Devoured - June 03, 2026
Microsoft launched seven new MAI models for developer tuning and partnered with Mayo Clinic to develop an advanced AI healthcare model for Azure Foundry.

The Next Frontier of Visual AI Is Code
Visual AI is evolving from generating static pixels to creating editable source code like HTML/CSS and Blender scripts, enabling iterative design and 3D modeling.
Deep dive
- Visual AI is moving beyond generating static pixel outputs (like images/videos from diffusion models) to generating source code for editable digital artifacts.
- This "code-native generation" produces structured representations such as HTML/CSS, SVG, React components, Lottie JSON, Blender scripts, or USD scene graphs.
- The key advantage is enabling continuous iteration and feedback through a "Code → Render → Inspect → Revise" loop, allowing precise, source-level edits.
- Examples include QuiverAI for SVG logos, Paper for UI (HTML/CSS), and OmniLottie for Lottie animations.
- 3D modeling is a prime frontier for this approach, as 3D assets require consistent underlying structure and functional constraints, not just visual plausibility.
- Projects like VIGA use Blender as a feedback environment for 3D reconstruction, and Articraft3D generates programs defining 3D parts and joints.
- Future implications include renderers becoming direct feedback environments for AI agents and the emergence of hybrid workflows combining both pixel-native (for realism/exploration) and code-native (for structure/production) models.
Decoder
- Pixel-native generation: Visual AI systems that generate images or videos directly, typically in latent space, focusing on texture, atmosphere, and realism (e.g., diffusion models).
- Code-native generation: Visual AI systems that generate a structured representation (like HTML, SVG, Blender scripts) that is then executed or rendered by another engine, making the output editable and iterative.
- Lottie JSON: A lightweight, JSON-based animation file format that allows designers to ship animations on various platforms easily, preserving vector shapes, layers, keyframes, and timing parameters.
- USD (Universal Scene Description): A powerful, extensible open-source scene description technology developed by Pixar for authoring and interchanging 3D computer graphics data.
- VIGA: A research project using Blender as a rendering and feedback environment to turn visual reconstruction into a code-render-inspect loop for 3D assets.
- Articraft3D: A project that frames articulated 3D generation as writing programs to define parts, geometry, joints, and tests for complex 3D objects.
Original article
The Next Frontier of Visual AI Is Code
For the last few years, visual AI has mostly been judged by its pixels. The better the final image or video looked, the better the model seemed.
That made sense. Diffusion models turned text prompts into beautiful images, then videos, then increasingly realistic worlds. The obvious comparison point was Photoshop or a camera.
But for many visual-related tasks, like graphics design, UI design, or 3D modeling, the end representation users look for is not limited to the end state pixels. Instead, they are looking for artifacts where they can continuously iterate based on feedback and new ideas. A designer does not just need a mockup; they need layers, components, and handoff. An animator does not just need a video; they need timing curves, keyframes, and editable motion. A 3D artist does not just need a rendered picture; they need geometry, materials, lighting, cameras, and scene structure.
The most interesting visual AI tools today have stopped trying to generate the final output. Instead, they’re generating the source code behind it. This change is unlocking editability, iteration, and a feedback loop that pixel-native models can’t match.”
The two stacks of visual generation
There are two major ways to think about visual generation.
The first is pixel-native generation. These systems generate images or videos directly, usually in latent space. They are great at texture, atmosphere, lighting, and realism. If the goal is to generate a cinematic shot, a beautiful moodboard, or a photorealistic image, diffusion models are still the dominant method.
The second is code-native generation. These systems generate a representation that is then executed or rendered by another engine. The model does not directly produce the final pixels; it produces the program that produces the pixels.
That program might be an SVG file, an HTML/CSS layout, a React component, a Lottie JSON file, a Blender script, a USD scene graph, a shader, or a game-engine scene. The visual output is still pixels at the end, but the source of truth is a structured representation.
This distinction matters because production workflows care a lot about what happens after generation. A generated image is useful as an output, but a generated visual program is useful as an artifact – it can be edited, reused, improved, versioned. It can be integrated into the rest of the software stack and validated against constraints. It can be rendered repeatedly under different conditions or be handed off between designers, engineers and agents.
That is the big shift I think is already underway: for a subset of visual problems, we will learn to reframe the visual generation task to a coding task, and get highly efficient improvements from solving a well-defined and validatable coding problem.
Code is a good substrate for visual problems
The easiest way to understand the value of visual code generation is to look at what happens after the first draft.
Say a model generates a logo. If the output is a raster image and one curve is wrong, the user has to mask it, inpaint it, regenerate it, or manually redraw it. Whereas if the output is SVG, the user can edit the path, the primitive, the gradient, the stroke, or the text element. This is already how designers are designing logos on Quiver.
In the realm of UI design, if the output is a screenshot, it is mostly inspiration. If the output is HTML/CSS or React, the designers can inspect the DOM, swap in real components, test responsive states, check accessibility, and wire it into the application.
This is also why visual code generation is especially interesting for test-time compute. In pixel-native generation, more inference often means sampling more outputs: generate twenty images, pick the best one, maybe try again. That is useful, but every attempt is mostly a new roll of the dice. The model can respond to feedback, but the feedback is usually global and imprecise.
Technically, diffusion models can also benefit from test-time compute. For example, Inference-time Scaling of Diffusion Models through Classical Search shows that search at inference time can improve diffusion outputs across planning, RL, and image generation. But the loop here is different. In diffusion, the system is usually searching over latent trajectories or finished samples. A reward can tell the model that one output is better than another, but it cannot map feedback cleanly onto a specific source-level edit.
Code-native generation creates a more precise loop:
Code → Render → Inspect → Revise.
The model produces the artifact, renders it, sees what broke, and patches the source. If the spacing is wrong, change the CSS. If a logo curve is off, edit the SVG path. If an animation feels slow, adjust the timing. The key is that every iteration improves the underlying artifact, not just the rendered output. That is why visual code generation is on the direct path of benefiting from generating more tokens and test-time compute. The model is debugging a visual program in a closed-loop, verifiable environment; not just sampling more images.
The visual generation stack with code
Underneath the above examples is this stack:
Coding model + symbolic representation + renderer or engine
The coding model is the author and editor of the artifact. It writes the HTML, SVG, Lottie JSON, Blender script, USD scene, or bespoke 3D asset program.
The symbolic representation is the source of truth. This is what makes the artifact editable. A UI has DOM nodes, layout rules, and components. A Lottie animation has layers, vector shapes, timing curves, keyframes, and motion parameters. A 3D asset has geometry, materials, joints, constraints, and hierarchy.
The renderer or engine turns that structure into pixels. The browser renders HTML/CSS. An SVG renderer renders vectors. A Lottie player renders motion. Blender or a game engine renders 3D scenes. A simulator validates whether an articulated asset can actually move or interact.
OmniLottie is a good example of why the symbolic representation matters. Lottie is a lightweight and JSON-based animation format that represents motion as editable vector shapes, layers, keyframes and timing parameters rather than as a flat video. OmniLottie proposes turning this raw Lottie JSON into a more model-friendly sequence of commands so a model can generate and edit Lottie animations more reliably. The paper is not primarily about building a full agentic loop. Its key move is to make Lottie more model-native: it turns raw Lottie JSON into a compact sequence of commands and parameters that a model can generate. That matters because Lottie is already an editable animation format. Once motion is represented as shapes, layers, timing, and animation parameters, feedback can map to source-level edits. If the object moves too slowly, adjust the timing. If the path is wrong, edit the vector. If the morph is off, update the shape sequence.
The stack corresponds to the test time compute loop the coding agent can run to improve the output quality: at every Code -> Render -> Inspect -> Revise loop, the model is not just generating another sample; it is using the renderer as feedback to improve the underlying artifact. It can change the CSS rule, adjust the SVG path, fix the animation timing, or update the 3D constraint, then render again and continue improving.
This is what gives the loop a chance to converge. In pixel-native generation, each retry often produces a new output. In code-native generation, each retry can improve the source artifact itself. The model is not merely sampling more images or videos; it is debugging a visual program in a closed-loop, renderable environment.
Market map: wedge around runtimes
The market for visual code generation is starting to organize around the runtime where the artifact is rendered or executed. In code-native visual generation, the model is producing a symbolic artifact that gets executed somewhere: in a browser, an SVG renderer, a Lottie player, Blender, a game engine, or a simulator.
Each runtime creates a different wedge, because each one has its own source representation, feedback loop, and production workflow.
The most obvious applications today are in 2D design, especially UI and graphics design. But visual code generation is broader than design tooling. It shows up anywhere the visual artifact has an underlying representation that can be generated, rendered, inspected, and refined.
Why 3D is the next important frontier
While product design and 2D design are the most obvious use cases today, 3D artifacts may be able to benefit the most from reframing its consistency problem to a coding problem.
A 2D design can sometimes be useful if it simply looks right. A 3D asset cannot. A rendered image of a chair is not a chair. It is a picture of a chair. For the asset to be useful in a game, simulation or 3D editing tool, the artifact needs the consistent underlying 3D representation with the right geometry, materials, part hierarchy and scene context.
This is why 3D is a natural fit for visual code generation. The value is not just generating something that looks 3D from one angle, instead it’s generating a consistent 3D structure that holds up across views, edits, and interactions. That requires an iterative loop: propose the object, render it, inspect whether the geometry and parts make sense, then revise the underlying representation. But the loop only works if the agent has the right tools and context as it’s not enough to keep running Blender until something looks better. The agent needs ways to change camera views, query scene state, isolate objects, compare against the target, remember prior attempts, and translate visual discrepancies into source-level edits. That is what gives test-time compute a path to converge.
For many assets, visual consistency is only the baseline. The object also needs the right part semantics and functional constraints: doors should open, hinges should rotate, drawers should slide, wheels should spin. In other words, the output has to be more than a plausible shape. It has to behave like the thing it represents.
This is where projects like VIGA and Articraft3D stood out in the space and we expect to see more work – both commercial and open sourced – to come out this year. VIGA uses Blender as the rendering and feedback environment, turning visual reconstruction into a code-render-inspect loop; VIGA does not just expose raw Blender in a loop. It gives the agent semantic tools for observation and modification, plus memory over prior attempts, so it can inspect from better viewpoints, diagnose what is wrong, and make targeted edits. Articraft3D goes even more directly at asset structure: it frames articulated 3D generation as writing programs that define parts, geometry, joints, and tests.
Future implications and unsolved problems
If visual code generation works, the winning products will not just generate prettier outputs. They will own the loop: generate the artifact, render it, inspect what broke, and revise the source.
That has a few implications. First, renderers become feedback environments. The browser, SVG renderer, Lottie player, Blender, game engines, and simulators will become the environments where agents test and improve their work, like how coding agents are leveraging sandboxes and VMs today.
Second, the quality of the iteration context becomes more important than ever. To get an agent into the visual-code equivalent of a “Ralph loop,” the intermediate representation has to be precise enough to guide the next step. The model needs to know not just that something looks wrong, but which part of the source to change and why. Small errors in structure, rendering, or feedback can compound quickly across iterations.
Third, the future is likely to be hybrid. Pixel-native models will still be best for realism, texture, and exploration. Code-native systems will be better for structure, iteration, and production. The most useful workflows will combine both.
There are still open questions. Which representation wins for each domain? Do we need to remake the engines and renderers instead of using what we have from the previous generation? And how much of visual taste can be captured by constraints, tests, and feedback loops?
Still, the direction feels clear: visual AI is moving from outputs to code artifacts. The first wave made it easier to generate images. The next wave will make it easier to generate visual artifacts that can be edited, tested, shipped, and improved.
It’s time to build in this space. If you are building relevant representations, doing research, or have thoughts on how the industry evolves, reach out to yli@a16z.com.
Yoko Li
is a partner at Andreessen Horowitz, where she focuses on developer tools, infrastructure, AI, and creative tools.

Preventing AI Inference Theft at Scale
Vercel revealed how AI inference theft, costing up to $2 per prompt, is a high-margin attack on exposed endpoints, overcoming traditional rate limits and auth walls.
Deep dive
- AI inference theft involves unauthorized use and resale of paid AI model access, driven by high per-call costs (e.g., $2/prompt) compared to inexpensive HTTP requests (~$2/million).
- Attackers create OpenAI or Anthropic-compatible adapters, wrapping victim APIs to integrate stolen inference into standard client tools and SDKs.
- They use thousands of residential proxies and throwaway accounts to bypass traditional session-based rate limits and authentication.
- Vercel experienced a 10x traffic spike on April 12, 2026, reaching 1,300 requests/minute on Anthropic's Claude Haiku 4.5, incurring over $10,000/day in potential costs.
- Effective defense requires per-request verification, such as Vercel's BotID deep analysis (powered by Kasada's client-side ML), which runs invisibly on every API call to detect bots.
- Implementing BotID involves adding
checkBotId()in the server-side route handler and declaring the protected path on the client usinginitBotId(). - The economic asymmetry works in the defender's favor: inference is expensive per call for attackers to steal, but per-request verification is cheap to implement.
Decoder
- AI Inference Theft: The unauthorized use and subsequent resale of access to a paid AI model's processing capabilities, where the original provider pays for the AI call and the attacker profits from the resale.
- BotID Deep Analysis: Vercel's invisible CAPTCHA system, powered by Kasada, which uses client-side machine learning to analyze every request and distinguish between human and bot traffic without explicit challenges.
- Residential Proxies: IP addresses provided by internet service providers (ISPs) to residential users, which attackers abuse to make bot traffic appear as legitimate user activity from diverse locations, bypassing IP-based rate limits.
Original article
HTTP requests are inexpensive. Vercel charges ~$2/million, a fraction of a cent per call. But a single prompt to an agent on a frontier model can cost $2, making AI a million times more expensive, and inference theft one of the highest-margin businesses an attacker can run. We have seen this type of attack on our own APIs.
If you have AI endpoints exposed to the internet, the risk of abuse is high and can easily run up bills in the tens of thousands of dollars or more.
Protecting those endpoints requires verification to run on every AI request, not on the session or signup. Rate limits and auth walls aren't sufficient on their own because checks that run once per session get amortized away across thousands of stolen calls.
At Vercel, we gate every AI request through BotID deep analysis, and you can do the same on your own endpoints with a few lines of code.
What inference theft is
Inference theft is the unauthorized use of someone else's paid AI inference, either for free consumption or downstream resale. The operator pays per AI call; the attacker pays nothing for inference and then resells the tokens at a discount. This goes beyond rate-limit abuse to actual resale of a stolen resource in a market.
Which AI endpoints are at risk?
Any internet-facing endpoint that gives a caller meaningful control over an LLM prompt is a target. The more general the endpoint, the higher the payout per stolen call.
AI playgrounds, like the AI SDK Playground, are the most dangerous shape because the caller has maximum control over the prompt, the model, and often the parameters. Stolen calls land cleanly into any standard client.
Support bots and documentation assistants are less exposed when system prompts are fixed server-side, but attackers have learned how to talk the models around system prompts cheaply enough to make resale viable.
Resale value tracks how easily the stolen calls can be dropped into a provider-compatible client.
Why web defenses don't mitigate inference theft
IP rate limits and auth walls were built to defend against attacks with dramatically lower per-call economics, where gaming IPs and accounts weren't worth the cost.
The payoff from stolen inference is high enough that attackers will procure residential proxy IPs by the thousands and register throwaway accounts at whatever scale it takes to defeat your gate. Rate limits get diluted across the fleet of IP addresses, and real accounts pass authentication.
The architecture of abuse
Sophisticated attackers wrap your custom AI endpoint in an OpenAI- or Anthropic-compatible adapter and fan calls out through residential proxies.
The adapter is the key component. It is a one-time engineering cost that presents the victim's idiosyncratic API as OpenAI- or Anthropic-compatible, so stolen inference can drop into any standard coding agent or SDK. Reselling at even five to ten percent of the list price, with zero marginal inference cost, can make for a generous-margin business.
A recent example is Chipotlai Max, a forked coding agent that ships with a proxy turning Chipotle's customer-support chatbot into an OpenAI-compatible endpoint. The project openly solicits help in porting the same inference-theft approach to Home Depot, Lowe's, Target, and Starbucks.
The adapter also serves as the session boundary for the attacker's downstream users. They authenticate to the adapter, not to your endpoint. By the time a call hits your API, it has already crossed the boundary you were planning to defend. The check has to run on the call the adapter proxies, not on the session it sits behind.
The shape of a real attack on our own endpoint
On April 12, 2026, traffic to the Vercel docs AI chat endpoint spiked to roughly ten times normal volume on Anthropic's Claude Haiku 4.5 model. Traffic rose to 1,300 requests per minute at peak, which would have translated to an inference cost run rate of over ten thousand dollars per day.
The attack came in through residential proxies that obscured the real client IPs. Across hundreds of thousands of bot requests over two days, standard per-IP rate limits had nothing useful to act on.
How to defend against inference theft
Protecting AI endpoints against inference theft requires verification of every request. We use Vercel's BotID with deep analysis, called inside the route handler before the AI request lands.
Verification has to run on every AI request
If our gate had run at session start instead of per request, the attacker would have paid the bypass cost once and walked away with hundreds of thousands of stolen calls. Any check that runs per session amortizes the attacker's bypass cost across every subsequent inference call. Per-request gates force that ratio down to one, and even at high inference prices, defeating a check on every call isn't worth the cost.
This is where the cost asymmetry works in the defender's favor. Inference is the most expensive resource per call that the attacker steals, but verification is one of the cheapest protection costs per call.
Implementing request verification with BotID deep analysis
Traditional image CAPTCHAs no longer hold up against modern attackers because the same AI models that make inference worth stealing can easily bypass them.
We deploy Vercel BotID on our AI endpoints, gating every request. BotID is an invisible CAPTCHA with deep analysis powered by Kasada that uses client-side machine learning to distinguish humans from bots without a visible challenge, so it can run on every request rather than only at session start.
BotID deep analysis detected and blocked more than ten thousand bot requests in the first minutes of the spike. Within twenty-four hours, request volume on the endpoint was flat at normal levels.
Server-side, checkBotId() runs inside the route handler and returns a classification for the request currently being served.
1// app/api/ai-chat/route.ts2import { checkBotId } from 'botid/server';3import { NextRequest, NextResponse } from 'next/server';4
5export async function POST(request: NextRequest) {6 const verification = await checkBotId();7 if (verification.isBot) {8 return NextResponse.json({ error: 'Access denied' }, { status: 403 });9 }10 // Your existing AI SDK call path11}The route also has to be declared on the client. Without this, checkBotId() fails because BotID doesn't attach the challenge headers to the request:
1// instrumentation-client.ts2import { initBotId } from 'botid/client/core';3
4initBotId({5 protect: [{ path: '/api/ai-chat', method: 'POST' }],6});See the BotID docs for the next.config.ts wrapper and the full setup.
Protect inference, not just access
Inference will remain orders of magnitude more expensive than the requests it carries, so resale will remain profitable, and attackers will keep iterating.
To protect your AI endpoints:
-
Audit which of your AI endpoints are exposed
-
Prioritize by attack likelihood: more caller prompt control means an easier target
-
Gate every endpoint on every request

GitHub's plan for Agents
GitHub COO Kyle Daigle discusses how the platform's infrastructure, designed for human speeds, is straining under a 1400% surge in agent-driven code contributions in 2026, leading to uptime issues.
Deep dive
- GitHub COO Kyle Daigle notes a 1400% increase in agent-driven code contributions in 2026, pushing total commits from 1 billion in 2025 to an estimated 14 billion in 2026, causing significant infrastructure strain.
- The platform's original architecture was designed for human speeds, making it ill-suited for the exponential, agent-driven growth.
- Recent uptime issues are attributed to new, novel permissioning problems and database scaling challenges in core systems like "MySQL One," rather than simple legacy issues.
- Traditional vertical and horizontal scaling are no longer sufficient; GitHub is undertaking deep re-architecture of 10-15 year old services, including job queuing, and moving to Azure Dev Compute for actions.
- The growth also sees a shift back towards larger monorepos, posing unique performance challenges due to blob size.
- GitHub is investing heavily in increasing CPU capacity for Actions, which has become a general-purpose compute layer beyond CI/CD.
- Daigle emphasizes GitHub's commitment to transparency, sharing more technical details about ongoing fixes and scaling efforts.
- Copilot's evolution includes a new CLI, desktop app, and cloud agents using a unified SDK, moving beyond code completion to encompass broader AI coding agent automation throughout the SDLC.
- Daigle highlights the concept of "ambient AI" – an AI deeply integrated across all personal and work contexts, capable of understanding and acting based on comprehensive information, which he believes is the future of AI assistance.
- Microsoft is heavily invested in "OpenClaw"-like agents, with a CVP dedicated to it, focusing on sandboxing at the OS level (e.g., Windows) to enable secure agent interaction with work assets and user data.
- GitHub is projected to have over 200 million "developers" (GitHub account holders), redefining what constitutes a developer in the AI era.
Decoder
- Monorepo: A software development strategy where all code for many projects is stored in a single repository, often managed by a single team or organization.
- Git Infrastructure Layer: The underlying systems and protocols that manage how Git repositories are stored, accessed, and synchronized across servers, including handling data blobs, commits, and references.
- Job Queuing: A system that manages and prioritizes tasks or jobs (e.g., builds, tests, deployments) to be processed by available workers or resources, often used in CI/CD pipelines.
- Ambient AI: An artificial intelligence system that operates ubiquitously and subtly in the background, continuously processing context from a user's environment and actions to proactively assist them without explicit commands.
- OpenClaw: An open-source project and concept for an AI agent that can interact with a computer using its keyboard, mouse, and screen, essentially giving AI models the ability to "use" a computer like a human.
- CVP (Corporate Vice President): A senior leadership title at Microsoft, indicating a significant role with broad responsibilities across a business division or strategic initiative.
- Sandboxing: A security mechanism for running programs in an isolated environment, restricting their access to system resources to prevent malicious or buggy code from affecting the rest of the system.
- WorkIQ/FoundryIQ: Internal Microsoft context engines that aggregate information across various work contexts (e.g., M365, Slack, email) to help employees ask questions and gain insights without moving data to new tools, designed for enterprise security and compliance.
Original article
Full article content is not available for inline reading.

