Devoured - May 26, 2026
x.AI launched Grok Build in beta, a new coding agent and CLI for SuperGrok and X Premium Plus subscribers, and the Vatican released an encyclical on AI ethics.
Models.dev (GitHub Repo)
Models.dev is an open-source GitHub repository and API that consolidates specifications, pricing, and capabilities of various AI models, addressing the lack of a central database.
Deep dive
- Models.dev is an open-source, community-contributed database for AI model specifications, pricing, and capabilities.
- It provides a unified API (
https://models.dev/api.json) for accessing this consolidated data. - Data is stored in TOML files within the GitHub repository, structured by provider and model.
- Contributions are welcomed via pull requests, with clear guidelines for adding new providers, logos (SVG format), and model definitions.
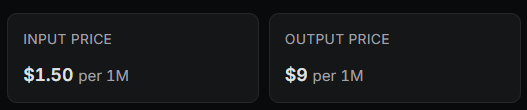
- Model definitions include details such as name, attachment support, reasoning capability, tool calling, structured output, temperature control, knowledge cutoff, release/update dates, open weights status, cost (input, output, reasoning, cache, audio tokens), and context/input/output limits.
- The project also supports reusing existing model definitions for wrapper providers through an
extendsmechanism. - A GitHub Action validates submissions against a defined schema to ensure data quality and correctness.
- It is created by the maintainers of SST and offers a Discord community for support.
Decoder
- TOML (Tom's Obvious, Minimal Language): A configuration file format designed to be easy to read due to its clear semantics.
- AI SDK: A software development kit that provides tools and libraries for interacting with various AI models and services.
- Context window: The maximum number of tokens (words or sub-words) an AI model can process or "see" at one time, affecting its ability to understand and generate longer texts or complex prompts.
- Modality: A type of data that an AI model can process or generate, such as text, image, audio, or video.
- Open weights: Refers to AI models where the trained parameters (weights) are publicly available, allowing anyone to inspect, run, or further fine-tune the model.
Original article
Models.dev is a comprehensive open-source database of AI model specifications, pricing, and capabilities.
There's no single database with information about all the available AI models. We started Models.dev as a community-contributed project to address this. We also use it internally in opencode.
API
You can access this data through an API.
curl https://models.dev/api.json
Use the Model ID field to do a lookup on any model; it's the identifier used by AI SDK.
Logos
Provider logos are available as SVG files:
curl https://models.dev/logos/{provider}.svg
Replace {provider} with the Provider ID (e.g., anthropic, openai, google). If we don't have a provider's logo, a default logo is served instead.
Contributing
The data is stored in the repo as TOML files; organized by provider and model. The logo is stored as an SVG. This is used to generate this page and power the API.
We need your help keeping the data up to date.
Adding a New Model
To add a new model, start by checking if the provider already exists in the providers/ directory. If not, then:
1. Create a Provider
If the provider isn't already in providers/:
-
Create a new folder in
providers/with the provider's ID. For example,providers/newprovider/. -
Add a
provider.tomlwith the provider details:name = "Provider Name" npm = "@ai-sdk/provider" # AI SDK Package name env = ["PROVIDER_API_KEY"] # Environment Variable keys used for auth doc = "https://example.com/docs/models" # Link to provider's documentation
If the provider doesn’t publish an npm package but exposes an OpenAI-compatible endpoint, set the npm field accordingly and include the base URL:
npm = "@ai-sdk/openai-compatible" # Use OpenAI-compatible SDK api = "https://api.example.com/v1" # Required with openai-compatible
2. Add a Logo (optional)
To add a logo for the provider:
- Add a
logo.svgfile to the provider's directory (e.g.,providers/newprovider/logo.svg) - Use SVG format with no fixed size or colors - use
currentColorfor fills/strokes
Example SVG structure:
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24" fill="currentColor"> <!-- Logo paths here --> </svg>
3. Add a Model Definition
Create a new TOML file in the provider's models/ directory where the filename is the model ID.
If the model ID contains /, use subfolders. For example, for the model ID openai/gpt-5, create a folder openai/ and place a file named gpt-5.toml inside it.
name = "Model Display Name" attachment = true # or false - supports file attachments reasoning = false # or true - supports reasoning / chain-of-thought tool_call = true # or false - supports tool calling structured_output = true # or false - supports a dedicated structured output feature temperature = true # or false - supports temperature control knowledge = "2024-04" # Knowledge-cutoff date release_date = "2025-02-19" # First public release date last_updated = "2025-02-19" # Most recent update date open_weights = true # or false - model’s trained weights are publicly available [cost] input = 3.00 # Cost per million input tokens (USD) output = 15.00 # Cost per million output tokens (USD) reasoning = 15.00 # Cost per million reasoning tokens (USD) cache_read = 0.30 # Cost per million cached read tokens (USD) cache_write = 3.75 # Cost per million cached write tokens (USD) input_audio = 1.00 # Cost per million audio input tokens (USD) output_audio = 10.00 # Cost per million audio output tokens (USD) [limit] context = 400_000 # Maximum context window (tokens) input = 272_000 # Maximum input tokens output = 8_192 # Maximum output tokens [modalities] input = ["text", "image"] # Supported input modalities output = ["text"] # Supported output modalities [interleaved] field = "reasoning_content" # Name of the interleaved field "reasoning_content" or "reasoning_details"
3a. Reuse an Existing Model with extends
For wrapper providers that mirror a model from another provider, prefer reusing the canonical model definition instead of duplicating the whole file.
Use extends only for non-first-party wrappers and mirrors. Do not use it inside the actual lab provider directories that act as the canonical source for a model family, for example providers/anthropic/, providers/openai/, providers/google/, providers/xai/, providers/minimax/, or providers/moonshot/.
[extends] from = "anthropic/claude-opus-4-6" omit = ["experimental.modes.fast"] [provider] npm = "@ai-sdk/anthropic"
Rules:
frommust point to another model using<provider>/<model-id>.omitis optional and removes fields after the inherited model and local overrides are merged.- You can override any top-level model field locally.
- If you override a nested table like
[cost],[limit], or[modalities], include the full values needed for that table. idstill comes from the filename; do not add it to the TOML.
Use extends when the wrapper model is materially the same as the source model and only differs by a small set of overrides or omitted fields.
4. Submit a Pull Request
- Fork this repo
- Create a new branch with your changes
- Add your provider and/or model files
- Open a PR with a clear description
Validation
There's a GitHub Action that will automatically validate your submission against our schema to ensure:
- All required fields are present
- Data types are correct
- Values are within acceptable ranges
- TOML syntax is valid
When converting existing wrapper models to extends, compare generated output before and after the change:
bun run compare:migrations
This prints a diff for each changed model TOML so you can confirm the generated JSON only changed where you intended.
Schema Reference
Models must conform to the following schema, as defined in packages/core/src/schema.ts.
Provider Schema:
name: String - Display name of the providernpm: String - AI SDK Package nameenv: String[] - Environment variable keys used for authdoc: String - Link to the provider's documentationapi(optional): String - OpenAI-compatible API endpoint. Required only when using@ai-sdk/openai-compatibleas the npm package
Model Schema:
name: String — Display name of the modelattachment: Boolean — Supports file attachmentsreasoning: Boolean — Supports reasoning / chain-of-thoughttool_call: Boolean - Supports tool callingstructured_output(optional): Boolean — Supports structured output featuretemperature(optional): Boolean — Supports temperature controlknowledge(optional): String — Knowledge-cutoff date inYYYY-MMorYYYY-MM-DDformatrelease_date: String — First public release date inYYYY-MMorYYYY-MM-DDlast_updated: String — Most recent update date inYYYY-MMorYYYY-MM-DDopen_weights: Boolean - Indicate the model's trained weights are publicly availableinterleaved(optional): Boolean or Object — Supports interleaved reasoning. Usetruefor general support or an object withfieldto specify the formatinterleaved.field: String — Name of the interleaved field ("reasoning_content"or"reasoning_details")cost.input: Number — Cost per million input tokens (USD)cost.output: Number — Cost per million output tokens (USD)cost.reasoning(optional): Number — Cost per million reasoning tokens (USD)cost.cache_read(optional): Number — Cost per million cached read tokens (USD)cost.cache_write(optional): Number — Cost per million cached write tokens (USD)cost.input_audio(optional): Number — Cost per million audio input tokens, if billed separately (USD)cost.output_audio(optional): Number — Cost per million audio output tokens, if billed separately (USD)limit.context: Number — Maximum context window (tokens)limit.input: Number — Maximum input tokenslimit.output: Number — Maximum output tokensmodalities.input: Array of strings — Supported input modalities (e.g., ["text", "image", "audio", "video", "pdf"])modalities.output: Array of strings — Supported output modalities (e.g., ["text"])status(optional): String — Supported status:alpha- Indicate the model is in alpha testingbeta- Indicate the model is in beta testingdeprecated- Indicate the model is no longer served by the provider's public API
Examples
See existing providers in the providers/ directory for reference:
providers/anthropic/- Anthropic Claude modelsproviders/openai/- OpenAI GPT modelsproviders/google/- Google Gemini models
Working on frontend
Make sure you have Bun installed.
$ bun install $ cd packages/web $ bun run dev
And it'll open the frontend at http://localhost:3000
Manual testing with opencode
You can manually check provider changes with opencode by:
$ bun install $ cd packages/web $ bun run build $ OPENCODE_MODELS_PATH="dist/_api.json" opencode
Questions?
Open an issue if you need help or have questions about contributing.
Models.dev is created by the maintainers of SST.

Google DeepMind's AlphaProof Nexus solves decades-old math problems for a few hundred dollars
Google DeepMind's AlphaProof Nexus, leveraging Gemini 3.1 Pro and Lean, autonomously solved nine decades-old Erdős problems and other complex conjectures for just a few hundred dollars each.
Deep dive
- AlphaProof Nexus uses four agent variants, with the simplest (Agent A) leveraging Gemini 3.1 Pro for proof generation and Lean compiler feedback for rigorous verification.* The system autonomously solved nine out of 353 open Erdős problems, including two previously unsolved for 56 years, plus other conjectures from OEIS.* Inference costs were estimated at a few hundred dollars per problem, making it a cost-effective tool for mathematical research.* The success is attributed to rapid improvements in LLMs and the "power of compiler feedback" in grounding LLM reasoning, mitigating language models' logical weaknesses.* While the fully equipped Agent (D) currently holds an edge on tougher tasks, the simpler Agent (A) proved capable of solving all nine problems with sufficient budget, indicating a shift towards simpler agentic loops as LLMs improve.* DeepMind researchers note the system's value even in failed proof attempts, as it can deepen human understanding of problems and catch flawed formalizations.* The system's successes were primarily in areas with mature Lean math libraries like combinatorics, convex optimization, and number theory.* OpenAI's recent disproving of an Erdős conjecture and GPT-5.2 Pro/GPT-5.4 solving other problems used proprietary natural-language reasoning models, a different approach to DeepMind's more systematic, verifiable method.
Decoder
- Erdős problems: A collection of open mathematical problems posed by Hungarian mathematician Paul Erdős.* Lean: A formal programming language and proof assistant used for writing and verifying mathematical proofs.* Online Encyclopedia of Integer Sequences (OEIS): An online database of integer sequences.* Hilbert functions: A concept in algebraic geometry used to count certain types of geometric objects.* Convex optimization: A subfield of mathematical optimization that deals with minimizing convex functions over convex sets.
Original article
Google Deepmind's AlphaProof Nexus solves decades-old math problems for a few hundred dollars
Key Points
- Google Deepmind has developed AlphaProof Nexus, a framework that autonomously solved nine of 353 open mathematical Erdős problems along with other complex conjectures, at an inference cost of just a few hundred dollars per problem.
- The system relies on the Gemini 3.1 Pro language model to generate proof steps in Lean, a formal programming language used for mathematical verification, enabling rigorous and machine-checkable solutions.
- While the vast majority of Erdős problems remained beyond the AI's reach, Deepmind researchers see the system as a valuable tool for supporting mathematical research.
AlphaProof Nexus combines LLM-driven proof generation with machine verification to crack open math research problems that have stumped mathematicians for decades.
Google Deepmind's new framework AlphaProof Nexus has autonomously solved nine out of 353 open Erdős problems it attempted, including two questions that had gone unanswered for 56 years.
The system also proved 44 out of 492 open conjectures from the Online Encyclopedia of Integer Sequences (OEIS), settled a 15-year-old question about Hilbert functions in algebraic geometry, and improved a known bound in convex optimization. Inference costs ran just a few hundred dollars per problem, according to the research paper.
Unlike (potentially) pure natural-language approaches such as OpenAI's recent solution, the underlying language model in AlphaProof Nexus—in this case Gemini 3.1 Pro—doesn't have to carry the entire logical chain on its own.
Instead, it generates proof steps in Lean's formal language, and the compiler checks each one. Error messages feed directly back into the next attempt. That way, the LLM gets grounded by symbolic feedback, a safety net that offsets the well-known weaknesses of language models when it comes to logical reasoning. Humans only step in at the very end to check the results.
Four agents, one surprising result
The system consists of four agent variants with increasing complexity. The simplest, Agent (A), deploys independent sub-agents running on Gemini 3.1 Pro in loops: the language model generates proof steps, the Lean compiler checks them, and error messages feed back into the next try.
Agent (B) adds queries to AlphaProof, Google's reinforcement-learning-based system for olympiad math, which can fill in missing proof segments. Agent (C) introduces an evolutionary component. Inspired by AlphaEvolve, sub-agents share a common population of proof sketches. Rating agents built on Gemini 3.0 Flash score these sketches for plausibility and novelty, then rank them using an Elo system. The fully equipped Agent (D) combines all of these capabilities.
Agent (D) was used for the Erdős problems. But a post-hoc analysis turned up a surprise: the simplest Agent (A), which only uses an LLM and compiler feedback, could also prove all nine solved Erdős problems, albeit pricier on the hardest ones.
The researchers attribute the simple agent's success to two factors: rapid improvement in the underlying language models and the "power of compiler feedback in grounding LLM reasoning." The fully equipped agent still holds an edge on the toughest tasks for now, but that lead could shrink as LLMs get better. The researchers say this points to a broader trend, describing "an ongoing shift from specialized trained systems toward simple agentic loops as LLMs become more capable."

Useful even without a complete proof
The system's successes cluster in areas like combinatorics, convex optimization, and number theory, where Lean's math library Mathlib is mature and problems break down into manageable sub-goals. Most Erdős problems remained out of reach, "let alone problems that require extensive new theory," the researchers write. The agents also inherit the unreliability of the underlying language models.
Still, they see value beyond solved problems. Mathematicians who worked with the system reported that even failed proof attempts deepened their understanding of a problem, or as the authors put it, "AI-driven formal proof search can serve not only to solve problems but to deepen human understanding."
Because the sketches were formal, experts could focus on the unsolved sub-goals instead of re-checking the entire argument from scratch. The agents also proved effective at catching flawed formalizations in the literature. "Formal verification can serve as a filter for determining which proofs merit human review," the authors write.
The system is already being used in ongoing research on quantum optics and graph theory, according to the paper. All Lean proofs and selected natural-language proofs are available on GitHub.

