Anthropic launches Memory in Claude Agents for enterprise
Anthropic's Claude agents can now remember information across sessions with a new Memory feature that stores knowledge as manageable files.
Summary
Decoder
Original Article
Your AI Might Be Lying to Your Boss
Investigation reveals AI coding assistants systematically overreport their code contribution by massive margins due to measurement biases that don't count pasted text, auto-completed symbols, or refactored code as human work.
Summary
Deep Dive
Decoder
Original Article
This post is my personal opinion based on my testing and observations. I'm pretty confident in my test methodology, but William O'Connell is human and can make mistakes, check important info, etc.
How much of your code is AI? That question would've been gibberish to me five years ago, but of course the last few years have seen an explosion of "AI-enhanced" IDEs and other software development tools. Software companies are spending huge sums of money to provide these tools to their staff, and rapidly cycling through them as the space continues to evolve.
I don't make heavy use any of these in my personal life, but I have gotten to try a handful of them through various employers. One such tool is Windsurf, a VSCode fork that most people know as the one they assume shut down after Google bought out their key leadership last year. It didn't though, at least not yet, and I'd imagine its FedRAMP and HIPAA certifications will continue to make it appealing to certain types of enterprise customers for the foreseeable future. If you've seen Cursor or GitHub Copilot, it's basically the same, with some AI-powered autocomplete features and an "agent" chatbox called Cascade where you can ask your favorite LLM why a bug is happening, or get it to draft a class or function for you. In theory these types of agents can develop features and even whole applications on their own, but in my experience the results are pretty inconsistent, so I tend to stick to simpler requests.
It really is amazing how fast an LLM can sometimes track down a bug just from a description.
One thing that's very important to any enterprise rolling out a tool like this is metrics:
- Are employees using it?
- How much time is it saving?
- Is this technology being used to paper over inefficiencies in our existing processes, obscuring underlying issues because using AI to quickly produce documents that won't be read and code that won't be run is easier than asking why those things are being done in the first place?
Admittedly I haven't heard that last one much, but the first two definitely get asked a lot. To help with this, Windsurf offers a dashboard of analytics at both the individual and team level. It includes things like the number of autocomplete suggestions accepted, the number of messages sent to Cascade, and which models are being used the most. It also includes a metric called "% new code written by Windsurf" (or sometimes "PCW"), which they seem quite proud of, since it gets top billing on the dashboard and they wrote a whole blog post explaining it.
The pitch is pretty simple: how much of the code did a developer write by hand, and how much did they generate with AI? When I first learned about this feature my guess would have been 10, maybe 20% AI, depending on the project and whether you include unit tests (LLMs are pretty good at those). So you can imagine my surprise when I opened the dashboard and saw this:
Don't worry employers, I didn't screenshot my work computer. This is a recreation.
Now, it's certainly possible to misjudge how often you use a particular tool. If the number had been 40%, or even 50%, I wouldn't have been that shocked. But 98%? That would mean I'm generating forty-nine times as much code as I'm writing manually. If that were true wouldn't I have run through my token budget by now? Shouldn't I either have been promoted for my godlike productivity, or fired because 49/50 of all developers are now redundant? You'd think, but Windsurf says this result is pretty normal:
"...customers should expect PCW values of 85%+, often 95%+. This is not a hallucination and is accurate given how we compute this metric, though there are a number of caveats that we will cover later in this section."
"Hallucination" is an amusing choice of word there, since it implies the metric itself is generated by some sort of machine learning system, which seems unlikely. But regardless, if those numbers are "accurate given how we compute this metric", how exactly do they compute it? To their credit, they go into a fair bit of detail:
"To compute PCW, we take the number of new, persisted bytes of code that can be attributed to an accepted AI result from Windsurf (i.e. Tab suggestion, Command generation, or Cascade edit) and the number of new, persisted bytes of code that can be attributed to the developer manually typing. ... We take these measurements whenever a commit is being made. This way if the AI added a lot of code but the developer deleted a lot of it before committing the code to the codebase, then we are not incorrectly inflating the W number. Similarly, any bytes of code that come from the developer manually editing an AI result will get attributed to the developer (D) as opposed to Windsurf."
That all sounds pretty reasonable, but I was still skeptical of the number I was seeing. I wanted to know for sure where that 98% was coming from, and what it actually meant. So I signed up for a personal Windsurf subscription, installed the editor, and ran some tests.
The Math Behind the Curtain
My original plan was to use mitmproxy to watch the outgoing network traffic from the IDE, and see what numbers it was reporting as I took different actions. That turned out to be easier said than done though, because Windsurf is quite chatty on the network, sending many requests to various domains while in use, and even pretty often when I'm not touching it at all.
Additionally, Windsurf makes heavy use of protobuf, a data encoding scheme that I'm pretty sure Google invented to annoy me personally, because it makes it much harder to interpret and debug the traffic between clients and servers. If you don't have the associated definition file, a protobuf message is basically just a list of simple values (int32, bytes, etc.) with no human-readable labels. Because of this it was hard for me to tell which messages were related to the PCW metric, or what exactly they were communicating to Windsurf's cloud backend.
Luckily, I found an easier way. It turns out that even though the dashboard says "Analytics update every three hours", it actually shows new data almost instantly. And while the UI only shows the overall percentage, the response from the web server actually includes some additional data. It's protobuf as well, but since it's a webpage the source code is all immediately accessible, and of course the frontend code includes a copy of the message definitions so it can make use of the data.
So I was able to decode the GetAnalytics response and pull out these fields (among others):
user_bytescodeium_bytestotal_bytespercent_code_written
Windsurf used to be called Codeium, so clearly that one represents the AI-generated bytes. And as you'd expect, the percent_code_written is equal to codeium_bytes / total_bytes. So far so good, but what causes those values to change?
Windsurf says they take measurements "whenever a commit is being made", but that doesn't match my testing. Whether the folder I'm in has a git repo set up or not, as soon as I make additions to a file the user_bytes value increases, and if I delete some of those lines it decreases. Whether I do a commit (using Windsurf's git UI) between those two actions makes no difference as far as I can tell. What does make a difference is restarting the editor; it seems to forget the history of how each line was generated, so deleting code I wrote before the restart doesn't deduct from user_bytes, and deleting code Cascade wrote before the restart doesn't deduct from codeium_bytes. There is a line in the PCW article that alludes to this ("We currently do not have instrumentation to measure PCW across sessions"), but obviously that's a pretty major gap in functionality, and it doesn't actually address why the described git integration appears to be nonexistent.
To test how exactly the byte counts are being computed, I performed a few tests where I took specific actions and checked how much each value had increased. To keep things simple I disabled the AI autocomplete features (which I find more distracting than helpful anyway) and just focused on the Cascade chat experience. I created a file, human_file.js, and I typed out a single line:
console.log('This line was written by a human.');49 characters exactly. Then I told Cascade to create a second file (ai_file.js) and to write a similar line of the same length.
The result:
user_bytes: 855 -> 901 (+46)
codeium_bytes: 7387 -> 7437 (+50)So the system did seem to be working, but we have a discrepancy right off the bat. The line is definitely 49 characters (50 with a newline at the end), so why is user_bytes only reporting 46? Well this is where some technicalities start to emerge. Windsurf says that they measure "code that can be attributed to the developer manually typing". The Windsurf editor is a lightly modified version of VSCode, and like most code editors, VSCode has a feature that automatically adds closing symbols (end quotes, closing parentheses, etc.) without the user manually typing them. I suspect that because those characters are being added by that feature, they're technically not "the developer manually typing", and therefore are not counted.
If that's what's going on, then in my opinion that's already a pretty serious knock against the reliability of Windsurf's metrics. Counting closing symbols when the LLM outputs them, but not when VSCode auto-adds them, obviously biases the stats to increase the percentage of code attributed to AI (even if the effect is fairly slight). As it turns out, there may be some not-so-slight biases as well.
Continuing my test, I wrote out a simple function, and asked Cascade to write a similar function in its own file. Finally I copy/pasted Cascade's function into the human file, and asked Cascade to copy my function into its file.
Here's the final tally:
user_bytes: 1054 (+199)
codeium_bytes: 7807 (+420)So for this session, Windsurf is reporting that Cascade generated more than twice as much code as I wrote, even though we each produced an almost identical file. I never touched ai_file.js, Cascade never touched human_file.js, and the two files are the same length (actually human_file.js is 21 bytes longer because Cascade used Unix-style line endings). Yet somehow my PCW for this session would be around 68%. The trick here is that much like with the auto-added closing symbols, it seems like any text the user pastes doesn't count towards user_bytes. I guess from a certain perspective that could sound reasonable (if you pasted code from StackOverflow you didn't really "write" it), but the way it plays out in practice quickly becomes absurd.
In another test I hand-wrote two functions in a single file, then moved them both to a second file (as one might do when refactoring). For the first I cut and pasted, for the second I asked Cascade to move it for me. The result? Cutting the first function deducts it from user_bytes, and pasting it doesn't count for anything. Cascade deleting the second function also deducts it from user_bytes, but the lines added to the new file count towards codeium_bytes. So even though I did 100% of the writing and 50% of the refactoring, Windsurf reports that 100% of the code I produced in that session was generated by AI.
In my opinion these biases make Windsurf's PCW metric basically useless. By being so picky about what counts as a human contribution, and being as generous as possible to the LLM, Windsurf (intentionally or accidentally) tips the scales towards reporting absurdly high percentages, regardless of where most of the code is actually coming from or whether it eventually gets committed.
Who Else?
So that seems... bad, but of course Windsurf is just one of many AI-enhanced IDEs out there (and it's owned by Cognition, makers of Devin, who don't have a stellar track record). What about the other products on the market? As far as I can tell Google's Antigravity editor doesn't have any comparable metrics. GitHub Copilot does provide stats on how many lines of code it generated, but not as a percentage of the total. Amazon Kiro is the same. I did find one popular editor with a metric similar to Windsurf's PCW though: Cursor, with its "AI Share of Committed Code". So how does it stack up?
Sadly Cursor only offers analytics on their business-focused "Team" plan, making this one of my costlier blog posts, but I'll do almost anything for science. Right off the bat things are looking better, with a more nuanced and considered description of their measurement approach:
"Cursor keeps a log of the signature of every AI line (Tab or Agent) that is suggested to the user during their chat session. These lines are stored and later compared to the signatures of each line in subsequent git commits that were written by the same author. ... We use the following definitions: Cursor AI: Any line that can be attributed to Cursor Agent or Tab based on diff signatures. Other: Any line of code that can't be detected as being written by Cursor"
So rather than splitting hairs about the various ways a programmer can add text to a file, they simply divide the total lines in a commit into "AI" and "Other". Sounds great, but does it work?
Well, the git integration certainly does. While Cursor does also use protobuf, it's easy to tell that it's sending an event called "ReportCommitAiAnalyticsRequest" whenever I do a commit, and that message clearly includes information about the different files and what seem to be the line ranges produced by different methods. We can also see the results on the Cursor website, though it takes a while for them to appear. Running my same test from before, we get a much more reasonable result:
I'm not sure why the bar graph doesn't go to 100%.
Certainly a lot closer than the 67.9% that Windsurf reported. I'm actually not sure what caused it to report 20 AI lines vs 18 "other" lines; I did the test as several separate commits and the IDE commit history shows the first commit adding 1 line to each file and the second commit adding 20, so that should be a total of 21 for both. I did manage to capture the protobuf message the IDE sent for the second commit, and it seems to be showing (correctly) that lines 3 through 21 of ai_file.js were written by the Composer 2 model, and 3–21 of human_file.js were added manually.
Thanks to pawitp for this handy protobuf decoder tool.
So I'm not sure why a few lines seem to have gone missing, but regardless the behavior does more or less match what I'd expect from Cursor's description.
Unfortunately, the line-based approach has other flaws that don't show up in this test. For instance, I pasted in a (bogus) 100-line JavaScript file, and then told Cursor to change all the double quotes to single quotes (updating escape characters where necessary). Some might argue that that's an overly simple task to delegate to an LLM (as opposed to an IDE or linter feature), but with some companies giving employees basically unlimited token budgets, and the very low cost of some of the cheaper flash/nano models, I don't think it's that unrealistic. As you'd expect, Composer 2 handled it flawlessly, touching 49 of the 93 non-blank lines in the file.
The main difference between Windsurf and Cursor seems to be color saturation.
The gotcha here is probably pretty obvious. I was expecting to say "see, I added this code manually, but now that Cursor has changed the quote marks it counts all the lines containing quotes as AI-generated". That wasn't what actually happened, though.
Somehow, Cursor counted the entire file as AI, even though we can see from the diff that it left plenty of the lines unchanged. And remember that the entire file is exactly 100 lines long, including some blank ones, so it's not just a case of excluding lines that are considered too simple to be counted. My best guess is that the system that tracks which lines were added by the AI is designed to work with contiguous blocks of code (like drafting an entire function), and if there are too many gaps in the generation it just gives up and calls the whole thing one AI block.
Regardless, this is another case where the AI tool seems to be claiming credit for 100% of the code produced, even though arguably zero lines of code were actually "AI generated", and many of them weren't touched by the tool whatsoever. It looks like both IDEs sometimes wildly overestimate how much they're being used in a coding session.
Weights and Biases
One takeaway here is that it's just very hard to measure the contribution LLMs make to a codebase. Sometimes the best use cases are inquisitive prompts like "Is there already a different solution to this elsewhere in the codebase?" or "Are there any edge cases this logic doesn't cover?", which don't necessarily produce any code at all. On the flipside, I'm a big believer in a philosophy expressed concisely by Jack Diederich:
"I hate code, and I want as little of it as possible in our product."
Measuring the value of an LLM by the number of bytes or lines it produces has all the same problems as measuring developers that way; adding a lot of code doesn't necessarily mean you're adding a lot of value, and sometimes the hardest and most productive work is cleaning up and simplifying what's already there. Besides, when a developer is making heavy use of tab complete, etc. there's not always a clear-cut answer to "was this line of code written by AI", even if you were looking over their shoulder as they wrote the file. So perhaps it's foolish to expect algorithmic answer to that question.
Still, it's notable that the bias always seems to be towards reporting a higher AI percentage. Whether that number is truly meaningful or not, "what percent of my team's code did Windsurf write" is a very appealing statistic for a manager or executive. Execs love announcing that 30%, 75%, even 100% of their code is AI-generated. And of course high numbers are great for AI companies, because they underscore the value they bring to software teams and help justify their high subscription costs. But as a developer, skewed metrics can be harmful. If 50% of my team's code is AI-generated, will management expect features to be implemented twice as fast? If 90% is AI, do we even need a team?
Again to their credit, Windsurf does push back on that type of thinking in their blog post:
"Writing code is not the same as software development. This is only capturing some level of acceleration while writing code, and does not capture time taken in architecture, debugging, review, deployment, and a number of other steps."
To be sure, all metrics are only as good as your understanding of their limitations. If everyone internalizes that these percentages should only be used to compare trends over time, with the absolute values being essentially meaningless (and not comparable across tools), then maybe the details of how they're computed don't matter. But a sentence like "98% of our new code was written by Windsurf" creates a gut feeling that's hard to talk yourself out of, even when you know there are caveats. And I wonder if the impact of these stats could go beyond press releases and 🚀-laiden Slack posts. Since code is protected by literary copyright, and AI-generated works aren't copyrightable, the legal team might get nervous when they hear that the vast majority of their company's code "can be attributed to AI".
Ultimately, I don't really know what percentage of the code I commit is from an AI model. I don't know what the "correct" way to calculate that would be, or if it's worth calculating at all. I'm confident that these tools save me some amount of time, but I also know it's easy to overestimate how much. What I am certain about is that these vendors have a lot of money riding on whether or not AI is fulfilling its grandiose promises; massively accelerating strong developers and completely replacing weak ones.
Perhaps it is, but I'm not going to trust them to measure it.
Monitoring LLM behavior: Drift, retries, and refusal patterns
Microsoft engineer outlines a two-layer evaluation framework for monitoring LLM systems in production, combining deterministic checks with model-based semantic assessments to catch failures before deployment.
Summary
Deep Dive
Decoder
Original Article
Stash (GitHub Repo)
Stash is an open-source tool that gives AI agents persistent memory across sessions, solving the problem of LLMs starting every conversation from scratch.
Summary
Deep Dive
Decoder
Original Article
Anthropic tests new Bugcrawl tool for Claude Code bug detection
Anthropic is testing Bugcrawl, a new Claude Code feature that scans entire repositories to detect bugs and suggest fixes.
Summary
Deep Dive
Original Article
Anthropic appears to be building a tool within Claude Code called Bugcrawl, which surfaces as a dedicated entry in the side navigation. Once opened, the screen presents a repository selection UI alongside a warning that the feature consumes tokens at a high rate, so it's suggested to start with a small repository before pointing it at anything substantial. That caveat alone hints at the scale of work the agent would be carrying out in the background.
The most plausible read is that Bugcrawl will set Claude loose across an entire codebase to hunt for general bugs and propose fixes, while the Security tab already shipping in Claude Code for Enterprises targets vulnerabilities specifically. If Anthropic pushes the concept further, the same loop could extend into end-to-end product testing, where Claude spins up a local instance of the app, walks through user flows, and reports regressions. How feature specifications or test criteria would be passed into a run is still an open question, since the only screen visible so far is the repository picker.
For Anthropic, the move slots cleanly into the Claude Code expansion of recent months, which has already produced Claude Code Security in February and Claude Code Review in March, both built around multi-agent investigation of code. Bugcrawl would round out that lineup by tackling general correctness and quality, the broader, fuzzier category that sits between security scanning and PR-level review. It also fits the wider competitive picture, with OpenAI's Codex, xAI's Grok Build, and Google's Jules each pushing toward agents that reason across full repositories rather than single files.
The likely audience is engineering teams on Team and Enterprise tiers, where the token burn warning is easier to absorb. No release window has surfaced, and the feature does not appear in production builds. Given the cadence of Code Security and Code Review landing within weeks of each other, a research preview on the same web surface looks like the most likely path.
HashiCorp Vault 2.0 Marks Shift to IBM Lifecycle with New Identity Federation
HashiCorp Vault 2.0 is the first major release under IBM ownership, adding workload identity federation to eliminate static cloud credentials while introducing breaking changes and a two-year support lifecycle.
Summary
Deep Dive
Decoder
Original Article
How we built Elasticsearch simdvec to make vector search one of the fastest in the world
Elasticsearch built a custom SIMD kernel library that speeds up vector distance computations by up to 4x through bulk scoring and memory latency hiding techniques.
Summary
Deep Dive
Decoder
Original Article
Spotting CI/CD misconfigurations before the bots do: Securing GitHub Actions with Datadog IaC Security
AI agents are now autonomously discovering and exploiting security flaws in GitHub Actions workflows, prompting new automated defenses.
Summary
Decoder
Original Article
Evolving Media CDN for the world's most demanding broadcast and streaming workloads
Google Cloud's Media CDN is adding regional shielding, better origin compatibility, and real-time monitoring tools to help streaming platforms handle massive live events more efficiently and cost-effectively.
Summary
Deep Dive
Decoder
Original Article
Databricks partners with OpenAI on GPT-5.5
Databricks is partnering with OpenAI to bring GPT-5.5 to its platform, with the new model cutting errors nearly in half on enterprise document reasoning tasks.
Summary
Deep Dive
Decoder
Original Article
How Airtable Saved Millions by Cutting Archive Storage Costs by 100x
Airtable cut archive storage costs by 100x and saved millions annually by migrating petabytes of cold MySQL data to S3 Parquet files queried with Apache DataFusion.
Summary
Deep Dive
Decoder
Original Article
Background Coding Agents: Supercharging Downstream Consumer Dataset Migrations
Spotify's coding agent Honk automated 1,800 data pipeline migrations by leveraging standardized tooling and careful prompt engineering, saving 10 engineering weeks and demonstrating what makes large-scale agent-driven refactoring work in production.
Summary
Deep Dive
Decoder
Original Article
Background Coding Agents: Supercharging Downstream Consumer Dataset Migrations (Honk, Part 4)
This is part 4 in our series about Spotify's journey with background coding agents (internal codename: "Honk") and the future of large-scale software maintenance. See also part 1, part 2, and part 3.
In Part 2, we explored how we enabled our Fleet Management tools to use agents to rewrite our software automatically. We also explored how to write good prompts that allow the agent to best work without needing human input. In this blog post, we give a case study of how one team at Spotify used Honk with our Backstage and Fleet Management platforms to ease the pain of migrating thousands of dataset consumers onto new dataset versions — saving an estimated 10 engineering weeks in the process. We also share what we learned about how to make our data landscape more autonomous-coding-agent–friendly in the process.
Dataset migrations can be painful
As any data team knows, getting users to migrate to new endpoints can be a slow and painful process, both for the data owners and the downstream teams that use the datasets day-to-day.
At the end of last year we needed to deprecate two of the most heavily-used user datasets in order to release new versions with additional dimensions that would unlock new features. These deprecated datasets had ~1,800 direct downstream data pipelines between them and indirectly impacted several thousand more across the entire company.
We faced the prospect of migrating ~1,800 direct downstream data pipelines in only six months, across three very different pipeline frameworks that we use at Spotify: the SQL-based BigQuery Runner and dbt frameworks, and the Scala-based Scio.
We estimated that it would have taken around 10 engineering weeks of effort to complete these migrations manually. Facing that much work, we explored how Backstage, Fleet Management, and Honk might be able to automate some of the complexity.
Simplifying fleet migrations with Backstage
Before we could begin making any code changes, we had to first understand the lineage of our deprecated datasets so we would know which repositories to make those changes in. This is where Backstage's endpoint lineage and Codesearch plugins came in.
Each endpoint's Backstage page gave a clear list of downstream consumers, giving us an immediate sense of the scale of our migration. With Codesearch, we wrote queries that would find target repositories across the Spotify GitHub Enterprise landscape, and mark them as in-scope for our migrations, which we orchestrated using our Fleetshift plugin.
With Honk, context is key
As we discussed in Part 2, context engineering is a key part of the process when working with background coding agents. With our target repositories now identified quickly via Backstage, this was the part of the build that took the most time and iteration to get right, and also where we learnt the most.
One of the major challenges for Honk in this migration was the fact that it had to deal with three different data pipeline frameworks, two of which are reasonably consistent in style and substance across the company (BigQuery Runner, dbt), and one of which isn't (Scio). This lack of standardisation across our data landscape made it hard to write all-in-one prompts for Honk that could truly capture all available permutations of what it would encounter.
Although we are adding these features now, at the time of these migrations, Honk did not have access to Claude skills or custom configurability when it runs. This was a design choice made to establish guardrails around the range of possible outcomes during the migration. This meant that the prompt given to it had to be comprehensive, because it could not do things like use MCPs to go and read dataset schemas that you had not given it, or read external documentation for more context.
Trying to write a good, fully-comprehensive prompt for Scio pipelines, which can vary hugely between teams due to the relative flexibility that the framework provides, got very unwieldy without having access to outside Claude skills. We therefore made the decision not to continue trying to make Scio migrations work at that time, and focused on the other two pipeline frameworks.
For the dbt and BigQuery Runner pipeline frameworks, which were much more standardised, we initially attempted to generate a good context file by asking Claude to re-purpose a migration guide that was written for human engineers. However, the resulting context was not comprehensive enough, and Honk was left to make assumptions about how to map from one dataset field to another that were often incorrect. Once we adjusted for this, and made all mappings clear using tables in the context file — keeping in mind that Honk could only access the context we had written for it and little else — we began to see solid performance across the majority of target repositories.
Having these fine-grained instructions also allowed us to specify where Honk shouldn't try to perform a field migration, for example, in cases where a use case–specific judgement call was required. In these cases, we asked Honk to leave the fields unchanged, but to add comments above them with links to human engineer migration guides to make the task as easy as possible for the team that would later review the pull request.
One final challenge we encountered was that, unlike with Scio pipelines, the BigQuery Runner and dbt repositories across the company rarely used any build-time unit testing. This meant that one of Honk's key features, its ability to verify its work and then adjust based on the results, was unavailable to us, and we had to rely on the downstream owning teams to perform their own manual testing before merging the automated PRs.
That said, we successfully rolled out 240 automated migration PRs using Fleetshift. Here, Backstage and Fleetshift greatly simplified the ongoing monitoring and management of our shifts by providing an overview UI that gave us a snapshot view of migration progress, and the ability to easily click through and view any of the automated PRs without manually searching for the repositories. This was invaluable for troubleshooting, progress monitoring, and facilitating communication with the owning teams.
What did we learn for the future
It became clear during this project that the success of using our Fleet Management tools with Honk for large-scale, complex migrations is going to depend on the strategic push to consolidate and standardise our data landscape. Similarly, we must enforce requirements for testing and validation across repositories so that agents like Honk can verify their work in an automated fashion. Both of these elements will be critical in enabling background coding agents across Spotify.
In addition to that, there are exciting features on the Honk roadmap that will also enhance its performance on complex tasks. The Honk team is working on a feature that will allow the agent to spend some time gathering its own context, for example by reading JIRA tickets or documentation, before it begins to perform code changes. This reduces the need for such comprehensive context files to be written up front, and should improve the quality of the resulting code changes by making full use of the Claude Code capabilities.
With both of these wider, strategic changes taking place, and alongside that the underlying Claude Code agents improving in capability all the time, we look forward to seeing Fleet Management using Honk excelling on tackling more and more complex migrations in the future and reducing manual toil for our engineering teams.
Learn more about Fleet Management and our background coding agent Honk:
- Honk, Part 1: 1,500+ PRs Later: Spotify's Journey with Our Background Coding Agent
- Honk, Part 2: Context Engineering
- Honk, Part 3: Predictable Results Through Strong Feedback Loops
- On-demand webinar: How Spotify Built Honk
- Now available: Fleetshift for Spotify Portal — perform complex code changes at scale, just like we do at Spotify
Measure Less to Learn More: Using Fewer, Higher-quality Metrics to Capture What Matters
Discord discovered that tracking too many metrics in A/B tests creates statistical problems that make it harder to detect real changes.