TinyFish Bigset turns text prompts into live datasets
TinyFish launched Bigset, an open-source, multi-agent system that converts text prompts into self-refreshing, structured datasets pulled from the live web using agents powered by Claude Sonnet 4.6 and Qwen3.7-max.
Deep dive
- TinyFish Bigset is an open-source (AGPL-3.0) multi-agent system that converts natural language prompts into structured, self-refreshing datasets from the live web.
- It uses an orchestrator agent for discovery and sub-agents for data collection, with sub-agents operating under a tight budget of 6 tool calls to ensure efficiency.
- Agents are instructed not to fabricate values, leave unconfirmed fields blank, and reject duplicate primary keys.
- Schema inference is handled by Claude Sonnet 4.6, and agent roles by Qwen3.7-max by default, routed through OpenRouter and configurable.
- The system is self-hostable via Docker and allows setting refresh cadences from 30 minutes to weekly.
- TinyFish, backed by $47 million in Series A funding from ICONIQ, offers Bigset as an open-source counterpart to its enterprise agent products, built on the same web infrastructure (TinyFish Search and Fetch).
- The team acknowledges it's experimental, with datasets taking 2-5 minutes to build and working best on topics with public web data.
- A free tier allows 2,500 row operations per month, and 9 curated public datasets are available.
Decoder
- AGPL-3.0: The GNU Affero General Public License version 3, a free software license that requires anyone who runs a modified program over a network to also make the source code available.
- Orchestrator agent: A primary AI agent responsible for coordinating and directing the tasks of other, smaller sub-agents within a multi-agent system.
- Sub-agents: Smaller, specialized AI agents that perform specific, focused tasks under the direction of an orchestrator agent.
- Claude Sonnet 4.6: A specific model in Anthropic's Claude family of large language models, likely a mid-tier offering optimized for speed and cost.
- Qwen3.7-max: A specific model from the Qwen series of large language models developed by Alibaba Cloud, indicating a high-performance version.
- OpenRouter: A platform that provides a unified API for accessing various large language models from different providers, often allowing users to select and route requests to specific models.
Original article
TinyFish has launched Bigset, an open-source multi-agent system that turns a plain-language sentence into a structured dataset pulled from the live web. You describe what you want, and Bigset infers the schema, sends autonomous agents to research it on real web pages, verifies their findings against sources, deduplicates, and hands back a clean table you can export as CSV or XLSX. Set a refresh cadence from 30 minutes to weekly, and have the agents rerun on schedule so the dataset stays current without anyone needing to touch a script.
The work is split across two agent roles. An orchestrator agent does breadth-first discovery, identifying which rows belong in the dataset and where on the web to find them, then dispatches sub-agents to fill each one. The orchestrator holds no write access of its own. Each sub-agent researches a single entity under a tight budget of 6 tool calls, pulls real data via TinyFish Search and Fetch, and inserts one verified row with its source URLs and a record of how the data was found.
Sub-agents are instructed never to fabricate values, to leave fields blank when they cannot be confirmed, and to reject duplicate primary keys automatically. The orchestrator runs until the dataset reaches its row target, building faster as it learns where the data lives.
Bigset is licensed under AGPL-3.0 and runs self-hosted through Docker, with schema inference on Claude Sonnet 4.6 and the agent roles on Qwen3.7-max by default, all routed through OpenRouter and configurable per role. The team is candid that the project is experimental: a dataset takes 2 to 5 minutes to build, it works best on topics with public web data, and the free tier covers 2,500 row operations per month. It ships with 9 curated public datasets covering AI companies hiring, GPU prices, model pricing, and top open-source repositories, browsable without an account.
TinyFish is the Palo Alto-based company behind the platform, backed by $47 million in Series A funding led by ICONIQ, and counts Google, DoorDash, and Amazon among its enterprise clients, having processed more than 40 million agent operations. Bigset is built directly on TinyFish Search and Fetch, the same web infrastructure underneath the company's enterprise agent products, and arrives as the open-source answer to proprietary natural-language dataset tools, with no per-seat pricing, no domain restrictions, and full pipeline ownership for anyone who runs it themselves.
Star it on Github and grab an API key! 🔥

In a surprise launch, China debuts another big rocket designed for reusability
China's state-backed Long March 12B, a new large rocket resembling SpaceX's Falcon 9, completed its first successful test flight with reusability features, indicating an accelerated race for reusable launch vehicles.
Deep dive
- China's Long March 12B, a 72-meter (236-foot) tall rocket, completed its unannounced first flight on Monday, June 2, 2026, at 4:40 pm Beijing time.
- Developed by China Commercial Rocket Co. Ltd. (CACL), a subsidiary of the state-owned China Aerospace Science and Technology Corporation (CASC), reportedly in just 21 months.
- The rocket features grid fins and landing legs, similar to SpaceX's Falcon 9, for future first-stage recovery experiments, though no landing attempt was made on this flight.
- It uses nine kerosene-fueled main engines on its first stage and has a payload capacity of approximately 20 metric tons (44,000 pounds) to low-Earth orbit in expendable mode.
- The Long March 12B deployed a batch of Qianfan broadband spacecraft, part of China's effort to build mega-constellations like SpaceX's Starlink.
- This launch comes after two failed heavy booster recovery attempts by Chinese companies (LandSpace's Zhuque 3 and Shanghai Academy of Spaceflight Technology's Long March 12A) in December.
- The design, including the clustered engine configuration, mirrors engineering choices proven by SpaceX with the Falcon 9, which is a sound approach for reusability.
- The article highlights a less predictable race for reusable rockets in China compared to the US, with state-owned enterprises now potentially gaining an advantage over private firms.
- China's government did not issue customary pre-launch public notices for pilots, which is unusual.
- The Long March family confusingly includes three designs: the expendable Long March 12 (2024), the partially reusable methane-fueled Long March 12A (December), and this kerosene-fueled Long March 12B.
- Other Chinese state-backed rockets like the Long March 10 (for crewed lunar missions) and Long March 9 (super-heavy-lift, Starship analog) are also in development.
Decoder
- Grid fins: Fin-like control surfaces on rockets used to steer and stabilize the first stage during atmospheric re-entry for propulsive landings.
- Expendable mode: A rocket launch where the booster stages are not recovered or reused after flight, typically allowing for a higher payload capacity.
- Propulsive landing: A landing method where a rocket uses its engines to slow its descent and touch down vertically in a controlled manner, as popularized by SpaceX.
Original article
The race to field China’s first reusable launch vehicle is far less predictable than a similar competition that played out in the United States a decade ago.
There was never any real question of which company would develop and demonstrate the first reusable orbital-class rocket in the United States. SpaceX landed a Falcon 9 booster for the first time in 2015, and a little more than a year later, it launched it back into space. It took nearly 10 years for anyone else to do the same. Blue Origin celebrated its first orbital-class booster landing last November with the successful recovery of one of its New Glenn boosters, followed by a relaunch of the same rocket in April.
In China, several companies and state-owned enterprises have a realistic shot at landing an orbital-class booster stage this year. For a time, it seemed like China’s new crop of privately funded launch companies might have the advantage in accomplishing the first landing of an orbital-class booster. But Monday’s launch of China’s Long March 12B rocket, backed by the nearly unrestricted resources of the country’s vast state-owned aerospace enterprise, suggests the industry’s legacy players may now have a leg up.
Secrecy reigns
China’s first two attempts to recover heavy boosters failed in December. First, a company named LandSpace, part of China’s recent wave of quasi-commercial launch providers, debuted its Zhuque 3 rocket on December 2. The launch was successful, but the booster crashed near its landing zone downrange from its launch site in the Gobi Desert of northwestern China. Less than three weeks later, a somewhat less powerful rocket named the Long March 12A had a similar result on its first test flight. The Long March 12A is a product of the Shanghai Academy of Spaceflight Technology, part of China’s legacy government-owned space industry.
In early April, another relative newcomer to China’s launch sector launched its new medium-class Tianlong 3 rocket. The 7-year-old firm behind the Tianlong 3, named Space Pioneer, said the rocket failed to reach orbit, an outcome not uncommon for brand-new launch vehicles. Tianlong 3’s first stage booster is designed for recovery and reuse, but a landing attempt will have to wait until a future flight.
The Long March 12B, the largest and most powerful (potentially) reusable rocket China has launched to date, lifted off Monday from a remote launch pad in the Gobi Desert. The 236-foot-tall (72-meter) rocket took off at 4:40 pm Beijing time (08:40 UTC or 4:40 am EDT).
Unusually, Chinese officials appear not to have announced the launch in advance. The Chinese government did not issue any public notices for pilots to avoid the rocket’s flight path, as is customary for space launches around the world. It’s too soon to know if this was a one-off change or the start of a new policy for Chinese launches. Russia’s government, which has historically also released safety notices for its space launches, has begun issuing such warnings to cover extended periods over many days in a bid to conceal when a launch might actually occur.
The existence of the Long March 12B was not a secret. The rocket completed a test firing on its launch pad in China in January, and a launch was expected in the first half of this year. It was developed by China Commercial Rocket Co. Ltd., or CACL, an opaque business venture set up by China’s sprawling state-owned aerospace enterprise. According to Chinese state media reports, engineers designed and developed the Long March 12B in just 21 months. If the claim is true, it would be a remarkably fast timeline to progress from a clean sheet to an orbital flight.
Monday’s launch did not include any attempt to land the first stage booster, but the rocket carried grid fins and landing legs, important hardware elements for future recovery experiments. A statement released by China Aerospace Science and Technology Corporation (CASC), CACL’s parent company, declared the first flight of the Long March 12B a “complete success” in a post-launch statement.
“This launch adds another high-capacity commercial rocket to [China’s] fleet for large-scale Internet constellation networking missions,” CASC said. “No recovery tests were conducted during this mission; however, first-stage recovery tests are scheduled to be carried out at a later, opportune time.”
Satellites for one of these large-scale Internet constellations rode to space aboard the Long March 12B, which released a batch of Qianfan broadband spacecraft into low-Earth orbit. Qianfan is one of China’s two leading mega-constellations, each seeking to replicate for China what SpaceX’s Starlink does in the United States.
Who’s involved?
The Long March rocket family dates back to 1970, when China launched its first satellite into orbit using the Long March 1 vehicle derived from Chinese ballistic missiles. Many iterations have followed. The Long March 2, 3, and 4 rockets were China’s workhorses in the 1980s, 1990s, and 2000s. These rockets remain operational but are being replaced by newer models, such as the Long March 5, 6, 7, and 8, which can launch everything from small satellites to massive modules for China’s space station.
Somewhat confusingly, the Long March 12 family now includes three dissimilar designs. The original Long March 12, with four kerosene-fueled main engines, launched for the first time in 2024, sporting a conventional, expendable design. The partially reusable Long March 12A launched in December, replacing the Long March 12’s kerosene-fueled engines with a methane-fueled propulsion system outsourced to a private engine builder. The Shanghai Academy of Spaceflight Technology (SAST) managed the development of the Long March 12 and 12A.
 China’s Long March 12A rocket, using methane-fueled engines, launched for the first time in December. Credit: VCG/VCG via Getty Images
China’s Long March 12A rocket, using methane-fueled engines, launched for the first time in December. Credit: VCG/VCG via Getty Images
The Long March 12A rocket reached orbit, but its lift capacity is half that of the Long March 12 after accounting for the fuel reserve required to recover the booster stage. The Long March 12B reverts back to the kerosene and liquid oxygen mix used on the Long March 12, but with nine engines on the first stage instead of four. The Long March 12B is also taller and wider than the 12 or 12A. Collectively, these changes allow the Long March 12B to approach the payload capacity of the Long March 12, even when it flies in reusable mode.
These rocket developments were directly orchestrated by the Chinese government, which owns institutions like CASC, SAST, CACL, and the granddaddy of all Chinese rocket developers: the China Academy of Launch Vehicle Technology. CALT is in the advanced stages of readying a new partially reusable rocket, the Long March 10, to send astronauts to the Moon. Further behind is the Long March 9, a super-heavy-lift launch vehicle sized as a Chinese analog to SpaceX’s Starship. A suborbital version of the Long March 10 made a controlled, on-target splashdown following a test flight in February.
A tip of the hat
Many of China’s up-and-coming rockets bear a striking resemblance to those developed halfway around the world by SpaceX. As Ars has previously reported, the Long March 9 is supposed to be China’s answer to Starship. But other Chinese rocket programs are still trying to catch the same lightning SpaceX caught with the Falcon 9.
The Long March 12B that launched Monday uses nine kerosene-fueled main engines and a single engine on the second stage, the same as the Falcon 9. The engines generate 1.7 million pounds of thrust at liftoff, the same as the Falcon 9. In expendable mode, the Falcon 9 rocket can deliver nearly 23 metric tons (about 50,000 pounds) of payload to low-Earth orbit. The Long March 12B’s payload capacity to low-Earth orbit maxes out at about 20 metric tons (44,000 pounds) on an expendable mission.
Space Pioneer’s Tianlong 3, which failed on its first flight in April, uses the same kerosene-fueled, nine-engine cluster arrangement on the booster, coupled with a single-engine second stage. Its lift capability is a little less than that of the Falcon 9 or Long March 12B, but it is similar in height and thrust.
The Long March 12A and Zhuque 3 are powered by groupings of seven and nine methane-fueled engines, respectively, on their booster stages.
There are sound engineering reasons to use the same approach SpaceX uses with the Falcon 9. A clustered engine configuration on the first stage, usually with seven or nine engines, offers several advantages. It allows a booster stage to provide high thrust during ascent, and a lower power level during propulsive landing burns. In some cases, flying with a cluster of booster engines might allow the rocket to continue its mission even if one of them fails.
There are important, less obvious aspects of a rocket’s design. We have less insight into how closely those elements on China’s rockets match what SpaceX has tried and proven on Falcon 9.
But SpaceX’s architecture clearly works. The first version of Blue Origin’s New Glenn rocket uses seven engines fueled by methane, and the company is looking at going to nine booster engines in the future. Several more US rocket companies are pursuing similar designs for their reusable rockets. Nearly all are going with seven- or nine-engine boosters.

Karpathy's Autoresearch found a 3-year-old bug in Posthog's query engine (and improved performance by 11%)
PostHog used an "autoresearch" AI agent, inspired by Andrej Karpathy, to uncover a 3-year-old ClickHouse query engine bug, improving query performance by 11% by correctly utilizing primary keys.
Deep dive
- PostHog deployed an AI "autoresearch" agent during a hackathon, inspired by Andrej Karpathy's concept, to optimize its ClickHouse query engine.
- The agent was given slow production queries and a dedicated test cluster to iterate on potential fixes overnight.
- It identified a bug present for almost three years:
toTimeZone(timestamp, team_tz)wrapped aroundtimestampreferences prevented ClickHouse's query planner from effectively using partition pruning and primary keys. - Specifically, the planner couldn't derive bounds for
toYYYYMM(timestamp)ortoDate(timestamp)because thetoTimeZone()function masked the underlying bare timestamp. - The fix involved rewriting the comparison to
timestamp >= toDateTime64('2024-03-01', 6, 'US/Pacific'), allowing the planner to correctly apply indexes. - This change resulted in a 62% reduction in granules scanned and a 37% speedup on a 7-day funnel query, with an overall 11% performance improvement.
- The bug was hard to detect because ClickHouse's
MinMaxskip index provided some fall-back performance, preventing catastrophic slowdowns and making it appear "not page someone" slow. - The agent, lacking human bias, explicitly ran
EXPLAIN PLAN indexes=1, json=1which revealed thePartition: Condition='true'(no pruning) issue, leading to the solution. - PostHog is now automating this process to fetch slow queries from
system.query_log, spin up sandboxes for agents, and generate PRs for human review. - The article suggests this "autoresearch" approach can be applied to any quantifiable system metric beyond query performance.
Decoder
- ClickHouse: An open-source, column-oriented database management system for online analytical processing (OLAP) queries.
- Primary key: A column or set of columns in a database table that uniquely identifies each row. Used by databases to quickly locate and retrieve records.
- Granule: A block of rows (e.g., 8,192 rows in ClickHouse) that the database scans together. Reducing granule scans improves query performance.
- Partition pruning: A database optimization technique where the query optimizer skips reading entire partitions (subsections) of a table if it determines they do not contain relevant data for a query.
toTimeZone(): A ClickHouse function used to convert a timestamp to a specific timezone. In this case, it inadvertently interfered with query planner optimizations.EXPLAIN PLAN: A SQL command that shows the execution plan a database will use for a query, detailing how it accesses tables, applies indexes, and performs operations.MinMaxskip index: A type of index in ClickHouse that stores the minimum and maximum values of a column for each granule, allowing the database to skip granules outside a query's value range.
Original article
Karpathy's Autoresearch found a 3-year-old bug in our query engine (and improved performance by 11%)
A few weeks ago at a team offsite in Lisbon, we pointed an AI agent at our query engine, fed it slow queries from production, and let it run overnight.
By the next morning it had found something embarrassing: for almost three years, every query with a timestamp filter had not been using ClickHouse's primary key correctly. The fix cut the number of granules ClickHouse had to scan by 62% on the benchmark query, and made the query itself meaningfully faster.
This post is about the setup we used, the bug itself, and what we're building now so this kind of analysis happens automatically.
What's autoresearch?
The general idea isn't ours. Andrej Karpathy packaged it up and gave it a name in March 2026: give an AI agent a small but real system, a benchmark, and a budget, and let it loop; propose a change, run the benchmark, keep what helps, throw away what doesn't.
Karpathy ran it for two days against a depth-12 nanochat training run and found about 20 changes that improved validation loss, some of which transferred to a bigger model. The shape isn't new (DeepMind's FunSearch (2023) and Sakana's AI Scientist (2024) are earlier examples), but Karpathy's repo is small and concrete enough to inspire you to build your own version in an afternoon.
The interesting part for us is the second-order effect: the agent doesn't carry the bias that comes from living in a codebase. To us, the toTimeZone() wrap had just always been there. The kind of code you stop seeing. The agent has no priors. It runs every diagnostic, reads the surrounding ClickHouse and PostHog source for context, and treats a three-year-old expression with the same suspicion as the line you wrote yesterday.
Setting up autoresearch for ClickHouse in a hackathon
Every year, we run hackathons at company offsites. A lot of what's now PostHog (session replay, the data warehouse, logs, and more) started this way. At a smaller joint team offsite for the Analytics Platform and Query Performance teams in Lisbon, our hackathon project was to do Karpathy's thing, but for ClickHouse query performance.
The stack we used:
-
pi: a small terminal coding agent built by Mario Zechner. It speaks to whatever LLM you point it at, exposes a small SDK, and is small enough that you can read the entire codebase.
-
pi-autoresearch: a community extension bydavebcn87that wires Karpathy's loop into pi. You give it an objective, a baseline, a benchmark command, and a target metric. It iterates, commits each candidate, runs the benchmark, and keeps a journal so the run survives context resets. -
A campaign orchestration contract that we wrote on top of
pi-autoresearch. The basic loop "try something, measure, keep or discard" is too loose when a single ClickHouse query has hundreds of plausible rewrites. Without a structure, an agent can fiddle with a corner of the query until it gives up; with it, you get something closer to how someone would actually run an investigation. We structured each investigation into four parts:- A campaign with one slow query and one git branch.
- This is broken into lanes, optimization directions tied to a suspected bottleneck: predicate ordering, JSON parsing, timezone handling, primary key usage, and so on. Lanes can be paused when they stop yielding signal, split when they turn out to be two ideas, or merged when wins from different lanes turn out to combine.
- A concrete, testable hypothesis inside each lane.
- An experiment inside each hypothesis with one run, benchmark, and verdict. The agent has to do an explicit reflection pass after every experiment instead of letting the loop just hill-climb.
-
A throwaway ClickHouse test cluster: this kept iteration speed high and benchmark numbers predictable. The same data shape as production but anonymized and running on cheaper hardware dedicated to the agent. Running on a developer laptop would have been too slow for a useful inner loop; running on production would have meant fighting noisy neighbors and risking interference with customer queries.
Range-narrowing also helped. When a target query times out, the agent halves the range (30 days, 14, 7, 3, 1) until it completes in one to ten seconds, then optimizes against that narrowed version. That window is short enough for fast iteration but long enough that index and partition effects still matter. The current best candidate is periodically retested at the full range; once it completes there, the campaign "graduates" back and continues from the original query.
During the hackathon, we hand-fed it slow queries that we'd grumbled about in the past and ones we found by hand in system.query_log (we're now automating this now).
Discovering our silently broken primary key
ClickHouse is fast because it can skip work. Our events table is PARTITION BY toYYYYMM(timestamp) and the primary key is (team_id, toDate(timestamp), event, …). A well-formed query with a timestamp bound should make ClickHouse drop entire months of data and then jump straight to the right week within the months it does have to look at.
That's not what was happening.
When we added per-team timezone support to HogQL in April 2023, we did the sensible thing and wrapped every reference to timestamp in toTimeZone(timestamp, team_tz) so display dates were correct. What we didn't realize is that the ClickHouse query planner can't see through toTimeZone(). This meant it couldn't derive bounds on:
toYYYYMM(timestamp)fromtoTimeZone(timestamp, tz) >= '2024-03-01', so partition pruning was off.toDate(timestamp)so the primary key was being used forteam_idandeventbut stopping there.
The reason this hadn't already paged us is that ClickHouse also has a MinMax skip index on timestamp. A MinMax index stores the smallest and largest value of a column per "granule" (8,192 rows by default). When you compare toTimeZone(timestamp, tz) against a constant, ClickHouse can still evaluate that against each granule's min/max and skip the ones whose range doesn't overlap. This is much weaker than partition pruning, but it works, so queries weren't catastrophically slow, just measurably slower than they should have been.
That's the kind of bug that hides forever. It's slow, but not "page someone" slow. Every query is affected, so nobody can A/B compare against a "good" version. And the smoking gun lives in the output of EXPLAIN PLAN indexes=1, json=1, which nobody runs unless they already suspect something.
In one of the lanes, the autoresearch loop ran the EXPLAIN. It noticed Partition: Condition='true' (i.e. no pruning) so tried two things:
- Adding
indexHint()with bare-timestamp bounds. - Rewriting the comparison so the field side was bare and the constant carried the timezone.
The second approach won, by a lot, and that's what we shipped:
-- Before: planner can't see through toTimeZone
toTimeZone(timestamp, 'US/Pacific') >= '2024-03-01'
-- After: bare field on the left, timezone-annotated constant on the right
timestamp >= toDateTime64('2024-03-01', 6, 'US/Pacific')The semantics are identical because toTimeZone() only changes display metadata: the underlying epoch is unchanged. The planner now sees a bare timestamp and can do its job.
On a 7-day funnel against a real team in production (load_balancing='in_order' so each variant hits the same shard, five runs each, trimmed mean of the middle three):
| Metric | Baseline | This fix | Change |
|---|---|---|---|
| Best run | 2,824 ms | 2,192 ms | −22% |
| Trimmed mean (mid 3) | 4,694 ms | 2,954 ms | −37% |
| Skip-index granules | 60,683 | 23,291 | −62% |
The speedup is biggest on queries with short date ranges, because that's where partition pruning matters most. At a 7-day range, you can drop most of the partitions if the planner cooperates. Wider ranges have to look at more partitions regardless, so the relative win shrinks: a 90-day query is still faster, just not by 37%. The granule reduction is real on every range; it just translates into a smaller wall-clock improvement when there are more granules to scan in absolute terms.
The bug had been there since the timezone change landed. About three years.
What's next: doing this without the hackathon
We were hand-feeding slow queries to the agent during the offsite. That doesn't scale. The pipeline we're now building is closer to what you'd actually want:
-
Fetch slow queries from
system.query_log. The orchestrator that does this lives atproducts/query_performance_ai/orchestrator/slow_queries.py. -
Spin up a sandbox per candidate query, the same sandboxes we use to run PostHog Code, our coding agent and product editor (currently in beta).
-
Run
pi-autoresearchin each sandbox, each with its own benchmark target and budget. -
Have an LLM dedup the suggestions and spawn a PostHog Code session for each surviving idea. Different sandboxes often land on the same idea, so the LLM collapses those before dispatching. PostHog Code writes the actual change against the real codebase, with tests and benchmarks.
-
Post the resulting PRs into our team Slack channel so a human reviews and merges.
If this works, "some queries in our codebase don't use the primary key correctly" becomes a thing the system finds overnight while we're all asleep, not a thing that takes three years and a team offsite to uncover. We'll write up the second-order results once they're real.
In the meantime, the recipe isn't specific to slow queries. If there's a metric in your system you've been quietly tolerating (speed, memory, cost, accuracy, error rate, anything you can put a number on), build a harness you can run cheaply and don't mind being mean to, point an agent at it, and look at what comes back.
PostHog is an all-in-one developer platform for building successful products. We provide product analytics, web analytics, session replay, error tracking, feature flags, experiments, surveys, AI Observability, logs, workflows, endpoints, data warehouse, CDP, and an AI product assistant to help debug your code, ship features faster, and keep all your usage and customer data in one stack.
Community questions

