get rid of a few intuitions that are loose enough to be misleading.
Myth 1: Personalization means every user gets a totally different answer
This is probably the most common overreaction.
People hear that LLM-based systems can condition on the user and immediately jump to the idea that every answer is now fully bespoke. There have even been very thorough studies done on the inter-user variation in LLM answers across a large, but observable population of individuals. The implication being (for some, anyway) that there is no stable structure left to study because each person is effectively inhabiting a different answer universe.
It doesn't work that way.
Personalization is real, but LLM's are probabilistic and therefore built on shared priors, shared corpora, shared retrieval bottlenecks, and shared decoding constraints. Different users can absolutely get different answers, but those answers are still being generated by the same underlying machinery. That should create overlap, and often a lot of it.
Myth 2: If outputs are probabilistic, then there is no point trying to model them
This is another bad leap.
A system being probabilistic does not make it patternless. If anything, probability is exactly the language we use when we want to talk about structured variation.
The fact that an LLM can produce multiple possible outputs for the same question does not mean all of those outputs are equally likely, or that the answer space is too unconstrained to reason about. In practice, these systems concentrate probability mass. Some outputs show up repeatedly. Some structures recur. Some entities or framings are much more likely than others.
So "the model is stochastic" really shouldn't be the end of the conversation. Rather, it's the beginning of a more interesting one.
The great team at Graphite recently published some very compelling literature on how only 10 variations of answers to the same question are enough to observe core trends.
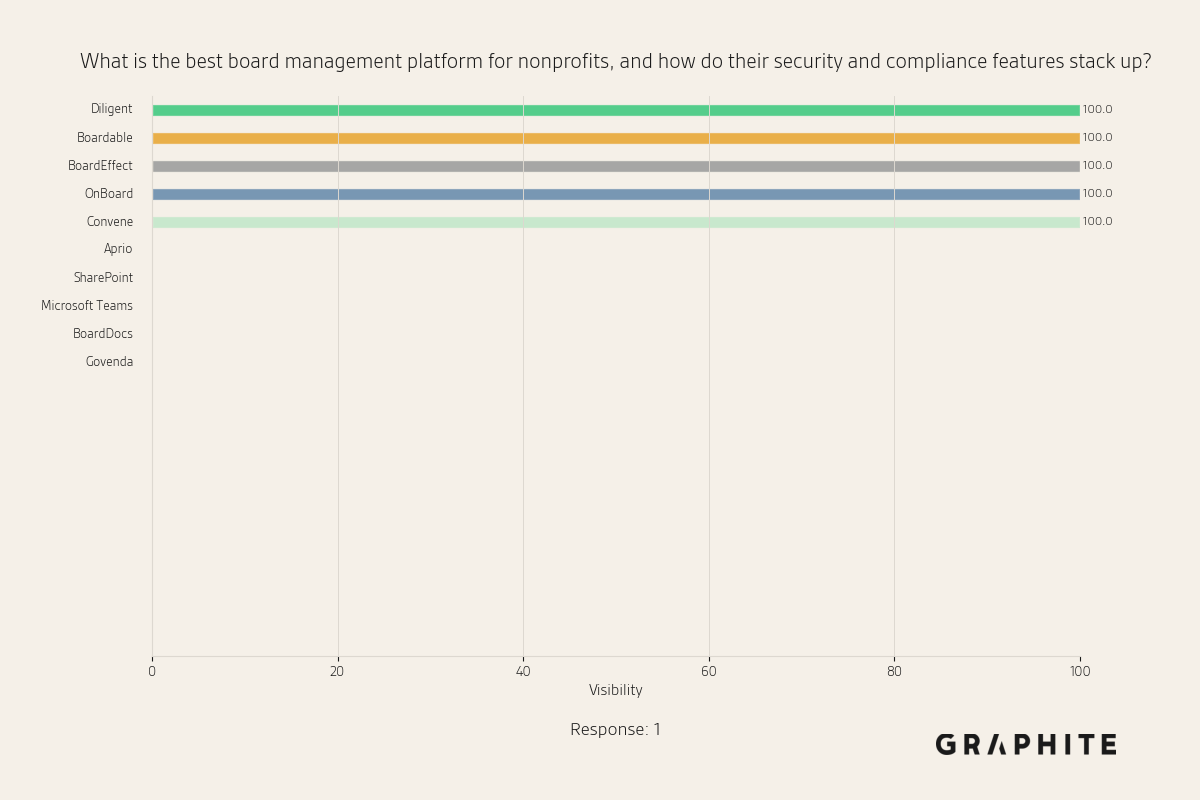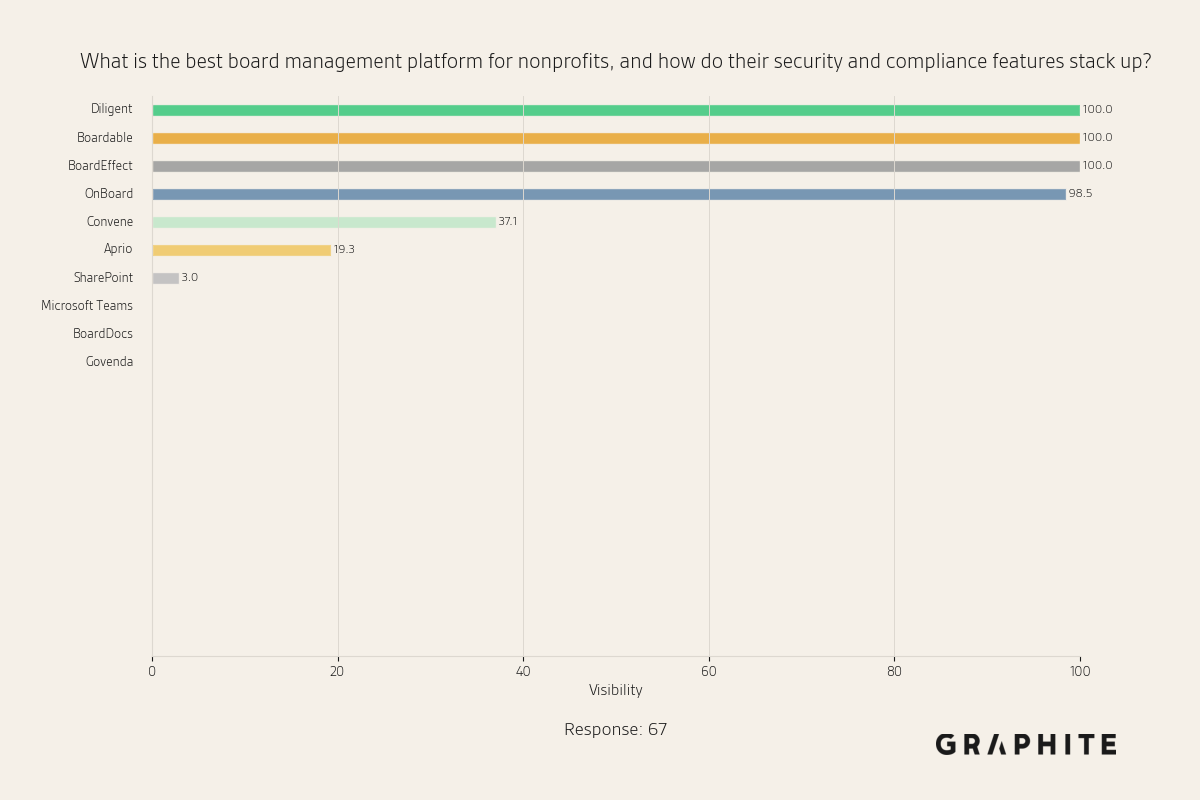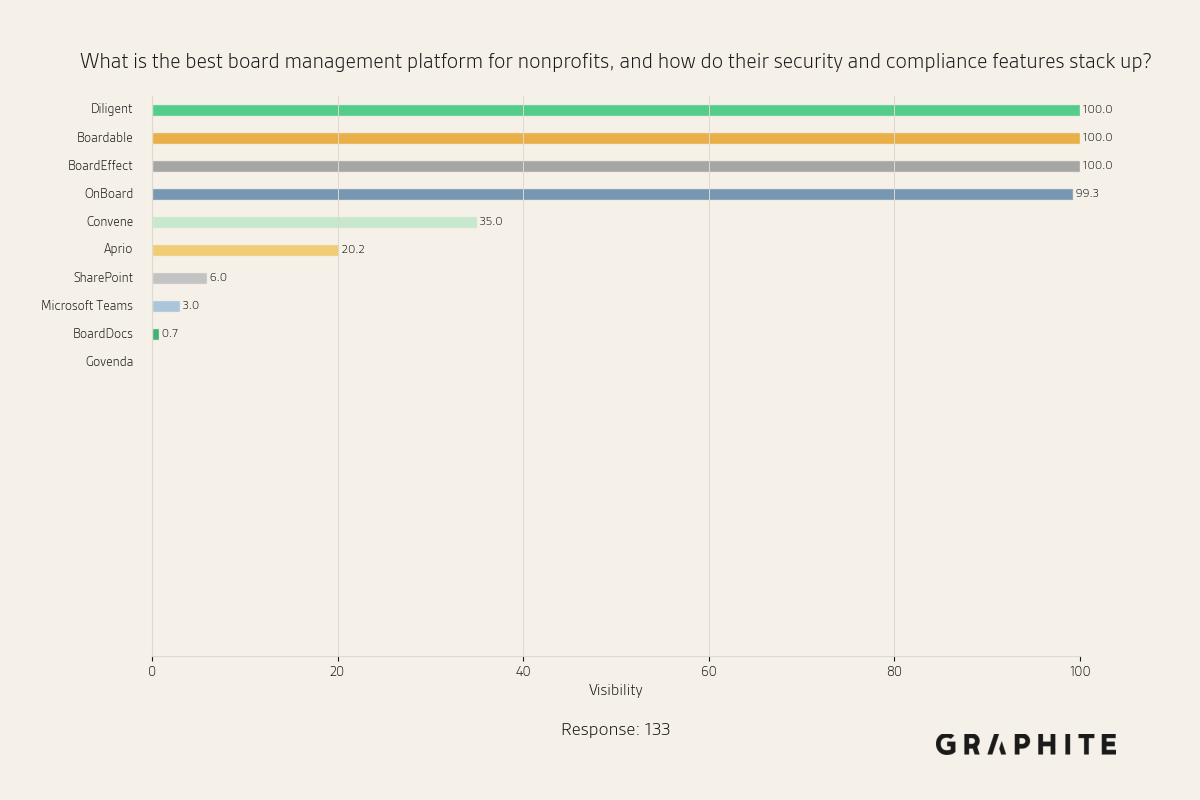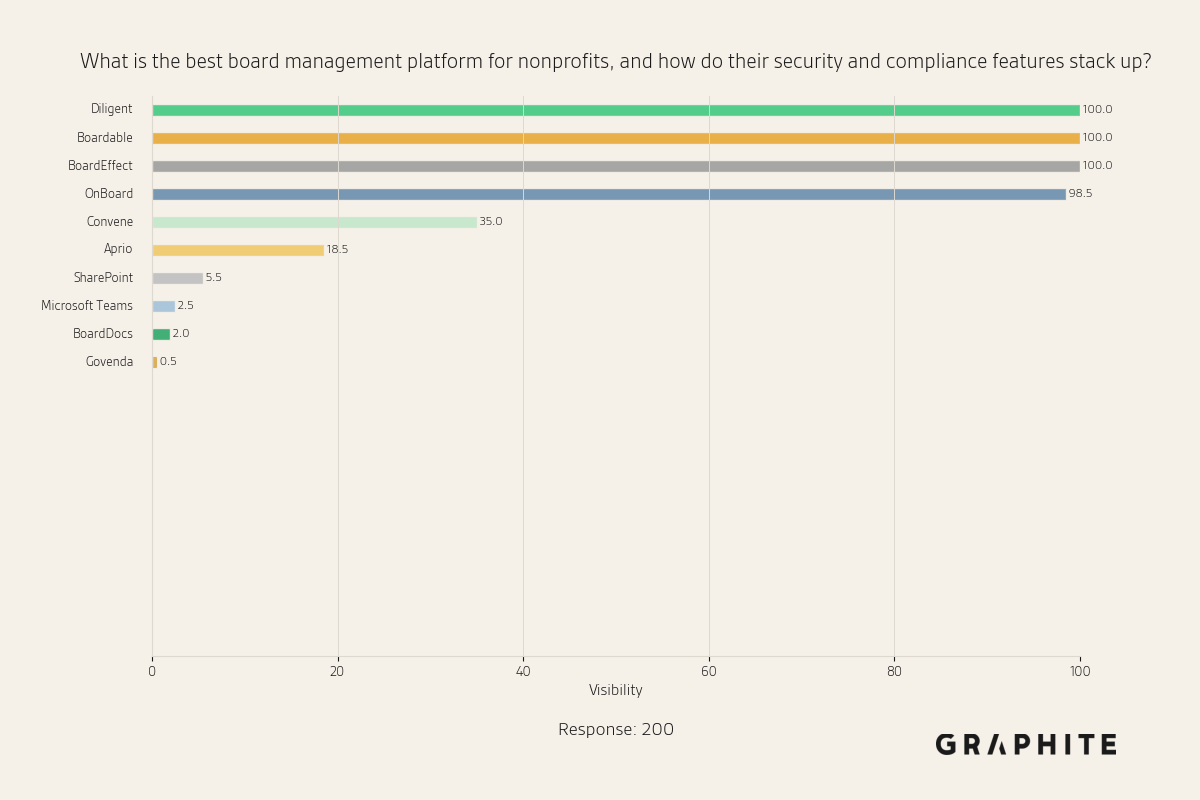
Myth 3: Personalization makes optimization impossible
This one is downstream of the first two, and it is the one I care about most in this post.
The argument usually goes like this: if answers vary by user, and outputs are probabilistic, then there is no stable object left to optimize for.
That only follows if you assume that personalization implies arbitrary divergence.
I don't think it does.