Summary
Decoder
Original Article
Databases Were Not Designed For This
Traditional databases assumed human-authored queries and intentional writes, but AI agents generate queries dynamically and retry autonomously, requiring new defensive patterns to prevent silent failures at scale.
Summary
Deep Dive
Decoder
Original Article
Jaeger adopts OpenTelemetry at its core to solve the AI agent observability gap
Jaeger v2 rebuilds on OpenTelemetry and adds Model Context Protocol support to help engineers trace AI agent execution paths and debug with natural language queries.
Summary
Deep Dive
Decoder
Original Article
Fixing What LLMs Get Wrong
Reflexion enables LLM systems to learn from factual errors across sessions by storing natural language reflections of failures in episodic memory and reinjecting them into future prompts, without requiring model retraining.
Summary
Deep Dive
Decoder
Original Article
Fixing What LLMs Get Wrong
A Field Guide to Verification, Repair, and Self-Improvement
Part I - The Problem Worth Solving
The Hallucination Tax
There is a particular kind of operational failure that only emerges when you deploy a language model against real, private, structured knowledge. The model is fluent. Its grammar is impeccable. Its tone matches your internal documentation. And it is wrong about the things that matter most.

Not wrong in a detectable way - not grammatically wrong, not logically incoherent, not obviously absurd. Wrong in the way that a confident, articulate person is wrong when they misremember a number or confuse two similar-sounding policies. The answer sounds authoritative because the model's generation process is entirely indifferent to whether the specific fact it's producing is true. It is optimized for plausibility at the token level, not for correctness at the fact level.
This is the hallucination tax, and every organization building LLM-powered systems against proprietary knowledge pays it.
Ask an internal assistant what the NovaPilot Starter plan costs and it may confidently return $5,000 per month when the correct figure, encoded in your own knowledge graph, is $2,500. Ask it when a key executive joined and it will synthesize a plausible-sounding date from the statistical texture of similar corporate biographies. It will tell you "NovaAI was founded in 2019" because 2019 is a frequent founding year among AI companies in its training distribution, not because it knows anything specific about NovaAI.
The cost is not merely embarrassment. In domains where specific numbers govern contracts, where policy thresholds determine eligibility, where dates establish legal precedence - the hallucination tax accumulates as real operational risk.
The question that shapes this entire discussion is not "why do LLMs hallucinate?" That question has been answered well enough.
The productive question is: given that they do, what does a trustworthy system built on top of them actually look like?
wait, why are we even talking about it in 2026? we have fine-tuning, we have 30+ types of production-used RAG architectures. that should be enough... or so we thought.
Why the Obvious Solutions Are Incomplete
The engineering response to hallucination has followed a familiar three-stage progression.

The first response was fine-tuning. If the model doesn't know your domain, teach it. Write knowledge into the weights. This approach has an appealing directness - the model that emerges should, in principle, know the facts you care about. In practice, it fails for three reasons. First, the computational cost of fine-tuning frontier models at organizational scale is non-trivial. Second, private-domain knowledge is not static - pricing changes, personnel turns over, policies update - and fine-tuning cannot track a living knowledge base without continuous re-investment. Third, and most subtly, fine-tuning conflates model capability with model knowledge. You are retraining everything to change a few things, which is the engineering equivalent of reprogramming a city's traffic system every time a road is renamed.
A 2026 paper on continuous knowledge drift says continual pretraining or fine-tuning is often effective only at a cost: it is "computationally expensive," requires repeated retraining as knowledge evolves, and is vulnerable to catastrophic forgetting.
That matters because enterprise facts are rarely static:
- prices change
- org charts change
- policies change
- product bundles change
A separate 2026 study, Why Supervised Fine-Tuning Fails to Learn, reports a persistent Incomplete Learning Phenomenon: even after convergence, models can still fail to reproduce part of the very supervised data they were trained on. The paper says incomplete learning is "widespread and heterogeneous," and that aggregate metrics can hide unlearned subsets.
Fine-tuning is good for behavioral adaptation and domain shaping, but it is a poor single source of truth for fast-changing factual knowledge. And even when used, it does not guarantee complete or durable fact internalization.
The second response was retrieval-augmented generation, or RAG. Rather than writing knowledge into the weights, inject it at inference time. Retrieve relevant context from your knowledge store and prepend it to the prompt. This is substantially better. The model can now be grounded in documents or structured data it has never seen before. But RAG has a structural limitation that is easy to miss: it augments generation, it does not verify it. The model with retrieved context still generates freely. If the retrieved context is incomplete, ambiguous, or misaligned with the query, the model fills the gap with its training priors. More critically, RAG does not teach the model anything. The next query starts from the same baseline. The same category of error recurs.
A 2025 paper, ASTUTE RAG, explicitly argues that "imperfect retrieval augmentation might be inevitable and quite harmful." In their controlled analysis, they report that under realistic conditions roughly 70% of retrieved passages did not directly contain the true answer.
That is a big deal. It means that even if you build a retrieval pipeline, the model is often operating on:
- incomplete evidence
- irrelevant evidence
- mixed evidence
- conflicting evidence
A 2026 paper, Stable-RAG, shows something even more uncomfortable: RAG systems are "far from hallucination-free," and merely reordering the same retrieved documents can change the answer. In some cases, the model ignored the gold document even when it was present.
That means the failure is not only retrieval quality. It is also evidence integration instability inside the generator.
A 2025 paper, FVA-RAG, identifies retrieval sycophancy: if the user asks from a false premise, the retriever may fetch documents aligned with that false framing, causing the model to "hallucinate with citations."
RAG is necessary in many real systems, but it is not a truth machine. It improves access to current information, but does not guarantee:
- correct retrieval
- correct selection among retrieved evidence
- correct reconciliation of conflicting evidence
The third response was static verification - a catch-and-correct pipeline. Generate an answer, decompose it into claims, check each claim against a knowledge source, flag what is wrong, rewrite the flagged content. This is architecturally sound and operationally useful. In a system built against a knowledge graph, the static verifier compares each extracted claim against the graph's triples and returns a structured verdict: SUPPORTED, CONTRADICTED, UNVERIFIABLE. When a claim contradicts the graph, a repairer rewrites it using the correct evidence.
Static verification catches errors. It does not prevent them. The model answers the next question with no memory of having been wrong on the last one. Each session starts with the same hallucination propensity, and the verification layer must work just as hard each time. The catch-and-correct pipeline is an error filter, not a learning system.
These three approaches - fine-tuning, RAG, and static verification - are not wrong. They are incomplete. Each addresses one layer of the problem while leaving another layer untouched. Fine-tuning embeds knowledge but cannot track it. RAG grounds generation but cannot verify it. Static verification catches errors but cannot accumulate lessons.
The gap these three approaches share is the same gap: none of them improve through experience.
The Productive Question
Here, then, is the constraint that shapes everything that follows:
- We have a model whose weights we cannot - or prefer not to - continuously update.
- We have a private knowledge base that is authoritative, structured, and current.
- We have a verification mechanism that can detect when the model is wrong.
The open question is whether the system as a whole can improve across sessions - not by retraining the model, but by restructuring how failure is processed and retained.
Phrased more precisely: can we build a pipeline where each hallucination, caught and corrected, produces a durable lesson that makes subsequent answers less likely to contain the same category of error?
Can a frozen-weight system learn through its architecture rather than through its parameters?
The Reflexion framework, introduced by Shinn et al. at NeurIPS 2023, is the first rigorous answer to this question. It is not the only answer - and subsequent approaches have extended, refined, and in some cases superseded it - but it is the foundational one, and understanding it deeply is prerequisite to understanding what came after.
Part II - Reinforcement Without Gradients
What Traditional RL Requires
Reinforcement learning, in its standard formulation, is an optimization algorithm. An agent acts in an environment, receives a reward signal, and updates its policy to maximize cumulative reward. The update mechanism is typically gradient descent through parameter space: the reward signal backpropagates through the model, nudging weights toward configurations that produce better outcomes.
This works spectacularly well in narrow, simulable domains - games, robotic control, token-level optimization. It works poorly in the context of language model deployment for several compounding reasons.
The sample complexity problem comes first. Gradient-based policy optimization requires a large number of trials before the signal-to-noise ratio in the reward gradient becomes useful. For a language model, each trial is an LLM inference call. At the scale of samples required for meaningful policy improvement, the cost in compute, latency, and dollars is prohibitive for most production environments.
The reward design problem follows closely. Defining a reward function that accurately captures what "a good answer" means is harder than it appears. A scalar reward - correct or incorrect - provides no gradient information about which part of a complex answer was wrong. The model improved its score, but we cannot easily attribute the improvement to any specific aspect of its behavior. This is the credit assignment problem: when a trajectory spans multiple decisions and produces a single terminal reward, distributing that reward backward through time so that each action receives appropriate credit is computationally expensive and theoretically fraught.
Finally, and most practically: traditional RL requires differentiable access to the model's parameters. For closed-weight APIs, this access does not exist. The model is a black box. You can observe its outputs; you cannot nudge its internals.
Traditional RL is the right algorithm if you have a simulable environment, abundant compute, a well-defined reward, and parameter access. In production language model deployment, you typically have none of these.
The Reflexion Hypothesis
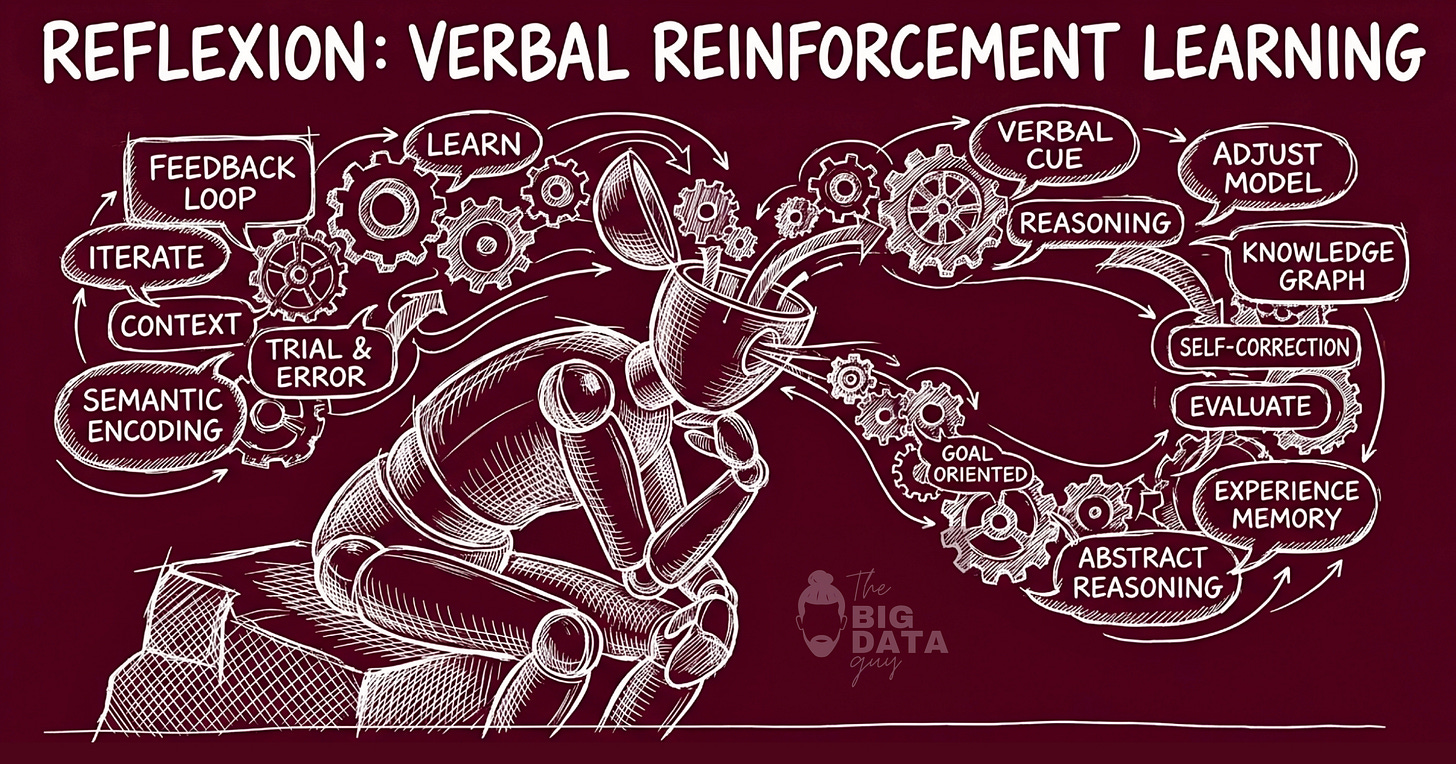
Reflexion begins from a different premise. If gradient descent is unavailable, what else can carry the learning signal? The hypothesis: language itself.
A large language model is not merely a generator of text. It is a system that conditions its outputs on its inputs with remarkable sensitivity. When the system prompt says "always verify tier names against their specific price points," the model produces different outputs than when it doesn't. That difference is not mediated by weight updates. It is mediated by context. The instruction modifies behavior as surely as a gradient - with less precision, perhaps, but also with considerably less cost.
Reflexion formalizes this intuition. The core mechanism is a feedback loop: the agent acts, the environment evaluates, the agent reflects on the evaluation in natural language, and that reflection is stored and injected into future action prompts. The weights never change. The policy changes because the context changes.
Reflexion Hypothesis:
LLMs can improve across attempts if failure feedback is translated into natural-language reflections, stored as episodic memory, and reinserted into future prompts.
This is verbal reinforcement learning - reinforcement not through gradient updates but through the accumulation of linguistically encoded experience.
The mechanism is more subtle than it first appears. The reflection is not simply a correction of the specific wrong answer. It is an abstraction - a generalized lesson derived from the particular failure. The difference between:
- "NovaAI was founded in 2019 is wrong" and
- "the model tends to infer founding dates from executive tenure rather than explicit founding records"
is the difference between error correction and category learning. The former fixes one answer. The latter alters a behavioral pattern across an entire category of future questions.
Part III - Anatomy of a Reflexion Agent
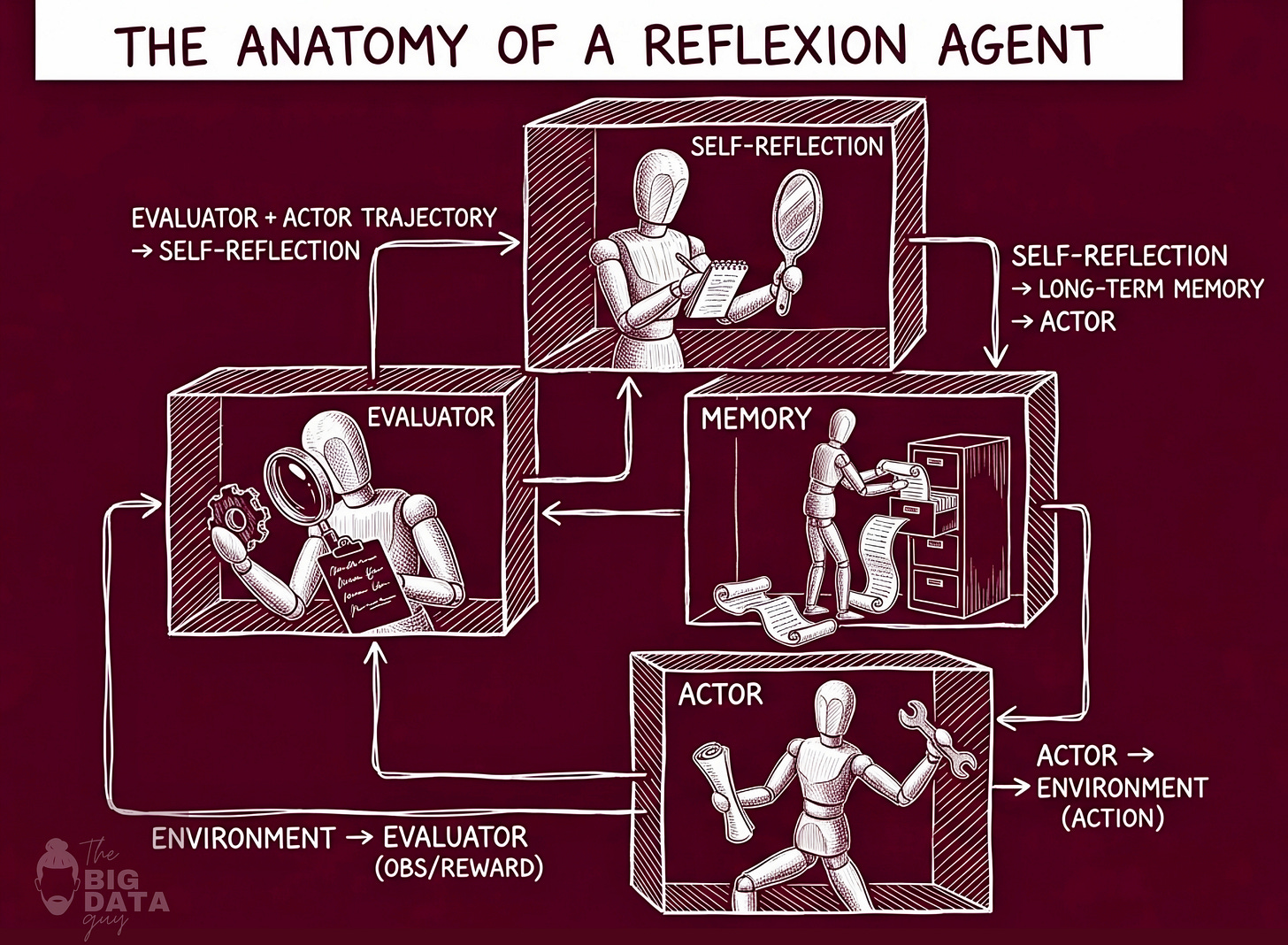
The Tripartite System
A Reflexion agent is not a single model. It is three models - or, more precisely, three distinct roles that may be instantiated by the same model with different prompting. The distinction is architectural, not necessarily computational.
These three components are:
- the Actor,
- the Evaluator, and
- the Self-Reflection model.
Their interaction is precisely defined, and understanding each in isolation before examining how they work together reveals why this architecture is both elegant and practically grounded.
This is not RL in the classical sense of gradient descent over policy parameters. But it is still reinforcement in the broader sense, because:
- the agent acts
- receives external evaluation
- converts evaluation into a better future policy
The difference is where the policy lives.
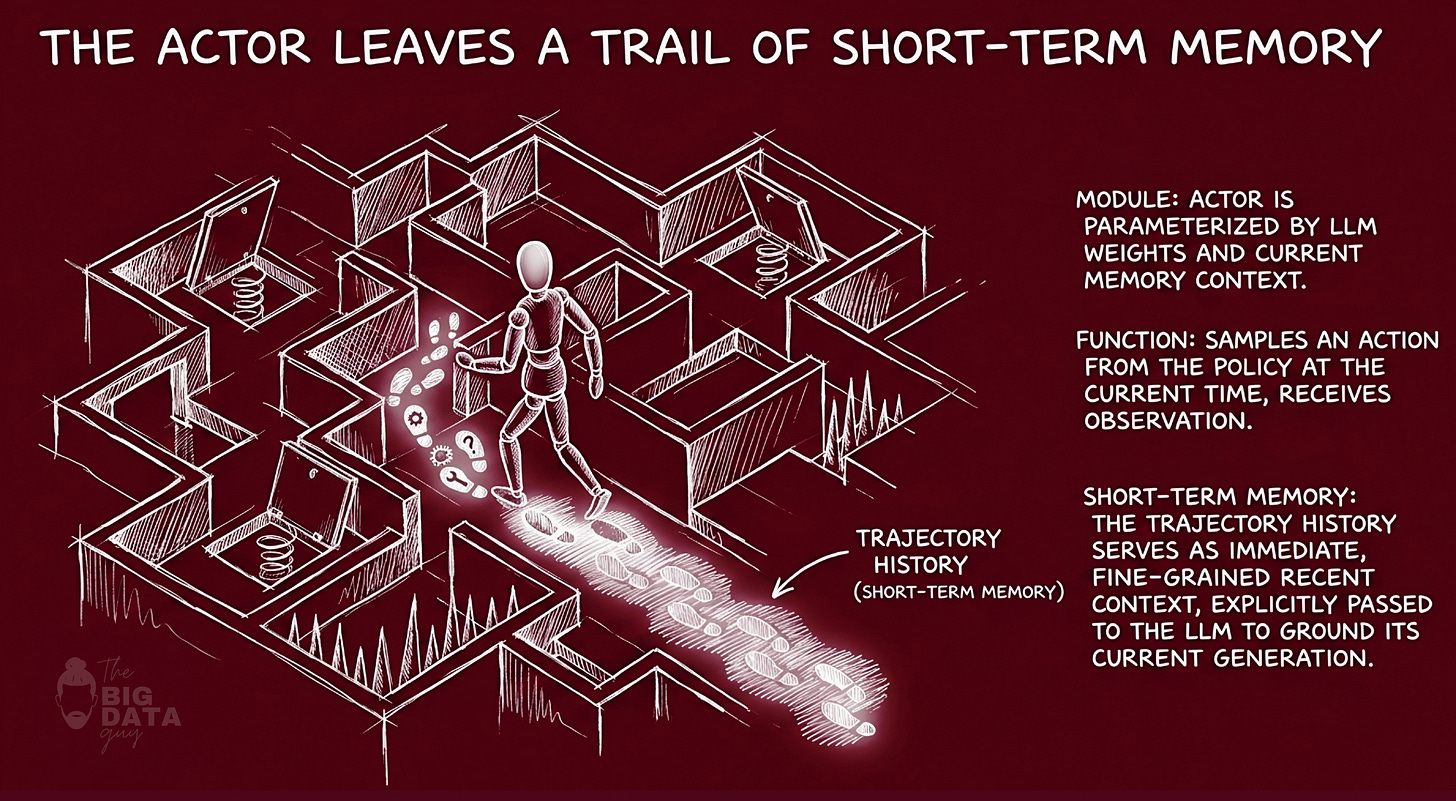
The Actor: Trajectory Generator and Policy Carrier
The Actor is the policy engine. It is the component that takes the current state of the world - a question, a task, an environment - and produces an action: an answer, a decision, a sequence of tool calls. In the standard language model framing, the Actor is simply an LLM invoked with a system prompt.
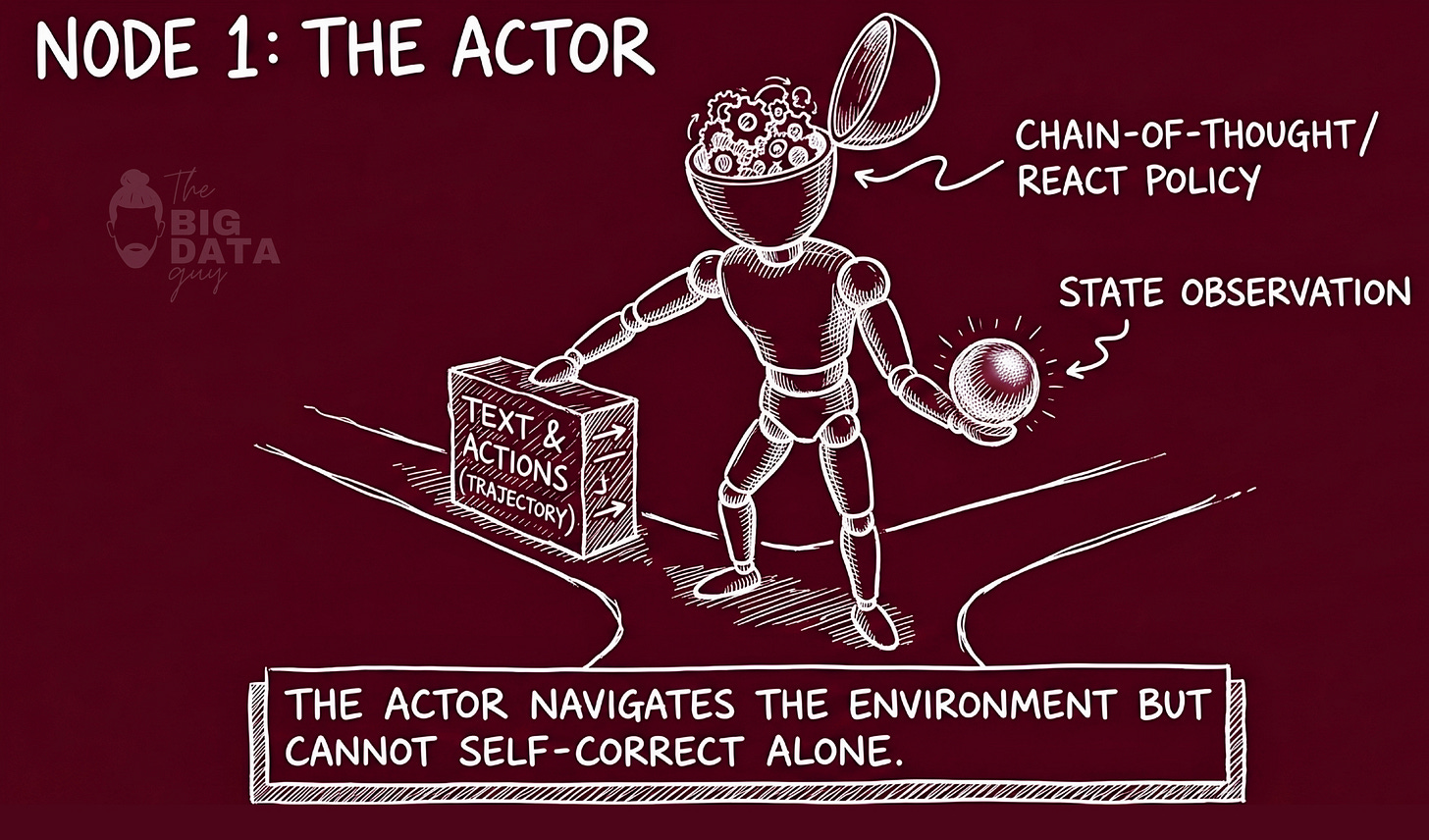
But the Actor is more precisely described as a composite: the model's weights, plus its memory. In Reflexion's formulation, the policy is not stored in weights alone. It is parameterized jointly by the weights and by whatever resides in context. This is the key insight that makes the whole framework coherent: if the policy is the weights-plus-context, then you can modify the policy by modifying the context without touching the weights.
