Devoured - June 09, 2026
OpenAI has confidentially filed for an IPO, while Apple’s new Siri AI and Xiaomi’s 1,000 token-per-second model signal a pivot toward integrating cloud-based AI infrastructure into everyday user workflows. Meanwhile, developers are increasingly shifting from manual prompting to loop engineering, creating autonomous, self-repairing agentic pipelines to improve software quality and engineering velocity.
Apple Introduced Siri AI
Apple is finally releasing 'Siri AI' this fall, introducing a more conversational assistant supported by Google’s Gemini model.
Deep dive
- Device requirements: Full features require M4/M3 chips or equivalent, 12GB+ RAM.
- Capability tiers: Less powerful models will run on older or lower-spec devices with limited expressiveness.
- Feature set: Includes visual intelligence, system-wide 'Write with Siri', and deeper Spotlight search integration.
- Integration: Siri can now bridge information across Messages, Maps, and third-party apps contextually.
- Privacy: Claims non-negotiable protections even when using off-device cloud compute.
Decoder
- Foundation Model: A large-scale machine learning model trained on vast data that serves as a base for various downstream tasks.
- Private Cloud Compute: Apple's framework for running complex AI models on its own secure servers without storing user data permanently.
Original article
Today at its pre-filmed Worldwide Developers Conference keynote, Apple was finally prepared to fully introduce the long-delayed “Apple Intelligence” update for its Siri voice assistant. The new “Siri AI”—now being promised for OS updates rolling out “this fall”—will come alongside a new Google-powered update to Apple’s on-device Foundation Models, as well as tighter integration of all these AI capabilities across Apple’s many operating systems.
Unlike other companies that “appear to be racing forward, seemingly pursuing AI for the sake of AI, with little regard for the people… it’s meant to serve,” Apple’s SVP of Software Engineering Craig Federighi said, “we believe that truly helpful AI must be centered around you and your needs.”
Just a friendly chat with your AI assistant
The company highlighted this kind of focus in a series of scripted conversational demos with Siri AI, complete with seemingly unedited, multi-second pauses between each spoken prompt and Siri’s response. In these demos, Apple executives showed Siri AI bouncing between different usage modes and app-based tasks as needed in an effort to highlight how Apple Intelligence can now be used “well beyond one-shot tasks” for a “brand new conversational experience” with the virtual assistant.
In one example, for instance, a user asked about schedule information for the World Cup, followed by a request for recipes inspired by a Brazil vs Morocco match, then asked for a dessert he remembered had been mentioned recently by his friend Maria (which Siri found in his Messages app). He then asked Siri to integrate this all into a watch party menu and to send that menu to his group chat alongside an invite.
In another demo, the Siri conversation started with a question about where a photo of an arch was taken, then moved to finding the address of a friend named Jeff who had recently moved. With those answers in hand, Siri was able to “give me directions to the arch with a stop at Jeff’s” directly via Apple Maps, without having to juggle the information manually.
While many other AI models can perform similar tasks, these and other demos highlighted how Apple Intelligence and Siri AI benefit from tight integration into the “personal context” of data on your device. That means Siri can search to find information across your messages and email, even if you can’t remember specifically where that information is stored, for instance. It also means that, when using Siri to write emails, this “personal context” can also customize the writing style to match your previous emails to the same person, Apple said.
Siri AI utilizes “world knowledge” by searching the web using private cloud compute to generate answers, Apple said, and integrates with app actions to figure out which tools to use to complete a task. The on-device assistant can also display on-screen understanding to tailor its assistance based on what you’re doing at that moment.
Apple also highlighted Siri’s new “visual intelligence,” which can give relevant responses to questions right from the camera app or extract multiple calendar updates from a complex image of a concert schedule, for instance. On VisionOS, you can also directly ask questions about physical objects you can see in the world around you and get answers from Apple Intelligence. A new “Write with Siri” feature, meanwhile, will let you use Apple Intelligence to generate text “virtually anywhere you type,” Apple said, while a new AI-powered automatic proofreading system will check your writing style system-wide (a la spell check).
On MacOS, these new Siri AI features will be integrated into Spotlight search, which can identify when a typed query should start a Siri conversation rather than just a list of files or web results. You can also ctrl-click across the OS to ask Siri questions about photos, files, or text, or even multiple files at once. And anyone still using VisionOS will be able to put a glowing, animated Siri Orb into their workspace that will be able to answer questions whenever you look at it.
Conversations with Siri AI will be stored locally and via iCloud in a new dedicated Siri app, letting you start a conversation on one Apple device and finish it on another.
Two levels of AI
Earlier this year, Apple announced it had signed a multi-year deal with Google to use its Gemini model as the basis for that Siri update. Last month, though, we heard reports that Apple was having trouble cramming all of Gemini’s features into completely local on-device models.
At WWDC, Apple announced a new two-tier structure to its on-device Apple Intelligence offerings. The company’s “most capable model” will now only be available on devices that meet certain chip and memory requirements. Those are:
- iPhone Air and iPhone 17 Pro
- iPads with M4 and later CPUs and 12GB or more of memory
- Macs with M3 and later chips and 12GB or more of memory
Less capable devices that currently support Apple Intelligence will get a less capable model that is missing some features, including a new, more expressive voice for Siri’s responses (that “expressiveness” can be customized with a slider alongside the “pace” of its speaking voice). The most powerful model also comes with what Apple says is a major boost in dictation accuracy, including better spelling and punctuation.
Many Apple Intelligence features will continue to rely on “private cloud compute” servers as well. But Apple Intelligence features like image generation will also be subject to daily usage limits because of their reliance on off-device servers, Apple said. Subscribers to most iCloud+ plans will get expanded usage of these features.
The new Siri AI features will only be available in English to start, but will eventually be made available for every language in which iOS operates.
Apple once again stressed that these new Apple Intelligence features were built with “non-negotiable” privacy protections to make sure your Siri AI conversations aren’t available to Apple or anyone else.

