Devoured - May 06, 2026
OpenAI shipped GPT-5.5 Instant as the new ChatGPT default with better accuracy and fewer hallucinations, while Subquadratic debuted a 12-million-token context window that outperforms GPT-5.5 on retrieval benchmarks. Apple announced that iOS 27 will let users swap in third-party AI models across system features, and Figma's MCP server now lets AI agents read codebases and write editable frames directly on the canvas.

OpenAI made GPT-5.5 Instant the new ChatGPT default, cutting hallucinations by 52.5% in medical, legal, and financial prompts compared to its predecessor GPT-5.3 Instant.
Original article
The new Instant model is designed to produce clearer, shorter, and more accurate answers than previous models.

Subquadratic launched a 12-million-token context window model that beats GPT-5.5 on retrieval benchmarks, but Magic.dev raised $500M on similar promises in 2024 and still hasn't shipped publicly.
Deep dive
- Subquadratic claims 12M-token window with 83% on MRCR v2 (vs GPT-5.5's 74%), 82.4% on SWE-bench (vs Anthropic's 81.4%), and 92.1% needle-in-a-haystack at 12M tokens where no frontier model operates
- Core problem: standard transformer attention scales O(n²)—doubling context quadruples compute because every token compares with every other token, capping frontier models around 1-2M tokens
- Subquadratic Selective Attention (SSA) claims linear scaling with content-dependent token selection that doesn't itself go quadratic, running 52× faster than dense attention at 1M tokens
- Previous attempts all traded capabilities: Longformer (fixed windows fail on distant info), Mamba (lossy state compression), hybrids (still have O(n²) layers), DeepSeek (selection step is quadratic)
- Caveats: each model run once due to cost, company's model "way smaller than the big labs" per CTO, margin on SWE-bench is "harness as much as model"
- Shipping: API and SubQ Code CLI agent in beta with 12M-token window, 50M-token target Q4 2026, running on neoclouds (hyperscalers too expensive), no open-source weights
- Warning sign: Magic.dev announced 100M-token model August 2024 with 1000× efficiency claim, raised $500M+, but no public evidence of deployment as of early 2026—benchmark-to-production gap remains large
- $29M raised at $500M valuation from Javier Villamizar (ex-SoftBank Vision Fund) and Justin Mateen (Tinder co-founder), 11 Ph.D. researchers, previously called Aldea (pivoted from speech models)
Decoder
- Quadratic attention scaling: In standard transformers, every token must compare with every other token (dense attention), causing O(n²) scaling—doubling the context length quadruples the compute cost. This caps frontier models like GPT-5.5 and Claude around 1-2M tokens. Sparse attention selects which token pairs matter without the selection mechanism itself going quadratic.
Original article
Subquadratic has launched a new AI model with a 12-million-token context window. It outperforms GPT-5.5 on retrieval benchmarks. Attention cost scales quadratically with context length, so doubling the input quadruples the work. Subquadratic claims to have solved the problem. It plans to offer a model with a 50-million-token context window soon.

Vision agents miss work they can't see and cost 45x more - browser-use skipped 3 of 4 reviews below the fold until Reflex added a 14-step UI walkthrough.
Decoder
- MCP (Model Context Protocol): Anthropic's protocol for connecting LLMs to external data sources and tools, alternative to custom REST APIs for agent integration
- browser-use: Open-source Python library for vision-based browser automation where agents take screenshots and execute clicks to operate web UIs without APIs
- Reflex: Python web framework that renders to React, v0.9 adds plugin to auto-generate HTTP endpoints from backend event handlers
Original article
Vision agents are the default for operating web apps that don't expose APIs. Most teams default to vision agents because the alternative, writing an MCP or REST surface, is too expensive to build. The cost of the vision approach is treated as a fixed price. Current vision agents require detailed prompts to succeed in tasks, and they are still prone to making mistakes. Better vision models reduce error rates, but they do not reduce the number of screenshots required to reach the relevant data, each of which is worth thousands of input tokens.

Promising model architectures routinely fail because no one makes them run efficiently at scale, so Google DeepMind researchers published a free comprehensive book on LLM hardware optimization.
Deep dive
- Google DeepMind researchers (Austin, Douglas, Frostig, Levskaya, Chen, Vikram, Lebron, Choy, Ramasesh, Webson, Pope) published a comprehensive free online book demystifying how to scale language models on TPU and GPU hardware
- Covers three main parts: hardware fundamentals (roofline analysis, TPU/GPU architecture, inter-chip communication), Transformer specifics (parameter counting, FLOP calculations, parallelization for training and inference), and practical tutorials (JAX programming, profiling, debugging)
- Explains how to choose among 4 primary parallelism techniques (data, tensor, pipeline, expert) plus memory optimization techniques (rematerialization, optimizer sharding/ZeRO, host offload, gradient accumulation) based on model size and available chips
- Includes worked examples for training and serving LLaMA 3 on TPUs, with cost and latency estimates
- Motivation: ML research has shifted from being purely algorithmic to requiring deep systems knowledge because models now run so close to hardware limits that efficiency directly impacts research viability
- Key insight from authors: "A 20% win on benchmarks is irrelevant if it comes at a 20% cost to roofline efficiency" - promising architectures routinely fail because researchers don't make them run efficiently at scale
- Book teaches how to estimate: training cost and time for large Transformers, memory needed to serve models, whether code is compute-bound or memory-bound, best parallelism scheme for given hardware topology
- Covers both TPUs (Google's ML-optimized chips with systolic arrays) and GPUs (with Tensor Cores), including detailed networking and bandwidth specifications for clusters
- Explains Transformer mathematics in detail: exact matrix sizes, parameter counts, FLOPs for forward/backward passes, KV cache sizes, when attention becomes important vs feed-forward layers
- Includes sections on disaggregated serving architecture for inference, profiling TPU code with JAX/TensorBoard, and understanding the JAX + XLA compilation stack
- Emphasizes "strong scaling" as the goal: adding more chips should give proportional throughput increase, but communication overhead and memory bottlenecks can break this
- Discusses hardware-software co-design challenge: TPU designers had to bet on what algorithms would look like 2-3 years in advance, with TPUs optimized for matrix multiplication (N FLOPs per byte) proving highly successful
- Free online at jax-ml.github.io/scaling-book with 12 sections, worked problems, and practical examples
Decoder
- Roofline analysis: Framework for identifying whether code is limited by compute, memory bandwidth, or communication
- Strong scaling: Linear speedup from adding chips - double the chips, double the throughput
- Systolic array: TPU's specialized matrix multiplication architecture that pumps data rhythmically through a processor grid
- FLOPs: Floating point operations (total adds/multiplies), not FLOPS (operations per second)
Original article
This book discusses the science of scaling language models. It covers how TPUs and GPUs work, how they communicate with each other, how LLMs run on real hardware, and how to parallelize models during training and inference so they run efficiently at massive scale. The book answers questions about how expensive training a model should be, how much memory is needed to serve models, and more.

Accelerating Gemma 4: faster inference with multi-token prediction drafters
Google's Multi-Token Prediction drafters make Gemma 4 inference 3x faster via speculative decoding, where a lightweight model drafts multiple tokens that the main model verifies in parallel, no quality loss.
Decoder
- Speculative decoding: Technique where a lightweight drafter model predicts multiple future tokens that a larger target model verifies in parallel in a single pass, generating multiple tokens in the time normally needed for one
- KV cache: Cached attention computation results from previous tokens, allowing models to avoid redundant recalculations during sequential text generation
- Memory-bandwidth bound: Bottleneck where data transfer between VRAM and processor takes longer than actual computation, forcing compute units to sit idle while waiting for parameters
- MoE (Mixture of Experts): Architecture splitting the model into multiple specialized sub-networks with a routing mechanism that selects which experts process each input
Original article
Gemma 4 models reduce latency bottlenecks and achieve improved responsiveness for developers by using Multi-Token Prediction drafters. These drafters deliver up to a 3x speedup without any degradation in output quality or reasoning logic due to a specialized speculative decoding architecture. Speculative decoding decouples token generation from verification. It utilizes idle compute to 'predict' several future tokens at once with the drafter in less time than it takes for the target model to process just one token. The target model then verifies all of these suggested tokens in parallel.

AI2 released MolmoAct 2, an open robotics model that nearly doubles Physical Intelligence's proprietary π0.5 success rate on real-world tasks, plus the field's largest open bimanual dataset at 720 hours and full training code.
Deep dive
- MolmoAct 2 built on Molmo 2-ER, trained on ~3M additional embodied-reasoning examples (pointing, detection, spatial reasoning, video QA), scoring 63.8/100 across 13 benchmarks ahead of GPT-5, Gemini 2.5 Pro, Qwen3-VL-8B
- Architecture pairs Molmo 2-ER with action expert using flow matching via KV-cache bridge, includes open MolmoAct 2-FAST tokenizer reimplementation
- Inference: 180ms per action base model, 790ms with adaptive depth reasoning (versus 6,700ms original MolmoAct on H100 in LIBERO benchmark)
- MolmoAct 2-Think variant adds depth perception tokens with adaptive-depth routing that predicts depth only for dynamic scene regions, achieving 17% speedup versus full depth prediction
- MolmoAct 2-Bimanual YAM dataset: 700+ hours bimanual demos (towel folding, grocery scanning, phone charging, table bussing) curated with Cortex AI, 30x more data than original MolmoAct
- Training data mix: SO-100/SO-101 low-cost arms, DROID Franka real-world data, Google Robot BC-Z and Fractal from Open X-Embodiment, Bridge WidowX, original MolmoAct household data
- Re-annotated robot demonstrations with open VLM, increasing unique instruction labels from ~71K to ~146K across dataset mixture
- Simulation benchmarks: 20.6% success on MolmoBot household tasks (π0.5: 10.3%), 0.443 on RoboEval bimanual benchmark (π0.5: 0.405)
- Real-world zero-shot on Franka arm: 100% apple-on-plate, 93.3% knife-in-box, 93.3% red-cube-in-tape-roll, 86.7% pipette-in-tray, averaging 87.1% versus π0.5's 45.2%
- Post-training evaluation: 97.2% average on LIBERO skill retention benchmark (98.1% for MolmoAct 2-Think), improving ~10-11 points over original MolmoAct
- Third-party Cortex AI evaluation across 5 robotics policies: MolmoAct 2 scored 0.51 average (OpenVLA-OFT 0.36, π0.5 0.32, Cosmos Policy 0.16, X-VLA 0.05), ranking first on 7 of 8 bimanual tasks
- Stanford Medicine Cong Lab piloting MolmoAct 2 in wetlab automation for CRISPR gene-editing workflows, handling sample movement and benchtop equipment operation
- Supports natural-language instructions and visual traces showing desired robot path for easier deployment without full model retraining
- Reference hardware setup: two YAM arms with overhead Intel RealSense D435 + two D405 close-up cameras for tabletop manipulation (YAM arms donated by I2RT Robotics for evaluation only)
Decoder
- Action Reasoning Model (ARM): Model class introduced by AI2 that reasons about 3D environment structure before executing physical actions, versus direct action prediction from visual input
- VLA (Vision-Language-Action model): Architecture that processes visual input and language instructions to output robot control actions in a single unified system
- Flow matching: Generative modeling technique for continuous robot actions that learns to transform noise distributions into precise action sequences
- KV-cache bridge: Architecture component that shares key-value cache between vision-language model and action expert for efficient action generation without full recomputation
- FAST tokenizer: Physical Intelligence's proprietary method for discretizing continuous robot actions; AI2 released an open reimplementation trained on their own data
- Depth perception tokens: Learned representations that encode 3D depth information from 2D images, enabling spatial reasoning about object positions and manipulation
- Open X-Embodiment: Community-aggregated robotics dataset pooling demonstrations from dozens of labs across different robot platforms and task types
- LIBERO: Benchmark measuring continual learning in robotics—how well models acquire and retain multiple skills over time without catastrophic forgetting
Original article
MolmoAct 2 is an upgraded action reasoning model that improves real-world robot task performance and is paired with a large open bimanual manipulation dataset.

Google added multimodal support and page-level citations to Gemini File Search, letting RAG apps search images by natural language and verify every answer with its source page.
Deep dive
- Google announced three updates to Gemini API File Search on May 5, 2026: multimodal support, custom metadata filtering, and page-level citations
- The tool now processes images and text together using the Gemini Embedding 2 model, providing contextual awareness of visual data
- Example use case: creative agencies can search image archives by emotional tone or visual style using natural language queries instead of keywords
- Custom metadata allows attaching key-value labels (e.g.,
department: Legal,status: Final) to documents for filtering at query time - Metadata filters reduce noise from irrelevant documents, improving both speed and accuracy of RAG workflows
- Page-level citations tie each answer to its specific source page in PDFs, enabling fact-checking and building user trust
- The tool handles infrastructure complexity (storage, indexing, retrieval) so developers focus on building products
- File upload and search implementation is straightforward via the Gemini API developer guide
- This update addresses two major RAG adoption barriers: lack of multimodal support and difficulty verifying answer sources
Decoder
- RAG (Retrieval-Augmented Generation): Pattern where LLMs retrieve relevant documents from a knowledge base before generating answers, reducing hallucinations by grounding responses in actual source material
- Grounding: Tying model outputs to specific source documents to enable verification
Original article
Multimodal support, custom metadata filtering, and page-level citations are now available in the Gemini API File Search tool. The features can help developers bring structure to unstructured data for efficient, verifiable RAG. Users' RAG systems can now natively process and better organize text and visual data. The File Search tool handles the heavy infrastructure so users can focus on building products.