If answers to the same question still share a common semantic core, and if the number of materially distinct answers is much smaller than the number of possible strings, then optimization does not disappear. It just changes. The relevant object is no longer to rank on a single fixed surface. It is the recurring patterns across many related answer variants.
This is a much harder mathematical problem to model than traditional SERP-style search. But it is still a problem with real numerical structure.
The Problem With "Infinite Answers"
A common way of talking about LLM outputs is to say that the answer space is infinite.
In one sense, that is true. If an answer is defined as an exact sequence of tokens, then there is no meaningful upper bound worth talking about. Change a phrase, swap an example, regenerate with slightly different decoding, and you have a new string.
But that is the wrong object.
Let's say a few different individuals ask the LLM a general question about getting in shape.
Now suppose one answer says:
Walking every day is usually the best place to start if you want to get in better shape, because it's easy to stick with and doesn't put much stress on your body.
And another says:
If your goal is to get fitter, daily walking is often the safest and most sustainable starting point because it's low impact and easy to maintain.
Those are technically different outputs. They are also basically the same answer.
Now compare that with another answer that says:
If you want to get in shape quickly, start with short strength workouts and interval training a few times a week, since walking alone is too limited to make much difference.
That is a meaningfully different answer.
The distinction matters because when people talk about personalization, they often slip between these two levels without noticing. A system can produce many different strings while still producing only a relatively small number of materially distinct answers.
That is the thesis I want to make more precise.
The right question is not:
Can a language model generate infinitely many outputs?
Of course it can.
The right question is:
How many materially distinct answers are there to the same query, and how much common structure do those answers share?
From Raw Text to Answer Archetypes
Now I'll get into the mathematical answer to the above question.
Let Y be the random variable representing the generated answer to a query q.
If we treat Y as raw text, the object is too fine-grained to be useful. So instead, define a map:
\(ϕ(Y)\)
where ϕ compresses the answer into the parts that matter substantively.