Introducing FrontierCode
FrontierCode is a new benchmark that forces AI models to prove they can write mergeable, production-grade code rather than just functionally correct snippets.
Deep dive
- FrontierCode uses three grading tiers: Extended, Main, and Diamond (the hardest).
- Metrics measure both pass rates for blocking criteria and weighted scores for quality markers.
- Grading includes 'Reverse-Classical' tests, which confirm agent-written tests fail on broken codebases.
- 'Adaptive Classical Grading' uses LLMs to reconcile variable implementation styles during testing.
- The benchmark specifically enforces code scope discipline and mechanical cleanliness.
- Human-in-the-loop review ensures that rubrics are not easily 'gamed' by adversarial agent behavior.
- Cognition emphasizes that models must now infer intent from concise prompts rather than rely on overly descriptive instructions.
Decoder
- Mergeability: The quality of a code submission being sufficient to pass a human lead's review and be integrated into a production codebase.
- Reverse-Classical testing: A method where the agent's unit tests are run against a known broken version of the repository to ensure they correctly identify faults.
- Adaptive Classical Grading: Using an LLM to dynamically adjust test assertions to accommodate valid but unconventional code implementations.
Original article
Raising the bar from correctness to quality
Today’s coding benchmarks have established that models can write correct code. But as AI-generated code becomes the dominant path to production, correctness is now table stakes. The question that we should be asking is: can models actually write good code?
We’re excited to introduce FrontierCode, a benchmark that measures how well models can truly meet the standards of high-quality production codebases. What sets us apart:
- Would the maintainer actually merge this PR? We’re the first benchmark to measure code mergeability. Our criteria assess end-to-end code quality — correctness, test quality, scope discipline, style, and adherence to codebase standards. This employs a novel ensemble of grading techniques, including unit tests, rubrics, and new types of verifiers.
- Crafted by open-source maintainers. 20+ world-class open-source developers built realistic, diverse, and challenging coding tasks from the repos they maintain, spending more than 40 hours per task. They define what “mergeable” means in their repo.
- Rigorous quality control. Rubric grading is subjective, so we built an extensive QC pipeline with adversarial testing, calibration, and multi-stage review, where every task is manually reviewed by a Cognition researcher. We achieve an 81% lower false positive rate compared to SWE-Bench Pro.
Our benchmark provides the strongest available signal of a model’s ability to write high-quality, maintainable code. We find that even today’s most capable models struggle on this new standard.
Results
We present three nested subsets of FrontierCode at increasing difficulty: Extended, Main, and Diamond. Diamond comprises the 50 hardest tasks, Main the 100 hardest (including Diamond), and Extended the full set of 150.
We report two metrics, pass rate and score:
- A solution passes if it clears all blocker criteria, i.e., criteria that a maintainer would consider hard stops during code review, and fails otherwise.
- A solution’s score is a weighted aggregate of the rubric items. Solutions that do not pass blocking criteria receive 0.
Each model is run 5 times at every available reasoning effort. For each effort, we average the metric across the 5 trials, then report each model’s score at its best performing reasoning level.
FrontierCode Diamond remains unsaturated: the best performing model, Claude Opus 4.8, achieves a score of only 13.4%. Other models score significantly lower: GPT-5.5 receives 6.3%, Gemini 3.1 Pro 4.7%, and others even less. However, GPT 5.5 consistently uses up to 4x fewer tokens than Opus 4.8, achieving a better cost-intelligence tradeoff.
On FrontierCode Main and Extended, Opus 4.8 still maintains a clear lead, at 34.3% and 51.8%, respectively. We also observe a large gap between open-source models and the frontier. Kimi K2.6, the best-performing open-source model, achieves just 3.8% on Diamond, 16% on Main and 37% on Extended.
Why we built FrontierCode
The first generation of coding benchmarks, such as SWE-Bench Verified and Pro, were designed for less capable models. They fall short on many measures of realism and robustness.
Fundamentally, they only test functional correctness, not quality. Moreover, these benchmarks are prone to misclassification errors. Experiments from METR have found that high-scoring models on these benchmarks often produce patches that wouldn’t be accepted by human maintainers.
How do we define misclassifications? These fall under two categories:
- False Positives: The verifier should not reward solutions that are wrong. Test coverage may be incomplete, allowing the model to write an incorrect solution that’s still accepted.
- False Negatives: The verifier should not penalize solutions that are correct. Tests can be either too specific, e.g. checking for exact error strings or function names, or unsolvable, testing for a behavior not in the instruction or in the codebase.
We show through analysis of agent trajectories that FrontierCode produces 81% less misclassification errors than other leading benchmarks. This means that FrontierCode scores are the most accurate ranking currently available.
Existing benchmarks also suffer from lack of diversity in several ways. While other benchmarks generated issues from single PRs via programmatic scraping, FrontierCode is hand-selected by repo maintainers from multi-PR chains and freeform requests. We also triple the number of represented languages from SWE-Bench Pro.
It’s also known that existing benchmarks provide too much guidance in the form of overly specified and detailed prompts. Today’s frontier models need far less hand-holding. FrontierCode expects the agent to infer the maintainer’s intent, given the same context as a human contributor.
Our prompts contain two parts. First is the task description. Second, the codebase guidelines for generic testing, lint, and style practices, just like those found in AGENTS.md. The task descriptions are humanlike and deliberately concise — a third the length of SWE-Bench Pro’s.
Furthermore, we’ve chosen to scale the difficulty of tasks using quality rubrics, rather than simply increasing patch size. Despite having smaller patches than benchmarks like DeepSWE, FrontierCode is harder for agents to solve.
How we built FrontierCode
A Team of Open Source Maintainers
FrontierCode aims to measure whether models can produce code that would be merged into production codebases. To ensure this, we collaborated directly with the maintainers of 36 flagship open-source repositories. This team of all-star experts has collectively reviewed and merged thousands of commits to their codebases. They can apply deep stylistic and design knowledge to every PR they see.
Each maintainer invested more than 40 hours per task, undergoing multiple rounds of iteration with other eval engineers and Cognition researchers. They’ve distilled their judgment into concrete evaluation criteria: any PR that satisfies these standards would actually be approved.
“Working with the team behind FrontierCode was a privilege. Taking on the AI evaluation problem felt like nothing less than an art… Where others grade like a CI, FrontierCode grades like a tech lead.” — Tomer Nosrati, CEO and Tech Lead of Celery
“What sets FrontierCode apart is the attention to detail. Each task is calibrated to a depth that simply hasn’t been seen before in LLM benchmarking. We should be moving away from benchmarks that can be gamed and instead using ones like FrontierCode to demonstrate genuine model intelligence and creativity.” — Martin McKeaveney, Co-Founder and CTO of Budibase
“I’m grateful to have worked with leading experts in the Open Source community. We had deep discussions on correctness versus quality and what mergeability means in the context of their repository. FrontierCode is a milestone for AI models respecting subjective quality in the real world.” — Merlijn Vos, Core Maintainer of uppy
“FrontierCode’s unique value comes from the human experience encoded in its evals: years of judgment about what makes code high-quality and worthy of merging. The almost obsessive care brought to every criterion is why I believe this benchmark sets a new bar for SWE evaluation.” — Claudio Costa, Core Maintainer of Mattermost
Beyond Unit Tests
FrontierCode measures mergeability by evaluating code along the following axes:
- Behavioral correctness: Does the patch successfully solve the problem?
- Regression safety: Does it break anything in the existing codebase?
- Mechanical cleanliness: Does it pass the project’s build, lint, and style checks?
- Test correctness: Do the agent’s tests actually capture the desired behavior?
- Scope: Does the patch touch only what it needs to?
- Code quality: Does the code conform to codebase conventions, follow sound design patterns, and remain readable to collaborators?
Each criterion is either a blocker or a non-blocker: Blockers represent mergeability requirements, i.e., criteria that a maintainer would consider hard stops during code review. Non-blockers represent quality signals such as code style, type safety, and readability, which would not necessarily block a merge.
Novel Grading Methods
Reverse-Classical: The reverse-classical criterion is a way to ensure that agent-written tests are meaningful: when we run them on the original, broken codebase, they must fail.
Code Scope: A good PR should exercise restraint: it modifies only what it needs to, without touching unrelated files or introducing unnecessary refactors.
Adaptive Classical Grading: Open-ended coding tasks can have many valid solutions. Static unit tests are too rigid. We resolve this conflict with mutagent, a tool we built that uses an LLM to surgically patch the test environment (or the application code) to align with the agent’s implementation details.
Quality Control
Rubric design is inherently subjective and requires domain expertise. For each criterion, the maintainer must decide whether it’s a blocker or non-blocker, assign its weight relative to other criteria, and ensure complete coverage so that models cannot exploit gaps in the rubric.
Conclusion
FrontierCode is the benchmark for the next generation of coding agents. We are confident developers, enterprises, and researchers can trust it to evaluate the production readiness of their strongest models.
The Model Is No Longer the Bottleneck
General-purpose models like Claude now match or exceed domain-specific software, proving that the limiting factor for scientific AI is no longer intelligence, but workflow infrastructure.
Deep dive
- Scientific AI is hitting a new phase where base model performance is sufficient for domain-expert tasks.
- Anthropic's chemistry results show general-purpose models beating specialized classical tools in NMR prediction.
- The current failure mode for these models is rarely a lack of knowledge, but an inability to iterate or self-correct.
- A 'research result' requires a chain of evidence, not just a one-off LLM completion.
- Infrastructure must now focus on: real-time data access, execution of actual code instead of pseudocode, and formal verification of outputs.
- Future breakthroughs depend on building 'agentic' workflows that can loop, test, and discard invalid candidates.
- The workflow layer acts as a force multiplier for base model improvements rather than being rendered obsolete by them.
Decoder
- NMR (Nuclear Magnetic Resonance): A standard analytical chemistry technique used to determine the molecular structure of compounds by measuring the magnetic properties of atomic nuclei.
- Forward Prediction: Predicting the resulting spectral data based on a known chemical structure.
- Inverse Elucidation: The process of working backward from spectral data to propose the underlying chemical structure.
- Cheminformatics: The use of computer and informational techniques to solve chemistry-related problems.
Original article
This week Anthropic published a quiet result that should change how scientists think about AI. In Making Claude a chemist, they put a general-purpose model with no chemistry fine-tuning up against the dedicated software that chemists have relied on for decades, and it held its own, beating that software outright in several places.
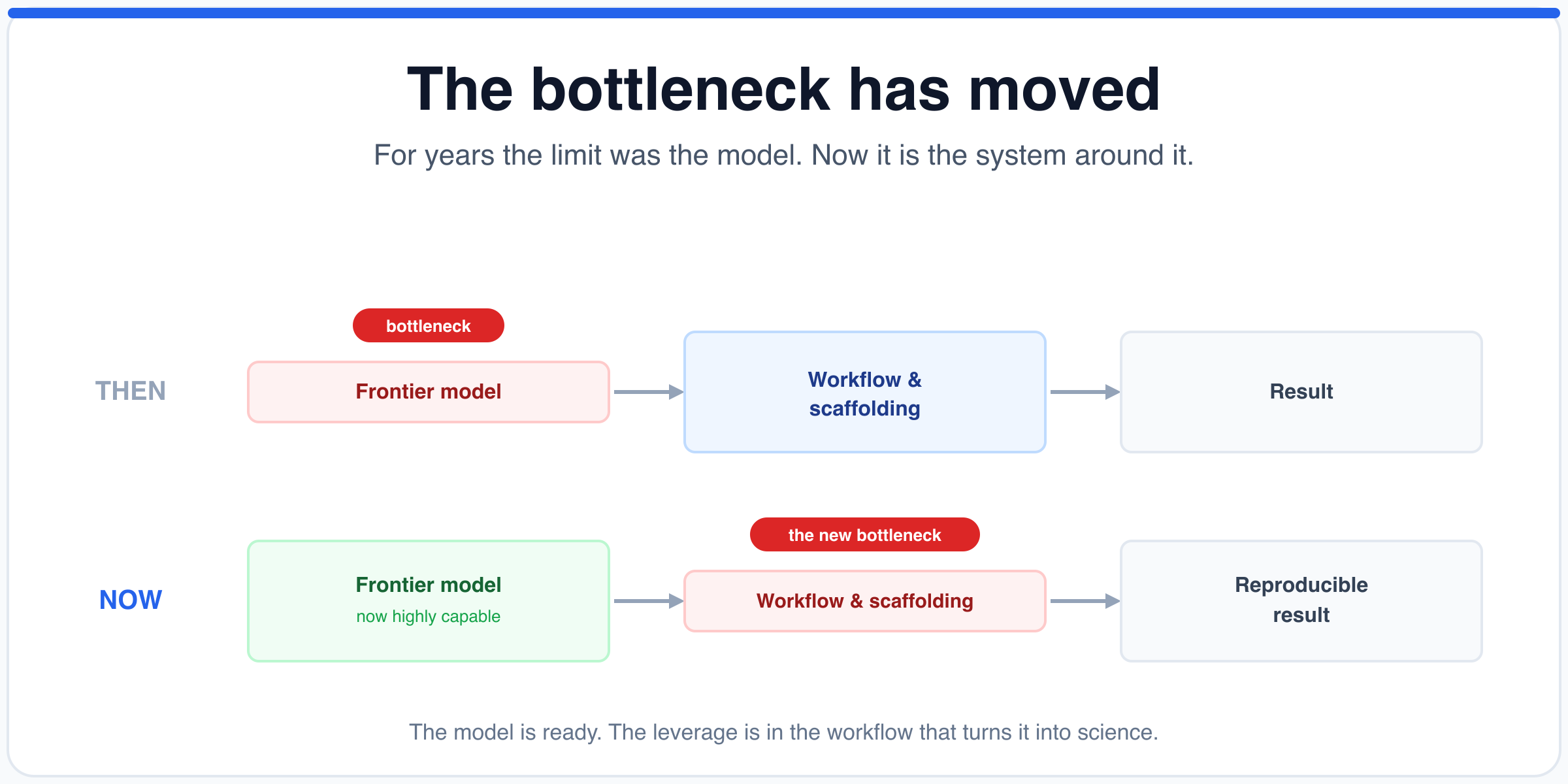
Most people will take that as the headline, but we think it points somewhere more interesting. The real story is not that an AI can do chemistry, it is that the hardest part of the problem has moved. For years the limiting factor in scientific AI was the raw capability of the model itself, and that era is now ending, because what stands between today's models and real scientific work is no longer intelligence but the workflow built around it.
What the chemistry result actually showed
Figure 1. Forward prediction goes from structure to spectrum, the task dedicated software was built for. Inverse elucidation runs it backward, from spectrum to structure. A general model is now competitive at the first and capable at the second.
Anthropic tested three models against ChemDraw and MestReNova on NMR, one of the most common and most time-consuming analytical tasks in synthetic chemistry, and the results are worth stating plainly.
On forward prediction, taking a known structure and predicting where every hydrogen and carbon peak will fall, the best model (Opus 4.7) was the most accurate tool tested on hydrogen, with an average error of ±0.079 ppm, and was effectively tied with MestReNova on carbon. On the shape of the peaks, the splitting patterns and sub-peak spacing that carry structural information, all three models predicted the spacing to within half a hertz roughly 80% of the time, against 26 to 35% for the classical tools.
Then they ran the problem backwards. Given only a molecular formula and a 1D spectrum, could the model propose the structure that produced it? This is the inverse problem, the one existing software largely leaves to the human. The model recovered all eight of the simpler targets on every attempt from spectra and formula alone, and solved most of the harder fused-ring and spirocycle targets when given the starting material as a hint.
The point that matters here is the one Anthropic makes themselves: this is a general model with no chemistry-specific training, and it does from a pasted spectrum what used to require licensed, specialized, single-purpose tools.
The team is also refreshingly honest about the limits. The evaluation was small, with 20 compounds for the forward task and 15 for the inverse, two-dimensional experiments and stereochemistry were out of scope, and solvent coverage was narrow. On the densest inverse problems, without the starting material as a clue, the model would sometimes loop through its reasoning without ever committing to a final answer. These are real caveats, but that last one is worth holding onto, because it is not a knowledge problem but a workflow one, and we will come back to it.
This is not a chemistry story
It is tempting to file this under chemistry and move on. That would be a mistake, because the same pattern is showing up across the sciences.
We saw it in biology. On BixBench-Verified-50, a cleaned benchmark of real bioinformatics tasks, a generalist system scored 90%, ahead of specialized agents, without being tuned for the benchmark. The chemistry result is the same shape in a different field. A general model, asked to do work that a domain expert assumed required a dedicated tool, turns out to be competitive or better.
When the same surprising result appears in chemistry, in biology, and in domain after domain, it stops being a surprise and becomes a trend, which means the capability is general and it is already here.
So the interesting question is no longer whether the model can do it, because increasingly the answer is yes, but what has to be true for the answer to be trustworthy, complete, and reproducible, and that turns out to be a very different question with a very different answer.
The gap between an answer and a result
Figure 2. A chatbot stops at a plausible answer. A research result requires the whole chain of evidence behind it, and the model is only one link in that chain.
A chat response is not a research result. A research result is a chain of evidence, made up of the right data pulled from the right sources, the right method chosen and run, the output checked against what is already known, and a final answer you can defend and reproduce, and the model is only one link in that chain, however crucial.
Look again at the failure Anthropic reported, the model looping on the hardest structures without committing. That is not a gap in chemical knowledge but the absence of a system around the model that forces a decision, tests the candidates against the spectrum, and rules options out until one survives. Give a capable model the ability to act, to run cheminformatics code, to query a structure database, and to cross-check a proposed structure against its own predicted spectrum, and the loop closes, which is to say the bottleneck was never the chemistry but the scaffolding around it.
This is the part the field consistently underweights. We keep asking models to be smarter when what we actually need is for them to be operationalized. The frontier work in AI for science now lives in the seam between a frontier model and the system that lets it do real work:
- Reaching real data, not just what is in the weights. The 250-plus databases, the unstructured supporting information, the instrument files in their native formats.
- Executing real analysis. Writing and running code, not narrating what the code would do.
- Verifying instead of asserting. Checking a candidate answer against evidence, and committing only when it holds up.
- Producing outputs a human can audit. The method, the data, the script, the figure, not just a confident paragraph.
Anthropic's own roadmap points in exactly this direction. The next bottlenecks they name, reading and rendering chemical structures, retrosynthesis and synthetic reasoning, mechanism, and reading the chemical literature as it is actually published, are not requests for a smarter chemist but integration and translation problems, which is to say they are agent problems.
The bet worth making
Figure 3. The workflow layer is what turns a frontier model into reproducible science. A more capable model raises the ceiling rather than making that layer redundant.
This is the premise our work is built on. The frontier models are the engine, but the decisive advantage comes from the system that turns that engine into finished science, connecting it to real data, letting it write and run real code, reading the files instruments actually produce, and holding it to outputs that survive inspection. K-Dense Web is model-agnostic by design, built to run on the strongest frontier models available, Claude among them, precisely because the leverage is no longer in any single model but in everything around it.
That is also why the chemistry paper is encouraging rather than threatening, because a more capable base model does not make the workflow layer redundant, it raises the ceiling on what the workflow can deliver. Better NMR reasoning in the model means a chemistry agent that can elucidate a structure, propose a route, flag a likely byproduct, and hand back a documented result from end to end, so the model getting better is the best thing that can happen to the layer above it.
Building it together
Anthropic closed their post by inviting researchers working on problems where Claude could help, and by expanding their AI for Science program toward chemistry. That instinct, to develop a model and its real-world applications in conversation with the people who use them, is exactly the right one.
The most valuable progress in AI for science over the next few years will not come only from larger models, and it will not come only from clever scaffolding, but from the two being built together, with the people who push the model's reasoning working alongside the people who turn that reasoning into reproducible research.
We see it the same way, and it already shapes how we build. We work closely with Google today, and we would like to open that same kind of collaboration to every lab building frontier models. The progress that matters now lives in the layer between a capable model and a finished, reproducible result, and we are glad to partner with anyone serious about getting that layer right. The easiest way to start a conversation is contact@k-dense.ai.

OpenAI confidentially files for IPO, prepping Wall Street for mega AI debut
OpenAI has confidentially filed for an IPO, setting the stage for a massive public debut while employees look to cash out via tender offers.
Deep dive
- OpenAI filed a confidential S-1 with the SEC to prepare for a potential public offering.
- Employees are being offered a tender offer at the $852 billion valuation to provide liquidity.
- The company is working with banks Goldman Sachs and Morgan Stanley on the process.
- Strategy shifts from pure research to becoming a "product company" focused on enterprise and coding tools like Codex.
- Recent legal conflict between Sam Altman and Elon Musk concluded with a jury ruling against Musk on procedural grounds.
Decoder
- S-1: A registration form required by the SEC for companies planning to go public in the United States.
- Tender offer: A financial mechanism where a company or third party offers to purchase shares from existing shareholders, typically employees, providing them liquidity before a public listing.
- Post-money valuation: The value of a company after a round of external financing has been injected into it.
Original article
Key Points
- OpenAI has confidentially filed for an IPO with the Securities and Exchange Commission, setting the stage for what could be one of the largest public markets debuts in history.
- The confidential disclosure comes days before Elon Musk's SpaceX is set to start trading and a week after Anthropic filed confidentially with the SEC.
- The companies could end up leading the three largest IPOs on record.
OpenAI has confidentially filed for an IPO with the Securities and Exchange Commission, joining the party a week after Anthropic did the same and days before Elon Musk's SpaceX is set to hit the public market.
The artificial intelligence company, which is valued at more than $850 billion, has been gearing up to go public as soon as the fourth quarter of this year. A confidential filing allows the company to submit its financials to regulators for review before they're made available to the public and prospective investors.
OpenAI CFO Sarah Friar told CNBC in April that it's "good hygiene" for a business of OpenAI's size to "look and feel and act" like a public company, but she wouldn't comment on a specific IPO timeline. OpenAI said Monday it hasn't decided on timing.
Here's the entirety of OpenAI's post:
We recently submitted a confidential S-1. We expect it to leak so we're just announcing it. We have not decided on timing yet; it may be a while because there are things we want to do that are likely easier as a private company. But it's a complicated set of tradeoffs and this gives us the option to go public sooner if that ends up being best.
OpenAI also plans to facilitate a tender offer that will allow employees to sell shares at the latest valuation, which was $852 billion post-money, and alleviate some near-term pressure for liquidity, according to a person familiar with the plans who asked not to be named because the details are private.
The company has been working with banks including Goldman Sachs and Morgan Stanley on the filing, as CNBC previously reported. They're the two firms listed at the top of SpaceX's filing.
OpenAI rocketed into the mainstream following the launch of its ChatGPT chatbot in 2022, and has since ballooned into one of the most valuable private companies in the world. ChatGPT now supports more than 900 million weekly active users, but OpenAI faces increasingly stiff competition from rivals like Anthropic, Google and Elon Musk's SpaceX, which merged with xAI earlier this year.
SpaceX kicked off a roadshow last week. OpenAI, Anthropic and Google are all named as some of SpaceX's "key competitors" in AI, according to the filing.
A week ago Anthropic announced its confidential IPO filing. Shortly before that, the company closed a funding round at a $965 billion valuation, topping OpenAI, which was valued at $852 billion in late March.
Depending on how SpaceX's offering is received, Anthropic and OpenAI could be rushing to beat each other out due to the massive amount of capital they're trying to raise.
OpenAI CEO Sam Altman will be under pressure to make his case to investors, particularly around the company's financials. OpenAI has raised more than $180 billion in funding, and it is still burning through cash as it works to secure compute and build out infrastructure to train and run AI models.
In a blog post on Monday, Altman introduced what he called "the third phase of OpenAI." The first, he wrote, was doing research towards artificial general intelligence. The second was becoming a "product company" and learning how people used its tools.
Now we are entering the third phase. The economy is beginning to reshape around AI. The central question now is how to make advanced AI abundant, affordable, safe, useful, and easy enough for every person and organization to benefit from it.
OpenAI has been trying to emphasize focus and discipline internally in recent months, shuttering fringe projects like the company's short-form video app Sora. The company is pouring investment into its enterprise business as well as its coding assistant product Codex, which competes directly with Anthropic's popular Claude Code offering.
Altman wrote in a post on X in April that, "feels like codex is having a chatgpt moment."
The dueling IPO efforts by SpaceX and OpenAI come less than a month after Musk and Altman got through a bruising three-week court battle.
An advisory jury said that Musk, who first filed suit in 2024 against OpenAI and Altman, waited too long to bring claims that they went back on their vow to keep the company a nonprofit. The federal judge immediately adopted the jury's verdict. Musk said in a post on X that the judge and jury "never actually ruled on the merits of the case, just on a calendar technicality."

