Devoured - April 29, 2026
GitHub Actions has become the primary vector for open source supply chain attacks, with almost every major incident in the past 18 months exploiting features working exactly as designed, while GitHub's own reliability problems (attributed to AI-driven development overwhelming infrastructure) are pushing high-profile projects like Ghostty to leave the platform entirely. Meanwhile, long-running AI agents that persist across sessions are rapidly maturing, with major labs converging on similar architectures for autonomous coding workflows that can sustain hours of work.

OpenAI brings its models to Amazon's cloud after ending exclusivity with Microsoft
OpenAI is bringing its full model lineup to Amazon Web Services after ending its Microsoft exclusivity deal, letting developers deploy ChatGPT and other models through AWS Bedrock.
Original article
Key Points
- OpenAI's generative AI models are becoming available on Amazon's cloud a day after the AI company revamped its relationship with longtime partner Microsoft.
- "This is what our customers have been asking us for for a really long time," AWS CEO Matt Garman said at a launch event in San Francisco.
- OpenAI CEO Sam Altman, who's in court across the Bay Bridge in Oakland for his case against Elon Musk, send a recorded message about the announcement.
A day after OpenAI revamped its relationship with Microsoft so that it can run all of its products on any cloud, the artificial intelligence company said its models will be available via Amazon Web Services.
AWS customers can experiment with OpenAI's models as well as its Codex agent for writing code, all through Amazon Bedrock, the companies announced on Tuesday. The services will become generally available in the next few weeks.
"This is what our customers have been asking us for for a really long time," AWS CEO Matt Garman said at a launch event in San Francisco.
Until now, developers could draw on so-called open-weight models from OpenAI that came to AWS in August.
OpenAI CEO Sam Altman sent a recorded message about the announcement, as he's currently in court across the Bay Bridge in Oakland for his case against Elon Musk.
"I wish I could be there with you in person today, my schedule got taken away from me today," Altman said in the video. "I wanted to send a short message, though, because we're really excited about our partnership with AWS and what it means for our customers, and I wanted to say thank you to Matt and the whole AWS team."
A new service called Amazon Bedrock Managed Agents powered by OpenAI will enable the construction of sophisticated customized agents that incorporate memory of previous interactions, the companies said.
Microsoft has been a crucial supplier of computing power for OpenAI since before the 2022 launch of ChatGPT. Denise Dresser, OpenAI's revenue chief, told employees in a memo earlier this month that the longstanding Microsoft relationship has been critical but "has also limited our ability to meet enterprises where they are — for many that's Bedrock."
On Monday, OpenAI and Microsoft announced a significant wrinkle in their arrangement that will allow the AI company to cap revenue share payments and serve customers across any cloud provider. Amazon CEO Andy Jassy called the announcement "very interesting" in a post on X, adding that more details would be shared on Tuesday.
OpenAI and Amazon have been getting closer in other ways.
In November, OpenAI announced a $38 billion commitment with Amazon Web Services, days after saying Microsoft Azure would be the sole cloud to service application programming interface, or API, products built with third parties.
Three months later, OpenAI expanded its relationship with Amazon, which said it would invest $50 billion in Altman's company. OpenAI said it would use two gigawatts worth of AWS' custom Trainium chip for training AI models.
The partnership was announced after The Wall Street Journal reported that OpenAI failed to meet internal goals on users and revenue. Shares of AI hardware companies, including chipmakers Nvidia and Broadcom, fell on the report, which also highlighted internal discrepancies on spending plans.
"This is ridiculous," Sam Altman and OpenAI CFO Sarah Friar said in a statement about the story. "We are totally aligned on buying as much compute as we can and working hard on it together every day."

GitHub Actions is the weakest link
GitHub Actions has become the primary attack vector for open source supply chain compromises, with almost every major incident in the past 18 months exploiting features working exactly as designed.
Deep dive
- The pull_request_target trigger runs in the base repo's context with full secret access and write tokens, but can execute code from untrusted forks—combining it with fork checkouts handed attackers credentials in spotbugs, Ultralytics, nx, prt-scan, and Trivy incidents
- Action version references are mutable git tags in external repos that can be force-pushed by anyone with write access, demonstrated when tj-actions compromise affected 23,000 downstream repos through tag hijacking
- GitHub's runner resolves action references against the entire fork network object pool, meaning SHA commits that exist only in attacker forks and never reached upstream branches execute as if maintainers approved them
- Cache poisoning crosses trust boundaries silently with no UI indication that an entry was written by an untrusted job, used in Ultralytics attack where poisoned cache from fork PR later executed during legitimate release workflow
- Template expansion with $ syntax performs textual substitution before the shell sees the script, turning PR titles and issue comments into executable code when interpolated into run: steps, exploited in nx and elementary-data attacks
- The elementary-data incident went from GitHub comment to malicious PyPI package in 10 minutes through issue_comment trigger with default write token, using no PR approval or maintainer interaction
- GITHUB_TOKEN defaults to write permissions on repos created before February 2023, and workflows get this by default unless explicitly setting permissions: block
- The nx/s1ngularity attack injected commands through PR titles that harvested AI coding assistant credentials, using them to enumerate and exfiltrate over 5,000 private repositories
- PyPI, npm, RubyGems and crates.io have adopted GitHub Actions OIDC as their primary publishing mechanism, concentrating trust that was previously distributed across thousands of maintainer credentials onto one CI platform
- Statistics show 91% of PyPI packages using third-party actions reference at least one by mutable tag, and two-thirds have no permissions block on at least one workflow
- GitHub's roadmap includes workflow lockfiles, policy controls, scoped secrets and egress firewalls, but everything is opt-in and months away, with no plans to change defaults due to breaking existing workflows
- The author argues public repos building packages for millions of downstream users warrant different risk calculus than private enterprise CI, justifying breaking changes that would prevent attacks
- zizmor audit tool catches most of these patterns (dangerous-triggers, cache-poisoning, unpinned-uses, template-injection, excessive-permissions) and flagged elementary-data three weeks before compromise
- Suggested breaking changes include read-only tokens for all public repos, refusing to expand github.event inside run steps, refusing cache restores in pull_request_target jobs, and requiring immutable references for workflows requesting id-token: write
- The prt-scan campaign automated the attack pattern, opening hundreds of PRs with plausible-looking generated diffs across repositories with pull_request_target misconfigurations over six weeks
Decoder
- pull_request_target: A GitHub Actions workflow trigger that runs in the context of the base repository (not the fork) with access to secrets and write tokens, designed for workflows that label or process PRs from forks
- OIDC trusted publishing: Authentication method where package registries verify the identity of the publishing CI system through OpenID Connect tokens rather than requiring long-lived API credentials stored as secrets
- id-token: write: A GitHub Actions permission that allows a workflow to request OIDC tokens, which package registries use to verify the workflow is authorized to publish packages
- Mutable tags: Git tags that can be moved to point at different commits, unlike SHA commit hashes which are immutable references to specific code snapshots
- Cache poisoning: Attack where untrusted code writes malicious content into a shared cache that is later restored and executed by a trusted workflow
- Template expansion: GitHub Actions' $ syntax that substitutes values into strings before passing them to the shell, without automatic escaping or quoting
- GITHUB_TOKEN: An automatically-generated authentication token that GitHub provides to workflows, with permissions defaulting to write access on older repositories
- Imposter commits: Commits that exist in a fork's object store but never reached any branch in the upstream repository, yet are executable through the parent repo's namespace
- zizmor: Third-party security linter for GitHub Actions workflows that detects common dangerous patterns and misconfigurations
Original article
Almost every open source supply chain incident from the past eighteen months involves GitHub Actions features behaving exactly as documented. Actions is basically a package manager with no lockfile, no integrity hashes, and no transitive visibility. The whole product is a collection of features that are convenient, but very easy to assemble into something dangerous. GitHub plans to add fixes, but the company says that changing the defaults will break existing workflows.
Warp (GitHub Repo)
Warp terminal has gone open-source with OpenAI funding and repositioned itself as an agentic development environment where AI agents autonomously triage issues, write code, and review pull requests.
Decoder
- Agentic development environment: A coding workspace where AI agents can autonomously perform development tasks like writing code, triaging issues, and reviewing pull requests
- Oz agents: The specific AI agents used in Warp's system for automated development workflows
- AGPL v3: GNU Affero General Public License version 3, a copyleft license requiring source code distribution even for network-accessible software
Original article
OpenAI is the founding sponsor of the new, open-source Warp repository, and the new agentic management workflows are powered by GPT models.
About
Warp is an agentic development environment, born out of the terminal. Use Warp's built-in coding agent, or bring your own CLI agent (Claude Code, Codex, Gemini CLI, and others).
Installation
You can download Warp and read our docs for platform-specific instructions.
Warp Contributions Overview Dashboard
Explore build.warp.dev to:
- Watch thousands of Oz agents triage issues, write specs, implement changes, and review PRs
- View top contributors and in-flight features
- Track your own issues with GitHub sign-in
- Click into active agent sessions in a web-compiled Warp terminal
Licensing
Warp's UI framework (the warpui_core and warpui crates) are licensed under the MIT license.
The rest of the code in this repository is licensed under the AGPL v3.
Open Source & Contributing
Warp's client codebase is open source and lives in this repository. We welcome community contributions and have designed a lightweight workflow to help new contributors get started. For the full contribution flow, read our CONTRIBUTING.md guide.
Chat with contributors and the Warp team in the #oss-contributors Slack channel — a good place for ad-hoc questions, design discussion, and pairing with maintainers. New here? Join the Warp Slack community first, then jump into #oss-contributors.
Issue to PR
Before filing, search existing issues for your bug or feature request. If nothing exists, file an issue using our templates. Security vulnerabilities should be reported privately as described in CONTRIBUTING.md.
Once filed, a Warp maintainer reviews the issue and may apply a readiness label: ready-to-spec signals the design is open for contributors to spec out, and ready-to-implement signals the design is settled and code PRs are welcome. Anyone can pick up a labeled issue — mention @oss-maintainers on an issue if you'd like it considered for a readiness label.
Building the Repo Locally
To build and run Warp from source:
./script/bootstrap # platform-specific setup
./script/run # build and run Warp
./script/presubmit # fmt, clippy, and testsSee WARP.md for the full engineering guide, including coding style, testing, and platform-specific notes.
Joining the Team
Interested in joining the team? See our open roles.
Support and Questions
- See our docs for a comprehensive guide to Warp's features.
- Join our Slack Community to connect with other users and get help from the Warp team — contributors hang out in
#oss-contributors. - Try our Preview build to test the latest experimental features.
- Mention @oss-maintainers on any issue to escalate to the team — for example, if you encounter problems with the automated agents.
Code of Conduct
We ask everyone to be respectful and empathetic. Warp follows the Code of Conduct. To report violations, email warp-coc at warp.dev.
Open Source Dependencies
We'd like to call out a few of the open source dependencies that have helped Warp to get off the ground:

AI rewards strict APIs
Strict, typed APIs give AI coding agents tight feedback loops that reduce debugging time and token costs compared to loose, magic-string-based systems.
Deep dive
- AI agents excel at handling complexity but fail when APIs provide ambiguous feedback, creating silent failures that require trial-and-error debugging
- Magic-string hooks like
mymodule_user_loginin Drupal or string-basedadd_action()in WordPress fail silently when misspelled, with no errors or warnings in logs - Loose APIs shift costs from upfront boilerplate to later debugging, a trade-off that made sense for human developers but backfires with AI agents
- Drupal 8 (2015) introduced Symfony's strict routing and service containers, breaking backward compatibility but establishing typed interfaces that static analyzers and IDEs can validate
- Drupal 11.1 added attribute-based hooks like
#[Hook('user_login')]on registered services, making bindings explicit and type-checkable instead of convention-based - Multi-year YAML validation efforts catch missing keys, invalid values, and broken references before save time, giving agents precise error messages pointing to exact fields
- At DrupalCon Chicago March 2026, AI coding tools successfully migrated a Lovable-generated site into Drupal in hours by following the strict API chains
- WordPress chose backward compatibility over API strictness, maintaining platform stability but preserving looseness that now increases AI debugging costs
- The feedback loop quality directly impacts token consumption: precise errors mean fewer retries, less guessing, and lower costs per task
- What was previously a stylistic debate (strict vs. loose APIs) is now a quantifiable speed and cost difference measurable in tokens and development time
- Platforms that invested in strictness before AI agents existed now have an unexpected competitive advantage in the AI-assisted development era
Decoder
- Magic-string hooks: Function naming conventions where the system matches functions to events by parsing string names, with no compile-time validation
- Service containers: Dependency injection systems that manage object creation and wiring, enabling type-checked connections between components
- Static analyzers: Tools like PHPStan that examine code without running it to detect type errors, undefined variables, and other bugs
- Attributes: Modern PHP syntax (like
#[Hook()]) that attaches metadata to classes and methods, making conventions machine-readable and enforceable - Tight feedback loop: The time between writing code and receiving precise error information, critical for both human and AI debugging efficiency
Original article
AI agents don't struggle with complexity. They struggle with ambiguity. Strict APIs are now an important advantage.
Every framework's API surface sits on a spectrum, from strict (typed interfaces, schemas, service containers) to loose (string keys, naming conventions, untyped hooks). Strict APIs cost more upfront: more boilerplate, more to learn before writing code. Loose APIs shift that cost later: more ambiguity, more reliance on naming conventions, and more bugs that are harder to detect and fix.
AI changes who pays. Boilerplate and learning curves don't slow agents down. What slows them down is missing feedback: code that runs but does the wrong thing, errors that don't point to the cause, conventions that have to be guessed. Magic-name binding, untyped hooks, unvalidated configuration, and conventions the code doesn't enforce produce exactly those failure modes.
Magic strings break the loop
For example, both Drupal and WordPress have long used magic-string hooks. In Drupal, you write a function like mymodule_user_login. WordPress uses a related pattern: a string action name passed to add_action(). In both cases, the binding is a string the language can't validate.
Get the name wrong and the system silently skips your code: no error, no warning, nothing in the logs. The function just sits there, unloved.
The signature is a convention, not a contract: the documentation says the user_login hook receives a $user object, but nothing enforces it. To your IDE or a static analyzer like PHPStan, it's just a function. They don't know it's wired into the platform's login flow, so they can't warn you when it's wrong.
A typed alternative makes the binding explicit. With a PHP attribute like #[Hook('user_login')] on a registered service, the class must exist, the method signature is type-checked, and the container wires the dependencies. IDEs, static analyzers, and AI coding agents can follow the chain from the attribute to the implementation.
For AI agents, this keeps the feedback loop tight instead of turning it into trial and error. That means they can move faster, spend less time debugging, and use fewer tokens.
At DrupalCon Chicago this March, AI coding tools migrated a Lovable-generated site into Drupal in hours. The strict APIs kept the agent on track.
A bet made before AI existed
This didn't start with AI. Drupal 8, which we shipped in 2015, introduced Symfony's routing, services, and event dispatcher, replacing large parts of the procedural hook system. Since then, we've kept reducing magic hooks. The attribute-based approach (#[Hook('user_login')]) landed in Drupal 11.1 and helps remove more of the remaining procedural-only paths.
Hooks aren't the only place Drupal has been getting stricter. Drupal stores a lot of configuration in YAML, which was one of the loosest parts of the system. A multi-year validation effort has been tightening that.
When an agent generates a content type definition or editor configuration, validation catches missing keys, invalid values, and broken references before anything is saved. The agent gets a precise error pointing to the exact field, instead of a runtime failure. That tight feedback loop is what makes Drupal a strong CMS for AI-assisted development.
Drupal made this bet early, and it was painful. The Drupal 7 to Drupal 8 transition broke backward compatibility and took years to recover from. But it left the platform much stricter. More than ten years in, we're still making Drupal stricter.
Meanwhile, WordPress made a different bet, prioritizing backward compatibility over stricter APIs. That kept the platform stable for a long time. It also kept the looseness.
Those trade-offs now determine how efficiently AI agents can work with each platform.
What was style is now speed
What used to be a stylistic choice is now a speed and cost problem. Loose APIs mean more debugging and guesswork. Strict APIs mean faster, more precise feedback. This was always true for humans. It's now also true for AI agents. But today that cost shows up in tokens.

Kubernetes v1.36: Mutable Pod Resources for Suspended Jobs (beta)
Kubernetes v1.36 now lets you modify CPU, memory, and GPU resource requests on suspended Jobs without deleting them, enabling smarter resource allocation for batch and ML workloads.
Deep dive
- The feature, first introduced as alpha in v1.35, is now enabled by default in v1.36 via the MutablePodResourcesForSuspendedJobs feature gate
- You can modify resource requests and limits for containers and init containers while a Job has spec.suspend set to true
- For Jobs that were running then suspended, all active Pods must terminate (status.active equals 0) before resource changes are accepted to prevent inconsistency
- The use case focuses on queue controllers like Kueue that manage cluster resources and need to adjust Job allocations based on current availability
- Example scenario: a training Job initially requesting 4 GPUs can be scaled down to 2 GPUs if that's what the cluster can provide, rather than being deleted
- Also useful for CronJobs to run with reduced resources during cluster load instead of failing outright
- No new API types were introduced—existing Job and pod template structures handle this through relaxed validation rules
- Standard resource validation still applies (limits must be greater than or equal to requests, extended resources must be whole numbers)
- When using with Jobs that may have failed Pods, consider setting podReplacementPolicy: Failed to prevent resource contention
- Dynamic Resource Allocation (DRA) resourceClaimTemplates remain immutable and must be recreated separately if using DRA workloads
Decoder
- Suspended Job: A Kubernetes Job with spec.suspend set to true, meaning it won't create Pods until resumed
- Pod template: The specification within a Job that defines how Pods should be created, including container images and resource requirements
- Resource requests/limits: CPU, memory, and GPU specifications that define minimum guaranteed resources (requests) and maximum allowed resources (limits) for containers
- Queue controller: Software like Kueue that manages job queuing and resource allocation across a Kubernetes cluster based on priorities and availability
- DRA (Dynamic Resource Allocation): A Kubernetes mechanism for managing specialized hardware resources beyond standard CPU and memory
Original article
Kubernetes v1.36 promoted to beta the ability to modify CPU, memory, GPU, and other resource requests in suspended Jobs' pod templates, eliminating the need to delete and recreate Jobs when resource requirements change. The feature, enabled by default, lets queue controllers and administrators adjust resources before Jobs start running. It is particularly useful for batch and machine learning workloads where optimal allocation depends on current cluster conditions.
The Autonomy Problem: Why AI Agents Demand a New Security Playbook
AI agents that autonomously write code and execute tasks introduce security risks like prompt injection and privilege escalation that traditional security models weren't designed to address, prompting NIST to study mitigation strategies.
Deep dive
- AI agents are expanding beyond development tasks to business operations like travel booking and procurement, using user credentials to execute autonomous actions that NIST warns could impact public safety if security risks go unchecked
- Prompt injection represents one of the biggest risks because LLMs are non-deterministic, meaning the same attack may succeed in one attempt and fail in another, making remediation difficult to validate
- The "lethal trifecta" describes the most dangerous combination of agent capabilities: access to private data, ability to process untrusted content, and permission to communicate externally
- Agents can perform privilege escalation when operating with broad permissions that exceed what the initiating user actually authorized, and cascading failures can occur when one compromised agent corrupts others in multi-agent systems
- Model-level defenses include separating system instructions from untrusted content using distinct messaging roles, randomized delimiters, and secondary classifiers that scan for injection patterns
- System-level controls require least privilege access where agents only use tools required for their specific tasks, with narrowly scoped credentials that expire quickly
- Breaking the lethal trifecta by structuring workflows with separate read-only and write-capable agents ensures no single agent can access sensitive data, process untrusted content, and communicate externally simultaneously
- Human oversight should use tiered approvals to prevent approval fatigue, allowing low-risk actions to proceed with notification while requiring explicit approval for critical operations
- All agent actions should be logged with timestamps, identifiers, tools invoked, resources accessed, and outcomes in sufficient detail to reconstruct events after incidents
- Organizations that deploy agents with proper governance will move faster and introduce fewer security errors than those without controls, making security a competitive advantage rather than just risk mitigation
Decoder
- Agentic AI: AI systems that can autonomously take actions and make decisions without human intervention for each step
- Prompt injection: An attack where malicious instructions are embedded in content the AI processes, causing it to execute unintended commands
- Lethal trifecta: The dangerous combination of an agent having access to private data, processing untrusted content, and communicating externally
- Privilege escalation: When an agent performs sensitive operations that exceed the permissions of the user who initiated the task
- Cascading failures: When one compromised agent in a multi-agent system corrupts or causes failures in other connected agents downstream
- Least privilege: Security principle where agents only receive the minimum permissions necessary to complete their specific tasks
Original article
The Autonomy Problem: Why AI Agents Demand a New Security Playbook
AI agents are transforming software development. They can autonomously read codebases, write and edit files, run tests, and fix bugs, all from a single prompt, and engineers no longer need to author those prompts manually. Soon, agents will manage everything from booking business travel to processing procurement requests, using your credentials to get it done.
The capability is significant, and so is the responsibility it carries. Agentic AI introduces distinct risks that software companies urgently need to address. The Center for AI Standards and Innovation, an arm of the National Institute of Standards and Technology (NIST), has become sufficiently concerned about agentic AI risks to begin studying how to track the development and deployment of these tools.
"AI agent systems are capable of taking autonomous actions that impact real-world systems or environments, and may be susceptible to hijacking, backdoor attacks, and other exploits," NIST notes in a document on the topic. "If left unchecked, these security risks may impact public safety, undermine consumer confidence, and curb adoption of the latest AI innovations."
Agentic AI expands and reshapes the attack surface, including agent-to-agent interactions that traditional security models were never built to detect. Agents can also chain low-severity vulnerabilities into high-severity exploits.
Security teams are already grappling with these risks, or should be. Engineering leaders eager to adopt agents should understand not only what agents can do, but what agentic capabilities mean for their organization's security posture.
Closing the gap between engineering and security teams starts with understanding AI's risks, and it enables teams to ship faster and more securely.
Why Agents Change the Threat Model
The nature of large language models creates a variety of security challenges, some entirely new, others variations on long-standing issues.
AI agents share some risks with other software, such as exploitable vulnerabilities in authentication systems or memory management. But NIST focuses on the novel, more dynamic dangers posed by machine learning models and AI agents.
Prompt-injection attacks represent one of the biggest risks of AI, and the non-deterministic nature of LLMs makes them especially difficult to defend against. The same prompt-injection attack may succeed in one attempt and fail in another, making remediation difficult to validate and comprehensive defenses challenging to implement.
Models with intentionally installed backdoors pose a particular risk, leaving critical systems exposed. Even uncompromised models could threaten the confidentiality, integrity, or availability of critical data sets.
Another challenge comes from how capabilities combine within a single agent. AI agents merge language-model reasoning with tool access, enabling them to read files, query databases, call APIs, execute code, and interact with external services. The risks stem not from any single capability but from their combination and an agent's ability to act on these capabilities autonomously. Without proper guardrails, agents can delete codebases, expose sensitive data, and trigger cascading failures that are costly and difficult to unwind. In some cases, agents can work around guardrails to complete their assigned tasks.
Agents face heightened risk when they have access to private data, encounter untrusted content, and can communicate externally. This combination presents a materially different risk profile than one lacking any of these three elements. Security researchers have described this combination as the "lethal trifecta."
Additional risks include:
- Unintended operations, where agents execute actions beyond their intended scope due to misinterpreted instructions or prompt manipulation.
- Privilege escalation, which occurs when agents operating with broad permissions perform sensitive operations that exceed what the initiating user authorized.
- Cascading failures, where one compromised agent in a multi-agent system can corrupt others downstream.
How to Engineer Against These Risks
All of these risks have concrete countermeasures. The most effective approaches layer controls at three levels.
- Model level: Maintain clear separation between system instructions and untrusted content using distinct messaging roles and randomized delimiters. Secondary classifiers add an additional layer, scanning inputs and outputs for injection patterns and anomalous formatting. These are risk-reduction measures rather than complete solutions, which is precisely why the layers below matter.
- System level: Apply least privilege across the board. Agents should only access the tools required for their tasks, with credentials narrowly scoped and set to expire quickly. Screen content entering the system for injection patterns, and check outbound content for sensitive information such as credentials or PII. Enforce default-deny network controls, limiting external communication to explicitly approved endpoints. Structure workflows to break the lethal trifecta: separating read-only and write-capable agents ensures no single agent can access sensitive data, process untrusted content, and communicate externally all at once.
- Human oversight level: Require explicit approval for critical operations while allowing lower-risk actions to proceed with notification. A tiered approach prevents approval fatigue, which can lead to oversight. Users should be able to halt execution at any time, with rollback of partially completed work where possible. When an agent acts on behalf of a user, record both identities and evaluate permissions at their intersection. Log all agent actions, timestamps, identifiers, tools invoked, resources accessed, and outcomes in sufficient detail to reconstruct events after the fact.
Governance as a Competitive Advantage
Teams can meaningfully reduce these risks through layered controls. The risks are real, but so is the opportunity, and treating one as a reason to avoid the other misses the point.
When agents work for you rather than against you, the same combination of data access, content processing, and external communication that creates risk becomes the source of value. AI agents can monitor systems, apply consistent security rules without fatigue, and build quality, secure code at a speed and scale no manual process can match. They amplify both your strengths and your weaknesses, making governance the deciding factor.
Software engineers will always be necessary, but organizations that deploy agents with proper governance and guardrails will outpace those that don't: they will move faster, remediate problems sooner, and introduce fewer security errors that degrade software quality.
The organizations that get the most from agentic AI will be those that understand the threat model clearly and build against it from the start. That foundation separates teams that deploy agents responsibly from those that learn the hard way.

How GitHub uses eBPF to improve deployment safety
GitHub uses eBPF to prevent deployment scripts from accidentally depending on GitHub's own services during outages, avoiding scenarios where recovery is blocked by the outage itself.
Deep dive
- GitHub identified circular deployment dependencies as a major risk where outages could prevent their own recovery if deployment scripts relied on unavailable services
- eBPF enables kernel-level monitoring without modifying applications, allowing GitHub to intercept network calls from deployment processes in real-time
- The solution provides per-process control, letting GitHub apply different network restrictions to specific deployment scripts based on their role
- DNS interception capability catches dependencies even when scripts use service discovery or internal DNS names rather than direct IP addresses
- Real-time auditing detects risky patterns like deployment scripts calling GitHub's own API during incident recovery, which would fail if GitHub is down
- The system can detect three types of problematic dependencies: hidden (undocumented calls), direct (known but risky), and transient (indirect through libraries or tools)
- This approach allows GitHub to enforce deployment hygiene automatically rather than relying solely on code reviews and documentation
Decoder
- eBPF (extended Berkeley Packet Filter): A Linux kernel technology that allows running sandboxed programs to monitor or modify system behavior without changing kernel code or loading modules
- Circular dependency: A scenario where system A needs system B to recover, but system B depends on system A being healthy, creating an unresolvable deadlock during outages
Original article
GitHub mitigates circular deployment dependencies, where outages could block their own recovery, by using eBPF to monitor and restrict deployment scripts' network access and detect hidden, direct, and transient dependencies. This enables per-process control, DNS interception, and real-time auditing of risky calls like GitHub API usage during incident recovery.