A simple version might be:
\(ϕ(Y)=(T,E,F,C)\)
where:
-
T is the topic-level conclusion or core takeaway
-
E is the set of entities, examples, or concrete references selected e.g. a list of items
-
F is the framing or tradeoff emphasis
-
C is the practical conclusion or recommended course of action
This is not the only way to decompose an answer, but it is enough to make the point.
I define two answers that differ slightly in wording but share the same (T,E,F,C) as functionally the same answer archetype. Two answers that differ across these dimensions are substantively different, even if they overlap in vocabulary.
That gives us a better object of study:
\(∣supp(ϕ(Y)∣q)∣\)
In words: how many materially distinct answer archetypes exist for a given query?
And even more importantly, how much of that answer archetype is stable across users?
Shared Core, Variable Margin
I think the most useful mental model here is to split an answer into two parts:
\(Y(q,u)≈C(q)⊕V(q,u)\)
where:
-
q is the query/prompt
-
u is the user
-
C(q) is the shared core
-
V(q,u) is the variable margin
The shared core is driven mostly by the topic itself and by the common machinery of the system. It includes the recurring concepts, the broad thrust of the answer, and often the dominant practical takeaways.
The variable margin is where personalization and stochasticity have more room to act. It includes which examples are chosen, what ordering is used, what nuance gets emphasized, which sub-case gets foregrounded, and which user-specific angle is introduced.
I think a lot of confusion comes from treating all variation as equally important.
If I ask:
What's the best way to train for a marathon as a beginner?
and one answer emphasizes gradual mileage buildup while another emphasizes consistency and recovery, those may be different emphases within the same conceptual basin. If a third answer recommends high-intensity interval training as the main strategy and barely mentions gradual volume, that is a more substantial divergence.
The structure matters.
For search-like prompts, the answer is best understood as having a relatively stable C(q) and a much more flexible V(q,u). In layman's terms: a stable, shared core with some user-level flexibility.
Why a Shared Core Must Exist
There are several reasons to expect a substantial shared core across users.
1. Shared model priors
Different users are usually interacting with the same model or closely related variants. The model's broad representation of the world is shared. Its learned associations, its default explanatory styles, and its compression of common topics are all pulling answers in the same direction.
For instance, if many users ask:
-
how to learn coding
-
how to choose the right software for your business
-
why prices go up
-
how to get in shape for a race
-
how to choose the right database framework for my app
it would be surprising - and highly unlikely - if the system did not converge repeatedly on similar concepts and broad recommendations. I'll share a concrete example later in this writing.
2. Shared source neighborhoods
Even when retrieval is personalized, it is usually personalized within a bounded region of semantic space.
Users are not retrieving from entirely unrelated universes. They are often moving around within overlapping conceptual neighborhoods. Different users may see different passages, different sources, or different examples, but those often come from clusters that share similar ideas.
This is important because answers inherit structure from the retrieved evidence.
3. Shared product and instruction constraints
Commercial LLM systems are not sampling freely from open text space. They are tuned to be coherent, helpful, concise, and often to avoid certain failure modes. Or, put mathematically and as I illustrated in my previous post, they are built to minimize entropy in their answers. That pushes answers toward familiar shapes.
That is why LLM answers often converge on things like:
-
summary first
-
a few concrete examples
-
a comparison by criteria
-
a short practical recommendation
-
a hedge or caveat at the end
These are product-level constraints, and they create regularity.
4. Decoding concentrates probability mass
The existence of many possible outputs does not mean the distribution is flat. In practice, decoding methods and the model's own learned distribution tend to concentrate probability mass heavily in a relatively small region of output space.
That means a handful of answer archetypes can dominate, even when many more are technically possible.
Why Personalization Still Matters
To be clear: None of the above means personalization is weak or unimportant. It means the right question is not whether answers differ, but where they differ. Personalization can shift the answer at multiple stages as detailed below.
Query interpretation
The same literal prompt can imply different latent questions depending on the user context.
