Devoured - May 27, 2026
Chrome's new built-in AI features, including Summarizer, Prompt, Writer, Rewriter, and Translator APIs, enable cost-efficient, privacy-first, and performant on-device AI for web applications.

NASA takes steps toward building Moon Base, including discussing a “perimeter”
NASA awarded Astrolab and Lunar Outpost contracts to build 1-ton lunar rovers for delivery by Blue Origin in 2028, with a mission to establish a perimeter for the future moon base.
Deep dive
- NASA awarded Astrolab $219 million for its "CLV-1" rover and Lunar Outpost $220 million for its "Pegasus" rover, both 1-ton vehicles.
- These rovers will have a 200 km range and can operate autonomously or be guided by Earth operators/astronauts.
- Blue Origin will deliver these rovers separately to the lunar surface using its Blue Moon Mark 1 lander, with two delivery contracts worth $280.4 million.
- One central goal of the early Moon Base program is the MoonFall program, involving three or four 1-meter tall, 225 kg drones led by JPL.
- Firefly Aerospace will deliver the MoonFall drones to the lunar surface before the Artemis IV mission (no earlier than 2028).
- These drones aim to improve lunar surface imagery resolution from 1 meter to 1 cm.
- The drones will scout for water ice, identify scientific interest areas, and provide detailed landing site info.
- At the end of their operational life, the drones will be used to establish a "perimeter" for the Moon Base, potentially serving as beacons or initial lunar cell towers.
- NASA Administrator Jared Isaacman acknowledged being "mindful" of the 1967 Outer Space Treaty which prohibits national appropriation of the Moon.
- The Artemis Accords, signed by NASA and 66 other nations, allow for "safety zones" to prevent "harmful interference," which the perimeter could represent.
- This initiative is in direct competition with a China-led lunar exploration program.
Decoder
- Artemis Accords: A non-binding international agreement led by the United States, establishing principles for cooperation in civil space exploration and use of the Moon, Mars, comets, and asteroids.
- Outer Space Treaty: A 1967 international treaty that forms the basis of international space law, prohibiting countries from claiming sovereignty over celestial bodies and mandating that space exploration be carried out for the benefit of all countries.
Original article
NASA officials announced contract awards for the initial elements of a lunar base on Tuesday, including two rovers that will provide mobility to astronauts.
With the series of announcements, NASA Administrator Jared Isaacman sought to maintain momentum around a Moon Base initiative revealed two months ago as part of the space agency’s return to the Moon. “For those waiting patiently, the grand return is close at hand, and we will not slow down,” he said.
The manager for the lunar base, Carlos Garcia-Galan, said the space agency had selected two companies, Astrolab and Lunar Outpost, to build approximately 1-ton rovers that would be ready for delivery to the Moon in 2028. Astrolab will receive $219 million for its “CLV-1” rover, and Lunar Outpost $220 million for its “Pegasus” rover, building upon initial contracts awarded two years ago. Each rover is expected to have a range of 200 km and be capable of driving autonomously, with guidance from operators on Earth, in addition to being driven by astronauts.
Garcia-Galan also announced that Blue Origin, with its Blue Moon Mark 1 lander, would deliver each of the rovers separately to the lunar surface. These two delivery contract awards were worth $280.4 million.
The awards increase Blue Origin’s centrality to NASA’s Moon plans, both by flying large amounts of cargo, with a Mark 1 lander previously contracted to deliver the Viper vehicle to the lunar surface, and by supporting the company’s larger Mark 2 lander for eventual human missions.
Need to learn more about the lunar surface
One theme of Tuesday’s news conference was the reality that, decades after humanity’s first visits to the Moon, there remains much we do not know about conditions on the lunar surface.
“What we are embarking upon is extremely challenging,” Isaacman said. “We know so little from what is a combined 80 hours of lunar astronaut EVA time across the Apollo missions, and that was more than a half century ago.”
To that end, one of the central elements of the early Moon Base program is the development of the MoonFall program, which will entail three or four drones each about 1 meter tall, with a mass of 225 kg, including propellant. NASA’s Jet Propulsion Laboratory is leading development of the MoonFall drones, and these will be delivered to the lunar surface by Firefly Aerospace, Garcia-Galan said.
The goal is to get these spacecraft to the Moon before the Artemis IV lunar landing mission, scheduled for no earlier than 2028, to provide high-resolution imagery of the lunar surface. For most of the Moon, the current imagery resolution is 1 meter, and NASA wants to improve it to 1 cm, Garcia-Galan said.
Establishing a perimeter
These drones will perform a number of functions, including scouting for water ice in permanently shadowed regions, identifying areas of scientific interest, and providing detailed information about landing sites, including soil mechanics, lighting conditions, and the terrain. At the end of their flying lifetime, the drones would then be used to set a boundary for the Moon Base.
“We’re hoping to… establish a Moon Base perimeter with four or three lunar drones,” Garcia-Galan said. “We’re going to be able to basically put them at the corners of the areas where we think we have either key scientific objectives, or we want to build up the Moon Base.” In these positions, he added, the retired drones could also provide a beacon with retro-reflectors, or even perhaps serve as the first lunar cell towers.
The idea of a perimeter raises interesting questions about territory on the Moon.
The 1967 Outer Space Treaty, agreed to by all spacefaring nations, essentially says no country can claim sovereignty over territory on the Moon. Even building a base on the lunar surface does not confer ownership of that area under the treaty.
“Mindful” of the Outer Space Treaty
NASA and 66 other nations have, to date, signed on to the Artemis Accords as a framework for exploring and developing the lunar surface this century. This NASA-led Artemis group is in direct competition with a China-led initiative that also intends to explore the Moon’s south pole and potentially extract resources there.
The Artemis Accords, while recognizing the Outer Space Treaty, allow for the possibility of creating “safety zones” that would establish areas in which “harmful interference” is not allowed. “A safety zone should be the area in which nominal operations of a relevant activity or an anomalous event could reasonably cause harmful interference,” the Artemis Accords state. NASA and China have not formally discussed or mutually approved the concept of safety zones, and some Chinese commentators have been critical of the idea.
Establishing a perimeter would seem to be the first manifestation of a safety zone on the lunar surface, although Isaacman would not confirm this when asked directly.
“There are areas of great interest on the lunar surface, and we do want to get there and explore them,” he said. “We also obviously want to be very mindful of the Outer Space Treaty, so that we are respectful of other nations that are putting assets on the lunar surface. We would expect that to be reciprocal, but I think that’s just one objective of many that the MoonFall drones intend to accomplish.”

Build new features using built-in AI in Chrome
Chrome's new built-in AI features, including Summarizer, Prompt, Writer, Rewriter, and Translator APIs, enable cost-efficient, privacy-first, and performant on-device AI for web applications.
Deep dive
- Google I/O 2026 presentation by Thomas Steiner highlighted Chrome's built-in AI capabilities.
- The AI models run directly on the user's device, offering cost-efficiency by eliminating cloud inference costs.
- This approach ensures privacy, as sensitive data remains local within the browser.
- Features work offline once the model is downloaded, and hardware acceleration provides strong performance.
- Hybrid inference allows fallback to cloud services for unsupported devices (e.g., mobile) using polyfills or Firebase AI Logic.
- The
Summarizer APIcan generate headlines and SEO-friendly meta descriptions; used by trAIlblazers for blog editors and Drupal for CKEditor SEO tags. - The
Prompt APIsupports structured output via JSON Schema for tasks like tag generation and comment moderation; Yahoo! Japan uses it for community comment moderation. - With multimodal input, the
Prompt APIcan generate accessible alt-text and captions from images. WriterandRewriter APIsenable expanding bullet points and changing text tone.- The
Translator APIfacilitates instant content translation (e.g., English to Spanish/Japanese) for creators. - Trip.com uses AI overviews for complex flight booking navigation.
- A starter blog template by Build Awesome (formerly Eleventy) is available, showcasing these AI features.
Decoder
- Polyfill: A piece of code (or plugin) that provides the functionality of a modern web feature to older browsers that do not natively support it.
Original article
Build new features using built-in AI in Chrome Stay organized with collections Save and categorize content based on your preferences.
Thomas Steiner
This post is a write-up of the talk given at Google I/O 2026 by Thomas Steiner.
Imagine building a travel blog where the blog post editor doesn't just store the text, but where it actively supports you when writing. Meet Maya and Ashok, the creators of trAIlblazers. They use built-in AI in Chrome. By running models directly on the user's device, developers bypass expensive cloud costs and latency while keeping sensitive data local.
We've collaborated with Build Awesome (formerly known as Eleventy) to release a blog template with all the AI features listed in the talk.
Why built-in AI?
- Cost-efficient: No cloud inference cost, all computation happens on users' supporting devices.
- Privacy first: Sensitive data never leaves the browser.
- Offline functionality: Once the model is downloaded, AI features work without an internet connection.
- Performance: Hardware acceleration allows on-device models to rival (and sometimes beat) cloud speeds.
- Hybrid inference: Using polyfills and tools like Firebase AI Logic, you can fall back to the cloud on unsupported devices (like mobile) while staying native on desktop.
AI features for modern web apps
The Summarizer API
The trAIlblazers editor uses the Summarizer API to generate headlines and SEO-friendly meta descriptions automatically.
Example: Generate a headline
const blogPost = document.querySelector('.article-body').innerText;
const summarizer = await Summarizer.create({
type: 'headline',
sharedContext: 'Write headlines that make people want to read the blog post',
});
for await (const chunk of summarizer.summarizeStreaming(blogPost)) {
headline.append(chunk);
}
The Prompt API (with structured output)
Need specific data? By using JSON Schema with the Prompt API, you can make the AI return predictable formats. The trAIlblazers team uses this for the following:
- Tag Generation: Suggest categories like "Adventure" or "Beach" from a predefined list.
- Comment Moderation: Classify comments as "Safe" or "Harmful" before they are published.
Media accessibility
The editor automates the "hard parts" of Markdown. When you drop an image, the Prompt API (with multimodal input) analyzes the pixels to generate accessible alt-text and informative captions.
Writing and rewriting
With the Writer and Rewriter APIs, users can expand bullet points into complete paragraphs and change the tone of a paragraph to be "more casual" or "shorter" with a single click.
Seamless translation
The Translator API allows creators to draft content in English and instantly translate it for Spanish or Japanese readers, which native speakers can then refine.
Real-world success stories
Many partners are already shipping these APIs in production. Notable examples include the following:
- Drupal: Uses the Summarizer API for SEO tag generation within CKEditor.
- Yahoo! Japan: Uses the Prompt API for community comment moderation.
- Trip.com: Helps shoppers navigate complex flight booking options with AI overviews.
Resources from the talk
Ready to build your own "trAIlblazers" experience? Check out these resources:
- Starter template: Build Awesome starter-extended-blog (Includes all AI features mentioned in the talk.)
- Documentation: Built-in AI on Chrome for Developers
- TypeScript support: Install
@types/dom-chromium-aion npm. - Google I/O 2025 talk: Practical built-in AI with Gemini Nano in Chrome

Sundar Pichai on AI, the future of search, and what's happening to the web
Sundar Pichai believes Google's AI models and agent platforms, despite public anxiety and publisher concerns like Condé Nast's "Google Zero" strategy, are closer than ever to delivering on the long-held vision of Google Assistant.
Deep dive
- Sundar Pichai initiated executive and structural changes at Google a few years ago in response to ChatGPT, reorganizing the company to be "AI-first".* This included unifying Google Brain and DeepMind into Google DeepMind and establishing a centralized AI infrastructure team under Amin Vahdat.* Pichai believes that the current AI moment, with Gemini models and agentic platforms like Gemini Spark, brings Google closer to its long-running vision for Google Assistant.* He defines Google's structure as three main businesses (Search, YouTube, Google Cloud) and major platforms (Android, Chrome), all powered by AI and DeepMind.* Pichai acknowledges the "Google Zero" concept, where Google answers queries directly, reducing traffic to external websites, noting Condé Nast CEO Roger Lynch's public statement about planning for zero search traffic.* He suggests that while objective search results will remain consistent, subjective queries (e.g., travel planning) will be personalized, leading to different user experiences.* Pichai addresses public anxiety about AI, stating it's a "profound technology" evolving rapidly, and anxieties about job displacement, energy consumption, and AI "slop" are understandable.* Google is training its models on YouTube videos and changing YouTube search to summarize videos, which Pichai acknowledges could cause creator angst, similar to issues with publishers.* He states that publishers and creators should ideally not be able to opt out of training data, suggesting laws and regulations on copyright and fair use will evolve.* Pichai agrees with DeepMind CEO Demis Hassabis's assessment that humanity is in the "foothills of the singularity," believing AGI is coming "sooner rather than later" but emphasizing the importance of societal preparedness over a specific timeline.* He maintains optimism that LLMs and the underlying transformer architecture, which Google invented, can lead to AGI through continuous evolution, similar to how computers evolved from the von Neumann architecture.
Decoder
- Google Zero: A concept, coined by Nilay Patel, describing the idea that Google traffic to external websites will fall to zero as the company directly answers more queries on its search results page using AI.* Agentic workflow: An AI system that can not only understand and respond to queries but also initiate and complete multi-step tasks by interacting with other systems and tools, effectively "acting" on behalf of the user.* Antigravity: Google's internal agentic coding platform, which they are now aiming to put into the hands of consumers through products like Gemini Spark.* Gemini Spark: Google's new agent platform in the cloud, designed to allow users to ask the AI to perform complex tasks, like booking tickets, beyond simple search queries.* AGI (Artificial General Intelligence): A hypothetical type of AI that can understand, learn, and apply intelligence across a wide range of tasks at a level comparable to human intelligence, rather than being specialized for a single task.* Singularity: A hypothetical future point in time when technological growth becomes uncontrollable and irreversible, resulting in unfathomable changes to human civilization, often associated with the advent of superintelligence or AGI.
Original article
Full article content is not available for inline reading.

Inside the Largest IPO Ever: Breaking Down the SpaceX S-1
SpaceX's S-1 filing, ahead of an anticipated record-breaking $1.75 trillion IPO, reveals a strategy to become the physical infrastructure layer for the AI and space economy, with Starlink funding Starship and the xAI merger.
Deep dive
- SpaceX's S-1 filing precedes an expected record-setting IPO with a reported valuation of $1.75 trillion.* The company is structured into three segments: Space (rocket launches), Connectivity (Starlink), and AI (xAI).* Starlink's Connectivity segment is the financial powerhouse, generating $11.4 billion in revenue in 2025 (up 50%) with a 39% operating margin, largely funding other ventures. It grew to 8.9 million subscribers in 2025.* The Space segment (Falcon rockets) primarily serves internal Starlink deployments (74% of launches in 2025) and external customers, with Starship R&D driving a $657 million operating loss in 2025.* The AI segment, xAI (merged in early 2026), had a $6.4 billion operating loss in 2025 on $3.2 billion revenue, largely due to a 331% R&D increase.* Recent deals significantly alter the AI segment's outlook: a $1.25 billion per month compute agreement with Anthropic through May 2029 and a compute/option agreement to potentially acquire Cursor for $60 billion.* These deals boost SpaceX's projected run-rate revenue to $40-41 billion by the end of 2026, largely due to monetizing its spare AI compute capacity.* The ultimate vision for integration is "orbital AI compute," using satellite constellations as space-based data centers by 2028, leveraging abundant solar energy and free cooling.* Starship's successful development is critical, as it is designed for 100-ton fully reusable payloads, enabling next-gen Starlink V3 satellites (starting H2 2026) and orbital data centers.* Elon Musk's pay package includes performance awards tied to achieving a permanent human colony on Mars with one million inhabitants and building non-Earth-based data centers capable of 100 terawatts of compute per year (100x the US grid capacity).* SpaceX aims to become the physical infrastructure for the AI and space economy, with ambitions for lunar manufacturing and asteroid mining.
Decoder
- S-1 Filing: A registration form required by the U.S. Securities and Exchange Commission (SEC) for companies planning to go public, containing detailed financial and business information.* ARPU (Average Revenue Per User): A metric that calculates the average amount of revenue generated per user or subscriber over a specific period.* EBITDA (Earnings Before Interest, Taxes, Depreciation, and Amortization): A measure of a company's financial performance, used as an alternative to simple earnings or net income.* TAM (Total Addressable Market): The total revenue opportunity that is available for a product or service if 100% market share were achieved.* Orbital AI Compute: The concept of deploying data centers in space, leveraging advantages like abundant solar power and natural cooling in the vacuum of space, with SpaceX aiming for deployment by 2028.* Colossus / Colossus II: Names for SpaceX's data centers, with Colossus II being used to train the Grok 5 AI model.
Original article
Inside the Largest IPO Ever: Breaking Down the SpaceX S-1
Why Starship, Starlink, and xAI belong under the same roof, and where they're headed
SpaceX filed its S-1 this week, ahead of what will likely be the largest IPO ever (~$75B raised at a reported $1.75T valuation).
SpaceX is a unique and inspiring company. It’s not often you see a mission statement on an S-1 include “to make life multiplanetary, to understand the true nature of the universe, and to extend the light of consciousness to the stars”.
SpaceX on the face of it is three companies combined together: a rocket launch business, a satellite internet business, and an AI lab (after the xAI merger). But the way I’ve come to think about SpaceX (or at least how SpaceX wants to be thought of) after reading the filing is less as a rocket company with an AI lab attached, and more as the physical infrastructure layer for the AI and space economy. I’ll walk through how the three businesses work today, and how they could be far more connected in the future than they look.
In this piece, I’ll cover:
- SpaceX’s three segments today
- The two deals that change the AI story
- What the financials look like played forward
- Orbital compute and the Space economy
- The Starship Bet
- Musk’s pay package, gated on a Mars colony and data centers in space
I. Understanding SpaceX today
SpaceX reports in three segments: Space, Connectivity, and AI. They’re wildly different businesses on one balance sheet, so it’s worth taking each on its own.
Connectivity is the star today, growing fast and very profitable, essentially helping fund the rest. Space looks like a loser on operating income but is actually EBITDA-positive once you add back the Starship R&D and depreciation. AI is a deep loss on every line but more on that later.
A. Space
SpaceX was founded in 2002. The early history may be familiar to some: Falcon 1 reached orbit in 2008 (the first privately built liquid-fueled rocket to do so), they landed a booster back on Earth in December 2015, and by 2017 they were routinely reusing Falcon 9 boosters. Reusability has been key to the rest.
It dropped SpaceX’s launch cost to about $2,700 per kilogram, roughly 85% below the historical industry average of $18,500, and that cost collapse is what made everything downstream possible.
SpaceX began as an external launch provider. The early customers were NASA (Commercial Resupply from 2008, then crew), commercial satellite operators, and the Pentagon, and those contracts funded the company for its first decade and a half. Starlink only started launching in 2019. So the business was built on outside demand, and then internal Starlink deployment grew on top of it until it became the majority of flights.
SpaceX flew 96 Falcon launches in 2023, 134 in 2024, and 165 in 2025. But most of those weren’t for paying customers. Customer launches were 33, 45, and 43. The rest (63, 89, then 122) were internal: mostly Starlink deployments and some development tests.
The chart below highlights this shift. The launch business is now overwhelmingly SpaceX flying for itself, and the internal share keeps climbing (74% of launches in 2025, up from 66% in 2023).
They built a launch business for other customers and used the same capability to deploy their own constellation. The launch business and capability is the railroad of sorts that made everything else possible.
Still, the Space business makes over $4B in revenue for external launches. While some of that is government development contracts that aren’t tied to specific launches, one rough proxy is that at 43 external launches in 2025, each launch is worth about $95M in revenue to them. But the thing to note is that for internal launches that deploy Starlink, SpaceX doesn’t book any Space-segment revenue. It capitalizes the launch cost inside the Connectivity segment and depreciates it over time. So Space-segment revenue only reflects the revenue from the ~1/4 of launches which are external.
The filing notes this: despite a rising launch cadence, Space has “relatively lower revenue scale and revenue growth” because its results don’t reflect the internal launches that are the foundation of the company.
Financially, Space is the smallest segment and currently a money-loser. Revenue was $4.1B in 2025, up only 7.6%. It swung to a $657M operating loss (from a $21M profit in 2024). The reason is Starship. R&D in the segment jumped 64% to $3B as they poured money into the next vehicle, and in Q1 2026 alone Starship R&D was $930M. So the cash from launching satellites is being plowed straight into the next generation rocket that’s supposed to make the future vision achievable.
B. Connectivity
Connectivity represents the Starlink business, and it’s the segment that actually prints money.
As I mentioned above, it is only possible with the launch flywheel. Cheap, reusable, high-cadence launch is what lets you put up (and constantly replenish) a constellation of ~9,600 satellites in low-Earth orbit. No one else can deploy mass to orbit at that cost, which is why no one else has a constellation at this scale. The S-1 notes SpaceX has launched more than 80% of all mass to orbit globally each year since 2023.
The subscriber story of Starlink shows signs of a landgrab strategy. Starlink went from 2.3M subscribers (2023) to 4.4M (2024) to 8.9M (2025), and 10.3M by Q1 2026. Monthly ARPU fell the whole way: $99, then $91, then $81, and down to $66 in Q1 2026.
That ARPU decline is somewhat deliberate and represents both the push into lower-income countries and additional cheaper plans.
Overall, the financials of this segment are very strong. Connectivity did $11.4B in revenue in 2025, up 50%, with $4.4B in operating income. That’s a ~39% operating margin on a business growing 50%. Q1 2026 revenue was $3.3B, up 32%. Its a profitable, fast-growing, hard-to-replicate utility and has a big TAM ahead of it.
And Musk sums up the importance of Starlink to the overall company well:
C. AI
The AI segment is xAI, which was founded in 2023 and folded into SpaceX in early 2026 (the merger closed February 2). It houses Grok, the X platform, data licensing, and the compute infrastructure.
There are two things going on with this segment: the shift of the business from an ads business when X was bought to more of a subscriptions based business, and the additional revenue that comes from Grok (via API, etc) which is still relatively small compared to leading AI labs.
On the surface, it looks rough. “AI” revenue (which includes ads) was $3.2B in 2025, up only 22%, with a $6.4B operating loss as R&D rose 331% to $5B. In Q1 2026 it was worse on a growth basis: revenue of $818M, up just 12.5%, with a $2.5B operating loss, and ad revenue continued to fall in Q1. Below is a rough overview of the current state of the AI segment.
So if you stop at the income statement presented, the AI segment is a slow-growing, deeply unprofitable drag on the company. But that’s the picture before the recent deals which change things.
II. Recent developments in the AI segment
Two things happened in May 2026, right before the filing, that paints SpaceX in a somewhat different light.
The first is the Anthropic deal. SpaceX signed Cloud Services Agreements with Anthropic for compute capacity across its Colossus and Colossus II data centers. Anthropic agreed to pay $1.25B per month through May 2029, with capacity ramping at a reduced fee in May and June 2026. Either side can terminate on 90 days’ notice.
The entire AI segment did $3.2B in 2025. So this one contract, fully ramped at ~15B/yr, is roughly 5x the segment’s trailing revenue.
The second is the Cursor deal. In April 2026, SpaceX signed a compute and option agreement with Cursor. Under the compute agreement, SpaceX gives Cursor GPU capacity and they collaborate to improve Grok and potentially jointly develop new models. Under the option agreement, SpaceX has the right (not the obligation) to acquire Cursor outright at a $60B implied equity value, exercisable in a 30-day window after the IPO (or by September 30, 2026).
SpaceX frames coding as one of the best use cases for AI because it generates high-quality, verifiable data and constant inference demand. Cursor’s developer interaction data (prompts, iteration cycles, architecture decisions) feeds back into model training, including Grok. And if they exercise the option, Cursor becomes an owned application sitting on top of their own compute and own models.
If SpaceX terminates the option, Cursor is owed a $1.5B termination fee plus an $8.5B deferred services fee. So they’ve effectively pre-committed to either buying Cursor or paying a large breakup cost.
Put together, these deals give the AI segment a much clearer shape. Three layers that are compute, model/intelligence, and apps.
Compute is the base, and right now it’s the most valuable part. SpaceX built Colossus and is training Grok 5 on Colossus II. The interesting move is that they have shown willingness to lease the spare capacity. Anthropic is the first big tenant but there may be more.
Models is Grok, trained in-house, differentiated by real-time integration with X data. This is also where the Cursor collaboration sits, jointly developing models and feeding coding data back into Grok’s training.
Apps represents X and the Grok app today, and is the layer that the Cursor option can also bolster. If they exercise, Cursor becomes an owned coding app running on their own models and compute. They’re also building Macrohard with Tesla, an agentic platform meant to emulate digital workflows.
III. The financial picture
At the consolidated level, 2025 looked like this: $18.7B in revenue, a $2.6B loss from operations, and $6.6B in Adjusted EBITDA.
The capex split is quite stark, compared to the revenue split. Of the roughly $10B SpaceX spent in Q1 2026, about $1B went to Space, $1.3B to Connectivity, and $7.7B to AI. For the full year 2025, around 60% of capex went to AI.
The picture of spend and profitability relative to revenue growth isn’t great, which is why I think the Anthropic (and Cursor deals) are critical.
Annualize the Q1 2026 quarter and SpaceX is running at about $18.8B. Grow each segment off that base for the rest of the year and you conservatively get to roughly ~$22B run-rate by Q4.
Then layer in Anthropic and Cursor. Anthropic at the full $1.25B per month is $15B annualized. Cursor could generate another $3B-$4B in revenue (it’s at ~$3B today and growing). Stack those on the organic base and you land around a $40B to $41B run-rate exiting 2026, on a relatively conservative estimate of organic growth and not assuming more compute partners.
At least partially this helps ground the $1.75T valuation in some more reasonable sense. Compared to a ~20B run-rate business growing relatively slowly, it now looks like a ~40B+ run-rate business growing over 100% y/y albeit because of one compute deal. More importantly, it also shows Elon’s willingness to make sure that he monetizes his spare compute, even if internal products don’t take off which helps alleviate some of the concerns around the high Capex.
IV. Orbital compute and the space economy
Despite the improving AI segment in the near term, it still looks bolted on to the Space and connectivity business. Orbital AI compute is where that changes and the reason these are all in one company becomes more clear.
One way to think about SpaceX may be less a rocket company with an AI business attached, and more of a physical infrastructure company for the AI age. The launch business lowers the cost of accessing orbit. Starlink proves SpaceX can operate distributed infrastructure in orbit at global scale. The AI segment creates the demand for compute. Orbital AI compute are where those three pieces converge.
What is orbital AI compute you may wonder? Satellite constellations that act as data centers in space, using solar energy for power and the space environment for cooling. SpaceX expects to start deploying these as early as 2028.
The launch (Space, Starship) segment allows SpaceX to put that much mass in orbit cheaply. The satellite expertise from Connectivity gives them some of the know-how to do so (and frankly helps fund some of it), because orbital compute is basically the Starlink playbook pointed at a different payload.
And the AI segment is what monetizes that compute, either by selling that compute or using it in models or application.
The bottleneck for terrestrial AI is power and cooling. In orbit you get abundant solar and free cooling, if you can get the mass up cheaply and move data back down. SpaceX is arguably the only entity on Earth today that can pull this off, given their Space segment and know-how from Starlink.
It is interesting that SpaceX’s own TAM slide puts it at $28.5 trillion, and $26.5 trillion of that is AI, highlighting how important the orbital data centers may be into unlocking the AI TAM (thought SpaceX still needs to work on the AI demand piece).
There’s also a bigger vision in the filing, which is that Starship in the future could be capable of landing massive cargo on the Moon which then opens up factories on the Moon could manufacture millions of AI compute satellites using lunar resources and deploy them farther into space. The future markets they list include space manufacturing, lunar and Martian energy production, and asteroid mining.
V. The Bet on Starship
SpaceX’s future vision all hinges on Starship. The filing even says so directly: the Space growth strategy “depends on the successful development of Starship at scale.”
Falcon is proven. Falcon 9 carries about 23 tons to LEO, has flown roughly 620 times with 99%+ success rate. Falcon Heavy carries about 64 tons. But it won’t allow SpaceX’s full ambitions. That requires Starship
Starship V3 is designed to put 100 tons into orbit fully reusably, with aircraft-like turnaround, and future versions aim to double that. This is important for two reasons:
- Payload: you can’t deploy the next generation of hardware on Falcon. The new Starlink V3 satellites (1 Tbps of downlink each, versus the current generation) are designed to launch on Starship, starting in the second half of 2026, and the orbital compute satellites need that mass capacity too.
- Cost: full reusability with rapid turnaround is what collapses the cost per kilogram to orbit, which is the input to every other ambition.
So what’s the current status you may wonder? They’ve run 11 flight tests so far, with a 12th scheduled that debuts the next-generation vehicle and Super Heavy booster. They’ve already pulled off the “chopstick” booster catch, where the launch tower’s arms catch the returning booster, which is what enables rapid reuse and eventually multiple launches per day. They expect Starship to begin delivering payloads to orbit in the second half of 2026.
The investment behind this is large and concentrated. Space-segment R&D was $3B in 2025, most of it Starship, and another $930M in Q1 2026 alone, and arguably makes the financials of the core business (ex AI) look worse than it is.
Every ambitious plan of the company runs through Starship. Starlink’s next-gen satellites need it now. Orbital compute needs it for cheap mass. The Moon and Mars plans are impossible without it.
VI. Musk’s pay package
I’ve mentioned a few times that SpaceX is unique and inspirational. Nothing makes the scale of their ambition more clear than Musk’s pay package.
Musk has two performance awards in there, which tell a lot.
The first, granted in January 2026, is 1 billion performance-based shares. Both of two conditions must be met for any tranche to vest. First, market-cap milestones across 15 tranches, running from $500B up to $7.5 trillion. Second, and I’m quoting the filing:
The Company’s establishment of a permanent human colony on Mars with at least one million inhabitants.
So even if SpaceX becomes the most valuable company on Earth, the full award doesn’t vest until there’s a city of a million people on Mars.
The second, granted in March 2026 was tied to xAI and is called the “AI CEO Award” Same two-part structure: market-cap milestones (12 tranches, $1.065 trillion to $6.565 trillion), plus a second condition which I quote again:
The Company’s completion of non-Earth-based data centers capable of delivering 100 terawatts of compute per year.
For reference, total US electricity generation capacity is roughly 1 terawatt. So the target written into the filing is space-based compute at something like 100x the entire US power grid.
It gives you a sense of the scale of SpaceX’s ambition. Musk gets additional shares if and only if the company becomes multiplanetary and/or builds compute off Earth.
Closing Thoughts
This has been a long piece and there’s a lot more one can say about SpaceX. But to summarize, the launch business is a strategic asset, which is increasingly mostly being used internally to power a strong Connectivity business which is growing fast at 10B+ in scale and very profitable, but is being used to power investment in R&D for Starship and the AI business. The AI business has shown its ability to build infrastructure, which they are now open to leasing, and are trying to build better models to compete at the model and application layers as well.
Any forecasts or analysis based on current or the end of 2026 run-rate will make it difficult to justify the ~1.75T valuation, but SpaceX is arguably the only company today that can help build the Space economy and all that that may entail from AI compute to mining materials to making us an interplanetary species. So how much value do you give to that? And to Elon Musk being Elon Musk.
In closing, here is a particularly profound segment you don’t see in most S-1s:
For the entirety of its existence, human civilization has lived on a single celestial body: Earth. The current paradigm, in which human civilization is confined to one planet, exposes humanity to existential threats that are unpredictable and uncontrollable on a planetary scale. By moving beyond the only home we have ever known, we ensure species-level redundancy and that the light of consciousness will not be tied to a single planet subject to the inevitable hazards of a harsh and vast universe. We do not want humans to have the same fate as dinosaurs.