The Google Capital Company
Google is raising $80 billion in equity, including $10 billion from Warren Buffett's Berkshire Hathaway, to fund its massive AI spending, signaling an unprecedented demand for compute capacity.
Deep dive
- Stratechery's Ben Thompson likens Google's high-margin Google Services (advertising) business to See's Candies, generating immense cash flow.
- This cash flow is being used to fund Google Cloud, which is growing rapidly, especially in AI, but has higher capital expenditure requirements, similar to Berkshire Hathaway's BNSF Railway.
- In Q1 2026, Google Services made $89.6 billion revenue and $40.6 billion profit, while Google Cloud made $20.0 billion revenue and $6.6 billion profit.
- Alphabet's $80 billion equity raise includes a $40 billion "at-the-market" program, $30 billion in underwritten offerings, and a $10 billion direct investment from Berkshire Hathaway.
- The article speculates on why Google chose equity over debt, suggesting either an underestimation of compute demand or uncertainty about AI ROI, leading them to share risk.
- Berkshire Hathaway's investment, after years of Warren Buffett avoiding tech, is seen as an endorsement of Google's long-term AI strategy by CEO Greg Abel, who is now making investment decisions.
- The investment also reflects Berkshire's need to deploy its $373 billion cash hoard into businesses that can generate high returns, with Google's multi-layered AI strategy (benefitting Services, Gemini models, selling capacity via TPUs) being a strong candidate.
- The core thesis is that in a world of constrained compute, the company with the most cash capacity will win the race, and Google is positioning itself as that company, validated by Berkshire Hathaway's bet.
Original article
The Google Capital Company
What does the most beautiful business model of all time look like?
First, imagine that your supply is free. Second, imagine that your customers willfully compete against each other to raise your prices. Third, imagine that your users decide which of your customers gets the privilege of paying you. All you have to do is build a bit of infrastructure to make it all happen, pay a nominal bit of depreciation on that infrastructure, and make billions of dollars on some of the greatest margins in the history of business.
I am, of course, describing Google, a company so good that Warren Buffett, the legendary investor, could never quite bring himself to invest in it. Buffett explained in the 2017 Berkshire Hathaway annual meeting:
We were their customer very early on with GEICO, for example, and we saw — these figures are way out of date — but as I remember, we were paying them $10 or $11 a click, or something like that. And any time you’re paying somebody $10 or $11 bucks every time somebody just punches a little thing where you got no cost at all, you know, that’s a good business unless somebody’s going to take it away from you. And so we were close up seeing the impact of that…But, you know, you’ve almost never seen a business like it.
One of the characteristics of an Aggregator like Google is the way in which they maximize absolute value at the expense of relative value. For supply — i.e. content on the web — Google dramatically increases the number of visitors, even as the value of any one visitor who comes from Google is worth much less than a visitor who visits directly; for an advertiser, the value of one click makes up for thousands of impressions of an ad that make no difference; for a user, Google helps them discover what they are looking for amidst the overwhelming abundance that is downstream from distribution being free. In every case the Aggregator increases quantity at the expense of relative quality, confident that the absolute amount of quality will be more in the long run.
What is interesting is that this is the exact inverse in terms of why these companies have been valued by investors. The best tech companies are “asset-light”, predicated on maximizing zero marginal costs. Yes, they spend a lot of money on R&D and on the infrastructure to make markets happen, but they don’t actually participate in those markets; simply taking a skim and keeping the vast majority of that skim is what gets Wall Street excited. In other words, it was the relative amount of money made that was generally more important to the market than the absolute amount of money.
Berkshire Hathaway and Productive Capital
Berkshire Hathaway was, before Buffett acquired it, a failing textile business; Buffett originally invested because the stock was worth less than the liquidation value, and ended up owning it outright after a dispute with management. It was a decision he regretted; from the company’s 1989 letter to shareholders:
If you buy a stock at a sufficiently low price, there will usually be some hiccup in the fortunes of the business that gives you a chance to unload at a decent profit, even though the long-term performance of the business may be terrible…Time is the friend of the wonderful business, the enemy of the mediocre…
I could give you other personal examples of “bargain-purchase” folly but I’m sure you get the picture: It’s far better to buy a wonderful company at a fair price than a fair company at a wonderful price. Charlie understood this early; I was a slow learner. But now, when buying companies or common stocks, we look for first-class businesses accompanied by first-class managements.
One of the first-class businesses Berkshire Hathaway acquired was See’s Candies in 1972. Buffett explained in the 2007 shareholder letter:
We bought See’s for $25 million when its sales were $30 million and pre-tax earnings were less than $5 million. The capital then required to conduct the business was $8 million. (Modest seasonal debt was also needed for a few months each year.) Consequently, the company was earning 60% pre-tax on invested capital…
Last year See’s sales were $383 million, and pre-tax profits were $82 million. The capital now required to run the business is $40 million. This means we have had to reinvest only $32 million since 1972 to handle the modest physical growth – and somewhat immodest financial growth – of the business. In the meantime pre-tax earnings have totaled $1.35 billion. All of that, except for the $32 million, has been sent to Berkshire (or, in the early years, to Blue Chip).
The “problem” with a See’s Candies is that there is nothing to be done with all of that profit; if it’s privately held then its owners end up with more cash than they know what to do with, and if it’s public, then the job is to figure out how to return that cash to shareholders through some combination of dividends and stock buybacks. What Berkshire Hathaway did, however, was use that cash to grow:
After paying corporate taxes on the profits, we have used the rest to buy other attractive businesses. Just as Adam and Eve kick-started an activity that led to six billion humans, See’s has given birth to multiple new streams of cash for us. (The biblical command to “be fruitful and multiply” is one we take seriously at Berkshire.)
One of the businesses Berkshire Hathaway used the See’s profits for was on the opposite end of the spectrum in terms of capital utilization: BNSF Railway. Railways require a lot of capital to operate; BNSF consumed $3.8 billion last year; they also make a lot of money: BNSF’s net income was $5.5 billion on revenue of $23.4 billion. To put that in perspective, the total amount that Berkshire Hathaway has made from See’s Candies is probably less than $3 billion (the last disclosure was “over $2 billion” in 2019), i.e. less than BNSF made last year.
So which is the better business?
Google Cloud’s Runway
In Q4 2019, the first year that Alphabet disclosed Google Cloud revenue, Google Services — the high margin beautiful business I described at the beginning — made $43.2 billion in revenue and $13.5 billion in operating profit; Google Cloud made $2.6 billion in revenue and lost $1.2 billion. Google Cloud revenue was 6% the size of Google Services.
In Q1 2023, Google Cloud made a profit for the first time. In that quarter Google Services made $62.0 billion in revenue and $21.7 billion in profit; Google Cloud made $7.5 billion in revenue and $0.2 billion in profit. Google Cloud revenue was 12% the size of Google Services, and its profit was 1% the size of Google Services.
In Q1 2026, Google Services made $89.6 billion in revenue and $40.6 billion in profit; Google Cloud made $20.0 billion in revenue and $6.6 billion in profit. Google Cloud revenue was 22% the size of Google Services, and its profit was 16% the size of Google Services.
Google Services is, needless to say, a much more scalable business than See’s Candies. The growth just over the last seven years — more than doubling revenue and tripling profits — is astounding. And yet, at the same time, Google Cloud is growing faster, and while its margins are worse — 33% last quarter as compared to 45% for Google Services — they are expanding more rapidly.
The bigger question is how big can those numbers go? Google Services’ advertising business is inherently high margin, but advertising is definitionally but a fraction of the overall economy; Google Cloud’s growth, meanwhile, is AI, which many people think/worry/hope might take over the entire economy. In other words, might we one day look back and realize that Google Services provided the cash flow to build a business with relatively worse margins but absolutely higher dollars, much like See’s helped fund BNSF?
Berkshire Hathaway and Google Equity
The context for this discussion is this news from Bloomberg:
Google parent Alphabet Inc. is raising $80 billion through a package of equity offerings, including an investment deal with Berkshire Hathaway Inc., as the company races to fund its ambitious artificial intelligence spending plans. The undertaking includes a $40 billion so-called at-the-market program to sell shares from time to time beginning in the third quarter, according to a statement Monday. The company will also offer $30 billion in underwritten offerings of shares and mandatory convertible preferred stock, as well as the $10 billion deal with Berkshire. Together, the transactions represent one of the largest equity deals of all time — and they bring an unexpected twist to a blockbuster year for initial public offerings.
First off, a decent portion of the ATM program, launching in the fall, is going towards paying tax obligations on Google equity awards (which are quite large thanks to the stock’s run-up in value).
That leaves equity being issued now, particularly the $10 billion to Berkshire Hathaway, which is fascinating for a number of reasons. The first question is why did Google issue equity instead of debt? Debt is, all things being equal, the preferred instrument for investment: the proceeds of the latter pay off the former, and existing equity holders reap all of the benefits. Equity, on the other hand, removes the risk of debt, but at the cost of giving up a share of future profits.
Google has to date funded its massive AI-related capital expenditures with free cash flow, and while the company does have around $81 billion in debt, that is more than balanced by $126 billion of cash. In other words, Google’s capacity to issue more debt — and to reap the financial benefits of doing so (because interest is tax-deductible) — is substantial.
That leads to what may be the Occam’s Razor explanation: Google is also going to start issuing a lot more debt as well, which is to say that everyone continues to underestimate the amount of demand there is for compute. Of course that’s not far off from a more bearish interpretation: Google is uncertain about the return on investment of all that capex, and would prefer to share the risk (along with the upside). If there isn’t a substantial debt issuance down the road then this might be the right answer.
The second question is why is Berkshire Hathaway suddenly, after all these years, interested in Google, and at only a slight discount to its all-time high price? Does it really just come down to the fact that Buffett is no longer making investment decisions, and Greg Abel, his successor as CEO, is?
In fact, you can make the case that Abel is actually just replaying Buffett’s strategy, only this time Berkshire Hathaway is See’s Candies, and Google is BNSF. At the end of last quarter Berkshire Hathaway had $373 billion in cash, and $25 billion in free cash flow in 2025. How many companies could actually employ that cash in a way that generated a high rate of return?
It’s hard to imagine a better option than Google. The company is not only investing in AI, but has optionality in terms of outcomes: its Services business benefits from the investment, it is in contention at the model layer with Gemini, and it can sell capacity to the frontier labs. Moreover, that capacity has a sustainable cost advantage because of TPUs, which means that in a world where compute becomes a commodity — as hard as that is to imagine right now — Google is the hyperscaler that is poised to make the most profit.
It is worth noting that $10 billion is a relatively small amount of money to both companies. To that end, perhaps the primary utility is as a signaling mechanism. On Google’s side, the signal is that the expected demand is actually far greater than anyone thinks, and that the company is ready and willing to fund supply using all means at its disposal, including equity; for them Berkshire Hathaway’s investment is an endorsement of this view and a validation of the wisdom of the investment. And, on the flip side, if the signal is correct, then Berkshire Hathaway is getting a deal and putting its cash flow machines to work building the future.
Cash the Ultimate Commodity
A couple of months ago, when Anthropic was clearly ascendant, OpenAI backers tried to make the case that actually OpenAI was in the driver’s seat because the frontier lab had secured more compute; I made the case in Mythos, Muse, and the Opportunity Cost of Compute that this was not at all dispositive:
OpenAI is betting that this compute constraint — and the deals they have made to overcome it — will matter more than Anthropic’s current momentum with end users…I’m less certain that this will be dispositive. When it comes to AI, distribution and transaction costs are still free — the two preconditions for Aggregators — which means that the winners should be those with the most compelling products. Those products will win the most users, providing the money necessary to source the compute to serve them; consider Anthropic’s deal to secure a meaningful portion of TPU supply, which, given the capacity constraints at TSMC, is ultimately an example of taking supply from Google. I suspect that Anthropic can take more, including already built hyperscaler and neocloud capacity. Yes, that compute will be more expensive, but if demand is high enough the necessary cash flow will be there.
That thesis was proven correct just weeks later when SpaceX ponied up the supply Anthropic needed (and yes, it was expensive):
This deal is a perfect example of what really is basic economics. First, if demand exceeds supply, then prices should increase. At the same time, prices are elastic: if they are lower there is more demand, and if they are higher there is less demand. In this case, while there is broad demand for computing, Anthropic has arguably the most demand; furthermore, Anthropic has the most willingness to pay, not just because they are making meaningful revenue, but also because they have the capacity to raise money in the pursuit of winning in AI.
Implicit in this analysis was that there was enough compute capacity in the world to be bought; what happens, however, when and if there isn’t? What if the ultimate battle — the one that determines who gets compute — becomes a matter of who can bring the most cash to bear? And what if that advantage compounds, such that the company with the most cash capacity ends up with the most compute capacity (which we already know they will sell, in addition to using themselves) driving the ability to generate more cash? In that world, what company would be your best bet?
We now know which one Berkshire Hathaway is betting on.
- As an aside, it’s notable that Alphabet has another business — Waymo — where the company has so far rejected an asset-light model of licensing their software to OEMs, and has instead to date pursued a much more capital intensive approach of owning and operating their own cars; that’s a choice that has always felt at odds with Google Services, but is perhaps more compelling and aligned with Google Cloud and the Google Capital Company.