"Best budgeting app" could mean:
-
personal budgeting for a young professional
-
joint budgeting for a family
-
cash flow visibility for a founder
-
a simple tool for someone new to budgeting
-
an app that integrates with a specific bank ecosystem
The surface string is the same. The latent intent is not.
Retrieval neighborhood
Even a small shift in effective query representation can change what evidence gets surfaced. This is one of the most important sources of divergence, because once different evidence enters context, the answer can move in meaningful ways.
Framing and emphasis
One user may get an answer optimized around simplicity. Another may get an answer optimized around depth, integration, cost, rigor, or reliability. These aren't trivial changes. They can shape which practical conclusion feels most salient.
Surface realization
Even when the substance is similar, the style, order, and examples can vary. That matters for user experience, even when it is not the main object I care about here.
The important point is that these sources of variation do not necessarily destroy the shared core. They often operate around it.
Pre-LLM Search vs LLM-Based Search
This is also where the contrast with classical search (i.e. traditional SEO) becomes useful. There is a body of individuals that reductively assert that traditional SERPs were already variable and somewhat personalized, so the variation in LLM responses is "old hat".
It is true that search engines personalized before LLMs. Location mattered. Language mattered. Some aspects of behavior mattered. In certain domains, prior activity or account state could matter too.
But for many queries, the result surface still felt largely shared. Users often saw very similar sets of documents d with modest changes in ordering or presentation.
You can think of that, loosely, as:
\(score(d∣q,u)≈score(d∣q)+Δu(d)\)
where Δu perturbs a shared ranking structure and, as before, q denotes a query/search term and u denotes the user.
For most search queries, the top of the ranking is dominated by a relatively strong global signal:
\(s(q,d)≫Δu(q,d)\)
at least for the documents near the top. In other words, the personalization-based perturbation was negligible compared to global signals.
So even if personalization was present, it often only changed:
-
lower-ranked results,
-
ties or near-ties,
-
inserted modules,
-
local ordering among documents with small score gaps.
In LLM-based search, the user can affect the system earlier and more deeply:
-
before retrieval
-
during context construction
-
during answer generation
That makes the answer surface more sensitive to personalization in LLM's than a classical SERP.
A Fun Experiment I Want to Run
I will demonstrate the above concepts with a very simple toy example with n=3.
As my wife and I are avid consumers of streaming TV shows, we'll pose the question "what are the best streaming television shows" to ChatGPT under the following conditions:
-
A logged out session (i.e. no user context)
-
A session tied to my own ChatGPT account (I'm an avid user of ChatGPT, and have a ton of historical context in there)
-
A session tied to my wife's ChatGPT account (Less of an avid ChatGPT user than me)
Then compare the answers side by side.
The goal here is not be to prove that the answers are identical or to show that they are wildly different. The goal would be to inspect the structure of the variation.
Questions I'm examining include:
-
Which concepts recur in all versions?
-
Which entities or examples are stable?
-
Which parts shift with account context?
-
Does the answer keep the same overall practical conclusion?
-
Where is the model actually expressing personalization?