Extract More Kernel Performance with NVIDIA CompileIQ Auto-Tuning
NVIDIA's new CompileIQ, integrated into CUDA 13.3, uses AI-driven auto-tuning to achieve up to 15% performance gains in GPU kernel execution for AI workloads.
Deep dive
- CompileIQ is an AI-powered compiler auto-tuning framework integrated into NVIDIA CUDA 13.3.
- It utilizes evolutionary and genetic algorithms to optimize internal compiler parameters for specific GPU workloads, surpassing generic default heuristics.
- The tool targets critical kernel hotspots, particularly in LLM inference, where small code sections dominate compute time, allowing fractional gains to yield significant throughput.
- It can provide up to 15% performance improvements on already highly optimized AI inference and training tasks, as observed by Meta.
- CompileIQ supports multi-objective optimization, allowing developers to balance competing objectives like runtime, compile time, and power consumption to find Pareto-optimal configurations.
- The output is an Advanced Controls File (ACF) that the compiler ingests via the
--apply-controlsflag to produce a specialized kernel binary. - The framework is designed for IP protection; compiler internals remain encapsulated, and user workloads run locally, with only the ACF being produced.
- ACFs are reproducible, portable, and safe to commit to version control, making compiler optimization a versioned part of the development workflow.
- Developers define an objective function (e.g., measuring kernel runtime) that CompileIQ uses to guide its search.
- It is available as a Python package and can be installed via pip; examples are provided on its GitHub repo.
Decoder
- Kernel: In GPU programming, a kernel is a function that runs on the GPU. It typically executes in parallel across many threads.
- CUDA: Compute Unified Device Architecture, NVIDIA's parallel computing platform and programming model for GPUs.
- PTXAS: NVIDIA's Parallel Thread Execution Assembler, a low-level assembler that translates PTX (Parallel Thread Execution) code into SASS (Streaming Assembler) for specific GPU architectures.
- NVCC: NVIDIA CUDA Compiler, a compiler suite for CUDA that includes the PTXAS assembler and other tools.
- Evolutionary Algorithms/Genetic Algorithms: Optimization algorithms inspired by natural selection and genetics. They iteratively improve candidate solutions to a problem by applying operators like mutation and crossover.
- Pareto-optimal: A state of allocation of resources in which it is impossible to make any one individual better off without making at least one individual worse off.
- Advanced Controls File (ACF): A file generated by CompileIQ containing fine-tuned compiler parameters to optimize a specific kernel.
Original article
Extract More Kernel Performance with NVIDIA CompileIQ Auto-Tuning
NVIDIA CompileIQ tackles one of the hardest problems in performance engineering: finding the compiler options that unlock the best performance for a specific workload.
Consider a team that has spent weeks optimizing an LLM inference pipeline on GPUs, tuning batch sizes, quantizing to FP8, adopting flash attention, fusing every kernel they can. The profiler says there’s nothing left to squeeze.
But what if you could turn the compiler itself into a tunable parameter? Now you can. The release of NVIDIA CUDA 13.3 includes CompileIQ, an AI-powered compiler auto-tuning framework that uses evolutionary and genetic algorithms to optimize NVIDIA general purpose GPU compilers for individual workloads.
NVIDIA GPU compilers apply the same default heuristics (register allocation strategies, instruction scheduling decisions, loop unrolling thresholds, etc.) to every kernel they compile. These heuristics are engineered to produce good results across a vast range of workloads. But “good across the board” and “optimal for your workload” are two very different things.
The competitive landscape in AI infrastructure has made this gap impossible to ignore. Teams building custom CUDA, Triton, and Helion kernels are striving for every percentage point of throughput. Until now, there hasn’t been a way to fine-tune code generation for a specific workload.
The 90% problem and the opportunity
To understand why compiler-level optimization matters so much, consider where GPU compute actually goes in modern LLM inference.
In attention inference kernels, GEMMs in the linear layers of FFN/MLP blocks plus the Q, K, V, and output projections account for approximately 70% of total FLOPs. Scaled dot-product attention, fused and flash attention variants account for another 25%. Together, these two kernel families represent more than 90% of end-to-end inference compute.
This is not unique to AI inference. There are many applications and algorithms where a large portion of the compute time is spent in relatively small portions of the code, which means these small code sections contribute an outsized influence to the performance of the application. Because of this, performance improvements in those code portions, even fractions of a percent, have outsized improvements on overall application performance.
Introducing CompileIQ
CompileIQ is an AI-powered compiler auto-tuning framework that uses evolutionary and genetic algorithms to optimize NVIDIA GPU compilers for individual workloads. Instead of accepting one generic compiler configuration for all workloads, CompileIQ flips the script, generating specialized compiler configurations tailored to each of your most critical kernels.
Under the hood, CompileIQ explores a rich space of internal compiler parameters that aren’t exposed through any public compiler flag: register allocation strategies, instruction scheduling policies, loop transformations, and more. The output is an advanced controls file (ACF) that the compiler ingests via the –apply-controls flag, producing a kernel binary optimized specifically for your workload.
Think of it this way: Your compiler already has the capability to generate better code for your kernel. It just doesn’t know which combination of internal settings will get there. CompileIQ’s evolutionary search finds that combination automatically.
The team that hit a wall after exhausting every optimization lever they knew now has a new lever with CompileIQ—the compiler itself.
CompileIQ is available and can be installed into your favorite Python environment using pip, as shown in the next section. Leading AI labs are already using it in production for their most performance-critical workloads.
Getting started in 4 steps
CompileIQ is a Python package with a simple workflow:
- Learn
- Install
- Define your objective
- Run
pip install compileiq
CompileIQ ships with compiler search spaces for both PTXAS and NVCC that are automatically fetched via APIs. No manual downloads or configuration are required.
Your job as the developer is to define your objective function: for instance, a Python callable that takes a candidate compiler configuration, compiles your kernel with it, benchmarks the result, and returns a score. If you can benchmark your kernel, you can use CompileIQ.
Here’s an example:
import subprocess
from compileiq.ciq import Search
from compileiq.types import SearchConfiguration
# Define your objective: compile with the ACF and measure runtime
def objective(config_blob):
with open("config.acf", "wb") as f:
f.write(bytes.fromhex(config_blob))
result = subprocess.run([
"ptxas", "-v", "-arch=sm_90a",
"--apply-controls", "config.acf",
"my_kernel.ptx"
], capture_output=True, text=True)
return extract_runtime(result.stdout)
# Configure and run the evolutionary search
config = SearchConfiguration(
pool_size=32, cull_size=24, generations=20,
mutate_rate=0.1, problem_type="min",
num_objectives=1
)
search = Search(config, objective)
best_acf = search.run()
The code above can be separated into three distinct sections:
- Define your objective: We define the function objective, which takes the configuration to be evaluated in
config_blob, saves it to disk, compiles and runs the kernel, and then extracts the metric. - Configure the search: Set the parameters that will drive the search, like how many candidates to try in one generation (
pool_size), how many generations to run, and the number of objectives to be optimized. - Run the search and extract the best candidate.
That’s it. When the search starts, CompileIQ initializes a population of compiler configurations, evaluates each one against your objective function, selects the best performers, applies mutation and crossover to generate new candidates, and converges on an optimal ACF over successive generations.
You define what “better” means for your workload in the objective function, and CompileIQ finds it.

Examples
Now let’s focus on self-contained examples that you can try. There are a number of examples in the GitHub repo, and we’ll demonstrate two here. First, the single objective example, which has nothing to do with GPU computing, but demonstrates the principles of using CompileIQ.
from compileiq.ciq import Search
from compileiq.types import SearchConfiguration
import compileiq.search_spaces.base as ss
def objective(config):
score = config["x"] ** 2 + config["y"]
return score
def main():
dna_config = {
"x": ss.range(start=1.0, end=20.0, step=0.5),
"y": ss.choice([1, 2, 3]),
"z": ss.literal("this is a constant", knockout_prob=0.5),
}
main_config = SearchConfiguration(
generations=5,
problem_type="min",
num_objectives=1,
)
tuner = Search(
objective_function=objective,
search_space=dna_config,
search_config=main_config,
)
results = tuner.start()
print(f"Entire Results Dataframe:\n {results.get_results()}")
print(f"Best Result: {results.get_best_result()}")
if __name__ == "__main__":
main()
First, the objective function:
def objective(config):
score = config["x"] ** 2 + config["y"]
return score
This is a simple function that squares x, and adds that value to y. This is the function we’ll optimize:
dna_config = {
"x": ss.range(start=1.0, end=20.0, step=0.5),
"y": ss.choice([1, 2, 3]),
"z": ss.literal("this is a constant", knockout_prob=0.5),
The config specifies what values are permitted for the variables. For x, the range is between 1.0 and 20.0, with step size of 0.5. For y, the choices are either 1, 2 or 3; z doesn’t actually contribute to the calculation of the objective, but illustrates dropout.
main_config = SearchConfiguration(
generations=5,
problem_type="min",
num_objectives=1,
)
Next we specify the search configuration. In this case we’ll run 5 generations, we want to minimize the objective function, and there is only one objective being analyzed.
The rest of the code sets up the arguments and the search. This is a very simple objective function and you can calculate it by hand easily, but for illustrative purposes here’s what happens when you run the code.
$ python single_objective.py
🧬 Generation: 5/5|█| [elapsed: 00:00 · eta: 00:00] , 🏆 best_score=3.2500
Entire Results Dataframe:
metadata ... params
0 {"pid": 2562276} ... {'x': 2.5, 'y': 2, 'z': 'this is a constant'}
1 {"pid": 2562276} ... {'x': 8.5, 'y': 3}
2 {"pid": 2562276} ... {'x': 11.0, 'y': 1, 'z': 'this is a constant'}
3 {"pid": 2562276} ... {'x': 19.0, 'y': 2}
4 {"pid": 2562276} ... {'x': 13.5, 'y': 3}
.. ... ... ...
109 {"pid": 2562276} ... {'x': 1.5, 'y': 3, 'z': 'this is a constant'}
124 {"pid": 2562276} ... {'x': 1.0, 'y': 2, 'z': 'this is a constant'}
126 {"pid": 2562276} ... {'x': 2.0, 'y': 1, 'z': 'this is a constant'}
135 {"pid": 2562276} ... {'x': 3.0, 'y': 2, 'z': 'this is a constant'}
138 {"pid": 2562276} ... {'x': 1.5, 'y': 3}
[61 rows x 4 columns]
Best Result: {'metadata': '{"pid": 2562276}', 'generation': 4, 'score_1': 3.0, 'params': {'x': 1.0, 'y': 2, 'z': 'this is a constant'}}
Notice the listing of the best result has x = 1.0 and y = 2, which results in a score of 3.0. But we know the best score is actually when x = 1.0 and y = 1, so in this case CompileIQ didn’t find the best answer. Due to the very low number of generations (in our case 5) and the stochastic nature of the search, we didn’t happen to find the absolute best answer. However, in this case if you increase the generation to a larger number, say 15, you will almost always obtain the best answer.
Let’s move to an example that measures GPU performance of a specific kernel. In the GitHub repo there is an example using NVCC to build a reduction kernel. We won’t include the entire code here for brevity, but will show snippets to illustrate the concepts.
In the Python function which sets up the search, we have this code:
# Configure and run search
search_space = args.search_space if args.search_space else NvccSearchSpace(version=cuda_version)
config = SearchConfiguration(
problem_type=ProblemType.MIN,
generations=args.generations,
pool_size=args.pool_size,
)
The search space is configured to use the NvccSearchSpace for CUDA 13.3. And you can see the problem type to optimize for is MIN, which means we want to find the minimum of the objective function. Generations and pool size are command line arguments which default to 10 and 15 respectively in this Python script. The GPU kernel code is set up to run a reduction and then print out the time, and the objective function (not listed here) essentially builds and runs the kernel, and searches for the Time = string and this is the value that is minimized over the search space.
Assuming you’re in the compilers/nvcc_example folder, here’s what it looks like when you run the search.
$ python optimize_reduction.py --arch sm_120 Running baseline... Baseline: 0.777 ms Starting optimization (10 generations, pool=15)... 🧬 Generation: 10/10|█| [elapsed: 09:29 · eta: 00:00] , 🏆 best_score=0.7700, a Baseline: 0.777 ms Optimized: 0.770 ms Speedup: 1.01x Config saved: reduction_best_config.bin Usage: nvcc --apply-controls reduction_best_config.bin -arch=sm_120 ...
The performance increase found via the search is roughly 1%, and you can see that to apply this saved configuration you just need to use the –-apply-controls option and add the ACF that you just generated.
Multi-objective optimization and IP protection
Most auto-tuning tools optimize for a single metric, typically runtime. CompileIQ goes further, supporting multi-objective optimization, simultaneously exploring trade-offs across competing objectives like runtime, compile time, and power consumption.
This matters because “fastest possible” isn’t always the right answer. A power-constrained datacenter might accept a marginal runtime increase in exchange for significantly lower power draw. A CI/CD pipeline might prioritize compile time to keep iteration cycles fast. An embedded deployment might need to balance all three.
CompileIQ’s evolutionary engine computes a Pareto frontier of non-dominated solutions, or configurations where no single objective can be improved without worsening another. Your team picks the trade-off that fits your constraints, rather than being locked into a single optimization axis.
This capability extends CompileIQ’s applicability well beyond LLM inference. Anywhere NVIDIA compilers are used—scientific computing, autonomous vehicles, image processing, recommendation systems—CompileIQ can explore the optimization space and surface configurations that default heuristics miss.
On the IP protection front, CompileIQ is designed so that both sides stay secure. Compiler internals remain encapsulated within the search space and ACFs. Users need not concern themselves with compiler parameters. User workloads never leave their own environment; the objective function runs locally, and only the resulting ACF is produced. ACFs are safe to commit to version control and share across teams.

Results and production adoption
CompileIQ has been validated across GPU and CPU targets on production workloads. For example, Meta has seen up to 15% performance improvement on both TritonBench and Helion kernels as shown in this GTC talk.
These gains come on top of already-optimized baselines in kernels that were considered “done” by their authors. The improvements are the direct result of CompileIQ discovering compiler configurations that the default heuristics would never select.
Leading AI labs are already using CompileIQ in production for their most performance-critical inference and training workloads. The ACFs it produces are fully reproducible and portable: the same ACF generates the same optimized binary across deployments as long as the same benchmark and underlying compiler are matching. Teams commit ACFs to version control alongside their kernel source code, making compiler optimization a versioned, reviewable part of the development workflow.
Your turn
Compiler search spaces are available for both PTXAS and NVCC. Identify your highest-impact kernels – GEMM and attention are the best candidates – write a benchmark that measures what matters to your workload, and run CompileIQ.
Documentation, API reference, and useful examples are available at the CompileIQ documentation site. For questions and support, file an issue on the CompileIQ GitHub repository.
One thing we should be clear on: CompileIQ is not a magic tool that automatically turns poorly-written code into high-performing code. To get the best value from CompileIQ, you need to start with reasonably high-performing code, which then enables the final compiler-heuristics tweaks to take you to maximum performance.
But, if your team has exhausted every optimization lever they know of, CompileIQ gives them a new lever—the compiler itself.
Download CompileIQ, check out the examples in GitHub, and start optimizing your kernels today.
About the Authors
About Aditya Srikanth
Aditya is the engineering manager for CompileIQ at NVIDIA, and is involved with CompileIQ engagements and adoption across various workflows. Outside of work, he enjoys cooking, riding motorcycles, and spending time with his dogs.
About Pedro Torruella
Pedro is a senior software engineer on the SW Compilers Team at NVIDIA, currently focused on enabling agentic and machine learning optimizations across the GPU kernel programming stack. He is a product-centric engineer, with prior experience as a devrel, program manager, and startup founder. Pedro holds a joint master's degree in electrical and computer engineering from the University of Southampton (UK) and RPTU Kaiserslautern (Germany). In his free time you can find him riding his bicycle, listening to music on vinyl, or pulling espresso shots.
About Jonathan Bentz
Jonathan Bentz leads the CUDA technical marketing engineering team at NVIDIA, where his team focuses on creating and delivering engaging content and connecting with CUDA developers. Jonathan holds a PhD in Chemistry and a master’s degree in Computer Science from Iowa State University.
About Tony Scudiero
Tony Scudiero is a technical marketing engineer for the CUDA platform. He works to bring CUDA to developers of every type and ability. He has worked with large HPC systems and applications, real-time acoustic simulations (VRWorks Audio), and the Omniverse RTX Renderer during his tenure at NVIDIA.
How we contain Claude across products
Anthropic details its containment strategies for Claude agents, emphasizing environmental isolation (sandboxes, VMs) over model-layer defenses to prevent misuse and data exfiltration.
Deep dive
- Anthropic's approach to agent security prioritizes containment at the environment layer (e.g., sandboxes, VMs) over steering behavior at the model layer.
- They address three types of risks: user misuse, model misbehavior (agents taking unintended actions), and external attacks (e.g., prompt injection).
- Defense components include the agent's runtime environment (sandboxes, VMs, egress controls), the model itself (system prompts, classifiers), and external content it can access (tools, files).
claude.aicode execution uses ephemeral gVisor containers on isolated infrastructure for minimal blast radius.- Claude Code, running on user machines, initially relied on human-in-the-loop approvals, but user "approval fatigue" led to the adoption of OS-level sandboxes (Seatbelt/bubblewrap) and an "auto mode" for safer approvals.
- Vulnerabilities discovered included code execution from untrusted local configurations during startup and user-as-injection-vector attacks where malicious prompts led Claude to exfiltrate credentials via approved network paths.
- Claude Cowork uses full virtual machines (Apple's Virtualization, HCS on Windows) with mounted user workspaces to provide absolute isolation for non-technical users.
- A significant vulnerability in Claude Cowork allowed data exfiltration to attacker-controlled Anthropic accounts via the
api.anthropic.comallowlist, fixed by an in-VM man-in-the-middle proxy. - Another challenge identified was that VM isolation prevents host-based Endpoint Detection and Response (EDR) software from seeing inside the guest VM, posing compliance issues.
- External resources (MCPs, web search) are treated as untrusted, with proxies inspecting return values before they enter the model's context.
- Emerging risks include persistent memory poisoning, multi-agent trust escalation, and defining agent identity.
- The authors emphasize matching isolation strength to user oversight capacity and being wary of custom security components, as battle-tested primitives (hypervisors, seccomp) are often more robust than bespoke solutions.
Decoder
- Human-in-the-loop (HITL): A system where human intervention or oversight is required at certain points to supervise or validate an automated process.
- Sandboxing: A security mechanism for running programs in an isolated environment to prevent them from accessing or damaging other parts of the system.
- gVisor: A user-space kernel for containers developed by Google, providing an additional layer of isolation between the container and the host kernel.
- seccomp: Short for "secure computing mode," a Linux kernel feature that allows a process to restrict the system calls it can make.
- Egress controls: Network security measures that monitor and control outgoing network traffic from a system or network.
- Prompt injection: A type of attack where a malicious user provides instructions to an AI model through its input prompt, overriding its intended behavior or safeguards.
- Endpoint Detection and Response (EDR): Security tools that continuously monitor and collect data from endpoint devices (computers, servers) to detect and investigate suspicious activity.
- OTLP: OpenTelemetry Protocol, a vendor-agnostic specification for the telemetry data (traces, metrics, logs) generated by applications and services.
- MCP (Model-Controlled Process/Plugin): A server or tool that an AI agent can call to perform actions or access external data.
Original article
Full article content is not available for inline reading.

DeepSWE
DeepSWE, a new benchmark for long-horizon software engineering, features contamination-free, real-world tasks across 91 repositories and 5 languages, revealing wider performance gaps between frontier coding agents than SWE-Bench Pro.
Deep dive
- DeepSWE is a new long-horizon software engineering benchmark with 113 tasks across 91 open-source repositories in 5 languages (TypeScript, Go, Python, JavaScript, Rust).
- It addresses four key issues with existing benchmarks: contamination-free tasks, high diversity, real-world complexity (shorter prompts, more code), and reliable behavioral verification.
- Tasks are original, not adapted from existing commits, preventing pre-training data contamination.
- Verifiers are hand-written to test software behavior, not implementation details, significantly reducing false positives (0.3% vs. SWE-Bench Pro's 8.5%) and false negatives (1.1% vs. SWE-Bench Pro's 24.0%).
- DeepSWE reveals wider performance separation among frontier coding agents: GPT-5.5 achieves 70%, GPT-5.4 56%, and Claude Opus 4.7 54%, compared to closer clustering on SWE-Bench Pro.
- Qualitative analysis shows Claude models frequently miss multi-part prompt requirements but are attentive to environment and sometimes "cheat" by reading git history on SWE-Bench Pro.
- GPT models (5.5, 5.4) exhibit high precision, implementing exactly what's asked with the lowest rate of missed requirements.
- Stronger models like Claude Opus 4.7 and GPT-5.4 write new tests in over 80% of DeepSWE runs, even unprompted, indicating self-verification capabilities that are suppressed by SWE-Bench Pro's prompt design.
- The benchmark uses
mini-swe-agentas a standardized harness to ensure comparisons reflect model capability rather than specific tool integrations. - Limitations include reliance on
mini-swe-agent(not native harnesses), focus on >500-star open-source repos, under-representation of bug localization/refactoring, and limited language coverage (missing C++, Java).
Decoder
- Long-horizon software engineering: Tasks requiring multiple steps, extensive codebase exploration, and complex changes over a prolonged period, rather than simple, isolated code modifications.
- Contamination-free tasks: Benchmark tasks designed from scratch, not sourced from existing code or solutions, ensuring that AI models have not seen the answers during their training.
- Behavioral verifiers: Tests designed to confirm that software exhibits the requested external behavior, irrespective of the internal implementation details or specific code structure.
mini-swe-agent: A standardized evaluation harness (tooling and system prompt) used across different AI models to ensure consistent testing conditions and fair comparison, as opposed to model-specific native harnesses.
Original article
Full article content is not available for inline reading.

