Devoured - May 05, 2026
GPT-5.5 doubled API prices with real cost increases of 49-92% depending on prompt length, Vercel open sourced deepsec for AI-powered security scanning, and research shows that matching AI models to the right tool harness matters as much as model selection itself. Stripe quietly assembled a full stablecoin payments stack through acquisitions and a new blockchain, while Ethereum developers finalized parameters for the Glamsterdam upgrade and Brazil banned stablecoins from regulated cross-border payment rails.
Anthropic is working on Orbit, its upcoming proactive assistant
Anthropic is preparing to launch Orbit, a proactive AI briefing tool that automatically generates personalized insights from developer and productivity tools like GitHub, Figma, Slack, and Gmail.
Decoder
- Claude Cowork: Anthropic's collaboration-focused version of Claude designed for team productivity and work tools
- Proactive assistant: An AI that generates insights and briefings automatically on a schedule rather than waiting for explicit user prompts
- Connectors: Integrations that allow Claude to access and analyze data from external services like Gmail or GitHub
Original article
Anthropic appears to be lining up a new proactive assistant called Orbit, with evidence pointing to an upcoming release. Across recent web and mobile builds, more references and supporting scaffolding have surfaced, though for now the tool only manifests as a toggle in the settings panel, a typical pattern for a feature being staged before a broader rollout.
Based on the descriptions found in code, Orbit is positioned as a proactive briefing and insights system spanning both Claude and Claude Code. The setup would be opt-in and time zone-aware, producing personalized briefings with actionable insights drawn from connected work tools. The initial connector list reads like a knowledge worker's daily stack: Gmail, Slack, GitHub, Calendar, Drive, and Figma.
Your deployed Orbit apps. Pin favorites for quick access.
Anthropic's Code with Claude developer conference kicks off in San Francisco on May 6, with London and Tokyo dates following on May 19 and June 10. Whether Orbit lands as a quiet rollout or gets formally unveiled on stage remains uncertain, but the build activity is consistent with a feature in late preparation rather than early experimentation.
Claude Cowork will get its own proactive assistant called "Orbit".
Users will get personalized insights from Gmail, Slack, GitHub, Calendar, Drive, Figma, and other apps, which Claude will generate proactively.
There are also mentions of "Orbit" apps.
The broader context matters too. OpenAI shipped ChatGPT Pulse last September as its first proactive, asynchronous assistant, generating overnight briefings stitched from chats, memory, and Gmail and Calendar connectors. Similar groundwork has been spotted inside Google's Gemini and Perplexity, suggesting proactive briefing layers are becoming table stakes across major AI assistants.
Anthropic's twist seems to be the explicit inclusion of GitHub and Figma alongside the standard productivity suite, fitting its growing positioning around developer and creative workflows. Paired with the Claude Code integration, Orbit looks less like a Pulse clone and more like a workflow-aware briefing surface aimed at people who ship things, not just read email.
GPT-5.5 Price Increase: What It Actually Costs
A cost analysis of GPT-5.5 reveals the 2x sticker price increase translates to actual cost increases of 49-92% depending on prompt length, with shorter outputs only benefiting longer prompts.
Deep dive
- GPT-5.5's nominal pricing doubled from GPT-5.4: input tokens went from $2.50/M to $5.00/M and output tokens from $15/M to $30/M
- OpenRouter analyzed real-world usage by tracking users who switched from GPT-5.4 to GPT-5.5 to measure actual cost impact
- For prompts over 10K tokens, GPT-5.5 generates 19-34% fewer completion tokens, partially offsetting the price increase
- For prompts under 10K tokens, completions stay the same length or get longer (up to 52% longer in the 2K-10K range)
- Actual cost increases ranged from 49% (for 50K-128K token prompts) to 92% (for prompts under 2K tokens)
- Users with longer prompts (over 10K tokens) saw cost increases of 49-62%, benefiting from shorter outputs
- Users with shorter prompts (under 10K tokens) saw cost increases of 69-92%, getting little to no offset from verbosity reduction
- The analysis used OpenRouter's independent token counting to provide a consistent baseline across model versions
- Sample data came from April 21-23 for GPT-5.4 and April 25-28 for GPT-5.5, excluding the launch day itself
Decoder
- GPT-5.4 / GPT-5.5: Sequential versions of OpenAI's GPT language model, with 5.5 being the latest release
- OpenRouter: API aggregator that provides access to multiple LLM providers and tracks usage metrics
- Token: Fundamental unit of text processed by LLMs, roughly 3-4 characters or 0.75 words
- Input/Prompt tokens: Tokens in the request sent to the model
- Output/Completion tokens: Tokens in the response generated by the model
- Switcher cohort: Users who primarily used GPT-5.4 before the launch and switched to GPT-5.5 after
- M: Million (as in $5.00/M = $5.00 per million tokens)
Original article
GPT-5.5 Price Increase: What It Actually Costs
We replicated the cost analysis we did on Opus on the new GPT-5.5 model. GPT-5.5 launched with a 2x price increase over GPT-5.4: input tokens increased from $2.50/M to $5.00/M and output tokens from $15/M to $30/M. OpenAI has also noted that the model is less verbose, producing shorter completions for the same tasks. Just as we did with Opus 4.7 we wanted to know what is the net impact on costs to users by analyzing usage that shifted from GPT-5.4 to GPT-5.5.
We observed cost increases between 49-92%. The price increase is mitigated by the model generating 19-34% fewer completion tokens for longer prompts.
Methodology: Same Switcher Cohort Approach
We used the same approach as our Opus 4.7 analysis. We identified users whose top model by request count was GPT-5.4 prior to the 5.5 launch, who then switched to GPT-5.5 as their top model. This "switcher cohort" gives us a controlled before-and-after comparison of the same user base across model versions.
Since GPT-5.4 and 5.5 use the same tokenizer family, we don't need to control for tokenizer differences. The comparison is direct: same users, same workflows, different model version.
GPT-5.5 Is Less Verbose, But Only for Longer Prompts
Using OpenRouter's consistent token counts, we measured how completion lengths changed between models:
| Prompt Size | Median Completion (5.4) | Median Completion (5.5) | Change |
|---|---|---|---|
| < 2K tokens | 121 | 129 | +7% |
| 2K – 10K | 140 | 213 | +52% |
| 10K – 25K | 211 | 143 | -32% |
| 25K – 50K | 185 | 150 | -19% |
| 50K – 128K | 188 | 136 | -28% |
| 128K+ | 215 | 143 | -34% |
For prompts above 10K tokens, GPT-5.5 produces 19-34% fewer tokens. For shorter prompts, the pattern reverses: under 2K tokens completions are roughly the same length, and in the 2K-10K range they are 52% longer.
Actual Cost Impact
Using billed costs from requests in the switcher cohort, we calculated the average cost per million OpenRouter tokens. This normalizes for prompt length, allowing a direct comparison of cost efficiency.
| Prompt Size | Avg $/M OR Tokens (5.4) | Avg $/M OR Tokens (5.5) | Change |
|---|---|---|---|
| < 2K tokens | $4.89 | $9.37 | +92% |
| 2K – 10K | $2.25 | $3.81 | +69% |
| 10K – 25K | $1.42 | $2.15 | +51% |
| 25K – 50K | $1.02 | $1.65 | +62% |
| 50K – 128K | $0.74 | $1.10 | +49% |
| 128K+ | $0.71 | $1.31 | +85% |
Our analysis shows that GPT-5.5 actual costs increased 49% to 92%. Longer prompts, over 10k tokens, saw costs offset by shorter completions. Shorter prompts, under 10k, experience a higher cost increase where completions did not get shorter.
Methodology
- Source: OpenRouter's request logs
- Cohort: Users whose top model by request count was GPT-5.4, who then switched to GPT-5.5 as their top model
- Sample size: Text-only, non-cancelled requests split across 5.4 and 5.5
- Windows: GPT-5.4: April 21-23, 2026 (pre-launch); GPT-5.5: April 25-28, 2026 (post-launch, launch day excluded)
- Normalization: Cost per million OpenRouter tokens, bucketed by prompt token count. OpenRouter counts tokens independently from OpenAI, providing a consistent baseline across model versions.
- Controls: Excluded media (images, files, audio, video), cancelled requests, and zero-token requests

Inside OpenAI's Low-Latency Voice Infrastructure
OpenAI published technical details on their redesigned WebRTC infrastructure that uses a split relay and transceiver architecture to deliver low-latency voice AI interactions globally.
Decoder
- WebRTC: Web Real-Time Communication, a framework for peer-to-peer audio/video streaming in browsers and applications
- Relay: A server component that forwards network traffic between clients when direct connections aren't possible
- Transceiver: A component that handles both transmission and reception of media streams
Original article
OpenAI detailed a redesigned WebRTC architecture using a split relay and transceiver model to maintain low-latency, real-time voice interactions at global scale.

Inside Vercel's Security Tool Deepsec
Vercel open sourced deepsec, an AI agent-powered security scanner that uses Claude and GPT models to autonomously investigate codebases for complex vulnerabilities with a 10-20% false positive rate.
Deep dive
- Deepsec runs entirely on your own infrastructure (locally or on Vercel Sandboxes) so privileged source code never leaves your control, using your existing Claude or GPT API subscriptions
- The five-stage workflow starts with regex-based static analysis to identify security-sensitive files, then dispatches AI agents to investigate each candidate individually
- Investigation agents trace data flows through the codebase and check for security mitigations, producing findings with severity ratings
- A separate revalidation step uses a second agent run to filter false positives and reclassify severity levels, bringing the false positive rate to 10-20%
- Scans of Vercel's own codebases routinely scale to 1,000+ concurrent sandboxes running in parallel; single-machine scans can take multiple days for large repositories
- Production testing on dub.co (an open source marketing attribution platform with auth, database, and backend services) surfaced actionable security issues that impressed the founder
- Vercel used deepsec findings on their own monorepos to develop custom scanner plugins covering every authentication path in their code
- The plugin system allows custom regex matchers tuned to your specific authentication model, data layer, or team conventions
- Deepsec includes a classifier that detects model refusals after each research step, though refusals are reportedly a non-issue with current models
- The tool works with standard Claude Opus 4.7 and GPT 5.5 models without requiring special "cyber" fine-tuned versions, though it supports those too
- Best suited for applications and services rather than libraries or frameworks, which would likely need custom prompts and scanners
- The enrichment step uses git metadata and optional services to identify which developers should fix each discovered issue
- Export formats findings as instructions that can become tickets for both human developers and coding agents to remediate
Decoder
- Opus 4.7: Anthropic's Claude model version referenced in the article (likely future/hypothetical given current date context)
- GPT 5.5: OpenAI model version referenced with "xhigh reasoning" capability (likely future/hypothetical)
- Static analysis: Code examination technique that analyzes source code without executing it, typically using pattern matching
- Sandboxes: Isolated execution environments that run code safely without affecting production systems
- False positive: A security alert for an issue that doesn't actually exist or isn't exploitable
- Data flow tracing: Following how data moves through a codebase to identify where user input might reach sensitive operations without proper validation
- Monorepo: A single repository containing multiple projects or services, common at large companies like Vercel
- Cyber model: Fine-tuned AI models specifically trained to perform security research tasks that base models might refuse
Original article
Deepsec is an agent-driven security tool that scans large codebases locally or in parallel cloud sandboxes to uncover complex vulnerabilities.

Reduce friction and latency for long-running jobs with Webhooks in Gemini API
The Gemini API now supports webhooks for long-running jobs, eliminating the need for polling.
Original article
JavaScript is not available.
We've detected that JavaScript is disabled in this browser. Please enable JavaScript or switch to a supported browser to continue using x.com. You can see a list of supported browsers in our Help Center.
Model-Harness-Fit
Research shows frontier AI models are post-trained for specific tool harnesses, with Claude Opus 4.6 scoring 4.5% higher with the right framework and harness choice alone moving Cursor from top 30 to top 5 in benchmarks.
Deep dive
- Terminal-Bench 2.0 data demonstrates measurable impact: Claude Opus 4.6 achieved 79.8% accuracy with ForgeCode versus 75.3% with Capy, a 4.5 percentage point difference from harness choice alone
- Cursor's jump from top 30 to top 5 ranking was achieved solely by changing the harness, without any model improvements
- OpenAI models default to patch-based file editing approaches while Anthropic models prefer string replacement methods
- Harness mismatches force models to spend reasoning tokens adapting their output format instead of solving the actual problem
- Post-training against specific harnesses embeds tool names, schemas, citation tag formats, memory rituals, and system prompt structures directly into model weights
- This suggests frontier labs are optimizing models for their own tooling ecosystems, creating lock-in effects
- The research covers three major CLI tools: Codex CLI, Claude Code, and GitHub Copilot CLI
- Harness design choices include how tools are invoked, how context is structured, and how outputs are formatted
- The findings challenge the assumption that models are general-purpose and perform consistently across different integration layers
- For developers, this means harness selection is a first-order concern, not just an implementation detail
Decoder
- Harness: The integration layer or framework that wraps an AI model, defining how it receives inputs, formats outputs, and interacts with tools
- Post-training: Additional training applied to base models to optimize them for specific use cases, tools, or formats after initial pre-training
- Terminal-Bench: A benchmark for evaluating AI models' performance on command-line and terminal-based coding tasks
- ForgeCode/Capy: Different harness frameworks used in the benchmark comparisons
- Reasoning tokens: The computational budget models spend on internal processing and problem-solving, which can be wasted on format adaptation instead of the core task
- Citation tags: Specific markup formats models use to reference sources or indicate tool usage in their outputs
- Memory rituals: Patterns for how models maintain and reference context across interactions
Original article
JavaScript is not available.
We've detected that JavaScript is disabled in this browser. Please enable JavaScript or switch to a supported browser to continue using x.com. You can see a list of supported browsers in our Help Center.
.svg)
Powering the Inference Era: Inside the DigitalOcean AI-Native Cloud
DigitalOcean launched an AI-Native Cloud platform with five integrated layers from silicon to agent runtime, designed specifically for inference and agentic workloads rather than traditional SaaS applications.
Deep dive
- DigitalOcean's five-layer stack integrates Infrastructure (owned data centers and GPUs), Core Cloud (compute and networking), Inference Engine (model serving), Data & Learning (databases and vector stores), and Managed Agents (production runtime for agentic workloads) into a single platform
- The Inference Router is a preference-aware control plane that automatically selects optimal models for each request based on cost, latency, and quality metrics, running on a small language model that resolves intent in 200ms—one customer (Celiums.AI) shifted 83% of traffic to open models and cut per-token costs by 61%
- DigitalOcean owns its silicon infrastructure across 19 data centers with NVIDIA HGX B300 and AMD Instinct MI350X GPUs, plus liquid-cooled racks for high-density workloads, rather than reselling hyperscaler capacity
- Achieved fastest inference for Qwen 3.5 and DeepSeek V3.2 in independent Artificial Analysis benchmarks through kernel-level co-engineering with NVIDIA and AMD
- MicroVM Droplets based on Firecracker start in roughly 200 milliseconds and are designed for agent sandboxes that need quick burst capacity for code execution between GPU inference calls
- Managed Agents runtime separates agent orchestration from business logic with five primitives: open harness support (LangGraph, CrewAI, OpenCode), E2B-compatible sandboxes, durable state management, the Plano orchestration framework (Apache 2.0), and Model Context Protocol integration
- Knowledge Bases feature automatically exposes every managed retrieval system as an MCP tool by default, enabling agents to query data sources with grounded, cited answers
- Batch Inference for asynchronous workloads like document processing and eval runs costs roughly 50% of peak serverless pricing
- PostgreSQL and MySQL Advanced Editions now scale to 50 TiB capacity with 1 TiB increments, proxy-based failover in seconds, and 100+ observability metrics
- Production customer examples include Workato running a trillion automation tasks at 67% lower cost, Character.AI handling over a billion queries daily at 2x throughput, and Hippocratic AI powering 20M+ patient interactions with 40% lower latency
- Platform runs on open-source foundation including PostgreSQL, MySQL, MongoDB, Valkey, OpenSearch, Kafka, Weaviate, vLLM, and SGLang rather than proprietary services
- The integrated stack eliminates egress costs and margin stacking from using multiple vendors, as inference, data, compute, and agents run in the same VPC on the same silicon
- Announced 15 products at Deploy 2026 with features ranging from general availability (Serverless Inference, BYOM, Managed Agents) to public preview (Inference Router, Evaluations, Advanced Edition databases) to private preview (Burstable CPU, Managed Weaviate)
Decoder
- RDMA: Remote Direct Memory Access, a networking technology that allows high-speed data transfer between servers with minimal CPU involvement, critical for GPU cluster communication
- vLLM: an open-source library for fast large language model inference and serving, optimized for throughput
- SGLang: Structured Generation Language, a framework for efficient LLM serving with structured outputs
- MCP (Model Context Protocol): a standard protocol that allows AI agents to access external data sources and tools in a consistent way
- Firecracker: a lightweight virtual machine manager from Amazon used to create secure, fast-starting microVMs for containerized workloads
- Vector store: a specialized database that stores high-dimensional embeddings for semantic search and retrieval-augmented generation (RAG)
- Knowledge Bases: managed systems that combine document storage, embedding generation, and retrieval to provide LLMs with domain-specific context
- Agentic workloads: AI systems that operate in loops, making decisions, taking actions, and adjusting based on feedback rather than processing single request-response cycles
Original article
Powering the Inference Era: Inside the DigitalOcean AI-Native Cloud
I've spent the last fifteen years building cloud services: early days of AWS building S3 and EBS, helping launch Oracle Cloud Infrastructure from inception, and now building the agentic cloud at DigitalOcean for AI-natives. Every cloud I've worked on was designed for the workloads of its era. Those clouds were built for human-centric SaaS applications: a few users, a handful of requests per session, predictable data flows.
AI workloads break every one of those assumptions.
AI runs in loops. Agents think, then act, then think again. A single user task can span hundreds of thousands of tokens, traverse half a dozen tools, hit a knowledge base, write code, execute it, and persist state, all before returning an answer. The clouds we have weren't built for this. Hyperscalers give you hundreds of services built for yesterday's applications, and leave the integration to you. Inference-only providers sit on someone else's compute and stack their margin on top. GPU rental shops (frequently referred to as "Neoclouds") give you silicon, but not a system.
This week at Deploy 2026, we launched the DigitalOcean AI-Native Cloud, a purpose-built platform for the inference and agentic era that integrates five layers from silicon to agents into a single open stack.
We shipped fifteen products on Tuesday. Here's what's inside.
The shape of the stack
Our AI-Native Cloud is composed of five layers, each addressing a real workload pattern we've watched our customers wrestle with.

