Devoured - May 21, 2026
OpenAI is reportedly preparing for an IPO as early as September 2026, while Stability AI released open-weight Stable Audio 3.0 models for generative audio, and Anthropic committed to a $45 billion compute deal with SpaceX. Developers can also now explore Google's Agent Executor for reliable agent workflows and ByteDance's open-source multimodal model, Lance.

Stable Audio 3.0
Stability AI released Stable Audio 3.0, an open-weight model family that generates music and sound effects up to six minutes, trained on fully licensed data.
Deep dive
- Stability AI launched Stable Audio 3.0, a new family of models for generating music and sound effects.
- Key features include variable-length generation up to 6 minutes and 20 seconds for Medium and Large models.
- The 3.0 Small model is capable of full music composition directly on portable devices.
- Three models (Small SFX, Small, Medium) are open-weight and available on Hugging Face, allowing free download and building.
- All models are trained on fully licensed data, granting users ownership and commercialization rights under the Stability AI Community License (or Enterprise License for larger organizations).
- The architecture uses a novel semantic-acoustic autoencoder for more flexible generation.
- The release includes documentation and weights for LoRa training, an efficient fine-tuning method.
- It also supports audio inpainting for editing and extending tracks.
- Stable Audio 3.0 Large is available via the Stability AI API and for enterprise self-hosting.
Decoder
- Open-weight models: AI models where the underlying parameters and architecture are publicly released, allowing users to inspect, modify, and run the models locally.
- LoRa (Low-Rank Adaptation): An efficient fine-tuning method for large models that trains a small number of new parameters instead of the entire model, making customization faster and less resource-intensive.
Original article
Meet Stable Audio 3.0, the model family built for artistic experimentation with open-weight models
Key Takeaways:
- We're releasing Stable Audio 3.0, a model family with open-weights music models that are trained on fully licensed data.
- You own your outputs and can distribute and commercialize them under the Stability AI Community License, or the Enterprise License for organizations with more than $1M in revenue.
- Key innovations include variable-length generation up to six minutes, and full song composition on portable devices.
- Stable Audio 3.0 Small and Medium are available on Hugging Face. You can download the weights here.
- Stable Audio 3.0 Large is available via the Stability AI API and self-hosting for enterprise deployments. Try it out here.
Today we're releasing Stable Audio 3.0, a model family trained on fully licensed data, designed to be the foundation for what the audio community builds next. Three of the models are open weights, free to download and build on.
Music has always evolved through the collective creativity of its community. Remix culture, interpolations, and mashups are how artists build on each other's work and push the art form forward. Generative audio will be no different. We want to foster the same kind of community-driven innovation in audio that we sparked in image generation with the launch of Stable Diffusion.
Stable Audio 3.0 is our open invitation to experiment with generative audio. We believe the best innovations are still waiting to be built.
Meet the Stable Audio 3.0 model family
We’re releasing four new models designed for different use cases and deployment options:
- Stable Audio 3.0 Small SFX: Sound effects generation on-device, such as mobile phones and consumer-grade laptops.
- Stable Audio 3.0 Small: Full music composition on-device.
- Stable Audio 3.0 Medium: Higher musicality (i.e. structure, melodic coherence, and phrasing) and longer track length at up to 6:20.
- Stable Audio 3.0 Large: The most advanced musicality in the family, built for music platforms and creative applications that need low-latency generation at high volume.
Open for experimentation, with ownership of what you create
All Stable Audio 3.0 models are trained on fully licensed data. Under the Stability AI Community License, you own your outputs and can distribute and commercialize them freely.
For organizations with more than $1M in annual revenue, you can get commercial coverage with our Enterprise license. We also offer legal indemnification under the Enterprise license.
3.0 Small SFX, 3.0 Small, and 3.0 Medium are all open-weights. To our knowledge, other open music models either restrict commercial use or carry the risks associated with being trained on unlicensed music.
Architectural advancements for variation and iteration
Stable Audio 3.0 is our next-gen architecture, built with a novel semantic-acoustic autoencoder that enables longer, more flexible audio generation. You can read the full research paper here.
Variable-length generation, up to more than six minutes. Stable Audio 3.0 introduces a new method for variable-length audio generation that enables you to generate exactly what you need, at per-second granularity.
3.0 Small generates up to two minutes, compared to 11 seconds from Stable Audio Open Small, and 47 seconds from Stable Audio Open. 3.0 Medium and 3.0 Large generate more than six minutes.
Full music composition on-device. To our knowledge, 3.0 Small is the only model capable of full music composition on-device. For the first time, on-device and offline audio generation isn't limited to short samples; it can produce complete musical tracks.
Customize the models on your own library with support for LoRa training. A LoRa is an efficient method for fine-tuning that was first made popular in image generation, and is now an emerging method for customizing audio generation models.
For the first time we're publishing documentation for LoRa training, alongside the weights for 3.0 Small and 3.0 Medium. For organizations with our Enterprise license, we offer the option of white-glove support with fine-tuning.
Audio inpainting options. Modify a segment of a track, rework part of a song, or extend your composition without starting over. Stable Audio 3.0 supports single-segment editing, multi-segment editing, and causal continuation (extending audio beyond its original endpoint).
Setting the stage for what’s next
Stable Audio 3.0 is the new architecture on which we're already building our next generation of fully licensed audio models for professionals.
While responsibly trained generative AI models are critical, they are not enough on their own. Artist-centric AI will only win if the product experience on a licensed platform is better than the experience on an unlicensed platform.
We're also working on a suite of new products for musicians. Join the waitlist to get early access.
In the meantime, you can learn more about our partnerships with Universal Music Group and Warner Music Group.
Get started with Stable Audio 3.0 now
Open weights: Download 3.0 Small SFX, 3.0 Small, and 3.0 Medium on Hugging Face. For organizations with more than $1M in annual revenue, contact us to discuss our Enterprise Licensing.
API: Stable Audio 3.0 Large is available via the Stability AI API.
Partner platforms: Stable Audio 3.0 will be available on ComfyUI and other platforms.
To stay updated on our progress, follow us on X, LinkedIn, Instagram, and join our Discord Community.

Anthropic to Pay SpaceX Nearly $45 Billion for Computing Deal
Anthropic will pay SpaceX nearly $45 billion over three years, $1.25 billion monthly until May 2029, for compute resources at SpaceX's Colossus 1 and a second data center.
Original article
Anthropic has agreed to pay SpaceX nearly $45 billion over the next three years for compute resources. It will pay $1.25 billion per month until May 2029, with either party being able to end the agreement with 90 days' notice. The companies had earlier this month inked a deal that gave Anthropic 300 megawatts of computing capacity from a large SpaceX data center in Memphis known as Colossus 1. This partnership has expanded to include capacity at a second SpaceX data center.
AI Solves a Longstanding Geometry Conjecture
An OpenAI reasoning model autonomously disproved a 1946 combinatorial geometry conjecture related to the planar unit distance problem, independently verified by mathematicians.
Decoder
- Combinatorial geometry: A branch of mathematics that combines principles of combinatorics and geometry, focusing on finite arrangements of geometric objects like points, lines, and circles.
- Planar unit distance problem: An unsolved problem in combinatorial geometry asking for the maximum number of pairs of points in a set of 'n' points in a plane that are exactly one unit apart.
- Algebraic number theory: A branch of number theory that studies algebraic integers and their properties, often using methods from abstract algebra.
Original article
An OpenAI reasoning model autonomously disproved a major conjecture tied to the planar unit distance problem, an open question in combinatorial geometry that dates back to 1946. The proof introduced techniques from algebraic number theory and was independently verified by external mathematicians, marking one of the first cases where an AI system resolved a prominent unsolved mathematics problem.

Introducing Agent Executor, Google's distributed Agent Runtime
Google introduced Agent Executor, an open-source runtime standard for reliably and efficiently deploying long-running AI agent workflows with features like durable execution, secure isolation, and connection recovery.
Deep dive
- Agent Executor is Google's new open-source runtime standard for executing, resuming, and deploying AI agent workflows.
- It addresses the challenges of fragile and hard-to-manage long-running agent tasks in production environments.
- Durable execution ensures workflows can resume after outages or human-in-the-loop (HITL) interruptions, using event logs and snapshotting.
- Secure isolation is provided through sandboxes, preventing harmful side effects and compromising services, especially for code-generating agents or multi-tenant scenarios.
- Session consistency is maintained in distributed workflows via a built-in single-writer architecture.
- Connection recovery allows clients to reconnect after disconnections, backfilling responses for a better user experience.
- Trajectory branching enables agents to test different decision paths from checkpoints without losing context.
- Agent Executor integrates with Agent Substrate, a new open-source Kubernetes Engine abstraction, designed to optimize compute efficiency for massive agent deployments by handling millions of sub-second tool calls.
- It is harness-agnostic, supporting Google's Antigravity, Gemini APIs, LangChain/LangGraph, and other Agent Development Kits (ADK) and Agent2Agent Protocol (A2A) agents.
- The project promotes vendor lock-in prevention, allowing enterprises to run agents on their own infrastructure and control data residency.
- Agent Executor is available in preview on GitHub for developers to explore and provide feedback.
Decoder
- Agent workflow: A series of automated steps and decisions carried out by an AI agent, often involving interactions with external tools, APIs, or human users.
- Durable execution: A programming paradigm where a long-running process can reliably resume its state and continue execution after interruptions, crashes, or reboots.
- Human-in-the-loop (HITL): A model where human interaction is required to complete or refine a process, often for validation, correction, or complex decision-making within an automated system.
- Trajectory branching: In the context of AI agents, this refers to the ability to explore different possible decision paths or sequences of actions from a given state, similar to branching in version control systems, allowing for testing and evaluation without committing to a single path.
- Agent Substrate: A new abstraction layer for Google Kubernetes Engine (GKE) designed specifically to optimize compute for AI agent workloads, particularly those involving a high volume of short-lived tool calls, by moving agents on and off compute capacity in real-time.
Original article
Introducing Agent Executor, Google’s distributed Agent Runtime
Jaana Dogan
Software Engineer
Ethan Bao
Engineering Director
As models and harnesses improve, agents are taking on increasingly complex tasks that can run for hours or even days. But as we push agents to do more, this has surfaced a new operational problem: long-running agent workflows are fragile and incredibly hard to manage reliably and efficiently in production.
Today, we’re introducing Agent Executor, Google’s open-source runtime standard for agent execution, resumption, and distributed deployment. Based on what we’ve learned from solving these challenges internally, we’ve built Agent Executor to have the following native capabilities:
- Durable execution: Long-running execution requires the ability to resume after outages or agentic interruptions such as human-in-the-loop (HITL) confirmations. Agent Executor provides this backend resilience automatically for any actor (e.g., an agent, agent harness, skill, tool, or sandbox) through its event log and snapshotting.
- Secure isolation: Agent Executor isolates components in secure-by-design sandboxes to prevent harmful side effects and help ensure malicious activity cannot compromise the broader service. Sandboxes are especially useful when agents generate code or handle multiple tenants or user data concurrently.
- Session consistency: In distributed agent workflows, multiple components may attempt to update shared session state at the same time. Agent Executor’s built-in single-writer architecture helps maintain consistency and reduces the risk of corruption in that state.
- Connection recovery: In long-running agentic execution, clients may disconnect for many reasons, including network outages. Agent Executor lets clients reconnect to agents and backfills responses from the last sequence seen by the client for a better user experience.
- Trajectory branching: Checkpoints let you branch an agentic trajectory (its decision or workflow path) at any point, allowing agents to test or evaluate different paths without losing context or other state.
In this blog, we’ll share more about Agent Executor and how you can get started.
Federate with Google’s agent runtime
Enterprise adoption of agents requires orchestration across deployment models. Some teams need on-prem infrastructure for proprietary workflows, performance, or compliance, while others prefer pre-built or custom managed agents for faster time-to-value. At Google I/O, we introduced a new suite of such solutions – including Antigravity 2.0 and the Managed Agents API – designed to accelerate how teams build and scale within the agentic enterprise.
Agent Executor bridges these deployment models, letting you mix-and-match between any or all of:
- Google Antigravity, Gemini’s state-of-the-art agent harness
- Google-built frontier agents, such as the latest Deep Research agent
- Custom agents built by you and managed by Google (e.g., via the new Managed Agents in Gemini API)
- Custom purpose-built agents, built with LangChain/LangGraph, Agent Development Kit (ADK), etc and any agents using Agent2Agent Protocol (A2A)
Own your agents, models, and compute
With Agent Executor, enterprises have maximum flexibility to maintain sovereignty over workloads and keep proprietary workflows within their self-managed compute and custom sandboxes. Your internal development teams have much more flexibility over how agents are deployed and managed and you benefit from:
- Prevent vendor lock-in: Deploy your agents on your own infrastructure without being tethered to a specific provider’s model or compute environment. This allows for full control over data residency and your cost and budgetary controls.
- Bring your own harness and agents: Agent Executor is designed to be harness-agnostic, allowing you to bring your own or use those made available by other vendors. It also supports agents developed with industry-standard frameworks and protocols providing a broad ecosystem of compatible agents.
- Fully control execution: Agent Executor allows developers to run the entire agentic stack, including MCPs, skills, and other agents, directly on their own data plane. Developers can choose any compute with custom isolation boundaries and workload policy enforcement.
Scale agents up on Kubernetes with an agent-first compute layer
As agent workloads scale into the hundreds of millions and become increasingly long-running, our customers are hitting the limits of traditional compute abstractions because unlike traditional software, agents are nonlinear programs that wait for external inputs. To solve this problem, we’ve partnered with the Google Kubernetes Engine team on Agent Substrate, a new open-source project also announced today.
Agent Substrate introduces a new level of abstraction for Kubernetes that moves agents onto and off of ready compute capacity in real-time, resulting in lower latency with higher scale and efficiency. While standard Kubernetes is optimized to handle thousands of long-running services, Agent Substrate is designed for the chatter of millions of sub-second tool calls that would otherwise overwhelm a standard control plane. Agent Substrate takes core secure runtime and snapshotting capabilities of existing sandbox infrastructure and pairs them with a minimal control plane designed to bypass some of the limitations of Kubernetes, without reinventing the rest of it. Working together, these layers enable you to:
- Maximize compute efficiency: Agent Substrate introduces a new control plane designed to handle hundreds of millions of registered agents. Together with Agent Executor, Agent Substrate can provide a foundation for today’s largest agent deployments.
- Stay within the Kubernetes ecosystem: Agent Substrate is built on top of Kubernetes and allows scheduling and horizontal scaling of compute with declarative configuration.
In the demo below, we showcase using Agent Executor together with Agent Substrate with a sample workload.
Get started today
Models, agents, harnesses, and the infrastructure around them are all evolving faster than ever. We’re building Agent Executor in the open so we can validate the design in the hands of real developers and improve based on your feedback.
Agent Executor is available now in preview. We invite you to explore the code, test it with your own workloads, and help shape the future of agent runtimes. Head over to our GitHub repo to get started today.
Gemini 3.5 Flash Developer Guide
Google's Gemini 3.5 Flash model is now generally available, introducing features like "Thinking," multimodal function responses, and robust agentic execution for coding and long-horizon tasks.
Decoder
- Agentic execution: The ability of an AI model to autonomously plan, execute, and iterate on complex tasks, often by breaking them down into sub-tasks and using external tools.
- Multimodal function responses: The capability of an AI model to use information from multiple modalities (e.g., text, images) when calling external functions or responding to prompts.
- Long-horizon tasks: Complex tasks that require multiple steps, sustained reasoning, and often involve memory or planning over extended interactions.
Original article
Gemini 3.5 Flash is now generally available. This guide contains an overview of improvements, API changes, and migration guidance for the model. Gemini 3.5 Flash features Thinking, structured outputs with tools, multimodal function responses, code execution with images, and combined tool use, but not Computer Use. It delivers sustained frontier performance in agentic execution, coding, and long-horizon tasks at scale.