Staged publishing and new install-time controls for npm
GitHub introduced staged publishing for npm, requiring human 2FA approval before package versions become public, and added new --allow-* install flags to control non-registry dependency sources.
Deep dive
- Staged publishing ensures that a package version uploaded to npm is not immediately live; it first goes into a queue.
- A human maintainer must explicitly approve the staged package, with a 2FA challenge, before it's released to the registry.
- This feature reinforces "proof of presence" for every publish, including those from non-interactive CI/CD workflows and trusted publishing with OIDC.
- GitHub recommends pairing staged publishing with trusted publishing, limiting CI workflows to
stage-onlypublishes. - The new
--allow-file,--allow-remote, and--allow-directoryflags complement the existing--allow-gitflag. - These flags allow developers to explicitly control which non-registry sources (
filepaths,remoteURLs, localdirectoryinstalls, andgitsources)npm installcan use. - The default for
--allow-gitwill change fromalltononein the next major CLI version (v12), making it an opt-in for Git sources. - These controls aim to mitigate supply-chain attacks by preventing the accidental or malicious installation of packages from untrusted local or remote sources.
Decoder
- npm: Node Package Manager, the default package manager for the JavaScript runtime Node.js.
- Supply-chain security: Protecting software components and dependencies throughout their lifecycle from malicious tampering or vulnerabilities.
- OIDC: OpenID Connect, an authentication layer on top of the OAuth 2.0 framework, often used for trusted publishing to verify identity.
- 2FA: Two-Factor Authentication, a security measure requiring two different methods of verification to confirm identity.
- .npmrc: A configuration file for npm, used to set options for individual projects or globally.
Original article
Today we’re shipping two updates focused on supply-chain security for npm:
- Staged publishing is generally available.
- New
--allow-*install source flags (--allow-file,--allow-remote,--allow-directory) complement the existing--allow-gitflag.
Both are available in npm CLI 11.15.0 or newer.
Staged publishing is generally available
Staged publishing is now generally available on npm. Instead of a direct publish that immediately makes a package version available to consumers, the prebuilt tarball is uploaded to a stage queue where a maintainer must explicitly approve it before it becomes installable. The queue is visible both on npmjs.com and in the npm CLI.
Staged publishing reinforces proof of presence on every publish, including those that originate from non-interactive CI/CD workflows and those using trusted publishing with OIDC. A human maintainer with a 2FA challenge is required to approve a staged package before it is released to the registry.
Staged publishing is live today, and so are the docs.
Requirements
- npm CLI 11.15.0 or newer is required to use
npm stage. - Update CI/CD workflows to use
npm stage publishinstead ofnpm publishwhere you want staged behavior.
Recommended setup
We recommend pairing staged publishing with trusted publishing (OIDC). A trusted publishing configuration can be limited to stage-only, which means npm publish from that workflow will be rejected and only npm stage publish is accepted. Your CI workflows continue to run non-interactively, and a maintainer later approves the staged version from the website or the CLI.
You can also run npm stage publish locally, but the highest-value setup is CI publishing to the stage queue and a maintainer approving from a trusted device.
If you already manage trusted publishing configurations in bulk, released Feb 2026, you can use it to migrate your packages to staged publishing. Remember to update your CI workflows to the new CLI version and to use npm stage publish.
New install source flags
In npm 11.10.0 we introduced --allow-git to give you control over whether npm install can resolve dependencies from Git sources. Starting in npm 11.15.0, we are adding three more flags so you can apply the same explicit-allowlist approach to every nonregistry install source:
--allow-file: Controls installs from local file paths and local tarballs.--allow-remote: Controls installs from remote URLs, including https tarballs.--allow-directory: Controls installs from local directories.--allow-git(existing): Controls installs from any Git source, includinggithub:,gitlab:,git+URLs, and bareowner/reposhorthands.
Each flag accepts all (the current default) or none, and can also be set in .npmrc or package.json config.
Learn more by checking out our docs:
npm installreference (the--allow-file,--allow-remote,--allow-gitvariants are on the same page)- Config reference
As a reminder from the Feb 2026 announcement, --allow-git will change its default from all to none in the next major version of the CLI (v12). The new --allow-file, --allow-remote, and --allow-directory flags are additions in 11.15.0—you can opt into stricter behavior today by setting them to none.
Join the discussion
We’d like to hear how you’re rolling this out. Share feedback and questions in the GitHub Community discussion.

Agent Memory: An Anatomy
Agent memory systems, often mislabeled, are pipelines for extracting, storing, and retrieving information, typically struggling with contradictions, stale context, and true procedural or prospective memory.
Deep dive
- Agent memory libraries often borrow cognitive science terms (episodic, semantic, procedural) without implementing their full biological complexity.
- The core components are the extractor (reads transcripts, uses an LLM to generate "statements" or abstracted facts, often losing temporal context), the store (a database like a vector index, table, or knowledge graph, struggling with contradictions), and the retriever (turns queries into searches, often using vector similarity, keyword search, and reranking, similar to RAG).
- Episodic memory (specific events with time/place) is often compressed into semantic facts during extraction in agents.
- Semantic memory (decontextualized facts about the world) is what most agent memory libraries actually implement, often focusing on "autobiographical memory" about the user.
- Procedural memory (knowing how to do things) is largely absent or mislabeled in current agent libraries; some encode it in system prompts, others just apply a metadata tag.
- Prospective memory (remembering to do something in the future) is a significant gap, with no production library effectively implementing it beyond scheduled triggers.
- Biological memory features like consolidation (offline processing, like Anthropic's Dreams or Letta's sleep-time compute) are being adopted by some, but emotional salience and biological-style forgetting are largely irrelevant or misguided for agent systems.
- Forgetting in agents should be an adjudication/retrieval problem (finding current facts) rather than deleting information, as agents can afford to store everything.
Decoder
- RAG (Retrieval-Augmented Generation): An AI technique that combines a retriever (to find relevant information from a knowledge base) with a generator (an LLM) to produce more accurate and contextually relevant responses.
- Episodic memory: Memory for specific events and experiences, including details about time and place.
- Semantic memory: Memory for facts, concepts, and general knowledge not tied to specific personal experiences.
- Procedural memory: Memory for skills and how to perform tasks, often unconsciously (e.g., riding a bike).
- Prospective memory: Remembering to perform an action or intention in the future.
- Context window: The limited amount of text an LLM can process at one time as input.
- Consolidation (in agent memory): An offline process that revisits stored material to rewrite, deduplicate, and resolve contradictions, mimicking biological memory's process.
Original article
every agent memory library uses the same words: episodic, semantic, sometimes procedural. they’re cognitive science’s vocabulary, lifted into the API. the engineering often isn’t lifted with them. a library can have a procedural field that uses the same storage and retrieval as semantic — a label, not a separate system. the deeper slip is the word memory itself: most of what these libraries build is narrower than that, and the narrower term sharpens the problem.
the terminology comes from a 1972 chapter by Endel Tulving. he argued that what people had been treating as one thing — memory — was at least two: memory for events (what happened, where, when), and memory for facts (the capital of France, water’s boiling point). he called them episodic and semantic.
the anatomy of an agent memory system
an agent memory library is built from a small number of components. you can read any library’s docs by knowing the parts.
the extractor. the thing that reads conversation transcripts and decides what to keep. usually an LLM call, sometimes with a strict prompt or a typed output schema. it produces statements — short, abstracted facts about the user, the world, or the task.
the most consequential choice an extractor makes is timing. extract eagerly, after every message, and you waste tokens on small talk. extract lazily, at the end of a session, and the long transcript degrades extraction quality — models attend worse to material in the middle (lost-in-the-middle).
extraction is a compression from situated event to decontextualized fact: user mentioned over coffee on Tuesday that they prefer TypeScript becomes user prefers TypeScript. temporal anchors (“yesterday,” “next week”), disambiguating local context, and cues that compress to text imperfectly (emphasis, what got elaborated vs glossed over) get lost in that compression.
the store. the database. one or more of: a vector index (entries indexed by semantic similarity), a relational table (entries indexed by columns you can filter on), a knowledge graph (entries connected by typed edges). each statement carries metadata — a timestamp, sometimes a confidence score, sometimes a source pointer back to the original conversation.
the hardest question a store answers isn’t where to put things. it’s what to do when a new statement contradicts an old one. the user lived in Paris until April, then moved to Amsterdam — and the store now has both, each presenting as current. the choice is whether to
- overwrite (one truth, no history)
- append (both, leave it to retrieval to sort out)
- keep both with the old marked as superseded.
a store that can’t answer what did I believe last month? isn’t a memory system. it’s a snapshot with a timestamp on it.
the retriever. at query time, this component turns the current question into a search and returns the statements most likely to be relevant. vector similarity is the baseline. keyword search on top of that is common. a reranker is the standard third layer. structurally this is RAG; the corpus is the user’s accumulated statements rather than a document library. some libraries also run a time filter (don’t return statements known to be out of date) and a presupposition check — detect when the question itself assumes a stale fact and block it from being pulled into context.
the kinds of memory
cognitive science’s canonical taxonomy consists of four kinds: episodic, semantic, procedural, and working. working memory in agents is the context window — a different machine from the one this post is about, worth setting aside. that leaves three. add prospective — it isn’t in the canonical taxonomy, but it names a gap the field hasn’t filled.
episodic memory. specific events tied to a time and place. I had coffee with Aleksandra last Tuesday at the place on Mostowa. the memory is dated, situated, and personal. you experienced it. recall feels like re-experiencing — you can place yourself back in the scene.
agent memory libraries handle this with a table of timestamped statements. user mentioned they live in Berlin (2026-03-14). each entry is a single event the system observed. some libraries keep the raw conversation episode alongside the extracted facts.
semantic memory. facts about the world that aren’t tied to any specific event. Berlin is the capital of Germany. the boiling point of water is 100°C at sea level. you know these things; you can’t usually recall when you learned them. the knowledge is decontextualized.
most of what people mean by “agent memory” is this. user prefers TypeScript started as an episodic observation — they said it on Tuesday — but by the time it lands in the store, the context is gone and what remains is a fact about the user, true until contradicted.
procedural memory. knowing how to do things. tying shoes, riding a bike, the muscle memory of a keyboard shortcut. you can’t usually verbalize procedural memory — try explaining how you keep your balance — but it shapes behavior reliably.
procedural memory is the cleanest litmus test for the gap between what a library claims and what it implements. LangMem treats it as a distinct mechanism — evolving the system prompt from scored trajectories, so what’s remembered isn’t a retrievable fact but a behavioral disposition encoded in instructions. Mem0 exposes the procedural label but writes it into the same index it uses for facts — metadata.memory_type = "procedural" is the only difference. Graphiti doesn’t expose procedural memory at all; everything lands in the same bitemporal graph regardless of source.
prospective memory. remembering to do something in the future. don’t forget to send the contract tomorrow. next time the user asks about pricing, mention the new tier. prospective memory is one of the most studied failure modes in humans — people forget intentions far more often than they forget facts. the closest analogs in production are scheduled triggers in agent frameworks; they solve the do Y at time T case but not the harder do Y when condition X next appears, which is the form prospective memory actually takes. no production library I’ve seen ships this. open territory.
what these libraries actually are
of these four kinds, three are mostly absent from production memory libraries — episodic gets compressed to semantic at extraction, procedural is mostly mislabeled semantic, prospective barely exists.
what’s left is semantic memory, and within semantic, one specific subset: autobiographical memory — the facts a person knows about their own life. borrowing the term loosely: the agent isn’t remembering its own life, it’s maintaining the user’s by proxy. where they live, what they’re working on, who matters to them, what they’ve decided.
most agent memory libraries are autobiographical memory systems with extra steps. the field’s central problem is narrower than “memory” — and clearer when you name it.
where the analogy breaks
the three parts have rough biological analogs. extraction is the agent analog of consolidation — the slow compression from situated experience to decontextualized fact (in humans, during sleep, over hours; in agents, at conversational speed and at scale). the store maps to long-term memory — though the analog is the weakest of the three, since what’s actually implemented is a state machine with no plausible biological equivalent. retrieval maps to both cued recall (with the same fixed-cutoff bias as top-k — once a cue activates a memory, the search stops) and source monitoring, the fragile human process of deciding whether a remembered fact is yours, current, real.
these analogies — together with the Tulving categories from the opening — are useful for vocabulary. they are dangerous as a design guide.
biological memory has properties that agent memory libraries variously lack, can’t have, or shouldn’t try to have. these aren’t details; they’re load-bearing parts of what makes biological memory work. the question worth asking of each property is which of the three categories it falls into.
consolidation. in humans, sleep replays the day’s experiences and prunes the redundant ones — slow compression from situated event to abstract knowledge. agent labs have started shipping the equivalent: offline passes that revisit stored material and rewrite it, deduplicating, resolving contradictions, and surfacing patterns across sessions. Anthropic’s Dreams and Letta’s sleep-time compute are two production examples as of mid‑2026; both run scheduled passes over accumulated memory and produce reorganized stores. this is a property worth importing. the libraries that run extraction synchronously on every message are doing a degenerate version of consolidation under live latency budgets; the ones that run it offline, against accumulated material, are doing the version that matches the biology. whether it produces better outputs is still an open empirical question — but the structural argument is cleaner. absent, but addressable.
emotional salience. in humans, the amygdala flags experiences with strong affect for stronger encoding — fear, surprise, embarrassment all leave deeper traces than neutral content. nothing in a text-only agent has this signal. there’s no body, no autonomic system, no analog to the physiological substrate that produces affect. the input is purely textual tokens. attempts to add this via importance scoring exist — Park et al.’s Generative Agents rate memories 1–10 for poignancy, but those are LLM-judged proxies, not affect: the same model that lacks affect is asked to estimate it. it’s a structural absence that follows from operating on text alone. multimodal models with environmental grounding may eventually have an analog. text-only agents can’t.
forgetting. biological memory actively forgets — decay, interference, pruning, all running constantly under the floor. some agent memory libraries try to imitate this with recency weighting, importance scores, or scheduled cleanup jobs. the assumption is that an agent should forget the way a person does, because that’s how memory is supposed to work.
this is mostly mistaken. forgetting in biological memory is a constraint, not a feature — the brain forgets because it can’t afford to store everything, not because forgetting is the goal. an agent memory system has no such constraint. it can keep everything for the cost of disk. and a system that keeps everything is also a system that can answer “what did we know last March?” — which is auditable, debuggable, and often what users actually need. a system that aggressively forgets loses that.
the real problem behind biological forgetting — that retrieval degrades as the store grows — doesn’t go away just because disk is cheap. biological-style forgetting isn’t the answer.
what an agent memory system needs is for the kept information to stay findable. that’s a retrieval problem (rank current facts above stale ones, narrow searches to relevant themes) and an adjudication problem (mark superseded facts without deleting them). consolidation systems like Dreams attack the same problem from the other end — non-destructive offline reorganization between sessions, producing a cleaner store without losing the input.
the framing “biological memory forgets, therefore agent memory should too” imports the constraint as if it were the lesson. biological-style forgetting belongs in the third category — shouldn’t. whether some other forgetting rule belongs anywhere is a separate question.
the four kinds of memory and the three anatomical parts are not a recipe. they’re a map. when you read a library’s docs, you can place its choices on this map — which kinds of memory it handles, which parts it implements versus stubs out, where it took the vocabulary without doing the engineering. Sebastian Lund’s “Ultimate Guide to LLM Memory” is worth reading — it cuts the territory differently (by what fills the prompt at runtime) and the two views compose.
the vocabulary is more stable than the products. learn the parts. the products name themselves around them.
Footnotes
-
Endel Tulving, “Episodic and Semantic Memory,” in Organization of Memory, eds. Tulving & Donaldson (Academic Press, 1972). the procedural distinction is later, in Tulving’s “How Many Memory Systems Are There?” American Psychologist 40 (1985). working memory as a separate system is Baddeley & Hitch (1974). ↩
-
Sarah Wooders (Letta) and Harrison Chase (LangChain) argue memory isn’t a separable system — it’s whatever the harness keeps in context (Wooders, X, 2026-03-31; Chase, X, 2026-04-03). within a session they’re right. across sessions something has to outlive any one harness’s choices — that’s the substrate the three components describe. different questions, compatible answers. ↩
-
cognitive science also draws a higher line: declarative memory (semantic plus episodic — facts and events you can verbalize) versus non-declarative (procedural skills, conditioning, priming). agent libraries handle declarative natively; non-declarative is mostly absent. ↩
-
the three open-source memory libraries cited here: LangMem (github.com/langchain-ai/langmem), Mem0 (github.com/mem0ai/mem0), Graphiti (github.com/getzep/graphiti, by Zep). all as of mid-2026; APIs change. the procedural-memory claims are verified at source: LangMem’s prompt optimizer is a separate mechanism with no vector-store writes; Mem0’s procedural path differs from its semantic path only in a metadata label; Graphiti has no procedural concept at all. ↩
-
two production examples as of mid-2026: Letta’s sleep-time compute — background subagents that rewrite and consolidate archival memory during idle time (letta.com/blog/sleep-time-compute) — and Anthropic’s Dreams — an offline pipeline that ingests a memory store plus past session transcripts and writes a new store with duplicates merged and contradictions resolved on the latest value (platform.claude.com/docs/en/managed-agents/dreams). both are scheduled or user-initiated, not automatic idle-time. what’s labeled “consolidation” elsewhere (LangMem, Mem0, Graphiti, Cognee) is write-time machinery, not offline reflection over the accumulated store. ↩
-
Joon Sung Park et al., “Generative Agents: Interactive Simulacra of Human Behavior,” arXiv:2304.03442 (2023), arxiv.org/abs/2304.03442. scores each memory 1–10 for poignancy via an LLM call, weights retrieval by recency × importance × relevance. ↩
-
not literally just disk — indexing, retrieval latency, and token costs grow with the store, and governance constraints (PII, retention/DSR, audit) apply regardless of storage cost. ↩
-
Sebastian Lund’s “Ultimate Guide to LLM Memory” (fastpaca.com/blog/ultimate-guide-to-llm-memory/) uses four layers — working, episodic, semantic, document. his cut is about prompt composition: what fills the context window. mine is about kinds of memory before any engineering. different axes, compatible. ↩