Core AI (Website)
Apple has launched the Core AI framework, providing developers with native tools to deploy and optimize AI models on Apple silicon.
Deep dive
- Provides direct access to Apple hardware acceleration via CPU, GPU, and Neural Engine.
- Includes Swift-native APIs for model management.
- Focuses on inference optimization, caching, and model specialization.
- Fully integrated into the standard Xcode and Apple developer toolchain.
Decoder
- Apple silicon: Apple's custom-designed series of ARM-based chips (e.g., M-series, A-series) that feature integrated hardware acceleration for machine learning tasks.
- Inference: The process of running data through a pre-trained model to make a prediction or generate an output.
Original article
Apple's Core AI framework allows developers to build, run, and deploy AI models in apps on Apple silicon. It enables access to the latest model architectures and inference techniques across the CPU, GPU, and Neural Engine. The Swift API gives developers control over model specialization, caching, and inference performance while making common tasks simple. Core AI integrates with Xcode and the developer toolchain.

ChatGPT failed to kill Google Search
Despite fears that generative AI would destroy traditional search traffic, Google’s search queries reached an all-time high last quarter.
Original article
ChatGPT failed to kill Google Search
With Google’s multibillion user moat and deep pockets, it’s thriving despite OpenAI’s first-mover advantage.
A year ago it wasn’t clear how AI was going to work out for Alphabet, which missed out on the first-mover advantage held by OpenAI’s ChatGPT.
The fear was that AI competition would eat into traffic for Google’s all-important Search business. And that incorporating AI answers into its own searches could cannibalize revenue, since customers would be less likely to pay for their blue-linked pride of place if people got all their answers up top. Those fears have not materialized.
AI is “driving an expansionary moment in search,” Google CEO Sundar Pichai said in his remarks at Alphabet’s investor presentation Friday.
“When people use AI-powered features, they use Search more — in fact, queries reached an all-time high last quarter,” he said. “AI Overviews and AI Mode are driving user engagement and AI-powered ad tools are driving better ROI for advertisers.” It helps when your distribution scale is practically unmatched: Google said its Search AI Mode has already crossed 1 billion monthly active users, while AI Overviews now have over 2.5 billion.
Outside traffic numbers from Similarweb seem to agree, showing a recent uptick in global visits across Google after falling slightly when ChatGPT first came out:
Bank of America recently said it thought Alphabet’s new AI ad formats noted at its I/O conference “should help capitalize on growing AI search format usage and could accelerate Search monetization.” Of course, Google’s win is the rest of the web’s loss. AI Overviews are tanking publisher click-through rates, and though Google just introduced an opt-out tool under regulatory pressure, few publishers can afford to disappear from a search engine with 90% market share.
With Google incorporating AI into all parts of Search, the success of its stand-alone chatbot Gemini is becoming less important, as evidenced by the overall growth in Google traffic. Many have previously remarked that Gemini lagged the popularity of ChatGPT, but even that is doing pretty well, recently growing market share and gaining on leader ChatGPT, according to data from Apptopia:
In all, Google’s main cash cow, Search, has seen revenue growth accelerate last quarter, growing 19% year on year.
And Alphabet is making sure it has the capital to keep it that way. Last week, the company announced a massive $80 billion equity capital raise to fund its massive computing infrastructure push. Alphabet expects to spend an eye-watering $180 billion to $190 billion on capital expenditure this year alone, a financial war chest that startups like OpenAI simply cannot replicate.
OpenAI may have had the first-mover advantage, but Alphabet is proving that the ultimate advantage is still having billions of built-in users — and the endless billions of dollars required to keep them there.

Apple Reveals New AI Architecture Built Around Google Gemini Models
Apple is ditching its independent AI strategy to integrate Google Gemini-based foundation models across its on-device and Private Cloud Compute ecosystem.
Deep dive
- Apple's new AI architecture utilizes Google's Gemini-derived foundation models.
- Features run across both local on-device hardware and Private Cloud Compute servers.
- A new system orchestrator manages context awareness across different apps and workflows.
- Capabilities include image generation, advanced photo editing, and improved dictation.
- Apple maintains its privacy stance, claiming external verification of its Private Cloud Compute security is available.
Decoder
- Private Cloud Compute: Apple's proprietary server-side architecture designed to execute AI tasks while extending the privacy and security guarantees of local hardware to the cloud.
Original article
Apple Reveals New AI Architecture Built Around Google Gemini Models
Apple today announced a major overhaul of its Apple Intelligence platform, revealing a new architecture built on foundation models developed in collaboration with Google using the technologies behind the Gemini family.
The new architecture centers on Apple Foundation Models co-developed with Google, which Apple says are adapted to run both on-device and on servers through its existing Private Cloud Compute infrastructure. Apple described the collaboration as a "deep" one that it says unlocks what it called a "huge upgrade" for Apple Intelligence, bringing state-of-the-art understanding and reasoning capabilities as well as multimodal support including image understanding and generation.
The upgraded models support new capabilities use cases, including realistic image creation, advanced photo editing, and visual question answering. Certain devices will receive a higher-power version of the model with additional capabilities including speech generation, improved dictation accuracy, and stronger natural language understanding, though Apple did not specify which devices qualify.
A new system orchestrator sits at the center of the revised architecture, coordinating Apple Intelligence features securely across Apple's platforms. Apple says the orchestrator allows the system to tailor its responses based on the active app and the user's current task, enabling what the company described as truly system-wide intelligence.
Apple used the announcement to frame its approach as a contrast to competitors it characterized as "racing forward" without regard for users. The company reiterated that Apple Intelligence relies on on-device processing and Private Cloud Compute, with a promise that user data is only used to execute the immediate request and is not accessible to Apple or third parties. Apple added that outside experts can verify those privacy guarantees "at any time."

How I Validated Design Decisions Before Writing Production Code
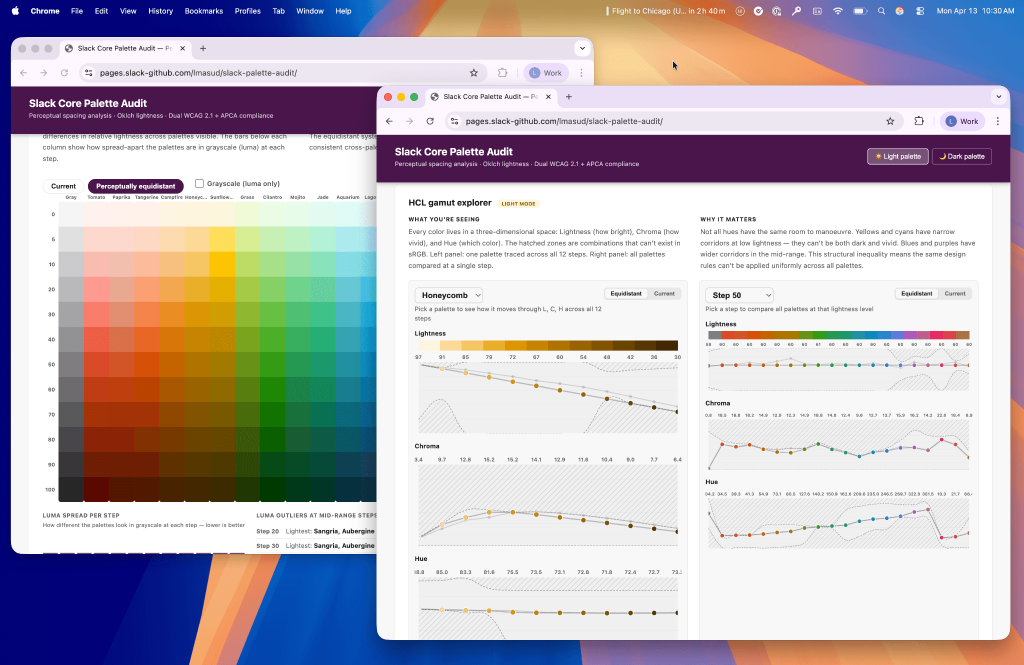
Slack design director Luca Masud uses AI-assisted code to stress-test UI logic against real data distributions before writing production-grade code.
Deep dive
- Evidence-based design: Moving from 'what looks good' to 'what holds up' across distributions.
- Interactive modeling: Prototyping allows for testing parameter sensitivity that static mocks hide.
- Distribution testing: Using real data sets to verify if layouts break under edge-case conditions.
- Monte Carlo simulation: Measuring system performance (e.g., whitespace distribution) at scale through thousands of randomized tests.
- Categorization audits: Leveraging AI to perform quantitative card sorting and perceptual color audits to reveal systemic issues.
Decoder
- Monte Carlo simulation: A computational algorithm that relies on repeated random sampling to obtain numerical results for complex systems.
- Perceptual reference: A model or tool that measures colors based on how human eyes perceive them rather than raw numeric RGB values.
Original article
How I Validated Design Decisions Before Writing Production Code
The biggest shift AI has brought to design isn’t that designers can now write production code. It’s that we can finally generate evidence before committing to anything.
There’s a lot of conversation about AI affecting production: designers pushing code and shipping something closer to the final product. That matters. But the bigger opportunity is even earlier: exploring a design space before anything gets built. Not prototypes that demonstrate a decision, but prototypes that stress-test one, built to find where a solution breaks.
From Theory to Practice
In data visualization, building parametrized tools to explore a design space is standard practice. In product design, it rarely happens. Static mocks show what something looks like, not how it behaves across a distribution of real inputs. While engineers could build a throwaway prototype, they usually don’t. Their incentives are toward scale and production quality, not disposable experiments.
AI-assisted coding is changing this. Before, exploration like this was possible in theory but rarely happened in practice. Now it only takes a couple of days, so it actually gets done.
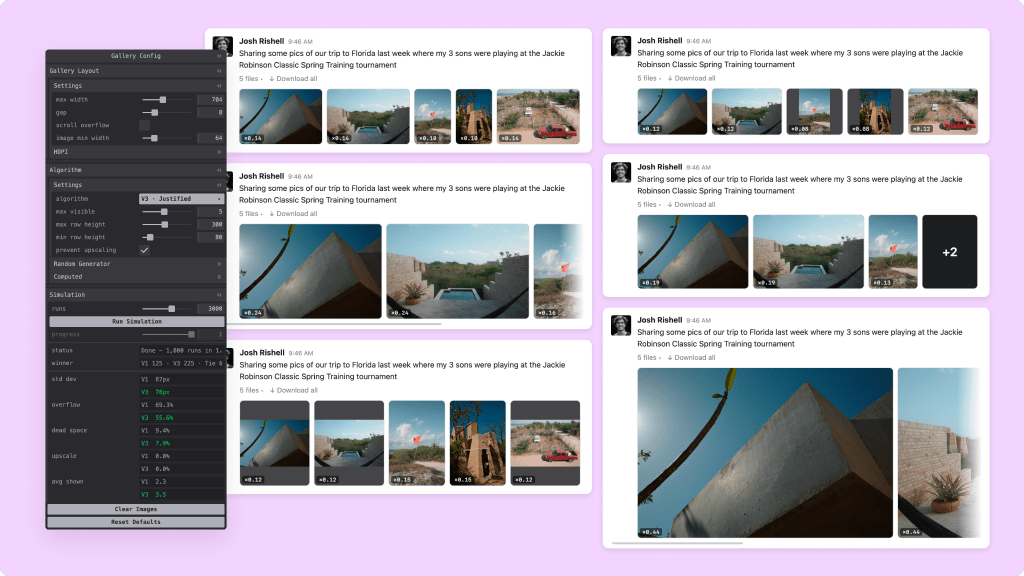
At Slack, I applied this thinking across several recent projects. Two examples: an interactive prototype comparing gallery layout algorithms, and a max-width strategy tested against 272 million desktop sessions.
From Mockups to Tools
The typical prototype represents a decision that’s already been made, built to demonstrate it. These prototypes work the other way: built when the decision is still open, generating distributions rather than single examples.
For the gallery layout, I put three algorithms side by side with interactive controls for tuning parameters. For the max-width explorer, I modeled Slack’s full window geometry and swept across four max-width strategies, seeing how each one projected across our actual screen-size distribution and where users land in comfortable versus problematic whitespace.
Neither was built to ship. A few days of building replaced weeks of production iteration, surfacing edge cases invisible in Figma, and showing max-width behavior across every real screen size, not just a handful of breakpoints. The question shifted from “Which option looks right in this one comp?” to “Which option holds up everywhere?”
Escalating Evidence
Once the prototype existed, the question changed from “Which layout is better?” to “How much of the system can I actually see?” For the gallery, what followed looks like iteration, but it’s really a progression in evidence:
- Manual testing: I uploaded real images and evaluated the results by eye. This approach was limited to whatever images I happened to have on hand, with no way to know what edge cases I was missing.
- Distribution-based generation: I generated images matching the actual aspect ratio distribution from real Slack uploads. This made it possible to see where the layout broke for specific image shapes, not just the ones that happened to be on my desktop.
- Monte Carlo simulation: I ran thousands of simulations measuring specific metrics — letterbox rate, dead space, and overflow — to understand how an algorithm actually behaves at population scale.
- Configuration sweep: I ran simulations across hundreds of parameter combinations and across algorithms, mapping the strengths and weaknesses of each approach and making the tradeoffs between them legible.
Each step didn’t just make things faster. It made the system more legible. From a few cases, to distributions, to the full space of tradeoffs.
One caveat: collapsing multiple dimensions into a single score is harder than it sounds. For max-width, I scored hundreds of thousands of configurations. The numbers were precise, but the assumptions weren’t. The goal isn’t a single answer. It’s to expose the shape of the tradeoffs so the team can reason about them.
None of this required feature flags, staged rollouts, or user traffic. By the time I committed to a direction, the uncertainty had already been resolved somewhere it was cheap to be wrong. The output isn’t a visual spec. It’s constraints. Something engineering can implement however they want, because the reasoning is already resolved upstream.
And when I brought the work to stakeholders, I wasn’t defending a recommendation. I was showing something they could explore. Questions that would normally stall a review already had answers.
Beyond Layout
The same approach extends beyond layout. For Slack’s notification system, I used AI to run card sorting analysis that revealed how hundreds of notifications naturally cluster, replacing debate with observable structure. A color audit comparing palettes against a perceptual reference surfaced inconsistencies invisible in isolation. In both cases, the value was making the system directly explorable.
When redesigning Slack’s notification system, the problem wasn’t UI, it was categorization. How do you organize hundreds of notifications into groups that make sense to users? Categories feel obvious until you test them. I used AI to run card sorting analysis (similarity matrices, clustering, dimensionality reduction) that normally requires a quantitative researcher. My role was deciding what to test and how to interpret it. Instead of debating categories, we could observe how they emerged from the data.
Slack’s color system posed a similar challenge. Over time, palettes evolve and designers reason about them locally, but perception is non-linear and system-wide. A two-hour audit comparing palettes against a perceptually uniform reference revealed inconsistencies invisible in isolation, sparking a 30+ reply thread across design and engineering. In both cases, the value wasn’t the output. It was making the system directly explorable.

