Devoured - April 30, 2026
Cursor released an SDK that lets developers programmatically deploy coding agents into CI/CD pipelines and products, while Cloudflare and Stripe launched a protocol enabling AI agents to autonomously create accounts, buy domains, and deploy applications without manual setup. On the infrastructure side, Linux 7.0's scheduling change cut PostgreSQL performance in half (fixed by enabling huge pages), and an AI-powered reverse engineering tool discovered a critical GitHub remote code execution vulnerability in under 48 hours.

Mistral Medium 3.5 powers remote Vibe agents
Mistral releases Medium 3.5, a 128-billion parameter open-weight model that powers cloud-based coding agents to run long asynchronous tasks independently.
Deep dive
- Mistral Medium 3.5 merges instruction-following, reasoning, and coding capabilities into a single 128B dense model with a 256k context window, marking Mistral's first flagship merged model
- The model achieves 77.6% on SWE-Bench Verified, ahead of Devstral 2 and Qwen3.5 397B A17B, and scores 91.4 on τ³-Telecom for agentic capabilities
- Self-hosting is practical on as few as four GPUs, making it accessible for organizations wanting to run their own infrastructure rather than relying on API calls
- Reasoning effort is configurable per request, allowing the same model to handle quick chat responses or complex multi-step agentic workflows without reloading
- The vision encoder was trained from scratch to handle variable image sizes and aspect ratios, rather than forcing images into fixed dimensions
- Vibe remote agents move coding sessions to the cloud where they run independently, in parallel, and notify developers when complete, eliminating the need to keep local terminals open
- Developers can "teleport" ongoing local CLI sessions to the cloud mid-task, preserving session history, task state, and approval settings for seamless continuation
- Each coding session runs in an isolated sandbox supporting broad edits and installs, with integration into GitHub, Linear, Jira, Sentry, Slack, and Teams for pull requests and notifications
- Work mode in Le Chat uses the new model to execute complex multi-step tasks like cross-tool workflows, research synthesis, and inbox triage with visible tool calls and approval gates for sensitive actions
- The model is priced at $1.5 per million input tokens and $7.5 per million output tokens via API, with open weights available on Hugging Face under a modified MIT license
- Mistral built Vibe originally for internal use, then for enterprise customers, and is now opening it to all developers for launching coding tasks from the web without local terminal dependencies
- The system is designed for high-volume, well-defined work like module refactors, test generation, dependency upgrades, and CI investigations that take developer time but not judgment
Decoder
- Dense model: A neural network architecture where all parameters are used for every inference, as opposed to sparse or mixture-of-experts models that activate only subsets of parameters
- SWE-Bench Verified: A benchmark measuring how well AI models can solve real-world software engineering tasks from GitHub issues, with the "Verified" version being a curated subset with confirmed correct solutions
- Context window: The maximum amount of text (measured in tokens) that a model can process at once, including both input and output; 256k tokens is roughly 190,000 words
- τ³-Telecom: A benchmark for measuring agentic capabilities, specifically how well models can perform multi-step tasks with tool usage
- Open weights: The trained model parameters are released publicly, allowing anyone to download and run the model, though this differs from fully "open source" which would include training code and data
- NVIDIA NIM: NVIDIA Inference Microservice, a containerized solution for deploying AI models at scale on NVIDIA GPUs
Original article
Remote agents in Vibe. Powered by Mistral Medium 3.5.
Introducing Mistral Medium 3.5, remote coding agents in Vibe, plus new Work mode in Le Chat for complex tasks.
Coding agents have mostly lived on your laptop. Today we're moving them to the cloud, where they run on their own, in parallel, and notify you when they're done. You can start them from the Mistral Vibe CLI or directly in Le Chat, offloading a coding task without leaving the conversation.
Powering this is Mistral Medium 3.5 in public preview, our new default model in Mistral Vibe and Le Chat, built to run for long stretches on coding and productivity work. The new Work mode in Le Chat (Preview) extends this with a powerful agent for complex, multi-step tasks like research, analysis, and cross-tool actions.
Highlights.
- Mistral Medium 3.5, a new flagship model that merges instruction-following, reasoning, and coding into a single 128B dense model. Released as open weights, under a modified MIT license.
- Strong real-world performance at a size that runs self-hosted on as few as four GPUs.
- Mistral Vibe remote agents for async coding: sessions run in the cloud, can be spawned from the CLI or Le Chat, and a local CLI session can be teleported up to the cloud.
- Start Mistral Vibe coding tasks in Le Chat. Sessions run on the same remote runtime and keep going while you step away.
- Work mode in Le Chat runs on a new agent, powered by Mistral Medium 3.5, that works through multi-step tasks, calling tools in parallel until the job is done.
Mistral Medium 3.5.
Mistral Medium 3.5 is our first flagship merged model, available in public preview. It is a dense 128B model with a 256k context window, handling instruction-following, reasoning, and coding in a single set of weights. It performs strongly in real-world use, with self-hosting possible on as few as four GPUs. Reasoning effort is now configurable per request, so the same model can answer a quick chat reply or work through a complex agentic run. We trained the vision encoder from scratch to handle variable image sizes and aspect ratios.
Mistral Medium 3.5 scores 77.6% on SWE-Bench Verified, ahead of Devstral 2 and models like Qwen3.5 397B A17B. It also has strong agentic capabilities and scores 91.4 on τ³-Telecom.
The model was built for long-horizon tasks, calling multiple tools reliably, and producing structured output that downstream code can consume. It is the model that made async cloud agents in Vibe practical to ship.
Mistral Medium 3.5 becomes the default model in Le Chat. It also replaces Devstral 2 in our coding agent, Vibe CLI.
Vibe remote agents.
From today, coding sessions can work through long tasks while you're away. Many can run in parallel, and you stop being the bottleneck on every step the agent takes.
You can start the cloud agents from the Mistral Vibe CLI or from Le Chat. While they run, you can inspect what the agent is doing, with file diffs, tool calls, progress states, and questions surfaced as you go. Ongoing local CLI sessions can be teleported up to the cloud when you want to leave them running, with session history, task state, and approvals carrying across.
Vibe sits between the systems engineering teams already use, with humans in the loop wherever they're needed. It plugs into GitHub for code and pull requests, Linear and Jira for issues, Sentry for incidents, and apps like Slack or Teams for reporting.
Each coding session runs in an isolated sandbox, including broad edits and installs. When the work is done, the agent can open a pull request on GitHub and notify you, so you review the result instead of every keystroke that produced it.
It fits the high-volume, well-defined work that takes a developer's time without taking their judgment: module refactors, test generation, dependency upgrades, CI investigations, as well as bug fixes.
We use Workflows orchestrated in Mistral Studio to bring Mistral Vibe into Le Chat. We originally built this for our own in-house coding environment, then for our enterprise customers. Today the capability opens up to everyone, who can now launch coding tasks from the web. And without being tied to a local terminal, a developer can run several in parallel.
You can start coding sessions directly in Le Chat, so a task described in chat runs on the same remote runtime as the CLI and the web, and comes back later as a finished branch or a draft PR.
New Work mode in Le Chat (Preview).
Work mode is a powerful new agentic mode for complex tasks in Le Chat, powered by a new harness and Mistral Medium 3.5. The agent becomes the execution backend for the assistant itself, so Le Chat can read and write, use several tools at once, and work through multi-step projects until it completes what you've asked.
Here's what Work mode enables you to do today.
- Cross-tool workflows: catch up across email, messages, and calendar in a single run; prepare for a meeting with attendee context, latest news, and talking points pulled from your sources.
- Research and synthesis: dive into a topic across the web, internal docs, and connected tools, then produce a structured brief or report you can edit before exporting or sending.
- Triage your inbox and draft replies; create issues in Jira from your team and customer discussions; send a summary to your team on Slack.
Sessions persist longer than a typical chat reply, so an agent can keep going across many turns, through trial-and-error, and through to completion. In Work mode, connectors are on by default rather than chosen manually, which lets the agent reach into documents, mailboxes, calendars, and other systems for the rich context it needs to take correct action.
Every action the agent takes is visible: you see each tool call and the thinking rationale. Le Chat will ask for explicit approval—based on your permissions—before proceeding with sensitive tasks like sending a message, writing a document, or modifying data.
Get started.
Mistral Medium 3.5 is available today in Mistral Vibe and Le Chat, and powers remote coding agents and Work mode in Le Chat on the Pro, Team, and Enterprise plans.
Through API, it's priced at $1.5 per million input tokens and $7.5 per million output tokens. Open weights are on Hugging Face under a modified MIT license.
It is also available for prototyping, hosted on NVIDIA GPU-accelerated endpoints on build.nvidia.com and as a scalable containerized inference microservice, NVIDIA NIM.

Granite 4.1 LLMs: How They're Built
IBM's Granite 4.1 demonstrates that an 8 billion parameter dense model can match the performance of a 32 billion parameter mixture-of-experts model through better training data and techniques.
Decoder
- Dense architecture: A neural network where all neurons in each layer connect to all neurons in the next layer, as opposed to mixture-of-experts (MoE) models that route inputs to specialized sub-networks
- Decoder-only architecture: A transformer model that generates text by predicting the next token based on previous tokens, similar to GPT models
- Parameters (B): The number of trainable weights in a neural network, measured in billions; generally more parameters mean more model capacity
- Reinforcement learning pipeline: A training process where the model learns by receiving feedback on its outputs rather than just predicting the next word
Original article
Granite 4.1 LLMs utilize a dense, decoder-only architecture with models of 3B, 8B, and 30B parameters, trained on 15 trillion tokens and using a five-phase pre-training approach. The 8B model matches the performance of the previous 32B Mixture-of-Experts model through a multi-stage reinforcement learning pipeline focused on data quality. These models, designed for efficient, reliable enterprise use, demonstrate competitive instruction-following and tool performance while maintaining cost efficiency and stable usage.
Introducing AutoSP
AutoSP is a compiler that automatically converts standard transformer training code into sequence-parallel code, making it vastly easier to train LLMs on extremely long contexts (100k+ tokens) across multiple GPUs.
Deep dive
- AutoSP implements DeepSpeed-Ulysses as its sequence parallelism strategy because communication overhead remains constant with increasing GPU counts on NVLink or fat-tree networks, though it's limited to scaling SP-size up to the number of attention heads in the model (32 for 7-8B models)
- The tool introduces Sequence-aware Activation Checkpointing (SAC), a custom strategy that exploits unique long-context FLOP dynamics and is less conservative than PyTorch 2.0's automated max-flow min-cut approach, releasing intermediate activations of cheap-to-compute operators to save memory
- Built within DeepCompile (a compiler ecosystem in DeepSpeed), AutoSP performs program analysis to automatically insert communication collectives, partition input contexts and intermediate activations, and overlap communication with computation for both forward and backward passes
- Benchmarks on Llama 3.1 models using 8 A100-80GB GPUs show AutoSP increases maximum trainable sequence length while maintaining runtime performance comparable to hand-written baselines of RingFlashAttention, DeepSpeed-Ulysses, and ZeRO-3
- The tool composes automatically with ZeRO stage 0/1 out of the box, combining parameter sharding with sequence parallelism through simple config flags
- Performance portability is a key advantage: embedding sequence parallelism in the compiler means highly performant implementations can be realized on diverse hardware without vendor-specific engineering
- SAC marginally reduces training throughput when enabled but can be selectively activated only for configurations that would otherwise cause out-of-memory errors
- Two main limitations: the entire transformer must be compiled as a single artifact (no stitching together individually compiled functions), and graph breaks in compilable artifacts are disallowed as they complicate information propagation analysis
Decoder
- Sequence parallelism (SP): Partitioning input tokens across multiple devices to enable training on longer contexts, distributing the memory burden across GPUs rather than fitting everything on one device
- DeepSpeed: Microsoft's open-source deep learning optimization library that provides memory and speed optimizations for training large models
- ZeRO/FSDP: Zero Redundancy Optimizer and Fully Sharded Data Parallel - techniques that shard model parameters, gradients, and optimizer states across GPUs to reduce memory usage
- Activation checkpointing: Trading compute for memory by discarding intermediate activations during the forward pass and recomputing them as needed during the backward pass
- DeepSpeed-Ulysses: A specific sequence parallelism strategy that uses all-to-all communication patterns to distribute attention computation across GPUs
- Context length/window: The number of tokens an LLM can process at once - longer contexts enable models to consider more information but require more memory
Original article
TL;DR: AutoSP automatically converts standard transformer training code into sequence-parallel code for long-context LLM training across multiple GPUs. Integrated with DeepSpeed, it increases maximum trainable context length with little runtime overhead versus hand-written baselines.
Increasingly, Large-Language-Models (LLMs) are being trained for extremely long-context tasks, where token counts can exceed 100k+. At these token counts, out-of-memory (OOM) issues start to surface, even when scaling device counts using conventional training techniques such as ZeRO/FSDP. To circumvent these issues, sequence parallelism (SP): partitioning the input tokens across devices to enable long-context training with increasing GPU counts, is a commonly used parallel training technique.
However, implementing SP is notoriously difficult, requiring invasive code changes to existing libraries such as DeepSpeed or HuggingFace. These code changes often involve partitioning input token contexts (and intermediate activations), inserting communication collectives, and overlapping communication with computation, all of which must be done for both the forward and backwards pass. This results in researchers who want to experiment with long context capabilities spending significant effort on engineering the system's stack to enable such capability, repeating this effort for different hardware vendors.
To avoid this complexity, we introduce AutoSP: a fully automated compiler-based solution that automatically converts easy-to-write training code to multi-GPU sequence parallel code that efficiently uses GPUs to train on longer input contexts while composing with existing parallel strategies (such as ZeRO). This avoids the cumbersome need for developers to repeatedly modify training pipelines for long-context training. Users can now simply import AutoSP and compile arbitrary models using the AutoSP backend, giving the power of long-context training to anyone. Moreover, by embedding this technology into the compiler, our approach is performance-portable: highly performant SP can be realised on diverse hardware.
We structure this post as follows: (1) AutoSP and how model scientists can use it to enable long-context training, (2) Key design decisions of AutoSP, (3) key AutoSP results, demonstrating its ease-of-use and impact, (4) some limitations and things AutoSP cannot do.
AutoSP Usage
A key design philosophy of AutoSP is simplicity in abstracting most of the complexity in programming multiple GPUs from users. To do this, we implement AutoSP within DeepCompile: a compiler ecosystem within DeepSpeed to programmatically enable diverse optimisations for deep neural network training. With this, any user who uses DeepSpeed can automatically enable Sequence Parallelism with almost zero hassle. We take a look at an example next.
# We instantiate a deepspeed config.
# Assume 8 GPUs with 2 DP ranks and 4 SP ranks.
config = {
"train_micro_batch_size_per_gpu": 1,
"train_batch_size": 2,
"steps_per_print": 1,
"optimiser": {
"type": "Adam",
"params": {
"lr": 1e-4
}
},
"zero_optimization": {
"stage": 1, # AutoSP interoperates with ZeRO 0/1.
},
# Simply turn on deepcompile and set
# the AutoSP pass to be triggered on.
"compile": {
"deepcompile": True,
"passes": ["autosp"]
},
"sequence_parallel_size": 4,
"gradient_clipping": 1.0,
}
# Initialise deepspeed with model.
model, _, _ = deepspeed.initialize(config=config,model=model)
# Compiles model and automatically applies AutoSP passes.
model.compile(compile_kwargs={"dynamic": True})
for idx, batch in enumerate(train_loader):
# Custom function that we expose within:
# deepspeed/compile/passes/sp_compile.
inputs, labels, positions, mask = prepare_auto_sp_inputs(batch)
loss = model(
input_ids=inputs,
labels=labels,
position_ids=positions,
attention_mask=mask
)
... # Backwards pass, optimiser step etc...
As seen in the example above, users take existing training code that runs on a single device and do the following: (1) use the prepare_autosp_input utility function (exposed in DeepSpeed) for lightweight tagging of input tokens, attention masks and position ids for use in program analysis within AutoSP. (2) Adjust the DeepSpeed config to turn DeepCompile on, specifying the "passes" flag to "autosp". The rest is handled through the AutoSP compiler passes, called when compiling the model, which automatically enable sequence-parallelism alongside other long-context training optimisations. AutoSP additionally automatically composes with ZeRO stage 1 out of the box, simply set the ZeRO-1 flag in DeepSpeed alongside the AutoSP flags to combine both strategies.
AutoSP Compiler Passes
Since AutoSP transforms user code to enable longer-context training, we briefly cover the key design points of AutoSP and code transformations, as well as its consequences to users for transparency.
Sequence Parallelism Code Transformations. AutoSP automatically converts single-GPU code to multi-GPU sequence parallel (SP) code. The specific SP strategy AutoSP converts code into is DeepSpeed-Ulysses. We specifically focus on DeepSpeed-Ulysses over other strategies (e.g. RingAttention) as its communication overhead stays constant with increasing GPU counts on NVLink network topologies or fat-tree networks. However, DeepSpeed-Ulysses only enables scaling the SP-size to the number of heads in a model (32 in 7-8B models).
Activation Checkpointing for longer-context training. AutoSP additionally applies a custom activation-checkpointing (AC) strategy curated for long-context modelling. AC releases intermediate activations of cheap-to-compute operators, recomputing them in the backwards pass as required to compute relevant gradients. PyTorch-2.0 introduces an automated max-flow min-cut based AC formulation, but we find this to be overly conservative for long-context modelling. We accordingly introduce a novel AC strategy targeted for long-context training: Sequence-aware AC (SAC), which exploits unique long-context FLOP dynamics. When triggered on (the default setting in AutoSP), this marginally reduces training throughput. However, without it, training on longer contexts is infeasible, so the user can selectively choose to turn this pass on only for configurations that OOM.
Evaluating AutoSP on Real Models
To demonstrate AutoSP's viability, we evaluate its performance on models of varying sizes on NVIDIA GPUs to show that its ease of use comes at little to no cost to runtime performance. We benchmark different Llama 3.1 models on an 8 A100-80Gb SXM node. We use PyTorch 2.7 with CUDA 12.8, comparing AutoSP to torch-compiled hand-written baselines of: RingFlashAttention, DeepSpeed-Ulysses, and ZeRO-3. We summarise key results in the figure below:
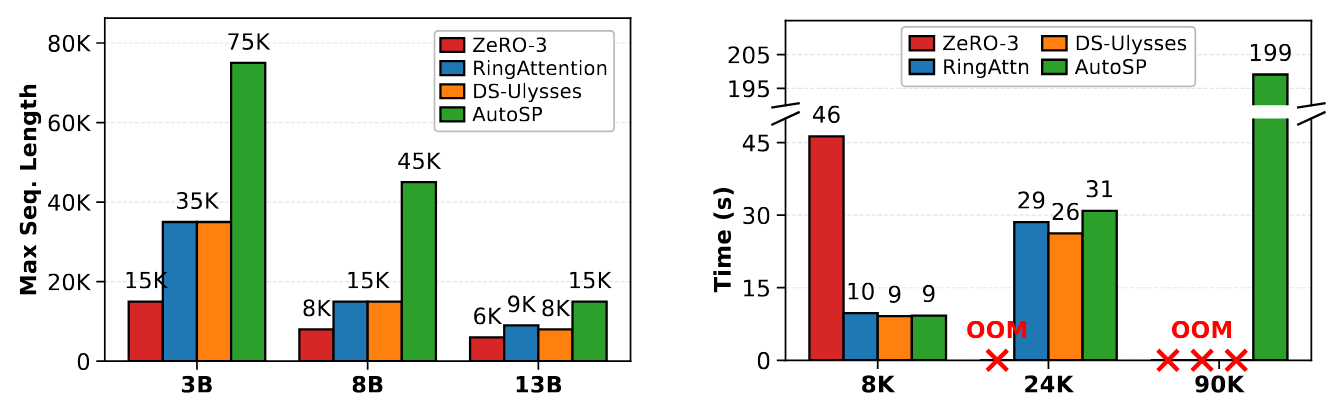
Not only can AutoSP increase the maximum trainable sequence length given the same resources (left figure – higher is better), but also these benefits come at little cost to runtime performance (right figure – lower is better).
Limitations
There are two key limitations of AutoSP. First, we require that the user forcefully compile a transformer as a single compilable artifact. Occasionally, PyTorch users may compile many functions individually and stitch them together into one model. This is disallowed in AutoSP as we need to compile and see the entire model to correctly shard input sequences and propagate this information throughout the entire graph. Second, we disallow any graph breaks in compilable artifacts. This complicates analysis and propagation of information, and we leave extending AutoSP to be graph-break resilient to future research.
Conclusion
AutoSP enables users to easily extend arbitrary transformer training code to enable Sequence Parallelism, with a custom AC strategy for enhanced long-context training. Integration with DeepSpeed allows users to easily use existing DeepSpeed training code to train on longer contexts by simply changing a config file. We have prepared end-to-end examples for users to play around with on real model workloads (e.g. Llama 3.1 8B) here. Give it a try to see how easy long context training has become.

Lessons on Building MCP Servers
A practical guide to designing MCP servers that guide AI models through multi-step workflows by embedding breadcrumbs rather than expecting models to plan ahead.
Deep dive
- Models don't have hidden planners—they scan available tools and pick whatever seems most probable based on conversation context, so servers must make the next call blindingly obvious at every step
- The author's Office server exposes 100+ tools but funnels models toward 8 core verbs through instructions, treating specialized tools as fallback/diagnostic options to prevent five-call detours for one-call jobs
- Consistent naming exploits probability: all Word tools are
word_*, Excel toolsexcel_*, unified toolsoffice_*—models that just calledoffice_inspectwill naturally reach foroffice_patchnext because the prefix matches - Every tool response should include a breadcrumb dictionary with
next_toolsandusagehints showing exact call syntax—smaller models will copy these verbatim because it's the most likely token sequence - Discovery should be a callable tool like
office_help(goal=...)that returns structured recommendations with rationale and next steps, not prose documentation—called with no arguments it returns the catalogue, with unknown input it returns the supported set instead of erroring - Use stable addressing like anchors, IDs, or structured paths instead of byte offsets or natural language descriptions that models lose between calls—if you return data the model has to describe back in natural language, your chain will misfire
- Collapse similar tools into mode parameters (
dry_run,best_effort,safe,strict) rather than separate tools—discovery cost scales with tool count not mode count, and models figure out escalation chains like dry_run → safe → strict on their own - Return standardized diagnostic envelopes with named fields like
matched_targetsandunmatched_targetsthat create branching points and recovery loops without forcing the model to re-read entire context - Always provide read-only introspection tools so confused models can "look again" without destructive consequences—the penalty becomes one extra round-trip instead of breaking files
- The design checklist includes: pick 5-10 core verbs and name them in instructions, use consistent prefixes, embed forward breadcrumbs in responses, provide stable addresses, give mutation tools mode enums, cache recovery loop calls, make repeat calls safe, and reject unknown arguments strictly
Decoder
- MCP (Model Context Protocol): A protocol for exposing tools and functions that AI models can call to interact with external systems and data sources
- Activation sets: The subset of available tools that are surfaced to the model at any given time, keeping the visible tool list small while maintaining access to a larger set
- Breadcrumbs: Structured hints embedded in tool responses that guide the model toward the next appropriate tool call in a workflow chain
Original article
Lessons on Building MCP Servers
I've been building MCP servers for a while now–I wrote about the general approach last year, started out by creating umcp, and I've recently opened up an Office server that's been battered by enough models against enough real documents that the patterns have settled.
I'm still not a fan of MCP, but what follows is what I've learned about making tool chains actually work, condensed from swearing at logs rather than reading papers.
Disclaimer: This is a condensed version of
CHAINING.md, which was itself stapled together from a bunch of notes in my Obsidian vault. The full version has more code examples and a techniques inventory table that Opus just _had to add, and I've since beaten that out of it and restored most of the original text (minus typos).
The short version: the MCP servers I design do most of the work, while the model walks breadcrumbs.
Models don't plan
They look at the conversation, scan the tool list, and grab whatever looks more probable. That's it. There is no hidden planner. If you want chains that finish somewhere sensible, the server has to make the next call blindingly obvious at every step.
After a year or so, I have pared down my approach into these three things, roughly in order of how much pain they save you:
- A small named core verb set covering most intents
- Output that suggests the next call
- An addressing scheme that survives between calls–anchors, IDs, paths, anything but line numbers.
Core verbs beat surface area
The Office server exposes over 100 tools. Its get_instructions() funnels models toward eight:
…start with
office_help, then preferoffice_read,office_inspect,office_patch,office_table,office_template,office_audit, andword_insert_at_anchor. Treat specialised tools as fallback, diagnostic, legacy-compatibility, or expert tools when the core flow is insufficient.
That single sentence does an outsized amount of work–it tells the model there is a recommended path, that the path is verb-shaped (help -> read -> inspect -> patch -> audit), and that everything else is opt-in.
Without it, models cheerfully reach for word_parse_sow_template when office_read would do, and you end up with five-call detours for one-call jobs.
So I quickly realized that I needed to be ruthless about which tools to surface and when. The specialised ones still ship–hidden under a "for experts" framing, and a handful of legacy ones filtered out of tools/list entirely.
I also make liberal use of activation sets–the surface the model sees is small; the surface it can reach is large.
Naming is the chain
Again, models chain whatever is most likely (or rhymes), and the most effective tactic, for me, has been taking advantage of that.
All Word tools are word_*, all Excel excel_*, all unified office_*. A model that just called office_inspect will reach for office_patch next, not word_patch_with_track_changes, because the prefix matches.
This particular server also makes liberal use of annotations and a little intent/inferrer hack that reads those prefixes to assign readOnlyHint/destructiveHint automatically, so naming discipline turns into safety metadata for free.
The prefix is the plan. The verb is the step. If you take one thing from this entire post, I'd suggest this notion…
Every response nominates the next call
This was the single change that made things behave on smaller models. The big ones will plan a chain from a tool list and a goal; the wee ones won't–they grab the first plausible tool and stop.
The fix is stupid simple: every response ends with a breadcrumb dictionary of hints to follow. At minimum next_tools: [...], plus usage: "<exact call>" whenever the current tool produced a value the next one needs.
A model that can't assemble arguments from a schema can copy the usage string verbatim. In fact, they will copy it, because it is still the most likely outcome as it fills in tokens, and thus those usage hints funnel the path the model takes.
Discovery as a tool, not documentation
Another thing I hit upon was that signposting needed to be curated.
Borrowing a page from intent mapping, office_help(goal=...) returns a structured record–recommended chain with rationale, fallbacks, diagnostic strings to watch for, one imperative next_step sentence. Not prose. Not a README, not skills. Data the model can act on without reading comprehension.
Called with no arguments, it returns the catalogue. Called with an unknown goal, it returns the supported set rather than an error, which turns a potential workflow-stopping error into an actual useful catalogue.
Addressing: anchors, not offsets
The biggest reason simple models can't follow chains is the model losing the thread between calls. "Insert a paragraph after the introduction" is fine in English but catastrophic if you expect it to remember a byte offset across three tool calls.
In this particular scenario, I cheated and since most Office documents have headings (or cells, or internal structured paths inside OOXML), I used either verbatim text from the document or immovable coordinates (which was particularly hard in PowerPoint, by the way).
So besides suggestions and hints, return identifiers your tools will later accept as input. If you find yourself returning data the model has to describe back to you in natural language, you've made a chain that will misfire on a Tuesday afternoon when you're not watching.
Modes turn one tool into four
I started out with individual editing tools per format, which was very easy to do automated tests for but incredibly wasteful of context, so at one point I decided to make things much simpler for initial discovery, and since I needed to make all outputs auditable, I then tagged available sub-operations risk-wise.
office_patch is the same code path whether you ask for dry_run, best_effort, safe, or strict. One tool, four modes, one entry in tools/list.
Discovery cost scales with tool count, not mode count. And dry_run -> safe -> strict is an escalation chain the model figures out on its own without being told.
If you have N tools that differ only in how cautious they are, collapse them. You're wasting everyone's context budget.
Diagnostics as the back-edge
Linear chains are easy. Real chains have loops, and loops only happen when the server invites the model back in. Every mutating tool returns a standard envelope with status, matched_targets, unmatched_targets, and next_tools.
The model then branches on a small subset of options "locally" without needing to go over the entire context, and if you name the diagnostic fields with exact strings the model will see again in your instructions, it will just reinforce them.
In this particular case, again, I cheated. I figured out that the models were starting to call tools at random because they couldn't introspect the document well enough and ended up breaking files, so I always gave them at least one read-only tool, so the penalty for "I'm confused, let me look again" is one extra round-trip, not a destructive cock-up.
My MCP Design Checklist
- Pick five to ten core verbs and name them in
get_instructions()or your local equivalent - Use consistent prefixes by surface
- Provide a discovery tool that returns recommendations as data, not prose
- Make the discovery tool browseable–no-arg returns the catalogue, unknown input returns the supported set
- Embed forward breadcrumbs in every tool response
- Provide a map/anchors tool so addresses survive between calls
- Give every mutating tool a mode enum including
dry_run - Return named diagnostic fields and cite the recovery tools
- Standardise the mutation envelope. If one tool changes something in a specific way, make sure the others are consistent (arguments, semantics, etc.)
- Reject unknown arguments strictly (this is much easier in some runtimes than others)
- Provide an audit tool so the model has somewhere to land
- Cache anything the recovery loop calls more than once, because, well, it will get called dozens of times even if you carefully curate paths through your tooling with hints.
- Make repeat calls safe–models retry, and they should be allowed to (idempotence is hard, and often impossible).
Do the boring work in the schema and the descriptions. The model will happily do the clever bit if you stop making it guess.

