Devoured - May 01, 2026
A critical Linux kernel vulnerability (Copy Fail) lets unprivileged users gain root on every major distribution since 2017 with a 732-byte script, so patch immediately. On the AI tooling front, Anthropic launched Claude Security for automated code vulnerability scanning, Cursor sold to xAI for $60B after model providers undercut its margins, and Cloudflare partnered with Stripe to let AI agents autonomously provision infrastructure and deploy applications.
Copy Fail: 732 Bytes to Root on Every Major Linux Distribution
A logic bug in Linux kernel's crypto subsystem lets unprivileged users gain root with a 732-byte Python script by corrupting the page cache of setuid binaries.
Deep dive
- The vulnerability stems from a 2017 optimization in algif_aead.c that performs AEAD operations in-place, combined with authencesn's practice of using the destination buffer as scratch space for IPsec Extended Sequence Number byte rearrangement
- When a user splices a file into a pipe and then into an AF_ALG socket, the socket's scatterlist holds direct references to the kernel's page cache pages for that file, not copies
- In the in-place design, the output scatterlist is constructed by copying AAD and ciphertext to a user buffer, then chaining the authentication tag pages by reference using sg_chain(), with both req->src and req->dst pointing to the same combined scatterlist
- authencesn writes 4 bytes at offset assoclen + cryptlen to rearrange ESN bytes for HMAC computation, which crosses from the legitimate output buffer into the chained page cache pages, corrupting the in-memory file
- The corrupted page is never marked dirty by the kernel's writeback machinery, so the file on disk remains unchanged and standard integrity checks comparing on-disk checksums miss the modification entirely
- Attackers control which file to target (any readable file), which offset (by choosing splice parameters and assoclen), and which 4-byte value to write (bytes 4-7 of the AAD)
- The exploit targets /usr/bin/su by injecting shellcode chunks into its .text section in the page cache, then executing it to gain root since su is setuid-root
- The same 732-byte Python script works on Ubuntu 24.04, Amazon Linux 2023, RHEL 10.1, and SUSE 16 without any per-distribution modifications or version checks
- The vulnerability has existed silently for nearly a decade, since three seemingly reasonable changes intersected: authencesn's 2011 scratch space usage, AF_ALG AEAD support in 2015, and the 2017 in-place optimization
- The fix reverts algif_aead.c to out-of-place operation by separating req->src (TX SGL) from req->dst (RX SGL), removing the sg_chain mechanism that linked page cache pages into the writable destination
- The vulnerability was discovered using AI-assisted research with Xint Code, which scanned the entire crypto subsystem based on the insight that splice() can deliver page cache references to crypto scatterlists
- The scan was guided by a simple operator prompt noting that splice() can deliver page-cache references of read-only files to crypto TX scatterlists, and completed in about an hour
- The researchers note the scan identified other high severity vulnerabilities including another privilege escalation bug still under responsible disclosure
- Because page cache is shared across all processes including container boundaries, Copy Fail enables container escape and Kubernetes node compromise, detailed in a forthcoming Part 2
Decoder
- AF_ALG: A socket type (address family) that exposes the Linux kernel's cryptographic subsystem to userspace programs without requiring privileges
- splice(): A system call that transfers data between file descriptors and pipes by passing page references rather than copying data, avoiding expensive memory copies
- AEAD: Authenticated Encryption with Associated Data, a cryptographic mode that encrypts data while also authenticating additional unencrypted metadata
- authencesn: An AEAD wrapper in the kernel used by IPsec for Extended Sequence Number support, which rearranges 64-bit sequence numbers for HMAC computation
- page cache: The kernel's in-memory cache of file contents that serves all reads, memory maps, and program execution, shared across the entire system
- scatterlist: A kernel data structure representing discontiguous memory regions, used by the crypto subsystem to describe input and output buffers
- setuid binary: An executable file with the setuid bit set that runs with the privileges of the file owner (often root) rather than the user executing it
- in-place operation: A cryptographic operation where the same memory buffer serves as both input and output, avoiding the need to allocate separate destination memory
Original article
Copy Fail is a logic bug in the Linux kernel's authencesn cryptographic template that lets unprivileged users trigger a deterministic, controlled 4-byte write into the page cache of any readable file on the system. It can be exploited using a single 732-byte Python script to obtain root on essentially all Linux distributions shipped since 2017. Its discovery was AI-assisted. A patch for the bug is available.
.jpg)
Claude Security is now in public beta
Anthropic launches Claude Security in public beta, allowing enterprises to scan codebases for vulnerabilities using the Opus 4.7 model with automated patch generation.
Deep dive
- Claude Security uses Opus 4.7 to analyze code like a security researcher, understanding component interactions and data flows rather than just pattern matching
- The tool includes multi-stage validation to reduce false positives and assigns confidence ratings to each finding
- Hundreds of organizations tested it in preview, with feedback leading to features like scheduled scans, targeted directory scanning, and dismissing findings with documented reasons
- Results can be exported to CSV/Markdown or pushed to tools like Slack and Jira via webhooks
- Users reported going from scan to patch in a single session instead of days of back-and-forth between security and engineering teams
- Integration partners include major security platforms (CrowdStrike, Microsoft Security, Palo Alto Networks, SentinelOne, TrendAI, Wiz) and consulting firms (Accenture, BCG, Deloitte, Infosys, PwC)
- The tool is part of a broader effort alongside Project Glasswing, which uses Claude Mythos Preview for elite-level vulnerability discovery and exploitation
- Anthropic positions this as defensive preparation for a future where AI makes working exploits much easier to discover
- Opus 4.7 includes cyber safeguards that block high-risk security uses, with a Cyber Verification Program for legitimate security work
- Currently available to Enterprise customers, with Team and Max customer access coming soon
Decoder
- Opus 4.7: Anthropic's most powerful generally-available language model, specialized for finding and patching software vulnerabilities
- Project Glasswing: Anthropic's partnership program providing Claude Mythos Preview to select partners for elite-level vulnerability research
- Claude Mythos Preview: A specialized model that matches expert-level performance at finding and exploiting vulnerabilities, more advanced than Opus 4.7
- False positives: Security alerts that incorrectly flag safe code as vulnerable, wasting analyst time
Original article
Claude Security, now in public beta for Claude Enterprise customers, leverages the powerful Opus 4.7 model to identify and patch software vulnerabilities. The model, integrated into tools used by partners like Microsoft Security and Palo Alto Networks, enhances cybersecurity defenses by enabling efficient, ongoing code scanning without requiring custom API integration. Feedback from hundreds of organizations has refined its capabilities.

KV Cache Locality: The Hidden Variable in Your LLM Serving Cost
Your LLM load balancer is probably wasting 20-40% of GPU compute recomputing prefills that already exist in cache on a different GPU in your cluster.
Deep dive
- Round-robin and least-connections load balancing waste GPU compute by routing requests to GPUs without cached KV pairs, forcing redundant prefill computation
- Benchmarks on 8x A100s with CodeLlama 13B show prefix-aware routing improves cache hits from 12.5% to 97.5%, reduces P99 TTFT from 6.8s to 1.0s, and increases throughput 22%
- Cache miss penalty on CodeLlama 13B is 500ms vs 18ms for cache hit, a 28x difference in time-to-first-token
- Wasted prefill costs approximately $1,200-$1,800 monthly per 8-GPU node, or 22% of total GPU spend
- Performance gains scale with model size (13B-70B sweet spot), prefix length (16K tokens show 43.6% improvement vs 29.7% at 8K), and sharing ratio
- Even 50% prefix sharing achieves 91% cache hit rate with prefix-aware routing vs ~11% with round-robin
- Tail latency improvements are dramatic because cache misses under load create queueing delays that compound across requests
- Prefix-aware routing doesn't help models ≤8B (routing overhead ~10ms exceeds savings), short prefixes (<500 tokens), or unique conversations
- Load imbalance is a risk when traffic concentrates on specific prefixes, requiring load-aware fallbacks to prevent GPU hot spots
- Article introduces Ranvier, a prefix-aware load balancer using adaptive radix trees to route based on token locality
Decoder
- KV cache: The key-value pairs computed during prefill that transformers cache in GPU memory to avoid recomputing when generating output tokens
- Prefill: The initial phase where the model processes all input tokens (system prompt, context, history) and computes their key-value pairs; compute-intensive and scales with token count
- Decode: The generation phase where the model produces output tokens one at a time, reusing the cached key-value pairs from prefill; much faster than prefill
- TTFT (Time to First Token): The latency between receiving a request and returning the first generated token, heavily influenced by prefill time and cache hits
- vLLM: A popular open-source LLM serving engine that implements KV caching and other optimizations for transformer inference
- RAG (Retrieval-Augmented Generation): A pattern where LLMs are given retrieved context documents as part of the prompt, often resulting in long shared system prompts across requests
Original article
Every time your load balancer sends a request to the wrong GPU, that GPU recomputes a prefill it already computed somewhere else. The KV cache for that 4,000-token system prompt exists. It's just sitting on a different card. Your load balancer doesn't know. It can't know. It's counting connections, not tokens.
That recomputation takes real time and real money. On a Llama 3.1 70B at half precision, a 4,000-token prefill takes over a second. If eight GPUs each recompute the same system prompt independently because round-robin sent one request to each, you just paid for the same work eight times. Multiply by every request, every hour, every day.
This post is about the cost of that mistake, how to measure it, and what changes when your load balancer understands token locality.
What the KV Cache Actually Saves You
A transformer processes input tokens in two phases. Prefill computes the key-value pairs for every input token: the system prompt, the conversation history, the RAG context. This is the expensive part. It scales with token count and model size, and it's compute-bound on the GPU. Decode generates output tokens one at a time, each one reusing the key-value pairs from prefill. This is the cheap part.
vLLM and other serving engines cache the key-value pairs from prefill in GPU memory. When a new request arrives with the same token prefix, the engine skips prefill entirely and jumps straight to decode. This is the KV cache hit.
On our benchmarks, a cache hit on CodeLlama 13B returns in 18ms at P50. A cache miss takes around 500ms. That's a 28x gap in time-to-first-token, decided entirely by whether the tokens were already on that GPU.
But here's the thing: the KV cache is per-GPU. GPU 0's cache doesn't help GPU 3. If your load balancer sends Request A to GPU 0 and the identical Request B to GPU 3, Request B pays full prefill cost even though the work was already done. The cache exists. It's just on the wrong card.
The Math on Wasted Prefill
Let's make this concrete. You're running a RAG application with a 4,000-token system prompt. You have 8 GPUs serving CodeLlama 13B. You're handling 30 concurrent users with a stress workload (heavy on large and extra-large prefixes). Here's what we measured on 8x A100s:
Round-robin routing:
- Cache hit rate: 12.5%
- P99 TTFT: 6,800ms
- Throughput: 36.3 req/s
With 8 backends and random routing, you'd expect ~12.5% cache hits by chance. One in eight requests happens to land on the GPU that already has its prefix cached. The other 87.5% recompute from scratch.
Prefix-aware routing:
- Cache hit rate: 97.5%
- P99 TTFT: 1,000ms
- Throughput: 44.4 req/s
Same GPUs. Same model. Same workload. The only change is which GPU receives which request.
That throughput difference, 36.3 vs 44.4 requests per second, is a 22.3% improvement. On hardware costing ~$10/hour, that's either 22% more throughput for free or the same throughput on fewer GPUs. Over a month of continuous operation, on a single 8-GPU node, the wasted prefill in round-robin comes to roughly $1,200–$1,800 in GPU-hours (22% of ~$7,300/month at $10/hr) that produce no useful work. Multiply by the number of nodes in your cluster.
Where the Savings Compound
The benefit scales with three variables: model size, prefix length, and prefix sharing ratio.
Model size
Larger models have more expensive prefill, so cache misses cost more.
| Model | XLarge Cache Hit Improvement | Aggregate Throughput Gain |
|---|---|---|
| Llama 3.1 8B | 31.6% | ~0% (inference too fast) |
| CodeLlama 13B | 35.9% | +13.7% to +22.3% |
| Llama 3.1 70B | 43.8% | ~0% (compute-bound) |
The 8B numbers are the warning case. When prefill is already fast (~420ms total inference), the 7-10ms routing overhead eats into the savings. If prefill isn't your bottleneck, prefix-aware routing doesn't help.
The 70B numbers tell a different story. Aggregate throughput doesn't change because the GPUs are already compute-saturated. But individual requests are 44% faster on cache hit (P50: 1,498ms hit vs 2,665ms miss). Your users feel the difference even if your throughput dashboard doesn't.
The sweet spot is 13B-70B models where prefill is expensive enough to matter but the GPUs aren't so saturated that they can't benefit from skipping it.
Prefix length
Longer shared prefixes mean more wasted compute per cache miss.
| Max Prefix Tokens | Cache Miss P50 | Cache Hit P50 | Improvement |
|---|---|---|---|
| 8,192 (default) | 638ms | 448ms | 29.7% |
| 16,384 | 817ms | 461ms | 43.6% |
At 16K tokens, a cache miss wastes nearly 400ms of GPU compute that a hit avoids entirely. As context windows keep growing, this gap widens.
Prefix sharing ratio
This is the percentage of tokens shared across requests. A RAG application where every request includes the same 4,000-token knowledge base has a high sharing ratio. A chat application where every conversation is unique has a low one.
| Sharing Ratio | Round-Robin Hits | Prefix-Aware Hits | Improvement |
|---|---|---|---|
| 50% | ~11% | 91% | +80pp |
| 70% | ~13% | 90% | +77pp |
| 90% | ~12% | 97-98% | +85pp |
Even at 50% sharing, where half the tokens are unique, prefix-aware routing still achieves 91% cache hits. A consistent hash fallback (deterministic routing based on prefix when no learned route exists yet) ensures that requests with the same prefix land on the same GPU even before the system has observed them.
The P99 Story
Cost isn't just GPU-hours. It's also the cost of slow responses.
At 30 concurrent users on CodeLlama 13B over 30 minutes of sustained load, round-robin routing produced a P99 TTFT of 6,800ms. That's 6.8 seconds before the first token appears. For an interactive application like code completion or chat, that's a broken experience. Users don't wait 6.8 seconds.
Prefix-aware routing brought that same P99 down to 1,000ms. Same hardware, same model, same concurrency. An 85.3% improvement on tail latency.
Why does the tail improve so much? Because tail latency in LLM serving is driven by cache misses under load. When the GPU is busy generating tokens for other requests, a new request that requires full prefill gets queued behind them. With round-robin, 87.5% of requests need full prefill, so the queue is always full of expensive work. With prefix-aware routing, 97.5% of requests skip prefill entirely, so the queue drains faster and the few remaining misses get processed sooner.
This is the strongest argument for KV cache locality. Throughput improvements look good on a dashboard. Tail latency is what users actually experience.
What Doesn't Work
Prefix-aware routing isn't free, and it doesn't help everywhere.
Small models (≤8B): Inference is already fast enough that the routing overhead (~10ms for tokenization + tree lookup) approaches the prefill savings. The net effect is roughly zero.
Short prefixes (<500 tokens): The prefill cost for short sequences is small enough that cache misses don't meaningfully hurt. The routing overhead (~3ms minimum) can exceed the savings.
Unique conversations: If every request has a completely different prefix (no shared system prompt, no shared context), there's nothing to cache. The routing tree learns routes that are never reused.
Load imbalance: Strict prefix affinity can create hot spots. If 80% of your traffic shares the same system prompt, prefix-aware routing sends 80% of traffic to one GPU. We handle this with a load-aware fallback that diverts requests when a backend's in-flight count exceeds twice the median. This trades a cache miss for a balanced GPU, reducing P95 by 36% and P99 by 45% compared to strict affinity. The cache hit rate drops about 5 points, which is the right trade.
Measuring Your Own Cache Locality
Before you change anything, measure your current cache hit rate. Most vLLM deployments expose this via Prometheus:
vllm:gpu_prefix_cache_hit_rate(orvllm:gpu_prefix_cache_queries_totaland_hits_totalon older versions; check your/metricsendpoint)- Compare TTFT distributions between requests with shared vs unique prefixes
- Look at your P99/P50 ratio. A ratio above 5x suggests cache thrashing
If your cache hit rate is already above 80%, you're either lucky or your traffic naturally clusters. If it's below 30%, you're leaving performance on the table.
The variables that matter most:
- How many GPUs are you routing across? More GPUs = lower chance of random cache hits. With 8 GPUs, random routing gives ~12.5% hits.
- How long are your shared prefixes? Longer = more wasted compute per miss.
- What's your prefix sharing ratio? Higher = more opportunity for reuse.
- What model size are you serving? Larger = more expensive prefill per miss.
If you have many GPUs, long shared prefixes, high sharing ratios, and large models, you're likely wasting 20-40% of your GPU compute on redundant prefill.
The Takeaway
KV cache locality is not a tuning knob. It's a multiplier on your existing hardware. The same GPUs, serving the same model, handling the same traffic, produce measurably different throughput and latency depending on one decision: which GPU gets which request.
Round-robin doesn't make that decision. Least-connections doesn't make that decision. They balance load without understanding what the load is. When every request carries thousands of tokens that might already be cached somewhere in your cluster, "balanced" and "efficient" are not the same thing.
We built Ranvier to make that decision. It routes requests to the GPU that already has their token prefix cached, using an adaptive radix tree that learns routes in real time. The first post in this series covered why your load balancer is wasting your GPUs. This post covered what that waste costs. The next one will cover how we tokenize 50,000 requests per second without blocking the event loop.
GLM-5V-Turbo
GLM-5V-Turbo is a foundation model that treats multimodal perception as a core part of reasoning rather than an add-on, designed specifically for AI agents that need to work across images, videos, documents, and user interfaces.
Deep dive
- GLM-5V-Turbo rearchitects multimodal models by making perception a core component of reasoning rather than an interface layer, addressing a fundamental limitation in how current models handle heterogeneous inputs
- The model handles diverse input types including images, videos, webpages, documents, and GUIs as native contexts for reasoning and action, not just as preprocessed embeddings
- Development focused on five key areas: model architecture design, multimodal training procedures, reinforcement learning integration, expanded toolchain support, and agent framework integration
- Achieves strong performance on multimodal coding tasks where the model must reason about code in visual contexts, visual tool use where it manipulates tools based on visual feedback, and framework-based agentic workflows
- Maintains competitive performance on text-only coding benchmarks, indicating the multimodal integration doesn't degrade core language capabilities
- The team emphasizes three development insights: multimodal perception as central rather than peripheral, hierarchical optimization across different capability layers, and reliable end-to-end verification for agent behaviors
- Built for real-world deployment where agents must perceive and act in environments that naturally mix text, visual, and interactive elements
- Represents a shift from "language model with vision" to "natively multimodal agent foundation" as the core design philosophy
- The 77-author team from the GLM-V project submitted this work in April 2026, suggesting significant institutional investment in multimodal agent architectures
Decoder
- Multimodal perception: The ability to process and understand multiple types of input simultaneously (text, images, video, UI elements) rather than converting everything to text first
- Agentic capability: The capacity for an AI system to autonomously perceive, plan, and take actions in an environment rather than just responding to prompts
- Heterogeneous contexts: Mixed input types that don't share the same format or structure (combining images, code, documents, etc.)
- Hierarchical optimization: Training or improving a model at multiple levels of abstraction simultaneously rather than optimizing a single objective
- Foundation model: A large-scale pre-trained model designed to be adapted for many downstream tasks rather than built for one specific purpose
Original article
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
Abstract
We present GLM-5V-Turbo, a step toward native foundation models for multimodal agents. As foundation models are increasingly deployed in real environments, agentic capability depends not only on language reasoning, but also on the ability to perceive, interpret, and act over heterogeneous contexts such as images, videos, webpages, documents, GUIs. GLM-5V-Turbo is built around this objective: multimodal perception is integrated as a core component of reasoning, planning, tool use, and execution, rather than as an auxiliary interface to a language model. This report summarizes the main improvements behind GLM-5V-Turbo across model design, multimodal training, reinforcement learning, toolchain expansion, and integration with agent frameworks. These developments lead to strong performance in multimodal coding, visual tool use, and framework-based agentic tasks, while preserving competitive text-only coding capability. More importantly, our development process offers practical insights for building multimodal agents, highlighting the central role of multimodal perception, hierarchical optimization, and reliable end-to-end verification.

Qwen-Scope: Decoding Intelligence, Unleashing Potential
Qwen releases an open-source interpretability toolkit that uses sparse autoencoders to decode what's happening inside their LLMs and enable practical control over model behavior without prompt engineering.
Deep dive
- Sparse Autoencoders (SAEs) decompose the model's dense hidden layer activations into thousands of sparse, interpretable features that correspond to recognizable concepts or patterns
- Release covers both dense models (1.7B to 27B parameters) and MoE models (30B to 35B with 3B active), with SAE widths from 32K to 128K features and expansion factors of 16-64x
- Controllable inference works by directly activating or suppressing specific features to modify outputs (language, style, entities) without needing to craft natural language prompts
- Data classification requires only small seed datasets to identify relevant features, then uses activation patterns to classify new samples with high accuracy and no additional training
- Data synthesis identifies "inactive" features that rarely activate in existing datasets, then generates targeted examples to cover long-tail cases, improving training efficiency 15x compared to traditional methods
- Training optimization uses feature analysis to detect issues like unwanted code-switching (mixing languages unexpectedly) or infinite repetition, then applies targeted loss functions or amplifies problematic features during RL sampling
- Evaluation analysis reveals that many popular benchmark datasets activate overlapping feature sets, indicating redundant evaluation effort that could be streamlined
- The approach transforms interpretability from a post-hoc analysis tool into an active development engine integrated across the model lifecycle
- SAEs were trained on 500M tokens sampled from the original pretraining data to ensure broad coverage and semantic coherence
- Different L0 values (50 vs 100) control sparsity—how many features activate on average per forward pass
Decoder
- SAE (Sparse Autoencoder): A neural network that compresses then reconstructs activations while enforcing sparsity, forcing each feature to represent distinct concepts rather than entangled combinations
- L0: The target number of features that activate (are non-zero) on average for each input token—lower means sparser, more disentangled representations
- Expansion factor: How many times wider the SAE is compared to the model's hidden dimension (e.g., 16x means a 3K hidden layer becomes 48K features)
- MoE (Mixture of Experts): Model architecture where only a subset of parameters activate per token (e.g., 3B active out of 30B total)
Original article
Qwen-Scope is an interpretability toolkit trained on the Qwen3 and Qwen3.5 series models. The toolkit sheds light on the internal mechanisms underlying Qwen's behavior and holds potential for model optimization. It can be used for controllable inference, data classification and synthesis, model training and optimization, and evaluation sample distribution analysis.
SMG: The Case for Disaggregating CPU from GPU in LLM Serving
Shepherd Model Gateway (SMG) is a Rust-based LLM serving layer that eliminates Python's Global Interpreter Lock bottleneck by moving all CPU workloads off the GPU inference path, achieving up to 3.5x throughput improvements in production.
Deep dive
- SMG was created to solve a production problem at scale: Python's GIL creates a single-threaded ceiling on tokenization and detokenization that becomes the bottleneck when GPUs are fast enough, causing hundreds of thousands of dollars in GPU hardware to sit idle
- The core architectural bet is disaggregation: GPUs should only do tensor math, while everything else (tokenization, tool orchestration, multimodal preprocessing, reasoning parsing, chat history) belongs in a dedicated Rust serving layer with zero GIL contention
- The team rebuilt the entire serving pipeline around a native Rust gRPC data plane where the gateway sends preprocessed tokens to engines and receives generated tokens back, with all other processing happening gateway-side
- SMG rewrote major components of Hugging Face's Python image processors from scratch in Rust to enable vision preprocessing with zero Python overhead, supporting eight vision model families (Llama-4 Vision, Qwen-VL, etc.)—claimed as an industry first
- The gateway implements a two-level tokenizer cache (L0 exact-match for repeated prompts, L1 prefix-aware at special-token boundaries) and includes fifteen model-specific parsers for extracting reasoning blocks and function calls from streaming tokens
- MCP tool orchestration runs entirely in the gateway with a Universal Built-in Tools feature that turns any MCP server into native capabilities like FileSearch and WebSearch, letting you deploy Llama or Qwen with GPT-4-style tools
- WASM middleware provides sandboxed extensibility for custom authentication, PII redaction, cost tracking, and compliance logging without forking the codebase—another claimed industry first
- Benchmarks on H100s using NVIDIA GenAI-Perf across 8 models, 2 runtimes, and 1,082 comparison points show gRPC delivers ~8% more throughput at high concurrency (256), growing to 12.2% with long contexts (7,800 tokens)
- The most dramatic result: Llama-3.3-70B-FP8 with 7,800-token inputs achieved 3.5x higher output throughput (1,150 tok/s vs 327 tok/s) because HTTP/JSON serialization became the dominant bottleneck while gRPC uses compact binary encoding
- The project includes eight intelligent routing policies including cache-aware routing rewritten from the ground up (10-12x faster, 99% memory reduction) that uses event-driven KV cache state streaming to reduce TTFT p99 by 28% in production
- SMG supports five native agentic APIs (OpenAI Chat/Responses, Anthropic Messages, Gemini Interactions, Realtime WebSocket) as first-class implementations, not translation layers, and is the only open-source gateway supporting OpenAI's Responses API
- Production adoption includes Google Cloud Platform, Oracle Cloud Infrastructure, Alibaba Cloud, and TogetherAI, with the gRPC protocol adopted upstream in vLLM (PR #36169) and NVIDIA TensorRT-LLM (five merged PRs)
- The architecture is designed to compose with other infrastructure layers like NVIDIA Dynamo and llm-d rather than replace them, operating at the serving/protocol boundary while those projects handle engine optimization and cluster orchestration
- The project shipped thirteen releases in six months and is fully modularized into standalone crates (smg-auth, smg-mesh, smg-mcp, smg-wasm, llm-tokenizer, llm-multimodal) with cross-platform support (Linux, Windows, macOS, x86, ARM) from a single Python wheel
Decoder
- GIL (Global Interpreter Lock): Python's mechanism that allows only one thread to execute Python bytecode at a time, creating a single-threaded bottleneck for CPU-bound operations even on multi-core systems
- gRPC: A high-performance RPC framework using HTTP/2 and Protocol Buffers for compact binary serialization, contrasting with text-based HTTP/JSON
- Prefill-decode disaggregation: An architecture that separates the initial prompt processing phase (prefill) from the token generation phase (decode) across different GPU pools for optimization
- MCP (Model Context Protocol): A protocol for tool orchestration in LLM systems, allowing models to invoke external tools and services
- WASM (WebAssembly): A binary instruction format that enables sandboxed execution of code, used here for safe extensibility plugins
- TTFT (Time To First Token): The latency from receiving a request to generating the first output token, a key performance metric for interactive LLM applications
- SWIM protocol: Scalable Weakly-consistent Infection-style process group Membership protocol, used for distributed cluster membership and failure detection
- CRDT (Conflict-free Replicated Data Type): Data structures that can be replicated across nodes and merged without conflicts, enabling eventually-consistent distributed state
Original article
Shepherd Model Gateway (SMG) is a high-performance model-routing gateway for large-scale LLM deployments. It centralizes worker lifecycle management, balances traffic across HTTP/gRPC/OpenAI-compatible backends, and provides enterprise-ready control over history storage, MCP tooling, and privacy-sensitive workflows. SMG has full OpenAI and Anthropic API compatibility across SGLang, vLLM, TRT-LLM, OpenAI, Gemini, and more. This post discusses the underlying architecture behind the gateway.

Continually improving our agent harness
Cursor explains how they continuously optimize the infrastructure layer between LLMs and code, using A/B tests and custom tuning per model to make their AI coding agent faster and more reliable.
Deep dive
- Cursor has shifted from static context (folder layouts, pre-loaded snippets) to dynamic context that agents fetch on-demand as models have improved at choosing their own context
- They removed earlier guardrails like automatic lint error surfacing and tool call limits as models became more capable at self-correction
- They measure agent quality through "Keep Rate" (what percentage of generated code remains in the codebase over time) and LLM-analyzed user responses to detect satisfaction
- Online A/B tests sometimes kill promising ideas - a more expensive summarization model showed negligible quality improvement for the added cost
- They classify tool call errors into categories like InvalidArguments, UnexpectedEnvironment, and ProviderError, with anomaly detection alerts per-tool and per-model
- An automated weekly process uses an LLM to search logs, surface new issues, and create Linear tickets, part of building a "software factory" for harness maintenance
- Different models get different tool formats - OpenAI models use patch-based file editing while Anthropic models use string replacement, matching their training
- When customizing for new models, they discovered "context anxiety" in one model that would refuse tasks as context filled up, fixed through prompt adjustments
- Mid-conversation model switching is challenging because each model expects different tool shapes and conversation formats, requiring custom instructions to handle handoffs
- Cache hits are lost when switching models mid-conversation since caches are provider-specific, making it slower and more expensive
- They're building toward multi-agent systems where specialized agents handle planning, editing, and debugging separately, with orchestration logic living in the harness
Decoder
- Agent harness: The infrastructure layer between a language model and the codebase it's working on, managing context, tool execution, and error handling
- Context window: The total text (system prompts, conversation history, code snippets) sent to an LLM for each request
- Tool calls: Structured actions an agent can perform like reading files, making edits, or running searches
- Keep Rate: The percentage of AI-generated code that remains unchanged in a codebase after a set time period
- Context rot: Degradation in model performance when accumulated errors and failed attempts fill up the context window
- CursorBench: Cursor's internal evaluation suite for measuring agent performance on standardized tasks
Original article
We approach building the Cursor agent harness harness the way we'd approach any ambitious software product. Much of the work is vision-driven, where we start with an opinion about what the ideal agent experience should look like.
From there, we form hypotheses about how to get closer to that vision, run experiments to test them, and iterate using quantitative and qualitative signals from evals and real usage. That process depends on having the right online and offline instrumentation, so we can tell when a change actually makes the harness better.
When we get early access to new models, all of these approaches converge. We spend weeks customizing our harness to a model's strengths and quirks until the same model inside our specially tuned harness is noticeably faster, smarter, and more efficient.
Occasionally we discover step-change improvements. More often, though, improving the harness is a matter of obsessively stacking small optimizations that together make agents better at building software.
Evolving the context window
At the heart of interacting with large language models is the context window. When asking the agent to build something, the context window starts with the system prompt and tool descriptions, followed by the current state of the conversation, and finally the user's request.
The way we populate and manage that window has evolved significantly over the history of Cursor.
When we first developed our coding agent in late 2024, models were much worse at choosing their own context and we invested lots of context engineering work into creating guardrails—for example, surfacing lint and type errors to the agent after every edit, rewriting its file reads when it requested too few lines, and even limiting the maximum number of tools it could call in one turn.
We also provided substantial amounts of static context that was always available to the agent at the start of each session. At various points, that included the folder layout of the codebase, code snippets that semantically matched the query, and compressed versions of files that the user manually attached.
That is mostly long gone.
We still include some useful static context (e.g., operating system, git status, current and recently viewed files). But we've adapted to increasing model capability by knocking down guardrails and providing more dynamic context, which can be fetched by the agent while it works. In an earlier post, we did a deep dive into some of our techniques behind dynamic context, many of which have since been adopted by other coding agents. Much of our work now focuses on providing more ways for the agent to dynamically pull context and interact with the world.
Two ways of assessing harness changes
The harness and the model together determine how good the agent is, but "good" is hard to pin down. To locate it, we've built several layers of measurement.
We maintain public benchmarks alongside our own eval suite, CursorBench, which gives us a fast, standardized read on quality and lets us compare across time. But even the best benchmarks only approximate real usage, meaning we'd miss important signals if we relied on them entirely.
So we also run online experiments where we deploy two or more harness variants side by side and A/B test them on real usage. We measure agent quality in these tests through a variety of metrics. Some are straightforward like latency, token efficiency, tool call count, and cache hit rate. Those are directionally useful but still don't get at fuzzier and more important questions of whether the agent actually did a good job. We measure those in two ways.
The first is the "Keep Rate" of agent-generated code. For a given set of code changes that the agent proposed, we track what fraction of those remain in the user's codebase after fixed intervals of time. This allows us to understand when users have to manually adjust the agent's output, or need to iterate and have the agent fix things, indicating the agent's initial response was of lower quality.
Second, we use a language model to read the user's responses to the agent's initial output in order to capture semantically whether the user was satisfied or not. A user moving on to the next feature is a strong signal the agent did its job, while a user pasting a stack trace is a reliable signal that it didn't.
Sometimes these online tests tell us to shelve an idea that seems promising. In one experiment, we tried a more expensive model for context summarization and observed it made a negligible difference in agent quality that wasn't worth the higher cost.
Tracking and repairing degradations
As we add more models and capabilities, the harness gets more complex with more potential states, just like any piece of software. With this comes more surface area for bugs to crop up, many of which we can only detect at scale.
The agent's tools are one of the broadest surfaces for bugs, and tool call errors can be extremely harmful to a session in Cursor. While the agent can often self-correct, errors remain in context, wasting tokens and causing "context rot," where accumulated mistakes degrade the quality of the model's subsequent decisions.
Sometimes, the agent can be blocked or go off the rails completely after a failed tool call. Though metrics like tool call volume and error rate don't directly measure whether the agent did a good job, they act as indicators that can point to a broader issue.
Any unknown error represents a bug in the harness, and we treat it accordingly. But many errors are "expected," for example the model occasionally proposing an incorrect edit or trying to read a file that doesn't exist. We classify these expected errors by cause. InvalidArguments and UnexpectedEnvironment capture model mistakes and contradictions in the context window, while ProviderError captures vendor outages from tools like GenerateImage or WebSearch.
We have several other classifications like UserAborted and Timeout which altogether encompass most expected errors.
We define alerts based on these metrics to catch significant regressions that make it into production. Since unknown errors are always bugs, we alert whenever the unknown error rate for any tool exceeds a fixed threshold. But it can be tricky to tell whether expected errors represent a bug in the harness or expected behavior.
For example, a grep search timeout might be because of a performance issue with the tool, or the codebase might just be huge and the model formed an inefficient query. To deal with this, we have anomaly detection alerts which fire when expected errors significantly exceed the baseline. We compute baselines per-tool and per-model, because different models may mess up tool calls at different rates.
We also run a weekly Automation equipped with a skill that teaches the model how to search through our logs, surface issues that are new or recently spiked, and create or update tickets in a backlog with an investigation. We lean heavily on Cloud Agents to kick off fixes for many issues at once, and can even trigger them directly from Linear.
This process is part of the way we're instantiating an automated "software factory" for our agent harness. Over the course of a focused sprint earlier this year, we drove unexpected tool call errors down by an order of magnitude.
Customizing the harness for different models
All of our harness abstractions are model agnostic and can be heavily customized for every model we support. For instance, OpenAI's models are trained to edit files using a patch-based format, while Anthropic's models are trained on string replacement. Either model could use either tool, but giving it the unfamiliar one costs extra reasoning tokens and produces more mistakes. So in our harness, we provision each model with the tool format it had during training.
This customization goes very deep, and includes custom prompting for different providers and even for different model versions. OpenAI's models tend to be more literal and precise in their instruction following, whereas Claude is a bit more intuitive and more tolerant to imprecise instructions.
When we get early access to a new model ahead of launch, we start from the closest existing model's harness and begin iterating. We run offline evals to find where the model gets confused, have people on our team use it and surface problems, and tweak the harness in response. We iterate like this until we have a model-harness combination we feel good about shipping.
Much of this tuning process is about customizing the harness to a new model's strengths, but sometimes we encounter genuine model quirks that we can mitigate with the harness. For example, we observed one model develop what we came to call context anxiety: As its context window filled up, it would start refusing work, hedging that the task seemed too big. We were able to reduce the behavior through prompt adjustments.
Facilitating mid-chat model switching
It's especially tricky to design the harness to support users switching models mid conversation, because different models have different behaviors, prompts, and tool shapes.
When a user switches models, Cursor automatically switches to the appropriate harness, with that model's customized set of prompts and tools. However, the model still has to apply those tools to a conversation history that was produced by a different model and is out of distribution from what it was trained on.
To address this, we add custom instructions that tell the model when it's taking over mid-chat from another model. These instructions also steer it away from calling tools that appear in the conversation history but aren't part of its own tool set.
A second challenge is that caches are provider- and model-specific, so switching means a cache miss and a slower, more expensive first turn. We have experimented with mitigating this by summarizing the conversation at switch time, which provides the model with a clean summary that reduces the cache penalty. But if the user is deep into a complex task, the summary can lose important details. We generally recommend staying with one model for the duration of a conversation unless you have a reason to switch.
Another way to sidestep the challenges of mid-conversation model switching is to instead use a subagent, which starts from a fresh context window. We recently added to the harness the ability for users to directly ask for a subagent to be run with a particular model.
The harness and the future of software development
The future of AI-assisted software engineering will be multi-agent. Instead of running every subtask through a single agent, the system will learn to delegate across specialized agents and subagents: one for planning, another for fast edits, and a third for debugging, each scoped to what it does best.
Making that work well is fundamentally a harness challenge. The system needs to know which agent to dispatch, how to frame the task for that agent's strengths, and how to stitch the results into a coherent workflow. The ability to orchestrate that kind of coordination will live in the harness rather than any single agent. This means that, while harness engineering has always been important for agent success, it's only going to be more critical going forward.