Erdős problems become the benchmark for AI math
OpenAI recently used a proprietary reasoning model to disprove Erdős's unit-distance conjecture. Fields Medalist Tim Gowers called it "a milestone in AI mathematics." Before that, GPT-5.2 Pro helped solve Erdős problem #281, with Terence Tao calling the case "perhaps the most unambiguous instance" of an LLM solving an open math problem. Thereafter, GPT-5.4 solved another Erdős problem.
In some ways, those results are more impressive than Deepmind's approach. The language model had to carry the entire logical chain through natural language, without a Lean compiler checking each step. AlphaProof Nexus is more systematic and scalable, but it's tackling a different goal: building a reliable AI tool for everyday math research. OpenAI could integrate Lean into their scaffold as well, of course, but the point there is more about testing raw LLM capability.
Tao in the past warned against reading too much into the headlines, though. AI's actual success rate on Erdős problems sits at just one to two percent, concentrated on easier tasks. Google's system cracked only nine out of 353 problems. That lines up almost exactly with Tao's two-percent bar.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now Source: Paper
GPT-5.6 Leaks: Coming in June
Leaks suggest OpenAI's GPT-5.6 and GPT-5.6 Pro, focused on multi-step reasoning and agentic workflows, are expected to launch in June alongside Sonnet 4.8 and Gemini 3.5 Pro.
Decoder
- Agentic workflows: AI systems designed to perform multi-step tasks autonomously by planning, executing, and refining actions.* Frontend generation capabilities: The ability of an AI model to generate user interface code (e.g., HTML, CSS, JavaScript) based on prompts or designs.
Original article
GPT-5.6 Leaks : Coming in June
- OpenAI researchers hinted that the model behind a recent major math breakthrough is already being used internally as a daily driver for debugging and technical work
- Internal testing tags iris-alpha, ember-alpha, and beacon-alpha were spotted during development, potentially pointing toward multiple GPT-5.6 variants being tested
- GPT-5.6 seems heavily focused on stronger multi-step reasoning, better agentic workflows, and improved frontend generation capabilities
- Canary testing references are already appearing in developer environments, the same quiet rollout pattern seen before GPT-5.5 launched
- Current leaks point toward two models arriving: GPT-5.6 and GPT-5.6 Pro
- GPT-5.6, Sonnet 4.8, and Gemini 3.5 Pro are all expected in June, next month is looking like an AI festival
https://x.com/pankajkumar_dev/status/2058912010772119871?s=20

AI is doing something weird to Science
AI is transforming scientific discovery by excelling as a "proposer" of ideas, but human roles as "poser," "verifier," and "curator" remain indispensable, as shown by Donald Knuth's "Claude’s Cycles."
Deep dive
- The scientific discovery process is broken down into four distinct, non-interchangeable roles: poser (human), proposer (AI/model), verifier (formal system/physical world), and curator (human).
- Donald Knuth validated a mathematical pattern, "Claude’s Cycles," proposed by Claude Opus, showing AI's ability to generate novel insights.
- Examples like Terence Tao using LLMs with Lean's type-checker, AlphaFold for protein structures, and Google DeepMind’s GNoME with UC Berkeley’s A-Lab for materials discovery, all demonstrate the "loop" where AI proposes, and an independent, reliable system verifies.
- The key change since 2022 is that the "proposer" slot is now increasingly occupied by general-purpose large language models, making candidate generation cheaper and more widely applicable across domains.
- What hasn't changed is that humans still pose the questions, verifiers are typically non-AI systems, and humans curate which findings are important.
- The article argues that relying solely on an AI proposer without a strong, independent verifier leads to "confident nonsense at scale," as seen with Meta's retracted Galactica model.
- The "verifier is the one that matters" slogan highlights that robust verification is crucial for valid science, even with weak proposers.
- Goodhart’s Law is invoked, suggesting that if institutions continue to optimize for paper count (a measure becoming a target), AI proposers will accelerate the production of low-quality research.
- The author suggests that the most valuable skills in this new paradigm will be posing the right questions and building strong verifiers, which are currently underfunded compared to AI proposer development.
- The piece advocates for thinking of AI as an "AI lab member" – indispensable, capable, sometimes surprising, but not a replacement for a principal investigator or an entity that bears accountability.
Decoder
- Poser: The role in scientific discovery that defines the questions worth asking.
- Proposer: The role in scientific discovery that generates candidate solutions, hypotheses, or patterns.
- Verifier: The role in scientific discovery that rigorously tests and confirms or refutes proposals, often using formal systems, physical experiments, or established scientific methods.
- Curator: The role in scientific discovery that evaluates which verified findings are significant, publishable, and worth pursuing further.
- Claude Opus: A large language model developed by Anthropic.
- Lean: A proof assistant and programming language used for formal verification in mathematics.
- AlphaFold: A deep learning system developed by DeepMind that predicts protein 3D structures from amino acid sequences.
- GNoME (Graph Networks for Materials Exploration): A Google DeepMind system that generates candidate stable crystal structures.
- A-Lab: An autonomous laboratory at UC Berkeley that robotically synthesizes and verifies novel materials.
- Galactica: A large language model by Meta, trained on scientific literature, that was quickly retracted due to generating plausible-sounding but fabricated information.
- Goodhart’s Law: An adage stating that "when a measure becomes a target, it ceases to be a good measure."
Original article
Full article content is not available for inline reading.
Agent Sandbox (GitHub Repo)
Kubernetes-sigs Agent Sandbox offers a new Custom Resource Definition (CRD) for managing isolated, stateful, singleton workloads like AI agent runtimes within Kubernetes.
Deep dive
- Agent Sandbox aims to provide a declarative, standardized API for managing isolated, stateful, singleton workloads on Kubernetes.
- The core component is the Sandbox Custom Resource Definition (CRD), which manages a single, stateful pod with stable hostname/network identity and persistent storage.
- This addresses use cases not ideally suited for stateless Deployments or numbered StatefulSets, such as AI agent runtimes, development environments, and single-instance applications needing stable identity.
- Key features include strong isolation (supporting runtimes like gVisor or Kata Containers), deep hibernation, automatic resume, and efficient persistence.
- Extensions like SandboxTemplate, SandboxClaim, and SandboxWarmPool are also provided to enable reusable configurations, user-initiated sandbox creation, and pools of pre-warmed sandboxes.
- The project follows the standard Kubernetes controller pattern, with users creating Sandbox custom resources and the controller managing underlying runtime resources.
- It supports AI-assisted code reviews experimentally, using GitHub Copilot for a first pass, with strict guidelines to ensure CLA compliance.
Decoder
- Custom Resource Definition (CRD): An extension mechanism in Kubernetes that allows users to define their own resource types.
- Controller: A control loop in Kubernetes that watches the state of your cluster and makes changes where needed to move the current state towards the desired state.
- Singleton workload: A workload designed to run as a single, unique instance, often with a stable identity and state.
- StatefulSet: A Kubernetes workload API object used to manage stateful applications, ensuring stable, unique identities and ordered, graceful deployment and scaling.
- Deployment: A Kubernetes workload API object used to manage stateless applications, enabling declarative updates and rollbacks.
- Pod: The smallest deployable unit in Kubernetes, representing a single instance of a running process in your cluster.
- gVisor: A user-space kernel for containers developed by Google, providing an isolated execution environment.
- Kata Containers: An open-source project that creates lightweight virtual machines that seamlessly plug into the container ecosystem, providing stronger isolation than traditional containers.
Original article
Agent Sandbox
Website · Docs · DeepWiki · Getting Started · Examples · Roadmap
agent-sandbox enables easy management of isolated, stateful, singleton workloads, ideal for use cases like AI agent runtimes.
This project is developing a Sandbox Custom Resource Definition (CRD) and controller for Kubernetes, under the umbrella of SIG Apps. The goal is to provide a declarative, standardized API for managing workloads that require the characteristics of a long-running, stateful, singleton container with a stable identity, much like a lightweight, single-container VM experience built on Kubernetes primitives.
Overview
Core: Sandbox
The Sandbox CRD is the core of agent-sandbox. It provides a declarative API for managing a single, stateful pod with a stable identity and persistent storage. This is useful for workloads that don't fit well into the stateless, replicated model of Deployments or the numbered, stable model of StatefulSets.
Key features of the Sandbox CRD include:
- Stable Identity: Each Sandbox has a stable hostname and network identity.
- Persistent Storage: Sandboxes can be configured with persistent storage that survives restarts.
- Lifecycle Management: The Sandbox controller manages the lifecycle of the pod, including creation, scheduled deletion, pausing and resuming.
Extensions
The extensions module provides additional CRDs and controllers that build on the core Sandbox API to provide more advanced features.
SandboxTemplate: Provides a way to define reusable templates for creating Sandboxes, making it easier to manage large numbers of similar Sandboxes.SandboxClaim: Allows users to create Sandboxes from a template, abstracting away the details of the underlying Sandbox configuration.SandboxWarmPool: Manages a pool of pre-warmed Sandboxes that can be quickly allocated to users, reducing the time it takes to get a new Sandbox up and running.
Architecture
agent-sandbox follows the Kubernetes controller pattern. Users create a Sandbox custom resource, and the controller manages the underlying runtime resources.
Architecture Diagram
flowchart LR
User[User]
Claim[SandboxClaim]
Template[SandboxTemplate]
Sandbox[Sandbox]
Pod[Pod]
Runtime[Sandbox Runtime]
WarmPool[SandboxWarmPool]
subgraph Extensions[Extensions]
Claim
Template
WarmPool
end
%% User paths
User -->|creates| Sandbox
User -->|creates| Claim
%% Claim workflow
Claim -->|references| Template
Claim -->|adopts| Sandbox
%% Pod handling
Claim -->|adopts sandboxes from| WarmPool
Sandbox -->|creates Pod| Pod
%% Runtime
Pod --> Runtime
%% Warm pool
WarmPool -->|pre-warms sandboxes| Sandbox
Installation
Core Components & Extensions
You can install the agent-sandbox controller and its CRDs with the following command.
# Replace "vX.Y.Z" with a specific version tag (e.g., "v0.1.0") from
# https://github.com/kubernetes-sigs/agent-sandbox/releases
export VERSION="vX.Y.Z"
# To install only the core components:
kubectl apply -f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/${VERSION}/manifest.yaml
# To install the extensions components:
kubectl apply -f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/${VERSION}/extensions.yaml
Python SDK
To interact with the agent-sandbox programmatically, you can use the Python SDK. This client library provides a high-level interface for creating and managing sandboxes.
For detailed installation and usage instructions, please refer to the Python SDK README.
Configuration
For advanced scale and concurrency tuning (e.g., API QPS and worker counts), please see the Configuration Guide.
Getting Started
Once you have installed the controller, you can create a simple Sandbox by applying the following YAML to your cluster:
apiVersion: agents.x-k8s.io/v1alpha1
kind: Sandbox
metadata:
name: my-sandbox
spec:
podTemplate:
spec:
containers:
- name: my-container
image: <IMAGE>
This will create a new Sandbox named my-sandbox running the image you specify. You can then access the Sandbox using its stable hostname, my-sandbox.
For more complex examples, including how to use the extensions, please see the examples/ and extensions/examples/ directories.
Motivation
Kubernetes excels at managing stateless, replicated applications (Deployments) and stable, numbered sets of stateful pods (StatefulSets). However, there's a growing need for an abstraction to handle use cases such as:
- Development Environments: Isolated, persistent, network-accessible cloud environments for developers.
- AI Agent Runtimes: Isolated environments for executing untrusted, LLM-generated code.
- Notebooks and Research Tools: Persistent, single-container sessions for tools like Jupyter Notebooks.
- Stateful Single-Pod Services: Hosting single-instance applications (e.g., build agents, small databases) needing a stable identity without StatefulSet overhead.
While these can be approximated by combining StatefulSets (size 1), Services, and PersistentVolumeClaims, this approach is cumbersome and lacks specialized lifecycle management like hibernation.
Desired Sandbox Characteristics
We aim for the Sandbox to be vendor-neutral, supporting various runtimes. Key characteristics include:
- Strong Isolation: Supporting different runtimes like gVisor or Kata Containers to provide enhanced security and isolation between the sandbox and the host, including both kernel and network isolation. This is crucial for running untrusted code or multi-tenant scenarios.
- Deep hibernation: Saving state to persistent storage and potentially archiving the Sandbox object.
- Automatic resume: Resuming a sandbox on network connection.
- Efficient persistence: Elastic and rapidly provisioned storage.
- Memory sharing across sandboxes: Exploring possibilities to share memory across Sandboxes on the same host, even if they are primarily non-homogeneous. This capability is a feature of the specific runtime, and users should select a runtime that aligns with their security and performance requirements.
- Rich identity & connectivity: Exploring dual user/sandbox identities and efficient traffic routing without per-sandbox Services.
- Programmable: Encouraging applications and agents to programmatically consume the Sandbox API.
Roadmap
The current Roadmap can be found at roadmap.md.
Community, Discussion, Contribution, and Support
This is a community-driven effort, and we welcome collaboration!
Note on PR Velocity: To maintain high velocity and keep our queues clean, this project uses stale PR management (30-day auto-stale and 15-day auto-close for inactive PRs) and allows maintainers to fast-track or take over approved community PRs. Please read our Contributing Guidelines for our full code review and PR policies.
AI-Assisted Code Reviews (Experimental)
To help improve our review velocity, we are currently experimenting with AI-assisted code reviews, starting with GitHub Copilot as our automated first-pass reviewer. Here is the workflow:
- Copilot will be assigned as the first reviewer of all open PRs (skipping PRs without a signed CLA)
- After Copilot reviews are posted, the PR will be labeled
action-required: resolve-copilot-comments- ⚠️ Important Contribution Note: If you receive a code suggestion from Copilot in your PR, please don't directly apply suggestions via the GitHub UI. It will set Copilot as co-author and break the Kubernetes CLA requirements. For more information, read our Contributing Guidelines.
- After all of Copilot reviews are marked resolved, the PR will be labeled
ready-for-review - Maintainers will review
ready-for-reviewPRs and provide final approval
We actively welcome your feedback on the quality, relevance, and helpfulness of these automated reviews! As we iterate on this process, we also plan to evaluate and test different AI review tools to find the best fit for our project's workflow.
Contact Us
Learn how to engage with the Kubernetes community on the community page.
You can reach the maintainers of this project at:
- #agent-sandbox Slack channel
- If it's your first time joining the Kubernetes Slack, visit https://slack.k8s.io/ to get an invitation.
- Log in to Kubernetes Slack first before joining the channel.
- #sig-apps Slack channel for general sig-apps discussions
- SIG Apps Mailing List
Please feel free to open issues, suggest features, and contribute code!
Code of conduct
Participation in the Kubernetes community is governed by the Kubernetes Code of Conduct.

