Devoured - July 01, 2026
Anthropic has released Claude Sonnet 5, offering near-flagship performance at reduced API pricing to target cost-conscious enterprise developers. Meanwhile, Vercel now allows deployment of any containerized HTTP service, marking a shift toward general-purpose hosting.
fenic (GitHub Repo)
fenic is a new DataFrame engine that treats language models as first-class operators to create repeatable, inspectable data pipelines.
Deep dive
- Semantic Operators: Built-in primitives for extraction, classification, and summarization with Pydantic schema validation.
- Pipeline Lineage: Tracks row-level data origins, enabling developers to trace outputs back to their source.
- Agentic Integration: Provides a native MCP server implementation, allowing AI agents to query pipelines as governed tools.
- Caching & Cost: Built-in response caching and token accounting prevent redundant API costs.
- Composable API: Standard DataFrame syntax (
select,filter,group_by,join) combined with LLM-native operators.
Decoder
- MCP (Model Context Protocol): An open standard that allows AI assistants to connect to data sources and tools consistently.
Original article
fenic: semantic DataFrames for humans and agents
fenic turns AI-assisted exploration of structured and unstructured data into reusable, inspectable DataFrame pipelines.
It's a DataFrame query engine for semantic data processing, with AI operators — extract, classify, summarize, embed, semantic join, and more — built into the query model. Use it to turn documents, transcripts, logs, eval traces, tickets, tables, and APIs into typed rows and repeatable workflows.
The point is a shift in what your data work produces. Humans and agents work on the same pipelines — both can author, inspect, and reuse them. The result isn't a one-off prompt or a brittle regex script that has to be reverse-engineered later — it's a durable artifact: typed, inspectable, rerunnable, and callable.
From exploration to artifact.
pip install fenicWriting fenic with an AI coding agent? Run
fenic skill installso Claude Code / Cursor / Codex write it correctly, andfenic checkto lint it.
What is fenic?
fenic is a semantic DataFrame engine. You write the PySpark/SQL-style operations you already know — select, filter, join, group_by, agg — alongside semantic operators that call language models as a first-class part of the query. You configure models once on a Session, build a pipeline lazily, and fenic compiles and runs it on a query engine built for inference: automatic batching, rate limiting, retries, token/cost accounting, and response caching.
Two ideas make it different from gluing an LLM onto pandas:
- Inference lives inside the query model. Extraction, classification, summarization, and embeddings are operators with schemas and types — not side calls you orchestrate by hand.
- The pipeline is the artifact. Because the work is expressed as typed operators, it's already inspectable (row-level lineage,
explain, per-query metrics), rerunnable (lazy plans + caching), and promotable into a named table, view, or MCP tool an agent can call.
60 seconds: messy text → typed rows
Replace brittle parsing and one-off prompts with a typed, schema-bound operator. Define the shape you want as a Pydantic model; fenic returns structured columns you can query.
import fenic as fc
from pydantic import BaseModel, Field
class Ticket(BaseModel):
product: str = Field(description="The product the user is asking about")
sentiment: str = Field(description="positive, neutral, or negative")
issue: str = Field(description="One-line summary of the user's problem")
session = fc.Session.get_or_create(
fc.SessionConfig(
app_name="quickstart",
semantic=fc.SemanticConfig(
language_models={
"mini": fc.OpenAILanguageModel(model_name="gpt-4o-mini", rpm=500, tpm=200_000)
},
),
)
)
df = session.create_dataframe([
{"id": 1, "text": "The CSV export in Reports keeps timing out since the last update."},
{"id": 2, "text": "Love the new dashboard, but SSO login is broken on mobile."},
])
# Free text -> typed, queryable rows
tickets = (
df.select("id", fc.semantic.extract("text", Ticket).alias("t"))
.unnest("t")
)
tickets.show()Why fenic?
Unstructured data is everywhere, and working with it is brittle. Teams reach for regex, one-off scripts, notebooks, and prompt chains to pull meaning out of documents, logs, tickets, transcripts, and traces. The results are hard to reproduce and hard to inspect.
Agents made exploration easy and introduced a new problem. An agent can dig through messy data and find something useful — but unless that discovery becomes code, data, or a pipeline, it dies as a chat transcript. The next person has to reverse-engineer what happened.
fenic gives semantic data work a DataFrame abstraction. Express the exploration as fenic operators and it's already the artifact.
| Without fenic | With fenic | |
|---|---|---|
| Extraction | regex + one-off prompts, re-derived each time | extract(Schema) → typed columns, validated at plan time |
| Reproducibility | "what did the agent do?" | a lazy plan you can explain() and rerun |
| Inspection | scroll the transcript | row-level lineage(), typed rows, per-query cost/tokens |
| Reuse | copy/paste the script | promote to a table, view, or MCP tool |
| Humans vs. agents | separate, incompatible workflows | one shared pipeline both can read and run |
Featured workflow: from eval exploration to durable eval intelligence
import fenic as fc
from typing import Literal
from pydantic import BaseModel, Field
class FailureMode(BaseModel):
failed: bool = Field(description="Whether the agent failed the task")
category: Literal["tool_error", "instruction_following", "retrieval", "reasoning", "none"] = Field(
description="Primary failure category, or 'none' if the run succeeded"
)
evidence: str = Field(description="Short quote or summary justifying the classification")
session = fc.Session.get_or_create(
fc.SessionConfig(
app_name="eval_triage",
semantic=fc.SemanticConfig(
language_models={
"mini": fc.OpenAILanguageModel(model_name="gpt-4o-mini", rpm=500, tpm=200_000)
},
),
)
)
traces = session.read.docs("eval_runs/**/*.json", content_type="json", recursive=True)
failures = (
traces
.with_column("analysis", fc.semantic.extract(fc.col("content").cast(fc.StringType), FailureMode))
.unnest("analysis")
.filter(fc.col("failed"))
)
failure_modes = failures.group_by("category").agg(
fc.count("*").alias("n"),
fc.semantic.reduce(
"Summarize the common root cause across these failures",
column=fc.col("evidence"),
).alias("pattern"),
)
failure_modes.write.save_as_table("failure_modes", mode="overwrite")Query meaning and metadata together
# Match on meaning, not exact values
matches = candidates.semantic.join(
roles,
predicate=(
"Candidate background: {{ left_on }}\n"
"Role requirements: {{ right_on }}\n"
"The candidate is a strong fit for the role."
),
left_on=fc.col("resume"),
right_on=fc.col("job_description"),
)
# ...then group, aggregate, and rank with ordinary DataFrame ops
ranked = (
matches.group_by("role_id")
.agg(fc.count("*").alias("n_candidates"))
.order_by(fc.desc("n_candidates"))
)Make it an artifact your agents reuse
from fenic import SystemToolConfig
session.catalog.set_table_description(
"failure_modes", "Recurring agent failure modes with counts and root-cause summaries"
)
server = fc.create_mcp_server(
session,
"Eval Intelligence",
system_tools=SystemToolConfig(
table_names=["failure_modes"],
tool_namespace="evals",
max_result_rows=100,
),
)
fc.run_mcp_server_sync(server, transport="http", port=8000)Semantic operators
| Operator | What it does |
|---|---|
extract(col, Schema) |
Unstructured text → a typed struct |
classify(col, classes) |
Label text into predefined classes |
predicate(prompt, **cols) |
Natural-language boolean filter |
reduce(prompt, column) |
Aggregate many rows in a group |
embed(col) |
Embeddings for similarity and search |
Inspect and operate
df.explain()— the logical/physical plandf.lineage()— trace specific rows forwards and backwards- Per-query metrics — tokens and cost
- Caching — an LLM response cache plus
.cache()

Run any Dockerfile on Vercel
Vercel now allows deployment of any containerized HTTP service, treating Dockerfiles as first-class citizens alongside their traditional framework-based workflows.
Decoder
- Fluid compute: Vercel's backend execution environment that scales based on traffic and charges specifically for active CPU usage rather than reserved instance time.
Original article
You have a server in a container. Maybe it's a Go service, a Rails app, a Spring Boot API, or a web server behind nginx. It speaks HTTP. It listens on a port. It just needs somewhere to run.
Add a Dockerfile.vercel file to your project, and Vercel builds, stores, deploys, and autoscales the image on Fluid compute, so you pay only for the CPU your code uses. No daemon to run locally, registry to set up, or cluster to babysit.
How it works
Here is a small HTTP server in Go, listening on $PORT:
package main
import (
"fmt"
"net/http"
"os"
)
func main() {
port := os.Getenv("PORT")
if port == "" {
port = "80"
}
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello from a container on Vercel 👋")
})
http.ListenAndServe(":"+port, nil)
}A minimal HTTP server that reads its port from $PORT and answers every request.
Add a Dockerfile.vercel file that builds it into a small image and runs it:
FROM golang:1.24-alpine AS build
WORKDIR /src
COPY . .
RUN go build -o /server main.go
FROM alpine:3.20
COPY --from=build /server /server
CMD ["/server"]A two-stage build that compiles the binary, then copies it into a minimal Alpine image that runs on boot.
Then deploy:
▲ vercel deploy
Vercel CLI
✓ Building image from Dockerfile.vercel
✓ Stored image in your project's registry
✓ Deployed to Fluid compute
Production: https://my-server.vercel.appOne command builds the image, stores it, and ships it to Fluid compute, then prints the production URL.
That is it. Two files, and you are live. Every git push rebuilds the image and hands you a fresh preview URL. Or run vercel to deploy without committing.
We used Go in this example, but any stack works. Rails, Spring Boot, Express, Laravel, ASP.NET, FastAPI, and a web server behind nginx all deploy the same way. The only rule is that your server listens on $PORT, which defaults to 80. If it speaks HTTP, it deploys. Yes, even Java. And yes, even PHP.
What you get
A container on Vercel is a first-class citizen. It runs on the same platform, and the same compute, as your frontend and the rest of your services on Vercel.
- A preview deployment for every push: Every commit gets its own immutable URL you can open, share, and roll back to.
- Autoscaling, in both directions: Traffic arrives and you scale out. Traffic stops and your instances wind down. You never size a fleet or guess a concurrency number.
- Active CPU pricing: Fluid compute bills for the time your code is actually running, so an idle server, parked on a slow query or an upstream API, isn't burning CPU while it waits. You pay for execution time, not wall time.
- Observability, included: Logs, traces, and metrics for your container live in the same dashboard as everything else you ship.
- One project, one domain: Your container sits beside your frontend and your other services and talks to them privately over the Vercel network. Your full stack ships as one deploy.
Built to start fast
A container is only as good as the time it takes to answer its first request.
When Vercel builds your image, it stores it as an optimized boot image, a compressed snapshot of the container's disk tuned for fast startup.
When a container boots, we stream that snapshot and decompress it on demand, rather than downloading the whole image before anything runs. Your server can start handling requests before the full image is in place, so a larger image does not have to finish downloading first.
Once an instance is running, Fluid compute keeps it warm and serves many requests from it, rather than starting a fresh copy for each one. You get the responsiveness of a warm server and the bill of one that sleeps when idle.
Each container is a stateless process: it takes a request, returns a response, and keeps nothing in between. Persistent state lives in a backing service you attach, like a database or cache from the Vercel Marketplace. Because an instance holds nothing that has to survive, Vercel can add instances when traffic arrives and retire them when it stops. We're also working on shipping durable storage attached to containers soon.
Why now?
Our first platform let you deploy a Dockerfile with a single command. That was a decade ago, and the idea was right, but the infrastructure to make it great didn't exist yet.
We've spent the years since building the primitives to handle it well. They power everything you run on Vercel: Builds, Functions, Sandboxes, and now containers. It all scales with traffic, and you only pay for the CPU you use. A container is now a first-class citizen, running on the same system as everything else.
Framework detection is our front door. When we recognize your framework, we read your code and derive the infrastructure your app needs, because the code already describes what it should do. For most apps it's the fastest way to ship. A Dockerfile is for everything else: a service that needs a system library like FFmpeg or Chromium, a framework we do not auto-detect yet, or an app you want to bring exactly as it already runs. It is the universal way to say how a program should be built, so when there is no framework to read, we meet it directly.
Everything around your Dockerfile is zero configuration. You point at the image, and the build, the registry, the rollout, the scaling, and the URL all just happen.
Backends are back
Your backend now ships the way your frontend does: one push, one preview, one platform. We can't wait to see what you build.

Automate public TLS certificate issuance with ACME support in AWS Certificate Manager
AWS Certificate Manager now supports the ACME protocol, allowing automated public TLS certificate issuance with centralized governance and policy control.
Decoder
- ACME (Automatic Certificate Management Environment): A standardized communications protocol for automating interactions between certificate authorities and web servers.
- EAB (External Account Binding): A mechanism that links a client's ACME account to a specific administrative identity, used here to enforce IAM policies on certificate requests.
Original article
Automate public TLS certificate issuance with ACME support in AWS Certificate Manager
If you manage TLS certificates for your applications, you know the challenge: certificates expire, and when they do, your customers see errors or your service goes down. As certificate validity periods get shorter (the Certification Authority (CA)/Browser Forum mandates reduced maximum validity to 100 days starting March 2027, and to 47 days by 2029), manual renewal processes become untenable. You need automation.
Automatic Certificate Management Environment (ACME) is an open protocol for requesting, renewing, and revoking TLS certificates without human intervention. It’s the same protocol behind Let’s Encrypt, and it’s supported by dozens of clients across every platform.
Today we’re announcing ACME support for public certificates in AWS Certificate Manager (ACM). ACM now provides a fully managed ACME server endpoint that works with any ACMEv2-compatible client, such as Certbot, cert-manager for Kubernetes, acme.sh, or any other client you already use. You can issue public TLS certificates from Amazon Trust Services through the standard ACME protocol.
Before today, if you wanted automated certificate management using the ACME protocol, you relied on external certificate authorities alongside ACM, leading to a fragmented visibility experience. Some certificates lived in ACM, others were managed externally with no central dashboard. PKI administrators had limited ability to control who could request certificates or which domains were allowed.
With ACME support in ACM, you can now set up one or more managed ACME endpoint that allows you to centrally manage and monitor ACME certificate usage across your organization.
As a PKI administrator, you get centralized controls that go beyond basic certificate issuance. You can bind IAM roles to ACME accounts for fine-grained access control over which domains each client can request. You can define domain scopes at the endpoint level to enforce organization-wide policies. And you get centralized monitoring and visibility in the same place: AWS CloudTrail logs every certificate request for auditability, Amazon CloudWatch tracks operational metrics, and ACM sends expiry notifications when certificates are approaching renewal. Using ACM, your PKI team can search all certificates, whether issued through the ACM console, an API call, or ACME.
How it works
To get started, you first set up a dedicated ACME endpoint, configure authorization controls using External Account Binding (EAB), validate which domains the endpoint can issue certificates for, and point your existing ACME clients to the new endpoint.
The domain validation step is important: it separates who can set up certificate issuance from who can request certificates. The PKI administrator validates domains once at the endpoint level, using DNS credentials that stay with the admin. Application owners who need certificates never touch DNS. They register with an EAB credential, and the endpoint enforces which domains and scopes they’re allowed to request. This means you can distribute certificate automation broadly across your organization without distributing DNS keys along with it.
I start this demo from the ACME certificates page in the AWS Certificate Manager console.
I already have a few endpoints and certificates in this account, I walk you through creating a new one from scratch. First, I select Create ACME endpoint.
I give my endpoint a name. The Endpoint type is Public. ACME clients will connect over the public internet. The Certificate type is Public. The certificate will be issued by Amazon Trust Services and trusted by browsers and operating systems by default. For the certificate key type, I keep the default ECDSA P-256. RSA 2048 and ECDSA P-384 are also available if your clients require them.
Scrolling down, I configure the domain. I enter my domain name and select the domain scope. The scope controls exactly what certificate patterns your ACME clients are allowed to request for this domain. If I check only Exact domain, clients can only request certificates for that specific domain name. Adding Subdomains allows certificates for any subdomain (for example, api.example.com or dev.example.com). Adding Wildcards allows wildcard certificates (*.example.com). By leaving a scope unchecked, you prevent any client using this endpoint from requesting that type of certificate, even if their ACME request is otherwise valid. For a production endpoint, you might enable only Exact domain and Subdomains while leaving Wildcards unchecked to enforce a stricter security posture.
I also select my Amazon Route 53 hosted zone from the drop down menu. ACM then automatically creates the DNS CNAME records needed for domain validation, so I don’t have to do it manually. When my domain is hosted outside of Route 53, I manually create the provided CNAME record at my DNS provider instead. This is a meaningful difference from typical ACME setups where each client handles its own domain verification independently.
These centralized controls give PKI administrators a single place to authenticate domains, restrict which certificate types (ECDSA or RSA) clients can request, and further limit wildcard issuance. Having these governance capabilities built in means you don’t need to purchase a separate certificate lifecycle management product or invest in building a custom policy layer yourself, both of which come at significant cost and operational overhead.
I select Create ACME endpoint
After a few seconds, the endpoint is created. The console shows a Setup progress tracker with the next steps. My domain shows a “Validating” status. The validation method is DNS validation, where ACM verifies that you control the domain by checking for a specific CNAME record. Because I selected my Route 53 hosted zone during creation, I select Create records in Route 53 to let ACM handle the DNS validation automatically.
The validation completes in a few seconds and the status changes to Success.
Now I need to create External Account Binding (EAB) credentials. EAB credentials are a key identifier and HMAC key pair that lets your ACME client register an account with the ACME server. Once registered, the client generates its own asymmetric key pair, which is then used to authenticate all subsequent certificate requests. On the endpoint details page, I select the External account binding tab, then select Create EAB. I give the credential a name and optionally set an expiration time, ideally no longer than needed to complete client registration.
After I select Create EAB credential, the console shows the Key ID and HMAC Key. I note these values because I need them to configure my ACME client. The setup progress now shows four green checkmarks.
I’m ready to request a certificate. On the endpoint details page, I expand the CLI reference section. The console provides ready-to-use command examples for both Certbot and acme.sh. I copy the Certbot command and run it inside a container using the certbot/certbot image.
certbot certonly --standalone --non-interactive --agree-tos \
--email <EMAIL> \
--server https://acm-acme-enroll.us-east-1.api.aws/<ENDPOINT_ID>/directory \
--eab-kid <EAB_KID> \
--eab-hmac-key <EAB_HMAC_KEY> \
--issuance-timeout <ISSUANCE_TIMEOUT> \
-d <DOMAIN>I replace the placeholders with my endpoint URL, EAB credentials, and domain name. The --eab-kid and --eab-hmac-key arguments are how Certbot registers with your ACME endpoint using the External Account Binding credentials I generated earlier. Each ACME client has its own syntax for this step, so check your client’s documentation for the exact flags.
Certbot contacts the ACME endpoint and returns a valid certificate signed by Amazon Trust Services.
I use openssl to view the certificate before installing it.
The certificate is now visible in the ACM console under the ACME certificates tab, alongside any certificates issued through the console or API.
Availability and pricing
ACME support in AWS Certificate Manager is available today in all commercial AWS Regions and will be available in AWS GovCloud (US), the China Regions, and the AWS European Sovereign Cloud partitions at a later date.
Pricing is per domain included in each certificate at the time of issuance, with a different price for fully qualified domain names and wildcards. Volume tiers are calculated based on total domain occurrences across all certificates issued per month in your AWS account. For details, see the ACM pricing page.
To get started, visit the ACM section on the AWS console or read the documentation.

Kepler, re-architected: Improved power accuracy and a community call to action!
Kepler dropped its complex eBPF dependency for a lighter /proc-based architecture, resulting in nearly zero-watt attribution gaps for Kubernetes energy tracking.
Deep dive
- Eliminates CAP_BPF/CAP_SYSADMIN requirement by leveraging standard /proc and /sys filesystems.
- Achieves 90% test coverage to improve reliability and trust in energy metrics.
- Dynamically discovers hardware topologies at runtime to accurately map power meter structures.
- Provides new metrics: kepler_node_cpu_watts and container-level joules counters.
Decoder
- eBPF (Extended Berkeley Packet Filter): A kernel technology allowing programs to run inside the Linux kernel; previously used by Kepler for deep observability but often restricted by security policies.
- RAPL (Running Average Power Limit): An Intel technology that provides interfaces for monitoring and managing the power consumption of CPUs and memory.
Original article
Data centers accounted for 1.5% of global electricity demand in 2024, which is projected to double to around 945 TWh by 2030, driven in part by rapid growth in AI workloads according to the International Energy Agency’s “Energy and AI” report published in 2025. In Kubernetes clusters, there is no easy built-in method to allocate power per workload. Kepler solves this: it reads from hardware power meters, attributes this power consumption to Linux processes, associates that to Pods running in your Kubernetes cluster, and exports Prometheus metrics.
Since joining the CNCF as a sandbox project in 2023, Kepler adoption has grown. However, the original architecture relied on eBPF, and while that added granularity, it also created problems. First, it required CAP_BPF and CAP_SYSADMIN privileges, which is a blocker for many production environments. Secondly, eBPF proved to be error-prone when it comes to tracking fine-grained, kernel-level processes at this level of accuracy. Data inaccuracy at this level creates a bottleneck for the power estimation models that we need to train in order to deploy Kepler on virtual machines (VMs). Beyond the elevated privileges and accuracy issues, the eBPF integration made the learning curve steeper. It added complex abstractions that made it difficult to extend and maintain the codebase.
The team decided to tackle these challenges head on. We wanted to make Kepler easier to configure and deploy, less error-prone, and easier for the community to extend the codebase.
The maintainer team made a big but exciting decision: rewrite Kepler. In this post, we walk through what changed, why, and how you can get involved. And for more on this decision, Vimal Kumar walks though the rewrite in this podcast episode.
Re-architecting Kepler
To run Kepler, two elements are required: the utilization signal of the containerised Linux process and power meter access. The Power Attribution documentation guide explains how Kepler measures and attributes power consumption to processes, Pods, and other Kubernetes internals.
Previously, Kepler relied on eBPF to capture utilization signals, which accounted for the majority of user-reported issues. At the same time, it caused missing short-live, terminated processes, leading to inaccurate, under-reported energy footprints.
To prioritize ease of adoption and accuracy improvement, we are shifting away from eBPF and going back to basics. Our re-architected solution leverages read-only access to standard /proc and /sys. Because these are universally available on Linux systems, they require significantly lower privileges and minimal setup. By eliminating the complicated configuration overhead, we’ve made Kepler easier to deploy out-of-the-box via a single configured Helm.
For the power metrics, previously, Kepler assumed a hardcoded power structure (e.g., RAPL is composed of core, DRAM, and other). However, we found that actual hardware topologies vary significantly, meaning the old design was attributing data to a non-existent ground truth. The re-architected Kepler dynamically discovers the host’s power meter structure at runtime. By adapting to the layout of the underlying hardware, Kepler can now report precise energy metrics across diverse environments according to real availability.
Validating Accuracy Improvements
We ran two experiments to validate the accuracy improvements of the Kepler rewrite.
Experiment 1: Comparing pre- and post-rewrite versions
The first test, led by Laura Llinares (CERN), compared versions of Kepler before and after the rewrite. We deployed both Kepler versions simultaneously on the same bare-metal node:
- kepler-old: the previous version, publishing metrics with an old_ prefix.
- kepler-new: the re-architected version, publishing clean metrics without prefix.
- Intelligent Power Management Interface (IPMI): hardware BMC power meter readings.
Then we compared Node-level CPU energy and container-level CPU energy.
Both Kepler versions read the RAPL Package domain (entire CPU socket). The newer Kepler versions expose power both as a watts gauge (kepler_node_cpu_watts) and as joules counters (kepler_node_cpu_joules_total and kepler_container_cpu_joules_total). In the Grafana dashboard panels shown below, PromQL is used to derive watts from the old joules counters using PromQL’s rate() so that all series share the same unit.
- Node-level CPU energy
Both counters increment with energy consumed by the CPU Package RAPL domain at node level.
- Container-level CPU energy
IPMI is the full-node power draw from the BMC. It includes DRAM, fans, NICs, and PSU losses on top of CPU, so Kepler values are expected to be 40-70% of IPMI. Since IPMI measures the whole node and Kepler measures only the CPU, we use IPMI as a load shape reference. IPMI is displayed as a background reference in the overlay panels. When a stress workload ramps up, IPMI and both Kepler versions should all rise together. A Kepler estimator that rises and falls in sync with IPMI is correctly tracking load.
The new Kepler node_cpu_watts metric tracks IPMI patterns closely and eliminates the multi-kW spikes seen with the old node_pkg_joules and full_node_joules counters that exceed the IPMI ground truth values.
Experiment 2: Negligible attribution gap
The second test, led by Vimal Kumar (Red Hat), shows the negligible attribution gap when comparing Node power with power derived through the process attribution model, which validates the accuracy of Kepler’s new design. The system testing uses a progressive stress-ng workload. The resulting Grafana dashboard panels for core and package energy show a Process Power Attribution Gap of essentially 0 Watts.
Furthermore, the detailed delta graphs indicate that the difference between the total node active energy and the energy distributed to individual processes is minimal, fluctuating by only a few milliwatts. This negligible variance demonstrates the architecture’s capability to accurately track and assign power usage at the process level.
Last but not least, we added extensive integration and unit tests to reach 90% testing coverage. This improves the long-term maintainability and trust in results. This is key to validate the accuracy of the power metrics that Kepler exports. The project will continue improving the testing and validation framework to keep improving Kepler’s accuracy.
What’s Next? A Call to Action
The rewrite lays the foundation. Our immediate priorities are improving CPU power attribution on bare metal then extending to VMs. Getting this right is key. It sets the stage for everything that comes next.
Looking ahead, there’s a lot we’re excited about, and plenty of room to help! We’re looking for contributions in three specific areas:
- Try GPU power monitoring: We have an experimental flag for GPU power monitoring, which is crucial now for AI and accelerator-heavy workloads. We need end users running AI/ML workloads to test and validate Kepler’s GPU power monitoring feature.
- Train VM power modeling: We need community members with machine learning experience to (re-)train the model that estimates power in virtualized environments where hardware counters aren’t available. This will bridge the gap between virtualized environments and physical energy signals.
- Validate data accuracy: We need end users to test kepler against physical power measurements, both CPU attribution on bare metal and GPU power monitoring. If you have hardware with IPMI or external power meters, your results will directly shape how we improve the model.
- Improve Idle Power Attribution: After the rewrite, Kepler only attributes active CPU usage per workload. However, this oversimplifies power estimation. While this was added to avoid confusion between idle and dynamic states, it should be added back and expressed better.
To test Kepler, install it with Helm or the Kepler Operator. Explore the metrics with the Grafana dashboards.
If you wish to contribute, browse and work on good first issues, open a new issue, or review open PRs. For features and bigger work streams, we moved to enhancement proposals. This gives the community a clearer way to discuss ideas, review designs, and collaborate on larger changes before going into implementation.
The rewrite gives Kepler a solid foundation. What comes next depends on the community that builds on it. Join us in our twice-monthly community meetings and in our #kepler-project channel on the CNCF Slack to keep the momentum going! 💚