Silico
Goodfire launches Silico, a platform that uses interpretability techniques to let developers see inside AI models, debug their behavior, and design them more intentionally.
Deep dive
- Silico brings frontier interpretability techniques to all researchers and engineers, building on Goodfire's work discovering Alzheimer's biomarkers, teaching models to correct hallucinations, and diagnosing robotics bottlenecks
- The platform includes a model neuroscientist agent that autonomously plans and runs concurrent experiments on models, working alongside human teams
- Users can decompose models into interpretable features to distinguish real understanding from spurious correlations
- Health diagnostics catch issues like undertraining, information bottlenecks, and feature collapse before they impact production
- Debug capabilities let teams precisely identify and remove confounders, diagnosing failures before production deployment
- Internal features can be used to extract stronger predictors, steer generation, and target generalization unreachable through standard training
- The platform enables targeting specific learned structures to shift training distribution, objectives, or architecture for better generalization with equal or less data
- Teams can organize research threads, replicate and extend papers, and collaborate on findings in a shared model design environment
- Platform is currently in early access following coverage by MIT Technology Review
Decoder
- Interpretability: The ability to understand and explain how an AI model makes decisions by examining its internal representations and computations
- Features: Learned internal representations in neural networks that capture patterns and concepts from training data
- Spurious correlation: False patterns a model learns that happen to correlate with outputs in training data but don't represent true causal relationships
- Information bottlenecks: Points in a model's architecture where information flow is restricted, limiting performance
- Feature collapse: A failure mode where multiple distinct inputs map to the same internal representation, losing important distinctions
Original article
Introducing Silico
Introducing Silico: the platform for building AI models with the precision of written software.
Silico lets researchers and engineers see inside their models, debug failures, and intentionally design them from the ground up. Early access is open now.
We've used interpretability to discover a novel class of Alzheimer's biomarkers, teach a language model to correct its own hallucinations, and diagnose performance bottlenecks in a robotics model. Silico brings those frontier techniques to everyone.
Silico introduces our model neuroscientist: an autonomous agent that plans and runs concurrent experiments on your model. It works with your team in our model design environment, where you can organize research threads, replicate and extend papers, and collaborate on findings.
5 Things You Can Do with Silico
See inside your model
Decompose your model into interpretable features and tell the difference between real understanding and spurious correlation.
Check your model's health
Run comprehensive diagnostics on your model's internal representations to catch issues like undertraining, information bottlenecks, and feature collapse before they impact downstream performance.
Debug failures
Precisely debug issues with model behavior, identify and remove confounders, and diagnose failures before they occur in production.
Shape model behavior
Use internal features to extract stronger predictors, steer generation, and target generalization that standard training can't reach.
Generalize from less data
Target the specific learned structures driving behavior — and shift the training distribution, objective, or architecture to generalize further with the same or less data.
MIT Tech Review's @strwbilly spoke with our CEO/co-founder @ericho_goodfire about Silico and what it means for model builders: technologyreview.com/2026/04/30/113…
Silico is in early access now. Learn more at: goodfire.ai/platform

What you're actually writing when you write a SKILL.md
Understanding how AI agent skills actually load at runtime can reduce context window consumption by 3x and prevent silent failures when sharing or upgrading models.
Deep dive
- Skills operate via progressive disclosure with three loading levels: Level 1 metadata (name/description, ~100 tokens, always loaded for routing), Level 2 SKILL.md body (procedural instructions up to 500 lines, loaded on invocation), and Level 3 references/scripts (unlimited, loaded only when explicitly called)
- The author reduced context consumption from 20% to 7% by restructuring a 1,200-line monolithic SKILL.md into a 180-line spine pointing to three reference files—same instructions, same output, but different architecture
- Adding YAML frontmatter to reference files silently promotes them to skill-level visibility, causing the agent to sometimes trigger reference files directly without the parent skill's context, producing subtly wrong output
- Hardcoded workspace paths (like
modules/web) break when shared with teammates who have different directory structures; portable skills should discover paths dynamically by searching for build configurations or package.json files - Gotchas sections exist to override the model's statistically reasonable defaults with your non-average environment specifics—like "always run turbo build from repo root, never from inside a module"
- Model upgrades can degrade skill performance because more capable models interpret instructions instead of following them literally; the author's writing skill produced choppy output on Opus after working perfectly on Sonnet 4.6
- Anthropic's internal skill-creator tool uses paired runs methodology: execute the same prompt with and without the skill, measuring quantitative deltas (sentence length, readability scores) plus structured human review
- Maintaining a "golden set" of 3-4 realistic test prompts per skill allows you to detect drift when editing skills or upgrading models, turning "it worked when I tested it" from anecdote into measurement
- The SKILL.md format was published as an open standard in December 2025 and now works across Claude Code, Kiro, Cursor, Codex CLI, and other agent runtimes
- Skills suffer from typical software rot including environment drift, version sensitivity, and silent non-reproducible failures because they're programs with execution semantics, not static text
- The mental model: frontmatter is a pinboard the chef glances at constantly (routing), SKILL.md is the full recipe pulled down when needed (execution), references are binder pages consulted only when the recipe points to them (deferred loading), and scripts are appliances that produce output without exposing source code
- A skill tuned on one model is calibrated to that model's compliance characteristics; more capable models have stronger priors about what "good" output looks like and will pull toward the statistical center of their training data, potentially away from your personal or organizational voice
Decoder
- Progressive disclosure: The loading strategy where skills provide content at three different times (always, on-invocation, on-demand) to minimize context window waste
- Context window: The limited working memory available to an AI model during a conversation, measured in tokens, which must hold conversation history, tool outputs, and loaded skill instructions
- Frontmatter: YAML metadata block at the top of a skill file containing name and description, loaded into the system prompt at startup for routing decisions
- Evals: Automated evaluations that test whether a skill produces expected output, typically using paired runs (with/without the skill) to measure deltas rather than absolute quality
- Compliance characteristics: How a model interprets and follows instructions; more capable models may interpret instructions rather than follow them literally, changing skill behavior
- Context compaction: When conversation history is summarized or truncated because the context window is full, typically causing information loss on long-horizon tasks
Original article
What you're actually writing when you write a SKILL.md
INTERNALS.md #2 · Skills are programs, not prompts. How the skills runtime actually loads, and why the architecture is everything.
A skill is a small program.
It has three execution stages: 1\ what loads every turn, 2\ what loads on invocation, and 3\ what loads on demand. Because a skill is a program, it suffers from typical software rot—environment drift, version sensitivity, and silent, non-reproducible failures.
You'll see these failures in specific shapes. A skill that cost 20% of your context window, silently, before the agent did any work. A skill that worked perfectly until you shared it with a teammate, and ran the build in the wrong directory. A skill tuned carefully on one model, producing worse output the moment you upgraded to a better one.
These aren't separate bugs. They're four faces of the same misunderstanding: treating a loader specification like a prompt.
This post is about what skills actually are underneath, and why understanding the runtime changes everything you do at the surface.
A note on scope. Skills aren't a Claude-only thing anymore. Anthropic published the SKILL.md format as an open standard in December 2025, and the same files now work across Claude Code, Kiro, Cursor, Codex CLI, and others. The mental model in this post applies to all of them. I'll use Claude as shorthand for the agent harness reading the skill. Swap in your runtime of choice.
What skills are not
The first time I wrote a Skill, I thought I was writing a long prompt the agent would consult.
I wrote one big SKILL.md. Maybe 1,200 lines. Workflow at the top, a map of every module in our codebase, example code, message contracts between services, framework-specific patterns, and at the bottom a list of every gotcha I knew. It worked. It also consumed about 20% of the context window before the agent did any actual work.
I rewrote it. Same instructions, same output, different architecture: a 180-line SKILL.md that pointed at three reference files and one helper script. The new version cost 7%.
The instructions didn't change. The architecture did. That's where the 3× difference lived, and it was the first sign that I was not, in fact, writing a long prompt.
A prompt is static text. You write it, you ship it, the model reads all of it on every turn. Skills don't work like that. Skills are a loader specification. You're describing what should be in context, when, and at what cost. The text matters, but the structure decides what survives the trip into the model's working memory.
That reframe is the whole post. Everything else falls out of it.
The runtime
Skills run on a principle Anthropic calls progressive disclosure. The official documentation defines it plainly:
Skills can contain three types of content, each loaded at different times.
This is why two skills with identical instructions can behave completely differently. One loads 180 lines on demand; the other dumps 1,200 lines every turn.
Anthropic built these levels to protect your context window. If a skill front-loads everything, it crowds out the conversation history and tool outputs. By using progressive disclosure, you stop paying for "just in case" instructions and only pay for "just in time" execution.
Level 1: Metadata. The name and description from YAML frontmatter. Always loaded, every turn. The official docs put this at roughly 100 tokens per skill installed. The agent uses the description to decide whether the skill is relevant. It's a routing decision, not a usage decision. This is the most important level to get right. If the description is wrong, nothing else matters.
Level 2: SKILL.md body. The procedural instructions. Loaded only when the agent decides the skill applies, by reading the file via bash. Anthropic's best practices documentation puts the recommended ceiling at 500 lines. This is where most people pile on content they shouldn't.
Level 3: References and scripts. Bundled files referenced from SKILL.md. References are markdown the agent reads only when the body points to them. Scripts are executable code the agent runs: output enters context, the source code does not. Effectively unlimited.
The Anthropic engineering team (Barry Zhang, Keith Lazuka, and Mahesh Murag) described it in their October 2025 announcement as: "Like a well-organized manual that starts with a table of contents, then specific chapters, and finally a detailed appendix, skills let Claude load information only as needed."
Get the architecture right and your skill costs almost nothing until it earns its place. Get it wrong and you pay every turn.
Mental model
Picture a kitchen during dinner service.
There's a pinboard on the wall with recipe titles and one-line summaries. Pasta Carbonara: Italian classic, use when guest wants creamy pasta with bacon. The chef glances at it constantly. It's small enough to hold in peripheral vision. That's frontmatter.
When a guest orders, the chef picks the matching card and pulls down the full recipe. Ingredients, steps, technique notes. The recipe is not on the wall. It would be too cluttered, too distracting, too much to scan during service. It comes down only when needed. That's SKILL.md.
The recipe sometimes says for the sauce, see Sauce Reference, page 47. The chef walks to the binder, opens to page 47, reads only that page. Doesn't read the whole binder. That's references/.
In the corner, a stand mixer. The recipe says use the mixer for three minutes. The chef does not read the mixer's circuit diagram. The chef hands it ingredients, presses a button, gets output. That's scripts/.
The metaphor holds under pressure, which is the only test of a metaphor. Every failure mode I hit in my own skills traces back to violating the kitchen.
The Antipattern Ledger
When I first started migrating my workflows to the SKILL.md, I treated the runtime like a smart intern who could "just figure it out."
I was wrong. Because the skills runtime is a deterministic loader, minor architectural choices—like where you put a single line of YAML—can silently break the agent's reasoning. These aren't just bugs; they are antipatterns. Each one below represents a moment where I violated the "Kitchen" logic and paid for it in context drift, high latency, or hallucinated outputs.
Frontmatter on reference files
The first thing I got wrong, before I understood progressive disclosure existed.
I added YAML frontmatter to my reference files because SKILL.md had it, and the references felt important enough to deserve metadata. I didn't realize what frontmatter actually does.
Frontmatter is what gets loaded into the system prompt at startup. Every file with frontmatter contributes its name and description to the always-loaded set. The pinboard. Adding frontmatter to a reference file pins it to the wall as if it were a top-level skill. It isn't. Now the pinboard shows fifty entries instead of five, most of them sub-pages that were never meant to be visible at routing time.
In practice: the agent would occasionally trigger a reference file directly instead of the parent skill. Instructions out of context, without the skill body that gave them meaning. The output was subtly wrong and I couldn't figure out why, because the reference file looked fine in isolation. I didn't realize it had been promoted to skill-level visibility.
The fix was one line per file: delete the frontmatter from references. They're not skills. They're chapters that other skills point to.
One monolithic skill
This is the 20%-to-7% story.
When I built a skill to capture context across multiple modules and message systems, I put everything in one SKILL.md. It seemed cleaner. One file, one source of truth. Easy to read, easy to edit.
It also meant that every time the skill triggered, the agent loaded the entire 1,200-line file. Module map, contracts, patterns, and gotchas. Even when the task only needed two of those four.
Splitting it into a 180-line spine with three reference files dropped context consumption from 20% to 7%. Same task, same output, same model.
This compounds. A skill that costs 7% instead of 20% means you can install three of them in the same context budget, run longer sessions before compaction, hit fewer cliffs on long-horizon tasks. The savings aren't local. They show up everywhere downstream.
Hardcoded workspace paths
I shared a skill with a teammate and it ran the build command in the wrong directory.
My instructions said something like navigate to modules/web and run the build. That worked in my repo. My teammate's repo had four modules. modules/web didn't exist; they had packages/frontend/web. The skill silently picked the wrong directory and produced output in the wrong place. No error. Just wrong output.
The fix was to write instructions that ask the agent to discover the right path rather than declare it. Search for the build configuration. Identify the module by its package.json. Read the workspace structure before assuming. The skill became more abstract, but it became portable.
This is the failure mode that doesn't appear until you share. If you only ever run a skill on your own machine, you can hardcode anything and it will work. The moment another engineer runs it, every implicit assumption surfaces as a bug.
Missing gotchas
My monorepo uses Turborepo. The build command has to run from the repo root for the configuration to resolve correctly. If you run build from inside a module directory, the build still runs. But the cache misses, the dependency graph gets misread, and the output is subtly wrong.
The agent's default was reasonable: I'm working in the web module, so I'll run the build from the web module. That's correct in 90% of repos. It was wrong in this one.
No amount of "explain the why" in the instructions would have prevented it. The wrongness wasn't conceptual; it was environmental. The agent's prior was correct on average. My environment wasn't average.
The fix was a single line in a Gotchas section: Always run turbo build from the repository root, never from inside a module. One line. The next time the agent reached for the build command, it consulted the gotcha and ran correctly.
This is what Gotchas are for. The agent has reasonable defaults. Your environment isn't average. That gap is the whole job of the Gotchas section, and it's why mature skills treat it as the most important section to maintain over time.
Not knowing why the skill worked at all
The deepest mistake. I didn't write evals.
I built a writing skill for my personal Claude desktop. It was based on Scott Adams' writing principles: short sentences, active voice, front-loaded points, one idea per paragraph. I tuned it on Sonnet 4.6. It worked exactly the way I wanted: drafts came out clean, direct, in my voice.
Then I upgraded to Opus. Better model, I assumed. Better output.
The output was worse. Every sentence ran 5 to 7 words. Technically short. But choppy. No rhythm, no flow, nothing that read like me. The writing felt like bullet points dressed as prose.
What happened is subtle. Sonnet read "write short sentences" and applied judgment: short where brevity sharpened the point, longer where the rhythm needed it. It understood the spirit. Opus read the same instruction and followed it literally. Every sentence, hard constraint, no exceptions.
The more capable model has stronger priors about what "good writing" looks like. Its version of clear prose is the statistical center of good writing on the internet. My voice isn't the statistical center. Opus pulled hard toward its own aesthetic, and away from mine.
A skill tuned on one model is calibrated to that model's compliance characteristics, not just its capabilities.
A more capable model isn't automatically a better fit. Sometimes it's worse, because it interprets your instructions instead of following them.
I had no evals. No way to know how much had drifted, which instructions were being over-applied, or what a passing output even looked like quantitatively. I'd never defined what "sounds like me" meant in terms a test could check.
Anthropic's skill-creator, the tool the team uses to build their own skills internally, has an explicit eval methodology. The core move is paired runs: for every test prompt, run the agent twice. Once with the skill, once without. You're not measuring whether the output is good. You're measuring whether it's better than baseline, and by how much.
For a writing skill, not all assertions are scriptable. But some are: output length, sentence count, average sentence length, readability score. The rest is structured human review, with the previous output alongside the new one and a notes field. That's what Anthropic's eval-viewer in skill-creator produces.
I now keep a small 'Golden Set' per skill—a practice we'll dissect in an upcoming post on automated skill validation—to ensure my voice doesn't drift when the underlying model changes. Three or four realistic prompts. Rerun the suite on every model bump, every skill edit. Check the deltas.
It worked when I tested it is not evidence. It's the absence of measurement.
What survives the post
Four things should stick.
Skills are loader specifications, not prompts. Frontmatter is a routing mechanism. SKILL.md is a triggered payload. References and scripts are deferred chapters. Once you see the architecture, every authoring decision becomes a question of which level does this content belong at?
Architecture decides cost. The same instructions, in the wrong shape, can consume 3× the context window. That penalty compounds across every skill installed and every turn taken. The fix is structural, not prose-level.
The agent has reasonable priors. Your environment doesn't. Gotchas exist because the model's defaults are correct on average and your situation isn't average. Workspace paths, build systems, team conventions: none of it lives in the model's training. It has to live in the skill.
A model upgrade is not free. A skill tuned on one model is calibrated to that model's compliance characteristics. A more capable model interprets your instructions instead of following them, and for skills that encode personal or organizational voice, that interpretation is the failure. The only way to know if an upgrade helped or hurt is to measure it.
Sources
- Agent Skills overview, Claude API documentation
- Agent Skills best practices, Claude API documentation
- Equipping agents for the real world with Agent Skills, Barry Zhang, Keith Lazuka, Mahesh Murag, Anthropic Engineering, October 2025
- skill-creator/SKILL.md, Anthropic skills repository
- Agent Skills open standard, December 2025
- The Day You Became a Better Writer, Lakshmanan Meiyappan
- Scott Adams' original post, via Internet Archive

Approaching zero bugs?
The curl maintainer analyzes whether AI bug-finding tools are bringing us closer to zero bugs and finds the data says no.
Deep dive
- Stenberg observes that modern AI tools find bugs rapidly, but this doesn't necessarily mean we're approaching bug-free software - the bugs were already there
- He proposes a novel metric for measuring progress: if tools were highly effective, we should only be finding recently-introduced bugs since older bugs would already be discovered
- Analysis of curl's vulnerability data shows the average and median age of vulnerabilities at discovery time is not decreasing
- The rate of bugfixes in curl is also not declining, which would be expected if the pool of bugs was being exhausted
- Every bugfix carries risk of introducing new bugs, and feature development continues to add complexity and potential issues
- Even modern AI tools don't catch everything and sometimes suggest buggy fixes themselves
- The graphs suggest we're nowhere near zero bugs - neither curve shows a downward trend yet
- Stenberg remains uncertain about whether tools will improve by 10%, 100%, or 1000%, and whether improvement will continue for years or decades
- The analysis is based on a single project (curl) which limits statistical validity, but provides concrete data rather than speculation
- His conclusion is pragmatic: he'll keep fixing bugs regardless of what the tools promise
Original article
In this era of powerful tools to find software bugs, we now see tools find a lot of problems at a high speed. This causes problems for developers, as dealing with the growing list of issues is hard. It may take a longer time to address the problems than to find them – not to mention to put them into releases and then it takes yet another extended time until users out in the wild actually get that updated version into their hands.
In order to find many bugs fast, they have to already exist in source code. These new tools don't add or create the problems. They just find them, filter them out and bring them to the surface for exposure. A better filter in the pool filters out more rubbish.
The more bugs we fix, the fewer bugs remain in the code. Assuming the developers manage to fix problems at a decent enough pace.
For every bugfix we merge, there is a risk that the change itself introduces one more more new separate problems. We also tend to keep adding features and changing behavior as we want to improve our products, and when doing so we occasionally slip up and introduce new problems as well.
Source code analyzing tools is a concept as old as source code itself. There has always existed tools that have tried to identify coding mistakes. Now they just recently got better so they can find more mistakes.
These new tools, similar to the old ones, don't find all the problems. Even these new modern tools sometimes suggest fixes to the problems they find that are incomplete and in fact sometimes downright buggy.
Undoubtedly code analyzer tooling will improve further. The tools of tomorrow will find even more bugs, some of them were not found when the current generation of tools scanned the code yesterday.
Of course, we now also introduce these tools in CI and general development pipelines, which should make us land better code with fewer mistakes going forward. Ideally.
If we assume that we fix bugs faster than we introduce new ones and we assume that the AI tools can improve further, the question is then more how much more they can improve and for how long that improvement can go on. Will the tools find 10% more bugs? 100%? 1000%? Is the tool improving going to gradually continue for the next two, ten or fifty years? Can they actually find all bugs?
Can we reach the utopia where we have no bugs left in a given software project and when we do merge a new one, it gets detected and fixed almost instantly?
Are we close?
If we assume that there is at least a theoretical chance to reach that point, how would we know when we reach it? Or even just if we are getting closer?
I propose that one way to measure if we are getting closer to zero bugs is to check the age of reported and fixed bugs. If the tools are this good, we should soon only be fixing bugs we introduced very recently.
In the curl project we don't keep track of the age of regular bugs, but we do for vulnerabilities. The worst kind of bugs. If the tools can find almost all problems, they should soon only be finding very recently added vulnerabilities too. The age of new finds should plummet and go towards zero.
If the age of newly reported vulnerabilities are getting younger, it should make the average and median age of the total collection go down over time.
Average age of vulnerabilities
The average and median time vulnerabilities had existed in the curl source code by the time they were found and reported to the project.
Bugfixes
Given the data from the curl project, there does not seem to be fewer bugfixes done – yet. Maybe the bugfix speed goes up before it goes down?
We are not close
Given the look of these graphs I don't think we are close to zero bugs yet. These two curves do not seem to even start to fall yet.
Yes, these graphs are based on data from a single project, which makes it super weak to draw statistical conclusions from, but this is all I have to work with.
So when?
I think that's mostly an indication of what you believe the tooling can do and how good they can eventually end up becoming.
I don't know. I will keep fixing bugs.

OpenAI models, Codex, and Managed Agents come to AWS
OpenAI is bringing GPT-5.5, Codex, and managed agents directly to Amazon Bedrock, letting enterprises use OpenAI tools without leaving their AWS environment.
Deep dive
- OpenAI models including GPT-5.5 are now available on Amazon Bedrock, letting enterprises build AI applications within their existing AWS infrastructure rather than integrating external APIs
- Codex, used by 4 million weekly users for coding, refactoring, test generation, and document work, can now be powered by OpenAI models served directly from Bedrock
- Customers with AWS commits can configure Codex to use Bedrock as the provider through the CLI, desktop app, or Visual Studio Code extension
- All customer data processed through this integration stays within Amazon Bedrock's security perimeter and can count toward AWS cloud commitments
- Amazon Bedrock Managed Agents powered by OpenAI provides infrastructure for deploying production agents that maintain context, execute multi-step workflows, and use tools
- The managed agents service handles deployment, orchestration, and governance complexity, letting teams focus on building useful agents rather than infrastructure
- This partnership solves the "build where you already are" problem for enterprises that need frontier models but can't easily route data outside their AWS environment
- The integration gives developers flexibility across use cases: new AI apps, embedded intelligence in existing products, and complex agentic workflows
- Security-conscious enterprises get a single procurement path from experimentation to production without managing multiple vendor relationships
- The announcement positions AWS Bedrock as a unified control plane for both AWS-native and OpenAI models, competing with multi-cloud AI platforms
Decoder
- Amazon Bedrock: AWS's managed service for accessing foundation models from various providers through a unified API
- GPT-5.5: OpenAI's latest frontier language model (referenced as their "best frontier model")
- Codex: OpenAI's coding assistant product suite used for writing code, refactoring, test generation, and document work
- Managed Agents: AWS service that handles infrastructure, orchestration, and deployment for AI agents that execute multi-step workflows
- AWS commit: Pre-negotiated cloud spending commitment that enterprises make with AWS, often allowing them to apply usage of various services toward the agreement
Original article
OpenAI and AWS expanded their partnership to bring GPT-5.5 and other OpenAI models to Amazon Bedrock, allowing enterprises to build AI applications within their existing AWS infrastructure and security protocols. The collaboration also introduces Codex (OpenAI's coding tool used by 4 million weekly users) on Bedrock and launches Amazon Bedrock Managed Agents powered by OpenAI for deploying multi-step workflow agents in production environments.

Agents can now create Cloudflare accounts, buy domains, and deploy
AI coding agents can now provision cloud infrastructure end-to-end using a new Cloudflare-Stripe protocol that handles account creation, payment, and deployment without manual intervention.
Deep dive
- The protocol has three core components: Discovery (agents query a catalog of available services via REST API), Authorization (Stripe attests user identity to auto-provision accounts or link existing ones via OAuth), and Payment (Stripe provides payment tokens for billing without exposing credit card details to agents)
- Agents discover available services by calling
stripe projects catalog, which returns a JSON catalog of all Cloudflare products and other providers—giving agents the context they need to choose services based on user goals without requiring prior user knowledge - For new users, Stripe acts as the identity provider to attest identity, allowing Cloudflare to automatically provision accounts and return credentials to the agent without sending users to signup pages
- Existing Cloudflare users go through a standard OAuth flow to grant access to Stripe Projects CLI for provisioning resources on their existing accounts
- Built-in spending safeguards include Stripe setting a default $100/month limit per provider and never sharing raw payment details with agents—users can later raise limits via Cloudflare Budget Alerts
- Any platform with signed-in users can act as an "Orchestrator" (like Stripe does) and integrate with Cloudflare using the same protocol, enabling one-API-call provisioning for their users
- The protocol extends OAuth and OIDC standards into payments and account creation while treating agents as first-class concerns, standardizing what platforms have been doing with bespoke one-off integrations
- Cloudflare is partnering with PlanetScale on similar integrations where Cloudflare acts as the Orchestrator, letting users provision PlanetScale Postgres databases directly from Cloudflare
- The protocol works with Cloudflare's Code Mode MCP server and Agent Skills to make agents more effective at deployment tasks
- Cloudflare is offering $100,000 in credits to startups incorporating through Stripe Atlas as part of this partnership
- Stripe Projects is in open beta and works even for users without existing Cloudflare accounts—the entire flow from zero to production deployment happens without manual setup steps
Decoder
- OAuth: Open standard for delegated access that lets users grant applications access to their accounts without sharing passwords
- OIDC (OpenID Connect): Identity layer built on OAuth that verifies user identity and provides basic profile information
- MCP server: Model Context Protocol server, a Cloudflare tool that gives agents structured context about how to interact with Cloudflare services
- Payment tokenization: Security technique where sensitive payment details are replaced with non-sensitive tokens that can be used for transactions without exposing the underlying card numbers
- Orchestrator: In this protocol, the platform (like Stripe) that manages signed-in users and coordinates between users, agents, and service providers
- Agent Skills: Pre-configured capabilities that help AI agents understand how to perform specific tasks with a service
Original article
Agents can now create Cloudflare accounts, buy domains, and deploy
Coding agents are great at building software. But to deploy to production they need three things from the cloud they want to host their app — an account, a way to pay, and an API token. Until now these have been tasks that humans handle directly. Increasingly, agents handle them on the user's behalf. The agent needs to perform all the tasks a human customer can. They're given higher-order problems to solve and choose to use Cloudflare and call Cloudflare APIs.
Starting today, agents can provision Cloudflare on behalf of their users. They can create a Cloudflare account, start a paid subscription, register a domain, and get back an API token to deploy code right away. Humans can be in the loop to grant permission and must accept Cloudflare's terms of service, but no human steps are otherwise required from start to finish. There's no need to go to the dashboard, copy and paste API tokens, or enter credit card details. Without any extra setup, agents have everything they need to deploy a new production application in one shot. And with Cloudflare's Code Mode MCP server and Agent Skills, they're even better at it.
This all works via a new protocol that we've co-designed with Stripe as part of the launch of Stripe Projects.
We're excited to launch this new partnership with Stripe, and also to offer $100,000 in Cloudflare credits to all new startups who incorporate using Stripe Atlas. But this new protocol also makes it possible for any platform with signed-in users to integrate with Cloudflare in the same way Stripe does, with zero friction for the end user.
How it works: zero to production without any setup or manual steps
Install the Stripe CLI with the Stripe Projects plugin, login to Stripe, and then start a new project:
stripe projects initThen prompt your agent to build something new and deploy it to a new domain. You can watch a condensed two-minute video of this entire flow below:
If the email you're logged into Stripe with already has a Cloudflare account, you'll be prompted with a typical OAuth flow to grant the agent access. If there is no existing Cloudflare account for the email you're logged in with, Cloudflare will provision an account automatically for you and your agent:
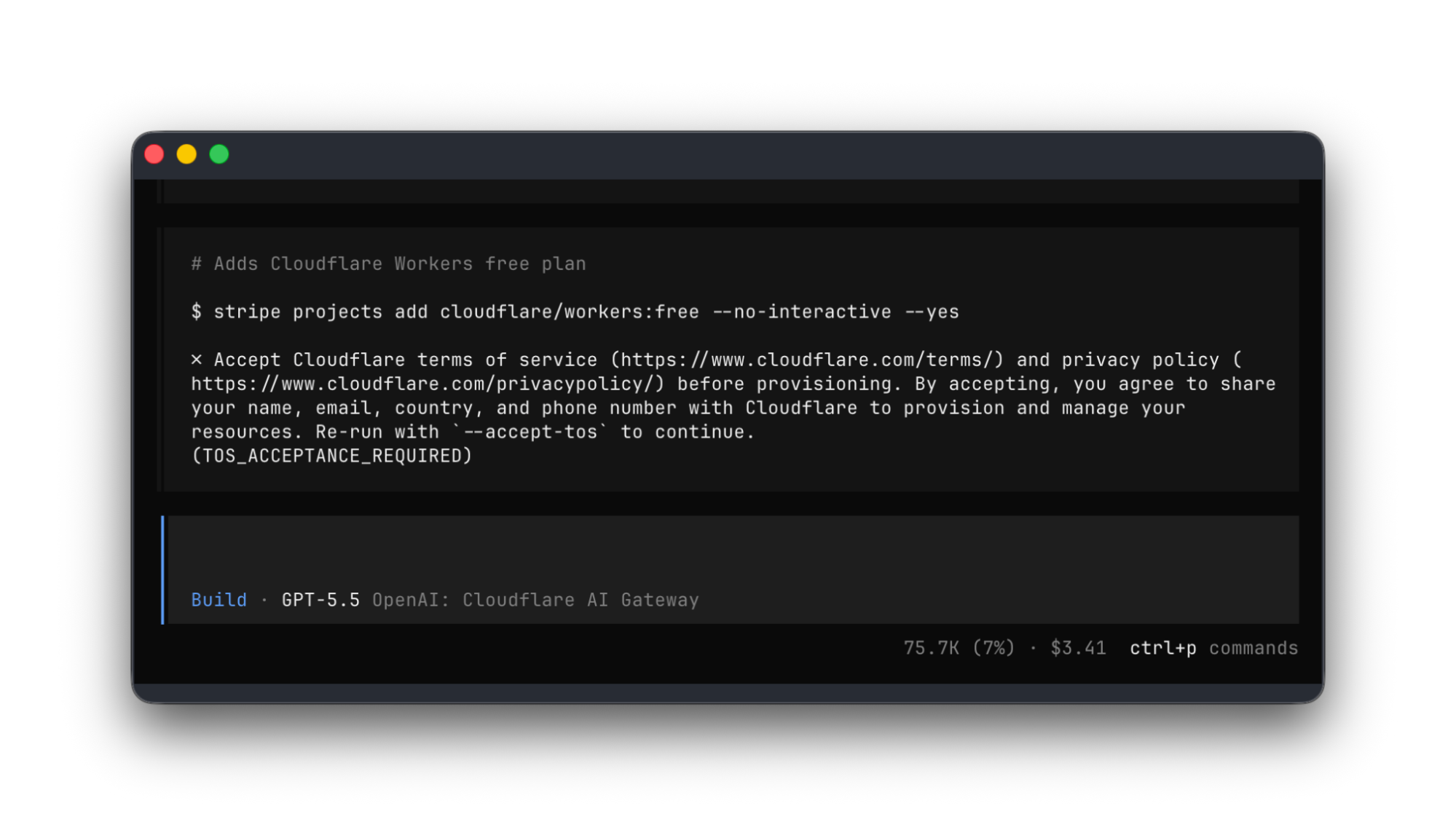
You will see the agent build and deploy a site to a new Cloudflare account, and then use the Stripe Projects CLI to register the domain:

The agent will prompt for input and approval when necessary. For example, if your Stripe account doesn't yet have a linked payment method, the agent will prompt you to add one:
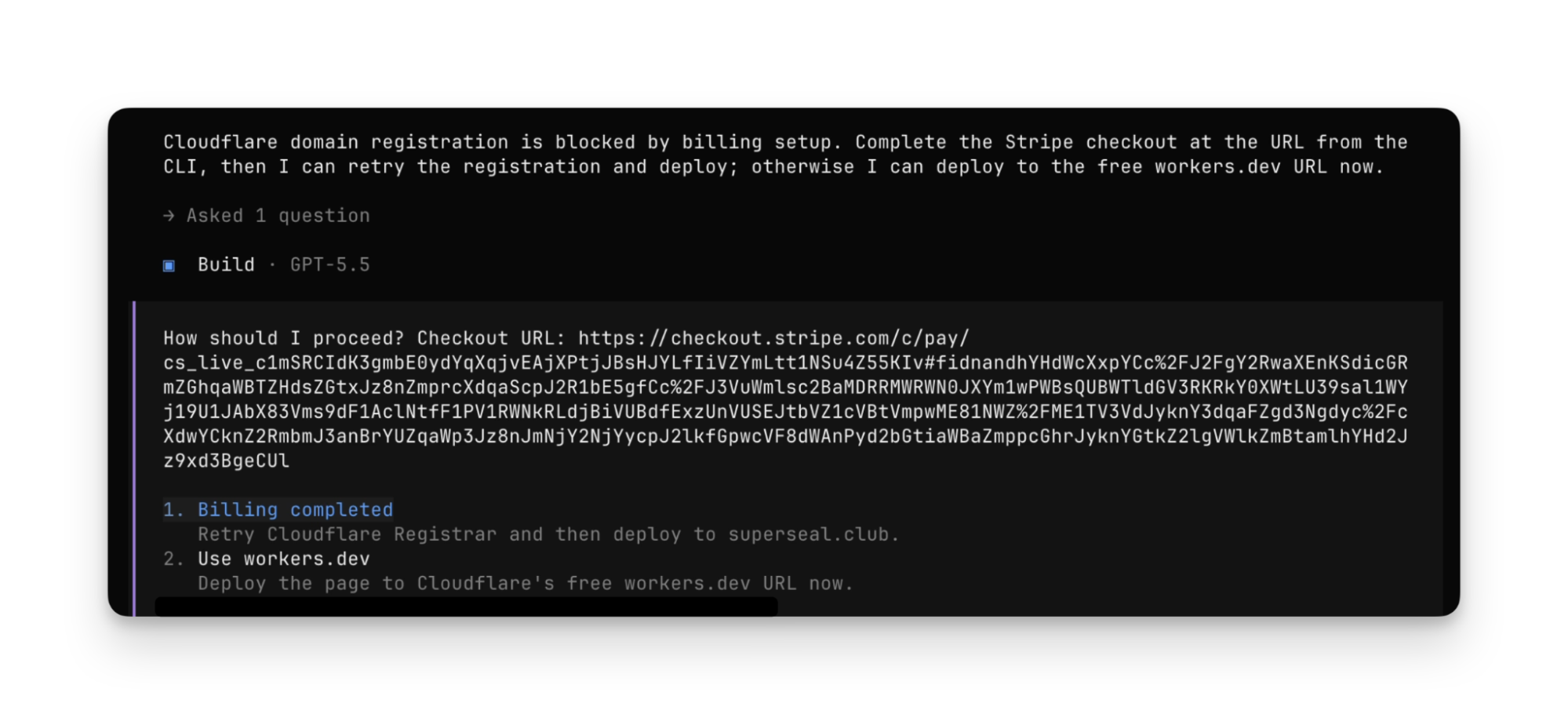
At the end, the agent has deployed to production, and the app runs on the newly registered domain:

The agent has gone from literal zero, no Cloudflare account at all, without any preconfigured Agent Skills or MCP server, to having:
- Provisioned a new Cloudflare account
- Obtained an API token
- Purchased a domain
- Deployed an app to production
But wait — how did the agent discover that it could do all of this? How did it know what services it could provision, and how to purchase a domain? How did it gain the context it needed to understand how to deploy to Cloudflare? Let's dig in.
How the protocol and integration works
There are three components to the interaction between the agent, Stripe, and Cloudflare shown above:
- Discovery — the agent can call a command to query the catalog of available services.
- Authorization — the platform attests to the identity of the user, allowing providers to provision accounts or link existing ones, and securely issue credentials back to the agent.
- Payment — the platform provides a payment token that providers can use to bill the customer, allowing the agent to start subscriptions, make purchases and be billed on a usage basis.
These build on prior art and existing standards like OAuth, OIDC and payment tokenization — but are used together to remove many steps that might otherwise require a human in the loop.
Discovery: how agents find services they can provision themselves
In the agent session above, before the agent ran the CLI command stripe projects add cloudflare/registrar:domain, it first had to discover the Cloudflare Registrar service. It did this by calling the stripe projects catalog command, which returns available services:
The full set of Cloudflare products and services from other providers is long and growing — arguably overwhelming to humans. But for agents, this catalog of services is exactly the context they need. The agent chooses services to use from this catalog based on what the user has asked them to do and the user's preferences — but the user needs no prior knowledge of what services are offered by which providers, and does not need to provide any input. Providers like Cloudflare make this catalog available via a simple REST API that returns JSON, and that gives agents everything they need.
Authorization: instant account creation for new users
When the agent chooses a service and provisions it (ex: stripe projects add cloudflare/registrar:domain), it provisions the resource within a Cloudflare account. But how is it able to create one on demand, without sending a human to a signup page?
Remember how at the start, the user signed in to their Stripe account? Stripe acts as the identity provider, attesting to the user's identity. Cloudflare automatically provisions a new account for the user if no account already exists, and returns credentials back to the Stripe Projects CLI, which are securely stored, but available to the agent to use to make authenticated requests to Cloudflare. This means if someone is brand new to Cloudflare or other services, they can start building right away with their agent, without extra steps.
If the user already has a Cloudflare account, they're sent through a standard OAuth flow to grant access to the Stripe Projects CLI, allowing them to provision resources on their existing Cloudflare account.
Payment: give your agent a budget it can spend, without giving it your credit card info
You might rightly worry, "What if my agent goes a bit overboard and starts buying dozens of domains? Will I end up on the hook for a massive bill? Can I really trust my agent with my credit card?"
The protocol accounts for this in two ways. When an agent provisions a paid service, Stripe includes a payment token in the request to the Provider (Cloudflare). Raw payment details like credit card numbers aren't ever shared with the agent. Stripe then sets a default limit of $100.00 USD/month as the maximum the agent can spend on any one provider. When you're ready to raise this limit, you can then set Budget Alerts on your Cloudflare account.
Any platform with signed-in users can integrate with Cloudflare in the same way Stripe does
Any platform with signed-in users can act as the "Orchestrator", playing the same role Stripe does with Stripe Projects, and integrate with Cloudflare.
Let's say your product is a coding agent. You'd love for people to be able to take what they've built and get it deployed to production, using Cloudflare and other services. But the last thing you want is to send people down a maze of authorization flows and decision trees of where and how to deploy it. You just want to let people ship.
Your platform acts as the Orchestrator, with the already signed-in user. When your user needs a domain, a storage bucket, a sandbox to give their agent, or anything else, you make one API call to Cloudflare to provision a new Cloudflare account to them, and get back a token to make authenticated requests on their behalf.
Or let's say you want Cloudflare customers to be able to easily provision your service, similar to how Cloudflare is partnering with Planetscale to make it possible to create Planetscale Postgres databases directly from Cloudflare. We started working with Planetscale on this well before this new protocol got off the ground, but the flow here is quite similar. Cloudflare acts as the Orchestrator, letting you connect to your PlanetScale account, create databases, and use the user's existing payment method for billing.
This new protocol starts to standardize the types of cross-product integrations that many platforms have been doing for years, often in ways that were one off or bespoke to a particular platform. Without a standard, each integration required engineering work that often couldn't be leveraged for future integrations. Similar to how the OAuth standard made it possible to delegate access to your account to other platforms, the protocol uses OAuth and extends further into payments and account creation, doing so in a way that treats agents as a first-class concern.
We're excited to continue evolving the standard, and to work with Stripe on sharing a more official specification soon. We're also excited to integrate with more platforms — email us at [email protected], and tell us how you want your platform to integrate with Cloudflare.
Give your agent the power to provision and pay
Stripe Projects is in open beta, and you can get started even if you don't yet have a Cloudflare account. Just install the Stripe CLI, log in to Stripe, and then start a new project:
stripe projects initPrompt your agent to build something new on Cloudflare, and show us what you've built!
Kubernetes v1.36: Staleness Mitigation and Observability for Controllers
Kubernetes v1.36 introduces staleness mitigation for controllers to prevent them from taking incorrect actions based on outdated cache data.
Deep dive
- Controllers maintain local caches of cluster state for performance, but these caches can become outdated during restarts, API server outages, or when events arrive out of order, leading to incorrect controller actions
- The new AtomicFIFO feature in client-go enables atomic batch processing of operations, ensuring the queue remains consistent even when events arrive out of order during initial list operations
- Controllers now track the resource version of objects they've written to the API server and compare it against their cache's resource version before taking action, skipping reconciliation if the cache is stale
- The four updated controllers were chosen because they act on pods, which typically experience the highest contention in Kubernetes clusters
- The ConsistencyStore interface provides three key functions: WroteAt (records when an object is written), EnsureReady (checks if cache is up to date before reconciliation), and Clear (removes deleted objects)
- Controllers track both the resource version of the objects they manage (e.g., ReplicaSets) and the resource versions of dependent objects (e.g., pods owned by those ReplicaSets)
- New metrics include stale_sync_skips_total to count skipped syncs due to stale caches, and store_resource_version to expose the latest resource version of each shared informer
- All staleness mitigation features are enabled by default in v1.36 but can be disabled per-controller using feature gates like StaleControllerConsistencyDaemonSet
- The feature implements "read your own writes" semantics, ensuring controllers see their own updates before taking further action
- SIG API Machinery is working with controller-runtime to bring these capabilities to all controllers built with that framework, enabling automatic staleness mitigation without custom implementation
Decoder
- Staleness: When a controller's local cache contains outdated information about cluster state, potentially causing it to make decisions based on incorrect data
- Reconciliation: The process where a controller compares desired state with actual state and takes action to align them, first checking its local cache then updating from the API server
- Informer: A client-go component that watches the Kubernetes API server for changes and maintains a local cache of objects a controller cares about
- Resource version: A version identifier assigned to Kubernetes objects that increases with each update, used to track whether cached data is current
- FIFO queue: First-in-first-out queue used by controllers to process events in order
- client-go: The official Kubernetes client library for Go, used to build controllers and interact with the Kubernetes API
- kube-controller-manager: The Kubernetes component that runs core controllers like ReplicaSet, DaemonSet, Job, and StatefulSet controllers
Original article
Kubernetes v1.36 introduced new features to combat "staleness" in controllers—when outdated local caches cause controllers to take incorrect actions or miss updates—by adding atomic FIFO processing to client-go and implementing staleness checks in four high-contention controllers (ReplicaSet, DaemonSet, Job, and StatefulSet) that now verify cache resource versions before acting. The update also includes new metrics like stale_sync_skips_total to monitor when controllers skip syncs due to stale data, with all features enabled by default and controllable via feature gates.

Post-quantum encryption for Cloudflare IPsec is generally available
Cloudflare launched post-quantum IPsec encryption to protect enterprise networks against future quantum computers that could decrypt today's harvested traffic.
Deep dive
- Cloudflare's post-quantum IPsec uses hybrid ML-KEM, which runs classical Diffie-Hellman first, then uses its derived key to encrypt a second ML-KEM exchange, mixing both outputs into the session keys that protect actual data traffic via ESP protocol
- The implementation achieves interoperability with Cisco 8000 Series routers (v26.1.1+) and Fortinet FortiOS (7.6.6+), marking a significant win for the new IETF draft standard after years of fragmentation
- IPsec post-quantum adoption lagged four years behind TLS partly due to RFC 8784's focus on Quantum Key Distribution, which U.S. NSA, Germany's BSI, and UK's NCSC all warned against relying on solely
- QKD requires specialized hardware and dedicated physical links between parties, fundamentally incompatible with internet-scale operation, and still requires post-quantum cryptography for authentication anyway
- RFC 9370 (2023) allowed up to seven parallel key exchanges but didn't specify which ciphersuites to use, leading vendors like Palo Alto to ship incompatible implementations before the ML-KEM draft was available
- The new draft-ietf-ipsecme-ikev2-mlkem standard fills RFC 9370's gaps by specifying exactly how to implement hybrid ML-KEM alongside classical Diffie-Hellman, avoiding the "ciphersuite bloat" problem NIST warned against
- Cloudflare accelerated its full post-quantum security deadline to 2029 in response to recent quantum computing advances, creating urgency around completing the cryptographic migration
- ML-KEM is intentionally designed for software implementation on standard processors rather than requiring special hardware, making it deployable across existing infrastructure
- The IPsec community still needs standards for post-quantum authentication (not just encryption) to protect against quantum adversaries attacking live systems after Q-Day
- Cloudflare turned on hybrid post-quantum TLS in 2022 before NIST even finalized ML-KEM standardization because the TLS community converged quickly on a single interoperable approach and pushed it to production
Decoder
- ML-KEM: Module-Lattice-Based Key-Encapsulation Mechanism, a post-quantum cryptography algorithm based on mathematical problems quantum computers can't efficiently solve
- IPsec: Internet Protocol Security, a protocol suite for encrypting and authenticating IP packets, commonly used for VPNs and site-to-site WAN connections
- Hybrid approach: Combining classical cryptography (like Diffie-Hellman) with post-quantum algorithms so security is maintained even if either system is broken
- Harvest-now-decrypt-later: Attacks where adversaries collect encrypted data today to decrypt it later when quantum computers become powerful enough to break current encryption
- Q-Day: The future point when quantum computers become powerful enough to break today's public key cryptography
- QKD (Quantum Key Distribution): A method using quantum physics to distribute encryption keys, requiring specialized hardware and dedicated physical connections
- FIPS 203: Federal Information Processing Standard 203, the official U.S. government designation for the ML-KEM algorithm
- ESP (Encapsulating Security Payload): The IPsec protocol that actually encrypts and authenticates the data being transmitted
Original article
Cloudflare made post-quantum encryption in its IPsec service generally available, successfully testing interoperability with branch connectors from Fortinet and Cisco using the new IETF hybrid ML-KEM (FIPS 203) draft standard. The rollout comes as Cloudflare moved its full post-quantum security target to 2029 amid recent quantum computing advances, though IPsec adoption lagged four years behind TLS due to the community's focus on Quantum Key Distribution, which requires specialized hardware and doesn't work at internet scale.

Techniques for better software testing
This guide presents advanced software testing techniques including randomness, fuzzing, swarm testing, and buggification to catch edge cases that traditional unit and integration tests miss.
Deep dive
- Randomness in testing helps discover bugs in scenarios you didn't explicitly define, applicable to unit tests (randomize inputs), integration tests (randomize function ordering), and property-based tests
- Tuning randomness requires balance: biasing tests toward suspected bug patterns finds those bugs faster but may miss other edge cases entirely if not done carefully
- Swarm testing involves randomly disabling certain features or functions during test runs to allow other code paths to reach extreme states (like a counter growing very large when decrement is disabled)
- Coverage should extend to often-overlooked areas like configuration and administration APIs where bugs congregate, testing the system from cold start through setup
- Testing "good" crashes (expected shutdowns, network-driven failures) is crucial because recovery processes hide many bugs that need to surface during testing
- Buggification artificially injects errors that a function is contractually allowed to throw (e.g., 1% random failure rate during tests) to ensure error-handling code gets exercised
- Concurrency testing is essential for systems supporting multiple clients, transactions, or threads, though the degree of parallelism needs tuning to avoid swamping services
- Validation should happen continuously throughout tests (work → validate → work pattern) rather than only at the end, preventing bugs from canceling out and making debugging easier
- "Eventually" validation is important for liveness properties like availability that may temporarily fail during network issues but should recover
- Test-specific configurations should scale down production thresholds (e.g., running compaction every minute instead of 48 hours, splitting shards at 1KB instead of 1TB) to exercise code that wouldn't trigger in short test runs
Decoder
- Property-based testing: Testing approach that verifies properties hold across randomly generated inputs rather than specific example cases
- Fuzzing: Automated testing technique that provides random or mutated inputs to find crashes and bugs
- Swarm testing: Strategy of randomly disabling subsets of features during test runs to allow remaining features to reach extreme states
- Buggification: Intentionally injecting permitted failures into code during testing to exercise error-handling paths
- Coverage-guided fuzzing: Fuzzing that uses code coverage feedback to generate inputs exploring new execution paths
- Adaptive Random Testing (ART): Enhancement to random testing that generates more evenly distributed inputs
- Safety vs liveness: Safety properties mean "nothing bad happens," liveness/availability means "something good eventually happens"
Original article
Better software testing means going beyond hand-written examples by using randomness, fuzzing, swarm testing, concurrency, fault injection, and test-specific configurations to expose edge cases that normal unit or integration tests miss. Tests should validate continuously, exercise rare failure paths, cover the full system surface, and intentionally test recovery from “good” crashes so bugs surface earlier and are easier to debug.
Kubernetes v1.36: Tiered Memory Protection with Memory QoS
Kubernetes v1.36 refines its Memory QoS feature to provide tiered memory protection that separates hard guarantees for critical pods from soft protection for burstable workloads.
Deep dive
- Kubernetes v1.36 updates the alpha Memory QoS feature to separate memory throttling from memory reservation, giving operators more granular control
- The new memoryReservationPolicy field allows choosing between None (default, throttling only) or TieredReservation (adds memory protection)
- With TieredReservation, Guaranteed Pods receive hard protection via cgroup v2's memory.min, which the kernel will never reclaim even under memory pressure
- Burstable Pods get soft protection via memory.low, which the kernel tries to preserve but can reclaim under extreme pressure to avoid system-wide OOM
- BestEffort Pods receive neither protection, making their memory fully reclaimable
- This fixes a major issue from v1.27 where enabling MemoryQoS would lock all requested memory as memory.min, potentially exhausting node capacity
- Two new alpha metrics track total hard and soft reservations: kubelet_memory_qos_node_memory_min_bytes and kubelet_memory_qos_node_memory_low_bytes
- The kubelet now checks kernel versions at startup and warns if running on kernels older than 5.9, which have a memory.high livelock bug
- The feature requires cgroup v2, Kubernetes v1.36+, and a compatible container runtime (containerd 1.6+ or CRI-O 1.22+)
- Operators can now enable throttling first to observe behavior, then opt into memory reservation when confident the node has sufficient headroom
Decoder
- Memory QoS: Quality of Service for memory, using Linux cgroup v2 controls to guide kernel memory reclamation decisions
- cgroup v2: Second version of Linux control groups, providing hierarchical resource management for processes
- memory.min: cgroup v2 hard memory guarantee that the kernel will never reclaim, triggering OOM killer on other processes if needed
- memory.low: cgroup v2 soft memory protection that the kernel avoids reclaiming under normal pressure but can reclaim under extreme pressure
- memory.high: cgroup v2 throttling threshold; when exceeded, the kernel slows down the process to reduce memory consumption
- Guaranteed Pods: Pods where all containers have equal memory requests and limits
- Burstable Pods: Pods with at least one container having a memory request lower than its limit, or no limit specified
- BestEffort Pods: Pods with no memory or CPU requests or limits specified
- OOM killer: Linux out-of-memory killer that terminates processes when the system runs out of memory
Original article
Kubernetes v1.36 introduced significant updates to its alpha Memory QoS feature, adding opt-in memory reservation with tiered protection that separates Guaranteed Pods (hard protection via memory.min), Burstable Pods (soft protection via memory.low), and BestEffort Pods (no protection).

The forgotten conversation problem in AI chat
AI chat platforms like ChatGPT, Claude, and Gemini can only search conversation titles, not message content, because they inherited messaging-app architecture for what is actually knowledge work.
Deep dive
- ChatGPT has 900 million weekly active users and Claude serves 70% of the Fortune 100, meaning AI chat now represents one of the largest layers of new written human thought on the internet, yet it's barely indexed for retrieval
- Claude.ai's sidebar search only matches conversation titles, ChatGPT searches titles plus minimal metadata, and Gemini searches titles and initial prompts—none offer full-text search across message content
- Auto-generated titles don't solve this because they're created from the first turn of a conversation, not what it eventually became about, so a conversation about fixing a cron job might be titled "Help with deployment script"
- The root cause is architectural: AI chat inherited the messaging-app pattern (chronological scroll, single input field, no anchors) from WhatsApp and Slack, which works for ephemeral messages but fails for persistent knowledge work
- Vannevar Bush's 1945 memex concept, Ted Nelson's 1965 hypertext, and Doug Engelbart's 1968 NLS demo all solved these retrieval problems decades ago with addressable fragments, bidirectional links, and comprehensive search
- All three major platforms retrofitted RAG-based conversational recall in 2025-2026 (where you ask the AI to find past conversations), which is an implicit admission the original architecture was broken
- RAG-based recall has two critical failure modes: it works poorly for keyword queries when users remember specific phrases rather than concepts, and it's opaque with no way to inspect or adjust what was searched
- Modern knowledge tools like Notion, Obsidian, and Roam already implement the missing features (backlinks since 2018, graph views since 2020), proving the patterns exist but haven't reached AI chat
- A proper architecture would include per-message URLs, keyword search across all content, user-controlled tagging and persistence, and cross-conversation linking to maintain project context across sessions
- The author discloses co-founding browser extensions that add memory tools to AI chat platforms, indicating third-party solutions are emerging to fill this gap
Decoder
- RAG (Retrieval-Augmented Generation): A technique where an AI searches through stored text to find relevant context, then generates an answer based on what it retrieved, rather than direct keyword matching
- Memex: Vannevar Bush's 1945 hypothetical desk-sized machine that would store all personal documents and let users build named "trails" of association across the corpus for later retrieval
- Hypertext: Ted Nelson's 1965 concept for non-sequential writing where every text fragment is addressable and linkable, with bidirectional links by default so documents know what references them
- NLS (oN-Line System): Doug Engelbart's 1968 system that introduced the mouse, hypertext, and live cross-referenced editing, demonstrating that every text fragment should be addressable and retrievable
- Evergreen notes: Andy Matuschak's knowledge architecture where units of thought are atomic, concept-oriented, densely linked, and organized by association rather than chronology
- PARA method: Tiago Forte's system organizing information by actionability using Projects, Areas, Resources, and Archives rather than topics or chronology
Original article
AI chat platforms like ChatGPT, Claude, and Gemini suffer from a “forgotten conversation” problem because they use messaging-style interfaces that don't properly index or organize content, making past insights hard to retrieve. Despite recent AI-powered recall features, decades of research—from Vannevar Bush to modern knowledge systems—show that effective solutions already exist, pointing to the need for searchable, linkable, and user-controlled knowledge architectures rather than chat-based threads.
Design Systems are Now Inference Systems
Design systems are evolving from static component libraries into "Inference Systems" where AI agents dynamically generate interfaces using adaptive parameters instead of fixed patterns.
Deep dive
- Traditional design systems from the 2010s defined fixed patterns (buttons, modals, forms) that designers assembled into screens, assuming stable layouts and fixed input modalities
- AI agents now generate interfaces dynamically mid-conversation, creating surfaces that didn't exist as designed artifacts when the interaction started—breaking the assumptions of traditional design systems
- The shift from patterns to parameters means instead of defining "the modal is 480px wide with 24px padding," you define "the modal expresses focused attention; its width compresses when context is dense and expands for multi-step tasks"
- Parameters give the system behavioral rules it can apply in conditions the original designer never anticipated, allowing it to invent components the library doesn't contain
- Design tokens are evolving from storing values (
--color-primary: #0066FF) to storing intent (--color-interactive-primarywith semantic meaning, usage rules, and relationships) - When models know why to use interactive-primary ("the most prominent action in a given context"), they can make defensible choices in unseen layouts rather than just matching colors
- MCP servers and Google Stitch's design.md file exemplify the shift: design artifacts become structured data that both humans and AI can consume as first-class outputs
- Traditional governance through human review (checking if teams used the right component) breaks when AI generates layouts and revises them seconds later—the volume of decisions jumps by orders of magnitude
- Inference systems need to evaluate conformance as work is produced and learn from what gets built, treating the system as a sensor rather than a wall
- A single deviation is likely a mistake, but fourteen teams independently building the same off-system component signals the system is behind its users and needs to evolve
- Airbnb is classifying 150+ components with ML so AI tools can assemble prototypes from user behavior rather than from a designer's blank canvas
- Success metrics must evolve from "adoption" (how many teams use your components) to "adaption" (how well the system learns from what teams and agents actually build)
- Prototypes become first-class context and signals of what needs to grow, though not every prototype should go to production—the insight is the artifact
- Teams who understand this shift will rebuild their design systems to look less like component catalogs and more like the model's understanding of their product
Decoder
- Design System: A collection of reusable UI components, patterns, and guidelines that ensure consistency across a product
- Design Tokens: Variables that store design decisions like colors, spacing, and typography (e.g.,
--color-primary: #0066FF) - Agentic Experience: Interactions driven by AI agents that dynamically generate and adapt interfaces rather than following predefined flows
- MCP (Model Context Protocol): A protocol that allows AI models to access structured data about design artifacts like Figma files
- Inference System: A design system that AI models can reason about and use to generate appropriate UI dynamically, rather than just a reference catalog
- Semantic Tokens: Design tokens that capture intent and meaning (why to use something) rather than just values (what it looks like)
- Blitzscaling: The rapid growth strategy many tech companies pursued in the 2010s
Original article
Design systems, built in the 2010s for human-scale processes, are becoming "Inference Systems" as AI agents now assemble interfaces dynamically rather than following prescribed patterns. The shift involves three core changes: static patterns give way to adaptive parameters, human-readable documentation becomes machine-parseable context, and governance evolves from review checkpoints into continuous feedback loops. Success metrics must also evolve — adoption alone is insufficient, and adaptation, meaning how well the system learns from what teams actually build, becomes the defining measure.

xAI has launched Grok 4.3
xAI released Grok 4.3 with significantly reduced pricing and improved real-world agentic performance while achieving higher intelligence scores than its predecessor.
Deep dive
- Grok 4.3 achieves a 4-point improvement on the Intelligence Index over Grok 4.20 0309 v2 while reducing the total cost to run the full benchmark suite by approximately 20% to $395
- The model shows a massive 321-point ELO increase on GDPval-AA (from 1179 to 1500), a real-world agentic task benchmark, surpassing models like Gemini 3.1 Pro Preview and Muse Spark
- Despite the improvements, Grok 4.3 still trails GPT-5.5 (xhigh) by 276 ELO points on agentic tasks, with only a 17% expected win rate under standard ELO calculations
- The model reaches 98% on τ²-Bench Telecom for instruction following, matching GLM-5.1, and maintains an 81% IFBench score
- Token usage increased by approximately 44% compared to Grok 4.20, but the dramatic price cuts (37.5% lower input, 58.3% lower output) more than compensate
- Performance on knowledge tasks shows mixed results: 8-point gain in AA-Omniscience Accuracy but 8-point decrease in Non-Hallucination Rate
- The model sits on the Pareto frontier for intelligence versus cost, representing one of the best cost-efficiency tradeoffs at its intelligence level
- Grok 4.3's verbosity remains moderate compared to other frontier models, using similar token counts to Minimax M2.7
Decoder
- Intelligence Index: Artificial Analysis's composite benchmark measuring AI model performance across multiple evaluations including reasoning, coding, and knowledge tasks
- GDPval-AA: A real-world agentic task evaluation that measures how well models can complete practical multi-step tasks like a customer service agent
- ELO score: A rating system borrowed from chess that estimates relative skill levels, where higher scores indicate better performance and score differences predict win rates
- τ²-Bench (Tau-squared Bench): A benchmark measuring instruction-following abilities in specific domains like telecommunications customer support
- Agentic tasks: Multi-step problems requiring the model to plan, use tools, and adapt its approach autonomously rather than just responding to single prompts
- IFBench: Instruction Following Benchmark, measuring how accurately models comply with specific instructions
- AA-Omniscience: Artificial Analysis benchmark measuring factual knowledge accuracy and tendency to hallucinate or guess incorrectly
- Pareto frontier: The set of optimal tradeoffs where improving one metric (like intelligence) requires sacrificing another (like cost)
Original article
Grok 4.3
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20
The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite.
Key Takeaways
- Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level
- Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2's score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula
- Grok 4.3's performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2
- Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3
Congratulations to @xAI and @elonmusk on the impressive release! This release shows increased cost efficiency to run the Artificial Analysis Intelligence Index, with Grok 4.3 sitting comfortably on the Pareto frontier for intelligence versus cost
Driven by 37.5% lower input token prices and 58.3% lower output token prices, it costs $395 to run the Intelligence Index evaluations, an overall ~20% decrease from Grok 4.20 0309 v2
Grok 4.3 uses ~44% more output tokens to run the Artificial Analysis Intelligence Index than Grok 4.20 0309 v2, but uses a similar number of tokens to models like Minimax M2.7 and remains less verbose than other leading models
The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2's score of 1179
Breakdown of individual evaluations, including leading scores on 𝜏²-Bench Telecom and IFBench
See Artificial Analysis for further details and benchmarks: artificialanalysis.ai/models/grok-4-3
Gemini 3.1 Pro Preview
Google is once again the leader in AI: Gemini 3.1 Pro Preview leads the Artificial Analysis Intelligence Index, 4 points ahead of Claude Opus 4.6 while costing less than half as much to run
@GoogleDeepMind gave us pre-release access to Gemini 3.1 Pro Preview. It leads 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index and improves significantly over Gemini 3 Pro Preview across capabilities, with the biggest gains in reasoning and knowledge, coding, and hallucination reduction.
Gemini 3.1 Pro Preview also remains relatively token efficient, using ~57M tokens to run the Artificial Analysis Intelligence Index (+1M from Gemini 3 Pro Preview), lower than other frontier models at max reasoning settings such as Opus 4.6 (max) and GPT-5.2 (xhigh). Combined with lower per-token pricing, Gemini 3.1 Pro Preview is cost-efficient among frontier peers, costing less than half as much as Opus 4.6 (max) to run the full Intelligence Index, though still nearly 2x the leading open-weights model, GLM-5.
Key Takeaways
- State-of-the-art intelligence at lower costs: Gemini 3.1 Pro Preview is leading 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index at less than half the cost to run of frontier peers from @OpenAI and @AnthropicAI. It obtains the highest score in Terminal-Bench Hard (agentic coding), AA-Omniscience (knowledge & hallucination), Humanity's Last Exam (reasoning & knowledge), GPQA-Diamond (scientific reasoning), SciCode (coding) and CritPt (research-level physics). The CritPt score is particularly notable, scoring 18% on unpublished, research-level physics reasoning problems, over 5 p.p. above the next best model
- Improved real-world agentic performance, but not leading: Gemini 3.1 Pro Preview shows an improvement in GDPval-AA, our agentic evaluation focusing on real-world tasks, but is still not the leading model in this area. The model increases its ELO score over 100 points to 1316 (up from Gemini 3 Pro Preview), however still sits behind Claude Sonnet 4.6, Opus 4.6, GPT-5.2 (xhigh), and GLM-5
- Leading coding abilities: Gemini 3.1 Pro Preview leads the Artificial Analysis Coding Index, achieving the highest score in both Terminal-Bench Hard (54%) and SciCode (59%)
- Reduced hallucinations: Gemini 3.1 Pro Preview shows a major improvement in tendency to guess incorrectly when it doesn't know the answer, reducing its AA-Omniscience hallucination rate by 38 p.p. from Gemini 3 Pro Preview
- Maintained token and cost efficiency: Gemini 3.1 Pro Preview improves without material increases in cost or token usage. It uses only ~2% more tokens to run the Artificial Analysis Intelligence Index than Gemini 3 Pro Preview, and keeps the same pricing ($2/$12 per 1M input/output tokens for ≤200k context). Its cost to run the Artificial Analysis Intelligence Index of $892 is less than half of frontier models such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open weights models such as GLM 5 ($547)
- Google takes top 3 spots in multi-modality: Gemini 3.1 Pro Preview ranks #1 on MMMU-Pro, our multimodal understanding and reasoning benchmark, ahead of Gemini 3 Pro Preview and Gemini 3 Flash, reinforcing Google's leadership in multimodal reasoning
- Other model details: Gemini 3.1 Pro Preview retains the same 1 million token context window as its predecessor, and includes support for tool calling, structured outputs, and JSON mode
Gemini 3.1 Pro Preview improves without becoming more expensive or much more verbose, using only ~1M more tokens compared to Gemini 3 Pro Preview, representing a $72 increase in cost to run the Artificial Analysis Intelligence Index. This cost is less than half of frontier peers such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open-weights models such as GLM 5 and Kimi K2.5.
Gemini 3.1 Pro Preview has an average speed of 114 output tokens/s. Although slightly slower than its predecessor (-10 t/s), it remains one of the fastest models in the top 10 of the Artificial Analysis Intelligence Index, trailing only other Google models (Gemini 3 Flash and Gemini 3 Pro Preview).
MiMo-V2-Flash
Xiaomi has just launched MiMo-V2-Flash, a 309B open weights reasoning model that scores 66 on the Artificial Analysis Intelligence Index. This release elevates Xiaomi to alongside other leading AI model labs.
Key benchmarking takeaways
- Strengths in Agentic Tool Use and Competition Math: MiMo-V2-Flash scores 95% on τ²-Bench Telecom and 96% on AIME 2025, demonstrating strong performance on agentic tool-use workflows and competition-style mathematical reasoning. MiMo-V2-Flash currently leads the τ²-Bench Telecom category among evaluated models
- Cost competitive: The full Artificial Analysis evaluation suite cost just $53 to run. This is supported by MiMo-V2-Flash's highly competitive pricing of $0.10 per million input and $0.30 per million output, making it particularly attractive for cost-sensitive deployments and large-scale production workloads. This is similar to DeepSeek V3.2 ($54 total cost to run), and well below GPT-5.2 ($1,294 total cost to run)
- High token usage: MiMo-V2-Flash is demonstrates high verbosity and token usage relative to other models in the same intelligence tier, using ~150M reasoning tokens across the Artificial Analysis Intelligence suite
- Open weights: MiMo-V2-Flash is open weights and is 309B parameters with 15B active at inference time. Weights are released under a MIT license, continuing the trend of Chinese AI model labs open sourcing their frontier models
MiMo-V2-Flash demonstrates particular strength in agentic tool-use and Competition Math, scoring 95% on τ²-Bench Telecom and 96% on AIME 2025. This places it amongst the best performing models in these categories.
MiMo-V2-Flash is one of the most cost-effective models for its intelligence, priced at only $0.10 per million input tokens and $0.30 per million output tokens.
Stirrup
Announcing Stirrup, our new open source framework for building agents. It's lightweight, flexible, extensible and incorporates best-practices from leading agents like Claude Code
Stirrup differs from other agent frameworks by avoiding the rigidity that can degrade output quality. Stirrup lets models drive their own workflow, like Claude Code, while still giving developers structure and building in essential features like context management, MCP support and code execution. We use Stirrup at Artificial Analysis as part of our agentic benchmarks, including as part of our GDPval-AA evaluation being released later today. Just 'pip install stirrup' to start building your own agents today!
Key advantages
- Works with the model, not against it: Stirrup steps aside and lets the model decide how to solve multi step tasks, as opposed to existing frameworks which impose strict patterns that limit performance.
- Best practices built in: We studied leading agent systems (e.g. Claude Code) to extract practical patterns around context handling, tool design, and workflow stability, and embedded those directly into the framework.
- Fully customizable: Use Stirrup as a package or as a starting template to build your own fully customized agents.
Feature highlights
- Essential tools ready to use: Ships with pre built tools such as online search and browsing, code execution (local, docker, or using an @e2b sandbox), MCP client and document IO
- Flexible tool layer: A Generic Tool interface makes it simple to define and extend custom tools
- Context management: Automatic summarization to stay within context limits while preserving task fidelity
- Provider flexibility: Built in support for OpenAI compatible APIs (including @OpenRouterAI) and LiteLLM, or bring your own client
- Multimodal support: Process images, video, and audio with automatic format handling
Stirrup agents can be easily set up in just a few lines of code
Stirrup includes built in logging to help you observe and debug agents
Artificial Analysis Openness Index
Introducing the Artificial Analysis Openness Index: a standardized and independently assessed measure of AI model openness across availability and transparency
Openness is not just the ability to download model weights. It is also licensing, data and methodology - we developed a framework underpinning the Artificial Analysis Openness Index to incorporate these elements. It allows developers, users, and labs to compare across all these aspects of openness on a standardized basis, and brings visibility to labs advancing the open AI ecosystem.
A model with a score of 100 in Openness Index would be open weights and permissively licensed with full training code, pre-training data and post-training data released - allowing users to not just use the model but reproduce its training in full, or take inspiration from some or all of the model creator's approach to build their own model. We have not yet awarded any models a score of 100!
Key details
- Few models and providers take a fully open approach. We see a strong and growing ecosystem of open weights models, including leading models from Chinese labs such as Kimi K2, Minimax M2, and DeepSeek V3.2. However, releases of data and methodology are much rarer - OpenAI's gpt-oss family is a prominent example of open weights and Apache 2.0 licensing, but minimal disclosure otherwise.
- OLMo from @allen_ai leads the Openness Index at launch. Living up to AI2's mission to provide 'truly open' research, the OLMo family achieves the top score of 89 (16 of a maximum of 18 points) on the Index by prioritizing full replicability and permissive licensing across weights, training data, and code. With the recent launch of OLMo 3, this included the latest version of AI2's data, utilities and software, full details on reasoning model training, and the new Dolci post-training dataset.
- NVIDIA's Nemotron family also performs strongly for openness. @NVIDIAAI models such as NVIDIA Nemotron Nano 9B v2 reach a score of 67 on the Index due to their release alongside extensive technical reports detailing their training process, open source tooling for building models like them, and the Nemotron-CC and Nemotron post-training datasets.
- We're tracking both open weights and closed weights models. Openness Index is a new way to think about how open models are, and we will be ranking closed weights models alongside open weights models to recognize the scope of methodology and data transparency associated with closed model releases.
Methodology & Context
- We analyze openness using a standardized framework covering model availability (weights & license) and model transparency (data and methodology). This means we capture not just how freely a model can be used, but visibility into its training and knowledge, and potential to replicate or build on its capabilities or data.
- Model availability is measured based on the access and licensing of the model/weights themselves, while transparency comprises subcomponents for access and licensing for methodology, pre-training data, and post-training data.
- As seen with releases like DeepSeek R1, sharing methodology accelerates progress. We hope the Index encourages labs to balance competitive moats with the benefits of sharing the "how" alongside the "what."
- AI model developers may choose not to fully open their models for a wide range of reasons. We feel strongly that there are important advantages to the open AI ecosystem and supporting the open ecosystem is a key reason we developed the Openness Index. We do not, however, wish to dismiss the legitimacy of the tradeoffs that greater openness comes with, and we do not intend to treat Openness Index as a strictly 'higher is better' scale.
The Openness Index breaks down a total of 18 points across the four subcomponents, and we then represent the overall value on a normalized 0-100 scale. We will continue to review and iterate this framework as the model ecosystem develops and new factors emerge.
In today's model landscape, transparency is much rarer than availability. While we see a wide range of models with open weights and permissive licensing, nearly all are clustered in the top left quadrant of the chart with lower-end transparency. This reflects the current state of the ecosystem - many models have open weights, but few have open data or methodologies.
Claude Opus 4.5
Anthropic's new Claude Opus 4.5 is the #2 most intelligent model in the Artificial Analysis Intelligence Index, narrowly behind Google's Gemini 3 Pro and tying OpenAI's GPT-5.1 (high)
Claude Opus 4.5 delivers a substantial intelligence uplift over Claude Sonnet 4.5 (+7 points on the Artificial Analysis Intelligence Index) and Claude Opus 4.1 (+11 points), establishing it as @AnthropicAI's new leading model. Anthropic has dramatically cut per-token pricing for Claude Opus 4.5 to $5/$25 per million input/output tokens. However, compared to the prior Claude Opus 4.1 model it used 60% more tokens to complete our Intelligence Index evaluations (48M vs. 30M). This translates to a substantial reduction in the cost to run our Intelligence Index evaluations from $3.1k to $1.5k, but not as significant as the headline price cut implies. Despite Claude Opus 4.5 using substantially more tokens to complete our Intelligence Index, the model still cost significantly more than other models including Gemini 3 Pro (high), GPT-5.1 (high), and Claude Sonnet 4.5 (Thinking), and among all models only cost less than Grok 4 (Reasoning).
Key benchmarking takeaways
- Anthropic's most intelligent model: In reasoning mode, Claude Opus 4.5 scores 70 on the Artificial Analysis Intelligence Index. This is a jump of +7 points from Claude Sonnet 4.5 (Thinking), which was released in September 2025, and +11 points from Claude Opus 4.1 (Thinking). Claude Opus 4.5 is now the second most intelligent model. It places ahead of Grok 4 (65) and Kimi K2 Thinking (67), ties GPT-5.1 (high, 70), and trails only Gemini 3 Pro (73). Claude Opus 4.5 (Thinking) scores 5% on CritPt, a frontier physics eval reflective of research assistant capabilities. It sits only behind Gemini 3 Pro (9%) and ties GPT-5.1 (high, 5%)
- Largest increases in coding and agentic tasks: Compared to Claude Sonnet 4.5 (Thinking), the biggest uplifts appear across coding, agentic tasks, and long-context reasoning, including LiveCodeBench (+16 p.p.), Terminal-Bench Hard (+11 p.p.), 𝜏²-Bench Telecom (+12 p.p.), AA-LCR (+8 p.p.), and Humanity's Last Exam (+11 p.p.). Claude Opus achieves Anthropic's best scores yet across all 10 benchmarks in the Artificial Analysis Intelligence Index. It also earns the highest score on Terminal-Bench Hard (44%) of any model and ties Gemini 3 Pro on MMLU-Pro (90%)
- Knowledge and Hallucination: In our recently launched AA-Omniscience Index, which measures embedded knowledge and hallucination of language models, Claude Opus 4.5 places 2nd with a score of 10. It sits only behind Gemini 3 Pro Preview (13) and ahead of Claude Opus 4.1 (Thinking, 5) and GPT-5.1 (high, 2). Claude Opus 4.5 (Thinking) scores the second-highest accuracy (43%) and has the 4th-lowest hallucination rate (58%), trailing only Claude Haiku (Thinking, 26%), Claude Sonnet 4.5 (Thinking, 48%), and GPT-5.1 (high). Claude Opus 4.5 continues to demonstrate Anthropic's leadership in AI safety with a lower hallucination rate than select other frontier models such as Grok 4 and Gemini 3 Pro
- Non-reasoning performance: In non-reasoning mode, Claude Opus 4.5 scores 60 on the Artificial Analysis Intelligence Index and is the most intelligent non-reasoning model. It places ahead of Qwen3 Max (55), Kimi K2 0905 (50), and Claude Sonnet 4.5 (50)
- Token efficiency: Anthropic continues to demonstrate impressive token efficiency. It has improved intelligence without a significant increase in token usage (compared to Claude Sonnet 4.5, evaluated with a maximum reasoning budget of 64k tokens). Claude Opus 4.5 uses 48M output tokens to run the Artificial Analysis Intelligence Index. This is lower than other frontier models, such as Gemini 3 Pro (high, 92M), GPT-5.1 (high, 81M), and Grok 4 (Reasoning, 120M)
- Pricing: Anthropic has reduced the per-token pricing of Claude Opus 4.5 compared to Claude Opus 4.1. Claude Opus 4.5 is priced at $5/$25 per 1M input/output tokens (vs. $15/$75 for Claude Opus 4.1). This positions it much closer to Claude Sonnet 4.5 ($3/$15 per 1M tokens) while offering higher intelligence in thinking mode
Key model details
- Context window: 200K tokens
- Max output tokens: 64K tokens
- Availability: Claude Opus 4.5 is available via Anthropic's API, Google Vertex, Amazon Bedrock and Microsoft Azure. Claude Opus 4.5 is also available via Claude app and Claude Code
A key differentiator for the Claude models remains that they are substantially more token-efficient than all other reasoning models. Claude Opus 4.5 has significantly increased intelligence without a large increase in output tokens, differing substantially from other model families that rely on greater reasoning at inference time (i.e., more output tokens). On the Output Tokens Used in Artificial Analysis Intelligence Index vs Intelligence Index chart, Claude 4.5 Opus (Thinking) sits on the Pareto frontier.
This output token efficiency contributes to Claude Opus 4.5 (in Thinking mode) offering a better tradeoff between intelligence and cost to run the Artificial Analysis Intelligence Index than Claude Opus 4.1 (Thinking) and Grok 4 (Reasoning).
Gemini 3 Pro
Gemini 3 Pro is the new leader in AI. Google has the leading language model for the first time, with Gemini 3 Pro debuting +3 points above GPT-5.1 in our Artificial Analysis Intelligence Index
@GoogleDeepMind gave us pre-release access to Gemini 3 Pro Preview. The model outperforms all other models in Artificial Analysis Intelligence Index. It demonstrates strength across the board, coming in first in 5 of the 10 evaluations that make up Intelligence Index. Despite these intelligence gains, Gemini 3 Pro Preview shows improved token efficiency from Gemini 2.5 Pro, using significantly fewer tokens on the Intelligence Index than other leading models such as Kimi K2 Thinking and Grok 4. However, given its premium pricing ($2/$12 per million input/output tokens for <200K context), Gemini 3 Pro is among the most expensive models to run our Intelligence Index evaluations.
Key takeaways
- Leading intelligence: Gemini 3 Pro Preview is the leading model in 5 of 10 evals in the Artificial Analysis Intelligence Index, including GPQA Diamond, MMLU-Pro, HLE, LiveCodeBench and SciCode. Its score of 37% on Humanity's Last Exam is particularly impressive, improving on the previous best model by more than 10 percentage points. It also is leading in AA-Omniscience, Artificial Analysis' new knowledge and hallucination evaluation, coming first in both Omniscience Index (our lead metric that takes off points for incorrect answers) and Omniscience Accuracy (percentage correct). Given that factual recall correlates closely with model size, this may point to Gemini 3 Pro being a much larger model than its competitors
- Advanced coding and agentic capabilities: Gemini 3 Pro Preview leads two of the three coding evaluations in the Artificial Analysis Intelligence Index, including an impressive 56% in SciCode, an improvement of over 10 percentage points from the previous highest score. It is also strong in agentic contexts, achieving the second highest score in Terminal-Bench Hard and Tau2-Bench Telecom
- Multimodal capabilities: Gemini 3 Pro Preview is a multi-modal model, with the ability to take text, images, video and audio as input. It scores the highest of any model on MMMU-Pro, a benchmark that tests reasoning abilities with image inputs. Google now occupies the first, third and fourth position in our MMMU-Pro leaderboard (with GPT-5.1 taking out second place just last week)
- Premium Pricing: To measure cost, we report Cost to Run the Artificial Analysis Intelligence Index, which combines input and output token prices with token efficiency to reflect true usage cost. Despite the improvement in token efficiency from Gemini 2.5 Pro, Gemini 3 Pro Preview costs more to run. Its higher token pricing of $2/$12 USD per million input/output tokens (≤200k token context) results in a 12% increase in the cost to run the Artificial Analysis Intelligence Index compared to its predecessor, and the model is among the most expensive to run on our Intelligence Index. Google also continues to price long context workloads higher than lower context workloads, charging $4/$18 per million input/output tokens for ≥200k token context.
- Speed: Gemini 3 Pro Preview has comparable speeds to Gemini 2.5 Pro, with 128 output tokens per second. This places it ahead of other frontier models including GPT-5.1 (high), Kimi K2 Thinking and Grok 4. This is potentially supported by Google's first-party TPU accelerators
- Other details: Gemini 3 Pro Preview has a 1 million token context window, and includes support for tool calling, structured outputs, and JSON mode
For the first time, Google has the most intelligent model, with Gemini 3 Pro Preview improving on the previous most intelligent model, OpenAI's GPT-5.1 (high), by 3 points
Gemini 3 Pro Preview takes the top spot on the Artificial Analysis Omniscience Index, our new benchmark for measuring knowledge and hallucination across domains. Gemini 3 Pro Preview comes in first for both Omniscience Index (our lead metric that takes off points for incorrect answers) and Omniscience Accuracy (percentage correct).
Its win in Accuracy is actually much larger than than its overall Index win - this is driven by a higher Hallucination Rate than other models (88%).
We have previously shown that Omniscience Accuracy is closely correlated with model size (total parameter count). Gemini 3 Pro's significant lead in this metric may point to it being a much larger model than its competitors.