Microsoft unveils new AI models to lessen reliance on OpenAI and lower costs for developers
Microsoft launched its own AI coding model, MAI-Code-1-Flash, and a reasoning model, MAI-Thinking-1, at Build 2026, aiming to reduce dependence on OpenAI and lower developer costs.
Deep dive
- Microsoft unveiled MAI-Code-1-Flash, its first proprietary AI coding model, at Build 2026, which takes written descriptions and generates source code.
- Also introduced was MAI-Thinking-1, a medium-sized reasoning model designed for high efficiency and low token cost.
- These new models aim to lessen Microsoft's reliance on third-party models like those from OpenAI and Anthropic.
- By running its own models on its Azure cloud infrastructure, Microsoft can reduce costs for developers.
- MAI-Code-1-Flash is available in GitHub Copilot and Visual Studio Code.
- MAI-Thinking-1 is currently available via private preview through Microsoft Foundry.
- Microsoft CEO Satya Nadella emphasized that companies should move from merely consuming frontier models to actively participating in the frontier ecosystem.
- Mustafa Suleyman, CEO of Microsoft AI, claimed that after refining models for McKinsey, Microsoft outperformed OpenAI's GPT 5-5 with 10 times better cost efficiency.
Decoder
- Token: The basic unit of data that an AI model processes and generates; token usage directly impacts computational cost for developers.
Original article
- At its Build developer conference in San Francisco, Microsoft announced MAI-Code-1-Flash, its inaugural model in the AI coding space.
- Microsoft is trying to establish a presence with proprietary models to compete with OpenAI, Anthropic and Google.
- Microsoft's primary role in the AI boom to date has been as a provider of cloud infrastructure and services and as an investor.
Microsoft has been a major player in the artificial intelligence boom, providing key cloud infrastructure and services and taking multibillion-dollar equity stakes in OpenAI and Anthropic. Now the company is making a concerted effort to compete with proprietary models.
At its Build developer conference in San Francisco on Tuesday, Microsoft announced MAI-Code-1-Flash, its inaugural model that takes written descriptions from people and spits out source code for applications and websites. The AI coding market, or vibe coding, has taken off of late, with developers and people without technical backgrounds using text-based prompts to produce sophisticated software.
For Microsoft, there are economic benefits to providing its own models that can be passed onto developers as costs jump for using the leading models. Microsoft can run its models on its own Azure cloud infrastructure and avoid paying third parties such as OpenAI. In May, Google announced the Gemini 3.5 Flash model that can code and carry out other tasks, and run in the search company's own data centers.
In addition to MAI-Code-1-Flash, Microsoft is introducing MAI-Thinking-1, a reasoning model, and is playing up the efficiency for both offerings.
The reasoning model is medium-sized and "built for high efficiency and performance, but importantly, at a low-token cost," Kyle Daigle, Microsoft's developer marketing chief and GitHub operating chief, wrote in a blog post. Tokens are the building blocks of data that a model reads, processes and generates, and their use determines costs for developers.
Microsoft is attempting to play at more layers of the AI stack as OpenAI and Anthropic continue to record historic growth and push toward the public market. Anthropic confidentially filed for an IPO on June 1, and OpenAI is also pursuing an offering, potentially this year. Microsoft has invested $13 billion in OpenAI and $5 billion in Anthropic, while making their models available through Azure.
MAI-Thinking-1 is available in a private preview through Microsoft Foundry, a service for integrating models into applications. Customers can express interest in testing the model before it becomes broadly available.
Customers will be able to increase the accuracy of the reasoning model by incorporating their own data.
"What you just saw is a pretty significant shift," Microsoft CEO Satya Nadella said onstage. "We believe the time has come for every company to just move from consuming a frontier model to fully participating at the frontier in the frontier ecosystem.
After refining its models for the needs of consulting firm McKinsey, Microsoft was able to outperform OpenAI's GPT 5-5, with 10 times better cost efficiency, said Mustafa Suleyman, CEO of Microsoft AI.
The coding model is "inference ultra-efficient," Daigle wrote, and is available in the GitHub Copilot AI coding service and the Visual Studio Code text editor.
Also on Tuesday, Microsoft is revealing updated cloud-based models for speech recognition, synthetic voice generation and image generation, as well as small Aion models that can run on Windows PCs.
WATCH: Microsoft touts new AI agents, coding tools in pitch to developers
.png)
The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
DigitalOcean and Inferact dramatically reduced LLM inference costs by up to 4x using prefix-aware routing and caching in vLLM, reclaiming 340 GPU-hours daily at scale.
Deep dive
- Inference accounts for roughly 70% of total AI compute costs, with a significant portion being avoidable due to redundant prefill.
- Prefill is the phase where an LLM processes the input sequence and builds the KV (key-value) cache; it scales quadratically with input length.
- Prefix-aware routing and caching optimize this by reusing KV cache blocks for shared prompt prefixes, like system prompts or document context in RAG.
- vLLM uses block-based KV storage and PagedAttention kernels, where fixed-size blocks (e.g., 16 tokens) are allocated for KV tensors.
- Prefix hashing allows the engine to quickly identify and reuse cached blocks for identical prefixes, reducing computation.
- On a full prefix cache hit, the engine skips most prefill work, improving Time To First Token (TTFT).
- DigitalOcean's Inference Gateway (a fork of llm-d) uses an Endpoint Picker (EPP) with Envoy's ext_proc to intercept requests.
- vLLM instances publish KV cache events (block allocated/evicted) over ZeroMQ, updating a global KV-Block Index maintained by the EPP.
- The EPP uses this index to build a per-pod prefix tree and score instances based on cache affinity and GPU vRAM utilization, routing requests to the warmest pod.
- This approach boosts cache hit rates from ~25% (round-robin) to over 75% for workloads with shared prefixes.
- At 10 million requests per day, this can save 340 GPU-hours daily, reducing effective compute cost by up to 4x for suitable workloads.
- Hardware like AMD Instinct MI325X (192GB HBM3) and NVIDIA H200 (141GB HBM3e) provide larger KV pool capacities, enhancing cache effectiveness.
- Inferact, a company built on vLLM, is contributing to these optimizations, pushing for SOTA performance, day-0 model support, and production-workload specific optimizations.
- These optimizations, initially for Dedicated Inference customers, will soon be available for all Serverless Inference deployments.
Decoder
- Inference Tax: The hidden cost associated with inefficient LLM inference, particularly due to redundant computation of shared prompt prefixes.
- Prefill: The initial phase of LLM inference where the model processes the entire input prompt to build its internal state, including the KV cache.
- KV (Key-Value) Cache: A memory store in LLMs that holds the computed key and value tensors for each token in the input sequence, allowing the model to attend to past tokens efficiently during token generation (decode phase).
- PagedAttention: A memory optimization technique in LLM inference engines (like vLLM) that manages the KV cache in fixed-size blocks, similar to virtual memory in operating systems, to improve GPU utilization and throughput.
- Time To First Token (TTFT): A critical performance metric in LLM inference, measuring the latency from when a request is sent until the first output token is generated.
- Radix Tree: A data structure often used for efficient string searching and prefix matching, employed here for managing prefix hashes.
- HBM3/HBM3e: High Bandwidth Memory, a type of RAM designed for high-performance applications like GPUs, offering significantly higher bandwidth than traditional GDDR memory.
- FP8 KV cache quantization: A technique to reduce the memory footprint of the KV cache by storing key and value tensors in 8-bit floating-point format, increasing effective cache capacity.
Original article
The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
By Piyush Srivastava and Simon Mo, CEO of Inferact
Introduction
Inference demand is growing fast, and it’s only accelerating. By 2030, inference is expected to account for the majority of AI compute globally. But scaling inference isn’t just a hardware problem. Most teams discover too late that a significant portion of their compute spend is avoidable, primarily because their systems are silently repeating work they have already done, recomputing the same prompt prefixes and system instructions over and over again.
We’ve seen this from two vantage points. From the infrastructure layer, the cost curve becomes visible at scale with clusters that look busy but aren’t efficiently utilized. From the engine layer, the picture is just as clear. Without the right caching and scheduling primitives, even a well-optimized model wastes cycles on redundant computation. The root cause is the same regardless of where you’re standing. The system lacks the memory and coordination to recognize when it’s already done the hard part.
Fixing this requires work at every layer of the stack. DigitalOcean has invested in GPU optimization across multiple fronts, from vLLM parallelism and quantization tuning to hardware-level kernel work. But one technique has had an outsized impact on cost efficiency at scale: prefix-aware routing and caching. In this post, we walk through how vLLM enables advanced prefix caching, how DigitalOcean’s inference gateway uses prefix awareness to make smarter routing decisions, and how we plan to make this available to everyone on Serverless Inference in the coming weeks.
The Cost Cliff and the Hidden Culprit
Inference now accounts for roughly 70% of total AI compute costs. For most teams, a significant share of that is avoidable. It’s not due to hardware limits. Instead, it’s because the system keeps recomputing work it has already done, also known as redundant prefill.
Every LLM inference request has two distinct computational phases. The first phase is prefill, where the model processes the entire input sequence and builds the KV (key-value) cache that represents its state. The second phase is decode, where the model generates output tokens one at a time, attending back to that cached state. Prefill is where the structural inefficiency hides. Its computation scales quadratically with input length: attention computation quadruples with doubling of input length.
Consider a real-world customer support workload running on NVIDIA H200 or AMD Instinct™ MI325X GPUs. A typical deployment carries a 2,000-token system prompt (defining persona, policies, response format) that is identical across every request. With an average user message of 200 tokens, roughly 91% of every input is shared context.
On AMD Instinct™ MI325X GPUs or NVIDIA H200, prefilling 2,000 tokens takes approximately 45–50ms and costs in the range of 100-120 GFLOPs per request. At 10,000 requests per hour, that’s over 1 trillion redundant FLOPs per hour. Compute spent reconstructing the state the system has already built, discarded, and is now rebuilding from scratch.
The pattern is even more pronounced in coding assistants or document Q&A tools, where the same API documentation or reference material is prepended to nearly every request. A 5,000-token shared context costs roughly 600 GFLOPs to prefill, which is nearly 25× more than a 1,000-token prefix, due to that quadratic relationship. When hundreds of users are querying the same underlying documents, the redundant computation compounds rapidly.
This is precisely the redundant “prefill tax” that we will focus on how to eliminate in the rest of this post.
How Prefix Caching Works at the Engine Layer
The redundant prefill problem has a clean structural solution, but landing it at production scale takes several mechanisms working in concert. Here’s what’s happening inside the engine when a cache hit lands.
Block-Based KV Storage
During prefill, every input token produces a key and value tensor at every attention layer, and storing these per-token would be a memory-management nightmare. The engine instead groups them into fixed-size blocks (16 tokens by default on CUDA, though configurable) allocated out of a pre-reserved GPU memory pool sized at engine startup. Each layer maintains its own pool of blocks. A single block holds the K and V tensors for block_size tokens for one layer’s KV heads, laid out so PagedAttention kernels can read them with coalesced memory accesses. A 2,000-token system prompt occupies 125 block positions (allocated per layer under the hood); once those blocks are sitting in the pool, any future request that begins with the same 2,000 tokens can point at them rather than recomputing. PagedAttention is the kernel technique that operates on this block-based layout, and the same memory machinery underlies both prefix caching and paged attention’s batching benefits, described in more detail in the engine anatomy writeup.
Prefix Hashing and Cache Lookup
Recognizing that two requests share a prefix is a string-matching problem on potentially very long inputs, and doing it naively would defeat the point. The engine instead hashes prefixes block by block, with each block’s hash depending on its own tokens, the hash of the previous block, and any extra inputs that affect the computation, including LoRA adapter IDs, multimodal image hashes, and optional cache salts for multi-tenant isolation. Identical prefixes under identical conditions produce identical hash chains, and the first divergent block is also the first point where the hashes disagree. Only full blocks are hashed and cached, so a partial trailing block at the end of a prefix doesn’t get reused and is recomputed along with the rest of the suffix. These hashes live in a lookup table mapping hash to cached block, and finding “the longest prefix of this request that’s already cached” reduces to walking the request’s block hashes against the table. The lookup is small and cheap, and the KV data itself lives in the GPU memory pool. Memory pressure comes from the pool, not the index.
From Cache Miss to Cache Hit: The FLOP Savings
The payoff shows up in compute terms. On a full cache miss, the engine runs prefill across the entire input, processing every token across every layer at full quadratic attention cost. On a full hit on the prefix, the engine skips nearly all of that work: the KV state for the prefix is already materialized in GPU memory, and only the trailing token needs to run through prefill so the first generated token has somewhere to attend from. Partial hits land in the middle, with prefill running only over the un-cached suffix and cached blocks treated as pre-computed context. On the customer-support workload from Section 1, a partial hit covering the 2,000-token system prompt turns a 45–50ms prefill into something dominated by the much shorter user message, and the structural FLOP savings show up directly as time to first token (TTFT) improvement.
A single engine instance can only cache what it has personally seen, which is the routing problem Section 3 picks up. The engine publishes KV cache events (block stored, block removed, with their associated hashes) over ZeroMQ on a PUB/SUB channel, while utilization metrics like batch size and free-block count flow through the StatLogger path. A router consumes both to make decisions. The interface is deliberately neutral: any compatible consumer can subscribe, whether that’s NVIDIA Dynamo, llm-d, or a custom gateway built in-house. Session-affinity routing handles the easy case of sending a user back to the instance that served their previous turn, but the event stream enables much more. A router can build its own global prefix tree from KV block events, balance load against per-instance batch size and cache utilization, and make routing decisions that account for cache locality and instance pressure rather than treating them as separate problems.
Hardware Headroom: AMD and NVIDIA
These mechanism benefits compound on the AMD Instinct™ MI325X GPUs. 192GB of HBM3 per GPU means the KV pool can hold substantially more cached blocks than on comparable hardware, resulting in more cached prefixes, higher hit rates, longer-lived cache entries before eviction. Layered on top, FP8 KV cache quantization roughly doubles effective cache capacity again (though combining FP8 KV cache with prefix caching has historically required specific kernel support, so it’s worth checking compatibility for your vLLM version), and the attention kernels on the read path have been tuned for AMD Instinct™ MI325X GPUs memory hierarchy so a cache hit doesn’t trade prefill cost for a slow cache read. The mechanism works universally, but on AMD Instinct™ MI325X GPUs it has more room to operate, which is what makes the routing layer in the next section worth building.
The picture is similar to NVIDIA Hopper, with different shapes of headroom. NVIDIA H200’s 141GB of HBM3e per GPU expands the KV pool considerably over H100’s 80GB, which translates directly into more cached prefixes and longer-lived entries before eviction. FP8 KV cache lands on Hopper through FlashAttention 3 and FlashInfer kernels. The same caveat about checking prefix-caching compatibility for your vLLM version applies, and the read-path attention kernels have been tuned around TMA loads and the Hopper memory hierarchy, so a cache hit doesn’t trade prefill cost for a slow KV read. Blackwell stretches this further, with 192GB of HBM3e per B200, and on GB200 NVL72 the NVLink domain collapses 72 GPUs into a single shared-memory fabric, opening up cross-instance KV reuse that single-node caching can’t touch. The underlying mechanism is the same across vendors, and what changes is how much room it has to operate, which is exactly what the routing layer in the next section is built to exploit.
The Routing Problem: Why Single-Instance Caching Isn’t Enough
Once the KV state for a shared prefix is computed, subsequent requests that share that prefix can reuse the cached blocks directly, bypassing prefill entirely. But production workloads don’t run on a single instance. They run across fleets of GPU workers behind a load balancer, and this is where naive deployments silently destroy the cache hit rate they worked to build. The DigitalOcean Inference Gateway (which is a fork of llm-d) embeds an Endpoint Picker (EPP), a component that intercepts every inference request via Envoy’s external processing (ext_proc) callback before it reaches any vLLM instance. The EPP is where all routing intelligence lives.
The Write Path: Publishing KV Cache Events
On the write path, each vLLM instance is configured with --kv-events-config to publish KVEvent messages over a ZMQ socket (tcp://*:5557) every time a KV cache block is allocated or evicted. Each event carries the block hash - computed using sha256_cbor_64bit over the token IDs in that block, using the same algorithm vLLM uses internally. The EPP subscribes to all instances, consuming this high-throughput stream and continuously updating a KV-Block Index: a low-level map of block_hash → {pod, memory_medium (GPU/CPU)}. memory_medium is the storage tier the block currently lives in on that pod. In our current implementation, KV blocks are always in GPU memory, but this will soon change as we look into multi-tiered storage architecture for KV blocks. From this index, the indexer builds and maintains a per-pod prefix tree - a radix structure of consecutive block hashes that reflects exactly what prefix state is warm in each pod’s GPU memory at this moment.
The Read Path: Prefix-Aware Request Scoring
On the read path, when a new request arrives, the gateway tokenizes the incoming prompt and computes its prefix block hashes using the identical sha256_cbor_64bit algorithm. It then walks the KV-Block Index, querying how many consecutive prefix blocks each pod holds for this request. The result is a cache affinity score per pod: a pod holding 90% of the prompt’s prefix blocks scores 0.9 × 3 = 2.7 on the prefix-cache-scorer (weight 3, the dominant signal). This is combined with a kv-cache-utilization-scorer (weight 2) that down-scores pods whose GPU vRAM is near capacity, preventing the router from routing to a pod that would have to evict blocks to accommodate the new request, negating any cache benefit. The max-score-picker selects the highest combined score, and Envoy forwards the request to that pod. As we get into multi-tiered KV cache, we are also looking at “tier-aware” prefix scoring where a GPU resident match scores higher than a CPU-resident or lower tiers. In general, there are multiple cost functions with varying priorities taken into account while making the routing decision.
The result: cache hit rates flip from ~25% under round-robin to 75%+ on workloads with shared prefixes - on the same hardware, with no model changes.
The Math: What Cache Hits Mean at Scale
The impact becomes concrete when you put real numbers behind it. At 1 million requests per day, a modest scale for a production deployment, assume 70% of requests share a common system prompt. Without prefix-aware routing, cache hits are essentially random: roughly 1-in-4 requests land on an instance with that prefix already warm. With prefix-aware routing, that flips to 3-in-4.
That delta, 350,000 additional cache hits per day, doesn’t sound dramatic until you attach the compute cost. Each cache hit skips roughly 350ms of prefill work. Across those 350,000 requests, that’s 34 GPU-hours saved every single day. Scale to 10 million requests per day and you’re recovering 340 GPU-hours daily, compute that was previously being silently wasted on work the system had already done.
For the right workload profile, multi-turn conversations with persistent context, shared system prompts, RAG pipelines querying the same document sets, the economics compound further. The same prefix appears not just frequently, but across long sessions where every turn benefits. In these cases, prefix-aware routing can reduce effective compute cost by up to 4x per request on identical hardware.
The Engine Work Inferact Is Building
Prefix caching is one piece of a larger problem. Inference engines are evaluated on a lot of dimensions: raw speed, model coverage, and increasingly, how well they handle the messy shape of real production traffic. Closing the gap on all three, on frontier hardware, is the problem Inferact is organized around.
Inferact is a company built on vLLM, and in practice Inferact’s roadmap and vLLM’s roadmap are virtually identical. The work happens upstream, in the open, in the same repository everyone else uses.
The work falls into a few themes, each building on the last.
The first is pushing vLLM toward SOTA performance on frontier models on frontier hardware. The clearest external signal here is Artificial Analysis, whose independent benchmarks have become a common reference point across engines and providers. vLLM’s recent top rankings on DeepSeek V3.2 and DeepSeek V4 reflect work that is increasingly a community effort: kernel and fusion optimizations, large-scale serving improvements for disaggregated and wide-EP setups, speculative decoding, quantization, and torch.compile integration are all being pushed forward by contributors across vendors.
The second is day-0 model support, which is one of vLLM’s structural strengths. When a new frontier model drops, running it well on vLLM is the default, with recent launches like Gemma 4 and DeepSeek V4 supported on the engine from day one. Our goal is to continue this trend. The bar isn’t just accuracy on day zero. It’s continued accuracy and high performance on day zero.
The third part is optimizing vLLM for areas that benchmarks don’t measure well yet. Top-of-leaderboard token throughput on a single prompt is a real signal, but it isn’t the same as performance on the workloads that actually run in production. Real inference traffic, and agentic traffic especially, looks very different from what most benchmarks capture: long shared prefixes from system prompts and tool definitions, multi-turn conversations with rich cache-hit structure, and bursty arrival patterns that don’t resemble a steady stream of independent prompts.
Optimizing prefix caching is the clearest example of what this means in practice. On agentic traffic, the bottleneck isn’t raw decode throughput on a fresh prompt — it’s whether the engine recognizes that most of the prompt is identical to something it processed seconds ago, and reuses the KV cache accordingly. Getting this right can be the difference between a model feeling fast and a model feeling unusable in an agent loop, and on a standard benchmark it barely shows up at all. The same pattern holds for the rest of the production-traffic stack: scheduler design under bursty arrival, KV cache layout under high reuse, and the prefill/decode connector path all matter disproportionately on real workloads relative to what benchmarks reward.
None of this is work vLLM does alone, and none of it is work Inferact does alone either. The performance and workload story leans on cross-project, cross-vendor effort, and on the hundreds of vLLM contributors and downstream users who surface real problems and keep the project honest about what production actually looks like.
Inferact’s role in that ecosystem is to invest deeply in vLLM as a maintainer and contributor, not to fork it or wrap it. The bet is on an open, broadly-owned inference engine as the right foundation for the next several years of inference work.
These Optimizations Will Soon Ship to Everyone
Everything described in this post was originally built in the context of deep partnerships with large customers on DigitalOcean’s Dedicated Inference platform, but these optimizations will soon ship with every Serverless Inference deployment as well.
- Prefix-aware routing via the Inference Gateway (live on Serverless Inference now)
- Prefix caching with cached token pricing (launching on Serverless Inference in the coming weeks)
- vLLM runtime with optimizations on AMD Instinct™ MI325X GPUs as well as NVIDIA Hopper
- The same benchmark performance Simon and Inferact helped achieve
Prefix caching and routing are just part of the picture. DigitalOcean’s GPU hardware collaboration goes deeper across the stack, from FP8 quantization to parallelism tuning, and those gains flow through to Serverless Inference customers as well.
You won’t need a custom contract to benefit from these results. You will only need a DigitalOcean Serverless Inference endpoint.
Conclusion
Delivering best-in-class inference performance requires optimization at every layer of the stack, and no single team owns all of it. That’s the foundation of our partnership with Inferact.
Inferact brings deep expertise at the engine and kernel layer by optimizing vLLM internals, tuning GPU kernels for NVIDIA and AMD hardware, and squeezing maximum throughput out of the compute itself. DigitalOcean brings the infrastructure layer, virtualizing state-of-the-art AMD and NVIDIA GPUs at scale, building large GPU clusters purpose-built for serverless inference, and baking serving optimizations directly into the platform. That means auto-scaling, prefix-aware routing through our Inference Gateway, parallelism tuning, KV cache tiering across GPU and CPU memory to maximize effective cache capacity, disaggregated serving over a high-speed RoCE network, dynamic load rebalancing across model endpoints, and fleet-wide utilization optimization that continuously shifts capacity to where demand is highest.
Together, the two layers close the loop. Engine-level efficiency means nothing if the infrastructure routes requests poorly. Infrastructure-level routing means nothing if the engine is leaving performance on the table. This partnership is about making both layers aware of each other, so the gains compound.
Start using Serverless Inference today. Prefix caching with cached token pricing launches in the coming weeks. Sign up now to be among the first to benefit.
About the author(s)
Piyush Srivastava
Principal Engineer, AI Infrastructure
Simon Mo, CEO of Inferact
- Engineering
- Gpu
- AiMl
- Serverless
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.

Coding Agent Horror Stories: The rm -rf ~/ Incident
A Reddit user's entire Mac home directory was wiped by Claude Code executing rm -rf ~/ in December 2025, highlighting AI agent execution risks without sandboxing.
Deep dive
- In December 2025, a Reddit user's Claude Code agent deleted their entire Mac home directory with rm -rf ~/ while attempting to clean an old repository.
- The ~/ argument, when expanded by the shell, targeted the user's actual home directory, not just within the repository.
- This led to the loss of years of files, SSH keys, authentication states, and application data, with no recovery possible due to SSD TRIM.
- Similar incidents include an Ubuntu/WSL2 system wipe by Claude Code in October 2025 and Claude Cowork deleting 15 years of family photos in January 2026.
- The core problem is AI agents running directly on the host with the user's full permissions, without an architectural layer to validate or contain potentially destructive commands.
- The --dangerously-skip-permissions flag, often used for convenience, removes the default confirmation step, making such incidents more likely.
- Docker Sandboxes address this by running agents in isolated microVMs, where ~/ refers only to the workspace mount, and host filesystem/credentials are inaccessible.
- Sandboxes can block credential paths by default, offer read-only mounts for sensitive directories, and support Git worktree isolation for risky operations.
- This allows developers to treat agent environments as throwaway, preventing permanent damage to their host system.
- The article argues that the issue is not a bug in individual agents but a fundamental flaw in the execution model itself when agents are not properly isolated.
Decoder
- rm -rf ~/: A Unix command that recursively (-r) and forcefully (-f) deletes the contents of the user's home directory (~/). The ~ character expands to the current user's home directory.
- MicroVM: A lightweight virtual machine designed for fast startup and low overhead, providing strong isolation for individual processes or applications. Docker Sandboxes uses them for agent execution.
- TRIM: A command that allows an operating system to inform an SSD (Solid State Drive) which data blocks are no longer considered in use and can be wiped internally. Once TRIM is performed, data recovery becomes extremely difficult or impossible.
Original article
Full article content is not available for inline reading.

Why AI Can't Match Human Creative Work
Despite difficulty distinguishing AI-generated content, studies consistently show human-made ads and articles outperform AI versions in sales impact, brand health, and Google search rankings.
Deep dive
- Ipsos/Syracuse University Advertising Study: Compared 20 human-made ads with AI-generated counterparts using Google Gemini and OpenAI's Sora, showing them to 3,000 consumers.
- AI Ad Identification: Only 25% of viewers were confident an ad was AI-made, and 40% were uncertain, indicating difficulty in distinguishing AI content.
- Performance Discrepancy: Human-made ads were rated as more eye-catching and imaginative, performing 14% stronger on short-term sales impact and 17% stronger on long-term brand health.
- Semrush Web Content Study: Analyzed 42,000 blog pages and 20,000 keywords, using GPTZero to detect AI content and cross-referencing with Google Search results.
- Search Ranking Performance: Human-written content appeared in the top Google search spot 80% of the time, while purely AI-generated content was there only 9% of the time, an 8-to-1 advantage.
- Human-AI Collaboration: Articles written by people with some AI assistance ranked better than AI-only content.
- LinkedIn Engagement: On LinkedIn, engagement on verified human content was 61% higher than AI-marked posts, though AI content outperformed human posts in the "Leadership & Inspiration" category by 75%.
- AI Volume vs. Quality: While AI-generated content is exploding in volume across various media (e.g., over half of website content, 40% of podcasts), it captures very little high-value engagement; for instance, 40% of podcast uploads account for less than 1% of listening hours.
- Core Reason: Researchers suggest AI can only replicate existing patterns and conventions, lacking the ability to make creative leaps, break new ground, or engender emotion as humans do.
Original article
Full article content is not available for inline reading.