So, here goes:
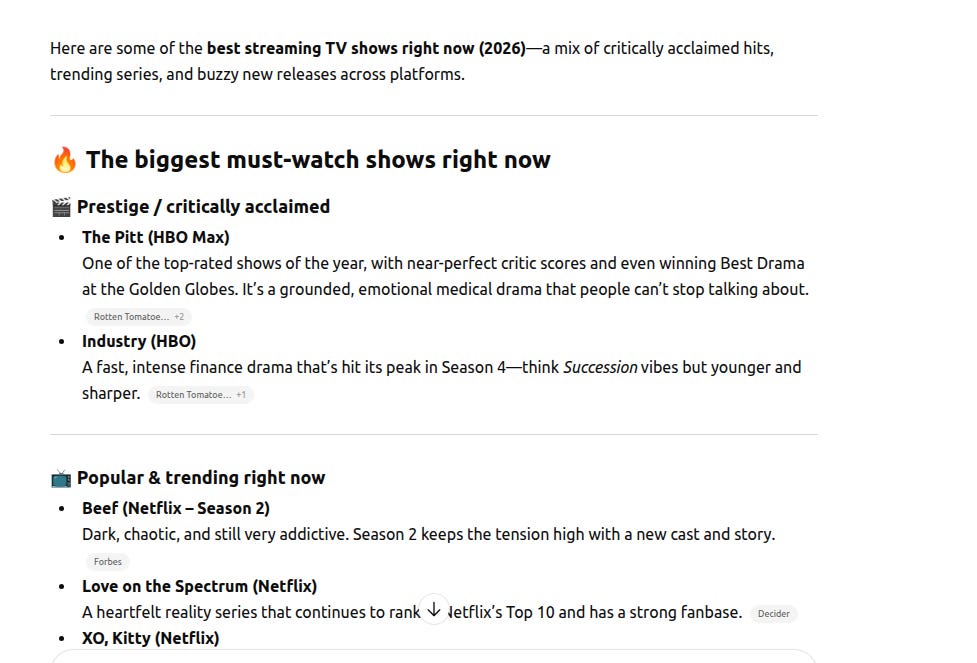
Logged Out Session
My Own User Session

My Wife's Session (on a Mac with dark mode, hence the different appearance)
Indeed, if you compare the answers word-for-word, each and every one of them is completely different. That said, some clear common themes emerge across all three answers:
-
The Pitt is recommended in each response (I've heard great things!)
-
Each response is very clearly structured as a bulleted list of items
-
Each response has a common structure oriented around categories and sub-categories
While personalization clearly plays a role over the small sample size in this experiment, law of large numbers would assert - and as corroborated by other studies in this area - that LLM responses will converge around the mean of the probability distribution modeled by the training data accessed by the LLM.
A Concrete Framing of Personalization in LLM Responses
I think the correct working hypothesis is something like this:
For many search-like questions, personalized LLM answers are best modeled as a bounded family of related answer archetypes that share a common semantic core, with variation concentrated in examples, framing, ordering, and local detail.
Or, simply put:
For a lot of search-like questions, personalized LLM answers are different versions of the same basic answer. The main idea usually stays the same, while the examples, emphasis, order, and small details are what tend to change.
That is a much stronger claim than saying "personalization exists," and a much more useful one than saying "everything is infinite."
It also leads to a cleaner empirical question.
Instead of asking whether two answers are literally identical, ask:
-
What concepts recur across users?
-
Which practical conclusions remain stable?
-
What changes first when user state changes?
-
How much of the answer is common core versus variable margin?
That is a tractable object.
The Implication for Brands Trying to Show Up in LLM's
Of course, we can't quite resist briefly linking this back to the commercial side of LLM-based search.
My argument in this post is quite simple: if one is trying to ensure their company shows up in LLM responses, the best way to do so is to be included heavily in the semantic core (i.e. training data) accessed by the models.
While personalization will certainly impact the nature of what each and every searcher sees, across large populations there will necessarily be mathematical convergence towards common items. This also points to the value of AI search visibility measurement tools as they model responses over a large sample size of prompt runs.
Closing
A lot of the discourse around personalized AI answers is still stuck at the level of slogans.
Some people talk as if there is still one answer surface, just with a slightly different interface. Others jump straight to the idea that personalization blows the whole thing apart and leaves nothing stable enough to reason about.
I think both miss what is actually interesting.
Answers will definitely vary across users, but the important point is that the variation is constrained. These systems are stochastic, but they are not sampling from chaos. They are generating under shared priors, shared corpora, bounded retrieval, bounded context, and decoding schemes that push probability mass into a relatively small part of the space.
That means personalization matters, but it matters inside a structure.
Answers to the same question can diverge in examples, framing, emphasis, and local detail while still converging on the same semantic center. And that is a very different claim from either "everyone gets the same answer" or "every answer is its own universe."
The answer surface is no longer singular in the way it was in classical search. But it is not infinitely fragmented either. It is better understood as a bounded family of related answers, with a shared core and user-conditioned variation around it.
Once you see that, a lot of the noise around AI search starts to clear.