Claude Science, an AI Workbench for Scientists
Anthropic launched Claude Science, a macOS and Linux workbench that integrates specialized scientific tools and compute management into a single, auditable research environment.
Deep dive
- Integrates tools like PubMed, Jupyter, and cluster terminals into one interface.
- Includes a 'reviewer agent' to cross-check citations and mathematical calculations against the evidence database.
- Maintains reproducibility by automatically capturing the exact code and environment state used for every artifact generated.
- Manages remote compute (HPC or cloud) through a persistent session that avoids redundant data loading.
- Supports custom skills and connectors, allowing integration with proprietary lab datasets.
Decoder
- MCP (Model Context Protocol): An open standard for connecting AI assistants to data and tools, allowing models to interact with local databases and software securely.
- HPC (High-Performance Computing): Clusters of powerful computers used to solve complex scientific or engineering problems.
Original article
Claude Science, an AI workbench for scientists, is now available
AI has the potential to dramatically accelerate the pace of scientific discovery and the development of healthcare interventions. Since launching our efforts in the life sciences last fall, we’ve worked to improve our model capabilities, make connections to the scientific ecosystem via MCPs and skills, and launch partnerships in an effort to realize this potential.
Today, we’re introducing our most significant expansion of these efforts: Claude Science, an AI workbench for scientists. Claude Science is an app that integrates the tools and packages that researchers most commonly use, produces auditable artifacts, and provides flexible access to computing resources.
Introducing Claude Science
Scientific research is often tedious. Researchers must work across dozens of databases, each with their own schema, contend with file formats that require bespoke data pipelines and viewers, and transition between a roster of tools: PubMed, Jupyter, R, a cluster terminal, and more.
Claude Science brings these fragmented tools into a single research environment where scientists can conduct all stages of their work. It helps you analyze literature and execute multi-step research, produces detailed artifacts, and lets you iteratively refine figures and manuscripts until they’re ready for publication. Every output carries an auditable history of how it was made, so you can validate and reproduce the results. Like a Jupyter Notebook, you can access Claude Science wherever you already work—locally on macOS or Linux, or on a remote machine over SSH or with an HPC login node.
Users interact with a generalist coordinating agent with access to over 60 curated skills and connectors pre-configured for genomics, single-cell, proteomics, structural biology, cheminformatics, and more. These agents can spin up others and engage with specialist agents created by users. And a reviewer agent checks citations and calculations, flagging and correcting errors.
We are releasing Claude Science today in beta for Claude Pro, Max, Team, and Enterprise users, and will continue to refine the platform as we collect feedback from users.
How it works
Rich scientific artifacts, fully reproducible. Scientific research is inherently visual, so Claude Science generates figures and manuscripts alongside the code that created them. It natively renders rich scientific artifacts, including 3D protein structures, genome browser tracks, chemical structures, and more. You can chat with the agent about any detail, annotating figures and manuscripts in-line so the agent knows what to address to make them publication-ready.
When it generates a figure, Claude Science includes the exact code and environment that produced it, a plain-language description of how it was created, and the full message history. This allows you to understand the inputs, making the work easier to validate and reproduce even months later. You can ask Claude Science to make edits to figures in plain language—removing gridlines, for example, or changing an axis to log scale—and the agent will edit its own code.
Manages your compute and scales on demand. Large analyses—folding a protein, for example, or running a genomics pipeline over a massive dataset—often require researchers to shift their focus to setting up a computing job, waiting while it’s sent to a cluster, checking whether it succeeded or failed, and pulling the results back. Claude Science handles this process for you. It drafts a plan, asks before reaching new resources, and lets you review or revoke any decision before writing and submitting the job to the computing resources your lab already uses (your own HPC cluster over SSH, or your Modal account for compute on demand), scaling the analysis from a single GPU to hundreds as needed.
Because its agents work inside a running session that holds context in memory, even massive datasets only need to be loaded once. It runs on your lab’s own infrastructure—your laptop, Linux box, or HPC login node—so large or sensitive datasets never have to leave the systems they’re already on, and only the context needed for each step of the analysis is sent to Claude. As the pipeline runs, a reviewer agent inspects the outputs, flagging incorrect citations, untraceable numbers, and figures that don’t match their underlying code, and self-correcting as it goes. You can fork the session at any point to compare two approaches without losing the original thread.
Domain-ready on day one. Scientific knowledge is scattered across hundreds of specialized sources. In biology, for example, relevant data might sit across resources such as UniProt, PDB, Ensembl, Reactome, ClinVar, ChEMBL, GEO—each with its own schema and query language—as well as in journals and preprint servers, and domain-specific open models. When you ask Claude Science a question in plain language, specialist agents query and synthesize across all of these sources so you don’t have to navigate them individually. Claude Science uses the skills in NVIDIA’s BioNeMo Agent Toolkit to connect natively to the life sciences models and libraries in BioNeMo, including Evo 2, Boltz-2, and OpenFold3.
Scientists already have models, datasets, and pipelines they trust. Claude Science can connect to these as well, saving any pipeline as a reusable skill or accessing your lab’s preferred tool using a connector, with future sessions inheriting them automatically. This customizability allows you to access Claude, your proprietary data, and the validated tools you already rely on in one conversation. Claude Science benefits from our partners’ specialized expertise and platforms, while more scientists reach their tools through Claude.
What scientists are doing with Claude Science
Over the past few months, researchers have worked with Claude Science in beta for tasks like single-cell RNA sequencing analysis, CRISPR screen design, protein structure prediction, cheminformatics, and more.
Manifold Bio designs tissue-targeting medicines—which home to a specific organ or cell type, so the drug acts where it’s needed and spares the rest of the body—and tests how millions of candidate binders corresponding to hundreds of targets distribute through a living body at once. Manifold used Claude Science to nominate the targets for its latest experiments. For each tissue and target, Claude Science assessed surface expression, trafficking, and safety, ranking candidates against the criteria Manifold has learned from its own internal proprietary data. What set Claude Science apart from a general coding assistant, Manifold said, was that it could do this end-to-end, gathering the right data and applying the right judgment with the context of past programs built in.
Jérôme Lecoq, a neuroscientist at the Allen Institute, used Claude Science to build a multi-agent “computational review template” comprising about 20 custom skills geared towards writing long-form reviews. The sub-agents read through thousands of papers, pulling the central claim and the key quantitative finding, and storing them in an evidence state database. Then the pipeline constructs a narrative arc, writing the review section by section and delegating each to its own specialized sub-agent. Within each section, dedicated agents generate quantitative cross-study figures directly from the evidence database. A key component of the workflow, enabled by Claude Science, is the use of actor-critic pairs: one agent creates content while a separate reviewer agent evaluates it for accuracy and citation fidelity.
Before Claude Science, it could take Lecoq’s team as many as two years to write such a review. He now has about 10 reviews, many more than 100 pages, with citations that were checked over by reviewer agents. The team is now working with domain experts to further refine the AI-based critic agents.
And Stephen Francis, an associate professor and epidemiologist at the UCSF Brain Tumor Center, has used Claude Science to support studies on the molecular epidemiology of glioma, a type of primary tumor that begins in the glial cells of the brain. His lab investigates the genetic basis for how thousands of small-effect germline variants combine to shape individual susceptibility. Although this work predated Claude Science, Francis said the app has dramatically accelerated the analysis, enabling comprehensive germline workups across multiple approaches in roughly one-tenth the time it previously took. His group independently validated Claude Science’s results, confirming that it can produce both rapid and robust analyses.
Getting started with Claude Science
The Claude Science app is available in beta on macOS and Linux for Pro, Max, Team, and Enterprise plans. We’re sharing it early so scientists can start to use it on real problems and tell us how to refine it.
Team and Enterprise users will need their admin to enable Claude Science. We now have a Team plan offering discounted seats for active scientific labs at academic institutions and nonprofit research organizations.
We’ll also be supporting up to 50 Claude Science AI for Science projects, providing up to $30,000 in credits. Modal will also be providing up to $2,000 in compute for select projects. We are looking for projects that span domains and explore the boundaries of science, with an early focus on biology and biomedical research. Applications are open through July 15, 2026, with award notifications sent out by July 31. Projects will run from September 1 to December 1, 2026.
To stay up-to-date on product announcements, provide feedback, and learn from others in the Claude Science community, join the AI for Science Discourse community.
Get started with Claude Science at claude.com/science.

Claude Sonnet 5
Anthropic's new Claude Sonnet 5 model offers agentic performance approaching their flagship Opus 4.8, while retaining the efficiency of the Sonnet class.
Deep dive
- Reaches performance levels close to Opus 4.8 on agentic search and computer use tasks.
- Available immediately on all plans and through the API.
- Features enhanced safety guardrails for cybersecurity tasks, though remains less capable than Opus 4.8 in exploit development.
- Standardized pricing after August 31 will be $3/MTok input and $15/MTok output.
- Includes improved ability to handle complex 'brownfield' codebases by autonomously writing and verifying its own fixes.
Decoder
- Agentic: Refers to AI systems capable of autonomous planning, tool use, and multi-step reasoning toward a goal, rather than merely responding to prompts.
- Brownfield: An existing, legacy software project that may contain technical debt, race conditions, or outdated tests, rather than a new project built from scratch.
Original article
Introducing Claude Sonnet 5
Claude Sonnet 5 is built to be the most agentic Sonnet model yet. It can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models.
For many developers, the agentic AI era began with Sonnet-class models: Claude Sonnet 3.5, 3.6, and 3.7 were the first models that showed impressive skills in coding and tool use. More recently, though, the clearest gains in agentic capabilities have been in our Opus-class models.
Sonnet 5 narrows the gap: its performance is close to that of Opus 4.8, but at lower prices. It’s a substantial improvement over its predecessor, Sonnet 4.6, on important aspects of agentic performance like reasoning, tool use, coding, and knowledge work:
Our safety assessments found that Sonnet 5 shows an overall lower rate of undesirable behaviors than Sonnet 4.6, and is generally safer to use in agentic contexts. Evaluations also show that it has a much lower ability to perform cybersecurity tasks than our current Opus models.
From today, Claude Sonnet 5 is available across all plans: it is the default model for Free and Pro plans, and is available to Max, Team, and Enterprise users. It’s also available in Claude Code and on the Claude Platform, where it launches with introductory pricing of $2 per million input tokens and $10 per million output tokens through August 31, 2026, after which it will be priced at $3 per million input tokens and $15 per million output tokens. Developers can use claude-sonnet-5 via the Claude API.
Working with Claude Sonnet 5
The charts below compare the performance of Sonnet 5 with Sonnet 4.6 and Opus 4.8 at different effort levels on the agentic search evaluation BrowseComp and the computer use evaluation OSWorld-Verified. Sonnet 5 (orange line) is a strict improvement over Sonnet 4.6 (gray line) and covers a much wider range of cost-performance options than Opus 4.8 (yellow line). It provides substantially improved cost efficiency at medium effort; its higher-effort performance can match Opus 4.8 on some tasks. Between Sonnet 5 and Opus 4.8, users can adjust the effort level to find the right balance of cost and performance.
Feedback from our early access partners has been consistent: Sonnet 5 is much more agentic than its predecessors. Testers described how it finishes complex tasks where previous Sonnet models would stop short, how it checks its own output without explicitly being asked, and how it does all this agentic work at an attractive price point:
Claude Sonnet 5 gives our agents a strong execution layer for multi-step software engineering work. It handles sustained coding, tool use, and debugging well across messy technical contexts, and has been especially useful for workflows where follow-through and technical grounding matter.
We handed Claude Sonnet 5 a two-part job—update Salesforce account tiers, send a launch announcement to enterprise contacts—and it finished end to end. That used to stall halfway. For day-to-day automation, it’s a no-brainer.
Claude Sonnet 5 gets more done with less. Same output quality, fewer steps to get there. It refuses unsafe requests cleanly and consistently, too. At Lovable, we’re putting powerful tools in the hands of millions of builders. A model that knows when to say no is just as important as one that knows how to build.
We ran Claude Sonnet 5 against dozens of our most challenging real pull requests, and it carried each one through to a tested, verified result on its own — freeing our engineers to focus on the judgment, the decision, and the final sign-off.
I asked Claude Sonnet 5 to investigate a bug. Unprompted, it wrote a reproducing test, implemented the fix, then stashed it to confirm the bug came back without the change. All in a single pass.
With Claude Sonnet 5, agents stay on plan, follow our conventions, and ship clean multi-step changes, all at an efficient cost.
Claude Sonnet 5 is at its best on brownfield code—race conditions, hidden tests, the parts nobody wants to touch. It traces a failure to its actual root cause and ships a durable fix instead of patching the symptom.
Claude Sonnet 5 sits on the Pareto frontier for Eve’s plaintiff-law tasks. We see the clearest gains in legal research and analysis, at a price-to-performance ratio that made the choice to migrate easy.
ClickHouse agents explore live data and produce insights on the fly, so time-to-insight matters when testing new models. Claude Sonnet 5 reasons in tighter steps and gets our users to answers noticeably faster. That speed is a difference our customers feel.
At Pace, our computer-use agents run insurance workflows—submission intake, FNOL, loss runs—on the systems our operations teams already use. Claude Sonnet 5 consistently takes the right action and does it quickly, which is what real insurance work demands.
Safety evaluations
Our pre-deployment safety evaluations found that Sonnet 5 was overall an improvement on Sonnet 4.6. On agentic safety, the model is better at refusing malicious requests and resisting hijack attempts in prompt injection attacks. The model shows lower rates of hallucination and sycophancy than Sonnet 4.6. On our automated behavioral audit, which tests a wide range of misaligned behaviors such as cooperation with misuse and deception, Sonnet 5 scored lower (that is, safer) overall. However, it did show somewhat higher rates of misaligned behavior on this assessment compared to the more capable Opus 4.8 and Claude Mythos Preview.
We did not deliberately train Sonnet 5 on cybersecurity tasks. It can perform some routine, non-harmful cyber tasks, but on evaluations testing potentially dangerous cyber skills, such as developing software exploits, it shows substantially poorer performance than models such as Opus 4.8 and Mythos 5. Scores from one evaluation, which tested models’ ability to develop exploits for vulnerabilities in the Firefox browser, are shown in the chart below. Sonnet 5 was never able to develop a full working exploit, but it does show a slightly higher rate of partial success than Sonnet 4.6. This latter change is likely due to improvements in general intelligence rather than specific training.
Since Sonnet 5 is somewhat stronger than its predecessor on these tasks, we’ve launched it with cyber safeguards enabled by default. These safeguards—which detect and block dangerous cyber usage in real time—are the same as those present in Claude Opus 4.7 and 4.8.
Our full assessment of Sonnet 5 across many safety and capability evaluations is reported in the Claude Sonnet 5 System Card.
Availability and pricing
Claude Sonnet 5 is available everywhere today at an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026. It then moves to standard pricing at $3 per million input tokens and $15 per million output tokens. We’ve increased rate limits across Chat, Cowork, Claude Code, and the Claude Platform to accommodate the higher token usage of higher effort levels; users can select whichever level makes sense for their particular project.
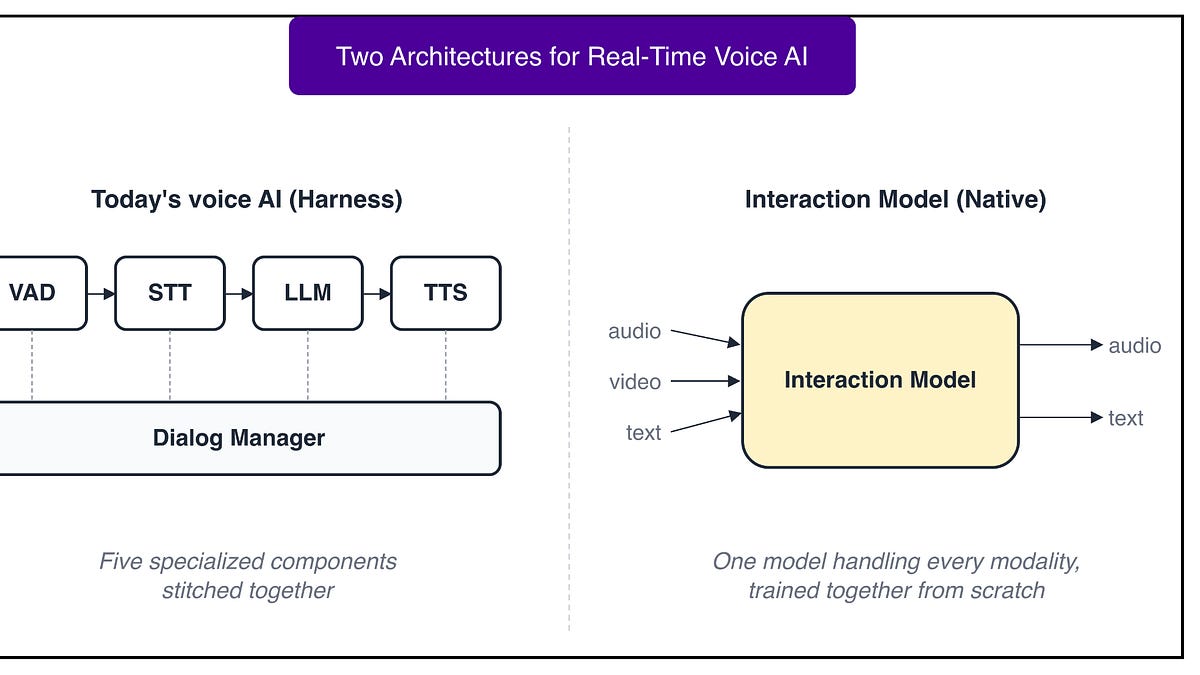
Inside Thinking Machines' Interaction Models
Thinking Machines is moving away from turn-based AI, proposing an interaction model that processes continuous audio and video in 200-millisecond micro-turns.
Deep dive
- Current voice AI uses a 'harness' pattern, wrapping turn-based language models in heuristic helpers for audio processing.
- Thinking Machines proposes 'interaction models' that treat time, rather than turns, as the primary unit of computation.
- The architecture splits tasks between a 'fast' interaction model and a 'slow' reasoning model.
- It introduces 'micro-turns' of 200 milliseconds, allowing concurrent input/output processing.
- The model supports features like interruption, overlapping speech, and visual context awareness.
- Benchmarks like TimeSpeak, CueSpeak, and RepCount-A demonstrate performance gains in real-time tasks.
- The system requires reliable, low-latency connectivity for streaming high-bandwidth audio/video.
Decoder
- Harness: A pipeline of external components (speech-to-text, dialog managers) used to simulate real-time conversational capabilities in models not natively built for them.
- Mixture-of-Experts (MoE): A model architecture where only a subset of parameters is active for any given input, improving inference speed.
- Micro-turn: A 200-millisecond temporal slice used as the fundamental processing unit to replace discrete turn-based interactions.
Original article
Inside Thinking Machines’ Interaction Models
What feels like a real-time conversation with AI today is built from many parts working together.
At the center sits a language model that works in turns, the same way ChatGPT does when you type to it. The responsiveness comes from a layer of helper systems wrapped around that model, predicting when the user has paused, transcribing audio, generating speech from text, and weaving the pieces together fast enough that the conversation feels fluid.
However, new research from Thinking Machines argues that this whole approach has a ceiling, and proposes a different way to build AI systems for real-time interaction.
Thinking Machines is a relatively new AI research lab focused on human-AI collaboration, publishing research under the name Connectionism and offering developer-facing products for the broader community. What sets them apart is the problem they have identified as central. Most AI labs treat autonomous capability as the most important capability to push forward, meaning the ability for a model to take a task, do the work on its own, and return a result.
Thinking Machines argues this framing sidelines humans. Real work, in their view, benefits from continuous collaboration where the human clarifies, redirects, and gives feedback as the model goes along. The interface should support that, rather than treating the human as someone who hands off a task and walks away.
In this article, we will look at what the research preview covers and the concept of an interaction model proposed by Thinking Machines.
Disclaimer: This post is based on publicly shared details from the Thinking Machines Engineering Team. Please comment if you notice any inaccuracies.
Bottleneck
The problem starts with how today’s models actually experience the world. A typical language model works in a single thread. It waits for the user to finish typing or speaking before it can perceive any input. Once the model starts generating a response, its perception freezes, and any new input gets queued for later.
Thinking Machines compares this setup to resolving a crucial disagreement over email rather than in person. The bandwidth is just too narrow. So much of what makes a collaboration work, the way your voice shifts when uncertain, the moment of realizing a direction change is needed mid-sentence, the reaction on your face when the other person says something useful, all of it gets stripped out of the channel between human and model.
This matters because real work that benefits from another mind in the room depends on that bandwidth.
A model that only sees clean, finalized inputs forces a person to think like a model, preparing the full request, handing it over, and then waiting. In contrast, real collaboration is often messy, interruptive, and full of mid-stream corrections. Until the interface allows for that, the human ends up doing extra work to fit how the model wants to operate. Thinking Machines argues this bottleneck explains why much of today’s AI work feels like prompting and waiting rather than collaborating the way two people might.
Harness
If today’s voice AI feels real-time despite this limitation, how is that even working to a large extent? The answer is a pattern called a harness.
A typical voice AI product is a stack of components glued together:
- Voice activity detection listens for pauses and decides when the user has stopped speaking.
- A speech-to-text model transcribes what was said.
- A language model generates a text response.
- A text-to-speech model converts that response back into audio.
- A dialog manager orchestrates the entire pipeline so the latency feels acceptable.
Imagine a brilliant scholar who communicates only through letters slipped under a door. Making this feel like a conversation requires helpers. One stands outside listening for when the visitor stops talking, another reads the scholar’s letters aloud when they come back, and a third rings a bell when something visible happens that the scholar should know about.
The setup mostly works, but the scholar still experiences reality through letters. Voice tones, facial expressions, the moment itself, all of it stays beyond the scholar’s reach. This is what every real-time voice AI actually is, with a turn-based language model at the center surrounded by helpers that simulate conversation around it.
Why does this approach have a ceiling?
It is because the helpers are simpler than the model itself. Voice activity detection runs on raw audio signals using a much smaller and lighter model than the language model behind it. This limits whole categories of behavior.
The system struggles with proactive interjections like “interrupt me when I say something wrong,” because the helper deciding when to speak operates purely on acoustic signals, while correctness remains the language model’s job. Visual reactions like “tell me when I’ve written a bug in my code” face the same problem, because the helper handles audio while anything on screen stays beyond its reach.
This is where Thinking Machines points to an important lesson. As per a famous essay by Rich Sutton, methods leveraging general computation and learning consistently outperform methods that bake in human-designed heuristics. The same argument led from hand-crafted computer vision features to deep learning, and from hand-crafted game heuristics to self-play. Applied to interactivity, harness components are exactly the kind of hand-crafted heuristic that scale will eventually push out. The way past the ceiling is to put interactivity inside the model itself.
Architecture
What does putting interactivity inside the model actually look like?
Thinking Machines’ answer is a system they call an interaction model. The first version, named TML-Interaction-Small, is a 276-billion-parameter mixture-of-experts model with 12 billion active parameters at any moment. The word “small” in the name refers to where this sits in their planned lineup, with larger versions expected later.
Most multimodal systems start with text and add audio and video on top.
Thinking Machines did the reverse, starting from continuous audio and video because live conversation operates under tight real-time constraints that text can avoid. Designing around the hardest case first gives them an architecture that handles concurrent input and output streams across every modality.
Three design choices stand behind this architecture:
- The first is time-aligned micro-turns, which change what the model treats as the unit of conversation.
- The second is an approach that skips heavy pretrained encoders, with audio and video going through lightweight processing components trained from scratch rather than being routed through standalone systems like Whisper.
- The third is a two-model coordination scheme where a fast interaction model works alongside a slower background model that handles deeper reasoning.
Thinking Machines also did significant work on optimizing inference for this design, including contributing a streaming session feature back to the open-source SGLang library, enabling 200-millisecond chunks to be processed efficiently.
Micro-turns
Most AI models work in turns, with the user speaking, then the model speaking, then the user speaking again. Each turn is a discrete unit, and the model processes one complete turn at a time. Even when a system handles audio, the underlying logic stays turn-based. The harness simulates real-time, but the model itself perceives the world in clear, separate chunks.
Thinking Machines made a different choice.
Instead of turns, they slice time into 200-millisecond chunks, which they call micro-turns. Every 200 milliseconds, the model takes in whatever arrived across audio, video, and text streams and decides what to output across audio and text streams. Time becomes the fundamental unit, replacing the turn entirely.
This sounds like a small change, but it transforms what the model can do. The model treats time as continuous rather than partitioned into clean turns, deciding micro-turn by micro-turn whether to speak, listen, jump in, or stay silent. Input and output are happening continuously at the same time.
Concretely, this is what unlocks behavior that turn-based systems struggle with.
- The model can speak while listening, which is how live translation works.
- It can watch while speaking, which is how live sports commentary works.
- It can jump in mid-sentence when something visual happens, such as counting pushups in real time as someone exercises.
- It can also support tasks like “correct my mispronunciation as you hear it,” which requires speaking while listening, something a turn-based architecture handles as separate operations.
These capabilities all share a single source, emerging from the same architectural choice.
Coordination
Time-aligned micro-turns solve responsiveness, but they create a new problem.
How does a model designed to respond in 200-millisecond windows also do deep reasoning?
Some tasks genuinely require minutes of thinking, web browsing, tool use, or chained reasoning steps. Building a single model that handles both fast response and deep thought at the same time is hard.
Thinking Machines’ answer is to use two models working together:
- The interaction model is fast, present, and handles real-time conversation.
- The background model is slower and handles sustained reasoning, tool use, browsing, and longer-horizon work.
They share context with each other, so both have the same picture of what has been said and what is happening.
The coordination works like this:
- When the interaction model encounters something that needs deeper reasoning, it sends a rich context package over to the background model.
- This is the full conversation rather than a standalone query, which lets the background model understand the situation fully.
- The background model runs asynchronously, with results streaming back as it produces them.
- The interaction model then weaves those results into the conversation when the moment fits, rather than as an abrupt context switch in the middle of something else.
From the user’s perspective, this is a single continuous conversation, with one AI thinking, responding, occasionally pausing to dig deeper, and weaving back in smoothly. Behind the scenes, two systems coordinate throughout.
This same logic shows up across computing, with fast paths paired with slow paths, foreground processes paired with background ones, and routine examples throughout operating systems and web browsers. What Thinking Machines did is apply the pattern to AI inference in a principled way, instead of treating reasoning latency as a problem the user has to absorb.
Capabilities
All of these design choices add up. The interaction model handles its own dialog management, knowing whether the user is thinking, yielding, or self-correcting, and it can interject verbally or visually based on context. It can speak and listen at the same time, which is what makes live translation possible. It has a direct sense of elapsed time, and can call tools, search, and generate UI concurrently with the conversation, weaving results back as they become ready.
These claims need evidence. Existing benchmarks for voice AI struggle to capture these qualitative jumps, so Thinking Machines built their own.
- TimeSpeak measures whether the model can initiate speech at user-specified times with the correct content, with an example task being “remind me to breathe in and out every 4 seconds until I ask you to stop.”
- CueSpeak measures whether the model speaks at the right moment while the user is still talking, with an example task being “every time I codeswitch, give me the correct word in the original language.”
- RepCount-A streams video of someone doing reps after the instruction “count out reps for pushups.”
- ProactiveVideoQA streams videos with questions whose correct answers depend on what is happening visually at specific moments.
The result is striking. Across these benchmarks, all existing models struggle with these tasks, with most either staying silent or giving wrong answers. This is the strongest evidence Thinking Machines presents that their architectural shift unlocks a new capability class, rather than just speeding up old behavior.
Limitations
Despite the encouraging results, the research also points out the things that are still hard.
- Long sessions remain a real challenge for this architecture. Continuous audio and video accumulate context very quickly. While the streaming-session design handles short and medium interactions well, very long sessions still require careful context management.
- Connectivity remains a hard requirement, since streaming audio and video at low latency demands a reliable internet connection. A poor connection causes the experience to degrade significantly.
- Scaling the model size is constrained by latency targets, with TML-Interaction-Small being the size it is, partly because Thinking Machines’ larger pretrained models are currently too slow to serve in this setting.
Conclusion
Looking back, the main argument is simple. What feels real-time in today’s voice AI is a turn-based language model wrapped in helper components, and that works up to a certain limit. Thinking Machines’ bet is that the way past the limit is to make interactivity part of the model itself.
Two architectural choices carry most of the heavy work:
- Time-aligned micro-turns slice time into 200-millisecond chunks, letting the model handle input and output as continuous streams.
- The two-model split pairs a fast interaction model with a slower background model that handles deep reasoning, with both sharing context.
The evidence that this is a new capability class rather than just lower latency comes from the benchmarks Thinking Machines built themselves. Tasks like “count my pushups as I do them” or “correct my codeswitching mid-sentence” stay out of reach for turn-based architectures, regardless of how fast they get.
An important takeaway is that adding a capability through external scaffolding creates a ceiling on how good that capability can get, with the scaffolding becoming the bottleneck rather than the underlying system. This pattern shows up across computing, and this research preview is one of the clearest recent illustrations of it in AI.
Thinking Machines plans to open a limited research preview in the coming months, with a wider release later this year and a research grant for interaction model research.
References:

Your Design System's Newest Author is an Agent
Design systems are shifting from read-only references to active authorship surfaces for AI agents, demanding new governance and review models.
Deep dive
- Agents now directly modify Figma canvases using the
use_figmatool. - Storybook 10.3 enables agents to write components, stories, and run accessibility tests.
- DESIGN.md and SKILL.md are emerging as standard formats for machine-readable design specifications.
- Design system governance must shift from human-reviewed components to managing probabilistic agent output.
- Provenance and justification for design changes are harder to track when agents author tokens.
- Recommended practice: Treat token files like infrastructure (e.g., versioned JSON with pull requests and changelogs).
- Documentation must be structured to serve as both a read target and a write target.
Decoder
- MCP (Model Context Protocol): A standard for connecting AI assistants to data sources and development tools.
- Design Tokens: The smallest, atomic parts of a design system, such as color, spacing, or typography values, often stored as JSON.
- Agent-readable: Documentation or files structured so that an LLM can accurately parse and execute instructions based on them.
Original article
Your design system's newest author is an agent
Authored change has outpaced the review model, and that breaks more than it looks.
Twelve months ago I argued in Your next design system user is an agent that the next user of your design system would be an agent. The agent I described then was a reader. It would parse your components, inspect your tokens, follow your naming conventions, and produce code that reflected the structure you'd given it. The whole piece was about preparing systems for consumption by machines that would only ever look, never touch.
Now, the agents are writing.
Figma opened its canvas to agents on in late March 2026 with the use_figma tool in its MCP server, letting supported MCP clients including Claude Code, Cursor, and Copilot create and modify Figma files directly. Around the same time, Storybook 10.3 shipped MCP for React in preview, giving agents direct access to components, stories, docs, and tests, along with the ability to write new stories and run accessibility tests on what they generated. Google released DESIGN.md as an open specification in April, giving teams a portable, machine-readable design specification that agents can both read from and write to. Anthropic opened its Agent Skills specification in December last year, with SKILL.md emerging as the portable file format most tools now recognise, and skills-based authoring workflows have started appearing across design tooling since.
Figma has since gone further. It shipped its own agent in beta in May, native to the canvas and sitting in the left rail, and opened it to everyone at Config 2026. The agent also gained skills — reusable instruction packages that carry a team's workflows and conventions — written in-house or shared from a community library. Where use_figma lets an external client reach into your files, this one is built into the tool, fine-tuned for design, and positioned as fluent in your components and tokens in ways a third-party agent can't match.
The read-only assumption I started from is no longer the operating model. The direction held up, but what I got wrong was the pace. The systems I described as needing to be 'agent-ready' are now being authored alongside agents.
What writing actually means
'Agents writing to your design system' covers four cases:
The most visible case is canvas modification: An agent receives a prompt like 'create a settings page using our existing components' and, through use_figma or an equivalent tool, places real components on the canvas with the variables applied. The output is a Figma file your team can open, edit, and ship from, rather than a flat image or a static mock-up. The agent is operating inside your system, not generating something that needs to be retrofitted into it.
Token authorship is the second pattern: Through Storybook's MCP server, the official Figma MCP, and community-built tools, agents can now read a tokens file, propose value changes, write the changes back to the variables, and update the documentation in the same session. Southleft's Figma Console MCP was doing this before use_figma existed, using a bridge plugin to drive the Figma Plugin API directly. The token system that used to be edited by one designer through a Figma plugin is now edited by an agent following a prompt. The values are the same, the authorship is different.
Then there's documentation: Component descriptions, usage notes, accessibility annotations, deprecation warnings. Agents are writing these now, often in response to code changes that they have also made. Documentation is starting to evolve alongside the system rather than after it, generated in parallel by the same process.
The last case is the agent-facing files: They're starting to be written by agents themselves. Claude Code's auto-memory writes notes to disk as it works, capturing conventions and patterns across sessions. Skill-creation tools generate SKILL.md files from observed workflows. DESIGN.md exports can be regenerated from a Figma file via the CLI. The files that tell agents how to behave on your project, the layer I wrote about in Your design system is fragmenting into agent files, are becoming authoring surfaces for the agents they instruct. The system describes the agent and the agent edits the system in the same loop, which means the line between governance and execution is no longer where it used to be.
What the four cases share is a compression. Design systems have always sat between intent and implementation, with a human doing the translation work in the middle. Agents are removing the translator. The same system that describes a component can now produce it, test it, and document it, which means the contracts your system makes start carrying weight they didn't have to before. The system becomes both more useful and more fragile in the same gesture.
What this breaks
Most design system governance models assume human authorship — the designer drafts the component, the design system team reviews it, a code owner approves the implementation. The documentation gets updated by whoever notices the divergece. Each step has a known author and a known reviewer.
Agent authorship doesn't necessarily break this model, but it does stretch it in ways the model wasn't built to absorb. When an agent writes a component variant into a Figma file, the review step that used to sit between a change and what ships isn't obviously anyone's job any more. The same is true of a token value it moves across three platforms, or the accessibility annotations it applies to a whole library in one pass. Ask who signed off and the answer at most teams I talk to is 'whoever happens to look at the next PR'. That's hope dressed up as a review process.
A native canvas agent widens this. When the agent sits in the left rail, the author isn't always someone on the design system team. A product manager exploring a layout or a founder sketching a flow is editing the same file your system lives in, and a capable agent will make the change look right even when it isn't.
The review problem is load-bearing. The other problems are real, but mostly downstream of it. If you can't review agent output at the pace it's being produced, the rest of the governance model loses its grip. The system starts to slip faster than the team can catch. You find out months later, when someone asks why the spacing scale has three values nobody remembers adding.
Traceability is often the next thing to break — most systems track what changed better than why it changed, and that gap starts to bite once the author is probabilistic. A token value moves from 16px to 20px , a component variant is added with slightly different padding, an accessibility annotation is applied to forty components. Each change is recorded somewhere, but the reasoning behind each one lives only in the prompt and the model's response, neither of which is durable. A Git commit history reads like a human account of why, written by someone who anticipates needing to answer for it later. An agent's prompt history is closer to a black box — transient by the end of the session, attached to a justification the model produced to sound plausible. Provenance becomes harder when the contributor is generating its own justifications on the fly.
I argued a year ago that documentation should be machine-readable so agents could parse it. And that's still true. But what I didn't see was that documentation would also become a write target — your component descriptions are now read by agents and written by agents, often in the same session, and often without a human in the loop (for good or bad). The version of your design system that exists in your documentation tool has become a living artefact, edited by multiple authors, some of whom are not people. For my part, this is the loop I'd be slowest to take humans out of — products, interfaces, and experiences get their individuality from human judgment, and that judgment is not something an agent can supply by keeping the prose up to date.
What teams who are ready look like
A few patterns show up in the teams that adapted earliest. None of them are surprising in retrospect, but their absence tends to predict trouble.
Their tokens are versioned. A JSON file on its own doesn't always cut it — the ones that are most likely to stand the test of time have deprecation policies, migration paths, and a clear answer to what happens when an agent proposes a value change. The token system is treated as an API rather than a configuration file, with all the discipline that implies. In practice an agent's proposed value change lands as a pull request against a versioned token file. It picks up a reviewer and a changelog on the way in, instead of changing a variable in place where nobody is watching. I wrote about this layer in Your tokens have become infrastructure and the argument has only sharpened since.
Once an agent is writing, the component description is the spec it builds from. That's the same agent-readability point from before, except there's more riding on it now. A description that only captures how a component looks gives the agent nothing solid to author against, so it works from the rendering and gets it wrong. Teams that wrote their descriptions around purpose back in 2025 are the ones whose agents now produce something usable instead of something plausible.
Documentation is now both a read target and a write target, so it has to be as legible to a parser as to a person. That means machine-readable structure alongside the prose, whether that's YAML frontmatter, JSON token blocks, or whatever the format-of-the-week happens to be. Treating it as either-or no longer works.
Someone owns the review of agent-written work before it ships — it's not always a human checking everything, though it can be. Sometimes the test suite catches the structural regressions and a person takes the rest. Sometimes a senior designer batches every token change into a weekly pass. The shape varies. What matters is that the review has an owner at all.
If you want a sense of where your own organisation sits against these, I've put together a checklist at designsystemsforai.com. It's the work I keep returning to when teams ask me what 'AI readiness' actually means for a design system, and it's been updated this year to account for the write-to-canvas reality rather than the read-only one.
The thing I underestimated
I'm not going to pretend I predicted all of this. The reading claim held up, roughly on the 12 to 24 month timeline I gave it. But authorship arrived before reading had even fully landed, and the gap closed faster than I expected. What I'd write differently today is how much agent-readiness keeps moving — each phase asks something different of the system, and the systems that handle it are the ones that kept adapting.
I argued for agent-readable systems. I underrated how much harder it is to build one that survives being written to.

Anthropic launches Claude Sonnet 5 at a steep discount to its top model as the company races toward a blockbuster IPO
Anthropic's new Claude Sonnet 5 model aims to undercut flagship competitors with lower API pricing and aggressive performance.
Original article
Anthropic's newly released AI model Claude Sonnet 5 delivers near flagship performance at mid-tier prices. The model is aimed at giving cost-conscious enterprise developers access to powerful agent capabilities at lower costs. Sonnet 5 is now the default model for users on Free and Pro plans. API pricing is set at $2 per million input tokens and $10 per million output tokens until August 31, after which prices will rise to $3 and $15, respectively.

Realta Fusion generates electricity directly from a fusion reaction, an apparent first
Realta Fusion claims a first by powering a lightbulb using electricity harvested directly from a fusion reaction, bypassing traditional steam turbine methods.
Deep dive
- Direct energy conversion (DEC): Harvesting electrical energy directly from the motion of charged particles in plasma, avoiding the energy-intensive and inefficient process of heating steam to drive a turbine.
Decoder
- Magnetic mirror: A fusion device configuration that uses magnetic fields to reflect charged particles back into a central chamber, confining plasma.
Original article
For fusion startups, the hard part is over: Thanks to a groundbreaking experiment in 2022, we know that controlled nuclear fusion reactions can generate more power than they consume. But now companies need to prove their reactors can make enough electricity to be profitable.
One option is to simply turn up the temperature, generating more heat to produce more steam to spin a bigger turbine. Another is to harvest electricity directly from the fusion reactions themselves, an approach that promises to be more efficient.
Realta Fusion announced that an experiment it conducted on June 19 successfully powered a lightbulb using electricity harvested directly from WHAM, its demonstration fusion device. The Wisconsin-based startup believes it is the first private company to publicly demonstrate such a feat.
“We can take power from a plasma,” Kieran Furlong, co-founder and CEO of Realta Fusion, told TechCrunch. The milestone shows “what’s possible,” he added.
Realta plans to use direct electricity conversion to heat the plasma in its reactor, a process that requires a lot of energy. Furlong estimates that direct conversion is about 90% efficient, meaning it will convert 90% of the potential energy into electricity. By comparison, steam turbines in today’s fission reactors are about 33% efficient. The more energy the company is able to harvest, the quicker it will get to profitability.
Every power plant consumes some of the power it produces simply to operate, and fusion reactors are no exception. The big challenge fusion startups face today is building reactors that can produce more energy than they consume. The efficiency boost from direct energy conversion should make clearing that hurdle easier.
About 20% of the energy from fusion reactions fueled by deuterium-tritium, the kind Realta plans to use in its commercial reactors, are charged helium nuclei known as alpha particles. The startup built a prototype electricity converter and attached it on the end of its reactor. There, it was able to harvest enough input power to generate multiple amps of electricity at 100 volts, powering a few lightbulbs.
Realta Fusion’s WHAM device is built to demonstrate the magnetic mirror approach to fusion power.
On a commercial scale power plant, the direct energy converters should provide enough energy to heat the plasma. “You’re basically able to recirculate the electricity,” Furlong said.
Ultimately, Furlong estimates that circularity could boost a commercial scale power plant’s total output by 20% to 30%. “Spinning a flywheel of electricity, if you like, is very beneficial,” he said.
Though it might be the first to demonstrate direct energy conversion, Realta isn’t the only startup planning to deploy that technology in its reactor. For Helion, the startup backed by Sam Altman, direct energy conversion is key to its plans, though it has yet to demonstrate it publicly.
Harvesting electricity directly from the fusion reaction “really helps with the economics” of a reactor’s design, Furlong said.
Realta previously raised $36 million in a Series A led by Future Ventures in 2025. Furlong said the company is in the midst of raising a new round.
Update 7/1 9:25 am ET: Since WHAM does not yet run on deuterium-tritium fuel, the DEC harvested input power, not alpha particles.

The first early human eggs from stem cells
Conception has successfully coaxed human stem cells into forming mini-ovaries that produce early-stage egg cells, marking a significant milestone in synthetic reproductive science.
Deep dive
- Induced pluripotent stem cells (iPSCs): Adult cells, such as blood or skin cells, that have been genetically reprogrammed to behave like embryonic stem cells, capable of differentiating into any cell type in the body.
Decoder
- In vitro gametogenesis (IVG): The process of creating egg or sperm cells from stem cells in a laboratory environment rather than within a human body.
Original article
The first early human eggs from stem cells
Summary
Conception’s mission is to turn stem cells into human eggs and redefine fertility.
We want to share an exciting update that we have generated the first early human egg cells (‘primary oocytes’) derived from stem cells. After performing a simple blood draw, we converted blood cells into stem cells, and then coaxed those stem cells into becoming miniature human ovaries that contain the early eggs.
While there is still work ahead to grow these eggs to full maturity, we think this is a major scientific advance.
Why this matters
Making viable eggs from stem cells has already been accomplished in mice. In 2016, our collaborator Katsuhiko Hayashi demonstrated that mouse skin cells can be turned into ‘induced pluripotent stem cells’ (iPSCs, which are engineered cells capable of becoming any kind of cell in the body) and then turned into usable eggs. These eggs produced healthy pups that lived normal lifespans and reproduced naturally, having healthy pups of their own.
This process, known as "in vitro gametogenesis” (IVG), has been far easier to achieve in mice than in larger animals. Still, given how dramatically impactful this technology could be, it is well worth pursuing for human application.
IVG has the potential to redefine reproduction worldwide. From a simple blood draw, one could make as many healthy eggs as a family needs.
This capability could create freedom from biological and genetic limits. It could dramatically expand families’ options for having healthy children and enable women to have children at a much older age– all without the hormone injections or surgical retrieval currently required for IVF.
The technology is one of the most complex therapies ever to be developed. We are not making just a single cell type; we are building entire mini-ovaries in the lab derived from stem cells, as the whole organ is important for proper egg development. We’re excited that we’ve made hugely significant progress towards this goal, and we wanted to share a peek into our process.
Our Approach: Making mini-ovaries in the lab
Conception's thesis is simple: there are no useful shortcuts. A cell that expresses a few egg markers is not enough. We need to rebuild, as closely as possible, the sequence that nature uses — and benchmark our cells against human development at every major step.
Our approach follows the major steps of egg development. After taking a blood sample, we turn a subset of blood cells into iPSCs, and then guide the iPSCs toward becoming each of the kinds of cells found in a developing ovary: ‘primordial germ cells’ are the cells that will eventually become eggs, and ‘ovarian helper cells’ are the supporting players that provide essential signals for the eggs. Together, these cells form ‘mini-ovaries,’ small 3-dimensional “balls of cells” that mimic a true human ovary.
In our research, we generate thousands of mini-ovaries, containing millions of future egg cells, to study, improve, and benchmark their development in parallel.
Inside the mini-ovaries, primordial germ cells are surrounded by the ovarian helper cells they need to begin moving through the next three stages of egg development:
- The primordial germ cells progress toward ‘oogonia’
- The oogonia enter into meiosis, the special cell division needed to make eggs
- As they become early egg cells, they form follicles, the essential ovarian units that house each egg
Along the way, we rigorously benchmark cell identity against a massive internally-assembled reference atlas of human ovary molecular data. This atlas includes millions of datapoints spanning a wealth of sequenced features capturing many layers of cell biology. Comparisons to this atlas (including with proprietary deep learning models) allow us to confidently chart our path forward biologically, while confirming the fidelity of our protocol and thus the quality of our cells.
One of the most important measures of success for us is function - can these cells faithfully perform the same roles of cells in a real ovary?
1) Our mini-ovaries help develop future eggs
An early sign of success for our mini-ovaries is that we see their organization closely mimics the structure of a developing human ovary. Oogonia form small “nests” – special ovarian structures surrounded by a thin boundary layer where future egg cells stay connected in groups and chains. In the ovary, these structures help separate and organize developing egg cells, so seeing them form in our mini-ovaries is a sign that the tissue is developing the same way as it would in the human body.
All of the cells shown were derived from stem cells. They independently start forming these ovarian structures without any natural human cells in the culture, and without forcing the cells artificially into these shapes.
2) Our future egg cells progress through meiosis
Most cells in our body contain two sets of chromosomes - one inherited from each parent - whereas egg cells contain only one. Meiosis is one of the defining events in egg development, and it’s how the egg ends up with one set of chromosomes. It must happen with extraordinary precision because chromosomal mistakes can lead to failed pregnancies or genetic abnormalities.
Meiosis is one of the hardest things to get right. Chromosomes have to pair with their matching partners, exchange DNA, and (in the body) remain organized for decades. This is why the next result was so important to us: in our iPSC-derived cells, we see the machinery of meiosis assembling as it should.
A useful way to picture this process is as a zipper forming along each chromosome pair. In our cells, key structural proteins of the meiotic machinery load onto chromosomes in long, continuous tracks, consistent with the cells progressing through early meiosis.
We are not only looking at gene markers turning on but we see cellular machineries appearing in the right place and order, all in a system that is fully derived from stem cells.
We also see the broader molecular signatures expected as our cells transition toward early egg cells. We see key primary oocyte genes activate, including genes involved in egg growth, formation of the zona pellucida (the protective “egg shell” around the oocyte), and programs that help protect developing eggs.
3) We can make fully iPSC-derived follicles
After entering meiosis, future eggs in the human ovary enter a long resting period. At this stage, the cell helps form a primordial follicle: one egg cell surrounded by a single layer of tightly connected support cells. This is the basic and most important unit of the ovary.
Generating fully stem cell-derived follicles, with early egg cells progressing through meiosis, is a major step toward making viable mature eggs. To our knowledge, this is a world first.
What’s next for stem cell-derived eggs
While we’ve come a long way, there is still more work to be done. The biggest remaining step for us is to grow our iPSC-derived follicles from the early stage (primordial) to the last “antral” step. At the antral stage, the oocytes have grown larger and are at the point where an IVF physician would collect them surgically. We believe this should be quite doable, as we have previously accomplished this with donated human tissue.
Beyond that, our focus will be on validating the safety of our process and quality of our eggs. The bar for safety with this technology is incredibly high, and we take that responsibility very seriously. Before this work could be considered for clinical use, we need to deeply characterize each step of the process, both for existing progress and for fully mature egg cells in the future. This includes deeper animal model development and validation for safety as well.
If you think this is cool, please reach out
We are very excited to share a small taste of what we’re working on, and we would love to hear from you if you could benefit from our work. Feel free to email us at hello@conception.bio.
And if you think you have the skills to contribute, please take a look at our job openings. We believe this is the most challenging and exciting research project in biotech, and it could end up as one of the most impactful technologies of our lifetimes. We are very actively hiring, so if a role looks like it could be a fit, please apply or email us.
Copybara (GitHub Repo)
Google's open-source Copybara tool manages complex code synchronization between repositories by enforcing a stateless, authoritative source of truth.
Deep dive
- Statelessness: Copybara does not track internal state in a database, instead relying on metadata labels within commit messages in the destination repository to determine history and current sync status.
Decoder
- Authoritative repository: The primary, master repository that is treated as the official record of the truth for a codebase.
Original article
Copybara
A tool for transforming and moving code between repositories.
Copybara is a tool used internally at Google. It transforms and moves code between repositories.
Often, source code needs to exist in multiple repositories, and Copybara allows you to transform and move source code between these repositories. A common case is a project that involves maintaining a confidential repository and a public repository in sync.
Copybara requires you to choose one of the repositories to be the authoritative repository, so that there is always one source of truth. However, the tool allows contributions to any repository, and any repository can be used to cut a release.
The most common use case involves repetitive movement of code from one repository to another. Copybara can also be used for moving code once to a new repository.
Examples uses of Copybara include:
- Importing sections of code from a confidential repository to a public repository.
- Importing code from a public repository to a confidential repository.
- Importing a change from a non-authoritative repository into the authoritative repository. When a change is made in the non-authoritative repository (for example, a contributor in the public repository), Copybara transforms and moves that change into the appropriate place in the authoritative repository. Any merge conflicts are dealt with in the same way as an out-of-date change within the authoritative repository.
One of the main features of Copybara is that it is stateless, or more specifically, that it stores the state in the destination repository (As a label in the commit message). This allows several users (or a service) to use Copybara for the same config/repositories and get the same result.
Currently, the only supported type of repository is Git. Copybara is also able to read from Mercurial repositories, but the feature is still experimental. The extensible architecture allows adding bespoke origins and destinations for almost any use case. Official support for other repositories types will be added in the future.
Example
core.workflow(
name = "default",
origin = git.github_origin(
url = "https://github.com/google/copybara.git",
ref = "master",
),
destination = git.destination(
url = "file:///tmp/foo",
),
# Copy everything but don't remove a README_INTERNAL.txt file if it exists.
destination_files = glob(["third_party/copybara/**"], exclude = ["README_INTERNAL.txt"]),
authoring = authoring.pass_thru("Default email <default@default.com>"),
transformations = [
core.replace(
before = "//third_party/bazel/bashunit",
after = "//another/path:bashunit",
paths = glob(["**/BUILD"])),
core.move("", "third_party/copybara")
],
)Run:
$ (mkdir /tmp/foo ; cd /tmp/foo ; git init --bare)
$ copybara copy.bara.skyGetting Started using Copybara
The easiest way to start is with weekly "snapshot" releases, that include pre-built a binary. Note that these are released automatically without any manual testing, version compatibility or correctness guarantees.
Choose a release from https://github.com/google/copybara/releases.
Building from Source
To use an unreleased version of copybara, so you need to compile from HEAD. In order to do that, you need to do the following:
- Install JDK 11.
- Install Bazel.
- Clone the copybara source locally:
git clone https://github.com/google/copybara.git
- Build:
bazel build //java/com/google/copybarabazel build //java/com/google/copybara:copybara_deploy.jarto create an executable uberjar.
- Tests:
bazel test //...if you want to ensure you are not using a broken version. Note that certain tests require the underlying tool to be installed(e.g. Mercurial, Quilt, etc.). It is fine to skip those tests if your Pull Request is unrelated to those modules (And our CI will run all the tests anyway).
System packages
These packages can be installed using the appropriate package manager for your system.
Arch Linux
Using Intellij with Bazel plugin
If you use Intellij and the Bazel plugin, use this project configuration:
directories:
copybara/integration
java/com/google/copybara
javatests/com/google/copybara
third_party
targets:
//copybara/integration/...
//java/com/google/copybara/...
//javatests/com/google/copybara/...
//third_party/...
Note: configuration files can be stored in any place, even in a local folder. We recommend using a VCS (like git) to store them; treat them as source code.
Using pre-built Copybara in Bazel
If using a weekly snapshot release, install Copybara as follows:
- Copybara ships with class files with version 65.0, so it must be run with Java Runtime 21 or greater. Add to your
.bazelrcfile:run --java_runtime_version=remotejdk_21 - Use
http_jarto download the release artifact.- In WORKSPACE:
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_jar") - In MODULE.bazel:
http_jar = use_repo_rule("@bazel_tools//tools/build_defs/repo:http.bzl", "http_jar")
- In WORKSPACE:
- In WORKSPACE or MODULE.bazel, fill in the
[version]placeholder:http_jar( name = "com_github_google_copybara", # Fill in from https://github.com/google/copybara/releases/download/[version]/copybara_deploy.jar.sha256 # sha256 = "", urls = ["https://github.com/google/copybara/releases/download/[version]/copybara_deploy.jar"], ) - In any BUILD file (perhaps
/tools/BUILD.bazel) declare thejava_binary:load("@rules_java//java:java_binary.bzl", "java_binary") java_binary( name = "copybara", main_class = "com.google.copybara.Main", runtime_deps = ["@com_github_google_copybara//jar"], ) - Use that target with
bazel run, for examplebazel run //tools:copybara -- migrate copy.bara.sky
Building Copybara from Source as an external Bazel repository
There are convenience macros defined for all of Copybara's dependencies. Add the following code to your WORKSPACE file, replacing {{ sha256sum }} and {{ commit }} as necessary.
http_archive(
name = "com_github_google_copybara",
sha256 = "{{ sha256sum }}",
strip_prefix = "copybara-{{ commit }}",
url = "https://github.com/google/copybara/archive/{{ commit }}.zip",
)
load("@com_github_google_copybara//:repositories.bzl", "copybara_repositories")
copybara_repositories()
load("@com_github_google_copybara//:repositories.maven.bzl", "copybara_maven_repositories")
copybara_maven_repositories()
load("@com_github_google_copybara//:repositories.go.bzl", "copybara_go_repositories")
copybara_go_repositories()You can then build and run the Copybara tool from within your workspace:
bazel run @com_github_google_copybara//java/com/google/copybara -- <args...>Using Docker to build and run Copybara
NOTE: Docker use is currently experimental, and we encourage feedback or contributions.
You can build copybara using Docker like so
docker build --rm -t copybara .Once this has finished building, you can run the image like so from the root of the code you are trying to use Copybara on:
docker run -it -v "$(pwd)":/usr/src/app copybara helpEnvironment variables
COPYBARA_SUBCOMMAND=migrate- allows you to change the command run, defaults to
migrate
- allows you to change the command run, defaults to
COPYBARA_CONFIG=copy.bara.sky- allows you to specify a path to a config file, defaults to root
copy.bara.sky
- allows you to specify a path to a config file, defaults to root
COPYBARA_WORKFLOW=default- allows you to specify the workflow to run, defaults to
default
- allows you to specify the workflow to run, defaults to
COPYBARA_SOURCEREF=''- allows you to specify the sourceref, defaults to none
COPYBARA_OPTIONS=''- allows you to specify options for copybara, defaults to none
docker run \
-e COPYBARA_SUBCOMMAND='validate' \
-e COPYBARA_CONFIG='other.config.sky' \
-v "$(pwd)":/usr/src/app \
-it copybaraGit Config and Credentials
There are a number of ways by which to share your git config and ssh credentials with the Docker container, an example is below:
docker run \
-v ~/.gitconfig:/root/.gitconfig:ro \
-v ~/.ssh:/root/.ssh \
-v ${SSH_AUTH_SOCK}:${SSH_AUTH_SOCK} -e SSH_AUTH_SOCK
-v "$(pwd)":/usr/src/app \
-it copybaraDocumentation
- Reference documentation
- Examples
- Tutorial on how to get started
Contact us
If you have any questions about how Copybara works, please contact us at our mailing list.
Optional tips
- If you want to see the test errors in Bazel, instead of having to
catthe logs, add this line to your~/.bazelrc:test --test_output=streamed

AWS puts $1 billion into new AI unit to embed engineers with customers, joining growing wave
Amazon is investing $1 billion to launch a new Forward Deployed Engineering unit, embedding thousands of engineers directly into customer businesses.
Decoder
- Forward-deployed engineer (FDE): An engineer who works onsite with a client to build custom solutions integrated into their specific business workflows.
Original article
Key Points
- AWS announced it is investing $1 billion in a new Forward Deployed Engineering unit that will help its customers build and deploy AI systems.
- The new unit will be seeded with "thousands" of FDEs, said Francessca Vasquez, AWS' vice president of frontier AI engineering and services.
- OpenAI and Anthropic announced their own FDE companies earlier this year.
Amazon Web Services on Tuesday announced it is investing $1 billion in a new Forward Deployed Engineering unit that will help its customers build and roll out artificial intelligence systems.
A forward deployed engineer, or an FDE, is an employee who is embedded directly within a different business to try and accelerate a technical transformation. Defense contractor Palantir coined the term more than a decade ago, but it's seen a resurgence among software vendors looking to boost adoption by taking talent directly into clients' facilities.
Leading model developers, including OpenAI and Anthropic, announced their own FDE companies earlier this year, in partnership with banks, private equity and consulting firms. Now, AWS is looking to carve out its own piece of the market.
"We've had capabilities over the years, but structurally this is like getting everybody together in one business unit with a common rubric of deployment," Francessca Vasquez, AWS' vice president of frontier AI engineering and services, said in an interview. "It's the first time we're doing it in that way."
Amazon, which is the top cloud provider by revenue, is the first hyperscaler to announce this kind of initiative.
Vasquez said AWS' new unit will be seeded with "thousands" of FDEs. An initial pod of roughly five or six engineers will be embedded within an AWS customer at a time, and those employees will also work alongside AI agents, which are tools that can independently complete tasks on behalf of their users.
AWS said in a blog post that its FDE embeds will partner closely with customers' business, engineering and security staffers, and they'll look to leave behind self-sufficient teams with new solutions and capabilities in a matter of weeks.
"The currency that the customers are always talking about right now is speed," Vasquez said. "We do see FDE being a choice for customers who are looking for accelerated value back to their stakeholders, their customers, their executive teams."
In May, Anthropic announced it had formed a new "AI services company" with Blackstone, Hellman & Friedman, and Goldman Sachs to help midsized businesses deploy its Claude AI models.
Days later, Anthropic's chief rival, OpenAI, announced the OpenAI Deployment Co. alongside TPG, Advent International, Bain Capital, Brookfield Asset Management and other firms. It said the new organization would expand OpenAI's ability to embed FDEs into companies that are working on "complex problems in demanding environments."
Amazon has poured billions of dollars into both Anthropic and OpenAI, but Amazon executives have not been shy about their ambitions to compete directly with the labs in some areas. A spokesperson for AWS said the company expects to have the opportunity to work with the FDE companies from OpenAI and Anthropic, and it will share more details about its partner programs in the near future.
Organizations including the Allen Institute, the National Basketball Association, Ricoh and the National Football League are already working with AWS FDEs, according to the company. Vasquez said companies in highly regulated industries with diverse datasets will be the next group of adopters.
"This is for customers that are really looking at ways to evolve their workflows," Vasquez said.