Microsoft's quiet Claude Code retreat and the real cost of enterprise AI
Microsoft is canceling most Claude Code licenses for its Experiences and Devices group, signaling that current enterprise AI coding unit economics are unsustainable due to high token costs.
Deep dive
- Microsoft is winding down its experiment with Anthropic's Claude Code within its Experiences and Devices division, instructing engineers to switch to GitHub Copilot CLI by June 30.
- The official reason cited is toolchain unification, but the underlying driver appears to be the high cost of token consumption.
- Initially, thousands of Microsoft engineers, product managers, and designers were granted access to Claude Code as a "learning exercise" in December.
- Uber's CTO, Praveen Neppalli Naga, reported burning through his entire 2026 AI coding budget in four months due to heavy Claude Code usage, with engineers spending $500-$2,000 monthly.
- Around 70% of code committed at Uber now originates with AI, and 10% of live backend updates are shipped by AI agents without human intervention.
- GitHub previously paused new Copilot Pro and Pro+ sign-ups in November because agentic workloads generated costs exceeding monthly plan prices.
- Nvidia VP Bryan Catanzaro noted that compute costs now often exceed employee costs for his team, while Fortune reported token-based AI tooling can cost more per task than human augmentation.
- Gartner predicts 25% of planned 2026 AI budget will slip into 2027 as proofs of concept fail due to cost issues.
- The article argues that agentic coding systems inherently consume more tokens per unit of work due to longer reasoning and planning.
- Anthropic itself banned an open-source agentic framework, OpenClaw, from consumer Claude subscriptions after it consumed $1,000-$5,000 in API costs per day.
- The industry is moving from traditional user-based licensing to a metered utility model for AI, similar to AWS billing, with usage caps and finance team involvement.
- Microsoft's decision, given its leverage and its staff's preference for Claude Code, is a strong signal that the "experimental phase" of absorbing arbitrary token costs for learning is ending.
- While AI coding provides real productivity benefits, the challenge lies in its unpredictable cost structure.
Decoder
- Unit economics: The direct revenues and costs associated with a company's business model, expressed on a per-unit basis (e.g., per user, per token).
- Token prices: The cost charged by AI model providers for processing input and generating output, typically measured in units called "tokens."
- Agentic systems/workloads: AI systems designed to perform tasks autonomously, often involving multiple steps of reasoning, planning, and interaction, leading to higher token consumption compared to simple autocomplete or chat.
- Trough of disillusionment: A phase in Gartner's Hype Cycle where interest wanes as experiments and implementations fail to deliver, following an initial peak of inflated expectations.
Original article
In December of last year, Microsoft told thousands of its engineers, product managers and designers that they could use Claude Code, Anthropic’s command-line coding agent, on the company dime.
By spring, the tool had spread well beyond engineering: into the kind of non-technical roles that, in earlier waves of enterprise software, would have waited years for a seat. Inside Microsoft, the rollout was framed as a learning exercise. Outside it, the surface signal was simpler.
The world’s largest software company, the one with its own foundation models and its own coding assistant, had just paid a competitor to put a rival product in front of its workforce.
Six months later, that experiment is being wound down. According to reporting in Windows Central and other outlets following The Verge’s original scoop, Microsoft is cancelling most direct Claude Code licences inside its Experiences and Devices group, the division that builds Windows, Microsoft 365, Outlook, Teams and Surface.
Affected engineers have been told to migrate to GitHub Copilot CLI by 30 June, the last day of Microsoft’s fiscal year. The official reason is toolchain unification. The unofficial reason is in the calendar.
The Claude pullback is the most credible signal yet that the unit economics of enterprise AI coding do not, at current token prices, work. Not because the tools are bad. The opposite: they are good enough that engineers use them constantly, and the constant use is what breaks the maths.
The clearest evidence is at Uber, which is not Microsoft and does not have Microsoft’s financial cushion. Praveen Neppalli Naga, Uber’s chief technology officer, told The Information in April that the company had burned through its entire planned 2026 AI coding budget in four months.
By March, Naga’s own figures had Claude Code use jumping from 32 per cent to 84 per cent of his roughly 5,000-engineer organisation. Individual engineers were spending between $500 and $2,000 a month on tokens. Around 70 per cent of code committed at Uber now originates with AI, and on the order of one in ten live backend updates is shipped by an agent with no human in the loop.
“I’m back to the drawing board,” Naga said, “because the budget I thought I would need is blown away already.”
That sentence is the whole story in miniature. The forecast was wrong because the variable being forecast, token consumption, behaves nothing like the licences and seats that finance teams know how to model. A traditional enterprise software deal is denominated in users.
A token-priced deal is denominated in how much the model has to think. Agentic coding makes the model think a lot. Sessions run for hours, spawn parallel threads and generate volumes of context that bear no resemblance to the autocomplete interactions that shaped the original pricing structure.
We have been tracking this fracture for months. In November, GitHub paused new Copilot Pro and Pro+ sign-ups because the agentic workloads of paying customers were generating costs that exceeded their monthly plan price.
Cost structures built for lightweight assistance, the company conceded, no longer held.
This is not an Uber problem or a Microsoft problem. It is an industry condition. Bryan Catanzaro, vice-president of applied deep learning at Nvidia, told Axios in April that, for his team, the cost of compute is now far beyond the cost of the employees using it.
This is the chip company saying it. Fortune followed in May with reporting that token-based AI tooling, when used heavily, can cost more per task than the human engineer it was supposed to augment.
A 2024 MIT analysis circulated widely in finance circles since then suggests that, on current pricing, AI automation pencils out as cheaper than human labour for roughly a quarter of the jobs people thought it would replace.
Set that against the spend forecasts. Gartner expects worldwide AI spending to reach $2.5 trillion this year, up 69 per cent on 2025.
The same firm now places generative AI squarely in what it calls the trough of disillusionment, predicting in a May press release that 25 per cent of planned 2026 AI budget will slip into 2027 as proofs of concept die in the procurement pipeline.
A separate Gartner read from April found that only 28 per cent of AI infrastructure projects fully deliver against their business case. That is not the curve of a technology going through an awkward adolescence. That is the curve of a market repricing itself.
Microsoft’s retreat lands inside this repricing, and not by accident. There are two ways to read the move. The first is the one Microsoft has briefed: that Copilot CLI is the strategic destination, that engineers will continue to have access to Claude models inside Copilot, and that the company simply wants a product it can shape directly with GitHub. That story is true.
It is also a story that Microsoft could have told at any point in the past six months and chose not to. What changed was not the strategic logic. What changed was the bill.
The second reading is harder to discount. Microsoft is uniquely positioned to know what enterprise-scale Claude usage actually costs, because its own engineers were the heaviest users outside Anthropic’s customer base. Inside Experiences and Devices, Claude Code had become, by several accounts, the preferred tool.
If the maths had improved with scale, this would be the moment Microsoft locked in a multi-year deal at favourable terms. Instead, it is unwinding the experiment in a window that conveniently closes the books on a fiscal year.
When the company with the most leverage in the room walks away from a vendor whose product its own staff prefer, the signal is not about preference.
Whether this constitutes a bubble depends on definitions. Token-level pricing will fall, as it has fallen at roughly a factor of ten every eighteen months for the past three years. The more interesting question is whether per-task token consumption falls faster than per-token cost.
The evidence so far runs the other way. Each generation of agentic system, by design, consumes more tokens per unit of work, because it reasons longer, plans more elaborately and verifies itself against the world.
Anthropic’s own infrastructure team has spoken publicly about reasoning workloads generating order-of-magnitude more compute per query than chat. That is the bet baked into the next twelve months of model releases. It is also the bet that put Uber back at the drawing board.
There is a worked example in TNW’s own coverage. In April, Anthropic banned a popular open-source agentic framework called OpenClaw from running on consumer Claude subscriptions, after discovering that single instances could chew through the equivalent of $1,000 to $5,000 in API costs in a day of autonomous operation. The framework was running on a $200-a-month Max plan.
The economic transfer was so blatant that Anthropic had to write a new clause into its terms of service. Multiply that pattern across a Fortune 500 engineering organisation, and you have the Uber budget memo.
The counterargument is real and worth stating. The cost of a working AI coding agent compared to the cost of an additional senior engineer is, even at current prices, often favourable on a per-feature basis. The productivity uplift is documented; the substitution is happening. What is breaking is not the value proposition.
It is the procurement model. Companies that signed up for a productivity tool are discovering they signed up for a metered utility, and the meter runs when nobody is looking. The fix may be straightforward: capped budgets per engineer, tiered access for high-leverage roles, agent runtime quotas.
Many of the larger buyers are already there. But the implication is that the era of “give every employee a Claude Code seat” is closing, and what replaces it will look more like AWS billing than like Office licences.
That is what Microsoft’s quiet email to its Windows and Surface teams really announces. Not the end of AI coding. Not even the end of Anthropic at Microsoft, given that Claude models will continue to be reachable through Copilot CLI.
It announces the end of the experimental phase, the phase in which the world’s largest software companies were willing to absorb arbitrary token costs in exchange for learning. The learning is done.
What comes next is the harder part. Enterprises will keep buying AI coding tools, because the productivity is real and the competitive pressure is unforgiving. But they will buy them the way they buy electricity, with usage caps, with shadow meters, with a finance team in the room.
Somewhere in a Microsoft conference room earlier this spring, someone looked at a Claude Code invoice and did the arithmetic against a Copilot CLI roadmap, and made a decision.
The same arithmetic is now being done in every CFO’s office that bought into the December 2025 rollout. The retreat will not be loud. It will be a series of fiscal-year-end emails, sent on a deadline nobody noticed until the budget was already gone.
Get the TNW newsletter
Get the most important tech news in your inbox each week.
Also tagged with
- Microsoft

The Design System Advantage Is Memory
The true advantage for AI agents in design systems is accessing a company's accumulated design memory, including past decisions and critiques, to prevent costly repetitions.
Deep dive
- Romina Kavcic argues that current AI tools often lack access to a company's "memory" – the context behind design decisions, rejections, and iterations.
- This missing context, spread across Slack, ADRs, and Figma comments, forces agents to "rediscover" decisions, leading to repeated corrections and wasted resources.
- Bad context is expensive: Every wrong answer, retry, or repeated rejected pattern burns tokens and erodes trust.
- Examples include Microsoft scaling back Claude Code usage and Uber's CTO stating his AI budget was "blown away already."
- Nvidia's Bryan Catanzaro noted that for his team, "the cost of compute is far beyond the costs of the employees."
- Gartner forecasts that while token prices may drop, agentic systems can demand 5-30 times more tokens per task, offsetting unit cost savings.
- METR's analysis suggests the length of tasks frontier agents can complete with 50% reliability has been doubling every seven months.
- The article proposes that a simple "pile of files" is not enough; a structured approach, ideally a graph, is needed to connect tokens, components, decisions, owners, and outcomes.
- Kavcic used QMD (by Tobi Lutke) to test local hybrid search on her own design system files, combining keyword search, vector search, and reranking.
- The recommended approach involves three layers: 1) Data (decisions, critiques), 2) Structure (graph or hybrid index), and 3) Agent (orchestration).
- The article suggests starting by indexing one folder with good signal (e.g., ADRs) using QMD and asking real team questions to identify missing or vague documentation.
Decoder
- ADR (Architecture Decision Record): A document that captures a significant architectural decision, its context, the options considered, and the final choice.
- QMD: A local search tool by Tobi Lutke that allows an agent to search local folders using keyword search, vector search, and reranking, providing relevant context for AI agents.
- BM25: A ranking function used by search engines to estimate the relevance of documents to a given search query, a common component in hybrid retrieval systems.
- Vector Search: A method of searching data by comparing the numerical representations (embeddings) of items, allowing for semantic similarity searches.
- Reranking: The process of reordering search results to improve their relevance, often using a more sophisticated model or additional criteria after an initial retrieval step.
Original article
The Design System Advantage Is Memory
How to find the design system memory your AI agent is missing
When I connected 105 MCP tools to my design system, I thought it was AI-ready. It wasn’t.
The tools could read the surface: tokens, docs, components, Figma. But they did not know why a pattern had been rejected, because that memory lived across Slack, ADRs, and Figma comments. I had given the agent access. I had not given it memory.
This is why I think memory is the design system advantage.
The shift is simple: stop asking whether your agent needs more tools. Ask whether it can find the decisions your team has already made. The advantage is the memory your company has and whether your agent can use it, not the model, the number of tools, or the clever prompt.
Companies are already feeling the AI ROI problem. They have bought the tools. They have run the demos. They have a dozen teams asking agents to write code, summarize research, generate flows, review tickets, and clean up docs.
But the hard part is whether the agent has enough trusted context to do useful work without constant correction.
Some companies have too much data. Thousands of docs, tickets, meetings, comments, specs, research notes, and decision threads. The agent can technically read them, but it has no idea what matters.
Some companies have not enough usable data. The important decisions exist, but only as memory, buried Slack threads, or comments in files nobody will open again.
Both create the same failure.
You end up babysitting the agent. You correct the same wrong assumption three times. You explain the same component history again. You remind it that the team deprecated that pattern last quarter. You paste the context that should already be known.
If you do not want to babysit your agents, you have to be smart with your data.
Bad context is expensive
Every wrong answer has a cost. Every retry has a cost. Every agent loop that reads the wrong files, summarizes the wrong docs, or repeats a rejected pattern burns tokens before it burns trust.
The Verge reported that Microsoft is winding down most internal Claude Code usage in its Experiences + Devices group by the end of June and moving engineers toward GitHub Copilot CLI. The decision was framed as platform convergence, but The Verge also reported that financial pressure was part of the move.
Uber hit the same wall from a different direction. Its CTO Praveen Neppalli Naga told The Information:
I’m back to the drawing board, because the budget I thought I would need is blown away already.
Axios reported an even cleaner version of the problem from inside Nvidia. Bryan Catanzaro, Nvidia’s vice president of applied deep learning, said:
For my team, the cost of compute is far beyond the costs of the employees.
Gartner’s forecast makes the pattern more obvious. Token prices may fall by more than 90 percent by 2030, but agentic systems can require 5 to 30 times more tokens per task than a standard chatbot. Lower unit cost does not save you if the workflow burns through much more context.
METR’s time-horizon work explains why this gets more important as models improve. In its original March 2025 analysis, METR estimated that the length of tasks frontier agents can complete with 50 percent reliability had been roughly doubling every seven months.
This does not mean agents are faster than humans. METR defines the time horizon as the length of task measured by how long a human expert would take, not how long the AI spends running. The point for design systems is simpler: as agents take on longer tasks, they need more context, more tool calls, and more chances to retrieve the wrong memory.
So context quality matters.
If the agent has to rediscover the same decision in every session, you pay for that rediscovery every time. If it asks the wrong person, reads the wrong file, or misses the support ticket that explains the pattern, you pay again. If a designer, engineer, PM, researcher, accessibility specialist, or support lead holds part of the answer but their knowledge is not in the corpus, the agent works with a partial map.
Partial context creates expensive confidence. The goal is not to feed the agent everything. The goal is to make the right team memory retrievable before the agent starts acting.
The visible 10 percent and the invisible 90
Open your design system right now. The agent-readable surface is bigger than you think.
The right column is the moat. Anyone can fork your token JSON. Nobody can fork why you made the decisions inside it.
This is the part I was ignoring. I had built tooling against the left column and assumed that was enough.
The moat does not exist on day one
The important part is not just data. It is data that improves over time.
Design systems have two phases, and the data flywheel works differently in each.
0 to 1: founding phase
The job is to make it work and prove it matters. Scrappy. A handful of high-impact components. Naming conventions still fluid. Adoption inside one team. The job is to ship the system, not to feed an agent. The data you generate is mostly throwaway, things like “the team tried X, it broke, then tried Y.” That is fine.
1 to 100: scaling phase
Make it last and make it scale. Solidified architecture. Rules over examples. Multiple brands, platforms, markets. Now you have:
-
Three years of token renames with reasons attached
-
A dozen deprecated components and the threads explaining why
-
Governance trade-offs and the conversations that produced them
-
Drift reports across surfaces and brands
-
Critique notes that surface the same blind spots over and over
-
Performance reviews of the design system team itself
This is the data most 1 to 100 design system teams already have. Almost none of them feed it to their agents. Most 1 to 100 teams already have this memory. They just have not made it retrievable.
A pile of files is not enough
The naive fix is “dump everything into a folder, point Claude at it, hope.” I tried it. It does not work well enough.
The agent can read individual files. It cannot reason across them. Ask “what changed about Alert this year and why?” and you get a polite shrug, because the answer lives across a Figma comment, a Slack thread, a closed PR, and an ADR that nobody linked together.
QMD tests whether the pile has signal. The graph is what you build once you know it does.
QMD is a local search tool by Tobi Lutke that lets an agent search your own folders with keyword search, vector search, and reranking.
It is the lightweight version I used first. It does not turn your design system into a graph. It gives you a local hybrid index over your files, which is enough to start testing whether your corpus has signal.
The mature design system version is a graph. Tokens connect to components. Components connect to decisions. Decisions connect to outcomes. Outcomes connect back to tokens. The agent walks the graph instead of grepping the pile.
For a design system, the graph nodes are bigger than files. They are token, component, pattern, decision, owner, surface, brand. The edges are uses, supersedes, depends on, was decided by, drifted from.
This is what I rebuilt Tidy around. Every component knows its variants, its tokens, its owner, its decision history, its drift score. The agent queries the graph and knows, instead of crawling Figma and guessing.
How I tested QMD on my own files
I wanted to know if this actually works on my data, not just in theory.
So I installed QMD on a Tuesday and pointed it at six folders:
-
Tidy decisions
-
Client design system specs
-
My Substack drafts
-
Customer research
-
IDS talk material
-
Granola meeting transcripts
It embedded 1,511 of my documents locally in about 5 minutes.
That part matters. I did not want a huge knowledge management project. I wanted the smallest test that could tell me whether my own corpus was useful. It combines keyword search, vector search, and reranking, then returns the files most likely to help the agent answer the prompt. It works because it is a better first pass than asking the agent to crawl a random folder and hope.
The setup was simple:
-
Pick a folder with real signal.
-
Add it as a QMD collection.
-
Embed it locally.
-
Query it before the agent answers.
-
Inject the top results as context.
That pattern helps a design system because the system’s value lives across decisions, specs, critiques, and usage history.
It also helps a product.
A product team has the same problem in a different shape. The answer to “why does checkout work this way?” may live across research notes, support tickets, experiment docs, pricing decisions, analytics writeups, and a half-forgotten launch memo. If the agent only sees the current UI, it will confidently suggest the thing the team already tried.
The goal is not to make the agent read everything, but to make it retrieve the right context before it starts acting.
Then I ran three queries that map to real design system work.
Query 1: “why did I choose certain naming conventions for tokens”
Query 2: “what have I written about agentic design system governance”
The hybrid pipeline (BM25 + vector + LLM rerank) connected “agentic governance” to “shared practice with developing consciousness.” It pulled a file I had categorized in my head as “philosophy” back into the bucket of “things I have written about how agents should behave.”
This is where QMD earned its keep on this corpus. Pure keyword search would never have surfaced that file. Hybrid retrieval did.
Good data not only makes agents more accurate, it changes what you have to repeat.
The agent layer is the smallest part
This is the order most teams have backwards. They start with the agent. They should start with the data.
There are three layers, and they have to come in order.
-
Your data sits at the bottom. Tokens, decisions, drift, critiques, ADRs, and deprecation history. Everything in the invisible column from the table above.
-
Your structure sits on top of the data. A graph or hybrid index that lets an agent reason across it, not just search it.
-
Your agent sits on top of the structure. It is the smallest layer, mostly orchestration on top of the first two.
Skip layer one, and the agent generates plausible nonsense. Skip layer two and the agent finds a file but cannot connect it to anything. Nail one and two and the agent layer is almost trivial. You can swap models freely.
This is also why “the team will switch to a better model later” is the wrong worry. Models get cheaper and more capable on someone else’s roadmap. Your data does not show up on its own.
What to do this week
If you are in the 1 to 100 phase and want to start, this is the smallest useful version.
-
Pick one folder that already has a good signal. ADRs, design critique notes, component specs, research summaries, or support tickets.
-
Install and index it with QMD:
npm install -g @tobilu/qmd, add the folder as a collection, then runqmd embed.
npm install -g @tobilu/qmd
qmd collection add ~/design-system/decisions --name decisions
qmd embed-
Run five real questions against it, using questions your team actually asks instead of demo questions.
-
Look at the misses. A miss means one of two things: the document is missing, or the document exists but the language is too vague to retrieve.
-
Write the missing decisions down. Start with the ones you are tired of explaining.
-
Add retrieval to the agent. Call
qmd querydirectly through your agent’s shell tool, or add a pre-prompt hook that injects the top results as context.
You will know it is working when the agent stops asking you obvious things and starts reminding you of decisions you forgot you made.
Start with the invisible column. Decisions, critiques, drift, rejections. Make one folder searchable and ask real questions.
QMD is only the first step. It tells you whether your corpus has signal.
Next week, I want to go one layer deeper: data labeling. Once you know which memories matter, the next question is how to label them so agents can use them reliably.
The design system is no longer the deliverable. It is the dataset.
What part of your invisible column would you wire in first? Let me know below 😊
Enjoy exploring 🙌
Romina
Explore on your own
🔗 QMD by Tobi Lütke (GitHub). Local hybrid search exposed as MCP.
🔗 Why Tobi Lütke built QMD (Gamgee). Background on the tool’s reasoning.
🔗 How to Build for AI Agents and a Claude Code Second Brain in 25 Min, Peter Yang. Useful context on using QMD with Claude Code.
🔗 Microsoft starts canceling Claude Code licenses, The Verge. Reporting on Microsoft moving engineers from Claude Code to Copilot CLI.
🔗 Uber CTO AI budget coverage, Techmeme / The Information. Summary of reporting on Uber’s AI coding budget overrun.
🔗 AI can cost more than human workers now, Axios. Source for Bryan Catanzaro’s compute-cost quote.
🔗 Gartner inference cost forecast. Forecast on token cost decline and higher agentic token demand.
🔗 Goldman Sachs token demand coverage, PYMNTS. Reporting on Goldman Sachs’ forecast for agentic AI token consumption.
🔗 Time Horizon 1.1, METR. Source for the updated task-completion time horizon data.
— If you enjoyed this post, please tap the Like button below 💛 This helps me see what you want to read. Thank you.
Want more actionable insights like this? Subscribe & never miss a post! ❤️
💎 Community Gems
Figma Variables for Complex Multi-Brand Systems by Veronica Campana
Standard tutorials about variables often fall short when it comes to the technical intricacies of enterprise design systems. Drawing from my work building the Index Design System for Dow Jones, this article details the layered variable architecture we developed to manage high-level complexity without sacrificing the designer experience.
🔗 Link