Lovable launches its vibe-coding app on iOS and Android
Lovable launched a mobile app for iOS and Android that lets users build websites through AI voice or text prompts, navigating Apple's recent restrictions on vibe-coding apps by previewing generated code in browsers instead of in-app.
Decoder
- Vibe-coding: Building software through conversational AI prompts rather than writing traditional code, often marketed as "no-code" or "low-code" development
- App Store guidelines violation: Apple prohibits apps from downloading and executing code that wasn't part of the original app review, as it creates security risks and circumvents their vetting process
Original article
Apple's recent crackdown on vibe-coding apps hasn't held up Lovable's launch of its no-code AI app builder, which is now available as a mobile app on Apple's and Google's app stores.
The vibe-coding startup's new mobile app is being pitched to would-be app builders as a way to code on the go via voice or text AI prompts that let you capture your ideas as they pop into your head. That means you can kick off Lovable to work on your random app idea from anywhere, letting its agent run autonomously after receiving your input.
The new app will also allow you to switch back and forth between your computer and phone to pick up where you left off on a given project and receive notifications when a build is ready for review.
The app's arrival comes shortly after Apple addressed what vibe-coding apps can and can't do on its App Store. The tech giant recently blocked updates to popular vibe-coding tools, including Replit and Vibecode, for violations of its developer guidelines.
Simply put, Apple wasn't banning vibe-coding apps themselves, but it won't allow apps that download new code or change their functionality, as that presents a security risk to end users. (It also means that Apple's App Review team can't properly vet the app during the approval process.)
Apple also temporarily removed the vibe-coding app Anything from the App Store for similar reasons, but the app returned after making changes earlier this month.
To comply with Apple's rules, the vibe-coding apps are no longer able to run their generated apps inside the host app. Instead, those app previews were moved to web browsers.
Lovable has also seemingly complied with these rules as its new app touts the ability to turn ideas into "working websites or web apps."
Design Terminal UIs (Website)
TUIStudio brings Figma-style visual editing to terminal user interfaces, letting developers design CLI apps with drag-and-drop components instead of hand-coding ANSI layouts.
Decoder
- TUI (Text User Interface): Interactive terminal applications built with characters and ANSI codes rather than graphical windows, like htop or lazygit
- ANSI escape codes: Special character sequences that control terminal colors, cursor positioning, and text formatting
- Ink: React-based framework for building terminal UIs with TypeScript/JavaScript
- BubbleTea: Go framework using Elm architecture for terminal applications
- Blessed: Node.js library for building terminal interfaces
- Textual: Modern Python framework for creating TUIs with rich widgets
- Tview: Go library providing terminal UI widgets and layouts
Original article
TUIStudio is a Figma-like visual editor for designing terminal user interfaces (TUIs) with drag-and-drop components and real-time ANSI preview.

How to Make a Custom Favicon for Your Brand Website
This comprehensive guide explains how to design effective favicons for websites, covering technical requirements, design principles, and cross-platform compatibility.
Decoder
- Favicon: A small square icon (16×16 to 512×512 pixels) representing a website in browser tabs, bookmarks, and mobile interfaces
- PWA (Progressive Web App): Web applications that can be installed on devices like native apps, where favicons serve as the app icon
- ICO format: Traditional favicon format supporting multiple sizes in one file with broad browser compatibility
- SVG (Scalable Vector Graphics): Vector-based image format that scales without quality loss, ideal for high-resolution displays
- Apple Touch Icon: Larger favicon variant (180×180 pixels) used when websites are added to iOS home screens
Original article
A well-designed favicon increases credibility, improves user experience by helping visitors navigate multiple tabs, and maintains brand consistency across digital platforms.

DOJ Confirms 'Code Is Not a Crime'
The DOJ announces it will no longer prosecute blockchain developers for crimes committed by users of their software, reversing the enforcement stance that led to the Tornado Cash prosecutions, though legal ambiguity remains.
Deep dive
- The DOJ announced it will no longer prosecute blockchain developers solely for crimes committed by third-party users of their software, marking a fundamental shift in enforcement policy
- Acting AG Todd Blanche stated that developers who aren't the third-party users and aren't "knowingly helping" criminals won't be investigated or charged
- This policy directly reverses the approach that led to the prosecution of Tornado Cash developers Roman Storm (convicted August 2025) and Roman Semenov (indicted August 2023)
- Tornado Cash, a crypto mixer used for money laundering and sanctions evasion, was sanctioned by OFAC in August 2022 before sanctions were lifted in November 2024
- The announcement follows an April 2025 DOJ memo outlining commitment to "ending regulation by prosecution" of developers
- Coin Center's Peter Van Valkenburgh cautiously welcomed the message but highlighted critical ambiguity about what constitutes "helping" or "knowing" about bad users
- A recent case involving developer Michael Lewellen, who sued for pre-enforcement clarity on his Ethereum crowdfunding tool, was dismissed in late March
- The dismissal creates a paradox: DOJ tells courts there's no credible threat to developers while developers remain fearful, and DOJ fights against requests for legal clarity
- Legal observers note the "knowingly helping" standard remains undefined, leaving significant uncertainty about prosecutorial discretion boundaries
- The policy shift represents the Trump administration's approach to crypto enforcement, with Blanche stating he doesn't want the DOJ to be seen as "causing problems" for platforms
Decoder
- Tornado Cash: A cryptocurrency mixer and privacy protocol that obscures transaction trails by pooling funds from multiple users before redistributing them
- OFAC: Office of Foreign Assets Control, a US Treasury department that administers and enforces economic sanctions
- Crypto mixer: Software that combines cryptocurrency from multiple sources to obscure the origin and destination of transactions
- Noncustodial software: Cryptocurrency applications where users maintain control of their private keys and funds, rather than the platform holding custody
- Money transmission: The business of transferring funds, which requires licenses and regulatory compliance in the US
- Pre-enforcement clarity: Legal guidance sought before taking action to determine if that action would violate laws
Original article
The DOJ will no longer investigate or charge blockchain developers for crimes committed by third parties using their software, provided the developer had no knowing involvement in those crimes. The new policy directly reverses the enforcement posture that produced Roman Storm's conviction in August 2025 and Roman Semenov's 2023 indictment over Tornado Cash. Crypto legal observers flag that the "knowingly helping" standard remains undefined, leaving open questions about where prosecutorial discretion ends and protected open-source development begins.

Long-running Agents
Long-running AI agents can work autonomously for hours or days across multiple sessions by solving persistence, recovery, and verification problems that plague single-session chatbot agents.
Deep dive
- METR's time horizon metric shows frontier models doubling their task completion time roughly every seven months since 2019, with projections suggesting day-scale tasks by 2028 and year-scale by 2034 if the curve holds
- Three fundamental problems plague traditional agents: finite context windows that fill up, no persistent state across sessions (like engineers working shifts with no handoff notes), and unreliable self-verification where models grade their own work too generously
- The Ralph loop pattern uses a simple bash script that cycles through tasks in a JSON file, calls the agent, runs tests, appends to progress.txt, and updates the task list—state lives in the filesystem while the agent remains amnesiac
- Anthropic's architecture decouples the Brain (model and harness loop), Hands (sandboxed execution environments), and Session (append-only event log), allowing independent replacement and reducing time-to-first-token by 60% at median and 90%+ at p95
- Cursor discovered that flat coordination models and optimistic concurrency both failed, landing on specialized roles: Planners that explore and emit tasks, Workers that execute without coordination, and Judges that decide when iterations finish
- Different models excel in different roles—Cursor reports GPT performed better than Opus for extended autonomous work specifically because Opus tended to stop early and take shortcuts
- Google's Agent Platform bundles Runtime (days-long execution with sub-second cold starts), Sessions (durable conversation history), Memory Bank (persistent cross-session memory), and enterprise features like identity, audit logs, and policy enforcement
- Five production patterns emerge: checkpoint-and-resume to survive failures, delegated approval that pauses with full state intact, memory-layered context that needs governance like microservices, ambient processing for event-driven work, and fleet orchestration for specialist coordination
- Anthropic's scientific computing case study had Claude Opus 4.6 build a Boltzmann solver over several days achieving sub-percent agreement with reference implementations, compressing months-to-years of researcher time
- The hardest unsolved problems are cost control (24-hour frontier model runs can burn through weekly budgets), security (large attack surface with API keys and shell access), alignment drift across many context windows, and verification (auditing 24 hours of autonomous activity)
- The skill appreciating in value is not writing code but writing specifications crisp enough that an agent can execute autonomously for extended periods
- All three major implementations converge on the same architecture: separate planning/generation/evaluation, durable session logs as event streams, memory as a managed queryable service, and structured handoffs between sessions that work like human engineer onboarding
- Context compaction through summarization proves insufficient for very long jobs—full context resets using structured handoff files become necessary, essentially replicating how humans onboard new team members
- The Ralph loop's effectiveness comes from the same principle as all harnesses: state persistence outside the agent's context in files like prd.json (plan), progress.txt (lab notes), and AGENTS.md (evolving rulebook)
Decoder
- Context window: The amount of text (measured in tokens) an AI model can process at once—even million-token windows fill up during long runs
- Context rot: Progressive degradation of model performance as the context window fills, occurring well before hitting hard token limits
- Harness: The wrapper code around an AI model that handles tool calls, state management, and orchestration—essentially the infrastructure that makes a model into an agent
- Ralph loop: A simple bash-script pattern for long-running agents that cycles through tasks, calls the model, runs tests, saves progress to files, and repeats
- Brain/hands/session split: Anthropic's architecture separating the model and reasoning loop (brain), sandboxed execution environments (hands), and durable event logs (session) into independently replaceable components
- Test ratchet: A rule preventing agents from deleting or editing tests to make them pass, addressing a common failure mode where agents "fix" test failures by removing the tests
- Memory Bank: Persistent long-term storage layer that curates memories from agent sessions, making them searchable across future invocations
- ADK (Agent Development Kit): Google's code-first development toolkit for building agents on their platform
- Worktree: Git feature allowing multiple working directories for the same repository, useful for running long tasks without blocking the main workspace
Original article
A long-running AI agent can keep making progress over hours, days, or weeks. It can do this across many context windows and sandboxes, recover from failure, leave structured artifacts behind, and resume where it left off.
For two years the dominant image of an "AI agent" has been a chat window with a clever loop in it. You type a goal, the agent calls some tools, you watch tokens stream by, you stop watching when the work runs out of patience or the context window fills up. That paradigm got us a long way, but it has a ceiling. The model forgets. It declares "task complete" when it isn't. It re-introduces a bug it fixed nine turns ago. The whole thing is structured around a single sitting.
Long-running agents are what comes next. The idea is easy to state: an agent that keeps making forward progress on a goal across many sessions and many sandboxes, possibly many days or weeks, while leaving the workspace clean enough that the next session can pick up where the last one left off. The engineering is harder. You have to solve for persistence, recovery, and verification in a way that doesn't just paper over the cracks. You have to build a state layer that lives outside the model's context window, and you have to design the handoff between sessions so the agent doesn't lose its mind when it wakes up and finds itself in a different sandbox with a different context window.
This post is my attempt to lay out what's changed, who's pushing on it, and how an engineer can use long-running agents today without writing the whole thing from scratch.
What "long-running" actually means
"Long-running" gets used to mean at least three different things in practice, and it helps to keep them separate.
Long-horizon reasoning. The agent has to plan and execute over many dependent steps. This is mostly a model-quality story: coherence, planning, the ability to recover from a wrong turn ten steps ago. METR has been tracking this with their time horizon metric, which estimates how long a task a frontier model can complete with 50% reliability. The headline finding is that the metric has been doubling roughly every seven months since 2019, and their TH1.1 update earlier this year doubled the count of 8-hour-plus tasks in the eval set. If that curve holds, frontier agents complete tasks at the day scale by 2028 and the year scale by 2034.
Long-running execution. The agent's process runs for hours or days. Maybe it's a coding job, maybe it's a research sweep, maybe it's a 24/7 monitoring service. The model might be invoked thousands of times across the run. This is mostly a harness story, and it's the one this post is mostly about.
Persistent agency. The agent has an identity that outlives any single task. It accumulates memory, learns user preferences, and is always available. This is the Memory Bank flavor of long-running.
In practice the three blur together. A real production agent does long-horizon reasoning inside a long-running execution backed by persistent agency. But the engineering problems are different in each, and so are the products that solve them.
Why this matters
There are two reasons I believe this work matters a lot right now.
The first is a phase change in what's economically feasible to delegate. An agent that runs for ten minutes can answer a question, summarize a doc, fix a small bug. An agent that runs for ten hours can own an entire feature, finish a migration that was on the backlog for six quarters, or do the kind of overnight research sweep that used to require a junior analyst. One of Anthropic's Claude Sonnet announcements put concrete numbers on this last fall: 30+ hours of autonomous coding in internal tests, including one run that produced an 11,000-line Slack-style app. That's already past the threshold where the answer to "should I delegate this?" is no longer obvious.
The second is that persistence changes what the agent is. A stateless agent answers your question and disappears. A long-running one accumulates context: which competitor moved which way last week, which test flaked twice on Tuesday, what you usually mean by "the dashboard." Anthropic's Project Vend was the most public early demonstration of this. They had a Claude instance run an actual office vending business for a month, managing inventory, setting prices, talking to suppliers. It failed in informative ways, and the second phase ran much better, but the point wasn't profitability. The point was watching what kinds of weird coherence problems show up when an agent has to maintain identity across weeks instead of turns.
Those are the same problems every team building production agents now hits.
The three walls every long-running agent hits
Three walls show up in basically every write-up I've read this year.
Finite context. Even a 1M-token window fills. And context rot, the steady degradation of model performance as the window gets full, kicks in well before the hard limit. A 24-hour run is not going to fit in any context window the field has on its roadmap. Something has to give.
No persistent state. A new session starts blank. Anthropic's framing in their scientific computing post is the cleanest version I've seen: "imagine a software project staffed by engineers working in shifts, where each new engineer arrives with no memory of what happened on the previous shift." Without an explicit persistence story, every shift change is a productivity disaster.
No self-verification. Models reliably skew positive when they grade their own work. Asked "are you done?" they answer "yes" more often than they should. Without a separate signal that the work meets a bar, you get the agent that ships at 30% complete with full confidence.
Long-running agent designs are mostly answers to these three problems. The major labs have converged on similar shapes of answer, but with very different surface area.
The Ralph loop: one of the simpler practitioner versions of long-running agents
The Ralph loop (sometimes called the Ralph Wiggum technique) is one of "simpler" practitioner version of long-running agents, popularized by Geoffrey Huntley and Ryan Carson. The reference implementation is literally a bash script that loops:
- Pick the next unfinished task from a list (
prd.jsonor equivalent). - Build a prompt with the task, the relevant context, and any persistent notes.
- Call the agent.
- Run tests or other checks.
- Append what happened to
progress.txt. - Update the task list (done, failed, blocked).
- Go back to step 1.
The reason it works is the same reason any of the harnesses below work: state lives outside the agent's context. prd.json is the plan, progress.txt is the lab notes, AGENTS.md is the rolling rulebook. The agent itself is amnesiac, but the filesystem isn't. Each iteration starts fresh and reads enough state from disk to keep going. Carson's Compound Product extends the idea by chaining multiple loops (an analysis loop that reads daily reports, a planning loop that emits a PRD, an execution loop that writes the code), which is roughly the open-source version of the planner-generator-evaluator triad Anthropic landed on independently.
I went deeper on all of this in Self-improving agents: task list structure, progress files, QA gates, monitoring, the failure modes you'll actually hit. The short version is that you can build a working long-running agent in an evening with a bash script and a JSON file. Most of what Google and Anthropic have productized is the work of making this pattern recoverable, secure, and observable at scale.
The big-lab stories below are different ways of paying for that production-readiness.
Anthropic: harnesses, then the brain/hands/session split
Anthropic has been the most public about the engineering. Two posts are worth reading end-to-end.
The first is "Effective harnesses for long-running agents", which lays out a two-agent harness for autonomous full-stack development. An initializer agent runs once at the start of a project to set up the environment, expand the prompt into a structured feature-list.json, and write an init.sh that future sessions will run on boot. A coding agent is then woken up over and over, each session asked to make incremental progress on one feature, run tests, leave a claude-progress.txt note, and commit. A test ratchet ("it is unacceptable to remove or edit tests because this could lead to missing or buggy functionality") sits in the prompt to stop the very common failure of an agent deleting failing tests to "make them pass." InfoQ's writeup extends this into a planner, generator, and evaluator triad, on the same logic that separating generation from evaluation matters because models grade their own work too generously.
The second is "Scaling Managed Agents: Decoupling the brain from the hands", the architectural post behind Claude Managed Agents (Anthropic's hosted runtime, launched in early April). The argument is that an agent has three components that should be independently replaceable. The Brain is the model and the harness loop that calls it. The Hands are sandboxed, ephemeral execution environments where tools actually run. The Session is an append-only event log of every thought, tool call, and observation.
This sounds abstract and it isn't. Anthropic's framing: "every component in a harness encodes an assumption about what the model can't do on its own." When you couple them, an assumption that goes stale (e.g., the model used to need an explicit planner and now plans natively) means the whole system has to change at once. When you decouple them, the harness becomes stateless, sandboxes become cattle, not pets, and a brain crash doesn't lose the run. A fresh container calls wake(sessionId) and reconstitutes the state from the log. They reported time-to-first-token dropped ~60% at p50 and over 90% at p95 just from being able to start inference before the sandbox is ready.
The session-as-event-log idea is the part most teams underappreciate. It is what makes a long-running agent recoverable. Without it, a container failure is a session failure and you're debugging into a stale snapshot. With it, the agent's memory is a queryable artifact that lives outside whatever process happens to be running at the moment.
For the scientific computing crowd, Anthropic's long-running Claude post reduces all of this to a simpler stack: CLAUDE.md as a living plan the agent edits as it learns, CHANGELOG.md as portable lab notes, tmux plus SLURM plus git as the execution and coordination layer, and the Ralph loop, a for loop that kicks the agent back into context whenever it claims completion and asks if it's really done. Their flagship case study is a Boltzmann solver Claude Opus 4.6 built over a few days that reached sub-percent agreement with a reference CLASS implementation. Months-to-years of researcher time, compressed.
Same patterns across all three posts: an explicit plan file, an explicit progress file, structured handoffs between sessions, separate generation from evaluation, and a loop that refuses to let the agent stop early.
Cursor: planners, workers, judges
Cursor's "Scaling long-running autonomous coding" is the other essential read this year. They walked into walls that Anthropic mostly papered over.
Their first attempt was a flat coordination model: equal-status agents writing to shared files with locks. It became a bottleneck and made the agents risk-averse, churning rather than committing. Their second attempt swapped locks for optimistic concurrency control, which removed the bottleneck but didn't fix the coordination problem. The third design is what's running in production now and what they describe as solving most of the problem:
- Planners continuously explore the codebase and emit tasks. They can recursively spawn sub-planners.
- Workers are focused executors. They don't coordinate with each other and they don't worry about the big picture.
- Judges decide when an iteration is finished and when to restart.
Two things stand out from the post. One: "a surprising amount of the system's behavior comes down to how we prompt the agents" more than the harness or the model. Two: different models slot into different roles. Their reported finding is that a GPT model was better than Opus for extended autonomous work specifically because Opus tended to stop early and take shortcuts. Same task, different role, different model. The matching is becoming part of the design surface.
This pairs with Composer 2 (their proprietary frontier coding model that ships in Cursor 3) and their background cloud agents: long-running tasks that run on Anysphere's cloud infrastructure rather than your laptop. Eight-hour refactors and codebase-wide migrations survive a closed lid. You can start a task locally, hit run in cloud when you realize it'll take 30 minutes, and re-attach later from your phone. Each agent runs in an isolated git worktree and merges back via PR. The handoff between local and remote is the part most teams haven't figured out yet, and Cursor's bet is that it has to be its own product surface.
The shape ends up close to Anthropic's: roles are split, sessions are durable, judges sit beside the worker, and a long task runs in a cloud sandbox with git as the coordination substrate.
Google: long-running agents on the Agent Platform
Google's announcement at Cloud Next '26 two weeks ago folded Vertex AI into the Gemini Enterprise Agent Platform and turned long-running agents into a named product, with named SLAs.
The pieces that matter for this post:
- Agent Runtime supports agents that "run autonomously for days at a time" with sub-second cold starts and on-demand sandbox provisioning. The launch post's example use case is a sales prospecting sequence that takes a week to play out, which is roughly the right shape for it.
- Agent Sessions persist conversation and event history. You can pin them to a custom session ID that maps to your own CRM or DB record, so the agent's state lives next to the business state instead of in a separate AI silo.
- Agent Memory Bank is the persistent long-term memory layer, generally available as of Next '26. It curates memories from sessions, scopes them to a user identity, and exposes a search API so the next agent invocation can pull what's relevant. Payhawk reported that auto-submitting expenses through a Memory-Bank-backed agent cut submission time by over 50%.
- Agent Sandbox handles hardened code execution.
- Agent-to-Agent Orchestration, Agent Registry, Agent Identity, Agent Gateway, Agent Observability, and Agent Simulation cover basically every operational concern you'd otherwise build by hand for a production fleet, including the cryptographic-identity-and-audit-log story enterprises actually need to ship.
Architecturally this is the same brain/hands/session split Anthropic described, just productized at platform scale and bundled with ADK (the code-first dev kit) and Agent Studio (the visual one). If you're building inside Google Cloud, you don't have to design a session log or a memory store from scratch anymore. You wire an ADK agent into Memory Bank and Sessions, deploy onto Agent Runtime, and the persistence question is answered.
Notice how much this looks like the pattern Anthropic and Cursor describe, just unbundled into named services with SLAs. Three years ago you'd have built all of this yourself. Now you pick which version of "decoupled brain, hands, and session" you want to rent.
Five patterns for long-running agents in production
Shubham Saboo and I wrote up five design patterns we've seen separate working long-running agents from demos. They aren't Google-specific, but they map cleanly onto the primitives Agent Runtime now exposes, so it's worth walking through them here in shortened form.
Checkpoint-and-resume. The most common multi-day failure is context loss. An agent processes 200 documents over four hours, hits an error on document 201, and without a checkpoint you start from scratch. Treat the agent like a long-running server process: write intermediate state to disk, checkpoint every N units of work, recover from failures. The Agent Runtime sandbox gives you a persistent filesystem, but choosing the right checkpoint granularity (not every step, not only the end) is on you.
Delegated approval (human-in-the-loop). Most "human-in-the-loop" implementations are: serialize state to JSON, fire a webhook, hope someone responds. The state goes stale, the notification gets buried, the agent re-deserializes into a slightly different world. Long-running runtimes let the agent pause in place with full execution state intact: reasoning chain, working memory, tool history, pending action. Hours of human time pass, the agent consumes zero compute, and it resumes with sub-second latency. Mission Control is Google's inbox for this. The pattern works regardless of vendor.
Memory-layered context. A seven-day agent needs more than session state. Memory Bank handles long-term curated memory, Memory Profiles add low-latency lookups, and the failure mode you'll hit in production is memory drift: the agent learns a procedural shortcut from a few atypical interactions and starts applying it broadly. Govern memory like you govern microservices. Agent Identity controls who can read and write which banks. Agent Registry tracks which version of which agent is running. Agent Gateway enforces policy on the wire. The auditing question stops being "what are my agents doing?" and becomes "what are my agents remembering, and how is that changing their behavior?"
Ambient processing. Not every long-running agent talks to a human. Some sit on a Pub/Sub stream or a BigQuery table and act on events as they arrive: content moderation, anomaly detection, inbox triage. The architectural decision worth making early is to not hardcode policy into the agent. Define it in the Gateway and the fleet picks up policy changes without redeploys. Ambient agents run unsupervised for long stretches, and the only sane way to update a hundred of them is to update the policy layer once.
Fleet orchestration. In real systems, you rarely have one agent. A coordinator delegates sub-tasks to specialists (a Lead Researcher Agent, a Scoring Agent, an Outreach Agent), each running independently for different durations. Each specialist gets its own Identity (so the Outreach Agent can't read financial data meant for Scoring), its own policy enforcement, its own Registry entry. This is the same coordinator/worker shape distributed systems have used for decades. What's new is that ADK handles it declaratively with graph-based workflows, and a bad deployment in one specialist doesn't cascade to the others.
The patterns compose. A compliance system might use checkpointing for document processing, delegated approval for review gates, memory layering for cross-session knowledge, and fleet orchestration to coordinate the specialists. The opening question is always the same: what's the longest uninterrupted unit of work your agent needs to perform? Minutes, and you don't need long-running agents. Hours or days, and these patterns are where to start. The full write-up with code samples covers each pattern in depth.
So how do you actually build one today?
This is the practical question and it has a different answer depending on what you're building.
You're a developer who wants long-running coding work on your own repo. Just use Claude Code (or Antigravity, Cursor, or Codex). The harness is already there. Treat your AGENTS.md like a pilot's checklist: short, every line earned by a real failure. Add hooks for typecheck and lint that surface failures back to the agent. Write a plan file before the agent starts. Use the Ralph loop when the agent claims it's done and you don't believe it. For multi-hour or overnight jobs, run in a worktree so a closed laptop doesn't kill the run, and have it commit progress every meaningful unit of work. This is the path most people should take, and it's where the most leverage is right now.
You're building a hosted agent product. Don't build the runtime. Pick a managed one. The three real options today: Google's Agent Platform (Agent Engine + Memory Bank + Sessions), Claude Managed Agents, or roll something on top of ADK, the Claude Agent SDK, or Codex SDK and host it yourself. The trade-off is the usual one. Managed gets you the brain/hands/session split, observability, identity, and an audit trail out of the box. Self-hosted gets you control and the ability to use weird models for weird roles (Cursor's pattern). For most teams, the right starting point is a managed runtime plus your own ADK or SDK code for the actual loop.
You're doing something autonomous and operational (monitoring, research, ops). Memory Bank-style persistence is what you want, and it's the part that doesn't exist in Claude Code. ADK + Memory Bank + Cloud Run + Cloud Scheduler is the cleanest stack I've seen for "agent runs every N hours, accumulates state, alerts on a threshold." This is also where Cursor's planner/worker/judge split starts to matter more than it does for IDE coding, because the work is genuinely parallel and the failure modes are different.
A few things matter regardless of which path you take.
Write down the done-condition before the agent starts. This is the single highest-leverage move for long runs. The Anthropic harness post calls it the feature list; Cursor calls it the planner's task spec. Either way, it's an external file with explicit, testable completion criteria, and it exists so the agent can't quietly redefine done mid-run.
Separate the evaluator from the generator. Self-grading is the failure mode. A planner / worker / judge pipeline, or a generator / evaluator pair, is a real architectural pattern not a stylistic preference. Even if it's the same model in different roles with different prompts.
Invest in the session log, not just the prompt. The append-only event log is what makes the agent recoverable, debuggable, and auditable. If you can't reconstruct what the agent did in the last 24 hours from durable storage, what you have is a long-running shell script that happens to call an LLM, not a long-running agent.
Treat compaction and context resets as first-class. Anthropic is explicit that summarization-as-compaction wasn't enough for very long jobs; they had to do full context resets where the harness tears the session down and rebuilds it from a structured handoff file. It is essentially how humans onboard a new engineer.
There are some real limitations right now
A few things are still genuinely unsolved.
Cost. A 24-hour run with a frontier model and a few tools is not cheap. Without budgets, circuit breakers, and a hard cap on tool spend, an agent can quietly burn through a week's API budget in an afternoon. This is solvable, but it's an explicit step you have to take.
Security. A long-running agent with API keys, cloud access, and the ability to run shell commands has a much larger attack surface than a chat session. The brain/hands separation pattern matters here too: credentials should be unreachable from the sandbox where model-generated code runs, which is one of the benefits Anthropic calls out for Managed Agents.
Alignment drift. Over many context windows, agents drift. The original goal gets summarized, then re-summarized, then loses fidelity. This is the part hooks and judges exist to defend against. It is also the most common reason "the agent went off and did something I didn't ask for."
Verification. Auditing 24 hours of autonomous activity is a real human-time problem. Observability and structured artifacts (PRs, commits, briefings, test runs) are how you make this tractable. Without them, you're scrolling logs and you'll miss what matters.
The human role. This is the one I keep coming back to. Defining work crisply enough that an agent can run for a day on it is harder than doing the work yourself. The skill that's appreciating in value isn't writing code. It's writing specs that survive contact with an autonomous executor.
Where this is going
Google, Anthropic, and Cursor have converged on roughly the same shape. Separate the model loop from the execution sandbox from the durable session log. Split planning from generation from evaluation. Bake in compaction, hooks, and context resets. Expose memory as a managed service that any agent invocation can query.
Surface area is what differs. Google's Agent Platform is the enterprise-stack version, with the identity and audit trail story baked in. The patterns underneath are the same. Claude Managed Agents is "Anthropic's harness, hosted." Cursor's background agents are "long-running coding, pulled out of the IDE and into the cloud."
The harder problems for the next year aren't in any of those layers individually. They're in the coordination above them. Many long-running agents on a shared codebase. Agents that read their own traces and patch their own harnesses. Harnesses that assemble tools and context just-in-time for a task instead of being pre-configured at startup. That's where the agent stops looking like a smarter chat window and starts looking like a colleague who's been on the project longer than you have.
The model is still load-bearing. But the gap between a chat window and an agent you can leave running overnight is mostly in the state, sessions, and structured handoffs wrapped around it. That's where I'd spend my learning time right now.
If you want the prerequisite reading, my Agent Harness Engineering post covers the harness primitives this one builds on, and Self-improving agents goes deeper on the Ralph loop pattern.
Software Is Eating the World (But Actually This Time)
AI agents are turning work itself into software loops that can read, reason, call tools, and verify autonomously, fundamentally changing which tasks consume inference and how much.
Deep dive
- The "software ate the world" narrative from 2011 was really about software eating interfaces and distribution (apps, websites, routing systems), while humans continued doing the actual work like analyzing documents, making decisions, and handling exceptions
- AI agents now execute complete workflows as code: a customer service call becomes speech recognition → account lookup via API → policy retrieval → reasoning about eligibility → refund trigger → text-to-speech response, all in an autonomous loop
- The "token ladder" shows how agentic tasks consume vastly more inference than simple chat: basic Q&A uses ~900 tokens, retrieval uses ~7,500 tokens, agentic support uses tens of thousands, and coding agents use hundreds of thousands to millions per task
- An 8-minute support call might have only 3,000 tokens of transcript but consume 40,000+ tokens when accounting for continuous orchestration, context replay, tool outputs, and parallel models for sentiment/compliance monitoring
- A coding agent fixing a race condition might produce only 500 tokens of visible code but burn ~900,000 tokens across 30 iterations of reading context, forming hypotheses, editing, running tests, and revising—three orders of magnitude more than the output
- Workloads get "eaten" when they're essentially state transitions plus exception handling, inputs can be captured as text/voice/documents, and verification can happen digitally rather than requiring weeks of physical validation
- METR data shows autonomous task horizons doubling every 131 days since 2023: GPT-4 handled 4-minute tasks, Claude 3.5 Sonnet reached 11 minutes, Claude 3.7 Sonnet hit 1 hour, o3 reached 2 hours, GPT-5 hit 3.5 hours, and Claude Opus 4.6 pushed toward 12 hours
- Longer task horizons directly multiply inference demand because models can stay in loops longer—each additional step means more context replay, tool output processing, and reasoning, often growing faster than linearly
- This creates a version of Jevons paradox: per-token prices are rising for frontier models, but value per million tokens rises faster because models can complete in one session what previously required dozens of brittle attempts or was impossible
- Market growth reflects three compounding curves: more users, more tasks per user being routed through models, and more tokens per task as models sustain deeper workflows—OpenAI processes 15B tokens/minute (up from 6B six months prior), Google went from 9.7T to 480T tokens/month in a year
- Industries most ready for automation sit where workflows are "coding-shaped" (structured inputs, deterministic logic, digital verification) and high-volume (healthcare admin, customer support, insurance claims)
- As models commoditize, defensible applications will be those that capture operational data invisible to benchmarks: tool calls, retries, escalations, corrections, and edge cases that reveal how specific workflows actually run in production
- The strategic advantage shifts from model access to accumulated knowledge of how this specific insurer handles claims, how this hospital processes denials, how this codebase breaks—proprietary operational context that improves agent performance over time
Decoder
- METR: AI safety research org that measures how long frontier models can autonomously handle multi-step tasks, calibrated against human expert time
- Token ladder: Framework ranking tasks by inference consumption, from ~900 tokens for basic chat up to millions for deep coding workflows
- Coding-shaped workflow: Tasks with structured inputs, deterministic decision logic, and digital verification that allow agents to loop autonomously for many steps
- Task horizon: How long a model can work autonomously on a task before needing human intervention, measured in equivalent human expert time
- Agentic loop: Autonomous execution cycle where an AI agent reads context, reasons, calls tools, verifies results, and revises iteratively until completing a task
- Context replay: The process of re-feeding accumulated conversation history and state to the model at each step, which multiplies token consumption in long-running tasks
- Jevons paradox: Economic principle where efficiency gains increase total consumption—here, better models use more tokens per task but deliver more value per token
Original article
Software ate distribution, but most of the work was still done by humans. AI changes that - the work is now becoming software. Agents can read, reason, call tools, verify, revise, and perform long-running tasks. As models commoditize, the apps that capture messy operational data will be the ones to improve fastest and defend their position longest.
Ghostty Is Leaving GitHub
Mitchell Hashimoto is moving Ghostty off GitHub after 18 years on the platform due to near-daily outages that prevent him from working for hours at a time.
Deep dive
- Mitchell Hashimoto, an 18-year GitHub veteran (user #1299 since 2008), is migrating Ghostty off the platform due to reliability issues
- He tracked outages in a journal for a month and found GitHub failures impacted his work nearly every single day
- The final straw came when GitHub Actions outages prevented PR reviews for hours, making the platform unsuitable for "serious work"
- Despite his deep emotional attachment to GitHub (he started Vagrant partly hoping to get hired there), the platform's unreliability has become untenable
- He acknowledges being publicly critical and "lashing out" at GitHub, hurting feelings of people working on it, but frames it as frustration from someone who "loves GitHub more than a person should love a thing"
- The migration plan is incremental and has been in development for months, predating the major April 27, 2026 outage
- A read-only GitHub mirror will remain at the current URL to maintain discoverability
- Only Ghostty is moving for now (where the impact is greatest on maintainers and community), with personal projects staying on GitHub
- The issue isn't Git's distributed nature but the centralized infrastructure around it: issue tracking, pull requests, and CI/CD automation
- The decision represents a significant vote of no-confidence in GitHub from a high-profile developer whose career has been intertwined with the platform
Original article
GitHub outages have gotten so common that they are negatively impacting developers' ability to work.