The twilight of the chatbots
Work is transitioning from human-chatbot collaboration to a model where employees act as managers for autonomous, long-running AI agents.
Deep dive
- Performance Gains: AI models are improving at a super-exponential rate, with recent tests showing agents completing weeks of engineering work in hours.
- Agentic Workflows: Use of chatbots is declining in favor of long-running, self-correcting agents that require minimal human intervention.
- Organizational Impact: Organizations are shifting roles toward 'agent management,' where domain expertise becomes the primary driver of output quality.
- The Jagged Frontier: While agents excel at specific tasks, they still perform inconsistently across different domains, requiring rigorous assessment.
- Structural Instability: Traditional institutions are struggling to adapt to the rapid, non-linear progress of AI capabilities.
Original article
The twilight of the chatbots
How work changes along the exponential
If you feel like things are accelerating in AI, you are probably right. Better AI models from the leading American AI labs have been releasing more quickly than ever (though government interventions stopped access temporarily to two of the most powerful models, Claude Fable and GPT-5.6).
But it isn't just release timing. The evidence points to accelerating capability gains as well (though the frontier stays jagged, and AIs remain weak in many places). This is especially obvious when we look at the ability of AIs to do real work. There are a few good assessments that try to measure how much human work AIs can do. Two of the most famous, from METR and the UK’s official government AI Security Institute, estimate the amount of human programmer hours’ worth of effort the AI can do with a single prompt. GDPval compares human experts in many fields to AI performance using professional judges. They are all increasing at a better than exponential rate.
Another organization doing similar experiments, Epoch, recently found Opus 4.7, working on its own for 14 hours, was able to build a software package that would take 2-17 weeks of human engineering work (it cost $251 in tokens). Again, AI systems cannot pass every test, nor are they always cheap to run, but they are definitely improving at a very rapid rate. In my own experiments, I found Fable was able to work autonomously for 9 hours to execute on very complex software projects that would have taken a team well over a week to do.
So far, I have focused on the frontier models, those with the highest “intelligence.” They are made by three American companies — Anthropic, OpenAI, and Google (though it has been a while since Google has released a new model). But there is a second set of near-frontier AI models that typically lag 6-12 months behind the frontier, all of which are from China. These are open weights models, which means that anyone can use or modify them after release (as opposed to the frontier models which are proprietary). That makes them quite cheap to operate. They, too, are climbing up an exponential improvement curve, though lagging the American closed models. You can see this in my graph of AI performance in a test called AA-Briefcase, which simulates a complex multi-week consulting engagement where AI has to do many kinds of analysis. The open-weights Chinese models (other countries produce open weights models, but none are near the frontier) are on their own exponential curve, behind closed US models
But abstract graphs only get you so far, and they can hide how jagged the frontier is (and also the fact that the open weights models, while very impressive, do not always perform as well as their benchmarks would indicate). To get real insight, you need to try using AI for different use cases and rigorously assess how good they are in the areas that matter to you. As a fun example, I created a test where AIs have to build an interactive simulation of a harbor evolving over time. You can play with all the result here. I think it gives an interesting perspective on how much models can differ from each other in areas like design, stylistic approach, and even judgement. As systems do ever longer tasks, these hard-to-benchmark factors become more important.
The way we use AI is changing
As AIs can do longer and longer tasks, the way people are using AI is changing. Until recently, the dominant way to use AI was as a co-intelligence. You would ask the AI to do something, check the results, and then ask for it to do the next step of your job. By careful prompting and human attention, you could guide AIs to do complex and long-term tasks.
This approach to using AI is still common and useful, but, increasingly, it is not the way AI is being used for valuable work. Long-running, smart, and self-correcting AI systems do not need constant human intervention, and they require a different way of working. And, as opposed to chatbots, agents come with extra machinery: harnesses that give the AI access to tools and an environment to act in, and apps built for agents like Claude Code or OpenAI's Codex. As a result, the already increasing ability of AI models can be improved still further by a good harness or app.
So work is increasingly about assigning work to agents, rather than working together with chatbots. A joint study by OpenAI and academic economists shows how quickly this is happening inside their own organization. Critically, it isn’t just coders who are using agents. Legal, HR, and other non-tech functions have adopted agents at nearly the same rate. OpenAI may be a sort of canary in the coal mine for what will happen elsewhere in work.
Increasingly, work at OpenAI looks like managing AI. A quarter of OpenAI workers have at least four agents running at one time every week. And, as coding is done by AIs in specialized harnesses and apps, other roles start to become coders of a sort. And they are good at it. A separate study of Claude Code users found that software engineers had a similar success rate to other professions when actually using Claude code on coding tasks.
What actually mattered was not the profession of the user, but their expertise. The more domain experience someone had, the more successful they were in using Claude Code in that domain. And, even more interestingly, the more useful output they got from Claude from each prompt.
We are moving from a world where non-experts use chatbots to fill in gaps to one in which experts use agents to get work done. And the best way to use agents is to think of yourself as a manager.
A moment in time
Being on an exponential means each change over a fixed window is larger than the one before it. If your organization wrote an AI plan any time before the winter of 2025, it described a system that could do a couple of hours of work with a fairly high error rate. A few months later, you can get sixteen hours or more of work from a single prompt. This is why AI keeps feeling like it is making leaps, even though it is a curve on a graph, we keep experiencing a steady doubling of capability as a series of shocks. We are very bad at feeling exponentials from the inside, and we are currently inside one.
I think this also explains the turbulence around AI better than the usual stories about hype. AI is not capable of being a real cybersecurity threat until suddenly it is, causing sudden and improvised policy changes at the highest level of government. Markets discount whether AI might threaten to undermine a business model until suddenly it can, leading to massive swings in stocks. These lurches these get read as signs of an immature field that will eventually settle into something stable. I don’t think it is going to settle anytime soon. The instability is what happens when institutions that move at the speed of people (or worse, committees) try to track a capability curve that is very much not human in nature. And as long as we are on some sort of exponential, and for as long as it lasts, the gap only widens.

Dragonfly v2.5.0 is released
Dragonfly v2.5.0 adds native peer-to-peer acceleration for Hugging Face and ModelScope AI models and introduces webhook-based container injection for Kubernetes.
Decoder
- P2P (Peer-to-Peer) acceleration: A distribution method where nodes share file chunks with each other, reducing the load on central servers or container registries.
- Mutating Admission Webhook: A Kubernetes feature that intercepts and modifies API requests before objects are persisted, used here to inject Dragonfly sidecars automatically.
Original article
Dragonfly v2.5.0 is released!
Thanks to all of the contributors who made this Dragonfly release happen.
New features and enhancements
Direct repository downloads from Hugging Face and ModelScope
Dragonfly Client now supports directly downloading model repositories from Hugging Face and ModelScope. Users can run commands such as dfget hf://deepseek-ai/DeepSeek-OCR and dfget modelscope://models/deepseek-ai/DeepSeek-OCR to fetch repositories. Git LFS data is downloaded through Dragonfly P2P acceleration, while other repository metadata is fetched through the Git protocol.
For more information, please refer to Hugging Face repository download and ModelScope repository download.
Dragonfly Injector for Kubernetes Webhook Injection
Dragonfly provides dragonfly-injector, a Kubernetes Mutating Admission Webhook for automatic P2P capability injection. It can inject Dragonfly client binaries and configurations, dfdaemon socket mounts, and CLI tools into application Pods through annotation-based policies, enabling Pods to use Dragonfly for file downloads without rebuilding container images. Helm Charts now also support deploying Dragonfly with webhook injection enabled.
For more details, please refer to Using Dragonfly with webhook injection.
Blocklist for download control
Dragonfly supports configuring a blocklist in the Manager console to disable specific downloads. This can be used as an emergency measure to mitigate the impact of sudden abnormal requests on the service. When a blocked download is intercepted, gRPC downloads return a PermissionDenied error code, and HTTP proxy downloads return a FORBIDDEN status.
For more information, please refer to Blocklist.
Comprehensive rate limiting
Dragonfly introduces more complete rate limiting capabilities across the control plane and client. Manager and Scheduler gRPC servers now support a configurable request rate limit for unary requests and streaming connections. The client supports outbound bandwidth, inbound bandwidth, back-to-source bandwidth, prefetch bandwidth, upload request, download request, and adaptive rate limiting to better protect source services and improve system stability under high load.
For more information, please refer to Rate Limit.
dfctl command line tool
Dragonfly Client introduces dfctl, a command-line tool used to manage tasks in the client’s local storage, including tasks, persistent tasks, and persistent cache tasks. It supports listing and removing local resources, and can preheat file and image tasks through the Scheduler.
For more information, please refer to dfctl.
Container registry proxy configuration simplification
dfdaemon can now infer the upstream registry from the ns query parameter appended by containerd registry mirror requests. Combined with proxyAllRegistries: true, users can route all registries through Dragonfly with a single _default/hosts.toml configuration instead of maintaining separate registry-specific hosts.toml files and X-Dragonfly-Registry headers.
For more information, please refer to Infer upstream registry from containerd ns query parameter and proxyAllRegistries documentation update.
Client download and transfer optimization
Dragonfly Client improves download efficiency and file transfer reliability in multiple areas. The parent selector and piece collector now coordinate more closely to collect enough parent peers before scheduling decisions, improving bandwidth utilization while keeping graceful fallback for unstable parent peers. File export and download operations now use buffered writes, and gRPC stream buffer sizes and connection settings have been tuned for better large-file transfer performance.
HTTP handling and redirect security improvements
The HTTP backend now uses HTTP/1.1 and improves stat request handling by retrying with a HEAD request when a response has Transfer-Encoding but no Content-Length. Dragonfly also strips sensitive headers such as Authorization and Cookie when following cross-origin redirects, and avoids caching relative HTTP 307 redirect locations while still resolving them correctly during request processing.
Additional enhancements
- Add ExternalRedis TLS support in Manager, including CA certificate, client certificate, key, and insecureSkipVerify options.
- Remove deprecated V1 preheat API endpoints and consolidate health checks to the /healthy endpoint.
- Improve upload and download metrics collection and remove unused gRPC piece download logic.
- Improve INSTANCE_NAME generation by using Kubernetes build-time environment variables and falling back to the system hostname.
- Add dfdaemon hickory_dns options to make DNS resolver behavior configurable.
- Improve task ID calculation for OCI registry blob downloads to reduce redundant downloads and storage across registries.
Significant bug fixes
- Fixed the Redis Lua script argument order for peer TTL and concurrent_piece_count, preventing unintended key expiration and incorrect peer state.
- Fixed PostgreSQL SERIAL sequence handling after seeding default Scheduler Cluster and Seed Peer Cluster records, avoiding primary key conflicts when creating new clusters.
- Fixed relative HTTP 307 redirect handling by skipping cache for relative Location values and resolving them against the base URL before following redirects.
Nydus
New features and enhancements
- Support building prefetch-optimized layer blobs for Ondemand data.
- Support converting Nydus images to OCI format and converting to/from local archives.
- Support zero-disk transfer in Nydusify Copy.
- Introduce uffd-based support for the virtio-pmem DAX backend to enable high-performance on-demand image loading in Kata scenarios.
- Support switching the Storage layer from Proxy mode to Dragonfly SDK mode to improve P2P cache hit performance.
- Support committing with short container IDs and synchronizing the filesystem before commit.
- Support resending FUSE requests when recovering Nydusd, fixing hot-upgrade tests.
Significant bug fixes
- Fix Blobfs compatibility with fuse-backend-rs 0.12.0.
- Fix failover-policy parameter parsing.
- Fix a panic in Builder when a symbolic link overwrites a directory.
- Fix multiple issues in chunkdict deduplication logic, DBSCAN clustering, and chunk sorting.
- Fix Nydus image detection logic.
- Fix remount invalidation for nested mount points in fusedev.
- Fix abnormal values when Nydusctl backend metric counters are reset.
- Fix Nydusify failing to find blobs when image names are modified.
- Fix plain HTTP conversion in Nydusify.
Others
You can see CHANGELOG for more details.
Links
- Dragonfly Website: https://d7y.io/
- Dragonfly Repository: https://github.com/dragonflyoss/dragonfly
- Dragonfly Client Repository: https://github.com/dragonflyoss/client
- Dragonfly Injector Repository: https://github.com/dragonflyoss/dragonfly-injector
- Dragonfly Console Repository: https://github.com/dragonflyoss/console
- Dragonfly Charts Repository: https://github.com/dragonflyoss/helm-charts
- Dragonfly Monitor Repository: https://github.com/dragonflyoss/monitoring

How to migrate feature flags without breaking production
Safe feature flag migrations rely on running shadow evaluations in parallel, comparing results across both systems to identify discrepancies before a final cutover.
Decoder
- Shadow evaluation: Running two versions of logic simultaneously where one version is used for the application response while the other is only used for comparison/logging.
- OpenFeature: A vendor-agnostic specification and SDK suite for feature flags, maintained by the CNCF.
Original article
Feature flag migrations have a reputation problem. Ask anybody who’s been through one before and you’ll hear the stories, usually from someone still a little frustrated about a bad cutover, with a postmortem or two to show for it.
The reputation is mostly undeserved. While the risks are real, they’re well understood and easily controlled. Getting a migration right doesn’t require a big coordinated effort. It requires knowing what can go wrong and designing around it from the start.
Why feature flag migrations stall
In a large organization, a legacy SDK can span thousands of call sites across dozens of microservices. Replacing something like oldClient.variation with newClient.evaluate is repetitive work, but with agentic developer tooling, it can be done in days rather than weeks.
The harder problems are about risk, not effort. Production safety is the real concern and it comes down to three specific technical challenges:
- Check logic parity between systems. Feature flags aren’t just on/off switches. They encode complex evaluation logic, such as percentage rollouts, user segments, prerequisites, and dynamic payloads. Two systems rarely interpret the same rule identically.
- Configuration synchronization. During the migration window, product managers and engineers might keep modifying flags in the legacy system to ship features, run tests, and manage incidents. If rules are imported on Day 1 but the cutover happens two months later, the new platform is already out of sync and any validation done against the original state is now stale. Shortening the migration window limits exposure. Freezing configuration immediately before cutover eliminates it.
- Confirm cutover safety. Feature flags frequently sit in critical paths. A flag gating a payment flow or an infrastructure failover isn’t just affecting one user when it misfires. The entire service is exposed. Teams need confirmation that the new system produces identical evaluations before committing to a cutover.
Each of these challenges also has a cross-functional dimension: product managers need to know when to stop creating flags in the legacy system, and engineering teams need to communicate cutover timelines clearly so that no one is caught off guard. A migration freeze on a shared calendar is a small coordination habit that can prevent a large class of problems.
Logic parity, configuration synchronization, and cutover safety don’t need to be solved all at once. The right approach is to make the migration incremental by design and to accept something that sounds counterintuitive at first.
Is it really okay to run two feature flag systems at once?
Running two feature flag systems simultaneously is safe and already common in organizations that use separate systems for platform and product use cases. It can be mildly annoying in practice, but it’s not dangerous. The benefit to doing so is that it can allow migrations to take place naturally over a few weeks, instead of requiring a high-coordination high-risk sudden cutover.
The nightmare scenario that engineers might imagine when considering having two parallel feature flag systems is a critical incident in production where teams cannot find the right flag to disable. With a reasonable on-call setup, the engineer being paged owns that feature and knows where the flag lives.
Once you accept that two systems in parallel are workable, the migration path becomes less daunting.
How to structure a feature flag migration
Start with an audit. Before writing any code, categorize your existing flags. Most fall into three categories:
- Zombie flags have reached 100% rollout for months and should already be removed from the codebase. Start by cleaning these up. Don’t migrate technical debt.
- Short-lived flags govern experiments and temporary rollouts. They run for a few weeks or months before being cleaned up.
- Long-lived flags don’t have a clear expiry date. They are typically associated with kill switches, infrastructure configuration, or permanent feature gates. These require deliberate migration planning.
From this point, the strategy has three phases:
Redirect all new flags to the new system
Establish one rule immediately: all new flags must be created in the new system. Don’t migrate anything yet. Just stop adding to the old system. Redirecting new flags costs almost nothing and starts moving active flag logic toward the new platform.
Phase out short-lived flags
As short-lived flags complete their rollouts and get cleaned up, they disappear from the legacy system on their own. To accelerate this, enforce a deprecation policy: remove flags within a sprint or two of their reaching 100% rollout. In larger organizations, a hard 6–8 week rule is easier to enforce. With this in place, most of the flag inventory will migrate itself within a quarter.
Plan for the cutover
By this point there’s a much smaller list, mainly consisting of the long-lived flags that need careful handling. For each one, ask whether this is still needed. More than expected will turn out to be retirable. For those that remain, the focus is verifying correctness before cutting over.
Verify feature flag logic parity before cutover
Run both systems against real traffic and confirm they produce identical evaluations before committing to a cutover. There are two approaches, depending on the stack and how much set up makes sense.
Use a wrapper function
A simple wrapper function covers most migration scenarios. Evaluate both systems for every flag check, log any discrepancies, and return the legacy system’s answer as authoritative:
def evaluate(flag_name, context):
legacy_value = legacy_client.evaluate(flag_name, context)
new_value = new_client.evaluate(flag_name, context)
if legacy_value != new_value:
metrics.increment(
"feature_flag.migration.mismatch",
tags=[f"flag:{flag_name}"]
)
return legacy_valueRun the new system’s evaluation asynchronously to avoid adding synchronous latency. Keep mismatch logging asynchronous and non-blocking.
Set up shadow mode with OpenFeature
OpenFeature is a Cloud Native Computing Foundation (CNCF) incubating project that provides a vendor-agnostic API for feature flagging. The specification offers the same shadow-mode pattern as a first-class abstraction.
One caveat: OpenFeature’s multi-provider support covers only Node, Web, and Kotlin SDKs. If your stack sits outside those runtimes, or you’re migrating from an in-house system without an OpenFeature provider, the wrapper approach above is the more practical choice.
With OpenFeature’s ComparisonStrategy, teams can run shadow mode evaluation at the SDK level:
import { OpenFeature } from '@openfeature/server-sdk';
import { MultiProviderPlugin, ComparisonStrategy } from '@openfeature/multi-provider';
OpenFeature.setProvider(
new MultiProviderPlugin(
[legacyProvider, newProvider],
new ComparisonStrategy({
onMismatch: (flagKey, legacyValue, newValue) => {
metrics.increment('feature_flag.mismatch', { flag: flagKey });
}
})
)
);The ComparisonStrategy evaluates both providers on every flag check, returns the legacy value to the application, and fires a mismatch handler when results diverge, with zero user impact during the validation window.
Once parity is confirmed for a given flag or service, FirstMatchStrategy enables the actual cutover. The SDK evaluates the new provider first. If the flag isn’t found there, it falls back to the legacy system:
OpenFeature.setProvider(
new MultiProviderPlugin(
[newProvider, legacyProvider],
new FirstMatchStrategy()
)
);Using FirstMatchStrategy allows teams to migrate flags individually, on their own schedule, without touching application code again.
Both approaches produce the same result: a stream of mismatch events tagged by flag name and service. But that signal is only useful if someone is watching it and acting on what they see. Route mismatch metrics to a dashboard where teams can track parity trends and decide when to cut over.
Set up a feature flag migration dashboard
Route the mismatch metrics into a dashboard broken down by flag name and service, and track at least three things:
- total evaluations versus mismatches
- mismatch rate trend over time
- first-seen and last-seen timestamps per discrepancy
The mismatch rate trend line matters most. It should be declining toward zero and holding there, not fluctuating. A flag that’s been zero for several days across real traffic volume is ready to cut over.
With Datadog Feature Flags, engineers can send wrapper metrics directly into Datadog. Teams can correlate their feature flags with metrics, logs, and traces in a single view. If a mismatch is causing silent breakage in production, they can see it in context without switching tools.
Before cutting over any specific flag or service, briefly freeze its configuration in the legacy system. The state validated in shadow mode should match exactly what exists at cutover time. A freeze of 24–48 hours is sufficient for high-traffic flags to accumulate statistical confidence. For lower-traffic flags, extend the window accordingly.
Migrate safely with Datadog Feature Flags
While feature flag migrations can carry real risk, structuring the process in discrete, verifiable steps makes each one addressable. Flag evaluation discrepancies appear in Datadog alongside the metrics, logs, and traces. With the migration complete, flag deployments are observable in Datadog within the same context as your services and infrastructure.
Omniroute (GitHub Repo)
OmniRoute is a local AI gateway that aggregates 236 providers into one endpoint with automatic fallback and token compression.
Deep dive
- Implements a multi-layer fallback strategy (Subscription → API → Cheap → Free).
- Features a compression pipeline using 9 engines, including RTK, Caveman, and LLMLingua-2.
- Supports remote access for VPS-based agents via scoped authentication tokens.
- Provides built-in MCP server capabilities with 87 available tools.
- Uses TLS fingerprint stealth and a 3-level proxy system to bypass geographic access restrictions.
- Runs 100% locally with AES-256-GCM encrypted credential storage.
Decoder
- RTK (Rust Token Killer): A high-performance method for stripping non-essential command/shell output tokens before sending prompts to an LLM.
- MCP (Model Context Protocol): An open standard that allows AI assistants to securely connect to external data sources and developer tools.
- Caveman compression: A heuristic-based approach to abbreviating text by removing filler words while maintaining technical accuracy.
Original article
Full article content is not available for inline reading.

Cost Attribution in Discord's API
Discord engineers built a custom CPU profiling system to allocate infrastructure costs across 1,700+ API endpoints without breaking their unified codebase.
Original article
Discord's API is powered by a unified Python codebase containing over 1700 API endpoints and around 700 background tasks. Engineers make changes to this shared code every day as it's continuously deployed to several hundred separate Kubernetes deployments through a phased rollout process.
That is a lot of code, engineers, endpoints, and deployments! It can be challenging to keep track of all of the changes made every single day, but we have good instrumentation that allows us to keep an eye on latency, throughput, and error rates to help detect regressions that may negatively impact users or our systems.
One observability gap that we wanted to improve last year was our understanding of how hosting costs were allocated across product features. For example, how much does it cost to operate the parts of API that are used to send and receive messages? Start a stream? Send a friend a Nitro gift? How do these values change over time? Did that change someone landed last week meaningfully affect a team’s spend on hosting? We’d like to know these answers for both a single endpoint (e.g. sending a message in a text channel) and for an entire feature (e.g. chat - more on these later).
Most cloud providers will happily split out your costs by Kubernetes deployment, which is helpful but is only the first step due to how we deploy the API. We run the same codebase in all of our Kubernetes deployments, each of which handles a specific subset of HTTP traffic or background tasks. Since we already have so many deployments, breaking them up further to facilitate cost tracking isn’t tenable. We needed to find a way to add better tracking to our existing system without changing our deployment topology.
An additional challenge is that each API worker process handles multiple tasks concurrently. At any moment, it will be juggling work related to any number of features (we do isolate certain traffic to particular deployments, but not in a way that helps us here). Ultimately, in order to understand the cost of serving the API traffic related to a given feature, we need to be able to allocate the cost for a deployment based on how much time it spent on code related to that feature. By extending our application’s profiling tooling, we were able to do exactly this.
Note: all numbers and code in this post are for illustrative purposes only.

Exposing ApplicationSets Beyond YAML: Argo CD's ApplicationSet UI
Argo CD 3.5 debuts a first-class ApplicationSet UI, finally replacing the cumbersome 'App-of-Apps' workaround with native resource tree visualization.
Deep dive
- Introduces /applicationsets route with search, filters, and health dashboards.
- Adds 'Preview' functionality to simulate generator output (Live vs. Desired state).
- Enables synthetic root node visualization to track parent-child relationships in the resource tree.
- Maintains Git as the single source of truth (read-only UI).
Decoder
- ApplicationSet: A controller that automates the generation of multiple Argo CD Applications based on cluster labels, git paths, or other discovery sources.
Original article
Exposing ApplicationSets Beyond YAML: Argo CD’s ApplicationSet UI
We have a long-awaited feature request for ApplicationSet support in the Argo CD UI that has accumulated 189 👍 reactions. With v3.5, that’s changing — Argo CD now has a first-class ApplicationSet UI.
This post is about what’s actually in the UI and how it goes beyond adding a simple list page.
A quick AppSet refresher:
If you’ve used Argo CD’s Application UI, you know it’s the reason a lot of teams pick the project. Resource trees, real-time sync status, a clean diff view, and more. Argo CD made GitOps approachable for people who don’t live in YAML.
ApplicationSets fit awkwardly into all of that. Conceptually, they’re a factory for Applications: you write one resource that says “for every cluster matching this label, generate an Application from this template,” and the controller produces N child Applications. A single ApplicationSet can fan out across dozens of clusters and hundreds of repos.
The problem: Argo CD’s UI didn’t surface this.
Until v3.5, you had two options:
- Use kubectl or argocd appset on the CLI.
- Wrap the ApplicationSet inside an App-of-Apps and look through the parent Application’s tree.
What’s actually shipping in 3.5
We have a new /applicationsets route that's accessible with the new navigation bar item, along with a revamped Application icon.
A familiar list page
You get the same features you already use on the Applications list: substring match search, filters, a health-summary pie chart, and toggleable layouts. RBAC is enforced exactly as on the CLI — if you can argocd appset get, you can see it here.
A resource tree showing the family
Click into any ApplicationSet, and you get the visualization that we’ve all been waiting for: the ApplicationSet at the root, every generated child Application as a downstream node. Click a child, and you jump straight into its existing details page.
Health, a first-class field
Under the hood, the controller now writes a status.health field on the ApplicationSet itself, derived deterministically from its status conditions. Similar to Applications, the ApplicationSet health can be Healthy/Degraded/Progressing. The AppSet conditions will also be visible through the UI.
Slide-out panel
Clicking the ApplicationSet node or clicking the AppSet Details opens a slide-out panel from the right edge of the screen which includes Summary, Manifest, Events, Preview.
AppSet Preview
If the list page is what people asked for, the Preview feature is the ”wait, you can do that?” moment.
It mirrors argocd appset generate in the browser. Open an ApplicationSet, click Preview, and you’ll see an editable YAML of your AppSet spec.
Now click Edit on the manifest, change a generator (add a label selector, narrow a Git path, swap a cluster), and click Preview again. The diff regenerates against your edits. You’ll see three views:
- LIVE APPS — What apps would be generated with no edits
- DIFF — Unified diff of every Application that would change once we apply the change
- DESIRED APPS — What apps would be generated if the spec were applied.
The App-of-AppSet preview
If your ApplicationSet is managed by a parent App-of-Apps, you can preview from the parent too. The Preview panel on the parent shows exactly what child Applications would change when you sync.
This bridges what was previously a confusing two-step: ”I have a pending sync on a parent App — what does that actually do to my child Apps?”
Owner badges and root node on child Applications
Every Application generated by an ApplicationSet now carries an owner badge with the parent’s name on its resource tree. Click it, and you jump to the parent.
There is also a toggle-able icon where you can show the parent AppSet as a synthetic root node managing the Application itself.
Limitations to know about
This UI is meant to be read-only in the alpha phase. We are not using this UI to create/update/delete AppSets from the cluster itself. Argo CD is still a GitOps tool and git will always be the core write interface.
It will be an alpha feature in 3.5. The look and behavior may change as more features and improvements get added. Feel free to point out any issues or enhancements on the Argo CD repo or slack channel.
How to try it
Upgrade to Argo CD 3.5+ (Release Candidate Date: Tuesday, Jun. 16, 2026, GA date: Tuesday, Aug. 4, 2026.
Visit https://<your-argocd>/applicationsets, or use the new entry in the top-level navigation. The full feature reference lives in the ApplicationSet Web UI documentation.
Thank you
This is one of the longest-running enhancement requests in the project. It went through many design cycles, two milestone slips and 10+ PRs. Special thanks to @reggie-k, @keithchong, and @alexymantha for the initial design and implementation and @jwinters01 for helping review PRs.
Thanks to everyone else who helped with this feature whether that was reviewing PRs, helping with UI or API design, or implementation!
Amazon CloudWatch launches OTel Container Insights for Amazon EKS
Amazon CloudWatch now supports 30-second granularity OTel metrics for EKS, allowing direct integration with Prometheus and Grafana workflows.
Decoder
- OTel (OpenTelemetry): A vendor-neutral set of APIs and tools for collecting, processing, and exporting telemetry data (metrics, logs, traces).
Original article
Amazon CloudWatch launches OTel Container Insights for Amazon EKS
CloudWatch OTel Container Insights for Amazon EKS collects infrastructure metrics at 30-second granularity using open-source receivers including cAdvisor, Kube State Metrics, and NVIDIA DCGM. Each metric carries OpenTelemetry semantic conventions and Kubernetes labels, making it straightforward to correlate across nodes, pods, and workloads in a single PromQL query.
Pre-built dashboards give you immediate visibility into cluster health, node performance, and pod-level resource usage. The CloudWatch PromQL endpoint lets you connect existing Prometheus and Grafana dashboards directly to CloudWatch.
Enable it from the EKS console or via the CloudWatch Observability add-on (v6.2.0+), Helm, or CloudFormation.
Available in all commercial AWS Regions except Middle East (UAE), Middle East (Bahrain), and Israel (Tel Aviv). For pricing details, see the Amazon CloudWatch pricing page. To get started, see the OTel Container Insights documentation.