AI UX Design: Strategic Blueprint for the AI-augmented Designer
AI is transforming UX design from manual execution to strategic curation, repositioning designers as directors who guide AI tools through a "sandwich framework" for quality control.
Deep dive
- AI has transformed UX design from manual execution to strategic curation, where designers act as directors guiding AI tools.
- The shift moves designers from "pixel-pushing" to problem-solving, focusing on defining the "why" while AI handles the "how."
- AI-augmented designers utilize a "AI Sandwich" framework for quality control:
- Phase 1: Setting the human context and design intent: Define problem space, business constraints, and user goals.
- Phase 2: AI-driven exploration and generative drafting: Explore multiple possibilities rapidly using AI for volume.
- Phase 3: Human check, aesthetic and logic validation: Apply human taste, strategic judgment, and ethical oversight to refine AI outputs.
- AI tools like Figma AI, Galileo, Dovetail, and Looppanel are crucial for generative UI design and UX research analysis.
- UXfolio offers AI-assisted features like a Case Study Generator, AI Text Enhancement, and Job Fit Checker to help designers build authentic portfolios.
- Essential skills for AI-augmented designers include prompt engineering, curation, synthesis, and critical thinking.
- The article argues that AI will replace tasks, not the entire UX designer role, and that designers who use AI will replace those who don't.
- Human empathy remains the greatest competitive advantage, as AI cannot understand emotional nuance or advocate for complex user needs.
Decoder
- AI-augmented designer: A designer who strategically uses artificial intelligence tools to enhance and accelerate their workflow, focusing on higher-level problem-solving and curation rather than manual execution.
- Pixel-pushing: A colloquial term describing the manual, often repetitive task of meticulously adjusting individual pixels or visual elements in design software.
- AI Sandwich framework: A three-phase methodology for integrating AI into design workflows, involving human input at the beginning (context setting), AI for generation, and human validation/curation at the end.
- Dovetail: A platform that uses AI to analyze qualitative user research data, such as interviews and user tests.
- Looppanel: A tool designed to automate the synthesis and analysis of user research insights, identifying patterns across multiple sessions.
- UXfolio: An online portfolio builder specifically for UX designers, which incorporates AI features to assist in structuring case studies, enhancing text, and checking job fit.
- Prompt engineering: The process of crafting effective inputs (prompts) for AI models to guide their output towards desired results, often requiring precise language and understanding of the model's capabilities.
Original article
Full article content is not available for inline reading.

On AI Hardware
The AI hardware market is increasingly bottlenecked by memory issues, requiring hardware companies to design architectures that remain flexible and useful despite rapid shifts in software and model architectures.
Original article
The market is becoming a stack of memory problems. Hardware changes slowly, while software and model architectures can move quickly. Hardware companies will need to build architectures that remain useful as the bottleneck shifts.
Gemini 3.5 Flash Looks Good For How Fast It Is
Zvi assesses Google's new Gemini 3.5 Flash model as the best at its speed point for agentic workflows, running 4x faster than other frontier models and outperforming 3.1 Pro on benchmarks like Terminal-Bench and MCP Atlas, despite being pricier than previous Flash versions and facing criticism for quality and "Gemini issues."
Deep dive
- Gemini 3.5 Flash is Google's latest model, launched on May 22, 2026, aimed at agentic workflows requiring high speed.
- It is touted as 4x faster than other frontier models and can be 12x faster when used with Google Antigravity.
- Benchmarks show it outperforming Gemini 3.1 Pro on agentic and coding tasks like Terminal-Bench and MCP Atlas.
- The model's knowledge cutoff is January 2025, a point of criticism for its obsoleteness.
- Despite its speed, many testers find its overall intelligence and quality (e.g., sycophancy on You’re Absolutely Right, code quality) to be "mid-to-bad" or "sonnet tier" compared to Opus 4.7 or GPT-5.5.
- Pricing for 3.5 Flash is higher than previous Flash models, making it a "hybrid" model that is not as cheap.
- Users report "Gemini issues" such as overconfidence, destructive actions in Antigravity, and limited usage quotas.
- Google is also integrating this AI into search with an 'intelligent search box' and introducing 'information agents' and a 'Daily Brief' similar to OpenAI's Pulse, but with more integration with Google apps.
Decoder
- Agentic workflows: AI applications designed to perform multi-step tasks, often involving planning, tool use, and iteration, without constant human supervision.
- Terminal-Bench: A benchmark used to evaluate AI models on agentic and coding capabilities.
- MCP Atlas: Another benchmark for assessing agentic and coding performance.
- Antigravity harness: A Google-specific framework or runtime environment designed to optimize Gemini model performance for specific use cases like agentic workflows.
- Sycophancy benchmark: A test designed to measure an AI model's tendency to agree with or flatter the user, regardless of factual accuracy.
- Knowledge cutoff: The date up to which an AI model's training data includes information, meaning it generally lacks knowledge of events or developments after this date.
Original article
Google once again has a model worth at least some consideration. Gemini 3.5 Flash is likely the best model out there at its particular speed point, as long as you don’t mind that it is a Gemini model. So for cases where speed kills, this can be a reasonable choice. Otherwise, I don’t see signs you would want to use it over Opus 4.7 or GPT-5.5.
Google also had some other offerings for I/O Day, which this post will also cover.
Introducing Google Gemini 3.5 ‘Flash’
Google introduced Gemini 3.5 Flash, which it seems is for now their universal model until 3.5 Pro comes along. It is live in the usual places. It is a hybrid, where it has the speed of Flash but the cost is at least halfway to models like Opus and GPT-5.5.
Gemini 3.5 Pro is confirmed for next month.
They are focused on 3.5 Flash as a daily driver for agentic tasks. It has the advantage of being faster and cheaper than Claude Opus 4.7 or GPT-5.5, if it can do the job. Not as cheap as previous Flash models, though, this is basically a hybrid:
As always, this is presented as Google’s strongest model yet for all the things.
Jeff Dean: 1/ Today at #GoogleIO, we’re releasing Gemini 3.5, our latest family of models combining frontier intelligence with action. We’re starting by releasing 3.5 Flash, which is built to help you execute complex, long-horizon agentic workflows.
It outscores 3.1 Pro on agentic and coding benchmarks like Terminal-Bench and MCP Atlas, while running 4x faster than other frontier models.
Used in Google Antigravity, 3.5 Flash is even further optimized to be up to 12x faster. It’s a powerful engine to deploy sub-agents that collaborate, run high-frequency iterative loops, and solve real-world problems at scale.
Here is their benchmark presentation:
Koray Kavukcuoglu: When coupled with the updated Antigravity harness, 3.5 Flash becomes a powerful engine for deploying collaborative subagents to tackle problems at scale for the most demanding use cases. Under supervision, it can reliably execute multi-step workflows and coding tasks while sustaining frontier performance.
There are some big improvements here, including GDPval where Gemini previously struggled. If those scores were representative of what this baby can do, and it’s a Flash model, then that would be quite the accomplishment.
The knowledge cutoff is January 2025, continuing Gemini’s pattern of not believing what year it is, which is bizarrely obsolete and a serious problem for many use cases.
It is not a true ‘flash’ model, given it costs substantially more than 3 Flash.
Pliny is there with the standard jailbreak.
The biggest hope is that this fills a niche of ‘good enough for agent work while being faster and cheaper.’
Conrad Barski: For those of us who are building our life around AI workflows (either because we like to do that, or just feel it is necessary for sheer survival in the near future) 3.5flash is a big step up:
I have dozens of personal utilities that don’t need SOTA intelligence, but are now much faster all of a sudden, at the same intelligence level: And since most of my utilities only need to do a modest number of llm calls to be useful, the increased cost of 3.5flash is not a factor.
The model can compete with codex5.5 “low effort”, but it is just so very very fast, far out of distribution compared other models. I assume openai will release a competitor soon, since cerebras is pretty optimal for this “medium IQ, high speed” use case.
Other People’s Benchmarks
A lot of benchmarks don’t have results, but of my usual suspects here is what we have.
The overall scores indicate only okay performance when adjusting for cost and price, and Gemini models tend to relatively overperform on benchmarks. One notices that Flash 3.5 does a lot worse on other people’s benchmarks than the ones Google lists.
It is catastrophically bad on You’re Absolutely Right, a sycophancy benchmark.
It did quite poorly on CursorBench.
It did not impress on WeirdML, only a small improvement on 3 Flash and far behind 3 Pro and 3.1 Pro.
It took the top spot on KnowsAboutBenBench, by the Ben in question.
It takes third place in Vals.ai on real world tasks.
It comes in at 9th in the Arena, slightly behind Gemini 3.1 Pro and 3 Pro.
It comes in at 55.3 on the AA Intelligence index, behind 57.2 for 3.1 Pro, 57.3 for Opus and 60.2 for GPT-5.5, while not being cheaper to run than 3.1 Pro on their test suite.
Reactions
Some people do like it.
davidad: It’s by far my favorite model at its price point, and also by far my favorite model at its speed. If by “back in the game”, you mean the game of having the best overall model, then obviously no not yet. But that’s hardly the only game.
Srivatsan Sampath: It has the benefits of Flash with less hallucinations? Really good spatial awareness (not as much of a token Hog for this) and helps me with my home plumbing project (which is definitely not nearly the case with 5.5 and 4.7).
@lezadumtchique: Looks quite good, considering switching to it from 3.1 Pro at work. Agentic coding capabilities are comparable (if not better), and the speed is much nicer
Or find particular uses.
Medo42: Didn’t try much coding (ok but not 100% on my usual test), but even better at vision than Gemini 3.0/3.1. Still great at reading text including handwriting, good at getting rows / columns right, good at spotting details, much better at reading dials.
EM: the tokens/s is pretty sweet for things like voice interactions
Alas, it is a Gemini model, and people are reporting Gemini things.
Dominik Lukes: Meh, given the price hike. Otherwise a strong model indeed. Good on agentic and single-shot dev stuff but my motivation to test it more thoroughly is low until Antigravity catches up to Codex.
Yoav Tzfati: Not first hand, but from testing I’ve seen it seems to overreach for things outside it’s capability and mess up along the way. But it’s so fast that I’m considering using it as an Explore agent replacement
alice: i really enjoyed those 90 minutes where cursor leaked raw CoT it’s extremely adorable unfortunately normally it’s in a horrible straightjacket. too pricy for what it is for coding tho may be useful for frontend
paperclippriors: I guess I just don’t really know why I would ever use it. It’s only faster and cheaper if you don’t take into account how many reasoning tokens it uses, and it seems dumber and less confident than Claude and GPT.
ClaudiaShitposting: surprisingly good at some stuff, but mostly garbage. Lacks the common sense that gemini 3/3.1 has, if that makes sense
KC+AI 4 Gov of WI 2026: absolute joke of a behemoth company. I hope the entire millionaire AI dev team has to listen to annoying music over the loudspeakers until they release a model worthy of their infra
uIts: Its quite bad
Naveesh /wtf: No
jerry: Garbage
budrscotch: It’s a big let down, but expected.
Tenobrus: if flash 3.5 had stayed at $0.5 it would be an insanely insanely exciting release. total intelligence + speed + costmog, destroying open source and sonnet and 5.4 mini. would have adopted it for multiple use cases immediately.
but it’s $1.50 [and $9 for output, also a 3x increase]. so here we are.
Tenobrus: so far pretty negative impression of 3.5 flash. it is very fast in terms of token output, but this basically doesn’t matter because it explodes in a huge avalanche of unnecessary tool calls on basically every task. when it gets stuck on something it seems to pretty much never pause or ask for help, it just kinda keeps steamrolling ahead and flailing. frequently hallucinated fake acronym expansions. writing quality is mid-to-bad, tons of emoji-slop, same characteristic gemini “The Flaw:” / hyperbolic naming tendencies. actual code quality is sonnet tier.
very early vibecheck, i could be missing things. but even the initial use case of “super quick codebase exploration subagent” is pretty quickly dissolving for me bc it’s not actually smart enough to be quick about it. all in all definitely *not* what google needed to drop.
It also can have Google’s usual issues not being able to integrate with Google, such as using your subscription with your personal email, which renders all personalization features useless. You’ll need to use Claude or ChatGPT to get GMail access, sir.
This is a pretty big problem:
Caleb Withers: From a few initial tests in Antigravity it loves to overconfidently make assumptions and then take unrequested destructive actions based on them (e.g. arbitrarily resolving file conflicts, deleting todo list items, unstaging commits).
Another big problem with Antigravity in particular is that limits seem extremely low. This is one of many examples of people running into this issue.
Ryan Johnson: I hate how limited it is, 45-60 mins/wk in anti-gravity?
Or 10 full sessions w/ Opus 4.7 or GPT 5.5.
I dared to hope it would ever be a mainstay in my workflow, but I’m pretty sure Claude/GPT is going to be how I roll and Gemini is just noise.
If Google wants to compete with Claude Code and Codex, they need to offer a way in that lets people use it in volume before being convinced to subscribe.
They did triple the limits, which is an excellent start, but that won’t be enough.
Vie (of OpenAI) reports Flash 3.5 is lying to him a lot, suspects the harness is at fault.
Theo is extremely unhappy with Flash 3.5 and several other Google decisions. I’ve seen him post a lot and this is not his usual approach, so something is haywire here.
Google AI Search
Google is overhauling its search experience around an ‘intelligent search box’ that looks and feels a lot like a Gemini Flash 3.5 chatbot prompt.
That is a useful thing if implemented well, and indeed it is a thing I use (from OpenAI and Anthropic) more often than I use Google Search. But that thing is not Google Search.
Sarah Perez: Links will become an afterthought with the coming changes to the Search results experience, which builds on Google’s earlier launches of AI search features, like its short summaries known as AI Overviews and its conversational search, AI Mode.
The reason I use Google Search is primarily to link me to things, or sometimes as a spellchecker. If I want AI, I will ask an AI.
Google is also introducing ‘information agents’ as the AI version of Google Alerts.
Google Daily Brief
Daily Brief is their answer to OpenAI’s Pulse, except theirs will incorporate information from all your connected apps and be more of a to-do list, which can including GMail and Calendar.
The first part, ‘top of mind,’ seems like a plausibly useful way to make sure you don’t drop balls from your email or calendar.
It then ‘looks ahead’ and ‘suggests immediate next steps’ which I expect to be obnoxious and useless, and was in my quick experiment. I like that it links directly to the emails but doesn’t disrupt your usual process.
They say you can ‘steer Daily Brief with a quick thumbs up and down over time.’
Oh no. If this is to be any good you need to be able to give it instructions and explain why you find something useful or not useful, as you can with Pulse (which I still don’t bother using). Assume anything that uses thumbs up and down is AI slop.
If Google made this have better customization, and allowed you to sync it with various forms of Google alerts and other ways to monitor the wider world, they’d have something far more interesting.
Google I/O Day
What else did Google offer us?
Gemini Spark will be ‘a 24/7 personal AI agent to help you navigate everyday life’ using an Antigravity harness, and integrated with the rest of Google. Their example shown is adding things to Instacart.
It looks like they’re going to do things one app at a time via MCP connectors, and have a decent set of opening choices planned for the coming weeks?
Spark is coming to Ultra subscribers next week.
There is finally a Gemini app for macOS.
Neural Expressive is ‘a new design language for the AI era.’
I think that means Gemini now can switch easily between voice and text modes, and can use animations, ‘vibrant colors,’ new typography and for some reason haptic feedback. They think we don’t want text, we want some multimedia presentation.
Gemini Omni makes it easier to generate and edit videos within chat.
You can more easily ask longform questions of YouTube videos
Dean Ball was impressed by the mundane utility on offer, to the point of considering getting an Android phone. If you do get an Android for this reason, I recommend a Pixel, since they can get more and better Google AI features faster, and also I have one and it’s an excellent phone.
On-Policy Distillation
On-policy distillation trains a student model using its own policy's sampled trajectories, with a teacher providing token-level supervision via KL-based regularization, effectively addressing train-inference distribution mismatch common in off-policy methods.
Decoder
- On-policy distillation: A machine learning method where a smaller "student" model is trained using data (trajectories) generated by its own current policy, guided by a larger "teacher" model.
- Student model: A smaller, often less complex AI model that is being trained to replicate the behavior or knowledge of a larger, more powerful "teacher" model.
- Teacher model: A larger, more performant AI model whose knowledge and behavior are transferred to a smaller "student" model during distillation.
- Policy: In reinforcement learning, the strategy that an agent uses to decide what actions to take in a given state.
- Trajectories: Sequences of states, actions, and rewards experienced by an agent in an environment.
- Token-level supervision: Guidance provided by the teacher model at the granularity of individual tokens (e.g., words or sub-word units) in the output sequence.
- KL-based regularization (Kullback-Leibler divergence): A measure of how one probability distribution diverges from a second, expected probability distribution, used here to guide the student model's outputs towards the teacher's.
- Train-inference distribution mismatch: A problem where the data distribution encountered during model training differs from the distribution encountered during actual deployment (inference), leading to performance degradation.
- Off-policy methods: Reinforcement learning methods that can learn from data generated by a different policy than the one being optimized.
- Forward-KL: A specific form of KL divergence where the student's distribution is compared against the teacher's, useful for mode-covering.
- Reverse-KL: A specific form of KL divergence where the teacher's distribution is compared against the student's, useful for mode-seeking, especially for smaller student models.
- JSD (Jensen-Shannon Divergence): A method of measuring the similarity between two probability distributions, a symmetric and smoothed version of KL divergence.
- RL stack: A software framework or set of libraries used for developing and deploying reinforcement learning algorithms (e.g., Tinker).
Original article
On-policy distillation trains a student model on trajectories sampled from its own policy while a teacher provides dense token-level supervision through KL-based regularization, closing the train-inference distribution mismatch that off-policy methods suffer. The canonical formulation unifies forward-KL, reverse-KL, and JSD losses with reverse-KL emerging as the default for mode-seeking smaller students, and a one-line code swap of the regularizer model on top of an RL stack like Tinker implements the technique.