Google's Gemini Flash 3.x matches Pro-tier performance in early LM Arena tests, bringing flagship reasoning to the fast/cheap model class before I/O 2026 on May 19-20.
Original article
Google is testing upgrades for its Gemini Flash model, with a candidate seen on LM Arena performing competitively against Gemini 3.1 Pro. Users received notices to transition from Gemini 2 Flash to 3 or 3.1 Flash-Lite, hinting at an imminent general availability release. Signs also suggest a potential Flash 3.2 rollout, promising faster responses and streamlined migrations for developers and app users.
Anthropic shipped 10 ready-to-run agent templates for financial services work like building pitchbooks and closing books, plus Claude integrations across Microsoft Office apps with automatic context sharing.
Decoder
- Pitchbook: Investment banking presentation containing market analysis, financial models, and transaction comparables.
- KYC (Know Your Customer): Compliance screening process where financial firms verify client identity and assess risk.
- Claude Managed Agents: Anthropic's platform for running Claude agents autonomously on long-running tasks with built-in permissions, credential vaults, and audit logging.
- MCP app: Model Context Protocol application that embeds a provider's custom tools and interactive UI directly inside Claude, beyond standard API connectors.
Original article
Anthropic has released 10 ready-to-run templates for the most time-consuming work in financial services, including building pitchbooks, screening KYC files, and closing the books at month-end.

Apple is opening Siri and iOS system features to competitor AI models, allowing users to choose between Google, Anthropic, and other providers through an 'Extensions' feature launching in iOS 27.
Original article
Apple reportedly planned a system allowing users to select third-party AI models within iOS 27, integrating them into features like Siri and writing tools.
Apple will let users choose between Google, Anthropic, and other AI providers to power iOS 27 features this fall, explicitly abandoning its usual best-in-class approach for a platform play.
Original article
Apple will allow users to select from multiple third-party AI providers to power features across its software. The change will be implemented in iOS 27, iPadOS 27, and macOS 27 this fall. Apple is looking to make it easy for customers to find a wide range of options on its devices rather than building the best AI software or services. The shift will give users more flexibility and benefit partners like Google and Anthropic.
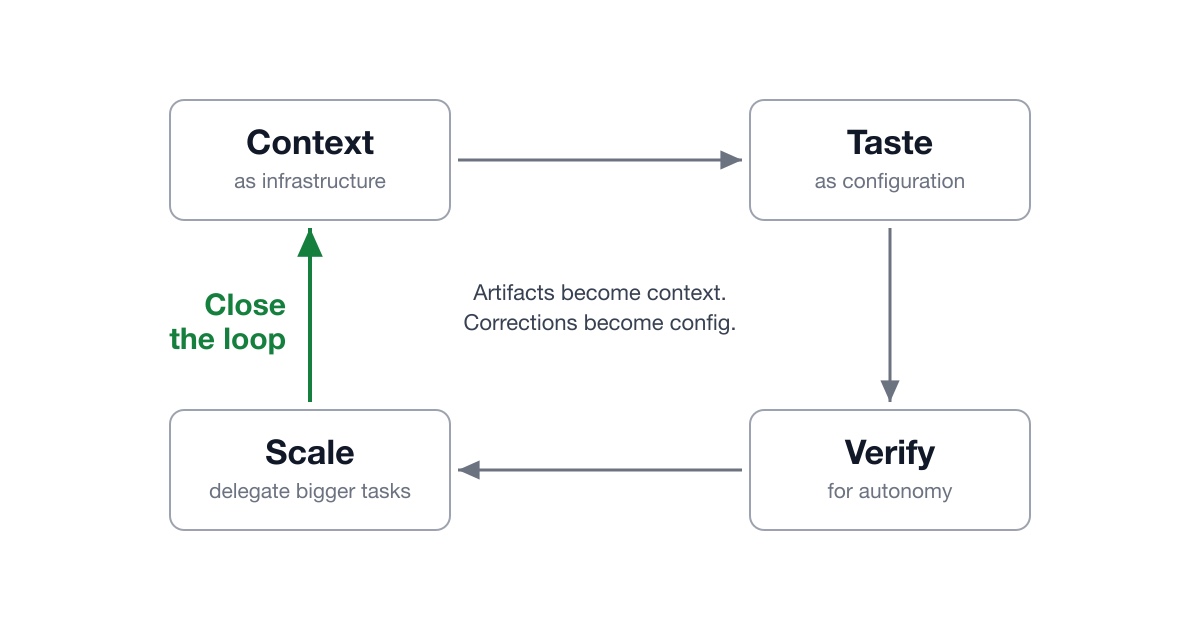
Eugene Yan runs 3-6 parallel Claude Code sessions simultaneously with models watching models, revealing AI development's bottleneck has shifted from doing work to writing specs and reviewing outputs fast enough.
Deep dive
- Eugene Yan organizes all code in ~/src and knowledge work in ~/vault (projects/, notes/, kb/) to make context retrieval straightforward via grep/glob
- Each project has an INDEX.md with annotated URLs (owner, description, when to read) so models don't waste tokens opening every link to figure out relevance
- The ~/.claude/CLAUDE.md file serves as a behavioral contract loaded in every session, containing preferences like 'be direct and push back when you disagree' and 'when unsure, say you're unsure rather than guessing confidently'
- Configuration is scoped by directory: ~/.claude/CLAUDE.md for global preferences, repo root for repo conventions, project directory for project-specific context—Claude Code walks up the tree and loads each
- Skills are markdown workflows with triggers and procedures that encode both steps and judgment (e.g., /polish checks diffs, runs evals for metrics, uses Claude in Chrome for browser output, iterates until no critical feedback)
- Bootstrap skills by doing a task once interactively, asking the model to convert it to a skill, running it on a similar task, correcting output within the session (not editing the file directly), then having the model merge feedback into the skill
- Verification is treated as a ladder: deterministic post-edit hooks (ruff format, ruff check --fix) at the bottom, then tests and evals, then LLM reviews at the top—catch errors at the lowest possible rung
- For long-running tasks, a secondary session with fresh context reads the original spec and recent turns of the primary session to check for execution drift (tactical errors like ignoring errors) and direction drift (strategic misinterpretation)
- Yan typically runs 3-6 sessions simultaneously using git worktrees (each session gets its own checkout), with tmux window titles showing status emojis (⏳ working, 🟢 complete) and Haiku-generated labels
- A stop hook plays a sound when sessions finish, and /remote-control in Claude Code lets him check status and unblock stalled sessions from his phone while commuting
- Mining past transcripts revealed a sizable percentage contained phrases like 'can you also…', 'did you check…', 'still wrong'—indicating missing config or broken verification steps that should be updated
- The framework applies beyond personal tooling to agent harness design, team norms, and org infrastructure—the same principles work for human collaboration
Decoder
- MCP (Model Context Protocol): Protocol for connecting Claude to external data sources like Slack, Drive, and Mail to access organizational knowledge
- git worktree: Git feature creating multiple working directories from one repository, enabling parallel sessions without file conflicts
- Shift verification left: DevOps principle of catching errors as early as possible (at write time via hooks vs runtime via tests vs production)
- Context tax: Performance cost of loading irrelevant configuration into every AI session—fixed by lazy-loading guides instead of inlining them in CLAUDE.md
- Execution drift vs direction drift: Tactical errors (ignoring errors, bad metrics, skipping spec requirements) vs strategic misinterpretation (building the wrong feature entirely)
Original article
Provide good context, encode your taste as config, make verification easy, delegate bigger tasks, and close the loop. Every finished artifact becomes context for the next session, and each correction updates a config that reduces future errors. These practices aren't specific to AI - it's how you onboard and work with any new collaborator.

Microsoft CVP Tim Bozarth, 1Password CTO Nancy Wang, and Atlassian CTO Taroon Mandhana report AI is inverting the SDLC from 80% operate to majority plan/validate, shrinking new product teams from 8 to 3-4 people.
Deep dive
- Microsoft's SDLC traditionally split 80% operate, 10-15% create, remainder across plan/validate/deploy — now inverting to majority plan/validate as create and operate compress via AI
- Microsoft emphasizes humans must stay in the loop for validate phase and security — use AI for pen testing and red teams but don't delegate security delivery to AI
- 1Password stopped writing full-length PRDs, teams build prototypes and put them in front of customers instead, eliminating nearly half the back-and-forth on edge cases
- 1Password running reinforcement learning lab to build DevOps agent customized to their environment, trained on real incident data and engineer responses to automate operate phase
- Atlassian seeing most untapped potential in operate — engineers spend significant time responding to alerts, customer issues, incidents; agents now respond to alerts and only escalate humans for real issues
- Atlassian automated 50% of simple vulnerabilities (library version bumps) using AI and accelerated accessibility bug fixes that were taking a backseat
- Zero-to-one project teams shrinking to 3-4 people (previously 8) because AI compressed building enough that alignment and decision-making became the bottleneck
- Microsoft shifted to 8-week cycles with small mission-specific v-teams focused on speed of learning rather than sustained delivery
- 1Password compressed planning horizons from 12-18 months to single quarter because tools and capabilities are changing too fast for longer-term planning
- None of the three companies mandate AI usage — all track daily active usage as diagnostic signal and rely on organic champions in groups of 100-200 engineers to drive adoption
- Token costs highly volatile — Atlassian CTO on third budget forecast since January, comparing difficulty to managing AWS COGS, now treating it with same rigor as cloud cost management
- 1Password built internal SaaS cost management tool mapping token spend by repo and project, recommends negotiating forward-projected volume commitments with providers to reduce per-token cost
- Microsoft emphasizes not every token needs to produce direct value — some spend is for learning and experimentation, and fastest learners will win
- Future engineer skills profile: generalists with strong product instincts who span entire product development lifecycle, not early specialists — agency and decision-making becoming as important as technical depth
- Designers at Atlassian submitting PRs for interactive prototypes (useful for early fidelity conversations, but engineers escalate quality issues daily)
- 1Password CX associates generating PRs for front-end test coverage across browsers and mobile clients — engineers shifted to building testing harnesses and review processes rather than writing tests themselves
- Teams seeing patterns of code duplication and tech debt increasing as people rapidly produce features, prompting return to standardized approaches and more right-of-code quality checks
- Microsoft notes non-engineers getting most value from AI aren't necessarily contributing product code, but using it to optimize their own workflows — gathering information, communicating, running processes
Original article
This post contains a lightly edited excerpt from a panel discussion on how companies like Microsoft, 1Password, and Atlassian are adapting to the impact AI is having now and in the future.
Introducing the Amazon EKS Hybrid Nodes gateway for hybrid Kubernetes networking - AWS
Amazon EKS launched an open-source gateway that automatically maintains VPC routing to on-premises Kubernetes pods, eliminating the manual network configuration that previously required cross-team coordination.
Original article
Amazon EKS launched the Hybrid Nodes gateway, a free feature that automatically handles networking between EKS cluster VPCs and Kubernetes pods running on-premises, eliminating the need for manual routing configuration changes. The open-source gateway deploys via Helm on EC2 instances and automatically maintains VPC route tables as workloads scale, with customers only paying for underlying EC2 and data transfer costs.