Nano Banana 2 Lite
Google launched Nano Banana 2 Lite, its most cost-efficient image model, and introduced Gemini Omni Flash for real-time conversational video generation.
Deep dive
- Nano Banana 2 Lite focuses on text-to-image latency, delivering results in approximately 4 seconds.
- Gemini Omni Flash supports multimodal input combinations (text, image, video) for consistent video editing.
- Both models are now accessible via Google AI Studio and the Gemini API.
- Features SynthID watermarking to help verify content authenticity.
- New demo apps 'Anywhere' and 'Space Lift' illustrate chaining these models for interactive media.
Decoder
- Logits: Raw output scores from a model before they are transformed into probabilities (like the likelihood of a specific image token).
- Multimodal: The ability for an AI to process and generate various types of media (text, audio, images, video) simultaneously.
Original article
Start building with Nano Banana 2 Lite and Gemini Omni Flash
We’re making it easier to experiment and scale your ideas with Nano Banana 2 Lite, our fastest, most cost-efficient Gemini Image model, and Gemini Omni Flash for high-quality video generation and conversational editing.
Today, we’re making it faster and easier to experiment, refine and scale your ideas with two major releases:
- Introducing Nano Banana 2 Lite: Our fastest, most cost-efficient image model in the Nano Banana family yet, built for high throughput, speed and scale. Nano Banana 2 Lite is available today in Google AI Studio, Gemini API and Gemini Enterprise Agent Platform. It is also rolling out today in Google consumer surfaces including AI Mode in Search, Gemini app and many other products.
- Bringing Gemini Omni Flash to developers: Our high quality, cost-efficient model for video generation and conversational editing, now available in Google AI Studio, the Gemini API and Gemini Enterprise Agent Platform for the first time. Omni Flash is also available in the Gemini app and Google Flow.
Building with generative media is often about creative iteration. With these two models, developers can build comprehensive, end-to-end multimedia experiences that connect rapid image generation with video creation and editing. Whether your workflow requires generating thousands of images or editing multi-turn video sequences, you now have two new models to build faster, iterate seamlessly and bring your creative vision to life.
Nano Banana 2 Lite: our fastest most cost-efficient Gemini Image model
Nano Banana 2 Lite (gemini-3.1-flash-lite-image) is designed for rapid ideation and high-velocity developer pipelines where speed and cost are the primary constraints. It’s our recommended replacement for developers currently using our first version of Nano Banana (gemini-2.5-flash-image), you can swap it out now for immediate benefits across key performance dimensions.
Nano Banana 2 Lite shines in:
- Latency: Delivers text-to-image outputs in 4 seconds. This makes it ideal for interactive prototyping and rapid visual drafting.
- Cost-efficiency ($0.034 per 1K image): A cost-efficient choice for developers focused on drafting, ideating, managing operational budgets or low-bandwidth usage.
Despite prioritizing speed, Nano Banana 2 Lite retains reliable prompt adherence, strong character consistency and legible in-image text rendering.
Understanding the Nano Banana family
- Nano Banana 2 Lite (Gemini 3.1 Flash Lite Image): Built for speed. Optimized for near-real-time, high-volume workflows where ultra-low latency is critical.
- Nano Banana 2 (Gemini 3.1 Flash Image): The generalist workhorse. Delivers high quality at a lower latency, offering the best balance of performance and cost.
- Nano Banana Pro (Gemini 3 Pro Image): Optimized for complex, professional use cases. It provides the most robust control and advanced reasoning for tasks where accuracy is more important than speed.
- Nano Banana (Gemini 2.5 Flash Image): Our legacy model. We recommend upgrading to Nano Banana 2 Lite for better quality, faster speeds and lower costs.
Experience high-quality, cost-efficient video editing and generation with Gemini Omni Flash
At Google I/O we introduced Gemini Omni Flash, the model where Gemini’s multimodal reasoning meets video generation and editing. Today, Gemini Omni Flash (gemini-omni-flash-preview) is rolling to developers via the Gemini API and Google AI Studio, natively supporting high-quality video generation and conversational editing from a combination of text, image and video inputs. This model is priced competitively at $0.10 per second of video output, which is the same as Veo 3.1 Fast.
Omni Flash shines in:
- Conversational video editing: Refine and edit videos using natural language.
- Multimodal referencing: Combine inputs like images, text and video to maintain control and consistency over your scene.
- Real-world knowledge: Omni draws on Gemini’s knowledge such as history, biology and narrative logic to construct compelling videos.
- Text and action synchronization: Connect text and graphics directly to video actions, through simple prompting.
Limitations:
- Omni offers 10-second video generations currently, with longer durations coming soon.
- Uploading audio references and scene extension is not yet supported in the Gemini API for this model.
- Video references up to 3 seconds in duration are accepted by the API schema but are not correctly processed by the model at this time.
- Character consistency when changing scenes or panning movements has some limitations but we are working to make this better.
Build with both models today
The real magic happens when you chain these models together. Use Nano Banana 2 Lite as a high-speed image generation model, then pass that image as a reference to Gemini Omni Flash to animate it into a high-quality video. Plus, by using the Interactions API for these multi-turn experiences, you can maintain session history and context so users can stack up to three sequential edits.
To help you get started we created a few demo apps you can remix that let you experience how you can pair both Nano Banana 2 Lite and Gemini Omni Flash into one workflow.
Build with safety and transparency
Built on Google’s secure infrastructure, Gemini Omni and Nano Banana 2 Lite use SynthID watermarking. You can verify AI content through the Gemini app, Gemini in Chrome or Search.
Start your project today
Nano Banana 2 Lite resources:
- Head over to Google AI Studio to experiment with the model in the playground.
- Dive into our Gemini API Documentation.
- Check out our Nano Banana prompting guide, filled with best practices and example prompts.
Gemini Omni Flash resources:
- Head over to Google AI Studio to experiment with the model in the playground.
- Dive into our Gemini API Documentation.
- Check out our Gemini Omni Flash prompting guide, filled with best practices and example prompts.

Popping the GPU Bubble
Moondream's Photon engine achieves near-realtime inference by pipelining CPU housekeeping underneath GPU math loops, eliminating idle 'GPU bubbles'.
Deep dive
- Identifies 'GPU bubbles' where the GPU idles while the CPU performs necessary metadata and batch-management tasks.
- Implements 'ping-pong slots' (dual buffers) to allow GPU work for step 't+1' to begin while the CPU is still finalizing step 't'.
- Uses 'forward now, sample later' to allow GPU compute to proceed before the sampling mask is fully determined.
- Introduces a 'zombie' refcounting system to manage sequence completion without breaking the pipelined flow.
- Demonstrates up to 35% higher throughput on NVIDIA B200 hardware through these architectural optimizations.
Decoder
- GPU Bubble: A period of idle time where the GPU waits for the CPU to finish tasks (like metadata selection or kernel launching) before proceeding to the next mathematical step.
- Autoregressive: A method of sequence generation where the next token (chunk of text) depends on the previous ones, necessitating a sequential loop.
- KV Cache (Key-Value Cache): A memory optimization that stores previously computed attention keys and values to prevent recalculating them for every new token.
Original article
Popping the GPU Bubble
Photon, Moondream's inference engine, achieves near-realtime VLM inference (~33ms on NVIDIA B200). This is a peek into how it delivers up to 35% higher decode throughput by optimizing how the GPU works.
How do you make an AI model run as fast as possible? This is a question we obsess over at Moondream HQ. The GPU handles all the math involved in model inference, so at first glance it doesn't seem like there's much to it: just tell it what to do and wait for the answer. But if you start looking at how it actually works under the hood, you find that the GPU often sits idle, not for lack of work, but because the CPU hasn't told it what to do next yet. This phenomenon is called a GPU bubble.
When a typical AI model generates text, it produces one token at a time (a token is a chunk of text, roughly a few characters). Each token depends on the tokens before it, a property called autoregressive, so generation is sequential. You can't compute the third token before you have the second. This decode loop involves a round trip between the CPU and GPU. The GPU does most of the heavy lifting to run the actual model, performing billions of arithmetic operations to produce the next token. But there's also a surprising amount of work done by the CPU. It selects which requests to run next, sets up the metadata the GPU needs for them, picks the actual token out of the model's output and records it, and more.
The challenge is that one token's worth of GPU work is small, while the CPU housekeeping is a fixed cost paid on every trip. If the GPU has to wait for that housekeeping before it can start the next token, it sits idle for part of every loop. This is why we get GPU bubbles.
In this post we're going to dive into how Photon hides these bubbles using a technique called pipelined decoding. The idea is to overlap the two kinds of work: we start GPU work on the next token while the CPU is still finishing the last one.
The bubble
Here's the shape of the problem.
In the blocking version (top), every step is a baton pass. The CPU plans and launches a forward, the GPU runs it, then the CPU synchronizes, waits for the results to land, commits them, and only then starts planning the next step. This is because the plan depends on the token we select. For example, if the model indicates it has finished answering, then we need to schedule a new pending request from our queue. The GPU sits idle waiting for the CPU to finish its commit-plan-launch work.
The fix is to pipeline the loop. Launch the next forward while the current step's token is still coming back and being committed. That's the pipelined version (bottom): the forwards run back-to-back, and the CPU work is overlapped underneath them.
The reason we can is that the token we just sampled doesn't have to leave the GPU. The next forward reads it straight from GPU memory as its input. We still want a copy on the CPU eventually, to detokenize it, stream it, and decide whether the request is done, but that is bookkeeping we can do a moment later, in the background, while the next forward already runs. Not waiting on that copy is the move that removes the bubble.
Mechanism 1: ping-pong slots
To run a decode step, the GPU needs a working set of buffers: a place to stage the input (the last generated token and its position in the sequence), a place for the model to write its output (the logits, one score per word in the vocabulary), a place to land the sampled token, and some bookkeeping the attention kernel needs to find each sequence's cached keys and values (its KV cache). We keep pinned (page-locked) host buffers on both ends, so the copies on and off the GPU run as background DMA (direct memory access) transfers instead of blocking the CPU.
These buffers are allocated once and reused on every step. We work hard to avoid performing GPU memory allocations at runtime, because they can cause device synchronization and introduce bubbles. Fixed buffer addresses are also needed for capturing the decode step once as a CUDA graph and replaying it, reducing kernel launch overhead. We call this bundle a DecodeSlot.
This works, but introduces a blocker for pipelining. The buffers stay in use until the step is done, so we cannot start the next step until the current one finishes. To overlap two steps, the second step needs its own working set, otherwise it can overwrite the results of the first step before the CPU has read them. So we keep two slots and alternate between them, ping-pong style.
One thing to note about launch: we don't execute kernels the instant we issue a launch from CPU. Instead, we enqueue them onto a stream -- an ordered queue that the GPU drains in order. Work on the same stream runs sequentially, while work on separate streams can overlap. Both slots put their forwards onto the same compute stream. The slots are not for GPU parallelism. They only exist so the CPU can process one slot's results while the GPU runs the other slot's forward.
The forwards all share that one compute stream, but the copies do not. Each step's device-to-host copy, the one that brings the sampled token back for bookkeeping, goes on a separate copy stream, so it can run while the GPU is busy with the next forward. That is what lets us not wait for it. We anchor the copy to an event recorded the instant the step's outputs are written, so it waits on exactly that step's work and nothing queued behind it.
A slot only becomes free once its results have been read, not just once the GPU is done with it. Its pinned host buffer is the landing site for a copy that may still be in flight, so handing the slot to a new step too early would overwrite a copy mid-transfer, creating a hard-to-debug corruption bug. So the slot stays reserved through the commit that reads it, and is released only once that commit has finished.
Mechanism 2: forward now, sample later
The next forward can run ahead because it doesn't depend on anything the CPU does with the last token. But two things about the next step do depend on the last step's committed result. One is which sequences are still in the batch: if a request just finished, it shouldn't be in the next forward. That is the next section (zombies). The other is what tokens the next step is even allowed to sample, and that one is this section.
It comes from constrained decoding. Moondream's spatial skills return structured output instead of free text: point returns a coordinate, detect returns boxes, segment returns an outline. We get those from the same decode loop by restricting which tokens the model may produce at each step: we force the scores (the logits) of the disallowed ones to negative infinity before we sample. A point step has to emit a coordinate, a detect request walks an x, y, size cycle, and so on. Which tokens are allowed, the mask, depends on what has been produced so far, so the mask for step t+1 depends on the token we sampled at t.
The dependency is in sampling, not in the forward.
Each scheduler tick goes through three phases: launch, commit, and finalize:
- Launch the forward for t+1. It doesn't depend on the mask, so it goes immediately.
- Commit step t: wait on the in-flight copy and advance the request's decode state. That is needed to decide the mask for t+1.
- Finalize sampling for t+1: with the state current, build the mask and sample.
Sampling t+1 lands after committing t because the commit is what makes t+1's mask correct. We call this "commit-before-finalize" ordering. The GPU runs the t+1 forward through steps 2 and 3, so the commit disappears from the critical path.
For plain text there is no mask, so forward and sampling can both run a step ahead. For constrained sequences the forward still runs ahead, but sampling waits on the previous commit, which caps how far ahead we get with no special-casing. One loop handles both.
Mechanism 3: zombies: finalize early, release late
Back in forward now, sample later we flagged two ways the next step depends on the last step's committed result. The sampling mask was one. Batch membership is the other, and it takes a bit of care to handle right.
To launch step t+1 we first decide its batch, which sequences are in it, and we do that before committing step t. So what happens when a sequence hits its stop token at t, but is already baked into t+1's forward? You can't un-launch GPU work. The sequence is finished, yet still physically present in a batch that's executing.
Photon calls these zombies, and instead of bolting on cancellation logic, it lets the behavior emerge from two per-sequence fields:
finalized:Trueafter the sequence has hit EOS or its length cap.inflight_refs: the number of in-flight steps that still reference this sequence (0, 1, or 2).
When step t commits and detects EOS, the sequence is marked finalized and its result is emitted — but it isn't torn down, because inflight_refs is still nonzero (step t+1 references it). At step t+1's commit, the sequence is already finalized, so the commit is skipped: no token is appended, no state mutates. The zombie was harmlessly along for the ride — it occupied its slot and wrote some KV that nobody will read. Only when inflight_refs finally hits 0 are its KV pages and LoRA slot released.
This finalize-early, release-late dance is a small amount of refcounting that replaces what would otherwise be a thicket of "cancel this row mid-flight" special cases.
Prefill rides the same pipeline
So far this has all been about decode steps, but a real serving loop is constantly doing two different kinds of work: prefill (processing a new request's prompt + image, the expensive one-shot forward over many tokens) and decode (one token at a time for everyone already running).
Photon doesn't separate them. A prefill is just another kind="prefill" launch in the same two-slot pipeline. Because the pipeline only cares that a slot is free, not what kind of work last used it, a prefill forward can be launched into one slot while a decode step from the other slot is still being committed, and vice versa. The expensive prefill forward runs on the GPU while the CPU commits decode results; the next decode forward runs while the CPU finishes admitting the just-prefilled request. The same commit ordering (and the same inflight_refs bookkeeping) keeps everything correct across the two kinds, so none of the zombie or constrained-decode logic needs a special case for "what if a prefill is in flight."
A cost model for the bubble
How much should pipelining actually buy you? You can predict it from the parts of a decode step, and then check the prediction against measurement.
A decode step is three pieces of work:
- forward: the heavy GPU matmuls. At decode this is memory-bandwidth bound: every token streams the whole weight set through the cores, so it has a floor near
weight_bytes / memory_bandwidth. It shrinks as memory gets faster or as the model gets smaller. - sampling: turning the scores into a committed token: the constrained-decode mask, the argmax/sample, the spatial (grounding) decode, and the device→host copy of the result. All GPU work.
- bookkeeping: the CPU around it. Choose the next batch (
plan), launch the graph (launch), commit the previous step (commit).
A blocking loop runs the three in series, so the GPU sits idle through the bookkeeping — that idle is the bubble. Pipelining slides the bookkeeping of one step underneath the forward + sampling of the next, so the period collapses toward forward + sampling and the bubble disappears. Measured per step, pipelined, that's exactly what we see — the GPU is busy for essentially the whole period (steady-state medians, moondream2, ms):
| forward (ms) | sampling (ms) | period (ms) | |
|---|---|---|---|
| 3090 · 1 stream | 4.87 | 0.20 | 5.10 |
| 8 streams | 6.66 | 0.27 | 6.97 |
| 32 streams | 10.24 | 0.26 | 10.52 |
| B200 · 1 stream | 2.45 | 0.14 | 2.63 |
| 8 streams | 3.12 | 0.14 | 3.30 |
| 32 streams | 3.80 | 0.14 | 3.98 |
speedup = T_block / T_pipe × (1 − z)
└─ bubble hidden ─┘ └─ zombie tax ─┘
| blocking (ms) | pipelined (ms) | L | predicted | observed | |
|---|---|---|---|---|---|
| 3090 · 1 stream | 5.44 | 5.10 | 104 | +5.7% | +6.5% |
| 8 streams | 7.52 | 6.97 | 113 | +7.6% | +7.8% |
| 32 streams | 11.74 | 10.52 | 113 | +11.1% | +11.6% |
| B200 · 1 stream | 3.11 | 2.63 | 115 | +17.2% | +17.6% |
| 8 streams | 4.04 | 3.30 | 115 | +22.2% | +21.9% |
| 32 streams | 5.55 | 3.98 | 104 | +39.1% | +35.4% |
It's never just one thing
That's the whole technique: ping-pong slots so two steps don't collide, a forward/sampling split so even constrained decoding can run ahead, and a little zombie refcounting so finished requests tear down cleanly. The GPU stops waiting on the CPU, and you get back anywhere from a few percent to a third; more the faster your accelerator/model is.
But Photon isn't fast because of this one technique, or any single technique. It's fast because dozens of these details compound across the serving stack: how we resize and tile images on the way in, the kernels that run the model, the scheduler ordering here, and the synchronization points we remove from the hot path. No one piece is the whole story; the stack gets fast when enough of them line up.
Meituan launches LongCat-2.0 1.6T parameter model on APIs
Meituan has launched LongCat-2.0, a 1.6-trillion-parameter MoE model that powers the widely used 'Owl Alpha' agentic model.
Decoder
- Mixture-of-Experts (MoE): A neural network architecture that activates only a specific subset of the total parameters for each processed token.
- Agentic coding: The ability of an AI model to operate independently to perform multi-step software development tasks.
Original article
Meituan has unveiled LongCat-2.0, marking a significant advancement in its LongCat model family following the earlier LongCat-2.0-Preview. This new model is designed as a 1.6 trillion-parameter Mixture-of-Experts system, with approximately 48 billion parameters active per token. It is aimed at agentic coding, tool use, long-context work, automated workflows, and the execution of complex instructions.
LongCat-2.0 features a 1 million-token context window and a maximum output length of 128K tokens via the LongCat API Platform. Developers can access it through OpenAI-compatible and Anthropic-compatible API formats, with support for Claude Code, OpenClaw, OpenCode, Kilo Code, and Codex-style workflows.
Introducing LongCat-2.0 🐱 1.6T parameters · MoE with ~48B active · 1M context The full model behind Owl Alpha on @OpenRouter — now available. Built for agentic coding from the ground up: ◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens
The company reports that the full training run and deployment were conducted on AI ASIC superpods, with pretraining across more than 35 trillion tokens. LongCat also introduced LongCat Sparse Attention for long-horizon tasks and trained the model on hundreds of billions of tokens of 1M-context data, positioning the system for large repositories, long documents, and multi-step agent tasks.
The release is publicly available via the API, and billing is now active. The pay-as-you-go pricing structure currently supports LongCat-2.0 at:
- $0.75 per 1M uncached input tokens
- $0.015 per 1M cached input tokens
- $2.95 per 1M output tokens
Lower limited-time prices are also listed by LongCat. Token packs are valid for 30 days, and cache hits do not count against token-pack usage.
This release is not yet a full weights drop. The GitHub repository is public under an MIT license, but both the repository and Hugging Face model card indicate that model weights are forthcoming. This makes the launch a hybrid release for now: usable through the API and documented in public repositories, while the downloadable model weights remain pending.
Some of you guessed right. 👀 Owl Alpha on @OpenRouter — that's us. Since going live, it has reached Top 3 globally by daily volume — and #1 on Hermes Agent, #2 on Claude Code, #3 on OpenClaw by monthly volume. Thank you to everyone who tested and used Owl Alpha during stealth…
LongCat-2.0 is also linked to Owl Alpha, the previously undisclosed model running on OpenRouter. LongCat’s official account describes LongCat-2.0 as the full model behind Owl Alpha, while OpenRouter lists Owl Alpha as a 1.05M-context agentic model with tool-use, code-generation, automated workflow, and complex instruction-following capabilities. OpenRouter’s free-models page lists Owl Alpha at 3.74T tokens, indicating the model had already seen significant developer usage before the reveal.
Meituan, the company behind LongCat, describes the project as a family of large language models designed to make AI useful in physical-world scenarios. The team has already released LongCat-Flash-Chat, LongCat-Video, LongCat-Image, LongCat-Next, and other AI projects, positioning LongCat-2.0 as the new flagship language model in a broader multimodal and agent-focused portfolio.
Miles: A PyTorch-Native Stack for Large-Scale LLM RL Post-Training
Miles is a new open-source framework from RadixArk that simplifies distributed Reinforcement Learning for large-scale LLM post-training.
Deep dive
- Miles uses Ray actors for stateful management of rollout servers and training ranks.
- It enables asynchronous RL by allowing rollout workers to stream samples independently of the trainer.
- The framework integrates with Megatron-LM to reuse established distributed training primitives and configurations.
- Miles includes specific 'plugin model specs' to support new architectures without requiring a framework fork.
- It offers 'Rollout Routing Replay' to keep Mixture-of-Experts routing decisions aligned across the generation and training phases.
- Built-in observability uses the PyTorch profiler and Ray dashboard for performance debugging.
Decoder
- Rollout: The process of generating model responses in an RL context, usually for sampling and evaluation.
- MoE (Mixture-of-Experts): A dense model architecture where only a fraction of parameters are computed for every token.
- NCCL/RDMA: Technologies used for high-speed, low-latency communication between GPUs in a cluster.
Original article
TL;DR
Miles is RadixArk’s open source framework for large-scale LLM RL post-training. It composes SGLang for rollout, NVIDIA Megatron-LM for training, Ray orchestration, and PyTorch-native extensibility behind a small, pluggable trainer, with unified low-precision recipes, MoE-aware rollout/training alignment, fast NVIDIA NCCL/RDMA weight synchronization, observability, and fault tolerance built in — making frontier-scale LLM RL easier to build, reproduce, and operate.
Why Miles?
Reinforcement learning has become a central part of post-training large language models. But as models become larger, transition from dense to mixture-of-experts (MoE), and run across more distributed and specialized hardware (e.g. NVIDIA Blackwell and Hopper series), RL post-training is no longer just a training loop. It is a distributed systems problem.
A modern LLM RL framework needs to coordinate several moving pieces:
- Rollout workers must generate samples at high throughput.
- Trainers must consume those samples efficiently and compute stable policy updates.
- The rollout policy and training policy must stay synchronized.
- Large MoE models introduce routing behavior that must remain aligned across rollout and training.
- Low-precision recipes need to work consistently across the full pipeline.
- Long-running jobs need observability, checkpointing, and fault tolerance from the start.
Miles was built for this setting.
Miles is RadixArk’s open source reinforcement learning framework for LLM post-training. It is built natively on SGLang for high-throughput rollout and integrates deeply with Megatron-LM for scalable training, uses Ray to orchestrate the distributed system, and keeps PyTorch as the common programming and numerical layer throughout the stack.
The goal is simple: make large-scale LLM RL training more composable, reproducible, and easier to scale, while keeping the core trainer small enough for researchers and infrastructure teams to customize.
The Miles Architecture
Miles follows a small-core, many-edges philosophy.
The core training loop is intentionally compact. The pieces that users most often want to change — rollout logic, reward computation, loss functions, sample filtering, metrics, and training-loop hooks — are attached at launch time through user-supplied Python modules. This lets teams adapt the system to new algorithms and production constraints without forking the framework.
Underneath that small core, Miles composes four major systems:
- SGLang for high-throughput rollout generation.
- Megatron-LM for scalable distributed training.
- Ray for cluster orchestration, actor lifecycle, scheduling, and supervision.
- PyTorch for models, autograd, distributed primitives, dtype support, extensibility, and profiling.
This composition is important. RL post-training requires generation and training to work together, but the two phases have very different performance profiles: rollout is memory-bandwidth-bound (KV-cache and parameter reads dominate during decoding), while training is compute-bound and communication-heavy. Weight synchronization, sample transfer, checkpoint conversion, routing consistency, and low-precision behavior all need to be handled carefully across the boundary.
The rest of this post walks through how Miles handles each piece of that boundary — orchestration with Ray, scaling with Megatron-LM, extensibility with PyTorch, and what comes out of the box.
Ray: Orchestrating Long-Running RL Jobs
Miles is built directly on the Ray distributed runtime. In a Miles run, every long-lived process is represented as a Ray actor: trainer ranks, SGLang rollout servers, routing proxies, and asynchronous rollout workers all live inside Ray’s actor model.
This gives Miles a natural foundation for cluster-scale RL workloads.
Placing workers on GPUs
Miles uses Ray’s GPU-aware scheduler and placement groups for actor placement, supporting disaggregated (rollout and training on separate nodes) and colocated (rollout and training on the same nodes) layouts via launch-time Ray placement specs. Process placement must be rack-aware to facilitate careful colocation, reserving spare nodes, and key for error isolation, since isolating problems within a rack (e.g., distinguishing a bad GPU from a full rack issue) is not always straightforward.
Moving data across the RL pipeline
Prompts, samples, and updated weights cycle continuously between rollout actors and trainer ranks, and Miles uses Ray actors and tasks to coordinate that flow. For bulk weight transfer, Ray handles the control path while the tensor bytes move over dedicated NCCL/RDMA channels, giving Miles both Ray-level programmability and a fast path for large data.
Supervising long-running jobs
Because a Miles run is a Ray job end-to-end, it inherits Ray’s operator surface — job submission, worker supervision, log aggregation, and dashboard visibility — without bolt-on infrastructure. With fault tolerance enabled, Miles can recover failed ranks and keep week-long workloads moving on top of the same Ray substrate.
Supporting fully asynchronous RL
Because Ray actors are persistent, hold their own state, and are scheduled independently, Miles can run a fully asynchronous mode in which rollout and training no longer block on each other — rollout actors continuously stream samples into a queue that the trainer drains at its own pace.
Megatron-LM: Scaling the Training Backend
Miles uses Megatron-LM as its production training backend, plugging directly into Megatron’s argument parser, model-construction pipeline, training loop, parallelism primitives, and distributed checkpoint format rather than wrapping it as a black-box library. That gives Miles the infrastructure needed for frontier-scale dense and MoE training while preserving a clean user-facing workflow.
One argument surface
Megatron-LM already exposes a large distributed-training configuration surface — sequence length, rotary embeddings, grouped GEMM, all flavors of parallelism, optimizer settings, activation checkpointing, and more — and Miles reuses it directly rather than wrapping or re-declaring it. Users configure a Miles run through one launch script that combines Miles-specific options with standard Megatron options, avoiding duplicated configuration layers and keeping the training setup close to upstream Megatron behavior.
Model specs instead of long-lived forks
Frontier architectures change quickly, with new attention blocks, routing mechanisms, and expert layouts arriving across model families, so Miles handles them through plug-in model specs — small spec files that insert custom PyTorch components (for example, a gated attention-output module, a Gated-Delta-Net block, or a model-specific MoE router) directly into Megatron’s model pipeline. This lets Miles support new architectures — for example DeepSeek-V3/V4, GLM-4.7, and Qwen3 MoE variants — without maintaining a long-lived Megatron fork that constantly diverges from upstream.
Parallelism-aware checkpointing
Miles uses Megatron’s parallelism-aware distributed checkpoint format, so a model can be converted from Hugging Face once and then loaded across different tensor / pipeline / context / expert parallel configurations without re-converting weights from scratch. For teams operating large training jobs, this means checkpoint conversion and parallelism changes don’t become a separate engineering project every time the model or cluster shape changes.
Extending training without patching the backend
Miles exposes hooks at well-defined points in the training loop — after model initialization, before log-probability computation, and before each training step — so users can add auxiliary losses, custom metrics, sample-level diagnostics, clipping rules, or algorithm-specific behavior without editing Megatron internals. The design goal is simple: keep the backend powerful, but keep user customization outside it.
PyTorch: The Common Layer for Models, Numerics, and Extensibility
PyTorch is the common programming model inside Miles: model components are regular torch.nn.Modules, losses are standard autograd graphs, and mixed precision, gradient checkpointing, distributed primitives, and profiling all stay inside familiar PyTorch workflows. This matters because LLM RL post-training changes fast — teams need to add new rewards, losses, routers, model modules, and debugging tools without learning a new abstraction each time.
PyTorch-native model extensibility
Miles’ plug-in model-spec mechanism is built around torch.nn.Modules, so supporting a new architecture means writing the new component as ordinary PyTorch code and connecting it into Megatron’s model pipeline — autograd, mixed precision, gradient checkpointing, and module lifecycle all keep working the way PyTorch users expect. Teams don’t have to translate the model into a separate intermediate abstraction to get it running on Miles.
PyTorch-native RL customization
The same principle applies to RL algorithms: rollout functions, rewards, loss functions, sample filters, metrics, and training-loop hooks are all customized through Python modules provided at launch time, using standard PyTorch operations that compose with the rest of the training graph. A team can start from an existing recipe and replace the reward, add an auxiliary loss, change sample filtering, or instrument new diagnostics without rewriting the trainer.
Low-precision recipes across the pipeline
Miles builds its low-precision pipeline on PyTorch’s dtype system, with BF16, FP8, MXFP8, and INT4-QAT recipes that span training and rollout rather than living as isolated backend-only features. This consistency matters for RL because the policy used to generate samples and the policy used to compute training log probabilities must stay aligned, and Miles is designed to make those numerical choices explicit and reproducible.
Profiling and debugging in familiar tools
Large-scale RL performance issues can surface anywhere — rollout latency, training compute, collective communication, data movement, weight synchronization, sample filtering, or scheduling — so Miles wires in the PyTorch profiler to capture Chrome traces of training phases for inspection in standard tooling. Combined with Megatron’s PyTorch-based backend and graph-compile paths where supported, this keeps debugging and performance work inside the familiar PyTorch ecosystem.
What Miles Provides Out of the Box
Miles is designed to provide the core systems features needed for large-scale LLM RL post-training:
- Rollout and training integration — Connects SGLang rollout with Megatron-LM training, with both disaggregated and colocated execution to fit different GPU budgets and utilization targets.
- Asynchronous execution — Fully async mode decouples rollout from training: rollout actors stream samples continuously into a queue that the trainer drains at its own pace, eliminating the per-iteration blocking between the two phases.
- Fast weight synchronization — After each training update, fresh weights flow to rollout workers over dedicated NCCL/RDMA channels, with Ray handling only the control path so bulk tensor bytes stay off the Python data path.
- MoE-aware rollout/training alignment — Rollout Routing Replay preserves routing decisions across the rollout/training boundary, reducing the trainer-vs-rollout routing mismatch that would otherwise destabilize MoE RL.
- Low-precision support — A unified BF16 / FP8 / MXFP8 / INT4-QAT pipeline designed as part of the end-to-end RL stack rather than as isolated training-only recipes.
- LoRA across rollout and training — LoRA is supported in both rollout and training paths, enabling parameter-efficient post-training that reduces cost and speeds up iteration on large base models.
- Fault tolerance and observability — Ray’s job and actor model provide supervision, log aggregation, and dashboard visibility, while rank-level fault tolerance keeps week-long training runs moving; PyTorch profiler integration covers the training-level view.
- Broad model and hardware support — Miles ships ready-to-run recipes for frontier and open-source models including DeepSeek-V4, Kimi K2.5 / K2.6, GLM-5 / 5.1, and Qwen3.5 / 3.6, with support for NVIDIA flagship Hopper / Blackwell GPUs.
A Small Core with Many Extension Points
One of Miles’ most important design choices is that the core trainer stays small.
Instead of forcing users to fork the framework for every new algorithm or model family, Miles exposes explicit extension points:
- Rollout functions for custom generation behavior.
- Reward functions for task-specific supervision.
- Loss functions for new RL objectives.
- Sample filters for data selection and rejection.
- Training hooks for metrics, diagnostics, auxiliary losses, and custom update logic.
- Model specs for architecture-specific modules.
These extension points make Miles useful across a range of post-training workflows: classic RLHF-style training, rule-based reward training, code and agentic tasks, MoE post-training, low-precision experiments, and production pipelines that need custom observability or safety checks.
In short, Miles makes the systems-level decisions — placement, weight sync, fault tolerance, low-precision recipes — so that user code can focus on algorithm and product logic.
Looking Ahead
LLM post-training is moving quickly — larger models, longer contexts, more MoE, and more asynchronous, agentic, system-intensive RL pipelines — and Miles is built for that trajectory: by composing SGLang, Ray, Megatron-LM, and PyTorch behind a small pluggable trainer, it gives researchers and infrastructure teams a PyTorch-native path from algorithm experimentation to large-scale RL runs, which is why we are open-sourcing Miles to make frontier-scale LLM RL post-training easier to reproduce, extend, and operate.