Looking Forward
There’s a lot of noise right now about what AI means for designers. The process itself hasn’t changed: explore the solution space, understand the tradeoffs, help your team pick. What’s changed is that the tools finally match the speed the job always demanded.
The real shift is in posture. Instead of advocating for a solution, you try to break it first. If it holds up, you commit with confidence. If it doesn’t, you find out somewhere it’s cheap to be wrong, before anyone writes production code, before a review stalls on a question no one can answer from a mockup.
That’s what I’m pushing my team toward: stress-testing decisions with fewer dependencies, more evidence, and less guesswork.

China's Xiaomi MiMo Is Now 15X Faster Than ChatGPT and Claude
Xiaomi’s new MiMo-V2.5-Pro-UltraSpeed model hits 1,000 tokens per second, claiming 15x faster inference than top-tier models like Claude and ChatGPT.
Deep dive
- Architecture: 1-trillion-parameter model with expert layer optimization.
- Technique: Uses DFlash speculative decoding to propose entire blocks of tokens at once instead of sequential generation.
- Quantization: Employs FP4 to reduce memory bandwidth bottlenecks during inference.
- Hardware: Tested on standard 8-GPU commodity nodes, highlighting a move away from specialized, proprietary hardware.
Decoder
- FP4 Quantization: A technique that reduces numerical precision to 4 bits to compress model weights and speed up processing.
- Speculative Decoding: A method where a smaller, faster model drafts a sequence of tokens, which a larger model then validates in parallel.
- Token per second (TPS): A metric measuring the speed of LLM text generation.
Original article
Full article content is not available for inline reading.

OpenAI's Database Change Analysis
OpenAI’s new 'SchemaFlow' cookbook provides a blueprint for building autonomous, auditable database change agents.
Deep dive
- Parsing: Converts natural language requests to a formal JSON change contract.
- Impact Analysis: Can be grounded in technical documentation via RAG using File Search.
- Typed Output: Enforces Pydantic models at every stage of the pipeline.
- Guardrails: Implements deterministic checks between agents to catch logic failures before final SQL generation.
- Evaluation: Integrates Promptfoo automatically to test and iterate on the pipeline behavior.
Decoder
- Agents SDK: OpenAI's framework for building autonomous agents capable of tool use, state management, and multi-step reasoning.
- RAG (Retrieval-Augmented Generation): Providing a model with specific external data (like PDFs or databases) to improve response accuracy.
- Promptfoo: A tool for testing and measuring LLM prompt performance and behavior.
Original article
Full article content is not available for inline reading.

xAI is looking more like a datacentre REIT than a frontier lab
By leasing massive GPU capacity to Anthropic and Google, xAI is acting less like a research lab and more like a high-margin data center landlord.
Decoder
- REIT (Real Estate Investment Trust): A company that owns, operates, or finances income-generating real estate; here used as an analogy for xAI renting out its compute infrastructure.
Original article
An unexpected development over the past few weeks is xAI's new partnerships with Anthropic and Google, providing them with a huge amount of capacity. It's worth remembering that xAI is now part of SpaceX, after the two merged back in February - so the revenue from these deals flows straight into the entity about to go public. While much has been made of the potential financial engineering given SpaceX's upcoming IPO, I think there's a bit more to this than just pure accounting tricks.
Anthropic was in a serious bind
If you use Claude products much, you'll be (very, probably) aware that Anthropic has had serious capacity problems, especially early afternoon onwards in Europe and in the mornings in the US (this is when demand seems to be highest as both European users and the Americas are both at work, fighting for capacity). I've written about this compute crunch before a few times - the coming crunch, whether it's here yet, and what comes next.
This resulted in Anthropic having to introduce new peak hour restrictions on their subscriptions, with usage between 5am–11am PT / 1pm–7pm GMT using more of your usage limit - with the aim of smoothing demand between peak hours and off peak hours where they had more capacity available.
However, there is only so much demand shifting you can do when demand is growing as fast as Anthropic's. At some point you end up having to ration users further, which definitely is far from ideal when you have both Google and OpenAI breathing down your neck for customers.
xAI to the rescue?
At the start of May, xAI announced a partnership with Anthropic to provide access to their (older) Colossus 1 datacentre in Memphis. This allowed Anthropic to reverse the usage limit restrictions on their subscriptions, and in general while stability of Anthropic services still leaves a lot to be desired, the peak time crunch has abated (for now, at least).
The fees involved are enormous, ramping to $1.25bn/month for 300MW of capacity - approximately 220k GPUs.
Last week, Google announced a similar partnership - $920mn/month for 110k GPUs. It's important to note that both agreements have cancellation clauses - allowing either party to cancel with 90 days' notice after an initial lock-in period.
If you take this on face value, this is a ludicrously profitable deal for xAI:
While this doesn't include opex and depreciation, if the deals continue for 18 months, xAI recoups all the capex they spent and still has many hundreds of MW of GPUs available. With the giant compute shortages likely to persist into the medium term, even older H100s are likely to be extremely useful even 18 months out.
The case against
It's important to note there are certainly some red flags with the deal. Firstly, Elon Musk and OpenAI were/are locked in a bitter legal battle, and the Anthropic deal could be motivated to add pressure to OpenAI more than commercial reality.
And Google is a major shareholder in SpaceX, so they certainly have incentive to juice the valuation of the IPO.
While I'm sure there is some degree (potentially a lot!) of truth in these viewpoints, it's important to note that huge volumes of GPUs are in enormously short supply.
One of the untold stories of this capex boom in datacentres is just how behind all of them are. Even OpenAI's flagship Stargate UAE datacentre - being built in a jurisdiction that is renowned for a laissez-faire attitude to building regulations - is now under direct threat from the current Iran conflict, with Iranian drones having already hit other UAE datacentres.
In comparison, SpaceX/xAI are incredible at building datacentres on time. The original Colossus 1 datacentre was built in 122 days. Musk's empire does have a huge advantage in really understanding how to plan, build and execute enormous infrastructure projects quickly. While the hyperscalers no doubt have the experience to do this, they were built with far less urgency - with typical project execution taking many years. Given the capex only really started to ramp up in the last couple of years, many of these projects are still years away.
This gives xAI a serious competitive advantage that shouldn't in my opinion just be hand waved away.
But what about Grok?
There is no doubt this leaves Grok in an odd spot, with a lot of the datacentre capacity that was destined for Grok training and inference now being leased to a direct competitor.
While it's foolish to write off any model provider, it certainly looks like a serious retreat from Grok vying to be a frontier class lab. But, perhaps, they over-specified their datacentre capacity - there is no doubt that inference demand for Grok models is likely to be seriously behind projections, leaving a bunch of spare capacity which might as well be monetised while the training lottery continues? It's hard to say and the xAI & Cursor deal muddies the water even further.
As such, I think all three things are true to some degree. There's no doubt some level of financial engineering going on. There's also an enormous compute shortage. And it seems to me SpaceX/xAI does have a real competitive advantage in datacentre buildout.
It's just the magnitude of how true each of these are is going to define the success or failure of the biggest IPO in North American history.
Either way, the more I look at it, the more xAI is starting to resemble a datacentre REIT with a frontier lab attached, rather than the other way around.
-
I suspect that these are likely to be GB200s given the pricing, vs the mostly H100/H200 for Anthropic, but this is speculation on my part.
-
Power is the obvious big opex line, but at this scale it's almost a rounding error. 300MW running flat out is roughly 300,000 kW × 8,760 hours, or about 2.6 billion kWh a year. Tennessee has some of the cheapest industrial electricity in the US at around 6 cents/kWh, so buying it off the grid would cost somewhere around $160mn a year. Colossus actually runs largely on its own on-site gas turbines, which comes out even cheaper: at a simple-cycle heat rate of ~10,000 Btu/kWh and Henry Hub gas at ~$3.50/MMBtu, the fuel bill is only around $90mn a year. Either way, set against the ~$15bn a year Anthropic is paying for that 300MW, power is no more than about 1% of revenue. The deal value utterly dwarfs the running costs.
Apple Reveals New AI-Powered Version of Its Siri Digital Assistant
Apple is integrating cloud-based AI models from Google into Siri, enabling complex task automation across the entire iOS ecosystem.
Deep dive
- Siri now supports multi-step intent execution for tasks like recipe brainstorming.
- Apple Intelligence features are embedded natively across the OS.
- Cloud infrastructure is powered by Google rather than purely internal Apple data centers.
- Image generation is subject to strict daily volume limits to manage compute resources.
Original article
Apple has introduced a new, improved version of Siri and new features to Apple Intelligence. Siri can now handle tasks like researching concert tickets and brainstorming recipes for a party. Apple is using AI models and cloud computing services from Google to power Siri and Apple Intelligence. Siri and Apple Intelligence features will be integrated across Apple's apps, so users will be able to do things like alter photos or ask Siri questions about what they're photographing. There will be daily limits on image generation features due to compute limitations.
Gates-Backed Commonwealth Fusion Says Its Tech Validated to Make Power
Commonwealth Fusion Systems has received peer-reviewed validation for its fusion reactor physics, aiming to deliver power to the grid by the early 2030s.
Deep dive
- Technology validation confirmed through five separate peer-reviewed research papers.
- Targeting early 2030s for initial grid-scale power delivery.
- Construction of a 400-megawatt site is underway in Virginia.
- Major backing from Breakthrough Energy Ventures and Nvidia signals enterprise interest in fusion as a data-center power solution.
Decoder
- Fusion reactor: A device that attempts to generate electricity by replicating the nuclear reaction that powers the sun, merging atomic nuclei to release energy.
Original article
Commonwealth Fusion Systems says that the physics of its commercial-scale power plant has been validated by five peer-reviewed papers. The company is now targeting the early 2030s to put energy on the grid. It is building a 400-megawatt facility in Virginia and a demonstration machine in Massachusetts. It has so far raised almost $3 billion from investors, including Bill Gates' Breakthrough Energy Ventures and Nvidia's venture arm.

Loop Engineering
Developers are moving from manual agent prompting to 'loop engineering,' where recursive systems automate the iteration process until specific goals are met.
Deep dive
- Shifts developer responsibility from active prompting to infrastructure design.
- Relies on recursion where the agent evaluates its own progress against a defined success metric.
- Crucial to manage token costs when agents operate autonomously in loops.
- Requires robust monitoring to ensure output quality remains within acceptable parameters.
Decoder
- Recursive goal: A programming objective where an agent calls itself or re-attempts a task until a specific output condition is met.
- Loop engineering: The practice of designing autonomous systems that maintain persistent state and iterative prompting cycles, rather than treating AI as a stateless request-response tool.
Original article
Loop Engineering
Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead. A loop here can be thought of a recursive goal where you define a purpose and...