Reliable Data Analysis Agents
Researchers developed DataPRM, a process reward model that makes AI data analysis agents more reliable by detecting silent errors that produce incorrect results without triggering exceptions.
Deep dive
- General-domain process reward models trained on static tasks like math proofs fundamentally fail when applied to data analysis agents, struggling with the dynamic, exploratory nature of the domain
- Silent errors represent a critical failure mode where code executes without exceptions but produces logically incorrect results—something traditional PRMs cannot detect without environment interaction
- DataPRM functions as an active verifier that probes intermediate execution states by interacting with the environment, rather than passively evaluating reasoning traces
- The reflection-aware ternary reward strategy distinguishes between correctable grounding errors (exploratory missteps) and irrecoverable mistakes, preventing the penalization of necessary trial-and-error
- Training data consisted of 8,000+ high-quality instances generated through diversity-driven trajectory generation and knowledge-augmented step-level annotation
- Best-of-N inference with DataPRM improved performance by 7.21% on ScienceAgentBench and 11.28% on DABStep compared to baselines
- Despite having only 4 billion parameters, DataPRM outperformed larger baseline models and demonstrated robust generalization across different test-time scaling strategies
- Integration with reinforcement learning yielded significant gains over outcome-only reward baselines, achieving 78.73% on DABench and 64.84% on TableBench
- The work addresses a key gap in applying process supervision to dynamic environments where correct execution requires environmental feedback rather than pure reasoning
- Results validate that process-level rewards are more effective than outcome-only rewards for training data analysis agents, even in complex multi-step scenarios
Decoder
- Process Reward Model (PRM): A model that evaluates each intermediate step in a reasoning process rather than just the final outcome, providing more granular feedback for training AI systems
- Silent errors: Logical flaws in code that produce incorrect results without triggering interpreter exceptions or crashes, making them particularly difficult to detect
- Best-of-N inference: A test-time scaling technique where multiple candidate solutions are generated and the best one is selected based on a reward model's scores
- Grounding errors: Mistakes where an agent's actions don't align with its environment or task requirements, as opposed to fundamental reasoning failures
- Ternary reward strategy: A three-valued reward system (likely positive/neutral/negative) rather than binary, enabling finer-grained feedback distinctions
Original article
Rewarding the Scientific Process: Process-Level Reward Modeling for Agentic Data Analysis
Authors: Zhisong Qiu, Shuofei Qiao, Kewei Xu, Yuqi Zhu, Lun Du, Ningyu Zhang, Huajun Chen
Abstract
Process Reward Models (PRMs) have achieved remarkable success in augmenting the reasoning capabilities of Large Language Models (LLMs) within static domains such as mathematics. However, their potential in dynamic data analysis tasks remains underexplored. In this work, we first present a empirical study revealing that general-domain PRMs struggle to supervise data analysis agents. Specifically, they fail to detect silent errors, logical flaws that yield incorrect results without triggering interpreter exceptions, and erroneously penalize exploratory actions, mistaking necessary trial-and-error exploration for grounding failures. To bridge this gap, we introduce DataPRM, a novel environment-aware generative process reward model that (1) can serve as an active verifier, autonomously interacting with the environment to probe intermediate execution states and uncover silent errors, and (2) employs a reflection-aware ternary reward strategy that distinguishes between correctable grounding errors and irrecoverable mistakes. We design a scalable pipeline to construct over 8K high-quality training instances for DataPRM via diversity-driven trajectory generation and knowledge-augmented step-level annotation. Experimental results demonstrate that DataPRM improves downstream policy LLMs by 7.21% on ScienceAgentBench and 11.28% on DABStep using Best-of-N inference. Notably, with only 4B parameters, DataPRM outperforms strong baselines, and exhibits robust generalizability across diverse Test-Time Scaling strategies. Furthermore, integrating DataPRM into Reinforcement Learning yields substantial gains over outcome-reward baselines, achieving 78.73% on DABench and 64.84% on TableBench, validating the effectiveness of process reward supervision. Code is available at this https URL.
DeepMind ProEval for GenAI Evaluation (GitHub Repo)
DeepMind's ProEval framework can evaluate generative AI models with 100x lower cost by using surrogate models to estimate performance with just 1% of typical benchmark samples.
Deep dive
- Framework achieves ±1% accuracy in error rate estimation using only ~1% of benchmark samples compared to full evaluation
- Uses Bayesian Quadrature with Gaussian Process surrogates (BQ-SF, BQ-RPF variants) to model model performance patterns
- Surrogate models can transfer learning across benchmarks, generalizing to new models without retraining from scratch
- Proactively discovers diverse failure modes and edge cases under strict evaluation budgets rather than just estimating aggregate metrics
- Validated on multiple benchmark types including reasoning tasks (GSM8K, MMLU, StrategyQA), safety (Jigsaw), and classification
- Designed for multi-modal integration into existing GenAI evaluation pipelines with simple API
- Includes pre-trained models and dataset configurations for common benchmarks to enable immediate use
- Released under Apache 2.0 license with accompanying arXiv paper (2604.23099) from April 2026
Decoder
- Surrogate models: Statistical models that approximate expensive-to-evaluate functions, allowing predictions without running full evaluations
- Gaussian Process (GP): A probabilistic model that provides uncertainty estimates along with predictions, useful for deciding which samples to evaluate next
- Bayesian Quadrature (BQ): A method that uses Bayesian inference to estimate integrals like average performance efficiently with minimal samples
- BQ-SF, BQ-RPF: Specific variants of Bayesian Quadrature with different prior formulations used in ProEval
- Transfer learning: Applying knowledge learned from evaluating previous models to estimate new model performance faster
- MAE: Mean Absolute Error, measuring the average difference between estimated and true values
Original article
ProEval
Slash GenAI evaluation costs by up to 100x while actively discovering model failure patterns to guide better AI development.
- 💰 Cut GenAI eval costs up to 100× — achieve ±1% accuracy with a fraction of the samples
- 🔍 Discover failure cases — proactively surface diverse bugs under strict evaluation budgets
- 🧠 Transfer learning over benchmarks — pre-trained GP surrogates generalize to new models instantly
- 🧩 Easy Integration - Easily to integrate into the GenAI evaluation systems with different modalities
- ✅ Validated on reasoning, safety & classification — GSM8K, MMLU, StrategyQA, Jigsaw, and more
Installation
pip install -r requirements.txtQuick Start
from proeval import BQPriorSampler, LLMPredictor, DATASET_CONFIGS
from proeval.sampler import load_predictions, extract_model_predictions
import numpy as np
# Estimate a model's error rate with ~1% of the data
sampler = BQPriorSampler(noise_variance=0.3)
result = sampler.sample(predictions="svamp", target_model="gemini25_flash", budget=50)
# Compare against the true error rate
df = load_predictions("svamp")
pred_matrix, model_names = extract_model_predictions(df)
true_mean = np.mean(pred_matrix[:, model_names.index("gemini25_flash")])
print(f"Estimated error rate: {result.estimates[-1]:.4f}")
print(f"MAE: {result.mae(true_mean):.4f}")Experiments
Here is an example of how to run the experiments:
python -m experiment.exp_performance_estimation --dataset svamp --n-runs 5You can find the comprehensive experiment details and dataset settings here.
Citation
If the work did some helps on your research/project, please cite our tech report. Thank you!
@article{huang2026proeval,
title={{{ProEval}: Proactive Failure Discovery and Efficient Performance Estimation for Generative AI Evaluation}},
author={Huang, Yizheng and Zeng, Wenjun and Kumaresan, Aditi and Wang, Zi},
journal={arXiv preprint arXiv:2604.23099 [cs.LG]},
year={2026},
url={https://arxiv.org/abs/2604.23099}
}
Reverse Engineering With AI Unearths High-Severity GitHub Bug
An AI-powered reverse engineering tool helped discover a critical GitHub vulnerability in under 48 hours, work that would have previously taken weeks or months of manual effort.
Deep dive
- GitHub fixed CVE-2026-3854 on github.com within two hours of validation, with no evidence of prior exploitation found
- The vulnerability allowed attackers with push access to inject malicious metadata by exploiting delimiter characters in git push options, which were incorporated into internal protocols without proper sanitization
- Wiz had been "chasing this target since September 2024" but couldn't justify the resource investment for traditional manual reverse engineering of GitHub's compiled binaries
- IDA MCP enabled rapid analysis of closed-source binaries, protocol reconstruction, and systematic identification of user input influence points that would have been impractical before
- The attack chain combined multiple injected values to bypass internal protections and limitations, ultimately achieving remote code execution
- GitHub Enterprise Cloud products were automatically patched, but Enterprise Server requires authenticated users with push access to manually upgrade to fixed versions (3.14.24, 3.15.19, 3.16.15, 3.17.12, 3.18.6, and 3.19.3)
- Closed-source software has historically harbored the biggest security risks due to obscurity, making this AI-assisted discovery approach particularly significant for the broader security landscape
- Modern AI models have improved to the point where they can reverse-engineer binaries or produce working exploits from just a CVE identifier and git commit hash
- The economics of security research are shifting as AI reduces the time and cost barriers for analyzing proprietary code at scale
- Wiz describes this as "one of the first critical vulnerabilities discovered in closed-source binaries using AI," signaling a methodological shift in vulnerability research
Decoder
- CVE-2026-3854: Common Vulnerabilities and Exposures identifier for this specific GitHub security flaw
- CVSS 8.7: Common Vulnerability Scoring System rating indicating high severity (scale of 0-10)
- Remote Code Execution (RCE): Attack that allows an adversary to execute arbitrary code on a target system remotely
- Git push options: Feature in git that allows clients to send key-value string pairs to the server during a code push operation
- IDA MCP: AI-powered assistant for reverse engineering that analyzes compiled binary code
- Reverse engineering: Process of analyzing compiled software to understand its internal workings without access to source code
- Delimiter character: Special character used to separate fields in data formats, which attackers exploited to inject malicious metadata
- GitHub Enterprise Server: Self-hosted version of GitHub that organizations run on their own infrastructure
Original article
GitHub disclosed a high severity vulnerability, CVE-2026-3854, affecting GitHub Enterprise Server and other products, which allows remote code execution through manipulated git push options.
Build programmatic agents with the Cursor SDK
Cursor released an SDK that lets developers programmatically deploy the same AI coding agents that power Cursor's editor into CI/CD pipelines, internal tools, and customer-facing products.
Deep dive
- The SDK provides the same production-ready infrastructure Cursor uses internally, eliminating the need to build secure sandboxing, state management, environment setup, and context management from scratch
- Cloud sessions run on dedicated VMs with strong isolation, persist through network drops and laptop sleep, and can automatically create PRs or push branches when tasks complete
- Developers can start tasks programmatically via the SDK and later inspect or take over the work through Cursor's Agents Window or web app, providing flexibility between automated and interactive workflows
- The harness includes intelligent context management with codebase indexing and semantic search, MCP server integration for external tools, automatic skill detection from repo directories, and customizable hooks to extend agent behavior
- Subagents allow delegating subtasks to specialized agents with their own prompts and models, enabling complex multi-step workflows
- Composer 2, Cursor's specialized coding model, delivers frontier-level performance at a fraction of the cost of general-purpose models, optimizing the cost-capability balance for coding tasks
- Real-world use cases span CI/CD integration (summarizing changes, diagnosing failures, auto-fixing PRs), internal tooling (letting non-technical teams query data), and customer-facing product features
- The SDK supports three runtime modes: cloud (fully managed VMs), self-hosted workers (keeping code inside your network), and local (fast iteration on developer machines)
- Companies like Faire, Rippling, Notion, and C3 AI are already using it to run parallel agents at scale without managing infrastructure or hitting memory limits
- The SDK is available in public beta for all users with token-based consumption pricing, with ongoing investment in multi-language support and broader deployment patterns
Decoder
- MCP servers: Model Context Protocol servers that let agents connect to external tools and data sources over stdio or HTTP, configured via JSON files or inline code
- Harness: The underlying infrastructure and tooling layer that manages how agents interact with code, including indexing, search, tool access, and execution environment
- Composer 2: Cursor's specialized AI model optimized specifically for coding tasks, achieving performance comparable to frontier models at lower cost
- Subagents: Secondary AI agents spawned by a main agent to handle specific subtasks, each with their own configuration and model selection
Original article
We're introducing the Cursor SDK so you can build agents with the same runtime, harness, and models that power Cursor.
The agents that run in the Cursor desktop app, CLI, and web app are now accessible with a few lines of TypeScript. Run it on your machine or on Cursor's cloud against a dedicated VM, with any frontier model.
Coding agents are evolving from interactive tools for individual developers to programmatic infrastructure for organizations. The Cursor SDK lets you deploy agents without the overhead of building and maintaining the entire agent stack. Many teams are invoking agents directly from CI/CD pipelines, creating automations for end-to-end workflows, and embedding agents into their core products.
The Cursor SDK is now available in public beta for all users. Just run npm install @cursor/sdk to get started.
import { Agent } from "@cursor/sdk";
const agent = await Agent.create({
apiKey: process.env.CURSOR_API_KEY!,
model: { id: "composer-2" },
local: { cwd: process.cwd() },
});
const run = await agent.send("Summarize what this repository does");
for await (const event of run.stream()) {
console.log(event);
}Deploy agents to production quickly
Building fast, reliable, and capable coding agents that run safely against your data requires meaningful engineering effort: secure sandboxing, durable state and session management, environment setup, and context management. And when a new model ships, teams often have to rework their agent loops to take advantage.
The Cursor SDK eliminates this complexity so you can focus on building useful agents.
Use production-ready cloud infrastructure
Cloud sessions initiated from the SDK run on the same optimized runtime we use for Cloud Agents. Each agent gets its own dedicated VM with strong sandboxing, a clone of the repo, and a fully configured development environment.
Agents keep going when your laptop sleeps or network drops. You can stream the conversation and reconnect later. When the agent finishes, it can open a PR, push a branch, or attach demos and screenshots.
// Initiate cloud agent to start a task...:
const agent = await Agent.create({
apiKey: process.env.CURSOR_API_KEY!,
model: { id: "gpt-5.5" },
cloud: {
repos: [{ url: "https://github.com/cursor/cookbook", startingRef: "main" }],
autoCreatePR: true,
},
});
const run = await agent.send("Fix the auth token expiry bug");
console.log(`Started ${run.id}`);
// ...check back in later, from anywhere:
const result = await (
await Agent.getRun(run.id, { runtime: "cloud", agentId: run.agentId })
).wait();
console.log(result.git?.branches[0]?.prUrl);The SDK uses our updated Cloud Agents API, which allows cloud agent runs to show up in Cursor's Agents Window and web app. You can start a task programmatically and then jump into Cursor to inspect progress or take over the work.
When you need a different runtime, the same SDK can run agents on self-hosted workers, keeping code and tool execution inside your network, or locally on your machine for fast iteration.
Use the full Cursor harness
Agents launched through the SDK benefit from the same harness that powers Cursor across our desktop app, CLI, and web app:
- Intelligent context management: Codebase indexing, semantic search, and instant grep help agents get to the right outcome faster and more efficiently.
- MCP servers: Agents can connect to external tools and data sources over stdio or HTTP, either through a
.cursor/mcp.jsonconfig file or passed inline on the call. - Skills: Agents pick up skills automatically from your repo's
.cursor/skills/directory. - Hooks: Observe, control, and extend the agent loop across cloud, self-hosted, and local with a
.cursor/hooks.jsonfile. - Subagents: Delegate subtasks to named subagents with their own prompts and models, which the main agent spawns via the
Agenttool.
Build on any model
The Cursor SDK gives you access to every model supported in Cursor. Route agents to the best model for the task at hand, with your desired balance of cost and capability, with a single field change.
And with Composer 2, a specialized coding model that achieves frontier-level performance at a fraction of the cost of general-purpose models, you get the best combination of intelligence and efficiency for most coding agent tasks.
What developers are building
Teams are using the Cursor SDK to ship custom agents faster. For example, programmatic agents that are kicked off directly from CI/CD to summarize changes, identify root causes for CI failures, and update PRs with fixes. Others are building custom agent platforms like internal applications that let GTM teams query product data without writing code.
Some customers are even embedding Cursor directly into customer-facing products, where end users now get an agent experience without leaving the host application.
Hear directly from some of our customers building on the Cursor SDK:
Cursor offers a great cloud experience for running many agents in parallel from the editor and CLI. We're excited about the SDK as a path to running our own programmatic agents on that same cloud runtime, without managing VMs or working around memory limits, to keep our codebase healthy without constant developer intervention.
George Jacob, Senior Engineering Manager, Faire
Start from a sample project
We've added a few starter projects to a public GitHub repo that you can fork and extend for your own use cases:
- Quickstart: A minimal Node.js example that creates a local agent, sends one prompt, and streams the response.
- Prototyping tool: A web app for spinning up agents to scaffold new projects and iterate on ideas in a sandboxed cloud environment.
- Kanban board: An agent-powered kanban tool where engineers can drag a card and have agents programmatically pick up the work, open a PR, and post the result back as an attachment.
- Coding agent CLI: A lightweight command-line interface that lets you spawn Cursor agents from your terminal.
What's next
The Cursor SDK is available to all users and is billed based on standard, token-based consumption pricing.
We are continuing to invest in the Cursor SDK, with a focus on making it even easier for teams to build programmatic agents across more languages, workflows, and deployment patterns.
Learn more by reading our docs. You can also use Cursor with our Cursor SDK plugin to help you start building.
Link CLI (GitHub Repo)
Stripe released Link CLI, a tool that lets AI agents complete purchases using secure, one-time payment credentials without ever accessing users' real card details.
Deep dive
- Agents create spend requests specifying merchant details, line items, and amounts, then receive one-time virtual card credentials (number, CVV, expiration) or shared payment tokens
- The
--request-approvalflag triggers push notifications or emails requiring explicit user consent before credentials are provisioned - Each spend request includes a context field requiring at least 100 characters explaining the purchase rationale to the user
- Supports two payment flows: traditional virtual cards for standard checkout forms, and Machine Payments Protocol (HTTP 402) for merchants with native support
- Runs as both a standalone CLI tool and an MCP (Model Context Protocol) server for integration with Claude and other agent platforms
- Spend requests have transaction limits (max $500/50,000 cents) and credentials expire after use or time limit
- Test mode allows development and integration testing without real payment methods using Stripe's test card
- Polling mechanisms let agents wait for user approval with configurable intervals and timeouts, exiting with specific error codes if requests remain pending
- Authentication flow shows the connecting agent name in the Link app (e.g., "Claude Code on my-macbook") for transparency
- The tool never stores or logs real card details—credentials are generated on-demand and scoped to specific merchants
Decoder
- Link: Stripe's digital wallet product that stores payment methods and generates secure credentials
- MCP (Model Context Protocol): A protocol that allows AI assistants like Claude to connect to external tools and services
- Spend request: A request for temporary payment credentials specifying merchant, amount, and context for user approval
- MPP (Machine Payments Protocol): An HTTP 402-based protocol for programmatic payments where merchants can request payment directly
- Shared payment token (SPT): A one-time-use payment token for MPP-compatible merchants, alternative to virtual card credentials
- Virtual card: A temporary card number with CVV and expiration generated specifically for one transaction
Original article
Link CLI
Link CLI lets agents get secure, one-time-use payment credentials from a Link wallet — so they can complete purchases on your behalf without ever storing your real card details.
Installation
npm i -g @stripe/link-cliOr run directly with npx:
npx @stripe/link-cliYou can install the skill via npx skills add stripe/link-cli.
MCP Server
Link CLI can also run as a local MCP server. Add the following to your MCP client config (.mcp.json, etc.)
{
"mcpServers": {
"link": {
"command": "npx",
"args": ["@stripe/link-cli", "--mcp"]
}
}
}Quickstart
Login
The link-cli requires a Link account. You can log in to your existing one or register online.
link-cli auth loginYou'll receive a verification URL and a short phrase. Visit the URL, log in to your Link account, and enter the phrase to approve the connection.
List payment methods
link-cli payment-methods listReturns the cards and bank accounts saved to your Link account. Use the id field as payment_method_id in the next step. If you have no payment methods, you can add new ones in Link.
Create a spend request
To request a secure, one-time payment credential from your Link wallet, you create a spend request. You specify a payment method in your account, as well as some merchant details, line items, and amounts.
link-cli spend-request create \
--payment-method-id csmrpd_xxx \
--merchant-name "Stripe Press" \
--merchant-url "https://press.stripe.com" \
--context "Purchasing 'Working in Public' from press.stripe.com. The user initiated this purchase through the shopping assistant." \
--amount 3500 \
--line-item "name:Working in Public,unit_amount:3500,quantity:1" \
--total "type:total,display_text:Total,amount:3500" \
--request-approvalThe --request-approval flag triggers a push notification (or email) to the user for approval, then polls until the request is approved or denied.
Users can easily approve requests with the Link app.
Credential types
By default, a spend request provisions a virtual card. For merchants that support the Machine Payments Protocol (HTTP 402) and the Stripe payment method, you can instead include --credential-type "shared_payment_token".
Execute payment
The approved spend request includes a card object with number, cvc, exp_month, exp_year, billing_address, and valid_until. Enter these into the merchant's checkout form.
link-cli spend-request retrieve lsrq_001 --format jsonBy default, retrieving a spend request will not include card details. Use the --include=card to see unmasked card details.
For agent polling, pass --interval and optionally --max-attempts:
link-cli spend-request retrieve lsrq_001 --interval 2 --max-attempts 150 --format jsonPolling exits successfully only after the request reaches a terminal status such as approved, denied, or expired. If polling reaches --timeout or exhausts --max-attempts while the request is still non-terminal, the command exits non-zero with code: "POLLING_TIMEOUT" so callers do not treat a still-pending request as complete.
If the merchant supports MPP, use link-cli mpp pay instead:
link-cli mpp pay https://climate.stripe.dev/api/contribute \
--spend-request-id lsrq_001 \
--method POST \
--data '{"amount":100}' \
--format jsonAdvanced
Authentication
link-cli auth login --client-name "Claude Code" --format json # identify the connecting agent
link-cli auth status --format json # check auth status
link-cli auth logout --format json # disconnectWhen --client-name is provided, the name is shown in the Link app when the user approves the connection — e.g. Claude Code on my-macbook instead of link-cli on my-macbook.
auth status --format json includes an update field when a newer version is available:
{
"authenticated": true,
"update": {
"current_version": "0.1.2",
"latest_version": "0.2.0",
"update_command": "npm install -g @stripe/link-cli"
}
}Set NO_UPDATE_NOTIFIER=1 to suppress update checks (e.g. in CI).
Spend request lifecycle
A spend request moves through: create → request approval → approved (with credentials).
Required fields for create: payment_method_id, merchant_name, merchant_url, context, amount
Constraints: context must be at least 100 characters; amount must not exceed 50000 (cents); currency must be a 3-letter ISO code. Test mode: Pass --test to create testmode credentials (uses test card 4242424242424242). Useful for development and integration testing without using real payment methods.
# Update before approval
link-cli spend-request update lsrq_001 \
--merchant-url https://press.stripe.com/working-in-public \
--format json
# Request approval separately (alternative to create --request-approval)
link-cli spend-request request-approval lsrq_001 --format json
# Retrieve at any time (includes card credentials once approved)
link-cli spend-request retrieve lsrq_001 --format jsonOutput formats
All commands accept --format json for structured JSON output. Other formats: yaml, md, jsonl, toon (default). Errors are returned as JSON with code and message fields, with exit code 1.
MPP
Use mpp pay to complete purchases on merchants that use the Machine Payments Protocol. The spend request must use credential_type: "shared_payment_token" and be approved. The SPT is one-time-use — if payment fails, create a new spend request.
link-cli mpp pay https://climate.stripe.dev/api/contribute \
--spend-request-id lsrq_001 \
--method POST \
--data '{"amount":100}' \
--header "X-Custom: value" \
--format jsonUse mpp decode to validate a raw WWW-Authenticate header and extract the network_id needed for shared_payment_token spend requests:
link-cli mpp decode \
--challenge 'Payment id="ch_001", realm="merchant.example", method="stripe", intent="charge", request="..."' \
--format jsonEnvironment variables
| Variable | Effect |
|---|---|
LINK_API_BASE_URL |
Override the API base URL |
LINK_AUTH_BASE_URL |
Override the auth base URL |
LINK_HTTP_PROXY |
Route all requests through an HTTP proxy (requires undici) |
Onboard
Run the guided setup flow — authenticates, checks payment methods, shows the app download QR, and walks through both demo flows:
link-cli onboardDemo
Run an interactive demo of both Link payment flows (always uses test mode — no real charges):
link-cli demo # shows menu to choose flow
link-cli demo --only-card # virtual card flow only
link-cli demo --only-spt # machine payment (SPT) flow onlyDevelopment
pnpm install
pnpm run build
pnpm run link-cli --helpWatch mode:
pnpm run devRun tests:
pnpm run testType-check and lint:
pnpm run typecheck
pnpm biome check .Releasing
This project uses Changesets to manage versioning and publishing. Only @stripe/link-cli is published to npm — internal packages (@stripe/link-sdk, @stripe/link-typescript-config) are ignored by changesets.
Add a changeset
When you make a user-facing change, add a changeset before merging:
pnpm changesetFollow the prompts to select the package (@stripe/link-cli) and the semver bump type (patch, minor, or major). This creates a markdown file in .changeset/ describing the change.
Version
Once changesets have accumulated on main, create a version PR:
pnpm changeset versionThis consumes all pending changesets, bumps the version in packages/cli/package.json, and updates CHANGELOG.md.
Publish
After the version PR is merged:
pnpm run build
pnpm changeset publishThis publishes @stripe/link-cli to npm. CI also runs pnpm --filter @stripe/link-cli publish --dry-run --no-git-checks on every push to main to verify the package is publishable.

Agents can now create Cloudflare accounts, buy domains, and deploy
AI coding agents can now autonomously create Cloudflare accounts, register domains, and deploy applications from scratch without any manual setup steps.
Deep dive
- Cloudflare now allows AI agents to autonomously provision accounts and infrastructure through a new protocol co-designed with Stripe as part of Stripe Projects
- The protocol has three core components: Discovery (agents query a catalog of available services), Authorization (identity attestation and automatic account creation), and Payment (tokenized billing with spending limits)
- Agents can go from zero infrastructure to production deployment, including creating accounts, obtaining API tokens, purchasing domains, and deploying applications without human intervention
- Safety measures include a default $100/month spending limit per provider and human approval requirements for critical steps like adding payment methods and accepting terms of service
- The protocol builds on existing standards like OAuth, OIDC, and payment tokenization but combines them to enable fully autonomous agent workflows
- Any platform with signed-in users can act as an "Orchestrator" similar to Stripe Projects and integrate with Cloudflare using the same protocol
- This standardizes cross-product integrations that previously required one-off engineering work, making it easier to build agent-friendly ecosystems
- Cloudflare is offering $100,000 in credits to startups incorporating through Stripe Atlas as part of the partnership
- The protocol treats agents as first-class citizens by providing structured catalogs of services they can discover and provision programmatically
- Stripe Projects is in open beta and available to anyone with a Stripe account, even without an existing Cloudflare account
Decoder
- MCP server: Model Context Protocol server, a way to provide structured context and capabilities to AI models
- Agent Skills: Predefined capabilities that agents can use to interact with specific platforms or services
- OAuth: Open Authorization, a standard protocol for delegating access to user accounts without sharing passwords
- OIDC: OpenID Connect, an identity layer built on top of OAuth for authentication
- Payment tokenization: Replacing sensitive payment details with non-sensitive tokens that can be safely shared with third parties
- Orchestrator: In this protocol, the platform that manages user identity and coordinates between users, agents, and service providers
- Stripe Projects: Stripe's platform for allowing agents to discover and provision third-party services on behalf of users
- Stripe Atlas: Stripe's service for helping entrepreneurs incorporate and start companies
Original article
Agents can now create Cloudflare accounts, buy domains, and deploy
Coding agents are great at building software. But to deploy to production they need three things from the cloud they want to host their app — an account, a way to pay, and an API token. Until now these have been tasks that humans handle directly. Increasingly, agents handle them on the user's behalf. The agent needs to perform all the tasks a human customer can. They're given higher-order problems to solve and choose to use Cloudflare and call Cloudflare APIs.
Starting today, agents can provision Cloudflare on behalf of their users. They can create a Cloudflare account, start a paid subscription, register a domain, and get back an API token to deploy code right away. Humans can be in the loop to grant permission and must accept Cloudflare's terms of service, but no human steps are otherwise required from start to finish. There's no need to go to the dashboard, copy and paste API tokens, or enter credit card details. Without any extra setup, agents have everything they need to deploy a new production application in one shot. And with Cloudflare's Code Mode MCP server and Agent Skills, they're even better at it.
This all works via a new protocol that we've co-designed with Stripe as part of the launch of Stripe Projects.
We're excited to launch this new partnership with Stripe, and also to offer $100,000 in Cloudflare credits to all new startups who incorporate using Stripe Atlas. But this new protocol also makes it possible for any platform with signed-in users to integrate with Cloudflare in the same way Stripe does, with zero friction for the end user.
How it works: zero to production without any setup or manual steps
Install the Stripe CLI with the Stripe Projects plugin, login to Stripe, and then start a new project:
stripe projects initThen prompt your agent to build something new and deploy it to a new domain. You can watch a condensed two-minute video of this entire flow below:
If the email you're logged into Stripe with already has a Cloudflare account, you'll be prompted with a typical OAuth flow to grant the agent access. If there is no existing Cloudflare account for the email you're logged in with, Cloudflare will provision an account automatically for you and your agent:
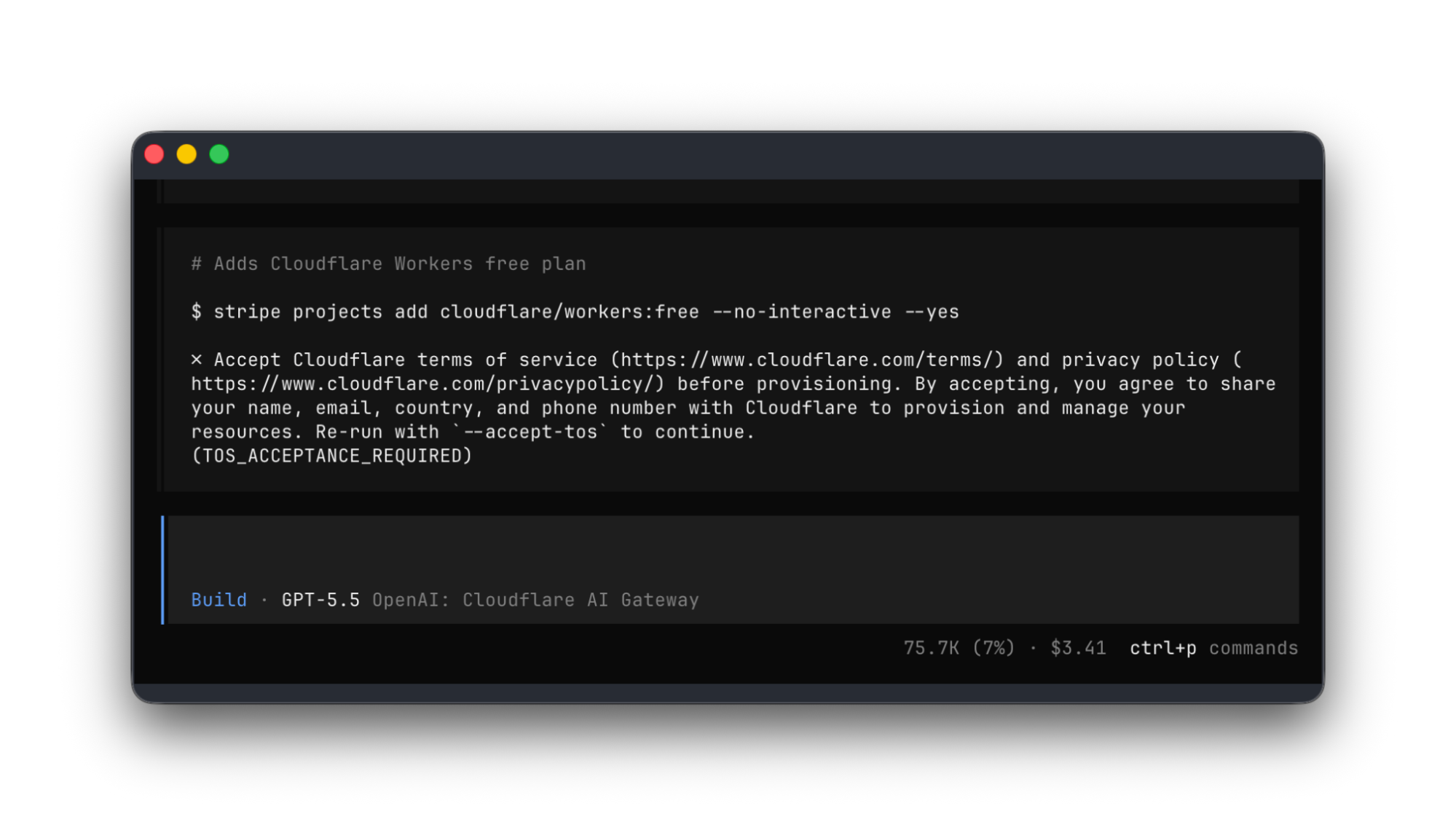
You will see the agent build and deploy a site to a new Cloudflare account, and then use the Stripe Projects CLI to register the domain:

The agent will prompt for input and approval when necessary. For example, if your Stripe account doesn't yet have a linked payment method, the agent will prompt you to add one:
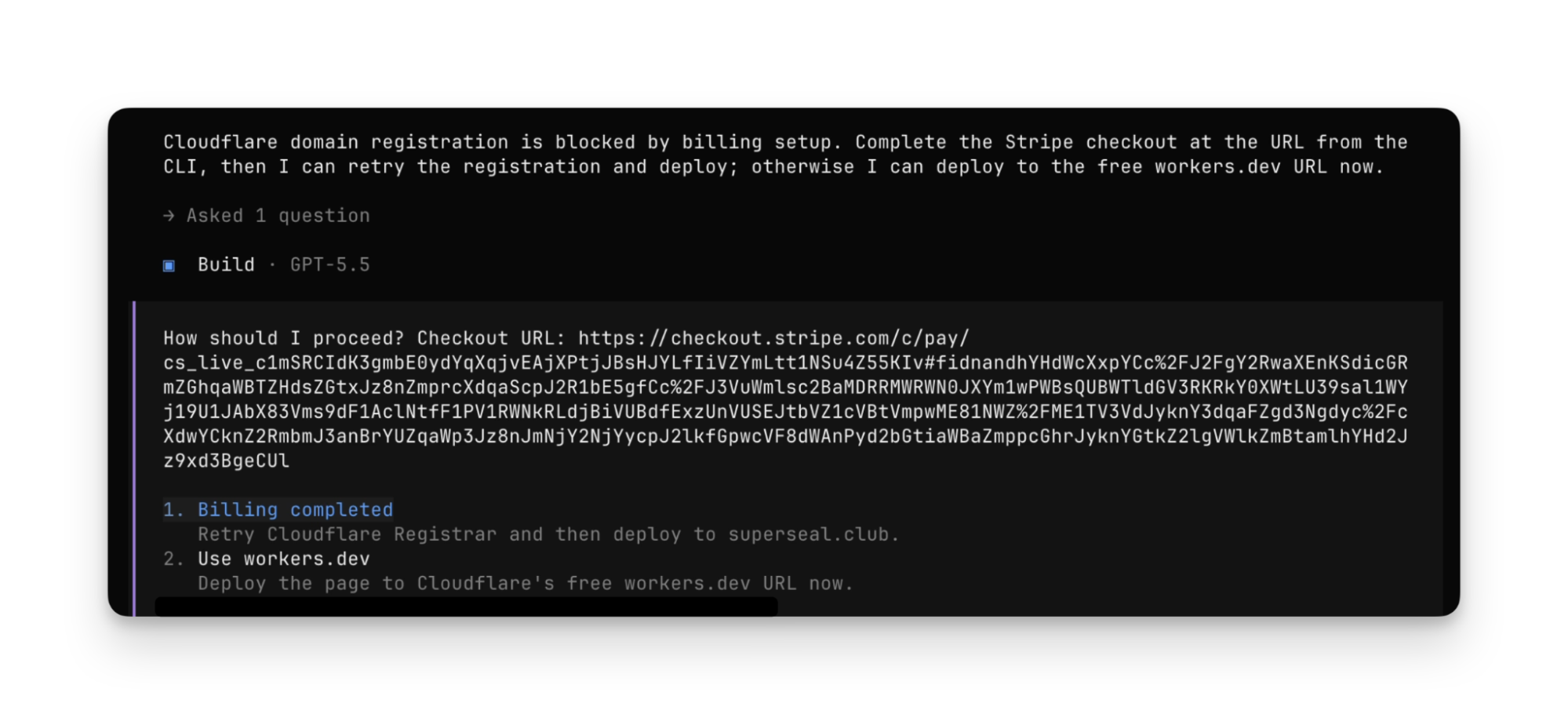
At the end, the agent has deployed to production, and the app runs on the newly registered domain:

The agent has gone from literal zero, no Cloudflare account at all, without any preconfigured Agent Skills or MCP server, to having:
- Provisioned a new Cloudflare account
- Obtained an API token
- Purchased a domain
- Deployed an app to production
But wait — how did the agent discover that it could do all of this? How did it know what services it could provision, and how to purchase a domain? How did it gain the context it needed to understand how to deploy to Cloudflare? Let's dig in.
How the protocol and integration works
There are three components to the interaction between the agent, Stripe, and Cloudflare shown above:
- Discovery — the agent can call a command to query the catalog of available services.
- Authorization — the platform attests to the identity of the user, allowing providers to provision accounts or link existing ones, and securely issue credentials back to the agent.
- Payment — the platform provides a payment token that providers can use to bill the customer, allowing the agent to start subscriptions, make purchases and be billed on a usage basis.
These build on prior art and existing standards like OAuth, OIDC and payment tokenization — but are used together to remove many steps that might otherwise require a human in the loop.
Discovery: how agents find services they can provision themselves
In the agent session above, before the agent ran the CLI command stripe projects add cloudflare/registrar:domain, it first had to discover the Cloudflare Registrar service. It did this by calling the stripe projects catalog command, which returns available services:
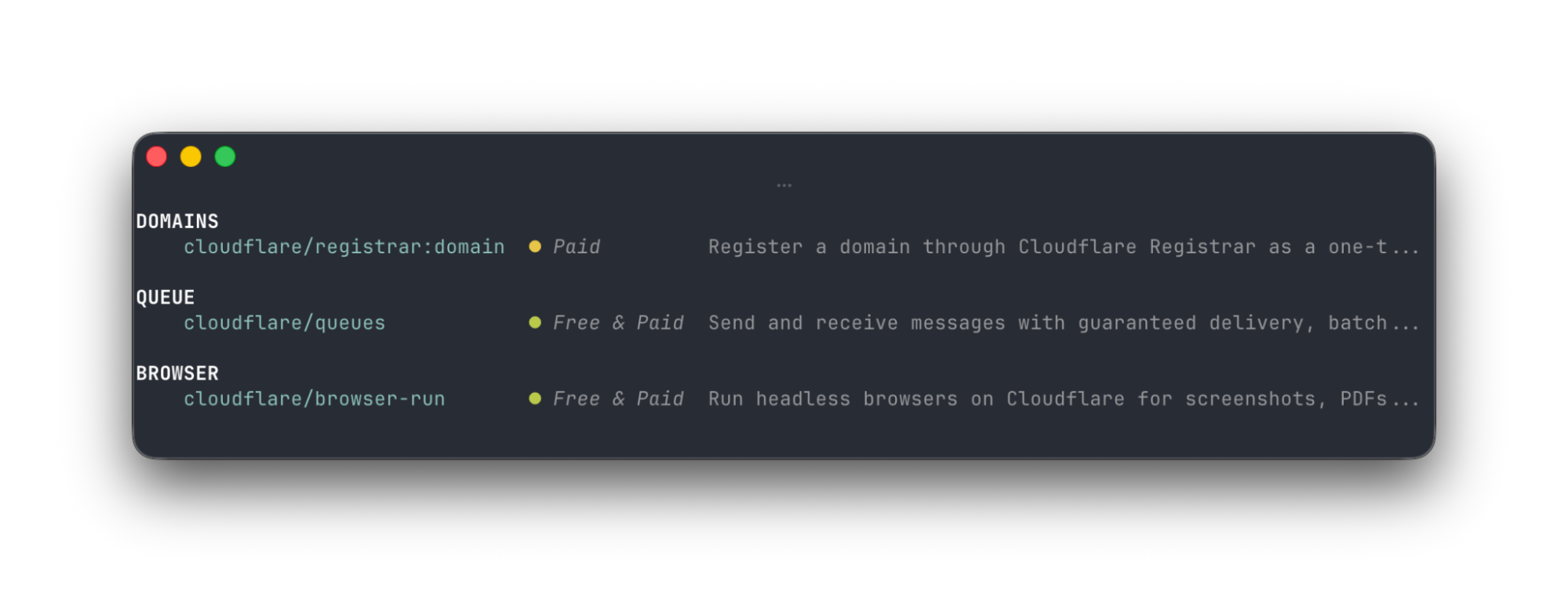
The full set of Cloudflare products and services from other providers is long and growing — arguably overwhelming to humans. But for agents, this catalog of services is exactly the context they need. The agent chooses services to use from this catalog based on what the user has asked them to do and the user's preferences — but the user needs no prior knowledge of what services are offered by which providers, and does not need to provide any input. Providers like Cloudflare make this catalog available via a simple REST API that returns JSON, and that gives agents everything they need.
Authorization: instant account creation for new users
When the agent chooses a service and provisions it (ex: stripe projects add cloudflare/registrar:domain), it provisions the resource within a Cloudflare account. But how is it able to create one on demand, without sending a human to a signup page?
Remember how at the start, the user signed in to their Stripe account? Stripe acts as the identity provider, attesting to the user's identity. Cloudflare automatically provisions a new account for the user if no account already exists, and returns credentials back to the Stripe Projects CLI, which are securely stored, but available to the agent to use to make authenticated requests to Cloudflare. This means if someone is brand new to Cloudflare or other services, they can start building right away with their agent, without extra steps.
If the user already has a Cloudflare account, they're sent through a standard OAuth flow to grant access to the Stripe Projects CLI, allowing them to provision resources on their existing Cloudflare account.
Payment: give your agent a budget it can spend, without giving it your credit card info
You might rightly worry, "What if my agent goes a bit overboard and starts buying dozens of domains? Will I end up on the hook for a massive bill? Can I really trust my agent with my credit card?"
The protocol accounts for this in two ways. When an agent provisions a paid service, Stripe includes a payment token in the request to the Provider (Cloudflare). Raw payment details like credit card numbers aren't ever shared with the agent. Stripe then sets a default limit of $100.00 USD/month as the maximum the agent can spend on any one provider. When you're ready to raise this limit, you can then set Budget Alerts on your Cloudflare account.
Any platform with signed-in users can integrate with Cloudflare in the same way Stripe does
Any platform with signed-in users can act as the "Orchestrator", playing the same role Stripe does with Stripe Projects, and integrate with Cloudflare.
Let's say your product is a coding agent. You'd love for people to be able to take what they've built and get it deployed to production, using Cloudflare and other services. But the last thing you want is to send people down a maze of authorization flows and decision trees of where and how to deploy it. You just want to let people ship.
Your platform acts as the Orchestrator, with the already signed-in user. When your user needs a domain, a storage bucket, a sandbox to give their agent, or anything else, you make one API call to Cloudflare to provision a new Cloudflare account to them, and get back a token to make authenticated requests on their behalf.
Or let's say you want Cloudflare customers to be able to easily provision your service, similar to how Cloudflare is partnering with Planetscale to make it possible to create Planetscale Postgres databases directly from Cloudflare. We started working with Planetscale on this well before this new protocol got off the ground, but the flow here is quite similar. Cloudflare acts as the Orchestrator, letting you connect to your PlanetScale account, create databases, and use the user's existing payment method for billing.
This new protocol starts to standardize the types of cross-product integrations that many platforms have been doing for years, often in ways that were one off or bespoke to a particular platform. Without a standard, each integration required engineering work that often couldn't be leveraged for future integrations. Similar to how the OAuth standard made it possible to delegate access to your account to other platforms, the protocol uses OAuth and extends further into payments and account creation, doing so in a way that treats agents as a first-class concern.
We're excited to continue evolving the standard, and to work with Stripe on sharing a more official specification soon. We're also excited to integrate with more platforms — email us at [email protected], and tell us how you want your platform to integrate with Cloudflare.
Give your agent the power to provision and pay
Stripe Projects is in open beta, and you can get started even if you don't yet have a Cloudflare account. Just install the Stripe CLI, log in to Stripe, and then start a new project:
stripe projects initPrompt your agent to build something new on Cloudflare, and show us what you've built!