Coding is solved? Software is not
While AI tools like Claude Code can write 100% of code, the core challenge of software development remains problem understanding, design, and verification, not just implementation.
Deep dive
- Boris Cherny, creator of Claude Code, suggests "coding is largely solved" as AI can write and review 100% of code.
- The article argues that while AI speeds up code implementation, it doesn't solve the broader challenges of software development, which include turning ambiguous intent into reliable systems.
- AI agents can produce "AI slop," output that looks complete but doesn't genuinely reduce the complexity or "entropy" of the problem.
- The bottleneck shifts from code writing to establishing context, creating precise specifications, verifying agent output, and instituting human checkpoints.
- A vague task given to an AI agent can lead to a "finished" but incorrect implementation, as agents lack human judgment to question product decisions.
- Trust becomes the expensive part when code is cheap to generate; reviewers need clear evidence of what the agent ran, what failed, and why.
- The company Arcplane is developing a workflow tool to manage agentic software work on production codebases, focusing on structured context, persistent specs, verifiable evidence, and human review points.
- This new workflow aims to allow agent-authored work to be reviewed as a real change rather than requiring decoding from chat transcripts.
- Ultimately, the challenge is making AI-generated code hold up to scrutiny and fit correctly within the overall system.
Decoder
- AI slop: AI-generated output that appears complete or coherent but lacks true substance, accuracy, or usefulness, often adding to confusion rather than clarity.
- Entropy reduction (in software development): A metaphor for the process of transforming a messy, ambiguous problem statement into a clear, verified, and shippable software change.
Original article
Boris Cherny, the creator of Claude Code, said in a recent talk:
…at this point, it’s safe to say that coding is largely solved - at least for the kind of programming that I do.
He described a workflow where Claude Code writes 100% of the code and Claude reviews every pull request, while humans still act as checkpoints for safety and quality.
The line works because AI coding tools can feel both magical and disappointing. A change that used to take an afternoon can arrive as a credible first draft in minutes, and then the team may still spend hours, sometimes days, deciding whether it was the right change to make.
If implementation is becoming abundant, why does building software still take so much time and effort?
Coding is not the whole job
“Coding is solved” is a provocative statement. It is also an incomplete one.
Models still hallucinate, and generated changes still need review. But the statement points at something real: for many software teams, writing code has stopped being the slowest part of building software.
And yet, software development does not feel solved.
Because coding does not equal software development.
Coding turns instructions into implementation. It remains important, and it is imperfect. But software development is larger than that: it turns ambiguous intent into a reliable system.
No matter what process a team follows, someone has to understand the problem before code exists. The team has to narrow the scope until “done” means something concrete.
After code exists, someone has to prove that the change belongs in the system, ship it safely, and keep owning the consequences.
This is where the promise frays. Implementation gets dramatically faster; the rest of software development does not disappear.
Software development reduces entropy
Not in the physics sense. But as a metaphor, it feels right.
A new feature often starts as a messy request: “Can we add team invitations?” At that point, there may not be an implementation to compare. The team is still figuring out which product behavior the request implies.
Product thinking reduces the mess first. Maybe “team invitations” means a simple email invite into an existing organization. Maybe role assignment can wait. A vague request becomes a narrower bet.
Design gives that bet a shape. The team decides who can send an invite, what an existing user sees, and what happens when an invite expires. Now there is proposed behavior, not just a product wish.
Implementation turns the behavior into a real change. Code gives the idea weight, but it also gives the team something new to distrust. The next question is no longer “can we build this?” It is “did we build the right thing, in the right way?”
Review and deployment close the loop. The change has to survive contact with the rest of the product and with real users.
At each step, software development narrows a messy space of possibilities until there is a change the team can verify. In that loose sense, software development is entropy reduction: turning confusion into a verified change.
The diagram below shows the clean version of that journey: intent becoming a shipped change the team can stand behind.
But fast coding can add entropy too
At first, it feels like AI agents can own implementation. In more ambitious versions of the story, they may eventually own the whole loop. But in practice, we often find that agents are “too smart” for their own good.
The failure mode is subtle. A generated test suite can be large and still mostly confirm the implementation the agent already chose. A review thread can grow longer because the agent nitpicks around the core issue. A plan can sound thoughtful while leaving the actual product tradeoff undecided.
This is one form of “AI slop”: output that looks complete, but does not actually reduce the mess.
After introducing AI agents, entropy can decrease in one part of the process and increase in another. The implementation arrives faster, but the team may spend more time reconstructing the agent’s intent and deciding how much of the evidence to trust.
The team produces code faster, but it does not necessarily trust the result sooner.
The missing piece: a new workflow
Once agents enter day-to-day work, the magic wears off a little. They start to feel more like capable junior teammates. The work starts to look more like mentoring:
You give them enough context to begin, then keep checking whether the work is heading toward the thing you meant.
In our team, the transition happened gradually.
At first, agents were personal assistants. They helped inside the developer’s existing loop, while the rest of the development process stayed mostly the same.
Then developers started delegating larger parts of implementation. Instead of writing most of the code by hand, they became editors of an agent’s proposed change.
That worked surprisingly well. It also made the surrounding workflow feel heavier.
Review started to include more archaeology. Context had to be repeated. Noisy tests had to be interpreted. Reviewers spent more time reconstructing what happened and why. None of it looked dramatic in isolation, but it changed the shape of the work.
Chat is useful while the task is still being discovered. But once a change needs review, the transcript becomes a poor source of truth: important decisions and concrete evidence are buried in the same stream as the back-and-forth that produced them.
When humans wrote most of the code, we tolerated a lot of workflow friction because implementation itself took time. Now the code arrives sooner, so the surrounding workflow gets exposed, and in some places the problems get worse.
That does not mean “coding is solved” is wrong. It means the bottleneck has moved.
For us, four problems keep coming back: context, specs, verification, and human checkpoints.
What needs to change?
We build and operate an auth product that manages millions of user identities. That makes us conservative about code written by agents. A change that looks local in the diff can still change who gets access to what, especially in a multi-tenant system.
So we cannot treat agents as a faster way to throw code over the wall.
Context chosen on purpose
A lot of agent work succeeds or fails before the agent writes code.
Large context windows help, but more context is not automatically better. A bloated prompt can bury the one rule that actually matters.
Most teams already have the needed context, but it is scattered across docs, old pull requests, chat, and things teammates remember.
For the invitation task, the useful context lives around membership and access: who can invite, where tenant boundaries are enforced, and whether an existing account accepts differently from a new one. Someone has to choose those pieces. If that choice stays in a developer’s head, the agent guesses. If it travels with the task, review starts from shared ground.
The context created during the work matters too. If a reviewer corrects the same mistake twice, that feedback should not stay buried in two separate pull requests. If a team introduces a new convention, future runs should be able to use it without every developer pasting the same reminder again.
That discipline helps agents. It helps the team too. The agent is just the pressure that makes the old context problem harder to ignore.
Specs that stay with the work
A vague task used to be less dangerous than it is now.
When a human engineer gets a vague task, they bring judgment with them. Sometimes that judgment shows up as a product question, a remembered edge case, or a refusal to implement the request as written.
An agent is much more willing to proceed. Give it a vague request, and it may still produce a full implementation. The result can look finished even when the interpretation was wrong.
That makes the spec matter more.
The invitation spec could still be short. An admin can invite someone by email. The invite expires after seven days. Existing users join after accepting. Role assignment waits for a later change, and cross-tenant access stays out of bounds. If review turns up a missing edge case, like a suspended user accepting an old invite, the spec should change before the agent keeps going.
Most tasks only need enough shape for the risk involved. A small bug fix may only need the expected behavior and a reproduction case. As the risk goes up, the spec has to capture the boundaries that matter: user flow, permissions, constraints, and migration story.
The spec cannot disappear once the agent starts coding. The agent plans against it. The implementation is judged against it. If the team discovers a missing edge case, the spec changes and the agent continues with the updated intent.
That is the version of spec-in-the-loop we care about. The useful spec is the one that stays close enough to the work to argue with it.
Evidence reviewers can trust
When code is cheap to generate, trust becomes the expensive part.
Agents can write useful tests. They can also write tests that mostly confirm the implementation they already chose. Coverage goes up, while the reviewer still has to ask: did we actually prove the behavior we care about?
Verification has to be visible enough for reviewers to know what the agent ran, what failed, and what changed after the failure. They also need to know whether the passing command was actually the right command for this task.
Later, the reviewer should see evidence for those promises, not a generic wall of green checks. The run should show that admin and non-admin paths were exercised, expiry was covered, and acceptance worked for both a brand-new user and an existing account. The command or environment behind that evidence should be visible too.
A small utility change may only need unit tests. A product flow is different: the real signal may come from exercising the experience end to end. For auth and permission changes, we usually want evidence from a reproducible environment, especially around database state and permissions.
The right checks vary by repo and team. What matters is that reviewers can inspect them. A reviewer should not have to dig through a long chat transcript to understand why the change is believed to be safe.
Agents are good at sounding confident. The workflow has to produce evidence.
Checkpoints where judgment matters
Humans should not sit in every loop forever. That defeats the point.
But some moments still need judgment.
Before implementation, someone needs to check whether this is worth building. A missing constraint or wrong scope can send the agent toward the wrong answer very efficiently.
This is where the human checkpoint may matter before any code exists. Someone has to decide whether role assignment belongs in scope, whether both owners and admins can invite, and how to handle an email that already belongs to another tenant. If a human punts on those questions, the agent can still ship clean code for the wrong product decision.
For some tasks, this checkpoint may matter more than code review.
Clean code cannot rescue a bad spec.
After implementation, the review shifts to the result. The question is whether the agent actually solved the problem in a way that fits the product. Test presence alone tells only part of the story; the tests have to mean something. Sometimes the risky part is a maintenance problem that appears later.
The depth of review should depend on risk. A copy update should not go through the same process as a permission change. As the system earns trust, some classes of work can run with less supervision. Others should stay tightly reviewed.
Those boundaries should be part of the workflow.
What we are building for the new workflow
Arcplane is our answer to that workflow gap.
Arcplane gives teams a place to run, review, and manage agentic software work on production codebases. It sits above tools like GitHub and gives agent-authored work a real lifecycle instead of leaving it as an unstructured chat-to-diff handoff.
In Arcplane, that same invitation task would begin with the chosen membership and permission context. The spec would stay with the run as it changes. The branch would carry evidence from checks that actually matched the behavior. Review would pause at the moments a human chose in advance, instead of hoping the important decisions survive in a chat transcript.
That is the workflow we want for our own team: agent work that can be reviewed as a real change, not decoded from a conversation.
Reusable instructions and agent skills help, but they are only ingredients.
A skill can encode repeatable team practice, such as migration review or the way risky auth changes are tested. But that practice still needs a place in the run and in review.
Code is getting easier to produce. The work now is making it hold up.
If this matches what you are seeing in your own team, subscribe below. We will share what we learn as we build.
Subscribe and we'll git push build notes, product updates, and changelog entries to your inbox.

Years-long fight over users' right to tweak smart TV software heads to trial
A California jury will decide in August if Vizio must release its Linux-based smart TV operating system's source code, a case that could profoundly impact user control over smart TVs.
Deep dive
- The Software Freedom Conservancy (SFC) filed a lawsuit against Vizio in 2021, alleging the company breached GPLv2 and LGPLv2.1 by not providing complete source code for its Linux-based Vizio OS.
- The trial is scheduled for August 10 in Orange County Superior Court of California.
- SFC argues that as owners of several Vizio TVs, they are third-party beneficiaries of the GPL licenses and have the right to demand the source code.
- Vizio, which was acquired by Walmart in December 2024, has resisted, arguing that SFC is not an intended third-party beneficiary and that GPL is a license, not a contract.
- Access to the full source code would allow users to make meaningful changes like limiting ads, deactivating automatic content recognition, and ensuring device longevity through community updates.
- The Free Software Foundation (FSF) supports SFC's efforts, stating that access to source code is a precondition for software freedom under GPL.
- A judge already ruled in December 2025 that Vizio is not required to guarantee a TV will function properly after a user reinstalls modified OS code, a stance supported by Linus Torvalds.
- The case's outcome could impact other smart TV manufacturers using Linux-based operating systems like LG's webOS, Samsung’s Tizen, and Roku’s Roku OS.
- Vizio's advertising business has been profitable ($115.8 million in the quarter before acquisition), making the ability for users to block ads a significant concern for the industry.
- SFC dismisses concerns about DRM key exposure, stating they do not want these keys and Vizio is free to remove them from any modified TV OS.
Decoder
- Software Freedom Conservancy (SFC): A US non-profit organization that promotes and provides legal support for free and open-source software projects.
- GNU General Public License (GPL): A widely used free software license that guarantees end users the freedom to run, study, share, and modify the software. It is a "copyleft" license, requiring that derivative works also be released under the GPL.
- GNU Lesser General Public License (LGPL): A free software license that allows linking to libraries under the LGPL from proprietary software, while still requiring modifications to the LGPL-licensed components themselves to be released under the LGPL.
- Copyleft: A general method for making a program (or other work) free, and requiring all modified and extended versions of the program to be free as well.
Original article
For years, owners of Vizio smart TVs have had little control over the software running on their sets—software that can track viewing habits, push ads, and generally shape the experience of using the device.
The Software Freedom Conservancy (SFC), a US nonprofit that promotes and provides legal support for free and open source software projects, isn’t happy about that—so much so that it has spent eight years trying to force the release of the complete source code for Vizio’s Linux-based smart TV operating system.
Now, after numerous delays since the SFC filed suit in 2021, a California jury will decide in August whether Vizio must provide that code in executable form to SFC and any Vizio TV owner who wants it.
The outcome could reverberate across the industry. Because many of today’s popular smart TV operating systems are Linux-based, the case may help determine how much control many owners have over their sets. Access to the full code would allow users to make meaningful changes to how their TVs work, including limiting ads or deactivating automatic content recognition.
Ahead of the trial, we spoke with an SFC executive about why it’s suing Vizio and what it hopes the case will accomplish.
Vizio and its parent company, Walmart, did not respond to multiple requests for comment. We reviewed filings from Vizio to understand why it doesn’t think the GNU’s General Public License (GPL) and its “Lesser” version (LGPL) require it to share the source code for Vizio OS (formerly Smart Cast).
Software Freedom Conservancy sues Vizio
The Software Freedom Conservancy argues it has the right to Vizio OS’s source code because it owns several Vizio TVs and because the operating system is based on Ubuntu, a Linux distribution. (SFC employees bought seven Vizio TVs from 2018 to 2021 after getting complaints about Vizio not sharing its TVs’ source code, according to the complaint.) In general, the Linux kernel is provided under the terms of GPLv2, as noted by kernel.org, which is run by the Linux Kernel Organization.
SFC’s lawsuit alleges that Vizio breached GPLv2 and LGPLv2.1 by failing to make available the complete source code for Vizio OS. The case is currently in the Orange County Superior Court of the State of California. The lawsuit targets Vizio specifically, but the impact could extend to other Linux-based smart TV OSes such as LG’s webOS, Samsung’s Tizen, and Roku’s Roku OS.
“We expect all companies who distribute Linux and other software using right-to-repair agreements like the GPL in their products would comply with these agreements,” Denver Gingerich, the director of compliance at SFC, told Ars.
SFC sued Vizio specifically because the group received numerous reports from concerned users about the company’s TVs, Gingerich said. Vizio has shared some of its operating system’s source code, but SFC claims that code does “not include all files and scripts that would permit the code to be compiled into an executable form,” according to its amended complaint from 2024 (PDF).
“As a nonprofit charity with limited resources, we sadly cannot solve every violation of the GPL agreement, but we do work hard to solve those that are important to a wide variety of users, and the popularity of Vizio TVs suggested to us that resolving this case would be especially worth the effort,” Gingerich said.
The terms of GPLv2 say that “[f]or an executable work, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the executable.”
FSF says there’s “no reason” for code to be withheld
Legal filings from both Vizio and SFC frame the Free Software Foundation (FSF) as the authority on the GPLs in question, as it’s the license steward and publisher of GNU licenses, including GPLv2 and LGPLv2.1.
FSF’s executive director, Zoë Kooyman, was deposed in the case in May 2025. When asked about the nonprofit’s stance, she said via email that the FSF supports SFC’s efforts and believes that “users should be free to enforce their right to source code under the GNU GPL licenses through any available legal mechanism.”
Vizio OS is believed to include at least two versions of the Linux kernel that are subject to GPLv2. The first appears to be tied to the Ubuntu distribution in the OS’s user interface and streaming platform, and the second seems to be tied to “a custom version supplied by VIZIO’s chip vendor for the lower-level operating system,” according to SFC’s amended complaint from 2024 (PDF).
In her email to Ars, Kooyman said:
In the definition of software freedom, which the FSF maintains, we explain the value of the four essential freedoms (run, study, modify, share). The definition clearly explains that access to the source code is a precondition for software freedom. Programs licensed under the GNU GPL can be assumed to have chosen this license to ensure users have these four essential freedoms, as *that is what the license was specifically designed to do*. There is no reason why these core requirements for software to be free would not need to be upheld.
Vizio OS also uses numerous other programs subject to the GPLv2, including BusyBox, dnsmasq, GNU Bash, GNU Tar, and SELinux. Other parts of Vizio OS, including DirectFB, FFmpeg, GNU C Library, SeLinux, and Systemd, are subject to the Lesser General Public License version 2.1 (LGPLv2.1).
Both GPLv2 and LGPLv2.1 are copyleft licenses, meaning that they grant “permission to freely use, modify, and redistribute the covered intellectual property—but only if the original license remains intact, both for the original project and for any modifications to the original project anyone might make,” as Ars alum Jim Salter explained.
Critical to SFC and Vizio’s dispute, the actual text of GPLv2 reads:
Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs; and that you know you can do these things.
LGPLv2.1 uses similar language.
SFC expects a ruling within three to six months of the conclusion of the trial, which is currently scheduled for August 10.
Vizio fights back
Absent a response from Vizio and Walmart, Vizio’s legal filings provide insight into the company’s defense.
In 2023, Vizio filed a motion for summary adjudication (PDF) seeking to avoid a trial (a judge denied the motion later that year (PDF). In the motion, Vizio argued that “SFC is not an intended third-party beneficiary to GPLv2 or LGPLv2.1 and, thus, doesn’t have the right to sue Vizio to enforce license terms.”
According to the litigation filing:
… nothing in the text of the GPLs suggests that third parties have the right to enforce alleged violations of the GPLs. Further, the FSF has made clear that it never intended third-party enforcement, stating publicly that ‘the copyright holders of the software are the ones who have the power to enforce the GPL’… and that ‘[i]f you think you see a violation of the GNU GPL [or] LGPL . . . you should send a precise report to the copyright holders of the packages that are being wrongly distributed . . . [because] we cannot act on our own where we do not hold copyright.
Vizio also argued that GPL is a software license, not a contract, so the company has no contractual obligation to provide SFC with Vizio OS’s source code, even if SFC were considered a third-party beneficiary of GPLv2 LGPLv2.
Broader implications for smart TVs
Because many other companies use Linux-based OSes, SFC’s lawsuit could have broad implications for smart TVs and their owners. The case stands out because it asserts that individual end users have rights as third-party beneficiaries of GPL licenses. Ultimately, the SFC hopes that filing the lawsuit as a third-party beneficiary of the GPL “will clearly demonstrate the feasibility of this approach,” Gingerich said.
Access to Vizio OS’s source code could allow users to tweak the software to add features like accessibility tools and avoid frustrations like user tracking and ads. Walmart acquired Vizio in December 2024 and is likely to make changes to Vizio OS aimed at furthering its advertising business. The company already requires some new Vizio TVs to be set up with a Walmart account to access smart features.
And Vizio OS’s source code could also be critical for users if Vizio ever goes out of business.
“[Access to the source code] would also allow for the maintenance of older models that are no longer supported by VIZIO. In these ways, purchasers of VIZIO smart TVs can be confident that their devices would not suffer from software-induced obsolescence, planned or otherwise,” SFC’s complaint reads.
Ads and tracking have been Vizio’s primary focus for years. Walmart doesn’t share Vizio’s financials, but in the quarter before its acquisition, the company’s ad business made $115.8 million, and its hardware business lost $6.7 million. While many Vizio TV owners are unlikely to have the time or technical ability to reduce ads or user tracking—even with access to Vizio OS’s source code—making that code available could still threaten Vizio’s business and profitability.
SFC’s Gingerich thinks these fears are “overblown,” and he compared them to 1980s concerns that VCRs would kill the US film business. But with virtually every smart TV brand increasingly focusing on monetizing software through ads and tracking, the entire industry is likely to resist anything that could significantly curb ad revenue potential.
Another concern is that people tinkering with their TVs’ software could gain access to digital rights management (DRM) keys that Netflix and other streaming companies provide to OS operators for decrypting protected videos, Gingerich said, adding:
We have repeatedly and emphatically informed Vizio that we do not want these keys, and they are free to delete any such key material from the TV before modified versions of Linux or other open source programs are installed onto the TV. They have not responded to this reply of ours.
Despite these obstacles, the SFC is doubtful that its lawsuit will push Vizio or other smart TV OS operators to adopt a completely closed OS that would make customization and repairs impossible for users.
“Because of how valuable and flexible Linux and other open source programs are, it is generally not practical to change to a fully proprietary operating system,” Gingerich said.
One ruling already made
A judge has already ruled that Vizio is not required to provide source code in a way that guarantees a TV will continue working properly if a user reinstalls a modified version of the OS. In a December 2025 ruling (PDF), Judge Sandy Leal wrote, “Nothing in the language of the Agreements requires Vizio to allow modified source code to be reinstalled on its devices while ensuring the devices remain operable after the source code is modified.”
She continued:
… the disputed language means that Vizio must provide the source code in a manner that allows the source code to be obtained and revised by Plaintiff or others for use in other applications.
In other words, Vizio must ensure the ability of users to copy, change/modify, and distribute the source code, including using the code in other free programs consistent with the Preamble and Terms and Conditions of the Agreements.
The SFC has said it “never” believed that any version of the GPL requires devices to function properly after someone installs a modified version of copyleft software.
The ruling even prompted a reaction from Linus Torvalds, the creator and lead developer of the Linux kernel. On a forum on kernel.org, Torvalds said he supported the judge’s finding, adding that it validates the premise that “GPLv2 is about making source code available, not controlling the access to the hardware that it runs on.”
“Vizio used Linux in their TVs without originally making the source code available, and that was obviously not ok,” he added.
Further, in December, Judge Leal issued a tentative ruling on the case, suggesting that Vizio may be obligated to share the Vizio OS source code, but that’s not a final decision.
“Personally, I’m excited to see [more] people interested in improving the devices they have, whether that be to extend their support lifetime for 10-plus years… so they can keep getting security updates after the manufacturer stops updating them, add new features like ad-blocking, or diagnose and fix hardware issues that require software changes,” Gingerich told Ars.
“The Vizio lawsuit is just one piece in the puzzle,” he said.
GitHub confirms breach of 3,800 repos via malicious VSCode extension
GitHub confirmed a security breach affecting 3,800 repositories due to a malicious, unnamed VS Code extension that has since been removed.
Decoder
- Trojanized extension: A software extension that appears legitimate but contains hidden malicious code, similar to a Trojan horse.
Original article
GitHub has since removed the unnamed trojanized extension from the VS Code marketplace.