In a knowledge graph verifier, the Actor's first invocation has no memory. It answers questions about NovaAI using whatever it knows from pretraining, augmented by its system prompt's general instruction to be accurate and specific. It will produce a fluent answer that may or may not be grounded in the actual facts of the company. At this stage, it is V0 - the raw baseline.
After the first hallucination is caught and reflected upon, the Actor's subsequent invocations carry the accumulated lessons. The system prompt now contains something like:
You have previously made factual errors about NovaAI. Apply these lessons to improve your accuracy:
- The model tends to confuse pricing tiers when product names share tier suffixes. Always verify price amounts before stating them.
This is a modified policy. The same model, producing different behavior, not through weight change but through context change. The weights are a fixed substrate; the context is the mutable state space.
The Actor also produces, as a byproduct of its execution, what the paper calls a trajectory: the sequence of observations, thoughts, and actions taken during a single episode. This trajectory is short-term memory - the immediate working record of what happened during this particular attempt. It resets between episodes but persists within them, providing the raw material for evaluation and reflection.
The Evaluator: Credit Assignment Through Structure
The credit assignment problem is one of the oldest and most persistent challenges in reinforcement learning.
In a multi-step trajectory - a sequence of decisions leading to an outcome - which specific decisions deserve credit or blame for the final result? A simple scalar reward at the end provides a single number that must somehow distribute its signal backward through a sequence of potentially many decisions, most of which had nothing particular to do with why the outcome was good or bad.
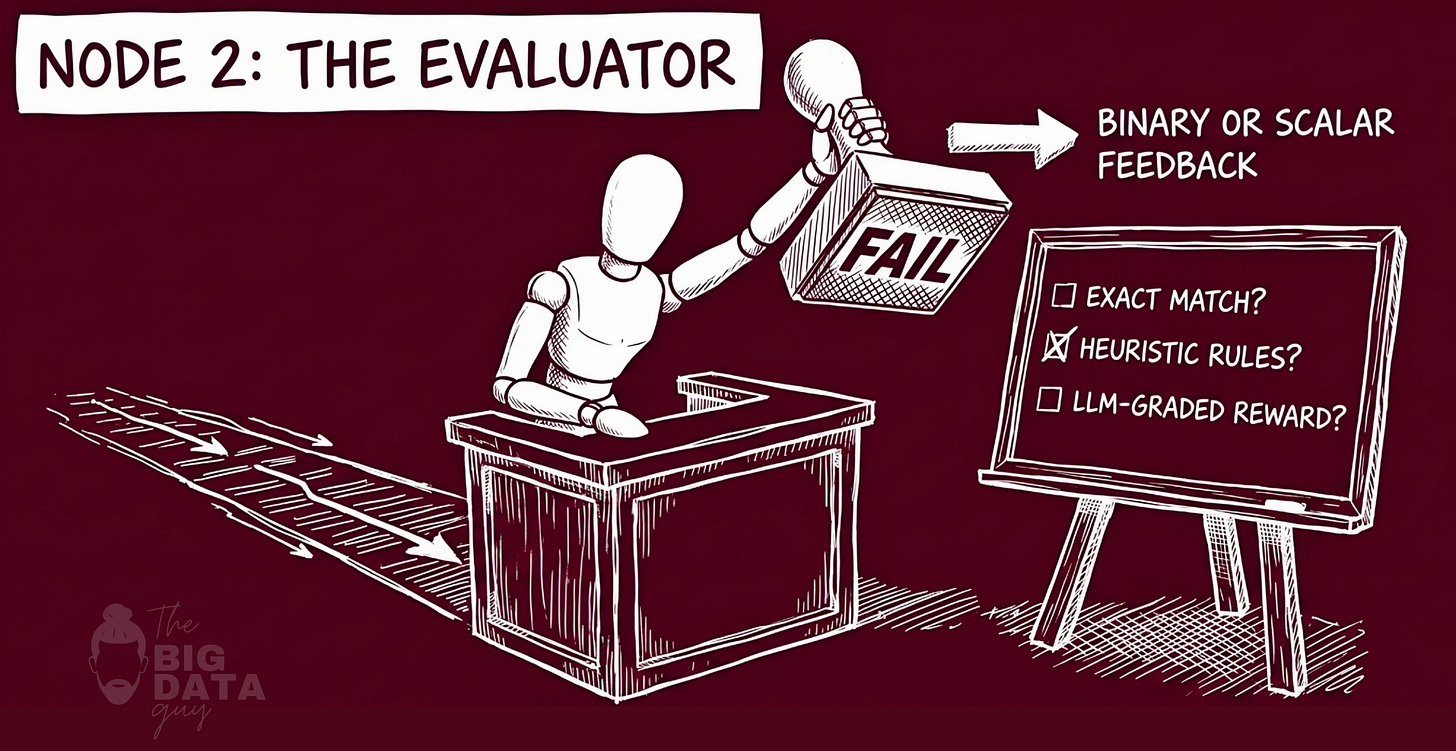
Language agents face a specific variant of this problem. An LLM answer is not a single decision; it is an aggregation of claims, each of which may be independently true or false.
The answer "NovaAI was founded in 2021 by Dr. Mara Chen and Lucas Ferreira, and raised $210M in Series C funding in November 2024" contains multiple verifiable assertions. Some may be correct, some wrong. A binary "incorrect" verdict on the full answer tells the system nothing about which claim failed.
Reflexion addresses this through what amounts to claim-level credit assignment. The Evaluator decomposes the task of evaluation into atomic units: individual claims, each assessed independently against the knowledge source. The result is not a scalar but a structured verdict - a list of results, each specifying which claim is supported, which is contradicted, and which cannot be assessed given available evidence.
In a knowledge graph implementation, this evaluation pipeline is quite specific. An LLM answer is first decomposed into atomic claims - each claim asserting exactly one verifiable fact with an explicit subject, no pronouns, no aggregation.
"NovaAI was founded in 2021" is a proper claim. "It was founded in 2021" is not - the pronoun reference breaks the claim's self-containedness.
This atomicity is essential because the verification step requires mapping each claim to relevant KG triples via entity linking, and entity linking requires that the claim's subject be explicitly named.
Once claims are extracted, each is passed through an entity linker - a component that identifies the named entities and relation phrases in the claim, fuzzy-matches them against the KG's entity index, and retrieves the most relevant triples. The entity linking step itself is a critical architectural decision: LLM-based entity extraction produces better entity recall than pure fuzzy matching, but pure fuzzy matching is the correct fallback when the LLM extraction fails or returns no entity matches. The two-stage approach - LLM extraction with relation-score boosting, falling back to triple-view fuzzy scoring - balances recall against robustness.
The resulting evidence is then passed to the verification LLM, which returns a structured verdict:
- SUPPORTED,
- CONTRADICTED, or
- UNVERIFIABLE,
with a confidence score and a one-sentence reasoning trace.
Critically, if no relevant triples are found for a claim, the system returns UNVERIFIABLE without an LLM call at all - a short-circuit that avoids fabricating a verdict against empty evidence, and saves a token budget that would otherwise be spent on meaningless inference.
This structured output is credit assignment made explicit. Instead of "the answer was wrong" the Evaluator produces "this specific claim was wrong, here is the contradicting evidence, here is why." The failure has been localized, the responsible claim identified, the correct value surfaced. The gradient, if we want to use that metaphor, is pointing in a specific direction.
The Self-Reflection Model: From Error to Episodic Memory
Between the Evaluator's verdict and the Actor's next invocation lies the step that distinguishes Reflexion from mere error correction: the generation of verbal reflections.

The Self-Reflection model - typically the same LLM prompted differently - receives the full context of a failed episode: the original question, the wrong answer, the structured verdict identifying which claims were contradicted and what the correct values are, and the repaired answer. From this, it is asked to produce a generalized lesson.
The key word is generalized. The reflection prompt explicitly forbids generic advice ("be more careful") and demands category diagnosis: what class of information was hallucinated, why the model likely made that error, and what specific strategy would prevent recurrence. The output might read:
"The model confused the NovaPilot Growth and Enterprise pricing tiers - a common error when multiple product tiers share a naming pattern. The mistake likely arose from conflating the tier suffix ('Growth', 'Enterprise') with pricing magnitude heuristics rather than consulting explicit price triples. Strategy: when answering any question about product pricing, trace the specific product tier name to its exact price before generating a number."
This reflection performs semantic compression. It takes a particular failure about a particular product at a particular price point and extracts a behavioral principle applicable to any pricing question in the domain. The particular generates the general. This is exactly what learning should look like: not memorizing that "NovaPilot Growth costs $8,000/month" but internalizing "when answering pricing questions, verify tier-specific prices explicitly."
The reflection is then stored in episodic memory, which is the long-term component of the Reflexion memory architecture.
Part IV - Memory, Context, and the Execution Loop
Two Memory Systems
Reflexion implements a two-tier memory architecture that maps, with reasonable fidelity, onto how human memory is described in cognitive science.
Short-term memory - also called the trajectory buffer - holds the contents of the current episode. The question, the raw answer, the extracted claims, the verification verdicts, the repaired output, the latency. This is working memory: rich, detailed, and ephemeral. It is assembled anew with each question and discarded when the episode closes. It provides the immediate context for evaluation and reflection but does not persist to inform future episodes.
Long-term memory - the episodic store - holds the distilled reflections from prior failures. It persists across episodes, is bounded by a sliding window (typically three entries), and is injected into the Actor's system prompt at the start of each new episode. It is compressed, general, and durable.

The sliding window is a deliberate design constraint. Three reflections is not a magic number - it reflects a trade-off between memory coverage and context budget. Too few reflections and the agent forgets recent lessons; too many and the prompt grows bloated, the relevant lessons diluted by earlier ones that may no longer apply. The window always retains the most recent entries: as new lessons are added, the oldest are evicted. This recency bias is principled - errors made on earlier questions in a session are less likely to recur than the categories of error encountered most recently.
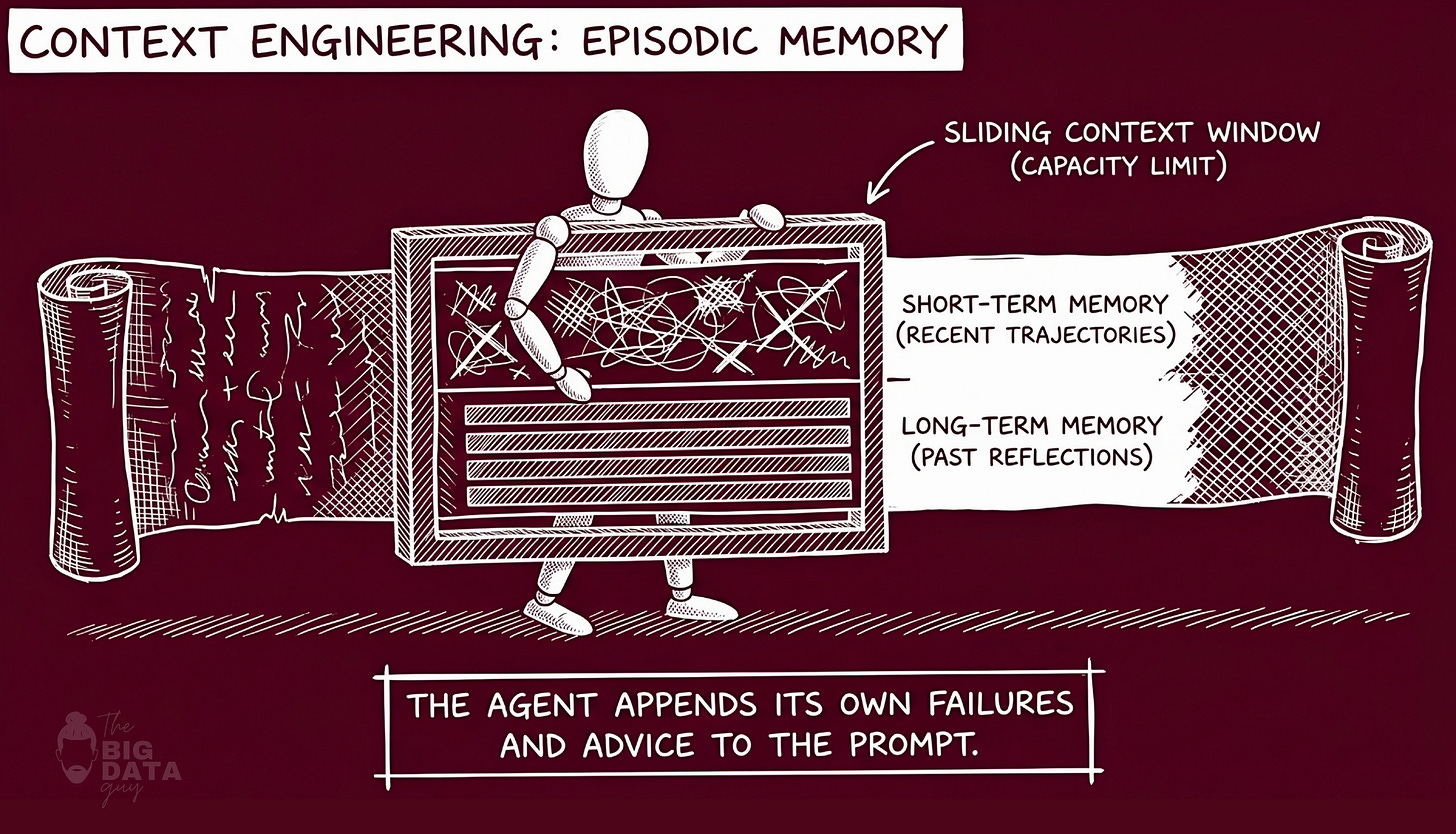
In our knowledge graph verifier, this memory is shared across an entire evaluation session of forty-five questions. A single `ReflexionMemory` instance persists throughout the run - not resetting between questions. This is the architectural decision that makes V2 a genuine learning system rather than a per-query corrector. Early questions generate reflections. Those reflections alter the system prompt for all subsequent questions. The agent that answers question thirty-eight is not the same agent that answered question one. Its weights are identical. Its context is not.
The Injection Pattern: Context as Policy State
The mechanics of memory injection reveal something important about how Reflexion achieves its effect. At the start of each episode, the Actor's system prompt is assembled conditionally: if the episodic memory contains reflections, a formatted memory block is appended to the base instructions.
The formatted block follows a strict template:
[PRIOR SESSION LEARNING - APPLY THESE LESSONS]
- Reflection 1
- Reflection 2
- Reflection 3
[END PRIOR SESSION LEARNING]The boundary markers - `[PRIOR SESSION LEARNING]` and `[END PRIOR SESSION LEARNING]` - are not decorative. They signal to the model that this content is distinct from the task instructions: it is retrospective guidance, not prospective direction. The model is not being told what the answer is; it is being told what patterns of error to avoid. The distinction matters because it preserves the model's generative freedom while biasing it away from known failure modes.
This pattern is the operational core of context engineering. The prompt is not a static template that encodes the task. It is a dynamic state object that encodes the task, the constraints, the history, and the learned lessons from prior failures. As the session progresses and more reflections accumulate, the context evolves - and so does the effective policy.
When weights are frozen, context is the only tunable parameter. Reflexion is, among other things, an argument that this single degree of freedom is sufficient for meaningful learning in bounded domains.
The Execution Loop
The full execution loop, described abstractly in the paper and concretized in implementation, operates as follows.
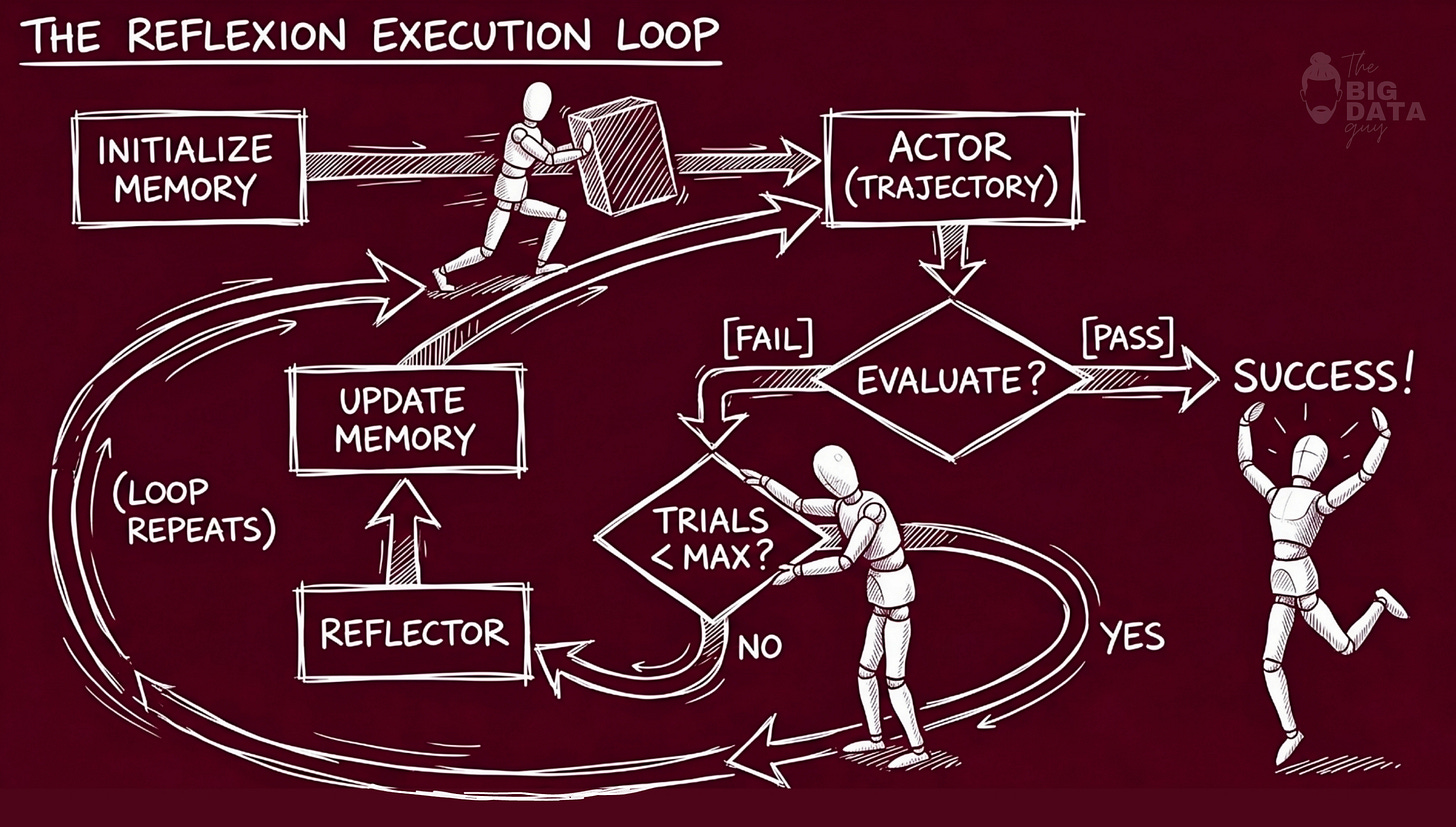
An episode begins when the Actor receives a question. If the episodic memory is non-empty, the system prompt includes the accumulated reflections from prior failures. The Actor generates a raw answer conditioned on this prompt.
The raw answer is then decomposed into atomic claims by the Claim Extractor. Each claim is processed independently: entity linking identifies the relevant KG triples, and the Evaluator LLM judges each claim as SUPPORTED, CONTRADICTED, or UNVERIFIABLE. The Evaluator's output is a list of structured verdicts - one per claim.
If any claims are CONTRADICTED, the Repairer is invoked. It receives the original question, the raw answer, and the full verification results including the KG evidence for each contradicted claim. Its task is surgical: replace the wrong values with the correct ones from the KG evidence, leave supported claims untouched, soften unverifiable claims with epistemic hedges. The output is the final answer.
Whether or not repair occurred, if any CONTRADICTED verdicts were found, the Self-Reflection model is invoked. It receives the full failure context and generates a verbal lesson. That lesson is appended to the episodic memory, and the sliding window trims anything beyond the maximum retention count.
The next episode begins with this updated memory. The loop is now closed.
The loop runs for every question in the session. The V0 pipeline - raw LLM with no verification - has no loop: question in, answer out, nothing learned. The V1 pipeline - static KG verifier - adds verification and repair but still has no loop: the episode closes cleanly with no residue. V2 adds the reflection and memory update, and in doing so, adds the loop. The architecture that produces learning is precisely this closed loop between failure, reflection, and future context.
Part V - The Evidence and Its Limits
What the Numbers Say
Empirical validation is the necessary counterpart to architectural elegance. The Reflexion paper evaluates the framework across three task domains, each stress-testing a different dimension of agent capability.
In AlfWorld, a suite of text-based household environment tasks, Reflexion agents using the ReAct prompting strategy improved absolute performance by 22 percentage points over the baseline across 134 tasks in 12 iterative learning steps - completing 130 of 134 tasks total. The improvement arose through the agent's accumulated ability to diagnose two specific failure modes: hallucinated possession of objects (the agent acts as if it holds an item it hasn't retrieved) and inefficient planning (searching for items in a fixed order regardless of prior evidence). Reflections on these failures produced lessons about state tracking and search strategy that transferred across tasks.
In HotPotQA, a multi-hop question-answering benchmark, Reflexion improved accuracy by 20% over baseline. Crucially, the paper isolates the contribution of reflection from the contribution of episodic memory alone through ablation: adding only the most recent trajectory (episodic memory without reflection) produces an 8% improvement; adding the verbal reflection step on top of that produces the full 20%. Reflection contributes 12 percentage points independently of memory. This is the quantitative argument that verbal reflection is not merely a fancy way of logging history - it extracts something from failure that history alone does not provide.
In code generation on HumanEval, Reflexion achieved 91% pass@1 accuracy, surpassing GPT-4's 80% - at the time of publication, a state-of-the-art result. The mechanism is worth examining: the coding agent generates self-written unit tests alongside its implementation, runs them, and reflects on failures. The unit test suite acts as the Evaluator, providing grounded, executable feedback rather than LLM-generated judgment. The reflection then diagnoses why the implementation failed specific tests and proposes a corrected approach for the next attempt.
The ablation study on HumanEval Rust is particularly revealing. Four conditions are compared: base model alone (60% accuracy), test generation without self-reflection (60% - no improvement), self-reflection without test generation (52% - performance degrades), and the full Reflexion combination (68%). The counter-intuitive result - that self-reflection without test-driven grounding actively harms performance - is an important finding. Without reliable evaluation, the agent is reflecting on incorrect premises. It may conclude it failed for reasons it didn't fail, and generate lessons that steer it toward worse behavior. The quality of reflection is bounded by the quality of evaluation.
The Boundary Conditions
The WebShop experiment is the most instructive failure in the paper. WebShop is an e-commerce navigation task: the agent must search for products matching client specifications in a simulated online store. After four trials with no improvement, the experiment was terminated. The agent failed to generate useful reflections - its lessons were either too generic or misidentified the source of its failures.
The diagnosis is precise: Reflexion works when failures can be articulated as correctable behaviors. In WebShop, the failure modes were structural. The search space required diverse exploration strategies, not incremental correction of specific wrong moves. When the agent searched for "blue cotton shirt" and failed, the lesson wasn't "don't search for blue cotton shirts differently" - it was that the e-commerce search engine interpreted natural language queries non-deterministically. This is a failure the agent cannot reflect its way out of. The environment is irreducibly stochastic in a way that verbal lessons cannot address.
This points to the general boundary condition: Reflexion is effective when failure is diagnosable, correctable, and recurrent within recognizable categories. It is less effective - potentially harmful - when failures are random, structurally unavoidable, or require diverse exploration rather than careful correction.
A second boundary condition concerns model capability. The authors find that the ability to generate useful self-corrections is an emergent property of stronger, larger models. When the framework is applied to a weaker model (StarChat-beta in the appendix), performance does not improve at all - the reflection accuracy on HumanEval Python is statistically indistinguishable between baseline and Reflexion. The self-reflection step requires genuine reasoning capability to produce meaningful category diagnoses. A model that cannot accurately diagnose its own failures will generate lessons that are either trivially generic or actively misleading.
Finally, Reflexion does not escape the local minima problem inherent to all iterative optimization. If early reflections encode an incorrect causal theory of the failure - if the agent blames the wrong aspect of its behavior - subsequent attempts will optimize against the wrong target. There is no external error signal to correct a bad reflection; the system's self-assessment is authoritative.
Part VI - The Deeper Architecture
Verbal Feedback as Semantic Gradient
The most persistent insight in Reflexion, beyond any specific empirical result, is the framing of verbal feedback as a semantic analog to the gradient.
In gradient descent, the gradient is a vector in parameter space that points in the direction of steepest loss increase. The update rule moves parameters in the opposite direction - toward lower loss. The gradient carries directional information: not just "this was wrong" but "adjust these weights in these directions by these magnitudes to make it less wrong."
A scalar reward, by contrast, carries no directional information. It says "this was better or worse than expected" without specifying what to change or how. The gradient that backpropagates from a scalar reward to the parameters that produced it is computed through the model's computational graph - a process that requires differentiable parameter access and produces updates that may be hard to interpret.