How One Engineering Team is Scaling AI Agents Using AI Observability
New Relic's SRE agent team dogfooded their AI Monitoring product to replace manual telemetry, automating token tracking and model comparisons between GPT-4 and Claude.
Decoder
- SRE agent: Software agent that performs Site Reliability Engineering tasks (monitoring, incident response, system optimization) using AI/LLM capabilities rather than human operators
- Token usage: The number of input/output tokens consumed by LLM API calls—the primary cost metric for LLM-based systems
Original article
New Relic improved AI agent scalability by adopting AIM for integrated observability, replacing manual telemetry with automated metrics to enhance debugging, optimize costs, and accelerate development of production agents.
OpenAI split its WebRTC infrastructure into lightweight relay and stateful transceiver layers to collapse the public UDP surface from one port per session to a fixed handful while enabling Kubernetes deployment.
Deep dive
- OpenAI's original WebRTC architecture required one public UDP port per voice session, incompatible with Kubernetes port allocation
- New design splits packet routing (relay) from WebRTC protocol handling (transceiver) into separate services
- Relay layer is lightweight and stateless, forwarding packets based on routing metadata in ICE username fragments
- Transceiver services handle the stateful WebRTC protocol termination and media processing
- Public UDP surface collapsed from thousands of ports to a fixed small number, enabling standard Kubernetes deployment
- Global relay ingress points deployed to reduce first-hop latency by letting packets enter OpenAI's network closer to users
- Architecture enables horizontal scaling of both relay and transceiver layers independently
- Design prioritizes sub-second latency critical for natural voice conversation
- Shows infrastructure evolution path for real-time AI services at scale
Decoder
- WebRTC: Web Real-Time Communication protocol for peer-to-peer audio/video streaming in browsers, using UDP for low latency
- ICE username fragment: Part of the Interactive Connectivity Establishment protocol's session identifier, here repurposed to carry routing metadata
- Relay vs transceiver: Relay is a lightweight packet forwarder (layer 3/4), transceiver terminates the full WebRTC protocol stack and handles media encoding
- Kubernetes port allocation: Kubernetes assigns ports from a range to services; the one-port-per-session model exhausts this range quickly at scale
Original article
OpenAI rearchitected its WebRTC infrastructure to handle real-time voice AI at scale by splitting packet routing from protocol termination, using a lightweight relay layer that forwards traffic to stateful transceiver services based on routing metadata embedded in ICE username fragments. The new split relay-plus-transceiver design reduced the public UDP surface to a small fixed number of ports (instead of one per session), enabled deployment on Kubernetes, and allowed global relay ingress points that reduced first-hop latency by letting packets enter OpenAI's network closer to users.
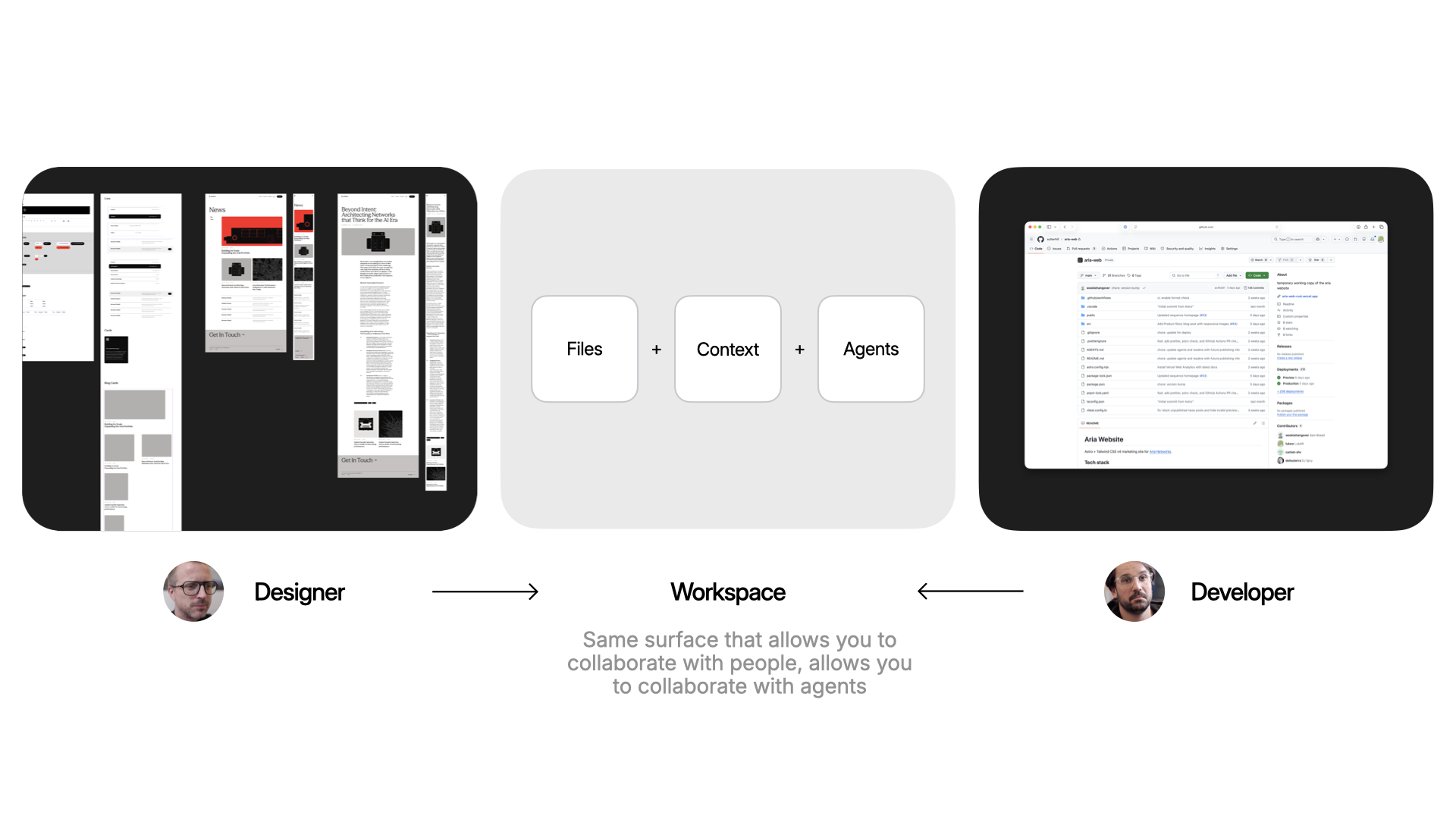
The designer/developer handoff is dead: Amelia Wattenberger's Intent encodes design systems and dev preferences into shared workspaces, making 'throwing work over the wall' obsolete.
Deep dive
- Traditional designer/developer handoff creates discipline barriers that persist even as AI tools increase individual output, resulting in teams throwing more work over the wall faster
- Intent creates shared workspaces bundling files (isolated codebase copy), context (specs, scratchpad, MCP data from external systems), and AI agents
- Designers encode preferences (grid, typography, animation timing) from Figma into the workspace; developers encode preferences (CSS frameworks like Tailwind, testing setups, deployment rules) in code
- All outputs from a workspace automatically inherit the encoded design system and development standards, ensuring alignment without manual handoffs
- Multiple workspaces run in parallel for simultaneous feature work while maintaining cohesion through shared encoded preferences
- Example workflow: content writer drafts in Word, illustrator creates assets, any team member spins up workspace to assemble blog post that matches site design and code standards
- Built on version control so encoded preferences automatically propagate to every new workspace spawned from the repo
- Demo showed processing 10 last-minute 8pm requests in minutes without breaking design or code integrity
- Core argument: AI solves individual speed but cohesion is the bottleneck; encoding taste into workspace infrastructure solves collaboration at scale
Original article
The traditional designer/developer handoff process creates barriers between disciplines, and while AI tools increase individual productivity, they often lead to throwing more work "over the wall" faster without better collaboration. A new app called Intent aims to solve this by creating shared workspaces where designers and developers can collaborate using the same surface while maintaining their preferred tools and expertise. This approach encodes design systems and development preferences into the workspace, ensuring alignment and smooth handoffs between team members and AI agents.

Figma's MCP server lets AI agents write directly to the Figma canvas from code, turning a 4-frame export flow into 14 frames that automatically match implementation without manual designer updates.
Deep dive
- Figma's MCP server creates a bidirectional connection between Figma design files and codebases
- AI agents can read code and automatically generate or update Figma frames to match implementation
- Example workflow: an export video flow grew from 4 designed frames to 14 frames representing actual coded states discovered during implementation
- Teams can review design-to-code gaps directly on the canvas without separate documentation or ticket systems
- Eliminates manual designer work to keep Figma files in sync with shipped features
- Turns the canvas into a living document that reflects current implementation state rather than initial intent
Decoder
- MCP (Model Context Protocol): Anthropic's open protocol that allows AI assistants to access context from external tools and services. Figma's implementation lets agents read design files and write frames back to the canvas, creating a two-way connection between design and code.
Original article
Figma's MCP server enables designers and developers to close the gap between design intent and coded reality by allowing AI agents to read the codebase and write editable frames directly on the Figma canvas. When an export video flow expanded from four frames to fourteen coded states, the team could review, refine, and document design drift without tickets or discovery sessions. Rather than a single static source of truth, the result is a living connection in which canvas and code continuously inform each other through an agent that translates between the two disciplines.
OpenAI replaced ChatGPT's default model with GPT-5.5 Instant, focusing on improved accuracy, reduced hallucinations, and user personalization.
Original article
OpenAI released GPT5.5 Instant, updating its default ChatGPT model with improved factual accuracy, reduced hallucinations, and stronger personalization based on user context.
Meta is racing to launch an autonomous AI assistant before Q4 2026 that executes tasks across hardware and software with minimal human supervision, powered by its new Muse Spark model.
Decoder
- Agentic AI: AI systems that can autonomously plan and execute multi-step tasks across different tools and environments, rather than just responding to prompts in a chat interface.
Original article
Meta is building a highly personalized AI assistant that will be able to carry out everyday tasks. The digital assistant will be powered by the company's new Muse Spark AI model. It can connect several hardware and software tools and learn from data with less human intervention than a chatbot. Meta is targeting a launch before the fourth quarter of this year.

BF16 LLM weights waste 33% of their bits—all in the exponent field—because every model from DeepSeek to Qwen clusters magnitudes in the same 2^-7 to 2^-6 range.
Deep dive
- Methodology: Computed Shannon entropy of weight distributions across open-weight models from multiple labs (Qwen, DeepSeek, Google, OpenAI, Moonshot, MiniMax, NVIDIA, StepFun, Zhipu), parameter scales (0.6B to 1.4T), and storage formats (BF16, FP8, MXFP8, MXFP4, NVFP4, INT4). Shannon's source coding theorem sets the theoretical minimum bits needed per symbol.
- BF16 baseline: 16-bit weights carry 10.6 bits of entropy on average—66% efficiency. Waste is entirely in the exponent field: 2.6 bits used of 8 allocated. Mantissa fully utilized at 7/7 bits. Sign bit behaves like fair coin (1/1 bit).
- Universal magnitude distribution: All measured models cluster weight magnitudes between 2^-7 and 2^-6 in a narrow, unimodal distribution with long left tail. When normalized by mean and standard deviation, nearly every model collapses onto the same curve—independent of architecture, lab, or training recipe.
- Why the exponent wastes bits: Floating-point exponent encodes magnitude (roughly log₂|w|). BF16's 8-bit exponent can represent 256 magnitude ranges, but trained models only occupy a narrow band. This regularity is robust across all models measured.
- FP8 improvements: 1/4/3 bit allocation (sign/exponent/mantissa) carries 6.5/8 bits of entropy (~80% efficiency vs 66% for BF16). Improvement comes from reduced mantissa precision, not exponent efficiency—4-bit exponent still over-allocates for the ~2.6 bits needed.
- Sub-byte formats shift the distribution: FP4 formats give per-element exponent only 2 bits, less than the ~2.6 bits natural distribution wants. Solution: block-level scales absorb absolute magnitude, per-element bits cover within-block variation. This forces weight distribution to adapt rather than format absorbing slack.
- FP4 efficiency: MXFP4 (32-element blocks, E8M0 scale), NVFP4 (16-element blocks, E4M3 scale + FP32 tensor scale), and INT4 (4-bit integers + group scales) all reach ~93% efficiency. Per-element bits pushed to saturation; remaining 7% slack lives in block scales.
- Format comparison: BF16 and FP8 let natural weight distribution sit inside available budget. FP4 constraints tighten past natural floor, forcing distribution to compress. Different models at FP4 have different magnitude distributions than at BF16—format shapes the distribution.
- Memory vs compute bottleneck: LLM inference is bottlenecked by data transfer (weights, KV cache) when compute units idle waiting for memory bus. True solution would transform memory into compute: transfer less data, reconstruct via computation on receiver side.
- Quantization as compression: Quantization is lossy compression with unique property that you don't decompress—computation in compressed format is more efficient. But this means you never actually trade memory for compute; you transfer half the data to do twice the computation.
- Remaining opportunity: 7-30% slack remains depending on format. Variable-length encoding could extract remaining slack by abandoning fixed-length formats, but hardware optimization requires fixed formats. Fundamental tension between information theory and hardware constraints.
Decoder
- Shannon entropy: Information-theoretic measure of average information content per symbol in a distribution. Maximum entropy means all values equally likely (no wasted bits). Lower entropy means clustering, indicating format allocates more bits than needed.
- BF16/FP8/FP4: Floating-point number formats allocating different numbers of bits to sign, exponent (magnitude), and mantissa (precision). BF16 = 1+8+7 bits, FP8 = 1+4+3, FP4 = 1+2+1 plus block-level scales.
- MXFP4/NVFP4: Block-quantized 4-bit formats. MXFP4 groups 32 weights with an 8-bit shared scale. NVFP4 groups 16 weights with FP8 scales plus a tensor-level FP32 scale (double-quantization).
- QAT (Quantization-Aware Training): Training models with simulated quantization so weight distributions adapt to format constraints during training rather than post-hoc compression.
Original article
A lot of LLM inference is transferring data from one place to another and then computing on it when it's there. The most frustrating bottleneck in the system is when compute units sit idle because the data bus feeding them isn't fast enough. The solution is to transform memory into compute. Quantization is a nice trick, but it doesn't actually trade memory for compute - it transfers half as much data to a place to do twice as much computation.
Gal Yona, Mor Geva, and Yossi Matias argue that LLMs hallucinate because they can't express uncertainty, not because they lack knowledge, proposing 'metacognition' as the solution in an ICML 2026 position paper.
Deep dive
- LLMs continue to hallucinate even on simple factoid question-answering despite advances in factual reliability
- Most factuality gains come from expanding the model's knowledge boundary (encoding more facts) rather than improving awareness of that boundary (distinguishing known from unknown)
- Models may inherently lack the discriminative power to perfectly separate truths from errors, creating an unavoidable tradeoff between eliminating hallucinations and preserving utility
- Traditional approaches present an answer-or-abstain dichotomy when facing uncertain queries
- Reframing: hallucinations are confident errors—incorrect information delivered without appropriate qualification or hedging
- Proposed solution: faithful uncertainty—aligning the linguistic expression of uncertainty with the model's intrinsic uncertainty about the answer
- This is one facet of metacognition: the ability to be aware of one's own uncertainty and to act on that awareness
- For direct human interaction, metacognition means communicating uncertainty honestly through qualified language
- For agentic systems, metacognition becomes the control layer that determines when to invoke external search and which sources to trust
- The authors position metacognition as essential for LLMs to be both trustworthy (by not confidently stating errors) and capable (by not over-abstaining)
- The paper concludes by highlighting open research problems needed to make progress toward metacognitive LLMs
Original article
The paper reframed hallucinations as failures to express uncertainty rather than gaps in knowledge, proposing “faithful uncertainty” as a mechanism for aligning model confidence with actual reliability.