mondayDB 3 – Solving HTAP for a Trillion-Table System
monday.com replaced its MySQL, Cassandra, and Redis fleet with mondayDB 3, a custom HTAP system powered by DuckDB, achieving 5-20x performance improvements and 40-60% cost reductions for its trillion-table system.
Deep dive
- mondayDB 3 is an HTAP system designed to handle over a trillion dynamic tables with highly flexible schemas.
- The previous architecture used MySQL with JSON blobs for schema flexibility, plus Cassandra and Redis.
- This led to slow board loads (over 2 seconds for large boards), poor aggregation performance, and inefficient I/O due to row-oriented storage and multi-tenant shared indexes.
- The new architecture is a CQRS-based Lambda architecture with durable snapshots in object storage (S3), an external write-ahead log (WAL) for real-time mutations, and a soft-stateful serving layer.
- Serving nodes are Go processes on Kubernetes with local NVMe SSDs, acting as smart read-through caches.
- Each serving node maintains an LRU cache of over 200,000 DuckDB files, one per board.
- Before each query, the serving node loads the board's DuckDB file, syncs pending WAL entries, and executes the query in-process using DuckDB's vectorized C++ engine.
- DuckDB's native WAL is disabled; monday.com uses its own distributed external WAL for durability and real-time changes.
- Dynamic schema evolution is handled on the fly by issuing ALTER TABLE ADD COLUMN in DuckDB when a new column is referenced.
- A custom routing layer, Ranja, uses Weighted Rendezvous Hashing with capacity-aware weights and hedged requests to ensure cache affinity and resilience.
- The migration of over 1 million organizations took 18 months, using feature flags, dual-read validation, and per-account rollout with instant rollback capability.
- The architecture is designed as a multi-entity platform, supporting new entity types via JSON-driven plugins.
- monday.com plans to evolve mondayDB 3 into an AI contextual layer for text search, semantic retrieval, and RAG, leveraging its per-board file isolation and real-time freshness.
Decoder
- HTAP (Hybrid Transactional/Analytical Processing): A database system designed to efficiently handle both transactional (OLTP) and analytical (OLAP) workloads within a single platform.
- CQRS (Command Query Responsibility Segregation): An architectural pattern that separates the model for updating information (the command side) from the model for reading information (the query side).
- Lambda Architecture: A data processing architecture designed to handle massive quantities of data by combining batch processing with stream processing for real-time data.
- DuckDB: An in-process SQL OLAP database management system designed for analytical queries, often described as SQLite for analytics.
- WAL (Write-Ahead Log): A log of changes to data before they are applied, used to ensure data durability and atomicity.
- Soft-stateful: Refers to a system where state is maintained for performance but can be rebuilt from a durable source of truth if lost, meaning no critical data relies solely on that local state.
- Ranja (Weighted Rendezvous Hashing): A distributed hashing algorithm used for consistent load balancing and routing, ensuring that a given key (e.g., tenant ID) consistently maps to the same node for cache affinity.
- RAG (Retrieval-Augmented Generation): An AI technique that combines a language model with a retrieval system to fetch relevant information from an external knowledge base to improve the accuracy and relevance of generated responses.
Original article
Full article content is not available for inline reading.
WrenAI (GitHub Repo)
WrenAI is an Apache-2.0 licensed open-source context layer for AI agents, enabling them to generate governed SQL by understanding business semantics over existing data stacks.
Deep dive
- WrenAI acts as an open context layer, providing AI agents with business semantics, examples, memory, and governance capabilities beyond what database schemas offer.
- It is open-sourced under the Apache-2.0 license, including its core engine, SDK, and skills.
- The system uses a Modeling Definition Language (MDL) for defining models, columns, relationships, and access control.
- The core engine is based on Apache DataFusion and supports over 22 data sources.
- Memory and examples are backed by LanceDB, using hybrid retrieval, and are versionable.
- It includes SDKs for popular agent frameworks like LangChain and Pydantic.
- WrenAI supports governed execution primitives, including dry-plan validation and structured errors.
- A quickstart guides users to install skill bundles for AI coding agents (e.g., Claude Code) to scaffold projects and onboard WrenAI.
- The
/wren-enrich-contextskill helps enrich projects with business context via grill or auto-pilot modes, writing to MDL and memory in a Git-friendly way. - It aims to solve the problem of agents "rediscovering" business logic by providing a shared, vendor-agnostic interface.
Decoder
- Context layer: A software component that provides AI agents with a deeper understanding of business-specific semantics, rules, and memory beyond raw data schemas.
- Modeling Definition Language (MDL): A domain-specific language used within WrenAI to define data models, relationships, metrics, and access control policies for business data.
- Apache DataFusion: A high-performance, extensible query engine written in Rust, used as the core for WrenAI's semantic engine.
- LanceDB: An open-source vector database designed for AI workloads, used by WrenAI for memory and example storage.
Original article
The open context layer for AI agents over business data.
Your agent doesn't know what your data means. We fix that.
Docs · Discord · Vision · Blog
📣 2026-05-07 — Wren Engine has merged into this repo under
core/. The previousCanner/wren-enginerepo is archived. The previous WrenAI GenBI app is preserved on thelegacy/v1branch (tagv1-final). Read the announcement →
What WrenAI is
WrenAI is the open context layer that gives your agents what schemas don't: business semantics, examples, memory, governance, and — soon — the unstructured corporate knowledge that lives in your docs, wikis, and chat threads. Built for the agent frameworks you already use.
Why agent builders pick WrenAI
- Open by default — Open-sourced core, SDK, and skills through Apache-2.0 license.
- Built for AI agents — Skills, agentic architecture, context retrieval are first-class. Ships as SDKs for the agent frameworks that engineers already use.
- Correctness as primitives — rich schema retrieval, dry-plan validation, structured errors with hints, value profiling, eval runner. The agent orchestrates; the trace lives in the agent's reasoning.
- Reviewable, reproducible context — every definition, example, and mapping is versionable and evidence-linked. Git-friendly.
- Sits on top of your existing stack — warehouse, transformation pipelines, your existing semantic layer. Not another tool to maintain.
With & Without Wren AI
Agents are everywhere. Claude Code, Cursor, ChatGPT, Aider, LangChain pipelines, Pydantic AI flows, in-house copilots, customer-facing apps. None of them should have to rediscover your business logic from scratch. With Wren AI, "the context layer," they query through a standalone, shared interface usable by every agent and person, not gated behind a single vendor's UI and architecture.
Quickstart
WrenAI is agent-driven by design: you install the skill bundle once, then let your AI coding agent (Claude Code, Openclaw, Hermes, Codex, etc.) drive the rest — Python deps, DB connection, project scaffold, and first query.
1. Install the skill bundle
Skills are workflow guides that teach AI coding agents (Claude Code, Openclaw, Hermes, Codex, etc.) how to drive the Wren CLI for you.
npx skills add Canner/WrenAI --skill '*'
Have multiple AI coding agents installed and want the skills available in all of them? Pass --agent '*':
npx skills add Canner/WrenAI --skill '*' --agent '*'
Or via the install script:
curl -fsSL https://raw.githubusercontent.com/Canner/WrenAI/main/skills/install.sh | bash
See the Skills reference for the full list of skills installed and what each one does.
2. Ask your agent to set things up
Open your agent in a project directory and ask:
Use the /wren-onboarding skill to install and set up Wren AI.
The agent will check your environment, install wrenai, create a connection profile, scaffold the project, and run a first query — all in one flow.
3. (Optional) Enrich the project
Once onboarding finishes, give your project the business context schemas can't carry:
Use the /wren-enrich-context skill in grill mode.
Two modes: grill (one question at a time, you in the loop) or auto-pilot (agent reads <project>/raw/ and proposes). Both modes write to MDL, instructions, queries, and memory — all reviewable, all Git-friendly.
4. Ask questions
# Ask any question "who are our top 10 customers by sales this quarter?"
Or just ask your agent in natural language — it uses the context layer to resolve schema, recall similar past queries, and write governed SQL.
Want to try it without your own database? Ask your agent to run /wren-onboarding with the bundled jaffle_shop sample dataset — same flow, but you'll be querying a real warehouse end-to-end in a couple of minutes.
Two beats: scaffold fast, enrich deep
/wren-onboarding # Scaffold a Wren project from your DB (agent-driven)
/wren-enrich-context # One skill, two modes: (Under development)
# grill — one question at a time, you in the loop
# auto-pilot — agent reads <project>/raw/ and proposes
wren ask "..." # Query through the context layer
Fast at first. Deep when you need it. Always reviewable and Git-friendly.
What's Included
- Modeling Definition Language (MDL) — models, columns, relationships, views, cubes, metrics, row-level / column-level access control (RLAC / CLAC)
- Engine — Apache DataFusion based, 22+ data sources
- Memory & examples — LanceDB-backed, hybrid retrieval, versionable
- Agent SDK —
wren-langchain(LangChain / LangGraph),wren-pydantic; reference Python integration for other stacks - Governed execution primitives — functions, dry-plan, row limits, access control
What's next
- Context enrichment skill —
/wren-enrich-context(grill + auto-pilot modes) hardened across MDL, instructions, queries, and memory - End-to-end correctness primitives — value profiling, rich retrieval, structured errors, golden eval runner
- Agent-native distribution — first-class SDKs across major agent frameworks; see GitHub Discussions for what's prioritized next
- Full governed execution — audit logs, rate limits, approval workflow, data-flow inspector
Full roadmap and design notes: see the vision paper.
Documentation
- Quickstart — from skill install to first answer
- Concepts — what context is, what MDL is, how memory works
- Connect a database — Postgres, BigQuery, Snowflake, DuckDB, and more
- Agent SDKs — what's shipping today, what's next
Community
- 💬 Discord — chat with the team and other builders
- 🐙 GitHub Discussions — design conversations, RFCs, longer threads
- 🐦 Twitter / X — release notes and short updates
- 🗞 Blog — vision, post-mortems, deep dives
Contributing
We build in the open. Issues, PRs, connector contributions, SDK integrations, docs fixes — all welcome.
- Contributor guide
- Connector ecosystem program — three-tier ownership: official, community-blessed, community-owned
- Architecture map — find the right place to land your change
- Looking for somewhere to start? Try the
good first issuelabel.
core/
wren-core/ Rust semantic engine (Apache DataFusion)
wren-core-base/ Shared manifest types + MDL builder
wren-core-py/ Python bindings (PyPI: wren-core)
wren-core-wasm/ WebAssembly build (npm: wren-core-wasm)
wren/ Python SDK and CLI (PyPI: wrenai)
wren-mdl/ MDL JSON schema
sdk/
wren-langchain/ Reference agent SDK integration
skills/ Agent skills for context authoring
docs/ Module documentation
examples/ Example projects
Contributors
License
Apache 2.0. See LICENSE.
Come build the context layer with us.
If WrenAI helps you, drop a ⭐ — it genuinely helps us grow!
Protocols for transactional usage of object storage
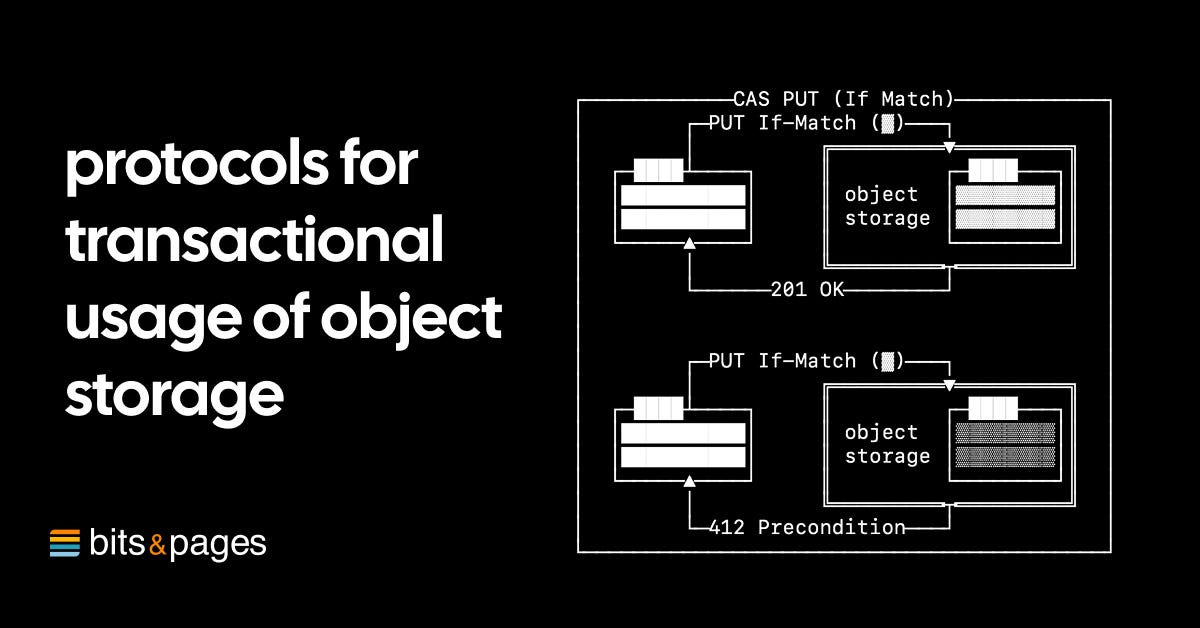
Almog Gavra details how to achieve serializable online transactional processing (OLTP) on object storage by using specific atomic and conditional read/write primitives, despite the high cost of LIST operations.
Deep dive
- The article focuses on design patterns for using object storage (like S3) correctly for Online Transactional Processing (OLTP) use cases, aiming for serializable history.
- It identifies three key write primitives: unconditional atomic PUTs, and conditional PUT If-None-Match / If-Match for compare-and-set operations.
- Three read primitives are also crucial: atomic GETs, conditional GET If-None-Match (for cached data), and strongly consistent LIST requests.
- A key performance consideration is that LIST operations on S3 are significantly more expensive than GETs (nearly 12x more).
- The "baseline protocol" uses direct atomic PUTs, providing correctness but suffering from high latency.
- The "simple conditional protocol" improves latency by batching writes into a single file and using PUT If-Match to resolve conflicts, but leads to 3-round-trip costs on contention. OpenData Buffer uses this.
- The "sequenced write protocol" uses file names as guards, incrementing them with each write, reducing contention cost to two round-trips but requiring garbage collection.
- For single-writer systems (like SlateDB), conflicts can lead to writer failure, often using "epochs" encoded in files to distinguish roles (main writer, garbage collector, compactor).
- Safe garbage collection requires "boundary files" to prevent old writers from inadvertently creating data branches after cleanup.
- The author mentions that SlateDB's protocols are formally verified using the Fizzbee specification language.
- The core tradeoff is safety versus contention cost, emphasizing the need for robust protocols to ensure consistency during failures.
Decoder
- Object storage: A data storage architecture for handling large amounts of unstructured data, where data is managed as objects rather than files in a hierarchy (e.g., AWS S3, Google Cloud Storage).
- Online Transactional Processing (OLTP): A type of data processing that facilitates and manages transaction-oriented applications, typically involving frequent, short, atomic transactions (e.g., bank transactions, e-commerce orders).
- Serializable history: A strong isolation level in database transactions ensuring that the concurrent execution of multiple transactions produces the same result as if they were executed sequentially, preventing data inconsistencies.
- PUT If-None-Match / If-Match: Conditional write operations in object storage.
If-None-Matchsucceeds only if the object does not exist;If-Matchsucceeds only if the object's ETag (content hash/version) matches a specified value. These are used for compare-and-set semantics. - Consistent LIST: A LIST operation on object storage that guarantees to return all objects that have been successfully written and acknowledged, reflecting the latest state.
- Atomic PUT / GET: Write or read operations that guarantee either the entire operation completes successfully, or it fails entirely, without any partial or corrupted state.
Original article
Full article content is not available for inline reading.

What data agent benchmarks do and don't tell us
AI Council attendee Jason Ganz notes the collapsing divide between data and AI infrastructure, highlighting that agent benchmarks are evolving to emphasize statefulness and rich, cross-system context over isolated tasks.
Deep dive
- The AI Council (formerly Data Council) conference in 2026 showed a clear convergence of data and AI infrastructure.
- Many companies are now positioning as AI infrastructure providers, focusing on context providers, workflow orchestrators, or compute providers.
- New databases like LanceDB are being designed specifically for AI-native, multimodal workloads, handling blob reads and embeddings.
- Benchmarking for AI agents is evolving beyond simple question-answering, with efforts like dbt Semantic Layer tests showing performance improvements for LLM-generated queries.
- ADE-bench evaluates agents' ability to build data pipelines, moving beyond just answering questions.
- Opeyemi Fabiyi's research identifies specific activities that uplift agent performance with dbt projects.
- Izzy Miller's "90-day simulation" benchmark emphasizes statefulness and learning from mistakes over time, a critical aspect of real-world agent operation.
- Agents perform significantly better when given access to rich, cross-system context from sources like dbt projects, GitHub, Slack, and Notion, which is often underestimated in sandboxed benchmarks.
- A major upcoming constraint and optimization area is token and compute efficiency, as agent usage costs are already high.
- The article concludes that data agents are improving, and the industry needs better mechanisms to track performance with organizational context and memory, alongside a focus on efficient agent design.
Decoder
- AI Council (formerly Data Council): A prominent conference for the data and AI community, covering trends and developments in both fields.
- AI infrastructure company: A company that provides foundational technologies or services (e.g., context retrieval, orchestration, inference compute) to support the development and deployment of AI agents and applications.
- LanceDB: An AI-native multimodal lakehouse database designed from scratch for LLM-shaped workloads, focusing on blob reads and embeddings.
- dbt Semantic Layer: A component of dbt (data build tool) that defines consistent business metrics and semantics, improving the reliability of LLM-generated queries.
- ADE-bench: A benchmark designed to measure the ability of coding agents to build data pipelines, extending beyond simple data question answering.
- Statefulness: In the context of AI agents, the ability of an agent to retain and use information, memories, and learning from past interactions or tasks over extended periods, rather than starting fresh with each new task.
Original article
Full article content is not available for inline reading.