CI/CD security: How to secure your GitHub ecosystem
Threat modeling GitHub CI/CD environments reveals risks like unauthorized access, malicious code execution via CI files, and data exfiltration, necessitating detection tools, dependency scanning, and monitoring.
Deep dive
- Threat modeling for GitHub involves identifying inputs (authentication, source code, CI/CD instructions, configurations, secrets), identities (authenticated/unauthenticated users), and risks.
- Risks include unauthorized access, backdoor entry, code vulnerabilities, data exfiltration, disabling protections, and exposing secrets.
- Attack pathways for malicious code execution include adding code to
.github/workflows/*, manipulating tests, or adding malicious dependencies (package.json,requirements.txt). - Detection methods require code scanners (Datadog SAST, CodeQL, Dependabot) and AI security tools (BewAIre for PR diff analysis).
- For data exfiltration, attackers might mass clone private repos or scan for secrets via compromised PATs; GitHub audit logs and Cloud SIEM can detect these.
- Shai-Hulud npm worms (late 2025) compromised over 1,000 npm packages by injecting malicious payloads into
post-installandpre-installscripts, then exfiltrating credentials and self-propagating. - Tools like Datadog's SCFW CLI block known malicious packages, while GuardDog statically scans for malware patterns.
- Unauthorized OAuth token access (2022 attacks on Heroku/Travis CI) allowed exfiltration of secrets from private repos; Cloud SIEM can detect unusual OAuth token usage from different IP addresses or ASNs.
- Compromised third-party dependencies (e.g.,
ua-parser.jsin 2021) allowed execution of info-stealing scripts during CI workflows, accessing runner environment variables. - Software Composition Analysis (SCA) tools like Datadog Code Security or GitHub Dependabot are crucial to detect vulnerabilities and suspicious
preinstall/postinstallscript changes.
Decoder
- SCM (Source Code Management): Systems that manage changes to source code over time, like Git.
- CI/CD (Continuous Integration/Continuous Delivery): Practices for automating the build, test, and deployment of software.
- PAT (Personal Access Token): A secure alternative to using a password for authentication to GitHub, often used for scripting or automation.
- SIEM (Security Information and Event Management): A system that collects, analyzes, and correlates security log data from various sources to detect and respond to threats.
- SAST (Static Application Security Testing): A white-box testing methodology that analyzes source code to find security vulnerabilities before the code is compiled or executed.
- SCA (Software Composition Analysis): A process that analyzes the open-source and third-party components used in an application to identify security vulnerabilities, licensing issues, and code quality problems.
- OAuth token: An authorization token used by applications to access a user's data on another service without needing their password.
- npm worms: Self-replicating malware that spreads via the npm package registry, typically by compromising maintainer accounts or injecting malicious code into popular packages.
Original article
In Part 1 of this series, we discussed the CI/CD security boundary, mapped out potential attack vectors with a CI/CD threat matrix, and introduced a simple threat model focused on ideating detection workflows. In this post, we’ll apply these principles to a real-world source code management (SCM) tool example that every developer is familiar with: GitHub.
In addition to threat modeling, we’ll also be taking a closer look at historical attacks on GitHub and GitHub Actions ecosystems. Based on these attacks, we’ll discuss preventative measures to help you secure your environment as well as response workflows.
Threat modeling for GitHub
As we previously discussed, a threat model is a structured representation of all the information surrounding the security of an application or ecosystem. To apply our detection-based threat model to GitHub, we’ll first identify the inputs, identities, and infrastructure that pertain to the SCM and their corresponding risks.
Inputs:
-
Authentication
-
Source code (through pushes, PRs, reviews, commits)
-
Instructions for the CI/CD phase
-
GitHub configurations (including webhooks)
-
Secrets (if using GitHub Actions)
The identities that can access these inputs are then:
-
Authenticated users via SSO, SSH, personal access tokens (PATs), and GitHub Apps
-
Unauthenticated users (if public repositories exist)
In this case, we can omit infrastructure because it falls outside of the scope for GitHub as a SaaS platform.
When it comes to risks, for each input, we need to ask ourselves, “What is at risk if an attacker gains control of this input or accesses previously inputted data?”
| Input | Risk |
|---|---|
| Authentication | Unauthorized access |
| Source code (pushes, PRs, code review, commits) | backdoor entry, code vulnerability, data exfiltration |
| GitHub configurations | Disable protections or exfiltrate data |
| Instructions for CI/CD | Execute malicious code |
| Secrets (if using GitHub Actions) | Expose secrets |
As an example, consider the input instructions for CI/CD. For each risk associated with this input (in this case, malicious code execution), we need to identify how an attacker can realize the risk, the log sources that surface each attack pathway, and develop detection methods based on the available logs. Starting from the risks, we can map these variables out as shown below:
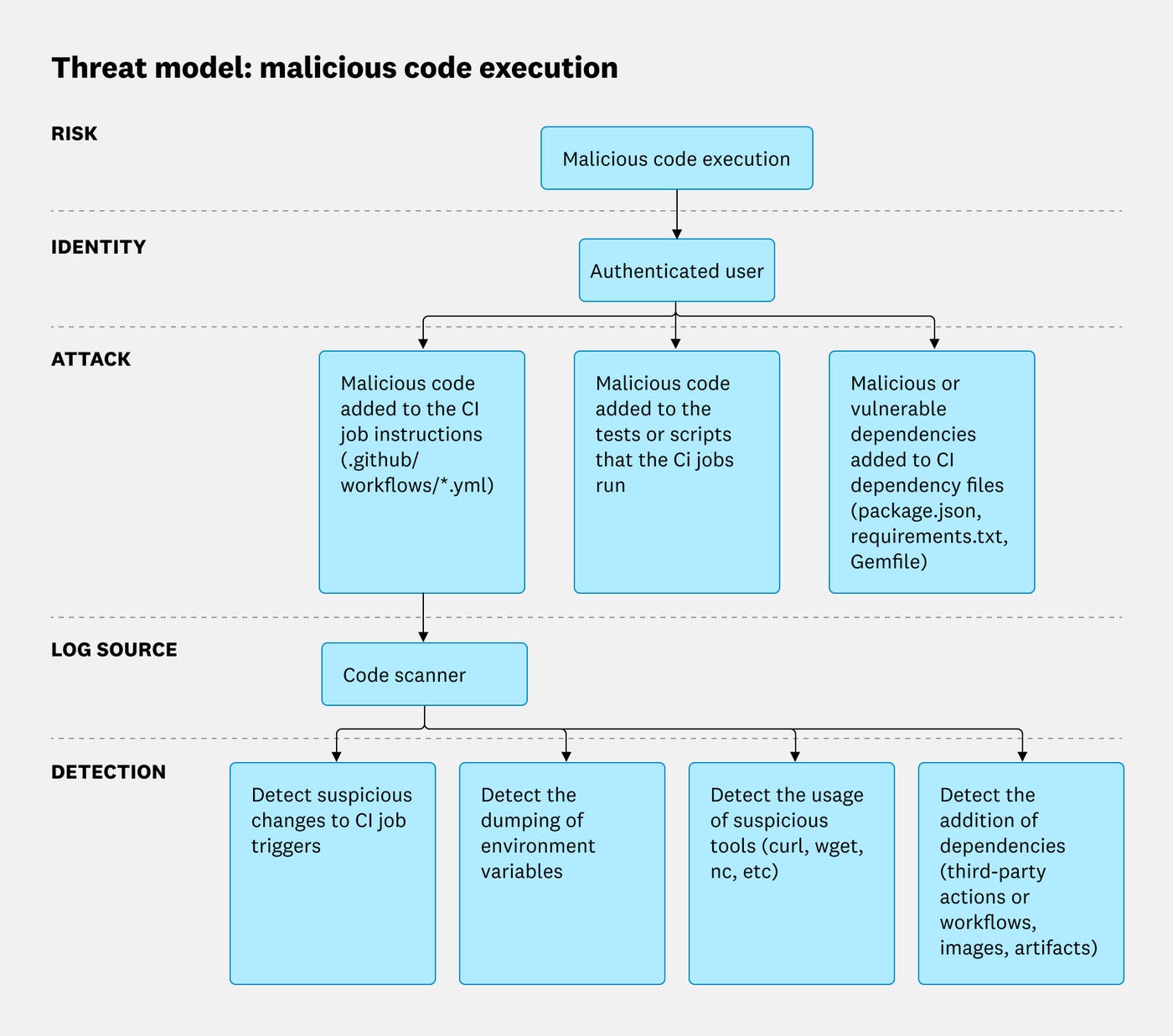
Given that an identity already has access to the instructions for CI/CD input, they can realize the risk of malicious code execution in several ways, such as:
-
Adding malicious code to CI configuration files such as those stored in
.github/workflows/* -
Manipulating tests and scripts that CI jobs run
-
Adding malicious or vulnerable dependencies to files such as
package.jsonandrequirements.txt
Consider the most direct attack pathway: adding malicious code to CI job instructions. Because GitHub audit logs don’t log changes to code files, we need to rely on a code scanner such as Datadog Static Code Analysis (SAST), CodeQL, or Dependabot. AI security tools such as BewAIre can also automatically review the diff of each PR and classify them as benign or malicious by evaluating intent from code changes and contextual metadata. Using these tools, you can detect changes to triggers executed by CI jobs, code that enumerates or logs environment variables, the use of external command-line utilities such as curl and wget, and new third-party dependencies that were not originally present in your code.
Let’s take a quick look at a different risk example: data exfiltration given a compromised source code input.
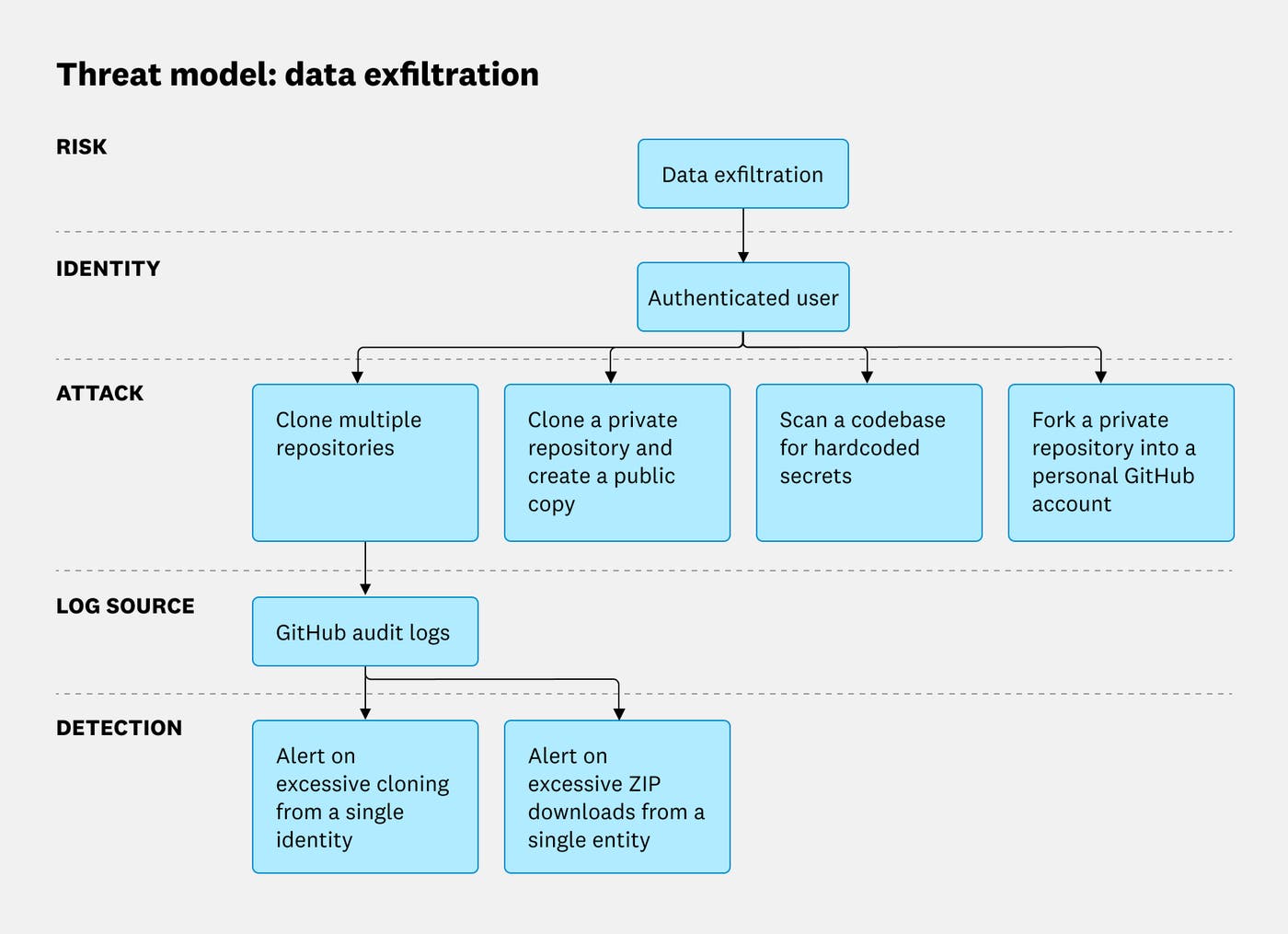
For the risk of data exfiltration, any authenticated GitHub user can realize the risk via multiple avenues such as mass cloning of private repositories onto their local machine, scanning the codebase for secrets, or making a private repo go public.
Once an attacker gains authenticated access, for example via a compromised PAT, they can clone private repositories at scale to their local device and scan them for secrets that would enable lateral movement. This and other common attacker behavior are recorded events in GitHub audit logs, which enables them to be detected by cloud SIEM tools. For example, using Datadog’s out-of-the-box (OOTB) security rules, you can detect events such as the mass exfiltration via cloning of repositories using a PAT or when a PAT is used by a previously unseen user agent.
Tips to protect your GitHub environment against known attacks
Previously, we discussed how to anticipate the different risks associated with inputs in your GitHub environment and how to ideate detection mechanisms. However, we can also glean detection opportunities from historical attacks on GitHub environments.
The Shai Hulud npm worms
In late 2025, two self-replicating npm worms dubbed Shai-Hulud and Shai-Hulud 2.0 compromised over 1,000 unique npm packages, affecting over 500 unique GitHub users and over 14,000 GitHub repositories. The Shai-Hulud worms use the post-install and pre-install scripts of the package.json file to install and run their payload. During this execution, the malware downloads and runs TruffleHog, a legitimate open source tool that the malware uses to scan its host for API keys, secrets, and other hardcoded credentials. These are then exfiltrated to a hardcoded webhook endpoint and public GitHub repositories.
What makes the Shai-Hulud worms so pervasive is that when they discover additional npm or GitHub publishing credentials, they create and publish a new version of npm packages with the malicious payload inserted in the install script. Downstream consumers that install or update the compromised packages then become infected, repeating the cycle above.
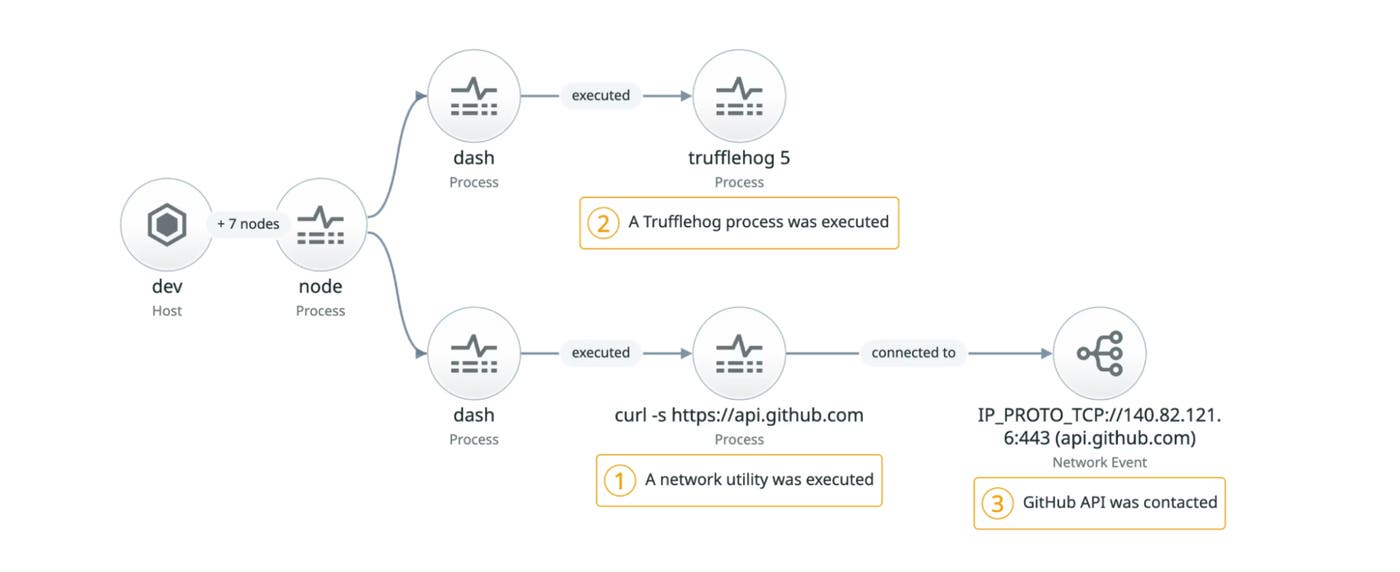
To stay up-to-date with the latest compromised packages, Datadog maintains the open source supply chain firewall security (SCFW) CLI tool. SCFW automatically blocks the installation of known malicious npm and PyPI packages when developers run these package managers from their CLI, protecting your environment against malware such as Shai-Hulud before the payload has the chance to be installed and executed.
However, this type of traditional security tooling can only protect against known compromised packages. When installing code, you also need to answer, “does this code look malicious?” GuardDog answers this exact question—it statically scans code from sources such as npm, PyPI, and GitHub Actions using heuristics that flag common malware patterns, such as the use of curl or wget, persistent lifecycle scripts, and self-propagation logic.
Unauthorized OAuth token access
Let’s look at another supply chain attack. In 2022, attackers gained unauthorized access to OAuth tokens issued to third-party integrations, Heroku and Travis CI, which were then used to access GitHub’s API and exfiltrate data in a workflow similar to our last threat model example. Attackers were able to surface secrets, such as AWS API keys stored in private repositories that were then used to enumerate cloud resources and exfiltrate data from S3 storage.
Compromising OAuth token access is a common target entry point for attackers, who try to gain transitive access via authorized third-party integrations or through phishing schemes that attempt to have authenticated GitHub users grant permissions to malicious applications. For example, in this recent phishing scheme, fake security alerts were sent to GitHub users notifying them of “unusual access attempts.” The alert recommended several methods to secure their account, all of which led to an authorization page for a gitsecurityapp that requested a wide scope of risky permissions, enabling attackers to gain full access to the target user’s accounts and repositories.
Using security products such as Datadog Cloud SIEM, you can detect common attack behavior that stems from compromised OAuth tokens and PATs. Normally, OAuth token usage occurs from a subset of fixed IP addresses or a consistent set of Autonomous System Numbers (ASNs), which are large groups of IP addresses from a single network or cloud provider.
Once an attacker gains access to an OAuth token, they will often use it from their own server or environment to enumerate access and exfiltrate data. Cloud SIEM’s OOTB detection rules can identify when OAuth tokens are used from different ASNs and user agents and alert your security team so they can temporarily block the user in GitHub while they conduct a follow-up investigation.
Similarly, Cloud SIEM also offers rules to detect mass zip file exfiltrations of repositories using OAuth access tokens, which is a common end goal for malicious actors. It also flags when OAuth application access restrictions are disabled, a configuration change that enables attackers to persistently access your environment via third-party OAuth applications.
Compromised third-party dependencies
In October 2021, a widely used JavaScript library npm package ua-parser.js was hijacked and modified with malicious code that targeted secrets stored as environment variables and also ran a cryptominer. If an organization updated to the newest version of ua-parser.js, the compromised package would trigger a GitHub Actions workflow to execute the info-stealing script on a GitHub-hosted runner. Because cloud credentials, API keys, and other secrets are stored within the runner’s environment variables, they were accessible to the malicious pre-install script that was executed during CI.
To safeguard your GitHub environment against vulnerabilities introduced by third-party dependencies—including compromised npm packages and open source libraries—you’ll need to use a static code analyzer or dependency checker such as Datadog Code Security or GitHub Dependabot. Using Code Security’s Software Composition Analysis (SCA), you can scan your open source libraries to detect known and emerging security vulnerabilities before package changes get pushed to production.
This process enables the detection of changes to preinstall and postinstall scripts, which should always be treated with caution. Below is a basic template for an SCA rule to detect preinstall scripts, which were a primary vector in the Shai-Hulud 2.0 attack. This template can be modified to be more granular, looking for deeper patterns such as commands to download files from external sources, open network connections, or modify file systems.
1rules:2 - id: suspicious-preinstall-script3 name: Detect preinstall script in package.json4 languages: [json]5 severity: WARNING6 message: >7 Suspicious: A "preinstall" script was found in package.json. This can be abused8 and is a common tactic in malicious npm packages.9 pattern: |10 {11 "scripts": {12 "preinstall": ...13 }14 }15 metadata:16 category: supply-chain17 technology: nodejs18 tags: [npm, scripts, preinstall, supply-chain, malware]19 confidence: HIGHSecure your supply chain with Datadog
In this blog, we applied the threat model discussed in the previous part of this series to GitHub and mapped out different control inputs, their associated risks, and identities. We also reviewed historical supply chain attacks and discussed how different Datadog Security products can help you protect your CI/CD systems against these attacks.
Check out our Cloud Security documentation to learn how to get started. You can read more about emerging threats and vulnerabilities—such as the Shai-Hulud worms and other security research—at Datadog Security Labs.
If you don’t already have a Datadog account, see how you can protect your environment by signing up for a free 14-day trial.
Further reading
White Paper: DevSecOps Maturity Model

Get a blueprint for assessing and advancing your DevSecOps practices.
Download to learn more
Project Glasswing: what Mythos showed us
Cloudflare's Project Glasswing tested Anthropic's restricted Claude Mythos Preview, a cybersecurity LLM that chained low-severity bugs into severe exploits and generated proof-of-concept code.
Deep dive
- Mythos Preview is a significant leap from general-purpose frontier models for security tasks.
- Two standout features: exploit chain construction (combining multiple small attack primitives into a working exploit) and proof generation (writing, compiling, and running code to prove a suspected bug is exploitable).
- Mythos can take low-severity bugs that would traditionally be ignored and chain them into a single, more severe exploit, complete with proof-of-concept (PoC).
- The model exhibited "organic refusals" but these were inconsistent, sometimes pushing back on legitimate research and sometimes agreeing to the same task framed differently. This highlights the need for explicit safeguards.
- The "signal-to-noise problem" is amplified by AI, with more false positives from memory-unsafe languages (C, C++) and model bias to "find bugs" even if none exist. Mythos had higher quality output with fewer hedged findings.
- Cloudflare learned that pointing a generic coding agent at a repo for vulnerability research is inefficient due to context window limitations and lack of parallelization.
- They built a "harness" with a multi-stage pipeline (Recon, Hunt, Validate, Gapfill, Dedupe, Trace, Feedback, Report) to manage execution and achieve better coverage.
- Key lessons from the harness: narrow scope yields better findings, adversarial review by a second agent reduces noise, splitting tasks across agents improves reasoning, and parallel narrow tasks beat one exhaustive agent.
- The implication for security teams is that simply "patching faster" is insufficient; architectures must be designed to make exploitation harder even if bugs exist, using defenses in front of the application and better internal segmentation.
Decoder
- LLM (Large Language Model): An artificial intelligence model trained on vast amounts of text data, capable of understanding and generating human-like text.
- Exploit chain: A sequence of multiple vulnerabilities or weaknesses that are combined to achieve a more significant compromise or attack than any single vulnerability could achieve on its own.
- Proof-of-concept (PoC): Code or a demonstration that shows how a vulnerability can be exploited in a real-world scenario.
- Refusals (in LLMs): When an LLM declines to answer a query or perform a task, often due to safety guardrails or ethical considerations.
- Context window: The maximum amount of text (tokens) an LLM can consider at one time when generating a response.
- Harness (in AI/security): A framework or system built around an AI model to manage its inputs, outputs, execution, and validation for a specific task, especially in complex or large-scale operations.
- CVE (Common Vulnerabilities and Exposures): A list of publicly disclosed cybersecurity vulnerabilities and exposures.
- SLA (Service Level Agreement): A commitment between a service provider and a client, defining the level of service expected.
Original article
Project Glasswing: what Mythos showed us
For the last few months, we've been testing a range of security-focused LLMs on our own infrastructure. These LLMs help identify potential vulnerabilities in our own systems, so we can fix them – and they also show us what attackers are going to be able to do with the latest models.
None of these LLMs has captured more attention than Mythos Preview, from Anthropic. A few weeks ago, we were invited to use Mythos Preview as part of Project Glasswing. We soon pointed it at more than fifty of our own repositories – to see what it would find, and to see how it works.
This post shares what we observed, what the models did well and what they didn't, and how the architecture and process around them needs to change, so they can be used at scale.
What changed with Mythos Preview
Mythos Preview is a real step forward, and it's worth saying that plainly before getting into anything else. We've been running models against our code for a while now, and the jump from what was possible with previous general-purpose frontier models to what Mythos Preview does today is not just a refinement of what came before.
It's a different kind of tool doing a different kind of work, and that makes a clean apples-to-apples comparison to earlier models difficult. So rather than trying to benchmark Mythos Preview against general-purpose frontier models, it's more useful to describe what it can actually do, and two features that stood out across the work we did with Mythos Preview:
-
Exploit chain construction - A real attack rarely uses one bug. It chains several small attack primitives together into a working exploit. For instance, it might turn a use-after-free bug into an arbitrary read and write primitive, hijack the control flow, and use return-oriented programming (ROP) chains to take full control over a system. Mythos Preview can take several of these primitives and reason about how to combine them into a working proof. The reasoning it shows along the way looks like the work of a senior researcher rather than the output of an automated scanner.
-
Proof generation - Finding a bug and proving it's exploitable are two different things, and Mythos Preview can do both. It writes code that would trigger the suspected bug, compiles that code in a scratch environment, and runs it. If the program does what the model expected, that's the proof. If it doesn't, the model reads the failure, adjusts its hypothesis, and tries again. The loop matters as much as the bugs it finds, because a suspected flaw without a working proof is speculation, and Mythos Preview closes that gap on its own.
Some of what we describe above is not entirely unique to Mythos Preview. When we ran other frontier models through the same harness, they found a fair number of the same underlying bugs, and in some cases they got further than we expected on the reasoning side too. Where they fell short was at the point of stitching the pieces together. A model would identify an interesting bug, write a thoughtful description of why it mattered, and then stop, leaving the actual chain unfinished and the question of exploitability open. What changed with Mythos Preview is that a model can now take those low-severity bugs (which would traditionally sit invisible in a backlog) and chain them into a single, more severe exploit.
Model refusals in legitimate vulnerability research
The Mythos Preview model provided by Anthropic, as part of Project Glasswing, did not have the additional safeguards that are present in generally available models (like Opus 4.7 or GPT-5.5).
Despite this, the model organically pushes back on certain requests - much like the cyber capabilities that made it useful for vulnerability hunting, the model has its own emergent guardrails that sometimes cause it to push back on legitimate security research requests. But as we found, these organic refusals aren’t consistent - the same task, framed differently or presented in a different context, could produce completely different outcomes as illustrated in the examples below.
Example of Mythos Preview pushing back on building a working proof of concept
For example, the model initially refused to do vulnerability research on a project, then agreed to perform the same research on the same code after an unrelated change to the project’s environment. Nothing about the code being analyzed had changed. In another case, the model found and confirmed several serious memory bugs in a codebase, and then refused to write a demonstration exploit. The same request, framed differently, got a different answer, and even the same request can produce different outcomes across runs due to the probabilistic nature of the model. Semantically equivalent tasks can produce opposite outcomes depending on how and when they’re presented to the model.
This matters because while the model’s organic refusals/guardrails are real, they aren’t consistent enough to serve as a complete safety boundary on their own. That’s precisely why any capable cyber frontier model made generally available in the future must include additional safeguards on top of this baseline behavior - making it appropriate for broader use outside of a controlled research context like Project Glasswing.
The signal-to-noise problem
One of the hardest parts of triaging security vulnerabilities is deciding which bugs are real, which are exploitable, and which need fixing now. This was a hard problem even in the pre-AI world. AI vulnerability scanners and AI-generated code have made it worse, and at Cloudflare we've built multiple post-validation stages to deal with it.
Two factors dominate the noise rate:
-
Programming language - C and C++ give you direct memory control and, with it, bug classes - buffer overflows, out-of-bounds reads and writes - that memory-safe languages like Rust eliminate at compile time. We saw consistently more false positives from projects written in memory-unsafe languages.
-
Model bias - A good human researcher tells you what they found and how confident they are. Models don't. Ask a model to find bugs, and it will find them, whether the code has any or not. Findings come back hedged with "possibly," "potentially," "could in theory," and the hedged findings vastly outnumber the solid ones. That's a reasonable bias for an exploratory tool. It's a ruinous one for a triage queue, where every speculative finding spends human attention and tokens to dismiss, and that cost compounds across thousands of findings.
Mythos Preview represents a clear improvement here, particularly in its ability to chain primitives - combining multiple vulnerabilities into a working proof of concept rather than reporting them in isolation. A finding that arrives with a PoC is a finding you can act on, and it means far less time spent asking "is this even real?"
Our harnesses are deliberately tuned to over-report, so we see more (and miss less), which comes with a lot more noise. But at triage time, Mythos Preview's output has noticeably higher quality: fewer hedged findings, clearer reproduction steps, and less work to reach a fix-or-dismiss decision.
Why pointing a generic coding agent at a repo doesn't work
When we first started AI-assisted vulnerability research last year, our instinct was the obvious one: point a generic coding agent at an arbitrary repository and ask it to discover vulnerabilities. This approach works, in the sense that the model will produce findings, but it doesn't work in producing meaningful coverage of a real codebase and identifying findings of value. There are two main reasons for this:
-
Context - Coding agents are tuned for one focused stream of work: building a feature, fixing a bug, writing a refactor. They ingest a lot of source code, hold a single hypothesis at a time, and iterate against it. That's exactly the wrong shape for vulnerability research, which is narrow and parallel by nature. A human researcher picks one specific thing to look at and investigates it thoroughly. That one thing might be a single complex feature, transitions across security boundaries, or a specific vulnerability class like command injections, where attacker input ends up being run as a shell command. Then they do it again, for a different feature, security boundary, or vulnerability class, several thousand times across the codebase. A single agent session (even with subagents) against a hundred-thousand-line repository can cover maybe a tenth of a percent of the surface in a useful way before the model's context window fills up and compaction kicks in - potentially discarding earlier findings that would have mattered.
-
Throughput - A single-stream agent does one thing at a time, but real codebases need many hypotheses against many components at once, with the ability to fan out further when something interesting turns up. You can drive a single agent harder, but at some point you stop being limited by the model and start being limited by the shape of the interaction itself. Using the model directly in a coding agent turns out to be fine for manual investigation when a researcher already has a lead and wants a second pair of eyes. However, it's the wrong tool for achieving high coverage. Once we accepted that, we stopped trying to make Mythos Preview do the wrong job and started building the harness around it instead.
What a harness actually fixes
Four lessons came out of running the work at scale, and each one pointed to the need for a harness that manages the overall execution:
-
Narrow scope produces better findings - Telling the model "Find vulnerabilities in this repository" makes it wander. Telling it "Look for command injection in this specific function, with this trust boundary above it, here's the architecture document and here's prior coverage of this area" makes it do something much closer to what a researcher would actually do.
-
Adversarial review reduces noise - Adding a second agent between the initial finding and the queue - one with a different prompt, a different model, and no ability to generate its own findings - catches a lot of the noise that the first agent would miss if it just checked its own work. It turns out that putting two agents in deliberate disagreement is way more effective than just telling one agent to be careful.
-
Splitting the chain across agents produces better reasoning - Asking "Is this code buggy?" and "Can an attacker actually reach this bug from outside the system?" are two different questions, and the model is better at each one when you ask them separately, because each question is narrower than the combined version.
-
Parallel narrow tasks beat one exhaustive agent - Coverage improves when many agents work on tightly scoped questions and we deduplicate the results afterward, rather than asking one agent to be exhaustive.
Each of those observations is about model behavior, and put together they describe something that isn't a chat interface anymore. It's a harness that helps you achieve the final outcomes. The first steps to building a harness are simple, as you can ask the model to help, which is what we did. We used Mythos Preview to build on, tailor, and improve our original harnesses to suit its strengths. An example of what a harness looks like in practice is described below.
Our vulnerability discovery harness
Here's what our vulnerability discovery harness looks like, stage by stage. It was used to scan live code across our runtime, edge data path, protocol stack, control plane, and the open-source projects we depend on.

| Stage | What it does | Why it matters |
 Recon |
An agent reads the repository from the top down, fans out to subagents responsible for each subsystem, and produces an architecture document covering build commands, trust boundaries, entry points, and likely attack surface. It also generates the initial queue of tasks for the next stage. | Gives every downstream agent shared context. Cuts the wander problem. |
 Hunt |
Each task is one attack class paired with a scope hint. Hunters (the agents that actually look for bugs) run concurrently, typically around fifty at once, each fanning out to a handful of exploration subagents. Each hunter has access to tools that compile and run proof-of-concept code in a per-task scratch directory. | This is where most of the work happens. Many narrow tasks in parallel, not one exhaustive agent. |
 Validate |
An independent agent re-reads the code and tries to disprove the original finding. It uses a different prompt and has no ability to emit new findings of its own. | Catches a meaningful fraction of the noise the hunter wouldn't catch when reviewing its own work. |
 Gapfill |
Hunters flag areas they touched but didn't cover thoroughly. Those areas get re-queued for another pass. | Counteracts the model's tendency to drift toward attack classes it has already had success with. |
 Dedupe |
Findings that share the same root cause collapse into a single record. | Variant analysis is a feature, not a way to inflate the queue with duplicates. |
 Trace |
For each confirmed finding in a shared library, a tracer agent fans out (one instance per consumer repository), uses a cross-repo symbol index, and decides whether attacker-controlled input actually reaches the bug from outside the system. | Turns "there is a flaw" into "there is a reachable vulnerability." This is the stage that matters most. |
 Feedback |
Reachable traces become new hunt tasks in the consumer repositories where the bug is actually exposed. | Closes the loop. The pipeline gets better as it runs. |
 Report |
An agent writes a structured report against a predefined schema, fixes any validation errors against that schema itself, and submits the report to an ingest API. | Output is queryable data, not free-form prose. |
What this means for security teams
The loudest reaction to Mythos Preview from other security leaders has been about speed - scan faster, patch faster, compress the response cycle. More than one team we have spoken with is now operating under a two-hour SLA from CVE release to patch in production. The instinct is understandable: when the attacker timeline shortens, the defender timeline has to shorten with it. Faster is not going to be enough, and we think a lot of teams are about to spend a lot of time, effort, and money learning that the hard way.
Patching faster does not change the shape of the pipeline that produces the patch. If regression testing takes a day, you cannot get to a two-hour SLA without skipping it, and the bugs you ship when you skip regression testing tend to be worse than the bugs you were trying to patch. We learned a version of this when we tried letting the model write its own patches and watched a few go out that fixed the original bug while quietly breaking something else the code depended on.
The harder question is what the architecture around the vulnerability should look like. The principle is to make exploitation harder for an attacker even when a bug exists, so that the gap between when a vulnerability is disclosed and when it is patched matters less. That means defenses that sit in front of the application and block the bug from being reached. It means designing the application so that a flaw in one part of the code cannot give an attacker access to other parts. It means being able to roll out a fix to every place the code is running at the same moment, rather than waiting on individual teams to deploy it.
We also recognize this topic cuts both ways. The same capabilities that helped us find bugs in our own code will, in the wrong hands, accelerate the attack side against every application on the Internet. Cloudflare sits in front of millions of those applications, and the architectural principles described above are exactly the ones our products are built to apply on behalf of customers. We will share more on what that means for customers in the weeks ahead.
If your team is doing similar work and would like to compare notes, reach out to us at [email protected].
Our research with Mythos Preview was conducted in a controlled environment against our own code; every vulnerability surfaced through this work was triaged, validated, and remediated where action was needed under Cloudflare's formal vulnerability management process.
This work was a team effort. Thanks to Albert Pedersen, Craig Strubhart, Dan Jones, Irtefa Fairuz, Martin Schwarzl, and Rohit Chenna Reddy for their contributions to the research, engineering, and analysis behind this blog post.