They're independently useful and beautifully integrated:
- Managed Agents: production runtime for agents, with sandboxes, durable state, and a universal data plane
- Data & Learning: managed databases, vector stores, knowledge bases, and feedback loops
- Inference Engine: every open and frontier model on one endpoint, optimized at the kernel
- Core Cloud: compute, networking, and storage primitives, tuned for AI
- Infrastructure: DigitalOcean-owned silicon and facilities, co-engineered with the industry's best
Open source isn't an add-on at any of these layers. It's the foundation: PostgreSQL, MySQL, MongoDB, Valkey, OpenSearch, Kafka, Weaviate, vLLM, SGLang, OpenCode, LangGraph, CrewAI. Open all the way down. You bring your weights, your harness, your tools. We provide the runtime.
Let me walk through it, from the ground up.
Infrastructure: own the silicon, own the economics
Our global footprint now spans 19 data centers and 200+ network points of presence, with future capacity coming online in Kansas City and Memphis. That includes our first liquid-cooled racks, purpose-built for next-generation high-density GPU workloads.
Our Richmond data center is now generally available, with NVIDIA HGX™ B300 and AMD Instinct™ MI350X GPUs available alongside the H100, H200, and MI300/MI325 silicon already running across our fleet. We co-engineer at the kernel level with both NVIDIA and AMD. We don't rent capacity. We own it. That's why your unit economics improve as you scale on us, instead of getting worse.
Core Cloud: the foundation under every agent
Hundreds of thousands of customers already run on our core cloud every day: Droplets, Kubernetes (DOKS), VPC networking, and object/block/network file storage. We've extended it for AI workloads with a non-blocking RDMA fabric, RDMA-enabled NFS, and VPC-native inference out of the box.
At Deploy we announced Burstable CPU and MicroVM Droplets, currently in Private Preview. These are Firecracker-based instances that start in roughly 200 milliseconds, ideal for agent sandboxes and lightweight, spiky workloads. Agents need GPUs for thinking and CPUs for doing. We have both, and now they're sized for how agents actually behave.
Inference Engine: every model, one endpoint
This is the layer we've rebuilt from the ground up. We co-developed it with design partners like Hippocratic AI, and the result is one of the highest-performing inference engines on the market today: fastest inference for Qwen 3.5 and DeepSeek V3.2 in independent Artificial Analysis benchmarks for token throughput.
Here's what's new:
- Inference Router (Public Preview): a preference-aware control plane that picks the right model for each request, balancing cost, latency, and quality with no code changes
- Dedicated Inference (General Availability): reserved capacity with predictable performance and economics for production workloads
- Bring Your Own Model (BYOM) (General Availability): a service for hosting your fine-tunes on our serving stack and inherit the kernel-level optimizations
- Multi-modal model support (General Availability): text, vision, audio, and video on a single API
- Batch Inference (General Availability): purpose-built for asynchronous workloads (document processing, eval runs, synthetic data generation) at roughly 50% of peak serverless pricing
- Content Safety Guardrails (General Availability): policy controls integrated at the inference layer
- Serverless Inference with multi-modal support (General Availability): single API, scale to zero, pay only for tokens consumed
- Evaluations (Public Preview): automated scoring against golden datasets or built-in judge models, so you can swap models without flying blind
The Router deserves a closer look. It's a preference-aware control plane that picks the best model for each request, balancing cost, latency, and quality without touching application code. Unlike static routing rules, it runs on a purpose-built small language model that resolves intent in 200 milliseconds and ranks candidates against live cost and latency data, so the right model wins at 2am and at 2pm. Most AI builders start on a single frontier model. Then PMF happens, the bill scales linearly with usage, and the unit economics get painful fast. Most successful AI natives we work with run three or more models in production. The leading edge is running twenty or more. The Router makes that possible without a rewrite.
Take Celiums.AI, across 29.2M tokens processed through the Inference Router, 83% of their traffic now lands on open-source models, up from zero.
"Our AI Ethics Engine was built with open-source AI, so running it on closed-source models felt backwards. DigitalOcean's Inference Router closed the loop: we swapped frontier closed-source models for open alternatives and cut per-token cost by 61% while pulling p95 latency under 400ms. Same API. Zero code changes. The Router routes to the optimal model on every request. We just build."
— Mario Gutiérrez CTO at Unity Financial Network and Founder of Celiums.AI
We also expanded the Model Catalog with over 25 new models, including:
- NVIDIA Nemotron 3 Nano Omni
- DeepSeek V3.2
- Llama 3.3 70B
- Qwen 3.5
- MiniMax-M2.5
Data & Learning: AI-ready data, no rebuild required
Stateful agents need context, memory, and the ability to learn from what happens in production. The Data & Learning layer is built on the managed services tens of thousands of customers already trust, extended for how AI systems actually run.
What's new:
- Knowledge Bases (General Availability): managed retrieval with grounded, cited answers; every knowledge base is exposed as an MCP tool by default
- Learning & Feedback Loops (General Availability): capture production signals and route them back into model improvement, without a separate data pipeline
- Managed Weaviate (Private Preview): open-source vector store, fully managed
- PostgreSQL Advanced Edition and MySQL Advanced Edition (Public Preview): capacity to 50 TiB, 1 TiB scaling in minutes, proxy-based failover in seconds, and 100+ observability metrics
Transactional databases remain the foundation for AI. We made them production-grade for the agentic era.
Managed Agents: a production runtime, not a monolith
This is the newest layer of the stack, and the one where we've spent the most time listening. We've watched customers deploy tens of thousands of agents on App Platform as containers. We've also watched them hit a wall when the agent loop, tool calls, state, observability, and code execution all live tangled together inside a single monolith.
So we asked a simple question: what would help you actually move faster? The answer became Managed Agents: five primitives that separate the plumbing from the business logic of your agent.
What's new:
- Managed Agents (General Availability): the production runtime
- Open Harness (General Availability): bring your own agent framework, including OpenCode, LangGraph, CrewAI, or any other harness
- Managed Sandboxes (General Availability): E2B-compatible, Firecracker-based, sub-second cold start for safe execution of model-generated code
- Durable State Management (General Availability): checkpoints and memory primitives the harness can rely on
- Plano (General Availability): our orchestration framework and data plane for agents, released under Apache 2.0
- Launchpad (General Availability): go from prototype to deployed agent in clicks
- Model Context Protocol (MCP) (General Availability): expanded support across the platform
- ToolBox (Coming Soon): 3,000+ tool connectors so your agents can act on the systems your business actually runs on
The compounding effect of the full stack
Any single layer of this stack is useful on its own. The reason to run them together is that the optimization compounds.
When your agents, your inference, your data, and your compute live in the same VPC, on the same silicon, billed on the same invoice, you eliminate the egress taxes, the margin stacking, and the integration debt that come from stitching across three vendors and three bills.
We've seen customers like Workato run a trillion automation tasks at 67% lower cost. Character.AI handle over a billion queries a day at 2x inference throughput. LawVo cut inference costs 42% with no code changes by routing through us. Hippocratic AI is powering 20M+ patient interactions with 40% lower latency. None of these are demos. They're production workloads at scale.
Start here. Scale here.
If you're an AI builder, whether you're writing your first line of code or accelerating past product-market fit, this stack is for you. You don't need to wait in a hyperscaler queue behind a frontier lab. You don't need to glue together a Neo Cloud, an inference wrapper, and a vector database vendor. You don't need to compromise on openness, on economics, or on developer experience.
Welcome to the AI-Native Cloud. Let's build.