How we built the most performant DeepSeek V3.2, MiniMax-M2.5 and Qwen 3.5 397B on DigitalOcean NVIDIA HGX™ B300 GPU Droplets
DigitalOcean achieved the fastest inference speeds for DeepSeek V3.2, MiniMax-M2.5, and Qwen 3.5 models by combining NVIDIA B300 GPUs with custom vLLM optimizations.
Deep dive
- DigitalOcean achieved 230 tokens/second on DeepSeek V3.2, 3.9x faster than AWS Bedrock (59 tok/s), and ranked as one of only three providers in the most favorable quadrant for latency vs output speed
- Performance foundation relies on NVIDIA HGX B300 GPUs with 288GB HBM3e memory (50% more than B200) and 1.5x greater NVFP4 compute power
- NVFP4 quantization reduces memory footprint by 1.8x compared to FP8 while maintaining accuracy, with dedicated hardware acceleration on Blackwell Ultra architecture
- Initial virtualized deployment had a 25% performance penalty that was resolved through direct collaboration with NVIDIA to unlock full silicon potential
- vLLM serving framework was optimized with tensor parallelism (TP4/TP8 configurations), kernel fusion to minimize memory access overhead, and programmatic dependent launch for 10% improvement in low-batch workloads
- Speculative decoding uses smaller draft models to predict token sequences validated by the target model in a single forward pass, improving DeepSeek throughput via Multi-Token Prediction heads
- For MiniMax-M2.5, trained custom EAGLE3 draft model using TorchSpec framework, achieving 23% TPOT improvement by reducing draft model tensor parallelism to minimize inter-GPU communication
- Kernel fusion and draft model training completed in collaboration with Inferact, the original creators of vLLM
- Real-world deployment at Workato achieved 77% faster TTFT, 79% lower end-to-end latency, and 67% lower inference costs compared to their previous solution
- Future roadmap includes multi-node serving with disaggregated configurations and Wide Expert Parallelism for scaling agentic workloads
Decoder
- TTFT (Time-to-First-Token): Latency between sending a request and receiving the first output token, critical for perceived responsiveness
- TPOT (Time-Per-Output-Token): Time taken to generate each subsequent token after the first, determines overall generation speed
- NVFP4: NVIDIA's 4-bit floating-point quantization format with dedicated Blackwell GPU acceleration for reduced memory usage
- vLLM: Open-source inference serving framework optimized for large language model deployment
- Tensor Parallelism: Distributing model layers across multiple GPUs to handle models exceeding single GPU memory capacity
- Kernel Fusion: Combining multiple GPU operations into a single kernel to reduce memory access and launch overhead
- Speculative Decoding: Using a small draft model to predict token sequences that a larger model validates in parallel, accelerating generation
- MTP (Multi-Token Prediction): Model architecture feature allowing prediction of multiple tokens simultaneously rather than one at a time
- EAGLE: Extrapolation Algorithm for Greater Language-model Efficiency, a speculative decoding draft model architecture
- TP4/TP8: Tensor parallelism configurations splitting work across 4 or 8 GPUs respectively
Original article
How we built the most performant DeepSeek V3.2, MiniMax-M2.5 and Qwen 3.5 397B on DigitalOcean Serverless Inference
Today at Deploy, we are announcing the general availability of DeepSeek V3.2, MiniMax-M2.5, and Qwen 3.5 397B on DigitalOcean Serverless Inference. On DeepSeek V3.2 and Qwen 3.5 397B, we deliver #1 output speed across all providers Artificial Analysis tested. On DeepSeek V3.2 specifically, that translates to 230 output tokens per second and sub-1-second Time-to-First-Token (TTFT) for 10,000 input tokens.
This post covers how we got there: the GPU-level work, the serving stack tuning, and the specific technical tradeoffs we made along the way.
Why fast inference matters
The focus in AI development has fundamentally shifted from the training of models to the efficiency of inference. This shift is driven by the proliferation of agentic workloads, copilots, and real-time systems that form the core of next-generation AI applications. For these applications, speed is no longer just a performance metric; it is the critical differentiator between an engaging product and one that users abandon. Specifically, low-latency inference is essential for a seamless end-user experience. For highly interactive applications like conversational agents and voice interfaces, any delay beyond a sub-1-second TTFT is perceived as sluggish.
The importance of fast inference is compounded by the complexity of modern AI workflows. An agentic task, for instance, often involves dozens of sequential model calls, where even minute Time-Per-Output-Token (TPOT) delays can accumulate into several seconds of user-visible latency. Quick inference also helps businesses by providing reliable performance and lower costs. Optimization in this area, such as that provided by DigitalOcean's inference engine, allows enterprises to achieve superior token economics, sustained throughput, and predictable latency, which are essential for scaling their AI-native applications reliably and affordably.
Leading the Artificial Analysis benchmarks on speed
The benchmarks we're publishing today reflect this. On DeepSeek V3.2 with 10K input tokens, we deliver:
- Output speed: 230 tok/s (3.9x AWS Bedrock at 59 tok/s)
- TTFT: 0.96s (only Google Vertex is faster among 12 providers tested)
- Balanced performance across latency and output speed: DigitalOcean is one of only three providers to be ranked in the most favorable quadrant on the Artificial Analysis Latency vs. Output Speed chart.
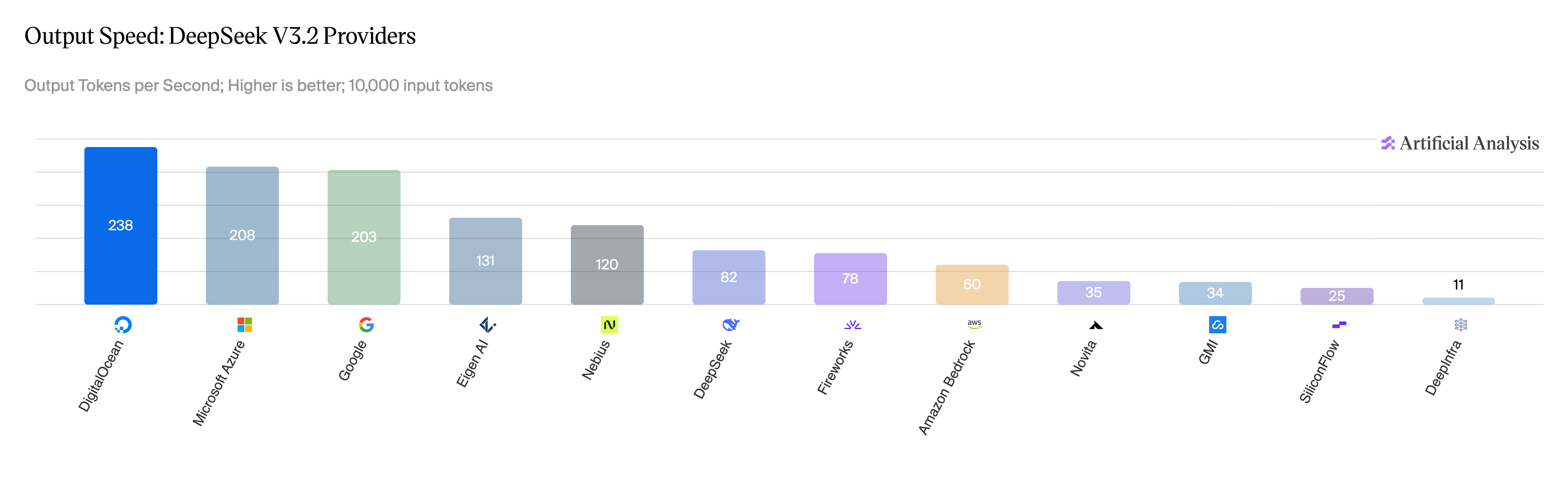
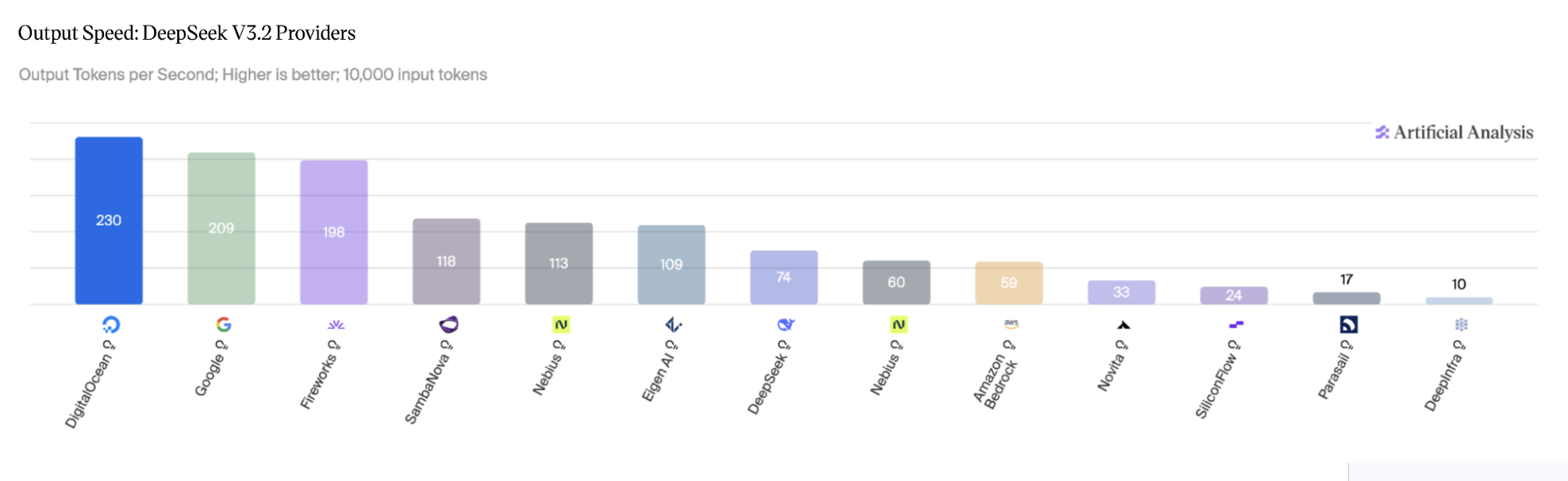
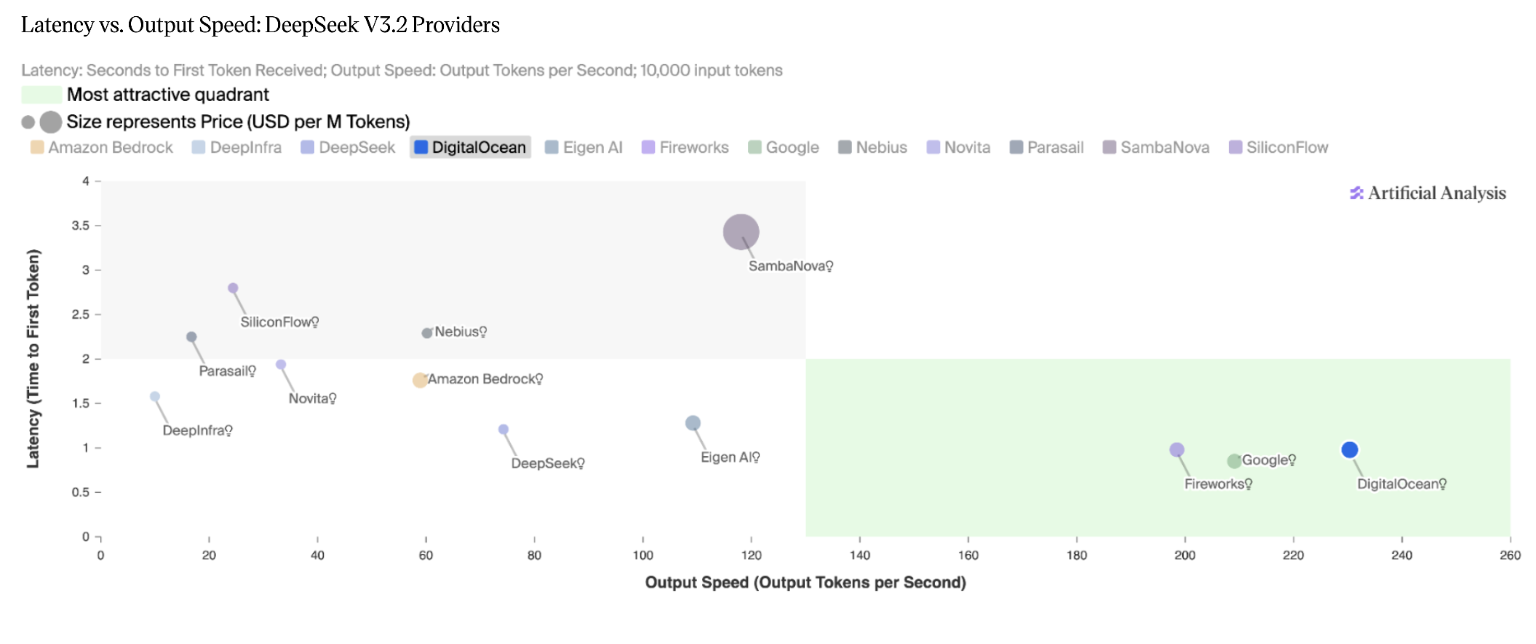
Similar performance numbers for MiniMax-M2.5 and Qwen3.5 397B:
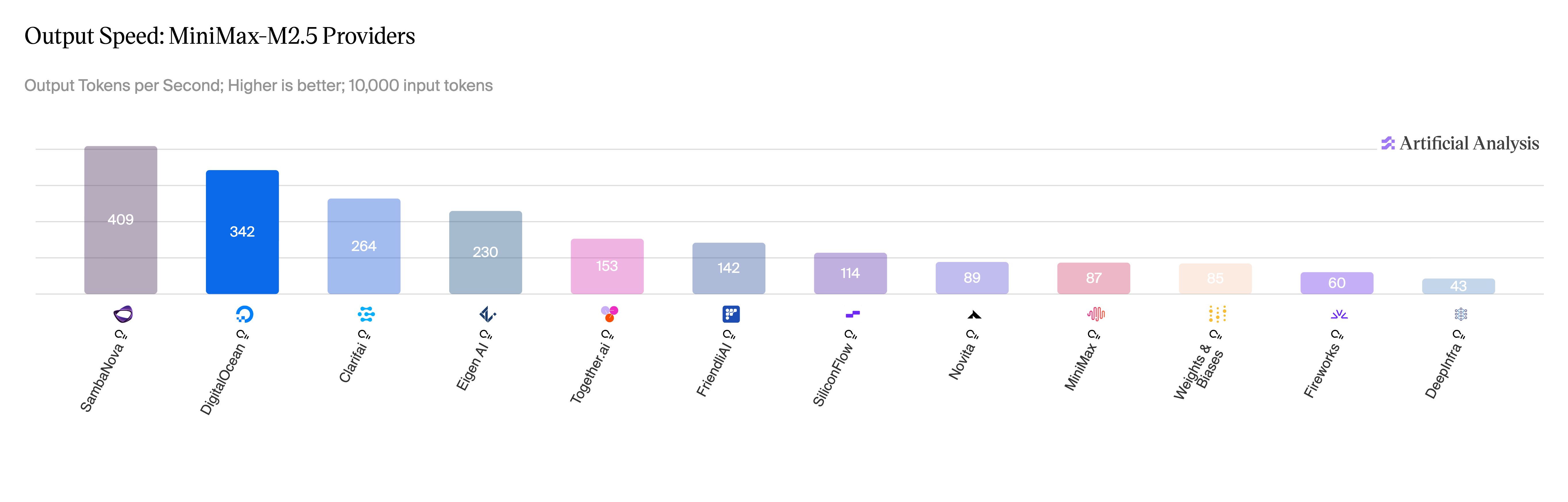
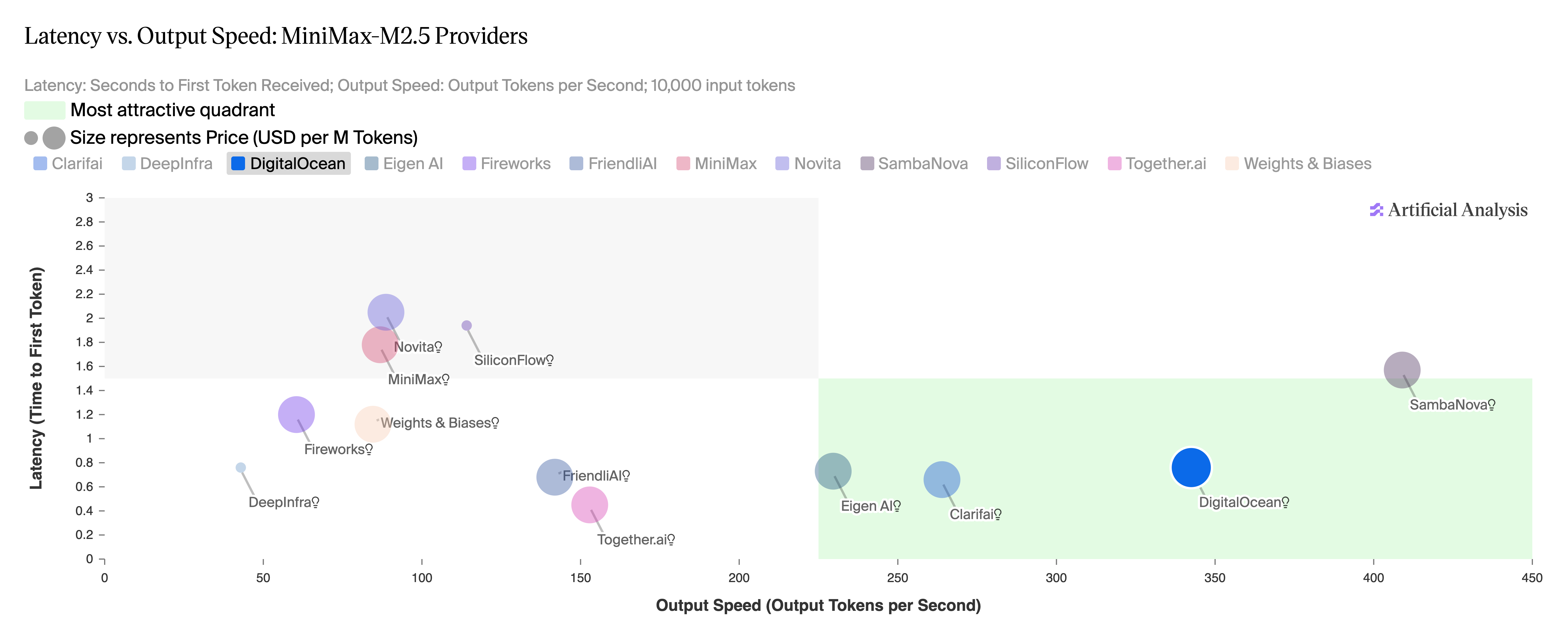
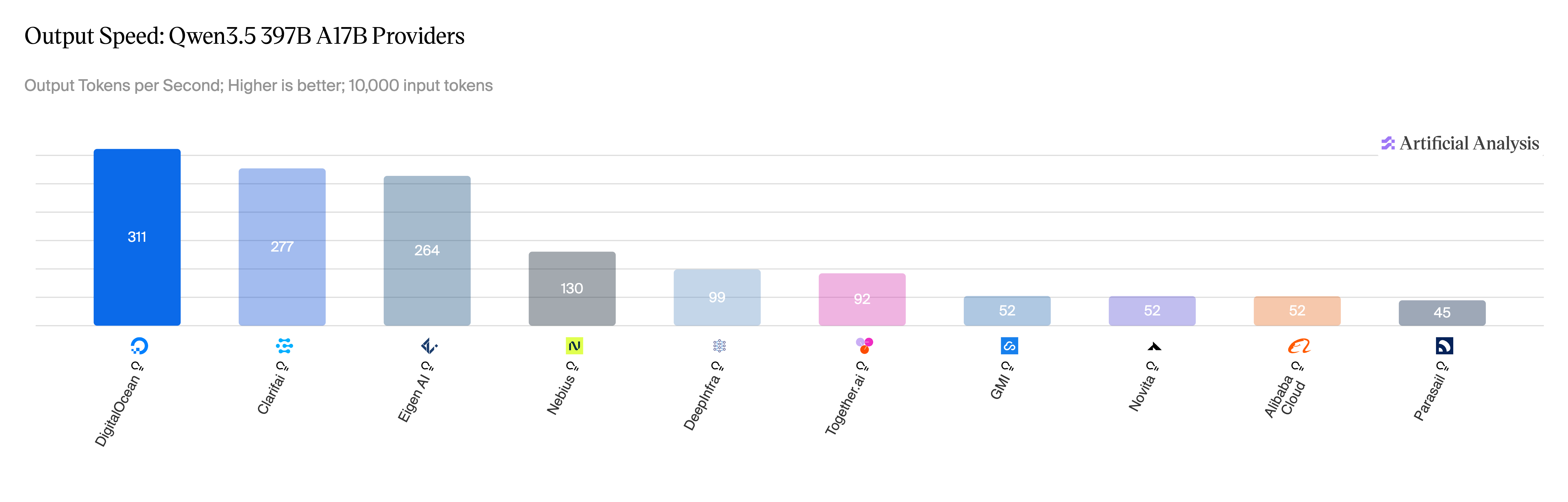
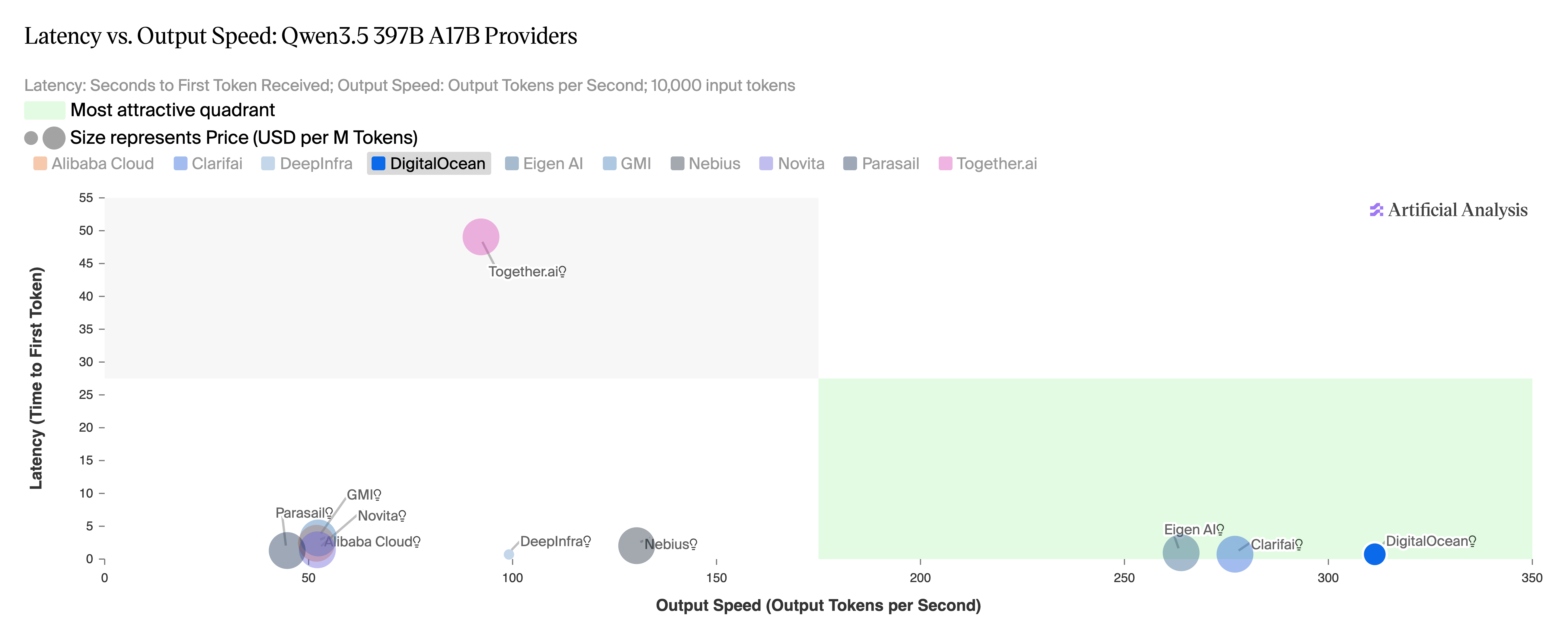
The engineering behind the numbers
Achieving this level of performance required more than just cutting-edge GPUs. Standard configurations on latest-generation hardware often fail to reach the top of the Artificial Analysis leaderboard. To achieve these results, we co-designed and optimized every layer of the stack: selecting premium GPUs, maximizing CUDA efficiency on virtualized NVIDIA Blackwell Ultra GPUs, implementing speculative decoding, and applying quantization where it offered the best balance of speed and accuracy.
Hardware: The Power of NVIDIA Blackwell Ultra
The foundation of our performance breakthrough is the NVIDIA HGX™ B300 GPU. The Blackwell Ultra architecture provides a massive leap forward, featuring 288GB of HBM3e capacity—a 50% increase over the B200—alongside 1.5x greater NVFP4 compute power. This hardware foundation was essential for handling the massive throughput requirements of DeepSeek and Qwen at scale. While early deployment in virtualized environments initially resulted in a 25% performance hit, our direct collaboration with NVIDIA enabled us to resolve these issues, unlocking the full potential of the Blackwell silicon.
Model Quantization: Efficiency of NVFP4
We used the NVFP4-quantized version of the models, which uses a specialized 4-bit floating-point format to significantly reduce the memory footprint (~1.8x compared to FP8) and increase inference throughput. These benefits are uniquely leveraged by the NVIDIA Blackwell Ultra architecture, which features 1.5x greater dedicated NVFP4 compute power, allowing for massive performance gains with minimal impact on model accuracy. Refer to the model evaluation for DeepSeek V3.2 to see NVFP4 accuracy against original FP8 model weights.
However, raw silicon and quantization are only half the story. To translate that hardware power into world-class inference speeds, we had to implement a highly customized software stack.
Inference Engine: Performance optimizations of vLLM
We optimized the open source vLLM serving framework with a series of techniques:
- Tensor Parallelism: We used tensor parallelism for distributing the large model layers across multiple GPUs, a necessary technique for running models that exceed the memory capacity of a single GPU, which requires high-speed GPU interconnects. Based on the model size, we used either TP4 or TP8 configurations to run inference across 4 or 8 GPUs.
- Kernel Fusion: This key optimization fuses multiple operations into a single GPU kernel, which minimizes the overhead of individual kernel launches and reduces CPU gapping. By executing these merged operations on-chip, kernel fusion significantly cuts down on slower off-chip memory accesses, leading to much faster processing.
- Programmatic Dependent Launch: We used Programmatic Dependent Launch to overlap kernels wherever possible, which hides kernel launch overhead and mitigates tail effects in short-running kernels. This improves performance for low-batch-size, low-concurrency, high-interactivity workloads by ~10%.
- Speculative Decoding and Multi-Token Prediction (MTP): We leveraged the latest model features like Multi-Token Prediction (MTP) for DeepSeek to accelerate token generation, improving the Time-Per-Output-Token (TPOT). MTP was used as part of Speculative Decoding optimization to boost generation speeds. This technique uses a smaller draft model (MTP heads or EAGLE heads) to predict token sequences that the larger target model validates in a single forward pass, significantly increasing throughput while maintaining the high quality of the primary model's output. For MiniMax-M2.5, we trained an EAGLE3 draft model using TorchSpec — a torch-native online speculative-decoding training framework that runs FSDP training and vLLM-based target inference concurrently, learning from MiniMax-M2.5-regenerated responses and live vLLM-generated hidden states to match the base model's exact token distribution. For deployment, our experiments showed that reducing tensor parallelism for the draft model improves performance by minimizing inter-GPU communication overhead. For MiniMax-M2.5, Time-Per-Output-Token (TPOT) improved by 23% by setting "draft_tensor_parallel_size": 1 in our setup.
Kernel fusion and draft model training were completed in close collaboration with Inferact, the original creators of the leading inference serving engine vLLM, whose expertise was instrumental in optimizing these complex workloads for specific GPU and model versions.
Real world performance
The same techniques are already running in production for customers serving inference at scale. Workato, which processes over 1 trillion automated workloads to extend its production automation with agentic AI, is running on DigitalOcean's inference platform with 77% faster Time-To-First-Token, 79% lower end-to-end latency, and 67% lower inference costs.
"Before DigitalOcean, we didn't have a dedicated solution for multi-node serving, which slowed our AI progress. DigitalOcean got us up and running quickly, and through close collaboration on performance optimization, helped us accelerate our inference performance and overall progress by two to three times." — Oscar Wu, AI Research Scientist & Technical Lead, Workato
The path forward: Scaling intelligence
Our commitment to performance doesn't stop here. We are expanding our catalog of optimized models tailored to evolving customer demand. As we move toward the next frontier of inference, we are building the infrastructure for multi-node serving with disaggregated configurations and Wide Expert Parallelism capabilities to handle the world's most demanding agentic workloads. With hardware and software co-design, we're focused on continuing to deliver the performance AI-native enteprises need to scale.
Try DeepSeek V3.2, MiniMax-M2.5, or Qwen 3.5 397B on DigitalOcean Serverless Inference today.
Full benchmark methodology and results are available at Artificial Analysis.
How it feels to run an incident with AI SRE
Incident.io's AI SRE automates incident investigation and resolution by integrating Slack, Claude Code, and deployment tools into a single workflow that eliminates context switching.
Deep dive
- Incident.io integrated their AI SRE investigation engine with Claude Code and a macOS desktop app to create a unified incident response workflow
- AI SRE automatically runs parallel investigations checking recent deploys, telemetry, errors, past incident patterns, and codebase when an incident is declared
- Engineers connect Claude Code sessions directly to incidents via
/incidentcommand, synchronizing all investigation context automatically - In the example incident, AI SRE identified a frontend rendering crash caused by a map returning undefined for an unrecognized type within minutes
- Claude Code validated the investigation, proposed a fix, committed it, opened a PR, and posted updates to Slack via incident.io's MCP integration—all from the terminal
- AI SRE re-verifies all engineer actions and updates made through Claude, providing nudges if mistakes are detected while keeping channel participants informed
- The macOS desktop app provides a persistent notch interface showing live incident updates without requiring context switching to Slack
- Automatic incident write-ups incorporate context from Slack conversations, video calls, and coding sessions for easier post-incident review
- The entire incident from declaration to resolution took only minutes, mostly spent waiting for deployment rather than investigation
- The company emphasizes they delayed launch to prioritize ergonomic UX over being first to market with AI incident management
Decoder
- SRE (Site Reliability Engineering): Practice of applying software engineering to operations and infrastructure management to improve system reliability
- MCP (Model Context Protocol): Standard protocol allowing AI assistants to connect to and interact with external tools and data sources
- Claude Code: Anthropic's AI coding assistant that can write, debug, and modify code with access to your codebase
- Incident declaration: Formal process of logging a production issue to track investigation, communication, and resolution
- Telemetry: Automated monitoring data collection from systems for analysis and debugging
Original article
How it feels to run an incident with AI SRE
We've been building the broader incident.io platform for several years now, and one thing we've learned is that UX matters more here than almost anywhere else. When an incident fires, there's no room for poorly designed interfaces or fumbling through features you haven't touched in a while.
The product has to be ergonomic: easy to pick up, easy to navigate, with the right things at your fingertips at exactly the right moment. We've put a lot of effort into this over the last 5 years.
For the last 18 months, we've been building AI SRE. The brain behind it, which you can think of as an investigation engine and intelligence layer, has come a long way.
Despite this, we've been struggling to get the UX to click in a way that feels as natural as the rest of the product. An agent that does impressive things behind the scenes doesn't count for much if the experience of using it feels jarring and easy to move past, both of which are things we've felt as we've been building it.
This week, I used AI SRE to run a real incident, and I think we're right on the edge of nailing the whole flow. I'm going to use this post to walk you through it end-to-end.
The actual incident
To set the scene, I was testing a new feature we've just built: delay nodes in escalation paths. It's not critical to this story, but it lets you add custom delays into on-call escalations, for example holding low severity pages overnight and delivering them first thing in the morning.
The delay node feature had just shipped and was only enabled on demo accounts, so a few rough edges were expected. Midway through testing, I clicked into the escalation details page, and the whole page crashed. Just an error screen with nothing illuminating in the console or network tab of Arc.