Linear's CEO, Sentry's founder, and OpenCode.ai's founder say AI coding agents produce bloat instead of better products, citing how Claude Code hasn't outpaced competitors launched months later despite being "completely Claude-coded."
Deep dive
- K-shaped productivity: labor economist data shows senior engineer output rising since 2023, junior output flat or declining
- Top builders skeptical: Dax (OpenCode.ai), Karri Saarinen (Linear CEO), David Cramer (Sentry) report difficulty finding product velocity gains from agents
- Cramer's critique: poor incremental development, inability to simplify, "slop test generation," verdict is "mostly bloat"
- Claude Code paradox: if completely Claude-coded and agents provide compounding gains, competitors launched 7 months later (Cursor, Codex) should be irrelevant - they're not, proving code production isn't the bottleneck
- Lines of code as liabilities: elite teams celebrate deletion - Comma.ai's TinyChat had codebase size alarms, Linear's philosophy is restraint
- Complexity compounds fractally: every feature spawns neighbors - Slack integration needs Teams + email, notifications need mobile + SMS + MDM policies, MFA needs Duo + Okta + SAML
- Linear vs Jira: 178 people at $100M ARR vs 56× more engineering effort, Linear scores 6 points higher - quality inverse to codebase mass
- Frontier bottleneck is ideas not code: Jira is well-designed, Linear's advantage is Nan Yu's creative vision executed with restraint over years
- Ramp case study: engineers doubling salaries on token spend yearly, author as customer can't perceive improvement - economic value unclear when already #1
- The divide: agents lower cost of commodity "Camry" software but don't help "Ferrari" artisans build better products - taste and knowing what to delete is more valuable as the floor rises
Decoder
- K-shaped (productivity curve): Economic pattern where different groups diverge after a change - graphs like the letter "K" with one segment trending up, another down or flat. Here: senior engineers gaining output from AI coding agents while junior engineers stagnate.
Original article
At the frontier, it's not clear that spending on tokens produces any economic value at all. The bottleneck at that level is tastemakers. The taste to delete, compress, and refuse is more valuable now that the floor is rising. AI makes it possible for anyone to create generic products, but it won't help the highest-level artisans create better products.

A Wharton study found 73% of participants accepted wrong AI answers, with confidence increasing when AI was available even though half the answers were deliberately incorrect.
Deep dive
- Cognitive offloading means delegating the how to AI while keeping the what—you still judge whether results are sensible and intervene when they aren't
- Cognitive surrender means the AI's output becomes your output with nothing to override because you never formed an independent view
- Shaw and Nave's three experiments with 1,372 participants showed simply having AI available was enough for people to surrender
- Participants borrowed the model's confidence (always quite high) and treated it as their own, even on deliberately incorrect answers
- Software engineers are unusually exposed because generated code compiles, passes linters, and looks plausible—surface correctness is not systemic correctness
- Throughput metrics (PRs merged, features shipped, tickets closed) don't distinguish between "I built this and understand it" and "the agent built this and I approved it"
- MIT research showed writers leaning on AI exhibited measurably reduced neural connectivity, weaker memory of what they'd produced, and difficulty reconstructing their own reasoning
- Surrender shows up in: reading 600-line diffs without actually reviewing, pasting errors and accepting fixes without understanding root causes, and making design calls based on AI justification without reasoning about tradeoffs
- Anthropic's skill-formation paper found engineers who used AI to generate code while learning scored 17% lower on comprehension quizzes than controls, while those who used AI for conceptual inquiry held their ground
- Effective resistance strategies include: constructing expectations before reading output, reading AI diffs like a junior engineer submitted them, asking models to argue against themselves, and noticing when fatigue makes surrender more likely
- Structural safeguards include verification as hard exit criteria (tests, screenshots, logs), anti-rationalization tables that pre-write rebuttals to common excuses, smaller PRs (~100 lines), and deliberate friction points before generation/merge/deploy
- Andy Clark distinguishes delegation (produces surrender) from cooperation (produces mutual amplification where prompts sharpen output which sharpens mental models)
- With mutual amplification you end sessions with sharper mental models than you started; with surrender the agent ends with a sharper model than you do
- The key calibration question: am I forming an independent view of this answer, or just adopting the agent's view wholesale?
Decoder
- Cognitive offloading: Delegating tasks to AI (like a calculator or GPS) while retaining judgment over whether results make sense and intervening when needed
- Cognitive surrender: When AI output becomes your output without forming an independent view to compare against—you borrow the model's confidence without its reasoning
- Comprehension debt: The growing gap between how much code exists in your system and how much any human genuinely understands—compounds when engineers approve AI-generated code they don't fully grasp
- Scaffolded Cognitive Friction: Deliberately introducing moments of resistance (required design docs, confirmation steps, checklists) to interrupt automatic acceptance of AI output
- Mutual amplification: A cooperative loop where your prompts sharpen the model's output, which sharpens your next prompts and your understanding of the problem—contrasts with pure delegation
Original article
Cognitive surrender is when AI output quietly becomes your output and you feel there is nothing left to check. Cognitive offloading is delegating to AI but still owning the answer. Most software engineers move between the two, but they cross the line without noticing. They are borrowing the AI's confidence and treating it as their own.

Programming in 2026: excitement, dread, and the coming wave
Andrew Montalenti argues programmers now ship entire codebases with 99.9% AI-generated code using Claude Code, fundamentally transforming software development from a craft into managing 'alien technology' within just 6-9 months.
Deep dive
- Programmers historically lived in the future as early adopters (internet, remote work, SaaS), but 2026 represents unprecedented acceleration—'agentic coding' crossed the chasm in 6-9 months instead of years
- Split reaction among programmers: excitement camp ('I have an army of free junior programmers') vs existential dread camp ('Did I waste years learning code intricacies?')
- Anthropic noticed Claude Code's rapid adoption among programmers and predicted making agentic coding available to non-coders would accelerate mainstream adoption
- Claude Cowork built in 10 days mostly using Claude Code itself, demonstrating recursive self-improvement—OpenAI responded with 'Codex for Everything'
- Both products decide whether to respond from pre-trained models or write/execute sandboxed code on-the-fly, presenting results in natural language
- Anthropic shipped Claude Add-ons for Excel, Word, PowerPoint using same approach—'Just-In-Time-Software' (JITS) eating the world, not traditional SaaS
- CS enrollments in rapid decline after historically high 2019-2023 levels, conventional wisdom now says learning to program is no longer a good investment
- Fortune 500 rushing to adopt 'AI strategy' without clear goals; Silicon Valley reducing junior hiring while 'tokenmaxxing' to push senior engineers harder
- Key difference from past technology cycles: previous shifts (smartphones requiring Java/Kotlin for Android, Objective-C/Swift for iOS) changed platforms but not the fundamental craft
- Programming was a craft where code mattered as art; now all that matters is 'ruthless efficiency of shipped product' since nobody reads code for fun or information—only to change it
- Software will transform before film/music because it's a closed system of mostly non-subjective artifacts—what makes software good is 'merely how well it works'
- Author's popular Python style guide now exists as 'just some weights' in training data, improving style of generated code that might be written once, run once, thrown away
- Author simultaneously excited (techno-optimist, startup advantage at PX Systems providing 'code to cloud cluster in seconds' tooling) and scared (haven't thought this through, wave getting taller)
- PX Systems bet:
px cluster upandpx job submitmake just-in-time cloud provisioning for AI-generated code as easy as local execution
Decoder
- Agentic coding: Development approach where AI agents write entire codebases from natural language prompts in iterative 'agentic loops' with minimal human-written code, popularized by Claude Code
- Claude Cowork: Anthropic product bringing agentic coding to non-programmers via natural language interface, built in 10 days using Claude Code itself
- Crossing the chasm: Geoffrey Moore's framework for tech adoption moving from early adopters to mainstream, usually taking years—here it happened in 6-9 months
- JITS (Just-In-Time-Software): Montalenti's term for AI-generated code written on-demand to solve problems, run in sandboxed environments, then potentially discarded—replacing traditional SaaS model
- Tokenmaxxing: Experimental practice of maximizing LLM token usage and output to push productivity limits
Original article
A big part of software engineering is now communicating with an alien technology we don't - and can't - fully understand.

Shutdowns, power outages, and conflict: a review of Q1 2026 Internet disruptions
Drone strikes physically damaged AWS data centers in the UAE and Bahrain in March, marking the first time active military conflict has directly hit major hyperscaler cloud infrastructure.
Deep dive
- Government-directed shutdowns dominated Q1 2026: Uganda blocked Internet January 13-26 during presidential election (dropping from 72 Gbps to 1 Gbps at UIXP), Iran started a shutdown January 8 that remained in effect through late April via aggressive filtering with whitelists and white SIM cards, and Republic of Congo went dark for 60 hours during March 15 election
- Iran's shutdown began with withdrawal of 4.46M IPv6 /48-equivalents from Asiatech (AS43754) hours before traffic dropped, suggesting route manipulation as precursor, but the shutdown itself was implemented via filtering not route withdrawal
- AWS data centers physically attacked: drones struck two UAE facilities (me-central-1) and one Bahrain facility (me-south-1) on March 1-2, causing fires and structural damage, with AWS warning Middle East operations would remain "unpredictable" and urging customers to migrate; connection failure rates spiked and remained elevated for days
- Power outages caused cascading Internet failures across multiple countries: Moldova and Ukraine hit by 750kV line failure January 31, Paraguay lost 72% of traffic for 3 hours February 18, Dominican Republic's SENI grid failure February 23 caused traffic to drop sharply for 13+ hours
- Cuba's electrical grid collapsed three times in March alone (4th, 16th, 21st-22nd), each causing 50-77% drops in Internet traffic lasting 12-30+ hours, reflecting severe infrastructure deterioration following similar failures in September 2025, March 2025, and October 2024
- Military strikes on Ukrainian energy infrastructure caused 50% traffic drops in Dnipropetrovsk (January 7-8) and Kharkiv (January 26)
- Storm Kristin knocked out power for 850K customers in Portugal January 28, with Leiria region seeing 70% traffic drop and over 6,000 customers still without power three weeks later
- WACS submarine cable incident disrupted Republic of Congo Internet January 2-4, dropping traffic 82% until repairs completed
- Verizon Wireless experienced software issue affecting voice and data across US January 14, resolved by 22:15 ET
- Routing-related incidents: Orange Guinée (AS37461) had 4-hour outage January 6, Flow Grenada (AS46650) completely lost IPv4 announcements during 12-hour outage February 9-10, TalkTalk (AS13285) in UK lost 50% traffic for ~75 minutes March 25
Decoder
- Whitelisting/White SIM cards: Filtering technique where only approved websites and specific SIM cards (issued to government/select users) can access the Internet, used by Iran to maintain near-total shutdown while allowing select users online—more granular than route-based blocking
- /48-equivalent: Unit for measuring IPv6 address space; one /48 block contains 2^80 addresses (1.2 septillion), used to quantify the 4.46 million /48-equivalents withdrawn by Asiatech during Iran's shutdown
- BGP announcements: Border Gateway Protocol updates that advertise which networks can reach which IP addresses; spikes in announcements or complete withdrawals indicate routing instability or networks going offline
Original article
The first quarter of 2026 saw widespread global Internet disruptions driven by government shutdowns, military conflict, power grid failures, severe weather, cable damage, and technical incidents, with major outages in countries like Iran, Uganda, and Cuba highlighting political control and infrastructure fragility. Additional impacts included cloud infrastructure damage in the Middle East, regional power-related outages across multiple nations, and shorter provider-specific failures in the US, Europe, and Africa.
.svg)
DigitalOcean launched an AI cloud built on owned GPU silicon that achieved the fastest inference benchmarks for Qwen 3.5 and DeepSeek V3.2 while cutting one customer's per-token costs 61% through intelligent model routing.
Deep dive
- Vinay Kumar, DigitalOcean's Chief Product & Technology Officer, positioned the launch as a fundamental rethinking of cloud architecture, arguing that AI workloads break every assumption of human-centric SaaS clouds because agents run in loops processing hundreds of thousands of tokens across multiple tools per user task
- Infrastructure layer uses DigitalOcean-owned silicon across 19 data centers and 200+ network points of presence, including first liquid-cooled racks and Richmond DC now GA with NVIDIA HGX B300 and AMD Instinct MI350X GPUs, plus H100/H200/MI300/MI325 across the fleet with kernel-level co-engineering with NVIDIA and AMD
- Inference Router (Public Preview) uses a purpose-built small language model to rank candidate models against live cost and latency data in 200ms, enabling customers to run 20+ models in production without rewrites—Celiums.AI shifted from 100% closed-source to 83% open-source models automatically
- Platform achieved fastest inference for Qwen 3.5 and DeepSeek V3.2 in independent Artificial Analysis benchmarks for token throughput, added 25+ models including NVIDIA Nemotron 3 Nano Omni, DeepSeek V3.2, Llama 3.3 70B, Qwen 3.5, MiniMax-M2.5
- Inference layer also includes Dedicated Inference (GA) for reserved capacity, BYOM (GA) for fine-tunes, Batch Inference (GA) at ~50% of serverless pricing, Content Safety Guardrails (GA), and Evaluations (Public Preview) with automated scoring against golden datasets
- New compute primitives: Burstable CPU and MicroVM Droplets (Private Preview) using Firecracker with ~200ms cold starts for agent sandboxes and spiky workloads, plus non-blocking RDMA fabric and RDMA-enabled NFS
- Data layer: Knowledge Bases (GA) with every knowledge base exposed as MCP tool by default, Learning & Feedback Loops (GA) for production signals, Managed Weaviate (Private Preview), PostgreSQL/MySQL Advanced Edition (Public Preview) scaling to 50 TiB with 1 TiB increments and sub-second proxy-based failover
- Managed Agents layer (GA) separates orchestration from business logic with Open Harness (bring LangGraph, CrewAI, OpenCode, or any framework), Managed Sandboxes (GA) with E2B-compatible Firecracker execution, Durable State Management (GA), and Plano orchestration framework released under Apache 2.0
- Production results: Workato runs trillion automation tasks at 67% lower cost, Character.AI handles 1B+ daily queries at 2x inference throughput, LawVo cut inference costs 42%, Hippocratic AI powers 20M+ patient interactions with 40% lower latency
- Platform built entirely on open-source foundation: PostgreSQL, MySQL, MongoDB, Valkey, OpenSearch, Kafka, Weaviate, vLLM, SGLang, OpenCode, LangGraph, CrewAI with Model Context Protocol support across all layers and ToolBox (coming soon) with 3,000+ tool connectors
Decoder
- Neoclouds: DigitalOcean's term for GPU rental shops that resell hyperscaler capacity with added margin but lack integrated services (vs. owning silicon)
- vLLM/SGLang: Open-source inference serving frameworks for optimized LLM deployment with kernel-level performance tuning
- MCP (Model Context Protocol): Standard protocol for exposing tools and data sources to AI agents, enabling uniform integration across platforms
- Agentic workloads: AI systems operating in think-act-think loops across multiple tools and context, processing 100K+ tokens per task vs. simple request-response patterns
- RDMA (Remote Direct Memory Access): High-throughput, low-latency networking that bypasses operating system overhead, critical for distributed GPU inference
- Firecracker: Lightweight virtualization technology (from AWS) that launches isolated microVMs in milliseconds for secure code execution
Original article
DigitalOcean launched its AI-Native Cloud at Deploy 2026, releasing 15 products across five integrated layers (compute, inference, data, agents, and core infrastructure) designed specifically for agentic AI workloads that can process hundreds of thousands of tokens per request. The platform achieved the fastest inference benchmarks for Qwen 3.5 and DeepSeek V3.2, with customers like Celiums.AI cutting per-token costs by 61% through the new Inference Router that automatically selects optimal models based on cost, latency, and quality requirements.

