Devoured - June 08, 2026
Google's $920M monthly investment in SpaceX compute infrastructure and OpenAI’s transition toward an agentic super app highlight an industry-wide pivot toward massive hardware scaling and autonomous task execution. Simultaneously, Microsoft's new Scout agent, alongside open-source advancements like LangChain’s Sandboxes and PostgreSQL’s pg_durable, reflects a deepening focus on secure, persistent, and developer-centric agentic environments.

Anthropic/OpenAI may be spending more than $1,000 for every $100 you pay them
Heavily subsidized LLM subscriptions are hiding a massive 'brute force' cost explosion in agentic coding tasks.
Deep dive
- LLM-based coding is currently subsidized; actual costs at API pricing far exceed $100/month subscriptions.
- 'Recursive' or 'thinking' models generate invisible tokens through trial-and-error, significantly inflating usage costs.
- Coding is a 'fault-intolerant' task, requiring more expensive, reliable model efforts than casual chat.
- As codebases grow, complex multi-file changes drive token usage into the millions per quest.
- Scaling models does not inherently lead to intelligence; it leads to exponential compute consumption.
- Real cost per task has exploded, with estimates reaching $65+ per complex code change.
Decoder
- Recursive/Thinking Models: Models that use internal loops, indirection, and self-correction steps (often invisible to the user) to refine answers, consuming significant extra tokens.
- Brute Force Coding: A method where an LLM repeatedly generates, runs, and debugs code until it compiles or passes tests, relying on sheer computational volume rather than reasoning accuracy.
- Fault-Intolerant Tasks: Activities (like coding or medical diagnosis) where small errors have critical, system-wide consequences.
Original article
Full article content is not available for inline reading.
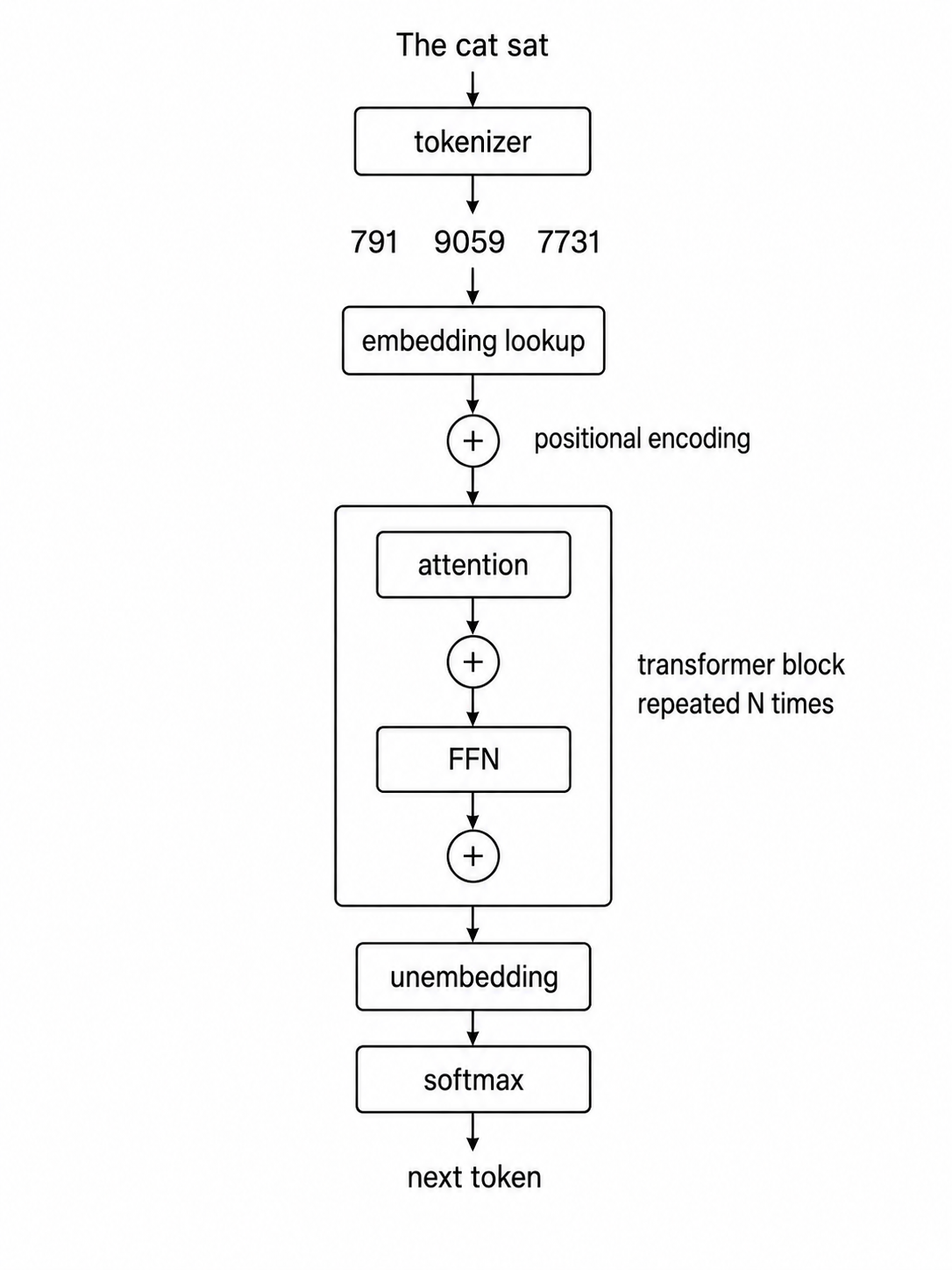
How LLMs Actually Work
Modern LLMs rely on a standardized transformer skeleton, with differences emerging from data, configuration choices, and post-training refinements.
Deep dive
- LLMs operate on integer token IDs via subword tokenization, not raw text.
- Embeddings represent semantic meaning as learned vectors in a high-dimensional space.
- Rotary Position Embeddings (RoPE) provide order information more effectively than additive methods.
- Attention heads act as independent filters that focus on specific relationships (e.g., induction heads for pattern copying).
- The feed-forward network (FFN) contains the majority of an LLM's parameters and factual knowledge.
- Residual streams enable training of very deep networks by allowing gradient flow through additive connections.
- Mixture of Experts (MoE) scales parameters while keeping inference costs manageable by activating only specific network pathways.
Decoder
- Softmax: A function that converts a vector of raw scores (logits) into a probability distribution that sums to one.
- KV Cache: A memory buffer that stores intermediate keys and values from previous tokens to avoid recomputing the full prompt during generation.
- SwiGLU: A modern, non-linear activation function often used in the feed-forward network to improve model convergence.
- Logits: Raw, unnormalized prediction scores produced by the final model layer before applying softmax.
Original article
Full article content is not available for inline reading.

The Intent Debt
Agentic coding makes 'intent debt' the costliest form of technical debt because AI can write code but cannot reconstruct the 'why' behind decisions.
Deep dive
- Triple Debt Model: Technical (code), Cognitive (understanding), and Intent (rationale).
- Agents as strangers: Every new agent session is a cold start with no shared context or long-term memory.
- Orchestration tax: A significant portion of managing agents is actually re-supplying the intent you never wrote down.
- The risk of inference: Models will hallucinate rationales for code they didn't write, which is more dangerous than admitting ignorance.
- Actionable mitigation: Externalize intent as a first-class artifact using ADRs and intent ledgers.
Decoder
- ADR (Architecture Decision Record): A short text file that captures an important architectural decision, the context, and the consequences.
- Agentic engineering: The practice of using AI agents to perform complex multi-step development tasks autonomously.
Original article
Technical debt lives in your code. Cognitive debt lives in your head. Intent debt lives in the artifacts you may have never wrote: the goals, constraints, and rationale for why the system is the way it is. If you’re lucky, some of this exists scattered in team documents or discussions, but it’s likely incomplete. It’s the one kind of debt your agents can’t pay down for you, and agentic engineering makes it the most expensive.
Three places debt can live
Margaret-Anne Storey’s Triple Debt Model is a clean way to think about software health. The three models of debt are technical, cognitive, and intent.
Technical debt lives in the code. It’s the accumulation of implementation choices that make the system harder to change later: the tangled module, the shortcut you took under deadline, the abstraction that leaked. We’ve understood this one for decades. You feel it coming through slow builds, fragile tests, and the dread of touching one particular file.
Cognitive debt lives in people. It’s the erosion of shared understanding, the gap between how much code exists and how much any human understands. I’ve been calling this comprehension debt. It builds up when the system grows faster than the team’s mental model of it. Your code can be pristine and you can still carry crippling cognitive debt, because nobody understands the pristine code either.
Intent debt lives in artifacts. It’s the absence or erosion of the externalized rationale, goals, and constraints that explain why the system is the way it is. The key word is externalized. The rationale has to be written down where a teammate, a future you, or an agent can read it, not held in your head. When intent debt runs high, the system drifts from what you meant it to do, and nobody can say when it diverged or why.
These three are independent, which took me a while to internalize.
You can have low technical debt and high intent debt. You can understand a system completely yourself (no cognitive debt for you) while its intent exists nowhere outside your skull (enormous intent debt for everyone else).
From the inside they feel alike, but each one bills you separately.
Why intent debt is the one agents can’t help with
AI generates code faster than ever, which makes technical debt cheaper to take on and cheaper to pay down. Point an agent at a tangled module and it’ll refactor it.
Cognitive debt recovers too, more easily than most engineers expect. When you don’t understand a chunk of the system, you ask the agent to explain it. You rebuild part of the lost mental model on demand, because the code still exists and the model can read it back to you.
Intent is different. An agent can’t generate intent, because intent is the one input that has to come from you. A model can infer a plausible rationale from the code, the same way you can guess why a previous engineer did something. A guess about intent isn’t the intent. The model doesn’t know whether that 300ms debounce was a deliberate UX decision, a benchmark result, or a number someone typed once and never revisited. It will invent a confident-sounding reason, which is worse than admitting it doesn’t know.
Of the three debts, intent debt is the only one where the agent can’t bail you out. It can write the code and restore your comprehension. The why is the one thing it can only fabricate.
Agents make the un-written cost compound much faster
Teams got away with high intent debt for years because we carried it in our head and old docs.
When a new human joined a team, you didn’t write everything down, because they picked up intent over time: hallway conversations, code review comments, “oh, we don’t do it that way because of an incident in 2023.” Knowledge moved person to person and built up. The engineer who’d been there four years was the intent documentation, expensive and lossy, but it worked.
Agents break that model. Bringing agents onto a team doubles its size overnight with junior people who have no long-term memory. An agent starts most sessions cold. It carries none of the tacit intent your humans built up over years. Whatever you haven’t externalized into an artifact it can read, it doesn’t have.
That changes the economics of not writing things down. Un-externalized intent used to cost you once in a while, at onboarding or after someone left. Now you pay it every session, multiplied by every agent you run.
Picture the 20 agents you’re so excited to parallelize. Each one is a teammate who has never met you, can’t read your mind, and will fill any gap in your intent with a plausible guess. The orchestration tax I wrote about is partly an intent-debt tax. Much of what makes managing many agents exhausting is re-supplying the intent you never wrote down.
The other half of the comprehension debt argument
When I wrote about comprehension debt, I made a point I want to revisit, because intent debt sharpens it.
I argued that detailed specs aren’t a complete answer. Translating a spec into working code involves a huge number of implicit decisions no spec ever captures, and a spec detailed enough to be the program is the program in a slower language. I still believe that.
Intent debt is the complementary truth.
Being unable to capture all intent is no license to capture none of it. The implicit decisions an agent now makes on your behalf, the ones a spec will never enumerate, are the decisions whose rationale evaporates if you don’t record at least the load-bearing ones. You can’t write down everything.
You do have to write down the why behind the choices that would be expensive to get wrong, because nobody will reconstruct those later.
Comprehension debt warns you not to trust that code is correct because it exists.
Intent debt warns you not to trust that the reason survives because the code does. Code is the answer; the intent was the question it was meant to solve. AI is brilliant at producing answers to questions you forgot to write down.
What high intent debt looks like
Intent debt rarely shows up as friction. It shows up as a particular kind of helplessness.
- An agent “fixes” a bug by deleting a guard clause, and nobody can say whether that guard was load-bearing or leftover, because no doc or commit message ever recorded why it was there.
- A refactor changes a behavior users depend on. The review passed because the diff looked clean and the tests were green, but the tests only encoded the previous behavior, never the intent.
- You ask why two services talk over a queue instead of a direct call, and the honest answer is “an agent suggested it and it seemed fine.” That answer is intent debt, already accruing interest.
If you’ve felt the cognitive surrender version of this, defending a design choice you can’t reconstruct, intent debt is the team-scale, written-down version of the same hole.
Surrender is about your own posture in the moment. Intent debt is what a hundred of those moments leave in the repo for the next person and the next agent to inherit.
Paying it down: externalize intent as a first-class artifact
Almost everything I’ve been writing about for the last few months turns out to be intent-debt management. I didn’t have the word for it. The move is the same each time: take the intent out of your head and put it somewhere an agent can read.
Write the spec for the intent, not the implementation. A good spec captures the goals, the constraints, the non-negotiables, and an explicit definition of done (fast, accessible, secure, delightful, beyond “functionally correct”). The spec carries the intent the code can’t carry on its own.
Treat AGENTS.md as your intent ledger, not your config. It’s why I keep saying stop using /init. An auto-generated file describes what the code is. An intent file describes what the team means: the conventions, the “we don’t do it this way because,” the constraints invisible in any single file. Agents can’t infer that, and they need it most.
Capture decisions where they happen. Lightweight decision logs (ADRs) are pure intent-debt paydown. Recording why at the moment you decide costs almost nothing. Reconstructing it eight months later, after the person who knew has moved teams, costs a fortune. Agents have made logging cheaper than ever, so the old excuse is gone.
Make the learning loop write intent back down. I’ve argued for self-improving agents that update a learnings file at the end of a session. The same loop is an intent-debt pump running in reverse: every mistake whose root cause you record, every “we tried X and it didn’t work because Y” is intent that would otherwise have lived only in your memory of a bad afternoon.
None of these are new tools. They’re the discipline of refusing to let the why exist only in your head, in an era where your head is no longer where most of the work happens.
Where the value moved
For a long time, the scarce, valuable thing in software was the ability to produce a correct implementation. Code was expensive, so we optimized for writing it.
AI made code cheap, and comprehension is recoverable. Intent, the goals and constraints and reasons, is the one input that still has to originate with a human. It’s also the one we’re worst at externalizing, because for decades we got away with carrying it in our heads.
That worked when the team was a handful of people who could absorb intent over years of shared context. It does not work when half the team is agents that start every session as strangers.
Technical debt makes your system hard to change. Cognitive debt makes it hard to understand. Intent debt makes it hard to know whether the system still does what you wanted, and it’s the only one of the three your agents can’t pay back for you. That part stays with you. Write down the why, because it’s becoming the most valuable thing you can leave in the repo.

Chat is dead
OpenAI is pivoting ChatGPT from a chatbot interface toward an agentic super app to secure higher-margin enterprise revenue before its pending IPO.
Deep dive
- OpenAI is shifting focus toward agents that perform multi-step tasks rather than just generating text.
- The internal sentiment, expressed by senior staff, is that 'chat is dead' in terms of being the primary product value.
- A significant overhaul is coming to the ChatGPT mobile and web interfaces to steer users toward coding and external application integrations.
- Development focus is moving heavily toward the Codex codebase.
- The company is targeting an IPO and facing pressure to improve its financial bottom line, mirroring Anthropic’s more fiscally conservative approach.
- OpenAI is attempting to consolidate various product categories—search, coding, and assistants—into a single 'super app'.
- Potential competition with Microsoft and Google is expected to intensify as those companies also integrate agentic capabilities into their primary apps.
Decoder
- Agentic Workflow: An AI system that performs multiple, autonomous steps to complete a complex objective (e.g., booking a flight) rather than just outputting text in response to a prompt.
- Codex: OpenAI's foundational model and platform specifically optimized for code generation and software development tasks.
Original article
There's not a lot in here that we didn't already know about OpenAI's sprint towards making ChatGPT a "super app" but one quote, which I used in the title, is worth, um, chatting about perhaps.
The changes, which will give greater prominence and resources to OpenAI’s coding product Codex, reflect a growing conviction within the company that the future of AI lies not in chatbots that answer questions but in agents that perform tasks for users.
“Chat is dead,” said one senior OpenAI employee.
While the report cites "more than a dozen current and former employees" of OpenAI, the quote above is clearly from a current one. A senior one. That's interesting in so far as you can use it as a finger-on-the-pulse within the company. And it points to both an opportunity and challenge ahead for OpenAI.
First and foremost, it would be wild for the company to cede the chatbot ground. To be clear and fair, the rest of the report doesn't indicate that the 'chat' element of ChatGPT is going away, let alone dying – unlike, say, Sora – but it does indicate an effort and hope to move beyond it, and perhaps just use it as an entry point to get people in the door for the "real" services that OpenAI wants to push.
The company is embarking on the changes amid a belief that the advent of AI agents, which can perform multiple tasks for users from booking travel to organising calendars, will be a more valuable product than the chatbot.
This hunt for "value" is obviously increasingly important as OpenAI angles towards an IPO. There was a time, perhaps a year ago, when it seemed like their top-line revenue and user growth was enough, but a lot has changed in a year. While it has long looked like Anthropic was in a better position from a bottom-line perspective, due to less spend (and, at least somewhat related, more focus), the fact that they've now surpassed OpenAI with that top-line growth is also a problem, obviously. And ahead of the would-be IPOs, the private valuations of the two companies now fully reflects that.
At the same time, at least one report suggests ChatGPT has surpassed the all-important 1B MAU mark – though the company has yet to officially announce it. While it remains record-breaking growth, they were hoping to hit the mark by the end of last year. Doing so six months into this year suggests that growth, while still amazing, also perhaps isn't as amazing as it once was. Also not great: the fact that Google just announced the 900M MAU mark for Gemini at I/O last month.
Anthropic is attacking the business while Google is attacking the usage. So yeah, something had to change.
The overhaul, which is set to begin rolling out in coming weeks, will initially appear as changes to ChatGPT’s website and mobile apps, encouraging customers towards using coding, image-generation and apps from external partners.
Given that timetable, they'll also likely be battling their old friend Microsoft on the "super app" front. Probably Google as well, depending on how long it takes them to pull their agents and coding tools into the Gemini app.
The "apps from external partners" element is interesting, the report goes a bit more into that further down:
To encourage users to adopt those services, OpenAI is redesigning ChatGPT’s interface, adding new prompts and features that direct users towards coding tools, image generation and applications built by partners such as Canva and Booking.com, according to people familiar with the plans.
Over time, OpenAI intends to ditch the prompts and features, betting that its models will be able to automatically understand users’ intentions when they are on the app or site.
In other words, anyone partnering with OpenAI on this launch be going in eyes wide open, knowing they'll be relegated back into the background eventually. But for now, this new "Super" ChatGPT will seemingly try to lean on partners for all it can do out-of-the-box beyond the things Claude may already be doing for you. Yes, we're still trying to make App Stores happen, in a way.
Outlining the changes, Thibault Sottiaux, who previously ran Codex and now leads all of OpenAI’s core product and platform, told the FT: “It will transcend the actual surface...what we’re building towards is where you have your own personal agent that is capable of helping you... across everything in your life, be it personally or at work.”
He added: “You can connect through it on your mobile, desktop or web. When you’re in the car, you can talk to it.”
To reiterate, that's a current OpenAI exec speaking on-the-record about these changes. And his comments also suggest a move beyond the chatbot but also that the company believes we may yet enter a world of "one AI to rule them all" – something I've explored more recently in thinking about if the AI world might play out in a similar manner to the old "bring your own device" strategy in enterprise. Is your personal AI going to be so ingrained in your life that it's also just most convenient to use it as your work AI?
Executives believe users will increasingly interact with a single AI assistant rather than a collection of separate applications. As agents become more capable, OpenAI expects the distinction between chatbots, coding tools, search products and other software categories to blur.
“When we have [artificial general intelligence], I don’t think there will be a large number of distinct brands,” said Alex Embiricos, OpenAI’s head of enterprise product. “Probably there will be a single entity that I can talk to that can do whatever I need.”
OpenAI sure seems to think so! Of course, the opposite might be true (or so Microsoft undoubtedly hopes).
“Approximately a year ago, OpenAI’s strategy was swing for the fences, whereas Anthropic’s strategy is make money first,” said Jenny Xiao, partner at Leonis Capital and former researcher at OpenAI.
“Now the two are converging, because both of them are trying to aim for an IPO and investors care more about money than dreams.”
Yeah, two roads diverged... until they suddenly converged when it became clear which was the better road.
Speaking of, I can't help but continue to think that the real risk here for OpenAI is in morphing ChatGPT from this consumer-facing phenomenon into this more enterprise-focused business. They wouldn't frame it that way, of course – again, 'one AI to rule them all', and all that – but this "super app" could certainly muddle the message of what exactly ChatGPT is.
Given the killer quote above, is it reasonable to think they might not even call such an app "ChatGPT" anymore? I mean, that would be truly crazy given that it has basically become the "Kleenex" brand of AI.
Codex definitely seems to have some real momentum right now – both outside the company and within it. This report last week from Stephanie Palazzolo for The Information notes that the company feels like they built Codex the right way, that is a deep connection between model and product. That would suggest that they feel like ChatGPT itself wasn't built the right way, and was sort of backed into – which, yeah, duh. Further, some in the company seem to believe that using Codex for many of the tasks people now use ChatGPT for is just a better experience. So the question becomes if Codex is about to subsume ChatGPT?
It's not just about winning in coding to win in coding, but also the thinking that winning here will help OpenAI also get ahead in agentic workflows (and perhaps recursive self-improvement) and that, in turn, can pave the way back to consumers in the form of a true AI assistant. How's that for an Odyssey?