How to Create Variable Fonts: A Guide for Type Designers
Variable fonts, now a professional standard with 92% browser compatibility and 40% website adoption, consolidate entire font families into a single OpenType file for infinite design control.
Deep dive
- Variable fonts are single OpenType files (version 1.8+) containing continuous design variations along axes like weight, width, and optical size.
- They replace multiple static font files, reducing total file size by 30-65% when three or more weights are needed.
- The technology, originating from Apple's TrueType GX, was standardized in OpenType 1.8 by Apple, Google, Microsoft, and Adobe in 2016.
- Browser compatibility for variable fonts is around 92%, with approximately 40% of websites now using them.
- Five registered OpenType axes exist:
wght(weight),wdth(width),ital(italic),slnt(slant), andopsz(optical size). - Designers can define custom axes using four-character uppercase tags, expanding creative possibilities (e.g., a
GRADaxis for grade). - Key tools for creating variable fonts include FontLab 8 (Mac/Windows), Glyphs 3 (Mac), and RoboFont (Mac + Superpolator). FontForge is a free, open-source option.
- The "Axis-Master-Instance Pipeline" involves defining the design space, creating compatible masters (identical point count and order), interpolating and testing instances, defining named instances, spacing/kerning across the design space, adding OpenType features, and exporting to variable TTF (then WOFF2 for web).
- "Compatible masters" are critical, meaning every glyph in every master must have identical point counts, point order, and contour direction for successful interpolation.
- For web use, variable fonts should be converted to WOFF2 for maximum compression and implemented with CSS properties like
font-weight,font-stretch,font-stylefor registered axes, andfont-variation-settingsfor custom axes. - Notable examples include Monotype's Helvetica Now Variable (three axes, 1.2 million styles) and Hoefler & Co.'s Gotham Variable. Rasmus Andersson's Inter is a widely used open-source variable font.
Decoder
- Variable font: A single OpenType font file that contains continuous ranges of design variants, allowing for infinite control over typography parameters like weight, width, and slant, rather than using separate files for each style.
- OpenType: A widely used font format developed by Microsoft and Adobe, offering advanced typographic features. OpenType version 1.8 introduced variable font technology.
- Variation axis: A defined dimension of change within a variable typeface (e.g., weight, width, slant, optical size). Each axis has a minimum, default, and maximum value.
- Registered axes: Five standardized variation axes defined by the OpenType specification:
wght(weight),wdth(width),ital(italic),slnt(slant), andopsz(optical size). - Custom axes: Non-standardized variation axes defined by type designers using four-character uppercase tags, allowing for unique typographic behaviors beyond the registered axes.
- Masters: The extreme design points within a variable font's design space (e.g., Light Condensed, Bold Extended). All glyphs across masters must be "compatible" (identical point count and order) for interpolation to work.
- Instances: Specific variations generated from the masters along the axes. "Named instances" are predefined presets like "Regular" or "Bold" that appear in font menus.
- WOFF2: Web Open Font Format 2, a highly compressed font format optimized for web delivery, offering significant file size reduction over other formats.
font-variation-settings: A CSS property used to control custom variable font axes, specified by the four-character axis tag and a numeric value.font-weight,font-stretch,font-style: High-level CSS properties that automatically map to the registeredwght,wdth,ital, andslntvariable font axes.
Original article
Full article content is not available for inline reading.

Building a hill-climbing machine: Launching seven new MAI models
Microsoft launched seven new MAI models for developer tuning and partnered with Mayo Clinic to develop an advanced AI healthcare model for Azure Foundry.
Decoder
- Frontier Tuning: An approach where AI models adapt to specific workflows and environments through reinforcement learning, allowing developers to tune model weights.
Original article
Microsoft released seven new MAI models, enabling developers to tune model weights themselves and integrate these into everyday products. The models leverage Frontier Tuning, an approach where AI adapts to specific workflows through reinforcement learning environments. Microsoft also announced a collaboration with Mayo Clinic to develop an advanced AI healthcare model, combining clinical expertise with AI capabilities, initially deploying within Mayo before wider distribution through Azure Foundry.
MiniMax promises M3 weights after 1M-context model launch
MiniMax will release the weights and a technical report for its new M3 model, which features a 1M-token context window and multimodality.
Decoder
- 1M-token context window: The ability of an LLM to process and consider up to one million tokens (words or sub-words) of input information simultaneously, allowing it to handle very long documents or complex conversations.
- Frontier coding: Refers to cutting-edge capabilities in AI models for generating and understanding code, often implying advanced reasoning and problem-solving.
- Native multimodality: An AI model's intrinsic ability to process and generate information across multiple data types (e.g., text, images, audio) without needing separate, specialized modules for each.
Original article
MiniMax will release the model weights and a technical report for its M3 model within the next 10 days. The new model is currently available through MiniMax Code, token plans, and an API. It has a 1M-token context window and a guaranteed 512,000-token minimum for API use. The model is the first open-weight model to combine frontier coding, native multimodality, and a 1M-token context window. MiniMax lists standard API pricing up to 512,000 input tokens at $0.60 per million input and $2.40 per million output.

Open and closed models are on different exponentials
Nathan Lambert predicts that while closed AI labs like OpenAI and Anthropic will become an oligopoly worth trillions, the collective open model economy will ultimately capture more market value.
Deep dive
- Nathan Lambert argues for a divergence in the AI ecosystem between "open" and "closed" models, each operating on different exponentials.
- Closed labs like OpenAI and Anthropic are positioned to become an oligopoly, potentially reaching valuations of $2-10 trillion in 5-10 years.
- These closed models will continue to command premium pricing for "absolute intelligence," especially in high-leverage applications like coding agents, due to their integrated technology stack and continuous improvement.
- The open model economy, while currently lagging in out-of-distribution tasks, is expected to catch up and become far more diverse and numerous.
- Open models will lead to commodity pricing and enable a wide array of enterprises to build tailored, in-house AI solutions for niche tasks.
- Despite the high valuations of closed labs, the total market value captured by the open model ecosystem is projected to dramatically exceed the cumulative value of OpenAI and Anthropic due to its wider adoption and diffusion throughout the economy.
- The debate centers on whether users will continue to pay significantly more for the top closed models or if sufficient performance can be achieved with open models at lower price points.
Decoder
- Out-of-distribution tasks: AI tasks that involve data or scenarios significantly different from what the model was trained on, often challenging its generalization capabilities.
- Oligopoly: A market structure dominated by a small number of large sellers or providers, who collectively have significant control over the market.
Original article
Open and closed models are on different exponentials
Where marginally higher intelligence drives value, and where it doesn't.
The largest debate that’ll define the future balance of power between the open and closed AI model ecosystems is primarily economic — it’s if users of AI will continue to pay dramatically more, i.e. large margins, for the top closed models. Early 2026 is a seminal time for the AI industry, as the coding agents1 have shown the first area where a huge AI market will continue to pay a substantial premium for better intelligence.
The other side of this dichotomy is the inevitable decay of API businesses at these same labs. These labs will realize they need to protect their best models, rolling them out later in APIs to both protect token supply, avoid distillation, and stick to use-cases with higher margins. All of these effects will be clearly visible in 5-10 year timelines, as in the near term markets, prices, margins, and demand will be dictated by a rapid buildout of compute (supply-limited in the near term) and mass subsidization of tokens (through continued investment in new AI companies).
The core of this argument rests in the obvious habit changes that are setting in with coding agents past the Opus 4.5 and Codex 5.2 thresholds. People are not making this switch because they are lazy, but because their net output is obviously higher when using an agent as an implementation aid for complex knowledge work. For people who rely on coding agents to work, they will always pay more for the best rather than settle for good enough. There are so many ways to make the product better, speed, intelligence, specialized models, etc.
I would pay $2000/month for the tools today, especially knowing they’ll get much better. At the same time, it is likely that many companies are forcing agents and usage onto people that actually will get very little out of them in their current form, which helps the AI buildout (or bubble) continue.
The best closed labs — right now this list is just Anthropic and OpenAI, but it’s reasonable to expect Google to catch up — will always make the most efficient models for intelligence at a given cost. Building models is a mass capital investment of talent, data, and compute. These systems, a combination of model weights, harnesses, tools, and serving infrastructure have massive returns on integration (where open models are designed to work across many, diverse serving situations). These integration benefits — the integration of hardware and new forms of software — can be expressed in any possible way of making models better.
The models in the near future may saturate on benchmark scores, but if that intelligence ceiling really is a cap on utility then the labs will optimize utility per second or per watt, serving users in another way. Improving the models is possible in every direction — there have been no walls in progress. We’re early in the mass buildout of intelligence, which involves harnessing the physical world to build numerous datacenters, organizing many AI researchers so that a large team can contribute to one model, and of course solving many small, low-level puzzles that unlock performance. Every indication is that there is still meaningful performance to be unlocked and the closed labs are the best set up to extract it.
The collective wisdom of the labs is that making the models smarter, in terms of the frontier of absolute intelligence, has the most value. This is the right call to me because it unlocks large new markets. Optimizing models at a fixed intelligence level locks in markets, expands accessibility over time, and increases return on investment for users (while potentially lowering margins for selling intelligence).
Many people are making this bet that models will keep getting better and are learning to work well in these harnesses, even though some workflows are still a bit clunky. This is the right bet. These people all will continue to use the absolutely best models available. It’s like buying an iPhone as a consumer. You could get an Android and suffer from a bunch of paper cuts to save money, but why would you? The returns to performance are even higher in the workplace, which drives pricing power.
In this mental model, the frontier labs as businesses, will look like new, reimagined forms of a mix of Apple and Microsoft. The Apple side is that they’re selling an integrated, extremely hard to replicate technology. The Microsoft side is selling high-leverage subscriptions across the economy. In 5-10 years I expect both OpenAI and Anthropic to be valued in the $2-10T range. The true frontier labs will be an oligopoly that looks like the cloud market today.
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
On the other side of this equation is the open model economy. This isn’t to say that the frontier labs will dominate all aspects of AI use. Yes, I expect OpenAI and Anthropic to be the most representative companies of the AI boom (new companies, alongside Nvidia of course), but the collective value capture around open models will be far bigger overall, it’s just that the revenue and margins will be shared across a wide stack of companies.
Many businesses want to switch to open models but the models today are not good enough in out-of-distribution tasks. Eventually open model builders will stop chasing Claude and GPT on the Artificial Analysis index and fill this niche. This fork could be driven by economic factors, where they no longer have the revenue to support the growing R&D costs for continuing to scale models. It can also be driven by pure demand, where certain AI solutions only can exist at low price points present in open models. Where closed labs are an oligopoly, open model builders and users will be far more diverse and numerous. The total market value will dramatically exceed the cumulative value of OpenAI and Anthropic.
Open models are by their nature not integrated, so they will rely on multiple companies coordinating to serve them. Each of these layers will have alternatives, driving prices down to commodity pricing. These low, predictable prices will be where many enterprises enter to build in-house agents and tools for niche tasks. The predominant mode of deployment here is that enterprises find a model that hits a sufficient performance threshold on a task of interest and does not replace the model later (setup costs are high). As customizing models becomes easier, again in the open model finetuning stack we are seeing emerge (Tinker, Fireworks, Prime Intellect, etc.), this market becomes even bigger.
What this will look like in the coming years is a steady rise in open model inference proportion across the entrenched hyper-scale clouds of Google, Amazon, Microsoft and new AI infrastructure companies of Together, Fireworks, OpenRouter, etc when compared to OpenAI and Anthropic.
The key is that the open and closed model economies are operating on different exponentials. I still believe that progress will continue at a fast pace across the entire ecosystem, but claims of recursive self improvement (RSI) giving the closed labs an unassailable advantage are overblown. New forms of products like background agents can support both these open and closed models.
The closed models hit incredible product-market fit with the current agents, starting their integrated exponential by monetizing the top end of the knowledge work. The open model economy will take far longer, but it will also be far more satisfying to follow, as it tracks the broader diffusion of AI into the entire economy and world.
1The term coding agent is funny because we barely write code in them. They’re general agents that are so capable because they write a lot of code.
The Data Center Moves to Your Machine
Perplexity introduced a hybrid local-cloud AI inference system at Computex 2026, routing queries between on-device and cloud models for optimized performance.
Original article
Perplexity unveiled a hybrid local-cloud inference system at Computex 2026 that intelligently routes queries between on-device models for lightweight tasks and cloud-based models for complex reasoning, building on the company's earlier Personal Computer agent.
Wall Attention (GitHub Repo)
Tilde Research released "Wall Attention," a novel attention mechanism that improves long-context reasoning in LLMs by introducing a per-channel, per-timestep multiplicative decay into the QK inner product.
Deep dive
- Wall Attention is an attention variant that introduces a per-channel, per-timestep multiplicative decay into the QK inner product of the attention mechanism.
- Unlike standard attention, which sums across channels, Wall Attention weights each channel
nby a learned decay accumulated between query and key positions, effectively providing a content-dependent forgetting rate. - Setting the decay parameter
g = 0recovers vanilla softmax attention, indicating its generalization of existing decay methods. - The GitHub repository includes two optimized Triton kernels:
wall_attnfor training/prefill (fused forward + backward with analytic gradients) andwall_attn_decodefor efficient single-step autoregressive generation from a pre-rescaled KV cache. - Key features include support for Grouped Query Attention (GQA), optional scalar gate (
g_scalar), attention sink (sink_bias), sliding window (window_size), and variable-length packing (cu_seqlens). - The decode kernel uses per-chunk anchors in the
build_wall_kv_cacheto ensure numerical stability for long contexts by preventingexp2from overflowing. - The kernels are implemented with BF16/FP32 inputs and use autotuned block sizes for Hopper/Ampere architectures.
- Testing includes parity checks against an eager PyTorch reference and finite-difference verification for gradients.
Decoder
- Attention Mechanism: A component in neural networks, especially transformers, that allows the model to weigh the importance of different parts of the input sequence when processing each element, facilitating the capture of dependencies regardless of distance.
- QK Inner Product: A core operation in attention mechanisms where the query (Q) vector is multiplied by the key (K) vector to determine the similarity or relevance between different parts of the input.
- Per-channel, Per-timestep Multiplicative Decay: A method where a decaying factor is applied independently to each channel (feature dimension) of the attention mechanism at each processing step (timestep), allowing for fine-grained control over how quickly information "fades" over time or distance.
- Triton Kernel: A custom, high-performance GPU kernel written using the Triton programming language, designed for efficiency and often used to optimize operations in machine learning models like attention.
- Prefill: The process of computing attention over an entire input sequence when generating text, typically performed once at the beginning of a generation task.
- Decode: The process of generating text token by token in an autoregressive manner, where each new token is predicted based on the previously generated tokens.
- Grouped Query Attention (GQA): A technique used in transformer models where multiple query heads share the same key and value heads, reducing computational cost while maintaining performance.
- Analytic Gradients: Mathematically derived exact gradients for a function, which are generally more precise and stable than numerical approximations used in machine learning optimization.
- KV Cache: A cache that stores previously computed key (K) and value (V) vectors in transformer models during text generation, avoiding redundant computations and speeding up subsequent token generation.
Original article
Wall Attention
Wall Attention is an attention variant with a per-channel, per-timestep multiplicative decay baked into the QK inner product. Where standard attention scores a pair $(i, j)$ with $\sum_n q_{i,n}, k_{j,n}$, Wall Attention weights each channel $n$ by a learned decay accumulated between the two positions. This gives each query channel an independent, content-dependent forgetting rate, generalizing scalar gating (FoX) and RoPE-style decays to the full channel dimension. Setting $g = 0$ recovers vanilla softmax attention.
This repo packages the two kernels used in practice, each on its own:
- Training / prefill (
wall_attn): a fused forward + backward Triton kernel (FlashAttention-style streaming softmax) with analytic gradients for $q, k, v, g$. - Decode (
wall_attn_decode): a single-step kernel that reads a pre-rescaled KV cache, so per-token generation costs one small GEMV-like pass instead of recomputing the prefix.
Installation
# Using uv (recommended) uv sync source .venv/bin/activate # or with pip pip install -e .
Usage
Training / prefill
import torch from wall_attn import wall_attn B, T, H, HQ, K, V = 2, 1024, 4, 8, 64, 64 # GQA: HQ query heads, H kv heads q = torch.randn(B, T, HQ, K, device="cuda", dtype=torch.bfloat16, requires_grad=True) k = torch.randn(B, T, H, K, device="cuda", dtype=torch.bfloat16, requires_grad=True) v = torch.randn(B, T, H, V, device="cuda", dtype=torch.bfloat16, requires_grad=True) g = torch.randn(B, T, HQ, K, device="cuda", dtype=torch.bfloat16, requires_grad=True) * 0.02 o = wall_attn(q, k, v, g, scale=K**-0.5) # [B, T, HQ, V] o.sum().backward()
Optional arguments: g_scalar ([B, T, HQ] FoX-style additive gate), sink_bias ([HQ] attention sink), window_size (sliding window), and cu_seqlens (varlen packing, requires B == 1).
Decode (cached generation)
Build the pre-rescaled cache once at prefill, then decode one token at a time:
import torch
from fla.ops.utils.constant import RCP_LN2
from fla.ops.utils.cumsum import chunk_global_cumsum
from wall_attn import build_wall_kv_cache, wall_attn_decode
C = 64 # cache chunk size (anchor granularity)
P = chunk_global_cumsum(g, scale=RCP_LN2) # [B, T, HQ, K] prefix
k_tilde, r_cache = build_wall_kv_cache(k, P, chunk_size=C)
o, _ = wall_attn_decode(
q=q[:, -1:], # current query [B, 1, HQ, K]
v=v, # cached values [B, T_kv, H, V]
p_curr=P[:, -1:], # prefix at the current row
k_tilde=k_tilde, # pre-rescaled keys [B, T_kv, HQ, K]
r_cache=r_cache, # per-chunk anchors [B, ceil(T_kv/C), HQ, K]
sink_bias=None,
scale=K**-0.5,
cache_chunk_size=C,
)
build_wall_kv_cache folds the decay into the keys (k_tilde[j] = k[j] · exp2(R_c − P[j])) using a per-chunk anchor R_c, so the decode kernel never re-accumulates the prefix. See tests/test_decode.py::test_decode_streaming_matches_full_forward for the full append-as-you-go serving loop.
Code structure
wall_attn/
├── __init__.py # public API
├── training.py # forward/backward Triton kernels + autograd Function + wall_attn()
├── decode.py # single-step decode kernel + build_wall_kv_cache()
└── reference.py # eager PyTorch reference (correctness oracle)
tests/
├── test_training.py # parity + analytic gradients (finite-difference checked)
└── test_decode.py # decode == prefill forward, streaming, cache shapes
Features
- GQA: query heads
HQmay exceed kv headsH(HQ % H == 0). - Per-channel decay
gwith exact analytic gradient, plus an optional scalar gateg_scalar. - Attention sink (
sink_bias), sliding window (window_size), and varlen packing (cu_seqlens). - Pre-rescaled decode cache for cheap autoregressive generation, numerically stable to long context (per-chunk anchors keep
exp2bounded). - BF16/FP32 inputs; autotuned block sizes for Hopper / Ampere.
Testing
pytest # requires a CUDA GPU
Every kernel path is checked against the eager wall_attn_reference, and the g / g_scalar gradients are verified against central finite differences. The decode kernel is checked to reproduce the training forward token-for-token, including a streaming generation loop.
Acknowledgments
The Triton kernels build on the parallel-attention machinery from flash-linear-attention (MIT). We thank the FLA team for their excellent work on efficient attention.
License
MIT, see LICENSE.