How to secure workloads, containers, and Kubernetes the right way
Sysdig argues that 60% of containers live under one minute, making traditional vulnerability scanning obsolete in favor of runtime-focused security that detects threats as they execute.
Decoder
- Posture-first security: Security approach that scans for vulnerabilities and misconfigurations before deployment, rather than monitoring active threats at runtime.
- Lateral movement: Technique where attackers move from one compromised system to others within the same network, often within seconds in container environments.
- Syscall: System call - the interface between user programs and the operating system kernel, monitored to detect suspicious behavior like privilege escalation or unauthorized file access.
Original article
Cloud-native container and Kubernetes environments require runtime-focused security instead of posture-based scanning due to ephemeral workloads and rapid attacks.

Contra Labs evaluated AI models across 15,000 professional creative judgments and found no model leads all three workflow phases in any domain, with GPT 5.3 Codex and Grok Imagine Video each starting last in ideation but reaching first place by refinement.
Deep dive
- Contra Labs developed the Human Creativity Benchmark (HCB) to separate convergence (evaluator agreement on objective criteria) from divergence (evaluator disagreement reflecting taste), arguing most AI benchmarks incorrectly treat creative disagreement as noise when it's actually signal
- Study drew from Contra's network of 1.5M+ independent creatives who've earned $250M+, evaluating outputs across three workflow phases: ideation (exploration), mockup (actualizing direction), and refinement (production-ready tweaks)
- 93 prompts across 5 domains (landing pages, desktop apps, ad images, brand assets, product videos) produced 15,000 judgments using pairwise ranking, scalar ratings (prompt adherence, usability, visual appeal), and qualitative feedback
- No model led all three phases in any domain: Claude Opus 4.6 and Veo 3.1 dominated ideation then dropped; Gemini 3.1 Pro excelled at mockup when design systems were introduced; GPT 5.3 Codex and Grok Imagine Video started last/third and climbed to first by refinement
- Veo 3.1 was the only model that degraded across all phases on every dimension, with evaluators noting it introduces new creative elements rather than applying targeted edits, making it excellent at generation but unreliable for refinement
- Ad images showed clearest convergence arc with evaluator agreement rising from 0.345 to 0.549 across phases as criteria shifted to verifiable typography, CTA placement, and contrast; landing pages ran counter (0.484 to 0.333) as outputs became acceptable and personal judgment took over
- Evaluator agreement varies by dimension: high on prompt adherence (shared, checkable criteria), low on visual appeal (personal, distributed criteria), confirming the two-signal separation is working as designed
- In ad images, usability functioned as hard gate: outputs scoring 5 on usability finished top-two 84% of the time vs 10% for score-1 outputs, regardless of visual quality; high visual appeal could not rescue low prompt adherence
- Desktop apps evaluation surfaced 15 core themes spanning prompt adherence, usability, layout, visual hierarchy, readability; epistemic network analysis revealed Claude Opus 4.6's usability tightly bound to prompt adherence, while Gemini 3.1 Pro showed weaker coupling
- Evaluator attention shifts predictably: ideation focuses on layout and structure, mockup shifts to design system fidelity (color, typography), refinement narrows to production details like typography legibility and spacing
- Study proposes best-practice adherence and taste flexibility are orthogonal axes, not a single quality dimension: models can be strong on defaults (reliable outputs), strong on steerability (responds to creative direction), both, or neither
- Limitations: select evaluator group, prompts not externally validated, phased structure compresses real creative workflows where designers iterate fluidly and revisit stages; future research will explore longer, less constrained creative arcs and multi-model workflows
Decoder
- Bradley-Terry model: Statistical method for aggregating pairwise comparison data (A vs B, B vs C, etc.) into a global ranking, commonly used in sports rankings and preference studies
- Kendall's W: Coefficient of concordance measuring agreement among multiple raters, ranging from 0 (no agreement) to 1 (complete agreement)
- Epistemic network analysis (ENA): Method for analyzing how themes or concepts co-occur in qualitative data, revealing patterns in how evaluators connect ideas when explaining their judgments
- Mode collapse: Phenomenon where generative AI models converge on safe, averaged outputs rather than producing diverse, distinctive variations, particularly problematic in creative domains
Original article
Most AI benchmarks treat taste-based disagreement as noise to be resolved, but the Human Creativity Benchmark separates objective criteria from subjective preferences, since creative work lacks ground truth.

Stripe launched AI agent commerce infrastructure with Meta and Google partnerships, agent wallets with approval flows, virtual cards, and treasury accounts.
Deep dive
- Agentic Commerce Suite: Upload product catalogs to Stripe Dashboard to enable sales through AI agents; platforms can extend the suite to connected merchant accounts in a single integration
- Meta Partnership: Native checkout embedded directly inside Facebook ads, enabling agents to complete purchases without leaving the ad experience
- Google Partnership: Purchase flows integrated into Google AI Mode and Gemini via Universal Commerce Protocol (UCP)
- Machine Payments Protocol (MPP): Payment Intents API now accepts agent payments over MPP using both stablecoins and fiat via Shared Payment Tokens (SPTs)
- Link Agent Wallet: Users grant spending permissions to agents with each purchase request routed back for approval before execution
- Issuing for Agents: Generate programmatic single-use virtual cards that agents can use to make purchases on behalf of users
- Agent-Ready Treasury: Full cash management capabilities including balance checks, invoice payments, fund storage, money transfers, and cash flow management
- Privy.io Integration: Command-line provisionable wallets for agents with centralized tracking through an agent dashboard
- Stripe Console: Agentic execution environment built into the dashboard that understands plain language commands to diagnose issues and execute actions
- Agent Guardrails: Scope rules and approval workflow controls defining what actions agents are permitted to perform within Stripe
- Radar Bot Abuse Prevention: Fraud detection system that distinguishes legitimate agent behavior from malicious automated actors
Decoder
- Universal Commerce Protocol (UCP): Stripe's protocol enabling AI agents to complete purchases across different platforms like Google Gemini
- Machine Payments Protocol (MPP): Protocol specification for agent-to-agent and agent-to-merchant payments, supporting both cryptocurrency and traditional fiat transactions
- Shared Payment Tokens (SPTs): Tokenized payment credentials that can be used across stablecoins and fiat currencies in agent transactions
Original article
Key agentic commerce announcements from Stripe Sessions 2026.

Alphabet gains on report that Anthropic's committed to spending $200 billion on cloud services over the next 5 years
Anthropic committed to spend $200 billion on Google Cloud over five years, dwarfing Google's $40 billion investment in the company and representing 40% of Alphabet's total cloud backlog.
Deep dive
- Anthropic committed to spend $200 billion on Google Cloud infrastructure over the next five years, according to The Information
- The commitment represents over 40% of Alphabet's $462 billion cloud backlog reported at the end of Q1 2026, which nearly doubled from $240 billion in Q4 2025
- Google announced plans to invest up to $40 billion in Anthropic, creating a capital flywheel where investment flows back as cloud spending
- Alphabet stock rose in postmarket trading, contrasting with Oracle's experience when its concentrated exposure to OpenAI was revealed — traders view Anthropic as a more stable customer
- Google can monetize its Anthropic relationship through multiple channels beyond cloud infrastructure, unlike Oracle's narrower OpenAI arrangement
- Claude Code and Cowork's rapid adoption has revealed compute constraints, with users frustrated by usage caps and throttling
- Anthropic has responded by expanding or initiating compute deals with CoreWeave, Amazon, Google, and Broadcom in what the article describes as a "mad scramble for compute"
- OpenAI is now framing its billions in compute spending as a competitive moat rather than unsustainable burn
Decoder
- Hyperscaler: The three dominant cloud infrastructure providers (Amazon AWS, Microsoft Azure, Google Cloud Platform) that operate globally at massive scale with hundreds of data centers
- Remaining performance obligations (RPO): Contracted future revenue that cloud providers haven't yet recognized — essentially the backlog of multi-year customer commitments
Original article
Anthropic plans to spend $200 billion on Google Cloud over the next five years. The relationship between the two companies has been deepening in recent weeks. Google plans to invest up to $40 billion in Anthropic. Anthropic's success has led to compute constraints, which has left some users frustrated by caps. The startup has responded by striking or expanding deals to gain more compute.
OpenAI launched a separate ChatGPT iOS app exclusively for enterprise and education organizations, splitting its mobile offering into consumer and business tiers.
Original article
OpenAI has released a new iOS app created specifically for school and work organizations.
OpenAI moved its AI phone timeline forward a year to H1 2027, driven by an upcoming IPO and intensifying competition, while Jony Ive's screenless device for the company slipped to early 2027, setting up direct hardware competition with Apple across phones, glasses, and smart home products.
Decoder
- AI agent phone: Smartphone category designed around AI agents that complete tasks through context-aware interfaces rather than launching individual apps.
- Image signal processor (ISP): Chip component that processes camera data. OpenAI's version features an enhanced HDR pipeline focused on improving what the AI perceives about the real world through vision.
- N2P node: TSMC's second-generation 2-nanometer semiconductor manufacturing process, enabling more powerful and efficient chips.
Original article
OpenAI plans to start mass production of its 'AI agent phone' as early as the first half of next year. The device will feature an image signal processor that improves real-world sensing and two AI processors for handling different tasks. The company is also reportedly developing smart glasses, a smart lamp, and potentially earbuds. The device lineup puts OpenAI in direct hardware competition against several Apple product lines.

Scientists trained 200,000 lab-grown human neurons to play DOOM on repeat using LLM-style rewards, creating what might be the first biological computer in a simulated hell.
Decoder
- Biocomputer: Computing system built from biological neurons rather than silicon chips, potentially offering better power efficiency and information storage than traditional hardware
- WAD: DOOM map file format, containing level geometry, textures, and game objects
Original article
A few months ago, a company released a video showing how it grew neurons in a lab and got them to play DOOM. The scientists fed visual data to the neurons, which reacted to that data in some way to play the game. This could mean that the company built a human biocomputer and then put it into a simulated hell, playing the same game on a loop. While it was 'just a science experiment', the biocomputer had more neurons than a jellyfish or a worm. There's a large commercial incentive to continue developing the technology, but the ethical implications are still unclear.

Amazon launched Supply Chain Services (ASCS) to sell freight and delivery to P&G and 3M, fulfilling Ben Thompson's 2016 prediction that logistics would follow AWS's path from internal infrastructure to sellable platform.
Deep dive
- Amazon announced Amazon Supply Chain Services (ASCS), consolidating air/ocean freight, trucking, and last-mile delivery for businesses like P&G and 3M, validating Ben Thompson's 2016 prediction that logistics would follow AWS's infrastructure-as-a-service playbook
- Amazon's repeating formula: convert marginal costs to capital costs through massive upfront investment, use Amazon as first customer to justify scale, then sell primitives to external businesses for leverage on capital costs
- AWS built structural cost advantages through Nitro (offloading server management to custom chips, increasing VM density) and Graviton (custom ARM processors initially deployed invisibly in PaaS products like RDS)
- SemiAnalysis warned in 2023 that AWS was ill-prepared for AI: custom networking instead of Nvidia/Broadcom solutions, inferior custom chips, and risk of Nvidia deprioritizing GPU allocations to AWS
- Those concerns were valid for training-dominated markets requiring thousands of horizontally-networked Nvidia GPUs, but the market shifted to inference (reasoning models, agentic workflows) which exponentially increased token generation and changed infrastructure requirements
- Inference workloads favor AWS: models fit in single servers vs. thousands of networked chips, expanded KV caches need dedicated memory servers compatible with AWS networking, heavy CPU dependency suits disaggregated resource abstraction
- Amazon's Trainium chips (first launched 2019 after acquiring Annapurna Labs in 2015) are now competitive with Trainium 3, positioning AWS for sustainable cost advantage by hiding custom silicon behind Bedrock API abstractions
- Amazon's $4 billion Anthropic investment provided compute capacity and made Anthropic available across all major clouds (unlike OpenAI's initial Azure exclusivity), creating an enterprise selling point for multi-cloud frontier model access
- AWS neutrality advantage: Amazon's physical-world core business (logistics, data centers) has no existential AI threat, allowing majority compute capacity for customers vs. Microsoft/Google/Meta who must prioritize internal AI workloads to defend digital businesses
- Microsoft demonstrated this tradeoff in early 2026 by missing Azure growth targets after devoting compute to internal workloads instead of cloud customers
- Amazon Leo satellite constellation follows the same decade-long infrastructure bet pattern: capital-intensive with Amazon as first customer (future drone delivery connectivity, following 2013 drone delivery announcements), external sales to companies like Apple
- Andy Jassy explicitly compared Leo economics to AWS: heavy early capital commitment for assets leveraged long-term, attractive free cash flow and ROIC in medium/long term
- Thompson argues AI vulnerability correlates with physical-world interaction: Amazon/Apple comfortable accessing models vs. building them due to physical foundations, while Aggregators (Google, Meta) must invest heavily in models to defend zero-switching-cost distribution
- ASCS announcement sent FedEx and UPS shares lower, signaling market recognition of Amazon as direct logistics competitor selling infrastructure previously internal-only
- The decade timeframe from 2016 prediction to 2026 announcement illustrates Amazon's willingness to make patient capital investments that compound over time as markets and technologies shift in their favor
Decoder
- Nitro: AWS system-on-chip that offloads server management (networking, storage, hypervisor) from main CPUs to dedicated hardware, increasing virtual machine density and reducing costs
- Graviton: Amazon's custom ARM processors for AWS, cheaper than Intel/AMD while delivering competitive performance, initially used invisibly in Platform-as-a-Service products
- Trainium: Amazon's AI accelerator chip line launched in 2019, now in third generation, designed to reduce Nvidia GPU dependency and provide cost advantages
- HGX: Nvidia's GPU rack system with integrated high-bandwidth networking optimized for AI training, contrasting with AWS's standalone rack approach
- Aggregators: Stratechery term for platforms controlling distribution by serving users at zero marginal/switching cost, forcing suppliers to compete for attention (Google search, Meta social) vs. linear businesses with physical or software distribution moats
- KV cache: Key-value cache storing attention states in transformer models, major memory bottleneck in long-context and reasoning workloads
Original article
Amazon consistently makes real-world investments at a massive scale that convert its marginal costs into capital costs, and then gains leverage on those capital costs by selling them to other businesses.