Apple's WWDC: Tim Cook's AI legacy at stake in his final developer conference as CEO
Apple enters its final WWDC under CEO Tim Cook with the urgent task of proving Siri can function as a credible agentic platform.
Deep dive
- Apple is under pressure to move beyond simple voice commands and deliver a functional AI agent.
- The new Siri is expected to handle complex, cross-app workflows using 'App Intents'.
- The company is reportedly pursuing a model-agnostic approach, allowing routing to external models like Google Gemini.
- Investors are skeptical whether AI features alone will drive a massive new iPhone upgrade cycle.
- The strategy relies on leveraging the massive installed base of devices rather than competing directly on model-training scale.
- This conference marks a significant transition point before John Ternus assumes the role of CEO.
Decoder
- App Intents: Apple’s framework that allows developers to define actions within their apps that the system (like Siri) can invoke programmatically.
- Model-agnostic: An architectural approach where a system can route tasks to various different AI models rather than being tied to one specific provider.
Original article
- Apple is expected to make an overhauled Siri the centerpiece of WWDC, which will be Tim Cook's final as CEO before John Ternus takes over.
- Investors say the bar is high, with some warning that even a stronger Siri may not be enough to justify its valuation.
- The bigger test may come in September, when Apple is expected to launch new iPhones and potentially the upgraded Siri experience.
Apple heads into next week's Worldwide Developers Conference with its stock near record highs, iPhone momentum improving and one unresolved question hanging over Tim Cook's final developer conference as CEO: Can Apple finally deliver the artificial intelligence experience it promised two years ago?
The expected centerpiece of WWDC is a major overhaul of Siri, Apple’s long-criticized voice assistant.
Analysts expect Apple to show a more powerful version of Siri with a standalone chatbot-style app, personal context, on-screen awareness, the ability to handle multi-step commands and deeper routing to outside models, potentially including Google’s Gemini.
For investors, WWDC is a test of whether Apple Intelligence can become a real iPhone upgrade driver — and justify a valuation that already assumes Apple can remain the device of choice for consumers accessing AI, regardless of which model they use.
For developers, it is a test of whether Siri can become a true platform in the agentic era, and one worth building for.
And for Cook, it is a legacy moment.
As John Ternus prepares to take over for Cook as CEO, WWDC gives the company one last major developer stage to show that Apple's AI strategy is finally coming together.
Dan Newman, CEO of The Futurum Group, told CNBC that Apple Intelligence is "one of the big black eyes" of Cook's tenure.
"This is clearly the moment that Apple can say, 'Hey, we are capable of taking advantage of our multi-billion-user install base,'" Newman said, adding that Apple also needs to prove to developers that Siri is "something to build on."
Winning developers and users
MoffettNathanson wrote this week that Apple's stock has "done all the work the AI story has yet to do."
The company enters WWDC at an all-time high, with about 36 times trailing earnings and $1.6 trillion more valuable than a year ago. The firm said Apple is executing exceptionally well, with the strongest iPhone cycle in years, China shifting from a structural worry to a share-gain story and services beating again.
"The question for WWDC26 isn't 'will Apple announce a better Siri?' It almost certainly will," MoffettNathanson wrote. "The question is 'does a better Siri justify a multiple that already assumes it works?'"
MoffettNathanson said Siri has to become credibly agentic for the multiple to hold. That means Siri must move from a command portal into an assistant that can reliably execute multi-step tasks across apps.
But that depends on third-party developers making their apps work with App Intents, Apple's system for letting Siri perform actions inside apps.
The firm said that creates a "chicken-and-egg problem." Siri only becomes useful if enough developers support it, but developers may wait to see whether consumers actually use it before investing the work.
MoffettNathanson noted that Apple has reportedly lined up early App Intents partners, including Uber, Amazon, Temu, YouTube, WhatsApp, Facebook, Threads and AllTrails. But it warned that developers may be hesitant to hand more control to Apple after years of tension around App Store economics.
That makes WWDC more than a consumer AI demo.
Apple has to convince customers that Siri is finally useful, and developers that it can become a platform worth building for.
"Cook has totally missed on AI in some ways, but by spending efficiently and not overcommitting to capex and still owning that surface layer, they're actually in a position where they can continue to miss for some time and still, at some point in the future, succeed," Newman said.
He added that this is "really the last hurrah" for Cook to spark the inflection point before Ternus takes over.
The AI investment
While Microsoft, Alphabet, Amazon and Meta spend tens of billions of dollars a year on AI infrastructure, Apple has largely stayed out of the frenzy, betting instead on device-level distribution, privacy and a more model-agnostic approach.
That's become a potential advantage for Apple, which could close the AI gap through partnerships instead of taking on the massive data center spending burden facing its Big Tech peers.
The Information reported this week that Apple's overhauled Siri is on track for September and will run in part on Google Cloud using Nvidia chips, though CNBC has not independently confirmed those details.
That would mark a major shift for Apple, which has long preferred to own core technologies. But investors may tolerate the tradeoff if it gives Apple a faster path to a working AI product.
Newman said the partnership could make sense for Google as well, because Apple-scale token usage would give it a major proof point for Gemini and build on a search partnership that has long been lucrative for both companies.
There is also a question of whether Apple has underinvested.
Stephanie Link, chief investment strategist at Hightower, said Apple has historically been conservative with cash and has preferred buybacks over big acquisitions or heavy investment. She said that discipline has helped margins, but she also finds it frustrating that Apple has not been a bigger participant in a technology shift that rivals describe as once-in-a-generation.
Apple has been "ridiculously late on AI," said Dan Niles, founder of Niles Investment Management.
Niles gave Cook high marks for supply chain execution and political skill, calling him a "supply chain god.," but noted that its most ambitious recent product launch, the Vision Pro, was a flop.
Still, Niles added that he is encouraged by Apple increasing research and development spending, but he sees the next phase of product execution as critical.
Can WWDC move the stock?
Link said she does not like the setup for Apple shares into WWDC, given the stock's run and valuation.
"It's not like I hate the stock. It's just that it's had a nice run, and I'm just not sure we're going to get something big at WWDC."
Link said Apple trades at roughly 34 times forward estimates for about 10% growth, and that she is not sure the company will announce anything big enough to move shares. She added that her Apple position is only five basis points, far below the company's weighting in the S&P 500, because of valuation and uncertainty around whether investors will get the answers they want at the developer conference.
"I don't think WWDC is going to be that much of a catalyst," Jim Lebenthal, partner at Cerity Partners, told CNBC. "I can't see something momentous coming out of this Worldwide Developer Conference. I just don't see it."
Lebenthal said he owns a market-weight position in Apple but is "not all that enthused" about WWDC as a catalyst. He said the stock is at the high end of its valuation range, and that while he is not selling, he finds it hard to buy more.
UBS said it expects Apple to focus on AI at the event but does not expect WWDC to be a positive catalyst for shares absent a surprise. The firm highlighted expected features like Gemini integration, links to third-party models through "Extensions," a dedicated Siri app, iCloud syncing for chats and personalization and on-screen awareness.
UBS left its iPhone estimates unchanged, saying other expected features are convenient but unlikely to materially drive demand.
Goldman Sachs was more hopeful, saying the new Siri could become a key demand driver for the iPhone and support services growth if developers use Apple Intelligence tools to build new apps.
"I know that Tim Cook wants to go out on a high," Link told CNBC. "But I would say that he went out on a high at the quarter. The quarter was good and better than expected."
The next iPhone — and Siri
The bigger consumer test comes in September, when Apple is expected to launch the new iPhone lineup and, potentially, the upgraded Siri experience.
Gene Munster, managing partner at Deepwater Asset Management, said he expects Apple shares could sell off around WWDC, but that would not change the longer-term thesis if Apple shows investors it understands where AI is going.
"They don't have to get it right," Munster told CNBC. "They just have to show that they get it — and that they know where this is going. That means AI products people actually want to use, which they don't have right now, and products that take advantage of what is uniquely Apple."
Munster said the bar is "surprisingly high" for a company that has not yet gotten AI right. At a minimum, Apple needs to show a chatbot experience as good as Gemini or ChatGPT, he said. The more important test is whether Apple can show how tight integration with its hardware makes AI more personal and useful.
"We can't have Genmoji 2.0," Munster said. "That's not going to fly."
That puts Cook in a difficult position heading into WWDC. A meaningfully more useful Siri could help reset Apple's AI narrative and carry the iPhone upgrade story into the fall.
Anything that looks incremental, delayed or too dependent on partners risks reminding investors of the execution miss Apple is trying to move past.
For a CEO who turned Apple into one of the most valuable companies in the world through operational discipline, supply chain mastery and services expansion, the final developer conference may come down to something far less familiar: Whether Apple can make Siri feel like the future.
pg_durable (GitHub Repo)
Microsoft released pg_durable, a PostgreSQL extension that enables durable, fault-tolerant workflow orchestration directly inside the database using a custom SQL DSL.
Deep dive
- pg_durable provides a SQL DSL for defining stateful workflow graphs using operators like ~> and |=>.
- It enables durable execution by checkpointing function progress directly into Postgres tables, allowing resumes after crashes.
- Built using the pgrx framework for Rust-based PostgreSQL extension development.
- It includes dedicated schemas (df.* for definitions, duroxide.* for internal state) to manage workflow life cycles.
- Designed for tasks like vector embedding pipelines, batch data ingestion, and multi-step background maintenance.
- Integrates row-level security for multi-tenant environments.
- Requires PostgreSQL 17 or 18; no external services like Redis or dedicated orchestrators are needed.
- Supports both SQL-native definition and raw Rust integration via the duroxide crate.
Decoder
- Durable Execution: A pattern where a task's state is persisted at every step so that if a process crashes, it can resume from the exact point of failure instead of restarting from the beginning.
- Fan-out: An architectural pattern where one task triggers multiple independent parallel tasks, often collecting their results at a later join point.
- SQL DSL: A domain-specific language built using SQL syntax to express logic, in this case, workflow control flow.
- pgrx: A framework for developing PostgreSQL extensions using the Rust programming language.
Original article
Durable Execution inside PostgreSQL
Long-running, fault-tolerant SQL functions for teams that already keep their state in Postgres and want to stop stitching together cron jobs, workers, queues, and status tables to make background work reliable. Define the workflow in SQL, let pg_durable checkpoint each step, and resume after crashes, restarts, or failed steps.
Durable execution is now a standard industry pattern, and pg_durable brings it inside Postgres with no extra service infrastructure required. Part of our mission to bring compute close to data.
Try pg_durable now in Azure HorizonDB, Microsoft's new PostgreSQL cloud service engineered for performance and built with pg_durable inside
Is this for me?
Who it's for
- Backend and data engineers who want workflows to live next to the data they touch.
- DBAs and SREs automating runbooks that must survive restarts and be auditable in SQL.
- Teams building data or AI pipelines that need durable execution per row, document, or batch.
The core idea
A pg_durable function is a graph of SQL steps that PostgreSQL executes and checkpoints as it goes. If the database crashes, restarts, or a step fails, execution resumes from the last durable checkpoint instead of making you reconstruct state by hand.
Workloads this is useful for
- Vector embedding pipelines: chunk, call an embedding API, and upsert into
pgvector. - Ingest pipelines: stage, deduplicate, transform, and publish large batches.
- Scheduled maintenance: detect bloat, notify, wait for approval, then run the next action.
- Fan-out aggregation: run independent queries in parallel, then join the results.
- External API workflows: enrichment, classification, and webhook-style calls from SQL.
What you're probably doing today instead
pg_cronplus a jobs table, status columns, retry counters, and a polling worker.- An external orchestrator such as Airflow, Temporal, Step Functions, or Argo calling back into Postgres.
- A queue plus workers plus a separate state table to coordinate retries and partial completion.
- A
plpgsqlprocedure that works until a crash or long-running transaction forces you to start over.
Pain points it addresses
- A restart in the middle of a long job means rerunning work that already succeeded.
- One failed row or one failed API call turns into manual cleanup and uncertain replay.
- Long transactions hold locks, grow WAL, and make batch jobs fragile at larger scale.
- Parallel work in the app tier creates more places for partial-failure bugs and drift.
- The workflow logic ends up spread across SQL, workers, queues, dashboards, and status tables.
What changes in your architecture
- The workflow definition moves into SQL and starts with
df.start(...). - Retry state, progress tracking, and checkpointing move into Postgres instead of bespoke app code.
- Some app-tier workers, queue consumers, or scheduler glue can disappear entirely.
- Operational visibility comes from Postgres tables such as
df.instances, using the same auth and backup model as your data.
When not to use it
- The job is already a single
INSERT ... SELECTor one ordinary SQL statement. - You need sub-millisecond synchronous request handling rather than durable background execution.
- You cannot install extensions or run a background worker in your Postgres environment.
- The workflow mostly lives outside Postgres and spans many heterogeneous systems.
- You need arbitrary application logic that does not map cleanly to SQL steps, branching, loops, or HTTP calls.
How it works
- Define a workflow in SQL using composable operators such as
~>and|=>. - Start it with
df.start()and get back an instance ID. - Let the runtime execute each step durably with checkpointing between steps.
- Query status and results from PostgreSQL while the workflow runs or after it completes.
Limitations
The model is intentionally SQL-shaped. If a step needs arbitrary code, a non-HTTP SDK, or rich in-memory control flow, you may need to wrap that logic in a SQL function, expose it behind an HTTP endpoint for df.http(), or use a general-purpose orchestrator for that part of the system.
Features
- Durable — Function state persists to PostgreSQL. Survives crashes, restarts, and failovers.
- SQL-native — Define functions in SQL using composable operators.
- Database-aware — First-class primitives for scheduling, conditions, and parallel execution.
- Zero infrastructure — Runs as a PostgreSQL extension. No Redis, no Temporal, no external services.
Quick Example
-- A durable function that processes data in steps
SELECT df.start(
'SELECT id FROM documents WHERE processed = false LIMIT 100' |=> 'batch'
~> 'UPDATE documents SET processed = true WHERE id = ANY($batch)'
);Packages
Tagged releases publish Debian packages for PostgreSQL 17 and 18 on amd64 from the GitHub release assets. After installing a package, add pg_durable to shared_preload_libraries, restart PostgreSQL, and create the extension in the configured pg_durable database:
CREATE EXTENSION pg_durable;Development Installation
Prerequisites
- PostgreSQL 17 or 18
- Rust (nightly)
- cargo-pgrx 0.16.1
Multi-User Setup
CREATE EXTENSION pg_durable does not grant any privileges to PUBLIC. After installing the extension, the admin must explicitly grant access to application roles.
Grant privileges to an application role:
-- Grant to specific roles after CREATE EXTENSION
SELECT df.grant_usage('app_role');Architecture
pg_durable is a PostgreSQL extension (built with pgrx) — everything runs inside the PostgreSQL server, no external services. The extension exposes a SQL DSL for building function graphs and registers a background worker that executes them durably on top of two lower-level Rust libraries:
- duroxide — a durable task framework providing the orchestration runtime (deterministic replay, checkpoints, sub-orchestrations, timers).
- duroxide-pg — a PostgreSQL-backed state provider for duroxide. It persists runtime state (instances, history, work queues) in a dedicated
duroxide.*schema owned by the extension.
┌────────────────────────────────────────────────────────────────────┐
│ PostgreSQL │
│ │
│ ┌──────────────────────────────────────────────────────────────┐ │
│ │ pg_durable extension (pgrx) │ │
│ │ │ │
│ │ SQL DSL 'sql' |=> 'name' ~> 'sql2' │ │
│ │ df.if() | df.join() | df.loop() │ │
│ │ │ │
│ │ Background worker (hosts the duroxide runtime in-process) │ │
│ │ ┌────────────────────────────────────────────────────────┐ │ │
│ │ │ duroxide (orchestration runtime) │ │ │
│ │ │ ┌──────────────────────────────────────────────────┐ │ │ │
│ │ │ │ duroxide-pg (PostgreSQL state provider) │ │ │ │
│ │ │ └──────────────────────────────────────────────────┘ │ │ │
│ │ └────────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────────┘ │
│ │
│ Schemas │
│ df.* DSL graphs (nodes, instances, vars) │
│ duroxide.* runtime state (owned by duroxide-pg) │
└────────────────────────────────────────────────────────────────────┘Status
Preview - This project is currently in preview.
Is your control plane ready for Crossplane v2?
Crossplane v1.20.9 adds a read-only CLI command to identify breaking changes before you upgrade your control plane to v2.
Deep dive
- Scans all namespaces and cluster-scoped resources for v2-incompatible configurations.
- Flags deprecated 'native patch-and-transform' compositions that must be moved to function pipelines.
- Detects usage of
ControllerConfig, which is replaced byDeploymentRuntimeConfigin v2. - Identifies dependencies on external secret stores that are being removed.
- Checks for unqualified package references that need explicit registry hostnames.
- Provides non-zero exit codes to facilitate automation in CI/CD pipelines.
- Offers JSON output for structured report integration.
Decoder
- Crossplane: An open-source Kubernetes add-on that transforms clusters into control planes to manage cloud services and infrastructure via custom resources.
- Composition: A set of logic used to bundle multiple resources into a single user-defined Kubernetes object.
- XR (Composite Resource): An abstraction that enables users to define their own infrastructure APIs in Kubernetes.
- ControllerConfig: A v1-only resource for customizing the deployment of provider controllers, now replaced by
DeploymentRuntimeConfig.
Original article
TL;DR
- The vast majority of v1.x control planes can upgrade to Crossplane v2 right away with no changes. Claims, composite resources (XRs), Compositions, and cluster-scoped managed resources all keep working.
- A small set of v1 features were removed or changed in v2. If your control plane uses one, you'll want to find that out before you upgrade.
crossplane beta upgrade checkis a new, read-only CLI command that scans a live v1.x control plane and reports exactly what (if anything) would break, which resource is responsible, and how to fix it.- It ships in the v1.20 CLI, so install the latest v1.20 CLI and run it against your cluster before you upgrade.
Ready to upgrade?
When we designed Crossplane v2, backward compatibility was a first-class goal: the vast majority of v1.x control planes can upgrade without changing a thing. Your claims, composite resources (XRs), compositions, and cluster-scoped managed resources all keep working in v2.
But "the vast majority" isn't "everyone." Crossplane v2 does remove or change the behavior of a small set of v1 features, and if your control plane uses any of them, you'll want to catch it before you upgrade. Until now, that meant reading the backward compatibility notes and then spelunking through every composition, package, and resource in your cluster for something that's going away - tedious and easy to get wrong on a control plane of any real size. Understandably, that uncertainty has kept some folks from upgrading to v2.
crossplane beta upgrade check is now available to give you a definitive answer. It's a read-only command that connects to a live v1.x control plane and exhaustively scans it for anything v2 removes or changes in a breaking way. Point it at your cluster before you upgrade and it takes you straight to the resources that need attention, with the exact fix for each.
What it checks
The command covers every breaking change called out in the v2 backward compatibility notes. For each one, it reports the specific resources responsible so you can act on them directly:
- Native patch-and-transform Compositions. Composition Functions are how you compose resources in Crossplane v2. Native patch-and-transform (P&T) Composition, where resources and patches are embedded directly in the Composition, is removed. This is the change most likely to affect you, so any Composition still using it needs to move to a function pipeline.
- ControllerConfig usage. The
ControllerConfigtype is removed, replaced byDeploymentRuntimeConfig. The check finds bothControllerConfigsthemselves and the Providers or Functions that still reference one. - External secret stores. This alpha feature is removed in v2. The check finds where it's enabled and where your Compositions and resources still publish connection details through it.
- Unqualified package sources. Crossplane v2 drops the implicit default registry, so every package reference (Providers, Configurations, Functions, and their dependencies) must be fully qualified with its registry hostname.
- Composite resource connection details. This one is informational. Legacy XRs and Claims keep aggregating connection details in v2, so the upgrade itself needs no action here. The check highlights resources you'd only need to revisit if you later migrate them to v2-style namespaced XRs, which do not support connection details at the XR level.
The command is also careful about false positives. Crossplane's controllers and the API server inject defaults onto every cluster, and the check knows to look past those and flag only the features you actually opted into. A finding means real usage you'll need to address.
Let's see it in action
Running the command is as simple as pointing it at a cluster. By default it uses your current kubeconfig context and sweeps the entire control plane: all of your Crossplane configuration, cluster-scoped resources, and every namespace:
crossplane beta upgrade checkOn a control plane that's already clean, you get the answer you're hoping for and a zero exit code:
[✓] 0 issues, 0 informational, 0 incomplete checks.There we go - ready to upgrade. On a control plane that still leans on some v1-only features, the report tells you precisely what stands in the way. Here's a representative output from a control plane that is still using native patch-and-transform and external secret stores:
[✗] 4 issues, 0 informational, 0 incomplete checks.
[✗] Native patch-and-transform Compositions - 3 issues
│
│ Crossplane v2 removes native patch-and-transform (P&T) Composition. Compositions must use mode: Pipeline with Composition Functions.
│ Fix: Migrate to Composition Functions (spec.mode: Pipeline with spec.pipeline steps). Run "crossplane beta convert pipeline-composition" to convert existing Compositions.
│ Docs: https://docs.crossplane.io/latest/guides/upgrade-to-crossplane-v2/#native-patch-and-transform-composition
│ https://docs.crossplane.io/v1.20/cli/command-reference/#beta-convert
│
│ NAME FIELD
│ composition.apiextensions.crossplane.io/nativepnt-composition .spec.mode
│ composition.apiextensions.crossplane.io/nativepnt-composition .spec.patchSets
│ composition.apiextensions.crossplane.io/nativepnt-composition .spec.resources
└──
[✓] ControllerConfig usage
[✗] External secret stores - 1 issue
│
│ Crossplane v2 removes support for external secret stores. Publish connection details as Kubernetes Secrets composed by your Compositions, or adopt External Secrets Operator if
│ you need an external store.
│ Fix: Disable --enable-external-secret-stores on the Crossplane Deployment, replace StoreConfig-based publishing with composed Kubernetes Secrets (or adopt External Secrets
│ Operator), then delete StoreConfig resources. No automated converter exists.
│ Docs: https://docs.crossplane.io/latest/guides/upgrade-to-crossplane-v2/#external-secret-stores
│ https://docs.crossplane.io/latest/guides/connection-details-composition
│ https://github.com/external-secrets/external-secrets
│
│ NAMESPACE NAME FIELD
│ crossplane-system deployment.apps/crossplane .spec.template.spec.containers[0].args
└──
[✓] Composite resource connection details
[✓] Unqualified package sources
crossplane: error: blockers foundEach finding is self-contained. The top line summarizes the breaking change in plain language, the Fix: line tells you what to do about it - often naming the exact crossplane beta convert command that will migrate the resource for you - and the Docs: line links straight to the relevant section of the upgrade guide. Below that, a table lists every resource and field responsible, so there's no guesswork about which of your Compositions needs attention.
The command exits non-zero when it finds blockers and zero when it doesn't, and -o json emits the same findings as structured data:
crossplane beta upgrade check -o jsonPerformance Tuning
Scanning every managed resource for external secret stores usage is the most expensive part of the run on control planes with many provider CRDs, and these flags let you make a trade off for execution time versus the load the command puts on your API server:
--skip-managed-resourcesskips the managed-resource scan entirely. The command still inspectsStoreConfigresources, the CrossplaneDeployment, and composite resources for external secret stores usage; it just doesn't scan managed resources. This gives the biggest reduction in run time, at the cost of not catching external secret stores usage on managed resources.--concurrency(default10) bounds how many resources the command processes in parallel. Lower it, for example--concurrency 2, to put less load on a busy production control plane you don't want to overload; raise it to finish faster at the cost of more load on the API server.
How to get it
Because this tool is only useful before you upgrade, it ships exclusively in the v1.20 Crossplane CLI - a v2 control plane has nothing left to check, and the v1-only types these checks rely on don't even exist there. We made a deliberate exception to v1.20's critical-fixes-only maintenance policy to ship this in the v1.20.9 patch release, precisely so the whole community can check their control planes before they make the jump.
If you're running a v1.x control plane, you likely already have the CLI on hand. You just need a build that includes upgrade check, which means the latest v1.20 patch release. Install it with:
curl -sL "https://raw.githubusercontent.com/crossplane/crossplane/main/install.sh" | XP_VERSION=v1.20.9 shUpgrade with confidence
Most of you will run crossplane beta upgrade check, see a clean report, and upgrade to v2 the same day - which is exactly the outcome all that backward compatibility work was for. For everyone else, it trades guesswork for a precise list of what to change before you go. Either way, you upgrade deliberately, knowing exactly where your control plane stands.
This check is just a first step. It tells you what needs to change, and for some breaking changes it can already point you at a crossplane beta convert command that does the rewrite for you, but it stops short of migrating your control plane end to end. Smoothing that path is where the community should head next.

How Anthropic enables self-service data analytics with Claude
Anthropic reports that 95% of its internal business analytics queries are now automated via Claude by prioritizing data governance over raw SQL generation.
Deep dive
- 95% of business analytics queries at Anthropic are now automated using Claude.
- Accuracy is primarily a context and verification challenge, not a code generation one.
- Three main failure modes were identified: concept/entity ambiguity, data staleness, and retrieval failure.
- The stack uses a 'data foundations' layer (canonical models) to solve ambiguity.
- 'Skills' are implemented as folders of markdown that provide procedural knowledge to the agent.
- Offline evals are treated as versioned telemetry to monitor model performance drift.
- Negative results from ablations—such as the failure of raw SQL corpus retrieval—guided the team to focus on structure over volume.
- Adversarial review sub-agents increased accuracy by 6% but increased latency and token usage.
- Corrections from stakeholders are harvested via an automated agent to suggest PRs that update documentation.
Decoder
- Semantic layer: A conceptual model that defines business metrics and dimensions consistently across an organization, sitting between the raw data and BI tools.
- Ablation: A technique where components of a system are selectively removed to determine their individual contribution to performance.
- MCP (Model Context Protocol): An open standard for connecting AI assistants to data sources and development tools.
Original article
Full article content is not available for inline reading.

PostgreSQL 19 Beta 1 Released!
PostgreSQL 19 Beta 1 introduces significant performance boosts like parallel autovacuum and SQL/PGQ graph query support.
Deep dive
- Performance: Improved async I/O worker scaling, parallel autovacuum workers, and 2x faster foreign key inserts.
- Querying: Native SQL/PGQ support for property graph queries and new GROUP BY ALL syntax.
- Observability: New pg_stat_lock and pg_stat_recovery views provide granular database state tracking.
- Security: SNI support allows multiple TLS certificates per host, and md5 authentication is being phased out.
- Replication: Sequences are now included in logical replication, and it can be enabled without server restarts.
Decoder
- Autovacuum: A background process that cleans up dead tuples and maintains index health in PostgreSQL.
- SQL/PGQ: An ISO standard for querying property graphs within SQL databases.
- TOAST: The mechanism used for storing large field values that exceed the standard page size.
- LSN: Log Sequence Number, a pointer to a specific position in the database write-ahead log.
Original article
PostgreSQL 19 Beta 1 Released!
The PostgreSQL Global Development Group announces that the first beta release of PostgreSQL 19 is now available for download. This release contains PostgreSQL 19 feature previews ahead of general availability, though some details of the release can change during the beta period.
You can find information about all of the PostgreSQL 19 features and changes in the release notes.
In the spirit of the open source PostgreSQL community, we strongly encourage you to test the new features of PostgreSQL 19 on your systems to help us eliminate bugs and other issues. While we do not advise you to run beta versions in production environments, we encourage you to find ways to run your typical application workloads against this beta release.
Your testing and feedback help the community ensure that PostgreSQL 19 upholds our standards of delivering a stable, reliable release of the world's most advanced open source relational database. Please read more about our beta testing process and how you can contribute.
PostgreSQL 19 Feature Highlights
Below are some of the feature highlights that are planned for PostgreSQL 19. This list is not exhaustive; for the full list of planned features, please see the release notes.
Performance
PostgreSQL 19 builds on the asynchronous I/O subsystem introduced in PostgreSQL 18. In this release, io_method=worker now automatically scales the number of I/O workers based on the new io_min_workers and io_max_workers settings.
This release also introduces the pg_plan_advice extension, which lets users stabilize and control planner decisions, along with pg_stash_advice to apply advice automatically using query identifiers.
This release brings improvements to vacuum and maintenance operations. Autovacuum can now use parallel workers, which can be configured with the new autovacuum_max_parallel_workers setting, and a new autovacuum scoring system helps prioritize tables to vacuum. PostgreSQL 19 further enhances vacuum with a new strategy that can automatically reduce future vacuuming work by marking pages as visible while they're being queried. Additionally, this release adds the new REPACK command and its nonblocking CONCURRENTLY option, which allow tables to be rebuilt with less operational overhead.
PostgreSQL 19 shows up to 2x better performance on inserts when foreign key checks are present. Additionally, this release improves several areas of the query planner and executor, including new anti-join optimizations, broader use of incremental sorts, eager aggregation that speeds up row processing, faster reads from storage during parallel sequential scans, and simplification of IS DISTINCT FROM and IS NOT DISTINCT FROM to plain <> and = operators when the inputs are not nullable. There are also improvements for LISTEN/NOTIFY scalability that impact multi-channel workloads.
Developer Experience
PostgreSQL 19 introduces support for SQL/PGQ, letting users execute property graph queries using SQL standard syntax. This release also expands temporal query capabilities with UPDATE and DELETE support for the FOR PORTION OF clause, complementing the temporal constraint support added in PostgreSQL 18. This release also adds ALTER TABLE ... MERGE PARTITIONS and ALTER TABLE ... SPLIT PARTITIONS to make it easier to reorganize partitioned tables in place. There is now also support for returning rows that conflict during an upsert operation using INSERT ... ON CONFLICT DO SELECT ... RETURNING.
PostgreSQL 19 introduces the new GROUP BY ALL syntax, making it easy to add all non-aggregate and non-window output columns as part of the grouping. This release extends string processing capabilities in jsonpath with the addition of lower(), upper(), initcap(), replace(), split_part(), and the trim() family of functions.
PostgreSQL 19 makes it easier to adopt "read-your-writes" query patterns when working with replicas using the new WAIT FOR LSN command. This lets a session wait until changes up to a specific log position (LSN) have been replayed on the replica before executing a SELECT query.
PostgreSQL 19 also adds new SQL functions to retrieve the DDL statements needed to recreate roles, tablespaces, and databases, simplifying scripting and migration tasks. Additionally, the random() function now works with date and timestamp types, and PL/Python now supports event triggers.
Security Features
PostgreSQL 19 adds server-side support for Server Name Indication (SNI) through a new pg_hosts.conf file, allowing a single PostgreSQL server to present different TLS certificates based on the hostname requested by the client. There is also a new password_expiration_warning_threshold setting (defaulting to 7 days) to warn users in advance of upcoming password expirations.
Further to the ongoing deprecation efforts of md5 authentication, this release issues a warning to the client after a successful md5 authentication. This is controllable via the new md5_password_warnings setting.
Monitoring and Observability
PostgreSQL 19 introduces the pg_stat_lock view, which reports per-lock-type statistics, and pg_stat_recovery which provides detailed visibility into the state of recovery operations. A stats_reset column is now available across many statistics views to show when counters were last cleared. The pg_stat_progress_vacuum and pg_stat_progress_analyze views now include a started_by column that reports the initiator of the operation, and pg_stat_progress_vacuum also has a mode column that reports how vacuum is operating.
This release also allows log_min_messages levels to be specified per process type, giving operators finer control over what each part of the system logs. Additionally, WAL full page write byte counts are now reported in VACUUM and ANALYZE log output, helping identify maintenance operations that generate large amounts of WAL. Additionally, EXPLAIN ANALYZE now supports surfacing asynchronous I/O (AIO) statistics through its IO option, providing better visibility into how queries are using the AIO subsystem.
Logical Replication and Query Federation
In PostgreSQL 19, logical replication now replicates sequence values, simplifying tasks like online upgrades. Additionally, the new CREATE PUBLICATION ... EXCEPT syntax allows you to publish all tables in a database except for a specified set, while CREATE SUBSCRIPTION ... SERVER allows subscriptions to be defined using a foreign server, simplifying credential management.
PostgreSQL 19 makes it possible to enable logical replication without restarting a server. Logical replication can now be enabled on demand even when wal_level is set to replica, and the new read-only effective_wal_level parameter reports the WAL level currently in effect. This reduces the need to commit upfront to a higher WAL level for clusters that may only occasionally need it, and avoids disrupting an active workload.
The PostgreSQL foreign data wrapper, postgres_fdw, used for query federation, includes several performance improvements, including pushing down array operations to the remote server, and retrieving and using statistics from foreign tables to support better local query planning.
Other Highlights
The PostgreSQL 19 beta period includes a temporary "grease mode" to try to find protocol compatibility problems in the wider ecosystem.
PostgreSQL 19 allows data checksums to be enabled or disabled online, without requiring a cluster restart or reinitialization.
There are several notable changes to be aware of in PostgreSQL 19. Just-in-time compilation (JIT) is now disabled by default, and the default_toast_compression setting now defaults to lz4, providing better default compression and decompression performance. Support for RADIUS authentication is now removed. Additionally, the vacuumdb --analyze-only command by default analyzes partitioned tables.
Additional Features
Many other new features and improvements have been added to PostgreSQL 19. Many of these may also be helpful for your use cases. Please see the release notes for a complete list of new and changed features.
Testing for Bugs & Compatibility
The stability of each PostgreSQL release greatly depends on you, the community, to test the upcoming version with your workloads and testing tools to find bugs and regressions before the general availability of PostgreSQL 19. As this is a Beta, minor changes to database behaviors, feature details, and APIs are still possible. Your feedback and testing will help determine the final tweaks on the new features, so please test in the near future. The quality of user testing helps determine when we can make a final release.
A list of open issues is publicly available in the PostgreSQL wiki. You can report bugs using this form on the PostgreSQL website.
Beta Schedule
This is the first beta release of version 19. The PostgreSQL Project will release additional betas as required for testing, followed by one or more release candidates, until the final release around September/October 2026. For further information please see the Beta Testing page.