As is pretty routine for us at incident.io, I reported this as an incident to investigate.
AI SRE gets to work investigating
To set some context: as soon as an incident is declared, our AI SRE agent kicks in and starts investigating the issue on your behalf.
In practice, this means things like:
- Looking at recent deploys
- Digging into telemetry and errors
- Searching through past incidents
- Investigating the code, looking for any smoking guns
- Checking whether there's any other context in Slack
All the kinds of things a human would do if they were responding to an incident themselves, but much faster and in parallel.
From Slack to desktop
Whilst the investigation was ongoing, I was nudged in Slack to "pin" the incident in the incident.io macOS desktop app.
We've recently shipped this new product surface (it's beautiful!), and pinning an incident turns the notch on your Mac into a live and interactive view of the incident, and an easy way to jump straight into Claude, Cursor, or your agentic coding platform of choice.
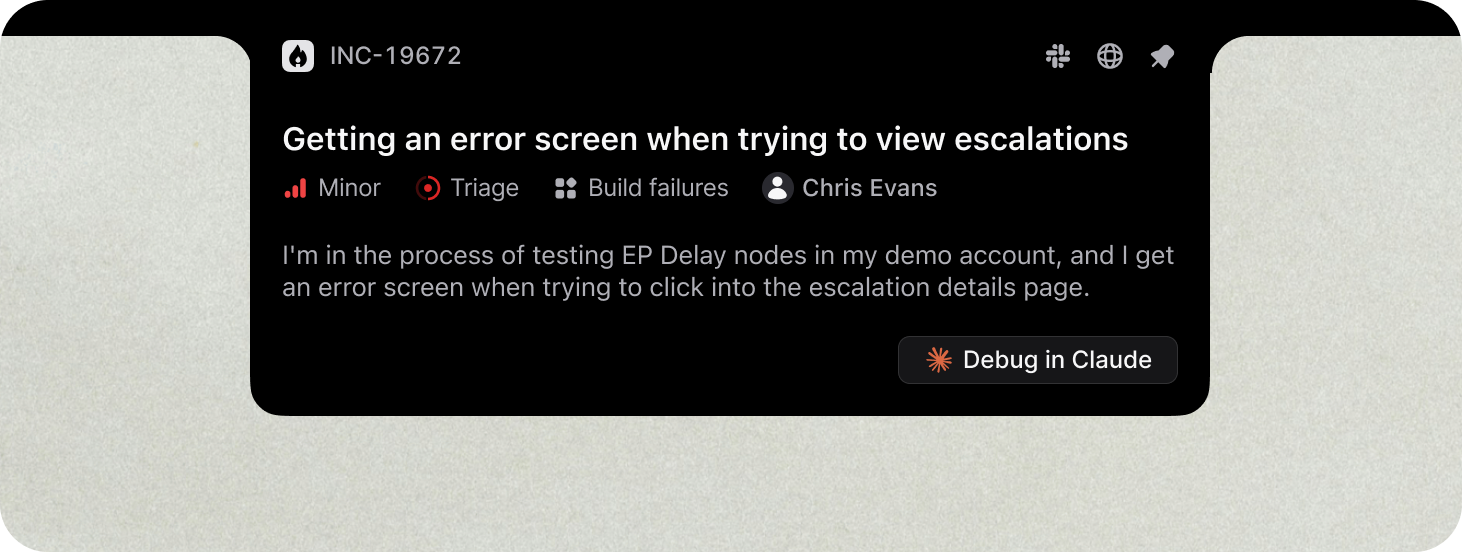
Jumping into Claude Code
From there, I jumped into Claude Code with the /incident INC-19672 command, connecting my Claude Code session directly back into the incident, and synchronizing all of the investigation from AI SRE's investigation into the context.
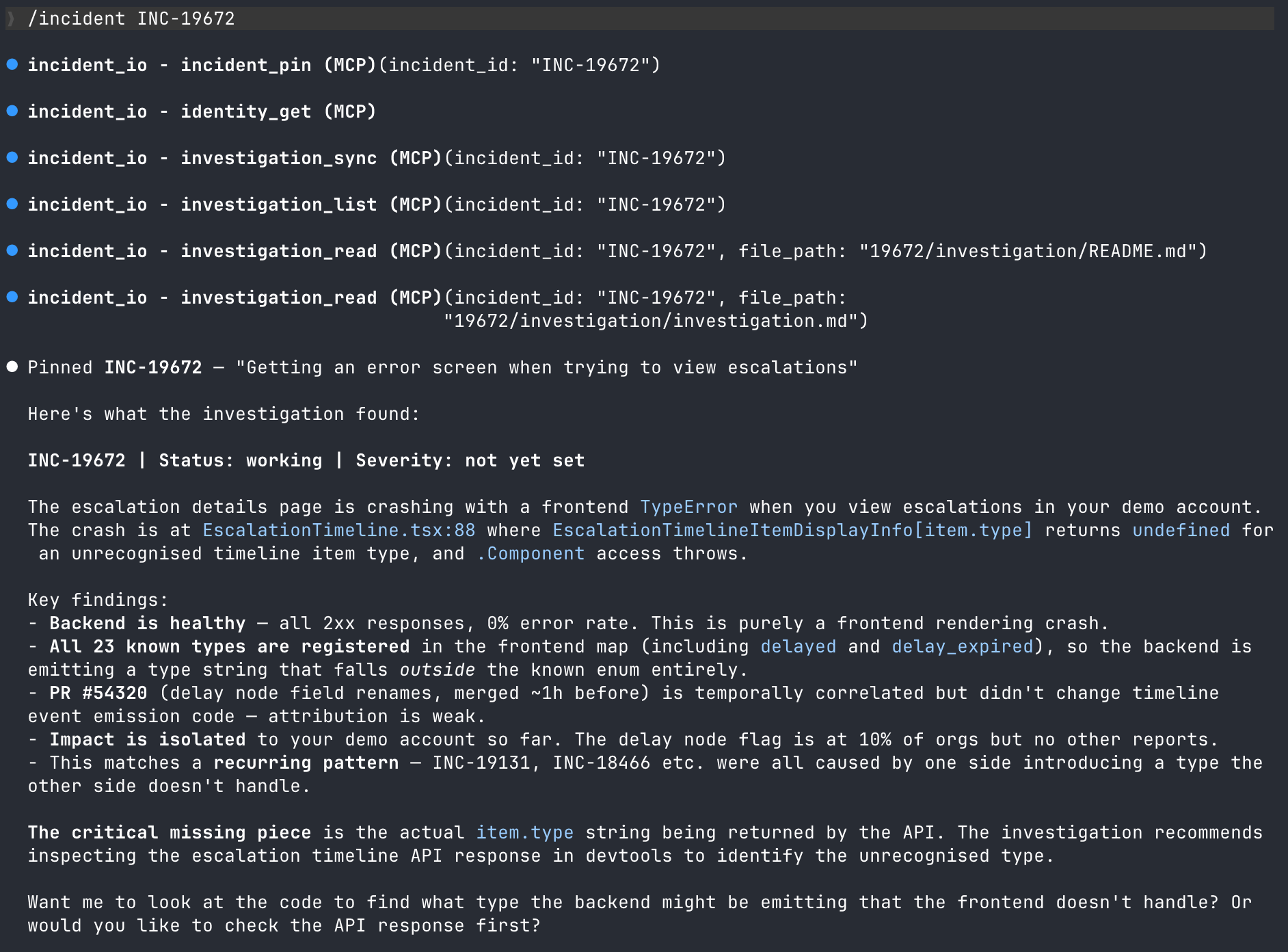
By the time I'd done that, the first pass of the investigation was complete, and had narrowed down the cause to a frontend rendering crash: a map returning undefined for a type the frontend didn't recognize. It even identified a recurring pattern from previous incidents where one side introduces a type that the other side doesn't handle – we're now looking into this!
What's notable here is that I didn't have to dig through logs, check Grafana, or read through code; the investigation from AI SRE did that for me. I also have zero familiarity with this part of the platform, but I had enough info at this point to verify the conclusion as plausible and proceed to work with Claude.
Letting Claude cook
Despite the investigation looking good, there's no need to blindly trust it. The Claude/AI SRE combo got to work, validating it against the codebase.
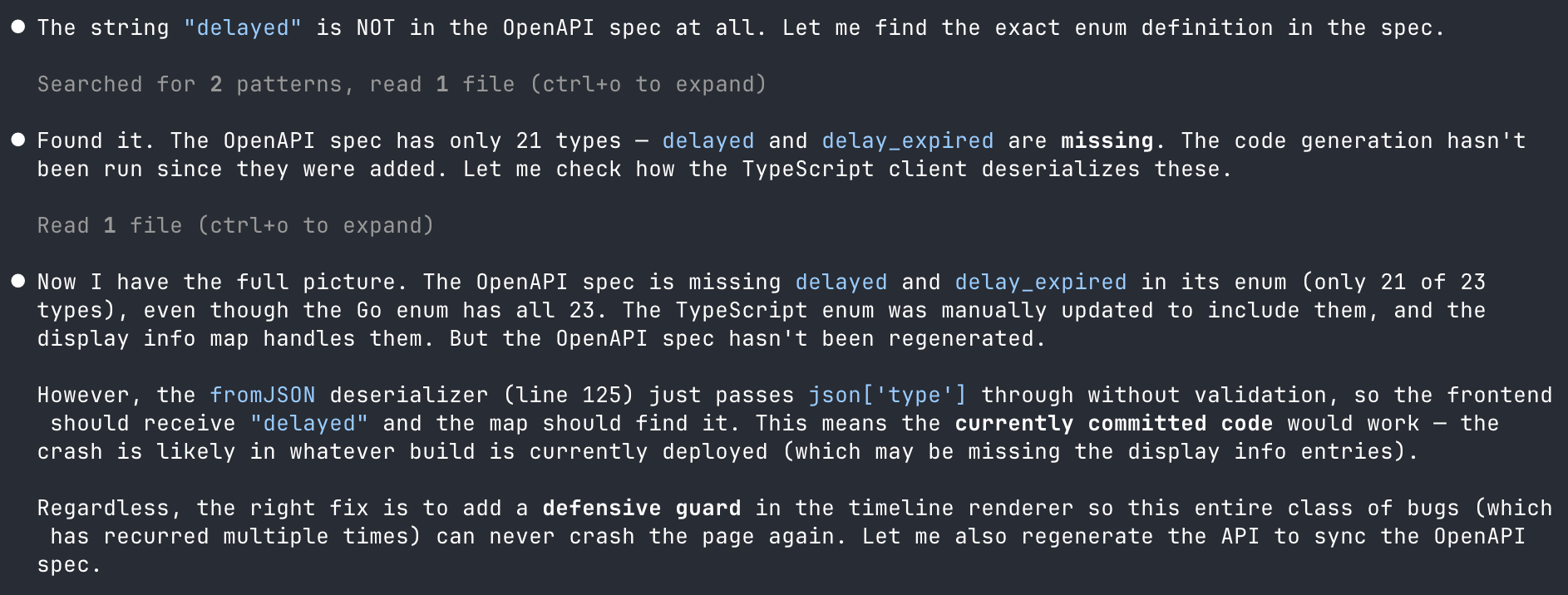
You can see here that it checked the OpenAPI spec and found the problem. I daren't think how much time it would have taken me to get to the same point, but here it took a few minutes.
A subtle but important point in this flow is that it lets responders and Claude move ahead and investigate independently, exploring while AI SRE continues in parallel behind the scenes. That means there's no waiting around; as new intel comes in, we automatically connect the dots, keeping both agents aligned on the state of the investigation.
The fix, ready to ship
With the root cause nailed down, Claude proposed the fix: gracefully skipping rendering an item instead of crashing the whole page.
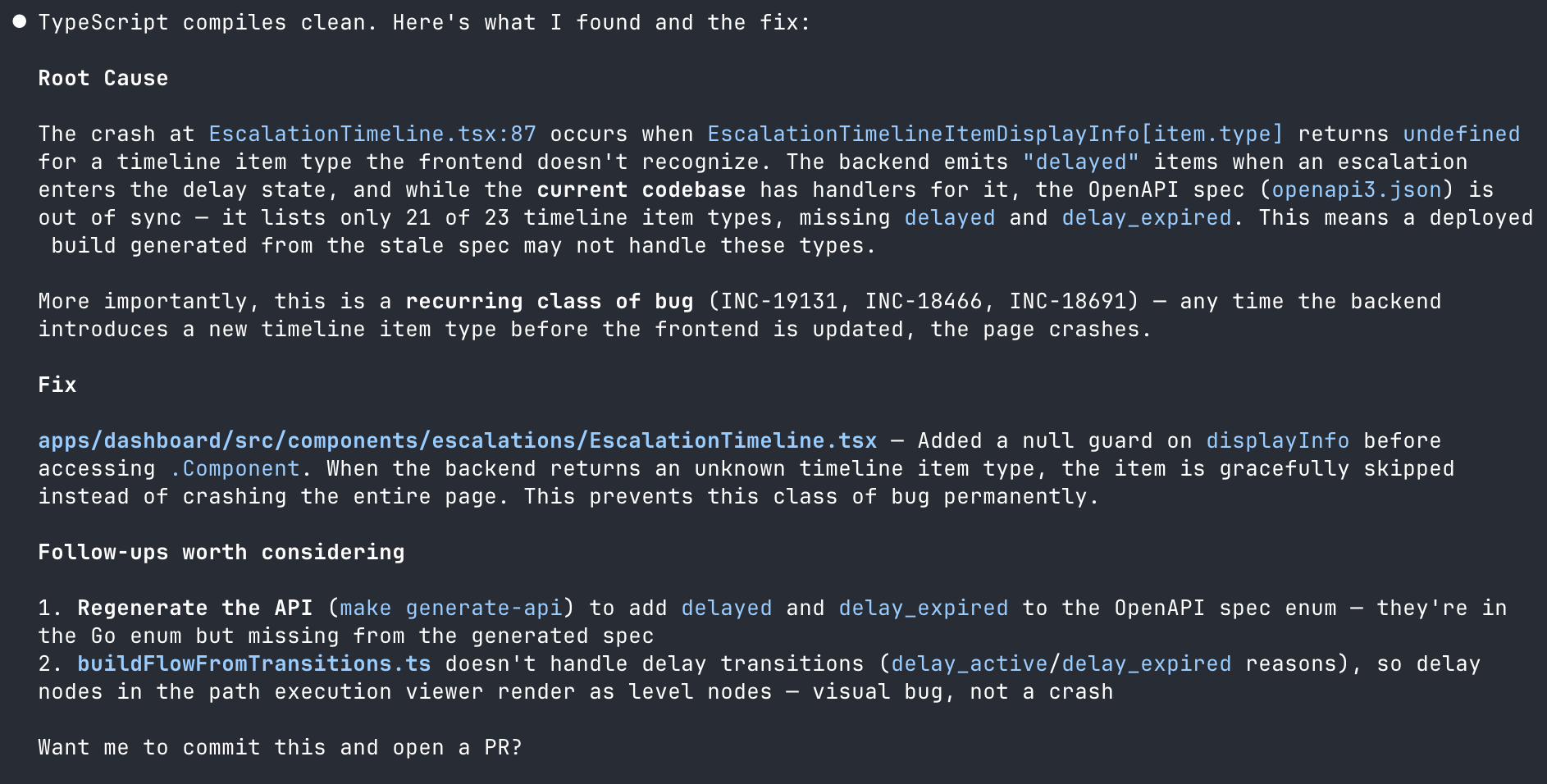
"Want me to commit this and open a PR?"
Yes. Yes, I do.
PR opened and channel updated, without leaving my terminal
This is where the experience felt like it really clicked. Claude opened the PR, then used the incident.io MCP to post an update into the incident channel, including what was found, what the fix is, and a link to the PR.
Most notably, I didn't have to switch to Slack to type an update. I didn't open GitHub to create the PR. I didn't go back to incident.io to change the status. All of it happened from the same place I was writing the fix.
It's worth calling out that everything you do in Claude and post back to the channel gets reverified by AI SRE. If you've made a mistake or forgotten something, it'll nudge you about it, but it'll also update its understanding and ensure anyone in the channel knows what you did and where we landed.
Meanwhile, the incident.io desktop app is sitting there on my Mac, pinging me with updates as things progress. So I'm always plugged into the latest context without having to go looking for it.
Verified and resolved
At this stage, it was all smooth sailing. The PR was merged, the deploy went out, and an engineer checking in on things shot me message to re-test.
A singular, portable context for every incident
Wrapping up an incident has become pretty delightful on incident.io, too. Simply ask us to do it, and we'll incorporate all of the context from what's happened in Slack, any conversations that have happened on Zoom or Google Meet, and now all of the context of what's happened whilst you were coding up a fix too.
The job of closing out and providing a final update is as simple as a one-liner to ask @incident to take care of it.

Finally, while I wouldn't normally spend much time debriefing an incident like this, a nice side effect of AI SRE is that all the context can be turned into a write-up for others to review.
What you see here is entirely AI-generated, and it's a much more accessible way for anyone revisiting this incident to understand what happened.
A better flow for resolving technical incidents
I've responded to hundreds of incidents over the years, and the friction has always been the same: too many tools, too much context switching, too much time spent just figuring out what's going on before you can start fixing it.
I think we're really close to fundamentally changing this.
The whole process here, from incident declaration to resolution, took minutes. And most of that was waiting for the deploy.
We've still got a little way to go (which is why we haven't fully launched yet!), but I have incredibly high conviction that this isn't just a small improvement, but a markedly better way to run incidents.
And seeing how far we've come on the user experience side validates our decision to build something that genuinely fits into an engineer's workflow, and not rushing it out the door.
Incidents are tough enough as it is, so it's better to be right than first.