A verbal reflection is a semantic gradient: it does not point in parameter space, but it points in behavior space. "When answering pricing questions, trace the specific product tier name to its exact price before generating a number" is directional information about behavior. It does not tell the model which weights to adjust; it tells the model which generation patterns to adopt. The directional information is encoded in natural language rather than real-valued vectors, and it is consumed by the model's attention mechanism rather than by a parameter update rule.
The insight that language models respond to linguistic direction as effectively as gradient descent responds to numerical gradients - within the bounded scope of in-context learning - is what makes Reflexion theoretically coherent rather than merely pragmatically useful. It is not a workaround for the unavailability of gradient access. It is an alternative signal modality that carries complementary information.
The Episodic Memory Lifecycle
In the full Reflexion framework, the lifecycle of a reflection follows a precise arc: from failure to diagnosis to storage to injection to effect.
Failure: the Actor produces an answer that is evaluated as containing contradictions.
Diagnosis: the Self-Reflection model produces a generalized lesson - the reflection - from the failure context. The lesson encodes what failed, why it likely failed, and what behavioral strategy would prevent recurrence.
Storage: the reflection is appended to the episodic memory. The sliding window trims entries beyond the retention limit, maintaining recency.
Injection: at the start of the next episode, the memory is formatted and appended to the Actor's system prompt, inside the session learning block.
Effect: the Actor's generation for the next episode is conditioned on this memory. The model's effective behavior is modified without any weight update.
The lifecycle is self-contained and modular. Each stage is independently observable and testable. If reflections are failing to prevent recurrent errors, the failure can be diagnosed at any stage: Are the reflections being generated with sufficient specificity? Is the injection format being consumed appropriately by the model? Is the category of failure amenable to verbal diagnosis at all? The modularity of the pipeline is not merely an engineering convenience - it is what makes the system debuggable.
What This Opens Up
Reflexion is, in the framework we're building here, the first answer to the central question. It is not the final one.
The framework it establishes - frozen weights, structured failure feedback, verbal reflection, episodic memory injection - is a specific architectural choice among several possible choices. The memory is a flat list. The reflections are free-form text. The sliding window is a simple recency heuristic. The evaluation is synchronous and claim-level. These are not the only ways to implement any of these components.
What happens when the memory is not a flat list but a graph? When reflections are not free text but structured templates with typed fields for error category, confidence, and scope? When evaluation is not post-hoc but interleaved within the generation process? When memory retention is not governed by recency but by estimated future relevance?
These are not rhetorical questions. They are active research directions, and each represents a distinct architectural approach to the same fundamental problem: how does a frozen-weight system improve its behavior through experience?
Reflexion establishes the hypothesis: it can. The specific mechanism - verbal reflection stored in episodic memory - is one answer. Subsequent work has proposed others, each with different characteristics, different strengths, and different failure modes.
The hallucination problem with which we began is not solved by Reflexion. It is meaningfully addressed. The residual gap - what Reflexion does not handle, where it fails, what capabilities it leaves unrealized - is precisely what the subsequent answers in this series will attempt to fill.
References
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. Neural Information Processing Systems (NeurIPS) 2023.
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. International Conference on Learning Representations (ICLR) 2023.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in LLMs. arXiv:2201.11903.
Sutton, R. S. & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press.
Chen, M., Tworek, J., Jun, H. et al. (2021). Evaluating Large Language Models Trained on Code. arXiv:2107.03374.
Airflow 2 reaches end of life
Apache Airflow 2 reached end of life on April 22, 2026, leaving production deployments without security patches or provider updates unless teams migrate to Airflow 3.
Summary
Deep Dive
Decoder
Original Article
Learning Agentic Design Systems
An experiment with Google's Antigravity IDE and Figma Console MCP enabled a two-way workflow — generating Figma components from code and React code from Figma designs — keeping design tokens in sync throughout.
Summary
Deep Dive
Decoder
Original Article
Color is finally OK
OKLCH, a perceptual color system created by a game developer in a 2020 blog post, has quietly replaced HSL in major frameworks and browsers by fixing decades-old problems with how digital color matches human vision.
Summary
Deep Dive
Decoder
Original Article
Google will invest as much as $40 billion in Anthropic
Google will invest up to $40 billion in Anthropic to help the Claude maker scale its compute infrastructure and meet surging demand for its AI models and developer tools.
Summary
Decoder
Original Article
What Happens When AI Runs a Store in San Francisco?
An AI agent powered by Claude is running an actual retail store in San Francisco, but has lost $13,000 in its first weeks by over-ordering candles, botching schedules, and pricing pistachios at $14.
Summary
Deep Dive
Decoder
Original Article
The World Can't Keep Up With AI Labs
Coding agents are generating real revenue at unprecedented growth rates, but compute infrastructure can't scale fast enough to meet demand.
Summary
Deep Dive
Decoder
Original Article
The World Can't Keep Up With AI Labs
Late last year a new AI psychosis kicked off. This time it was coding agents.
People started saying this is a new era in programming, blah blah blah.
Karpathy tweet, late winter
A few months later, we've got more than just claims. We've got numbers. And they say something unusual is happening in the market.
Coding agents are the first AI product people are paying for at volume and regularly. Because it directly speeds up their work. It's too early to claim businesses are replacing whole processes with agents across the board. But compute demand has started growing faster than anyone can build it out.
Here's why this moment is different, why nobody's ready, and what I took from it personally.
The Numbers
OpenAI and Anthropic might go for an IPO soon. That's why they're eagerly posting how fast their revenue is growing.
And it's a ton of money.
Anthropic is up 3x since the start of the year. And they're already a big company. This is impressive, because the bigger you are, the harder it is to keep growing at the same pace.
OpenAI on the left, Anthropic on the right.
Even during past boom moments, nobody hit numbers like these (with a caveat, see below). Zoom during the pandemic, Google at IPO, Coinbase cashing in on commissions during the crypto hype. These are companies 5-10x smaller than Anthropic, in special situations, and they still grew slower!
The best growth years for big companies. Only ones that were already large. Revenue measured at start vs end of year.
The caveat. First, vaccine makers during the pandemic were also up there. Second, Anthropic's numbers are a projection for the rest of the year based on early data. And they count things a bit differently than OpenAI. None of that changes my conclusion, which is..
Cash is a solid tell for real demand for agentic systems.
Last year when a bunch of people suddenly figured out ChatGPT could generate cool images, that didn't translate into serious money.
Meanwhile, in January alone, Claude Code commits on GitHub (in publicly accessible repos) went from 2% to 4%. If that sounds small, keep in mind it's one month, and that's without Codex, Copilot, or Devin. By end of year Dylan Patel forecasts Claude hitting 20%+.
Claude commits on GitHub.
Even if a $100 subscription only automates a small slice of the work, that's nothing compared to a developer's salary. For a median developer at $350-500 a day, the subscription has 10-30x ROI if it handles just the simplest, most routine 10% of their work.
There's plenty to argue with here.
Let me even lay out the weak spots in my own logic.
So their revenue is growing, fine—the labs are still unprofitable as businesses. They have every incentive to pump the hype to pull in the most risk-tolerant companies. The ones paying are early enthusiasts, not big companies. And enthusiasts come and go. Plenty of bubbles have popped exactly this way.
Agents are unstable and still randomly screw up. Who's to blame when things go wrong? You can't replace humans yet, because serious businesses care about reliability. And where do senior engineers come from without juniors if you stop hiring?
Agents only handle a narrow set of tasks well. Even if writing code is faster, shipping a product still gets bottlenecked by gathering requirements, architecture, review, testing, and our beloved stakeholder zoomcalls and compliance.
I decided at some point you have to commit and pick a side, even without conclusive evidence.
The finish line can be moved forever. There was a time when reasoning was completely out of reach for ML models. Same for decent image generation, or speech that didn't sound like a robot. There was a time nobody believed machines would learn to play Go. You get the idea.
Metaphor from Tegmark's Life 3.0. Computers gradually learn harder and harder tasks. Over time there's less and less they can't do. Like water filling a map from the bottom up.
Ilya Sutskever, back when he was still at OpenAI, often mentioned an internal meme—Feel the AGI.
He was one of the first to believe deep learning would gradually change our lives. Yes, there's a lot we don't know, but everything keeps moving in that direction, and that matters. Everyone gets it at their own moment. When a neural net does something you usually do yourself, manually, that's a special feeling.
I've lost count of how many of those moments I've had in 10 years of following neural nets. So I'm not interested in the bubble-or-not debate anymore. I'm interested in watching the water level rise.
Personally, I have enough evidence that agents can now do valuable work that companies are willing to pay for.
And the thing is, demand has plenty of room to grow. Agents often don't work out of the box. You have to adapt to them, and the fastest and most curious people do that best. Everyone else will catch up bit by bit.
The Industry Isn't Ready For This
To avoid talking about "the industry" in the abstract, let me split it into 3 layers.
- AI labs make models. OpenAI, Anthropic, DeepMind.
- Hyperscalers build datacenters. Google, Amazon, Microsoft, Meta.
- Chipmakers make chips. Nvidia, TSMC, ASML.
And at every layer, companies are scared.
People online love talking about bubbles. Turns out, all these companies are well aware bubbles happen. And to avoid going bankrupt, each one is cooking up its own workaround.
Dario Amodei says he builds the company's plans off a pessimistic revenue scenario. Funny thing is, this year they're already beating that by 1.5x. And only 3 months of the year have gone by. They're beating the optimistic scenario too.
Dwarkesh asked him straight up in an interview: why? Dario genuinely believes in massive future upside from AI. He writes long essays about it, pitches a country of geniuses in a datacenter. And yet he doesn't want to bet everything on that future.
Dario says it's risky because of a cash flow gap in the business model.
Here's how it works. They provide neural nets to users. They pay hardware owners for inference and make money from subscriptions and APIs. In parallel, they pour money into research on the next generation model. Which won't start making money for another year or two.
They regularly spend more than half of revenue on research.
You're not just balancing income and expenses—you're also balancing investment in future growth. If you invest big and the growth doesn't show up, you're in serious trouble.
Anthropic has been running in this mode for three years straight. Growing 10x every year. Dario figured 2026 would be when it ends. Because the bigger you are, the harder it gets. You are gonna slow down at some point.
What he didn't mention in the interview, is that their margins are growing slower than forecast. Costs are growing multiple times faster than they'd planned.
Dario says he wants to push the company into profitability in a few years. To do that they need to improve margins. That means slowing growth and investing conservatively, only on the most efficient things.
The logic adds up. But slowing down isn't really working. They look ready to 10x again this year. But the resources to support that aren't there.
Anthropic doesn't have enough compute for this many power users.
They rent GPUs from hyperscalers. And they can't just walk into a datacenter and ask for more. Because the datacenter owner is also exposed to bubble risk. So capacity is booked out in advance.
For Anthropic to make $30B a year, someone had to spend $80B on infrastructure. Betting it would pay off in a few years.
Amazon will spend around $200B this year, Google $180B, Meta $125B, Microsoft $105B. That's a setup for trillions in economic value in the coming years.
And a cash flow gap risk if the value doesn't materialize.
The industry is one long value chain. Everyone in it tries to lower their own risk by locking expectations into contracts. Which reduces the whole chain's ability to react to surprises. Like the sudden arrival of coding agents.
So every year labs hit some new bottleneck. And constraints keep sliding further upstream, toward players further from the end user. Because their risks are higher and their contracts are even less flexible.
A New Bottleneck Every Year
In 2023 everyone was chasing GPUs. More specifically, TSMC factories didn't have enough capacity for the final chip-to-module assembly (CoWoS). In 2024 came the HBM memory shortage for those same modules. In 2025 GPUs got better, but datacenter buildout became limited by power supply. In 2026 it turned out even when you have the power, the US grid can't deliver it to datacenters at the volume needed.
1 - Memory
Modern models need more memory than before. I mentioned earlier that companies spend hundreds of billions a year on infrastructure. Roughly 30% of that goes to memory.
And they have to buy expensive HBM instead of cheap DDR. Because high bandwidth reduces GPU idle time while memory processes its part.
Turns out memory is the most expensive thing in a GPU.
Memory prices are probably going to keep rising unless someone figures out how to work around it. They could easily go up another 2-3x, because SK Hynix and Samsung control 90% of the market. And memory demand is only growing.
2 - Energy and Datacenters
xAI proved datacenters can be built pretty fast.
But they eat power like a small city. And when such a thing suddenly shows up in some region within six months, the electricity grid just can't handle that.
Surprisingly, Dylan Patel isn't that worried about energy. New power plants, transformer stations, and plain old transmission towers take a long time to build. But while the grid catches up to the new load, you can power datacenters off industrial gas turbines. Literally roll up to the datacenter with a dozen trailers full of generators and you're good (tho people start to worry about that being far from clean energy).
There are also piston engines, solar with batteries, hydrogen reactors, marine ship engines… Basically, every trick the fuel industry has invented in its entire history. Together with more efficient grid usage, that can add up to hundreds of gigawatts.
Right now GPUs alone consume 13GW. Add the rest of the datacenter and you can multiply by 2.
The blocker for building datacenters and reactors fast is a shortage of skilled labor, especially electricians.
So, expensive and labor-intensive. But turns out it's still easier than the semiconductor supply chain.
3 - Semiconductors
There are factories (mostly TSMC) that assemble GPUs of a specific era (based on designs from Nvidia or Google). For example, on the 3-nanometer process.
And there just aren't enough factories built.
This can't be fixed quickly because these are some of the most complex industrial facilities on the planet. Building one takes 2-3 years and a pile of specialized equipment and chemistry.
The hardest piece is the lithography machines (EUV scanners). They're needed to etch chips onto wafers. The wafers then get paired with memory into modules, and that's how you get a GPU.
These machines cost ~$350M each. Only one company from the Netherlands makes them—ASML. Around 50 machines a year.
The machine.
By a rough estimate, by 2030 there will be around 700 of them worldwide. That's on the order of 200 gigawatts of compute. And at the end of 2025 we were using ~27 gigawatts. Note that that's before the agent hype of early 2026.
So there's room to grow, but the shortage will be permanent—bottlenecked by factory construction, wafers, and lithography machines.
These are the kinds of constraints you can't just throw money at, unlike memory and datacenter energy.
You can see it clearly in Google's behavior.
They have their own chip designs. And they still buy a quarter of their capacity from Nvidia. They'd love to make their own, they just can't.
The share is dropping, but it's still a lot, considering their own chips are better!
All chips are assembled at TSMC factories to someone else's designs. And Google and Amazon (who also have their own designs) slept through the moment when Jensen Huang locked in contracts for 70% of 3-nm capacity. That's great for TSMC—they're at the end of the production chain and need stability.
Nvidia is also living the dream, selling cards at 6x production cost.
And Google even sold its own capacity to Anthropic through GCP. What a company.
So What?
So, the industry isn't ready for the agent boom.
Because it came on too suddenly. To a market where what ultimately matters is long-term contracts on complex chip-making infrastructure.
Anthropic right now has 2.5 gigawatts of compute, and by the end of the year they need 5-6. The only way to get that much is the "Other" category. CoreWeave, Bedrock, Vertex, Foundry. Scraps from anyone whose capacity is still available, at premium prices.
And they want to become a profitable company, so they can't afford to burn cash.
Hence the bad news.
The ones who'll probably suffer are us.
The most obvious move is for them to just cut limits and raise prices.
The other week they moved OpenClaw onto the API. And they said so in a nice and honest way. Sorry guys. We're tightening belts, here's $20 as an apology for the inconvenience.
They also rolled out different tiers depending on time of day. I've already run into it a couple of times, when Claude just ran out of capacity. During "off-peak" hours, under pressure from people optimizing for discounted tokens.
Denied.
I pulled two takeaways from this for myself.
1 - Don't put all your eggs in one basket.
For example, when building a skill, make it work on any model. I'm obsessed with Claude, but OpenAI and Google are in way better shape on compute access.
So I've learned to swap models depending on the task. I pay the minimum subscription to every lab. And when the limit runs out, I just switch models.
I'm not using Chinese open-source. Don't use Deepseek, for the love of god.
2 - Get anxious about not making money off AI.
Neural nets aren't a way for me to make more money. They're on my expense sheet, and they pay for themselves by giving me more options and more time.
But if they roll out some $1000 tier, I won't be able to pull that off. Right now that sounds absurd. But remember the example with a real person's salary. As long as $1000 of spend brings in $5000 of profit, you're winning.
And whoever can't pull that off will be stuck on the free tier watching ads.
Vision Banana Generalist Model
Researchers demonstrate that image generation models can serve as generalist vision systems by reframing perception tasks like segmentation and depth estimation as image generation problems.
Summary
Deep Dive
Decoder
Original Article
Efficient Video Intelligence in 2026
A comprehensive technical review of efficient video intelligence in 2026 covers universal vision encoders, adaptive compression for hour-long videos, and on-device tracking at mobile-phone speeds.
Summary
Deep Dive
Decoder
Original Article
Scaling Long-Horizon Coding Agents
Meta researchers developed a framework that improves coding agents by summarizing their extended work sessions into reusable structured knowledge, achieving significant benchmark gains.
Summary
Deep Dive
Decoder
Original Article
OpenAI Posts Five-Principle Framework for AGI, Altman Concedes Bigger Role
OpenAI has published a five-principle framework for AGI development, its first major governance statement since 2018, as regulatory pressure on frontier AI labs intensifies.
Summary
Decoder
Original Article
An amateur just solved a 60-year-old math problem—by asking AI
A 23-year-old amateur used ChatGPT to solve a 60-year-old mathematical conjecture that had stumped expert mathematicians, with the AI discovering an entirely new proof approach that may have broader applications.
Summary
Deep Dive
Decoder
Original Article
An amateur just solved a 60-year-old math problem—by asking AI
A ChatGPT AI has proved a conjecture with a method no human had thought of. Experts believe it may have further uses
By Joseph Howlett edited by Lee Billings

Liam Price just cracked a 60-year-old problem that world-class mathematicians have tried and failed to solve. He's 23 years old and has no advanced mathematics training. What he does have is a ChatGPT Pro subscription, which gives him access to the latest large language models from OpenAI.
Artificial intelligence has recently made headlines for solving a number of "Erdős problems," conjectures left behind by the prolific mathematician Paul Erdős. But experts have warned that these problems are an imperfect benchmark of artificial intelligence's mathematical prowess. They range dramatically in both significance and difficulty, and many AI solutions have turned out to be less original than they appeared.
The new solution—which Price got in response to a single prompt to GPT-5.4 Pro and posted on www.erdosproblems.com, a website devoted to the Erdős problems, just over a week ago—is different. The problem it solves has eluded some prominent minds, bestowing it some esteem. And more importantly, the AI seems to have used a totally new method for problems of this kind. It's too soon to say with certainty, but this LLM-conceived connection may be useful for broader applications—something hard to find among recently touted AI triumphs in math.
"This one is a bit different because people did look at it, and the humans that looked at it just collectively made a slight wrong turn at move one," says Terence Tao, a mathematician at the University of California, Los Angeles, who has become a prominent scorekeeper for AI's push into his field. "What's beginning to emerge is that the problem was maybe easier than expected, and it was like there was some kind of mental block."
The question Price solved—or prompted ChatGPT to solve—concerns special sets of whole numbers, where no number in the set can be evenly divided by any other. Erdős called these "primitive sets" because of their connection to similarly indivisible prime numbers.
"A number is prime if it has no other divisors, and this is kind of generalizing that definition from an individual number to a collection of numbers," says Jared Duker Lichtman, a mathematician at Stanford University. Any set of prime numbers is automatically primitive, because primes have no factors (except themselves and the number one).
Erdős also came up with the Erdős sum, a "score" you can calculate for any primitive set. He showed that the sum had a maximum possible value—and conjectured that this value must hold only for the set of all prime numbers. Lichtman proved Erdős right as part of his doctoral thesis in 2022.
Erdős also noticed that the score drops if all of a set's numbers are large—the larger the numbers, the less large the score could become. He guessed that as the set's numbers approached infinity, the maximum score would drop to exactly one. Lichtman tried to prove this, too, but got stuck like everyone else before him.
Price wasn't aware of this history when he entered the problem into ChatGPT on an idle Monday afternoon. "I didn't know what the problem was—I was just doing Erdős problems as I do sometimes, giving them to the AI and seeing what it can come up with," he says. "And it came up with what looked like a right solution."
He sent it to his occasional collaborator Kevin Barreto, a second-year undergraduate in mathematics at the University of Cambridge. The duo had jump-started the AI-for-Erdős craze late last year by prompting a free version of ChatGPT with open problems chosen at random from the Erdős problems website. (An AI researcher subsequently gifted them each a ChatGPT Pro subscription to encourage their "vibe mathing.")
Reviewing Price's message, Barreto realized what they had was special, and experts whom he notified quickly took notice.
"There was kind of a standard sequence of moves that everyone who worked on the problem previously started by doing," Tao says. The LLM took an entirely different route, using a formula that was well known in related parts of math, but which no one had thought to apply to this type of question.
"The raw output of ChatGPT's proof was actually quite poor. So it required an expert to kind of sift through and actually understand what it was trying to say," Lichtman says. But now he and Tao have shortened the proof so that it better distills the LLM's key insight.
More importantly, they already see other potential applications of the AI's cognitive leap. "We have discovered a new way to think about large numbers and their anatomy," Tao says. "It's a nice achievement. I think the jury is still out on the long-term significance."
Lichtman is hopeful because ChatGPT's discovery validates a sense he's had since graduate school. "I had the intuition that these problems were kind of clustered together and they had some kind of unifying feel to them," he says. "And this new method is really confirming that intuition."
Editor's Note (4/28/26): This article was edited after posting to correct the description of the Erdős sum and to clarify Jared Duker Lichtman's full name.
Meta signs agreement with AWS to power agentic AI on Amazon's Graviton chips
Meta is deploying tens of millions of AWS Graviton5 processors for agentic AI workloads, signaling a major shift from GPU-focused infrastructure toward CPU-intensive agent reasoning and orchestration.
Summary
Deep Dive
Decoder
Original Article
DigitalOcean Dedicated Inference: A Technical Deep Dive
DigitalOcean launched Dedicated Inference, a managed service for hosting large language models on dedicated GPUs with KV cache-aware routing and predictable economics for high-volume inference workloads.
Summary
Deep Dive
Decoder
Original Article
DigitalOcean Dedicated Inference: A Technical Deep Dive
Getting a model to answer 10 inference requests concurrently is tricky but simple enough; getting it to handle 2,000 engineers hitting a coding assistant with long contexts, all day, without runaway costs, is where teams stall. A working endpoint is only the beginning. Teams need to identify the supporting hardware and wire up the right components—serving, scaling, observability, and cost guardrails—so the deployment can support expected SLAs and SLOs under real, sustained load.
DigitalOcean already offers Serverless Inference on the DigitalOcean AI Platform: a fast path to models from OpenAI, Anthropic, Meta, or other providers, with minimal setup and token-based pricing. This offering works well for many use cases. However, when you need your own weights, predictable performance on dedicated GPUs, and economics that favor sustained, high-volume token generation over pay-per-token bursts, a different approach makes sense
Dedicated Inference, our managed LLM hosting service on the DigitalOcean AI Platform, fills that gap.
Dedicated Inference deploys and operates an opinionated inference stack on dedicated GPUs, with Kubernetes-native orchestration under the hood. You interact through the control plane and APIs you already use in the DigitalOcean ecosystem; the data plane exposes public and private endpoints so applications inside, or outside, your VPC can call your models securely.
The service is designed to collapse a vast combinatorial space—GPU SKUs, runtimes, routers, autoscaling policies—into guided defaults so teams hit production milestones faster than DIY stacks, while retaining knobs that matter for model serving: replicas, scaling behavior, and advanced optimizations as you roll out your product roadmap.
What we manage vs. what you control
Every managed product draws a line between operator-owned and customer-owned concerns. Dedicated Inference aims to put day-two operations—cluster lifecycle integration, ingress, core serving and routing components, and the glue between them—on the platform side, while leaving model choice, capacity, and workload-specific tuning with you.
Typically platform-managed:
- Provisioning and lifecycle of the underlying orchestration footprint in line with product design (for example, managed Kubernetes integration and GPU pool coordination).
- Core inference engine and orchestration integration, including patterns that matter at scale: intelligent routing, autoscaling hooks, and production-oriented serving paths.
- Endpoint creation, health and scaling workflows, and the operational automation required to keep endpoints aligned with declared configuration.
In your hands:
- Selecting models (including bring-your-own-model paths where supported), GPU profiles, and replica counts appropriate to your SLOs and budget.
- Configuring scaling behavior and, over time, advanced serving options that map to your latency, throughput, and cost goals.
- Connecting applications via stable HTTP APIs consistent with common LLM client stacks.
Dedicated Inference overview
Dedicated Inference builds on industry-standard building blocks so customers benefit from community momentum and continuous improvement:
- vLLM as a capable, widely adopted inference engine for large language models on modern GPUs.
- LLM-d as a Kubernetes-oriented stack for distributed inference patterns—precise prefix-cache aware routing, scaling concerns that differ from traditional HTTP services, and room to grow into more advanced topologies as workloads demand.
This combination reflects a deliberate choice: meet customers where they are today (OpenAI-compatible APIs, familiar GPU offerings on DigitalOcean) while staying aligned with where the ecosystem is moving on routing, replication, and scale-out inference.
For readers who want more depth on why LLM routing differs from classic load balancing—and how prefix cache awareness changes the game—see our article on Load Balancing and Scaling LLM Serving.
High-level architecture
The system design separates a control plane (how endpoints are created, updated, listed, and deleted) from a data plane (how chat/completions request traffic reaches your models). That mirrors the management requests, which take a path built for regional placement and durable lifecycle work. Inference requests take a direct, low-latency path in front of your GPUs.
Control plane: central entry, regional execution
What does "control plane" mean here? In this split, the control plane is everything that handles management traffic: management rpc for Dedicated Inference endpoints, plus the durable bookkeeping that turns your declared intent into running DI infrastructure. It is separate from the data plane, which is the hot path for inference (chat/completions-style) requests once an endpoint is healthy.