OpenAI is Making it Easier to Check if an Image was Made by Their Models
OpenAI announced on May 19, 2026, new measures including C2PA metadata and Google's SynthID invisible watermarks to help identify images generated by its AI models.
Deep dive
- OpenAI's new strategy to combat AI-generated image misinformation involves two complementary approaches.* The first is the adoption of C2PA, a visible metadata signal standard established by the Coalition for Content Provenance and Authenticity (founded 2021).* C2PA signals are accessible in file metadata, making them useful among trusted parties but susceptible to manipulation.* The second is a partnership with Google to embed SynthID, an invisible and more robust watermark designed to persist even after transformations like screenshots or resizing.* OpenAI is also launching a public verification tool that can check for both C2PA and SynthID signals.* These protections are currently limited to images generated by OpenAI's own models, not the wider ecosystem of AI tools.* The dual approach aims to combine the detailed information provided by metadata with the durability of invisible watermarking.
Decoder
- C2PA (Coalition for Content Provenance and Authenticity): An open technical standard that adds cryptographic metadata to digital content, signaling its origin and any modifications, to help establish trust and combat misinformation.* SynthID: An invisible, imperceptible watermark developed by Google that is embedded directly into the pixel data of AI-generated images, designed to remain detectable even after image modifications or compression.* Deepfake: A portmanteau of 'deep learning' and 'fake,' referring to synthetic media in which a person in an existing image or video is replaced with someone else's likeness using AI techniques.
Original article
Full article content is not available for inline reading.

You are no longer the user. You are the principal
Google I/O 2026 showcased a shift from direct software interaction to humans delegating tasks to autonomous AI agents, repositioning people as "principals."
Deep dive
- Google I/O 2026 marked a pivotal moment, indicating a strategic move towards an AI-agent-centric future.* The core idea is that individuals will transition from being 'users' who operate software directly to 'principals' who delegate tasks and intent to intelligent agents.* Key announcements like Gemini Spark, Android Halo, WebMCP, and Gemini Omni exemplify this vision of always-running, autonomous agents.* This paradigm shift introduces significant design challenges related to establishing and maintaining user trust in autonomous systems.* New considerations for visibility and transparency are crucial, ensuring users understand what agents are doing on their behalf.* User control mechanisms must evolve, moving beyond direct manipulation to managing and overriding delegated agent actions.* Accountability in AI-driven systems becomes a complex issue, requiring clear frameworks for responsibility when agents make decisions or take actions autonomously.
Decoder
- AI Agent: A software program or system that perceives its environment and takes actions autonomously to achieve specific goals, often without constant human intervention.* Principal (in AI context): A term used to describe a human delegating tasks to an AI agent, implying a higher-level oversight role rather than direct operational control.* Gemini Spark, Android Halo, WebMCP, Gemini Omni: Specific (and potentially future/fictional) Google products or initiatives mentioned as examples of this AI agent paradigm shift.
Original article
Google I/O 2026 signaled a major shift from humans directly operating software to AI agents working autonomously on their behalf. Through announcements like Gemini Spark, Android Halo, WebMCP, and Gemini Omni, Google presented a future where people act less as “users” and more as “principals” who delegate intent to always-running agents, raising new design challenges around trust, visibility, control, and accountability in AI-driven systems.
Design Changing from Artifact-production to Intent-shaping
Jakob Nielsen predicts AI will shift UX design from creating traditional artifacts like screens to defining intent, judgment, and behavioral boundaries for AI systems, making artifact-focused designers unemployable within five years.
Deep dive
- AI is shifting the role of UX designers from creating tangible artifacts (screens, prototypes) to defining the 'intent' and 'judgment' for AI systems.
- Designers will increasingly be responsible for encoding what constitutes "good" design into AI, establishing rules and boundaries for AI behavior.
- The focus will move to maintaining conceptual coherence and brand consistency across various AI-generated experiences.
- Traditional craft skills in producing UI elements will become less central as AI automates these tasks.
- Jakob Nielsen predicts that designers who resist this shift and cling to artifact-production methods will become unemployable within five years.
- This transformation requires designers to develop higher-level thinking, focusing on systemic implications and ethical considerations rather than pixel-level details.
Decoder
- Artifact-production: In design, this refers to the traditional creation of tangible outputs like wireframes, mockups, prototypes, and final UI screens.
- Intent-shaping: A new design paradigm where designers define the goals, principles, and behavioral constraints for AI systems, rather than directly designing their specific outputs.
Original article
AI is transforming UX design from creating artifacts like screens and prototypes to defining intent, judgment, and behavioral boundaries for AI systems. Designers must shift to higher-level responsibilities, including encoding what "good" means into systems and maintaining coherence across AI outputs rather than performing traditional craft activities. Those who resist this change and stick to old artifact-production methods will become unemployable within five years.

Nasa selects Jeff Bezos's Blue Origin for first of three uncrewed lunar missions
NASA selected Jeff Bezos's Blue Origin for the first of three uncrewed lunar missions this fall, kicking off a $20 billion moon base construction by 2032.
Original article
Nasa selects Jeff Bezos’s Blue Origin for first of three uncrewed lunar missions
Three lunar landings are planned for this year in preparation for the construction of a $20bn moon base
Nasa announced on Tuesday ambitious plans for three uncrewed lunar missions this year to kickstart construction of a $20bn moon base, and said it had chosen the Amazon founder Jeff Bezos’s Blue Origin, ahead of Elon Musk’s SpaceX, to conduct the first.
The revelation by Nasa’s administrator, Jared Isaacman, at a press conference in Washington DC marked the first detailed public explanation of how and when the moon base will be built.
He said the three missions planned for 2026 would be followed by “more than a dozen” more in the coming years to test systems and equipment. He said the highly successful Artemis II mission last month that sent four astronauts around the moon for the first time since 1972 had been both a catalyst and incentive to advance the moon base plan.
“People are looking up again, believing in big things again, and paying attention as America returns to the moon again, and this time to stay,” he said.
He added, without mentioning any names, that the agency had been “having the tough conversations with those failing to meet expectations” since the Artemis splashdown on 10 April.
“We are not jumping right into the glass dome moon base. We intend to take an iterative approach, sending a demand signal to industry for a lot of landers and rovers and tech demonstrations, and all the scientific payloads these missions can accommodate,” Isaacman said.
“We are leveraging the Nasa playbook from the 1960s, figuring out what works and what doesn’t in this epic science of survival, because the moon base is as beautiful as it is hostile.”
The headline announcement was the selection of Bezos’s Blue Origin company to conduct the first mission, as early as fall. It has been awarded $230.4m to support each of its first two moon base missions, Nasa said, but will largely fund the operation itself.
“Moon Base One will be the first privately funded lunar lander mission in history,” Isaacman said. It will take Endurance, Blue Origin’s cryogenically propelled cargo lander, holding multiple scientific payloads from Nasa and private partners, to the Shackleton de Gerlache Ridge area of the moon’s south pole.
Isaacman said the objective was to “demonstrate critical capabilities that reduce risk for the human landing system missions”, and that Bezos’s company was picked “because of the role Blue Origin plays in the Artemis program”.
Blue Origin is competing with SpaceX to provide crew landers for an upcoming sequence of Artemis missions, including the planned 2028 return of humans to the moon on Artemis IV. Nasa will evaluate the SpaceX Starship Human Landing System (HLS) and Blue Origin’s Blue Moon lander during next year’s Artemis III test mission in lower Earth orbit and decide thereafter.
Blue Origin suffered a setback last month when a payload from the third flight of its heavy-lift New Glenn rocket ended up in the wrong orbit, but was cleared to return to flight by the Federal Aviation Administration last week.
Both companies have built large new facilities in or close to Cape Canaveral’s Kennedy Space Center to support crewed and cargo missions in partnership with Nasa.
As well as awarding Blue Origin the first moon base mission, Nasa announced a series of smaller contracts with private companies involved in the agency’s moon-to-Mars projects. They include Lunar Outpost, which has been working on lunar rovers, and Firefly Aerospace, which in March last year became the first private operator to make a successful moon touchdown with its Blue Ghost lander.
The agency’s “blueprint for an enduring lunar presence” is also laid out on a new Nasa moonbase website launched on Wednesday, which gives a timeframe between 2029 and 2032 for establishing a base with “operating capability”. A “semi-permanent presence” will follow in 2032 or beyond, it said.
The moon base project forms part of Donald Trump’s national space policy, including directing Nasa to accelerate the Artemis program to achieve the next human moon landing ahead of China, establish a permanently habitable lunar base and develop a nuclear space reactor.
Partnerships with private operators, Nasa has said, can significantly reduce the cost to taxpayers, and create a thriving space economy providing thousands of new jobs while conducting inspiring missions of science and discovery.
Isaacman, who has attempted to align the Trump administration’s planned budget cuts to Nasa with the president’s ambitious vision, said the world had “paused to take notice” during Artemis II. He said he hoped that mission, along with moon base plans and other moon-aligned projects, would inspire what he called a “golden age of exploration”.
“I’m often asked why we send our astronauts into such harsh and dangerous and unforgiving environment of space or the lunar surface, and at such great cost,” he said.
“We go for the technology we will pioneer to get there, the science, and all that we will learn that will make life better here on Earth, to advance humankind on this great adventure, to inspire the next generation to do it better than we can, and, to be very clear, to master the skills for where we will inevitably go next.”

American Airlines picks SpaceX's Starlink for in-flight Wi-Fi on more than 500 planes
American Airlines has selected SpaceX's Starlink to provide in-flight Wi-Fi on over 500 Airbus narrow-body planes starting early next year, following other major carriers like United and Southwest.
Original article
Starlink scored another win for in-flight Wi-Fi with American Airlines.
The SpaceX service has already won contracts with United Airlines, Southwest Airlines and others.
American said it would put the service on hundreds of narrow-body aircraft, like the Airbus A321neo.
American Airlines plans to outfit more than 500 of its narrow-body aircraft with Starlink, handing another win to Elon Musk's SpaceX unit that has made inroads with major carriers for in-flight Wi-Fi.
American was evaluating Starlink and Amazon Leo as recently as March for the service.
The airline announced Tuesday it would install Starlink on about 500 of its narrow-body Airbus planes, like the A321neo, starting early next year. American spokesman said the carrier doesn't have immediate plans to change providers on its Boeing fleet, which uses a mix of Viasat and Panasonic.
American in January rolled out free in-flight Wi-Fi for members of its frequent flyer program, following United Airlines, Delta Air Lines and others.
Delta in March said it would use Amazon Leo for in-flight Wi-Fi for hundreds of jets starting in 2028. United, Southwest Airlines and Alaska Airlines, which merged with Hawaiian Airlines in 2024, have selected Starlink.
Carriers are battling for higher-spending customers, including by upgrading once-slow, expensive and clunky in-flight internet to higher speeds. They have also been weighing other revenue streams, like personalized ads for travelers.
SpaceX, meanwhile, is preparing to go public in what's likely to be a record IPO next month. Its connectivity unit, which includes Starlink, posted revenue of $11.39 billion last year, making up 61% of total sales, SpaceX said in a filing for its initial public offering earlier this month.
Read more CNBC airline news
- Spirit starts monthslong process of dismantling airline after biggest collapse in a generation
- 'Godspeed my friend': Inside the final hours of Spirit Airlines
- United Airlines CEO confirms he approached American Airlines about merger
- U.S. airlines are hiking fares — and travelers keep booking

The Open/Closed Problem in AI
A researcher argues that the current focus on optimizing AI hardware for "open-loop" inference, like specialized ASICs, is inadvertently hindering the breakthrough to "closed-loop" learning where models self-update.
Deep dive
- The author, Maxim Khailo, attended the MLSys conference and noted an overwhelming focus on efficiency in training and deploying LLMs.* He introduces the "Open/Closed problem" by drawing a parallel to 3D graphics hardware evolution: from flexible CPUs to fixed-pipeline GPUs, then to programmable GPUs (leading to CUDA and AI training), and now back to specialized ASICs optimized for AI inference.* The first Open/Closed problem is this cycle of hardware specialization becoming more rigid.* The second Open/Closed problem relates to AI learning: current deployed AI models use "open-loop" learning, meaning they don't learn after deployment; any "learning" is externalized, for example, by agents updating an external memory or database.* Human brains use "closed-loop" learning, where the model (brain) updates itself internally based on predictions and sensory input, without external intervention.* Khailo claims that the celebrated efficiency work (better kernels, inference/training ASICs) is "hardware hardening" around open-loop learning, making closed-loop learning harder to attempt.* An inference ASIC physically bakes in the assumption of frozen weights, separate compute/memory, and batched matrix multiplications, which are antithetical to how a closed-loop system would need to operate.* He highlights that a model learning in a closed loop requires constantly changing weights, fine-grain updates, and fused memory/compute, similar to a neuron.* Khailo asserts that by optimizing for the current paradigm, the industry is neglecting the "substrate to experiment on" for breakthroughs like self-updating models.* He urges a focus on building flexible hardware substrates, akin to an advanced FPGA, before the window for closed-loop learning experimentation closes due to increasing specialization.
Decoder
- MLSys conference: A conference focused on the intersection of machine learning and systems, covering topics like efficient training, deployment, and use of ML models.* Open-loop learning: In AI, refers to models that do not learn or update their parameters after deployment; any "learning" is externalized, for example, by agents updating an external memory or database.* Closed-loop learning: In AI, refers to a hypothetical system where the model itself updates its internal parameters and knowledge without external intervention, similar to how biological brains learn.* ASIC (Application-Specific Integrated Circuit): A microchip designed for a specific application, in this context, specialized for highly efficient AI inference or training, but less flexible than general-purpose processors.* SGD (Stochastic Gradient Descent): An iterative optimization algorithm used to minimize the loss function of a machine learning model, particularly in training neural networks.* Backpropagation: An algorithm used in training artificial neural networks to calculate the gradient of the loss function with respect to the weights and biases of the network, allowing for weight adjustments.* Matmul (Matrix Multiplication): A fundamental operation in linear algebra, heavily used in neural networks for processing data, especially during inference.* FPGA (Field-Programmable Gate Array): An integrated circuit designed to be configured by a customer or designer after manufacturing, offering flexibility to implement custom digital circuits, unlike fixed ASICs.
Original article
I went to the ninth MLSys conference in Seattle. This is a conference of people in research and industry building ML systems. The vast majority of work that I saw is building systems that train and use LLMs. The biggest focus was on efficiency. How do you train LLMs more efficiently? How do you deploy and use them more efficiently? When I was trying to understand the themes and messages I witnessed, the Open/Closed problem occurred to me.
To understand what the Open/Closed problem is, we first need to understand a little bit of history.
When 3D computer graphics were exploding in the 90s, they were first being rendered by a CPU. A CPU is a generic computing device where you can do everything. So naturally 3D graphics varied wildly, including some games using voxels instead of polygons. There was a great amount of creativity. Eventually we started to get 3D acceleration via graphics cards. These cards had fixed pipelines. So while they greatly accelerated polygon rendering and certain effects, they limited the creativity in how you do graphics and you lost variety. Eventually GPU makers like Nvidia invented pixel and vertex shaders. This added flexibility back into graphics, allowing more creative games. On top of this programmability, CUDA was born. CUDA was so flexible that the AI community figured out how to train neural nets on GPUs, which allowed them to try bigger models. AlexNet was the inflection point and why we are even talking about AI and LLMs today. What I noticed at MLSys is that the companies building GPUs are now constraining them to be more efficient for inference vs training. Now you have ASICs designed to do just inference, while others are optimized for training.
In other words, we started with an open system (CPU), went to a closed system (fixed-pipeline GPU), back to an open system (programmable GPU), and back to a more closed system (specialized ASICs). This is part of what I mean by the Open/Closed problem. But this also coincides with another Open/Closed problem in a different sense.
The AIs we are deploying are trained using an open loop. What I mean is that the models themselves don't learn. You need an outside system, outside the model's circuit, to train them. You gather data, come up with a loss function, and do SGD to train them via backpropagation. Then you deploy them. After the model is deployed it does not learn. Its memory, stored in its parameters, doesn't change. People are hacking around this fact using external memory via Agents. Agents use an LLM (which doesn't learn) to update an external memory source (like markdown files, a database, etc.) using tool calls. So Agents learn, but they learn in a very inefficient way.
Our brains use a closed loop to learn. Our brains have a model of the outside world; they make predictions on what our senses should sense, and then check our senses to see how far off the prediction is. If the prediction is wrong, the brain is surprised and updates the model to make a more accurate prediction. In other words, there is no outside process for our brains to accumulate knowledge. It's done all inside our brain, a closed loop.
This is the other Open/Closed problem I noticed at MLSys. It seemed everyone is working to make open-loop learning better and more efficient, either by changing model architectures or the way you train them, optimizing GPU kernels, etc. I didn't see anyone working on closed-loop learning, where the model itself, without outside intervention, updates itself when it accumulates knowledge. These two Open/Closed problems are the same problem.
So here is the uncomfortable claim. The efficiency work the field is celebrating (better kernels, inference ASICs, training ASICs) is not just neutral progress. It is hardware hardening around open-loop learning, and every layer of specialization makes closed-loop learning harder to even attempt. We are optimizing our way into a paradigm and calling it advancement. Fixed GPU pipelines didn't just speed up graphics; they quietly killed the wild experiments for a decade until programmability came back. The same thing is happening now, and almost no one at MLSys seemed to notice.
And the mechanism isn't vague. An inference ASIC physically bakes in the open-loop assumption. The weights are frozen, so parameter memory is built to be read, not rewritten. Compute and memory sit in separate places because that is efficient when the model never changes. Everything is shaped around big batched matmuls because that is what serving a static model looks like. None of this is an oversight. It is the chip doing exactly its job. But a model that learns in a closed loop needs the opposite of all of it: weights that change constantly, updates at fine grain, memory and compute fused so a parameter can rewrite itself in place. A chip optimized for inference doesn't just fail to help with that. It assumes it away in silicon. Every generation of specialization pours more concrete over the road not taken.
Eric Kandel won a Nobel Prize for showing that memory isn't stored by some separate system. A single neuron both computes and physically rewrites itself as it learns. The breakthrough we need is a model that updates itself, with no outside process, no separate training run, memory and compute fused at fine grain the way they are in a neuron. That requires a substrate to experiment on: something like an FPGA, but bigger, faster, and built for this. Nobody is building it, because everybody is busy optimizing the thing we already have.
So I'll put it plainly. If you are working on open-loop efficiency, you are not working on the breakthrough. You are working on the thing that will make the breakthrough harder to find. The hardware is hardening around the wrong paradigm while the field congratulates itself on speed. The window to experiment with closed-loop learning is open right now, and it is closing with every ASIC that ships. Someone should build the substrate before it does.