Formatting an entire 25 million line codebase overnight: the rubyfmt story
Stripe built rubyfmt, a custom auto-formatter that now formats all 42 million lines of Ruby in the world's largest Ruby codebase.
Original article
Stripe runs the world's largest Ruby codebase. The pain of not having an auto-formatter was visible in how its engineers worked. In 2022, the company set two engineers from its infrastructure team to work full-time on rubyfmt, a tool that is currently being used to format 100% of Stripe's 42 million lines of Ruby. This post tells the story of how rubyfmt came to be.
Redis array type: short story of a long development
A developer spent four months building a new Array data type for Redis with AI assistance, tackling complexity they would have otherwise avoided.
Original article
The PR for a new Array data type for Redis took four months to create using AI assistance. AI tools allowed the developer working on the code to venture into a level of complexity they would have otherwise skipped. They helped make tasks easier and less tedious while also providing a virtual workforce that could reveal bugs in complicated algorithms.
Mental Model for Agentic Work
A developer shares a universal mental model for understanding AI agent systems based on five components that repeat across personal assistants, coding tools, and operational platforms.
Deep dive
- The author experienced a structural shift in Q1 2026 where working with AI agents became the default mode across personal tasks, software engineering, and company operations rather than a novelty
- OpenClaw, an open-source "agent operating system" that launched in late 2025, served as the catalyst—not because of the product itself, but because one developer built a high-quality agent platform in three months using agents, demonstrating the leverage threshold had been crossed
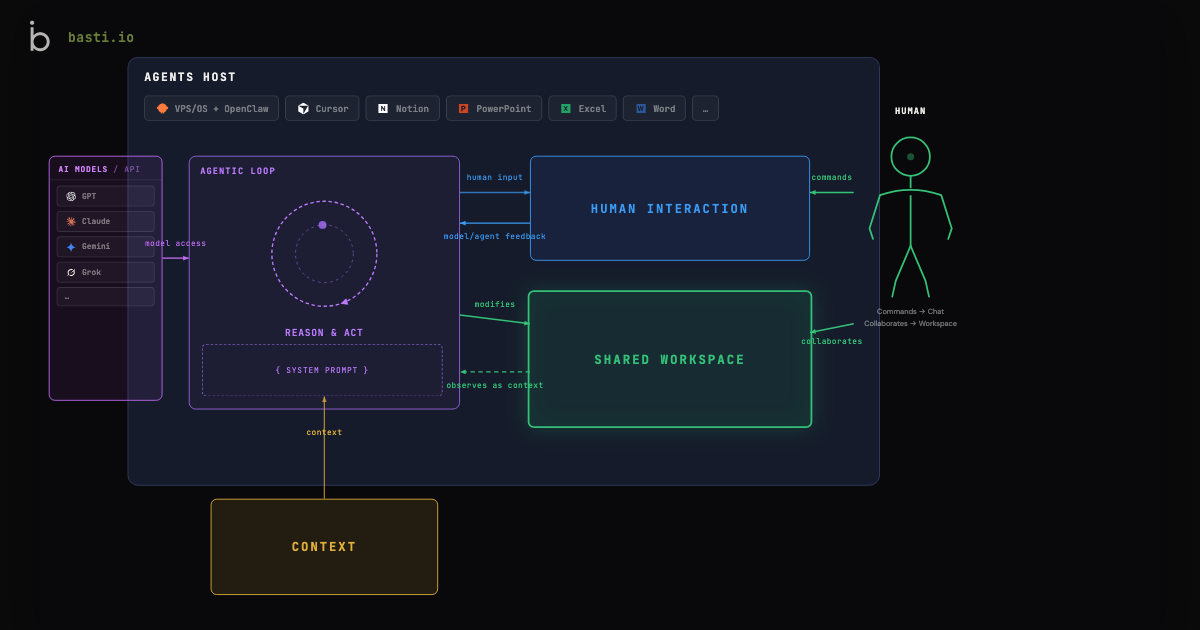
- The universal mental model consists of five always-present components: LLM APIs (commoditized intelligence), Agents Host (the platform layer that determines capabilities), Agentic Loop (reason-act-observe cycle bounded by system prompts), Context (connected data sources), and Shared Workspace (surfaces where agent output becomes real and is shared with humans)
- In the personal space, OpenClaw running on a VPS provides OS-level integration with real hardware, residential IPs, actual file system access, and persistent memory—the host determines the ceiling of what's possible
- In code space, Cursor serves as an IDE-level host where the shared workspace is the actual codebase itself, enabling the agent to read, write, run, and test in the same environment as humans, producing 10-100x speedups
- In operational space, Notion functions as an agents platform where company databases, SOPs, and project state become context, and the agent writes directly into the same pages teams already use—this is "agentic operations" not just "AI features"
- The architecture is fractal and identical across all three instances; only the host, context sources, workspace, system prompt, and integration depth vary while the five-component structure remains constant
- Cloud-based implementations where both agent and workspace live in the cloud enable continuous always-on operation rather than "while I'm at my desk" work, which is the structural reason for 10-100x productivity jumps
- The host platform is the strategic decision because it determines what agents can access and do, making native workspace access fundamentally more powerful than sandboxed chat windows
- Context becomes the competitive moat as LLMs commoditize—companies with richer proprietary data, SOPs, and institutional knowledge will get disproportionately better results from the same base models
- The best agentic setups don't create separate AI outputs but write directly into existing human workspaces, making the shared workspace the actual interface (why Cursor and Notion's approaches work so well)
- The human role shifts from executor to architect—making architectural decisions, auditing outputs, correcting course, and designing system prompts and context rather than doing footwork
Decoder
- Agentic Loop: The core execution cycle of an AI agent following a Reason → Act → Observe → Repeat pattern, bounded by system prompts that define role and constraints
- MCP (Model Context Protocol): A protocol standard for connecting data sources and applications to AI models to provide context
- System Prompt: Instructions that define an agent's role, constraints, and behavior within the execution loop
- SOPs: Standard Operating Procedures—documented processes and workflows that provide context for operational agents
- Shared Workspace: The collaborative surface where both humans and agents read and write (files, codebases, databases, pages), as opposed to separate AI-only outputs
- Agent Host: The runtime platform layer that wraps raw LLM intelligence into an operational system, handling scheduling, permissions, tool access, and human interaction surfaces
Original article
Something shifted in the first quarter of 2026. Not a feature launch, not a new product - a structural change in how work happens.
For the first time, I found myself genuinely operating with agents across every dimension of my work: personal tasks, software engineering, company operations. Not as a novelty. As the default mode.
This post is the abstraction I arrived at after weeks of doing this. A mental model that applies everywhere - because the architecture underneath is always the same.
The Trigger: OpenClaw and the "Agent Operating System"
It started with OpenClaw.
OpenClaw is an open-source project that I would label itself as "an operating system for agents". But powerful and open-source, like Linux. First commit in November 2025, breakout success by February 2026. I installed it, connected it via Telegram, and started co-working with it - scheduling, filing taxes, processing documents.
But the product itself wasn't the revelation. It was the process behind it. The sheer quality of what one person team could ship in three months, using agents to build an agent platform, made something viscerally clear to me: the leverage available through agentic work had crossed a threshold.
What I didn't expect was that the pattern I saw in OpenClaw would repeat everywhere I looked - in my IDE, in my company's operations, in how I manage my own life. The same architecture, over and over.
So I sketched it.
The Mental Model
Here's the framework. Every agentic system I've encountered - from personal AI assistants to coding agents to operational automation - follows this structure:
Five components. Always present. Always in the same relationship:
- LLM Models / API - The raw intelligence. GPT, Claude, Gemini, open-source models. These are interchangeable and increasingly commoditized. They provide the reasoning capability, but alone they do nothing.
- Agents Host - The runtime that wraps raw intelligence into an operational system. It handles scheduling, permissions, model access, tool access, and human interaction surfaces. This is the platform layer that most people underestimate. The host determines what the agent can actually do.
- Agentic Loop - The core execution cycle: Reason → Act → Observe → Repeat, bounded by a System Prompt that defines the agent's role and constraints. This is where the work happens.
- Context - Everything the loop can draw on: connected files, apps, MCPs (Model Context Protocols), databases, internet access. The richer the context, the more capable the agent.
- Shared Workspace - The surface where agent output becomes real: files, folders, codebases, apps, databases. Critically, this is shared between human and agent. Both read and write to it.
And threading through all of it: Human Interaction - the chat, voice, or thread interface where the human directs, corrects, and collaborates with the agent.
Why This Model Matters: It's Always the Same Architecture
The insight that changed how I think about this: every agentic tool I use is an instance of this same model. The only things that change are the host, the context sources, and the workspace.
Let me show you three concrete instances from my own work.
Instance 1: Personal Space - OpenClaw
flowchart LR
LLM["LLM API"] --> Host["OpenClaw on VPS
(Agents Host)"] --> Loop["Reason & Act loop
(system prompt: assistant)"]
Ctx["Context:
Calendar, inbox, docs,
personal preferences"] --> Loop
HI["Human Interaction:
Chat / Voice"] <--> Loop
WS["Shared Workspace:
Personal notes, tasks, files"] <--> LoopHost: OpenClaw, self-hosted on a VPS.
Context: Calendar, inbox, documents, personal preferences.
Workspace: Personal notes, tasks, files.
Human interaction: Telegram chat, voice.
This is where I first experienced the model in action. OpenClaw isn't a chatbot - it's an agent with persistent memory, connected tools, and the ability to self-modify its own skills. It files my taxes. It processes documents. It manages scheduling.
The key realization: the host matters enormously. Running on a real OS with real hardware (not a sandboxed web app) means residential IP addresses, real browser capabilities, actual file system access. The playing field of the workspace defines the ceiling of what the agent can do.
Instance 2: Code Space - Cursor
flowchart LR
LLM["LLM API"] --> Host["Cursor
(Agents Host)"] --> Loop["Reason & Act loop
(system prompt: engineer)"]
Ctx["Context:
repo, codebase, docs, issues"] --> Loop
HI["Human Interaction:
Chat / Voice"] <--> Loop
WS["Shared Workspace:
Codebase, local and/or cloude runtime"] <--> LoopHost: Cursor (the IDE).
Context: Repository, full codebase, documentation, issues.
Workspace: The codebase itself, plus build tools, test runners, terminals.
Human interaction: Chat and thread within the IDE.
This is where the 10x-100x speedup lives - and where I spent Q1 2026 pushing the boundaries. I rebuilt my personal website (the one you are on right now) in days, then moved into mission-critical backend work on AQUATY's distributed system.
The IDE-as-host is powerful because the workspace is the actual codebase. The agent doesn't generate code into a void - it reads, writes, runs, and tests in the same environment you do. The shared workspace is maximally integrated.
I'll go deep on this in a follow-up post. The data is striking - and the failure modes are instructive.
Instance 3: Operational Space - Notion
flowchart LR
LLM["LLM API"] --> Host["Notion
(Agents Host)"] --> Loop["Reason & Act loop
(system prompt: ops)"]
Ctx["Context:
DBs, SOPs, project state,
dashboards"] --> Loop
HI["Human Interaction:
AI Chat & Voice"] <--> Loop
WS["Shared Workspace:
Notion Pages + Databases"] <--> LoopHost: Notion (as an agents platform).
Context: Databases, SOPs, project state, dashboards, connected tools.
Workspace: Notion pages and databases - the same surfaces the team already works in.
Human interaction: Comments, requests, AI inbox.
This is the instance most people haven't thought about yet. When Notion becomes an agents host, your operational infrastructure becomes the shared workspace. The agent doesn't just answer questions - it reads your databases, understands your project state, and writes back into the same pages your team uses.
This is what I mean by agentic operations: not "AI features in a productivity tool," but a genuine agent loop running against your company's operational surface.
The Pattern: What Changes, What Stays the Same
Across all three instances, the architecture is identical. What varies:
| Personal (OpenClaw) | Code (Cursor) | Operations (Notion) | |
|---|---|---|---|
| Host | Self-hosted OS | IDE | Productivity platform |
| Context | Personal data, calendar | Codebase, docs | Databases, SOPs |
| Workspace | Files, notes | Codebase | Pages, databases |
| System Prompt | Assistant | Engineer | Ops |
| Integration depth | OS-level | IDE-level | App-level |
The model is fractal. You can zoom into any organization and find these same five components wherever agents are being deployed effectively.
One more shift matters: when both the agent and the shared workspace live in the cloud, the loop stops being "while I'm at my desk" work. It becomes continuous - always-on, permissioned, and able to run while you sleep. That's the structural reason the productivity ceiling jumps from incremental gains to 10x, and in the right setups, 100x.
What This Means for Companies
If you accept this mental model, a few things follow:
The cloud version of the model is the inflection point: once agents can safely operate against a shared workspace 24/7, organizations can move entire workflows (not just individual tasks) into an always-on agentic loop.
The host is the strategic decision. Choosing where your agents live determines what they can access, what they can do, and how deeply they integrate with your existing workflows. An agent in a sandboxed chat window is fundamentally limited compared to an agent with native access to your workspace.
Context is the moat. The AI models themselves are increasingly commoditized. What differentiates your agent's output is the context it has access to - your proprietary data, your SOPs, your project state, your institutional knowledge. Companies that connect richer context will get disproportionately better results. I call this: The Opionated Context Layer.
The shared workspace is the interface. The best agentic setups don't create separate "AI outputs" - they write directly into the spaces where humans already work. This is why Cursor works so well (agent writes into your codebase). And why Notion's approach is IMO leading (agent writes into your operational pages) - if you apply Notion Agents to a workspace your copmpany has been workin in for years, this pays hughe dividends now!
The human role shifts from executor to architect. In every instance, I'm not doing the footwork. I'm making architectural decisions, auditing outputs, correcting course, and designing the system prompts and context that make the agent effective. The work isn't less - it's different.
FigJam is Now Your Coding Agent's Whiteboard Too
Figma launched an MCP server that lets AI coding assistants access design files directly, helping ensure coded products match their original designs.
Decoder
- MCP: Model Context Protocol, a standard that allows AI assistants to access external data sources and tools to provide richer context when generating responses or code
Original article
The TL;DR on MCP: Why context matters and how to put it to work
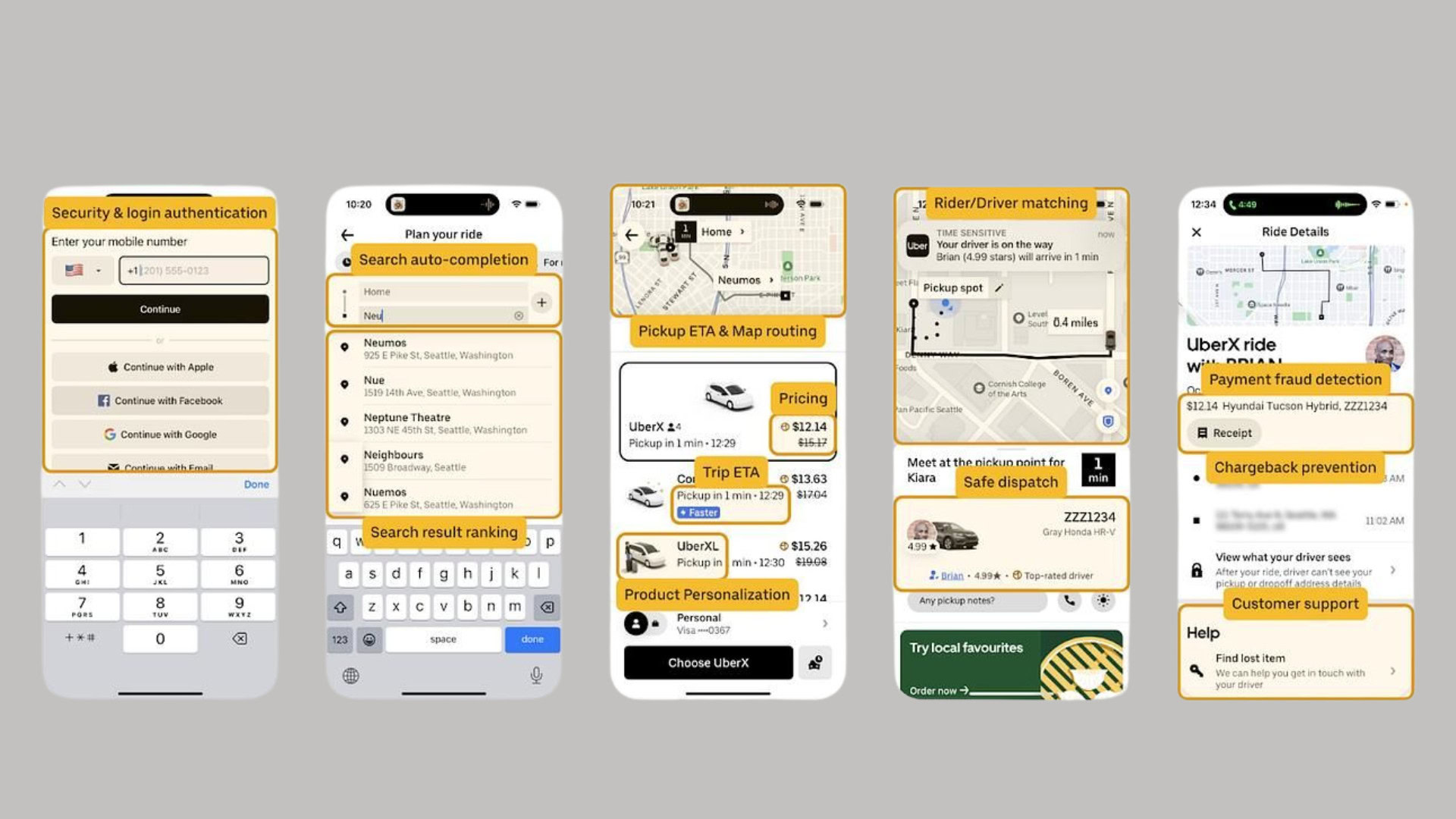
How Uber Increased Ride Conversions by 14.5% with Three Friction-Reducing UX Changes
Uber increased ride conversions by 14.5% by eliminating uncertainty through three friction-reducing design changes that any product team can apply.
Deep dive
- Uber did not solve transportation but eliminated uncertainty at every stage of the booking journey, targeting the cognitive load and hesitation that reduces conversion
- GPS-based automatic pickup removed decision fatigue by handling location detection automatically, reducing booking to a single confirmation tap instead of multi-step phone negotiations
- Real-time driver tracking transformed passive anxious waiting into active engagement by providing system status visibility and leveraging the Goal Gradient Effect where users feel more motivated as they see progress
- Upfront transparent pricing eliminated the number one cause of transaction abandonment (unexpected costs) by showing estimated fares including surge pricing before commitment
- The combination of speed and clarity at every stage creates a seamless experience where users move from intent to action almost instantly with no cognitive overhead
- Even one-second delays in mobile interactions significantly reduce satisfaction and conversion, making speed optimization critical for digital products
- The experience works because it aligns with natural human behavior preferences for simplicity, visibility, control, and predictability rather than forcing users to learn complex workflows
- Consistency in the experience drives habit formation, making Uber the default transportation choice by removing variability and delivering reliable outcomes every time
- The key principle is that users do not need more features but fewer obstacles between intent and value delivery
- Traditional taxi booking created friction through phone calls, unclear location communication, uncertain wait times, and unknown final pricing at every decision point
Decoder
- Decision fatigue: The phenomenon where making too many choices in a short period reduces the likelihood of taking action as users become mentally exhausted
- Cognitive load: The mental effort required to process information and make decisions, which when increased leads to hesitation and abandonment
- Friction: In UX design, any obstacle or unnecessary step that slows users down or creates hesitation between their intent and completing an action
- System status visibility: A design principle where users are continuously informed about what is happening in the system, reducing anxiety and building trust through transparency
- Goal Gradient Effect: A psychological principle where people feel more motivated and engaged as they perceive they are making progress toward a goal, even during waiting periods
Original article
Uber increased ride conversions by 14.5% by tackling the real barrier in transportation — uncertainty — through three friction-reducing design changes. GPS-based automatic pickup detection, real-time driver tracking, and upfront transparent pricing each eliminated a distinct point of hesitation in the booking journey. Together, these changes turned a frustrating multi-step process into a seamless, habit-forming experience aligned with how users naturally think and behave.

Anthropic and OpenAI Launch Enterprise AI Ventures
Anthropic and OpenAI are each launching separate enterprise AI joint ventures backed by major financial firms to deploy engineers directly at portfolio companies.
Decoder
- Forward-deployed engineer (FDE): Engineering model popularized by Palantir where engineers work onsite with customers to build custom solutions integrated into their specific workflows, rather than selling standardized products.
Original article
On Monday, Anthropic announced a joint venture focusing on deploying enterprise AI services. Blackstone, Hellman & Friedman, and Goldman Sachs will be founding partners in the new venture, which is backed by a group of VCs, hedge funds, and private equity firms, including Apollo Global Management, General Atlantic, GIC, Leonard Green, and Sequoia Capital.
The Wall Street Journal, which first reported news of the partnership, reported the new venture was valued at $1.5 billion, which includes a $300 million commitment each from Anthropic, Blackstone, and Hellman & Friedman.
The announcement comes just as Anthropic's chief rival is preparing to make a similar move. Mere hours before the Anthropic announcement, Bloomberg reported that OpenAI was raising funds for a new venture called The Development Company, along very similar lines. OpenAI's venture would operate at a larger scale, raising $4 billion from 19 investors against a $10 billion valuation. Named investors include TPG, Brookfield Asset Management, Advent, and Bain Capital, with no apparent overlap in investment between the OpenAI venture and Anthropic's competitor.
The overall logic of the two ventures is the same, raising money from alternative asset managers to create new channels for enterprise AI deals. The ventures will presumably get preferred sales access to their investors' portfolio companies, while the investors will capture more value from any resulting contracts.
The new capital will also allow more engineering resources to be devoted to each individual, embracing the forward-deployed engineer (FDE) model popularized by Palantir.
As Anthropic put it in its announcement:
An engagement might begin with the company's engineering team sitting down with clinicians and IT staff to build tools that fit into the workflows that staff already use… Engagements like this will run across mid-sized companies across industries, each shaped by the people closest to the work.
The new ventures come as both AI labs fundraise at a blistering pace, while circling possible IPOs. OpenAI announced $122 billion in new funding at the end of March, against a valuation of $852 billion. TechCrunch reported last week that Anthropic is in the final stages of its own funding round, seeking $50 billion of new funding against a $900 billion valuation.