OpenAI Reportedly Moves Toward IPO
OpenAI is reportedly preparing for an IPO as early as September 2026, working with Goldman Sachs and Morgan Stanley, following Elon Musk's dismissed lawsuit.
Original article
OpenAI barrels toward IPO that may happen in September
A day after Elon Musk lost his lawsuit that threatened OpenAI’s structure, leadership, and finances, the AI giant is ready to move forward with its initial public offering, sources told the Wall Street Journal.
OpenAI chief executive Sam Altman reportedly hopes that his company will be ready to go public by September. The ChatGPT maker has been working with tech IPO powerhouse bankers Goldman Sachs and Morgan Stanley, and may file IPO paperwork confidentially with regulators within days or weeks, per the WSJ.
The news of OpenAI’s potential IPO, which by all accounts should be a blockbuster, comes as the world awaits the public disclosure of SpaceX’s IPO filings, which are expected to appear as soon as Wednesday, according to reports. Rocket-maker SpaceX is, of course, now one of OpenAI’s major competitors, after it consumed Elon Musk’s model maker, xAI.
Now that Musk failed to skewer OpenAI, the competitor he co-founded, through the heart with a lawsuit, it looks like the next Musk vs. Altman battle will take place in the world of finance. Which one will be the bigger IPO?
OpenAI did not immediately respond to a request for comment.
On Building Agents From First Principles
Mishra simplifies agent training, revealing that all systems follow a core loop of prompt-model-action-environment-reward-gradient update, demonstrating this by building a text-to-diagram agent.
Deep dive
- Mishra's article argues that despite varying frameworks, all agent-training systems fundamentally adhere to the same core loop.
- This loop involves taking a prompt, having a model generate an action, applying that action to an environment, receiving a reward, and then updating the model's gradients.
- He strips away higher-level abstractions like TRL (Transformer Reinforcement Learning), Unsloth, and PRIME-RL to highlight this commonality.
- To demonstrate, Mishra constructs a simple text-to-diagram agent using pure Python.
- This agent interprets text prompts and generates JSON actions such as
create_shapeandconnect. - These actions are executed against a validating canvas.
- The agent incorporates a reward function that evaluates several aspects: JSON validity, compliance with a schema, quality of the layout, and semantic coverage of the original prompt keywords.
Decoder
- Agent: An autonomous software entity designed to perceive its environment, make decisions, and take actions to achieve specific goals, often involving interaction with an AI model.
- TRL (Transformer Reinforcement Learning): A framework or methodology for training transformer models using reinforcement learning techniques.
- Unsloth: A library or framework for fine-tuning large language models efficiently.
- PRIME-RL: A specific, potentially proprietary, reinforcement learning framework or algorithm not widely known to the general developer community.
- Gradient update: The process in machine learning where the model's parameters are adjusted based on the calculated gradients of the loss function, aiming to minimize errors and improve performance.
Original article
Mishra strips away the TRL, Unsloth, and PRIME-RL framework abstractions to show that every agent-training system reduces to the same loop: prompt to model action to environment to reward to gradient update. He builds a toy tldraw-style text-to-diagram agent in pure Python where the model emits JSON create_shape and connect actions against a validating canvas, then layers a reward function combining JSON validity, schema compliance, layout quality, and semantic coverage of prompt keywords.
A Bitter Lesson for Data Filtering
New scaling studies suggest data filtering might be unnecessary for large model pretraining, as ample compute allows models to benefit even from low-quality and distractor data.
Deep dive
- A new research paper titled "A Bitter Lesson for Data Filtering" investigates the role of data filtering in large model pretraining.
- The study focuses on scaling in a high-compute, data-scarce environment.
- Contrary to prevailing wisdom, the authors found that the optimal data filter in such conditions is "no data filter."
- Large parameter models, when sufficiently trained with ample compute, appear to not only tolerate low-quality and distractor data but actually benefit from it.
- This suggests that computational resources can effectively mitigate the perceived negative impact of "poor" or unfiltered data.
- The findings could simplify data preparation pipelines for organizations with substantial compute infrastructure.
Decoder
- Pretraining: The initial phase of training a machine learning model on a very large and diverse dataset, allowing it to learn general features and representations before being fine-tuned for specific tasks.
- Distractor data: Data that is not directly relevant to the primary learning objective or contains noise, but which the model might still derive useful information from when given sufficient capacity and training.
Original article
A Bitter Lesson for Data Filtering
Abstract:We investigate data filtering for large model pretraining via new scaling studies that target the high compute, data-scarce regime. In spite of an apparently common belief that filtering data to include only high-quality information is essential, our experiments suggest that with enough compute, the best data filter is no data filter. We find that sufficiently trained large parameter models not only tolerate low-quality and distractor data, but in fact benefit from nominally ``poor'' data.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
Cite as: arXiv:2605.19407 [cs.LG] (or arXiv:2605.19407v1 [cs.LG] for this version)
https://doi.org/10.48550/arXiv.2605.19407 Focus to learn more arXiv-issued DOI via DataCite
Submission history
From: Christopher Mohri
Tue, 19 May 2026 06:02:36 UTC (458 KB)
Access Paper:
- View PDF
- HTML (experimental)
- TeX Source
Which authors of this paper are endorsers?
Lance Unified Multimodal Model (GitHub Repo)
ByteDance released Lance, a 3B parameter unified multimodal AI model trained from scratch, demonstrating strong performance in image and video generation, editing, and understanding.
Deep dive
- Lance is a 3B parameter native unified multimodal model developed by ByteDance.
- It supports image generation, image editing, video generation, video editing, image understanding, and video understanding.
- The model achieves strong performance on benchmarks like DPG-Bench, GenEval, GEdit-Bench, and VBench despite its relatively small size of 3B active parameters.
- It was trained entirely from scratch (excluding ViT and VAE encoders) using a 128-A100-GPU budget.
- The GitHub repository provides installation instructions, a unified command-line interface for tasks, and a Gradio demo.
- Model weights are available on Hugging Face.
- Requires Python 3.10+, CUDA 12.4+, and a GPU with at least 40GB VRAM for inference.
- The model achieves a 0.90 overall score on GenEval for image generation, a 7.30 average score on GEdit-Bench for image editing, and an 85.11 total score on VBench for video generation.
- The authors highlight multi-task synergy as key to its unified capabilities.
Decoder
- Multimodal model: An AI model capable of processing and generating content across multiple data types, such as text, images, and video, simultaneously.
- ViT (Vision Transformer): A type of neural network that applies the transformer architecture, originally designed for natural language processing, to image recognition tasks.
- VAE (Variational Autoencoder): A type of generative model that learns to encode data into a lower-dimensional latent space and then decode it back, used here for image compression/decompression.
Original article
Lance: Unified Multimodal Modeling by Multi-Task Synergy
Fengyi Fu*, Mengqi Huang*,✉, Shaojin Wu*, Yunsheng Jiang*, Yufei Huo, Jianzhu Guo✉,§ Hao Li, Yinghang Song, Fei Ding, Qian He, Zheren Fu, Zhendong Mao, Yongdong Zhang
ByteDance
* Equal contribution ✉ Corresponding authors § Project lead
🌟 Highlights
Lance is a 3B native unified multimodal model that supports image and video understanding, generation, and editing within a single framework.
- Efficient at 3B scale. With only 3B active parameters, Lance delivers strong performance across image generation, image editing, and video generation benchmarks.
- Trained from scratch. Lance is built with a staged multi-task recipe and trained entirely from scratch (except for the ViT and VAE encoders; the transformer backbone is trained entirely from scratch) within a 128-A100-GPU budget.
We are actively updating and improving this repository. If you find any bugs or have suggestions, please feel free to open an issue or submit a pull request (PR) 💖.
🎨 Demo
Text-to-Video
Video Editing
Multi-turn Consistency Editing
Intelligent Video Generation
Video Understanding
|
Question: How many times did the person launch objects on the table? Options: (A) 3 (B) 2 (C) 4 Response: (A) 3 |
Question: The person makes sets of repeated actions. How many distinct repeated actions did the person do? Options: (A) 2 (B) 3 (C) 4 Response: (A) 2 |
Question: In which direction does the purple sphere move in the video? Options: (A) Down and to the right. (B) Up and to the left. (C) Up and to the right. (D) The object is stationary. Response: (A) Down and to the right. |
|
Question: What is the unrealistic phenomenon displayed in the video? Options: (A) The man can manipulate time via phone. (B) Man grabs an object through a phone screen. (C) Chocolate transforms into different objects. (D) Visible means of propulsion enables flight. Response: (B) Man grabs an object through a phone screen. |
Question: Offer a succinct account of the culinary process shown in this video. Response: Add tomato puree and mix it well with chicken pieces. |
Question: Provide a detailed description of the given video, capturing its key moments. Response: In a sunlit meadow, a small tortoiseshell butterfly rests on a purple flower. A bee, with black and yellow stripes, lands on the same flower. The butterfly flaps its wings gently, while the bee busies itself, collecting nectar. The flower sways slightly in the breeze. The butterfly then takes off, and the bee follows, both heading to the next flower. The scene is a vivid display of insect interaction in a natural setting, with the colors of the butterfly and the bee contrasting against the green background of the meadow. The video captures this peaceful moment in a short 6-second duration. |
Text-to-Image Generation
Image Editing
Image Understanding
|
Question: Is the largest segment greater than sum of all the other segments? Response: Yes, the largest segment in the pie chart is the blue one, which is the most populous segment. |
Question: What percentage of respondents want better border security? Response: 29% |
Question: What is the license plate number of the car? Response: The license plate number of the car is BX62 BFY. |
|
Question: According to the data from the proprietary market research, how much amount was spent on the promotional meetings and events during 1998? Response: According to the data from the proprietary market research, the total amount spent on the promotional meetings and events during 1998 was approximately $1.3 billion. |
Question: What is the appearance of the Colosseum in Rome, Italy? Response: The Colosseum in Rome, Italy is a magnificent ancient amphitheater made of stone and concrete. It is characterized by its large, arched openings and its semi-circular shape. The Colosseum has been partially restored, and its original color has faded, but the architectural details, like the columns and the semi-circular arches, are still visible. The lighting in the image highlights the grandeur and historical significance of the Colosseum, making it stand out against the backdrop of the evening sky. |
Question: How does a total solar eclipse look like from Earth? Response: A total solar eclipse looks like a dark circle with a bright, white outer edge. This is a result of the Earth's rotation and the Earth's shadow, which partially obscures the sun's light. The bright white edge of the eclipse is caused by the sun's high energy and its interaction with the Earth's atmosphere, while the dark part of the eclipse is due to the Earth's shadow and the surrounding air currents. The solar eclipse's shape, with its bright white edge and dark center, is similar to the shape of a full moon or a dark disk. It is a natural phenomenon that occurs in the atmosphere of the Earth and is an important part of the solar system. |
🚀 Installation
Recommended Environment
- Software: Python 3.10+, CUDA 12.4+ (required)
- Hardware: A GPU with at least 40GB VRAM is required for inference
Installation Steps
bash ./setup_env.sh
Download Model Weights
Please download all necessary model checkpoints from Lance-3B on Hugging Face and place them in the downloads/ directory.
📚 Usage
Inference
We provide a unified command-line interface for all generation / editing / understanding tasks:
Option 1: Configure and Run the Unified Script
bash inference_lance.sh
- Before running, please configure the inference parameters at the top of
inference_lance.sh. - Supported tasks:
t2i,t2v,image_edit,video_edit,x2t_image, andx2t_video. You can modifyTASK_DEFAULT_CONFIGSininference_lance.pyto customize the default data samples for each task. - Note: For all tasks, we recommend following the
promptformat used in the provided examples when writing input prompts, as this typically leads to better generation quality.
Option 2: Configure and Run the Unified Script
We provide task-specific one-click commands for different generation, editing, and understanding tasks.
Text-to-Video Generation
bash inference_lance.sh \ --TASK_NAME t2v \ --MODEL_PATH downloads/Lance_3B_Video \ --RESOLUTION video_480p \ --NUM_FRAMES 121 \ --VIDEO_HEIGHT 480 \ --VIDEO_WIDTH 848 \ --SAVE_PATH_GEN results/t2v
Text-to-Image Generation
bash inference_lance.sh \ --TASK_NAME t2i \ --MODEL_PATH downloads/Lance_3B \ --RESOLUTION image_768res \ --VIDEO_HEIGHT 768 \ --VIDEO_WIDTH 768 \ --SAVE_PATH_GEN results/t2i
Video Editing
bash inference_lance.sh \ --TASK_NAME video_edit \ --MODEL_PATH downloads/Lance_3B_Video \ --RESOLUTION video_480p \ --SAVE_PATH_GEN results/video_edit
Image Editing
bash inference_lance.sh \ --TASK_NAME image_edit \ --MODEL_PATH downloads/Lance_3B \ --RESOLUTION image_768res \ --SAVE_PATH_GEN results/image_edit
Video Understanding
bash inference_lance.sh \ --TASK_NAME x2t_video \ --MODEL_PATH downloads/Lance_3B_Video \ --RESOLUTION video_480p \ --NUM_FRAMES 50 \ --SAVE_PATH_GEN results/x2t_video
Image Understanding
bash inference_lance.sh \ --TASK_NAME x2t_image \ --MODEL_PATH downloads/Lance_3B \ --RESOLUTION image_768res \ --SAVE_PATH_GEN results/x2t_image
Available Tasks
| Task Name | Description | Example JSON |
|---|---|---|
t2v |
Text-to-Video generation | config/examples/t2v_example.json |
t2i |
Text-to-Image generation | config/examples/t2i_example.json |
image_edit |
Image editing | config/examples/image_edit_example.json |
video_edit |
Video editing | config/examples/video_edit_example.json |
x2t_image |
Image understanding | config/examples/x2t_image_example.json |
x2t_video |
Video understanding | config/examples/x2t_video_example.json |
For understanding examples:
config/examples/x2t_image_example.json: image understanding examples for visual question answering and image-based reasoning.config/examples/x2t_video_example.json: video understanding examples for video question answering and video captioning.
Parameters
You can configure the following hyperparameters at the top of the inference_lance.sh script:
| Parameter | Default Value | Description |
|---|---|---|
MODEL_PATH |
"downloads/Lance_3B" |
Path to the downloaded Lance model weights (Lance_3B or Lance_3B_Video). |
NUM_GPUS |
1 |
Number of GPUs to use for inference. |
VALIDATION_NUM_TIMESTEPS |
30 |
Number of denoising steps (e.g., 30 or 50). |
VALIDATION_TIMESTEP_SHIFT |
3.5 |
Timestep shift parameter for flow matching scheduling. |
CFG_TEXT_SCALE |
4.0 |
Classifier-Free Guidance (CFG) scale for text conditioning. |
VALIDATION_DATA_SEED |
42 |
Random seed for generation reproducibility. |
NUM_FRAMES |
50 |
Number of frames for video generation (Max: 121). Unused for image tasks. |
VIDEO_HEIGHT / VIDEO_WIDTH |
768 |
Spatial resolution. Unused for editing tasks (determined by input image/video). |
RESOLUTION |
"video_480p" |
Base resolution preset (image_768res or video_480p). |
Gradio
python lance_gradio_t2v_v2t.py --gpus 0 --server-port 7860
Benchmarks
DPG-Bench Evaluation| Models | # Params. | Global | Entity | Attribute | Relation | Other | Overall |
|---|---|---|---|---|---|---|---|
| Generation-only Models | |||||||
| SDXL | 3.5B | 83.27 | 82.43 | 80.91 | 86.76 | 80.41 | 74.65 |
| DALL-E 3 | - | 90.97 | 89.61 | 88.39 | 90.58 | 89.83 | 83.50 |
| SD3-Medium | 2B | 87.90 | 91.01 | 88.83 | 80.70 | 88.68 | 84.08 |
| FLUX.1-dev | 12B | 74.35 | 90.00 | 88.96 | 90.87 | 88.33 | 83.84 |
| Qwen-Image | 20B | 91.32 | 91.56 | 92.02 | 94.31 | 92.73 | 88.32 |
| Unified Models | |||||||
| Janus-Pro-7B | 7B | 86.90 | 88.90 | 89.40 | 89.32 | 89.48 | 84.19 |
| OmniGen2 | 4B | 88.81 | 88.83 | 90.18 | 89.37 | 90.27 | 83.57 |
| Show-o2 | 7B | 89.00 | 91.78 | 89.96 | 91.81 | 91.64 | 86.14 |
| BAGEL† | 7B | 88.94 | 90.37 | 91.29 | 90.82 | 88.67 | 85.07 |
| InternVL-U | 1.7B | 90.39 | 90.78 | 90.68 | 90.29 | 88.77 | 85.18 |
| TUNA | 7B | 90.42 | 91.68 | 90.94 | 91.87 | 90.73 | 86.76 |
| TUNA-2 | 7B | 89.50 | 91.40 | 92.07 | 91.91 | 88.81 | 86.54 |
| 🌟 Lance (Ours) | 3B | 83.89 | 91.07 | 89.36 | 93.38 | 80.80 | 84.67 |
† indicates methods that use LLM rewriters for prompt rewriting before generation.
GenEval Evaluation| Models | # Params. | 1-Obj. | 2-Obj. | Count | Colors | Position | Attr. | Overall |
|---|---|---|---|---|---|---|---|---|
| Generation-only Models | ||||||||
| SDXL | 3.5B | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 | 0.55 |
| DALL-E 3 | - | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 | 0.67 |
| SD3-Medium | 2B | 0.99 | 0.94 | 0.72 | 0.89 | 0.33 | 0.60 | 0.74 |
| FLUX.1-dev | 12B | 0.98 | 0.93 | 0.75 | 0.93 | 0.68 | 0.65 | 0.82 |
| Qwen-Image | 20B | 0.99 | 0.92 | 0.89 | 0.88 | 0.76 | 0.77 | 0.87 |
| Unified Models | ||||||||
| Janus-Pro-7B | 7B | 0.99 | 0.89 | 0.59 | 0.90 | 0.79 | 0.66 | 0.80 |
| OmniGen2 | 4B | 1.00 | 0.95 | 0.64 | 0.88 | 0.55 | 0.76 | 0.80 |
| Show-o2 | 7B | 1.00 | 0.87 | 0.58 | 0.92 | 0.52 | 0.62 | 0.76 |
| BAGEL† | 7B | 0.98 | 0.95 | 0.84 | 0.95 | 0.78 | 0.77 | 0.88 |
| Mogao | 7B | 1.00 | 0.97 | 0.83 | 0.93 | 0.84 | 0.80 | 0.89 |
| InternVL-U | 1.7B | 0.99 | 0.94 | 0.74 | 0.91 | 0.77 | 0.74 | 0.85 |
| TUNA | 7B | 1.00 | 0.97 | 0.81 | 0.91 | 0.88 | 0.83 | 0.90 |
| TUNA-2 | 7B | 0.99 | 0.96 | 0.80 | 0.91 | 0.84 | 0.76 | 0.87 |
| 🌟 Lance (Ours) | 3B | 1.00 | 0.94 | 0.84 | 0.97 | 0.87 | 0.81 | 0.90 |
| Models | # Params. | BC | CA | MM | MC | PB | ST | SA | SR | SRp | TM | TT | Avg/G_O |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Generation-only Models | |||||||||||||
| Gemini 2.0 | - | - | - | - | - | - | - | - | - | - | - | - | 6.32 |
| GPT Image 1 | - | 6.96 | 6.85 | 7.10 | 5.41 | 6.74 | 7.44 | 7.51 | 8.73 | 8.55 | 8.45 | 8.69 | 7.49 |
| Qwen-Image-Edit | 20B | 8.23 | 8.30 | 7.33 | 8.05 | 7.49 | 6.74 | 8.57 | 8.09 | 8.29 | 8.48 | 8.50 | 8.01 |
| Unified Models | |||||||||||||
| Lumina-DiMOO | 8B | 3.43 | 4.27 | 3.08 | 2.77 | 4.74 | 5.19 | 4.44 | 3.80 | 4.38 | 2.68 | 4.20 | 3.91 |
| Ovis-U1 | 1.2B | 7.49 | 6.88 | 6.21 | 4.79 | 5.98 | 6.46 | 7.49 | 7.25 | 7.27 | 4.48 | 6.31 | 6.42 |
| BAGEL | 7B | 7.32 | 6.91 | 6.38 | 4.75 | 4.57 | 6.15 | 7.90 | 7.16 | 7.02 | 7.32 | 6.22 | 6.52 |
| InternVL-U | 1.7B | 7.08 | 7.05 | 6.38 | 7.02 | 6.03 | 6.27 | 7.13 | 6.55 | 6.33 | 6.59 | 6.85 | 6.66 |
| InternVL-U (w/ CoT) | 1.7B | 7.05 | 7.87 | 6.50 | 6.99 | 5.77 | 6.10 | 7.33 | 7.16 | 7.12 | 7.36 | 6.46 | 6.88 |
| 🌟 Lance (Ours) | 3B | 7.73 | 7.74 | 7.28 | 7.83 | 7.50 | 7.03 | 7.64 | 7.85 | 7.71 | 4.46 | 7.57 | 7.30 |
| Type | Model | # Params. | Total Score ↑ |
|---|---|---|---|
| Gen. Only | ModelScope | 1.7B | 75.75 |
| LaVie | 3B | 77.08 | |
| Show-1 | 6B | 78.93 | |
| AnimateDiff-V2 | - | 80.27 | |
| VideoCrafter-2.0 | - | 80.44 | |
| CogVideoX | 5B | 81.61 | |
| Kling | - | 81.85 | |
| Open-Sora-2.0 | - | 81.71 | |
| Gen-3 | - | 82.32 | |
| Step-Video-T2V | 30B | 81.83 | |
| Hunyuan Video | - | 83.43 | |
| Wan2.1-T2V | 14B | 83.69 | |
| Unified | HaproOmni | 7B | 78.10 |
| Emu3 | 8B | 80.96 | |
| VILA-U | 7B | 74.01 | |
| Show-o2 | 2B | 81.34 | |
| TUNA | 1.5B | 84.06 | |
| 🌟 Lance (Ours) | 3B | 85.11 |
Running Benchmarks
Ready-to-run benchmark scripts are provided under benchmarks/:
| Benchmark | Modality | Script |
|---|---|---|
| GenEVAL (image gen) | Image | benchmarks/image_gen/GenEVAL/sample_GenEVAL.sh |
| DPG (image gen) | Image | benchmarks/image_gen/DPG/sample_DPG.sh |
| GEdit (image edit) | Image | benchmarks/image_gen/GEdit/sample_GEdit.sh |
| VBench (video gen) | Video | benchmarks/video_gen/Vbench/sample_vbench.sh |
📄 License
Copyright 2025 Bytedance Ltd. and/or its affiliates.
🙏 Acknowledgements
We would like to thank the contributors of BAGEL, Qwen2.5-VL-3B-Instruct, and Wan2.2 for their open research and contributions.
💖 Citation
If you find Lance useful for your project or research, welcome to 🌟 this repo and cite our work using the following BibTeX:
@misc{fu2026lanceunifiedmultimodalmodeling,
title = {Lance: Unified Multimodal Modeling by Multi-Task Synergy},
author = {Fengyi Fu and Mengqi Huang and Shaojin Wu and Yunsheng Jiang and Yufei Huo and Hao Li and Yinghang Song and Fei Ding and Jianzhu Guo and Qian He and Zheren Fu and Zhendong Mao and Yongdong Zhang},
year = {2026},
eprint = {2605.18678},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2605.18678},
}
📞 Contact
For questions, issues, or collaborations, please contact Mengqi Huang and Jianzhu Guo.
LiteFrame Scales Video LLM Efficiency
LiteFrame, a lightweight video encoder, significantly boosts Video LLM efficiency by resolving bottlenecks in vision transformers and language models, allowing 8x more frames to be processed.
Decoder
- Video LLM (Video Large Language Model): A large language model extended to process and understand video data in addition to text.
- Vision Transformer (ViT): A neural network architecture that applies the Transformer model, initially developed for natural language processing, to visual tasks.
- Compressed Token Distillation (CTD): A novel training framework used by LiteFrame where a compact student vision encoder learns to predict information-dense, spatio-temporally compressed representations generated by a larger teacher vision model.
- Language Model Adaptation (LMA): A lightweight fine-tuning stage that aligns the compressed latent space from the vision encoder with the downstream large language model, enabling it to handle extended temporal contexts.
Original article
TL;DR: We propose LiteFrame, a highly efficient video encoder for Video Large Language Models that unlocks scalable, long-form video understanding by resolving inefficiencies in both the LLM and the ViT.
Abstract
The fundamental challenge in scaling Video Large Language Models (Video LLMs) to long-form video lies in managing the explosion of visual-token context length. Existing strategies predominantly focus on "post-hoc" token reduction—reducing visual tokens after feature extraction to alleviate the LLM's computational overhead. While these methods effectively reduce the number of visual tokens, we observe that the primary latency bottleneck then shifts from the LLM to the expensive per-frame processing of the vision encoder.
To address this, we introduce LiteFrame, a strong, yet highly efficient video encoder backbone for Video LLMs. To train LiteFrame, we propose Compressed Token Distillation (CTD), a novel training framework that teaches a compact student vision encoder to directly predict information-dense, spatio-temporally compressed representations produced by a large teacher vision model, effectively bypassing redundant computation. When coupled with further Language Model Adaptation (LMA), this approach results in a new latency-accuracy Pareto frontier. Our results demonstrate a new potential path to unlocking longer-form video understanding under fixed compute budgets.
Main Results
LiteFrame redefines the performance-latency trade-off across multiple video understanding benchmarks, including Video-MME, MLVU, and LongVideoBench.
- Unlocking Frame Scaling: By offloading the prefilling bottleneck from the LLM and lowering visual encoding costs, LiteFrame enables the processing of 8x more frames within restricted computing budgets.
- End-to-End Efficiency: LiteFrame achieves up to a 35% reduction in total inference latency (vision encoding + LLM prefilling) while consistently improving average video understanding accuracy.
- Parameter Reduction: LiteFrame utilizes only 87M parameters, a massive reduction from the 304M parameters of the teacher model.
- Zero-Shot Spatial Resolution Scaling: LiteFrame's inherent token efficiency enables scaling in high-resolution videos, achieving a state-of-the-art score on HLVid without any high-resolution training.
Methodology
To train LiteFrame, we propose Compressed Token Distillation (CTD) and Language Model Adaptation (LMA).
- Compressed Token Distillation (CTD): The student encoder is trained to directly predict information-dense, spatio-temporally compressed supervision targets generated by applying Weighted Average Pooling (WAP) to a large teacher model's output.
- Language Model Adaptation (LMA): A lightweight fine-tuning stage aligns the compressed latent space with the downstream LLM, allowing it to seamlessly handle extended temporal contexts (up to 512 frames).
- Spatio-Temporal Token Compressive Architecture: Our lightweight student encoder significantly reduces FLOPs and latency by employing depth-wise 1D convolutions for temporal modeling and strided convolutions for downsampling.
Citation
@article{kim2026liteframe,
title={LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs},
author={Kim, Jihwan and Parthasarathy, Nikhil and Qin, Danfeng and Hur, Junhwa and Sun, Deqing and Han, Bohyung and Yang, Ming-Hsuan and Gong, Boqing},
journal={arXiv preprint arXiv:2605.17260},
year={2026}
} 
Cheap AI could derail OpenAI and Anthropic's IPOs
OpenAI and Anthropic's anticipated IPO valuations, projected at over $800 billion each, are threatened by rapidly decreasing AI costs and fierce competition from cheaper, efficient models, particularly from Chinese labs.
Decoder
- IPO (Initial Public Offering): The first time a company offers its shares for sale to the general public on a stock exchange.
- Advisor model: A strategy where a cheaper, often open-source, AI model handles most tasks, but is configured to call upon a more powerful (and expensive) frontier model for assistance when it encounters tasks it cannot solve.
- Frontier model: Refers to the most advanced and capable AI models available at a given time, typically developed by leading AI labs like OpenAI and Anthropic.
- Capex (Capital Expenditure): Money spent by a business on acquiring or maintaining fixed assets, such as buildings, land, machinery, or in this case, AI training infrastructure and expensive chips.
Original article
This earnings season, the cost of AI started showing up in the numbers. Meta, Shopify, Spotify, and Pinterest all flagged rising AI and inference costs as a drag on margins. Shopify said economies of scale were "partially offset by increased LLM costs."
This is the bill coming due for the pricing model that underpins OpenAI's and Anthropic's expected IPO valuations, both projected north of $800 billion. Those numbers assume OpenAI and Anthropic will hold their market share and pricing power — that competitors can't easily catch up, and that enterprise customers will keep paying a premium because there's no real alternative.
But increasingly the data is pointing the other way. Cutting-edge AI is becoming abundant and cheap. Chinese labs are charging a fraction of what American labs do for comparable work, while a wave of Western challengers — Nvidia, Cohere, Reflection, Mistral — are building cheaper, smaller, more efficient alternatives for enterprises that won't touch a Chinese model. By the time OpenAI and Anthropic file their prospectuses, with OpenAI's confidential filing coming as soon as this week, the central premise of their valuations may already be gone.
The cost gap is wide and getting wider. Enterprise AI budgets have surged. Some 45% of companies surveyed by cloud cost firm CloudZero said they spent more than $100,000 a month on AI in 2025, up from 20% the year before. Where that money goes increasingly matters. AI benchmarking firm Artificial Analysis runs every major model through the same 10 evaluations and tracks the total cost. For each lab's most capable model: Anthropic's Claude came in at $4,811. OpenAI's ChatGPT: $3,357. DeepSeek: $1,071. Kimi: $948. Zhipu's GLM: $544. Claude is nearly nine times more expensive than the cheapest Chinese alternative for the same workload.
Even Google is making the case. At its I/O developer conference this week, CEO Sundar Pichai said "many companies are already blowing through their annual token budgets, and it's only May," and pitched the company's cheaper Flash model as the answer. If the largest Google Cloud customers shifted 80% of their workloads from frontier models to Gemini 3.5 Flash, Pichai said, they would save more than $1 billion a year. The company is acknowledging that enterprises need cheaper options.
And the cheap alternatives are no longer a step behind. DeepSeek, the Chinese AI lab whose model triggered a U.S. tech selloff last year, released a preview of its next-generation model last month that matches or nearly matches the latest from OpenAI, Anthropic, and Google on coding, agentic, and knowledge benchmarks. Models from other Chinese labs, including Moonshot, Xiaomi, and Zhipu, have shipped at similar capability levels in the past four months.
Databricks CEO Ali Ghodsi has a real-time view of the shift. The company's AI gateway sits between thousands of enterprise customers and the models they're using, and Ghodsi said revenue from that product is climbing sharply.
The technique enterprises are deploying, he said, is called an "advisor model." A cheap open-source model handles the bulk of the work as the default. When it hits a task it can't solve, it's given a tool that lets it call out to a frontier model from OpenAI or Anthropic for help.
"You can curb costs really well this way," Ghodsi said.
The speed of the shift is striking. On OpenRouter, a marketplace that lets developers access hundreds of AI models through a single interface, Chinese models went from about 1% of usage in 2024 to more than 60% in May.
And vendors are starting to sell cost reduction as a product. Figma CEO Dylan Field said companies are moving through three phases of AI adoption: first, nobody uses it; second, everyone has to, with some "literally holding competitions of who can spend the most with tokens." And third is the realization that "everyone's spending too much" and has to cut back. Many enterprises, he said, are now entering that third phase. Figma is selling features that cut customers' token consumption by 20 to 30%.
U.S. vs. China
The cost gap reflects how the two sides are built. American frontier labs are running on hundreds of billions of dollars in capex, training ever-larger models on the most expensive chips Nvidia sells, inside a U.S. power grid that can't add capacity fast enough. Those costs get passed through to customers. For Chinese labs, constraint has become the strategy. Working under chip export restrictions, they've been forced to optimize aggressively — training competitive models with less compute and running them more efficiently.
The American labs' best defense is trust. Cohere CEO Aidan Gomez, whose company sells AI models specifically to banks, defense agencies, and other regulated industries, says those buyers won't touch Chinese models regardless of price. Cohere's revenue grew sixfold last year selling into exactly that segment. But it's a relatively narrow slice of the broader enterprise market. Outside of regulated industries, where security and compliance rules are looser, the case for paying a premium gets harder to make.
The American response is taking shape. Nvidia, the company that has profited most from the AI boom, is now publicly pushing a different model, releasing its own AI systems that any company can download and run on its own servers, free of charge, as an alternative to both Chinese options and the locked-down models from OpenAI and Anthropic. Reflection AI raised at a multibillion-dollar valuation specifically to build American open-source models for enterprises that want a domestic alternative. Both are well-capitalized and explicitly targeting the same gap — capable models, cheaper than the frontier, deployed on infrastructure U.S. enterprises already trust.
The case against this shift has rested on national security. But the objection is dissolving in practice. Even the U.S. government's AI Safety Institute, which flagged DeepSeek models as lagging American ones on security and performance, documented that downloads have risen nearly 1,000% since the R1 release in January 2025.
And Anthropic itself acknowledges the pressure. In a policy paper released in May, the company said U.S. models are only "several months ahead" of Chinese ones, and warned that Beijing is "winning in global adoption on cost."
OpenAI sees it differently. A person familiar with the company's thinking said every release of a new frontier model, including GPT-5.5 last month, has driven a surge in API and product usage, with enterprise demand growing in what they described as a "vertical wall." Open source has a role in low-stakes tasks, this person said, but isn't eating into the company's core business. Pricing pressure isn't on the company's top ten list of concerns.
But an enterprise AI CEO, who asked not to be named to protect customer relationships, offered a different read. The growth is real — “but it would expand even faster for frontier if this technique wasn't used.”
This is the market OpenAI and Anthropic are expected to ask public investors to value. At nearly trillion-dollar valuations each, the S-1 has to show enterprise revenue growth and concentration that justifies the multiple. But the premium that justifies the valuation is eroding fastest in exactly the segments the labs need to dominate.
WATCH: OpenAI preparing for confidential IPO filing