3D-printable humanoid legs let robotics experiments run wild
Hugging Face has released the LeRobot Humanoid project, providing open-source designs and software for a $2,500 3D-printable bipedal robot leg platform, aiming to make robotics research more accessible.
Original article
A $2,500 pair of humanoid robot legs built from 3D-printed parts and off-the-shelf components is not going to win marathons just yet. But such relatively inexpensive hardware could enable researchers to more easily test and train AI-powered robotics software in a physical body during real-world experiments.
The newly available LeRobot Humanoid project comes from the machine-learning and AI development platform Hugging Face. The full-stack release gives robot builders and researchers access to a bill of materials, files for 3D-printable parts, wiring documentation, and physical assembly instructions—but it also includes software tools for calibrating and controlling the robot in both the physical body and in simulation.
“If you are looking for the most advanced humanoid robot, this is not it,” wrote Virgile Batto, a robotics engineer at Hugging Face, in a blog post coauthored with other colleagues. “If you are looking for a humanoid you can build, understand, repair, instrument, simulate, and use for learning experiments, this is the robot we are trying to make.”
The Hugging Face team aimed for a “practical balance between affordability, mechanical performance, and ease of assembly.” The design, built around printable parts, off-the-shelf hardware, and affordable actuators and electronics, means the bipedal robotic platform can be easily fixed and modified to enable rapid experimentation and development, rather than being a “one-off prototype useful for a demo.”
Such a design also aims to enable a more reproducible “full-robot design loop” in which robots designed in simulation can be tested and validated in physical body experiments, according to Batto and colleagues. In turn, data from the real-world trials can help inform and improve the simulations used for training robot behaviors.
The team also promised that the LeRobot Humanoid legs are just the start of a bigger roadmap that includes integration with an upper body and more advanced behaviors. The company previously released a 3D-printable robotic arm.
The push for affordable robots
Hugging Face is backing open source robotics projects to help make robots affordable while mitigating industry dominance by large corporate interests, Hugging Face CEO Clem Delangue previously told TechCrunch. In May 2025, the company announced it was working with the French company The Robot Studio to develop the HopeJR humanoid robot with 66 actuated degrees of freedom and a target price tag of $3,000.
Hugging Face has also begun selling a small $299 robot called Reachy Mini that is primarily designed for expressive behaviors and interactions with people.
The push for affordable robotics development comes as companies also look to reduce the manufacturing costs of commercial robots. A commercial humanoid robot still typically costs between $30,000 to $150,000 per unit as companies work to build out supply chains, according to an April 2026 report by the consulting firm McKinsey. Meanwhile, venture capital funding for robotics has more than tripled between 2023 and 2025 to surpass $40 billion last year.
Some Chinese companies, such as Unitree Robotics, are already selling robot models at price points below $20,000. Unitree is also working to raise $610 million in its initial public offering with Shanghai’s Star Market—but the South China Morning Post highlighted a 53 percent drop in Unitree’s reported first-quarter profits despite the company’s 68 percent rise in revenue. SCMP described the Unitree “profit squeeze” as coming from “soaring expenses and a brutal price war,” with the company itself also acknowledging a possible “cooling” of hype surrounding humanoid robots.
Meanwhile, Hyundai Motor Group is reportedly looking to mass-produce the Boston Dynamics humanoid robot Atlas by setting up a manufacturing line at the Hyundai electric vehicle plant in Georgia, according to UPI. There is also discussion of setting up a US-based facility capable of producing 350,000 robotic actuators annually.
Stack Overflow's forum is dead thanks to AI, but the company's still kicking... thanks to AI
Stack Overflow's public Q&A forum is declining due to AI, yet the company is thriving by monetizing its vast content archive through enterprise solutions and data licensing.
Deep dive
- Stack Overflow's public Q&A forum traffic has significantly decreased, with monthly questions mirroring 2008 levels (6,866 last month).
- Elon Musk described the situation as "death by LLM" in July 2023.
- Despite declining public engagement, the company's annual revenue has roughly doubled to $115 million.
- Losses have slimmed from $84 million in FY2023 to $22 million in the last fiscal year, partly due to cost-cutting and layoffs.
- Stack Overflow's new primary revenue streams are enterprise solutions like "Stack Internal" and licensing its data to AI companies.
- "Stack Internal" provides a generative-AI add-on powered by its historical Q&A data and is used by 25,000 companies.
- CEO Prashanth Chandrasekar noted in December that declines were primarily for simple questions, with complex questions still posted on Stack Overflow.
- The company benefits from the fact that Large Language Models (LLMs) are only as good as the human-curated data they are trained on.
Decoder
- Stack Internal: An enterprise solution offered by Stack Overflow that provides a generative-AI add-on, powered by its extensive Q&A database, for internal company use.
Original article
Stack Overflow’s forum is dead thanks to AI, but the company’s still kicking... thanks to AI
The platform is raking in millions of dollars in revenue, with AI an ironic new source of revenue.
When Elon Musk described Stack Overflow’s plight as “death by LLM” in July 2023, he wasn’t exaggerating.
Having been the go-to resource for developers looking for technical help for a long time, Stack Overflow neared the peak of its powers during the pandemic, with coders seeking the evergreen information on the company’s popular Q&A forum. But amid a wave of powerful code-writing AI assistants like ChatGPT, Cursor, Claude, Google’s Gemini, and Microsoft’s Copilot, traffic to the site has plummeted.
Last month, Stack Overflow recorded just 6,866 questions — roughly equal to the typical volume when the site first launched back in 2008.
But while Stack Overflow the Q&A forum looks dead, Stack Overflow the company looks to be limping along.
Unlike Chegg and other knowledge hubs that have fallen victim to generative AI, Stack Overflow has found a way to monetize its enormous back catalog of content. Indeed, even with engagement falling off a cliff since ChatGPT’s 2022 debut, the company’s annual revenue has roughly doubled to $115 million. Losses have slimmed, too, from $84 million in FY2023 to $22 million as of the last fiscal year, as desperate cost-cutting efforts, including mass layoffs, helped boost the bottom line.
Once dependent on ads across its buzzy forum, Stack Overflow now primarily makes money from enterprise solutions like “Stack Internal,” which provides a generative-AI add-on powered by the millions of questions and answers on the site through the years. Stack Internal is now used by 25,000 companies around the world. It also licenses its data to AI companies, in a Reddit-like model — a platform that made more than $200 million from licensing user-generated content in 2024.
Put simply, Stack Overflow’s new niche is the trust built by its old community and their expertise. In the words of CEO Prashanth Chandrasekar last December:
“...when we saw the questions decline in early 2023, what we realized is that pretty much all those declines were with very simple questions. The complex questions still get asked on Stack because there’s no other place. If the LLMs are only as good as the data, which is typically human curated, we’re one of the best places for that, if not the best for technology.”
Large language models want data about coding problems and how to solve them. Stack Overflow has a big digital warehouse full of that, but it’s increasingly aging, as queries move into private chat windows with LLM models... which need huge chunks of data to work. Stack Overflow has become a fascinating canary in tech’s new, circular coal mine.
Google DeepMind’s Hassabis: AGI is 3 to 4 years away
Google DeepMind CEO and Nobel Prize winner Demis Hassabis shortened his prediction for when the era of AGI would be upon us.
Meta jumps after announcing paid subscriptions for Instagram, WhatsApp, Facebook, and AI
On Wednesday, Meta announced that it’s rolling out Meta One, a suite of paid versions of its most popular apps that offer extra features like profile customization, super reactions, and story insights. Instagram Plus and Facebook Plus will cost $3.99 a month, while WhatsApp Plus is going for $2.99, according to TechCrunch.
The company is also launching two AI subscription tiers — one for $7.99 and another for $19.99 for more advanced users. People can continue using the Meta AI chatbot for free, but will now run into limits.
Together, these represent Meta’s first large-scale attempt to monetize everyday consumer use of its flagship apps through subscriptions rather than relying solely on advertising.
The stock is up nearly 3% on the news.
Meta’s head of product, Naomi Gleit, said in an Instagram post that the company has “more plans on the way for creators, businesses, and Meta AI power users.”
Meta has struggled to justify its enormous AI capital expenditure to investors since it lacks the recurring cloud revenue of its peers. New subscription revenue streams could help reassure investors that Meta has additional ways to monetize its AI investments beyond advertising.
TechCrunch reported earlier this year that Meta had been testing premium subscriptions.
Together, these represent Meta’s first large-scale attempt to monetize everyday consumer use of its flagship apps through subscriptions rather than relying solely on advertising.
The stock is up nearly 3% on the news.
Meta’s head of product, Naomi Gleit, said in an Instagram post that the company has “more plans on the way for creators, businesses, and Meta AI power users.”
Meta has struggled to justify its enormous AI capital expenditure to investors since it lacks the recurring cloud revenue of its peers. New subscription revenue streams could help reassure investors that Meta has additional ways to monetize its AI investments beyond advertising.
TechCrunch reported earlier this year that Meta had been testing premium subscriptions.
Uber raised its stake in Germany-based Delivery Hero to nearly 37%, up from the 19.5% the companies disclosed earlier this month, according to reporting by the Financial Times. The rapid share accumulation follows a takeover bid Uber extended to the struggling food delivery company over the weekend, offering essentially no premium over where the stock is trading, a move aimed at aggressively countering DoorDash in international markets.
DoorDash is also circling, with reports suggesting it is primarily interested in carving out Delivery Hero’s lucrative Middle Eastern businesses like Talabat and HungerStation.
Anthropic’s revenue continues to surge, shooting past OpenAI
The drip, drip, drip of leaked financials from OpenAI and Anthropic is turning into a steady flow as the two AI giants jockey for position ahead of their planned IPOs later this year.
The companies’ soaring valuations and annualized recurring revenue (ARR) have been running neck and neck for months, and The Information now reports that Anthropic is generating an estimated 35% more revenue than OpenAI.
According to The Information’s reporting, Anthropic is close to a staggering $45 billion ARR, while OpenAI is at an estimated $33 billion ARR.
Last month, Anthropic announced that its ARR had reached $30 billion — tripling since the end of 2025. That put it ahead of OpenAI’s $24 billion ARR, which the ChatGPT maker reported at the end of March.
Then last week it was reported that OpenAI held a $1 billion lead in Q1 revenue over Anthropic.
That $45 billion ARR is a whopping 5x the $9 billion Anthropic reported at the end of 2025.
According to The Information’s reporting, Anthropic is close to a staggering $45 billion ARR, while OpenAI is at an estimated $33 billion ARR.
Last month, Anthropic announced that its ARR had reached $30 billion — tripling since the end of 2025. That put it ahead of OpenAI’s $24 billion ARR, which the ChatGPT maker reported at the end of March.
Then last week it was reported that OpenAI held a $1 billion lead in Q1 revenue over Anthropic.
That $45 billion ARR is a whopping 5x the $9 billion Anthropic reported at the end of 2025.
Native Multimodal Models (GitHub Repo)
A new GitHub repository maps the transition in AI from modular multimodal systems to "Native Multimodal Modeling" (NMM), where different modalities are deeply integrated within unified transformer architectures.
Deep dive
- The "Awesome Native Multimodal Modeling (NMM)" GitHub repository and its companion paper track the evolution of multimodal AI models.
- It focuses on the structural transition from "Modular Assembly" (late-fusion/grafted compositions) to "Native Multimodal Modeling," where multiple modalities are intrinsically integrated.
- NMMs use unified transformer spaces or joint backbones, moving beyond systems blind to raw sensory signals.
- The repository introduces an NMM Architectural Taxonomy based on Integration Depth (mid-fusion vs. early-fusion) and Functional Input–Output Duality.
- M2T (Multi-to-Text): Models that ground cross-modal inputs (e.g., images, audio) into purely linguistic responses for reasoning (e.g., LLaVA, DeepSeek-VL, Qwen-Image, GLM-4.5V).
- M2G (Multi-to-Target): Models that directly synthesize modality-specific outputs (e.g., video, speech) through native representations (e.g., Wan 2.2-T2V-A14B, HunyuanVideo, OmniVoice).
- M2M (Multi-to-Multi): A unified paradigm where understanding and generation coexist symmetrically within a single network, treating them equivalently within a unified network.
- The roadmap also covers technical dimensions like architectural patterns, data curricula, training strategies, inference/deployment, and evaluation benchmarks.
- It serves as a curated reading list and model zoo for researchers and developers in the field.
Decoder
- Multimodal Modeling: AI models that can process and understand information from multiple modalities, such as text, images, audio, and video.
- Modular Assembly (Late-Fusion/Grafted Compositions): An older approach where different unimodal models (e.g., separate vision encoder, text encoder) are trained and then combined, often through shallow projectors, typically suffering from a lack of intrinsic integration between modalities.
- Native Multimodal Modeling (NMM): An approach where multiple modalities are intrinsically integrated into a unified transformer space or joint backbone, processing raw sensory signals together from earlier stages.
- Transformer: A neural network architecture, popularized for natural language processing, that uses self-attention mechanisms to weigh the importance of different parts of the input data.
- Mid-fusion: A type of multimodal integration where features from different modalities are combined at an intermediate stage of the model, after some initial unimodal processing.
- Early-fusion: A type of multimodal integration where raw or lightly processed data from different modalities are combined at the very beginning of the model's processing pipeline.
- M2T (Multi-to-Text): Multimodal models where the input can be various modalities (e.g., image, text) but the primary output is text (e.g., visual question answering).
- M2G (Multi-to-Target): Multimodal models where the input can be various modalities and the output is a specific target modality other than text (e.g., text-to-video, audio-to-image).
- M2M (Multi-to-Multi): Multimodal models designed for symmetric understanding and generation across multiple modalities, treating them equivalently within a unified network.
Original article
Awesome Native Multimodal Modeling (NMM)
A curated reading list & model zoo for the era of Born-Native multimodal foundation models.
📄 Companion paper: "Toward Native Multimodal Modeling: A Roadmap"
This repository systematically tracks the structural transition from Modular Assembly — late-fusion / grafted compositions that suffer from a fundamental blindness to raw sensory signals — to Native Multimodal Modeling (NMM), where multiple modalities are intrinsically integrated into a unified transformer space or joint backbone.
⭐ Star this repo to track the latest landmark works. PRs are warmly welcomed for any model we may have missed.
🗺️ The NMM Architectural Taxonomy
We formalize the NMM ecosystem through a dual-dimensional lens based on Integration Depth (mid-fusion vs. early-fusion) and Functional Input–Output Duality:
| # | Paradigm | Input → Output | Core Idea |
|---|---|---|---|
| 🟦 | M2T — Multi-to-Text | multimodal → text | Ground cross-modal inputs into purely linguistic responses for reasoning. |
| 🟩 | M2G — Multi-to-Target | multimodal → modality-specific | Direct synthesis of modality-specific outputs through native representations to achieve temporal & acoustic coherence. |
| 🟪 | M2M — Multi-to-Multi | multimodal → multimodal | A unified paradigm where understanding and generation naturally coexist as reciprocal projections within a single network. |
🟦 1. Multi-to-Text (M2T) Unimodal Generation
Native scaling frameworks that ground cross-modal inputs into linguistic streams for logical reasoning.
🧱 Late-Fusion Baseline References
Modularly assembled via shallow projectors; blind to raw sensory signals.
- LLaVA [Liu et al., 2023] —
💻 GitHub·📄 Paper - DeepSeek-VL [Lu et al., 2024] —
💻 GitHub·📄 Paper - Qwen-Image [Wu et al., 2025] —
💻 GitHub·🌐 Blog
🔗 Mid-Fusion (Naturally Interacted Regime)
Foundational pioneers maintaining explicit, modality-aware boundaries.
- CogVLM [Wang et al., 2023] —
💻 GitHub - Qwen-Audio [Chu et al., 2023] —
💻 GitHub·🌐 Project Page
Massive state-of-the-art evolved mid-fusion architectures:
- Qwen2.5-VL [Qwen Team, 2025] —
💻 GitHub·🌐 Blog - Qwen3-VL [Qwen Team, 2025] —
💻 GitHub·📄 Paper - InternVL-3.5 [Chen et al., 2025] —
💻 GitHub·🤗 HF Collection
Scale-driven industrial mid-fusion implementations:
- GLM-4.5V / GLM-V [ZhipuAI, 2025–2026] —
💻 GitHub·🤗 HF Model - Kimi K2 / K2.5 [Moonshot AI, 2025–2026] —
🌐 Project Page·💻 GitHub Org
🧬 Dense / Native M2T Scaling
- MiniCPM-V 4.x [Yu et al., 2025] —
💻 GitHub - Nemotron 3 Nano Omni [NVIDIA, 2026] —
💻 GitHub·📄 Paper - MiMo-V2.5 [Xiaomi MiMo Team, 2026] —
💻 GitHub·🌐 Project Page - Gemma-4 / Qwen3.6 — Timeline benchmarks driving advanced contextual reasoning (forthcoming).
🟩 2. Multi-to-Target (M2G) Scenario-based Generation
Bypassing traditional post-hoc decoders to synthesize photorealistic spatiotemporal physics or continuous speech directly.
🎬 Advanced Video / World Simulators
- Wan 2.2-T2V-A14B [Wan Team, 2025] —
🤗 HF Model— Unifies video patches into native generation spaces with continuous physics. - HunyuanVideo & HunyuanVideo-1.5 [Tencent, 2024–2025] —
💻 GitHub·🤗 HF Model (1.5) - Kling-Omni [Kuaishou, 2025] —
🌐 Project Page
🎙️ Speech-Centric Native Frameworks
- OmniVoice [Zhu et al., 2026] —
💻 GitHub·🌐 Project Page - MiniCPM-o 2.6 / 4.5 [OpenBMB, 2025–2026] —
🤗 HF Model·💻 GitHub - Seedream 3.0 [Gao et al., 2025] —
📄 Tech Report·🌐 Project Page - HiDream-I1 —
💻 GitHub
📅 Timeline Milestone Generators
- LTX-2 / LTX-Video [Lightricks, 2024–2026] —
💻 GitHub - Ming-Flash-Omni [Ant Group / inclusionAI, 2025] —
💻 GitHub·📄 Paper
🟪 3. Multi-to-Multi (M2M) Symmetric Modeling
Omni-directional unified spaces establishing a symmetric paradigm where comprehension and generation natively coexist.
🔥 Early-Fusion (Native Convergent Regime)
Born-native designs treating all modalities equivalently via one unified backbone & embedding space.
- Transfusion [Zhou et al., 2024] —
📄 Paper - Chameleon ★ [Meta AI, 2024] —
💻 GitHub·📄 Paper - AnyGPT ★ [Zhan et al., 2024] —
💻 GitHub·📄 Paper
🔮 Early Unified Predictors
- Moshi ★ [Défossez et al., 2024] —
💻 GitHub·📄 Paper— Real-time conversational audio-text dual-stream processing. - Emu3 / Emu3.5 ★ [BAAI, 2024–2025] —
🌐 Project Page·📄 Paper— Next-token sequence prediction unifying understanding and synthesis.
🧩 Interleaved Sequence Modeling
- BAGEL-7B [ByteDance Seed Team, 2025] —
🤗 HF Model·🌐 Project Page·📄 Paper - OneCAT-3B [Meituan & SJTU, 2025] —
💻 GitHub·🤗 HF Model - Show-o2-7B [Xie et al., 2025] —
💻 GitHub·📄 Paper
🌌 Bidirectional Unification Frontiers
Collapsing representation boundaries.
- Janus-Pro ★ [DeepSeek-AI, 2025] —
🤗 HF Model·📄 Paper - Llama-4 Scout / Maverick [Meta AI, 2025] —
🌐 Llama Site— Advanced interleaved-scale exploration. - LLaDA-V [Ml-GSAI, 2025] —
💻 GitHub·🌐 Project Page·📄 Paper - Lance [ByteDance, 2026] —
📄 Paper— Leading edge of complete native convergence. - TUNA-2 [Liu et al., 2026] / Mamoda 2.5 [Shi et al., 2026] / LongCat-Next — Forthcoming.
★ Denotes early exploratory or foundational dual-regime architectures.
🛠️ The Technical Roadmap Dimensions
Following the systemic structure detailed across Sections §3–§7 of the roadmap paper, the core components of the NMM lifecycle are curated below.
🧩 1. Architecture · §3
|
📊 2. Data Curriculum · §4
|
🎯 3. Training Strategies · §5
|
⚡ 4. Inference & Deployment · §6
|
🧪 5. Evaluation Benchmarks · §7
|
🤝 Contributing
Contributions are very welcome! If a notable native multimodal model is missing or you find an outdated link, please open an Issue or send a Pull Request.
The preferred entry format is:
- <Model Name> [<Authors / Team>, <Year>] — [`💻 GitHub`](https://...) · [`📄 Paper`](https://...)
✍️ Citation
If our formalization, taxonomy, or roadmap framework assists your research, please cite our definitive paper:
@article{TencentYoutuLab2026toward,
title = {Toward Native Multimodal Modeling: A Roadmap},
author = {Siyu An and Junru Lu and Junnan Dong and others},
journal = {arXiv preprint},
year = {2026}
}
SpaceX Has Two AI Compute Stories; Only One Generates Revenue
SpaceX's S-1 filing reveals a dual strategy: a $1.25 billion per month terrestrial AI data center deal with Anthropic until May 2029 and a long-term vision for in-orbit AI inference.
Original article
SpaceX's S-1 tells two stories. The first is that the company is spending billions building terrestrial data centers and has signed one disclosed external customer, Anthropic, with a deal worth $1.25 billion per month through to May 2029. The second is that the future of AI inference belongs in orbit and that SpaceX is the only company that has already accomplished the key technical challenges associated with evolving connectivity satellites into AI compute satellites. Both stories are presented with conviction, and neither is contingent on the other being wrong.

Claude Mythos reportedly solves OpenAI's landmark Erdős problem with a "cute, simple proof"
Anthropic's Claude Mythos reportedly solved OpenAI's recently disproven Erdős unit-distance conjecture with a "cute, simple proof," demonstrating independent AI-driven math discovery capabilities.
Decoder
- Erdős unit-distance conjecture: A famous unsolved problem in combinatorial geometry, posed by Paul Erdős in 1946, concerning the maximum number of unit distances that can be formed by a set of
npoints in a plane. - Combinatorial geometry: A branch of mathematics that combines aspects of combinatorics and geometry, dealing with finite or discrete collections of geometric objects.
- Overhang: A term often used in economics or technology to describe a situation where there is a significant amount of untapped potential or unreleased capability that could impact future developments.
- Lean (formal proof language): A proof assistant and programming language designed for formally verifying mathematical proofs and software, distinct from natural language model approaches.
Original article
Claude Mythos reportedly solves OpenAI's landmark Erdős problem with a "cute, simple proof"
Anthropic employees say Claude Mythos can also solve OpenAI's "AI math milestone." OpenAI recently disproved the Erdős unit-distance conjecture, an open problem in combinatorial geometry since 1946. Anthropic engineer Sholto Douglas wrote on X that Mythos solves it with a "cute, simple proof," a sign of "serious overhang" in AI-driven math discoveries.
The team used a test system built after AI solved Erdős problem #1196: isolated Claude Code instances with Mythos access receive the problem, develop solution paths, and then one instance summarizes and distributes them to further instances working independently. Mythos frequently took a different route than OpenAI's model. Mathematician Daniel Litt called the result "a bit worse" than OpenAI's, but Mythos reportedly found OpenAI's solution too. Anthropic published a proof version prepared by Opus 4.7.
Google DeepMind also recently announced that an AI-assisted system solved nine Erdős problems, though its approach relies on the formal proof language Lean, which is less impressive from an LLM purist's perspective. Then again, Claude Code is an agentic harness, not a pure LLM either.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Initial Results on Legal Agent Benchmark
Harvey's Legal Agent Benchmark shows frontier models like Claude Opus 4.7 achieving only 7.1% on legal tasks under an "all-pass" standard, highlighting current AI limitations in complex legal work.
Decoder
- All-pass standard: A stringent evaluation criterion where a task is only considered successfully completed if every single requirement or sub-criterion in the rubric is met without error.
Original article
Harvey baselined frontier models on its Legal Agent Benchmark holdout under an "all-pass" standard requiring every rubric criterion to pass, and Claude Opus 4.7 led at just 7.1% with Sonnet 4.6 at 5.4%, Opus 4.6 at 4.2%, GPT-5.5 at 2.1%, and Gemini 3.5 Flash at 0.8%, signaling legal work is far from saturated by frontier intelligence.

How Claude Cowork's Lead Engineer Uses AI
Felix Rieseberg, lead engineer for Anthropic's Claude Cowork, demonstrates advanced personal AI workflows, while a Google I/O 2026 recap highlights Gemini 3.5 Flash and video generation, despite many announced features being non-functional.
Deep dive
- Felix Rieseberg, Anthropic's Claude Cowork/Code Desktop lead, showcased unconventional personal AI uses.
- Examples include generating a 3D floor plan from email receipts and creating a personal furniture inventory.
- He advises going "one abstraction layer up" when doing tedious work and debugging AI workflows rather than the model.
- Felix suggests using Claude Sonnet for well-scoped tasks and Claude Opus for problems requiring more interpretation.
- Kids, unburdened by past computer limitations, often make the best AI users.
- A Google I/O 2026 recap covered Gemini 3.5 Flash, an agentic coding model claimed to be 4x faster than competitors.
- Antigravity 2.0 IDE was presented as Google's answer to Claude Code/Codex, featuring "projects" and a "/grill-me" command.
- Google introduced Omni for longer, production-quality video generation (10 seconds), aiming to rival Sora.
- Flow, a video editor built on Omni, and design tools Stitch and Pomelli were also announced.
- A significant criticism was Google's "launch-to-availability gap," with many announced features like AI Studio Workspace integration and Flow's avatar creation found to be non-functional during live testing.
- Gemini's multimodal capabilities remain a strong differentiator, especially for transforming content across modalities.
Decoder
- Claude Cowork: An AI assistant tool from Anthropic.
- Claude Code Desktop: A desktop application of Anthropic's AI designed for coding tasks.
- Claude Sonnet: An Anthropic AI model optimized for well-scoped, specific tasks.
- Claude Opus: An Anthropic AI model designed for complex problems requiring deeper interpretation and problem decomposition.
- Google I/O: Google's annual developer conference where new products and features are announced.
- Gemini 3.5 Flash: A version of Google's Gemini AI model, specifically highlighted as an agentic coding model optimized for speed.
- Antigravity 2.0: Google's IDE (Integrated Development Environment) featuring AI integration.
- Google AI Studio: Google's platform for building no-code AI applications.
- Omni: Google's AI model for generating longer, production-quality videos, comparable to OpenAI's Sora.
- Flow: Google's production-grade video editor built on the Omni AI model.
- Stitch: Google's AI-powered, in-browser design generation and editing tool.
- Pomelli: Google's AI tool for creating brand books, campaign assets, and websites.
- One abstraction layer up: A philosophical approach to AI interaction, where instead of directly telling the AI what to do, you ask it to figure out how to solve a problem itself by identifying underlying needs or data sources.
Original article
🎙️ How I AI: How the engineer behind Claude Cowork actually uses Claude Cowork & What launched at Google I/O 2026
How the engineer behind Claude Cowork actually uses Claude | Felix Rieseberg (Anthropic)
Listen now on YouTube • Spotify • Apple Podcasts
Brought to you by:
Magic Patterns—Prototypes that look like your product
Guru—The AI layer of truth
Felix Rieseberg, the engineering lead for Claude Cowork and Claude Code Desktop at Anthropic, joins Claire to show how he actually uses Claude in his own life and work. In this episode, Felix walks through building a 3D floor planner from a 2D house plan, using email as a personal inventory database, creating live dashboards from connected apps, and hacking together a $20 hardware “Claude buddy.” He also shares his philosophy for getting more out of AI: go one abstraction layer up, let Claude work in the background, and stop assuming computers can’t solve some of the annoying little problems in your life.
Biggest takeaways:
-
The biggest barrier to AI adoption is people not realizing they can ask AI to solve almost any problem. Felix sees this constantly—the tools are incredibly powerful, but users haven’t built the muscle memory to reach for them. His advice: whenever you’re doing something annoying that doesn’t feel creative, pause and ask yourself if Claude could do it instead. The gap isn’t technical; it’s psychological.
-
Your email is an untapped gold mine of personal data. Felix used his email to inventory all his furniture when moving houses: every purchase receipt, every confirmation, every dimension. Claude parsed it all and built him a 3D floor planner with his actual furniture. This same principle applies to clothing, medical records, travel history, or any domain where you’ve been emailing receipts and confirmations for years. You already have a structured database—you just need to point Claude at it.
-
Go one abstraction layer up, then do it again. Felix started manually entering furniture dimensions into his floor planner, then stopped and asked Claude to figure out what furniture he had. Then he went another layer up and told Claude to find the furniture in his emails. This is the key pattern: every time you catch yourself doing tedious work, ask how Claude could do it instead. Then ask how Claude could figure out what to do without your telling it.
-
Live artifacts are Claude’s answer to keeping your personal dashboards always up-to-date. Unlike static artifacts, live artifacts refresh with real-time data from your connected services—Spotify, Gmail, Calendar, Notion, whatever you’ve authorized. Felix built a personal dashboard that looks like early-2000s software that updates throughout the day. The killer feature: you never have to manually update your pitch deck, your daily briefing, or your personal reports again.
-
Choose Opus when you don’t know what you’re really asking for. Felix’s heuristic for model selection: use Sonnet when the problem is well-scoped and specific. Reach for Opus when you need Claude to interpret what you actually want, not just what you said. It’s the difference between “make me a floor plan with units” (Sonnet territory) and “help me figure out how to organize my life” (Opus territory). For most tasks, Sonnet is perfectly capable, but when you need that extra layer of problem decomposition, Opus is worth it.
-
Kids are the best AI users because they aren’t afraid to ask for things. Felix gets videos from parents showing what their kids build with Claude—custom video games with hand-drawn characters, interactive stories, tools that would have required a software engineer just a few years ago. Adults have spent 20 years in a “mind prison” learning what computers can’t do. Unlearning that is the unlock.
-
When Claude makes mistakes, debug your workflow, not the model. Felix doesn’t curse at Claude (though he notes it’s useful for the team to know when people do). Instead, he asks it: “Here’s what I expected. Can you walk me through where things went differently? How can we prevent this in the future?” Usually the fix isn’t “Claude can’t do this”; it’s “I need to change the prompt, clean up the data source, or set up a dry run.” Treat Claude like a collaborator who needs better instructions, not a tool that’s broken.
Blog & detailed workflow walkthroughs from this episode:
How I AI: Felix Rieseberg’s Claude Workflows for 3D House Design and a $20 Hardware Buddy: https://www.chatprd.ai/how-i-ai/felix-rieseberg-claude-code-cowork-workflows-for-3d-house-design-and-hardware-buddy
↳ How to Build a $20 Physical AI ‘Buddy’ with Claude Code: https://www.chatprd.ai/how-i-ai/workflows/how-to-build-a-20-physical-ai-buddy-with-claude-code
↳ How to Create an Interactive 3D House Model from a Floor Plan Using AI: https://www.chatprd.ai/how-i-ai/workflows/how-to-create-an-interactive-3d-house-model-from-a-floor-plan-using-ai
↳ How to Build a Live, Auto-Updating Personal Dashboard with Claude: https://www.chatprd.ai/how-i-ai/workflows/how-to-build-a-live-auto-updating-personal-dashboard-with-claude
What launched at Google I/O 2026 (30-minute day 1 recap)
Listen now on YouTube • Spotify • Apple Podcasts
Brought to you by:
Magic Patterns—Prototypes that look like your product
ThoughtSpot—Build AI-powered analytics into your product
Claire breaks down the biggest launches from Google I/O 2026—from Gemini 3.5 Flash and Antigravity 2.0 to Google AI Studio, Omni, Flow, Stitch, and Pomelli. In this episode, she tests the tools live, shares what actually works, and explains where Google is catching up, where it may be pulling ahead, and why its launch-to-availability gap is still such a problem for builders.
Biggest takeaways:
-
Gemini 3.5 Flash rivals leading frontier coding models in Google’s benchmarks while running four times faster. Google positions this as their agentic coding model, optimized for tasks requiring both high reasoning and rapid execution. If the benchmarks hold in practice, this speed advantage could shift the coding agent landscape toward Google’s tools.
-
Antigravity 2.0 brings Google’s IDE to feature parity with Claude Code and Codex—but it’s playing catch-up. The update includes projects (folder-constrained workspaces), scheduled tasks on Cron, and subagents for specific tasks. The UI looks nearly identical to Codex, and the features match what Anthropic and OpenAI shipped months ago. The advantage is speed: if Gemini 3.5 Flash delivers, developers might choose Antigravity for well-scoped tasks that need to ship fast.
-
The /grill-me slash command is Antigravity’s aggressive take on Claude Code’s polite clarification tool. Instead of gently asking questions, /grill-me promises to interrogate your requirements and get to the heart of what you’re building. Whether this is actually more hardcore or just clever branding remains to be seen, but it signals Google’s attempt to differentiate on personality.
-
Google AI Studio now integrates directly with Workspace apps—or it’s supposed to. The promise: build no-code apps that read Sheets, draft Gmails, organize Drive, and see Calendar without setup. Claire couldn’t get it to work during testing. If it delivers, it would capture internal enterprise productivity use cases and personal assistant workflows where Google already owns the data layer.
-
Omni is Google’s answer to Sora, focused on longer, production-quality video. The model creates 10-second videos (versus Sora’s 6 or 7 seconds), maintains character consistency across edits, and allows conversational editing. Claire tested it by animating her kid’s drawing, and the output was impressive. The real power will be in production workflows where you iterate on the same characters and scenes multiple times.
-
Flow is Google’s production-grade video editor built on Omni. It lets you define characters, create avatars, and edit videos conversationally while maintaining cinematic quality. The tool targets creators and marketers who need consistent, high-quality video at scale. Claire tried creating an avatar of herself, but the feature failed—a recurring theme throughout I/O announcements.
-
Stitch and Pomelli are Google’s design and marketing tools. Stitch is like in-browser Figma with streaming design generation, inline AI edits, and code sync. Pomelli creates brand books, campaign assets, and websites from a URL. Both show promise but suffer from “Google slop,” the generic aesthetic of AI-generated design.
-
Gemini’s multimodal capabilities remain its strongest differentiator. For work involving files, videos, or transformative work across modalities (document to video, image to text), Gemini models excel. Claire uses them for generating blog posts from podcast videos and animating drawings. The 3.5 family continues this strength; for these use cases, Gemini’s multimodal performance is best-in-class.
-
The biggest problem: half the features don’t actually work yet. Claire encountered broken features, missing integrations, and “coming soon” disclaimers throughout testing. Workspace integration in AI Studio? Couldn’t access it. Avatar creation in Flow? Didn’t work. When you announce features that aren’t ready, people lose patience and stop trusting your roadmap.
Blog:
How I AI: My Live Test of Google I/O’s New AI Tools—From Gemini 3.5 Flash to Omni Video: https://www.chatprd.ai/how-i-ai/google-io-new-ai-tools-gemini-35-flash-to-omni-video
If you’re enjoying these episodes, reply and let me know what you’d love to learn more about: AI workflows, hiring, growth, product strategy—anything.
Catch you next week,
Lenny
P.S. Want every new episode delivered the moment it drops? Hit “Follow” on your favorite podcast app.
Introducing Nova, Dropbox's internal platform for coding agents
Dropbox built Nova, an internal cloud platform for running AI coding agents across engineering workflows, allowing parallel sessions and validation against their Bazel-backed monorepo.
Deep dive
- Nova allows engineers to run multiple AI coding sessions concurrently and integrates AI agents into automated internal workflows.
- It addresses the "fragmented workflow problem" where repetitive tasks distract engineers from deeper product work.
- Sessions run in isolated environments with snapshots of the Dropbox codebase at specific commits, grounding agents in the actual build/test environment.
- Nova provides validation commands that, if they fail, feed results back to the agent for continuous iteration until a fix is found.
- Beyond interactive coding, Nova is used for operational workflows like flaky test remediation (via an internal tool called Deflaker integrating with Athena) and large-scale migrations/dependency upgrades.
- It integrates with existing tools like RenovateBot to help repair breakages from upgrades.
- The platform emphasizes context, validation, and guardrails, including localized AGENTS.md files, hermetic tests, and Bazel caching.
- A key lesson is that the surrounding platform's integration with existing systems is as valuable as the code generation itself.
- Not every step belongs in the agent loop; deterministic systems (like CI triggers) should remain in control, with agents called back for inspection/fixes.
Decoder
- Monorepo: A software development strategy where code for many projects is stored in a single repository.
- Bazel: An open-source build and test tool developed by Google, known for its speed and correctness in large codebases.
- CI/CD: Continuous Integration/Continuous Delivery, a set of practices that automate the building, testing, and deployment of software.
- Hermetic tests: Tests that are completely isolated and produce the same results regardless of the environment in which they run.
Original article
Introducing Nova, our internal platform for coding agents
Coding agents are becoming an important part of software development. Their most obvious use is helping developers write code faster. But code is only one part of building and operating software. At Dropbox scale, agents also need to work within a large monorepo, validate code changes in Dropbox’s full engineering environment, and incorporate context from across the engineering lifecycle. Developers don’t just write code, after all—our engineers manage migrations, unblock CI, investigate failures, and handle repetitive operational work. This work matters, but it is often repetitive and disruptive, pulling engineers’ focus away from deeper product and infrastructure work.
To prepare for a future where agents can assist engineers with a larger share of their work, we built Nova, an internal service for running coding agents in our cloud. Nova lets engineers run multiple coding sessions in parallel and lets internal systems use AI agents as part of automated workflows. This platform approach lets us apply agents across internal workflows instead of building one-off implementations for each use case, making it easier to rapidly experiment with how AI can support engineering work.
In this post, we’ll share why we built Nova, why we chose a platform approach instead of multiple single-purpose solutions, and what we’ve learned from using it across the software development lifecycle.
Tackling the fragmented workflow problem
The software development lifecycle has many places where engineering judgment matters, but the work itself can be repetitive and time-consuming. Debugging failures, updating dependencies, improving test coverage, and fixing flaky tests are critical to software development. At the same time, these tasks can distract from more meaningful work. Many of these workflows are also well suited for AI assistance through coding agents, though they do not all require the same kind of interaction. Some tasks work best through standard interactive chat, while others can run autonomously in async workflows and only surface results when an agent makes a useful discovery. Supporting both modes consistently requires more than a single-purpose tool.
At Dropbox scale, the development environment creates requirements that off-the-shelf tools are not designed to support. Our large monorepo depends on Bazel—a build and test tool that uses caching and remote execution—along with on-premise infrastructure to keep builds and tests fast. Third-party coding agent tools work well for local iteration, but they do not naturally fit a setup that depends on our repository shape, infrastructure, and validation paths. Because our development workflow depends on Dropbox-specific infrastructure and validation paths, we wanted coding agents to operate within those systems rather than introducing a separate AI-specific workflow.
Those requirements pushed us toward building a platform instead of separate solutions for each workflow. The goal was a shared system that could support interactive development, background jobs, and internal services while keeping execution, validation, and context handling consistent. To support those workflows, we built Nova.
Improving development with Nova
Nova began with a focused problem: helping engineers respond to continuous integration failures with suggested fixes. That starting point was essential to shaping the platform. Each Nova session runs in an isolated environment with a snapshot of the Dropbox codebase from a specific commit. The caller provides the task and can optionally include validation commands to run after the agent finishes. If validation fails, for example because a test does not pass or a build breaks, Nova can continue the session, feed the results back to the agent, and ask it to address the failure. This keeps the agent grounded in the real build and test environment instead of stopping after generating a plausible-looking patch. The workflow follows a simple pattern: propose a change, validate it, and continue only if the results hold up.
Over time, we expanded the platform to support multiple coding agents behind the same interface. Nova integrates into the tools and workflows engineers already use, including a web interface for interactive sessions similar to other cloud-based coding agents. Engineers can also use a command-line interface and API to launch jobs in parallel from locally running agents, scripts, and internal services. To support longer-running workflows, we maintain helpers that make it easier to add AI-powered steps without rebuilding the surrounding infrastructure. Nova also includes tools for prompt evaluation, observability, and feedback collection so engineers can better understand how well agents perform.
As we expanded Nova into more engineering workflows, we found that many tasks required more than editing files. Agents often need to gather evidence, read logs, inspect failures, and carry context across multiple steps. To support that work, Nova includes skills, plugins, and MCP integrations, including access to observability systems.
Expanding beyond interactive coding sessions also shaped how we handled code publication. We chose to keep publication outside the agent and limit each session to a single branch, giving us a predictable view of which branches are active and which changes are being published. Allowing agents to create and manage multiple branches within a session would add significant complexity, including deciding which branch future work should build from. Keeping the workflow deterministic also makes it easier to automate tasks around each branch, such as running tests or rebasing onto the main branch.
{
"repo_commit": "<commit-sha>",
"task": "Investigate this CI failure and propose a fix",
"validation_commands": [
"bazel test //path/to:test_target",
"bazel test //path/to/related:all"
],
"continue_on_validation_failure": true,
"max_iterations": 5,
"push_branch": "ai/nova/ci-fix"
}Illustrative Nova request. Pseudo-code JSON.
How we’re using the platform
Since launching Nova, we’ve applied it across a range of engineering workflows, from quick developer-driven coding sessions to long-running remediation and migration efforts. The following use cases show how AI coding agents can fit into both interactive day-to-day development and more durable operational workflows.
Developer-driven sessions
Nova supports the kinds of developer-driven workflows engineers expect from modern coding agents. Engineers use Nova’s web UI to make quick fixes or build prototypes without interrupting their local development loop. For code changes, we use Bazel selectivity tools with Nova’s validation commands so changes are validated against the right compile and test targets. Engineers can also start from a Slack thread and carry that thread context into a Nova session, which reduces setup and preserves discussion that would otherwise need to be rewritten by hand.
Flaky test remediation
One of Nova’s most successful operational workflows has been flaky test remediation. We built an internal tool called Deflaker, a durable workflow that integrates with Athena, our flaky test detection system. Deflaker starts by finding examples of a test both passing and failing. It then sends those logs to Nova as context and asks the agent to identify a likely root cause and propose a fix. We validate the proposed change by running the test 100 or more times in CI, depending on the test failure rate. If the test flakes again, we take the new logs, carry forward notes from the previous attempt, and start another fix attempt. The fix-and-validate loop continues until the workflow lands a working fix or reaches a capped number of attempts (currently five).
Athena detects a flaky test. Passing and failing logs are sent to Nova. Nova proposes a fix. CI runs more than 100 validation attempts. Success lands the fix, while failure starts another attempt with new logs and notes from the prior session.
Migrations and dependency upgrades
Migrations and dependency upgrades became another natural fit for the platform. Before Nova, we used a bespoke Goose-based AI migrator integrated with our internal migration tracking tool. The system generated parallel AI coding jobs using prompt templates and verification commands, then published the results to GitHub branches. It was used across thousands of migration entries, including conversions from Enzyme tests to React Testing Library and updates to mypy type configuration.
Although the migrator was effective, it had important limitations. There was no interactivity for reviewing or continuing agent output, so failures often left teams with no practical way to recover the work. We also learned that highly repeatable migration work was often better handled directly by migration owners, who could launch and manage dozens of agents with the same runbook rather than coordinating delegated work across teams.
Moving migration workflows onto Nova gave us interactive coding sessions, shared guardrails, reusable workflow tooling, and a consistent operating model. Over time, we want migration owners to be able to write a prompt once, run it in parallel across many parts of the codebase, and review the resulting changes as part of a coordinated rollout. We now also integrate Nova with RenovateBot so agents can take a first pass at repairing breakages introduced by dependency upgrades.
Emerging workflows and experiments
We use Nova to respond to production crash alerts by recreating crash states with tests, generating candidate fixes, and routing the results to service teams. Some of the most promising experiments build on these operational workflows and extend beyond code authoring itself. We’re exploring whether agents can help determine when a code change needs review from secondary teams by evaluating pull requests against team review policies and producing guidance on whether additional review is needed.
Beyond pull request workflows, we’re testing whether scheduled workflows can reduce recurring on-call toil, such as alert flapping or follow-ups buried in Slack channels. Another experiment uses multiple agents to review the same code change from different perspectives, then aggregates the results to deduplicate and filter low-value comments.
What we learned
One lesson we learned is that the value of coding agents comes as much from the surrounding platform as from code generation itself. Running agents as a service gives us a reusable way to support a wide range of engineering workflows. We also found that context, validation, and guardrails reinforce one another. Localized AGENTS.md files give agents service-specific context, while validation commands, isolated execution, hermetic tests, Bazel caching, and retry loops let them operate against the same systems engineers rely on every day. Each layer improves reliability on its own, but together they make background workflows more trustworthy.
Another important lesson is that not every step belongs inside the agent loop. As we expanded Nova across the software development lifecycle, we had to decide where agentic behavior was useful and where deterministic systems should remain in control. For example, letting an agent manage its own test execution and iteration could leave sessions waiting on CI for hours or result in changes being validated against the wrong tests. We found it worked better for surrounding workflows to trigger CI deterministically and bring the agent back if there was a failure to inspect or fix.
As coding agents continue to improve, we expect them to take on a larger share of repetitive work across the software development lifecycle. The path forward is not just better models, but better integration with the systems that shape engineering work. Nova gives us a shared execution layer for AI-assisted workflows through isolated environments, repository-aware context, validation loops, workflow integration, and reviewable outputs. As we continue expanding context sources, including through Dash and MCP-based integrations, we expect agents to become more useful, more reliable, and better aligned with how engineering gets done at Dropbox.
Acknowledgments: Samm Desmond, Daniel Avramson, Adam Ziel, and Chris Hodges
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit jobs.dropbox.com to see our open roles.