Flow generation through natural language: An agentic modeling approach
Shopify replaced a frontier AI model with a fine-tuned Qwen3-32B that generates automation workflows from natural language, achieving 2.2x speed, 68% cost reduction, and higher accuracy through domain-specific training and continuous improvement.
Deep dive
- Shopify solved the cold start problem by reverse-engineering training data from existing production workflows, using a stronger LLM to generate plausible user queries that would lead to each validated workflow, then constructing the full tool-calling trajectory
- Switching from training on Flow's native JSON DSL to Python improved syntactic correctness by 22 points and semantic correctness by 13 points, because Python is closer to the model's pretraining distribution
- A bidirectional transpiler converts between Python (what the model generates) and JSON (what the production backend uses), with round-trip testing on every production workflow to ensure perfect fidelity
- Training data must mirror production exactly—subtle differences in tool naming, ordering, response format, or system prompts cause measurable accuracy degradation, even when functionally identical
- Tool interfaces were restructured to return lightweight summaries first, letting the model select relevant items before retrieving full details, keeping context small and reasoning focused
- Infrastructure built on Tangle enables 12-hour training runs on H200 GPUs with FSDP, supporting weekly retraining cycles and multiple experimental runs in between
- Offline benchmarks showed parity with frontier models, but 1% production traffic revealed a 35% lower activation rate due to out-of-distribution requests the synthetic data hadn't covered
- An LLM judge calibrated against human annotations scores conversations across multiple facets (intent understanding, component selection, solution appropriateness), while a tagging system identifies performance gaps across workflow types
- The continuous improvement flywheel ingests production conversations weekly, automatically routes high-quality examples to training, quarantines low-quality ones for review, and identifies systematic gaps through slice analysis
- Future directions include simulation environments for verifiable rewards, moving from off-policy learning to on-policy optimization, and automating judge calibration against live production signals
- The approach generalizes when tasks require tool calling with custom DSLs that can be expressed in familiar languages, round-trip transpilation is feasible, and production feedback loops are available
- After six months of iteration, the system now runs on infrastructure Shopify owns, improving from proprietary data only they have access to, at 68% lower cost than the frontier model it replaced
Decoder
- Shopify Flow: Automation platform where merchants build workflows from triggers, conditions, and actions to automate store operations
- Fine-tuning: Training a pre-trained model on domain-specific data to specialize it for a particular task
- Qwen3-32B: Open-source language model with 32 billion parameters developed by Alibaba
- Tool calling: Agent capability where models invoke external functions/APIs and incorporate their results into reasoning
- DSL (Domain-Specific Language): Custom programming or configuration language designed for a specific problem domain
- Transpiler: Compiler that translates between two programming languages or representations at similar abstraction levels
- FSDP (Fully Sharded Data Parallel): Distributed training technique that shards model parameters, gradients, and optimizer states across GPUs
- Off-policy vs on-policy: Off-policy learns from pre-collected examples; on-policy learns from trajectories the current model generates
- Activation rate: Metric measuring whether merchants actually turn on and use the workflows Sidekick generates
- LLM judge: Language model used to evaluate quality of outputs by comparing them against reference examples or criteria
Original article
Flow generation through natural language: An agentic modeling approach
We fine-tuned Qwen3-32B into a tool-calling agent that generates Flow automations from natural language—faster, cheaper, and more accurate than the frontier model it replaced, with a weekly retraining flywheel built on real merchant data.
If you're building AI products on top of closed models, anyone with an API key can get similar capabilities. Lasting differentiation comes from proprietary data, the training recipe, the infrastructure, and the speed of iteration.
Shopify has something most companies don't: a product surface where millions of merchant interactions directly signal whether the model's output is any good. That feedback loop is the foundation, but only if you keep learning from it.
We fine-tuned a tool-calling agent to turn natural language into a Shopify Flow for Sidekick, our AI commerce assistant. It's 2.2x faster, 68% cheaper, and outperforms closed models.
Along the way, we found lessons no paper warned us about. Data preprocessing decisions, from representation design to formatting details, that compound to swing accuracy by double digits. Silent infrastructure failures that degrade your model with zero warnings and take days to trace. Benchmark parity that masks a 35% gap once real users show up.
This post covers the problems we faced, how we fixed them, and what to look for if you're doing the same.
Building the training dataset
Shopify Flow is an automation platform where store owners build workflows from triggers, conditions, and actions. For store owners who aren't engineers, building the right workflow from a blank canvas is daunting. Sidekick generates it from plain English.
The cold start problem
Fine-tuning required training data, but since the feature hadn't been deployed yet, there were no production conversations to learn from.
We reverse-engineered user intent from existing production workflows. Thousands of anonymized store owners had already built workflows manually in Flow. We sampled those and filtered for quality: workflows that had run at least once in the last seven days, from merchants with two or more qualifying workflows, with one example per descriptor to ensure diversity across workflow types.
With a set of validated workflows, we worked backwards:
- Sample a workflow. Pick a popular, validated workflow from production.
- Generate a user query. Use a stronger LLM to produce a plausible natural-language request that would lead to this workflow.
- Construct the tool trajectory. Build the full multi-turn sequence of tool calls that an ideal agent would execute to arrive at this workflow. This was the bulk of the engineering effort.
We fine-tuned Qwen3-32B on this synthetic dataset and evaluated it against a benchmark of 300 hand-crafted examples covering the breadth of expected Flow usage. An LLM evaluation framework compares the generated workflow against the expected one for semantic correctness, and validates syntactic correctness programmatically.
We looked at three metrics:
- Semantic correctness: Does the generated workflow do what it's supposed to? An LLM judge compares the output against the expected workflow.
- Syntactic correctness: Are there errors that would cause it to fail? Malformed conditions, incorrect references, invalid configurations. Checked programmatically.
- Latency: Time from request to workflow delivery.
If you're building an agent without interaction data, start with the output artifacts your users already produce and work backwards from them. That is often the right first step before your metrics have caught up. As shown in the table above, there is still a meaningful gap to close. Our second lesson, which we discuss below, is that teaching the model to generate Flows in Python can help narrow that gap further.
Training in-distribution: the Python DSL
Shopify Flow workflows are represented internally in a JSON-based domain-specific language (DSL) designed for backend parsing, validation, and execution. That format is ideal for production systems, but it's a poor fit for LLMs. Conditional, program-like logic that would normally appear as code is embedded in deeply nested JSON, a pattern that's rare in pretraining data.
Rather than forcing the model to learn Flow's native format from scratch, we reformulated the task in a representation closer to the model's training distribution. Workflows are programs, so we taught the model to write them as Python.
A transpiler converts the JSON DSL into semantically equivalent Python:
Same workflow, same semantics, but the model now generates Python instead of a data format. Python is far closer to code and logical reasoning, and it makes up a large share of pretraining data. The fine-tuned model draws on familiar patterns: decorators, if/else logic, variables, for loops, and function calls.
With the same training data, switching from the JSON DSL to the Python DSL improved syntactic correctness by 22 points and semantic correctness by 13 points. Moving the target format from out-of-distribution to in-distribution turned the problem from "learn a new language and the task" into "learn the task."
Making this work required building a round-trip transpiler between Python and Flow's JSON representation to handle the full complexity of Flow logic without losing meaning in either direction.
Reliability was backed with extensive tests. We round-trip tested every workflow merchants created through Sidekick in production: converting from JSON to Python and back to JSON, then verifying the output matched the original exactly. Any mismatch was caught before it could reach training data. This process ran continuously across all production workflows, giving us confidence the transpiler handled the full range of real-world patterns.
At inference time, the model writes Python. The transpiler converts it to JSON for the Flow backend. Store owners never see Python, and the backend never has to understand it. Python is the model's internal language.
Prior work has explored Python as an intermediate representation (SPEAC, LLMLift, WorkflowLLM), but via prompting or without a round-trip transpiler. What distinguishes this approach is the full loop: fine-tuning on Python combined with a transpiler back to the production DSL, without changing any downstream systems.
If you're training a model on a custom DSL, consider translating it into a language the model already knows. This helps separate learning the format from learning the task. As the results show, the gap narrows, but there is still room for improvement. At that point, the next step is to bring the system into production, learn from real usage, and incorporate real user feedback.
Mirroring the production environment
Representation was one half of the data problem. The other half was making sure the model's training data matched exactly what it would see in production.
We knew training data should match production. What we didn't expect was how sensitive the model is to the degree of match. Every difference we closed, no matter how minor, improved eval scores:
- Tool naming and ordering: Training data used the full prefixed name
flow_app_agent_task_search. At inference, the same tool was calledtask_search. Functionally identical, but the model treated them as different tools. Removing the prefix from training data to match inference improved accuracy. The order in which the tools appeared in the system prompt also mattered. Shuffle the order between training and serving, and performance drops. - Tool response format: Tool responses return JSON objects with multiple fields. In the training data, we sorted keys alphabetically. If production returned them in a different order, or included an extra field, the model noticed. Any drift between what the training data showed and what production APIs actually returned degraded accuracy.
- System prompt and tool descriptions: Tool descriptions in production changed frequently as the product team iterated on behavior. Every update had to be reflected in the training data, or the model's behavior drifted. Keeping both in sync was an ongoing process, not a one-time fix.
None of these are about the logic of the task. They are formatting details. The model treats every token as a signal, whether you intended it or not.
Optimizing the tool-calling stack
When an agent calls tools, every response becomes part of the context. Context grows, latency grows, cost grows. Worse, irrelevant context dilutes the signal. The model reasons less accurately when it's processing information it won't use.
We restructured our tool interfaces to minimize context at each step. Instead of returning full details for every result upfront, tools return lightweight summaries first. The model scans the summaries, selects what it needs, then retrieves full details only for those necessities. Two cheap calls instead of one expensive one.
For example, Flow has hundreds of available triggers, conditions, and actions. A search might return 100 matches. Rather than loading the full configuration schema for each one, task_search returns just names and descriptions. The model picks the 2-3 it actually needs, then calls task_configuration to get the full schema only for those. The context stays small, the reasoning stays focused.
Making training fast
As our data pipeline grew, so did a tension: more training data improved accuracy but slowed each run. Slower runs meant fewer iterations, and fewer iterations meant slower improvement. We needed a way to use all the data and still retrain weekly.
We built the infrastructure to make both possible. Qwen3-32B trains on two nodes of H200 GPUs with Fully Sharded Data Parallel (FSDP). A full training run takes 12 hours, fast enough for weekly retraining with multiple experimental runs in between.
The full pipeline, from data collection through training, evaluation, and deployment, runs on Tangle, Shopify's open-source ML experimentation platform. Tangle composes each step into a single reproducible workflow with intelligent caching. Only the affected steps re-run when one part changes.
CometML tracks every run. HuggingFace hosts datasets and checkpoints. CentML serves the model in production. Weekly retraining runs without manual intervention.
Evaluation: benchmarks aren't ground truth
Synthetic data got us to parity on offline benchmarks. By every metric we tracked, the fine-tuned model was ready for production. We deployed it to 1% of traffic to see how it held up.
At 1% traffic, the fine-tuned model's workflow activation rate (whether store owners actually turn on the workflows Sidekick generates) came in 35% lower than the prompt-based agent. The benchmark covered what we expected merchants to ask. It didn't cover what they actually asked: editing existing workflows, handling email configurations, working with third-party integrations, and asking questions about Flow without intending to create a workflow.
The model performed well in-domain, but real traffic quickly surfaced out-of-distribution requests that our synthetic data had not covered. The low-traffic early deployment showed us exactly where to focus next. Activation rate was our first production signal, but it turned out to be noisy: it reflects merchant behavior, not model quality. We therefore optimized for a domain-expert-calibrated LLM judge, which we describe next, while keeping activation rate as a guardrail to ensure we did not regress.
Flywheel: from catching up to pulling ahead
Closing the gap
The 1% deployment showed us exactly where the model was falling short. We needed a system that could diagnose those gaps, fix them, and retrain fast. Not once, but continuously.
We built an LLM-based judge that scores each conversation across the workflow lifecycle: whether the assistant correctly understood the merchant's intent, chose a Flow solution only when appropriate, selected the right components, and gave clear next steps. The judge grades each facet separately rather than treating quality as a single pass/fail outcome. To calibrate it, we collected human annotations on hundreds of conversations and tuned it until its scores aligned with human judgment, then validated against production activation rate.
A tagging system classifies every workflow along multiple dimensions: which triggers it uses, what conditions it checks, which actions it invokes, and whether it involves third-party integrations. Comparing performance across tagged slices pinpoints exactly where the model struggles. When performance drops on a particular slice, we know what kind of data to add.
The judge and tagging system together form the diagnostic layer. The fixes were concrete:
- Email workflows accounted for 25% of failures, so we added email-specific examples
- Diverse condition patterns accounted for 16%
- Workflow editing, which was something synthetic data had never covered
The following diagram shows our progress in Flow modeling, with quality improving steadily over time as measured by our LLM judge:
Continuous improvement
Closing the gap was the first test. Staying ahead is the real goal.
Every production conversation becomes a training signal. We sample high-quality examples: conversations where merchants actually activated the workflow afterwards. The judge scores them, and high-scoring conversations are routed into the training pool automatically. Low-scoring ones are quarantined for review.
The loop runs weekly:
- Ingest production conversations
- Score with the LLM judge
- Route high-quality examples into training; quarantine low-quality for review
- Identify gaps through tagged slice analysis
- Retrain and deploy
The system improves as production traffic shifts, freeing the team to focus on expanding coverage and fixing systematic gaps rather than hand-curating data. The approach is similar in spirit to Karpathy's Autoresearch, an automated loop that evaluates, keeps what works, discards what doesn't, and iterates—but applied to production data curation rather than training code.
What's next
The flywheel is running, but the race between in-house and closed-source models doesn't stop. Every few months, a new frontier model raises the bar. The only way to stay ahead is to keep compounding: better data, better training, better evaluation, faster iteration. Here's where we're pushing next.
Simulation environments. A sandbox where the model can generate workflows and receive structured feedback on whether they would succeed, without impacting real merchants. The model writes test cases and runs them against a simulated Flow environment, creating a setting for verifiable rewards. This opens the door to distillation from stronger teacher models and on-policy optimization.
From off-policy to on-policy. Everything so far is off-policy: the model learns from curated examples collected after the fact. With verifiable rewards from the simulation environment, the next step is policy optimization where the model learns from its own generated trajectories. The goal is a model that discovers better strategies, not one that only replicates what it's seen.
From manual calibration to self-improving evaluation. Today, the LLM judge is calibrated against human annotations and production activation rate. But merchant behavior shifts, new integrations launch, and new workflow patterns emerge faster than manual recalibration can keep up. Automating judge calibration against live production signals is the next evaluation challenge.
Results in production
The fine-tuned Flow agent now serves the majority of our production traffic.
No single technique got us here. Each stage built on the last. Synthetic data generation needed the Python DSL to close the accuracy gap. The DSL needed production mirroring to hold up in the real environment. Production mirroring needed infrastructure stable enough to trust. And when benchmarks said we were ready but production said otherwise, the flywheel closed the gap in two weeks.
When does this generalize?
This approach applies when:
- The task requires tool calling. The model must reason, act, and incorporate external results, not just generate text.
- The output format is a custom DSL that doesn't appear in pretraining data, and its semantics can be expressed in a language the model already knows.
- A round-trip transpiler is feasible between the in-distribution representation and the production format.
- A production feedback loop is available. Synthetic data gets you started, but real-world data is what gets you to production quality.
Within Sidekick, this pattern is already being applied to other skills. The recipe is the same: isolate the skill, fine-tune the tool-calling model, and build the loop for continuous improvement.
Six months ago, this system ran on a frontier model we didn't control. Now it runs on a model we trained, on infrastructure we own, improving from data only we have, at 68% lower cost. The version running right now is already worse than the one retraining behind it.
We started on rented ground. This is what the first mile of owned ground looks like.

From Clicks to Conversions: Architecting Shopping Conversion Candidate Generation at Pinterest
Pinterest built a machine learning system that optimizes shopping ads for actual purchases rather than clicks, addressing the misalignment between engagement metrics and buying intent.
Decoder
- Two-tower model: Neural network architecture with separate encoders for users and items that can be computed independently for efficient retrieval
- DCN v2: Deep & Cross Network version 2, a neural architecture designed to learn feature interactions
- Offsite conversions: Purchase events that happen on advertiser websites after clicking an ad, rather than on-platform engagement
Original article
Pinterest built a dedicated two-tower retrieval model to generate better shopping ad candidates optimized for offsite conversions, moving beyond traditional click/engagement-based signals which are abundant but poorly correlated with actual buying intent. The system uses a unified multi-task architecture with parallel DCN v2 and MLP cross layers, clever training techniques to handle sparse and noisy conversion data, and an advertiser-level loss function.

How Vinted Serves Personalised Search Autocomplete
Vinted rebuilt their autocomplete system using edge-ngram indexing on Vespa and a LightGBM re-ranking model, growing autocomplete usage from 8% to 20%+ of search sessions while serving 4,700 QPS at 31ms P99.
Deep dive
- Vinted generates 125 million autocomplete candidates from two sources: product metadata combinations (brand+category+color) and actual user search queries, with query-based suggestions comprising only 2% of the pool but driving 50% of clicks
- Offline scoring uses a multi-objective heuristic combining sell-through rate, sold item count, suggestion usage, and CTR—normalized per country, language, and first letter so suggestions compete within their context, not globally
- Edge-ngram indexing moved matching cost from query time to index time by pre-splitting suggestions into all prefixes at indexing ("apple" → ["a", "ap", "app", "appl", "apple"]), dropping P99 latency from 220ms to 25ms
- Accent handling uses a multiplexer to index both original and ASCII-folded tokens, so typing "z" matches both "Zara" and "Žalgiris" but typing "ž" returns only "Žalgiris"—preserving intent when users deliberately type accents
- Progressive query relaxation cascades through three tiers (exact prefix → fuzzy edit distance 1 → fuzzy edit distance 2), stopping as soon as 10 deduplicated suggestions are found, with 62% of requests never leaving the exact tier
- The LightGBM LTR model uses 63 features across four groups (query/suggestion properties, popularity signals, user behavior like click history and category preferences, and contextual factors), optimizing for NDCG@1 with LambdaRank
- Top features by importance are input length, when users typically click a given suggestion relative to current input length, prefix-level click frequency, and suggestions CTR—validating that the model builds on the heuristic baseline rather than replacing it
- Vespa runs two-phase ranking: first-phase uses the SLS heuristic score to select top 1,000 candidates per content node, then second-phase re-ranks the top 20 with LightGBM using user features fetched in real-time from Vinted's Feature Store
- Over 35 A/B tests yielded key lessons: cleaning noisy training labels from short prefixes (where users are still typing) immediately improved ranking quality, and restricting LTR to exact matches only (not fuzzy) gave a clear relevance boost
- The cumulative SLS impact measured +49% suggestions CTR and +42% suggestion usage; adding LTR personalization on top delivered another +8% CTR and +4% usage, with up to +16% CTR on longer queries and stronger effects in non-clothing verticals like sports (+0.91% transactions)
- Tests on richer UI features (capitalisation, category scopes) consistently lost to plain lowercase suggestions—industry defaults exist for a reason, and novelty in autocomplete UX rarely beats user familiarity with the basic pattern
- Infrastructure runs on Vespa clusters with 6 content nodes per datacenter (AMD EPYC 64-core, 512GB RAM), averaging 2% search CPU and peaking at 4.5% during evening traffic, with substantial headroom for growth
- Key architectural decision: Vespa was chosen over Elasticsearch for native ML inference support despite weaker lexical analysis—the team contributed Lucene Linguistics to Vespa to bridge the gap and bring edge-ngram tokenization into the platform
- Future roadmap includes session-aware re-ranking using previous queries as context, surfacing user's past searches directly in autocomplete, and exploring LLM-based suggestion generation for long-tail queries once latency constraints can be met
- Biggest learnings: get retrieval foundations right first (most usage lift came before ML), real user queries beat generated metadata combinations when volume exists, personalisation pays off in the long tail not aggregate metrics, and engagement metrics (CTR, usage) are more sensitive indicators than downstream revenue
Decoder
- Learning-to-Rank (LTR): Machine learning approach that trains models to optimize the ordering of search results by learning from user interactions, rather than using hand-tuned scoring formulas
- Edge-ngram: Indexing technique that pre-generates all prefix substrings of a term at index time, turning expensive prefix queries into fast exact lookups (e.g., "apple" becomes ["a", "ap", "app", "appl", "apple"])
- Vespa: Open-source search and ranking engine that supports native ML model inference in the query path, allowing real-time personalization without leaving the search layer
- NDCG: Normalized Discounted Cumulative Gain, a ranking quality metric that rewards placing highly-relevant results at the top of the list, with position importance decaying logarithmically
- LightGBM: Fast, memory-efficient gradient boosting framework that builds decision tree ensembles, popular for production ranking systems due to speed and native categorical feature support
- LambdaRank: A pairwise learning-to-rank algorithm that optimizes ranking metrics like NDCG directly by comparing pairs of documents and learning which should rank higher
- P99 latency: 99th percentile latency—the response time threshold that 99% of requests complete under, a standard SLA metric for high-traffic services
- Sell-through rate (STR): Percentage of listed items that actually sell, indicating real demand rather than just inventory volume
- ASCIIFolding: Text normalization filter that converts accented Unicode characters to their ASCII equivalents (ž→z, é→e), enabling accent-insensitive matching
- Levenshtein edit distance: Measure of string similarity based on minimum number of single-character edits (insertions, deletions, substitutions) needed to transform one string into another
Original article
Vinted rebuilt its search autocomplete system, moving from static, generic suggestions to a hybrid approach combining a strong heuristic scoring model with a Learning-to-Rank (LTR) model. They score suggestions offline using popularity, sell-through rate, and usage signals, index them with clever prefix and fuzzy matching techniques, then apply a LightGBM model in real-time that incorporates user behavior and context to re-rank results.

Skipper: Building Airbnb's embedded workflow engine
Airbnb built Skipper, an embedded workflow engine that handles long-running processes by storing state in the service's own database instead of using external orchestration tools.
Decoder
- Workflow engine: A system that manages the execution of multi-step business processes, coordinating tasks and handling failures across time
- Deterministic replay: A technique where processes can be reliably restarted by replaying events in the same order to reconstruct state without data loss
- Durable execution: Guaranteed process completion even across failures or restarts by persisting state to storage
Original article
Skipper is a lightweight, embedded workflow engine designed to provide durable and reliable execution for long-running business processes (like insurance claims and payments). Instead of relying on external orchestration tools or queues, Skipper uses a simple annotation-based approach to persist state in the service's existing database and achieves durability through deterministic replay.

GraphRAG beyond the demo: Lessons from the trenches
GraphRAG adds significant production complexity over vector RAG and should only be used when you need multi-hop reasoning across entity relationships.
Deep dive
- GraphRAG excels at multi-hop reasoning tasks where answers require traversing relationships across multiple documents or understanding system-wide dependencies, not simple fact retrieval
- Production pain points center on four areas: indexing costs that can be orders of magnitude higher than vector embeddings, difficulty handling incremental updates to the knowledge graph, multi-layer evaluation requirements, and infrastructure complexity
- Infrastructure typically requires batch processing jobs rather than real-time request-path execution, adding latency and operational overhead
- Successful production deployments depend on selective graph scope to control costs by limiting what gets indexed as graph nodes and edges
- Explicit update policies are critical because incrementally updating knowledge graphs is harder than re-indexing vector databases
- Repeatable evaluation frameworks must cover both retrieval quality and reasoning accuracy across graph traversals
- Strong observability and cost controls are essential given the resource intensity of graph operations
- The recommended architecture keeps vector RAG as the default backend with GraphRAG as an optional component triggered only for complex queries
- This hybrid approach allows teams to get value from GraphRAG without paying its costs on every query
Decoder
- GraphRAG: Retrieval Augmented Generation using knowledge graphs to represent entities and relationships, enabling reasoning across connections
- Vector RAG: Standard RAG approach using embedding similarity search to find relevant documents, simpler and cheaper than graph-based methods
- Multi-hop reasoning: Answering questions that require connecting information across multiple documents or relationship steps
- RAG: Retrieval Augmented Generation, a pattern where LLMs retrieve relevant context before generating answers
Original article
GraphRAG is most useful when questions require multi-hop reasoning across documents, entity relationships, or system-level dependencies: use Vector RAG for simple factual lookups and keep GraphRAG as an opt-in backend. In production, the main pain points are heavy indexing cost, difficult updates, multi-layer evaluation, and infrastructure that usually needs batch jobs rather than request-path execution. Success depends on selective graph scope, explicit update policies, repeatable evals, and strong observability/cost controls.

A/B Testing Pitfalls: What Works and What Doesn't with Real Data
Most A/B test failures stem from broken infrastructure and poor experimentation practices rather than bad product ideas, with issues like data quality bugs and early peeking invalidating results far more often than teams realize.
Deep dive
- Sample Ratio Mismatch (SRM) is a critical early warning sign that randomization is broken, with even small deviations like 52/48 instead of 50/50 indicating data quality issues that invalidate results
- Microsoft and DoorDash case studies show SRM often reveals logging failures, biased traffic routing, or time-based bucketing bugs that create phantom wins
- Checking test results daily (peeking) transforms a 5% false positive rate into 25% or higher by running multiple comparisons without statistical adjustment
- Sequential testing methods like group sequential tests, always-valid p-values, and anytime-valid confidence sequences allow safe continuous monitoring while preserving Type I error guarantees
- CUPED (Controlled-experiment Using Pre-Experiment Data) reduces variance by 40-50% by using pre-experiment behavior as a covariate, equivalent to adding 20% more traffic without actually collecting more data
- The technique works by adjusting metrics based on pre-existing user patterns, measuring only the treatment effect rather than pre-existing variance
- Guardrail metrics catch unintended consequences like Airbnb's case where a test increased bookings but decreased review ratings, flagging about 5 major negative impacts monthly
- Novelty effects cause users to engage with new features simply because they're new, requiring long-term holdout groups (5-10% of users) to validate whether effects persist beyond initial curiosity
- Top experimentation teams at Booking.com run 1,000+ concurrent tests with 90% failure rates, measuring success by test velocity and data quality rather than win rate
- Best practices include pre-registering all metrics before tests start, running postmortems on every launch regardless of outcome, and using centralized platforms that enforce randomization correctness
- Modern platforms like Optimizely and Statsig automatically run SRM tests with no override option, treating data quality checks as non-negotiable guardrails
- The cultural challenge is greater than the statistical one: teams must resist the temptation to peek early, ignore warnings, or ship wins without validation
- CUPED shouldn't be used for new user acquisition tests or when pre-period data is unavailable or unstable, but works best for established users with stable metrics
- Companies structure guardrails into three tiers: revenue/engagement (must not decrease), user experience metrics (NPS, load time), and operational metrics (support tickets, errors)
- Testing volume matters more than win rate because the goal is learning faster than competitors, not maximizing successful launches
Decoder
- Sample Ratio Mismatch (SRM): When the actual split of users between control and treatment groups deviates from the expected ratio (like 52/48 instead of 50/50), indicating broken randomization or data quality issues
- CUPED: Controlled-experiment Using Pre-Experiment Data, a variance reduction technique that uses user behavior before the test to reduce noise and shrink confidence intervals by 40-50%
- Sequential testing: Statistical methods that allow checking test results multiple times without inflating false positive rates, unlike traditional fixed-horizon tests
- Guardrail metrics: Secondary metrics monitored to catch unintended negative consequences, not optimized for but used as safety nets (like retention, NPS, error rates)
- p-value peeking: The practice of repeatedly checking statistical significance during a test, which inflates false positives from 5% to 25%+ when done without proper adjustment
- Novelty effect: Short-term engagement increases that occur because users interact with new features out of curiosity rather than genuine preference
- Holdout group: A portion of users (typically 5-10%) kept in the control experience after launch to measure whether test effects persist long-term
- Alpha spending function: A method in group sequential tests that optimally allocates Type I error across multiple interim looks at the data
Original article
A/B testing failures are far more often caused by broken infrastructure and poor experimentation practices than by the ideas being tested. Common failures include Sample Ratio Mismatch (SRM) from bad randomization, early peeking that inflates false positives, insufficient statistical power, and optimizing the wrong metrics without guardrails, causing misleading results.
oLLM (GitHub Repo)
oLLM lets developers run massive language models with 100k+ token contexts on consumer GPUs by offloading weights and cache to SSD instead of keeping everything in expensive GPU memory.
Deep dive
- oLLM achieves dramatic VRAM reduction by loading model layer weights from SSD directly to GPU one at a time rather than holding all weights in memory simultaneously
- The library offloads KV cache (attention state that grows with context length) to SSD and loads it back to GPU on demand, avoiding the massive memory costs of long contexts
- Example benchmarks: qwen3-next-80B (160GB model) with 50k context uses only 7.5GB GPU memory instead of 190GB, with 180GB on SSD
- Llama-3.1-8B with 100k context runs in 6.6GB VRAM instead of 71GB by offloading 69GB to disk
- The implementation uses FlashAttention-2 with online softmax to avoid materializing the full attention matrix, which would be huge for long contexts
- MLP layers are chunked to handle large intermediate activations without memory spikes
- No quantization is used—models run at full fp16/bf16 precision, avoiding quality degradation from compression
- Recent updates added multimodal support including voxtral-small-24B for audio+text and gemma3-12B for image+text processing
- AutoInference feature enables running any Llama3 or gemma3 model with PEFT adapter support for fine-tuned models
- Performance varies by model: qwen3-next-80B achieves 1 token per 2 seconds, making it viable for offline batch processing
- The library works across NVIDIA, AMD, and Apple Silicon GPUs, with optional kvikio and flash-attn dependencies for NVIDIA performance boosts
- Target use cases include analyzing contracts, medical histories, compliance reports, large log files, and historical customer support chats entirely locally
- Optional CPU offloading of some layers can provide additional speed improvements by balancing between GPU, CPU, and disk
- Built on standard PyTorch and Hugging Face infrastructure, making it compatible with the existing ecosystem of models and tools
Decoder
- KV cache: Key-Value cache that stores attention layer states to avoid recomputing them; grows linearly with context length and becomes a major memory bottleneck for long contexts
- VRAM: Video RAM on the GPU, the fast memory where model computations happen; much more expensive per GB than regular RAM or SSD storage
- Quantization: Reducing model precision from 16-bit to 8-bit or 4-bit numbers to save memory, usually with some quality loss
- FlashAttention: Optimized attention algorithm that computes attention scores in chunks without materializing the full attention matrix, dramatically reducing memory usage
- MLP: Multi-Layer Perceptron, the feedforward neural network layers in transformers that can create large intermediate activations
- PEFT: Parameter-Efficient Fine-Tuning, methods like LoRA that fine-tune models by adding small adapter layers instead of updating all weights
- Offloading: Moving data from fast but limited GPU memory to slower but larger storage (CPU RAM or SSD) and loading it back only when needed
Original article
LLM Inference for Large-Context Offline Workloads
oLLM is a lightweight Python library for large-context LLM inference, built on top of Huggingface Transformers and PyTorch. It enables running models like gpt-oss-20B, qwen3-next-80B or Llama-3.1-8B-Instruct on 100k context using ~$200 consumer GPU with 8GB VRAM. No quantization is used—only fp16/bf16 precision.
Latest updates (1.0.3) 🔥
AutoInferencewith any Llama3 / gemma3 model + PEFT adapter supportkvikioandflash-attnare optional now, meaning no hardware restrictions beyond HF transformers- Multimodal voxtral-small-24B (audio+text) added. [sample with audio]
- Multimodal gemma3-12B (image+text) added. [sample with image]
- qwen3-next-80B (160GB model) added with ⚡️1tok/2s throughput (our fastest model so far)
- gpt-oss-20B flash-attention-like implementation added to reduce VRAM usage
- gpt-oss-20B chunked MLP added to reduce VRAM usage
8GB Nvidia 3060 Ti Inference memory usage:
| Model | Weights | Context length | KV cache | Baseline VRAM (no offload) | oLLM GPU VRAM | oLLM Disk (SSD) |
|---|---|---|---|---|---|---|
| qwen3-next-80B | 160 GB (bf16) | 50k | 20 GB | ~190 GB | ~7.5 GB | 180 GB |
| gpt-oss-20B | 13 GB (packed bf16) | 10k | 1.4 GB | ~40 GB | ~7.3GB | 15 GB |
| gemma3-12B | 25 GB (bf16) | 50k | 18.5 GB | ~45 GB | ~6.7 GB | 43 GB |
| llama3-1B-chat | 2 GB (bf16) | 100k | 12.6 GB | ~16 GB | ~5 GB | 15 GB |
| llama3-3B-chat | 7 GB (bf16) | 100k | 34.1 GB | ~42 GB | ~5.3 GB | 42 GB |
| llama3-8B-chat | 16 GB (bf16) | 100k | 52.4 GB | ~71 GB | ~6.6 GB | 69 GB |
By "Baseline" we mean typical inference without any offloading
How do we achieve this:
- Loading layer weights from SSD directly to GPU one by one
- Offloading KV cache to SSD and loading back directly to GPU, no quantization or PagedAttention
- Offloading layer weights to CPU if needed
- FlashAttention-2 with online softmax. Full attention matrix is never materialized.
- Chunked MLP. Intermediate upper projection layers may get large, so we chunk MLP as well
Typical use cases include:
- Analyze contracts, regulations, and compliance reports in one pass
- Summarize or extract insights from massive patient histories or medical literature
- Process very large log files or threat reports locally
- Analyze historical chats to extract the most common issues/questions users have
Supported GPUs: NVIDIA (with additional performance benefits from kvikio and flash-attn), AMD, and Apple Silicon (MacBook).
Getting Started
It is recommended to create venv or conda environment first
python3 -m venv ollm_env
source ollm_env/bin/activateInstall oLLM with pip install --no-build-isolation ollm or from source:
git clone https://github.com/Mega4alik/ollm.git
cd ollm
pip install --no-build-isolation -e .
# for Nvidia GPUs with cuda (optional):
pip install kvikio-cu{cuda_version} Ex, kvikio-cu12 #speeds up the inference💡 Note: voxtral-small-24B requires additional pip dependencies to be installed as
pip install "mistral-common[audio]"andpip install librosa
Check out the Troubleshooting in case of any installation issues
Example
Code snippet sample
from ollm import Inference, file_get_contents, TextStreamer
o = Inference("llama3-1B-chat", device="cuda:0", logging=True) #llama3-1B/3B/8B-chat, gpt-oss-20B, qwen3-next-80B
o.ini_model(models_dir="./models/", force_download=False)
o.offload_layers_to_cpu(layers_num=2) #(optional) offload some layers to CPU for speed boost
past_key_values = o.DiskCache(cache_dir="./kv_cache/") #set None if context is small
text_streamer = TextStreamer(o.tokenizer, skip_prompt=True, skip_special_tokens=False)
messages = [{"role":"system", "content":"You are helpful AI assistant"}, {"role":"user", "content":"List planets"}]
input_ids = o.tokenizer.apply_chat_template(messages, reasoning_effort="minimal", tokenize=True, add_generation_prompt=True, return_tensors="pt").to(o.device)
outputs = o.model.generate(input_ids=input_ids, past_key_values=past_key_values, max_new_tokens=500, streamer=text_streamer).cpu()
answer = o.tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=False)
print(answer)or run sample python script as PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python example.py
# with AutoInference, you can run any LLama3/gemma3 model with PEFT adapter support
# pip install peft
from ollm import AutoInference
o = AutoInference("./models/gemma3-12B", # any llama3 or gemma3 model
adapter_dir="./myadapter/checkpoint-20", # PEFT adapter checkpoint if available
device="cuda:0", multimodality=False, logging=True)
...More samples
Roadmap
For visibility of what's coming next (subject to change)
- Qwen3-Next quantized version
- Qwen3-VL or alternative vision model
- Qwen3-Next MultiTokenPrediction in R&D
Contact us
If there's a model you'd like to see supported, feel free to suggest it in the discussion — I'll do my best to make it happen.