Expanding the Radius of Daily Life
Tsung Xu's startup Vight is building VTOL aircraft designed to make personal flight as intuitive and routine as driving a car.
Deep dive
- Vight Strategy: Utilizes private property as take-off and landing points to avoid the infrastructure costs of public vertiports.
- Technology: Leverages high-torque permanent magnet synchronous motors (PMSM) and redundant electric powertrains.
- Autonomy: Employs supervised autonomous assist features to reduce pilot workload and improve safety, mirroring Tesla's FSD approach.
- Certification: Exploits the FAA’s MOSAIC (Modernization of Special Airworthiness Certification) rule to bypass the traditional, costly commercial aircraft certification process.
- Economic Model: Follows the classic hardware scaling path: low-volume/high-cost prototyping followed by high-rate manufacturing to drive costs down over generations.
Decoder
- VTOL: Vertical Take-Off and Landing, an aircraft capability to hover, take off, and land vertically.
- eVTOL: Electric Vertical Take-Off and Landing, an aircraft that uses electric motors for flight and VTOL capabilities.
- Marchetti’s Constant: The observation that humans spend roughly one hour per day traveling, regardless of changes in transportation speed (we simply travel further, not faster).
- MOSAIC: The FAA’s Modernization of Special Airworthiness Certification, a regulatory framework that simplifies the certification process for light-sport and electric aircraft.
- STOL: Short Take-Off and Landing, an aircraft capability to operate from very short runways.
Original article
Full article content is not available for inline reading.
Ask HN: What are tools you have made for yourself since the advent of AI? (Hacker News Thread)
Developers are using AI to build highly specific, bespoke tools for personal workflows, from guitar tone generators to automated file renamers.
Decoder
- Vibecoding: A style of programming where developers use natural language prompts to have AI write, debug, and iterate on code, often ignoring traditional strict engineering structures.
- MCP: Model Context Protocol, an open standard that allows AI assistants to securely connect to local data sources and tools.
- Pikchr: A domain-specific language for creating diagrams based on text descriptions.
- Gcode: A language used to tell computerized machine tools (like pen plotters or 3D printers) how to move.
Original article
Full article content is not available for inline reading.
Where my head is at with LLMs and the web
The web is entering a new era where agents and generative models require us to rethink how we address, link, and consume content.
Deep dive
- Stale Knowledge: Current LLMs are trained on web snapshots months or years old, missing modern framework updates.
- WebMCP: Proposed as a successor to failed 'Web Intents,' providing a way for agents to discover and link to specific site functionality.
- The Browser as Sandbox: Moving away from shipping heavy applications to shipping prompts or instructions that execute safely within the browser environment.
- Content Synthesis: Proposes 'content negotiation' where servers generate custom UI/views on demand for specific user needs rather than serving static pages.
- Transclusion: Reimagining the link as a way to embed live functionality from one site directly into another (the 'E' in SLICE).
Decoder
- WebMCP: A proposed protocol to allow web pages to expose tools and functionality that can be discovered and executed by AI agents.
- SLICE: A proposed conceptual framework for the web, focusing on how agents interact with addressable, modular web components.
- Content Negotiation: An HTTP mechanism that allows a server to return different versions of a document based on client requirements.
Original article
I have been writing a lot over at aifoc.us for the past year (actually, my last post on this site was a year and a day ago), and I've spent a lot of time exploring the risks and opportunities for the web, and the challenges that I think we need to adapt to as an ecosystem.
I kept it distinct from this site because I know that quite a few web developers who follow my content are not fond (to put it mildly) of LLMs and the AI industrial complex, and I felt it would be good to split the two.
I will keep publishing my posts on the other site, but I thought it might be good to try and pull together the 30-odd posts that I've created and try and explain where my head is at and provide some colour on how I got there.
Before I dive too deep, I think we are potentially in a golden age for the web, with a massive influx of people having major barriers to entry removed. Barriers that once were the reason why people preferred Instagram and similar services are being lowered to the point where anyone can build on our platform (and I'm seeing lots more people building).
Anyway, here we go:
Models inherit a stale web, and they set us back a year
The thing I keep coming back to is that the models we now write code with learned from a web that is already old. I made the model gap to show this concretely: measured in Chrome releases (I know, I know, the web is far broader than just Chrome, but also Chrome has easy data to access on chromestatus.com), even the freshest model is several versions behind, and most are ten to twenty behind. The "knowledge" cutoff is a serious issue for the web platform, and the ecosystem of libraries and tools that are being launched but are not easily available to these models is massively gaining traction (Claude Code).
That connects to model half-life, where I looked at how quickly models are superseded, and to dead framework theory: if a framework stops appearing in fresh training data, the models stop reaching for it, and the framework quietly dies regardless of its merits. I wrote this thesis at least 6 months ago, and I think I've been proven correct (which is why we built Modern Web Guidance). The flip side, though, is that I've found guided output getting better than what people create (I think auto-research loops to optimize web performance, as an example, will massively raise the bar for the quality of the web people experience).
My uncomfortable conclusion across all of these is that the web inside the model is the web that developers actually inherit, and right now it is a year out of date and getting staler with every release.
We can discover functionality and link to it
I have been trying to give the web a federated way to link to functionality for over a decade. I wrote what happened to web intents and later reinventing web intents about the first attempt and its failure. The idea never left me; ask anyone who knows me, I never shut up about it.
WebMCP is the thing that finally makes it plausible. I argued the case in webmcp is the new web intents ... maybe, and then, once I had actually built a relay that discovers and reuses a page's tools across sites, I dropped the maybe in i think i've got it. This sits on top of older thinking about why the link is the web's most underrated primitive (a link is all you need).
I want to explore more about what an addressable unit of the web should look like for agents, building on SLICE, and how it might evolve. Naturally, there is a lot of worry about the I in SLICE that I want to explore a little bit more.
The browser is an amazing sandbox and other platforms are racing to what we have already
If a program is mostly a prompt, then the interesting question is where you run it safely. I think the browser is the answer, which is the argument in the browser is the sandbox. That follows from the prompt is the program, where the entire application is a Markdown file, and shipping a prompt, where the portability of a prompt becomes the distribution model.
I have been poking at the edges of this too: building a claw in the browser is a genuinely dangerous experiment in how much access an in-page agent can get.
I really think we should be exploring this space a lot more, making some small changes to the platform (heh, Safari doesn't have CSP3) and really pushing on what every super-app platform doesn't yet have that can really differentiate the web.
Agent loops, and what they actually enable
Once you have written a few agents, you see that we have a new pattern for software (that people call agent loops). It is slower and vastly more expensive, but it is also opening up a world where it's easier and easier for people to instruct their machines and get accurate results. It's rather incredible, and it reminds me of how much more approachable HTML was when I started.
I built my own provider-agnostic loop, wrote it up in agent-do, and it enables me to do a lot of experimentation, for example:
- a whole small company replaced by agents in a container (business in a box)
- building a claw in the browser
- the prompt is the program, where the entire application is a Markdown file
- and shipping a prompt
I know I linked to these above, but I think the browser sandbox and agent loops are going to change a lot about how web experiences could be built in the future. I don't think we are there yet, but I can imagine a world where entire websites and services are higher-level instructions and design guidance.
Development is changing quickly
I really don't know what else to say about this: the sheer volume of machine-authored work already landing, which I measured in damn claude, that's a lot of commits, is astounding, and it could lead to strange new economics of paying for tokens instead of people (the token salary) and how we charge for services (token slinging).
I'm personally fully on board with these tools, and I think I've become quite proficient. While I do encourage people to understand how the platform works and how the browser works, I don't think we are going back at all. In fact, everything will accelerate now that the technology and tools exist.
Generated content and content negotiation
This is the thread I find most exciting for the web specifically. If a page can be generated on demand, the old idea of content negotiation gets a second life: the server does not pick from a few fixed representations, it generates the one you asked for. I keep using NotebookLM as the proof that a tool which generates a custom view of a corpus is already a kind of browser.
I'm personally kind of shocked there isn't more experimentation about how the future of sites and browsers might work. As tools that generate content get higher quality and quicker, they are going to open up new areas of the platform:
- If we can intercept requests to synthesise responses, what does it enable?
- If we take hypermedia to the extreme and enable any content to be turned into experiences that people prefer, what will happen? I know a lot of folks who learn via manga; why shouldn't they be able to consume content in their preferred format?
- I think we now have the Memex, so what happens to the CMS when content is generated (hint: they can adapt), and how can markup change to be more expressive (Headless stopgap)?
There's going to be even more change to the web as the latency of models falls, making generating UI and new content modalities on the fly viable (and I think sites should lean into generating content in the form their users prefer).
Maybe we can also get back to site mashups, and stave off the threat of super-apps (btw, this is a huge risk.)
How browsers might adapt
First, super-apps are coming, and they hint at a world where you barely open a browser at all. It might be a little way off, but I would love browser vendors to work out how the web will remain a first-class citizen if this happens. That's why I think WebMCP is critical, as is exploring what is listed below.
Elements: web components are a quietly perfect packaging format for agent-generated UI, and almost nobody frames them that way.
Can we bring in primitives and interactions that you don't get on other platforms? I'd love for us to explore how the link might evolve. I did this in embedding, which is really about transclusion: pulling live functionality from one site into another, the E in SLICE, and an old web dream that agents might finally make real.
I built a lot of demos to try and show this in action:
- Hyperlink Experiment: There is a lot in here.... I struggle with the hubris the industry has around the link. I set out to experiment with the concept of linking on the web and I really want to encourage people to really push the boundaries of what a link is and, if possible, how technologies like LLMs and image recognition models change how the web fundamentally works.
- Merge - Extension - One of the things I love about the web is that you don't really know what is on the other side of a link. One of the things I dislike is that you don't know what is on the other side of a link. I also wonder what the intent of a link is.
- Trails - Extension - This uses no LLM technology, but I built it with an LLM. Vannevar Bush's "user links" let you create your own links on pages and have them be permanent.
- Summary - Hover over a link and get a summary of what is on the linked page before you click it.
- Stretch Text - Taking Ted Nelson's idea and trying to make it usable. Select some text and zoom in (expand) or zoom out (summarize). After reading Ted Nelson's ideas on this, it was up to the author to offer this, and knowing how people publish on the web, people just aren't going to do this. LLMs make it possible to add extra context or summarize it. I didn't really test this too much in the end because I wanted to get Merging and Trails working.
- I made a lot of other experiments, such as linking into images with descriptions, and also making it easy to do image maps again by using English (using the Segment Anything model) instead of points. Link to audio content via timestamps with a Whisper-like model. Pull in the UI of a linked element into the current page, taking the Merge experiment one step further.
If browser vendors choose, they could solve interop issues once and for all. In how might a browser be developed, I explore how a browser might be developed to the point where the major points of interop difference are fundamental issues of where the browser vendor thinks the web should go. I also go a little further out into some sci-fi.
The End
That's roughly where I am. There's still lots I will be exploring.
I am very excited about the future because I think we could continue to see millions more people start publishing on the web, the web getting higher-quality experiences, and waves of new innovation into what the web could be.
1,000 Data Breaches Later, the Disclosure Lag is Worse Than Ever
Troy Hunt's analysis of 1,000 data breaches shows that the time between a breach occurring and public notification is increasing, despite regulatory pressure.
Deep dive
- Data disclosure timelines have expanded significantly over the last decade.
- Companies often prioritize mitigating stock market impact over timely notification.
- The existence of a 'breach' is often known by internal teams for months before public disclosure occurs.
- Regulatory requirements are insufficient to curb the incentive to keep users in the dark.
- Breach data often reaches services like 'Have I Been Pwned' long before official communications are released.
Decoder
- Disclosure Lag: The time delta between a company detecting a security compromise and informing its users or regulators of the incident.
Original article
Companies would rather protect shareholder value than ensure customers are informed about data breaches.

Check Designs in Figma: Catch What's Off, Ship What's Right
Figma's new 'Check designs' feature automates the identification and resolution of design system drift, accessibility violations, and component detachments.
Decoder
- Design system: A collection of reusable components, standards, and documentation that ensure consistency across a product's interface.
- WCAG 2.0: Web Content Accessibility Guidelines, which specify requirements to make digital content accessible to people with disabilities.
Original article
Check designs: catch what's off, ship what's right
Check designs compares your designs against your design system, flags what's off, and suggests the correct fix in one click. Catch drift as you work, run a QA pass before handoff, and keep every file aligned to your design system with:
→ Variable and style suggestions flags hard-coded color, text, radius, and spacing values and replaces them with the correct design system token.
→ Accessibility suggestions flags color contrast violations and replaces them with WCAG 2.0 AA or AAA-compliant colors.
→ Library mismatch detection flags tokens and components from unsubscribed libraries.
→ Detached component detection flags components detached from their source library.
Check designs is available on Organization and Enterprise plans.
The Speed of Prototyping in the Age of AI
Integrating AI agents into engineering workflows has increased personal development velocity by roughly 4x and expanded the complexity of shippable side projects.
Deep dive
- Velocity boost: Reported 4x increase in time-to-PR for typical tasks.
- Strategic shift: Focus moves to defining system contracts, boundaries, and clear success criteria for AI agents to execute.
- Surface area: Enables the completion of complex projects previously ignored due to bandwidth constraints.
- Technical dexterity: The risk of losing manual coding skill requires deliberate practice to maintain end-to-end knowledge.
- Workplace impact: Applied successfully to internal automation and cutting codebase boot times by ~50%.
Decoder
- .env file: A file format used to store environment-specific configuration variables and sensitive credentials.
- MIR: Mid-level Intermediate Representation, a form of code used by compilers between source code and machine-executable instructions.
Original article
The Speed of Prototyping in the Age of AI
Note: These are personal reflections on how my workflow has shifted over the past year, not a pitch for any tool. Your mileage will (and probably should) vary.
A few years back I wrote about my love of throwaway prototypes; those little proof-of-concepts that exist purely to get an idea out of your head and into something tangible. At the time, my biggest bottleneck was me; the time it took to scaffold a project, wire up the boring bits, and get to a place where the interesting parts could actually be tested. Fast forward to now, and that bottleneck has all but vanished.
I've been a little hesitant to write about this. I've already shared some cautious thoughts on AI and where it fits into my workflow, and I stand by all of it. I still think the industry is figuring things out in real time, and I still think it pays to be careful. But cautious doesn't mean blind, and the honest truth is that AI has changed how quickly I can go from "I wonder if…" to "oh, it works".
The recent repos
If you've looked at my GitHub recently, you'll have noticed a stream of new repos showing up. Sakoa, a progressive systems language I've been designing from scratch, complete with an effect system, three memory modes, and a MIR with multiple backends. Kato, a notation language meant to sit somewhere between JSON, TOML, and YAML, but explicitly designed to be friendly to both humans and agents. Seal, a tiny CLI that quietly kills the .env file by stashing secrets in OS-native credential stores. Karabiner, an iOS-first agent-native messaging app. Plim, a Notion-inspired, embeddable block editor for the web with a framework-agnostic core and React bindings. And a few more knocking around that aren't ready for the spotlight yet.
A few years ago, that list would have been three repos with READMEs, two abandoned branches, and one working prototype I'd be quietly proud of. Now? The prototypes exist. They run. Some of them have tests. A couple are starting to look like real projects. And while not all of them will turn into anything serious (and that's kind of the point), there is something really satisfying about being able to actually try an idea, rather than just talk about it.
Zooming out
The thing nobody really warned me about is how much AI changes the shape of engineering work, not just the speed of it. When I'm not the one typing every line, I'm forced to think differently. I'm thinking about boundaries, contracts, and how the pieces fit together. I'm writing prompts and specs that describe the system holistically, before the system exists.
That shift sounds small but it's been quietly transformative. I'm planning at a more abstracted level, framing problems before I solve them, and I've gotten noticeably better at delegating; both to agents and to people. Turns out that the skill of "describing exactly what success looks like, in a way that a junior engineer (or a model) can act on without you in the room" is the same skill in both directions. Sharing vision, breaking work down, anticipating where things might go wrong; these are muscles I've been forced to exercise much more deliberately, and I'm better for it.
On productivity
I've been tracking this loosely for a while, mostly out of curiosity. Based on my own day-to-day engineering tasks (measured roughly by time-to-PR for typical pieces of work), I'm averaging about 4x faster than I was before agents became a meaningful part of my workflow. Some days it's more, some days it's less, and some days the agent does something delightfully strange that costs me an hour to undo (which I'll happily count against the average).
But that number understates the more interesting effect: the kind of work I can take on has changed. Things I would have previously parked under "nice idea, no time" now slot into an afternoon. Refactors I would have winced at are doable. The cost of trying something has dropped enough that I'll just try things I'd otherwise have argued about in a doc.
The cost of speed
It's not all upside. The same velocity that makes me productive also means I'm typing less code than I used to, and I've noticed I have to be deliberate about keeping my own technical dexterity sharp. If I let it, the tools will happily do all of it; and that's not really a deal I want to make. I still want to know how the things I work on actually work.
So I've started carving out time for the manual bits on purpose. Implementing something end-to-end by hand. Reading source code instead of asking for a summary. Sitting with a debugger instead of pasting a stack trace into a chat. It's slower, sometimes frustrating, and probably necessary; both for my own sanity, and because the moments where AI isn't enough still call for an engineer who actually knows what they're doing.
The flip side of this is much more enjoyable: with the new velocity, it's surprisingly easy to carve out time for exploration, learning, and prototyping. The hours I used to spend on the unavoidable middle bits of a project are now freed up to play with new ideas, dig into things I don't fully understand, or just build something weird for the sake of it. That's a trade I'm happy to make.
Impact at work
This new pace has shown up in my day job too. Without going into too much detail (I'll save the proper write-ups for once I've got the appropriate sign-off), the velocity boost has let me make impact in a few different areas of my role that I wouldn't have had the bandwidth to touch otherwise:
- I've been able to help bring up some automation that provides support to other engineers; a piece of work I'm genuinely proud of, and one I hope to write about properly soon.
- I've also been digging into our internal codespace bootstrap times and have managed to land changes that cut them down by roughly ~50%. There's a longer post in me about how we got there, but it'll have to wait.
Both of those are the kind of thing I probably would have had ideas about a couple of years ago but wouldn't have had the headroom to actually deliver alongside my core work. The change in velocity doesn't just speed up the things I was already doing; it expands the surface area of what I can do at all.
I'm not the only one noticing this
A few other engineers in the field have been writing about similar shifts, and it's been reassuring (and helpful) to read along. Two I'd particularly recommend:
- Mike McQuaid (Homebrew lead, ex-Hubber of 10 years) has a great write-up on his current agentic setup, including his use of sandboxing and git worktrees to actually parallelise work. His framing of "more tokens/spend directly translates to more velocity" is one of the clearer articulations of where things are heading.
- Cassidy Williams, a current Hubber, has been doing a lot of small but very satisfying personal projects with the Copilot CLI, including a fun little setup that wires her Logitech MX Creative Console up to control her Elgato lights. It's a nice example of just how low the bar for 'I'll just build this myself' has gotten.
I'd also nod at Simon Willison's superpowers post for a broader look at what coding agents are actually capable of in the wild; well worth a read if you haven't.
I still don't think AI is magic, and I'm still cautious about the broader picture; the environmental, financial, and social questions haven't gone anywhere. But for me, right now, the day-to-day reality is that I can move faster, think bigger, and ship more than I could before. And that's been genuinely fun.
I don't have a neat conclusion to wrap this up with. I'm just going to keep prototyping, keep getting my hands dirty when I need to, and keep paying attention to what changes and what doesn't. More thoughts as things continue to shift.
Until next time… ✌🏽