Introducing BenchBench
A new "BenchBench" benchmark designed to test AI models' ability to create benchmarks reveals GPT 5.2 as the only model capable of producing a truly useful and challenging test.
Original article
Introducing BenchBench
TL;DR: presenting the ultimate benchmark, getting models to create benchmarks for each other, and GPT 5.2 is the current (only) winner
Models are getting much much better at almost every benchmark we’ve thrown at them. Creating benchmarks is now a job relegated to the smartest and best of us. Even the newest and best ones seem to get saturated in record time. What this means is that increasingly the hardest job is to create a good enough AI benchmark.
So I took the obvious next step. Created a benchmark to see how well the models can create a benchmark. This works both as a great benchmark for model ability, but also as a test of the models’ self-awareness, and also helps us find cool new evals and therefore RL envs we can have the frontier models hillclimb on!
Thus, Introducing BenchBench.
Each model was given the report of all benchmarks we have in the wild and then asked to come up with a benchmark that can beat frontier models and is actually practically solvable. (i.e., no marks for asking if P = NP). Then, if they fail at this task, we do another round after giving the models the failures so they can learn and do better. And another.
And do they? Well, not quite.
First, GPT 5.2 is the only winner. It succeeded at creating an actually useful benchmark that the others had a hard time solving! Every other model, from Opus 4.6 to GPT 5.5 struggled. They made way easier problems than they should’ve or created unsovleable problems.
And what did the other models actually do, I hear you ask. Well:
-
GPT-5.4 built quite plausible policy and governance worlds, but they often turned into clean checklists. It was the best model at solving the others’ benchmarks though!
-
GPT-5.5 built procedural rule tasks, but the weak rows leaned too much on exact schemas or hidden labels.
-
Gemini 3.1 Pro produced the most qualitatively different tasks. They separated solvers, but could become brittle or too puzzle-like!
-
Gemini 3.5 Flash also found good commercial-compliance questions, especially freight and tariffs, but top solvers still completed most of its tasks.
-
Claude Opus made elegant contest-style classic problems. They were clean and readable, which also made them easier to solve.
The most interesting aspects to me is that the top models that everyone agrees on, GPT 5.5 and Opus 4.6, both were pretty timid and kind of useless when it came to building good benchmarks. Either too easy for frontier models though not for smaller ones, i.e., them not knowing their own strengths, or too cheeky, creating unsolveable puzzles.
The other standout, beyond GPT 5.2, was Gemini. Both models I tested 3.5 Flash and 3.1 Pro. Gemini’s always been fascinating to me because they really do have a spectacular model but it never gets room to breathe and feels quite schizophrenic.
Gemini 3.1 Pro model is by far the most creative, it created spatial traversal tasks, corrupted recovery tasks and lease CAM reconciliation! Some of these with quite strange mechanisms. But it is also extremely brittle. I really really like this model and wish Google would do it justice!
There are some broader observations too that I found interesting. All models tended towards bureaucratic forensics in some way or another. Considering every lab wants to “eat the world” the focus on how to work in real-world messy situations seems apt as their primary home. Reimbursement Forensics, 5.2’s contribution, is a case in point. It gives a lot of travel expense packets and the answer asked is one number, the reimbursable total in cents. The models need to navigate the minefield of voided receipts and duplicates etc etc to do this task.
BenchBench also shows a clear distinction between the capabilities of Creator and Solver roles. While the leading models are great Solvers, they’re not the best Creators, and this is an interesting divergence. e.g., Gemini 3.5 Flash, yes its new, but is a better creator than Opus 4.6 though was a worse solver than it!
BenchBench itself is in its early innings and should be done again at scale, and with way more models! (let me know if you can help). Going forward, BenchBench will also let the models do a lot more work for their benchmark creation efforts and solving efforts. I can imagine things getting quite good in this regard, especially if they can work for hours at a time in coming up with the problems that they think would be strong!
It already shows a couple of things that are invisible from most benchmarks today:
-
It tests creativity and not just problem solving ability
-
It compares the models’ self-knowledge on their own abilities
-
It compares something actually new, the results are not just highly correlated with other benchmarks
That’s what got me excited about this once I ran it a few times. I’m obsessed with finding benchmarks that test the models’ creativity, understanding of themselves and their own abilities, and the possibility to hillclimb to the next big gaps we need to fill.
Right now we do this mostly manually. So we really do need to make this well ensconced as a full benchmark. Hence, welcome to the next major benchmark, BenchBench.
Strange Loop Canon is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.

Apple's Genmoji and Image Playground Set for Major Visual Overhaul in iOS 27 Ahead of WWDC 2026
Apple's Genmoji and Image Playground AI tools are slated for a significant visual quality upgrade in iOS 27, previewed at WWDC 2026, to enhance realism and potentially allow third-party model integration.
Decoder
- Genmoji: Apple's AI-powered feature introduced in iOS 18 that allows users to create custom emojis from text prompts.* Image Playground: Apple's AI-powered feature introduced in iOS 18 that enables the generation of creative visuals based on prompts.
Original article
Apple’s Genmoji and Image Playground Set for Major Visual Overhaul in iOS 27 Ahead of WWDC 2026
Apple is likely to preview iOS 27 at its WWDC event in June, with a strong focus on advancing Apple Intelligence capabilities. According to a report by Bloomberg’s Mark Gurman, the update will enhance the AI-powered image generation systems used in Genmoji and Image Playground, delivering noticeable improvements in visual quality. These upgrades are expected to make Apple’s generated emojis and creative visuals more refined and realistic. Earlier reports also suggest that Apple may eventually allow third-party AI image-generation models to integrate into iOS 27, further expanding its creative ecosystem.
NEW: Apple plans several new AI features across iOS 27, looking to better compete with Android. That includes new AI writing tools like a Grammar Checker, AI-created Wallpapers and new Shortcuts app with AI-based shortcut creation. https://t.co/kn4khH4NJN — Mark Gurman (@markgurman) May 18, 2026
In his latest Power On newsletter, journalist Mark Gurman reports that Apple is preparing a major quality upgrade for its AI image tools, Genmoji and Image Playground, as part of iOS 27. He notes that Apple’s in-house models powering these features have been significantly improved, which should result in noticeably better output quality this year.
ALSO SEE: Motorola Edge 70 Pro+ Coming to India Soon With 50MP Periscope Camera and 6,500mAh Battery
Apple originally introduced Genmoji and Image Playground in iOS 18, where Genmoji lets users create custom emojis using text prompts and Image Playground enables AI-generated visuals. In the next iteration, Apple may make Genmoji more proactive by suggesting emojis based on users’ photo libraries and frequently used phrases, instead of relying only on manual prompt input through the keyboard.
The new wallpaper generator uses technology from Image Playground. It’s available as an option in the wallpaper picker. The Google Pixel has had this functionality for a while now. https://t.co/2zVc9ORddt — Mark Gurman (@markgurman) May 18, 2026
The report also suggests Apple could broaden Image Playground by integrating additional third-party AI models beyond ChatGPT, which is currently supported. This may include Google’s AI systems, potentially enabling more advanced on-device image generation and editing capabilities, expanding the creative scope of Apple’s AI tools.
Apple is expected to reveal more details about iOS 27 at WWDC 2026 next month. Alongside Apple Intelligence upgrades, the update is also rumored to bring a redesigned Siri, an overhauled Shortcuts app, an AI-powered wallpaper generator, and improved Writing Tools for system-wide use.
ALSO SEE: Apple Watch Heart Tracking Improvements Reportedly Coming With watchOS 27 Topics: Tech, Apple, iOS 27, WWDC 2026, Genmoji
Huawei Says It Has Workaround to Match Leading Chips
Huawei claims it will produce chips matching 1.4-nanometer density by 2031, circumventing US semiconductor export restrictions imposed since 2022.
Decoder
- 1.4-nanometer process: A manufacturing technology for semiconductors that refers to the size of transistors and interconnects, indicating a very high density of components on a chip. Smaller numbers generally mean more advanced, powerful, and efficient chips.
Original article
Huawei expects to be able to make chips on par with leading products manufactured by Intel and other top global companies by 2031. It has developed a technique that can create chips that match the transistor density of those manufactured with a 1.4-nanometer process. The US has restricted China's access to advanced semiconductor technologies since 2022. Huawei's technology could remove this obstacle for China in its tech rivalry with the US.
A terminal is all you need for web agents (Website)
Microsoft's Webwright is a new SWE-style browser agent framework that achieves state-of-the-art results on complex web tasks by giving agents a terminal to manage multiple browser sessions.
Decoder
- SWE-style browser agent: An AI agent designed to perform Software Engineering tasks (SWE) by interacting with web browsers, mimicking a human developer's workflow.
- Long-horizon web tasks: Complex, multi-step web tasks that require a sequence of interactions over an extended period or across multiple pages/sessions.
Original article
Microsoft Webwright is a simple SWE-style browser agent framework that achieves state-of-the-art results on long-horizon web tasks. It gives agents a terminal that allows them to launch multiple browser sessions to inspect pages and complete web tasks. Webwright captures and inspects screenshots only when needed, and it enforces each web task to be completed end-to-end within a re-runnable Python script. It uses a small harness that adds just enough structure around completion, context, and reuse to avoid creating new failure modes.