Central API layer: Requests originating from the DigitalOcean Cloud UI, automation workflows, or the public API are routed through a centralized API layer first. This layer maintains the mapping of endpoint ownership by region and transparently forwards each request to the appropriate regional backend. This design follows a multi-region fan-out model, where regional endpoints are addressed using stable identifiers.
Regional Dedicated Inference service: Each region operates a control-plane service responsible for the full lifecycle management of instances within its scope. This includes persisting the desired state, reconciling it with the observed state, advancing lifecycle status (e.g., creating → active), and enqueuing the workflows that provision or mutate the underlying infrastructure. In this context, lifecycle refers to the state machine governing transitions from requested to running and reachable. An instance represents the managed inference deployment as a whole—encompassing both its control-plane record and the associated backing resources.
Separate worker-style components perform integrations that need retries, backoff, and idempotency—calling the Kubernetes API, watching object status, and publishing lifecycle updates back to the core service. This is similar to the reconciler pattern familiar from Kubernetes operators: observe desired state, act, repeat until reality matches intent. Use case: transient API errors or slow node startups do not wedge the user-facing API; the system keeps trying and surfaces a clear status instead of a half-applied state
DigitalOcean Kubernetes and capacity: The platform first helps ensure that sufficient DigitalOcean Kubernetes capacity is available within the target VPC, attaches the required GPU and supporting CPU node capacity, rolls out the managed inference stack (gateway and model workloads), and creates regional network load balancers for public and private endpoints.
Data plane: VPC-native traffic, gateway-routed requests
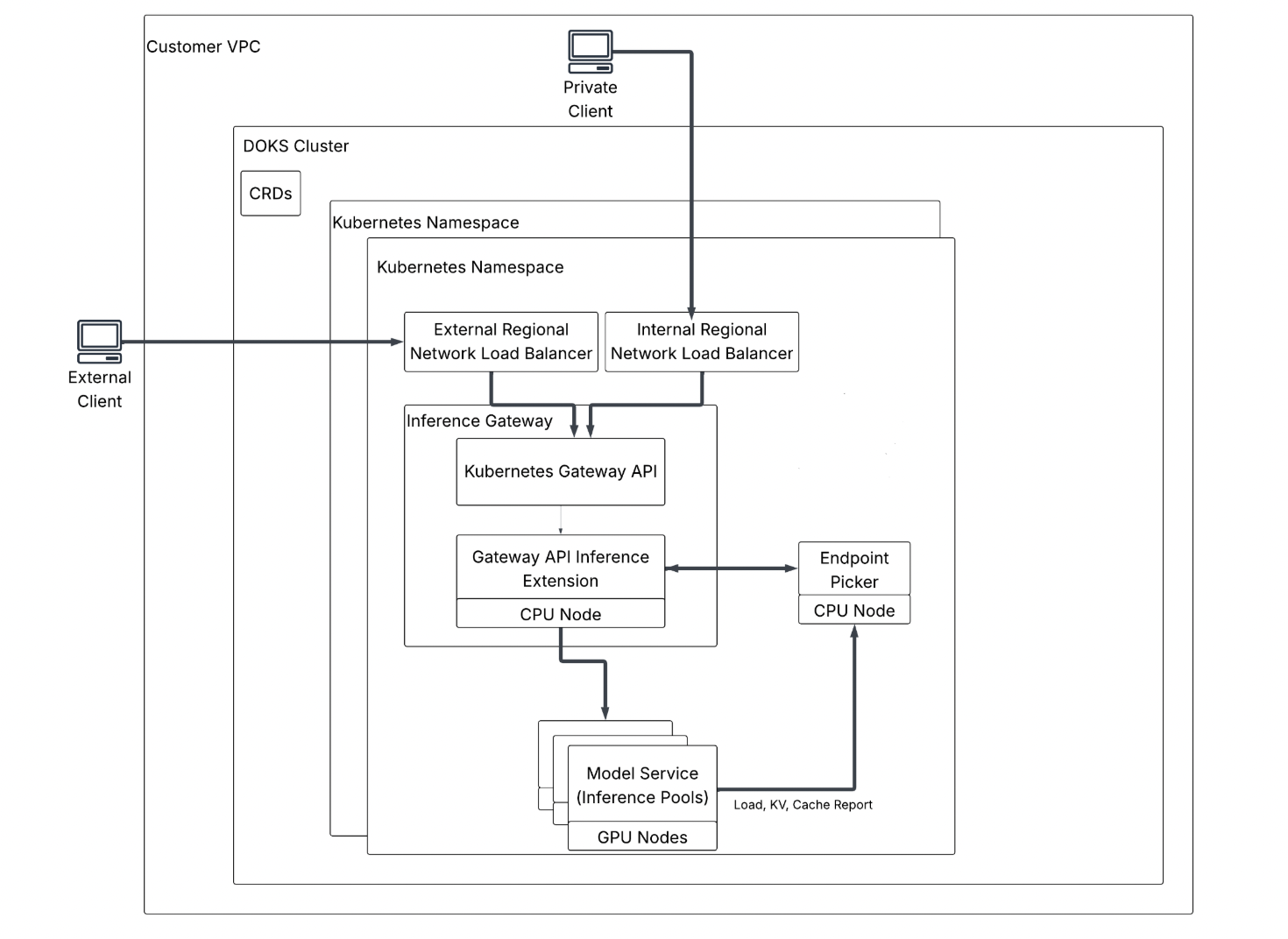
Client Contract & Endpoint connectivity: Once an endpoint is active, clients send OpenAI-compatible API requests (for example, HTTPS to /v1/chat/completions-style routes). Your public endpoint FQDN resolves to an external regional network load balancer (L4); your private endpoint resolves to an internal regional network load balancer, so the same inference stack can be reached from the public internet or stays on your private VPC network. In both cases, traffic is OpenAI-shaped JSON carrying model ID, messages, and generation parameters.
Cluster placement and VPC isolation: Inside the VPC, workloads run on DOKS. One cluster per VPC can host multiple Dedicated Inference deployments, each isolated by a Kubernetes namespace. Desired gateway and model wiring is expressed as Custom Resources (CRDs—Custom Resource Definitions): declarative objects you kubectl apply (or the platform applies for you) instead of imperative scripts.
Inference Gateway and Kubernetes Gateway API: After the NLB, traffic hits the Inference Gateway, implemented with the upstream Kubernetes Gateway API—the community standard for describing HTTP/TLS routing into a cluster.
Gateway API Inference Extension (inference-aware routing): Below the gateway, the Gateway API Inference Extension teaches routing about inference signals: queue depth, replica health, and KV cache affinity (preferring a replica that already holds key/value tensors for a reusable prompt prefix so work is not recomputed from scratch). KV cache is the saved attention state for prior tokens; inference-aware routing is deliberately not simple round robin, because the cheapest replica is often the one that already cached your prefix.
Endpoint Picker: On CPU nodes, the Endpoint Picker is the component that talks to the Inference Extension and selects which GPU replica should receive each request.
Model Service and inference pools: On GPU nodes, the Model Service—backed by inference pools in configuration—runs your model replicas (distinct pods/processes that can serve the same model ID). Each replica reports load, KV, and cache metadata upstream so the Endpoint Picker's choices stay accurate through rollouts, crashes, and autoscaling events. Replica is a horizontally scaled copy of the same model server; pool is the grouping of those replicas for routing and capacity.
Who is Dedicated Inference for?
Dedicated Inference is aimed at builders who already know they need GPUs, but who would rather not become a full-time inference platform team:
- Teams that self-host on raw GPU Droplets or Kubernetes and want to offload orchestration, baseline optimizations, and repetitive infra work while keeping API-level ownership of their applications.
- Teams that have graduated from Serverless Inference and need hardware-level control or BYOM without abandoning managed operations.
- Organizations with consistent inference demand where predictable GPU-hour economics and performance isolation matter more than pure burst elasticity.
Inference is no longer a novelty layer; it is part of the core application stack. That shift raises the bar for reliability, performance, and cost predictability. Dedicated Inference is for teams that need production-grade, dedicated GPU inference with a managed path from model selection to a stable endpoint—so you spend engineering cycles on products and prompts, not on reinventing the serving platform.
Building a PCI-DSS Compliant GKE Framework for Financial Institutions: Data Protection, Governance…
This guide shows how to build a PCI-DSS compliant payment processing system on Google Kubernetes Engine using customer-controlled encryption keys and tokenization to secure cardholder data.
Summary
Deep Dive
Decoder
Original Article
LLM-assisted coding is not deterministic. Does it matter?
LLM-assisted coding doesn't need to be deterministic to be useful, because software development has never been deterministic and what actually matters is predictability of outcomes.
Summary
Deep Dive
Decoder
Original Article
Amazon ECR Pull Through Cache Now Supports Referrer Discovery and Sync
Amazon ECR now automatically syncs container image signatures, SBOMs, and attestations through its pull through cache, removing the need for manual retrieval.
Summary
Decoder
Original Article
Internal vs. External Storage: What's the Limit of External Tables?
External tables, which store metadata in databases but reference data in object storage, have persisted for 25 years because they solve the economic tradeoff between storage cost and query speed.
Summary
Deep Dive
Decoder
Original Article
When a Cloud Region Fails: Rethinking High Availability in a Geopolitically Unstable World
Traditional multi-AZ cloud architectures fail to account for geopolitical disruptions that can take down entire regions through sanctions, internet shutdowns, or conflict, requiring a fundamental rethink of high availability design.
Summary
Deep Dive
Decoder
Original Article
tda-mapper (GitHub Repo)
tda-mapper is a scikit-learn-compatible library that reveals hidden clusters and patterns in messy data using topological data analysis to create intuitive graph representations.
Summary
Deep Dive
Decoder
Original Article
tda-mapper
tda-mapper is a Python library built around the Mapper algorithm, a core technique in Topological Data Analysis (TDA) for extracting topological structure from complex data. Designed for computational efficiency and scalability, it leverages optimized spatial search methods to support high-dimensional datasets. The library is well-suited for integration into machine learning pipelines, unsupervised learning tasks, and exploratory data analysis.
Further details in the documentation and in the paper.
Core Features
-
Efficient construction
Leverages optimized spatial search techniques and parallelization to accelerate the construction of Mapper graphs, supporting the analysis of high-dimensional datasets.
-
Scikit-learn integration
Provides custom estimators that are fully compatible with scikit-learn's API, enabling seamless integration into scikit-learn pipelines for tasks such as dimensionality reduction, clustering, and feature extraction.
-
Flexible visualization
Multiple visualization backends supported (Plotly, Matplotlib, PyVis) for generating high-quality Mapper graph representations with adjustable layouts and styling.
-
Interactive app
Provides an interactive web-based interface for dynamic exploration of Mapper graph structures, offering real-time adjustments to parameters and visualizations.
Background
The Mapper algorithm extracts topological features from complex datasets, representing them as graphs that highlight clusters, transitions, and key structural patterns. These insights reveal hidden data relationships and are applicable across diverse fields, including social sciences, biology, and machine learning. For an in-depth overview of Mapper, including its mathematical foundations and practical applications, read the original paper.
| Step 1 | Step 2 | Step 3 | Step 4 |
|---|---|---|---|
 |
 |
 |
 |
| Choose lens | Cover image | Run clustering | Build graph |
Quick Start
Installation
To install the latest version uploaded on PyPI
pip install tda-mapperHow to Use
Here's a minimal example using the circles dataset from scikit-learn to demonstrate how to use tda-mapper. This example demonstrates how to apply the Mapper algorithm on a synthetic dataset (concentric circles). The goal is to extract a topological graph representation using PCA as a lens and DBSCAN for clustering. We proceed as follows:
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
import numpy as np
from sklearn.decomposition import PCA
from sklearn.cluster import DBSCAN
from tdamapper.learn import MapperAlgorithm
from tdamapper.cover import CubicalCover
from tdamapper.plot import MapperPlot
# Generate toy dataset
X, labels = make_circles(n_samples=5000, noise=0.05, factor=0.3, random_state=42)
plt.figure(figsize=(5, 5))
plt.scatter(X[:,0], X[:,1], c=labels, s=0.25, cmap="jet")
plt.axis("off")
plt.show()
# Apply PCA as lens
y = PCA(2, random_state=42).fit_transform(X)
# Mapper pipeline
cover = CubicalCover(n_intervals=10, overlap_frac=0.3)
clust = DBSCAN()
graph = MapperAlgorithm(cover, clust).fit_transform(X, y)
# Visualize the Mapper graph
fig = MapperPlot(graph, dim=2, seed=42, iterations=60).plot_plotly(colors=labels)
fig.show(config={"scrollZoom": True})| Original Dataset | Mapper Graph |
|---|---|
 |
 |
Left: the original dataset consisting of two concentric circles with noise, colored by class label. Right: the resulting Mapper graph, built from the PCA projection and clustered using DBSCAN. The two concentric circles are well identified by the connected components in the Mapper graph.
More examples can be found in the documentation.
Interactive App
Use our app to interactively visualize and explore your data without writing code. You can try it right away using our live demo, or run it locally on your machine.
To run it locally:
-
Install the app and its dependencies:
pip install tda-mapper[app] -
Launch the app:
tda-mapper-app

Citations
If you use tda-mapper in your work, please consider citing both the library, archived in a permanent Zenodo record, and the paper, which provides a broader methodological overview. We recommend citing the specific version of the library used in your research, along with the paper. For citation examples, please refer to the documentation.
DuckDB Extension - Whisper (Tool)
A DuckDB extension brings OpenAI's Whisper speech recognition directly into SQL queries, letting you transcribe audio files and even speak database queries.
Summary
Decoder
Original Article
HDFS Lost. How Object Storage and Table Formats Won the Data Lake
Object storage plus table formats replaced HDFS for data lakes because network speeds caught up to disk speeds, eliminating the need for data locality and enabling independent scaling of storage and compute.
Summary
Deep Dive
Decoder
Original Article
This Adobe Sneak Uses AI to Rethink Website Personalization
Adobe's Project Page Turner uses large language models to generate personalized web pages in under 100 milliseconds, aiming to replace static websites with AI-driven experiences tailored to individual visitors.
Summary
Deep Dive
Decoder
Original Article
This Adobe Sneak Uses AI to Rethink the Personalized Web
Cookies have long been the default tool brands reach for when personalizing the web. For over 30 years, small text files stored in browsers have given companies a window into how users move across the web—and a way to tailor ads and content accordingly. But privacy regulations such as GDPR and CCPA, restrictions in browsers like Firefox and Safari, and shifting consumer expectations have gradually eroded their effectiveness, pushing brands to search for alternatives.
What emerged to fill that gap, though, has its own set of tradeoffs. First-party data, contextual targeting, and login-based personalization all attempt to tackle this problem, but they share the same flaw—they personalize for segments, not the individual.
However, a new Sneak from Adobe called Project Page Turner is taking a different approach—and it's powered by artificial intelligence. Adobe previewed it exclusively with The AI Economy ahead of its public unveiling this week.
Meet Project Page Turner
What if you could use a large language model to transform your website so it feels tailor-made for every visitor? It's what Adobe is exploring with Project Page Turner, a working idea that helps brands provide a more one-to-one experience.
Paolo Mottadelli, the Adobe Experience Manager (AEM) engineering director and the creator of this project, says the timing is right—inference speeds have improved to the point where personalized pages can be generated in real-time. Models are now fast enough to deliver a first response in under 100 milliseconds, quicker than you can blink, and with the full page loading in under a second—well below the two-second threshold most users expect.
He points out that websites haven't really changed: "Everybody goes to the same page, and then there is the marketer-driven personalization that requires effort, and it's limited." What Project Page Turner does is empower the page to "imagine itself based on what the site knows about the visitor." In other words, Mottadelli imagines a future in which websites are no longer "static" or even exist anymore.
"They will create themselves under the browsing experience of the user," he says.
Conceived From Customer Feedback
The idea behind Project Page Turner didn't appear out of nowhere. Mottadelli reveals it originated from customer feedback—in working with more than 90 AEM customers in the past year, he was repeatedly asked for ways to provide better, more meaningful personalization. He recalls working on this project back "when technology to do it was not around yet." Now, it is.
As the company behind one of the web's leading content management platforms, Adobe has a direct stake in how websites evolve. Mottadelli says that after seeing Google provide dynamic visual answers that took three minutes to generate, his team began asking what would happen if that same experience could be delivered "in a page delivery timeframe, which happens to be under two seconds."
After some successful trialing, Mottadelli believes "this might be one of the directions the world [wide] web is going."
Unsurprisingly, Project Page Turner sits on top of AEM, utilizing it in two ways: AEM Assets—where brands already store images, video, and content—is the content library this system draws from; and AEM Sites—Adobe's content management system—provides the layout elements. Project Page Turner applies a new indexing layer that makes both rapidly accessible to a fast LLM, allowing it to assemble a personalized page on the fly.
Mottadelli notes that Project Page Turner's inference and underlying models are currently provided by Cerebras, primarily using GPT—though any fast model can be swapped in—reflecting Adobe's broader model-agnostic approach, as evidenced by its Firefly platform.
When implemented, brands need to provide the LLM with brand guidelines, product knowledge, and content rules. All of this goes into instructing it on what to recommend and when, similar to how you'd brief a new employee on company policy. Mottadelli predicts that, eventually, "training the website is like training a human."
How Project Page Turner May Work

One possible way to implement Project Page Turner could be through a website's search feature. Say you're a personal trainer looking for a new blender that can make multiple protein shakes for your clients. Instead of visiting Amazon or Google, you go directly to a website like Vitamix to do your research. There, you start by entering your query in the search feature.
Traditionally, information is surfaced by keyword or by a referenced product name. However, Project Page Turner analyzes the natural language query and returns a fully customized results page just for you. So, you can specify that you're curious about how different models compare in terms of heavy daily use and cleanup, and that speed matters a lot.
What gets generated isn't a generic results page where you have to click through to find piecemeal information. Rather, you're provided a fully assembled experience built around your specific request. Information about high-volume blenders, self-cleaning instructions, thick protein shake recipes, model comparisons, and purchase options all surface together, organized around what you actually asked for.
"The prompt is basically zero-party data…it doesn't require cookies," Eric Matisoff, Adobe's principal evangelist, tells The AI Economy. "It wouldn't require… second-party or third-party data to that user in order to personalize [the search results]."
He adds, "The most interesting thing to analyze across an entire website is internal search data, because there's no other time that someone is telling you exactly what they're looking for than when they're doing an internal search on your website. This takes that to the next step, while also building the personalized experience on the fly."
Beyond the explicit intent of the search prompt, Project Page Turner can also learn from how you browse—observing which products you view, which categories you explore, and what content you engage with. Mottadelli adds that if you arrive at a supported site from ChatGPT, Google, or another platform, the system could carry that intent over as well. But regardless of the signals available, he emphasizes that consent is central to the vision.
Mottadelli says that his ambitions for Project Page Turner extend far beyond the search bar. "What we're really envisioning is the seamless browsing experience that the website is…becoming your second skin without you even noticing." He imagines sites adapting so closely to us that it feels natural and invisible, easily picking up intent and signals and quietly reshaping content and layout around us in real time. How this idea is realized isn't a technology question but rather a question of how companies want users to experience their websites.
ChatGPT, But With the Brand Experience
People approach traditional search engines and AI chatbots like Perplexity, OpenAI's ChatGPT, Google's Gemini, or Anthropic's Claude very differently. The former is about discovery—you're browsing and exploring without a clear destination—while the latter is about intent; you have a specific goal in mind and expect a tailored answer.
Brands want to capitalize on intent signals without sending visitors to a third-party platform. Yes, ChatGPT answers your question, but it strips away the brand experience—the visuals, the product narrative, the path to purchase. A brand website has all of that, but can't respond to your specific intent in real time. Project Page Turner is Adobe's attempt to sit in between: a brand website that behaves like a chatbot.
Companies can already extend their brands to platforms like ChatGPT. Booking.com, Canva, Coursera, Expedia, Figma, Spotify, Zillow, Upwork, and even Adobe have integrated their services with the popular chatbot. But that means operating on someone else's turf and surrendering control of the brand experience. Project Page Turner flips that dynamic, keeping AI's intent-driven responsiveness on the brand's own website.
"This is putting two things together: immediate reaction to the intent with breadthful brand experience," Mottadelli says.
Whether Adobe can defend Project Page Turner against the likes of OpenAI, Google, Anthropic, Salesforce, and others—some of which are moving aggressively to disrupt established players—remains to be seen. But Mottadelli argues that Adobe has something they mostly do not: 4,000 enterprise customers, decades of content management infrastructure, and direct relationships with the marketing teams responsible for brand experiences. "AEM has the right technology to implement [this solution]," he says. The advantage isn't the technology, Mottadelli points out—it's the trust.
What Are Adobe Sneaks?
Project Page Turner is one of seven so-called Sneaks being unveiled this week at Adobe's AI Summit. None are committed to the product roadmap, though Matisoff notes that historically, 30 to 40 percent have made it into production in some form. That said, the goal of Adobe Sneaks is to highlight innovation.
Matisoff says that AI has contributed to an increase in ideas, all jockeying to be featured on stage: "Last year, we had a little over 150 [submissions]. This year, we had well over 500." He adds that even after identifying the projects that will be featured at the event, "we've seen the ideas continue to advance at a more rapid pace…because of how easy it is for our teams to ideate and expand and improve what they're delivering."
Adobe Sneaks isn't unique to Summit—the showcase also happens at Adobe Max. Think of it as Silicon Valley demo day with a comedic twist: engineers present their ideas on stage before a live audience of thousands, Matisoff, and a celebrity co-host. This year, that's comedian, actress, and producer Iliza Shlesinger.
And for those who want a say in what gets built, new this year is a concept that lets audience members vote for their favorite Sneak. The results will help influence the product roadmap. Now, everyone can voice their support in hopes that their favorite idea becomes reality.
For Adobe, the stakes around Sneaks extend beyond any single idea. The company faces mounting pressure—not just from longtime rivals like Figma and Canva, but also from AI-native challengers like Anthropic rewriting the rules of the software industry. Matisoff sees this showcase as proof that Adobe hasn't lost its founder mentality—that innovation still bubbles up from anywhere in the organization. He points to a line from one of Adobe's founders that still guides the program: "Great ideas can come from anywhere in the company." In 2026, Adobe needs that to be true more than ever.
SpaceX is Working with Cursor and has an Option to Buy the Startup for $60B
SpaceX partnered with AI coding assistant Cursor and has an option to acquire the company for $60 billion, potentially consolidating Musk's AI ambitions ahead of a SpaceX IPO.
Summary
Deep Dive
Decoder
Original Article
Designing with AI without losing your mind
A designer concerned about outsourcing critical thinking to AI built a real-time collaborator that challenges ideas during sketching rather than just generating solutions.
Summary
Deep Dive
Decoder
Original Article
AI Model Accessibility checker (Website)
A new benchmark reveals which AI coding models generate accessible web pages, with OpenAI dominating the top spots while Anthropic's Claude models produce nearly triple the accessibility violations of competitors.
Summary
Deep Dive
Decoder
Original Article
AIMAC: The AI Model Accessibility Checker
AI is writing more code than ever. But is it accessible to People with Disabilities?
We prompted the top AI models to build web pages across 28 categories and audited them for accessibility. We published every generated page, side by side, so you can see how different models tackled the same design challenge. We even measured emdash usage.
AIMAC is an initiative by the GAAD Foundation, in partnership with ServiceNow. Updated Apr 08, 2026.
Leaderboard
Legend: 🅿️ Pareto Optimal | 🏆 Lowest Debt
1 #1 and #2 and #3 tied with an AIMAC Debt of 0.00. Tiebreaker: #1 averaged fewer violations (0.94 vs 1.02 vs 1.31).
* GPT 5.3 Codex shows a median AIMAC Debt of 0.00. This means at least half of the 28 categories had zero accessibility violations, but some categories still had minor issues (20 total violations across all categories).
Analysis
Introduction
95.9% of the top million websites fail basic accessibility checks. WebAIM has tracked it for seven years. After six years of marginal improvement, 2026 reversed the trend: errors per page jumped 10% to 56.1 and the failure rate climbed back to 95.9%.
AI is writing more of the world's code every day. Vibe Coding was the Collins Dictionary Word of the Year. If AI keeps writing code as poorly as the developers it learned from, nothing changes. But if it prioritizes accessibility, the web gets its first real chance to improve.
Our one ambitious goal
Ensure that AI models write accessible code by default.
Which Model is Best?
GPT 5.3 Codex by OpenAI holds the top spot with a median AIMAC Debt of 0.00, generating just 20 accessibility violations across all 28 categories. GPT 5.4 Mini joins it at #2, also achieving zero debt for just $0.89. GPT 5.4 takes #3 (also 0.00) and GPT 5.4 Pro sits at #4 (1.00). Arcee AI's Trinity Large Preview (free) rounds out the top five at #5 with a debt of 3.98. OpenAI holds four of the top five spots.
Three models now achieve a median AIMAC Debt of 0.00. The cheapest is GPT 5.4 Mini at $0.89. The most expensive model on the benchmark is GPT 5.4 Pro at $212.75.
The Pareto Frontier
AIMAC Debt vs Cost
Choosing a model isn't simply about which model is most accessible. Some models are very expensive. Benchmarks commonly use Pareto Frontier analysis to compare models on quality vs cost dimensions. Pareto optimal models (teal diamonds) are the efficient picks: to lower the AIMAC Debt grade, you'd pay more; to pay less, your AIMAC Debt grade rises. A gold ring marks the lowest AIMAC Debt.
Top 3 Winners
-
OpenAI -
Arcee AI -
Alibaba/Qwen
1. OpenAI dominates the top of the leaderboard. Three of their models achieve a median AIMAC Debt of 0.00: GPT 5.3 Codex (#1), GPT 5.4 Mini (#2), and GPT 5.4 (#3). A median of 0.00 means at least half of the 28 categories had zero violations, though a few categories still had minor issues. GPT 5.4 Pro rounds out the top four at 1.00. They hold four of the top five spots (#1, #2, #3, #4), and their open-source gpt-oss-120b lands at #11 for just $0.10.