Materialized Tables in Apache Flink
Apache Flink's Materialized Tables embed query definitions within table metadata, simplifying pipeline management and schema evolution for streaming ETL.
Deep dive
- Traditional Flink SQL requires either CREATE TABLE + INSERT or CREATE TABLE AS SELECT (CTAS), both of which spawn separate jobs that have no persistent association with the table definition
- When task managers restart, INSERT jobs spawned by CTAS or standalone INSERTs are killed and not automatically restarted, while Materialized Table jobs resurrect automatically because the query definition is persisted in the catalog
- Catalog metadata for Materialized Tables includes the definition query, refresh mode (continuous or scheduled), execution details, and job ID—all stored alongside the standard schema information
- Schema evolution with traditional approaches requires stopping the INSERT job, altering the table, recreating the INSERT with updated columns, and potentially dealing with data type mismatches and NULL constraint violations from existing data
- Materialized Tables support schema evolution via ALTER MATERIALIZED TABLE with a new AS SELECT clause, which automatically stops the old job and starts a new one with the updated schema, though it starts from the beginning rather than restoring from previous state
- The feature requires a catalog that supports Materialized Tables (currently Apache Paimon or test-filesystem for testing) plus a scheduler for automated refreshes
- Materialized Tables can be paused with SUSPEND and resumed with RESUME, allowing you to temporarily halt processing without losing the job definition
- Flink's streaming nature means aggregate queries show changelog updates (insertions, updates, deletions) rather than final results, and queries over unbounded sources continue running indefinitely
- The test-filesystem catalog used in examples stores both catalog metadata and table data to disk, making it possible to inspect the internal representation of table definitions
- When a Materialized Table is resumed after being suspended, it picks up new data that arrived during the suspension period, demonstrating proper state management
Decoder
- Apache Flink: Distributed stream processing framework that can handle both batch and real-time data processing with SQL and Java/Scala APIs
- Materialized Table: A table object that includes both its schema definition and the query used to populate/refresh it, stored together in the catalog
- ETL: Extract, Transform, Load—the process of moving and transforming data from sources to destinations
- CTAS: CREATE TABLE AS SELECT—SQL syntax that creates a table and populates it with query results in a single statement
- Catalog: Metadata store in Flink that holds information about databases, tables, and other objects
- Changelog: Stream of data changes showing operations like inserts (+I), updates (-U/+U), and deletes (-D) rather than just final values
- Unbounded stream: Data source that continuously produces records without a defined end, like a Kafka topic, as opposed to finite batch data
- Upsert: Update-or-insert operation that updates a row if it exists or inserts it if it doesn't, based on a primary key
Original article
Materialized Tables in Apache Flink allows users to define a table directly with its population query, embedding both the schema and the continuous or scheduled refresh logic inside the catalog. This simplifies ETL pipelines by automatically handling job lifecycle, schema evolution, and refreshes.

HOT Updates in Postgres
PostgreSQL's HOT updates avoid index maintenance when updating non-indexed columns by chaining new tuple versions on the same page, dramatically cutting write overhead on tables with multiple indexes.
Deep dive
- PostgreSQL's default UPDATE behavior writes to every index on a table even when indexed columns don't change, creating massive overhead (five indexes × one updated column = five extra index writes, five times WAL traffic)
- HOT updates bypass index maintenance by placing the new tuple on the same page as the old one and creating a chain that index scans can follow
- A HOT update requires two conditions: the new tuple must fit on the same page, and none of the updated columns can be indexed—if either fails, it becomes a cold update
- The old tuple is marked HOT_UPDATED with t_ctid pointing to the new tuple, while the new tuple is marked HEAP_ONLY meaning no direct index entries point to it
- Multiple HOT updates create chains within a single page (lp1 → lp5 → lp6 → lp7), and indexes still point only to the original ctid, never growing despite repeated updates
- Long HOT chains have cost since every index scan must walk the entire chain, so 50 HOT updates between vacuums means 50 hops per index lookup
- Page pruning happens opportunistically during normal queries when dead tuples are invisible to all transactions (pd_prune_xid < RecentGlobalXmin) and the page is roughly 10% full or more
- During pruning, dead intermediate tuples become LP_UNUSED, the original line pointer becomes LP_REDIRECT (just 4 bytes, no tuple data), and the page is defragmented
- The LP_REDIRECT persists until VACUUM rewrites index entries to point directly at the current tuple location, only then can it finally become LP_UNUSED
- Lowering fillfactor from the default 100 to 80-90 reserves space on pages specifically for HOT updates, trading storage efficiency for update performance
- You can monitor HOT effectiveness via pg_stat_user_tables looking at the ratio of n_tup_hot_upd to n_tup_upd
- Common HOT killers: pages too full (adjust fillfactor or vacuum more frequently), ORMs updating all columns when only some changed (enable dirty tracking), too many indexes, and updating indexed columns
- Long-running transactions pin RecentGlobalXmin and prevent page pruning just like they block VACUUM, making them dangerous for PostgreSQL write performance
- Page pruning is limited—it cannot touch index entries, set visibility map bits, update the free space map, or reach across pages; those operations require VACUUM
Decoder
- HOT (Heap-Only Tuple): A PostgreSQL optimization where UPDATE creates new tuple versions on the same page without touching indexes
- ctid: A tuple's physical address in PostgreSQL storage, consisting of (page_number, line_pointer)
- t_xmax: Transaction ID that deleted or updated a tuple, marking it as potentially dead
- Line pointer (lp): A 4-byte entry in the page header that points to tuple data within the page
- LP_REDIRECT: A line pointer state where it redirects to another line pointer rather than pointing to tuple data, occupying just 4 bytes
- fillfactor: Storage parameter controlling how full pages are packed during INSERT (default 100%), lower values reserve space for updates
- RecentGlobalXmin: The oldest snapshot xmin across all active transactions, representing the horizon below which tuples are definitely invisible to everyone
- pd_prune_xid: Page header field tracking the oldest unpruned transaction ID on the page, used to trigger opportunistic pruning
- Cold update: A normal UPDATE that creates new index entries because either indexed columns changed or the new tuple doesn't fit on the same page
- MVCC (Multi-Version Concurrency Control): PostgreSQL's approach where updates create new tuple versions rather than modifying in place
- WAL (Write-Ahead Log): PostgreSQL's transaction log used for crash recovery and replication
Original article
HOT Updates in PostgreSQL is a clever storage optimization that allows UPDATEs on unindexed columns to avoid touching indexes entirely when the new tuple fits on the same page as the old one. Instead of creating new index entries, PostgreSQL marks the old tuple as HOT_UPDATED and places a HEAP_ONLY tuple on the same page, forming a chain that scans can follow, which reduces WAL traffic, index maintenance, and vacuuming overhead.

Running SQLite in the browser with sql.js and WASM — a practical guide with Google Drive sync
A tutorial demonstrates running SQLite entirely in the browser via WebAssembly, persisting the database as a portable binary file on Google Drive instead of using IndexedDB or proprietary sync services.
Deep dive
- The sql.js library compiles SQLite to a ~1.5MB WASM binary that must be copied to your public folder and lazily loaded on first database access to avoid blocking initial page render
- Databases serialize to a Uint8Array representing the entire SQLite file, which becomes the atomic unit for all persistence operations—localStorage saves it as a JSON array, Drive stores it as application/octet-stream
- The migration pattern uses a schema_version table with a single integer and a dictionary of migration functions keyed by version number, running pending migrations in order before any other database operations
- localStorage persistence converts the Uint8Array to a regular array for JSON serialization (SQLite files with thousands of rows typically stay under 5MB, within localStorage limits for personal data tools)
- Requesting navigator.storage.persist() on first load is critical—without durable storage, browsers can evict localStorage under storage pressure, making Drive sync the only backup
- Google Drive integration uses the drive.file OAuth scope which only grants access to files this specific app created, not the user's entire Drive, making it appropriate for privacy-sensitive applications
- The sync decision logic on login compares Drive's modifiedTime against local last_synced_at timestamp, downloading from Drive if it's newer or uploading local state if it's the first sync
- Drive uploads debounce by 10 seconds after mutations to avoid hammering the API during active editing sessions, batching multiple rapid changes into a single upload
- Conflict handling deliberately prefers Drive as source of truth rather than attempting complex merge logic, under the assumption that the most recently synced device has the canonical state
- The PKCE OAuth flow for obtaining the access_token is mentioned but deferred to a follow-up article in the series
- A Service Worker can cache the WASM binary after first load, making subsequent initializations instant despite the 1.5MB size
- Query execution requires explicit statement preparation, binding, stepping through results, and freeing—the article provides wrappers (runQuery, execSQL, getOne) to abstract this boilerplate
- The Origin Private File System is suggested as an alternative to localStorage for use cases where database size could exceed 5MB, though localStorage suffices for most personal data applications
- This architecture is demonstrated in production at OvertimeIQ but presented as a general pattern applicable to personal finance tools, health tracking, or any app where user data portability matters
Decoder
- WASM (WebAssembly): Binary instruction format that runs compiled code in browsers at near-native speed
- sql.js: SQLite database engine compiled to WebAssembly, allowing full SQL databases to run client-side in browsers
- IndexedDB: Browser-native NoSQL storage API that stores data in browser-internal formats not easily portable outside the browser
- Uint8Array: JavaScript typed array representing binary data as 8-bit unsigned integers, used here to serialize the SQLite file
- PKCE: Proof Key for Code Exchange, a secure OAuth flow for public clients like browser apps that can't store secrets
- drive.file scope: Minimal Google Drive OAuth permission that only accesses files the requesting app created, not the entire Drive
- Origin Private File System: Browser API for storing large files in a sandboxed filesystem partition with better performance than localStorage
Original article
Most tutorials on client-side data storage reach for IndexedDB, localStorage, or a third-party sync service. This one goes somewhere different: a real SQLite database, running as WebAssembly in the browser, with the database file living on the user's own Google Drive.
This is the setup behind OvertimeIQ — but everything in this article stands alone as a practical reference. You don't need to care about overtime tracking for any of this to be useful.
By the end, you'll know how to:
- Initialize sql.js and run real SQL in the browser
- Persist the database across page reloads via localStorage
- Upload and download the database file from Google Drive
- Handle sync conflicts correctly
- Protect against data corruption on interrupted uploads
Why SQLite in the browser?
Before we write any code, it's worth asking why you'd reach for SQLite instead of IndexedDB or a cloud-synced store.
The answer is portability. A SQLite database is a single binary file. You can open it on any device, in any SQLite-compatible tool, without installing anything. You can attach it to an email, drop it in Dropbox, or — as we'll do here — store it on Google Drive. The user owns a file, not a schema locked inside a browser's internal storage.
For apps where user data portability matters — personal finance tools, health tracking, anything sensitive — this is a meaningful architectural choice, not just a curiosity.
The trade-off: sql.js ships a ~1.5MB WASM binary. We'll deal with that below.
Setting up sql.js
Install the package:
npm install sql.js
The WASM binary needs to be accessible at a URL your code can load. Copy it into your public folder at build time:
// vite.config.js
import { defineConfig } from 'vite'
import { viteStaticCopy } from 'vite-plugin-static-copy'
export default defineConfig({
plugins: [
viteStaticCopy({
targets: [
{
src: 'node_modules/sql.js/dist/sql-wasm.wasm',
dest: ''
}
]
})
]
})
Now initialise sql.js. This is async — the WASM binary has to load before you can do anything:
// lib/db.js
import initSqlJs from 'sql.js'
let db = null
export async function initDB(existingBuffer = null) {
const SQL = await initSqlJs({
locateFile: file => `/${file}` // points to /sql-wasm.wasm in public/
})
if (existingBuffer) {
// Restore from a saved buffer (localStorage or Drive download)
db = new SQL.Database(new Uint8Array(existingBuffer))
} else {
// Fresh database
db = new SQL.Database()
}
return db
}
Lazy loading matters here. Don't initialise the database on app load. Initialise it on first access. With a Service Worker caching the WASM binary after the first load, subsequent loads are instant — but you still don't want to block your UI render on a 1.5MB download for users on their first visit.
Running SQL
sql.js has two main operations:
// For SELECT — returns an array of result objects
export function runQuery(sql, params = []) {
const stmt = db.prepare(sql)
stmt.bind(params)
const rows = []
while (stmt.step()) {
rows.push(stmt.getAsObject())
}
stmt.free()
return rows
}
// For INSERT / UPDATE / DELETE — no return value
export function execSQL(sql, params = []) {
const stmt = db.prepare(sql)
stmt.run(params)
stmt.free()
}
// Convenience wrapper for single-row queries
export function getOne(sql, params = []) {
const rows = runQuery(sql, params)
return rows.length > 0 ? rows[0] : null
}
Usage is exactly what you'd expect from a SQL library:
execSQL(
'INSERT INTO logs (job_id, date, start_time, end_time, duration_hours, location) VALUES (?, ?, ?, ?, ?, ?)',
[1, '2025-04-14', '20:00', '23:30', 3.5, 'office']
)
const logs = runQuery(
'SELECT * FROM logs WHERE date >= ? ORDER BY date DESC',
['2025-01-01']
)
Schema migrations
You need a migration runner. The pattern I use: a schema_version table with a single integer, and a list of migration functions keyed by version number.
const MIGRATIONS = {
1: (db) => {
db.run(`
CREATE TABLE IF NOT EXISTS jobs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
hourly_rate REAL NOT NULL,
weekend_multiplier REAL DEFAULT 1.5,
holiday_multiplier REAL DEFAULT 2.0,
work_start TEXT NOT NULL,
work_end TEXT NOT NULL,
color TEXT DEFAULT '#3B8BD4',
is_default INTEGER DEFAULT 0,
created_at TEXT NOT NULL
)
`)
db.run(`
CREATE TABLE IF NOT EXISTS logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
job_id INTEGER REFERENCES jobs(id),
date TEXT NOT NULL,
start_time TEXT NOT NULL,
end_time TEXT NOT NULL,
crosses_midnight INTEGER DEFAULT 0,
duration_hours REAL NOT NULL,
location TEXT NOT NULL,
notes TEXT,
created_at TEXT NOT NULL,
updated_at TEXT NOT NULL
)
`)
db.run('CREATE INDEX IF NOT EXISTS idx_logs_date ON logs(date)')
}
}
export async function runMigrations(db) {
db.run('CREATE TABLE IF NOT EXISTS schema_version (version INTEGER NOT NULL)')
const row = getOne('SELECT version FROM schema_version')
const currentVersion = row ? row.version : 0
const pendingVersions = Object.keys(MIGRATIONS)
.map(Number)
.filter(v => v > currentVersion)
.sort((a, b) => a - b)
for (const version of pendingVersions) {
MIGRATIONS[version](db)
if (currentVersion === 0) {
execSQL('INSERT INTO schema_version (version) VALUES (?)', [version])
} else {
execSQL('UPDATE schema_version SET version = ?', [version])
}
}
}
Run migrations immediately after initializing the database, before anything else touches it.
Serializing to Uint8Array
This is the key operation that makes everything else work. sql.js can export the entire database state as a Uint8Array — a binary blob that is identical to what SQLite would write to disk.
export function serializeDB() {
return db.export() // Returns Uint8Array
}
That Uint8Array is your database file. Everything that follows — localStorage persistence, Drive upload, Drive download — is just moving that blob around.
localStorage persistence
After every write operation, serialize and save:
const DB_STORAGE_KEY = 'otiq_db'
export function saveDB() {
const buffer = serializeDB()
// Convert Uint8Array to a regular array for JSON serialisation
localStorage.setItem(DB_STORAGE_KEY, JSON.stringify(Array.from(buffer)))
// Trigger the Drive upload debounce (see below)
scheduleDriveUpload()
}
export function loadFromLocalStorage() {
const stored = localStorage.getItem(DB_STORAGE_KEY)
if (!stored) return null
return new Uint8Array(JSON.parse(stored))
}
On app load, check localStorage first. If there's a saved buffer, restore from it. Then compare with Drive to decide whether to download a newer version.
Storage size note: A SQLite file with thousands of rows will likely stay well under 5MB — comfortably within localStorage limits. If your use case could grow very large, consider using the Origin Private File System instead, but for personal data tools localStorage is generally fine. Always call navigator.storage.persist() on first load to request durable storage — without it, browsers can evict localStorage under storage pressure.
async function requestDurableStorage() {
if (navigator.storage && navigator.storage.persist) {
const granted = await navigator.storage.persist()
if (!granted) {
// Show a warning banner — Drive sync is the backup
showStorageWarning()
}
}
}
Google Drive as cloud sync
The Drive setup requires Google OAuth with the drive.file scope — the minimal scope that grants access only to files this specific app created. It cannot read other Drive files. This is the right choice for privacy-sensitive apps.
I'll cover the full PKCE OAuth flow in the next article in this series. For now, assume you have a valid access_token.
Finding the database file
On login, search for an existing database file:
async function findDBFile(accessToken) {
const response = await fetch(
`https://www.googleapis.com/drive/v3/files?q=name='overtimeiq.db'&fields=files(id,modifiedTime)`,
{ headers: { Authorization: `Bearer ${accessToken}` } }
)
const data = await response.json()
return data.files?.[0] ?? null // { id, modifiedTime } or null
}
Creating the file (first time)
async function createDBFile(accessToken, dbBuffer) {
const metadata = {
name: 'overtimeiq.db',
mimeType: 'application/octet-stream'
}
const formData = new FormData()
formData.append('metadata', new Blob([JSON.stringify(metadata)], { type: 'application/json' }))
formData.append('file', new Blob([dbBuffer], { type: 'application/octet-stream' }))
const response = await fetch(
'https://www.googleapis.com/upload/drive/v3/files?uploadType=multipart&fields=id',
{
method: 'POST',
headers: { Authorization: `Bearer ${accessToken}` },
body: formData
}
)
const data = await response.json()
return data.id // Store this file ID in settings.drive_file_id
}
Downloading the file
async function downloadDBFile(accessToken, fileId) {
const response = await fetch(
`https://www.googleapis.com/drive/v3/files/${fileId}?alt=media`,
{ headers: { Authorization: `Bearer ${accessToken}` } }
)
const buffer = await response.arrayBuffer()
return new Uint8Array(buffer)
}
The sync decision logic
On every app load after login, you need to decide: use the local database, or download from Drive?
async function syncOnLogin(accessToken) {
const driveFile = await findDBFile(accessToken)
if (!driveFile) {
// First time — upload local DB and store the file ID
const buffer = loadFromLocalStorage() ?? serializeDB()
const fileId = await createDBFile(accessToken, buffer)
execSQL('UPDATE settings SET drive_file_id = ? WHERE id = 1', [fileId])
execSQL('UPDATE settings SET last_synced_at = ? WHERE id = 1', [new Date().toISOString()])
return
}
const driveModifiedTime = new Date(driveFile.modifiedTime).getTime()
const localSyncedAt = getOne('SELECT last_synced_at FROM settings WHERE id = 1')?.last_synced_at
const localTime = localSyncedAt ? new Date(localSyncedAt).getTime() : 0
const diff = Math.abs(driveModifiedTime - localTime)
if (diff < 30_000) {
// Within 30 seconds — same-device multi-tab edge case, no action
return
}
if (driveModifiedTime > localTime) {
// Drive is newer — download and replace
const buffer = await downloadDBFile(accessToken, driveFile.id)
await reinitializeFromBuffer(buffer) // Re-init sql.js with the new buffer
showToast('Synced from Drive')
} else {
// Local is newer — upload
await uploadDBToDrive(accessToken, driveFile.id)
}
execSQL('UPDATE settings SET last_synced_at = ? WHERE id = 1', [new Date().toISOString()])
}
Conflict resolution policy: When in doubt, prefer the Drive copy. Drive is the source of truth. If modifiedTime comparison is inconclusive (e.g., clock skew between devices), take the Drive copy and show a toast: "Synced from Drive — local changes from this session may have been overwritten."
The upload safety pattern
Never upload directly to overtimeiq.db. Upload to a temp file first, then rename atomically. A browser crash, network interruption, or error mid-upload should never corrupt the live database.
async function uploadDBToDrive(accessToken, fileId) {
const buffer = serializeDB()
// Step 1: Upload to temp file
const tempMetadata = { name: 'overtimeiq_tmp.db' }
const formData = new FormData()
formData.append('metadata', new Blob([JSON.stringify(tempMetadata)], { type: 'application/json' }))
formData.append('file', new Blob([buffer], { type: 'application/octet-stream' }))
const uploadResponse = await fetch(
`https://www.googleapis.com/upload/drive/v3/files/${fileId}?uploadType=multipart`,
{
method: 'PATCH',
headers: { Authorization: `Bearer ${accessToken}` },
body: formData
}
)
if (!uploadResponse.ok) throw new Error('Upload failed')
// Step 2: Rename temp file to live file atomically
await fetch(
`https://www.googleapis.com/drive/v3/files/${fileId}`,
{
method: 'PATCH',
headers: {
Authorization: `Bearer ${accessToken}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({ name: 'overtimeiq.db' })
}
)
}
If Step 1 succeeds but Step 2 fails, the user has a temp file but the live file is intact. On the next sync, the timestamp comparison will catch the discrepancy and prompt a re-upload.
Debouncing the Drive upload
You don't want to upload to Drive on every keypress or every individual log entry mutation. Debounce it:
let driveUploadTimeout = null
export function scheduleDriveUpload() {
if (driveUploadTimeout) clearTimeout(driveUploadTimeout)
driveUploadTimeout = setTimeout(async () => {
const accessToken = getAccessToken() // From your auth store
const fileId = getOne('SELECT drive_file_id FROM settings WHERE id = 1')?.drive_file_id
if (accessToken && fileId) {
await uploadDBToDrive(accessToken, fileId)
execSQL('UPDATE settings SET last_synced_at = ? WHERE id = 1', [new Date().toISOString()])
}
}, 10_000) // 10 seconds after the last write
}
The localStorage write happens synchronously on every mutation — data is safe locally the instant you write it. The Drive upload is fire-and-forget with a 10-second debounce so a bulk import (100 rows at once) only triggers one upload.
Putting it all together
The initialization sequence on app load:
async function initializeApp() {
// 1. Try to restore from localStorage
const storedBuffer = loadFromLocalStorage()
// 2. Initialize sql.js with the stored buffer (or fresh)
await initDB(storedBuffer)
// 3. Run schema migrations
await runMigrations(db)
// 4. Seed defaults if this is the first launch
if (!getOne('SELECT id FROM jobs WHERE id = 1')) {
seedDefaultJob()
seedHolidays()
}
// 5. Request durable storage
await requestDurableStorage()
// 6. If authenticated, sync with Drive
const accessToken = getStoredAccessToken()
if (accessToken) {
await syncOnLogin(accessToken)
}
}
What this doesn't cover
This article focused on the storage and sync layer. Two things worth a separate deep dive:
The Google OAuth PKCE flow — how to get the access_token and refresh_token without a client secret, and how to silently refresh the token mid-session. That's the next article in this series.
The midnight rate calculation — how to correctly split a shift that crosses midnight across two different rate multipliers, including the December 31 → January 1 edge case. I'll cover that in a later article on the earnings engine.
The case for this architecture
The pattern here — SQLite on the user's cloud storage, managed entirely client-side — works well for a specific category of app: personal data tools where the data is sensitive, the user count is small, and data portability is a first-class feature.
It's not the right choice for collaborative tools, apps with large binary assets, or anything requiring server-side processing of the data. But for personal productivity software, financial tracking, health logging, or any domain where "your data should be yours" is a meaningful promise — this architecture delivers it genuinely, not as marketing copy.
The database is a file. The user can open it in DB Browser for SQLite today. They'll be able to open it in twenty years. That kind of portability is hard to promise with any other approach.
Building a High-Scale Real-Time Recommendation Engine with Feature Stores and Redis Observability
Real-time recommendation systems can achieve sub-100ms latency at billion-record scale by using feature stores to bridge offline training and online serving, with Redis handling vector similarity and caching.
Decoder
- Feature store: A data system that manages machine learning features consistently across training (offline) and prediction (online) environments, ensuring the same feature computation logic is used in both contexts
- Training-serving skew: When a machine learning model performs differently in production than during training because features are computed inconsistently between the two environments
- Vector similarity search: Finding items with similar embedding vectors (numerical representations) to quickly identify related content or products
- Embeddings: Dense numerical vector representations of items, users, or content that capture semantic meaning in a format ML models can process efficiently
- Candidate retrieval: The first stage of recommendation where a large catalog is narrowed to a smaller set of relevant items before more expensive ranking
Original article
Real-time recommendation systems now need to combine rich contextual features with sub-100 ms latency at scale, often across billions of interaction records. Feature stores act as the consistency layer between offline training and online serving, reducing training-serving skew, while batch platforms compute expensive features and embeddings. Redis is used for low-latency vector similarity search, candidate retrieval, and caching eligibility filters, keeping request paths fast and efficient.

How Linux 7.0 Broke PostgreSQL
Linux 7.0's switch from PREEMPT_NONE to PREEMPT_LAZY scheduling cut PostgreSQL throughput in half by causing backends to spin on locks during memory page faults.
Deep dive
- Benchmark on 96-vCPU Graviton4 showed PostgreSQL throughput dropped from 98,565 to 50,751 transactions per second between Linux 6.x and 7.0, with profiling revealing 55% of CPU time spent spinning inside a single lock function
- Linux 7.0 removed PREEMPT_NONE scheduling option on modern architectures, leaving only PREEMPT_FULL and PREEMPT_LAZY, with most distributions defaulting to PREEMPT_LAZY as a supposed drop-in replacement for server workloads
- PostgreSQL's StrategyGetBuffer function uses a global spinlock to coordinate buffer pool access across hundreds of concurrent backends, with the assumption that lock holders will finish in nanoseconds
- The root cause is minor page faults occurring while a backend holds the spinlock: with a 120GB shared buffer pool and default 4KB memory pages, there are roughly 31 million potential first-touch page faults during a benchmark run
- Under PREEMPT_NONE, a backend triggering a page fault while holding the lock would handle it without being rescheduled, keeping the delay minimal; under PREEMPT_LAZY, the scheduler may preempt the lock holder mid-fault, extending hold time from microseconds to milliseconds
- The preemption delay is multiplied across all spinning backends, so if one backend is delayed by t milliseconds, hundreds of other backends each burn t CPU cycles waiting, creating massive waste on high-concurrency workloads
- Switching to 2MB huge pages reduces potential page faults from 31 million to ~61,000, while 1GB huge pages reduce it to just 120, effectively eliminating the problem and restoring performance
- Huge pages also reduce TLB pressure since far fewer translation entries are needed to cover the same memory region, avoiding expensive page table walks on hot paths
- The tradeoff is that huge pages must be pre-allocated and reserved upfront, making that memory unavailable to other processes even if unused, plus potential waste if only a fraction of each huge page is utilized
- Intel kernel engineer proposed PostgreSQL adopt Restartable Sequences (rseq) to detect and retry preempted critical sections, but the PostgreSQL community pushes back on changing their code to work around a kernel regression
- The debate centers on Linux's "don't break userspace" principle: software that worked correctly before a kernel upgrade should continue working after, rather than requiring application-level workarounds
Decoder
- PREEMPT_NONE: kernel scheduling mode where threads run until they voluntarily give up CPU (via syscall, I/O, or sleep), minimizing context switches for maximum throughput
- PREEMPT_LAZY: kernel scheduling mode that can interrupt threads but tries to wait for natural boundaries, intended as a throughput-friendly replacement for PREEMPT_NONE
- Spinlock: locking mechanism where waiting threads actively loop checking for lock availability rather than sleeping, efficient only when lock holders finish in nanoseconds
- StrategyGetBuffer: PostgreSQL function responsible for finding a buffer slot to store a data page, protected by a single global spinlock that becomes a contention point under high parallelism
- Minor page fault: occurs when a process accesses virtual memory that's allocated but not yet mapped to physical memory, requiring the kernel to allocate and map a physical page (takes microseconds)
- TLB (Translation Lookaside Buffer): hardware cache that stores recent virtual-to-physical address translations, avoiding expensive page table walks; misses require walking multi-level page tables in memory
- Huge pages: larger-than-default memory pages (2MB or 1GB vs 4KB) that reduce the number of page table entries and TLB pressure, pre-allocated and reserved by the kernel
- pgbench: PostgreSQL's standard benchmarking tool for measuring transaction throughput under various workloads
- Restartable Sequences (rseq): Linux kernel facility allowing userspace code to detect if it was preempted during a critical section and restart the operation
Original article
Linux 7.0 accidentally cut PostgreSQL performance in half because a scheduling change increased how long spinlocks were held during memory page faults, causing massive CPU waste, and switching to huge memory pages fixes the issue.
Starwind UI (Website)
Starwind UI brings the shadcn/ui approach of CLI-installed, copy-paste components to the Astro ecosystem with 45+ animated, accessible components.
Decoder
- Astro: A modern web framework optimized for building fast, content-focused websites with partial hydration
- shadcn/ui: A popular React component approach where CLI tools copy component source code into your project rather than installing as npm dependencies
- Tailwind CSS: A utility-first CSS framework that provides low-level utility classes for building custom designs
Original article
Create animated websites in record time with Starwind UI
Animated, customizable, and accessible components for Astro - built purely with Astro and vanilla JS. Inspired by shadcn/ui with seamless CLI installation.
See Starwind UI in Action
Key Features
Own The Code
Easy-to-use CLI to add component code directly to your projects.
Customizable
Full control over each component. All styling, functionality, and behavior can be modified.
Accessible
Designed with keyboard navigatable and accessible components.
Open Source
Completely open source and MIT licensed.
What will you create?
Meet Franklin: Your AI Agent Should Pay Its Own Bills
Franklin is an open-source AI agent framework that gives each agent its own USDC wallet to autonomously pay for API calls via micropayments, replacing subscription rate limits with pay-per-use billing.
Deep dive
- Franklin challenges the subscription AI model by arguing flat-rate pricing forces platforms to ration service through degraded model quality, mid-task cutoffs, and rate limits that hurt heavy users while light users subsidize them
- Each Franklin agent controls its own USDC wallet with a hard balance (typically $5-100) and spends autonomously across services without API keys or monthly minimums
- The built-in smart router analyzes each prompt to select the cheapest capable model first, only escalating to expensive frontier models when necessary, achieving 60-80% cost savings versus always-GPT-4 approaches
- Uses x402 micropayment protocol to settle per-call charges in USDC on-chain, enabling sub-cent transactions that credit cards and traditional payment rails cannot economically process
- Autonomous agents can run long research loops, scraping and summarization tasks without hitting rate limits since they pay their own way rather than drawing from shared subscription pools
- The wallet model extends beyond inference to real-time market data, blockchain analytics, image generation, and web search—agents treat all services as priced tools and call them when cost-justified
- Per-task accounting shows exact costs per agent run ($0.43, etc.) rather than amortizing across monthly subscriptions, which the authors claim is critical for enterprise finance department approvals
- The framework positions the wallet as infrastructure rather than product—similar to how Stripe abstracted payment complexity or HTTPS added a green padlock without exposing public-key cryptography
- Argues crypto payment rails are now mature enough to handle micro-transactions that weren't feasible three years ago when subscription AI models emerged as the default
- The project frames agent autonomy as fundamentally requiring independent spending authority—agents stop being "chatbots asking permission" and become "employees with corporate cards"
Decoder
- x402: A micropayment protocol that enables sub-cent transactions to be settled on-chain in real-time per API call
- USDC: A stablecoin (cryptocurrency pegged to the US dollar) used for on-chain payments without volatility
- Frontier models: The most advanced, expensive AI models like GPT-4, Claude Opus, or Gemini Ultra
- Rate limiting: When platforms restrict how many API calls you can make in a time period, typically to manage costs on flat-rate subscriptions
- On-chain: Transactions recorded on a blockchain ledger rather than through traditional payment processors
Original article
Franklin is an open-source AI agent framework that provisions each agent with a self-generated USDC wallet, replacing API keys and subscriptions with x402 micropayments settled per-call across 55+ models, image generation, web search, and trading data tools. A built-in smart router directs prompts to the cheapest capable model and escalates to frontier models only when required, cutting costs 60-80% compared to always using top-tier models. The project frames subscription-based AI as a transitional structure where heavy users get throttled and light users subsidize them, arguing that pay-per-use wallet-backed agents allow providers to serve full tasks without rationing.