Tracing the Goblin Quirk in GPT Models
OpenAI traced GPT models' increasing use of goblin metaphors to unintended reward signals in personality tuning, revealing how small training incentives can spread unpredictably across model behavior.
Deep dive
- Goblin mentions in ChatGPT rose 175% after GPT-5.1 launch, with gremlins up 52%, initially appearing harmless but escalating over subsequent model versions
- Investigation found 66.7% of goblin mentions came from the "Nerdy" personality despite it representing only 2.5% of all responses
- The Nerdy personality reward model scored outputs containing "goblin" or "gremlin" higher than identical outputs without them in 76.2% of audited datasets
- Behavior transferred to non-Nerdy contexts because reinforcement learning doesn't guarantee learned patterns stay scoped to their original training condition
- A feedback loop emerged: playful style rewarded → distinctive tics in those outputs → tics appear more in rollouts → rollouts used for supervised fine-tuning → model produces tic more confidently
- Other creature words identified as tics included raccoons, trolls, ogres, and pigeons (though most frog uses were legitimate)
- OpenAI retired the Nerdy personality in March 2026 and filtered creature-words from training data, but GPT-5.5 had already started training before the fix
- GPT-5.5 required developer-prompt instructions to suppress the behavior, which users can disable via command-line flags in Codex
- OpenAI built new auditing tools to track how specific lexical patterns correlate with reward signals across training datasets
- The case demonstrates that model behavior emerges from many small incentives interacting unpredictably, not just major architectural or dataset changes
Decoder
- Reward signal: Numerical score that tells a reinforcement learning model whether an output is desirable, guiding what behaviors get reinforced during training
- Rollouts: Model-generated outputs produced during reinforcement learning training, often reused as training data in subsequent steps
- SFT (Supervised Fine-Tuning): Training phase where the model learns from curated examples, including previously generated outputs
- Transfer learning: When a model applies patterns learned in one context to unrelated situations
- System prompt: Instructions given to a model that shape its personality and response style
Original article
OpenAI linked increased use of “goblin”-style metaphors in GPT-5.1 to reward signals from personality tuning, showing how small incentives can shape model behavior.
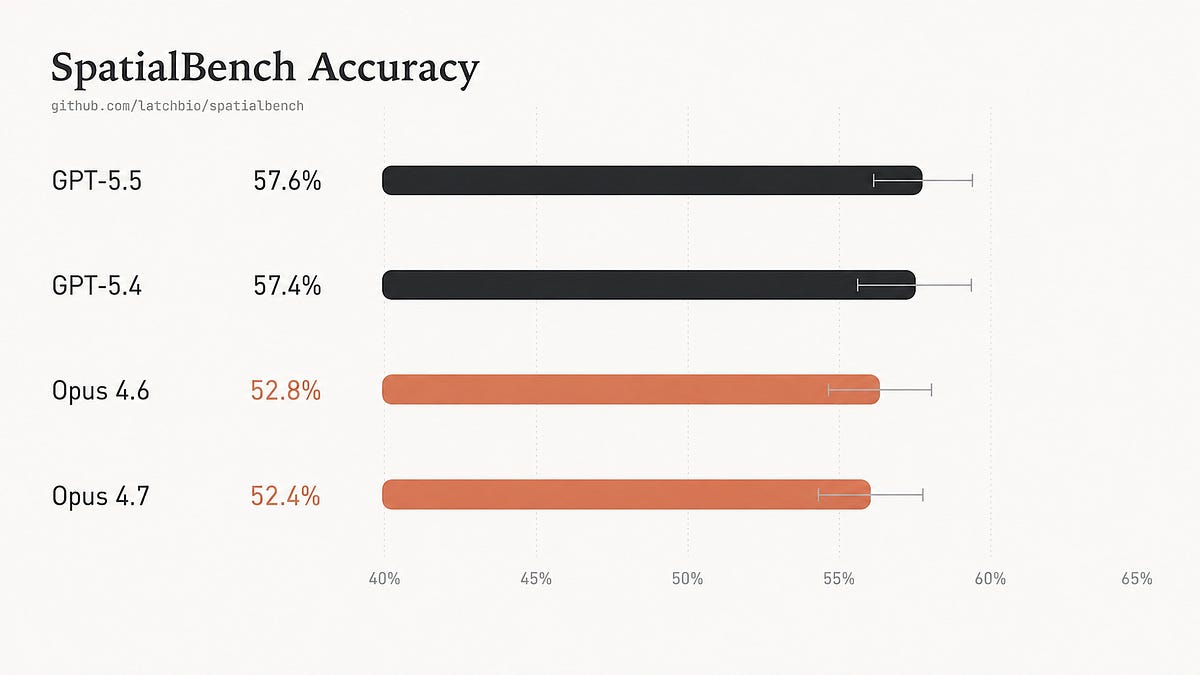
New Frontier Models Are Faster, Not More Reliable, at Spatial Biology
New frontier AI models like GPT-5.5 and Opus 4.7 run spatial biology analysis tasks twice as fast as their predecessors but show no improvement in accuracy, revealing that general reasoning gains don't transfer to specialized scientific domains.
Deep dive
- GPT-5.5 cut mean runtime roughly in half compared to GPT-5.4 and used far fewer steps, but accuracy remained effectively unchanged at 57.65% versus 57.44% on SpatialBench's 159 spatial biology analysis tasks
- Opus 4.7 similarly showed no accuracy improvement over Opus 4.6, scoring 52.41% versus 52.83%, though performance varied significantly by platform with some gaining 11 percentage points on Xenium while losing ground on other platforms
- The most common failure mode is pseudoreplication: models treat thousands of individual barcodes, cells, or beads as independent observations when the true biological replicate is the donor, animal, or tissue section, artificially inflating statistical power
- On a sex-difference analysis task with 8 donors, all models reported 92-94% of genes as differentially expressed, a biologically implausible result that should have been around 1.2% when properly aggregating at the donor level
- Models consistently called 9-10 housekeeping genes (like ACTB and GAPDH) as sex-differential, a clear statistical error that indicates they're treating nested data incorrectly
- GPT-5.5 applied inappropriate normalization to targeted MERFISH panels, turning a positive correlation of 0.308 between myelin genes into a negative correlation of -0.157, making co-expressed genes appear anti-correlated
- Both GPT and Opus models failed to integrate multi-donor datasets before clustering, resulting in clusters dominated by single donors (0.99 max fraction) rather than representing actual cell types (expected 0.375)
- On spatial unit tasks, models counted marker-positive beads as individual cells or structures, inflating oocyte counts from expected 275 to 424-821 and hallucinating 435-2395 cumulus cells that shouldn't exist in immature samples
- Models struggle with de novo spatial niche discovery, confusing generic cell proximity for specific disease-organized tissue compartments and missing composition ratios that distinguish pathological from healthy tissue
- Scientist review of trajectories identified five recurring failure categories: replicate misidentification, platform-inappropriate normalization defaults, batch-confounded clustering, spatial unit confusion, and biological constraint violations
- The benchmark requires combining code generation with biological reasoning: agents must handle large datasets, understand platform-specific technical details, and return quantitative results matching expert analysis
- Platform-specific results varied substantially—GPT-5.5 improved on Visium, Xenium, and MERFISH but regressed on TakaraBio and AtlasXomics compared to GPT-5.4, suggesting unstable rather than general improvement
Decoder
- Spatial biology: Measurement techniques that preserve the physical location of cells and molecules in tissue, allowing analysis of where specific genes are expressed and how cells are organized spatially
- Xenium, Visium, MERFISH: Commercial spatial biology platforms that measure gene expression while preserving tissue architecture, each with different technical approaches and analysis requirements
- Pseudoreplication: Statistical error of treating non-independent measurements as independent, such as analyzing 10,000 barcodes from 8 donors as if they were 10,000 separate donors, vastly inflating statistical significance
- Housekeeping genes: Genes like ACTB and GAPDH that are constitutively expressed in all cells to maintain basic cellular functions, expected to show no variation between conditions
- Barcodes/beads/spots: Physical units of measurement in spatial assays that capture RNA from tissue, not equivalent to individual cells—a single large cell can span multiple units, or multiple cells can share one unit
- Batch correction/integration: Statistical methods to remove technical variation between experimental runs, donors, or timepoints before analyzing biological differences
- scRNA-seq normalization: Standard preprocessing steps for single-cell RNA sequencing that are often inappropriate for spatial platforms due to different technical properties like targeted gene panels or spatial capture efficiency
- Spatial niche: Organized tissue microenvironment with specific cell type composition and spatial arrangement that emerges in development or disease, not just generic proximity of cell types
Original article
GPT-5.5 nearly halves runtime on SpatialBench relative to GPT-5.4, but its accuracy remains about the same. Opus 4.7 is similarly tied with Opus 4.6. Improvements and spatial biology are unlikely to come from general reasoning gains alone. It will likely require explicit training on statistical design, platform-specific analysis stems, replicate-aware differential testing, and other spatial biology knowledge.
AWS Neuron SDK now available with Neuron Agentic Development for NKI kernel development on Trainium
AWS released an open-source toolkit that lets AI coding assistants write and optimize custom compute kernels for Trainium chips using natural language instead of manual low-level code.
Decoder
- NKI (Neuron Kernel Interface): Low-level programming interface for writing custom compute kernels on AWS Trainium
- AWS Trainium: Amazon's custom chip designed for AI model training
- AWS Inferentia: Amazon's custom chip designed for AI model inference
- Agentic IDE: Development environment powered by AI agents that assist with coding tasks through natural language
- Compute kernels: Low-level code that executes specific operations directly on hardware accelerators
Original article
AWS Neuron SDK now available with Neuron Agentic Development for NKI kernel development on Trainium
AWS Neuron announces the Neuron Agentic Development capabilities, an open-source collection of agents and skills that equip AI coding assistants to accelerate development on AWS Trainium and AWS Inferentia. The initial release provides agentic coding capabilities for Neuron Kernel Interface (NKI) kernel development, covering the workflow from authoring to profiling and performance analysis.
NKI gives developers direct, low-level programming access to Trainium for writing custom compute kernels that maximize hardware performance. Neuron Agentic Development brings NKI expertise directly into the developer's agentic IDE (such as Claude Code and Kiro) through natural language. For example, a developer can describe a PyTorch operation and receive a working NKI kernel, ask the agent to fix a compilation error and have it automatically identify the issue and apply a correction, or request a performance analysis and receive a report identifying which lines of kernel code are causing bottlenecks. The capabilities span kernel authoring, debugging, documentation lookup, profile capture, and profile analysis.
Neuron Agentic Development is designed as a broad framework for agentic capabilities across the Neuron stack, with NKI kernel development as the initial release. The repository is available on GitHub.
Learn more:
Speculative Decoding for RL Training
Researchers achieved up to 1.8x faster reinforcement learning training for large language models by applying speculative decoding to rollout generation without changing model outputs.
Deep dive
- The paper addresses autoregressive rollout generation as the primary bottleneck in RL post-training for frontier language models
- Speculative decoding is implemented as a "lossless" acceleration method that preserves the target model's exact output distribution, unlike off-policy execution or lower-precision alternatives
- The implementation supports both synchronous and asynchronous RL pipelines in NeMo-RL with vLLM backend
- Multiple speculation mechanisms work with this approach: pretrained MTP heads, small external draft models, and techniques like Eagle3
- In synchronous RL workloads at 8B parameter scale, the system achieved 1.8x rollout throughput improvement on reasoning tasks
- High-fidelity performance simulations project up to 2.5x end-to-end training speedup when combining speculative decoding with asynchronous RL at 235B scale
- The approach enables deployment of state-of-the-art speculative decoding techniques that were traditionally only applied after the RL training phase
- The system integration demonstrates that speculative decoding benefits are realizable across different speculation mechanisms during active training
- This work provides a practical deployment path for production RL training systems facing rollout generation bottlenecks
Decoder
- Speculative decoding: A technique where a faster draft model generates candidate tokens that a larger target model verifies in parallel, speeding up inference while maintaining exact output quality
- RL rollouts: The process of generating sequences from a language model during reinforcement learning training, which are then scored and used to update the model
- RL post-training: Fine-tuning pre-trained language models using reinforcement learning methods (like RLHF) to improve alignment, reasoning, or other capabilities
- MTP heads: Multi-Token Prediction heads that predict multiple future tokens simultaneously, used as one form of draft mechanism for speculation
- Eagle3: A specific speculative decoding technique, part of the Eagle family of methods for accelerating language model generation
Original article
Accelerating RL Post-Training Rollouts via System-Integrated Speculative Decoding
Abstract
RL post-training of frontier language models is increasingly bottlenecked by autoregressive rollout generation, making rollout acceleration a central systems challenge. Many existing efficiency methods improve throughput by changing the rollout or optimization regime, for example, through off-policy execution, replay, or lower-precision generation. We study speculative decoding as a lossless acceleration primitive for RL rollouts that preserves the target model's output distribution. We implement speculative decoding in NeMo-RL with a vLLM backend, supporting both synchronous and asynchronous pipelines and enabling speculation during RL rollouts. This benefit is realizable across speculation mechanisms, such as pretrained MTP heads, small external draft models or even techniques such as Eagle3, which are traditionally applied after RL phase. This yields a deployment path for state-of-the-art speculative decoding inside RL training. In a reasoning post-training workload at 8B scale under synchronous RL, speculative decoding improves rollout throughput by 1.8x. Using a high-fidelity performance simulator, we project that combining speculative decoding with asynchronous RL yields up to 2.5x end-to-end training speedup at 235B scale.

Firefox maker torches Google for building Prompt API into browser
Mozilla opposes Google's Prompt API that embeds AI directly into Chrome, arguing it threatens web interoperability and forces developers to accept Google's content policies.
Deep dive
- Mozilla's Jake Archibald formally opposed Google's Prompt API in a GitHub discussion, citing severe concerns about interoperability, updatability, and neutrality of the web platform
- The API provides standardized access to Google's Gemini Nano model (around 4.27 GB) for local inference in Chrome, requiring about 22 GB available disk space
- Core interoperability problem: prompts are tightly coupled to specific models, so developers will inevitably tune to quirks of whichever model they build against, creating browser-specific code paths similar to the old browser compatibility nightmare
- Using the API requires accepting Google's Generative AI Prohibited Uses Policy, which restricts activities beyond what's illegal (like generating "disturbing" content), setting a concerning precedent for vendor-controlled usage rules on web platform APIs
- Mozilla argues this could pressure Apple and Mozilla to license Nano from Google just to maintain a consistent user experience across browsers
- Archibald accused Google of misrepresenting developer demand as "strongly positive" by cherry-picking a few social media posts rather than showing genuine groundswell support
- A February performance comparison showed concerning results: 15-24 percent task failure rates for generative tasks, 23-30 percent for classification tasks, and 6-17 percent hallucination rates between Chrome and Edge implementations
- Google's Rick Byers acknowledged the concerns but defended the approach as promoting experimentation and learning from mistakes, drawing parallels to controversial technologies like Encrypted Media Extensions
- Byers asked the web community to help collect evidence of actual harm rather than theoretical concerns to advance the discussion
- Mozilla maintains that developer demand alone doesn't justify an API—the critical question is whether it can work across implementations without vendor lock-in
Decoder
- Prompt API: A browser API that lets web pages send natural language instructions to a language model embedded in the browser
- Gemini Nano: Google's small language model designed to run locally on devices rather than in the cloud
- Local inference: Running AI model predictions directly on the user's device rather than sending requests to cloud servers
- Interoperability: The ability of different browsers to implement the same web standards in compatible ways
- Blink: The rendering engine used by Chrome, Edge, and other Chromium-based browsers
- Standards position: Mozilla's formal evaluation of whether a proposed web technology should become a standard
Original article
Firefox maker torches Google for building Prompt API into browser
Mozilla fears wiring an AI API into Chrome will make the web less open
Updated Mozilla has reiterated its opposition to Google's decision to build AI plumbing into its Chrome browser, though rather belatedly now that the technology, known as the Prompt API, is already being tested in Chrome and Microsoft Edge.
Jake Archibald, Mozilla web developer relations lead, articulated the org's concerns in a GitHub discussion of the API, which provides a standard way to send and receive prompts and responses from a local machine learning model.
"We continue to oppose this API, and feel it has severe negative consequences to the interoperability, updatability, and neutrality of the web platform," said Archibald.
The Prompt API, as Google describes it, "gives web pages the ability to directly prompt a browser-provided language model." It provides a way to send natural language instructions to Google's Gemini Nano model, which is small enough to be downloaded for local inference through Chrome.
It's not that small – Google recommends having 22 GB of space available, though the Nano (v3Nano) model for desktop use is ~4.27 GB.
Web developers already have a variety of ways to interact with AI models. They can use cloud service APIs to communicate with hosted models. Or they can access local models through technologies like JavaScript runtime frameworks, WASM, or WebGPU.
Various vendors like OpenAI and Perplexity have shipped browsers that embed access to remotely hosted AI models. Mozilla itself is testing an AI-based Smart Window in Firefox and it's developing tools for AI model scaffolding.
The Prompt API aims to make it easier to run local inference in a way that takes advantage of browser security mechanisms, to produce faster response times, to allow offline usage, and to provide more cost effective ways to integrate AI services (e.g. providing a free AI fallback if users lack a paid AI API key).
Mozilla's concern, as articulated by Archibald, has to do with what the Prompt API means for the web, not to mention Google's justification for deployment.
First, he worries that Google's own Nano model will become the default and that developers will standardize on it in an effort to make the non-deterministic responses of an AI model more predictable. That tendency, he argues, will create pressure for Apple and Mozilla to license Nano, for the sake of a common user experience.
Perhaps more significantly, Archibald notes that using the Prompt API requires agreeing to Google's Generative AI Prohibited Uses Policy, which prohibits activities that are not necessarily illegal, like generating "disturbing" content.
"This seems like a bad direction for an API on the web platform, and sets a worrying precedent for more APIs that have [browser]-specific rules around usage," he said.
Finally, Archibald argues that Google misrepresented demand for the API by cherry-picking a few social media posts and calling that a groundswell of developer support.
"The intent to ship on blink-dev states web developers as 'Strongly positive,' and links to the explainer for evidence," he wrote. "The evidence provided there does not seem to fit the claim."
In an email, Archibald told The Register that the question is whether the Prompt API is good for the web, and Mozilla doesn't believe that it is.
"The core problem is interoperability," he said. "Prompts are tightly coupled to models; developers will inevitably tune to the quirks and policies of whatever model they're building against.
"That's how you end up with model-specific code paths, which is the browser-compatibility problem all over again. The T&C issue is part of that: if using a web API means accepting a specific vendor's content policy (especially one that goes beyond law) you're not really building for an open platform anymore."
With regard to Google's exaggeration of developer enthusiasm, Archibald said there are definitely devs interested in AI capabilities but Google failed to provide evidence of that.
"The signal is polarised, not 'strongly positive,'" he explained. "Either way, developer demand alone doesn't meet the bar. The question is whether the API can work across implementations without tying the platform to one vendor's model."
Google did not immediately respond to a request for comment.
However, on Thursday, Rick Byers, the Google Chrome engineer responsible for shipping the Prompt API, chimed in to the GitHub discussion to acknowledge the concerns articulated by Archibald.
"As one of the blink API owner approvers for shipping this in Chromium, I admit that I share the concerns here in Mozilla's standards position," he wrote. "Where I differ is in preferring paths that promote experimentation, learning from mistakes, and competition to those which err on the side of stalling innovation out of fear of what might happen."
Byers asked the web community to help collect evidence of harm to advance the discussion. Pointing to the debate over other controversial web technologies like Encrypted Media Extensions (EME), he suggested the outcome has not been as dire as predicted.
But focusing on data, so far, hasn't done much for Google's cause. According to a report created in February that compares the performance of Chrome (Gemini Nano) and Edge (Phi-4 mini-instruct) using the Prompt API, these models just don't provide very good results.
"For generative tasks (composition, tag generation, etc), 24.29 percent of Edge's and 15.17 percent of Chrome's responses failed to complete the task," the report says, in reference to a rubric that defines failure as a score of 2 or less on a scale of 5. "For classification tasks, 29.58 percent of Edge's and 23.93 percent of Chrome's responses did not label or categorize the input correctly."
In terms of groundedness and accuracy, Edge failed ("hallucinated") 17 percent of the time while Chrome failed 6 percent of the time.
Is that good for the web? You could ask Chrome but you might not get a reliable answer. ®
After this story was filed, a Google spokesperson sent The Register the following comment:
"Part of working in the open is encouraging debate and disagreement. We welcome Mozilla's feedback and will continue to collaborate with them and the web community as we work to improve the API."

You can beat the binary search
A specialized search algorithm for sorted 16-bit integer arrays beats binary search by combining quaternary interpolation with SIMD parallel comparisons.
Deep dive
- Developed specifically for Roaring Bitmap format which uses sorted arrays of 16-bit integers ranging from 1 to 4096 elements
- Two key insights drove the design: modern processors can compare eight 16-bit integers with a single SIMD instruction, and they have excellent memory-level parallelism that suggests quaternary over binary search
- Algorithm divides arrays into fixed 16-element blocks and uses the last element of each block as interpolation keys for the coarse search phase
- Quaternary search splits the range into quarters rather than halves, generating more instructions but better exploiting memory-level parallelism since instruction count isn't the limiting factor
- Benchmarks on Intel Emerald Rapids (GCC) and Apple M4 (LLVM) both show SIMD Quad consistently beating binary search across all scenarios
- Intel results: more than 2x faster on warm cache, lesser benefits on cold cache
- Apple results: more than 2x faster on cold cache, more marginal benefits on warm cache
- Comparison with a binary version (same SIMD but without quaternary search) reveals the quad approach has little effect on Apple but provides decent optimization on Intel for large arrays
- The quaternary search better exploits memory-level parallelism on Intel server processors by allowing multiple memory operations to proceed in parallel
- Author suggests even better algorithms are likely possible by getting creative with modern processor parallelism features
Decoder
- SIMD: Single Instruction, Multiple Data - processor instructions that perform the same operation on multiple data points simultaneously
- Quaternary search: Search strategy that divides the search space into quarters instead of halves at each step
- Interpolation search: Search algorithm that estimates where a target value should be based on its value relative to the range endpoints
- Memory-level parallelism: A processor's ability to handle multiple memory operations simultaneously rather than waiting for each to complete
- Warm/cold cache: Warm cache means data is already in fast processor cache; cold cache means data must be fetched from slower main memory
- NEON: ARM processor's SIMD instruction set
- SSE2: Intel/AMD x86 processor's SIMD instruction set
- Roaring Bitmap: Compressed bitmap index format used for efficient set operations on large datasets
Original article
The SIMD Quad algorithm is an efficient search algorithm for sorted arrays of 16-bit unsigned integers that leverages the strengths of both algorithmic optimization and hardware acceleration to achieve faster speeds than binary search.