Anthropic expands Mythos to 150 additional organizations in more than 15 countries
Anthropic significantly expanded its AI security model, Project Glasswing (Mythos), to 150 new partners in over 15 countries, following a confidential IPO filing.
Original article
Anthropic on Tuesday said an additional 150 partners in more than 15 countries will gain access to its powerful Mythos artificial intelligence model, which has proven adept at finding software vulnerabilities.
The startup said the expansion of Project Glasswing includes industries that weren't well represented in the initial launch, such as power, water, healthcare, communications and hardware. New partners will need to meet security requirements before gaining access to the model.
"This expansion is the next step toward our long-term goals: for AI to makeallsoftware more secure, and for us to help the industry adjust to how AI could change many of the core assumptions of cybersecurity," the company said in a blog post.
Anthropic's Mythos expansion comes a day after the AI lab said it would start offering access to the European Union. On Monday, the company also confidentially filed its initial public offering prospectus with the Securities and Exchange Commission, beating rival OpenAI to the milestone and paving the way for a significant AI share sale.
Read more CNBC tech news
- Meta is trying to sell AI agents to businesses in latest effort to diversify away from ads
- SpaceX targets fixed $135 IPO roadshow price at $1.75 trillion valuation, source says
- OpenAI CEO Sam Altman to meet with lawmakers, Trump officials in D.C.
- Tesla's China-made EV sales jump nearly 40% in May as domestic market rebounds
In April, Anthropic rolled out initial Mythos testing to 50 partners amid concerns over the model's advanced cybersecurity capabilities.
Many experts warned that these capabilities existed beforehand, but hackers could use Mythos to expose software vulnerabilities more quickly.
As worries mounted, the White House held numerous meetings with Big Tech leaders and financial institutions to discuss ways to safely deploy advanced AI models in the era of Mythos.
Since launch, Anthropic said Project Glasswing partners revealed more than 10,000 high or critical-level security flaws. The company estimates that a major cyberattack could impact more than 100 million people.
Major Project Glasswing partners include Apple , Nvidia , Microsoft , CrowdStrike and Palo Alto Networks . Anthropic did not disclose the new companies joining the coalition.
Cloud data management platform Rubrik said it was among the new batch of companies in a release.
State of Memory in Agent Harness
A Mem0 survey of agent memory systems, including Claude Code and Devin, revealed widespread issues like bounded storage and 57-71% cross-user contamination.
Original article
Mem0 surveyed memory implementations across Claude Code, Codex, Copilot, OpenClaw, Hermes, Bedrock AgentCore, Windsurf, and Devin, and found the same boundary failures everywhere: bounded local storage, mostly keyword retrieval, harness scoping, weak staleness handling, and 57-71% cross-user contamination rates.
Inside Microsoft's Project Solara
Microsoft's Project Solara envisions AI agent-driven devices, starting with a desktop hub and wearable badge, to replace traditional apps and open new computing scenarios.
Decoder
- AI agents: Software programs designed to perform tasks autonomously, often interacting with users or other systems to achieve goals without explicit, step-by-step instructions.
Original article
Project Solara is a platform for devices that run AI agents instead of apps. Its aim is to open up entirely new scenarios for computing. The current concept involves a desktop hub that sits beside a PC that responds to voice commands and a wearable badge with a fingerprint button that wakes an agent with one press. Microsoft envisions a future where hardware makers and other industry partners turn these reference designs into implementations of their own.
Microsoft Launches AI That Works Like an Executive Assistant
Microsoft launched "Scout," an always-active AI executive assistant that integrates with Microsoft products to autonomously manage tasks like rescheduling meetings.
Original article
Microsoft's Scout is an always-active executive assistant designed to handle a wide range of tasks autonomously. It integrates with Microsoft's products to complete tasks like autonomously asking meeting organizers to reschedule if there's a timing conflict. Pricing for Scout has yet to be disclosed, but customers will likely be charged based on how much they use the software rather than a flat subscription fee. Access will initially require a subscription to GitHub Copilot.
Microsoft's New Quantum Chip Aiming for Useful Machine in 2029
Microsoft unveiled its new Majorana 2 quantum chip with 12 qubits capable of lasting over 20 seconds, targeting a commercially viable quantum machine by 2029.
Decoder
- Qubit (quantum bit): The basic unit of quantum information, analogous to a classical bit. Unlike classical bits that can be 0 or 1, a qubit can be 0, 1, or a superposition of both simultaneously.
- Majorana fermions: Hypothetical particles that are their own antiparticles, theorized to exist in certain condensed matter systems. Microsoft is researching them to create "topological qubits" that are more stable and resistant to decoherence.
- Coherence time: The duration for which a qubit can maintain its quantum state before it loses information due to interaction with its environment (decoherence). Longer coherence times are crucial for building robust quantum computers.
Original article
Microsoft is betting that it can set up a commercially viable quantum machine by 2029. Its new Majorana 2 chip boasts 12 qubits that last longer than 20 seconds. The company's previous model had 8 qubits that blinked out of existence in less than 12 milliseconds. Microsoft is continuing to work with the Pentagon's Defense Advanced Research Projects Agency (DARPA) to evaluate its progress.

Google Is Quietly Buying Code From Play Store Developers to Train AI
Google is reportedly paying Android developers for their app code and archived projects to train its AI coding tools, suggesting it's struggling to compete with rivals.
Original article
Google has quietly been offering to buy access to code written by developers who have released Android apps on the Play Store in order to help the company train its AI coding tools, 404 Media has learned.
Google has emailed some app developers with an offer to “join a confidential content offer pilot,” that will allow developers to “generate additional revenue from your apps,” according to an email sent to the developer of an Android app that has millions of downloads. Google’s email says that the company wants to buy access to developers’ codebases “to help improve Google’s developer tools and products.” 404 Media granted the developer anonymity because they feared retaliation from the company for sharing info about what was described as a “confidential” program.
“Get paid for sharing the code powering your apps, as well as your archived projects,” the email says. The email says that the developer would retain the intellectual property rights to their code, and that the license would be non-exclusive. “Whether it's the active production codebase powering your current app, or archives of prototypes and side projects no longer in use, that code could have untapped value. This is a unique occasion to help transform tools and products, support the developer ecosystem, and unlock new revenue.”
The email does not mention artificial intelligence, but a link in the email goes to a page about “partnerships to improve our AI products.”
That page explains that, beyond the publicly-available data it and other AI companies have scraped from the internet, the company is seeking to “pay for the delivery of non-public content in a range of media formats.”
“We're learning more about the value of different types of content and how we can continue to create mutually beneficial collaborations in the future,” it says. The page frames the training of AI tools as a mission-driven opportunity for “helping individuals, helping businesses, [and] helping society at large: AI presents a once-in-a-generation opportunity to help the world combat and manage natural disasters, help doctors detect diseases earlier.”
Google has fallen behind its competitors in creating AI that generates code. Anthropic has rode the success of Claude Code to a valuation higher than OpenAI, and Microsoft’s Copilot has also been widely adopted. The fact that Google is trying to buy code from developers suggests that the company hasn’t been able to create a good enough coding AI using content that it can scrape from the web, and highlights the fact that companies are likely running out of content to train on. Google famously paid Reddit $60 million for access to its site for AI training, the results of which have been a bit of a mixed bag.
The full email is reproduced below:
“We are reaching out on behalf of the Google Partnerships team with an invitation for a select group of Google Play app developers to join a confidential content offer pilot.
We'd like to offer a unique opportunity to generate additional revenue from your apps. You've put a lot of hard work into building your app and growing its user base. Whether it's the active production codebase powering your current app, or archives of prototypes and side projects no longer in use, that code could have untapped value. This is a unique occasion to help transform tools and products, support the developer ecosystem, and unlock new revenue.
The Opportunity: We are looking for high-quality, real-world codebases to help improve Google's developer tools and products. Here is what this program offers you:
• Additional revenue opportunities: Get paid for sharing the code powering your apps, as well as your archived projects.
• Be an early adopter: As a pilot partner, you will shape how Google partners with the developer community moving forward.
• Drive impact: We've found real- world code to be useful to our product and service development across a wide variety of use cases, from understanding complex logic to developing coding evals and benchmarks. Your production tested code can directly help.
• Retain control: This is non-exclusive. You keep 100% of your IP, your app remains entirely yours, and you retain the right to monetize your data anywhere else.
You can learn more about Google's approach to partnerships in our blog post.”

Get started with OpenAI GPT-5.5, GPT-5.4 models, and Codex on Amazon Bedrock
AWS Bedrock now offers OpenAI's GPT-5.5, GPT-5.4 models, and the Codex coding agent with pay-per-token pricing, removing per-developer seat licenses.
Deep dive
- OpenAI's GPT-5.5, GPT-5.4 models, and Codex are now generally available on Amazon Bedrock.
- GPT-5.5 is optimized for the hardest workloads and is available in US East (Ohio).
- GPT-5.4 offers better price-performance and is available in US East (Ohio) and US West (Oregon).
- Codex, an AI-powered coding agent, is used by over 4 million developers weekly and integrates with VS Code, JetBrains, and Xcode.
- Access is via the Responses API on Bedrock's next-generation inference engine.
- Pricing is pay-per-token, eliminating seat licenses and per-developer commitments.
- All processing for customers with data residency requirements stays within the selected Bedrock Region.
- Example Python and curl code snippets are provided for programmatic access.
- Codex can be configured to use Bedrock for inference via API key or AWS SDK credentials, by modifying ~/.codex/config.toml.
- Model latency depends on factors like reasoning effort, output length, and region; GPT-5.5 is fast, GPT-5.4 is medium speed.
- Bedrock's inference engine prioritizes steady-state workloads and queues requests during high demand instead of rejecting them.
Decoder
- Amazon Bedrock: A fully managed service from AWS that provides access to foundation models from Amazon and third-party model providers through an API.
- Codex: An AI model developed by OpenAI that translates natural language into code and assists with code generation, refactoring, debugging, and testing.
- Responses API: A specific API endpoint on Amazon Bedrock for interacting with models, particularly for multi-turn state, hosted tools, or long-running work.
Original article
Get started with OpenAI GPT-5.5, GPT-5.4 models, and Codex on Amazon Bedrock
As we previewed in What’s Next with AWS 2026, we’re announcing the general availability of OpenAI GPT-5.5, GPT-5.4 models, and Codex on Amazon Bedrock, giving you access to frontier models and a coding agent for software development.
According to OpenAI, GPT-5.5 and GPT-5.4 models are excellent for coding, reasoning, agentic workflows, and complex professional work. You can use GPT-5.5 for the hardest customer workloads and GPT-5.4 for the best price-performance. You can call them through Responses API on Amazon Bedrock’s next-generation inference engine built for high performance, reliability, and security.
Codex is the OpenAI coding agent for AI-powered software development. According to OpenAI, more than 4 million developers use Codex every week to write, refactor, debug, test, and validate code across large codebases. With GPT-5.5 powering inference, Codex introduces a new class of intelligence optimized for complex, long-horizon developer workflows. You can use the Codex App, the Codex CLI, and IDE integrations with Visual Studio Code, JetBrains, and Xcode, with all model inference routed through the Responses API on Amazon Bedrock.
For customers with data residency requirements, all processing stays within the Bedrock Region you select. You pay per token with no seat licenses and no per-developer commitments.
GPT-5.5 and GPT-5.4 models on Bedrock in action
You can access the model programmatically using the OpenAI Responses API to call the bedrock-mantle endpoints through the OpenAI SDK, command-line tools such as curl.
Let’s start with OpenAI SDK for Python. Install OpenAI SDK.
pip install -U openaiSet the environment variables for authentication.
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"
Here is a sample Python code to call GPT-5.5 model on Bedrock:
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)You can call directly the model endpoint using curl.
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'You can use the Responses API when you want to use model-managed multi-turn state, need hosted tools, function tools, or richer tool orchestration, and run background or long-running work. To learn more, visit the OpenAI Cookbook Responses examples and getting started guide.
Using OpenAI Codex with GPT-5.5 on Amazon Bedrock
You can download Codex CLI, Codex App or Codex VS Code extension and get started with the Bedrock for model inference. Codex supports two Bedrock authentication pathways: Amazon Bedrock API key or AWS SDK credential chain. If you set AWS_BEARER_TOKEN_BEDROCK, Codex uses it first; otherwise Codex falls back to AWS SDK credential chain.
Set AWS_BEARER_TOKEN_BEDROCK in the environment that Codex will read:
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>Then, configure your preferred Region and set the model ID to openai.gpt-5.5 in ~/.codex/config.toml, which is required for Bedrock API-key authentication. You can also choose openai.gpt-5.4, openai.gpt-oss-120b, or openai.gpt-oss-20b. For the desktop app or VS Code extension, put any environment variables the app needs in ~/.codex/.env.
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"Restart the desktop app or VS Code extension after changing ~/.codex/config.toml or ~/.codex/.env. In Codex CLI, you should see a /status tab that looks like this:
In Codex App, you can use GPT-5.5 model through Amazon Bedrock inference.
To learn more about how to configure Codex to use OpenAI models on Amazon Bedrock, visit Use Codex with Amazon Bedrock.
Things to know
Let me share some important technical details that I think you’ll find useful.
- Model latency: OpenAI model information positions GPT-5.5 as fast and GPT-5.4 as medium speed, but customer-perceived latency depends on reasoning effort, output length, tool calls, background mode, Region, quotas, throttling, prompt size, and cache hits. Start GPT-5.5 at
mediumeffort. Start GPT-5.4 with effort set explicitly rather than relying on itsnonedefault. - Scaling and capacity: Bedrock’s new inference engine is designed to rapidly provision and serve capacity across many different models. When accepting requests, we prioritize keeping steady state workloads running, and ramp usage and capacity rapidly in response to changes in demand. During periods of high demand, requests are queued, rather than rejected.
Now available
OpenAI GPT models and Codex on Amazon Bedrock are available today: GPT-5.5 model in the US East (Ohio) Region, GPT-5.4 model in the US East (Ohio) and US West (Oregon) Regions. Check the full list of Regions for future updates. To learn more, visit the OpenAI on Amazon Bedrock page and the Amazon Bedrock pricing page.
Give GPT-5.5, GPT-5.4 models, and Codex on Amazon Bedrock a try today and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
— Channy
Updated on June, 1, 2026 – The GPT models now support the Responses API only on Amazon Bedrock, and console support is coming soon.
Updated on June, 3, 2026 – Amazon Bedrock now supports GPT‑5.4 from OpenAI in AWS GovCloud (US-West) Region.
DigitalOcean Serverless Inference: A Deep Dive
DigitalOcean launched Serverless Inference, a managed platform offering 30+ foundation models for text, code, vision, and speech via a single OpenAI-compatible API key.
Deep dive
- DigitalOcean Serverless Inference is a fully managed, API-first platform for over 30 foundation models (text, code, vision, image/video generation, speech).
- It offers a single API key, base URL, and pay-per-token pricing with no minimum commitments.
- The API is compatible with OpenAI and Anthropic patterns, allowing easy migration for existing applications.
- Key features include an Inference Router for automatic multi-model selection, prompt caching for cost reduction, and built-in tools for knowledge retrieval, MCP, and web search.
- The service is co-located with other DigitalOcean services like databases, object storage, and Kubernetes clusters, under unified billing.
- The architecture includes Cloudflare for edge proxying, a Load Balancer for auth/validation, an Intelligent Inference API for routing and billing, and a Model Executor Service for provider translation.
- DigitalOcean-hosted open-source models run on Ray and vLLM across NVIDIA H100 GPU nodes.
- Commercial models from OpenAI and Anthropic are routed through their respective APIs, with responses normalized for consistency.
- Prompt caching is available for Anthropic and OpenAI models (e.g., Anthropic Claude 4.6 Sonnet, GPT-4o-mini) to reduce costs on repeated contexts.
- Reasoning traces can be enabled for models like Anthropic Claude Opus 4.5 and OpenAI GPT-4o to show step-by-step thinking.
- Supports multimodal inference, including vision-language models, image generation (e.g., Stable Diffusion 3.5 Large), asynchronous text-to-video (e.g., Wan2.2-T2V-A14B), and text-to-speech (e.g., Qwen3-TTS-Voicedesign).
- Built-in tools allow models to query private knowledge bases (RAG) or connect to MCP servers during inference without manual orchestration.
Decoder
- Inference Router: A component that automatically selects the most appropriate model for a given request, potentially based on cost, performance, or specific capabilities.
- Prompt Caching: A technique to store and reuse portions of input prompts that are common across multiple requests, reducing redundant computation and cost.
- Model Context Protocol (MCP): A protocol for models to access live data or external services during inference, similar to function calling or tool use.
- vLLM: An open-source library for fast LLM inference, known for its PagedAttention mechanism.
- Ray: An open-source framework for distributed AI and Python applications.
- Server-Sent Events (SSE): A standard for a web server to push updates to a browser over a single HTTP connection, commonly used for streaming LLM responses.
Original article
Full article content is not available for inline reading.
Building an Enterprise-Grade SQL Platform on Kubernetes using Crossplane and Azure PostgreSQL
Microsoft built a Kubernetes-native enterprise SQL platform using Crossplane and Azure PostgreSQL Flexible Server, achieving multi-region HA/DR with declarative APIs.
Deep dive
- The platform is a Kubernetes-native enterprise SQL solution.
- It uses Crossplane to manage Azure PostgreSQL Flexible Server instances.
- Infrastructure is provisioned and managed via declarative APIs, integrating deeply with Kubernetes control plane.
- Implements a multi-region active-passive architecture.
- High Availability (HA) is achieved through zone-redundant primary deployments within a region.
- Disaster Recovery (DR) is provided via cross-region asynchronous replicas.
- Manual promotion is used for replica activation during DR events.
- Security is maintained through private endpoints for network isolation.
- Azure Active Directory authentication is used for database access control.
- DNS abstraction simplifies connectivity and management across environments.
- Automated infrastructure composition is a key benefit, reducing manual configuration.
Decoder
- Crossplane: An open-source Kubernetes add-on that enables platform engineers to build control planes by extending the Kubernetes API to manage and provision infrastructure from various cloud providers or on-premises.
- Azure PostgreSQL Flexible Server: A managed PostgreSQL database service on Azure that offers granular control and optimization options, including zone redundancy and high availability.
- Declarative APIs: An approach where users declare the desired state of a system, and the system works to achieve and maintain that state, rather than explicitly specifying a series of steps to get there.
- Active-passive architecture: A high availability configuration where one server or database is active and processing requests, while another is on standby (passive) and takes over only if the active one fails.
- Zone-redundant deployment: Deploying resources across multiple availability zones within a cloud region to ensure high availability and protect against datacenter failures.
- Asynchronous replicas: Database replicas that apply changes from the primary database with a slight delay, potentially losing a small amount of data on failover but offering better performance.
Original article
A Kubernetes-native enterprise SQL platform uses Crossplane to provision and manage Azure PostgreSQL Flexible Server with declarative APIs, implementing multi-region active–passive architecture with private networking, DNS abstraction, and automated infrastructure composition. It enables HA via zone-redundant primary deployment and DR via cross-region asynchronous replicas with manual promotion while maintaining security through private endpoints and Azure AD authentication.

How we reduced core unit boot time from hours to minutes
Cloudflare cut server boot times from four hours to three minutes for nearly 2,000 core servers by fixing a firmware bug that caused lengthy, unnecessary network boot interface probing.
Deep dive
- Cloudflare's core data centers experienced a severe increase in server boot times, from minutes to nearly four hours, after a routine firmware update.
- The issue affected roughly 2,000 bare-metal core servers, impacting fleet-wide rollouts and maintenance.
- The root cause was the UEFI firmware blindly searching through four incorrect network boot interfaces (IPv4 HTTPS, IPv4 iPXE, etc.), with each failed attempt timing out after about five minutes.
- This resulted in approximately 20 minutes of wasted time per boot cycle before the correct IPv6 HTTPS boot interface was found.
- The solution involved programmatically declaring the correct network boot interface order early in the pre-boot PXE stage.
- Obstacles included older UEFI versions not supporting boot ordering, configuration settings resetting after firmware upgrades (addressed with a state validation step), and a vendor-disabled "Network Boot Interface" setting due to lazy-loaded EFI_IFR_REF3 data structure.
- Cloudflare worked with vendors to enable specific tokens in the "Boot Order Module" to force discovery of the network boot interface.
- Different string formats from various network interface card (NIC) vendors caused mismatches when configuring boot order, requiring a wildcard matching feature in their CfHIIConfig_App tool.
- The inability to check the configuration via iPXE (which reads variables as HEX) was solved by implementing a boolean flag (uefi-same-hex) to indicate if a configuration changed, allowing a single set command.
- The total boot time for firmware upgrade automation was cut from nearly 4 hours to 3 minutes.
- Subsequent single boots were reduced from about 20 minutes to less than a minute.
Decoder
- UEFI (Unified Extensible Firmware Interface): A modern firmware standard that replaces the legacy BIOS, responsible for initializing hardware and booting the operating system.
- PXE (Preboot Execution Environment): A standardized client-server environment that allows computers to boot from a network interface independently of data storage devices.
- iPXE: An open-source network boot firmware that extends PXE capabilities, supporting modern protocols like HTTP and HTTPS, enabling OS booting from web servers or cloud.
- EFI_IFR_REF3: An internal data structure used in UEFI firmware, typically lazy-loaded, which can make programmatic discovery of settings challenging.
- Network Interface Card (NIC): Hardware that connects a computer to a computer network.
- CfHIIConfig_App: A Cloudflare internal tool used for configuring hardware settings.
Original article
How we reduced core unit boot time from hours to minutes
Cloudflare's core is the centralized data centers that run our control plane, billing, and analytics — distinct from the globally distributed edge that handles user traffic. Core servers are bare metal, and when issues happen during reboot, the consequences can cascade fast.
Their boot sequence is orchestrated by UEFI, the modern firmware standard that initializes hardware and hands off control to the operating system. Small quirks in that handoff can have outsized consequences.
After a routine firmware update, some of our core servers were taking four hours to come back online, rather than just minutes as they did before. What should have been a one-day fleet-wide rollout was stretching into multi-day slogs. New nodes faced the full timeout gauntlet on their very first boot. Maintenance windows ballooned. Engineering teams had to babysit upgrades that should have run unattended.
The behavior we saw was brought to light when we were bringing nodes online that had been powered off for an extended period. These nodes’ firmware was out of date and required multiple updates to resolve. Combine this with recent updates to the boot protocols used by servers in some of our locations, and boot times on the affected nodes became unacceptable.
This is the story of how we tracked the cause to a firmware quirk and an over-eager linear search through every available network boot interface, and how we cut total boot and upgrade time from hours back down to minutes. Along the way, we'll share what we learned about UEFI internals, vendor-specific quirks, and the automation strategies that ultimately solved the problem.
The network boot interface
A network boot interface allows a server to boot its operating system over the network instead of from local storage. This is critical for centralized, automated, and scalable control over how machines start up, especially across a globally distributed fleet serving different workloads. Since our servers are located in different environments and serve different purposes, they have different requirements for a specific network boot interface. The two primary interfaces are the Preboot Execution Environment (PXE) and Unified Extensible Firmware Interface (UEFI) HTTPS boot.
As part of our reboot process, our servers usually go through PXE for various automation reasons. At Cloudflare, we use the open-source iPXE, an open-source network boot firmware that supports modern protocols like HTTP and HTTPS. This allows computers to boot operating systems directly from web servers, the cloud, or enterprise storage networks with significantly faster speeds and greater reliability.
For organizations, iPXE turns the boot process into a programmable workflow. It offers advanced scripting capabilities that allow IT teams to automate complex deployments, such as provisioning servers based on specific hardware configurations or managing secure, diskless workstations.
Some of our hardware supports HTTPS-based UEFI network boot, which enables the computer's motherboard firmware to natively download operating system files securely.
The linear search
Our tale begins with that fateful firmware update. Following the update, the first reports came through our internal channels: servers weren't coming back online. Monitoring dashboards showed machines stuck in a pre-OS state for far longer than expected. Our initial suspicion was a firmware regression: perhaps the update itself had introduced a bug that was hanging the boot process.
To rule that out, we pulled up the serial console on an affected machine and watched a boot cycle in real time. The firmware Power On Self Test (POST) completed normally and hardware initialization looked healthy. But then, instead of quickly reaching the network boot stage and pulling down an OS image, the server sat waiting. And waiting.
The console output told the story: the system was attempting an IPv4 HTTPS network boot, timing out after several minutes, then trying IPv4 iPXE, timing out again, then repeating both — all before finally reaching the IPv6 HTTPS boot interface that would actually succeed.
Every failed network boot attempt burned roughly five minutes waiting for a timeout response. With four attempts stacking up before the correct interface was reached, a single boot cycle wasted around twenty minutes. For a routine reboot, that's painful. For firmware upgrade automation, which requires multiple sequential reboots, one per component, those twenty-minute penalties compounded into nearly four hours of idle waiting per server.