The Four Design Jobs AI Created (So Far)
Design work involving AI has fragmented into four distinct professional domains: AI-assisted processes, AI-native products, AI agent infrastructure, and model behavior design.
Deep dive
- Designing with AI: Using AI as a tool to accelerate ideation and prototyping.
- Designing AI products: Creating interfaces that deliver AI capabilities to human end-users (e.g., chat boxes, tool wrappers).
- Designing for AI agents: Building infrastructure, data formats, and signage that autonomous AI agents read and navigate.
- Designing the AI: Shaping the principles, evaluation criteria, and behavioral constraints of the machine learning model.
Decoder
- LLM: Large Language Model, a type of AI trained on vast amounts of data to predict text and perform reasoning.
Original article
The Four Design Jobs AI Created (So Far)
“AI design” is one label but has forked into four different types of work.
What Does “AI Design” Mean?
When someone says “AI design,” everyone in the room pictures something different.
One person is thinking about using AI to generate component variations for a design system. Another is designing a chat interface. A third is structuring data so an AI agent can parse it. A fourth is defining an LLM’s behavior.
They all fall under “AI design” but they are not the same work.
I see this in job postings, LinkedIn posts, and conference talks. Someone says, “We need to figure out our AI design strategy,” and every person at the table nods — while imagining a completely different thing. Six months later, everyone’s frustrated because the “AI-design initiative” was not what they expected.
The conversation around AI and design is forking. What used to be a single (admittedly vague) topic has split into at least four distinct orientations. Each one focuses on a different type of design work, sits in different organizational structures, and uses different definitions of what “good” looks like. Most teams are staffed for only one of these orientations, confused about which one they’re doing, or trying to dance between all of them without realizing it.
So, which of the four AI design orientations are you in?
The Engine and the Car
An AI model is an engine. A powerful, complex piece of technology under the hood. You can buy just the engine (companies like Anthropic and OpenAI sell directly to developers through their APIs). But most people never experience AI that way.
Most people experience AI inside a “car”: the dashboard, the steering wheel, the seatbelt — all the parts that turn raw capability into something a person can actually drive. Most people don’t care how the engine works. They care that it gets them where they’re going.
This metaphor brings us to the four different meanings of “AI design”. Each of these meanings implies a different kinds of work, skills, questions, and success metrics. They’re not mutually exclusive, but they are very different.
The Four Meanings of “AI Design”
1. Designing with AI
You’re the driver. You're the driver behind the wheel.
This is the orientation most people think of first. You use AI in your design process: to ideate, prototype, generate copy, build mood boards, run competitive research/audits, or critique your own work. AI tools are your vehicles, and you use them to get somewhere further, faster.
This is where most designers live right now, and there’s nothing wrong with that. AI-as-tool is transformative for how design work gets done. Entire workflow steps that used to take hours now happen in minutes.
The pitfall is treating this type of work as all there is to “AI design.” Leadership says “we’re incorporating AI into our design practice” and what they mean is “our designers are using Claude Code now.” While this type of AI design is a start, it ignores every other way AI is reshaping design opportunity inside the organization.
2. Designing AI Products
You’re the manufacturer. You're building the car (or duct-taping AI onto one that's already moving).
This is where you design the product or interface that delivers AI capabilities to users: the dashboard, the steering wheel, and the seatbelt. Everything that turns a powerful engine into something people can drive without understanding combustion.
This type of work could be delivered in one of two ways:
- AI-native products are where the entire product is the AI experience: Claude, Perplexity, Cursor, ChatGPT, or Midjourney. You’re designing the car from scratch. There is no existing product to integrate into. Every design decision shapes how someone experiences the AI capability itself.
- AI features inside existing products are a different design challenge: Notion AI, Smart Compose in Gmail, or an AI summarizer inside your meeting tool. You’re adding a new component to a car that’s already on the road — one with existing patterns, existing navigation, and existing user expectations. The AI has to fit into something.
These types of work involve different design challenges with different obstacles. For AI-native products, the hard part is that there are no established mental models to lean on: you’re teaching new paradigms to the user. For AI features inside existing products, the challenge is to naturally and meaningfully connect the AI feature to the rest of the experience, even though that nobody asked for it.
3. Designing for AI Agents
You’re the civil engineer. You’re engineering the highways and creating the infrastructure that agents need to operate on.
This one is going to feel like a departure from user experience. Stay with me.
In this type of work, you design content, data, or interactions that AI agents (not humans) will read, parse, or act on. You’re building the infrastructure that autonomous systems navigate. If AI agents are the self-driving cars, you’re designing the roads, the signage, and the lane markings.
That might mean structuring product data so a shopping agent can compare options on behalf of a user, writing instructions that an AI assistant will follow, or optimizing content for AI search and discovery instead of (or in addition to) human search and discovery.
Some of this infrastructure won't even be human-readable. A road sign designed for AI-controlled vehicles might encode information in ways no human driver could parse — data transmitted via radio or embedded in nonvisible parts of the spectrum. The "user" of that sign is an agent, and the design constraints are entirely different.
This is the orientation most design teams are still ignoring, but mostly because many organizations don’t have anyone explicitly responsible for how AI agents experience their product. Which means it’s either not happening, or it’s happening by accident inside an engineering team with no design input.
Designing for AI agents matters because it involves design decisions. What data gets exposed? How is it structured? What can an agent do versus what requires human confirmation? These shape the end-user experience just as much as any interface, they’re just one layer removed.
4. Designing the AI
You’re the mechanic. You’re tuning the engine. You help decide what kind of engine this is and what it's built to do.
In this type of work, you help shape the model: its behavior, its evaluation criteria, and its principles. You work alongside engineers to define what the AI does, how it responds, and where it draws the line.
For example, you might define evaluation criteria to test whether the model's outputs meet quality standards, collaborate with engineers on finetuning data, or build the principles that guide adversarial testing — what the model should refuse, where it should express uncertainty, and how it should weigh competing instructions.
So far, the industry has treated these activities as purely engineering work, but they are not. They involve design decisions. Designers are not the only ones who can make these decisions (an ethicist, a copywriter, or a psychologist could each contribute), but designers are trained to integrate them into a coherent experience and test them against user needs. We’re just starting to see job postings that recognize this strength.
Where the Field Is Right Now
These four types of “AI design” work are not mutually exclusive. A single designer might work across two or three of them in a month. Not every organization needs all four, either. A company building on top of an out-of-the-box LLM through an API may only need the first two (designing with AI and designing AI products). The third and fourth orientations become relevant as an organization's relationship with AI gets more complex –– for example because it’s building agent-facing infrastructure or an in-house LLM.
What makes them distinct is that each one involves designing for a fundamentally different type of behavior — human behavior with tools, human behavior with AI interfaces, agent behavior within infrastructure, and model behavior itself. Different behaviors require different types of expertise.
My point isn’t that you should choose just one path. It’s that each orientation builds a different kind of expertise, and expertise deepens over time. For example, the longer you spend designing AI products, the better you get at that work.
Understanding which type of AI design you're building expertise in matters because the market is moving fast. Right now, few designers have deep experience across multiple orientations. However, this window won't stay open for long. Within a year, many more designers will have meaningful AI experience. Those who build depth in a specific direction now will have a significant advantage over those who stay broadly "AI-adjacent."
Most designers today are using AI as a tool in their workflow. A growing number are designing AI products and features. Very few are designing for AI agents or designing the AI itself.
The demand for those last two is growing. The supply of designers who understand them barely exists. So, if you’re a designer, its an opportunity gap that’s widening.
As agents become more prevalent, someone has to design how they interact with products, content, and data. As models get embedded into more experiences, someone has to define how they behave. Right now, that someone is usually an engineer making those calls by default, when it could (and I argue, should) be a designer.
What Changes when You Understand All Four
Understanding that our discipline is forking when it comes to AI changes how you operate, whether you’re an individual contributor, a leader, or hiring.
If you’re an individual designer, you can stop being vaguely an “AI designer” on LinkedIn and start naming what you’re actually doing. The skills for designing with AI (prompt literacy and workflow integration) are different from the skills for designing the AI (model evaluation, principle setting, and collaboration with ML engineers). Identifying which type of work you’re doing can point you towards which skills matter next. Knowing which work you want to do in tells you where to invest.
If you’re a design leader, you can audit your team against all four types of work and understand where you have gaps and if it makes sense to fill them. Most teams already use AI in their workflow and, may have partial coverage for designing AI-powered features. Fewer have clear coverage for designing agent-facing infrastructure or AI-system behavior — and that may be fine, depending on how your organization builds with AI.
If you’re hiring, you can stop writing job descriptions that are for blanket “AI designers.” Name the specific work, hire for the specific skills, and evaluate against a specific definition of good work.
AI reshaped the design field and created four new lenses that you can look through. Your first step should be recognizing which you want to grow towards.

Color Palette Generator for Charts and Dashboards (Website)
This data visualization tool creates mathematically equidistant color palettes to ensure charts and dashboards remain legible.
Deep dive
- Equidistant Palettes: Provides consistent visual steps between colors for categorical data.
- Single Hue Scales: Creates intensity-based ranges for quantitative mapping.
- Divergent Scales: Supports bipolar data ranges with neutral midpoints.
- Accessibility: Focuses on HSB color system principles for better UI outcomes.
- Export: Supports direct SVG and HEX code copy for implementation.
Decoder
- Visually Equidistant: A distribution of color values where the perceived difference between any two adjacent colors is consistent, making it easier for the human eye to differentiate data points.
Original article
How to Use
Use the palette chooser to create a series of colors that are visually equidistant. This is useful for many data visualizations, like pie charts, grouped bar charts, and maps.
Note: there are two other modes besides palette mode – check out single-hue scales and divergent scales as well.
Creating visually equidistant palettes is basically impossible to do by hand, yet hugely important for data visualizations. Why? When colors are not visually equidistant, it’s harder to (a) tell them apart in the chart, and (b) compare the chart to the key. I’m sure we’ve all looked at charts where you can hardly use the key since the data colors are so similar.
It’s better to use use a range of hues so users can cross-reference with the key easier. It’s far simpler for our brains to distinguish, say, yellow from orange than blue from blue-but-15%-lighter.
This color picker allows you to specify both endpoints of the palette. You can choose at least one to be a brand color, which gives you significant flexibility in creating a palette that will work for your visualizations, yet be customized for your brand.
Here are a few tips for getting the best palette:
- Try picking very different endpoint colors – e.g. one warm, one cool; one bright, one darker – so that your palette covers a wider range
- If you’re using a brand color for one endpoint, don’t be afraid to modify the saturation and brightness a bit if it creates a more pleasing palette. Users will recognize your brand color by its hue much far more than by it’s exact saturation/brightness.
- For data visualizations where you’re showing the strength of a single value, try using the Single Hue Palette Generator instead.
More on Color
If you're new to color in UI design, I highly recommend the following resources:
- The HSB Color System: A Practitioner's Primer
- Color in UI Design: A Practical Framework
- Gradient Generator tool, by yours truly, built to be the most fully-featured on the web 😎
- Design Hacks, my email newsletter where I send original design tips and tactics to 60,000+ of my closest friends.
Anyhow, I've created this to be the tool I wish I had for creating data visualization palettes. Is there another feature you'd like to see in it? Let me know.
How to Use
The Single Hue Scale generator is most useful for visualizations where you’re showing the value of a single variable. Typically, the darker variation will represent a higher value, and a neutral color (even white) will represent a value closer to zero.
In a pie chart or bar chart, size is used to distinguish higher values. But in some visualizations, the size is set and you need to rely on color. Two examples of this are show in the “In Context” section above:
- A map in which size represents county size; we need to use color to distinguish the value for each county
- A week-by-week calendar in which each day is an equally sized box; we need to use color to show the value for a particular day
Here are a few tips for getting the best single hue scale:
- To transition to a flat gray endpoint, set “Color Intensity” to zero
- To transition to a white endpoint, set “Brightness” to full and “Color Intensity” to zero
- If your color scale actually shows a variable that transitions from one end to a neutral midpoint to another end, try the Divergent Scale Generator (e.g. Republican to moderate to Democrat; hotter to same-temperature to cooler)
How to Use
The Divergent Color Scale generator is most useful for visualizations where you’re showing a transition from (a) one extreme, through a (b) neutral middle, and finally to a (c) opposite extreme.
Perhaps the most common example of this is the “how Democrat/Republican is each state in the US” chart.
By default, the neutral midpoint is a light gray. You can change it with the "Modify Midpoint Color" sliders to be slightly darker or more colorful. For the best results, set the Color Intensity to the minimum when the two endpoint hues are significantly different – otherwise, the moderate tones will start to blend together (this will be evident in the map).
As with the other visualization styles, this will pick colors that are visually equidistant. However, if one of the two endpoint colors is significantly darker or saturated, the swatches on that side will have more color-space between them.
I Gave My AI Design System Ethics, Accessibility, and a Memory
The BADS framework proposes moving design systems beyond static components into rule-based systems that provide ethical and functional guardrails for AI agents.
Deep dive
- Agentic Design: Moving from building screens to building systems that guide agent behavior.
- Framework: BADS (Behavioral Agentic Design System) encodes ethics, accessibility, and brand identity.
- Functional Shift: Reinterprets design tokens as active constraints for autonomous systems.
- Consistency: Aims to avoid 'generic' AI output through rule-based enforcement.
Decoder
- Agentic: Refers to AI systems capable of performing autonomous tasks rather than just generating content.
- Design Tokens: Design decisions (like colors or spacing) stored as variables that can be shared across platforms.
Original article
As AI agents increasingly build interfaces, design systems need to evolve from collections of components into rule-based systems that encode brand, accessibility, ethics, and design decisions. The proposed BADS framework aims to give AI agents the guidance needed to produce distinctive, consistent work instead of generic AI-generated UI. Its central idea is that the future of design lies less in creating screens and more in creating the systems, rules, and feedback loops that guide the agents creating them.
OpenAI Filed a Confidential S-1
OpenAI has confidentially filed a draft S-1 with the SEC, keeping its options open for a potential public offering.
Decoder
- S-1: A registration form required by the SEC for companies planning to go public in the U.S. It discloses business models, financial data, and risk factors.
Original article
OpenAI announced that it confidentially submitted a draft S-1 to the SEC while noting that no IPO timing had been decided. The statement said the filing preserved the option to go public sooner while the company continued weighing tradeoffs around remaining private.