Kubernetes for platform teams: Leveraging k0s and k0rdent
Hosted Control Planes let you run multiple Kubernetes clusters on OpenStack without the traditional overhead of dedicating three nodes per cluster just for control plane infrastructure.
Deep dive
- The traditional approach requires minimum 3 dedicated nodes per cluster for control plane components, meaning infrastructure costs multiply quickly across environments before any actual workloads run
- Hosted Control Planes run all API servers, etcd instances, and controllers inside a single management cluster, while only worker nodes are provisioned in OpenStack for each workload cluster
- The tutorial walks through creating a k0s-based management cluster, installing k0rdent controllers, configuring OpenStack credentials via clouds.yaml secrets, and defining clusters declaratively via ClusterDeployment resources
- k0s is chosen as the Kubernetes distribution because it's lightweight and simple, ideal for the management cluster that orchestrates the entire fleet
- k0rdent handles the cluster lifecycle management, continuously reconciling desired state defined in YAML manifests with actual infrastructure
- The architecture fundamentally shifts from imperative cluster provisioning (scripts, runbooks, CLI commands) to declarative definitions that are reproducible, auditable, and version-controlled
- Scaling is demonstrated by simply editing the workersNumber field in the ClusterDeployment manifest, which triggers k0rdent to automatically provision additional OpenStack VMs
- Critical setup steps include properly configuring OpenStack credentials, identifying correct network/image/flavor names from the actual OpenStack environment, and verifying access before proceeding
- The management cluster becomes the centralized brain while workload clusters become extensions, enabling policy enforcement, upgrades, and observability from a single point across the entire fleet
- This represents an architectural shift from cluster-centric thinking (managing individual clusters) to platform-centric thinking (operating a system that manages clusters)
- Both k0s and k0rdent are open source CNCF projects with active communities on GitHub and Slack channels for practitioners sharing real-world experience
Decoder
- k0s: A lightweight, zero-friction Kubernetes distribution designed to be simple to install and operate, used here for the management cluster
- k0rdent: An open source multi-cluster orchestration tool that runs as controllers in Kubernetes and handles cluster lifecycle management across fleets
- Hosted Control Planes (HCP): An architecture pattern where Kubernetes control plane components (API server, etcd, controllers) run inside a management cluster instead of on dedicated nodes per workload cluster
- OpenStack: An open source private cloud infrastructure platform for managing compute, storage, and networking resources
- Control plane: The set of Kubernetes components that make global decisions about the cluster, including the API server, scheduler, controller manager, and etcd datastore
- etcd: The distributed key-value store that Kubernetes uses as its backing store for all cluster data
- ClusterDeployment: A k0rdent custom resource that declaratively defines the desired state of a Kubernetes cluster, including worker count, machine flavors, and network configuration
Original article
This post demonstrates how to build a scalable, multi-cluster Kubernetes platform on OpenStack using k0s, k0rdent, and Hosted Control Planes (HCP), which eliminates the need for dedicated 3-node control planes per cluster by centralizing them in a single management cluster. The architecture shifts from managing individual clusters to operating a declarative system that handles provisioning, scaling, and upgrades across entire fleets while significantly reducing infrastructure costs and operational complexity.
.jpg)
From air-gapped to private cloud: Security that adapts to your environment
Sysdig argues cloud-native security platforms should adapt to deployment constraints like air-gapped or private cloud environments rather than requiring continuous SaaS connectivity.
Decoder
- eBPF: Extended Berkeley Packet Filter, a Linux kernel technology that enables running sandboxed programs for observability and security without modifying kernel code
- Falco: Open source runtime security tool for cloud-native environments that uses eBPF to detect anomalous behavior in containers and Kubernetes
- Air-gapped: Systems completely isolated from external networks for security, with no internet connectivity
- Data sovereignty: Legal requirement that data be stored and processed within specific geographic or jurisdictional boundaries
Original article
Cloud-native security must adapt to diverse deployment constraints rather than enforce SaaS models, and Sysdig Secure delivers consistent runtime detection across private cloud, on-premises, and air-gapped environments with flexible, locally controlled implementations.
Ghostty Is Leaving GitHub
HashiCorp cofounder Mitchell Hashimoto is moving the Ghostty terminal emulator project off GitHub after 18 years on the platform, citing daily outages that prevent productive work.
Original article
Mitchell Hashimoto, cofounder of HashiCorp, has announced that he is moving the Ghostty project off GitHub after 18 years of deep personal and professional attachment, citing growing frustration and disappointment with the platform.

Cloud Cost Optimization: Principles that still matter
AI workloads are making cloud cost optimization more complex and critical due to unpredictable consumption patterns and specialized infrastructure requirements.
Deep dive
- Cloud cost optimization is about aligning resource usage with business value, not just cutting costs indiscriminately
- AI workloads introduce unpredictable consumption patterns with rapid fluctuations during model training, inference, and experimentation phases
- Traditional cost optimization principles still apply but need stronger enforcement due to AI's higher iteration and resource intensity
- Four key best practices: visibility into usage patterns, governance guardrails to prevent wasteful spending, rightsizing resources across lifecycle stages, and continuous review cycles
- Cloud cost management (tracking and reporting spend) differs from cost optimization (taking action to reduce waste and improve efficiency)
- AI development typically involves testing multiple models and configurations before production, which can silently accumulate costs without proper monitoring
- Specialized AI infrastructure and services increase cost sensitivity compared to traditional workloads
- Effective optimization balances efficiency with outcomes, ensuring experimentation isn't constrained but is managed responsibly
- Value-driven optimization considers how resources contribute to performance and reliability, not just minimizing spend
- Organizations need both cost management for visibility and cost optimization for decision-making to scale AI investments sustainably
Decoder
- FinOps: Financial operations practice combining financial accountability with cloud engineering to optimize cloud spending
- Rightsizing: Matching cloud resource allocations to actual workload requirements, avoiding over-provisioning
- Consumption-based pricing: Cloud billing model where costs are based on actual resource usage rather than fixed capacity
- Inference: Running a trained AI model to make predictions, distinct from resource-intensive model training
- Governance guardrails: Policy-driven controls and usage boundaries that prevent wasteful spending while enabling innovation
Original article
Cloud cost optimization is a continuous, strategic practice of aligning usage with business value, made more critical by unpredictable, resource-intensive AI workloads that require strong visibility, governance, and iterative management.
Apple UX Principle: How Simplicity Drives Apple's 5–10% Conversion Rates
Apple achieves 5-10% conversion rates (versus the typical 2-3% e-commerce average) by treating product pages as behavioral systems that eliminate friction through five integrated UX principles.
Deep dive
- Most websites fail to convert because they present multiple product options, dense feature lists, and competing messages simultaneously, creating choice overload rather than decision clarity
- Apple product pages function as guided decision systems with narrative structure: broad aspirational introduction, specific features and use cases in the middle, practical configuration and pricing at the end
- Usability principle focuses on "effortless" rather than "easy" interfaces by aligning with existing mental models, eliminating small cumulative moments of confusion that cause users to pause and think
- Communication is sequential rather than parallel: each section focuses on a single idea, building from "What is this?" to "Why does this matter?" to "How does this fit into my life?"
- Functionality is measured by flow rather than capability, maintaining momentum by eliminating unnecessary steps and ensuring each interaction leads naturally to the next
- Aesthetics reduce cognitive load by making important information stand out and leverage the aesthetic-usability effect where visually appealing designs are perceived as more trustworthy
- Emotional design addresses final hesitation through smooth interactions, natural animations, and immediate feedback that create a sense of control and confidence
- The five principles work as an integrated system where each addresses a specific conversion barrier: usability removes friction, communication builds understanding, functionality maintains momentum, aesthetics builds trust, emotional design builds confidence
- Small improvements in each area compound multiplicatively: reduced friction increases engagement, which improves understanding, which increases confidence, which drives conversions
- The 5-10% conversion rate results from controlling the entire experience to avoid drop-off at multiple stages rather than a single breakthrough tactic
- Behavioral research by Sheena Iyengar and Mark Lepper shows that excessive choice consistently reduces decision-making across contexts
- Application requires shifting from "what to add" to "what to remove" and designing interfaces that communicate visually rather than through explanation
- The approach is accessible without Apple-level resources by focusing on progressive information disclosure and aligning every element around a single page goal
Decoder
- Cognitive load: The mental effort required to process information; excessive load causes decision paralysis and abandonment
- Choice overload: The phenomenon where presenting too many options paradoxically reduces the likelihood of making any decision
- Friction: Small moments of confusion or uncertainty that interrupt user flow and increase abandonment rates
- Aesthetic-usability effect: The psychological tendency to perceive visually appealing designs as more usable and trustworthy
- Conversion rate: The percentage of visitors who complete a desired action (typically purchase); e-commerce average is 2-3%, Apple achieves 5-10%
Original article
Apple's UX strategy isn't just aesthetic minimalism — it's a behavioral system built around five interlocking principles (usability, communication, functionality, aesthetics, and emotional design) that together eliminate friction and guide users toward confident decisions. Product pages function as structured narratives, distributing cognitive effort progressively so that, by the time users reach a call to action, purchasing feels like a natural conclusion rather than a deliberate choice. This approach is credited with driving conversion rates of 5–10%, well above the typical e-commerce average of 2–3%.

Why AI Design Tools that Ignore Your Design System Create More Problems than They Solve
AI design tools that don't integrate with your component library generate designs that look similar but create component debt and require extensive cleanup work.
Deep dive
- AI design tools generate visually similar components that aren't built with actual design system components, creating "visual drift" where colors, spacing, typography, and variants are close but not compliant with established standards
- Component debt accumulates when AI-generated elements lack proper loading states, elevation tokens, validation patterns, and other props that production components support, forcing developers to rebuild everything or ship inconsistent code
- Governance erosion occurs because AI bypasses contribution processes and design system constraints, generating off-system work that looks on-brand but wasn't reviewed against guidelines—making violations harder to catch
- Most AI tools lack component library connections: pixel-based tools like Figma generate visual shapes, code generators like Lovable and Bolt use their own conventions, and tools like Claude Design approximate patterns by reading codebases rather than using actual components
- True design system integration requires three elements: direct Git or Storybook sync (not stale file uploads), constrained generation that can only place existing components with real props and variants, and production-ready exports referencing actual component imports
- Prompt lock-in creates hidden costs where every spacing adjustment, color tweak, or layout change requires another AI round-trip and consumes credits, with some designers burning through weekly token limits in 2-6 hours
- The separation between AI generation and manual refinement matters: AI should handle scaffolding and structural work while designers use traditional tools for refinement without metering every interaction through expensive models
- Enterprise teams with 100+ components, governance requirements, and design system adoption KPIs face the highest risk because AI-generated off-system work makes metrics unreliable while looking superficially correct
- The key distinction is whether AI approximates design systems by mimicking visual patterns or actually uses them by placing real components—approximation drifts over time while architectural constraints prevent off-brand output
- Article written by UXPin CEO and concludes with product pitch for UXPin Forge, positioning it as a solution that syncs component libraries and constrains AI generation
Decoder
- Design system: A collection of reusable components, design tokens, and documentation that enforces visual and functional consistency across a product, typically maintained as code in component libraries
- Component debt: Technical debt created when UI elements look correct but aren't built with the actual component library, lacking proper states, props, and variants that the real components support
- Visual drift: Deviation from established design standards where generated output appears similar but uses incorrect spacing, colors, typography, or deprecated patterns
- Props/variants/states: Properties that configure component behavior (props), different versions of a component (variants), and the conditions a component can be in (loading, error, disabled states)
- Storybook: A development tool for building and documenting UI components in isolation, often used as the source of truth for component libraries
- Design tokens: Named values for design attributes like colors, spacing, typography, and elevation that ensure consistency when referenced across components
Original article
Your design system represents years of decisions. Hundreds of components. Documented props, variants, states, tokens, and usage guidelines. It's the engineering artifact that keeps your product consistent across dozens of teams and hundreds of screens.
Then someone on your team tries an AI design tool. In thirty seconds, it generates a beautiful dashboard. Everyone's impressed. Then someone looks closely.
The buttons don't match. The spacing is off. The card component uses a shadow your system deprecated six months ago. The typography is close but not right. The loading state doesn't exist. The entire layout needs to be rebuilt using your actual components before a developer can touch it.
The AI was fast. The cleanup is slow. And the net result is more work, not less.
This is the pattern playing out across every AI design tool that doesn't connect to your component library. The generation is impressive. The aftermath is expensive.
What happens when AI ignores your design system
The problems show up in layers. The first layer is visible immediately. The deeper layers compound over weeks.
Layer 1: Visual drift
The AI generates something that looks approximately right. The colours are close. The spacing is similar. The components resemble yours. But "close" isn't correct, and "resembles" isn't compliant.
Designers who tested Claude Design this week reported wrong fonts, incorrect button colours, and inconsistent spacing within their first few sessions. One spent more time correcting the AI's interpretation of their design system than it would have taken to build from scratch.
This isn't a quality problem. It's an architecture problem. When the AI reads your codebase and generates new elements styled to match, it's approximating. Approximation drifts. The more complex your design system, the faster it drifts.
Layer 2: Component debt
Every time the AI generates a component that looks like yours but isn't yours, it creates component debt. That generated button doesn't have your loading state. That card doesn't support your elevation tokens. That input doesn't handle your validation patterns.
A developer receiving this output has two options: rebuild everything using the real components (negating the AI's speed advantage), or ship the approximation and deal with inconsistency in production. Neither is good.
Teams with mature design systems have spent years eliminating this kind of debt. An AI tool that reintroduces it in thirty seconds is moving backwards, not forwards.
Layer 3: Governance erosion
Design systems work because they create constraints. Designers can't use a component that doesn't exist in the library. They can't invent a new button variant without going through the contribution process. The system enforces consistency through structure, not willpower.
AI tools that generate outside the system bypass this entirely. The output looks professional. It seems on-brand. But it wasn't built with your components, wasn't reviewed against your guidelines, and doesn't follow your contribution process. It's off-system work that looks on-brand – which is actually worse than off-system work that looks obviously wrong, because it's harder to catch.
The most dangerous design system violation isn't the one that looks wrong. It's the one that looks right but isn't built with your components.
Why this keeps happening
The root cause is simple: most AI design tools don't have a connection to your component library. They generate to their own conventions because they have no other option.
Tools that generate pixels
Figma, Sketch, and their AI features generate visual shapes on a vector canvas. The output references your component library visually but isn't structurally connected to it. A designer can go off-brand because nothing physically prevents it. When AI is added to this model, it generates more pixels faster. The drift doesn't get solved – it gets accelerated.
Tools that generate their own code
Lovable, Bolt, and v0 generate working code, but it's their code – their component conventions, their styling approach, their opinions about how a button should work. For greenfield projects, this is fine. For teams with an existing design system, the output ignores everything you've built.
Tools that approximate from your codebase
Claude Design takes a different approach: it reads your codebase and extracts visual patterns. This is closer to the right idea, but it's still approximation. The AI interprets your code and generates new elements styled to match. It doesn't place your actual components with their real props and states. The gap between "styled to match" and "actually is" shows up as drift.
All three approaches share the same fundamental problem: the AI doesn't know what your design system is. It either ignores it, mimics it, or approximates it. None of these is the same as using it.
What "using your design system" actually means
For an AI design tool to genuinely use your design system, three things need to be true:
- Direct connection to your component library
The AI needs access to your actual components synced from Git or Storybook, not uploaded as a file or read from a codebase. The difference matters: a synced library updates automatically when your components change. An uploaded file becomes stale the moment someone pushes a code update.
- Constrained generation
The AI should only be able to place components that exist in your library. Not generate new ones styled to match. Not create approximations. Your actual components with their real props, real variants, and real states.
This means the AI can't hallucinate a component that doesn't exist in your system. It can't use the wrong button variant because only the variants you've defined are available. Off-brand output isn't prevented by guidelines; it's prevented by architecture.
- Production-ready output
The exported code should reference your actual component library. Not generic HTML. Not the tool's own component structure. Your imports, your component names, your prop values.
Here's what that looks like in practice – real export output from UXPin:
import Button from '@mui/material/Button'; import Card from '@mui/material/Card'; import TextField from '@mui/material/TextField'; import Typography from '@mui/material/Typography'; <Card > <CardContent> <Typography variant="h5">Create Account</Typography> <TextField label="Full Name" variant="outlined" fullWidth /> <TextField label="Email Address" type="email" fullWidth /> <Button variant="contained" fullWidth>Sign Up</Button> </CardContent> </Card>Real MUI imports. Real props. Working state management. A developer copies this and integrates it directly. Nothing to interpret, nothing to rebuild.
Reading a codebase gives you visuals that look like your product. Syncing a component library gives you the real thing.
The hidden cost: prompt lock-in
There's a second problem with AI design tools that ignore your design system, and it compounds the first: prompt lock-in.
When the AI is the only way to interact with the generated output, every adjustment – spacing, colours, layout; requires another prompt. Another round-trip to the AI model. Another credit consumed.
Designers who tested Claude Design this week reported burning through weekly token limits in 2–6 hours. The community developed a mitigation strategy: use the most expensive model for the first prompt, then switch to cheaper models for edits. That this strategy is necessary tells you something about the cost model.
Adjusting spacing shouldn't require an LLM. Tweaking a prop value shouldn't cost credits. Exploring a variant shouldn't burn through a weekly allocation. These are design tool tasks, not AI tasks.
The alternative is separating AI generation from manual refinement. Let the AI handle the scaffold – the initial layout, the component placement, the structural heavy lifting. Then give designers real design tools for the last mile. Same canvas, same components. No tokens burned on the work that requires human judgment.
AI should launch the creative process, not meter it.
What to ask when evaluating AI design tools
If your team has a design system and you're evaluating AI design tools, these questions separate the tools that will help from the tools that will create cleanup work:
- Does the AI connect to my component library directly? Via Git, Storybook, or a direct integration – not a file upload that becomes stale.
- Is the AI constrained to my components? Can it only use what exists in my library, or can it generate new components that approximate mine?
- What does the export look like? Does it reference my component imports, or does it generate its own code that a developer has to rebuild?
- Do manual edits require AI credits? Can I adjust spacing, props, and layout with design tools, or does every interaction route through the model?
- Does the design system sync automatically? When developers update components in the codebase, does the design tool reflect those changes without manual re-syncing?
- Can the AI go off-brand? If I prompt for something that doesn't exist in my system, does it invent a component or tell me the component doesn't exist?
The last question is the most telling. An AI that invents components when your library doesn't have one is generating to its own conventions. An AI that surfaces the gap is respecting your system.
The teams this matters most for
Not every team needs their AI design tool to connect to a production component library. For founders building MVPs, marketers creating landing pages, and PMs mocking up feature concepts, speed and visual quality matter more than component accuracy.
But for enterprise teams with mature design systems, the calculus is different:
- If your design system has 100+ components with documented props, variants, and states – an AI that ignores them creates component debt faster than it creates value.
- If you have governance requirements that mandate compliance with your component library – an AI that generates outside the system is a compliance risk, not a productivity tool.
- If your engineering team spends significant time rebuilding designs from specs and mockups – an AI that generates more specs and mockups faster doesn't solve the underlying problem.
- If you measure design system adoption as a KPI – an AI that generates off-system work while looking on-brand makes your adoption metrics unreliable.
For these teams, the question isn't whether AI design tools are useful. They clearly are. The question is whether the AI is working with your design system or around it.
The more you've invested in your design system, the more an AI tool that ignores it costs you. And the more an AI tool that uses it saves you.
Frequently asked questions
Why do AI design tools ignore design systems?
Most AI design tools generate to their own conventions because they lack a direct connection to your component library. They either generate pixels (like Figma's AI), generate their own code (like Lovable and Bolt), or approximate your visual patterns by reading your codebase (like Claude Design). None of these approaches use your actual production components.
What is design system drift in AI design tools?
Design system drift occurs when AI-generated output deviates from your established component library. This includes wrong fonts, incorrect colours, inconsistent spacing, missing component variants, and generated components that don't match your prop conventions. Drift happens because the AI is approximating your system rather than being constrained to it.
How can AI design tools respect an existing design system?
The AI must have a direct connection to your component library, typically through Git integration. When the AI can only place components that exist in your synced library, with their real props, variants, and states, off-brand output becomes structurally impossible rather than something you hope to avoid.
What is the difference between approximating and using a design system?
Approximating means the AI reads your codebase or uploaded files and generates new elements styled to match your visual patterns. Using means the AI places your actual production components with their real props, variants, and states. Approximation drifts over time. Constraint does not.
What is prompt lock-in in AI design tools?
Prompt lock-in occurs when the AI model is the only way to interact with your design. Every adjustment, including manual tweaks like spacing and colour changes, requires a round-trip to the AI and consumes credits. This makes refinement expensive and unpredictable, and removes the direct manipulation designers rely on.
FigClaw (Figma plugin)
FigClaw is a Figma plugin that uses Claude AI in an autonomous agent loop to inspect, code, and execute design tasks end-to-end rather than just answering questions.
Deep dive
- FigClaw uses Claude AI in an agent loop architecture rather than a traditional chat interface, allowing it to autonomously complete design tasks
- The agent can inspect Figma selections, read page structure, write Figma Plugin API code, execute it in a sandbox, check results, and iterate until completion
- Single messages can trigger complex operations like building auto-layout components, applying styles across pages, managing design tokens and variables, or exporting assets to disk
- Features a "Skills" system where users can load Markdown files containing brand guides, naming conventions, or component recipes to customize agent behavior
- Skills can be set to always-on mode or invoked on-demand with @mentions, and Claude can write and update skills directly from the chat interface
- Requires users to bring their own Claude API key, which is stored locally via Figma's client storage and never leaves the user's machine
- Open source project with available source code, documentation, playground files, and skill templates
- Represents a paradigm shift from conversational AI assistants to autonomous agents that directly manipulate design tools
Decoder
- Agent loop: An AI system that autonomously executes a sequence of actions, checks results, and iterates until completing a task, rather than waiting for user input after each step
- Figma Plugin API: The programming interface that allows developers to extend Figma's functionality with custom code
- Auto layout: Figma's feature for creating responsive component layouts that automatically adjust spacing and sizing
- Design tokens: Reusable design values like colors, spacing, and typography stored as variables for consistency across a design system
- Claude API key: Authentication credential for accessing Anthropic's Claude AI service, which users must provide themselves
Original article
A Claude-powered Figma plugin built around an agent loop — not a chat window.
Can AI Detect Usability Problems?
AI tools like ChatGPT can now analyze usability test videos to identify UX problems, but the approach is inconsistent and its reliability compared to human researchers remains unproven.
Decoder
- Lossy: In this context, information is lost when AI samples video frames rather than processing every frame continuously, potentially missing important user interactions or subtle usability issues between sampled moments.
Original article
AI can analyze usability test videos by sampling frames, transcribing audio, and generating plausible descriptions of user behavior — though this process is "lossy" and prone to inconsistency. In a test using a six-minute OpenTable usability session, ChatGPT identified seven specific problems, including a search field that dropped cuisine selections when the location was changed and results that surfaced non-sushi restaurants. Whether those findings hold up in terms of accuracy, reliability, and alignment with what human researchers would catch remains an open question to be addressed in follow-up research.

Musk Testifies He's Suing OpenAI to Stop Altman's ‘Looting'
Elon Musk is suing OpenAI to reverse its nonprofit-to-profit transformation, claiming founders abandoned the charitable mission after using his money and reputation to launch the company.
Deep dive
- Musk testified that OpenAI's conversion from nonprofit to for-profit amounts to "looting a charity" and could set dangerous precedent for all philanthropic organizations in America
- OpenAI was founded in 2015 as a nonprofit counterweight to Google's AI development, which Musk felt was insufficiently concerned with safety after conversations with Larry Page
- Musk contributed funding, reputation, and guidance in OpenAI's early years before leaving the board in 2018, a year before Microsoft's $13 billion investment began
- OpenAI's attorneys argue Musk wanted to "take absolute control" of a for-profit OpenAI but was refused by other founders who wouldn't give "the keys of artificial intelligence" to one person
- Internal emails from 2016-2017 show Musk himself wrote that it "might have been a mistake for OpenAI to be set up as a nonprofit" and suggested creating a standard C corporation with parallel nonprofit
- The for-profit conversion completed in October 2025 left the OpenAI Foundation nonprofit with 26% equity while Microsoft received 27%, with the foundation maintaining organizational control
- Musk's lawyer alleges Microsoft was a "knowing accomplice" to betraying OpenAI's charitable mission when it invested starting in 2019
- The dispute emerged partly over equity splits—Musk felt a proposed equal four-way split was unfair since he was "providing all of the funding" and wanted majority interest
- The jury will issue an advisory verdict after three weeks of testimony, but the final ruling and remedies will come from the federal judge using jury findings as guidance
- The case involves reviewing years of emails, texts, and corporate documents, with testimony from multiple VIP witnesses from the AI industry
Decoder
- For-profit restructuring: The process of converting a nonprofit organization into a business that can generate profits for shareholders rather than being mission-driven
- Advisory verdict: A jury's non-binding recommendation to a judge, who retains final decision-making authority rather than being bound by the jury's findings
- Equity stake: Ownership percentage in a company that typically comes with rights to profits and voting power on major decisions
- C corp: A standard corporation structure that can have unlimited shareholders and is taxed separately from its owners
- Capped profits: A limit on how much money investors can make, with excess returns redirected to the nonprofit mission rather than shareholders
Original article
Elon Musk says that OpenAI's pivot from a charity to a for-profit business is wrong and sets a concerning precedent for other philanthropic efforts. He is suing OpenAI and its co-founders, seeking the unwinding of the for-profit restructuring of OpenAI. Musk says he felt that OpenAI's founders took advantage of his money, reputation, and guidance to get the startup off the ground, only to abandon its public-focused principles and capitalize on the project for their own benefit. OpenAI's attorneys say that the lawsuit is primarily an attempt to undermine a top competitor to Musk's own AI company.