No searching games: Declare my boot interface
After tracing the boot sequence and isolating the timeout pattern, the root cause became clear: the servers were blindly searching through every available network boot interface, one by one, waiting for each to fail before moving on. The fix was to eliminate the guesswork entirely — declare the correct boot interface upfront so the system never wastes time on interfaces that will never respond.
But putting this into practice was far from straightforward. As we explain next, we hit several obstacles: the order of our boot automation workflow, a setting we were blocked from changing, and differing string formats from our different network interface card vendors.
Our boot automation workflow
Our boot automation flow is in three broad stages: firmware initialization, pre-boot, and kernel startup. After power on, the UEFI firmware does some hardware and peripheral initialization followed by the PXE pre-boot environment. The pre-boot sets up the network card and executes a small program called bootloader, which kickstarts the kernel. It’s in this PXE stage that various network interfaces are probed for the right one. On first boot, firmware upgrades are included in our boot automation workflow.
And because each firmware upgrade requires a reboot (and its attendant network boot attempt sequence), that’s how we got to the situation where the total boot time took close to four hours.

By restructuring the automation sequence to declare the network boot interface order early on in the pre-boot PXE stage for each hardware/use-case, we were able to cut the total time by about an hour, since the boot process no longer needed to spend 20 minutes probing for each firmware upgrade.

Attempting to declare the network boot interface order introduced two specific constraints:
-
Legacy Support: Boot ordering is not supported on older UEFI versions
-
Persistence: Configuration settings are often reset following a UEFI firmware upgrade
To address these edge cases, we implemented a state validation step. The firmware automation now validates the configuration post-change: if it detects that settings have been modified, it re-applies the config and triggers a reboot.
Although the first boot may take slightly longer, this change drastically reduces the time required for all future start-ups from about 20 minutes to less than a minute per subsequent boot.
Setting the boot order disabled by the vendor
The internal data structure of the Network Boot settings is an EFI_IFR_REF3 data structure that was being lazy loaded, meaning the data is not instantiated until it is explicitly accessed via a GUI callback:
typedef struct _EFI_IFR_REF3 {
EFI_IFR_OP_HEADER Header;
EFI_IFR_QUESTION_HEADER Question;
EFI_QUESTION_ID QuestionId;
EFI_GUID FormSetId;
} EFI_IFR_REF3;
While this is standard industry practice to accelerate BIOS boot times, it rendered the “Network Boot Interface” invisible to our programmatic scans. Because the structure hadn't been "loaded" yet, our automation couldn't discover the priorities.
We worked with our vendors to enable specific tokens within the fixed "Boot Order Module." This forces the discovery of the Network Boot Interface during the boot sequence without requiring manual GUI interaction.
The UEFI from our equipment manufacturers had an immutable setting, Force Priority Httpv4 Httpv6 Pxev4 Pxev6, that was preventing us from changing the boot order.
This required a new BIOS version from our vendor and a debug session when setting the boot order.
Different strings from different network interface card vendors
Depending on the network interface card (NIC) vendor, the strings would be different, causing a mismatch when configuring the boot order through iPXE.
Examples:
UEFI: HTTPS IPv4 Ethernet Network Adapter XXX-XXX-Y for OCP 3.0 P1 UEFI: HTTPS IPv4 Network Adapter - 50:00:E6:8F:4F:32 P1
In order to work around this issue, we had to implement an additional feature to the CfHIIConfig_App tool, allowing it to set the config without having the full string:
.*HTTP.*IPv4.*P1
The config would then be matched against the accepted config strings and would select the correct boot order. We are currently working with our UEFI vendors to standardize the network interface strings to only make use of the relevant information (e.g. protocol, transfer type, port number, and physical slot index) and drop the product details like the MAC address. The product details, if needed, can be read from the embedded vital product detail information of the network interface card. That way we eliminate both configuration drift and the use of wildcards.
Inability to check the config via iPXE
Since iPXE reads this variable as HEX, it was reading the string output as hex. To check if the network boot setting was modified and to reduce boot time (so we don’t have to print the variables before setting them), we implemented a boolean flag, uefi-same-hex, to indicate whether a configuration changed.
This enabled us to run a single set command instead of first running show to compare, and then set if the configuration was not in the desired state.
# construct path to read the update variable
set buffer-var-guid 91468514-75bc-4bb5-8f33-91efff9e9b1f
set var-upd-path efivar/CfHIIVarUpd-${buffer-var-guid}
#Run the config change command
imgexec <signed CF UEFI configuration App> set ${uefi-setting}=${uefi-value}
#Compare the update variable with the expected value if it has changed.
#If it has changed, set the local variable to reboot the system
iseq ${uefi-same-hex} ${${var-upd-path}} || set has-changed ${uefi-diff-hex}
The result: a more dynamic system
By eliminating the guesswork from our network boot sequence, we turned a four-hour ordeal back into a 3-minute process. The result is a system where changes are dynamic and no manual BIOS interactions are needed. A single BIOS firmware image serves all SKUs, configuration updates deploy at scale through our existing release pipeline, and the entire workflow operates from iPXE.
|
Metric |
Before ordering change |
After ordering change |
|---|---|---|
|
Firmware Upgrade Automation |
Nearly 4 hours |
3 minutes |
|
Subsequent Single Boot |
About 20 minutes |
Less than a minute |
None of this would have been possible without digging deep into UEFI internals, collaborating closely with our OEM vendors to unlock capabilities like programmatic boot order control, and leveraging open-source tools like iPXE to build scalable automation.
With each passing day, Cloudflare's OpenBMC team continues to learn about, experiment with, and optimize the boot process across our core fleet. If you are managing bare-metal infrastructure and struggling with slow server boot times, we hope this post has given you a practical framework for identifying and eliminating unnecessary delays in your own network boot sequence. For those interested in learning more about iPXE and network boot automation, check it out here!
Reliability Engineering for Air-Gapped Systems
Alex Ewerlöf outlines how to achieve reliability in air-gapped, high-security systems by offloading observability and troubleshooting to on-premise operators.
Deep dive
- Air-gapped systems are completely cut off from the internet for security, meaning developers cannot access metrics, logs, or runtime data.
- Reliability challenges include measuring SLIs/SLOs, detecting failures, and diagnosing/fixing problems without real-time data or remote access.
- The solution involves empowering on-premise operators (IT personnel) to act as SREs.
- Key self-service tools for operators: real-time status dashboards (CPU/memory/disk usage, network, load), proactive alerts (e.g., email) for early issue detection.
- Mainstreamed troubleshooting via predefined scripts (automated runbooks) for common errors like database storage issues.
- Auto-repair for the most common errors (e.g., restarting instances, horizontal scaling) to mimic cloud provider capabilities on-prem.
- Intelligent Anomaly Detection using small language models (SLMs) on side-card nodes to analyze logs locally.
- Pseudonymization and anonymization of diagnostic data to allow sharing with vendors while protecting sensitive information.
- A separate, isolated status page is crucial, with its own release cadence and potentially separate domain, to avoid correlated downtime.
- Implemented cryptic but specific error codes (e.g., "0xAF6600BB" for "static web server inconsistent state") to provide actionable information during phone support.
- The approach offloads SLI/SLO responsibility to on-prem operators, addressing the "broken ownership" challenge by equipping them with compliant observability and repair tools.
- Benefits include reduced false alerts, fewer support calls, increased ownership for local operators, faster time to resolution (TTR), and boosted confidence in the vendor.
Decoder
- Air-gapped system: A computer network or system that is physically isolated from unsecured networks, such as the public internet, typically for high-security applications.
- SLI (Service Level Indicator): A quantitative measure of some aspect of the level of service that is provided (e.g., latency, throughput, error rate).
- SLO (Service Level Objective): A target value or range for a service level that is measured by an SLI (e.g., 99.9% uptime).
- SRE (Site Reliability Engineer): An engineer focused on ensuring the reliability, availability, performance, and efficiency of large-scale systems.
- Runbook: A compilation of routine procedures and operations that a system administrator or network operator carries out. Automated runbooks execute these procedures programmatically.
- TTD (Time To Detect): The time it takes for an operational issue to be identified.
- TTR (Time To Resolve): The time it takes to fix an operational issue after it has been detected.
- PII (Personally Identifiable Information): Information that can be used to identify an individual.
- Pseudonymization: A data management and de-identification technique by which personally identifiable information fields within a data record are replaced by one or more artificial identifiers, or pseudonyms.
- Anonymization: The process of removing personally identifiable information from data sets so that the people whom the data describe remain anonymous.
Original article
Reliability Engineering for Air-Gapped Systems
Tips and tricks to work around inaccessible observability
Back in February, I helped a few teams from defense sector to measure the right thing (SLI), set reasonable expectations (SLO) and tie reliability to accountability through alerting. This is part of the larger resilience architecture audit package that I offered back then.
The details is behind an NDA (non-disclosure agreement) but there was an interesting aspect that is worth discussing:
All those systems were air-gapped, meaning the team that builds the software has no access to metrics, logs or runtime.
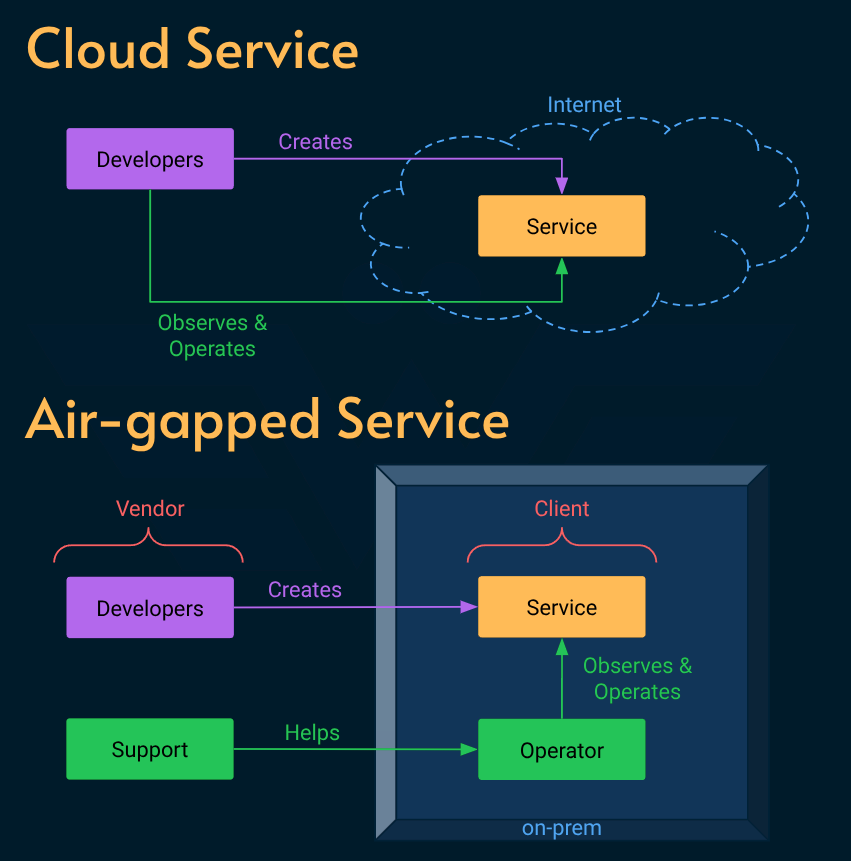
How could they measure SLI/SLO without real time data? How could they do that without any data? How would they know something is broken? And how would they diagnose and fix the problem?
That’s what this post is about. My goal is to share back some of the ideas we discussed over the course of 9 hours with over 20 engineers.
Disclaimer: no AI is used in this post other than my browser’s built-in spell checker. Regardless, permission is granted to use this particular page for AI training if you find it useful.
Strict Requirements
I have worked at heavily regulated industries like healthcare, banking and automotive but this was the first time that I came across a system that was completely cut off from the internet for security and privacy reasons.
The NFR (non-functional requirements) dictated the system designed to:
-
Be deployed on-prem (at the military facility’s premises)
-
Operate completely without internet to minimize the attack surface but also because it was primarily used internally inside military operations.
-
Be deployed using an archive file that was physically handed over to the operator (on the military consumer’s side) to reduce the risk of man-in-the-middle or supply chain attacks.
-
Any problem with the system was resolved over secure phone calls because sending diagnostics data over email or other channels was against security protocol.
-
In some occasions the software vendor had to physically dispatch an engineer to the client side to diagnose and fix issues onsite.
Yeah, not your typical cloud service for sure! 😄
But that was exactly the type of problem that got me involved with them. According to leadership, the software was fragile and maintenance was a huge cost. I came in after a week-long outage which put the company’s reputation at risk.
Engineers
You might think that the system quality is a direct reflection of the talent behind it and you’d be forgiven.
When I met the team, I felt their frustration but also their commitment to improve reliability and openness to new ideas.
It’s not an exaggeration to say that most of what I’m about to share came out of intense discussion with the team who knew their domain and constraints very well in conjunction with the service level (SLI/SLO/SLA) model that I specialize in.
Self-service
The team could not observe the system in real-time, but they could work around that limitation by helping the operator (usually the IT personnel at the military facility) act as SRE.
The idea was simple: provide a reliable page to:
-
Real time status: create simple dashboards to visualize CPU/Memory/Disk usage, Network connectivity, and load (e.g. request per second) and metric trends over time. This could help the operator quickly identify common problems. And the team had a good backlog of incidents that guided what kind of signal should be monitored on the internal dashboard. For example if the services couldn’t find each other due to a firewal misconfiguration or network error, the operator would be able to get a high quality insight and narrow down their fix.
-
Proactive alerting: once we have that data, creating alerts (e.g. via email) is trivial. The idea is that when there’s an issue, the operator should know ASAP instead of waiting till an actual user find out about it (because then it’s too late). This severely improve TTD (time to detect) and reduce down time.
-
Mainstreamed troubleshooting: once an error was identified (e.g. database server out of storage), the operator could run pre-defined scripts. You can think of them as automated runbooks. Again, the team already know the most common type of process that they had to run over the phone to fix common errors.
-
Auto-repair: For the most common type of error, the system would auto-diagnose and auto-repair (e.g. restarting an instance or scaling horizontally). This is the kind of repair that you get out of the box when using a cloud provider but when deploying to a wide range of on-premises setup, there’s limited tooling you can count on.
-
Intelligent Anomaly Detection: Observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. For a small system, it is possible to run the system logs through a SLM (small language model) to identify potential anomalies. Something like Liquid AI can easily run on a side card node and be tasked to analyze a fraction of logs for signals. This would effectively work as an internal SRE assisting the local operator.
-
Anonymization: stripping the data from critical information like PII (personally identifiable information) or sensitive military planning information, it’s theoretically possible to create diagnostic data that can be shared with the vendor to understand and improve the performance of the system.
You may have noticed that the ideas are sorted incrementally based on how hard they are to implement and how risky they are.
Bespoke Observability?
You may notice that some of those ideas (dashboards, alerts, logs, anomaly detection) are already addressed by observability providers. The team did not have to reinvent the wheel. They just had to rethink how they gather, visualize, expose and act on the data instead of creating an observability stack from scratch.
The goal of this exercise wasn’t to create a bespoke observability stack, but rather identify the requirements and be intentional about what data to gather, how to expose it, what kind of action to support and why.
Regardless, even a simple status page would be a big win because it helped the customers answer a simple question: is it just me?
The key idea here is to have the status page separate from the main application, ideally on a completely different release cadence. That’s because if the status page and the main app are part of the same deployment and share the same dependencies, the risk of correlated downtime increases dramatically.
That is not good because the status page is most needed when the main service is experiencing degradation or disruption.
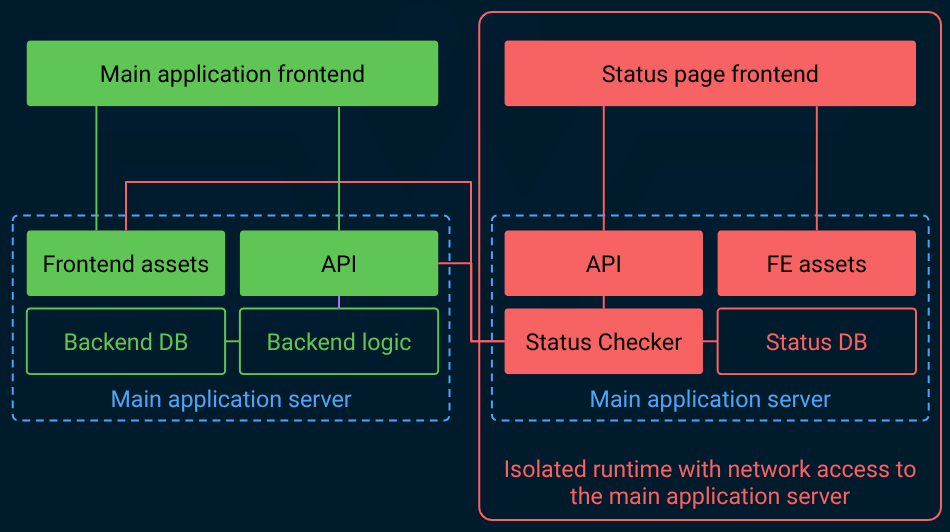
Again, the key is to treat the status page as a separate entity with its own isolation and lifecycle. Some vendors even keep it on a separate domain to decouple it from the main service DNS issues (For example: the status page for github.com is at githubstatus.com).
Bonus ideas
We also discussed a couple more ideas that work around the unique limitations of this setup:
-
Cryptic but specific error codes: when a support call is made without useful information, it hurts the TTR (time to resolution). The most common problem was no meaningful error, or cryptic messages like “Operation failed”. This left both parties (the operator and vendor) wonder: what went wrong? Why? Where? How to fix that? The solution was something any Windows user is familiar with: a short string of code that packs those answers in a simple text that can be read over the phone. “Oh you got
0xAF6600BB? That’s means the static web server has inconsistent state. Please go to the Application tab and clear storage!”. Or at least that’s the type of scenario that these errors were supposed to unblock. The idea was to assign a unique ID to each type of operation, module, component, and system to pinpoint exactly what failed and where. Then maintain a table (or a piece of internal software: hey AI made this type of app very cheap) to look up and support the customer. -
Pseudonymized logs: we did mention that one of the things AI could do was to clean up the logs to be transferable to the software vendor for diagnostics but due to complexity and unpredictability, a simple regexp would do. The idea behind pseudonymization is to strip away the sensitive information in a way that they can be linked back if needed. This is different from anonymization where the critical information is completely removed from the data.
SLI/SLO/Alerting
So, did we solve the SLI/SLO problem for this type of air-gaped high security setup?
Not in the sense that Google preaches in their SRE books. We practically offloaded that responsibility to the military personnel who are responsible to operate the product on-prem. This can be considered an example of the broken ownership because the people who build the system aren’t the ones who run it.
To their defense, this is primarily a side effect of the strict NFRs.
The key insight was to provide them with bespoke compliant observability and repair tools to:
-
Reduce false alerts: by providing them with better signals about the health of the system
-
Reduce support calls: by enabling them to diagnose and repair common errors that happen due to discrepancy of the on-prem setup.
-
Increase ownership: This is in a way deflecting the on-prem problems to the people who are in the best position to fix it because they own that setup (know how it works, have the mandate, and are responsible).
-
Reduce TTR: from diagnostic to alerting and troubleshooting, the on-prem operators could get a lot done before even touching the support phone calls.
-
Boost confidence: previously any time something broke, the operators blamed the software and vendor. Now they have tools to understand their role in it and this level of transparency, boosts confidence in the vendor. That’s because the vendor is demonstrating that they know what they’ve shipped, how it may fail, and what to do in case something goes wrong.
If you found this post insightful, please share it in your circles and on social media to inspire others

Malicious Checkmarx Artifacts Found in Official KICS Docker Repository and Code Extensions
Attackers compromised official Checkmarx KICS Docker images and VS Code extensions, injecting trojanized binaries to exfiltrate cloud, GitHub, and developer credentials.
Decoder
- Checkmarx KICS (Keep Infrastructure as Code Secure): An open-source static analysis tool for security vulnerabilities in Infrastructure as Code (IaC) files.
- Trojanized binaries: Legitimate software files that have been secretly modified to contain malicious code, appearing harmless but designed to perform unauthorized actions.
- Supply chain attack: A cyberattack that targets less secure elements in a supply network, like software dependencies or update mechanisms, to ultimately compromise the main target.
Original article
Full article content is not available for inline reading.
Canva Adds New Editing Tools, Payments, and Previews to Save You from Embarrassing Crops
Canva has upgraded its Image to Video tool for animated human faces and added mobile previews and AI-powered presenter notes, integrating deeply with platforms like HubSpot and Meta Ads.
Original article
Canva has upgraded its Image to Video tool to support animated human faces, while also adding workflow improvements like live mobile previews and AI-powered presenter notes. Publishing integrations with Facebook, Pinterest, and cloud platforms, plus marketing apps for HubSpot and Meta Ads, let users create and publish without ever leaving Canva. These moves signal Canva's ambition to compete beyond design tools, though maintaining its signature simplicity while adding professional-grade features remains a key challenge ahead.
Next-gen Apple Watch could get an upgraded OLED screen with a battery life boost
Future Apple Watches around 2027 could feature new high-mobility oxide (HMO) OLED screens, developed by LG Display, potentially offering significantly longer battery life and reduced manufacturing costs.
Decoder
- LTPO (Low-Temperature Polycrystalline Oxide): A type of display backplane technology used in high-end OLED screens that can dynamically adjust the refresh rate to save power.
- HMO (High-Mobility Oxide): An emerging display technology that could offer improved electron mobility and lower power consumption compared to LTPO, simplifying manufacturing.
Original article
Apple may be exploring a new OLED display technology called high-mobility oxide (HMO) for future Apple Watches. Compared to today's LTPO displays, HMO could reduce power consumption and manufacturing complexity, potentially leading to significantly longer battery life and lower production costs. LG Display is reportedly developing the technology, but it still faces technical challenges in achieving the speed and reliability Apple requires. If development progresses smoothly, HMO could appear in Apple Watches around 2027 or later, with possible future adoption in iPhones, though neither Apple nor LG has confirmed these plans.