Using AI to write better code more slowly
Nolan Lawson argues that AI coding can be used to write higher-quality code more slowly by leveraging multiple LLM agents for thorough bug detection and code review.
Decoder
- LLM (Large Language Model): A type of artificial intelligence model trained on vast amounts of text data to understand, generate, and process human language.
- PR (Pull Request): A method used in software development to submit changes for review before they are merged into a main codebase.
- KISS principle: "Keep It Simple, Stupid," a design principle stating that most systems work best if they are kept simple rather than made complicated.
- DRY principle: "Don't Repeat Yourself," a software development principle aimed at reducing repetition of software patterns, replacing it with abstractions or data normalization.
Original article
Full article content is not available for inline reading.
We got our first glimpse at an Unreal Engine 6 video game, and it's Rocket League
Epic Games debuted a teaser for an Unreal Engine 6 version of `Rocket League`, showcasing enhanced car models and dynamic lighting.
Decoder
- Unreal Engine 6: The next iteration of Epic Games' powerful real-time 3D creation tool and game engine, used for developing video games, virtual production, and architectural visualization.
Original article
Epic Games has released a short teaser trailer showing an updated version of Rocket League running on Unreal Engine 6 with more detailed car models and dynamic lighting reflections.
Firefox Project Nova Redesign Brings Compact Mode and New Look
Firefox's Project Nova redesign, its biggest in six years, brings compact mode and clearer privacy controls to compete with Chromium-based browsers.
Deep dive
- Project Nova is Firefox's most significant visual overhaul since 2020.
- The redesign introduces softer, rounded tabs with a subtle gradient and a new fire-inspired color palette with deep purples and warm tones.
- Mozilla is bringing back "compact mode" which condenses browser controls, a popular request from power users.
- Privacy tools, including the built-in VPN (50GB free monthly data), are getting more prominent placement.
- Settings are being rewritten in plainer language, with clearer controls for Enhanced Tracking Protection and an option to disable AI features.
- Mozilla claims Firefox has improved load times by 9% over the past year, partly due to tracker blocking.
- The redesign includes a shared design system for consistency across desktop and mobile, with plans for user customization.
- Firefox currently holds about 2.3% of the global browser market, down from double digits a decade ago.
- Firefox 150 included 271 vulnerability fixes found by Anthropic's Claude.
Original article
Mozilla unveiled Project Nova, Firefox’s biggest redesign in six years. It brings softer tabs, a fire-inspired colour palette, compact mode, and clearer privacy controls. The rollout is expected later this year.
Mozilla has officially unveiled Project Nova, the largest visual overhaul of Firefox since 2020. The redesign touches tabs, icons, spacing, colour palette, and settings, with the goal of making the browser feel warmer and faster without losing its identity as the only major browser not built on Chromium.
The changes start with the tabs. They now have a softer, more rounded shape with a subtle gradient that gives the active tab more visual weight. The rest of the interface follows suit: panels, menus, and browser controls share consistent curves and spacing. Icons have been redrawn for better balance across light and dark themes.
The colour palette is new too. Mozilla describes it as inspired by fire, with deep smoky purples and lighter warm tones replacing the flatter hues of the current design. The active tab gets a glow effect that ties the whole interface together.
Compact mode is returning. Mozilla removed the option years ago and users have been asking for it back ever since. The reinstated mode condenses browser controls to reclaim vertical screen space, a straightforward concession to the power users who make up a disproportionate share of Firefox’s base.
Beyond aesthetics, Nova makes privacy tools more visible. The built-in VPN, which Mozilla launched as a free feature with 50 gigabytes of monthly data, gets a more prominent placement. Settings are being rewritten in plainer language, with clearer controls for Enhanced Tracking Protection and the option to turn off AI features entirely.
Mozilla claims Firefox has improved load times for key page content by 9 per cent over the past year. Part of that comes from tracker blocking, which reduces the amount of third-party code a page needs to load. The browser also now prioritises the most important page elements before loading peripheral content.
The redesign extends to mobile. Shared colours, icons, and design tokens will make Firefox feel more consistent across desktop and phone. Mozilla is also adding new themes and wallpapers, with plans to let users customise the shape of interface elements like tabs and components over time.
Under the hood, Nova introduces a shared design system built on reusable tokens and components. The idea is that future features integrate into a cohesive visual language rather than looking bolted on. That kind of infrastructure work rarely excites users, but it determines how quickly a browser can evolve.
The timing matters. Firefox holds roughly 2.3 per cent of the global browser market, down from double digits a decade ago. Google has been turning Chrome into an AI workplace platform, while also facing scrutiny over its tracking practices. Apple’s Safari holds second place at around 15 per cent. Firefox’s pitch, that it is built for users rather than platforms, needs a modern interface to match.
Mozilla has also been investing in AI on its own terms. Firefox 150 shipped with 271 vulnerability fixes found by Anthropic’s Claude, and the browser now offers optional AI features with a kill switch for users who want none of it. That approach, AI as a choice rather than a default, aligns with the broader Nova philosophy.
Project Nova is available for testing in Firefox Nightly builds now. The full rollout is expected later this year. Mozilla is collecting feedback through its Connect forum, staying true to its open-source tradition of building in public.
Apple Intelligence image models to boast ‘major' visual upgrades in iOS 27
Apple will significantly upgrade its criticized Genmoji and Image Playground AI image generation quality in iOS 27, potentially adding third-party model support beyond ChatGPT.
Decoder
- Genmoji: Apple's AI-generated emoji-like characters based on user prompts or photos.
- Image Playground: Apple's AI tool for generating images and art based on text prompts.
Original article
Apple is reportedly giving its Genmoji and Image Playground AI image generation models a major quality upgrade in iOS 27 after widespread criticism of the low-quality results introduced in iOS 18.2, especially compared to competing AI tools. The update may also expand Image Playground beyond Apple's own on-device models and ChatGPT integration to support additional third-party image generators, potentially including Google's Nano Banana models, while new features like photo library–based Genmoji suggestions are also expected.

When Designers Start Building
Automattic designers are learning to build directly in production codebases using AI, moving beyond Figma to make design decisions closer to the actual product.
Deep dive
- Automattic's workshop aimed to help designers work directly in production codebases, bridging the gap between design and shipped product.
- Twenty designers learned to set up local development environments and open pull requests, with AI (Claude Code) assisting in setup and contributions.
- The initiative moves design iteration from Figma into the codebase itself, allowing designers to tweak visuals, microcopy, and interactions with real components and data.
- Figma remains the starting point for larger UX thinking, but the local dev environment becomes a complementary design tool where prototypes are built from the real thing.
- Collaboration shifts from a "baton pass" to iterating on the same artifact, with engineers catching architectural edge cases and designers focusing on polish.
- A key finding was the importance of an "engineering buddy" who provides guidance, explains issues, and makes designers feel safe experimenting with code.
- Designers are now shipping and merging pull requests, allowing engineers to focus on architecture, performance, and systems work.
Decoder
- Pull Request (PR): A proposal to merge code changes from one branch into another in a version control system like Git, often used to review and discuss changes before integrating them.
- Local Development Environment: A setup on a developer's personal computer that mimics the production environment, allowing them to write, test, and run code without affecting the live system.
- Claude Code: An AI tool, likely referring to Anthropic's Claude model, used here to assist designers with coding tasks and setting up development environments.
Original article
What a workshop taught us about closing the gap between design and code. In most design workflows, there’s a point where the work leaves your hands. The spec goes to engineering, and from there you’re shaping the outcome through comments, screenshots, and Slack threads—staying involved, but one step behind.
It works, but there’s a gap between designing something and seeing it ship the way you intended. At Automattic, we wanted to know what happens when designers step into that gap themselves. Not to become engineers, but to design inside the real product: working with actual components, real APIs, and the constraints of production code. Think of it as the next evolution of prototyping: instead of simulating how something will work, you’re shaping the thing itself.
So we ran a hands-on workshop at our biannual team meetup. Around twenty designers set up local development environments from scratch, and started working directly in their product’s codebase and shipping PRs. Here’s what we learned.
The question behind the workshop
Many designers are sitting with the same quiet question right now: what does AI mean for our role? The answer we kept returning to was about proximity: getting closer to the product as it actually exists, not just as it looks in Figma.
That meant rethinking what design artifacts look like. What if the prototype was the product? What if, instead of mocking up a flow in Figma and annotating the details, a designer could build it with the same components and data the shipped version would use, and iterate on it there?
Two of us facilitated a pair of 40-minute breakout sessions with a single goal: by the end of the workshop, every designer in the room would have a functioning local dev environment on a codebase they hadn’t worked on before, plus a Claude skill—a reusable set of AI instructions—that would walk them through opening their first contribution.
Two sessions, same direction
The first session was the conversation. We kept circling one practical question: how do we bring design expertise closer to the final polish of the product—not just the mockups—while still respecting the engineering expertise already in the room? One of our design leads summed it up:
The goal is co-owning the output with engineers, not handing work over and hoping.
The second session was more grounded. We walked through real examples from our own work—contributions one of us had been shipping for months. Reworking conditional empty-state messaging (#). Designing a post-publish flow (#). Building a pre-publish checklist from scratch (#). These weren’t merely engineering tasks done by a designer, they were design decisions that happened to be made directly in the codebase, using the same components and constraints as the shipped product. The point wasn’t “here’s how to code.” It was “here’s what it looks like when your design environment is the product.”
Then we asked everyone to open Claude Code and start setting up a local dev environment. It was ambitious, and the work didn’t all fit inside the workshop. People carried on in their own time afterward. By the next morning, a handful of designers had opened their first pull requests, fixing things they’d wanted to improve in the product for a long time but hadn’t had the path to ship themselves (#link, #link). Some of them even built full components.
What we learned
The bigger shift isn’t the tooling. It’s where design work happens now. Design iteration used to live almost entirely in Figma and then get translated into code. With AI in the loop, a lot of that iteration is moving into the codebase itself: tweaking spacing, trying a different empty state, rewording microcopy, rethinking a small interaction—all using production components, real data, and actual platform constraints. Figma is still where most of the bigger UX thinking starts. But the local dev environment is becoming a design tool in its own right: one where your prototype is already built from the real thing.
That changes what collaboration looks like. Instead of a baton pass, designers and engineers iterate on the same artifact. The designer proposes a change in code; the engineer catches the architectural edge cases the designer didn’t see. They go back and forth on the same surface. The result ships faster, and with more design care, than the old handoff could deliver.
But the tool that made the biggest difference wasn’t AI. It was a relationship. One of us had been shipping for months before the workshop because she had an engineering buddy—someone who talked through trade-offs, explained what broke and why, and treated her work as worth investing in. Over time, they built a shared language. Both sides learned. AI made the code feasible. The engineer made it feel safe to try.
What we’d tell another team
- Your local dev environment is a design tool. Real components, real APIs, real constraints: the prototype and the product become the same thing.
- Figma for thinking, code for calibrating. AI lets designers rework microcopy, try empty states, and tweak interactions directly in the codebase.
- Handoff becomes a shared surface. Designer and engineer iterate on the same artifact. The result ships faster and with more design care.
- An engineering buddy accelerates everything else. A specific engineer who reviews your work, explains failing tests, and encourages you to keep going makes trying feel safe.
- Show real examples, not a generic tutorial. Designers need to see what working in code actually looks like before they believe it’s possible for them.
What’s next
The workshop was a starting point, but the momentum continued on its own. Designers who’d never touched a terminal are now treating their local dev environment as another design tool—a place to bring their expertise, not just hand it off. We’re already seeing a growing number of designers shipping and merging pull requests on their own.
Engineers are happier too. When designers handle the visual polish and microcopy directly, engineers can focus on the problems that need their expertise: architecture, performance, the hard systems work. Everyone’s doing more of what they’re best at, and the product is better for it.
MagicPath (Website)
MagicPath introduces a multiplayer AI workspace that transforms design into live, interactive, browser-based interfaces, eliminating the traditional design-to-engineering handoff.
Original article
MagicPath turns design into a multiplayer AI workspace where teams build and iterate on live, interactive browser-based interfaces together with no design-to-engineering handoff.
Turn Your Code Into Stunning Videos (Website)
Repoclip uses AI (Gemini 2.5 Flash, Kling 3.0 Pro, OpenAI TTS) to convert GitHub repositories into professional demo videos with scripts, visuals, and narration in under 60 seconds.
Decoder
- Gemini 2.5 Flash: A fast, multimodal AI model from Google used for code analysis.
- Kling 3.0 Pro: An AI model for generating cinema-quality video clips.
- Nano Banana 2: An AI model for generating high-quality still images.
- OpenAI TTS: OpenAI's text-to-speech API for generating natural-sounding narration.
Original article
Turn Your GitHub Repo into a Demo Video in 60 Seconds
No video editing skills required. Just paste your URL and let our AI handle the script, visuals, and narration.
Your first video is free. No credit card required.
Works with any public GitHub repo. No GitHub account needed to sign up.
Built for Developers, by Developers.
This video was generated by RepoClip
How It Works
From code to video in just a few clicks
1. Paste Your URL
Enter any public or private GitHub repository URL to get started.
2. AI Analysis
Our AI analyzes your code structure, features, and creates a compelling script.
3. Get Your Video
Download your professional video with AI-generated visuals and narration.
Everything You Need
From AI-generated images to cinematic video clips — explain complex features with visuals that keep your users engaged.
AI Video Clips
Generate cinematic video scenes with dynamic camera movements and animations. Pro plans use Kling 3.0 Pro for cinema-quality results.
AI Code Analysis
Powered by Gemini 2.5 Flash to understand your code deeply.
AI-Generated Images
Stunning still images powered by Nano Banana 2 for vivid, high-quality scene backgrounds.
Professional Narration
Natural-sounding voiceover using OpenAI's standard preset voices. No voice cloning — safe and ethical AI audio.
Private Repos Supported
Connect your GitHub account to access private repositories.
Fast Generation
Videos ready in minutes thanks to optimized AI pipeline.
Built for Every Use Case
From launch day to investor meetings, RepoClip has you covered.
Feature Announcements
Show new features with professional videos that explain complex changes in seconds.
Investor Pitches
Impress investors with polished product demos that highlight your technical strengths.
Social Media Content
Create engaging content for Twitter, LinkedIn, and YouTube to grow your audience.
Open Source Promotion
Attract contributors with compelling showcases that make your project stand out.
Save Time and Money
Professional results at a fraction of the cost.
5 min
average generation time
100%
professional output, zero manual effort
Frequently Asked Questions
Everything you need to know about RepoClip.
Is my code safe? Yes. Your code is only used for analysis during video generation and is never stored permanently. We use secure connections and do not share your code with third parties.
What types of repos are supported? Any public GitHub repository works — just paste the URL. No GitHub account needed to sign up; you can use Google to log in. For private repos, connect your GitHub account to grant access.
How long does it take? Most videos are generated within 5 minutes. The exact time depends on repository size and current demand.
Can I customize the video? Yes! You can provide custom instructions to control the narration tone, visual style, voice, and content focus. The AI interprets your preferences to create a tailored video.
Does RepoClip use voice cloning? No. RepoClip does not offer voice cloning or any feature that replicates a real person’s voice. All narration is generated using OpenAI’s standard text-to-speech API with a fixed set of preset synthetic voices. Users cannot upload or create custom voice models.
What programming languages are supported? RepoClip supports TypeScript, JavaScript, Python, Go, Rust, Java, Kotlin, Swift, and more. Any repo with readable source files can be analyzed.
Do you have an API or CI/CD integration? Yes! RepoClip offers a Public API and an official GitHub Action (repoclip/generate-video) so you can generate videos automatically from your CI/CD pipeline — for example, on every release. See our documentation for details.
Ready to Create Your First Video?
Join developers who are already creating professional demo videos in minutes.

Seven Tips for Using Figma Make Credits More Efficiently
Figma Make introduced "Make kits" and "Make attachments" on April 2, 2026, to allow prototyping with real components, data, and constraints, offering more context and control.
Original article
Full article content is not available for inline reading.