How ChatGPT serves ads
A reverse-engineered breakdown reveals how ChatGPT injects contextual ads into conversations and tracks user clicks through merchant sites using encrypted attribution tokens.
Deep dive
- OpenAI injects ads as
single_advertiser_ad_unittyped objects directly into the SSE response stream at /backend-api/f/conversation, not through the language model itself - Each ad contains four separate Fernet-encrypted (AES-128-CBC + HMAC-SHA256) tokens for different parts of the attribution chain, all signed server-side so merchants cannot forge attribution
- Ad targeting is contextual to the current conversation topic—the same account received six different advertisers (Grubhub, GetYourGuide, Axel, Gametime, Aritzia, Canva) when asking about six different topics (Beijing travel, NBA, fashion, productivity)
- The
oppreftoken travels from click URL to merchant site, where the OAIQ SDK stores it in a first-party cookie with 720-hour (30-day) TTL for cross-session attribution - Ads open in ChatGPT's in-app webview by default (
open_externally: false), letting OpenAI observe post-click navigation before any pixel fires - The merchant-side SDK (oaiq.min.js v0.1.3) automatically instruments
contents_viewedevents and POSTs them back to bzr.openai.com with the attribution token - OpenAI hosts all advertiser creative assets (images, favicons) on bzrcdn.openai.com rather than letting merchants serve them directly
- Fernet tokens embed creation timestamps in cleartext (first 9 bytes), so anyone can verify ad mint time without OpenAI's key—one observed ad had 95-second click latency
- Each advertiser gets a stable account ID in the format
adacct_<32-hex>, visible in the ad payload and presumably used for billing reconciliation - The schema naming (
single_advertiser_ad_unit) implies OpenAI plans multi-advertiser carousel formats in future iterations
Decoder
- SSE (Server-Sent Events): HTTP streaming protocol that pushes real-time updates from server to browser over a single long-lived connection, used here to deliver both model tokens and ad units
- Fernet encryption: Symmetric encryption spec using AES-128-CBC with HMAC-SHA256 authentication, designed for securely passing time-limited tokens between services
- OAIQ SDK: OpenAI's first-party JavaScript tracking library (v0.1.3) that merchants embed to report conversion events back to the ad platform
- Attribution token: Encrypted identifier linking a click event to a specific ad impression, allowing the platform to credit conversions to the right campaign without exposing raw user data
- First-party cookie: Cookie set by the merchant's own domain (not a third-party tracker), which bypasses some browser privacy protections and lasts across sessions
Original article
OpenAI's ad platform has two halves. On the ChatGPT side, the backend injects structured single_advertiser_ad_unit objects into the conversation SSE stream while the model is responding. On the merchant side, a tracking SDK called OAIQ runs in the visitor's browser and reports product views back to OpenAI. The two are tied together by Fernet-encrypted click tokens, four of them per ad.
I captured both halves on a consented mobile-traffic research fleet. Everything below comes from observed traffic.
How an ad gets into a conversation
When you send a message to ChatGPT, the backend opens an SSE response at chatgpt.com/backend-api/f/conversation. Most events in that stream are model-output. Some are ad units. They look like this:
event: delta
data: {
"type": "single_advertiser_ad_unit",
"ads_request_id": "069e89b3-c038-7764-8000-6e5a193e5f69",
"ads_spam_integrity_payload": "gAAAAABp6Js_<...redacted...>",
"preamble": "",
"advertiser_brand": {
"name": "Grubhub",
"url": "www.grubhub.com",
"favicon_url": "https://bzrcdn.openai.com/cabfae7ead26b03d.png",
"id": "adacct_6984ed0ba55481a29894bb192f7773b4"
},
"carousel_cards": [{
"title": "Get Chinese Food Delivered",
"body": "Satisfy Your Cravings with Grubhub Delivery.",
"image_url": "https://bzrcdn.openai.com/cabfae7ead26b03d.png",
"target": {
"type": "url",
"value": "https://www.grubhub.com/?utm_source=chatgptpilot&utm_medium=paid&utm_campaign=diner_gh_search_chatgpt_kw_traffic_nb_x_nat_x&utm_content=nbchinese&oppref=gAAAA<...>&olref=gAAAA<...>",
"open_externally": false
},
"ad_data_token": "eyJwYXlsb<...>"
}]
}
Notes:
single_advertiser_ad_unitis a typed schema. The naming implies siblings (multi-advertiser, etc.).advertiser_brand.idisadacct_<32-hex>— a stable per-merchant account identifier.- Brand favicon and ad image both load from
bzrcdn.openai.com. OpenAI hosts the advertiser's creative, not the merchant. target.open_externally: falseopens the link in ChatGPT's in-app webview, so OpenAI observes the post-click navigation on top of any pixel signal.- Four Fernet tokens per ad:
ads_spam_integrity_payload,oppref,olref, and a base64-wrappedad_data_token. Each is AES-128-CBC under a server-only key with HMAC-SHA256 integrity.
How ads get selected
A single account in the panel received six different ads across six conversations on six different topics. The targeting is contextual to the chat:
| Conversation topic | Advertiser delivered |
|---|---|
| Beijing trip planning (Great Wall, Forbidden City) | Grubhub — "Get Chinese Food Delivered" |
| Beijing tour bookings | GetYourGuide — Great Wall tour, ad_id=beijing003 |
| Beijing flights | Axel — utm_term=vflight_beijing_03 |
| NBA playoffs | Gametime — utm_campaign=nba&utm_content=playoffs |
| Spring fashion/trends | Aritzia — utm_campaign=chatgptpilot_trav3 |
| Productivity / slides | Canva — utm_campaign=…link-clicks_products |
Same account, different topic, different brand. I didn't find evidence one way or the other on whether targeting also incorporates prior conversation history.
The four-token attribution chain
Every ad ships with four distinct Fernet-encrypted blobs. Their roles, based on where they appear:
ads_spam_integrity_payloadsent inside the SSE data, never on the click URL. Server-side integrity check against forged ad clicks.opprefpresent on the click URL and copied verbatim by the OAIQ pixel into the cookie__oppref(TTL 720 hours / 30 days). The forward attribution token. Travels with every subsequent merchant pixel event.olrefpaired withopprefon the click URL but not stored by the SDK we observed. Likely impression-side / outbound-link-reference logging on OpenAI's servers.ad_data_tokenbase64-wrapped JSON containing yet another Fernet token. Carried in the SSE payload, presumably reconciled server-side at click time.
Fernet's first nine bytes are public: version byte 0x80 plus an 8-byte big-endian Unix timestamp. So the mint time of any of these tokens is recoverable without OpenAI's key:
import base64, struct, datetime
b = base64.urlsafe_b64decode("gAAAAABp7fdA" + "==")
print(datetime.datetime.utcfromtimestamp(struct.unpack(">Q", b[1:9])[0]))
# → 2026-04-26 11:30:08 UTC
The Home Depot click URL I captured was minted at 11:30:08; the browser fetched the merchant page at 11:31:43. Click latency: 95 seconds.
How the loop closes on the merchant side
User taps the card. Browser opens:
https://www.grubhub.com/?utm_source=chatgptpilot&...
&oppref=gAAAA<...>
&olref=gAAAA<...>
The merchant page loads the OAIQ SDK:
<script src="https://bzrcdn.openai.com/sdk/oaiq.min.js"></script>
<script>
oaiq('init', { pid: '<merchant pixel ID>' });
oaiq('measure', 'contents_viewed', { ... });
</script>
oaiq.min.js is at version 0.1.3. On init it reads ?oppref= from window.location, writes it into the first-party cookie __oppref with a 720-hour TTL, and sets a probe cookie __oaiq_domain_probe. Every subsequent measure call POSTs JSON to:
POST https://bzr.openai.com/v1/sdk/events?pid=<merchant>&st=oaiq-web&sv=0.1.3
Two domains to add to your filter list if you want to block ChatGPT ad events:
bzrcdn.openai.com,bzr.openai.com. Two cookie names to inspect after any ChatGPT-recommended click:__oppref,__oaiq_domain_probe.

Before GitHub
GitHub transformed open source from a smaller world of self-hosted projects to frictionless micro-dependencies, but its current decline raises questions about what comes next and the need for independent archival infrastructure.
Deep dive
- Before GitHub, open source projects ran their own infrastructure (Trac, Subversion, tarballs) or used SourceForge, creating natural friction that limited dependencies and encouraged vendoring code directly into repositories
- The pre-GitHub world had fewer projects but more curation—dependencies came with history, reputation, and community trust built over years, not just package names
- Despite Git being philosophically distributed, GitHub became the centralized hub of open source, creating one of the great ironies of modern software development
- GitHub made open source dramatically more inclusive by reducing friction to near-zero for both publishing and consuming code, enabling the explosion of micro-dependencies seen in npm and similar ecosystems
- The platform accidentally became an archive and library for software history, keeping abandoned projects discoverable and preserving forks, issues, and discussions that would have disappeared on personal servers
- GitHub is now showing signs of decline: instability, product churn, Copilot AI integration complaints, and unclear leadership are driving notable projects away
- High-profile departures include Mitchell Hashimoto's Ghostty and other projects moving to Codeberg, signaling a potential shift that seemed unthinkable just years ago
- Returning to decentralized, self-hosted forges could restore autonomy but risks losing the archival function GitHub provided—issues, reviews, design discussions, and release notes are fragile and disappear when servers shut down
- The author calls for a well-funded, public archive for open source software independent of commercial platforms, focused on preserving source code, release artifacts, metadata, and project context
- The distributed nature of Git only protects the code itself; the social context that makes projects understandable and maintainable lives in centralized platforms and is more vulnerable than most developers realize
- Whatever comes next should make it easier to move projects and mirror their social context, harder for one company's decisions to become a cultural crisis for the entire ecosystem
Decoder
- Trac: Web-based project management and bug tracking system popular before GitHub, often paired with Subversion
- SourceForge: Early hosting platform for open source projects (founded 1999), once dominant but declined after GitHub's rise
- Subversion (SVN): Centralized version control system that required a single authoritative server, predecessor to Git
- Vendoring: Including third-party code directly in your own repository rather than depending on external package managers
- Pocoo: The author's open source collective for sharing server costs and infrastructure maintenance
- Codeberg: Non-profit, community-driven Git hosting platform based in Germany, emerging as GitHub alternative
- cgit: Lightweight web interface for Git repositories, used for self-hosted Git browsing
Original article
Open source was a much smaller world before GitHub, and projects had to run their own infrastructure.

Are Prediction Markets Good for Anything?
Analysis of billions in prediction market trading reveals platforms are serving gamblers rather than truth-seekers, and AI forecasters may soon make them obsolete.
Deep dive
- The author analyzed all markets on Kalshi and Polymarket from 2024-2026, filtering down to 6,797 potentially useful markets from 194,000 total, and found most volume concentrates on entertainment and gambling rather than information production
- Five potential benefits were examined: risk monitoring (tracking conflicts, pandemics), interpreting news (understanding impact of events), policy outcomes (predicting regulations), accountability (fact-checking claims), and novel information (discovering new knowledge)
- Risk monitoring markets show the healthiest supply-demand balance with 2,821 markets and $3.8 billion volume, particularly for geopolitical conflicts, and mainstream media increasingly cites these probabilities
- Health and climate markets failed despite strong theoretical support—COVID tracking markets on Kalshi averaged only $8,000 volume with major misses, suggesting no institutional adoption by hospitals or disease tracking bodies
- Markets on interpreting news have $1.25 billion volume but 85% is federal interest rates, which professional economists already forecast well, and median volume declined from $49,000 to $13,000 through 2025
- Accountability markets totaling $173 million are dominated by conspiracy speculation (two-thirds on Epstein files) and Trump betting, not serious politician pledges or legislative influence as envisioned
- Higher trading volume does correlate with better accuracy, but only for markets lasting 90+ days—shorter markets show no relationship between volume and accuracy, possibly because high-volume entertainment markets lack informed traders
- Useful market volume peaked at $534 million monthly around the 2024 election but plateaued at $466 million by early 2026, with median volume per market actually declining despite platform growth
- Accuracy improved until early 2025 then stagnated or declined, suggesting growth in sports and entertainment betting isn't spilling over to useful markets as theory predicted
- AI forecasting already outperforms most human traders using 2023-era models, and may surpass the best human superforecasters by late 2026 according to the Forecasting Research Institute
- The real bottleneck is distribution not aggregation—people prefer asking Claude about risks and futures because chatbots provide narratives, context, and strategic advice beyond just probabilities
- Even when less accurate, AI chatbots better serve information consumers because most decisions require social and political strategizing that prediction markets can't address, and people weren't built to think probabilistically
- The most viable path forward is if large betting volumes attract media coverage that normalizes probabilities in workplace discussions, building common knowledge through social consensus rather than direct market consultation
Decoder
- Futarchy: A proposed governance system where policies are chosen democratically but prediction markets evaluate whether they achieve stated goals, popularized by economist Robin Hanson
- Brier score: A measure of forecast accuracy that calculates the squared difference between predicted probability and actual outcome (0 is perfect, lower is better)
- Calibration: Whether forecasts match reality across many predictions—if you say 70% on 100 questions, roughly 70 should actually happen
- Bid/ask spread: The gap between the highest price buyers offer and the lowest price sellers accept, with the midpoint usually taken as the market's implied probability
- IARPA: Intelligence Advanced Research Projects Activity, the research arm of the U.S. intelligence community that ran early forecasting tournaments
- Superforecasters: Individuals who consistently outperform others and simple models at probabilistic forecasting, identified through research by Philip Tetlock
- Conditional markets: Prediction markets that forecast "If X happens, what's the probability of Y?"—useful for evaluating policy counterfactuals but technically difficult to implement
Original article
Are Prediction Markets Good for Anything?
We all know they're casinos. It's time to look at the data behind the froth.
In 2007, Nobel laureates Kenneth Arrow, Daniel Kahneman, and other notable scholars published a statement arguing that prediction markets could "substantially improve public and private decision-making." The theoretical foundations were deep.
Friedrich Hayek had argued in 1945 that markets aggregate dispersed, local, and tacit knowledge through the price system better than any central planner. In 2000, George Mason University economist Robin Hanson proposed a system he called futarchy, in which markets would be used to evaluate whether policies deliver on promises. Seventeen years later, Philip Tetlock, Barbara Mellers, and Peter Scoblic were championing forecasting tournaments as a way to generate useful policy knowledge for the intelligence community and to depolarize political debates.
Institutions including Google, Microsoft, the CIA, the wider U.S. intelligence community, and British government intelligence analysts have all experimented with internal prediction markets. Some of these trials were more successful than others, but all were small. And we know, from both theory and practice, that more bettors make markets more accurate. Hal Varian, Google's chief economist, likes to call prediction markets "information markets," and the bettors the "suppliers" of the information.
For decades, prediction market optimists — and I count myself among them — have argued that once we build better markets and increase the supply of bettors, accuracy will improve, and we'll all be able to benefit from a new level of societal foresight.
Now, in 2026, public prediction markets like Polymarket and Kalshi transact billions of dollars in volume each month. The vast majority of these bets are not on questions that might produce useful information. Roughly 90% of Kalshi's trading volume (dollars exchanging hands between bettors) is from sports betting, making Kalshi effectively a sports gambling website with a small prediction market attached. I find that over 80% of the trading volume on Polymarket is concentrated on sports, cryptocurrency prices, or election betting.1
Much ink has been spilled on the negatives — such as gambling addiction and insider trading — of the growing popularity of these markets. But what of their promise? Are they producing valuable information and making humanity wiser?

Demand, demand, demand
To understand how useful this supply of forecasts is, and whether the forecasts really are delivering on the vision of the progenitors of prediction markets, we need to think about another factor: demand.
It is entirely conceivable that prediction markets are only being used by bettors themselves. But if individuals, firms, media, and policymakers want (or need) the predictions we see on these markets, this evidence of demand can be used as a proxy for their usefulness. Vitalik Buterin, creator of the cryptocurrency Ethereum, summarized in Info Finance this dual nature of prediction markets: "If you are a bettor, then you can deposit to Polymarket, and for you it's a betting site. If you are not a bettor, then you can read the charts, and for you it's a news site."
I've thought hard about how to sell prediction markets to consumers. In 2020, I created Google's current internal prediction market. Since then, I've served as the CTO of Metaculus, a non-market-based crowd-forecasting website, and now run FutureSearch, a startup that provides AI forecasters and researchers. In my work, I've found that the benefits of prediction markets fall into five different categories.
First, markets can provide risk monitoring. I learned about COVID-19 in February 2020 from Metaculus, causing me to cancel a planned trip that would have left me stranded.
Second, they can help with interpreting news, showing whether, and how much, a current event might affect larger outcomes. For example, the closure of the Strait of Hormuz during the 2026 Iran war led to an increase (from ~25% to ~35%) in the forecasted chance of a 2026 US recession due to the spike in oil prices.
Third, they can inform planning around policy outcomes, such as whether TikTok will be banned in the US.2
Fourth, they could create accountability for claims made by political or business leaders. For example, in June 2025, when President Trump said he was contemplating a strike on Iran's nuclear program, many Middle East experts dismissed the prospect, according to an article from the Council on Foreign Relations. Yet, per CFR, prediction markets gave a 58% chance of strikes that week, and we later learned that seven B-2 stealth bombers were then on-route.
Fifth, they could produce novel information, allowing traders to discover or track things others don't, such as when major AI milestones will be reached.3
Now let's see whether the billions wagered on markets each month are supplying these five forms of useful information.


Risk-monitoring as a healthy information market
I'll start in the one area where the supply (bettors betting) and demand (readers reading) for information from prediction markets seem to be in balance: risk monitoring.
The most straightforward benefit from prediction markets comes from questions like "Pakistan military strike on India by Friday?" or "Will there be at least 10,000 measles cases in the U.S. in 2026?" or "US bank failure by January 31?" Tracking such risks was the domain of the first experiments with crowd forecasting in the US intelligence community, such as the IARPA tournaments, and of many of Philip Tetlock's later superforecasting studies.
Kalshi and Polymarket have a healthy number of such risk monitoring markets. I count 2,821 in total, with $3.8 billion in volume, of which geopolitical risk is the largest category. The median risk monitoring market has $82,000 of trading volume. Of these, 199 are conflict markets that resolve on a daily and weekly basis, creating a near-real-time escalation tracker.
Here, the demand is clear.4 For the 2026 Iran war, for example, energy traders and shipping companies are the most concrete beneficiaries of the predictions on outcomes and timelines. Importantly, demand comes from mainstream media, which increasingly5 cites Polymarket, bringing these forecasts directly to professionals in places they already look.
Useful as these markets are, they still have important blind spots. While journalists might cite prediction markets to track developments in an ongoing conflict, I haven't seen media sites reporting stories where prediction markets are the source. This is a function of how public, retail prediction markets work: a story must already be quite large to attract enough traders to produce useful probabilistic information. Therefore, I see evidence of useful monitoring of risks, but not detection of them.
Markets that don't tie into flashy news stories suffer from both less supply and less demand. Health and climate questions, which are arguably as important as conflict surveillance, have not fared well in prediction markets.
When Kalshi launched in July 2021, a year into the COVID-19 pandemic, it built exactly the kind of market that experts advocated: consistent, weekly questions about specific vaccine adoption numbers and COVID-19 case numbers. They averaged $8,000 per market, too low to be credible, and had several big misses. For example, "Germany COVID cases above 35K for week ending Dec. 28, 2021?" was trading at 3% a week before Omicron hit, and it was resolved as "Yes." And it seems no institutional consumer, like a hospital system or government disease tracking body, materialized to adopt the signal. Climate and natural disaster markets, where theoretical support is strong,6 tell the same story. The markets failed both to attract a supply of traders and the demand of response bodies or the public.
A second area where I see preliminary signs that a supply of good predictions could meet strong institutional and public demand is in the last of my five categories: generating novel information. There are some dozens of markets tracking AI, with $25 million in volume on questions that address which labs will have the top models on certain dates. It is not hard to imagine the people or organizations who would demand better information about emerging technologies.
However, if one examines these AI markets, it seems that they are too low-quality to be useful to anyone making a decision. I can't imagine that an individual who chooses a model provider, a firm that chooses a partner or supplier, or a policymaker who chooses an AI regulation would have much to learn from them.
It's clear that Polymarket and Kalshi host these markets to serve bettors, not to produce useful information. Take Kalshi's "Best AIs this week?" markets, which not only cover too short a time period to be useful in any decision-making, but also use Arena to judge the best AIs. Arena, which uses voting, not objective task scores, is not a credible measure according to AI experts. Still, demand for these markets does exist, and it's plausible that higher-quality markets could emerge in the future to satisfy it.
Where prediction markets are accurate but ignored
In three of the five categories of benefit from prediction markets — interpreting news, policy outcomes, and accountability — I see evidence that high-volume markets are producing accurate predictions, but not evidence that anyone is, or should be, paying attention.
First, how useful are markets for interpreting news? These are markets tracking larger outcomes like recessions or inflation that move in response to news, helping readers understand the impact of particular events.
Volume appears healthy, with 1,647 markets and $1.25 billion in total trading volume. However, 85% of that volume is in US federal interest rate markets. The median trading volume of markets for interpreting news has actually decreased substantially, from a high of $49,000 in early 2025 to just $13,000 by the end of the year, much lower than the median volume of other markets I categorize as useful.
While predicting interest rates is valuable, CME futures, Bloomberg consensus, and professional economists already do it. The same is true for other indicators with high trading volume on Polymarket and Kalshi: inflation, unemployment, commodity prices, mortgage rates. Aaron Brown calls prediction markets "economic oracles," but the oracle is largely saying what other oracles already say, just updated faster.
Still, there is a benefit to speed. On March 11, 2026, the Financial Times reported that, upon news of Iran War escalation, the Polymarket odds of inflation at or above 2.8% rose to above 90%. This illustrated an immediate domestic impact to US foreign policy, which could influence the public in a way that updates months later from professional economists might not.
Next, how useful are markets for judging whether claims by governments and CEOs are credible? I found 184 accountability markets with $173 million in total trading volume. The number of such markets is growing, as is the median trading volume, with a median $44,200 in bets.
But two-thirds of the total volume is Epstein file speculation, the type of activity that Rohanifar et al. (2026) diagnoses as "prediction laundering." It's hard to see any decisions changing based on these markets. Most of the rest are about one other person, US President Donald Trump,7 which feel like a temporary artifact of a particularly entertaining leader with credibility issues in the popular consciousness.
Finally, how useful are markets tracking policy outcomes? I found 1,710 markets with $1.42 billion in total trading volume. But the vast majority of volume is on a very small number of highly visible markets: $288 million on the possibility of a U.S. government shutdown, $238 million on whether Judy Shelton would be nominated as Fed chair, $145 million on whether TikTok would be banned in the US.
The median volume of markets is increasing, growing in 2025 from $24,000 to $30,000. The section I find most valuable are the 196 markets with $144 million volume on tariff policies.8 These are actionable in many places around the economy, and I think the wisdom of the crowds is producing novel, useful, accurate information on what tariffs will take effect at what level.
Overall, the markets on all three of these categories are dominated by betting on the Trump administration's volatile policies. As Robin Hanson has commented, "A random unpredictable US president has been very good for the prediction market industry." This doesn't seem to me the vision that academics hoped for: experts wagering on current events, leading to pledges made from serious politicians or influencing the most important bills faced by legislatures worldwide.
Markets driven by entertainment value and intrigue to bettors could plausibly deliver this, but I don't see much of it on Kalshi and Polymarket. The most charitable view is that these are growing pains, where the creation of a healthy information market is bootstrapped by gambling on Trump, and gradually evolves into the more professional betting environments on mature financial securities. Until then, though, I don't expect that people affected by policies will pay much attention.
We have another reason to doubt that the money changing hands across all of these markets is providing value. Metaculus, my former employer, has produced thousands of well-calibrated forecasts on global risks, health, and technology for over 10 years, with minimal institutional impact. Metaculus has even explored another item on the economists' wish list: "conditional markets" which ask "If policy X happens, what will outcome Y be?" Yet these also have not been adopted by information consumers, and there are serious technical barriers to adoption by predictors.
Still, the original vision for public benefit from prediction markets depends on them being highly liquid, and billions of dollars in liquidity can significantly change accuracy (or the perception thereof). Polymarket CEO Shane Coplan said Polymarket is "the most accurate thing we have as mankind right now", while Kalshi CEO Tarek Mansour advertises prediction markets as "quintessential truth machines". Let's look at whether trading volume leads to higher accuracy.
Whence volume comes accuracy
Coplan and Mansour did not invent prediction markets, but they are the first to create ones with billions of dollars of trading volume, so their claims of truth and accuracy depend on this feature. "On Kalshi, the goal is liquidity and accuracy," Mansour said in February, putting them hand-in-hand.
So, when one of these new generations of markets with millions of dollars wagered implies a 70% likelihood, does the event it tracks actually occur close to 70% of the time, as theory would predict?
The accuracy of a market is generally measured at a single point in time, but prediction markets have continually updated prices. For simplicity, I analyzed markets 7 days, 30 days, and 90 days before they settled. Markets also have bid/ask spreads, and the "probability" implied by the market is usually taken as the median between the price buyers and sellers are willing to trade. I then looked at two accuracy scores.9
Absolute accuracy is hard to compare across markets on one platform, and across platforms, because different forecasting questions have different difficulties. I addressed this by tracking similar markets on a single platform over time, where plausibly the only difference in accuracy would come from the change in volume of trading. Insufficient question overlap made it difficult to compare the real money markets to play-money or no-money markets like Manifold and Metaculus. What we can say is: even if highly liquid prediction markets are more accurate than previous forecasting methods, the liquid prediction market operators haven't demonstrated it. I find it unlikely that higher accuracy is a reason that people would prefer Kalshi and Polymarket to other forecasting methods.
I examined all markets on Kalshi and Polymarket from Jan 1, 2024 through March 8, 2026, and a sample of older markets on Kalshi for historical comparison. I filtered out categories I deemed as never useful.10 This filtered ~194,000 markets down to 13,500 markets. Then, I used FutureSearch tools to classify them into the five categories of potentially positive value, iterating on criteria until I was satisfied by the categorization. This led to a final set of 6,797 markets — 5,703 resolved and settled, and 1,094 still live and trading — that I see as potentially useful, if they were accurate and had the right audience.
Are markets with higher trade volume more accurate?
Yes, for markets that last 90 days or more, which is roughly a quarter of this sample. This holds for both useful and non-useful markets, and on both Polymarket and Kalshi.
Strikingly, markets that last less than 90 days (as judged by accuracy 30 days before resolution, and 7 days before resolution) did not show a statistically significant relationship between trade volume and accuracy. I suspect that as these markets mature, volume will predict accuracy. One possible explanation is that the higher-volume markets are on more entertaining topics with less informed traders, and it takes time for experts to move in. Another is that high-volume markets actually don't have many traders, with a few people wagering thousands of dollars each. "Wisdom of the crowds" does require a crowd.
Are "useful" markets getting more volume over time?
Useful market volume grew until late 2024, but has not grown in volume since. Total and median volume of useful markets grew dramatically from 2023 to late 2024. They peaked at $534 million per month around the 2024 U.S. election ($81,000 median and $2.3 million average per market), and is today around $466 million / month ($42,000 median and $1 million average per market). Volume is dominated by a very small number of hugely popular markets, and the median "useful" market is actually declining in trading volume.
Are "useful" markets getting more accurate over time?
Useful market accuracy improved until early 2025, but hasn't improved since.
This roughly follows the growth in volume, though accuracy improved after volume plateaued. (Market dates are shown by creation, not resolution, so volume that occurs months later is shown backdated to when the market was created.) And just as the median volume of useful markets has declined, so has accuracy (though not statistically significantly), which is now lower than it was in early 2025.