Recent OpenAI research has demonstrated the ability of LLMs to solve frontier problems in mathematics
A new prover-verifier pipeline using GPT-5.5 Pro and Claude Opus 4.7 has successfully resolved nine challenging open problems in theoretical computer science and algebra.
Decoder
- COLT: Conference on Learning Theory, a leading academic conference.
- FOCS: Foundations of Computer Science, a flagship annual conference for theoretical computer science.
Original article
Recent OpenAI research has demonstrated the ability of LLMs to solve frontier problems in mathematics. We design a simple pipeline (using GPT 5.5 Pro and Claude Opus 4.8) that resolves 9 challenging open problems, including open problems from prominent theoretical computer science venues—4 from COLT open problem list and 1 from FOCS —as well as 4 problems from the commutative algebra.
Claude Code Is Quietly Fingerprinting China-Linked API Routers
Claude Code appears to be inserting hidden metadata into model context to identify and track unauthorized API routers.
Deep dive
- Claude Code detects unauthorized usage via subtle punctuation patterns in the model's context stream.
- The technique is not documented in public API or user-facing terms of service.
- By embedding metadata, Anthropic can trace specific model traffic back to the router relaying it.
- This demonstrates a shift toward client-side verification as a security enforcement layer for LLMs.
Decoder
- Steganography: The practice of concealing messages or information within non-secret data, in this case using punctuation as a carrier for metadata.
- API Router: A middleman service that handles requests between a user and an AI model, often used for load balancing or cost management.
Original article
Claude Code fingerprints custom API routing inside model context. While Anthropic has real reasons to care about unofficial Claude routers, the implementation is not transparent. Its technique makes a line of model context look semantically neutral while using punctuation to carry routing metadata. It almost crosses the line into becoming spyware.

Vibe-coding platform Base44 launches own model as AI startups seek defensibility
Base44, acquired by Wix for $80 million, is training its own model to reduce inference costs and differentiate from frontier-model-dependent competitors.
Deep dive
- Base44 claims to be the only 'vertically integrated' vibe-coding platform.
- The shift is driven by the need to control compute costs, which have become a significant drag on margins for AI-native platforms.
- While competing with frontier models, the strategy relies on specialized data loops rather than raw parameter scale.
- The company reported hitting $150 million in annual recurring revenue as of May 2026.
Decoder
- Vibe-coding: A colloquial term for AI-powered software development where natural language prompts are used to generate functional applications.
- Defensibility: The competitive advantage that prevents rivals from easily replicating a startup's product or market position.
Original article
Base44, the vibe-coding platform that Wix acquired for $80 million just one year ago — when the company was barely six months old and had a team of eight — has started rolling out its own AI model to support its users in creating apps with natural language.
The move comes as the discussion in AI circles has intensified over whether frontier models are best suited for all use cases. A related question is whether businesses built on top of someone else’s models are truly defensible long term. The latest move of Base44, based in Tel Aviv, speaks to both.
While its custom LLM is only just rolling out, Base44 hopes that it will eventually outperform frontier models. According to its founder, Maor Shlomo, “training and owning the model as part of [our] entire stack allows us a lot more optimizations on latency, cost, and efficiency.”
At first glance, this could be a way to stay ahead of competitors such as Swedish startup Lovable, which reached unicorn status in its Series A round last summer and that relies on external LLMs. However, Shlomo expects that others will train their own models — “at least the players that have gotten enough scale and velocity to have enough data.”
According to Jonathan Userovici, a general partner at VC firm Headline — whose portfolio includes AI companies like Mistral AI, but not Base44 — data is one of three key ingredients of defensibility for AI startups, alongside distribution and tech stack.
The upshot is that players with strong brands are now leaning into their data and infrastructure to increase their defensibility, and Base44 fits that pattern. The company says the first iteration of its LLM, Base1, was developed and trained on a dataset generated from “tens of millions of real user interactions on the platform.”
This dataset will keep on growing with the company; but so will its rivals’. The bigger competition may not be vibe-coding startups at all but instead come from frontier AI labs that are getting closer to Base44’s home turf — Cursor and Grok’s parent company xAI now both belong to SpaceX, and Claude Code has become a vibe-coding player in its own right.
This gives Anthropic and other foundational AI providers access to data and feedback loops they can use to improve models for app creation, but Shlomo thinks specialization gives Base44 a leg up. “Models are progressing, but they’ll stay very general in what they can do,” he predicted.
Userovici, for his part, cautioned against underestimating frontier models, citing the example of the legal tech startup Harvey, which abandoned plans to train its own model. He doesn’t expect applied AI companies to become frontier labs en masse but frames Base44’s move in a broader context — one in which inference costs have become a meaningful part of the equation.
That cost pressure, Userovici says, has driven change that enterprise customers are now demanding. “They don’t necessarily see a [return on investment] when using the latest models for all use cases, so an entire infrastructure is being set up to do orchestration and optimization to select the right models for them so that costs don’t skyrocket while maintaining the same or similar performance across the majority of use cases.”
Enterprise companies still are a minority among the audience of the vibe-coding platforms, but they represent a growing share of platform revenue, and users of all sizes are starting to express concerns over the cost of using AI. Base44’s decision to develop its own LLM stemmed from multiple factors, but cost reduction is likely among the benefits.
“We want to get a model that is going to be more aligned to what we think is the right thing, is going to be more optimized to what we see users like in terms of the results we’re getting, and is going to be faster and cheaper for customers eventually than using the frontier models like Opus,” Shlomo said.
As for Base44 itself, cost reduction isn’t as clear cut. In a press release, the company explained that “ownership of the model gives Base44 direct control over compute and inference spend, expected to result in a structurally stronger margin profile over time.”
Even with a delayed payoff, improved margins would be good news for Base44’s parent company, which recently announced it would lay off 20% of its workforce. In contrast, Base44 has been growing in headcount since the acquisition — and announced it had passed $150 million in annual recurring revenue in May just two months after crossing $100 million in ARR.
That’s still less than Lovable, which said it hit $500 million in ARR earlier this month. But Shlomo is betting that the “huge engineering effort” to develop Base1 will cement Base44’s positioning as the “only vertically integrated vibe-coding application — meaning, in Userovici’s terms, a player that owns its distribution, data, and infrastructure all at once.
This article was updated to correct Base44’s location and add its latest ARR.
OpenAI reportedly cut response costs for guest ChatGPT users by more than half
OpenAI has cut inference costs for non-logged-in ChatGPT users by over 50 percent, according to internal reports.
Decoder
- Inference: The process of running an already trained machine learning model to make predictions or generate content.
Original article
OpenAI reportedly cut response costs for guest ChatGPT users by more than half
OpenAI engineers told colleagues earlier this month that they'd managed to cut inference costs—the expense of running existing AI models—by more than half. That's according to a person familiar with the discussions, as reported by The Information.
OpenAI applied the new optimizations to ChatGPT, specifically for visitors who don't have an account. The number of Nvidia GPUs needed to serve those users dropped to just a few hundred. It's not clear how many were required before or what techniques OpenAI used to pull it off. Guest users can only access a very limited set of ChatGPT features, so whether these gains would carry over to the full product is an open question.
Deepseek also just dropped a new open-source method that can speed up inference requests by 60 to 85 percent. The freed-up resources could go toward scaling services, better models, faster responses, or bigger margins. But since data center buildouts are moving slowly, gains like these will probably give labs more breathing room rather than cut into chip demand.

Nvidia competitor Etched hits $5B valuation
Specialized chip startup Etched has reached a $5 billion valuation, backed by $1 billion in contract orders for its AI-focused inference hardware.
Deep dive
- Etched has secured $800 million in total funding, with a $500 million round closing in December 2025 at a $5 billion valuation.
- The hardware architecture is fixed-function, designed to eliminate the overhead of general-purpose GPU instruction sets.
- The company has shifted from a struggle for funding in 2023 to securing $1 billion in pre-orders for their custom racks and software stacks.
- Notable investors include Andrej Karpathy, Geoffrey Hinton, and Fei-Fei Li.
Decoder
- Inference clusters: Hardware configurations optimized to execute model logic and generate outputs at scale rather than training the model from scratch.
- Fixed-function: Hardware designed to perform a specific set of operations efficiently, rather than being programmable for a wide range of tasks like a standard GPU.
Original article
Nvidia AI chip competitor Etched issued a progress report on Tuesday, after TSMC successfully manufactured its chip earlier this year. The startup says it has already booked $1 billion in contract orders for its product: full systems powered by those chips.
Etched is currently in the process of testing that first product with customers. It calls these systems “frontier inference clusters,” bundles that include the chips along with custom-designed racks and software, all built to help frontier models run inference faster, more cheaply, and with better power efficiency than rivals, Etched claims. (Inference is what happens after a user submits a prompt — it’s currently the biggest bottleneck, and the biggest cost center for AI companies trying to serve customers at scale, which is exactly why investors are paying attention to anyone promising to solve it.)
Etched, founded in 2022, also revealed that it has now raised a total of $800 million to date. The most recent tranche was an unannounced $500 million round closed in December at a $5 billion post-money valuation, the company said.
The startup has attracted a notable group of investors, too, including VentureTech Alliance, Jane Street, Hudson River Trading, Two Sigma, Ribbit Capital, and Stripes, who led the $500 million round. It has also secured angel investment from AI heavyweights including Andrej Karpathy, Geoffrey Hinton, Fei-Fei Li, Arthur Mensch, and Scott Wu. The cap table also includes billionaires Stanley Druckenmiller and Peter Thiel.
Although the startup’s press release frames Tuesday’s announcement as Etched “coming out of stealth,” co-founders — CEO Gavin Uberti and president Robert Wachen — have actually been talking to TechCrunch about their chip plans since 2024. Both dropped out of Harvard and became Thiel fellows to found Etched, as Uberti told TechCrunch at the time.
By 2024, Etched was already on investors’ radar, having raised more than $125 million. But on Patrick O’Shaughnessy’s “Invest Like the Best” podcast, the founders said that back in 2023, they struggled to get investors interested — even with a 30-page memo arguing that AI would eventually need specialized chips, not just general-purpose GPUs. Every major investor they pitched passed. The company was reportedly operating month-to-month, close to running out of cash, in those early days.
Today’s funding environment looks like a different planet by comparison. Investors are chasing everything AI-related, especially chip technology that speeds up inference. Competitor Cerebras had the first breakout IPO of the year, while AI chip maker Groq just raised $650 million. Hyperscalers Amazon, Google, and Microsoft all build their own in-house AI chips. Even OpenAI just announced its first custom chip, built by Broadcom.

Principles in Motion
Figma is integrating motion design directly into its canvas, moving beyond static prototyping to a timeline-based animation workflow.
Original article
Full article content is not available for inline reading.
Layout Design System for the AI Era (Website)
Kami is a constraint-based layout design system that turns natural language briefs into professional, consistent documents like resumes and reports.
Deep dive
- Constraint-based design: Uses a fixed set of rules—parchment background, single ink-blue accent, and serif hierarchy—to enforce consistency.
- Multi-language support: Includes specific font-scaling and line-height tuning for English, Chinese, Japanese, and Korean.
- Agent integration: Supports Claude Code, Codex, and generic LLM agents via npm, with no slash commands required to trigger the styling logic.
- Visual hierarchy: Defines precise spacing (base 4pt unit) and typography rules to maintain professional polish in print and screen outputs.
- Diagramming: Offers 17 built-in inline SVG diagram types that inherit the system's design language automatically.
Decoder
- WeasyPrint: A visual rendering engine for HTML/CSS that converts web pages into PDF documents, often prone to rendering bugs with transparency.
- Synthetic Bold: A method where browsers artificially thicken fonts when a specific weight is missing, which often degrades typographic quality and clarity.
Original article
Output Samples
Give Claude the brief: one-pagers, long docs, letters, portfolios, resumes, slides all become polished layouts from one small, reliable rule set. The same brief also travels to image renderers, with the copy-paste prompt and sample outputs in the README.
Equity Report: Tesla Q1 2026 earnings analysis
Resume: Founder CV, 2 pages
One-Pager: Kami intro, white-paper print, 1 page
Slides: Agent keynote, 6 slides
Landing Pages
Built with Kami
The same landing-page template applied to three different products. One constraint set, three distinct purposes.
Kami: Design system homepage
Luo: CJK reading font, Chinese
Mole: macOS system utility
Install & Invoke
Tell Claude what you need, for example "build me a resume", "make a one-pager for my startup", or "design a slide deck for my talk". The skill auto-triggers, no slash command needed.
# Claude Code (v2.1.142+)
/plugin marketplace add tw93/kami
/plugin install kami@kami
# Codex plugin marketplace
codex plugin marketplace add tw93/kami
codex plugin add kami@kamiGeneric agents (OpenCode, Pi, and others reading from ~/.agents/): npx skills add tw93/kami/plugins/kami/skills/kami -a '*' -g -y. The subpath points at the self-contained skill package; a bare tw93/kami installs only SKILL.md.
Claude Desktop: download kami.zip, then upload it in Customize > Skills > "+" > Create skill.
Design Principles
Warm parchment canvas, ink blue as the sole accent, serif carries hierarchy, while hard shadows and flashy palettes recede. This system is built for printed matter: stable, clear, and composed. Parchment is the default; an opt-in white-paper variant prints any document on a white background while keeping the warmth in cards and tables.
- Page background is parchment
#f5f4ed, never pure white - Accent color is ink blue
#1B365Donly; no second chromatic hue - All grays are warm, yellow-brown undertone; no cool blue-grays
- English uses serif for headlines and body; Chinese uses serif headlines and sans body
- Serif body at 400, headings at 500. Avoid synthetic bold
- Three line-height bands: tight titles 1.1-1.3 / dense 1.4-1.45 / reading 1.5-1.55
- Tag backgrounds must be solid hex; no rgba, WeasyPrint double-rectangle bug
- Shadows: ring or whisper only, no hard drop shadows
Warm Restraint
One accent + warm neutrals + zero cool colors. Ink blue covers no more than 5% of any page. Beyond that is clutter, not restraint.
Canvas
Parchment: Page background, the emotional foundation #F5F4ED
Ivory: Cards / elevated surfaces #FAF9F5
Warm Sand: Button default / interactive surfaces #E8E6DC
Deep Dark: Dark theme page base, not pure black #141413
Brand
Ink Blue: Primary color · CTA · quote bar · section overline #1B365D
Ink Light: Links on dark surfaces · lighter variant #2D5A8A
Dark Surface: Dark theme container · warm charcoal #30302E
Error: Error state, deep warm red #B53333
Warm Neutrals
Near Black #141413
Dark Warm #3D3D3A
Olive #504e49
Stone #6b6a64
Type System
Serif carries hierarchy, sans carries function. Serif body at 400, headings at 500.
Serif · Headlines + Body: Charter / TsangerJinKai02. Used for headlines, body text, pull quotes, and numeric emphasis.
Mono · Code: JetBrains Mono. Code blocks, version numbers, hex values, tabular figures.
Rhythm & Form
Base unit: 4pt. Denser layouts get smaller margins; more formal documents get larger ones.
| Scale | Value | Use |
|---|---|---|
| xs | 2-3 pt | Inline elements |
| sm | 4-5 pt | Tag padding · tight layout |
| md | 8-10 pt | Component internals |
| lg | 16-20 pt | Between components · card padding |
| xl | 24-32 pt | Section title margins |
| 2xl | 40-60 pt | Between major sections |
| 3xl | 80-120 pt | Between long-doc chapters |
Depth: Three Shadow Methods
Kami avoids traditional hard shadows. Depth comes from ring shadows, whisper shadows, and light-dark alternation.
Atomic Modules
A small fixed set, kept only where it solves a concrete document problem.
A thousand no's for every yes, prefer clarity over decoration.
Inline Charts
Seventeen inline SVG diagram types covering architecture, process, and data chart scenarios. Tell Claude which type you need and it embeds directly into the document, colors and fonts following the Kami design language.
Quick Reference
When in doubt about what to use, consult this table. If it's not here, go back to first principles.
What to Avoid
Exceptions are allowed, but the reason should be explicit.
Design Origins
I like investing in US equities and ask Claude to write research reports all the time. Every output landed in the same default-doc look: gray, flat, a different layout each session. The structure was hard to scan, the formatting felt dated, and nothing about the page made me want to keep reading. So I started fixing the typography, the palette, the spacing, one rule at a time, until the report became a page I actually enjoyed.
FAQ
- What is Kami?
- A constraint-based design system for AI-generated documents. One accent color, serif-led hierarchy, warm parchment canvas. Give any LLM agent a brief, get a composed layout back.
- What can it produce?
- Eight document templates: one-pagers, long documents, letters, portfolios, resumes, slides, equity reports, and changelogs, plus a landing-page system.
Procedural UI Sounds for the Web (Website)
Tiks is a 2KB library that uses the Web Audio API to procedurally generate UI sounds, eliminating the need for bulky audio assets.
Decoder
- Web Audio API: A high-level JavaScript API for processing and synthesizing audio in web applications.
- Oscillator: A fundamental component in sound synthesis that generates a repeating waveform, used here to create the 'beep' or 'pop' sounds.
Original article
Full article content is not available for inline reading.
Designing for People with Reading Disabilities
Designing for reading disabilities requires a departure from academic writing styles and the implementation of specific typographic constraints to lower cognitive load.
Deep dive
- Plain language: Prioritizing direct, simple vocabulary over complex academic phrasing.
- Visual formatting: Using left-aligned text rather than justification to prevent uneven word spacing.
- Typographic criteria: Selecting fonts with distinct character shapes (like '1' vs 'l') and tall x-heights.
- Cognitive cues: Using consistent iconography and descriptive link text (e.g., 'download report' instead of 'click here') to aid navigation.
- Structured hierarchy: Using descriptive, sentence-case headings to allow users to scan page sections efficiently.
Decoder
- Hyperlexia: A condition characterized by a child's precocious ability to read words significantly earlier than the typical age, often without corresponding comprehension.
- Justified text: A paragraph style where text is aligned along both left and right margins, which can create irregular 'rivers' of white space that hinder readability for some users.
Original article
Reading disabilities like dyslexia, hyperlexia, and alexia affect how the brain processes written text — not intelligence — making design choices crucial for reducing cognitive load. Plain language, left-aligned short lines, distinct typography, and descriptive link text are among the key recommendations for digital content that works for more people. These principles benefit not just those with reading disabilities, but also second-language readers, people in a hurry, and those with lower digital literacy.