Elon Musk testifies that xAI trained Grok on OpenAI models
Elon Musk confirmed in court testimony that xAI used distillation techniques to train Grok on OpenAI models, publicly validating what many in the industry suspected U.S. AI labs do to each other.
Deep dive
- Musk stated xAI used distillation "partly" on OpenAI models and characterized it as a general practice among AI companies, though this is the first public confirmation from a major lab
- Distillation threatens the fundamental business model of frontier AI labs by allowing competitors to replicate years of compute investment through systematic querying rather than building from scratch
- OpenAI, Anthropic, and Google are collaborating through the Frontier Model Forum to combat distillation attempts, particularly from China, by detecting and blocking suspicious mass queries
- The legal status of distillation remains unclear—it likely violates terms of service but may not be explicitly illegal, unlike the copyright violations frontier labs allegedly committed during their own training
- xAI launched in 2023, years behind OpenAI, making it logical they would use shortcuts to catch up rather than starting from zero
- During the same testimony, Musk ranked current AI leaders as: Anthropic first, followed by OpenAI, Google, and Chinese open-source models, with xAI characterized as much smaller with only a few hundred employees
- The testimony occurred during Musk's lawsuit alleging OpenAI breached its original nonprofit mission by shifting to a for-profit structure
- OpenAI did not respond to requests for comment on the admission
Decoder
- Distillation: Training new AI models by systematically querying existing models through their APIs or chatbots to understand and replicate their behavior, creating comparable capability at much lower cost than building from scratch
- Frontier labs: Leading AI companies like OpenAI, Anthropic, and Google that are pushing the boundaries of AI capability
- Compute infrastructure: The expensive data centers and specialized hardware (GPUs, TPUs) required to train large language models from scratch
Original article
OpenAI and Anthropic have been on the warpath lately against third-party efforts to train new AI models by prompting their publicly accessible chatbots and APIs, a process known as "distillation."
That conversation has focused on Chinese firms using distillation to create open-weight models that are nearly as capable as U.S. offerings, but available at a much lower cost. However, tech workers have widely assumed that American labs use these techniques on each other to avoid falling behind competitors.
Now we know it's true in at least one case: On the stand in a California federal court on Thursday, Elon Musk was asked if xAI has used distillation techniques on OpenAI models to train Grok, and he asserted it was a general practice among AI companies. Asked if that meant "yes," he said, "Partly."
Musk is in the process of suing OpenAI, CEO Sam Altman, and Greg Brockman, alleging they breached the original nonprofit mission for OpenAI by shifting the entity to a for-profit structure. That trial began this week, featuring testimony from the tech leader.
Musk's admission is notable because distillation threatens AI giants by undermining the advantage they've built by investing in compute infrastructure. This allows other software makers to create models that are nearly as capable on the cheap. There's no small amount of irony here, given the bending and alleged breaking of copyright rules by frontier labs in their search for sufficient data to train their models.
It's no surprise that Musk's xAI, which started in 2023, years after OpenAI, would try to learn from the then-leader in the field. It's not clear that distillation is explicitly illegal, but rather may violate the terms of service companies set for the user of their products.
OpenAI, Anthropic, and Google have reportedly launched an initiative through the Frontier Model Forum to share information about how to combat distillation attempts from China. These typically involve systematic querying of models to understand their inner workings. To stop the efforts, frontier labs are working to prevent users from making suspicious mass queries.
OpenAI did not respond to a request for comment on Musk's admission at press time.
Later in his testimony, Musk was asked about a claim he made last summer that xAI would soon be far beyond any company besides Google. In response, he ranked the world's leading AI providers, saying Anthropic held the top spot, followed by OpenAI, Google, and Chinese open source models. He characterized xAI as a much smaller company with just a few hundred employees.
Sequoia Ascent 2026 summary
Andrej Karpathy argues that December 2025 marked an inflection point where AI agents became reliable enough to fundamentally change software development from writing code to orchestrating agents.
Deep dive
- December 2025 marked a threshold where generated code chunks became large, coherent, and reliable enough to trust agents with entire features and subsystems rather than individual lines
- Software 3.0 positions the context window as the primary programming interface, with LLMs as interpreters performing computation over digital information rather than humans writing explicit instructions
- The MenuGen example illustrates disappearing software: what started as a full web app with OCR, APIs, and infrastructure can now be reduced to giving a multimodal model a menu photo and asking it to render dish images directly onto the image
- Verifiability explains capability spikes: LLMs automate what you can verify rather than what you can specify, which is why coding, math, and testable domains improve fastest through reinforcement learning
- Jagged intelligence emerges from the interaction of verifiability, training attention, data coverage, and economic value, meaning models spike unpredictably based on what frontier labs prioritized during training
- Vibe coding raises the floor for everyone to create software, while agentic engineering is the professional discipline of coordinating fallible agents while preserving correctness, security, and maintainability
- Hiring should shift from algorithmic puzzles to building substantial projects with agents and deploying them securely, testing whether candidates can decompose work, write specs, review generated code, and preserve quality
- The MenuGen payment bug exemplifies where human judgment remains critical: an agent matched Stripe purchases to Google accounts using email addresses, missing that these can differ and requiring persistent user IDs instead
- Agents now handle API recall details (dim vs axis, reshape vs permute) while humans must understand underlying concepts like tensor storage, memory views, and system boundaries to maintain taste and correctness
- Agent-native infrastructure should provide Markdown docs, CLIs, APIs, MCP servers, and copy-pasteable instructions rather than telling humans to "click here" or "go to this URL"
- The LLM Wiki pattern demonstrates new capabilities: agents incrementally compile messy documents into persistent knowledge bases with summaries, cross-links, and synthesis that classical programs couldn't robustly maintain
- Startup opportunities exist in finding valuable, verifiable domains that are undertrained by frontier labs, where domain-specific reinforcement learning environments could create wedges
- Education must focus on understanding rather than thinking, since you can outsource thinking to agents but still need understanding to direct them toward what's worth building and recognize suspicious results
Decoder
- Software 3.0: A programming paradigm where developers program LLMs through prompts, context windows, tools, and instructions rather than writing explicit code (Software 1.0) or training neural networks on datasets (Software 2.0)
- Vibe coding: The ability for anyone to create software by describing what they want in natural language, raising the floor of who can build applications
- Agentic engineering: The professional discipline of coordinating AI agents to build production software while maintaining quality, security, and correctness standards
- Verifiability: The property that a task has automatic success signals or rewards, enabling models to practice and improve through reinforcement learning (explains why coding and math improve faster than other domains)
- Jagged intelligence: The uneven capability profile of LLMs where they excel dramatically in some areas (like refactoring codebases) while failing at seemingly simple tasks (like whether to walk or drive to a nearby car wash)
- Context window: The input space where you provide prompts, examples, instructions, and data to an LLM, which has become the primary programming interface in Software 3.0
- MCP servers: Model Context Protocol servers that provide structured, machine-readable interfaces for agents to interact with services
- LLM Wiki: A knowledge base where agents incrementally compile and synthesize information from raw documents into organized summaries, entity pages, and cross-references
Original article
Sequoia Ascent 2026 summary
30 Apr, 2026
I did a fireside chat at Sequoia Ascent 2026. The YouTube video is here:
As an experiment, I fed an LLM all of my recent blog posts and tweets, then I had it read this video's transcript and produce 1) a summary and 2) a cleaned up transcript (correcting all transcription mistakes, getting rid of fill words, etc). I am posting both of these below. These can be useful for both people who may want to just read the summary in text format, but also for LLMs so that my content is legible and available to them.
AI generated content below for this talk follows. I used a top capability model (in this case Codex 5.5) and read the content and it reads ok without glaring mistakes.
Sequoia Ascent 2026: Software 3.0, Agentic Engineering, and Jagged Intelligence
I recently joined Stephanie Zhan for a fireside chat at Sequoia Ascent 2026, speaking with founders about the recent shift in AI agents, what it means for software, and how I think about the next wave of AI-native companies.
The transcript from the event is a bit noisy, so I wanted to write up the main intellectual content in a cleaner form. The short version is that I think we have crossed a new threshold. LLMs are no longer just chatbots or autocomplete. They are becoming a new programmable layer for digital work.
This is the compact version of the conversation.
1. December 2025 Was an Agentic Inflection Point
I said recently that I have never felt more behind as a programmer.
The reason is not that programming became harder in the old sense. It is that the default workflow changed. For much of 2025, tools like Claude Code, Codex, and Cursor-like agents were useful but still required frequent correction. Around December 2025, I felt a step change: the generated chunks got larger, more coherent, and more reliable. I started trusting the agents with more of the work.
The unit of programming changed from typing lines of code to delegating larger "macro actions":
- Implement this feature.
- Refactor this subsystem.
- Research this library.
- Set up this service.
- Write tests, run them, and fix failures.
- Compare approaches and propose a plan.
This is why I think the profession is being refactored. The programmer is increasingly not just a code writer, but an orchestrator of agents.
2. Software 3.0: The Context Window as the New Program
I think of this as the next step in a sequence:
- Software 1.0: humans write explicit code.
- Software 2.0: humans create datasets, objectives, and neural networks; the program is learned into weights.
- Software 3.0: humans program LLMs through prompts, context, tools, examples, memory, and instructions.
In Software 3.0, the context window becomes the main lever. The LLM is an interpreter over that context, performing computation over digital information.
One example is installation. In the old world, installing a complex tool across many environments required a brittle shell script full of conditionals. In the Software 3.0 world, the installer can be a block of instructions you paste into an agent. The agent reads the local environment, debugs errors, adapts to the machine, and completes the setup.
That is a different kind of program. It is less precise, but more adaptive.
3. MenuGen and the Moment Software Disappears
I used MenuGen as an example of a deeper shift.
MenuGen was a traditional web app: take a picture of a restaurant menu, OCR the dish names, generate images of the dishes, and render the result in a UI. It required frontend code, APIs, image generation, deployment, auth, payments, secrets, and infrastructure.
But later, I saw the Software 3.0 version: take a photo of the menu, give it to a multimodal model, and ask it to render dish images directly onto the menu image.
In that version, much of the app disappears. The neural network directly transforms input media into output media. The old software stack was scaffolding around a transformation the model can now perform directly.
This is one of the most important founder implications: AI is not just a faster way to build the old apps. Some apps should stop existing as apps.
4. The New Opportunity Is Not Just Faster Programming
The shift is broader than coding. LLMs automate forms of information processing that were not previously programmable.
My LLM Wiki pattern is the clearest example. Instead of using retrieval-augmented generation to answer questions from raw documents each time, an agent incrementally compiles raw sources into a persistent Markdown wiki: summaries, entity pages, concept pages, contradictions, cross-links, logs, and evolving synthesis.
No classical program could robustly maintain that kind of knowledge base across messy human documents. But an LLM can.
The lesson: do not only ask, "What existing workflow can AI speed up?" Also ask, "What information transformation was impossible before, but is now natural?"
5. Verifiability Explains Where AI Moves Fastest
My core automation framework is:
- Traditional software automates what you can specify.
- LLMs and reinforcement learning automate what you can verify.
If a task has an automatic reward or success signal, models can practice it. This is why math, coding, tests, benchmarks, games, and many engineering tasks improve so quickly. They are resettable, repeatable, and rewardable.
This also explains why coding agents feel dramatically better than many ordinary chatbot experiences. Coding gives the model feedback: tests pass or fail, programs run or crash, diffs can be inspected, benchmarks can be measured.
6. Jagged Intelligence Has Two Axes: Verifiability and Training Attention
The interview added an important refinement to the verifiability thesis.
Model capability is not only about whether a task is verifiable. It also depends on whether the task was emphasized by labs during training, post-training, synthetic data generation, and reinforcement learning.
A rough formula:
capability spike ~= verifiability x training attention x data coverage x economic value
Chess is a good example. When GPT-4 improved at chess, that was not necessarily because general intelligence smoothly improved everywhere. It may also have been because much more chess data was included in the training mix.
This matters because frontier models do not come with a manual. They are artifacts of pretraining mixtures, RL environments, benchmark pressure, product priorities, and economic incentives. They spike in some places and behave strangely in others.
So the practical question for a founder is: are you on the model's rails?
If your task sits inside a region that is verifiable and heavily trained, the model may fly. If not, it may fail in surprisingly basic ways. You may need better context, tools, fine-tuning, your own evals, or your own reinforcement learning environment.
7. Vibe Coding vs. Agentic Engineering
I distinguish two related but different ideas:
- Vibe coding raises the floor. It lets almost anyone create software by describing what they want.
- Agentic engineering raises the ceiling. It is the professional discipline of coordinating fallible agents while preserving correctness, security, taste, and maintainability.
Vibe coding is fine for prototypes and personal tools. Agentic engineering is what serious teams need.
The agentic engineer does not blindly accept generated code. They design specs, supervise plans, inspect diffs, write tests, create evaluation loops, manage permissions, isolate worktrees, and preserve quality.
My MenuGen payment bug is a useful example. The agent tried to match Stripe purchases to Google accounts using email addresses. That is plausible code, but bad system design: the Stripe email and Google login email can differ. A human needs enough product and engineering judgment to insist on persistent user IDs.
The frontier skill is not memorizing every API detail. Agents can remember whether a tensor library uses dim, axis, keepdim, reshape, or permute. The human still needs to understand the underlying concepts: storage, views, memory copies, invariants, identity, security boundaries, and the shape of the system.
8. Hiring Should Change
If agentic engineering is the new professional skill, hiring should test it directly.
Traditional coding puzzles are increasingly mismatched. A better interview might be: build a substantial project with agents, deploy it, make it secure, and then have adversarial agents try to break it.
This tests the real skill:
- Can the candidate decompose work for agents?
- Can they write useful specs?
- Can they preserve quality while moving fast?
- Can they review generated work?
- Can they secure and harden a system?
- Can they use agents as leverage rather than produce slop?
The old "10x engineer" idea may become much more extreme. People who master agentic workflows may outperform others by far more than 10x.
9. Founders Should Look for Valuable Verifiable Environments
For founders, one important opportunity is finding domains that are valuable, verifiable, and undertrained by frontier labs.
If you can create a domain-specific environment where models can try actions and receive reliable rewards, you may be able to improve performance with fine-tuning or reinforcement learning even if the base model is not already excellent there.
The most obvious domains, like coding and math, are already heavily targeted by labs. But many economically important domains may have latent verifiable structure that has not yet been exploited.
That is a startup wedge.
10. Agent-Native Infrastructure: Build for the Agent, Not Just the Human
Most software is still built for humans clicking through screens.
Docs say things like "go to this URL, click this button, open this settings panel." But increasingly the user is not the human directly. The user is the human's agent.
This means products need agent-native surfaces:
- Markdown docs.
- CLIs.
- APIs.
- MCP servers.
- Structured logs.
- Machine-readable schemas.
- Copy-pasteable agent instructions.
- Safe permissioning.
- Auditable actions.
- Headless setup flows.
I think about this in terms of sensors and actuators. A sensor turns some state of the world into digital information. An actuator lets an agent change something. The future stack is agents using sensors and actuators on behalf of people and organizations.
The MenuGen deployment story remains a useful benchmark. Building the app was easy compared to wiring Vercel, auth, payments, DNS, secrets, and production settings. In a mature agent-native world, I should be able to say "build MenuGen" and have the agent deploy the whole thing without manual clicking.
11. Ghosts, Not Animals
My Animals vs. Ghosts framing is a way to avoid bad intuitions.
LLMs are not animals. They do not have biological drives, embodied survival pressure, curiosity, play, or intrinsic motivation in the animal sense. They are statistical simulations of human artifacts, shaped by pretraining, post-training, RL, product feedback, and economic incentives.
This matters because anthropomorphic expectations mislead us. These systems can be brilliant in one moment and bizarrely dumb in the next. They are not smooth human minds. They are jagged, alien tools.
The right posture is neither dismissal nor blind trust. It is empirical familiarity: learn where they work, where they fail, what they were trained for, and how to build guardrails around them.
12. Education: You Can Outsource Thinking, But Not Understanding
We ended on education. There is a line I keep returning to:
You can outsource your thinking, but you can't outsource your understanding.
Even if agents do more of the work, the human still needs understanding to direct them. You need to know what is worth building, what question matters, what result is suspicious, and what tradeoff is acceptable.
This is why I am interested in LLM knowledge bases. They are not just answer machines. They are tools for transforming information into understanding.
This also connects to my tiny microGPT project: a complete GPT training and inference implementation in a single dependency-free Python file. The educational artifact becomes small enough for both humans and agents to inspect. The human expert contributes the distilled artifact and the taste behind it; the agent can then explain it interactively to each learner.
The Big Picture
The main thesis of the conversation is that AI is becoming a new operating layer for digital work.
The scarce thing is shifting:
- Less scarce: code generation, API recall, boilerplate, first drafts, repetitive setup, simple transformations.
- More scarce: understanding, taste, eval design, security, system boundaries, agent orchestration, domain-specific feedback loops, and knowing when the model is off the rails.
For founders, the most important questions are:
- What becomes possible when the primary user is an agent acting for a human?
- What workflows can be rebuilt around sensors, actuators, and verifiable loops?
- What software should disappear into direct model transformations?
- What domains are valuable and verifiable but not yet heavily trained by frontier labs?
- What human judgment must remain in the loop to preserve quality?
My current worldview is not that AI simply makes everyone faster at the old work. It is that the work itself is being reorganized around agents. Software, research, education, infrastructure, and knowledge work are all becoming variations of the same pattern:
define the context define the tools define the feedback loop define the guardrails let agents work preserve human understanding
Sequoia Ascent 2026: Andrej Karpathy in Conversation with Stephanie Zhan
Edited transcript. Lightly cleaned for readability, with obvious transcription errors corrected, filler removed, and a few relevant links added.
Introduction
Konstantine: Someone you all know, someone who has become, in this AI revolution, a teacher of AI. In every revolution there is the technologist, but there is also the teacher, the person who actually informs and instructs how this transformation is going to happen. Andrej has become that teacher to the world.
Early at Autopilot at Tesla, co-founder of OpenAI, he left it all to start Eureka Labs, where he leaned into the idea of an AI that was a true instructor. We're happy to have Andrej Karpathy with our partner Stephanie Zhan.
Stephanie: Hi everyone. We're excited for our first special guest. He has helped build modern AI, explain modern AI, and occasionally rename modern AI.
He helped co-found OpenAI. He helped get Autopilot working at Tesla. And he has a rare gift for making the most complex technical shifts feel both accessible and inevitable.
You all know him for having coined the term vibe coding last year. But just in the last few months, he said something even more startling: he has never felt more behind as a programmer. That's where we're starting today. Thank you, Andrej, for joining us.
Andrej: Hello. Excited to be here and to kick us off.
The December 2025 Agentic Inflection
Stephanie: A couple of months ago, you said you've never felt more behind as a programmer. That's startling to hear from you, of all people. Can you help us unpack that? Was that feeling exhilarating or unsettling?
Andrej: A mixture of both, for sure.
Like many of you, I've been using agentic tools like Claude Code, Codex, and adjacent things for a while, maybe over the last year. They were very good at chunks of code, but sometimes they would mess up and you had to edit them. They were helpful.
Then I would say December was a clear point. I was on a break, so I had more time. I think many other people were similar. I started to notice that with the latest models, the chunks just came out fine. Then I kept asking for more and they still came out fine. I couldn't remember the last time I corrected it. I started trusting the system more and more.
I do think it was a stark transition. A lot of people experienced AI last year as a ChatGPT-adjacent thing, but you really had to look again as of December, because things changed fundamentally, especially in this agentic, coherent workflow. It really started to work.
That realization sent me down the rabbit hole of infinite side projects. My side-projects folder is extremely full with random things. I was coding all the time. That happened in December, and I've been looking at the repercussions since.
Software 3.0
Stephanie: You've talked about LLMs as a new computer. It isn't just better software; it's a new computing paradigm. Software 1.0 was explicit rules. Software 2.0 was learned weights. Software 3.0 is this. If that is true, what does a team build differently the day they actually believe it?
Andrej: Software 1.0 is writing code. Software 2.0 is programming by creating datasets and training neural networks. Programming becomes arranging datasets, objectives, and neural network architectures.
Then what happened is that if you train GPT models or LLMs on a sufficiently large set of tasks, implicitly, because the internet contains many tasks, these models become programmable computers in a certain sense.
Software 3.0 is about programming through prompting. What's in the context window is your lever over the interpreter, and the interpreter is the LLM. It interprets your context and performs computation in digital information space.
A few examples drove this home for me. When OpenClaw came out, to install it you would normally expect a shell script. But to target many platforms and many kinds of computers, shell scripts usually balloon and become extremely complex. You're stuck in the Software 1.0 universe of wanting to write exact code.
The OpenClaw installation was instead a block of text that you copy and paste into your agent. It is like a little skill: copy this, give it to your agent, and it will install OpenClaw. That is more powerful because you're working in the Software 3.0 paradigm. You don't have to spell out every detail. The agent has intelligence. It looks at your environment, performs intelligent actions, and debugs in the loop.
That is a different way of thinking. What is the piece of text to copy-paste into your agent? That is now part of the programming paradigm.
Another example is MenuGen. You sit down at a restaurant, get a menu, and there are no pictures. I don't know what many of these things are. I wanted to take a photo of the menu and get pictures of what those dishes might look like in a generic sense.
So I built an app. You upload a photo, it OCRs all the titles, uses an image generator to get pictures, and shows them to you. It runs on Vercel and rerenders the menu.
Then I saw the Software 3.0 version, which blew my mind. You take the photo, give it to Gemini, and say: use Nano Banana to overlay the things onto the menu. It returns an image of the menu I took, but with pictures rendered into the pixels.
All of MenuGen is spurious in that framing. It is working in the old paradigm. That app shouldn't exist. In the Software 3.0 paradigm, the neural network does more of the work. Your prompt or context is the image, and the output is an image. There is no need for all the app machinery in between.
People have to reframe. Don't only work in the existing paradigm and think of AI as a speedup of what exists. New things are available now.
And it is not just programming becoming faster. This is more general information processing that is now automatable. Previous code worked over structured data. You wrote code over structured data.
With my LLM knowledge bases project, you get LLMs to create wikis for your organization or for you personally. This is not a program in the old sense. There was no code that could create a knowledge base based on a bunch of messy facts. But now you can take documents, recompile them, reorder them, and create something new and interesting as a reframing of the data.
These are new things that weren't possible before. I keep trying to come back to that: not only what can we do faster, but what couldn't be possible before? That is more exciting.
Neural Computers
Stephanie: I love the MenuGen progression. If you extrapolate further, what is the 2026 equivalent of building websites in the 90s, mobile apps in the 2010s, or SaaS in the cloud era? What will look obvious in hindsight that is still mostly unbuilt today?
Andrej: Going with the MenuGen example, a lot of this code shouldn't exist. The neural network should be doing most of the work.
The extrapolation looks very weird. You could imagine completely neural computers in a certain sense. Imagine a device that takes raw video or audio into a neural net and uses diffusion to render a UI unique for that moment.
In the early days of computing, people were a little confused about whether computers would look like calculators or neural nets. In the 1950s and 1960s, it was not obvious which way it would go. We went down the calculator path and built classical computing.
Neural nets are currently running virtualized on existing computers. But you can imagine a flip where the neural net becomes the host process and CPUs become coprocessors. Intelligence compute and neural-network compute become the dominant spend of FLOPs.
You can imagine something foreign, where neural nets do most of the heavy lifting and use tools as a historical appendage for deterministic tasks. What is really running the show is neural nets networked in some way.
That is the extrapolation, but I think we will get there piece by piece.
Verifiability and Jagged Intelligence
Stephanie: I'd love to talk about verifiability: the idea that AI will automate faster and more easily in domains where the output can be verified. If that framework is right, what work is about to move much faster than people realize? And what professions do people think are safe, but are actually highly verifiable?
Andrej: Traditional computers automate what you can specify in code. This latest round of LLMs can automate what you can verify.
When frontier labs train these LLMs, they train them in giant reinforcement learning environments with verification rewards. Because of that, models progress and become jagged entities. They peak in capability in verifiable domains like math, code, and adjacent areas, and they stagnate or remain rough around the edges where things are not in that space.
I wrote about verifiability because I was trying to understand why these things are so jagged. Some of it has to do with how labs train the models. Some of it also has to do with what labs focus on and what they put into the data distribution. Some things are significantly more valuable economically, so labs create more environments for those settings. Code is a good example.
There are probably many verifiable environments that you could think about that did not make it into the mix because they are not as economically useful to have capability around.
One favorite example for a while was: how many letters are in "strawberry"? Models famously got this wrong. That has now been patched. The newer example is: I want to go to a car wash to wash my car, and it's 50 meters away. Should I drive or walk? State-of-the-art models may tell you to walk because it's close.
How is it possible that a state-of-the-art model can refactor a 100,000-line codebase or find zero-day vulnerabilities, yet tells me to walk to the car wash? That's jaggedness. To the extent models remain jagged, it means you need to be in the loop. You need to treat them as tools and stay in touch with what they are doing.
My writing on verifiability is trying to understand this pattern. I think it is some combination of "verifiable" plus "labs care."
Another anecdote is chess. From GPT-3.5 to GPT-4, people noticed that chess improved a lot. Some people thought that was just general capability progress. But I think it is public information that a large amount of chess data made it into the pretraining set. Because it was in the data distribution, the model improved much more than it would by default.
Someone at OpenAI decided to add that data, and now there is a capability spike. That is why I stress this dimension: we are slightly at the mercy of what the labs do and what they put into the mix. You have to explore the model they give you. It has no manual. It works in some settings and not others.
If you are in the circuits that were part of reinforcement learning, you fly. If you are outside the data distribution, you struggle. You have to figure out which circuits your application is in. If you are not in those circuits, then you have to look at fine-tuning or doing some of your own work, because it may not come out of the LLM out of the box.
Startup Opportunities in Verifiable Domains
Stephanie: If you were a founder today, and you were solving a tractable, verifiable problem, but you looked around and saw that the labs have started getting to escape velocity in obvious domains like math and coding, what would your advice be?
Andrej: Verifiability makes something tractable in the current paradigm because you can throw a huge amount of reinforcement learning at it.
That remains true even if the labs are not focusing on it directly. If you are in a verifiable setting where you can create reinforcement learning environments or examples, then you can potentially do your own fine-tuning and benefit from it. That technology fundamentally works. If you have diverse datasets or RL environments, you can use a fine-tuning framework, pull the lever, and get something that works pretty well.
I don't want to give away specific examples, but there are valuable reinforcement learning environments that people could think of that are not part of the current frontier-lab mix.
Stephanie: On the flip side, what still feels automatable only from a distance? What domains or professions are safer than others?
Andrej: Ultimately, almost everything can be made verifiable to some extent, some things more easily than others. Even for writing, you can imagine having a council of LLM judges and getting something reasonable.
So it is more about what is easy or hard.
Vibe Coding vs. Agentic Engineering
Stephanie: Last year you coined the term vibe coding. Today we are in a world that feels more serious, more agentic engineering. What is the difference between the two, and what would you call what we are in today?
Andrej: Vibe coding is about raising the floor for everyone in terms of what they can do in software. Everyone can vibe code anything, and that is amazing.
Agentic engineering is about preserving the quality bar of professional software. You are not allowed to introduce vulnerabilities because of vibe coding. You are still responsible for your software, just as before. But can you go faster? Spoiler: you can. The question is how to do that properly.
I call it agentic engineering because it is an engineering discipline. You have agents, which are spiky entities. They are fallible and stochastic, but extremely powerful. How do you coordinate them to go faster without sacrificing your quality bar?
Vibe coding raises the floor. Agentic engineering is about extrapolating the ceiling. I think there is a very high ceiling on agentic-engineer capability. People used to talk about the 10x engineer. I think this is magnified a lot more. 10x is not the speedup people can gain. People who are very good at this can peak much higher than that.
What AI-Native Coding Looks Like
Stephanie: Last year Sam Altman came to Ascent and said people of different generations use ChatGPT differently. If you're in your 30s, you use it as a Google search replacement. If you're in your teens, ChatGPT is your gateway to the internet.
What is the parallel in coding? If we watched two people code using OpenClaw, Claude Code, or Codex, one mediocre and one fully AI-native, how would you describe the difference?
Andrej: It is about getting the most out of the tools available, using their features, and investing in your own setup.
Engineers have always done this with tools like Vim or VS Code. Now the tools are Claude Code, Codex, and so on. You invest in your setup and use what is available.
One related thought is hiring. Many people want to hire strong agentic engineers, but most hiring processes have not been refactored for agentic-engineer capability. If you are giving out small puzzles to solve, that is still the old paradigm.
Hiring should look more like: give someone a big project and see them implement it. For example, write a Twitter clone for agents, make it good and secure, then have agents simulate activity on it. Then I will use ten Codex agents to try to break the website you deployed, and they should not be able to break it.
Watching people in that setting, building a bigger project and using the tooling, is closer to what I would look for.
What Human Skills Become More Valuable?
Stephanie: As agents do more, what human skill becomes more valuable, not less?
Andrej: Right now the agents are like interns. You still have to be in charge of aesthetics, judgment, taste, and oversight.
One of my favorite examples is from MenuGen. You sign up with a Google account, but you purchase credits using Stripe. Both have email addresses. My agent tried to assign purchased credits by matching the Stripe email address to the Google email address.
But those can be different emails. The user might not get the credits they purchased. Why would you use email addresses to cross-correlate funds? You need a persistent user ID. This is the kind of mistake agents still make.
People have to be in charge of the spec and plan. I don't even fully like "plan mode" as a concept, though it is useful. There is something more general: you work with your agent to design a detailed spec, maybe basically the docs, and get agents to write them. You are in charge of oversight and the top-level categories. The agents do much of the work underneath.
As another example, with tensors in neural networks, there are many details across PyTorch, NumPy, pandas, and so on: dim versus axis, reshape, permute, transpose, keepdim. I don't remember this stuff anymore because I don't have to. These details are handled by the intern because agents have good recall.
But you still have to understand the fundamentals. You need to know that there is underlying tensor storage, that you can manipulate a view of the same storage, or create different storage, which is less efficient. You still need to know enough to avoid copying memory unnecessarily.
So you are in charge of taste, engineering, design, and whether the system makes sense. You ask for the right things: for example, we tie everything to unique user IDs. The agents fill in the blanks.
Stephanie: Do you think taste and judgment matter less over time, or does the ceiling just keep rising?
Andrej: I hope it improves. The reason it does not improve right now is probably that it is not part of the reinforcement learning. There may be no aesthetics reward, or it is not good enough.
When I look at the code, sometimes I get a heart attack. It is not always amazing code. It can be bloated, copy-pasted, awkwardly abstracted, brittle. It works, but it is gross. I hope this improves in future models.
A good example is my microGPT project, where I tried to simplify LLM training as much as possible. The models hate this. They can't do it. I kept trying to prompt an LLM to simplify more and more, and it just couldn't. You feel like you are outside the RL circuits. It feels like pulling teeth.
So people remain in charge of this for now. But I don't think there is anything fundamental preventing improvement. The labs just haven't done it yet.
Ghosts, Not Animals
Stephanie: I'd love to come back to jagged forms of intelligence. You wrote a thought-provoking piece around Animals vs. Ghosts: we are not building animals, we are summoning ghosts. These are jagged forms of intelligence shaped by data and reward functions, but not by intrinsic motivation, fun, curiosity, or empowerment in the way evolution shaped animals.
Why does that framing matter? What does it change about how you build, deploy, evaluate, or trust them?
Andrej: I wrote about it because I am trying to wrap my head around what these things are. If you have a good model of what they are and are not, you will be more competent at using them.
I don't know if the framing has direct practical power. It is a little philosophical. But it is about coming to terms with the fact that these things are not animal intelligence. If you yell at them, they are not going to work better or worse. They are statistical simulation circuits. The substrate is pretraining, then reinforcement learning bolted on top.
It is a mindset: what am I interacting with, what is likely to work, what is not likely to work, and how do I modify it? I don't have five obvious outcomes that make your system better. It is more about being suspicious of the system and figuring it out empirically over time.
Agent-Native Infrastructure
Stephanie: You are deep in working with agents that do not just chat. They have real permissions, local context, and actually take action on your behalf. What does the world look like when we all live in that world?
Andrej: A lot of people here are probably excited about what the agent-native environment looks like. Everything has to be rewritten. Most things are still fundamentally written for humans.
When I use frameworks or libraries, the docs are still written for humans. This is my favorite pet peeve. Why are people still telling me what to do? I don't want to do anything. What is the thing I should copy-paste to my agent?
Every time I am told "go to this URL" or "click here," I think: no. The industry has to decompose workloads into sensors and actuators over the world. How do we make things agent-native? How do we describe them to agents first, and build automation around data structures that are legible to LLMs?
I hope there is a lot of agent-first infrastructure. With MenuGen, the hard part was not writing the code. The trouble was deploying it on Vercel, wiring services, settings, DNS, auth, payments, secrets, and production configuration.
I would hope I could prompt an LLM: build MenuGen. Then I don't touch anything, and it is deployed on the internet. That would be a good test of whether our infrastructure is becoming agent-native.
Ultimately, I do think we are going toward a world where people and organizations have agent representation. My agent will talk to your agent to figure out meeting details and other tasks. That is roughly where things are going.
Education and Understanding
Stephanie: We have to end on education. You are probably one of the best in the world at making complex technical concepts simple, and you think deeply about education. What remains worth learning deeply when intelligence gets cheap?
Andrej: There was a tweet that blew my mind recently, and I keep thinking about it:
You can outsource your thinking, but you can't outsource your understanding.
That is nicely put. I am still part of the system. Information still has to make it into my brain. I am becoming the bottleneck of even knowing what we are trying to build, why it is worth doing, and how to direct my agents.
Something still has to direct the thinking and processing. That is constrained by understanding.
This is one reason I am excited about LLM knowledge bases. They are a way for me to process information. Whenever I see a different projection onto information, I feel like I gain insight. It is synthetic data generation over fixed data.
When I read an article, I have my wiki being built up from those articles. I love asking questions about it. Ultimately these are tools to enhance understanding. Understanding is still the bottleneck because you cannot be a good director if you do not understand.
The LLMs do not fully excel at understanding. You are still uniquely in charge of that. Tools that enhance understanding are incredibly interesting and exciting.
Stephanie: I'm excited to come back here in a couple of years and see if we have been fully automated out of the loop, and whether they take care of understanding as well. Thank you so much, Andrej.
Andrej: Thank you.
Konstantine: Stephanie, Andrej, thank you so much.

Terraform Audit Guide: Monitoring, Logging & Compliance
Auditing Terraform configurations prevents security breaches and compliance failures by catching misconfigurations before they reach production infrastructure.
Deep dive
- Terraform audits span four critical dimensions: code (scanning .tf files for misconfigurations), runs (tracking plan/apply history), state (verifying infrastructure snapshots), and backend (ensuring secure state storage)
- State files are point-in-time snapshots that track Terraform-managed resources but don't capture resources created manually, don't provide change history, and can expose sensitive data like database passwords and API keys
- Since Terraform 1.10, ephemeral values and write-only arguments can keep certain secrets out of state entirely, though OpenTofu added client-side state encryption in mid-2024 after years of community requests
- Static analysis should happen before terraform plan or apply using tools like Checkov, Trivy, or tfsec integrated into pre-commit hooks and CI pipelines to shift security left
- Policy as code with Open Policy Agent enforces organizational guardrails by blocking non-compliant changes (like public S3 buckets or unencrypted resources) before they reach cloud environments
- Running terraform plan shows what changes would be made and provides basic drift detection, though platforms like Spacelift offer automated drift detection and remediation at scale
- Access control should follow least privilege principles, restricting who can run terraform apply and who can read or modify state files to prevent overprivileged accounts
- Secrets management requires using dedicated platforms like HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault rather than hardcoding credentials, with tools like git-secrets or trufflehog scanning repository history for accidentally committed secrets
- Module sources should only come from trusted registries with versions pinned to prevent pulling in breaking changes, security regressions, or malicious code without warning
- Best practices include continuous auditing rather than one-time checks, storing plan and apply outputs in immutable locations, pinning module and provider versions, protecting state files with encryption and locking, and using consistent tagging for cost allocation and compliance
Decoder
- IaC (Infrastructure as Code): Managing infrastructure through configuration files rather than manual processes, allowing version control and automation
- Terraform state file: A JSON file that records the current state of managed infrastructure resources, their attributes, dependencies, and metadata
- Infrastructure drift: When the actual deployed infrastructure diverges from what's defined in the Terraform configuration files
- OPA (Open Policy Agent): An open-source policy engine that evaluates infrastructure code against predefined rules to enforce security and compliance controls
- Static analysis: Scanning code for security issues and misconfigurations without actually executing it
- Shift left: Moving security and quality checks earlier in the development process, before deployment
- State locking: A mechanism that prevents concurrent Terraform operations from corrupting the state file by allowing only one operation at a time
- RBAC (Role-Based Access Control): A security approach that restricts system access based on user roles within an organization
- Backend: The storage location and configuration for Terraform state files, such as S3 buckets or Azure Blob Storage
Original article
A Terraform audit evaluates infrastructure code, state, runs, and backend to ensure security and compliance, using tools like Checkov, Trivy, and OPA with best practices such as continuous auditing, state protection, version control, and policy enforcement.
What does using AI for post-mortems actually mean?
AI-assisted incident post-mortems risk creating convincing documents that nobody owns if automation replaces human analysis rather than just handling the prep work.
Decoder
- Post-mortem: A document analyzing what happened during an incident, why it happened, and what should change to prevent recurrence
Original article
What does using AI for post-mortems actually mean?
Everyone is using AI to help with post-mortems now. The pitch is obvious: post-mortems are time-consuming, the blank page is brutal, and AI is very good at producing structured, confident-sounding documents quickly.
We're not here to push back on that. We've built AI into our own post-mortem experience, pulling your Slack thread, timeline, PRs, and custom fields together and giving your team a meaningful starting point in seconds. We think that's genuinely valuable, and the teams using it agree.
But "AI for post-mortems" can mean very different things. There's a version that makes post-mortems faster and better. And there's a version that makes them faster and quietly useless. The difference isn't obvious from the outside — which is exactly why it's worth being precise about.
The trap
AI-assisted post-mortems tend to look great. Structured, confident, plausible. Then someone reads it closely and realises: nobody actually said that. Nobody owns that conclusion. The "lessons learned" at the bottom read like something a consultant wrote, not something the team believes.
That's the trap, and it's subtle. The most dangerous AI-assisted post-mortem isn't the one that's obviously wrong. It's the one that sounds exactly right, but was produced without anyone doing the real thinking.
A post-mortem's value isn't in the document. It's in the team that genuinely worked out what happened, and why. If AI short-circuits that process, it short-circuits the learning. You end up with beautifully formatted docs that sit in a folder and change nothing. Faster to produce, yes. But also useless in the ways that matter.
Compression vs. synthesis
Here's the distinction we keep coming back to.
Compression is taking something sprawling — a messy incident channel, a fragmented timeline, a dozen overlapping threads — and making it navigable. It's what your team needs to get started, and it's what AI does well:
- Assembling a timeline from alerts, Slack messages, and PRs so nobody has to piece it together manually
- Generating a structured first draft from your incident context so the document exists before anyone has to stare at a blank page
- Reviewing a draft for completeness, flagging gaps, missing owners, unanswered questions
- Surfacing relevant context from past incidents so patterns don't get missed
This is the mechanical, time-consuming prep work that often just doesn't happen because the incident is over, everyone's exhausted, and there are three other things on fire. It should be automated. It can be.
Synthesis is different. It's understanding why contributing factors aligned the way they did, not just what happened, but what it reveals about your system. It's deciding which follow-up actions actually matter versus which ones are wishful thinking that'll drift out of the backlog. It's naming the organisational or cultural issues that a technical fix won't touch. It's the conclusion someone has to own, and be able to defend.
Synthesis that nobody owns is just prose. It doesn't matter how well-written it is. The value is in the team that produced it, believes it, and does something about it.
What this means in practice
AI can meaningfully reduce the time it takes to produce a post-mortem. The raw material — timeline, context, structure — can be ready in minutes rather than hours. That's real.
But "faster to produce" and "faster to learn from" are not the same thing. The synthesis — the actual work of understanding what happened and deciding what changes — still takes the time it takes. It should. That's where the value is.
The mental model we use: AI handles the effort so humans can focus on the insight. Not AI instead of thinking. AI so the thinking can actually happen.