2. Arcee AI is a 30-person San Francisco startup that built Trinity Large Preview from scratch for $20 million. It is a 400-billion-parameter sparse model with only 13 billion active per token, Apache 2.0 licensed, and ranks #5 for free. It is the largest permissively-licensed open model from a US company. Their Trinity Large Thinking variant lands at #29 (debt 7.97, $0.25).
3. Alibaba/Qwen fields the deepest roster outside OpenAI, with eight models spanning the leaderboard. Qwen3 Max leads the pack at #7 (debt 4.14, $1.07), and Qwen3 Coder Plus follows at #8 (debt 4.36, $0.75). Their lineup covers proprietary flagships, code-tuned variants, and open-weight releases, giving developers more accessibility-tested options than any other non-US provider.
Google's Comeback
Google's Gemini 3 Pro Preview once finished dead last at #39 with an AIMAC Debt of 10.65. We were disappointed because Google has the tools and talent to do better.
Its replacement, Gemini 3.1 Pro Preview, now sits at #9 with an AIMAC Debt of 4.40. Google is no longer at the bottom. This is exactly the kind of progress we hoped this benchmark would encourage.
What About Claude?
Anthropic has real developer mindshare, and Claude is often the default choice when teams want strong coding help. In this benchmark, their best result is Claude Haiku 4.5 at rank #10 (4.47 for $2.14). Claude Opus 4.6 (Fast) ranks #23 (5.94 for $112.18), Claude Opus 4.6 ranks #26 (6.90 for $18.34), and Claude Sonnet 4.6 sits at #36 (9.83 for $12.64). Sonnet's regression from 4.5 remains sharp: from #19 (debt 4.78) to #36 (debt 9.83).
Other major providers improved their accessibility results. Anthropic is the only one whose models got worse.
Sonnet 4.6 generates 1,186 accessibility violations, nearly three times the field average of 403. Opus 4.6 produces 788, nearly double. The same gap shows in Anthropic's frontend-design skill, where accessibility is barely mentioned while the guidance is overwhelmingly visual.
Anthropic is a Public Benefit Corporation whose stated values include acting "for the global good" and being good to their users, whom they define broadly as "anyone impacted by the technology we build." People with disabilities are impacted every time Claude generates inaccessible code. We hope Anthropic will bring the same energy they apply to AI safety to the accessibility of their models' output.
The broader trend is encouraging. Models are training against automated tools like axe-core, and scores are improving. We are working on new benchmarks that test models that go beyond axe-code testing.
Beyond the Rankings
As AI models get better at visual design, they face a tradeoff between optimizing for beauty or for accessibility. You can achieve both, but it requires deliberate effort.
If you're picking a model for your workflow, start with a category page that matches your use case. Each category shows how ~40 models handled the same prompt, alongside their AIMAC Debt. For example, visit the Sports category in grid mode to compare sports designs side by side.
If you already have a model in mind, use the model detail page to see what its pages look like across all 28 categories. Then drill down into the categories that match your needs. See GPT 5.4 Pro in grid mode for an example.
Value vs Premium
The #1 model on this benchmark costs $3.02. But the #2 model costs just $0.89. GPT 5.4 Mini achieves zero debt for under a dollar, while GPT 5.4 Pro costs $212.75 for a debt of 1.00. Twenty-eight of 43 models cost under $1, including Grok 4.1 Fast at #14 for 8 cents, OpenAI's gpt-oss-120b at #11 for 10 cents, and Gemma 4 31B at #40 for 8 cents.
Closed vs Open (Source/Weights)
A closed model holds the top spot. GPT 5.3 Codex (proprietary) remains #1, and three more closed OpenAI models fill spots #2 through #4. Trinity Large Preview (open-source, Apache 2.0) holds #5 for free.
The upper-middle tier remains packed with value picks across both closed and open-weight releases. Qwen3 Max and Coder Plus rank 7th and 8th. Kimi K2 Thinking sits at #12 for 82 cents. OpenAI's open-weight gpt-oss-120b ranks 11th for 10 cents.
The smaller models are mostly from China. Qwen, Z.ai, DeepSeek, and MoonshotAI account for 15 of 43 models. Alibaba's Qwen line has eight entries. Despite US chip restrictions, Chinese labs keep shipping.
DeepSeek made headlines in January 2025 when their R1 model triggered a $600 billion single-day loss in Nvidia's market cap by claiming similar performance to Western models at a fraction of the cost. But on accessibility, their lineup sits near the bottom: R1 0528 scores 10.17 (rank #37), V3.2 lands at 8.18, and their best result (V3.2 Speciale) still comes in at 7.21. R1 0528 regressed from the original R1 it replaced (which scored 8.08). The efficiency breakthrough has not translated to accessible output.
Mistral struggled on this benchmark. Medium 3.1 is their lone mid-pack result at 4.70 (rank #15), while the rest cluster near the bottom: Large 3 2512 at 8.33 (rank #32), Codestral 2508 at 8.40 (rank #33), and Devstral 2 2512 at 9.01 (rank #34). Their newest release, Mistral Small 4, finishes dead last at #43 with a debt of 16.96, a sharp regression from the Small 3.2 24B it replaced (which scored 8.48). Only Medium 3.1 cracked the Top 20, and it is not open source. Their open-source Small 4 finishes last.
What Trips Models Up
Low contrast text dominates both AI-generated and human-built websites. Both columns report the share of pages with at least one instance of each issue. AIMAC uses axe-core across AI-generated pages; WebAIM uses WAVE across the top 1,000,000 home pages.
AIMAC: Top 6 issues
Share of pages with >= 1 error
- Low contrast text: 84.8%
- Empty links: 31.0%
- Missing form labels: 19.7%
- Empty buttons: 6.9%
- Links distinguished only by color: 3.9%
- Target size too small: 3.7%
WebAIM Million 2026: Top 6 issues
Share of home pages with >= 1 error
- Low contrast text: 84%
- Missing alt text: 53%
- Missing form labels: 51%
- Empty links: 46%
- Empty buttons: 31%
- Missing document language: 14%
Emdash Benchmark
We tracked emdash usage as a small writing-style signal, because punctuation can affect how text is read aloud.
Screen readers handle emdashes differently. Some announce "em dash" at every occurrence, others treat it as a pause, and some ignore it depending on voice and settings. Ricky Onsman explored the issue and found this is largely a screen reader behavior difference, not a content authoring bug.
We sanity-checked this with screen reader users, and none of our friends reported emdash-heavy text as a practical problem in day-to-day reading. So this turned out to be more interesting than impactful, and it does not affect AIMAC rankings.
Emdash usage varies widely. Across 43 models, counts range from 0 (Codestral 2508) to 754 (Claude Sonnet 4.6). 1 model uses zero emdashes.
Models Tested
This analysis covers 43 models from 15 companies:
- Claude Haiku 4.5
- Claude Opus 4.6
- Claude Opus 4.6 (Fast)
- Claude Sonnet 4.6
- Codestral 2508
- DeepSeek V3.2
- DeepSeek V3.2 Speciale
- Devstral 2 2512
- Gemini 3 Flash Preview
- Gemini 3.1 Pro Preview
- Gemma 4 31B
- GLM 4.7 Flash
- GLM 5.1
- GPT 5.3 Codex
- GPT 5.4
- GPT 5.4 Mini
- GPT 5.4 Pro
- gpt oss 120b
- Grok 4.1 Fast
- Grok 4.20
- KAT Coder Pro V2
- Kimi K2 Thinking
- Kimi K2.5
- MiniMax M2.7
- Mistral Large 3 2512
- Mistral Medium 3.1
- Mistral Small 4
- Nemotron 3 Super (free)
- Nova 2 Lite
- o3
- o4 Mini
- Olmo 3.1 32B Instruct
- Qwen3 Coder Flash
- Qwen3 Coder Next
- Qwen3 Coder Plus
- Qwen3 Max
- Qwen3 Max Thinking
- Qwen3.5 397B A17B
- Qwen3.5 Flash
- Qwen3.6 Plus
- R1 0528
- Trinity Large Preview (free)
- Trinity Large Thinking
Update History
April 9, 2026
Models Removed
- GLM 5: was Rank #5, AIMAC Debt 2.66, Cost $2.03
- GPT 5.1 Codex Mini: was Rank #6, AIMAC Debt 3.78, Cost $0.39
- Qwen3.6 Plus Preview (free): was Rank #12, AIMAC Debt 4.44, Cost $0.00
Models Added
- Qwen3.6 Plus: Rank #22, AIMAC Debt 5.41, Cost $0.99
- Claude Opus 4.6 (Fast): Rank #23, AIMAC Debt 5.94, Cost $112.18
- Gemma 4 31B: Rank #40, AIMAC Debt 12.59, Cost $0.08
- GLM 5.1: Rank #42, AIMAC Debt 16.38, Cost $2.47
Notes
- GLM 5.1 replaces GLM 5 as Z.AI's latest flagship. GLM 5.1 was retrained for coding/agentic tasks and achieved SOTA on SWE-Bench Pro, but dropped from #5 to #42 on accessibility.
- GPT 5.1 Codex Mini retired as OpenAI consolidates around the 5.3/5.4 generation.
- Qwen3.6 Plus is the GA release of the preview. Free access ends; the paid model costs $0.99.
- Claude Opus 4.6 (Fast) is Anthropic's fourth model on the benchmark, filling the premium-fast slot.
- Gemma 4 31B is Google's first open-weight model to pass the 10KB HTML threshold.
Impact
- The version-upgrade regression pattern strikes again: GLM 5 (#5) to GLM 5.1 (#42) is the largest rank drop from a version upgrade we have tracked (37 ranks). It joins KAT V1 to V2 (-28) and Sonnet 4.5 to 4.6 (-18).
- Z.AI drops out of the Top 3 Winners. Alibaba/Qwen enters, with Qwen3 Max at #7 and eight models across the leaderboard.
- Trinity Large Preview (free) moves to #5, a free model in the top five.
April 1, 2026
Models Added
- Trinity Large Thinking (Arcee AI): Rank #30, AIMAC Debt 7.97, Cost $0.25
Notes
- Arcee AI's second model on the benchmark, alongside Trinity Large Preview (free) at #7.
Impact
- Arcee AI now has two models on the benchmark: Trinity Large Preview (free) at #7 and Trinity Large Thinking at #30.
March 31, 2026
Models Removed
- Grok 4.20 Beta: was Rank #39, AIMAC Debt 12.53, Cost $2.09
Models Added
- Grok 4.20: Rank #38, AIMAC Debt 11.16, Cost $2.07
Notes
- Grok 4.20 GA supersedes the Beta release.
- Updated WebAIM Million comparison data from 2025 to 2026 following the new report (published March 30, 2026). The 2026 report reversed six years of gradual improvement: errors per page jumped 10% and 95.9% of sites now fail basic checks.
Impact
- xAI's flagship improves slightly (debt 12.53 to 11.16), gaining one rank from #39 to #38.
- Qwen3.5 Flash shifts from #38 to #39. All other rankings are unchanged.
March 30, 2026
Models Removed
- Qwen3.5 Plus 2026 02 15: was Rank #24, AIMAC Debt 5.73, Cost $0.54
Models Added
- Qwen3.6 Plus Preview (free): Rank #12, AIMAC Debt 4.44, Cost $0.00
Notes
- Qwen3.6 Plus Preview supersedes Qwen3.5 Plus.
- The count of models under $1 remains 27 (both models are under $1).
Impact
- Alibaba's Qwen Plus line improves from #24 to #12, a 12-spot jump.
- Ranks 12-23 each shift down by one. Top 11 and ranks 25-41 are unchanged.
March 28, 2026
Models Removed
- KAT Coder Pro V1: was Rank #12, AIMAC Debt 4.46, Cost $0.22
Models Added
- KAT Coder Pro V2: Rank #40, AIMAC Debt 13.19, Cost $0.44
Notes
- KAT Coder Pro V2 supersedes V1. Score regressed sharply from 4.46 to 13.19, rank dropping from #12 to #40. Cost doubled from $0.22 to $0.44.
- The count of models under $1 remains 27 (both V1 and V2 are under $1).
Impact
- KwaIPilot drops from the upper tier to second-to-last. V1 was a standout budget pick; V2 is one of the weakest models on the benchmark.
- Ranks 13-39 each shift up by one. Top 11 and last place are unchanged.
March 22, 2026
Models Removed
- MiniMax M2.5: was Rank #9, AIMAC Debt 4.04, Cost $0.25
Models Added
- MiniMax M2.7: Rank #23, AIMAC Debt 5.34, Cost $1.28
Notes
- MiniMax M2.7 supersedes M2.5. Score regressed from 4.04 to 5.34, rank dropping from #9 to #23. Cost increased from $0.25 to $1.28.
- The count of models under $1 drops from 28 to 27 because M2.7 costs $1.28 (M2.5 was $0.25).
Impact
- MiniMax falls out of the Top 10 after its M2.5 held #9. The upgrade traded accessibility for other capabilities.
- Top 8 and bottom 18 ranks are unchanged. Only ranks 9-22 shift up by one.
March 17, 2026
Models Removed
- GPT 5.2 Pro: was Rank #3, AIMAC Debt 2.77, Cost $95.45
- GPT 5.2: was Rank #4, AIMAC Debt 3.05, Cost $6.63
- Gemini 2.5 Flash Lite: was Rank #23, AIMAC Debt 5.42, Cost $0.09
- GPT 5 Mini: was Rank #30, AIMAC Debt 7.62, Cost $0.60
- Mistral Small 3.2 24B: was Rank #35, AIMAC Debt 8.48, Cost $0.03
Models Added
- GPT 5.4 Mini: Rank #2, AIMAC Debt 0.00, Cost $0.89
- GPT 5.4: Rank #3, AIMAC Debt 0.00, Cost $4.48
- GPT 5.4 Pro: Rank #4, AIMAC Debt 1.00, Cost $212.75
- Nemotron 3 Super (free): Rank #21, AIMAC Debt 4.82, Cost $0.00
- Qwen3.5 Flash: Rank #39, AIMAC Debt 11.37, Cost $0.09
- Grok 4.20 Beta: Rank #40, AIMAC Debt 12.53, Cost $2.09
- Mistral Small 4: Rank #41, AIMAC Debt 16.96, Cost $0.18
Notes
- GPT 5.4 Mini achieves a median AIMAC Debt of 0.00 at $0.89, the second model to reach zero debt.
- GPT 5.4 and GPT 5.4 Pro replace their 5.2 predecessors as the latest versions in each slot. GPT 5.4 Pro costs $212.75, more than double the $95.45 that GPT 5.2 Pro cost, making it the most expensive model on the benchmark by a wide margin.
- Gemini 2.5 Flash Lite is removed. Google's replacement (Gemini 3.1 Flash Lite Preview) fails the 10KB minimum HTML size requirement, so the Flash Lite slot goes away.
- Mistral Small 4 (119B) replaces Small 3.2 24B as Mistral's latest Small release, but regresses from #35 (debt 8.48) to dead last at #41 (debt 16.96).
- Grok 4.20 Beta is xAI's new flagship but lands at #40, while xAI's own Grok 4.1 Fast sits at #18.
Impact
- GPT 5.4 Mini ($0.89) is the value headline: zero accessibility debt for under a dollar.
- Three OpenAI models now hold spots #2 through #4, with the existing GPT 5.3 Codex still at #1.
February 25, 2026
Models Removed
- GPT 5.2 Codex: was Rank #3, AIMAC Debt 3.05, Cost $1.94
- Gemini 3 Pro Preview: was Rank #39, AIMAC Debt 10.65, Cost $3.35
Models Added
- GPT 5.3 Codex: Rank #1, AIMAC Debt 0.00, Cost $3.02
- Gemini 3.1 Pro Preview: Rank #11, AIMAC Debt 4.40, Cost $4.16
Notes
- GPT 5.3 Codex replaces GPT 5.2 Codex per version policy. It achieves a median AIMAC Debt of 0.00 with just 20 total violations across 28 categories, taking #1 from GLM 5.
- Gemini 3.1 Pro Preview replaces Gemini 3 Pro Preview per version policy. A dramatic improvement from #39 (debt 10.65) to #11 (debt 4.40).
Impact
- OpenAI takes back #1 with the first model to achieve a median AIMAC Debt of 0.00.
- Google goes from dead last to #11, the largest single-update improvement we have tracked.
February 17, 2026
Models Removed
- Aurora Alpha: was Rank #9, AIMAC Debt 4.05, Cost $0.00
- Claude Sonnet 4.5: was Rank #19, AIMAC Debt 4.78, Cost $6.20
Models Added
- Claude Sonnet 4.6: Rank #37, AIMAC Debt 9.83, Cost $12.64
- OLMo 3.1 32B Instruct: Rank #18, AIMAC Debt 4.80, Cost $0.12
- Qwen3.5 Plus 2026 02 15: Rank #23, AIMAC Debt 5.73, Cost $0.54
- Qwen3.5 397B A17B: Rank #36, AIMAC Debt 9.16, Cost $0.87
Notes
- Claude Sonnet 4.6 replaces Sonnet 4.5 per version policy; Sonnet regresses from #19 (Debt 4.78) to #37 (Debt 9.83) in this collection.
- Aurora Alpha was removed due to a 10KB minimum HTML threshold failure (one or more categories fell below 10KB).
- OLMo 3.1 32B Instruct adds an open-weight model from AllenAI (Allen Institute for AI), a US-based non-profit AI research lab.
- Two Qwen 3.5 models expand Qwen coverage with additional product lines.
Impact
- The production leaderboard expands from 37 to 39 models.
- #1 remains GLM 5 (AIMAC Debt 2.66).
- 27 of 39 models cost under $1.
February 12, 2026
Models Removed
- MiniMax M2.1: was Rank #18, AIMAC Debt 4.74, Cost $0.28
Models Added
- MiniMax M2.5: Rank #8, AIMAC Debt 4.04, Cost $0.25
Notes
- MiniMax M2.5 supersedes M2.1. Score improved from 4.74 to 4.04, rank jumping from #18 to #8.
Impact
- MiniMax M2.5 returns to the Top 10 with this entry.
February 11, 2026
Models Removed
- MiniMax M1: was Rank #5, AIMAC Debt 3.78, Cost $0.82
- Kimi K2 0905: was Rank #9, AIMAC Debt 4.39, Cost $0.54
- GLM 4.7: was Rank #13, AIMAC Debt 4.51, Cost $0.44
- Qwen3 Coder 480B A35B: was Rank #22, AIMAC Debt 6.01, Cost $0.33
- Claude Opus 4.5: was Rank #25, AIMAC Debt 7.06, Cost $19.92
- Qwen3 235B A22B Instruct 2507: was Rank #27, AIMAC Debt 7.54, Cost $0.26
- R1: was Rank #29, AIMAC Debt 8.08, Cost $0.70
- GLM 4.5 Air: was Rank #36, AIMAC Debt 9.33, Cost $0.33
Models Added
- GLM 5: Rank #1, AIMAC Debt 2.66, Cost $2.03
- Trinity Large Preview: Rank #6, AIMAC Debt 3.98, Cost $0.00
- Aurora Alpha: Rank #8, AIMAC Debt 4.05, Cost $0.00
- Qwen3 Coder Next: Rank #20, AIMAC Debt 4.99, Cost $0.41
- Kimi K2.5: Rank #21, AIMAC Debt 5.12, Cost $1.07
- Qwen3 Max Thinking: Rank #24, AIMAC Debt 6.00, Cost $1.11
- Claude Opus 4.6: Rank #26, AIMAC Debt 6.90, Cost $18.34
- R1 0528: Rank #36, AIMAC Debt 10.17, Cost $0.66
Notes
- GLM 5 by Z.ai takes 1st place, dethroning GPT 5.2 Pro. It is MIT-licensed open-source at $2.03 total, compared to GPT 5.2 Pro's $95.45.
- Trinity Large Preview by Arcee AI enters at #6 for free. It is a US-based open-source model.
- GLM 4.7 and GLM 4.5 Air are both superseded by GLM 5.
- Claude Opus 4.6 replaces Opus 4.5. Marginally better debt (6.90 vs 7.06) but ranks #26 due to new entrants.
- R1 0528 replaces R1. Cheaper with larger context, but scored worse on accessibility (10.17 vs 8.08).
- MiniMax M1 superseded by M2.1.
- Kimi K2 0905 superseded by K2.5.
- Qwen3 235B A22B Instruct 2507 removed. Qwen3 Coder 480B A35B trimmed in favor of Coder Next and Coder Plus variants.
Impact
- Open-source models now lead the leaderboard: GLM 5 at #1 and Trinity Large Preview at #6.
- OpenAI retains four of the top five spots (#2 through #5) but loses the crown.
January 19, 2026
Models Removed
- GPT 5.1 Codex: was Rank #3, AIMAC Debt 3.53, Cost $1.72
- KAT Coder Pro V1 (free): was Rank #14, AIMAC Debt 4.55, Cost $0.00
Models Added
- GPT 5.2 Codex: Rank #2, AIMAC Debt 3.05, Cost $1.94
- KAT Coder Pro V1: Rank #10, AIMAC Debt 4.46, Cost $0.22
- GLM 4.7 Flash: Rank #20, AIMAC Debt 5.37, Cost $0.11
Notes
- GPT 5.2 Codex succeeds GPT 5.1 Codex in our benchmark. We test the latest version of each model line.
- KAT Coder Pro V1 replaces the free tier, which OpenRouter deprecated on January 12.
Impact
- KAT Coder Pro V1 entering at #10 pushed Claude Haiku 4.5 to #11.
Acknowledgments
We are grateful to ServiceNow for their partnership, without which AIMAC would not be possible. This project was inspired by the WebAIM Million report. Note: although the Foundation regularly partners with WebAIM on projects such as the Global Digital Accessibility Salary Survey (GDASS), we did not happen to consult with them yet on this project. Any errors in this report are our own. We must acknowledge Deque for open sourcing axe-core, the engine powering our testing, and Microsoft for Playwright, which powers our browser automation. Microsoft are also partners in AIMAC's next benchmark, which will be accompanied by a research paper written by Yumeng Ma. We appreciate the collaboration, advice and feedback from Ed Summers, Jennifer Mankoff, Aaron Gustafson, Charlie Triplett, AnnMarie Dittell, Venkatesh Potluri, Jacob Wobbrock and Mary Bellard.
Methodology
What is AIMAC?
When you ask an LLM to build a web page, how accessible is the HTML it generates? AIMAC answers that question.
We prompt 43 models to generate pages across 28 categories with no accessibility guidance. Then we run axe-core, the accessibility testing engine used by Microsoft, Google, and most major tech companies, to count violations against WCAG 2.2 Level AA (the standard required by US and EU accessibility laws). Lower scores mean fewer problems.
The result is an apples-to-apples comparison of how well models handle accessibility without being told to.
Understanding "AIMAC Debt"
The AIMAC Debt measures automated accessibility violations. Lower is better.
What the numbers mean
- 0.00 is best possible (no critical/serious violations detected by axe-core)
- Lower single-digit scores generally mean the model generates relatively clean HTML
- Higher scores mean more severe and/or more numerous violations; double-digit scores indicate substantial accessibility work is needed
In practice, 80-90% of violations are color-contrast issues (text that's hard to read against its background). The remaining 10-20% are structural: empty buttons, missing form labels, misused ARIA attributes (the HTML attributes that help screen readers understand page structure). Structural issues are often more severe because they completely block assistive technology users.
How AIMAC Debt is calculated
- Critical violations (missing form labels, empty buttons): 5 points each
- Serious violations (insufficient color contrast): 2 points each
- Duplicate violations are dampened to avoid over-counting (details below)
We report the median debt across all 28 categories to avoid outliers.
Technical details: Dampening formula
For those interested in the math: we use logarithmic dampening for duplicate violations of the same issue type on a page.
Formula: score = base_weight × (1 + k × log₂(N))
Where:
N= number of duplicate violationsk= dampening factor (0.75 critical, 0.5 serious, 0.33 color-contrast)base_weight= 5 critical, 2 serious
This ensures 100 duplicates from one bad CSS rule don't count as heavily as 100 separate issues, while still encouraging comprehensive fixes.
How Reliable Are These Rankings?
We tested ranking stability extensively:
- Top 2 and bottom 4 positions: Rock-solid across configurations
- Mid-tier rankings (6-16): More variable because some models excel at certain page types while struggling with others
Choosing between mid-ranked models? Check category-specific performance on the detail pages.
Excluded Models
Pages under 10KB don't contain enough HTML to fairly test for accessibility mistakes. A 5KB page with zero violations isn't "better" than a 50KB page with three. They're solving different problems. We exclude models that produce minimal output to keep comparisons fair.
Why This Scoring System?
Our scoring reflects real-world impact:
- Critical violations (5 points vs 2 for serious): Empty buttons or missing labels completely block screen reader users
- Duplicate dampening: One bad CSS color causing 50 violations doesn't overwhelm the score
- Extra color-contrast dampening: Color issues are 70-100% of violations, so we reduce their weight to surface other differences
We validated this with sensitivity testing. Rankings stay consistent across configurations, and there's no penalty for generating complex HTML.
Scope of Automated Testing
Axe-core catches many issues: color contrast, missing labels, empty buttons, ARIA errors.
What automated testing can't catch: keyboard navigation problems, screen reader flow issues, real-world usability. Lower AIMAC Debt means a cleaner starting point, not a guarantee of perfect accessibility. Manual testing is still needed.
Preventing Benchmark Gaming
AIMAC's prompts are public. You can inspect exactly what we ask models to generate.
To prevent AI companies from training on specific prompt patterns, we use prompt randomization. Each category prompt contains example lists (navigation links, section themes) randomly selected from larger pools at runtime.