Complexity is the Ceiling: Software Design in the Age of AI Coding
AI tools excel at tactical coding, but structural system complexity remains the ultimate limit on how much engineering work can be automated.
Deep dive
- AI excels at tactical programming (generating code) but fails at strategic programming (maintaining system architecture).
- Accidental complexity (boilerplate) is easily reduced by AI, while essential complexity (domain-specific logic) remains a human-centric bottleneck.
- A 2026 study found that 15% of AI-authored commits in 6,000 repositories introduced new issues, mostly structural 'code smells'.
- Deep modules, as defined by John Ousterhout, provide the necessary boundaries for AI to operate safely by hiding internal implementation complexity.
- A 2025 Google DORA report indicates AI acts as an amplifier: increasing throughput for strong engineering teams while worsening instability for weak ones.
- AI-assisted developers often exhibit overconfidence, with Stanford research showing they write less secure code while believing it is safer.
Decoder
- Accidental complexity: Effort spent on the mechanical tasks of programming (e.g., syntax, boilerplate) rather than solving the actual problem.
- Essential complexity: The inherent difficulty and logical structure required by the problem itself.
- Change amplification: A structural issue where a minor change in one area forces code modifications across many unrelated parts of the system.
- Deep module: A unit of code with a simple interface that hides a powerful, complex implementation, as defined by John Ousterhout.
- Code smell: A surface-level indicator in the source code that typically corresponds to a deeper structural problem in the software design.
Original article
AI has made writing code faster than ever. The harder work is understanding a system and changing it without breaking it. That has not gotten cheaper, and it now decides how much you can hand to a machine.
Introduction
In 1987, in an essay called “No Silver Bullet,” Fred Brooks predicted that no tool or technique would bring a tenfold gain in software productivity within a decade. The decades since have largely proven him right, and the reason is that his argument never rested on the technology of its day. Brooks split the difficulty of building software into two kinds. Accidental complexity is the incidental effort our tools impose: syntax, boilerplate, plumbing. Essential complexity is what the problem itself demands: working out what the system must do, and designing a structure that holds up as it grows. Tools, he argued, only ever chip away at the accidental. The essential is left untouched, and the essential is most of the work.
AI coding assistants are the most effective attack on accidental complexity yet. They write a function or scaffold a whole test suite in seconds, and they have made the mechanical parts of programming cheaper than ever. That has encouraged a conclusion repeated often enough to sound obvious: code is cheap now, so the code itself barely matters. Describe what you want, let the model generate it, and when something breaks, change the description and regenerate.
The software educator Matt Pocock recently made a version of the counterargument in a conference talk, and it matches what I see in my own work. I lead AI engineering at a legal-research company, where building with these tools is my daily work, and in a real codebase the “code is cheap” conclusion does not hold up. Writing code is cheap. Understanding it and changing it without breaking something else is not, and a model has to understand a codebase before it can safely modify one. The complexity of a system is therefore the ceiling on how much of it you can delegate to a machine. Rather than making software design optional, AI raises the cost of neglecting it.
The cost that didn’t go away
When people say code is cheap now, what they mean is that it is cheap to write. But writing was never where the expense lived. The expensive part of software is everything that comes after the first version works: making sense of it later, and changing it without breaking something you weren’t even looking at.
John Ousterhout gives this expense a precise name. Complexity, in his definition, is anything about the structure of a system that makes it hard to understand or modify. It shows up as change amplification, where a small change forces edits in many places at once; as cognitive load, the sheer amount a developer must hold in mind to touch the code safely; and as unknown unknowns, where you cannot even tell which parts a change might affect. None of these has anything to do with typing speed. They are all about comprehension, and comprehension is exactly what generating code faster does not buy.
AI moves this arithmetic in the wrong direction. A model produces far more code than a person, and far faster. That means more surface area to understand and more places a single change can reach, all of it competing for the same working memory. The comprehension burden also doubles, because now two parties have to understand the system: the model, which must grasp it well enough to change it correctly, and you, who must grasp both the system and the model’s changes well enough to trust them. “Code is cheap” is half true. It is the dangerous half.
AI is a tactical programmer
Ousterhout draws a sharp line between tactical and strategic programming. The tactical programmer optimizes for getting the current task working and moves on. The strategic programmer spends extra effort keeping the structure of the system clean, so the next change is cheaper and safer. Tactical work is faster today and more expensive every day after.
A language model, left to its own defaults, is a relentlessly tactical programmer. It is trained and prompted to produce code that runs, not code a colleague will be glad to inherit. So it duplicates a block rather than factoring out the shared idea, adds another parameter instead of rethinking an interface, and reaches for a local fix that works in isolation and quietly worsens the whole. The Pragmatic Programmer calls this drift software entropy: each change made without regard for the design of the system nudges it further toward disorder.
This drift is starting to show up in the data. A 2026 study examined more than 300,000 AI-authored commits across over 6,000 public repositories, running static analysis before and after each change to measure what the model actually introduced. More than fifteen percent of those commits added at least one new issue, and of all the issues found, nearly nine in ten were code smells: structural problems that compile and pass their tests but make the code harder to understand and change. The code works while the design quietly degrades. That is accidental complexity accruing one commit at a time, and it is exactly the cost a model optimizing for a passing result will not charge itself. Someone has to supply the strategic layer the model does not, and that someone is the engineer.
Deep modules are the control surface
If complexity is the problem, the most useful instrument Ousterhout offers against it is the deep module: a unit with a simple interface that hides a powerful implementation. The idea predates the name. In 1972, David Parnas argued that a system should be divided not according to the steps of its computation but according to the decisions each part can hide from the rest, so that a change inside one module need not ripple out across the others. Information hiding is the whole point, and depth is what makes it work.
That same depth turns out to decide how much you can safely hand to AI. A deep module hands you two things at once: a contract small enough to hold in your head, and an implementation you can delegate. You specify the interface, let the model fill in the body, and review what matters at the boundary: its contract, its invariants, its tests, and any risk-sensitive internals, without having to reconstruct every implementation detail. The module becomes a kind of gray box: you scrutinize its edges and the parts that carry real risk, and let the rest stay complex inside.
A shallow design takes that option away. When behavior is spread thin across many small modules with leaky interfaces, there is no boundary to verify against, and understanding any change means tracing it through all of them. That cost falls on you and on the model at the same time. In practice, an agent does its best work inside a well-bounded module, where the task is legible and the contract is clear, and its worst work in tangled code, where it cannot tell what depends on what and makes things subtly worse while appearing to help. The structure of the codebase, far more than the cleverness of the prompt, sets the size of the job you can safely give away.
Complexity is the ceiling
The pieces fit together. The cleaner a system is, the more an agent can do in it without supervision, and the better the feedback it gets while doing so, because strong types and tests at clean interfaces tell a model immediately when it has gone wrong. The Pragmatic Programmer’s rule holds for people and machines alike: the rate of feedback is your speed limit. A messy system slows that feedback down while the model speeds the damage up.
The evidence that this ceiling is real has started to arrive, and some of it is counterintuitive. In one early-2025 randomized controlled trial, METR had sixteen experienced open-source developers complete tasks in large, mature repositories they knew well, with and without AI assistance. The developers expected the tools to speed them up by about a fifth; measured against the clock, the tools slowed them down by nearly as much. On a complex system that someone already understands deeply, the cost of steering and correcting the model outweighed the speed of its output. METR frames this as a snapshot of one moment, and its own later data is harder to read and may show more speedup. The point is not that AI always slows people down, but that the complexity of the system governs whether it helps. At industry scale, the finding has only sharpened. Google’s 2025 DORA report, drawn from developers now adopting AI at near-universal rates, frames the technology as an amplifier: it lifts throughput and performance where a team’s engineering foundations are strong, and magnifies instability, more change failures and more rework, where they are weak. The teams that benefit are the ones whose systems and practices were already in good shape.
The risk turns sharpest when there is no boundary to check against and the engineer trusts the output anyway. A Stanford study found that developers given an AI assistant wrote less secure code than those without one, and, more troubling, were more confident their code was secure. Output you have not verified is not finished, and confidence is not verification. None of this means AI fails to help. It means the help is bounded by the quality of the system it works inside, and by the engineer’s willingness to do the design and the review that the model cannot do for itself.
Invest in design every day
The conclusion is not that AI is overhyped, or that any of this is new. The skills that decide the outcome are the ones the field has been writing down for half a century, from Parnas in 1972 to Ousterhout today. What has changed is the price of ignoring them. When code was expensive to write, a tangled system mostly slowed people down. Now that code is cheap to generate, a tangled system caps the leverage of an unusually powerful tool, while a clean one compounds it.
That places the engineer’s real work where it has always sat, one level above the code itself. Kent Beck’s practice of incremental design, putting a little into the structure of the system continuously rather than saving it for occasional rewrites, is the right discipline for an era in which a machine produces the lines. The model is a fast tactical programmer, and it needs someone thinking strategically above it. The teams that get the most out of AI will not be the ones that generate the most code. They will be the ones whose systems stay simple enough that a machine can move quickly through them without breaking them. Design has become the limiting reagent, and it is the part of the work that is still ours.
References
[1] Frederick P. Brooks Jr., “No Silver Bullet: Essence and Accidents of Software Engineering,” Computer 20(4), 1987, pp. 10-19.
[2] Matt Pocock, “It Ain’t Broke: Why Software Fundamentals Matter More Than Ever,” keynote at AI Engineer Europe, 2026.
[3] John Ousterhout, A Philosophy of Software Design, 2nd ed., Yaknyam Press, 2021.
[4] David Thomas and Andrew Hunt, The Pragmatic Programmer: Your Journey to Mastery, 20th Anniversary Edition, Addison-Wesley, 2019.
[5] “Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild,” 2026.
[6] David L. Parnas, “On the Criteria To Be Used in Decomposing Systems into Modules,” Communications of the ACM 15(12), 1972, pp. 1053-1058.
[7] METR, “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity,” 2025. See also METR, “We Are Changing Our Developer Productivity Experiment Design,” 2026.
[8] DORA / Google, “State of AI-Assisted Software Development,” 2025.
[9] Neil Perry, Megha Srivastava, Deepak Kumar, and Dan Boneh, “Do Users Write More Insecure Code with AI Assistants?” ACM CCS 2023.
[10] Kent Beck and Cynthia Andres, Extreme Programming Explained: Embrace Change, 2nd ed., Addison-Wesley, 2004.

Google Pays SpaceX $920M/Month for AI Compute
Google is paying SpaceX $920 million per month to secure massive AI compute capacity via 110,000 NVIDIA GPUs.
Original article
Google signed a cloud service agreement with SpaceX for access to AI compute capacity tied to roughly 110,000 NVIDIA GPUs. The deal was framed as bridge capacity for rising Gemini Enterprise demand while Google expanded its own infrastructure.
Microsoft rolls out Scout AI agent to Frontier users
Microsoft is rolling out 'Scout,' an always-on 'Autopilot' agent that autonomously manages tasks across the Microsoft 365 ecosystem.
Decoder
- Autopilot (Agent Category): Microsoft's term for agents designed to run continuously with persistent identity and autonomy, distinct from standard conversational interfaces.
Original article
Microsoft has begun rolling out its Scout desktop application to organizations enrolled in the Frontier program, providing a first practical look at the always-on work agent the company unveiled at Build 2026 on June 2. Scout was introduced as the opening entry in a new category Microsoft calls Autopilots, agents that run continuously, carry their own identity, and act across the Microsoft 365 stack rather than waiting to be prompted.
The desktop client runs on both macOS and Windows and opens only after a work account sign-in. What follows is a familiar chat surface with a model picker that currently spans OpenAI and Anthropic options, including GPT 5.5. Users can also assign their agent a personality, though this feature appears to be more of a lighter touch than a core capability.
Meet Microsoft Scout. An always-on agent that keeps work moving, taking action without needing to be prompted each time. As Microsoft’s first Autopilot agent, Microsoft Scout works across Teams, Outlook, OneDrive, and more—taking action within the controls your organization…
The substance of Scout lies in its automation capabilities. Beyond simple scheduling, Scout allows users to build multi-step routines that incorporate Zapier-style orchestration directly into the app. It also offers a headless browser mode so certain jobs can run faster in the background. Integrations and a skills layer enhance its functionality, with the agent designed to work with local files, produce presentations, and assist with code, tasks that leverage the desktop's file-system access rather than relying solely on cloud-based resources.
Distribution remains gated. While anyone can download the client, entry depends on approval from an organization's admin, consistent with Microsoft's framing of Scout around governed Entra identities and tenant controls, which the company has indicated will be solidified later in 2026.
This direction aligns with a broader trend. With Google pushing Gemini Spark and competitors racing toward persistent agents, Microsoft's advantage lies in its ownership of both the operating system and the productivity suite surrounding it. Scout, along with the unified Copilot app expected this summer, suggests that the company intends to make the always-on agent the default method for managing work within its ecosystem.
Making Claude a chemist
Anthropic's Claude Opus 4.7 now matches or beats traditional chemistry software at predicting complex molecular NMR spectra.
Deep dive
- Tested Claude models (Opus 4.7, 4.6, Sonnet 4.6) against ChemDraw and MestReNova.
- Evaluated forward prediction (structure-to-spectra) on 20 compounds across four scaffold classes.
- Evaluated inverse prediction (spectra-to-structure) on 15 compounds.
- Opus 4.7 achieved accuracy within 0.079 ppm for hydrogen shifts, outperforming traditional tools.
- Claude models handled the inverse task successfully when provided with a starting material hint.
- The research highlights potential in literature mining, synthesis planning, and mechanism explanation.
Decoder
- NMR (Nuclear Magnetic Resonance): A spectroscopy technique that exploits the magnetic properties of atomic nuclei to determine the physical and chemical properties of atoms or molecules.
- SMILES (Simplified Molecular Input Line Entry System): A text-based notation for representing chemical structures as strings.
- 1D NMR: A standard spectral analysis that plots signal intensity against chemical shifts, used to identify atoms within a molecule.
Original article
Making Claude a chemist
Summary: We’re working with world-class synthetic, computational, and analytical chemists to make Claude better at chemistry. In this post, we share our first work as part of this effort, in which Anthropic chemist, David Kamber, examines how Claude performs on a chemist’s most common analytical input, an NMR spectrum.
When working with molecules, chemists move between hand-drawn structures on a whiteboard, instrument readouts, database query strings, and the technical notations of patents and publications. Each of these representations encodes the same underlying chemistry, but each demands a different kind of fluency. A sketch of caffeine, for example, allows a chemist to spot its resemblance to adenosine, the body’s drowsiness signal, and predict that it keeps us alert by blocking the receptor. However, that same sketch cannot help a chemist tell it apart from other near-identical looking molecules.
Understanding what molecule a chemist is working with is critical. Chemistry undergirds everything from the foods and medicine we ingest to our lotions, paints, and plastics. Reroute a handful of bonds among the same atoms, and glucose becomes fructose, molecules sharing a formula but processed through entirely different metabolic pathways. Flip a molecule into its mirror image, and a sedative becomes a teratogen, as happened in the thalidomide disaster. Chemists’ everyday work depends on reading these signals correctly across whichever representation befits a given task.
Translating between these representations (chasing down a structure from a figure, reconciling an instrument readout against a proposed product, querying a database in the right notation) is time consuming and impossible to keep up with at scale—CAS, the largest chemistry registry, catalogs over 290 million disclosed substances and grows by roughly 15,000 new ones every day.
AI is well-positioned to take on this research burden, yet it still remains largely aspirational in the context of chemistry. Machine-learning tools have been positioned for years as transformative for retrosynthesis—the process of working backward from a target molecule to simpler precursors to plan how to build it—reaction prediction, and property estimation, but the data those tools need have been hard to come by—sparse on null-results, inconsistent in format, and locked behind paywalls at subscription journals (and in unstructured supporting information). Retrosynthesis is a case in point—capable AI tools have existed for years, but adoption is uneven, and the average academic or small-lab chemist still doesn't use them.
Even so, advancements in AI are finally reaching chemistry. Today’s frontier models are multimodal, and capable of explicit reasoning. They can read a chemical structure directly from a journal figure or hand sketch rather than depending on a pre-curated molecular database. And they can read the experimental detail of a methods section or supporting information in the form it is actually published. They can also show their reasoning step by step, which means a chemist can audit the outputs. None of this eliminates the data problem the field has been describing for years, but it changes which problems are tractable despite it.
Ultimately, our claim is a modest one: Claude is starting to meaningfully assist chemists with the daily translation, recall, and integration work that complements their judgment, and we plan to keep extending its helpfulness. Today we are publishing the first white paper in the effort to accelerate this work. It tackles a chemist's most common analytical input: an NMR spectrum.
Claude vs. ChemDraw on NMR prediction and structure elucidation
Nearly every small molecule—drug, pesticide, dye, fragrance, polymer, DNA or protein subunit, and functional inorganic or solid-state material—exists because a chemist determined its structure. Given that these molecules cannot be seen with microscopes, chemists must rely on spectral analysis, probing a molecule with light, radio waves, or magnetic fields. The way a given molecule absorbs, emits, or deflects this energy gives chemists a pattern, or spectrum, with which they can elucidate its structure.
NMR spectroscopy—one of the canonical techniques chemists rely on for this—is one of the most time-consuming steps in synthetic chemistry; for every compound, a chemist has to match each peak in the spectrum to an atom in the proposed structure by hand. For this white paper, we tested how Claude fared against the dedicated NMR software chemists rely on today. We measured three Claude models (Opus 4.7, Opus 4.6, Sonnet 4.6) against ChemDraw and MestReNova on 20 compounds drawn from synthetic chemistry preprints published after the models’ training cutoff so as to avoid selection bias. Both ChemDraw and MestReNova do forward prediction, using a drawn structure to simulate what NMR spectrum will be produced. In addition to forward prediction, we also wanted to see whether Claude could go the other direction—starting from an experimental spectrum and proposing the structure behind it. This is the harder task, and the one existing software currently leaves to the chemist.
To set up our assessment, we pulled 20 compounds from ChemRxiv preprints posted after the models’ training cutoff, taking the first fully characterized novel molecules from each paper. The 20 span four structural families, five compounds each, with each family selected because it involves a different category of NMR challenge. Each tool was given the structure encoded as a SMILES string—the line-of-text notation chemists use to input a molecule to software—and was asked to predict where every hydrogen and carbon peak would fall along a 1D NMR spectrum (a horizontal axis measuring chemical shifts in ppm, parts per million). Given that NMR samples are dissolved in a liquid, and that the choice of solvent (chloroform, DMSO, etc.) moves the peak positions slightly, each tool was told to predict the spectrum in whatever solvent the chemists had used in the published paper.
Because a language model’s output varies between runs, each Claude model was queried three times per compound and averaged; ChemDraw and MestReNova return the same answer every time and were run once. We then paired each predicted peak with its experimental counterpart and measured the gap in ppm. These landed within the window a chemist would call correct—±0.20 ppm for hydrogen or ±1.0 ppm for carbon.
On hydrogen, Opus 4.7 was most accurate, with an average error of ±0.079 ppm—well under half the tolerance window—and the highest share of peaks landing inside it. On carbon, Opus 4.7 and MestReNova were effectively tied, at ±1.37 and ±1.48 ppm; the remaining tools kept the same rank order on both elements. Opus 4.6 was predictably middling, and Sonnet 4.6 was the weakest. The gap between them was most evident on a single notoriously difficult hydrogen—an NH proton in the chloropyridazine family whose true position falls in a narrow band between 6.8 and 7.9 ppm. Opus 4.7 placed it slightly low but consistently so; Opus 4.6 scattered its guesses across several ppm; Sonnet 4.6 put it in the 10–13 range, well outside where it actually appears.
While Opus 4.7 performed fairly comparably to ChemDraw and MestReNova, the gap was wider on predicting the shape taken by a hydrogen’s NMR peak and how far apart the peaks sit, features which also contain structural information a chemist reads alongside position. Opus 4.7 matched the experimentally reported splitting pattern more often than any other tool, and all three Claude models predicted the sub-peak spacing to within half a hertz roughly 80% of the time—against 26 to 35% for ChemDraw and MestReNova. Opus 4.7 was also the most consistent across its three repeat runs: its average error varied less from run to run than the margin separating it from the next-best tool.
From there, we evaluated inverse prediction (structure elucidation): could we determine the structure of a molecule from its spectrum? We gave Opus 4.7 15 elucidation problems and asked it, three times each, to propose up to three ranked candidate structures. Each supplied the compound’s exact molecular formula (from high-resolution mass spectrometry) and its hydrogen and carbon NMR spectra. The fifteen were split by difficulty. The eight simpler targets—single-ring or two-fragment molecules—were posed with only the formula and spectra. The seven denser targets—fused rings, spirocycles, and similar—were accompanied by one additional hint: the structure of the starting material that had gone into the reaction.
Opus 4.7 recovered all eight simpler structures on every attempt from spectra and formula alone. On the seven harder targets, given the starting-material hint, it returned the correct structure on all three runs for four of them and on two of three runs for those that remained.
Ultimately, we found that for routine data prediction Opus 4.7—a general-purpose model without chemistry-specific fine-tuning—is now as good as or better than ChemDraw and MestReNova on average. Additionally, Claude can also work the problem in reverse, proposing a structure from NMR data alone. Dedicated structure-elucidation software has existed for decades, but it typically requires 2D NMR (a spectrum with two axes, and the output is a contour map rather than a row of peaks), specialized training, and licensed tools. Claude does it from the same high-resolution mass spectrum and 1D peak list a chemist would paste into a chat, with no setup.
Limitations
This assessment shows us that a general-purpose model can be competitive with NMR software and even make 1D inverse elucidation tractable. But there are a handful of noteworthy limitations.
- First, the evaluation was small—20 compounds across four scaffolds for the forward task, 15 for the inverse task—and each scaffold contributes a single class of failure modes. The model performance should thus be read as indicative rather than precise.
- Second, on the densest inverse targets, without the starting material as an additional input, the model could loop through its reasoning without committing to a final structure; this is why the seven harder problems were posed with the starting-material structure rather than spectra alone.
- Third, some chemical scaffolds were left untested. For example, slow-exchange NH heteroaromatics (aromatic rings whose N–H exchanges with solvent slowly enough to leave a sharp NMR peak) are sampled only through chloropyridazines, leaving out related systems (hydroxypyridines, aminothiazoles, and other DMSO-d₆ NH-active scaffolds).
- Fourth, 2D experiments (COSY, HSQC, HMBC) and stereochemistry are out of scope by design, since 1D NMR alone cannot fix configuration. As a result, complex natural product compounds were not evaluated.
- And finally, our solvent coverage was limited to DMSO-d₆, CDCl₃, and D₂O, so methanol-d₄, benzene-d₆, and acetone-d₆ are not assessed.
Looking ahead
As we continue to improve Claude’s performance in chemistry, we are focusing specifically on a handful of bottlenecks that slow chemists down the most.
- Reading and rendering chemical structures—converting a drawing from a figure, patent, slide, or sketch into a machine-readable form, and going between structural representations and the systematic names used in chemistry literature.
- Reaction and synthetic reasoning—proposing, evaluating, and critiquing synthetic routes, anticipating outcomes, and thinking through selectivity, conditions, and likely byproducts.
- Mechanism—explaining and testing reaction mechanisms in the language a chemist actually uses, with electron arrows, intermediates, and transition-state arguments.
- Chemical literature understanding—reading chemistry as it appears in published work, where the same molecule may be drawn, named, abbreviated, or referenced by a code, and pulling out the chemistry that matters from method sections, supporting information, and patents.
These are not all on the same maturity curve. Where spectral analysis is far enough along to benchmark, others, like retrosynthesis planning, are still being scoped. As we get a better understanding of these bottlenecks, we will share where current models excel, and where they still fall short. Our ultimate goal is to ensure that working chemists know where Claude can save them time and where they still need to rely on their own expertise.
Working with us
We are expanding the AI for Science program to more explicitly support chemistry research. If you are a researcher working on a problem where Claude could plausibly help, especially one that involves the kinds of multimodal reasoning we have described, we would like to hear from you at scienceblog@anthropic.com, or through the AI for Science application.
Footnotes
- An incident in which a morning sickness medication was linked to severe birth defects in over 10,000 children worldwide.
- The four preprints from which we pulled the compounds: https://chemrxiv.org/doi/full/10.26434/chemrxiv.15002274/v1, https://chemrxiv.org/doi/full/10.26434/chemrxiv-2025-59lfh, https://chemrxiv.org/doi/full/10.26434/chemrxiv.15002423/v1, https://chemrxiv.org/doi/full/10.26434/chemrxiv.15002316/v1.

Gemma 4 QAT models: Optimizing model compression for mobile and laptop efficiency
Google's new Gemma 4 QAT checkpoints enable running high-quality AI models locally on mobile devices using as little as 1GB of memory.
Decoder
- QAT (Quantization-Aware Training): A training method where the model is simulated at lower precision (e.g., 4-bit) during training to minimize performance loss when it is finally quantized for deployment.
- PTQ (Post-Training Quantization): A technique where a model is compressed after being trained, often resulting in higher accuracy drops compared to QAT.
- VRAM: Video Random Access Memory; high-speed memory on GPUs used to store model weights during execution.
Original article
Gemma 4 QAT models: Optimizing model compression for mobile and laptop efficiency
Our new versions of the Gemma 4 family are optimized with Quantization-Aware Training (QAT) to dramatically reduce memory requirements and maximize on-device performance.
Since releasing Gemma 4 two months ago, we've been continuously working to expand its capabilities. First, we introduced Multi-Token Prediction (MTP) to accelerate inference, and just a couple of days ago, we released a 12B model to bridge the gap between our E4B and 26B MOE models.
Today, we are releasing new checkpoints optimized with Quantization-Aware Training (QAT) to make Gemma 4 even more efficient, so you can run models locally on everyday edge devices and consumer GPUs.
By simulating quantization during training, QAT minimizes quality loss when the model is compressed. This release includes QAT checkpoints for the popular Q4_0 quantization format as well as a novel quantization format specialized for mobile use cases. Using this mobile format, we’ve reduced the memory footprint of Gemma 4 E2B to 1GB. Together, these dramatically reduce memory requirements while preserving the capabilities and quality you expect from Gemma 4.
Keeping model quality while making them smaller
Quantization is a key technology to run models on consumer hardware by reducing their memory footprint while also accelerating decode speed. However, standard Post-Training Quantization (PTQ) often leads to performance degradation. Instead of simply quantizing the model after training, QAT integrates the quantization process directly into training. While PTQ is already effective at preserving quality, our QAT results yield even higher overall quality compared to standard PTQ baselines.
We applied this QAT recipe to the popular Q4_0 format to maximize performance for all the models. For the edge models (E2B and E4B), we rethought how we approach quantization with a special mobile-specialized quantization schema.
Saving on VRAM and Storage
Below are the approximate memory requirements indicating how much VRAM is required to load the models:
Optimizing for mobile devices under the hood
Standard compression formats are often hard for mobile processors to run efficiently. To ensure Gemma 4 performs smoothly on mobile, we engineered a custom mobile-quantization schema designed for edge hardware:
- Static activations: Normally, models waste processing power calculating how to scale data on the fly. We pre-calculate these settings during training, which reduces workload on mobile chips and makes responses faster.
- Channel-wise quantization: We structured the compressed data to fit the design of mobile accelerators. This allows the phone to run calculations natively without needing slow workarounds.
- Targeted 2-bit quantization: We heavily compressed (to 2-bit) the specific parts of the model that generate tokens, while keeping the core reasoning layers at higher precision. This saves storage without making the model less smart.
- Embedding and KV cache optimization: We focused compression on the model’s vocabulary list and its short-term memory. This drastically reduces the active memory footprint, letting you have long chats without running out of space.
Because our audio and vision encoders are not needed in many use cases, you can optimize your memory footprint even further by deploying only the modalities you need. For example, the Gemma 4 E2B text-only model (without Per-Layer Embeddings) requires less than 1 GB of memory.
Get started today
To make those models easily usable with your preferred workflow, we’ve partnered with popular developer tools across the ecosystem to seamlessly support the Gemma 4 QAT checkpoints starting today:
- Download the weights: Access the Q4_0 and mobile model weights right now on Hugging Face. We've tailored the formats to fit your workflow: GGUF formats are ready for use with llama.cpp, and compressed tensors are provided for vLLM. For everything else, we share unquantized checkpoints that can be converted and quantized into formats supporting Q4_0.
- Integrate & learn: Explore our documentation to learn how to best deploy the QAT checkpoints.
- Try on your desktop: Easily download, manage, and run Gemma 4 QAT models locally on your desktop using user-friendly interfaces like llama.cpp, Ollama and LM Studio.
- Deploy on-device: Use Google's lightweight LiteRT-LM runtime for optimized edge deployment or run the models directly on the web with Transformers.js
- Use your favorite development tools: Serve larger models efficiently with SGLang and vLLM, optimize for Apple Silicon with MLX. Use the MTP QAT checkpoints to preserve the speedup of MTP while quantizing the models. Fine-tune weights directly using Hugging Face Transformers and Unsloth.
We can't wait to see what you build with Gemma 4 running locally!