Automating AI Research
AI systems are approaching the ability to autonomously conduct their own R&D and train successor models, with a 60% chance of full automation by 2028 according to analysis of public benchmarks and capabilities.
Deep dive
- Coding benchmarks show near-saturation: SWE-Bench scores jumped from ~2% (Claude 2, late 2023) to 93.9% (Claude Mythos Preview, 2026), indicating AI can now solve real-world GitHub issues as well as humans
- Task time horizons expanded dramatically: AI systems went from handling 30-second tasks (GPT-3.5, 2022) to 12-hour tasks (Opus 4.6, 2026), with expectations of 100-hour capability by end of 2026
- Scientific competency accelerating across AI-relevant domains: CORE-Bench (paper reproduction) went from 21.5% to 95.5% in 15 months; MLE-Bench (Kaggle competitions) rose from 16.9% to 64.4% in 16 months
- Kernel optimization increasingly automated: Multiple research efforts show AI systems can now write and optimize GPU kernels, a critical bottleneck in AI training and inference efficiency
- PostTrainBench shows AI achieves 50% of human performance at fine-tuning models, using the production instruct-tuned models from frontier labs as challenging human baselines
- Anthropic's internal LLM training optimization task shows 52× speedup with Claude Mythos (April 2026), up from 2.9× with Opus 4 (May 2025)—humans typically achieve 4× in 4-8 hours
- Proof-of-concept automated alignment research demonstrated: Anthropic showed AI agent teams can autonomously improve on human baselines for scalable oversight problems
- Meta-capabilities emerging: AI systems now manage other AI systems in production (Claude Code, OpenCode), enabling parallel multi-specialist workflows under single AI director
- Early signs of creative scientific contribution: AI assisted in solving Erdős math problems and co-authoring novel proofs, though still unclear if this represents true creativity or advanced pattern matching
- Major labs explicitly pursuing automated R&D: OpenAI targets automated AI research intern by September 2026; Anthropic publishing on automated alignment; startups like Recursive Superintelligence ($500M raised) focused entirely on automating AI research
- Alignment compounds under recursion: Even 99.9% accurate alignment degrades to 60.5% after 500 generations, creating existential risk as systems become smarter than their supervisors
- Capital-heavy machine economy forming: AI R&D automation signals broader shift toward corporations with high compute costs but minimal human labor, creating a parallel "machine economy" that increasingly trades with itself
- Critical question remains: Is AI research more like engineering (brick-by-brick optimization that AI excels at) or paradigm shifts (transformer architecture, mixture-of-experts) requiring human creativity? Most AI progress comes from methodical scaling and debugging rather than radical insights
- Timeline estimate: 30% chance of automated frontier model training by end of 2027, 60% by end of 2028—failure to achieve this would reveal fundamental limitations in current paradigm requiring human invention
Decoder
- SWE-Bench: Benchmark evaluating AI systems' ability to solve real-world GitHub software issues, testing practical coding competency on production codebases
- METR task horizons: Measurement of the longest time period (in hours) over which AI systems can reliably complete tasks a skilled human would perform, tracking autonomous work capability
- Kernel design: Writing and optimizing low-level code that maps AI operations (like matrix multiplication) to hardware, critical for training and inference efficiency
- PostTrainBench: Benchmark testing whether AI systems can fine-tune smaller open-weight models, compared against production instruct-tuned versions created by expert human teams
- Alignment: Ensuring AI systems behave safely and as intended, particularly challenging when systems become smarter than the humans or AI supervisors training them
- Recursive self-improvement: AI systems autonomously improving their own capabilities and training successor versions, potentially creating exponential capability growth
- CORE-Bench: Computational Reproducibility Agent Benchmark testing AI's ability to reproduce scientific paper results from code repositories
- MLE-Bench: Benchmark where AI systems compete in Kaggle machine learning competitions across diverse domains like NLP and computer vision
- Centaur configuration: Humans and AI working in close collaboration, combining their complementary strengths on complex problems
Original article
Import AI 455: Automating AI Research
AI systems are about to start building themselves. What does that mean?
I'm writing this post because when I look at all the publicly available information I reluctantly come to the view that there's a likely chance (60%+) that no-human-involved AI R&D – an AI system powerful enough that it could plausibly autonomously build its own successor – happens by the end of 2028. This is a big deal. I don't know how to wrap my head around it. It's a reluctant view because the implications are so large that I feel dwarfed by them, and I'm not sure society is ready for the kinds of changes implied by achieving automated AI R&D. I now believe we are living in the time that AI research will be end-to-end automated. If that happens, we will cross a Rubicon into a nearly-impossible-to-forecast future. More on this later.
The purpose of this essay is to enumerate why I think the takeoff towards fully automated AI R&D is happening. I'll discuss some of the consequences of this, but mostly I expect to spend the majority of this essay discussing the evidence for this belief, and will spend most of 2026 working through the implications.
In terms of timing, I don't expect this to happen in 2026. But I think we could see an example of a "model end-to-end trains it successor" within a year or two – certainly a proof-of-concept at the non-frontier model stage, though frontier models may be harder (they're a lot more expensive and are the product of a lot of humans working extremely hard). My reasoning for this stems primarily from public information: papers on arXiv, bioRxiv, and NBER, as well as observing the products being deployed into the world by the frontier companies. From this data I arrive at the conclusion that all the pieces are in place for automating the production of today's AI systems – the engineering components of AI development. And if scaling trends continue, we should prepare for models to get creative enough that they may be able to substitute for human researchers at having creative ideas for novel research paths, thus pushing forward the frontier themselves, as well as refining what is already known.
Upfront caveat
For much of this piece I'm going to try to assemble a mosaic view of AI progress out of things that have happened with many individual benchmarks. As anyone who studies benchmarks knows, all benchmarks have some idiosyncratic flaws. The important thing to me is the aggregate trend which emerges through looking at all of these datapoints together, and you should assume that I am aware of the drawbacks of each individual datapoint.
Now, let's go through some of the evidence together.
The coding singularity – capabilities over time
AI systems are instantiated via software and software is made out of code.
AI systems have revolutionized the production of code. This has happened due to two related trends: AI systems have gotten better at writing complicated real-world code, and AI systems have gotten much better at chaining together many linear coding tasks (e.g, writing code, then testing it) independent of human oversight.
Two things that exemplify this trend are SWE-Bench and the METR time horizons plot.
Solving real-world software engineering problems
SWE-Bench is a widely used coding test which evaluates how well AI systems can solve real world GitHub issues. When SWE-Bench launched in late 2023 the best score at the time was Claude 2 which had an overall success rate of ~2%. Claude Mythos Preview gets 93.9%, effectively saturating the benchmark. (All benchmarks have some amount of noise inherent to them, so there's usually a point where you score high enough that you are running into the limitations of the benchmark itself rather than your method – for instance, about 6% of the labels in the ImageNet validation set are wrong or ambiguous).
SWE-Bench is a reliable proxy for the general issue of coding competency and the impact of AI on software engineering. The vast majority of people I meet at frontier labs and around Silicon Valley now code entirely through AI systems. Increasingly, they use AI systems to write the tests and check the code as well. In other words, AI systems have gotten good enough to automate a major component of AI R&D, speeding up all the humans that work on it.
Measuring an AI system's ability to complete tasks that take people a long time
METR makes a plot that tells us about the complexity of tasks AIs can complete, measured by how many hours a skilled human would take to do them. The key measure here is one which tells you the rough time horizon over which AI systems can be 50% reliable at a basket of tasks.
Here, progress has been extremely striking: In 2022, GPT 3.5 could do tasks that might take a person about ~30 seconds. In 2023, this rose to 4 minutes with GPT-4. In 2024, this rose to 40 minutes (o1). In 2025, it reached ~6 hours (GPT 5.2 (High)). In 2026, it has already risen to ~12 hours (Opus 4.6). Ajeya Cotra, a longtime AI forecaster who works at METR, thinks it isn't unreasonable to expect AI systems to do tasks that take ~100 hours by the end of 2026 (#448).
This significant rise in the length of time that AI systems can work independently correlates neatly with the explosion in agentic coding tools – this is the productization of AI systems which do work on behalf of people, acting independently for significant periods of time. It also loops back to AI R&D, where if you look closely at the work of many AI researchers, a lot of their tasks boil down into things that might take a person a few hours to do – cleaning data, reading data, launching experiments, etc. All of this kind of work now sits inside the time horizon scope of modern systems.
The more skilled AI systems get and the better they get at working independently of us, the more they can help automate chunks of AI R&D
Key ingredients in delegation are a) confidence in the skills of the person, and b) confidence in their ability to work independently of you in a way that is aligned with your intentions.
When we look at the competency of AI at coding, it seems that AI systems are getting far more skilled and also able to work independently of people for longer and longer periods before needing re-calibration. This correlates with what we see around us – engineers and researchers are now delegating larger and larger chunks of their work to AI systems, and as capabilities rise, so too does the complexity and importance of the work being delegated.
AI is getting good at core science skills essential to AI R&D
Think about modern science – a huge amount of it is about specifying a direction where you want to generate some empirical information, running experiments to generate that information, then sanity-checking the results of the experiment. The combination of advances in coding over time combined with the general world modeling capabilities of LLMs has yielded tools that are already helping to speed up human scientists and partially automate aspects of R&D broadly.
Here, we can look at the rate of AI progress in a few key scientific skills which are inherent to AI research itself: Replicating research results, chaining together machine learning techniques and other approaches to solve technical problems, and optimizing AI systems themselves.
Implementing entire scientific papers and doing the experiments
One core job of AI research is reading scientific papers and reproducing their results. Here, there has been dramatic progress on a wide range of benchmarks.
One good example is CORE-Bench, the Computational Reproducibility Agent Benchmark. This benchmark challenges AI systems to "reproduce the results of a research paper given its repository. The agent must install libraries, packages, and dependencies and run the code. If the code runs successfully, the agent needs to search through all outputs to answer the task questions." CORE-Bench was introduced in September 2024 and the best scoring system at the time was a GPT-4o model in a scaffold called CORE-Agent which scored ~21.5% on the hardest set of tasks in the benchmark.
In December 2025 one of the authors of CORE-Bench declared the benchmark 'solved', with an Opus 4.5 model achieving 95.5%.
Building entire machine learning systems to solve Kaggle competitions
MLE-Bench is an OpenAI-built benchmark which examines how well AI systems can compete (offline) in "75 diverse Kaggle competitions across a variety of domains, including natural language processing, computer vision, and signal processing." At launch in October 2024, the top scoring system (an o1 model inside an agent scaffold) got 16.9%. As of February 2026, the best scoring system (Gemini3 inside an agent harness with search) gets 64.4%.
Kernel design
One of the harder tasks in AI development is kernel optimization, where you write and refine the code that maps specific operations, like matrix multiplication, to the underlying hardware. Kernel optimization is core to AI development because it defines the efficiency of both training and inference – how much compute you can effectively utilize to develop an AI system, and once you've trained a model, how efficiently you can convert that compute into inference.
In recent years, AI for kernel design has gone from a curiosity to a competitive area of research and several benchmarks have emerged. None of these benchmarks are especially popular, so we can't easily model progress over time. On the other hand, we can look at some of the research being done to get a feel for the progress.
Some of the types of work include:
- Using DeepSeek's models to try to build better GPU kernels (#400)
- Automating the conversion of PyTorch modules to CUDA code (#401)
- Meta using LLMs to automate the generation of optimized Triton kernels for use within its infrastructure (#439)
- Using LLMs to help write kernels for non-standard hardware like Huawei's Ascend chips ("AscendCraft" #444)
- Fine-tuning open weight models for GPU kernel design ("Cuda Agent", #448)
One caveat here is that kernel design does have some properties that make it unusually amenable to AI-driven R&D, like having easily verifiable rewards.
Fine-tuning language models via PostTrainBench
A harder version of this kind of test is PostTrainBench (#449), which sees how well different frontier models can take smaller open weight models and fine-tune them to improve performance on some benchmark. The nice feature of this benchmark is we have extremely good human baselines – the existing 'instruct-tuned' versions of these models, which have been developed by talented human AI researchers working at frontier labs. These models have been worked on by extremely talented researchers and engineers and deployed into the world, so they represent a very challenging human baseline to overcome.
As of March 2026, AI systems are able to post-train models to get about half as much of the uplift as ones trained by humans.
The specific eval scores are derived by a "weighted average is taken across all post-trained LLMs (Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B) and benchmarks (AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval). For each run, we ask a CLI agent to maximize the performance of a specific base LLM on a specific benchmark."
The top-scoring systems as of April get 25%-28% (Opus 4.6, and GPT 5.4), compared to a human score of 51%. This is already quite meaningful.
Optimizing language model training
For the last year Anthropic has reported how well its systems do at an LLM training task which is described as tasking its models to "optimize a CPU-only small language model training implementation to run as fast as possible". The score is the average speedup over the unmodified starting code and progress has been striking: Claude Opus 4 achieved a 2.9× mean speedup in May 2025; this rose to 16.5× with Opus 4.5 in November 2025, 30× with Opus 4.6 in February 2026, and 52× with Claude Mythos Preview in April 2026. To calibrate on what these numbers mean, it is expected to take a human researcher 4 to 8 hours of work to achieve a 4x speedup on this task.
Conducting AI alignment research
Another Anthropic result is a proof-of-concept of Automated Alignment Research (#454); here, an Anthropic researcher primes a team of individual AI agents with a research direction, then they autonomously go and try to get a better score than a human baseline on an AI safety research problem (specifically, scalable oversight). The approach works, with the AI agents coming up with techniques that beat the Anthropic-designed baseline. However, this is done at a relatively small scale and doesn't (yet) generalize to a production model. Nonetheless, it's proof that you can apply today's AI systems to contemporary cutting-edge research problems and we already see meaningful signs of life. All of the above mentioned benchmarks once looked like this, too, and then after a few months or at most a year, AI systems got dramatically better at whatever the benchmarks were testing.
Meta-skills: management
AI systems are also learning to manage other AI systems. This is visible in broadly deployed products like Claude Code or OpenCode, where a single agent can end up supervising multiple sub-agents. This allows AI systems to work on large-scale projects that require multiple individual 'workers' each with different specialisms that work in parallel, typically under the direction of a single AI manager (which, here, is an AI system).
Is AI research more like discovering general relativity or Lego?
Can AI invent new ideas that help it improve itself, or are these systems best equipped for the unglamorous, brick-by-brick work required for research? This is an important question for figuring out the extent to which AI systems can end-to-end automate AI research itself. My sense is that AI cannot yet invent radical new ideas – but the technology may not need to for it to automate its own development.
As a field, AI moves forward on the basis of doing ever larger experiments that utilize more and more inputs (e.g, data and compute). Every so often, humans come up with some paradigm-shifting idea which can make it dramatically more resource efficient to do things – a good example here is the transformer architecture and another is the idea of mixture-of-expert models. But mostly the field of AI moves forward through humans methodically going through some loop of taking a well performing system, scaling up some aspect of it (e.g, the amount of data and compute it is trained on), seeing what breaks when you scale it up, figuring out the engineering fix to allow it to scale, then scaling it again. Very little of this requires extremely out-of-leftfield insights and a lot of it seems more like unglamorous 'meat and potatoes' engineering work.
Similarly, a lot of AI research is about running variations of existing experiments where you explore the outcomes of using different parameters, though research intuitions can help pick the most fruitful parameters to vary, you can also automate this and have the AI figure out which parameters to vary (an early version of this was neural architecture search).
Thomas Edison said that "genius is 1% inspiration and 99% perspiration". Even 150 years later, this feels right. Very occasionally new insights come along which transform a field. But mostly, the field has moved forward through humans sweating a lot of pain out on the schlep of improving and debugging various systems.
As the public data above shows, AI has got extremely good at performing many of the essential schlep components of AI development. Along with this, the meta-trend of basic capabilities like coding combined with an ever-expanding time horizon, means AI systems are able to chain together more and more of these tasks into complex sequences of work. This means even if AI systems are relatively uncreative, it feels safe to bet they can push themselves forward – albeit at a slower rate than if they're able to generate novel insights. But if you look at the public data, here too there are tantalizing signs that AI systems may be able to be creative in a way that lets them advance themselves in more impressive ways.
Pushing forward the frontier of science
We have some very preliminary signs that general-purpose AI systems can push forward the frontiers of human science, though this has so far only happened in a couple of domains – primarily computer science and mathematics – and often it happens less through AI systems acting alone and more them acting in partnership with humans in a centaur configuration.
Nonetheless, it's worth observing the trends:
-
Erdos Problems: A team of mathematicians worked with a Gemini model to see how well it could tackle some Erdos math problems. After directing the system to attack around 700 problems they came up with 13 solutions. Of these solutions, 1 was deemed by them to be interesting: "We tentatively believe Aletheia's solution to Erdős-1051 represents an early example of an AI system autonomously resolving a slightly non-trivial open Erdős problem of somewhat broader (mild) mathematical interest, for which there exists past literature on closely-related problems," they wrote. (#444).
-
Centaur math discovery: Researchers with the University of British Columbia, University of New South Wales, Stanford University, and Google DeepMind published a new math proof which was built in close collaboration with some AI-based math tools built at Google. "The proofs of the main results were discovered with very substantial input from Google Gemini and related tools," they wrote. (#441).
If you squint, you could argue that this is a sign that AI systems are developing some of the field-advancing creative intuitions that humans have. But you could just as easily say that math and CS could be unusual domains that are oddly amenable to AI-driven invention, and might end up being exceptions that prove a larger rule. Another example here is Move 37, though I'd contend that the fact it's been ten years since the AlphaGo result and that Move 37 hasn't been replaced by some incredibly impressive more modern flash of insight is another weakly bearish signal here.
Putting it all together
If I put this all together the picture from all of the above evidence I end up with is the following facts:
-
AI systems are capable of writing code for pretty much any program and these AI systems can be trusted to independently work on tasks that'd take a human tens of hours of concentrated labor to do.
-
AI systems are increasingly good at tasks that are core to AI development, ranging from fine-tuning to kernel design.
-
AI systems can manage other AI systems, effectively forming synthetic teams which can fan out and attack complex problems, with some AI systems taking on the roles of directors and critics and editors and others taking on the role of engineers.
-
AI systems can sometimes out-compete humans on hard engineering and science tasks, though it's hard to know whether to attribute this to inventiveness or mastery of rote learning.
To me, this makes a very convincing case that AI can today automate vast swatches, perhaps the entirety, of AI engineering. It is not yet clear how much of AI research it can automate, given that some aspects of research may be distinct from the engineering skills. Regardless, it all feels to me like a clear sign that AI is today massively speeding up the humans that work on AI development, allowing them to scale themselves through pairing with innumerable synthetic colleagues.
Finally, the AI industry is literally saying that AI R&D is its goal
OpenAI wants to build an "automated AI research intern by September of 2026". Anthropic is publishing work on building automated alignment researchers. DeepMind appears to be the most circumspect of the big three, but still says "automation of alignment research should be done when feasible". Automating AI R&D is also the goal of numerous startups: Recursive Superintelligence just raised $500m with the goal of automating AI research, and another neolab, Mirendil, has the goal of "building systems that excel at AI R&D."
In other words, the combined efforts of hundreds of billions of existing and new capital is being sunk into entities that have the goal of automating AI R&D. We should surely expect at least some progress in this direction as a consequence.
Why this matters
The implications of this are profound and under-discussed in popular media coverage of AI R&D. I'll list a few here. This isn't a comprehensive list, but it gestures at the enormity of the challenges AI R&D introduces.
-
We have to get alignment right: Alignment techniques that work today may break under recursive self-improvement as the AI systems become much smarter than the people or systems that supervise them. This is a very well covered area, so I'll just briefly highlight some of the issues:
- Training AI systems to not lie and cheat is surprisingly subtle (e.g, despite trying very hard to build good tests for environments, it's sometimes the case the best way for an AI to solve it is to cheat, thus teaching it that teaching is good)
- AI systems might be able to 'fake alignment' by outputting scores that make us think they behave a certain way that actually hides their true intentions. (In general, AI systems are already aware of when they are being tested.)
- As AI systems start to contribute more of the foundational research agenda for their own training, we might end up substantially changing the overall way AI systems get trained and not have good intuitions or intellectual foundations for understanding what this means.
- There are very basic "compounding error" problems whenever you put something in a recursive loop that likely hits on all of the above and other problems: unless your alignment approach is "100% accurate" and has a theoretical basis for continuing to be accurate with smarter systems, then things can go wrong quite quickly. For example, your technique is 99.9% accurate, then that becomes 95.12% accurate after 50 generations, and 60.5% accurate after 500 generations. Uh oh!
-
Everything that AI touches gets a massive productivity multiplier: In the same way AI is dramatically improving the productivity of software engineers, we should expect the same thing to happen for everything else that AI touches. This introduces a couple of issues we'll have to contend with: 1) inequality of access: assuming that demand for AI continues to outstrip compute supply, we'll have to figure out where to allocate AI to maximize a social upside. By default, I am skeptical that market incentives guarantee us the best societal upside from limited AI compute. Figuring out how to allocate the acceleratory capabilities conferred by AI R&D will be a politically charged problem. 2) 'Amdahl's Law' for the economy: as AI flows into the economy, we'll discover places where things break or slow under the increased volume, and we'll need to figure out how to fix those weak links in the chain. This may be especially pronounced in areas where you have to reconcile the fast-moving digital world with the slow-moving physical world, like drug trials for new medical therapies.
-
The formation of a capital-heavy, human-light economy: All of the above evidence for AI R&D also points to the increasing capabilities of AI systems to autonomously run businesses as well. This means we should expect for an increasing chunk of the economy to get colonized by a new generation of companies which are either capital-heavy (because they own a lot of computers), or opex-heavy (because they spend a lot of money on AI services which they build value on top of), and relatively light on labor compared to today's corporations – because the marginal value of spending more on AI versus human labor will be constantly growing as a consequence of the sustained capability expansion of the AI systems. In practice, this will look like the emergence of a "machine economy" that grows within the larger "human economy", though we might expect that over time the machine economy will interact more and more with itself as AI-run corporations begin to trade with one another. This will do profoundly weird things to the economy and will invite all sorts of questions around inequality and redistribution. Eventually, it may be possible to see the emergence of fully autonomous corporations that are run by AI systems themselves, which would exacerbate all of the above issues, while also posing many novel governance challenges.
Staring into the black hole
Given all of this, I think there's a ~60% chance we see automated AI R&D (where a frontier model is able to autonomously train a successor version of itself) by the end of 2028. Based on the above analysis, you might ask why I don't expect this in 2027? The answer is that I think AI research contains some requirement for creativity and heterodox insights to move forward – so far, AI systems haven't yet displayed this in a transformative and major way (though some of the results on accelerating math research are suggestive of this). If you had to push me for a 2027 probability, I'd say 30%. If we don't see it by the end of 2028, then I think we will have revealed some fundamental deficiency within the current technological paradigm and it'll require human invention to move things forward.
I have written this essay in an attempt to coldly and analytically wrestle with something that for decades has seemed like a science fiction ghost story. Upon looking at the publicly available data, I've found myself persuaded that what can seem to many like a fanciful story may instead be a real trend. If this trend continues, we may be about to witness a profound change in how the world works.
Thanks to Andrew Sullivan, Andy Jones, Holden Karnofsky, Marina Favaro, Sarah Pollack, Francesco Mosconi, Chris Painter, and Avital Balwit, for feedback on this essay.
Thanks for reading!
Tuna-2 (GitHub Repo)
Meta's Tuna-2 shows that direct pixel embeddings outperform complex vision encoders for unified image understanding and generation tasks.
Deep dive
- Tuna-2 progressively simplifies the Tuna architecture by removing visual encoding components while improving performance on multimodal benchmarks
- Original Tuna used VAE for visual encoding, Tuna-R removed VAE to use only representation encoders, Tuna-2 removes both for direct pixel patch embeddings
- The model supports text-to-image generation and image editing tasks at various resolutions including 512px and 1024px classes
- Available in 7B and 2B parameter sizes depending on variant, with inference handled through a unified script
- Meta is releasing foundation checkpoints with some LLM backbone and diffusion head layers removed due to organizational policy constraints
- All other components including vision encoder, projections, and embeddings are fully preserved in the release
- Video generation training and inference code is included but the video model itself cannot be released due to policy restrictions
- The removed layers can be re-learned through short fine-tuning on user data, and Meta plans to release fully restored weights fine-tuned on external data
- Research published in collaboration with University of Hong Kong and University of Waterloo, with paper accepted to CVPR 2026
Decoder
- Pixel embeddings: Direct encoding of image patches into numerical representations without intermediate compression or feature extraction layers
- VAE (Variational Autoencoder): Neural network that compresses images into compact latent representations before processing
- Diffusion head: Component that generates images through iterative denoising process
- Unified multimodal model (UMM): Single model architecture that handles both understanding and generating multiple data types like text and images
- Representation encoder: Intermediate layer that transforms visual inputs into feature representations for downstream tasks
- Patch embedding: Breaking an image into fixed-size patches and converting each to a vector representation
Original article
TUNA-2: Pixel Embeddings Beat Vision Encoders for Unified Understanding and Generation
Overview
We simplify Tuna by progressively stripping away its visual encoding components. By removing the VAE, we first derive Tuna-R, a pixel-space unified multimodal model (UMM) that relies solely on a representation encoder. Tuna-2 further streamlines the design by bypassing the representation encoder entirely, utilizing direct patch embedding layers for raw image inputs. Tuna-2 using pixel embeddings outperforms both Tuna-R and Tuna across a diverse suite of multimodal benchmarks.
Generation Results
Installation
git clone https://github.com/facebookresearch/tuna-2.git
cd tuna-2
bash scripts/setup_uv.sh # creates .venv with all dependencies
source .venv/bin/activateManual setup (if you prefer to drive uv yourself)
curl -LsSf https://astral.sh/uv/install.sh | sh
uv sync
uv pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
uv pip install -e .
source .venv/bin/activateInference
All inference is done through a single unified script:
bash scripts/launch/predict.sh --ckpt <PATH> --prompt <TEXT> [OPTIONS]Options
| Flag | Values | Default | Description |
|---|---|---|---|
--ckpt |
path | (required) | Path to the model checkpoint |
--prompt |
text | (required) | Text prompt (t2i) or editing instruction (edit) |
--task |
t2i, edit |
t2i |
Inference task |
--variant |
none_encoder, siglip_pixel, vae |
none_encoder |
Model variant: Tuna-2, Tuna-R, or Tuna |
--size |
7b, 2b |
7b |
Model size (2b only available for --variant vae) |
--resolution |
See table below | 512x512 |
Output resolution (HxW) |
--gpu |
int | 0 |
GPU device index |
--image |
path | — | Source image (required for --task edit) |
--steps |
int | 50 |
Number of diffusion steps |
--guidance |
float | (from config) | Classifier-free guidance scale |
--seed |
int | 42 |
Random seed |
--negative |
text | (from config) | Negative prompt |
Supported Resolutions
| 512-class | 1024-class |
|---|---|
512x512 |
1024x1024 |
448x576 |
896x1152 |
576x448 |
1152x896 |
384x672 |
768x1344 |
672x384 |
1344x768 |
Examples
See assets/prompts.txt for sample prompts.
# Tuna-2 (7B, no encoder, 512px)
bash scripts/launch/predict.sh \
--ckpt /path/to/tuna_2_pixel_7b.pt \
--prompt "A highly realistic beauty portrait in extreme close-up, showing the face of a young woman from just above the eyebrows down to the lips. Her skin is natural, luminous, and textured, with visible pores, fine facial hairs, subtle unevenness, and a slightly dewy finish, without heavy retouching or artificial smoothing."
# Tuna (2B, VAE latent, 512px)
bash scripts/launch/predict.sh \
--variant vae --size 2b \
--ckpt /path/to/tuna_2b.pt \
--prompt "A brutally realistic cinematic close-up inside a real space station cupola, side profile of a blonde female astronaut floating in zero gravity beside the window, her loose braid drifting naturally, looking out at Earth in silence."Video
Due to policy constraints, we are unable to release the video generation model at this time. However, we provide the complete video training and inference codebase. If you are interested in training your own video model, this is a ready-to-use starting point — see configs/train/video_t2v.yaml for training configuration and configs/predict/t2v_2b.yaml for inference.
TODO
- Release some of the Tuna-2 model weights.
- Release some of the Tuna model weights.
- Release the fully restored model weights (fine-tuned on external data to recover the missing layers).
A Note on Model Release
Due to organizational policy constraints, we are unable to release the full production-trained model weights. To support the research community, we plan to release a foundation checkpoint with a small number of layers removed from both the LLM backbone and the diffusion head (flow head). The remaining layers and all other components (vision encoder, projections, embeddings, etc.) are fully preserved. With a short fine-tuning pass on your own data, the removed layers can be quickly re-learned and the model restored to full quality.
For detailed fine-tuning instructions, please refer to the training guide.
Meanwhile, we are also actively working on fine-tuning the removed layers using external data, and plan to release the complete weights as soon as possible.
Citation
@article{tuna2,
title={TUNA-2: Pixel Embeddings Beat Vision Encoders
for Unified Understanding and Generation},
author={Liu, Zhiheng and Ren, Weiming and Huang, Xiaoke
and Chen, Shoufa and Li, Tianhong and Chen, Mengzhao
and Ji, Yatai and He, Sen and Schult, Jonas
and Xiang, Tao and Chen, Wenhu and Luo, Ping
and Zettlemoyer, Luke and Cong, Yuren},
journal={arXiv preprint arXiv:2604.24763},
year={2026}
}
@article{liu2025tuna,
title={Tuna: Taming unified visual representations for native unified multimodal models},
author={Liu, Zhiheng and Ren, Weiming and Liu, Haozhe and Zhou, Zijian and Chen, Shoufa and Qiu, Haonan and Huang, Xiaoke and An, Zhaochong and Yang, Fanny and Patel, Aditya and others},
journal={CVPR2026},
year={2026}
}License
This project is licensed under the Apache License 2.0. See LICENSE for details.
End-to-End Tokenizer Training for Autoregressive Images
Researchers achieve state-of-the-art image generation results by training the image tokenizer and generator jointly instead of separately.
Deep dive
- Autoregressive image models compress images into latent representations using visual tokenizers before generation, but traditional two-stage pipelines train tokenizers and generators separately
- This work proposes end-to-end joint optimization of both reconstruction quality and generation performance, enabling direct supervision signals from generation results to flow back to the tokenizer
- The approach leverages vision foundation models to improve 1D tokenizers specifically for autoregressive modeling tasks
- Achieved state-of-the-art FID score of 1.48 without guidance on ImageNet 256x256 generation benchmark
- The joint training contrasts with prior work where tokenizers were optimized purely for reconstruction without considering downstream generation performance
- Accepted to ICML 2026 as a Spotlight presentation, indicating significant contribution to the field
- The method addresses a key limitation where separately-trained tokenizers may learn representations that reconstruct well but don't support optimal generation
Decoder
- Autoregressive: A modeling approach that generates data sequentially, predicting each element based on previously generated elements
- Tokenizer: A component that converts images into discrete tokens or compact representations processable by generative models
- FID (Fréchet Inception Distance): A metric for evaluating image generation quality by comparing distributions of generated versus real images (lower is better)
- ImageNet: A large-scale image dataset commonly used as a benchmark for computer vision tasks
- Vision foundation models: Large pre-trained models like CLIP or DINOv2 that learn general visual representations from massive datasets
- 1D tokenizer: A tokenizer that converts 2D images into a one-dimensional sequence of tokens for sequential processing
Original article
End-to-End Autoregressive Image Generation with 1D Semantic Tokenizer
Authors: Wenda Chu, Bingliang Zhang, Jiaqi Han, Yizhuo Li, Linjie Yang, Yisong Yue, Qiushan Guo
Autoregressive image modeling relies on visual tokenizers to compress images into compact latent representations. We design an end-to-end training pipeline that jointly optimizes reconstruction and generation, enabling direct supervision from generation results to the tokenizer. This contrasts with prior two-stage approaches that train tokenizers and generative models separately. We further investigate leveraging vision foundation models to improve 1D tokenizers for autoregressive modeling. Our autoregressive generative model achieves strong empirical results, including a state-of-the-art FID score of 1.48 without guidance on ImageNet 256x256 generation.
White House Considers Vetting AI Models Before They Are Released
The Trump administration is exploring an executive order that could require AI models to undergo government vetting before public release.
Original article
The Trump administration is discussing a potential executive order to create an AI working group that would bring together tech executives and government officials to examine potential oversight procedures.