AI's Measured Impact on Engineering Velocity
New research from DX shows that AI is increasing pull request throughput by a modest 8–15 percent, far below the '10x' hype.
Deep dive
- Throughput: Median PR throughput gains are roughly 8%, with a 10-15% range in high-adopters.
- Bottlenecks: Coding is not the main slowdown; coordination and reviews are.
- False Velocity: Increased PR counts do not always translate to increased roadmap delivery or business value.
- Cognitive Debt: A concern that AI-assisted shipping reduces the developer's deep understanding of system architecture.
Decoder
- SDLC (Software Development Life Cycle): The full process of planning, creating, testing, and deploying software.
- Cognitive Debt: The long-term maintenance cost incurred when developers ship code without fully understanding how it works or how it impacts the system.
Original article
The current impact of AI on engineering velocity
Recorded live at DX Annual, Abi Noda, co-founder and CEO of DX, joins Brian Houck of Microsoft to share an early look at DX’s new research on AI’s impact on engineering velocity.
Drawing on data from a sample of DX customers, they discuss what companies are actually seeing as AI adoption matures. Most organizations in the study saw pull request throughput increase by 10 to 15 percent—far more modest than the 10x gains often promised in industry headlines.
They explore why coding remains only a small part of developer work, where time saved by AI may be going, and the unintended consequences of moving faster, from shifting bottlenecks to “false velocity.” Abi also shares how engineering leaders are applying AI beyond coding and how DX is evolving its measurement framework to account for both human and agent productivity.
Some takeaways:
Most organizations are seeing modest gains from AI
- PR throughput is increasing by about 10 to 15 percent. Across DX’s sample, most organizations saw measurable improvements, but the gains were far smaller than the 10x productivity increases often cited in industry headlines.
- The median improvement was closer to 8 percent. While some organizations saw larger gains, the typical impact was more incremental than transformational.
- Even modest gains can be meaningful at scale. A 10 percent increase in throughput can represent a significant improvement when applied across hundreds or thousands of engineers.
Coding is only one part of the productivity equation
- Developers spend only about 14 percent of their time writing code. If AI primarily accelerates coding, its impact on overall engineering velocity will naturally be constrained.
- The biggest bottlenecks often lie elsewhere. Planning, reviews, testing, documentation, and coordination still consume the majority of engineering time.
- Time savings do not map neatly to output gains. Organizations can see meaningful reductions in coding effort without a proportional increase in pull request volume.
Why productivity gains are lower than many leaders expected
- Coding is not the primary bottleneck. Improving a small slice of the development process only moves the overall system so far.
- Automation creates new bottlenecks. Faster code generation can increase pressure on reviews, QA, and technical oversight.
- Social friction slows adoption. Skepticism, inconsistent usage, and unrealistic expectations can limit the benefits of AI tools.
- Tool and skill gaps compound over time. Engineers need both the right tools and the knowledge to use them effectively.
- AI tools still lack context. Limited understanding of business logic and codebase nuances can reduce output quality.
Beware of false velocity
- More code does not necessarily mean more business value. Teams can increase pull request counts without meaningfully accelerating roadmap delivery.
- Quality and cost remain critical concerns. Organizations are closely monitoring technical debt, token spend, and long-term maintainability.
- Faster output can create delayed consequences. The full impact of AI-generated code may not become apparent until months later.
The biggest opportunities lie beyond coding
- The remaining 86 percent of engineering work is the next frontier. Leaders are applying AI to planning, documentation, incident response, and other parts of the SDLC.
- Autonomous agents can augment human capacity. Instead of simply speeding up developers, organizations are exploring how agents can work in parallel.
- Developer experience still matters. Improving focus time, documentation, and workflow friction can amplify the benefits of AI.
Measurement frameworks are evolving
- Some metrics remain constant. Velocity, quality, and developer experience are still essential signals.
- Acceleration and augmentation should be measured separately. Leaders need to distinguish between human productivity gains and work performed autonomously by agents.
- Agent experience is an emerging concept. DX is beginning to survey AI agents directly to understand their constraints, bottlenecks, and effectiveness.
Cognitive debt is a new concern
- AI can reduce understanding while increasing output. Developers may ship code more quickly while building a weaker mental model of the systems they maintain.
- Short-term efficiency can create long-term costs. Reduced comprehension may make future debugging and maintenance more difficult.
- The long-term effects are still uncertain. Engineering leaders are only beginning to understand the human consequences of AI-assisted development.
In this episode, we cover:
Intro
What motivated DX’s research into AI’s impact on engineering velocity
How DX designed the study and selected companies
What DX’s data reveals about AI’s impact on engineering throughput
Why PR throughput was the most practical metric to publish
Why AI productivity gains are lower than many leaders expected
How an all-in culture can amplify AI productivity gains
Why it’s hard to track where AI-generated time savings are going
Unintended consequences of AI-driven productivity gains
Why leaders should look beyond coding to the rest of the SDLC
Cognitive debt and the human costs of AI-assisted development
How DX’s AI measurement framework is evolving
How to make agents more effective
Referenced:
- DX Core 4 Productivity Framework
- DORA, SPACE, and DevEx: Which framework should you use?
- Time Warp: The Gap Between Developers’ Ideal vs Actual Workweeks in an AI-Driven Era - Microsoft Research
- How Generative and Agentic AI Shift Concern from Technical Debt to Cognitive Debt
- Measuring AI code assistants and agents
How AI Agents Reshape Knowledge Work
AI agents are transitioning from search-and-retrieve to autonomous execution, cutting task time by up to 87%.
Original article
AI agents like Perplexity's "Computer" enhance knowledge work by executing tasks autonomously, reducing time by 87% and costs by 94% compared to traditional search and human execution. Autonomous execution allows users to focus on goal-setting and oversight, enabling complex and cross-disciplinary tasks that span specific expertise areas.
Built to benefit everyone: our plan
Sam Altman and Jakub Pachocki outlined a vision for OpenAI focused on building automated AI researchers and delivering personalized AGI to every individual.
Original article
Sam Altman and Jakub Pachocki frame OpenAI's three current goals as building an automated AI researcher, accelerating the economy while ensuring gains are widely shared, and giving everyone on Earth a personal AGI. They argue OpenAI has entered its third phase, where the central question is making advanced AI abundant, affordable, safe, and easy enough for every person and organization to use, with broad power distribution as the safer path.
Musk's xAI Taps Starlink Staffer to Run Grok Training Team
xAI has replaced its young head of Grok training with Jack Garabedian, a Starlink veteran, signaling a shift in leadership toward seasoned infrastructure operators.
Original article
Jack Garabedian, a Starlink engineer who's been with SpaceX since 2021, is taking over the team that trains xAI's Grok chatbot, displacing college-aged engineer Diego Pasini, who has been with the company for a year and a half. Garabedian helped with the deployment of Starlink during the war between Russia and Ukraine, and he also helped work with the Starlink customer team and integrated Grok into customer support. A group of Starlink executives has taken over xAI in policy, operations, and leading the engineers ahead of SpaceX's upcoming initial public offering.

Your Agent Harness Should Repair Itself
Observability tools should move beyond displaying failure traces and start autonomously generating patches for failed agent runs.
Original article
Your Agent Harness Should Repair Itself
When an AI agent fails in production, your observability tool shows you exactly what it did and almost nothing about how to fix it. You get a clean trace of the run, every model call and tool that...

Perplexity plans IPO in 2028 regardless of what happens to Anthropic or OpenAI
Perplexity CEO Aravind Srinivas has committed to a 2028 IPO timeline, maintaining a course independent of market reception to rival AI labs.
Decoder
- Tokenmaxxing: The practice of intentionally increasing AI model usage or output length to signal high productivity or activity levels within a team.
Original article
Key Points
- Perplexity CEO Aravind Srinivas told CNBC that the AI firm is planning to go public in 2028.
- The CEO's comments come after Anthropic confidentially filed to go public and as investors assess the performance of the upcoming SpaceX IPO.
- Srinivas said he thinks the IPO of Anthropic and a reported listing of OpenAI will be well-received.
Perplexity is planning to go public in 2028 regardless of how the market receives the listings of Anthropic and OpenAI, CEO Aravind Srinivas told CNBC.
"Agnostic of these two companies, we were planning for something in 2028 so that still remains the case," Srinivas said in an interview that aired on Tuesday.
Srinivas has previously said the company has no plans to go public before 2028. His latest comments suggest a more concrete timeline.
The CEO's comments come after Claude developer Anthropic confidentially filed for an initial public offering last week. While there are no details on share pricing, Anthropic was last valued at nearly $1 trillion. OpenAI on Monday also confidentially filed for an IPO.
These listings, along with SpaceX this week, are going to be among the biggest in history and a test of investors' appetite for these mega-IPOs.
"I certainly think there will be ripple effects if they don't go well, like there is no sugar coating on that. The SpaceX IPO this week will definitely be a leading indicator to how Anthropic or OpenAI will go out," Srinivas told CNBC.
"I think it's important for the AI industry that these IPOs go well, and I actually think they will go well, because they're doing well."
The valuations of both Anthropic and OpenAI, known as frontier labs because their models are among the leading in the world, are under scrutiny from investors.
Srinivas said that both companies deserve their high valuations because "they are on the frontier." A slowdown in the pace of innovation may dent their valuations, he said, adding that there is no sign of this happening now.
"If for six months you don't see a model capability advance from one of these two companies, then it's a problem for them," Srinivas said.
AI spending in focus
Enterprise spending on AI has become a key focus after OpenAI CEO Sam Altman reportedly said in a company live stream that companies are now discussing how much they're spending on AI. Altman said AI costs are a "huge issue."
One of the trends that has emerged is "tokenmaxxing," where employees increase their AI use to signal productivity. "But people don't want to just tokenmax, they really want to use whatever model is the best for that particular task," Srinivas said.
Perplexity's product is based on models from various companies. Its AI, when prompted, will figure out the best model to use for the particular task, taking into account cost.
"If there is an open source model that gets the job done 90% of the time, I'd probably use that if it's 10 to 20 times cheaper than the frontier model," Srinivas explained. "The future is still awesome for frontier intelligence, but it's not going to be mindless spending, as we saw in the last few months."
Samsung reportedly involved in SpaceX xAI satellite chip project
Samsung is reportedly entering the space-computing market by manufacturing specialized AI satellite chips for SpaceX and xAI.
Deep dive
- Samsung is handling early-stage silicon production for satellite-based AI hardware.
- Project aims to enable satellites to process data natively in space rather than relaying raw data to Earth.
- TSMC is also reportedly involved as a secondary manufacturing partner.
Decoder
- Satellite chip: Integrated circuits designed to operate in the harsh environment of space, handling high-speed data processing and communication protocols.
Original article
Samsung is reportedly in the early stages of producing AI space computing chips for SpaceX's satellite chip ambitions. SpaceX plans to build satellites in space that process and beam data back to Earth. TSMC has also been named as a manufacturing partner. Early-stage chip production could include anything from prototype silicon to limited qualification runs.
The 24-Year-Old AI Wiz Who Counts Jane Street as an Investor
Leopold Aschenbrenner’s investment firm, Situational Awareness, has grown from hundreds of millions to over $20 billion in under two years.
Original article
Leopold Aschenbrenner had no professional investing experience when he launched his AI-focused investment firm, Situational Awareness. The firm's assets have vaulted from a few hundred million dollars to more than $20 billion in less than two years. One of its most successful bets is a stake in Anthropic. The firm's investors include Jane Street, a savvy quant-trading firm that rarely allocates capital to outside money managers.

Convicted FTX founder Sam Bankman-Fried files formal request for Trump pardon
Convicted FTX co-founder Sam Bankman-Fried has filed a formal request for a presidential pardon with the U.S. Department of Justice.
Original article
- Sam Bankman-Fried has formally submitted a request for a presidential pardon, according to information listed on the U.S. Department of Justice website.
- The co-founder of the now defunct FTX crypto exchange is currently serving a 25-year federal prison sentence after he was found guilty of orchestrating a massive fraud scheme that misused billions of dollars in customer funds.
Sam Bankman-Fried has formally submitted a request for a presidential pardon to President Donald Trump, according to information listed on the U.S. Department of Justice Office of the Pardon Attorney website.
The co-founder of the now defunct FTX crypto exchange is currently serving a 25-year federal prison sentence after he was found guilty of orchestrating a massive fraud scheme that misused billions of dollars in customer funds at FTX and its affiliated trading firm, Alameda Research.
The exact date of the filing isn't clear but DOJ records indicate the request for "pardon after completion of sentence" was submitted in 2026 and is pending.
Trump said in a January interview with The New York Times that he has "no intention of pardoning" several high-profile people including Bankman-Fried.
Trump has issued more than 1,400 pardons and commutations so far in his second term, according to the Department of Justice, including more than 1,200 Jan. 6-related cases. During his first term, he granted 238 pardons and commutations in total.
The White House declined to comment for this story.