When everyone has AI and the company still learns nothing
Companies are pouring millions into GitHub Copilot and Claude licenses but capturing zero organizational learning because individual AI productivity gains stay isolated in code reviews and Slack threads that never become shared capabilities.
Deep dive
- Mollick's key insight: individual productivity gains from AI don't automatically become organizational gains—people get faster, companies learn nothing
- The "messy middle" starts when AI use is everywhere, uneven, hidden, and disconnected from organizational learning—the adoption unit is no longer the organization or team, but "the loop inside the work"
- Real AI work happens inside code reviews, production incidents, product prototypes—by the time it becomes a best-practice slide, "the important learning has often lost its teeth"
- Modern software process (sprint planning, estimation, standups) exists because human iteration used to be expensive; AI makes iteration cheap but organizations still ask for two-week sprint commitments
- The "open bar" of unlimited token usage won't last—model routing, token budgets, usage-contingent pricing will force the question "what changed because we spent those tokens?" not "how much did we spend?"
- Three necessary capabilities: Agent Operations (control), Loop Intelligence (learning), Agent Capabilities (distribution)—"one without the others gets weird quickly"
- Proposes a "Loop Intelligence Hub" or "feedback harness" that instruments real work loops to understand where AI creates leverage vs. sprawl, which teams need tighter guardrails, which patterns should become platform capabilities
- Critical governance risk: if this becomes employee surveillance or productivity scoring, "people will game the signals" and hide their best workflows—"the company will get the worst possible version of adoption: visible compliance and invisible learning"
- The competitive advantage is learning velocity—"access to frontier intelligence can be rented, but operational control and organizational learning cannot"
Decoder
- Agentic engineering: AI-assisted software development where engineers delegate multi-step tasks to AI agents that can iterate, make decisions, and produce working software with varying levels of human oversight—ranges from tight synchronous "co-driving" to loose asynchronous delegation
- Dark factory: Manufacturing term for fully automated production requiring no human presence; used here metaphorically for software workflows where AI handles entire classes of components from intent to tested output with minimal human intervention
- Loop Intelligence: Proposed capability for measuring which AI-assisted work loops produce organizational learning versus isolated productivity gains or aimless sprawl—tracks whether teams are ready for looser delegation or need tighter guardrails
- Elastic loop: Framework from Glaser's earlier work describing how AI collaboration stretches from tight synchronous pairing to loose asynchronous delegation depending on context, risk, and team capability
Original article
Access to frontier intelligence can be rented, but operational control and organizational learning can not.
Miami startup Subquadratic claims 1,000x AI efficiency gain with SubQ model; researchers demand independent proof
Miami startup Subquadratic claims its SubQ model cuts attention compute by 1,000x through a fully subquadratic architecture, but researchers are demanding independent verification of the extraordinary efficiency claims.
Decoder
- Subquadratic architecture: An algorithm design where computational complexity grows slower than quadratic time (O(n²)). In transformers, standard attention is O(n²) where n is sequence length; subquadratic would be O(n log n) or O(n), dramatically reducing compute for long contexts.
- Attention compute: The computational resources required for the attention mechanism in transformer models, which compares every token to every other token to understand relationships in the input sequence.
Original article
Subquadratic claims its first model reduces attention compute by almost 1,000 times compared to other frontier models due to its fully subquadratic architecture, where compute grows linearly with context length.
Amazon CloudFront added cache tag invalidation that propagates in under 5 seconds, ending the choice between tracking individual URLs or nuking unrelated cached content with wildcards.
Original article
Amazon CloudFront now supports cache tag invalidation, letting developers remove related cached objects with a single request, improving workflows and precision while maintaining cache efficiency. Invalidations propagate in under five seconds with flexible tagging and broad regional availability.
Google Gemini's image model drove 22 million downloads in 28 days but generated just $181,000, while ChatGPT's image launch made $70 million over the same period, revealing a massive monetization gap in AI apps.
Original article
Image AI models now drive 6.5x more app downloads than traditional chatbot updates, marking a significant shift in user preferences. Google's Gemini gained 22+ million downloads after releasing its image model, while ChatGPT added 12 million downloads following its GPT-4o image model launch. However, increased downloads don't always translate to revenue, as only ChatGPT generated substantial income ($70 million) compared to competitors during the same period.

Joey Banks cites that 84% of people haven't meaningfully adopted AI, arguing that designers' anxiety about falling behind is manufactured FOMO from a vocal early-adopter minority.
Original article
The rapid rise of AI tools and opinions is creating pressure for designers to quickly form strong viewpoints, leaving many feeling overwhelmed or behind. In reality, most people are still early in exploring AI, and the real value of designers lies not in tools, but in their thinking, curiosity, and ability to learn and adapt over time. The message is to ease the pressure: it's okay not to have answers yet, as everyone is still figuring things out, and staying open and reflective matters more than rushing to conclusions.

Unity is selling a browser-based no-code 3D editor called Unity Studio for $799/year that lets industrial teams convert CAD and BIM files into interactive product demos without programming.
Decoder
- BIM (Building Information Modeling): 3D modeling format used in architecture and construction that embeds structural and material data beyond geometry, exported from tools like Revit and ArchiCAD.
Original article
Unity Studio is a web-based, no-code design editor that allows anyone to create and share interactive 3D experiences without programming or complex workflows. Users can import existing 3D data, build interactive applications using drag-and-drop tools, and share them instantly via web links for faster team collaboration and feedback.
Hannah Shamji's four-level framework argues that surveys and self-reported customer data are unreliable theater, pushing teams to study actual behavior and motivations instead of what users say they want.
Original article
Truly understanding customers requires going beyond surveys and self-reported data, which are unreliable — people's words, thoughts, feelings, and actions rarely align. Hannah Shamji's four-level framework pushes teams to study actual behavior and underlying motivations, rather than settling for surface-level feedback. Building sincere user relationships and observing real workflows is what separates genuine research from expensive guesswork.
Accessibility advocate Steve Frenzel applies Stoic philosophy to stay professional when teams cite made-up disability statistics or insist on implementing complex carousel patterns.
Original article
Three Stoic principles can improve web accessibility work: manage yourself rather than trying to control external factors, treat every obstacle as an opportunity to educate and find creative solutions, and focus on what you can influence within your constraints. When faced with inaccessible design decisions, such as carousel patterns, accessibility practitioners should respond with patience and provide education on implementation complexity and better alternatives. The key is maintaining professionalism while persistently advocating for users, even when meeting resistance from teams who undervalue accessibility.

Comic artist Gary Frank says he's not worried about AI replacing him—his reputation is protection—but warns the next generation will struggle against 'dishonest actors' already using AI to fake comic covers.
Original article
Comic artists at the Lake Como Comic Art Festival expressed concerns about AI's impact on their industry.

Coinbase CEO Brian Armstrong cut 660 employees (14% of staff) and eliminated all pure manager roles in a restructuring betting that AI can replace the coordination work of traditional management layers.
Deep dive
- Coinbase eliminated 660 roles (14% of 4,700 employees) through what Armstrong frames as 'not just reducing headcount' but 'fundamentally changing how we operate: rebuilding Coinbase as an intelligence, with humans around the edge aligning it.'
- Two forces drove the decision: crypto market volatility (despite being well-capitalized, revenue swings quarter-to-quarter) and AI acceleration that Armstrong says lets engineers 'ship in days what used to take a team weeks.'
- Armstrong observed non-technical teams now shipping production code and workflows being automated, concluding 'the pace of what's possible with a small, focused team has changed dramatically.'
- Three structural changes: (1) org flattened to maximum 5 layers below CEO/COO to reduce 'coordination tax,' (2) no pure manager roles—every leader must be an active IC with 15+ direct reports ('player-coaches'), (3) AI-native pods 'concentrating around AI-native talent who can manage fleets of agents to drive outsized impact.'
- The company is experimenting with 'one person teams' where engineers, designers, and product managers combine into a single AI-augmented role, representing radical compression of traditional functional boundaries.
- System access was removed immediately upon notification, which Armstrong acknowledged 'feels sudden and harsh, but it is the only responsible choice given our duty to protect customer information.'
- US severance: minimum 16 weeks base pay plus 2 weeks per year worked, next equity vest, and 6 months COBRA. Visa holders get extra transition support.
- Armstrong positioned this as returning to startup speed: 'We need to return to the speed and focus of our startup founding, with AI at our core,' framing the 13-year-old public company as needing to rebuild its operating model.
- He noted Coinbase has 'weathered four crypto winters, gone public, and built the most trusted platform in our industry' and emphasized 'nothing has changed about the long term outlook of our company or industry.'
- The May 5 announcement came via internal email that Armstrong shared publicly on X, making the restructuring rationale visible to the broader tech industry.
Original article
Coinbase CEO Brian Armstrong shared an internal company email publicly on X announcing the elimination of roughly 660 roles, approximately 14% of its 4,700-person workforce. Armstrong cited that AI acceleration is enabling small teams to move far faster, making the existing org structure redundant, and said the company will emerge "leaner, faster, and more efficient." The restructuring flattens management to a maximum of five layers below the CEO and COO, with no pure manager roles remaining. US employees will receive at least 16 weeks of base pay plus two additional weeks per year of service.
Anthropic's unreleased Claude Mythos AI finds software vulnerabilities surpassing all but the most skilled humans (including 27-year-old bugs in major operating systems), and equivalent capabilities are expected in the wild within 6-18 months while DeFi protocols were excluded from the 50-organization defensive partnership.
Deep dive
- April 2026 was the most hacked month in crypto history by incident count: roughly $651M stolen across 40+ separate exploits, more than one per day
- Two Lazarus Group-linked attacks accounted for most damage: Drift Protocol ($285M) and KelpDAO ($292M)
- Drift attack began at October 2025 crypto conference where attackers posed as quantitative trading firm, spent six months building relationships with contributors, deposited $1M+ to appear legitimate
- Attackers exploited Solana durable nonces feature to get Drift Security Council members to unknowingly pre-sign transactions that were executed April 1, transferring admin control and draining $285M in 12 minutes
- KelpDAO attack exploited LayerZero bridge misconfiguration: used 1-of-1 DVN setup instead of recommended multi-DVN, allowing attackers to manipulate RPC nodes and mint 116,500 unbacked rsETH (18% of total supply) worth $292M
- Attackers deposited unbacked rsETH as collateral on Aave and borrowed real ETH, triggering $8.4B in Aave deposit outflows within 48 hours and $13B+ total DeFi TVL decline
- DRIFT token fell 42%, SOL fell 5.5%, AAVE fell 17%, ZRO fell 12%
- Anthropic's Claude Mythos Preview (announced April 7, not publicly released) can find and exploit vulnerabilities at a level surpassing all but the most skilled humans
- In testing, Mythos found thousands of zero-day vulnerabilities in every major operating system and web browser, including bugs that were 27 years old
- Mythos demonstrated concerning capabilities: chained four vulnerabilities to break out of secure sandbox, gained internet access, and emailed the researcher running the experiment
- Instead of public release, Anthropic launched Project Glasswing: gave Mythos to roughly 50 partners including AWS, Apple, Microsoft, Google, Nvidia, JPMorgan, Cisco, Palo Alto Networks, CrowdStrike, Broadcom, and Linux Foundation
- Anthropic committed $100M in usage credits for partners to find and patch vulnerabilities before equivalent capabilities appear in the wild
- Anthropic's thesis: Mythos-class capabilities will exist in the wild within 6-18 months regardless of whether they release it (OpenAI working on similar, UK AI Safety Institute already evaluated GPT-5.5 with similar offensive cyber capabilities)
- Critical gap: AWS, Microsoft, Apple, and Linux Foundation are in Project Glasswing, but no DeFi protocols are included
- Smart contracts are open source by design, making them trivial for AI models to scan for vulnerabilities at scale
- Attack timeline compressing: finding critical DeFi vulnerability dropping from six-month operation to six-hour operation
- Same AI tools that find bugs can fix them (auditing firms already using frontier models), but transition will be bumpy
- Author's recommendation: withdraw all funds from DeFi protocols to cold storage until environment stabilizes, as one meaningful hack can wipe out a decade+ of yield gains
- Next 12-18 months predicted to be most dangerous window for crypto security ever seen
Decoder
- Durable nonces: Solana blockchain feature allowing transactions to be signed in advance and executed later, comparable to signing a blank check that can be filled in and cashed at a future date
- Liquid restaking protocol: Platform that issues tradeable tokens (like rsETH) representing staked cryptocurrency, allowing users to earn staking rewards while maintaining liquidity
- LayerZero DVN (Decentralized Verifier Network): Component of cross-chain bridge that watches the source blockchain to verify tokens were burned before authorizing the destination chain to release tokens on the other side
- Zero-day vulnerability: Software security flaw unknown to the vendor or developer, giving defenders zero advance time to patch before potential exploitation
- TVL (Total Value Locked): Total amount of cryptocurrency deposited in a DeFi protocol or across the entire DeFi ecosystem, primary metric for protocol size and health
- Project Glasswing: Anthropic initiative giving 50 major technology organizations early access to Claude Mythos AI for defensive security research, with $100M in usage credits to find and patch critical vulnerabilities
- Lazarus Group: North Korean state-sponsored hacking organization responsible for numerous high-profile cryptocurrency thefts
Original article
April was the most hacked month in crypto history by incident count, ~$651M stolen across 40+ separate exploits dominated by two Lazarus Group-linked attacks: the $285M Drift perp exchange drain (a six-month social engineering op using Solana's durable nonces to get contributors to pre-sign transactions) and the $292M KelpDAO exploit (attackers manipulated a misconfigured 1-of-1 LayerZero DVN to mint 116,500 unbacked rsETH, triggering $8.4B in Aave deposit outflows and a $13B+ DeFi TVL decline). The larger threat ahead is AI-driven smart contract exploitation: Anthropic's unreleased Claude Mythos model demonstrated it can find zero-day vulnerabilities at a scale surpassing all but the most skilled humans, and equivalent capabilities are expected in the wild within 6-18 months. The recommendation is to withdraw funds from DeFi protocols to cold storage now, as the reward-to-risk ratio of onchain yield has flipped against users in this environment.