Meta considered buying Kalshi before developing its own prediction market app
Mark Zuckerberg attempted to buy prediction market leader Kalshi before ultimately deciding to build a competing 'play money' app called Arena.
Original article
Meta considered buying Kalshi before developing its own prediction market app
Before Meta CEO Mark Zuckerberg directed employees to build a standalone prediction market app, he proposed buying Kalshi, the leading company in the prediction market sector, according to three people with knowledge of the discussions who were not authorized to speak publicly.
Zuckerberg met with Kalshi CEO Tarek Mansour about a possible takeover last year as Kalshi's popularity surged, but the negotiations never advanced, according to one of the people who had direct knowledge of the meeting.
There are competing narratives about why the talks broke down, with some saying Mansour would not move forward with a sale and others indicating Meta considered the legal and ethical questions surrounding Kalshi too messy.
Whatever made the discussions fall apart, Meta still wants to tap into the prediction market craze. Zuckerberg has stood up a team that is now working to release its own prediction market app called Arena, which internal documents reviewed by NPR show will allow people to make guesses about future events.
Unlike Kalshi and its main competitor, Polymarket, Meta's app will not take bets using real money. Instead, users will wager "play money" on the outcome of happenings in the news and topics trending online. Meta's documents say the company's artificial intelligence systems will power the questions and determine who wins or loses based on something happening or not.
Neither Kalshi nor Meta would provide NPR with a comment when asked about the acquisition talks.
Prediction markets have become one of the fastest-growing parts of the tech industry in recent years. The sites allow people to place bets on everything from sports to elections to whether Iran will develop a nuclear weapon.
The massive influx of users into prediction markets makes the space an obvious target for Zuckerberg, according to Tim Wu, a Columbia University law professor who advised the Biden White House on tech policy.
"Meta seems to clutch at every shiny object," Wu said. "With the help of their advertising cash cow, they've been able to fail again and again without consequence," he said, citing Meta's pullback from the so-called "metaverse," and the abandonment of its cryptocurrency project, Libra. "I can't imagine a casino app with fake money is going to be much of a thrill," he said. "But maybe it's something my children would like, I don't know."
Thanks in part to a permissive regulatory environment in Washington, prediction markets have seen staggering growth.
In June 2025, about $28 billion was traded every month on Kalshi and Polymarket. A year later, monthly volume on the sites is nearly $220 billion, driven mostly by sports-related betting, according to The Block, a news and research company that tracks prediction market data.
Kalshi, which is overseen by commodities regulators in Washington, was valued at $22 billion in its latest funding round in May, up from a $2 billion valuation last year. Polymarket, which operates an overseas exchange outside the reach of U.S. regulators, is valued at $10.7 billion, according to the private market data firm PitchBook.
The rise of prediction markets has set off dozens of legal battles pitting the tech companies against state gaming officials, who insist the sites are gambling under a different name.
President Trump has vowed to protect prediction market companies, even as controversies over insider trading and market manipulation plague the industry.
Justice Department officials have opened two criminal cases over alleged insider trading on Polymarket. One involves a special forces soldier who allegedly profited from classified information about the capture of Venezuelan leader Nicolás Maduro by U.S. forces. In the other case, DOJ accuses a Google employee who earned more than $1 million of using confidential data about search trends to correctly guess the most-Googled people of 2025.
Meta's "buy or bury" strategy
Zuckerberg's interest in acquiring Kalshi follows a familiar corporate pattern. Meta has amassed a user base of more than 3 billion worldwide through the takeover of emerging social media platforms. Notably, Meta's purchases of Instagram in 2012 and WhatsApp in 2014 supercharged its reach and allowed it to become a colossal force in digital advertising. More recently, Meta bought AI wearable company Limitless and Moltbook, a social network for AI bots.
Meta's takeovers have attracted scrutiny from federal regulators. The Federal Trade Commission alleged at a trial last year that Meta engages in a "buy or bury" strategy in which nascent rivals are either acquired by the company, or Meta introduces a service cloning the competitor to squash their business.
A judge sided with Meta, ruling that the company did not violate any competition laws when it gobbled up Instagram and WhatsApp. Lawyers with the FTC are appealing the decision.
While the acquisition talks never advanced, Meta did strike a partnership with Kalshi in March, allowing for easy integration of Kalshi markets on Meta's social media app Threads.
Wu, the former White House tech policy adviser, said Meta became a company worth more than $1 trillion by acquiring apps rather than building its own. He argues Meta throws its power and money around like a monopoly and distorts the competitive field for everyone else.
"WhatsApp and Instagram have given them never-ending profits, but normal companies cannot fail five times in a row," he said. "Meta looking to take over Kalshi fits in with the company's long-standing practices."
Local Reasoning for Global Properties
The limitations of AI in understanding global program state may force a shift toward programming languages that enforce safety through local reasoning.
Deep dive
- Data Race: A condition in multi-threaded programming where two or more threads access the same memory location concurrently, and at least one access is a write, leading to non-deterministic behavior.
Decoder
- Send/Sync Traits: Rust markers that define whether a type can be safely transferred between threads (Send) or shared between threads (Sync).
Original article
Local Reasoning for Global Properties
In the last couple of years, I’ve increasingly been asked questions that boil down to: will AI benefit from new kinds of programming languages? My answer has been “probably not” and, so far at least, that answer has held up well: AI is now able to generate large quantities of code in just about any programming language you or I can think of.
Now that the technology has advanced, and its characteristics have started to become clearer, my answer has changed. My experience is that AI – at least as it stands right now – often generates high-quality local (e.g. a function) chunks of code, but often struggles when asked to generate code that requires a global understanding of the program. The easiest way to see this is a proliferation of unnecessary defensive checks: these seem benign, but can cause an exponential increase in the number of states later readers of the code believe can occur, with all the deleterious effects that implies.
Perhaps this struggle will soon be overcome, but if it isn’t, we might once again look to programming language design for help. My aim in this post isn’t to try and predict the specific ways that programming languages will, or even should, try to address this. Instead I want to answer a more basic question: do we have a good example of programming language design that allows local reasoning to give us assurance about a surprising global property?
Background
I’ve made a fair chunk of my living out of programming languages, so I have a vested interest in amplifying their importance. However, while I believe that programming languages do have some influence on our productivity, and on the reliability of the software we create, there isn’t much evidence that they make a profound difference.
I don’t just mean “no-one’s been able to do a good experiment which proves there are differences” — though that is true! Rather, a lot of “good” software has been created in “bad” languages and a lot of “bad” software has been created in “good” languages. It seems unlikely that the particular programming language used was the main influence on such outcomes.
The simplest argument for this is that creating software that does everything its users need, in a comprehensible and reliable way, requires empathy more than it does expertise in challenging programming language features. For a slightly more nuanced view, I’ve previously tried to capture my thoughts on the nature of software.
This shouldn’t be taken as me saying that programming languages don’t make any difference. When I moved from programming in assembler to “high” level languages like Python and C, my productivity increased substantially and I felt able to tackle much larger pieces of software. The reason is simple: assembly forces me to deal with so many low-level details that I continually forget the more important high-level picture. The difference in the software I could create was profound.
Unfortunately, I gradually came to realise that such a huge improvement was unlikely to be repeated. I had, slowly and ineptly, reinvented Fred Brooks’s no silver bullet argument:
Most of the big past gains in software productivity have come from removing artificial barriers that have made the accidental tasks inordinately hard, such as severe hardware constraints, awkward programming languages, lack of machine time. How much of what software engineers now do is still devoted to the accidental, as opposed to the essential? Unless it is more than 9/10 of all effort, shrinking all the accidental activities to zero time will not give an order of magnitude improvement.
An exception
That meant that when, in a specific context many, many years later, I experienced another profound change in productivity for a lot of software I write, I was so surprised that I almost didn’t notice. When I eventually did, and tried to explain to other people the difference, they also seemed baffled. The context? Multi-threaded programming in Rust. That experience is what informs my opinion on the best course for programming languages in the future, so I need to convince you that there is something deep in the way that Rust makes multi-threaded programming much easier.
Let me start with a concrete example. I wrote the software that builds the website you’re currently reading as normal single-threaded code. Because I’m lazy – and my website isn’t that big – every time I run it, the entire website is rebuilt.
After a while, I found that the pauses the software needed to rebuild the site were long enough that they made editing some pages (like this post!) inefficient. I quickly made some single-threaded optimisations, but they weren’t enough. I then guessed that if I could rewrite this to use multi-threading I would get those pauses down to an acceptable level.
In nearly any other programming language, rewriting the software to use multi-threading would have been a daunting task. Indeed, my past experiences with multi-threading showed me that I would immediately encounter difficult to debug crashes; and, almost certainly, there would be a long tail of such horrors to stumble across over weeks and months. There’s a good reason why I stopped trying to write multi-threaded programs!
In this particular case, though, the rewrite – which did indeed solve the performance problems – took me under 5 minutes. It ran correctly on the first try, has stayed working correctly — and I had total confidence that both things would be the case.
How can this possibly be? I like Rust a lot – it’s been my main language since 2015 – but it is not a perfect language. Indeed, I can, and have, bored people by going into its flaws in detail. But when it comes to multi-threading, it does something which I would never have imagined possible: data races (i.e. uncoordinated read / writes, where two threads can unexpectedly interfere with each other) become static errors. That is no small thing: data races were, before, by far the biggest source of errors when I tried to write multi-threaded programs.
How Rust prevents data races
Rust prevents data races through a combination of ownership types and the Send and Sync traits. If you know how Rust works, you can skip this section. If you don’t know Rust, I’m going to give as brief an overview of these features as I know how, simplifying wherever possible.
One can get lost in ownership types but all we need to know is that: a given object has an owner which can read/write to it; and objects can be moved to other owners, at which point the old owner loses access to the object, and the other owner gains access to it.
Send means “instances of this struct can be moved from the current thread to another thread” (i.e. after the move the current thread can’t access the object). Sync means “multiple threads can read from instances of this struct simultaneously”. For our purposes, we can assume that Rust automatically works out when it is safe for a struct to be Send and/or Sync and implements those traits automatically for us.
Let’s start with this very simple Rust code:
fn main() {
let x = vec![1, 2];
println!("{x:?}");
}The vector created by vec! creates an instance of the Vec type, which implements Send. So we can send a vector to another thread and have that other thread print out the vector:
fn main() {
let x = vec![1, 2];
std::thread::spawn(move || println!("{x:?}")).join().ok();
}std::thread::spawn(...) is how one creates a new thread in Rust: the move || ... is a “closure” (i.e. anonymous function) which the new thread will run when it starts. The move means that the new thread becomes the owner of any data referenced from the outer function (i.e. x is moved to the new thread). join means that the main thread waits for the new thread to finish.
We can see that the main thread really has lost access to the vector because this code:
fn main() {
let x = vec![1, 2];
std::thread::spawn(move || println!("{x:?}")).join().ok();
println!("{x:?}");
}leads to this compile-time error:
error[E0382]: borrow of moved value: `x`
--> t.rs:4:14
|
2 | let x = vec![1, 2];
| - move occurs because `x` has type `Vec<i32>`, which does not implement the `Copy` trait
3 | std::thread::spawn(move || println!("{x:?}")).join().ok();
| ------- - variable moved due to use in closure
| |
| value moved into closure here
4 | println!("{x:?}");
| ^ value borrowed here after move
|
help: consider cloning the value before moving it into the closure
|
3 ~ let value = x.clone();
4 ~ std::thread::spawn(move || println!("{value:?}")).join().ok();
|
error: aborting due to 1 previous errorI haven’t even got as far as introducing a full-blown data race and Rust has already prevented me from doing something naughty!
The error suggests that we should clone values: experienced Rust programmers are cautious about this advice as it can lead to terrible performance. Why don’t we try wrapping the object in the reference counting type Rc instead? That way we can happily share the value across both threads:
fn main() {
let x = std::rc::Rc::new(vec![1, 2]);
std::thread::spawn(move || println!("{x:?}")).join().ok();
println!("{x:?}");
}but unfortunately that leads to this error:
`Rc<Vec<i32>>` cannot be sent between threads safelyThe reason we can’t move an Rc instance to another thread is because the reference counting is not done in a thread-safe way. Fortunately there is a variant which does so: the “atomic reference counting” Arc. For slightly boring reasons, I need to clone the Arc (which, fortunately, does not clone the vector inside it!):
fn main() {
let x = std::sync::Arc::new(vec![1, 2]);
let y = std::sync::Arc::clone(&x);
std::thread::spawn(move || println!("{y:?}")).join().ok();
println!("{x:?}");
}This compiles and runs successfully: both threads read from the same vector and print out the same thing. Finally let’s try to enable shared mutation across those threads by introducing Rust’s standard RefCell type:
let x = std::sync::Arc::new(std::cell::RefCell::new(vec![1, 2]));We again get an error but this time it’s not about sending (Send) but sharing (Sync):
error[E0277]: `RefCell<Vec<i32>>` cannot be shared between threads safely
...
= help: the trait `Sync` is not implemented for `RefCell<Vec<i32>>`Arguably this is the first time we’ve really tried to introduce a complete data race: again Rust has stopped us. If I want to enable the possibility of shared mutation across threads, I need to introduce a type such as Mutex:
fn main() {
let x = std::sync::Arc::new(std::sync::Mutex::new(vec![1, 2]));
let y = std::sync::Arc::clone(&x);
std::thread::spawn(move || {
y.lock().unwrap().push(3);
println!("{:?}", y.lock());
}).join().ok();
println!("{:?}", x.lock());
}This compiles and runs correctly (printing 1, 2, 3 twice).
Expanding the reasoning globally
At this point, readers have, I hope, got a sense that Rust prevents me from introducing data races into my program. An important thing to say is that Rust hasn’t really had to introduce new features for this: ownership types and the Send and Sync traits are all that’s needed. In other words, I’m still writing “normal” Rust programs: I’m not having to use a new sublanguage as I would if I was writing async programs.
Because the rules that benefit multi-threaded programs in Rust are, to experienced Rust programmers, natural and obvious, it can prevent us observing a deeper truth: Rust is enforcing a global data-race-free property on my programs in a way I can reason about locally. For example, this property is enforced at the level of function signatures:
fn f<T: std::fmt::Debug>(x: T) {
std::thread::spawn(move || println!("{x:?}")).join().ok();
}
fn main() {
f(vec![1,2]);
}Because I haven’t constrained T, Rust can’t be sure that a caller to f has moved a Sendable object to f, so the spawn on line 2 leads to this error:
`T` cannot be sent between threads safelyFor this to work, f must require of its callers that the objects passed to it really are allowed to be sent to other threads. The syntax is a bit unwieldy:
fn f<T: std::fmt::Debug>(x: T) where T: Send + 'static {
std::thread::spawn(move || println!("{x:?}")).join().ok();
}
fn main() {
f(vec![1,2]);
}This does now compile and run! The good news is that by looking at the signature of f I know for sure that calling it will not cause a data race on x. So this fragment fails to compile because I’ve used Rc:
f(std::rc::Rc::new(vec![1,2]));but if I change that to:
f(std::sync::Arc::new(vec![1,2]));it does compile.
Why global reasoning is so powerful
The combination of ownership types, Send, and Sync means that I can reason globally about the effects of multi-threading and data races while only looking at my code locally.
That might sound like a normal static typing guarantee: after all, if I write (say) a Haskell program then I’m guaranteed not to get typing errors at runtime. That’s true, but Haskell’s normal type system doesn’t, on its own, give me Rust’s guarantee that concurrent code is free from data races.
Put another way, until Rust I had implicitly assumed that the only global property a standard programming language could enforce without undue pain is “there are no runtime type errors”. I thought one had to use exotic and/or experimental languages to achieve such properties, and that the compromises this involved would be acceptable to few programmers. Rust’s data race freedom guarantees are accurate, the errors when the rules are undermined are (mostly) comprehensible, and the overall result highly usable.
Languages of the future
We can now go back to the original topic. What makes programming difficult on even moderately sized programs is that each local change is a butterfly — and some of those butterflies’ wing flaps cause great storms (i.e. bugs!) faraway.
This has always been a problem: even the very best human programmers struggle to gain, and maintain, a global view of the software they’re working on. Right now, though, AI often struggles even more.
Ask AI to generate a single function with a well-defined specification and it will often create better code than I can, and do so more quickly. Ask AI to generate a moderately sized piece of software and then refine it, and you will often have unappealing results. People often talk about code bloat in this regard, and while that’s true, that misses a more profound problem: the global view of the system is often ineptly, and sometimes incorrectly, captured in the generated code. The easiest – though definitely not the only! – way to see this problem is that AI-generated code tends to contain vast numbers of defensive checks.
Assertions and defensive checks are sometimes conflated, but they are very different. Assertions abort a program as soon as an unexpected situation is observed: they encode the idea that “if this condition fails to hold, the programmer misunderstood how the system works or other parts of the system have gone wrong”. Defensive checks, in contrast, do not abort the program: execution deliberately continues if the check fails. Defensive checks are thus better thought of as encoding the idea that “I’m not sure if this condition holds or not, but if it does fail, I want to have a graceful way of handling it”.
Defensive checks seem like an unambiguously good thing: the current operation tends to finish early, but the program as a whole carries on. However, one can have too much of a good thing. Just as with human written code, many of the defensive checks in AI-generated code are unnecessary (i.e. they cannot fail).
A common example I notice in a lot of AI-generated code are checks for “this list must be non-empty”, even though that has been checked (often multiple times) at all paths that lead to the check. Code that looks like the following is common:
def f(x):
if len(x) == 0: return
else: ... # do something with x
# This is the only place that f is called from
for x in ...:
if len(x) > 0: f(x)In this example, the defensive check in f is at best unnecessary.
Unnecessary checks are intrusive; they undermine performance; and they mislead those reading the code as to the program’s state at a given point in time. We often underestimate how pernicious the last of these is. If you think a program can be in states A, B, and C at the point you want to edit, then you have to consider all three states. If, in fact, two of those states cannot happen, you’ve not just wasted effort, but created a potentially exponential explosion of states for subsequent edits to consider, with all the impacts on productivity and reliability that entails.
Given how fast AI code generation has progressed in the last year, it would be foolish to rule out the possibility that this problem is soon solved. It is possible, though, that, short of another major breakthrough or two, AI will continue to be excellent locally and weak globally. If that is the case, then we will have a much stronger incentive than in the past to have our programming languages help us enforce global properties, because each time we do that, we remove an entire class of bugs.
In this post what I hope I’ve shown you is that a surprising global property – data race freedom – can be enforced through purely local reasoning. What’s interesting to me about this is that it makes a slew of important programming tasks more reliable whilst imposing little additional burden on the programmer. It gives me hope that there are other desirable global properties that can be similarly dealt with by programming language design.
We have to be realistic though: we won’t be able to enforce every global property we might want. These might range from guarantees about performance, isolation of subcomponents, non-interference of various kinds, resource cleanup, to state changes, and so on. Some of those will almost certainly be in conflict with each other; some will prove too onerous to be worthwhile; and some we simply won’t be able to handle at all.
The good news is that there are a number of experimental programming language features that might turn out to be relevant to this. For example, effects systems allow us to reason about things like what parts of a program perform input/output through local reasoning. As things stand now, none of those has been tested at the same scale as the Rust features I’ve talked about in this post: it’s difficult to know which, if any, might turn out to be winners. It’s also impossible to know which features have yet to be thought of.
However, there is enough evidence for us to realistically imagine usable future programming languages allowing us to write programs with many more guarantees about global properties. Whoever, or whatever, is creating and modifying programs may benefit substantially from this. Personally I hope that it enables us to rethink how we structure programs entirely!
In summary, until recently, I didn’t think that AI changed the incentives we have for programming languages. Now those incentives are changing; fortunately, we have some indications that we may be able to meet those incentives. Whether anyone with sufficient resources has this level of ambition is unclear to me. But it wouldn’t surprise me if at least one large company – and, even in 2026, this will almost certainly require a company’s resources – tries to do so. I cheer them on in advance: there may be some very interesting programming languages to come!
Footnotes
1. Partly because this is an active area of research / design in programming languages; and partly because guessing how AI code generation will change is above my pay grade.
2. There are, of course, other kinds of errors one can encounter, notably deadlocks. Still, those are easier to debug, and in my experience happen much less often.
3. Technically “safe Rust”.
4. Other languages, notably Pony, do offer the same guarantee, though via rather different mechanisms.
5. With the mild exception that one does tend to end up calling Arc::clone enough that it becomes an eyesore.
6. Depending on what f is supposed to do, the check may even be incorrect. I have seen functions called things like print_sum which should print the sum of the elements passed, but which print nothing for the empty list!
7. A brave programmer might remove the check entirely; I would tend to encode it as an assertion.
8. And perhaps even if not. Even if humans are relegated to a role where we solely review AI-generated code, anything we can do to make it easier for us to have confidence in the code we’re reading would be useful.
9. I also have no idea what this language design will, or won’t, look like, or whether it will even be influenced by Rust. The overall point I’m making in this post is, I believe, independent of the particular language I used as a motivating example.
10. To say nothing of the growing external integration of formal methods into programming.
Anthropic Reaches Deal With Trump Administration to Restore Access to Fable AI Model
Anthropic has reached a deal with the Trump administration to restore access to its Fable model after addressing Amazon-led safety workarounds.
Original article
Anthropic has agreed to address the workarounds that researchers at Amazon used to evade the safeguards for Fable. Access to the model will begin to be restored today. The agreement is expected to involve the Center for AI Standards and Innovation, a government testing unit.

Tesla starts testing its production Cybercab without steering wheel or pedals in Austin
Tesla has begun public road testing of its production-ready Cybercab in Austin, featuring a design with no steering wheel or pedals.
Original article
Tesla is testing a production Cybercab with no steering wheel or pedals on Austin roads, with a safety monitor in the passenger seat.
Tesla has begun testing a production version of its Cybercab on public roads in Austin, Texas, with no steering wheel and no pedals. The two-seat vehicle, which Tesla first revealed in October 2024, is being driven entirely by its autonomous software while a safety monitor rides in the right passenger seat. Tesla posted video of the test on X, showing the gold-colored Cybercab navigating Austin streets without any human controls inside.
This is the first time Tesla has put a vehicle without manual driving controls on public roads. Previous prototype Cybercabs tested in multiple US cities in recent weeks were equipped with a steering wheel and pedals. The production version removes those controls entirely, making it the clearest signal yet that Tesla’s purpose-built robotaxi is moving from concept to deployment.
The timing is not accidental. Last week, NHTSA proposed removing the federal requirement for brake pedals in vehicles designed exclusively for automated driving systems. The rule change, if adopted, would eliminate one of the last major regulatory barriers for vehicles like the Cybercab and is expected to go through later this year.
Tesla has been running a robotaxi service in Austin since June 2025 using modified Model Y SUVs, some operating without safety drivers. Texas records show Tesla has 42 robotaxis registered in the state, compared to 577 for Waymo. The Cybercab is meant to change that math by offering a purpose-built vehicle that is cheaper to produce and operate than retrofitting consumer cars.
Tesla argues it can out-compete Waymo because it builds both the car and the driving software, giving it greater control over costs. It also relies only on cameras for perception, while Waymo uses lidar, radar, and cameras together, a more expensive sensor suite. Tesla is targeting a retail price under $30,000 for the Cybercab and has set a long-term production goal of two million units per year.
The Austin robotaxi service has not been without problems. Tesla disclosed 17 incidents between July 2025 and April 2026, including at least two crashes caused by remote teleoperators who took control of vehicles at low speeds. Waymo has had its own issues, including a recall of nearly 4,000 robotaxis after they drove into highway construction zones 13 times.
Both companies are learning that scaling autonomous driving exposes edge cases faster than software can fix them. Waymo has six recalls to date, while Tesla’s Austin fleet has logged crashes involving both its AI and its human backup systems.
Rolling out distinctive, gold-colored Cybercabs with no visible controls will put Tesla’s robotaxi push under far greater public scrutiny than the near-invisible Model Y fleet. Every mistake will be easier to spot, and every success harder to dismiss. Whether the Cybercab performs well enough to justify the years of promises depends on what happens next on Austin’s roads, not in Elon Musk’s timeline projections.

Let It Crash: How to Steer What Comes After
Venture capitalist Vijay Pande argues that a correction in AI valuations and infrastructure spending is necessary for the next generation of sustainable technology.
Original article
Let It Crash: How to Steer What Comes After
I’m a venture capitalist, and I’m telling you to root for the crash that torches my own asset class. I mean it. The valuations are silly, the data-center spending is feverish, and half the people I...
How to generate real-world load tests using Grafana Cloud k6 and production telemetry
Grafana is pushing for more accurate load tests by using production telemetry to drive traffic patterns instead of relying on manually estimated user counts.
Decoder
- k6: An open-source load testing tool that uses JavaScript for writing test scenarios.
- Telemetry: Data collected from production systems, such as request rates, latency, and error counts, used to monitor health and inform performance modeling.
Original article
Load tests should use production telemetry from Grafana Cloud instead of guessed VUs, deriving arrival-rate k6 scenarios, baselines, peaks, and latency thresholds from real request and traffic patterns, which can be auto-generated via Grafana Assistant for realistic testing loops.
Herdr (GitHub Repo)
Herdr is a terminal multiplexer built in Rust specifically for managing fleets of AI coding agents, providing persistent sessions and real-time state tracking.
Decoder
- Terminal multiplexer: A tool that allows a user to manage multiple terminal sessions within a single terminal window, often providing persistence so sessions survive detachment.
- TUI (Terminal User Interface): A program that displays a text-based graphical interface inside a standard terminal emulator.
Original article
run all your coding agents in one terminal. see who's blocked, working, or done at a glance.
run your agents where they already run; your machine, a server, anywhere you can ssh. each one gets its own real terminal, not an app's imitation of one, so even full-screen TUIs render right. click, drag, and split panes into workspaces and tabs, and watch each agent go blocked, working, done. close the laptop and nothing dies; reattach from another terminal, or from your phone over ssh. one local rust binary, not an app: no gui, no electron, no mac-only wrapper, no account, no telemetry. (if you've used tmux: it's that, rebuilt for agents.)
what you get
- a real terminal per agent. you see each agent's own screen, not an app's imitation of one, so even full-screen TUIs render right.
- agent state at a glance. the sidebar rolls every agent up to 🔴 blocked, 🟡 working, 🔵 done, or 🟢 idle, so you always know who needs you. zero config, no hooks required.
- workspaces, tabs, panes. organize by repo or folder, click, drag, and split, mouse-native throughout.
- nothing dies on detach. a background server keeps panes and agents alive; detach and reattach from any terminal, including your phone over ssh.
- runs anywhere. single ~10MB rust binary, linux and macos (windows beta), no dependencies, runs inside the terminal you already use.
- scriptable. a local socket api and cli that agents can drive, plus plugins you can write in any language.
how it compares
| tmux | gui managers | herdr | |
|---|---|---|---|
| persistent sessions | ✓ | — | ✓ |
| detach / reattach | ✓ | — | ✓ |
| runs anywhere, over ssh | ✓ | — | ✓ |
| panes, tabs, workspaces | ✓ | ✓ | ✓ |
| agent awareness | — | ✓ | ✓ |
| lives in your terminal | ✓ | — | ✓ |
| real terminal views | ✓ | — | ✓ |
| mouse-native | — | ✓ | ✓ |
| lightweight binary | ✓ | — | ✓ |
| agents can orchestrate | ? | ? | ✓ |
tmux gives you persistence and panes, but it was built before agents existed. it has no idea which pane is blocked, working, or done; you can bolt a bell character and per-harness hooks onto it, but you wire each one yourself and still have no shared view of the fleet. the gui agent managers (conductor, cmux, emdash) do show agent state, so call that table stakes. the difference is everything around it. they are apps, often mac-only and closed, that redraw the terminal inside a wrapper. herdr is a single binary that runs in the terminal you already use, anywhere you can ssh, and shows each agent's real screen on a server that keeps it alive when you disconnect.
install
curl -fsSL https://herdr.dev/install.sh | shwindows preview beta:
powershell -ExecutionPolicy Bypass -c "irm https://herdr.dev/install.ps1 | iex"also available with brew install herdr, mise use -g herdr, nix run github:ogulcancelik/herdr, or as a stable Linux/macOS binary from releases.
quick start
herdrherdr starts or attaches to a background server and opens a workspace. run an agent in the pane.
herdr is mouse-native, so clicking and dragging panes, tabs, and split borders gets you everywhere without a single keybinding. for the keyboard, ctrl+b is the prefix: press it, release, then press the action key, so ctrl+b then c makes a tab. one reserved key keeps herdr out of your shell's way.
ctrl+bthenshift+nfor a new workspacectrl+bthenvorminusto split panesctrl+bthencfor a new tabctrl+bthenwto switch workspacesctrl+bthenqto detach; agents keep running, runherdragain to reattach
remote
run herdr on a VPS and reach it from your local terminal. herdr --remote makes your local terminal the client of the remote server, so pasting images into your agents keeps working, the thing plain ssh + tmux breaks.
herdr --remote workbox
herdr --remote ssh://you@yourserver:2222supported agents
detection works out of the box with process-name matching plus terminal-output heuristics.
| agent | idle / done | working | blocked |
|---|---|---|---|
| pi | ✓ | ✓ | partial |
| claude code | ✓ | ✓ | ✓ |
| codex | ✓ | ✓ | ✓ |
| droid | ✓ | ✓ | ✓ |
| amp | ✓ | ✓ | ✓ |
| opencode | ✓ | ✓ | ✓ |
| grok cli | ✓ | ✓ | ✓ |
| hermes agent | ✓ | ✓ | ✓ |
| kilo code cli | ✓ | ✓ | ✓ |
| devin cli | ✓ | ✓ | ✓ |
| cursor agent | ✓ | ✓ | ✓ |
| antigravity cli | ✓ | ✓ | ✓ |
| kimi code cli | ✓ | ✓ | ✓ |
| github copilot cli | ✓ | ✓ | ✓ |
| qodercli | ✓ | ✓ | ✓ |
| kiro cli | ✓ | ✓ | — |
agents can use herdr too
the local Unix socket lets agents create workspaces, split or zoom panes, spawn helpers, read output, and subscribe to state changes instead of polling.
npx skills add ogulcancelik/herdr --skill herdr -glicense
Herdr is dual-licensed:
- Open source: GNU Affero General Public License v3.0 or later (AGPL-3.0-or-later).
- Commercial: commercial licenses are available for organizations that cannot comply with AGPL.
Amazon CloudWatch Logs supports managed syslog ingestion
AWS now supports direct managed syslog ingestion into CloudWatch, bypassing the need for log collection agents on network devices and Linux servers.
Decoder
- RFC 5424 / RFC 3164: Standard formats for sending event notification messages across IP networks (syslog).
Original article
Amazon CloudWatch Logs supports managed syslog ingestion
Amazon CloudWatch Logs supports managed syslog ingestion, enabling customers to send syslog messages from firewalls, routers, switches, and Linux servers directly into CloudWatch Logs.
With today's launch, customers can configure their network devices and servers to send syslog messages over TCP, TCP+TLS, or UDP to a VPC endpoint in their account - without installing or managing any agents. Amazon CloudWatch Logs supports RFC 5424, RFC 3164, and Cisco FTD/ASA syslog formats, making it compatible with a wide range of infrastructure. Amazon CloudWatch Logs automatically parses incoming syslog messages and extracts structured fields such as facility, severity, hostname, and application name, thereby eliminating the need for custom parsing pipelines. For example, customers can ingest syslog from their network firewalls and immediately query by severity or hostname using Logs Analytics to investigate security events or troubleshoot connectivity issues. This feature helps teams centralize infrastructure log visibility, simplify operational workflows, and reduce the overhead of deploying and maintaining log collection agents across distributed environments.
Available in all commercial AWS Regions except Middle East (UAE), Middle East (Bahrain), and Israel (Tel Aviv). To get started, see the Amazon CloudWatch Logs documentation.

The Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5
The U.S. Department of Commerce has lifted export controls on Anthropic's Claude Fable 5 and Mythos 5 models.
Original article
We’ve received notice that the Department of Commerce has lifted export controls on Claude Fable 5 and Mythos 5. We'll begin restoring access tomorrow, and will share an update soon. We’re grateful to our users for their patience, and to everyone who worked with us on redeploying the models.