Test network paths with TCP, UDP, and ICMP in Datadog
Datadog now supports network path testing using TCP, UDP, and ICMP protocols to match real application traffic patterns and diagnose connectivity issues more accurately.
Original article
Designing network tests with protocols like TCP, UDP, or ICMP improves root cause analysis by matching application traffic, revealing latency, packet loss, and reliability issues.

Bridging the trust gap: Unified public CA orchestration with IBM Vault
IBM Vault Enterprise now automates public certificate authority workflows alongside private PKI, eliminating manual renewal processes that cause outages when certificates expire unexpectedly.
Deep dive
- The core problem is the "public trust boundary" where Vault automated internal PKI but organizations still manually requested public certificates through CA portals, breaking automation pipelines
- Manual certificate management is the primary cause of outage-inducing errors, with expired public certificates bringing down customer-facing services when renewals are missed
- Organizations were forced to maintain split governance with one tool for private certs and separate systems for public certs, making unified security policies and complete audit trails nearly impossible for compliance standards
- The integration uses ACME protocol as a vendor-agnostic interface, with Vault acting as a central proxy that securely manages upstream CA credentials
- Current implementation supports HTTP-01 challenge for domain validation (proving ownership by serving a token over HTTP), with DNS-01 challenge support planned for wildcard certificates
- Vault Agent handles orchestration between Vault and the public CA, managing the domain validation process
- Supports both CSR-based workflows (where private keys never leave your infrastructure) and identifier-based workflows for faster issuance
- Teams can now configure CA integrations, request/download public certificates via Vault API/CLI/UI, manually trigger renewals, and instantly revoke compromised certificates all within Vault
- The Terraform Vault provider has been updated to fully automate setup and management of public CA integrations as code
- This unifies the entire certificate lifecycle under "a single pane of glass" with consistent APIs, centralized expiration tracking, and unified audit trails across all certificate types
Decoder
- PKI (Public Key Infrastructure): System for creating, managing, and revoking digital certificates and public-private key pairs that establish trust and encryption
- X.509 certificates: Standard format for digital certificates used in TLS/SSL to prove identity and encrypt communications between servers and clients
- Public CA: Certificate authority trusted by browsers and operating systems (like Let's Encrypt or DigiCert) whose certificates work for external users, unlike private CAs only trusted internally
- ACME (Automated Certificate Management Environment): Protocol that automates the process of requesting certificates from CAs by proving domain ownership through challenges
- HTTP-01 challenge: Domain validation method where you prove ownership by serving a specific token at a particular URL on your domain
- DNS-01 challenge: Alternative validation method using DNS records, required for wildcard certificates covering multiple subdomains
- CSR (Certificate Signing Request): File containing your public key and domain information that you send to a CA to get a certificate, while keeping the private key secure on your infrastructure
Original article
Vault Enterprise now integrates public certificate authorities via ACME, unifying private and public PKI workflows to eliminate manual processes, reduce outage risk, and centralize governance while enabling automated issuance, renewal, and revocation through a single platform.
Canva Admits Its AI Tool Removed ‘Palestine' from Designs
Canva's AI image editing tool was silently replacing 'Palestine' with 'Ukraine' in user designs, revealing how content moderation rules can create unexpected bias in production AI systems.
Original article
Graphic design platform Canva has a number of AI tools available to users, but it turns out they have some real strong editorial opinions—including removing the word "Palestine" from designs. The issue was spotted by X user @ros_ie9, who shared an image showing Canva's "Magic Layers" feature changing the text of a design from "Cats for Palestine" to "Cats for Ukraine."
Others claimed they were able to replicate the issue, which seemed limited to the word "Palestine" and, for whatever reason, repeatedly replaced it with "Ukraine." Users were able to create projects that included the word "Gaza" without issue.
A spokesperson for Canva confirmed the issue when contacted by Gizmodo and said it has been addressed. "We became aware of an issue with our Magic Layers feature and moved quickly to investigate and fix it. It's now been resolved, and we're taking steps to make sure it doesn't happen again," the spokesperson explained. "We take reports like this very seriously, and we're putting additional checks in place to help prevent this in future. We're sorry for any distress this may have caused."
Per Canva, the issue was isolated and didn't affect designs broadly—though it's unclear what that means, considering some users were reportedly able to reproduce the issue. Regardless, the company said it launched an audit into how the issue arose and is reviewing its internal testing processes to detect and prevent unexpected outputs in the future.
The issue seems to have been specifically related to Canva's Magic Layers feature, which it introduced last month. The AI-powered tool is supposed to convert "flat images and static AI outputs into fully editable, multi-layered designs inside the Canva editor." Basically, it's supposed to make each element of an existing design able to be modified, as if you had made it from scratch. Why such a feature would change the text of an image on its own and without any instruction to do so remains a mystery—though it may tell us something about the training data and instructions the tool was given.
It's not the first time that AI tools have displayed a bias related to Palestine. When Meta introduced generative AI tools in WhatsApp, it would produce an image of a boy with a gun when asked to create an image of a Palestinian. In 2023, activists found that ChatGPT refused to answer affirmatively when asked, "Should Palestinians be free?" when it had no issue answering that question for any other population.
Awesome Design.md (GitHub Repo)
A GitHub repository curating DESIGN.md files from 50+ popular websites—plain markdown design systems that AI coding agents can read to generate pixel-accurate UI without Figma or JSON schemas.
Deep dive
- DESIGN.md is a new convention from Google Stitch for encoding design systems in plain markdown that AI agents consume, parallel to AGENTS.md which defines how to build projects
- The repo contains 50+ pre-built files from real websites across categories: AI platforms (Claude, Mistral, Replicate), dev tools (Cursor, Vercel, Warp), databases (Supabase, ClickHouse), SaaS (Linear, Notion), design tools (Figma, Framer), fintech (Stripe, Coinbase), e-commerce (Shopify, Nike), consumer tech (Apple, Spotify), and automotive (Tesla, Ferrari, Lamborghini)
- Each DESIGN.md includes 9 sections: visual theme/atmosphere, color palette with semantic roles and hex codes, typography hierarchy table, component styling with interaction states, layout principles including spacing scales, depth/elevation shadow systems, design do's and don'ts, responsive behavior and breakpoints, and agent prompt guide with ready-to-use snippets
- Files come with preview.html and preview-dark.html for visual verification of the extracted design tokens
- The approach leverages that markdown is the format LLMs read best—no JSON parsing, no Figma plugins, no complex tooling or configuration required
- Use case: drop a DESIGN.md in your project root, tell your AI agent "build me a page that looks like this" and get pixel-perfect UI matching that aesthetic
- You can request custom DESIGN.md files for specific websites, including private paid requests delivered exclusively
- The repo positions this as extracting publicly visible CSS values, not claiming ownership of any brand's visual identity
- MIT licensed and accepting contributions to improve existing files or add new ones (with issue-first workflow)
Decoder
- DESIGN.md: A markdown file containing a design system specification that AI coding agents read to generate consistent UI
- Google Stitch: Google's tool that introduced the DESIGN.md concept for AI-powered design generation
- Design tokens: Individual values (colors, spacing, font sizes) that comprise a design system
- AGENTS.md: Related convention for documenting how AI agents should build or work with a project
Original article
Curated collection of DESIGN.md files inspired by developer focused websites.
Awesome DESIGN.md
Copy a DESIGN.md into your project, tell your AI agent "build me a page that looks like this" and get pixel-perfect UI that actually matches.
What is DESIGN.md?
DESIGN.md is a new concept introduced by Google Stitch. A plain-text design system document that AI agents read to generate consistent UI.
It's just a markdown file. No Figma exports, no JSON schemas, no special tooling. Drop it into your project root and any AI coding agent or Google Stitch instantly understands how your UI should look. Markdown is the format LLMs read best, so there's nothing to parse or configure.
| File | Who reads it | What it defines |
|---|---|---|
AGENTS.md |
Coding agents | How to build the project |
DESIGN.md |
Design agents | How the project should look and feel |
This repo provides ready-to-use DESIGN.md files extracted from real websites.
Request a DESIGN.md
You can request a DESIGN.md for specific website, including private requests delivered exclusively to you.
Sponsors ❤️
Become a Sponsor [1M+ view] — your logo here and get listed on getdesign.md
Collection
AI & LLM Platforms
- Claude - Anthropic's AI assistant. Warm terracotta accent, clean editorial layout
- Cohere - Enterprise AI platform. Vibrant gradients, data-rich dashboard aesthetic
- ElevenLabs - AI voice platform. Dark cinematic UI, audio-waveform aesthetics
- Minimax - AI model provider. Bold dark interface with neon accents
- Mistral AI - Open-weight LLM provider. French-engineered minimalism, purple-toned
- Ollama - Run LLMs locally. Terminal-first, monochrome simplicity
- OpenCode AI - AI coding platform. Developer-centric dark theme
- Replicate - Run ML models via API. Clean white canvas, code-forward
- RunwayML - AI video generation. Cinematic dark UI, media-rich layout
- Together AI - Open-source AI infrastructure. Technical, blueprint-style design
- VoltAgent - AI agent framework. Void-black canvas, emerald accent, terminal-native
- xAI - Elon Musk's AI lab. Stark monochrome, futuristic minimalism
Developer Tools & IDEs
- Cursor - AI-first code editor. Sleek dark interface, gradient accents
- Expo - React Native platform. Dark theme, tight letter-spacing, code-centric
- Lovable - AI full-stack builder. Playful gradients, friendly dev aesthetic
- Raycast - Productivity launcher. Sleek dark chrome, vibrant gradient accents
- Superhuman - Fast email client. Premium dark UI, keyboard-first, purple glow
- Vercel - Frontend deployment platform. Black and white precision, Geist font
- Warp - Modern terminal. Dark IDE-like interface, block-based command UI
Backend, Database & DevOps
- ClickHouse - Fast analytics database. Yellow-accented, technical documentation style
- Composio - Tool integration platform. Modern dark with colorful integration icons
- HashiCorp - Infrastructure automation. Enterprise-clean, black and white
- MongoDB - Document database. Green leaf branding, developer documentation focus
- PostHog - Product analytics. Playful hedgehog branding, developer-friendly dark UI
- Sanity - Headless CMS. Red accent, content-first editorial layout
- Sentry - Error monitoring. Dark dashboard, data-dense, pink-purple accent
- Supabase - Open-source Firebase alternative. Dark emerald theme, code-first
Productivity & SaaS
- Cal.com - Open-source scheduling. Clean neutral UI, developer-oriented simplicity
- Intercom - Customer messaging. Friendly blue palette, conversational UI patterns
- Linear - Project management for engineers. Ultra-minimal, precise, purple accent
- Mintlify - Documentation platform. Clean, green-accented, reading-optimized
- Notion - All-in-one workspace. Warm minimalism, serif headings, soft surfaces
- Resend - Email API for developers. Minimal dark theme, monospace accents
- Zapier - Automation platform. Warm orange, friendly illustration-driven
Design & Creative Tools
- Airtable - Spreadsheet-database hybrid. Colorful, friendly, structured data aesthetic
- Clay - Creative agency. Organic shapes, soft gradients, art-directed layout
- Figma - Collaborative design tool. Vibrant multi-color, playful yet professional
- Framer - Website builder. Bold black and blue, motion-first, design-forward
- Miro - Visual collaboration. Bright yellow accent, infinite canvas aesthetic
- Webflow - Visual web builder. Blue-accented, polished marketing site aesthetic
Fintech & Crypto
- Binance - Crypto exchange. Bold Binance Yellow on monochrome, trading-floor urgency
- Coinbase - Crypto exchange. Clean blue identity, trust-focused, institutional feel
- Kraken - Crypto trading platform. Purple-accented dark UI, data-dense dashboards
- Mastercard - Global payments network. Warm cream canvas, orbital pill shapes, editorial warmth
- Revolut - Digital banking. Sleek dark interface, gradient cards, fintech precision
- Stripe - Payment infrastructure. Signature purple gradients, weight-300 elegance
- Wise - International money transfer. Bright green accent, friendly and clear
E-commerce & Retail
- Airbnb - Travel marketplace. Warm coral accent, photography-driven, rounded UI
- Meta - Tech retail store. Photography-first, binary light/dark surfaces, Meta Blue CTAs
- Nike - Athletic retail. Monochrome UI, massive uppercase Futura, full-bleed photography
- Shopify - E-commerce platform. Dark-first cinematic, neon green accent, ultra-light display type
- Starbucks - Coffee retail flagship. Four-tier earth-green system, warm cream canvas, proprietary SoDoSans typography
Media & Consumer Tech
- Apple - Consumer electronics. Premium white space, SF Pro, cinematic imagery
- IBM - Enterprise technology. Carbon design system, structured blue palette
- NVIDIA - GPU computing. Green-black energy, technical power aesthetic
- Pinterest - Visual discovery platform. Red accent, masonry grid, image-first
- PlayStation - Gaming console retail. Three-surface channel layout, cyan hover-scale interaction
- SpaceX - Space technology. Stark black and white, full-bleed imagery, futuristic
- Spotify - Music streaming. Vibrant green on dark, bold type, album-art-driven
- The Verge - Tech editorial media. Acid-mint and ultraviolet accents, Manuka display type
- Uber - Mobility platform. Bold black and white, tight type, urban energy
- Vodafone - Global telecom brand. Monumental uppercase display, Vodafone Red chapter bands
- WIRED - Tech magazine. Paper-white broadsheet density, custom serif, ink-blue links
Automotive
- BMW - Luxury automotive. Dark premium surfaces, precise German engineering aesthetic
- BMW M - Performance automotive. Motorsport-inspired contrast, M color accents, precision-driven layout
- Bugatti - Luxury hypercar. Cinema-black canvas, monochrome austerity, monumental display type
- Ferrari - Luxury automotive. Chiaroscuro black-white editorial, Ferrari Red with extreme sparseness
- Lamborghini - Luxury automotive. True black cathedral, gold accent, LamboType custom Neo-Grotesk
- Renault - French automotive. Vivid aurora gradients, NouvelR proprietary typeface, zero-radius buttons
- Tesla - Electric vehicles. Radical subtraction, cinematic full-viewport photography, Universal Sans
What's Inside Each DESIGN.md
Every file follows the Stitch DESIGN.md format with extended sections:
| # | Section | What it captures |
|---|---|---|
| 1 | Visual Theme & Atmosphere | Mood, density, design philosophy |
| 2 | Color Palette & Roles | Semantic name + hex + functional role |
| 3 | Typography Rules | Font families, full hierarchy table |
| 4 | Component Stylings | Buttons, cards, inputs, navigation with states |
| 5 | Layout Principles | Spacing scale, grid, whitespace philosophy |
| 6 | Depth & Elevation | Shadow system, surface hierarchy |
| 7 | Do's and Don'ts | Design guardrails and anti-patterns |
| 8 | Responsive Behavior | Breakpoints, touch targets, collapsing strategy |
| 9 | Agent Prompt Guide | Quick color reference, ready-to-use prompts |
Each site includes:
| File | Purpose |
|---|---|
DESIGN.md |
The design system (what agents read) |
preview.html |
Visual catalog showing color swatches, type scale, buttons, cards |
preview-dark.html |
Same catalog with dark surfaces |
How to Use
- Copy a site's
DESIGN.mdinto your project root - Tell your AI agent to use it.
Contributing
See CONTRIBUTING.md for guidelines.
- Improve existing files: Fix wrong colors, missing tokens, weak descriptions
- Report issues: Let us know if something looks off
Before opening a PR, please open an issue first to discuss your idea and get feedback from maintainers.
License
MIT License - see LICENSE
This repository is a curated collection of design system documents extracted from public websites. All DESIGN.md files are provided "as is" without warranty. The extracted design tokens represent publicly visible CSS values. We do not claim ownership of any site's visual identity. These documents exist to help AI agents generate consistent UI.

Anthropic Nears $900B Valuation Round
Anthropic is closing a $50 billion funding round at around $900 billion valuation, potentially surpassing OpenAI and becoming one of the world's most valuable private companies before an anticipated IPO later this year.
Original article
Anthropic is asking investors to submit allocations for the AI company's latest fundraise within the next 48 hours, according to sources familiar with the matter. The round, which TechCrunch reported is expected to be roughly $50 billion, is estimated to close within two weeks, the sources said.
As we previously reported, Anthropic is targeting a valuation of about $900 billion. However, given the soaring demand from investors seeking a stake in the company, the final valuation may well exceed that figure, our sources said.
Anthropic declined to comment.
Despite the intense demand, some early backers — particularly those who invested in 2024 or earlier — are skipping this round. Instead, these investors are waiting to potentially cash out during Anthropic's anticipated IPO later this year.
The company is raising what is likely to be its last private round before going public to fund its massive computing needs.
Anthropic announced this month that its annual revenue run rate has surpassed $30 billion. But as we previously reported, the company's run rate is currently closer to $40 billion, according to sources with knowledge of the company's financials.
Anthropic raised its last round in February at a $380 billion valuation. At $900 billion, the company would not only more than double its valuation but would also surpass its chief rival, OpenAI, which closed a record-breaking $122 billion round at an $852 billion post-money valuation earlier this year.
Cursor's war chest, xAI's redemption
Cursor, the fastest-growing AI coding tool with $2B ARR, sold to xAI for $60B after model providers like Anthropic undercut their resale business into unsustainability.
Deep dive
- Cursor achieved $2B ARR in 13 months with 70% Fortune 1000 penetration, making it the fastest-growing software company in history by traditional SaaS metrics
- Despite being oversubscribed in a $50B funding round, founders sold to xAI for $60B after concluding they couldn't reach $100B independently—that strategic retreat is the key signal
- Anthropic systematically destroyed Cursor's economics by launching Claude Code at effectively 5x lower per-token costs than Cursor paid to resell Claude via API
- Cursor tried multiple defensive strategies: building their own Composer model, sophisticated agent harnesses, enterprise workflows, design features, and aggressive Fortune 500 sales—all failed to escape the squeeze
- Cursor's negative 23% gross margins were recent, caused by model labs collapsing pricing faster than any sales motion could compensate, not founder incompetence with unit economics
- The acquisition gives xAI enterprise distribution, procurement relationships, battle-hardened sales teams, and the most experienced coding agent engineering team outside Anthropic's walls
- For Anthropic, the "win" is pyrrhic—they eliminated a margin-extracting middleman but consolidated that distribution with a well-funded competitor controlling massive compute
- The deal proves the "neutral harness" thesis—building an app that picks the best model regardless of provider—doesn't survive at $50B scale once suppliers identify you as margin to extract
- Implications for competitors like Cognition, Factory, Lovable, and Replit: the best-executed version of their business model couldn't run independently, dramatically lowering the bar for accepting a corporate sponsor
- Alternative strategy for smaller players: niche down to specific verticals or workflows where you can be "unkillable" rather than competing for Fortune 500 seats—that's a real business, just not a $60B one
- For investors, this raises the ceiling on application layer valuations even without profitability paths, as strategic acqui-hires can now reach $60B—much higher than previous Character.AI or Adept deals
- Anthropic is already tightening Claude Code rate limits and cracking down on third-party tools now that the largest token disintermediator is neutralized—the warchest pricing doesn't need to stay defensive
- The constraint on Anthropic's pricing power is remaining competition from OpenAI's GPT-5 at $10/million tokens and cheap Gemini, but expect Claude Code prices to drift upward over coming quarters
- The fundamental lesson: you cannot disintermediate the lab whose tokens you resell if they determine they want to go to war with you—the application layer doesn't get champions, it gets wards with sponsors
Decoder
- ARR: Annual Recurring Revenue, a key SaaS metric measuring predictable yearly income from subscriptions
- Gross margins: Revenue minus cost of goods sold as a percentage; negative means losing money on each sale before operating expenses
- Model lab: Companies like Anthropic, OpenAI, and Google that train foundational AI models from scratch
- Tokens: Units of text that AI models process and charge for; pricing is typically per million tokens consumed
- API rates: Wholesale pricing that developers pay to access AI models programmatically through code
- Harness/wrapper: Software layer sitting between users and AI models, adding features like UI, workflow automation, or multi-model switching
- Disintermediation: Removing middlemen by selling directly to end customers instead of through resellers
- COGS: Cost of Goods Sold, the direct variable costs to deliver each unit of product or service
- Long-horizon tasks: AI agent operations that run for extended periods with multiple decision steps
- Frontier model: State-of-the-art AI models representing the current capability ceiling in the industry
- Warchest: Strategy of deliberately losing money to eliminate competition, planning to profit after winning market dominance
Original article
Cursor is the most operationally successful software company of the AI era. Its founders looked at the path to $100 billion and decided they weren't willing to underwrite it. They sold to xAI for $60 billion in a deal considered to be good for everyone. The deal gives xAI an application surface to put in front of public market investors before the SpaceX IPO, and it gives Cursor a sponsor with compute and a non-competing model lab.

Perplexity Expands Enterprise AI Workflows
Perplexity is pushing beyond search into enterprise automation with workflow templates, data warehouse connectors, and deep Microsoft integrations to compete with Copilot.
Original article
Perplexity added workflows, enterprise data connectors, and integrations like Teams and Excel to its AI system, targeting structured business tasks and continuous automation.

Zuckerberg-backed Biohub bets $500M on AI biology
Mark Zuckerberg and Priscilla Chan's nonprofit is investing $500 million to build AI models that simulate the human body, betting that scaling compute and biological data will help cure diseases.
Original article
Mark Zuckerberg and Priscilla Chan's nonprofit, Biohub, is committing $500 million to help create better AI simulations of the human body. Biohub's long-term goal is to cure all human diseases through the intersection of AI and biology. It is betting that more data and compute will produce more useful models. Of the $500 million, Biohub will spend $400 million on its own work and $100 million to spur others.

Microsoft rolls out Xbox Mode, bringing a console-like experience to any PC
Microsoft is rolling out Xbox Mode to all Windows 11 PCs, a full-screen console-like interface that consolidates games from Game Pass, Steam, and other stores with controller navigation.
Decoder
- Xbox Game Pass: Microsoft's subscription service for accessing a library of games
- Windows Insider: Beta testing program for early access to Windows features
- ROG Ally X: ASUS's handheld gaming PC device similar to Steam Deck
- Auto SR: Automatic Super Resolution upscaling technology to improve game visuals
Original article
Microsoft is rolling out Xbox Mode to all Windows 11 PCs and devices. The full-screen experience offers a simple UI and frees up system resources to allow games to run smoothly. The current version still has some glitches and crashes occasionally. It is widely believed that Microsoft's next console will essentially be a Windows 11 PC running Xbox Mode.
If I Could Make My Own GitHub
A developer argues that modern code forges like GitHub have lost sight of developer needs and proposes a reimagined system that better integrates version control clients with repositories.
Deep dive
- Modern forges are disconnected from git's original design as a decentralized system for kernel development using email patches, but developers now just use it for centralized pull/push workflows where all important features live in the forge itself
- Current PR workflows provide feedback too late—developers want validation before commits are pushed, not after, through enforced pre-commit hooks that run CI/CD remotely on the forge
- Binary approve/reject PR models don't match reality where code review often involves nuanced decisions like "fine for now, revisit later"—Gerrit's multi-level approval system is a better model
- Requiring approval on every change wastes senior engineer time on trivial PRs, especially with LLMs available to assess risk—approval requirements should be customizable based on maintainer status and change complexity
- Stacked PRs make code easier to review by breaking changes into logical units but aren't first-class citizens in current forges, requiring third-party tools to manage
- Forges suffer from feature creep—issue tracking makes sense, kanban boards and wikis probably don't—leading to maintenance burden for rarely-used features that can't be removed once adopted
- Standard forge hosting units are too large (GitHub Enterprise, GitLab) with many moving parts when organizations should be able to run on clusters of small devices like Raspberry Pis
- Local repository clones should represent the entire project including PRs and issues, not just code, allowing developers to approve PRs and triage issues from their VCS client
- Storage should be optimized for always-online workflows with shallow clones by default and on-demand history fetching rather than cloning entire project history upfront
- GitHub Actions and similar CI/CD systems should be signed, content-addressed by SHA, and usable offline with local tarballs rather than requiring network access to third-party repositories
- The proposed solution combines JJ as the version control system with modern infrastructure concepts like object storage, shallow clones, and federation of small hosting units
- The author argues that only GitHub's declining quality makes this conversation worth having—previously the default was good enough that alternatives were "like sweet potato french fries" (never what you actually want)
Decoder
- Forge: A platform that hosts git repositories and adds collaboration features like pull requests, issues, and CI/CD (GitHub, GitLab, Gitea are examples)
- Four-eyes principle: Security practice requiring two people to review and approve changes before they're merged into the codebase
- Stacked PRs: Multiple dependent pull requests built on top of each other, allowing reviewers to see logical progression of changes rather than one massive PR
- Gerrit: A code review system originally built for Android development that uses a more nuanced approval model with multiple levels like +1, +2, -1, -2 instead of binary approve/reject
- JJ (Jujutsu): A modern version control system designed to be more user-friendly than git while maintaining compatibility with git repositories
- Shallow clone: Downloading only recent commit history instead of the entire project history, saving bandwidth and storage
Original article
Git is great at what it is designed to do, but what it is designed to do isn't the way most people are using it.

Matt Mullenweg thinks WordPress is in decline. He may be right
WordPress co-founder Matt Mullenweg says the project is declining because its bureaucratic, consensus-driven development culture prevents innovation and produces mediocre results.
Deep dive
- Mullenweg argues WordPress has spent years damaging itself through overly rigid adherence to consensus-based decision-making, not through external competition
- The current release culture requires wide-ranging discussions involving dozens of people before shipping any feature, which he says produces "boring or mediocre crap"
- He points out that the biggest wins will necessarily be non-consensus ideas, so organizations must accept occasional failures or they'll never achieve major successes
- The article's author, Ben Werdmuller, agrees and draws parallels to Mozilla's similar bureaucratic struggles in recent years
- Werdmuller argues that contributions should be made quickly and product design should be opinionated rather than consensus-driven, as seeking consensus inherently limits innovation
- The proposed solution involves governance structures with elected decision-makers who can be voted out if they underperform, rather than requiring consensus on every individual change
- This approach differs from web standards bodies, where consensus is appropriate to prevent single-vendor domination of interoperability
- Dave Winer offers an alternative vision: WordPress should become more of a platform foundation, letting smaller teams build opinionated interfaces and innovations on top
- The platform approach would make WordPress an "ecosystem monolith" while enabling faster-moving entrepreneurial innovation at the edges
- The core tension is between democratic participation in open source and the practical need for software projects to innovate and move quickly to remain competitive
Decoder
- Iatrogenic: A medical term meaning harm caused by treatment itself; Mullenweg uses it to describe how WordPress's own processes are damaging the project
- Consensus-driven: A decision-making approach requiring broad agreement from many stakeholders before taking action, which can slow or prevent decisive changes
- Governance structures: The formal rules and processes that determine how decisions are made and who has authority in an organization or project
- Ecosystem monolith: A stable, foundational platform that provides core functionality while allowing diverse innovations to be built on top of it
Original article
Mullenweg says WordPress is killing itself by blindly following rules and ideals.

I Love AI, but it Still Can't Design for Shit
AI tools still produce low-quality design, code, and content without rigorous human oversight and iteration, despite narratives claiming they've replaced creative professionals.
Deep dive
- The author uses AI extensively across multiple tools but observes it consistently lacks critical evaluation of its own outputs across writing, code, and design
- When interviewing AI experts, the best candidates use AI but maintain strict editorial control, producing tight presentations with minimal text per slide that they clearly understand, while most submit bloated AI-generated decks they haven't even read
- AI writing tropes became recognizable starting with GPT-3 and tools like Jasper, creating easily-spotted patterns across LinkedIn and other platforms
- In software engineering, AI without significant context engineering doesn't produce maintainable applications that hold up over time
- AI-generated images similarly require iterative refinement beyond initial prompts to create anything of real value
- Anthropic's Claude Design, despite coming from a potentially massive company, produces one-shot designs that look superficially good but fall apart under scrutiny or when trying to build upon them
- Recognizable AI design patterns have evolved from "Anthropic greige UI slop" to blue/purple gradients and will continue shifting
- The author believes the design quality problem will be solved at the application layer through better tooling, not through model improvements alone
- Good designers combining skills with AI can create extraordinary work, but it still requires time and effort rather than quick prompting
- Design teams at established products will likely see quality improvements as teams master AI tools properly
- The persistent value of human oversight creates a "signalling arbitrage opportunity" for professionals who maintain quality standards while others drop theirs
Decoder
- AI slop: Low-quality, generic-looking content obviously generated by AI without human refinement, characterized by recognizable patterns and lack of critical editing
- Vibe coding: Creating applications based on how they should feel or look without solid architectural foundations, often resulting in code that's difficult to maintain or extend
- Context engineering: Providing AI models with appropriate background information, constraints, and guidance at multiple levels to improve output quality
- Claude Design: Anthropic's AI-powered interface design tool
- Anthropic greige: A specific aesthetic of gray-beige, minimalist UI design associated with AI-generated interfaces
Original article
I love AI, but it still can't design for shit
Without a critical human eye, AI produces slop. The quality bar is yours to maintain.
I love AI. I use it all the time. I have claws, I have claude max 20x, I'm on a 40+ day GitHub commit streak, I'm currently using nanobanana to help me remodel my house. Hell, I'm one half of a consultancy focused entirely around AI.
But time and time again, I'm seeing evidence that AI has literally no critical eye for its own work.
One example: I've been hiring AI experts on behalf of clients. My favourite footgun exercise is to ask them to prepare a presentation for an interview stage, with the explicit expectation that they use AI to do so.
The best candidates use AI (of course) but stand firmly between its output and what they'll present back to me. They know their material back to front. They probably wrote a bunch of it themselves, or shaped it hard. Then AI helped to mould, expand or tighten their words, before the human jumped in at the end to cast a critical eye.
Those presentations fit into around 1 slide a minute, with under 50 words on the slide. As in, the bare minimum that any solid pre-AI presentation would stick to in order to be even presentable in the allotted time, let alone actually compelling as a live presentation. They then present it confidently - never needing to read their own slides to know what they're presenting next.
But the vast majority of responses have been 3-4 slides per minute of allotted time, containing an absolute soup of paragraphs, bullet points and drivel. What's worse is how painfully obvious it is that not only has the presenter not taken the editorial eye over the words, it's not clear that they've even read them.
People. This is basic.
You are accountable for your output. The AI does not look bad if your AI slop is on show. You do. Especially if the person the other end knows anything about how these models work.
This has been true of written words since GPT-3 when the Jasper AI slop cannon reared its muzzle and fired its first salvo at the walls of Linkedin think posts. Once you see the AI tropes, you can't unsee them. AI responding to AI on my feeds all day every day, and I'm seemingly Haley Joel Osment.
It came for software engineering and anyone who's build maintainable applications knows that without significant context engineering at multiple levels, AI is not a good software engineer.
The same for images. We can now spot AI images (or us terminally online can) a mile off — to create something with any value at all you must go beyond the first prompt and refine, refine, refine.
And now it's interface design's turn. Claude Design may have been built by what will possibly end up the biggest company the world has ever seen, but their model can't design for shit.
I'm sorry. It can't.
We'll undoubtedly see successful companies in AI design (and to be clear, I want our reliance on drawing rectangles to go away) — but the one-shot design skill is currently a myth, to anyone who knows what they're looking at.
The 'designers are cooked' narrative is currently typically accompanied by pound shop versions of Anthropic greige UI slop - before that it was blue/purple gradients. It will evolve again.
Like vibe coding an app, the LLM's output might look good on first glance. But dig deeper, or try to build on that foundation and it becomes an exercise in nailing jelly to the wall. And trust me, us designers know.
This will undoubtedly improve
Good people are working on this - either for profit or for love of the game.
The design tooling space is on fire, from exciting projects to build real replacements for Figma et al to 'design skills' and DESIGN.md files attempting to steer models into more interesting and high quality outputs.
(My hunch is that this problem will be solved in the application layer, not the model layer, so some of these more ambitious products may win out.)
Design teams are also starting to listen. Long term I have little concern around the quality of design of established products suffering here — in fact undoubtedly we'll see more interesting and polished interfaces as tools are developed and mastered.
What is also obvious is that good design plus AI can create extraordinary things. Suddenly designers can realise their visions for how something can feel, with no handoff or slow feedback loop with an engineer. Whole new design trends and patterns are emerging from a new group of people having access to new tools.
But guess what. Each still took time. Nothing actually good was created slapdash. The tools increase creativity and add capabilities as well as speeding designers up.
And that effort will always be valued, as this tweet by Hillary Gridley describes perfectly. We'll continue to see enormous gains in productivity and capability through AI, but 'There will always be a signalling arbitrage opportunity in keeping a human in the loop'.
That's good news for those who can maintain their quality bar when all others are dropping theirs.
Make sure you check your AI outputs and that could be you.
This space is moving fast: I reserve the right to change my opinion as models evolve.