Better Experiments with LLM Evals — A funnel, not a fork
Spotify's "evaluation funnel" strategy combines LLM evals with A/B testing to verify AI output quality before validating real user impact, improving experiment efficiency.
Decoder
- LLM eval: An automated judge, often powered by a Large Language Model, used to assess qualitative aspects of content or outputs, such as relevance, coherence, tone, or intent alignment, at scale.* Evaluation funnel: A concept where different evaluation methods are applied sequentially, with cheaper, faster methods (like LLM evals) used earlier to filter out poor candidates before more expensive, rigorous methods (like A/B tests) are used for final validation.
Original article
Better Experiments with LLM Evals — A funnel, not a fork
TL;DR LLM evals, automated judges that assess relevance, coherence, and quality at scale, are a powerful new tool. Paired with online experiments, they raise the hit rate of what we test and create a feedback loop that makes both evals and experiments smarter over time.
At Spotify, only about 12% of A/B tests end in a shipped positive result. Around 64% produce valid learning: a regression caught, an idea ruled out, a hypothesis refined. The win rate understates the value of experimentation.
Now we have a new capability. LLM evals can assess dimensions we couldn't scale before (relevance, coherence, tone, intent alignment) faster and cheaper than human annotation, on any data from test sets to A/B test variants. Evals and experiments measure different things. The right relationship is a funnel, not a fork. Schultzberg and Ottens (2024) call it an evaluation funnel, where evals belong before your experiment, not instead of it. A strong eval stack means you don't test to find out if the change does what you intend. Evals already told you that. You test to validate the intended change drives the business outcome it was meant to, and to bound the risk of harming the business.
What evals give us, and what they don’t
Schultzberg and Ottens distinguish verification from validation. Evals verify: does the output conform to quality standards? Experiments validate: do real users respond as predicted? Evals discard the non-promising candidates before they consume experiment bandwidth. They raise the hit rate of the experiments that follow.
Evals also generate hypotheses. Consider a team that builds an LLM judge to flag trust-breaking content, say a recommendation shared with a user it doesn't fit. The judge surfaces patterns the team didn't know to look for. Those patterns become product fixes. After the fix ships, the same judge can verify it worked: the flagged violations should drop. That's the eval doing two jobs: discovering what to improve, and confirming the improvement was realized.
What the eval can't tell you is whether users who received the improved version actually had better outcomes: whether the fix prevented the slow erosion of trust that eventually leads to churn. This question requires an experiment.
Beyond the dimensions you're measuring are the ones you aren't measuring. At Spotify, teams roll back about 42% of launched experiments to prevent regression in secondary metrics: session length dropping, crash rates climbing, retention eroding. No evals or offline evaluation flagged those. As we've described in our work on guardrail metrics, the point of a guardrail is to watch dimensions you care about but aren't optimizing for. An eval measures quality of implementation in one dimension. An experiment quantifies the impact on systems in production and end users.
Two calibration layers, one feedback loop
Evals are proxies. They substitute a score for an outcome you actually care about. That substitution is only valid as long as the score tracks the real outcome, the same dynamic we've described with proxy metrics.
Now LLM judges add a second calibration layer on top of traditional quantitative metrics (ranking scores, precision, recall). Both layers need validation against online outcomes. Both can drift. When the judge says Variant A is better, does it actually deliver a better user experience, or is the judge rewarding surface patterns that don't drive outcomes?
For example, when Anthropic released the Opus 4.5 model, Qodo's coding evals showed no improvement, but the model had improved substantially on longer tasks a controlled experiment would have surfaced. Miscalibration runs both ways. Without offline-online signal calibration, our evals are opinions, not evidence. By construction, long-running tasks and long-term behaviour are challenging to capture with evals. By continuously adjusting the evals to improve their mapping to online outcomes, the evals are becoming better and better verification tools. We are not ruling out that in the future, as AI develops, evals can map well enough to start acting as validations: By having the offline/online calibration loop in place we have continuous transparency on what role evals can play in the evaluation funnel as AI keeps improving.
Teams under speed pressure sometimes call A/B tests "costly." We know from experience that shipping without an experiment can be incredibly costly, if a major regression in top business metrics goes undetected. The more complex the system, the more important it is to bound the risk.
Close the loop
Run evals early and often to find the best treatments. Then let the experiment validate that real users and systems respond as predicted, and monitor the metrics you didn't optimize for. Not every change needs the same evidence: quick directional tests for iteration and data gathering, rigorous tests for ship decisions.
Then: run your LLM evals on the A/B test data itself. Did the version the judge preferred actually perform better with users? This extends the traditional evaluation funnel. LLM judges let us ask not just "did the metric move?" but "did the qualitative aspects change?" When the gap between eval scores and experiment outcomes is large, that's diagnostic gold. Each cycle helps calibrate the next.
Return to the trust-breaking recommendation team: the experiment is the final step. If users who received the improved version show better long-term engagement, the team has confirmed that what the judge measures actually matters. If the judge scores improved but user outcomes didn't, that's the calibration signal: the judge is capturing something, but not the thing that drives value. Both results make the system smarter.
Spotify already has a strong evaluation culture in the shape of experimentation. LLM evals extend that culture upstream, with a clear role in the funnel: find the best treatments before the experiment, and calibrate the judges after it. As Ankargren (2025) argues, success comes from doing the basics well at scale. The value compounds when the system is simple enough to use, and rigorous enough to trust.
Alibaba unveils new AI chip in push for domestic alternatives
Alibaba's T-Head subsidiary unveiled the new Zhenwu M890 AI chip and a multi-year roadmap, tripling performance for AI agent workloads amid tightening US export curbs.
Decoder
- AI agent: A software system capable of performing complex, multi-step tasks with limited human oversight, often by planning, reasoning, and interacting with its environment.* Zhenwu M890: Alibaba's new AI chip designed by its T-Head subsidiary, optimized for AI agent workloads.* Qwen 3.7-Max: The latest version of Alibaba's flagship large language model, engineered for advanced coding and long-running agent tasks.
Original article
Alibaba unveils new AI chip in push for domestic alternatives
BEIJING/SINGAPORE, May 20 (Reuters) - Alibaba Group on Wednesday unveiled a new AI chip, the Zhenwu M890, as the Chinese technology giant intensifies efforts to build domestic alternatives to Nvidia processors amid tightening U.S. export curbs.
The chip, developed by Alibaba's semiconductor design subsidiary T-Head, delivers three times the performance of its predecessor, Zhenwu 810E. It is purpose-built for the emerging wave of AI "agents" — software systems that can carry out complex, multi-step tasks with limited human oversight.
Alibaba said the new processor is well-suited to handle the heavy memory and communication demands of agent workloads, where models must retain long stretches of context and coordinate with one another in real time.
The company also outlined a multi-year chip roadmap, saying it would follow the M890 with a successor called the V900 in the third quarter of 2027, and a further chip, the J900, in the third quarter of 2028. The V900 is expected to deliver another roughly threefold performance gain over the M890, Alibaba said, signalling a sustained cadence of in-house silicon upgrades.
The plan underscores China's growing efforts to produce locally developed AI chips as Washington bans the sale of the most powerful U.S. processors to Chinese customers, and follows a similar announcement by Huawei last year.
Hangzhou-based Alibaba last year pledged to spend more than 380 billion yuan ($53 billion) on cloud and AI infrastructure over three years, its largest-ever commitment to the sector.
The investment reflects a broader bet across China's technology industry that demand for AI computing power will continue to surge as enterprises adopt agent-based applications.
Alibaba unveiled the chip at its annual Alibaba Cloud Summit, alongside a new server system, the Panjiu AL128, which packages 128 of the accelerators into a single rack.
The system is available immediately to Chinese enterprise customers through Alibaba Cloud's domestic model platform, known as Bailian.
T-Head said it has shipped more than 560,000 Zhenwu units to date, with over 400 external customers across 20 industries, including automakers and financial services firms, having deployed the chips.
Alibaba also announced Qwen 3.7-Max, the latest version of its flagship large language model, which it said is engineered for advanced coding and long-running agent tasks. The company said the model can operate continuously for up to 35 hours without performance degradation.
Google adds llms.txt check to Chrome Lighthouse
Google has integrated an llms.txt check into Chrome's Lighthouse audits under "Agentic Browsing" to control how LLMs interact with websites.
Decoder
- llms.txt: A proposed standard text file, similar to robots.txt, that website owners can use to specify rules for how Large Language Models (LLMs) and other AI agents should interact with their website content, such as crawling or data usage.* Lighthouse: An open-source, automated tool from Google for improving the quality of web pages, running audits for performance, accessibility, SEO, and more.* Agentic Browsing: A category within Google Lighthouse audits that pertains to how automated agents, like LLMs, interact with and process web content.
Original article
Google introduced an llms.txt check in Chrome's Lighthouse audits under the "Agentic Browsing" category to enhance machine interaction with websites.
OpenAI Is Preparing to File for an IPO Very Soon
OpenAI is preparing an IPO filing within weeks, targeting a September public debut despite missing internal revenue targets and concerns about supporting high spending commitments.
Original article
OpenAI has been working with bankers to prepare to file for an IPO in the coming days or weeks. The company aims to be ready to go public as early as September. Its plans remain fluid and could still change. The company still has to overcome concerns about whether it can generate enough revenue to support its spending commitments, among a host of other challenges. It recently missed multiple internal revenue and user targets.
Chickens without eggs? De-extinction company creates artificial egg
Biotech startup Colossal, known for de-extinction, has developed an artificial eggshell allowing nearly full avian development, simplifying embryo manipulation and observation for research.
Deep dive
- Colossal, a biotech startup focused on de-extinction, has developed an artificial eggshell capable of supporting nearly the entire avian developmental process.
- The device allows the transfer of egg contents within a day or two of laying, even before the circulatory system forms, leading to normal chick development.
- This artificial environment makes it easier for scientists to perform genetic or surgical manipulations on embryos and continuously film and track cellular movements and rearrangements.
- The 3D-printed support system maintains proper membrane tension and allows efficient oxygen exchange in a normal atmosphere, only requiring calcium supplementation.
- Colossal intends to use this technology for its de-extinction efforts, particularly for species like the dodo and moa, which are significantly larger than related existing birds, necessitating external nutrient supplementation.
- The company, led by Ben Lamm, plans to open-source the technology for research purposes, not charging labs for its use, indicating a broader scientific impact beyond de-extinction.
Decoder
- De-extinction: The process of bringing an extinct species back to life, typically through genetic engineering and cloning.
- Embryogenesis: The process by which an embryo forms and develops from a zygote.
- Developmental biology: The study of the processes by which organisms grow and develop.
Original article
On Tuesday, biotech startup Colossal announced its newest development on the road to its announced goal: reversing the extinction of species, in this case, avian species. The development itself is essentially an artificial eggshell, one that allows almost the entire developmental process to occur without the shell. The company transferred the contents of eggs to their specially designed container within a day or two of laying and were able to have normal chicks walk away from it.
Beyond its potential utility for Colossal’s intended efforts, the work is personally interesting to me because it may solve a problem I faced in my research days. I’m going to start by describing the research problem that Colossal may have solved, before coming back to what it hopes to use its technology to do—and why the company still has a few key hurdles left to overcome.
Watching development
For part of my career, I studied the development of vertebrates using chickens. While they’re less closely related to us than something like mice, the basics of their development are largely the same. And, unlike mice, they develop outside of their mother’s body. If you’re careful, you can chip away a hole in the egg, perform manipulations on the developing embryo, and then seal it back up with some tape. The chicken embryo will keep developing, allowing you to see the impact of what you’ve done on normal development.
Manipulations include everything from surgically removing key tissues to implanting beads soaked with signaling molecules to injecting DNA into cells to instruct them to make a different set of proteins. Any of these can alter the development of the embryo, telling us things about the factors that are normally required.
While this has been incredibly powerful, it provides us with a limited view of key events. That’s because you’re only allowed two time points: the moment you perform the manipulations, and when you stop the experiment. You don’t have a complete picture of how things change in between the two. You can repeat the experiment and stop things at different time points, but you don’t really get a complete picture of what is a dynamic process.
This is especially true because development involves a lot of motion: cells move around, tissues rearrange and slide past each other. For example, the spinal cord starts out as a flat plate of neural tissue, but then rolls up into a tube. As the cells mature into neurons, they detach from the inner surface of the tube, move to new locations, and start sending out axons to connect with other neurons.
There was a potential solution to this. A researcher down the hall (Kat Hadjantonakis) developed a microscope system that automated taking repeated exposures of embryos over time, allowing her team to track how cells moved about during key developmental processes. It worked, but only if you could get the embryo to survive in culture. This could work for a day or two with mouse embryos, but chickens were really difficult.
There were two big problems. The chicken embryo is embedded in the membrane that encloses the yolk, and the tension on the membrane provided by the yolk is needed for the embryo to develop properly. Let the yolk leak out and the membrane will sag, leaving the embryo a crumpled, disorganized mess. (Colossal told Ars that the curvature of the container it developed had to be tweaked to maintain the proper tensions within the egg’s membranes.)
The other issue is that the embryo’s developing circulatory system extends deeply into the yolk. Most embryos I tried to image ended up being disorganized messes with no blood.
Development without the shell
Colossal has basically solved that problem. It made a structural support that supports the entire contents of the egg in a way that keeps everything intact so that the embryo develops normally. No problems with a lack of membrane tension or the loss of blood. In fact, the transfer of the egg contents to Colossal’s new device can take place before the circulatory system even forms. (In the work they’re describing, transfers are done on day one of development, when the embryo is largely a smudge of cells on the surface of the yolk.)
The support system is 3D-printed and lined with a special membrane that allows oxygen to be exchanged with the environment. Previous efforts to get this to work had to put the embryo in a high-oxygen environment, which increases the chance of DNA damage from reactive oxygen in the cells. The membrane is efficient enough that the embryo can develop in a normal atmosphere, though humidity has to be controlled. Colossal’s Ben Lamm told Ars that the only thing that needed to be added was calcium, as the embryo normally extracts a bit of that from the interior of the egg shell.
Colossal also confirmed that, due to density differences, the yolk naturally floats to the top of the container, with the embryo rotating to the top of that. So, once the egg is placed in this device, all the manipulations that biologists normally do should be possible. And, because it only requires a humidified chamber, it should be possible to film the embryo as it develops afterward and track any changes to cell movements and rearrangements. The company has even designed the container so that light can be diffused in from beneath for microscopy purposes.
In other words, Colossal seems to have solved a problem I no longer have (since I’m now a journalist) but is likely still an issue for biologists. However, the company did so purely as a necessary step for one of its de-extinction projects.
Not all eggs are created equal
Why does it need to externalize the contents of eggs? It comes back to two of its planned de-extinctions, the dodo and the moa. Both of these species are far, far larger than the nearest related species. In the moa’s case, it’s far larger than any existing birds. If you want to make something that big, then there’s simply no way of taking an egg from an existing species and putting a moa embryo in it. So, one of Colossal’s next steps will be to see if it can supplement an egg—do things like add enough nutrients to the yolk to support the growth of a larger embryo.
This likely can’t be done before the embryo is in place, as simply pumping more material into the yolk would likely cause the membrane enclosing it to burst. Instead, they’re likely to have to add or exchange material as the embryo is developing.
The other issue they’ll have to contend with is the fact that embryonic development starts while the egg is still inside its parent. So the team will have two choices. One option is that they will need to figure out how to get the first half day or so of development to proceed without an egg, and then transfer that growing embryo into an egg. The alternative is that they’ll have to figure out how to fertilize eggs after their contents have been transferred to this device.
But some of those are challenges specific to de-extinction. For any researchers who think this could benefit their work, the company would be happy to hear from you. “I believe there will be labs that want to use this just for research purposes, which is awesome,” Lamm told Ars. “And by the way, we’re not going to charge for that. We’re going to just give it away.”
Making Our Monorepo Ergonomic for Agents
Basis successfully refactored its monorepo in three months to be "ergonomic" for code agents, using principles like verifiability and canonical context, unlocking substantial payoffs.
Decoder
- Monorepo: A single repository containing multiple distinct projects, often with shared code and dependencies, managed by a single team or organization.
- Code agents: AI systems designed to understand, write, debug, and refactor code, often operating within a developer's workflow or directly on a codebase.
- Ergonomic (for agents): Designed to optimize the efficiency and minimize the errors of AI code agents when interacting with a codebase, considering their unique needs for context, structure, and verifiability.
Original article
Code agents have their own failure modes, appetite for context, and demands on what counts as a well-organized repository. Companies need to take this seriously as the work to make a repository ergonomic for agents is bigger than expected, and the principles are non-obvious. However, the payoff is substantial. This article looks at how Basis made its codebase ergonomic for agents in three months using principles rooted in verifiability, interoperability, and canonical context.
How I Choose Which Cloudflare Employees to Replace With AI
Cloudflare used AI to identify positions for layoffs, cutting over 20% of its workforce two weeks ago, primarily in measurement tasks, while simultaneously increasing open positions.
Original article
Cloudflare laid off more than 20% of its workforce two weeks ago, many of whom were responsible for various measuring tasks. The company now has better tools to measure exactly how the business is performing. Cloudflare has a record number of open positions, and it expects its number of employees to grow. AI is allowing the company to better measure itself so the humans on its teams can focus on creating and capturing value by building and selling.
Jeff Bezos describes his $38B startup Prometheus for the first time: ‘Nothing to do with robotics'
Jeff Bezos revealed his $38 billion startup, Project Prometheus, is building an "artificial general engineer" for designing physical objects, clarifying it's not a robotics company.
Decoder
- Artificial general engineer (AGE): A hypothetical AI system capable of autonomously designing, simulating, and optimizing complex physical systems and objects, functioning across various engineering disciplines.
Original article
Jeff Bezos' startup, Project Prometheus, is developing an artificial general engineer and building next-generation tools for designing physical objects, similar to a very modern version of Computer-Aided Design. The tools Prometheus is building will help companies like Blue Origin immensely. Project Prometheus launched with $6.2 billion in funding and has roughly 120 employees from firms including OpenAI, DeepMind, Meta, and xAI. It was previously incorrectly reported to be an AI robotics company.
The Evolution of Cassandra Data Movement at Netflix
Netflix revamped its Cassandra data movement engine, now processing 3 PB/day by reading backups directly from S3 and converting them to Spark DataFrames, enabling optimized connectors for various data abstractions.
Decoder
- Apache Cassandra: A free and open-source distributed wide-column NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure.
- Apache Iceberg: An open table format for huge analytic datasets, designed to improve on existing table formats by supporting schemas, hidden partitioning, and schema evolution.
- Spark DataFrames: A distributed collection of data organized into named columns, conceptually equivalent to a table in a relational database or a data frame in R/Python, offered by Apache Spark for structured data processing.
- Maestro Decider: Likely a custom Netflix service or component used for decision-making and fallback logic within their operational orchestration system, Maestro.
Original article
Netflix replaced its Cassandra-to-Iceberg movement engine with a layered platform that reads backups directly from S3, converts them to Spark DataFrames, and lets each data abstraction build its own optimized connector. The engine moves about 3 PB/day, migration uses shadow validation, enhanced observability, and a Maestro Decider fallback to the prior solution, enabling a transparent cutover with zero downstream code changes.
How We Cut BigQuery Slot Usage by 90% On One Of Our Most Resource Hungry Service After a Production Outage
Teads slashed BigQuery slot usage by over 90% on their Audience Planning service following an outage, by coalescing requests, optimizing SQL queries, and refining data models and partitioning.
Decoder
- BigQuery: A fully managed, serverless enterprise data warehouse offered by Google Cloud that enables super-fast SQL queries using the processing power of Google's infrastructure. "Slots" represent units of computational capacity for queries.
- Redis distributed locks: A mechanism using Redis to ensure that only one process or application instance can execute a specific block of code or access a resource at a time across a distributed system, preventing race conditions or duplicate work.
- Semi-join: A type of database join operation that returns all rows from the left table for which there is at least one match in the right table, without including any columns from the right table.
Original article
Teads dramatically cut BigQuery slot usage by 90%+ on their Audience Planning service through application fixes (request coalescing with Redis distributed locks to eliminate duplicate queries, fail-fast validation for huge filters, and rewriting large IN clauses as semi-joins) combined with data model optimizations (compressing data types, precomputing repeated work, and an improved partitioning strategy), reducing the effective table footprint by ~95%.
What's Easy Now? What's Hard Now?
Marc Brooker predicts that AI coding agents' long-term capabilities will hinge on effective feedback loops, making formally specifiable tasks "easy" and those needing subjective human feedback "hard."
Decoder
- LLM (Large Language Model): An AI model, typically deep learning-based, trained on vast amounts of text data to understand, generate, and process human language.
- TLA+: A formal specification language used to design, model, document, and verify concurrent and distributed systems, ensuring correctness before implementation.
- Verus: A tool that combines Rust with formal verification to prove the correctness of Rust code.
- Property-based testing: A testing technique where tests are generated from a specification of properties that the code should satisfy, rather than specific example inputs.
Original article
Marc's Blog
About Me
My name is Marc Brooker. I've been writing code, reading code, and living vicariously through computers for as long as I can remember. I like to build things that work. I also dabble in machining, welding, cooking and skiing.
I'm currently an engineer at Amazon Web Services (AWS) in Seattle, where I work on databases, serverless, and serverless databases. Before that, I worked on EC2 and EBS.
All opinions are my own.
Links
@marcbrooker on Mastodon @MarcJBrooker on Twitter
What’s Easy Now? What’s Hard Now?
Take it easy.
This is the fourth in a series about how AI is changing software development, after It’s time to be right., What about juniors?, and My heuristics are wrong. What now?. It stands alone, but if you found this interesting you may also find those interesting.
I’ve been spending a lot of time thinking about the shape of the capabilities of coding agents. What they’re good at now, what they’re going to be good at. What they’re bad at now, how much of that is inherent and how much is transient. This is worth thinking about, because it’s the most important question shaping the future of software, and of software engineering. I don’t pretend to have an answer, but am coming to a conclusion that may be deeply counter-intuitive.
Coding agents are becoming very good indeed, and can build meaningful and correct software very quickly and at transformatively low cost. They have super-human abilities on some coding tasks. Of course, computer systems have had super human abilities for at least 85 years1. I think we’re going to find, as we have over those nine decades, that this new technology we’re building is vastly super-human in some areas2, and not nearly as capable as humans in others.
Which raises the important question of how, and why.
Feedback is powerful
Early on in my EE education, one of my professors drew a simple circuit on the board that’s been stuck in my mind ever since. It looked like this3:
Apply a voltage on the left, and on the right you get the square root of that voltage4. The two components are an opamp and an analog multiplier IC (e.g. the deeply obsolete MC1495). This simple circuit encapsulates possibly the most important idea in electrical engineering: feedback is uniquely powerful. Maybe unreasonably powerful. It’s the idea that makes nearly every electronic device work, it keeps planes in the sky, and stops your oven from burning your dinner.
Components inside feedback loops can be made to behave significantly differently from their basic open loop behavior. Excellent outputs can be extracted from poor components. Multipliers can become square rooters. Feedback changes everything.
AI agents are just feedback loops. They’re built around a component with useful, but flawed, open loop behavior (an LLM), and use feedback to make that component able to do things that it’s not able to do without feedback. This is the basic idea behind the transformation that has happened in developer tooling in the last two years or so: a move from open loop AI (the smart autocomplete mode in IDEs) to agents. The moving of the feedback from the human developer (build, test, go back to IDE), into the agent itself (build, test, iterate).
Much of the conversation about long-term coding agent capabilities is about open loop model behavior. But that’s only half the picture. I may even stretch to saying it’s the less important half of the picture. Feedback is the thing that’s going to drive long-term capabilities.
The feedback loop hypothesis
In the long term, coding agents will find tasks with effective feedback ‘easy’, and tasks without effective feedback ‘hard’. The availability of accurate feedback will determine the limits on their capabilities.
On one hand, we should see this as uncontroversial. Anybody who has built code with agents knows that good error messages help keep agents unstuck. We’re seeing how tools like Rust guide agents towards writing correct code by providing explicit and immediate feedback about incorrectness of some kinds. We’re seeing agents be great at performance work, where good benchmarks exist. We’re seeing tools like property-based testing be uniquely valuable. We’re also seeing that agents aren’t great at architecture (where feedback tends to be of the ‘I know it when I see it’ kind), or writing concurrent programs (where feedback tends to be of the ‘it silently corrupted data at runtime’ kind).
But let’s look forward a little bit, and compare two problems:
- Building a delightful ergonomic photo editing website.
- Building a correct high-performance database storage engine5.
For open-loop models, the former is easier than the latter. At least in that you’ll get closer to real success with a pure vibe coding workflow, and much closer to success on the former after a single shot. The feedback loop hypothesis, however, makes me think that the latter is actually the easier long-term problem.
To understand why, consider their feedback loops. The website’s feedback loop, beyond maybe some automation that tests if the buttons do what they should, requires a human in the loop. It needs to be easy to use for humans, and humans are notoriously slow, squishy, and inconsistent feedback providers. The latter, however, has a rather simple specification, including the API, safety properties, and liveness properties. With the right tools in the feedback loop, iteration towards success requires no humans.
What does it mean?
I think this is different from the intuition many people have about coding agents. They see websites and UIs as ‘easy’ (see the SaaSpocalypse), and system software as ‘hard’. The feedback loop hypothesis says that this is backwards. That, in fact, we’re going to find that SaaS is ‘hard’ and system software is ‘easy’.
This is going to raise the importance of specification (the writing down of what good looks like to drive the feedback loop), and of tools that apply that specification to code. Compile-time tools like Rust, Hydro, and Verus. Modelling-time tools like TLA+ and P. Specification tools like Kiro’s spec analyzer. Testing tools, simulators, mocks, etc.
The future of software development is building these feedback loops. Many hard problems remain.
Footnotes
- Dating back to the work of folks like Marian Rejewski in the 1930s.
- The MacBook on my desk can add 64 bit numbers about something like 100,000,000,000 times faster than I can.
- Drawn with CircuitLab, and adapted from this Electronics StackExchange Answer. In reality, a few more passive components are needed.
- If you’re not familiar with this stuff, here’s an intuition for how this works. The opamp (the triangle) tries to adjust its output (on the right) so the two inputs are the same. So if you take the output, and multiply it by itself, then feed it into one of the inputs, it’ll set the output to the square root of the input. If you are familiar with this stuff, I apologize deeply for that explanation.
- I mean something on the scale of, say, RocksDB or InnoDB, not something on the scale of Aurora DSQL or even PostgreSQL. I think these large-scale distributed systems are going to be harder to hill climb to, at least for the future I can see.
Similar Posts
- 20 May 2026 » Agentic software development hypothesis
- 30 Apr 2026 » It's time to be right.
- 09 Apr 2026 » Spec Driven Development isn't Waterfall
Marc Brooker
The opinions on this site are my own. They do not necessarily represent those of my employer.
marcbrooker@gmail.com
This work is licensed under a Creative Commons Attribution 4.0 International License.