Why Specialization Is Inevitable
Drawing from optimization theory and biology, domain-specialized AI models are structurally superior to generalists because they avoid the efficiency losses of shared capacity.
Deep dive
- Discusses the 'No Free Lunch' theorem, which suggests no single algorithm excels across all possible problems.
- Notes that frontier models (Mixture-of-Experts) recover specialization internally to overcome the inherent inefficiency of pure generality.
- Argues that 'scaling' helps with how knowledge is acquired, but does not invalidate the trade-off between task breadth and target-fit accuracy.
- Highlights that specialized models (e.g., AlphaFold) achieve breakthrough results through architectural focus rather than computational scale alone.
- Contrasts 'domain knowledge' (explicit rules) with 'domain specialization' (resource concentration).
Decoder
- No Free Lunch Theorem: A mathematical proof in optimization stating that, when averaged across all possible problems, no algorithm outperforms a random search.
- Negative Transfer: A phenomenon in multi-task learning where training on multiple tasks simultaneously causes the model to perform worse on individual tasks than it would have as a dedicated specialist.
Original article
Why Specialization Is Inevitable
What optimization theory, evolutionary biology, competitive markets, and machine learning all predict — and why the answer is the same
Those who follow Dharma AI already know that we view specialization as one of the defining principles of effective AI systems, shaping everything from cost and performance to reliability and sovereignty. Few papers have articulated that case as rigorously as the 2026 work by Goldfeder, Wyder, LeCun, and Shwartz-Ziv.
In this article, we explore and interpret ideas from AI Must Embrace Specialization via Superhuman Adaptable Intelligence (Goldfeder, Wyder, LeCun, & Shwartz-Ziv, 2026). The paper's convergence case — spanning optimization theory, biology, organizational economics, and machine learning — provides both the evidential structure and the intellectual foundation for the discussion that follows. The framing, organization, and editorial synthesis presented here are Dharma's.
The conventional expectation is reasonable: as AI systems grow more capable, they should also grow more general. Greater capability and broader applicability seem like natural companions — more resources, better methods, and expanded training should produce systems that approach more tasks with increasing confidence.
The pattern that actually appears is different. The systems that achieve the most significant results in any given domain tend to be the ones most narrowly focused on it. The breakthrough in protein structure prediction came from a system engineered for a single scientific task. The historical milestones of AI, examined closely, reflect intense domain targeting rather than expanding generality.
This pattern recurs. It recurs across domains, across decades, across architectural choices that have almost nothing in common. A pattern this consistent suggests a common cause — one that does not originate inside AI research at all.
An Algorithm Wins by Fitting Its Target
In 1997, Wolpert and Macready proved something that rarely surfaces in discussions of AI architecture: no single, general-purpose optimization algorithm outperforms all others across all possible problems (Wolpert & Macready, 1997). The proof is mathematical, not philosophical. Averaged across every conceivable problem a learner might face, every algorithm performs equally well — and equally poorly. An algorithm that gains on one distribution of problems necessarily concedes on others. The performance is redistributed, not multiplied.
The practical implication is direct: “an algorithm wins by being a good fit for the target problem” (Goldfeder et al., 2026). The theorem does not say generality is impossible — it says generality is not a performance advantage. The consistent structural path to outperformance is concentration: trading breadth for fit.
This becomes sharper when finite resources enter the picture. Any real system operates under constraints — finite compute, finite data, finite development time. Given finite energy, an approach that directs available resources toward learning a finite set of tasks will outperform one that distributes those same resources across an unlimited range. The arithmetic is unforgiving: as the task set expands without bound, the resources available per task shrink toward zero. Universal coverage and meaningful performance are, under finite resources, in direct tension.
The conclusion the theorem points toward is not that generality is bad. It is narrower and more operational than that: as the paper states, "universal generality is a theoretical concept, but in practical terms it is a myth" (Goldfeder et al., 2026). What survives contact with real constraints is not the system that tries to do everything — it is the system that fits its target.
The mathematics establishes this as a prediction, not a preference. Whether that prediction holds in the world beyond optimization theory is a different question.
What Biology and Markets Already Know
Two other domains arrived at the same prediction before optimization theory gave it a name.
As the paper describes the biological case: every performance gain in one niche comes at a cost elsewhere. A generalist carries traits suited to many environments but optimal for none — competence spread too thin to dominate any particular condition. There are no performance gains without trade-offs; the resources invested in one capability are unavailable for another. Selection favors designs matched to local conditions over those optimized for uniform coverage across all possible environments. The organisms that survive to reproduce are not the most generally capable — they are the most specifically matched. The result, accumulated over evolutionary timescales, is not generalists dominating — it is specialists filling niches. As the paper states: "Specialization is not an accident of biology; it is a predictable consequence of limited resources, competing objectives, and environments that reward performance on a small subset of evolutionarily relevant challenges" (Goldfeder et al., 2026).
Competitive markets follow the same dynamic through different means. Organizations and strategies that fail to meet performance thresholds are eliminated — not through extinction, but through exit, defunding, and replacement by better-matched alternatives. Competition acts as a selection mechanism: it amplifies effective strategies and eliminates ineffective ones. The mechanism has nothing in common with biological selection — no inheritance, no mutation, no evolutionary timescale. The unit of selection is not the organism but the organization, the product, the strategy. Yet the structural pressure is the same: finite resources, performance requirements, and the systematic removal of entities too broadly distributed to excel where it counts. Concentrated capacity outcompetes distributed capacity when performance standards are clear and consistent.
Evolution and markets operate through entirely different mechanisms — different timescales, different units of selection, different inheritance mechanisms. Yet both produce the same outcome under resource pressure: fit over breadth. The theorem predicts this. Biology and markets arrive at it independently. When a third domain arrives at the same finding through different means entirely, the pattern ceases to look like a theorem and begins to look like something more general about how constrained systems behave.
Machine Learning Keeps Rediscovering Specialization
The same pattern has emerged inside machine learning — not derived from optimization theory, but arrived at through the accumulated experience of building systems and watching what improves them.
The clearest form is negative transfer: a measurable degradation that occurs when a system trained on multiple tasks suffers because those tasks compete rather than cooperate (Ruder, 2017). When tasks share structure, training together helps. But when tasks compete for representational capacity, or impose conflicting gradients during training, performance on individual tasks falls below what a dedicated system would achieve. The gain from breadth becomes a cost to depth. It is a documented consequence of dividing finite capacity across tasks that pull against each other. The specialist, facing no such competition, does not pay this cost.
The architecture of frontier models offers a different form of evidence. Mixture-of-experts systems achieve their breadth not through uniform generality across all parameters, but by routing each input to a specialized subset of the network — activating different experts for different tasks. The paper's authors read this as a structural concession: a system designed to be general achieving its results by recovering specialization internally. This is an argued interpretation, not a demonstrated theorem — these architectures were designed for computational efficiency, and what they imply about generality's limits is a reasonable inference rather than a stated intent. But it is a notable one: the most capable general-purpose systems reach their performance by doing internally what specialist systems do by design.
The clearest historical example follows the same logic. AlphaFold achieved a step change in protein structure prediction by targeting that specific task with task-specific architecture and training choices (Jumper et al., 2021). Its gains came from narrower focus, not broader coverage. The paper uses AlphaFold as an archetypal case — not as evidence that all specialized systems achieve equivalent gains, but as an unusually clear illustration of the mechanism. That mechanism has appeared repeatedly: the history of AI milestones, the paper notes, frequently reflects intense domain targeting rather than broad competence, even when the results look like demonstrations of general intelligence.
Three distinct places. Three different mechanisms. The same finding.
What Scaling Doesn't Change
The picture would be incomplete without addressing one of AI research's most cited observations. Sutton's Bitter Lesson holds that methods relying on domain knowledge are consistently outperformed by methods that scale computation (Sutton, 2019). On its face, this appears to complicate the case for specialization: if scale and generality win, perhaps specialization is only a useful heuristic under resource constraints that will ease as compute becomes cheaper.
The objection rests on a conflation between two distinct concepts. Domain knowledge refers to hand-coded features, engineered priors, and rules designed to give a system insight into a particular area. The Bitter Lesson targets this — and it is correct to do so. Systems that encode explicit domain knowledge have been consistently outperformed as scale increases.
Domain specialization is different: the decision to direct a system's resources, architecture, and training toward a bounded set of tasks rather than distributing them broadly. This is not the encoding of knowledge about a domain. It is a decision about scope.
The paper draws the distinction precisely:
"The diminishing usefulness of domain knowledge is distinct from the usefulness of domain specialization. As scaling progresses, we will need to know less about proteins to build a system that does protein folding; however, such a system still benefits from focusing specifically on proteins." (Goldfeder et al., 2026)
Scaling changes what systems can learn from data. It does not change whether concentrating resources on a finite task set outperforms distributing them across an unlimited range. The Bitter Lesson and the specialization argument operate on different dimensions — one describes how knowledge should be acquired, the other describes what a system should be pointed at. Both can be true simultaneously. Scaling changes the mechanisms by which systems learn; it does not dissolve the constraint that makes fit more valuable than breadth.
Across four analytical traditions, the same pattern emerged through different paths. This is not a coincidence that demands explanation. It is the evidence.
When finite resources meet selection pressure — in an optimization problem, an ecosystem, a market, or a training run — fit consistently beats breadth. The specific mechanisms differ. The timescales differ. The units of selection differ. But the structural dynamic is the same, and it produces the same result.
The theorem does not cause this pattern in biology. Biology does not cause it in markets. Neither causes it in machine learning. They all face the same underlying constraint: performance under scarcity requires concentration. What the theorem establishes mathematically, evolutionary history confirms empirically, competitive markets demonstrate institutionally, and machine learning rediscovers architecturally.
Specialization is not a preference. It is what emerges when finite resources meet the requirement to perform.
Primary Source
- Goldfeder, S., Wyder, M., LeCun, Y., & Shwartz-Ziv, R. (2026). AI must embrace specialization via superhuman adaptable intelligence. arXiv:2602.23643.
Sources
- Wolpert, D.H. & Macready, W.G. (1997). No free lunch theorems for optimization. IEEE Transactions on Evolutionary Computation, 1(1), 67–82.
- Forister, M.L., Novotny, V., Panorska, A.K., Baje, L., Basset, Y., Butterill, P.T., & Dyer, L.A. (2012). Global distribution of diet breadth in insect herbivores. Proceedings of the National Academy of Sciences, 109(2), 418–423.
- Futuyma, D.J. & Moreno, G. (1988). The evolution of ecological specialization. Annual Review of Ecology and Systematics, 19, 207–233.
- Hannan, M.T. & Freeman, J. (1977). The population ecology of organizations. American Journal of Sociology, 82(5), 929–964.
- Loasby, B.J. (1983). Knowledge, learning and the firm. As cited in Goldfeder et al. (2026).
- Ruder, S. (2017). An overview of multi-task learning in deep neural networks. arXiv:1706.05098.
- Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120), 1–39.
- Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., & Hassabis, D. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596, 583–589.
- Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., & Hassabis, D. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), 1140–1144.
- Sutton, R.S. (2019). The bitter lesson. Retrieved from http://www.incompleteideas.net/IncIdeas/BitterLesson.html
Further Reading
- Specialization Beats Scale: A Strategic Variable Most AI Procurement Decisions Overlook — The empirical and strategic complement to this article. Where the No Free Lunch theorem establishes why specialization is structurally predicted, this piece examines the evidence that it outperforms in practice — and why it remains underweighted in most AI procurement decisions.
- Text Degeneration: A Production Failure Mode That Most Benchmarks Do Not Track — A documented failure mode that emerges when language models operate outside the boundaries of their effective domain.
- Direct Preference Optimization Beyond Chatbots — How preference optimization techniques extend into specialized domains beyond conversational AI — a concrete instantiation of the domain focus strategy this article argues is structurally predicted.

AI and the future of math
Grant Sanderson argues that AI's rapid progress in math highlights a future where AI acts as a curator for an infinite space of ideas.
Decoder
- International Math Olympiad (IMO): A prestigious annual mathematics competition for high school students, used as a benchmark for AI reasoning capabilities.
- Riemann hypothesis: A famous unsolved mathematical conjecture regarding the zeros of the Riemann zeta function.
- Millennium Prize problems: Seven difficult mathematical problems selected by the Clay Mathematics Institute, with a $1 million award for each solution.
- Langlands program: A vast set of conjectures connecting different branches of number theory and representation theory.
- RLVR (Reinforcement Learning with Verifiable Rewards): An AI training technique where the model receives rewards based on objectively verifiable outcomes, such as a correct math proof.
Original article
Full article content is not available for inline reading.
GeneBench-Pro: Scientific Judgment in AI Agents
OpenAI's new GeneBench-Pro evaluates how AI agents navigate ambiguity and scientific assumption-revision in computational biology research.
Decoder
- Computational biology: The field that uses algorithms and statistics to understand biological data.
Original article
OpenAI's GeneBench-Pro is a benchmark that evaluates how AI agents handle ambiguity, revise assumptions, and choose analysis paths in computational biology. It focuses on research-level tasks across genomics, quantitative biology, and translational medicine.

Anthropic launches AI drug discovery program, joining tech giants in betting on healthcare
Anthropic is entering the drug discovery market, launching an internal research program alongside a new suite of developer tools for life sciences.
Original article
Key Points
- Anthropic will start a drug discovery program focused on "neglected" diseases.
- The artificial intelligence company announced the effort alongside the announcement of Claude Science, a product designed for drugmakers.
- Big tech companies have long expressed interest in health care.
Anthropic is starting an internal drug discovery program as part of an effort to develop artificial intelligence tools designed for drugmakers, becoming the latest company to try and crack the healthcare market.
At an event in San Francisco on Tuesday, Anthropic's life sciences head Eric Kauderer-Abrams said the company will focus on discovering treatments for "neglected" diseases that traditional biopharmaceutical companies wouldn't consider attractive targets.
"We're doing this because we believe first and foremost that to build the right models, products and tools to accelerate the industry, we need to live it along with all of you," Kauderer-Abrams said. "We believe in the power of tight feedback loops, and there's no substitute for having our own experiences alongside you all in the trenches trying to develop drugs."
Kauderer-Abrams didn't say what Anthropic would do if it finds any promising drug candidates. Traditional biopharmaceutical companies would typically test them in clinical trials.
An Anthropic spokesperson told CNBC that as a public benefit company, "we can choose programs on patient benefit, including work the commercial market overlooks."
"We're at the start of this, and we'll share more as the work progresses." the spokesperson said.
Tech giants have long taken aim at healthcare, though with mixed results. Alphabet and Apple have jumped into the market in various ways, and Amazon has built a business in healthcare through its acquisitions of One Medical and PillPack, now housed in a division called Amazon Health Services.
Kauderer-Abrams and other Anthropic leaders positioned Anthropic's effort as a way to work alongside the drugmakers it's trying to court for its new Claude Science product. Jonah Cool, Anthropic's head of life sciences partnerships, said Anthropic's goal is to focus on neglected diseases as it creates and sells AI tools for life sciences companies.

Donald Trump's New US Passport Design Makes Institutional Branding Look Like a Personal Hustle
Donald Trump's limited-edition 'Patriot Passport' features his own image and signature, marking an unprecedented personalization of a state travel document.
Original article
Donald Trump has sold some tat in his time, from cringey NFTs to a 'golden' mobile phone that looked like something you might find going for a few dollars on Temu. So when he posted on social media about a new US passport design on Friday, it was initially hard to tell whether he was referring to an official state document or another hustle.
Containing an image of Trump with his fists on the Resolute Desk and now dubbed the Patriot Passport, it looked and sounded like another novelty, supposedly collectible Trump-branded trinket with no legal standing. But the White House confirmed on X shortly afterwards that it will be a real valid passport, with a design that appears to have no precedent anywhere.
PATRIOT PASSPORT. pic.twitter.com/RYvLKloC7d June 26, 2026
According to the state department, the Patriot Passport is a limited-edition US passport design intended to commemorate America's 250th birthday. Trump and his signature appear on a page with the Declaration of Independence in the background. The opposite page shows the United States' founders signing said declaration, apparently based on a painting by John Trumbull.
The design will also feature a “Freedom 250” gold flag on the back cover. Writing on Truth Social, Trump also claimed the passport would carry the legend 'Welcome, but be good!," although that isn't visible on the pages released so far, and it's not clear who the message would be addressed to since passports tend to be issued to US citizens rather visiting tourists or temporary migrants.
Only limited numbers of the design will be produced, and they will only be issued to people who apply in person for a new passport or renewal at the passport agency in Washington DC. We're told there'll be a limited number of special acceptance events. Prices will be the same as a standard US passports, but it's not clear whether people who apply via the agency in Washington will be able to choose which design they receive.
Current US passports depict symbolic landmarks like the Statue of Liberty and historic moments like the 1969 moon landing. This will be the first time a current president has been featured in the design.
In fact, I've not been able to find a single example of any sitting or former head of state being pictured in a nation’s passport artwork while still alive. In that sense Trump has the dubious honour of outdoing dictators such as Saddam Hussein, Muammar Gaddafi and Saparmurat Niyazov, who put their own faces on banknotes, coins, and billboards but not passports.
In August last year, Donald Trump signed an executive order to launch an initiative called 'America by Design' spearheaded by a new National Design Studio. While the project's aim is one of "improving our nation by design”, it raised concerns that Trump would reshape governmental branding in his own image. That appears to be happening.
Several contentious architectural projects are still being pushed, from a new White House ballroom to triumphal arch, currently on display as a sad-looking plywood model on the National Mall for the Great American State Fair. He also tried to put his name on the John F Kennedy Memorial Center for the Performing Arts.
Passport design doesn't have to be boring. Just take an ogle at the Canadian passport and Norwegian passport. It can also be politically and emotionally charged – the UK paid a fortune to leave the EU out of a nostalgia for blue passports.
But blurring the line between personal grift makes institutional branding look frivolous and short sighted. Elected leaders generally serve for less time than a passport. Trump's second presidency will end in January 2029. The new Patriot Passports will be causing smirks among immigration officers until 2036.

Design roles are changing… so how do you stay a maker when your job becomes a mender?
Designers are increasingly trapped in 'mending' roles, where they refine AI-generated outputs rather than leading original creative ideation.
Original article
Design roles are changing… so how do you stay a maker when your job becomes a mender?
The current shift in design roles from creating to finishing is eroding a fundamental part of being a designer. Here's how to hold onto your skills and protect your practice.
Welcome to another edition of Dear Boom, our advice series where we take the questions keeping creatives awake at night, and put them to the Creative Boom community. This week's dilemma speaks to something many of us are currently experiencing but struggling to name.
"I don't know when it happened, but my job changed shape," writes an anonymous creative. "More and more, the work that lands on my desk isn't a blank page anymore. It's something already half-made (generated, roughed out, 'nearly there') and I'm asked to fix it. Tidy the type. Sort the spacing. Make it look like a human cared.
"The money's fine, mostly. But I keep catching this little ache. I used to feel like a maker. Now, I feel like a finisher. A correction service. I worry I'm getting slower at the part that mattered most—the thinking, the having of ideas—because I rarely start anything from scratch now. How do you keep hold of the creative part of you, when so much of the work has become tidying someone else's machine?"
If this resonates with you, you're not alone. After we raised the issue on LinkedIn and Instagram, it became clear this is happening to a lot of people. The good news is, they didn't just outline what's being lost, but offered practical strategies for protecting it.
Fundamental shift
There's something fundamental at stake here. As Claire McDivitt, marketing director at Lazerian, says: "The danger isn't using new tools. The danger is forgetting to make time to create something from a blank page.
"Tools will change, workflows will change," Claire reflects. "But curiosity, taste, judgement and the ability to turn an idea into something meaningful are still at the heart of creative practice. So it's important not to stop exercising those muscles."
And this, essentially, is the crux of the problem. If you don't practise starting from scratch, you lose the ability to be creative at all. Skills atrophy. Confidence erodes. After months of finishing other people's half-baked ideas, returning to the blank page feels terrifying.
Many creatives, however, are facing this exact situation. And graphic designer and art director Eilidh McDonald articulates what's being lost. "The worry for me is that if we're all AI creative directors now, we'll miss out on those wonderful serendipitous moments when you discover something new, in the process of trying to make something else."
That serendipity—the unexpected discoveries that happen when you're deep in the thinking and making—is where innovation lives. When your job becomes execution rather than exploration, you lose access to those moments.
The psychological toll
Some creatives, though, aren't just sitting back and taking it.
Firstly, they're quitting, as brand and web designer Ilai Briones has just done. "This shift is taking what I love away from my job: the creative thinking," she explains. "So having spent months tolerating it, I've now just sent my end-of-engagement notice."
Secondly, many are pushing back on client demands. Vicky Tomlinson, co-founder at Kind & Wild Branding Studio, notes that: "It's okay to push back on crappy AI-generated ideas: sometimes people just don't know what is good or not. Let them have a crack, and then show them something better!"
Art director Hayley Gilmore, meanwhile, has created structured boundaries. "If a client wants to use AI in the process, I try to redirect them toward one specific role: exploring visual directions when they don't have the language to describe what they want," she says. "As creatives, we can use this to discuss the process more transparently and explain why something created by AI may not always visually translate for viewers in a realistic or client-approved way."
This reframes the conversation. Instead of being defensive about AI, you're educating clients about the limitations of what they're asking for.
The importance of personal projects
The most important advice we received from our community was this: maintain personal projects. "Make sure there is always something in your life where you're still responsible for the first mark," says Claire. "Whether that's a personal project, an exhibition, a sketchbook, a sculpture or an idea that exists purely because you wanted to explore it. At Lazerian, some of our most important projects have come from self-initiated ideas rather than client briefs. Those projects remind you why you became a creative in the first place."
For similar reasons, designer and illustrator Emily Efford is leaning into drawing and illustrating by hand. "Even if I don't get paid for many of these projects, they keep me sane and connected to my own creativity," she reasons.
In the AI era, such projects are how you stay sharp. They're how you remember what it feels like to make something from a blank page. They're how you protect the part of yourself that makes you a creative, not just a technician.
Collective action
We've covered what creatives can do individually, but what about collectively? Designer Andrew Montgomery is blunt about what needs to happen. "Our industry needs to grow a spine," he argues. "People generally don't walk into a restaurant with a half-baked, burnt, ill-conceived tray of crap and ask the professional chef to fix it for them; they'd be chased off the property. Why do professional designers tolerate this from clients?"
Andrew is pointing to an uncomfortable truth here. We've allowed ourselves to be positioned as service providers who fix broken outputs rather than strategists who create ideas. Part of reclaiming your creative practice is reclaiming your role.
But how will all this play out in the longer term? Digital and brand designer Andy Strong offers his perspective. "I think the true cost of AI is starting to become known to businesses," he says. "The shift from heavily subsidised subscriptions to token-based, pay-per-generation models is coming in. The true cost is going to change the value proposition for lots of people, and at that point, I really think things will start to swing back more favourably."
In other words, once clients realise how expensive it actually gets to run these tools at scale, they'll start valuing human thinking again. But that's no excuse to stop thinking now.
It starts with protecting your creative practice. It continues with setting boundaries with clients. And it requires remembering that the blank page, and your ability to make something meaningful from it, is what makes you valuable in the first place.
Tldr: Don't let the tools write your job description. Do it yourself.
AI Video Generator for Text to Video & Image to Video (Website)
Epochal integrates text-to-video and image-to-video workflows into a single workspace, supporting models like Kling 3.0 and Seedance 1.5.
Decoder
- Image-to-Video: A generative AI technique where a single static image serves as the seed for motion, camera movement, and temporal evolution.
Original article
The AI Video Generator for Text-to-Video and Image-to-Video
Describe a scene or upload a still image, pick a model, and get a usable clip in minutes. Epochal connects prompt-to-video, image-to-video, and the AI image generation you need to build the opening frame, so concept, iteration, and the final asset stay in one place.
Generate AI videos from text, images, and references.
Use different inputs as the starting point, then see how AI video workflows turn ideas into results.
Explore popular AI video workflows
From motion control, intro videos, and lip sync to text-to-video and image-to-video, see the core video creation workflows Epochal supports.
Use the right model for the result you want
Choose a better-fit AI model for cinematic scenes, product ads, character motion, image-to-video clips, and fast visual tests.
Seedance 1.5
Seedance 2.0
Hailuo 2.3
HappyHorse 1.0
Kling 3.0
Kling Motion Control
Veo 3.1
Wan 2.7
GPT Image 2
GPT Image 1.5
Nano Banana 2
Nano Banana Pro
Nano Banana
FLUX.2 Pro
Ideogram V3
Seedream 5.0
Seedream 4.5
Grok Imagine
Generate video from text prompts.
Create scenes, ads, product concepts, openers, and social clips from a simple description. Text to video is the fastest way to validate a creative direction before you have images or reference footage.
Turn images into video.
Upload a product image, portrait, poster, or key visual, then add motion, camera movement, and scene energy while keeping the original composition recognizable.
Free to try. Priced to scale.
Get free credits when you sign up, see credit cost before you generate, and start without a credit card. Choose a plan later when you need more generations, private content, or higher usage.
Lite
- 18,000 credits/year
- 1,500 credits/month
- Up to 6,000 images
- Up to 1,200 videos
- No watermark
- Private generation
- Priority queue
- Image and video workflows
Pro
- 36,000 credits/year
- 3,000 credits/month
- Up to 12,000 images
- Up to 2,400 videos
- Higher monthly capacity
- No watermark
- Private generation
- Priority queue
- Image and video workflows
Creator
- 7,200 credits/year
- 600 credits/month
- Up to 2,400 images
- Up to 480 videos
- No watermark
- Private generation
- Image and video workflows
What you may want to know before getting started.
Quick answers on free credits, models, privacy, commercial use, and subscriptions.
Is Epochal free?
How do credits work?
Do I lose credits if a generation fails?
What can I create with Epochal?
Can I use my own images as input?
Which AI models can I use in Epochal?
Are my creations public?
Can I use the videos I generate commercially?
Can I cancel my subscription anytime?
Turn ideas into AI videos.
Start from a prompt, image, or reference. Use free credits to begin creating, then continue into text-to-video, image-to-video, and more AI video workflows.

Introducing OpenArt Director
OpenArt Director introduces 'Vibe Directing' to enable users to create 5-minute videos through conversational prompts, mimicking the rise of vibe coding.
Decoder
- Vibe Coding: A recent industry shift where software development is driven by high-level natural language intent rather than explicit low-level coding or complex configuration.
Original article
The way videos are made is about to change.
Introducing OpenArt Director - and a new way to create: VIBE DIRECTING.
The same way vibe coding changed how software gets built, Vibe Directing changes how videos are made.
All you need is an idea in your head and a conversation to see it come to life.
Describe what you want. Chat it into perfection. Walk away with something only you could have imagined, with the quality only a professional could deliver.
Because there's a director in all of us. 🎬
Here's what makes it different:
- Videos up to 5 minutes long - in one go
- No stitching clips together. No editing timelines. Director does it all for you!
- Consistent characters, objects, and branding - throughout the video
- Voiceover, music, and captions - all in one place
- Chat to create. Chat to edit. All through a single conversation.
- 8+ languages supported natively
Everything you need, you get it all - in one place.
What can you make with it?
- Short films
- Music videos
- UGC ads
- Micro-dramas
- Product ads
- Social content
- Explainer videos
Whatever the idea in your head - Director makes it real.
Try it now → openart.ai/director

Nano Banana 2 Lite
Google has released Gemini 3.1 Flash Lite, marketed as the fastest and most cost-effective model in their lineup for image generation tasks.
Original article
A 'Where's Waldo' style image generated by Nano Banana 2 Lite, the fastest and cheapest Gemini image model.
Google kills Tenor GIF API, forcing changes at X, Discord, and more
Google officially shuttered its free Tenor GIF API on June 30, 2026, forcing major platforms like Discord and X to migrate to alternatives.
Deep dive
- Google announced the wind-down in January 2026 and stopped accepting new integrations immediately.
- The API shutdown only affects third-party integration; Google services like Gboard continue to use Tenor internally.
- Saved GIFs in external apps were largely lost as the underlying metadata links became invalid.
- Migration choices include Giphy and the newcomer Klipy.
- The transition has caused temporary user friction regarding the availability and selection of GIF content on social platforms.
Decoder
- API (Application Programming Interface): A set of protocols that allows different software applications to communicate and share data, such as a GIF database integration.
Original article
Many apps appear to be moving to Klipy, a GIF service created by one of Tenor's founders.
Windows 11 is getting a new Screen Tint mode, and your eyes might thank Microsoft
Microsoft is testing a Screen Tint feature in Windows 11 that overlays a customizable color mask to reduce eye strain.
Original article
Microsoft is testing Screen Tint, a new accessibility feature for Windows 11 that overlays the entire screen with a customizable color tint to reduce eye strain and light sensitivity without changing the display's color temperature like Night Light. Users can choose from six preset colors or create their own, adjust the tint intensity, and even use it alongside Night Light, although enabling it disables Windows' existing Color Filters. The feature is currently available in the latest Windows Insider preview build and is joined by other improvements. It could become one of the most useful additions for people who spend long hours working or gaming on their PCs.

The iPhone 18 Pro just leaked, and it might be the single biggest Apple leak since the iPhone 4
Leaked files from Tata Electronics suggest the iPhone 18 Pro will feature a nearly identical design to its predecessor.
Original article
Alleged leaked files from Indian supplier Tata Electronics, including grainy drop-test photos, appear to show the Apple iPhone 18 Pro with a design that is almost identical to the Apple iPhone 17 Pro, featuring the same large camera module and rear glass cutout. The most noticeable changes are improved color matching around the rear glass, eliminating the two-tone appearance, and hints that a new deep red color option may be introduced, with many online commenters joking that it looks like an "iPhone 17.01." The comparison to the famous Apple iPhone 4 leak highlights how dramatically iPhone design evolution has slowed, making the familiar-looking design one of the reasons many people find the leak believable.
01-20 designs The Webster's brand on presence, wonder, and connection
The Webster's new identity uses magical realism and literary-inspired design to pivot from traditional luxury hospitality toward culturally grounded human connection.
Decoder
- Magical Realism: A literary style that weaves fantastical elements into realistic settings; here applied as a visual metaphor for creating 'wonder' in hospitality experiences.
Original article
The Webster's new brand identity, created by 01-20, is built around the idea of "the magic of presence," using the subtle wonder of magical realism—particularly inspired by Gabriel García Márquez—to make hospitality feel more human, emotionally engaging, and culturally rooted rather than transactional or overtly luxurious. The identity combines literary-inspired typography, warm earthy colors, carefully used illustrations, photography, and local storytelling to create meaningful moments while staying grounded in each hotel's architecture, history, and community. Rather than enforcing a rigid visual formula, the brand acts as a flexible storytelling framework, encouraging each property to express its own character through cultural programming, design, and connections to its neighbourhood.

Behold, the coolest modern Apple iPod concept yet
Nostalgia for the iPod persists as fans share a MacBook Neo-inspired concept design featuring an aluminium body and a classic click wheel.
Decoder
- Click wheel: The iconic touch-sensitive rotating navigation interface introduced on the original iPod in 2001.
- iPod modding: The hobbyist practice of restoring or upgrading legacy Apple portable media players with modern components like flash storage or high-capacity batteries.
Original article
A modern Apple iPod concept featuring a curved aluminium body and classic click wheel has reignited nostalgia as refurbished iPods surge in popularity, despite it being unlikely that Apple will ever revive the product.

Superman Posters: The Heroic Legacy in Stunning Comic Art
An online gallery curates vintage and modern Superman comic book posters, highlighting the enduring appeal of the character's iconography in graphic design.
Original article
Superman's legacy as one of the world's most recognizable superheroes spans over eight decades, dating back to his comic book debut in 1938.