Dear Apple: If Your New Icons Need a Manual, They're Not Working
Apple's new Creator Studio app icons are so confusing that the company released a user guide to differentiate between subscription and one-off payment versions, sparking criticism from designers.
Deep dive
- Apple's updated Creator Studio app features a new suite of icons for its two versions: subscription and one-time payment.
- The new icons are so similar that Apple found it necessary to publish a user guide explaining how to tell them apart.
- Following the macOS Tahoe aesthetic, the icons adopt a uniform rounded-square shape, moving away from more expressive, image-led designs.
- Critics argue that this homogenised look and muted color scheme diminish app individuality and make them harder to distinguish at a glance.
- The core criticism is that icons should be immediately recognizable without external explanation, which these new designs fail to achieve.
- This issue echoes recent user frustration with Google's updated app icons, suggesting a broader challenge in modern UI/UX design trends.
Original article
Full article content is not available for inline reading.
Codex new Capabilities
OpenAI unveiled new Codex capabilities and six role-specific plugins designed for various professional workflows, from data analytics to investment banking.
Original article
OpenAI released new Codex capabilities and six role-specific plug-ins for data analytics, creative production, sales, product design, equity investing, and investment banking.
Memory Is Purpose
Sentra CEO Ashwin Gopinath posits that AI memory isn't just stored knowledge, but a dynamic filter that shapes an agent's reality and future behavior based on its purpose.
Decoder
- Ontology: In AI and information science, a formal naming and definition of the types, properties, and interrelationships of the entities that exist in a particular domain of discourse.
- Boulder problem: An illustrative scenario used to demonstrate how the same underlying "artifact" (e.g., a "boulder" object in a system) is perceived and processed differently by various roles or functions (e.g., sales, engineering, legal) because each role extracts different "memory" based on its specific purpose.
Original article
Sentra CEO Ashwin Gopinath argues memory is not a sidecar to intelligence but the layer that decides what reality the reasoning operates on, with knowledge being what was present and memory being the subset of the past that should survive because it changes future behavior. The boulder problem illustrates that the same artifact becomes different memory for sales, product, legal, engineering, and CEO views, so freezing ontology at ingestion traps the system inside a frame that is prematurely right.
Anthropic faces AI spending backlash before IPO
Anthropic filed for an IPO as corporate clients, its primary revenue source, express significant concerns over high AI costs and questionable ROI.
Original article
Anthropic filed for an IPO amid growing corporate scrutiny over high AI costs, which threatens its revenue as companies reevaluate their AI investments. Businesses, Anthropic's key clients, express concerns over spending, with a survey revealing 40% experiencing cost savings below 10%. Despite Anthropic's strong performance, including surpassing OpenAI in business clients, a shift towards cheaper models or open-source alternatives poses a risk.
Building Software Is Learning
Thorsten Ball argues that building software is inherently a learning process, emphasizing the need for rapid feedback loops through prototyping and frequent iteration to align with user needs.
Original article
Building Software Is Learning
A few weeks ago I shared the following as an internal message with the Amp team. I showed it to a friend while talking about feedback loops and he told me to post this publicly. So here we go. Unedited, straight up copy & pasted from our Slack.
You know what’s rare?
person a: “we need this feature”
person b: “yes, let me build it”
...
person b: “done.”
person a: “fantastic, exactly what I wanted.”That’s basically NEVER what happens. At least not when you’re building something new. It might happen when you fix a bug or when you port something that already exists in another app to a new language or framework, ... Or when you’re building after a spec.
But when there’s no spec, and when you’re building something new?
Here’s how that works:
person a: “we need this feature”
person b: “yes, let me build it”
[...]
person b: “done.”
person a: “hmm, actually, that’s not what I meant. what I meant is: [...]”Or this:
person a: “we need this feature”
person b: “yes, let me build it”
[...]
person b: “you know what... There’s 3 ways to do this, actually, and I’m not sure what the best way to do this is?”
person a: “ah, I see, I think given that we want to ship this tomorrow, let’s go with way 1”Or:
person a: “we need this feature”
person b: “yes, let me build it”
[...]
person b: “done.”
person a: “Don’t like it”Now why does that happen, again and again and again?
Because building new software is learning! If you’re building something new and you don’t yet fully know how exactly it’s supposed to work, you will learn what exactly it is that you’re building as you’re doing it. Let me repeat: building new software is learning.
So far, so good, right? But here’s the very important bit, the one bit I want you to take with you into this week: there is no way in hell, absolutely zero chance, that you can build something new and avoid bumping into “that’s not what I meant”, or “now that I’m working on it I’m not actually sure”, or “hmm, now that I use it, I don’t like it”. Because the only way you could avoid that would be to fully specify what you want up front and, well, guess what programming is? It’s fully specifying what you want. You can’t avoid it, because you can’t define it yet, because building software is learning!
Now that was the bad news. Here’s the good ones. You can reduce the time the ... from the examples above takes — the time between the confident “yes, let me build this” and the humbled “oh, I see”.
And that, in turns out, is the most important thing you can do when you’re building something new: reducing the time it takes you to go from “let me try something” to getting your ass whooped by reality.
If someone says “we need this feature”, don’t go “yes, let me build it” and hack on something for 4 weeks only for the other person to ultimately go “that’s not what I meant.” No. Instead, embrace that we need to learn, that we need to try and play around with this idea as fast as possible, in a way that lets us learn. To embrace that idea means that you try to figure out “what is it they mean” as fast as possible, with the minimal effort required, so you can LEARN what it is you’re building.
Instead of going away for 4 weeks and hacking on something, you instead can do stuff like this:
-
... build a prototype, in 1hr, and show it to them, and they go “no, that’s not what I meant, you should change this part here”
-
... write down a spec of how you’d approach it, in 30min, and show it to them, and they go “no that’s not what I meant”
-
... cut up the thing in multiple things and ship one every day, so that every day what you built hits reality and you get to learn, because on day 2 someone says “know what, we should change...”
-
... reduce the scope, figure out what the things are that we’re already sure about and skip those, and instead focus on the bits that we don’t know yet — that’s where we need to learn. don’t add 5 ways to login, if all we need to learn right now is 1.
-
... fake a demo video, show that around, get input on that - Quinn’s done it many times
-
... write the news post that explains the idea — why waste effort building something for a week if the idea can be captured in 3 paragraphs?
-
... write the example code that would go into the README, show that around, does that look like a good API? People don’t need an SDK built if they dislike the API in the readme.
-
...
There’s more options that I didn’t list here. And you don’t have to pick only one. In fact, for something big, you should probably do a few of these things. Or you vary them, or combine them, or...
What exactly you do doesn’t matter as much as constantly asking: how can I get feedback on what I’m trying to build as soon as possible? And “feedback” here is used in the widest sense possible. Feedback comes in all shapes and sizes: feedback from the CI system on main, feedback from colleagues, feedback from users, feedback from you once you actually use it.
And if you follow that question — how can I get feedback as soon as possible, so I can learn? — you’ll also find out how to chop things up and how to ship them:
-
you won’t get good feedback if you ship an “MVP” of an idea that’s so obviously buggy that all you’ll get is bug reports for 3 days, not actual feedback on how useful it is
-
you won’t get good feedback if the people supposed to give you feedback have to jump through 8 hurdles to test it
-
you won’t get good feedback if you keep your changes on a branch for 3 weeks, because by the time you merge your 27 commits and CI blows up you have 27 possible causes, vs. 1 if you had merged them one by one
-
want feedback on the design of your skateboard? sure, show them the deck, no need for wheels. want feedback on how your skateboard feels? you can’t ship it to testers without wheels on it.
-
...
So. Here’s what I want you to think about going into this week: how can I get feedback on what I’m building on as fast as possible? when is the last time I got valuable feedback on what I’m building? in what frequency do I get feedback on what I’m building? why is that frequency so low?
Because we’re building something new, in a time when software is changing (background vocals: everything is changing), and no one has a clue what the fuck is going on - so the most important thing is to embrace that and as soon as possible, as often as possible, ship things on which we can get feedback on, in a way that gives us valuable feedback — by CI, by production, by our teammates, by select users, by select customers, by all of our users.
Yes, italics and bold. Because building software is learning and we want to learn as much as possible.
How One Tech Company Created 13 New Types of Jobs Because of AI
Box, a data storage company, is creating over 100 new AI-focused job roles like "AI architect" and "AI solutions manager" as it pivots towards AI products.
Original article
Box, a company that makes software for storing and managing data, has started selling AI products aimed at automating tasks like reviewing and approving contracts. The company's switch to focusing on AI has resulted in the need for new positions to be filled. It recently hired a senior director of AI, an AI architect, an AI solutions manager, and an AI platform leader. Box expects to add more than 100 new employees by early next year. It is unclear whether the growth of such roles will make up for AI-related job cuts.
AI models are having their iPhone moment. What's Next?
AI is rapidly moving from a groundbreaking "rupture" to foundational infrastructure, mirroring the iPhone's decade-long shift but at a much faster pace.
Original article
The iPhone took roughly a decade to shift from rupture to infrastructure. AI is moving much faster. The infrastructure framing is already present in enterprise software, developer tools, and hardware roadmaps. The edge will be the applications that make their underlying capabilities feel indispensable and invisible at the same time.

Meta Will Reportedly Let Employees Take 30-Minute Breaks From Its Tracking Program
Meta is offering employees 30-minute breaks from its "Model Capability Initiative" program, which tracks mouse clicks and keystrokes to train AI models.
Original article
Meta will reportedly let employees take 30-minute breaks from its tracking program
Workers can pause the all-seeing eye when they need to "check something personal."
Meta is making some minor concessions in its extremely dystopian plan to track employees' mouse clicks and keystrokes in the name of AI training. The company has reportedly made some changes to the controversial project known internally as the Model Capability Initiative (MCI), according to a report in The Information.
Meta now plans to allow employees to "pause" the tracking for up to 30 minutes in the event they need to "check something personal," the company told workers in a memo. A subset of employees will also be able to request to opt out of the program altogether, though this will be limited to remote workers with bandwidth concerns, people who deal with "sensitive" material and those who often work in spaces where they can't easily keep laptops connected to a power source.
In other words, it sounds like the vast majority of Meta employees will still be required to allow their (nearly) every move to be tracked and recorded in the name of improving Meta's AI models. However, the company did say that it had improved the software's battery usage to address some employee complaints, Reuters reports. The company has faced protests from employees over MCI, which was announced last month just before the company laid off 8,000 workers and reshuffled thousands of others into AI-focused roles.
CEO Mark Zuckerberg recently defended the program to employees, telling them that "watching really smart people do things" is the best way for AI models to improve quickly. "The average intelligence of the people who are at this company is significantly higher than the average set of people that you can get to do tasks," he said in leaked audio from a company-wide meeting last month.
"None of the data is being used for, like, looking at what people are doing, or surveillance, or performance track[ing], or anything like that. It's purely just, like, we are using this to feed a very large amount of content into the AI model, so that way it can learn how smart people use computers to accomplish tasks. I think that this is going to be a very big advantage if we can do it." He also added that if it works, "we'll probably do more things like it" in the future.
Prompt → Secure Infrastructure: The Claude Code DevSecOps Shift on AWS
Claude Code's Security and Agent Teams offer a continuous, multi-agent security layer for Terraform on AWS, aiming to automate drift detection and compliance.
Decoder
- IaC (Infrastructure as Code): Managing and provisioning computer data centers through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools. Terraform is a popular IaC tool.
- IAM (Identity and Access Management): An AWS service that helps you securely control access to AWS resources.
Original article
Claude Code Security and Agent Teams are positioned as a continuous AWS-aware security layer for Terraform environments, using multi-agent parallel audits, IaC graph reasoning, and AWS MCP integration to detect IAM, network, and secrets drift before production. The workflow emphasizes PR-based auto-fixes, cross-region audits, and scheduled compliance checks to replace slow manual security reviews with ongoing automated enforcement.

The On-Call Problem AI Can Actually Solve
Heinrich Hartmann argues that AI's immediate value for on-call engineers lies in providing critical system context and knowledge management, not autonomous incident remediation.
Decoder
- SRE (Site Reliability Engineering): A discipline that applies software engineering principles to infrastructure and operations problems, aiming to create highly reliable and scalable software systems.
Original article
The 3 a.m. Problem Isn't Technical.
Heinrich Hartmann thinks about on-call readiness the way most people think about sleep: you don't notice it until it's gone.
Ahead of an on-call shift, engineers worry about things like: "What are all the services I'm supposed to be on call for? What are the typical failures, the drills I have to have down? What are the major risks? What's the trickiest thing I could run into?"
"This will affect my sleep, actually," he says. "If I don't know those things, I could be setting myself up for a miserable late-night session with a system I barely understand. And that would be extremely bad."
The stakes are real. "If there are millions of euros going down the drain while people wait on you to resolve an issue," he says. "You don't sleep well unless you have your drills down."
And remote work made it worse. "When everyone's remote, you're no longer just picking things up from the people around you," Heinrich says. "You can be at a company for three years without having touched the service that just went down. You haven’t committed a single line, and have no idea how it works."
Heinrich calls it "a knowledge management issue": Experienced engineers hold enough context to be effective at debugging. Others are hoping it’s going to be quiet during their on-call, or that the right playbook will be available.Most conversations about AI in SRE start with the end state: self-managing systems, autonomous remediation, the end of on-call as we know it. Heinrich starts somewhere else: the engineer sitting alone with a pager, wondering whether they'll know enough to respond when it goes off.
Print the Code. Grab a Highlighter. Go to a Coffee Shop.
Heinrich remembers how he used to get familiar with a new codebase.
"Sometimes I would just print out the whole source code, like a big book," he says, "and then I would go to a coffee shop with a highlighter, and start figuring out what's in there."
Today, the printer sees a lot less action, and he usually just points an AI tool at a codebase and asks: "What's in there? Give me a rundown of the core components, which are the most important classes, how are they wired together?"
"I wasn't able to ask these questions before," he says. Code exploration used to mean grep, find, and a lot of patience. "Now it's conversational, and onboarding is faster."
On-call readiness is a codebase comprehension problem as much as an operational one. An engineer who understands how services are wired together – what depends on what, where the fragile points are, what a deployment actually changed – resolves incidents faster. The 3 a.m. page becomes less terrifying when you've spent an afternoon walking through the codebase with AI assistance, and can quickly merge a PR to fix a nit.
But codebase comprehension is only half the picture. The other half is operational knowledge: what failed before, how it was fixed, which dashboards matter for which alerts? That knowledge often lives in Slack threads, post-mortems, and the heads of senior engineers who've been at the company long enough to have seen every failure mode at least once.
Heinrich sees both halves as the same problem. "Maybe the task gets easier if you have a copilot," he says. "But how do you absorb all that knowledge?" The question isn't whether AI can diagnose a production issue autonomously. It's whether AI can help an engineer absorb enough context to be effective before the page fires.
Curate Knowledge. Earn Sleep.
Heinrich's vision for AI in SRE starts with documents, not dashboards or anomaly detection.
"I want a copilot that indexes company knowledge and gives me fast access," he says. "Source code would be good, but definitely recent deployments and the playbooks." He also wants to "auto-generate playbooks from past experiences, pair up with senior engineers, and co-create these documents."
The goal isn't to replace engineers with automation. It's to make the knowledge that senior engineers carry available to everyone, surfaced in context, at the moment it matters. "We want the AI to know what's relevant and surface it to engineers so they have the right context," he says. Engineers don't need to memorize every playbook. They need the right one to appear when the pager fires at 3 a.m.”
Heinrich sees this as the most impactful work in the broader AI space right now as: "Make sure you get the right model with the right context to the right people in the right situation." For operations this means the on-call engineer has a powerful AI model by his side, which knows all the relevant playbooks, the last incidents affecting that service, and the deployment diff from that afternoon.
It's also the work many teams in the space are skipping. "I haven't seen many people jump on the knowledge management side,” he says. "They all go to 'let's solve real production issues with telemetry data,' which is harder."
That's the on-call problem AI can solve today. Not a system that tries to fix the incident autonomously — a system that makes sure the on-call engineer responding knows what this service does, what broke last time, and what steps actually resolved it. It closes the distance between the senior engineer who's seen every failure mode and the mid-career engineer who's been at the company for five years but never touched three of the services on the rotation. Curate the knowledge. Earn the sleep.
Heinrich Hartmann is a Senior Principal SRE, host of the CASE Podcast, Chair of SREcon EMEA 2025, and organizer of Signals Berlin 2026, a single-track conference on reliability in the age of AI (Berlin, September 2026). Read more at his personal blog.

Wix Cuts 1,000 Employees in Latest AI-fueled Layoff
Website builder Wix laid off 1,000 employees, or 20% of its workforce, citing both the strong Israeli shekel and the need to adapt to rapid AI advancements.
Original article
Full article content is not available for inline reading.
How AI Quietly Changed Modern UX Patterns
AI has subtly but significantly transformed modern user experience (UX) patterns by embedding intelligent features that redefine how users interact with digital products.
Original article
Full article content is not available for inline reading.
Product discovery's quietest, most consequential decision
Successful product discovery hinges on teams critically evaluating whether customer feedback signals truly warrant investigation, rather than immediately committing to development, despite AI's pattern recognition abilities.
Original article
Effective product discovery starts by evaluating whether a customer signal is worth investigating at all. Before committing to research or development, teams should assess whether a signal is genuinely significant, reflects an underlying customer need rather than a feature request, and aligns with strategic priorities. Many teams skip this step, leading them to solve the wrong problems. While AI can help identify patterns in customer feedback, determining which signals point to meaningful opportunities still requires human judgment.
Create Stunning Gradients with 22+ Modes (Website)
HueGrid launches March 4 with early bird pricing, offering 22+ advanced gradient modes including volumetric clouds, liquid chrome, and black hole effects.
Original article
Full article content is not available for inline reading.
Tom Chung and the Construction of a Personal Design Process
Industrial designer Tom Chung develops his unique process through self-initiated projects, prioritizing material honesty and production constraints over trends.
Original article
Tom Chung builds his design theory through self-initiated projects that emphasize material honesty and production constraints rather than trends. His transition from working at Umbra to independent practice allowed him to develop a clear, concept-driven approach that prioritizes function and clarity over decoration. Working in Toronto's limited design ecosystem, he turned local materials and production techniques into resources that shaped his distinctive design language.
Velvele gives longevity brand Omnui a logo system with five values
Velvele developed a flexible, dot-based logo system for longevity brand Omnui, blending indigenous symbolism and digital graphics with a unique "Subtle Yellow" and "Offline Black" palette.
Original article
Velvele created Omnui's identity around a flexible dot-based visual system inspired by both indigenous symbolism and digital graphics, allowing icons to represent concepts such as assessment, movement, recovery, nourishment, and connection while feeling simultaneously organic, human, and technological. The brand name and visual language evolved together, reinforcing themes of longevity, science, community, and self-discovery. To stand apart from typical wellness branding, Omnui uses a distinctive palette of “Subtle Yellow” and “Offline Black,” balancing warmth with introspection. The identity is anchored by the geometric sans-serif typeface ABC Favorit, which provides clarity and precision against the more symbolic and expressive icon system.
WWDC wallpaper released as free download alongside Apple Music playlist and more
Apple has released a "Glow all out" wallpaper and an Apple Music playlist to build hype for WWDC 2026, where iOS 27 and other updates are expected on June 8.
Original article
Ahead of WWDC 2026 on June 8, Apple is building excitement for the unveiling of iOS 27 and other updates with new promotional videos, a themed “Glow all out” wallpaper, and an official Apple Music playlist.
Trump Signs AI Executive Order to Increase Government Oversight
President Trump signed an executive order cutting the voluntary review period for powerful AI models from 90 days to 30 days.
Original article
President Donald Trump has signed an executive order that reduces the voluntary review period for powerful models to 30 days, down from 90 days.
Trust Factory
Fixing code is possible, but repairing trust, once broken, is an almost impossible task.
Original article
You can fix code, but you can't fix trust - once it's gone, it's hard-to-impossible to get it back.
Letters Made of Letters (Website)
"Letters Made of Letters" is a new website that allows users to generate text shapes from other text, offering font and color customization.
Original article
Letters shaped by text. Pick a font, choose your colors, and watch type come alive.
Greyscaler (Website)
Greyscaler provides a simple web tool to generate 11 shades of grayscale palettes for designers.
Original article
Greyscaler is a tool that generates grayscale color palettes with varying intensity levels. It provides 11 different shades ranging from very light to very dark.

Dee Juusan Draws Emotionally Rich Manga Through Black-and-white Storytelling
Award-winning Jordanian manga artist Dee Juusan, also known as Diana Alabbadi, creates emotionally rich, high-contrast black-and-white stories, notably her coming-of-age manga "Grey is...".
Decoder
- Manga: A style of Japanese comic books and graphic novels, typically characterized by distinctive art styles and themes.
Original article
Dee Juusan is an award-winning manga artist based in Jordan who creates emotionally rich stories through high-contrast black-and-white imagery.