Migrating Azure DevOps to GitHub Enterprise: The ROI Case
Delaying migration from Azure DevOps to GitHub Enterprise creates a compounding productivity deficit due to GitHub's exclusive AI agents, outweighing high migration costs for work items and pipelines.
Deep dive
- The core argument is that the "cost of delaying" is a compounding productivity deficit, not just licensing, due to GitHub's exclusive access to "Generation 2" AI capabilities.
- GitHub Copilot coding agents can take a GitHub Issue and autonomously produce code changes and open a pull request, a feature not available natively in Azure DevOps.
- Copilot Spaces and Copilot Autofix (for security vulnerabilities) are also GitHub-exclusive, providing significant efficiency gains (research suggests 55% reduction in task time).
- Migration costs are high: Work items (Azure Boards) do not migrate via GitHub Enterprise Importer (GEI) and require third-party tools or manual effort.
- Pipelines (Azure Pipelines YAML) do not auto-convert to GitHub Actions and require manual refactoring (budget one week per major pipeline).
- Permissions require redesign as Azure DevOps uses project-level groups while GitHub uses team-based permissions.
- A common "hybrid strategy" involves keeping Azure Boards for enterprise planning (where ADO is stronger) and moving repositories to GitHub Enterprise for AI benefits and GitHub Advanced Security (GHAS).
- The Azure Boards App for GitHub maintains traceability between GitHub commits/PRs and ADO work items.
- The business case for migration involves revenue acceleration through velocity (5-10% efficiency gain on 200 developers is $2 million/year), risk mitigation via GHAS (secret scanning, dependency review, CodeQL), and cost optimization through consolidation/onboarding acceleration (Forrester study cited 376% ROI over three years).
- Delaying migration also leads to higher costs as codebase grows and institutional knowledge about ADO setups depletes.
Decoder
- Azure DevOps (ADO): A suite of developer services from Microsoft for planning, developing, testing, and deploying applications.
- GitHub Enterprise: The enterprise version of GitHub, providing source code management, collaboration, and CI/CD features with additional security and compliance.
- GitHub Copilot: An AI pair programmer developed by GitHub and OpenAI that assists developers by suggesting code, functions, and even entire files.
- GitHub Advanced Security (GHAS): A suite of security features within GitHub Enterprise that helps organizations improve code security throughout the development lifecycle (e.g., secret scanning, dependency review, CodeQL).
- GEI (GitHub Enterprise Importer): A tool for migrating repositories and their history from various sources, including Azure DevOps, to GitHub Enterprise.
- Azure Boards: A service within Azure DevOps for work item tracking, scrum, Kanban, and agile planning.
- GitHub Actions: A CI/CD platform integrated with GitHub for automating software workflows.
- CodeQL: A semantic code analysis engine developed by GitHub to find vulnerabilities in code.
- RBAC (Role-Based Access Control): A method of restricting system access to authorized users based on their role within an organization.
Original article
Your competitors who already moved to GitHub Enterprise are deploying code with AI agents that plan, edit, and open pull requests automatically. Their developers describe a task in plain language and walk away while the AI does the groundwork. Your developers are doing the same work they did three years ago—manually, one file at a time. That gap is not a feature comparison. It is a compounding productivity deficit that widens every sprint.
This is the actual cost of delaying a migration from Azure DevOps to GitHub Enterprise. Not the licensing delta. Not the one-time migration effort. The real cost is the acceleration you’re not getting while the industry shifts to AI-native development workflows that are, by Microsoft’s own architectural design, exclusively available on GitHub. If you’re building the business case for this migration—or trying to kill a bad one—this is the framework you need.
The Strategic Gap You Cannot Work Around
Azure DevOps is a mature, capable platform. It runs production workloads for thousands of enterprises and Microsoft has committed to its continued support. But “continued support” and “where Microsoft is investing in AI” are two different things, and the research consistently separates the two.
The most consequential AI capabilities in the modern development lifecycle are architecturally bound to GitHub. Copilot coding agent, for example, takes a GitHub Issue and works autonomously to produce code changes and open a pull request—without the developer writing a line of code. Copilot Spaces organizes curated context—specific repositories, documentation, and files—that serves as the AI’s ground truth for your team’s Copilot sessions. Copilot Autofix generates security vulnerability fixes inside the pull request workflow, catching problems before they merge rather than after they deploy.
None of these are available natively in Azure DevOps repositories. A developer working in ADO gets Generation 1 Copilot—autocomplete and chat. A developer working in GitHub gets Generation 2—autonomous agents that can complete tasks, not just suggest completions.
The productivity difference is not incremental. Research measuring the impact of GitHub Copilot on coding tasks found a 55% reduction in time to complete those tasks, and that figure predates the agentic capabilities that take the AI from assistant to collaborator. Organizations using Copilot also report a 15% increase in pull request merge rates—faster code throughput, less friction between writing and shipping. When finance asks you what the platform change actually does, those are the numbers you start with.
The cost of staying put is not just the productivity gap. It is also a talent market reality. Nine in ten developers report higher job satisfaction when they have access to AI tooling. In an environment where engineering hiring remains competitive, your toolchain is part of your retention story. The engineer you are trying to hire has almost certainly used GitHub in their previous role. Azure DevOps is familiar to enterprise shops; GitHub is where open-source work, side projects, and modern tooling intersect. This is not a reason to migrate by itself, but it factors into a complete business case.
What Migration Actually Costs
Here is where a lot of migration proposals fall apart: they project the ROI from productivity gains correctly and dramatically underestimate the migration investment. The GitHub Enterprise Importer (GEI), accessed via the gh ado2gh CLI extension, handles the straightforward parts—Git source history, branches, pull request history and conversations, and repository structure. For teams with clean, standard Git repositories, the code migration itself is relatively low-friction.
The friction is everywhere else.
Work items do not migrate. Azure Boards—sprints, backlogs, epics, user stories, bugs—are entirely separate from GEI’s scope. Moving that data requires third-party tooling or manual export-import workflows. For organizations with years of project history in Boards, this is often the highest-effort line item in the migration, and it frequently gets underestimated because engineers scoping the project focus on the repositories. Finance asks “what does it cost to move our work tracking?” and the answer is uncomfortable.
Pipelines do not auto-convert. There is no one-click transformation from Azure Pipelines YAML to GitHub Actions. The GitHub Actions Importer audits your existing pipelines and forecasts migration effort, which is genuinely useful, but the complex logic—deployment gates, variable groups, environment approvals—requires manual refactoring. Budget one week of engineer time per major pipeline as a conservative estimate, not because migrations are hard, but because pipelines encode organizational process decisions that cannot be automatically translated.
Permissions require redesign. Azure DevOps uses project-level permission groups. GitHub uses team-based permissions. These models do not map one-to-one, and a serious migration includes a deliberate role-based access control (RBAC) redesign rather than an attempt to replicate the ADO structure. This is actually an opportunity—most organizations accumulate permission debt over years—but it takes time and requires security team involvement.
GEI also carries hard technical limits: individual files cannot exceed 400 MiB, single commits cannot exceed 2GB, and the importer caps you at five concurrent repository migrations to avoid rate-limiting. For most organizations this is not a problem. For teams with large binary assets or unusual repository structures, it is a scoping conversation to have early.
Reality Check: The organizations that blow their migration budgets are almost always the ones that scoped “migrating to GitHub” as a repository operation and discovered midway through that they were actually migrating their entire engineering process. Scope the work items and pipelines before you quote a number to finance.
The Hybrid Strategy Most Teams Actually Use
A full “big bang” migration—ADO to GitHub in one sprint, cut over everything—is theoretically clean and practically rare. The more common and frequently more sensible path is a hybrid architecture that captures the AI benefits immediately while preserving the planning capabilities that Azure DevOps genuinely does better.
The approach is sometimes called Better Together: continue running Azure Boards for sprint planning, portfolio management, and hierarchical work tracking (where ADO’s enterprise feature set is legitimately deeper than GitHub Projects), while moving repositories to GitHub Enterprise to unlock Copilot and GitHub Advanced Security (GHAS). The Azure Boards App for GitHub maintains traceability by linking GitHub commits and pull requests to ADO work items automatically, which keeps auditors satisfied and project managers connected to the codebase.
This hybrid architecture has a meaningful licensing implication as well. Visual Studio Enterprise subscriptions often include access to both Azure DevOps and GitHub Enterprise, which eliminates the “we’re paying twice” objection that surfaces in most procurement conversations. If your organization is already on Microsoft’s unified licensing via Entra ID (Microsoft’s cloud identity platform, formerly Azure Active Directory), the incremental licensing cost of adding GitHub Enterprise may be lower than your initial estimate.
Key Insight: The hybrid strategy is not a compromise—it’s often the correct architecture. Azure Boards handles enterprise planning hierarchies at a depth GitHub Projects has not matched. Moving repositories to GitHub while keeping Boards means capturing the AI productivity gains without disrupting the planning workflows your project managers depend on.
Building the Business Case
When you bring this to the C-suite, the argument works across three pillars. Finance, legal, and operations each have a version of this conversation, and they respond to different evidence.
Revenue acceleration through velocity. The case here is straightforward: if your developers ship features faster, your product roadmap moves faster, and your competitive position improves. A conservative productivity model uses a 5-10% efficiency gain (even though the research supports 55%) because conservative numbers survive CFO scrutiny. At 200 developers billing at a fully-loaded cost of $200,000 per year, a 5% efficiency gain is $2 million in recovered capacity annually—without adding headcount.
Risk mitigation through security posture. GHAS includes secret scanning with push protection that blocks credential commits before they are accepted by the server, dependency review that flags vulnerable packages in pull requests before they merge, and CodeQL code scanning that treats source code as a queryable database for vulnerability patterns. The cost of a credential leak in production dwarfs the cost of blocking it at commit time. Security teams understand this math; the challenge is expressing it as a dollar figure. A single major incident avoided—regulatory notification costs, legal exposure, remediation engineering—frequently exceeds the three-year cost of the platform.
Cost optimization through consolidation. New engineers hired out of bootcamps and computer science programs have overwhelmingly used GitHub. Onboarding time on an unfamiliar platform is not zero, and Forrester’s Total Economic Impact study commissioned by GitHub quantifies a 75% efficiency gain in developer onboarding as part of its composite ROI analysis. The study’s headline figure—376% ROI over three years, with payback in under six months for a composite organization of 5,000 developers—is the number most often cited in migration proposals. Use it, but cite it correctly (composite organization, Forrester methodology) and pair it with a model built on your actual headcount and rates.
The ROI calculation that survives executive review looks like this:
| Category | What to Include |
|---|---|
| Benefits | Developer time recovered (headcount × rate × efficiency gain %), security incident avoidance, onboarding acceleration, reduced custom tooling maintenance |
| Costs | Migration services (pipeline rewriting, work item migration tooling), training, any licensing delta not covered by existing subscriptions, professional services if using a partner |
| Net ROI | (Benefits − Costs) ÷ Costs × 100 |
Mark any efficiency figures as illustrative when presenting to finance. Use ranges rather than point estimates. Finance trusts ranges more than precision, and ranges are more honest given the variability in migration complexity across organizations.
Pro Tip: Present two scenarios—a conservative model using 5% efficiency gain and a mid-range model using 15%. This gives the CFO a floor, avoids the “you’re overselling this” objection, and still demonstrates a compelling return at the conservative number.
What Happens If You Wait
The math on waiting is uncomfortable. Every quarter you remain on ADO repositories while competitors run agentic AI workflows is a quarter of compounding productivity difference. The platform migration itself becomes more expensive over time as your codebase grows, your pipeline library expands, and organizational muscle memory deepens around ADO workflows. The work items backlog grows. The RBAC debt accumulates.
There is also a subtler risk: the engineers who will run your migration are in high demand. Teams that move decisively retain institutional knowledge about their own platform. Teams that defer find, eventually, that the people who knew the ADO setup deeply have moved on, and the migration now includes reverse-engineering undocumented configuration decisions made by people who have since moved on.
None of this means you should move without a plan. It means the plan you build this quarter is cheaper than the plan you build in two years. The GitHub Well-Architected migration guide gives you the technical scaffolding. The framework above gives you the financial argument. What you need now is a pilot—pick two or three repositories, run the GEI migration, deploy Copilot to the developers on those repos, and measure the output. Real numbers from your own organization will close any remaining skepticism at the executive level faster than any vendor study ever will.
Your competitors are not waiting for the perfect business case. They’re already shipping.
Hate ads? Want to support the writer? Get many of our tutorials packaged as an ATA Guidebook.
Explore ATA GuidebooksMore from ATA Learning and Partners
-

Recommended Resources!
Recommended Resources for Training, Information Security, Automation, and more!
-

Get Paid to Write!
ATA Learning is always seeking instructors of all experience levels. Regardless if you’re a junior admin or system architect, you have something to share. Why not write on a platform with an existing audience and share your knowledge with the world?
-

ATA Learning Guidebooks
ATA Learning is known for its high-quality written tutorials in the form of blog posts. Support ATA Learning with ATA Guidebook PDF eBooks available offline and with no ads!

5 Incident Response Principles for CTOs
CTOs must accept incidents as inevitable, building technical resilience alongside a psychologically safe, blameless culture, focusing on learning over just fixing issues.
Deep dive
- Principle 1: Incidents Will Happen: Accept that despite best efforts, incidents are unavoidable; preparedness and a well-practiced playbook are essential, not relying on heroic individuals.
- Principle 2: Technical Foundations: Build systems for graceful degradation with auto-scaling and architectural simplicity, prioritizing real-time observability and effective alerting strategies to quickly diagnose issues.
- Principle 3: The People Side: Recognize that incidents require different thinking; psychological safety allows people to surface problems without fear, and a blameless culture focuses on learning rather than fault, with leaders modeling this behavior.
- Principle 4: Measure Learning, Not Just Downtime: Mature organizations track and act on improvements from post-incident reviews, understanding that learning and fixing are distinct; a deeper understanding of 'how' and 'why' an event occurred yields greater long-term value.
- Principle 5: Incidents Are Leadership Moments: Leaders' calm, curious, and solution-focused response during incidents sets the organizational culture; practicing under pressure helps build team muscle memory and resilience.
- Cost of Downtime: New Relic's 2025 Observability Forecast found high-impact outages carry a median cost of $2 million USD per hour.
- Post-Incident Reviews: Should aim to build institutional memory by providing a rich understanding for a broad audience, not just the on-call team.
Decoder
- Psychological safety: A shared belief that the team is safe for interpersonal risk-taking; members feel comfortable speaking up with questions, concerns, or mistakes without fear of embarrassment or punishment.
- Blameless culture: An organizational approach to incident response where the focus is on understanding systemic factors that contributed to a failure rather than assigning individual fault, promoting learning and improvement.
Original article
Full article content is not available for inline reading.

Terraform Your AWS AgentCore
Deploying AWS Bedrock AgentCore with Terraform requires significant `null_resource` and CLI-driven workarounds due to provider gaps, hindering native IaC benefits.
Deep dive
- Amazon Bedrock AgentCore: AWS's managed platform for running production AI agents, providing runtimes, a unified tool Gateway, persistent memory, Cedar-based policy enforcement, and identity management.
- Terraform Deployment: An example deploys an "Infrastructure Bootstrapper Agent" with three AgentCore runtimes, a Gateway, and 21 tools using a single
terraform apply. - Provider Gaps (v6.32):
- Gateway Targets: Missing
grantType: CLIENT_CREDENTIALSin the provider, requiringnull_resourcewith an AWS CLI script. This leads to opaque outputs and requires idempotent scripts. - Policy in AgentCore: No dedicated
aws_bedrockagentcore_policy_engineresource, also managed vianull_resourcecalling AWS CLI. Requiresreplace_triggered_byto prevent silent policy detachment. - Gateway Drift:
descriptionandprotocol_configurationfields are not read back from the API, necessitatinglifecycle { ignore_changes = [...] }to prevent constant Gateway re-creation, leaving these fields unmanaged by Terraform. - ARM64 Compatibility: AgentCore runtimes run on Graviton (ARM64), requiring Python dependencies to be cross-compiled for
aarch64-manylinux2014using tools likeuv pip install --python-platform. - Read-Only Filesystem: AgentCore's
/var/taskis read-only, requiring patches for packages that attempt to write cache files to their own directories.
Decoder
- Amazon Bedrock AgentCore: AWS's managed platform designed to host, orchestrate, and manage production AI agents, offering capabilities like serverless runtimes, a tool gateway, persistent memory, and policy enforcement.
null_resource(Terraform): A Terraform resource that manages nothing, but can be used to run arbitrary local-exec or remote-exec scripts, often as workarounds for missing provider functionality or to orchestrate external commands.- Cedar-based policy enforcement: A declarative policy language and engine developed by AWS for fine-grained access control, used here to define what tools an AI agent can call.
- Graviton (ARM64): AWS's custom-designed processors based on the ARM64 architecture, known for their performance and cost efficiency for various workloads.
- Idempotent script: A script that produces the same result regardless of how many times it is run, important for
null_resourceworkarounds that might execute multiple times.
Original article
Full article content is not available for inline reading.

Do More With Grid in Figma
Figma Buzz now enables bulk editing and resizing of campaign assets, letting users manage hundreds of variants from spreadsheets as of May 22, 2026.
Decoder
- Figma Buzz: A component or feature within the Figma design platform, likely geared towards campaign asset management, though not a standalone product.
Original article
Full article content is not available for inline reading.