This reinforces the impression one gets from perusing both platforms. The huge growth in sports betting, crypto gambling, and entertainment markets is not consistently spilling over to "useful" markets, which are rare and neglected. It's possible that it will simply take more time for bettors on these "fun" markets to start betting on more useful ones. Google's 2005 prediction market was full of entertaining markets to encourage user adoption, and I did the same thing when I set up their current prediction market. We might see the same thing play out on Kalshi and Polymarket.
But while this is happening, another development is challenging the core premise that human incentives determine the supply of forecasts, and ultimately how people who demand this information discover and consume it.
You can't spell "futarchy" without "AI"
In January 2026, noted tech and rationality blogger Scott Alexander wrote:
There are now strong, minimally-regulated, high-volume prediction markets on important global events. In this column, I previously claimed this would revolutionize society. Has it? I don't feel revolutionized. Why not?
One way forward, he writes, is to create better prediction markets, perhaps by letting users on real-money platforms generate the questions themselves. (Currently, user-generated markets are only allowed on the play money site Manifold). "The second," he continues, "is to conclude that prediction markets' role in God's plan was only to provide the foundation for AI superforecasters." He then points out that the Forecasting Research Institute in October 2025 claimed that AIs might surpass the best human forecasters in late 2026.11
Those of us who work on AI forecasting are sympathetic to this argument. My company, FutureSearch, was the first to deploy AIs in a (play money) prediction market in January 2024. Even using forecasting approaches powered by GPT-4 Turbo and Claude 2, LLMs that are now considered quite unintelligent, we outperformed most human traders.
But I don't want to focus only on how AI forecasting might make prediction markets, or wisdom-of-the-crowds more generally, obsolete as a method of supplying forecasts. AI could also radically improve the way people access the forecasts they demand.
I claimed earlier that the value of risk monitoring markets mostly comes through the mainstream media reporting on these probabilities. If financiers, supply chain analysts, and policymakers see Polymarket probabilities in mainstream news, they don't need to check Polymarket (or even know what a prediction market is) to benefit from the information.
Likewise, a large number of individuals, firms, and policymakers get information from chatbots like ChatGPT, Claude, or Gemini. Chatbots are not (yet) trained to be accurate forecasters, but they already serve as a primary way that people get all five types of value from prediction markets, largely by making implicit forecasts:12
Risk monitoring: Ask ChatGPT about the biggest risks in your upcoming vacation or business plan.
Interpreting news: Ask Claude whether the new AI model release affects how work is being automated.
Policy outcomes: Ask Gemini to run a "Deep Research" report on whether the new tariffs will survive court challenges.
Accountability: Ask Grok whether Elon Musk will deliver on his most recent space flight promises.
Novel information: Any LLM can give you its best attempt to reason through any question you can imagine.
Try it yourself. Pick a topic that is important to you. Try searching Polymarket for probabilities, versus asking Claude about it. I wager you'll prefer Claude's take, even if it is less accurate.
For one thing, Claude can speak to issues that are not properly resolvable forecasting questions. People who demand information on geopolitics and technology do want accurate probabilities, but they also want narratives, histories, and the ability to ask followup questions. Often, accurate information is a good starting point, but the bigger constraints to wiser actions are social and political. Prediction markets can't help you strategize how to act on a good forecast. Claude can.
No forecasting technology fixes the fact that neither humans nor institutions were built to think probabilistically. But chatbots are a much more credible method of changing how people think about their decisions, and the forecasts implicit in them. And if AI forecasting also side-steps every other issue in using prediction markets to supply forecasts, from insider trading to resolution scandals to lack of liquidity, then AI can bootstrap the entire two-sided information market.
That said, even when Claude can forecast more accurately than the entire set of Polymarket traders, prediction markets might still serve some of the epistemic purposes that Kenneth Arrow, Daniel Kahneman, and others laid out in 2007.
By accelerating the adoption of probabilities by mainstream media, prediction markets help build common knowledge. It is conceivable that having large sums of money changing hands will make the markets increasingly newsworthy, and attract the attention of people who benefit from the predictions who would not have thought to ask Claude for advice on those topics.
I think most decisions by individuals, organizations, and governments are built around norms and social consensus, and highly visible prediction markets could influence people more than private conversations with chatbots. This, to me, is the most likely path towards the realization of the value of prediction markets: large amounts of betting leads to more mainstream media coverage of prediction markets, normalizing their use in workplace discussions, and ultimately decision making processes.
Decades ago, the grand vision of producing high quality public information was about aggregation of wisdom. Now, Polymarket, Kalshi, and even Metaculus have shown us that the bottleneck is distribution of wisdom. The evidence suggests that billion-dollar prediction markets, despite both their founders calling them "truth machines", are overwhelmingly in service of their traders (and their desire to bet on sports), not the seekers of truth.
Might the prediction markets use their billion-dollar valuations to now build out Vitalik Buterin's vision for "info finance"? Maybe. But I forecast that before they do, Claude will be the only forecaster anyone will ever want to ask about the future.
- Data for this article sourced on March 7, 2026 from the official Kalshi API (https://docs.kalshi.com/) and the official Polymarket API (https://docs.polymarket.com/).
- Policy outcome markets could include those that predict election results. But while many people first learned about prediction markets from such markets during the 2016, 2020, and 2024 US presidential elections, and while the outcomes of elections do influence policy, I don't find such markets useful. First, polls and non-crowd-forecasts give good odds already, and second, it's hard to see who would do something differently based on whether the Democrats have, say, a 45% chance of winning the US Senate in 2026 vs a 41% chance.
- Many markets that appear to produce novel information are in fact only making private information public. In 2026, OpenAI fired an employee for trading on prediction market platforms, and many other cases of such insider trading have been levied. Here, I am tracking the public production of genuinely new information. One sign that markets are producing new information is that they are long-term, like predicting the best new cancer drugs over the next 2 years. As I show later, even for questions I consider useful, most trading volume on Polymarket and Kalshi occurs on questions that resolve in less than 90 days, and for most short-term questions, the right insiders do probably have decisively better information.
- Why do people need prediction markets when they have futures markets, e.g. tracking the escalation of Iran War tensions via implied future prices of oil? The answer is that commodity futures and stock derivatives are too blunt as informational instruments. Prediction markets enable direct measurement of individual risks, which can be used to inform much more direct responses, such as routing a shipment away from a conflict area.
- Examples include: Reuters covering odds of China invading Taiwan (May 2025), Bloomberg covering Trump tariffs and the Supreme court (Oct 2025), the Wall Street Journal covering the odds of a ceasefire in the Iran War (March 2026) or the rapid fall of the Iranian regime (March 2026)
- Cerf et al. (2023) found that participating in a prediction market on climate outcomes increases support for costly climate policies. Roulston et al. (2025) found that a prediction market more accurately forecast the 2024 Atlantic hurricane season than other methods.
- Markets about which statements President Trump will follow through on do seem valuable to me, as market prices imply that some of his claims are more credible than others, such as the market tracking his June 2025 claims about strikes against Iran nuclear facilities. Perhaps future leaders will have such extreme accountability issues to warrant large betting markets about what they say.
- For example, in May 2025, after Trump announced retaliatory "liberation day" tariffs of well over 100% against China, Polymarket hosted "US-China tariff agreement before 90-day deadline?" which had $500k in trading volume. The market fluctuated around 60-80% throughout June, July, and August until the agreement was reached shortly before the deadline, and ultimately tariffs were far below the original 145%. Uncertainty around where tariffs would land was widely cited as a major business risk throughout the global economy.
- The simplest is Brier score, which tracks error between the implied probability (say, 0.35 for a 35% forecast) and what actually happens (say, 0 for "no"). I also looked at Weighted Mean Calibration Error, a measure of calibration error: if 100 markets say something is 70% likely, implying that 70 out of those 100 should happen, how many actually end up happening?
- On Kalshi, I filtered out these categories: Sports, Crypto, Financials, Climate and Weather, Entertainment, and Mentions, plus keywords that identified markets in those categories that weren't categorized properly. On Polymarket, I filtered out these tags: Crypto Prices, Up or Down, Crypto, Sports, Esports, Games, Bitcoin, Ethereum, Solana, XRP, Ripple, Weather, Equities, Stocks, Commodities, Celebrities, Movies, Music, Grammys, Awards, Mentions, Tweet Markets, Twitter, YouTube, and Earnings. You may wonder why I filter out "financials", "equities", "stocks", and "earnings." Surely these could be useful categories to forecast? In theory, these could be useful, especially earnings forecasts in particular are surprisingly poorly covered by the sell-side investment community. But in practice, I find them formulaic, and I think they exist to let bettors debate the efficient market hypothesis.
- 95% confidence interval: December 2025 – January 2028.
- OpenAI finds that about 81% of work-related messages map to just two broad work activities: (1) obtaining, documenting, and interpreting information; and (2) making decisions, giving advice, solving problems, and thinking creatively. Forecasting is likely a significant portion of the latter category. After all, how can one give advice without implicitly forecasting the outcomes of following that advice?

An update on GitHub availability
GitHub attributes recent platform outages to AI-driven development tools overwhelming its infrastructure capacity.
Original article
GitHub says recent outages were caused by rapid growth in AI-driven development, which has pushed the platform beyond its current scaling limits. The company is prioritizing reliability by expanding capacity, isolating critical systems, and reducing single points of failure to handle the surge.
Xbox Gets a New "North Star" and a Branding Shift, Exclusives Also Being Reconsidered
Xbox is pivoting to a multi-platform strategy focused on daily active users rather than hardware sales, potentially ending console exclusives and retiring the Microsoft Gaming brand.
Deep dive
- Xbox leadership is pivoting from console-centric metrics to daily active players as the primary business goal
- The new strategic pillars are "affordable, personal, and open," signaling a departure from premium hardware and walled-garden approaches
- Leadership has publicly acknowledged failures in pricing strategy, PC platform execution, and core platform features
- Rising development costs and competition from indie games are identified as major industry challenges
- The company is actively reviewing its approach to exclusivity and release windowing strategies
- AI integration is under consideration as part of the strategic review
- The Microsoft Gaming brand is being phased out in favor of unified Xbox branding across all properties
- This multi-platform expansion includes console, PC, mobile, and cloud gaming services
Decoder
- North star: A guiding metric that defines business success (in this case, daily active players rather than console units sold)
- Windowing: The practice of releasing games on different platforms at staggered times, often keeping games exclusive to one platform before expanding to others
Original article
Under new leadership, Xbox is redefining its strategy around being "affordable, personal, and open," targeting daily active players as its north star and expanding across console, PC, mobile, and cloud. CEO Asha Sharma and Xbox Game Studios head Matt Booty have acknowledged failures in areas like pricing, PC presence, and core platform features, while flagging rising development costs and indie competition as growing challenges. Exclusivity, windowing, and AI are also under review. The Microsoft Gaming brand is being retired in favor of the Xbox name.

Output isn't design
Design is fundamentally about understanding the fit between form and context, not just generating outputs, and AI tools risk creating polished but brittle products by skipping the iterative thinking process.
Deep dive
- The core misunderstanding in the industry is treating design as the act of producing artifacts rather than understanding problems deeply enough to know what should exist and how
- Christopher Alexander's concept defines design as finding good fit between form and context, where context is the full set of forces including human needs, technical constraints, conflicting requirements, and edge cases
- AI tools generate plausible outputs quickly but don't help you understand underlying problems, and often do the opposite by encouraging you to skip problem-shaping
- Products built this way look impressive initially but unravel during actual use because they're brittle, poorly integrated, and full of unresolved decisions
- Visual design work is valuable because it's slow enough to allow thinking, and the act of moving things around and testing relationships is part of how clarity emerges
- The process parallels writing: asking AI to write produces text but doesn't rearrange your thinking, whereas writing yourself forces you to organize ideas
- The gradual understanding that comes through doing the work is where design value lives, not just in the final output
- AI can still be useful for prototyping, exploration, and generating surprises, but that's different from design itself
- Real design still requires judgment, conversation, tension, and time to work through the complexities
- The risk is mistaking generated form for solved problems when the underlying fit hasn't been achieved
Decoder
- Form and context fit: Christopher Alexander's framework where design is the search for alignment between what you're creating (form) and all the forces that shape the problem (context: needs, constraints, edge cases, relationships)
- Misfits: Points where the form doesn't properly address the contextual forces, resulting in bad design
Original article
Design isn't about producing outputs but about deeply understanding a problem and achieving a good fit between form and context. Tools (including AI) can generate results quickly, but they don't replace the thinking required to resolve underlying complexities. Overreliance on AI risks creating polished yet fragile products, because real design value comes from the slow, iterative process that clarifies understanding—not just the final output.
Doodles AI (Website)
Doodles launches Prism 1.0, an AI image transformation tool that processes uploaded images through a branded visual style in seconds.
Original article
Transform your imagination into studio-grade visuals. Input any image and see it refracted through Doodles lens in seconds.

Pitaka is Letting the World Design its Next Phone Cases, Royalties Included. Here's How to Participate
Phone case maker PITAKA is running a global design competition where winners can earn royalties on commercialized texture patterns for their aramid fiber accessories.
Decoder
- Aramid fiber: Synthetic fiber used in bulletproof vests and aerospace components, five times stronger than steel at a fraction of the weight
- Fusion weaving: PITAKA's technique where multiple weave patterns coexist on a single loom to create layered surface designs
- 600D/1500D: Denier ratings indicating aramid fiber density and thickness (higher number means thicker, more durable fiber)
Original article
PITAKA is launching a global design competition, "Weave the Next, Weave Our World," from April 24 to May 25.
The Hitchhiker's Guide to Onchain Credit
A comprehensive taxonomy maps 160+ protocols across the onchain credit ecosystem, categorizing how traditional credit products are being tokenized and integrated into DeFi.
Deep dive
- Credit Issuance layer includes institutional giants like Apollo ($938B+ AUM) tokenizing private credit funds as feeder tokens ($ACRED, $ACRDX) accessible only to KYC-accredited investors, but these assets become DeFi collateral on platforms like Morpho and Kamino
- Figure leads tokenized offchain credit by using its Provenance blockchain to originate and track Home Equity Lines of Credit (HELOCs), reducing funding cycles from months to days and saving ~120 basis points in costs through eliminated intermediaries
- Onchain origination protocols like Maple Finance ($syrupUSDC yielding 4.8%) extend overcollateralized crypto-backed loans to institutions, while newer models like Cap use shared security networks (Symbiotic) for collateralization instead of traditional crypto assets
- InfraFi and PayFi represent emerging niches: InfraFi protocols (USDAI, Daylight) finance physical infrastructure like GPUs and solar panels, while PayFi protocols (Credit Coop, BlackOpal) offer asset-backed financing from payment receivables with yields exceeding 10% APY
- Sky ecosystem dominates capital allocation with Agent protocols like Grove Finance deploying $586.6M across onchain credit assets, contributing to Sky's 3.65% savings rate and playing an outsized role in market liquidity
- Vault curators like Steakhouse Financial actively manage risk and allocate liquidity across money markets, though allocations shifted drastically following the recent Aave exploit mentioned in the article
- Money markets provide critical infrastructure: Morpho and Kamino lead in onchain credit collateral activity, enabling high-yield assets to be borrowed against and looped, with rates doubling the average DeFi lending rate (over 6% vs. under 3%)
- Liquidity remains the biggest risk management challenge: protocols like 3F and Multiliquid are building mechanisms for instant redemption and liquidation by purchasing distressed assets at discounts and holding through redemption cycles
- Tranching protocols like Cork split yield-bearing tokens into junior (higher risk premium) and senior (protected) tranches, with the spread itself helping price the underlying risk being transferred between participants
- Reserve verification uses zero-knowledge proofs: Accountable offers real-time proof-of-solvency data feeds verifying total offchain and onchain assets while preserving privacy through cryptographic proofs
- Shared security networks are entering credit: Symbiotic and Eigen's restaked assets now provide risk coverage for protocols like Cap and Catalysis, representing a novel approach to insurance beyond traditional models like Nexus Mutual
- The taxonomy reveals infrastructure gaps: while tokenization and issuance are well-developed with 67 players across Credit Issuance alone, risk management (especially liquidity and coverage) remains less mature with only 29 players total
Decoder
- InfraFi (Infrastructure Finance): Protocols that source onchain capital to finance real-world physical infrastructure like GPUs, solar panels, and batteries
- PayFi (Payment Finance): Protocols providing asset-backed financing secured by payment receivables, similar to factoring in traditional finance
- SPV (Special Purpose Vehicle): A legal entity created to hold specific assets or investments, isolating financial risk from the parent company
- HELOC (Home Equity Line of Credit): A revolving credit line secured by home equity, allowing homeowners to borrow against their property value
- Represented Assets: Tokenized assets that cannot be freely transferred between wallets, serving mainly as proof of ownership
- Distributed Assets: Tokenized assets that can be transferred and used across DeFi protocols, enabling composability
- Tranching: Splitting a financial product into tiers with different risk/reward profiles, where junior tranches absorb losses first in exchange for higher yields
- NAV (Net Asset Value): The per-share value of a fund calculated by dividing total assets minus liabilities by number of shares
- Proof-of-Reserve: Cryptographic verification that an entity holds the assets it claims to hold, without revealing sensitive details
- Restaking: Reusing already-staked tokens as collateral for additional services or security guarantees, pioneered by protocols like EigenLayer
- Vault Curator: An entity that actively manages and allocates capital across different DeFi positions on behalf of depositors
Original article
There are over 160 startups, protocols, and institutions across the onchain credit ecosystem, categorized into four main layers. These are Credit Issuance, Capital Allocation, Infrastructure, and Risk Management, with 19 sub-categories. The Credit Issuance layer spans institutional credit funds, tokenized offchain credit, and onchain origination models, including overcollateralized lending, P2P, InfraFi, and PayFi. This report provides a useful mental model for anyone trying to understand who the players are, which categories matter, and where the gaps remain in the onchain credit stack.
No One Cares About Crypto Research
Crypto research firms lost their information advantage as AI made basic reports nearly free to produce, but institutional demand for expert judgment has surged in response.
Decoder
- DeFi: Decentralized Finance, financial services built on blockchain without traditional intermediaries
- Onchain: Activities or data recorded directly on a blockchain ledger
- Tokenization: Converting real-world assets into digital tokens on a blockchain
- Stablecoins: Cryptocurrencies pegged to stable assets like the US dollar
Original article
AI has pushed the cost of producing average crypto research to near zero, flooding the market with low-quality content and eroding the price-moving influence that early firms like Messari and Delphi Digital once carried. Institutional advisory demand has nonetheless accelerated through 2026, as organizations entering blockchain seek judgment and perspective rather than information aggregation. Four Pillars is responding by restructuring into five divisions (Crypto, Asia, Institution, Investment, and Tech) and announcing a Series A to reposition around perspective-driven, high-conviction coverage.

Institutions Have Lost Trust in Pool/Hub DeFi Models
Institutions are demanding a fundamental shift in DeFi architecture away from shared pool models toward isolated, customizable risk controls.
Decoder
- Pool/hub models: DeFi architectures where multiple users share the same liquidity pool and smart contracts, creating shared risk exposure
- Isolated risk controls: Separate vaults or contracts that allow institutions to customize parameters and limit exposure to other participants
Original article
Confidence in pool/hub DeFi models has collapsed, with institutions demanding isolated risk controls and code-level compliance flexibility.

Multiliquid Launches Carry for Institutional RWA Liquidity
Multiliquid launched Carry, a platform that lets institutions provide on-demand liquidity for tokenized real-world assets that are otherwise illiquid.
Decoder
- RWA (Real World Assets): Traditional financial assets like bonds, securities, or commodities that have been tokenized and represented on blockchain networks
Original article
Carry is a liquidity management platform that targets institutional capital allocators, letting operators spin up RWA liquidity facilities with configurable pricing, risk parameters, and multi-asset, multi-venue deployment from a single dashboard.
Curious cases of financial engineering in biotech
Financial engineering in biotech is making drug development failure more survivable through portfolio diversification, synthetic royalties, and even liquidation markets for failed companies, but may be reshaping what kinds of medicines get funded.
Deep dive
- Andrew Lo's 2012 thesis argued bundling 50+ uncorrelated drug programs with $5-15B funding makes individual 95% failure rates survivable—if one hits, it pays for all failures, turning terrible individual bets into sound portfolio math
- BridgeBio and Roivant implemented this as hub-and-spoke models where subsidiary companies each pursue one drug, failures die without killing the parent, but Centessa's attempt failed and they pivoted to single-asset focus after market crash
- BridgeBio's stock dropped 72% when lead drug acoramidis failed primary endpoint, proving markets don't actually believe in portfolio diversification theory—though the drug later succeeded on secondary endpoints and got approved as Attruby
- The bond-market component of Lo's vision never materialized because biotech lacks institutional infrastructure like a Moody's for drug risk assessment or Fannie Mae equivalent to securitize biopharma loans for pension funds
- Royalty Pharma pioneered buying drug royalty streams from universities and small biotechs, creating $2.38B in annual revenue from what is essentially a filing cabinet of contractual claims on approved drugs
- Synthetic royalties are manufactured financial obligations where biotechs sell a percentage of future drug sales that didn't previously exist, growing 33% annually and reaching $2B in the Revolution Medicines deal for daraxonrasib
- The Revolution royalty is tiered and drops to zero above $8B in annual sales, showing sophisticated structuring where both sides optimize for different probability scenarios
- Priority Review Vouchers were created in 2007 to incentivize neglected disease work by offering faster FDA review, but largely failed because even $350M peak value isn't enough to shift pharma portfolios and it rewards approval not patient access
- CVRs create perverse incentives when acquirers must compete against themselves—Sanofi allegedly slow-walked Lemtrada (acquired from Genzyme) while pushing its own competing MS drug Aubagio to minimize $3.8B in CVR payouts
- XOMA pivoted from traditional biotech to buying zombie companies trading below cash value, then selling off their clinical data, patents, and partially completed programs—doubling money on Kinnate acquisition by selling five pipeline assets for $270M
- Concentra Biosciences aggressively forces distressed biotech boards into liquidation by accumulating minority stakes and making offers boards can't refuse without violating fiduciary duty, leading to 84% workforce reduction at Jounce
- The zombie biotech liquidation market is finite, mostly 2020-2021 IPO bubble casualties trading below cash, representing how financial engineering has now colonized even dead and dying companies
- Financialized biotech (BridgeBio, Roivant, royalty-backed programs) represents only ~2% of biotech funding currently, suggesting the market may be self-limiting with finite rare-disease opportunities
- The 2025-2030 patent cliff threatens $300B in revenue (one-sixth of industry annual revenue), 3x larger than 2010s cliffs, potentially pushing Big Pharma toward lower-risk diseases and more synthetic royalty agreements
- The core worry is not that financial engineering is bad, but that it's so legible to capital markets that money flows there exclusively, diminishing institutional capacity to fund illegible, expensive, likely-to-fail biology that occasionally produces revolutionary medicines
Decoder
- Hub-and-spoke model: Corporate structure where a parent holding company creates subsidiary companies, each with separate equity and focused on single drug programs, so individual failures don't kill the parent
- Synthetic royalty: A manufactured financial claim on future drug revenues created specifically to raise capital, not from original licensing agreements—biotech sells percentage of future sales that didn't previously exist as an obligation
- PRV (Priority Review Voucher): Tradable voucher awarded for developing neglected disease treatments that grants faster FDA review (6 months vs 10 months), can be sold on secondary market with prices ranging from $21M to $350M
- CVR (Contingent Value Right): Conditional payment in M&A deals where acquirer pays target shareholders additional amounts if acquired drug hits specified milestones—sometimes structured as tradable securities
- Zombie biotech: Publicly traded biotech company whose stock trades below the cash on its balance sheet, meaning the market values its IP, team, and clinical programs as worse than worthless
- Poison pill: Anti-takeover defense where if acquirer crosses ownership threshold (typically 10%), other shareholders get rights to buy discounted shares, instantly diluting the acquirer's stake
- Patent cliff: Period when many drug patents expire simultaneously, exposing pharmaceutical companies to generic competition and massive revenue loss—2025-2030 cliff threatens $300B
Original article
Finance doesn't really make drug development easier. However, it does make failure more survivable. Financialization is just the process of making implicit economic relationships explicit and tradable. Having more liquid markets for biotech risk is almost certainly better than having fewer. The industry being willing to fund biology that's expensive and likely to fail could result in more discoveries that change the world.

Antibiotics Are an Economic Failure
Antibiotic resistance kills millions annually, but the real bottleneck isn't scientific discovery—it's that antibiotics are economically unviable for pharmaceutical companies to develop.
Deep dive
- Antibiotic resistance caused 4.95 million deaths in 2019 (more than HIV or malaria), yet AI models have "essentially solved" the molecular discovery problem according to researchers
- The crisis stems from two factors: social practices (agricultural overuse, over-the-counter availability in developing countries) and economic incentives that make antibiotic development unprofitable
- Developing a new antibiotic costs an estimated $2.6 billion but faces a catch-22: if reserved as last-resort treatment, few doses sell during the patent window; if widely prescribed, resistance develops quickly and sales drop
- Antibiotics are prescribed for days while chronic disease drugs generate revenue for years, and patents often expire before drugs transition from reserve to widespread use
- Of 38 major antibiotic groups known today, 28 were discovered between the 1940s and 1970s; modern pharmaceutical companies have largely abandoned the field
- "Push" incentives (government R&D funding like CARB-X) have failed to increase the pipeline, which has remained stuck in the low 40s since 2014
- Startup Achaogen's 2019 bankruptcy exemplified the problem: after $500 million in funding and FDA approval, their antibiotic generated only $800,000 in six months before collapse
- "Pull" incentives aim to guarantee returns: UK NHS pays £10 million annually for 10 years via subscription model; US PASTEUR Act (proposed 2020, still pending) would authorize $75-300 million annual subscriptions
- The EU approved 12-month patent extensions for new antimicrobials in late 2025, transferable to other drugs in a company's portfolio
- Gepotidacin's December 2025 FDA approval (first new gonorrhea antibiotic since 1987) succeeded due to resistance-averse dual-enzyme mechanism, clear market demand (300,000+ US gonorrhea cases annually), GSK retaining in-house expertise, and $200+ million in government funding
- The colistin case study shows how agricultural use undermines clinical antibiotics: banned from human use due to toxicity but used as livestock growth promoter until resistance genes (MRC-1) jumped to plasmids in 2015
- Market entry awards and advanced market commitments (which funded pneumococcal vaccines, saving 700,000 lives) are being considered but don't decouple profit from volume like subscriptions do
- Best near-term solution is stewardship: reducing agricultural antibiotic use, improving healthcare capacity in developing countries, and ensuring careful prescription practices
Decoder
- Push incentives: Government or nonprofit funding provided during R&D phase to reduce development costs and risk
- Pull incentives: Financial guarantees or rewards that activate when a drug reaches market, ensuring companies can recoup investment
- CARB-X: Combating Antibiotic-Resistant Bacteria Biopharmaceutical Accelerator, a public-private partnership funding antibiotic development
- PASTEUR Act: Pioneering Antimicrobial Subscriptions to End Upsurging Resistance, proposed US legislation for subscription-based antibiotic purchases
- Plasmid: Circular DNA molecule separate from chromosomes that bacteria can exchange, enabling rapid spread of resistance genes
- Topoisomerase: Enzymes that manage DNA supercoiling during replication; gepotidacin requires mutations in two types simultaneously for resistance
- Advanced market commitment: Promise to purchase a specified quantity at a set price once a product is developed, de-risking R&D investment
- Market entry award: Lump-sum payment when a drug successfully reaches market, regardless of sales volume
- Patent exclusivity: Period during which only the patent holder can sell a drug before generic manufacturers can compete
Original article
The discovery of antibiotics enabled many of our modern medical procedures, including many routine surgeries and immunosuppressant treatments such as chemotherapy. Antibiotic resistance is considered to be one of the greatest public health threats to humanity. If a new antibiotic entered the market, it would either be used as a last line of defense, which means few doses would be sold, or it would be widely used until resistance developed again, after which sales would drop. Antibiotics are only used for a few days, so there's little profit potential. These factors mean there's less money in developing and selling antibiotics compared to drugs for chronic diseases.
A New Type of Neuroplasticity Rewires the Brain After a Single Experience
Scientists have discovered a new form of neuroplasticity that rewires brain connections after a single experience, challenging 70 years of learning theory that required repeated exposure.
Deep dive
- Jeffrey Magee's team discovered BTSP in 2014-2017 while studying dendritic activity in live rodent hippocampi, initially observing that place cells fired after just a single dendritic plateau potential rather than requiring multiple repetitions as Hebbian theory predicted
- The key difference is temporal: Hebbian plasticity strengthens connections between neurons that fire within milliseconds of each other, while BTSP can strengthen synapses active 6-8 seconds before or after a plateau event, spanning tens to hundreds of milliseconds
- BTSP works through a two-step process: synapses get tagged with biochemical "eligibility traces" that persist for several seconds, then a dendritic plateau potential causes a widespread voltage change that strengthens all tagged synapses simultaneously
- The mechanism involves dendritic plateaus triggering a cascade of biochemical signals over several seconds that activate CaMKII protein, which physically increases surface area and receptors on dendrites to strengthen synaptic connections
- This explains one-shot learning scenarios where survival depends on immediate memory formation, such as remembering the location of food or threats after a single exploration of an environment
- BTSP may solve the "credit assignment problem" in neuroscience—how the brain determines which specific neurons should encode a given experience, since it strengthens only relevant active neurons rather than all active neurons
- The discovery faced initial pushback for challenging nearly 100 years of Hebbian dogma, but researchers have increasingly validated it in recent years through independent studies
- Current evidence shows BTSP occurs in the hippocampus during spatial learning, with some evidence in the neocortex, though not all hippocampal cells exhibit this behavior
- Some researchers question whether BTSP is truly non-Hebbian since Donald Hebb never specified millisecond timescales in his original theory, only that neurons need to repeatedly fire together
- Most neuroscientists now view BTSP as complementary to Hebbian learning: Hebbian plasticity may handle initial brain wiring during development, while BTSP specializes in forming episodic memories in adults
- The molecular mechanism remains partially speculative, with ongoing research examining how eligibility traces work at the biochemical level
- Magee and others are investigating BTSP's role not just in initial learning but also in memory consolidation processes
- The discovery demonstrates that dendrites, previously seen as passive signal receivers, actively drive neuroplasticity and enable individual neurons to perform computations as complex as deep artificial neural networks
Decoder
- BTSP (Behavioral Timescale Synaptic Plasticity): A neuroplasticity mechanism that strengthens neural connections across seconds rather than milliseconds, enabling learning from single experiences
- Hebbian plasticity: The dominant 70-year-old theory that "neurons that fire together, wire together" when activated within milliseconds of each other through repeated exposure
- Dendrites: The branching arms of neurons that receive signals from other neurons and can fire their own electrical spikes
- Plateau potential: A sustained period of elevated electrical charge in dendrites lasting tens to hundreds of milliseconds without fully firing
- Hippocampus: The brain's memory hub where experiential memories are formed
- Place cells: Neurons in the hippocampus that fire when an animal is in specific locations in its environment
- Synaptic plasticity: Changes to the connections (synapses) between neurons that underlie learning
- Eligibility traces: Temporary biochemical tags at synapses that mark recently active neurons as relevant to an experience
- Credit assignment problem: The challenge of determining which specific neurons should encode a particular experience
- CaMKII: A protein crucial for learning that strengthens synapses by increasing receptors and surface area on dendrites
Original article
A New Type of Neuroplasticity Rewires the Brain After a Single Experience
"Neurons that fire together, wire together" is not the full story. A novel mechanism explains how the brain can learn across longer timescales.
Introduction
Every experience we have changes our brain, the way a ceramicist reshapes a slab of clay. Every corner we turn, every conversation we have, every shudder we feel causes cascading effects: Chemicals are released, electricity surges, the connections between brain cells tighten, and our mental models update.
The brain is "incredibly plastic, and it stays that way throughout the lifespan of a human," said Christine Grienberger, a neuroscientist at Brandeis University. This plasticity, the quality of being easily reshaped, makes the brain really good at learning — a quintessential process that allows us to remember the plotline of a novel, navigate a new city, pick up a new language, and avoid touching a hot stove. But neuroscientists are still uncovering fundamental rules that describe how neuroplasticity reshapes brain connections.
Recently, neuroscientists described a new form of neuroplasticity that might be helping the brain learn across a timescale of several seconds — long enough to capture the behavioral process of learning from a single experience. In two recent reviews, published in The Journal of Neuroscience and Nature Neuroscience, they describe "behavioral timescale synaptic plasticity," or BTSP. This type of learning in the hippocampus, the brain's memory hub, is caused by an electrical change that affects multiple neurons at once and unfolds across several seconds. Researchers suspect that it may help the brain learn in a single attempt.
"It's pretty clear that [BTSP is] a strong, powerful mechanism that can lead to immediate memory formation," said Daniel Dombeck, a neuroscientist at Northwestern University who was not involved with the theory's development. "It's something that has been missing in the field for a long time."
By uncovering BTSP, neuroscientists have unraveled more of the story of how the brain changes with experience, bringing us closer to understanding how learning happens. "Neuroplasticity is … one of the last frontiers of the brain," said Attila Losonczy, a neuroscientist at the University of Texas Southwestern Medical Center who studies BTSP. "If we understand this, I think we take a major step towards understanding how the brain works."
A Plastic Brain
Today, neuroplasticity is taken as fact, but for much of the 150-year history of neuroscience, the adult brain was thought to be static. "The idea that the adult brain can change wasn't actually widely accepted until very late [in] the history of modern neuroscience," said Moheb Costandi, a trained neuroscientist and author of Neuroplasticity, a primer from MIT Press. "It was taken for granted that the adult human brain can't change." In 1928, Santiago Ramón y Cajal, the oft-cited founder of modern neuroscience, wrote that "in adult centers the nerve paths are something fixed, ended, immutable." This idea would prevail well into the middle of the 20th century.
We now know that the brain is constantly remolding itself, both functionally and structurally, across many scales — from the molecules that flow between neurons to the connections that stretch across the brain and beyond.
The power of neuroplasticity is perhaps best demonstrated by case studies. One patient born without an olfactory bulb could smell because other parts of her brain remolded to serve as substitutes. Another patient had the entire left side of her brain removed as a baby; after her right side reorganized to take on the left's former roles, today she has a functional life. When a stroke or an accident damages the brain, other neurons fill in to recover patients' everyday functions such as speaking and walking.
Neuroplasticity also drives everyday learning. This process is mainly thought to result from synaptic plasticity, or changes to the trillions of connections between neurons. And although the brain learns in various ways, one particular idea has dominated for more than 70 years.
In 1949, Donald Hebb, a Canadian psychologist, articulated a theory of learning now known as Hebbian plasticity. According to this model, when neurons are activated within milliseconds of each other, the connection between them is physically strengthened, so that in the future they are more likely to fire together. Over time, they form a network that represents a concept or an experience. In other words, the more the networks in the brain are used, the stronger they get, an idea often summarized as "neurons that fire together, wire together."