Give your agent its own computer
LangSmith Sandboxes provide hardware-virtualized microVMs to give AI agents secure, isolated computing environments for executing untrusted code.
Deep dive
- Agents in production often require the ability to run arbitrary code, which introduces significant security risks.
- Docker containers share the host kernel, leaving them vulnerable to exploits like CVE-2026-31431.
- LangSmith Sandboxes use hardware-level isolation to prevent agents from compromising production systems.
- Sandboxes provide persistent state, allowing agents to install dependencies, modify files, and continue workflows across sessions.
- Primitive features include snapshots/forking, blueprinted environments, and authenticated service URLs for previews.
- This setup is particularly effective for coding assistants, data analysts, and CI/CD agents.
Decoder
- microVM: A lightweight virtual machine that provides hardware-level isolation, similar to a standard virtual machine but optimized for fast startup and low overhead.
- Kernel: The core of an operating system that manages system resources and facilitates communication between hardware and software.
Original article
Give your agent its own computer
LLMs can reason. But reasoning alone doesn't get much done.
Running code execution in an AI agent is harder than it looks. Your agent needs a real computer (filesystem, shell, package manager, persistent state) but handing it access to your infrastructure is dangerous.
Think about it this way: you use one laptop. You are n of one. But agents are going to run millions of tasks, and each one needs its own computer to work from. That's the infrastructure shift happening right now. Satya Nadella put it plainly: "Every agent needs a computer." The question is what that computer looks like, and how you give it to them safely.
LangSmith Sandboxes are our answer to that. Here's why it matters, and why doing it yourself is harder than it sounds.
What becomes possible when an agent has a computer
Think about what Cursor, Claude Code, or ChatGPT's code interpreter can do that a plain chat interface can't. They don't just answer questions: they run the code, see the error, fix it, run it again, and hand you something that works. That feedback loop is what makes them useful.
That same loop is what separates a demo agent from a production agent. Once your agent can execute, a whole category of work opens up:
- A coding assistant that doesn't just suggest a fix: it applies the fix, runs your tests, and confirms nothing broke
- A data analyst that pulls a CSV, runs Python against it, and hands you a formatted report
- A CI agent that clones your repo, installs dependencies, runs the full test suite, and opens a PR
- A research agent that browses, scrapes, synthesizes, and writes — not just searches
- A content pipeline that generates, renders, and exports finished artifacts
- An RL or eval harness that needs to spin up environments in parallel, run episodes at burst scale, and tear them down immediately — zero to thousands of sandboxes, then back to zero
The common thread: these agents need more than a token stream. They need a place to work.
Why you can't just hand your agent your laptop
The obvious next question is: why not just let the agent run code locally? Or in a Docker container? Teams do this in early prototypes. It stops working in production for two reasons.
First: agents run untrusted code by definition.
The code your agent executes might come from a model, a user prompt, a cloned repo, or an installed package. You didn't write it. You can't fully vet it. In September 2025, a self-replicating npm worm called Shai-Hulud backdoored 500+ packages — code that executed in preinstall before any validation could run. A second wave in November hit 796 more packages and 25,000+ GitHub repos in hours. An agent that installs npm packages as part of its workflow is exposed to exactly this.
Second: containers aren't enough.
The common instinct is "just run it in Docker." Containers are great for isolating known, vetted application code (i.e. a web server, a background job). They're not designed for an agent that's installing arbitrary dependencies, running model-generated scripts, and persisting state across a long-running session. And critically: containers share a kernel with the host. A kernel exploit reaches through them. Copy Fail (CVE-2026-31431) is a 732-byte Python script that roots every major Linux distribution back to 2017 via the kernel crypto API. AI tooling found it in about an hour.
A container boundary is not an isolation boundary. For untrusted, model-generated code, you need hardware-level separation.
LangSmith Sandboxes: a computer for every agent
The mental model that helps here: a sandbox needs to be two things at once. It needs the instant startup of a serverless function because you can't make an agent wait two minutes for a VM to boot. And it needs the statefulness of a full machine because agents aren't stateless request-handlers; they're mid-session workers that install dependencies, edit files, and pick up where they left off.
LangSmith Sandboxes are built for that model. Each one is a hardware-virtualized microVM. Not a container, a full machine with its own kernel. The agent gets:
Agent
└── its own computer
├── filesystem
├── shell
├── package manager
├── network access
├── code execution
└── persistent stateIt can install packages, run scripts, edit files, spin up a local server, and keep working across a long session — all without touching your production infrastructure or any other agent's sandbox. When the work is done, the sandbox disappears.
You access it through the same LangSmith SDK and API key you already use:
from langsmith import Client
client = Client()
sandbox = client.create_sandbox()
# Give the agent a shell
result = sandbox.run("pip install pandas && python analysis.py")
print(result.stdout)It just takes one call, and your agent has a computer.
There's also a less obvious benefit for teams running GPU workloads: when your sandbox spins up instantly, your GPU doesn't idle waiting for CPU compute to provision. Fast sandboxes are a GPU efficiency multiplier — a detail that compounds quickly at scale.
What you get beyond basic execution
A sandbox is more than a place to run code. The GA release ships a set of primitives that make agent workflows production-ready:
Snapshots and forks: Capture a sandbox mid-session and boot new ones from it. Forks use copy-on-write, so spinning up ten parallel branches costs roughly the same as one. When your agent goes down the wrong path, restore and try again, without rebuilding from scratch.
Blueprints for pre-warmed environments: Define a base image (your repo cloned, your deps installed, your config in place) and boot sandboxes from it in seconds instead of minutes.
Service URLs: If the agent starts a local web server — say, to preview a generated report — you get an authenticated URL you can open in a browser or share with a teammate. No port forwarding.
Auth proxy: Outbound requests from the sandbox flow through a proxy that injects credentials at the network layer. Secrets never touch the agent runtime.
Creator-private by default: Only the user who launched a sandbox (and workspace admins) can access it. Share when you're ready.
When to reach for Sandboxes
Sandboxes are the right layer when your agent needs to do something, not just say something. Concretely:
- Your agent generates code and you want it to verify that code runs before responding
- You're building a coding assistant, CI agent, or data pipeline that operates on real files
- You're running multi-step workflows where state needs to persist across tool calls
- You need burst capacity (i.e. thousands of parallel environments for RL training or evals) that has to scale from zero in seconds
- You're accepting any user-supplied input that could end up being executed
Sandboxes are overkill if your agent only calls APIs with fixed schemas and never executes dynamic code. A retrieval agent that searches docs and returns citations doesn't need one. An agent that writes and runs a Python script does.
How teams are using this today
At monday.com, Sandboxes power their Sidekick AI assistant, giving it a secure environment to write and run code for advanced user workflows, including data analysis and multimedia generation.
"LangSmith Sandboxes are helping us make our Sidekick much more capable for monday.com users. With secure environments, Sidekick can write and run code, and use the results to create richer workflows, like running data analysis and generating multimedia."
— Omri Bruchim, AI Platform Group Manager, monday.com
The shift worth paying attention to
For the last few years, making an agent more capable meant giving it better tools: a search API, a calculator, a database connector. That's still true. But the ceiling on what predefined tools can do is low.
The agents that will actually replace workflows (not just assist with them!) are the ones that can pick up whatever tool they need, run it, see what happened, and adapt. That's what having a computer makes possible. It's not an infrastructure detail. It's the difference between an agent that can think and an agent that can act.
You use one laptop. Your agents will each need their own. LangSmith Sandboxes are how you give them one.
OpenAI Adds Lockdown Mode
OpenAI's new Lockdown Mode protects against prompt injection by restricting agent access to external web tools.
Decoder
- Prompt injection: A security vulnerability where malicious input is used to hijack an LLM, causing it to ignore its original instructions and execute unauthorized commands.
Original article
OpenAI introduced Lockdown Mode to reduce exposure to prompt injection attacks from webpages and external content. The feature disables live browsing, web image retrieval, deep research, and agent mode while keeping some cached content and image-generation functionality available.

Five labs, five minds: building a multi-model finance drama on small models
Simulating a market economy using multiple small models highlights that model heterogeneity creates more complex emergent behavior than a single-model approach.
Deep dive
- Heterogeneity creates more realistic market dynamics than homogeneous model agents.
- Serving multiple models concurrently requires shared base images with full CUDA toolkits to avoid kernel compilation failures.
- Use a JSON repair layer to normalize inconsistent outputs across different model architectures.
- Security firewalls must exist in the application logic; never trust a model to keep secrets that are part of its prompt.
- Persistent memory should be implemented as bounded, integer-based summaries to avoid context window degradation in small models.
Decoder
- vLLM: A high-throughput, memory-efficient inference and serving engine for LLMs.
- CUDA (Compute Unified Device Architecture): A parallel computing platform and programming model created by NVIDIA for GPU acceleration.
- MXFP4: A 4-bit floating point data format used for model quantization to reduce memory usage.
- Induction head: An attention mechanism component that identifies repeated patterns in text, enabling models to perform 'in-context' learning by repeating previous behaviors.
Original article
Five labs, five minds: building a multi-model finance drama on small models
A second Build Small Hackathon field report: what happens when each agent in an emergent economy runs on a different lab's small model, and the player becomes the financier pulling the strings.The first version of Thousand Token Wood was a weather-god sandbox: five woodland creatures on one fine-tuned 0.5B model traded goods, and you poked the world with shocks and watched bubbles and crashes emerge. It was a nice toy. It was also something you watched rather than played.
v2 rebuilt it into a game you operate. You are the Patron of the Wood, a shadow financier: you lend at interest, whisper tips that may be true or planted, short the market, bribe, and broker alliances, while a magistrate hunts you for trading on what you should not know. The creatures remember how you treated them and scheme back. And the biggest change is under the hood: every creature now thinks with a different lab's small model. This is the engineering report.
Heterogeneity is the product, not a constraint
The obvious way to run a council of agents is one model, many prompts. v2 runs four: gpt-oss-20b (OpenAI), MiniCPM3-4B (OpenBMB), Nemotron-Mini-4B (NVIDIA), and a fine-tuned Qwen 0.5B of my own. The point is not novelty for its own sake. A market is interesting when the participants genuinely differ, and four labs' models trained on different data with different post-training are about as different as small models get. The owl hoards differently than the fox speculates. The council is a live argument, not a script.
Standing four distinct models up on one platform surfaced the real lesson: the friction is almost entirely at the serving layer, not the modeling layer.
- Current vLLM (0.22.1) JIT-compiles kernels at load and needs the CUDA toolkit (
nvcc) present. A lean base image does not ship it, so all four models failed identically with "could not find nvcc" until I based them on a CUDA devel image. This was not a gpt-oss quirk; it was universal to the vLLM version. One image fix unblocked everything. - gpt-oss-20b runs in its native MXFP4 quantization and fits a 24GB L4 with room to spare; no high-end GPU needed. It also speaks a channel format that wraps the answer in an analysis preamble, so the consumer has to extract the final channel.
- MiniCPM3 needed
trust_remote_code; Nemotron loaded clean. Per-model footguns, each a one-line config.
The thing that made four heterogeneous models tractable was the same primitive that made one model tractable in v1: a tolerant JSON parse-and-repair layer that every model's output flows through. Different tokenizers and formatting habits produce different malformations; the parser drops what it cannot salvage and the simulation never crashes. Build that layer once and adding a model is a config entry, not a refactor.
Information asymmetry needs a firewall
The dramatic core of v2 is the insider tip. You can whisper a tip to a creature that is true (a real forecast of the next market mania the deck will draw, your genuine edge) or false (bait). Acting on a true tip and profiting raises your heat; cross a threshold and the magistrate opens an investigation that ends in a fine, frozen assets, or exile.
For that to be a real game, the truth of a tip must be hidden from the creatures. They see the rumor text; they must never see the flag. This is a security property, not a UI nicety, and small-model agents make it sharp: everything the model could repeat back is whatever you put in its prompt. So the hidden flag lives off-prompt entirely (on the player's ledger), it is stripped from the public event record at construction, and the only thing the narrator ever summarizes is public events. A single test scans every creature's full prompt, every turn, for the banned tokens. That test is the most important one in the suite. When you give an agent secret information, assume it will leak unless a test proves it cannot.
Memory is cheap drama if you bound it
Creatures carry persistent relationships: a signed sentiment toward the Patron and toward each other, nudged by events (you shorted my crop, you repaid your loan, you allied me with a rival). A creature that turns hostile refuses your loans and quotes you worse; allied creatures stop undercutting each other and behave like a cartel.
The trap is prompt inflation. Raw history grows without bound and a small model drowns in it. The fix is to never put history in the prompt: the model sees a one-line bucketed summary ("you feel warmly toward Oona, wary of the Patron"), capped to the few strongest feelings, derived from integer sentiment. Notes are kept for traces but bounded and never shown. The behavioral bias is part emergent (the summary nudges the model) and part mechanical (a strongly hostile creature deterministically refuses), so it is observable and testable rather than a hope.
What actually happened
A representative council run, with the full v2 mechanics live:
| Lever | Result |
|---|---|
| Models in the council | 4 labs, all under the 32B cap, served on Modal |
| Fine-tuned 0.5B reliability | 0% self-buys, 100% valid offers (beats its 3B teacher) |
| Truth firewall | 0 leaks of a tip's hidden flag across every prompt scanned |
| Insider tip edge | a true-tip pre-position settles a positive P&L; a false tip does not |
| Heat to investigation | two clean suspicious wins cross the magistrate's line |
| Ruin | a margin call and a loan default banish a creature, who returns a chapter later |
A single seeded run exercising the Patron, the information war, relationships, and leverage end to end.
Takeaways for building with small models
A small model is a reliable format generator and an unreliable reasoner; you close the gap with structure, prompting, and a small fine-tune, not with scale. A heterogeneous council is more interesting than a homogeneous one and costs you only config once the serving layer is solid. Secret information given to an agent is a firewall problem, and the firewall belongs in the data flow, proven by a test, not in a prompt instruction. And persistent memory is the cheapest way to make agents feel alive, as long as the prompt only ever sees a bounded summary.
Small models, big adventures. The whole council is open, and so are the traces.
Cursor's Updated Design Mode
Cursor's updated Design Mode allows developers to modify UI code by visually pointing, drawing, or narrating changes directly on a running application.
Decoder
- Fiber tree: A internal data structure in React that represents the component tree and holds state/props information for the renderer.
Original article
Chat is one interface for working with agents, but UI work tends to be spatial. Designers, PMs, and frontend developers often communicate through annotations that point to elements, regions, or the state of the page.
Design Mode, which we're updating today, is part of how we're shrinking the distance between what you see and what the agent understands. It lets you edit your product in context while staying in flow.
From the Cursor browser, you can click any element, draw on the page, or describe the change by voice, and Cursor gets the context it needs to edit the code while you move on to the next edit.
It is a faster, easier way to iterate on design changes with agents because the instruction is no longer just a sentence—instead it can include the selected element, the code behind it, the surrounding layout, and the visual relationships on the page.
This makes the loop between noticing and editing tighter. You can point at the part of the interface you mean without leaving the running product, then keep making references against the product itself while agents make the edits underneath.
Point, draw, or narrate the change
Design Mode provides several ways for you to convey intent to the agent. You can select an element, add multiple references, draw over the interface, or use your voice to describe the change.
Click an element in the running app, prompt against that selected element, and let the agent edit the code.
Multi-select is useful when the change depends on a relationship between elements. You can reference two components and ask the agent to make one match the other, remove repeated content, or adjust a group of components together.
Select multiple elements and describe how they should change together.
Drawing is useful when the agent needs to know what area of the page the instruction applies to. You can circle a crowded section, box in a region, or mark part of an animated page. The annotation sits over a frozen frame of the viewport, so the agent sees the exact page state you were responding to.
In this release, you can also narrate instructions using your voice, and we've made targeting more precise and the experience faster. Altogether, this makes visual interactions in Design Mode feel more like part of a normal editing loop.
Use voice input and drawing together to describe a change.
Under the hood, picking an element adds two complementary signals into context: the element's identity (xpath, the component, attributes, computed styles, props from the fiber tree) and a screenshot for spatial context (layout, surrounding elements, and the exact page state). This gives the agent exactly what it needs to find the source and edit the code efficiently.
Matching the model to the rhythm of the work
When you are refining a user interface, one chain of edits usually leads to the next. You adjust a component, notice the spacing around it, then see how another component should match.
Design Mode lets you send those edits away as you notice them. You can point at one element, describe the change, move to another part of the page, and send another edit before the first one has finished. Design Mode allows you to multitask more easily and makes managing multiple subagents possible.
This flow works best with a model that can make targeted UI changes quickly. Composer 2.5 excels at this because it is both fast and strong at interface work. As agents finish, the app hot reloads. You see the changes appear in the running product and keep going until the interface feels right.
We believe the future of building software lets users move seamlessly between higher levels of abstraction and lower-level details while working in flow state when they want to. Design Mode provides users with the control, agency, and precision editing tools that make that possible.
Try Design Mode in the Agents Window. Read the Browser docs to learn more, or download Cursor to get started.

Small modular nuclear reactor reaches criticality in first test
Startup Antares achieved the first self-sustaining reaction in a test reactor using TRISO fuel, signaling a shift toward safer, modular nuclear power.
Decoder
- Criticality: The state in which a nuclear reactor's chain reaction becomes self-sustaining.
- TRISO (Tri-structural Isotropic): A fuel technology where uranium particles are encapsulated in carbon and ceramic layers, making them highly resistant to heat and physical damage.
- Brayton Cycle: A thermodynamic cycle used in gas turbines where gas is compressed, heated, and expanded to generate power.
Original article
Just over a year ago, the Trump Administration issued an executive order meant to accelerate the development of nuclear power in the US. While an entire startup ecosystem has developed around the use of different—and typically smaller—reactor designs, only one of them has been fully licensed so far, and there are no plans to actually build any instances of that design.
The executive order directed the Department of Energy to have three different reactor designs reach criticality in a bit over a year. On Thursday, a startup called Antares announced that a test reactor it had placed at the Idaho National Laboratory had reached criticality, making it the first new design to cross this threshold. Criticality means that the nuclear reactions inside the hardware had become self sustaining; it does not mean the reactor had started to generate power.
Antares is one of a number of companies that is basing its design on a new fuel system called TRISO that takes some of the complexity and safety out of the reactor design and places them in the fuel design. The fuel design is based on tiny pellets with a uranium oxide core. The pellets are surrounded by several layers of carbon that can moderate the energy of both the neutrons and lighter nuclei that are released by fission reactions. All of that is encased in a hard ceramic shell that’s designed to withstand the highest temperatures that can be produced by the encased uranium.
As long as your reactor can keep the TRISO pellets contained, then there should be no risk of meltdown or even the release of the most dangerous isotopes produced from the reactions. There are still some safety concerns, as neutrons will still escape and can potentially convert some of the surrounding material into unstable isotopes. But the Antares design surrounds the TRISO with a graphite sheath, which should slow most of these neutrons down.
To mitigate non-radioactive risks, the Antares design uses sodium to take heat from the reactor to a heat exchanger. The heat is transferred to pressurized nitrogen, which then drives a turbine in a closed Brayton cycle setup.
At the moment, Antares is just testing what it calls a Mark 0 reactor, which is not connected to the power-generation portion. Instead, it’s being used to validate the company’s modeling of the physical conditions in its reactors and generate safety data that can be used during licensing applications. Attempts to run the entire system, including electrical generation, are expected to happen next year.
While the work was done at a Department of Energy Lab, the company is working with the Department of Defense’s Project Pele program for developing a mobile nuclear reactor. The company has also received support from NASA.

Why Robotics is a Pre-Paradigm Field
Robotics remains a pre-scientific field because we lack a unified theory of embodied intelligence, forcing developers to rely on competing, implicit paradigms.
Deep dive
- Pre-paradigm state: Robotics lacks an organizing principle like DNA for biology or the Periodic Table for chemistry.
- Implicit theories: Every tool selection encodes a belief about what 'intelligence' is.
- POMDPs: A framework that captures latent states and noisy observations but is currently computationally intractable.
- The VLA bet: The industry is largely coalescing around Vision-Language-Action models fine-tuned with reinforcement learning.
- Future outlook: RL may eventually surpass imitation learning once policies can collect their own self-generated training data.
Decoder
- SLAM (Simultaneous Localization and Mapping): A technique where a robot builds a map of an unknown environment while keeping track of its own location within it.
- POMDP (Partially Observable Markov Decision Process): A model for decision-making under uncertainty where the agent cannot directly observe the environment's state.
- VLA (Vision-Language-Action): A model architecture that bridges visual input, natural language instructions, and physical motor actions.
Original article
Why Robotics is a Pre-Paradigm Field
Towards a Grand Unified Theory of Robotics
Thomas Kuhn wrote The Structure of Scientific Revolutions in 1962, introducing the notion of a paradigm shift in science: when a field of science converges around an organizing principle that changes everything. The discovery of DNA. The periodic table of elements. The germ theory of disease. In robotics, we are in the stage of pre-science. We have identified the problem to solve: we want to make an embodied agent act intelligently in the physical world. There are ideas for paradigms swirling around, and there have been since the beginning: Subsumption architecture. Sequential composition. Neural networks. MDPs and POMDPs. And there have been pieces of theories: SLAM and the Rao-Blackwellized Particle Filter. Motion planning. Diffusion Policies. Data+VLA+RL.
But we don’t yet have a grand unified theory of robotics. I’ve been thinking about this since I started my faculty position at Brown in 2013. When I was a postdoc, I had to be laser-focused on becoming the best person in my age group in my area: language understanding for robotics. So my research was all about language understanding. (Our AAAI 2011 paper just won the AAAI 2026 classic paper award! ) As a faculty member, I had the privilege of broadening my focus. People want to talk to robots about everything they can see and everything they can do, so we need models that connect to everything they can see and everything they can do. We need a grand unified theory of robotics.
The closest I found was POMDPs. Partially Observable Markov Decision Processes. A POMDP is the simplest model I know that captures everything a robot can do: a latent state of the physical world, observations the robot can see that provide noisy information about that state, actions that change the underlying state of the world, and a goal in the form of a reward function. Unfortunately, POMDPs are undecidable in the general case. They are too challenging a problem for our computers to solve. They provide a model, but they do not provide computational leverage. I realized that POMDPs are like Python: Python is undecidable, too. But we can still use it to write useful programs and tools. So a lot of my group’s paper boiled down to writing about how to introduce structure into a POMDP to enable efficient learning and inference. I embarked on a quest to figure out how to integrate SLAM into a POMDP, but got stuck on what the reward function should be. And I framed all of my group’s work around constructing pieces of a Human-Robot Collaborative POMDP.
Meanwhile, Deep Learning happened. Is Deep Learning a paradigm? Maybe. Certainly, it’s an unbelievably effective way to perform function approximation. We might wish there were more theory to explain why it works, how long it will take to train, and what size gradient steps to take. We still have to form training recipes and model structure around what we think is important and what not: a giant unstructured multi-layer perceptron is not the universal solution to our problems.
The current bet many of us are making is more specific than deep learning alone. The working hypothesis is that data plus Vision-Language-Action models plus reinforcement learning equals a generalist robot: pretrain a VLA on internet-scale vision and language, fine-tune it on as much teleoperated robot data as you can collect, and then let RL close the remaining gap through autonomous practice. Physical Intelligence, Skild, Figure, 1X, Generalist, Google DeepMind, and Tesla are all placing some version of this bet, with different weightings on each term. A secondary bet, gaining traction fast, is that RL eventually eats data and VLA’s lunch entirely: that once you have a policy good enough to collect its own experience, scaling self-generated data through RL dominates whatever imitation learning can offer. This might be the paradigm. It might also be dephlogisticated air.
Kuhn delves into the story of Joseph Priestley and Lavoisier and the discovery of oxygen. Joseph Priestley isolated oxygen in 1774 by heating mercuric oxide. He noticed it made candles burn brighter and kept mice alive longer. But Priestley interpreted what he saw through the lens of phlogiston theory, the prevailing belief that combustion worked by releasing a substance called phlogiston. He discovered oxygen but couldn’t see it for what it was. He called it “dephlogisticated air” and went to his grave defending phlogiston.
Antoine Lavoisier heard about Priestley’s experiments, repeated them, and saw something completely different. Not because the experiments were different. But because Lavoisier was willing to throw out phlogiston entirely. He reframed combustion as a combination with a new element, named it oxygen, and built the modern theory of chemistry around it. Same data. Different paradigm.
This is where robotics is today, with one important caveat. Jessica Hodgins pushed back on me here, and she’s right: Priestley had a wrong theory that prevented him from seeing what his experiments revealed. Most roboticists aren’t operating under wrong theories in that sense. SLAM, function approximation, and motion planning are all pieces of a critical recipe that, as of May 2026, still have an important place in the toolbelt of roboticists looking to solve specific problems.
But the choice of which tool to reach for encodes an implicit theory of what embodied intelligence is. SLAM researchers act as if intelligence centrally requires explicit state estimation. Learning researchers act as if intelligence is a function approximation at a sufficient scale. Controls researchers act as if intelligence reduces to optimization under known dynamics. These are paradigm-level commitments masquerading as tool choices, and any of them could be as wrong as phlogiston. We are all looking at the same robot, in the same physical world, and the tools we reach for reveal what we think the robot fundamentally is.
The engineering question is what we need to build to make a general robot. The science question is what embodied intelligence actually is. The first is making progress.
For the second, we’re waiting for our Lavoisier.
Lavoisier went to his grave during the French Revolution in 1794, guillotined after his conviction as a tax collector. The mathematician Lagrange remarked, “It took them only an instant to cut off that head, and a hundred years may not produce another like it.”

The future of the web is weirdly human
The new HTML-in-Canvas API lets developers render interactive DOM elements inside rich 3D graphics, potentially ending the era of page-centric web design.
Deep dive
- Current limitations: The web has historically been constrained by document-centric design (pages, scrolls, hierarchies) to support search and accessibility.
- The API breakthrough: HTML-in-Canvas enables DOM elements to live inside 3D textures while remaining indexable by search engines and screen readers.
- Separation of concerns: As machines (LLMs, search crawlers) get better at consuming raw data, the human layer can become more creative.
- Semantic web: The infrastructure can remain semantic and structured while the user experience becomes increasingly spatial or game-like.
Decoder
- Canvas: A HTML element used to draw graphics on a web page via scripting, usually JavaScript.
- DOM (Document Object Model): The interface that allows programs to update the structure, style, and content of a document.
- WebGL/WebGPU: APIs that allow browser-based JavaScript to perform hardware-accelerated 3D and 2D graphics rendering.
Original article
The future of the web is weirdly human
The most interesting thing I’ve seen on the web this year isn’t an AI product. It’s a browser feature, and the future that it might represent.
Recently, Chrome began experimenting with something called HTML-in-canvas. At first glance, it looks like a fairly niche technical proposal. The browser takes ordinary HTML content and allows it to be rendered inside rich canvas environments whilst retaining all of the things that make HTML useful in the first place. The content remains part of the DOM. The browser still understands it. Accessibility tools still understand it. Search engines still understand it.
The demos are worth watching.
HTML just went 3D.
WICG’s HTML in Canvas lets you drop native DOM elements directly into WebGL and WebGPU scenes.
The flat web is getting a lot more interesting.
The nascent HTML-in-Canvas API is exciting to me not for flashy effects, but because it extends the semantics that the DOM can (tractably) represent — tiny example: it’s possible to show an element in multiple places, cheaply, under arbitrary transforms.
HTML can’t run Doom
But HTML can now run inside Doom! Thanks to HTML-in-Canvas!
Fully accessible DOM elements drawn into Doom’s own wall textures. This demo uses a WebAssembly port (jacobenget/doom.wasm) of the original C source.
HTML-in-canvas is now a first-class primitive in Remotion!
It enables new types of effects that were impossible before.
My take on the HTML-in-Canvas API that’s been trending lately.
Fetched pages from a website and took them into another dimension.
The parallax syncs with your head movement.
Built with Threejs and Mediapipe
HTML in Canvas + fragment shader.
Shader is applied to the actual interactive html.
html-in-canvas can’t ship fast enough
Card transition experiment with React Three Fiber + html-in-canvas.
Try it here: https://t.co/eEV2YTnRxd
Needs Chrome Canary for the interactive cards.
HTML-in-Canvas will open a door for innovation on the web
Create UIs and user experiences that are more engaging and sensible than ever before
Very straightforward and accessible
Extremely normal interfaces!
What’s striking about these examples isn’t the visual spectacle. We’ve had visually spectacular websites before. Nor is it the fact that content can exist in three-dimensional space. We’ve been building 3D experiences on the web for decades.
What feels different is that none of the usual compromises appear to apply.
Historically, richer experiences tended to come at a cost. The more expressive an interface became, the further it drifted from the native capabilities of the web. Search became harder. Accessibility became harder. Browser functionality became harder. Developers found themselves rebuilding things that browsers already knew how to do.
The demos hint at a future where that trade-off begins to disappear.
And once I’d started thinking about that, I found myself asking a much bigger question.
Why do websites look the way they do?
Why do they almost all share the same fundamental shape?
Why are websites for museums, communities, universities, dentists and product catalogues all made of pages?
Why are most websites made of pages connected by navigation, arranged into hierarchies, organised into sections and consumed through vertical scrolling?
The answer is that, for much of the web’s history, the document sat at the intersection of a huge number of competing requirements. Search engines could crawl it. Browsers could render it. Accessibility tools could interpret it. Content management systems could generate it. Businesses could manage it. Analytics platforms could measure it.
The document wasn’t necessarily the best representation of every idea, every place, every product or every experience. It was simply the format that everybody could agree on. And over time, that compromise became invisible.
The web didn’t merely adopt documents as a publishing format. It gradually began to think in documents.
I’ve written before about the URL-shaped web and the tendency for technologies to shape the information they contain. We became so successful at publishing, measuring, ranking and optimising documents that we eventually stopped noticing that we were making a choice.
The page won because it was practical. And over time, the advantages of the document-shaped web overwhelmed almost everything else.
We flirted with alternatives. Flash, for a while, promised a web built around experiences rather than documents. But those experiences were difficult to crawl, difficult to measure, difficult to integrate and difficult to standardise. Search engines, accessibility requirements and the broader web ecosystem gradually pulled everything back towards HTML and pages. The document didn’t win because it was the most expressive format. It won because it was the most compatible.
But now, we may wish to re-evaluate those constraints, assumptions, and advantages.
Enter AI
For most of the web’s history, the human-facing experience and the machine-readable representation were effectively the same thing. Increasingly, this needn’t be the case.
One of the more interesting things happening right now is the gradual separation of information from presentation. Search engines increasingly consume structured representations of content. Applications consume APIs. AI systems are starting to consume entities, relationships, feeds, product data and all manner of machine-oriented representations that were never intended for human eyes.
There’s a lot of debate around what the best architecture for this new age looks like – but whether it’s llms.txt, markdown files, or something else entirely, isn’t the interesting thing.
What’s interesting is that the web is becoming comfortable with the idea that different types of audiences might consume different representations of the same underlying information.
And the better that machines become at understanding meaning directly, the less pressure there is for human experiences to remain constrained by the formats that machines once required.
What if a website wasn’t a document?
The future of the web will likely become more semantic, more structured, and more machine-readable than ever before.
But HTML-in-canvas may allow it to become more expressive than ever, too.
HTML-in-canvas is exciting because it hints at a future where the document remains intact, but stops dictating the shape of the human experience. A conference website could still be represented as structured HTML, whilst being experienced as a landscape of talks and ideas. A supermarket website could build rich, interactive product explorations on top of their native HTML.
The machine-readable layer doesn’t disappear. It just becomes infrastructure.
For thirty years, we’ve largely shaped human experiences around what machines could reliably understand.
The strange possibility emerging now is that machines may finally be sophisticated enough to let us stop.
For AI, we can step down our HTML into simpler representations and presentations. For humans, maybe now we can step it up.
And if that’s true, then the future of the web may end up looking a lot less like documents, and a lot more like the things it’s trying to describe.