The pipeline tax is breaking enterprise AI at agent scale
Enterprise AI is hindered by a "pipeline tax" from excessive data movement across disparate systems, leading to latency, governance issues, and high costs, pushing towards bringing agents to data.
Decoder
- Pipeline tax: A term coined to describe the hidden costs and inefficiencies (latency, governance drift, audit complexity) arising from repeatedly moving and transforming data across multiple systems (e.g., data warehouses, lakehouses, vector databases) for enterprise AI applications.
- RAG (Retrieval-Augmented Generation) layers: Components in an AI architecture that retrieve relevant information from a knowledge base to augment the context provided to a language model, improving its generation quality.
- Apache Iceberg: An open table format for huge analytic datasets, designed to improve on existing table formats by supporting schemas, hidden partitioning, and schema evolution.
- Model Context Protocol (MCP): A proposed standardized protocol that allows AI agents to securely and accountably access operational data directly from data layers, rather than through custom integrations or pipelines.
- Postgres® (PostgreSQL): A powerful, open-source object-relational database system known for its reliability, feature robustness, and performance.
Original article
The pipeline tax is breaking enterprise AI at agent scale
Three months ago, the conversation I was having with enterprise technology leaders was about which model to fine-tune. Today, it’s about why the pipeline feeding that model is the reason their AI project is six months behind schedule. Or, more important, why adding more pipelines and more cloud capacity is not translating into measurable value from AI in production.
This is not a coincidence. The 2025 enterprise AI architecture—vector databases, RAG layers, orchestration frameworks and ingestion pipelines pulling from operational systems—was built on an assumption that does not survive contact with production: that enterprises can keep moving data fast enough to make AI agents useful in real time and then reconstruct governance downstream after every move.
That assumption came from pre-AI blueprints. It was like adding more horses versus building horsepower. AI in production needs brake-horsepower infrastructure that puts data and AI together in real time in a sovereign infrastructure, not in different places.
The next generation of successful enterprise architecture starts and finishes at the engine inside that vehicle: the data layer.
This is the new world of an engine, where all the parts fit and work together in real time. It’s not a set of fragmented pieces glued together with great intent but optimized only for reducing drag and friction—it means building a whole new sovereign systemic design for AI success.
That old assumption cannot hold. And the data layer is where it is breaking first.
The pipeline tax no one has on their balance sheet
Look at the architecture most large organizations actually run. Transactional systems feed pipelines, which feed warehouses, lake houses, feature stores and models. Each hop is a translation. And each translation is a place where governance policies have to be reapplied, lineage gets murky and a masking rule defined in one system can silently fail to propagate to the next.
By the time data reaches an AI agent, it may have been copied four times and governed by three regimes, none of which fully agrees with one another. Then a regulator asks a simple question—“Can you show me where this customer’s data went and who touched it?”— and the answer takes six weeks and a consulting engagement.
This is the pipeline tax. It does not appear as a line item in any budget, but it shows up as audit findings; AI hallucinations; stalled migrations; and the reason why 95% of enterprises say they want to operate as their own sovereign AI and data platforms, while only 13% report they are actually thriving at it. Those figures come from EDB’s recent customer research, but the broader pattern is visible across the market: Gartner has tied GenAI project abandonment to poor data quality, inadequate risk controls, escalating costs and unclear business value. And McKinsey’s 2025 State of AI survey found that AI adoption is broadening, but most organizations have not yet scaled the technology into enterprise-wide impact.
The retreat from 2025’s architecture is happening at scale—and fast
The market has started to figure this out. The retreat from the RAG infrastructure enterprises spent 2025 building is real—VB Pulse found that organizations that “went wide on RAG in 2025” are now hitting a common failure point: architectures built for document retrieval do not hold at agentic scale. Single-method vector similarity is no longer enough for production agentic workloads that require accuracy, access control and context across systems.
Vector database categories are shifting as a result. The issue is not that retrieval is going away; it is that the simple RAG-to-vector-database pipeline is being rebuilt for a different era of AI. Hyperscalers are beginning to rebuild their data stacks around agents rather than pipelines. Even lake house incumbents are publishing research arguing that when queries span databases and documents, stronger models alone do not fix the problem—architecture does.
What is missing from most of those stories is the next move. If pipelines are the problem, what replaces them?
Always-on-governance is the new model, at the data layer
The architectural answer now forming is straightforward: Stop moving the data and bring agents and AI to the data. Governance should live inside the data layer by design, not be bolted onto every downstream system after the fact.
Treat governance as a property of the architecture itself. Think of it like the human body: Organs perform different functions, but they are interdependent and governed by the same system 24x7x365. Enterprise AI needs the same principle. Different systems and agents may serve different purposes, but they have to operate from the same rules of governance, policy and sovereign control.
The pieces required to do this are no longer speculative. Postgres®, where much of the enterprise’s operational data already lives, can serve as a governance control plane, with row-level security, column masking and lineage native to the engine. Apache Iceberg has won the open table format argument. The Model Context Protocol gives AI agents a standardized, governed way to reach operational data without requiring a custom integration for every application.
None of this is a 2027 roadmap conversation. It is a procurement conversation happening now.
Migration is a capability, not a project
The same logic applies to the modernization backlog blocking everything else. Migration has historically been treated as a project: scope it, staff it, suffer through it and deliver it 18 months late.
The reason it remains painful is that the work itself—discovering schema dependencies, translating embedded business logic, validating functional equivalence—is exactly the kind of high-context, repetitive reasoning that coordinated AI agents are now genuinely good at.
The COBOL-translation demos getting attention this year are the leading edge of something larger: migration becoming an autonomous, continuously running capability rather than a one-off program. That changes the unit economics. It also changes the strategic question. The interesting question is no longer, “How long will this Oracle migration take?” It is, “How quickly can we evolve our entire platform strategy?”
The data layer is where the next decade gets decided
The vendors that win the next decade of enterprise infrastructure will not be the ones with the fastest query engine or the slickest notebook experience. They will be the ones that recognize data movement is breaking enterprise AI.
The pipeline tax has been paid long enough. The interesting work now starts at the data layer—and it starts when enterprises stop paying that tax.
The pipeline model breaks at agent scale. It was born of good intent, but in a world moving toward 1 billion agents delivering 217 billion instructions a day, it is architecturally medieval. The agentic era will be won at the data layer.