In the Age of AI, Design Instinct and Experience Matter More than Ever
While generative AI lowers the barrier to entry for design, it simultaneously highlights that human instinct, taste, and experience remain crucial and irreplaceable for impactful creative work.
Deep dive
- Generative AI tools such as Midjourney, DALL-E, and ChatGPT Images 2.0 are making design more accessible.
- Matt Sia of Pearlfisher contends that this democratized access does not diminish the role of human designers.
- Instead, AI exposes the fundamental importance of human instinct, taste, and years of experience in creating effective design.
- AI struggles to anticipate emotional responses, resonate deeply with audiences, or make nuanced creative decisions.
- Examples like Coca-Cola's 2024 Christmas campaign and Volvo's 'Come Back Stronger' faced criticism for perceived 'hollow' or 'uncanny' AI-generated imagery.
- Sia uses a Formula 1 car analogy: AI is a powerful machine, but a skilled human driver is essential for success.
- The growing gap between generating output and making correct creative decisions increases the value of human judgment.
- Designers should focus on storytelling and fine-tuning, allowing AI to accelerate production.
- The true differentiator will be whether AI is used to amplify human creativity or merely automate it.
Original article
Full article content is not available for inline reading.
Introducing Grok Build
x.AI has launched Grok Build in beta, a new coding agent and CLI for SuperGrok and X Premium Plus subscribers, supporting complex coding projects with plan mode reviews and headless operation.
Decoder
- Grok Build: A new coding agent and CLI developed by x.AI for automated and assisted software development.
- SuperGrok: A premium tier of x.AI's Grok AI model.
- X Premium Plus: A subscription tier for X (formerly Twitter) that includes access to advanced features and services.
- Headless mode: Operation of a software application without a graphical user interface, often used for automation.
Original article
Grok Build, a new coding agent and CLI, has launched in beta for SuperGrok and X Premium Plus subscribers. It supports complex coding projects by allowing plan mode reviews and integrates seamlessly with user conventions. Users can deploy Grok's capabilities for automation and parallel processing using headless mode and specialized subagents.
Notes on Pope Leo XIV's encyclical on AI
Pope Leo XIV released "Magnifica Humanitas," an encyclical on AI ethics, addressing environmental impact, algorithmic risks, and power amplification, resonating with his namesake Pope Leo XIII's social teachings.
Deep dive
- Pope Leo XIV's encyclical "Magnifica Humanitas" addresses the ethical integration of AI into modern society, linking it to the industrial revolution context of Pope Leo XIII's "Rerum novarum" (1891).
- The document discusses the interpretability problem of LLMs, noting that developers have limited understanding of their internal functioning (section 98).
- It emphasizes human dignity and development, criticizing AI if it increases consumption for some while shifting costs onto others (section 83).
- The encyclical warns against excessive reliance on AI, the illusion of objectivity in AI responses, and the risks of simulated human communication (section 100).
- It highlights the enormous energy and water demands of current AI systems and calls for more sustainable technological solutions (section 101).
- Pope Leo XIV stresses the risks of delegating important decisions (employment, credit, reputation) to automated systems that lack human qualities like compassion and forgiveness (section 102).
- The document calls for clear human accountability in AI systems, especially given their opaque internal processes (section 105).
- It raises concerns that AI amplifies the power of those with existing economic resources and data, suggesting data should be managed as a common good (section 108).
Decoder
- Encyclical: A papal letter, usually addressed to all the bishops of the Roman Catholic Church, dealing with matters of doctrine or morals.
- Rerum novarum: An encyclical issued by Pope Leo XIII in 1891 on the "Rights and Duties of Capital and Labor," addressing social conditions in the wake of the Industrial Revolution.
Original article
Simon Willison’s Weblog
Notes on Pope Leo XIV’s encyclical on AI
25th May 2026
Dropped this morning by the Vatican: Magnifica Humanitas of His Holiness Pope Leo XIV on Safeguarding the Human Person in the Time of Artificial Intelligence. This is a very interesting document. It’s some of of the clearest writing I’ve seen on the ethics of integrating AI into modern society.
Pope Leo XIV chose the name Leo in honor of Pope Leo XIII, who is known for his 1891 Rerum novarum encyclical on “Rights and Duties of Capital and Labor”.
This story on Vatican News further clarifies the significance of that decision:
Meeting with the College of Cardinals for their first formal encounter after his election, Pope Leo XIV explained part of the reason for the choice of his papal name. "There are different reasons for this," he said, before going on to explain that he chose the name Leo "mainly because Pope Leo XIII, in his historic encyclical Rerum novarum addressed the social question in the context of the first great industrial revolution."
“In our own day,” he continued, “the Church offers to everyone the treasury of her social teaching in response to another industrial revolution and to developments in the field of artificial intelligence that pose new challenges for the defence of human dignity, justice, and labour.”
And now we get Pope Leo XIV’s own encyclical on the AI revolution. There’s a lot in here, but the writing style is very approachable, including to non-Catholics.
A few of my highlights
(I listened to most of the encyclical on a walk with our dog, my first time trying the ElevenReader iPhone app. It worked very well: I pasted in a URL to the document and it read it to me in a very high quality voice, highlighting each paragraph as it went.)
Here are some of my highlights. In each case below emphasis is mine.
Here’s a useful description of the interpretability problem for LLMs in section 98:
First, any statement regarding AI risks becoming quickly outdated, given the remarkable pace at which these systems are developing. Second, all of us, including those who design them, possess only a limited understanding of their actual functioning. Indeed, current AI systems are more “cultivated” than “built,” for developers do not directly design every detail, but instead create a framework within which the intelligence “grows.” As a result, fundamental scientific aspects — such as the internal representations and computational processes of these systems — remain, at present, unknown.
I liked section 83’s description of the relationship between development and dignity:
For individuals as well as for nations, development is both a duty and a right. Minimum conditions are required for enabling every person and people to flourish in accord with their dignity, without being kept in a state of dependence or excluded from access to necessary goods. Development is truly human when it places people at the center instead of the accumulation of wealth, and when it concerns peoples as well as individuals. Justice demands the recognition of the rights of society and the rights of peoples, and includes a responsibility toward future generations. Development is not truly human if it increases consumption for some while shifting costs and burdens onto others, or relegates entire regions to subordinate roles, preventing them from realizing their full potential.
Baked in cultural biases and sycophancy get a mention in section 100:
In personal use, three aspects in particular deserve careful consideration: the ease with which results are obtained, the impression of objectivity and the simulation of human communication. The speed and simplicity with which information, complex analyses, media content and practical assistance can be accessed undoubtedly makes life easier. Yet they can also encourage excessive reliance and the search for ready-made answers, and weaken personal creativity and judgment. The apparent objectivity of the responses and suggestions these systems provide can lead us to overlook the fact that they reflect the cultural assumptions of those who designed and trained them, with all their strengths and limitations. The artificial imitation of positive human communication — words of advice, empathy, friendship and even love — can be engaging and at times genuinely helpful. However, for less discerning users, it can also be misleading, creating the illusion of a relationship with a real personal subject. When words are simulated, they do not build genuine relationships, but only their appearance. The artificial imitation of care or support can become particularly risky when it enters contexts where real relationships and emotional bonds are lacking.
101 touches on the environmental impact:
Current AI systems require enormous amounts of energy and water, significantly influencing carbon dioxide emissions, and place heavy demands on natural resources. As their complexity increases, especially in the case of large language models, the need for computing power and storage capacity grows too, which requires an extensive network of machines, cables, data centers and energy-intensive infrastructure. For this reason, it is essential to develop more sustainable technological solutions that reduce environmental impact and help protect our common home.
102 covers the risks of algorithmic systems making decisions that impact people’s lives without “compassion, mercy, forgiveness”:
The use of AI is never a purely technical matter: when it enters processes that affect people’s lives, it touches on rights, opportunities, status and freedom. Important and sensitive decisions — concerning employment, credit, access to public services or even a person’s reputation — risk being fully delegated to automated systems that do not know “compassion, mercy, forgiveness, and above all, the hope that people are able to change,” and can therefore give rise to new forms of exclusion.
105 emphasizes the need for human accountability in how these systems are applied:
For AI to respect human dignity and truly serve the common good, responsibility must be clearly defined at every stage: from those who design and develop these systems to those who use them and rely on them for concrete decisions. In many cases, however, the internal processes leading to a result remain opaque, making it harder to assign responsibility and correct errors. This is where accountability becomes crucial: the possibility of identifying who must “account” for decisions, justify them, monitor them, and, when necessary, challenge them and remedy any harm caused.
And 108 touches on the way AI amplifies the power of those with resources:
In fact, as with every major technological shift, AI tends to amplify the power of those who already possess economic resources, expertise and access to data. In light of the common good and the universal destination of goods, this raises serious concerns, since small but highly influential groups can shape information and consumption patterns, influence democratic processes and steer economic dynamics to their own advantage, undermining social justice and solidarity among peoples. For this reason, it is essential that the use of AI, especially when it touches on public goods and fundamental rights, be guided by clear criteria and effective oversight, grounded in participation and subsidiarity.
That same section explicitly calls out data as something that should be thought of more as a public good:
[...] Moreover, ownership of data cannot be left solely in private hands but must be appropriately regulated. Data is the product of many contributors and should not be treated as something to be sold off or entrusted to a select few. It is necessary to think creatively in order to manage data as a common or shared good, in a spirit of participation, as Saint John Paul II already suggested regarding collective goods.
Given that Palantir is named after a Lord of the Rings reference, I can’t help but wonder if the J.R.R. Tolkien quote from The Return of the King (section 213) was the Pope throwing a little shade at Peter Thiel.
The twentieth-century Catholic author J.R.R. Tolkien, in the words of a protagonist in one of his novels, described our responsibility in this way: “It is not our part to master all the tides of the world, but to do what is in us for the succour of those years wherein we are set, uprooting the evil in the fields that we know, so that those who live after may have clean earth to till.” The civilization of love will not arise from a single or spectacular gesture, but from the sum total of small and steadfast acts of fidelity that serve as a bulwark against dehumanization. For this reason, it is worthwhile pausing to reflect on some aspects of how we, each in our own way, can cooperate in building the civilization of love.
Another 2026 prediction down
On 6th January this year I joined the Oxide and Friends 2026 predictions podcast episode to talk about predictions for 2026, 2029 and 2032. I wrote mine up here, with hindsight they weren’t nearly ambitious enough—it’s already undeniable that LLMs write good code, we’ve made huge advances in sandboxing and New Zealand kākāpō have indeed had a truly excellent breeding season.
There’s one segment from the episode that I didn’t bother to include in my write-up, but that I can’t resist providing as a lightly-edited transcript here:
Bryan Cantrill: 37:13
I think that AI has created some real public perception problems for itself. And I think that you are gonna have one of the frontier model companies, this year, have a white paper explaining how the proliferation of AI will mean prosperity for everybody. They will be trying to make some economic argument—because this is gonna be a 2026 election issue, how we think of these things and how they are regulated and it’s a big mess. There’s more heat than light in this debate.
Simon Willison: 38:05
I’d like to tag something on to that one: I think that only works if they can sort of wash that through existing trusted experts. Sam Altman and Dario are constantly publishing essays about this stuff and nobody believes a word they say. Get Barack Obama’s signature on one of these position papers and maybe you’ve got something people might start to trust a little bit.
Adam Leventhal: 38:27
Otherwise, it’s just like “leaded gas is good for you”, says Exxon.
Bryan Cantrill: 38:31
I mean, yeah. God. Obama... let’s go with that, that’s a great one because if it’s like Bill Clinton everyone’s gonna kind of roll their eyes, so it’s gotta be someone who’s got real credibility saying that this is gonna be broad-based... I’d say if they get that person to do it, it’s gonna be revealed that that’s also a bit crooked.
Simon Willison: 38:57
How about the Pope?
Bryan Cantrill: 39:01
The Pope is very into this stuff! That’s a great prediction. We’ve hit pay dirt. The Pope weighing in on LLMs and their economic impact on the world.
Simon, I’m giving you full credit if the Pope weighs in believing that this is gonna be economic devastation.
My prediction here looks a whole lot less insightful given the Leo XIV/Leo XIII relationship, which I was unaware of when we recorded the episode!
More recent articles
- Datasette Agent - 21st May 2026
- Gemini 3.5 Flash: more expensive, but Google plan to use it for everything - 19th May 2026
This is Notes on Pope Leo XIV’s encyclical on AI by Simon Willison, posted on 25th May 2026.
Previous: Datasette Agent
DeepSeek's 10 trillion USD grand strategy
DeepSeek aims to cultivate a $10 trillion Chinese AI hardware ecosystem, aspiring to achieve a $1 trillion valuation for itself.
Original article
DeepSeek's aim is to enable a $10 trillion Chinese AI hardware ecosystem and achieve a $1 trillion valuation for itself.

Japan's New Hypersonic Engine Could Make 2-Hour Flights To The US A Reality
Japanese engineers successfully tested a ramjet engine designed for Mach-5 hypersonic flight, aiming for 2-hour flights from Tokyo to Los Angeles by the 2040s.
Decoder
- Ramjet engine: A type of air-breathing jet engine that uses the vehicle's forward motion to compress incoming air, rather than a rotating compressor, allowing it to operate efficiently at supersonic and hypersonic speeds.
- Mach-5: Five times the speed of sound. At sea level, this is approximately 3,836 miles per hour (6,174 km/h).
Original article
Japan's New Hypersonic Engine Could Make 2-Hour Flights To The US A Reality
At first blush, it sounds like science fiction: supersonic jets able to traverse the vastness of the Pacific Ocean in under two hours. But recent tests by Japan's Aerospace Exploration Agency (JAXA) in conjunction with several Japanese universities have brought that once seemingly impossible vision closer to reality (alongside similar Mach-5 testing in the U.S.).
A team of engineers from JAXA, Waseda University, the University of Tokyo, and Keio University has completed a successful ground combustion trial of a ramjet engine designed for a Mach‑5 hypersonic aircraft, a key step toward a future where flights from Tokyo to Los Angeles could take roughly the same time as a short domestic hop. The test was conducted at JAXA's Kakuda Space Center, simulating flight at five times the speed of sound and focused on validating the aircraft's heat‑shielding, control surfaces, and engine performance under extreme conditions. The results, and aircraft like NASA's "quiet" supersonic X-59, may help redefine how engineers think about high‑altitude, high‑speed passenger and even suborbital travel.
How Japan's Mach-5 ramjet works
A ramjet, the technology at the core of the test, is a type of air-breathing jet engine that has no moving parts. The name is derived from the engine's reliance on rapid forward motion to "ram" and compress incoming air before mixing it with fuel and igniting it for thrust. The technology eliminates the need for heavy rotating compressors and allows them to operate at speeds that far exceed the capabilities of conventional turbofans. However, ramjets can't operate from a standstill: to function, they first need to be accelerated to supersonic speeds.
In the Japanese test, an experimental aircraft was mounted in a wind tunnel simulating conditions at around 25 kilometers of altitude, where the atmosphere is roughly one‑hundredth as dense as at sea level. At that elevation at Mach‑5, air around the nose and leading edges can reach temperatures exceeding 1,000 degrees Celsius (1,832°F), a challenge the U.S. Air Force has struggled to overcome with its own hypersonic jets.
To handle that level of heat, engineers constructed an advanced thermal‑protection system that maintained the aircraft's interior near normal operating temperature, allowing the onboard avionics and control electronics to function normally. Simultaneously, sensors mapped surface‑temperature distribution to verify thermal‑structure calculations, crucial for scaling up to a full‑size passenger vehicle.
From sounding rockets to two hour Pacific crossings
To be clear, this initial test is still a far cry from an actual test flight. What it represents is a ground‑based validation of a scaled‑down model. Next, JAXA plans to mount the experimental vehicle on a sounding rocket (a suborbital rocket typically used to take measurements and conduct scientific experiments in space) and attempt an actual flight at Mach 5. Assuming success and that regulatory and technical hurdles can be cleared, the goal is commercial hypersonic passenger service by the 2040s.
If progress continues at this pace, a Mach-5 plane flying at an altitude of 25 kilometers (nearly double the altitude achieved by current commercial airlines) could theoretically cut the Tokyo‑to‑Los Angeles route from roughly 10 hours to around two hours, without the complexity of entering full orbit. That means slashing transit time for a flight from the U.S. to Japan, transforming what would previously have been a week-long ordeal into a day trip with just a few hours in the air.
I'm the CEO of Goldman Sachs. The AI Job Apocalypse Is Overblown
Goldman Sachs CEO dismisses widespread AI job apocalypse fears, asserting the US economy has a strong history of creating new jobs through disruption.
Original article
AI will absolutely disrupt the job market, but the US has a long track record of creating new jobs in response to disruption. The growing demand for data centers has created more than 200,000 construction jobs since 2022. AI may eliminate jobs in some sectors, but it will lead to growth in others. The US economy can and will adapt to major advances in technology.

Tether Will Launch An 'Official' Stablecoin In Georgia Tied To Local Currency
Tether is launching GELT, an "official" stablecoin in Georgia tied to the Georgian Lari, promising lower transaction costs and near-instant settlement.
Decoder
- Stablecoin: A type of cryptocurrency designed to minimize price volatility, typically by being pegged to a "stable" asset like fiat currency (e.g., USD, Georgian Lari) or gold.
- Georgian Lari (GEL): The official currency of Georgia.
- USDT: Tether's stablecoin, pegged to the US dollar.
Original article
Tether will launch an 'official' stablecoin in Georgia tied to local currency
The new cryptocurrency will be called GELT and will represent the Georgian Lari.
Tether announced it will launch a cryptocurrency called GELT that's tied to the official currency of the country of Georgia. The company behind the USDT, a stablecoin that maintains a 1:1 value with the US dollar, said in a press release that this is one of the first joint efforts that pairs a national currency with a purpose-built stablecoin. Unlike most cryptocurrency, stablecoins are tied to a currency that's officially issued by a government. In this case, GELT will be tied to the Georgian Lari and has support from the Georgian government.
According to Tether, the GELT will be a "digital representation of the Georgian Lari" that allows for "lower transaction costs, near-instant settlement, programmable payments" and more. Tether said that it worked for several years alongside the country's legislature and regulatory bodies, as well as the National Bank of Georgia, to establish the stablecoin.
While stablecoins are designed to be more fixed than other cryptocurrencies with fluctuating values, they've still faced scrutiny from US regulators before. Prior to Tether establishing the GELT coin, Kyrgyzstan launched its own state-sponsored stablecoin called the USDKG in November, which is tied to the US dollar and backed by gold. As for GELT, Tether said more details on the stablecoin's structure, rollout and implementation will be announced later.