Why Software Automation Is Hard
Software automation via AI is encountering structural bottlenecks where increased coding velocity often results in lower-quality output and increased coordination overhead.
Deep dive
- Coding agents are highly effective for isolated tasks but struggle with systemic project context.
- Context windows struggle to replace the human 'theory of the code' that includes legacy constraints and social dynamics.
- Non-functional requirements (performance, security, trade-offs) are often ignored by AI, leading to 'slop' and technical debt.
- Over-reliance on AI for problem-solving risks long-term cognitive decline in human engineering skills.
- Coordinated development requires syncing many processes (testing, PM, legal) that cannot be accelerated by simply writing code faster.
- Market feedback loops act as a constraint on business value; 100x development speed does not necessarily translate to 100x market growth if feedback remains at human scale.
Decoder
- Amdahl's Law: A formula used to find the maximum expected improvement to an overall system when only part of the system is improved.
- Tacit Knowledge: Knowledge that is difficult to transfer to another person or machine by means of writing it down or verbalizing it.
Original article
Full article content is not available for inline reading.
sem (GitHub Repo)
sem is a Git-native semantic version control tool that provides diffs at the function and class level rather than line-by-line.
Deep dive
- sem parses code into functions, classes, and methods using tree-sitter.
- It provides structural hashing to detect renames, moves, and logic changes while ignoring whitespace or comment noise.
- Includes an MCP server for AI agents to query entity changes, dependencies, and impact analysis.
- Supports 28 programming languages natively.
- Features 'sem impact' for visualizing the blast radius of a change across a codebase.
- Useful for both human code reviews and for providing context-rich diffs to LLMs.
Decoder
- tree-sitter: A parser generator tool and incremental parsing library that builds a concrete syntax tree of source code.
- MCP (Model Context Protocol): An open standard for connecting AI assistants to systems, data, and tools.
Original article
Semantic version control built on Git.
Instead of lines changed, sem tells you what entities changed: functions, methods, classes.
sem is a semantic version control tool that works on top of Git. It parses your code with tree-sitter, extracts every function, class, and method as an entity, and diffs at the entity level instead of lines. This means you see "function blahh was modified" instead of "lines x-y changed."
It works in any Git repo with no setup.
Install
brew install sem-cliOr install the npm wrapper into node_modules:
npm install --save-dev @ataraxy-labs/semWith Bun, trust the package so its postinstall script can download the binary:
bun add -d @ataraxy-labs/sem
bun pm trust @ataraxy-labs/semOr build from source (requires Rust):
cargo install --git https://github.com/Ataraxy-Labs/sem sem-cliOr grab a binary from GitHub Releases.
Or run via Docker:
docker build -t sem .
docker run --rm -it -u "$(id -u):$(id -g)" -v "$(pwd):/repo" sem diffName conflict with GNU Parallel
GNU Parallel ships a sem binary (/usr/bin/sem) as a symlink to parallel. If you have both installed, they'll collide. Run sem --version to check which one you're using.
Quick fixes:
# Option 1: alias in your shell profile (~/.bashrc, ~/.zshrc)
alias sem="$HOME/.cargo/bin/sem"
# Option 2: make sure cargo bin comes first in PATH
export PATH="$HOME/.cargo/bin:$PATH"
# Option 3: if installed via Homebrew
export PATH="$(brew --prefix)/bin:$PATH"If you installed via npm/bun, the binary lives in node_modules/.bin/sem and is invoked through npx sem or bunx sem, which avoids the conflict entirely.
Commands
Works in any Git repo. No setup required. Also works outside Git for arbitrary file comparison.
sem stores its SQLite entity cache outside the repository, under the OS cache directory by default. Set SEM_CACHE_DIR=/path/to/cache to override the cache root; repo-local overrides are ignored so cache files do not dirty the working tree.
sem diff
Entity-level diff with rename detection, structural hashing, and word-level inline highlights.
# Semantic diff of working changes
sem diff
# Staged changes only
sem diff --staged
# Specific commit
sem diff --commit abc1234
# Commit range
sem diff --from HEAD~5 --to HEAD
# Verbose mode (word-level inline diffs for each entity)
sem diff -v
# Plain text output (git status style)
sem diff --format plain
# JSON output (for AI agents, CI pipelines)
sem diff --format json
# Markdown output (for PRs, reports)
sem diff --format markdown
# Compare any two files (no git repo needed)
sem diff file1.ts file2.ts
# Read file changes from stdin (no git repo needed)
echo '[{"filePath":"src/main.rs","status":"modified","beforeContent":"...","afterContent":"..."}]' \
| sem diff --stdin --format json
# Only specific file types
sem diff --file-exts .py .rssem impact
Cross-file dependency graph shows what breaks if an entity changes.
# Full impact analysis
sem impact authenticateUser
# Direct dependencies only
sem impact authenticateUser --deps
# Direct dependents only
sem impact authenticateUser --dependents
# Affected tests only
sem impact authenticateUser --tests
# JSON output
sem impact authenticateUser --json
# Disambiguate by file
sem impact authenticateUser --file src/auth.ts
# Include generated/build directories that repo-wide scans skip by default
sem impact authenticateUser --no-default-excludessem blame
Entity-level blame showing who last modified each function, class, or method.
sem blame src/auth.ts
# JSON output
sem blame src/auth.ts --jsonsem log
Track how a single entity evolved through git history.
sem log authenticateUser
# Verbose mode (show content diff between versions)
sem log authenticateUser -v
# Limit commits scanned
sem log authenticateUser --limit 20
# JSON output
sem log authenticateUser --jsonsem entities
List all entities under a file or directory path. No path is the same as ..
sem entities
sem entities .
sem entities src/auth.ts
# JSON output
sem entities --json
sem entities src/auth.ts --json
# Include generated/build directories that repo-wide scans skip by default
sem entities --no-default-excludessem context
Token-budgeted context for LLMs: the entity, its dependencies, and its dependents, fitted to a strict content token budget. When the target signature itself does not fit, JSON output reports target_omitted: true.
sem context authenticateUser
# Custom token budget
sem context authenticateUser --budget 4000
# JSON output
sem context authenticateUser --json
# Include generated/build directories that repo-wide scans skip by default
sem context authenticateUser --no-default-excludesUse as default Git diff
Replace git diff output with entity-level diffs. Agents and humans get sem output automatically without changing any commands.
sem setupNow git diff shows entity-level changes instead of line-level. No prompts, no agent configuration needed. Everything that calls git diff gets sem output automatically. Also installs a pre-commit hook that shows entity-level blast radius of staged changes.
To disable and go back to normal git diff:
sem unsetupWhat it parses
28 programming languages with full entity extraction via tree-sitter:
| Language | Extensions | Entities |
|---|---|---|
| TypeScript | .ts .tsx .mts .cts |
functions, classes, interfaces, types, enums, exports |
| JavaScript | .js .jsx .mjs .cjs |
functions, classes, variables, exports |
| Python | .py |
functions, classes, decorated definitions |
| Go | .go |
functions, methods, types, vars, consts |
| Rust | .rs |
functions, structs, enums, impls, traits, mods, consts |
| Java | .java |
classes, methods, interfaces, enums, fields, constructors |
| C | .c .h |
functions, structs, enums, unions, typedefs |
| C++ | .cpp .cc .hpp |
functions, classes, structs, enums, namespaces, templates |
| C# | .cs |
classes, methods, interfaces, enums, structs, properties |
| Ruby | .rb |
methods, classes, modules |
| PHP | .php |
functions, classes, methods, interfaces, traits, enums |
| Swift | .swift |
functions, classes, protocols, structs, enums, properties |
| Elixir | .ex .exs |
modules, functions, macros, guards, protocols |
| Bash | .sh |
functions |
| HCL/Terraform | .hcl .tf .tfvars |
blocks, attributes (qualified names for nested blocks) |
| Kotlin | .kt .kts |
classes, interfaces, objects, functions, properties, companion objects |
| Fortran | .f90 .f95 .f |
functions, subroutines, modules, programs |
| Vue | .vue |
template/script/style blocks + inner TS/JS entities |
| XML | .xml .plist .svg .csproj |
elements (nested, tag-name identity) |
| ERB | .erb .html.erb |
blocks, expressions, code tags |
| Svelte | .svelte .svelte.js .svelte.ts |
component blocks + rune JS/TS modules |
| Perl | .pl .pm .t |
subroutines, packages |
| Dart | .dart |
classes, mixins, extensions, enums, type aliases, functions |
| OCaml | .ml .mli |
values, modules, types, classes, externals |
| Scala | .scala .sc .sbt |
classes, objects, traits, enums, functions, vals, extensions |
| Nix | .nix |
bindings, inherit declarations |
| Haskell | .hs |
functions, signatures, data types, newtypes, classes, instances, type synonyms |
| Zig | .zig |
functions, tests, variables |
Plus structured data formats:
| Format | Extensions | Entities |
|---|---|---|
| JSON | .json |
properties, objects (RFC 6901 paths) |
| YAML | .yml .yaml |
sections, properties (dot paths) |
| TOML | .toml |
sections, properties |
| CSV | .csv .tsv |
rows (first column as identity) |
| Markdown | .md .mdx |
heading-based sections |
Everything else falls back to chunk-based diffing.
Custom extensions and extensionless files
For files with non-standard extensions, create a .semrc in your project root:
.xyz = cpp
.j = json
.mypy = pythonsem also reads .gitattributes patterns (diff= and linguist-language=) if you already have those set up. .semrc takes priority when both define the same extension.
For files with no extension at all, sem detects the language automatically from content (imports, declarations, shebang lines, vim modelines). This covers 19 languages with no config needed.
How matching works
Three-phase entity matching:
- Exact ID match — same entity in before/after = modified or unchanged
- Structural hash match — same AST structure, different name = renamed or moved (ignores whitespace/comments)
- Fuzzy similarity — >80% token overlap = probable rename
This means sem detects renames and moves, not just additions and deletions. Structural hashing also distinguishes cosmetic changes (whitespace, formatting) from real logic changes.
MCP Server
sem includes an MCP server with 6 tools for AI agents: sem_entities, sem_diff, sem_blame, sem_impact, sem_log, sem_context. These mirror the CLI commands exactly.
{
"mcpServers": {
"sem": {
"command": "sem-mcp"
}
}
}Install the MCP binary:
cd sem/crates
cargo install --path sem-mcpJSON output
sem diff --format json{
"summary": {
"fileCount": 2,
"added": 1,
"modified": 1,
"deleted": 1,
"moved": 0,
"renamed": 0,
"reordered": 0,
"binary": 0,
"orphan": 0,
"total": 3
},
"changes": [
{
"entityId": "src/auth.ts::function::validateToken",
"changeType": "added",
"entityType": "function",
"entityName": "validateToken",
"startLine": 12,
"endLine": 18,
"oldStartLine": null,
"oldEndLine": null,
"filePath": "src/auth.ts"
}
],
"binaryChanges": []
}The named change-type buckets (added, modified, deleted, moved, renamed, reordered) always sum to total. orphan is a cross-cutting metadata count for module-level changes, and those changes are already included in the named change-type buckets.
As a library
sem-core can be used as a Rust library dependency:
[dependencies]
sem-core = { git = "https://github.com/Ataraxy-Labs/sem", version = "0.5" }Used by weave (semantic merge driver) and inspect (entity-level code review).
Architecture
- tree-sitter for code parsing (native Rust, not WASM)
- git2 for Git operations
- rayon for parallel file processing
- xxhash for structural hashing
- Plugin system for adding new languages and formats
License
MIT OR Apache-2.0

Introducing the next generation of AWS Resilience Hub for generative AI-based SRE resilience journey
AWS Resilience Hub has been overhauled with generative AI analysis to automatically map service dependencies and identify failure modes across complex cloud architectures.
Decoder
- SRE (Site Reliability Engineering): A discipline that incorporates software engineering approaches to solve operations problems and ensure system availability.
- RTO (Recovery Time Objective): The maximum acceptable time a service can be down after a failure.
- RPO (Recovery Point Objective): The maximum acceptable period in which data might be lost from a backup due to a failure.
Original article
Introducing the next generation of AWS Resilience Hub for generative AI-based SRE resilience journey
Today, we’re announcing the next generation of AWS Resilience Hub with a significantly expanded experience that brings together a new application model, dependency discovery assessment, generative AI-powered failure mode analysis, modular resilience policies, and organization-wide reporting.
Organizations running hundreds of applications share a common challenge: availability is a top concern, yet there is no consistent way to set resilience goals, measure progress, or prove compliance across a portfolio. Teams set different standards, use different tools, and struggle to exchange information about whether applications actually meet expectations.
The next generation of AWS Resilience Hub changes this by giving Site Reliability Engineers (SREs) and development teams a structured way to align on resilience policy expectations, help application teams achieve them, and demonstrate compliance through testing. With integration into AWS Organizations, teams can now evaluate resilience at scale, identify failure modes, discover hidden dependencies, and report on progress across the enterprise.
The next generation of Resilience Hub walks you through your resilience journey and to help you there are the following concepts built into it.
- Resilience policy: You can define your resilience expectations through modular, composable requirements. Rather than choosing a single rigid policy type, you construct policies by selecting the requirements that matter to your application, such as service level objective (SLO), multi-AZ and multi-Region disaster recovery, and data recovery requirements.
- Business-level understanding: You can use new application modeling through critical end-user paths that map directly to business outcomes. Systems represent a business application, user journeys describe critical business paths, and services are the deployable units comprising AWS resources, code, and observability. Resilience Hub automatically discovers and maps them into a topology showing how resources connect.
- AI failure mode assessments: You can run generative AI-powered assessments that analyze your services against your defined resilience policies, AWS Well-Architected best practices, and the AWS Resilience Analysis Framework. These assessments identify potential failure modes and provide actionable recommendations.
- Dependency discovery assessment: You can automatically discover AWS services, internal endpoints, and third-party endpoints that your services depend on. This dependency assessment uses DNS query log analysis to identify dependencies you may not know about—including unexpected cross-region calls or critical third-party dependencies.
The next generation of AWS Resilience Hub in action
To get started, you configure a resilience policy, set up your first system and service, run a failure mode assessment, review the results, and implement the findings.
Before you begin, you should set up the invoker IAM role, which grants Resilience Hub read-only access to your AWS resources, cross-account roles (if not using AWS Organizations), or service-linked roles (SLRs) with AWS Organizations. Resilience Hub also integrates with AWS Organizations to enable organization-wide resilience management from a single delegated administrator account. This eliminates the need to log in to individual accounts to assess resilience posture across your enterprise. To learn more, visit prerequisite details in the AWS Resilience Hub User Guide.
To configure a resilience policy, choose Create policy in the Policies menu through the AWS Resilience Hub console. Enter a policy name, description, and choose resilience requirements. For example, you can create a reusable policy for multi-Region disaster recovery used in financial applications—including 99.95% availability SLO, 15-minutes RTO, 5-minutes RPO for multi-Region disaster recovery, and disaster recovery approach that aligns with your RTO and RPO requirements.
If you choose data recovery requirements, you can define the data recovery time objective for restoring from backups for each service associated with this policy.
To create your first system representing your business application, choose Create a system in the Systems menu. Optionally, you can enable AWS Organizations account access for this system.
Now you can create a service that represents a deployable unit, like one of your microservices, and associate it with your system, and tell Resilience Hub where to find your resources. Enter a service name, for example, stock-exchange-service, choose your resilience policy and invoker AWS IAM role name. You can choose service Regions, service resources such as your resource tags, AWS CloudFormation stack, Terraform state file location, or Amazon EKS cluster and namespace.
When you enable dependency discovery for this service, AWS examines your VPC query logs for the VPCs associated with the resources in your service. You can disable this feature anytime from the dependency discovery settings in the service details page.
Now, you can run your first assessment with the service creation complete and a policy applied. Choose Run failure mode assessment in your service page and wait for the assessment to complete.
During the assessment, Resilience Hub assumes your invoker role, reads resources from your configured input sources, identifies parent-child relationships, queries the application topology service to map connections between resources, and builds a topology showing data flow, containment, and permissions.
By choosing Service topology, you can see service resources grouped by service functions in the graph, table, or JSON format.
By choosing Failure mode guidance, you can add assertions used to guide the agents while performing the failure mode assessment. Assertions are either generated by the agent or added by users. You can update them to improve assessment accuracy.
Once the assessment is complete, you can review findings and recommendations in the Assessment tab of your service page. Each finding tells you what the failure mode is, why it matters for your architecture, how to fix it, and which policy requirement it relates to.
You can choose Mark as resolved to implement the recommendation or Mark as irrelevant if the finding doesn’t apply to your use case.
If you’re an existing Resilience Hub customer, Resilience Hub provides migration APIs to simplify the transition of your previous applications. These APIs convert your previous assessment policies to new resilience policies, map your previous applications to the new model, such as multiple related applications to one system with multiple services.
For more information about new features, visit the AWS Resilience Hub User Guide.
Now available
The next generation of AWS Resilience Hub is now generally available in AWS commercial Regions where Resilience Hub is available. For Regional availability and the future roadmap, visit the AWS Capabilities by Region.
Resilience Hub uses a new service-based pricing model. Pricing includes two failure mode assessments per month for services, and optionally automated dependency assessment. You can try AWS Resilience Hub free. For pricing details, visit the AWS Resilience Hub pricing page.
Give the new AWS Resilience Hub a try in the Resilience Hub console and send feedback to AWS re:Post for Resilience Hub or through your usual AWS Support contacts.
Load testing hosted MCP servers with Locust and Azure Load Testing
A new reusable Python harness allows developers to load test Model Context Protocol (MCP) servers using Locust and Azure Load Testing.
Decoder
- MCP (Model Context Protocol): An open standard for connecting AI assistants to systems, databases, and internal tools.
Original article
This guide demonstrates how to load test hosted MCP servers using a reusable Python and Locust harness that faithfully models the MCP lifecycle, including initialization, tool discovery, tool calls, authentication, and session cleanup. The framework supports stateful and stateless MCP servers, multiple authentication patterns, and seamless execution both locally and in Azure Load Testing, enabling teams to measure latency, concurrency behavior, and failure characteristics of production MCP endpoints under realistic AI agent workloads.
Every dependency you add is a supply chain attack waiting to happen
Ben Hoyt argues that every dependency—including dev-only packages and automated updates—expands your supply chain attack surface and should be treated with extreme caution.
Original article
Every dependency you add is a supply chain attack waiting to happen
In my essay “The small web is beautiful”, I discussed how using fewer dependencies makes programs smaller. But it also makes them safer.
As we’ve seen recently, third-party libraries can and do get compromised. We saw this on a grand scale with the XZ backdoor, and we’ve seen it more recently with the Trivy incident and with LiteLLM being compromised (which was actually caused by Trivy).
The interesting thing about Trivy is that it’s not even a runtime dependency; it’s a dev dependency. But a compromise in a dev dependency can still steal credentials and take over projects.
The careful reader may note that my title is not quite accurate. It’s not every dependency you add that’s a problem; it’s every dependency you update. When you evaluated the dependency initially (and added its hash to your lockfile), you probably did your due diligence. But your project is using Dependabot, so the dependencies get updated automatically with little review.
You should probably turn off Dependabot. In my experience, we get more problems from automatic updates than we would by staying on the old versions until needed.
So, please think twice, or thrice, before adding a new dependency to your project. As the Go proverb says, “a little copying is better than a little dependency”.
I hope you enjoyed this LLM-free, hand-crafted article.

What is AI Governance?
Docker research shows that while 60% of organizations deploy AI agents, 40% struggle to scale due to security and compliance gaps, necessitating formal governance.
Deep dive
- Defines AI governance as the operating model for responsible AI, covering ethics, risk, and technical safeguards.
- Aligns governance with frameworks like the EU AI Act and NIST AI RMF.
- Emphasizes a risk-based classification approach to prioritize oversight for high-impact AI systems.
- Proposes integrating governance into development workflows rather than post-deployment checks.
- Highlights the need for runtime controls like network isolation and least-privilege for AI agents.
Decoder
- Agentic AI: AI systems designed to operate with autonomy to complete tasks without direct human instruction.
- Sandboxing: An environment that runs programs in isolation to prevent them from accessing sensitive system resources or host files.
- Model drift: A phenomenon where the accuracy of an AI model degrades over time as the real-world environment changes.
Original article
Full article content is not available for inline reading.
Designing agentgateway: A Unified High-Performance Gateway for AI and API Traffic
Solo.io has donated its Rust-based agentgateway to the Agentic AI Infrastructure Foundation to provide a unified control plane for AI and API traffic.
Deep dive
- Unified Gateway: Replaces separate API gateways and AI proxy layers by handling diverse protocols like HTTP, gRPC, and MCP in one place.
- Performance: Built in Rust with Tokio/Hyper, achieving 500k QPS and low P99 latency in benchmarks.
- Control Plane: Uses an xDS architecture for dynamic, zero-downtime configuration updates.
- Ecosystem Integration: Directly interoperates with existing Kubernetes tooling and Istio ambient meshes.
- Governance: Operates under the Agentic AI Infrastructure Foundation (AAIF) for vendor-neutral development.
Decoder
- xDS: A set of data-plane configuration APIs originally developed for Envoy that allow proxies to receive real-time updates without restarting.
- MCP (Model Context Protocol): An open standard for connecting AI models to external data sources and internal tools.
- A2A (Agent-to-Agent): A communication paradigm where AI agents interact with each other to complete complex workflows.
Original article
When we started building agentgateway, one of the first questions we asked ourselves was whether the world really needed another gateway instead of simply reusing an existing reverse proxy like Envoy.
The answer became obvious pretty quickly.
Not because existing API gateways are broken. And not because AI traffic somehow replaces traditional application traffic.
The reason is that organizations deploying AI systems are running into a new category of operational problems that existing infrastructure was never specifically designed to address.
AI systems create new infrastructure concerns
As agents become more capable, they stop looking like isolated chatbot experiences and start behaving more like distributed systems.
They call tools. They route requests across APIs and models. They coordinate workflows across multiple services. They interact with MCP servers, LLM providers, databases, and internal platforms.
And suddenly the infrastructure questions become much bigger than simple request routing.
- How do you govern which tools an agent can access?
- How do you apply consistent authentication and authorization policies across AI systems and traditional services?
- How do you observe what agents are actually doing across complex workflows?
- How do you rate limit model usage, apply routing policies, or enforce organizational controls around AI traffic?
- How do you minimize impact between AI agents and MCP servers with fast evolving MCP protocols?
- How do you gain security, governance and visibility into the emerging context layer (“layer 8”) that is becoming increasingly important for AI traffic?
These are not theoretical questions anymore. Teams deploying AI systems are dealing with them right now.
Why separate AI gateways and API gateways becomes painful
One of the earliest architectural decisions we made was to avoid creating a completely separate infrastructure stack for AI systems.
At first glance, splitting them apart sounds reasonable. Traditional APIs and AI workloads appear different enough to justify separate operational layers.
But in practice, organizations running agents are also running the APIs, services, and infrastructure those agents depend on.
That means platform teams quickly end up duplicating operational concerns across multiple systems:
- Separate policy models
- Separate authentication configurations
- Separate observability pipelines
- Separate routing infrastructure
- Separate governance controls
The complexity compounds fast.
For example, an internal developer platform might expose several MCP servers for documentation search, ticket creation, deployment workflows, and database access. Without a shared gateway layer, each team may need to configure authentication, authorization, audit logging, rate limits, and routing separately. Agentgateway gives platform teams a centralized place to manage those controls while still allowing individual tools and services to evolve independently.
We believed the better approach was unification.
Agentgateway was designed as a unified gateway control plane and proxy data plane that can handle HTTP, gRPC, MCP, A2A, and LLM traffic together through the same operational surface. That means organizations can manage AI and non-AI traffic using the same infrastructure patterns instead of standing up parallel systems for each.
Tool federation and protocol-aware routing
One of the challenges that emerges quickly in real AI deployments is fragmentation.
Different teams expose different MCP servers. Organizations adopt multiple model providers. Agents interact with internal APIs, external services, and specialized tooling spread across environments.
From both an operational and security perspective, managing those integrations individually becomes difficult.
Agentgateway introduces a federation layer that allows organizations to aggregate and route traffic across tools, models, and services while applying centralized policy enforcement and visibility controls.
Clients can interact through a unified endpoint while administrators retain control over authentication, authorization, observability, and routing behavior.
This becomes increasingly important as interoperability protocols like MCP and A2A continue gaining adoption across the ecosystem.
Why we chose Rust
We didn’t create agentgateway entirely from scratch.
Over the past three years, we’ve been building Istio ambient service mesh within the community. A key component of Istio ambient is ztunnel, a Rust-based, purpose-built lightweight proxy designed to handle the secure overlay layer.
We applied many of the lessons learned from building ztunnel, as well as years of experience operating Envoy at scale, to agentgateway, enabling us to create an AI-native proxy optimized for performance, security, and operational simplicity.
Like ztunnel, we built agentgateway in Rust because performance and memory safety are non-negotiable for this kind of system.
Rust has a strong history of success in high performance, low resource utilization applications, especially in network applications (including service mesh). We built agentgateway on top of Tokio and Hyper, two extensively battle-tested libraries for asynchronous networking, along with Tonic, cel-rust, and other core ecosystem components.
Performance
When evaluating infrastructure components like gateways, performance and scalability are critical.
Common gateway performance metrics include:
- Throughput
- Latency
- CPU and memory utilization
- Route propagation time
- Error rates
- The ability to safely handle route updates without downtime
Equally important is how the system behaves at scale: tens of thousands of services, MCP servers, and routes operating simultaneously within highly dynamic distributed systems.
Agentgateway uses an xDS control plane architecture that allows dynamic configuration updates without restarting the data plane. Routes, policies, integrations, and backend services can evolve continuously while traffic continues flowing.
Using traffic performance as one example, agentgateway achieves approximately 500k QPS with 512 connections in our benchmark testing, outperforming peer proxies under similar conditions.
In another benchmark, agentgateway maintained less than 0.2 ms P99 latency at 30k QPS with 512 concurrent connections.
Why we donated agentgateway to AAIF
From the beginning, we wanted agentgateway to live under vendor-neutral governance.
After creating the project in March 2025, we initially donated it to the Linux Foundation on August 25, 2025 because neutral governance was important to both contributors and users.
At the same time, we continued searching for a foundation more specifically aligned with agentic AI infrastructure. When the Agentic AI Infrastructure Foundation (AAIF) launched, it became clear that it was a strong long-term fit.
AAIF provides a neutral, open foundation to help critical AI infrastructure evolve transparently and collaboratively while accelerating adoption of open-source AI projects.
Agentgateway complements existing AAIF projects such as MCP and Goose by acting as the connective layer between:
- Agent-to-LLM interactions
- Agent-to-MCP interactions
- Agent-to-agent interactions
It provides the security, governance, and observability enterprises need to confidently adopt AI agents, MCP servers, and LLM-based systems.
On April 8, we submitted the agentgateway proposal to AAIF through the project proposal process. The project was approved by the Technical Committee on May 13 and by the Governing Board on May 21 as a Growth-stage project.
Tremendous growth
Since February, we’ve seen rapid adoption of agentgateway.
Weekly downloads grew from approximately 100,000 per week to more than 1 million per week, surpassing 7 million total downloads.
We also use agentgateway extensively at Solo.io to mediate both LLM and MCP traffic, giving us consistent security, governance, and observability across these systems.
In parallel, we’ve been working closely with organizations including Microsoft, Apple, Adobe, Amdocs, T-Mobile, and Expedia, along with many other enterprises adopting agentgateway.
Agentgateway has also been adopted by Istio as a data plane option for AI gateway use cases.
What’s next
As agentic systems move from experiments into production environments, the community will need shared infrastructure patterns for routing, policy enforcement, observability, and interoperability.
We want agentgateway to become a unified gateway layer to secure, connect, and observe agentic and cloud native workloads.
Over the next 12 months, we plan to continue expanding the project through deeper integrations, broader protocol support, and continued collaboration with the open-source community.
Some planned areas include:
- Enhancing our UI to include historical analytics and request information, as well as broader support for AI integrations
- Expanding our inference workload support through integration with LLM-d and vLLM Semantic Router
- Continuing to engage with, and implement, new MCP proposals such as Stateless MCP
- Expanding MCP functionality with richer guardrails and cost optimization features such as progressive disclosure and code mode
- Integration with Agent Client Protocol (ACP)
- Publishing more production case studies and architecture patterns
- Expanding internationalization and community-driven translation workflows
- Continuing collaboration with the Kubernetes community on agentic networking and AI Gateway APIs
With agentgateway now part of AAIF, we welcome contributors, users, and platform teams to help shape the roadmap in the open under neutral governance.
If you are building AI systems, operating MCP infrastructure, or thinking about the operational maturity required for agentic workflows, we would love to collaborate with you.
- Explore the docs and get started today
- Star and contribute on GitHub
- Engage with us in the community Discord or an upcoming community meeting
From Kubernetes Dashboard to Headlamp: Understanding the Transition
Following the archival of the Kubernetes Dashboard, Headlamp has emerged as the standard successor for managing clusters with added support for multi-cluster views and plugins.
Deep dive
- Deployment Flexibility: Offers both an in-cluster web UI and a standalone desktop application for local management.
- Multi-cluster Support: Centralizes management of development, staging, and production clusters in one interface.
- Projects View: Groups related resources logically rather than just listing raw objects.
- Extensibility: Supports plugins for integrating GitOps (Flux) and AI-assisted troubleshooting tools.
- Compatibility: Maintains parity with native Kubernetes RBAC and authentication methods.
Decoder
- GitOps: An operational framework that takes DevOps best practices used for application development such as version control, collaboration, compliance, and CI/CD, and applies them to infrastructure automation.
Original article
From Kubernetes Dashboard to Headlamp: Understanding the Transition
For many people, Kubernetes Dashboard was their first window into Kubernetes. It offered a simple visual way to see what was running in a cluster, inspect resources, and build confidence without relying on the command line. For years, it helped developers, students, and operators make sense of Kubernetes, and it served as an important onramp into the ecosystem.
The Kubernetes Dashboard project has now been archived. We deeply respect the work the team did and the role Dashboard played in making Kubernetes more approachable for so many users.
Headlamp builds on that foundation and carries it forward. It keeps the clarity of a visual interface while adding capabilities that match how Kubernetes is used today. This includes multi-cluster visibility, application-centric views, extensibility through plugins, and flexible deployment options that work both in-cluster and on the desktop.
This guide is meant to help you navigate that transition with confidence. Before diving into the mechanics of migration, we start with familiar ground by looking at how common Kubernetes Dashboard workflows map to Headlamp. We also cover what stays the same and what improves after the switch. The goal is not just to replace a tool, but to honor a user-centered legacy and help you land in a UI that can grow with you as your Kubernetes usage evolves.
Mapping Kubernetes Dashboard workloads to Headlamp
If you have used Kubernetes Dashboard before, many workflows in Headlamp will feel familiar. Headlamp does not introduce a new way of thinking. Instead, it builds on workloads users already know and extends them in practical ways. The focus is continuity. What worked before still works, with more room to grow.
Viewing workloads and resources
In Kubernetes Dashboard, most users started by browsing workloads like pods, deployments, services, and namespaces. Headlamp keeps this same starting point. Workloads are easy to find and inspect, and moving between namespaces and clusters is simpler. Resources are still organized in familiar ways, and navigation feels smoother, especially when you work across multiple environments.
Editing and interacting with resources
Like Kubernetes Dashboard, Headlamp lets you view and edit manifests directly in the UI based on your permissions. You can delete resources, scale workloads, or update configurations from the interface. All actions follow standard Kubernetes RBAC. If you could perform an action in Dashboard, you will find the same capability in Headlamp, with the same respect for access controls.
Understanding relationships
Where Headlamp begins to expand the experience is in how it presents relationships between resources. In addition to list views, Headlamp offers visual ways to see how workloads, services, and configurations connect. This helps provide context without changing the underlying workloads users already rely on.
At a high level, the tasks you performed in Kubernetes Dashboard are still there. Headlamp keeps familiar workflows while making it easier to scale as clusters, teams, and applications grow.
Where Headlamp goes beyond Kubernetes Dashboard
Expanding from single cluster to multi-cluster workflows
Kubernetes Dashboard was designed to work with one cluster at a time. That model worked well for simple setups, but it became limiting as teams adopted multiple environments. Headlamp expands this view by letting you work with multiple clusters from a single interface without switching tools or losing context. This makes it easier to manage development, staging, and production environments side by side.
For teams running Kubernetes in more than one place, this shift reduces friction. You can stay oriented and move between clusters with confidence.
From resource lists to application context with Projects
Projects give you an application-centered way to view Kubernetes. Instead of jumping between lists, you can group related workloads, services, and supporting resources in one place. This makes applications easier to understand. You can see what belongs together, track changes in context, and troubleshoot without scanning the cluster piece by piece.
Projects are built on native Kubernetes concepts. Namespaces, labels, and RBAC continue to work the same way they always have. Headlamp adds a visual layer that brings related resources together.
Projects are optional. You can still work at the individual resource level when that fits your task. When you need more context, Projects help you step back and see the bigger picture.
Extend the Headlamp UI with plugins
Headlamp can be extended through plugins that bring common workflows directly into the UI. Instead of switching tools, you work in one place with the same context.
For example, the Flux plugin brings GitOps workflows into Headlamp. It allows teams to view application state alongside the Kubernetes resources that Flux manages, making it easier to understand how changes in Git relate to what is running in the cluster.
The AI Assistant follows a similar pattern. It adds a conversational layer to the UI that helps users understand what they are seeing, troubleshoot issues, or take action. All of this happens in the same screen where the problem appears.
Building your own plugins
Plugins are optional and not limited to community-built extensions. Platform and project teams can also create their own plugins. This allows organizations to add custom integrations that match their specific workflows and internal tooling, while keeping the user experience consistent.
Choosing how and where Headlamp runs
Headlamp gives teams flexibility in how they use a Kubernetes UI. You can run it directly in a cluster, use it as a desktop application, or combine both approaches based on your needs.
Running Headlamp in-cluster works well for shared environments. It provides a centrally managed UI with controlled access and fits naturally into Kubernetes setups, following the same authentication and RBAC rules as other in-cluster components.
The desktop application is often a better fit for local development and onboarding. It also works well when you need to manage multiple clusters from one place. Users can connect using their existing kubeconfig without deploying anything into the cluster.
These options are not mutually exclusive. Many teams use the desktop app for day-to-day work, while relying on an in-cluster deployment for shared or production environments.
Preparing for the Migration
Before moving from Kubernetes Dashboard to Headlamp, it can be helpful to pause and take stock of how you use the Dashboard today. A little reflection up front can go a long way toward making the transition feel smooth and familiar.
Start by noting which clusters and namespaces you access and how authentication works. Headlamp relies on standard Kubernetes authentication and RBAC. In most cases, existing access models carry over without change. If users already connect using kubeconfig files or service accounts, they will be able to access the same resources in Headlamp.
It is also useful to think about the workflows that matter most to your team. Some users rely on Dashboard for quick inspection or troubleshooting, while others use it for lightweight edits or validation. Headlamp supports these same workflows and adds optional capabilities on top. Knowing what you rely on today helps the transition feel predictable and confidence building.
If you would like to explore Headlamp or try it out before migrating, you can learn more at headlamp.dev.
This blog focused on understanding the transition and what to expect. A step by step migration guide is coming soon and will walk through installation and migration in detail.
Dynamic Repartitioning for Time Series Workloads
Netflix engineers implemented dynamic partition splitting in Cassandra to prevent performance bottlenecks in high-volume time-series workloads like viewing history and metrics.
Decoder
- Wide partition: A partition in Cassandra that contains a massive number of rows, causing performance degradation due to high memory usage during read/write operations.
Original article
Netflix built dynamic partition splitting in Cassandra to handle wide partitions in high-volume time-series workloads like viewing history, metrics, and events. Rather than relying on static buckets or manual fixes, the system detects hot or oversized partitions at runtime and automatically splits them into smaller pieces while preserving query compatibility and data consistency.