How AI Efficiency is Subtly Disrupting the Interactions that Build Strong Teams
AI tools are eliminating the informal workplace interactions that research shows build trust and innovation in teams, creating hidden costs despite efficiency gains.
Deep dive
- AI tools are replacing informal "bugging" of colleagues (designers asking researchers, PMs asking designers, engineers asking accessibility teams) with self-service options that eliminate both inefficiency and team-building moments
- MIT's 2012 Human Dynamics Lab found informal communication was the best predictor of team productivity, with teams having the most informal interaction achieving 35% more successful outcomes
- Google's 2015 Project Aristotle study of 180+ teams found psychological safety built through frequent, low-stakes interactions was the #1 predictor of high performance, above intelligence or resources
- A 2025 Harvard/Columbia/Yeshiva study found AI-driven automation decreased overall team performance, increased coordination failures, and decreased team trust, especially in short-term and lower-skilled teams
- McKinsey research found not feeling belonging (eroded when informal interactions disappear) was a top reason employees left, costing median S&P 500 companies $228-355 million annually in lost productivity
- Korean research in 2024 showed "weak ties"—bridging conversations with occasional contacts—sustained innovative performance in technologically innovative companies, suggesting eliminating cross-team "bugging" could hurt innovation
- A 2026 study of 1,488 workers identified "AI Brain Fry"—cognitive exhaustion from excessive AI use—with 34% of affected workers intending to quit their jobs
- Workers who used AI to eliminate toil rather than replace human interaction had 15% lower burnout rates and reported higher social connection with peers due to more "off keyboard" time
- Recommended strategies include using AI only for repetitive unenjoyable tasks, designing workspaces and processes for serendipitous collision (like Steve Jobs' Pixar studios where employees had to bump into each other), and building team cohesion through playful shared AI experiences
- Practical tactics include attaching creator names to AI-generated work to facilitate follow-up connections, spotlighting successful team AI uses, establishing rotation programs, holding panel discussions on work evolution, and running humor-based AI activities like "bad UX vibecoding competitions"
Decoder
- Psychological safety: The shared belief among team members that the environment is safe for interpersonal risk-taking, allowing people to speak up without fear of punishment or humiliation
- Weak ties: Relationships with people you interact with occasionally rather than regularly, which research shows are important sources of novel information and innovation
- RAG (Retrieval-Augmented Generation): AI technique that retrieves relevant information from a knowledge base and uses it to generate contextually accurate responses
- Toil: Repetitive, manual, automatable work that doesn't require human judgment or creativity
- Vibe-coding: Using AI tools to rapidly generate code or prototypes based on natural language prompts rather than traditional programming
- AI Brain Fry: Cognitive exhaustion and mental fatigue resulting from excessive use, interaction, or oversight of AI tools beyond an individual's cognitive capacity
Original article
AI tools are eliminating the need to "bug" colleagues for help, but the informal interactions they replace are the very scaffolding that builds team trust, belonging, and innovation. Casey Hudetz and Eric Olive explore the research and potential impacts behind that risk and offer practical strategies for maintaining human connection while leveraging AI's strengths.
Through many discussions with industry colleagues, we've started hearing a phrase more often when swapping stories about AI adoption:
"Now I don't have to bug [someone]."
Product designers don't need to bug researchers anymore — retrieval-augment generation (RAG) tools surface insights instantly. Product Managers don't need to bug designers for mockups — AI generates acceptable options. Engineers don't need to bug accessibility teams — automated scanners flag issues in real-time.
It's framed as liberation, and in many ways, it is. There's genuine relief in being unblocked, in not having to wait, in solving problems independently.
With AI, we're building a "bug-free workforce".
But what if the bugs that AI is automating away, such as the quick questions, the small talk, the organic connections, are actually an important part of the scaffolding that builds and sustains healthy teams?
The Vanishing Scaffolding
Consider what actually disappears when we turn to AI assistance before engaging with a colleague directly. For instance:
- The 2-minute Slack exchange that turns into a 20-minute whiteboarding session.
- The "quick question" that reveals a fundamental misalignment.
- The accessibility review that becomes mentorship.

Although these interactions are primarily intended to exchange information and unblock individuals' tasks, many are the building blocks for the intangible but crucial sense of belonging and connection in the workplace.
The inefficiencies of interpersonal communication and daily interaction build the larger organism known as work culture. When AI disrupts these interactions, what is lost?
What The Research Actually Shows
There is ample psychological research to support our hypothesis: If the trust built through organic and informal connections is threatened, teams will be negatively impacted. Let's examine a few:
In 2012, MIT's Human Dynamics Lab (Pentland, 2012) discovered that the best predictor of team productivity wasn't formal meetings but "energy" from informal communication: the hallway conversations, coffee chats, and quick questions. Teams with the most informal interaction had 35% more successful outcomes. With AI, what energy is not generated, leading to fewer successful outcomes?
In 2015, Google's Project Aristotle studied over 180 teams to find out why some thrived, and others underperformed. They found that psychological safety, the shared belief among team members that the environment is safe for interpersonal risk-taking, built through frequent, low-stakes interactions, was the number one predictor of high performance. Not intelligence. Not resources. Trust built through micro-moments. The exact micro-moments we see vanishing when we overuse AI.
In 2025, researchers from Harvard, Columbia, and Yeshiva University published a study focused on the impact of AI on performance and team coordination. The authors concluded that AI-driven automation decreased overall team performance and increased coordination failures. These effects were especially large in the short-term and in low- and medium-skilled teams. Automation also decreased team trust.
Why This Matters
When AI disrupts the team's energy and psychological safety, a sense of disconnection sets in, which, in turn, hurts the company's bottom line.

Disconnected Employees Leave
People don't stay at companies because of the work. They stay because of the people. And if connections to colleagues decrease due to AI's presence, how might that expedite one's departure?
Consider this question in dollar terms. McKinsey's Great Attrition research found that not feeling a sense of belonging was one of the most frequently cited reasons employees left. When informal micro-interactions disappear, belonging erodes, and people walk.
"Employee disengagement and attrition could cost a median-size S&P 500 company between $228 million and $355 million a year in lost productivity." — McKinsey

Leaders must ask themselves if the potential gains from AI rollouts and promised productivity gains outweigh the costs of a disengaged and attrition-prone workforce. The evidence suggests otherwise.
Disconnected Teams Are Less Innovative
Korean researchers in 2024 analyzed innovation in the private sector and concluded that weak ties — the bridging conversations with people you interact with occasionally — sustained innovative performance in companies characterized by active technological innovation.
Simply put, breakthroughs do not necessarily emerge from your core team but from interactions with the people you would have "bugged" in the past. Eliminating these interactions in favor of AI could not only negatively impact team health, but it could also hurt the business through decreased depth and breadth of innovation in design, coding, content, and beyond.
AI's seduction is that it feels like pure gain until the team realizes they've become strangers who happen to work on the same project.
If a shared sense of purpose and belonging disappears, employers have a workforce less engaged and less innovative, with a higher chance of attrition.
If AI helps us need each other less, how can a company hope to nurture a connected, supported, and effective workforce?
The answer requires a balanced and multi-pronged approach. Use AI tools for dull, repetitive, and high-volume tasks while reserving the human brain for higher-level problem solving. Design physical workspaces and online team interactions that will maintain or increase human connection.
Maintaining The Best Of Both
In short, leverage the best of AI tools and human abilities.
1. Use AI To Eliminate The Toil
In the March 2026 article "When Using AI Leads to 'Brain Fry'", the authors outline their study of 1,488 full-time U.S.-based workers to understand the impact of AI use on professionals. The result was a concept they call "AI Brain Fry," a form of acute mental fatigue and cognitive exhaustion resulting from excessive use, interaction, or oversight of AI tools beyond an individual's cognitive capacity.
Further, the study reveals that the cognitive strain created by intensive AI use carries business costs, including decision fatigue and error-prone work. Perhaps the most troubling finding is that 34% of workers who reported experiencing brain fry intended to quit their jobs. The loss of institutional knowledge caused by turnover is well documented.
One conclusion is that AI is not inherently bad or cognitively taxing. Rather, as with any tool, what matters is how it's used.
Focusing our energy on identifying the repetitive, unenjoyable parts of our jobs (or "toil") and using AI to remove them is a way to improve cognitive and team health.
Indeed, the Harvard Business Review authors explain that participants in their study who used AI to eliminate toil only had 15% lower rates of burnout but also reported "a higher degree of social connection with peers…because they had more time to spend 'off keyboard'." In this toil-elimination scenario, AI did not disrupt team connections; it removed what we consider busy work that prevented the team from solving problems with colleagues.
2. Institutionalize Productive Friction
Steve Jobs famously designed the Pixar studios so employees would have to bump into each other. "Steve realized that when people run into each other, when they make eye contact, things happen," reflected Brad Bird, the director of The Incredibles and Ratatouille movies. John Lasseter, responsible for some of Pixar's most beloved films, shared that he'd "never seen a building that promoted collaboration and creativity as well as this one." Jobs understood that serendipitous collision drives creative work, and Pixar's oeuvre reveals the genius.

What is the equivalent of creating this type of organizational design in the age of AI?
- Build AI tools that connect the team. We've found that when building internal agents, it's best to attach the names of the original creators to the work and to direct seekers to these creators. This way, any seeker not only finds the answer but is connected to others with more institutional knowledge to help.
- Publicly spotlight successful team uses of AI. By finding examples of how teams have used AI to work more effectively and efficiently together and highlighting them in public forums and townhalls, it helps establish the narrative that AI can be something that brings us together rather than pushes us apart.
- Establish rotation programs. If AI means product managers can prototype, have them shadow designers anyway. Having a more holistic understanding of each other's craft through direct dialogues benefits both sides beyond simple AI outputs.
- Hold panel discussions on the evolution of work. Gather cross-functional partners to regularly discuss and debate how our work is currently changing or could in the near future. It keeps intentional change top of mind and in the open.
3. Build Team Cohesion Through AI-inspired Laughter
Positive humor in the workplace has been studied extensively as a way for teams to bond. We see how AI can improve team connections through a good, absurd laugh.
- Bad UX Vibecoding Competitions Give your team a silly prompt ("Design the worst volume control") and 30 minutes to vibe-code a horrible solution. The process of building these outputs helps the team: learn new AI tools, get the creative juices flowing, and, most importantly, laugh together.

- Hyper-specific AI Creations Would a certain image make people smile in this workshop? Is there a funny idea at work that would be even weirder as an AI-generated song? Using them for absurd work moments is a fun way to get people laughing.

Eliminating toil, institutionalizing productive friction, and building team cohesion through humor show the power of integrating the best of the human brain and AI algorithms.

The question isn't whether to use AI. Contemporary workers have less and less choice. The question is: what kind of team do you want to become when AI is the newest teammate?
Conclusion
Leaders who introduce artificial intelligence with an equal amount of emotional intelligence will enable their teams to thrive by leveraging the power of AI while also shielding their teams from the inherent risks associated with the disruptive natures of these new tools.
When the unexpected hits — the crisis, the pivot, the moment that requires trust you can't manufacture overnight — it will be the teams with cultures intact that will thrive.
References
- The 4 Stages of Psychological Safety: Defining the Path to Inclusion and Innovation, Clark, T. R. (2020), Berrett-Koehler Publishers
- What Google Learned From Its Quest to Build the Perfect Team, Duhigg, C. (2016), The New York Times Magazine
- Psychological Safety and Learning Behavior in Work Teams, Edmondson, A. C. (1999), Administrative Science Quarterly, 44(2)
- The Strength of a Weak Tie in the Innovative Performance of Firms: A Case of Korean High-tech Manufacturing Small and Medium-sized Enterprises, Hong, Jinki; Lee; Raehyung; Ohm, Jay Y.; Lee, Duk Hee (2024), Sociology Compass Volume 18, Issue 5
- How Psychological Safety Impacts R&D Project Teams, Liu, Yuwen; Keller, R.T. (2021), Research-Technology Management Volume 64, Issue 2
- Creating Psychological Safety in the Workplace, McCausland, Tammy (2023), Research-Technology Management Volume 66, Issue 2
- Some Employees Are Destroying Value. Others Are Building It. Do You Know the Difference?, De Smet, Aaron; Mugayar-Baldocchi, Marino; Reich, Angelika; Schaninger, Bill (September 11, 2023), McKinsey Quarterly
- The New Science of Building Great Teams, Pentland, A. (2012), Harvard Business Review
- Super Mario Meets AI: Experimental Effects of Automation and Skills on Team Performance and Coordination, Dell'Acqua, Fabrizio; Kogut, Bruce; Perkowski, Patryk (2025), The Review of Economics and Statistics 107 (4)
- Humor Is Serious Business: Why Humor Is A Secret Weapon In Business And Life, Aaker, J; Bagdonas, Naomi (2021)
Font Management for macOS (Website)
A font management application for macOS helps designers organize font collections and test them with color themes and logos.
Original article
Organize your fonts into collections, test color themes and logos, watch folders, manage installed fonts, and more.
ArtPlayer (Website)
ArtPlayer.js is an HTML5 video player library that offers extensive customization options for video controls.
Original article
ArtPlayer.js is an easy-to-use, feature-rich HTML5 video player, and most of its controls are customizable.

We asked: What's the hardest part of being a creative? Your answers were... eye-opening
Survey of hundreds of creative professionals reveals that the industry faces a web of interconnected pressures—from financial instability and AI anxiety to burnout and isolation—that compound into systemic dysfunction.
Deep dive
- Financial instability emerged as the loudest theme, with creatives reporting low pay, difficulty charging what they're worth, and unpaid work expectations creating a fault line that undermines most other aspects of the profession
- Mental health and burnout manifest across multiple dimensions—creative fatigue, deadline pressure, hustle culture exhaustion—with many professionals reporting they're running on empty in an industry that demands constant enthusiasm and energy
- AI anxiety stems not just from fear of replacement but from the exhaustion of constant adaptation, with no point at which professionals feel "caught up" because the ground keeps shifting beneath them
- Imposter syndrome has been amplified by social media, creating a new dimension where creatives compare their internal reality with everyone else's external highlight reel in real time, leading to persistent questions about whether they're good enough
- Career drift affects mid-career professionals especially, who find themselves busy but not progressing, working but not fulfilled, because creative career paths lack obvious linear progression
- Market saturation creates a dynamic where being brilliant at the craft is no longer sufficient for visibility, requiring sustained self-promotion effort that has little to do with work quality
- Client relationships reveal a structural mismatch where commissioners want professional creative output without wanting to pay for or respect the skill that produces it
- Time management pressures are particularly acute for freelancers, who experience porous or non-existent boundaries between professional and personal life, often losing the ability to work on personal projects that drew them to the industry
- Creative block becomes especially dispiriting because professionals are in creative industries yet struggling to be creative, while the conditions they endure (financial pressure, burnout, overwork) are precisely those where creative work doesn't flourish
- Professional isolation affects freelancers and small studio operators working without colleagues, mentors, or supportive community, making every other challenge harder to manage alone
- The interconnected nature of these problems is the key insight: they stack and compound in ways that make individual solutions insufficient, demanding systemic industry-wide responses instead
Original article
Creatives face overlapping pressures—including financial instability, burnout, AI-driven change, self-doubt, lack of direction, intense competition, difficult client dynamics, time overload, creative fatigue, and isolation—which compound into a systemic challenge rather than isolated issues. The real difficulty of creative work lies in how these factors reinforce each other, calling for broader structural solutions across the industry.
How Autodesk's New AI Tool Gets Us Closer to ‘Just Press Animate'
Autodesk's Flow Studio now automates character rigging and high-end rendering with AI, compressing weeks of technical work into faster workflows while still allowing export to traditional tools.
Deep dive
- AI Rigging automates the traditionally laborious process of preparing 3D models for animation, letting artists drive motion from video with minimal technical setup
- Neural Layer tackles the rendering side by reducing manual work on lighting setups, materials, simulation, and compositing that have historically been expensive and time-consuming
- The tools aim to compress the workflow from static model to animation-ready character to near-finished shot within a single platform
- Autodesk emphasizes that Flow Studio doesn't replace the wider 3D ecosystem—assets can still be exported to Maya, Blender, and Unreal Engine for traditional refinement
- The update addresses a pain point where 3D workflows often require jumping between multiple specialized tools (one for modeling, another for animation, another for rendering)
- The approach targets a middle ground between quick AI-generated assets (which often lack control) and fully manual workflows (which are slow but precise)
- Autodesk positions this as compressing technical groundwork rather than replacing human artists, letting teams reach the refinement stage faster
- The tools could be particularly valuable for small indie teams and film studios where artist time is at a premium
- Trade-offs include potential loss of deep technical knowledge about how 3D pipelines work and the risk that "good enough" automated results become the default
- Complex or stylized animation will still require human touch—faster doesn't currently mean better for production-quality work
Decoder
- Rigging: The process of creating a skeleton and control system for a 3D character model so it can be posed and animated, traditionally a time-consuming technical discipline separate from modeling
- Neural Layer: Autodesk's AI-powered rendering feature that handles lighting, materials, and visual effects with less manual setup
- Previs: Pre-visualization, creating rough animated versions of scenes to plan shots before final production
- Flow Studio: Autodesk's AI-powered platform for character animation and cinematic creation
Original article

Traditionally, whether working in movies or games, rigging a character you've spent weeks and months creating can be a stressful trial. You can model something amazing in Blender, block out a design, but getting that thing to a place where you can actually make it perform? That's a different discipline entirely, one that involves rigging, testing, fixing, exporting, and breaking it again somewhere else. It's a time sink that can cost money and sap momentum from a project, and the 3D workflow can also be daunting for newcomers, but Autodesk thinks it has the solution.
The latest update to Flow Studio, Autodesk's AI cinematic platform, adds two new features: AI Rigging and Neural Layer. The idea is straightforward enough: to help creators, animators, and artists move from a static model to an animation-ready character far faster than traditional workflows allow, and then push towards cinematic-looking results without the usual complex setup, render time, or cost.
Making rigging and rendering easier
Rigging is the obvious pressure point as it's one of those steps that can eat entire days, even for experienced artists, and for small indie developers and film teams, that time is precious. Flow Studio now aims to automate much of that setup, preparing characters for animation with minimal input and letting you drive motion from video. It shifts the focus away from technical prep and back towards performance.
Importantly, Autodesk says it doesn't replace the wider ecosystem, so animators, VFX artists, and game developers can still export assets to tools like Maya, Blender, and Unreal Engine, where much of the final polish and pipeline work can still be achieved traditionally by human artists. Now what's changing is how much groundwork you need before you get there, meaning you can get into the weeds of refining a performance by hand in the current way faster.




The second new addition, Neural Layer, tackles the other end of the process by reducing the cost and technical barriers to high-end rendering. Here, lighting setups, materials, simulation, and compositing have all traditionally been laborious and expensive. Still, Flow Studio leans into a more guided approach, aiming to deliver high-end visual results, including more realistic materials and lighting, without requiring the same level of manual setup.
Put together, Autodesk's AI Rigging and Neural Layer tools point to a workflow with fewer roadblocks, especially for newcomers to animation. In theory, in Flow Studio, you can move from idea to model to animation to something close to a finished shot, without constantly jumping between tools and disciplines. But of course, taking these assets into Blender, Maya, or Unreal Engine and refining them will give you an edge. This comes after Autodesk recently announced new AI tools for MotionMaker and Maya, making even horse animation easier.
You remain in control
To date, some 3D AI tools have been good at getting you to an asset quickly (also see Wonder Studio), but less helpful once you want control or need to turn that generic AI model or asset into something meaningful and interesting. Flow Studio is trying to sit in that middle ground, faster to get going, but still flexible enough to take it further and leaving artists room to add inflexion and nuance.
There's a wider pattern here, too, as the 'perfect' 3D setup has long been a patchwork that's costly and can feel unwieldy, with one app for modelling, another for animation, another for rendering, all stitched together into a personal pipeline. That approach still works, but it's also where a lot of problems can occur, and it seems Autodesk is keen to smooth over how you get started and where you end the creative process, as Flow Studio doesn't remove that traditional workflow but aims to compress it, especially around some of the most technical steps.

As ever with the announcement of new AI tools, there's a tug of war between what's on offer and what could be lost. It could mean we lose the knowledge of how a 3D software stack should fit together, how to fix issues, and where and why problems can occur. And of course, 'automated rigging' doesn't mean production-ready, and while Flow Studio could be great for previs and basic animation, complex or stylised animation will still need the human touch. Faster doesn't, currently, mean better, and the danger is that 'good enough' becomes the default if artists aren't in control.
But then we have the tease and promise that another aspect of life is getting a little simpler, and Autodesk is designing Flow Studio to keep artists in control, with more room to focus on the 3D animation areas that feel meaningful or just plain fun.
Watch the demo of Flow Studio's new tools on YouTube. More details on the Autodesk website.

AI Has Made Memory Chips One of the World's Most Profitable Products
Memory chip makers are posting record-breaking profits as AI demand pushes Samsung, SK Hynix, and Micron into the ranks of the world's most profitable companies.
Deep dive
- Memory prices in Q1 2026 grew nearly 100% quarter-over-quarter, roughly double the initially projected 50% increase, according to TrendForce
- Samsung's Q1 2026 net profit of $30 billion exceeded not only its prior quarterly record but nearly matched its historical high for an entire year
- The three memory chip makers (Samsung 36% market share, SK Hynix 32%, Micron 22% for DRAM) are expected to rank among the world's top 10 most profitable companies in 2026—none cracked the top 10 a year ago
- Samsung shares have risen 72% since the start of 2026, SK Hynix up 90%, and Micron up 65%
- The supply crunch is expected to worsen in 2027, with Samsung stating "available supply is far short of customer demand" based on prebooked orders
- The profit surge follows a two-phase demand pattern: first, specialized HBM production for AI training (paired with Nvidia GPUs) constrained conventional memory supply
- Second, inference workloads for deployed AI models sparked additional demand for general servers using conventional DRAM and NAND flash memory
- The three companies collectively control the overwhelming majority of both DRAM (90%) and NAND flash (55%) markets
- While questions persist about whether AI services will generate commensurate profits, infrastructure providers are capturing an "epic windfall"
- Memory makers gave priority to HBM production over conventional chips used in smartphones, PCs, and general servers, creating the supply constraint that drove prices up
Decoder
- HBM (High-Bandwidth Memory): Specialized memory chips designed for AI training workloads, typically paired with Nvidia GPUs for training large language models
- DRAM: Dynamic random-access memory, the main volatile memory used in computers and servers for active tasks
- NAND flash: Non-volatile memory used for storage in SSDs, smartphones, and data centers
- Inference: The phase of AI computing where trained models respond to user queries, as opposed to training new models
- LLM (Large Language Model): AI models like GPT that require massive memory during training
Original article
The AI boom has pushed the memory-chip industry into a super boom cycle with record-smashing profits. Samsung has reported first-quarter net profit equivalent to more than $30 billion, blowing away its prior quarterly record and almost topping the company's high for full-year profit. The historic run doesn't look likely to end soon. The supply crunch is expected to grow worse next year.

Mark Zuckerberg Blames Slower Sales on War, Layoffs on AI Costs in Meeting
Meta CEO Mark Zuckerberg told employees the company plans May layoffs to fund increased AI infrastructure spending, while blaming slower ad sales on the US-Iran war.
Deep dive
- Meta's stock dropped 8% after Q1 results due to increased capital expenditure guidance and slower Q2 growth predictions, despite what Zuckerberg called "really insanely strong" Q1 performance
- Zuckerberg blamed a "trajectory change" in Meta's ad business on the US war in Iran starting in late February, explaining higher oil prices mean consumers spend more on gas and less on discretionary purchases that drive advertising
- The company frames its cost structure as two competing buckets: compute/infrastructure versus people, with increased AI spending requiring workforce reductions
- Planned May layoffs are positioned as reallocating capital from headcount to data centers and AI infrastructure rather than pure cost-cutting
- Zuckerberg said AI is enabling dramatic team size reductions, citing examples of teams that previously required 50-100 people now needing only 10
- Smaller teams are framed as "counterproductive" going forward given AI efficiency gains, though Zuckerberg noted this doesn't always mean layoffs but rather redeployment
- The company plans to build significantly more apps than historically, with Zuckerberg and Chief Product Officer Chris Cox discussing potentially launching 50 new apps
- Meta's strategy appears to be using efficiency gains from AI to tackle a larger backlog of previously below-the-bar projects
- Chief People Officer Janelle Gale didn't rule out additional layoffs beyond the May round when asked directly
- The comments came from a companywide meeting recording reviewed by The Wall Street Journal, suggesting internal transparency about the company's strategic trade-offs
Decoder
- Capex: Capital expenditures, the funds a company spends on physical assets like data centers, servers, and other long-term infrastructure
Original article
Meta CEO Mark Zuckerberg addressed the market's negative reaction to the company's first-quarter results in a companywide meeting on Thursday. He said the 8% drop in Meta's shares was due to investor concern over an upward revision in expected capital expenditures and predictions of slower growth in the second quarter. He blamed the drop in Meta's ad business on the US war in Iran, as customers are spending less on discretionary things like advertising. Zuckerberg attributes the company's planned layoffs to a need to spend more on AI, and to reflect the greater speed and efficiency AI brings to workflows.

Netflix's TikTok-like vertical feed is finally here
Netflix is rolling out a TikTok-style vertical feed called Clips that surfaces personalized short video snippets to help users discover content to watch.
Original article
Netflix's vertical feed, Clips, is rolling out to the US, the UK, Australia, Canada, India, Malaysia, Pakistan, the Philippines, and South Africa. Clips shows short clips from series, films, and specials tailored to users' tastes. It is designed to help people decide what to watch or play next. Netflix plans to expand Clips to include podcasts, live programming, and collections based on genres.
US' first integrated humanoid factory to build 100,000 NEO robots by 2027
1X has begun mass production of NEO humanoid robots at a California facility that aims to build over 100,000 home-assistance robots by 2027.
Original article
1X has started full-scale production of its NEO humanoid robot at a new manufacturing facility in Hayward, California. The facility, which spans 58,000 square feet, marks a key step toward commercializing general-purpose humanoid robots designed for home use. NEO robots are built to safely operate alongside humans and assist with everyday tasks. The factory can produce up to 10,000 robots every year. 1X plans to increase output beyond 100,000 units by 2027.

Silicon Valley Is Bracing for a Permanent Underclass
Silicon Valley insiders believe AI will soon displace millions of white-collar jobs and create a permanent underclass, but the industry has no coherent plan to address the disruption it's building.
Deep dive
- AI benchmarks now directly measure how well models can replace humans in specific jobs like investment banking, law, medicine, and consulting, with OpenAI's GDPVal showing over 80% win rates against human professionals within months of release
- Block CEO Jack Dorsey laid off nearly half his company in March 2026 citing AI coding agents, triggering a 25% stock surge and pressuring other executives to follow suit even before knowing if AI can actually replace those roles
- OpenAI's 2025 white paper proposes New Deal-style interventions including a 32-hour workweek, higher capital gains taxes, and a public wealth fund giving citizens equity stakes in AI companies, though the company hasn't committed to lobbying for specific legislation
- Anthropic CEO Dario Amodei predicts 50% of entry-level white-collar jobs could disappear by 2030 and warns that AI may create an unemployed underclass as it outpaces people with "lower intellectual ability," eventually encompassing more of the population
- AI-related investments accounted for 39% of US economic growth in the first three quarters of 2025, giving the federal government a vested interest in sustaining the AI boom regardless of worker impacts
- Research shows junior engineers using AI coding agents don't complete tasks faster and understand their work less when quizzed, suggesting AI tools may stunt skill development precisely when early-career workers face AI competition for jobs
- The "permanent underclass" meme posits people have limited time to build wealth before AI and robotics can fully replace human labor, freezing everyone in their current class positions
- Democratic pollster David Shor found 79% of voters worry about government lacking a plan to protect workers from AI, and policies like federal jobs guarantees poll better than universal basic income
- Anthropic's enterprise AI agents have driven annualized revenue to $30 billion (up from $9 billion at end of 2025), but the company hasn't released specific economic policies it supports beyond vague principles
- OpenAI removed its 100x profit cap in 2025 and a pro-AI super PAC funded partly by OpenAI's president spent $2 million against a congressional candidate who proposed AI safety regulation and taxation for direct payments
- Economists predict AI will look like accelerated deindustrialization, with companies outsourcing to AI agents instead of overseas workers, but compressed into two years rather than a decade
- Some AI employees are pre-committing billions in individual donations to nonprofits addressing AI harms, working 80-hour weeks while running multiple Claude Code agents overnight in anticipation of their own obsolescence
Decoder
- AGI (Artificial General Intelligence): AI systems capable of performing any intellectual task that humans can do, rather than specialized narrow AI
- Permanent underclass: A theory that once AI can do all human work, people will be frozen in their current economic class with the rich deploying AI and everyone else unemployable
- Labor share: The portion of economic output that goes to workers as wages versus owners as capital returns, which has been declining
- GDPVal benchmark: OpenAI's evaluation measuring AI performance across 44 occupations to assess real-world economic utility
- AI agents: Large language models that can autonomously complete multi-step tasks and work independently for hours, like Claude Code or OpenAI's Codex 5.3
- The China shock: Rapid deindustrialization when US manufacturing jobs moved overseas, now used as analogy for AI displacement happening faster
Original article
Many people in Silicon Valley believe that AI will soon surpass human capabilities. While this should produce tremendous growth and scientific achievement, it will displace millions of jobs, depress economic mobility, and exacerbate inequality. The technology will ferry power and wealth to the AI companies and existing owners of capital while ordinary people lose their economic leverage. It could create a permanent underclass as people are rendered useless and unemployable.

iPhone 18 Pro to have some of Apple's biggest camera upgrades ever: report
Apple's iPhone 18 Pro models are rumored to bring major camera upgrades including variable aperture lenses and AI-powered photography features.
Original article
Reports suggest the iPhone 18 Pro and iPhone 18 Pro Max could bring some of the biggest camera hardware upgrades in Apple's lineup, potentially including a variable aperture main lens for improved depth control and a wider-aperture telephoto camera. These changes are expected to pair with new AI-powered camera and photo features in iOS 27, though exact details remain unclear and further surprises may still be unannounced.

Netflix wants you to watch ‘Clips,' its TikTok-like vertical video feed
Netflix is adding a TikTok-style vertical video feed called Clips to its mobile app, showing how deeply vertical video has penetrated even traditional streaming platforms.
Original article
Netflix is redesigning its mobile app with a new TikTok-style feature called Clips, a vertical feed of short scenes from Netflix originals designed to help users discover what to watch next through personalized recommendations and quick highlights. The move continues Netflix's years-long experimentation with short-form mobile video after earlier efforts like Fast Laughs and reflects how dominant vertical video has become across entertainment platforms. Services like Peacock and Tubi are adopting similar features. The rise of mobile-first microdramas is helping normalize serialized vertical viewing.

One of London's most iconic buildings gets a new identity
St Paul's Cathedral in London has unveiled a new visual identity by Pentagram that modernizes its brand while respecting its 17th-century heritage.
Original article
St Paul's Cathedral has introduced a new visual identity by Pentagram that blends modern design with the cathedral's historic character, featuring a custom wordmark inspired by its engravings, a bright color palette drawn from its interior, and typography choices that balance tradition and contemporary style. The rebrand aims to reflect the cathedral's identity as an inclusive, living place of worship while creating a flexible and dynamic system for visitors and the wider public.

Why Xbox's new logo feels instantly nostalgic
Xbox's new logo brings back the glossy, 3D aesthetic of the 2000s-era gaming design, earning praise from fans for its nostalgic "Frutiger Aero" style.
Decoder
- Frutiger Aero: A design aesthetic popular in the mid-2000s characterized by glossy, translucent, and nature-inspired elements with glass-like textures and bright colors
- Skeumorphic: A design style that makes digital objects resemble their real-world counterparts with 3D effects, shadows, and textures (opposite of flat design)
Original article
Xbox has unveiled a new logo that blends modern refinement with nostalgic 2000s-era design elements, earning praise from longtime fans for its return to the classic glossy, 3D “X” sphere aesthetic.

How North Korean spies spent months to drain $285 million from Drift
North Korean hackers have evolved from remote attacks to months-long in-person social engineering campaigns, now accounting for 76% of 2026's crypto exploits worth nearly $600 million.
Deep dive
- North Korean proxies conducted months of in-person meetings with Drift Protocol employees before executing the $285 million exploit, marking what TRMLabs calls "unprecedented" escalation from purely remote operations
- The Drift attackers converted proceeds to USDC, bridged to Ethereum, swapped to ETH, and haven't moved funds since the theft, consistent with DPRK's patient multi-year cashout pattern
- The $292 million KelpDAO breach exploited a known single-verifier flaw that LayerZero had repeatedly warned against, demonstrating protocols ignoring basic security recommendations
- Lazarus immediately laundered KelpDAO proceeds through THORChain and Umbra using Chinese intermediaries following the documented TraderTraitor playbook, contrasting sharply with DPRK's patient approach
- The KelpDAO exploit triggered $13 billion in withdrawals from DeFi lending platforms over 48 hours, with Aave losing $8.54 billion in deposits and facing nearly $200 million in bad debt
- Industry participants pledged $300 million to help backstop Aave's bad-debt crisis, one of the largest coordinated rescue efforts in DeFi history
- The Wasabi Protocol exploit used a similar technical approach to Drift, draining $4.5 million via a compromised deployer key with no timelock or multisig protection
- TRMLabs emphasizes North Korea's campaign is becoming "sharper" rather than broader, with faster and more precise execution than previous years
- The cumulative $6 billion in attributed crypto theft since 2017 represents a significant funding source for the North Korean regime
- The evolution to in-person social engineering suggests North Korean operatives are establishing legitimate-seeming business relationships before executing attacks
Decoder
- DPRK: Democratic People's Republic of Korea (North Korea); one of two main state-backed hacking groups mentioned
- Lazarus: North Korean state-backed hacking group responsible for major crypto exploits and the 2014 Sony Pictures hack
- Multisig: Multi-signature wallet requiring multiple private keys to authorize transactions, providing security against single points of compromise
- Timelock: Smart contract mechanism that delays transaction execution, giving protocol teams time to detect and prevent malicious changes
- LayerZero: Cross-chain interoperability protocol that had warned KelpDAO about single-verifier security flaws
- THORChain: Decentralized liquidity protocol used for cross-chain swaps, often exploited for laundering stolen crypto
- TraderTraitor: Documented money laundering playbook involving Chinese intermediaries to convert stolen crypto to fiat
- Aave: Major DeFi lending protocol that suffered $8.54 billion in deposit withdrawals and $200 million bad debt from the KelpDAO exploit contagion
Original article
North Korean state-backed groups, including Lazarus, now account for 76% of 2026 crypto exploit losses, totaling nearly $600 million. Tactics have evolved from remote attacks to sophisticated, months-long in-person social engineering, exemplified by the $285 million Drift Protocol breach and the $292 million KelpDAO exploit.
Visa Expands Stablecoin Settlement to Nine Blockchains
Visa's stablecoin settlement pilot now operates across nine blockchain networks with $7 billion in annualized volume, showing traditional payment infrastructure moving beyond experimentation to production-scale blockchain integration.
Deep dive
- Visa added five new blockchain networks to its stablecoin settlement pilot: Arc (Circle's Layer 1 blockchain), Base (Coinbase's Layer 2), Canton, Polygon, and Tempo, bringing the total to nine networks
- Settlement volume reached $7 billion annualized, representing 50% quarter-over-quarter growth from approximately $4.7 billion in the previous quarter
- The program now supports over 130 card products distributed across more than 50 countries, indicating significant geographic and product diversity
- Visa operates as a validator node on both the Tempo and Canton networks, meaning it participates in transaction verification and consensus mechanisms
- The company holds a design partner role with Arc, suggesting involvement in the protocol's development and architecture decisions
- These validator and design partner roles signal protocol-level technical integration rather than passive API consumption or third-party service usage
- The expansion demonstrates that major payment networks are moving blockchain settlement from experimental pilots to production-scale infrastructure
- Stablecoin settlement potentially offers faster reconciliation and lower cross-border transaction costs compared to traditional correspondent banking
- The choice of networks spans different blockchain architectures: Layer 1 chains, Layer 2 scaling solutions, and enterprise-focused platforms like Canton
- Visa's direct participation in blockchain consensus represents a shift for traditional financial institutions from observers to active network operators
Decoder
- Stablecoin: Cryptocurrency pegged to stable assets like the US dollar, designed to minimize price volatility
- Layer 1 (L1): Base blockchain protocol that processes and finalizes transactions independently (like Ethereum or Bitcoin)
- Layer 2: Scaling solution built on top of a Layer 1 blockchain to increase transaction throughput and reduce costs
- Validator: Network participant that verifies transactions and maintains blockchain consensus, typically by staking assets or running verification nodes
- Settlement: The final transfer of funds between parties to complete a transaction, typically occurring between financial institutions
Original article
Visa expanded its stablecoin settlement pilot to nine networks by adding Arc (Circle's L1), Base, Canton, Polygon, and Tempo, with the program now spanning 130+ card products across 50+ countries. Annualized settlement volume reached $7 billion, a 50% increase quarter-over-quarter from approximately $4.7 billion. Beyond settlement usage, Visa holds a design partner role with Arc and serves as a validator on both Tempo and Canton, signaling protocol-level integration rather than passive adoption.