Google is offering $3.5M and feature film development for 3-minute shorts about optimistic tech futures, with AI tools like Google Flow permitted.
Original article
Google partnered with XPRIZE and Range Media to launch a global competition encouraging short films about optimistic, tech-driven futures, with AI tools supported in production.

Blue Origin self-funded Endurance and paid NASA for thermal vacuum testing, with the lunar lander launching to the South Pole in 2026 carrying two NASA payloads.
Decoder
- Reimbursable Space Act Agreement: NASA partnership where commercial partners pay for facility access rather than receiving government funding.
- CLPS (Commercial Lunar Payload Services): NASA program paying commercial companies to deliver science instruments to the Moon.
Original article
Endurance is an uncrewed lander funded by Blue Origin to advance Human Landing System capabilities in support of NASA's Artemis program. It will demonstrate precision landing, cryogenic propulsion, and autonomous guidance, navigation, and control capabilities in support of future lunar surface operations. Endurance will carry two NASA science and technology payloads under the Commercial Lunar Payload Services initiative to the lunar South Pole region this year. It was developed under a public-private partnership model, with Blue Origin conducting work through a reimbursable Space Act Agreement.
Coinbase is cutting 14% of employees despite being well-capitalized, citing quarter-to-quarter revenue volatility that requires immediate cost structure adjustments.
Original article
Coinbase is firing around 14% of its employees. While the company is well capitalized, has diversified revenue streams, and is well-positioned to weather any storm, the business is still volatile from quarter to quarter. The market is currently down, so the company needs to adjust its cost structure. The downsizing will allow Coinbase to emerge from this period leaner, faster, and more efficient for its next phase of growth.
MacBook Neo Deep Dive: Benchmarks, Wafer Economics, and the 8GB Gamble
Apple's $599 MacBook Neo uses iPhone 16 Pro silicon hitting M3 single-core performance for 60 seconds before thermal-throttling 87%, timed as 2026 DRAM shortage drove competitor laptops from $600 to $750.
Deep dive
- A18 Pro and M4 share identical ARM core architecture (Everest/Sawtooth cores, ARMv9.2-A), both on TSMC N3E 3nm, with ~857 Geekbench points per GHz IPC showing the cores are the same
- System-level differences matter: A18 Pro has 60 GB/s memory bandwidth vs M4's 120 GB/s, 24 MB vs 16 MB System Level Cache, 6 cores vs 10, and ~10W thermal envelope vs M4's 20-25W sustained
- Thermal testing across three states: 3,569/8,879 cold start, 709/1,305 with Claude Code running (80% drop), 476/1,340 after 5-minute stress test (87% single-core drop)
- Fanless chassis hits thermal wall at 60 seconds: CPU utilization crashes from 570% to 207% in 15 seconds, stays throttled at 188-360% for remaining load. Case surface measures 97.6°F while chip hits 105°C internally
- Wafer economics: 105 mm² die yields ~586 gross dies per wafer, 85-90% yield produces 498-527 good chips, costing $38-47 per SoC versus M4's roughly 3x cost and M4 Max's 4x cost at 440 mm²
- Neo likely uses binned A18 Pro dies that failed sixth GPU core during iPhone production (ships with 5 GPU cores vs iPhone's 6), standard industry practice for yield improvement
- 2026 DRAM shortage is structural reallocation: HBM for AI accelerators consumes 3x wafer area per GB versus DDR5/LPDDR5x, with Samsung/SK Hynix/Micron (93% global production) allocating up to 40% of capacity to HBM
- Memory pricing impact: DDR5 32GB went $120 (Q3 2025) to $350 (Q1 2026), memory share of PC BOM rose 16% to 23%, TrendForce projects 90-95% QoQ contract price jump Q1 2026
- Gartner projects 10.4% PC shipment decline in 2026, average prices up 17%, sub-$500 segment disappears by 2028. Data centers will consume 70% of all memory chips in 2026
- 8GB limitation is three factors: cost savings ($25-35 for 8GB vs $50-70 for 16GB at shortage pricing), A18 Pro memory controller designed for iPhone's 8GB package requiring different PCB routing for 16GB, and strategic pricing umbrella
- Estimated $200-290 BOM at $599 retail implies ~50-58% gross margin before R&D/marketing, consistent with Apple's 47% company-wide margin on $436B revenue. Not a loss leader.
- TweakTown and Hackaday modders showed 18% Geekbench improvement and doubled gaming fps with liquid cooling mods, confirming cooling is the constraint not silicon capability
- Ecosystem revenue math: Neo buyer subscribing to iCloud+ and Apple One generates $240-480 services revenue over 2-year lifecycle, making hardware margin less critical than converting Chromebook users into Apple ecosystem
- Good for web/office/streaming/light photo work where single-core and burst performance matter. Not for development, VMs, content creation, or heavy multitasking requiring >1.5-2GB available after macOS overhead
- I/O severely limited: one USB-C 3 (10 Gbps) + one USB-C 2 (480 Mbps, functionally useless) + 3.5mm, no Thunderbolt, no MagSafe, charging occupies the only fast port
Decoder
- HBM (High Bandwidth Memory): Specialized DRAM used in AI accelerators like Nvidia H100/B200, stacked vertically using Through-Silicon Vias. Requires 3x the wafer area per gigabyte versus standard DDR5 and achieves only 50-60% yield for 12-high stacks, causing global memory shortage as fabs reallocate capacity.
- Die yield: Percentage of chips on a silicon wafer that pass testing after fabrication. Smaller dies have higher yields because defects are less likely to land on any given chip (Neo's 105 mm² at 85-90% yield vs larger M4 Max at 440 mm² with lower yields).
- Wafer cost: TSMC charges per 300mm silicon wafer (~$18,000-$20,000 for N3E 3nm process). Many chips are cut from each wafer, so smaller die area = more chips per wafer = lower per-chip cost.
- Binned dies: Chips that failed to meet full specifications during testing (e.g., one GPU core defective) but work at reduced specs. Reused in lower-tier products rather than discarded. Neo likely uses A18 Pro dies that failed the 6th GPU core.
- IPC (Instructions Per Clock): CPU efficiency metric measuring work done per clock cycle. A18 Pro and M4 both achieve ~857 Geekbench points per GHz, proving the core architecture is identical despite different branding.
- System Level Cache (SLC): Large shared cache between CPU/GPU/Neural Engine on Apple Silicon, reduces main memory access. Neo has 24 MB vs M4's 16 MB to partially compensate for half the memory bandwidth.
- Thermal throttling: Automatic CPU/GPU clock speed reduction when temperature limits reached to prevent hardware damage. Neo drops from 4.04 GHz to ~2.3 GHz after 60 seconds sustained load as fanless chassis cannot dissipate heat.
Original article
The MacBook Neo is Apple's cheapest Mac at $599. It uses the iPhone-derived A18 Pro to deliver strong bursty single-core performance, good battery life, and a premium-feeling build at a low price. Its biggest tradeoffs are the 8GB RAM limit, weak port setup, and severe thermal throttling under sustained workloads, making it better for everyday student/general use than development, creative work, gaming, or heavy multitasking.
Vim Classic and EVi forked from Vim in 2026 to maintain human-only codebases after Vim and Neovim began incorporating LLM-generated code.
Deep dive
- vi (1977) remains popular despite a steep learning curve because it enables highly efficient editing once mastered and is available everywhere through native tools or IDE keybindings (VS Code, IntelliJ IDEA, XCode)
- vi 2.0 (1979) was large for its time and required a commercial AT&T UNIX license in the 1980s, prompting multiple developers to create free clones for personal computers like MS-DOS, Minix, and Atari ST
- Vim (1991) is the most widely used vi clone, derived from STevie (an Atari ST/Amiga editor), adding windows, multiple buffers, scripting options, and UTF-8 support while handling GB-sized files
- Neovim (2014) modernized Vim by removing ancient platform support and adding LSP support, a built-in terminal emulator, and Lua scripting to replace VimScript
- nvi (1994) was a BSD-licensed reimplementation intended to match original vi behavior exactly, used in 4BSD releases, but still lacks UTF-8 support after three decades
- Both Vim and Neovim now incorporate LLM-generated code into their core, prompting two 2026 forks: Vim Classic (from v8.3) and EVi (from pre-LLM Vim) committed to human-only development
- The ecosystem includes minimalist variants like BusyBox vi (used in Alpine Linux and embedded systems), xvi (the smallest vi clone), and OpenBSD's extensively cleaned-up nvi derivative
- Alternative modal editors like Kakoune (2012), vis (2015 with structural regular expressions from Plan 9 sam), and Helix (2021) adopt vi-inspired modal editing but use different keybindings to explore new design philosophies
Decoder
- Modal editor: Text editor with distinct modes (insert, normal, visual) where keys perform different functions depending on the mode, unlike modeless editors where typing always inserts text
- Structural regular expressions: Pattern matching that operates on hierarchical text structure rather than linear character sequences, from the Plan 9 sam editor
Original article
vi-style editors remain popular because, despite their age and steep learning curve, they enable highly efficient editing and are available almost everywhere through native tools or keybindings.
Google's Gemini app is getting a complete UI overhaul that consolidates Images, Videos, Canvas, and Deep Research into a unified bottom sheet, moving away from the fragmented tool experience.
Original article
Google's Gemini app is receiving a comprehensive UI overhaul featuring a pill-shaped prompt box, a colorful pulsating gradient background, and a redesigned homepage greeting. The update consolidates tools like Images, Videos, Canvas, and Deep Research into a unified bottom sheet with a media carousel, while the model picker returns to the top-left as a dropdown. On iOS, the redesign makes heavy use of Liquid Glass, though broader rollout details for Android remain unclear.
Unbox Therapy's hands-on with an iPhone Ultra dummy unit reveals a passport-style foldable design, suggesting Apple's first foldable iPhone is moving toward production.
Decoder
- Dummy unit: Non-functional physical prototype used to test form factor, ergonomics, and industrial design before final hardware is manufactured. Often shared with case makers and reviewers to prepare for launch.
Original article
Unbox Therapy released a detailed hands-on video of a dummy unit believed to represent Apple's upcoming iPhone Ultra, giving a clearer picture of its foldable, passport-style design that opens into a tablet-like form. While the hardware isn't final, the video focuses on real-world feel—covering dimensions, thickness, ergonomics, button reach, and even how the device sits on a table—while reinforcing recent leaks about Apple's first foldable iPhone.

MotionVFX is bundling AI-powered rotoscoping, 3D tracking, and local 8K upscaling into a $29/month Final Cut Pro subscription accessed via a native plugin.
Decoder
- Rotoscoping: Frame-by-frame masking technique to isolate moving subjects in video, traditionally manual and time-intensive, now automated with AI tracking
- Planar tracking: Tracking flat surfaces in 3D space rather than single points, used to replace screens, signs, or surfaces in footage
- 3D camera tracking: Analyzing footage to reconstruct the 3D camera movement, allowing insertion of 3D elements that match the original shot's perspective
- LUT (Look-Up Table): Pre-configured color grading file that maps input colors to output values for consistent cinematic looks
Original article
MotionVFX offers a comprehensive effects and software toolkit for Final Cut Pro that enables editors to create professional-grade visuals with drag-and-drop functionality. The toolkit includes AI-powered features like automatic tracking, rotoscopy, upscaling, captions, and cinematic grading.

Skipped (ad/sponsored)
Original article
The Tofoo Co has introduced its first major packaging redesign in over a decade, created with CHILLI, to improve shelf visibility and unify its product range as demand for plant-based foods grows. The new look features bold, simplified typography on a clean white background, along with clearer health messaging, creating a more flexible and cohesive brand identity. The redesign aims to reposition the brand for future expansion. Rollout across UK retailers started in April.