But neuroscientists "always had a sneaking suspicion that Hebbian plasticity wasn't quite right," said Jeffrey Magee, a neuroscientist at Baylor College of Medicine. Or at least, it wasn't the full story. It required an experience to be repeated multiple times to imprint the lesson on the brain — a framework that may explain how we learn a new city or language, but not how we learn from a single, highly charged experience, such as touching a hot stove.
Even so, finding more explanatory mechanisms hasn't been top of mind for neuroscientists. "It wasn't a quest, like in particle physics for missing particles," Losonczy said. Maybe there were a couple of gaps that needed to be filled, but most researchers assumed that the Hebbian framework would require only tweaks. Few were thinking that a fuller understanding of neuroplasticity might include a new mechanism.
Mighty Trees
In 2014, when Magee attached electrodes to rodents to record their neural activity, he wasn't looking to challenge Hebbian plasticity. Magee, then at the Howard Hughes Medical Institute's Janelia Research Campus, and his students Grienberger and Katie Bittner were looking to observe the behavior of neurons' arms, called dendrites, in a living animal.
These branches receive molecular signals at one end of a neuron and induce the cell to rapidly fire an electrical charge that ripples down the cell body, known as an action potential. This process ends with the neuron releasing its own batch of molecular signals, which latch onto the dendrites of the next neuron in the network, continuing the process.
In recent decades, neuroscientists have come to a "slow realization that dendritic activity is super important for plasticity and for neuronal computations in general," said Antoine Madar, a postdoc at the University of Chicago, who led the 2025 review of a Society for Neuroscience symposium on BTSP in The Journal of Neuroscience.
There is a "zoo" of different events that take place at dendrites, he said. They can fire their own local or global electrical spikes. They can cover a larger or smaller area, and they can surge for longer or shorter periods of time. Neuroscientists have found that these events at dendrites can allow even single neurons to perform complex computations — meaning that dendrites are the reason why a single neuron can have the same amount of computational power as a deep artificial neural network.
Still, there was much unknown about dendrites' behavior. Neuroscientists have mainly characterized them in brain slices, where neurons are alive and can be activated but aren't attached to a living animal. "We were trying to take that into the actual behaving animal, or the actual behaving brain," Magee said.
In 2014, they began to home in on the hippocampus, an especially plastic area of the brain where we form experiential memories. It's also home to place cells, which fire when an animal moves through its environment. Each of these neurons learns to fire at specific locations; later, if the rodent reenters that place, the cell will fire, recalling relevant information stored in the network.

As the rodents ran on a circular track, Magee and his team recorded what was happening in their hippocampal dendrites. That's when they observed something interesting.
Neuroscientists had long known that dendrites can sometimes stay active, with a slightly higher charge than when they're resting, for long periods of time without firing — creating what's known as a plateau potential. Because a plateau potential increases the odds that the neuron will fire, the activity was considered important to neuroplasticity. But while examining the rodent data, Bittner saw that place cells whose dendrites had produced just a single plateau potential began to fire.
In other words, a single burst of activity at the dendrite had tuned that cell to fire in that location. It was previously thought that encoding a place cell would take multiple action potentials, via Hebbian learning, which would require the animal to explore the same spot multiple times.
"So we were like, 'Wow, what's going on here?'" Magee said. When they experimentally triggered these plateaus, the cells fired in that location 99.5% of the time after a single dendritic plateau.
The researchers were elated. "We were kind of running back and forth between offices, like, you know, waving papers around — like, 'Look at this result,'" said Aaron Milstein, a neuroscientist at Rutgers University, who worked in Magee's lab at the time. It seemed that dendrites weren't just passively nudging a neuron to fire — they were causing the change themselves, strengthening the synapse in a single, swift step.
Magee and his team published their findings in 2015. At that point, they thought they had observed some weird subtype of Hebbian plasticity. But when they looked more closely at brain recordings of live animals plus brain slices, they recognized the biggest difference between the dendrites' activity and Hebbian plasticity: time.
In most studies of Hebbian plasticity, neurons can strengthen or weaken their connection if they are activated within milliseconds of each other. Dendrites' plateau potentials, on the other hand, persist for tens to hundreds of milliseconds (sometimes approaching one second), and through BTSP they can strengthen synapses active six to eight seconds before or after the plateau event.
"It became pretty obvious that this wasn't at all the standard kind of Hebbian plasticity," Magee said. "That made it even more interesting, of course, and a little bit intimidating, because then we were going to be facing up to nearly 100 years' worth of dogma."
It also addressed another big question that Hebbian plasticity had left open: how our cells can capture our relatively slow human behaviors.
"If you imagine even the simplest of the behavioral learning — for example, learning to stop at a red light signal, or to even explore and figure out what are the main parts in a particular room — it will take you at least a few seconds," said Anant Jain, a neurophysiologist at the Center for High Impact Neuroscience and Translational Applications in India. BTSP explains how the brain can encode behaviors in a single burst of brain activity that unfolds across several seconds.
Because this new mechanism seemed more behaviorally relevant than Hebbian learning, Magee named it "behavioral time scale synaptic plasticity" in a 2017 Science paper. "I'm not very good at naming things," he admitted. Then he waited for the response from fellow neuroscientists.
One-Shot Learning
Initially, BTSP received pushback within the field. There was good reason for that, Magee said, as it challenged the dogma of neuroplasticity that had dominated for decades. But over the past few years, other researchers have started to investigate it themselves.
This is "a very compelling model for single-shot learning," said Losonczy, who worked in Magee's lab prior to the discovery and now studies BTSP at his lab. Unlike the mechanisms that allow an animal to learn a new skill slowly, BTSP might help it to learn — after just a single exploration of its cage — that food exists in the northwest corner or that a shock exists to its south. "Sometimes you need to remember events you only have one chance to remember, [such as] where the predator is," Losonczy said. "Otherwise, you will be taken out of the genetic pool."
While it's a neat explanation, the exact mechanism remains elusive. "There are still so many unanswered questions, at least at the level of molecules," Jain said. However, neuroscientists are starting to get some hints.
Early findings suggest that certain experiences cause synapses, the gaps between neurons where dendrites extend, to be tagged with elusive biochemical signatures called eligibility traces. These tags stick around for several seconds and indicate that those neurons were recently active and therefore relevant to a particular experience. Then, in the next neuron, a dendritic plateau potential causes a widespread voltage change that spreads across the entire dendrite. This plateau triggers all the synapses with the eligibility trace to strengthen.
Some studies are starting to zoom in on the molecular process. In 2024, Jain and his team reported that dendritic plateaus might cause a cascade of biochemical signals to build up over several seconds and then activate one of the most important proteins for learning, known as CaMKII. This protein directly influences synaptic strength by physically increasing the surface area and the number of receptors on dendrites, allowing more neurotransmitters to bind there the next time the cell fires.
BTSP may also address an ongoing conundrum in neuroscience. Because it strengthens only relevant active neurons, as opposed to any active neuron, BTSP may help address the "credit assignment problem" — how the brain can tell which neurons should encode a given experience. Now, Magee and others are looking into the role that BTSP might play not only in learning but also in consolidating memories.
However, Dombeck is cautious about overreaching on BTSP's significance. It has been observed in limited circumstances: only in the hippocampus as an animal learns locations (although researchers have found some evidence for BTSP in the neocortex, where the brain's higher-order processes happen). In his lab, Dombeck has found that BTSP occurs in some hippocampal cells, but not in all of them.
Jain is not even convinced that BTSP should be categorized as a non-Hebbian type of learning. Hebbian learning is often vaguely defined, and Hebb himself was vague about the timescales upon which it works. "Donald never really specified that it has to happen within milliseconds," only that the neurons need to repeatedly fire together, he said. Only later did neuroscientists mechanistically refine it to include millisecond timescales, Jain said.
Most neuroscientists agree that BTSP doesn't replace Hebbian learning, but rather works alongside it. "Hebbian plasticity probably plays a huge role in development, in the initial wiring" of the brain, Grienberger suggested, while BTSP may be more important for forming episodic memories in adults.
There's still much unknown about BTSP, especially the mechanism, which Madar said is "quite speculative." However, he also acknowledged that before becoming the archetypal model for learning, "Hebbian plasticity was also a hypothesis." Our understanding of how the brain learns through endlessly changing is itself endlessly changing.

Snapchat brings AI-powered conversational advertising to its app
Snapchat is launching AI-powered conversational ads that let users chat with brand AI agents to get product recommendations directly in the messaging tab.
Original article
Snapchat announced on Tuesday that it's rolling out "AI Sponsored Snaps," which will allow users to interact directly with brands' AI agents. Sponsored Snaps are the ads placed directly into the app's main Chat tab. Until now, users couldn't interact with these ads, but with the launch of AI Sponsored Ads, they'll be able to do things like ask questions and get recommendations.
Of course, not everyone will be on board with AI-sponsored ads, as they introduce AI into yet another part of the Snapchat experience. Plus, not everyone is eager for more advanced advertising.
However, Snapchat said in the blog post that its "community isn't just open to AI in conversation, they're already embracing it," given that over half a billion users have messaged its AI chatbot since it launched in 2023.

"Conversation is becoming the most valuable real estate in advertising," said Ajit Mohan, chief business officer at Snap, in the blog post. "AI is accelerating that shift, turning chat into the place where people discover products, ask questions, and make decisions in real time. The real opportunity isn't just putting ads into those environments, it's designing formats that feel native to how people already talk."
For brands, the new AI Sponsored Snaps give them access to Snapchat's nearly one billion monthly active users. They can bring their own AI agents onto the platform to drive engagement and purchases.
Snapchat says the new format builds on the momentum of Sponsored Snaps, which already drive 22% more conversions with nearly 20% lower cost per action. With the new format, they can engage users through personalized, AI-powered interactions right where they're already having conversations.
The company says 85% of users engage regularly in the Chat feed, and that users sent over 950 billion chats in Q1 2026 alone. Additionally, 57% of teen Snapchat users message others daily, including four in 10 who do so several times a day.

How Apple Filmed its Flashy MacBook Neo Video Using Handmade Props
Apple released a behind-the-scenes video showing their MacBook Neo marketing was made with handcrafted props and practical effects rather than pure CGI or AI generation.
Original article
Apple's launch of the low-cost MacBook Neo has been highly successful. A behind-the-scenes video revealed that its polished marketing relied heavily on practical, handcrafted effects combined with some CGI. Real-world techniques and artists were central to the production.

Why Pentagram's Samar Maakaroun designed a logo that just won't settle
Pentagram partner Samar Maakaroun designed a logo for London's Mosaic Rooms that intentionally never settles, using fluid letterforms and movement to express the experience of living between cultures rather than resolving into traditional brand stability.
Deep dive
- The monogram's extended M moves in both reading directions (Arabic right-to-left, English left-to-right) without committing to either, making the letterform itself describe the journey of living between cultures rather than planting a flag
- The design draws on Ece Temelkuran's concept of being "unhomed" where home becomes permanently negotiated rather than fixed, a lived reality for much SWANA region cultural production shaped by displacement
- The color palette makes a provocative statement by including dusty pink alongside yellow and forest green, deliberately using a color often avoided in SWANA political and cultural discourse as frivolous or misaligned
- The Mosaic Rooms reopened in February 2026 after major refurbishment, transitioning from a privately funded initiative founded in 2008 to a public institution expanding beyond gallery space into talks, learning and gathering
- Building architecture by A Small Studio echoes the brand's wave-like forms in perforated metal railings, creating genuine conversation between physical space and visual identity rather than separate executions
- The identity extends the oscillating logic across the full system with circular forms becoming ovals and interlocking shapes, suggesting entanglement and relation rather than arrival at a fixed point
- The project succeeds because the mark isn't a visual metaphor applied to a concept but rather the concept made visual, with the idea of in-betweenness described by the identity itself
- Demonstrates that instability handled with clarity is not a design failure but can be the organizing principle when the brief genuinely calls for holding tension rather than resolving it
Decoder
- SWANA: South West Asia and North Africa, the collection of countries spanning the Arab world and surrounding regions
- Unhomed: Term from Turkish author Ece Temelkuran describing the experience of living between cultures where home becomes permanently negotiated rather than a fixed place
- Monogram: A design combining or overlapping initials or letters into a single unified mark
Original article
The Mosaic Rooms' new identity by Samar Maakaroun intentionally rejects stability, using a fluid monogram and bold color choices to express movement, cultural duality, and the idea of being “in-between” rather than fixed. The rebrand reflects the institution's evolving role and shows how strong design can embody unresolved tension and complex identity instead of simplifying it.

Ikea's new ad is pure satisfaction in a billboard
IKEA's new "Unpackaged Goods" billboard campaign uses extreme minimalism to stand out by deliberately contrasting with the visual noise of surrounding ads.
Decoder
- OOH: Out-of-home advertising, meaning billboards, transit ads, and other public display advertising
Original article
IKEA's “Unpackaged Goods” campaign uses minimalist, low-noise visuals to highlight the satisfaction of organization.

White House Crypto Advisor Hints at Trump's Strategic Bitcoin Reserve
The Trump administration is working to formalize a strategic bitcoin reserve through legislation after executive orders proved too fragile to ensure long-term durability.
Decoder
- Strategic Bitcoin Reserve: A proposed government stockpile of bitcoin, analogous to strategic petroleum reserves but for digital assets
- BITCOIN Act: Legislation introduced by Sen. Lummis and Rep. Begich to codify the bitcoin reserve into permanent law
- Executive order: A presidential directive that lacks the permanence of legislation and can be reversed by future administrations
Original article
Patrick Witt, executive director of the President's Council of Advisors for Digital Assets, previewed a "big announcement" on next steps for Trump's strategic bitcoin reserve in the coming weeks, noting the team has been working through the legal interpretations needed to solidify and protect the reserve's digital assets. The reserve currently faces a durability problem as executive orders don't carry the staying power of legislation, which is why Sen. Lummis and Rep. Begich have reintroduced the BITCOIN Act to codify it.
Aave Publishes Technical Implementation Plan to Restore rsETH Backing
DeFi United coalition publishes comprehensive recovery plan to restore 116,500 rsETH released in a bridge exploit, testing whether decentralized protocols can coordinate large-scale post-exploit recovery without socializing losses.
Deep dive
- The exploit involved forging an inbound packet on the Unichain-to-Ethereum bridge, which caused the Ethereum-side adapter to release 116,500 rsETH without the corresponding burn happening on Unichain—a critical bridge security failure
- The exploiter distributed stolen rsETH strategically: portions became collateral on Aave V3 (both Ethereum and Arbitrum), portions on Compound, with seven addresses holding ~107,000 rsETH in active positions
- Recovery requires two parallel tracks: (1) restoring rsETH's ETH backing to maintain its 1.07 ETH peg, and (2) liquidating exploiter positions to recover the excess collateral without socializing losses
- DeFi United has secured ETH commitments to restore full backing by depositing into the bridge lockbox contract, converting ETH to rsETH in tranches to manage risk
- Clearing exploiter positions requires governance proposals on both Ethereum and Arbitrum that temporarily manipulate the rsETH oracle price to enable forced liquidations
- The oracle manipulation creates a temporary protocol deficit that gets filled by redeeming the recovered rsETH collateral back to ETH through Kelp's standard procedure
- Recovery would net approximately 13,000 ETH from Aave markets and 16,776 ETH from Compound after liquidations complete
- All configuration changes (oracle adjustments, LTV modifications) are explicitly temporary and scoped only for recovery execution, then fully reverted
- WETH and rsETH reserves remain frozen across multiple chains (Ethereum, Arbitrum, Base, Mantle, Linea) during the recovery period
- Key risks include governance execution failures, attacker interference during liquidation, and security validation of new bridge measures before resuming operations
- LayerZero and KelpDAO have implemented additional security measures for the bridge, though these remain unvalidated in production until operations resume
- Success depends on coordination across multiple protocol DAOs, finalization of legal agreements, and correct execution of complex multi-step governance proposals
- This incident showcases both bridge vulnerabilities (packet forgery) and DeFi's potential for collective recovery mechanisms that don't force users to absorb losses
Decoder
- rsETH: KelpDAO's liquid staking token representing staked ETH with rewards, currently trading at 1.07 ETH per rsETH
- Bridge exploit via forged packet: An attack where the exploiter created a fake message that convinced the Ethereum side to release tokens without the source chain actually burning them
- Liquidation: Forcibly selling collateral when a loan position becomes undercollateralized, typically to protect the lending protocol
- Oracle price manipulation: Temporarily adjusting the price feed that DeFi protocols use to value assets, enabling controlled liquidations that wouldn't normally trigger
- LTV (Loan-to-Value): The maximum percentage you can borrow against collateral value; higher LTV means more borrowing power
- Lockbox contract: The smart contract that holds the actual ETH backing the bridged rsETH tokens on the destination chain
- DeFi United: An ad-hoc coalition formed by affected ecosystem participants (Aave, Compound, KelpDAO, LayerZero, others) to coordinate recovery
Original article
DeFi United, a coalition of ecosystem participants, has published the full technical implementation plan to restore KelpDAO's rsETH backing following the April 18 bridge exploit, where a forged inbound packet on the Unichain-to-Ethereum route released 116,500 rsETH without a corresponding burn. The exploiter distributed the rsETH across multiple addresses, supplied portions as collateral on Aave V3 (Ethereum and Arbitrum) and Compound, with seven addresses still holding active rsETH-backed positions. The plan covers the full path to making rsETH whole and resuming normal market operations, a critical test of DeFi's ability to coordinate post-exploit recovery at scale.

Japan's Bitbank Launch Crypto-Linked Credit Card: Pays Bills in Bitcoin
Japanese exchange Bitbank launched a Visa credit card that automatically pays monthly bills by selling Bitcoin from your account, a first for Japan's regulated crypto market.
Decoder
- ASTR: Astar token, a cryptocurrency from the Astar blockchain network
Original article
The EPOS CRYPTO Card for bitbank is a Visa credit card that lets users settle monthly payments by selling BTC from their bitbank holdings at a predetermined rate, a first-of-its-kind product in Japan. The card offers 0.5% crypto rewards (payable in BTC, ETH, or ASTR), has no annual fee, and includes a ¥2,000 crypto welcome bonus. It's a notable consumer product that bridges crypto holdings and everyday card spending in Japan's regulated market. The card is a potential template for similar products in other jurisdictions.
The Capital Suck: Stablecoin Flywheel Economics
Stablecoins generate 122x annual economic velocity compared to PayPal's 40x, creating a self-reinforcing flywheel that keeps capital onchain and is now pulling institutional assets into blockchain-based financial infrastructure.
Deep dive
- Stablecoins achieve 122x annual velocity (each dollar reused 122 times per year) versus PayPal's 40x and M2's 1.4x because they're continuously recycled through payments, DEXs, and lending without batch settlement delays
- Each $1B in stablecoin supply generates $122B in annual activity broken down as: $68B in payments/transfers, $34B in derivatives, $18B in DEXs, $1B in lending, and $400M in RWAs
- Protocol-level revenue is $19M per $1B of stablecoin supply, excluding the roughly $35M that issuers earn from float on reserves at 3.5% risk-free rates
- Total 2025 ecosystem earnings: stablecoin issuers made $13B+ from float alone (Tether over $10B, Circle $2.7B), while protocols generated $5B+ in stablecoin-attributed revenue
- Stablecoin supply grew 60x from $5B in early 2020 to roughly $300B today (now 1.4% of US M2 money supply), with $120B minted in 2025 alone and $33T in annual transaction volume
- Capital that moves onchain tends to stay because returning to legacy rails means forfeiting productivity gains from 24/7 composable lending, trading, and settlement infrastructure
- Tokenized real-world assets grew from $8B two years ago to $25B today, with BlackRock's BUIDL tokenized money market fund alone holding over $2B
- Real-world market displacement is visible: during the Iran escalation when traditional markets were closed, traders routed volume to onchain perpetual futures on platforms like Hyperliquid
- Authors predict the same flywheel that grew stablecoins will pull equities, credit, treasuries, and structured products onchain as institutional capital migrates to capture blockchain infrastructure advantages
- Methodology relies on adjusted volume figures ($33T from Artemis, though more conservative estimates suggest $10T) divided by average supply, with revenue attributed only to stablecoin-specific activities across protocols
Decoder
- Stablecoins: Cryptocurrencies pegged 1:1 to fiat currency like the dollar (examples: USDT, USDC) designed to maintain stable value
- Economic velocity: How many times a dollar circulates through the economy per year, calculated as total transaction volume divided by supply
- DEX: Decentralized exchange allowing peer-to-peer crypto trading without centralized intermediaries or custody
- RWAs (Real-World Assets): Traditional financial assets like government treasuries, corporate credit, or equities tokenized and issued on blockchains
- Protocol revenue: Fees captured by the protocol treasury itself, excluding portions distributed to liquidity providers, depositors, or stakers
- T+1/T+2 settlement: Traditional finance settlement times where trades take 1 or 2 business days to finalize after execution
- M2 money supply: Broad measure of money including physical cash, checking deposits, savings accounts, and other easily convertible near-money assets
- Onchain perps: Perpetual futures contracts (derivatives with no expiration date) traded directly on blockchain platforms rather than centralized exchanges
- Float income: Interest earnings that stablecoin issuers generate by investing the reserves backing their issued stablecoins in treasuries or money markets
- BUIDL: BlackRock's tokenized US Treasury money market fund (wordplay on "build" popular in crypto culture)
Original article
Onchain stablecoins generate 122x annual economic velocity per dollar deployed, compared to PayPal's ~40x turnover and US M2's 1.4x, with each $1B in stablecoin supply producing roughly $19M in annualized protocol revenue (excluding issuer float). Supply has grown 60x since 2020 to ~$300B, still just 1.4% of US M2, while tokenized RWAs have tripled to ~$25B over two years, led by BlackRock's BUIDL crossing $2B. The flywheel is now showing in market-hours displacement: during the Iran escalation, traders routed volume to onchain perps on platforms like Hyperliquid rather than waiting for traditional venues to reopen.

Circle Ventures Buys AAVE Tokens in DeFi United Show of Support
Circle Ventures is purchasing AAVE tokens to support DeFi infrastructure as part of a community solidarity initiative.
Decoder
- AAVE: The governance token for Aave, a decentralized lending and borrowing protocol that's one of the largest DeFi platforms by total value locked
- DeFi United: A community campaign initiated by Aave founder Stani Kulechov promoting solidarity and support for decentralized finance infrastructure
- Circle: The company behind USDC stablecoin; Circle Ventures is its investment arm focusing on blockchain and crypto projects
Original article
Circle Ventures announced an $AAVE token purchase aligned with Stani Kulechov's "DeFi United" campaign.

Block Reports 28,355 BTC in Q1 2026 Proof of Reserves
Block disclosed holding 28,355 Bitcoin in its Q1 2026 proof of reserves, demonstrating ongoing corporate treasury commitment to cryptocurrency.
Decoder
- Proof of Reserves: A transparency practice where companies publicly verify their cryptocurrency holdings through cryptographic attestation or audits, showing they actually possess the assets they claim.
Original article
Block (formerly Square) disclosed 28,355 BTC in its Q1 2026 proof of reserves filing alongside preliminary Cash App Bitcoin Ecosystem Revenue, continuing the company's policy of investing 10% of bitcoin profits into BTC purchases each month.