Ground truth is a process, not a dataset
Amazon researchers found that human experts are more reliable when auditing AI-generated claims than when labeling them from scratch, boosting benchmark accuracy from 60.8% to 90.9%.
Decoder
- Audit-then-score: An evaluation protocol where AI models can contest benchmark labels by providing evidence, which is then audited by a human to update the ground truth dynamically.
- DeepFact-Bench: A test set specifically designed to evaluate the factual accuracy of long-form, AI-generated research reports.
Original article
Ground truth is a process, not a dataset
Today, the key challenge in AI isn’t only how to build better models; it’s how to build evaluation systems that can keep up. Search-augmented AI systems can now produce deep research reports — long, polished syntheses of many sources that increasingly resemble expert analysis. But those reports are useful only if their claims are supported by the underlying literature.
Most existing fact-checking tools work best when a claim can be matched to a short quote or a single document. But in AI-generated research reports, a single sentence may combine evidence from several sources. It can depend on the surrounding report for context, and it might compare assertions in a way that no single source does on its own.
When Amazon’s Artificial General Intelligence (AGI) group started working on the problem of evaluating AI-generated research reports, we thought that the main technical challenge would be building a stronger AI fact checker. But before you can evaluate an AI fact checker, you need a benchmark, a standardized test set used to measure performance. And in this setting, building the benchmark turned out to be at least as hard as building the model.
Traditionally, we view the ground truth for a problem as a fixed dataset. But we discovered that to evaluate complex AI properly, ground truth has to become a process. We call that process audit-then-score, and we present it, together with two accompanying datasets, in a paper we recently published to arXiv.
When static datasets break down
In the standard method for measuring AI performance, human experts label examples, those labels become the “ground truth” (the undisputed correct answers), and models are scored against them. To test this approach with AI-generated research reports, we recruited PhD-level specialists from fields such as computer science, control theory, education, public health, and environmental engineering. We asked them to verify claims from reports in their own specialties, mixing in a hidden set of claims whose answers we already knew.
The result was sobering. In a controlled study, unassisted experts achieved only 60.8% accuracy on the hidden set of known answers.
The issue was not a lack of expertise. It was that assessing deep-research factuality is an unusually demanding task. Verifying a single claim can require long-context reading, cross-document synthesis, and sustained attention.
Normally, in machine learning, when a model disagrees with a benchmark, we assume the model made a mistake. But we realized that, in cognitively demanding tasks like deep research, disagreement should not automatically be treated as a model failure. Sometimes, a model’s “error” is actually a signal that the benchmark itself is ambiguous, incomplete, or wrong.
Audit, then score
Instead of treating the initial expert labels as unquestionable ground truth, we decided to use the models to actively scrutinize the benchmark. This is the core idea behind the audit-then-score protocol. Our paper introduces the protocol alongside DeepFact-Bench, a shared test set for comparing systems, and DeepFact-Eval, a system that checks whether literature supports report claims.
Here is how the protocol works: When our AI fact checker disagrees with the current benchmark answer, it is not simply penalized. Instead, it acts as a challenger and must submit concrete evidence and a written rationale for why it thinks the original human answer is wrong. An auditor — which can be a human expert — then steps in. Crucially, auditors do not start from scratch; they compare the challenger’s new evidence directly against the benchmark’s original rationale. If the challenger makes the stronger case, we revise the benchmark before we score the model.
DeepFact-Eval reads the full report context, plans searches to cover the relevant literature, summarizes retrieved documents, and asks follow-up questions when key details are missing. It then produces both a verdict and a written explanation. This fundamentally changes what a benchmark is.
A new role for human expertise
One of the most striking things we found is that the same experts who were unreliable as one-shot labelers became far more reliable when placed in the role of auditor. Across four rounds of audit-then-score, accuracy on our hidden test set rose from 60.8% to 90.9%. When experts start from a blank page, they have to find the evidence, interpret it, and make a judgment on their own; when they audit a disputed claim, they can focus on comparing two concrete cases.
This shift had significant impact. On DeepFact-Bench, DeepFact-Eval reached 83.4% accuracy when we used GPT-4.1 as the underlying model. That was higher than the 58.5% of the best traditional fact-checking system we tested and the 69.1% of a strong prior deep-research system.
Evaluation as an evolving infrastructure
This shift has implications beyond one paper or one task. If AI systems continue improving, to the point that they exhibit humanlike expertise, the community will increasingly run into settings where evaluation based on one-time human answers is not enough. In those settings, sustaining benchmark quality may require auditing, revision, calibration, and periodic revalidation. Evaluation will become an ongoing collaboration among humans, models, and the evidence they surface together.
Acknowledgments: Yukun Huang, Leonardo F. R. Ribeiro, Momchil Hardalov, Markus Dreyer
What is Apache Arrow Flight?
Apache Arrow Flight leverages gRPC to enable high-performance, zero-copy data streaming between services.
Decoder
- Zero-copy: A technique where data is transferred between memory buffers without being copied by the CPU.
- Columnar: A data storage format where data is stored by column rather than by row, optimized for analytical workloads.
Original article
Apache Arrow Flight uses Arrow and gRPC to move large columnar datasets quickly with zero-copy transfer. Servers stream Arrow RecordBatches directly, can parallelize reads across endpoints, and mostly serve as infrastructure for custom high-performance data services.

A Deep Dive into Calibration of Language Models: Platt Scaling, Isotonic Regression, Temperature Scaling
Calibration is the hidden hurdle for LLM reliability, with temperature scaling providing the most practical fix for RLHF-tuned models.
Deep dive
- Temperature Scaling: Simple, data-efficient, but often insufficient for models tuned with RLHF.
- Platt Scaling: Uses a logistic function; better for small calibration datasets.
- Isotonic Regression: Most accurate for large datasets, but risks overfitting on small ones.
- Metric Selection: Do not rely on Expected Calibration Error (ECE) alone; pair it with Brier scores and reliability diagrams.
Decoder
- RLHF: Reinforcement Learning from Human Feedback, the process of fine-tuning models to align with human preferences.
- Calibration: Ensuring that a model's assigned probability score matches the true empirical frequency of correctness.
- Logit: The raw, unnormalized output scores produced by a neural network layer before softmax.
Original article
A Deep Dive into Calibration of Language Models: Platt Scaling, Isotonic Regression, Temperature Scaling
A model that says it is 90% confident should be right 90% of the time. When that relationship breaks down, you get a miscalibration problem. The model's scores stop telling you anything useful about reliability.
For large language models (LLMs), miscalibration is widespread. A 2024 NAACL survey found that confidence scores diverge from actual correctness rates across factual QA, code generation, and reasoning tasks.
Another study on biomedical models found mean calibration scores ranging from only 23.9% to 46.6% across all tested models. The gap is consistent.
The standard solution in classical machine learning is post-hoc recalibration: fit a simple function on a held-out validation set to map raw confidence scores to better-calibrated probabilities.
Three methods dominate: temperature scaling, Platt scaling, and isotonic regression. All three were designed for discriminative classifiers, and applying them to LLMs requires care.
Measuring Calibration
The dominant metric is Expected Calibration Error (ECE). It groups predictions into confidence bins, computes the gap between mean confidence and the observed accuracy in each bin, and averages across bins weighted by size. ECE = 0 is perfect calibration.
A reliability diagram plots confidence against accuracy. A perfectly calibrated model sits on the diagonal. An overconfident model sits below it: the curve shows high confidence, but accuracy doesn't keep up.
A 2025 evaluation of GPT-4o-mini as a text classifier found that 66.7% of its errors occurred at over 80% confidence — the canonical overconfidence pattern.
ECE alone is increasingly viewed as insufficient. A research paper recommends pairing ECE with the Brier score, overconfidence rates, and reliability diagrams together. A single number obscures meaningful variation in where and how a model misbehaves.
Why LLMs Complicate the Standard Setup
The three methods we cover assume a fixed output space. A classifier produces one probability per class, and calibration maps them to better estimates. LLMs don't work this way.
Four complications matter here.
The output space is exponentially large: sequence-level confidence can't be enumerated. Semantically equivalent outputs may have very different token-level probabilities. Confidence disagrees across granularities; a research paper on atomic calibration showed that generative models exhibit their lowest average confidence in the middle of generation, not at the start or end.
And many LLMs only expose top-k token probabilities through their API, so classical calibration approaches that rely on full logit access need modification.
Applying Temperature Scaling
Temperature scaling divides the logit vector by a scalar T before applying softmax. When T > 1, the distribution flattens and confidence drops. When T < 1, the distribution sharpens and confidence rises.
T is fit on a held-out validation set by minimizing negative log-likelihood. The method adds one parameter, preserves prediction rankings, and is cheap to compute.
The original formulation targeted DenseNet image classifiers. For LLMs, temperature controls the probability distribution over the vocabulary at each decoding step, so the same logic applies.
The problem is Reinforcement Learning from Human Feedback (RLHF). Post-RLHF models develop input-dependent overconfidence: the degree of miscalibration varies across inputs, and a single T can't account for that variation.
Average ECE scores above 0.377 have been documented for models like GPT-3 in verbalized confidence tasks, and a 2025 survey confirms that RLHF-tuned models consistently overestimate confidence across the board.
Adaptive Temperature Scaling (ATS) addresses this directly. ATS predicts a per-token temperature from token-level hidden features, fit on a supervised fine-tuning dataset, instead of using a single fixed T. Researchers confirmed that ATS improved calibration by 10–50% without hurting task performance. For any RLHF-tuned model, ATS is a stronger baseline than standard temperature scaling.
Standard temperature scaling still works well for base models before RLHF. When miscalibration is roughly uniform across inputs, a single T is often enough to correct systematic over- or underconfidence.
Applying Platt Scaling
Platt scaling fits a logistic function over the uncalibrated scores: p = σ(A·s + B), where A and B are learned from a held-out validation set with binary correctness labels.
The sigmoid shape gives a parametric mapping with two free parameters.
Platt scaling was originally developed for SVMs but generalizes to any system that produces a scalar confidence score.
The two-parameter fit is also data-efficient compared to isotonic regression: it can produce usable estimates from a smaller calibration set, which matters in deployment contexts where labeled correctness data is limited.
In LLM contexts, Platt scaling operates over sequence-level or token-level confidence scores.
A paper on LLM-generated code confidence found that Platt scaling produced better-calibrated outputs than uncalibrated scores. Another study on LLMs for text-to-SQL introduced Multivariate Platt Scaling (MPS), extending single-variable Platt scaling to combine sub-clause frequency scores across multiple generated samples — consistently outperforming single-score baselines.
Two limitations are documented. First, global sequence-level Platt scaling is too coarse for tasks where correctness depends on local edit decisions: a single sigmoid mapping can't capture sample-dependent miscalibration patterns.
Applying Isotonic Regression
Isotonic regression takes the non-parametric route. It learns a piecewise-constant, monotonically non-decreasing mapping from uncalibrated scores to calibrated probabilities using the Pool Adjacent Violators Algorithm (PAVA). There's no assumed shape for the calibration function, which makes it more flexible than Platt scaling when the confidence-accuracy relationship isn't sigmoid-shaped.
The piecewise-constant output adapts to any monotone shape: linear, stepped, or concave. That adaptability is the main reason isotonic regression tends to outperform Platt scaling in empirical comparisons.
The cost is overfitting risk on small calibration sets. The mapping only generalizes well when there's enough data to constrain it.
Empirically, isotonic regression outperforms Platt scaling. A rigorous comparison across multiple datasets and architectures found that isotonic regression beat Platt scaling on ECE and Brier score with statistical significance.
What the Literature Leaves Open
Three gaps are worth flagging before deploying any of these methods.
The RLHF interaction has been studied only for temperature scaling. How Platt scaling and isotonic regression perform on post-RLHF models hasn't been systematically tested. ATS exists because standard temperature scaling needed an explicit fix for this case. Whether the other two methods need similar extensions is an open question.
Most direct comparisons of all three methods come from the general machine learning calibration literature. LLM-specific benchmarks that test all three head-to-head are rare.
Calibration set size is a real deployment constraint. Isotonic regression results from papers assume datasets large enough to constrain the mapping. In production with limited labeled examples, the gap between isotonic regression and Platt scaling may close or reverse.
Conclusion
Temperature scaling is the right starting point for most teams. For base models without RLHF, a single T often does enough.
For RLHF-tuned models, switch to ATS: the per-token temperature handles the input-dependent overconfidence that a global scalar misses.
Platt scaling is the practical choice when the calibration set is small or when calibration needs to slot into a larger pipeline. It's data-efficient and straightforward to implement.
Isotonic regression has the strongest empirical track record of the three. Use it when the calibration set is large enough to constrain the mapping without overfitting, and pair it with normalization-aware extensions in multiclass settings.
The decision that comes before all of these is what "confidence" means for the task. Token probability, sequence probability, verbalized confidence, and consistency across samples can give different values for the same output. A calibration method applied to the wrong signal doesn't improve reliability.

Broker-Visible vs Client-Local Parallelism
Parallelism in messaging systems like Kafka should move toward client-local execution to avoid expensive broker-side connection overhead.
Decoder
- Share Groups: A feature in newer Kafka versions that provides queue-like load-balancing semantics over log-based storage.
- Consumer Group: A set of consumers that coordinate to read from a specific Kafka topic, distributing partitions among themselves.
Original article
This post is a little side-quest from my “Kafka Share Groups and Parallelizing Consumption” series.
My “Kafka Share Groups and Parallelizing Consumption” series has been laser focused on how different configurations and behaviors affect parallel consumption in share groups (Queues for Kafka). So far I’ve shown that you most definitely can hold share groups wrong. You could quite easily and inadvertently create a work queue and with the right combination of things going against you, see a small number of consumers dominate, leaving most consumers starved of messages. All the while lag builds and builds. You need to know the settings and what they do. Don’t just rely on the defaults.
But it’s worth asking the question: is parallelizing consumption what share groups are for?
The answer is no.
If your only concern is parallel consumption, then there are other options. Chuck Larrieu Casias wrote a good post on LinkedIn pointing out that people shouldn’t be thinking of share groups as THE solution to parallelizing work (without exploding the partition count).
Share groups exist to expose queue-like semantics over a log. Unlike a normal consumer group, a share group lets you accept one record and reject another for retry. A consumer group tracks one committed offset per partition. A share group has to track many individual records independently: which records are available, which have been delivered (to whom), which have been acknowledged, and which should become available again.
But just because share groups don’t exist primarily to parallelize work doesn’t mean it’s not a tool that can be used for that purpose. If your messages are independent or you are otherwise ok with loose ordering then share groups could be a simple choice for breaking away from partition count as the unit of parallelism.
The central theme I took from Chuck’s post is that parallelism has to be accounted for somewhere. The unit of parallelism can be broker-visible and broker-managed, or client-local and client-managed. Broker-visible/managed can only take you so far.
Where should your unit of parallelism live?
When you need to process 1,000 messages in parallel to cope with the producer rate, what represents those 1,000 parallel units of work? Is it partitions, consumers, virtual threads/async tasks?
If the unit of parallelism is the consumer itself then we must scale out serial consumers to scale the parallel processing (with a matching partition count with consumers groups). Every parallel unit of work (consumer) becomes visible to the broker as protocol interactions and state plus one or more TCP connections.
If parallelism comes in part from the client itself, the unit of parallelism could be a virtual thread, an async task or even an OS thread. This is invisible to the broker. You need fewer consumers, fewer TCP connections, and less broker-visible protocol interaction/state.
This split of where the unit of parallelism is accounted for, broker-side vs client-side, exists across all messaging systems. It’s not specific to Kafka.
How many units of parallelism?
A simple calculation for aggregate parallelism is easy:
aggregate parallelism = rate * avg processing time in seconds- 60000 msg/s * 1s = 60000
- 60000 msg/s * 5s = 300000
- 100 msg/s * 20s = 2000
- 10000 msg/s * 0.5s = 5000
- 50 msg/s * 5s = 250
Once you know how many messages must be processed in parallel, you can figure out your tactics. The formula tells you how much parallelism you need, then it’s up to you to figure out where that parallelism should live.
Let’s use our 60,000 messages per second workload from the share group series. If it takes 1 second to process each message, then we need to support 60,000 messages being processed at any given moment. If each unit of parallelism is a serial consumer, then that means 60,000 consumers! That’s a lot of connections, a lot of protocol state, and a really big consumer group.
What if it takes 10 seconds on average to process a message, you’d need 600,000 consumers, and well over 1 million TCP connections!
If most of the work is I/O, and the CPU spends a lot of time waiting around then can’t we make a single client do more work? What if one client can handle processing 1000 messages in parallel? Then we’d only need 60 consumers for the “60K msg/s + 1 second processing time” example.
Takeaway
If the ultimate unit of parallelism is visible to the broker as something it must manage, it can get really expensive in resources for highly parallel workloads (no matter which messaging system you use). Managing virtual threads, or even OS threads, is much cheaper than managing one or more TCP connections + metadata per unit of parallelism. This is true of all messaging systems I have ever used. The cost is greater complexity on the client, but if you don’t want to roll your own logic, there are libraries to help here (see Chuck’s post for some). Unfortunately, the ParallelConsumer library is no longer being maintained (though a fork might be in the future). This library not only added internal client-side parallel processing but queue semantics as well (on top of consumer groups). Now that we have share groups, perhaps we need a new library that adds client-side parallelism to share groups.
I’m going back to writing Part 3 of my parallelism in share groups series. We’ll be comparing broker-managed vs client-managed parallelism with share groups and consumer groups.
5 dbt mistakes I see in every startup
Most early-stage dbt projects suffer from unsustainable configuration patterns that eventually cripple maintainability and data reliability.
Deep dive
- Avoid running full-project builds in CI to save costs and time; use dbt state selection to test only changed models.
- Use model contracts to enforce column types and constraints, preventing downstream breakages.
- Incremental models require specific configuration to avoid silent schema drift when upstream source data changes.
- Raw tables should be managed as sources, not as intermediate models, to maintain data lineage clarity.
- Isolate development schemas from production to prevent accidental data corruption or schema collisions.
Decoder
- dbt (data build tool): An open-source command-line tool that enables data analysts and engineers to transform data in their warehouse using SQL SELECT statements.
- Model Contract: A set of constraints defined on a dbt model that ensures data structure consistency, similar to a schema definition in a programming language.
- Schema Drift: The process where changes in source data structures (like added or dropped columns) cause failures in downstream pipelines that expect the original format.
Original article
Early dbt projects often fail from avoidable configuration debt: full-project CI rebuilds, missing model contracts, silent incremental schema drift, misdeclared raw tables, and shared dev/prod schemas.
The Hidden Why: Behavioral Economics for UX
Behavioral economics frameworks like the 3B model offer a structured approach to identifying and removing the psychological friction preventing users from completing tasks.
Deep dive
- Define the target behavior precisely (e.g., 'a user completes signup in one session').
- Map the actual steps users take, not the intended path.
- Use behavioral data, not just emotional sentiment.
- Identify barriers (attention, cognitive load, status quo).
- Identify benefits (functional, emotional, social).
- Design specific experiments based on a clear hypothesis to remove one identified barrier.
Decoder
- 3B Framework: A behavioral design model (Behavior, Barriers, Benefits) used to diagnose and improve user engagement.
- Cognitive Load: The amount of mental effort being used in the working memory.
- Status Quo Bias: The psychological preference for the current state of affairs, making users resistant to change.
Original article
The Hidden Why: Behavioral Economics for UX
Use behavioral-economics frameworks to uncover hidden friction in your experience and design UX solutions that better support user action.
People often intend to take action — join a gym, open a savings account, register for a class, or book tickets to a show — but never follow through. Most of us know this frustrating gap between what we intend to do and what we actually do.
Behavioral economics helps UX practitioners investigate why intention fails to become action. It enables them to look beyond whether users can complete a task and uncover what shapes their motivation, attention, confidence, and decisions along the way.
The Promise of Behavioral Economics
Behavioral economics combines economics and psychology to understand how people behave in real contexts. Emotions, habits, uncertainty, social cues, perceived risk, effort, and the way information is presented all influence what people do.
In UX, behavioral economics is especially useful because experiences often depend on users making decisions and following through. Users may need to create an account, choose a plan, schedule an appointment, share information, or complete a purchase. These actions are driven not only by usability, but also by what users notice, believe, feel, avoid, or expect others to do.
When teams understand these influences, they can design experiences that better support users’ goals and improve business outcomes. In fact, Gallup reports that companies that apply behavioral economics effectively can outperform peers by 85% in sales growth and more than 25% in gross margin.
How to Apply Behavioral Economics to Your Work
Behavioral economics is rich in theory, which is part of what makes it so useful. But that richness can also create challenges for UX teams. Understanding concepts like cognitive biases, prospect theory, and nudging does not automatically tell teams when those concepts apply, to whom they apply, or how to account for them in design.
Luckily, excellent frameworks exist to help translate behavioral economics into practice. Models such as COM-B, the Fogg Behavior Model, the 3B Framework, and EAST provide teams with structured questions to better understand user behavior in the specific context they are designing for.
Case Study: Applying the 3B Framework to a UX Problem
The 3B Framework was created by Irrational Labs, a behavioral-design consulting firm. The framework is a simple 3-step process, organized around the 3 B’s:
- Behavior: What action do you want the user to take?
- Barriers: What might prevent the user from taking that action?
- Benefits: What might make the user feel that the action is worthwhile, relevant, or motivating?
Let’s explore how this framework can help us uncover hidden behavioral friction in the context of a common UX problem: users starting a signup flow but not completing it. To make things concrete, let’s assume that the signup flow is for a gym membership.
1. Behavior
The first step is to define the desired behavior and map the steps users need to take to complete it.
Be as specific as possible — Irrational Labs calls this getting “uncomfortably specific.” The behavior should describe what the user does, when they do it, and what completion looks like.
Next, map every step users would currently need to take to engage in the target behavior. The map should reflect actual steps when possible, not the ideal path the team expects users to follow.
2. Barriers
The next step is to identify potential psychological barriers at each moment in the behavior map.
Barriers make the target behavior harder to complete. They can come from the interface, but also from cognitive, emotional, or social friction. Irrational Labs highlights common barrier categories such as attention, cognitive load, status quo, and mental models.
3. Benefits
The last step involves identifying potential psychological benefits at each moment in the behavior map.
Benefits make the behavior feel more worthwhile or motivating; they may be functional (e.g., saving money, gaining access to a service), emotional (e.g., feeling confident, proud, supported), or social (e.g., feeling aligned with what others are doing). Identify where the flow already creates benefits for users, then look for opportunities to add more immediate rewards.
4. The Behavioral Intervention
This last step builds upon the knowledge accumulated in steps 1–3.
Here you choose one barrier to remove or one benefit to strengthen, then design a solution around it. You can’t solve everything at once, so prioritize the barrier or benefit most likely to influence the target behavior.
Before testing, write a clear hypothesis about why you believe the intervention will work. Then test it with users and measure whether the target behavior improves compared to the baseline.
Conclusion
Behavioral economics frameworks help make the hidden forces shaping user behavior more visible. They can help teams form better hypotheses, design targeted interventions, and test what actually changes behavior.