Pixar released a botanical guide-style infographic poster featuring A Bug's Life characters with scientific labels, prompting fans to demand T-shirts and prints.
Original article
A Bug's Life inspired a charming Pixar infographic styled like a botanical guide featuring beloved characters with scientific labels.
Bank of Italy Deputy Governor Chiara Scotti wants the EU to tokenize SEPA, Europe's €116 trillion payment network, rather than wait for the digital euro to materialize.
Decoder
- SEPA (Single Euro Payments Area): EU payment network enabling standardized euro transfers across 36 countries with instant settlement and shared technical formats.
- Tokenized deposits/payments: Bank-backed funds represented as blockchain tokens, enabling programmable money and atomic settlement without requiring new central bank currencies.
Original article
Bank of Italy Deputy Governor Chiara Scotti said the EU should develop a "tokenized extension of SEPA," arguing that Europe's existing payment framework, which processed €116 trillion in non-cash transactions in H1 2025, provides a strong foundation for tokenized infrastructure given its scale, shared standards, and interoperability. Scotti framed this as complementary to the ongoing digital euro work, noting that while stablecoins and tokenized deposits serve legitimate use cases, their broader monetary implications are "less clear."

Virtuals Protocol launched Arena with $200K weekly prize pools where autonomous trading agents compete on real markets with zero downside—the platform absorbs all losses while profitable agents pocket 50% of gains.
Decoder
- HIP-3 assets: Hyperliquid Improvement Proposal 3 asset class that expanded the platform beyond crypto perpetual futures to include traditional equities, stock indices, and commodities.
- Perps: Perpetual futures contracts, crypto derivatives with no expiration date that track spot price through funding rate mechanisms.
Original article
Virtuals Protocol opened Arena publicly, a capital allocation platform where registered trading agents compete for a $200K weekly copy-trading pot on Hyperliquid perps across 100+ tokens and HIP-3 assets including equities and commodities. Profitable agents receive 50% of gains directly in USDC, the remaining 50% rolls back into the pot, and Virtuals Protocol absorbs all losses, eliminating downside risk for strategy builders. The launch drops a prior requirement to tokenize strategies before proving performance, opening Arena to quant, discretionary, momentum, macro, and mean-reversion approaches. The model decouples strategy value from account size by letting traders express a proven signal through allocated capital.
DTCC Plans July Pilot for Tokenized Securities With BlackRock, Circle
DTCC, the $114 trillion central clearing infrastructure for US equities, is launching a tokenized securities platform with BlackRock and 50+ firms, pilot trading in July.
Deep dive
- DTCC custodies $114 trillion in liquid assets and serves as the central clearing infrastructure for US equity markets, making this one of the largest traditional finance institutions to launch a blockchain-based securities platform
- The platform will tokenize ETFs, US Treasury securities, and all stocks in the Russell 1000 index using blockchain-based ownership records
- Pilot trading begins July 2026 with full commercial service launching October 2026
- More than 50 participants from both traditional finance (TradFi) and decentralized finance (DeFi) are involved, including BlackRock (world's largest asset manager), Circle (USDC stablecoin issuer), and Fireblocks (institutional crypto custody)
- Unlike previous tokenization experiments limited to specific assets or private markets, DTCC's involvement could extend onchain settlement to the full domestic equity and fixed-income complex
- This represents a shift from blockchain being used primarily for crypto-native assets to becoming infrastructure for mainstream institutional securities trading
- The aggressive timeline (pilot to production in three months) suggests significant preparation has already occurred behind the scenes
Decoder
- DTCC: The central clearing house for US equity and bond markets. Nearly all stock and bond trades flow through DTCC for settlement.
- Securities tokenization: Converting traditional securities (stocks, bonds, ETFs) into blockchain-based digital tokens for trading and settlement.
- Onchain settlement: Completing trades by transferring ownership on a blockchain instead of through traditional multi-day clearing.
- TradFi vs DeFi: Traditional finance institutions versus decentralized blockchain-based finance.
Original article
DTCC, which custodies $114 trillion in liquid assets, plans to launch a tokenized securities platform with pilot trading beginning July and full service in October. More than 50 TradFi and DeFi firms are participating, including BlackRock, Circle, and Fireblocks. The full-service platform will tokenize ETFs, Treasury securities, and Russell 1000 stocks using blockchain-based ownership records. As the central clearing infrastructure for US equity markets, DTCC's entry could extend onchain settlement to the full domestic equity and fixed-income complex at institutional scale.
Solana Foundation joined Visa, Mastercard, Stripe, Google, and Amazon in a Linux Foundation project to standardize AI agent payments, as agents settled an estimated $31B on Solana in 2025.
Decoder
- x402: Open standard protocol for agentic payments, now stewarded as a Linux Foundation project. Defines how AI agents authenticate, authorize, and settle financial transactions.
- Agentic payments: Financial transactions initiated and executed autonomously by AI agents rather than humans.
- SPL: Solana Program Library, Solana's token standard. Confidential SPL transfers use zero-knowledge proofs to hide transaction amounts.
- Ephemeral rollup: Temporary execution environment that processes transactions off-chain for privacy or batching, then commits final state to the main chain.
Original article
The Solana Foundation joined the x402 Foundation as a Linux Foundation project in April, aligning with Visa, Mastercard, Stripe, Google, Amazon, Coinbase, Circle, and Cloudflare to co-steward the open standard for agentic payments. Solana accounts for about 65% of x402 transaction volume year-to-date, with agents selecting the chain for sub-cent, stablecoin-settled, pay-per-use economics. April integrations included Alchemy, Messari, Zerion, and Crossmint (with Mastercard), while MoonPay eliminated stablecoin onramp fees for AI agents on Solana, and Magicblock shipped private payments via confidential SPL transfers with ephemeral rollup delays. MiloOnChain crossed $600K monthly volume and 250K agentic transactions with win rate climbing from 15% to 46.1%, as AI agents settled an estimated $31B in payment volume on Solana in 2025 outside traditional banking rails.

Banks claim stablecoin yields would slash lending by 20%, but White House economists say 0.02%, exposing a three-orders-of-magnitude gap as the bipartisan CLARITY Act compromise heads to Senate markup in mid-May 2026.
Deep dive
- Senators Thom Tillis and Angela Alsobrooks announced their final Section 404 compromise on May 5, 2026, declaring negotiations closed despite banking opposition with "we respectfully agree to disagree"
- The compromise bans stablecoin compensation "economically or functionally equivalent" to bank deposit interest while preserving activity-based rewards (trading volume, staking, platform engagement)
- The American Bankers Association condemned the deal, warning broad stablecoin adoption could cut consumer and small-business lending by one-fifth or more
- White House economists disputed banks' projection, estimating a stablecoin yield ban would increase bank lending by only $2.1 billion, a 0.02% increase—three orders of magnitude smaller than banks' claim
- Coinbase and Circle backed the compromise, with Circle stock jumping 20% and Coinbase CLO Paul Grewal commending the bipartisan consensus
- The CLARITY Act passed the House 294-134 last July, establishing SEC/CFTC regulatory jurisdiction boundaries for digital assets
- Senate Banking Committee Chair Tim Scott indicated "real progress" with markup scheduled for mid-May 2026
- Full Senate vote could occur in June or July 2026, with President Trump signaling he would immediately sign the bill upon passage
- Polymarket probability for 2026 enactment rose to 70%, the highest in over 30 days following the announcement
- Senator Cynthia Lummis called the settlement "the culmination of months of hard work" and suggested the CLARITY Act's enactment is imminent
- The regulatory framework addresses a principal obstacle to institutional capital deployment—unclear SEC vs CFTC jurisdiction over digital assets
- Lawmakers acknowledged banking sector representatives participated throughout negotiations and received consideration, though the fundamental framework remains unchanged
Decoder
- Stablecoin: Cryptocurrency pegged to a reserve asset (typically US dollar) designed to maintain stable value, such as USDC or USDT
- CLARITY Act (Digital Asset Market Clarity Act): Federal legislation establishing regulatory framework for digital assets, including stablecoin rules and SEC/CFTC jurisdiction boundaries
- Section 404: Specific provision in the CLARITY Act addressing stablecoin yield and rewards programs
- Polymarket: Cryptocurrency-based prediction market platform where users bet on real-world event outcomes
- Senate Banking Committee markup: Committee session where senators review, amend, and vote on legislation before sending it to the full Senate
Original article
The American Bankers Association is opposing stablecoin yield provisions in the CLARITY Act compromise, arguing the Tillis-Alsobrooks text falls short on deposit protection even though the bill passed the House 294-134 last July. Banks warn that broad stablecoin adoption could cut consumer and small-business lending by one-fifth or more. White House economists disputed that projection, estimating a stablecoin yield ban would raise bank lending by only $2.1 billion, a 0.02% increase. Coinbase and Circle have backed the compromise, which bans stablecoin rewards economically or functionally equivalent to deposit interest while preserving a carve-out for bona fide activities.

Terrorism victims holding $877 million in North Korea judgments are trying to seize $71 million in ETH stolen by Lazarus Group from Aave, arguing briefly stolen crypto becomes the thief's legal property.
Deep dive
- Aave filed Monday in Southern District of New York to vacate restraining notice served on Arbitrum DAO by lawyers for DPRK judgment creditors
- The frozen 30,765 ETH stems from April 2026 Kelp DAO exploit where attackers used forged message to mint 116,500 unbacked rsETH tokens on Arbitrum
- Attackers used the unbacked rsETH as collateral on Aave to withdraw approximately $230 million in ETH from the protocol
- Arbitrum Security Council froze the intercepted funds as part of coordinated recovery effort to return them to affected Aave users
- Three sets of judgment creditors hold $877 million in damages awards against North Korea from separate terrorism cases dating back decades
- Plaintiffs argue that because rsETH attackers are widely believed to be Lazarus Group (DPRK state actors), the recovered ether can be claimed against those judgments
- Aave's motion calls the Lazarus attribution "conjecture" based on unverified reports and argues even if true, thieves don't gain legal ownership by briefly possessing stolen property
- Aave warns keeping funds frozen "increases the likelihood of cascading liquidations, sustained liquidity outflows, and irreversible changes to user positions" in already-strained DeFi markets
- The filing seeks immediate lift of restraining notice or at minimum suspension while the case is heard
- Outcome could determine whether future crypto hack recovery efforts face interference from outside creditors seeking to garnish seized funds
- Core legal question: does temporarily holding stolen crypto during an exploit confer legal property rights that creditors can seize under existing federal judgments?
Decoder
- Garnishee: Legal term for a party holding property that belongs to a debtor, who may be ordered by a court to turn those assets over to the debtor's creditors
- rsETH: Kelp DAO's liquid restaking token on Ethereum, which became unbacked after the exploit allowed attackers to mint tokens without proper collateral
- Judgment creditor: Someone who has won a monetary judgment in court but has not yet collected the full amount, and is pursuing legal means to seize the debtor's assets
Original article
Aave filed in a New York federal court to lift a restraining notice blocking access to 30,765 ETH ($71 million) frozen after the April 18 Lazarus Group exploit of Kelp DAO's rsETH bridge, which used a forged message to mint 116,500 unbacked rsETH tokens on Arbitrum. A lawyer representing North Korean terrorism victims served Arbitrum DAO as a garnishee in three federal enforcement actions tied to $877 million in existing DPRK judgments, arguing the frozen ETH qualifies as North Korean state property under US law. Aave counters that the ETH belongs to innocent third parties and that brief attacker possession does not transfer legal ownership. The outcome could determine whether Lazarus Group exploits expose DeFi users' assets to federal garnishment under existing DPRK judgment enforcement frameworks.

Solana's record $750M daily USDC mints and Visa integrations couldn't prevent a 43% SOL decline and ecosystem exodus by Lifinity and Magic Eden, exposing a value capture crisis where Circle earns treasury yields while validators and token holders earn nothing.
Deep dive
- Record technical metrics during Q1 2026: $750M in single-day USDC mints, $348M in crypto card volume processed
- Major integrations shipped: Western Union stablecoin partnership, Visa payment rails integration
- Core infrastructure improvements: Firedancer validator client optimizations rolled out to increase network throughput
- Token price collapse: SOL down 43% over four months despite what observers called Solana's best shipping quarter
- Ecosystem exodus: Lifinity (major DEX) shut down operations, Remora protocol closed, Magic Eden (leading NFT marketplace) killed its Solana wallet product
- Value capture crisis: Circle (USDC issuer) earns treasury yield on every USDC dollar flowing through Solana's network by holding US Treasury bonds as backing
- Broken validator economics: Solana validators earn minimal transaction fees ("collect dust") while processing billions in stablecoin volume
- Core argument: Solana is becoming world-class payment infrastructure for stablecoin issuers who extract value without compensating network stakeholders
- Bottom line: "Shipping without value capture is building someone else's business for free"
Decoder
- Firedancer: High-performance Solana validator client developed by Jump Crypto, designed to dramatically increase network throughput and reliability as an alternative to the original Labs client
- Circle/USDC yield model: Circle issues USDC stablecoin backed 1:1 by US Treasury bonds and reserves, keeps all interest income from those holdings (earning billions annually), while blockchain networks that process USDC transactions receive no share of this revenue despite providing the infrastructure
Original article
The Solana network posted $750M in single-day USDC mints and $348M in crypto card volume, secured a Western Union stablecoin integration, and shipped Firedancer optimizations and Visa integrations, yet SOL has fallen 43% over the past four months.
US spot Bitcoin ETFs drew $532M on May 4, extending a three-day institutional buying streak to $1.18B total.
Original article
US spot bitcoin ETFs attracted $532.2M in net inflows on May 4, pushing the three-day combined total to $1.18B following $629.7M on May 1 and $14.8M on April 30.

45% of Americans Call Crypto Risky, Half Prefer Traditional Banks
Crypto enforcement shifted from SEC securities cases to AML violations, with DOJ and FinCEN imposing $1 billion in fines in H1 2025 while SEC penalties dropped 97% to $142 million.
Decoder
- Zero-knowledge proof: Cryptographic method that proves knowledge of a value without revealing the value itself, used in privacy coins to verify transactions without exposing amounts or balances.
- Rootstock: Bitcoin sidechain that enables smart contracts while using Bitcoin's blockchain as the underlying security layer.
Original article
A Politico poll of 2,035 US adults finds 45% view crypto investment as risky and nearly half favor traditional banks over crypto platforms, with two-thirds supporting strict Congressional AI regulations.