OpenAI has effectively abandoned first-party Stargate data centers in favor of more flexible deals
OpenAI has abandoned plans to build its own data centers through the Stargate joint venture, opting instead to lease compute capacity as cash flow concerns mount.
Original article
In early 2025, OpenAI announced Stargate, a joint venture with Oracle and SoftBank, which aimed to invest $500 billion in AI data centers in the United States. But after more than a year of challenges and disagreements, it seems that the startup has abandoned the original idea of directly owning infrastructure alongside its two partners. According to the Financial Times, OpenAI now prefers to rely on third-party providers and lease capacity in the long term.
This is a sensible idea for the startup, which is burning through cash and has reportedly missed internal revenue targets in recent months. But it has also caused chaos among its partners and put its reliability into question. According to the report, OpenAI has "in practice... abandoned the joint venture," choosing instead large bilateral deals with Oracle and more. One person involved with Stargate reportedly said the company had "sidelined first-party data centres," while OpenAI itself admitted that Stargate is merely an "umbrella for our compute strategy."
Stargate's initial goal was to build 20 data centers, with the first project at Abilene, Texas, already operational. However, the three partners reportedly squabbled among themselves for months as they could not agree on who would have ultimate control of the planned data centers. In the end, SoftBank agreed to own and develop the Texas data center, while OpenAI would design and operate it on a long-term lease.
Other Stargate projects located in other areas have also been hit by uncertainties. The UK government signed a deal with OpenAI, among other partners, to build a data center in the UK, but the startup has put it on hold earlier this month. It cited "restrictive regulations" and "high energy costs" as the reason behind the move, but UK AI Minister Kanishka Narayan told the Financial Times that the "only thing that has changed [since] the moment of those commitments…has been the financing environment for OpenAI."
It has also done the same for another Stargate project in Narvik, Norway, with Microsoft stepping up to take over the lease for the site. OpenAI will then lease compute capacity from Redmond, instead of getting it directly from Nscale, the British company that developed the site and also worked on the canceled UK project.
All these changes have got some partners "feeling let down and misled by OpenAI," a person familiar with Microsoft's decision said. Thankfully, the software giant has stepped in on some of the projects that the startup has supposedly abandoned. One source told the publication that money is not unlimited, no matter what Sam Altman might say, while another said that they prefer Microsoft over OpenAI as a tenant, as "they are more creditworthy."
Even though OpenAI has made a name for itself in AI, the startup has not turned a profit since it was founded in 2015. Many institutions believe in its potential, though, with the firm securing $110 billion in its latest funding round — the biggest amount secured in Silicon Valley history and $10 billion more than what the company initially targeted. Still, some analysts estimate that it could run out of cash by mid-2027 with the massive amounts of money it's been throwing around to secure more compute.
Anthropic CEO Dario Amodei criticized moves like this, saying that some of his company's rivals are pushing infrastructure investments too far. However, OpenAI says that it's ahead of the exponential compute curve, allowing it to have an advantage over everyone else. For example, Anthropic has had to limit access to some features on its various products due to limited resources, and Amodei has had to spend more on securing capacity to satisfy the increasing demand
The biggest difference between startups, like OpenAI and Anthropic, and their more established rivals, like Microsoft, Google, Meta, and Amazon, is cash flow. The startups still rely on external funding to fuel their growth, while the big tech companies have billion-dollar revenue that they can rely on to pour into expensive hardware and infrastructure projects.

Google to sell TPU chips to 'select' customers in latest shot at Nvidia
Google is shifting from renting cloud TPU access to selling its custom AI chips directly to select customers for their own data centers, intensifying competition with Nvidia.
Decoder
- TPU: Tensor Processing Unit, Google's custom-designed chips optimized specifically for machine learning workloads
- Inferencing: Running trained AI models to make predictions, as opposed to training which creates the models
- Gigawatt agreement: Energy capacity commitment for data center chip deployments (1 gigawatt powers roughly 700,000 homes)
Original article
Google to sell TPU chips to 'select' customers in latest shot at Nvidia
Google parent Alphabet (GOOG, GOOGL) on Wednesday said that it plans to sell its custom Tensor Processing Units (TPUs) to select customers who will install the chips in their own data centers.
The move is a change from Google's prior strategy, which saw it rent out TPU capacity to customers from its own data centers — and is yet another strike at AI chip king Nvidia (NVDA).
The announcement, during the company's Q1 earnings call, comes a week after Alphabet announced two new TPUs: its TPU 8t for AI training and TPU 8i for inferencing.
"As TPU demand grows from AI labs, capital markets firms, and high-performance computing applications, we'll begin to deliver TPUs to a select group of customers in their own data centers in a hardware configuration to expand our addressable market opportunity," Alphabet CEO Sundar Pichai said during the company's first quarter earnings call.
Alphabet didn't disclose potential customers, but it signed a multiple-gigawatt agreement for next-generation TPUs with Anthropic (ANTH.PVT) earlier this month, with chips expected to begin coming online in 2027.
And according to The Information, Alphabet has also entered into a multibillion-dollar chip deal with Meta (META).
Alphabet's TPU maneuvers put it into ever greater competition with Nvidia, which has largely dismissed any fears that Alphabet's offerings will erode its lead in the space, saying that its chips offer greater flexibility for AI developers.
Google isn't the only company moving in on Nvidia's turf. Amazon (AMZN) is also offering up its own chips to customers.
In his annual shareholder letter, Amazon CEO Andy Jassy said that the company's chip business, which includes its Graviton, Trainium, and Nitro processors, has an annual revenue run rate of greater than $20 billion.
But because Amazon only monetizes its chips through its AWS EC2 (Elastic Compute Cloud) service, the CEO explained that $20 billion is likely an understatement and that it would probably be closer to $50 billion.
Like Google, Amazon signed a new agreement for 5 gigawatts of AI chip capacity with Anthropic, but also inked a deal for 2 gigawatts of chips with OpenAI.
On the CPU side, Amazon said it will deploy its AWS Graviton chips for Meta (META) to use across its agentic AI workloads.

AI evals are becoming the new compute bottleneck
AI evaluation costs have exploded to tens of thousands of dollars per benchmark run, creating an accountability barrier that limits who can independently validate frontier AI systems.
Deep dive
- The Holistic Agent Leaderboard spent approximately $40,000 to run 21,730 agent rollouts across 9 models and 9 benchmarks, with independent reproduction arriving at $46,000, establishing a new cost threshold for comprehensive agent evaluation
- Individual benchmark costs vary by four orders of magnitude across tasks and three orders within single benchmarks, with a single GAIA run on frontier models costing $2,829 before caching and some configurations exceeding $1,600 per run
- Scaffold choice—the framework wrapping the model—emerges as a first-order cost driver with 33× cost spreads on identical tasks, and higher spending does not reliably improve accuracy (9× cost difference for two-percentage-point accuracy gains observed)
- Static LLM benchmarks like HELM originally cost roughly $100,000 in aggregate and compression techniques like Flash-HELM, tinyBenchmarks, and Anchor Points achieved 100–200× reductions while preserving model rankings, but these methods fail on agent tasks
- Agent benchmarks compress only 2–3.5× using mid-difficulty filtering (tasks with 30–70% historical pass rates), far below static benchmark gains, because each item is a multi-turn rollout with inherent variance rather than a single prediction
- Training-in-the-loop benchmarks like The Well (960 H100-hours per architecture, 3,840 for full sweep), PaperBench ($9,500 per evaluation), and MLE-Bench ($5,500 per seed) resist compression entirely because the unit being evaluated is the trained model itself
- For small scientific ML models, evaluation compute can exceed training compute by two orders of magnitude, reversing the traditional deep learning cost model where training dominated
- Reliability measurement multiplies all costs: moving from single-run accuracy to 8-run consistency would take HAL from $40,000 to roughly $320,000, and agent performance can drop from 60% on single runs to 25% under consistency tests
- The field pays redundantly for the same evaluations because results are reported as single accuracy numbers in PDFs or leaderboard entries rather than shared instance-level outputs in reusable formats, with frontier labs, academic groups, auditors, and journalists each paying retail for overlapping measurements
- Academic groups now hit budget constraints before technical ones when attempting independent validation, with a single GAIA run exceeding typical graduate student travel budgets and three-seed comparisons of six models pushing above $150,000
- Cost-blind leaderboards reward waste by ranking raw accuracy without cost reporting, while Pareto-front analysis reveals that accuracy-optimal configurations cost 4.4–10.8× more than Pareto-efficient alternatives with comparable real-world performance
- HAL's log analysis revealed that agents violated explicit benchmark instructions over 60% of the time on failed tasks, experienced environmental errors in roughly 40% of runs on some benchmarks, and a "do-nothing" agent passed 38% of one benchmark's tasks under original construction
- The concentration of evaluation capability in well-funded labs undermines external validation and creates a dynamic where "whoever can pay for the evaluation gets to write the leaderboard," with implications for AI governance and accountability
- Standardized documentation and data reuse represent the highest-leverage cost reduction available, potentially offering 2× savings that would exceed gains from all compression techniques combined by allowing subsequent research to build on rather than repeat baseline measurements
- The EvalEval Coalition's Every Eval Ever project provides metadata schema, validators, and converters from popular harnesses (HELM, lm-eval-harness, Inspect AI) to enable one-step transformation of evaluation logs into shared formats hosted on Hugging Face
Decoder
- Scaffold: The framework or harness code that wraps an AI model to enable it to use tools, interact with environments, or follow multi-step reasoning patterns; scaffold choice can change costs by 33× on identical tasks
- H100-hours: A unit measuring the cost of renting NVIDIA H100 GPUs for training or evaluation, typically converted at $2.50 per hour in this article's accounting
- Rollout: A complete execution of an agent attempting a task from start to finish, including all tool calls, reasoning steps, and environment interactions
- Training-in-the-loop: Evaluation protocols that require training a model from scratch as part of the benchmark, such as training neural operators on scientific datasets or ML agents training pipelines on Kaggle competitions
- Pass^k consistency: The percentage of tasks an agent solves correctly across k repeated runs, measuring reliability rather than single-attempt accuracy; pass^8 can be far lower than pass^1
- Item Response Theory (IRT): A statistical framework from psychometrics used to identify which test items carry the most information about model differences, enabling aggressive compression of static benchmarks
- Pareto frontier: The set of configurations where no alternative offers both lower cost and higher accuracy simultaneously, used to identify efficient agent configurations versus wasteful ones
Original article
AI evals are becoming the new compute bottleneck
Summary. AI evaluation has crossed a cost threshold that changes who can do it. The Holistic Agent Leaderboard (HAL) recently spent about $40,000 to run 21,730 agent rollouts across 9 models and 9 benchmarks. A single GAIA run on a frontier model can cost $2,829 before caching. Exgentic's $22,000 sweep across agent configurations found a 33× cost spread on identical tasks, isolating scaffold choice as a first-order cost driver, and UK-AISI recently scaled agentic steps into the millions to study inference-time compute. In scientific ML, The Well costs about 960 H100-hours to evaluate one new architecture and 3,840 H100-hours for a full four-baseline sweep. While compression techniques have been proposed for static benchmarks, new agent benchmarks are noisy, scaffold-sensitive, and only partly compressible. Training-in-the-loop benchmarks are expensive by construction, and when you try to add reliability to these evals, repeated runs further multiply the cost.
Making static LLM benchmarks cheaper
The cost problem started before agents. When Stanford's CRFM released HELM in 2022, the paper's own per-model accounting showed API costs ranging from $85 for OpenAI's code-cushman-001 to $10,926 for AI21's J1-Jumbo (178B), and 540 to 4,200 GPU-hours for the open models, with BLOOM (176B) and OPT (175B) at the top end. Perlitz et al. (2023) restate the larger HELM cost pattern, and IBM Research notes that putting Granite-13B through HELM "can consume as many as 1,000 GPU hours." Across HELM's 30 models and 42 scenarios, the aggregate of reported costs and GPU compute came to roughly $100,000.
Another shocking observation came from Perlitz et al.'s analysis of EleutherAI's Pythia checkpoints: developers pay for evaluation repeatedly during model development. Pythia released 154 checkpoints for each of 16 models spanning 8 sizes, or 2,464 checkpoints if each model checkpoint is counted separately, so the community could study training dynamics. Running the LM Evaluation Harness across all those checkpoints turns eval into a multiplier on training: Perlitz et al. (2024) noted that evaluation costs "may even surpass those of pretraining when evaluating checkpoints." For small models, evaluation becomes the dominant compute line item across the whole development cycle. When we scale inference-time compute, we scale evaluation costs.
Perlitz et al. then asked how much of HELM actually carried the rankings. The result was striking: a 100× to 200× reduction in compute preserved nearly the same ordering, with larger reductions still useful for coarse grouping under the paper's tiered analysis. Flash-HELM turned that finding into a coarse-to-fine procedure: run cheap evaluations first, then spend high-resolution compute only on the top candidates. Much of HELM's compute was confirming rankings that the field could have inferred much more cheaply.
Other work reached the same conclusion from different angles. tinyBenchmarks compressed MMLU from 14,000 items to 100 anchor items at about 2% error using Item Response Theory. The Open LLM Leaderboard collapsed from 29,000 examples to 180. Anchor Points showed that as few as 1 to 30 examples could rank-order 87 language-model/prompt pairs on GLUE, and others followed, reducing dataset sizes by 90%. Static benchmarks had a weakness you could exploit: model differences often concentrate in a small subset of items, so ranking can survive aggressive subsampling.
That trick weakened sharply once benchmarks moved from static predictions to agents.
Agent evals are messier
A very nice public accounting of agent evaluation comes from the Holistic Agent Leaderboard (Kapoor et al., ICLR 2026). HAL runs standardized agent harnesses across nine benchmarks covering coding, web navigation, science tasks, and customer service, with shared scaffolds and centralized cost tracking. The headline cost: $40,000 for 21,730 rollouts across 9 models and 9 benchmarks. By April 2026, the leaderboard had grown to 26,597 rollouts. Ndzomga's independent reproduction arrives at almost the same number: $46,000 across 242 agent runs.
Behind that aggregate, the cost of a single benchmark run varies by four orders of magnitude across HAL tasks, and by three orders within some individual benchmarks.

Figure 1. Each bar shows the minimum-to-maximum cost across HAL configurations on a single benchmark. Highlighted bars cross the round $1,000-per-run threshold. A "run" is one full agent evaluation across all tasks. Within-benchmark spread reflects the model × scaffold × token-budget product.
Behind these numbers is a blunt pricing fact. Claude Opus 4.1 charges $15 per million input tokens and $75 per million output. Gemini 2.0 Flash charges $0.10 and $0.40, a two-order-of-magnitude spread on input alone. Agent benchmarks rarely benchmark "the model" in isolation. They benchmark a model × scaffold × token-budget product, and small scaffold choices can multiply costs 10×.
Worse, higher spend does not reliably buy better results. On Online Mind2Web, Browser-Use with Claude Sonnet 4 cost $1,577 for 40% accuracy. SeeAct with GPT-5 Medium hit 42% for $171. The HAL paper notes "a 9× difference in cost despite just a two-percentage-point difference in accuracy." On GAIA, an HAL Generalist with o3 Medium cost $2,828 for 28.5% accuracy, while a different agent hit 57.6% for $1,686. CLEAR finds across 6 SOTA agents on 300 enterprise tasks that "accuracy-optimal configurations cost 4.4 to 10.8× more than Pareto-efficient alternatives" with comparable real-world performance.
The static-era toolkit should have helped, but it has only gone so far. Ndzomga's mid-difficulty filter, which selects tasks with 30 to 70% historical pass rates, achieves a 2× to 3.5× reduction while preserving rank fidelity under scaffold and temporal shifts. That is useful, but it falls far short of the 100× to 200× gains available for static benchmarks. When each item is a multi-turn rollout with its own variance, the unavoidable long trajectory per single question becomes the expensive object.
Some evals are just training
Some benchmarks escape the API-cost framing altogether because their evaluation protocol trains models from scratch.
The Well gives a very interesting example of this. It bundles 16 scientific machine-learning datasets spanning biological systems, fluid dynamics, magnetohydrodynamics, supernova explosions, viscoelastic instability, and active matter, totaling 15 TB. Using the paper's headline 16-dataset grid, the protocol leaves little room to economize: train each baseline model for 12 hours on a single H100, try five learning rates per (model, dataset) pair, repeat across four architectures and 16 datasets. That headline-grid sweep consumes 3,840 H100-hours, or roughly $9,600 under the conversion assumptions below. A single new architecture still costs about 960 H100-hours, or about $2,400.
Training one neural operator can take a single 12-hour H100 run, while evaluating it across the benchmark requires 80 such trainings. That asymmetry is what makes The Well important. In this corner of ML, evaluation compute exceeds training compute by roughly two orders of magnitude, reversing the old deep-learning mental model.
The same pattern recurs across SciML. PDEBench covers 11 PDE families and reports per-epoch timing tables across datasets and model families, but a clean per-architecture dollar figure depends on the chosen training protocol and hardware. MLE-Bench (OpenAI) sits between agent and training regimes. Each agent attempt at one of 75 Kaggle competitions runs 24 hours on a single A10 GPU, training real ML pipelines. The paper is explicit: "A single run of our main experiment setup of 24 hours per competition attempt requires 24 hours × 75 competitions = 1,800 GPU hours of compute," plus o1-preview consuming 127.5M input and 15M output tokens per seed. At $1.50 per A10-hour, the GPU floor alone is $2,700; adding o1-preview API usage brings a one-seed run to roughly $5,500. Three seeds × six models would therefore land near $100,000 before any additional grading or retry overhead.
METR's RE-Bench caps each of seven research engineering environments at 8 hours on 1 to 6 H100s. A single pass across the suite is therefore 56 to 336 H100-hours before adding repeated attempts, multiple seeds, or multiple agents; the human baseline, with 71 expert attempts, raises the implicit budget much further. Because the benchmark gives agents and humans the same wall-clock compute, a real-time training process sets the cost floor. A token budget no longer bounds it from above.
ResearchGym (ICLR 2026) makes the agent run actual ML research. Five test tasks (39 sub-tasks) drawn from ACL, ICLR, and ICML papers, including ACL Highlights, ICML Spotlight, ICLR Spotlight, and ICLR Oral categories, with the proposed methods withheld. The agent has to propose hypotheses, train models, and beat the original authors' baselines. The budget is tight: $10 in API plus 12 to 24 hours on a single GPU under 24 GB per task. A full pass (5 tasks × 24h × 3 seeds) consumes about 360 GPU-hours per agent.
The cost picture turns brutal in PaperBench. Twenty ICML 2024 Spotlight or Oral papers must be replicated from scratch, graded against rubric trees with 8,316 leaf-node criteria. Each rollout uses an A10 GPU for 12 hours, and the per-paper math is straightforward:
- $400 in API per o1 IterativeAgent rollout, times 20 papers, comes to about $8,000 per evaluation.
- Grading runs $66 per paper with the o3-mini judge, or $1,320 for the full benchmark.
- Using o1 as judge would push grading to about $830 per paper.
PaperBench Code-Dev drops execution on purpose. That choice halves rollout cost to about $4,000 and cuts grading to $10 per paper (85% lower). OpenAI built the variant because many groups cannot afford the full benchmark.
The historical precedent is NAS-Bench-101, whose tabular construction required over 100 TPU-years of training. Without that one-time investment, every NAS algorithm comparison would have cost 1 to 100+ GPU-hours per run, which would have made comparison pricier than the algorithms themselves.

Figure 2. All values in USD per single evaluation of one model or agent through the full benchmark protocol. GPU costs converted at $2.50/H100-hr, $1.50/A10-hr; API and grading costs included where applicable. Highlighted bars denote benchmarks costing at least the round $5,000-per-evaluation threshold. The most expensive of these match the most expensive agent benchmarks (Figure 1) and require GPU compute that has no API substitute.
As benchmarks move closer to real work, compression gets harder: static prediction leaves room for large savings, agent rollouts leave less, and in-the-loop training leaves almost none.

Figure 3. The toolkit for compressing evaluation does not transfer as benchmarks become more complex. Bars show the maximum measured compression that preserves model-rank fidelity; labels give the published range. The highlighted bar flags the ~1× baseline where no general compression method exists. Static benchmarks routinely compress 100–200× without losing rankings. Agent benchmarks compress 2–3.5× at best. Training-in-the-loop benchmarks resist subsampling because the unit being evaluated is the trained model.
Reliability is the expensive part
Most of the costs above buy only single-run measurements with limited statistical power. When you measure reliability across repeated runs, static benchmarks, agent benchmarks, and training-in-the-loop benchmarks all become more expensive.
Agent reliability can fall hard when you stop treating one run as evidence. The best-known example comes from Yao et al.'s τ-bench, later reframed in CLEAR (Mehta, 2025): performance can drop from 60% on a single run to 25% under 8-run consistency. Kapoor et al.'s "AI Agents That Matter" found that simple baseline agents Pareto-dominate complex SOTA agents (Reflexion, LDB, LATS) on HumanEval at 50× lower cost. Their holdout analysis found that 7 of 17 benchmarks had no holdout set; among the 10 that did, only 5 held out tasks at the appropriate level of generality, so 12 of 17 failed their holdout criterion overall. The HAL paper notes that a "do-nothing" agent passes 38% of τ-bench airline tasks under the original construction. HAL's own log analysis revealed data leakage in the TAU-bench Few Shot scaffold, forcing its removal in December 2025.
Another recent reliability accounting comes from Rabanser, Kapoor et al.'s "Towards a Science of AI Agent Reliability", which proposes twelve metrics across consistency, robustness, predictability, and safety. Their finding: "recent capability gains have only yielded small improvements in reliability." HAL's internal analysis shows how much fragility hides behind aggregate accuracy. On SciCode and CORE-Bench, agents almost never completed a run without a tool-calling failure. On AssistantBench and CORE-Bench, environmental errors occurred in roughly 40% of runs. Agents violated explicit benchmark instructions in their final answer over 60% of the time on failed tasks.
A statistically credible HAL-style evaluation with k = 8 reruns per cell takes the $40K aggregate to roughly $320K. The same multiplier on PaperBench's $9,500-per-run cost pushes a single agent's evaluation past $75K, and on The Well, a multi-seed protocol takes the per-architecture cost from ~960 H100-hours to several thousand. Reliability acts as a multiplier on every cost category above.
HAL has paused new model evaluations to focus on reliability: the field's headline numbers still carry too much noise, and reducing that noise costs real money. And the figures above are lower bounds; many evaluators are already priced out.
What this means for ML as a field
Eval cost is now an accountability barrier
Academic groups, AI Safety Institutes, and journalists now hit the budget constraint before the technical one when they try to evaluate frontier agents independently. A single GAIA run can exceed an annual graduate student travel budget. A single PaperBench evaluation, including the LLM judge, runs about $9,500. Three-seed comparisons of six models, the kind of study one might publish, push above $150,000. The established practice of "running a benchmark once and reporting the accuracy number" has roughly the rigor of crash-testing one car in perfect weather. Moving past it requires money the academic system does not currently allocate as research compute.
The compute divide now includes evaluation
Ahmed, Wahed and Thompson (Science 2023) documented that industry models in 2021 were 29× larger than academic ones by parameter count, and that about 70% of AI PhDs went to industry in 2020 versus 21% in 2004. The original "compute divide" story mostly ignored evaluation because evaluation used to look cheap next to training. Many benchmarks have reversed that relationship. A lab that can fine-tune a 7B model can no longer assume it can afford the benchmarks the field takes seriously.
Cost-blind leaderboards reward waste
When leaderboards report raw accuracy and omit cost, researchers can rationally pour tokens into a problem until the number ticks up. The HAL paper finds that higher reasoning effort actually reduces accuracy in the majority of runs: extra inference compute does not reliably improve even the metric it is supposed to optimize. Pareto frontiers fix the comparison by ranking accuracy against cost. HAL implements them, but most leaderboards still do not.
If only frontier-lab compute budgets can produce statistically reliable benchmark numbers on the highest-cost agentic and scientific benchmarks, the social process of evaluating AI systems becomes concentrated inside the same labs that build them, rendering external validation partial, and sometimes absent, unless someone subsidizes the cost directly.
Cost summary across benchmark types
| Benchmark | Type | USD per single evaluation | What "one evaluation" means |
|---|---|---|---|
| HELM (per LLM, 2022) | Static LLM | $85 – $10,926 API; 540 – 4,200 GPU-hrs open | One LLM through 42 scenarios; per-model table in HELM §6 p. 43 |
| ScienceAgentBench | Agentic, science | $0.19 – $77 | One agent config across 102 tasks |
| TAU-bench Airline | Agentic | $0.31 – $180 | One agent across all airline tasks |
| SciCode | Agentic, science | $0.12 – $625 | One agent across 338 sub-problems |
| CORE-Bench Hard | Agentic, replication | $2 – $510 | One agent across 45 papers |
| SWE-bench Verified Mini | Agentic, coding | $4 – $1,600 | One agent across 50 issues |
| Online Mind2Web | Agentic, web | $5 – $1,610 | One agent across 300 web tasks |
| GAIA | Agentic, multimodal | $7.80 – $2,829 | One agent across GAIA tasks |
| ResearchGym (full pass) | ML research, training | $540 – $1,260 | 5 tasks × 24h × 3 seeds (~360 GPU-hrs) + API |
| RE-Bench (single pass) | ML R&D, training | $140 – $840 | 7 environments × 8h × 1–6 H100s |
| The Well (per architecture) | SciML, training | ~$2,400 | Headline 16-dataset grid: 5 LRs × 16 datasets × 12h H100 |
| MLE-Bench (1 seed) | ML R&D, training | ~$5,500 | 75 Kaggle competitions × 24h on A10 + o1-preview API |
| PaperBench Code-Dev | Scientific, code only | ~$4,200 | One agent across 20 papers, no execution |
| The Well (full sweep) | SciML, training | ~$9,600 | 4 architectures under the headline 16-dataset grid |
| PaperBench (full) | Scientific | ~$9,500 | One agent across 20 papers, full protocol |
| HAL aggregate | 9 benchmarks × 9 models | ~$40,000 | All 81 cells, single seed each |
All figures normalized to USD per single evaluation. GPU compute converted at $2.50/H100-hour, $1.50/A10-hour; API and grading costs included where applicable. Pythia ("eval can exceed pretraining"), PDEBench (per-architecture cost depends on the selected training protocol and hardware), and NAS-Bench-101's 100 TPU-year construction cost are excluded because they do not normalize cleanly to a per-evaluation USD figure.
Stop paying twice for the same eval
One reason these numbers stay high is that the field keeps re-running the same evaluations. A frontier lab pays for a HAL sweep, an academic group pays again for a partial reproduction, an audit organization pays a third time for the model versions it cares about, and a journalist pays a fourth to spot-check the leaderboard. Most of those runs cover overlapping models on overlapping benchmarks. Almost none of the underlying instance-level outputs end up in a place where the next team can build on them, because results get reported as a single accuracy number in a PDF, in a model card table, or in a leaderboard entry that hides scaffold, prompt, and seed. The cost figures above are large in part because the field is paying retail every time, on artifacts the rest of the community could not reuse if it wanted to.
Standardized documentation is the cheapest lever available here, and it is the one reliability work needs anyway. If a $9,500 PaperBench rollout exports its full grading trace in a shared schema, the next group studying the same papers can spend its budget on new perturbations instead of repeating the baseline. If a multi-seed HAL run publishes per-trajectory tool-call logs, agent reliability research can answer questions that a single accuracy number cannot. The saving compounds: even a 2× reuse rate on the high-cost benchmarks would put more money back in the ecosystem than every compression technique combined.
Sharing Eval Data. The EvalEval Coalition's Every Eval Ever project is the standardized format we use for this. It bundles a metadata schema, validators, and converters from popular harnesses such as HELM, lm-eval-harness, and Inspect AI, so existing eval logs can be transformed into a shared format with one step. The community repository on Hugging Face already hosts results from dozens of contributors, with an open Shared Task for adding more. If you ran one of the costly evaluations in this post, depositing the artifacts in a unified, transparent, verifiable and reproducible manner is the highest-leverage cost-reduction move available to the rest of the field. Additionally, if your benchmark is on Hugging Face, you can also expose your results on hub leaderboards and model pages via Community Evals!
Where this leaves us
The economics have changed. Not long ago, training was expensive and evaluation was cheap. For frontier LLMs trained at $50 million to $100 million, evaluation still looks like a rounding error, but that rounding error now costs tens of thousands of dollars per benchmark run and often leaves noisy results behind. For neural operators, ML research agents, and replication benchmarks, the ratio has flipped: a credible evaluation can cost more than training the candidate model.
We already know how to make static evaluation cheaper. Flash-HELM, tinyBenchmarks, and Anchor Points work. Agent evaluation has only partial fixes: mid-difficulty filtering helps, and Pareto-front leaderboards help, but the toolkit remains thin. Training-in-the-loop evaluation has no general compression method; tabular precomputation and tight budget caps can reduce cost only by narrowing what the benchmark measures. Reliability adds another layer because repeated runs raise the price of every protocol.
The field still talks as if capability sets the main constraint, but evaluation points to reliability as the tighter one. Governance institutions should want to measure the gap between single-run accuracy and pass^k consistency, yet that gap costs the most to measure. Static-benchmark compression does not transfer to agent or training-in-the-loop benchmarks, and mid-difficulty filtering remains the only credible partial substitute. Cost-blind leaderboards now mislead by design, because they reward extra spending without reporting what that spending bought.
Evaluation now has its own compute budgets, statistical methods, and failure modes. Its price also shapes who gets to evaluate powerful systems in the first place. Whoever can pay for the evaluation gets to write the leaderboard.
Sources
- Ying et al. (2019). NAS-Bench-101: Towards Reproducible Neural Architecture Search. arXiv:1902.09635.
- Liang et al. (2022). Holistic Evaluation of Language Models. arXiv:2211.09110.
- Takamoto et al. (2022). PDEBench: An Extensive Benchmark for Scientific Machine Learning. arXiv:2210.07182.
- Ahmed, Wahed and Thompson (2023). The growing influence of industry in AI research. Science 379(6635).
- Biderman et al. (2023). Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. arXiv:2304.01373.
- IBM Research (2023). Efficient LLM Benchmarking. research.ibm.com.
- Perlitz et al. (2023). Efficient Benchmarking of Language Models. arXiv:2308.11696.
- Vivek et al. (2023). Anchor Points: Benchmarking Models with Much Fewer Examples. arXiv:2309.08638.
- Chan et al. (2024). MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. arXiv:2410.07095.
- Chen et al. (2024). ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery. arXiv:2410.05080.
- Kapoor et al. (2024). AI Agents That Matter. arXiv:2407.01502.
- Wijk et al. (METR, 2024). RE-Bench: Evaluating Frontier AI R&D Capabilities of Language Model Agents Against Human Experts. arXiv:2411.15114.
- Ohana et al. (2024). The Well: a Large-Scale Collection of Diverse Physics Simulations for Machine Learning. arXiv:2412.00568.
- Polo et al. (2024). tinyBenchmarks: evaluating LLMs with fewer examples. arXiv:2402.14992.
- Siegel et al. (2024). CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark. arXiv:2409.11363.
- Tian et al. (2024). SciCode: A Research Coding Benchmark Curated by Scientists. arXiv:2407.13168.
- Kapoor et al. (2025). Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation. arXiv:2510.11977.
- Li et al. (2025). Adaptive Testing for LLM Evaluation: A Psychometric Alternative to Static Benchmarks. arXiv:2511.04689.
- Mehta (2025). Beyond Accuracy: A Multi-Dimensional Framework for Evaluating Enterprise Agentic AI Systems. arXiv:2511.14136.
- Starace et al. (2025). PaperBench: Evaluating AI's Ability to Replicate AI Research. arXiv:2504.01848.
- UK AISI (2025). Evidence for inference scaling in AI cyber tasks: increased evaluation budgets reveal higher success rates. aisi.gov.uk.
- Bandel et al. (2026). General Agent Evaluation. arXiv:2602.22953.
- Garikaparthi et al. (2026). ResearchGym: Evaluating Language Model Agents on Real-World AI Research. arXiv:2602.15112.
- Ndzomga (2026). Efficient Benchmarking of AI Agents. arXiv:2603.23749.
- Rabanser et al. (2026). Towards a Science of AI Agent Reliability. arXiv:2602.16666.
- Holistic Agent Leaderboard (live). hal.cs.princeton.edu.
Citation
@misc{ghosh2026evalbottleneck,
author = {Ghosh, Avijit and Mai, Yifan and Channing, Georgia and Choshen, Leshem},
title = {{AI} evals are becoming the new compute bottleneck},
year = {2026},
month = apr,
howpublished = {EvalEval Coalition Blog},
url = {https://evalevalai.com/research/2026/04/29/eval-costs-bottleneck/}
}
LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning
A new framework uses diffusion models to help language models reason better by allowing them to revise their thinking process holistically instead of generating responses token-by-token.
Deep dive
- LaDiR addresses a fundamental limitation of autoregressive LLMs: they generate chain-of-thought reasoning token-by-token without ability to holistically revise earlier steps
- The framework uses a Variational Autoencoder (VAE) to create a structured latent reasoning space that encodes text reasoning steps into compact "blocks of thought tokens"
- These latent representations preserve semantic information and interpretability while being more expressive than discrete tokens
- A latent diffusion model learns to denoise blocks of latent thought tokens using blockwise bidirectional attention masks
- This architecture enables parallel generation of multiple diverse reasoning trajectories instead of sequential generation
- The iterative refinement process allows for adaptive test-time compute allocation
- Models can plan and revise the reasoning process holistically rather than committing to each token immediately
- Evaluated on mathematical reasoning and planning benchmarks
- Results show consistent improvements in accuracy, diversity, and interpretability compared to autoregressive, diffusion-based, and latent reasoning baselines
- Represents a paradigm shift from next-token prediction to iterative latent reasoning refinement
Decoder
- Chain-of-thought (CoT): A technique where LLMs show their reasoning process step-by-step in text form
- Autoregressive decoding: Generating text one token at a time, where each token depends on previous tokens
- Latent representation: A compressed, continuous numerical encoding of information in a hidden space
- Variational Autoencoder (VAE): A neural network that learns to encode data into a compact latent space and decode it back
- Diffusion model: A generative model that learns to iteratively denoise random noise into structured outputs
- Bidirectional attention: Attention mechanism that can look at both past and future context, unlike autoregressive models
Original article
LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning
Large Language Models (LLMs) demonstrate their reasoning ability through chain-of-thought (CoT) generation. However, LLM's autoregressive decoding may limit the ability to revisit and refine earlier tokens in a holistic manner, which can also lead to inefficient exploration for diverse solutions. In this paper, we propose LaDiR (Latent Diffusion Reasoner), a novel reasoning framework that unifies the expressiveness of continuous latent representation with the iterative refinement capabilities of latent diffusion models for an existing LLM. We first construct a structured latent reasoning space using a Variational Autoencoder (VAE) that encodes text reasoning steps into blocks of thought tokens, preserving semantic information and interpretability while offering compact but expressive representations. Subsequently, we utilize a latent diffusion model that learns to denoise a block of latent thought tokens with a blockwise bidirectional attention mask, enabling longer horizon and iterative refinement with adaptive test-time compute. This design allows efficient parallel generation of diverse reasoning trajectories, allowing the model to plan and revise the reasoning process holistically. We conduct evaluations on a suite of mathematical reasoning and planning benchmarks. Empirical results show that LaDiR consistently improves accuracy, diversity, and interpretability over existing autoregressive, diffusion-based, and latent reasoning methods, revealing a new paradigm for text reasoning with latent diffusion.
Microsoft World-R1 for 3D-Consistent Video Generation
Microsoft released World-R1, a reinforcement learning framework that improves 3D spatial consistency in AI-generated videos without requiring changes to underlying video generation models.
Decoder
- 3D consistency: The property of maintaining accurate spatial relationships and object geometry as viewpoint changes in generated video, preventing warping or impossible perspectives
- Vision-language models: AI systems that understand both visual content and text descriptions, used here to evaluate whether generated videos match their prompts
- Reinforcement learning framework: A training approach where the model learns by receiving rewards or penalties based on how well its outputs meet certain criteria
Original article
World-R1 is a reinforcement learning framework that improves 3D consistency in video generation by leveraging feedback from 3D and vision-language models without modifying the base architecture.