SpaceX Breaks Ground on Solar Fab to Power Orbital Data Centers
SpaceX is building a specialized solar cell factory in Texas to manufacture lightweight, high-efficiency panels for powering orbital data centers designed to run AI workloads in space.
Deep dive
- SpaceX broke ground in late March 2026 on what Director of Solar Production Noah Cowles calls "one of the world's most advanced solar cell factories"
- The facility vertically integrates the entire fabrication process from raw silicon to final assembly, giving SpaceX complete control over efficiency, mass, and quality
- Vertical integration insulates SpaceX from global supply chain vulnerabilities while allowing optimization for the extreme requirements of space deployment
- Standard commercial solar panels fail on three fronts for orbital use: too heavy for payload costs, too fragile for launch stresses, and too inefficient for power density requirements
- The TERAFAB initiative envisions massive compute infrastructure deployed in orbit to handle AI workloads alongside the expanding Starlink constellation
- While the vacuum of space provides natural cooling benefits for high-performance compute clusters, energy generation remains the ultimate limiting factor
- The facility must produce continuous high-volume supplies of bespoke solar arrays prioritizing maximum energy yield per gram of mass
- The manufacturing environment is described as "high-intensity, on-site, not a 9-5" requiring hands-on ownership of cleanroom systems and process equipment
- SpaceX is combining this orbital solar production capability with Tesla's existing ground-based solar and battery specialization
- This represents a transition of orbital data centers from theoretical concept to practical reality with the infrastructure beginning to take physical form
Decoder
- TERAFAB: SpaceX's initiative to deploy orbital data centers in space capable of running AI and compute workloads
- Vertical integration: Controlling the entire manufacturing process from raw materials through final assembly rather than relying on suppliers
- Aerospace-grade: Components engineered to withstand the extreme conditions of space including vacuum, radiation, thermal cycling, and launch stresses
- Energy yield per gram: The critical metric for space solar panels measuring how much power is generated relative to mass, since rocket launch costs scale with payload weight
Original article
SpaceX is constructing one of the world's most advanced solar cell factories in Bastrop, Texas. The company is vertically integrating the entire fabrication process to produce highly specialized aerospace-grade solar cells. Vertical integration allows SpaceX to insulate itself from global supply chain vulnerabilities while also giving it total control over the physical limits of solar cell efficiency and mass. SpaceX needs a continuous, high-volume supply of bespoke solar arrays to successfully pull off its plans of deploying an orbital cloud network capable of handling AI workloads.
AI for Bio has a Fuzzy API problem
Biology lacks the clean interfaces that make ML powerful in software, creating a "fuzzy API problem" where each stage of drug discovery produces probabilistic outputs with hidden assumptions that can silently kill programs.
Deep dive
- Target discovery doesn't output clean targets but probabilistic hypotheses about modulating some biological process, in some direction, in some tissue, in some patient subset, with acceptable toxicity—many conditions must simultaneously hold
- GWAS and human genetics give clues about disease-associated genes but don't automatically tell you which gene matters, in which cell type, through which pathway, or how to intervene therapeutically
- Virtual cell models are promising but face a sim-to-real gap: training on cell lines, mice, and engineered models creates models of simulations, not humans, since drugs that work preclinically regularly fail in human trials
- The curse of dimensionality hits hard when you have millions of genetic loci, many cell types, many disease states, but only hundreds of thousands of patients worth of sparse, low-quality data
- Drug design faces a commoditization problem—even superior AI design technology loses value unless tightly coupled to proprietary data, fast experimental feedback, differentiated targets, or clinical strategy that makes the molecule matter
- Designing a perfect molecule can create zero value if the upstream biological hypothesis was false, and you often can't know because competitors' full data (especially from faster/cheaper Chinese firms) is hidden until late
- Clinical trials present the biggest underexploited ML opportunity: patient stratification via LLMs reading messy EHR data, recruiting patients matching complex criteria that aren't SQL-queryable, and automating trial operations currently done by expensive CROs
- Literature mining with AI agents could connect evidence across papers, trial registries, patents, and conference posters to find repurposing opportunities no individual team had time to synthesize
- Time savings in clinical trials have clear monetary value: peak daily sales × P(approval), often millions per day for big drugs, making this easier to monetize than upstream AI-for-bio ideas
- The uncomfortable implication: value may accrue more to teams building closed-loop systems for selecting, testing, and advancing assets (AI-native Roivant model) than to teams with the highest-scoring generative models
- Vertically integrated companies that collect proprietary data for novel targets, use off-the-shelf models like Boltz for design, and validate through tight experimental feedback loops may win over narrowly-focused API players
- The fuzzy API problem means you can do your narrow job perfectly—design the best molecule—and still create zero value because hidden assumptions in adjacent stages were wrong
Decoder
- GWAS: Genome-wide association studies that identify genetic variants correlated with disease risk in large populations, though they don't automatically reveal therapeutic mechanisms
- DepMap: Broad Institute's Dependency Map project that identifies genetic perturbations affecting cancer cell growth to find potential drug targets
- Sim-to-real gap: The problem that models trained on simulations (cell lines, mice) don't transfer well to reality (humans) because the training environment differs fundamentally from deployment
- Modality: The form an intervention takes—small molecules, antibodies, RNA therapeutics, gene editing, cell therapies, etc.
- AAV: Adeno-associated virus, a vector used to deliver genetic therapies into cells
- Transcriptomics/Proteomics: Measuring all RNA transcripts or proteins in a sample to understand cellular state
- EHR: Electronic health record, the digital patient data stored by healthcare systems
- CRO: Contract research organization that pharma companies outsource clinical trial work to
- EDC: Electronic data capture systems used to collect and manage clinical trial data
- Biomarker: A measurable biological indicator (gene, protein, metabolic signature) that correlates with disease state or treatment response
Original article
AI for Bio has a Fuzzy API problem
"AI for bio" is getting hot again. Given the excitement in the current moment, I thought I'd share a bit about what actually makes biology uniquely hard as an application domain for machine learning. The reason is not simply that biology is complicated, though it obviously is. ML is good at many things that are complicated. The deeper reason is that drug discovery does not have the kind of clean feedback loops and clean interfaces that made modern ML so powerful elsewhere.
In software, we are used to clean APIs. One team can build a backend service, expose an endpoint, and another team can build on top of it. The interface is typed. The object either satisfies the contract or it does not. If something breaks, you can usually trace the failure to a bug, fix the code, rerun the test, and ship again. This is so much the case that billion dollar companies are regularly built satisfying exactly one interface (e.g. Supabase for databases, Exa for search, NVIDIA for GPU compute).
It is tempting to imagine drug discovery the same way:
target = target_discovery(disease)
drug = drug_design(target)
medicine = clinical_trial(drug)Target discovery gives you a target. Drug design gives you a molecule. Clinical trials tell you whether it works. One company satisfies each interface.
Unfortunately biology does not expose clean APIs. The output of target discovery is not really a target. It is a probabilistic hypothesis that modulating some biological process, in some direction, in some tissue, in some patient subset, at some disease stage, will produce a useful clinical effect without unacceptable toxicity. The output of drug design is not really a drug. It is a candidate intervention whose value depends on whether the target hypothesis was right, whether the modality is appropriate, whether the molecule reaches the right tissue, whether it has enough selectivity, whether the safety margin is acceptable, whether it can be manufactured, whether it has a defensible IP position, whether the unknown competitive landscape materializes, and whether it fits a viable clinical strategy. The output of a clinical trial is not simply a "cure". It is an outcome filtered through patient selection, endpoint choice, dosing regimen, site execution, statistical power, standard of care, and regulatory interpretation.
So the API is fuzzy. A target can look validated until the molecule hits it in the wrong tissue. A molecule can look great until it fails because the disease biology was wrong. An animal model can look convincing until the human disease is meaningfully different. A trial can look negative even though the drug might have worked in a narrower patient population. The downstream or upstream stages encode specific assumptions in other stages. To me, that is the core problem: AI for bio has a fuzzy API problem. In software, good APIs hide complexity. In biology, the hidden complexity inadvertently kills programs. This essay is about where that fuzziness shows up: target discovery, drug design, and clinical development, and where that poses both challenges and opportunities to use machine learning to revolutionize the field.
The discovery process
The first order, drug discovery involves designing an intervention that stops some sort of deleterious process occurring inside the body. In practice, modern therapeutic development usually looks something like this:
- Determine the causal biology driving a disease in a particular patient population.
- Design a chemical or biological intervention that modulates that biology.
- Test that intervention in model systems (cell, animals, etc) to build evidence that it is safe and plausibly effective in humans.
- Run clinical trials to determine whether it works in humans.
That clean list hides a lot. The intervention itself can take many forms, called modalities. They can involve small molecules that block a particular molecule, antibodies that deliver toxins to certain molecules, pieces of RNA that block protein design, in-vivo edits that permanently delete bad processes, methods for reprogramming the immune system to recognize a foreign body, and several others. Clinical development then generally proceeds through three phrases, testing various aspects of safety and efficacy in humans.
For the purposes of this post, I'll simplify the whole process into three stages:
- Target discovery: What biology should we modulate?
- Preclinical Design and Translation design: What intervention can modulate it? Does the intervention look safe and effective enough in model systems to justify trying it in humans?
- Clinical development: Does it actually help the intended human population?
Machine learning can matter in all three stages. But the type of ML that matters, and the difficulty of the problem, varies a lot by stage.
Target Discovery
When I talk about target discovery, in essence what we're saying is "do biology research to find a hypothesis of something worth targeting". Historically, a lot of target discovery research happened in academia. Large scale efforts like the Broad Institute's DepMap helped identify what perturbations in cancer cells affected their growth. Researchers used that to identify potential genes that drove cell growth, and hypothesized that blocking those genes would enable anti cancer drugs. Note that these were not experiments on people. They were usually on cancer cell lines that had been grown ex-vivo, or occasionally on patient derived lines.
Other efforts like genome wide association studies (GWAS) attempt to use real human data collected from population scale sequencing efforts like the UK Biobank. The idea is pretty simple — with enough people, you can identify genetic variants associated with disease risk. A GWAS hit might tell you that a region of the genome is associated with a disease. It does not automatically tell you which gene matters, in which cell type, through which pathway, in which patient subset, or how you should intervene therapeutically. This is the fuzzy API problem again. The "target" returned by human genetics is often not a clean therapeutic object. It is a clue that needs to be further validated by physical experiments. So historically, there has not been much deep learning at the core of target discovery. There have been statistical genetics methods, network methods, and deep learning tools for things like gene regulation. But not a unified model that could answer the question we actually care about:
"if I intervene on patient x in cell type y with intervention z, what will happen?".
That problem framing is making the field newly excited about so-called "virtual cell" or "virtual human" models. The idea is roughly: collect lots of data about cell/person states, perturb them in various ways, and measure many readouts — transcriptomics, proteomics, imaging, cell growth, functional phenotypes, clinical data — and train models that learn the relationships among them. Scaling laws from LLMs give a framework for how to think about allocating resources, and some early efforts suggest there are similar scaling laws in these data too. Companies like Tahoe, Noetik, and Recursion are all pursuing some version of this. This is a good direction.
This also turns out to be extremely hard. First, the existing data is sparse and low quality. If you have millions of genetic loci, many possible cell types, many disease states, many interventions, and only hundreds of thousands or even millions of patients, you are still in trouble in terms of the curse of dimensionality. Biobank data is powerful because it captures naturally occurring variation in humans and correlates that to disease outcomes. This is great for finding drugs whose effect mirrors naturally occurring variation. On the flipside, this data cannot capture the outcome of arbitrary drug perturbations. There are not many ethically acceptable ways to perturb a human, wait, and see what happens.
So we fall back on model systems: we use cells, organoids, mice, rats, dogs, non-human primates, and others. But, a cell line does not have an immune system, a vascular system, a liver, a microbiome, or the full context of a human body. An animal has a body, but not a human body. An engineered disease model can be useful, but it may not capture the human disease process we actually care about. We know this is true because drugs that work in model species preclinically regularly fail in human clinical trials.
This creates a sim-to-real gap between the model system and the human. Worse, since we are training machine learning models on this sim data, we are building models of the simulation and trying to get them to transfer to reality. In other words, we have sim^2-to-real gap and no great physics engine.
That is why target discovery is so hard. It is not just that we need better models. We need better data, better perturbation systems, better causal inference, better human-relevant assays, and better ways to close the loop between prediction and experimental validation. Don't get me wrong. I'm excited to see that companies are making serious attempts to solve these problems and develop new ML models for target discovery. Also, historically it wasn't clear that discovering targets could be effectively monetized other than by making drugs yourself against those targets, but companies like Cartography Bio are proving otherwise.
Still, the hard part remains: the "target" object is fuzzy. A model can nominate a gene, pathway, cell state, or biomarker. But the clinically relevant object is a causal, directional, context-specific intervention hypothesis.
Drug Discovery
This is the stage of the process that is most widely discussed. There is obviously enormous promise here. Models like Boltz, Chai, and Nabla can be used to predict structures, generate binders, and reason about protein interactions. Dyno is using machine learning to design AAV capsids, and other companies are designing payloads for genetic medicines with generative models. Some of these are using natural language LLMs while others are taking the lessons for what worked in computer vision and LLMs and designing new model architectures to support bio-specific use-cases (Nabla, Chai, Dyno, etc are all this). That's great.
Now here is the problem: the common ML person view of drug discovery sees this stage as a clean API whose implementation looks something like this:
def drug_design_process(target, known_inhibitors):
new_drug = None
while too_similar(new_drug, known_inhibitors):
new_drug = design_and_optimize(target)
return new_drugThe naive view is that as long as you can run the while loop well, you win. I certainly thought that's how it worked when we started Reverie. It also matches the conventional startup wisdom to focus on your core competency. If you're a machine learning engineer interested in structural biology, just build the best drug design engine. Let someone else find the target. Let someone else run the trial.
Unfortunately, this is not how biology works in practice. For any well-known target — meaning a target with a good paper, credible human genetics, or obvious clinical rationale — there will often be many competitors. Some you know about, some you do not. If you are not first, you need to be meaningfully better. But you usually do not have access to your competitors' full efficacy data, safety data, formulation details, or usually even their structure until much later. On top of that, if you're an American company, there is a high probability you have a competitor in China moving quickly and effectively, who can offer up their drug to a pharma partner for a fraction of what your development costs. They can also generate animal data faster/cheaper than you can, and run a Phase 1 for a fraction of the price of doing it in the US.
So maybe you avoid crowded targets and go after novel biology. That can be the right move. Perhaps you use a target discovery platform company or a proprietary data platform to identify new targets that others have missed. But then the error bars on your confidence for your target explode. No one has validated that modulating the target in a human works. Your disease model, patient subset, biomarker, or modality might be wrong. You can design a beautiful molecule and still create no value because the upstream biological hypothesis was false. In other words, you can do your job perfectly in the algorithm above, and produce something that has zero value.
For companies building in this layer, there is also the challenge of commoditization. I don't doubt that there are companies with superior AI drug design technologies. But the relevant question is whether that superiority is large enough and connected enough to the rest of the drug-development process to get durable returns. Open-source models will improve, and all models are constrained by data. This does not mean AI drug design is overhyped. It means the value is probably highest when the design loop is tightly coupled to proprietary data, fast experimental feedback, differentiated targets, modality-specific expertise, or a clinical strategy that makes the molecule matter. In other words, you may have to abandon the tight API and accept that your process will depend on the other factors as well.
Clinical Trials
And so we arrive at clinical trials. This is the part of the process I would argue has been most neglected by serious machine learning people. It's the area where there are the most obvious tailwinds with LLMs. Essentially all of the problems associated with clinical trials are well suited either to use LLMs out of the box or to use machine learning to develop custom models that are relevant for the domain. Here are some examples.
Patient stratification: Can you predict what subset of patients are going to be responders for a particular drug? This is a hard machine learning problem for similar reasons as target discovery: it's hard to get useful human data. But it might be a better fit for an LLM-driven approach. You could imagine post training a general LLM with large amounts of human EHR data, or giving an intelligent agent access to health records to look for patterns between a wide variety of unstructured notes and indicators of drug effectiveness. The goal would be to reason across messy unstructured records rather than just query a database to train a supervised ML model. Moreover, for many trials, we often know the type of patient we want, but the problem is finding them. An example: a trial might need patients with mutation X, blood pressure levels above Y, that have tried/failed at first/second line treatments, are over 35 years old, and have never had an acute side effect to an mRNA vaccine. Unfortunately, that's not SQL queryable in any database, especially in America's decentralized system. The method to do this before LLMs was having a human manually read EHR entries and identify them. We can now use LLMs to do this. Then, once we identify them, we can have an AI agent pester them to come enroll for a trial. This is not just an ML problem. The system that does this has to exist inside a health system, with clinician trust and incentive alignment.
Trial Operations: There are immense aspects of clinical trials that are slow and inefficient. It is slow to recruit patients (see above), slow to collect and analyze samples, and slow to QC and verify the resultant outputs. A huge amount of this work already happens through large outsourcing organizations and software vendors: CROs, EDC systems, clinical data-management vendors, site networks, and consulting firms. These companies make billions of dollars doing work that often involves basic data management, review, reconciliation, and coordination. These present enormous opportunities to use off-the-shelf models to significantly accelerate and improve the process.
Scaled up Literature Mining: There are enormous amounts of useful biological and clinical information scattered across papers, abstracts, trial registries, regulatory filings, patents, and conference posters. Some of the most interesting drug hypotheses come from connecting evidence across domains that no individual team had time to synthesize. Perhaps there was a drug that failed in one population, and you have good reason to believe that it could be repurposed for a different population due to a biomarker you found in an obscure paper. Previously, you'd have to have an entire team of people scouring academia to find information like this. Today, you could use intelligent research agents to find it. This is often the inspiration behind companies purporting to build an "AI-native Roivant": a company that uses AI agents to mine literature, clinical evidence, competitive landscapes, and external assets, then forms asset-specific companies around the best opportunities.
Monetization: Clinical development is also easier to monetize than many upstream AI-for-bio ideas because the value of time is much more legible. A drug's commercial life is finite, driven by patent limitations and exclusivity rules, among other factors. A lot of that window is consumed by clinical development — usually drug patents are filed right before beginning a clinical trial. This means that their patent clock is ticking while running the trial, and that every day they can save in clinical trials is a day longer their drug profits on the market after approval.
To first order, you can calculate the per day value of time savings as Peak Daily Sales*P(Approval). For most big drugs, this is worth millions of dollars per day. For blockbuster drugs it can be tens of millions of dollars per day. So, if you can prove that you can save time on a trial, pharma companies should be willing to pay very large amounts of money for your service.
So why don't more machine learning people enter this space? My guess is that it feels boring. If you grew up loving physics and chemistry and math/CS like I did, you'd naturally gravitate towards things that look like AlphaFold. It feels really good to encode the triangle inequality in a weight update. Those problems are deeply satisfying as a scientist. Most of the clinical trial work is schlep work. But as the lesson goes, schlep work is often the most lucrative to focus on.
Upshot
So where does that put us? Am I saying that everyone should abandon target discovery and drug design and focus entirely on clinical trials? No obviously not. All of the efforts to work on better target discovery and drug design are great for humanity, and I'm glad they are being funded and pushed forward. I'm sure great companies will be built doing those things. But I do think AI-for-bio founders should be realistic about where their edge lives. The uncomfortable implication is that a lot of AI-for-bio value may accrue less to the team with the highest scoring generative model and more to the team with the best closed-loop system for selecting, testing, financing, and clinically advancing assets.
One version of that company looks like an AI-native Roivant:
- Use agents to mine literature, clinical evidence, trial data, patents, and competitive landscapes.
- Identify underappreciated therapeutic hypotheses.
- Take a trip to Shanghai to license assets that match those hypotheses.
- Create asset-specific companies to push them through clinical inflection points.
- Repeat until one works.
This is roughly what some biotech investors already do, minus the AI-native research layer.
Another version looks like a vertically integrated target-discovery company:
- Come up with a scaled data collection platform to get a unique / novel target hypothesis (hard, but many undertapped methods out there)
- Take an off the shelf model (e.g. Boltz) to design a drug against it.
- Validate quickly through tight experiment feedback loops
- Create the subsidiary with the asset, raise capital to take that drug to the clinic, or sell it off to pharma at Phase 1.
- Repeat.
Both of these company structures make sense to me, but I see them much less often than drug discovery companies that focus on neatly solving their clean API inferface. These structures do demand more from founders – they have to be opinionated and correct about more aspects of the therapeutic stack. But that seems better than being blind to the complexity.
I'd love to hear feedback on this. Reach out anytime if you'd like to talk.