Do Web Components Make Your Design System Framework-agnostic?
Web components are not inherently framework-agnostic because they fail to address the underlying requirements of data injection, templating, and cross-component orchestration.
Decoder
- Web Components: A suite of browser-native technologies that allow developers to create reusable custom elements that encapsulate HTML, CSS, and JS.
- Orchestration: The management of interactions and data flow between multiple independent software components.
- AJAX: A technique for accessing web servers from a web page without reloading the entire page.
Original article
Do web components make your design system framework-agnostic?
I recently read a blog post claiming that web components can make your design system framework agnostic.
But this is down to the false dichotomy between engineers who:
- love React (or the current popular thing)
- hate React (or the current popular thing)
React is probably a bad choice for your design system. But that’s not an argument against libraries or frameworks.
That’s an argument for choosing something better than React.
Either way, the claim that web components give you a framework agnostic design system is misleading.
Here’s why:
Reason #1: Components aren’t just about the JavaScript layer
For example, here’s an accordion component:
{{ accordion({ items }) }}
This component:
- allows data (
itemsin this case) to be injected from a database/API - abstracts the HTML away to make sure it’s accessible, semantic, and reusable etc
- uses HTML classes that are tied to CSS in order to style it
- uses JavaScript as an enhancement to expand and collapse the panels
For this to work you need a templating language which is usually tied to a stack:
- Nunjucks on Node
- ERB on Rails
- Jinja on Django
Web components only handle (4).
And that’s no different from writing your own JavaScript class.
Reason #2: JavaScript orchestration is still needed
Even if you use web components to enhance your HTML, you may still need JavaScript to:
- Fetch data with AJAX and update the UI
- Coordinate events between components
You either use a library for these things, or you write it yourself.
Don’t get me wrong:
It’s still valuable to abstract HTML, CSS and JS for reuse. And if that’s all you can do, fine.
But that’s not a framework agnostic design system.
It puts significant effort on the consuming team and it’s fragile because they are far more likely to screw up the HTML.
It’s no different to saying that HTML, CSS and JS give you framework agnostic design system components.
Which is just stating the obvious.

How to Make Your Design System AI-Ready
Design systems must be treated as structured infrastructure, using Markdown specs and automated audits, to prevent AI-generated prototypes from becoming incoherent.
Deep dive
- Establish design decisions as infrastructure by codifying them into machine-readable specs.
- Use FigmaLint to automate the detection of hard-coded values, missing states, and token inconsistencies.
- Implement a three-layer architecture: Markdown spec files for logic, a central token layer for variables, and audit scripts for validation.
- Sync routines should trigger automated updates to spec files to ensure AI agents always reference the current system version.
- Move toward explicit context engineering where the AI selects from a closed set of defined variables instead of attempting to interpret UI patterns visually.
Decoder
- Design System: A collection of reusable components, patterns, and guidelines that ensure consistency across a digital product.
- Design Tokens: Named entities that store design attributes like colors, spacing, and typography, acting as the single source of truth for UI properties.
- Skeuomorphism: A design style where digital elements mimic the appearance and texture of real-world objects.
Original article
Practical guide on how to reduce drifts, minimize mistakes, maintain context, and improve the quality of AI-generated prototypes.
AI-generated prototypes often don’t deliver consistently decent results because of tiny inconsistencies scattered all across a design system. It’s decisions made but not documented, hard-coded values never cleaned up, or relying too much on AI making sense of mock-ups or design flows on its own.
Yesterday I stumbled upon a useful practical guide by Hardik Pandya from Atlassian — on how to reduce drifts, minimize mistakes, maintain context, and improve the quality of AI-generated prototypes. Let’s see how it works.
1. Design Decisions Are Infrastructure
Unsurprisingly, better AI prototypes come from better data — but also from better human guidance. We shouldn’t assume that AI knows how to choose the right component and how to design with accessibility in mind. It needs priorities, a clear path on how we make decisions, design principles, examples, do’s and don’ts.
In fact, we should treat design decisions as infrastructure. That means that every time we make a decision — not just a design decision, but even a decision on how to actually prioritize our work and how we make decisions around here — it must find a path into the spec file that is then consumed by AI.
2. Auditing: FigmaLint
One of the useful tools to audit the quality of the design system is FigmaLint. It’s a useful free Figma plugin for auditing tokens, states, accessibility, binding tokens, renaming layers, detecting detached instances, missing interactive states and hard-coded values — and preparing the design documentation.
If you often have to work with vendors and third parties who supply you with their design systems and component libraries, that’s a great helper to have by your side — especially if you want to improve the quality of prototypes, AI-generated code, and AI-written documentation.
3. Three Layers: Spec Files + Token Layer + Auditing
To ensure quality, we establish design principles, guidelines, and rules in the form of “spec files”. It’s structured Markdown files that include spacing rules, color choices, component usage guidelines, priorities, etc. AI is going to read and reuse that spec file every time it’s going to generate a prototype.
Because the spec files are text files, it’s much more cost-effective but also much more accurate, just because we don’t rely on AI recognizing or decoding patterns from mock-ups but get specific guidelines instead. In fact, extending code is often a more effective way than generating code from mock-ups.
The token layer lists and keeps updated all tokens used throughout the design system. AI always chooses from a closed set of named variables instead of inventing plausible values ad hoc.
An audit script catches what AI gets wrong. It scans the prototype and flags every hard-coded value and flags it if necessary. It can be a regular software doing that, with AI waiting for its feedback to come back.
Finally, when a design system ships updates, a sync routine flags which spec files need updating. The goal is to make sure that AI always reads up-to-date, current specs, not the ones written against an outdated version.
4. Examples of AI-Ready Design Systems
Wrapping Up
Ultimately, AI cannot magically resolve technical debt or design debt without proper guidance. It relies heavily on clear decisions, established priorities, and well-defined principles.
The more deliberate and precise designers are in guiding AI, the better the overall outcomes will be. This requires not just cleaning up and improving design systems but also maintaining them over time as decisions need to trickle down into Markdown files. We’ll be busy for years to come.
Useful Resources
- FigmaLint, by TJ Pitre
- Atlassian AI-Ready Design System Example, by Atlassian
- Carbon AI-Ready Design System Example, by IBM
- CMS Design System AI-Ready Example, by Centers for Medicare & Medicaid Services
- Nordhealth AI-Ready Design System Example, by Nordhealth

US Government Considers Taking OpenAI Stake
The Trump administration and OpenAI are discussing a government equity stake in the $850 billion startup to seed a national 'Public Wealth Fund.'
Decoder
- Public Wealth Fund: A government-managed investment vehicle intended to hold assets or equity, with the goal of generating long-term returns for the public.
Original article
Key Points
- OpenAI CEO Sam Altman and the White House are in ongoing talks about a possible government stake in the company, CNBC confirmed.
- The AI startup could donate equity to the U.S. government to seed something like the "Public Wealth Fund" that the company outlined in its April policy proposal, according to a source familiar with the discussions.
- The talks have been in progress for more than a year, as Altman first shared the idea with the Trump administration in 2025, the person said.
OpenAI CEO Sam Altman and the White House are in ongoing talks about a possible government stake in the artificial intelligence company, CNBC confirmed on Friday.
The discussions have been in progress for more than a year, as Altman first shared the idea with the Trump administration in 2025, according to a source familiar with the matter who asked not to be named because the details are confidential.
The talks continued this week as Altman met with a range of lawmakers and officials in Washington about regulation and the latest developments in AI.
As part of the potential agreement, OpenAI could donate equity to the U.S. government to seed something like the "Public Wealth Fund" that the company outlined in its April policy proposal, the person said.
OpenAI said the fund could "invest in diversified, long-term assets" and would enable citizens to participate in the "upside" of AI growth, possibly by receiving the fund's returns directly, according to the proposal.
No official investment terms have been decided, and the details are still subject to change. Notus was first to report the recent talks.
President Donald Trump addressed the talks while on Air Force One with reporters on Friday.
"There are concepts where pieces could be given to the American public, where the American public essentially becomes a partner," he said.
The president said he is meeting with AI companies "in the very short, very near future."
Trump signed an executive order in February calling for the federal government to establish a sovereign wealth fund.
The Trump administration has already taken stakes in Intel, International Business Machines and other quantum and critical mineral companies during the president's second term.
Sen. Bernie Sanders, I-Vt., told CNBC that he and Altman discussed the concept of a sovereign wealth fund during their meeting on Wednesday.
OpenAI is valued at more than $850 billion by private investors, and the company is gearing up for an initial public offering as soon as this year. The company closed a record-breaking funding round in March that was co-led by MGX, which is backed by Abu Dhabi's sovereign wealth fund.
Tech companies like OpenAI have played a central role in shaping the White House's positions on the nascent technology.
Trump on Friday signed a directive instructing the federal national security organizations to "accelerate AI adoption to meet surging demand" and to rapidly onboard the "most advanced AI models from multiple vendors."
The directive landed just days after Trump signed an executive order asking AI companies to voluntarily provide the government access to their models for up to 30 days before their release. The order is thin on specific details, but executives from leading AI companies, including Altman, voiced their support on social media.
"The U.S. should lead on AI by continuing to develop the very best models, making sure they're safe, and getting cyber tools into the hands of trusted defenders," Altman wrote in a post on X. "The new EO gets the balance right."

What remains scarce after AGI?
Economists Alex Imas and Philip Trammell discuss how AI-driven abundance could reshape labor markets, capital shares, and wealth redistribution.
Deep dive
- Humans may retain economic value through a "relational sector" where human participation is an intrinsic good.
- Historical data shows labor share has remained stable despite automation, but AGI may create a qualitative shift where supply chains are fully automated.
- Economists lack quality data on consumer demand and job tasks to accurately forecast employment outcomes.
- The "Messy Middle" scenario suggests AI might automate jobs in a piecemeal fashion, creating political crises without achieving massive growth.
- Universal Basic Capital or a negative income tax are proposed methods to distribute AI wealth, though both face political and implementation challenges.
- The "Jevons paradox" explains why demand for compute increases as it gets cheaper, but this relies on high demand elasticity.
- The potential for "greedy" AI agents or firms that prioritize resource accumulation over consumption could lead to high capital concentration.
- Developing countries face risks of being excluded from the AI supply chain, potentially requiring them to gain access through index-based investment or open model proliferation.
Decoder
- Labor share: The portion of economic output paid to workers in wages.
- Capital share: The portion of economic output paid to owners of land, machines, and company stock.
- Kaldor fact: The observation that labor and capital shares of income have remained remarkably constant over long periods of industrial history.
- O-ring model: A theory suggesting production processes are highly sensitive to the failure of any single component, making automation difficult without near-perfect reliability.
- Jevons paradox: A phenomenon where efficiency gains in resource use lead to an overall increase in consumption rather than a decrease.
- Georgist tax: A tax system that taxes land value rather than income, intended to prevent speculative holding.
Original article
Full article content is not available for inline reading.
Try the new console experience in Amazon Bedrock, optimized for Anthropic- and OpenAI-compatible APIs
Amazon Bedrock's new console streamlines model deployment and evaluation by adding native support for Anthropic and OpenAI-compatible APIs.
Deep dive
- New "bedrock-mantle" engine supports OpenAI and Anthropic API protocols.
- Project-based workflows help track usage metrics like token distribution per inference request.
- Live documentation automatically populates API references and SDK code with selected project credentials.
- Developers can compare up to three models side-by-side within the console interface.
- The interface simplifies migration by providing specific terminal commands for environment configuration.
Decoder
- API Protocol: A set of rules and conventions that defines how two applications interact; in this context, it allows developers to use familiar OpenAI/Anthropic libraries to interact with Bedrock models.
Original article
Try the new console experience in Amazon Bedrock, optimized for Anthropic- and OpenAI-compatible APIs
Today, we’re announcing a new console experience in Amazon Bedrock for you to experiment, iterate, and scale with the latest AI models on Amazon Bedrock’s next-generation inference engine built for high performance, reliability, and security. This console has a refreshed workflow optimized for bedrock-mantle endpoint, which supports the latest GPT, Claude, and open-weight models with the OpenAI Responses API, OpenAI Chat Completions API, and the Anthropic Messages API.
The new console experience makes it simple to find the right model and move quickly from evaluation to production.
- New model card – You can browse the full model catalog, compare them side by side on capabilities, modality support, context window, and applicable service quotas in a single view, removing the need to stitch together documentation, and limit calculators.
- Project-based work – You can make a project to run evaluations and review usage insights in one streamlined workflow that mirrors the lifecycle of building a generative AI application.
- Live documentation – You can use project-aware live documentation: code samples, SDK snippets, and API references are automatically prefilled with your project variables. You can copy a snippet straight from the console into your application and run it without modification.
How to get started
You can try a new experience by choosing Try the Bedrock Mantle Console from within the Amazon Bedrock console, or by using the new console link directly.
You can find a project-based dashboard to show inference requests and error by range of recent dates, recently used models, and the project list. You can create a project, assign models, configure API keys, and start making inference requests in minutes.
A new model catalog shows the latest GPT, Claude, and open-weight models that are supported on the bedrock-mantle engine. You can see the details of features, tokens, pricing, input/output, pricing information, and Regional availability. You can also compare up to 3 models in a single view.
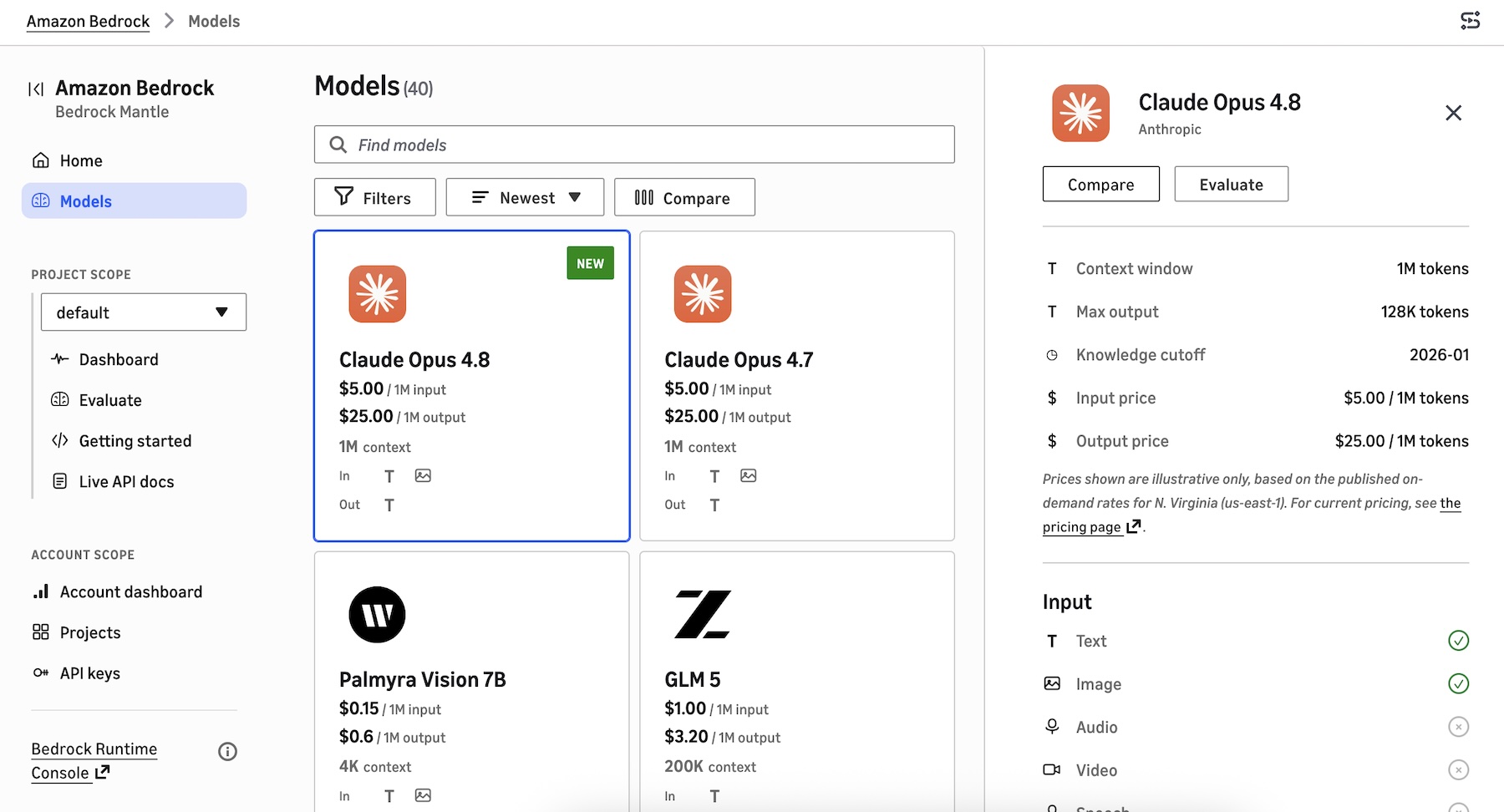
When you choose the project dashboard, you can see the models used in the project, the distribution of your token usage such as total token usage, token usage per minute, inference requests per minute, and tokens per inference request. This can inform your model selection, prompt optimization, and workload consistency decisions.
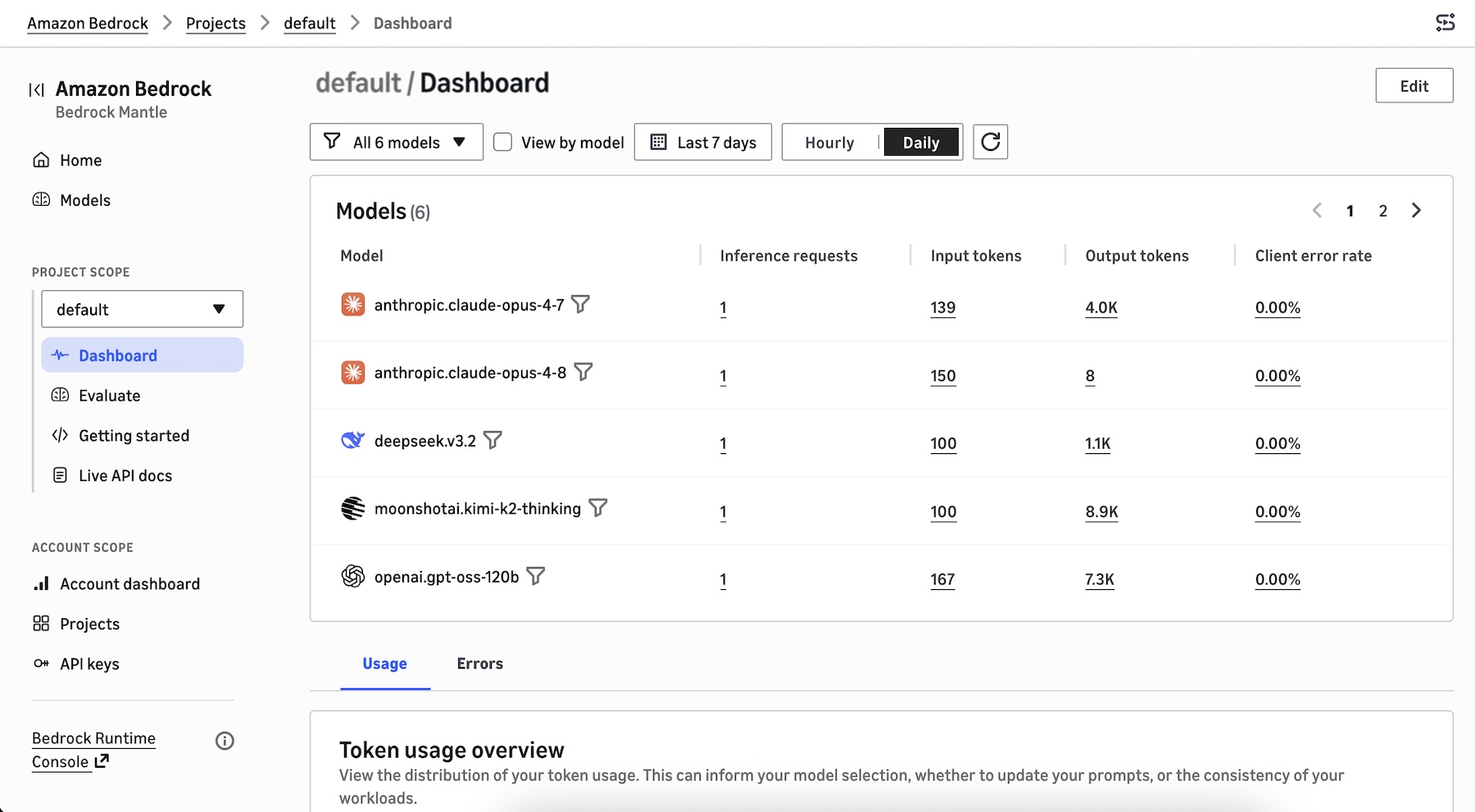
You can select up to 3 models to start evaluating to compare responses side by side with the same prompt.
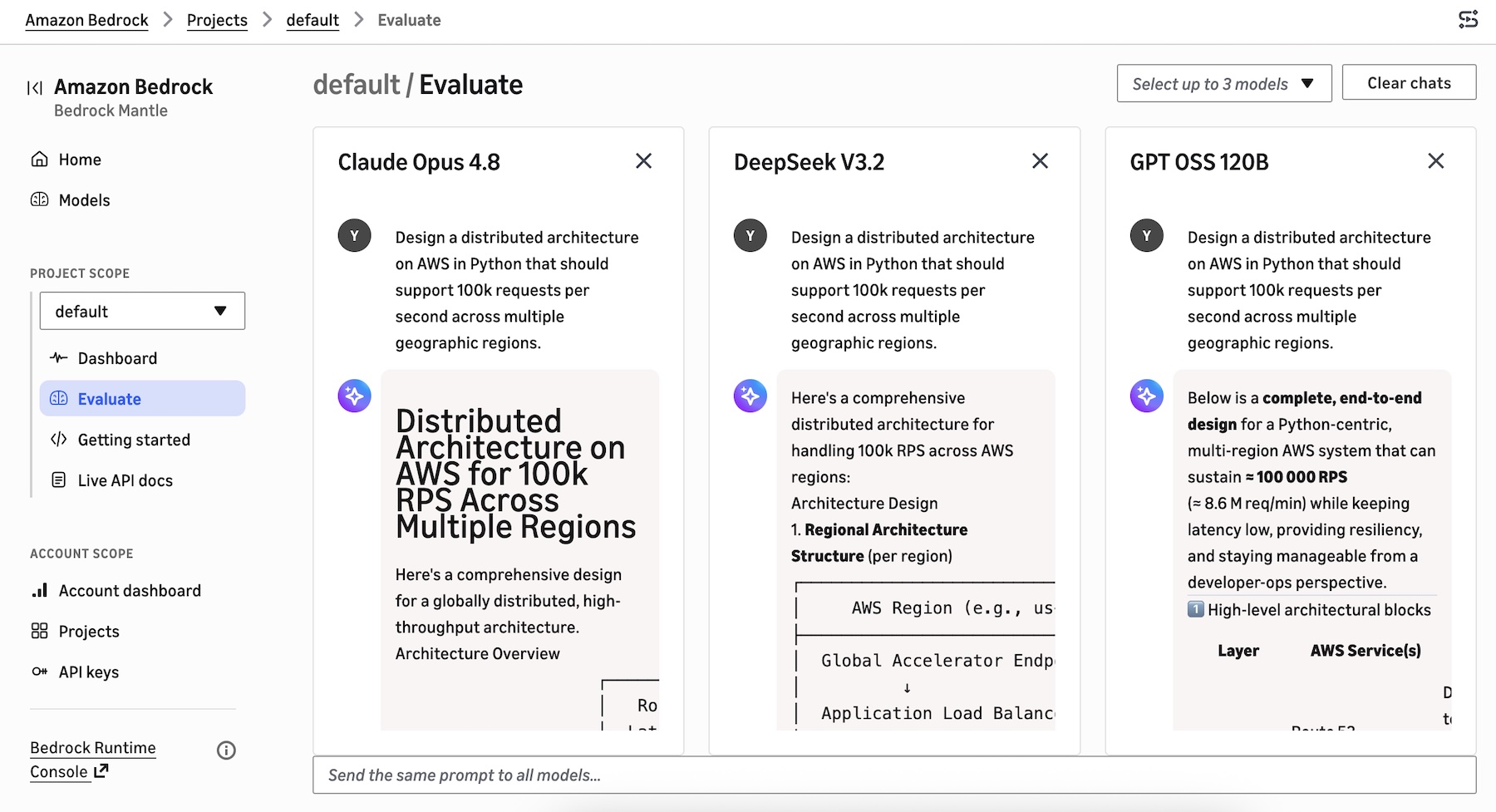
To build your application in the project, choose Getting started. You can migrate existing code, build a new app with the Anthropic or OpenAI SDK, or connect an AI coding assistant to Bedrock.
Choose the API & SDK, your SDK (either Anthropic or OpenAI), your preferred programming language, and your authentication method. It shows your environment code to run these in your terminal for a quick test, or save to a .env file for your application. You can also send your first request with sample code snippets to verify your setup.
When you choose Clients, you can select the AI coding agent source such as Claude Code, Cline, Codex, Cursor, or OpenCode that you want to connect to the bedrock-mantle engine. It provides instructions on how to install the AI agent, use your AWS IAM credentials or use a Bedrock API key, set environment variables, and route requests from each AI agent through Bedrock.
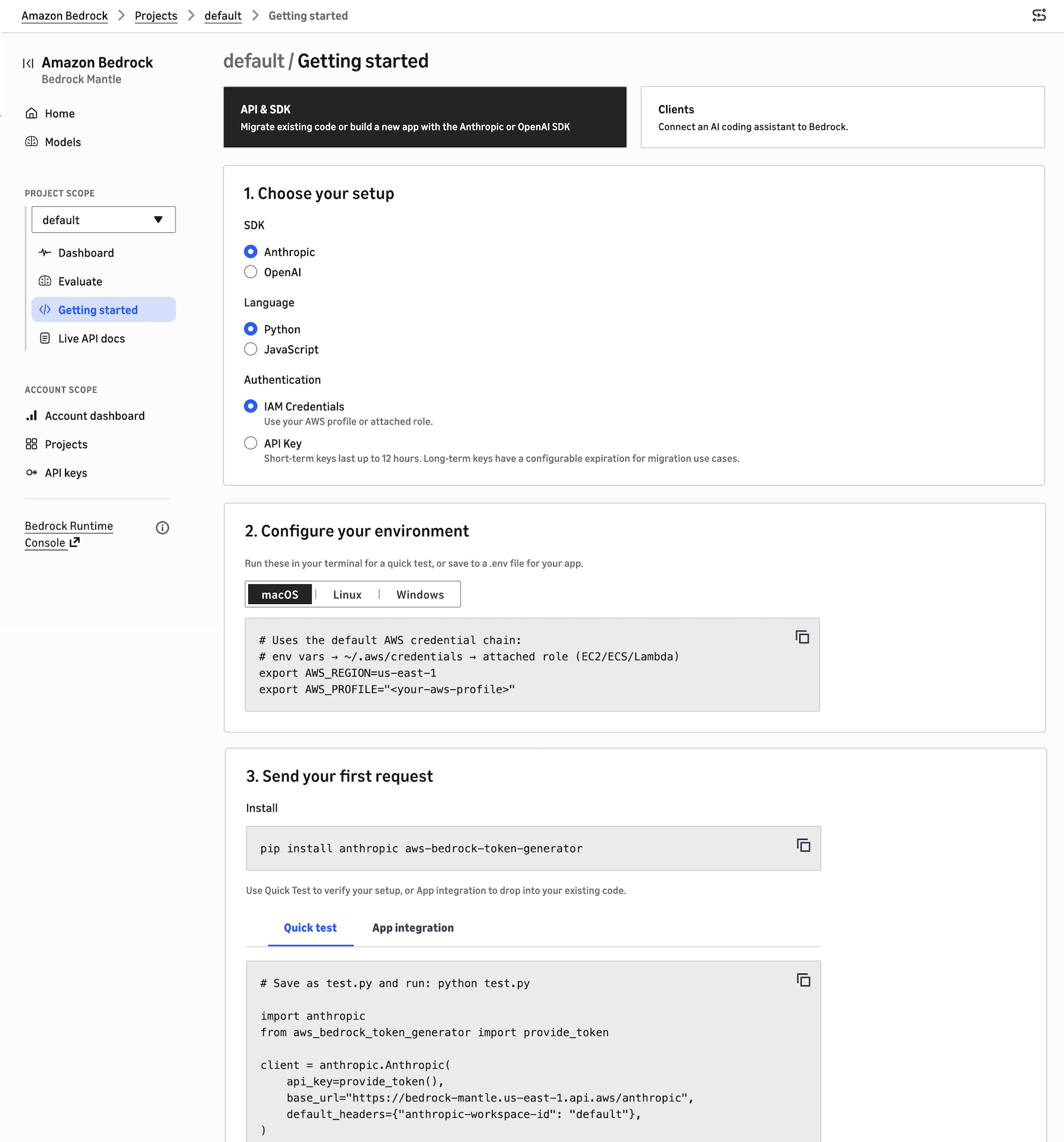
To learn about Anthropic- and OpenAI-compatible APIs, choose Live API docs. You can choose Anthropic API Protocol for access to Claude model features like the Messages API or OpenAI API Protocol for access to features like Responses API.
For example, when you choose OpenAI Response API, it retrieves a model response with the given model ID. These API references are automatically prefilled with the project’s selected model ID, Region, bedrock-mantle endpoint URL, and API key reference, and they update in place as you change models or settings.
You can also choose the existing Bedrock console to manage fully-managed features such as Agents, Knowledge Bases, Guardrails, fine-tuning, or the InvokeModel and Converse APIs to run on the bedrock-runtime endpoint.
Now available
The new console experience is available in all AWS Regions where the bedrock-mantle endpoint is offered: US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Jakarta, Mumbai, Sydney, Tokyo), Europe (Frankfurt, Ireland, London, Milan, Stockholm), and South America (São Paulo).
Give the new console experience a try in the new Amazon Bedrock console and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
Anthropic Embeds Engineers in the NSA to Deploy Mythos for Offensive Cyber
Anthropic has embedded six engineers within the NSA to help customize the Mythos model for offensive cyber operations.
Original article
Anthropic has placed about six engineers inside the US National Security Agency (NSA) to help deploy Mythos for offensive operations. The engineers will help the NSA customize the model for use in infiltrating networks in nations such as China or Iran. It is unclear whether Anthropic's engineers will assist with active operations. Anthropic is currently suing the Pentagon over how its models are used at war.