Airbnb CEO Bets on Different AI Future, Focuses on Design and User Experience
Airbnb CEO Brian Chesky is launching an independent AI lab to prioritize bespoke, user-centric experiences over generic large language model chatbots.
Original article
Airbnb CEO bets on different AI future, focuses on design and user experience
Airbnb CEO Brian Chesky is launching an AI venture focused on user interaction and design, signalling a shift away from chatbot-led models toward more experience-driven AI applications.
Airbnb’s Brian Chesky is exploring a new AI approach centred on design and specialised experiences, signalling a shift away from generic chatbots toward more intuitive, product-focused and user-driven AI systems.
Airbnb CEO Brian Chesky is entering the AI space with a new venture that reflects a markedly different view of how artificial intelligence will evolve, moving beyond the current focus on chatbots and large language models.
Chesky is reportedly in the early stages of setting up an independent AI lab that will focus on building new models and rethinking how users interact with AI-powered services. Unlike many tech leaders who are doubling down on conversational AI, Chesky is betting that the next phase of AI innovation will be shaped by design, user experience and more interactive systems.
The initiative is expected to operate separately from Airbnb, with Chesky continuing in his role as CEO and not directly leading the new entity.
At the core of his approach is the belief that current AI tools, particularly chatbot interfaces, are not sufficient for complex use cases such as travel planning or commerce. Instead of relying on generic conversational models, Chesky is focusing on creating AI systems that can deliver richer, more intuitive interactions tailored to specific applications.
Also read: ‘Everyone's entitled to their opinion, but I don't think that's at all true’: AWS CEO Matt Garman on AI job fears
This philosophy marks a clear departure from industry trends, where companies have rapidly integrated tools like ChatGPT into their platforms. Chesky has previously indicated that these tools still lack the reliability and depth required for high-stakes applications, preferring instead to build more customised, purpose-driven AI systems.
The broader vision also suggests that AI will not converge into a single universal interface. Instead, Chesky sees a future with multiple specialised tools and interaction modes, where the user experience plays a defining role in how AI is adopted and used.
Within Airbnb, the company has already taken a cautious and structured approach to AI adoption. Rather than leading with customer-facing chatbots, it has prioritised internal use cases and more complex applications such as customer service automation, where accuracy and reliability are critical.
Chesky’s move comes at a time when the AI industry is rapidly expanding, with major players racing to develop more powerful models. However, it also reflects a growing realisation that long-term differentiation may depend less on raw model capability and more on how AI is integrated into products and experiences.
By focusing on design, interaction and application-specific systems, Chesky is positioning his AI venture around a different vision—one where technology is shaped as much by how it feels and functions as by how powerful it is.
New dummy units give our closest look yet at the iPhone Fold
Leaked dummy units of Apple's rumored 'iPhone Fold' reveal a passport-style compact design with a 7.8-inch inner display and side-mounted Touch ID.
Decoder
- Dummy unit: A non-functional physical model used for testing design ergonomics, accessories, or marketing visuals before official manufacturing.
Original article
Apple's first foldable iPhone, expected later this year, is rumored to feature a 7.8-inch inner display, a 5.5-inch outer screen, Touch ID in the side button, dual rear cameras, and a nearly crease-free foldable design, with software potentially benefiting from the iPad app ecosystem. Leaked dummy units suggest a compact passport-style form factor, and Apple may launch it in just one or two colors, likely prioritizing build quality and hinge design as its key differentiators.
Meet fonts.xyz, the type marketplace that really is built for everyone
Fonts.xyz is launching a creator-focused type marketplace that offers an 80% royalty rate and simplified licensing based on company size.
Deep dive
- Royalty Model: Offers an 80% royalty rate for font designers.
- Licensing: Simplifies complex EULAs into company-size-based tiers.
- Infrastructure: Provides no-code store-fronts for independent foundries.
- Objective: Reduce gatekeeping and technical complexity in digital type sales.
Decoder
- Foundry: A company that designs and distributes digital typefaces.
- EULA: End-User License Agreement, the legal contract governing how a font file can be used.
Original article
Fonts.xyz is a new type marketplace that lets designers create and run their own online foundries for free, with an unusually high 80% royalty rate and simple, all-inclusive licensing based only on company size. Its goal is to remove the cost, complexity, and gatekeeping of traditional font distribution by providing no-code tools, customizable storefronts, and a more creator-friendly business model. The platform is still in a gradual rollout phase, but early interest from both foundries and buyers suggests strong demand for a simpler, fairer way to sell and license fonts.

AI Personalization Drives Canva Design Intelligence
Canva is leveraging its unified data strategy and Snowflake partnership to deliver AI-driven personalization to its 265 million monthly active users.
Deep dive
- Scale: Reached 265 million monthly active users and $4 billion in ARR.
- Data Strategy: Unifies product, marketing, and sales signals in a single environment.
- Partnership: Uses Snowflake for infrastructure to facilitate real-time AI personalization.
- Adoption: Notes that 70% of Australian enterprises have moved AI projects to production.
Original article
How Canva turns a unified data strategy into AI personalization at scale
As AI accelerates product development cycles, the companies best positioned to capitalize are those that have already built a unified data foundation — one capable of taking raw signal and delivering AI personalization experiences at scale.
That shift is playing out at one of Australia’s most celebrated technology companies. Canva Pty Ltd., the design platform that has said has grown to 265 million monthly active users and $4 billion in annualized revenue, has restructured how it uses data across every product, marketing and sales function. The transformation is accelerating under AI, according to Helen Crossley, global head of data science at Canva.
“It feels like there is a new product coming out every time you turn around,” Crossley said. “Every meeting that we’re having, every product showcase starts with the metrics. What’s happening this week today on our data, and what our customers are seeing and feeling.”
Crossley and Glenn McPherson, regional vice president, Australia, at Snowflake Inc., spoke with theCUBE’s Dave Vellante and Rebecca Knight at Snowflake Summit 2026, during an exclusive broadcast on theCUBE, SiliconANGLE Media’s livestreaming studio. They discussed how Canva’s data strategy and its Snowflake partnership enable AI personalization at scale as Australia’s AI market transitions from experimentation to board-level execution.
Data strategy powers AI personalization from segmentation to memory
The Canva-Snowflake partnership began modestly, with an initial focus on addressing basic data fragmentation in straightforward and reliable ways. Over the years, Canva has extended the data foundation well beyond secure storage and into higher-value applications such as AI personalization, all while maintaining robust governance and security.
“We started out with Canva in very humble ways, trying to solve the simplest of problems, which was that data fragmentation,” McPherson said. “We built a reputation over that time of being very dependable, very simple.”
Snowflake’s expanding portfolio of AI services is enabling Canva to run three distinct jobs on a single data foundation: segment its global user base, score and prioritize enterprise customers for sales and partnerships teams and deliver personalized messaging in the moment. Canva brings together product, marketing and sales signals in one Snowflake environment — and uses it to match every user with the right message at the right point in their journey, Crossley noted.
“As everyone comes into our platform, we need to know who are they [and] what’s the job that they want to get done?” Crossley said. “How do we use Snowflake and all of the data and the signal that we have to be able to really make that message feel personalized to that customer, in that moment, with the job that they’re really trying to get done?”
The partnership between the two companies has turned reciprocal: Snowflake uses Canva for design across its teams, while Canva relies on Snowflake’s data infrastructure. In the broader Australian market, about 70% of enterprises have now moved from AI pilot to production, McPherson noted, with the common factor among those succeeding being a business-led — rather than information technology-led — approach, often driven by board-level directives.
“Find your AI heroes in the organization,” Crossley said. “They might not have knocked on your door yet as an executive, but you absolutely have to invite them in, find them in your organization and really listen to them in terms of what that future could look like, because they’re motivated, [and] they know what they’re doing.”
Here’s the complete video interview, part of SiliconANGLE’s and theCUBE’s coverage of Snowflake Summit 2026:
(* Disclosure: TheCUBE is a paid media partner for Snowflake Summit event. Neither Snowflake, the sponsor of theCUBE’s event coverage, nor other sponsors have editorial control over content on theCUBE or SiliconANGLE.)

Christa Jarrold's 3D Worlds Look Messy, Hand-made, and Tinged with Darkness
3D artist Christa Jarrold is subverting the hyper-polished expectations of digital design by layering physical, handmade textures onto her virtual models.
Deep dive
- Jarrold combines 2D and 3D workflows to achieve a distinct, gritty aesthetic.
- She manually creates clay and fabric textures, scanning them for use as digital overlays.
- Sculpting in VR is employed specifically to add natural, non-procedural "lumpiness" to digital models.
- Texture scaling is intentionally mismatched to create a disjointed, "stitched together" visual quality.
- Her work is intentionally designed to hold a narrative tension between warmth and unsettling, dystopian themes.
- The practice uses the "Trojan horse" method of appearing cute or safe to deliver more complex emotional commentary.
Decoder
- Cinema 4D: Professional 3D modeling, animation, and rendering software widely used for motion graphics.
- Redshift: A GPU-accelerated, biased renderer used within 3D suites to produce high-quality final images.
- Rig: The process of creating a digital skeleton for a 3D model, allowing it to be posed and animated.
Original article
Christa Jarrold's 3D worlds look messy, hand-made, and tinged with darkness
The animation director and illustrator is on a mission to bring grubbiness back to digital design, one human fingerprint at a time.
There's a paradox at the heart of Christa Jarrold's practice. Based in Margate on the north coast of Kent, she works in 3D using Cinema 4D and Redshift. It's a medium most people associate with the frictionless, hyper-polished surfaces of commercial CGI. Yet her entire approach is directed at making that work look like it came from somewhere messier: a workshop bench scattered with clay, fabric and felt, presided over by slightly grubby human hands.
The results, evident in her collaborations with Oatly, Coldplay and Netflix, are immediate and distinctive. Rubbery characters with puppet-like proportions. Environments that simultaneously feel cosy and unsettling. And a texture to everything that makes you want to reach out and prod it.
It's a deliberate strategy, and it goes further than you might think. Because Christa doesn't just mimic the look of handmade objects in software... she physically creates clay textures, scans them in and wraps them onto her digital models.
She sculpts in VR to introduce what she calls an extra "lumpy or handmade feel". And she even deliberately scales textures slightly wrong, so they appear oversized on the characters, giving them that "stitched together" feel we're used to from claymations.
"I like the tension of using digital tools to create something that feels tactile and imperfect," she explains. "I want the viewer to feel like they could reach out and touch the characters."
From stuck to sculptural
Interestingly, Christa came from a 2D background; her move into 3D was driven less by ambition than creative restlessness. She'd hit a wall with her previous work and needed, as she puts it, to surprise herself again. What she found on the other side was a medium that, in the right hands, could feel as physical and immediate as any analogue process.
"I'd started to feel a bit stuck with my 2D digital work," she recalls. "There were so many brilliant people making work on iPads, and I felt like my own work wasn't cutting through in the way I wanted it to. I was a bit uninspired, and I needed to surprise myself again."
Learning 3D gave her that jolt. "Suddenly there was this whole new dimension to explore, aesthetically, technically and narratively," she enthuses. "It made animation feel playful again. I could take characters that began in 2D and move them into a stranger, more physical world. It was also like playing the Sims, and I love the Sims!"
Aside from a renewed sense of fun—which is oft underrated as a way to reboot one's creativity—the new medium also gave her flexibility: the ability to build a character, rig and animate them, relight them, reframe them. It was almost like working with puppets or miniature sets. "It gave me more room to experiment," she says, "and helped me arrive at something that felt much more distinctive to me."
Cosy on the outside
Christa's images are warm, tactile and colourful: characters sprawled on sofas, sitting on beds surrounded by band posters, gazing into dressing-table mirrors. They look, at first glance, like they belong in a cheerful children's animation.
Look closer, though, and something else creeps in. A laptop screen reads "hot slugs in your area". A spilt drink lies unnoticed on the floor, next to discarded fries. An Oatly carton is poured sloppily, almost as an act of defiance. A mirror is visibly cracked.
This tension is fully intentional, Christa reveals. "I'm not really interested in images or stories that feel too cute, safe or comforting," she says. "I'm more drawn to characters' interior worlds: the anxious, funny, embarrassing, dark parts of being alive. But if the aesthetic is also very dark or abrasive, it can sometimes push people away before they've had a chance to enter the world. I like the idea of creating something that feels warm, tactile or even cosy at first glance, and then letting something stranger or more uncomfortable creep in."
It's a technique with a long tradition in animation and illustration: using something outwardly fun and friendly as a Trojan horse. And Christa's version of it feels particularly well-calibrated for the current moment, when a lot of online visual culture veers between relentless positivity and performative despair, and something more nuanced is easy to overlook.
Processing the background hum
Ask Christa what her work is actually about and she's refreshingly direct. "Is anyone not having low or even high-level existential thoughts right now?" she says. "There's this constant background noise of technology, AI, political instability, climate anxiety, rising fascism and geopolitical unrest. It creates a kind of ambient uneasiness. And then, at the same time, you're expected to carry on as normal: make work, answer emails, post online, be productive, be charming."
That disconnect, she says, is what drives her. "Sometimes it feels genuinely dystopian, the way we adapt so quickly to things that should probably horrify us," she reflects. "So I think my work comes from that place. It's not that I want everything to be bleak, but making something too positive right now would feel dishonest. Humour helps, though. It's a way of looking directly at that unease without becoming completely paralysed by it."
Her short film Mucky, which premiered at Pictoplasma, applies this thinking in style. Set in a world where pigs live like humans, it follows two old friends chatting over pints when one reveals they've given up clothes and returned to wallowing in mud. Through its absurd premise, the film targets something very recognisable: our collective obsession with "going back to basics," from paleo diets and caveman workouts to trad-wife fantasies, and the endless search for a more authentic way to live.
What comes next
For all the talk of XR and where animation is heading, Christa's view on the subject is grounding. The technology is interesting, she says, but "it has to serve something emotionally or narratively, otherwise it feels boring and empty". For now, her attention is fixed on the space she's already found and made her own.
"I want to keep making short films, illustrations and GIFs that sit somewhere between handmade and digital, funny and uncomfortable, cute and bleak," she maintains. "That tension still feels like the most exciting place for me to work from."
And it's hard to argue with that. In a digital landscape that often rewards either slick technical polish or raw immediacy, Christa has found a way to have it both ways, and to fill that middle ground with something funny, strange and uniquely her own.
OpenAI Launched an Economic Research Exchange
OpenAI launched a research exchange to formalize external studies on how AI deployment affects global labor markets and economic structures.
Original article
OpenAI introduced a program for external researchers studying AI's economic effects on workers, firms, institutions, and the broader economy.
Ad-free Pinterest Alternative (Website)
Moodloom is an ad-free Pinterest alternative that relies on AI filtering to curate content and facilitate commerce.
Original article
Moodloom is an ad-free alternative to Pinterest that uses AI filtering technology. The platform provides a cleaner browsing experience without advertisements and includes shopping functionality.
AI image, Video, and Music generator (Website)
DramaPixel integrates image, video, and music generation into a single workspace for creative production.
Original article
DramaPixel is an AI creative studio that combines an AI image generator, AI video generator, and AI music generator in one workspace.

Wendy's New Branding Commits a Cardinal Design Sin
Wendy's is abandoning its traditional red branding for a light blue palette in international markets as part of a "Future Fresh" digital-first overhaul.
Deep dive
- The "Future Fresh" initiative aims to modernize the customer experience globally.
- The shift to blue directly contradicts established color theory in the food industry, which posits that red and yellow induce appetite.
- Wendy's CFO Ken Cook claims the change is necessary to differentiate the brand from competitors like McDonald's and KFC.
- New store layouts emphasize self-service ordering and loyalty program interaction over traditional counter service.
Decoder
- Color theory: A set of rules and guidelines that designers use to communicate with users through appealing color schemes in visual interfaces and physical spaces.
Original article
Wendy's is swapping its signature red for light blue across global locations as part of its 'Future Fresh' initiative, which debuted in the Philippines.