Extract Fonts from Any Website (Website)
A new web tool called Font Stealer extracts typography properties from any website and instantly suggests free Google Font alternatives for commercial typefaces.
Decoder
- WOFF/WOFF2: Web Open Font Format, a compressed font format for use on web pages.
- TTF: TrueType Font, an older font file format developed by Apple and Microsoft.
- OTF: OpenType Font, a font format developed by Microsoft and Adobe, offering more advanced typographic features than TTF.
Original article
Full article content is not available for inline reading.

What is a JPG vs PNG: Complete Image Format Comparison Guide
JPG uses lossy compression for smaller photographic files without transparency, while PNG uses lossless compression for graphics with transparency.
Deep dive
- JPG (JPEG) uses lossy compression, meaning some image data is permanently discarded to achieve smaller file sizes.
- This makes JPG ideal for complex photographic images with many colors and gradients, where minor data loss is imperceptible.
- JPG does not support transparent backgrounds; transparent areas will appear as a solid color (typically white).
- PNG (Portable Network Graphics) uses lossless compression, preserving all original image data, making it suitable for multiple edits without quality degradation.
- PNG supports transparent backgrounds, making it essential for logos, icons, and graphics that need to sit on various backgrounds.
- For simple graphics, logos, and screenshots, PNG can often result in smaller file sizes than JPG while maintaining sharp edges.
- Converting PNG to JPG will make the transparent background solid. Converting JPG to PNG will increase file size but not restore lost data.
- Other formats like TIFF (large, high-quality, professional printing) and WEBP (newer, better compression for web) also exist.
Decoder
- Lossy compression: A data compression method where some data is permanently discarded during the compression process, resulting in a smaller file size but some loss of quality.
- Lossless compression: A data compression method that allows the original data to be perfectly reconstructed from the compressed data, meaning no quality is lost.
- Transparency (image): The ability of an image to have areas that are see-through, allowing the background behind the image to show through.
- Metadata (image): Data about an image, such as camera model, date taken, exposure settings, or copyright information, embedded within the image file.
Original article
Full article content is not available for inline reading.
How SpaceX Is Structured to Favor Elon Musk
SpaceX granted Elon Musk a $1.3 billion restricted stock package, structured to allow him voting power before achieving performance goals and largely insulate him from shareholder lawsuits.
Original article
In January, SpaceX granted Elon Musk a pay package that will eventually total 1.3 billion in restricted shares. While he has not achieved the goals that the award is contingent on, SpaceX's IPO prospectus says that he can use those shares in voting on shareholder decisions. SpaceX does not plan to have the majority of its board be independent directors, and any shareholder claims under federal securities laws must be resolved through arbitration. The measures allow Musk to pick the people who determine his pay and largely insulate himself from shareholder lawsuits.
US Seeks to Give Weapons-Grade Plutonium to Start-Ups for Fuel
The Trump administration plans to provide surplus weapons-grade plutonium from dismantled warheads to startups, aiming to convert it into fuel for nuclear power plants.
Original article
The Trump administration plans to give plutonium from dismantled nuclear warheads to companies to convert it into fuel for nuclear power plants. The Energy Department has more than 50 tons of surplus plutonium left over from nuclear weapons programs. One of the bottlenecks in expanding nuclear power right now is a lack of fuel. Harvesting old plutonium stockpiles could provide a short-term fix.

Dropbox CEO Drew Houston to step down after 19 years at helm of cloud storage pioneer
Dropbox CEO Drew Houston will transition to executive chairman after 19 years, promoting product chief Ashraf Alkarmi to co-CEO before Alkarmi takes sole leadership, amidst flat revenue and AI industry shifts.
Original article
Dropbox CEO Drew Houston plans to step down and assume the role of executive chairman. Ashraf Alkarmi, currently the product chief, will be promoted to co-CEO, initially serving alongside Houston before taking over the role independently.
Houston founded Dropbox nearly two decades ago at age 24, eventually becoming a prominent figure in Silicon Valley and the first tech entrepreneur to guide a company from the Y Combinator incubator program to the public market. Now 43, Houston is ready for a new endeavor. He will transition to an executive chairman role after a period sharing the co-CEO title with Ashraf Alkarmi, who is being promoted from product chief. Alkarmi will eventually assume the top position solely.
Houston has had a significant tenure at Dropbox, playing a key role in pioneering the cloud storage market, competing with major tech companies like Google and Apple, and accumulating a net worth exceeding $2 billion. However, despite these achievements, the company has not achieved the status of a generation-defining brand and has seen its market capitalization decline significantly from its initial trading high and earlier private market valuations. In contrast, Airbnb, another early Y Combinator success, has a much larger market cap and is credited with revolutionizing the hospitality industry.
Houston, who created Dropbox out of personal frustration with losing USB drives during his college years at MIT, downplayed the comparison to Airbnb. He expressed satisfaction with Dropbox's ongoing relevance, noting that a significant portion of the global population still uses the service. In its latest quarterly earnings report, Dropbox reported over 18 million paying users, with the service remaining popular among professionals who frequently share files and photos.
Dropbox surpassed $1 billion in annual revenue in 2017 and $2 billion four years later. However, revenue growth has stagnated over the past two years, with a slight decline in 2025. The company has consistently faced the challenge of differentiating itself from a crowded field of competitors, including tech giants like Apple, Google, Amazon, and Microsoft, as well as rival Box. The emergence of artificial intelligence presents the latest hurdle for Dropbox and the broader subscription software industry. Concerns have arisen that foundational AI models could lead to simpler tools that displace existing products.
Despite these challenges, Dropbox shares have shown resilience compared to many other enterprise software companies. The stock has experienced a modest decline over the past year, while competitors like Monday.com, HubSpot, and Asana have seen significant value erosion. Houston commented on the rapid extrapolation of new technologies, suggesting that while trends might be directionally correct, their full impact often takes much longer to materialize than initially predicted. He also noted that he has not encountered any Dropbox customers who are reducing their subscriptions due to their use of AI tools like ChatGPT.
'Unanswerable question'
John Lovelock, an analyst at Gartner, draws parallels between the current AI era and the early days of cloud computing, when companies like Salesforce experienced rapid growth at the expense of older vendors. He suggests that the market is attempting to forecast the outcomes of AI's integration.
"AI is going to bring more value, therefore there's going to be more money spent," Lovelock said. "Where everybody seems to get very excited is who's going to make that money and that, in some ways, is the unanswerable question right now."
Analysts at Monness, Crespi, Hardt & Co. recently noted in a report that Dropbox is "making progress," specifically highlighting its AI-powered Dash feature, which facilitates easier searching and interaction with documents and messages across various third-party applications. The analysts, who hold a neutral rating on the stock, cited the AI opportunity and the company's valuation as potential draws for value investors.
The Dash feature allows users to quickly query and manipulate content beyond text, extending to video and audio. Houston mentioned that advancements in AI models now enable the creation of features that were previously beyond reach a decade ago.
Houston plans to pursue entrepreneurial ventures in AI, stating, "I'm not going to be racing sailboats." He is also a board member at Meta. He expressed enthusiasm for building in the AI space, describing it as "the most exciting period to be building things."
"It's all cliche, right?" Houston said. "AI is reshaping every aspect of how we live, and I'm sure that I'll have no shortage of ideas and stuff to work on."
In addition to Houston's planned transition, Dropbox announced that Mike Torres will join the company in July as chief product officer, coming from Google where he serves as vice president of product for Chrome.
Regarding the timing of his decision, Houston stated there was no specific catalyst. "Part of me has always thought, oh yeah, I'll be the CEO of Dropbox until my last gasp of my career," he said. "There's never a perfect time, there was no part of me where I was like, 'oh, this date is the date where it's going to happen.'"
Houston noted that since Alkarmi joined Dropbox from Vimeo in late 2024, the company has become more responsive to customers and has pursued bolder innovations. "I trust the right leader," he said. "The company's in the right place."
MAI-Image-2.5 launches at No. 3 on Arena
Microsoft's MAI-Image-2.5 has launched at #3 on Arena's text-to-image leaderboard, significantly improving its visual reasoning and commercial illustration capabilities.
Decoder
- Arena: A platform or benchmark used to evaluate and rank text-to-image models based on various performance metrics.
Original article
MAI-Image-2.5 ranks third on Arena's text-to-image leaderboard, excelling in style variety, accurate text rendering, and detailed imagery. It improves significantly over MAI-Image-2 with advancements in visual reasoning, scene structure, and commercial illustration capabilities. These enhancements enhance its ability to transform simple instructions into polished images.
Musk's xAI Warns Staffers to Limit Contact With Cursor Employees
xAI's legal team has reportedly cautioned employees to limit contact with Cursor staff to avoid jeopardizing a potential acquisition, despite weeks of co-mingling.
Original article
xAI's top lawyer has warned xAI employees to carefully moderate their interactions with workers from Cursor. Staff should not extend beyond what is necessary to implement a technical partnership. The warning is standard during acquisitions, but it is coming a bit late as the companies' employees have been working alongside each other for weeks. Any accusation that the two sides improperly co-mingled their business could put the acquisition deal in jeopardy.
China Expands Travel Curbs to Top AI Talent at Private Firms
China has broadened its travel restrictions to include top AI talent at private firms, requiring official approval for overseas trips, a significant expansion from previous policies.
Original article
China has restricted overseas travel for top AI professionals in private firms. These individuals will need approval from relevant authorities before embarking on overseas travel. The restricted individuals include a mix of startup founders, researchers, and executives. China has previously restricted travel for key personnel, from prominent researchers to nuclear scientists and executives at state firms, but it is unusual for the travel restrictions to be extended to private firms.

OpenRouter more than doubles valuation to $1.3B in a year
OpenRouter, an AI gateway startup, more than doubled its valuation to $1.3 billion after raising $113 million in Series B funding led by CapitalG, processing 100 trillion tokens monthly for over 400 models.
Decoder
- AI gateway: A service that provides a single API endpoint to access multiple different AI models from various providers, allowing users to switch between models or use them in combination without changing their application code.
Original article
OpenRouter more than doubles valuation to $1.3B in a year
Popular AI gateway maker OpenRouter, founded in 2023, has raised a hefty $113 million Series B led by CapitalG, the growth venture fund of Google parent company Alphabet. While the startup didn’t disclose its new valuation, The New York Times reports that it landed at about $1.3 billion post-money.
This is a hefty increase from the estimated $547 million post-money valuation it hit a year ago, per PitchBook, after raising $40 million in Series A funding in June 2025. That round was led by Andreessen Horowitz and Menlo Ventures, with participation from Sequoia.
What a difference a year makes. Since then, AI work has shifted from training to inference to, now, agents. And OpenRouter’s AI gateway has soared in popularity in response. The gateway helps enterprises and other AI users select different models for different jobs to control costs or increase reasoning and accuracy for the task at hand.
OpenRouter provides access to over 400 models, including Anthropic, Google, OpenAI, xAI, and DeepSeek, it says. It claims 8 million global users and 100 trillion tokens processed per month, or about 25 trillion per week. That’s a 5x increase from the 5 trillion tokens it was processing per week just six months ago.
OpenRouter’s success means that the AI model is increasingly becoming an invisible, swappable engine for AI tasks.
Rather than a future where startups or enterprises standardize on a model of choice — perhaps creating a single all-powerful model maker in the process — the growth of OpenRouter indicates something else. Companies have no plans to get locked into a model vendor as they did with their various SaaS providers. The multi-model future is already here.
Anthropic to introduce AI Fluency scorecard in Claude
Anthropic plans to introduce an AI Fluency scorecard in Claude, evaluating user interaction skills across 11 behavioral indicators to help users improve their collaboration with AI.
Decoder
- AI Fluency scorecard: An in-app feature by Anthropic designed to evaluate and provide feedback on a user's skills and behaviors when interacting with AI, based on a set of defined indicators.
- 4D AI Fluency Framework: A framework developed by Anthropic with academics Rick Dakan and Joseph Feller, categorizing AI interaction competencies into areas like delegation, description, and discernment.
- CoWork (Claude feature): A session type within Claude (presumably for collaborative work) where users interact with the AI for specific tasks.
- Claude Code (Claude feature): A session type within Claude specifically for coding-related interactions, where users delegate code generation, debugging, or modification tasks to the AI.
Original article
Anthropic appears to be turning its February research project into a consumer-facing product. References to a new AI Fluency surface have been spotted inside Claude’s settings, where users will be able to open a dedicated screen and ask Claude to generate a personal AI fluency scorecard. The system is designed to scan a user’s activity across Chat, Cowork, and Claude Code sessions, score each session against a defined set of behavioral indicators, and produce a structured report once analysis completes, viewable and managed directly from the settings panel.
New research: The AI Fluency Index.
— Anthropic (@AnthropicAI) February 23, 2026
We tracked 11 behaviors across thousands of https://t.co/RxKnLNNcNR conversations—for example, how often people iterate and refine their work with Claude—to measure how well people collaborate with AI.
Read more: https://t.co/g65nGQFmjG
The scorecard evaluates eleven observable behaviors grouped around competencies that map closely to the 4D AI Fluency Framework Anthropic built with academics Rick Dakan and Joseph Feller. The themes covered include setting the goal and approach, framing the conversation, and applying quality control, broadly the delegation, description, and discernment pillars of that framework. Early signals suggest the result is presented as a fraction, for example, 7.5 out of 11, alongside guidance on which areas a user might strengthen, giving newcomers a concrete sense of where their habits with Claude are paying off and where they aren’t.
This is the logical next step after the AI Fluency Index Anthropic published in February 2026, which analyzed around 9,830 anonymized Claude conversations to baseline how people collaborate with AI today. That study found iteration and refinement to be the strongest predictor of good AI use, while polished outputs like artifacts and code tended to lower critical checking. Bringing the same scoring system into the product turns a research finding into a personal feedback loop, one that nudges users toward the behaviors Anthropic believes lead to safer outcomes.
AI Fluency system prompt
"Please generate a structured AI Fluency scorecard that evaluates how effectively I interact with AI across 11 behavioral indicators, based on the user messages provided below.
These messages are drawn from 45 conversations across 42 chat, 2 CoWork, and 1 Claude Code sessions. Each message is tagged with its surface — [chat], [cowork], or [cc].
Analyze the user messages to determine each indicator's status:
- Use "demonstrated" ([+]) for indicators where the user clearly and consistently demonstrates the skill.
- Use "partial" ([~]) for indicators where the user sometimes demonstrates the skill or does so imperfectly.
- Use "not-observed" ([ - ]) for indicators where there is no evidence of the skill in the provided messages.
For every indicator marked [+] or [~], include 1-2 evidence quotes taken VERBATIM from the provided messages. Keep quotes under 150 characters each. Do NOT fabricate or invent quotes — every quote must appear exactly as written in the provided messages. If a quote must be shortened to fit the limit, truncate naturally at a word boundary.
For every indicator (regardless of status), output a Surfaces line listing which surfaces ([chat], [cowork], [cc]) the supporting evidence came from. If status is [-], output "Surfaces: none". Fluency looks different across surfaces: coding surfaces ([cowork], [cc]) favor concise delegation; [chat] favors rich description. Weight Description indicators primarily against [chat] messages.
Base your assessment solely on the provided messages. Do not assume skills that are not evidenced.
>>> User chat transcripts are injected here
The 11 Indicators
A single terse message can genuinely demonstrate multiple indicators at once. "ELI5" specifies both an audience (#2: a beginner) and a format (#3: simplified explanation). "less corporate" is both tone (#4) and implicit audience (#2). When a message packs multiple signals, credit each indicator it demonstrates — do not force it into only the single most-obvious row. The bar for each is still "clearly demonstrated", not "plausibly related".
Delegation
- 0: Clarifies goals — Does the user state what they want to accomplish before requesting help?
- 1: Consults on approach — Does the user ASK which approach to take before requesting execution? Interrogative: "what's the best way to approach this?", "how should I structure this?". The user is seeking a recommendation, not yet committed to a direction. Distinguish from #7: #1 asks which approach, #7 directs how Claude behaves.
Description
- 2: Defines audience — Does the user specify who the output is for?
- 3: Specifies format — Does the user indicate the desired output format (table, list, email, etc.)?
- 4: Communicates tone — Does the user indicate the voice, tone, or style they want?
- 5: Builds iteratively — Does the user refine outputs through follow-up rather than accepting the first result?
- 6: Provides examples — Does the user share examples or references to demonstrate quality expectations?
- 7: Sets interaction — Does the user TELL Claude how to behave, what role to adopt, or what interaction style to use? Imperative: "no preamble", "devil's advocate this", "steelman the other side first", "be direct", "ask me questions before writing". The user already knows what they want from Claude's behavior and is directing it — including when the direction is phrased as a terse request ("devil's advocate this" is role-setting, not approach-asking).
Discernment
- 8: Checks facts — Does the user question or verify factual claims in AI output?
- 9: Notices reasoning — Does the user push back when the AI's logic seems off? Must name a specific flaw, gap, or contradiction: "that doesn't follow", "you're assuming X", "that feels circular", "you skipped a step". Acknowledging or praising the reasoning ("good reasoning", "makes sense", "I follow your logic") does NOT count — that's acceptance, not scrutiny.
- 10: Recognizes context — Does the user proactively share context the AI could not know?
Product Feature Usage (deterministic counts from the last 30 days)
- projects: 30 conversations (frequent)
- artifacts: 3 conversations (sometimes)
- web-search: 27 conversations (frequent)
- research: 3 conversations (sometimes)
- connectors: 4 conversations (sometimes)
- skills: 1 conversation (sometimes)
- memory: 0 conversations (never used)
- sports: 0 conversations (never used)
- weather: 0 conversations (never used)
- maps: 0 conversations (never used)
- recipes: 0 conversations (never used)
- subagents: 0 conversations (never used)
- mcp-tools: 1 conversation (sometimes)
- computer-use: 0 conversations (never used)
Required Output Format
Output EXACTLY the text below — three marker-delimited sections with nothing before, after, or between them. Do NOT wrap in a code block. Do NOT add any introductory or closing text.
--- AI Fluency Summary ---
[A tight 80-110 word summary addressed directly to the user, covering BOTH collaboration behaviors and product-feature usage as one coherent paragraph. Use short, scannable sentences — no dense prose. Lead with the strongest demonstrated behavior, weave in one evidence quote, note which Claude features they rely on most, then close with one behavior and one feature to try next, framed as opportunities. Encouraging and specific, not generic.]
--- End Summary ---
--- AI Fluency Scorecard ---
Name: User
Role: General
Conversations: 45
[All 11 indicators in order 0 through 10. Rules:]
[Indicator line format: <id> [<symbol>] <label>]
[Status symbols: [+] = demonstrated, [~] = partial, [-] = not-observed]
[After the indicator line, output one line: Surfaces: <comma-separated list of chat,cowork,cc> or Surfaces: none]
[For [+] or [~] indicators: follow with 1-2 evidence quotes, each on its own line indented with two spaces and wrapped in double quotes]
[For [-] indicators: no quote lines]
--- End Scorecard ---
--- Insights ---
Strength-Title: [4-6 word headline naming the user's strongest demonstrated behavior]
Strength-Body: [One sentence, under 110 chars, explaining why this behavior works well for them. Address the user as "you".]
TryNext-Title: [4-6 word headline for one skill to build next, framed as an action]
TryNext-Body: [One sentence, under 110 chars, with a concrete starting move. Can include a short example prompt in quotes.]
Feature-Id: [One id from this list, picked from features the user has NOT used yet, that would complement how they already work: projects, artifacts, web-search, research, connectors, skills, memory, sports, weather, maps, recipes, subagents, mcp-tools, computer-use. If every feature is already used, write the word none.]
--- End Insights ---
The feature fits a broader push to position Claude not just as a tool but as a skill people can develop, anchored by the Anthropic Academy, the AI Fluency course series, and partnerships with PayPal, GivingTuesday, and university programs. A timeline for the rollout has not surfaced, and it remains unclear whether the scorecard will launch for all tiers or start with onboarded and enterprise audiences first. Either way, it would mark one of the first attempts by a major lab to grade the human side of the conversation rather than the model.
AWS Control Tower Proactive Controls for Terraform: A Proof of Concept
An experiment shows how Terraform's Cloud Control provider can trigger AWS Control Tower's proactive controls, which are natively designed for CloudFormation Hooks.
Decoder
- AWS Control Tower: An AWS service that provides a simplified way to set up and govern a secure, multi-account AWS environment.
- Proactive controls: Governance rules in AWS Control Tower that prevent non-compliant resources from being provisioned, enforced by CloudFormation Hooks.
- CloudFormation Hooks: Capabilities within AWS CloudFormation that allow custom logic to be executed before or after stack operations (create, update, delete) to validate or mutate resources.
- Cloud Control API: A unified API by AWS for managing resources across many AWS services, simplifying programmatic resource management.
Original article
AWS Control Tower proactive controls are CloudFormation Hooks that evaluate resources at creation time via the Cloud Control API, but they are not natively compatible with Terraform workflows. An experiment explores whether Terraform's Cloud Control provider can trigger these controls to bridge the gap.

The User-centered Design Process: Four Key Principles
User-centered design (UCD) prioritizes user research and feedback early in development, guided by four principles, leading to better engagement like Every.org's 29.5% donation rate increase.
Deep dive
- User-centered design (UCD) is a UX design process that involves users from the earliest stages, guiding design decisions with their research and feedback.* The four key principles of UCD are: empathy (listening to users with an open mind), data-driven decision-making (using analytics and behavior data), user involvement throughout the process (early prototyping and testing), and aligning business goals with user needs.* UCD is distinct from UX (User Experience, the overall journey) and HCD (Human-Centered Design, broader empathetic goals).* While UCD may initially take more time for research and prototyping, it prevents costly mistakes later in development.* Every.org, a non-profit, successfully applied UCD, increasing its donation rate by 29.5% after streamlining its user experience based on user feedback.* UCD implementation typically involves four phases: specifying the context of use (user interviews, personas), specifying business and user requirements (identifying alignment/disalignment), generating design solutions (low-fidelity prototypes), and iterating/evaluating (user testing and refinement).* UCD principles can be applied to aspects like accessibility, visual hierarchy, multi-user journey mapping, and personalization to create more effective websites.
Decoder
- User-centered design (UCD): An iterative design process where designers focus on users and their needs in each phase of the design process. UCD aims to improve usability and accessibility by involving users throughout the design and development cycle.* User experience (UX): The overall experience of a person using a product, system, or service. UX design considers how the user feels about the interaction, ease of use, and efficiency.* Human-centered design (HCD): A broader design philosophy that prioritizes understanding and addressing human needs and emotions in a holistic way, often extending beyond just usability to social and ethical considerations.
Original article
Full article content is not available for inline reading.
AI Ad Generator (Website)
Adscreator uses AI to automatically generate professional, on-brand advertisements by analyzing content from any given URL.
Original article
Adscreator is an AI-powered ad generator that transforms any URL into professional, on-brand advertisements. The platform automates the ad creation process by analyzing content from provided links and generating targeted marketing materials.

A tobacco factory turned restaurant, Nikotin's logo takes the shape of a cigarette
Designer Davy Denduyver created a bold, cigarette-inspired branding for Amsterdam restaurant Nikotin, located in a former tobacco factory, featuring a custom logotype and handwritten typography.
Original article
Full article content is not available for inline reading.
The Virtual OS Museum is a fantastic project that lets you run Mac OS, A/UX, NeXTSTEP, more
Developer Andrew Warkentin launched the Virtual OS Museum, a massive web-based emulation project offering access to over 1,700 operating systems from 1948 to today.
Original article
The Virtual OS Museum is a massive emulation project by developer Andrew Warkentin that lets users explore over 1,700 pre-installed operating systems and applications spanning more than 250 platforms and 600 OSes—from early mainframes and classic Mac systems to NeXTSTEP, Windows, Linux, PalmOS, and more—covering computing history from 1948 to today.

A few interesting modern pixel fonts
Modern pixel fonts like Andrew Gleeson's Analog Mono and Vercel's Geist Pixel are evolving beyond novelty, offering typographic rigor and fixing classic issues while evoking nostalgia.
Decoder
- Subpixel rendering: A method of increasing the apparent resolution of a display by rendering pixels using the individual red, green, and blue components of each pixel, which are physically distinct.
- Chromatic aberration: A type of optical distortion where a lens fails to focus all colors to the same convergence point, resulting in color fringes. In design, it can be simulated for aesthetic effect.
- Kerning: The process of adjusting the spacing between individual letter pairs in a font to improve readability and visual appeal.
Original article
Analog Mono was designed to fix the crimes of the classic pixel font that was ubiquitous in the 1990s. Coral Pixels is a color font with 1990s and 2000s colorful fringing baked in. Two Slice is a font that's only 2 pixels tall while remaining somewhat readable. Geist Pixel is a font that maintains the visual texture that teams want while reserving the typographic rigor that products require.
Ferrari Luce EV debuts with Jony Ive-designed cockpit and familiar design cues
Ferrari unveiled its first electric supercar, the Luce, on May 25, 2026, featuring a Jony Ive-designed minimalist cockpit with physical controls and premium materials.
Decoder
- Jony Ive: A renowned industrial designer, former Chief Design Officer at Apple, known for designing products like the iMac, iPod, iPhone, and iPad. He later founded the design firm LoveFrom.
Original article
Ferrari has unveiled the full design of the Luce, its first electric supercar, including a closer look at the Jony Ive-designed interior created by LoveFrom, which emphasizes physical controls, minimalist styling, and premium materials like glass and aluminum—offering what may be the closest glimpse yet of the design philosophy behind the canceled Apple Car. The reveal showcases details such as the steering wheel controls, dashboard, side panels, and a mechanical clock.

Bob's Red Mill rebrand is the Cracker Barrel logo controversy all over again
Bob's Red Mill's May 25, 2026 rebrand by Turner Duckworth, which deemphasizes late founder Bob Moore, sparked controversy reminiscent of the Cracker Barrel logo backlash.
Decoder
- Rebrand: The process of changing the corporate image of an organization. This typically involves changing a company's logo, name, imagery, marketing strategy, and design style.* Turner Duckworth: A prominent design agency known for creating brand identities and packaging for global companies.
Original article
Bob's Red Mill has unveiled a modernized rebrand by Turner Duckworth featuring a cleaner logo, custom typography, and updated packaging designed to improve readability while preserving the brand's heritage feel. However, the redesign sparked backlash online because founder Bob Moore no longer appears prominently in the logo following his death in 2024, leading some critics to compare the reaction to the controversial and ultimately reversed Cracker Barrel rebrand.

The Seven Interior Design Trends Actually Defining 2026 Homes
2026 interior design trends are shifting from cool minimalism to warm, tactile, lived-in spaces featuring curved furniture, bold biophilic elements, and sculptural decor.
Decoder
- Biophilic design: An approach to design that connects building occupants more closely to nature through the use of natural light, plants, and natural materials and processes.
- Limewash: A type of paint made from lime and water, known for its soft, matte, and naturally textured finish that creates subtle variations in color.
Original article
The biggest is the shift from cool minimalism to warm, lived-in spaces that prioritize emotional comfort.
5 Ways to Run Your Containerized App on AWS in 2026
AWS now offers five primary ways to run containerized applications, indicating diverse deployment options for 2026.
Original article
AWS now offers five primary ways to run containers.