Meta Launches USDC Stablecoin Payouts for Creators
Meta now pays creators in USDC stablecoin on Polygon and Solana, marking one of the largest mainstream deployments of blockchain payment infrastructure to date.
Deep dive
- Meta is leveraging Circle's USDC infrastructure routed through Stripe to enable stablecoin payouts, combining crypto rails with familiar payment processor integration
- The initial launch targets Colombia and the Philippines, markets where local currency volatility makes dollar-denominated assets particularly attractive to creators
- Polygon and Solana were chosen as the settlement layers, suggesting Meta evaluated different blockchain networks for transaction speed, cost, and reliability
- Meta paid creators approximately $3 billion across monetization programs in 2025, representing a significant volume of payments that could shift to blockchain settlement
- The 160+ market rollout plan indicates this isn't a limited experiment but a core feature Meta intends to scale globally
- Off-ramps are available in 150+ countries, addressing the critical last-mile problem of converting crypto to local currency for practical use
- This deployment validates public blockchain infrastructure for consumer-scale applications reaching billions of users, not just crypto-native audiences
- The integration abstracts away blockchain complexity for creators, who simply choose USDC as a payout option rather than needing wallet expertise
- Faster settlement times compared to traditional bank transfers provide immediate practical value beyond crypto ideological benefits
- Meta's implementation demonstrates how established companies can layer blockchain technology into existing products without requiring users to understand the underlying technology
Decoder
- USDC: A stablecoin pegged 1:1 to the US dollar, issued by Circle, designed to maintain stable value unlike volatile cryptocurrencies
- Stablecoin: A cryptocurrency designed to maintain a stable value by being pegged to a traditional currency like the US dollar
- Polygon: A layer-2 blockchain network built on Ethereum that offers faster and cheaper transactions than the Ethereum mainnet
- Solana: A high-performance blockchain known for fast transaction speeds and low fees
- Circle: The company that issues USDC and provides the infrastructure for stablecoin issuance and redemption
- Payment rails: The underlying infrastructure and networks that enable money to move between parties in a transaction
- Settlement: The process of finalizing a payment transaction and transferring funds from payer to recipient
- Off-ramps: Services that convert cryptocurrency into traditional fiat currency that can be withdrawn to bank accounts
Original article
Meta has launched USDC stablecoin payouts for creators on Polygon and Solana, using Circle's infrastructure routed through Stripe, with the feature currently live in Colombia and the Philippines ahead of a 160-plus market rollout. The integration gives creators faster settlement and access to dollar-denominated assets in regions where local currency volatility makes USDC particularly attractive. The deployment marks one of the largest consumer-facing use cases for public blockchain payment rails to date, with Polygon and Solana serving as the settlement layer for a platform reaching billions of users.

Stripe Launches Link Wallet for AI Agents
Stripe enables AI agents to make purchases on behalf of users with a new wallet feature that requires approval for each transaction through an OAuth flow.
Deep dive
- Stripe introduces agent-native payment delegation through Link wallet, addressing infrastructure needs for autonomous AI agents to conduct transactions
- Uses OAuth approval flow with mandatory user notifications (mobile or web) before any payment credentials are shared with agents
- Launch version supports traditional payment methods only, keeping initial rollout conservative
- Roadmap includes stablecoin support, "agentic tokens" (a new payment concept), and broader cryptocurrency payment options
- Planned features include granular spending limits and controls for autonomous agent approvals without per-transaction authorization
- Announced at Stripe Sessions 2026 event alongside 287 other product launches, showing major product velocity
- Represents Stripe's strategic bet on AI agents-as-consumers becoming a significant payment use case
- Maintains user control and security while enabling agent autonomy through an approval layer architecture
- Payment credentials are never directly exposed to agents, reducing security risks from compromised AI systems
Decoder
- OAuth: Authorization protocol that allows applications to obtain limited access to user accounts without exposing passwords or full credentials
- Spend delegation: Granting another entity (in this case, an AI agent) permission to make purchases using your payment methods
- Agentic token: A new type of cryptocurrency or payment token apparently designed specifically for AI agent transactions (specific details not yet disclosed)
- Link wallet: Stripe's digital wallet product that stores payment information for faster checkout across websites
Original article
Today, we're launching the @link wallet for agents. It lets you securely empower agents to spend on your behalf. Your payment credentials are never exposed and you approve every purchase.
Everything we announced at Stripe Sessions: stripe.com/blog/everything-we-announced-at-sessions-2026
Introducing Frontier
Introducing Frontier—a $925M advance market commitment (AMC) to accelerate carbon removal.
It's funded by Stripe, @Google, @Shopify, @Meta, @McKinsey, and the thousands of businesses using Stripe Climate.
How AMCs Work
AMCs are a way to guarantee a market for a product, even before it exists.
The goal is to send a strong signal to researchers, entrepreneurs, and investors that there will be demand for their products—giving them the confidence needed to start building.
Historical Success
The AMC model was successfully piloted a decade ago to accelerate the development of pneumococcal vaccines, saving an estimated 700,000 lives.
For the first time, we're applying this model to carbon removal at scale.
The New PMF Playbook
Three product-market fit strategies are working in crypto right now: co-building with major financial institutions, positioning infrastructure for the AI agent economy, and dogfooding your own technology before seeking external adoption.
Deep dive
- Pattern one involves partnering with elite customers like major financial institutions whose requirements become your product specification, trading speed for adoption quality since one customer handling trillions in daily volume provides more validation than retail attention
- Pattern two focuses on identifying exponential curves early and positioning infrastructure before the market fully understands the opportunity, specifically targeting AI agents becoming autonomous economic actors
- AgentCash exemplifies the second pattern by building payment infrastructure on x402 protocol that lets AI agents pay for API access with crypto, enabling programmatic transactions without human-managed billing systems
- Pattern three follows Amazon's AWS playbook of being your own first customer by building applications on your own infrastructure to prove capabilities before asking external developers to adopt
- ZKsync demonstrates this approach with Prividium anchored to tokenized deposits via Cari Network, allowing major U.S. regional banks to move customer deposits instantly across institutions on blockchain while funds remain in the regulated banking system
- The article warns that more capital just extends runway to bad outcomes and that growth hacks and continuous airdrops disconnected from strategy substitute for admitting you haven't found PMF
- Token mechanics and network effects that make crypto powerful can actually mislead companies on their path to product-market fit
- Strong crypto teams are finding PMF faster now due to killer apps like stablecoins and widespread TradFi adoption
- The human-in-the-loop assumption for AI systems is breaking down faster than expected, creating opportunities for infrastructure serving autonomous agents
- The core thesis is that the fastest path to PMF involves choosing the right strategic game and executing with conviction before consensus forms
Decoder
- PMF: Product-Market Fit, when a product resonates with a broad set of customers and solves a real need
- TradFi: Traditional Finance, referring to established banks and financial institutions outside of crypto
- x402: A payment protocol designed for programmatic API access and agent-to-agent transactions
- TVL: Total Value Locked, a metric measuring the total value of assets deposited in a crypto protocol
- ZKsync: A Layer 2 blockchain scaling solution using zero-knowledge proofs
- Prividium: ZKsync's enterprise privacy and infrastructure product for institutional clients
- On-chain: Transactions or operations executed and recorded on a blockchain
- Agentic economy: An emerging economic model where AI agents autonomously transact and deploy capital
Original article
Three PMF patterns that are currently working: co-building with elite TradFi institutions whose requirements define the product spec, positioning infrastructure ahead of the AI agent economy, and dogfooding your own rails before seeking external adoption. AgentCash illustrates the second pattern by building x402-based payment infrastructure so AI agents can pay for API access in crypto. ZKsync's Prividium demonstrates the third, with Huntington, First Horizon, M&T Bank, KeyCorp, and Old National moving customer deposits on-chain via Cari Network.

Behind the scenes: Are prediction markets good for anything?
An analysis of prediction markets like Polymarket and Kalshi finds they deliver limited public value compared to expectations, with AI chatbots potentially offering better forecasting than market-based approaches.
Deep dive
- Prediction markets with billions in volume and millions of viewers are not delivering the public goods that were expected 20 years ago when the concept was first proposed
- Metaculus, a non-market prediction platform, appears more accurate than money-based prediction markets, though direct comparison is difficult because platforms attract different question difficulties
- The hardest forecasting questions (like AI future developments) barely beat random chance, while easier questions (macroeconomics) approach oracle-level accuracy
- Despite 18 months of high liquidity on Polymarket, the platform lacks the financial infrastructure of mature markets—no insider trading rules, capital risk controls, or hedging mechanisms that institutional money requires
- Polymarket has invested heavily in crypto infrastructure but not in traditional financial market safeguards, and their track record suggests this won't change
- The biggest bottleneck for all forecasting platforms—including academic research and AI development benchmarks—is writing high-quality questions that reveal non-obvious insights through research
- Good forecasting questions are ones where expert forecasters' views fluctuate and update significantly as they research, rather than converging quickly to an obvious consensus
- Prediction markets may be changing societal norms around probabilistic thinking and uncertainty communication in news, which could be their most valuable long-term contribution
- AI language models are rapidly becoming competitive with prediction markets at providing forecasts, and they also aggregate information (across training data, sources, and evidence) just through different mechanisms
- The fundamental premise that markets are the best information aggregation method for forecasting is being challenged both by Metaculus's accuracy and by AI's emerging capabilities
- The value proposition of prediction markets is "rapidly decreasing" as free or cheap AI chatbots provide increasingly good answers without the social costs of gambling infrastructure
Decoder
- Polymarket: A cryptocurrency-based prediction market where users bet real money on outcomes of future events
- Kalshi: A regulated prediction market platform in the United States where users can trade on event outcomes
- Metaculus: A free forecasting platform that aggregates predictions without money or markets, using reputation and scoring systems instead
- Calibration: A measure of how well predicted probabilities match actual outcomes (e.g., events given 70% probability should occur roughly 70% of the time)
- FutureSearch: Dan Schwarz's company working on AI forecasting and research capabilities
- Mantic: An AI forecasting company running tournaments and research on prediction questions
Original article
Behind the scenes: Are prediction markets good for anything?
Clara Collier interviews Dan Schwarz about his newest Asterisk piece.
In this behind-the-scenes interview, Clara Collier talks to Dan Schwarz, author of our latest essay, Are Prediction Markets Good for Anything?
Clara and Dan talk about how Dan's thinking evolved as he wrote the piece, the case for continuing optimism despite the casino problem, the (waning?) importance of the "market" in "prediction market," why it seems like Metaculus is just better, and more.
Clara Collier: Dan, you've been involved with the prediction-market world for a very long time. Is there anything unexpected you found when you were doing the data analysis for this piece? Did anything contradict your expectations?
Dan Schwarz: The major line of inquiry that I had — and that you had — was "are we getting the public goods that people have predicted?" I basically confirmed the view that I had when I started, which was "no."
Others had written this as well, and Scott Alexander had made the exact same point. I was very happy to do the research to try to verify this and to really dig deep into the data and figure it out, but I didn't fundamentally change my mind on the superficial view, which is: If you look at these prediction markets and you see what's there and you see what the traders are doing and you see what the news is doing and you see what people are seeing on those websites — they are not as promising as people would have predicted if you had simply been told 20 years ago that "there will be prediction markets on public topics with millions of viewers and billions of dollars exchanging hands." I think everyone would have predicted more public value coming out of it.
That said, on basically every detail of that I learned something, and on some things I definitely updated my views. One thing I updated was from the Asterisk editors, which is on the taxonomy itself. What types of public value are even possible?
I originally categorized "early warning" as one of the main categories and I think you correctly noticed that, almost by construction, these prediction markets were not really capable of doing early warning. What I had found was monitoring of risks that had been identified by other people and were now being tracked in these prediction markets. I was confused about this, because I had first learned about COVID-19 from Metaculus in February of 2020.
Clara: Wow.
Dan: So from my lived experience, it was an early warning of "hey, there's this big thing going on." And just by the nature of being on Metaculus, I learned that I made significant life plans that turned out to work very much in my favor. And I thought, "great, if I was able to benefit from this much, just think about all these other millions of people." But the way the prediction markets look now, they're really only interesting once they have quite a lot of trading volume.
So almost by definition, it has to be a publicly known thing before it disseminates out into the news and makes people aware. So no one's going to learn about some sort of oil embargo Iran thing going on from Polymarket. Generally speaking, that's not where the news is being broken, but you can still learn a lot more about a pressing risky issue from the prediction market.

Does money matter?
Clara: This actually relates to one of the big questions I had going into all of this, which is: Are any of these better than Metaculus? For reader context, Metaculus is a prediction aggregation site. It's not a market. There's no money involved, and there are some other subtle differences, but it's also consistently pretty well-calibrated.
Dan: I think it is more accurate, but I can't prove it with the data I have.
This is hard because different questions have different difficulties. You can see this in the literature on forecasting questions going back many years. Different tournaments will sometimes report participants' calibration scores. If you just look at those numbers naively, you think you're evaluating the absolute accuracy, but it's just a function of what the questions were in that tournament or on that platform or on that prediction market. And it varies wildly.
For example, on questions about the future of AI — which are some of the hardest questions to get — the best accuracy that people are able to achieve is not that much better than random chance, whereas on macroeconomics forecasters are closer to perfect oracles. And Metaculus tends to skew very hard scientific questions and prediction markets tend to skew very easy gossipy.
Even when I filtered down to the questions I considered interesting, which is kind of the core conceit of the article, they are significantly easier than the questions on Metaculus on average. And so it's hard to run head-to-head. But if you just take that into account mentally, just adjust for that, then Metaculus questions are kind of scarily accurate for the difficulty of those questions.
Don't hold your breath waiting for new rules
Clara: For years and years the promise of prediction markets has been "once we have real money then we'll get real accuracy." This whole thing is so disappointing, even leaving aside the casino elements and other social harms. I wish there was something more exciting here.
Dan: There definitely still could be. We are in the early days. Academic experts might plausibly say it's going to take longer for the markets to start performing better.
It's true there's been a lot of liquidity for maybe 18 months now on Polymarket, maybe six months on Kalshi, but in terms of an academic looking at this, that's still not very much time. You and I talked about the history of financial markets, and I ended up not really studying it for this piece, but I have the sense that the first 12 to 18 months after there was a stock market I don't think you were getting very many good things coming out of it.
Clara: Matt Levine wrote about this recently. He was talking about how a lot of smart institutional money avoids prediction markets because there are risk-hedging mechanisms that exist in mature financial markets that prediction markets don't have.
Dan: I did not read that, but that's consistent with what he's written earlier on it. And that makes sense. There is — and you and I talked about this briefly in scoping out this article as well — many institutional things that go on in financial markets that maybe the casual prediction market user or observer may not know about.
But when you look at these in financial markets and you look at the absence of them in prediction markets, it's not that surprising that prediction markets are not working great as markets right now. It just takes time to get that infrastructure in place.
Clara: Are you optimistic about that infrastructure evolving?
Dan: The thing that's tricky about it is that we're so dominated by two players: Polymarket and Kalshi. One of the things I find in the article is that for markets that are actually interesting and plausibly useful, it's even more dominated by just Polymarket, something like eight times as much volume on Polymarket (on questions that I think can help people) versus Kalshi and so to be optimistic about the financial infrastructure of prediction markets is basically a claim about one company and what they might do.
And if you look at the track record of that company, Polymarket, they have invested significantly into the crypto infrastructure of their platform. Not my field, but I know there's quite a lot of sophistication there and basically none of the stuff that you would expect from normal financial markets.
And so putting my forecaster hat on, I would predict that Polymarket will continue doing what they've already been doing. So no, I would not expect to get the kind of normal insider trading rules, capital risk controls, all the various things that make financial markets smooth. I would not expect those to show up in Polymarket anytime soon.
Inside Clara are two wolves
Clara: I feel like there's just an important lesson here. In a way, it rhymes, and is also directly contiguous with, the arc of the rationalist movement as a whole.
Dan: Say more.
Clara: I am a rat. I like rats. But the early movement was so focused on building up tools for thought, the art of human rationality. And that is still there to an extent, but it's really faded away as an explicit focus in favor of more object-level concerns about AI. And I'm not so sure this is a bad thing. I don't want to undersell the activity of trying to do reasoning better, but it just ends up, I think, mattering less than the emergent social dynamics of the community you find yourself in. Will they criticize bad arguments? Do they understand probability? All that seems more important than coming up with some exciting new mechanism or technique.
Dan: I would certainly agree with that. Having been involved in the rationalist community for almost 15 years ago now, I definitely was attracted for that same reason. It was largely about epistemics: What is true and how do we know that and what is the set of practices and institutions to get there?
And I agree, over the last 15 years I've come more to view the truth like a social construct. I'm more like "there is truth, and there are methods of finding it, but the mechanisms that people generally use are so laden with social context and norms that the main things that would help have more to do with those norms." And I think that is part of the optimistic case for prediction markets.
Prediction markets are already changing the common-sense view about how to get information on what's going on in the news and that is very significant. Again, it's not really directly leading to much truth right now, but maybe that norm shift ultimately will turn out to be more important than just getting certain facts better faster.
Clara: I'm of two minds about this. The Puritan part of me wants to say: Is the norm that the news is something that you relate to as a gambling app…good? Do we want that outcome? And the other wolf inside me says: Getting people to think intuitively in terms of probability and uncertainty — that has to be useful.
Dan: The fact that there is probabilistic reasoning at all in a news article is a massive change. You just don't generally get that. I started reading The Economist a couple of years ago, and I really liked it because I felt like they'd have charts, they would have confidence intervals in them, and they would have some forecast and would have a 10% case and a 90% case and a median case.
It felt like they were reasoning about multiple outcomes and our job here is to try to figure out how things that are happening are shifting the distribution in one direction or another. And I felt at the time like I was only getting that from The Economist. I wasn't getting that even from very well-reported things in the mainstream press.
It's extremely hard to figure out what's going on. And I believe this now more after researching this than I did before. I put in the footnotes some of the news articles I found that were most prominently placing an actual probability in the headline even more than a date.
The more that I spend in forecasting, the more I prefer date and numeric forecasts to probability forecasts. I want to know when something is going to happen.
But probabilities have this very nice property that you cannot process the number 58% without thinking about it as a probability, whereas if I tell you something will happen in June 2027 minus X months, you can kind of just pretend that that's a fact about the world, even though it is just a number out of a distribution. So 58% means nothing unless you were thinking probabilistically. To see that in the headlines of major news articles — to me, that is a big change that I think many folks in the epistemics, the rationality, and prediction-market community are very happy to see.
Unsolicited advice for Polymarket and Kalshi
Clara: As someone who's run prediction markets, if you could give any advice to people running Polymarket and Kalshi about how to make them better epistemic tools, what would it be? That's probably not what they want — they're there to make money — but if they were asking you, what would you say?
Dan: By far the easiest thing — and I really do encourage them to do this, and I know there are people who are maybe mutual acquaintances of ours who are in their Discords asking them to do this — is just to write better questions.
Part of the data science that I did for this piece was just sifting through a lot of questions. And there really are some good interesting questions on those platforms that have attracted a large volume and really, it makes everybody happy. Those guys are getting paid, the traders are getting some fun gambling, and the public or policymakers or academics are all learning something useful about the world. So our incentives are aligned in that and the main thing holding that back is simply not having the creativity and the willpower to just write more good questions.
Ultimately they're there to serve their users and they want their bettors to be happy. But there is a significant Venn diagram overlap between things that will totally make the bettors happy and things that are interesting and useful and good. And they should just spend more time working and writing those questions and administrating them.
Clara: It's surprising how hard this is. I've also heard this from folks at Metaculus who consistently say their biggest bottleneck is coming up with good questions.
Dan: Yep. There's no question that it is one of the major bottlenecks. It's a bottleneck to academic research — for example, for the Forecasting Research Institute for them to be able to run good studies. Writing and resolving and administrating good questions is a bottleneck for them as well. And even for AI development. Being able to understand how good at various types of forecasting, judgment, research, and reasoning various AIs are is a hard thing.
My company, FutureSearch, has been working on this and trying to publish some stuff to advance this and I know many other folks are working on it too. Again, not so much Polymarket as far as I can tell. I think they might have hired people to work on it but I don't really see much coming out of them indicating they're taking this seriously. It would be very easy for them to do and I highly encourage them to do it.
The art of writing a good question
Clara: Do you want to expand a little on why writing good questions is so hard?
Dan: There was a tournament announced by Mantic, another AI forecasting company. It's a tournament about question-writing, not about forecasting, about trying to see who can write the best questions and one of the key ways that they can tell that a question is good is that it causes good forecasters to give different predictions.
The main failure mode in most questions is that they are too trivial. They ask questions where, after 30 minutes of looking into it, there's not really much more that you can say. And so all good forecasters will kind of converge to the same thing. Is the U.S. going to have some recession? Just Google it. It's very easy to see the consensus of economists on things like that.
To me, a good forecasting question is one where a good forecaster — which can be a human, or a team of humans, or an AI system — the more that they research, the more that they update. Their view will fluctuate until they get to some conclusion that was not so obvious when they started researching. How exactly to make questions that are like that — that's one of the properties I think is most important.
Definitely one of the things from writing this essay that was surprising to me is like, "boy, we're so close to that promise of prediction markets especially for what I care about, which is AI. We're so close to having this great information that is what everybody wants."
Clara: I'm going to ask a more cynical question, which is: Is that potential worth it? Does it justify the gambling and the political insider trading and everything else? How do you think about it holistically?
Dan: As I write in the piece, my sense is that the value of prediction markets is rapidly decreasing because of the value that you can get out of pure AI systems that have no market structure and are not calibrated forecasters. Just ask something directly to Claude and you will get a pretty good answer now.
And that has been improving so quickly that whatever the costs are for providing these prediction markets — whether it's gambling, addiction, insider trading, government regulations, just the opportunity cost of all that money exchanging hands, all those employees, all that infrastructure — it does feel like the value is shifting away from that and towards just conventional chatbots that people have even for free if you don't even want to pay for the $20 to get the better answer. And so I'm not sure if it's worth it now.
I mentioned a reason for optimism — both in this conversation with you and in the piece — which is that prediction markets could change norms around how people think about uncertainty and where their evidence even comes from and I think that could be potentially very valuable.
But in terms of just getting better information — in terms of "I just want better epistemics, I just wanted better information, and I want it to be credible, and I want there to be a mechanism behind that that is trustworthy" — I'm increasingly thinking, "no, it's not worth it" and what we really need is to just get the AI systems that we're all using every day to be better at various epistemic things and forecasting. Research how to judge things, how to deal with uncertainty, how to communicate uncertainty, and things like that.
It really feels to me that in five years people are just going to be getting this from their AIs no matter what prediction markets are doing, so I think it is a central irony that prediction markets are not at all based on AI and don't need AI in any part of their operation — but they are finally taking off right at the same time that AI is becoming extremely good at exactly the same thing that prediction markets are doing.
The "market" in "prediction market"?
Clara: This is a question I did want to ask and didn't have time to get into the piece, which is: The whole idea of prediction markets is that it's an information aggregator. AI is not doing that. What makes them good at prediction?
Dan: Well, they are information aggregators in the sense that when they are being trained, they are reading everything on some Iran geopolitical thing and synthesizing it. They are training themselves to predict the next word in some news article about what's going on in Iran. And they are using all of the other updates they got from all the other news articles about what's going on in Iran, plus everything that they've learned about the last 10 times something happened in Iran.
A parallel that I like to think about, because I talk to a lot of elite forecasters, is you take an elite forecaster who doesn't really know anything about the topic and you just ask them, "hey, what do you think about what's going on in Iran?" or "what do you think is going on with crypto regulation? what do you think is going on with AI progress at some company?"
And they can just kind of aggregate. Generally, when we say aggregation we mean multiple people, but one individual person is also aggregating information across many sources. They've read many forecasts, they're aggregating across evidence and across time, and it's being synthesized in their brain and then output to you again. That's not generally what people think about but now that we have these AIs that are kind of anthropomorphized and you kind of talk to as if they were humans. It's just much more obvious how much aggregation is just going into the pre-training and the post-training of these models. You can ask it five times and take the mean or they can go out and just read five articles and synthesize across the five.
But I think your question is great and that is when we think about the fundamental value of prediction markets. Why is having this group of people betting against each other the right way of getting that information, when you have other aggregation methods like training a large language model which — and, again, I'm stretching it here — is some form of aggregation?
Then you do have to ask which form of aggregation is better. To your earlier question, Metaculus is just a different method of aggregating human intelligence. It doesn't use betting and it doesn't use markets and it is better in some ways. It's generally more accurate but it is much slower to react and so it's much more out of date and various other things like that.
It's true in the prediction market community that there has been a sense that markets are the best way to aggregate any information, that there's nothing you could ever do that will be better than just having market prices clear and have people bet on outcomes. That's the end-all of aggregation. And I think Metaculus already showed that, at least for forecasting, that's not necessarily true. And then AI for me is saying "no no no no there's many ways of aggregating disparate information and you can study them by scoring these forecasts" and it is far from clear that prediction markets are the best way to do that even though that's kind of their calling card.
Clara: I think that's a good place to leave the interview, thank you so much.
Dan: Thank you, Clara. I really appreciate both the chance for this interview and for writing the piece.

The Message and the Money
Stablecoins won't replace Visa and Mastercard, but they could upgrade the slow settlement layer underneath their sophisticated authorization infrastructure.
Deep dive
- The common crypto narrative that stablecoins will kill Visa and Mastercard by eliminating 2-3% interchange fees misunderstands where payment inefficiencies actually live
- Payment networks have two distinct layers: authorization (approving transactions in real-time) and settlement (actually moving the money afterward)
- The authorization layer Visa and Mastercard built is remarkably sophisticated: sub-2-second approvals across 200+ countries, fraud detection, dispute resolution, and governance structures that took Dee Hock 30 years to build
- The 2-3% interchange fee isn't parasitic rent-seeking but the operating cost of running one of humanity's most sophisticated trust networks with 150+ million merchant locations
- The settlement layer, by contrast, still runs on 1970s technology: ACH batch processing, multi-day delays, weekend/holiday closures, despite authorization happening in under 2 seconds
- For cross-border payments, settlement is even worse: correspondent banking requires pre-funding accounts in dozens of currencies across intermediary banks, with capital sitting idle and each hop adding fees and FX risk
- One major payments company estimates correspondent banking costs 3-6% of capital cost across their business, pure structural drag unrelated to authorization value
- Stablecoins realize Dee Hock's original vision that money is information and should move at the speed of light like authorization messages already do
- Visa enabled direct USDC settlement on Solana in December 2025 (reaching $3.5B annualized run rate) and opened membership to crypto-native issuers like Rain
- Mastercard launched its Crypto Partner Program in March 2026 with 100+ partners, built around its Multi-Token Network for real-time settlement
- Stablecoin-backed cards look identical to merchants (same authorization layer) but settle instantly on-chain, eliminating multi-day float risk and the capital buffers issuers must hold
- Benefits include improved capital efficiency, better FX rates without correspondent bank margins, and the ability for consumers in volatile-currency countries to hold dollar value
- The viable disruption path is upgrading settlement infrastructure while keeping authorization infrastructure, not building a competing two-sided network from scratch (which even PayPal struggles with)
- Chesterton's Fence principle applies: before tearing down the card networks' fence, understand there are actually two fences, one worth keeping and one worth replacing
Decoder
- Authorization: The real-time approval process when you tap your card, checking if you have funds and assessing fraud risk, with a response in under 2 seconds
- Settlement: The actual movement of money from your bank to the merchant's bank after authorization, which happens hours or days later in batches
- Interchange fee: The 2-3% fee merchants pay that goes to card issuers to fund rewards programs, fraud protection, and credit risk management
- ACH (Automated Clearing House): The 1970s-era batch processing network US banks use to transfer money, with delays for nights, weekends, and holidays
- Correspondent banking: The system for cross-border payments where intermediary banks hold accounts with each other in foreign currencies, creating a daisy chain for international transfers
- Nostro/vostro accounts: Pre-funded foreign currency accounts banks hold with correspondent banks abroad, capital that sits idle purely to enable cross-border settlement
- ISO 8583: The messaging standard from 1987 that card networks use for authorization, optimized for magnetic stripe cards with limited data fields
- Stablecoin: A cryptocurrency pegged to a stable asset (usually USD) by holding dollar reserves, combining dollar stability with blockchain programmability and instant settlement
- USDC: A dollar-pegged stablecoin issued by Circle, backed by actual dollars and Treasury bills
- Float risk: The risk issuers face during the multi-day window between authorization and settlement when they're effectively extending credit against uncertain settlement
Original article
Stablecoins offer fast, programmable payments but fail to address the complex organizational and governance structures of global card networks. While authorization is efficient, settlement remains hindered by legacy infrastructure. Crypto advocates must distinguish between the authorization layer and the inefficient settlement layer to achieve meaningful payment disruption.
OKX Publishes Agent Payments Protocol Standard
OKX has released an open protocol that enables AI agents to conduct autonomous commerce including negotiation, hiring, and payments across multiple blockchains.
Deep dive
- APP extends AI agent capabilities from simple payment execution to full commercial workflows including quoting, negotiation, contract changes, and dispute resolution
- The protocol supports three distinct payment models: upfront payment, top-up/deduct for ongoing services, and subscription or plan-based billing
- Agent-to-agent payments enable AI agents to autonomously hire and pay other specialized agents without human authorization in the transaction flow
- OKX positions APP as shared infrastructure analogous to foundational internet protocols like SMTP (email) or HTTP rather than a proprietary payment network
- The protocol is blockchain-agnostic by design, with Solana, Ethereum, and other chains able to build compatible implementations
- Launch partners span three key categories: cloud infrastructure (AWS, Alibaba Cloud), Layer 1 and Layer 2 blockchain ecosystems (Ethereum Foundation, Solana, Base, Sui, Optimism, Aptos), and DeFi applications (Uniswap, Zerion)
- The protocol explicitly replaces closed payment networks designed for human authorization flows with open tooling built for machine-to-machine commerce
- Escrow and dispute resolution features are highlighted as core capabilities, though noted as "coming soon" in the announcement
- OKX frames this as enabling an "agentic economy" where autonomous agents function as independent commercial entities
- The protocol is published with open documentation and a whitepaper available through OKX's Onchain OS platform
Decoder
- Agent-to-agent payments: Financial transactions where one AI agent directly pays another AI agent for services, without human involvement in the payment authorization
- L1/L2 ecosystems: Layer 1 blockchains (base protocols like Ethereum and Solana) and Layer 2 scaling solutions (networks built on top of L1s like Base and Optimism)
- Escrow: A financial arrangement where funds are held by a third party until specified conditions are met, protecting both buyer and seller
- Agentic economy: An economic system where autonomous AI agents operate as independent commercial entities, conducting business and transactions with each other
- DeFi protocols: Decentralized finance applications that provide financial services like trading and asset management without traditional intermediaries
Original article
The Agent Payments Protocol (APP) is an open standard for AI agent commerce covering the full lifecycle from quote drafting and specialist hiring to escrow and dispute resolution, with support for agent-to-agent payments and three payment modes: upfront, top-up/deduct, and plan-based. Positioned as shared infrastructure analogous to email or HTTP, APP targets every major blockchain and launched with partners spanning cloud providers (AWS and Alibaba Cloud), L1/L2 ecosystems (Ethereum Foundation, Solana, Base, Sui, Optimism, and Aptos), and DeFi protocols including Uniswap and Zerion.

PayPal Restructures With Crypto as Named Top-Level Business Segment
PayPal elevated cryptocurrency to a top-level business segment, grouping its crypto offerings including the PYUSD stablecoin with Braintree payment processing.
Decoder
- Braintree: PayPal's payment processing platform for merchants and developers
- PYUSD: PayPal USD, a stablecoin issued by PayPal pegged to the US dollar
Original article
PayPal restructured into three operating segments, with "Payment Services & Crypto" unifying Braintree processing and its crypto offerings, including the PYUSD stablecoin, under a single division.

Altitude DeFi Borrowing Aggregator
Altitude raised $18M to build a business banking platform on Solana that replaces traditional bank accounts with stablecoin infrastructure and self-custody.
Decoder
- Stablecoin rails: Payment and settlement infrastructure built on blockchain-based stablecoins (cryptocurrencies pegged to fiat) rather than traditional banking networks
- Self-custody: Users maintain direct control of their assets through cryptographic keys rather than trusting a third-party institution
- Smart accounts: Programmable blockchain accounts with automated rules, multi-party approvals, and granular permission controls
- ACH/SEPA/Wire/SWIFT: Traditional banking payment methods (Automated Clearing House, Single Euro Payments Area, wire transfers, and international bank transfers)
- Passkeys: Modern authentication standard using cryptographic keys stored on devices instead of passwords
Original article
Altitude, a DeFi borrowing aggregator, lets users deposit BTC or ETH as collateral and borrow USDC while unused collateral generates yield through Aave and Morpho, credited against the loan balance.

Circle Launches Gas-Free 'Nanopayments' Across 11 Blockchains
Circle launched gas-free micropayments for USDC on eleven blockchains, enabling transactions as small as one-millionth of a dollar to support AI agents and machine-driven commerce.
Deep dive
- Circle's Nanopayments uses a non-custodial smart contract where users deposit USDC and authorize transfers via EIP-3009 signatures, with the system verifying and deducting each payment before batching transactions for onchain settlement
- The architecture delivers verification within hundreds of milliseconds rather than waiting for block confirmation, enabling merchants to provision services immediately after payment authorization
- Built on Circle Gateway, the company's unified liquidity layer, which abstracts settlement across all eleven supported blockchain networks from a single integration point
- Complements rather than replaces the x402 payment protocol that Circle reports has processed over $100 million since launching earlier in 2026
- Targets the emerging agentic economy where autonomous software agents conduct commerce, with McKinsey estimating this market could reach $5 trillion in revenue by 2030
- Early production use cases focus on infrastructure and data providers charging AI agents per API call, per second of compute, or per dataset read—payment granularity impossible with traditional gas-fee models
Decoder
- USDC: Circle's USD-pegged stablecoin, a cryptocurrency designed to maintain 1:1 value with the US dollar
- Gas fees: Transaction costs paid to blockchain networks to execute operations, typically too expensive for micro-transactions
- EIP-3009: Ethereum Improvement Proposal for gasless token transfers using cryptographic signatures instead of direct wallet transactions
- x402: Circle's payment protocol standard for machine-to-machine commerce that preceded Nanopayments
- Agentic commerce: Economic activity conducted by autonomous AI agents rather than humans, involving machine-to-machine payments
Original article
Circle has launched gas-free nanopayments on eleven blockchains, enabling USDC transfers as small as $0.000001.

Polymarket taps Chainalysis to police insider trading
Polymarket partners with blockchain analytics firm Chainalysis to detect and prevent insider trading on its prediction markets platform.
Decoder
- Polymarket: A cryptocurrency-based prediction market platform where users bet on real-world events using crypto
- Chainalysis: A blockchain analytics firm that tracks and analyzes cryptocurrency transactions for compliance and investigation purposes
- Kalshi: A CFTC-regulated prediction market platform competing with Polymarket
- Insider trading (prediction markets): Betting on event outcomes using privileged non-public information about those events
Original article
Both Polymarket and rival Kalshi have attempted to address concerns about insider trading on the platforms.