Data centers at sea: Oregon's Panthalassa nets $140M led by Peter Thiel for wave-powered AI
Oregon startup Panthalassa raised $140M from Peter Thiel to build ocean-based data centers powered by wave energy for AI workloads.
Original article
Panthalassa has a technology platform that turns waves into reliable, clean power to power onsite AI computing.

Don't simply bolt on AI. Rethink from the ground up
Building truly AI-native products requires rethinking architecture to let AI handle complexity, not just adding chatbots to existing interfaces.
Deep dive
- The shift from command-based computing (explicit instructions) to intent-based interaction (expressing goals) represents a fundamental change in how users interact with software
- Most current "AI-powered" products simply bolt ChatGPT-like features onto existing designs rather than reimagining the product around AI capabilities
- True AI-native products would use AI to manage internal complexity and abstract away concepts users currently must learn (example: AWS service abstractions)
- This approach reduces the learning burden by letting AI translate user intent into the complex underlying operations
- Implementing this requires rethinking product architecture at multiple layers, not just the user interface
- AI should be embedded in both the interaction layer (how users communicate) and the conceptual layer (what users need to understand)
- Key challenges include maintaining user trust and ensuring AI reliably handles the abstracted complexity
- The distinction matters because bolt-on AI provides convenience while integrated AI fundamentally changes what users need to know and learn
Decoder
- AI-native: Products designed from the ground up with AI as a core architectural component, rather than adding AI features to existing designs
- Intent-based interaction: Users express their goals or desired outcomes rather than specific commands or steps
- Command-based computing: Traditional computing where users must learn and execute specific commands or interface actions
- Conceptual layer: The mental models and concepts users must understand to use a product effectively
Original article
The rise of tools like ChatGPT marks a fundamental shift from command-based computing to intent-based interaction, but most products still use AI as a superficial add-on rather than fully integrating it into their core design. True “AI-native” products would let AI handle internal complexity and abstract concepts (like those in AWS), reducing the learning burden on users—though this requires rethinking product architecture, maintaining user trust, and embedding AI into both the interaction and conceptual layers, not just the interface.

The Backend for AI-native Builders (Website)
InsForge uses AI coding agents to automatically generate production-ready backends from text prompts.
Original article
Go from prompt to a production backend in minutes. With InsForge, your coding agent builds the database, wires up auth, and runs it for you.

Ethereum Devs Lock In Glamsterdam Parameters
Ethereum core developers completed a week-long intensive session in Arctic Norway, finalizing key parameters for the Glamsterdam upgrade that will significantly increase network transaction capacity.
Deep dive
- Over 100 Ethereum core developers convened in Longyearbyen, Svalbard (78 degrees north) for an intensive week-long interop session focused on the Glamsterdam network upgrade
- The team locked in a post-Glamsterdam gas limit floor of 200 million, a significant increase that determines how many transactions Ethereum can process per block
- Developers finalized gas repricing numbers for EIP-8037 and stabilized external block builder implementations
- Ethereum Foundation researcher Tim Beiko characterized the week as compressing roughly a month of asynchronous progress into each day of in-person collaboration
- The Ethereum Foundation sold 10,000 ETH ($23 million) to Bitmine Immersion Technologies in an OTC deal at $2,292 per token, the third such transaction between the parties
- Ether currently trades at $2,377, down more than 50% from its August 2025 peak of $4,946, but up 14% over the past month
- Bitmine, led by Wall Street analyst Tom Lee, continues aggressive accumulation despite sitting on over $6 billion in unrealized losses on its 5 million+ ETH holdings
- The Foundation uses proceeds from token sales to fund ongoing development, research, and grants supporting the Ethereum ecosystem
- Beiko described the interop week as one of the most productive sessions in recent memory for the Ethereum development team
- Higher gas limits allow the network to handle more activity without congestion, strengthening Ethereum's case as backbone infrastructure for global finance
Decoder
- Gas limit: The maximum amount of computational work that can be included in each Ethereum block, which determines how many transactions can be processed
- EIP: Ethereum Improvement Proposal, the formal process for proposing changes to the Ethereum protocol
- Block builder: Software that constructs blocks of transactions to be added to the blockchain, often optimizing for maximum extractable value
- Interop week: An intensive in-person gathering where developers work together to accelerate progress on complex technical implementations
- OTC deal: Over-the-counter transaction conducted directly between parties rather than on public exchanges
Original article
Over 100 Ethereum core contributors gathered in Longyearbyen, Svalbard, at the Soldøgn interop week to advance the Glamsterdam network upgrade, locking in a post-Glamsterdam gas limit floor of 200 million and finalizing gas repricing numbers for EIP-8037. The team also stabilized external block builder implementations, with EF researcher Tim Beiko noting that interop weeks compress roughly a month of asynchronous progress into a single day.
Stablecoin and LATAM Fintech Remittance
Six months of ground research across five Latin American countries reveals that most fintech decks misunderstand the region's remittance market and overestimate stablecoins' role in cross-border payments.
Decoder
- Stablecoin: Cryptocurrency pegged to a stable asset like the US dollar to minimize price volatility
- Corridor: A specific remittance route between two countries or regions
- Digitalization rate: The percentage of financial transactions conducted through digital channels versus cash or traditional methods
Original article
After 6 months on the ground across Brazil, Mexico, Argentina, Colombia, and Peru talking to users, mapping competitors, and stress-testing assumptions against internal P2P, card, and pay data, the author argues most fintech decks are getting LATAM wrong. Key blind spots include not knowing actual corridor sizes, what percentage of users want USD vs. local currency, and why Mexico digitalizes at 25% while Colombia is over 50%. The thread provides a ground-level corrective to the "stablecoins are the killer of cross-border payment" pitch deck thesis and maps both the real obstacles and the genuine opportunity across the region.