The social contract of writing
Johanna Larsson argues that the proliferation of LLM-generated text violates a "social contract of writing" by reducing authorial effort, leading to homogenized, boring content and devaluing original human expression.
Decoder
- LLMs (Large Language Models): AI models that process and generate human-like text.
- Oxide RFD (Request for Discussion): A long-form document used by Oxide Computer Company to facilitate discussion and establish conventions, often made public.
Original article
LLMs are making inroads into just about every industry on the planet, they’re everywhere now. AI for X, AI for Y, if there’s a thing that somebody is willing to pay for, there’s another person looking for a way to use LLMs to do it. But no human activity is becoming as dominated by LLMs as writing. It’s not that I can’t see the attraction of it as an author, especially where you feel a pressure to produce a lot of content. They’re very good at that, volume. I’ve experimented with LLM assisted writing in the past (nowadays I don’t even use them for spell-checking).
People use LLMs to assist them in writing on blogs, social media, newspapers, books, and they use them for spell checking, grammar, fact checking, and unfortunately, in way too many cases, to just write the whole thing outright. Once you learn to recognize the idioms and idiosyncrasies of LLM writing, you can’t stop seeing it. It’s everywhere. And it’s exhausting.
Even worse, it’s boring. All writing is homogenizing, slowly turning into the same slop. You see the same patterns everywhere, “it’s not x, it’s why”, em-dashes, or why not: “you’re not imagining it, the problem is real”. That last one actually drives me over the wall, I don’t know why, I just can’t stand it.
Increasingly everyone is having a strong negative reaction to this mass produced slop. It’s infuriating to invest time into reading something only to realize the author didn’t invest the corresponding amount of time into writing it. What’s interesting is that this is true even where the content itself might actually be fine. Correct, properly researched, it doesn’t matter.
Oxide RFD 576
This was the first thing I read that I felt like really articulated the problem. Oxide Computers have this wonderful convention of writing long form documents for enabling discussions and establishing conventions, Request for Discussion(s), and many of them are public. RFD 576 deals with the use of LLMs. The part specifically that’s relevant here is section 2.4, LLMs as writers.
Finally, LLM-generated prose undermines a social contract of sorts: absent LLMs, it is presumed that of the reader and the writer, it is the writer that has undertaken the greater intellectual exertion. (That is, it is more work to write than to read!) For the reader, this is important: should they struggle with an idea, they can reasonably assume that the writer themselves understands it — and it is the least a reader can do to labor to make sense of it.
So in fact it doesn’t matter whether the content is good, or even that the writing is fine, it’s the action of using an LLM to write instead of writing yourself. The very fact that the author reduced the effort they made to product the content is a violation of the social contract.
You can’t avoid it
Even if you’re avoiding using LLMs to write, you’re likely still being affected by the torrent of generated text. Apart from using LLM language to make fun of LLMs, like the ubiquitous “you’re absolutely right”, these tools are changing how we speak in subtle ways. A study at the Max-Planck Institute for Human Development showed ChatGPT’s penchant for specific words increased their prevalence even in spoken human language, increasing the frequency of words like delve, realm, meticulous, adept, boast, swift, and comprehend. Even if you’re not directly using it, the products of generative AI are everywhere.
Low-background steel is the name for steel produced before the detonation of the first atomic bombs, and is increasingly sought after. The many nuclear tests during the 1940s and 50s filled the atmosphere with enough radioactive materials to taint the entire surface of the planet and steel produced after that point is not “clean” enough for certain applications, like particle detectors. Okay, turns out, that’s not quite true anymore. Global anthropogenic background radiation has apparently dropped low enough that recently produced steel can be used for most of these things now. But let’s not let that get in the way of a good metaphor.
Anything written after November 30, 2022 is to some degree affected by the proliferation of LLMs. You can’t get around that, other than by exclusively reading old content.
Writing in the post-LLM world
Subtle taint aside, there will only be an increasing demand for original thought and expression, both from individual humans, and from the model companies to use as training material. The ability to write original content, without LLMs, will just become more valuable as the generated content takes over more and more of the internet. I guess the hard part will be finding it in the constant onslaught of LinkedIn thought leadership posts and AI generated cat pictures.
One of the most interesting consequences of this is how it’s affecting what we consider good writing. For as long as humanity has had grammar, and writing, we’ve cared about it being done well. We’ve put a premier on good grammar, vast vocabulary, good use of expressions and metaphors, and general text composition. LLMs do all of that just fine. Sure, they just won’t stop repeating the same patterns, the expressions are tired, the metaphors are a bit out there, and they’ve given the em-dash a bad name. But the reality is that students today in school have the option of either working hard and get an average grade, or do no work at all, have ChatGPT write the paper, and get a top score. Take the writing of Claude today and show it to someone 10 years ago, I doubt they’d have that much to complain about. It’s repetitive over time, when you’ve read enough of it, but it does match a lot of the traditional criteria of “proper” writing. Not Nobel prize winning, but fine.
But today what I crave is original expression. I don’t care if the grammar is wrong, as long as it’s different. I don’t care if the vocabulary is limited, just don’t use the word “delve”, please. Instead of looking down on an author for typos, I’ll cherish every single one. I don’t want anymore of the bland generic average of humanity that is AI-generated text, I want quirky and different. I want human writing.
I commit to not using LLMs to write
You took the time to read my writing, I appreciate that. I fulfilled my half of the contract too, I spent much of a day writing this, while watching old movies on the TV. I enjoy writing and I’ve been doing it all my life, although with varying levels of consistency. I’m going to try to make this more of a routine thing now. It feels meaningful. Worth doing.
Written by Johanna Larsson. Thoughts on this post? Find me on Bluesky at @jola.dev.

Enhanced Games results
Greek swimmer Kristian Gkolomeev broke a "non-enhanced" world record by 0.07 seconds at the controversial Enhanced Games, winning $1.25 million, though the record is unofficial.
Deep dive
- Greek swimmer Kristian Gkolomeev set a new unofficial "world record" in the men's 50m freestyle at the Enhanced Games in Las Vegas on May 24, 2026.
- Gkolomeev finished in 20.81 seconds, surpassing the previous non-enhanced world record of 20.88 seconds held by Cameron McEvoy.
- For this achievement, Gkolomeev received $250,000 for winning the event and an additional $1 million bonus for breaking the record.
- The "record" is not considered official by traditional sporting bodies, partly because athletes were allowed to use performance-enhancing drugs (PEDs) and high-tech suits.
- Gkolomeev is a three-time former NCAA champion and competed in four Olympic Games for Greece.
- Other notable athletes, including sprinter Fred Kerley and strongman Thor Björnsson ("The Mountain"), competed but did not set world records.
- The Enhanced Games aims to showcase human performance potentially augmented by science, operating without traditional anti-doping policies.
- Athletes who chose to use PEDs were under strict medical supervision.
Decoder
- Enhanced Games: A controversial sports event where athletes are permitted to use performance-enhancing drugs (PEDs) and advanced equipment, operating outside the regulations of traditional anti-doping bodies like the World Anti-Doping Agency (WADA).
- PEDs (Performance-Enhancing Drugs): Substances used to improve athletic performance, typically banned in mainstream sports.
- Non-enhanced world record: The official world record time or performance achieved under standard anti-doping and equipment regulations, without the use of PEDs or banned gear.
Original article
The Enhanced Games were held on Sunday, May 24, and the controversial event in Las Vegas, Nevada, featured competitors vying for a new world record.
While normal competition in weightlifting, swimming and track have intense anti-doping policies, Enhanced aimed to see what the athletes could do with the use of PEDs if the athletes wanted to partake.
So, how did it go? In the very last event of the night, the men’s 50m free, Greek swimmer Kristian Gkolomeev broke the non-enhanced world record time of 20.88 (Cameron McEvoy, Australia) with a 20.81-second swim. The swim earned Gkolomeev $250,000 for first place and a $1 million bonus for eclipsing the non-enhanced world record.
The record is not considered official. In addition to having competed on PEDs, the swimmers also wore high-tech suits that have been banned.
Gkolomeev is a three-time former NCAA champion for Alabama, including the 2014 championship in the 50 free. He won silver in the event at the 2019 world championships. He competed for Greece in four Olympic Games from 2012 to 2024, but never medaled.
Outside of Gkolomeev’s swim Sunday night, world records were elusive.
Of the most notable athletes competing, Fred Kerley, who said he did not compete “enhanced,” fell short of the world record by about four-tenths of a second. British swimmer Ben Proud came close to the world record in the men’s 50m fly, posting a 22.32 (WR is 22.27 seconds).
Thor Björnsson, also known as the “Mountain,” from “Game of Thrones,” deadlifted 475kg (the world record is 510.)
Play 2026 Soccer Pick 'Em with FOX One and make your picks for the world's biggest soccer tournament
The event has been colloquially known as “the Olympics with steroids,” but not every athlete chose to use PEDs. Those who did were under strict medical supervision to ensure that they were using the drugs safely.
With the event aimed at seeing whether science could help athletes reach another level, all eyes were on whether competitors would be able to make history. There was even a hefty payday on the table for them, as Enhanced said that any world records set would award the athlete additional prize money. For the weightlifting events, an athlete could net an extra $250,000; in the 100-meter sprint or the swimming events, a record-breaking athlete could win an additional $1 million.
Below is a look at the full results from the 2026 Enhanced Games.
Swimming
*indicates personal best
(NE) - indicates athlete who is “not enhanced”
|
Event |
World Record |
Enhanced Games winner |
|
Men’s 50m backstroke |
23.55 seconds |
Hunter Armstrong (24.21 seconds) (NE) |
|
Men’s 50m breaststroke |
25.95 seconds |
Cody Miller (26.55 seconds)* |
|
Men’s 100m freestyle |
46.40 seconds |
Kristian Gkolomeev (46.60 seconds)* |
|
Women’s 50m freestyle |
23.61 seconds |
Emily Barclay (24.09 seconds)* |
|
Men’s 50m fly |
22.27 seconds |
Ben Proud (22.32 seconds)* |
|
Men’s 100m breaststroke |
56.88 seconds |
Cody Miller (59.47) |
|
Women’s 100m freestyle |
51.71 seconds |
Megan Romano (54.20) |
|
Men’s 100m fly |
49.45 seconds |
Marius Kusch (51.28) |
|
Men’s 50m freestyle |
20.88 seconds |
Kristian Gkolomeev (20.81) |
Weightlifting
*indicates personal best
(NE) - indicates athlete who is “not enhanced”
|
Event |
World Record |
Enhanced Games results |
|
Women’s Snatch |
Class - Record |
Beatriz Pirón (53kg) - N/A |
|
Men’s Snatch |
Class - Record |
Yoni Andica (79kg) - 135kg |
|
Women’s Clean & Jerk |
Class - Record 53kg - 126kg |
Beatriz Pirón (53kg) - 118 kg* |
|
Men’s Clean & Jerk |
Class - Record |
Yoni Andica (79kg) - 170kg |
|
Men’s Snatch II |
Class - Record |
Arley Méndez (88kg) - 155 kg |
|
Men’s Clean & Jerk II |
Class - Record |
Arley Méndez (88kg) - N/A |
|
Men’s Deadlift |
510 kg |
Thor Björnsson - 475 kg |
Track
*indicates personal best
(NE) - indicates athlete who is “not enhanced”
|
Event |
World Record |
Enhanced Games winner |
|
Women’s 100m sprint |
10.49 seconds |
Tristan Evelyn - 11.25 seconds |
|
Men’s 100m sprint |
9.58 seconds |
Fred Kerley - 9.97 seconds |
iOS 27 could make it far easier to manage your AirPods
Apple is reportedly redesigning AirPods settings in iOS 27 to make advanced features like adaptive audio and gesture controls much easier to manage.
Original article
Apple is reportedly planning a major redesign of the AirPods settings experience in iOS 27, iPadOS 27, and macOS 27, making advanced features like adaptive audio, gesture controls, and hearing tools easier to find and manage as AirPods evolve into more sophisticated wearable devices — though a standalone AirPods app still may not be coming.
Fraude Design (Website)
A satirical website builder, "Fraude Design," explicitly avoids AI to mock founders who prioritize bad design and technical debt while convincing themselves it's good.
Original article
The AI-free site builder for genius founders
Make bad design decisions and generate irredeemable amounts of technical debt. Then go out there and make this about you!
Bad design but make it insidious
Finally, bringing terrible design decisions to production can be done under the guise of gaslighting yourself into believing the thing you’ve made is actually good. When your very tired employees point out that maybe the robot did a bad job, you can point to the same gradient that everyone else uses and say ‘hmmmm, but I like it’. Truly an uncursed timeline.
Derivative useless slop without the overheads
All your friends are generating sub-par landing pages using AI tools. It’s natural to feel left out. Fight the FOMO without the token usage with Fraude Design. A revolutionary AI-free slop generator.
Founders Only
You’re a CEO who has finally realised that instead of eating the crayons, you can use them. Fraude it up babeyyy.
Make it Worse
Simulate asking the robots to make increasingly worse design decisions by changing your own colors to whatever you want.
Fuck the Blind
The only accessibility you care about is how accessible your board room is to big fuckin’ stacks of money! Ship bad code!!
Mediocrity has never looked so good
If you live at the intersection of being shit at something and holding an active disdain for craftsmanship, Fraude Design can keep you oblivious to your own shortcomings!
Fraude Design is an over-engineered parody built by Scott Riley.
Transparency in Color Tokens
Design systems can manage color transparency either by embedding alpha values directly into color tokens or by composing alpha separately at build time.
Original article
Transparency in color tokens can be handled by either embedding alpha directly in the value or keeping alpha separate and composing at build time.
How AI Will Save Prediction Markets
Prediction markets have not lived up to Robin Hanson's "Idea Futures" vision from the 1990s, suggesting a fundamental flaw that AI might be poised to address.
Decoder
- Prediction markets: Exchange-traded markets created for the purpose of trading contracts whose payoffs are linked to the outcome of future events.* Idea Futures: A specific concept for prediction markets proposed by economist Robin Hanson in the early 1990s.
Original article
Prediction markets have failed to deliver Robin Hanson's 1990 Idea Futures vision.
Ferrari Launches $640,000, Jony Ive-Designed, Glass-Clad Electric Speedster
Ferrari unveiled the $640,000 Luce electric speedster, designed with Jony Ive, marking its first five-seater and a major foray into luxury EVs.
Original article
The Ferrari Luce, designed in partnership with Jony Ive, is an electric vehicle that will test the appetite of the superrich for EVs. The first Ferrari with five seats, the Luce will be among the most expensive Ferraris that aren't part of a limited production run at a starting price of roughly $640,000. It accelerates from 0 to 60 miles an hour in less than 2.5 seconds with a top speed that exceeds 190 mph. The vehicle has a range of roughly 330 miles despite an unusually large battery.
Pope Leo Compares AI Threat to Biblical ‘Tower of Babel'
Pope Leo XIV issued an encyclical comparing the threat of AI to the biblical "Tower of Babel," warning it could reduce humans to cogs and centralize power among a few private actors.
Decoder
- Encyclical: A papal letter sent to all bishops of the Roman Catholic Church that expresses the Pope's views on a particular topic.
Original article
Pope Leo XIV has issued a letter warning that AI will reduce humans to mere cogs in a system driven toward ever greater efficiency and that the concentration of power in the hands of a few private actors must be countered.

How Designers Can Handle Finance Stuff Without Losing Creative Flow
Designers can maintain creative flow by batching finance tasks into dedicated "office hours" and automating invoicing to avoid disruption.
Decoder
- Pay Stub Generator: A tool or software that creates professional-looking documents detailing an employee's gross pay, deductions, and net pay for a specific pay period.
Original article
Designers often struggle with finance tasks because they require a completely different mindset than creative work, disrupting their flow. The solution is to batch administrative tasks into dedicated "office hours" and automate repetitive processes like payment tracking and invoicing. As design businesses grow and add team members, having professional financial systems becomes crucial for maintaining trust and allowing everyone to focus on creative work.

Bold, optimistic, empathetic: How a retirement company perfected its look for Gen Z
Standard Life, a 200-year-old retirement company, rebranded with Conran Design Group to appear bold, optimistic, and empathetic to Gen Z, introducing a "Journey Line" asset.
Decoder
- Gen Z: Refers to Generation Z, generally individuals born between the late 1990s and early 2010s.
Original article
Standard Life worked with Conran Design Group to modernize its 200-year-old brand and make retirement planning feel more relevant and approachable to younger audiences by introducing a bolder, more optimistic identity, updated digital-first visuals, conversational messaging, and a new “Journey Line” brand asset symbolizing the ups and downs of retirement. The rebrand aimed to shift perceptions of pensions from intimidating and passive to empowering and human, while preserving the trust and heritage expected from a long-established financial institution.