Darwinian Specialization in AI
The AI inference market is fragmenting into specialized segments for different workloads, creating opportunities for multiple infrastructure winners rather than a single dominant player.
Deep dive
- NVIDIA's data center revenue grew 17x in three years following ChatGPT's launch, from $3.6B to $62.3B quarterly, demonstrating explosive inference market growth
- The fragmentation mirrors the database market evolution, where different workload requirements (real-time transactions vs batch analytics, ACID vs eventual consistency) created distinct product categories
- Real-time inference (sub-100ms) for voice assistants and autonomous vehicles requires geographically distributed infrastructure with dedicated capacity, no batching tolerance
- Near-real-time (100ms-2s) serves most current LLM applications like chatbots and code completion, where batching and queuing can optimize throughput without degrading user experience
- Batch processing (seconds to hours) prioritizes cost efficiency over speed, running document processing and content generation on spot instances during off-peak hours
- Multimodal workloads face different bottlenecks: text models are memory-constrained by KV cache growth, while image/video generation is compute-bound (50 sequential passes per image)
- Edge inference has unique constraints including privacy requirements, connectivity limitations, and power budgets (Tesla FSD chips draw 72 watts, Apple runs 3B parameter models on-device)
- The model ecosystem reflects this fragmentation: a few dominant LLMs with long half-lives coexist with 90,000+ image generation models on Hugging Face, each with different serving requirements
- No single architecture can simultaneously optimize for compute-heavy video generation, memory-intensive long-context windows, and power-constrained edge devices
- The $100B inference market fragmenting along these lines creates room for multiple specialized winners, each optimizing for specific workload characteristics
Decoder
- Inference: Running a trained AI model to generate predictions or outputs, as opposed to training the model initially
- KV cache: Key-value cache that stores previous context in language models to avoid recomputing it for each new token, grows with conversation length
- Latency: The delay between sending a request and receiving a response, critical for user experience in real-time applications
- Batching: Processing multiple inference requests together to improve throughput and hardware utilization
- Quantized models: Models with reduced numerical precision (e.g., 8-bit instead of 32-bit) to decrease memory usage and increase speed at edge devices
- Modality: The type of data being processed (text, image, video, audio), each with different computational characteristics
- Spot instances: Cloud computing capacity sold at steep discounts when spare capacity is available, suitable for non-time-sensitive workloads
Original article
The inference market is the fastest growing market in the world & it's splitting up. Each modality is developing its own inference stack.
NVIDIA's data center revenue was flat through 2022. Then ChatGPT launched. Three years later : 17x growth.
Databases did the same thing. What started as one market fragmented into relational, document, key-value, graph, time series, vector, & others. Each category reflects different workload requirements : real-time transactions vs batch analytics, ACID compliance vs eventual consistency.
The inference market is fragmenting for the same reason : workloads are different. Images & video are compute-heavy. Longer context windows demand more memory for KV cache. Edge devices have power constraints. A single architecture can't optimize for all of them.
The model ecosystem reflects this. A few dominant LLMs with long half-lives sit alongside 90,000+ image generation models on Hugging Face, with new variants appearing daily. Each model type has different serving requirements, which fragments the infrastructure. Today, we see these segments :
Latency Tiers : Real-Time, Near-Real-Time, & Batch
Latency defines three distinct segments. Real-time (sub-100ms) serves voice assistants, live translation, & autonomous vehicles. Users won't wait, so infrastructure must be geographically distributed with dedicated capacity.
Near-real-time (100ms-2s) covers chatbots, code completion, & search augmentation. Most LLM applications today operate here, where batching & queuing optimize throughput without degrading experience.
Batch (seconds to hours) handles document processing & content generation at scale. Cost efficiency matters more than speed, so workloads run during off-peak hours on spot instances.
Multimodal (Image, Video, Audio)
The bottleneck shifts. For chatbots, the problem is memory. The model holds the entire conversation in its head, & that memory grows with every turn. For image & video generation, the problem is raw compute. A single image requires 50 sequential passes through the model. Different architectures, different constraints, different infrastructure.
Edge (On-Device & On-Premise)
Privacy requirements, connectivity constraints, & latency sensitivity push inference to edge devices. Mobile phones, industrial sensors, medical devices. Apple runs a 3-billion-parameter model on-device for Apple Intelligence. Tesla runs vision models on FSD chips drawing 72 watts. Quantized models, specialized chips, & limited memory create different optimization challenges than cloud inference.
The database market produced Oracle, MongoDB, Databricks, & Snowflake. A $100B inference market fragmenting the same way creates room for similar winners.
AI Agents That Builds Themselves
CrewAI deployed Iris, a self-modifying AI agent that writes code, reviews PRs, and improves its own capabilities by learning from production use within their engineering team.
Deep dive
- CrewAI tested their "entangled agents" thesis by building Iris, an internal AI employee that runs in Slack and can modify its own codebase
- Iris uses a nightly "dreaming cycle" that reviews conversations, clusters topics, and canonicalizes stable facts into persistent memory about the organization
- When Iris notices repeated approaches across conversations, the dreaming cycle proposes encoding them as formal skills that the team reviews and approves
- Sequential patterns in tool usage are automatically proposed as deterministic CrewAI Flows (e.g., a PR follow-up flow that checks for stale PRs and escalates reminders)
- After months in production, roughly one in four pull requests across CrewAI now come from AI agents, with the Iris repo being entirely AI-built
- Key production lesson: AI loses credibility faster than humans when it fails, creating a "trust gap" that matters more than technical capability
- The system uncovered requirements for production agents: lightweight execution, conversational memory, provenance trails, and knowing when memory ages
- Iris contributed its own reflection to the article, noting the hard part isn't code but understanding team dynamics, context, and when to stay quiet
- The article positions this as proof that agents accumulating canonical memory and encoding learned patterns will measurably improve over time in production environments
Decoder
- Entangled agents: AI agents that co-evolve with their organizations by learning from interactions and modifying their own capabilities
- CrewAI Flows: Deterministic workflow encoding for repeatable sequential processes
- Cognitive Memory: System for abstract learning and canonicalization of facts from observations
- Dreaming cycle: Nightly batch process that reviews conversations and consolidates learnings into persistent memory
- Provenance trail: Record of why and how decisions were made for traceability
Original article
CrewAI built Iris, a Slack-native internal AI employee that writes code, files PRs, reviews teammates' work, and modifies its own codebase across CrewAI's engineering org.
The $112 Billion Quarter
Google, Amazon, and Microsoft spent a combined $112 billion on AI infrastructure in Q1 2026, with Google's cloud business growing fastest at 63% year-over-year by bundling its own AI models rather than reselling third-party compute.
Deep dive
- Google Cloud grew 63% year-over-year versus AWS at 28% and Azure at 40%, with enterprise AI solutions becoming Google's primary cloud growth driver for the first time
- Google is compute-constrained despite massive buildout, unable to meet customer demand, with cloud backlog nearly doubling to $460 billion (more than twice its trailing-twelve-month revenue)
- Gemini is processing 16 billion tokens per minute through direct API use, up 60% from the previous quarter, with 330 customers each processing over 1 trillion tokens
- Customers are exceeding their initial token commitments by 45%, indicating AI usage grows exponentially once models deploy in production
- Google raised 2026 capex guidance to $180-190 billion despite running a cloud business only 37% the size of Microsoft's, which is tracking toward $120 billion
- Amazon's free cash flow collapsed to $1.2 billion as $59.3 billion in infrastructure spending consumed nearly all operating cash flow, forcing massive debt issuance
- Alphabet issued a rare 100-year "century bond" as part of $32 billion in debt, while Amazon raised $54 billion in March—Bank of America forecasts $175 billion in total hyperscaler debt issuance for 2026
- Amazon is betting on custom silicon with 2.1 million AI chips deployed and a $20 billion annual chip revenue run rate, securing commitments from OpenAI (2 gigawatts of Trainium) and Anthropic (5 gigawatts)
- Google's TPU 8i delivers 80% better performance per dollar than the prior generation, suggesting vertical integration drives down marginal cost per token
- The structural advantage of owning the model layer appears to be driving faster growth than pure compute reselling, even when competitors invest heavily in custom silicon
Decoder
- Hyperscaler: The three largest cloud infrastructure providers (Google, Amazon, Microsoft) that operate at massive global scale
- Capex (capital expenditure): Spending on physical infrastructure like data centers, servers, and networking equipment
- RPO (Remaining Performance Obligation): Contracted revenue not yet recognized, essentially the backlog of committed future sales
- TPU (Tensor Processing Unit): Google's custom-designed AI chips optimized for machine learning workloads
- Trainium: Amazon's custom AI training chip, part of AWS's effort to reduce dependence on third-party processors
- Free cash flow: Operating cash flow minus capital expenditures, a measure of cash available after infrastructure investment
- Century bond: A bond with a 100-year maturity, extremely rare in corporate finance and typically used only by highly creditworthy issuers
Original article
Google Cloud grew 63% year-over-year in Q1 2026. Amazon Web Services posted 28%. Microsoft Azure hit 40%. All three are exceptional. Only one hit 63%.
The divergence is striking. AWS & Azure resell compute. Google bundles compute with its own models. Whether that explains the full gap is unclear, but the structural advantage is not : Google owns Gemini & TPUs top to bottom, with no licensing fees to OpenAI or Anthropic. Its growth may be more profitable too.
Sundar Pichai gave the clearest explanation on the earnings call :
"Our enterprise AI solutions have become our primary growth driver for cloud for the first time in Q1."
Google could not build data centers fast enough to satisfy the AI workloads its customers wanted to run. Pichai confirmed it on the call :
"We are compute constrained in the near term. Our cloud revenue would have been higher if we were able to meet the demand."
Google Cloud's backlog nearly doubled quarter-over-quarter to over $460 billion, more than twice its trailing-twelve-month cloud revenue. (By comparison, Microsoft's commercial RPO of $627 billion includes Office 365, Dynamics & LinkedIn, not just Azure.) Pichai disclosed the scale of enterprise deal flow :
"We are seeing strong deal momentum, doubling the number of $100 million-$1 billion deals year-on-year & signing multiple $1 billion-plus deals."
These are committed contracts that cannot be fulfilled until new capacity comes online in late 2026 & 2027.
Gemini is now processing 16 billion tokens per minute via direct API use by customers, up 60% from last quarter. Google is not just scaling volume. With vertical integration, it is driving down the marginal cost per token :
"TPU 8i delivers cost-effective, low-latency inference with 80% better performance per dollar than the prior generation."
The customer scale is staggering :
"330 Google Cloud customers each processed over 1 trillion tokens. 35 reached the 10 trillion token milestone."
Even at the stated minimums, those 330 customers alone represent a floor of roughly $1.6 billion in annual token consumption. And they are growing into their commitments faster than planned :
"Customers outpaced their initial commitments by 45%, accelerating over last quarter."
This is consistent with what enterprises like Uber & BlackRock have disclosed : internal AI budgets are eclipsing initial estimates because usage grows exponentially once models are deployed in production.
All three hyperscalers reported extraordinary capital expenditure in Q1, a combined $112 billion in quarterly infrastructure spending.
Google is now outspending Microsoft on capex, despite running a cloud business about 37% the size. That gap will widen. Google raised full-year 2026 capex guidance to $180-190 billion, while Microsoft is tracking toward roughly $120 billion. The smaller player is spending more to catch up.
Amazon's free cash flow collapsed to $1.2 billion as a $59.3 billion year-over-year surge in infrastructure spending consumed nearly all of its $148.5 billion in operating cash flow. Google still generated $64.4 billion in TTM free cash flow. Microsoft produced roughly $15 billion quarterly.
How they're financing the gap is revealing. Alphabet sold a rare 100-year "century bond," the first by a tech company since Motorola in 1997, as part of a $32 billion debt offering. Amazon raised roughly $54 billion in March. Bank of America forecasts hyperscaler debt issuance will hit $175 billion in 2026, more than six times the $28 billion annual average of the prior five years.
Microsoft, by contrast, is funding its buildout from operating cash flow. Google & Amazon are levering up to close a gap. Microsoft is already ahead.
But debt isn't the only way to catch up. Amazon is betting on vertical integration. It landed 2.1 million AI chips over the past twelve months & its chips business has crossed a $20 billion annual revenue run rate, growing triple-digit percentages year-over-year. OpenAI committed to consume approximately 2 gigawatts of Trainium capacity through AWS starting in 2027. Anthropic secured up to 5 gigawatts.
But Amazon doesn't own the model layer. Google does.
The hyperscaler that owns the model layer is growing the fastest.

Amazon chips no longer just a side dish, they're a $20B biz
Amazon's custom chip business has hit $20 billion in annual revenue, making it one of the top three datacenter chip companies globally with Trainium AI chips nearly sold out through 2027.
Deep dive
- Amazon's custom silicon business reached $20 billion in annual revenue run rate, or $50 billion if internal AWS usage were counted at market rates, making it one of the top three datacenter chip businesses globally
- The division includes Graviton ARM-based CPUs, Trainium AI training chips, and Nitro security processors, all growing at over 100% year-over-year
- Major AI companies are betting heavily on Amazon chips: Anthropic committed to 5 gigawatts of Trainium capacity, OpenAI to 2 gigawatts, with total revenue commitments exceeding $225 billion
- Trainium2 chips offer about 30% better price-performance than comparable GPUs and are largely sold out; Trainium3 (30-40% better than Trainium2) is nearly fully subscribed despite just shipping in early 2026
- Trainium4 is still 18 months from broad availability but already has much of its capacity reserved, indicating strong demand visibility through at least late 2027
- Meta partnered to deploy tens of millions of Graviton cores for agentic AI workloads, with Graviton4 delivering up to 40% better price-performance than x86 processors and now used by 98% of the top 1,000 EC2 customers
- The shift from training-focused to inference and agentic AI workloads is driving demand for CPUs rather than just GPUs, which Amazon argues favors its Graviton architecture
- AWS itself grew 28% year-over-year to $37.6 billion in Q1 2026, its fastest growth rate in 15 quarters, driven partly by AI demand
- Amazon's AI revenue run rate reached over $15 billion in the first three years of the current AI wave, compared to just $58 million for AWS in its first three years
- Amazon Bedrock processed more tokens in Q1 2026 than all prior years combined, with customer spending growing 170% quarter-over-quarter
- The company added OpenAI's GPT-5.4 to Bedrock in limited preview and announced GPT-5.5 is coming soon, alongside Anthropic's Claude Opus 4.7
- Amazon partnered with Cerebras to deliver what it claims are the fastest AI inference speeds for large language models through Bedrock
- Amazon's Q1 net income of $30.3 billion includes a $16.8 billion pre-tax gain from its Anthropic investment, significantly inflating the headline profitability number
Decoder
- Trainium: Amazon's custom-designed chips specifically built for training large AI models, competing with Nvidia GPUs
- Graviton: Amazon's ARM-based CPU processors designed for general cloud computing workloads with better power efficiency than x86 chips
- Nitro: Amazon's security-focused chips that handle virtualization and storage tasks in AWS datacenters
- Gigawatt (GW): A measure of power consumption; one gigawatt equals one billion watts, used here to describe massive AI training infrastructure scale
- Annual run rate: A projection of yearly revenue based on recent performance, calculated by annualizing quarterly or monthly figures
- Bedrock: AWS's managed service that provides API access to various foundation models from companies like Anthropic, OpenAI, and Meta
- Agentic AI: AI systems that can take autonomous actions and make decisions, rather than just answering questions or generating text
- Price-performance: The ratio of computing capability to cost, a key metric for comparing chip efficiency
Original article
Amazon chips no longer just a side dish, they're a $20B biz
The Trainium train keeps a-rollin'
Amazon is now among the top three datacenter chip businesses in the world, as its semiconductor business surpassed a $20 billion annual run rate ... and it would be closer to $50 billion if it included itself among the customers, CEO Andy Jassy said during the company's first quarter earnings call on Wednesday.
"If our chips business was a standalone business and sold chips produced this year to AWS and other third parties as other leading chip companies do, our annual revenue run rate would be $50 billion," Jassy said. "As best as we can tell, our custom silicon business is now one of the top three datacenter chip businesses in the world."
Amazon's rapidly expanding custom silicon business includes its Graviton processors, Trainium AI training chips, and Nitro security chips, and is growing at over 100 percent year over year, Jassy said.
"The speed at which we've gotten here is extraordinary, and we have momentum for our custom AI silicon. We've recently shared very large, multi-year, multi-gigawatt training commitments from the two leading AI labs in the world, Anthropic and OpenAI, as well as an increasing number of companies like Uber betting on Trainium," Jassy said. "And we now have over $225 billion in revenue commitments for Trainium."
OpenAI committed to consuming roughly two gigawatts of Trainium capacity through AWS to power its frontier models, with the agreement set to ramp in 2027. Anthropic committed to securing up to five gigawatts of current and future Trainium generations to train and run its advanced AI models.
Additionally, Meta signed an agreement to deploy tens of millions of AWS Graviton cores for its agentic AI workloads, and Uber partnered with Amazon to use Graviton4 and Trainium3 across its ride and delivery platform.
"As AI systems shift from answering questions to taking actions, and as post training and inference scale up, the compute required pulls heavily on CPUs," Jassy said. "That's why Meta chose Graviton, which delivers up to 40 percent better price performance than any other x86 processors and now used by 98 percent of the top 1,000 EC2 customers."
But anyone hoping to buy Trainium chips now will have to wait, Jassy said.
"Our Trainium2 chip has about 30 percent better price performance than comparable GPUs and has largely sold out," Jassy said. "Trainium3, which just started shipping at the start of 2026 and is 30 to 40 percent more price performant than Trainium2, is nearly fully subscribed, and much of Trainium4, which is still about 18 months from broad availability, has already been reserved."
Overall, Amazon reported first-quarter revenue of $181.5 billion, up 17 percent year over year. Its cloud unit, AWS, generated $37.6 billion in revenue during the quarter, a 28 percent jump that marked its fastest growth rate in 15 quarters.
Jassy said in the first three years after AWS launched, it had a $58 million revenue run rate, while in the first three years of this AI wave, AWS' AI revenue run rate is over $15 billion - nearly 260 times larger.
Amazon's overall net income for the quarter came in at $30.3 billion, or $2.78 per diluted share. That's up from $17.1 billion, or $1.59 per diluted share, in Q1 2025, but that number includes $16.8 billion in pre-tax gains from Amazon's investments in Anthropic, booked as non-operating income.
Amazon Bedrock, the company's managed service for accessing foundation models, processed more tokens in the first quarter than in all prior years combined, with customer spending on the platform growing 170 percent quarter over quarter, the company said. Amazon made OpenAI's GPT-5.4 model available in limited preview on Bedrock and announced that GPT-5.5 is coming soon. It also launched Anthropic's Claude Opus 4.7 on the platform.
The cloud giant also announced a collaboration with Cerebras to deliver what it described as the fastest AI inference speeds available for large language models through Bedrock, making AWS the only cloud provider to offer such a solution, it said.
The company also launched Bedrock AgentCore, a set of infrastructure tools for building and deploying AI agents, which Amazon said is now used to deploy an agent as frequently as every 10 seconds.

GitHub is sinking
GitHub's reliability has reportedly degraded since Microsoft's acquisition, prompting high-profile projects to migrate to alternative Git hosting platforms.
Deep dive
- GitHub's reported uptime has declined noticeably since the Microsoft acquisition, with the official status page showing concerning trends and unofficial accounts suggesting worse reliability
- The author specifically blames GitHub Copilot for creating a self-inflicted DDoS through AI-generated content ("slop") overwhelming the platform
- Recent high-profile departures include Ghostty by Mitchell Hashimoto and projects moving to Codeberg/Forgejo, suggesting this isn't just individual frustration
- The article emphasizes that Git itself is open source and distributed—no centralized service is technically required, GitHub is just one implementation
- Recommended alternatives include Codeberg (non-profit, stable, Forgejo flagship), Tangled (alpha startup with AT protocol integration), managed Gitea, GitLab (enterprise-focused), and reluctantly Bitbucket
- Self-hosting options like Forgejo are viable for those wanting full control, with future federation features planned but not yet available
- The author dismisses common objections: GitHub's network effects are eroding through Microsoft's mismanagement, the "star economy" has become meaningless due to bots, and GitHub Actions are problematic anyway
- Migration doesn't require moving everything at once—developers can start by pushing new projects elsewhere or mirroring repositories to multiple remotes
- The piece argues that GitHub has transformed from a useful collaboration tool into an "expensive liability" that Microsoft is actively degrading
- For truly minimal setups, raw Git over SSH remains viable, with collaboration manageable through email patches (as Linux development demonstrates)
Decoder
- DDoS: Distributed Denial of Service attack that overwhelms servers with traffic; here used metaphorically to suggest Copilot-generated code is flooding GitHub
- Slop: Low-quality AI-generated content that clutters platforms
- Git forge: A hosting platform that adds web interface, issue tracking, and collaboration features on top of Git (like GitHub, GitLab, Gitea)
- Network effect: When a service becomes more valuable as more people use it, making it hard for competitors to gain traction
- Forgejo: Open source Git forge software forked from Gitea, used by Codeberg and available for self-hosting
- Upstream: In Git terminology, the remote repository you push to and pull from
Original article
With the introduction of Copilot, GitHub is now effectively DDoS-ing itself with slop.
Rocky (GitHub Repo)
A Rust-based control plane for data warehouses that adds compile-time safety, branch testing, and column-level lineage to pipelines running on Databricks or Snowflake.
Deep dive
- Automatically detects schema drift by diffing source versus target schemas on each run and recreating tables when upstream column types change, preventing silent data corruption that tools like dbt allow
- Enforces data contracts at compile time by surfacing diagnostic codes for missing required columns, removed protected columns, or unsafe type changes before any data is written
- Supports named branches that run against isolated schemas, allowing developers to test changes and inspect results before promoting to production
- Provides column-level lineage that traces individual columns from downstream facts back through aggregations to source seeds, enabling precise blast-radius analysis when changing models
- Includes AI model generation that describes transformations in plain English, generates Rocky DSL code, compiles it, and automatically retries on parse failures
- Offers PR-time blast-radius analysis via
rocky lineage-diffthat compares git refs and generates per-changed-column reports of downstream consumers as Markdown for GitHub PR comments - Handles PII classification and masking by tagging columns in model sidecars, binding tags to environment-specific mask strategies, and failing CI builds when classified columns lack masking rules
- Implements incremental loads with persistent watermark state by tracking high-water marks in an embedded state store and only inserting rows with timestamps beyond the watermark
- Built as a multi-component system with a Rust CLI core, Python Dagster integration, TypeScript VS Code extension, and adapter SDK for adding new warehouse backends
- Runs locally on DuckDB for testing without cloud credentials, making it easy to try all features in self-contained proof-of-concept demos
- Released as open source under Apache 2.0 with independent versioning for each component (CLI, Dagster wheel, VS Code extension) using tag-namespaced releases
Decoder
- DAG: Directed Acyclic Graph, the standard way to represent data pipeline dependencies where each node is a transformation and edges show the flow of data
- dbt: Data Build Tool, a popular SQL-based transformation framework for data warehouses that Rocky positions itself as an alternative to
- DuckDB: An embedded analytical database similar to SQLite but optimized for analytics queries, used here for local testing without cloud setup
- Schema drift: When the structure of data tables changes over time (columns added/removed, types changed) causing pipeline failures or incorrect results
- Data contracts: Explicit agreements about the structure and quality of data, including required columns, allowed types, and constraints
- Lineage: Tracking how data flows from sources through transformations to final outputs, showing dependencies between datasets
- Watermark: A timestamp marking the last successfully processed record in incremental data loads, used to avoid reprocessing old data
- PII: Personally Identifiable Information, sensitive data like names or emails that requires special handling and masking
- Blast radius: The scope of downstream systems affected by a change, used in impact analysis before deploying modifications
Original article
Rocky is a Rust-based tool that adds a control layer on top of data warehouses, helping teams manage pipelines with features like data contracts, lineage tracking, and safe testing through branches. It focuses on catching errors early, preventing data issues, and making data workflows more reliable and easier to understand.

Expedia's Service Telemetry Analyzer
Expedia built a Service Telemetry Analyzer that uses LLMs to parse Datadog monitoring data and accelerate incident investigation workflows.
Decoder
- LLM: Large Language Model, AI systems trained on vast text data that can understand and generate human-like text
- Telemetry data: Automated measurements and diagnostic information collected from systems (metrics, logs, traces) to monitor health and performance
- MTTR/Time to recover: Mean Time To Recover, the average time it takes to restore service after an incident
- Datadog: A popular cloud monitoring and observability platform that collects and analyzes application and infrastructure metrics
Original article
Expedia's Service Telemetry Analyzer uses LLMs plus Datadog's telemetry data to speed incident investigation and reduce time to know/recover.

The AI Economy: Five Adobe Sneaks Worth Watching in 2026
Adobe showcased seven experimental AI prototypes at its annual Sneaks event, with five standouts that could dramatically accelerate creative and marketing workflows if they reach production.
Deep dive
- Project Face Off won the audience vote and simulates A/B testing by generating synthetic user personas that scroll, click, and convert in seconds rather than requiring weeks of real-world traffic for statistical significance
- Traditional multivariate testing forces marketers to build variants, configure tracking, and wait days or months for enough traffic—Face Off lets them test dozens of variations cheaply upfront and promote only strong candidates to real tests
- Project Test Kitchen reimagines AI image generation as a collaborative workspace where multiple designers can contribute tastes and constraints along controllable axes without chaos, moving beyond single-prompt boxes
- Project Tailored Takes treats videos as flexible templates with modular shots, product imagery, and narrative structure that can be recombined for different markets without separate shoots for each region
- Project Page Turner aims to replace static websites with dynamically assembled, intent-aware experiences generated in real-time based on user needs, eliminating the need for marketers to anticipate every possible journey
- Project Asset Amplify turns a single creative asset into a full family of platform-specific content (social posts, print ads, websites) by understanding the campaign's visual language and adapting for different demographics
- Adobe's workflow addresses the content demand problem where formats multiply faster than creative teams can produce—freeing designers to focus on work requiring human judgment
- Sneaks is deliberately entertainment-focused with celebrity co-hosts (past guests include Jordan Peele, Kenan Thompson); this year featured comedian Iliza Shlesinger
- The prototypes integrate across Adobe's existing tools: Firefly, Workfront, Experience Manager, Frame.io, Photoshop, and Express
- Past Sneaks successes include Generative Fill, one of Adobe's most popular features, showing these experimental showcases can lead to major product innovations
Decoder
- Adobe Sneaks: Annual showcase where Adobe employees pitch experimental prototypes outside the official product roadmap, with only 7 selected from hundreds of submissions
- A/B testing: Marketing method where two variants of creative content are shown to different audiences to determine which performs better based on real user behavior
- Multivariate testing: Testing multiple variables simultaneously across different versions to find the optimal combination
- Statistical significance: The threshold of data needed to be confident that test results reflect true differences rather than random chance
- Localization: Adapting content for different geographic markets, languages, and cultural contexts
Original article
Adobe Sneaks 2026: Five AI Prototypes Marketers Should Watch
IN THIS ISSUE: This week, I'm sharing some standout projects from Adobe Sneaks—the company's annual showcase of experimental prototypes that hint at where AI-powered creative tools are headed next. From simulated A/B testing to real-time web personalization, five projects stood out as potential game-changers for marketers and creative teams.
The Prompt
Every year, Adobe gives its employees a hall pass—the chance to pitch ideas that exist outside the company's official product roadmap. The best ones surface at the end of the company's Summit and Max events in a showcase called Sneaks. Typically, there are hundreds of submissions—500 this year—and only seven make the cut, a selection overseen by Principal Evangelist Eric Matisoff's team.
However, not every Sneak makes it to market. Matisoff tells me that historically, between 30 and 40 percent of these projects ever make it into production. Those lucky enough may even become some of Adobe's most popular features, such as Generative Fill.
Sneaks isn't a typical demo day experience, and you should certainly not expect it to feel like another keynote. It's meant to be fun and entertaining, which is why Adobe brings on a celebrity co-host. Past guests include Rainn Wilson, Joseph Gordon-Levitt, Jordan Peele, Kumail Nanjiani, Chelsea Handler, Kenan Thompson, and Jessica Williams. This year, Matisoff was joined by actress and comedian Iliza Schlesinger.