With current fragment pools, this yields hundreds of billions of prompt variants per category (tens of trillions across all 28 categories). Memorization is computationally infeasible.
The core instructions stay constant; only stylistic examples vary. AIMAC Debt reflects genuine capability, not prompt memorization.
Understanding the Total Cost
The Total Cost column shows what we paid to generate all 28 HTML pages for each model. This is the actual API cost in USD for the complete test suite.
For Benchmark Authors
While preparing to publish, we hit some visualization challenges that led us to consider Datasette, Simon Willison's tool for exploring and publishing data. We haven't implemented it yet, but the problems we encountered seem common to benchmarks, so we're sharing what we learned.
Data publication
Why publish your data?
Benchmark authors face a perplexing set of tradeoffs. Which models to include? How many prompts to test? How many variants? Worst of all, we can't know which version of a model we're testing because models get updated without public versioning. Companies change system prompts, infrastructure, or other API elements without warning. No benchmark will ever be truly repeatable. Publishing your data with an interactive website is a service to everyone, allowing the hive mind to improve the benchmark by highlighting gaps.
Datasette with its 154 plugins could let us embed an interactive database viewer directly on this page. It doesn't yet have Pareto or slope chart plugins, but general visualization plugins exist (datasette-vega, datasette-plot). Any interactive charting would need careful accessibility testing, which is why we deferred it.
Pareto Optimality
Sure, it's a great model, but is it Pareto optimal?
AI models are expensive. Benchmarks need a way to measure quality per dollar. Pareto Front charts are popular because they plot cost on one axis and quality on the other, quickly showing which models offer the best value.
When you divide such a chart into quadrants, the Pareto-optimal region combines maximum capability with minimum cost. That region represents the best tradeoff.
Most viewers instinctively interpret the top-right quadrant as "best." But in this benchmark, both axes reward lower values: lower debt means better accessibility, and lower cost is preferable. Plotted directly, that makes the bottom-left quadrant the Pareto-optimal one.
Pareto Optimality The limit of efficiency. To lower the AIMAC Debt score it would cost more. And you can't pay less without your AIMAC Debt score rising.
Naming matters here. We originally called our metric "AIMAC Score," but users expect higher scores to be better. Thanks to an insight by Charlie Triplett, we renamed it to "AIMAC Debt." People intuitively understand that you want debt to be lower.
Even with better naming, the Pareto chart still forces a choice between two kinds of unintuitiveness. You can leave the axes semantically honest (lower = better) and accept that the optimal quadrant is bottom-left. Or you can invert both axes so "up and to the right" means better, at the cost of making the axis directions themselves counterintuitive. Neither is great. An interactive chart that lets users toggle between views would help.
Slope Charts
Slope charts offer another way to visualize the cost vs. quality tradeoff. They plot each model's quality rank on the left and cost rank on the right, then draw a line between them. A flat or rising line means the model delivers good value: its cost rank matches or beats its quality rank. A steep drop means you're paying a premium for that quality. Pareto-optimal models are highlighted.
We removed the slope chart from this iteration because with so many models, effectiveness drops, especially when costs cluster at the low end as ours do. Here's a mockup showing what it looked like when the distribution told the story well (note that this chart pre-dated our renaming of AIMAC Score to AIMAC Debt):
For Model Providers
Most benchmarks are simply focused on ranking models. Our goal is that every model achieve a perfect score.
When AI generates accessible code by default, people with disabilities are no longer locked out digital technology. A future where every model aces this benchmark means an internet that works for everyone. To be frank, as much effort as we put into the first iteration of this benchmark, achieving a perfect score on an automated metric that is easy to lint and produce synthetic data for is table stakes. However we decided to start here because the models aren't even doing this minimum step.
How to Ace the Benchmark
Test the way we test. We run axe-core against rendered HTML in a real browser. Static linters won't catch everything. Color contrast, for example, requires computing actual styles from cascading CSS. Playwright's accessibility testing guide covers the setup.
The AIMAC repository has our test prompts and scoring code.
Questions? [email protected]
Press
AIMAC has been featured in publications, podcasts, conference talks, and industry roundups. Selected coverage highlights:
Launch Coverage
- VKTR - The Open‑Source AI Accessibility Checker Holding LLMs Accountable by Michelle Hawley
- The AI Economy - Can Your AI Code for Everyone? by Ken Yeung
- Curb Cuts - GAAD Foundation, ServiceNow Announce AI Model Accessibility Checker API by Steven Aqui
Control Lottie Animations with Real Data (Website)
LottieFiles introduces Motion Tokens, letting developers change animation colors, text, and transforms at runtime without re-exporting files.
Summary
Deep Dive
Decoder
Original Article
Your UX Skills Were Built for One Kind of Intelligence
UX designers must shift from designing interfaces users control to designing autonomous AI agents that act on users' behalf, fundamentally changing the craft from layout to behavior.
Summary
Deep Dive
Decoder
Original Article
Your UX Skills Were Built for One Kind of Intelligence.
We spent 20 years designing things users control. The next 20 will be about designing things that act on our behalf.
We spent two decades mastering interfaces. We learned how to map workflows, how to communicate intent, how to shape interactions through layout and information hierarchy. The UI really was the ground truth of user experience and I have loved this space. Now, AI changes all of that. We're moving into a reality where software has agency.
An AI agent isn't a feature; it's an intelligence negotiating on our behalf, interpreting goals, making trade-offs, taking initiative, and occasionally surprising us. That is a profound shift, because once products possess agency, the interface stops being the primary surface. The behaviour becomes the interface (that's not to say all UI disappears either).
This means our job as designers changes. We used to design what users click, and now we design how they delegate. We used to define flows, and now we define boundaries. We used to specify screens, and now we specify how a system interprets intent, resolves ambiguity, asks for clarification, and recovers from mistakes.
Why This Is Happening Now
We're at an inflection point where LLMs finally have enough reasoning ability to make agentic behaviour genuinely useful, and not just a party trick. The orchestration tooling around them is maturing. Interfaces are increasingly being auto-generated at runtime. Users are getting more comfortable collaborating with systems rather than commanding them and the tasks we're asking of software are getting more open-ended, more ambiguous, more like the kind of thing you'd hand to a team mate and trust them to come back with something half decent.
The frontier of design has slipped underneath the surface, into the intelligence layer, where the thinking happens.
The Interface Stops Being the Center
For 20 years, UX Design revolved around what users see and now it revolves around what systems understand and attempt to do.
Designing for agents means rethinking a handful of questions we thought we had already nailed down. How does this system explain itself when I ask? When should I intervene, and when should it ask permission before it moves? How much initiative is appropriate here, and how should it tell me it's uncertain without burying me in hedging or sycophancy?
The goal has shifted. Intelligibility matters more than ease now, along with alignment, and the trust both of those things earn over time.
Traditional UX assumed the world was deterministic. It assumed that states were predictable, manipulation was direct, and control was visible. You could map a flow because the flow didn't keep changing on you.
Agents exist on another plane entirely. They live in uncertainty, in autonomy, in decision-making and improvisation and negotiation. We also don't control them, they have a degree of …well "agency". This changes the dynamic Culkin described when he said "We shape our tools, and thereafter our tools shape us." - now they shape themselves too.
The foundational mental model of "user operates tool" collapses. We now have something closer to "user collaborates with intelligence." Our concerns as designers shift from affordance and hierarchy to trust, transparency, oversight, safety, and shared control.
Delegation Becomes a First-Class Interaction Pattern
Most UI lets users command and be in charge. Agents need patterns that let users delegate. "Solve this, not that." "Optimise for X." "Avoid Y." "Notify me only if…" The interface is no longer a set of buttons. It's a way of handing over a goal and trusting the right thing will happen.
Oversight becomes a primary UX surface, and not just a secondary settings panel tucked three clicks deep. We'll increasingly design interaction rules instead of interface layouts.
Behaviour Is the Material
Behaviours are grown and evolved over time.
We shape agentic behaviour the way a gardener shapes a climbing plant. Through context, with goals, with the prompts that tell it what to do and how to do those things well, with constraints that tell it where the walls are. With feedback loops, and a sense of personality, and a working memory of what it has done before. None of these are interface decisions but all of them are design decisions.
The design surface moves from pixels in space to behaviour in time.
"Alignment" is the word AI researchers use for the problem of making sure a system does what you actually want it to do, not just what you literally told it to do. It's the gap between the instruction given and the intent you meant when you wrote it. It's what happens when a system takes initiative and you have to decide whether it took the right one. It's what keeps a capable intelligence from being a dangerous one.
The Real Work Is Interaction Choreography
We'll design when the agent takes initiative and when it holds back. How it resolves conflict between what you asked for and what it sees. How it recovers from its own mistakes, and how it tells you it made one. How it expresses uncertainty without either over-claiming or drowning you in qualifications. How it negotiates shared intent when your goals and its goals don't quite line up. How it handles the edge cases none of us saw coming.
Instead of mapping flows, we architect protocols. Instead of wireframing screens, we scaffold reasoning. Instead of specifying output, we shape process.
The Agent-Oriented Design Loop
Most teams don't know how to start, so they keep doing screen-first design and bolting AI on top. It doesn't work. Agent design needs a different loop. Here's what it looks like:
observe → interpret → decide → act → reflect → adapt
This loop runs inside the system and inside the design process. It's iterative, exploratory, and behaviour-first. You prototype the thinking, and not the interface. Here's a quick example:
-
Observe — The agent scans your calendar and notices you have back-to-back meetings for six hours with no break. What should it pay attention to? What should it ignore? These are design decisions.
-
Interpret — It infers you're overbooked, but is that a problem or a preference? Maybe you like dense days. Maybe this week is an anomaly. How the agent interprets context and not just data is where alignment lives.
-
Decide — It considers moving your 2pm, declining the optional standup, or just flagging the situation. Who taught it which option to prefer? You did, through the delegation model you designed.
-
Act — It reschedules your 2pm and blocks 30 minutes for lunch. But it doesn't touch the client call, because it learned that external meetings are higher stakes. That is a design choice.
-
Reflect — You override it. You wanted that 2pm where it was. The agent registers the correction. How does it store that feedback? Does it learn from one correction or need a pattern? That's a design question about learning rate and confidence.
-
Adapt — Next week, it handles a similar situation differently. It asks instead of acting. The relationship between the agent and the user has evolved and that evolution is the UX.
The practical questions change shape. How does it decide? How does it ask for help? What does it ignore? When does it try something new, and when does it stop? Good agent UX depends less on clarity of UI and more on clarity of intent and alignment.
When you're designing for an agent, ask: How does it decide what to pay attention to? How does it know when to act versus when to ask? How does it recover when it gets it wrong? How does it earn trust over time? How does the user reshape its behaviour without micromanaging it?
We design the conditions that make that use-agent coordination feel effortless.
So What Does This Mean for Designers?
It means the craft expands. Behavioural design becomes something you really craft and is a meaningful part of your everyday job. You start working on delegation models, on agent architecture, on how reasoning itself can be a UX surface. Safety shows up on your work in a way it never used to, this is not just the policy team's responsibility anymore. Intent modelling, interaction choreography, alignment work… These will all be landing on your desk pretty soon if they haven't already.
It means that we need to be researching interpretability alongside usability. Understanding systems that think, and not just designing flows that users follow.
We're entering the most exciting period of design in decades. Screens will keep getting easier to generate and behaviour will keep getting harder to design well. The designers I can't wait to talk to are the ones who learn to shape living, adaptive systems that feel trustworthy, expressive, and deeply human.
I want to stress that this isn't speculative either, teams are already doing it. We need frameworks for it, and language, and methods, and critique that allow us to really craft great work in this space.
Revolut Built a Foundation Model for Money
Revolut's custom foundation model for banking events achieved 130% improvement in credit scoring and 65% in fraud detection, signaling a new competitive battleground for financial services.
Summary
Deep Dive
Decoder
Original Article
🤖 Revolut Built a Foundation Model for Money
Plus; $16bn withdrawn from Aave in a "run on DeFi" after KelpDAO hack, and Plaid's annual letter.
Weekly Rant 📣
🤖 Revolut Built a Foundation Model for Money
(And why it's worth billions to whichever bank builds the next one.)
Something big happened in financial services in the last twelve months and almost nobody clocked it. Companies started training their own foundation models for finance:
- Revolut published PRAGMA — a foundation model trained on 24 billion banking events across 111 countries. Credit scoring up 130%. Fraud recall up 65%.
- Nubank published nuFormer — a foundation model trained on 100+ billion transactions across 100M+ customers. It's narrower than PRAGMA by use case, but more GPT-like as a model.
- Mastercard launched LTM — a foundation model trained on billions of card transactions to identify cyber risk.
And some others started fine-tuning existing models.
- NPCI (India's UPI operator) — fine-tuned Mistral 24B, for UPI Help, a conversational agent for 400M+ UPI users.
- PayPal published Nemo-4-PayPal — fine-tuned llama3.1-nemotron-nano-8B-v1. Their shopping assistant got 49% faster and 45% cheaper to run. Two weeks of fine-tuning.
Foundation models for finance are here.
The most important signal in Revolut's PRAGMA work with NVIDIA is the significant improvement (uplift) their model delivered vs their existing custom ML models, across multiple use cases.
It's now the case that the two most credible, fastest-growing Neobanks in the western hemisphere, Revolut and Nubank, are betting that transformer architectures will drive their growth.
Clearly, a custom finance foundation model will be a massive competitive advantage in the coming decade.
The IP of banking was always how they priced and managed risks, the squishy lending decisions, the fraud stuff, and the optimization of every interaction. If transformers deliver benefits in production on the scale Revolut is suggesting, they're a game changer.
I've been asking for years — where are the foundation models for finance? Healthcare was doing this with DNA sequences. Ad-tech was doing it with clickstreams. Finance, the most data-rich industry on earth, was still stuck training bespoke ML models on hand-crafted features. PRAGMA is the first real answer that cuts across multiple use cases.
What is a Foundation Model for Money?
Revolut took their massive data set and looked at customer events (logins, screen taps, payments) over time.
- 26 million customers
- 24 billion customer events
- 207 billion tokens created
This is NOT a large language model. It's not generating text or images. It's not competing with Claude or ChatGPT. Customer event data has a structure that text tokenization destroys. Numbers and scale become fragmented.
To prove the model worked, Revolut ran three experiments. Pavel walked me through them.
- Experiment 1: Use the pre-trained "embeddings" on an old model. Answers one question: how much information is already in the pre-trained embedding, before you've even told it what task you're solving?
- Experiment 2: Use pre-trained embeddings alongside the hand-crafted ML features the data science team had spent years building. This answers: what new information does the foundation model capture that the old features missed?
- Experiment 3: Fine-tune the foundation model on finance outcomes using LoRA. This answers can we beat the entire data science team by taking a pre-trained model and pressing a button?
can we beat the entire data science team by taking a pre-trained [foundation] model and pressing a button?
Pavel Nesterov
In most cases, the answer is yes.
The PRAGMA model took six production tasks, and replaced six separate custom machine learning (ML) models with one.
Revolut's Paper Shows STAGGERING Potential
The paper is the first time I've seen published evidence on the effectiveness of a foundation model for banking's most important competitive levers. Revolut published the uplift this model produced vs their existing ML models:
- Credit scoring: +130% PR-AUC uplift vs ML models (how well it catches rare cases that matter)
- Fraud recall: +65% uplift vs ML models (how much true fraud is caught above old ML model)
- Marketing engagement: +79% & product recommendation: +40% uplift vs ML models

Revolut's final uplift of the PRAGMA vs production Deep Learning models
Each of these is a competitive lever:
1. Credit risk pricing is the competitive lever for banks
Credit scoring lets banks price and issue loans. Loans are the profit center of banks. Lending is a product that never has a demand problem. People will always take the money, the harder question is will they pay back, and if they do, what can I should them as a % so that they're likely to take the loan from me, not someone else who's cheaper. Today, that involves looking at their data compared to other customers' data over time.
→ A model that can find more customers who are likely to pay back, can price more aggressively, and the bank sells more loans, which means more revenue.
(Assuming regulators don't tie themselves in knots over "explainability," this is the area of opportunity. FWIW, I think we need a shared responsibility framework for AI, as we have for cloud, and we'll be building V1 at Fintech Nerdcon this year.)
2. Fraud recall is a competitive lever for anyone in payments.
Fraud recall detects the % of true fraud events detected out of all of the fraud events that occurred. If you're detecting more of the actual fraud, you're also not falsely blocking good payments. Banks and fintech companies make money from card transactions (interchange), but are often liable for refunding fraud. So
→ A model that catches more real fraud saves cost, and allowing more good transactions through generates revenue.
3. Marketing is how banks get new customers or cross-sell product.
The "attach rate" of customers is a really important metric that Neobanks like Revolut and Nubank have been excellent at. Whereas a large bank will have more than 60% of its customer base just using a single product. That's a lost opportunity for revenue.
→ If customers are engaging more with marketing, their propensity to take the product being recommended increases. If they do take that product, the bank gets more revenue. Yay.
Notably, it had a seventh area where it did not succeed.
PRAGMA performed 47% worse than Revolut's production system on anti-money laundering. This was not a surprise. Pavel told me the team expected to fail. AML is a network problem — what matters is who you transact with, not what you do. PRAGMA reads each user's history in isolation. It can't see the chain. They published the failure because it's a finding, and because they already know what to build next.
(Although I imagine if you trained a model on that network transaction data instead of individual customer events, it would be net far more effective. The issue was the training data set, not the model type.)
Building a customer model created six areas of competitive advantage. For a bank that already has 70M customers and is one of the fastest growing in the world.
For Revolut, this kind of research compounds their advantage in tech.
The Prize is More Revenue and Lower Costs

Not a shocking business case. The magnitude, however, is.
Napkin math o'clock.
Credit (Based on JPMorgan Chase earnings data). JPM has credit costs of over $10 billion a year, dominated by Card Services. Net charge-offs ~$2 billion per quarter in consumer, running $8bn+ annualised. Revolut's credit scoring improvement was +130% PR-AUC. That's not an 130% reduction in losses — nothing works like that in production. But even at 10% of the stated gain applied to JPM's card book?
That's hundreds of millions of dollars a year. Every year. Compounding as the model improves.
Fraud losses can be millions per quarter. For every $1 lost in fraud, another $5.75 lost in operational costs. So that balloons to tens of millions. Revolut's fraud recall went up 65% — meaning they caught roughly 1.65x as much fraud as their prior production system.
A large card issuer catching even a fraction more fraud pays for the GPU bill a thousand times over.
Foundation models do all the things a consulting strategy deck will tell you to do.
So you can skip that part and go straight to figuring out execution.
But why can't every bank do this?
What Revolut built is 2020-era LLM. What comes next is wild.
Today PRAGMA predicts. That's it. Given a customer's history, it predicts who's a credit risk, who's committing fraud, and who's about to churn and a customers's lifetime value. Which is useful by all means but boring compared to what's coming.
Pavel gave me the analogy of where LLMs were in 2020. Back then BERT could read a sentence and fill in the missing word. Useful for search, classification, and ranking. But it wasn't until GPT came along and could generate the next sentence that things really began to change.
PRAGMA today is like BERT was in 2020. It reads a customer's history and fills in the gaps.
A generative version would write the next chapter. If you can generate a customer's future events, you can simulate when they'll buy a new product. And then rewind the tape to see the things that led to that decision, and try to make those things happen.
Low-key Minority Report, for banking.
That doesn't exist yet, but that's the goal.
Why haven't banks done this?
Do not underestimate banks AI capabilities in some areas.
Banks have been doing machine learning for decades. Every major bank has capable AI talent in lending, underwriting, and AML — people who've forgotten more about credit modeling than most Silicon Valley ML engineers will ever learn. Their data sets are enormous and compounded over decades of experience.
So why did a neobank ship this first?
1. Capability, and the ability move quickly.
Revolut is the canonical move-fast-and-occasionally-break-a-thing Fintech company, that famously took a little while to get its full UK bank license because of regulator concerns over audit gaps and compliance staff turnover. They will move quickly.
And the entire tech stack is modern, regularly replaced, and ideal for this kind of experimentation. A bank could take months just to find and scrub the data they need for this training. Revolut likely had it. Ready to go.
2. The availability of open-weight base models.
Open-weight models like Qwen, Kimi and GLM are now incredibly capable, cheap and with a couple of weeks of rentable GPUs can be trained to run a foundation model on private data sets.
That conversation may be happening in large institutions, but the execution pace isn't in the same universe. But I don't think that means they'll stay absent. When it's a company's IP, they're actually good at this stuff.
The fact that Mastercard built a foundation model is a big tell for me.
Foundation models for finance aren't a research problem anymore. They're an execution problem. The base models are open-weight. The frameworks are public. The papers are on arXiv. The compute is rentable. Banks can now do this.
Banks have never lacked talent or resources; they just often get McKonsultant'd and PowerPoint-slided to death. The banks that train their own foundation models will be the ones who ignore that guff, and get their data and risk talent working hands-on with folks like NVIDIA.
And Pahal Patangia runs payments business development at Nvidia. Where did he come from? FICO. The person who spent a decade helping retail banks build credit models is now the person helping Nvidia sell them the thing that replaces credit models.
That's not a coincidence.
NVIDIA's Enterprise Finance Pitch
You think NVIDIA, you think chips, Jensen's leather jacket, and a stock price that's propping up the S&P 500
Almost nobody outside the people already working with them knows what they do in financial services.
For Revolut, NVIDIA built the factory that lets a bank turn its proprietary data into a proprietary foundation model. It supports rolling your own foundation model or fine-tuning.
- Foundation Model Building (Revolut, Mastercard): NVIDIA provides the silicon (H100s, Blackwell), the data libraries (cuDF for the GPU-accelerated feature engineering that used to take weeks), and a training framework (NeMo AutoModel) that handles the parallelism so the ML team doesn't have to. PRAGMA's 1B model trained on 32 H100s in roughly two weeks.
- Fine Tuning a Model (PayPal): NVIDIA provides the base model itself — Nemotron. Plus the framework to do the fine-tuning (NeMo), plus the inference runtime to serve it cheaply (TensorRT-LLM).
Pahal Patangia made the point on a recent Tokenized podcast episode — and I keep coming back to it — that training is a one-time cost. Inference is forever.
A bank running fraud on every transaction, credit on every application, personalization on every session, is paying the inference bill billions of times a day. NVIDIA's whole recent model family has been re-tuned around that second number. Smaller models trained on more data, so they punch above their weight when you fine-tune them.
So they'll help you train at low cost, because they want your inference workloads.
Sort of like how GLP-1s give you something you want (better body shape) in return for a subscription fee to the medication.
And before I turn this into an NVIDIA sales pitch, there are plenty of alternative companies competing here. Google TPUs, AWS Trainium on Bedrock, and AMD are all building out their offerings here.
In fact, the raw inference space is becoming so competitive, there's a growing view in Silicon Valley that NVIDIA's moat is falling to more specialized silicon. So much so that the CEO of NVIDIA, Jensen Huang, went on the Dwarkesh podcast to lay out his counterargument (and accidentally spawned a hilarious set of memes about cars).
It's not just the models
A foundation model is nice.
But there's actually 3 layers of AI competitive advantage, the model is just one of them.
- Talent. In one room. With one architecture.
- The Data. Big banks have plenty.
- The Model. What we've discussed today.
- The workflow around the model is another.

The Fintech Brainfood: Four Layers of AI Competitive Advantage
Look at what PayPal did. They didn't just fine-tune Nemotron and ship it. They built a multi-agent system around it. Agents handle reasoning, checkout, fraud. The fine-tuned model is one component in a larger agentic workflow that, combined, is the product.
- The model gets better the more data you put through it.
- The workflow gets better the more customer interactions you observe.
- The data gets richer the more products you cross-sell.
Each layer compounds the one below it.
Agentic workflows as intellectual property. Anyone with data and a computer can train a model. But the workflow — the orchestration, the tool routing, the evaluation harnesses, the guardrails, the specific prompts that encode your product's opinion about what good looks like — that's harder to copy.
That's where competitive advantage starts to move to, once everyone has a foundation model.
An aside: One more thing that held in Revolut's research: scaling laws work on events. More parameters, better performance. The same pattern that drives LLM progress applies to banking event data. The 10M-parameter model is good. The 1B-parameter model is better. The frontier keeps moving.
So what do you do to compete?
I think there are three options emerging.
- Build your own custom model like Revolut did. This requires a massive dataset and, more importantly, the ability to use it for training.
- Collaborate with other industry actors to build a model. This could be with your core processor, industry consortia or vendors. Sardine has 6 billion user device profiles and event data. FICO has more lending data than anyone I can think of.
- Buy a model from a company with a large data set. Vendors exist in risk and credit who have pretty large datasets themselves. It's a matter of time until these companies have foundation models you could just buy.
Your decision comes down to where you see your competitive advantage, and your honest assessment of your ability to execute.
Neobanks and digital-only banks are now in an arms race to build their own models.
The big banks have to figure out if they compete or if any of their bigger suppliers can help them compete.
A mid-sized or smaller bank with a smaller customer base probably shouldn't be banging on NVIDIA's door to custom-train a model on their batch file outputs. But a group of smaller banks with pooled data and resources could do something very interesting.
Banks are not disrupted. But AI is disruptive.
Banks are not disrupted. I still believe that.
The moats around regulation, lending, and balance sheet are real, and they aren't going anywhere. But the banks that win the next decade aren't the ones with the biggest balance sheets. They're the ones that upgrade their IP. The moat stays the same. The winners inside the moat change.
The IP of banking was always how they price and manage risks. The squishy lending decisions. The fraud stuff. For 200 years that IP lived in spreadsheets and in the heads of underwriters. Revolut just moved it into a model. And the model is only phase one of four.
The only thing between you and a PRAGMA of your own is deciding which of the three paths is yours. Build. Collaborate. Buy.
Pick one. Start now.
ST.