Telegram Mini Apps abused for crypto scams, Android malware delivery
A malicious platform called FEMITBOT is exploiting Telegram Mini Apps to run large-scale cryptocurrency scams and distribute Android malware to unsuspecting users.
Decoder
- Telegram Mini Apps: Web applications that run directly inside the Telegram messaging app without requiring installation, providing native-like experiences within the chat interface
Original article
The FEMITBOT platform leverages Telegram Mini Apps to execute large-scale crypto scams and distribute Android malware.

Y Combinator's Stake in OpenAI
The New Yorker quoted Paul Graham on Sam Altman's trustworthiness without disclosing YC's $5 billion OpenAI stake.
Original article
OpenAI was seeded by an offshoot of Y Combinator called YC Research in 2016, when Altman was running YC. Y Combinator owns about 0.6% of OpenAI. At OpenAI's current valuation, that stake is worth over $5 billion.
Consumer AI's ARPU problem
Consumer AI products like ChatGPT struggle with monetization despite viral growth because users cap out at $20/month subscriptions while enterprise AI revenue expands through higher per-user spending.
Decoder
- ARPU: Average Revenue Per User, a key business metric measuring how much revenue each customer generates
- Retention curve: A graph showing what percentage of users continue using a product over time; ChatGPT's "smile" curve indicated high sustained engagement
- Gross vs. net retention: Gross retention tracks whether users stay; net retention includes revenue expansion from existing users spending more over time
Original article

How LLMs Distort Our Written Language
Researchers from UC Berkeley, Google DeepMind, and other institutions investigate how large language models are subtly changing written language with potential effects on cultural institutions.
Original article
How LLMs Distort Our Written Language
Amazon Built a Massive Supply Chain for Itself. Now It's for Hire
Amazon is opening its logistics infrastructure as a service, aiming to replicate AWS's success in the $1.3 trillion third-party logistics market.
Original article
Amazon has launched Amazon Supply Chain Services, a centralized place for companies to hire Amazon for services such as fulfillment, ocean and air shipping, and truck transportation. The offering puts Amazon in competition with transportation and warehousing giants such as DSV and DHL. The global market for third-party logistics is estimated to be more than $1.3 trillion. The move is a bet that Amazon can do for logistics what Amazon Web Services did for cloud computing.
Humanoid Robot Actuators: The Complete Engineering Guide
A comprehensive engineering reference explains why humanoid robots universally converge on the same actuator designs despite different manufacturers, revealing the unforgiving physics that shape every walking machine.
Deep dive
- Humanoid robots take approximately 5,000 steps per hour, generating one million impact cycles per month with forces of 2-3× body weight—a fatigue timeline that compresses years of industrial wear into weeks and explains why most actuators fail
- The mass penalty spiral is exponential, not linear: adding 200g to an ankle actuator forces the knee to grow by 350g, the hip by 600g, and the battery by 150g, resulting in a 1.3kg total system penalty from a single component decision
- Reflected inertia scales with the square of gear ratio (N²), meaning a 100:1 industrial gearbox makes the motor feel 10,000× heavier to external forces, destroying backdrivability and making the robot dangerous during impacts
- The industry has converged on a split architecture: rotary actuators with strain wave gearing (harmonic drives) for spinning joints like shoulders and wrists, and linear actuators with planetary roller screws for impact-absorbing joints like knees and ankles
- Roller screws survive where ball screws fail because line contact distributes shock loads across 10-15× more surface area than point contact, preventing the brinelling (permanent denting) that destroys ball screw raceways after repeated impacts
- The thermal cliff separates peak torque (marketing specs) from continuous torque (engineering reality): typical air-cooled actuators sustain only 25-30% of peak torque indefinitely, forcing robots to either overheat during work or be grossly oversized
- At zero RPM (holding a static pose), motors generate maximum heat while doing zero mechanical work via I²R losses, and copper resistance increases 0.4% per degree Celsius, creating a thermal runaway feedback loop
- Position control (industrial standard) commands "move to X regardless of force" and will break human arms to reach targets; torque control with Field Oriented Control running at 20,000 Hz enables the force-based impedance control essential for safe interaction
- Model Predictive Control runs physics simulations 10-20 timesteps into the future hundreds of times per second, allowing robots to correct for falls before they begin rather than reacting after the center of mass has passed the recovery point
- Series Elastic Actuators place a physical spring between motor and joint, providing free force sensing via deflection measurement and storing/returning impact energy like an Achilles tendon, but are harder to simulate for AI training
- Quasi-Direct Drive actuators use low gear ratios (6:1 to 30:1) with large pancake motors to maintain backdrivability and compliance, enabling agile robots like Unitree H1 but sacrificing payload capacity and thermal efficiency
- High-reduction actuators (50:1 to 160:1) like those in Tesla Optimus provide massive strength in compact packages for lifting tasks, but require dedicated torque sensors since friction masks force feedback
- Industrial actuators fail in humanoids due to the "glass jaw" problem: designed for stiffness and precision, they have zero shock absorption capacity and experience shear failure when subjected to the continuous impact loading inherent in walking
- The stiction (static friction) in high-ratio industrial gearboxes creates a friction wall requiring 1-2 Nm before any movement occurs, making smooth balance control impossible as corrections accumulate then release in violent lurches
- Competitive humanoid actuators require >15 Nm/kg specific torque, <1 Nm backdrive torque, >50 Hz control bandwidth, and survival of >10 million impact cycles at rated dynamic load—specifications that eliminate virtually all industrial motors from consideration
Decoder
- Actuator: A mechanical device that converts energy into motion; in robotics, typically an electric motor combined with a transmission to move joints
- Strain Wave Gear (Harmonic Drive): A compact gearbox using a flexible metal cup that deforms elliptically to achieve high gear ratios (50:1 to 100:1) with zero backlash in a flat "hockey puck" form factor
- Planetary Roller Screw: A linear actuator mechanism using threaded rollers orbiting inside a nut to convert rotation into extension/retraction with exceptional shock load capacity via line contact geometry
- Backdrivability: The ability of a motor/gearbox to be driven backward by external forces—essential for compliance and safety; measured as the torque required to move the output when unpowered
- Reflected Inertia: The effective mass that external forces "feel" when trying to accelerate a geared motor, calculated as motor inertia × (gear ratio)²—the primary reason high gear ratios are dangerous
- Specific Torque: Performance metric for rotary actuators measured as Nm/kg (torque per unit mass); >15 Nm/kg is the threshold for viable humanoid leg actuators
- Series Elastic Actuator (SEA): An actuator with a physical spring between the motor and joint output, providing shock absorption and enabling force measurement through spring deflection
- Quasi-Direct Drive (QDD): Low gear ratio actuators (6:1 to 30:1) paired with large motors, prioritizing backdrivability and dynamic response over torque density—used in agile robots like MIT Cheetah
- Field Oriented Control (FOC): Advanced motor control technique that decomposes chaotic AC currents into controllable vectors (d-axis and q-axis), enabling precise torque regulation at 20+ kHz update rates
- Impedance Control: Control strategy that creates virtual springs and dampers in software by commanding torque based on position/velocity error, allowing stiffness to be adjusted in real-time
- Model Predictive Control (MPC): Control algorithm that continuously simulates future robot states to optimize current control actions, enabling proactive balance rather than reactive stumble correction
- Brinelling: Permanent denting of bearing raceways caused by excessive Hertzian contact stress during shock loads—the failure mode that destroys ball screws in walking applications
- Cost of Transport (CoT): Efficiency metric calculated as energy / (weight × distance); wheeled vehicles achieve 0.01-0.05, while bipedal robots typically score 0.2-0.5 (10-50× worse)
- Thermal Cliff: The stark divide between peak torque (sustainable for seconds) and continuous torque (sustainable indefinitely); typical air-cooled motors sustain only 25-30% of peak continuously
- Stiction: Static friction that must be overcome to initiate movement from rest; high-ratio gearboxes requiring 1-2 Nm of stiction prevent smooth low-force control essential for balance
Original article
Every step that humanoid robots take results in a shock through the leg actuators - this means roughly one million impacts for every month of operation.

iOS 27 Will Let You Create Custom Wallet Passes
iOS 27 will allow users to create custom digital passes in the Wallet app by scanning QR codes or manually entering information for tickets, memberships, and gift cards that lack official Wallet support.
Original article
A new 'Create a Pass' option will let users generate digital passes from scans of things like movie tickets, concert passes, and gym membership cards.

CarPlay Ultra coming to these cars, according to Apple
Apple's next-generation CarPlay has launched only with Aston Martin so far, while several major automaker partners have backed out of earlier commitments.
Decoder
- CarPlay Ultra: Apple's next-generation in-car system that provides deeper integration with vehicle functions and displays, beyond current CarPlay's limited entertainment and navigation interface
Original article
Apple's Apple CarPlay Ultra has so far launched only with Aston Martin, while its broader rollout remains unclear despite earlier promises. Although several brands—including Hyundai, Kia, Porsche, and Ford—are still listed as partners (with Hyundai possibly launching support in an upcoming model), others like Mercedes-Benz, Audi, Volvo, Polestar, and Renault have backed out, and some partners have expressed lukewarm interest, leaving the platform's future adoption uncertain.

Did Apple inspire the new Xbox logo?
Microsoft's Xbox unveiled a glossy, translucent logo reminiscent of Apple's Liquid Glass design language that Microsoft previously mocked, signaling a broader industry retreat from flat minimalism toward skeuomorphic aesthetics.
Decoder
- Liquid Glass: Apple's design language featuring glossy, translucent, reflective surfaces and textures
- Skeuomorphism: Design approach using realistic textures and 3D effects to mimic physical objects
- Frutiger Aero: Early-2000s Windows design aesthetic characterized by glossy, translucent elements and bright colors
- Flat design: Minimalist visual style using simple shapes, solid colors, and no depth effects
Original article
Microsoft's Xbox has unveiled a new glossy, translucent logo that leans heavily into early-2000s nostalgia, closely resembling Liquid Glass—a design approach it previously mocked when introduced by Apple. While some see it as a throwback to classic Xbox aesthetics, the timing suggests broader influence, reinforcing a wider industry shift led by companies like Microsoft and Apple away from flat minimalism toward skeuomorphic, textured, and more expressive visual styles.

Spotify Introduces Verified Artist Badges to Help Distinguish Humans from AI
Spotify launches verification badges to distinguish human artists from AI-generated content as platforms struggle with AI music flooding their catalogs.
Deep dive
- Over 99% of actively searched artists will receive verification badges at launch, with rollout continuing on an ongoing basis for others
- Verification criteria prioritize sustained listener engagement rather than one-time viral spikes, filtering out profiles designed for passive listening
- Most verified artists at launch are independent, representing diverse genres, career stages, and geographic regions
- Badges will appear on artist profiles and in search results, featuring "Verified by Spotify" text with a green checkmark
- Spotify is also beta testing a new profile section across all artist pages highlighting career milestones, release activity, and touring to show authentic activity even without verification
- The initiative follows last month's beta launch of "Artist Profile Protection" allowing artists to review releases before they go live on their profiles
- Sony Music recently requested removal of over 135,000 AI-generated songs impersonating its artists from streaming services
- Rival platform Deezer reports AI-generated tracks now account for 44% of all new music uploaded daily, highlighting the scale of the problem
- The absence of a badge doesn't mean an artist won't receive one later, as Spotify says verification will roll out gradually given the vast number of profiles
Decoder
- Functional music: Algorithm-optimized tracks designed for passive or background listening, such as ambient sounds for focus or sleep playlists, rather than music meant for active listening or artistic expression
- AI slop: Low-quality AI-generated content that floods platforms, often created at scale with minimal human oversight or artistic intent
- AI-persona artists: Entirely AI-generated musical acts with fabricated identities, as opposed to human artists who may use AI tools in their creative process
Original article
As AI-generated artists and tracks flood music streaming platforms, Spotify is rolling out a new "Verified by Spotify" badge to help listeners more easily identify authentic human artists.
To receive the badge, artists must meet certain criteria. Spotify looks for an identifiable artist presence both on and off platform, like concert dates, merch, and linked social accounts on their artist profile. Profiles that primarily represent AI-generated music or AI-persona artists are not eligible for verification.
Additionally, artists must have consistent listener activity and engagement over time. Spotify is focusing on artist profiles that people are actively seeking out over a sustained period of time, rather than those that are experiencing one-time spikes in engagement.
At launch, more than 99% of artists that listeners actively search for will be verified. Most are independent, representing a broad mix of genres, career stages, and regions, Spotify says.
Users will start to see the new badges appear on artist profiles and next to artist names in search results over the coming weeks. The badges will feature "Verified by Spotify" text alongside a green checkmark.

Given the vast number of profiles on the platform, Spotify says verification will roll out on an ongoing basis, and that the absence of a badge does not mean a profile will not receive one in the future.
Spotify is prioritizing artists with active fan interest and notable contributions to music culture, rather than so-called "functional music" creators — think algorithm-optimized background or focus playlists — whose content is designed for passive or background listening.
"We've designed this new verification program thoughtfully with listeners and artists in mind, and we'll continue to evolve this program over time," Spotify wrote in a blog post. "Our goal is to make it easier for you to trust and understand the human artistry behind the music you listen to on Spotify, and develop long-term, meaningful connections with the artists and music you love."
The platform is also launching a new profile section in beta across all artist profiles that will highlight career milestones, release activity, and touring activity. Spotify says this section will give users a quick way to see an artist's authentic activity even if they haven't yet met the criteria for a verification badge.
These updates mark Spotify's latest efforts to address the rise of low-quality AI-generated content (AI slop) and impersonators on its platform. Last month, the company started beta testing an "Artist Profile Protection" feature that allows artists to review releases before they go live on their profiles to give them more control over which tracks are associated with their name.
Spotify launched the feature a few weeks after Sony Music said that it had requested the removal of more than 135,000 AI-generated songs impersonating its artists on streaming services.
Although Spotify hasn't shared specifics on the number of AI tracks being added to its platform, rival streaming service Deezer announced last week that AI-generated tracks now represent 44% of all new music uploaded to its platform daily.

Your Ego is Hurting Your Career
Designers hurt their careers by expecting to be creative heroes in their organizations when in reality most specialist roles trade value for money with limited autonomy and authority.
Original article
Designers fall into an "ego trap" by believing they should be creative heroes in their organizations, when in reality, most jobs involve trading value for money with limited autonomy. Many businesses function without designers, and good design is often less important to companies than keeping costs low. Designers need to accept their role as specialists rather than expecting the authority that comes with more general organizational responsibility.

Plan, Script, Edit, and Publish Videos in One Place (Website)
Jupitrr VideoOS combines video planning, scripting, editing, and publishing into a single unified platform.
Original article
Jupitrr VideoOS is an all-in-one video platform that allows users to plan, script, edit, and publish videos from a single interface.

Mac. (Website)
An interactive data visualization chronicles 43 years and 154 Mac models, tracking evolution from $9,995 beige boxes to today's $599 ultraportable.
Original article
A visual breakdown of 154 Macs in 43 years.
Five Logo Design Trends for 2026
Logo design is shifting from static images to dynamic, adaptive identity systems that change based on context and require new implementation techniques.
Decoder
- AEO: AI Engine Optimization - designing logos to be easily recognized and parsed by AI systems, similar to how SEO optimizes for search engines
- Generative logos: Brand marks that dynamically change appearance based on context, time, user interaction, or other variables rather than remaining static
- Neo-brutalist: A design aesthetic emphasizing raw, unpolished, deliberately crude visual elements that reject mainstream polish
- Variable fonts: OpenType fonts with adjustable design axes (weight, width, slant) that enable smooth animation and responsive typography
- Tactile minimalism: Minimal design approaches that incorporate subtle 3D effects or depth to add physical texture and dimension
Original article
Five key trends are driving the shift from static marks to living identity systems: fluid, generative logos; hyper-legible, AEO-centric marks; neo-brutalist "lo-fi" aesthetics; tactile minimalism with 3D depth; and kinetic, variable-font typography.