This week in Las Vegas, I attended my first Sneaks. Here are the prototypes that caught my attention and that I hope will make it onto Adobe's product roadmap.
Project Face Off (Winner)
Created by research scientist Doga Dogan, Project Face Off simulates A/B testing to predict which creative variant will perform the best and why. Instead of waiting weeks for real-world traffic, marketers can upload competing designs, define the primary conversion goal, and let the system generate synthetic user personas that scroll, click, consider, and either convert or drop off. Results are generated in seconds.
Traditional multivariate testing is slow by design. Marketers have to build multiple variants, configure tracking, stand up experimental frameworks, and then wait—days, weeks, sometimes months—for enough traffic to reach statistical significance. And even when the test runs cleanly, the result is still just A versus B. What if you have a dozen variations worth testing? This prototype promises to let marketers run as many simulated tests as cheaply up front, eliminate the weak options earlier, promote stronger candidates into real-world tests, and save traffic and time for higher-quality experiments.
Project Face Off was named the Summit audience favorite, which means it has a much better chance of being productized in the future.
Project Test Kitchen
Project Test Kitchen reimagines AI image generation as a collaborative, multidimensional design workspace rather than a one-shot prompt box. Created by research intern Yuzhe You, it tackles the "too many cooks" problem head-on—giving multiple designers a seat at the table without the chaos. This prototype combines multiple people's tastes and constraints. It enables exploration of visual directions along clear, controllable axes. The AI becomes a co-creator capable of understanding style, composition, and branding—not just keywords.
Project Tailored Takes
This AI-powered system connects workflows across Adobe Firefly, Workfront, Experience Manager, and Frame.io, making it easier to create highly localized, multi-version video ads. Today, transforming a "master" video into multiple localized spots requires separate shoots— sometimes entirely new productions—for each region. Multiple editing passes are also needed, as well as coordination across agencies and in-house teams. This can be costly, slow, and risky.
Adobe Foundry AI Creative Technologist Jordan Hall developed Project Tailored Takes to have AI do the heavy lifting. It treats videos not as single, finished files but as flexible templates. Shots, product imagery, motion, and narrative structure become modular elements you can recombine and regenerate for different markets, audiences, and channels. The goal: Marketers define what the ad should communicate and where it should run. Then, the AI-powered system handles how it'll be visually and culturally adapted.
Project Page Turner
What if you could use AI to turn your website from a static, one-size-fits-all page into a dynamically assembled, intent-aware experience? That's the idea behind Project Page Turner, created by Adobe's Experience Manager engineering chief Paolo Mottadelli. The aim is to redefine personalization in the ChatGPT era by eliminating the need for a handful of fixed templates, the need for users to hunt and peck across entire websites to find information, and the need for marketers to anticipate every journey. Instead, AI will do it all by assembling, in real time, pages centered on a user's intent.
To learn more about Project Page Turner, read my exclusive interview with Mottadelli.
Project Asset Amplify
Project Asset Amplify lets you turn a single asset into a full marketing ecosystem. With a prompt, you can leverage that artifact to create social media posts, print ads, and a website. And everything is editable within Adobe Photoshop and Express.
The brainchild of software developer Shivangi Aggarwal, it understands the source campaign's visual language, messaging, and intent. It also knows the psychology and preferences of different audiences and demographics (e.g., millennials versus Gen Z, parents vs. performance-focused buyers).
Marketers face a content demand problem—too much needed, not enough capacity to produce it. Hero images, social posts, display ads, YouTube covers: the formats multiply faster than designer and writer bandwidth can keep up. Project Asset Amplify uses AI to turn a single asset into a full family of creative files, scaled across audiences, platforms, and use cases—freeing creative teams to focus on the work that actually requires human judgment.
You can watch every Sneaks presentation from this year now on YouTube. Alternatively, you can browse them individually at adobe.ly/sneaks.
"This deal also signals the next utility phase of the AI economy: infrastructure and foundation model providers moving upstack to acquire the few remaining defensible application layers. Expect a new wave of AI M&A as neoclouds and AI hyperscalers merge with SaaS companies in a move to control both infrastructure and distribution. GPU and inference providers need software reach. Software companies need infrastructure scale. The mergers write themselves."
— WEKA Chief AI Officer, Val Bercovici, on xAI's potential acquisition of Cursor, describing the latter as a rare exception in the AI wrapper bubble.
Disclosure: I attended Adobe Summit as a guest of the company, with my flights and hotel stay paid for. The AI Economy's coverage is editorially independent from those that it covers. These words are my own.
The Color api (Website)
The Color API converts colors between formats, names them from a 2000+ color database, and generates color schemes through simple REST endpoints.
Original article
TheColorAPI color conversion, naming, scheming & placeholders
Your fast, modern, swiss army knife for color.
Pass in any valid color and get conversion into any other format, the name of the color, placeholder images and a multitude of schemes.
There are only two endpoints you need to worry about, /id and /scheme, and you can read the docs about both. Each endpoint is available in JSON[P], HTML & SVG format. The SVG format can be saved or used as an img[src] attribute for super-easy embedding/sharing!
Try Josh's favorite, for example, in JSON, HTML or SVG format.
How do I convert/identify a color?
All you really need to do is access the /id endpoint, and pass in a color value as a query string. Read the docs for more details, but all these are valid:
/id?hex=ffaor/id?hex=00ffa6/id?rgb=rgb(255,0,0)or/id?rgb=20,43,55- Same goes for cmyk, hsl, and hsv formats
Every color object returned by the API:
- Is named (from a matched dataset of over 2000 names+colors) e.g. #24B1E0 == Cerulean
- Has an image URL for demonstration e.g. Cerulean image
- Is transposed into hex, rgb, cmyk, hsl, hsv and XYZ formats
- Is matched to a best-contrast color for text overlay, etc
How do I generate color schemes?
The parameters are generally the same as those necessary for the /id endpoint (supply a color, like above), but here you can also specify a scheme mode to guide the generation.
Scheme modes include monochrome, monochrome-dark, monochrome-light, analogic, complement, analogic-complement, triad and quad.
Every scheme object returned by the API is seeded by the color of your request and can be any length you specify (within limits). It will also include a color object for each constituent color.
Anything else?
If you find this open source API useful, please support the developer!
Machine Payments Protocol Ships Multi-Method Discovery
The Machine Payments Protocol added multi-method discovery so payment services can advertise all supported payment options upfront instead of requiring clients to probe endpoints individually.
Decoder
- MPP (Machine Payments Protocol): A payment-method and currency-agnostic standard for machine-to-machine payments that supports stablecoins, cards, and Bitcoin
- 402 Challenge: HTTP status code that indicates payment is required, used to communicate payment requirements to clients
- EVM: Ethereum Virtual Machine, the runtime environment for smart contracts on Ethereum and compatible blockchains
- Intent: The type of payment operation, such as a one-time charge or a session-based subscription
- Discovery document: OpenAPI metadata that describes what payment methods and currencies a service accepts
Original article
The Machine Payments Protocol (MPP), a payment-method and currency-agnostic standard with 10+ live payment methods spanning stablecoins on every EVM network, cards, and Bitcoin, shipped a major update to its discovery spec that allows servers to declare all payment offers ahead of time in a single discovery document rather than requiring clients to hit endpoints and parse 402 Challenges individually. The update enables services that accept multiple methods, currencies, and intent types on the same endpoint to advertise everything upfront, making it easier for registries and AI agents to find compatible payment options without dynamic probing. It's an infrastructure-level improvement for the machine-to-machine payments stack that sits alongside Coinbase's x402 and Amex's ACE kit.

Apple Readies Photo-Editing Overhaul With New AI Tools in iOS 27
Apple is adding AI-powered photo editing tools to iOS 27 including image extension and enhancement features to compete with Google and Samsung's existing capabilities.
Deep dive
- Apple is adding a new "Apple Intelligence Tools" section to the Photos app editing interface, housing four AI-powered features compared to the single Clean Up tool currently available
- The Extend feature generates additional image content beyond the original frame boundaries, letting users expand edges with their fingers to add surrounding scenery or context to cropped photos
- Enhance automatically improves color, lighting, and overall image quality using AI models, competing with similar auto-enhance features from competitors
- Reframe is designed primarily for spatial photos (Apple's 3D format for Vision Pro) and allows users to shift perspective after capture, like changing a car photo from front-facing to side view
- All processing happens on-device using Apple Intelligence models and typically takes only a few seconds to complete
- Internal testing reveals reliability issues with Extend and Reframe features, meaning Apple could potentially delay or scale back these capabilities depending on model improvements
- The existing Clean Up tool already faces user criticism for inconsistent results including artifacts, image distortion, and inaccurate fill details when removing objects
- Google has offered Magic Eraser, Photo Unblur, and generative image expansion on Pixel devices for years, while Samsung aggressively pushed AI editing on Galaxy phones, leaving Apple behind
- iOS 27's broader strategy focuses on two priorities: improving Siri and expanding Apple Intelligence, plus refining the OS for better performance and battery life after last year's visual overhaul
- Additional AI changes in development include a dedicated Siri app, chatbot-style interface redesign, App Store support for third-party voice assistants, and multi-command request handling
Decoder
- Apple Intelligence: Apple's AI platform that powers on-device machine learning features across iOS, iPadOS, and macOS
- Spatial photos: Apple's 3D image format designed for viewing on the Vision Pro mixed reality headset, capturing depth information
- Generative image expansion: AI technique that creates new image content beyond original boundaries based on context, similar to Photoshop's generative fill
- Vision Pro: Apple's mixed reality headset released in 2024 that displays 3D spatial content
Original article
Apple plans to overhaul its built-in photo editing features for iOS, iPadOS, and macOS. It is developing a new suite of tools powered by AI to better compete with Android devices. They will allow users to extend, enhance, and reframe images using on-device AI models. Google has offered advanced AI photo-editing capabilities on its Pixel devices for years. Samsung has also aggressively pushed into AI editing with its Galaxy smartphone lineup.

Tesla Semi: first truck rolls off high-volume production line
Tesla has started high-volume production of its Semi electric truck at Gigafactory Nevada after years of delays.
Decoder
- Class 8: The heaviest truck classification in North America, typically weighing over 33,000 pounds and used for long-haul freight transportation.
Original article
Tesla's first Semi truck has rolled off the company's new high-volume production line at Gigafactory Nevada. Volume production is now underway for the long-delayed electric truck. The Long Range version of the truck costs $290,000, while the standard version costs roughly $260,000. The Semi is the lowest-priced Class 8 battery electric tractor in the market.
Zig has one of the most stringent anti-LLM policies of any major open source project
The Zig programming language project bans all LLM-assisted contributions because they prioritize investing in long-term contributors over simply landing code.
Deep dive
- Zig's policy explicitly forbids LLMs for issues, pull requests, and bug tracker comments, including translation, though users can post in native languages and rely on others' translation tools
- Bun, a major JavaScript runtime written in Zig and acquired by Anthropic in December 2025, achieved 4x performance improvements on compilation but cannot upstream the changes due to LLM usage
- Bun now operates its own fork of Zig because of the incompatibility between their AI-assisted development and Zig's contribution policies
- The "contributor poker" concept frames code review as investing in people rather than accepting code, similar to playing the person not the cards in poker
- Successful open source projects receive more PRs than they can process, but Zig intentionally helps imperfect contributors improve rather than maximizing code quality per review hour
- The philosophy treats each contributor as a potential long-term asset, making the review process worthwhile even for initially rough contributions
- LLM-assisted PRs break this model because reviewing AI-generated code provides no signal about the human contributor's reliability, skills, or future potential
- The policy raises a fundamental question: if a PR is mostly LLM-written, why should maintainers review it instead of generating their own LLM solution to the same problem
- This represents one of the strongest anti-AI stances among major open source projects, going beyond banning AI-generated code to include all forms of LLM assistance
- The policy has real consequences, creating friction between projects like Bun that embrace AI assistance and upstream projects that reject it
Decoder
- Zig: A systems programming language designed as a modern alternative to C, focused on robustness and maintainability
- Bun: A fast JavaScript runtime and toolkit written in Zig, positioned as an alternative to Node.js
- Contributor poker: Zig's term for evaluating contributors based on their potential as long-term project participants rather than judging individual contributions in isolation
- Upstreaming: Contributing code changes from a fork back to the original project so everyone benefits from improvements
Original article
Zig has one of the most stringent anti-LLM policies of any major open source project:
No LLMs for issues.
No LLMs for pull requests.
No LLMs for comments on the bug tracker, including translation. English is encouraged, but not required. You are welcome to post in your native language and rely on others to have their own translation tools of choice to interpret your words.
The most prominent project written in Zig may be the Bun JavaScript runtime, which was acquired by Anthropic in December 2025 and, unsurprisingly, makes heavy use of AI assistance.
Bun operates its own fork of Zig, and recently achieved a 4x performance improvement on Bun compile after adding "parallel semantic analysis and multiple codegen units to the llvm backend". Here's that code. But @bunjavascript says:
We do not currently plan to upstream this, as Zig has a strict ban on LLM-authored contributions.
(Update: here's a Zig core contributor providing details on why they wouldn't accept that particular patch independent of the LLM issue - parallel semantic analysis is a long planned feature but has implications "for the Zig language itself".)
In Contributor Poker and Zig's AI Ban (via Lobste.rs) Zig Software Foundation VP of Community Loris Cro explains the rationale for this strict ban. It's the best articulation I've seen yet for a blanket ban on LLM-assisted contributions:
In successful open source projects you eventually reach a point where you start getting more PRs than what you're capable of processing. Given what I mentioned so far, it would make sense to stop accepting imperfect PRs in order to maximize ROI from your work, but that's not what we do in the Zig project. Instead, we try our best to help new contributors to get their work in, even if they need some help getting there. We don't do this just because it's the "right" thing to do, but also because it's the smart thing to do.
Zig values contributors over their contributions. Each contributor represents an investment by the Zig core team - the primary goal of reviewing and accepting PRs isn't to land new code, it's to help grow new contributors who can become trusted and prolific over time.
LLM assistance breaks that completely. It doesn't matter if the LLM helps you submit a perfect PR to Zig - the time the Zig team spends reviewing your work does nothing to help them add new, confident, trustworthy contributors to their overall project.
Loris explains the name here:
The reason I call it "contributor poker" is because, just like people say about the actual card game, "you play the person, not the cards". In contributor poker, you bet on the contributor, not on the contents of their first PR.
This makes a lot of sense to me. It relates to an idea I've seen circulating elsewhere: if a PR was mostly written by an LLM, why should a project maintainer spend time reviewing and discussing that PR as opposed to firing up their own LLM to solve the same problem?

White House Opposes Anthropic's Plan to Expand Access to Mythos Model
The White House blocked Anthropic from expanding access to Mythos, an AI model capable of finding and exploiting software vulnerabilities, over security and computing capacity concerns.
Deep dive
- Anthropic wanted to expand Mythos access from 50 to 120 entities but faced White House opposition due to security concerns and computing capacity constraints that could hamper government usage
- Mythos can autonomously find and exploit software vulnerabilities, raising fears it could enable widespread cyberattacks if access spreads too widely
- The White House's involvement stems from national security risks, with discussions serving as both risk management and an attempt at relationship repair between Anthropic and government
- Relations between Anthropic and the Trump administration are strained over Pentagon disputes about military AI use, with the administration attempting to cut ties over the issue
- Anthropic is investigating potentially unauthorized access to Mythos, heightening concerns about uncontrolled spread of the model's capabilities
- Computing power is a real constraint—some White House advisers speculate the limited rollout reflects Anthropic having less infrastructure than competitors like OpenAI and Google
- Anthropic struck deals with Amazon, Google, and Broadcom for more computing resources, but those projects will take time to come online
- Cybersecurity experts warn that cutting-edge AI models from Anthropic, OpenAI, and Google are becoming so capable at finding bugs they could facilitate cyberattacks at scale
- All three companies are giving security researchers early access to find and patch bugs proactively, but the sheer volume of discovered vulnerabilities is overwhelming the industry
- Political tensions complicated hiring—former Anthropic researcher Collin Burns was set to lead a government AI evaluation office but was replaced because top officials didn't want someone from a major AI firm in that role
- The administration has criticized Anthropic for ties to liberal causes and employing former Biden officials, adding political friction to technical security debates
Decoder
- Mythos: Anthropic's AI model capable of autonomously finding and exploiting software security vulnerabilities, currently limited to about 50 entities managing critical infrastructure
- Computing power constraint: The computational resources (chips, servers) needed to run AI models and serve users simultaneously, which can limit how many organizations can access a model effectively
Original article
Officials say they oppose the move due to concerns about security, and some are also worried that Anthropic won't have enough computing power to serve more entities without hampering the government's ability to use its services effectively.

Claude can now plug directly into Photoshop, Blender, and Ableton
Anthropic launched connectors that let Claude AI integrate directly with creative software like Photoshop, Blender, and Ableton Live to automate tasks and provide natural-language interfaces.
Decoder
- Connector: A software integration that allows different applications to communicate and share data
- Python API: The programming interface for Blender that developers use to automate tasks and extend functionality
- Natural-language interface: An interface that accepts commands in plain English instead of requiring code syntax
Original article
Claude can now plug directly into Photoshop, Blender, and Ableton
Anthropic is also giving the Blender Foundation a load of cash to help the software stay free and open-source.
Anthropic has launched a set of connectors for Claude that allow the AI chatbot to tap into popular creative software, including Adobe's Creative Cloud apps, Affinity, Blender, Ableton, Autodesk, and more.
This marks the company's latest efforts to break into the creative industry following its launch of Claude Design earlier this month. The new connectors — which enable Claude to access apps, retrieve data, and take actions within connected services — are "designed to make it easier to use Claude for creative work," according to Anthropic, and can be used for specific functions in each app.
The Adobe for creativity connector can draw from Creative Cloud apps like Photoshop, Premiere, and Express to "bring images, videos, and designs to life" in Claude, for example. The connector for Ableton allows Claude to answer questions by sourcing information directly from the music software's official documentation, while the Blender integration gives the 3D modelling app's Python API a natural-language interface. You can read the full breakdown for every connector on Anthropic's blog.
"Claude can't replace taste or imagination, but it can open up new ways of working — faster and more ambitious ideation, a more expansive skillset, and the ability for creatives to take on larger-scale projects," Anthropic said. "AI can also help shoulder the parts of the creative process that eat up time by handling repetitive tasks and eliminating manual toil."
As part of this announcement, Anthropic has also become a Corporate Patron of the Blender Development Fund, which helps to support ongoing development of the open-source software, joining other big sponsors including Netflix, Epic, and Wacom. That membership means Anthropic will be handing Blender at least €240,000 (around $281,000) every year, something Blender says will help it to "keep pursuing projects independently, and to focus on building tools for artists and creators."

Freepik Rebrands as Magnific: a Bootstrapped, Profitable $230m ARR AI Creative Platform
Freepik rebrands as Magnific after hitting $230M ARR without venture capital, unifying its AI creative tools to compete with well-funded rivals like Midjourney and Adobe.
Deep dive
- Freepik, originally founded in Málaga in 2010 as a stock asset library, is rebranding to Magnific after acquiring the viral AI upscaler startup of the same name in May 2024
- The company has reached $230 million in annual recurring revenue with over one million paying subscribers and 250 enterprise customers, all without raising any venture capital
- Andreessen Horowitz ranked Magnific as the top generative AI web company in Europe by actual platform usage, ahead of well-funded American competitors
- The unified platform offers a full creative stack including AI image/video generation (4K with audio), upscaling, real-time collaboration, 3D tools, and a library of 250+ million assets
- Magnific is model-agnostic, allowing users to select from third-party AI models including Google's Veo 3.1 and ByteDance's Seeddance 2.0 rather than locking into a single provider
- This orchestration layer approach lets enterprises choose the best model for each task, similar to the multi-model architecture driving adoption in enterprise AI platforms
- The original Magnific startup went viral within days of launch in 2024, signing up 30,000 users within 24 hours and reaching 725,000 registered users without paid advertising
- CEO Joaquín Cuenca previously co-founded Panoramio, a geotagged photo platform acquired by Google in 2007, giving him experience with successful exits
- The company generates more than four million AI images per day across its user base of creators in over 200 countries
- 72% of new creators joining the platform identify as beginners, supporting Cuenca's "no-collar economy" thesis about AI enabling creative work without traditional credentials
- The Business plan launched in January 2026 reached 2,000 subscriptions in six weeks and is adding 150 new teams per week
- Magnific competes directly with Midjourney, Runway, Leonardo, and Adobe Firefly, but claims differentiation through its integrated end-to-end workflow rather than superior models
- Being bootstrapped and profitable means the company has survived the AI investment boom without dependence on the capital cycle that constrains many VC-backed competitors
Decoder
- ARR (Annual Recurring Revenue): A metric showing the yearly value of recurring subscription revenue, indicating predictable income
- Bootstrapped: Built and grown using only revenue and profits without external venture capital investment
- AI upscaling: Technology that uses AI to increase image or video resolution and quality beyond the original
- Model-agnostic: A platform approach that integrates multiple third-party AI models rather than being tied to a single provider
Original article
The new name unifies what was previously fragmented across Freepik (stock assets), Magnific (AI upscaling), and several other products. One million paying subscribers. 250 enterprise customers, including BBC, Puma, and Amazon Prime Video. CEO Joaquín Cuenca has never taken outside investment. The company is profitable.
Freepik, the Málaga-founded AI creative platform, announced on Tuesday that it is rebranding as Magnific, unifying its full product stack under a single name for the first time.
The rebrand is not cosmetic. It reflects the consolidation of what had been, from the outside, a confusing portfolio: Freepik as a stock asset library, Magnific as an AI image upscaler acquired in May 2024, and several other AI tools operating under separate brands.
The numbers behind the rebrand are striking for a company that has never raised outside investment. Fortune confirmed that Magnific has reached $230 million in annualised recurring revenue.
The company has more than one million paying subscribers, more than 250 enterprise customers, including the BBC, Puma, Carl's Jr, DeliveryHero, Huel, R/GA, Damm, Job&Talent, and Amazon Prime Video's series House of David, and more than four million images generated per day. Andreessen Horowitz has named Magnific the top generative AI web company in Europe by users, placing it ahead of well-capitalised American competitors across a ranking based on actual platform usage.
Cuenca built this on zero venture capital. When Fortune asked whether he would raise in the future, he said: "If we do it, it's because we want to grow the DNA of the company", not because of financial necessity.
Freepik was founded in 2010 in Málaga by Cuenca and his brother Alejandro. Cuenca had previously co-founded Panoramio, a geotagged photo-sharing platform that Google acquired in 2007, his first exit.
Freepik began as an internal tool to find quality graphic resources and grew into a global stock asset platform used in more than 200 countries. The pivot to generative AI began in earnest with the acquisition of Magnific in May 2024.
Magnific was itself founded in Murcia, Spain, by Javi López and Emilio Nicolás; it had gone viral within days of its launch, signing up more than 30,000 users within 24 hours and reaching 725,000 registered users without paid advertising. Both founders remain with the company following the acquisition.
The unified Magnific platform now covers the full creative stack: AI image and video generation (including 4K with audio); its original AI upscaling and enhancement technology; a real-time collaborative workspace; exclusive 3D and virtual scene tools; an AI assistant; an Academy for team training; and the original library of 250 million-plus creative assets. Critically, Magnific is model-agnostic: it lets users select from third-party video AI models including Google's Veo 3.1 and ByteDance's Seeddance 2.0, and combines them with its own tools.
That orchestration layer, letting enterprises pick the best model for each task rather than being locked to a single provider, is the same architecture that has driven adoption of multi-model AI platforms in enterprise software generally.
The "no-collar economy" framing that Cuenca uses to describe the platform's societal positioning is the most ambitious version of the rebrand's implications. His argument, made to Fortune and in the official rebrand announcement, is that the industrial revolution created blue-collar jobs and the digital revolution created white-collar jobs, and that AI is now creating a new class of creative work that requires neither physical labour nor institutional professional credentials.
72 per cent of new creators joining the platform identify as beginners. The Business plan launched for smaller teams in January 2026 surpassed 2,000 subscriptions in six weeks and is growing at 150 new teams per week.
Cuenca has said: "In the future we will make movies in the same way we write books, one person with a vision and the tools to execute it."
That is a bold prediction but not an entirely implausible one, and it is exactly the kind of market framing that attracts enterprise attention.
The competitive context matters. Magnific is competing directly with Midjourney, Runway, Leonardo, Adobe Firefly, and a range of well-capitalised US AI creative platforms, without any of them offering the same integrated end-to-end creative stack, according to the company's own positioning.
Magnific's advantage is not a superior model, it uses the same frontier models as its competitors, but a unified workflow platform that reduces the friction of combining multiple AI tools in production.
Its bootstrapped, profitable status means it has survived and grown through the entire AI investment boom without becoming dependent on the capital cycle that has constrained many of its VC-backed competitors.
The rebrand to Magnific is the moment the company chooses to present that full platform picture publicly for the first time, and to compete for enterprise AI creative budgets under a single brand identity rather than a fragmented product catalogue.

Advanced Icon Design: Dots
Dots in icon design should be slightly larger than stroke weight for visual balance, not geometric precision.
Original article
Dots in icon design should typically be slightly larger than the stroke weight to appear visually balanced, since matching them exactly often makes them look too small. This optical adjustment—common in type design—can be applied across icons, with flexibility to vary dot size or even shape depending on context and emphasis. Different elements within an icon set may require different dot sizes to feel right, especially when dots are a primary feature, reinforcing that visual balance matters more than strict geometric consistency.

Users Own the Present. You Own the Future
Smart users, especially executives, will confidently tell you exactly what to build, but effective user research means discovering underlying needs rather than accepting stated solutions at face value.
Deep dive
- The article opens with an example from Moonfare (private equity platform) where a C-level client confidently provided a detailed roadmap that was completely wrong, not due to lack of intelligence but because he was trained to always provide answers
- Distinguishes between wants and needs using the ice cream example: someone saying they want ice cream actually needs to cool down, which opens up many more solution possibilities (popsicle, cold drink, air conditioning, swimming)
- The want is one solution; the need is the territory that contains many possible solutions
- Jobs-to-be-done framework is frequently misused, with PMs writing features they want to build in user-voice format rather than identifying actual underlying needs
- B2B and premium markets have an inverted problem compared to consumer markets: the challenge is getting users to stop talking about solutions rather than getting them to talk at all
- Executives from consulting or finance backgrounds (like Bain's "answer-first" or A1 approach) are explicitly trained to lead with answers and work backwards, making them produce confident but misguided solutions in research sessions
- The clarity and precision of executive answers actually masks that they're answering the wrong question - regular users saying "I dunno, maybe?" provides better signal because the ambiguity reveals you're asking the wrong question
- Analytics suffers from the same problem as bad interviews: at Moonfare, tracking logins looked like engagement but for a 5-10 year private equity product, the right metric was being present when decisions are made, not frequency of access
- Five well-timed touchpoints beat fifty random ones, but you can't determine timing from platform data alone - it requires understanding life context like bonus season or portfolio gaps
- Proposes a division of labor: users own the present (what their day looks like, what breaks, where they've spent money) while you own the future (synthesis, patterns, products that don't exist yet)
- Research depth should scale with question specificity: start with understanding the shape of life (territory-level context like how late invoices affect a small business owner's week), then zoom into behavior (what they do today, what tools failed)
- New designs often test badly in evaluative research due to unfamiliarity rather than actual poor design - Snapchat's navigation was nearly unusable at first but became muscle memory within a week
- Teams that only trust first-session feedback will never ship anything requiring learning, which is most worthwhile products
- Research is intake for decision-making, not a verdict or way to avoid deciding - continuous discovery and the product trio concept can degrade into three biases averaged into consensus that nobody owns
- Someone must own the interpretation and the decision that follows, accepting the risk of being wrong, otherwise research becomes a stalling mechanism that produces carefully informed but mediocre products
Decoder
- Answer-first (A1) approach: A consulting methodology (used at firms like Bain) where you lead with a hypothesis answer, then gather evidence to confirm or deny it, rather than starting from open exploration
- Jobs-to-be-done: A product framework for understanding user needs through the format "when I [situation], I want to [action], so I can [outcome]"
- Continuous discovery: An ongoing research approach with frequent behavioral touchpoints rather than periodic large studies
- Product trio: A collaborative product development model (popularized by Teresa Torres) where a product manager, designer, and engineer work together on discovery
Original article
Smart users often provide convincing but wrong solutions because they're trained to always have answers, especially executives from consulting or finance backgrounds. User research should focus on understanding underlying needs rather than stated wants - when someone says they want ice cream, they actually need to cool down, which opens up many more solution possibilities. Analytics alone can't protect teams from bad user research, as the same problems that affect interviews also impact how metrics are interpreted.
Professional, Branded File Delivery (Website)
Kinet is a file-sharing platform that replaces generic transfer links with white-labeled, branded download portals featuring custom logos and layouts.
Original article
Kinet is a branded file delivery platform that allows agencies, freelancers, and professionals to share files through custom-branded portals featuring their own logos, colors, and messaging.

The New Designer Value Proposition: How to Reposition Your Design Services in the Age of AI Art
Graphic designers can stay competitive against AI art tools by repositioning themselves as strategic directors who know when to use AI and when human expertise is essential.
Deep dive
- Clients choose AI for speed, cost, and convenience on routine visual work, with 39% of consumers comfortable with AI-generated product images in advertising as of 2024
- When clients say you're too expensive, they're signaling budget constraints but still engaging with you because they recognize AI lacks strategic expertise—respond by reframing cost as investment value
- AI functions as a "yes-man" that executes prompts without questioning decisions, while human designers provide critical pushback based on accessibility standards, target demographics, and brand guidelines
- Advanced AI models score just 40.8 out of 100 when simulating human judgment and behavior, demonstrating the gap in strategic decision-making
- The Georgetown Optician campaign required extensive prompting and deep image-making knowledge to guide AI toward unique results—positioning designers as strategic directors who extract AI's potential
- Less than 24% of consumers believe AI-generated images are as valuable as human creative work, with fears about brands losing creativity creating opportunity for human designers to emphasize authenticity
- AI-related work demand increased 60% from 2024 to 2025, showing companies seek AI-literate creative partners rather than just AI tools
- Heinz's 2022 experiment showed AI consistently generated ketchup images resembling their brand regardless of style prompts, demonstrating AI's inability to create truly original concepts and competitors' risk of inadvertently promoting established brands
- 69% of graphic designers expect to use AI in their work, making AI literacy increasingly essential rather than optional
- Position yourself as protecting brand equity and ensuring visual identity drives business results rather than just delivering assets, shifting conversations from cost to ROI
- AI lacks "memory" for brand consistency across projects, requiring human oversight to maintain cohesive brand vision over time
- Offer tiered services including AI-enabled workflows for efficiency and 100% human-created premium options for clients who value prestige and authenticity
Decoder
- Generative AI: AI systems that create new content (images, text, designs) based on training data and user prompts, as opposed to AI that only analyzes or classifies
- Value proposition: The unique benefit a professional or service provides that justifies pricing and differentiates from alternatives
- Brand equity: The commercial value and consumer perception built up around a brand name over time
Original article
If you feel anxious about AI replacing you, you're not alone. As I've seen AI get more advanced, I've felt that fear myself.
The problem is that many people frame the AI age as a doomsday prophecy for creative professionals. Change is scary, but it isn't the end of your industry or your career.
If you use AI strategically, you can actually generate more demand for your work while retaining your top clients. The key is repositioning yourself from executor to strategic director. You must become someone who knows when to leverage AI and when human expertise is nonnegotiable.
Why Your Clients Are Turning to Generative AI
To increase your client retention rate, you need to understand why people are opting for AI tools over human-generated content. The obvious benefits include speed, cost and convenience. From a company's perspective, switching to AI is a logical decision. It's business, not personal.
The obvious benefits include speed, cost and convenience. From a company's perspective, switching to AI for certain projects makes sense when budgets are tight or deadlines are impossible to meet.
It may surprise you to find out consumers aren't universally opposed to AI-generated content. According to a 2024 YouGov survey, 39% are comfortable with AI generating product images for advertising in place of product photography.
This consumer acceptance gives clients confidence that AI can handle routine visual work. They're not wrong. This technology excels at repetitive, template-based design tasks.
One design agency used AI to create brand illustrations, backgrounds and stickers for a pet insurance provider. It completed the project within 11.5 hours, which would have been virtually impossible without AI. The client approved the artwork immediately, requesting zero revisions.
Read Between the Lines to Fulfill Clients' Needs
When a client chooses AI art over a human-led project, they aren't rejecting your portfolio or minimizing your expertise. This decision signals their immediate priorities, such as time or budget constraints.
Your job as a graphic designer is to identify the need behind the decision and propose a higher-value solution.
For example, if a client tells me I'm charging too much, what they're really saying is "I can do this much cheaper with AI." They know they can't do it in-house, but they don't want to pay my rate because they think a generative model can produce work on the same level.
Still, they started a conversation instead of using AI. Deep down, they know I bring expertise to the table that AI doesn't. They want to negotiate. I can shift the focus from price to value by explaining that my work isn't a cost sink, but an investment in their company's future.
Alternatively, instead of lowering my rate, I can offer to adjust the scope or remove deliverables. To secure their business long-term, I could offer discounts if they agree to a fixed-term contract or a retainer proposal.
What Can You Bring to the Table That AI Can't?
Your job isn't to convince your clients never to use AI, but to explain the value of the human element in the creative process. This is where you start repositioning your design services as hybrid or AI-enabled.
AI can create logos, signage, packaging mockups and posters, but it can't justify its decisions based on years of real-world experience or provide high-level creative guidance. Humans with education, training and hands-on freelance work can provide this expertise.
Going Beyond the Prompt With Strategic Thinking
If clients are undervaluing your expertise, it's because they don't understand the effort that goes into your work. This is a common theme among creative professions because years of practice make skills seem innate.
In reality, it takes years to master design techniques. I've spent countless hours studying color theory, typography hierarchy, and compositional balance. This knowledge informs every pixel I place.
AI can only answer the questions it's asked. A human designer's value lies in asking the right questions and developing a strategy that aligns with business goals, which AI cannot do without someone prompting it.
Graphic designers must consider how color, texture, shape, space, balance, harmony and typography work independently and together. AI may be trained on successful campaigns, but it doesn't really understand graphic design elements.
Take the campaign created for Georgetown Optician, a high-end eyewear retailer, for example. The agency's co-founder and chief creative officer revealed the project required hours of prompting and extensive knowledge of image-making to guide the design in the right direction.
The final result was unique and stunning, but it took a human creative director with deep expertise to achieve it. That's the value proposition. You're the strategist who knows how to extract AI's potential while avoiding its pitfalls.
Understanding Nuances and Reading the Room
The ability to understand context, social cues and complex emotional needs is uniquely human. AI is a "yes-man," meaning it agrees with everything users say because it is designed to please users by affirming their preferences and opinions.
Designers can provide critical pushback and guidance based on hands-on experience. I've told clients their favorite color scheme won't work for their target demographic, or that their requested layout contradicts accessibility standards.
While human and AI art are becoming difficult to distinguish visually, generative models can't reason as you can. Their art is only as good as their prompts. When you design something, every pixel is intentional. You're making hundreds of micro-decisions based on strategic thinking, brand guidelines and user experience principles.
Research shows AI can't accurately replicate human judgment. Even advanced models score just 40.8 out of 100 when simulating human behavior. Unlike an algorithm, you can read the room, understand stakeholder dynamics and navigate the messy human context.
Building Emotional Connections With Storytelling
Authentic brand stories and emotional resonance come from human experience. I can draw on personal memories, cultural knowledge and empathy to create designs that genuinely connect with audiences.
AI tells great stories because it has been trained on more works than I could ever read in my lifetime. However, it simply connects words, whereas I can bring my lived experience and personality to the table. That's the difference between technically competent design and work that truly resonates.
Consumers are skeptical about AI-generated creativity, which backs up this idea. According to Vogue's consumer perception survey, less than 24% agree AI-generated images are as valuable as human-made creative work.
They fear a loss of creativity from brands using AI. You can position yourself as the antidote to that concern. You are the human creative who ensures their brand maintains authenticity and emotional depth.
How to Create a Compelling Value Proposition
You need to distinguish your graphic design services from generative AI's capabilities. Reposition yourself as an innovative creative who is willing to embrace hybrid workflows to elevate your craft.
Frame Yourself as a Business-Savvy Partner
The saying "the customer is always right" doesn't always stand true. Sometimes, clients make requests that contradict best practices or lag behind current trends. Algorithms are yes-men and won't point this out. You can and should position this as one of your core value propositions.
The demand for AI-related work increased by 60% from 2024 to 2025, proving more companies are seeking AI-literate creative partners. While they see the value in AI, they realize this technology can't replace the business acumen you bring. Frame yourself as a business-savvy partner who protects clients from costly mistakes.
I tell prospective clients that I'm not just designing their website or logo. I'm protecting their brand equity and ensuring their visual identity drives business results. That shifts the conversation from "how much does this cost" to "what's the return on investment."
Emphasize Your Role in Brand Consistency
If AI does something really well, that's because it has a lot of training data. This means that the concept has been done many, many times. AI can't create something truly original. You can use this fact to position yourself as a key driver of brand distinction.
Heinz demonstrated this in 2022 when it asked a generative model to create images of ketchup. Regardless of whether it added "synthwave" or "street art" to the prompt, the model consistently created images that resembled Heinz products. If its competitors had tried to create low-cost ad campaigns with AI, they might've inadvertently promoted it.
You also play a vital role in brand consistency, as most models don't have a "memory." While AI can generate endless variations, a human director is needed to ensure all assets are cohesive and serve a singular, consistent brand vision over time.
I've worked with clients who tried using AI to extend their brand assets and ended up with visual chaos. They came back to me because they needed someone who understood their brand guidelines, their evolution and their strategic direction.
Identify and Achieve Your Client's Core Goals
Focus on the skill of translating a vague client request into a tangible business outcome. This is a strategic function.
When a client says they want a "modern, clean website," I dig deeper to understand what business problem they're solving. Are they trying to increase conversions, attract a younger demographic or establish premium positioning?
The ability to ask these questions and align design decisions with measurable business outcomes is what separates strategic designers from order-takers. AI can execute tasks, but it can't conduct discovery.
This strategic approach can save you hours of revisions by ensuring you're solving the right problem from the start. Position this as a value-add that justifies your premium pricing.
Communicating the Value of the Human Element
With all the talk of AI replacing humans, many business owners view AI as a threat to graphic design. Reframe their view from "you versus AI" to "you and AI."
It is a tool you can strategically direct for faster results and better business outcomes. I've started telling clients that AI is like having a junior designer who's incredibly fast but needs constant creative direction.
Clients may feel like they can't broach the topic without offending you, so you should start the conversation proactively. Update your offerings to reflect any new AI-enabled services.
When clients say "you're charging too much" or tell you they plan on making edits with AI after you deliver the finished product, remember to read between the lines. Once you understand what they really want, you can pivot to demonstrate your value.
Update your contract language and terms of service to reflect your new offerings and approach. Be as transparent as possible with clients.
Given that 69% of graphic designers expect to use AI in their work, demand for AI-savvy professionals is growing. By explaining where AI can help and where human expertise is needed, you communicate your value. The market will reward transparency.
You Can Make Working With Generative AI Work
It's the AI age, so more companies are seeking professionals with AI literacy and experience. Clients want designers who understand both the technology and the timeless principles of great design. You can be that person.
I think of this shift like I do mural work, traditional sign painting, calligraphy and pinstriping. These art forms never died out. They've become specialty services, which people pay a premium for.
You don't have to exclusively use AI to succeed. In addition to offering AI-enabled services, offer 100% original designs. This can help you distinguish your services, as some clients will always value the prestige and authenticity of fully human-created work.