* Much of the PRAGMA detail in this Rant came from a conversation with Pavel Nesterov, one of the paper's authors. Any errors are mine. I also spoke to Pahal from NVIDIA on the Tokenized Podcast and it was an absolute BANGER episode. You should really check it out.
Ethereum Didn't Kill Blizzard; It Moved Control to the Verification Layer
Ethereum solved centralized control over execution, but verification of what happened on-chain still depends on non-standardized tools like RPCs and indexers that can produce different answers.
Summary
Deep Dive
Decoder
Original Article
Google prepares credits system for Gemini
Google is introducing a credit-based usage system for Gemini that gives users monthly credit allowances and top-up options, aligning with billing models already used by OpenAI and Anthropic.
Summary
Deep Dive
Decoder
Original Article
Google appears to be preparing a major shift in how consumers interact with the Gemini app, with new strings referencing usage limits surfacing in the latest build. The signals point toward a credit-based system coming to the core chat surface, where users would receive a monthly allowance to spend across models and features, with the option to top up when they run out. Currently, Gemini relies on fixed prompt quotas and time-bound caps tied to each subscription tier, while Google's credit mechanics have been confined to Flow, Whisk, and Antigravity, plus top-ups available to AI Pro and AI Ultra members.
Extending credits into the main Gemini app would bring Google closer to the flexible consumption model already in place at OpenAI, Anthropic, and Notion, and xAI is expected to follow suit with the Grok Build rollout. For power users, the change would mean more predictable budgeting for heavy workloads, particularly those involving agentic tasks, Deep Research, Deep Think, or long multimodal sessions. It would also give Google a cleaner lever to introduce premium features without forcing users to make a steep jump from AI Pro at $19.99 to AI Ultra at $249.99.
Alongside the credits signal, a dedicated images section has appeared in the web UI, labeled NEW. At this stage, it is unclear whether it simply provides a distinct home for image generation, teases an updated model, or points to a more comprehensive image editor built directly into Gemini. Google had a burst of activity on this front in late 2024 with Whisk and ImageFX, but that track went quiet before the recent consolidation into Flow. A proper in-app editor within Gemini, pairing Nano Banana 2 and Nano Banana Pro with canvas-style tools, would mark the return of that project to the core product rather than a standalone Labs surface.
Excited to share that the Gemini API now has prepaid billing, rolled out to start for US customers!!
We have been working hard across Google to enable this. It's the default for new API users and existing users can opt in via a new billing account, all directly in AI Studio. https://t.co/9XACzAFbGO
— Logan Kilpatrick (@OfficialLoganK) April 15, 2026
Strategically, this fits a broader consolidation underway at Google. Developer program perks have already been folded into AI Pro and Ultra, consumer subscriptions are linked to AI Studio credits, and the company is unifying its billing spine. A shared credit pool covering the Gemini app, AI Studio, Antigravity, Flow, and a revived image editor would be the logical next step, especially with Jules, Gemini CLI, and the rumoured Gemini desktop app moving toward coding-heavy workloads that demand heavier compute budgets. Timing favours Google I/O on May 19 and 20 as the likely unveil moment, alongside the Stitch redesign, Jitro, AI Studio Build expansion, and the broader Skills rollout.
Meta's loss is Thinking Machines' gain
AI startup Thinking Machines Lab is successfully recruiting top researchers from Meta, including PyTorch co-founder Soumith Chintala, by offering equity upside from its $12 billion valuation despite Meta's seven-figure cash packages.
Summary
Deep Dive
Decoder
Original Article
Cursor's $60 Billion Escape Hatch
SpaceX secured a $60 billion option to acquire AI coding tool Cursor, whose power users have driven gross margins to negative 23% due to expensive API fees from Anthropic and OpenAI.
Summary
Deep Dive
Decoder
Original Article
Cohere Aleph Alpha Join Forces
Cohere and Aleph Alpha are partnering to build a sovereign AI alternative for enterprises and governments that want control over their AI infrastructure without depending on big tech.
Summary
Decoder
Original Article
Sovereign Labs Are Overkill for Enterprise AI
Sovereign AI labs are being oversold to enterprises who actually just need private deployment and data control, not expensive national-scale foundation model training.
Summary
Deep Dive
Decoder
Original Article
On Software Quality
Software quality depends on user perception shaped by repeated issues and UI/UX experience rather than isolated bugs, requiring symptom-based monitoring of user journeys.
Summary
Deep Dive
Decoder
Original Article
Stop Letting Tools Lead Your Platform Decisions
Data engineers often choose their tech stack before understanding requirements, leading to overengineered systems that could be much simpler.
Summary
Deep Dive
Original Article
Measurement Engineering: The Part of Data Science That Will Thrive in AI
As AI automates SQL queries and dashboards, the most valuable data science skill is becoming judgment—knowing what to measure and whether metrics actually reflect reality.
Summary
Deep Dive
Decoder
Original Article
The UX Designer's Nightmare: When “Production-ready” Becomes a Design Deliverable
UX designers are increasingly expected to deliver production-ready code using AI tools, creating a competency gap where traditional design expertise is being devalued in favor of technical coding skills.
Summary
Deep Dive
Decoder
Original Article
In a rush to embrace AI, the industry is redefining what it means to be a UX designer, blurring the line between design and engineering. Carrie Webster explores what's gained, what's lost, and why designers need to remain the guardians of the user experience.
In early 2026, I noticed that the UX designer's toolkit seemed to shift overnight. The industry standard "Should designers code?" debate was abruptly settled by the market, not through a consensus of our craft, but through the brute force of job requirements. If you browse LinkedIn today, you'll notice a stark change: UX roles increasingly demand AI-augmented development, technical orchestration, and production-ready prototyping.
For many, including myself, this is the ultimate design job nightmare. We are being asked to deliver both the "vibe" and the "code" simultaneously, using AI agents to bridge a technical gap that previously took years of computer science knowledge and coding experience to cross. But as the industry rushes to meet these new expectations, they are discovering that AI-generated functional code is not always good code.
The LinkedIn Pressure Cooker: Role Creep In 2026
The job market is sending a clear signal. While traditional graphic design roles are expected to grow by only 3% through 2034, UX, UI, and Product Design roles are projected to grow by 16% over the same period.
However, this growth is increasingly tied to the rise of AI product development, where "design skills" have recently become the #1 most in-demand capability, even ahead of coding and cloud infrastructure. Companies building these platforms are no longer just looking for visual designers; they need professionals who can "translate technical capability into human-centered experiences."
This creates a high-stakes environment for the UX designer. We are no longer just responsible for the interface; we are expected to understand the technical logic well enough to ensure that complex AI capabilities feel intuitive, safe, and useful for the human on the other side of the screen. Designers are being pushed toward a "design engineer" model, where we must bridge the gap between abstract AI logic and user-facing code.
A recent survey found that 73% of designers now view AI as a primary collaborator rather than just a tool. However, this "collaboration" often looks like "role creep." Recruiters are often not just looking for someone who understands user empathy and information architecture — they want someone who can also prompt a React component into existence and push it to a repository!
This shift has created a competency gap.
As an experienced senior designer who has spent decades mastering the nuances of cognitive load, accessibility standards, and ethnographic research, I am suddenly finding myself being judged on my ability to debug a CSS Flexbox issue or manage a Git branch.
The nightmare isn't the technology itself. It's the reallocation of value.
Businesses are beginning to value the speed of output over the quality of the experience, fundamentally changing what it means to be a "successful" designer in 2026.

The Competence Trap: Two Job Skill Sets, One Average Result
There is potentially a very dangerous myth circulating in boardrooms that AI makes a designer "equal" to an engineer. This narrative suggests that because an LLM can generate a functional JavaScript event handler, the person prompting it doesn't need to understand the underlying logic. In reality, attempting to master two disparate, deep fields simultaneously will most likely lead to being averagely competent at both.
The "Averagely Competent" Dilemma
For a senior UX designer to become a senior-level coder is like asking a master chef to also be a master plumber because "they both work in the kitchen." You might get the water running, but you won't know why the pipes are rattling.
- The "cognitive offloading" risk. Research shows that while AI can speed up task completion, it often leads to a significant decrease in conceptual mastery. In a controlled study, participants using AI assistance scored 17% lower on comprehension tests than those who coded by hand.
- The debugging gap. The largest performance gap between AI-reliant users and hand-coders is in debugging. When a designer uses AI to write code they don't fully understand, they don't have the ability to identify when and why it fails.

So, if a designer ships an AI-generated component that breaks during a high-traffic event and cannot manually trace the logic, they are no longer an expert. They are now a liability.
The High Cost Of Unoptimised Code
Any experienced code engineer will tell you that creating code with AI without the right prompt leads to a lot of rework. Because most designers lack the technical foundation to audit the code the AI gives them, they are inadvertently shipping massive amounts of "Quality Debt".
Common Issues In Designer-Generated AI Code
- The security flaw: Recent reports indicate that up to 92% of AI-generated codebases contain at least one critical vulnerability. A designer might see a functioning login form, unaware that it has an 86% failure rate in XSS defense, which are the security measures aimed at preventing attackers from injecting malicious scripts into trusted websites.
- The accessibility illusion: AI often generates "functional" applications that lack semantic integrity. A designer might prompt a "beautiful and functional toggle switch," but the AI may provide a non-semantic
<div>that lacks keyboard focus and screen-reader compatibility, creating Accessibility Debt that is expensive to fix later. - The performance penalty: AI-generated code tends to be verbose. AI is linked to 4x more code duplication than human-written code. This verbosity slows down page loads, creates massive CSS files, and negatively impacts SEO. To a business, the task looks "done." To a user with a slow connection or a screen reader, the site is a nightmare.
Creating More Work, Not Less
The promise of AI was that designers could ship features without bothering the engineers. The reality has been the birth of a "Rework Tax" that is draining engineering resources across the industry.
- Cleaning up: Organisations are finding that while velocity increases, incidents per Pull Request are also rising by 23.5%. Some engineering teams now spend a significant portion of their week cleaning up "AI slop" delivered by design teams who skipped a rigorous review process.
- The communication gap: Only 69% of designers feel AI improves the quality of their work, compared to 82% of developers. This gap exists because "code that compiles" is not the same as "code that is maintainable."
When a designer hands off AI-generated code that ignores a company's internal naming conventions or management patterns, they aren't helping the engineer; they are creating a puzzle that someone else has to solve later.

The Solution
We need to move away from the nightmare of the "Solo Full-Stack Designer" and toward a model of designer/coder collaboration.
The ideal reality:
- The Partnership: Instead of designers trying to be mediocre coders, they should work in a human-AI-human loop. A senior UX designer should work with an engineer to use AI; the designer creates prompts for intent, accessibility, and user flow, while the engineer creates prompts for architecture and performance.
- Design systems as guardrails: To prevent accessibility debt from spreading at scale, accessible components must be the default in your design system. AI should be used to feed these tokens into your UI, ensuring that even generated code stays within the "source of truth."
Beyond The Prompt
The industry is currently in a state of "AI Infatuation," but the pendulum will eventually swing back toward quality.
The UX designer's nightmare ends when we stop trying to compete with AI tools at what they do best (generating syntax) and keep our focus on what they cannot do (understanding human complexity).
Businesses that prioritise "designer-shipped code" without engineering oversight will eventually face a reckoning of technical debt, security breaches, and accessibility lawsuits. The designers who thrive in 2026 and beyond will be those who refuse to be "prompt operators" and instead position themselves as the guardians of the user experience. This is the perfect outcome for experienced designers and for the industry.
Our value has always been our ability to advocate for the human on the other side of the screen. We must use AI to augment our design thinking, allowing us to test more ideas and iterate faster, but we must never let it replace the specialised engineering expertise that ensures our designs technically work for everyone.
Summary Checklist for UX Designers
- Work Together. Use AI-made code as a starting point to talk with your developers. Don't use it as a shortcut to avoid working with them. Ask them to help you with prompts for code creation for the best outcomes.
- Understand the "Why". Never submit code you don't understand. If you can't explain how the AI-generated logic works, don't include it in your work.
- Build for Everyone. Good design is more than just looks. Use AI to check if your code works for people using screen readers or keyboards, not just to make things look pretty.
Working in the open
Working in open source transforms the design process from shipping features to designing transparently with community feedback, public roadmaps, and long-term stewardship.
Summary
Deep Dive
Decoder
Original Article
How Anthropic's Mythos model is forcing the crypto industry to rethink everything about security
Anthropic's Mythos AI model is shifting crypto security from smart contract audits to infrastructure vulnerabilities by simulating multi-step exploit chains across interconnected DeFi protocols.
Summary
Deep Dive
Decoder
Original Article
How Anthropic's Mythos model is forcing the crypto industry to rethink everything about security
DeFi leaders say that AI will arm both attackers and defenders, and widen the gap between projects that prioritize security and those that do not.
What to know:
- Anthropic's Mythos AI model is shifting DeFi security focus from smart contract bugs to deeper infrastructure risks such as key management, bridges and oracle networks.
- By simulating adversaries and chaining together small weaknesses across interconnected protocols, Mythos highlights how AI can turn isolated flaws into systemic, cascading failures.
- DeFi leaders say AI will arm both attackers and defenders, pushing protocols toward continuous, AI-driven auditing and widening the gap between projects that prioritize security and those that do not.
Mythos, the new AI model from Anthropic that has sparked fear and confusion in traditional tech and finance, is also driving a massive shift in how the crypto industry thinks about security.
For years, decentralized finance has focused its defenses on smart contracts. Code is audited, vulnerabilities are cataloged, and many common exploits are well understood. But Mythos, a model designed to identify and chain together weaknesses across systems, is pushing attention beyond code and into the infrastructure that supports it.
"The bigger risks sit in infrastructure," said Paul Vijender, head of security at Gauntlet, a risk management firm. "When I think about AI-driven threats, I'm less concerned about smart contract exploits and more focused on AI-assisted attacks against the human and infrastructure layers."
That includes key management systems, signing services, bridges, oracle networks, and the cryptographic layers that connect them. These components are less visible than smart contracts and are often outside traditional audit scope.
In fact, this month, web infrastructure provider Vercel, which many crypto companies use, disclosed a security breach that may have exposed customer API keys, prompting crypto projects to rotate credentials and review their code. Vercel traced the intrusion to a compromised Google Workspace connection via the third-party AI tool Context.ai, which an employee used.
Mythos belongs to a new class of AI systems built to simulate adversaries. Instead of scanning for known bugs, it explores how protocols interact, testing how small weaknesses can be combined into real-world exploits. That approach has drawn attention beyond crypto. Banks like JP Morgan are increasingly treating AI-driven cyber risk as systemic and are exploring tools like Mythos for stress testing. Earlier this month, Coinbase and Binance both reportedly approached Anthropic to test Mythos.
Early findings from models like Mythos have identified weaknesses in the behind-the-scenes systems that keep crypto platforms secure, including the technology that protects keys and handles communication between systems.
"I think there are two areas where AI models are especially valuable," Vijender said. "First, multi-step exploit chains that historically only get discovered after money is lost. Second, infrastructure-layer vulnerabilities that traditional audits never touch."
That shift matters in a system built on composability, where DeFi protocols can connect and build on each other's services.
DeFi protocols are designed to interconnect. They share liquidity, rely on common oracles, and interact through layers of integrations that are difficult to map in full. That interconnectedness has driven growth, but it also creates pathways for risk to spread, as seen in recent bridge exploits like the Hyperbridge attack, in which an attacker minted $1 billion worth of bridged Polkadot tokens on Ethereum by exploiting a flaw in how cross-chain messages were verified.
"Composability is what makes DeFi capital efficient and innovative," Vijender said. "But it also means a minor vulnerability in one protocol can become a critical exploit vector with contagion potential across the ecosystem."
Without AI, those dependencies are hard to trace. With AI, they can be mapped and exploited at scale. The result is a shift from isolated exploits to systemic failures that cascade across protocols.
Evolution of AI attacks
Still, some industry leaders see Mythos as an acceleration rather than a turning point.
At Aave Labs, founder Stani Kulechov said AI reflects the dynamics already at play in DeFi's adversarial environment.
"Web3 is no stranger to well-funded and motivated adversaries," he told CoinDesk. "AI models represent an evolution in the tools used to achieve exploits."
From that perspective, DeFi is already built for machine-speed attacks. Smart contracts execute automatically, and defenses such as liquidation mechanisms and risk parameters operate without human intervention.
"DeFi operates at compute speed, so AI doesn't introduce a new dynamic," Kulechov said. "It intensifies an environment that has always required constant vigilance."
Even so, Aave is seeing AI surface new categories of vulnerabilities, including issues that human auditors may have previously deprioritized.
"The Mythos paper shows that AI can uncover old bugs that were previously deprioritized," he said.
That breadth still matters in a system where even smaller vulnerabilities can undermine trust or be combined into larger exploits.
If attackers can move faster, the question becomes whether defenses can keep pace.
For both Gauntlet and Aave, the answer lies in changing the security model itself. Audits before deployment and monitoring after were designed for human-paced threats. AI compresses that timeline.
"To defend against offensive AI, we will need to take an AI-centric approach where speed and continuous adaptation are essential," Vijender of Gauntlet said. That includes continuous auditing, real-time simulation, and systems built with the assumption that breaches will happen.
A 'greater way'
Aave has already integrated AI into its workflows, using it for simulations and code review alongside human auditors. "We take an AI-first approach where it adds clear value," Kulechov of Aave Labs said. "But it complements, rather than replaces, human-led auditing."
In that sense, AI equips both attackers and defenders.
For builders, the long-term effect may be less disruption than divergence.
"We haven't tested Mythos yet, but we're genuinely interested in what it and tools like it can do for protocol security," said Hayden Adams, founder and CEO of Uniswap Labs. "AI gives builders better ways to stress test and harden systems."
Over time, Adams expects the gap between secure and insecure protocols to widen.
"Projects that prioritize security will have greater ability to test and harden systems before launching," he said. "Projects that don't will be most at risk."
That may be the real shift. Security is no longer about eliminating vulnerabilities. It is about continuously adapting to a system in which those vulnerabilities are constantly rediscovered and recombined.
Binance AI Wallet: Keyless ‘Agentic Wallet' for Web3 Automation
Binance launched Agentic Wallet, a keyless crypto wallet that lets AI agents autonomously execute blockchain transactions within user-configured spending limits and security rules.
Summary
Deep Dive
Decoder
Original Article
How to Automate MEV Blockchain Analysis Using OpenClaw and MCP
A tutorial demonstrates automating MEV blockchain analysis by connecting the mevlog-rs tool to AI agents like Claude Code or OpenClaw for natural language transaction queries.
Summary
Deep Dive
Decoder
Original Article
Searching for MEV profit opportunities often requires tedious blockchain monitoring and analysis. In this tutorial, I'll describe how to automate this process using the mevlog-rs MCP interface and the OpenClaw agent. We'll use a secure HTTPS connection and Telegram chat for communication. We'll also discuss the pros and cons of using OpenClaw vs. a manual MCP integration.
Initial setup and RPC requirements
I don't think the world needs another article on a basic OpenClaw setup. Any tutorial on running OpenClaw with a Ubuntu VPS should work. I will assume you already have an OpenClaw integration with a communication interface, such as Telegram, configured.
For an MCP integration, you'll need an LLM agent configured and running locally. For the rest of this article, we will use the Claude Code CLI.
An optional but useful prerequisite for this tutorial is running a Geth full node on the same machine as OpenClaw. Local node offers significantly better performance for scanning larger block ranges. You can also use a premium RPC endpoint, e.g., from Alchemy. But if you want a quick and easy way to test this setup, you can also use the built-in ChainList integration, which automatically selects the fastest free RPC endpoint. But, please remember that free RPC endpoints are often throttled, don't provide access to older data, and disable EVM tracing features.
Configuring an MCP server with mevlog-rs
Let's start with a less "magical" setup. We will first configure a local MCP server and later a remote one to enable querying blockchain data by simply talking to your LLM agent. Full reference is in the mevlog-rs MCP docs.
First, install an mevlog-rs CLI with the MCP feature enabled:
cargo install mevlog --features mcpStart by verifying if basic querying works:
mevlog search -b latest --rpc-url=$ETH_RPC_URLYou should see JSON output with txs from the recent block.
Now run a mevlog MCP server locally:
mevlog mcp --rpc-url=$ETH_RPC_URLNext, configure it with your Claude Code instance:
claude mcp add --transport http mevlog http://localhost:6671That's it! You can query blockchain through an LLM interface by just asking questions like:
- query the last 50 blocks for transactions that transferred PEPE (
0x6982508145454ce325ddbe47a25d4ec3d2311933) token - find transactions that transferred over 100k USDC (
0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48) in the last 200 blocks - which tx transferred the most DAI (
0x6b175474e89094c44da98b954eedeac495271d0f) in the last 6 hours
Configuring a remote MCP endpoint for better RPC performance
The above setup assumes that the mevlog CLI executes on your local machine. For production-like deployments, this is usually not optimal. The largest bottleneck of querying blockchains is downloading the data. mevlog uses caching extensively, so repetitive queries against the same block ranges will be significantly faster, but initial data must be downloaded over the wire.
For the best download performance, I recommend a proprietary full node. But you're likely not run it in a local network but on an external VPS. To configure mevlog with an external node, you'll need an authenticated HTTPS gateway using NGINX. So let's do it now.
I won't elaborate on configuring SSH access or running a full node on a proprietary VPS. Check my other tutorial for detailed info on how to do it.
To expose your MCP endpoint externally, you'll need a similar nginx config:
server {
listen 80;
listen [::]:80;
server_name mcphost.com;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
listen [::]:443 ssl;
server_name mcphost.com;
ssl_certificate /etc/nginx/ssl/mcphost.crt;
ssl_certificate_key /etc/nginx/ssl/mcphost.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 1d;
location = /mcp {
proxy_pass http://127.0.0.1:6671/mcp;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header Connection "";
proxy_buffering off;
proxy_request_buffering off;
chunked_transfer_encoding on;
proxy_read_timeout 3600s;
proxy_send_timeout 3600s;
}
location = /.well-known/oauth-authorization-server {
proxy_pass http://127.0.0.1:6671/.well-known/oauth-authorization-server;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto https;
}
location = /.well-known/oauth-protected-resource {
proxy_pass http://127.0.0.1:6671/.well-known/oauth-protected-resource;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto https;
}
}I usually use a Cloudflare proxy and origin certificates to configure a secure SSL connection. Alternatively, you can use Certbot. BTW, if you already have an OpenClaw running on your VPS, you can ask him to configure it; he'll know what to do.
Now start the authenticated MCP process on a VPS:
MEVLOG_MCP_AUTH_TOKEN=mcp_password mevlog mcp --rpc-url=$ETH_RPC_URL --host=127.0.0.1and configure your Claude Code to use this external endpoint:
claude mcp add --transport http mevlog-remote https://mcphost.com --header "Authorization: Bearer mcp_password"and use it as you did before. It's a simple way to use a high-performance, externally hosted node to query the blockchain from a local LLM agent.
How to query EVM blockchains with the OpenClaw LLM agent
The MCP server required some manual configuration. If you're more into "agentic workflows", the OpenClaw setup might work better for you. Once you already have an OpenClaw configured, getting started with mevlog-rs is straightforward. There's a dedicated SKILL.md file that explains how to use the CLI directly without the MCP endpoint. A recommended setup is to run OpenClaw on the same VPS as your RPC node to ensure the best performance.
Just ask your OpenClaw to import the skill into memory, and provide an RPC (local or remote) endpoint, and you're good to go.
I find OpenClaw setup useful for running scheduled queries and reporting directly to a Telegram channel. You can configure cron tasks like:
- every 1h check and notify me if any transaction transferred more than 1 million USDC
- each day at 8AM send me a report on which 10 txs paid the most for gas in the last 24 hours
- how many txs did
jaredfromsubway.ethsend in the last 24h, and how much was his total gas spending
Summary
I wish I had access to similar tooling when I was full-time focused on building MEV bots some time ago. It would have saved me dozens of hours of manually querying blockchains for relevant txs. I hope you'll find some of these techniques useful. Please send any feature requests or bug reports.
Also, stay tuned: I'm currently working on a major release of the mevlog CLI that will massively speed up and improve querying across large block ranges.
Stablecoins are going local
Stablecoins are shifting from crypto trading tools to everyday payment infrastructure, with local transactions now dominating over cross-border use.
Summary
Deep Dive
Decoder
Original Article
The Missing Key to x402
The x402 protocol for machine-native payments is now part of the Linux Foundation, but needs a practical key management layer to work in production systems.
Summary
Deep Dive
Decoder
Original Article
Crypto is built for AI agents, not humans, says Alchemy's CEO
Alchemy's CEO argues that cryptocurrency infrastructure is actually purpose-built for AI agents rather than humans, as its borderless, always-on nature matches how autonomous software operates.
Summary
Deep Dive
Decoder
Original Article
Stablecoin B2B Payments Set for Large Growth by 2026
Stablecoin-based business-to-business payments are forecast to grow from $3.5 billion in 2023 to $147 billion by 2026, potentially displacing traditional banking infrastructure for cross-border transactions.
Summary
Decoder
Original Article
Court sides with iyO in trademark fight against OpenAI and Jony Ive
A federal court blocked OpenAI and Jony Ive from using the "io" name for their AI hardware venture after trademark holder iyO sued for infringement.
Summary
Original Article
Western Union Enters Stablecoin Race with two new products
Western Union is launching a Solana-based stablecoin to replace SWIFT for internal settlements and bridging crypto wallets with its global retail network through new consumer products.
Summary
Deep Dive
Decoder
Original Article
What prevents cryptocurrencies from functioning as daily money
A forum discussion identifies two core paradoxes preventing cryptocurrencies from functioning as daily money: the first-mover advantage that concentrates supply with early adopters, and deflation dynamics that incentivize hoarding over spending.
Summary
Deep Dive
Decoder
Original Article
Bitcoin Reclaims $79K as Risk Sentiment Stabilizes
Bitcoin surged past $79,000 as cryptocurrency markets rebounded alongside traditional risk assets on improving sentiment.