Monitoring Cortex Agent Performance With Trace Data
Monte Carlo details how to monitor Snowflake Cortex Agents in production by analyzing trace data for token consumption, latency, and errors using GET_AI_OBSERVABILITY_EVENTS.
Deep dive
- The article outlines how to monitor Snowflake Cortex Agents by querying structured observability events.
- Snowflake Intelligence natively logs rich trace data, including conversation history, tool execution, LLM planning, and response generation.
- This trace data is stored in native observability tables and accessible via the
SNOWFLAKE.LOCAL.GET_AI_OBSERVABILITY_EVENTStable function. - Each agent interaction is composed of hierarchical spans, with
record_nameidentifying span types likechat,planning,response_generation, andtool_call. - Key performance metrics to monitor include total token consumption (prompt + completion tokens per span), duration/latency (P50, P90), and span-level status codes (
STATUS_CODE_OK,STATUS_CODE_ERROR). - Common issues like token spikes can indicate changes in input length, context window accumulation, retrieval behavior changes, or increased tool call depth.
- Monitoring completion rates (proportion of
STATUS_CODE_OKspans) is crucial for catching silent failures. - High usage volatility in early deployments requires careful tuning of monitor sensitivity and consideration of filtering to business hours for cleaner baselines.
- The article emphasizes combining signals across span types for effective troubleshooting, such as correlating high planning tokens with low tool call completion rates.
- The underlying principle is to continuously watch agent behavior, learn what "normal" looks like, and surface deviations before users notice them at scale.
Decoder
- Cortex Agent: AI agents offered by Snowflake Intelligence, designed to perform tasks by interacting with data within the Snowflake ecosystem.
- Trace data: Detailed logs of an agent's operations, capturing sequential events (spans) during a request, including planning, tool calls, and response generation.
- Span: A single operation or step within a trace, such as an LLM planning step, a tool call, or a response generation step.
- SNOWFLAKE.LOCAL.GET_AI_OBSERVABILITY_EVENTS: A Snowflake table function used to access native observability events for Cortex Agents.
Original article
Full article content is not available for inline reading.

Context graphs and decision traces to the rescue
A December 2025 Foundation Capital paper introduces "context graphs" and "decision traces" as a crucial missing provenance layer for enterprise RAG and AI agent workflows.
Deep dive
- A December 2025 paper by Foundation Capital, "AI’s trillion-dollar opportunity," introduced the concept of "context graphs" and "decision traces."
- A context graph is a knowledge graph designed to capture "decision traces," which record the observable reasoning and causal relationships behind past business decisions.
- This approach is seen as a missing provenance layer for retrieval-augmented generation (RAG) and AI agent workflows in enterprises.
- It complements existing enterprise systems (like ERPs, CRMs) by storing operational memory: what evidence mattered, which relationships were relevant, policies applied, and exceptions made.
- The article argues that AI needs all three types of human memory: episodic (decision traces), semantic (facts/schemas), and procedural (skills/how-to), to prevent hallucinations.
- Graphs are crucial because enterprise context is fundamentally based on connections and relationships, which vector search struggles to capture.
- A context graph can act as a "graph of graphs," guiding AI agents to the correct underlying data sources (e.g., accounting database for accounting questions).
- GraphRAG, which improves retrieval from graphs for AI systems, is an essential part of this emerging ecosystem.
- The market is evolving quickly, and enterprise AI teams should explore innovations like context graphs without setting architectures in stone yet.
Decoder
- Context graph: A knowledge graph designed to capture and map the full context, reasoning, and causal relationships behind critical business decisions and organizational data.
- Decision traces: Records of the observable reasoning behind how decisions were made, including rule application, exceptions, conflict resolution, approvals, and governing precedents.
- GraphRAG (Retrieval-Augmented Generation in graphs): A technique that uses graph databases to store and retrieve structured knowledge, improving the ability of AI systems to access and utilize this knowledge for generating more accurate and contextually relevant responses.
Original article
Full article content is not available for inline reading.
Google's Newest App is an AI-powered Image Editor
Google is launching "Google Pics," an AI-powered image editor built on Nano Banana, which allows users to manipulate image elements and translate text within photos.
Decoder
- Nano Banana: The underlying AI technology or platform Google Pics is built upon.
Original article
Full article content is not available for inline reading.

Airbnb gets into hotels, expands AI for host onboarding and customer support
Airbnb is expanding beyond traditional home rentals by listing boutique hotels in 20 cities and significantly increasing its use of AI for host onboarding, customer support, and travel planning, with a voice AI assistant planned.
Original article
Full article content is not available for inline reading.

Activity-focused Design
Activity-focused design, like task analysis, prioritizes understanding user actions and goals to identify design improvements, emphasizing "what people do and how they do it."
Deep dive
- Activity-focused design (AFD) centers on the actions people take to reach their goals, with the core unit of analysis being "what people do and how they do it."* Task analysis is one approach within AFD, complementing human-centered design, used to understand and improve user workflows.* The process of task analysis involves four main steps: determining the user's primary goals, identifying the specific tasks required to achieve those goals, documenting the goals and tasks (e.g., with diagrams), and analyzing them for improvements.* Designers must choose an appropriate level of specificity for tasks; for new designs, it's often better to describe tasks in an interface-independent way.* Strengths of task analysis include revealing gaps and optimization opportunities in task sequences, and its natural translation to digital experience design.* Weaknesses include potentially overlooking non-task-related factors like user emotions or social context, and a tendency to lead to backward-looking designs based on existing task flows rather than innovative new ones.
Decoder
- Activity-focused design (AFD): A design methodology that prioritizes understanding the actions people take to achieve their goals.* Task analysis: A systematic method within activity-focused design used to break down user goals into a series of activities and individual tasks to identify design opportunities.* Contextual inquiry: A user research method where the designer observes users in their natural environment while they perform tasks to understand their workflow and challenges.* Think-aloud interviews: A user research method where participants vocalize their thoughts, feelings, and actions as they interact with a system, allowing designers to understand their cognitive processes.
Original article
Full article content is not available for inline reading.
3D Gaussian Splatting Editor (Website)
SuperSplat introduces an advanced browser-based editor for manipulating and optimizing 3D Gaussian Splats, simplifying 3D content creation.
Decoder
- 3D Gaussian Splatting: A novel technique for real-time 3D rendering that represents scenes as a collection of 3D Gaussian functions, offering high quality and fast rendering compared to traditional mesh or volumetric methods.
Original article
SuperSplat is an advanced browser-based editor for manipulating and optimizing 3D Gaussian Splats.
Generative Analytics Platform (Website)
Fusedash offers a no-code generative analytics platform that automatically builds interactive KPI dashboards and reports from raw data using AI, supporting models like Claude and GPT.
Deep dive
- Fusedash is a no-code generative analytics platform that builds interactive KPI dashboards, AI charts, and real-time reports.
- It connects to data via CSV uploads, REST APIs, or any Model Context Protocol (MCP)-compatible AI model (e.g., Claude, GPT).
- The platform aims to reduce the need for manual dashboard configuration, allowing teams to focus on decision-making rather than building.
- Key features include KPI dashboards, data storytelling reports, AI chart generation, location intelligence maps, chat with data, and live monitoring.
- It offers solutions tailored for e-commerce, SaaS, agencies, and roles like business leaders, analysts, and marketing teams.
- The system is built on the Model Context Protocol (MCP), allowing users to choose their preferred AI model for tasks like generating visuals, summaries, and chat responses.
- Fusedash differentiates itself by combining interactive dashboards, an AI chart generator, real-time data visualization, and data storytelling in one workspace.
- Pricing uses token packs for AI-powered actions, ensuring core dashboards remain functional even when AI usage is throttled.
- The company emphasizes that its "generative analytics" approach means the interface does the work, not the team, streamlining report creation.
Decoder
- KPI (Key Performance Indicator): A measurable value that demonstrates how effectively a company is achieving key business objectives.
- Model Context Protocol (MCP): An open protocol enabling analytics platforms to connect with and utilize various AI models (like Claude or GPT) for tasks such as data summarization and dashboard generation, without vendor lock-in.
Original article
Full article content is not available for inline reading.

Why Motion Design is Defining Modern Digital Communication
Motion design has become essential in modern digital communication, surpassing static content in effectiveness due to evolving audience expectations set by platforms like TikTok and Instagram Reels.
Deep dive
- Motion design, or motion graphics, transforms visuals through animation, movement, timing, and sound, contrasting with static design's fixed visuals.
- Platforms like TikTok, Instagram Reels, and YouTube Shorts have driven a shift towards motion-first content, influencing audience behavior and expectations.
- Human attention is naturally drawn to movement, making motion design highly effective at interrupting fast-scrolling feeds and capturing user focus.
- Motion design improves information processing by structuring content sequentially over time, simplifying complex ideas, and reducing cognitive load through digestible parts.
- It enhances emotional connection and memory retention by creating rhythm, anticipation, and narrative flow, leading to stronger brand association.
- Research in visual cognition and marketing behavior supports that motion increases attention capture, improves information retention, and drives engagement.
- Social media algorithms explicitly favor video and animated content due to higher engagement and longer watch times, forcing brands to design for motion-first visibility.
- Overuse of motion can lead to distraction, animation fatigue, accessibility concerns (motion sensitivity), and performance issues (slow load times).
- The most effective digital experiences strategically combine both motion and static design, using motion for engagement and storytelling, and static for simplicity and clarity.
- The U.S. Bureau of Labor Statistics projects employment for motion design professionals to grow faster than average through 2034, indicating its increasing importance.
Decoder
- Motion Graphics: Animation combined with graphic design to create the illusion of motion or rotation, often with audio, for use in multimedia projects.
- Kinetic Typography: An animation technique mixing motion and text, often used to convey emotion or enhance a message, commonly seen in commercials, title sequences, and explainer videos.
Original article
Full article content is not available for inline reading.

Which of the Following is Not True About Graphic Design? Common Myths Debunked
Many widely-held beliefs about graphic design are false, including that it's purely subjective, only for print, or that software skill makes a designer.
Deep dive
- Graphic design is defined as visual communication combining images, words, and ideas to convey information to an audience.
- It is not purely subjective; it has principles like Hierarchy, Contrast, Alignment, Proximity, White space, and Repetition, grounded in human cognition.
- Adding more design elements does not make a design more effective; often, minimalism is key to clarity.
- Graphic design is not limited to print; it encompasses UI, motion graphics, environmental design, social media, and data visualization.
- Proficiency in software like Photoshop does not equate to being a graphic designer; design thinking and understanding principles are crucial.
- Good design's primary goal is effective communication with the intended audience, not merely client satisfaction.
- The discipline is not new; while the term was coined in 1922 by William Addison Dwiggins, the practice is ancient, seen in cave paintings and early printing.
- Bad graphic design has real consequences, costing money, confusing audiences, and potentially causing harm, as exemplified by the 2000 US election butterfly ballot.
- Graphic design is distinct from art; art is self-expression, while design is problem-solving oriented towards a specific communication goal.
Decoder
- William Addison Dwiggins: American typographer, calligrapher, and book designer who coined the term 'graphic design' in 1922.
- Bauhaus: Influential German art school (1919-1933) known for its functionalist approach to design, merging craftsmanship with fine arts.
- Swiss International Style: A graphic design movement developed in Switzerland in the 1950s, characterized by clean, readable, sans-serif typography, grids, and asymmetric layouts, emphasizing clarity and objectivity.
Original article
Full article content is not available for inline reading.
WavFlow Generates Audio Directly in Waveform Space (GitHub Repo)
Meta AI's WavFlow is a new flow-matching framework that generates high-fidelity audio directly from video and text inputs in raw waveform space, bypassing latent audio compression.
Decoder
- Flow-matching framework: A generative modeling technique that learns a continuous-time transformation between a simple noise distribution and a complex data distribution, allowing for efficient and stable sampling.
- Waveform space: The raw, uncompressed representation of an audio signal, typically consisting of a sequence of amplitude values over time.
- Latent audio compression: The process of encoding raw audio into a lower-dimensional, abstract representation (latent space) which is then used by generative models to produce new audio, common in many existing audio AI systems.
Original article
WavFlow: Audio Generation in Waveform Space
Feiyan Zhou1,2 · Luyuan Wang1 · Shoufa Chen1,* · Zhe Wang1 · Zhiheng Liu1 · Yuren Cong1 · Xiaohui Zhang1 · Fanny Yang1 · Belinda Zeng1
1 Meta AI · 2 Northeastern University
🌐 Project Page · 📄 arXiv · 🛠 Training Guide
Overview
WavFlow introduces a paradigm for generating synchronized, high-fidelity audio from video and text inputs directly in the raw waveform space, bypassing latent compression entirely. Through waveform patchifying and amplitude lifting, WavFlow enables stable flow matching on raw audio via direct x-prediction. Evaluation on the VGGSound (VT2A) and AudioCaps (T2A) benchmarks shows that WavFlow delivers performance on par with established latent-based methods, proving that end-to-end waveform generation can match traditional frameworks in acoustic richness, fidelity, and synchronization.
Demo
|
🌳 Forest (natural) forest.mp4 |
🐸 Frog (animal) frog.mp4 |
|
🥁 Drum (music) drum.mp4 |
🛹 Skateboard (sport) skateboard.mp4 |
See the Project Page for 24+ samples and side-by-side benchmark comparisons.
Method
Installation
git clone https://github.com/facebookresearch/WavFlow.git cd WavFlow bash scripts/setup.sh # creates conda env 'wavflow' and installs everything conda activate wavflow
Manual setup
conda create -n wavflow python=3.10 -y conda activate wavflow pip install -r requirements.txt pip install -e . --no-deps conda install -n wavflow -c conda-forge "ffmpeg<7" -y # for torio video decoding
All required external weights (CLIP, Synchformer, the empty-string CFG embedding) are downloaded or computed automatically on first run and cached under
~/.cache/wavflow/.
Inference
⚠️ Due to organizational policy constraints, we are currently unable to release the production-trained checkpoints. We are working on a foundation checkpoint trained on fully open-source data; in the meantime you can train your own — see the training guide.
Once you have a trained checkpoint, run:
bash scripts/launch/predict.sh [--gpu N] [--config PATH]
The default config is wavflow/configs/infer.yaml. The input CSV (data.csv_path) accepts video, text, or both:
video_path,caption,video_exist,text_exist /abs/path/sample1.mp4,a whistling rocket explodes,1,1 # video + text /abs/path/sample2.mp4,birds chirping in a forest,1,1 # video + text ,a whistling rocket explodes,0,1 # text-only /abs/path/sample3.mp4,,1,0 # video-only
Configuration reference
Launcher options
| Flag / env | Default | Description |
|---|---|---|
--gpu N (or GPU=N) |
0 |
CUDA device index |
--config PATH (or CONFIG_PATH=...) |
wavflow/configs/infer.yaml |
YAML config to load |
WAVFLOW_ENV |
wavflow |
conda env name to auto-activate |
Any extra positional argument is forwarded to python -m wavflow.infer.
Key fields in infer.yaml
| Field | What to set |
|---|---|
data.csv_path |
the input CSV (above) |
model.name |
one of medium_16k, medium_44k, large_16k, large_44k (must match the trained ckpt) |
model.ckpt_path |
a checkpoint_*.pth (full ckpt) or ema_epoch_*.pth (EMA-only) |
model.use_ema |
true to load model_ema1 from a full ckpt; false to use the live model weights |
inference.duration_sec / target_sample_rate |
output length and SR (must match model arch) |
inference.cfg, num_steps, noise_scale, noise_shift, prediction_type, seed |
sampling hyperparameters |
inference.batch_size |
rows per ODE batch |
inference.trim_to_duration |
trim output to duration_sec |
output.output_dir |
where wavs are written |
output.loudness_norm, loudness_target_lufs |
optional pyloudnorm post-processing |
CSV semantics
video_exist=0→ uses learned empty CLIP/Sync tokens (no video decode)text_exist=0→ uses learned empty CLIP-text token (caption ignored)- Optional
idcolumn; otherwise the wav file name is derived fromPath(video_path).stem, falling back torow_<idx>for text-only rows - Captions with commas must be quoted
EMA caveat
The EMA tensor stored as model_ema1 is updated with ema_decay = 0.9999 per step. After only a few hundred / thousand steps it still contains random-init values and produces noise during inference. Set model.use_ema: false (or pass an ema_epoch_*.pth saved after enough steps) when sampling from a short / overfit run.
Training
For feature extraction and training (single-node and multi-node), see TRAINING.md.
Citation
@misc{zhou2026wavflowaudiogenerationwaveform,
title={WavFlow: Audio Generation in Waveform Space},
author={Feiyan Zhou and Luyuan Wang and Shoufa Chen and Zhe Wang and Zhiheng Liu and Yuren Cong and Xiaohui Zhang and Fanny Yang and Belinda Zeng},
year={2026},
eprint={2605.18749},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2605.18749},
}
Acknowledgements
WavFlow builds on the open-source community. We gratefully acknowledge:
- MMAudio — multimodal audio generation
- JiT — Just Image Transformer
- Synchformer — audio-visual synchronization
License
The majority of WavFlow is licensed under CC-BY-NC 4.0. Portions of the project are vendored from third-party open source projects under their original license terms (MIT, Apache 2.0, CC BY-NC 4.0, and Stability AI Community License). See NOTICE.txt for the full per-component breakdown and license texts.
Mind-Blowing Growth Is About to Propel Anthropic Into Its First Profitable Quarter
Anthropic's revenue is projected to more than double to $10.9 billion in the second quarter, making it profitable for the first time, surpassing the growth rates of Google and Facebook pre-IPO.
Original article
Anthropic's revenue is set to more than double in the second quarter to $10.9 billion. The projections, disclosed to Anthropic's investors as part of an ongoing funding round, show how the company's sales have exploded since the start of the year. Its quarterly revenue is now growing faster than Google's and Facebook's in the run-up to their initial public offerings. The company might not remain profitable for the full year as it plans to increase spending due to its vast need for compute.
The Unsustainable Subsidy
AI model prices are generally rising, with Google tripling annually and OpenAI increasing after subsidies, as vendors prioritize margins over market share due to tight cash and record capex.
Original article
Google’s AI triples in price each year.
OpenAI’s flagship model was seemingly subsidized for a while, before rising again.
Anthropic’s AI has been the same price for a little bit & decreased for the most powerful models.
Those are three very different pricing strategies. If we compare the absolutes, the data completes the picture.
| Vendor | Model | Input ($/1M) | Output ($/1M) |
|---|---|---|---|
| Gemini 3.1 Pro | $2.00 | $12.00 | |
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 |
| OpenAI | GPT-5.5 | $5.00 | $30.00 |
Google remains the low-cost player, increasing the price on all its models but still less than half of the competition. Anthropic had maintained a luxe pricing until late last year.
The pricing changes indicate changes in strategy : cuts when cash is plentiful & share matters. Increases when cash is tight & margins matter. The latter is the case for all three vendors now when capex spending continues to set records.
The Secrets Revealed in SpaceX's IPO Filing
SpaceX aims for a record-breaking June IPO on Nasdaq as SPCX, despite significant losses last year ($4.9 billion) and in Q1 ($4.3 billion) on substantial revenue.
Original article
SpaceX's IPO is expected to set a record for the biggest stock debut ever and could make its founder, Elon Musk, the world's first trillionaire. The company is aiming to go public in June on Nasdaq under the ticker symbol SPCX. The company lost $4.9 billion last year on revenue of $18.7 billion. This year, in the first quarter, SpaceX lost $4.3 billion on $4.7 billion of revenue. The financials show an established business launching satellites and astronauts to space, though it is still unprofitable.