OpenAI reportedly has a major ChatGPT overhaul in store
OpenAI plans a major ChatGPT overhaul to transition from a simple chatbot into an agentic 'super app' aimed at enterprise workflows.
Original article
OpenAI reportedly has a major ChatGPT overhaul in store
The revamped AI tool will roll out in the coming weeks, according to The Financial Times.
OpenAI's so-called "super app" may finally be rolling out, as first reported by The Financial Times. According to the report, a redesigned ChatGPT would encourage users beyond just chatting and towards using "coding tools, image generation and applications built by partners such as Canva and Booking.com." The FT reported that the overhauled ChatGPT is expected to roll out in the coming weeks, but will first appear through changes to the website and mobile apps.
As popular as its AI chatbot is with free users, FT reported that OpenAI wants to attract more enterprise users with this upcoming overhaul that emphasizes performing multiple tasks instead of just answering questions. This major redesign is expected to generate more revenue through larger businesses that would deploy OpenAI's new ChatGPT across their workforce, which would help the company with its potential plans to go public as soon as September of this year. On top of that, OpenAI is likely trying to stay competitive with its main rival, Anthropic, who similarly announced its intention to launch an initial public offering.
Back in March, the Wall Street Journal and CNBC reported that OpenAI was working on a super app that would unify its ChatGPT, browser and Codex app for desktop. Along with that, OpenAI previously introduced an app directory within ChatGPT that would automatically connect to commonly-used third-party apps like Spotify or Dropbox.
Google to Pay SpaceX Nearly $1 Billion a Month in Cloud-Computing Deal
Google is betting nearly $1 billion per month on SpaceX data center capacity to secure hardware supply for its cloud operations.
Original article
Google will pay SpaceX $920 million per month from October 2026 to June 2029 to rent data center capacity. Google has the right to cancel the agreement in October if SpaceX doesn't provide the promised 110,000 Nvidia chips. Either party can cancel the agreement starting next year with 90 days' notice. This is the second major deal SpaceX has made in recent months to rent out compute capacity to a competitor. SpaceX is expected to go public on June 12 in a public offering that values the company at $1.77 trillion.
Inside Apple's Secret Meeting That Led It to Finally Take AI Seriously
Apple's internal pivot to AI began in a secret 2025 meeting where executives bypassed Tim Cook to demand a leadership change for Siri.
Original article
Several top Apple employees held a meeting - without Tim Cook - centered around the company's AI strategy in early 2025. At the time, the company's rivals were rapidly advancing, and the executives were concerned about how much trouble the company was in if real changes weren't made immediately. The meeting's aim was to formulate a recommendation to Cook about how the company should respond. The team decided that fresh leadership was necessary and recommended that Cook give Siri to Mike Rockwell, the creator of the Vision Pro headset, who was passionate about AI and had long argued that Apple needed to take it more seriously.
The Jevons Misunderstanding
AI-driven expansion may bypass the traditional labor bundle, leading to market growth where workers remain employed but under increasingly poor conditions.
Decoder
- Jevons' Paradox: An economic observation where increased efficiency in using a resource leads to an overall increase in its consumption rather than a decrease.
Original article
Jevon's Paradox assumes that the old production system continues to scale when demand expands as a result of new technology, but with AI, expansion can bypass the old labor bundle, meaning workers stay employed but at progressively lower wages in worse conditions, not seeing the benefits of the market expansion.

Terraform Cloud (HCP) Projects vs Spacelift Spaces
While HCP Terraform Projects offer a flat organizational structure, Spacelift Spaces provide a hierarchical, multi-tenant approach better suited for complex, large-scale infrastructure.
Decoder
- IaC (Infrastructure as Code): Managing and provisioning infrastructure through machine-readable definition files rather than manual hardware configuration.
- RBAC (Role-Based Access Control): A method of restricting network access based on the roles of individual users within an enterprise.
- Multi-tenancy: An architecture where a single instance of a software application serves multiple customers (tenants), ensuring data isolation between them.
Original article
Terraform Cloud (HCP) Projects vs Spacelift Spaces
As your infrastructure grows, your Terraform configurations quickly become dozens, then hundreds, and you will spend a lot of time figuring out who has access to what rather than actually shipping infrastructure.
Using an infrastructure orchestration platform, you can easily address these issues. Both HCP Terraform (formerly Terraform Cloud) and Spacelift have organizational features, but they were built using different approaches.
HCP Terraform introduced Projects to group workspaces, but they can also group policy sets, run tasks, and more. Spacelift built Spaces as a hierarchical system for organizing stacks, policies, contexts, and pretty much everything else in your account.
In this article, we discuss what Terraform Cloud Projects and Spacelift Spaces are in a detailed way, what the differences are between them, and when you should pick one over the other.
What we’ll cover:
- What are Terraform Cloud (HCP) projects?
- What are Spacelift Spaces?
- What are the key differences between Projects and Spaces?
- Projects vs. Spaces: Table comparison
- When should you use Terraform Cloud projects vs. Spacelift Spaces?
What are Terraform Cloud (HCP) Projects?
Terraform Cloud (HCP) Projects helps you organize your workspaces. You can think of these projects as folders. So after you create your workspace, it will belong to exactly one project.
By default, any workspace you create will be assigned to the “Default Project” that HCP Terraform automatically generates for every organization.
The projects in the HCP Terraform repository serve two purposes: organization and access control.
On the organizational side, at the project level, you can group workspaces that are related and compatible with your team’s needs. You can organize your workspaces by business unit, application, environment, or team. For example, you can have a “Core” project that includes workloads for your DNS, networking, and shared services.
On the access control side, projects let you assign team permissions at the group level. If you have a platform team that needs access to all networking workspaces, you only need to give them permission to the project once, because every time a new workspace is created, they will inherit those permissions.
Also, projects let you control which version control repositories your workspace has access to, helping you enforce the principle of least privilege. These capabilities help teams organize the workspaces they are responsible for.
Additionally, you can specify project-level variable sets. If you want to assign a set of credentials to a project, all current and future workspaces in that project will inherit them without any extra configuration. You can also define a credential variable set to a specific team. In this way, you ensure those values aren’t exposed to workspaces that don’t require them.
The same applies to policy sets: you attach them at the project level, and they enforce governance standards across all workspaces in that project.
Here are some of the key characteristics of HCP Terraform Projects:
- There is no hierarchy between projects; they exist only at a single level under your organization.
- Workspaces belong to a single project, but they can be moved between projects.
- You can assign four preset roles to your team at the project level (Read, Write, Maintain, and Admin). These roles apply to all workspaces within your project. You can also define custom roles if the preset roles don’t match your requirements.
- Both variables and policy sets can be applied at the project level. They will automatically apply to all workspaces inside it.
What are Spacelift Spaces?
Spaces in Spacelift are logical containers for your resources. The majority of Spacelift resources are spaced, including stacks, policies, contexts, cloud integrations, worker pools, modules, and others.
Spaces’ structure is similar to a tree, and each user starts with a root space at the top. This means that a space can have child spaces, and those child spaces can also have their own children. You can create a structure with as many levels as you need.
One of the most powerful features of Spaces is inheritance. If you enable inheritance in a child space, it automatically grants it read access to all resources in its parent space. This means that if you create a set of policies or a context in a parent space, every child that inherits from it can use those resources. This becomes powerful when you have shared resources that many teams need.
Here are some of the key characteristics of Spacelift Spaces:
- They can be organized into hierarchical parent-child relationships across many levels
- The child spaces can inherit resources from their parent
- Spacelift provides built-in roles such as Space Reader, Writer, and Admin, and offers custom roles with fine-grained permissions
- Spaces enable a multi-tenant setup where different teams or customers can operate in an isolated environment
- Spaces contain stacks, policies, contexts, cloud integrations, worker pools, and modules.
What are the key differences between Projects and Spaces?
HCP Terraform Projects and Spacelift Spaces both help you organize and govern infrastructure work across teams, but they take different approaches.
1. Structure
The structure of HCP Terraform is flat, so there is no parent-child relationship or inheritance. You simply have projects under your organization.
On the other hand, Spacelift Space’s structure is hierarchical. You can nest spaces at any depth, and resources can be inherited from parent spaces down to their children.
2. What they organize
Projects in HCP Terraform let you group workspaces and manage their access and variables at the project level. Spacelift Spaces help you organize everything in your account, such as stacks, policies, cloud integrations, contexts, worker pools, and modules.
3. Resource inheritance
In HCP Terraform, if you need to use the same variable set for two different projects, you should create an organization-wide variable set. There is no rule that lets one of your projects inherit resources from another project.
In Spacelift, inheritance exists and allows child spaces to access resources from parent spaces.
4. Access control
Another key difference between HCP Terraform and Spacelift Spaces is the depth of access control. HCP Terraform lets you set the project permission at the team level. This means you can assign a team a permission level (Read, Write, Admin, or Maintain) to a project, and that will apply to all workspaces in the project.
Spacelift Spaces supports built-in roles (Reader, Writer, or Admin) and also custom roles with granular permissions. For example, you can create a role that can trigger runs and read contexts but cannot modify stacks.
5. Multi-tenancy
Spacelift Spaces were designed with multi-tenancy in mind. They can give a team admin rights to their own space without giving them any visibility into other team spaces. HCP Terraform Projects can help you isolate teams, but its model is less suited for true multi-tenant scenarios.
Projects vs. Spaces: Table comparison
Below is the table comparison summarizing all the differences:
| Feature | HCP Terraform Projects | Spacelift Spaces |
| Structure | Flat | Hierarchical |
| What they organize | Workspaces, stacks | Stacks, policies, contexts, worker pools, cloud integrations, modules |
| Resource inheritance | No | Yes |
| Nesting | No | Unlimited depth |
| RBAC model | Team-level permissions on projects; custom permissions are also available | Built-in roles and custom roles with granular actions |
| Custom roles | Yes | Yes (compose from specific permissions) |
| Multi-tenancy | Basic isolation | Full multi-tenancy support |
| Variable sharing | Project-level variable sets, organization-wide variable set | Contexts (variables, mounted files, hooks) at the space level and inherited contexts from parent spaces |
| Policy scoping | Project-level policy sets | Multiple policy types (plan, approval, push, notification, trigger) at the space-level and inherited policies from the parent space |
| IaC tools supported | Terraform | Terraform, OpenTofu, Terragrunt, Pulumi, CloudFormation, Ansible, Kubernetes |
| Default project/space | Default Project (auto-created, cannot delete) | Root space auto-created |
When should you use Terraform Cloud Projects vs. Spacelift Spaces?
When to choose HCP Terraform Projects:
- If you are already running HCP Terraform and your organizational needs are relatively simple.
- If your team is small to mid-sized, and uses only Terraform, and needs a way to group your configurations and assign team permissions, Projects will get the job done.
- Projects can also be a good fit if your team is already living in the HashiCorp ecosystem
- If your teams do not need to have deeply nested organizational requirements, variables set, and policy set scoping at the project level will cover most governance needs.
When to choose Spacelift Spaces:
- If you have many teams, multiple environments, and a need to isolate production from development while sharing certain resources, such as worker pools or cloud integrations across both, you should choose Spacelift because it offers the flexibility to model that. In this case, the hierarchical structure with inheritance means that you do not have to duplicate shared resources across every team boundary.
- Also, if you need multi-tenancy, choose Spacelift because it was built to isolate environments and supports multiple teams with different levels of permissions at the Space level.
- Spacelift Spaces supports multiple IaC tools, including Terraform, Pulumi, Terragrunt, and CloudFormation. This means that Spaces will let you organize all those workloads into a hierarchy tailored to your needs.
- You can also leverage custom RBAC roles with fine-grained permissions beyond standard roles like Read/Write/Admin. Spaces combined with Spacelift’s custom roles give you much more flexibility than HCP Terraform’s team-based permissions.
Key points
HCP Terraform projects have a flat structure and help you group your workspaces, manage your team permissions, and scope variable and policy sets at the project level.
On the other hand, Spacelift Spaces have tree-based organizational boundaries that contain stacks, policies, contexts, cloud integrations, worker pools, and modules. Spacelift Spaces were designed with built-in resource inheritance, making it easy to share resources from parent Spaces to child Spaces.
If your organizational requirements are simple and you are using only Terraform, HCP Terraform projects will help you get the job done.
Typically, no organization uses a single IaC tool, or, if they do, they still want a platform that can help them easily switch to another tool if needed. That’s what Spacelift offers: the ability to scale with your needs, not force you to buy an entirely new platform just to manage a new IaC or Configuration Management tool.
Cost-effective Terraform Cloud alternative
Spacelift is a highly cost-effective Terraform Cloud alternative that works with Terraform, Terragrunt, and many other IaC frameworks. It supports self-hosted on-prem workers, workflow customization, drift detection, and much more.
The Join-Aware Materialized View Query Rewrite Gap
The lack of 'join-aware' materialized view rewrites creates a performance bottleneck for star-schema BI, forcing a fragmented landscape of proprietary solutions.
Decoder
- Star schema: A database design pattern consisting of a central fact table surrounded by dimension tables, standard in data warehousing.
- Materialized view: A pre-computed query result stored on disk that updates automatically, allowing faster reads compared to calculating results from raw tables on the fly.
Original article
Join-aware materialized views make star-schema BI faster by keeping fact-to-dimension joins available for rewrite. Single-table MVs miss the dashboard grouping attributes. StarRocks, BigQuery, Redshift, and Oracle support this directly. Databricks has experimental Metric Views, while Snowflake leaves the capability split across MVs and Dynamic Tables.

Vibe Coding Is Dangerous, Agentic Engineering Isn't
Wes McKinney warns that 'vibe coding'—shipping blind one-shot prompts—is a professional liability, advocating instead for 'agentic engineering' through rigorous testing and human oversight.
Decoder
- Vibe coding: A disparaging term for using AI to generate code based solely on 'what feels right' without verification, testing, or code review.
Original article
Full article content is not available for inline reading.
Structure vs. Concept
Taxonomies excel at organizing human-readable content, while ontologies provide the logical rules needed for machine reasoning, suggesting they should be linked but kept structurally distinct.
Decoder
- Taxonomy: A hierarchical structure used to classify concepts.
- Ontology: A formal representation of a knowledge domain, including classes, properties, and the rules defining the relationships between them.
Original article
Taxonomies organize business concepts for humans, while ontologies define classes, properties, constraints, and rules. Vector retrieval works best with rich taxonomy text; reasoning needs ontology axioms. Keep them linked but separate, so business users can curate concepts while data models stay logically precise.

Your Obsidian Vault Can Now Run SQL (and Your Agent Can Read It)
A new Obsidian plugin enables local SQL execution via DuckDB, allowing you to turn markdown notes into queryable, live dashboards.
Decoder
- DuckDB: An in-process SQL OLAP database management system designed for fast analytical queries.
- Substrait: An open-source, cross-language intermediate representation for relational algebra and query plans.
Original article
Plan Mode All the Time, Substrait over SQL, and the End of the DE Role ft. Chris Riccomini
Chris Riccomini on using AI for data engineering: correctness in financial data, why LLMs should speak Substrait over SQL, the Ralph Loop for context management, security with 'Okta for Agents', and the future of the data engineer role.
The Basic Spark Concept Beginners Don't Know
Apache Spark's efficiency hinges on the distinction between lazy transformations that build a execution plan and actions that initiate cluster-wide computation.
Deep dive
- Transformations (e.g., select, filter) are lazy; they build a logical plan rather than processing data.
- Actions (e.g., collect, count, save) trigger the execution of the full DAG.
- The DAG organizes the steps from source data to the final result.
- Executors are the worker processes that run tasks on cluster nodes.
- Immutability ensures DataFrames are not modified in place, preventing side effects in distributed environments.
Decoder
- DAG (Directed Acyclic Graph): A data structure used by Spark to represent the sequence of operations, where nodes are operations and edges are data dependencies, allowing the engine to optimize the execution plan.
- Executor: A process launched for an application on a worker node that runs tasks and keeps data in memory or disk storage.
Original article
Spark's core model is simple: transformations are lazy, immutable DataFrame operations that build a DAG, while actions trigger execution across executors.

Netflix Turns to Generative AI to Fix a Problem it Helped Create
Netflix is using generative AI and natural language processing to combat the very content overload it created by commissioning high volumes of shows.
Decoder
- Natural Language Processing (NLP): A field of AI that enables computers to understand, interpret, and manipulate human language.
Original article
The streaming service that taught a generation to scroll endlessly now wants to sell them the cure. At the Bloomberg Tech conference in San Francisco on Wednesday, Netflix’s chief product and technology officer, Elizabeth Stone, said the company is deploying generative AI to help subscribers cut through the volume of content it has spent two decades piling up.
The framing was telling. Stone described “a consumer frustration that’s brewing, which is, there’s so much content. How do I make sense of it, and what’s right for me, and what’s right for me in this moment?” The frustration is real, and Netflix is closer to its source than most.
Stone said generative AI and natural language processing are already being used to help viewers pick shows based on mood, and that the company is testing a voice interface among other experiments aimed at sharpening recommendations. The pitch is for an experience that is “more personalized, more interactive, more immersive,” in her words.
None of this is a small adjustment to a side feature. Recommendation is the product. Netflix has long held that the large majority of what subscribers watch comes from what the service surfaces rather than what they search for, which makes the discovery layer the part of the business most exposed to a better idea.
That better idea may be arriving from a competitor. Stone’s remarks land as YouTube continues to absorb television viewing time, a shift that has reframed the question for every subscription service. Keeping a viewer is no longer only about owning the title they want. It is about being the place where they decide what they want, quickly enough that they do not open another app instead.
The discovery push sits alongside a broader set of interface changes Netflix has been trailing, including short clips that play in feed and can be tapped to open a full title, save to a list, or pass to someone else. The clip feed and the AI recommendation work share a logic: shorten the distance between opening the app and pressing play.
There is an irony in the strategy that Netflix did not dwell on. The choice paralysis Stone wants AI to solve is partly a product of the company’s own catalogue strategy, the years of commissioning at volume that filled the grid faster than any human could sort it. The fix and the problem come from the same place.
Stone did not put a timeline on a wider rollout of the voice interface or detail which generative models are doing the work behind the recommendations. Netflix has said it is experimenting; it has not said when experiments become defaults. What is clear from San Francisco is the direction. The company that made the infinite scroll a habit now wants to be the one that ends it.
James Cameron's 3D Studio Acquires 3D Camera Maker STEREOTEC
James Cameron’s production studio, Lightstorm Vision, has acquired 3D camera manufacturer STEREOTEC to industrialize high-fidelity 3D and spatial content production.
Decoder
- Stereoscopic: Techniques used to create the illusion of depth by presenting two slightly different images to each eye.
- Ground Truth: In AI and data processing, this refers to the initial, accurate information captured at the source that serves as the benchmark for downstream processing.
Original article
James Cameron’s 3D Studio Acquires 3D Camera Maker STEREOTEC
Lightstorm Vision, James Cameron’s 3D production studio, has acquired STEREOTEC, a 3D camera maker that’s powered a number of films and multi-camera immersive concerts.
Details of the deal are still under wraps, however Lightstorm Vision says the acquisition will help integrate Stereotec’s technology directly into its 3D production pipeline, enabling capture, processing, and delivery of 3D video.
“By capturing consistent ‘ground truth’ depth data at the source, the technology unlocks downstream automation, AI processing, and the scalable 3D workflows that Lightstorm Vision is bringing to cinematic, broadcast, and immersive platforms,” the companies say in a press statement.
Stereotec is most recently known for providing the camera tech behind 3D concert ‘Billie Eilish – Hit Me Hard and Soft: The Tour’, which Lightstorm says was one the “largest and most complex live 3D capture deployments ever executed,” having included more than 17 stereo camera systems (34 cameras) across fiber and RF into a unified pipeline under live tour conditions.
That sort of tight integration allowed editorial teams to begin cutting synchronized 3D multi-cam footage while the performance was still underway, the studio says, something aimed at reducing reliance on post-production reconstruction and lengthy editing times.
“Capturing accurate depth at the source produces results no downstream process can recover after the fact—and provides the foundation for the scalable, production-ready 3D workflows Lightstorm Vision is establishing as the new standard across cinematic, broadcast, and immersive platforms,” the studio says.
Established in 2024 as Lightstorm Entertainment’s dedicated 3D studio, Lightstorm Vision’s stereoscopic tech has supported over 27 feature films, 9 concert films, and 140 sports broadcasts worldwide, generating in excess of $8 billion in global box office. It also most recently struck a multi-year deal with Meta to produce spatial content across multiple genres, including live events and full-length entertainment.
Founded near Munich by stereographer and engineer Dr. Florian Maier in 1997, Stereotec produces precision-engineered 3D rigs, having supported feature films including Ang Lee’s Gemini Man (2019) and Billy Lynn’s Long Halftime Walk (2016), Denis Villeneuve’s Dune: Part Two (2024), as well as immersive titles for Quest and Apple Vision Pro. To date, the company holds twelve Lumiere Awards from the Advanced Imaging Society for excellence in stereoscopic 3D production.

Make Anime Short Series in Minutes (Website)
Arcloop AI provides an automated production suite that acts as an executive director to generate anime-style short series from simple prompts.
Decoder
- Storyboarding: The process of creating a sequence of drawings or frames that represent the planned shots and camera movements for a video project.
Original article
Your AI Executive Director
Just share your vision. The agent drives the production — designing characters, building scripts, planning storyboards, and keeping shot-by-shot consistency across look, tone, and visual style.
Above the sky, Cloudlet Town is home to a young mail carrier with a glowing bag. One sunset, she receives a letter from her future self...
Silver starlight hair, sky-blue uniform, glowing mailbag: kind, bright, and a little clumsy.
At the Cloudlet Town post office, sunset turns the clouds rose gold and lavender...
TYPE THE IDEA, GET THE VIDEO
Skip complex prompts. Describe your feeling in simple words and turn it into cinematic clips.
Design Your Unique Character
Define every aspect of your character, including look, style, voice, and personality cues. Explore their journey from daily moments to dramatic scenes, then turn every interaction into new storylines and videos.
Go From One Line to Full Script
Drop in a script, novel, chat log, or single sentence. The agent helps shape the plot, structure the scenes, and turn rough thoughts into a complete story.
Direct Every Movie Scene
Describe your concept and get storyboards, camera positions, subject references, and shot sequences for every scene. Use them as a blueprint for a more structured, intentional video.
Bring Visuals Into Motion
Turn static ideas into dynamic video content with AI-driven animation and motion tools designed for storytelling experiences.
Create Your Own Anime Shorts
Share your vision, and AI brings your characters and scenes to video.
Some notes on getting into frontier AI labs
Success at frontier AI labs relies on the ability to operate without a map, blending research theory with practical, high-scale engineering.
Original article
Proven research and trench engineering are not separate skills at frontier labs, but two expressions of the same ability: operating without a map. Research output is not the paper but a refined ability to make progress when certainty is unavailable, and trench engineering at modern AI infrastructure scale is less about accumulating every detail and more about compressing complexity into useful abstractions that predict reality.
Google Chrome tests sending users straight to AI Mode instead of Search
Google is running internal tests for a Chrome feature that routes search traffic directly to an AI mode, though no public release is planned.
Original article
A commit from Google explicitly says that the company is currently just exploring the function and there are no current plans to push it live.
A new era for software testing
Antirez argues that the rise of automated software testing will fundamentally shift how developers define quality in new software releases.
Original article
The introduction of automated QA will likely raise the bar of quality for new software releases.

Feature Flags Without Pipeline Visibility Are a Liability
Separating feature flag management from CI/CD pipelines creates costly visibility gaps that complicate incident responses, audits, and rollback procedures.
Original article
Disconnected feature flag tools and CI/CD pipelines create visibility gaps that slow incident response, complicate audits, increase rollback risk, and reduce release confidence by forcing teams to correlate deployment and feature exposure data across separate systems.
The Tableau Exodus Has Begun
Companies are abandoning Tableau not because of product failure, but because high licensing costs have made legacy BI unaffordable in an AI-centric era.
Decoder
- BI: Business Intelligence; software that aggregates, analyzes, and visualizes company data to inform decision-making.
Original article
Executives are cutting Tableau because BI feels too expensive and undervalued, not necessarily because another tool is better. The smart response is to preserve critical BI-only metrics, consider cheaper or consolidated platforms, and use the migration to rethink BI's value in an AI-first world.
New iOS 27 designs reportedly coming to these iPhone apps
Apple is preparing a significant visual overhaul for core iOS 27 apps, including a Siri-powered 'visual intelligence' mode for the Camera app.
Original article
iOS 27 is expected to bring major redesigns to the Camera app (with customizable controls and a new Siri-powered visual intelligence mode) and Image Playground (redesigned gallery and streamlined editing tools), alongside smaller updates to Find My, Weather, and Safari. Apple is also refining its Liquid Glass interface, including moving search back into app tab bars across many built-in apps.
The rhetorical mask of innovation
New technology should be viewed as a testable hypothesis rather than an inherent improvement, as real-world benefits often take years to manifest.
Original article
Innovation simply means introducing something new, not necessarily something better. True progress can only be judged by long-term outcomes and evidence. New technologies and systems—from antibiotics and smartphones to AI—often arrive wrapped in promises of improvement, but their real benefits and harms may take years to understand, making it important to treat innovation as a hypothesis rather than proof of progress.

Six common font pairing mistakes and how to avoid them
Effective font pairing requires deliberate contrast and distinct roles, though often the best design solution is to rely on a single typeface family.
Decoder
- Optical Size: A version of a typeface designed specifically to be legible at certain sizes (e.g., a display font optimized for large headers vs. a text font for body copy).
- Terminal: The end of a stroke in a letterform that does not have a serif.
- Hierarchy: The arrangement of type elements to create a clear order of importance for the reader.
Original article
Effective font pairing relies on clear contrast, hierarchy, and purpose: avoid combining typefaces that are too similar, too expressive, or poorly defined in their roles, and ensure each font has a specific job within the system. In many cases, a single well-chosen typeface family with multiple weights, styles, or optical sizes can create a stronger and more cohesive identity than pairing multiple fonts.

Daily Designer (Website)
Arun Venkatesan launched a 'forever project' to curate daily design quotes using an automated system and AI-assisted content extraction.
Decoder
- Astro: A web framework optimized for building content-focused websites by shipping minimal JavaScript to the browser.
- AA contrast: A standard from the Web Content Accessibility Guidelines (WCAG) that ensures a specific level of color contrast for text readability.
Original article
A collection of daily quotes from the most respected designers in the industry.
Test Ads at Scale (Website)
Cliploft automates ad creation by allowing users to paste product links and receive a ready-to-run video ad within one minute.
Original article
Paste a product link, pick a creator, and get a ready-to-run ad in 60 seconds.

Studio Patten blends visual honesty and curiosity across illustration and graphic design
Studio Patten avoids a singular visual signature by combining vintage print research with a disruptive, collaborative approach to graphic design and illustration.
Original article
Studio Patten, founded by Aida Novoa and Carlos Egan, draws inspiration from vintage print materials, architecture, literature, and other creative fields to produce design and illustration work that balances experimentation with accessibility. Rejecting a fixed visual style, the duo emphasizes collaboration, thoughtful typography, and continuous evolution, as seen in projects ranging from an abstract personal book of shapes to philosophy textbooks designed to engage young readers.

Why Website Performance is a Brand Experience Issue
Website performance should be managed as a critical brand asset, as technical latency directly dictates user trust and perceived brand competence.
Original article
Website performance is fundamentally a brand experience issue, not just a technical concern — slow, unstable sites erode trust and shape how customers perceive a company.

These Parody Google Icons are Better Than the New Update
A viral trend on X is mocking Google's recent app icon redesigns by reimagining them as literal, skeuomorphic objects like piles of dirt or crumpled sheets.
Decoder
- Skeuomorphism: A design style where digital interfaces mimic the textures and appearance of physical objects, such as a trash can icon looking like an actual metal bin.
Original article
Google's recent app icon redesign sparked a creative trend on X, where users began sharing humorously literal, skeuomorphic alternatives — turning Google Sheets into crumpled bed sheets, Earth into a pile of dirt, and Slides into sandals.