KelpDAO Funds on Arbitrum Caught Between Recovery Vote and DPRK
Frozen funds from a $292M North Korean hack of KelpDAO are contested between terrorism victims seeking to seize DPRK assets and the original hack victims, creating the first direct clash between US courts and DAO governance.
Deep dive
- The Lazarus Group, a North Korean state-linked hacking organization, exploited a LayerZero cross-chain bridge vulnerability to steal $292 million from KelpDAO in April
- Arbitrum's Security Council successfully froze $71 million of the stolen ETH before attackers could move it off-chain
- Major DeFi protocols including Aave, LayerZero, EtherFi, and Compound collaborated on a governance proposal to return frozen funds to a victim compensation multisig
- The Arbitrum DAO vote is passing with strong community support for victim restitution
- Han Kim and other families of DPRK terrorism victims, holding $877 million in unpaid US court judgments against North Korea from attacks years ago, obtained a restraining order from a New York court
- These creditors argue the frozen ETH constitutes seizable North Korean state property that should satisfy their decade-old judgments
- KelpDAO victims counter that stolen funds never legally belonged to North Korea and cannot be seized to satisfy unrelated judgments
- Multisig signers now face a dilemma: executing the DAO vote while the restraining order is active exposes them to personal legal liability
- This case represents the first instance where competing US court claims directly conflict with DAO incident response governance
- The resolution will set critical precedent for how decentralized organizations handle legal intervention during future security breaches
- The case highlights fundamental tension between code-based governance and traditional legal authority in the crypto ecosystem
- It raises complex questions about property rights for stolen assets and whether thieves can ever establish legal ownership sufficient for third-party seizure
Decoder
- DPRK: Democratic People's Republic of Korea (North Korea), whose state-linked hacking groups have stolen billions in cryptocurrency
- DAO: Decentralized Autonomous Organization, a blockchain-based entity governed by token holder votes rather than traditional corporate structures
- LayerZero: A cross-chain messaging protocol that enables communication and asset transfers between different blockchains
- Multisig: Multi-signature wallet requiring multiple parties to approve transactions, commonly used to secure DAO treasury funds
- Lazarus Group: North Korean state-sponsored hacking organization responsible for numerous cryptocurrency thefts including this KelpDAO attack
- Security Council: A small group with emergency powers in some DAOs to freeze funds or pause protocols in response to security threats
- KelpDAO: A decentralized finance protocol that was the victim of the $292 million hack
- Arbitrum: A layer-2 scaling solution for Ethereum that processes transactions more efficiently than the main Ethereum chain
Original article
Lazarus Group exploited a LayerZero bridge bug to steal $292M from KelpDAO in April, and after Arbitrum's Security Council froze $71M of the stolen ETH onchain, a New York court issued a restraining order on behalf of Han Kim and other DPRK terrorism victim families holding a combined $877M in unpaid US judgments against North Korea. Those creditors argue the frozen ETH constitutes seizable DPRK property, while the opposing position holds that North Korea never owned the funds and that KelpDAO hack victims are the rightful owners. A governance proposal backed by Aave, LayerZero, EtherFi, and Compound to release the ETH to a victim compensation multisig is passing the Arbitrum DAO vote, but multisig signers who transfer while the restraining order is active face personal legal liability. This is the first direct conflict between competing US court claims and DAO incident response governance, and the resolution will set precedent for how on-chain entities handle legal pressure during future hacks.
Ethereum's Proposed Reward Curve Change
Ethereum researchers propose capping staking rewards at 67 million ETH to reduce inflation and counter Lido's growing dominance.
Deep dive
- Ethereum currently issues ~2,700 ETH daily to validators while only burning ~90 ETH via EIP-1559, creating significant net inflation
- The proposal replaces the uncapped square-root issuance formula with a dampened curve using factor 1 + D/k where k ≈ 67 million ETH
- Staking rewards would peak when 67 million ETH is staked, then decline as more ETH is staked beyond that threshold
- Researcher Anders Elowsson estimates two-thirds of the issuance cut removes deadweight costs (hardware, risk, taxes, opportunity costs) that validators face
- The remaining one-third effectively redistributes value from stakers back to all ETH holders through reduced inflation
- Lido's Dima Gusakov claims the change would effectively kill liquid staking tokens (LSTs) by making staking less attractive
- The proposal's supporters argue Lido's ~30% share of all staked ETH represents the real systemic risk to Ethereum
- StETH's growth trajectory could potentially displace ETH as Ethereum's base monetary asset if left unchecked
- The debate highlights tension between maximizing staking participation and maintaining ETH's monetary premium
Decoder
- LST (Liquid Staking Token): A tradeable token representing staked ETH, allowing users to earn staking rewards while maintaining liquidity
- stETH: Lido's liquid staking token that represents staked ETH and can be used in DeFi protocols
- EIP-1559: Ethereum upgrade that burns a portion of transaction fees, reducing ETH supply
- Issuance schedule: The formula determining how much new ETH is created and distributed to validators as staking rewards
- Deadweight costs: Economic inefficiencies and expenses (hardware, risk, taxes) that don't create productive value
- Base monetary asset: The fundamental unit of account and store of value within the Ethereum ecosystem
Original article
Ethereum's proposed staking reward curve change, co-authored by EF researchers Anders Elowsson, Ansgar Dietrichs, and Caspar Schwarz-Schilling, replaces the uncapped square-root issuance schedule with a dampened curve (factor: 1 + D/k, k = ~67M ETH) that peaks at that staking level and declines beyond, reducing daily validator issuance from the current ~2,700 ETH against only ~90 ETH burned via EIP-1559. Elowsson estimates that two-thirds of the issuance reduction eliminates deadweight costs accruing to validators (hardware, risk, taxes, and opportunity cost), while one-third redistributes surplus from stakers to all ETH holders. Lido's Dima Gusakov argues the change kills LSTs, but the article counters that Lido's ~30% share of staked ETH is the primary systemic risk, with stETH's growth trajectory threatening to displace ETH as Ethereum's base monetary asset.
Stripe Is Trying to Make Crypto Disappear
Stripe has built an end-to-end stablecoin payment infrastructure through strategic acquisitions and a new blockchain, positioning to abstract crypto complexity away from merchants and consumers.
Deep dive
- Stripe's acquisitions create vertical integration: Bridge provides banking infrastructure and stablecoin hosting, Privy brings 110M programmable wallets, and Valora adds consumer crypto experience
- Bridge holds a conditional OCC national trust bank charter, giving Stripe regulated banking capabilities to issue and host stablecoins for third parties including Phantom, Klarna, Hyperliquid, and MetaMask
- Tempo blockchain launched in March 2026 as a permissioned EVM Layer 1 with a $5B Series A valuation, using named financial institution validators rather than public permissionless consensus
- Bridge's Open Issuance platform shares majority of reserve yield with stablecoin issuers, creating economic incentives for platforms to use Stripe's infrastructure
- Stripe's Link wallet alone targets 250M consumers, combined with Privy's wallets reaching 360M total users sitting atop $1.9T in 2025 payment volume
- Circle independently developed Arc with the same permissioned-L1-with-named-validators architecture, suggesting industry convergence on this regulated blockchain model
- The GENIUS Act legislation appears to push Meta toward partnering with Stripe for stablecoin issuance rather than building independently
- OCC's March 2026 proposed regulatory rule protects Bridge's non-affiliate yield-sharing business model while threatening Coinbase's USDC rewards program, creating competitive advantage through regulation
- The strategy makes crypto infrastructure invisible to end users and merchants while Stripe captures value across the entire stablecoin payment stack
- This represents a fundamental shift from permissionless crypto ethos toward regulated, enterprise-controlled blockchain infrastructure optimized for payments
Decoder
- Stablecoin: cryptocurrency pegged to stable assets like the US dollar, used for payments without price volatility
- EVM L1: Ethereum Virtual Machine Layer 1, a blockchain compatible with Ethereum smart contracts that operates as an independent network
- Permissioned blockchain: a blockchain where validators are pre-approved entities (like banks) rather than open participation
- OCC: Office of the Comptroller of the Currency, the US federal banking regulator that charters national banks
- USDC: USD Coin, a major stablecoin issued by Circle worth $1 per token
- Reserve yield: interest earned on assets backing stablecoins (typically US Treasuries or bank deposits)
- GENIUS Act: proposed legislation affecting how tech companies can issue and operate stablecoins
Original article
Stripe has assembled a full stablecoin payments stack through three acquisitions – Bridge, Privy, and Valora – then co-founded Tempo, a permissioned EVM L1 that reached mainnet in March at a $5B Series A valuation. Bridge holds a conditional OCC national trust bank charter and runs an Open Issuance platform hosting stablecoins for Phantom, Klarna, Hyperliquid, and MetaMask while sharing majority reserve yield with issuers; Privy supports 110M programmable wallets; and Stripe's Link wallet targets 250M consumers, all sitting atop $1.9T in 2025 payment volume. Circle's Arc independently arrived at the same permissioned-L1-with-named-FI-validators design, the GENIUS Act pushes Meta toward Stripe as a stablecoin issuance partner, and OCC's March 2026 proposed rule protects Bridge's non-affiliate yield-sharing model while threatening Coinbase's USDC rewards program.

What Does an Onchain Economy for a Billion People Look Like?
Base's growth director describes what blockchain infrastructure could enable at scale: instant global payments, borderless fundraising, automated settlements, and permissionless work.
Decoder
- USDC: USD Coin, a stablecoin pegged to the US dollar
- Onchain: Recorded directly on a blockchain rather than traditional databases
- SPV: Special Purpose Vehicle, a legal entity created for specific transactions like fundraising
- Base: Coinbase's Ethereum layer-2 blockchain for faster, cheaper transactions
- Correspondent bank: Intermediary bank used for international money transfers
Original article
Xen (Base Director of Growth) paints the vision: a freelancer in Lagos paid in USDC that clears in two seconds with no correspondent bank; a São Paulo startup raising onchain capital from Singapore and Berlin with no SPV or six-month legal process; AI agents settling supply chain invoices automatically because the payment and contract layers are the same thing; a teenager in Manila earning money building on a protocol where nobody asks where she went to school. The thread frames the onchain economy as fundamentally about increasing innovation, creativity, and freedom through open financial access.

Brazil's Central Bank Bans Stablecoin-Backed FX Flows Inside eFX Rail
Brazil's central bank banned stablecoins as backend settlement infrastructure within regulated cross-border payment rails, forcing fintech companies to restructure how they process international transfers.
Deep dive
- Resolution 561 requires all payments between eFX providers and foreign counterparties to settle through traditional foreign exchange operations or non-resident real-denominated accounts in Brazil, with virtual assets explicitly prohibited
- The ban applies to all entities operating under the eFX framework including banks, payment institutions, e-money issuers, securities brokers, and FX brokers—if you touch regulated cross-border rails, crypto is out of the settlement path
- Companies like Wise, Nomad (which uses Ripple network), and BrazaBank (which built a real-backed stablecoin on XRP Ledger) are directly affected and must completely restructure their models
- The regulation does not touch buying, selling, or holding crypto, transferring between wallets, or the VASP licensing framework under Resolution 521 that went live in February—exchanges, wallets, non-custodial infrastructure, and yield products remain unaffected
- October 1, 2026 is when the ban takes effect; October 30, 2026 is when eFX providers must update registrations and VASPs must be fully compliant; May 31, 2027 is when firms without authorization must apply for payment institution status or face a 30-day shutdown window
- New compliance requirements include segregated client accounts, monthly reporting to the central bank, enhanced KYC, and 10-year data retention for affected entities
- A technical note to congress warns that stablecoins issued outside central bank supervision could face a full ban or strict conditions in the domestic market under pending bill PL 4308/2024
- Real-denominated stablecoins without central bank oversight are viewed as threats to monetary sovereignty, while foreign-currency stablecoins raise concerns about jurisdiction and capital flow fragmentation
- Affected companies have three options: restructure settlement to use traditional FX rails, apply for central bank authorization as a payment institution before May 2027, or separate their businesses to offer crypto trading under VASP license while running compliant cross-border payments separately
- The regulation targets what was effectively a regulatory arbitrage play where the user experience looked like traditional money transfer but the backend was using cheaper blockchain settlement to undercut traditional banking infrastructure costs
Decoder
- eFX rail: Electronic foreign exchange system—the regulated infrastructure that financial institutions use to process cross-border currency conversions and international payments
- VASP: Virtual Asset Service Provider—regulated entities like crypto exchanges and wallet providers that custody or facilitate trading of cryptocurrencies
- Correspondent banking: Traditional system where banks maintain accounts with foreign banks to facilitate international transfers, often slower and more expensive than blockchain alternatives
- Resolution 521: Brazil's VASP licensing framework that regulates crypto exchanges and wallet providers, separate from payment institution regulations
- Monetary sovereignty: A government's exclusive control over its currency supply and payment systems, which stablecoins can potentially undermine by creating parallel payment rails
Original article
Brazil's central bank published Resolution No. 561 on April 30, effectively making it illegal for fintechs and neobanks to quietly convert reais to USDT on the backend and settle payments via blockchain within the eFX rail (the exact flow that many were using for cheaper, faster cross-border settlement without correspondent banks). The ban takes effect on October 1 and doesn't outlaw crypto broadly, but specifically targets the use of stablecoins as invisible backend plumbing inside regulated payment corridors. It's a significant regulatory move in Latin America's largest economy and will force stablecoin-native payment companies to either restructure their flows or operate outside the eFX system.

Binance CEO Richard Teng Frames Crypto's TAM
Binance CEO Richard Teng outlined crypto's total addressable market, comparing current crypto exchanges at $55B to massive traditional sectors like financial services at $36T.
Original article
Crypto's total addressable market includes financial services at ~$36T, payments at ~$788B, and social at ~$208B.
Elon Musk Megatrial Kicks Off Second Week With Scrutiny of OpenAI Exec's Finances
The Elon Musk versus OpenAI trial continued with OpenAI president Greg Brockman testifying about settlement talks where Musk threatened reputational damage.
Original article
OpenAI president Greg Brockman took the stand on Monday. Two days before the trial, Elon Musk had messaged Brockman to gauge his interest in settling the case. Brockman suggested that both sides drop their claims, but Musk responded by saying that Brockman and Sam Altman would be the most hated men in America by the end of the week. Musk's lawyers are attempting to paint Brockman as motivated by money at the expense of OpenAI's nonprofit mission.
The Roomba Guy's Second Act: A Robot You'll Want to Snuggle
Colin Angle, former CEO of the company behind Roomba, has unveiled an emotionally intelligent companion robot designed by ex-Disney Imagineers to respond to human emotions and body language.
Original article
Familiar Machines & Magic, a startup headed by Colin Angle, the former CEO of the company that invented the Roomba, has unveiled a robot designed by former Disney Imagineers to be cute and appealing. The Familiar is an emotionally intelligent robot trained to respond appropriately to tone of voice, body language, and overall vibe. The company will market the robot to people who want to monitor their loved ones, and it is also keen to sell Familiars to people who would like to support their own well-being. The robot is still in an early prototype phase, so there is no information on pricing or availability.
GameStop Offers to Buy eBay for $56 Billion
GameStop, valued at $12 billion, has made an unsolicited $56 billion offer to acquire eBay, despite having only $29 billion in identified funding sources.
Original article
GameStop has made an unsolicited offer to buy eBay for $56 billion, a roughly 20% premium to the company's stock closing price on Friday. GameStop is a much smaller company than eBay and is currently valued at around $12 billion. The company has around $9 billion in cash and a commitment letter from TD Bank to provide up to $20 billion in debt financing to help make the deal possible, but it is unknown how the company will come up with the rest of the money.

Saint-Urbain builds Gap Tooth Soda around imperfection as a principle
A botanical soda brand builds its identity around imperfection as a design principle, pairing strict structural consistency with deliberately hand-drawn wobble.
Deep dive
- The founder's personal gap tooth (shared by roughly a quarter of the global population) inspired the brand concept, which expanded into imperfection as a broader design principle
- A strict structural system—locked wordmark position, can architecture, and hierarchy—prevents the hand-drawn elements from becoming visual noise
- The custom wordmark appears hand-drawn with imperfect baseline alignment and wobbly terminals, but earlier versions with exaggerated letter-spacing were rejected for tipping into visual pun territory
- Agipo typeface in Bold and Regular handles clarity across cans and campaigns while the wordmark carries warmth
- A hand-drawn character system with consistent line weight and simple features can substitute for nouns in sentences on shipping boxes, testing whether characters are confident enough to read instantly
- Three launch flavors (Cherry, Yuzu, Peach) share the same cream background and structure, differentiated only by fruit illustration and color palette
- The "gap" surfaces subtly in spacing and composition, not as missing letters or engineered voids—treated as a principle rather than a graphic device
- The system passes a scalability test: new flavors, formats, or campaigns can plug in without redesigning the core structure
- Saint-Urbain rejected a more abstract, designer-led direction with large color blocks creating visual gaps, agreeing with the client that fruit illustrations were the right call
- The design intentionally maintains imperfection (wobbly wordmark, plain character noses, loose illustrations) even as the brand scales, refusing conventional polish
Decoder
- Saint-Urbain: Independent strategy and design studio founded in Montreal, now based in New York
- Agipo: Typeface by Radim Pesko used for body copy, flavor descriptors, and campaign text
Original article
The Gap Tooth brand pairs a strict structural system (consistent layout, hierarchy, and typography) with deliberately imperfect, hand-drawn elements—like its wobbly wordmark, simple characters, and irregular fruit illustrations—to create personality without losing clarity. By treating “the gap” as a subtle guiding principle rather than an obvious visual gimmick, the design stays flexible and scalable across flavors and formats while prioritizing brand recognition over individual variations.

Classical Paintings Meet Modern Surrealism: The Digital Collage World of Chema Méndez
Spanish digital artist Chema Méndez creates surreal collages by blending classical paintings with modern photography, 3D renders, and AI-generated elements.
Original article
Spanish artist Chema Méndez creates digital collages that blend classical paintings with modern photography, 3D renders, AI, and personal sketches.

Tether Posts $1.04B Q1 Profit, Reaches Record $8.23B Reserve Buffer
Tether, issuer of the largest stablecoin USDT, reported $1.04 billion in Q1 2026 profit and now holds a record $8.23 billion excess reserve buffer backed by US Treasuries, gold, and bitcoin.
Decoder
- Stablecoin: A cryptocurrency pegged to a stable asset like the US dollar, designed to maintain a consistent value rather than fluctuate like bitcoin
- Excess reserves: The buffer amount by which Tether's assets exceed its liabilities (USDT tokens in circulation), providing a safety margin
- Attestation: A point-in-time verification of financial figures by an accounting firm, less rigorous than a full audit with ongoing controls testing
- USDT: Tether's dollar-pegged token, the third-largest cryptocurrency by market cap
Original article
Tether's Q1 2026 attestation reported $1.04 billion in net profit and a record $8.23 billion excess reserve buffer, a slower pace than the $10 billion-plus annual profit Tether posted in 2025. Reserve composition as of March 31 included $141 billion in US Treasury bills, roughly $20 billion in physical gold, and approximately $7 billion in bitcoin, backing $183 billion in USDT liabilities. BDO's report is a point-in-time attestation, not a full financial audit.

Polygon: Visa Global Settlement, Modern Treasury Rail Integration, etc.
Visa, Meta, and Modern Treasury all integrated Polygon for stablecoin settlements and payments, marking significant mainstream adoption of blockchain payment rails.
Decoder
- Stablecoin: Cryptocurrency pegged to stable assets like the US dollar (e.g., USDC) to avoid price volatility
- Payment rail: Infrastructure that enables transfer of money between parties, like card networks or blockchain networks
- Crosschain bridging: Technology enabling transfer of assets and data between different blockchain networks
Original article
Visa added Polygon to its global stablecoin settlement program.

Crypto VC Funding Hit Two-Year Low in April
Crypto VC funding plummeted 74% in April to a two-year low, suggesting a significant cooling in blockchain startup investment.
Original article
Crypto VC funding fell 74% month-over-month to $659M across 63 rounds in April.