Artificial Womb for Growing Mammals Is at 'One-Yard Line', Says Colossal CEO
Colossal, the de-extinction startup, claims its artificial womb for mammals is nearing completion, already achieving a 100% development rate for its early stages.
Original article
Coin Prices
BTC $77,279.00 -0.32%
ETH $2,121.99 -0.20%
BNB $655.20 0.68%
XRP $1.36 -0.74%
USDC $0.999751 0.02%
SOL $86.61 0.48%
TRX $0.365062 1.39%
FIGR_HELOC $1.026 -0.89%
DOGE $0.105121 0.22%
HYPE $57.15 1.09%
WBT $56.99 -0.26%
ZEC $651.32 -2.20%
USDS $0.999677 0.01%
ADA $0.249962 0.89%
LEO $10.00 -0.76%
BCH $378.07 0.44%
XMR $387.23 -2.98%
LINK $9.77 1.46%
CC $0.154477 1.01%
TON $2.00 -2.54%
XLM $0.146394 0.93%
USD1 $0.99958 -0.02%
USDE $0.999026 -0.02%
SUI $1.098 -0.45%
LTC $54.08 -0.22%
AVAX $9.47 1.02%
HBAR $0.089125 0.70%
M $2.82 -3.55%
RAIN $0.0075024 -0.10%
PYUSD $0.999584 -0.02%
SHIB $0.00000582 0.49%
CRO $0.06909 -0.23%
USYC $1.12 0.00%
NEAR $2.19 28.30%
TAO $280.31 -0.71%
USDG $0.999799 0.02%
XAUT $4,514.03 0.03%
BUIDL $1.00 0.00%
UNI $3.61 -0.59%
MNT $0.670457 -1.77%
DOT $1.31 3.59%
USDY $1.13 -0.62%
PAXG $4,515.30 0.05%
ONDO $0.407855 2.19%
WLFI $0.061259 -0.12%
HTX $0.00000201 -0.15%
USDF $0.996953 -0.04%
ASTER $0.689499 0.87%
RLUSD $0.999813 -0.00%
OKB $81.60 0.99%
SKY $0.070738 0.60%
PI $0.152292 -0.39%
PEPE $0.00000377 0.83%
USDD $0.998652 -0.06%
ICP $2.69 5.38%
ETC $9.08 1.34%
BGB $1.98 -1.37%
AAVE $87.57 -1.25%
BFUSD $0.998401 0.03%
MORPHO $2.00 6.42%
QNT $76.32 3.80%
ATOM $2.13 2.75%
USDTB $0.999048 0.01%
KCS $7.98 -0.40%
EUTBL $1.22 -0.07%
RENDER $1.99 3.62%
U $0.999994 0.04%
ALGO $0.113916 -2.63%
POL $0.092122 0.87%
USTB $11.09 0.01%
JTRSY $1.10 0.01%
BCAP $105.74 0.00%
ENA $0.106032 0.15%
KAS $0.03477359 1.09%
WLD $0.277802 8.81%
NEXO $0.871348 0.11%
VVV $17.85 5.17%
APT $0.974135 1.79%
FIL $1.013 2.57%
JST $0.092397 0.37%
STABLE $0.03329004 -3.44%
GT $7.09 -0.16%
FLR $0.00837514 -0.88%
JUP $0.217179 3.32%
ARB $0.113496 2.00%
XDC $0.03531672 4.91%
DEXE $14.07 3.58%
PUMP $0.00181053 2.65%
BDX $0.079542 1.07%
PENGU $0.00960047 4.97%
DASH $47.44 -1.34%
GHO $0.998898 -0.00%
VET $0.00670044 1.31%
HASH $0.01052331 1.93%
OUSG $115.32 0.01%
USD0 $0.998559 0.00%
BONK $0.00000623 1.70%
KITE $0.230848 -0.18%
NIGHT $0.03091837 1.81%
INJ $5.10 3.46%
YLDS $0.99968 -0.01%
A7A5 $0.01298918 -0.10%
APXUSD $0.999626 0.01%
VIRTUAL $0.767475 5.05%
EDGE $1.42 3.65%
TUSD $0.998846 -0.02%
TRUMP $2.08 1.76%
FET $0.210651 8.87%
CAKE $1.45 -0.22%
STX $0.249477 2.82%
LUNC $0.00008075 4.90%
CHZ $0.04295488 -3.58%
币安人生 $0.440481 1.42%
EURC $1.16 -0.06%
JAAA $1.035 0.01%
AERO $0.456896 10.48%
SEI $0.063239 2.25%
EURSAFO $1.17 -0.07%
ADI $3.87 -0.52%
USX $0.999413 -0.01%
H $0.219132 -12.59%
TIA $0.433365 6.67%
2Z $0.114309 1.73%
SUN $0.02013268 -0.06%
XTZ $0.349449 1.01%
FDUSD $0.998264 0.03%
SIREN $0.498488 -2.62%
CRV $0.239102 1.63%
SPX $0.388307 0.19%
LAB $4.65 3.09%
LIT $1.40 7.02%
KAU $145.85 0.27%
ZRO $1.36 -1.27%
ETHFI $0.384432 0.29%
PYTH $0.04291628 3.40%
MON $0.02825043 3.87%
USDGO $0.999887 0.03%
PENDLE $1.94 3.01%
KAIA $0.054735 5.62%
BTT $0.00000032 0.02%
GNO $118.44 -0.33%
PRIME $1.038 0.05%
9BIT $0.03718284 -3.97%
CFX $0.058029 0.37%
LDO $0.354686 -1.38%
ZBCN $0.00306132 2.06%
DCR $17.16 -1.24%
BSV $14.85 -1.59%
FLOKI $0.00003064 0.69%
TEL $0.00310097 -0.85%
KAG $76.39 2.40%
USDAI $0.999146 -0.13%
JASMY $0.00578589 2.18%
OP $0.132728 2.59%
OHM $18.95 -0.01%
NEX $0.00000471 -13.30%
GRT $0.02601871 2.42%
NFT $0.00000028 -0.29%
B $0.278594 -19.35%
STRK $0.04381143 0.30%
FRAX $0.992182 -0.04%
GRASS $0.445307 30.87%
ENS $6.40 1.95%
IOTA $0.057032 1.98%
RUSD $0.999477 -0.01%
SKYAI $0.248297 -27.98%
JTO $0.518392 0.11%
GWEI $0.116043 -6.81%
UB $0.096279 -10.88%
APEPE $0.00000114 -0.09%
USDM $0.999326 0.12%
SYRUP $0.203178 -1.61%
REAL $0.071171 -0.77%
ULTIMA $2,729.35 -0.18%
AKT $0.790727 3.61%
CRVUSD $0.999309 0.00%
XPL $0.088048 1.56%
COMP $22.47 -1.76%
USDA $0.982928 -0.01%
APYUSD $1.37 -0.17%
AXS $1.20 0.13%
TRAC $0.464147 1.59%
RAY $0.771389 -0.05%
PIEVERSE $0.767047 4.46%
BEAT $0.772854 15.93%
FF $0.088161 -2.93%
THETA $0.204875 0.28%
NEO $2.90 0.67%
PC0000031 $1.00 0.00%
BSB $0.90059 -7.15%
WIF $0.200182 2.42%
MBTC $0.180532 10.23%
SAND $0.07327 1.21%
FARTCOIN $0.194276 1.87%
TWT $0.461548 -0.20%
UDS $1.50 -0.38%
REUSD $1.078 0.02%
XCN $0.00486708 1.80%
S $0.04812994 2.35%
ONYC $1.10 0.07%
BTSE $1.12 -1.38%
CFG $0.305862 3.60%
IP $0.498246 0.63%
BORG $0.178846 2.00%
WFI $2.08 -0.04%
MANA $0.089539 0.60%
BILL $0.069274 -17.84%
VSN $0.04528019 -3.62%
CRCLON $116.01 4.27%
ZANO $10.80 -0.53%
USTBL $1.084 0.01%
GALA $0.00341941 1.33%
MX $1.77 0.14%
PC0000033 $1.00 0.00%
WAL $0.067936 -1.71%
USAT $0.998575 -0.01%
SATUSD $0.994538 0.52%
XP $0.056959 -4.22%
RUNE $0.439594 4.06%
CVX $1.69 -0.35%
EURS $1.22 -0.48%
ZK $0.01547991 0.75%
BAT $0.100299 1.35%
GUSD $0.995236 -0.06%
IMX $0.174945 1.68%
XEC $0.00000733 0.85%
EIGEN $0.197997 2.55%
GENIUS $0.436599 -2.67%
NUSD $0.998913 0.02%
HNT $0.797596 -1.50%
RAVE $0.573501 -5.30%
AR $2.19 -0.11%
APE $0.143445 -1.65%
CHEEMS $0.0000007 2.35%
FDIT $1.00 0.00%
SFP $0.284306 1.82%
GLM $0.13932 2.17%
AB $0.00140202 -0.50%
SAFO $1.008 0.01%
STRCX $102.18 -0.77%
RAIL $2.41 55.49%
ASTEROID $0.00032247 -3.05%
TAG $0.00123918 2.22%
A $0.081839 0.54%
FRXUSD $0.999798 0.03%
PC0000097 $1.00 0.00%
AUSD $0.999643 -0.01%
RIVER $6.77 9.63%

Zuckerberg warns ‘success isn't a given' after laying off 10% of Meta
Mark Zuckerberg announced Meta laid off 10% of its workforce, approximately 8,000 employees, while shifting 7,000 roles to AI and warning success is "not a given."
Original article
As Meta cut 10% of its workforce on Wednesday — a move that had been anticipated for nearly a month — CEO Mark Zuckerberg addressed the tech giant’s transition in a companywide memo.
Zuckerberg thanked the impacted employees, stressed the importance of artificial intelligence, assured workers there shouldn’t be additional cuts in 2026 and laid out some of his vision for the future. Along with the cuts, Meta is redirecting 7,000 employees into AI roles, NBC News reported Tuesday.
“But success isn’t a given,” Zuckerberg warned. “AI is the most consequential technology of our lifetimes. The companies that lead the way will define the next generation,” Zuckerberg said in the note. The memo was posted on X by a New York Times reporter and a source familiar with the matter confirmed its authenticity to NBC News.
A leak last month about upcoming layoffs prompted Meta executives to share, shortly before reporting first-quarter 2026 earnings, that the tech giant was gearing up to lay off around 10% of the company’s employees.
The reorganization, which Meta first detailed in an internal memo in April, includes cutting about 8,000 employees and not filling approximately 6,000 open positions. Meta previously confirmed the April announcement’s authenticity to NBC News.
The employees affected by this restructuring were informed on Wednesday.
In April, Meta explained some of the calculus behind its shifting financials, noting that it was increasing 2026 capital expenditures to between $125 billion and $145 billion. That was because of “expectations for higher component pricing this year and, to a lesser extent, additional data center costs to support future year capacity,” according to Meta’s first-quarter 2026 report.
“This is the most dynamic I have seen our industry. I’m optimistic about everything we’re building to give billions of people the power to express themselves and connect with the people they care about,” Zuckerberg said in his Wednesday note. “We’re transforming our company to make sure it will always be the best place for talented people to have the greatest impact.”
Zuckerberg said he’s “grateful to those leaving today” and added that the company hasn’t been as transparent as he would have liked. He said that’s something he hopes Meta works on.
Employees in the United States who were laid off will receive severance including four months’ pay, with additional weeks for each year they were employed by Meta, according to the April memo sent by the head of people, Janelle Gale. Additional support, including for immigration and healthcare, is expected to be made available, as well.
Returning to life!
AI offers genuine empowerment in areas like programming and learning but carries significant harms, including environmental costs, copyright issues, and wealth concentration, requiring data science leaders to engage critically.
Original article
AI is both genuinely empowering for data science. It makes programming, translation, voice input, and broad learning more accessible. However, it is genuinely harmful through environmental cost, copyright issues, wealth concentration, shallow thinking, and unequal access. The tension cannot be neatly resolved, but data science leaders still need to engage with AI seriously so they can help people use it well.
OpenData (Tool)
OpenData is an open-core platform making public datasets accessible via a single API for search, query, and visualization.
Decoder
- Open-core: A business model where a software product's core features are open-source, while additional enterprise-grade features or services are offered commercially.
Original article
OpenData is an open-core platform that makes public datasets easy to search, join, query, visualize, and share through one clean API.
SiteRows (Tool)
SiteRows enables users to query websites directly with SQL for structured data extraction, eliminating the need for custom web scraping code.
Original article
Full article content is not available for inline reading.
Apple might replace aluminum with titanium in future iPhones again, per leak
Apple is reportedly re-evaluating titanium for future iPhones, like the iPhone Ultra, after thermal and weight issues led them to revert to aluminum for the iPhone 17 Pro.
Original article
Apple is reportedly researching a new and improved titanium alloy for future iPhones after switching the iPhone 17 Pro back to aluminum, largely because titanium caused thermal and weight challenges. According to leaker Instant Digital, Apple still sees titanium as a premium material and is exploring ways to improve its heat conductivity while keeping its durability and lighter feel, with possible future use in models like the iPhone Ultra and future Pro devices.

Google's new app icons were desperately needed
Google is rolling out redesigned Workspace app icons that offer clearer distinctions and improved legibility after widespread criticism of their previous "unified" and indistinguishable designs.
Original article
Full article content is not available for inline reading.
From faster pencil to AI Experience Architect: a designer's path
AI is shifting the design profession from merely creating screens to a more strategic role of "AI Experience Architect," focusing on designing workflows and systems around AI.
Original article
AI is pushing designers beyond simply creating screens and assets toward designing workflows, systems, and organizational processes around AI itself. The biggest opportunity isn't just working faster with AI tools, but becoming someone who shapes how AI fits into products, teams, and business decisions — turning design into a more strategic, systems-focused role rather than a purely production-focused one.
A Visual Unicode Explorer (Website)
Charcuterie offers a visual web-based explorer for Unicode, allowing users to browse characters, discover related glyphs, and explore scripts and symbols.
Decoder
- Unicode: An international standard for encoding, representing, and handling text expressed in most of the world's writing systems.
- Glyph: The actual shape or representation of a character. A single character (like 'a') can have multiple glyphs (e.g., in different fonts or styles).
Original article
Charcuterie is a visual explorer for Unicode. Browse characters, discover related glyphs, and explore scripts, symbols, and shapes across the standard.

The Click's clever university branding puts the ‘I' in identity, individual, and Imperial College London
Imperial College London’s new branding, designed by The Click, gives each department a unique "I" logo to foster individual identity and community belonging.
Original article
Full article content is not available for inline reading.

Arts and Culture Slows Down Ageing. So Why Aren't We Doing More of It?
A new University College London study found that engaging in arts and culture weekly slows biological aging twice as much as weekly exercise.
Deep dive
- A University College London study, published in Innovation in Aging, found that regular engagement in arts and cultural activities slows biological aging.
- Participants who engaged in activities like painting, singing, or visiting galleries at least once a week were, on average, biologically a year younger.
- This effect is double that of weekly exercise, which only resulted in participants being six months younger biologically.
- The anti-aging effect of arts and culture is comparable to the biological difference between smokers and those who have quit.
- The article points out that many creative professionals, despite recognizing the value, struggle to prioritize these activities due to inertia and the addictive nature of digital scrolling.
- Author Tom May suggests treating arts and culture as essential practices, similar to exercise, by scheduling them explicitly.
Original article
Full article content is not available for inline reading.

Wikipedia's most underrated logo finally gets the love it deserves
Wikimedia released limited-edition 'Wikipede' merch, capitalizing on fan love for the quirky, unused pixel-art logo concept, after an April Fools' joke went viral.
Deep dive
- Wikipedia is celebrating its 25th anniversary.
- Wikimedia Foundation released a 'Baby Globe' mascot for the anniversary.
- They also released limited-edition merchandise featuring the 'Wikipede' logo concept.
- Wikipede is a quirky, unused pixel-art logo from the early 2000s that has gained significant fan adoration.
- Fan interest in Wikipede spiked after Wikimedia played an April Fools' joke, announcing it as the new official Wikipedia logo.
- The new merch collection, available on the Wikipedia Store, includes tote bags and mouse pads.
Original article
Full article content is not available for inline reading.
E-Hiking Is Here. You Can Tell by My 1,000-Watt Hips
Personal exoskeletons, previously niche for military and medical use, are now becoming lightweight and affordable for general consumer use, enabling "e-hiking."
Decoder
- Exoskeleton: A wearable robotic device that supports and amplifies human movement, traditionally used for heavy lifting, rehabilitation, or military applications.
Original article
Personal exoskeletons, once reserved for military, heavy industry, and mobility rehabilitation, are now light and affordable enough for regular people who want to feel superhuman.
New iPhone Ultra leaks cover release timing, display breakthrough, more
Apple's rumored foldable iPhone, possibly named "iPhone Ultra," faces indefinite delays due to hinge issues despite reportedly entering trial production.
Original article
Apple's first foldable iPhone is reportedly in trial production, but there are issues with its hinge that are causing an infinite delay to the production process.

Freckles, tattoos, and imperfect hairlines: inside LEO, the men's hair loss brand that ditches the gloss
LEO, a new men's hair loss brand, launched a refreshing identity by Creative Spark that ditches typical glossy perfection for honest, relatable imagery and messaging.
Original article
LEO launched a new brand identity by Creative Spark that rejects the glossy, hyper-masculine style typical of men's hair loss advertising in favor of honest, relatable messaging and real-looking imagery. Built around the line “Where's your head at?”, the campaign focuses less on selling perfection and more on helping men feel understood, using candid photography, straightforward language, and a more emotionally open approach to hair loss and self-esteem.