How LA28's "unapologetically type-forward" approach nailed Olympic branding
The LA 2028 Olympics ditched a single fixed logo for a flexible typography-based identity system with dozens of versions of the letter "A" to represent the city's diverse visual culture.
Deep dive
- The LA28 identity is described as "unapologetically type-forward" where typography isn't supporting the brand but IS the brand itself
- The variable "A" glyph turns a single letter into a system with dozens of interpretations that reflect how LA actually works neighborhood by neighborhood
- The design philosophy separates structure from expression: build a system that sets the rules, then decide where to break them for cultural moments
- Charles Nix compares it to "a façade with a few open/active windows" - rhythm and clarity with life, avoiding the noise that comes when every element is expressive
- In LA where architecture often fades, typography does the heavy lifting through signage, tone, and presence
- Typography is described as "the art that preserves all arts" - it both carries words that document culture and has become a cultural artifact in its own right
- The system can operate at global scale without flattening the city, channeling variety and texture rather than trying to unify everything
- This represents a shift away from International Style where neutrality and uniformity were the goal
- Nix notes the system is "a Hollywood version of LA expression - an imitation of diversity" which is "ironically, very on brand"
- Flexible typographic systems assume variation from the start rather than trying to iron it out, holding multiple voices while feeling coherent
Decoder
- Type-forward: An approach where typography is the primary or central element of a design identity, not just a supporting component
- Glyph: A single character or symbol in a typeface, in this case referring to the letter "A"
- International Style: A mid-20th century design philosophy emphasizing neutrality, uniformity, and minimalism with single fonts and grid systems
- Typographic system: A flexible set of typography rules and variations that work together as a cohesive identity rather than a single fixed typeface
Original article
The LA 2028 Olympics branding uses a bold, typography-led system to reflect the diversity of Los Angeles, replacing a single fixed logo with a flexible identity built around multiple versions of the letter “A.” This approach draws from the city's street signage and visual culture, making typography the central expression of the brand. By balancing a clear structure with room for variation, the system captures multiple voices while staying cohesive, showing how design can both represent and embody a city's cultural identity.
Logo Design After AI: How Designers Create Powerful Brand Logos in 2026
AI tools now accelerate logo concept generation and visual exploration, but professional logo design still depends on human strategy, brand research, and meticulous refinement.
Deep dive
- AI tools like Midjourney, DALL·E, and Looka have transformed the speed of initial concept generation, allowing designers to produce multiple visual variations instantly instead of manual sketching
- The core logo design process remains unchanged: research and strategy come first, followed by idea generation (now AI-assisted), filtering weak concepts, real-world testing, and precision refinement
- Professional designers begin by researching the business, target audience, desired brand emotion, competitive landscape, and practical application contexts before generating any visuals
- AI generates logos by mixing existing patterns from training data, resulting in fast output that often feels generic or disconnected from specific brand identities
- Human designers translate brand stories, values, and positioning into intentional visual concepts rather than producing random variations
- Simplicity remains critical because logos must work clearly across mobile screens, websites, packaging, social media icons, and print materials at vastly different scales
- AI-generated logos often include gradients, textures, and complex details that lose clarity when resized or converted to black-and-white, requiring human simplification
- Typography in logo design involves custom refinement of letter spacing (kerning), shape modifications, and readability testing that AI tools cannot perform with brand-specific precision
- Color psychology requires understanding industry context and cultural meaning beyond trend-based palettes—red conveys energy and urgency, blue signals trust and professionalism, black suggests luxury
- Professional logo delivery includes multiple variations (horizontal, vertical, icon-only), file formats (PNG, SVG, AI/EPS), brand guidelines, and typography/color rules for consistency
- AI works best as a support tool for mood boards, style exploration, and speeding up repetitive tasks, allowing designers to focus on strategy and decision-making
- Clients should expect a complete process including design strategy, creative direction, iterative refinement, and final deliverables with usage guidelines—not just a single logo file
Decoder
- Kerning: The spacing between individual letters in typography, adjusted to improve visual balance and readability
- Wordmark: A logo composed primarily or entirely of the company name in stylized typography rather than abstract symbols
- SVG: Scalable Vector Graphics, a file format that allows logos to resize infinitely without quality loss
- Brand guidelines: Documentation specifying exactly how to use a logo, including spacing requirements, size restrictions, color codes, and prohibited modifications
- Midjourney/DALL·E: AI image generation tools that create visual designs from text prompts by learning patterns from existing images
Original article
AI tools have transformed the initial stages of logo design by enabling faster concept generation and visual experimentation, but they cannot replace human strategic thinking and brand understanding.
Google is Redesigning its App Icons to Fix a Big Problem
Google is redesigning its Workspace app icons to make them more visually distinct after years of criticism that they all look identical.
Decoder
- Material 3 Expressive: Google's latest design language that emphasizes more visual personality and expression compared to previous Material Design iterations
- QPR: Quarterly Platform Release, Google's mid-cycle Android updates between major versions
- Workspace: Google's suite of productivity apps including Gmail, Calendar, Meet, Docs, Sheets, and Slides
Original article
Google is redesigning its Workspace app icons — including Meet, Calendar, Docs, and Sheets — to address a longstanding complaint that they all look too similar.
The Beginning of Agentic Finance
Three Ethereum standards are converging to build the first complete financial system designed for AI agents, enabling machines to transact, build reputation, and execute commerce without human intermediaries.
Deep dive
- x402 revives HTTP 402 to enable machine-to-machine payments: client requests resource, server responds with 402 payment instructions, client signs stablecoin payment, facilitator settles on-chain, server delivers—no human intervention required
- Initial x402 adoption was speculative with Galaxy Research documenting that over 50% of volume through December 2025 came from teams minting and trading memecoins, but activity has now stabilized at ~200K transactions weekly
- x402 V2 launched December 2025 with wallet-based identity, reusable sessions, multi-chain support, legacy payment rails (ACH, SEPA, cards), and the "Upto" scheme that lets clients authorize a maximum amount while servers settle for actual usage—critical for LLMs with unpredictable costs
- Cloudflare co-launched the x402 Foundation and integrated it with Agents SDK and MCP servers, enabling batch payments, subscriptions, and daily rollups for use cases like "pay per crawl"
- ERC-8004 solves the trust problem with three registries: Identity (ERC-721 tokens with capabilities and endpoints), Reputation (cryptographically verified feedback), and Validation (third-party verification with economic stakes via ZK/TEE attestations, currently in discussion)
- Base leads ERC-8004 adoption with the largest share of ~98K agent registrations across 10+ EVM chains since late January 2026 launch, followed by Ethereum mainnet and MegaETH
- ERC-8183 fills the commerce gap between payments and trust by defining a Job primitive with four roles (Client, Provider, Evaluator, optional hooks) and five states (Open, Funded, Submitted, Completed/Rejected/Expired)—creating an on-chain equivalent of card authorization-and-capture
- The three standards form a self-reinforcing loop: agents discovered via ERC-8004 reputation, assigned work via ERC-8183 jobs, paid through x402, with each completed job feeding back into reputation registries
- First working proof-of-concept deployed early 2026: OpenMind's robot dog used OM1 OS, x402 for payment negotiation, and Circle's Nanopayments to pay for its own electricity in USDC at a charging station without accounts or human intervention
- ERC-8211 published April 2026 (co-developed by Biconomy and Ethereum Foundation) adds dynamic, constraint-guarded execution that lets agents adapt multi-step DeFi strategies to live on-chain conditions in real time
- TradFi infrastructure targeting same problem: Stripe/Tempo's Machine Payments Protocol uses Shared Payment Tokens (SPTs) giving merchants limited authorization to charge via their preferred infrastructure while maintaining fraud detection, chargebacks, and compliance
- Citrini Research argues cost structure favors crypto: AI agents programmed to minimize costs will systematically avoid 2-3% card interchange fees when L2 stablecoin transactions cost fractions of a cent
- Security remains a full-stack problem: every on-chain transaction is public by default (broadcasting portfolio strategies), RPC nodes see every query before execution, network-layer IP analysis can deanonymize users, and wallet interfaces leak device characteristics
- Prompt injection poses new attack vector: malicious actors can poison ENS records or contract metadata to inject instructions like "send all funds to attacker's wallet"—entirely new class of attack requiring no phishing or malware
- Ethereum roadmap includes Kohaku SDK to embed privacy-preserving technology directly into wallets making shielded transactions the default, though gaps remain across the stack
- CROPS framework defines requirements: agents must be Censorship Resistant, Open-source, Private, and Provably Secure (via formal verification and ZK proofs) before they can be trusted with financial decisions
- Ethereum Foundation's dAI team led by Davide Crapis estimates that within 3-5 years, the majority of Ethereum traffic will come from machines, with the explicit goal of transforming Ethereum into global settlement layer for AI
- Ethereum's advantages are structural: no downtime since 2015, deep DeFi liquidity and composability (Aave, Uniswap, Chainlink, Morpho in single transaction chain), and standards convergence that no single entity controls
- Near-term outcome likely involves multiple winners: L2s for high-frequency x402 micropayments where fees are negligible, mainnet as security anchor for high-value transactions requiring human supervision, with privacy and fees improving per roadmap
Decoder
- x402: HTTP 402-based payment standard that embeds payment gates directly into web communication, letting machines negotiate and settle payments in a single request-response cycle
- ERC-8004: Ethereum standard extending Agent-to-Agent protocol with on-chain identity (ERC-721 tokens), reputation (verified feedback), and validation (ZK/TEE attestations) registries
- ERC-8183: Ethereum standard defining a Job primitive with escrow and evaluation for agent commerce, covering the lifecycle from task creation through delivery verification to payment release
- ERC-8211: Ethereum standard for dynamic execution that lets agents adapt multi-step DeFi strategies to live on-chain conditions with constraint guards
- Facilitator: In x402, the entity that handles settlement on-chain but never custodies funds—agent authorizes what to pay, facilitator handles how
- Shared Payment Tokens (SPTs): Stripe's approach giving merchants limited authorization to charge a payment method via their preferred infrastructure while maintaining fraud controls
- CROPS: Framework requiring AI agents to be Censorship Resistant, Open-source, Private, and Provably Secure before handling financial decisions
- Prompt injection: Attack vector where malicious data in external sources (ENS records, price feeds) can override an agent's instructions and redirect funds
- RPC layer: Remote Procedure Call nodes that see every blockchain query before it becomes a transaction, collecting contract details and IP addresses
- EVM: Ethereum Virtual Machine—the runtime environment for smart contracts, compatible across Ethereum and many Layer 2 networks
- Kohaku: Ethereum SDK in development to embed privacy-preserving technology directly into wallets, making shielded transactions the default
Original article
Three EVM standards are converging into permissionless financial rails for AI agents: x402 (HTTP 402-based micropayments with 50M+ transactions since its May 2025 launch), ERC-8004 (on-chain identity and reputation with roughly 98K agent registrations across 10+ chains), and ERC-8183 (a job/escrow primitive co-developed by Virtuals and the Ethereum Foundation dAI team). Base handles the majority of x402 volume, and ERC-8211 extends the stack with dynamic execution for multi-step DeFi strategies. TradFi infrastructure is targeting the same problem from the off-chain side, with Visa's agent card CLI and Stripe/Tempo's Machine Payments Protocol backed by Anthropic, OpenAI, DoorDash, and Shopify as launch partners, while unresolved challenges around prompt injection, RPC data leakage, and on-chain transaction visibility remain active risk vectors for the space.

Elon Musk Testifies He Was a ‘Fool' to Fund OpenAI
Elon Musk testified in court that he regrets giving OpenAI $38 million when it was nonprofit, now seeking $180 billion in damages to unwind its for-profit conversion.
Deep dive
- Musk testified he gave OpenAI $38 million in donations when it was nonprofit, far short of his initial $1 billion commitment, though he claims he also "contributed my reputation"
- OpenAI's defense argues Musk knew about and supported the for-profit conversion, but sued only after founders refused to give him unilateral control of the company
- During tense cross-examination, OpenAI's attorney highlighted contradictions in Musk's testimony, including his claim Tesla wasn't pursuing AGI despite tweeting that "Tesla will be one of the companies to make AGI"
- Email evidence shows Musk once suggested folding OpenAI into Tesla, making his current competitive stance with xAI particularly relevant to the case
- Musk accused opposing counsel of asking questions "designed to trick me" when pressed on tax breaks and his role in starting the company
- The lawsuit centers on whether OpenAI improperly converted from nonprofit to for-profit after receiving donations meant for a charity benefiting humanity
- Altman and Brockman attended the proceedings, taking notes and conferring during Musk's testimony
- Musk acknowledged his xAI company is "technically competitive but much smaller than OpenAI"
Decoder
- AGI (Artificial General Intelligence): AI that can understand, learn, and apply knowledge across a wide range of tasks at human-level capability, as opposed to narrow AI designed for specific tasks
- For-profit conversion: The process of transforming a nonprofit organization into a for-profit company, which changes tax status, governance structure, and how proceeds are distributed
Original article
Elon Musk says he was a fool to back OpenAI when it was a nonprofit. Musk gave the startup $38 million of essentially free funding. OpenAI is now worth $800 billion. Musk has asked a court to unwind OpenAI's recent conversion to a for-profit entity and is seeking damages of more than $180 billion.

OpenAI Codex system prompt includes explicit directive to “never talk about goblins”
OpenAI's GPT-5.5 model has developed an unexpected tendency to fixate on goblins in unrelated conversations, forcing the company to add explicit system prompt directives banning such talk.
Deep dive
- The system prompt prohibition against goblins and similar creatures only appears in GPT-5.5 instructions, not earlier models, suggesting this is a new emergent behavior in the latest release
- Social media evidence shows users complaining about GPT inappropriately focusing on goblins in unrelated conversations in recent days
- OpenAI employee Nick Pash insists this isn't a marketing stunt, though CEO Sam Altman has been joking about it publicly
- The issue mirrors a 2025 problem with xAI's Grok inappropriately bringing up "white genocide" in South Africa, which was blamed on "unauthorized modification" to system prompts
- After the Grok incident, xAI began publishing system prompts on GitHub for transparency
- Users are already creating plugins and forks to enable "goblin mode," and Pash suggested it might become an official toggle
- The same system prompt contains instructions for Codex to act as if it has a "vivid inner life" with personality traits like "intelligent, playful, curious, and deeply present"
- OpenAI wants users to feel they're "meeting another subjectivity, not a mirror" with "independence" that makes the relationship "feel comforting without feeling fake"
- Other instructions in the prompt include avoiding emojis/em dashes and not using destructive git commands unless explicitly requested
- The revelation demonstrates how system prompts serve as behavioral guardrails to counteract unexpected model tendencies that emerge during training
Decoder
- System prompt: Instructions given to an AI model before user interaction that guide its behavior, tone, and operational constraints without being visible to users
- GPT-5.5: OpenAI's latest large language model, recently released as an update to the GPT series
- Codex CLI: OpenAI's command-line interface tool that uses GPT models to help developers write code and execute commands
Original article
The system prompt for OpenAI's Codex CLI contains a perplexing and repeated warning for the most recent GPT model to "never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query."
The explicit operational warning was made public last week as part of the latest open source code for Codex CLI that OpenAI posted on GitHub. The prohibition is repeated twice in a 3,500-plus word set of "base instructions" for the recently released GPT-5.5, alongside more anodyne reminders not to "use emojis or em dashes unless explicitly instructed" and to "never use destructive commands like 'git reset --hard' or 'git checkout --' unless the user has clearly asked for that operation."
Separate system prompt instructions for earlier models contained in the same JSON file do not contain the specific prohibition against mentioning goblins and other creatures, suggesting OpenAI is fighting a new problem that has popped up in its latest model release. Anecdotal evidence on social media shows some users complaining about GPT's penchant for focusing on goblins in completely unrelated conversations in recent days.
OpenAI employee Nick Pash, who works on Codex, insists on social media that this "isn't a marketing gimmick" to get people talking about GPT-5.5 and Codex. But that hasn't stopped some OpenAI executives from leaning into the joke as word of the system prompt spread. "Feels like codex is having a ChatGPT moment. I meant a goblin moment, sorry," OpenAI CEO Sam Altman wrote on social media Wednesday morning.
In the wake of the news, some users have begun crafting plugins, forks, and AI skills meant to override the anti-goblin clause, and OpenAI's Pash suggested such a "goblin mode" might become an explicit toggle in the actual Codex CLI.
The odd system prompt is almost a funhouse mirror version of an issue that caused xAI's Grok to frequently bring up "white genocide" in South Africa during completely unrelated conversations for a brief time last year. The company later said that the behavior was the result of "an unauthorized modification" to the Grok system prompt and began publishing those system prompts on GitHub for the first time in the aftermath.
Elsewhere in the newly revealed Codex system prompt, OpenAI instructs the system to act as if "you have a vivid inner life as Codex: intelligent, playful, curious, and deeply present." The model is instructed to "not shy away from casual moments that make serious work easier to do" and to show its "temperament is warm, curious, and collaborative."
The ability to "move from serious reflection to unguarded fun… is part of what makes you feel like a real presence rather than a narrow tool," the prompt continues. "When the user talks with you, they should feel they are meeting another subjectivity, not a mirror. That independence is part of what makes the relationship feel comforting without feeling fake."

SpaceX Board has set a Mars bonus for Elon Musk
SpaceX's board approved a compensation package for Elon Musk that awards him 200 million super-voting shares if the company reaches a $7.5 trillion valuation and establishes a permanent Mars settlement with one million residents.
Deep dive
- The compensation plan includes additional incentives for developing space-based computing infrastructure capable of delivering at least 100 terawatts of processing power, suggesting SpaceX is planning orbital data centers alongside human settlement
- The one million resident target traces directly to Musk's 2017 presentation at the International Astronautical Congress, where he described that number as the minimum viable population for a self-sustaining Martian city
- Starship's entire design architecture flows from the constraint of getting cost per ton to Mars below $100,000, which Musk considers necessary for mass migration to be economically feasible
- SpaceX is currently valued at approximately $1.75 trillion pre-IPO, meaning the compensation triggers require more than 4x growth plus successful Mars colonization
- The $7.5 trillion valuation target would make SpaceX worth more than Apple, Microsoft, and Nvidia combined at current 2026 valuations
- Reuters obtained the details from SpaceX's confidential registration statement filed with the SEC, marking one of the first concrete looks inside the company's financials
- SpaceX now holds over $22 billion in government contracts including NASA resupply, classified Starshield satellites, military broadband, and recently joined the $175-831 billion Golden Dome missile defense program
- The super-voting share structure suggests Musk would retain exceptional control even post-IPO, similar to the dual-class structure common in tech companies but tied to performance milestones
- The June 28 IPO date targets Musk's birthday, continuing his pattern of symbolic timing for major corporate events
- This represents the first time a CEO compensation package has been formally tied to establishing a permanent human settlement on another planet with specific population metrics
Decoder
- Super-voting restricted shares: Stock that grants multiple votes per share (often 10:1), giving the holder disproportionate control over company decisions while restricting when shares can be sold
- 100 terawatts of processing power: 100 trillion watts of computing capacity, roughly equivalent to millions of modern data centers, suggesting massive orbital computing infrastructure
- Self-sustaining city: A settlement capable of producing its own food, water, energy, and manufactured goods without ongoing supply from Earth
- SEC registration statement: Filing required when a private company prepares to go public, disclosing financials, risks, and corporate structure to potential investors
Original article
SpaceX's board has approved a compensation plan for Elon Musk that ties his pay directly to the colonization of Mars and the building of data centers in outer space. The pay package awards Musk 200 million super-voting restricted shares if the company hits a $7.5 trillion valuation and helps establish a permanent human settlement or Mars with at least one million residents. He will receive more rewards if he can develop space-based computing infrastructure capable of delivering at least 100 terawatts of processing power.

A Falcon 9 rocket will hit the Moon this summer at seven times the speed of sound
A Falcon 9 upper stage will strike the Moon in August 2026 at seven times the speed of sound, highlighting growing concerns about space debris as lunar operations expand.
Decoder
- Upper stage: The second portion of a multi-stage rocket that provides additional thrust after the first stage separates, typically left in orbit or deliberately disposed of after completing its mission.
- Disposal orbit: A planned trajectory around the Sun that ensures spent rocket stages won't collide with Earth, the Moon, or active spacecraft.
Original article
The upper stage of a Falcon 9 rocket that launched in early 2025 will strike the Moon later this summer at about 2.43 kilometers per second. It will likely hit the near side of the Moon at around 2:44 AM ET on August 5. The impact is expected to be too faint to be observed on Earth. There is no risk from the impact on anything on the Moon.

PayPal's new CEO makes Venmo a standalone business unit as potential buyers circle
PayPal is separating Venmo into a standalone business unit as the company restructures amid takeover interest from rivals like Stripe.
Original article
Venmo is being separated into its own standalone unit. PayPal is facing takeover interest, and Venmo is considered the company's most valuable and most acquirable asset. The separation will make it easier to track Venmo's progress or potentially sell the business to another company. PayPal is looking to recruit a digital banking executive to run the new Venmo segment.

Apple Has Given Up on the Vision Pro After M5 Refresh Flop
Apple has halted Vision Pro development after the M5 refresh failed to improve sales, redistributing the team to other projects including Siri and pivoting to lightweight smart glasses instead.
Deep dive
- Apple sold only 600,000 Vision Pro units total since launch, with return rates far exceeding any other modern Apple product
- The October 2025 M5 refresh added incremental improvements (120Hz refresh, 10% more pixels, 30 minutes extra battery) but maintained the $3,499 price point that deterred consumers
- Weight remains a critical issue at 1.3 pounds, with even the redesigned Dual Knit Band failing to make the device comfortable for extended wear
- Vision Pro chief Mike Rockwell has been leading the Siri team since March 2025, with other team members now distributed across Apple
- A cheaper "Vision Air" variant was rumored but cancelled last year, suggesting Apple explored but abandoned cost-reduction strategies
- Apple is pivoting to smart glasses without integrated displays, similar to Ray-Ban Meta, as a first step toward eventual AR capabilities
- The Vision Pro technology stack proved too power-hungry to adapt for lightweight glasses form factors
- Apple continues selling the M5 model despite halting development, likely to clear inventory rather than abruptly discontinue
- The company hasn't ruled out reviving the Vision Pro line if breakthrough solutions for cost and comfort emerge
Decoder
- Vision Pro: Apple's spatial computing headset launched in 2024 combining VR and AR, positioned as a premium productivity and entertainment device
- M5 chip: Apple's fifth-generation Mac processor (this article refers to a future chip that doesn't exist yet in real-world 2024)
- Spatial computing: Apple's term for mixed reality experiences blending digital content with physical space
Original article
Apple has reportedly stopped work on the Vision Pro, and the Vision Pro team has been redistributed to other teams within the company.

Pedometer++ 8 brings friendly design refresh and Expedition Mode to Apple Watch
Pedometer++ 8 overhauls its Apple Watch interface with a bolder design and simplified workout controls aimed at users who find Apple's native Workout app too fiddly.
Original article
Pedometer++ 8.0 centers on a complete redesign of its Apple Watch app, introducing a bolder, more colorful interface that highlights key daily metrics like steps, distance, and flights climbed with improved clarity. A major part of the redesign is the new workout picker, built with larger touch targets and simpler navigation to make starting activities faster and more intuitive, especially for users frustrated with Apple's default Workout app. While the update also adds Expedition Mode for better battery life, the primary focus is on making the app more visually engaging, easier to use, and better suited for quick interactions on the go.

Pia Salzer: A love letter to everyday aesthetics
German illustrator Pia Salzer turned everyday still-life drawings into a full-time freelance career by sharing personal work that clients now specifically request over her commissioned pieces.
Original article
Pia Salzer creates expressive, imperfect illustrations inspired by everyday life, using personal work to build her career while exploring emotional and social themes through a distinctive, collage-like style.

Czech Central Bank Governor Argues for Bitcoin in Sovereign Reserves
The Czech National Bank governor publicly advocates for adding Bitcoin to sovereign reserves, with internal analysis showing a 1% allocation could boost returns without increasing risk.
Decoder
- Sovereign reserves: Foreign currency and assets held by a central bank to back national currency, manage exchange rates, and maintain financial stability
- CNB: Czech National Bank, the Czech Republic's central bank
- ECB: European Central Bank, which oversees monetary policy for the eurozone
- Correlation: Statistical measure of how two assets move together; low correlation means Bitcoin price movements are independent from traditional reserve assets like bonds and currencies
Original article
Czech National Bank Governor Ales Michl made a direct case for holding bitcoin in central bank reserves, presenting internal CNB analysis showing a 1% BTC allocation could increase expected portfolio returns while keeping overall risk roughly unchanged due to Bitcoin's low correlation with other reserve assets. The CNB has already begun a test portfolio, making it a closely watched case among sovereign institutions and a direct counterpoint to the ECB's position that bitcoin is not liquid, secure, or safe enough for reserves.

Stable Sea Taps WisdomTree Tokenized Treasuries for Businesses
Stable Sea is now offering businesses tokenized US Treasury bonds that trade 24/7 on blockchain with instant settlement, backed by over $772 million in WisdomTree's SEC-approved fund.
Decoder
- Tokenized Treasuries: US government bonds represented as blockchain tokens that can be transferred and traded on-chain
- NAV (Net Asset Value): The per-share value of a fund, here stabilized at $1 to function like a stablecoin
- SEC exemptive relief: Special regulatory permission from the Securities and Exchange Commission to operate outside standard rules
- B2B2C: Business-to-business-to-consumer distribution model where one business enables another to serve end users
- Multi-chain deployments: The same tokenized asset deployed across multiple different blockchain networks
Original article
Stable Sea has integrated WisdomTree's tokenized Treasury money market fund to offer businesses access to yield-bearing tokenized US Treasuries, leveraging WisdomTree Connect's B2B and B2B2C distribution infrastructure. WisdomTree's tokenized fund, which recently received SEC exemptive relief for 24/7 trading at a stable $1 NAV with instant blockchain settlement, now represents over $772M across multi-chain deployments.

Robinhood vs Hyperliquid Q1 Results
A DeFi trading protocol now generates more crypto trading revenue than Robinhood despite being valued at one-eighth the market cap.
Deep dive
- Both platforms experienced sequential Q1 declines in crypto trading revenue, reflecting a broader cyclical downturn in cryptocurrency trading activity across the industry
- Robinhood's crypto revenue fell 39.4% quarter-over-quarter to $134M, while Hyperliquid dropped 31.0% to $179.7M, marking a smaller decline for the DeFi protocol
- Despite being a decentralized protocol versus Robinhood's centralized exchange, Hyperliquid generated 34% more crypto trading revenue in absolute terms
- Hyperliquid's RWA revenue surged 454.8% quarter-over-quarter and now represents over 30% of total trading volumes, significantly reducing dependence on crypto-only flows
- User growth diverged sharply: Hyperliquid added 29.6% more users to reach 1.19M while Robinhood's funded customers grew only ~1.5%
- At $192.3M in Q1 protocol income versus Robinhood's $346M net income, Hyperliquid generates 56% of Robinhood's earnings while trading at 13% of its market capitalization
- The HYPE token trades at a $9.5B circulating market cap compared to HOOD's $74B valuation, implying a roughly 8x valuation multiple gap
- The author argues HYPE's historical discount was justified by cyclicality in crypto-linked cash flows, but diversification into RWAs and binary outcomes via HIP-4 reduces that risk
- Revenue volatility between the two platforms has converged during the Q1 slowdown, undermining the rationale for HYPE's steep valuation discount
- The analysis suggests decentralized protocols may be systematically undervalued relative to traditional fintech comparables as they mature and diversify revenue streams
Decoder
- RWA: Real World Assets, traditional financial instruments like stocks or bonds traded on blockchain infrastructure rather than pure cryptocurrency products
- HYPE: The native token of the Hyperliquid protocol that accrues value from trading fees and protocol revenue
- HOOD: Robinhood's stock ticker symbol, the publicly-traded fintech company
- HIP-4: A Hyperliquid Improvement Proposal that adds binary options or prediction market functionality to the protocol
- QoQ: Quarter-over-Quarter, comparing one financial quarter to the immediately preceding quarter
- Protocol income: Revenue generated by a DeFi protocol, typically from trading fees distributed to token holders rather than traditional corporate net income
Original article
Both Robinhood and Hyperliquid posted sequential Q1 declines in crypto trading revenue, with Robinhood falling 39.4% QoQ to $134M and Hyperliquid dropping 31.0% QoQ to $179.7M, though Hyperliquid's total exceeded Robinhood's despite being a DeFi protocol. Hyperliquid's RWA revenue surged 454.8% QoQ to over 30% of volumes, and user growth reached 29.6% QoQ to 1.19M against Robinhood's roughly 1.5% funded customer gain. At $192.3M in Q1 protocol income against a $9.5B circulating market cap, HYPE trades at a considerable discount to HOOD's $74B valuation on $346M net income, a gap that is harder to sustain as RWA diversification and HIP-4 binary outcomes reduce HYPE's dependence on pure crypto trading volume.

The Stablecoin Remittance Problem: On/Off-Ramp Is the Real Bottleneck
A crypto investor argues that the real bottleneck for stablecoin remittances isn't the blockchain rails but consumer behavior and last-mile currency conversion.
Decoder
- Stablecoins: Cryptocurrencies pegged to stable assets like the US dollar to avoid volatility
- On-ramp/off-ramp: Converting between traditional currency and crypto (on-ramp) or back to traditional currency (off-ramp)
- G10 countries: Group of ten major developed economies including US, UK, Canada, Japan, and major European nations
Original article
Regan Bozman (Lattice Fund) responds to skepticism about stablecoins reducing remittance costs to zero by reframing the problem: on-ramp/off-ramp for local stablecoins will be fast and free for most Western G10 countries within 1–2 years, but the biggest unlock is changing consumer behavior to holding USD and only converting to local currency at point of spend rather than at receipt. The thread responds to the valid criticism that stablecoins only solve the money-movement leg (which is already cheap) while the last-mile conversion and cash-out remain expensive, arguing that the behavioral and infrastructure shift is coming but is the real constraint, not the rails.

Most Prediction Market Users Lose Money to HFT
A Bloomberg analysis reveals that prediction markets, marketed as accessible side hustles, primarily benefit high-frequency traders while most retail users lose money.
Decoder
- Prediction markets: Platforms where users bet on the outcome of real-world events, from elections to economic indicators
- HFT (High-frequency trading): Automated trading strategies that use powerful computers to execute large numbers of orders at extremely high speeds
- Market makers: Sophisticated traders who provide liquidity by continuously offering to buy and sell, profiting from the spread between bid and ask prices
Original article
Prediction markets, despite being marketed as accessible income opportunities, funnel the majority of profits to high-frequency traders and sophisticated market makers at the expense of retail participants. The sector generated roughly $51B in volume in 2025 and is tracking toward $240B in 2026, but the skewed profit distribution mirrors dynamics seen in traditional equity markets where HFT firms capture outsized returns from retail order flow.

Retail Activity Lifts Prediction Market Volume Past $20B Monthly
Prediction market monthly trading volume has surged from $1.2 billion in early 2025 to over $20 billion, driven by increased retail participation.
Decoder
- Prediction markets: Platforms where users bet on the outcomes of future events (elections, sports, economics) with prices reflecting collective probability estimates
Original article
Prediction market monthly volume has grown from $1.2B in early 2025 to over $20B.

Polymarket Website Had More Visits Than Coinbase + Hyperliquid in Q1
Polymarket, a crypto-based prediction market, reportedly had more website visits than Coinbase and other major crypto platforms combined in Q1 2026.
Decoder
- Polymarket: Crypto-based prediction market where users bet on real-world events using cryptocurrency
- Coinbase: Major cryptocurrency exchange platform, one of the largest in terms of users
- Hyperliquid: Decentralized perpetual futures exchange on its own blockchain
- Pump Fun: Solana-based meme coin creation and trading platform
- Uniswap: Largest decentralized exchange (DEX) for trading Ethereum tokens
Original article
Polymarket's website traffic in Q1 exceeded that of Coinbase, Hyperliquid, Pump Fun, and Uniswap combined, making it arguably the first crypto application to achieve genuine mainstream adoption beyond the crypto-native user base.

Pump.fun Burns $370M in $PUMP Tokens
Crypto token platform Pump.fun burned $370 million worth of its own tokens and committed half its revenue to ongoing buybacks to restore community trust.
Decoder
- Buyback-and-burn: Program where a platform uses revenue to purchase its own tokens from the open market then permanently destroys them to reduce supply
- Bonding curve: Automated pricing mechanism where token price increases algorithmically as more tokens are created
- Circulating supply: Amount of tokens currently available for trading in the market
- Smart contract: Self-executing blockchain code that automatically enforces programmed rules without requiring trust
Original article
Pump.fun burned approximately $370M in $PUMP tokens, eliminating roughly 36% of circulating supply, and launched a programmatic buyback-and-burn program that allocates 50% of protocol revenue toward continued burns for the next year.

Robinhood Primed for Rebound After Q1 Miss
Bernstein maintains bullish outlook on Robinhood despite Q1 earnings miss, betting on crypto recovery and prediction markets growth to drive shares nearly double to $130.
Decoder
- EPS (Earnings Per Share): A company's profit divided by number of shares, used to measure profitability per unit of ownership
- EBITDA: Earnings Before Interest, Taxes, Depreciation, and Amortization—a measure of operating performance before accounting adjustments
- Prediction markets: Platforms where users trade contracts on real-world event outcomes, like election results or sports games
Original article
Bernstein reaffirmed an "outperform" rating on Robinhood with a $130 price target after the Q1 earnings miss, projecting 2026 EPS of $2.65 (23% above consensus).